Iakes Ezkurdia [email protected] Michael Tress tress@cnio...
72
Predicci Predicci ó ó n n de de estructura estructura de de prote prote í í nas nas Iakes Iakes Ezkurdia Ezkurdia [email protected] [email protected] Michael Tress Michael Tress [email protected] [email protected] Gonzalo Gonzalo L L ó ó pez pez [email protected] [email protected] C.N.I.O. C.N.I.O. Grupo de Biolog Grupo de Biolog í í a a Computacional Estructural Computacional Estructural
Transcript of Iakes Ezkurdia [email protected] Michael Tress tress@cnio...

PredicciPrediccióónn de de estructuraestructura de de proteproteíínasnas
IakesIakes EzkurdiaEzkurdia [email protected]@cnio.esMichael TressMichael Tress [email protected]@cnio.esGonzalo Gonzalo LLóópezpez [email protected]@cnio.es
C.N.I.O.C.N.I.O.Grupo de BiologGrupo de Biologíía a Computacional EstructuralComputacional Estructural

El plegamiento de proteínas vienedeterminado por su secuencia de
aminoácidos
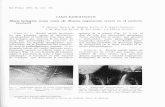
Las propiedades de las cadenas laterales afectan al empaquetamiento y a características locales como la estructura secundaria
Cadenas laterales
El plegamiento de una proteína se debe a una red estable de interacciones entre aminoácidos.

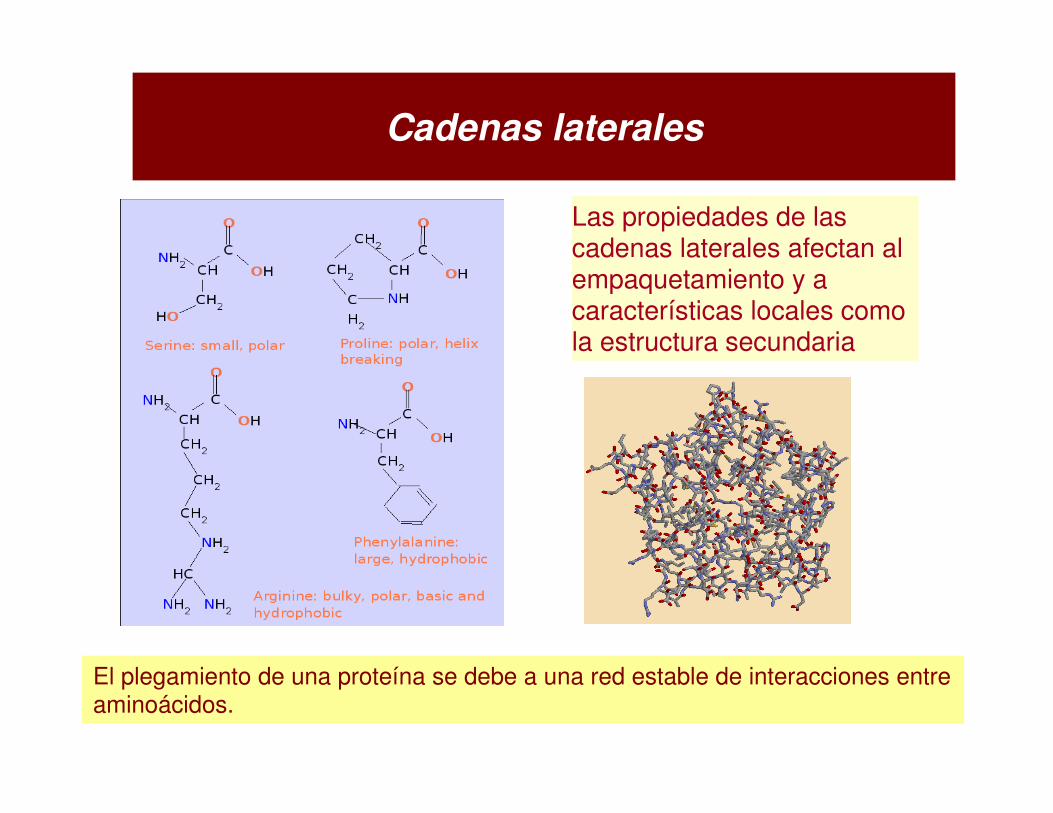
Por qué es importante predecir estructuras?
Obtención de secuencias de proteínas (a partir de DNA secuenciado) es rápido y barato. Con la obtención de estructuras ocurre lo contrario.
Por qué es importante predecir estructuras?
Resctricciones: X-ray -> obtención de un cristalNMR -> asignación del espectro

En definitiva, podemos generar
modelos de estructuras 3D para
proteínas de estructura desconocida
Proteínas con secuenciasmuy distintas pueden tenerun plegamiento similar:Divergencia y convergenciaevolutivasEspacio estructural
Espacio de secuencias
20%
En general, pequeñas variaciones en la secuencia de una proteína no afectan demasiado a la estructura 3D.

