
ETODI DI PREVISIONE DELLE INSOLVENZE UN ANALISI...
119
1 METODI DI P REVISIONE DELLE INSOLVENZE: UN’ ANALISI COMPARATA Franco Varetto Marzo 1999 3° Capitolo del libro G. Szego – F. Varetto “Il rischio Creditizio: misura e controllo” ed. Utet 1999
Transcript of ETODI DI PREVISIONE DELLE INSOLVENZE UN ANALISI...

1
METODI DI PREVISIONE DELLE INSOLVENZE: UN’ANALISI COMPARATA Franco Varetto Marzo 1999 3° Capitolo del libro G. Szego – F. Varetto “Il rischio Creditizio: misura e controllo” ed. Utet 1999

2
Metodi di Previsione delle Insolvenze: un’analisi comparata ____________________________ 1
1) INTRODUZIONE ___________________________________________________________ 3
2) L’APPROCCIO UNIVARIATO _________________________________________________ 5
3) L’APPROCCIO MULTIVARIATO: L’ANALISI DISCRIMINANTE ____________________ 7
4) L’APPROCCIO MULTIVARIATO: IL MODELLO LOGISTICO_____________________ 16
5) CRITICHE, VARIANTI ED ESTENSIONI _______________________________________ 20 5.1 Assenza di una teoria __________________________________________________________________ 24 5.2 Capacita' predittiva ex-ante ed ex-post _____________________________________________________ 24 5.3 Stabilità dei modelli __________________________________________________________________ 25 5.4 Industry relatives _____________________________________________________________________ 27 5.5 Scelta della metodologia ________________________________________________________________ 27 5.6 Definizione dei gruppi di imprese_________________________________________________________ 30 5.7 Composizione dei campioni di imprese_____________________________________________________ 32 5.8 Scelta degli indicatori __________________________________________________________________ 34 5.9 Problemi nell'uso degli indicatori_________________________________________________________ 37 5.10 Variabili qualitative __________________________________________________________________ 39
6) RISCHIO DI ROVINA _______________________________________________________ 42
7) ALTRI APPROCCI _________________________________________________________ 45 7.1 Metodi non Parametrici________________________________________________________________ 45 7.2 Teoria delle catastrofi __________________________________________________________________ 47 7.3 Survival Analysis _____________________________________________________________________ 49 7.4 Conjoint analysis _____________________________________________________________________ 51 7.5 Analisi Multicriteri ____________________________________________________________________ 52
8) IL CONTRIBUTO DELL’INTELLIGENZA ARTIFICIALE ________________________ 57 8.1 Sistemi Esperti _______________________________________________________________________ 57 8.2 Alberi decisionali _____________________________________________________________________ 61 8.3 Case-Based Reasoning _________________________________________________________________ 67 8.4 Reti Neurali _________________________________________________________________________ 69 8.5 Algoritmi Genetici ____________________________________________________________________ 78
8.5.1 Generazione genetica di funzioni lineari_________________________________________________ 82 8.5.2 Generazione di Score con regole genetiche ______________________________________________ 84
9) MODELLI AGGREGATI_____________________________________________________ 88
10) DAGLI SCORE ALLE PROBABILITA’ ________________________________________ 91
11) BREVI CONCLUSIONI _____________________________________________________ 94
APPENDICE I: Methodological Comparisons between most recent discriminant models - Comité Européen Des Centrales des Bilans ________________________________________________ 95
APPENDICE II: Il Sistema di Diagnosi dei Rischi di Insolvenza della Centrale dei Bilanci _____ 96
BIBLIOGRAFIA_____________________________________________________________ 102

3
1) INTRODUZIONE L’aumento rilevante dei crediti in sofferenza rispetto agli impieghi verificatosi a partire dal biennio 90/92 ha posto prepotentemente all’attenzione dei banchieri, degli studiosi e delle Autorità di Vigilanza il problema della valutazione, controllo e gestione del rischio di credito. Storicamente la valutazione del merito di credito delle imprese finanziate e la stima del rischio di credito sono stati considerati uno dei punti più importanti, se non addirittura il momento centrale, dell’attività bancaria. Più recentemente sia la riflessione scientifica che la messa a punto di strumenti gestionali sono state concentrate sui rischi di mercato ed in particolare su quelli connessi alle operazioni con derivati. Per i rischi di mercato è disponibile un ben codificato approccio metodologico, le cui linee generali sono incorporate nelle norme di vigilanza. Il processo di approfondimento metodologico dei rischi di credito ha finora proceduto più lentamente rispetto a quelli di mercato a causa anche di obiettive difficoltà della materia: la forma asimmetrica delle distribuzioni dei rendimenti delle operazioni di credito e la mancanza di ampie banche dati, estese per un sufficiente arco temporale, sono due tra gli elementi che hanno rallentato l’avanzamento su questo campo. Peraltro occorre sottolineare che proprio sul versante del controllo e della gestione dei rischi di credito le banche italiane stanno dimostrando una notevole sensibilità, cogliendo l’occasione di avviare profondi aggiornamenti delle procedure operative dei servizi crediti e la riorganizzazione di questi ultimi. Le migliori banche del sistema, infatti, seguendo di qualche anno l’esperienza delle banche estere, stanno rimettendo in discussione i propri criteri di affidamento e di pricing dei rischi creditizi, reimpostando in un’ottica di portafoglio di medio periodo la definizione della politica generale degli impieghi. Ne potrà derivare un miglioramento delle capacità di selezione dei crediti, abbinato anche al progressivo passaggio dal multiaffidamento alla stabilità delle relazioni di clientela (con i miglioramenti informativi che ne conseguono nel rapporto banca- impresa) ed alla integrazione orizzontale dei servizi bancari offerti alle imprese: l’integrazione tra il “lending”, il “corporate banking”, con i servizi di gestione dei pagamenti, di gestione valutaria e patrimoniale consentono alla banca di offrirsi come un completo partner finanziario alle imprese clienti. Si osservi che proprio l’allentamento del rigore della selezione dei crediti, indotto anche dall’aumento della concorrenza, è stato considerato tra le cause principali del peggioramento della qualità degli attivi bancari e dell’incremento delle sofferenze bancarie1. Questo capitolo è dedicato all’analisi comparata di diverse metodologie per la previsione precoce del rischio di insolvenze sulle imprese non finanziarie2 e discute alcuni approcci per la stima delle probabilità di insolvenza: queste ultime rappresentano uno dei punti chiave di qualunque sistema di valutazione e gestione dei rischi di credito e sono al cuore dell’approccio VAR al portafoglio crediti. In questa sede non vengono considerati nè l’analisi del processo di crisi aziendale nè i sistemi di gestione delle crisi e le ristrutturazioni aziendali che, pur essendo connessi con gli argomenti qui considerati, sono al di fuori degli obiettivi del capitolo.
1 Peraltro Morelli e Pittaluga (1998) hanno concluso, sulla base di un modello econometrico, che il principale fattore esplicativo dell’aumento delle sofferenze è rappresentato dal deterioramento dell’economia reale. 2 Non ci si occuperà ad esempio dei rischi riguardanti le famiglie, il credito al consumo o connessi a specifici strumenti, come le carte di credito.

4
Infine, larga parte della discussione dei differenti modelli di previsione delle insolvenze ha come riferimento l’utilizzo dei dati economico-finanziari delle imprese ricavati da un’accurata analisi dei bilanci aziendali. L’importanza di questo strumento è difficilmente sottovalutabile in un paese come l’Italia in cui la parte prevalente del debito delle imprese è presso il sistema bancario, in cui gli strumenti di debito collocati sul mercato (obbligazioni e commercial papers) sono meno che secondari ed in cui sul mercato azionario è quotata un’assoluta minoranza di imprese. Quest’ultimo pertanto non è in grado di essere preso quale punto di riferimento per la valutazione di mercato del rischio di credito e delle correlazioni tra i rischi riguardanti insiemi di imprese. Un’altra conseguenza della ridotta presenza del debito di mercato riguarda la limitatissima diffusione del rating. Entrambi questi elementi condizionano fortemente l’applicabilità di strumenti quali il Credit Metrics della J.P. Morgan. I bilanci aziendali, per contro, quando sono sistemati in ampie banche dati ed accuratamente elaborati possono costituire la base per una notevole varietà di applicazioni; inoltre opportunamente integrati con dati qualitativi, con informazioni ricavate dalla Centrale dei Rischi e con i movimenti dei conti bancari e con le previsioni dei business plans aziendali possono consentire di pervenire a stime attendibili dei rischi assunti dalla banca. Peraltro valutazioni di rischio basate sui bilanci rappresentano comunque un elemento imprescindibile, soprattutto nel caso di analisi riguardanti società non clienti della banca, per le quali non sono disponibili i dati di Centrale dei Rischi, le movimentazioni dei c/c e gli elementi qualitativi e previsivi: la stima delle componenti sistematiche del rischio di credito, condotte a partire da dati microeconomici, rientrano appunto in questo campo di applicazioni. Peraltro occorre rammentare i notevoli limiti informativi connaturati ai bilanci aziendali, limiti che il recepimento delle direttive europee sui conti aziendali hanno solo assai parzialmente attenuato3; i residui inquinamenti fiscali, gli effetti distorsivi dell’inflazione (gravi soprattutto nel passato), le indeterminazioni dei principi contabili nel trattamento delle attività immateriali, la convenzionalità e la flessibilità dei principi contabili rappresentano altrettanti fattori che condizionano l’espressività dei conti aziendali e la loro confrontabilità nel tempo e tra imprese. Un limite del bilancio che viene a volte evocato, e spesso enfatizzato, riguarda l’orientamento al passato che, in quanto strumento di reporting a consuntivo, ne presiederebbe la formazione e che contrasterebbe con l’orientamento al futuro che dovrebbe invece caratterizzare la valutazione di rischio. L’economia aziendale ha invece da lungo tempo chiarito le influenze che le prospettive economiche sia di breve termine (per le poste del circolante) sia di medio- lungo termine (per le immobilizzazioni) svolgono nelle valutazioni di bilancio. Inoltre, come i paragrafi successivi chiariscono, i modelli di stima dei rischi di insolvenza basati sui dati contabili mettono in luce notevoli capacità previsive: da questo punto di vista i consuntivi aziendali non svolgono una funzione sostanzialmente diversa dalle statistiche nazionali su cui sono costruiti i modelli econometrici macroeconomici.
3 Nel caso delle imprese minori, la possibilità di predisporre un bilancio in forma abbreviata costituisce un serio passo indietro rispetto alla situazione preesistente alla IV Direttiva.

5
2) L’APPROCCIO UNIVARIATO L’uso di indicatori di bilancio per la valutazione della situazione economico finanziaria delle imprese, specie ai fini delle analisi di credito, risale al periodo tra la fine del secolo scorso e gli inizi di questo e si è sviluppato rapidamente fin dagli anni ’20. L’approccio univariato esamina singolarmente i diversi indicatori cercando di percepirne gli elementi in grado di illustrare i punti deboli dell’impresa, lo stato attuale, i condizionamenti che gravano sul suo sviluppo futuro. L’insieme degli indicatori viene organizzato in un sistema coerente di analisi, orientato alla particolare prospettiva con la quale si guarda all’impresa: è l’analista finanziario che, sulla base di ragionamenti, di confronti con dati di settore e con parametri di riferimento, dell’esame sistematico della serie dei conti aziendali e degli indicatori ricavati raggiunge proprie conclusioni in merito alla situazione ed alle prospettive dell’impresa; l’uso integrato di altre informazioni sui programmi aziendali e di natura qualitativa consente di confortare le conclusioni precedenti e di comprendere meglio i meccanismi economici che stanno dietro ai valori contabili. Vi sono innumerevoli manuali di analisi finanziaria che illustrano tutto ciò. In questa sede importa sottolineare l’uso che viene fatto degli indicatori (o, più in generale, dei parametri ricavati dalle informazioni contabili) ai fini della valutazione dell’insolvenza: l’analisi univariata li considera individualmente, o in sistema, ma non fa alcun tentativo di combinarli insieme in una misura quantitativa di sintesi. W. Beaver (1966), in una famosa ricerca, ha esaminato la capacità predittiva di alcuni singoli indicatori rispetto al fenomeno dell’insolvenza. Nel suo lavoro, l’autore considera già varie problematiche, quali la definizione del concetto di insolvenza, l’uso di campioni con pari composizione di società sane e anomale, il riferimento ad una teoria dell’insolvenza aziendale, l’analisi degli errori di I e II tipo, l’approccio bayesiano, che saranno oggetto del dibattito scientifico negli anni seguenti nelle ricerche con metodologie multivariate. Beaver ha utilizzato un campione di 79 imprese anomale; la definizione di anomalia comprende il fallimento, l’insolvenza nei confronti dei propri prestiti obbligazionari, l’esistenza di scoperti sui conti bancari o sconfinamenti, il mancato pagamento di dividendi sulle azioni privilegiate. Il campione delle società sane, da confrontare con quelle anomale, è stato scelto estraendo casualmente un’impresa, per ogni società anomala, appartenente allo stesso settore ed alla stessa classe dimensionale in termini di attivo netto totale: il campione delle società sane ha svolto una funzione di confronto omogeneo con quello delle società anomale, per facilitare l’individuazione delle caratteristiche distintive tra i due gruppi, neutralizzando, o riducendo, l’effetto di variabili quali l’appartenenza settoriale o la scala dimensionale. Per ciascuna impresa Beaver ha calcolato una trentina di indicatori scelti tra quelli più citati e studiati nella letteratura, o dimostratisi più efficaci in studi precedenti; tali indicatori sono stati raggruppati in sei famiglie omogenee rispetto al significato economico. Il confronto tra le medie degli indicatori dei due campioni ha confermato il risultato di studi precedenti risalenti agli anni '30 e '40, mettendo in luce una sistematica differenza di livello e di andamento degli indicatori delle società anomale rispetto a quelli delle società sane. Il paragone dei soli valori medi, tuttavia, è troppo limitativo e concentra l’intera distribuzione dei valori degli indicatori in un solo punto. Per ottenere una migliore valutazione delle capacità diagnostiche degli indicatori, Beaver ne ha esaminato la sovrapposizione delle distribuzioni

6
calcolate separatamente sulle società sane e su quelle anomale, pervenendo sulla base di un test di classificazione dicotomica ad individuare un punto ottimale di separazione (cut-off) per gli indicatori, in grado di ridurre al minimo gli errori di attribuzione delle società ai due insiemi (sane-anomale). Sulla base di tali elaborazioni, Beaver ha trovato che il migliore indicatore per la previsione delle insolvenze è il rapporto tra cash flow4 ed i debiti totali che, nell’anno immediatamente precedente al momento dell’insolvenza o del fallimento (t-1), ha correttamente individuato l’87% delle società; negli anni precedenti al t-1 la performance, pur riducendosi, si mantiene su livelli molto buoni: 5 anni prima dell’insolvenza questo indicatore ha correttamente classificato il 78% delle società. Gli altri indicatori hanno messo in luce risultati inferiori, con percentuali di classificazione fortemente degradanti col procedere a ritroso dell’anno di osservazione delle variabili di bilancio. Gli indicatori con la minore capacità diagnostica sono risultati quelli connessi al circolante ed alla liquidità, che tradizionalmente erano in quell’epoca considerati dalla letteratura tra i più efficaci nella valutazione della capacità di credito delle imprese. L’analisi del comportamento nel tempo delle distribuzioni degli indicatori ha messo in luce andamenti assai consistenti con i risultati attesi: le distribuzioni delle società sane si sono mantenute stabili nel tempo, mentre quelle riguardanti le società anomale hanno avuto un progressivo spostamento verso la parte peggiore dei valori con l’avvicinarsi al momento dell’insolvenza, riducendo l’area della sovrapposizione con le distribuzioni delle sane 5. Come si vedrà in seguito questa divergenza di comportamenti sta alla base di ogni buon modello predittivo, soprattutto in un contesto multivariato in cui vengono mescolati i segnali provenienti dalle diverse variabili. In conclusione lo studio di Beaver ha dimostrato che i dati contabili rappresentano una fonte in grado di fornire informazioni utili per la identificazione precoce del rischio di insolvenza (o di fallimento). Non tutti gli indicatori tuttavia hanno la stessa capacità diagnostica: le variabili legate alla capacità di generazione di cassa ed alla struttura finanziaria hanno una rilevanza informativa migliore, sotto il profilo della insolvenza, rispetto alle variabili espressive della liquidità a breve termine. Quest’ultimo punto apre interessanti prospettive alla rivisitazione critica dell’approccio tradizionale dell’analisi del merito di credito incentrata sulla capacità dell’impresa di coprire con attività correnti i pagamenti a breve e rimette in discussione le basi di un'“ortodossia” di diagnosi finanziaria basata sull’equilibrio delle scadenze (percepite con i dati di consistenza trasmessi dagli stati patrimoniali aziendali). Si sottolinea in questa sede che questo particolare risultato che emerge dalla ricerca di Beaver verrà ritrovato anche in lavori successivi ed ha conferma anche nel nostro paese6.
4 Definito come somma dell’utile netto e delle quote ammortamento e svalutazione. 5 L’area di sovrapposizione è massima nel t-5 e minima nel t-1. 6 Si cfr. Varetto (1990).

7
3) L’APPROCCIO MULTIVARIATO: L’ANALISI DISCRIMINANTE Come è stato ricordato in precedenza, uno dei limiti della ricerca di Beaver consiste nell’uso individuale delle variabili economico-finanziarie, equivalente a considerare separatamente vari elementi dell’impresa: la redditività, la struttura finanziaria, la liquidità, e così via. Il passo successivo non può che essere quello di cercare di combinare insieme tutti i segnali che arrivano dalle diverse variabili e cercare di ottenere un segnale complessivo che individui in misura sintetica lo stato di salute dell’impresa dal punto di vista dei creditori: le varie prospettive con cui può essere esaminata un’impresa vengono così analizzate simultaneamente anziché essere valutate sequenzialmente. L’obiettivo finale non è ovviamente la concentrazione in un’unica informazione della pluralità di segnali che arrivano dai diversi indicatori, quanto quello di gestire in modo coordinato i trade-off che si instaurano tra le varie componenti del sistema-impresa. Una società ad esempio può essere migliore di un’altra in termini di redditività, ma molto peggiore per quanto riguarda la struttura finanziaria e lievemente peggiore in termini di liquidità: nel complesso, la prima è preferibile alla seconda o le è inferiore, oppure sono considerate equivalenti? La risposta può non essere facile, né evidenti possono essere le argomentazioni a sostegno. Un indicatore composito, sulla base di specifici rapporti di trade-off, combina i tre aspetti dell’esempio precedente e consente di ottenere un’unica misura di sintesi in cui i fattori di superiorità e di inferiorità siano tra loro compensati nello stesso modo (con gli stessi criteri) per le due società. Imprese profondamente differenti possono sotto questo aspetto essere giudicate complessivamente equivalenti. Il punto cruciale ovviamente risiede nel modo con il quale ricavare i pesi relativi (i fattori di scambio per così dire) con i quali ponderare i diversi indicatori. Anche se l’approccio multivariato è un innegabile avanzamento rispetto all’analisi univariata, quest’ultima tuttavia rappresenta uno strumento prezioso: come si vedrà più avanti, l’analisi del comportamento individuale degli indicatori costituisce uno dei primi passi per la corretta messa a punto di un modello multivariato; inoltre la tecnica degli alberi di decisione, discussa nella sezione dedicata all’Intelligenza Artificiale, esplora l’insieme delle società proprio sulla base di progressive bipartizioni dicotomiche che considerano una variabile per volta: gli alberi decisionali possono sotto certi aspetti essere considerati come una sequenza ottimizzata di successive analisi univariate. E. Altman7, alla fine degli anni ’60, ha applicato con successo l’analisi discriminante lineare alla previsione delle insolvenze: anche se questa tecnica era stata impiegata in studi precedenti, la pubblicazione dell’articolo di Altman ha aperto la strada ad un nutrito filone di critiche ed estensioni, oltre ad applicazioni in molti paesi. L’analisi discriminante lineare venne proposta nel ’36 da R. Fisher per la classificazione di un oggetto in due (o più) popolazioni note a priori: ciascuna popolazione è dotata di caratteristiche proprie, descritte in un contesto multivariato da una serie di variabili; l’oggetto da classificare viene osservato sulle stesse variabili ed in base alla maggiore o minore distanza complessiva, costruita pesando opportunamente le distanze individuali delle singole variabili, viene attribuito alla popolazione più prossima. Pur non essendo questa la sede per una disamina approfondita degli aspetti più tecnici dell’analisi discriminante, per i quali si rinvia alla lettura specializzata, può tuttavia essere utile richiamare
7 Altman (1968).

8
sinteticamente alcuni aspetti essenziali, limitati al caso di due popolazioni, che qui identificano le società sane e le società anomale. L’approccio di Fisher alla classificazione in un contesto multivariato consiste nel lavorare su una combinazione lineare delle variabili osservate sulle due popolazioni: tra tutte le combinazioni lineari possibili si utilizza quelle che rende massima la distanza media delle due popolazioni, a parità di varianza. In generale, dal punto di vista analitico si tratta di massimizzare il rapporto tra la varianza tra le popolazioni e la varianza nelle popolazioni. In questo modo le osservazioni delle variabili sull’oggetto (impresa) j-esimo vengono sintetizzate in un unico valore (score), che ne determina la classificazione sulla base della distanza dagli score medi delle due popolazioni: Sj=a1X1j + a2X2j + .... aiXij + .... + anXnj ove Sj = score dell’impresa j-esima ai = coefficiente della variabile Xi Xi = variabile descrittiva della caratteristica i-esima dell’impresa (xi indica il vettore colonna di tali variabili) Dati quindi 2 campioni (A;B), di numerosità NA e NB, riguardanti le due popolazioni note a priori, siano:
♦ XA e XB – le matrici ( nNA × ) e ( nN b × ) delle osservazioni sulle n variabili (X); ♦ Ax e Bx i vettori colonna delle medie delle variabili dei due campioni;
♦ BB
AA x
NN
xN
Nx += il vettore colonna delle medie complessive, in cui N = NA + NB
indica la numerosità totale dei campioni
♦ V = matrice nn × delle varianze e covarianze complessive, cioè calcolate sull’unione dei due campioni, rispetto alle medie x
La regola di classificazione lineare vale quindi:
l’impresa j-esima è attribuita alla popolazione A se
( ) ( ) ( ) ( )Bj1'
BAAj1'
BA xxVxxxxVxx −−<−− −− ,
altrimenti l’impresa è attribuita alla popolazione B.
Si osservi che ( ) 1'
BA Vxx −− rappresenta il vettore dei coefficienti della funzione lineare con cui pesare le variabili X per ottenere il punteggio (score) che sintetizza il profilo delle imprese. Pertanto lo score dell’impresa j-esima è dato da:
( ) j1'
BAj xVxxS −−=

9
mentre la media degli score della popolazione A, ovvero lo score corrispondente al centroide di A ( Ax ) è dato da ( ) A
1'BAA xVxxS −−=
ed analogamente è definito SB. La regola di classificazione lineare può quindi essere espressa in termini di distanze tra gli score: l’impresa j-esima è assegnata alla popolazione A se BjAj SSSS −<− ,
ovvero
BABAj SSper ),SS(21
S <+⋅<
altrimenti è assegnata alla popolazione B8. In termini geometrici il modello discriminante lineare è rappresentato nel grafico 1, per il caso di due variabili e due popolazioni.
Grafico 1. Sintesi grafica dell'analisi discriminante lineare
8 Una formulazione equivalente conduce alla seguente diseguaglianza:
0)2
xx(V)xx(xV)xx( BA1
BAj1
BA <+
−′−+′− −− , in cui il secondo termine rappresenta il valore della costante
che consente di centrare sullo zero il valore di cut-off degli score.
X1
Ax
Bx
X2 A
B
Y
SA
SB
S=a0+a1X1+a2X2

10
Sul piano X1, X2 sono riportate le imprese appartenenti ai due campioni delle popolazioni A e B, insieme alle medie complessive (centroidi) Ax e Bx ; i due insiemi non sono nettamente separati, ma hanno una certa sovrapposizione: con l’analisi discriminante si individua quella retta Y che meglio separa i due insiemi, ovvero che commette il minor numero di errori di attribuzione; tale retta ha la proprietà notevole che le proiezioni delle nuvole dei punti sulla retta S, perpendicolare ad essa, disegna delle distribuzioni con la minor area di sovrapposizione; la retta S rappresenta il luogo delle combinazioni lineari delle variabili, ovvero rappresenta la funzione discriminante lineare ottima, date le caratteristiche X1 e X2.
Come si vede la discriminante lineare semplifica grandemente l’analisi delle distanze tra le imprese in un contesto multivariato, grazie alla riduzione della dimensione delle caratteristiche osservate, ovvero grazie al passaggio dello spazio ad n dimensioni delle variabili X ad 1 dimensione della linea di punti S (la riduzione dimensionale in realtà passa da n a g-1 ove g è il numero delle popolazioni; nel caso in esame g = 2). Le imprese da classificare sono rappresentate da punti sulla retta degli score, sulla base dei quali è immediato e non equivoco effettuare degli ordinamenti. Si osservi anche che la scelta dei pesi (ai) non è effettuata soggettivamente dall’analista, ma è oggettiva e dipendente dalle caratteristiche delle due popolazioni: l’elemento soggettivo dell’analista finanziario entra in gioco nella scelta delle variabili (X) con le quali osservare le imprese. Più è ampia l’area della sovrapposizione tra le due distribuzioni, maggiore è l’incertezza della classificazione; nel caso limite di due distribuzioni nettamente separate non vi sono errori, nell’altro caso di perfetta sovrapposizione vi è la massima incertezza di attribuzioni: le caratteristiche osservate non forniscono alcun elemento per individuare l’appartenenza di un oggetto alla popolazione. Si noti che a stretto rigore il modello di Fisher può essere considerato non parametrico9 in quanto non fa alcuna ipotesi sulla forma delle distribuzioni delle variabili. A partire dai risultati di Fisher si sono sviluppati altri approcci che hanno migliorato ed esteso l’analisi discriminante, inquadrando il problema della classificazione nell’ambito di problemi di decisione in condizioni di incertezza. Un’importante estensione nell’ambito dei modelli parametrici riguarda il caso della classificazione ricorrendo al criterio delle massima verosimiglianza: l’impresa j-esima viene attribuita alla popolazione h-esima tale che sia massima la probabilità (ph (xj)) che l’impresa sia generata da quella popolazione. Nel caso in cui le popolazioni siano multinormali, il criterio di classificazione conduce ad una funzione discriminante quadratica; se inoltre le popolazioni hanno la stessa matrice di varianza e covarianza il modello si semplifica notevolmente e si riduce al caso di funzione discriminante lineare. Un’ulteriore estensione del modello base incorpora la conoscenza delle probabilità a priori delle diverse popolazioni ed i costi di errata classificazione. Siano pA(X) e pB(X) le probabilità (o densità di probabilità), note, che le due popolazioni generino l’impresa osservata; siano qA e qB le probabilità a priori che una generica impresa osservata provenga rispettivamente dalla popolazione A e dalla popolazione B. Le probabilità a posteriori sono calcolabili ricorrendo al teorema di Bayes:
9 Si cfr. ad esempio Vitali (1993).

11
( ) ( )( )Xp
XpqXAp AA ⋅
=
( ) ( )( )Xp
XpqXBp BB ⋅
=
B
ove p(X) = Σ qr⋅pr(X) = qA⋅pA(X) + qB⋅pB(X) r=A
La probabilità a posteriori p(AX) indica la probabilità che, data l’osservazione delle caratteristiche X sull’impresa esaminata, quest’ultima sia generata dalla popolazione A. L’impresa viene quindi attribuita alla popolazione A se: ( ) ( )XBpXAp > ovvero se qA⋅pA(X) > qB⋅pB(X)
e cioè se ( )( ) A
B
B
A
XpXp
>
Rimanendo nel caso di distribuzioni multinormali, pA(X) e pB(X) sono definibili come funzioni di densità di probabilità normali nelle variabili X. Con le consuete semplificazioni delle matrici di varianza e covarianza uguali tra le popolazioni, questo criterio converge ad una funzione discriminante lineare nella quale il valo re critico (cut-off di attribuzione) è spostato della quantità
A
B
ln , rispetto alla funzione originale di Fisher (ln = logaritmo naturale).
Nel caso limite in cui le probabilità a priori siano uguali (qB = qA), con l’inserimento nel modello di tali probabilità, conservando le altre semplificazioni, non si producono spostamenti nella funzione discriminante lineare. I costi di errata classificazione complicano ulteriormente il modello, ma consentono di aumentare il grado di realismo: l’errore di decisione infatti è diverso se si tratta di una società sana rispetto ad una società anomala. Gli errori che si possono commettere sono di due tipi: classificare sana un’impresa in realtà anomala e classificare anomala un’impresa in realtà sana. Non c’è dubbio che il primo tipo di errore sia molto più costoso del secondo: nel primo caso il finanziatore va incontro alla perdita totale o parziale degli interessi e del capitale, oltre a dover sostenere oneri legali ed amministrativi per la gestione dell’insolvenza (o del fallimento) e la riscossione di eventuali garanzie; nel secondo caso il costo è sostanzialmente dato dai redditi connessi all'opportunità di affari che si è persa considerando anomala la società. Si ritornerà ancora in seguito su questi problemi; in questa sede, ai soli fini di illustrazione di dettagli analitici dell’analisi discriminante, si consideri genericamente CAB il costo di classificare nella popolazione B l’impresa in realtà proveniente dalla popolazione A e CBA per il caso opposto.

12
Il criterio di decisione diventa pertanto quello di minimizzare il costo atteso degli errori di attribuzione; in termini analitici10 questo criterio si traduce nella regola di attribuire l’impresa esaminata alla popolazione A se
( )( ) ABA
BAB
B
A
CqCq
XpXp
>
in cui pA(X) e pB(X) sono anche qui definibili in termini di funzioni di densità normali multivariate. Mantenendo l’ipotesi di uguaglianza tra le popolazioni delle matrici di varianza e covarianza, la regola decisionale si semplifica in una funzione discriminante lineare il cui cut-off è spostato di una quantità pari a
AAB
BBA
qCqC
ln
rispetto alla funzione di Fisher. Quindi si può pensare alla semplice discriminante lineare multivariata come un caso particolare di un criterio di classificazione più generale per il quale valgono le ipotesi di normalità multivariata delle distribuzioni delle variabili, uguaglianza delle matrici di varianza e covarianza tra le popolazioni, identiche probabilità a priori e costi degli errori di classificazioni uguali (ovvero: nella messa a punto del modello vengono ignorate sia le probabilità a priori che i costi di errate classificazioni). Se si rimuove l’ipotesi di uguaglianza delle matrici di varianza e covarianza la regola di classificazione si trasforma in una funzione discriminante quadratica11. Le due grandezze qA e qB in termini semplicistici possono essere considerate come le proporzioni relative delle due popolazioni ovvero, quando non vengono specificate, come la dimensione relativa dei due campioni di società. Per questo, nelle applicazioni pratiche, quando vengono utilizzati campioni di pari numerosità di imprese (come nel caso di campioni di sane ed anomale tra loro “pareggiate” per anno, settore e classe dimensionale) e non vengono specificate le probabilità a priori né i costi di errate classificazioni, la funzione discriminante che si ottiene ha un cut-off centrato sullo zero e la funzione converge verso la semplice funzione lineare di Fisher. E. Altman nella sua prima ricerca, pubblicata nel 1968, ha applicato la versione più semplice della tecnica di analisi discriminante lineare ad un campione di 33 imprese industriali fallite nel periodo 1945-1965 e ad un campione “pareggiato” (per anno, settore e dimensione di attivo netto totale) di società sane, estratte casualmente dagli elenchi di Moody’s e di altre fonti. Il modello ottenuto, probabilmente il più citato nella letteratura in materia, è il seguente: Z = 0,012 ⋅ Capitale Circolante/Attivo netto + 0,014 ⋅ Riserve da utili/Attivo netto + 0,033 ⋅ Utile ante interessi e tasse/Attivo netto + 0,006 ⋅ Valore di mercato del Patrimonio netto/Debiti totali + 0,999 ⋅ Ricavi/Attivo Netto
10 Si cfr. Anderson (1984). 11 Per una più ampia illustrazione dei criteri decisionali si rinvia ad Anderson (1984), Altman -Avery - Eisenbeis - Sinkey (1981), Mardia – Kent – Bibby (1979), Hand (1993), McLachlan (1992).

13
La funzione include diverse componenti del sistema economico-finanziario dell’impresa: la redditività corrente, la redditività cumulata, la liquidità e l’equilibrio a breve termine, la struttura finanziaria e l’efficienza complessiva. La seconda variabile, oltre che incorporare prevalentemente l’effetto cumulato della redditività nel tempo e della politica dei dividendi, sembra catturare implicitamente anche l’età dell’impresa: l’evidenza empirica mette in luce che il fallimento è significativamente più probabile nei primi anni di vita dell’impresa. Tutti i coefficienti hanno il segno atteso. Si osservi che la quarta variabile rappresenta un indicatore di struttura finanziaria in cui la grandezza del patrimonio netto è valutata a valori di mercato: se il mercato azionario esprime correttamente le prospettive dell’impresa, i prezzi di borsa incorporano l’aspettativa dell’insolvenza ed il modello di Altman include implicitamente anche tale previsione. Sulla base di un test di significatività le variabili più importanti ai fini della capacità classificatorie sono la redditività e l’efficienza complessiva, mentre la variabile meno rilevante è la liquidità: questo risultato è in linea con le conclusioni di Beaver. La capacità diagnostica di questa funzione valutata nell’anno immediatamente precedente all’insolvenza 12 è molto buona: in media il 95% delle imprese sono classificate correttamente, con diversa entità dei due tipi di errori; l’errore di primo tipo, consistente nel classificare come sana un’impresa anomala, è del 6%, mentre l’errore di secondo tipo, riguardante la classificazione di un’impresa sana tra le anomale, è del 3%; la tabella seguente riporta sinteticamente questi risultati:
Tabella 1. Capacità diagnostica del modello di Altman al t-1 (dati %)
Classificazione
Anomale Sane Anomale
94 6
(Errore di I Tipo)
Gruppo effettivo Sane 3
(Errore di II Tipo) 97
Valutata rispetto agli anni precedenti l’insolvenza dal secondo al quinto, la funzione mette in luce un progressivo deterioramento (peggiore di quello di Beaver) delle capacità diagnostiche, sia sul campione originale di stima sia su campioni di controllo (compreso un insieme di imprese in vita che hanno sofferto di temporanee difficoltà economiche). Naturalmente è giusto attendersi una riduzione dell’efficacia del modello nel classificare le imprese man mano che si risale indietro nel tempo rispetto al momento dell’insolvenza: salvo casi di prolungata crisi, infatti, misurati in vari anni prima dell’insolvenza la distanza tra le società sane e quelle anomale tende a ridursi e le differenze tra i due insiemi si attenuano. La robustezza e stabilità del modello deve essere valutata anche alla luce della velocità di degrado della performance a ritroso. La classificazione delle società nel modello di Altman avviene confrontando lo score calcolato sulle variabili dell’impresa e un intervallo di cut-off; l’autore infatti, in luogo di determinare lo score di cut-off come media dei centroidi dei due campioni, individua un’area grigia (o zona di ignoranza) 12 Indichiamo convenzionalmente t-1; t-2; ... t-n gli anni precedenti al momento (anno t) dell’insolvenza o del fallimento.

14
nella quale gli errori di classificazione sono più elevati, corrispondente all’intervallo 1,81 ; 2,99 dello score, con 2,675 come valore puntuale di cut-off (per valori superiori alla soglia dell’area grigia l’impresa è considerata sana). Altman ha successivamente modificato il modello originale per ampliarne il campo di applicabilità13 : a) l’indicatore di struttura finanziaria è stato calcolato utilizzando il valore contabile del
Patrimonio Netto, anziché il valore di mercato, per rendere il modello (così ristimato) utilizzabile per le società non quotate;
b) il modello è stato ristimato senza l’indicatore di turnover (ultima variabile) per adattarlo alle società non industriali: questa variabile infatti incorpora in maggiore misura le influenze dell’appartenenza delle imprese ai settori industriali;
c) un ulteriore aggiustamento è stato effettuato per adattare il modello ai rischi di credito dei paesi emergenti (il Messico nel caso specifico), cercando di correlare il più possibile gli score della funzione discriminante con le classi di rating definite sulle obbligazioni statunitensi.
Nel 1977 Altman insieme ad altri autori14 ha messo a punto un nuovo modello (Zeta), basato anche su alcune critiche alla ricerca iniziale (Z) ricevute da vari studiosi. Il nuovo modello, stimato su un campione “pareggiato” di 53 società fallite e 58 sane (5 società anomale non disponevano di dati sufficienti), composto quasi in ugual misura da imprese industriali e da imprese commerciali, ha posto maggiore attenzione a vari aspetti: a) prima del calcolo degli indicatori sono stati condotti alcuni aggiustamenti ai dati di bilancio
per renderli più espressivi della effettiva realtà aziendale: la correzione più importante è stata la capitalizzazione dei contratti di leasing operativo e finanziario 15, ma rettifiche sono state anche condotte sulle riserve, sul capitale dei terzi minoritari, sul consolidamento delle consociate finanziarie, sulle attività immateriali, avviamenti ed altre spese capitalizzate;
b) è stata controllata l’eguaglianza della matrice di varianza-covarianza dei due campioni: accertata la diversità, è stata utilizzata l’analisi discriminante quadratica;
c) l’analisi dell’importanza relativa dei diversi indicatori che compongono il modello è stata effettuata ricorrendo a 6 test diversi;
d) sono state definite delle probabilità a priori ed una stima dei costi di errata classificazione. Il nuovo modello Zeta è composto da 7 variabili: 1) ROA, misurato come rapporto tra utili ante interessi e tasse e l’attivo netto totale; 2) Stabilità degli utili, calcolata con una misura normalizzata dello scarto quadratico medio
della stima intorno al trend decennale del ROA; 3) Servizio del debito, valutato con il rapporto tra utili ante interessi e tasse e gli oneri
finanziari totali; per aumentare la normalità della distribuzione, questa variabile è stata trasformata con il logaritmo decimale;
4) Redditività cumulata, misurata dal rapporto tra riserve da utili ed Attivo netto; 5) Liquidità, calcolata in base al tradizionale indicatore di liquidità corrente; 6) Capitalizzazione, misurata col rapporto tra il valore di mercato delle azioni ordinarie (media
dei prezzi degli ultimi 5 anni) e la somma delle azioni ordinarie, privilegiate e del totale dell’indebitamento;
7) Dimensione misurata dal logaritmo dell’attivo netto.
13 Si veda Caouette – Altman – Narayanan (1998) 14 Altman – Hadelman – Narayanan (1977) 15 Su questo punto Lawrence – Bear (1986) non rilevano una specifica efficacia diagnostica della capitalizzazione del leasing

15
Sulla base degli esperimenti effettuati, Altman ha trovato che la discriminante quadratica e quella lineare hanno dato grosso modo gli stessi risultati; quest’ultima, in particolare, è risultata più accurata nella classificazione sul campione di test. Pertanto l’intero modello è stato stimato con la tradizionale metodologia lineare, benché dal punto di vista teorico fosse preferibile quella quadratica. La funzione lineare dei 7 indicatori, la cui formula esatta è riservata, ha classificato correttamente nell’anno t-1 il 96,2% delle società fallite e l’89,7% delle sane; risalendo al t-5 l’accuratezza complessiva del modello è dell’ordine del 70% circa. Il punto ottimale di cut-off è stato definito assegnando le probabilità a priori ed i costi degli errori di classificazione:
Zeta di cut-off = 2s
1a
CqCq
ln
in cui qa e qs sono le probabilità a priori che ha un’impresa di fallire o di essere sana e C1 e C2 sono i costi dell’errore di primo e secondo tipo (impresa anomala considerata sana e viceversa). Il costo atteso dell’uso del modello Zeta ai fini decisionali è pertanto:
EC (Zeta) = s
a,s2s
a
s,a1a N
MCq
N
MCq ⋅+⋅
ove Na ed Ns rappresentano la numerosità dei campioni delle imprese anomale e sane ed Ma,s e Ms,a sono il numero delle imprese classificate erroneamente16. Le probabilità a priori assegnate sono rispettivamente: qa = 2% e qs = 98% I costi degli errori sono stati stimati pari al 70% per C1 e 2% per C2. Pertanto il cut-off accettato nel modello ammonta a:
Zeta di cut-off = 337,0298,07002,0
ln −=⋅⋅
intorno al quale Altman ha condotto un’analisi di sensitività. Lo spostamento del cut-off da zero (cut-off originale della funzione lineare in assenza di correzioni per le probabilità a priori e per i costi degli errori) al nuovo valore ha l’effetto di peggiorare il tasso di riconoscimento delle società anomale e di migliorare quello delle sane. Recentemente Altman17 ha lievemente modificato i costi dell’errore di primo tipo (62 invece di 70) portando il cut-off a –0,458. Come si vede in questo nuovo modello, le cui capacità diagnostiche sono migliori di quello iniziale, Altman ha separato la fase della messa a punto della funzione discriminante (funzione lineare con cut-off pari a zero, senza correzioni per probabilità a priori e costi d’errore) da quella dell’utilizzo decisionale della funzione stessa: quest’ultima fase, consistente nel semplice spostamento
16 EC (Sane) = qa ⋅ C1 è invece il costo della strategia di considerare sane tutte le imprese ed EC (prop) = qaqs C1 + qaqs C2 rappresenta il costo di una strategia con errori proporzionali alle probabilità a priori. 17 Cfr. Caouette e altri (1998).

