
IMPLEMENTAZIONE DI UN’ARCHITETTURA SICURA PER L’AES · round. Il Key Schedule `e usata in...
75
Politecnico di Milano Facolt` a di Ingegneria Corso di Laurea in Ingegneria Informatica IMPLEMENTAZIONE DI UN’ARCHITETTURA SICURA PER L’AES Relatore: Prof. Luca BREVEGLIERI Correlatori: Ing. Marco Domenico SANTAMBROGIO Ing. Paolo MAISTRI Tesi di Laurea di: Francesco Motta Matricola n. 653571 Davide Nazzari Matricola n. 652171 Anno Accademico 2005-2006
Transcript of IMPLEMENTAZIONE DI UN’ARCHITETTURA SICURA PER L’AES · round. Il Key Schedule `e usata in...

Politecnico di Milano
Facolta di Ingegneria
Corso di Laurea in Ingegneria Informatica
IMPLEMENTAZIONE DI UN’ARCHITETTURASICURA PER L’AES
Relatore: Prof. Luca BREVEGLIERI
Correlatori: Ing. Marco Domenico SANTAMBROGIOIng. Paolo MAISTRI
Tesi di Laurea di:Francesco MottaMatricola n. 653571Davide NazzariMatricola n. 652171
Anno Accademico 2005-2006

Le armi piu potenti nella
conquista della conoscenza sono
l’intelligenza e la curiosita
insaziabile che le fa da stimolo.
Isaac Asimov
Alla mia famiglia e a tutti quelli che mi sono stati vicini in questi anni
Davide
A una persona che mi ha dato tanto: mio nonno Francesco
Francesco

Indice
Introduzione vii
1 AES 1
1.1 Che cos’e . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Alcuni Concetti Matematici . . . . . . . . . . . . . . . . . . . 3
1.3 La Codifica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.4 La Decodifica . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.5 Il Calcolo della chiave . . . . . . . . . . . . . . . . . . . . . . . 15
1.6 Struttura Hardware . . . . . . . . . . . . . . . . . . . . . . . . 16
1.7 Sicurezza dell’AES . . . . . . . . . . . . . . . . . . . . . . . . 22
2 Concetti Generali 25
2.1 Rilevazione d’Errore . . . . . . . . . . . . . . . . . . . . . . . 25
2.2 FPGA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.2.1 Memoria di Configurazione di una Virtex . . . . . . . . 31
2.3 Tecniche per la Riconfigurazione . . . . . . . . . . . . . . . . . 33
2.3.1 Riconfigurazione Parziale . . . . . . . . . . . . . . . . . 33
2.4 Software e linguaggi utilizzati . . . . . . . . . . . . . . . . . . 37
2.4.1 VHDL . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.4.2 Modelsim . . . . . . . . . . . . . . . . . . . . . . . . . 37
2.4.3 Project Navigator . . . . . . . . . . . . . . . . . . . . . 38
3 La Soluzione Proposta 41
3.1 Implementazione della DataUnit . . . . . . . . . . . . . . . . . 41
3.2 Implementazione delle Righe . . . . . . . . . . . . . . . . . . . 43
iii

INDICE iv
3.3 Implementazione della DataCell . . . . . . . . . . . . . . . . . 44
3.4 Implementazione della KeyUnit . . . . . . . . . . . . . . . . . 46
3.5 Implementazione della ControlUnit . . . . . . . . . . . . . . . 48
3.6 Estensione per la Riconfigurazione . . . . . . . . . . . . . . . . 50
4 Verifica e Risultati 53
4.1 Simulazione con Modelsim . . . . . . . . . . . . . . . . . . . . 53
4.1.1 Simulazione in caso di Attacco . . . . . . . . . . . . . . 57
4.2 Spazio Occupato sulla FPGA . . . . . . . . . . . . . . . . . . 58
5 Conclusioni e Sviluppi Futuri 61
Bibliografia 64

Elenco delle figure
1.1 Algoritmo di Codifica . . . . . . . . . . . . . . . . . . . . . . . 8
1.2 SubByte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
1.3 Substitution-BOX . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.4 ShiftRow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.5 MixColumn . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
1.6 AddRoundKey . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.7 Algoritmo di Decodifica . . . . . . . . . . . . . . . . . . . . . 13
1.8 Inverse Substitution-BOX . . . . . . . . . . . . . . . . . . . . 14
1.9 Array w con chiave a 128 bit . . . . . . . . . . . . . . . . . . . 15
1.10 Architettura AES . . . . . . . . . . . . . . . . . . . . . . . . . 17
1.11 Standard DataUnit . . . . . . . . . . . . . . . . . . . . . . . . 18
1.12 DataUnit ad Alta Prestazione . . . . . . . . . . . . . . . . . . 21
2.1 Errori Codifica . . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.2 Errori Decodifica . . . . . . . . . . . . . . . . . . . . . . . . . 26
2.3 Rilevazione d’errore sulla SubByte . . . . . . . . . . . . . . . . 28
2.4 Struttura FPGA . . . . . . . . . . . . . . . . . . . . . . . . . 30
2.5 Colonna composta da piu Frame . . . . . . . . . . . . . . . . . 32
2.6 Tipi di colonne . . . . . . . . . . . . . . . . . . . . . . . . . . 32
2.7 Comunicazione tra moduli . . . . . . . . . . . . . . . . . . . . 36
2.8 Esempio di progetto con due moduli riconfigurabili . . . . . . 36
2.9 Simulazione in Modelsim . . . . . . . . . . . . . . . . . . . . . 38
2.10 Finestra principale di Project Navigator . . . . . . . . . . . . 39
3.1 Elenco segnali DataUnit . . . . . . . . . . . . . . . . . . . . . 42
v

ELENCO DELLE FIGURE vi
3.2 Due condizioni presenti nel Barrel Shifter per l’esecuzione della
ShiftRow . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.3 Riga di 4 DataCell . . . . . . . . . . . . . . . . . . . . . . . . 45
3.4 Schema della DataCell . . . . . . . . . . . . . . . . . . . . . . 46
3.5 Schema della KeyUnit . . . . . . . . . . . . . . . . . . . . . . 47
3.6 Stati della ControlUnit . . . . . . . . . . . . . . . . . . . . . . 49
3.7 Divisione FPGA . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4.1 Caricamento dei dati . . . . . . . . . . . . . . . . . . . . . . . 54
4.2 Round Normale . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3 ShiftRow in un Round Normale . . . . . . . . . . . . . . . . . 56
4.4 Round Finale . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
4.5 Rilevazione Attacco . . . . . . . . . . . . . . . . . . . . . . . . 57
4.6 Rilevazione Attacco nella DataUnit . . . . . . . . . . . . . . . 58
4.7 Tabella del Map su una Spartan xc3s200 . . . . . . . . . . . . 59
4.8 Tabella del Map su una Virtex xcv1000 . . . . . . . . . . . . . 60
4.9 Tabella del Map su una Spartan xc3s200 dopo la modifica . . 60

Introduzione
In questi ultimi anni la necessita di impedire a estranei di poter legge-
re informazioni riservate e diventata una questione sempre piu importante;
esempi classici sono l’e-commerce e il pagamento attraverso carte di credito.
Ecco quindi la necessita di crittografare dati riservati e l’utilita di algoritmi
per la crittografia come l’AES.
Nel 2000 il Rijndael e divenuto il nuovo standard con il nome di Advanced
Encryption Standard (AES), in sostituzione del suo predecessore DES (Data
Encryption Standard) ormai poco sicuro. Il Rijndael e uno degli algoritmi
piu avanzati nel suo campo: e un cifrario a blocchi con chiave simmetrica
che puo avere dimensione pari a 128, 192 e 256 bit ed e usato anche dalla
National Security Agency per crittografare documenti a livello Secret (chiave
di 128 bit) e Top Secret (chiave di 256 bit). L’intero processo di crittografia
e di dominio pubblico ed e ben documentato: questo fatto non diminuisce la
sicurezza dell’AES in quanto “la segretezza di un sistema crittografico non si
basa sulla segretezza dell’algoritmo usato ma sulla segretezza della chiave”1.
L’AES puo essere implementato su circuiti dedicati come ad esempio le
Smart Card, dove la chiave puo anche essere cablata all’interno; su circuiti
di questo tipo e possibile pero provocare degli errori. L’introduzione di errori
di computazione nel processo di cifratura e infatti una delle idee su cui si
basano alcuni attacchi; forzature di questo genere sono molto pericolose per-
che, attraverso lo studio degli errori introdotti, il crittoanalista puo risalire
alla chiave di cifratura. Variazioni della tensione di alimentazione o della
frequenza di clock, irraggiamento tramite laser o flash fotografici sono solo
alcuni strumenti usati per eseguire la manomissione dell’algoritmo. Si sono
1Pubblicato nel 1883 nel libro “La crittographie militaire” da August Kerckhoffs
vii

Introduzione viii
studiati anche diversi metodi basati su proprieta matematiche per forzare il
Rijndael ma questi non sono andati a buon fine se non su versioni semplificate
dell’algoritmo.
La nostra tesi si propone l’elaborazione di un’architettura sicura a questi
tipi di attacchi, ovvero che possa permettere la rilevazione degli errori indotti
da forzature esterne in fase di crittografia, per poi resettarsi e poter proseguire
con la cifratura. L’idea principale e di realizzare l’architettura su FPGA
per poter utilizzare una delle caratteristiche principali di questo dispositivo:
la riconfigurazione. Questa puo permettere di modificare la funzionalita e
quindi la struttura di una parte di FPGA o, come nel nostro caso, puo
permettere di resettare la parte di componente in cui si e verificato l’attacco
semplicemente ricaricando la configurazione iniziale. Per la rilevazione di
errore si utilizzera il metodo del bit di parita facendo riferimento all’articolo
“Error Analysis and Detection Procedures for a Hardware Implementation
of the AES”. Il bit di parita ha la qualita di poter essere utilizzato su ogni
singolo byte presente in ogni operazione dell’AES, avendo cosı una precisione
nella rilevazione dell’attacco molto alta. Ovviamente si poteva realizzare
l’architettura anche su circuiti dedicati inserendo componenti di ripristino per
la sostituzione di quelli soggetti ad attacco; in questo caso pero la tolleranza
agli attacchi e data dal numero di componenti di backup presenti.
Nel Capitolo 1 si andranno a descrivere le caratteristiche principali del-
l’AES mostrando dettagliatamente le operazioni svolte in codifica e decodifica
e il calcolo della chiave. In piu verra illustrata una possibile architettura in
grado di utilizzare il Rijndael per codificare e decodificare.
Nel Capitolo 2 si dara una panoramica generale sul rilevamento di er-
rore e sulla riconfigurazione parziale. In piu si parlera delle FPGA e degli
strumenti software utilizzati.
Nel Capitolo 3 si parlera della nostra implementazione, delle scelte
implementative fatte e degli eventuali problemi incontrati.
Nel Capitolo 4 si andranno a mostrare le simulazioni eseguite con mo-
delsim attraverso immagini e descrizioni; se ne illustrera una anche in caso

Introduzione ix
di attacco. Oltre alle simulazioni, si descrivera l’occupazione della FPGA da
parte dell’architettura.
Nel Capitolo 5 si mostreranno le conclusioni a cui si e arrivati.


Capitolo 1
AES
I seguenti paragrafi aiuteranno a comprendere meglio il funzionamento
dell’algoritmo attraverso una descrizione generale della codifica e della deco-
difica, entrando poi nello specifico di ogni singola operazione svolta; verran-
no spiegati inoltre alcuni concetti matematici per meglio comprendere come
queste vengano eseguite. Per concludere il capitolo si illustrera anche il cal-
colo della chiave, una possibile architettura in grado di utilizzare il Rijndael
per codificare e decodificare e come l’AES si possa considerare un algoritmo
sicuro.
1.1 Che cos’e
L’Advanced Encryption Standard e da considerarsi come il sostituto del
Data Encryption Standard (DES). Agli inizi degli anni novanta il progresso
tecnologico, infatti, rese evidente la debolezza del DES a causa soprattutto
della scarsa lunghezza della chiave; si istituirono cosı delle vere e proprie gare
il cui scopo era quello di violare lo standard attraverso un attacco “Brute
Force”1. La prima violazione avvenne nel 1997 e richiese 39 giorni, ma gia
l’anno successivo bastarono solo 22 ore.
Si diede quindi inizio a un concorso con lo scopo di stabilire quello che
1Attacco compiuto tentando tutte le chiavi possibili
1

CAPITOLO 1. AES 2
sarebbe stato il nuovo standard per la crittografia: l’AES. I criteri adottati
per la selezione furono:
1. cifrario a chiave simmetrica;
2. cifrario a blocchi;
3. lunghezza chiave pari a 128 o 256 bit;
4. blocchi di testo in chiaro pari a 64, 128 o 256 bit;
5. implementabile su smart Card;
6. facilmente implementabile in C o in java;
7. permettere la distribuzione dell’algoritmo a livello mondiale.
Il concorso duro 2 anni e nel 2000 fu scelto l’algoritmo presentato da Joan
Daemon e Vincent Rijmen, chiamato Rijndael, come nuovo standard.
Il Rijndael e un sistema di crittografia a chiave segreta simmetrica che puo
criptare un blocco di dati alla volta; questo blocco e composto da 128 bit. Un
algoritmo e detto a chiave segreta simmetrica se utilizza una sola chiave sia
per la cifratura che per la decifratura e questa, naturalmente, deve rimanere
segreta al di fuori degli organi comunicanti. Un modo sicuramente non fidato
per accordarsi sulla chiave, e di scambiarla in rete in quanto essa potrebbe
essere intercettata; uno dei metodi piu sicuri, ma non sempre fattibile, rimane
quello di incontrarsi di persona e non in rete, cioe out of band.
L’AES in codifica accetta un blocco di dati (chiamato anche plain text
o testo in chiaro) e una chiave, per produrre un blocco dati criptato della
stessa dimensione di quello in ingresso. La stessa cosa succede in decodifica
solo che ora il dato di ingresso e quello in precedenza criptato, e il dato in
uscita e il testo in chiaro. Come gia detto le chiavi usate sono le stesse.
I due processi principali in cui questo standard puo essere suddiviso ven-
gono eseguiti in parallelo e sono: la cifratura (decifratura) e lo Key Schedule
(inverse Key Schedule). Il Key Schedule (inverse Key Schedule) e una fun-
zione finalizzata ad espandere la chiave; essa genera, anche grazie all’utilizzo
della funzione chiamata KeyExpansion, delle sottochiavi (chiavi di round o

CAPITOLO 1. AES 3
Round Key) a partire dalla chiave principale (Cipher Key) e quindi associa,
attraverso la funzione denominata Round Key Selection, la chiave al proprio
round. Il Key Schedule e usata in codifica mentre l’inverse Key Schedule in
decodifica. Entrambe le coppie codifica/decodifica e Key Schedule/inverse
Key Schedule sono matematicamente uno l’inverso dell’altro.
1.2 Alcuni Concetti Matematici
Per capire a fondo il funzionamento dell’algoritmo di crittografia Rijn-
dael e utile conoscere almeno i concetti fondamentali che stanno alla base dei
Campi di Galois (GF = Galois Field). Di seguito viene riportata la defini-
zione di Campo di Galois per poi descrivere come le operazioni come somma
e prodotto vengano eseguite in questo campo.
Definizione Campo Di Galois: Sia Zp il campo finito degli interi mod p
(p e primo, altrimenti non sarebbe un campo), Zp[x] l’anello dei polinomi a
coefficienti in Zp, e sia m(x) ∈ Zp, m(x) irriducibile in Zp[x], δ(m) = n.
Chiamiamo campo di Galois rispetto al polinomio m(x), il campo costituito
dalle q = pn classi di congruenza mod m(x):
GF (q) = GF (pn) = Zp[x] mod m(x).
Dopo aver dato la definizione di Campi di Galois, si puo passare ora a
vedere come questi siano utilizzati.
Nell’AES ogni byte (sequenza di 8 bit) viene interpretato come un poli-
nomio in GF (28) in questo modo:
{b7, b6, b5, b4, b3, b2, b1, b0} ⇒ b7x7 + b6x
6 + b5x5 + b4x
4 + b3x3 + b2x
2 + b1x1 + b0
Ogni bit equivale ad un coefficiente del polinomio e il MSB (Most Significant
Bit) corrisponde a b7.
La somma di due polinomi nel campo finito si ottiene sommando modulo
p i coefficienti delle corrispondenti potenze della “x” nei due polinomi. Nel-
l’AES quindi la somma di due byte si ottiene effettuando la somma modulo

CAPITOLO 1. AES 4
2 dei bit corrispondenti. Questa operazione puo essere implementata come
uno XOR (⊕) bit a bit. Viene di seguito riportato un esempio di somma tra
polinomi sia in forma polinomiale che binaria:
(x6 + x4 + x2 + x + 1) + (x7 + x + 1) = x7 + x6 + x4 + x2
{01010111} ⊕ {10000011} = {11010100}
Il prodotto nel campo finito, invece, e ottenuto moltiplicando due poli-
nomi modulo un polinomio irriducibile di ottavo grado. Questo polinomio
nell’AES e:
m(x) = x8 + x4 + x3 + x + 1.
Naturalmente m(x) /∈ GF (28) e la sua rappresentazione esadecimale corri-
sponde a {11b}h. Questo tipo di moltiplicazione e associativa e ha come
elemento neutro {01}h. Inoltre per qualunque polinomio b(x), diverso da
zero e di grado inferiore a 8, si puo ricavare l’inverso b−1(x). Purtroppo non
esiste un’operazione semplice a livello byte per effettuare questo calcolo, ma
si puo realizzare un algoritmo funzionante partendo da un caso particolare:
la moltiplicazione per x.
Se moltiplichiamo un polinomio f(x)∈ GF (28) per x (o {00000010}b o
{02}h) otteniamo:
f(x) · x = p(x) = b7x8 + b6x
7 + b5x6 + b4x
5 + b3x4 + b2x
3 + b1x2 + b0x
Nel caso δ(f) < 7, avremo che p(x) apparterra a GF (28) perche avra come
grado massimo 7; nel caso invece δ(f) = 7 allora δ(p) = 8 e quindi non appar-
tera piu a GF (28) e bisognera ridurre p(x) modulo m(x). La riduzione puo
essere fatta sottraendo p(x) a m(x), ma si sa che in Z2 sottrarre equivale a
sommare quindi possiamo eseguire l’operazione di XOR come visto in prece-
denza. Il prodotto per x puo essere implementato con un left shift (equivale
a moltiplicare per {02}h il byte) mentre il modulo per m(x) (eseguito solo se
b7 = 1) puo essere implementato in uno XOR con {1b}h (la rappresentazione
esadecimale del byte meno significativo di m(x)). Chiamiamo la funzione che
effettua il prodotto di un polinomio per x o di un byte per {02}h xtime().

