Inferenza statistica e probabilit`a...
75
Transcript of Inferenza statistica e probabilit`a...


Inferenza statistica e probabilita Verosimiglianza
Parte IV
Inferenza statistica: le basi

Inferenza statistica e probabilita Verosimiglianza
Siamo interessati ad un fenomeno
In relazione ad esso possiamo osservare diversi elementicaratteristici, che chiameremo variabili
Il fenomeno puo essere circoscritto ad un determinato ambito(spaziale, temporale, ecc.) che induce alla definizione di unapopolazione
Ogni elemento della popolazione si dice unita statistica
Generalmente non possiamo esaminare l’intera popolazione(censimento). Possiamo pero osservare la/le variabili che ciinteressano su un suo sottoinsieme, cioe su un campione
E possibile utilizzare l’informazione proveniente dal campioneper capire quali siano le caratteristiche salienti del fenomenosull’intera popolazione? Se sı, come? −→ inferenza statistica

Inferenza statistica e probabilita Verosimiglianza
Fenomeno1 andamento della produzione nel settore manifatturiero in Italia
nel 20052 rendimento degli studenti universitari italiani iscritti alle facolta
di economia nel 20053 efficacia della politica pubblicitaria di un’azienda in Europa nel
primo trimestre 2006
Variabili1 numero di occupati nel settore, politiche fiscali, ammontare
degli investimenti nel settore, andamento del fatturato, . . .2 reddito familiare, situazione lavorativa, stato civile, localita di
residenza, scuola di provenienza, voto di maturita, sesso . . .3 canali utilizzati, caratteristiche dei consumatori (sesso, reddito,
livello di istruzione, nazionalita, ecc.), . . .

Inferenza statistica e probabilita Verosimiglianza
Popolazione1 Tutte le imprese operanti nel settore manifatturiero in Italia nel
20052 Tutti gli studenti iscritti nelle facolta di economia in Italia nel
20053 Tutti i potenziali clienti europei dell’azienda nel primo
trimestre 2006
Campione1 n imprese operanti nel settore manifatturiero in Italia nel 2005
scelte a caso2 n studenti iscritti nelle facolta di economia in Italia nel 2005
scelti a caso3 n potenziali clienti europei dell’azienda nel primo trimestre
2006 scelti a caso

Inferenza statistica e probabilita Verosimiglianza
Il campione e un sottoinsieme, di dimensione n, dellapopolazione
Il campione deve essere rappresentativo della popolazione:l’inclusione (esclusione) casuale di una unita statistica nondeve dipendere dalle caratteristiche dell’unita stessa.

Inferenza statistica e probabilita Verosimiglianza
Negli esempi precedenti non ha senso
1 costruire un campione di 300 imprese operanti nel settoremanifatturiero scelte a caso tra quelle con fatturato superiorea 30 milioni di euro
2 costruire un campione di 500 studenti scelti a caso tra imaschi iscritti a Ca’ Foscari
3 costruire un campione di 10000 potenziali clienti scelti a casotra i residenti a Parigi

Inferenza statistica e probabilita Verosimiglianza
Supponiamo pero di sapere che i potenziali clienti della nostraazienda si distribuiscono come segue: 70% in Italia, 20% in Franciae 10% in Germania.Supponiamo inoltre di voler costruire un campione di numerositafissata, per n = 10000.Ha senso costruire un campione di 7000 Italiani, 2000 Francesi e1000 Tedeschi scelti completamente a caso nei rispettivi paesi?

Inferenza statistica e probabilita Verosimiglianza
Nel seguito, qualora non diversamente specificato, supporremo chetutte le unita statistiche possano essere incluse nel campione con lastessa probabilita, in modo indipendente e che ogni unita statisticapossa essere estratta ripetutamente. Ipotizzeremo cioe che ilcampionamento sia casuale semplice, o bernoulliano.