16
dell’intercetta della funzione, ovvero del valore di cut-off, può essere effettuata direttamente dall’utilizzatore sulla base delle proprie aspettative a priori e sui propri costi degli errori . In tale modo viene separato il lavoro del ricercatore (produzione della funzione e degli score campionari) da quello dell’utilizzatore (analista di credito) che acquisisce gli score campionari e decide l’assegnazione della società in base al confronto tra essi e la soglia di cut-off definita sugli specifici elementi dell’utilizzatore stesso (probabilità e costi).
4) L’APPROCCIO MULTIVARIATO: IL MODELLO LOGISTICO Nel dibattito scientifico susseguente alla pubblicazione delle ricerche di Beaver e di Altman, uno dei temi più discussi riguarda la scelt a del metodo statistico adottato per la messa a punto dei modelli previsivi. Nella prossima sezione verranno discussi vari temi che sono rilevanti per una comprensione critica della logica di costruzione dei modelli di previsione dei rischi di insolvenza e per una corretta interpretazione dei risultati. Questa sezione invece riguarda una breve illustrazione dell’utilizzo della funzione logistica in alternativa all'analisi discriminante lineare (o quadratica): il modello logistico infatti è stato applicato in un numero rilevante di studi, specie in anni recenti. Come si è visto in precedenza, l’analisi discriminante lineare consiste nell’individuare la migliore combinazione lineare di indicatori in grado di distinguere al meglio due insiemi di società. Si può dimostrare che vi sono relazioni strette tra l’analisi discriminante lineare e la regressione lineare: i coefficienti della funzione lineare sono pari a quelli della regressione con i minimi quadrati ordinari a meno di un rapporto costante18. In effetti anche la regressione multipla è stata utilizzata in alcune ricerche sul rischio di credito. Questo approccio consiste nello stimare un modello che ha come dipendente una variabile qualitativa (dicotomica) che descrive l’appartenenza all’insieme delle società sane o anomale:
==
=anomalaimpresa se 1sanaimpresa se 0
y
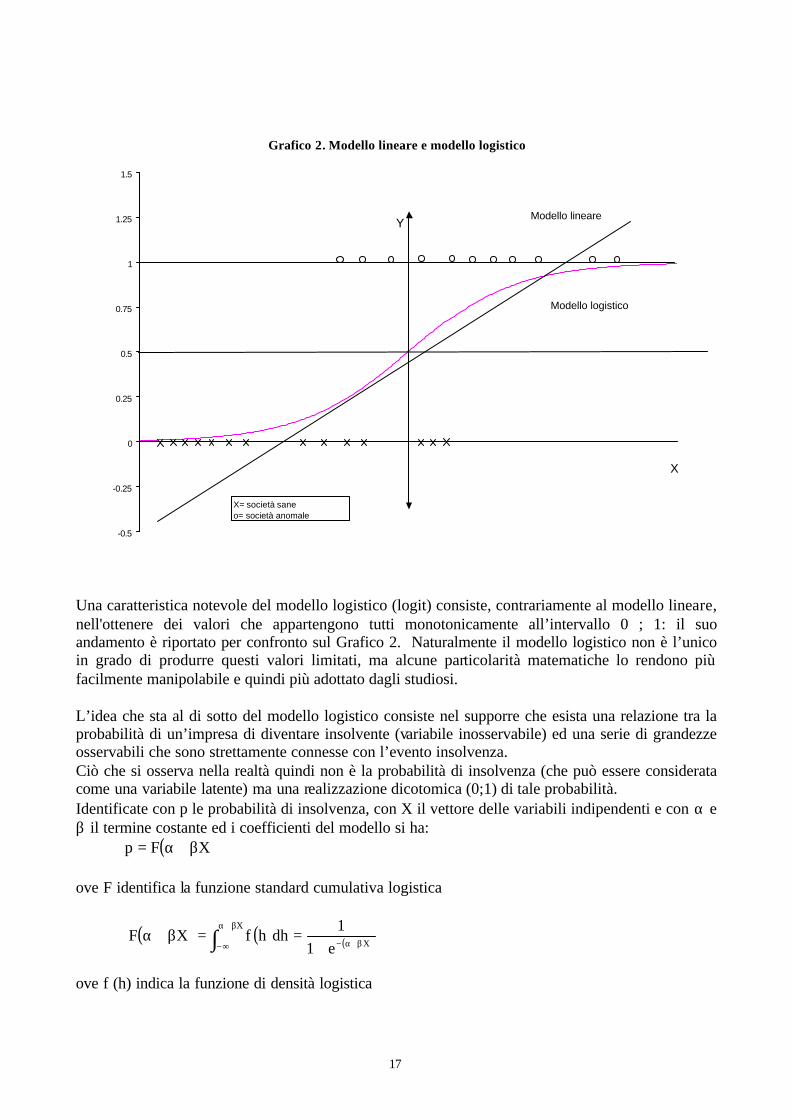
mentre gli indicatori di bilancio sono le variabili indipendenti. Una versione particolare della regressione, il linear probability model, interpreta la y come probabilità di appartenenza al gruppo. Questo procedimento comporta alcune difficoltà: la varianza degli errori della stima non è costante, determinando un problema di eteroschedasticità; esso può essere risolto con una procedura a due stadi, ma ciò non risolve altre questioni, come la non-normalità degli errori. Un altro problema riguarda il fatto che la stima della y non determina valori compresi tra 0 ed 1, come sarebbe logico per interpretare i risultati in termini di probabilità: valori stimati negativi o molto maggiori di 1 creano evidentemente difficoltà interpretative in termini probabilistici. Più i valori stimati si allontanano dall’intervallo 0 ; 1, più gli errori della stima aumentano. Sul grafico 2 è riportato un esempio di regressione lineare stimata tra la variabile dipendente (0;1) ed un indicatore di bilancio (X); le stime escono dall’intervallo ammissibile per le probabilità.
18 Cfr. Maddala (1983 e 1992).
17
Grafico 2. Modello lineare e modello logistico
Una caratteristica notevole del modello logistico (logit) consiste, contrariamente al modello lineare, nell'ottenere dei valori che appartengono tutti monotonicamente all’intervallo 0 ; 1: il suo andamento è riportato per confronto sul Grafico 2. Naturalmente il modello logistico non è l’unico in grado di produrre questi valori limitati, ma alcune particolarità matematiche lo rendono più facilmente manipolabile e quindi più adottato dagli studiosi. L’idea che sta al di sotto del modello logistico consiste nel supporre che esista una relazione tra la probabilità di un’impresa di diventare insolvente (variabile inosservabile) ed una serie di grandezze osservabili che sono strettamente connesse con l’evento insolvenza. Ciò che si osserva nella realtà quindi non è la probabilità di insolvenza (che può essere considerata come una variabile latente) ma una realizzazione dicotomica (0;1) di tale probabilità. Identificate con p le probabilità di insolvenza, con X il vettore delle variabili indipendenti e con α e β il termine costante ed i coefficienti del modello si ha:
( )XFp β+α= ove F identifica la funzione standard cumulativa logistica
( ) ( ) ( )X
X
e11
dhhfXFβ+α−
β+α
∞− +==β+α ∫
ove f (h) indica la funzione di densità logistica
-0.5
-0.25
0
0.25
0.5
0.75
1
1.25
1.5
X= società saneo= società anomale
Modello logistico
Modello lineare
X
Y

18
( )( )2h
h
e1
ehf
+=
L’ipotesi forte del modello riguarda quindi la forma della distribuzione di probabilità di insolvenza. Dalla relazione
( )Xe11
pβ+α−+
=
si ha
( )
pp1
e X −=β+α−
ovvero ( )
p1p
e X
−=β+α
in cui il termine di destra rappresenta l’”odd-ratio” (cioè il rapporto tra le probabilità dell’evento ed il suo complemento). Prendendo il logaritmo naturale si ottiene:
Xp1
pln β+α=
−
Nel linear probability model è p ad essere messo in relazione con α + βX, mentre nel modello logistico, come si vede, è il logaritmo dell’odd-ratio: in entrambi i casi le variabili esplicative sono connesse alla dipendente con una funzione lineare. Quella relazione è equivalente a considerare
( )( )
XXpXp
lnB
A β+α=
ove pA e pB sono le due densità di probabilità delle popolazioni A e B. Pertanto, applicando il teorema di Bayes secondo le stesse linee esaminate per l’analisi discriminante, si attribuisce l’osservazione alla popolazione A se
( )( ) A
B
B
A
lnXpXp
ln >
e quindi
A
B
lnX >β+α

19
Dalle relazioni precedenti emerge che quando α + βX = 0 , e (α+βX) = 1 e quindi p = 1-p, ovvero p = 0,5: il valore di cut-off, nel caso più semplice, si ha quando vi è perfetta incertezza in termini probabilistici, cui corrisponde un valore nullo dell’esponente della funzione logistica cumulata. Un modello assai simile a quello logistico è il probit. In quest’ultimo, l’ipotesi chiave riguarda la forma della distribuzione cumulata delle probabilità di insolvenza: invece di assumere che la forma della distribuzione sia la logistica cumulata, si ipotizza che essa sia la normale standardizzata cumulata:
( ) ( )∫β+α
∞−
−
π==β+α
X2
h 2
e21
dhhfXF
Benché le due distribuzioni siano diverse, i risultati sono tra di loro prossimi; la distribuzione normale tuttavia ha un grado di difficoltà nel trattamento matematico superiore alla logistica e pertanto nelle applicazioni è quest’ultima ad essere utilizzata in prevalenza. Prima di passare all’analisi critica dei diversi modelli proposti nella letteratura è importante sottolineare la profonda diversità concettuale che separa l’analisi discriminante dal modello logistico. L’analisi discriminante ipotizza implicitamente che le imprese osservabili siano tratte da due universi distinti dati; la rilevazione delle variabili di bilancio sulle imprese può essere di aiuto per trovare le caratteristiche rilevanti e per individuare da quale universo esse provengono effettivamente. L’analisi discriminante cerca pertanto di prevedere l’appartenenza a un gruppo, dopo aver osservato le variabili ritenute rilevanti per caratterizzare le diversità tra i due universi. Il modello logistico (o probit ed altri simili) invece, come anche la regressione multipla, ipotizzano che le imprese siano tratte casualmente da un unico universo cui appartengono e cercano di stimare una caratteristica specifica di tali imprese: il grado di salute ovvero la probabilità (logistica, normale, lineare) di insolvenza/fallimento. Tale caratteristica è immaginabile come una variabile latente continua, di cui sono osservabili solo due essenziali determinazioni estreme (0;1). Questi modelli quindi ipotizzano che vi sia una relazione causale tra le variabili osservate sui dati contabili e la variabile dipendente; ciò significa che questi modelli implicitamente suppongono una relazione di causa-effetto tra i fenomeni economici sintetizzati dalle variabili di bilancio (e di cui queste ultime costituiscono delle proxy) e lo stato di salute dell’impresa. Questa famiglia di modelli quindi non stima l’appartenenza dell’impresa ad un gruppo, ma il grado dello stato di difficoltà economico-finanziaria in cui versa l’impresa. Poiché i presupposti sono diversi, anche l’interpretazione del sistema di variabili e coefficienti che compongono i modelli è differente tra l’analisi discriminante e gli altri approcci. Nell’analisi discriminante non si stima un modello esplicativo dell’insolvenza ma si cerca di combinare insieme diverse variabili per avere un segnale unico, complesso, dell’appartenenza probabile ad un gruppo, dato a priori: gli indicatori che compongono la funzione discriminante (lineare o quadratica) vanno interpretati come segnali individuali che giustificano la loro presenza per il contributo marginale che danno al segnale complessivo. Nella regressione multipla, come nella logistica, invece gli indicatori rappresentano le variabili esogene che sono funzionali a spiegare la situazione dell’impresa dal punto di vista del creditore: gli indicatori giustificano la loro presenza nella misura in cui concorrono ad individuare le varie componenti del modello economico-finanziario che spiega lo stato di crisi dell’impresa o/e la sua evoluzione o/e il suo deterioramento. L’analisi discriminante tratta gli indicatori più come “segnali” di stato che come proxy quantitative di strutture e di risultati gestionali, in grado di sintetizzare i meccanismi economici sottostanti al sistema impresa.

20
5) CRITICHE, VARIANTI ED ESTENSIONI Alla pubblicazione delle ricerche di Beaver ed Altman ha fatto seguito un nutrito filone di studi orientati sia ad approfondire in modo critico vari aspetti metodologici, sia ad estendere l’applicazione dei modelli a campioni più ampi di società insolventi, a fenomeni connessi all’insolvenza, a realtà di paesi diversi. I vari filoni del dibattito scientifico ed applicativo durano tuttora, anche con la sperimentazione di tecniche nuove provenienti dal campo dell’intelligenza artificiale. All’argomento sono stati dedicati numeri monografici di riviste scientifiche, a testimonianza dell’interesse degli studiosi e degli operatori creditizi e finanziari. Anche in Italia il tema ha suscitato parecchio interesse, sia tra gli studiosi sia tra gli operatori finanziari e bancari, in particolare: questi ultimi hanno in tempi recenti aumentato l’attenzione dedicata a queste metodologie allo scopo di arricchire le tradizionali procedure di selezione del credito con nuovi strumenti. A partire dai lavori di Alberici (1975), Appetiti (1985) e Forestieri (1986), fino ai più recenti studi nella Banca d’Italia19, l’analisi discriminante e le altre tecniche di previsione delle insolvenze sono state applicate in vari contesti, dimostrando pienamente la loro fecondità. La Centrale dei Bilanci, nell’ambito di iniziative rivolte al sistema bancario, ha sviluppato fin dal 1988 un sistema di diagnosi dei rischi di insolvenza, basato sull’analisi discriminante, giunto oggi alla terza versione 20: una illustrazione generale del sistema della Centrale dei Bilanci è riportata nell’Appendice 2. Lo stesso tema è stato oggetto recentemente di una approfondita analisi comparata nell’ambito del Comitato Europeo delle Centrali dei Bilanci, di cui la Centrale dei Bilanci Italiana è socio fondatore, mettendo a confronto le diverse esperienze maturate nei principali paesi europei: l’Appendice 1 raccoglie in modo sintetico la descrizione di questi risultati. Prima di passare all’analisi dei problemi e delle critiche emerse nel dibattito scientifico sui metodi di previsione delle insolvenze, è utile sottolineare l’ampio spettro delle applicazioni cui essi hanno dato origine. Oltre al tradizionale campo della valutazione del rischio di fallimento di imprese non finanziarie, l’analisi discriminante e la famiglia delle regressioni parametriche (lineare, logistica, probit) sono state applicate, con più o meno elevato successo: a) alla classificazione dei finanziamenti bancari: i dati sui finanziamenti bancari, non essendo
debiti trattati sul mercato finanziario, sono particolarmente difficili da ottenere in quantità tali da consentire stime applicabili dei modelli. Gli analisti di credito generalmente adottano una classificazione dei finanziamenti in base a grandi categorie di rischio (rating interno alla banca); le categorie sono più o meno numerose a seconda del grado di dettaglio e di analiticità voluti21. Sono stati applicati modelli di Analisi discriminante lineare multipla (MLDA), regressioni lineari (OLS), Probit, Logit, oltre a tecniche meno diffuse, per cercare di riprodurre gli
19 Laviola -Trapanese (1997); Marullo Reedtz (1996). 20 La prima versione è illustrata in Varetto (1990), la seconda versione in Varetto-Marco (1994) e la terza in Varetto (1998 (a)). 21 Una classificazione standard spesso adottata nelle banche anglosassoni comprende 5 categorie: current (rischio accettabile), especially mentioned (vi sono elementi di debolezza nel debitore), substandard (rischio elevato); doubtful (rimborso assai problematico); loss (credito considerato inesigibile). Nelle ultime due categorie gli interessi attivi non sono più conteggiati. In alternativa a questo schema le banche adottano procedure di rating interno, in genere con un numero di classi comprese tra 7 e 12, oppure utilizzano direttamente gli schemi della società di rating più note (Standard & Poor’s e Moody’s).

21
schemi di classificazione degli analisti bancari e quindi contribuire sia alla revisione oggettiva delle pratiche, sia all’automazione del processo di selezione. In questo caso la difficoltà consiste nel forzare il modello ad effettuare una classificazione non tra due insiemi ma all’interno di una scala ordinale di gradazione del rischio in cui non sempre sono nettamente distinti i contorni esterni delle sottopopolazioni . In altre ricerche la classificazione è limitata a due gruppi: finanziamenti vivi e prestiti insoluti o ristrutturati (Dietrich – Kaylan (1982); Ward – Foster (1997); Lawrence – Arshadi (1995); Holt – Carroll (1980); Orgler (1970)). I tradizionali indicatori economico finanziari, tra cui la struttura finanziaria, la copertura con i flussi di cassa degli oneri finanziari e delle quote di rimborso, la redditività, il trend dei ricavi, oltre ad elementi riguardanti lo stato del prestito e la situazione del settore hanno messo in luce notevoli capacità diagnostiche. Chalos (1985) ha approfondito il problema del raccordo delle differenze tra sistemi statistici di decisione, valutazioni individuali (di singoli analisti) e valutazioni di gruppo (comitati di credito). Sotto il profilo metodologico l’uso del modello logistico multinominale ed il modello logit ordinato (ovvero probit ordinato) si sono rivelati proficui. Essi si basano sull’estensione a più di due gruppi del caso-base della regressione logistica (o probit) su due gruppi (Maddala (1983)). All’analisi dei prestiti bancari è stata dedicata un’analisi effettuata utilizzando unicamente i dati della Centrale dei Rischi (Alberici (1989)).
b) alla classificazione dei prestiti personali: la tipologia dei problemi è simile a quella esaminata nel punto precedente, ma l’analisi di questa tipologia di prestiti avviene tipicamente ricorrendo a questionari con valutazioni di tipo anagrafico, patrimoniale, occupazionale, e così via. Queste variabili possono quindi essere di tipo non continuo (Gardner – Mills (1989); Wiginton (1980)).
c) all’analisi del Rating delle Obbligazioni e delle cambiali finanziarie (commercial paper): è
questo uno dei campi tipici dell’applicazione delle tecniche di classificazione, con le quali si cerca di riprodurre, prevalentemente con dati di bilancio, lo schema concettuale adottato dalle società di rating per la valutazione del debito sia a breve termine sia a medio e lungo termine, negoziato sul mercato (Altman ed altri (1981); Pinches-Mingo (1973); Peavy-Edgar (1984); Carleton – Dragun – Lazear (1993)).
d) alle caratteristiche delle insolvenze nelle obbligazioni ad alto rischio ed alto rendimento
(Hakim- Shimko (1995); Huffman – Ward (1996)). e) alle liquidazioni volontarie: questo tipo di chiusura dell’attività di impresa, per cause diverse
da quelle dell’insolvenza, sono in genere difficili da valutare per la complessità di modellare i diversi motivi (le diverse convenienze) che stanno alla base di questa decisione. Per tale ragione le liquidazioni volontarie sono generalmente escluse dai campioni per la previsione delle insolvenze. Alla base della liquidazione, infatti, possono esserci sia la perdita di prospettive redditizie per il futuro, sia la conclusione di grossi progetti portati a termine, sia il cambiamento, anche traumatico, di condizioni ambientali esterne, sia lo scioglimento della compagine societaria, sia infine vere e proprie insolvenze latenti (Hudson (1987); Ghosh – Owers – Rogers (1991)).
f) all’analisi del credito commerciale: le imprese industriali vengono in questo caso esaminate
in quanto beneficiarie del credito di fornitura (Keasey-Watson (1986)).

22
g) alla valutazione dell’acquisizione ed incorporazione di società fallite: questa problematica può essere modellata come un processo di decisioni condizionate (ad albero), cui è applicabile la logistica a risposta sequenziale (Maddala (1983); Pastena – Ruland (1986); Theodossiou e altri (1996); Peel-Wilson (1989)).
h) alla distinzione tra società insolventi che finiscono in fallimento e quelle che, passando
attraverso un’amministrazione controllata, riescono a ristrutturarsi ed a rilanciarsi (Casey ed altri (1986)).
i) alle relazioni tra il mercato finanziario e l’insolvenza delle imprese o la sua anticipazione
con metodi previsivi: le ricerche in questo campo riguardano essenzialmente due prospettive. La prima intende valutare la capacità anticipativa dell'insolvenza/fallimento dell’impresa da parte del mercato: un mercato finanziario efficiente dovrebbe infatti essere in grado di incorporare tempestivamente le aspettative della futura insolvenza. In questo filone di analisi non sono ricompresi gli studi, commentati in altri capitoli di questo volume, mirati a stimare le probabilità di insolvenza implicite nei differenziali di tasso di rendimento delle obbligazioni delle imprese quotate sul mercato. Ugualmente non sono inclusi gli studi sulla redditività generata dall’investimento in azioni di imprese insolventi o prossime a procedure concorsuali. La seconda prospettiva intende esaminare il contenuto informativo dell’analisi di bilancio, ed in particolare dei segnali dei modelli di previsione delle insolvenze, alla luce del comportamento del mercato finanziario. L’evidenza empirica disponibile su entrambi i filoni di ricerca non è omogenea, tuttavia sembrano emergere nel complesso conclusioni favorevoli al paradigma del mercato efficiente (le ricerche riguardano per lo più i mercati anglosassoni): il comportamento dei prezzi azionari prima del manifestarsi del fenomeno dell’insolvenza, così come quello dei rendimenti, della volatilità, dei coefficienti Beta, mette in luce una significativa capacità anticipatoria del mercato, che riesce ad incorporare tempestivamente la maggior parte degli effetti dell’evento; peraltro non tutte le variabili espresse dal mercato hanno la stessa capacità anticipatoria (su questo punto vi sono divergenze tra le ricerche esaminate). Inoltre il mercato riesce ad includere nei prezzi una quota significativa del contenuto informativo dei risultati modelli di previsione delle insolvenze basate sui dati contabili: questa conclusione, che emerge da molti studi (ancorché non da tutti), è in linea con le conoscenze acquisite nelle ricerche sulle relazioni tra informazioni contabili e mercato azionario efficiente. Su questo campo di ricerca si può consultare, tra gli altri, Queen – Roll (1987); Katz-Lilien-Nelson (1985); Kaen – Tehranian (1990); Aharony – Jones – Swary (1980); Ro-Zavgren – Hsieh (1992); Theobald – Thomas (1982); Altman – Brenner (1981); Zavgren – Dugan – Reeve (1988); Wood-Piesse (1987); Kwon-Wild (1994); Castagna – Matolcsy (1981); El Hennawy – Morris (1983(a)); Dugan – Forsyth (1995).
l) alla valutazione delle eccezioni di continuità aziendale espresse dai revisori contabili: il bilancio d’esercizio è normalmente predisposto con l’ottica della continuità della vita dell’impresa (principio generale dell’impresa in funzionamento); quando questo presupposto viene a cadere, ovvero vi sono ragionevoli e fondati motivi per ritenere che l’impresa non sarà in grado di continuare la propria attività in futuro, i revisori contabili devono segnalare questo rischio in modo tempestivo ed accurato nell’ambito della loro relazione di certificazione.

23
A rigore, mancando il presupposto della continuità aziendale, le attività non possono più essere valutate al costo e le passività al valore nominale (come sono prevalentemente iscritte) ma si devono adottare i principi di valutazione dell’impresa in liquidazione (o di cessione se ricorre quest’altra eventualità), considerando i singoli beni non più come componenti strumentali alla gestione (il loro valore è indiretto e funzione delle capacità di produrre futuri redditi) ma come beni in sè stessi, realizzabili separatamente. L’immagine della situazione aziendale che si ottiene valutando le attività al valore di realizzo e le passività al valore di rimborso (senza attendere la naturale scadenza per le operazioni a medio e lungo termine) può essere molto diversa da quella trasmessa dal bilancio di funzionamento. Parallelamente i prezzi espressi da un mercato finanziario efficiente non dovrebbero più rappresentare l’aspettativa del valore attuale dei flussi di cassa attesi dalla gestione, ma dovrebbero esprimere il valore attuale dei flussi di cassa ricavabili dall’imminente liquidazione. Tanto più tempestivamente questo cambiamento di base valutativa viene incorporato nei prezzi in anticipo rispetto al manifestarsi delle prospettive dell’evento, tanto più il mercato finanziario è efficiente. Non è detto, tra l’altro, che il prezzo di mercato in ottica di cessazione dell’attività sia più basso di quello in funzionamento: dipende evidentemente dalle prospettive di economicità della gestione e anche del minor contenuto di rischio che può essere implicito nei flussi attesi dalla liquidazione (sono meno distanti nel futuro e in certi casi anche meno aleatori nelle stime). Allo scopo di aiutare i revisori ad individuare e segnalare le eccezioni alla continuità aziendale sono state messe a punto procedure amministrative basate su check- list più o meno articolate22, raccomandate nei principi di revisione. I modelli di previsione delle insolvenze sono stati applicati per valutare sia la capacità anticipatoria delle eccezioni alla continuità aziendale segnale dei revisori rispetto all’evento, sia, più semplicemente, la loro capacità a identificare correttamente i rischi di insolvenza grave, tali da pregiudicare la sopravvivenza dell’impresa, sia ancora il loro contenuto informativo nell’ambito di mercati finanziari efficienti. L’evidenza delle ricerche empiriche non è omogenea, ma sembrano emergere alcune conclusioni di fondo: i prezzi formati su un mercato efficiente incorporano il contenuto informativo delle eccezioni di certificazione dei bilanci già prima che queste divengano di pubblico dominio; la capacità informativa, in termini di nuove informazioni trasmesse agli investitori, è scarsa; vi è una relazione positiva tra le eccezioni di continuità aziendale e l’effettivo fallimento dell’impresa (o interruzione della sua gestione), ma tale connessione è debole, salvo i casi di società molto dissestate e con insolvenze gravi già realizzate o imminenti; in generale, anche se con evidenze contrarie, i modelli statistici di previsione delle insolvenze hanno una capacità predittiva superiore (a volte in misura significativa) ai giudizi dei revisori e quindi, questi ultimi possono giovarsi dei primi nelle loro valutazioni (Mutchler (1985); Bell-Tabor (1991); Koh (1991); Kennedy-Shaw (1991); Citron-Taffler (1992); Asare (1990); Koh –Killough (1990); Hopwood – McKeown – Mutchler (1988 e 1994); Cormier – Magnan – Morard (1994); Wilkins (1997); Altman (1993).
m) agli effetti dei cambiamenti di governo o di regime politico sui rischi di insolvenza (Hall-Stark (1986)).
n) alle imprese assicurative (Barniv (1990)) e bancarie: in quest’ultimo campo, oltre alle
ricerche pubblicate dalle Banche Centrali, si può utilmente consultare, tra gli altri, West (1985), Espahbodi (1991), Heyliger-Holdren (1991) e Kumar-Arora (1995). All’analisi della
22 A titolo di esempio si cfr. per l’Italia il Principio di Revisione n. 21 (1995).

24
rischiosità delle banche è stata dedicata attenzione anche in Italia: a questo proposito si veda De Luigi – Maccarinelli (1993).
o) all’analisi del rischio paese ed alla rischedulazione dei debiti dei PVS: per tutti si rinvia a Di
Mauro – Mazzola (1989). Il ricorso alle diverse metodologie di previsione delle insolvenze ha stimolato l’interesse all’approfondimento dei problemi, connessi alla loro applicazione ed ai limiti derivanti dalle semplificazioni che forzatamente si accompagnano all’uso concreto. In questa sede non si prendono in considerazione le verifiche empiriche su nuovi campioni o con insiemi più ampi di indicatori per controllare la robustezza e la stabilità dei risultati dei modelli proposti nella letteratura, come ad esempio Deakin (1972; 1977) quanto, piuttosto, si esaminano in qualche dettaglio i principali problemi metodologici ed operativi collegati alle varie metodologie; parallelamente sono presi in considerazione anche alcune evoluzioni che si ritengono importanti per il miglioramento delle capacità diagnostiche dei modelli.
5.1 ASSENZA DI UNA TEORIA Un primo problema di fondo, che vale per tutte le metodologie e non solo per l’analisi discriminante, riguarda la critica dell’assenza di una teoria di riferimento. I diversi modelli vengono messi a punto sostanzialmente in modo euristico, scegliendo gli indicatori e le altre variabili che forniscono i risultati più soddisfacenti in termini di performance e di stabilità dei risultati. Questa selezione è frutto di un processo di ricerca puramente empirico, con adattamenti che dipendono spesso dalle capacità individuali dei singoli ricercatori, e non si basa invece su una teoria dell’insolvenza (o della crisi) dell’impresa: lo testimonia la pluralità di modelli proposti nella letteratura, con variabili assai spesso diverse tra loro (anche se spesso solo nel contenuto di calcolo) e nel diverso grado di importanza attribuito. Il rischio di questa situazione consiste nel generare modelli che sono “sample-specific”, senza un’effettiva generalizzabilità: su quest’ultimo punto la terapia, parziale, in attesa di una teoria, consiste nel lavorare con campioni sempre più ampi e rappresentativi del reale comportamento della popolazione. Peraltro nell’economia aziendale, in quella industriale ed in quella finanzia ria sono disponibili alcuni schemi teorici parziali o sistemazioni in schemi teorici di osservazioni empiriche: si veda a titolo di esempio Argenti (1976); Hendel (1996); Jovanovic (1982); Gordon (1971).
5.2 CAPACITA' PREDITTIVA EX-ANTE ED EX-POST
Un secondo problema riguarda la vera natura dei modelli di previsione delle insolvenze (indipendentemente dalla metodologia usata): i diversi approcci hanno messo in luce in innumerevoli applicazioni di saper classificare le imprese con errori generalmente modesti. A rigore (Johnson (1970)) ciò significa che gli indicatori economico-finanziari sono dotati di una effettiva capacità discriminante ex-post; questi modelli, in altri termini, dimostrano che i gruppi di società che si intendono riconoscere hanno livelli o/ed andamenti dissimili degli indicatori di bilancio. Ciò può non significare però, su un piano strettamente concettuale, che gli stessi indicatori abbiano un potere predittivo ex-ante: per dimostrare quest’ultima ipotesi occorre rovesciare l’impostazione seguita (dal segnale di insolvenza agli indicatori) e lavorare nella direzione che va dagli indicatori all’insolvenza, ovvero dimostrare che certi livelli e/o andamenti degli indicatori implicano l’evento- insolvenza. La capacità diagnostica delle variabili di bilancio ex-post è accertata, ciò che va verificata è la capacità preduttiva ex-ante.

25
Sotto certi aspetti, peraltro questa critica privilegia il punto di vista logico-metodologico e rischia di essere fuorviante: ciò che effettivamente fanno i modelli di analisi dell’insolvenza è di valutare in quale misura le imprese sono distanti (in termini di score o di probabilità) da profili economico-finanziari tipici che possono ritenersi rappresentativi di società insolventi e di società sane, ovvero di individuare se nell’impresa in esame vi sono sintomi più o meno evidenti che si sono riscontrati sistematicamente in gruppi di imprese insolventi.
Il controllo delle capacità previsive può essere effettuato verificando la performance del modello con un insieme di imprese osservate su un periodo di tempo successivo alla finestra usata per la stima. Begley e altri (1996) hanno sottoposto a verifica i modelli di Altman e Ohlson usando dati recenti, distanti dal periodo in cui essi sono stati stimati, osservando una significativa riduzione delle performance.
5.3 STABILITÀ DEI MODELLI
Strettamente connesso con il punto precedente vi è il problema della stabilità nel tempo dei modelli. Non c’è dubbio che il mantenimento nel tempo della capacità diagnostica dei modelli si basa sulla stabilità delle relazioni individuate tra le variabili discriminanti e l’evento- insolvenza. In effetti un costruttore di modelli non può mancare di verificarne periodicamente le performance e di procedere a ri-stime quando la loro efficacia discriminante tende a ridursi: è esattamente questa la strada seguita in Europa dalla Banca di Francia, dalla Deutsche Bundesbank e dalla Centrale dei Bilanci italiana. Cambiamenti strutturali nel ciclo economico, variazioni del tasso d’inflazione e delle condizioni di permissività monetaria sono tra gli elementi che possono influenzare la stabilità temporale dei modelli23; nel nostro paese occorre aggiungere anche il cambiamento del sistema informativo di bilancio introdotto nel nostro ordinamento con il recepimento della IV direttiva europea sui conti annuali, ed in particolare le discontinuità che si sono venute a creare nelle serie storiche con l’adozione di bilanci in forma abbreviata da parte di molte imprese minori. Mensah (1984) per controllare la capacità diagnostica dei modelli in condizioni economiche diverse ha aggregato i dati delle imprese esaminate in quattro sottoperiodi del ciclo congiunturale in USA tra il gennaio ’72 ed il giugno ’80: crescita in stato stazionario, recessione, successiva crescita, stagflazione con recessione. Anche i cambiamenti dei criteri decisionali delle banche (o della normativa), possono influire sulla stabilità dei modelli: se ad esempio negli anni ’90 i creditori, anche spinti dalla concorrenza, sono disposti ad accettare un più elevato livello di indebitamento nelle strutture finanziarie delle imprese, i modelli stimati negli anni ’80 tenderanno a segnare un aumento del rischio di insolvenza, più elevato di quello effettivamente riscontrabile dai dati sul passaggio a sofferenza. Sull’adozione di una maggiore severità dei criteri di rating, da parte delle società di rating, percepita come un aumento della rischiosità delle emissioni obbligazionarie nel mercato americano si veda Blume e altri (1998). Peraltro la stabilità delle funzioni stimate è implicitamente adottata quando i bilanci delle società anomale vengono assemblati in pool in base alla distanza temporale dell’evento- insolvenza e non in base all’esercizio contabile. A causa del ridotto numero di osservazioni, infatti, i bilanci vengono spesso aggregati secondo lo schema seguente:
23 L’aspetto dell’inflazione su dati di bilancio può essere parzialmente corretto rettificando i conti aziendali per le variazioni del metro monetario (Platt -Platt - Pedersen (1994); Skogsvik (1990); Mensah (1983)).

26
Tabella 2.: Pooling dei bilanci Campioni di società anomale Data dell'evento insolvenza
T-1 T-2 T-3 … T-n Esercizi contabili: 1985 N11 N12 N13 … … … Nj1 … … … Njn … … … … … … 1999 … … … … …
In questo modo si fanno implicitamente le seguenti ipotesi:
a) l’insolvenza è il risultato di un processo omogeneo ( vi è un profilo tipico di insolvenza);
b) i sintomi dell’evento- insolvenza colpiscono le imprese in modo simile all’interno dello stesso periodo;
c) i sintomi sono diversi a seconda dei periodi. In tal modo si riesce a sfruttare al meglio la scarsa numerosità dei campioni di società anomale che sono in genere disponibili. Il controllo della razionalità di tale pooling può essere effettuato esaminando la stabilità temporale dei livelli medi e delle distribuzioni degli indicatori per anno dell’esercizio contabile e per anno di distanza dall’evento- insolvenza. Il solo controllo dei divari tra gli indicatori per anno di distanza dall’evento consente unicamente di verificare l’effettiva diversità temporale dei sintomi dell’insolvenza e di calibrare al meglio il periodo su cui effettuare la stima. In modo più rigoroso si possono mettere a confronto i coefficienti della funzione stimata sul pool di anni su cui si basa il modello con i coefficienti di funzione stimati per singoli sottoperiodi che compongono il pool24: se è verificata la stabilità del modello, almeno per la fase di stima, le differenze tra i coefficienti non dovrebbero essere significative (Negakis (1995)). Se il comportamento degli indicatori non è stabile nel tempo, i modelli tendono a perdere la loro efficacia predittiva. Se l’instabilità è molto pronunciata e deriva dalla influenza di fattori macroeconomici reali e monetari o/e settoriali o/e geografici, tra le variabili del modello possono essere inserite o delle dummies di settore e/o di anno (Cressy (1991)) e/o geografici oppure direttamente degli indicatori macroeconomici (tasso d’interesse, inflazione, variazione PIL, ...), settoriali e geografici (El Hennawy-Morris (1983(b)). Per ridurre il numero delle dummy, e gli effetti di multicollinearità, si può ricorrere alla cluster analysis o all’analisi fattoriale: quest’ultima consente di riassumere in pochi fattori il contenuto informativo di numerose serie macroeconomiche e settoriali. Questo approccio, tra l’altro, consente di condurre esperimenti per la stima degli effetti sulla situazione delle imprese indotti da recessioni o shocks economici (si veda anche Geroski-Gregg (1996); Kane e altri (1996); Richardson e altri (1998)). L’applicazione in chiave previsiva dei modelli che integrano dati d’impresa con dati di scenario macroeconomico e settoriale richiede evidentemente che siano alimentati oltre che dai bilanci prospettici delle società sotto esame anche dalle previsioni degli aggregati macro e settoriali.
24 Ovvero fare stime “time-varying coefficients”.

27
5.4 INDUSTRY RELATIVES
Una delle cause che può contribuire alla instabilità delle funzioni riguarda la diversa sensitività al ciclo dei diversi settori economici nel caso di modelli predittivi generali (ovvero di modelli che abbracciano un ampio spettro di settori). Idealmente sarebbe preferibile disporre di singoli modelli settoriali in grado di catturare le specificità delle imprese che vi operano, ma questo approccio è generalmente incompatibile con la limitatezza dei campioni di società anomale 25. Diventa quindi una scelta praticamente obbligata la costruzione di modelli generali, sui quali vengono raggruppati insiemi settoriali più omogenei possibile: è questa la strada seguita dalla Centrale dei Bilanci, che ha messo a punto separatamente modelli per le imprese industriali, modelli per quelle commerciali e modelli per quelle di costruzioni; nella stessa direzione ha operato la Banca di Franc ia (si veda anche Taffler (1984)). I modelli generali tendono quindi a riflettere gli andamenti medi dei settori che vi sono rappresentati: se i divari tra i livelli degli indicatori, o il loro andamento, sono troppo diversi ovvero è differente la sensitività al ciclo economico (cicli settoriali sfasati e di diversa ampiezza) si possono generare instabilità nei modelli ovvero un’eccessiva influenza di alcuni settori sul profilo medio dei risultati complessivi. Izan (1984), per ridurre l’influenza settoriale, ha proposto di lavorare con indicatori “industry relatives”, anziché con le variabili originarie: per migliorare la confrontabilità settoriale del mix delle imprese esaminate gli indicatori sono rapportati alla mediana (o media, in altri casi) annuale di settore. In questo modo Izan ha trovato significativi miglioramenti nella stabilità degli indicatori, nelle stabilità delle stime e nella robustezza delle funzioni ai cambiamenti della composizione dei campioni di imprese ed alle loro performance ex-post ed ex-ante. Platt e Platt (1990 e 1991) hanno raggiunto anche una variabile di crescita dell’impresa rapportata alla crescita del settore per catturare meglio gli effetti del ciclo economico specifico del settore. E’ possibile tuttavia che gli spostamenti delle medie di settore non siano dovute a instabilità ma a correlazione seriale tra le variabili. Altre ricerche che hanno impiegato gli industry-relatives non hanno peraltro trovato una forte evidenza della loro superiorità rispetto agli indicatori non aggiustati. Si osservi inoltre che per la concreta applicazione degli industry-relatives alla predizione ex-ante occorre disporre di una stima delle mediane future di settore con cui rettificare gli indicatori. Un altro modo per risolvere questo problema consiste nel calcolare gli industry-relatives sulla base di mediane di lungo periodo; questo approccio tuttavia, se facilita i confronti intersettoriali, riproduce gli effetti del ciclo economico, la cui correzione deve pertanto essere introdotta nel modello con un ulteriore strumento.
5.5 SCELTA DELLA METODOLOGIA Uno dei problemi cruciali riguarda la scelta della metodologia da adottare per la messa a punto del modello; mentre nei paragrafi successivi si prendono in considerazione tecniche di tipo non parametrico ed applicazioni tratte dall’intelligenza artificiale, qui si restringe la discussione agli approcci di gran lunga più diffusi: l’analisi discriminante e le tecniche parametriche lineare e 25 Sui modelli settoriali predisposti in un’ottica aggregata si rinvia al paragrafo 9.