CAPITOLO 1. AES 5
Ora con xtime() sappiamo effettuare il prodotto di un polinomio a(x)
per x; quindi usando ricorsivamente per n volte xtime() sappiamo anche
calcolare a(x) · xn. Sfruttando la proprieta distributiva del prodotto rispetto
alla somma in GF (28) possiamo quindi definire un algoritmo che risolva un
prodotto tra una qualunque coppia di polinomi a(x), b(x). Definiamo a(x) e
b(x) come:
a(x) = x6 + x4 + x2 + x + 1 = {57}h
b(x) = x4 + x + 1 = {13}h
a(x) · b(x) = a(x) · (x4 + x + 1) = ((a(x) · x4) + (a(x) · x) + (a(x) · 1)) = c(x)
Ci ritroviamo con c(x) che e una somma di termini che sappiamo calcolare
(sono prodotti di polinomi per potenze di x). Ora vediamo come funziona a
livello byte. Per prima cosa calcoliamo i prodotti per le potenze di x che ci
servono:
a(x) · x = {57}h · {02}h = xtime({57}h) = {ae}h
a(x) · x2 = {57}h · {04}h = xtime(xtime({57}h)) = xtime({ae}h) = 47h
a(x) · x3 = {57}h · {08}h = xtime({47}h) = {8e}h
a(x) · x4 = {57}h · {10}h = xtime({8e}h) = {07}h
Poi effettuiamo i calcoli per ottenere i risultati finali:
{57}h · {13}h = {57}h · ({10}h ⊕ {02}h ⊕ {01}h =
= ({57}h · {10}h)⊕ ({57}h · {02}h)⊕ ({57}h · {01}h) =
= {07}h ⊕ {ae}h ⊕ {57}h = {fe}h
Altri elementi molto utili per capire l’AES oltre ai byte, sono le word;
per word nel Rijndael si intendono dei polinomi di 4 termini con coefficienti
in GF (28):
[a3, a2, a1, a0] = a(x) = a3x3 + a2x
2 + a1x + a0
Ogni coefficiente ax e quindi considerato come un byte e i calcoli su que-
sti coefficienti avvengono come spiegato in precedenza, mentre i metodi per
somma e prodotto con le word sono riportati di seguito.
Dati due polinomi a(x) e b(x):

CAPITOLO 1. AES 6
a(x) = a3x3 + a2x
2 + a1x + a0
b(x) = b3x3 + b2x
2 + b1x + b0
la somma a(x) + b(x) si effettua sommando nel GF (28) i coefficienti di x con
lo stesso esponente:
a(x) + b(x) = (a3 ⊕ b3)x3 + (a2 ⊕ b2)x
2 + (a1 ⊕ b1) + (a0 ⊕ b0)
In base a quanto spiegato in precedenza, la somma tra word viene implemen-
tata calcolando lo XOR dei byte che hanno stesso peso:
[a3, a2, a1, a0] + [b3, b2, b1, b0] = [(a3 ⊕ b3), (a2 ⊕ b2), (a1 ⊕ b1), (a0 ⊕ b0]
Il prodotto tra a(x) e b(x) invece, si effettua calcolando inizialmente il
prodotto algebrico:
c(x) = c6x6 + c5x
5 + c4x4 + c3x
3 + c2x2 + c1x
1 + c0
dove:
c0 = a0 · b0
c1 = (a1 · b0)⊕ (a0 · b1)
c2 = (a2 · b0)⊕ (a1 · b1)⊕ (a0 · b2)
c3 = (a3 ·b0)⊕(a2 ·b1)⊕(a1 ·b2)⊕(a0 ·b3)
c4 = (a3 · b1)⊕ (a2 · b2)⊕ (a1 · b3)
c5 = (a3 · b2)⊕ (a2 · b3)
c6 = (a3 · b3)
Il polinomio c(x) ottenuto non e una word ma anch’esso deve ora poter
essere rappresentato da una parola di 4 byte. L’unico modo possibile e ridurre
c(x) modulo un polinomio di quarto grado, in modo da ottenere un polinomio
che al massimo sara di terzo grado. Nell’AES questo polinomio e :
x4 + 1
Quindi, se:
xi mod (x4 + 1) = xi mod 4
c(x) diventera:
c(x) = c6x2 + c5x + c4 + c3x
3 + c2x2 + c1x
1 + c0

CAPITOLO 1. AES 7
raccogliendo avremo:
c(x) = c3x3 + (c2 ⊕ c6)x
2 + (c1 ⊕ c5)x + (c0 ⊕ c4)
Questo prodotto che viene chiamato prodotto modulare (d(x) = a(x) ⊗b(x)) e puo essere implementato come:
d(x) = d3x3 + d2x
2 + d1x1 + d0
dove:
d0 = (a0 ·b0)⊕(a3 ·b1)⊕(a2 ·b2)⊕(a1 ·b3)
d1 = (a1 ·b0)⊕(a0 ·b1)⊕(a3 ·b2)⊕(a2 ·b3)
d2 = (a2 ·b0)⊕(a1 ·b1)⊕(a0 ·b2)⊕(a3 ·b3)
d3 = (a3 ·b0)⊕(a2 ·b1)⊕(a1 ·b2)⊕(a0 ·b3)
In forma matriciale i coefficienti dx possono essere scritti in questo modo:d0
d1
d2
d3
=
a0 a3 a2 a1
a1 a0 a3 a2
a2 a1 a0 a3
a3 a2 a1 a0
b0
b1
b2
b3
1.3 La Codifica
L’AES divide il testo in chiaro in blocchi da 128 bit, ulteriormente parti-
zionati in sottoblocchi da 8 bit; quest’ultimi costituiscono gli elementi della
matrice 4x4 (chiamata state) su cui l’algoritmo lavora. Anche la chiave viene
suddivisa in blocchi che costituiscono una matrice; questa a seconda della
lunghezza della chiave, avra dimensione 4x4 (chiave a 128 bit), 4x6 (chiave
a 192 bit) o 4x8 (chiave a 256 bit).
Qui di seguito riportiamo le notazioni che useremo per spiegare come
funziona l’AES:
• Word : rappresenta una singola colonna in una qualsiasi matrice usata;
• Nb: numero di word del blocco in ingresso. Nella versione base, ad
esempio, si ha Nb = 4. E quindi da considerarsi come il numero di
colonne della matrice state;

CAPITOLO 1. AES 8
• Nk: numero di word della chiave. In base alla lunghezza della chiave
Nk puo assumere i valori 4, 6, 8. E il numero di colonne della matrice
della chiave;
• Nr: numero di round in cui avviene la codifica. Il testo viene quindi
codificato in piu iterazioni ed Nr puo assumere i valori 10, 12 e 14 a
seconda della lunghezza della chiave.
L’algoritmo di codifica si basa su due funzioni principali: una serve per
determinare la chiave necessaria ad ogni round (KeyExpansion), l’altra per
la codifica vera e propria (Cipher).
La funzione di codifica, come mostrato anche in figura 1.1, elabora gli Nr
round e, di questi, Nr − 1 sono identici e codificano il messaggio attraverso
sottofunzioni che si svolgono in cascata: SubByte, ShiftRow, MixColumn
e AddRoundKey. L’unico round rimanente e differente dagli altri perche
elimina la MixColumn e aggiunge un ulteriore AddRoundKey; questo fatto
porta la KeyExpansion a fornire una chiave in piu rispetto al numero di
round.
Figura 1.1: Algoritmo di Codifica

CAPITOLO 1. AES 9
Si parte ora a illustrare piu nel dettaglio le varie operazione partendo dal-
la SubByte. Questa operazione sostituisce ad ogni elemento della matrice,
un valore proveniente da una funzione invertibile e non lineare. L’inverti-
bilita e necessaria in fase di decodifica, mentre la non linearita e un punto
di forza dell’algoritmo perche rappresenta un grande problema per i crittoa-
nalisti. L’operazione avviene in modo molto semplice: esiste una matrice
Substitution-Box (S-BOX vedi figura 1.3) in cui ogni possibile valore del by-
te ha un valore corrispondente associato; la funzione non fa altro che trovare
nella matrice il corrispettivo del dato in ingresso. La S-BOX ha dimensioni
16x16 in quanto il dato in ingresso e di 8 bit e puo quindi assumere 256 valori
distinti. Per creare la matrice di sostituzione, ogni byte viene sostituito con
il suo inverso nei campi di Galois (00h e mappato su se stesso dato che non
ha inverso) e in seguito viene applicata la trasformazione affine qui riportata,
su ognuno degli otto bit ottenuti:
bi = bi ⊕ b(i+4)mod8 ⊕ b(i+5)mod8 ⊕ b(i+6)mod8 ⊕ b(i+7)mod8 ⊕ ci
dove ci corrisponde all’i-esimo bit del byte 01100011.
Figura 1.2: SubByte
La seconda funzione descritta e la ShiftRow; essa e una delle piu semplici
operazioni dell’AES; consiste nello scalare, dopo l’operazione di S-BOX, i dati
da una cella alla sua adiacente. Questi dati vengono scalati verso sinistra di
un numero di posizioni pari al numero della riga (la riga zero e la prima, la
riga uno la seconda, . . . ). Dalla specifica quindi si ha che la prima riga, dopo
la ShiftRow, non subira cambiamenti, la seconda muovera i suoi dati verso
sinistra di una posizione, la terza di due posizione verso sinistra, la quarta

CAPITOLO 1. AES 10
Figura 1.3: Substitution-BOX
di tre sempre verso sinistra (in quest’ultimo caso si puo anche pensare che
vengano spostati di una posizione verso destra). Il tutto e mostrato in figura
1.4
Figura 1.4: ShiftRow
In un round normale, a seguito della ShiftRow si trova l’operazione di
MixColumn che lavora sulle colonne (o word) della matrice state. Essa con-
siste nel moltiplicare modulo x4 + 1 ogni colonna per il polinomio fissato
c(x):
c(x) = {03}h · x3 + {01}h · x2 + {01}h · x + {02}h.
Naturalmente i coefficienti di c(x) e i dati di ogni colonna sono polinomi in
GF (28) .

CAPITOLO 1. AES 11
La moltiplicazione avviene come spiegato nel paragrafo 1.2 e puo essere
espressa come: b0,c
b1,c
b2,c
b3,c
=
02 03 01 01
01 02 03 01
01 01 02 03
03 01 01 02
a0,c
a1,c
a2,c
a3,c
b0,c = (02 • a0,c)⊕ (03 • a1,c)⊕ a2,c ⊕ a3,c
b1,c = a0,c ⊕ (02 • a1,c)⊕ (03 • a2,c)⊕ a3,c
b2,c = a0,c ⊕ a1,c ⊕ (02 • a2,c)⊕ (03 • a3,c)
b3,c = (03 • a0,c)⊕ a1,c ⊕ a2,c ⊕ (03 • a2,c)
Figura 1.5: MixColumn
Fino a questo punto non si e ancora utilizzata la chiave di cifratura.
Questa viene utilizzata dall’ultima operazione che ora si andra a descrivere:
l’AddRoundKey. Considerando l’ingresso e la chiave (entrambi di lunghezza
pari a 128 bit) come due matrici 4x4 con elementi da 8 bit, l’unica cosa che
si fara e lo XOR tra i byte della matrice state e il corrispettivo byte di round
key (matrice della chiave) come mostra la figura 1.6:a0,0 a0,1 a0,2 a0,3
a1,0 a1,1 a1,2 a1,3
a2,0 a2,1 a2,2 a2,3
a3,0 a3,1 a3,2 a3,3
⊕
k0,0 k0,1 k0,2 k0,3
k1,0 k1,1 k1,2 k1,3
k2,0 k2,1 k2,2 k2,3
k3,0 k3,1 k3,2 k3,3
=
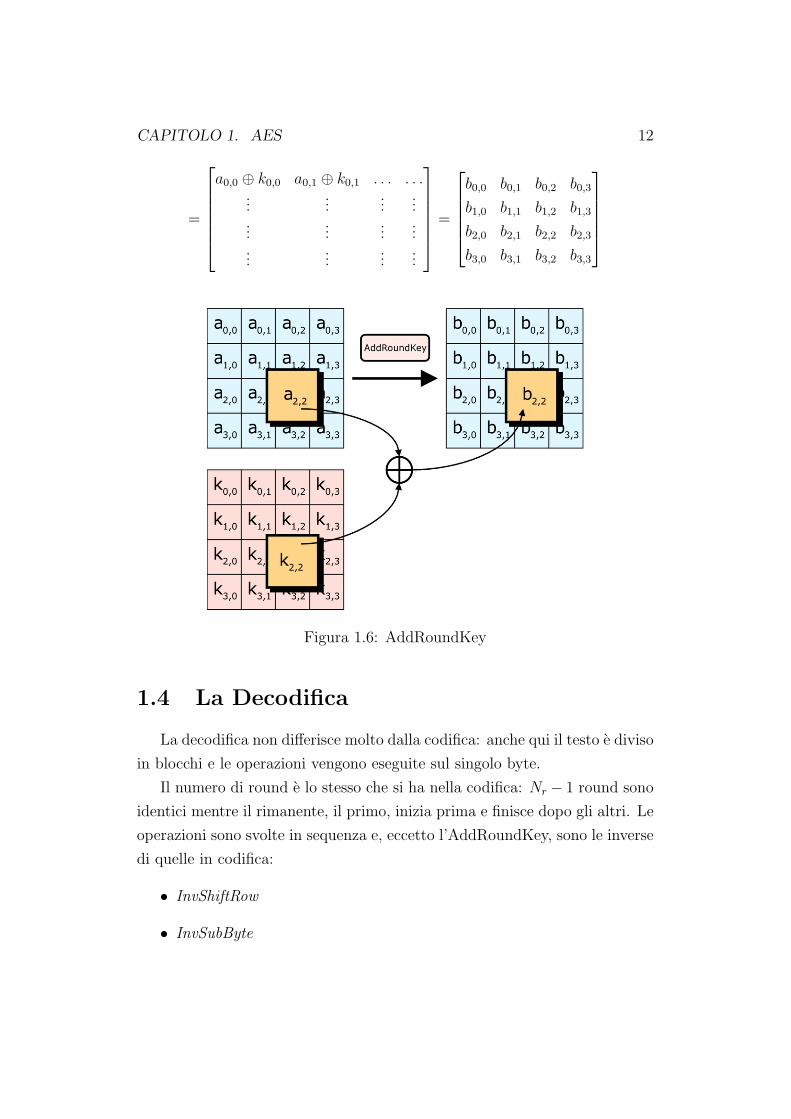
CAPITOLO 1. AES 12
=
a0,0 ⊕ k0,0 a0,1 ⊕ k0,1 . . . . . .
......
......
......
......
......
......
=
b0,0 b0,1 b0,2 b0,3
b1,0 b1,1 b1,2 b1,3
b2,0 b2,1 b2,2 b2,3
b3,0 b3,1 b3,2 b3,3
Figura 1.6: AddRoundKey
1.4 La Decodifica
La decodifica non differisce molto dalla codifica: anche qui il testo e diviso
in blocchi e le operazioni vengono eseguite sul singolo byte.
Il numero di round e lo stesso che si ha nella codifica: Nr − 1 round sono
identici mentre il rimanente, il primo, inizia prima e finisce dopo gli altri. Le
operazioni sono svolte in sequenza e, eccetto l’AddRoundKey, sono le inverse
di quelle in codifica:
• InvShiftRow
• InvSubByte
CAPITOLO 1. AES 13
• InvMixColumn
Nel round iniziale viene eliminata la InvMixColumn e al suo inizio viene
eseguito un ulteriore AddRoundKey. Siccome in decodifica la InvShiftRow e
la InvSubByte lavorano solo sulla matrice di stato, esse possono essere scam-
biate tra di loro; abbiamo quindi due diversi cifrari di decodifica equivalenti.
Un esempio dell’algoritmo di decodifica si puo osservare in figura 1.7.
Figura 1.7: Algoritmo di Decodifica
Si procede ora con la descrizioni delle operazioni di decodifica partendo
dalla InvShiftRow. Questa funzione opera sulle righe e gira i dati contenuti
nelle celle a seconda della riga che si sta considerando. In pratica e equivalente
al suo corrispettivo nella codifica, ma, mentre quest’ultima trasla i dati di
un offset verso sinistra, l’InvShiftRow li scala naturalmente verso destra.
La InvSubByte si svolge nello stesso modo della SubByte; l’unica differen-
za e la matrice di sostituzione utilizzata, che sara l’inverso di quella usata per
la codifica. Come abbiamo gia detto, la matrice di stato su cui lavora l’AES
ha dimensioni 4x4 ed ogni elemento e costituito da un byte che si puo rappre-
sentare con due cifre esadecimali. Quest’ultime indicano l’ascissa e l’ordinata