Genómica estructural

Bases de Bases de datosdatos de de estructurasestructuras de de proteproteíínasnas
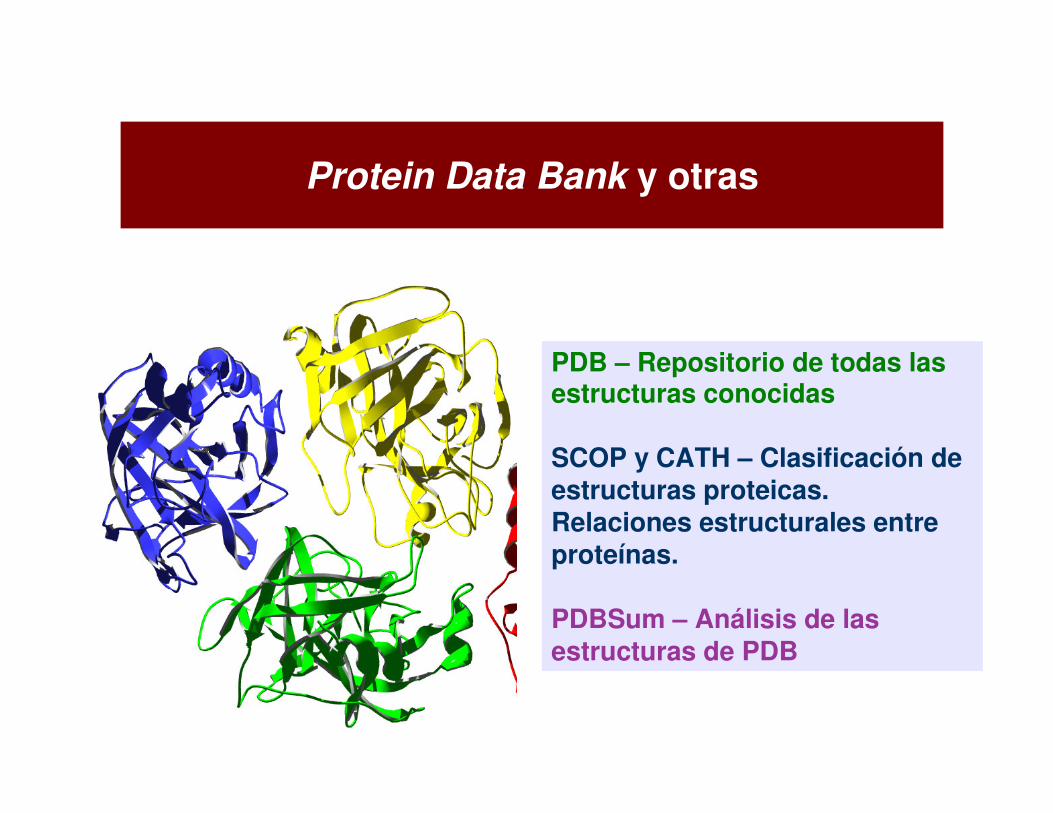
PDB – Repositorio de todas lasestructuras conocidas
SCOP y CATH – Clasificación de estructuras proteicas. Relaciones estructurales entre proteínas.
PDBSum – Análisis de lasestructuras de PDB
Protein Data Bank y otras
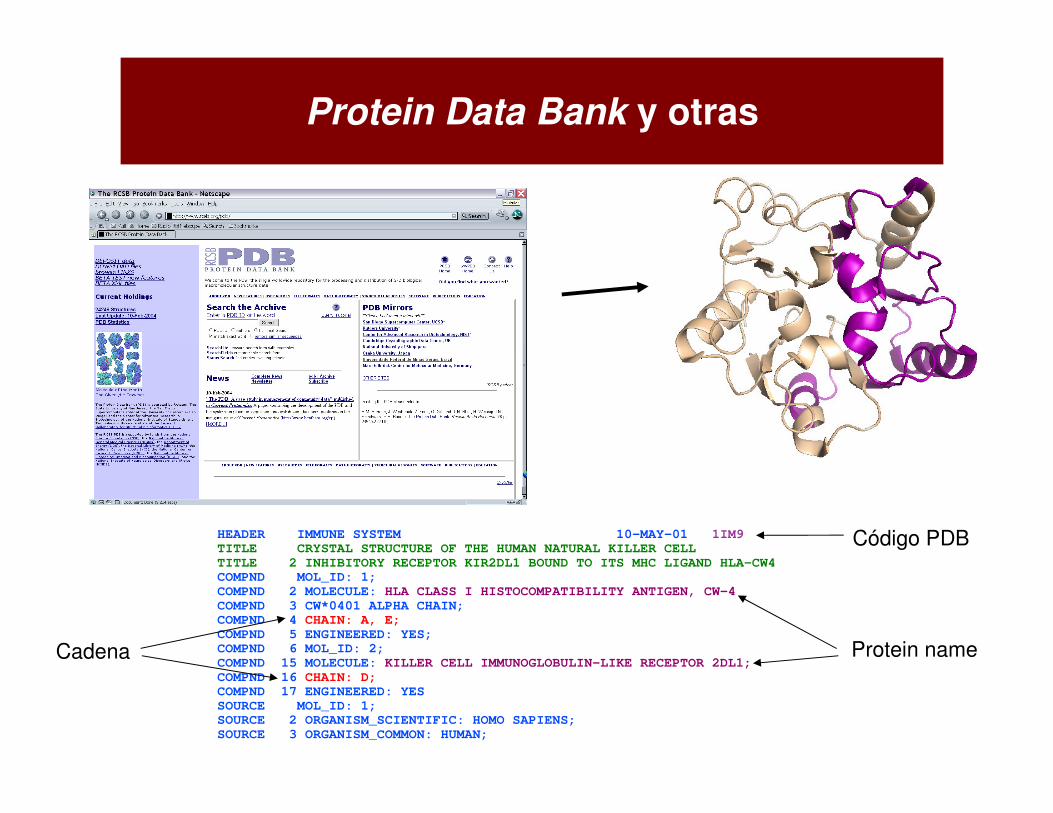
1CRN
HEADER IMMUNE SYSTEM 10-MAY-01 1IM9
TITLE CRYSTAL STRUCTURE OF THE HUMAN NATURAL KILLER CELL
TITLE 2 INHIBITORY RECEPTOR KIR2DL1 BOUND TO ITS MHC LIGAND HLA-CW4
COMPND MOL_ID: 1;
COMPND 2 MOLECULE: HLA CLASS I HISTOCOMPATIBILITY ANTIGEN, CW-4
COMPND 3 CW*0401 ALPHA CHAIN;
COMPND 4 CHAIN: A, E;
COMPND 5 ENGINEERED: YES;
COMPND 6 MOL_ID: 2;
COMPND 15 MOLECULE: KILLER CELL IMMUNOGLOBULIN-LIKE RECEPTOR 2DL1;
COMPND 16 CHAIN: D;
COMPND 17 ENGINEERED: YES
SOURCE MOL_ID: 1;
SOURCE 2 ORGANISM_SCIENTIFIC: HOMO SAPIENS;
SOURCE 3 ORGANISM_COMMON: HUMAN;
Código PDB
Protein nameCadena
Protein Data Bank y otras