28
logistiche (la probit viene sostanzialmente assimilata alla logit). Il riferimento generale, ove non espressamente indicato, riguarda il caso di discriminazione tra due gruppi. Già si sono visti nei paragrafi precedenti i presupposti diversi su cui si fondano l’analisi discriminante e le tecniche parametriche e pertanto qui si riconsiderano solo alcuni punti essenziali. L’analisi discriminante si basa essenzialmente sulle ipotesi che le medie degli indicatori dei due gruppi siano significativamente diverse, che la matrice delle varianze/covarianze dei due gruppi siano identiche e che la distribuzione degli indicatori sia di tipo normale multivariata. Qualora le matrici delle varianze/covarianze siano diverse, la metodologia più corretta è la discriminante quadratica. La normalità delle distribuzioni degli indicatori è una ipotesi rilevante anche per le tecniche parametriche lineari, mentre la logit e probit si basano sulla assunzione forte della forma (logistica e normale) della distribuzione delle probabilità di insolvenza. Com’è noto le ricerche empiriche hanno messo in luce che in generale la distribuzione degli indicatori non è di tipo normale 26 : ne possono risultare influenzati sia i test di significatività che i tassi di performance dei modelli. Tuttavia esperimenti condotti nella letteratura hanno messo in luce che gli effetti della violazione della normalità, per l’analisi discriminante lineare, per quella quadratica, per la regressione lineare e per quella logistica, non sono, generalmente, così dirompenti come la teoria statistica tende a sottolineare (Eisembeis (1977); Altman ed altri (1981(a)); Richardson-Davidson (1983)). Alcuni ricercatori, per migliorare la normalità delle distribuzioni o quantomeno per renderle simmetriche, procedono a trasformazioni delle variabili originali applicando spesso l’operatore logaritmico o la radice quadrata o il reciproco ovvero trasformando le variabili originali in ranghi (Hopwood e altri (1988); Perry-Cronan (1986)). Questo aggiustamento tuttavia ha notevoli limiti. Da un lato non è sempre possibile, salvo eliminare certe osservazioni (la trasformazione logaritmica ad esempio non è applicabile per indicatori con valori negativi o nulli), dall’altro l’aggiustamento introduce dei cambiamenti nelle relazioni tra le variabili, alterando sia le stime, sia l’interpretazione delle funzioni ottenute. La diversità delle dispersioni tra i due gruppi, ovvero delle matrici di varianza/covarianza, rende l’analisi discriminante lineare teoricamente meno efficiente di quella quadratica. Tale diversità, tra l’altro influenza i test sulle differenze tra le medie dei gruppi. Questo problema è specifico dell’approccio con l’analisi discriminante che si basa sull’ipotesi di esistenza di due popolazioni distinte, mentre non tocca nello stesso modo la regressione lineare o logistica che si basano sull’ipotesi di un’unica popolazione. Esperimenti teorici hanno messo in luce che effettivamente la discriminante quadratica ha una performance migliore di quella lineare, ma in generale non in modo sistematico nè troppo rilevante. Apparentemente gli elementi che influenzano questo risultato sono il numero delle variabili usate, l’entità effettiva delle differenze tra le matrici di varianza/covarianza, la numerosità dei campioni (Eisenbeis (1977)). Nelle ricerche applicate spesso le due discriminant i forniscono risultati simili ed in vari casi le funzioni lineari si rivelano globalmente migliori di quelle non lineari (ad esempio Altman e altri (1977); Karels-Prakash (1987)). Occorre sottolineare tuttavia che la discriminante quadratica genera un numero elevato di coefficienti, a volte di difficile interpretazione, dovendo tenere conto anche delle interazioni tra le variabili e dei termini quadrati: ciò significa che anche con un numero limitato di variabili tendono 26 Si osservi che anche se la distribuzione di due indicatori è normale non è detto che la loro distribuzione congiunta sia normale anch’essa.

29
a generarsi dei coefficienti con segni non corretti o di difficile comprensione economica. Come si vedrà meglio in seguito, è opinione di chi scrive che la condizione fondamentale per accettare un modello stimato riguarda la plausibilità economica dei segni dei coefficienti: i miglioramenti di non rilevante entità consentiti dalle funzioni quadratiche tendono ad accompagnarsi ad errori (o probabili errori) dei segni in numero significativo di coefficienti, causando il rigetto del modello sotto il profilo economico. Le stesse variabili stimate con una funzione lineare possono invece mantenere segni corretti. Anche per questo motivo la discriminante lineare risulta preferita in molte applicazioni. Peraltro in alcune ricerche si sono generate conclusioni conflittuali nel confronto tra l’analisi discriminante lineare e quella quadratica (ad esempio Deakin (1977)). Un ulteriore problema metodologico riguarda la valutazione della importanza relativa delle variabili delle funzioni, ovvero della loro capacità discriminatoria individuale. Mentre nelle regressioni lineari o logistiche questo problema può essere affrontato con i normali test che la statistica parametrica mette a disposizione, nel caso dell’analisi discriminante esso non ha una facile soluzione (Zavgren (1983)). Questa difficoltà dipende dal fatto che nella analisi discriminante lineare solo i rapporti tra i coefficienti sono unici, mentre i coefficienti stessi non lo sono, rendendo inutile l’applicazione di test per controllarne la diversità rispetto a valori tipo (l’ipotesi nulla ad esempio). Nella letteratura sono stati peraltro proposti vari metodi per valutare l’importanza relativa delle variabili senza pervenire ad un criterio di generale accettazione (Eisenbeis (1977)). Si osservi che sfruttando le relazioni tra l’analisi discriminante lineare e la regressione si può mettere a punto il modello con la prima e poi ristimarlo con la seconda ai soli fini di valutare l’efficacia individuale delle variabili. I limiti della regressione lineare (modello di probabilità lineare) risiedono oltre che nell’ipotesi sulla forma della distribuzione di probabilità anche nel fatto che le probabilità stimate escono dall’intervallo 0-1: in concreto questa metodologia ha avuto poche applicazioni nelle ricerche recenti. La regressione logistica ha una serie di vantaggi teorici che la fanno preferire alla regressione lineare e che consentono di disporre di vari test che ne facilitano l’interpretazione: questo è un vantaggio significativo rispetto alla analisi discriminante. Si osservi anche che, com’è stato sottolineato, la funzione discriminante lineare può essere inserita nell’espressione della logistica (l’argomento dell’esponente è una funzione lineare delle variabili) trasformando così la prima nella seconda: tuttavia i risultati non sono identicamente uguali a quelli che si ottengono stimando direttamente la regressione logistica sulle stesse variabili. Un problema che si ha nell’utilizzo della logistica riguarda la percezione da parte dell’analista dei cambiamenti delle probabilità che, a differenza del caso lineare, si muovono con velocità diverse lungo le varie fasi della curva. I movimenti lungo i rami degli asintoti prossimi allo zero ed all’uno generano percezioni di variazioni limitate della probabilità anche se in realtà gli spostamenti della situazione dell’impresa sono di notevole entità: ad esempio in una logistica il passaggio da una probabilità del 99,99% ad una del 99,9% sembra ininfluente all’analista finanziario, ma ad esso corrisponde un rilevante spostamento della situazione economico-finanziaria dell’impresa, sintetizzata dall’argomento lineare. Per contro nel tratto centrale obliquo della logistica movimenti relativamente piccoli della situazione dell’impresa si traducono in variazioni rilevanti della probabilità.

30
In conclusione quindi l’analisi discriminante lineare si dimostra robusta alla violazione delle ipotesi metodologiche sottostanti, specie quando sono usati grandi campioni (Lachenbruch (1975)), e produce in genere risultati non troppo diversi da quelli della regressione logistica (Ingram-Frazier (1982); Press-Wilson (1978); Casey-Bartczak (1985); Lo (1986); Bardos-Zhu (1998)). Pragmaticamente, nelle ricerche più recenti si è instaurata spesso l’abitudine di condurre stime con una pluralità di metodi (prevalentemente analisi discriminante lineare e logistica) e poi adottare quello con migliore performance sui campioni di controllo. Il ricorso a tecniche tipo bootstrap o jackknife consente di valutare la stabilità dei risultati con riutilizzo iterativo del campione di stima, quando la disponibilità di osservazioni non permette la separazione di un campione di controllo. La verifica della performance del modello su campioni di controllo (o con tecniche riconducibili ad essi) è di fondamentale importanza per accertarsi che i risultati non siano “sample-specific” ovvero che non si sia incappati in fenomeni di overfitting e quindi il modello non abbia capacità di generalizzazione.
5.6 DEFINIZIONE DEI GRUPPI DI IMPRESE La definizione dei gruppi di imprese ed il loro campionamento rappresentano scelte cruciali nella costruzione dei modelli. L’analisi discriminante funziona al meglio quando i due gruppi di imprese sono nettamente distinti con limitate sovrapposizioni; se queste ultime sono estese, viene a cadere uno dei presupposti di base di tale tecnica e può essere preferibile utilizzare una regressione logistica. La definizione di società anomale appare da un lato obbligata dagli obiettivi dell’analisi ma dall’altra deve spesso fare i conti con la limitata disponibilità di dati. Nel caso più restrittivo l’anomalia viene definita strettamente come fallimento o con l’inserimento dell’impresa in una delle procedure concorsuali previste nella normativa giuridica (amministrazione controllate, amministrazione straordinaria, ...). In casi meno restrittivi l’anomalia comprende vari tipi di insolvenza, di diversa gravità: dal protesto di effetti, all'insolvenza commerciale, alla violazione di vincoli contrattuali (covenants), alla classificazione bancaria di incaglio e sofferenza, alla eccezione sulla sopravvivenza dell’impresa da parte dei revisori. Questi fenomeni sono evidentemente tra loro interrelati (Beneish-Press (1995)). Theodossiou-Papoulias (1988) hanno definito anomale le società tenute in vita da aiuti e interventi governativi. Il rischio di adottare una definizione troppo sfocata di società anomala pone il problema di distinguere tra stato di difficoltà temporanea e crisi definitiva ed irreversibile. L’uso di dati di società fallite rende in parte il modello relativamente più facile da stimare, ma prende in considerazione solo l’evento estremo (la scomparsa dell’impresa o la gestione sotto controllo giudiziario) e può rivelarsi di minore utilità pratica per l’uso creditizio. Il ricorso a dati di società in sofferenza invece, o con insolvenze assimilabili a questa categoria 27, consente di percepire i segnali più tempestivi del processo di crisi aziendale e rende il modello di maggiore rilevanza pratica per le valutazioni creditizie. Per contro l’uso di dati di società in liquidazione è più delicato perché diventa spesso difficile distinguere i motivi economici sottostanti alla liquidazione e si possono mescolare segnali provenienti da processi decisionali molto diversi tra loro. La scelta delle società anomale dovrebbe avvenire con selezione casuale da un insieme rappresentativo di questa realtà; tuttavia i limiti di disponibilità dei dati fanno sì che vengano usate pressoché tutte le società a disposizione. 27 La Banca d’Italia definisce sofferenze i soggetti in stato di insolvenza (anche non accertato giudizialmente) o in situazioni sostanzialmente equiparabili.

31
La definizione di società sana è meno evidente di quello che si potrebbe pensare. Una prima possibilità riguarda semplicemente la scelta casuale di imprese da un elenco di società in vita; una definizione alternativa consiste nell’inserire condizioni da rispettare nella selezione delle società. La definizione di società in vita come gruppo con cui confrontare le società anomale ha il pregio della semplicità e facilita anche la stima delle probabilità a priori, ma tende a mescolare insieme imprese che possono trovarsi in situazioni molto diverse tra loro. Tra le società in vita, considerando tali semplicemente quelle che alla data usata per il confronto non sono incorse in fenomeni associati all’anomalia, possono esservi società eccellenti o società che non sono considerate anomale per motivi diversi da quelli economico-finanziari (ad esempio si tratta di società a proprietà statale o municipale, società con debiti garantiti, partecipate nazionali di gruppo esteri ritenuti solvibili,..) o società che diventeranno anomale nel periodo successivo. Per generare un campione di società confrontabili in modo economicamente attendibile, e non solo statisticamente corretto, con l’insieme di società anomale si possono introdurre dei filtri nella selezione puramente casuale dall’elenco delle società in vita, in modo da escludere le imprese eccellenti, che ne renderebbe troppo facile la separazione dalle anomale, e quelle vulnerabili. Queste ultime possono essere considerate come società in vita ma con elementi economico-finanziari di debolezza accentuata o di crisi (società in vita ma non finanziariamente sane). La preselezione tende pertanto ad isolare un campione di imprese sane che possono essere considerate rappresentative di "normali" ”condizioni di economica gestione. La difficoltà di questa procedura consiste nel non utilizzare variabili di preselezione che siano poi impiegate direttamente o indirettamente (sotto forma di variabili correlate) nelle stime del modello predittivo: le variabili di classificazione ed i criteri che definiscono i gruppi dovrebbero essere strettamente indipendenti. Il grafico seguente illustra la disposizione ipotetica dei diversi sottoinsiemi di imprese osservate su due variabili.
Grafico 3.Diverse sottopopolazioni di imprese
La separazione dei gruppi tra anomale e sane, come sopra definite, consente una corretta applicazione dell'analisi discriminante, ma apre il problema della successiva identificazione delle imprese vulnerabili.
X2
X1
Anomale
Vulnerabili
Normali
Eccellenti

32
Questo approccio è stato adottato ad esempio da Taffler (1982 e 1983); è impiegato fin dal 1988 dalla Centrale dei Bilanci ed è stato utilizzato anche dalla Banca di Francia (Ghesquiere-Micha (1983), Bardos (1991)); Peel e Peel (1987) hanno adottato una specifica definizione di società vulnerabile, intesa come impresa non insolvente ma in perdita economica più o meno prolungata. Gilbert e altri (1990) hanno adottato una definizione simile, in termini di perdite cumulate; Johnsen-Melicher (1994) hanno definito il concetto di imprese vulnerabili in termini generali, come quelle non insolventi ma “finanziariamente deboli”, con basso ranking nelle classifiche azionarie di Standard & Poor’s. Naturalmente la separazione delle società vulnerabili da quelle anomale è più difficile in quanto le situazioni economico-finanziarie dei due gruppi sono più simili che tra i gruppi sane/anomale. Si osservi che la definizione restrittiva del concetto di impresa sana, nell’analisi a due gruppi, pone problemi metodologici per la estrapolabilità alla intera popolazione delle performance ottenute in sede di stima (per una breve discussione si veda anche Marais (1979)).
5.7 COMPOSIZIONE DEI CAMPIONI DI IMPRESE
La numerosità dei campioni è un ulteriore aspetto metodologico di grande rilevanza per la effettiva applicazione dei modelli. In teoria la numerosità dei campioni di imprese dovrebbe riflettere quella delle popolazioni e se ad esempio nel sistema economico le società fallite sono il 5% del totale, la numerosità dei campioni di società fallite e società sane dovrebbe rispettare la proporzione 5/95. In tal modo il modello stimato sarebbe direttamente applicabile al contesto reale (salvo la correzione per i costi degli errori): le probabilità a priori coinciderebbero infatti con quelle campionarie e non sarebbe necessario inserire ulteriori aggiustamenti. Un tale approccio, statisticamente ineccepibile, tende tuttavia a generare grandi sovrapposizioni delle distribuzioni delle variabili (si veda ad esempio il Grafico 4.)
Grafico 4. Distribuzione della variabile X1
Ohlson (1980) ad esempio ha utilizzato un campione di 105 società anomale confrontate con 2058 società sane: la numerosità molto diversa tra i due gruppi non ha tuttavia fatto riferimento a probabilità a priori predeterminate. Nella grande maggioranza delle applicazioni tuttavia si tende ad utilizzare una numerosità dei campioni paritetica (50/50) ovvero con parziali deviazioni dal campione bilanciato. Questa scelta si basa su diverse motivazioni tra cui: ottenere una più netta identificazione delle differenze tra i due
X1
Freq
Sane Anomale

33
gruppi, ridurre la varianza delle stime dei coefficienti, diminuire i costi di selezione delle imprese e di elaborazione dei modelli. Questo approccio, quindi, scompone in due fasi la messa a punto dei modelli di previsione delle insolvenze: in una prima fase si stima il modello con una composizione campionaria decisa dal ricercatore sulla base di proprie convenienze e tenendo conto dei condizionamenti esistenti sulla disponibilità delle informazioni; in una seconda fase di introducono nel modello le correzioni per tenere conto di probabilità a priori diverse dalla composizione campionaria. Questa correzione è favorita dal fatto che l’influenza della probabilità a priori si riflette sul valore della costante della funzione e non sui coefficienti delle variabili (sugli effetti della specificazione delle probabilità a priori sui modelli predittivi si veda anche Houghton (1984), mentre Zmijewski (1984) discute alcune distorsioni introdotte nei modelli da campionamenti non casuali). Si osservi peraltro che la stima delle probabilità a priori non è assolutamente facile né rapida, non appena la definizione di società anomala non è limitata ai soli fallimenti o procedure concorsuali (i cui dati possono essere rintracciati nelle statistiche giudiziarie) ma si estende a protesti e sofferenze. Anche una definizione delle società sane, più restrittiva di quella semplice delle società in vita, pone problemi complessi: quale sia la probabilità a priori di essere una società vulnerabile o eccellente non è evidente. Per un approccio basato sulla teoria dell’informazione per la valutazione delle probabilità di insolvenza si veda (Zavgren (1985)); il metodo è stato approfondito da Keasey-McGuinness (1990). Si consideri inoltre che l’abbinamento bilanciato tra società anomale e sane viola il concetto di casualità del campionamento, in quanto la selezione delle imprese si basa sulla conoscenza ex-post di alcune caratteristiche, quali l’anno di insolvenza, il settore, la dimensione: ne risulta condizionata la capacità predittiva in un contesto decisionale ex-ante (Piesse-Wood (1992)). Peraltro la correzione al modello va estesa anche al costo degli errori e, a meno che i costi degli errori di I e II tipo siano uguali, questa componente contribuisce a ridurre lo squilibrio tra probabilità a priori e composizioni campionarie. Ad esempio dato il rapporto campionario di stima di 50/50 ed un rapporto 5/95 tra le probabilità a priori anomale/sane, se si ritiene che il rapporto tra gli errori di I (classificare sana un’impresa anomala) e di II tipo (classificare anomale un’impresa sana) è circa di 19 ad 1 (ovvero classificare in modo errato un’impresa anomala costa circa 20 volte di più che sbagliare nel classificare un’impresa sana) si ha una completa neutralizzazione dalle correzioni ed il modello stimato diventa direttamente utilizzabile nelle applicazioni pratiche. Sulla stima dei costi diretti ed indiretti degli errori si può vedere tra gli altri Altman (1984); Johnson e altri (1993); Chen e altri (1997) e Gaber (1986); per alcune valutazioni sui costi di fallimento in Italia si rinvia a Barontini (1997). A conoscenza di cui si scrive non sono disponibili statistiche sui costi non solo bancari (diretti ed indiretti) per la gestione delle sofferenze, degli incagli e dei protesti. Clarke-McDonald (1992) tra l'altro osservano che per un completo calcolo economico del beneficio del modello di previsione dell’insolvenza occorre tenere conto non solo dei costi di errate classificazioni, ma anche dei proventi derivanti dalle corrette classificazioni. Peraltro Taffler (1983) sottolinea che poiché in realtà nessuna decisione è presa solo sulla base dei risultati del modello di previsione delle insolvenze, il costo effettivo degli errori di decisione sono più difficili da valutare di quanto sia riportato nella letteratura: ad esempio dovrebbe essere considerato anche il costo opportunità del tempo dell’analista finanziario dedicato all’esame delle pratiche di credito. Nella sua ricerca pertanto Taffler usa un rapporto 1:1 dei costi di errate decis ioni.

34
5.8 SCELTA DEGLI INDICATORI La scelta degli indicatori su cui stimare il modello rappresenta un altro momento cruciale dell’intero processo. Generalmente viene calcolato un certo numero di indicatori sui campioni di imprese in modo da avere una prospettiva d’analisi assai vasta; poi sulla base di test e di valutazioni del ricercatore viene isolato un insieme ridotto di variabili ritenute più promettenti e su questa base viene effettuata la parte finale rappresentata dalla stima vera e propria. E’ essenziale compiere alcune operazioni preliminari prima dello studio delle capacità discriminanti degli indicatori: controllo delle inversioni di segno, individuazione degli outliers, verifica della monotonicità del segnale economico-finanziario. Dell’esame della normalità delle distribuzioni degli indicatori si è già fatto cenno in precedenza. Vi sono indicatori il cui denominatore può assumere segni sia positivi che negativi: in questi casi occorre gestire nel modo appropriato le inversioni di segno in modo da evitare di generare dei segnali contraddittori rispetto alla situazione economica effettiva. Ad esempio il rapporto tra oneri finanziari e Margine Operativo Lordo indica, tra l’altro, il peso del costo dell’indebitamento sulla gestione caratteristica dell’impresa: tanto maggiore è il rapporto, tanto peggiore è la situazione della società. Tuttavia se il Margine lordo è negativo, se non si introducono correzioni, si ottiene un valore basso che viene percepito come segnale di situazione favorevole. Un fenomeno analogo accade ad esempio nel calcolo del ROE in cui la presenza contemporanea di perdite d’esercizio e di patrimonio netto negativo genera dei tassi di profitto numericamente positivi. Occorre pertanto intervenire con aggiustamenti di calcolo, salvo che non si decida di utilizzare un altro indicatore che non manifesti gli stessi problemi, ovvero non si effettuino scomposizioni dell’indicatore complesso in due variabili più semplici usando denominatori con segno costante. Oltre a tale controllo, occorre procedere ad individuare gli outlier, ovvero valori degli indicatori economicamente corretti ma privi di significato effettivo, che si collocano agli estremi delle distribuzioni e che possono influire pesantemente sulle stime con metodi parametrici28. Per non perdere informazioni, gli outliers vengono in genere riportati a valori massimi accettabili. Infine un altro controllo consiste nella verifica della monotonicità del segnale: la monotonicità, in questa sede, significa che procedendo verso una direzione, a partire da un certo valore l’indicatore segnala una preferenza per uno dei gruppi di società; prima di quel valore, e procedendo nella direzione opposta, la preferenza va all’altro gruppo.
28 In un prossimo paragrafo si fa cenno all’uso di metodi non parametrici che sono più robusti nel trattamento degli outliers.
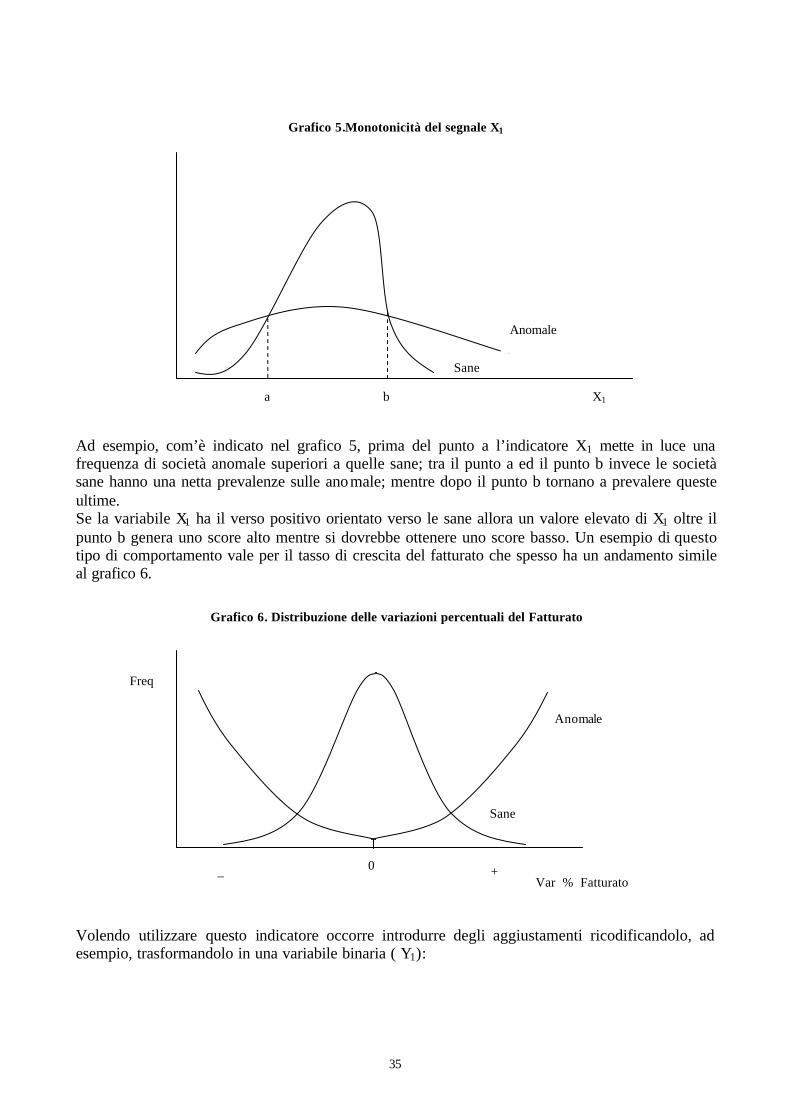
35
Grafico 5.Monotonicità del segnale X1
Ad esempio, com’è indicato nel grafico 5, prima del punto a l’indicatore X1 mette in luce una frequenza di società anomale superiori a quelle sane; tra il punto a ed il punto b invece le società sane hanno una netta prevalenze sulle anomale; mentre dopo il punto b tornano a prevalere queste ultime. Se la variabile X1 ha il verso positivo orientato verso le sane allora un valore elevato di X1 oltre il punto b genera uno score alto mentre si dovrebbe ottenere uno score basso. Un esempio di questo tipo di comportamento vale per il tasso di crescita del fatturato che spesso ha un andamento simile al grafico 6.
Grafico 6. Distribuzione delle variazioni percentuali del Fatturato
Volendo utilizzare questo indicatore occorre introdurre degli aggiustamenti ricodificandolo, ad esempio, trasformandolo in una variabile binaria ( Y1):
a b X1
Anomale
Sane
Var % Fatturato
Freq
Anomale
Sane
0 _ +

36
>=<=
≤≤=
bXper 0YaXper 0Y
bX aper 1Y
11
11
11
Con tale ricodifica si viene ad alterare la forma della distribuzione dell’indicatore ma si ottiene un segnale monotonico. Una strategia che si può utilmente adottare per ridurre il numero degli indicatori su cui concentrare gli sforzi consiste nell’applicare l’analisi fattoriale (o tecniche simili) all’insieme originario e selezionare un numero ridotto di fattori tale da preservare la maggior parte del contenuto informativo iniziale. Per ogni fattore si individua facilmente l’indicatore o gli indicatori (pochi) che risultano più correlati col fattore e si ottiene così una specie di selezione su base statistica delle variabili essenziali (nel senso che con il loro numero ridotto si riproduce la maggior parte del contenuto informativo originale), con ridotta multicollinearità. L’uso diretto degli score fattoriali per la stima dei modelli, tecnica impiegata ad esempio da West (1985), in generale non produce modelli ad elevate performance: una parte della spiegazione risiede nella riduzione di informazioni analitiche che il fattore determina, combinando insieme una molteplicità di variabili, il cui denominatore comune è essenzialmente la correlazione reciproca. La preselezione delle variabili è ottenibile anche con applicazioni di cluster analysis. La costruzione vera e propria del modello tuttavia, non disponendo di una teoria vera e propria dell’insolvenza ma solo di razionalizzazioni di osservazioni, è il passo più difficile e in parte il frutto di una selezione euristica delle variabili. Spesso nelle ricerche si cita il ricorso a tecniche di selezione guidata delle variabili più discriminanti basandosi su test statistici: la stepwise è lo strumento più frequentemente usato, sia per l’analisi discriminante che per le regressioni lineare e logistica. Tuttavia raramente la stepwise produce modelli ad elevata performance e spesso vengono inclusi indicatori instabili o che determinano segni errati dei coefficienti. Non è disponibile una tecnica che, dato un insieme di variabili, trovi il miglior sottoinsieme (quante e quali variabili) in grado di fornire il modello con la più elevata capacità classificatoria. In effetti non si può dimostrare che il modello messo a punto è il migliore, dato l’insieme delle variabili selezionabili per la sua costruzione. Procedure come quella di Furnival e Wilson possono comunque fornire un aiuto notevole. In ogni caso questo è proprio il campo in cui l’esperienza e le capacità del ricercatore fanno la differenza tra buoni modelli e modelli mediocri. Si tenga conto che la capacità predittiva degli indicatori è di tipo cumulativo: alcuni di essi possono avere uno scarso valore segnaletico individuale ma si rivelano molto efficaci in combinazione con altri. Anche la scelta del periodo di distanza dall’evento- insolvenza su cui stimare il modello è una scelta importante: la stima al t-1 è più facile e determina un modello basato su differenze piuttosto ampie tra i gruppi; non deve stupire che questi modelli perdano rapidamente efficacia se applicati a periodi precedenti; per contro stime al t-2, t-3, o ancora anteriori, mantengono buone capacità diagnostiche e sono in grado di conseguire notevoli miglioramenti di performance quando applicati al t-1. Stime precedenti al t-3, come t-4 o t-5 ancorché possibili, fanno sorgere un interrogativo sull’effettivo grado di realismo del modello. Ad esempio una stima al t-5 implicitamente incorpora l’idea che l’impresa anomala si è messa su un percorso di crisi che inevitabilmente la porta entro 5 anni (meglio: dopo 5 anni) all’insolvenza. Se si riflette su tutte le possibili manovre aziendali e gli

37
interventi che si possono effettuare in 5 anni si comprende il grado di arbitrarietà dell'assunzione. Stime così indietro nel tempo hanno senso se si vogliono individuare tempestivamente i sintomi di fragilità strutturali che, se associati a debolezze economiche persistenti, portano all’insolvenza, oppure se si lavora su settori o categorie di imprese con lunghi periodi di incubazione delle crisi. In ogni caso è essenziale sottoporre il modello a verifiche finali su campioni di controllo statisticamente indipendenti da quello di stima e su finestre temporali successive. E’ essenziale il controllo della correttezza dei segni delle variabili (è incredibile il numero delle ricerche pubblicate contenenti un numero più o meno alto di errori di segno!) e la verifica della plausibilità economica sottostante al modello.
5.9 PROBLEMI NELL'USO DEGLI INDICATORI
L’uso degli indicatori di bilancio per la previsione delle insolvenze ha stimolato varie riflessioni volte ad approfondire sia i loro limiti, sia i metodi per migliorarne la capacità diagnostica. Mossman e altri (1998), allo scopo di valutare i meriti di diversi approcci predittivi all’insolvenza hanno messo a confronto le performance di modelli costruiti con logiche diverse: un modello basato solo su indicatori di bilancio (quello originale di Altman del 1968), un modello basato su dati di flusso e due modelli basati su dati del mercato azionario. Dambolena e Khoury (1980) hanno inserito nella funzione discriminante da loro stimata alcune misure di stabilità quali lo scarto quadratico medio intorno ad una serie di diversi anni, lo scarto quadratico medio delle stime intorno ad un trend lineare, il coefficiente di variazione di una serie di vari periodi. Tali misure di stabilità hanno messo in luce significative differenze nei due gruppi di imprese. Si veda anche Betts-Belhoul (1987). Appetiti (1983; 1985), allo scopo di rendere più dinamica l’analisi del processo di insolvenza ha introdotto il calcolo del trend degli indicatori, regredendo i loro valori sugli anni (3) di serie storica; peraltro il breve periodo di osservazione disponibile ha ridotto il valore segnaletico dei trend. L’uso dei trend è stato utilizzato in varie altre ricerche, con risultati alterni ma spesso non determinanti (Collins (1980)). Edmister (1972) ha sottoposto a test diverse ipotesi sulla capacità segnaletica degli indicatori: industry-relatives, trend triennali, media triennale degli indicatori (in termini di industry-relatives), combinazione di medie e di trend. La multicollinearità tra le diverse definizioni di indicatori causa meno problemi all’analisi discriminante che non alle regressioni: il vincolo per l’analisi discriminante è dato dalla invertibilità della matrice di varianze/covarianze (Eisenbeis (1977); Zavgren (1983)). Nella funzione discriminante lineare trovata da Edmister gli indicatori sono ricondotti a variabili binarie sulla base di test con valori-soglia rispetto ai livelli degli indicatori, agli industry-relatives o ai trend. Theodossiou (1993) e Kahya-Theodossiou (1996) hanno impiegato una tecnica di analisi delle serie storiche per individuare i punti degli spostamenti permanenti negli andamenti degli indicatori delle società anomale rispetto a quelli delle società sane. Nell’ampio dibattito sull’efficacia degli indicatori di bilancio per la previsione delle insolvenze un posto a sè ha l’analisi delle capacità diagnostiche delle variabili basate sui flussi di cassa, che ha attirato l’attenzione di un certo numero di ricercatori: tra gli altri si vedano Gentry-Newbold-Whitford (1985 a e b; 1987); Casey-Bartczak (1985); Hoarau (1993); Ward (1994); Laitinen (1994); Aziz-Lawson (1989); Gombola e altri (1987)). L’evidenza empirica non è totalmente omogenea, ma dai risultati delle ricerche emergono alcune conclusioni generali: i dati basati sui flussi non contribuiscono a migliorare la capacità

38
classificatoria dei modelli anche per la loro elevata volatilità (Taffler (1982)); in particolare il flusso di cassa della gestione 29 ha un limitato potere predittivo, molto inferiore a quanto suggeriscono gli studiosi di analisi di bilancio; quest’ultimo risultato vale per diversi indicatori che utilizzano tale flusso di cassa, come flusso di cassa da gestione su totale debiti (o passività correnti o totale attivo o debiti finanziari), flusso di cassa da gestione sulla somma degli oneri finanziari, dividendi e quota di rimborso dei debiti (una delle varianti del “fixed charges coverage”). Per contro l’autofinanziamento mette in luce notevoli capacità diagnostiche; la stessa efficacia vale anche per variabili simili all’autofinanziamento, come il cash flow pari alla somma del risultato d’esercizio (più o meno rettificato), degli ammortamenti, accantonamenti e delle altre partite iscritte in conto economico cui non corrispondono effettivi movimenti finanziari. La spiegazione della eccellente capacità discriminatoria dell’autofinanziamento-cash flow va ricercata nel suo significato di concetto allargato di risultato economico: il risultato d’esercizio, quale grandezza finale del conto economico, risente di varie valutazioni contabili e si presta, entro certi limiti, a manipolazioni ed a discrezionalità più o meno ampie. L’autofinanziamento-cash flow si presenta quindi come grandezza più robusta, meno soggetta a manipolazioni, in grado di trasmettere un segnale più attendibile e stabile della redditività aziendale e della potenziale capacità dell’impresa di produrre internamente risorse finanziarie. Per contro il flusso di cassa della gestione soffre di un eccesso di compensazioni, essendo al netto delle variazioni del circolante operativo: le imprese in crisi infatti hanno problemi stringenti di tesoreria, specie nelle fasi finali del processo di decadimento che porta all’insolvenza. Per gestire tale vincolo, queste imprese intervengono sui termini di pagamento verso clienti e fornitori e sui livelli delle scorte, operando in modo da liberare ove possibile disponibilità finanziarie. I movimenti netti del circolante operativo pertanto spesso controbilanciano la riduzione dell’autofinanziamento, generando un flusso di cassa dalla gestione erratico o/e in controtendenza rispetto al deterioramento reddituale. La sensibilità al ciclo economico inoltre è generalmente maggiore per il flusso di cassa che per l’autofinanziamento-cash-flow, contribuendo a ridurre la stabilità dei modelli. L’analisi dinamica del processo di insolvenza è stata affrontata con una pluralità di approcci, oltre dall’uso dei trend degli indicatori. Keasey e altri (1990) hanno stimato diversi modelli usando come dipendente il numero di periodi dall’insolvenza, generando in questo modo varie sequenze di segnali che conducono all’insolvenza: il problema che sorge in questi casi riguarda l’inconsistenza dei pattern temporali di tali segnali che possono verificarsi per certe imprese (le diagnosi di sana e anomala si accavallano in modo incongruente). L’uso di trend e misure di stabilità può dare un contributo anche a rettificare implicitamente eventuali fenomeni di window dressing sui dati di bilancio (Falbo (1991)). Si osservi, a questo proposito, che modelli con molte variabili sono considerati più robusti al window dressing rispetto a modelli con un ridotto numero di indicatori: salvo che il modello includa variabili molto correlate, il window dressing non riesce ad influire contemporaneamente ed in modo omogeneo su parecchie di esse. E’ comunque importante che la definizione di calcolo degli indicatori sia effettuata nel modo più opportuno per ridurre il più possibile gli effetti indesiderati degli aggiustamenti contabili e delle difformità tra i bilanci di imprese che adottano principi diversi di valutazione, di rilevazione e di appostazione delle voci contabili. In certi casi l’uso di differenze prime tra gli indicatori o di trend su pochi anni amplifica, invece di ridurre, gli effetti degli inquinamenti puramente contabili sui dati. Pure Bozzolan (1992) ha calcolato funzioni diverse per i vari periodi (3) che separano l’impresa dall’insolvenza, inserendo tra le variabili di un certo periodo anche lo score generato dalla funzione del periodo precedente. 29 Misurato come differenza tra l’autofinanziamento operativo (ante oneri finanziari, dividendi ed imposte), o l’autofinanziamento a seconda degli studi, e la variazione del capitale circolante operativo.

39
Varetto e Marco (1994) hanno adottato un approccio diverso per l’analisi dinamica, ricorrendo a modelli “dotati di memoria”, che saranno più diffusamente illustrati nel paragrafo dedicato alle reti neurali. Più complessi sono gli approcci dei ricercatori che hanno tentato di identificare diverse fasi o diversi pattern economico-finanziari che conducono all’insolvenza. Lau (1987) ha inteso superare la dicotomia imprese sane/anomale proponendo una segmentazione delle imprese in 5 stati per approssimare il continuo della situazione economico-finanziaria dell’impresa; anziché stimare le società in uno dei 5 stati ha cercato di valutare la probabilità che l’impresa entri in ciascuno dei 5 stati. Gli stati che progressivamente descrivono il peggioramento della situazione aziendale sono rispettivamente: stabilità finanziaria, riduzione o cancellazione del pagamento dei dividendi, insolvenza tecnica su pagamenti, ammissione ad una procedura concorsuale, fallimento o liquidazione. Johnsen-Melicher (1994) hanno adottato un approccio simile a quelle di Lau, limitando a soli 3 gli stati possibili (sana, anomala, finanziariamente debole). Laitinen (1991), sulla base di uno schema concettuale semplificato, ha individuato tre processi di insolvenza alternativi: il primo tipo descrive l’impresa in insolvenza cronica, in cui tutti gli indicatori sono molto compromessi già al quarto anno prima dell’insolvenza; il secondo tipo riguarda l’impresa in crisi di ricavi, in cui l’indebitamento e la liquidità sono a livelli medi in tutti gli anni precedenti l’insolvenza, ma vi è un’insufficienza di ricavi e quindi di redditività; il terzo tipo concerne un’impresa in insolvenza acuta, in cui tutti gli indicatori si deteriorano drammaticamente nell’anno immediatamente precedente all’insolvenza. Laitinen (1993(a)) ha invece lavorato sulle fasi dei processi di insolvenza. Prendendo come riferimento uno schema descrittivo generale delle crisi aziendali, l’autore suddivide a priori in 4 fasi il processo che conduce all’insolvenza: una fase iniziale caratterizzata dal deterioramento di alcuni indicatori economici cruciali; in questa fase per l’identificazione dei rischi di insolvenza si possono utilizzare le differenze temporali di tali indicatori; la fase intermedia segue quella iniziale ed è caratterizzata dal lento declino o dalla stazionarietà degli indicatori; questa fase può essere identificata ricorrendo al calcolo dei trend degli indicatori; la fase finale è il terzo stadio del processo ed è caratterizzata dal declino delle performance ad un livello molto basso; in questo caso sono i livelli degli indicatori ad essere i migliori segnalatori; l’ultima fase è quella di uscita che generalmente non è osservabile, non essendo più disponibili i bilanci. Questa suddivisione in fasi può essere applicata, con specifiche qualificazioni, a diverse traiettorie di insolvenza, come quelle descritte in Laitinen (1991) e sintetizzate in precedenza. Il modello stimato deve quindi cercare di identificare la fase del processo di crisi per valutare se il rischio di insolvenza è imminente (fase 3), oppure se si è solo agli inizi (fase 1), con ampi margini per il salvataggio. A questi fini estremamente utile si rivela la disponibilità di informazioni sulle cause dirette dell’insolvenza, come quelle raccolte dalla Deutsche Bundesbank (1992); sfortunatamente questi dati non sono facilmente disponibili ed è raro che riguardino una raccolta sistematica di insiemi significativi di società.
5.10 VARIABILI QUALITATIVE
Le variabili di bilancio, pur essenziali per la costruzione di efficaci modelli predittivi delle insolvenze, forniscono solo una rappresentazione parziale della situazione complessiva dell’impresa. Per migliorare le capacità diagnostiche delle funzioni vari studiosi hanno avviato ricerche sull’uso di dati qualitativi.