CAPITOLO 1. AES 14
nella matrice di sostituzione inversa (chiamata“Inverse Substitution-Box”).
Un esempio della matrice si puo vedere in Figura 1.8.
Figura 1.8: Inverse Substitution-BOX
Come il suo corrispettivo nella codifica, la InvMixColumn lavora sulle
colonne considerandole come polinomi nei campi di Galois e le moltiplica
modulo x4 + 1 per il polinomio :
c−1(x) = {0b}hx3 + {0d}hx
2 + {09}hx + {0e}h
Questo polinomio e il polinomio inverso di quello usato per eseguire la Mix-
Column.
Come per la codifica anche per la decodifica l’unica operazione in cui verra
usata la chiave e l’AddRoundKey, operazione identica a quella di codifica:
infatti lo XOR e l’inverso di se stesso. Ad esempio se abbiamo:
{52}h ⊕ {41}h = {13}h
per riottenere il primo (o secondo) addendo, basta fare lo XOR tra il risultato
e il secondo (o primo) addendo:
{13}h ⊕ {41}h = {53}h o {52}h ⊕ {13}h = {41}h

CAPITOLO 1. AES 15
1.5 Il Calcolo della chiave
Come si e visto, ad ogni round e necessaria almeno una chiave e que-
sta viene calcolata in base a quella dell’iterazione precedente attraverso la
funzione KeyExpansion. Questa funzione genera un array indicato con w
(Expanded Key) contenente tutte le chiavi che verranno usate dall’algoritmo.
Le dimensioni di w dipendono dal numero di round (Nr) in codifica ed e pari
a Nb · (Nr + 1). In realta si puo scegliere se calcolare tutte le chiavi prima di
effettuare la codifica/decodifica oppure calcolarle ad ogni round.
Figura 1.9: Array w con chiave a 128 bit
L’i-esima word della RoundKey viene determinata da quella precedente
attraverso una funzione che varia a seconda dell’indice i stesso secondo la
formula (per il significato di Nk, Nb, Nr vedere il paragrafo 1.3):
Wi = Wi−1 ⊕ f(i mod Nk)
dove f(i mod Nk) e una funzione che vale
• SubWord(RotWord(Wi−1))⊕Rcon(i
Nk
) se i e multiplo di Nk
• SubWord(Wi−1) se i mod Nk = 4
• Wi−1 negli altri casi
dove il significato delle funzioni utilizzate e il seguente:
• SubWord : esegue la S-BOX sui 4 byte in ingresso;
• RotWord : operazione simile alla ShiftRow. Riceve in ingresso una
parola di 4 byte, ad esempio nella forma [a0, a1, a2, a3], e scala verso
sinistra i byte della parola ottenendo cosı [a1, a2, a3, a0];
• Rcon[k]: la struttura di questo elemento di 4 byte e la seguente:

CAPITOLO 1. AES 16
[{02}(i−1)h , {00}h, {00}h, {00}h]
dove {02}h = x e x ∈ GF (28). Rcon e quindi una potenza di x, che
partendo da i = 0, evolvera nel modo seguente : {01}h, {02}h, {04}h,
{08}h, {10}h.
1.6 Struttura Hardware
Si illustra ora una possibile architettura in grado di utilizzare il Rijndael
per codificare e decodificare. Prima si descrivera questa struttura per intero,
spiegando lo scopo di ogni singolo modulo; in seguito si vedranno due possi-
bili implementazioni della DataUnit enunciando anche le differenze tra loro
soprattutto per quanto riguarda le prestazioni.
L’architettura dell’AES consiste di quattro componenti principali: inter-
faccia, DataUnit, KeyUnit, CBC Unit.
L’interfaccia gestisce le comunicazioni tra l’ambiente esterno e gli altri
elementi del sistema.
La DataUnit e il modulo principale di tutta la struttura, in quanto
esegue tutte le operazioni per la codifica e per la decodifica grazie alla chiave
che riceve in ingresso ad ogni round. La DataUnit e composta da 16 celle
e da un certo numero di S-BOX; a seconda che si opti per una struttura
standard o ad alte prestazioni (High Performance DataUnit) il numero di
S-BOX potra essere o quattro o sedici.
La KeyUnit ha due scopi principali: immagazzinare la chiave di cifratura
e calcolare da questa tutte le altre. Per il calcolo della chiave si ha bisogno
di quattro S-BOX; per non aumentare lo spazio occupato si possono riusare
quelle della DataUnit.
La CBC Unit (Cipher Block Chaining Unit) e un’unita utilizzata per
aumentare la sicurezza dell’algoritmo da attacchi esterni. La sua funzione
e quella di fare lo XOR tra i 128 bit in ingresso e i 128 bit in uscita dalla
DataUnit dopo la cifratura; in questo modo i dati entranti nella DataUnit
saranno quindi diversi da quelli inviati dall’ambiente esterno. La stessa cosa
viene eseguita anche in fase di decodifica.

CAPITOLO 1. AES 17
Figura 1.10: Architettura AES
Si riporta di seguito una breve sintesi della sequenza di codifica in riferi-
mento alla figura 1.10: attraverso l’interfaccia, viene caricata nella KeyUnit
la chiave di cifratura. In seguito, attraverso il passaggio dall’interfaccia e dal-
la CBC Unit, i primi 128 bit da codificare vengono trasmessi alla DataUnit.
Qui poi verranno eseguiti i vari round necessari per la codifica, in base alla
dimensione della chiave. Naturalmente per ogni round la chiave corrispon-
dente viene fornita dalla KeyUnit, che la calcola anche grazie all’utilizzo delle
S-BOX nel ciclo di clock in cui la DataUnit non le utilizza. Arrivati alla fine
dell’ultimo round si ha finalmente il dato codificato; questo viene passato alla
CBC Unit 32 bit alla volta. Per la decodifica si procede in modo molto simile
a quello descritto, solo che le chiavi di round sono fornite in modo inverso
cioe la prima chiave utilizzata sara l’ultima della codifica e l’ultima sara la
chiave di cifratura (quella in ingresso in codifica).
Si passa ora a descrivere l’architettura dei vari moduli partendo da due
delle possibili implementazioni della DataUnit e passando poi al KeyUnit.
La Standard DataUnit e composta da 16 celle di dati (DataCell) e da 4 S-

CAPITOLO 1. AES 18
BOX; una DataCell e un registro in cui vengono memorizzati 8 dei 128 bit in
entrata, mentre la S-BOX non e altro che il dispositivo adibito all’esecuzione
dell’operazione di SubByte. Queste 16 celle sono organizzate in una matrice
4x4 e ogni colonna della matrice conterra in piu una S-BOX, come si puo
vedere in Figura 1.11
Figura 1.11: Standard DataUnit

CAPITOLO 1. AES 19
I dati entranti nell’unita vengono fatti scorrere nelle celle, colonna per
colonna da destra a sinistra. Il caricamento dei dati avviene in quattro cicli
di clock e durante il quarto, viene eseguita anche la prima operazione dell’al-
goritmo: l’AddRoundKey. Ora, dopo aver compiuto lo XOR tra i dati e la
chiave di cifratura, hanno inizio i round cosidetti normali; il contenuto di ogni
DataCell viene fatto scorrere verticalmente e dopo la SubByte, i dati dalla S-
BOX vengono rimandati alla riga zero. Quindi nel primo ciclo di clock di ogni
round normale, la SubByte e fatta sui dati della riga tre, al secondo su quelli
della riga due e cosı via. Il risultato in uscita dalle S-BOX arrivera alla riga
zero con due cicli di ritardo; questo ritardo e causato dall’implementazione
a pipeline della riga di S-BOX. Durante il trasferimento dalla riga zero alla
riga uno e posto un Barrel Shifter la cui funzione e di effettuare l’operazione
di InvShiftRow (in decodifica) o di ShiftRow (in codifica); il passaggio dal
Barrel Shifter non necessita di cicli di clock aggiuntivi, quindi per eseguire le
prime due trasformazioni (Inv-/SubByte e Inv-/ShiftRow) si hanno bisogno
di cinque cicli di clock.
Al sesto ciclo, si eseguono in parallelo le ultime due operazioni del round:
la Inv-/MixColumn e l’AddRoundKey. Durante questo ciclo si effettua anche
la KeyExpansion per il calcolo della nuova chiave; questo avviene attraverso
l’utilizzo della riga di S-BOX che non essendo usata dalla DataUnit, viene
sfruttata dalla KeyUnit.
L’ultimo round, chiamato round finale, e molto simile a quello normale
con l’unica differenza che, nel sesto ciclo di clock, l’unica trasformazione
svolta e l’AddRoundKey (la Inv-/MixColumn viene esclusa).
Facendo qualche calcolo e utilizzando una chiave da 128 bit (quindi con
un numero di round pari a 10), si ottiene che 64 e il numero di cicli necessari
per una codifica o per una decodifica. Infatti si hanno:
• 4 cicli per caricare i dati e eseguire la prima AddRoundKey (round
iniziale);
• 54 cicli per i round normali (6 • 9);
• 6 cicli per il round finale;

CAPITOLO 1. AES 20
A questi 64 cicli bisogna aggiungerne altri 4 cioe quelli che servono per
fornire i dati all’esterno.
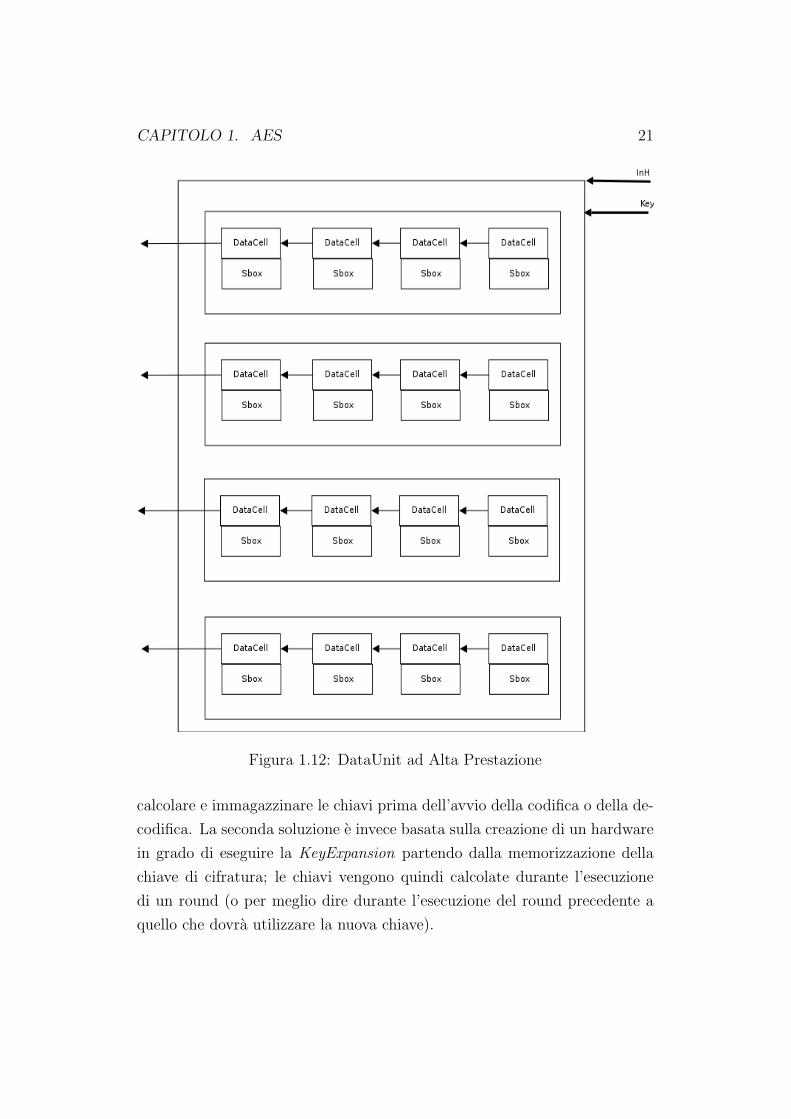
In contrapposizione alla DataUnit appena illustrata, si puo trovare quella
ad alte prestazioni; questa e costituita da 16 S-BOX, una per ogni DataCell.
In questo modo i dati non devono essere traslati da una riga alla successiva
per effettuare la SubByte consentendo cosı di completare un singolo round
in soli 3 cicli di clock. Per eseguire l’operazione di ShiftRow i dati in uscita
dalle S-BOX vengono traslati e riportati agli ingressi della riga stessa.
Di seguito riportiamo l’evoluzione di un round normale:
• nel primo ciclo di clock i dati vengono caricati nelle S-BOX per eseguire
l’operazione di Inv-/SubByte;
• nel secondo ciclo di clock le S-BOX danno in uscita i risultati del-
l’operazione, questi vengono traslati a seconda della riga per eseguire
l’operazione di ShiftRow e quindi caricati nella DataCell;
• nel terzo e ultimo ciclo vengono eseguite le operazioni di MixColumn e
di AddRoundKey.
Ovviamente anche la KeyUnit viene modificata per semplificare il design;
al suo interno ora si avranno 4 S-BOX in modo da non dover utilizzare quelle
della DataUnit.
Le modifiche prima illustrate permettono di eseguire la codifica/decodifica
in soli 34 cicli di clock anziche in 64. L’aggiunta di 16 S-BOX comporta un
aumento dello spazio occupato di circa il 43% considerando il numero di porte
usate.
Manca ora da descrivere la KeyUnit, componente che ha lo scopo di
memorizzare una chiave di round alla volta e di eseguire la funzione per
l’espansione della chiave. Come gia detto, siccome le S-BOX della DataUnit
non sono utilizzate in tutti i cicli di clock, queste possono essere riutilizzate;
facendo in questo modo si ha un risparmio di area abbastanza significativo.
In generale esistono due modi per implementare questa unita. La prima
prevede una implementazione software con l’utilizzo di una RAM, in modo da
CAPITOLO 1. AES 21
Figura 1.12: DataUnit ad Alta Prestazione
calcolare e immagazzinare le chiavi prima dell’avvio della codifica o della de-
codifica. La seconda soluzione e invece basata sulla creazione di un hardware
in grado di eseguire la KeyExpansion partendo dalla memorizzazione della
chiave di cifratura; le chiavi vengono quindi calcolate durante l’esecuzione
di un round (o per meglio dire durante l’esecuzione del round precedente a
quello che dovra utilizzare la nuova chiave).

CAPITOLO 1. AES 22
Se si sceglie di seguire la seconda via e di utilizzare una chiave di 128 bit,
la sequenza di operazioni e riportata di seguito. Per prima cosa viene caricata
la prima chiave e, se si e in codifica, vengono calcolate iterativamente le chiavi
successive dalla seconda all’undicesima; se invece ci troviamo in decodifica,
dopo la ricezione della chiave bisogna eseguire per dieci volte la KeyExpansion
in quanto la prima chiave di decodifica e l’undicesima della codifica.
Ad ogni nuova codifica si dovra ricaricare la chiave o, in decodifica, si
dovra sempre rieseguire la sequenza di KeyExpansion; si potranno quindi
aggiungere due registri da 128 bit: uno per la memorizzazione della chiave
di cifratura e uno per quello di decifratura. Questo portera ad un incre-
mento dello spazio utilizzato ma ad una riduzione del tempo di esecuzione,
soprattutto in decodifica.
1.7 Sicurezza dell’AES
Prima di descrivere i punti deboli dell’AES e gli attacchi conosciuti e
opportuno precisare cosa si intende per sicurezza di un sistema crittografico.
Con l’evoluzione tecnologica a cui stiamo assistendo e impossibile pensare
che un algoritmo rimanga inviolato in eterno; quello che si vuole evitare oggi
e che persone non autorizzate riescano a decifrare un testo crittografato in
tempi brevi. Prendiamo come esempio un algoritmo rimasto inviolato per
quasi trent’anni: il DES. Esso aveva una chiave di soli 56 bit e, nel periodo
in cui fu definito come standard, offriva un ampio margine di sicurezza; oggi
puo essere violato in poche ore con macchine dedicate.
L’AES ha chiavi molto piu lunghe rispetto al DES e, finora, attacchi
brute force non hanno avuto successo. Molti crittoanalisti sostengono che uno
dei punti deboli del nuovo standard sia la sua, ben documentata, struttura
matematica; e quindi possibile che in un prossimo futuro siano presentati
nuovi tipi di attacchi. Nel caso comunque vengano portati a buon fine degli
attacchi, a causa ad esempio di alcune debolezze della S-BOX, gli autori si
sono detti disponibili a sostituirla con una differente.
Uno dei possibili attacchi che si potrebbe portare all’AES e l’attacco Squa-
re. Square e di tipo chosen plaintext dove il crittoanalista puo scegliere una