ATOM 1 N THR 1 17.047 14.099 3.625 1.00 13.79 1CRN 70
ATOM 2 CA THR 1 16.967 12.784 4.338 1.00 10.80 1CRN 71
ATOM 3 C THR 1 15.685 12.755 5.133 1.00 9.19 1CRN 72
ATOM 4 O THR 1 15.268 13.825 5.594 1.00 9.85 1CRN 73
ATOM 5 CB THR 1 18.170 12.703 5.337 1.00 13.02 1CRN 74
ATOM 6 OG1 THR 1 19.334 12.829 4.463 1.00 15.06 1CRN 75
ATOM 7 CG2 THR 1 18.150 11.546 6.304 1.00 14.23 1CRN 76
ATOM 8 N THR 2 15.115 11.555 5.265 1.00 7.81 1CRN 77
ATOM 9 CA THR 2 13.856 11.469 6.066 1.00 8.31 1CRN 78
ATOM 10 C THR 2 14.164 10.785 7.379 1.00 5.80 1CRN 79
ATOM 11 O THR 2 14.993 9.862 7.443 1.00 6.94 1CRN 80
ATOM 12 CB THR 2 12.732 10.711 5.261 1.00 10.32 1CRN 81
ATOM 13 OG1 THR 2 13.308 9.439 4.926 1.00 12.81 1CRN 82
ATOM 14 CG2 THR 2 12.484 11.442 3.895 1.00 11.90 1CRN 83
ATOM 15 N CYS 3 13.488 11.241 8.417 1.00 5.24 1CRN 84
ATOM 16 CA CYS 3 13.660 10.707 9.787 1.00 5.39 1CRN 85
...
ATOM: una linea por cada átomo que incluye las coordenadascartesianas del átomo en el espacio
Átomo aminoácido Nº aa X Y Z B-factor
Protein Data Bank y otras
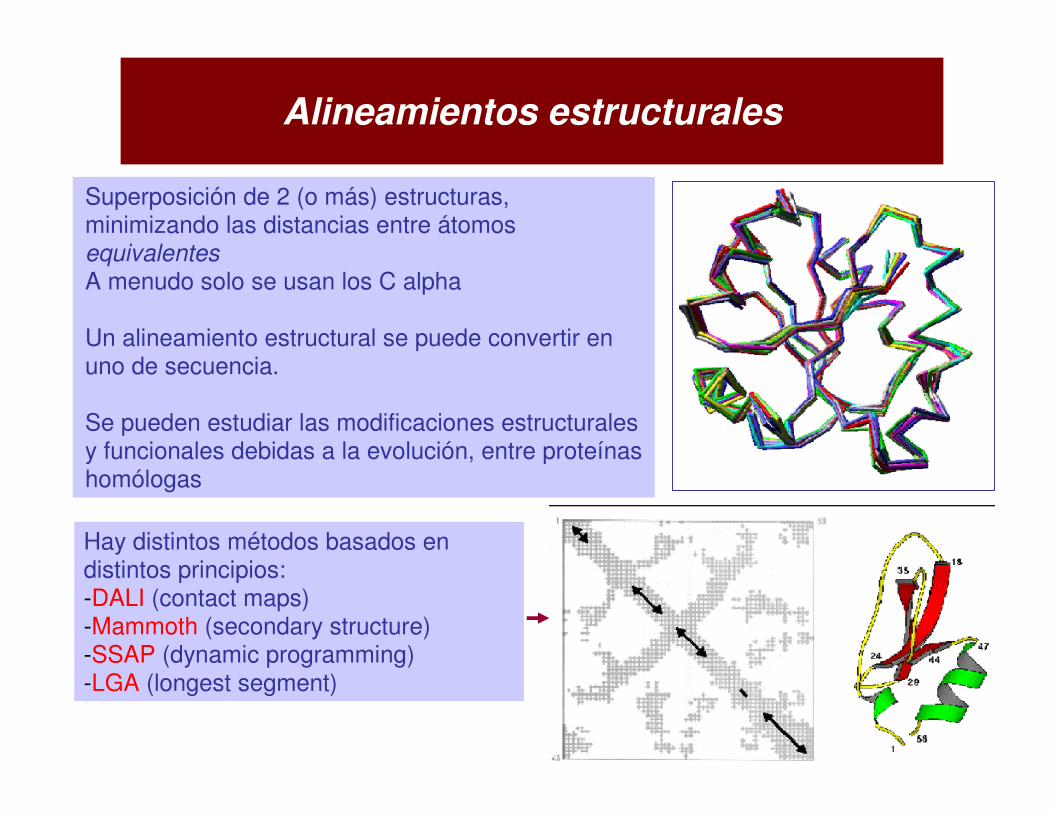
Superposición de 2 (o más) estructuras, minimizando las distancias entre átomosequivalentesA menudo solo se usan los C alpha
Un alineamiento estructural se puede convertir en uno de secuencia.
Se pueden estudiar las modificaciones estructuralesy funcionales debidas a la evolución, entre proteínashomólogas
Hay distintos métodos basados en distintos principios:-DALI (contact maps)-Mammoth (secondary structure)-SSAP (dynamic programming)-LGA (longest segment)
Alineamientos estructurales

Podemos comparar estructurashomologas, modelos, etc
RMSD: Root Mean Squared Deviation == distancia media entre átomos equivalentes
Similitud estructural

FAMILIA: Relación evolutiva obvia. Generalmente secuencias por encimadel 30% de identidad de secuencia.
SUPERFAMILIA: Probable origenevolutivo común. Pueden contenersecuencias disimilares pero lascaracterísticas estructurales y funcionales sugieren un origen común
FOLD: Alta similitud estructural. Proteínas que comparten la organización de los segmentos de estructura secundaria y las mismasconexiones topológicas
SCOP (Structural Classification of Proteins) �
Descripción de relaciones estructurales obtenidas de visu.

The CATH Database
Similar a SCOP. Hay 4 niveles de clasificación y se genera de forma semiautomática
Class: Estr. Secundaria y empaquetamiento
Architecture: Parecido a nivel de dominio
Topology (FOLD family): overall shape and connectivities.
Homologous superfamily: proteínas con un ancestro común. Busquedas por similitudde secuencia y posteriormentealineamientos estructurales usando el programa: SSAP

MSD: Macromolecular Structure Database
CE: Combinatorial Extension structure comparison and database
DALI: structural alignment program and database of alignments
LGA: structural comparison and structural alignments
CSA: collection of catalytic sites in the PDB
PDBSUM: collection of structural links for each template
FireDB: database of functionally important residues in structures
More Structural Databases/Alignment Programs

Predicción de características 1D
Gonzalo LGonzalo Lóó[email protected]@cnio.es
C.N.I.O.C.N.I.O.Grupo de BiologGrupo de Biologíía a
Computacional EstructuralComputacional Estructural

SumarioSumario
Introduccion
• Definición de características 1D.
• Estructura de proteínas
• Metodología: Implementación de un predictor.
Predicción de características 1D
• Estructura secundaria
• Desorden estructural
• Accesibilidad al solvente
• Proteínas transmembrana
• Otras características 1D

SumarioSumario
Introduccion
• Definición de características 1D.
• Estructura de proteínas
• Metodología: Implementación de un predictor.
Predicción de características 1D
• Estructura secundaria
• Desorden estructural
• Accesibilidad al solvente
• Proteínas transmembrana
• Otras características 1D

Definición de características 1D
• Denominamos características 1D de una secuencia a aquellas que pueden ser representadas por un único valor asociado a cada aminoácido (B. Rost).
• Estos valores suelen tomar la forma de etiquetas de estado, comopor ejemplo en el caso de la estructura secundaria (H->hélice, E->lámina, T->giro) �
• En algunos métodos, las asignaciones van acompañadas de un valor de fiabilidad.
• Las valores asociados pueden ser relativos (la accesibilidad al solvente puede representarse en porcentages) �

Definición de características 1D
• Algunas características 1D:
– Estructura secundaria
– Accesibilidad al solvente
– Modificaciones post-traduccionales
– Péptidos señal
– Regiones desordenadas
– Regiones transmembrana
• El estudio de estas propiedades ayuda a caracterizar funcional yestructuralmente una proteína.
– Los métodos de predicción de estructura basados en el reconocimiento del plegamiento, se nutren de estas técnicas
– Peptidos señal y regiones transmembrana -> localización celular
– Las modificaciones post-transcripcionales -> procesos biológicos como la regulación