Inferenza statistica e probabilita Verosimiglianza
Un comune vuole stimare la proporzione ignota, θ, di veicoli adalimetazione diesel che circolano in citta. A tale scopo incarica trestatistici, A, B e C di effettuare delle rilevazioni di dati e diproporre delle stime della proporzione ignota.I tre statistici si collocano ad un incrocio per osservare uncampione di veicoli

Inferenza statistica e probabilita Verosimiglianza
Lo statistico A fissa un numero di osservazioni pari a 10 edosserva:
ND,D,ND,ND,ND,D,ND,ND,ND,D
(D = Diesel, ND = Non Diesel)
Lo statistico B decide di rilevare le osservazioni in un arco di10 minuti. Osserva gli stessi veicoli rilevati da A
Lo statistico C decide di sospendere le rilevazioni quandoosservera tre veicoli ad alimentazione diesel. Osserva gli stessiveicoli rilevati da A e B

Inferenza statistica e probabilita Verosimiglianza
Posto che P(D) = θ, 0 ≤ θ ≤ 1, per ognuno dei tre statistici,come si puo definire un modello statistico?Definiamo una variabile casuale X tale che
Y =
{1 se e vero D0 se e vero ND
fY (y) =
{θ se y = 11− θ se y = 0
Il campione osservato sara y = [0, 1, 0, 0, 0, 1, 0, 0, 0, 1]′,determinazione della variabile casuale multivariata
Y = [Y1, . . . ,Y10]′
con componenti stocasticamente indipendenti.

Inferenza statistica e probabilita Verosimiglianza
A ritiene corretto quantificare la probabilita del campioneosservato, y, come quella di una particolare realizzazione diuna v.c. binomiale Bin(10, θ):
fY,A(y; θ) =
(10
3
)θ3(1− θ)7
B quantifica la probabilita della sequenza osservata come:
fY,B(y; θ) = (1− θ)θ(1− θ)(1− θ)(1− θ)θ(1− θ)(1− θ)
(1− θ)θ
= θ3(1− θ)7

Inferenza statistica e probabilita Verosimiglianza
C quantifica la probabilita della sequenza osservata come:
fY,C (y; θ) = P(decima diesel|2 nelle prime 9 sono diesel) ··P(2 nelle prime 9 sono diesel)
= θ
(9
2
)θ2(1− θ)7
=
(9
2
)θ3(1− θ)7

Inferenza statistica e probabilita Verosimiglianza
Definiamo ora tre funzioni, formalmente identiche alle tre funzionidi probabilita appena introdotte, viste pero come funzioni di θ enon di y:
LA(θ; y) = fY,A(y; θ) =
(10
3
)θ3(1− θ)7
LB(θ; y) = fY,B(y; θ) = θ3(1− θ)7
LC (θ; y) = fY,C (y; θ) =
(9
2
)θ3(1− θ)7
Possibile strategia
Per ciascuno dei tre statistici, A, B e C, i valori piu plausibili di θsaranno quelli a cui corrisponderanno valori elevati diLA(θ; y), LB(θ; y) e LC (θ; y) rispettivamente.

Inferenza statistica e probabilita Verosimiglianza
Figura 1: Esempio di analisi del traffico: funzioni di verosimiglianza perA, B e C.
0.0 0.2 0.4 0.6 0.8 1.0
0.00
0.10
0.20
θ
vero
sim
iglia
nza
ABC

Inferenza statistica e probabilita Verosimiglianza
Figura 2: Funzioni di verosimiglianza per A, B e C, rappresentazionealternativa
0.0 0.2 0.4 0.6 0.8 1.0
0.00
0.15
θ
vero
sim
iglia
nza
A
0.0 0.2 0.4 0.6 0.8 1.0
0.00
000.
0020
θ
vero
sim
iglia
nza
B
0.0 0.2 0.4 0.6 0.8 1.0
0.00
0.15
θ
vero
sim
iglia
nza
C

Inferenza statistica e probabilita Verosimiglianza
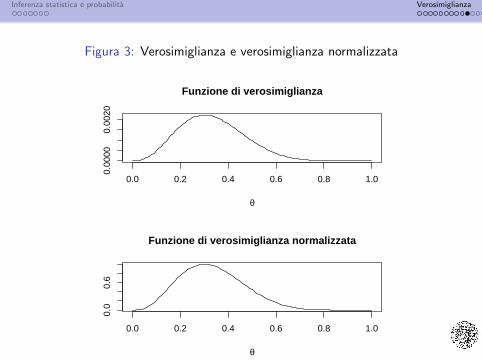
Definiamo la funzione di verosimiglianza come
L(θ; y) ∝ fY(y; θ)
e quindiL(θ; y) = θ3(1− θ)7
Se θ∗ e il punto di massimo assoluto di L(θ; y), possiamonormalizzare la funzione di verosimiglianza:
L∗(θ; y) =L(θ; y)
L(θ∗; y)
in modo tale che 0 ≤ L∗(θ; y) ≤ 1.
Inferenza statistica e probabilita Verosimiglianza
Figura 3: Verosimiglianza e verosimiglianza normalizzata
0.0 0.2 0.4 0.6 0.8 1.0
0.00
000.
0020
Funzione di verosimiglianza
θ
0.0 0.2 0.4 0.6 0.8 1.0
0.0
0.6
Funzione di verosimiglianza normalizzata
θ