CAPITOLO 1. AES 23
serie di testi in chiaro e i relativi cifrati per poi risalire alla chiave studiando
le differenze prodotte dai diversi testi. Basandosi sulla struttura a byte del-
l’AES il crittoanalista puo scegliere dei testi in chiaro tutti uguali tranne che
per un byte detto “attivo”. Elaborando i dati ottenuti dall’evoluzione delle
posizioni e delle trasformazione di tale byte, Square e in grado di eliminare
un dato numero di chiavi riducendo cosı lo spazio di ricerca. Anche se valido
questo attacco rimane parziale e necessita di un numero di plaintext pari a
232; inoltre era gia stato documentato dagli autori dell’algoritmo in fase di
presentazione e per ora e efficace solo su una versione ridotta dell’algoritmo.
Altri possibili attacchi riguardano la possibilita di esaminare l’energia
consumata dalle operazioni e la durata delle stesse al fine di poterle distin-
guere tra di loro, e ricavare cosı informazioni utili per la decifratura. E
possibile utilizzare queste tecniche grazie all’utilizzo di operazioni fisse come
quelle booleane e di rotazione delle righe.
L’ultimo attacco in termini di tempo studiato per attaccare l’algoritmo
AES, e quello che utilizza la tecnica chiamata “XSL” annunciato da Nicolas
Courtois e Josef Pieprzyk. Sebbene l’attacco sia matematicamente corretto
e impraticabile nella realta per via dell’enorme tempo macchina richiesto per
metterlo in pratica. Allo stato attuale la reale pericolosita dell’attacco XSL
e un punto interrogativo.
Oltre a questi tipi di attacco ne esistono altri atti ad introdurre nel siste-
ma degli errori di computazione. Ricordiamo quelli chiamati “Spike Attack”,
“Glitch Attack” e “Optical Attack”. Lo Spike Attack e un tipo di attacco
basato sul fatto che una smartcard deve essere in grado di tollerare delle
deviazioni di voltaggio. Quando questa deviazione e troppo alta si possono
verificare degli errori all’interno del sistema portando cosı a dei risultati er-
rati. L’Optical Attack e un attacco meno invasivo, in quanto utilizza la luce
come strumento per introdurre degli errori; e possibile ad esempio utilizzare
un semplice flash fotografico guidato da un microcontrollore per settare o
resettare una singola cella di memoria in un preciso istante di tempo. E uno
degli attacchi piu efficaci e pericolosi.
Oggigiorno l’AES e considerato un algoritmo veloce, sicuro e gli attacchi
fino ad ora presentati si sono rivelati degli interessanti studi teorici ma di

CAPITOLO 1. AES 24
scarsa utilita nella pratica: solo alcuni sono andati a buon fine ma sono
stati portati a versioni semplificate del Rijndael dove il numero dei round era
inferiore a quello previsto nello standard (7 con chiave da 128, 8 con chiave
da 192, 9 con chiave da 256). Anche il governo degli USA utilizza questo
standard per proteggere i dati SECRET (criptati con chiavi da 128 bit) e
TOPSECRET (criptati con chiavi da 256 bit) e garantire un ampio margine
di sicurezza per i prossimi decenni.

Capitolo 2
Concetti Generali
In questo capitolo si andra a fare una panoramica sulla rilevazione d’er-
rore e sulle varie metodologie che si possono usare per attuarla; tra queste
si parlera in particolare del bit di parita. Questa rilevazione e legata alla
riconfigurazione in quanto e proprio grazie ad essa che si rende possibile la
riconfigurabilita del sistema; quando si rileva un attacco l’architettura viene
riconfigurata. Si illustreranno quindi le varie tecniche di riconfigurazione e si
presenteranno anche dispositivi in grado di usufruire di queste tecniche: le
FPGA. Per concludere il capitolo verranno presentati i linguaggi e i software
da noi utilizzati per realizzare il tutto.
2.1 Rilevazione d’Errore
Nei precedenti capitoli e gia stato illustrato come sia possibile sfruttare
degli attacchi per trovare la chiave di codifica. Ovviamente tali attacchi
provocheranno degli errori che, nell’architettura proposta, possono verificarsi
nel Data-Path oppure nel Control-Path.
Nel caso del Data-Path si fa riferimento ad un errore che si verifica al-
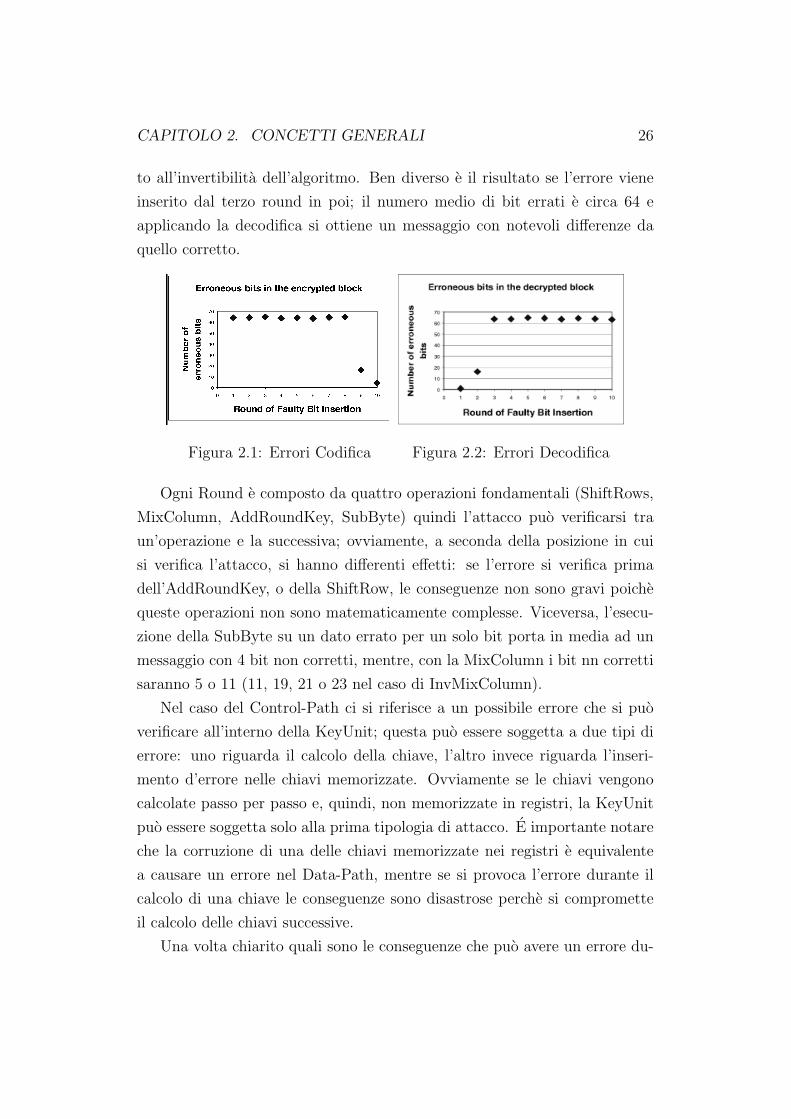
l’interno della DataUnit durante uno dei 10 round; come si puo vedere nelle
figure 2.1 e 2.2, l’inserimento dell’errore nel primo round comporta sull’uscita
un elevato numero di bit errati ma, se si decodifica questa stessa uscita, il
risultato differisce dal testo in chiaro di un solo bit. Questo aspetto e dovu-
25
CAPITOLO 2. CONCETTI GENERALI 26
to all’invertibilita dell’algoritmo. Ben diverso e il risultato se l’errore viene
inserito dal terzo round in poi; il numero medio di bit errati e circa 64 e
applicando la decodifica si ottiene un messaggio con notevoli differenze da
quello corretto.
Figura 2.1: Errori Codifica Figura 2.2: Errori Decodifica
Ogni Round e composto da quattro operazioni fondamentali (ShiftRows,
MixColumn, AddRoundKey, SubByte) quindi l’attacco puo verificarsi tra
un’operazione e la successiva; ovviamente, a seconda della posizione in cui
si verifica l’attacco, si hanno differenti effetti: se l’errore si verifica prima
dell’AddRoundKey, o della ShiftRow, le conseguenze non sono gravi poiche
queste operazioni non sono matematicamente complesse. Viceversa, l’esecu-
zione della SubByte su un dato errato per un solo bit porta in media ad un
messaggio con 4 bit non corretti, mentre, con la MixColumn i bit nn corretti
saranno 5 o 11 (11, 19, 21 o 23 nel caso di InvMixColumn).
Nel caso del Control-Path ci si riferisce a un possibile errore che si puo
verificare all’interno della KeyUnit; questa puo essere soggetta a due tipi di
errore: uno riguarda il calcolo della chiave, l’altro invece riguarda l’inseri-
mento d’errore nelle chiavi memorizzate. Ovviamente se le chiavi vengono
calcolate passo per passo e, quindi, non memorizzate in registri, la KeyUnit
puo essere soggetta solo alla prima tipologia di attacco. E importante notare
che la corruzione di una delle chiavi memorizzate nei registri e equivalente
a causare un errore nel Data-Path, mentre se si provoca l’errore durante il
calcolo di una chiave le conseguenze sono disastrose perche si compromette
il calcolo delle chiavi successive.
Una volta chiarito quali sono le conseguenze che puo avere un errore du-

CAPITOLO 2. CONCETTI GENERALI 27
rante la fase di codifica bisogna ora rispondere alla seguente domanda: come
si puo capire se un testo cifrato e corrotto, cioe se e soggetto ad un attacco? I
procedimenti piu semplici consistono nel decodificare il testo criptato e vede-
re se coincide con quello in ingresso, oppure nell’eseguire una seconda volta
la codifica. Le tecniche appena presentate sono sicuramente efficaci, l’attac-
co viene sicuramente rivelato, ma sono molto onerose in termini di tempo;
utilizzare una di queste tecniche porta a raddoppiare il tempo necessario per
la codifica. Esistono altre contromisure, che vanno comunque citate, che
sfruttano l’invertibilita dell’AES. Queste effettuano la verifica non piu alla
fine della codifica(decodifica), ma alla fine di ogni round: e noto che il primo
round di cifratura corrisponde all’ultimo in decifratura, il secondo al penul-
timo e via dicendo. Con queste considerazioni si comprende come sia facile
portare il controllo alla fine di ogni round; all’inizio di ognuno di essi i dati
in ingresso vengono memorizzati in un registro e prima di passare al round
successivo i dati in uscita vengono passati al corrispettivo round di decodi-
fica e il risultato confrontato con i dati memorizzati inizialmente; se i dati
corrispondono, non si e verificato alcun tipo attacco. E ovvio che il tempo
necessario per eseguire la codifica (decodifica) sara doppio di quello neces-
sario normalmente perche ogni round e seguito dal corrispettivo round di
decodifica (codifica). Inoltre si deve anche considerare un aumento dell’area
utilizzata dovuta ai comparatori e ai registri aggiuntivi.
Le tecniche sopracitate quindi sono efficaci, ma non efficienti perche com-
portano un aumento considerevole del tempo di computazione e, a volte,
anche un aumento di aria utilizzata. Quello che si vuole ottenere e una co-
pertura totale dell’errore e un aumento di spazio minimo. Sono stati fatti
diversi studi per avere risultati soddisfacenti e uno di questi e riportato nel-
l’articolo [4] da cui e stato preso lo spunto per questo elaborato. L’articolo
mostra come utilizzare un bit di parita per ogni byte del testo da codificare
per verificare la correttezza delle varie operazioni. Come si puo vedere dalla
figura, il controllo del bit di parita non e di tipo centralizzato bensı ogni
DataCell verifica se le varie operazioni sono andate a buon fine. Se si fosse
scelto di usare un singolo bit di parita per l’intera architettura questo avreb-
be coperto solo il 50% degli errori e inoltre il bit di parita in uscita dipende

CAPITOLO 2. CONCETTI GENERALI 28
da tutti i bit del blocco in ingresso e quindi il suo calcolo e lungo e complesso.
Se si vuole utilizzare il bit di parita per verificare la correttezza dei dati
e necessario implementare quattro funzioni per la predizione del valore del
bit di parita dopo le varie trasformazioni. Questa predizione sara poi messa
a confronto con il bit di parita del dato dopo le operazioni: nel caso siano
uguali si puo pensare che non sia avvenuto nessun attacco. Le operazioni di
AddRoundKey e ShiftRow non presentano grandi problemi in quanto, per la
prima, il calcolo del bit di parita si ottiene facendo lo XOR tra la parita del
dato in ingresso e quella della chiave utilizzata, mentre per la ShiftRow non
si ha la modifica della parita del byte; particolare attenzione va data invece
alle altre due operazioni: SubByte e MixColumn.
Per la SubByte e necessario considerare il bit di parita sulla matrice di
sostituzione: la S-BOX, normalmente, e implementata con una matrice di
256 elementi contenenti i valori che poi serviranno a sostituire gli otto bit
in ingresso. Introducendo il bit di parita i bit in ingresso diventano nove e
sara quindi necessario realizzare una nuova matrice, analoga alla precedente,
ma costituita da 512 elementi. In questo modo pero non sempre e possibile
individuare tutti gli errori introdotti nel sistema; infatti e possibile accedere
ad una posizione sbagliata della S-BOX pur avendo parita corretta. Una
soluzione al problema e la creazione di una nuova entita, denominata Pari-
tySBOX, che puo essere schematizzata come una matrice in grado di predire
il valore del bit di parita del dato in uscita dalla S-BOX.
Figura 2.3: Rilevazione d’errore sulla SubByte

CAPITOLO 2. CONCETTI GENERALI 29
La parita del byte in uscita dell’operazione di MixColumn dipende sia
dal byte in ingresso che dai vari fattori della funzione secondo le formule di
seguito riportate. Per la codifica si ha:
p0,c = (p0,c ⊕ p2,c ⊕ p3,c ⊕ s(7)0,c ⊕ s
(7)1,c)
p1,c = (p0,c ⊕ p1,c ⊕ p3,c ⊕ s(7)1,c ⊕ s
(7)2,c)
p2,c = (p0,c ⊕ p1,c ⊕ p2,c ⊕ s(7)2,c ⊕ s
(7)3,c)
p3,c = (p1,c ⊕ p2,c ⊕ p3,c ⊕ s(7)3,c ⊕ s
(7)0,c)
in decodifica invece:
p0,c = p0,c ⊕ p1,c ⊕ p2,c ⊕ s(5)0,c ⊕ s
(7)0,c ⊕ s
(5)1,c ⊕ s
(6)1,c ⊕ s
(5)2,c ⊕ s
(5)3,c ⊕ s
(6)3,c ⊕ s
(7)3,c
p1,c = p1,c ⊕ p2,c ⊕ p3,c ⊕ s(5)0,c ⊕ s
(6)0,c ⊕ s
(7)0,c ⊕ s
(5)1,c ⊕ s
(7)1,c ⊕ s
(5)2,c ⊕ s
(6)2,c ⊕ s
(5)3,c
p2,c = p0,c ⊕ p2,c ⊕ p3,c ⊕ s(5)0,c ⊕ s
(5)1,c ⊕ s
(6)1,c ⊕ s
(7)1,c ⊕ s
(5)2,c ⊕ s
(7)2,c ⊕ s
(5)3,c ⊕ s
(6)3,c
p3,c = p0,c ⊕ p1,c ⊕ p3,c ⊕ s(5)0,c ⊕ s
(6)0,c ⊕ s
(5)1,c ⊕ s
(5)2,c ⊕ s
(6)2,c ⊕ s
(7)2,c ⊕ s
(5)3,c ⊕ s
(7)3,c
dove pr,c indica la parita del byte presente nella riga “r” e nella colonna “c”
e s(i)r,c indica l’i-esimo bit del byte nella riga “r” e colonna “c”.
2.2 FPGA
Gli Array Logici Programmabili a Banchi, meglio conosciuti come FPGA
(Field Programmable Logic Array), sono una particolare classe di integra-
ti che e possibile riprogrammare per realizzare il progetto digitale voluto.
In generale le FPGA sono dei sistemi composti da migliaia di blocchi lo-
gici elementari che possono essere connessi tra loro in modo arbitrario; le
connessioni tra le varie celle sono effettuate grazie alla fittissima trama di
interconnessioni e di interruttori. Una possibile struttura di una FPGA si
puo vedere in figura 2.4; qui si possono notare i blocchi logici configurabili (o
CLB, Configurable Logic Block) che sono le unita funzionali e sono relativa-
mente di piccole dimensioni. Tra le CLB e presente una rete riconfigurabile
per permettere il collegamento tra una CLB ed un’altra.
Rispetto ai circuiti implementati su scheda, le FPGA sono programmabi-
li dall’utente finale. Questo aspetto e uno dei principali punti di forza delle

CAPITOLO 2. CONCETTI GENERALI 30
Figura 2.4: Struttura FPGA
FPGA, perche permette di ridurre i tempi di progettazione (non si deve rea-
lizzare anche la parte circuitale); inoltre se e necessario correggere il circuito
basta riprogrammare il dispositivo come meglio si adatta al progetto.
L’FPGA e fondamentalmente composta da una matrice di blocchi logici,
con una parte di essi che si interfacciano con l’esterno attraverso i blocchi di
Input/Output (IOB, Input Output Block) e un reticolo di piste elettriche che
collegano qualsiasi elemento dell’FPGA ad un altro. Tutti questi elementi
possono essere programmati dall’utente; programmare un blocco logico signi-
fica modificare la funzione logica da esso realizzata, mentre programmare un
blocco di interfaccia significa specificare la direzione del segnale o dei segnali
su quel blocco, o la possibilita di inserire dei resistori di pull-up/pull-down
su un segnale di ingresso/uscita. Infine, programmare le piste elettriche vuol
dire realizzare la connessione fisica fra un blocco e un altro. La programma-
zione dell’FPGA avviene attraverso programmi che spesso sono distribuiti