SumarioSumario
Introduccion
• Definición de características 1D.
• Estructura de proteínas
• Metodología: Implementación de un predictor.
Predicción de características 1D
• Estructura secundaria
• Desorden estructural
• Accesibilidad al solvente
• Proteínas transmembrana
• Otras características 1D

Aminoácidos esenciales
>Estructura Primaria
ASKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTT
GKLPVPWPTLVTTFSYGVQCFSRYPDHMKRHDFFKSAMPEGYVQERTIFF
KDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNV
YIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHY
LSTQSALSKDPNEKRDHMVLLEFVTAAGITHGMDELYK

Enlace peptídico
GlyPro
Diagramas de Ramachandran

Estructura secundaria (helice α)�
αα

Estructura secundaria (lámina �β)�
• Cadenas ββββ
αα
ββpp
ββaa

Estructura secundaria
• Giros

¿Se puede obtener analíticamente la estructura?
• Ha sido verificado para muchas proteínas, que la estructura 3D de una proteína (es decir su plegamiento) viene determinada esencialmente por la especificidad de la secuencia.
• Dificultad para obtener valores suficientemente precisos de parámetros físicos fundamentales para la resolución del problema.
• El cálculo pormenorizado de la influencia sobre cada resíduo del resto de los aminoácidos de la secuencia, así como del solvente resulta computacionalmente intratable.

Aproximaciones alternativas
+++ Extrapolación de estructura/función por homología de secuencia (secuencia→secuencia).
++ Reconocimiento de plegamiento / Threading (secuencia→estructura conocida).
+ Predicción de estructura ab initio (secuencia→→nueva estructura,
pero sólo aprox.) �

SumarioSumario
Introduccion
• Definición de características 1D.
• Estructura de proteínas
• Metodología: Implementación de un predictor.
Predicción de características 1D
• Estructura secundaria
• Desorden estructural
• Accesibilidad al solvente
• Proteínas transmembrana
• Otras características 1D

Construcción de un predictorPreparación (i)�
1.- Definición del problema
2.- Extracción de un conjunto de entrenamiento que debe:
– representativo de la realidad
– ser fiable, poco ruido
– estar limpio de redundancias
– debe estar equilibrado
3.- Determinar de qué datos disponemos que puedan contener información sobre el problema a resolver.
1.- Predicción de estructura secundaria
2.- Conjunto de entrenamiento:
• Conjunto de proteínas que contenga contenga estructuras con distintos plegamientos, con formas alfa, beta, giros, etc
3.- tipo de aminoácido, hidrofobicidad, ventana de residuos, información evolutiva, carga, etc.

4.- Decidir qué método vamos a usar para construir el predictor (Redes Neuronales, Algoritmos genéticos, HMMs, Sistemas basados en reglas, SVM, ...).
5.- Elegir una codificación de la información asociada al problema acorde a éste y compatible con el método elegido.
Construcción de un predictorPreparación (ii)�
4.- Redes Neuronales, SVM…
5.- Todo se puede representar como un vector numérico.
ej: el tipo de aminoácido es un vector de 20 dígitos (0,1) donde cada posición representa un tipo.

6.- Entrenar el sistema, es decir introducir la información sobre el problema, hasta que el método establezca una relación (normalmente compleja e imperfecta) entre ella y la solución del problema.
7.- Comprobar el éxito del predictor generado frente a un conjunto de validación independiente del de entrenamiento.
Construcción de un predictorPreparación (iii) �
6.- La red neuronal se construye acorde con los datos de entrenamiento. Nos valemos de la teoría de aprendizaje automático para alcanzar el aprendizaje óptimo.
7.- El conjunto de validación es de similares características al de entrenamiento, sin embargo el conjunto de datos es distinto.

SumarioSumario
Introduccion
• Definición de características 1D.
• Estructura de proteínas
• Metodología: Implementación de un predictor.
Predicción de características 1D
• Estructura secundaria
• Desorden estructural
• Accesibilidad al solvente
• Proteínas transmembrana
• Otras características 1D
1D Prediction
Fold Re-
cognition
Homology
Modelling
Por que es importante predecir Por que es importante predecir 1D1D
Muchos métodos de predicción de estructura utilizan predicción de estructura secundaria.Es muy importante para Fold Recognition y esencial para métodos ab-initio.Además se suele usar a posterioi para decidir qué modelo es el más plausible y refinarlo, comparando la estructura secundaria del modelo con la predicha.

Es el primer paso hacia la predicción de estructura
3D. El siguiente sería colocar los elementos de
estr. secundaria en el espacio
Se usa en Fold Recognition combinandola con
perfiles de secuencia.
Tambien puede ayudar a la predicción de funcion
de las proteínas por busquedas de motivos de
estructura secundaria similares.
PorPor queque eses importanteimportante la la prediccionprediccion de de estructuraestructura secundariasecundaria??

Estructura secundaria (DSSP)�
1 ASKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTT
TTGGGGSSEEEEEEEEEEEETTEEEEEEEEEEEETTTTEEEEEEEETT
51 GKLPVPWPTLVTTFSYGVQCFSRYPDHMKRHDFFKSAMPEGYVQERTIFF
SS SS GGGGHHHHSSS GGG B GGGGGG HHHHTTTT EEEEEEEEE
101 KDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNV
TTS EEEEEEEEEEETTEEEEEEEEEEE TTSTTTTT B S EEE
151 YIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHY
EEEEEGGGTEEEEEEEEEEEETTS EEEEEEEEEEEESSSS SEE
201 LSTQSALSKDPNEKRDHMVLLEFVTAAGIT HGMDELYK
EEEEEEEE TT SSEEEEEEEEEEES
T = giro estabilizado por P de H H = α-helice, ~4 aa por vueltaG = helice 310, ~3 aa por vueltaI = helice phi, ~5 aa por vueltaB = conformacion βE = conformacion β formando laminaS = giro (sin P de H)�
Kabsch and Sander (1983) Biopolymers 22, 2577-2637
DSSP estudia la est 2ª en archivos de coordenadas atómicas basándose en patrones que tienen en cuenta:
•Geometría
•Puentes de Hidrógeno

Primera generación de métodos
Métodos estadísticos basados simplemente en la tendencia de cada aminoácido a formar cada uno de los elementos de estructura secundaria
•Chou y Fasman en 1974, propusieron el primero de estos métodos. Emplearon estadísticas extraídas de las 15 estructuras resueltas por cristalografía de rayos-X en aquella época. Estas probabilidades fueron calculadas para cada resíduo por separado. Más adelante este método mostró una exactitud del 57% sobre 62 proteínas.
•Garnier (1978). Estimó las probabilidades para interacciones de pares de resíduos significativas, obteniendo una mayor fiabilidad (~60%).