Inferenza statistica e probabilita Verosimiglianza
Un gruppo di studiosi vuole capire in che misura, all’iniziodella primavera, una pianta si stia diffondendo in una foresta(popolazione).
Si individuano casualmente sulla superficie della foresta nquadrati di lato unitario, detti blocchi (unita statistiche).
Su ciascun blocco, i , si conta il numero di nuovi germogli, yi ,i = 1, . . . , n (osservazioni).
Si vuole valutare quante nuove piante germoglino mediamenteper ogni metro quadrato della foresta.

Inferenza statistica e probabilita Verosimiglianza
Se ipotizziamo che il numero di nuovi germogli non dipendadalla collocazione del blocco sul territorio, possiamo pensareche Yi , i = 1, . . . , n, siano n v. c. identicamente distribuite,cioe distribuite come la v. c. Y che rappresenta il modello dicomportamento della popolazione.
Poiche ipotizziamo che non vi sia alcun tipo di dipendenzaspaziale e i blocchi sono scelti a caso, possiamo pensare che idati yi siano determinazioni di n variabili casualistocasticamente indipendenti, Yi .

Inferenza statistica e probabilita Verosimiglianza
Un ragionevole modello statistico
Possiamo assumere che
Y = numero di nuovi germogli per metro quadrato
sia una variabile casuale di Poisson con parametro θ, ovveroY ∼ Po(θ), θ > 0 , con funzione di probabilita
fY (y ; θ) = P(Y = y ; θ) =
{e−θθy
y ! y ∈ {0, 1, 2, . . . }0 y /∈ {0, 1, 2, . . . }
con E (Y ) = Var(Y ) = θ.

Inferenza statistica e probabilita Verosimiglianza
Osserviamo n blocchi
y = [y1, . . . , yn]′ campione osservato
probabilita congiunta del campione osservato
P(Y = y; θ) = fY(y; θ)
=n∏
i=1
(e−θθyi
yi !
)
=e−nθθ
Pni=1 yi∏n
i=1 yi !
definiamo la funzione di verosimiglianza
L(θ; y) = e−nθθPn
i=1 yi

Inferenza statistica e probabilita Verosimiglianza
Supponiamo di osservare 3 nuovi germogli su un solo blocco:
L(θ; y) = e−nθθPn
i=1 yi
= e−θθ3
Supponiamo di osservare 1 nuovo germoglio su un solo bloccodiverso dal precedente:
L(θ; y) = e−θθ
Supponiamo di osservare 40 nuovi germogli su 60 blocchi:
L(θ; y) = e−60θθ40

Inferenza statistica e probabilita Verosimiglianza
Qual e il campione piu informativo?

Inferenza statistica e probabilita Verosimiglianza
Figura 4: Verosimiglianze su campioni diversi
0 5 10 15
0.00
0.20
Campione di dimensione 1
θ
Ver
osim
iglia
nza
0 5 10 15
0.0
0.3
Campione di dimensione 1
θ
Ver
osim
iglia
nza
0 5 10 15
0.00
0.04
Campione di dimensione 60
θ
Ver
osim
iglia
nza

Inferenza statistica e probabilita Verosimiglianza
Il modello statistico
Il campione osservato e una sequenza di valori,
y = [y1, . . . , yn]′
che possono essere visti come il risultato di un esperimentocasuale (l’estrazione casuale di n unita statistiche)
Ogni yi , i = 1, . . . , n, sara qundi una determinazione di unavariabile casuale Yi
Se il campionamento e casuale semplice allora le variabilicasuali Yi , i = 1, . . . , n, saranno stocasticamente indipendentie avranno tutte la stessa distribuzione di probabilita,rappresentabile attraverso la sua funzione di densita diprobabilita (o di probabilita) g0(y)

Inferenza statistica e probabilita Verosimiglianza
g0(·) rappresenta il comportamento del fenomeno nellapopolazione
A sua volta Y, sara una variabile casuale n−variata confunzione di densita di probabilita (o di probabilita)f0(y), y ∈ Rn:
f0(y) =n∏
i=1
g0(yi )

Inferenza statistica e probabilita Verosimiglianza
Scopo
Trarre delle conclusioni sulla distribuzione di Y , ovvero su g0,limitandone, per quanto possibile, il grado di incertezza.