40
Peel-Peel-Pope (1985; 1986) hanno aggiunto agli indicatori di bilancio anche alcune variabili qualitative volte a catturare vari fenomeni ritenuti direttamente pertinenti ai rischi di crisi aziendale: i ritardi temporali nella presentazione dei bilanci o la mancata presentazione; le dimissioni e le nomine di dirigenti; le quote azionarie possedute da questi ultimi nell’impresa da loro amministrata. In particolare il lag di presentazione dei bilanci ha messo in luce una significativa capacità segnaletica. Risultati simili sono stati ottenuti da Keasey-Watson (1988). In un lavoro successivo Peel-Peel (1988) hanno esteso l’analisi integrata di indicatori di bilancio con variabili qualitative alla valutazione della probabilità di insolvenza, differenziata in base al periodo che separa l’impresa dall’insolvenza (probabilità di diventare insolvente in t-1, t-2 o t-3, ovvero di rimanere sana). Tennyson e altri (1990) hanno esteso l’analisi qualitativa alla considerazione di una molteplicità di informazioni incluse nelle relazioni ai bilanci, quali: l’influenza di cambiamenti nell’ambiente esterno (inflazione, politiche generative, ...), l’evidenziazione di specifici problemi interni (gestione scorte, capacità produttiva ...), l’effetto della contabilizzazione del leasing e delle variazioni dei tassi di cambio, l’illustrazione delle decisioni finanziarie (nuovo indebitamento, gestione del circolante...), notizie sullo sviluppo dell’impresa, su particolari strategie (pricing dei prodotti, apertura nuove filiali)... e così via. Laitinen (1993(b)) ha ulteriormente ampliato l’analisi del contenuto informativo delle relazioni di bilancio, includendo anche valutazioni sul loro layout, linguaggio utilizzato, lunghezza, tono (ottimistico, pessimistico, ...) e firma. Keasey-Watson (1987), Daily-Dalton (1994) e D’Aveni (1989) hanno preso in particolare considerazione delle variabili qualitative di natura organizzativa, connesse alle caratteristiche del management, alla composizione dei consigli di amministrazione, alla corporate governance, al prestigio dell’impresa. Sorge peraltro in questi casi la difficoltà di valutare la correttezza dei segni delle variabili qualitative incluse nelle funzioni, oltre alle incertezze che si accompagnano alla codifica su scale numeriche di queste variabili. Le variabili qualitative, quando sono molto numerose, possono essere riassunte in pochi elementi essenziali ricorrendo all’analisi fattoriale (o tecniche simili). L’uso di variabili qualitative si giustifica non solo per comunicare al modello informazioni sull’ambiente esterno, sull’organizzazione, sui problemi interni, sulle principali decisioni chiave adottate dall’impresa, ma anche per contrastare con altre fonti l’eventuale window dressing condotto sui bilanci nelle fasi finali del processo di crisi: gli indicatori contabili tendono in questi casi a perdere efficacia e quindi le variabili qualitative possono rivelarsi un utile complemento informativo (Keasey-Watson (1987)). La Centrale dei Bilanci ha messo a punto uno specifico questionario qualitativo per la valutazione degli elementi di crisi, non solo finanziaria, dell’impresa, com’è illustrato più diffusamente nell’Appendice 2. Ooghe e altri (1995), in una rassegna di ricerche sulle imprese belghe, riportano l’utilizzo di variabili riguardanti l’esistenza di debiti assistiti da garanzia, di garanzie ricevute e di relazioni con società collegate. Quest’ultima informazione è utile per tenere conto del fatto che un’impresa in crisi può essere salvata dalla capogruppo, oppure che un gruppo in crisi può trascinare con sè anche società controllate sane. Von Stein-Ziegler (1984), oltre ad esaminare un insieme di variabili qualitative sul management e sull’impresa, hanno preso in considerazione le informazioni sui dati strettamente bancari di un campione di società, quali: i saldi contabili, i movimento dei conti, sconfinamenti, turnover degli

41
effetti, e così via. Tali dati, dopo essere stati aggiustati per stagionalità e componenti erratiche, si sono rivelati utili ai fini della previsione delle insolvenze. Anche la qualità intrinseca dei dati di bilancio, come l’esistenza di certificazione, l’assenza di eccezioni ai conti aziendali da parte di revisori e sindaci, il grado di prudenzialità delle va lutazioni (ovvero l’adozione di criteri più o meno conservativi nelle valutazioni delle partite contabili) e così via, si è rivelato un efficace segnale dei rischi aziendali. Questo tipo di variabili sono state ad esempio utilizzate recentemente dalla Deutsche Bundesbank. Peraltro l’uso di variabili qualitative può porre problemi nell’applicazione concreta dei modelli, quando tali informazioni non sono disponibili per le società sotto esame30, specie in sede di prima valutazione di credito. Esse inoltre pongono delicati problemi di definizione dei sistemi di codifica e di ampiezza delle metriche.
30 Al di là dei dati sull’esistenza di protesti e/o di incidenti nei pagamenti correnti e altri simili.

42
6) RISCHIO DI ROVINA A differenza dei modelli di previsione delle insolvenze visti nei paragrafi precedenti, l’approccio che si ispira al rischio di rovina fa riferimento a presupposti profondamente diversi e ad una ben precisa concezione teorica: mentre nei modelli discriminanti o logistici la selezione degli indicatori da includere nelle funzioni si basa prevalentemente sull’euristica, i modelli rischio di rovina individuano con maggiore chiarezza le variabili rilevanti. Il concetto di rischio di rovina è stato studiato nell’ambito del calcolo delle probabilità nei giochi d’azzardo (gambler’s risk of ruin) ed ha avuto varie applicazioni in campo finanziario ed assicurativo. Un giocatore inizia un gioco ripetuto con una dotazione iniziale di capitale pari ad M. Il gioco consiste di una sequenza di giochi statisticamente indipendenti in cui vince 1 unità di M con probabilità pari a p e perde la stessa unità con probabilità pari a q = 1-p. Il gioco ha termine se e quando il giocatore è rovinato, avendo perso tutto il suo capitale M. La sequenza Xo, X1 , X2, ........ Xn rappresenta il suo capitale dopo le giocate 0,1,2,..........n. Se vi sono dei vincoli superiori alle vincite, ovvero la probabilità di vincita è inferiore o uguale a quella di perdita (p ≤ q), la rovina è certa e l’unica variabile di interesse è sapere quando ciò avverrà, ovvero in quale periodo M = 0. Se invece p > q allora esiste una probabilità positiva di non essere rovinati (Vinso (1979) e Wilcox (1971)). Wilcox (1971; 1973), lavorando su questo schema di riferimento, ha proposto modelli di previsione delle insolvenze, intese come stima della probabilità dell’impresa di incorrere in rovina. Peraltro già Beaver (1966), per favorire l’interpretazione dei suoi risultati, aveva suggerito una visione dell’impresa che può essere considerata coerente con il principio del rischio di rovina e che è stato preso come punto di riferimento da Wilcox e da altri studiosi. Beaver considerava l’impresa come una specie di serbatoio di risorse liquide che viene alimentato con entrate e ridotto dalle uscite. Tale serbatoio funge da ammortizzatore contro le variazioni dei flussi di entrata ed uscita. Quando il serbatoio è esaurito l’impresa non è più in grado di far fronte ai propri impegni, onorando le scadenze di pagamento nei confronti dei propri creditori (banche, fornitori, dipendenti......). Le variabili cruciali di questo modello sono: la dimensione del serbatoio, l’entità del saldo tra entrate ed uscite, la variabilità nel tempo e la correlazione seriale di tale saldo. La trasposizione del modello rischio di rovina all’analisi dell’insolvenza delle imprese può avvenire in due prospettive diverse: la prima è quella della liquidità, la seconda segue una interpretazione patrimoniale. Il rischio di rovina in termini di liquidità misura la probabilità che l’impresa esaurisca le disponibilità di cassa e non sia più in grado di far fronte ai propri pagamenti: questa ottica modella una concezione strettamente finanziaria di insolvenza. La seconda ottica percepisce l’insolvenza in termini patrimoniali come l’esaurimento del capitale netto dell’impresa: perdite economiche prolungate nel tempo assorbono totalmente il patrimonio netto della società; se quest’ultimo non viene ricostituito, l’impresa si trova nella impossibilità (anche legale) di continuare la propria attività. E’ immediato trasporre questo schema concettuale nel modello rischio di rovina: l’impresa dispone ad un certo momento di un patrimonio netto pari a CN; ogni anno si succedono utili e perdite, che per semplicità si suppongono di pari ammontare in valore assoluto (±U); la probabilità che si verifichi un utile è pari a p, mentre q (< p) indica la probabilità di perdita.

43
La probabilità che l’impresa diventi patrimonialmente insolvente è pari a:
U
CN
pq
PR
=
in cui CN/U indica il numero di anni di perdite che l’impresa può sopportare prima della rovina (Wilcox 1971). Si osservi che in questo modello semplificato la sequenza degli utili e delle perdite è una successione di eventi statisticamente indipendenti del tipo random walk. Il modello rischio di rovina può essere rappresentato in termini di un processo casuale descritto da una matrice di transizione in cui uno degli stati è uno stato di assorbimento, che una volta raggiunto non può essere abbandonato: in ogni istante l’impresa appartiene ad uno degli stati possibili (gli stati possono essere infiniti) 0,1,2,...N… . A fine periodo l’impresa si sposta dallo stato N allo stato N + 1 con probabilità p oppure allo stato N – 1 con probabilità q (= 1-p). Se lo stato N corrisponde al caso di risorse (patrimoniali o liquide a seconda delle interpretazioni) nulle l’impresa non può più spostarsi (stato di assorbimento). La probabilità di raggiungere questo stato vale (Wilcox 1973):
>
≤
=qp se
pq
certa rovina qp se 1
PrN
N può essere stimato come l’ammontare delle risorse diviso per una stima della distanza in termini di risorse tra stati contigui (z). Per la stima di q/p si può considerare che (per p>q) esso è connesso al tasso medio di crescita (drift rate) delle risorse; ovvero (p – q)⋅z può essere visto come la crescita tendenziale media per periodo delle risorse lungo gli stati. (p – q)⋅z può quindi essere stimato come flusso di cassa medio o come risultato d’esercizio medio (a seconda della interpretazione di liquidità o patrimoniale), mentre z può essere calcolato come (Wilcox (1973)).
( ) ( ) aliquidativ ottica cassa di flusso del varianzamedio cassa di Flussoz 2 += oppure
( ) ( ) lepatrimonia ottica risultato del varianzamedio Risultatoz 2 += Dalle espressioni precedenti può essere ricalcolato q/p, osservando che questo rapporto può essere scritto come:
)qp(1)qp(1
pq
−+−−
=
Con questi elementi è possibile ricavare una stima della probabilità di rovina, intesa come incapacità di pagare (ottica liquidità) o come mancanza di solvibilità in senso patrimoniale.

44
N indica in sostanza la distanza dall’insolvenza, mentre p – q rappresenta il rapporto tra il tasso tendenziale di crescita delle risorse (liquide o patrimoniali) e la sua fluttuazione media. Se lo schema concettuale è chiaro, la sua applicazione, anche in versione semplificata, alla stima concreta della probabilità di insolvenza pone problemi complessi. Uno di questi riguarda proprio la definizione operativa del concetto di risorse, il cui contenuto è diverso a seconda degli studiosi. Nella interpretazione del modello nell’ottica di liquidità, lo stock di risorse non dovrebbe comprendere solo l’ammontare delle disponibilità, ma anche delle risorse potenzialmente attivabili dall’impresa in caso di bisogno, come l’ulteriore indebitamento ancora possibile, la riduzione potenziale dei crediti e delle scorte, l’allungamento possibile del debito di fornitura, la compressione dei dividendi, il disinvestimento di cespiti, l’emissione di azioni, ..... e così via. L’incertezza sui tempi di attivazione di tali risorse e i costi di conversione in liquidità delle attività sono anche esse va riabili che dovrebbero essere considerate. Le risorse in termini patrimoniali dovrebbero tenere conto anche del capitale azionario attivabile in tempi utili per fronteggiare i necessari ripianamenti. Un altro problema riguarda la forma della distribuzione di probabilità dei flussi annuali di risorse. Le grandezze di bilancio da considerare per stimare i modelli a rischio di rovina devono quindi essere indirizzate a misurare l’ammontare di risorse, con le precisazioni richiamate sopra, i flussi di cassa generati dalla gestione e i loro utilizzi, la variabilità seriale, i risultati economici dell’impresa e la loro variabilità. Se la sequenza dei flussi di cassa o dei risultati economici non è serialmente indipendente e stazionaria, occorre complicare ulteriormente il modello base per tenerne conto. Queste stime sono rese difficili dalla ridotta durata delle serie storiche di bilanci generalmente disponibili per le società insolventi. L’approccio rischio di rovina ha avuto alcune applicazioni, mettendo in luce risultati complessivamente interessanti, ancorché ancora insufficienti per valutarne la robustezza e la generalizzabilità, data anche la varietà delle definizioni di risorse e di flussi di risorse adottato nei diversi studi. Wilcox (1973) ad esempio ha stimato il proprio modello su un insieme di una cinquantina di società insolventi osservata tra il ’49 ed il ’71; Vinso (1979) ha preso in esame sia società elettriche sia una ventina di altre imprese con maggior contenuto di rischio (compagnie aeree, società petrolifere......); Laitinen (1995) ha stimato contemporaneamente due modelli a rischio di rovina: uno con ottica di liquidità ed uno con ottica patrimoniale; un terzo modello tiene conto della probabilità congiunta di entrambi i tipi di insolvenza. Al di là dei risultati in termini di capacità di classificazione, in alcuni casi superiore ad una funzione logistica stimata come modello di benchmark, il lavoro di questo studioso sottolinea l’importanza di distinguere meglio le varie tipologie di insolvenza allo scopo di mettere a punto modelli più mirati. Laitinen-Laitinen (1998) hanno approfondito l’analisi del rischio rovina in termini di liquidità, prendendo in esame alcuni modelli di gestione della tesoreria delle imprese. Olivotto (1989) ha effettuato un’applicazione del modello a rischio di rovina ad alcune grandi imprese italiane. Più in generale, Scott (1981) ha elaborato alcuni modelli teorici di insolvenza coerenti con l’impostazione del rischio di rovina.

45
7) ALTRI APPROCCI In questa sezione vengono rapidamente prese in esame alcune tecniche che sono state oggetto di attenzione da parte di vari studiosi per la previsione delle insolvenze. Attualmente, a conoscenza di chi scrive, non vi è ancora un corpus di risultati sufficientemente ampio e oggetto di dibattito approfondito che possa consentire una ragionevole e motivata conclusione sulla loro complessiva utilità e sugli effettivi benefici da esse derivabili rispetto alle metodologie illustrate nelle sezioni precedenti. Non viene peraltro qui considerato l’uso della cluster analysis sugli indicatori, o sui fattori (o componenti principali) su di essi costruiti, allo scopo di generare per via induttiva, ex-post, gli insiemi delle società sane ed anomale, individuando dai risultati le variabili maggiormente efficaci per la separazione dei raggruppamenti: questo approccio in generale produce risultati inferiori e meno stabili dell’analisi discriminante o delle regressioni (lineari o logistiche). La combinazione dell’analisi fattoriale e della cluster analysis è stata usata anche come premessa per l’analisi discriminante (Ali e altri (1995)) 31. 7.1 METODI NON PARAMETRICI Le restrizioni sulla forma delle distribuzioni delle variabili e sulle altre ipotesi metodologiche dell’analisi discriminante e delle regressioni (lineari e logistiche) hanno stimolato l’approfondimento di tecniche di classificazione che non risentano di tali vincoli. I metodi “distribution-free”, ovvero metodi non-parametrici, costituiscono un importante insieme di tecniche che sono a disposizione dello studioso per la stima di regole di classificazione, quando i dati campionari sono molto difformi da quanto richiesto dalle metodologie statistiche classiche, ovvero quando non si è in grado di formulare ipotesi attendibili sulle forme delle distribuzioni delle variabili e/o sulle funzioni di densità di probabilità32. Il metodo dell’istogramma ad esempio suddivide lo spazio compionario in celle disgiunte di uguale volume; la stima della funzione di densità di probabilità è ottenuta in base alla proporzione dei punti campionari che cadono nelle varie celle. Questo metodo può essere molto costoso in termini elaborativi perchè il numero delle celle cresce esponenzialmente col numero delle variabili e col numero delle suddivisioni che si vogliono effettuare su ciascuna variabile. Il metodo del kernel sostanzialmente calcola un stima della probabilità in base alla proporzione dei punti campionari che cadono in uno specifico volume; l’approccio opposto è adottato dal metodo k-nearest-neighbour (K-NN): si specifica la proporzione dei punti campionari e si ricerca il volume che li contiene (Hand (1981)).
31 In questo contesto è stato applicato anche lo scaling multidimensionale (Molinero e altri (1996) e Molinero-Ezzamel (1991)); tale tecnica, o piuttosto famiglia di tecniche, partendo da una matrice di prossimità tra un insieme di oggetti, consente di ottenere una rappresentazione geometrica con un numero di dimensioni limitato; ricorrendo allo scaling multidimensionale è ad esempio possibile ricavare una mappa delle vicinanze delle imprese in base alla distanza relativa su un certo numero di indicatori di bilancio (standardizzati per tenere conto delle diverse unità di misura). L’applicazione inversa consente di ottenere una mappa della vicinanza degli indicatori, invece che delle imprese, per facilitare l’individuazione del loro contenuto informativo. Il multidimensional scaling, come si vede, ha connessioni con l’analisi fattoriale e con la cluster analysis, anche se con proprie specificità. 32 Per una breve rassegna delle tecniche di discriminazione non parametrica si rinvia a McLachlan (1992).

46
I risultati ottenuti vengono opportunamente smussati in modo da ridurre le discontinuità e le asperrità delle distribuzioni. Vari studiosi hanno proposto altre tecniche di classificazione non parametriche, o di regressioni non parametriche; anche alcune metodologie illustrate nella sezione dedicata all’intelligenza artificiale possono essere considerate appartenenti alla famiglia delle tecniche non parametriche. Barniv-Raveh (1989) hanno proposto l’adozione di un approccio non parametrico basato sulla massimizzazione di un indice di separazione calcolato come rapporto tra la differenza tra le medie degli score dei due gruppi ed una media dei valori assoluti delle differenze incrociate tra gli score delle imprese del campione. Kolari-Caputo-Wagner (1996) hanno applicato sperimentalmente all’analisi del rischio delle banche commerciali una tecnica non parametrica (la “trait recognition”) derivata dall’analisi di prospezioni geologiche. Von Stein-Ziegler (1984) hanno confrontato i risultati di 3 tecniche non parametriche con l’analisi discriminante multipla e quadratica. Anche la programmazione lineare (con alcune varianti) è stata impiegata in qualità di tecnica non parametrica in sostituzione dell’analisi discriminante lineare. La programmazione lineare, infatti, non incorpora ipotesi parametriche sulla forma delle distribuzioni e consente di tenere conto facilmente dei costi di errata classificazione. Una delle formulazioni più semplici del problema di discriminazione con la programmazione lineare è il seguente:
scalarecpesi di vettorew
imprese di gruppi due sui osservate variabilidi matriciX,X
obiettivo variabiled:cuiin
0c
d)1(cwXd)1-(cwXVincoli
dMax obiettivo Funzione
21
2
1
==
==
>+≥⋅
≤⋅
Questo problema consiste nella massimizzazione della deviazione minima (d) in modo tale da suddividere lo spazio in due insiemi: un insieme chiuso d)-cxw( ≤′ ed un insieme aperto
d)cxw( +>′ . In questo modo viene in sostanza resa massima la deviazione minima dello score di ciascun gruppo di imprese dal punto di break-even c. Con la programmazione lineare è tuttavia facile incappare in seri problemi, quali l’ottenimento di soluzioni irrilevanti o di soluzioni non definite, la mancata identificazione di soluzioni ottime, la restrizione eccessiva dello spazio delle soluzioni raggiungibili, e così via. Koehler (1990) e Erenguc-Koehler (1990) hanno approfondito l'esame dei problemi che emergono in alcune classi di problemi di programmazione lineare impiegata nell’analisi discriminante. Östermark-Höglund (1998) hanno messo a confronto, su basa simulativa, l’analisi discriminante lineare e quadratica con

47
vari metodi di programmazione lineare e con il Recursive Partitioning Method, non ottenendo peraltro una chiara superiorità di un approccio rispetto ad un altro. Kolesar-Showers (1985) hanno applicato la programmazione a numeri interi al credit screening, mentre Gupta e altri (1990) hanno proposto l’utilizzo della goal programming quale miglioramento rispetto alla programmazione lineare: la loro funzione obiettivo è data dalla massimizzazione della somma ponderata delle distanze delle osservazioni sulle singole imprese dalla frontiera del gruppo cui esse si riferiscono e dalla contemporanea minimizzazione della somma ponderata delle violazioni della frontiera di separazione tra i gruppi. Sinuany Stern-Friedman (1998) hanno messo a punto un adattamento della DEA (Data Envelopment Analysis) per l’analisi discriminante. 7.2 TEORIA DELLE CATASTROFI All’analisi dei meccanismi economici che conducono all’insolvenza è stata applicata anche la teoria delle catastrofi. Com’è noto la teoria delle catastrofi è una branca della matematica che studia il comportamento qualitativo dei sistemi dinamici ed in particolare si occupa delle loro caratteristiche di stabilità strutturale: una catastrofe è una transizione discontinua, improvvisa, di un sistema da uno stato stabile ad un altro; i passaggi intermedi possono mancare oppure essere instabili ed il sistema non può fermarvisi a lungo. Il cambiamento improvviso del sistema deriva da piccole variazioni delle variabili che governano gli stati di equilibrio del sistema stesso. Sono stati individuati diversi tipi di catastrofi, alcuni dei quali di grande complessità. All’analisi delle insolvenze sono stati applicati schemi di catastrofi relativamente semplici, anche per la difficoltà di modellizzare specificamente il fenomeno della crisi d’impresa. Un sommario di queste ricerche è riportato in Gregory Allen – Henderson (1991). Il modello di catastrofe a cuspide, uno dei più semplici e dei più utilizzati nelle applicazioni di questa teoria nelle scienze sociali, collega il comportamento della variabile dipendente a due variabili di controllo. Nel caso in esame la variabile di stato (dipendente) rappresenta il rischio o la probabilità di insolvenza, ovvero il merito di credito dell’impresa; le variabili di controllo devono essere connesse alla variabile di stato e guidarne il comportamento con i loro cambiamenti. Il grafico 7 rappresenta in modo semplificato lo schema di catastrofe a cuspide:

48
Grafico 7.Schema di catastrofe a cuspide
La ricerca teorica deve individuare quelle variabili di controllo le cui variazioni sono tali da comportare cambiamenti “catastrofici” della variabile di stato: non qualunque variabile connessa al rischio di insolvenza è pertanto adatta ad essere inserita nel modello. In Scapens-Ryan-Fletcher (1981) le due variabili di controllo sono rispettivamente la redditività dell’impresa ed il rischio operativo; in Francis-Hastings-Fabozzi (1983) le due variabili di controllo sono la redditività e la liquidità. Ricorrendo alla semplificazione del grafico 7 si può schematizzare nel modo seguente il comportamento del sistema: l’impresa al tempo iniziale si trova nello stato indicato con Po; man mano che le variabili di controllo mutano, l’impresa si sposta verso il punto P1; se le forze che governano le variabili di controllo continuano ad agire, l’impresa si sposta improvvisamente dal punto P1 al punto P2, cadendo sulla superficie inferiore; P3 può indicare lo stato finale del sistema impresa. Questo modello descrive in termini semplificati, ad esempio, l’effetto di cambiamenti cumulativi della redditività, del rischio e della liquidità (o altre variabili rilevanti) sull’impresa: se l’impresa si trova già in una situazione limite, basta un cambiamento anche limitato in una variabile per far precipitare improvvisamente le sorti dell’impresa stessa. Cambiamenti delle variabili di controllo prima del punto limite o dopo tale punto comportano spostamenti del sistema impresa lungo traiettorie stabili o il permanere in stati di equilibrio. Modelli più complessi sono in grado di includere intere sequenze di salti “catastrofici”. Se sul piano descrittivo questo tipo di modelli presentano un indubbio interesse, la loro stima, pone problemi complessi; appare comunque prematuro ricavare conclusioni di ordine generale sull’efficacia di questo approccio.
P0
P1
P2 P3
Variabile di controllo X1
Variabile di controllo X2
Variabile di stato Y

49
7.3 SURVIVAL ANALYSIS La survival analysis rappresenta un’area molto importante della ricerca statistica con campi di applicazione assai vasti: dalla statistica clinica, all’analisi della durata di componenti meccanici, elettrici o di parti di macchine, alla ricerca sociologica, psicologica ed economica33. Nel campo clinico, ad esempio, la survival analysis prende in esame i dati di due campioni di soggetti, uno sano ed uno malato, ovvero uno sottoposto a terapia effettiva e l’altro cui viene somministrato un semplice placebo; l’obiettivo dell’analisi consiste nel valutare le probabilità di sopravvivenza dei soggetti esaminati, individuare le variabili che sono maggiormente influenti su tali probabilità e quindi consentire di valutare gli effetti di tali variabili. Gli elementi chiave della survival analysis sono la funzione di sopravvivenza (survivor function, S(t)) e la hazard function (h(t)); la funzione di sopravvivenza fornisce la probabilità che un soggetto ha di sopravvivere per un tempo superiore (T) ad un periodo specificato (t):
0S(t) ,per t1 S(t) 0,per t
tTper nzasopravvive di àProbabilit S(t)
=∞→==
>=
La hazard function fornisce il potenziale per istante di tempo che si verifichi l’evento oggetto di analisi (morte, esaurimento, rottura,…), condizionatamente al fatto che l’evento non si sia verificato prima:
t∆≥∆+<≤
=→∆
t)T|ttTP(tlimh(t)
0t
Si osservi che mentre S(t) riguarda la sopravvivenza, la h(t) si occupa dell’evento opposto; inoltre se S(t) è una probabilità, h(t) non è una probabilità ma un tasso condizionale del verificarsi dell’evento-morte: indica cioè la probabilità che l’evento accada tra t e t + ∆t, condizionata al fatto che il tempo di sopravvivenza è maggiore o uguale a t (è un tasso di probabilità per unità di tempo). Le relazioni tra S(t) ed h(t) sono le seguenti:
∫=
t
0
dr h(r)-
eS(t)
=
S(t)S(t)/dt d
-h(t)
Un ruolo importante nella survival analysis è svolto da modello di Cox: il Cox Proportional Hazard Model (CPH). In estrema sintesi il CPH esprime l’hazard function in termini esponenziali:
33 Sulle applicazioni economiche si veda , tra gli altri, Kiefer (1988).

50
∑⋅= =
⋅αn
1iii X
0 e(t)hX)h(t, ove le Xi sono le variabili esplicative delle capacità di sopravvivenza del soggetto e le αi sono i relativi coefficienti, mentre ho(t) (baseline hazard function) rappresenta la componente della hazard function quando le variabili esplicative sono tutte nulle (o non agiscono). Questa espressione del CPH fa l’ipotesi che le Xi non dipendano dall’effetto del tempo; una versione estesa del CPH consente di tenere conto di variabili esplicative dipendenti dal tempo. Nel CPH la funzione di sopravvivenza vale
[ ]∑
==
⋅αn
1iiXi
e0 (t)SX)S(t,
La popolarità del CPH deriva dalla sua generalizzabilità, ovvero adattabilità ad un’ampia varietà di situazioni, e dalla robustezza delle stime, che consentono di ottenere risultati confrontabili con modelli più precisi ma anche più limitati (ed usabili solo in casi specifici). La Survival analysis è stata applicata anche all’analisi delle insolvenze, con risultati interessanti. La survival analysis presuppone che le società sane e anomale provengano da una stessa popolazione sulla quale sono state osservate delle interruzioni della vita di alcune imprese (le anomale); l’insolvenza (quando non è associata al fallimento) può essere considerata come una interruzione della normale e regolare conduzione degli affari. Uno dei vantaggi della survival analysis riguarda la possibilità di specificare modelli che sfruttano meglio di altre tecniche l’insieme delle informazioni disponibili. Dato un certo arco temporale di osservazione, la variabile chiave di questo tipo di modelli è data dalla durata della vita dell’impresa prima della interruzione per causa di insolvenza; la durata di vita delle società sane copre per definizione l’arco temporale completo. Una specifica variabile dummy consente di identificare le società con vita limitata a causa dell’insolvenza da quelle con vita limitata pari alla durata dell’arco di tempo di osservazione (data censored). A differenza quindi dei modelli tradizionali (discriminanti o logistici) che utilizzano le osservazioni di un periodo ben preciso (t-1, t-2, …) dall’insolvenza, e che per questo possono essere qui definiti come modelli statici, quelli che si ispirano alla survival analisys utilizzano l’intera serie di osservazioni ed incorporano automaticamente in questo modo anche gli elementi dinamici. La risposta dei modelli di sopravvivenza è inoltre più flessibile di que lli tradizionali, in quanto non è limitata alla sola probabilità di essere sana o anomala ma riguarda la probabilità di sopravvivenza a vari anni. Bandopadhyaya (1994) ha esaminato la probabilità di uscita dalla procedura fallimentare (Chapter 11); Chen-Lee (1993) hanno applicato il CPH al settore petrolifero mentre Lane e altri (1986) lo hanno applicato al settore bancario; Cole-Gunther (1995) hanno studiato separatamente i determinanti dei fallimenti bancari ed i fattori che influiscono sui tempi entro i quali si manifesta il fallimento, modellando la separazione della popolazione delle banche in due sottoinsiemi, uno dei quali rappresenta in ogni periodo di tempo le banche che si prevede che falliranno. Luoma-Laitinen (1991) hanno applicato il CPH ad un campione di imprese finlandesi ottenendo performance prossime, ma inferiori, a quelle dell’analisi discriminante e della regressione logistica. Shumway (1998) ha dimostrato che l’hazard model può essere considerato come un modello logit multiperiodale e lo ha applicato ad un campione di società americane quotate, pervenendo a

51
performance globalmente migliori rispetto a quelle ottenute utilizzando il modello di Altman del 1968 ed il modello di Zmijewski (1984).
7.4 CONJOINT ANALYSIS
Come si è visto nelle sezioni precedenti, l’analisi discriminante lineare sintetizza la situazione economico-finanziaria dell’impresa in un punteggio determinato da una combinazione pesata degli indicatori rilevanti. Il contributo dell’analista risiede interamente nella loro individuazione, mentre i pesi sono ricavati dal processo di ottimizzazione di soluzione del modello. Nell’analisi dello stato di difficoltà delle imprese hanno avuto spazio anche modelli di scoring in cui l’analista, oltre ad individuare le variabili, fissa anche i pesi con i quali ponderarli nel giudizio complessivo. Tali pesi possono essere il risultato della propria esperienza oppure essere ricavati con un processo induttivo da esperimenti in cui vengono raccolte le valutazioni o i criteri di giudizio di analisti, banchieri, ricercatori. Tra gli altri, Tamari (1978; 1984) è stato uno dei pionieri in questo campo, mettendo a punto fin dagli anni ’60 un indice di rischio determinato come somma di punteggi parziali attribuiti a sei indicatori di bilancio; tali punteggi parziali sono determinati in base a specifiche scale numeriche definite per ciascun indicatore. Gli indicatori, le scale numeriche ed i pesi sono stati ricavati combinando l’esperienza dell’autore e di vari banchieri ed analisti di credito dell’epoca. Un approccio diverso, che verrà considerato anche nel successivo paragrafo, consiste nell’adottare la prospettiva tipica delle funzioni di utilità. Anziché tentare di ricostruire i meccanismi diretti di valutazione degli esperti, si chiede a loro di costruire un ordinamento delle imprese in base alle loro preferenze, usando un insieme preciso di variabili; la funzione di utilità media è ricavata dall’analisi degli ordinamenti e dalle connessioni tra questi ultimi e le variabili impiegate per le valutazioni (Varetto (1989)). La conjoint analysis, tra le molte tecniche disponibili, può essere adattata per queste finalità. Essa è una tecnica di analisi statistica multivariata che consente di manipolare variabili esogene non metriche. Essa è stata ampiamente applicata nel campo delle ricerche di mercato ed in particolare del comportamento d’acquisto dei consumatori. Data una serie di valutazioni globali su un insieme di prodotti alternativi forniti da un campione di clienti intervistati ed un insieme di attributi che descrivono tali prodotti, la conjoint analysis consente di misurare l’importanza relativa degli attributi. La valutazione complessiva viene scomposta in scale di utilità specifiche per i singoli attributi; la scomposizione viene effettuata in modo da rendere coerenti tra di loro le singole utilità. La Centrale dei Bilanci ha impiegato la conjoint analysis per la costruzione di uno score su dati qualitativi d’impresa, utilizzato per integrare lo score sui dati di bilancio (si veda Appendice II). In termini generali e ricorrendo per semplicità a funzioni di utilità additive, la valutazione globale dell’impresa i-esima può essere scritta come:
)(XV)(XV)(XVAU nin2i21i1i ++++= K
in cui Ui = utilità (o ordinamento di preferenza) totale assegnata all’impresa i-esima A = costante additiva per riferire al valore zero la base numerica delle preferenze Vj = funzione di valutazione (o di utilità) dell’attributo j-esimo Xji = valore assunto dall’attributo j-esimo sulla propria scala metrica
Dati Ui e le Xj, la conjoint analysis consente di ricavare A e le Vj.

52
Ui può essere semplicemente valorizzato pari a 0 e ad 1 per contraddistinguere le società sane e quelle anomale. Nel caso di dati qualitativi gli attributi misurano variabili come il posizionamento sul mercato, la qualità dei prodotti, la moralità del management, e così via. Lo stesso approccio può essere applicato alle variabili di bilancio: in questo caso Xji individua, ad esempio, la posizione in termini di decili dell’indicatore j-esimo; in altri termini le variabili continue rappresentate dagli indicatori sono ricondotte a variabili discrete, ripartendo il campo di esistenza degli indicatori in intervalli, non necessariamente ad ampiezza costante. Il modello può essere arricchito considerando espressioni più complesse, inserendo effetti di interazione tra le funzioni di valutazione individuali; queste ultime possono essere rappresentate da una semplice costante moltiplicativa oppure una funzione disegnata sulle specificità del singolo attributo. In ogni caso valgono anche per la conjoint anlysis le osservazioni effettuate a proposito dell’analisi discriminante e della regressione (lineare o logistica) sulla scelta degli indicatori e le loro caratteristiche. Nel caso della conjoint analysis, inoltre, è necessario porre cura particolare nello stabilire le metriche sulla base delle quali valutare le variabili-attributo: metriche troppo compatte non consentono di individuare le differenziazioni tra le imprese, mentre metriche troppo fini introducono inutili, e a volte dannose, complessità nei calcoli, generando problemi di coerenza nei segni delle Vj. I favorevoli risultati ottenuti dalla Centrale dei Bilanci con questo approccio ne suggeriscono ulteriori approfondimenti. 7.5 ANALISI MULTICRITERI L’analisi multicriteri è una parte molto importante della teoria delle decisioni e comprende una pluralità di metodi orientati ad assistere il decisore nella valutazione di diverse alternative d’azione contraddistinte da aspetti o da conseguenze non facilmente ordinabili. La difficoltà di generare ordinamenti tra diverse alternative ovvero di predisporre ordinamenti di preferenze di oggetti diversi (imprese nel nostro caso) dipende direttamente dalla necessità di considerare contemporaneamente una pluralità di caratteristiche (o di attributi o di criteri o di conseguenze) associate a tali oggetti. Salvo i casi fortunati in cui gli oggetti sono in relazione di progressiva dominanza reciproca su tutti gli attributi, cioè la prima impresa domina la seconda per tutte le caratteristiche considerate e quest’ultima domina la terza, e così via, determinare un ordinamento di preferenza è complesso e richiede la gestione delle contraddizioni tra le relazioni d’ordine che si possono stabilire tra le imprese, prendendo in esame le singole caratteristiche (Varetto (1989)). I metodi multicriteri hanno a che fare con problemi di questo tipo. In generale il punto di partenza dell’approccio multicriteri all’analisi delle imprese può essere schematizzato nella seguente tabella:

53
Tabella 3: Configurazione base dell'analisi multicriteri delle imprese
Attributi R1 R2 R3 ……. Rn
Ordinamento soggettivo (classi o ranghi)
Limiti sicuramente inaccettabili LI1 LI2 LI3 ……. LIn Limiti sicuramente accettabili LA1 LA2 LA3 ……. LAn
Imprese: Classi Ranghi ABC r1,ABC ……………………………………….. C1 1 BCD … C1 2 CDE … C2 3 EFG ……………………………..rn,EFG C2 … FGH C3 … ……… … … …
Gli attributi (o caratteristiche) sono le variabili che vengono considerate ai fini della valutazione: essi possono comprendere sia indicatori economico-finanziari, sia aspetti qualitativi riguardanti la posizione competitiva sul mercato, il management, i sistemi di controllo, e così via. Le prime due righe descrivono delle soglie di accettabilità o inaccettabilità della situazione dell’impresa: ad esempio, se il primo attributo (R1) riguarda il tasso di redditività sul capitale investito, ed i limiti sono rispettivamente –1% (LI1) e 8% (LA1), significa che l’impresa genera un tasso di profitto superiore od uguale all’8% la sua situazione, esaminata con riferimento a questo attributo, è sicuramente accettabile, mentre se è inferiore al –1% è sicuramente inaccettabile e se infine è compresa tra –1% e 8% il giudizio resta temporaneamente sospeso (ciò significa che anche perdite contenute, non superiori all’1% in valore assoluto, possono essere accettate in presenza di una posizione forte in altri attributi). Tali limiti possono essere indipendenti e disgiunti tra i vari attributi ovvero possono essere raggrupati in uno o più profili congiunti che descrivono combinazioni degli attributi (o fasce di combinazioni) accettabili o inaccettabili. Tali limiti possono essere stabiliti dal decisore in base alle sue preferenze oppure ricavati per deduzione dal processo di analisi se si dispone già dell’ordinamento delle imprese: quest’ultimo può essere un raggruppamento in classi (ad esempio le classi di rating) oppure una graduatoria ordinale. Disponendo dell’ordinamento, l’analisi multicriteri cerca di individuare le relazioni tra gli attributi che spiegano tale ordinamento. Se l’ordinamento manca, occorre lavorare sugli attributi e sulle preferenze del decisore per stabilire delle relazioni d’ordine tra le combinazioni con cui possono manifestarsi tali attributi e di qui ricavare l’ordinamento o una gerarchia di preferibilità delle imprese. L’analisi multicriteri comprende varie famiglie di tecniche che per maggiore chiarezza sono state classificate in categorie quali, ad esempio (Zopounidis (1995); Zopounidis-Dimitras (1998)):
a. la programmazione matematica ad obiettivi multipli: la programmazione lineare ed la goal
programming, vista in precedenza, sono esempi di tecniche che sono state impiegate in questo contesto;
b. la teoria dell’utilità multiattributo, con la quale si sintetizzano le preferenze del decisore sui
diversi attributi in un’unica grandezza. La funzione di utilità multicriteri viene scomposta in utilità
54
parziali sui singoli attibuti; la versione più semplice è la funzione di utilità additiva, nella quale le singole utilità parziali sono indipendenti tra loro e direttamente sommabili, mentre versioni più complesse, come quella moltiplicativa, consentono di tenere conto delle interazioni tra le utilità parziali (in Varetto (1989) sono riportati esempi di costruzione di funzioni di utilità multiattributi).
c. metodi di surclassamento: con questi metodi si possono ottenere ordinamenti delle imprese in
modo più flessibile rispetto alla funzione di utilità. Essi consentono di tenere conto dell’imprecisione e della na tura conflittuale delle valutazioni sui diversi attributi e permettono di includere dei giudizi e delle preferenze del decisore sia per i pesi da attribuire agli attributi sia per la definizione dei profili- limite delle categorie di imprese.
I ben noti metodi Electre appartengono a questa categoria. Essi, messi a punto essenzialmente da B. Roy e dai suoi collaboratori, costituiscono una vera e propria famiglia di tecniche adottate per gestire una grande varietà di situazioni e di complessità decisionali. Per una illustrazione generale si rinvia a Roy (1985). In Varetto (1989) è riportato un esempio di applicazione del metodo Electre II: esso stabilisce per ogni impresa delle relazioni di preordine in base alle quali una società è preferita ad un’altra se vi sono sufficienti elementi a suo favore. Tali relazioni compongono un grafo che connette tra loro le imprese. Per ciascuna vengono calcolati un indicatore di concordanza ed uno di discordanza, sulla base dei quali Electre II definisce una relazione di surclasssamento forte ed una debole, con cui viene generato l’ordinamento. Zopounidis (1995) e Zopounidis-Dimitras (1998) riportano vari studi in cui è stato applicato il metodo Electre Tri, un’evoluzione dell’Electre III34, che consente di effettuare una ripartizione delle imprese in più sottoinsiemi (ad esempio in classi di rischio). L’Electre Tri si applica al caso in cui siano disponibili (o sia definita dal decisore) delle categorie di imprese perfettamente ordinate, delimitate da profili di riferimento (uno alto ed uno basso), definiti rispetto agli attributi, com’è indicato nel grafico 8.
Grafico 8.Categorie di imprese e profili di riferimento in Electre Tri
34 Si veda anche Zopounidis e altri (1998).
P0 P1 P2 Py-1 Py
C1 C2 Cy
R1
R2
R3
Rn

55
Il profilo è il limite teorico tra due categorie successive. Electre Tri fornisce una classificazione delle imprese, come ad esempio: società sane, società anomale, e società da approfondire (riportato in Zopounidis (1995)); ciascuna categoria comprende un certo numero di imprese: la performance del modello può essere desunta direttamente quindi dalla sua capacità di corretta segmentazione del campione di imprese. I metodi della famiglia Electre non sono i soli a gestire le relazioni di surclassamento; in Varetto (1989) è stato esaminato, ad esempio, il metodo Promethee II.
d. Metodi di disaggregazione delle preferenze : questi metodi sono prossimi a quelli dell’utilità
multiattributo e se ne differenziano soprattutto per le modalità di identificazione delle utilità parziali dei singoli attributi e dei pesi con cui ponderarle. Nel caso delle utilità multicriteri si tenta di costruire direttamente la funzione, cercando di costruire con il decisore le curve di utilità parziali, in base a domande sulle sue preferenze, ed i pesi relativi. Nel caso dei metodi di disaggregazione, la ricostruzione della funzione avviene in modo indiretto, analizzando le scelte e le decisioni prese nel passato; la regressione multipla può essere uno strumento che si presta a individuare un modello di decisione che è il più compatibile con il comportamento passato del decisore. Zopounidis (1995) riporta studi in cui sono applicati all’analisi del rischio di insolvenza metodi di disaggregazione delle preferenze. I metodi multicriteri hanno come punti di vantaggio rispetto ad altre tecniche la flessibilità e la possibilità di incorporare relazioni deboli e conflittuali delle preferenze per i diversi attributi; inoltre consentono di manipolare senza problemi variabili continue e variabili qualitative. Per una migliore organizzazione dell’analisi delle variabili ai fini decisionali, esse possono essere raccolte per tematiche ed organizzate in modo gerarchico (si veda Srinivasan-Bolster (1990)). Essi inoltre non formulano alcuna ipotesi sulla forma delle distribuzioni di frequenza delle variabili. Essi tuttavia risentono di tutte le imprecisioni che si accompagnano alla individuazione delle preferenze dei decisori: in alcuni metodi, lievi cambiamenti dei pesi con cui ponderare le preferenze, o sulla base dei quali stabilire le relazioni di preordine, conducono a significativi combiamenti dei risultati. Inoltre quando il numero delle imprese è ampio e gli attributi sono molti, essi diventano rapidamente onerosi dal punto di vista computazionale. I risultati delle ricerche sul rischio di credito in cui sono stati applicati metodi multicriteri hanno messo in luce un’evidenza non sempre sistematica, dalla quale si può ricavare comunque una significativa efficacia classificatoria, prossima ed in alcuni studi superiore a quella delle tecniche statistiche. All’analisi delle insolvenze è stata recentemente applicata anche la teoria dei rough sets. Essa, introdotta da Z. Pawlak35, si basa sul principio che a ciascun oggetto può essere associata una certa informazione; due oggetti caratterizzati dalla stessa informazione sono indistinguibili; qualsiasi insieme di oggetti indistinguibili è chiamato un insieme elementare e forma un granulo di conoscenza; qualsiasi unione di insiemi elementari forma un insieme preciso, altrimenti l’insieme è vago (rough set); ciascun insieme vago può essere caratterizzato da una linea di confine che include gli oggetti che non possono essere associati con certezza all’insieme nè all’insieme-complemento. Partendo dalla consueta tabella di oggetti (imprese nel nostro caso), di attributi (indicatori di bilancio e/o variabili qualitative) e di ordinamenti già disponibili, la teoria dei rough sets arriva a proporre delle semplificazioni del numero degli attributi che descrivono gli oggetti, per pervenire ad 35 Per una breve introduzione alla teoria dei rough sets si può cfr. Pawlak (1998; 1997) e Zopounidis -Dimitras (1998).