CAPITOLO 2. CONCETTI GENERALI 31
gratuitamente dalla stessa casa produttrice (Xilinx ad esempio).
Per comprendere la potenza delle FPGA come le VIRTEX-II PRO e suf-
ficente dire che su un chip delle dimensioni di quello presentato, e possibile
implementare un progetto che richiederebbe 50 milioni di transistor per la so-
la logica, quindi di dimensione superiore ad un Pentium 4 o a una GeForce4.
Le FPGA sono spesso utilizzate nell’ambito biomedico, nell’automazione in-
dustriale, nella stazioni base radiomobili, nelle schede di acquisizione dati ad
uso scientifico, nei super computer, ovvero nei casi dove il costo unitario per
apparecchiatura e alto ma la tiratura bassa. Le FPGA diventano antiecono-
miche quando le produzione viene fatta su larga scala perche in questo caso
il costo del circuito dedicato e inferiore a quello della FPGA.
2.2.1 Memoria di Configurazione di una Virtex
Si passa ora a spiegare come e strutturata la memoria di configurazione
delle FPGA della Virtex: essa puo essere vista come un array di bit. Questi
bit sono raggruppati in frame verticali larghi un bit e si estendono dall’inizio
alla fine dell’array. Il frame e l’unita base della configurazione ovvero la piu
piccola porzione di memoria su cui si puo eseguire un operazione di scrittura
o lettura e vengono messi in gruppi chiamate colonne; queste possono essere
di tipo differente.
Ogni dispositivo contiene, come si puo vedere in figura 2.5, una colonna
centrale che include la configurazione dei quattro pin dei clock globali. Esi-
stono anche due colonne IOB che rappresentano la configurazione per tutti
gli ingressi e le uscite dell’FPGA. Le rimanenti colonne rappresentano la con-
figurazione delle colonne di CLB (composte da 48 frame) e la configurazione
dei segnali di I/O di quelle CLB. Esistono altri due tipi di colonne riguar-
danti la RAM: una serve per l’immagazzinamento dei dati, mentre l’altra per
l’interconnessione.
Lo spazio totale degli indirizzi e diviso in due tipi: RAM e CLB. Il tipo
RAM contiene solo le colonne SelectRAM. Il CLB contiene la configurazione
di tutte le altre tipologie di colonne.
I frame sono lette e scritte sequenzialmente con indirizzi discendenti per
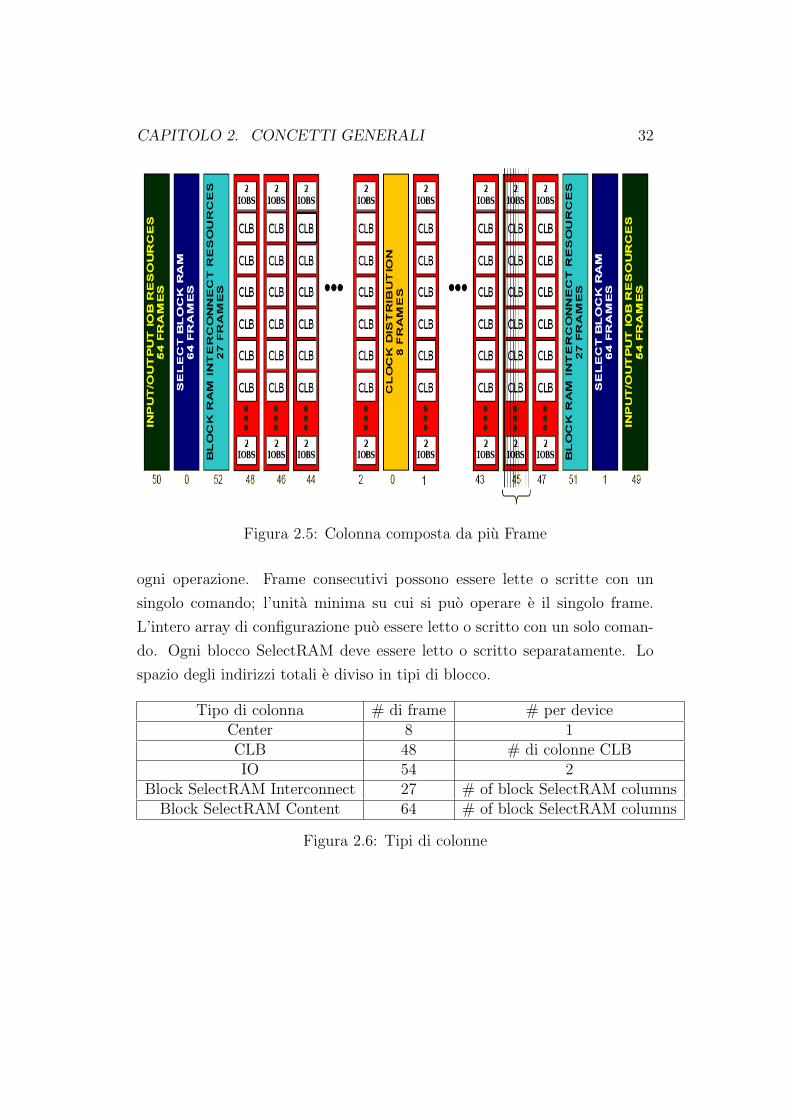
CAPITOLO 2. CONCETTI GENERALI 32
Figura 2.5: Colonna composta da piu Frame
ogni operazione. Frame consecutivi possono essere lette o scritte con un
singolo comando; l’unita minima su cui si puo operare e il singolo frame.
L’intero array di configurazione puo essere letto o scritto con un solo coman-
do. Ogni blocco SelectRAM deve essere letto o scritto separatamente. Lo
spazio degli indirizzi totali e diviso in tipi di blocco.
Tipo di colonna # di frame # per deviceCenter 8 1CLB 48 # di colonne CLBIO 54 2
Block SelectRAM Interconnect 27 # of block SelectRAM columnsBlock SelectRAM Content 64 # of block SelectRAM columns
Figura 2.6: Tipi di colonne

CAPITOLO 2. CONCETTI GENERALI 33
2.3 Tecniche per la Riconfigurazione
L’architettura delle FPGA della Xilinx Virtex hanno una caratteristica
molto utile: permettere ad alcuni moduli presenti nel progetto di cambiare la
propria funzionalita e quindi struttura, senza che il processo venga interrotto.
Di seguito viene illustrata la riconfigurazione parziale.
2.3.1 Riconfigurazione Parziale
Principalmente esistono due metodi per la riconfigurazione parziale di una
FPGA: il primo e chiamato Module-based (basato sui moduli), il secondo
Difference-based (basato sulle differenze).
La riconfigurazione Module-based permette di riconfigurare i singoli com-
ponenti all’interno dell’architettura. Questa richiede la presenza di un bus
speciale (Bus Macro Communication) per la comunicazione tra un modulo
e gli altri; questo non succede se i moduli sono completamente indipendenti
tra loro, quindi se non hanno segnali in comune. Senza la presenza di que-
sto bus non sarebbe possibile garantire il collegamento tra i moduli dopo la
riconfigurazione. Ogni volta che si esegue una riconfigurazione parziale, il
bus macro viene usato per stabilire quali collegamenti tra i moduli non sono
cambiati, garantendo cosı le giuste connessioni. Con la riconfigurazione a
moduli, una parte di circuito (che naturalmente sara stata segnalata come
riconfigurabile) non piu utile in quel momento, potra essere sostituita da un
altro modulo con funzioni diverse. La riconfigurazione a moduli puo essere
usata anche in quei casi in cui in un’architettura si verifica un errore; quan-
do questo viene individuato si avra la riconfigurazione del modulo difettoso
permettendo cosı alla struttura di tornare a funzionare correttamente.
L’altro metodo di riconfigurazione parziale quello difference-based, e com-
piuto apportando dei cambiamenti al componente, e generando poi un bi-
tstream basato sulle differenze tra le due strutture. Il passaggio di un modulo
da una implementazione ad un’altra e molto veloce e in piu il file di bitstream
generato, sara molto piu piccolo dell’intero bitstream del componente.
Si descrivera ora la tecnica per creare architetture dinamicamente riconfi-

CAPITOLO 2. CONCETTI GENERALI 34
gurabili proposta dalla Xilinx nell’articolo [5], attraverso i vincoli da applicare
sui moduli e sull’architettura.
Per prima cosa per poter utilizzare la riconfigurazione parziale, si deve
scomporre in sottoaree la FPGA. Ognuna di queste sottoaree conterra un
modulo sia esso fisso o riconfigurabile. Le seguenti proprieta devono essere
applicate ai moduli riconfigurabili:
• L’altezza di un modulo riconfigurabile deve sempre corrispondere al-
l’altezza del componente usato.
• La larghezza del modulo riconfigurabile deve occupare almeno quattro
slice e puo arrivare ad occupare tutto il componente, occupando pero
sempre un numero di slice multiplo di quattro. Una slice e da conside-
rarsi come una CLB (Configurable Logic Block) che ha coordinate “x”
e “y”.
• Tutti le risorse logiche all’interno dello spazio occupato dal modulo ri-
configurabile, sono da considerarsi appartenenti a questo modulo; fan-
no parte delle risorse logiche le slice, i TBUF, i blocchi di RAM, i
moltiplicatori, IOB (Input Output Block) e tutti i collegamenti.
• Il segnale di clock e sempre separato dal modulo riconfigurabile ed ha
un bitstream dedicato a lui.
• I blocchi di ingresso-uscita (IOB) all’interno della larghezza (immedia-
tamente sopra e sotto) di un modulo sono da considerarsi appartenenti
a quel modulo.
• Tutte le IOB che si trovano ai bordi del componente appartengono
ai moduli riconfigurabili se questi si trovano o all’estrema destra o
all’estrema sinistra.
• Lo spazio utilizzato per dei moduli riconfigurabili non possono essere
cambiati. La posizione e la regione occupata da ogni singolo modulo
riconfigurabile sono sempre fisse.

CAPITOLO 2. CONCETTI GENERALI 35
• I moduli riconfigurabili comunicano con gli altri, siano essi moduli fissi
o riconfigurabili, attraverso l’utilizzo di uno speciale bus chiamato Bus
Macro.
• Nessuna parte del progetto deve far uso di un modulo riconfigurabile
mentre lo si sta riconfigurando.
• Per evitare problemi di complessita, e meglio avere un numero minimo
di moduli riconfigurabili, idealmente uno solo.
Oltre ai vincoli sui moduli, bisogna seguire delle linee guida anche per
quello che riguarda l’implementazione dell’architettura, ad esempio in lin-
guaggio VHDL:
• il sistema generale deve essere fornito di un’entita di alto livello, di
solito chiamata top, in cui tutti i moduli funzionali vengono definiti
come delle black-box. Al suo interno dovra limitarsi solo a gestire gli
ingressi e le uscite, il segnale di clock; nessun altra logica si dovra
trovare nel top;
• Un modulo riconfigurabile deve comunicare con un qualsiasi altro mo-
dulo solo tramite l’utilizzo del Bus Macro;
• Se tra due moduli che devono comunicare tra loro esiste un modulo
riconfigurabile, allora i segnali devono passare attraverso due Bus Ma-
cro posti ai margini del modulo riconfigurabile, come si puo vedere in
figura 2.7. La comunicazione tra i moduli non puo avvenire nel caso in
cui si sia in fase di riconfigurazione;
• Tutti i clock usati dal sistema devono utilizzare le risorse di inter-
connessione globale; questo e importante per la buona riuscita della
riconfigurazione globale;
• I moduli riconfigurabili non devono condividere nessun segnale con gli
altri, eccetto il clock o i segnali di reset;
In figura 2.8 e possibile vedere un progetto con due moduli riconfigurabili.
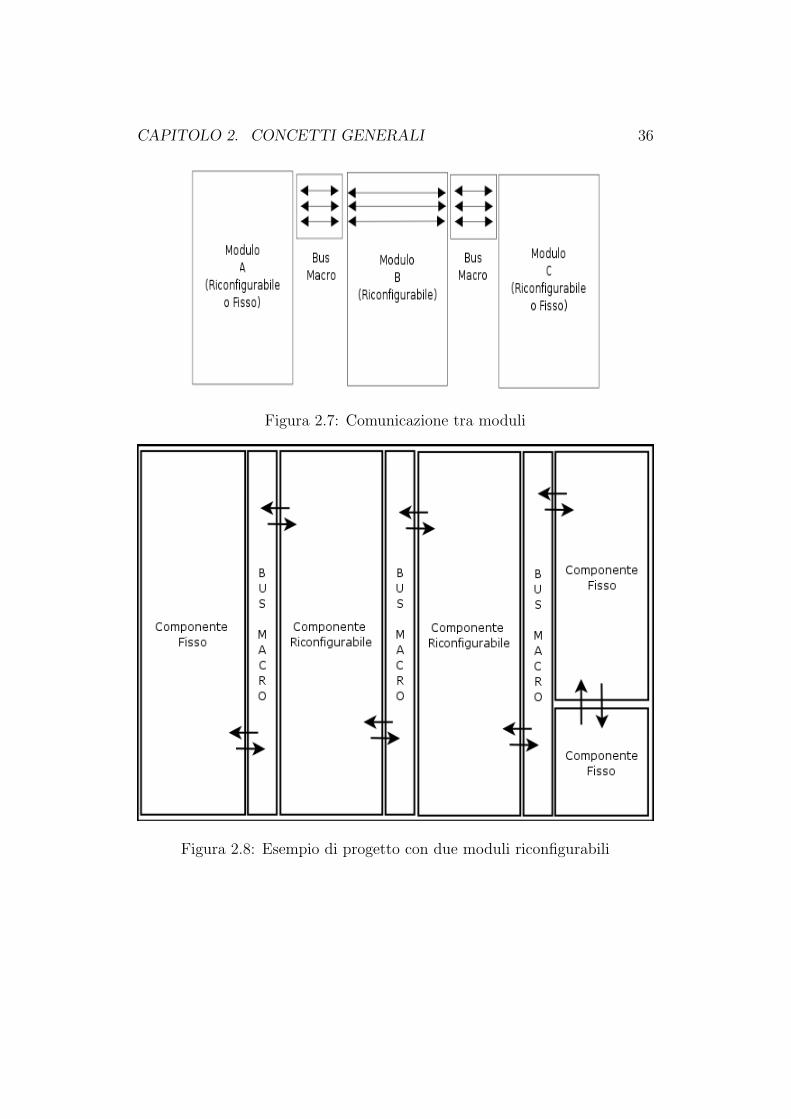
CAPITOLO 2. CONCETTI GENERALI 36
Figura 2.7: Comunicazione tra moduli
Figura 2.8: Esempio di progetto con due moduli riconfigurabili