Inferenza statistica e probabilita Verosimiglianza
Possiamo assumere che g0 sia una funzione di densita (diprobabilita) qualsiasi? In generale no.
Il modello statistico
a) La natura del fenomeno a cui siamo interessati
b) Le conoscenze che abbiamo acquisito in relazione ad esso
c) il tipo di campionamento
impongono dei vincoli su g0.In particolare possiamo pensare che g0 appartenga ad una famigliadi funzioni di densita (di probabilita):
g0 ∈ G
con G definita in modo coerente con a), b) e c)

Inferenza statistica e probabilita Verosimiglianza
Esempi
G = {l’insieme di tutte le funzioni di densita derivabili}G = {l’insieme di tutte le funzioni di densita log-concave}g(y ; θ) = θ1{1}(y) + (1− θ)1{0}(y), 0 ≤ θ ≤ 1 (equivalente aY ∼ Ber(θ))
g(y ; θ) = exp(−θ)θy
y ! 1{{0}∪N}(y), θ > 0 (equivalente aY ∼ Po(θ))
1A(y) = 1 se y ∈ A, 1A(y) = 0 altrimenti (1A(y) = 1 si dicefunzione indicatrice)

Inferenza statistica e probabilita Verosimiglianza
Modelli parametrici
Un modello statistico parametrico, o classe parametrica, e definitocome
G = {g(·; θ) : θ ∈ Θ ⊂ Rk , k ≥ 1}
Gli elementi di G sono funzioni (di probabilita o di densita diprobabilita) dello stesso tipo che si distinguono tra di loro per ilvalore del parametro, θ, che varia nello spazio parametrico Θ
La funzione di probabilita (di densita di probabilita) g0 sara unelemento di G caratterizzato da uno specifico valore del parametro,diciamo θ0.L’obbiettivo fondamentale della statistica parametrica e quindiquello di fare inferenza su θ0.

Inferenza statistica e probabilita Verosimiglianza
Spazio campionario
Lo spazio campionario, Y e l’insieme di tutti i valori che possonoessere assunti dal campione, y, per qualsiasi numerositacampionaria, n, compatibilmente con un dato modello statistico.

Inferenza statistica e probabilita Verosimiglianza
Riparametrizzazioni
Un modello statistico puo essere definito in diversi modiequivalenti, detti parametrizzazioni. Supponiamo che h sia unafunzione biunivoca da Θ a Ψ. Allora
G = {g(·; θ) : θ ∈ Θ}= {g(·;ψ) : ψ = h(θ), θ ∈ Θ}= {g(·;ψ) : ψ ∈ Ψ}

Inferenza statistica e probabilita Verosimiglianza
Esempio
G = {g(y ; θ) =exp(−θ)θy
y !: θ ∈ Θ = R+}
= {g(y ;ψ) =exp(− exp(ψ)) exp(ψ)y
y !: ψ = log(θ), θ ∈ Θ}
= {g(y ;ψ) =exp(− exp(ψ)) exp(ψ)y
y !: ψ ∈ Ψ = R}

Inferenza statistica e probabilita Verosimiglianza
Funzione di verosimiglianza
Sia G un dato modello statistico parametrico di cui y sia unaparticolare determinazione. Si dice funzione di verosimiglianza, osemplicemente verosimiglianza, la funzione L : Θ −→ R+ ∪ 0:
L(θ) = L(θ; y) = c(y)f (y; θ)
Quantifica la plausibilita dei valori del parametro θ ∈ Θ in relazione
ai dati osservati
e al modello statistico adottato.