Chou-Fasman
Glu, Met y Ala : fuertes formadores de hélices.Val, Ile y Tyr: fuertes formadores de láminas.Pro: fuerte tendencia a no formar hélices ni láminasGly: alto grado de libertad, favorece la formación de giros
Name P(a) P(b) P(turn) f(i) f(i+1) f(i+2) f(i+3)�
Alanine 142 83 66 0.06 0.076 0.035 0.058
Arginine 98 93 95 0.070 0.106 0.099 0.085
Aspartic Acid 101 54 146 0.147 0.110 0.179 0.081
Asparagine 67 89 156 0.161 0.083 0.191 0.091
Cysteine 70 119 119 0.149 0.050 0.117 0.128
Glutamic Acid 151 037 74 0.056 0.060 0.077 0.064
Glutamine 111 110 98 0.074 0.098 0.037 0.098
Glycine 57 75 156 0.102 0.085 0.190 0.152
Histidine 100 87 95 0.140 0.047 0.093 0.054
Isoleucine 108 160 47 0.043 0.034 0.013 0.056
Leucine 121 130 59 0.061 0.025 0.036 0.070
Lysine 114 74 101 0.055 0.115 0.072 0.095
Methionine 145 105 60 0.068 0.082 0.014 0.055
Phenylalanine 113 138 60 0.059 0.041 0.065 0.065
Proline 57 55 152 0.102 0.301 0.034 0.068
Serine 77 75 143 0.120 0.139 0.125 0.106
Threonine 83 119 96 0.086 0.108 0.065 0.079
Tryptophan 108 137 96 0.077 0.013 0.064 0.167
Tyrosine 69 147 114 0.082 0.065 0.114 0.125
Valine 106 170 50 0.062 0.048 0.028 0.053
Primera generación de métodos

• La principal característica de estos métodos es la utilización de ventanas de resíduos adyacentes en secuencia, incluyendo asíinformación de contexto a la predicción.
• Un gran número de algoritmos de predicción se usaron en esta
generación de métodos:
� Redes Neuronales Artificiales
� Teoría de Grafos
� Métodos basados en reglas
� Estadística multivariable
� ...
� Esta innovación acercó la predicción de estructura secundaria a la
barrera del 70% de fiabilidad.
Segunda generación de métodos

• Limitaciones
– Fiabilidad (prediccciones 3-estados < 70%)�
– Se obtienen bajas fiabilidades para cadenas-β
– La hélices y láminas predichas tienden a ser demasiado cortas.
• Debido a:
– El número de estructuras disponibles sigue siendo demasiado pequeño para extrapolar al espacio de secuencias. Difiriendo a veces entre distintos cristales para la misma secuencia.
– NO se tienen en cuenta los efectos provocados por resíduos situados a grandes distancias en secuencia (pero no en el espacio)�
Segunda generación de métodos

Iniciada por Levin en 1993 (~69%) y Rost y Sander en 1994 (PHD 72%) �
– La principal innovación de esta tercera generación es la inclusión de información evolutiva adicional en forma de alineamientos múltiples (Levin, 1993).
– Además, se resuelve el sesgo en las predicciones de cadenas-ββββbalanceando el conjunto de entrenamiento (dado que las estructuras contienen más hélices que láminas; Rost y Sander, 1994) �
Tercera generación de métodos

Red neuronal PHDInformación de secuencia de la familia de la proteína
Perfil derivado del alineamiento múltiple para una ventana de resíduos adyacentes
Rost et al. (1997) J. Mol. Biol. 270: 471-480
Tercera generación de métodos

– Varios métodos han seguido estrategias similares a PHD, mejorando sus resultados a través del prefiltrado de los alineamientos de entrada y la extensión de los perfiles mediante PSIBLAST introducido por David Jones en PSIPRED (1999) con fiabilidades próximas al 77% o mediante HMMs usados por Kevin Karplus et al. en SAMT99sec (1999).
– Otros métodos siguen una estrategia diferente, buscando el consenso de diferentes métodos, como es el caso de Jpred2 (Cuff y Barton, 2000).
Tercera generación de métodos

Ejemplos de fiabilidad de predicción de estructura secundaria
Métodos de Primera generación:Chou & Fasman, Lim, GORI
Métodos de Segunda generación:Schneider, ALB, GORIII
Métodos de Tercera generación:LPAG, COMBINE, S83, NSSP, PHD

Sequence based
Statistics
GOR1/GOR3 (1978/1987)$
DSC (1996)$Nearest neighbour methods
PREDATOR (1996)$
NNSSP (1995)$
Neural Networks Methods
PHD (1993)$
PsiPRED (1999)$
JNET (1999)$
Structure based
Hidden Markov Models
SAM-T99/SAM-T02 (1999/2002)$
Chow-Fassman (1974)$
Accuracy
57%
63%/66%
70%
75%
72%
74%
75.7%
73%??
~76%
Ejemplos de fiabilidad de predicción de estructura secundaria

Fiabilidad de PHD usando un conjunto de proteínas de prueba
La fiabilidad depende de la proteína

Problemas no resueltos
– NO se tienen en cuenta los efectos provocados por resíduos situados a grandes distancias en secuencia (pero no en el espacio)
– Proteínas con características inusuales deben tratarse con cuidado
– Las predicciones siguen cosiderando sólo tres estados
– Malos alineamientos producen malas predicciones