56
una rappresentazione essenziale della conoscenza sugli oggetti stessi, senza sacrificare il contenuto informativo originario. Da tale rappresentazione essenziale può essere ricavato un insieme di regole in grado di riprodurre la classificazione degli ogge tti. Nell’impiego della teoria dei rough set il decisore (banchiere, analista finanziario) svolge un ruolo essenziale: individua gli attributi che devono essere utilizzati; definisce le scale di valutazione degli attributi qualitativi e gli intervalli sulla base dei quali riportare ad intervalli discreti gli attributi che assumono valori continui; seleziona, tra le proposte dell’algoritmo di rough sets, l’insieme ridotto di attributi che sintetizza l’informazione originale; verifica la qualità delle regole di classificazione su campioni di controllo. Slowinski-Zopounidis (1995) e Dimitras e altri (1999) hanno applicato la teoria dei rough sets all’analisi dell’insolvenza di imprese greche e ne hanno messo in luce le notevoli capacità classificatorie. Greco ed altri (1998) hanno proposto un’estensione della teoria base dei rough sets, che ha determinato un miglioramento della capacità di classificazione di imprese insolventi.

57
8) IL CONTRIBUTO DELL’INTELLIGENZA ARTIFICIALE L’enorme sviluppo dell’intelligenza artificiale, che spazia in una grande varietà di campi, non poteva non avere riflessi anche sul problema di cui ci stiamo occupando. In effetti il processo di decisione di credito si presta particolarmente ad essere studiato ed affrontato con i procedimenti tipici dell’intelligenza artificiale. Il grande numero di approcci e tecniche dell’intelligenza artificiale rende impossibile, nel breve spazio di queste pagine, affrontare un’esauriente discussione su di esse, anche se limitata direttamente al dominio dell’analisi del credito; per questo motivo ci limitiamo a prenderne in esame solo una piccola parte, concentrandoci solo su alcune delle numerose tecniche disponibili. Il dibattito scientifico sui pregi ed i difetti delle diverse tecniche è assai vivo e lungi dall’essere concluso, né manca la discussione sui rispettivi vantaggi operativi che esse offrono nelle applicazioni pratiche. Ciò ha dato vita a diversi studi comparati, volti ad approfondire su specifici domini, le performance di strumenti alternativi ad essi applicabili. Ad esempio, nell’ambito del programma europeo Esprit, è stato realizzato il progetto Statlog, nell’ambito del quale sono state confrontate una ventina di tecniche diverse appartenenti alla statistica (analisi discriminante lineare, quadratica e regressione logistica, in primis) ed all’intelligenza artificiale, tra cui l’apprendimento automatico di regole, gli alberi decisionali e le reti neurali applicate ad otto problemi reali di classificazione, quali l’analisi delle immagini e diagnosi in medicina, ingegneria e finanza: in quest’ultimo campo è stato studiato il problema del rischio di credito, ottenendo risultati promettenti con l’uso di alberi decisionali, che, sui data-base utilizzati nel progetto, si sono rivelati in media migliori delle altre tecniche messe a confronto (Michie e altri (1994); King e altri (1994)). 8.1 SISTEMI ESPERTI
Al di là degli aspetti più strettamente classificatori, l’area fidi rappresenta un campo di applicazione di estremo interesse per l’intelligenza artificiale. Il dominio è noto ed, entro certi limiti, acquisibile e codificabile con uno dei vari metodi di organizzazione di basi di conoscenza; le attività connesse alla gestione dei crediti sono proceduralizzabili a diversi livelli di difficoltà e di completezza e raccordabili col sistema informativo complessivo della banca. In queste condizioni i benefici dell’automazione possono essere consistenti, a patto che sul piano organizzativo il sistema sia opportunamente collocato, per limitare l’ostilità con cui può essere accolto, e siano state addestrate adeguatamente le risorse umane destinate ad utilizzarlo: la conoscenza dei limiti del sistema è forse l’aspetto più importante che deve essere comunicato agli analisti di credito della banca36. Le applicazioni di sistemi esperti nell’area fidi sono state moltiplici, anche nel nostro Paese, ma con risultati spesso fortemente diversi, sia per quanto riguarda le dimensioni dei sistemi, le loro performance, la loro effettiva integrazione nell’uso quotidiano da parte degli analisti e nel più generale sistema informativo della banca. Storicamente i sistemi esperti hanno avuto degli alti e dei bassi, suscitando forti aspettative o generando cocenti delusioni; volta per volta sono stati messi a confronto con altri approcci che, almeno ad un primo esame, sembravano offrire significativi vantaggi in termini di efficienza, velocità e costi di sviluppo.
36 Sull’applicazione di sistemi esperti all’area fidi di veda, tra gli altri, Gardin e altri (1991), Nottola-Rossignoli (1993).

58
Un sistema esperto destinato all’analisi di credito ha, o dovrebbe avere, finalità più vaste della diagnosi del rischio di insolvenza: oltre a fornire un adeguato supporto per la valutazione dell’impresa, esso dovrebbe includere anche gli elementi per la decisione di nuovo affidamento o di rinnovo dell’affidamento in essere, l’entità dei fidi accordati e le forme tecniche di erogazione, le procedure per la rilevazione dei segnali di rischio nelle revisioni periodiche, l’integrazione con le informazioni della Centrale dei Rischi ed il collegamento con i dati sulla movimentazione dei conti bancari. L’emissione di report formali alle varie fasi del processo completa le funzionalità del sistema. In concreto, i sistemi esperti sono specializzati per aree di applicazione (prestiti personali, fidi commerciali, leasing, prestiti bancari, finanziamenti a medio e lungo termine…) e/o per segmento della filiera-credito (sistema per l’assistenza all’analisi dell’impresa, per il supporto all’istruttoria sull’operazione di finanziamento, per la consulenza finanziaria al cliente, per il controllo periodico dei rischi e del corretto utilizzo dei fidi basato sui dati di Centrale dei Rischi e sulle relazioni finanziarie correnti tra la banca e l’impresa, per il recupero dei crediti,…). I benefici dei sistemi, sul piano organizzativo, includono la formalizzazione della base delle conoscenze della banca in materia di affidamenti, il decentramento del processo decisionale e dei criteri di valutazione, l’omogeneità del trattamento delle pratiche di credito, il risparmio di tempo dell’analista che può concentrare la propria attenzione sui clienti che richiedono approfondimenti, il miglioramento dell’efficienza della banca che è in grado di interagire con i propri clienti in tempi rapidi, dando risposte tempestive, sollecitando trasparenza e chiarimenti fin dalle fasi iniziali del rapporto. La struttura logica di un sistema esperto è esemplificata nel grafico 9.
Grafico 9. Schema semplificato di un sistema esperto
La base di conoscenza (o memoria a lungo termine) rappresenta l’insieme delle informazioni specializzate sullo specifico dominio per il quale il sistema viene costruito; la conoscenza riguarda fatti o/e relazioni tra i concetti rilevanti in quel dominio. Solitamente la base di conoscenza viene generata da un ingegnere della conoscenza che intervista e discute con gli esperti del dominio, razionalizza gli elementi che ricava e ne fornisce una rappresentazione strutturata, utilizzabile dal sistema. Nel nostro caso gli esperti del dominio sono gli analisti di credito senior della banca mentre l’ingegnere della conoscenza non ha una formazione specifica sul dominio ma ha competenza sulle modalità di estrazione della conoscenza e sulle tecniche della sua organizzazione e rappresentazione
BASE DI CONOSCENZA
MEMORIA DI LAVORO
MOTORE INFERENZIALE
UTENTE

59
formale. Oltre agli esperti, anche la conoscenza codificata nelle ricerche pubblicate nella letteratura scientifica rappresenta una fonte importante di informazioni per l’ingegnere. La base di conoscenza è separata dal motore di inferenza e ciò consente all’ingegnere della conoscenza di preoccuparsi del suo contenuto e non di come quest’ultimo viene utilizzato dal sistema. L’estrazione della conoscenza dagli esperti del dominio e la sua formalizzazione rappresentano il punto più delicato ed importante dell’intero sistema esperto e la sua fase più lunga e (forse) costosa: occorre avere a disposizione buoni esperti per tutto il tempo necessario; un buon esperto non è solo un analista anziano, con alle spalle lunghi anni di pratica, ma soprattutto uno che ha razionalizzato le proprie conoscenze e che è in grado di parlarne in modo efficace e di trasmetterle in modo non distorto all’ingegnere (deve esprimere ciò che fa di fronte ad un caso concreto, non ciò che pensa di fare). La memoria di lavoro (o memoria a breve termine) contiene i fatti che riguardano il problema che si vuole risolvere. Il motore inferenziale è una procedura che lavora sui fatti contenuti nella memoria di lavoro e che va a ricercare nella base di conoscenza quegli elementi che sono compatibili (matching) con i fatti dello specifico problema; da tali elementi il sistema ricava una certa conclusione (intermedia o finale), che va ad aggiungersi al contenuto della memoria di lavoro; il processo continua fino a quanto il motore trova elementi nella base di conoscenza, rilevanti per l’elaborazione dei fatti noti o delle conclusioni ottenute a quello stadio. Sostanzialmente il motore inferenziale accoppia ad ogni ciclo un sottoinsieme di regole che soddisfano i contenuti della memoria di lavoro; quando più regole possono essere eseguite, il motore, con una procedura di risoluzione dei conflitti, sceglie a quale dare la precedenza. Vi sono vari metodi di rappresentazione della conoscenza, ma in questa sede ne tratteggiamo solo i due più spesso impiegati: le regole di produzione ed i frames, tralasciando altri come la logica dei predicati del primo ordine e le reti semantiche. Le regole sono delle proposizioni in cui una premessa specifica le condizioni che devono essere verificate per attivare la regola; la struttura logica della regola è la seguente: IF (premessa); THEN (conseguenza) Questo modo di strutturare la base di conoscenza è facilmente comprensibile ed intuitivo ed inoltre consente un approccio dinamico alla costruzione della base: si può iniziare con un sistema con poche regole e complicarlo progressivamente. Il motore inferenziale prende in esame le regole in base al contenuto della premessa; tutte quelle che hanno una premessa associabile con i fatti della memoria di lavoro vengono identificate con un contrassegno; nel caso in cui siano state identificate più regole, il motore attiva una procedura di selezione (l’attivazione può seguire un ordine di priorità delle regole oppure la semplice sequenza con la quale si presentano sulla base di conoscenza, e così via). Questa procedura (forward chaining) agisce sulle regole partendo dai fatti iniziali del problema esaminato e da quelli via via aggiunti dalle regole attivate. Il processo ha termine quando non vi sono più regole applicabili. Una procedura inversa (backward chaining) attiva le regole non partendo dalle premesse (parte sinistra della regola) ma dalle conseguenze (parte destra): questo approccio si propone di spiegare o giustificare un obiettivo finale, procedendo a ritroso nella ricerca progressiva delle regole che conducono gradualmente ad una serie elementare di ipotesi che sono compatibili con tale obiettivo.

60
La struttura a regole può essere completata con una indicazione della plausibilità (o grado di confidenza o fattore di certezza) delle conseguenze: IF (premessa); THEN (conseguenza); CON PROB=(p) ove p rappresenta la probabilità condizionale che le conseguenze siano vere, date le premesse. Un ulteriore perfezionamento consiste nell’aggiungere una quantificazione dell’utilità della regola: IF (premessa); THEN (conseguenza); CON PROB=(p); CON UTILITA’=(u) Ove u è misurata in base alla quantità di informazioni contenuta nella regola (il calcolo segue i principi della teoria dell’informazione). Se la struttura a regole ha dalla sua il vantaggio delle modularità e del dinamismo, pone problemi di efficienza quando le regole diventano numerose; è inoltre difficile assicurare la consistenza interna del sistema delle regole (vi è il problema di potenziali incoerenze o contraddizioni). Il Frame ha un approccio più statico alla organizzazione della conoscenza. Sostanzialmente esso è una rappresentazione strutturata della conoscenza che si fonda sul concetto di stereotipo (o di descrizione standardizzata), cioè sulla identificazione degli elementi chiave che descrivono compiutamente un oggetto o una situazione, un evento. Ad esempio, nel nostro caso, può essere definito il frame delle società insolventi, descrivendole con le caratteristiche cruciali che le contraddistinguono dagli altri tipi di imprese: redditività modesta o negativo, struttura finanziaria molto fragile, liquidità carente, e così via. La base di conoscenza è una collezione di frames e di collegamenti tra di essi. In termini concettuali il frame è uno strumento potente di organizzazione della conoscenza, che può essere articolata al suo interno in più sezioni: proprietà tipiche dell’oggetto; azioni che possono coinvolgere l’oggetto; regole che collegano proprietà o altri elementi rilevanti; eccezioni alla descrizione standard dell’oggetto, e così via. Il motore inferenziale, nel caso di frames, prende in esame, vari frame che possono essere rilevanti per la soluzione del problema, attivando le azioni ad essi connesse. Sia i sistemi a regole che a frames sono oggi arricchiti con la gestione della imprecisione (nel senso di vaghezza e non di carenza di conoscenza), col ricorso alla teoria degli insiemi fuzzy. La letteratura è ricca di sistemi esperti sviluppati per l’analisi di credito. Srinivasan-Kim (1988)37 hanno messo a punto un sistema esperto nel quale il processo di decisione di credito è organizzato su tre livelli con il ricorso all’Analitic Hierarchy Process. Shaw-Gentry (1988) sono ricorsi ad un meccanismo di induzione automatica delle regole per la messa a punto del loro sistema; ciò ha consentito di abbreviare i tempi di realizzazione, sfruttando analiticamente i casi disponibili secondo linee che sono illustrate meglio nella sezione successiva. Duchessi e altri (1988) hanno sviluppato un sistema esperto che rappresenta bene l’applicazione a regole tipica nell’analisi del merito di credito. Applicazioni simili si trovano in Talebzadeh e altri (1995) e Pau-Tambo (1990). Pinson (1992) è ricorso invece alla logica dei predicati del primo ordine. La Deutsche Bundesbank (1999) ha recentemente messo a punto un sistema esperto con regole semplificate per migliorare la classificazione delle imprese che si trovano nell’area grigia della funzione discriminante lineare del suo modello di valutazione del merito di credito, che viene applicato alle decisioni di risconto.
37 Si veda anche Srinivasan-Ruparel (1990)

61
Felisari (1993) ha descritto con ampiezza le caratteristiche di un sistema esperto adottato da una primaria banca italiana. Vi sono peraltro sistemi esperti sviluppati nel campo economico-finanziario la cui prospettiva non è strettamente la valutazione del merito di credito, ma la più generale diagnosi sulla situazione della società, con un contenuto sufficientemente articolato da poter essere utilizzato anche nella prospettiva del rischio di affidamento (Klein-Methlie (1990); Micha (1987)). Oltre ai sistemi esperti può essere utile infine accennare all’uso di sistemi di supporto alle decisioni (DSS) che spesso sono utilizzati dagli analisti bancari come aiuto per l’esame dei bilanci delle imprese e delle domande di credito. Alcuni DSS integrano procedure più strettamente amministrative con tecniche di analisi multicriteri: Zopounidis-Doumpos (1998) hanno integrato nel loro sistema un metodo di classificazione multicriteri basato su funzioni di utilità; Mareschal-Brams (1991) sono ricorsi alla metodologia Promethee, simile per certi versi al metodo Electre, per sviluppare il loro DSS. I sistemi esperti si rivelano estremamente utili per favorire una seria proceduralizzazione di alto livello delle competenze per l’esame delle pratiche di credito, ma soffrono di alcuni punt i deboli. Lo sviluppo di un sistema esperto in grado di affrontare con efficacia problemi complessi richiede molto tempo e la disponibilità di un team di esperti di elevata qualità, in grado di formalizzare, con l’aiuto dell’ingegnere, una base della conoscenza articolata ed esauriente. E’ essenziale quindi che un progetto di questa importanza e di un tale costo sia fatto proprio dalla direzione e l’organizzazione della banca sia preparata per tempo a riceverlo. Spesso queste condizioni non si verificano e ci si limita a codificare al meglio possibile conoscenze aziendali approssimative oppure ad acquisire all’esterno strumenti già disponibili. Inoltre, strettamente sul piano della predizione delle insolvenze, i sistemi esperti sono in generale più imprecisi rispetto agli strumenti esaminati nelle sezioni precedenti; una parte della spiegazione su questo punto può risiedere nel fatto che le basi di conoscenza tendono ad avere una portata generale per gestire l’intero processo di analisi e controllo delle domande di credito e fatalmente finiscono per essere meno focalizzate sulla specifica previsione delle insolvenze. Queste limitazioni hanno accresciuto l’interesse verso l’induzione automatica delle regole (rule induction) e, più in generale, verso gli strumenti di apprendimento automatico: maggiore celerità di individuazione delle regole e basi di conoscenze specializzate sono i vantaggi che si attendono da queste tecniche. Questi argomenti costituiscono l’oggetto dei prossimi paragrafi.
8.2 ALBERI DECISION ALI38 Le tecniche considerate in questo e nei successivi paragrafi appartengono ad una branca particolare dell'Intelligenza Artificiale: il Machine Learning, cioè l'Apprendimento Automatico. Questa branca comprende uno spettro piuttosto ampio di metodologie, quali ad esempio gli alberi decisionali, la rule induction, le reti neurali, il pattern-recognition (individuazione e riconoscimento di configurazioni), gli Algoritmi Genetici oltre a vari tipi di metodi statistici. L'interesse pratico per l'apprendimento automatico è aumentato in misura rilevante con la constatazione di alcuni limiti dei sistemi esperti. Come si è visto nel punto precedente, qualunque sia il formalismo adottato per la rappresentazione della conoscenza, la sua individuazione richiede una lunga e faticosa collaborazione tra uno o più esperti del dominio che si vuole studiare ed uno o più ingegneri della conoscenza: nel corso di numerose sedute questi ultimi cercano di acquisire dai primi la conoscenza rilevante per eseguire i 38 Questo paragrafo sintetizza parte del contenuto di Varetto (1998(a)).

62
compiti assegnati al sistema esperto. L'esperienza e le conoscenze interiorizzate dagli esperti del dominio devono essere individuate, estratte con tecniche apposite, ricondotte all'essenziale, ripulite da incongruenze ed infine riorganizzate e formalizzate in metodi utilizzabili dal sistema esperto. Il vero punto debole, che in sostanza può limitare la costruzione di sistemi esperti su domini ampi, è proprio la fase di estrazione e codifica della conoscenza. In quest'ottica ben si comprende il grande interesse con cui sono stati accolti i metodi di ricerca automatica di conoscenze e di estrazione di regolarità da insiemi di dati complessi e non sempre strutturati39. Nelle applicazioni dedicate alla diagnosi dei rischi di insolvenza, notevole interesse è stato dedicato ad una specifica classe di metodi di apprendimento: l'apprendimento da esempi. I metodi di ricerca ed esplorazione che lavorano su esempi sfruttano un'idea comune: il sistema riceve dall'ambiente esterno una serie di informazioni riguardanti vari casi concreti che appartengono ad un certo dominio (ad una classe specifica del dominio di interesse); operando su tali informazioni, il sistema deve individuare le caratteristiche simili tra quelle specifiche di singole categorie di casi e pervenire a generalizzazioni di criteri di scelta o di comportamento tali da poter essere applicati con successo anche a casi non compresi tra quelli usati per l'apprendimento (learning set o training set). Il processo di ottenimento di conoscenza, partendo da casi particolari e generalizzandone le regolarità individuate, si basa su un tipico ragionamento induttivo: l'inferenza induttiva infatti procede da asserzioni particolari per pervenire ad asserzioni generali in grado di spiegare fatti o descrivere situazioni; la capacità di generalizzazione, cioè la potenza predittiva delle asserzioni generali, va valutata su casi, fatti o situazioni nuove ed originali rispetto all'insieme a partire dal quale sono state tratte le asserzioni particolari. Da un punto di vista formale l'apprendimento di un concetto dagli esempi disponibili significa essere in grado di riconoscere tutti i casi che soddisfano le caratteristiche che connotano quel concetto. In quest'ottica l'apprendimento di concetti corrisponde alla formulazione di regole di classificazione che ripartiscano gli esempi in sottoinsiemi, ciascuno dei quali è descrittivo di un concetto particolare. La formalizzazione dell'apprendimento automatico da esempi in termini di regole di classificazione si è rivelato un approccio estremamente proficuo soprattutto nei compiti che implicano l'effettuazione di una diagnosi (nel campo medico, aziendale, tecnico, psicologico....). L'importanza dei metodi di apprendimento per induzione da esempi è stata messa in luce anche da studiosi e costruttori di sistemi esperti, basandosi sull'osservazione che per gli esperti è più facile produrre esempi specifici, positivi o negativi, di situazioni o fenomeni che si intendono studiare, rispetto ad offrire teorie o concettualizzazioni riguardanti situazioni o fenomeni con valenza più generale: sulla base degli esempi forniti dall'esperto, l'ingegnere della conoscenza procede all'estrazione della conoscenza rilevante per quel dominio. Per esempio è più facile per un esperto produrre casi di società fallite e di società sane che formulare una teoria sul fallimento dell’impresa oppure una teoria sui segnali finanziari generati dalle imprese nei differenti stadi che precedono l’insolvenza. I metodi di apprendimento automatico sono rivolti ad applicare tecniche di ricerca di regolarità e di generalizzazione di esempi riproducendo parzialmente il lavoro dell'ingegnere della conoscenza. 39 Per l'analisi dei complessi concetti di conoscenza e di apprendimento si rinvia alla letteratura specializzata.

63
E' evidente che, per quanto perfezionati, i metodi di apprendimento automatico non possono sostituire l'ingegnere della conoscenza 40; tuttavia, pur con notevoli limiti, se usati in modo opportuno, essi consentono di abbreviare notevolmente i tempi di messa a punto dei modelli di analisi. Inoltre varie tecniche di Machine Learning non risentono delle ipotesi limitative su cui sono fondati i tradizionali metodi statistici e possono essere considerate come tecniche non parametriche. Peraltro se sono piuttosto numerosi gli algoritmi di apprendimento automatico tramite esempi, occorre osservare che in molti casi essi rappresentano varianti o miglioramenti di metodi base o perfezionamenti delle strategie di ricerca delle regolarità nel learning set41. Gli Alberi Decisionali, nell'accezione con cui vengono usati nel Machine Learning, sono dei formalismi che consentono di ottenere in via automatica una o più classificazioni progressive di un insieme di oggetti a partire da una serie di caratteristiche osservate su di essi. L'idea centrale della costruzione di un albero decisionale consiste nell'effettuare successive partizioni disgiuntive dell'insieme degli oggetti in modo tale che i sottoinsiemi così ottenuti ad ogni stadio abbiano un contenuto più "puro" rispetto ai sottoinsiemi degli stadi precedenti 42. Esistono vari criteri con cui effettuare le partizioni; uno dei più adottati riguarda la metodologia messa a punto da R. Quinlan che per stimare il grado di impurità dei sottoinsiemi generati ha utilizzato il concetto di entropia. Il primo sistema progettato da questo studioso, l'ID3, ha riscosso notevole successo ed è stato preso come riferimento da numerosi altri ricercatori. L'ID3 ha subito nel corso del tempo vari perfezionamenti, orientati soprattutto a rimuoverne alcuni difetti: la versione più recente del sistema di Quinlan, il C4.5, è stato pubblicato nel '93 43. Com'è stato sottolineato nella letteratura scientifica in materia, oggi il "C4.5 induction algorithm is a state-of-the-art-top-down-method-for- inducing-decision-trees". Un albero decisionale è composto da una rete ordinata discendente di relazioni, articolate in una o più "foglie" che si dipartono da nodi decisionali o da nodi intermedi. Un nodo decisionale specifica i test che devono essere condotti su uno specifico attributo; per ciascun risultato possibile dei test si diparte dal nodo un ramo che può dare origine ad un sotto-albero. Una foglia rappresenta un punto terminale dell'albero e contraddistingue una classe di oggetti; se la foglia non è un punto terminale dell'albero ma rappresenta soltanto uno dei possibili risultati di un test di un nodo decisionale e funge da collegamento con un successivo nodo decisionale si chiama nodo intermedio. Per classificare un oggetto (del training set o di un campione indipendente) quindi è sufficiente partire dall'alto, dalla radice iniziale, dell'albero, eseguire il primo test, seguire il ramo appropriato in base al risultato ottenuto e procedere con i successivi test fino a quando si incontra una foglia: tale punto terminale rappresenta il particolare sottoinsieme o la particolare classe che contraddistinguere l'oggetto classificato. La suddivisione degli oggetti prosegue fino a quando tutti i sottoinsiemi comprendono solo oggetti appartenenti ad un'unica classe. 40 Quest'ultimo peraltro può giovarsi dei metodi di apprendimento automatico per esplorare diversi aspetti delle informazioni ricavate dall'interazione con gli esperti del dominio. 41 Il già richiamato progetto Statlog ha messo a confronto vari metodi di apprendimento automatico di regole, tra cui alcune procedure di induzione di alberi decisionali. 42 Per un'introduzione generale agli Alberi Decisionali si cfr. Breiman - Friedman - Olshen - Stone (1984): i metodi raccolti in questo testo hanno peraltro un riferimento di tipo prevalentemente statistico. 43 Si cfr. Quinlan (1993).

64
Uno dei problemi più importanti riguardanti gli Alberi Decisionali riguarda il fatto che spesso nelle applicazioni reali la complessità degli oggetti da classificare è tale che gli Alberi Decisionali indotti da essi risultano composti da numerosissimi rami e foglie, di difficile lettura ed interpretazione. Inoltre alberi troppo complessi danno spesso origine a fenomeni di overfitting in quanto troppo specifici dell'insieme di apprendimento, con conseguente limitazione della capacità di classificazione corretta di oggetti nuovi, non appartenenti al training set. Dopo la costruzione dell'albero, o in certi casi contestualmente ad essa, occorre pertanto procedere alla sua potatura se risulta troppo complesso. Nella letteratura sono stati proposti numerosi algoritmi (alcuni dallo stesso Quinlan) per la semplificazione razionale degli alberi complessi; tale semplificazione deve essere condotta evidentemente in modo da preservare la capacità di riconoscimento fondamentale dell'albero. La potatura in avanti si basa sull'idea di verificare, ogni volta che si procede ad utilizzare una nuova variabile, l'utilità effettiva di disporre delle nuove informazioni: quando tale utilità si rivela troppo bassa può essere opportuno accettare di terminare un sotto-albero con foglie contenenti un certo grado di impurità piuttosto che continuare nelle suddivisioni dei sottoinsiemi 44 La potatura a ritroso parte dall'albero completo e cerca di eliminare quei sottoinsiemi che contribuiscono meno alla sua capacità classificatoria. A differenza della potatura in avanti, che si pone il problema se valga la pena procedere ad ulteriori suddivisioni, la potatura indietro si chiede se si ottengono miglioramenti dalla rimozione di strutture e sotto-alberi precedentemente costruite. Una procedura generale per la semplicazione degli alberi complessi, sostituendo sotto-alberi con foglie terminali, si basa sul calcolo dell'errore che si commette utilizzando delle foglie impure (e che quindi incorporano una certa probabilità di commettere errori di classificazione) rispetto all'errore commettibile usando alberi troppo specializzati. Si tratta in altri termini di rendere più robusto l'albero, semplificandolo dei rami che possono essere più l'effetto dell'overfitting che il risultato dell'apprendimento di concetti (più l'effetto di rumore che della formalizzazione del contenuto informativo dalle variabili). La presenza nel training set di casi con informazioni non sempre accurate è una dalle cause di generazioni di alberi inutilmente complessi; è quindi necessaria un'attenta analisi dei casi su cui il sistema provvede all'apprendimento per evitare che siano inclusi esempi tra loro contraddittori, il cui effetto è senza dubbio quello di introdurre rumorosità nei dati. Per contro se si devono classificare nuovi oggetti che hanno caratteristiche significativamente diverse da quelle del training set, può essere opportuno procedere ad un nuovo addestramento del sistema e pervenire ad un nuovo albero decisionale. Un albero decisionale può essere direttamente convertito in un insieme di regole che possono aiutare a comprendere meglio i concetti incorporati nell'albero o prestarsi ad essere utilizzate con motori inferenziali in sistemi esperti. Le regole costituiscono una descrizione strutturata del cammino che occorre percorrere dalla radice dell'albero per arrivare a ciascuna foglia terminale. Si osservi che sebbene vi sia in generale un parallelismo tra Alberi Decisionali e la rappresentazione con regole, i due formalismi non sono sempre strettamente corrispondenti 45: gli Alberi Decisionali si prestano a trattare categorie di problemi che possono essere scomposti in concetti tra loro disgiuntivi; le regole da essi derivabili quindi sono mutuamente escludentisi e pertanto i loro sistemi costituiscono un caso particolare dei più generali sistemi a regole di produzione.
44 Quinlan ha utilizzato nei suoi primi lavori un criterio basato sul test χ2 . 45 In questo punto si veda anche Fum (1994) e Quinlan (1993).

65
Numerosissime sono le applicazioni degli alberi decisionali e le comparazioni tra i risultati ottenuti con tale tecnica rispetto ad altri approcci di rule-induction, oppure rispetto ad altre metodologie classificatorie. Chung-Tam (1993) hanno ad esempio confrontato le procedure ID3, AQ (una tecnica di rule-induction basata sul calcolo dei predicati) e le reti neurali nell’ambito della previsione delle insolvenze di banche minori. Liang e altri (1992) hanno messo a confronto la regressione logistica, la procedura ID3 per alberi decisionali e le reti neurali nell’ambito di una ricerca sul problema della valutazione delle scorte. Messier-Hansen (1988) hanno utilizzato la procedura ID3 per indurre un insieme di regole intorno al quale hanno costruito un sistema esperto dedicato all’analisi delle insolvenze. Srinivasan-Kim (1987) hanno impiegato a fini sperimentali l’analisi discriminante lineare e quadratica, la regressione logistica, la goal programming ed il Recursive Partitioning Algorithm (RPA) di Breiman e altri (1984) per la costruzione di alberi decisionali. RPA e Probit sono state invece prese in esame da Marais e altri (1984) per la classificazione dei prestiti bancari. Il RPA è stato applicato anche da Frydman-Altman-Kao (1984), paragonando i risultati con quelli ottenuti dai precedenti modelli discriminanti di Altman. Espahbodi e altri (1998) hanno confrontato tra loro il RPA, la regressione logistica e l’analisi discriminante per la previsione dell’insolvenza delle banche. I risultati di queste ricerche non sono univoci e a seconda dei casi la migliore classificazione è ottenuta con una tecnica piuttosto che un’altra; in generale tuttavia gli alberi decisionali si rivelano essere una metodologia semplice, robusta e con buone capacità diagnostiche. Un importante vantaggio tra l’altro riguarda la loro efficacia comunicativa delle ragioni della classificazione: in altri termini, essi sono trasparenti per l’analista, che è in grado di comprendere i loro risultati. La Centrale dei Bilanci (Varetto (1998(a))) ha applicato la tecnica di costruzione degli alberi decisionali ad un campione di imprese industriali sane ed anomale, le cui definizioni sono indicate sinteticamente nell’Appendice II. La metodologia adottata dalla Centrale dei Bilanci si ispira al C4.5 di Quinlan ed ai principi descritti nel paragrafo precedente, con alcuni cambiamenti. In particolare la procedura è stata adattata per poter operare con variabili continue e quindi direttamente con gli indicatori di bilancio invece che con la loro trasposizione in attributi qualitativi. L'uso diretto dei valori numeric i degli indicatori di bilancio consente, in questa fase sperimentale, di guadagnare in precisione e limitare i casi di possibile contraddittorietà delle situazioni delle imprese del campione di addestramento. Inoltre allo scopo di valutare la dipendenza dei risultati dal criterio di selezione delle variabili basato sull'entropia sono stati utilizzati anche altri criteri, quali: a. l'indice di diversità di Gini b. l'indice di Herfindahl c. la Twoing-rule di Breiman 46 oltre ad alcune varianti sulle loro definizioni base. Dalle numerose prove effettuate non sono emerse differenze di rilievo tra i vari metodi e pertanto in questa sede si fa riferimento esclusivamente ai risultati derivanti dall'applicazione del criterio entropico.
46 Breiman ed altri (1984).

66
La tecnica degli Alberi Decisionali è stata applicata ad un campione chiuso di imprese con almeno tre bilanci prima della manifestazione dell'insolvenza (1920 società sane e 1920 anomale) e ad un campione indipendente di 449 sane e 449 anomale con bilanci ad un anno dall'insolvenza. L'albero decisionale stimato al T-3 risulta composto da 163 regole disgiunte che esauriscono interamente l'insieme delle 3940 società: ciò significa che tutte le foglie terminali dell'albero contengono imprese di una sola classe e quindi sono tutte foglie pure. La complessità dell’albero è notevole: il grafico 10 riporta alcuni rami tratti dal tronco principale.
Grafico 10. Rami tratti dall'albero di decisione al T-3/K3
In alcuni casi inoltre la sequenza dei segni è in apparente contrasto con la logica economica. Delle 163 regole, tuttavia sono sufficienti le migliori 23 a classificare correttamente l'82,34% delle imprese sane e l'80,17% delle anomale. Questo albero applicato ai bilanci al T-1 dello stesso campione classifica correttamente il 90,92% delle imprese sane e il 96,92% delle anomale, mentre nel caso del campione indipendente i tassi di riconoscimento sono rispettivamente dell'83,19% per le imprese sane e 94,98% per le anomale. Negli alberi semplificati, mentre si ottengono livelli significativi di performance con un numero limitato di regole, generalmente la sequenza dei segni è coerente con la logica economica : la probabilità di incappare in cluster particolari di imprese descrivibili con indicatori con comportamento non monotonico aumenta rapidamente con il crescere del numero delle variabili utilizzate ; con alberi più semplici si rinuncia ad ottenere tutte foglie pure e quindi ad identificare a tutti i costi quei clusters particolari, facendoli rientrare tra gli errori di classificazione.
I(Struttura Finanziaria) (+)
I(Cash-Flow) I(Redditività)
<25 >25
I(Peso debito)
<10 >5
I(Peso debito1)
I(Peso debito2)
<6
<115 I(Liquidità)
Sane Anomale 0 1010
I(Struttura Finanziaria2) <25
I(Crediti Fornitori)
>2
I(Valore Aggiunto)
<177
I(Liquidità)
<94
Sane Anomale 997 6
I(Cash-Flow) <52
Sane Anomale 953 0
>44
>5

67
Gli Alberi Decisionali sono utili non solo quale ausilio per l’individuazione degli indicatori più rilevanti e pertinenti per la diagnosi ma anche come strumento per comprendere i concetti sottostanti al fenomeno aziendale che si vuole indagare. Inoltre l’analisi ottenuta dagli alberi completi (ante potatura) consente di individuare cluster di imprese con caratteristiche meno evidenti ed intuitive. Questa possibilità apre la strada ad affinamenti e miglioramenti della diagnosi. I risultati ottenuti in termini di classificazione mettono in luce infine sia la buona performance e stabilità degli Alberi Decisionali sia la loro robustezza rispetto agli outliers. Essendo uno strumento non parametrico, gli Alberi Decisionali non dipendono dalle ipotesi metodologiche tipiche della statistica parametrica (e dell’analisi discriminante in particolare). Per contro gli Alberi Decisionali risentono dei limiti dell’induzione pura su cui si basano: tali limiti peraltro sono comuni anche alla cluster analysis. L’ottimizzazione locale e non globale inoltre rappresenta un vincolo attualmente non superabile, se non si vuole cadere in problemi di natura combinatoria con difficoltà computazionali esplosive. La potatura dell’albero rappresenta un’operazione essenziale e per sua natura delicata: occorre semplificare l’articolazione eccessiva dei rami senza perdere contemporaneamente concetti importanti che la fase di addestramento dell’albero ha acquisito. La potatura dovrebbe prevedere anche il controllo della congruità economica dei segni dei test. Uno degli svantaggi degli Alberi Decisionali risiede nel tipo di risposta dicotomica (0/1 ; sana/anomala), mentre uno score continuo consentirebbe una migliore graduazione della situazione delle imprese: c’è in effetti un’ampia fascia di situazioni esistenti tra l’impresa-tipo “sana” e l’impresa-tipo “anomala”. Si osservi che non c’è contiguità tra analisi discriminante ed Alberi Decisionali : la stima di funzioni lineari con gli indicatori individuati come rilevanti dall’albero decisionale ha senso solo per una parte limitata di essi, ottenendo peraltro performances non elevatissime; quando la stima coinvolge un numero significativo di livelli dell’albero, si ricavano modelli in genere instabili e con segni errati ne i coefficienti. 8.3 CASE-BASED REASONING
Il Case-Based Reasoning (CBR) è un tipo di ragionamento approssimato che si basa sull’esperienza di casi simili già risolti per affrontare un particolare problema ed ottenere una soluzione. L’idea chiave del CBR è sostanzialmente quella di non sforzarsi ad identificare, codificare e formalizzare la conoscenza in uno specifico campo ma semplicemente di raccogliere un certo numero di casi-tipo già incontrati nel passato e di metterli a disposizione in archivi appositamente costruiti, in modo da poterli utilizzare come punti di riferimento per problemi che si dovessero presentare in futuro47. Il CBR si basa sull’assunto che per affrontare e risolvere un problema non è necessario comprendere i meccanismi causali che ne sono alla base (che, come si è visto, è lungo e costoso individuare e mettere a punto), ma è sufficiente andare a vedere come ci si è comporatati nel passato quanto l’azione del decisore ha avuto successo (o ha dato i risultati sperati) in situazioni simili: i casi risolti incorporano implicitamente le competenze e l’esperienza del decisore (dell’analista di credito, nel nostro contesto). Un sistema di CBR è articolato, in generale, in varie componenti: una libreria di casi, uno schema di indicizzazione, un meccanismo di matching e di reperimento, un sistema interpretativo. La libreria dei casi non è altro che la memoria delle esperienze del passato; i casi devono ovviamente essere ben strutturati per facilitare il successivo lavoro del sistema: le caratteristiche
47 Per un esame approfondito del CBR si rinvia a Kolodner (1993).