Inferenza statistica e probabilita Verosimiglianza
Esempio
Modello statistico: Y ∼ U [0, θ]
gY (y) =1
θ1[0,θ](y) θ > 0
1[0,θ](y) = 1 se y ∈ [0, θ], 1[0,θ](y) = 0 altrimenti.
Campione osservato:
y1 y2 y3 y4 y5
3.25 1.33 3.44 2.22 4.35
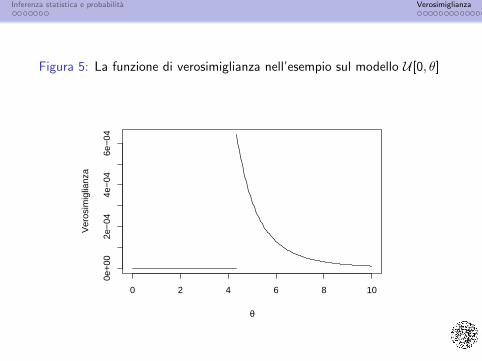
Funzione di verosimiglianza:
L(θ; y) =1
θ51[4.35,∞)(θ)
Θ = [4.35,∞).
Inferenza statistica e probabilita Verosimiglianza
Figura 5: La funzione di verosimiglianza nell’esempio sul modello U [0, θ]
0 2 4 6 8 10
0e+
002e
−04
4e−
046e
−04
θ
Ver
osim
iglia
nza

Inferenza statistica e probabilita Verosimiglianza
Per valori di θ piu piccoli di max{yi , i = 1, . . . , 5} = 4.35 lafunzione di verosimiglianza della Figura 5 si annulla: perche?
Perche per valori di θ minori di 4.35 il campione osservato nonsarebbe compatibile con il modello statistico adottato.

Inferenza statistica e probabilita Verosimiglianza
Statistica
Ogni funzione T (Y ) da Y a Rp, p ≥ 1 e indipendente da θ, si dicestatistica. Il valore t = T (y) corrispondente al campione osservato,y, si dice valore campionario della statistica.
Partizione indotta da una statistica
Ogni statistica definisce una partizione dello spazio campionario.Per qualsiasi t ∈ R
At = {y : y ∈ Y,T (y) = t} ⊆ Y
e l’insieme di tutti i campioni che danno luogo al valorecampionario t della statistica T (Y ).

Inferenza statistica e probabilita Verosimiglianza
Analisi del traffico (continua)
Consideriamo il modello dello statistico A e definiamo la statistica:
Y =
∑10i=1 Yi
10
Insieme supporto
IY =
{k
10, k = 0, 1, . . . , 10
}Funzione di probabilita
fY (y ; θ) =
{ (10k
)θk(1− θ)10−k y = k
10 , k = 0, . . . , 100 altrimenti

Inferenza statistica e probabilita Verosimiglianza
Nel campione considerato nell’esempio, T (y) = y = 0.3.
Se non conoscessimo il campione osservato, ma solo il valore di y , aquesto valore assoceremmo il sottoinsieme dello spazio campionario
A0.3 = {Tutti i campioni con 3 D e 7 ND}

Inferenza statistica e probabilita Verosimiglianza
Principio debole di verosimiglianza
Fissato un modello statistico, G = {g(·; θ) : θ ∈ Θ}, due campioniy e x ∈ Y, tali che
L(θ; y) ∝ L(θ; x)
forniscono informazioni equivalenti dal punto di vista inferenziale.

Inferenza statistica e probabilita Verosimiglianza
Analisi del traffico (continua)
Consideriamo ancora il modello dello statistico A e supponiamoche il campione osservato fosse
x = {1, 1, 0, 0, 1, 0, 0, 0, 0, 0}.
In tal caso,L(θ; x) ∝ θ3(1− θ)7
che e proporzionale alla verosimiglianza basata sul campioneconsiderato nella prima versione dell’esempio.Le informazioni fornite su θ dai due campioni sono equivalenti.

Inferenza statistica e probabilita Verosimiglianza
Principio forte di verosimiglianza
Un campione y riguardante il modello G = {g(·; θ) : θ ∈ Θ} e uncampione x riguardante il modello H = {h(·; θ) : θ ∈ Θ}, tali che
Lg (θ; y) ∝ Lh(θ; x)
devono condurre alle medesime conclusioni inferenziali.

Inferenza statistica e probabilita Verosimiglianza
Analisi del traffico (continua)
Consideriamo i modelli dello statistico A e dello statistico C che, incorrispondenza del campione osservato, y danno luogo alleverosimiglianze:
LA(θ; y) = fY,A(y; θ) = θ3(1− θ)7
LC (θ; y) = fY,C (y; θ) =
(9
2
)θ3(1− θ)7
Le due verosimiglianze sono proporzionali e, come abbiamo vistodanno le stesse informazioni su θ.