SumarioSumario
Introduccion
• Definición de características 1D.
• Estructura de proteínas
• Metodología: Implementación de un predictor.
Predicción de características 1D
• Estructura secundaria
• Desorden estructural
• Accesibilidad al solvente
• Proteínas transmembrana
• Otras características 1D
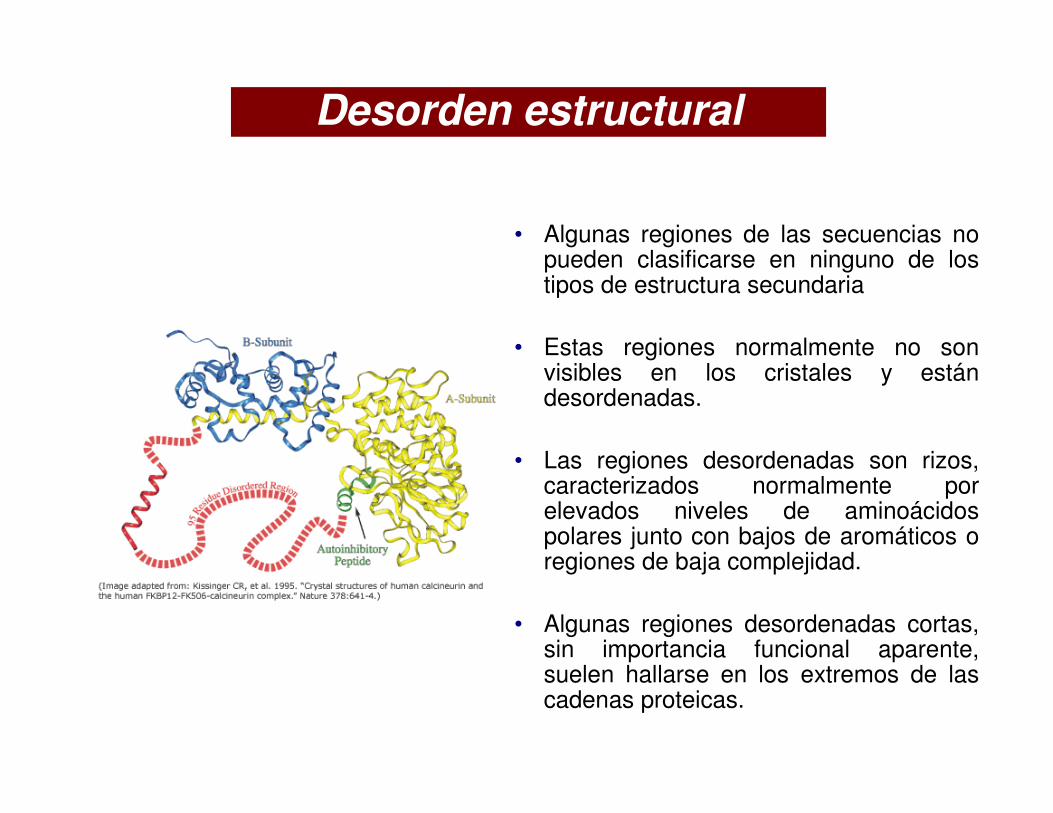
Desorden estructural
• Algunas regiones de las secuencias no pueden clasificarse en ninguno de los tipos de estructura secundaria
• Estas regiones normalmente no son visibles en los cristales y están desordenadas.
• Las regiones desordenadas son rizos, caracterizados normalmente por elevados niveles de aminoácidos polares junto con bajos de aromáticos o regiones de baja complejidad.
• Algunas regiones desordenadas cortas, sin importancia funcional aparente, suelen hallarse en los extremos de las cadenas proteicas.

Más desorden
• Las regiones más largas suelen estar conservadas en posición a lo largo de familias de proteínas. Estas regiones se relacionan con conexión entre dominios, sitios proteolíticos, así como con reconocimiento y unión tanto a ligandos como a otras proteínas.
• Suelen encontranse en ciertas enzimas, como en aquellas involucradas en el crecimiento y división celular o en fosforilación proteica.
• Entre ellas estas proteínas se hallan factores y reguladores de transcripción y kinasas entre otras. Ejemplo de proteína desordenada
el factor de crecimiento nervioso β
(PDB: 1bet), que sólo es estable
como dímero
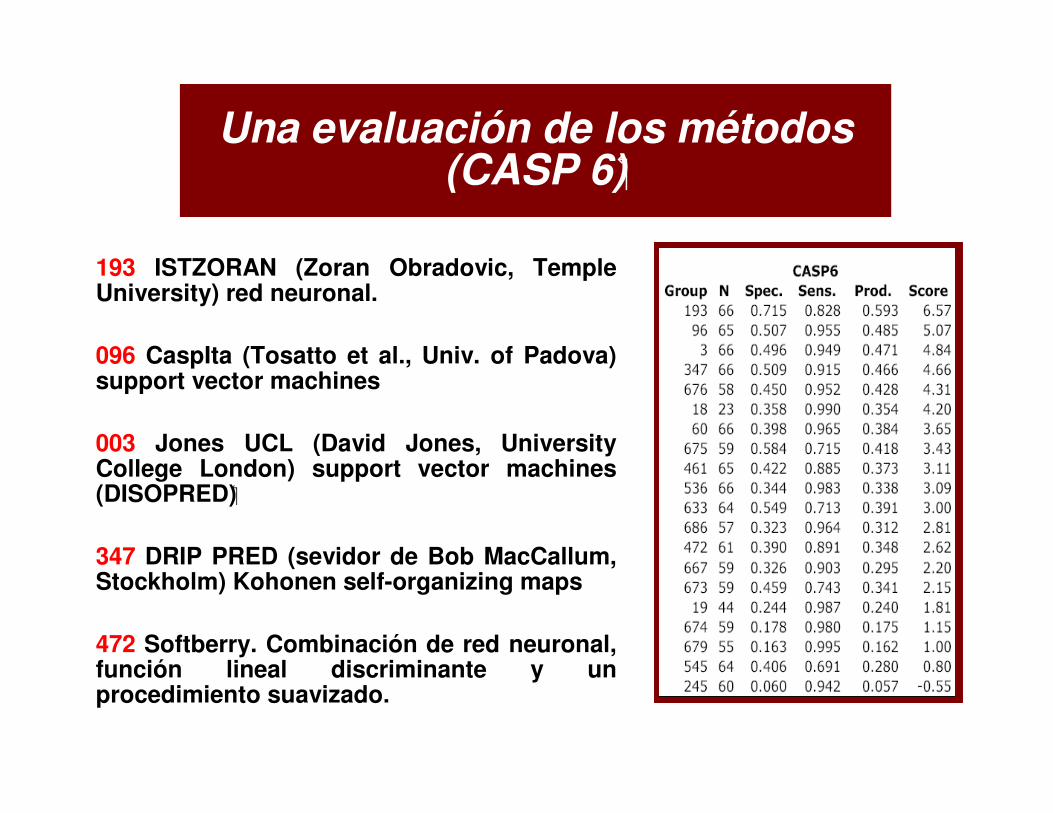
Una evaluación de los métodos(CASP 6)�
193 ISTZORAN (Zoran Obradovic, Temple University) red neuronal.
096 CaspIta (Tosatto et al., Univ. of Padova) support vector machines
003 Jones UCL (David Jones, University College London) support vector machines (DISOPRED) �
347 DRIP PRED (sevidor de Bob MacCallum, Stockholm) Kohonen self-organizing maps
472 Softberry. Combinación de red neuronal, función lineal discriminante y un procedimiento suavizado.