68
rilevanti devono essere identificate e codificate; le azioni ed i connessi risultati devono essere anch’essi correttamente associati ai casi e facilmente rintracciabili. Lo schema di indicizzazione ha direttamente a che fare con l’organizzazione della biblioteca dei casi ed è essenziale perchè gli stessi vengano rapidamente identificati ed utilizzati. Una organizzazione strutturata ad albero, ad esempio, facilita il ritrovamento dei casi rilevanti per il problema che si ha sotto esame, ma per altri versi può limitarne l’uso ad un campo troppo ristretto. Un altro aspetto cruciale riguarda il meccanismo di matching, cioè di valutazione della similarità dei casi passati a quello attuale (caso-target); una delle tecniche spesso usate consiste in un algoritmo di clusterizzazione del tipo nearest-neighbor matching, basato sul concetto di distanza tra gli attributi del caso in esame e quelli dei casi della biblioteca: lo score calcolato riflette semplicemente il grado di prossimità medio tra i casi e consente di scegliere il o i casi più vicini al caso-target. Il ricorso ai fuzzy sets consente anche nel CBR la gestione dell’imprecisione dei valori assunti dagli attributi nella biblioteca dei casi. Non sempre i casi del passato si adattano perfettamente al caso in esame e quindi è necessario un certo adattamento per poterne usare le esperienze. Si osservi che i casi storici possono essere ricavati sia dalla documentazione di effettive esperienze incontrate nel passato dal decisore, sia da ideal- tipi specificati dagli esperti nell’ambito della messa a punto del sistema: ritorna qui l’osservazione che spesso è più facile per l’esperto proporre esempi ed evidenze empiriche all’ingegnere della conoscenza che illustrare razionalmente l’articolazione dei ragionamenti seguiti nell’affrontare un problema. Come si vede il punto essenziale del CBR è che l’esperienza è una risorsa e come tale va accumulata, valorizzata e sfruttata. Uno dei punti deboli del CBR, che dipende logicamente da quell’assunto, riguarda il fatto che, se il problema da affrontare è effettivamente un caso di nuovo tipo rispetto a quelli visti in precedenza ed inseriti nella biblioteca, il CBR non trova un’esperienza pertinente e propone risposte di modesta qualità o irrilevanti: è necessario in questa evenienza risolvere il problema con altri strumenti e successivamente memorizzarlo come nuovo caso, arricchendo la biblioteca di riferimento. Naturalmente un numero troppo elevato di casi memorizzati, se da un lato aumenta la probabilità di potersi giovare dell’esperienza, dall’altro ha il difetto di rendere rapidamente oneroso il funzionamento del sistema dal punto di vista computazionale. Per migliorare l’efficacia dei sistemi basati sul CBR si è rivelata utile la loro integrazione con sistemi e regole orientati sia al reperimento dei casi rilevanti (knowledge-based retrieval), sia alla gestione dei problemi appartenenti ai cluster di casi più studiati e noti o per i quali è disponibile una base di conoscenza realmente operativa. Il CBR è stato applicato alla previsione delle insolvenze ed all’analisi dei fidi: la biblioteca dei casi è costituita da esempi di società insolventi ovvero dalle pratiche di credito tipicamente esaminate dalla banca. Wolf (1995) ha utilizzato il CBR per mettere a punto un sistema di supporto per l’analisi dell’affidabilità in una banca svizzera. Sinha-Richardson (1996) hanno applicato il CBR alla valutazione delle pratiche di affidamento, separando i casi in tre grandi categorie: credito concesso/regolamento rimborsato; credito concesso/insolvenza; credito non concesso. Bryant (1997) ha confrontato il CBR con la regressione logistica per la previsione delle insolvenze di imprese industriali e commerciali, trovando una netta superiorità diagnostica della seconda sul primo.

69
8.4 RETI NEURALI48 Le Reti Neurali (RN) sono un potente strumento di apprendimento automatico che si è rapidamente imposto all’attenzione degli studiosi di una pluralità di campi d’analisi. La flessibilità e l’efficacia delle RN sono tali che esse sono oggetto di continui avanzamenti sia teorici che applicativi; esse inoltre sono sempre più spesso integrate in alcune metodologie sia statistiche che di intelligenza artificiale, come i sistemi esperti neurali, le RN a logica fuzzy, e così via. La letteratura scientifica sulle RN è assai ampia, come enormemente vasta lo è quella delle loro applicazioni, anche considerando il solo campo dell’analisi economico finanziaria. Mentre si rinvia a testi specializzati per un esame approfondito delle RN 49, può essere di qualche utilità richiamare brevemente le loro caratteristiche essenziali. I modelli di elaborazione connessionista (reti neurali) sono composti da un grande numero di unità elaborative elementari; ogni unità è interconnessa con altre unità e ciascuna è in grado di effettuare calcoli realtivamente semplici. Il risultato elaborativo delle reti deriva dal loro comportamento collettivo piuttosto che da quello specifico di singole unità: il risultato, in altri termini, dipende da moltissime unità e da come queste interagiscono tra di loro secondo collegamenti di diversa intensità. I collegamenti non sono rigidi ma modificabili con processi di apprendimento generati dalla interazione della rete con il mondo esterno o con una batteria di segnali simbolici. Le singole unità e le connessioni che le legano possono essere rappresentate come nel grafico 11:
Grafico 11. Schema generale di unità neurale
Ogni unità (i) riceve input (xj) (o stimoli) dall’esterno, o da altri neuroni con cui è collegata, con intensità (pesi) pari a wji. L’input complessivo che il neurone i-esimo riceve è pari ad un potenziale (Pi):
ij
jjii S - xwP ∑ ⋅=
48 Questo paragrafo include una sintesi di Varetto-Marco (1994) 49 Si veda per tutti Rumelhart-McClelland (1991)
X1
X2
Xn
Pi yi
w1,i
w2,i
wn,i

70
ove “Si” rappresenta un valore di soglia di eccitazione che limita il grado di risposta del neurone agli stimoli ricevuti: ad esempio nelle funzioni di risposta “a salto”, solo se l’input complessivo che arriva dall’esterno e/o da altri neuroni è superiore ad Si il neurone emette un segnale di risposta. E’ possibile eliminare la soglia Si e sostituirla con un input (k) fittizio di valore pari ad 1 (xk = 1) e ponendo wki = Si, ottenendo l’espressione generale:
jin compreso èk ove xwPj
jjii ∑ ⋅=
in questo modo anche il valore di Si viene generato dal processo di apprendimento di rete. La risposta (yi) del neurone dipende dalla funzione di trasferimento all’esterno del potenziale (Pi). Una delle più utilizzate nella letteratura è la funzione logistica, secondo cui:
Pii e11
y−+
=
Generalmente la funzione di risposta determina valori compresi tra un minimo ed un massimo; nel nostro caso yi risulta compreso tra 0 ed 1. Di fatto la logistica raggiunge i valori estremi (0 ed 1) solo con pesi molto elevati e quindi nei casi concreti ci si accontenta di valori approssimati. L’uscita (yi) del neurone può essere sia un valore di risposta complessiva della rete (se esso è quello finale di uscita) sia l’input per i neuroni con cui l’unità i è interconnessa.
Le reti, costituite da molte unità elementari del tipo i-esimo, possono avere diversi gradi di complessità (in questa sede ci si occupa solo delle reti a funzionamento “in avanti”, feed-forward): le reti più semplici sono costituite da un solo strato di neuroni (al limite da un solo neurone) ciascuno dei quali è direttamente a contatto con gli stimoli esterni e genera direttamente le uscite dalla rete. Un tipo di rete un po’ più complicato comprende due strati: uno strato intermedio, nascosto, che riceve gli stimoli dall’esterno della rete ed uno strato di output che genera le risposte della rete (es. Grafico 12).
Grafico 12. Esempio di rete neurale a due strati
Reti maggiormente complesse comprendono più strati nascosti tra quelli di input e di output. Si possono costruire reti che abbiano dei circuiti di retroazione (feed-back) tra i neuroni di uno strato e quelli degli strati precedenti così come anelli di autoconnessione (in cui ad esempio un
Input esterni
Primo strato Secondo strato
(output)
Risposta di rete

71
neurone è connesso con se stesso e genera fenomeni di autopotenziamento cumulativo della funzione di risposta). Nella letteratura scientifica sono state messe in luce le notevoli limitazioni delle reti ad uno strato; in sintesi: le reti ad uno solo strato sono in grado di effettuare separazioni lineari dello spazio degli input (ad esempio il piano può essere bipartito in due settori con una retta), le reti a due strati possono generare forme geometriche convesse, mentre solo reti ad almeno tre strati consentono la separazione dello spazio degli input in forme di qualunque configurazione (la complessità delle regioni è determinata dal numero dei nodi). Non vi sono regole generali per stabilire il grado ottimale di complessità della rete (numero di strati intermedi e numero di neuroni che compongono ciascuno strato) al di là del numero di neuroni di ingresso e di uscita che generalmente sono determinati dal problema. L’aspetto cruciale delle reti di neuroni risiede nel fatto che i pesi delle connessioni non sono fissi ma possono essere modificati sulla base di una procedura di apprendimento derivata dal confronto tra le risposte della rete e le risposte desiderate. La procedura di apprendimento assume un ruolo fondamentale: si può dire che mentre nei programmi informatici tradizionali viene dichiarato esplicitamente al calcolatore come raggiungere un certo risultato, nelle reti neurali viene dichiarato un meccanismo con il quale il calcolatore completa o adegua la procedura per ottenere il risultato voluto. La rete, in altri termini, si comporta come un sistema dinamico adattivo che reagisce ai divari di risposta. I punti importanti del problema sono i seguenti:
1. occorre definire una procedura di apprendimento, cioè di correzione dei pesi ed una di
iterazione delle rettifiche (tutti i neuroni in parallelo, in modo casuale, uno alla volta); 2. occorre preparare una batteria di esempi (training set) rappresentativi del problema da risolvere; 3. occorre definire un livello di tolleranza massima dell’errore commesso dalla rete (accettabilità
della risposta); 4. occorre definire una procedura per la sottomissione degli esempi (in cicli sequenziali o in ordine
casuale) ed una di aggiustamento dei pesi (dopo ogni caso o dopo ogni gruppo di n casi); 5. occorre preparare una batteria di casi di verifica con cui controllare l’attendibilità delle risposte
della rete quando lavora con stimoli diversi da quelli ricevuti durante l’apprendimento (capacità di generalizzazione).
In sostanza: si fornisce alla rete una serie di input; su quella base la rete genera una risposta che viene confrontata con la risposta desiderata: se la risposta ottenuta coincide con quella voluta non si effettuano correzioni sui pesi, mentre se la diversità supera una certa tolleranza si introducono delle rettifiche nei pesi; l’apprendimento ricomincia con un nuovo caso di input. L’analisi di tutti i casi forniti costituisce il ciclo di apprendimento di estensione massima; possono essere definiti cicli su un numero limitato di casi. Dopo l’iterazione di un numero più o meno elevato di cicli, l’errore si riduce a livelli accettabili e, superata la batteria di controllo, l’apprendimento ha termine ed i pesi vengono bloccati: la rete ha raggiunto una configurazione di equilibrio stabile che rappresenta la sua “capacità di risolvere un problema” (o il livello di comprensione di un concetto). La rete è pronta per essere impiegata su casi reali, usando il valore dei pesi raggiunto nella fase di apprendimento. Si può dire che la configurazione dei pesi rappresenti la conoscenza incorporata nella rete: si tratta di una conoscenza non concentrata in singoli punti ma diffusa su tutta la rete e per utilizzarla occorre il contributo congiunto, sia pure semplice ed elementare, di tutti i neuroni e le connessioni che la compongono. Il fatto che la conoscenza sia distribuita spiega anche la buona tolleranza ai

72
guasti delle reti: anche se una (o qualche) unità va fuori uso, la rete in genere ne risente poco od in misura molto parziale. La conoscenza è accumulata con un processo di tipo puramente induttivo. Se si muta significativamente la configurazione iniziale dei pesi e si ripete il processo di apprendimento si ottiene una rete diversa dalla precedente ma in grado di fare lo stesso lavoro; configurazioni diverse dei pesi interni delle connessioni tra le unità producono lo stesso risultato. Ciò significa che è rilevante l’intero sistema di pesi, piuttosto che specifici pesi: ciò implica anche che, a parità di struttura di rete, vi sono modi diversi per configurare la conoscenza distribuita tra le connessioni. Come si può intuire, uno dei punti di forza delle reti neurali risiede nella loro plasticità, plasmabilità e capacità di adattamento, lento e graduale, alla realtà (vera o virtuale) cui sono sottoposte. Il meccanismo dell’apprendimento tocca parecchi problemi: a) la fase di apprendimento può essere molto lunga (apprendimento lento); b) il sistema può non raggiungere una configurazione stabile di minimo assoluto (riduzione
ottimale dell’errore) ma può bloccarsi in minimi relativi senza riuscire a spostarsi sull’ottimo; c) il sistema può dar vita a comportamenti oscillatori nella fase di apprendimento, in cui il punto
minimo viene raggiunto e superato per poi tornare indietro in un punto precedente; d) quando la situazione reale muta in misura significativa rispetto alla descrizione fornita dagli
esempi di addestramento occorre ripetere la fase di apprendimento; lo stesso vale quando la batteria degli esempi non è rappresentativa della realtà, del problema o del concetto di apprendere;
e) l’analisi dei pesi, ovvero lo studio della configurazione della conoscenza accumulata dalla rete, si presenta complessa e di difficile interpretazione: vi è, in altri termini, una scarsa trasparenza della rete per quanto riguarda l’esame della logica profonda con cui vengono generate le risposte.
Ciò rende difficile individuare le cause degli errori o delle anomalie nelle risposte (proprio per il concorso contemporaneo di tutte le unità della rete e delle loro connessioni alla determinazione delle risposte) così come la manutenzione selettiva delle unità della rete: una soluzione consiste, ove possibile, nello scomporre reti complesse in reti più semplici, tra di loro interconnesse, ciascuna dedicata alla generazione di specifiche categorie di risposte (controllabili e differenziate). Su questo punto si ritornerà in seguito. In ogni caso, ben si comprende come l’algoritmo che determina l’apprendimento della rete rivesta un’importanza fondamentale per la determinazione delle prestazioni finali della rete stessa. Il metodo che viene considerato qui è quello ben noto proposto da Rumelhart, Hinton e Williams50: l’algoritmo di retropropagazione dell’errore (Error Back Propagation). L’algoritmo propaga le influenze dell’errore a ritroso partendo dallo strato di output e risalendo gradualmente, attraverso gli strati intermedi, allo strato di input. La variazione del peso di una connessione segue un andamento inverso all’effetto del peso sull’errore: se quest’ultimo aumenta (diminuisce) al crescere del peso allora il peso stesso viene diminuito (aumentato). La modifica avviene in proporzione ad una costante (a) definita come tasso di apprendimento: fissare questo coefficiente è piuttosto complesso e non vi sono regole formali; tanto maggiore è la costante tanto maggiori saranno le variazioni dei pesi conseguenti al segnale di errore ma ciò può avere l’effetto di innescare comportamenti oscillatori; per contro, un tasso di apprendimento troppo basso allunga la fase di addestramento della rete o si può rimanere intrappolati in minimi locali.
50 Si veda Rumelhart – Hinton – Williams “L’apprendimento di rappresentazioni interne attraverso la propagazione dell’errore” , compreso in Rumelhart – McClelland (1991)

73
Anche per l’attribuzione dei pesi iniziali mancano regole precise; empiricamente si segue spesso la procedura di assegnarli in modo casuale e con valori non eccessivamente elevati. L’apprendimento ha termine quando l’errore medio quadratico sull’intero numero di casi di addestramento è ridotto al di sotto di una soglia prestabilita. Come si vede, la realizzazione di reti neurali non necessita di una specifica programmazione: occorre effettuare una progettazione del grado di complessità della rete e definire il metodo di aggiustamento dei pesi delle connessioni tra i vari nodi, ma poi è la rete stessa che, sulla base di una batteria di casi di addestramento, impara a generare specifici segnali e a tenere determinati comportamenti. Con l’addestramento la rete, per così dire, si autoprogramma, anche se l’autoprogrammazione non è che il risultato dell’adattamento graduale della rete ai segnali che si vogliono riprodurre; tale processo avviene senza che dall’estero l’uomo intervenga direttamente a definire l’intensità delle connessioni neurali.
Applicate al campo economico-finanziario le RN hanno potenzialmente numerosi vantaggi, tra cui: a) una buona capacità descrittiva dei fenomeni; b) una eccellente flessibilità e capacità di adattamento; c) una bassa sensibilità alla presenza di outliers; d) assenza di ipotesi sulla forma delle distribuzioni delle variabili; e) elevata tolleranza rispetto al tipo di variabili, alla loro misurazione ed alla forma della
distribuzione; f) irrilevanza della multicollinearità tra le variabili (i coefficienti non devono necessariamente
essere interpretati); g) possibilità di gestire relazioni non lineari. Per contro le RN, come si è visto, mancano di un corpus teorico che sia in grado di definire il tipo di architettura ottimale da usare nei vari problemi, i valori dei parametri di apprendimento e di controllo dei cicli, i valori di inizializzazione dei pesi, e così via. Inoltre la lo ro scarsa trasparenza rende difficile per l’analista comprenderne il reale funzionamento e valutare la plausibilità economica del modello che è stato appreso per via automatica: in questo aspetto fondamentale le RN si differenziano totalmente dagli alberi decisionali e dai sistemi esperti. L’applicazione delle RN alla previsione delle insolvenze è stato oggetto di numerosi studi, dei quali non è possibile rendere conto totalmente in queste pagine. Alcune raccolte di studi, come quelle di Trippi-Turban (1996), Aurifeille–Deissenberg (1998), Refenes (1995) includono studi di notevole interesse, dai quali, in generale, emergono risultati assai promettenti, sia nel campo della previsione delle insolvenze che in quello del Bond Rating. Si vedano anche le rassegne ragionate di Feldman–Kingdon (1995) e De Bodt e altri (1995); O’Leary (1998) ha esaminato vari studi dedicati alle insolvenze delle banche. Cadden (1991) ha applicato le RN all’analisi delle insolvenze adottando una trasformazione booleana degli indicatori ripartiti in quartili; Boritz e altri (1995) hanno messo a confronto le RN con altre tecniche di classificazione, quali l’analisi discriminante, la regressione logistica, la probit; confronti di questo genere sono stati condotti, tra gli altri, anche da Coats-Fant (1992), Serrano Cinca (1997), Daniels e altri (1997), Fanning-Cogger (1994), Maher-Sen (1997), Bardos-Zhu (1998). Back e altri (1996) hanno usato le RN per valutare la capacità diagnostica di variabili basate sui flussi finanziari rispetto a tradizionali indicatori di bilancio; Baetge-Uthoff (1998) hanno impiegato le RN su un campione di grande numerosità di imprese, integrando variabili economico-finanziarie con variabili di natura qualitativa; Barniv e altri (1997) hanno adottato le RN per distinguere tre diversi stati di uscita dalla procedura di fallimento (acquistata da terzi, ritorno alla gestione,
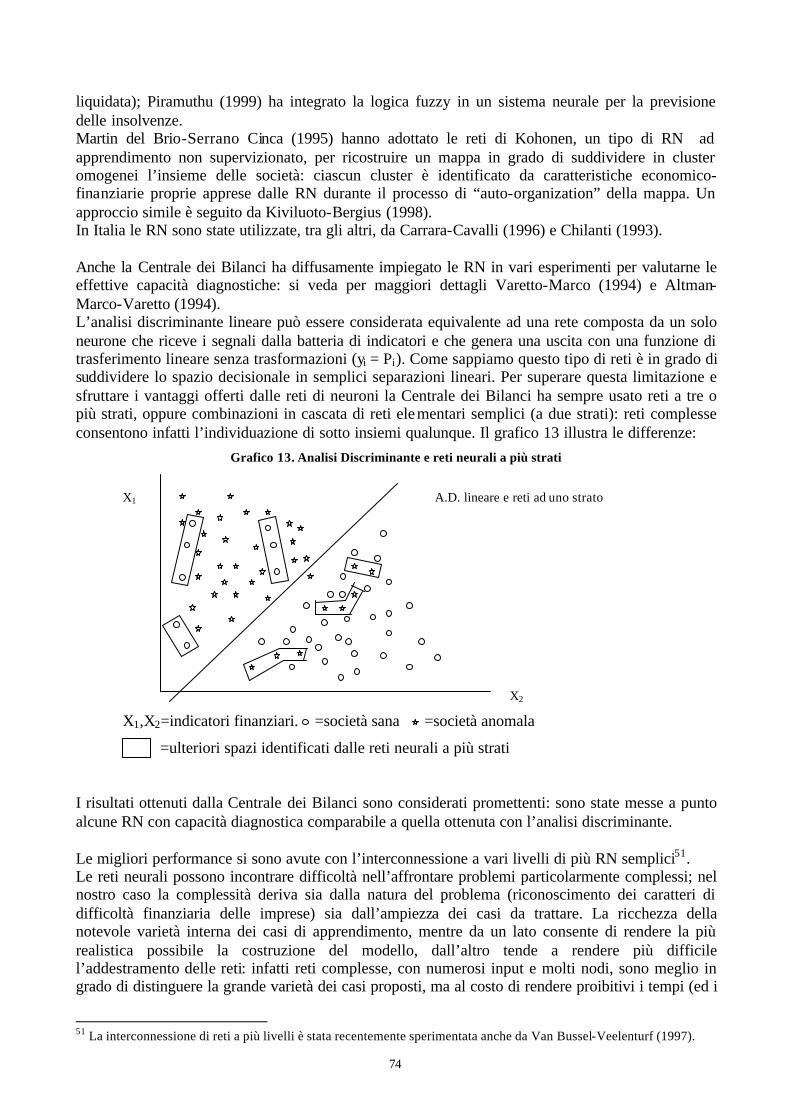
74
liquidata); Piramuthu (1999) ha integrato la logica fuzzy in un sistema neurale per la previsione delle insolvenze. Martin del Brio-Serrano Cinca (1995) hanno adottato le reti di Kohonen, un tipo di RN ad apprendimento non supervizionato, per ricostruire un mappa in grado di suddividere in cluster omogenei l’insieme delle società: ciascun cluster è identificato da caratteristiche economico-finanziarie proprie apprese dalle RN durante il processo di “auto-organization” della mappa. Un approccio simile è seguito da Kiviluoto-Bergius (1998). In Italia le RN sono state utilizzate, tra gli altri, da Carrara-Cavalli (1996) e Chilanti (1993). Anche la Centrale dei Bilanci ha diffusamente impiegato le RN in vari esperimenti per valutarne le effettive capacità diagnostiche: si veda per maggiori dettagli Varetto-Marco (1994) e Altman-Marco-Varetto (1994). L’analisi discriminante lineare può essere considerata equivalente ad una rete composta da un solo neurone che riceve i segnali dalla batteria di indicatori e che genera una uscita con una funzione di trasferimento lineare senza trasformazioni (yi = Pi). Come sappiamo questo tipo di reti è in grado di suddividere lo spazio decisionale in semplici separazioni lineari. Per superare questa limitazione e sfruttare i vantaggi offerti dalle reti di neuroni la Centrale dei Bilanci ha sempre usato reti a tre o più strati, oppure combinazioni in cascata di reti elementari semplici (a due strati): reti complesse consentono infatti l’individuazione di sotto insiemi qualunque. Il grafico 13 illustra le differenze:
Grafico 13. Analisi Discriminante e reti neurali a più strati
X1,X2=indicatori finanziari. =società sana =società anomala
=ulteriori spazi identificati dalle reti neurali a più strati I risultati ottenuti dalla Centrale dei Bilanci sono considerati promettenti: sono state messe a punto alcune RN con capacità diagnostica comparabile a quella ottenuta con l’analisi discriminante. Le migliori performance si sono avute con l’interconnessione a vari livelli di più RN semplici51. Le reti neurali possono incontrare difficoltà nell’affrontare problemi particolarmente complessi; nel nostro caso la complessità deriva sia dalla natura del problema (riconoscimento dei caratteri di difficoltà finanziaria delle imprese) sia dall’ampiezza dei casi da trattare. La ricchezza della notevole varietà interna dei casi di apprendimento, mentre da un lato consente di rendere la più realistica possibile la costruzione del modello, dall’altro tende a rendere più difficile l’addestramento delle reti: infatti reti complesse, con numerosi input e molti nodi, sono meglio in grado di distinguere la grande varietà dei casi proposti, ma al costo di rendere proibitivi i tempi (ed i
51 La interconnessione di reti a più livelli è stata recentemente sperimentata anche da Van Bussel-Veelenturf (1997).
X1
X2
A.D. lineare e reti ad uno strato

75
costi) dell’apprendimento; esse inoltre spesso tendono ad assumere comportamenti oscillatori o non convergenti, oltre ad essere spesso vittime della trappola dell’overfitting. Per contro reti più semplificate, con un minor numero di indicatori e di nodi, hanno una maggiore capacità di generalizzazione ma performance complessive più modeste. Una metodologia per affrontare questi problemi può consistere nello scomporre la rete complessiva, che la soluzione del problema richiederebbe, in reti più semplici tra loro collegate. Il grafico 14 illustra in termini semplificati l’articolazione delle reti impiegate dalla Centrale dei Bilanci.
Grafico 14. Interconnessione di reti semplici
� � � � � �
� � � � � � Sono state definite otto reti con struttura semplice (con uno strato nascosto ed uno di output), ciascuna specializzata in un ben preciso campo d’analisi economico-finanziaria: Struttura Patrimoniale, Sostenibilità dell’Indebitamento Finanziario, Liquidità, Redditività ed Autofinanziamento, Capacità di Accumulazione dei Profitti Lordi, Sostenibilità del Costo dell’Indebitamento, Efficienza Generale ed Indebitamento Commerciale. Ogni rete elementare è alimentata da un certo numero di indicatori, selezionati tra i più rappresentativi, appartenenti al campo d’analisi cui la rete è dedicata. Ogni rete è strutturata su due livelli: uno strato intermedio
Reti elementari di primo livello
Rete di secondo livello
Red
ditiv
ità
Liq
uidi
tà
Stru
ttura
Fi
nanz
iari
a

76
composto da un numero di neuroni pari al numero di input più uno ed uno strato di output composto da un solo neurone. L’output voluto assegnato a queste reti elementari è il valore binario 0;1 che contraddistingue le imprese sane e quelle anomale. Detto in altri termini, le singole reti elementari sono state addestrate a distinguere le società sane da quelle anomale basandosi su un’unica fonte specializzata di informazioni, sia pure con diversi segnali: è come se l’analista finanziairo per esprimere la propria diagnosi adottasse un’unica chiave di analisi della società. La rete di secondo livello ha il compito di coordinare i risultati delle otto reti elementari e di generare la risposta finale del sistema: questa rete riceve in ingresso gli output numerici delle otto reti elementari. Anche la rete di secondo livello ha una struttura semplice, con uno strato intermedio ed uno di output. La risposta voluta assegnata alla rete per l’apprendimento è ovviamente ancora il valore binario 0;1. Ciò significa che la rete di secondo livello viene addestrata a sintetizzare, cioè a combinare nel modo più appropriato, le conclusioni raggiunte dalle reti elementari: continuando l’esempio dell’analista finanziario, si può dire che dopo aver esplorato separatamente ben otto criteri di anlisi diversi egli trae le conclusioni considerando congiuntamente le opinioni che si è formato per ciascun criterio. In questo modo si son semplificate drasticamente le complessità di calcolo, spezzando in nove singoli addestramenti l’apprendimento che con le reti complesse è stato condotto globalmente; con tale scomposizione è stato utilizzato un numero di indicatori maggiore, rispetto alle reti integrate, ma è aumentato in misura meno che proporzionale il numero dei pesi da aggiornare nella fase di addestramento. Dal punto di vista dell’analisi dinamica, i risultati migliori sono stati ottenuti con l’utilizzo di reti dotate di memoria: lo schema più semplice di reti di questo genere è quello di comprendere tra gli input i valori ritardati delle variabili: il grafico 15 illustra un esempio di tali reti.

77
Grafico 15. Reti con input in memoria
Gli input di questo tipo di reti comprendono l’intera serie storica (triennale nel nostro caso) degli indicatori. Dal punto di vista della logica economica è come se si tentasse di riprodurre il ragionamento dell’analista finanziario quando esamina contemporaneamente (e non in sequenza) una serie storica di dati economico-finanziari: l’analista si forma la propria opinione sullo stato dell’impresa osservandone l’evoluzione sull’arco dell’intero periodo di tempo disponibile. Dal punto di vista logico le reti dotate di memoria equivalgono a regressioni in cui le variabili esogene compaiono con diversi lag temporali:
2nt3n1nt2nnt1n
2t2231t222t221
2t1131t112t1110
XaXaXa
XaXaXaXaXaXa ay
−−
−−
−−
⋅+⋅+⋅+
⋅+⋅+⋅+⋅+⋅+⋅+=
KKK
K
Input Strato intermedio
Uscita di rete
X1 t-1
X2 t-1
XN t-1
X1 t-2
X2 t-2
XN t-2
X1 t-n
X2 t-n
XN t-n

78
L’uso di reti dotate di memoria è facilitato dalla loro capacità di superare i problemi di multicollinearità. Meno buoni si sono rivelati i risultati delle RN, con due neuroni in uscita, per identificare contemporaneamente tre diversi insiemi di società (sane, anomale, vulnerabili). Se da un lato le RN hanno manifestato notevoli capacità classificatorie, dall'altro esse hanno messo in luce aspetti problematici, alcuni dei quali appaiono cruciali. Un primo aspetto riguarda i tempi di calcolo per la messa a punto della rete. La mancanza di una teoria sulla loro architettura e sulla definizione dei parametri di addestramento rende necessario un approccio gradualistico di prova ed errore per individuare il tipo di rete promettente: si consideri che i risultati migliori sono stati ricavati da reti quasi sempre diverse quanto a complessità, parametri di addestramento ed addirittura esistenza od assenza dei bias. L’esigenza di fare ripetute prove è un altro punto che va tenuto presente per l’utilizzo concreto della metodologia delle reti neurali. Un terzo punto riguarda il problema dell’overfitting, della capacità di generalizzazione della rete. Già abbiamo visto come le reti semplici siano più robuste da questo punto di vista, anche se esse non necessariamente producono performance classificatorie elevate. Conta la complessità della rete, ma conta anche saper arrestare l’addestramento al momento giusto prima di entrare in fasi oscillatorie o contraddittorie del profilo dell’errore e prima che la rete passi dalla estrazione della conoscenza “generale”, quella che serve per avere capacità di generalizzazione, alla acquisizione di conoscenze specifiche dei casi sottoposti per l’addestramento. La mancata di capacità di generalizzazione rende inutile una rete che abbia eccellenti risultati sul campione di stima. Il problema maggiore, dal nostro punto di vista, riguarda l’esistenza di comportamenti non plausibili delle reti. Essi sono intrinseci alla natura non lineare del modello matematico sottostante alle reti, che combina in modo complesso, e più volte, un gran numero di variabili. Tali comportamenti caratterizzano reti di qualunque complessità con almeno due input in ingresso. Le risposte non sono sempre monotoniche a variazioni delle variabili di ingresso che non siano sistematicamente nello stesso verso. L’entità e la frequenza dei comportamenti non logicamente ammissibili (per l’analista finanziario) sono crescenti con l’aumentare della complessità della architettura della rete. Solo reti estremamente semplici limitano la probabilità di incontrare nei casi concreti questi andamenti non accettabili. La costruzione di reti super-semplificate non può però essere una soluzione perchè il problema viene solo spostato in avanti: esso infatti si ripresenta immutato con la necessità di coordinare le reti semplici con altre di livello superiore. In realtà i comportamenti non plausibili che si presentano al variare dei valori degli ingressi sono intimamente collegati ad una parte rilevante degli errori che la rete commette nel riconoscere le società, tanto in sede di addestramento che nei campioni di controllo: variando in modo indipendente, e non nello stesso verso, i valori degli ingressi per riprodurre un caso di errore commesso dalla rete nei campioni, ci si imbatte spesso in uno degli esempi di comportamento implausibile. La capacità di generalizzazione è in altri termini anche capacità della rete di mantenere comportamenti coerenti, dal punto di vista della logica di diagnosi. 8.5 ALGORITMI GENETICI52 Gli Algoritmi Genetici (AG) sono una efficace procedura di ottimizzazione che viene applicata con successo notevole in un'ampia varietà di campi. In realtà più che riferirsi ad un'unica tecnica è più corretto parlare di una vera e propria famiglia di metodi che si ispirano ad un'idea base53.
52 Questo paragrafo sintetizza parte del contenuto di Varetto (1998(a) e 1998 (b)). 53 In questa sede non viene considerato il Genetic Programming, che rappresenta una delle più importanti estensioni dei GA. Per la Programmazione Genetica si rinvia a Koza, 1992.

79
Gli AG sviluppati da J. Holland 54 negli anni '60 e '70, si ispirano nella concezione fondamentale ai meccanismi della evoluzione naturale di tipo darwiniano. La selezione genetica e la riproduzione costituiscono i due processi fondamentali che stanno alla base dell'evoluzione delle specie e del loro adattamento al mondo esterno. La selezione identifica quali elementi di una popolazione sopravvivono per riprodursi e con la riproduzione ha luogo la ricombinazione dei geni. Un terzo processo, la mutazione genetica, introduce ulteriori cambiamenti che intervengono con maggiore rarità sui geni; pertanto il meccanismo della riproduzione con ricombinazione di geni determina un più rapido processo evolutivo rispetto alla semplice mutazione. Il processo selettivo si basa sul principio della adeguatezza dell'individuo alle esigenze imposte dal mondo esterno: non il più forte o il più alto o il più veloce sopravvivono, ma il più adatto. Implicita nel concetto di evoluzione è comunque l'idea di miglioramento progressivo della specie rispetto alle generazioni precedenti. Tra una generazione e quella successiva si producono cambiamenti piccoli, ma quelli favorevoli si cumulano nel tempo, generando, con il passare delle generazioni, cambiamenti grandi. Gli AG riprendono in modo stilizzato questi principi: applicati ad un problema, essi non lavorano su una particolare soluzione ma su popolazioni di soluzioni, facendole evolvere fino a convergere a livelli ritenuti ottimali. L'evoluzione avviene selezionando gli individui migliori di una popolazione e facendoli riprodurre con ricombinazioni dei loro geni in modo da ottenere una nuova popolazione di individui. Ogni individuo può essere visto in sostanza come un'ipotesi di soluzione del problema in esame: l'obiettivo degli AG consiste nel generare popolazioni successive di soluzioni le cui radici (geni) si trovano in quelle delle soluzioni più promettenti della popolazione precedente. Come ricorda D. Goldberg vi sono essenzialmente tre metodi base di ottimizzazione e di ricerca di soluzioni: il metodo analitico, quello enumerativo e quello casuale. Il metodo analitico utilizza le tecniche tipiche dell'analisi matematica per individuare i punti di massimo o di minimo delle ipersuperfici solutive: benché potente e razionalmente ben fondato, tale metodo soffre di alcuni punti deboli, quali la possibilità di farsi intrappolare in ottimi locali anziché globali e la dipendenza dalla esistenza delle derivate (ovvero la possibilità di calcolare i gradienti). Tale metodo quindi non è applicabile a domini in cui siano presenti discontinuità o ipersuperfici complesse. La tecnica enumerativa fa "semplicemente" l'esame di tutte le soluzioni possibili, in uno spazio finito e discreto di ricerca, identificando, alla fine del processo, la migliore. In concreto tuttavia tale metodo si rivela particolarmente oneroso sotto il profilo computazionale e quindi non applicabile per l'elevato numero di soluzioni possibili da prendere in esame. La ricerca casuale tenta di superare i limiti di applicabilità della tecnica enumerativa, ma in generale in processi di una certa lunghezza ed in presenza di spazi ampi di soluzione essi non consentono di pervenire a risultati migliori degli schemi enumerativi. Gli AG combinano procedure di ricerca casuale con tecniche di esplorazione di grande efficacia. Gli operatori fondamentali degli AG sono: a) la selezione e la riproduzione degli individui migliori b) la ricombinazione genetica (crossover) c) la mutazione casuale (mutation) dei cromosomi degli individui La selezione è un'operazione fondamentale che viene compiuta con l'ausilio di una funzione di valutazione dell'adeguatezza degli individui. La semplice duplicazione degli individui selezionati, 54 Per una introduzione generale agli AG si cfr. per tutti Goldberg, 1989.

80
riproducendoli uguali a quelli della popolazione precedente, non comporterebbe nessun beneficio in termini di esplorazione dello spazio delle soluzioni. Nel corso della riproduzione pertanto viene introdotta l'operazione di ricombinazione genetica: i geni di due individui selezionati per la riproduzione vengono scambiati tra di loro in modo da far evolvere la popolazione e consentire l'esplorazione di nuove porzioni di spazio (l'esplorazione avviene partendo dai punti più promettenti già individuati). L'operazione di mutazione, che si aggiunge alla ricombinazione dei geni, avviene con una probabilità molto bassa per non distruggere in profondità il patrimonio genetico accumulato con le precedenti selezioni: eseguita in questo modo la mutazione consente di arricchire la varietà degli individui presenti nella popolazione, evitando che quest'ultima tenda ad essere troppo uniforme e perda così la capacità di evolvere. Prima di descrivere i singoli passi logici che costituiscono una procedura di AG occorre affrontare due aspetti essenziali: la rappresentazione genetica delle soluzioni al problema da risolvere e la definizione della funzione di valutazione (fitness). Poiché gli AG operano su stringhe simboliche è necessario che le soluzioni che si intendono trovare siano rappresentate con un codice in grado di essere manipolato dall'algoritmo. Tale codifica genetica può assumere varie forme: in generale si impiega l'alfabeto binario composto da sequenze di 0 ed 1, ma vi sono casi in cui una codifica con altri simboli facilita l'utilizzo delle stringhe genetiche. Nel caso dell'analisi finanziaria del rischio di insolvenza la Centrale dei Bilanci, come si vedrà più oltre, ha utilizzato la codifica binaria. La funzione di fitness infine è preposta a valutare le prestazioni dei singoli individui che compongono le popolazioni: essa trasforma l'adeguatezza delle soluzioni proposte dagli AG in valori numerici proporzionali alla loro performance. I passi tipici di cui si compone una procedura di AG sono i seguenti: a) si genera casualmente la popolazione iniziale di individui (o genomi); b) per ogni individuo si calcola la fitness rispetto al problema da risolvere (cioè la bontà delle
soluzioni ipotetiche); c) si calcola il grado di omogeneità delle fitness dell'intera popolazione (bias); d) si ordinano gli individui in base alla loro fitness e si selezionano quelli idonei a generare la
successiva popolazione; e) si genera la successiva popolazione in base all'operazione di riproduzione di nuovi individui
partendo da quelli selezionati nella popolazione precedente; f) sulla nuova popolazione viene ripetuta la sequenza a partire dal punto b. La fase di riproduzione fa intervenire diversi operatori e principalmente il crossover e la mutation. Ad esempio si supponga che due individui-padre selezionati in una popolazione per la successiva riproduzione siano i seguenti:
A : 011001 B : 100110
Con il crossover prima si sceglie casua lmente un punto all'interno della stringa genetica nel quale entrambe le stringhe di A e B vengono tagliate e poi si valuta casualmente in base ad una certa probabilità (60-70%) se effettuare o no l'operazione; se la risposta è positiva, si procede allo scambio incrociato dei segmenti di stringa isolati con il taglio. Nell'esempio precedente se casualmente il punto prescelto è a metà delle due stringhe si ha:

81
A : 011 001 B : 100 110 che generano due nuovi individui- figlio: A': 011 110 B': 100 001 A' è il risultato della ricombinazione del primo segmento di stringa di A e del secondo segmento di B; B' è ottenuto ricombinando le stringhe complementari. Con l'operazione di mutation si sceglie casualmente un particolare bit da una stringa genetica anch'essa scelta a caso ed in base ad una certa probabilità (bassa, ad esempio 1/1000) lo si cambia in un altro bit; nell'esempio se era 0 si trasforma in 1 e viceversa. Così l'individuo-figlio B' può essere trasformato in: B*': 100101 ↑ se casualmente il quarto bit è stato assoggettato ad una operazione di mutation. L'operazione di Crossover può essere effettuata con schemi più complessi. La procedura b)- f) viene ripetuta fino a quando la popolazione converge verso individui sempre più omogenei: nell'ipotesi estrema di individui tutti uguali si raggiunge una situazione stabile in cui non si ha più alcuna evoluzione per crossover e le uniche possibilità di nuove esplorazioni sono limitate alle rare modificazioni genetiche. In generale, per arrestare il processo ci si accontenta di raggiungere un certo livello di uniformità (detto bias). La selezione degli individui-padre è di cruciale importanza; uno schema molto usato consiste nel ricorrere ad una specie di ruota di roulette modificata. Dopo aver calcolata la fitness di ogni individuo di una popolazione ed averle ordinate in base al valore numerico, se ne determina il peso relativo sul totale dei valori numerici. Tale percentuale rappresenta una sorta di bontà relativa dell'individuo rispetto agli altri. Con questa informazione viene costruita una ruota di estrazioni casuali degli individui con settori della ruota proporzionali alla loro bontà relativa. In tal modo la selezione degli individui per la riproduzione avviene estraendoli casualmente da una distribuzione di probabilità che favorisce gli individui migliori (più idonei a risolvere il problema in esame) e penalizza quelli con fitness più modesta, secondo il più classico dei principi darwiniani. Un altro schema possibile di selezione consiste nel cancellare da una popolazione un certo numero di individui peggiori sostituendoli con copia degli individui migliori; la riproduzione avviene per scelta casuale nella popolazione così modificata. Tanto più il numero degli individui peggiori eliminati è elevato tanto più si accelera il processo di convergenza genetica della popolazione: in questo modo però si corre il rischio di arrivare ad una convergenza prematura, impedendo l'esplorazione di nuove porzioni dello spazio delle soluzioni possibili. Per questo motivo in alcuni schemi il tasso di convergenza viene gradualmente ridotto col procedere delle popolazioni, oppure viene aumentata la probabilità di mutation.