Inferenza statistica e probabilita Verosimiglianza
Se, invece, il campione osservato da A fosse
x = {1, 1, 0, 0, 1, 0, 0, 0, 0, 0},
C si limiterebbe ad osservare
z = {1, 1, 0, 0, 1}.
perche il terzo veicolo diesel coincide con la quinta osservazione.

Inferenza statistica e probabilita Verosimiglianza
Quindi,
LA(θ; x) ∝ θ3(1− θ)7
LC (θ; z) ∝ θ3(1− θ)2
LA(θ; x)
LC (θ; z)∝ (1− θ)5
LA e LC forniscono informazioni diverse su θ

Inferenza statistica e probabilita Verosimiglianza
Figura 6: Confronto tra LA e LC
0.0 0.2 0.4 0.6 0.8 1.0
0.00
00.
010
0.02
00.
030
θ
Ver
osim
iglia
nza
AC

Inferenza statistica e probabilita Verosimiglianza
Statistiche sufficienti
Fissato un modello statistico G, una statistica T si dice sufficienteper θ se essa assume lo stesso valore in corrispondenza di duecampioni solo se ad essi corrispondono verosimiglianze equivalenti:
∀y, z ∈ Y : T (y) = T (z) ⇒ L(θ, y) ∝ L(θ, z) ∀ θ ∈ Θ

Inferenza statistica e probabilita Verosimiglianza
Y e sempre una statistica sufficiente
Modello binomiale (esempio dell’analisi del traffico):T =
∑ni=1 Yi e una statistica sufficiente. Un’altra statistica
sufficiente e Y.
Modello di Poisson (esempio della diffusione di una pianta inuna foresta): anche in questo caso T =
∑ni=1 Yi e Y sono
statistiche sufficienti.
Per un campione casuale semplice di dimensione n da unadistribuzione U[0,θ], una statistica sufficiente e
Y(n) = max{Y1, . . . ,Yn}

Inferenza statistica e probabilita Verosimiglianza
Consideriamo un campione di dimensione n da unadistribuzione normale con media ignota e varianza nota:Y ∼ N(θ, σ2).
funzione di densita di probabilita di Y
g(y) =1√2πσ
exp
{−(y − θ)2
2σ2
}funzione di densita congiunta del campione
fY(y) =1
(√
2πσ2)nexp
{−∑n
i=1(yi − θ)2
2σ2
}

Inferenza statistica e probabilita Verosimiglianza
verosimiglianza
L(θ; y) ∝ exp
{−∑n
i=1(yi − θ)2
2σ2
}= exp
{−∑n
i=1 y2i − 2θ
∑ni=1 yi + nθ2
2σ2
}= exp
{−∑n
i=1 y2i
2σ2
}exp
{2θ∑n
i=1 yi − nθ2
2σ2
}∝ exp
{2θ∑n
i=1 yi − nθ2
2σ2
}Quindi
∑ni=1 Yi e una statistica sufficiente per θ

Inferenza statistica e probabilita Verosimiglianza
Osservazioni
Ogni trasformazione biunivoca di una statistica sufficiente e asua volta sufficiente.
Se T (Y) e una statistica sufficiente, allora L(θ; y) dipende day solo attraverso T (y),ovvero:
L(θ; y) ∝ h(T (y); θ)
(segue immediatamente dalla definizione)

Inferenza statistica e probabilita Verosimiglianza
Teorema (di fattorizzazione di Neyman)
Fissato il modello G, la statistica T e sufficiente per θ se e solo sef (y; θ) puo essere fattorizzata come
f (y; θ) = u(y)h(T (y); θ)
Abbiamo gia dimostrato che se T e sufficiente, alloraL(θ; y) ∝ h(T (y); θ)

Inferenza statistica e probabilita Verosimiglianza
Dobbiamo ora dimostrare che g(y; θ) = u(y)h(T (y); θ) implica lasufficienza di T :
L(θ; y) ∝ f (y; θ)
= u(y)h(T (y); θ)
∝ h(t; θ)

Inferenza statistica e probabilita Verosimiglianza
Osservazione
Sia Y una variabile casuale discreta e sia IT l’insieme supporto diT (y). Per ogni t ∈ IT ,
fT (t; θ) =∑
y:T (y)=t
fY(y; θ)
= h(t; θ)∑
y:T (y)=t
u(y)
= h(t; θ)u∗(t)
La verosimiglianza L(θ; t) ∝ h(t; θ) e equivalente a L(θ; y).