SumarioSumario
Introduccion
• Definición de características 1D.
• Estructura de proteínas
• Metodología: Implementación de un predictor.
Predicción de características 1D
• Estructura secundaria
• Desorden estructural
• Accesibilidad al solvente
• Proteínas transmembrana
• Otras características 1D

Utilidad de la accesibilidad al solvente
• Al igual que con las predicciones de estructura secundaria, se puede estudiar la plausibilidad de las estructuras predichas por un método dado mediante el uso de la información de accesibilidad al solvente (usando DSSP o NACCESS).
• Además esta infomación puede ser de utilidad en otros ámbitos, como la predicción de superficies de interacción entre proteínas o de sitios funcionales. Roßbach et al. BMC Structural Biology 2005 5:7

Definición operativa
La mayoría de los métodos reducen el problema a la predicción de dos estados
Oculto: acc. relativa <16%
Expuesto: acc. relativa >= 16%
Ls

Información utilizada
Aunque la accesibilidad es una función de la hidrofobicidad, los métodos basados en perfiles de esta propiedad producen unas predicciones pobres.
La predicción de accesibilidad mejora por el uso de ventanas en secuencia.
Al igual que ocurre con la estructura secundaria, la accesibilidad al solvente es una propiedad sujeta a fuertes restricciones evolutivas, por lo que su predicción se beneficia del uso de alineamientos múltipes.
En la mayoría de los casos las metodologías usadas son pequeñas variaciones de las usadas en la predicción de estructura secundaria

Algunos métodos
• PHDacc y PROFacc (B. Rost) emplean redes neuronales e infomación de alineamientos múltiples. Son los únicos métodos que predicen valores reales para accesibilidades relativas (de una matriz con los valores 0, 1, 4, 9, 16, 25, 36, 49, 64, 81).
• JPred2 usa perfiles de PSIBLAST como entrada para sus redes neuronales y devuelve predicciones del tipo oculto/expuesto.
• Estos métodos tienen una porcentaje de acierto del 70-75%

SumarioSumario
Introduccion
• Definición de características 1D.
• Estructura de proteínas
• Metodología: Implementación de un predictor.
Predicción de características 1D
• Estructura secundaria
• Desorden estructural
• Accesibilidad al solvente
• Proteínas transmembrana
• Otras características 1D
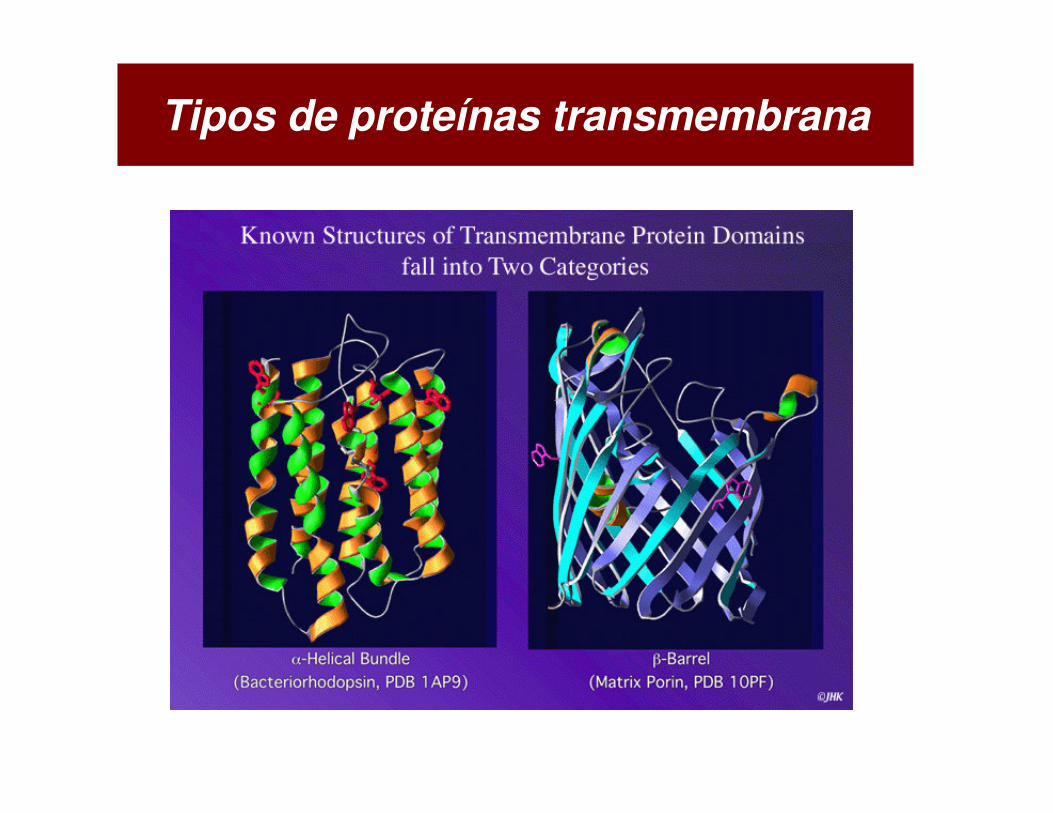
Tipos de proteínas transmembrana
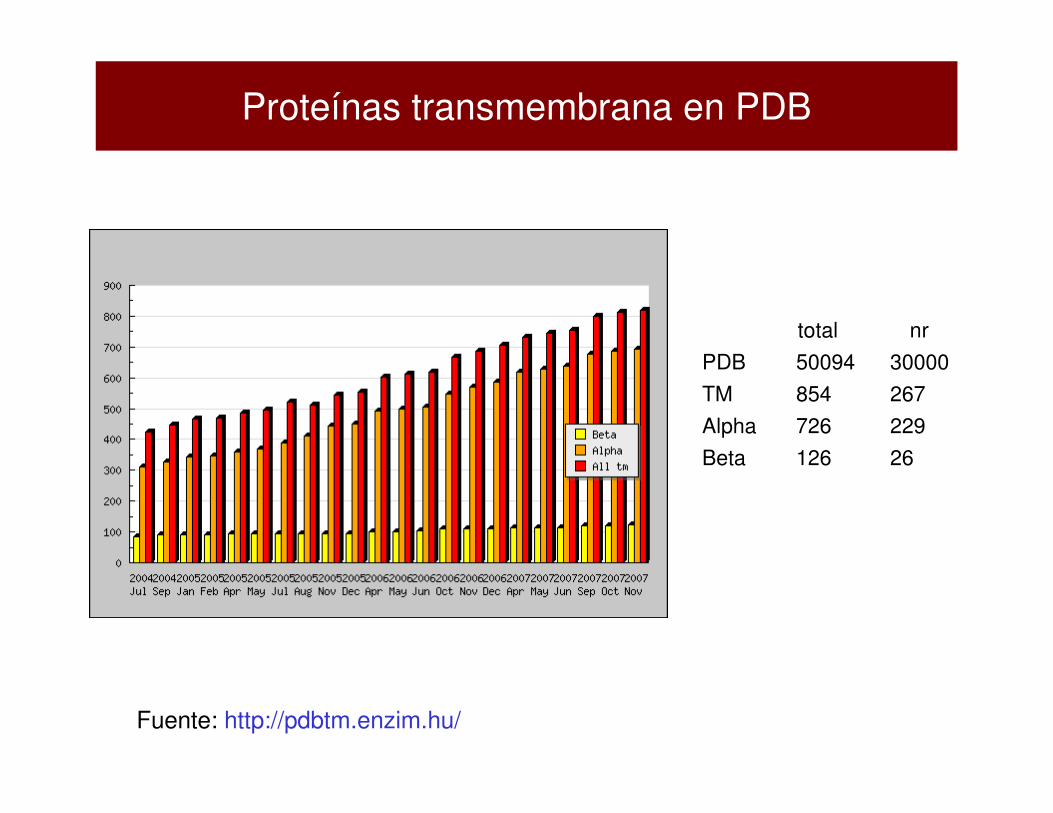
Proteínas transmembrana en PDB
total nr
PDB 50094 30000
TM 854 267
Alpha 726 229
Beta 126 26
Fuente: http://pdbtm.enzim.hu/