CAPITOLO 2. CONCETTI GENERALI 37
2.4 Software e linguaggi utilizzati
In questo paragrafo si da una breve introduzione degli strumenti utilizzati
per realizzare l’architettura; per prima cosa diamo una breve introduzione
del VHDL, per poi parlare dei programmi ModelSim e ISE.
2.4.1 VHDL
VHDL e l’acronimo di VHSIC Hardware Description Language e a sua
volta VHSIC e l’acronimo di Very High Speed Integrated Circuits. Il VHSIC e
un linguaggio standard usato per descrivere l’hardware da un livello astratto
ad un livello concreto. VHDL nasce dal lavoro svolto negli anni ’70 e ’80
dal Dipartimento della Difesa degli Stati Uniti d’America. Nel 1986 e stato
proposto come standard IEEE.
Insieme al Verilog e il linguaggio piu utilizzato per la progettazione di
sistemi elettronici digitali; e usato per la descrizione, la simulazione e la sintesi
dell’hardware e, a differenza di altri linguaggi come Java o C, non crea file
eseguibili, ma descrive le operazioni svolte dal circuito e la sua composizione.
Il codice generato viene poi passato a programmi che permettono di farne
una simulazione o una sintesi.
Il VHDL e quindi un linguaggio specializzato per il supporto delle carat-
teristiche di un progetto hardware e supporta descrizioni della funzionalita a
diversi livelli di astrazione (ad esempio: livello comportamentale, livello RT ,
livello logico). Come tutti i linguaggi HDL, le istruzioni si eseguono in modo
concorrente tranne che in alcuni costrutti detti processi in cui le istruzioni
vengono svolte sequenzialmente. I processi interagiscono in parallelo tra loro
e si scambiano informazioni tramite segnali.
2.4.2 Modelsim
Modelsim e un ambiente di simulazione e di debug per VHDL e Verilog,
sviluppato dalla Mentor e supportato anche dalla Xilinx. Permette di creare
o semplicemente modificare file in linguaggio VHDL e attraverso l’uso di un
file di test (anch’esso scritto in VHDL), e possibile simulare l’intera architet-
CAPITOLO 2. CONCETTI GENERALI 38
tura creata, in modo da poter osservare se il comportamento del progetto e
conforme o meno alla specifica. In questo file avviene la stimolazione degli
ingressi; funziona quindi come un’interfaccia con l’esterno.
Ovviamente la simulazione e un’aspetto molto vantaggioso perche per-
mette di osservare quale sara l’effettivo comportamento del circuito; oltre ad
osservare gli ingressi e l’uscita, si possono visualizzare anche i singoli segnali
interni per cercare di individuare eventuali errori prima di implementare il
progetto su scheda, con un notevole risparmio di tempo e di costi.
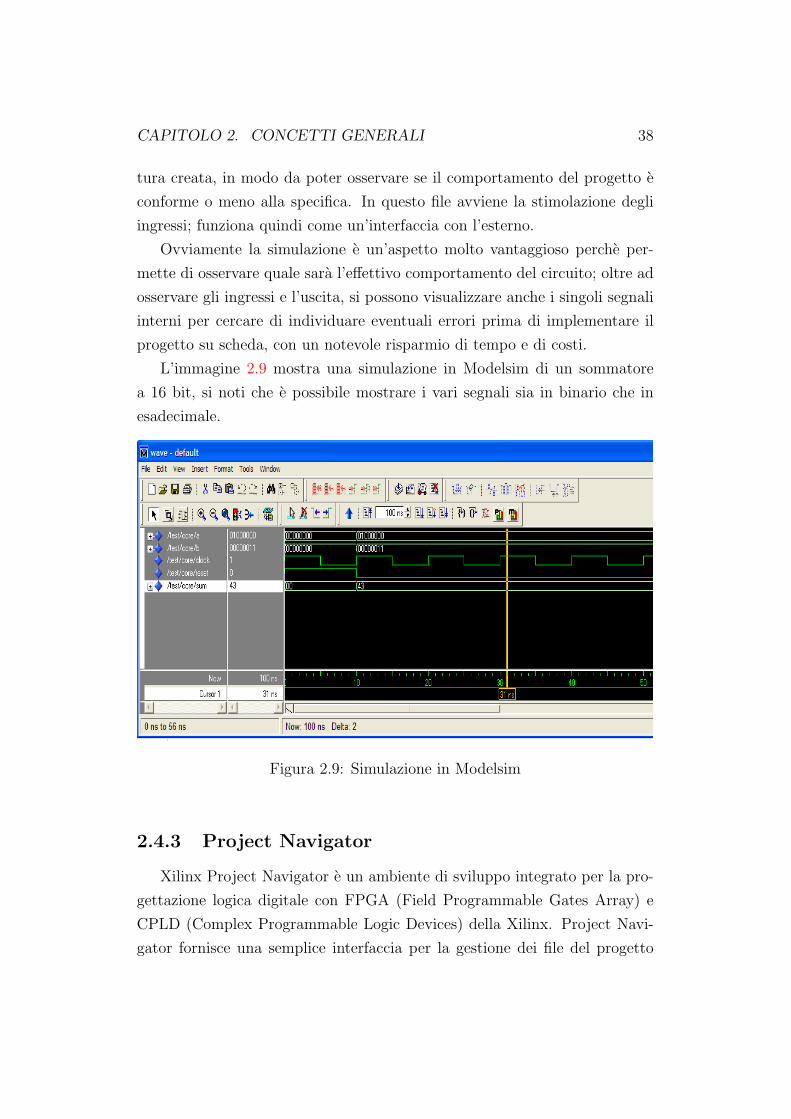
L’immagine 2.9 mostra una simulazione in Modelsim di un sommatore
a 16 bit, si noti che e possibile mostrare i vari segnali sia in binario che in
esadecimale.
Figura 2.9: Simulazione in Modelsim
2.4.3 Project Navigator
Xilinx Project Navigator e un ambiente di sviluppo integrato per la pro-
gettazione logica digitale con FPGA (Field Programmable Gates Array) e
CPLD (Complex Programmable Logic Devices) della Xilinx. Project Navi-
gator fornisce una semplice interfaccia per la gestione dei file del progetto
CAPITOLO 2. CONCETTI GENERALI 39
e in piu invoca automaticamente tutti i programmi per la simulazione e la
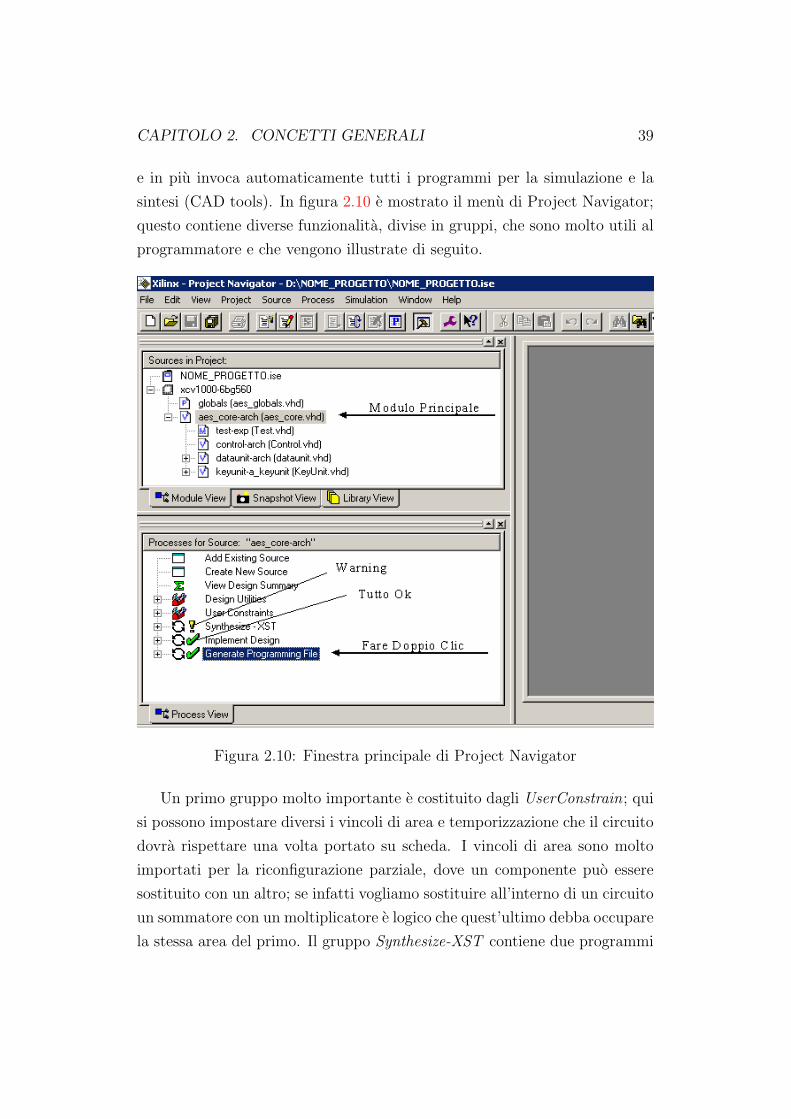
sintesi (CAD tools). In figura 2.10 e mostrato il menu di Project Navigator;
questo contiene diverse funzionalita, divise in gruppi, che sono molto utili al
programmatore e che vengono illustrate di seguito.
Figura 2.10: Finestra principale di Project Navigator
Un primo gruppo molto importante e costituito dagli UserConstrain; qui
si possono impostare diversi i vincoli di area e temporizzazione che il circuito
dovra rispettare una volta portato su scheda. I vincoli di area sono molto
importati per la riconfigurazione parziale, dove un componente puo essere
sostituito con un altro; se infatti vogliamo sostituire all’interno di un circuito
un sommatore con un moltiplicatore e logico che quest’ultimo debba occupare
la stessa area del primo. Il gruppo Synthesize-XST contiene due programmi

CAPITOLO 2. CONCETTI GENERALI 40
molto importanti: il primo controlla la correttezza del codice scritto, mentre
il secondo fa la sintesi del VHDL. Il successivo gruppo Implementation Design
permette di mappare l’intera architettura su FPGA tentando di rispettare i
vincoli imposti, mentre l’ultimo genera i file di configurazione per l’FPGA.

Capitolo 3
La Soluzione Proposta
Oltre ad implementare una possibile architettura per l’AES, il nostro
progetto e anche capace di effettuare la rilevazione d’errore nel caso di attacco
dall’esterno. Oggi infatti il Rijndael e uno degli algoritmi piu sicuri che si
conoscano ma, in linea teorica, e possibile provocare un errore in fase di
crittografia e, in base al risultato ottenuto, riuscire a ricavare la chiave. Con
la rilevazione d’errore l’architettura sara in grado di segnalare se in una fase
del percorso si sono verificate delle forzature.
Volendo portare l’architettura sulle FPGA presenti in laboratorio, si e
sviluppato il tutto cercando di risparmiare piu spazio possibile; si e quindi
deciso di seguire il modello architetturale piu conveniente in termini di occu-
pazione. Ecco perche la nostra scelta si e focalizzata sulla DataUnit a basse
prestazioni.
In questo capitolo si illustreranno le specifiche dei moduli da noi imple-
mentati, partendo dalla DataUnit; si descriveranno poi le righe e le celle che
compongono questa unita. Gli altri due moduli visti sono la KeyUnit e la
ControlUnit.
3.1 Implementazione della DataUnit
La nostra implementazione divide la DataUnit in cinque righe; quattro
di queste contengono le sedici DataCell (queste verrano indicate con Row0,
Row1, Row2, Row3) mentre una contiene le quattro S-BOX (denominata
41

CAPITOLO 3. LA SOLUZIONE PROPOSTA 42
Row SBOX). La DataUnit ha un ingresso da trentadue bit, per ricevere in
quattro cicli di clock l’intero testo da cifrare, e un ingresso da 128 bit per
la chiave di round. Compito di quest’unita e dividere il testo in ingresso in
sottogruppi da otto bit e mandarli alle righe. La stessa operazione viene fatta
per la chiave: anche questa e quindi divisa in sedici sottogruppi da otto bit
per fornire a ogni DataCell la chiave necessaria per eseguire l’AddRoundKey.
en t i t y datauni t i s port (inH : in s t d l o g i c v e c t o r ( 31 downto 0 ) ; −− i n g r e s s o
p inH : in s t d l o g i c v e c t o r ( 3 downto 0 ) ; −− pa r i t a i n g r e s s ok : in s t d l o g i c v e c t o r ( 127 downto 0 ) ; −− ch iave da 128 b i t
p k : in s t d l o g i c v e c t o r ( 15 downto 0 ) ; −− pa r i t a ch iavesbox in : in s t d l o g i c v e c t o r (31 downto 0 ) ;
p sbox in : in s t d l o g i c v e c t o r (3 downto 0 ) ;c t r l i n : in T CTRL IN ; −− i nd i c a se sono a t t i v i g l i i n g r e s s i o r i z z o n t a l i o v e r t i c a l ic t r l k e y : in T CTRL KEY; −− i nd i c a se s i s ta facendo o meno l ’ addroundkeyc t r l d e c : in T ENCDEC; −− i nd i c a se s i s ta cod i f i c ando o decod i f i c andoc t r l m i x : in T CTRL MIX; −− i nd i c a se s i s ta facendo o meno l a mixcolumnc t r l s u b : in T CTRL SUB; −− i nd i c a se s i s ta facendo o meno l a SubByte su i da t ictr l num sub : in i n t e g e r range 0 to 7 ;c lock , r e s e t : in s t d l o g i c ;r e s t a r t , broken : out s t d l o g i c ; −− s e g n a l i che ind i cano l a presenza d i a t t a c ch ioutH : out s t d l o g i c v e c t o r ( 31 downto 0 ) ; −− u s c i t a
p outH : out s t d l o g i c v e c t o r ( 3 downto 0 ) ; −− pa r i t a u s c i t aoutKey : out s t d l o g i c v e c t o r (31 downto 0 ) ; −−
p outKey : out s t d l o g i c v e c t o r (3 downto 0) ) ;end datauni t ;
Figura 3.1: Elenco segnali DataUnit
Ogni riga della DataUnit e collegata con la successiva tramite gli ingressi
verticali, quindi le uscite della riga “superiore” saranno gli ingressi di quella
“inferiore” (ad esempio le uscite della Row1 saranno collegate agli ingressi
della Row2). Lo stesso si verifica anche tramite la Row SBOX e la riga uno.
A causa del registro presente nelle celle, il passaggio e la memorizzazione dei
dati da una riga di DataCell all’altra avviene in un ciclo di clock (tranne
che tra Row0 e Row1 dove ne occorrono due; il perche e spiegato nel pa-
ragrafo 3.2) mentre, tra la riga delle S-BOX e la riga zero se ne utilizzano
tre; questo fatto e motivato dall’implementazione a pipeline della SubByte
che utilizza tre registri: uno nella S-BOX, uno nella Row SBOX e uno nel-
la DataCell. L’implementazione a pipeline viene usata per bilanciare i vari
percorsi presenti nell’architettura in modo da avere ad esempio, il percorso

CAPITOLO 3. LA SOLUZIONE PROPOSTA 43
per eseguire la SubByte simile a quello per eseguire la MixColumn insieme
con l’AddRoundKey.
Oltre al collegamento tramite gli ingressi verticali le quattro righe dati
sono connesse tra loro in modo da fornire i dati utili per eseguire la MixCo-
lumn; ogni cella infatti, per fare questa trasformazione ha bisogno dei dati
delle altre tre celle presenti nella stessa colonna.
La DataUnit permette alla KeyUnit di usare la riga di S-BOX per calcola-
re la chiave del round successivo: i dati provenienti dalla KeyUnit arriveranno
agli ingressi delle S-BOX solo quando si stanno eseguendo le operazioni di
MixColumn e di AddRoundKey, quindi mentre la SubByte non e eseguita
sui dati.
L’unita dati ha due uscite: una, outH, riporta i valori in uscita dalle righe
e l’altra, outKey, riporta sempre l’uscita delle S-BOX.
Oltre alle operazioni descritte in precedenza, la DataUnit ha il compito
di calcolare la parita del dato e, al suo interno, e stata implementata anche
la funzione svolta dalla CBC Unit descritta nel paragrafo 1.6
3.2 Implementazione delle Righe
Come gia detto, l’architettura presenta quattro righe al cui interno si
trovano quattro celle dati e una riga di sole S-BOX. Le righe composte da
DataCell sono praticamente identiche tra loro tranne che la Row0 che differi-
sce dalle altre tre per la presenza al suo interno di un Barrel Shifter. Questo
componente non e altro che un registro utilizzato con lo scopo di esegui-
re l’operazione di ShiftRow (alcune condizioni scritte in VHDL per eseguire
questa funzione si possono vedere in figura 3.2); questo e il motivo per cui il
passaggio e la memorizzazione dei dati dalla riga zero alla uno ha bisogno di
due cicli di clock.
Ogni riga dati ha quattro ingressi verticali per il collegamento con le altre,
un ingresso orizzontale per caricare i dati da criptare, dodici ingressi per
memorizzare i dati utili alla MixColumn in arrivo dalle altre righe, quattro
ingressi di otto bit per la chiave da utilizzare durante l’AddRoundKey; in
uscita troviamo invece l’uscita orizzontale da attivare quando i dati sono

CAPITOLO 3. LA SOLUZIONE PROPOSTA 44
i f ( ( ( c t r l s u b=S BOX and ( ctr l num sub=3 and c t r l d e c=S ENC) ) or ( ctr l num sub=7 and c t r l d e c=S DEC) ) ) then−− Tras la i da t i d i una po s i z i on e a s i n i s t r a
outA <= inD ;p outA <= p inD ;
outB <= inA ;p outB <= p inA ;
outC <= inB ;p outC <= p inB ;
outD <= inC ;p outD <= p inC ;
e l s i f ( ( ctr l num sub = 3 and c t r l d e c = S DEC) or ( ctr l num sub = 1 and c t r l d e c = S ENC) ) then−− Tras la i da t i d i t r e p o s i z i o n i a s i n i s t r a
outA <= inB ;p outA <= p inB ;
outB <= inC ;p outB <= p inC ;
outC <= inD ;p outC <= p inD ;
outD <= inA ;p outD <= p inA ;
Figura 3.2: Due condizioni presenti nel Barrel Shifter per l’esecuzione dellaShiftRow
pronti, le quattro uscite verticali per il passaggio dei dati da riga a riga e
le quattro uscite per fornire alle celle delle altre righe i dati per eseguire la
MixColumn. In tutte le righe si trovano poi alcuni segnali di controllo per
gestire le funzioni e le operazione da svolgere. In piu ogni segnale in ingresso
e uscita e accompagnato dal relativo segnale di parita, utile per rilevare se
in quella riga si e verificato un errore. Un esempio di una riga composta da
DataCell si trova in figura 3.3 (in figura non sono presenti i segnali di parita).
La Row SBOX e invece molto differente dalle altre righe appena descrit-
te: ha anch’essa quattro ingressi e quattro uscite verticali (con relativi bit di
parita) ma non presenta alcun collegamento per quanto riguarda la MixCo-
lumn o la chiave. Al suo interno si trova un registro per memorizzare i dati
in uscita che gia nel paragrafo 3.1 era stato indicato come uno dei registri
utili alla realizzazione della SubByte per ottenere la modalita a pipeline.
3.3 Implementazione della DataCell
All’interno della DataCell si trova un registro di otto bit per memorizza-
re i dati e un’entita con il compito di svolgere l’operazione di MixColumn.

CAPITOLO 3. LA SOLUZIONE PROPOSTA 45
Figura 3.3: Riga di 4 DataCell
Tramite poi uno semplice XOR con la chiave in ingresso viene implementato
anche l’AddRoundKey.
Gli ingressi che si possono trovare sono:
• un ingresso verticale per l’invio dei dati tra una riga e la successiva
spiegato nei precedenti paragrafi;
• un ingresso orizzontale utilizzato per il caricamento dei dati;
• tre ingressi su cui si possono trovare i dati da utilizzare per eseguire la
MixColumn;
• un ingresso per la chiave da usare durante l’AddRoundKey;
• sette ingressi per i vari segnali di controllo come ad esempio il Clock e
il Reset.
In uscita invece si hanno solo due segnali:
• un uscita con il dato “operato” cioe dopo che sul dato in ingresso sono
state effettuate la MixColumn e l’AddRoundKey;
• un uscita con il dato pronto per essere inviato alle altre celle della stessa
colonna.