82
La lezione implicita che si può trarre dagli AG è che anche gli individui di peggiore qualità non sono inutili, nel senso che possono esserci componenti del corredo genetico che si rivelano importanti per la ricerca di soluzioni più efficienti. La Centrale dei Bilanci ha applicato gli AG all’analisi del rischio di insolvenza 55. Gli esperimenti sono stati condotti lungo due linee differenti: la generazione genetica di funzioni lineari e la generazione genetica di score basati su regole.
8.5.1 Generazione genetica di funzioni lineari La funzione genetica lineare assume la forma: GSL = a0 + a1Rn1+a2Rj2+----+anRrn in cui: a0 indica la costante, ai indica il coefficiente i-esimo Rki indica il K-esimo indicatore della i-esima famiglia di indicatori L'algoritmo genetico deve scegliere la costante a0, i coefficienti ai e gli n indicatori tratti dalle n famiglie; l'analista finanziario stabilisce a priori i segni dei coefficienti ai (ma non quello della costante), il numero (n) delle famiglie e la lista degli indicatori appartenenti a ciascuna famiglia. A questo fine gli indicatori calcolati sui campioni di imprese sono stati ripartiti in un certo numero di famiglie. Per ogni indicatore è stato stabilito il segno con il quale deve comparire nella funzione genetica; per omogeneità, le famiglie sono state definite in modo che tutti gli indicatori inclusi abbiano lo stesso segno. La scelta dell'indicatore ottimale per ciascuna famiglia è stata impostata in termini genetici definendo una stringa di lunghezza sufficiente a rappresentare la numerosità degli indicatori. Ad esempio si supponga che una famiglia comprenda 15 indicatori; per rappresentare tale numero è necessaria una stringa di almeno 4 caratteri; infatti nel sistema binario, il numero 15 corrisponde a: 15= 1 1 1 1 Il numero binario: 0= 0 0 0 0 è stato riservato al caso in cui nella funzione genetica ottimale non compaia alcun indicatore di quella famiglia. Pertanto a seconda della stringa genetica generata dall'algoritmo è immediato risalire allo specifico indicatore da usare. Per quanto riguarda la costante ed i coefficienti degli indicatori si è adottato un approccio simile. Com'è noto gli AG maneggiano male i valori continui, mentre non hanno difficoltà con i valori discreti. Pertanto sono stati assegnati degli intervalli di valore alla costante e ciascun intervallo è stato rappresentato da una stringa genetica di lunghezza idonea. Lo stesso procedimento è stato adottato per i coefficienti degli indicatori, con la differenza che il loro intervallo di esistenza parte da zero e comprende solo valori positivi: è infatti il segno definito a priori che stabilisce qual è il valore che accompagna l'indicatore. Lo zero serve ad azzerare l'influenza dell'indicatore nella funzione.
55 Per un’analisi dettagliata dei risultati si rinvia a Varetto (1998 (a)).

83
Pertanto la stringa genetica complessiva è composta da 2·n+1 sottostringhe:
*������* *�������** **������* *������* �����* ����� *������* ���������* cost. a0
a1
Rh1
a2
Rj2
an
Rrn
in cui la lunghezza delle sottostringhe ai è variabile e dipende dal grado più o meno fine con cui se ne vuole esplorare l'intervallo di esistenza, mentre la lunghezza delle sottostringhe Rki dipende dalle numerosità degli indicatori nella famiglia i-esima. Gli operatori genetici di crossover e mutation sono stati applicati alle singole 2·n+1 sottostringhe. La funzione di valutazione è semplicemente il numero delle imprese sane ed anomale correttamente classificate. Ai fini del calcolo della fitness, l'impresa viene considerata sana se il valore della funzione genetica è positivo, mentre è considerata anomala se vale il contrario. Le performances ottenute dalla Centrale dei Bilanci sono estremamente confortanti: ma non ci si deve fermare ad esaminare solo i migliori individui delle due popolazioni finali selezionate dagli AG. Gli AG infatti mettono a disposizione dell’analista finanziario l’intera popolazione di soluzioni e non solo il migliore risultato ottenuto. L’analista dispone quindi di una più vasta informazione rispetto ad altri metodi di stima: infatti esaminando la popolazione finale delle funzioni genetiche è in grado di conoscere molto meglio lo spazio delle soluzioni prossime all’efficienza. Dal punto di vista geometrico la situazione è descrivibile come nel grafico 16, nel caso di funzioni con due indicatori:
Grafico 16. Confronto tra analisi discriminante lineare (AD - 1 funzione) e Funzioni Genetiche Lineari (FGL - popolazione di funzioni )
SANE
ANOMALE
AD _ _ _
FGL______ ______
X1
X2

84
Molte funzioni differiscono tra loro solo per piccole difformità nei coefficienti degli indicatori selezionati, ma molte altre includono effettivamente un set di indicatori diverso, anche solo parzialmente, da quello della funzione ottimale. L’analista finanziario può quindi identificare quali sono gli indicatori con un contenuto altamente espressivo del rischio di insolvenza indipendentemente dal fatto che siano incluse nella funzione ottimale. In altri termini, è come se l’analista finanziario disponesse di un’ampia valutazione di sensitività intorno al punto di ottimo: la sua comprensione dei fenomeni economici e finanziari dell’insolvenza ne risulta così accentuata. Dall’esame dell’intera popolazione di funzioni si possono ricavare tra l’altro le succedaneità tra gli indicatori e le compatibilità tra le diverse tipologie di profili finanziari descritti dai vettori degli indicatori. Questo esame è facilitato dal fatto che tutte le funzioni della popolazione sono economicamente plausibili perché i segni non sono lasciati alla determinazione dell’algoritmo, ma sono gestiti direttamente dall’analista finanziario. 8.5.2 Generazione di Score con regole genetiche
Con il secondo approccio gli AG sono stati impiegati dalla Centrale dei Bilanci per produrre un insieme di regole basate su test riguardanti il segno ed il valore di cut-off degli indicatori selezionati. La struttura delle regole è la seguente56: IF Rh1 > x1 THEN GSR=GSR ± V1 IF Rj2 > x2 THEN GSR=GSR ± V2
•
•
•
•
•
IF Rrn > xn THEN GSR=GSR ± Vn
IF GSR ≥ 0 THEN Impresa = SANA IF GSR < 0 THEN Impresa = ANOMALA La procedura genetica deve individuare le seguenti variabili: a) l'indicatore (Rki) K-esimo della famiglia i-esima b) il segno >< del test c) il valore numerico (xi) rispetto al quale deve essere effettuato il test (><) per l'indicatore (Rki) d) il valore dell'incremento o del decremento da applicare allo score genetico (GSR)57.
56)Si veda anche Kingdon - Feldman (1995). 57 Ovviamente all'inizio dell 'elaborazione di ogni società lo score genetico viene azzerato.

85
Pertanto la stringa genetica è formata da tante (n) sottostringhe, del tipo:
*****��* * **��������* ***����**** Rki indicatore
> <
xi
soglie di test Vi incremento score genetico
quante sono le famiglie di indicatori incorporate nei test. La soglia finale rispetto a cui confrontare lo score genetico è anche in questo caso lo zero. L'estrazione dei valori di xi e Vi segue la stessa tecnica di scomposizione in valori discreti di intervalli preassegnati già adottata nelle funzioni genetiche lineari. La determinazione del segno di Vi invece non viene lasciata all'AG ma è direttamente assegnata dalla connessione tra il segno della famiglia i-esima ed il verso del segno di disequazione del test. La numerosità ed il tipo di famiglie di indicatori sono prefissati dall'esterno . Al termine della sequenza dei test lo score genetico ottenuto corrisponde alla somma algebrica dei singoli score parziali; si osservi che, a differenza delle funzioni lineari in cui il va lore specifico degli indicatori contribuisce proporzionalmente al calcolo dello score complessivo, nel sistema basato sulle regole è rilevante solo sapere se il valore dell'indicatore è superiore od inferiore alla soglia di test; una volta stabilita l'esatta situazione lo score parziale che incrementa o diminuisce lo score totale è indipendente dallo specifico valore dell'indicatore dell'impresa. In questo senso lo score genetico basato su regole è più robusto agli outliers rispetto alle funzioni lineari, anche se per converso è meno sensibile alle differenze delle situazioni delle imprese. Di seguito è riportato un esempio di score calcolato con regole genetiche. ESEMPIO DI SCORE CON REGOLE GENETICHE SE I(cash-flow) > 4,7 THEN GSR = GSR + 2,4 SE I(composizione del debito) < 5,5 THEN GSR = GSR + 0,9 SE I(equilibrio finanziario) > 66,5 THEN GSR = GSR + 0,83 SE I(credito fornitori) < 168 THEN GSR = GSR + 1,87 SE I(liquidità) > 31 THEN GSR= GSR + 1,25 SE I(peso indebitamento) < 6 THEN GSR= GSR + 2,6 SE I(redditività) > -20 THEN GSR= GSR + 0,07 SE I(struttura finanziaria1) (+) < 14 THEN GSR= GSR - 2,9 SE I(struttura finanziaria2) (+) < 13 THEN GSR= GSR - 2,7 SE I(struttura finanziaria3) (-) < 24 THEN GSR= GSR + 2 Una generalizzazione dello schema precedente fa dipendere lo score parziale dal valore dell’indicatore utilizzato; per la generica regola n-esima si ha:
IF Rrn > Xn THEN GSR = GSR ± an.Rrn
L’algoritmo genetico deve in questo caso individuare, al posto di Vn, il valore del coefficiente an, il cui segno è predefinito dall’analista. L’incremento o la diminuzione dello score totale è proporzionale al valore dell’indicatore, solo quando quest’ultimo supera la soglia Xn.

86
Regole più complesse possono scomporre in segment i del campo di esistenza degli indicatori, definendo per ciascun segmento le variazioni più opportune (costanti, proporzionali o altre trasformate) da apportare allo score totale. Anche nel caso di sistemi di regole genetiche i risultati ottenuti dalla Centrale dei Bilanci sono confortanti. Nelle regole genetiche valgono gli stessi vantaggi visti a proposito delle funzioni genetiche lineari. L'analista finanziario, in questo caso, ha a disposizione un'intera popolazione di sistemi di regole, il migliore dei quali ha una performance di ottimo livello. Dall'esame dell'intera popolazione, l'analista è in grado di comprendere il ruolo più o meno cruciale giocato dai diversi indicatori nella struttura delle regole: le combinazioni che compaiono più di frequente identificano le variabili più efficaci nel catturare componenti del rischio di insolvenza. La differenza essenziale del sistema di regole rispetto alle funzioni lineari consiste nel diverso modo di suddividere gli insiemi di società nello spazio delle soluzioni. Mentre l'analisi discriminante lineare e le funzioni genetiche lineari generano nello spazio iperpiani continui, i sistemi di regole generano ipersuperfici composte da iperpiani uniti tra loro lungo spigoli angolati. Le ipersuperfici hanno la caratteristica notevole di essere monotoniche rispetto alla direzione dell'effetto economico degli indicatori sul rischio di insolvenza: è la gestione dei segni esterna alla procedura degli AG a generare tale comportamento geometrico delle ipersuperfici. La migliore o peggiore capacità di classificazione dei sistemi di regole genetiche rispetto alle funzioni lineari dipende dalla forma della dispersione degli insiemi delle società sane ed anomale nello spazio. I sistemi di regole risultano favoriti nei casi in cui gli insiemi di imprese si dispongano in blocchi distanziati tra di loro a diversi livelli di altezza e di profondità, mentre distribuzioni diffuse e sfumate tendono a favorire l'impiego delle funzioni lineari. Rispetto all’Analisi Discriminante gli Algoritmi Genetici consentono di ottenere funzioni lineari ottimizzate che non dipendono da ipotesi statistiche restrittive sulla normalità delle distribuzioni degli indicatori o sull’uguaglianza della matrice di varianze/covarianze. In particolare con gli Algoritmi Genetici è possibile gestire i segni dei coefficienti degli indicatori che entrano nella funzione, in modo da assicurare la razionalità economica del modello. Questa possibilità rappresenta un notevole vantaggio degli Algoritmi Genetici. Implicita negli Algoritmi Genetici vi è inoltre la capacità di esplorare in modo efficiente ampie porzioni dello spazio delle soluzioni possibili. Questa capacità insieme alla gestione dei segni dei coefficienti consente all’analista di sondare in profondità modelli che rappresentano possibili soluzioni al problema, essendo sicuro della tenuta logica dei modelli stessi sotto il profilo della loro interpretazione economica. Il secondo utilizzo sperimentale degli Algoritmi Genetici ha illustrato come sia possibile organizzare la diagnosi delle imprese sotto forma di test con valori soglia di un certo numero di indicatori ed ottenere come risultato uno score numerico continuo : anche questo rappresenta un vantaggio degli Algoritmi Genetici rispetto ad altre tecniche, come gli Alberi Decisionali, nelle quali il risultato dei test conduce ad una risposta di tipo dicotomico (SI/NO; sana/anomala). Lo score continuo generato da una batteria di test consente di rendere flessibili le funzioni lineari e di migliorare la loro capacità di separazione delle società. Non vi è un collegamento tra funzioni lineari genetiche e funzioni discriminanti lineari; infatti se si stimano funzioni discriminanti con gli indicatori che compongono la migliore funzione genetica si ottengono valori diversi sia della costante che dei coefficienti ; inoltre un certo numero di coefficienti calcolati dalla discriminante hanno segno diverso (e quindi economicamente errato) da quelli imposti alla funzione genetica. Solo se le funzioni comprendono pochi indicatori è più

87
probabile mantenere la concordanza dei segni; con un numero elevato di indicatori vi è un'elevata probabilità di incontrare indicatori fra loro correlati, con perdita di segno di quelli più deboli (con minore efficacia informativa). Ciò significa che mentre viene accettata come geneticamente ottimale una certa composizione di indicatori, gli stessi indicatori possono condurre ad una funzione discriminante che verrebbe rifiutata per incongruenza economica di alcuni segni dei coefficienti.

88
9) MODELLI AGGREGATI L’analisi dell’insolvenza delle imprese è stata esaminata dagli studiosi prevalentemente a livello microeconomico, dato il notevole interesse pratico a mettere a punto strumenti per la previsione dello stato di difficoltà delle imprese. Più rari e sporadici sono state le ricerche sui modelli aggregati di insolvenza. I modelli aggregati prendono in considerazione il fenomeno complessivo dei fallimenti per comparti settoriali o per l’intera economia ed hanno lo scopo sia di valutare l’entità della severità dei cicli recessivi ed i loro effetti sulla popolazione delle imprese, sia di individuare le variabili macroeconomiche che maggiormente influiscono sulla dinamica dei fallimenti e di qui ricavare elementi per la definizione della politica economica. Questa prospettiva non va ovviamente confusa con l’inserimento di variabili settoriali o macroeconomiche nei modelli di previsione microeconomica delle insolvenze: come abbiamo visto in paragrafi precedenti, tale integrazione ha lo scopo di migliorare la capacità diagnostica dei modelli micro, inserendo elementi dinamici che dipendono dallo stato dell’economia generale o dello specifico settore. Altman (1981) ha esaminato l’influenza di variabili macroeconomiche sulla dinamica dei fallimenti; questi ultimi hanno riguardato l’intera economia e sono misurati in termini di numero di imprese fallite per 10.000 imprese osservate negli archivi di Dun & Bradstreet. Le variabili macroeconomiche considerate sono la crescita economica generale in termini reali, la disponibilità di credito nell’economia, le attese degli investitori (misurate dall’andamento generale delle quotazioni del mercato azionario), la dinamica demografica della formazione di nuove imprese ed il tasso di inflazione. L’analisi congiunta di queste variabili tratteggia un quadro di riferimento semplice e plausibile dei meccanismi dello stato di difficoltà delle imprese: la crescita economica ha un effetto diretto sul livello delle vendite delle imprese e sulla diffusione, via effetti moltiplicativi, della crescita stessa tra i settori e tra le imprese; per contro il ciclo recessivo induce degli effetti-stress sui ricavi delle imprese e, quindi, sui loro flussi di cassa, tali che se si innestano su condizioni finanziarie già fragili possono generare nelle società l’avvio di spirali negative che le possono condurre all’insolvenza ed al fallimento; la stessa crescita dei fallimenti può determinare un aggravamento del ciclo recessivo, tramite la caduta del livello di attività provocato dalla diminuzione dei ricavi delle società in crisi; lo stato di difficoltà economica causato da riduzione dei ricavi fatalmente si traduce, presto o tardi, in difficoltà finanziarie, più o meno gravi a seconda della situazione di partenza dell’impresa e del livello di indebitamento già accumulato; se la disponibilità di credito è abbondante ed il suo costo modesto, l’impresa può essere in grado di gestire la crisi e di superare lo stato di difficoltà, integrando con risorse esterne la caduta dei flussi di cassa interni; anche l’inflazione, se è incorporata solo parzialmente nei tassi di interesse, può aiutare l’impresa sotto certi aspetti, consentendole di ripagare i debiti con moneta di peggiore qualità. Se invece i tassi di interesse sono alti, la pressione degli oneri finanziari sul conto economico può farsi insostenibile (soprattutto con debiti elevati); se, inoltre, la disponibilità di credito è limitata, e l’accesso ad emissioni azionarie reso improponibile a causa delle prospettive poco incoraggianti in cui versa l’impresa, la crisi può rapidamente evolvere in modo irreversibile; le imprese in difficoltà subiscono, in quest’ottica, l’effetto di razionamenti sia azionari che creditizi. Il fenomeno del fallimento, è un’osservazione nota, colpisce in misura relativamente maggiore le società con pochi anni di vita: difficoltà a far decollare i progetti di investimento, accumulazione ancora scarsa di risorse, mancanza di una consolidata esperienza di affari, maggiore fragilità ai

89
cambiamenti del ciclo sono tutti elementi che rendono più rischiose le imprese con 2-3 e fino a 5 anni circa di età; oltre quel periodo il tasso di fallimento si riduce: le imprese che sono stati capaci di sopravvivere alle difficoltà dei primi stadi di esistenza, che si sono sufficientemente irrobustite, accumulando risorse ed esperienza ed allargando le proprie dimensioni, hanno una probabilità di fallimento che si riduce col tempo. L’andamento complessivo dei fallimenti quindi è plausibilmente connesso con la demografia delle nuove nate nella popolazione delle imprese (l’intensità delle nuove costituzioni precede temporalmente l’intensità delle uscite per fallimenti)58. I risultati di Altman hanno messo in luce una dipendenza significativa dei fallimenti dalla crescita economica reale, dalla performance del mercato azionario, dalla crescita dell’offerta di moneta (proxy delle condizioni del mercato del credito) e dall’incremento della formazione di nuove imprese. Marco-Rainelli (1986) hanno stimato sull’economia francese un modello simile a quello di Altman. Platt (1989) ha esaminato l’andamento dei fallimenti a livello settoriale per l’economia americana: il suo modello ha preso in considerazione non solo variabili aggregate di settore e del mercato finanziario e creditizio, ma anche variabili economico-finanziarie tratte da dati di bilancio aggregati di settore; l’autore ha inoltre opportunamente considerato gli effetti di correlazione settoriale tra i tassi di fallimento, da cui sono emerse significative connessioni degli stati di difficoltà tra settori integrati verticalmente. Le connessioni tra i tassi di insolvenza settoriale sono stati studiati anche da Levy-Cheung-Chowdhury-Harvie (1995), nell'ottica di approfondire una sorta di effetto “diffusione del contagio” tra i diversi comparti dell’economia. Platt-Platt (1994(a)) hanno esaminato i tassi di fallimento per singolo Stato all’interno degli USA, identificando quattro sottoinsiemi di Stati all’interno dei quali vi è omogeneità delle condizioni che determinano la crisi delle imprese. Melicher-Hearth (1988) hanno approfondito le connessioni tra le insolvenze aggregate e le condizioni del mercato finanziario e creditizio. Takala-Viren (1996), in un’analisi sui determinanti macroeconomici dei fallimenti in Finlandia, hanno messo in luce l’influenza di questi ultimi sul tasso di crescita degli impieghi bancari. Hudson (1992) ha studiato la dinamica dell’ammontare del passivo medio delle società fallite, modellando la composizione del numero delle fallite tra grandi e piccole e medie imprese per separare gli effetti del cambiamento del mix dimensionale delle imprese sulla crescita del passivo medio delle società insolventi. Levy-Barniv (1987) hanno sviluppato un modello teorico delle relazioni tra fallimenti e variabili macroeconomiche, tra le quali le variazioni del Prodotto Lordo Nazionale e l’inflazione giocano un ruolo cruciale. Wilson (1997) ha utilizzato modelli logit aggregati di previsione delle insolvenze per settori e paesi per generare le evoluzioni prospettiche delle matrici di transizione delle probabilità di insolvenza per classi di rating: le caratteristiche di questo approccio sono illustrate più diffusamente in questo libro, nel capitolo curato da Marcella Bellucci. Goudie (1987) e Goudie-Meeks (1991) hanno integrato un modello macro-settoriale dell’economia inglese (il Cambridge Multisectoral Dynamic Model) con un modello di previsione delle insolvenze basato sull’analisi discriminante lineare: i risultati delle proiezioni macroeconomiche-settoriali vengono utilizzati per generare previsioni delle variabili economico-finanziarie a livello d’impresa; queste ultime rappresentano l’input della funzione discriminante e consentono di ottenere la previsione di insolvenza dell’impresa a vari periodi di distanza. 58 Sono, in quest’ottica, razionali le politiche governative di sostegno alle nuove innovative imprenditoriali per aiutarle a superare le difficoltà dei primi anni di vita.

90
L’applicazione sistematica dei due modelli macro-settoriale e discriminante-microeconomico all’intera popolazione delle imprese ha permesso di stimare, per vari scenari economici, la frequenza delle società che potrebbero entrare in crisi. Il punto più delicato di questa integrazione macro-micro risiede nella generazione delle variabili a livello d’impresa a partire dallo scenario macroeconomico (o settoriale) simulato: non a caso Goudie e Meeks hanno limitato i loro esperimenti alle grandi imprese, la cui quota sui dati aggregati di settore è rilevante e per le quali ha senso la trasposizione proposta dai due studiosi. Essi sono pervenuti ad una stima del comportamento complessivo del rischio di fallimento non con un modello macro di insolvenza ma dalla ricostruzione degli andamenti aggregati a partire dai dati delle singole imprese; gli scenari simulati di queste ultime incorporano le previsioni del modello macroeconomico. L’approccio aggregato all’analisi delle insolvenze, come si vede, ha varie finalità e può rivelarsi di estrema utilità. Rientrano tra queste, oltre a quelle illustrate in precedenza, la valutazione della componente sistematica del rischio di credito, la stima delle future probabilità a priori di rischio, l’analisi delle correlazioni per segmento paese/settore/area geografica/tipo di controparte (cioè per classi di controparti). L’analisi della componente sistematica rileva non solo per l’individuazione dei fattori generali che influenzano il rischio di intere aree o settori e di quelli specifici, connessi a fatti o comportamenti individuali d’impresa ma anche per l’utilizzo di questa conoscenza ai fini della valutazione del portafoglio crediti, della sua pianificazione nell’ambito delle strategie bancarie e del pricing delle operazioni finanziarie. Un’analisi della componente sistematica del rischio di credito è stata condotta dall’Associazione Nazionale fra le Banche Popolari (1996). L’analisi del fenomeno di diffusione del contagio, ovvero della propagazione dello stato di difficoltà tra le imprese e tra i settori è in parte connessa allo studio della componente sistematica del rischio di credito ed alle correlazioni per classi di controparti. La previsione dei fallimenti e delle insolvenze aggregate consente inoltre di formulare delle stime sulle future probabilità a priori della ripartizione della popolazione delle imprese tra società sane ed anomale: tali stime possono di conseguenza costituire l’input per l’uso decisionale dei modelli micro di previsione delle insolvenze individuali.

91
10) DAGLI SCORE ALLE PROBABILITA’ Le metodologie esaminate nelle sezioni precedenti assegnano alle imprese uno score, una probabilità derivata dallo schema teorico assunto implicitamente (come ad esempio nel caso di logit e probit), oppure una classe di appartenenza. Una volta ottenuti i risultati dai modelli di previsione delle insolvenze può essere opportuno tradurli in probabilità di insolvenza, specie nel caso in cui esse costituiscono la base per successive valutazioni di pricing del rischio di credito, del capitale a rischio assorbito dalle operazioni di credito, degli accantonamenti da iscrivere a bilancio sul portafoglio degli impieghi. In linea teorica vi sono diverse metodologie per derivare la stima delle probabilità di insolvenza, tra cui: a) valutazione per via analitica b) valutazione per via statistica c) valutazione dei tassi di mortalità d) valutazione MonteCarlo di scenari e) valutazione basata sui tassi di interesse di mercato f) valutazione basata sui prezzi azionari Non vengono qui considerate le problematiche della valutazione delle probabilità congiunte di insolvenze di più imprese contemporaneamente, nè le correlazioni tra le probabilità di insolvenza individuali o/e settoriali, nè la valutazione delle probabilità inattese di insolvenza; per la discussione di questi aspetti, anche in un’ottica di portafoglio, si rinvia al capitolo curato da M. Bellucci. La deduzione della probabilità di insolvenza sulla base della simulazione con metodi Monte Carlo di scenari aziendali (o settoriali) non viene discussa in questa sede: questo approccio, che richiede la formulazione di un modello di funzionamento specifico per l’impresa (o il settore), può essere applicato indipendentemente dall’impiego di metodologie di previsione delle insolvenze viste nelle sezioni precedenti. Si rinvia al capitolo di Marcella Bellucci anche per le valutazioni derivate dai tassi di interesse di mercato o dai prezzi azionari (o una loro stima effettuata a partire dai dati contabili) secondo l’approccio adottato da KMV. La determinazione delle probabilità di insolvenza per via analitica si basa sullo schema teorico implicito nel modello di previsione utilizzato: in questa sede ci si concentrerà esclusivamente sulle funzioni discriminanti lineari e sulla regressione logistica. Come si è visto in precedenza, adottando le ipotesi implicite che reggono le funzioni discriminanti lineari, la probabilità a posteriori di appartenenza all’insieme delle società anomale è data da, applicando il teorema di Bayes:
)X(p
q)AX(p)XA(p A⋅
=
ove X = vettore di variabili rilevanti per la previsione
p(A|X) = probabilità a posteriori di essere anomala qA = probabilità a priori di essere anomala p(X|A) = funzione di densità multivariata normale per le anomale e poiché p(X) = qA p(X|A) + qS p(X|S),

92
ove p(S|X) = probabilità a posteriori di essere sana qS = probabilità a priori di essere sana p(X|S) = funzione di densità multivariata normale per le sane si ha:
)SX(pq)AX(pqq)AX(p
)XA(pSA
A
⋅+⋅⋅
==
Nell’ipotesi in cui le distribuzioni di probabilità siano normali multivariate si possono sostituire le p(X|A) e p(X|S) con le espressioni in X derivate dalle funzioni discriminanti, ottenendo la semplificazione seguente59
bXae11
)XA(p++
=
e bXa
bXa
e1e
)XS(p+
+
+=
ove )xx(V)xx(21
lna AS1
ASA
S +⋅⋅′−⋅−
= −
variabilidelle medie delle vettorex
variabilidelle covarianze e varianzedelle matriceV)xx(Vb AS
1
==
−⋅= −
In sostanza l’esponente non è altro che lo score lineare calcolato correggendo l’intercetta per le probabilità a priori. Nel caso della regressione logistica, se la composizione dei campioni di stima rispetta quella delle popolazioni dell’universo, il calcolo della funzione fornisce direttamente la probabilità di insolvenza:
)X(e1
1p
β+α−+=
Se invece la composizione dei campioni di stima non rispetta quella delle popolazioni, occorre introdurre degli aggiustamenti. Tuttavia la funzione di verosimiglianza, data da
ii L1i
N
1i
Li )p1(p −
=
−⋅∏
in cui: N=NA+NS numerosità del campione Li = 0 per le sane = 1 per le anomale dipende esplicitamente dalla numerosità relativa dei campioni. Pertanto la stima delle probabilità a posteriori logistiche richiede la correzione dell’esponente per tenere conto non solo delle probabilità a priori, ma anche della composizione dei campioni (Maddala (1983); Bardos-Zhu (1998)):
59 Per le derivazione si veda, per tutti, Maddala (1983) o Altman-Avery-Eisenbeis -Sinkey (1981).

93
X)ßa(e
p+−+
=1
1
ove: S
A
A
S
qqln
NNlnaa ++=
Se le ipotesi metodologiche che sono alla base del modello discriminante, in particolare sulla normalità multivariata delle distribuzioni, non sono verificate, la probabilità a posteriori può essere stimata per via statistica, ricorrendo alle distribuzioni condizionali empiriche, calcolate su tutte le società disponibili. Il campo di esistenza dello score è ripartito in intervalli, all’interno dei quali sono misurate le numerosità delle società sane ed anomale; le probabilità a posteriori sono quindi calcolate, applicando il teorema di Bayes, come probabilità che l’impresa sia anomala (o sana) condizionata al fatto che lo score (Z) appartiene ad un centro intervallo (H):
)HZ(p
q)AHZ(p)HZA(p A
∈
⋅∈=∈
ove H = intervallo del campo di esistenza dello score Z e )SHZ(pq)AHZ(pq)HZ(p SA ∈⋅+∈⋅=∈
Questo approccio può essere applicato anche alla stima di probabilità a posteriori nelle regressioni logistiche: peraltro esso può condurre a stime molto diverse da quelle ottenute per via analitica dalla funzione logistica (Bardos-Zhu (1998)). Lo stesso approccio è proponibile non solo per altre tecniche di previsione che generano uno score o un ordinamento ma anche per gli alberi decisionali, in cui invece delle regioni dello score ci si riferisce alle foglie finali dell’albero. La valutazione delle probabilità di insolvenza può infine essere stimata ricorrendo alla costruzione di tassi di mortalità (o equivalenti statistici). I dettagli di questo approccio ed il suo utilizzo ai fini della valutazione del capitale a rischio sono discussi nel capitolo curato da M. Bellucci e quindi sono sufficienti pochi cenni in questa sede. I tassi di mortalità possono essere calcolati con diversi criteri, a seconda delle differenti definizioni del concetto di insolvenza e delle basi di riferimento60. Una possibilità consiste nel valutare i tassi di insolvenza misurando su un insieme di prestiti obbligazionari l’ammontare dei prestiti andati insoluti rispetto all’ammontare dei prestiti complessivi sotto osservazione; in alternativa, la misura dei tassi di insolvenza può essere calcolata rispetto alla numerosità dei prestiti insoluti invece che rispetto al valore monetario. Un approccio ormai standard, seguito con alcune varianti dalle società di rating, è costituito dalla rilevazione del numero (o del valore) dei prestiti insoluti per classe di rating: l’osservazione prolungata nel tempo consente non solo l’analisi delle probabilità cumulate di insolvenza ma anche la valutazione della variabilità seriale delle probabilità stesse; tale variabilità può rappresentare la base empirica per la stima della componente inattesa della probabilità di insolvenza. Gli stessi principi possono essere applicati ad una popolazione di prestiti bancari e, più in generale, ad una popolazione di imprese classificate per categorie di rating: l’osservazione delle imprese può
60 Per una discussione di questi problemi si veda, per tutti, Caouette e altri (1998)

94
essere riferita ad una popolazione chiusa rispetto ad un anno base oppure ad una popolazione a base mobile.
11) BREVI CONCLUSIONI In questo capitolo sono state prese in considerazione varie metodologie utilizzate per la stima del rischio individuale di insolvenza. I metodi statistici di ispirazione parametrica, analisi discriminante e regressione logistica sopra tutti, sono quelli che hanno avuto le applicazioni più numerose, nei più vari contesti e con il maggior numero di varianti e di aggiustamenti ai modelli base: su di essi, in particolare, è stata accumulata una consistente esperienza, che consente di soppesarne appieno i pregi e le debolezze e di valutare i contesti nei quali essi danno i risultati più attendibili. I metodi statistici non parametrici possono rivelarsi vantaggiosi quando la forma delle distribuzioni delle variabili è molto diversa da quella ipotizzata dai modelli parametrici – base. Gli altri approcci, pur interessanti e con risultati promettenti, sono stati adottati finora in un numero di ricerche complessivamente limitato. Ciò non consente, ad avviso di chi scrive, una chiara valutazione del loro contributo addizionale, rispetto alle metodologie più tradizionali. La survival analysis, in particolare, rappresenta un punto di vista di notevole interesse, che merita di essere approfondita con nuove ricerche ed applicazioni. L’intelligenza artificiale, che più che mai si rivela un campo di studi tra i più fecondi, mette continuamente a disposizione nuovi approcci e nuove metodologie. In questa sede ne sono state esaminate solo alcune: tutte quante hanno messo in luce peculiarità di notevole interesse e determinato risultati complessivamente interessanti. L’induzione automatica di regole di classificazione, ed il machine learning in senso più ampio, abbina i vantaggi della esplicazione dei criteri usati nelle specifiche attribuzioni delle società con una significativa capacità diagnostica e con basi teoriche non parametriche. La grande flessibilità e capacità di adattamento delle reti neurali ne rappresentano un indubbio e consistente vantaggio ma la loro mancanza di trasparenza ne costituisce, al momento, una seria limitazione che può condizionarne la concreta applicazione nel contesto creditizio. E’ possibile che l’integrazione tra metodi statistici e tecniche di intelligenza artificiale si affermino in futuro come nuovo paradigma di riferimento in questo campo, facilitato dalla crescente disponibilità di banche dati di ampie dimensioni. E’ tuttavia sulla base teorica del processo che conduce all’insolvenza che occorre investire risorse. Solo una migliore comprensione delle condizioni originarie e dei percorsi di crisi può far fare un salto effettivo di qualità alle metodologie di previsione delle insolvenze. L’individuazione di cluster omogenei, anche dal punto di vista della dinamica temporale, all’interno dell’insieme delle società anomale rappresenta un primo indispensabile passo; poichè, inoltre, i dati economico-finanziari sono lungi da offrire un quadro completo della situazione delle imprese, è necessario che i bilanci societari e le loro previsioni siano accompagnati da informazioni sugli altri aspetti della gestione aziendale.

95
APPENDICE I: Methodological Comparisons between most recent discriminant models - Comité Européen Des Centrales des Bilans
AUSTRIA FRANCE GERMANY ITALY U.K. AUTHOR OeNB BANQUE DE
FRANCE DEUTSCHE
BUNDESBANK CENTRALE
DEI BILANCI BANK OF
ENGLAND CENTRALE DE
BILANS
YEAR OF REALIZATION 1995 1995 1992 1997 1988
N. OF RELEASE 1st 1st of 3rd model 5th 3rd
TECHNIQUE LDA LDA (compared LDA LDA LDA
with LOGIT)
SAMPLE 103F,103G BASE SAMPLE: 677F, 677G 1920F, 19204G 30F, 61G (F=failed; G=good) F=3000; G=5000 &1885
VULNERABLE
TEST SAMPLE: F=3000; G=27000(a)
YEARS CONSIDERED IN 1976-1994 1989 TO 1993 G: 1990; F: 1987-90 1982-1995 THE SAMPLE (insolv. in 1990-92)
YEAR OF ESTIMATE T-3,T-2,T-1 T-1,T-2 AND T-3 T-3
(GATHERED)
PERFORMANCE (%) F:86.1 G:70.9 F: 69.1 - 79.6 F: 90.1, G: 88.4 90.10F; 93.28G(e) 96.7 (estimation sample) G: 72.0 - 74.4(b) 98.33 F; 95.10 G
T-1
N. OF RATIOS (main function): 5 7(c) 3 10 5 LIQUIDITY & WORK.CAPITAL 1 3 4 PROFITABILITY & CASH FLOW 1 2 3 1 FINANCIAL STRUCTURE & DEBT 3 1 4 ACTIVITY SIZE
QUALITATIVE VARIABLES NO NO NO NO NO
SECTORS:
INDUSTRY X(d) X(f) CONSTRUCTION COMMERCE OTHER ALL SECTORS X X
LEGAL FORM
LIMITED RESP. CO' X X X X X PARTNERSHIP, INDIVIDUAL CO' X X
(a) 154,056 OBSERVATIOS (e) PERFORMANCE ON FAILED/VULNERABLES: 54.01F, 74.54V IN T-3; 78.36F, 71.09V IN T-1 (b) DEPENDING OF THE SAMPLE (c) DETAILS NOT AVAILABLE (d) FOR CONSTRUCTION IT EXIST ANOTHER SCORE, THE SCORE "B" CREATED IN 1989 (f) OTHER MODELS FOR COMPANIES WITH ANNUAL REPORTS IN SIMPLIFIED FORM, FOR CONSTRUCTION AND COMMERCE ARE AVAILABLES

96
APPENDICE II: Il Sistema di Diagnosi dei Rischi di Insolvenza della Centrale dei Bilanci La Centrale dei Bilanci ha avviato fin dal 1988 un progetto permanente destinato all’avanzamento delle tecniche di valutazione dei rischi di credito, orientato a mettere a disposizione delle banche aderenti al proprio Sistema Informativo Economico-Finanziario un sistema per l’individuazione precoce della possibilità di insolvenza delle imprese. Il sistema, basato sull’analisi discriminante lineare, è stato aggiornato nel corso del 1997, giungendo alla 3a release : l’aggiornamento delle funzioni discriminanti viene effettuato periodicamente allo scopo di tenere conto dei cambiamenti strutturali del ciclo economico e di mantenere la capacità diagnostica del sistema. Il sistema è composto da insiemi articolati di funzioni specifiche per le imprese industriali, per quelle commerciali e per quelle di costruzioni; le funzioni per i comparti settoriali rimanenti e per le società di persone sono in corso di completamento. Inoltre i bilanci ordinari e quelli in forma abbreviata (predisposti dalle piccole società, con un insieme limitato di informazioni) sono trattati separatamente con funzioni distinte. Sono pertanto sei i sottosistemi che compongono il sistema complessivo. Le funzioni sono applicate anche ai bilanci consolidati. Ciascun sottosistema è costituito da due funzioni lineari operanti in sequenza : la prima funzione (F1) permette di distinguere tra imprese sane e imprese non sane (vulnerabili o anomale) ; la seconda interviene quando la F1 ha diagnosticato come non sana l’impresa esaminata e consente di separare le imprese effettivamente anomale da quelle solo vulnerabili. Il grafico17 riporta lo schema logico dell’articolazione delle due funzioni.
Grafico 17. Schema logico del sistema di diagnosi della Centrale dei Bilanci
Le formule esatte delle funzioni sono strettamente confidenziali e non sono rivelate al di fuori della Centrale dei Bilanci. Per facilitare quindi l’interpretazione dei risultati del sistema, la Centrale ha aggiunto alla coppia di funzioni base altre sei funzioni parziali (stimate con la stessa tecnica discriminante lineare su sottoinsiemi omogenei di indicatori) espressive delle più importanti aree di analisi economico-finanziaria :
1) struttura finanziaria 2) equilibrio finanziario 3) liquidità 4) accumulazione dei profitti 5) redditività e cash flow
1 F
IMPRESA SANA IMPRESA VULNERABILE O ANOMALA
IMPRESA VULNERABILE
IMPRESA ANOMALA
F1
F2

97
6) sostenibilità degli oneri finanziari Tutte queste funzioni parziali sono centrate rispetto allo zero e sono ordinate nello stesso senso, ai fini della intepretazione. La lettura complessiva delle sei funzioni parziali consente all’analista di individuare rapidamente gli elementi di difficoltà dell’impresa e di comprendere il significato della diagnosi delle due funzioni principali. Tutte le funzioni, comprese le sei funzioni parziali, sono stimate al tempo t-3 rispetto all’anno di interruzione della serie storica dei bilanci per cause di insolvenza. La scelta del periodo t-3 è stata effettuata allo scopo di accrescere la capacità anticipatrice delle diagnosi. La definizione di imprese anomale comprende non solo società dichiarate fallite ma anche imprese che sono state considerate insolventi da parte delle banche azioniste della Centrale dei Bilanci (crediti bancari definiti “in sofferenza”). Le imprese sane sono invece definite come quelle in condizioni “normali” di gestione, ottenute escludendo dalle società in vita quelle caratterizzate da situazioni economico-finanziarie in parte compromesse (in base a variabili diverse da quelle utilizzate nelle stime) ; queste ultime appartengono all’insieme delle società “vulnerabili”. Le funzioni sono state selezionate al termine di un lungo lavoro di preparazione dei dati e di elaborazione, nel corso del quale sono state stimate parecchie versioni di entrambe le funzioni: in quest’ambito sono state eliminate tutte quelle che contenevano coefficienti con segni non plausibili (pur se statisticamente significativi) alla luce delle conoscenze sui meccanismi economico-finanziari del processo di crisi delle imprese industriali; tra quelle rimaste sono state eliminate quelle con componenti instabili, considerando solo quelle che accrescevano nel tempo la capacità classificatoria delle imprese anomale e mantenevano (o aumentavano) quella relativa alle imprese sane. A parità di condizioni sono state selezionate le funzioni che rendono minimo l’errore di considerare sana un’impresa in realtà anomala. Per un migliore utilizzo dei risultati del sistema i punteggi combinati della F1 e F2 sono trasformati in nove Categorie di Rischio crescente :
1= Sicurezza elevata 2= Sicurezza 3= Ampia solvibilità 4= Solvibilità 5= Vulnerabilità 6= Vulnerabilità elevata 7= Rischio 8= Rischio elevato 9= Rischio molto elevato
Ciascuna impresa esaminata quindi viene classificata in una delle categorie di rischio, con motivazioni illustrate dai sei punteggi parziali. Il Sistema è distribuito su mainframe e su PC. In quest’ultima versione, per agevolare la lettura dei risultati, i punteggi delle funzioni sono riprodotti su grafici nei quali l’impresa esaminata viene collocata su due diversi sistemi di riferimento: 1) un sistema fisso, i cui assi rappresentano le diverse aree in cui sono separati i campi di
esistenza delle funzioni;

98
2) un sistema mobile rappresentato dalla mediana e dai quartili degli score osservati sulle imprese appartenenti allo stesso settore della società esaminata; questo secondo sistema consente di collocare l’impresa nel proprio mercato e di coglierne l’evoluzione relativa rispetto alle società di confronto.
I grafici successivi riproducono un esempio di società insolvente.
Grafico 18. F1 ed F2 e rating di una società insolvente

99
Grafico 19. Valutazioni parziali di riepilogo
Al momento in cui queste pagine sono scritte il Sistema di Diagnosi della Centrale dei Bilanci è adottato da 25 tra le maggiori banche italiane. Il Sistema di Diagnosi è una delle componenti di un più vasto Sistema di Valutazione dei Rischi di Credito della Centrale dei Bilanci la cui articolazione è sinteticamente riportata nel grafico 20.