El problema
• La obtención de estructuras tridimensionales de proteínas transmembrana es un gran problema, ya que raramente producen cristales y su estudio por NMR es muy complicado.
• De hecho aún no es posible una predicción de estructuras transmembrana a nivel atómico
Hernanz-Falcon P, Rodriguez-Frade JM, Serrano A, Juan D, del Sol A, Soriano SF, Roncal F, Gomez L, Valencia A, Martinez-A C, Mellado M. Nat Immunol. 2004 Feb;5(2):216-23.

Predicción de hélices transmembranaDos reglas básicas
(1) Las hélices transmembrana tienden a tener una logitud de 20-30 resíduos con una hidrofobidad total alta.
(2) Las regiones de conexión entre hélices del interior del citoplasma tienen una carga positiva mayor que las del exterior
TRUCO: las hélices transmembrana vistas en un alineamiento muliple de secuencia no suelen incluir gaps (restricción de longitud mínima) �

Region transmembrana
Region extracelular
Region citoplasmatica
Pero siempre hay excepciones

Algunos métodos de predicción de hélices transmembrana
MEMSAT - http://bioinf.cs.ucl.ac.uk/psipred/
Algoritmo de programación dinámica que hace predicciones basadas en tablas estadísticas compiladas de los datos de proteínas de membrana.
TMAP - http://www.mbb.ki.se/tmap/index.html
Usa estadíticas extraídas de perfiles de secuencia.
TopPred2 - http://bioweb.pasteur.fr/seqanal/interfaces/toppred.html
Promedia los valores de hidropatía con una ventana trapezoidal
HMMTOP - http://www.enzim.hu/hmmtop/
Se definen 5 estados estructurales y mediante HMMs para generar fragmentos de
secuencia que maximizen la frecuencia de cada estado.
PHDhtm - http://www.embl-heidelberg.de/predictprotein/
Combina redes neuronales, alineamientos múltiples y programación dinámica (proporciona un índice de fiabilidad).
DAS - http://www.enzim.hu/DAS/DAS.html
Utiliza alineamientos múltiples de un conjunto no redundante de proteínas de membrana.
TMHMM - http://www.cbs.dtu.dk/services/TMHMM/
Métodos estadísticos y HMMs que ayudan a mejorar la localización y orientación de hélices trans-membrana.

Ejemplo de predicción de topología

Fiabilidad
• Los métodos actuales dicen identificar correctamente >90% de los segmentos trasmembrana y predecir correctamente la topología en >80% de los casos.
• Sin embargo, el pequeño tamaño de los conjuntos de entrenamiento (hay 229 estructuras conocidas) hacen estas estimaciones poco fiables (¿~70%?) �
• Se sabe que todos los métodos tienden a predecir péptidos señal como helices transmembrana, así como a sobrepredecir en proteínas globulares.

También hay predictores de barriles beta
• Recientemente han aparecido algunos métodos orientados a la predicción de barriles beta en membrana externa de bacterias Gramm negativas. Se basan en HMM.
• PRED-TMBB• PROF-TMB
• La escasez de estructuras distintas disponibles (sólo 26) hace que resulte muy difícil evaluar la calidad de dichos métodos (75-80%).

SumarioSumario
Introduccion
• Definición de características 1D.
• Estructura de proteínas
• Metodología: Implementación de un predictor.
Predicción de características 1D
• Estructura secundaria
• Desorden estructural
• Accesibilidad al solvente
• Proteínas transmembrana
• Otras características 1D

Predicción de péptidos señal
Cadenas peptídicas cortas (3-60 aa) que dirigen el tranporte post-transduccional de una proteína
TIPOS: • Señales N-terminal: matriz mitocondrial, retículo endoplasmático, peroxisoma • Señales C-terminal: peroxisoma, RE
Transporte al núcleo (NLS) -Pro-Pro-Lys-Lys-Lys-Arg-Lys-Val-
Tranporte a RE H2N-Met-Met-Ser-Phe-Val-Ser-Leu- Leu-Leu-Val-Gly-Ile-Leu-Phe- Trp-Ala-Thr-Glu-Ala-Glu-Gln- Leu-Thr-Lys-Cys-Glu-Val-Phe- Gln-
Retención en RE -Lys-Asp-Glu-Leu-COOH
Transporte a matriz mitocondrial H2N-Met-Leu-Ser-Leu-Arg-Gln-Ser- Ile-Arg-Phe-Phe-Lys-Pro-Ala- Thr-Arg-Thr-Leu-Cys-Ser-Ser- Arg-Tyr-Leu-Leu-
Transporte a peroxisoma (PTS1) -Ser-Lys-Leu-COOH
Transporte a perosisoma (PTS2) H2N-----Arg-Leu-X5-His-Leu-

Servidores de predicción:PSORT – predicción de péptidos señal y sitios de localizaciónTargetP – predicción de localización subcelularSignalP – predicción de péptido señal
22542878163045254106TOTAL
1979480414190470199Predichas
27487421145537Exp. Verificadas
Sub-TotalVirusesEukaryotesBacteriaArchaea
Péptidos señal: algunos recursos disponibles
SPdb – http://proline.bic.nus.edu.sg/spdb/

Algunos predictores de otras características 1D(Modificaciones Post-Transcripcionales).
ExPASy Proteomics tools http://www.expasy.ch/tools/
ChloroP – predicción de péptidos de cloroplastoNetOGlyc – predicción de sitios de O-glicosilación en proteínas de mamíferoBig-PI – prediccíon de sitios de modificación por glycosil-phosphatidyl inositol(GPI)DGPI – predicciónde sitios de anclaje y rotura para proteínas modificadas por GPI
NetPhos – predicción de sitios de fosforilación (Ser, Thr, Tyr) en eucariotasNetPicoRNA - prediction of cleavage sites for proteases in the picornavirusNMT – predicción de N-miristoilacion en N-terminalesSulfinator – predicción de sitios de sulfatación en tirosinas

Prácticas de predicción 1D
http://ubio.bioinfo.cnio.es/Cursos/doctoradoUAM2008/Estructuras/Practicals1D/