CAPITOLO 3. LA SOLUZIONE PROPOSTA 46
Anche in questo caso ogni ingresso (tranne quelli riferiti ai segnali di
controllo) ed ogni uscita, e accompagnato dal proprio segnale di parita. E
proprio in questo modulo, infatti, che viene eseguita la rilevazione d’errore.
Nella figura 3.4 si puo vedere lo schema interno della DataCell.
Figura 3.4: Schema della DataCell
3.4 Implementazione della KeyUnit
Compito di questa unita e di calcolare la chiave necessaria ad ogni round
partendo da quella in ingresso.
Esistono due diverse implementazioni della KeyUnit: la prima prevede di
eseguire il calcolo delle varie chiavi in una fase di inizializzazione e poi me-
morizzare quelle ottenute in registri, la seconda prevede invece di calcolare
le chiavi nello stesso periodo in cui viene eseguita la codifica. La nostra im-
plementazione segue questa seconda strada; in questo modo si evitano errori

CAPITOLO 3. LA SOLUZIONE PROPOSTA 47
Figura 3.5: Schema della KeyUnit
che possono occorrere nei registri memorizzanti le varie chiavi, si risparmia
sull’area utilizzata e inoltre riusciamo a sfruttare le latenze della DataUnit.
Come si e gia detto per il calcolo della chiave si ha bisogno di quattro
S-BOX per eseguire l’operazione di SubWord ; per risparmiare sullo spazio,
la KeyUnit sfrutta le S-BOX della DataUnit quando questa sta eseguendo
le operazioni di AddRoundKey e MixColumn. In codifica le chiavi vengono
calcolate iterativamente partendo da quella fornita dall’utente, mentre in
decodifica e necessaria una prima fase di inizializzazione; infatti la prima
chiave a essere utilizzata e l’ultima della codifica e la chiave di cifratura
viene usata solo all’ultimo round.
Nella KeyUnit e presente un registo KeyStorage che permette di memo-
rizzare la prima chiave che deve essere usata. Questo e necessario perche
puo capitare di dover codificare piu blocchi di dati con la stessa chiave: in
codifica viene quindi salvata la chiave di cifratura mentre in decodifica viene

CAPITOLO 3. LA SOLUZIONE PROPOSTA 48
salvata l’ultima chiave evitando cosı di rieseguire l’inizializzazione.
In questo modulo viene anche calcolata la parita della chiave in ingresso
che, insieme alla chiave stessa, viene passata alla DataUnit.
3.5 Implementazione della ControlUnit
La ControlUnit e l’unita finalizzata a coordinare le varie operazioni da
eseguire e puo essere vista come una macchina a stati finiti. In base agli
ingressi che riceve, deve essere in grado ad esempio di scegliere se eseguire la
codifica o la decodifica, se far partire il calcolo della chiave per la decodifica
o se farla prelevare alla KeyUnit da un registro, se fornire i dati in uscita o
se continuare a cifrare, e cosı via. I segnali in ingresso alla ControlUnit sono:
• encdec: usato per decidere se si deve codificare o decodificare;
• go crypt: indicante il momento in cui la cifrature ha inizio;
• go key: segnala l’istante in cui la chiave di cifratura viene fornita per
poi essere memorizzata;
• key size: indica se la chiave deve essere da 128, 192 o 256 bit.
Naturalmente a questi vanno aggiunti il segnale di clock e di reset che sono
comuni a tutte le unita.
In uscita abbiamo svariati segnali ma qui verranno riportati solo quelli
piu significativi:
• ctrl dec: indica alle altre unita se ci troviamo in codifica o in decodi-
fica;
• ctrl mix, ctrl sub, ctrl key: se attivi, segnalano l’esecuzione o della
MixColumn o della SubByte o dell’AddRoundKey;
• ctrl in: indica se sono attivi gli ingressi orizzontali o quelli verticali;
• first enc: quando attivo comunica che il blocco dati che si sta cifrando
e il primo della serie;

CAPITOLO 3. LA SOLUZIONE PROPOSTA 49
• data out ok: quando attivo segnala che i dati sono stati correttamente
cifrati e sono pronti per essere consegnati all’esterno.
In figura 3.6 si puo vedere a grandi linee come funziona l’unita di controllo.
Figura 3.6: Stati della ControlUnit
Per costruire la nostra macchina a stati, ci avvaliamo di un segnale interno
che chiameremo state; questo segnale assumera ad ogni ciclo di clock un
valore differente in un campo limitato di possibilita.
Inizialmente State si trovera nello stato IDLE; in questo stato di ripo-
so verranno settati i vari segnali e, quando go key = 1, si avra l’acquisi-
zione della chiave per la cifratura. Prima di proseguire nello stato IDLE,
verra controllato il segnale encdec, che indica se dovremo codificare o deco-
dificare: nel caso si debba decodificare lo stato successivo sara quello chia-
mato ST KEY 0, il quale rappresenta il primo passo per l’esecuzione della
KeyExpansion. Dallo stato ST KEY 0 si passera allo stato ST KEY 1, poi
a ST KEY 2 e ST KEY 3: durante questi passaggi, vari segnali verrano mo-
dificati per poter eseguire l’espansione della chiave da parte della KeyUnit.
Arrivati allo stato ST KEY 3, si potra tornare o a state = ST KEY 0 (nel

CAPITOLO 3. LA SOLUZIONE PROPOSTA 50
caso ci siano ancora chiavi da calcolare) o a state = IDLE (nel caso si sia
arrivati a calcolare l’ultima chiave, quindi la prima per la decodifica).
Ora che abbiamo la chiave di decifratura, le strade tra la codifica e la
decodifica si uniscono; in entrambi i casi infatti con il segnale go crypt posto
a uno, passeremo allo stato indicato con ST DU L0, che corrisponde al primo
per il caricamento dati. I successivi stati saranno ST DU L1, ST DU L2 e
ST DU L3 nel quale sara eseguito anche l’operazione di AddRoundKey.
Dopo l’esecuzione dell’AddRoundKey, si passa alla sequenza di stati che
rappresentano un cosiddetto round standard di cui si e gia parlato nel pa-
ragrafo 1.3(per la codifica) e 1.4(per la decodifica); i valori assunti da state
in questo round vanno da ST DU R0 a ST DU R5. Arrivati a ST DU R5,
lo stato riassumera il valore ST DU R0 se si dovra compiere un’altro round
normale, altrimenti prendera il valore ST DU F0 corrispondente al primo
passo del round finale. Questo round continuera fino al valore ST DU F5,
dove il controllore si trovera all’ennesimo bivio: se go crypt e di nuovo uguale
a uno, cioe se si devono eseguire altre cifrature, avremo state=ST DU L0,
altrimenti state=ST DU O0. In entrambi i casi pero verra attivato il flag
data out ok, in quanto i dati devono essere messi a disposizione dell’utente.
Nel caso si stia eseguendo l’ennesima cifratura, la macchina a stati seguira di
nuovo il percorso appena descritto a partire dallo stato ST DU L0 e attivan-
do il segnale per eseguire lo XOR tra i dati in ingresso e quelli in uscita (viene
attivato il CBC), altrimenti il tutto si concludera passando alla sequenza di
stati che permette l’uscita dei dati; questi stati sono ST DU O0, ST DU O1,
ST DU 02.
Alla fine dell’intera cifratura, si ritornera allo stato di riposo IDLE.
3.6 Estensione per la Riconfigurazione
Per permettere la riconfigurazione dell’architettura proposta e necessa-
rio sottostare a differenti vincoli, alcuni sono gia stati citati nei paragrafi
precedenti (vedi 2.3.1) ma uno rimane ancora da analizzare e quindi sara og-
getto di questo paragrafo. Il vincolo che si andra ad analizzare riguarda la
dimensione dei canali di comunicazione tra i moduli riconfigurabili e non.

CAPITOLO 3. LA SOLUZIONE PROPOSTA 51
Tale canale ha una dimensione fissata di 32 bit; da cio si deduce che tra
moduli fissi e moduli riconfigurabili debbano passare, uno alla volta, dati di
dimensione pari a 32 bit.
L’intenzione iniziale, come mostrato in figura 3.7, era di dividere l’archi-
tettura generale in due parti: una riconfigurabile (composta solamente dalla
DataUnit) e una fissa (composta da KeyUnit e ControlUnit).
Figura 3.7: Divisione FPGA
Questi moduli comunicano tra loro attraverso i seguenti segnali:
• chiave da 128 bit passata dalla KeyUnit alla DataUnit;
• parita della chiave formata da 16 bit e anch’essa passata dalla KeyUnit
alla DataUnit;
• 32 bit della chiave da mandare alle S-BOX della DataUnit quando
questa non le utilizza;
• 4 bit per la parita della chiave del punto precedente;
• 32 bit passati dalla DataUnit alla KeyUnit dopo aver eseguito la S-BOX
sulla chiave;

CAPITOLO 3. LA SOLUZIONE PROPOSTA 52
• 4 bit per la parita della chiave del punto precedente;
Oltre ai segnali appena visti che riguardano solo la comunicazione tra
DataUnit e KeyUnit, ce ne sono altri nove che vengono inviati dalla Con-
trolUnit alla DataUnit: questi sono CTRL IN, CTRL KEY, CTRL DEC,
CTRL MIX, CTRL SUB, CTRL NUM SUB, FIRST ENC, DATA OUT OK,
CBC (per il significato di ogni singolo segnale fare riferimento al paragrafo
3.5) tutti di un bit tranne CTRL NUM SUB che e di tre. In totale si ha che
tra parte fissa e parte riconfigurabile la comunicazione avviene tramite 227
bit.
Naturalmente in questo modo il passaggio dei dati non e possibile avendo,
come detto, canali di 32 bit; bisogna quindi dividere la chiave da 128 bit in
quattro segnali da 32 bit (anche la sua parita viene divisa in quattro parti
da 4 bit).
Ora, essendo necessario spedire tutta la chiave alla DataUnit, si capisce
come sia vincolante dover attendere quattro cicli di clock per il solo trasfe-
rimento della chiave e aumentare cosı i cicli di ogni round da 6 ad un totale
di 10. I round normali per eseguire la codifica sono nove e si ottiene cosı un
totale di 104 cicli (9 • 10 + 10 + 4, ponendo 4 cicli per il caricamento dati
e 10 cicli anche per l’ultimo round) anziche 64. In definitiva si ottiene un
aumento di circa il 63% del tempo di elaborazione necessario per ogni blocco
dati, un costo non del tutto indifferente.
E vero che la dimensione massima di un bus per la comunicazione tra
moduli puo essere aumentata ma in definitiva diventa difficile trovare una
FPGA in grado di supportare un canale per la comunicazione di simili di-
mensioni. Si e deciso quindi di non implementare questa soluzione in quanto
rallenterebbe la parte di calcolo.
Tale metodologia presuppone che una volta verificatosi l’attacco si debba
bloccare la codifica, riprogrammare l’FPGA e far partire la codifica dall’ini-
zio. Con la riconfigurazione totale non si ha piu la divisione in parte fissa o
parte riconfigurabile ma tutta l’architettura e da considerarsi riconfigurabile.

Capitolo 4
Verifica e Risultati
In questo capitolo vengono mostrate alcune simulazioni dell’architettura
eseguite con Modelsim; si illustrera per prima cosa una normale simulazione
dell’architettura per far meglio comprendere al lettore il suo funzionamento
e successivamente verra simulato un’attacco in fase di codifica mettendo in
evidenza cio che accade. Si descrivera inoltre l’occupazione della scheda su
alcune FPGA.
4.1 Simulazione con Modelsim
In questo paragrafo si cerchera, attraverso una simulazione con Modelsim,
di presentare al meglio una fase di codifica; per la decodifica l’unica differenza
e l’istante di inizio della fase di cifratura vera e propria in quanto prima del
caricamento dei dati da crittografare si deve eseguire l’inizializzazione della
chiave. Per meglio visualizzare il tutto, nelle immagini verranno omessi i
segnali di parita.
Il ciclo di clock, utilizzato per sincronizzare la nostra architettura, ha un
periodo pari a 10ns e un duty cicle del 50% (cioe il periodo in cui il clock si
trova nello stato alto e uguale a quello in cui si trova nello stato basso).
Come si puo vedere nella figura 4.1, dopo aver eseguito due cicli di reset
e la ricezione della chiave che dura un ciclo di clock (da 20ns a 30ns), si ha
l’inizio della fase di caricamento dei dati dall’esterno. Questo procedimento
inizia memorizzando i dati nelle DataCell piu esterne e ad ogni ciclo di clock
53

CAPITOLO 4. VERIFICA E RISULTATI 54
questi vengono spostati alla cella adiacente. A 80ns (cioe dopo quattro cicli)
finisce questa fase di caricamento dati e viene eseguita la prima operazione
di AddRoundKey.
Figura 4.1: Caricamento dei dati
A seguito di questa prima operazione di AddRoundKey, iniziano i round
cosidetti normali. Ogni round e costituito da quattro operazioni SubByte,
ShiftRow, MixColumn e AddRoundKey che vengono svolte in sequenza. Nel-
l’immagine 4.2 si puo notare lo svolgersi di un normale ciclo di round. La
prima operazione, SubByte, dura ben 5 cicli di clock perche i dati devono
essere spostati da una riga alla successiva per raggiungere le S-BOX. Qui
si comprende la differenza tra l’architettura standard e quella ad alte pre-
stazioni: quest’ultima ha infatti sedici S-BOX, una per ogni DataCell, che
permettono di ridurre a due il numero di cicli necessari per effettuare la
SubByte.
Nella figura 4.3 viene mostrato come viene svolta la ShiftRow; i dati in

CAPITOLO 4. VERIFICA E RISULTATI 55
Figura 4.2: Round Normale
ingresso nella prima riga vengono riportati in uscita un ciclo dopo traslati di
un opportuno offset. Le ultime due operazioni, MixColumn e AddRoundKey,
vengono eseguite in un unico ciclo all’interno della DataCell.
Una volta eseguiti i round normali, si termina la fase di codifica con le
operazioni di ShiftRow, MixColumn e AddRoundKey che rappresentato il
round finale (figura 4.4); fatto questo i dati sono pronti per essere inviati
in uscita. Come si puo vedere i dati delle DataCell piu esterne vengono
concatenati e mandati in uscita e ogni cella trasmettera alla successiva quelli
immagazzinati.
Nel caso della decodifica, prima dell’acquisizione dei dati si ha una fase
di inizializzazione della chiave che serve a calcolare la prima chiave utile per
la decodifica; questa fase dura 41 cicli di clock. La chiave per la decifratura
verra memorizzata in un registro in modo da non dover piu eseguire questa
fase, onerosa in termini di tempo.