Inferenza statistica e probabilita Verosimiglianza
Teorema
Con riferimento ad un modello statistico G, la statistica T esufficiente per θ se e solo se la distribuzione di Y condizionata aT = t non dipende da θ, ovvero
fY|T=t(y; θ) = fY|T=t(y)

Inferenza statistica e probabilita Verosimiglianza
Dimostrazione ( solo per variabili casuali discrete)
Se fY|T=t(y; θ) = fY|T=t(y) allora
fY(y; θ) = fY|T=t(y)fT (t; θ)
Teorema di fattorizzazione ⇒ sufficienza di T
Se T e sufficiente, per il teorema di fattorizzazione si ha:
fY|T=t(y; θ) =fY(y; θ)
fT (t; θ)
=u(y)h(t; θ)
u∗(y)h(t; θ)
=u(y)
u∗(y)non dipende da θ
Quando Y e continua la dimostrazione e simile

Inferenza statistica e probabilita Verosimiglianza
Definizione (Statistiche sufficienti minimali)
Con riferimento ad un modello statistico G, la statistica T esufficiente minimale per θ se assume valori distinti solo su campioniche danno luogo a verosimiglianze non equivalenti, ovvero
T (y) = T (z) ⇔ L(θ; y) ∝ L(θ; z)

Inferenza statistica e probabilita Verosimiglianza
La statistica sufficiente minimale induce la piu piccolapartizione dello spazio campionario tra quelle definite dallestatistiche sufficienti.
E funzione di qualsiasi altra statistica sufficiente
Tra tutte le statistiche sufficienti e quella che ha dimensionepiu piccola.

Inferenza statistica e probabilita Verosimiglianza
Esempio
Y ∼ N(0, θ), θ > 0. Campione di dimensione 1.Verosimiglianza:
L(θ; y) ∝ 1
θ0.5exp
{−y2
2θ
}
T (Y ) = Y e T1(Y ) = Y 2 sono sufficienti, ma solo T1(Y ) esufficiente minimale. Consideriamo due campioni, x e y :
L(θ; y)
L(θ; z)= exp
{−y2 − z2
2θ
}non dipende da θ se e solo se y2 = z2: questo vale non soloquando y = z, ma anche quando y = −z.

Inferenza statistica e probabilita Verosimiglianza
Variabile casuale normale con media e varianza ignote
Modello statistico: Y ∼ N(θ1, θ2) θ = [θ1, θ2]′ ∈ Θ = R×R+
g(y ;θ) =1√
2πθ2exp
{−(y − θ1)
2
2θ2
}
Campione di dimensione n: Yn = Rn
Verosimiglianza:
L(θ; y) ∝ 1
θn22
exp
{−∑n
i=1(yi − θ1)2
2θ2
}

Inferenza statistica e probabilita Verosimiglianza
L(θ; y) ∝ 1
θn22
exp
{−∑n
i=1 y2i − 2θ1
∑ni=1 yi + nθ2
1
2θ2
}=
1
θn22
exp
{− t2 − 2θ1t1 + nθ2
1
2θ2
}
con t1 =∑n
i=1 yi e t2 =∑n
i=1 y2i
La statisticaT (Y) = [T1(Y),T2(Y)]′,
con T1(Y) =∑n
i=1 Yi e T2 =∑n
i=1 Y 2i , e sufficiente per θ

Inferenza statistica e probabilita Verosimiglianza
Due campioni, y e x danno luogo a verosimiglianze equivalentiquando
L(θ; y)
L(θ; x)= exp
{−T2(y)− T2(x)− 2θ1(T1(y)− T1(x))
2θ2
}non dipende da θ.
Cio avviene se e solo se T (y) = T (x).
Quindi T (Y) e sufficiente minimale

Inferenza statistica e probabilita Verosimiglianza
Siano
T ∗1 (Y) = Y e T ∗
2 (Y) = S2 =1
n
n∑i=1
(Yi − Y )2,
la statisticaT ∗(Y) = [Y ,S2]′
e una funzione biunivoca di T (Y), quindi e essa stessasufficiente minimale.

Inferenza statistica e probabilita Verosimiglianza
Esercizio
Si supponga di disporre di un campione casuale semplice didimensione n corrispondente al modello statistico: Y ∼ N(µ, θ)con media µ nota e varianza θ ignota.
1 Individuare lo spazio campionario e lo spazio parametrico
2 Determinare l’espressione della funzione di verosimiglianza
3 Individuare una statistica sufficiente minimale.