CAPITOLO 4. VERIFICA E RISULTATI 56
Figura 4.3: ShiftRow in un Round Normale
Figura 4.4: Round Finale
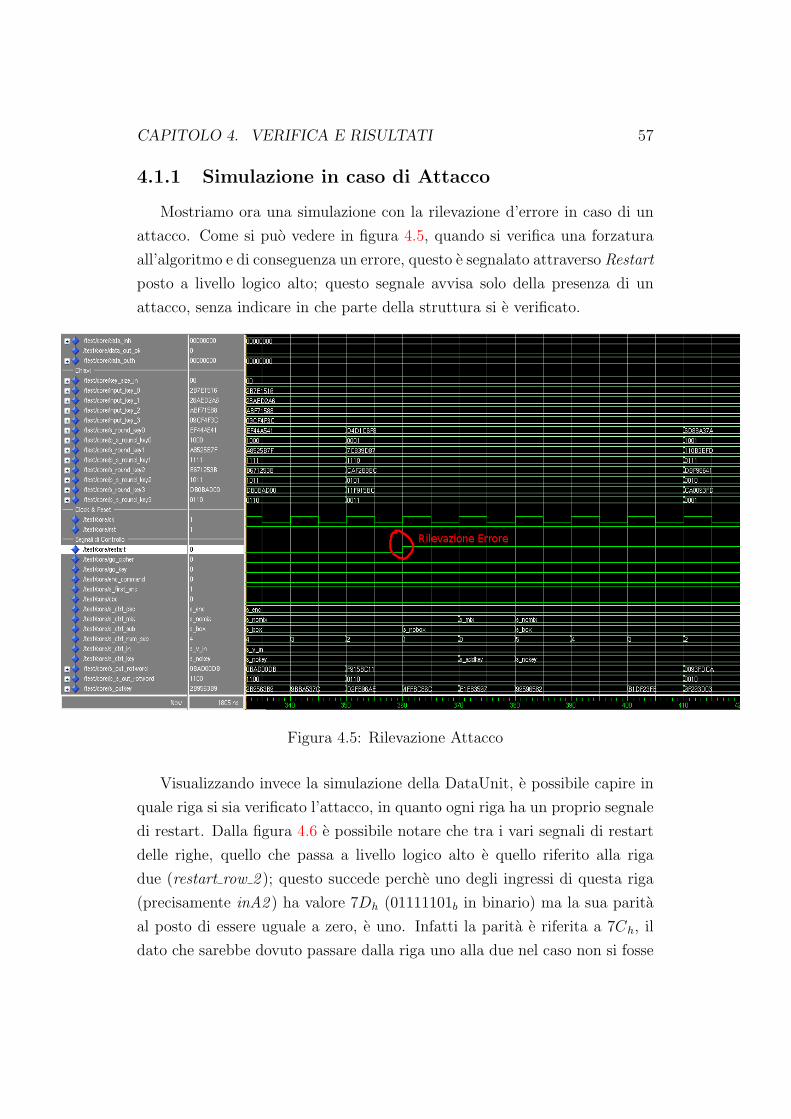
CAPITOLO 4. VERIFICA E RISULTATI 57
4.1.1 Simulazione in caso di Attacco
Mostriamo ora una simulazione con la rilevazione d’errore in caso di un
attacco. Come si puo vedere in figura 4.5, quando si verifica una forzatura
all’algoritmo e di conseguenza un errore, questo e segnalato attraverso Restart
posto a livello logico alto; questo segnale avvisa solo della presenza di un
attacco, senza indicare in che parte della struttura si e verificato.
Figura 4.5: Rilevazione Attacco
Visualizzando invece la simulazione della DataUnit, e possibile capire in
quale riga si sia verificato l’attacco, in quanto ogni riga ha un proprio segnale
di restart. Dalla figura 4.6 e possibile notare che tra i vari segnali di restart
delle righe, quello che passa a livello logico alto e quello riferito alla riga
due (restart row 2 ); questo succede perche uno degli ingressi di questa riga
(precisamente inA2 ) ha valore 7Dh (01111101b in binario) ma la sua parita
al posto di essere uguale a zero, e uno. Infatti la parita e riferita a 7Ch, il
dato che sarebbe dovuto passare dalla riga uno alla due nel caso non si fosse
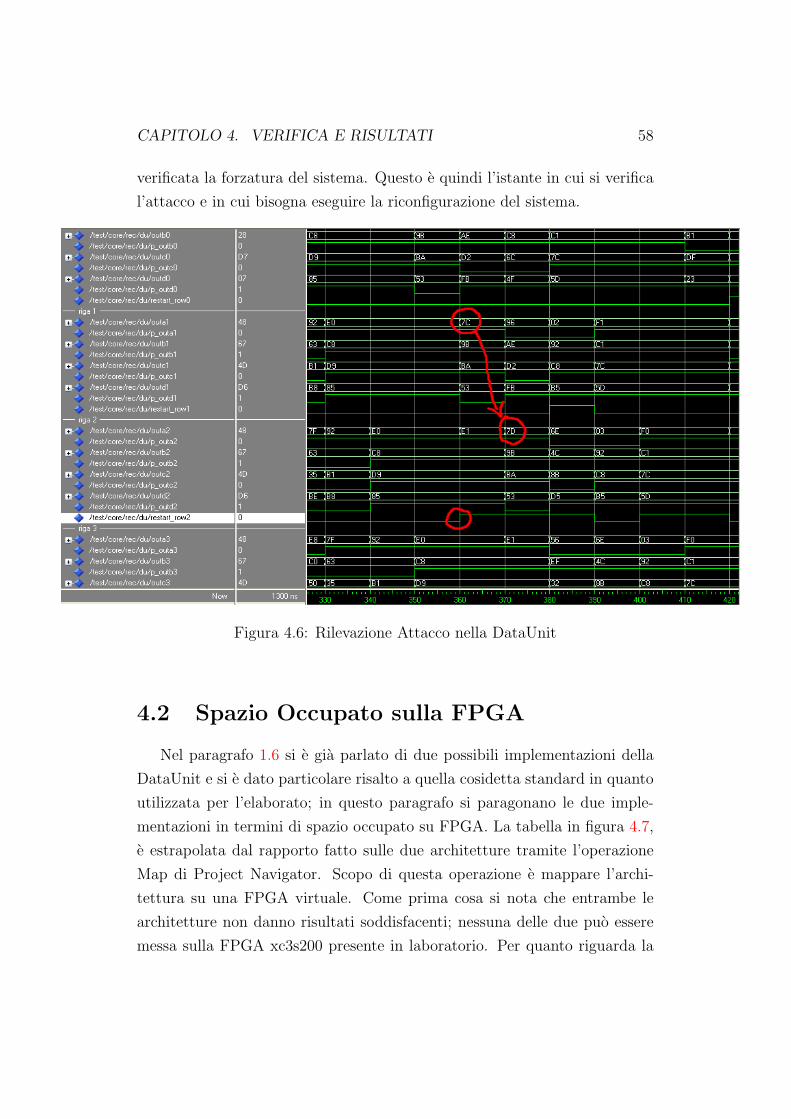
CAPITOLO 4. VERIFICA E RISULTATI 58
verificata la forzatura del sistema. Questo e quindi l’istante in cui si verifica
l’attacco e in cui bisogna eseguire la riconfigurazione del sistema.
Figura 4.6: Rilevazione Attacco nella DataUnit
4.2 Spazio Occupato sulla FPGA
Nel paragrafo 1.6 si e gia parlato di due possibili implementazioni della
DataUnit e si e dato particolare risalto a quella cosidetta standard in quanto
utilizzata per l’elaborato; in questo paragrafo si paragonano le due imple-
mentazioni in termini di spazio occupato su FPGA. La tabella in figura 4.7,
e estrapolata dal rapporto fatto sulle due architetture tramite l’operazione
Map di Project Navigator. Scopo di questa operazione e mappare l’archi-
tettura su una FPGA virtuale. Come prima cosa si nota che entrambe le
architetture non danno risultati soddisfacenti; nessuna delle due puo essere
messa sulla FPGA xc3s200 presente in laboratorio. Per quanto riguarda la

CAPITOLO 4. VERIFICA E RISULTATI 59
DataUnit ad alte prestazioni il risultato era previsto (come gia detto questa
ha sedici DataCell e occupa uno spazio notevole). Quello che invece e scon-
fortante e il risultato ottenuto con la DataUnit Standard; nonostante la sua
complessita sia inferiore rispetto quella sopracitata e nonostante non si sia
ancora tenuto conto dei bus di comunicazione tra i moduli, la tabella mo-
stra che i blocchi di input/output (IOB) della scheda sono comunque troppi
pochi.
Alte Prestazioni Basse PrestazioniTotal # Slice Registers(3840) 855 (22%) 696 (18%)
# used as Flip Flops 851 671# used as Latches 4 25
# of 4 input LUTs(3,840) 4627 (120%) 2953 (76%)# of occupied Slices(1920) 2319 (120%) 1699 (88%)
# of Slices containing only related logic 2111 (91%) 1699 (88%)# of Slices containing unrelated logic 208 0Total # of 4 input LUTs(3,840) 4627 (120%) 2957 (77%)
# of bonded IOBs(141) 233 (165%) 202 (143%)# of GCLKs(8) 1 2
Total equivalent gate count for design 36576 24060Additional JTAG gate count for IOBs 11184 9696
Peak Memory Usage 141 MB 128 MB
Figura 4.7: Tabella del Map su una Spartan xc3s200
Per il nostro progetto si e quindi pensato di usare, solo in linea teorica
in quanto non presente in laboratorio, una Virtex xcv1000; su questa scheda
il posizionamento avviene correttamente, anche con un buon risparmio di
spazio. A causa pero del bus di comunicazioni da usare per passare i dati
dalla parte riconfigurabile a quella fissa, e viceversa, non e possibile usufruire
della riconfigurazione parziale perche si avrebbe un rallentamento vistoso
delle prestazione come riferito nel paragrafo 3.6.
Passando dalla riconfigurazione parziale a quella totale i risultati non
cambiano per quanto riguarda l’utilizzo di spazio da parte dell’architettura,
ma questa volta, senza l’utilizzo del bus di comunicazione, l’unico problema
da risolvere riguarda gli input e gli output del progetto. Questo problema
puo essere risolto fornendo la chiave 32 bit alla volta in quattro cicli distin-
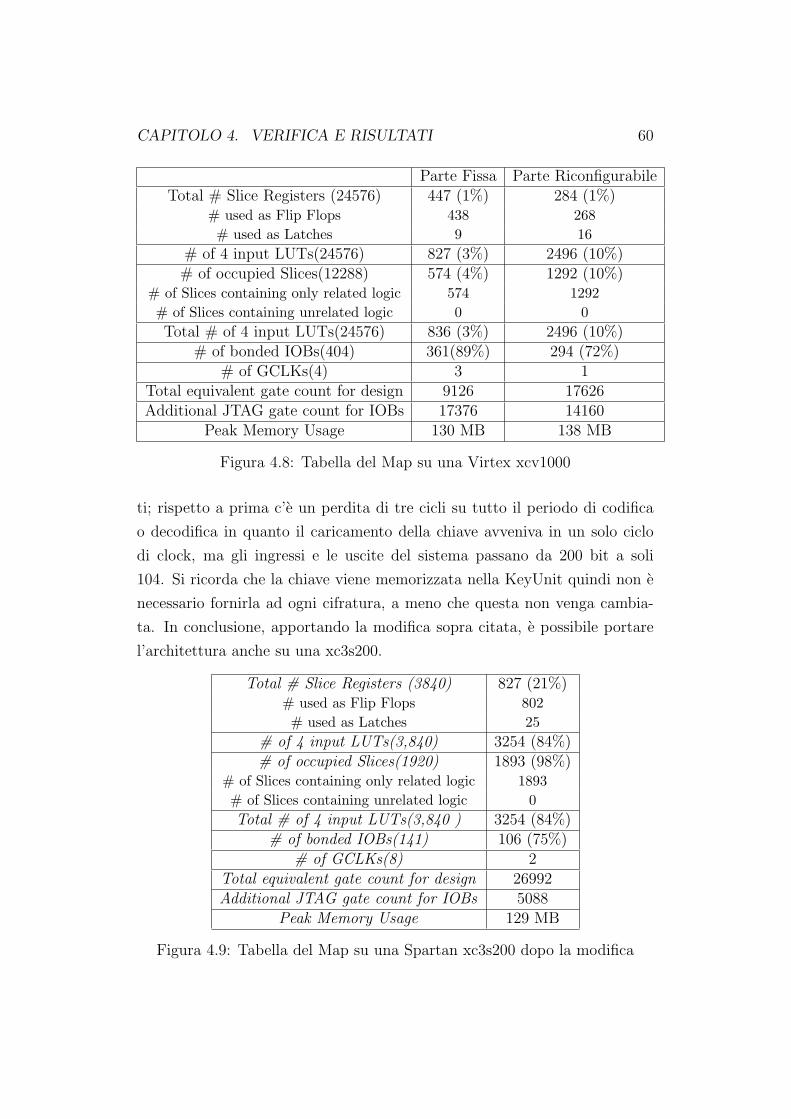
CAPITOLO 4. VERIFICA E RISULTATI 60
Parte Fissa Parte RiconfigurabileTotal # Slice Registers (24576) 447 (1%) 284 (1%)
# used as Flip Flops 438 268# used as Latches 9 16
# of 4 input LUTs(24576) 827 (3%) 2496 (10%)# of occupied Slices(12288) 574 (4%) 1292 (10%)
# of Slices containing only related logic 574 1292# of Slices containing unrelated logic 0 0Total # of 4 input LUTs(24576) 836 (3%) 2496 (10%)
# of bonded IOBs(404) 361(89%) 294 (72%)# of GCLKs(4) 3 1
Total equivalent gate count for design 9126 17626Additional JTAG gate count for IOBs 17376 14160
Peak Memory Usage 130 MB 138 MB
Figura 4.8: Tabella del Map su una Virtex xcv1000
ti; rispetto a prima c’e un perdita di tre cicli su tutto il periodo di codifica
o decodifica in quanto il caricamento della chiave avveniva in un solo ciclo
di clock, ma gli ingressi e le uscite del sistema passano da 200 bit a soli
104. Si ricorda che la chiave viene memorizzata nella KeyUnit quindi non e
necessario fornirla ad ogni cifratura, a meno che questa non venga cambia-
ta. In conclusione, apportando la modifica sopra citata, e possibile portare
l’architettura anche su una xc3s200.
Total # Slice Registers (3840) 827 (21%)# used as Flip Flops 802# used as Latches 25
# of 4 input LUTs(3,840) 3254 (84%)# of occupied Slices(1920) 1893 (98%)
# of Slices containing only related logic 1893# of Slices containing unrelated logic 0Total # of 4 input LUTs(3,840 ) 3254 (84%)
# of bonded IOBs(141) 106 (75%)# of GCLKs(8) 2
Total equivalent gate count for design 26992Additional JTAG gate count for IOBs 5088
Peak Memory Usage 129 MB
Figura 4.9: Tabella del Map su una Spartan xc3s200 dopo la modifica

Capitolo 5
Conclusioni e Sviluppi Futuri
Considerando la notevole importanza che hanno oggi internet e le comu-
nicazioni telematiche, e naturale pretendere che questi sistemi di telecomuni-
cazioni siano il piu possibile affidabili e sicuri attraverso sistemi di crittografia
robusti.
Cio che in questo nostro elaborato abbiamo realizzato e una struttura
in grado di rilevare gli attacchi e, in linea di principio, di tollerarli attra-
verso la predisposizione per la riconfigurazione. Si e visto che nonostante
i nostri sforzi l’architettura richieda risorse tali da non poter essere imple-
mentata su FPGA presenti in laboratorio se non dopo alcune modifiche e,
comunque, permette di sfruttare la riconfigurazione parziale solo sacrificando
le prestazioni in termini di tempo.
Si noti che l’idea alla base del nostro elaborato e comunque buona, infat-
ti la realizzazione di un’architettura resistente ai guasti su circuiti dedicati
comporta un notevole costo in termini di spazio, costi che si annullano uti-
lizzando la riconfigurazione sulle FPGA. Sulla base di queste considerazioni
e possibile ipotizzare alcuni sviluppi:
1. progettare una nuova architettura con lo scopo di ridurre gli ingressi,le
uscite e i segnali tra i moduli per permettere di utilizzare le FPGA
meno potenti e per permettere la riconfigurazione anche parziale senza
perdita di prestazioni in termini di tempo;
61

CAPITOLO 5. CONCLUSIONI E SVILUPPI FUTURI 62
2. studiare un’architettura che possa gestire chiavi anche da 192 e 256 bit
oltre che da 128 bit;
3. modificare la ControlUnit in modo da permettere l’utilizzo della nostra
implementazione per la riconfigurazione parziale.

Ringraziamenti
In questa sezione in cui possiamo sbizzarrirci a piu non posso senza dover
tener troppo conto della sintassi e della semantica italiana, vogliamo ringra-
ziare tutti quelli che in questi anni ci hanno sopportato e che ci hanno aiutato
a rendere questo viaggio meno tedioso; senza di loro questa nostra esperien-
za si sarebbe potuta trasformare in un tragico girone dantesco (anche se ci
siamo andati vicino).
A Vale per la sua canoscenza suprema della lingua inglese grazie alla
quale siamo riusciti a tradurre i piu difficili tra gli articoli, al Nova per la
sua eccentrica e carismatica voglia di fare ma soprattutto grazie ai suoi trip
mentali che ci hanno portati alla scoperta di nuovi mondi, alla Luisa grazie
per il suo barlume di stabilita in un luogo deviante quale il poli.
Vogliamo entrambi ringraziare le nostre famiglie per la fiducia riposta
nei nostri confronti anche nei momenti bui (per fortuna non ce ne sono stai
molti).
Ringraziamo anche l’Ingegner Marco Domenico Santambrogio e l’Ingegner
Paolo Maistri per averci seguito in questo progetto.
Nazza: infine da parte mia un ringraziamento ai “Mitici” (in rigoroso
ordine alfabetico: Corrado (Cocco), Enrico (Arrighe), Massimo (Berso) e
Michele (Chimele)) e agli altri amici che sarebbe troppo lungo nominare
tutti.
Fra: ringrazio ancora la mia famiglia e Angela, soprattutto quest’ultima,
per avermi sopportato in questo periodo di “sfaso”. Un altro grazie lo voglio
dare a tutte le persone che mi hanno permesso di arrivare fino a qui, quindi
grazie alla Dott.ssa Borgono, Angela di Cassina e Ronchi Arianna.
63

Bibliografia
[1] National Institute of Standards and Technology (NIST): “Federal In-
formation Processing Standards Publication 197 - Announcing the
Advanced Encryption Standard (AES)”, 26 Novembre 2001
[2] J. Daemen, V. Rijmen : “AES Proposal: Rijndael”, 1999
[3] S. Mangard, M. Aigner, S. Dominikus: “A Highly Regular and Scalable
AES Hardware Architecture”, IEEE Transaction on Computer Vol.52
No.4, pp. 483-491, Aprile 2003
[4] G. Bertoni, L. Breveglieri, I. Koren, P. Maistri, V.Piuri: “Error Analysis
and Detection Procedures for a Hardware Implementation of the Advan-
ced Encryption Standard”, IEEE Transaction on Computer Vol.52 No.4,
pp. 492-505, Aprile 2003
[5] Xilinx: “XAPP290”, Settembre 2004
[6] Xilinx: “XAPP151”, 20 Ottobre 2004
[7] J. Thorvinger: “Dynamic Partial Reconfiguration of an FPGA for
Computational Hardware Support”, Gennaio 2004
[8] R. Zunino: “Introduzione ai Dispositivi FPGA”, Edizione 2004
[9] M. D. Santambrogio: “Dynamic Reconfigurability in Embedded System
Design a Model for the Dynamic Reconfiguration”, 2001
[10] F. Cancare, S. Guddemi: “Un’Architettura per la Riconfigurabilita
Dinamica basata su Spartan-3”, 2005
64

BIBLIOGRAFIA 65
[11] L. Singhal, E. Bozorgzadeh: “Physically-aware Exploitation of
Component Reuse in a Partially Reconfigurable Architecture”, 2005
[12] M. Prada, R. Rossi: “Architettura Robusta per l’Algoritmo di Cifratura
AES”, DEI Politecnico di Milano, 2005
[13] S. Forcella, F. Forconi, S. Lai, D. Ninfo: “AES Advanced Encryption
Standard”
[14] Wikipedia: “http://wikipedia.org/”


