Inferenza statistica e probabilita Verosimiglianza
La famiglia esponenziale
La classe parametrica G e una famiglia esponenziale di ordine r se
g(y ; θ) = q(y) exp
(r∑
i=1
ψi (θ)ti (y)− τ(θ)
)θ ∈ Θ ⊆ Rk , k ≥ 1
dove r ≥ 1, ti (y), i = 1, . . . , r , sono funzioni di y indipendenti daθ e ψi (θ), i = 1, . . . , r , e τ(θ) sono funzioni di θ indipendenti da y .
Se
a0 +r∑
i=1
aiψi (θ) = 0 ∀θ ∈ Θ ⇔ ai = 0, i = 0, . . . , r
la famiglia esponenziale si dice ridotta.

Inferenza statistica e probabilita Verosimiglianza
Esempi
Se Y ∼ Bin(n; θ),
g(y ; θ) =
(n
y
)θy (1− θ)n−y
=
(n
y
)exp
{log
(θ
1− θ
)y + n log(1− θ)
}quindi r = 1, q(y) =
(ny), ψ(θ) = log
(θ
1− θ
), t(y) = y e
τ(θ) = −n log(1− θ).

Inferenza statistica e probabilita Verosimiglianza
Se Y ∼ N(θ1, θ2),
g(y ;θ) =1√
2πθ2exp
{−(y − θ1)
2
2θ2
}=
1√2πθ2
exp
{−y2 − 2θ1y + θ2
1
2θ2
}=
1√2π
exp
{θ1θ2
y − 1
2θ2y2 − θ2
1
2θ2− 1
2log(θ2)
}e quindi r = 2, q(y) = 1√
2π, ψ1(θ) = −θ1
θ2, ψ2(θ) = 1
2θ2,
τ(θ) =θ21
2θ2− 1
2 log(θ2), t1(y) = y e t2(y) = y2

Inferenza statistica e probabilita Verosimiglianza
Se Y ∼ Po(θ),
g(y ; θ) = exp(−θ)θy
y !
=1
y !exp(log(θ)y − θ)
e quindi r = 1, q(y) = 1y ! , ψ(θ) = log(θ), t(y) = y e
τ(θ) = θ.

Inferenza statistica e probabilita Verosimiglianza
Verosimiglianze della famiglia esponenziale
Se g(y ; θ) appartiene alla famiglia esponenziale, allora viappartiene anche f (y; θ):
f (y; θ) =n∏
i=1
q(yi ) exp
r∑j=1
ψj(θ)tj(yi )− τ(θ)
= q∗(y) exp
r∑j=1
ψj(θ)Tj(y)− τ∗(θ)
dove q∗(y) =
∏ni=1 q(yi ), Tj(y) =
∑ni=1 tj(yi ) e τ∗(θ) = nτ(θ).
Quindi,
L(θ; y) ∝ exp
r∑j=1
ψj(θ)Tj(y)− τ∗(θ)

Inferenza statistica e probabilita Verosimiglianza
Una conseguenza importante
Se g(y ; θ) appartiene alla famiglia esponenziale, allora
T (Y) = [T1(Y), . . . ,Tr (Y]′
e sufficiente minimale.

Inferenza statistica e probabilita Verosimiglianza
Famiglie esponenziali regolari
Una famiglia esponenziale si dice regolare se:
Lo spazio parametrico, Θ coincide con l’intero insieme per cuig(y ; θ) integra (somma) a 1 ed e un intervallo aperto in Rk ;
Le dimensioni di Θ e della statistica sufficiente minimalecoincidono;
ψ(θ) = [ψ1(θ), . . . , ψr (θ)]′ e invertibile;
le funzioni ψi , i = 1, . . . , r e τ(θ) ammettono derivate diqualsiasi ordine rispetto agli elementi di θ.

Inferenza statistica e probabilita Verosimiglianza
Se Y appartiene ad una famiglia esponenziale regolare di ordine 1 eΘ ⊂ R , allora
E [T (Y)] =τ∗′(θ)
ψ′(θ)
Var [T (Y)] =ψ′(θ)τ∗′′(θ)− ψ′′(θ)τ∗′(θ)
ψ′(θ)3
Dimostrazione: si veda Azzalini (2001).