100
Grafico 20. Sistema di valutazione dei Rischi di Credito - Centrale dei Bilanci
Il Sistema di Diagnosi è collegato con un Sistema Esperto che illustra gli aspetti essenziali della situazione economico-finanziaria dell’impresa e della sua evoluzione. Un apposito modulo di analisi qualitativa consente di completare l’analisi del bilancio della società (o del bilancio consolidato del gruppo), pervenendo ad una diagnosi complessiva, con l’assegnazione della società ad una Categoria di Rischio d’Impresa: il passaggio dalla Categoria di Rischio di Bilancio alla Categoria di Rischio d’Impresa è illustrato da un modulo esperto che opera su dati qualitativi.
Modulo Analisi Portafoglio Crediti
Modulo Valutazione Rischio ♦ Capitale assorbito ♦ Pricing del rischio
Sistema Rilevazione Controllo e Riclassificazione dei Bilanci
Sistema Diagnosi Rischi di Insolvenza
Score
Classe di Rischio (Rating di Bilancio)
Sistema Simulazione Scenari Economico Finanziari d'impresa
Sistema Esperto Analisi di Bilancio
Modulo Analisi Qualitativa
Sistema Esperto Qualitativo Score Qualitativo
Diagnosi Economico Finanziaria
Schede di Analisi e Previsioni Microsettoriali (in collaborazione)
Rating di impresa e
Diagnosi aspetti qualitativi della gestione
Modulo Analisi Dati CR Modulo Analisi Relazioni Banca/Impresa
Modulo Analisi di Operazioni di Credito
Rating
d'operazione IN
CO
RSO
DI R
EA
LIZ
ZA
ZIO
NE

101
Il terzo livello di Rischio, il Rischio d’Operazione, tiene conto della Categoria di Rischio d’Impresa e delle informazioni sulle caratteristiche finanziarie dell’operazione di credito (tipo, durata, garanzie, ...). Questi elementi concorrono all’analisi della qualità del Portafoglio Crediti ed alla eventuale definizione di Portafogli-Target, nonchè alla valutazione del capitale assorbito dalle operazioni di credito ed al corretto pricing da assegnare, sulla base della Classe di Rischio d’Impresa e della correlazione con gli altri crediti del portafoglio (attuale o progettato). Il Sistema che, come si vede, articola l’analisi in tre livelli di valutazione della rischiosità (il bilancio, l’impresa, l’operazione di credito), si giova del contributo di schede di analisi microsettoriali (sviluppate in joint-venture con terzi) e dei risultati dell’analisi dei dati di Centrale dei Rischi e delle relazioni bancarie con l’impresa (sviluppate su richiesta specifica della banca utente).

102
BIBLIOGRAFIA Aharony J. – Jones C. – Swary I. “An analysis of risk and return characteristics of corporate bankruptcy using capital market data” sul Journal of Finance, settembre, 1980 Alberici A. “Analisi dei bilanci e previsione delle insolvenze” ed. ISEDI, Milano, 1975 Alberici A. “Nuove frontiere nella gestione del rischio dei prestiti bancari” su Banche e Banchieri, n. 12, 1989 Ali H. – Charbaji A. – Tohme N. “Applying factor, cluster and multidiscriminant analysis for classifying firms based on their financial ratios” su Advances in Quantitative Analysis of Finance and Accounting, vol. 3, part. B, ed . Jai Press, NY, 1995 Altman E. “Financial ratios, discriminant analysis and the prediction of corporate bankruptcy”, sul Journal of Finance, settembre, 1968 Altman E. “Aggregate influences on business failure rates” su Finance, dicembre, 1981 Altman E. “A further empirical investigation of the bankruptcy cost question” sul Journal of Finance, settembre, 1984 Altman E. – Avery R. – Eisenbeis R. – Sinkey J. “Application of classification techniques in business, banking and finance” ed. Jai Press, NY , 1981 Altman E. – Brenner M. “Information effects and stock market response to sign of firm deterioration” sul Journal of Financial and Quantitative Analysis, marzo, 1981 Altman E. – Hadelman R. – Narayanan P. “Zeta analysis” nel Journal of Banking and Finance n. 1, 1977 Altman E. "Corporate financial distress and bankrupcty", II edizione, ed. J.Wiley, NY, 1993 Altman E. – Marco G. – Varetto F. “Corporate Distress diagnosis: comparison using linear discriminant analysis and neural network”, sul Journal of Banking and Finance, maggio, 1994 Anderson T. “An Introduction to multivariate Statistical Analysis” ed. J. Wiley, NY 1984 Appetiti S. “L’utilizzo dell’analisi discriminante per la previsione delle insolvenze”, Temi di Discussione n. 104, Banca d’Italia, Roma, 1983 Appetiti S. “L’analisi discriminante e la valutazione della fragilità finanziaria delle imprese” su Contributi alla ricerca Economica, Banca d’Italia, marzo, 1985 Argenti J. “Corporate collapse” ed. McGraw Hill, NY, 1976 Asare S. “The Auditor’s going concern decision: a review and implications for future research” sul Journal of Accounting Literature, Vol. 9, 1990

103
Associazione Nazionale fra le Banche Popolari, “La componente sistematica e quella “semi-specifica” del rischio di credito”, dicembre, 1996 Aurifeille J. – Deissenberg (eds) “Bio-mimetic approaches in management science” ed. Kluwer, Dardrecht, 1998 Aziz A. – Lawson G. “Cash flow reporting and financial distress models” su Financial Management, primavera, 1989 Back B. – Laitinen T. – Sere K. “Neural networks and bankruptcy prediction” in Advances in Accounting, vol. 14, ed. Jai Press, NY, 1996 Baetge J. – Uthoff C. “Development of a credit-studing- indicator for companies based on financial statements and business information with backpropagation-networks” compreso in Bol G. – Nakhaeizaden G. – Vollmer K. (eds) “Risk measurement, econometrics and neural network” ed. Springer, Heidelberg, 1998 Bandopadhyaya A. “An estimate of the hazard rate of firms under chapter 11 protection” sulla Review of Economics and Statistics, maggio, 1994 Bardos M. “Méthode des scores de la Centrale de Bilans”, Collection Entreprise, Banque de France, Parigi, 1991 Bardos M. – Zhu W. “Comparison of discriminant analysis and neural networks application for the detection of company failures” compreso in Aurifeille J. – Deissenberg (eds) “Bio-mimetic approaches in management science” ed. Kluwer, Dardrecht, 1998 Barniv R. “Accounting procedures, market data, cash flow figures and insolvency classification: the case of the insurance industry” su The Accounting Review, luglio, 1990 Barniv R. – Agarwal A. – Leach R. “Predicting the outcome following bankruptcy filing” su International Journal of Intelligent System in Accounting, Finance and Management, giugno, 1997 Barniv R. – Raveh A. “Identifying financial distress” su Journal of Business Finance & Accounting, estate, 1989 Barontini R. “Costi del fallimento e gestione delle crisi nelle procedure concorsuali” in AA. VV. “Gli strumenti per la gestione delle crisi finanziarie in Italia” ed. Mediocredito Lombardo, Milano, 1997 Beaver W. “Financial ratios on predictor of failure” su Empirical Research in Accounting, 1966 Begley J.– Ming J.– Watts S. “Bankruptcy classification errors in the 1980s” su Review of Accounting Studies, n. 4, 1996 Bell T. – Tabor R. “Empirical Analysis of audit uncertainty qua lifications” sul Journal of Accounting Research, autunno, 1991 Beneish M. – Press E. “Interrelation among events of default” su Contemporary Accounting Research, autunno, 1995

104
Betts J. – Belhoul D. “The effettiveness of incorporating stability measures in company failure models” sul Journal of Business Finance & Accounting, autunno, 1987 Blume M.– Lim F.– Mackinlay L. “The declining credit quality of U.S. Corporate Debt” sul Journal of Finance, agosto, 1998 Boritz J. – Kennedy D. – De Miranda A. “Predicting Corporate failure using a neural network approach” su International Journal of Intelligent Systems in Accounting, Finance and Managements, giugno, 1995 Bozzolan S. “Un modello dinamico per l’analisi e la previsione delle insolvenze aziendali” su AF n. 7, 1992 Breiman L. – Friedman J. – Olshen R. – Stone C. “Classification and regression trees” ed. Wadsworth, Pacific Grove, 1984 Bryant S. “A Case-based reasoning approach to bankruptcy prediction modeling” su International Journal of Intelligent Systems in Accounting, Finance and Management, settembre, 1997 Cadden D. “Neural networks and the mathematics of chaos” su IEEE, 1991 Caouette J. – Altman E.– Narayanan P. “Managing Credit Risk” ed. J. Wiley, NY, 1998 Carleton W.– Dragun B.– Lazear V. “The WPPSS Mess or "What’s in a Bond Rating?"” su International Review of Financial Analysis, n. 1, 1993 Carrara D. – Cavalli E. “Bankruptcy prediction”, compreso in Bertocchi E. – Cavalli E. – Komlosi S. (eds) “Modelling techniques for financial markets and bank management”, ed. Springer, Heidelberg, 1996 Casey C. – Bartczak N. “Using operating cash flow data to predict financial distress” sul Journal of Accounting Research, primavera, 1985 Casey C.– McGee U.– Stickney C. “Discriminating between reorganized and liquidated firms in bankruptcy” su The Accounting Review, aprile, 1986 Castagna A.– Matolcsy Z. “The market characteristics of failed companies” sul Journal of Business Finance & Accounting, inverno, 1981 Chalos P. “Financial distress: a comparative study of individual, model and committee assessments” su The Journal of Accounting Research, autunno, 1985 Chen G.– Cheung J.– Merville L. “Indirect cost of financial distress and sales performance” su Research in Finance, vol. 15, ed. Jai Press, NY, 1997 Chen K.– Lee C.J. “Financial ratios and corporate endurance” su Contemporary Accounting Research, primavera, 1993 Chilanti M. “Analisi e previsione delle insolvenze” su Finanza, Imprese e Mercati, n. 3, 1993

105
Chung H.M. – Tam K.Y. “A comparative analysis of inductive- learning algorithms” su International Journal of Intelligent Systems in Accounting, Finance and Management, gennaio, 1993 Citron D.– Taffler R. "The audit report under going concern uncertainties" su Accounting and Business Research, autunno, 1992 Clarke D.– McDonald J. “Generalized bankruptcy models applied to predicting consumer credit behavior” sul Journal of Economics and Business, febbraio, 1992 Coats P. – Fant F. “Recognizing financial distress patterns using a neural network tool” su Financial Management, autunno, 1992 Cole R.– Gunther J. “Separating the likelihood and timing of bank failure” sul Journal of Banking & Finance, settembre, 1995 Collins R. “An empirical comparison of bankruptcy prediction models” su Financial Management, estate, 1980 Cormier D. – Magnan M. – Morard B. “Evaluation de la pérennité de l’entreprise dans un contexte d’audit” su Economic et comptabilité, marzo/aprile, 1994 Cressy R. “Uk small firm bankruptcy prediction” sul Journal of Small Business Finance, n. 3, 1991 Daily C.– Dalton D. “Corporate governance and the bankruptcy firm” su Stategic Management Journal, ottobre, 1994 Dambolena I.– Khoury S. “Ratio stability and corporate failure” sul Journal of Finance, settembre 1980 Daniels H. – Kamp B. – Verkooijen W. “Modelling non- linearity in Economic classification with neural networks” in International Journal of Intelligent Systems in Accounting, Finance and Management, settembre, 1997 D’Aveni R. “Dependability and organizational bankruptcy” su Management Science, settembre, 1989 Deakin E. “A discriminant Analysis of Predictors of Business failure” sul Journal of Accounting Research, marzo, 1972 Deakin E. “Business failure prediction”, compreso in E. Altman – A. Sametz (eds) “Financial crises” ed. J. Wiley, NY, 1977 De Bodt E. - Cottrell M. - Levasseur M. "Le réseaux de neurones en finance" su Finance, giugno, 1995 De Luigi V.– Maccarinelli M. “L’assegnazione del rating alle banche” collana Ricerche, R93-14, Banca Commerciale Italiana, 1993

106
Deutsche Bundesbank “Analysis of business insolvency within the scope of the Deutsche Bundesbank’s credit assessment” sul Mounthly Report della Banca, gennaio, 1992 Deutsche Bundesbank “The Bundesbank's method of assessing the creditworthiness of business and enterprises ” sul Mounthly Report della Banca, gennaio, 1999 Dietrich R.– Kaplan R. “Empirical analysis of the commercial loan classification decision” su The Accounting Review, gennaio, 1982 Di Mauro F.– Mazzola F. “PVS e rimborso del debito estero: un’analisi probit su dati panel” su Contributi all’Analisi economica, Banca d’Italia, Roma, dicembre, 1989 Dimitras A. – Slowinski R. – Susmaga R. – Zopounidis C. “Business failure prediction using rough sets” su European Journal of Operational Research, aprile, 1999 Duchessi P .– Shawky H. – Seagle P. “A knowledge-engineered system for commercial loan decisions” su Financial Management, autunno, 1988 Dugan M.– Forsyth T. “The relationship between bankruptcy model predictions and stock market perception of bankruptcy” su The Financial Review, agosto, 1995 Edmister R. “An empirical test of financial ratio analysis for small business failure prediction” sul Journal of Financial and Quantitative Analysis, marzo, 1972 Eisenbeis R. “Pitfalls in the application of discriminant analysis in business, finance and economics” sul Journal of Finance, giugno, 1977 El Hennawy R. – Morris R. “Market anticipation of corporate failure in the UK” sul Journal of Business Finance & Accounting, autunno, 1983(a) El Hennawy R. – Morris R. “The significance of base year in developing failure prediction models” sul Journal of Business Finance & Accounting”, autunno, 1983(b) Erenguc S. – Koehler G. “Survey of mathematical programming models and experimenthal results for linear discriminant analysis” su Managerial and Decision Economics, ottobre, 1990 Espahbodi H. – Espahbodi P. – Peek G. “Classification procedures and prediction of failure/distress” su “Advances in Financial Planning and forecasting”, vol. 8°, Jai Press, NY, 1998 Espahbodi P. “Identification of problem banks and binary choice models” sul Journal of Banking and Finance, febbraio 1991 Falbo P. “Credit-scoring by enlarged discriminant models” su Omega, n. 4, 1991 Fanning K – Cogger K. “A comparative analysis of artificial neural networks using financial distress prediction”, su International Journal of Intelligent Systems in Accounting, Finance and Management, dicembre, 1994 Feldman K. – Kingdon J. “Neural networks and some applications to finance” in Applied Mathematical Finance, marzo, 1995.

107
Felisari G. “Il credito alle imprese: logica di valutazione e sistemi esperti” ed. Franco Angeli, Milano, 1993 Forestieri G. (a cura di) “La previsione delle insolvenze aziendali” ed. Giuffrè, Milano, 1986 Francis J. – Hastings H. – Fabozzi F. “Bankruptcy as a mathematical catastrophe” compreso in Research in Finance, ed. Jai Press, NY, vol. 4, 1983 Frydman H. – Altman E. – Kao D. “Introducing recursive partitioning for financial classification” sul Journal of Finance, marzo, 1984 Fum D. “Intelligenza Artificiale” ed. Il Mulino, Bologna, 1994 Gaber J. “Une évaluation des coûts de défaillance d’entreprise” su Revue Française de Gestion, gennaio-febbraio 1986 Gardin F.– Rossignoli C.– Vaturi S. “Sistemi esperti: banca e finanza” ed. Il Mulino, Bologna, 1991 Gardner M.– Mills D. “Evaluating the likelihood of default on delinquent loans” su Financial Management, inverno 1989 Gentry J.– Newbold P. – Whitford D. “Classifying bankrupt firm with funds flow components” sul Journal of Accounting Research, primavera, 1985 (a) Gentry J. – Newbold P.– Whitford D. “Predicting bankruptcy: if cash flow's not the bottom line, what is?” su Financial Analysis Journal settembre/ottobre 1985 (b) Gentry J. – Newbold P.– Whitford D. “Funds flow components, financial ratios and bankruptcy” sul Journal of Business Finance & Accounting, inverno, 1987 Geroski P. – Gregg P. “What makes firms vulnerable to recessionary pressure?” su European Economic Review, aprile, 1996 Ghesquiere S. – Micha B. “L’analyse des défaillances d’entreprise”, Rapport de Centrale de Bilans de la Banque de France, 1983 Ghosh C.– Owers J. – Rogers R. “The financial characteristics associated with voluntary liquidations” sul Journal of Business Finance & Accounting, novembre, 1991 Gilbert L. – Menon K. – Schwartz K. “Predicting bankruptcy for firm in financial distress” sul Journal of Business Finance and Accounting, primavera, 1990 Goldberg D. “Genetic algorithms in search, optimization and machine learning” ed. Addison – Wesley, Workinghom, 1989 Gombola M. – Haskins M. – Ketz E. – Williams D. “Cash flow in bankruptcy prediction” su Financial Management, inverno, 1987 Gordon M. “Towards a theory of financial distress” sul The Journal of Finance, n. 2, 1971

108
Goudie A. “Forecasting corporate failure” sul Journal of the Royal Statistical Society, Series A, n. 1, 1987 Goudie A.– Meeks G. “The exchange rate and company failure in a macro-micro model of the UK company sector” su The Economic Journal, maggio, 1991 Greco S. – Matarazzo B. – Slowinski R. “A new rough set approach to evaluation of bankruptcy risk”, compreso in Zopounidis C. (ed) “Operational tools in the management of financial risk” ed. Kluwer A.P., Dordrecht, 1998 Gregory Allen R. – Henderson G. “A brief review of catastrophe theory and a test in corporate failure context” su The Financial Review, maggio 1991 Gupta Y. – Rao R. – Bagchi P. “Linear goal programming as an alternative to multivariate discriminant analysis” sul Journal of Business Finance & Accounting, autunno, 1990 Hakim S. – Shimko D. “The impact of firm’s characteristics on junk-bond default” su Journal of Financial and Strategic Decision, estate, 1995 Hall G. – Stark A. “Bankrupty risk and the effect of conservative policy for 1979-81” su International Journal of Industrial Organization, settembre, 1986 Hand D. “Discrimination and classification” ed.J.Wiley, NY, 1993 Hendel I. “Competition under financial distress” sul Journal of Industrial Economics”, settembre, 1996 Heyliger W. – Holdren D. “Predicting small bank failure” su The Journal of Small Business Finance, n. 2, 1991 Hoarau C. “L’analyse du risque de faillire par le flux financiers” su Revue Française de Comptabilité, luglio/agosto 1993 Holt H. – Carroll R. “Classification of commercial bank loans through policy capturing” su Accounting, Organization and Society, n. 3, 1980 Hopwood W. – McKeown J. – Mutchler J. “A test of the incremental explanatory power of opinion qualified for consistency and uncertainty” su The Accounting Review, gennaio, 1984 Hopwood W. – McKeown J. – Mutchler J. “The sensivity of financial distress prediction models to departures from normality” sul Contemporary Accounting Research, autunno, 1988 Hopwood W. – McKeown J. – Mutchler J. “A reexamination of the auditor versus model accuracy within the context of the going-concern opinion decision” su Contemporary Accounting Research, primavera, 1994 Houghton K. “Accounting data and the prediction of business failure” sul Journal of Accounting Research, primavera, 1984 Hudson J. “The age, regional and industrial structure of company liquidations” sul Journal of Business Finance & Accounting, estate, 1987

109
Hudson J. “The impact of the new bankruptcy code upon the average liability of bankrupt firms” sul Journal of Banking and Finance, aprile, 1992 Huffman S. – Ward D. “The prediction of default for high yield bond issues” su Review of Financial Economics, inverno, 1996 Ingram F. – Frazier E. “Alternative multivariate tests in limited dependent variable models” sul Journal of Financial and Quantitative Analysis, giugno, 1982 Izan H. “Corporate distress in Australia” sul Journal of Banking and Finance, giugno, 1984 Johnsen T. – Melicher R. “Predicting corporate bankruptcy and financial distress” sul Journal of Economics and Business, ottobre, 1994 Johnson C. “Ratio analysis and the prediction of firm failure” sul Journal of Finance, n. 5, 1970 Johnson D. – Wolfe G. – Lynch L. “A market assessment of bankruptcy cost and liquidation costs” in E. Altman (ed) “Bankruptcy & distressed restructuring” ed. R. Irwin, NY, 1993 Jovanovic B. “Selection and the evolution of industry” su Econometrica, maggio, 1982 Kaen F. – Tehranian N. “Information effects in financial distress” sul Journal of Financial Economics, luglio, 1990 Kahya E. – Theodossiou P. “Predicting corporate financial distress: a time-series CUSUM methodology", Working Paper, Rutgers University, giugno, 1996 Kane G. – Richardson F. – Graybeal P. “Recession – induced stress and the prediction of corporate failure” su Contemporany Accounting Research, autunno, 1996 Karels G. – Prakash A. “Multivariate normality and forecasting of business bankruptcy” sul Journal of Business Finance and Accounting, inverno, 1987 Katz S. – Lilien S. – Nelson B. “Stock market behavior around bankruptcy model distress and recovery predictions” sul Financial Analyst Journal, gennaio/febbraio, 1985 Keasey K. – McGuinness P. “The failure of UK industrial firms for the period 1976-1984. Logistic analysis and entropy measures” sul Journal of Business Finance & Accounting, primavera, 1990 (a) Keasey K. – McGuinness P. – Short H. “Multilogit approach to predicting corporate failure” su Omega, n. 1, 1990 (b) Keasey K. – Watson R. “The prediction of small company failure”, su Accounting and Business Research, inverno, 1986 Keasey K. – Watson R. “Non financial symptoms and the prediction of small company failure” sul Journal of Business Finance & Accounting, autunno, 1987 Keasey K. – Watson R. “The non-submission of accounts and small company financial failure prediction” su Accounting and Business Research, inverno, 1988

110
Kennedy D. – Shaw W. “Evaluating financial distress resolution using prior audit opinions” su Contemporary Accounting Research, autunno, 1991 Kiefer N. “Economic duration data and hazard function” su Journal of Economic Literature, giugno, 1988 King R. – Henery R. – Feng C. – Sutherland A. “A comparative study of classification algorithms: statistical, machine learning and neural network” compreso in K. Furukawa – D. Michie – S. Muggleton (eds) “Machine intelligence” ed. Clarendon Press, Oxford, 1994 Kingdon J. – Feldman K. “Genetic algorithms and application to finance” in Applied Mathematical Finance, giugno, 1995 Kiviluoto K. – Bergius P. “MAPS for analyzing failures of small and medium-sized enterprises”, compreso in Deboeck G. – Kohonen T. (eds.) “Visual exploration in finance”, ed. Springer, Heidelberg, 1998 Klein M. – Methlie L. “Expert systems” ed. Addison Wesley, Workinghom, 1990 Koehler G. “Considerations for mathematical programming models in discriminant analysis” su Managerial and Decision Economics, ottobre, 1990 Koh H. – Killough L. “The use of multiple discriminant analysis in the assessment of the going concern status of an audit client” sul Journal of Business Finance & Accounting, primavera, 1990 Koh H. “Model predictions and auditor assessments of going concern status” su Accounting and Business Research, autunno, 1991 Kolari J. – Caputo M. – Wagner D. “Trait recognition: an alternative approach to early warning systems in commercial banking” sul Journal of Business Finance & Accounting, dicembre, 1996 Kolesar P. – Showers J. “A robust credit screening model using categorical data” su Management Science, febbraio, 1985 Kolodner J. “Case-based reasoning”, ed. Morgan Kaufmann, San Mateo, 1993 Koza J. “Genetic programming” ed. MIT Press, Cambridge, 1992 Kumar S. – Arora S. “A model for risk classification of banks” su Managerial and Decision Economics, marzo-aprile, 1995 Kwon S. – Wild J. “Informativeness of annual report for firm in financial distress” su Contemporary Accounting Research, autunno, 1994 Lachenbruch P. “Discriminant analysis”, ed. Hafner Press, NY, 1975 Laitinen E. “Financial ratios and different failure processes” sul Journal of Business Finance & Accounting, settembre, 1991

111
Laitinen E. “Financial predictors for different phases of the failure process” su Omega, marzo, 1993(a) Laitinen E. “The use of information contained in annual reports and prediction of small business failure” su International Review of Financial Analysis, n. 3, 1993(b) Laitinen E. “Traditional versus operating cash flow in failure prediction” sul Journal of Business Finance & Accounting, marzo, 1994 Laitinen E. “The duality of bankruptcy process in Finland” in the European Accounting Review, n. 3, 1995 Laitinen E. - Laitinen T. “Cash management behavior and failure prediction” sul Journal of business Finance & Accounting, settembre/ottobre 1998 Lane W. – Looney S. – Wansley J. “An application of the Cox proportional hazards model to bank failure” sul Journal of Banking & Finance, dicembre, 1986 Lau A. “A five-state financial distress prediction model” su Journal of Accounting Research, primavera, 1987 Laviola S. – Trapanese M. “Previsione delle insolvenze delle imprese e qualità del credito bancario”, Temi di Discussione n. 318, Banca d’Italia, Roma, 1997 Lawrence E. – Arshadi N. “A multinomial logit analysis of problem loan resolution choices in banking” sul Journal of Money, Credit and Banking, febbraio, 1995 Lawrence E. – Bear R. “Corporate bankruptcy prediction and the impact of leases” sul Journal of Business Finance & Accounting, inverno 1986 Levy A. – Barniv R. “Macroeconomic aspects of firm bankruptcy Analysis” sul Journal of Macroeconomics, estate, 1987 Levy A. – Cheung L. – Chowdhury K. – Harie C. “Interindustry linkages and business bankruptcy rates” compreso in Levy A. “Economic analysis of financial crises” ed. Avebury, 1995 Liang T.P. – Chandle r J. – Man I. – Roan J. “An empirical investigation of some data effects on the classification accuracy of probit, ID3 and neural networks” su Contemporany Accounting Research, autunno, 1992 Lo A. “Logit versus discriminant analysis” sul Journal of Econometrics, 1, 1986 Luoma M. – Laitinen E. “Survival analysis as a tool for company failure prediction” su Omega, n. 6, 1991 Maddala G. “Limited-dipendent and qualitative variables in econometrics” ed. Cambridge Univ. Press, Cambridge 1983 Maddala G. “Introduction to econometrics” 2a edizione, ed. MacMillan, NY, 1992

112
Maher J. – Sen T. “Predicting bond ratings using neural networks” su International Journal of Intelligent Systems in Accounting, Finance and Management, marzo, 1997 Marais D. “A method of quantifying companies’relative financial strength” discussion paper n. 4, Bank of England, Londra, 1979 Marais L. – Patell J. – Wolfson M. “The experimental design of classification models” sul Journal of Accounting Research, supplemento, 1984 Marco L. – Rainelli M. “Les disparitions des firmes industrielles en France” sulla Revue d’Économie industrielle, secondo trimestre, 1986 Mardia K. – Kent J. – Bibby J. “Multivariate analysis” ed. Academic Press, NY, 1979 Mareschal B. – Brans J. “Bankadviser: an industrial evaluation system” su European Journal of Operational Research, ottobre, 1991 Martin del Brio B. – Serrano Cinca C. “Self-organizing neural networks” compreso in Refenes A.P., “Neural networks in the capital markets” ed J. Wiley, NY, 1995 Marullo Reedtz P. “La rilevazione precoce delle sofferenze” documento presentato al Seminario “Le prospettive dell’Attività Bancaria”, Perugia, marzo, 1996 McLachlan G. “Discriminant analysis and statistical pattern recognition” ed. J. Wiley, NY, 1992 Melicher R. – Hearth D. “A time series analysis of aggregate business failure activity and credit conditions” sul Journal of Economics and Business, novembre, 1988 Mensah Y. “The differential bankruptcy predictive ability of specific price level adjustments” su The Accounting Review, aprile, 1983 Mensah Y. “An examination of the stationarity of multivariate bankruptcy prediction models” sul Journal of Accounting Research, primavera, 1984 Messier W. – Hansen J. “Inducing rules for expert system development: an example using default and bankruptcy data” su Management Science, dicembre, 1988 Micha B. “AIDE: un sistem esperto di diagnosi aziendale”, Documenti n. 3, Centrale dei Bilanci, Torino, aprile, 1987 Michie D. – Spiegelhalter D. – Taylor C. (eds) “Machine learning, neural and statistical classification” ed. Ellis Horwood, NY, 1994 Molinero C. – Ezzamel M. “Multidimensional scaling applied to corporate failure” su Omega, n. 4, 1991 Molinero C. – Gomez P. – Cinca C. “A multivariate study of Spanish bond ratings” su Omega, n. 4, 1996

113
Morelli P. – Pittaluga G. B. “Le sofferenze bancarie: tendenze e previsioni”, comprese in Masciandro D. – Porta A. (a cura di) “Le sofferenze bancarie in Italia”, Bancaria Editrice, Roma, 1998 Mossman C. – Bell G. – Swartz L. – Turtle H. “An empirical comparison of bankruptcy model” su the Financial Review, maggio, 1998 Mutchler J. “A multivariate analysis of the auditor’s going-concern opinion decisions” sul Journal of Accounting Research, autunno, 1985 Negakis C. “Robustness of greek business failure prediction models” su Rivista Internazionale di Scienze Economiche e Commerciali, marzo, 1995 Hoarau C. “L’analyse du risque de faillire par le flux financiers” su Revue Française de Comptabilité, luglio/agosto 1993 Nottola C. – Rossignoli C. “Applicazioni di sistemi esperti e reti neurali in campo finanziario” ed. Franco Angeli, Milano, 1993 Ohlson J. “Financial ratios and the probabilistic prediction of bankrupcty” sul Journal of Accounting Research, primavera, 1980 O’Leary D. “Using neural networks to predict corporate failure” su International Journal of Intelligent Systems in Accounting, Finance & Management, settembre, 1998 Olivotto L. “La previsione dell’insolvenza d’impresa mediante modelli probabilistici” su Finanza, Imprese e Mercati, n. 1, 1989 Ooghe H. – Joos P. – De Bourdeaudhuij C. “Financial distress models in Belgium” su The International Journal of Accounting, n. 3, 1995 Orgler Y. “A credit scoring model for commercial loans” sul Journal of Money, Credit and Banking, novembre, 1970 Östermark R. – Höglund R. “Assessing the multigroup discriminant problem using multivariate statistics and mathematical programming” sull’European Journal of Operational Research, luglio, 1998 Pastena V. – Ruland W. “The merger/bankruptcy alternative” su The Accounting Review, aprile, 1986 Pau L. – Tambo T. “Knowledge-based mortgage- loan credit granting and risk assessment” sul Journal of Economic Dynamics and Control, vol. 14, 1990 Pawlak Z. “Rough set approach to knowledge-based decision support” su European Journal of Operational Research, luglio, 1997 Pawlak Z. “Rough sets elements”, compreso in Polkowski L. – Skowron A. (eds) “Rough sets in knowledge discovery”, 1° vol, ed. Springer, Heidelberg, 1998

114
Peavy J. – Edgar M. “An expanded commercial paper rating scale” sul Journal of Business Finance & Accounting, autunno, 1984 Peel M. – Peel D. “Some further empirical evidence on predicting private company failure” su Accounting and Business Research, inverno, 1987 Peel M. – Peel D. – Pope P. “Some evidence on corporate failure and the behavior of non-financial ratios” su The Investment Analyst, gennaio, 1985 Peel M. – Peel D. – Pope P. “Predicting corporate failure – Some results for the UK corporate sector" su Omega, n. 1, 1986 Peel M. – Peel M. “A multilogit approach to predicting corporate failure” su Omega, n. 4, 1988 Peel M. – Wilson N. “The liquidation/merger alternative” su Managerial and Decision Economics, Vol. 10, 1989 Perry L. – Cronan T. “A note on rank transformation discriminant analysis” sul Journal of Banking and Finance, dicembre, 1986 Piesse J. – Wood D. “Issues in assessing MDA models of corporate failure” su British Accounting Review, marzo, 1992 Pinches G. – Mingo K. “A multivariate analysis of industrial bond ratings” sul Journal of Finance, marzo, 1973 Pinson S. “A multi-expert architecture for credit risk assessment” compreso in O’Leary D. – Watkins P. (eds) “Expert systems in Finance”, ed Elsevier, NY, 1992 Piramuthu S. “Financial credit-risk evoluation with neural and neurofuzzy Systems” su European Journal of Operational Research, gennaio, 1999 Platt H. “The determinants of interindustry failure” sul Journal of Economics and Business, maggio, 1989 Platt H. – Platt M. “Development of a class of stable predictive variables” sul Journal of Business Finance & Accounts, primavera, 1990 Platt H. – Platt M. “A note on the use of industry-relative ratios in bankruptcy prediction” sul Journal of Banking and Finance, dicembre, 1991 Platt H. – Platt M. “Business cycle effects on state corporate failure rates” sul Journal of Economics and Business, maggio, 1994 Platt H. – Platt M. – Pedersen J. “Bankruptcy discrimination with real variables” sul Journal of Business Finance & Accounting, giugno, 1994 Press S. –Wilson S. “Choosing between logistic regression and discriminant analysis” sul Journal of American Statistical Association, dicembre, 1978

115
Queen M. – Roll R. “Firm mortality: using market indicators to predict survival” sul Financial Analyst Journal, maggio/giugno, 1987 Quinlan J.R. “C4.5: programs for machine learning” ed. Morgan Kaufmann Publ., San Mateo, 1993 Refenes A.P. “Neural networks in the capital markets” ed J. Wiley, NY, 1995 Richardson F. – Davidson L. “An exploration into bankruptcy discriminant model sensitivity” sul Journal of Business Finance & Accounting, estate, 1983 Richardson F. – Kane G. – Lobingier P. “The impact of recession on the prediction of corporate failure” sul Journal of Business Finance & Accounting, gennaio-marzo, 1998 Ro B. – Zavgren C. – Hsieh S. “The effect of bankruptcy on systematical risk of common stock” sul Journal of Business Finance & Accounting, aprile, 1992 Roy B. “Méthodologie multicritére d’aide à la décision” ed. Economica, Parigi, 1985 Rumelhart D. – McClelland J. “PDP – Microstruttura dei processi cognitivi” ed. Il Mulino, Bologna, 1991 Scapens R. – Ryan R. – Fletcher L. “Explaining corporate failure: a catastrophe theory approach” sul Journal of Business Finance & Accounting, primavera, 1981 Scott J. “The probability of bankruptcy” sul Journal of Banking and Finance, n. 5, 1981 Serrano Cinca C. “Feedforward neural networks in the classification of financial information” su European Journal of Finance, settembre, 1997 Shaw M. – Gentry J. “Using an expert system with inductive learning to evaluate business loans” su Financial Management, autunno, 1988 Shumway T. “Forecasting bankruptcy more accurately” Working Paper, University of Michigan, Ann Arbor, marzo, 1998 Sinha A. – Richardson M. “A case-based reasoning system for indirect bank lending” su International Journal of Intelligent Systems in Accounting, Finance and Management, dicembre, 1996 Sinuany Stern Z. – Friedman L. “DEA and the discriminant analysis of ratios for ranking units” sull’European Journal of Operational Research, dicembre, 1998 Skogsvik K. “Current cost accounting ratios as predictor of business failure” sul Journal of Business Finance & Accounting, primavera, 1990 Slowinski R. – Zopounidis C. “Application of rough set approach to evaluation of bankruptcy risk” su International Journal of Intelligent Systems in Accounting, Finance and Management, marzo, 1995 Srinivasan V. – Bolster P. “An industrial bond rating model based on the Analytic Hierarchy Process” su European Journal of Operational Research, settembre, 1990

116
Srinivasan V. – Kim Y. “Credit granting: a comparative analysis of classification procedures” sul Journal of Finance, luglio, 1987 Srinivasan V. – Kim Y. “Designing expert financial systems: a case study of corporate credit management” su Financial Management, autunno, 1988 Srinivasan V. – Ruparel B. “CGX: an expert support system for credit granting” su European Journal of Operational Research, aprile 1990 Taffler R. “Forecasting company failure in the UK using discriminant analysis and financial ratio data” in the Journal of the Royal Statistical Society, Parte 3, 1982 Taffler R. “The assessment of company solvency and performance using a statistical model” su Accounting and Business Research, autunno, 1983 Taffler R. “Empirical models for the monitoring of UK Corporations” su Journal of Banking and Finance, giugno, 1984 Takala K. – Viren M. “Bankruptcies, indebtness and the credit crunch”, compreso in Bertocchi M. – Cavalli E. – Komlosi S. (eds) “Modeling techniques for financial markets and bank management” ed., Springer, Heidelberg, 1996 Talebzadeh H. – Mandutianu S. – Winner C. “Countrywide loan-underwriting expert system” su AI Magazine, primavera, 1995 Tamari M. “Financial ratios as a means of fo recasting bankruptcy” compreso in van Dam C. (ed) "Trends in financial decision making” ed M. Nijhoff, NY, 1978 Tamari M. “The use of a bankruptcy forecasting model to analyze corporate behavior in Israel” su Journal of Banking and Finance, giugno, 1984 Tennyson M.– Ingram R. – Dugan M. “Assessing the information content of narrative disclosures in explaining bankruptcy” sul Journal of Business Finance & Accounting, estate, 1990 Theobald M. – Thomas R. “Time series properties of liquidating company equity returns” sul Journal of Banking and Finance, dicembre, 1982 Theodossiou P. “Predicting shift in the mean of multivariate time series process” sul Journal of the American Statistical Association, giugno, 1993 Theodossiou P. – Kahya E. – Saidi R. – Philippatos G. “Financial distress and corporate acquisition” sul Journal of Business Finance & Accounting, luglio, 1996 Theodossiou P. – Papoulias C. “Problematic firms in Greece”, in Studies in Banking and Finance, vol. 7, 1988 Trippi R. – Turban E. (eds) “Neural networks in finance and investing”, ed. R. Irwin, Chicago, revised edition, 1996 Van Bussel J. – Veelenturf L. “Company viability prediction using neural networks with sparse data” sul Journal of Computational Intelligence in Finance, luglio/agosto, 1997

117
Varetto F. “Valutazioni con criteri multipli ed indicatori di bilancio” in Bollettino CERIS, Torino, n. 24, 1989 Varetto F. “Il sistema di diagnosi dei rischi di insolvenza della Centrale dei Bilanci”, Bancaria Editrice, Roma, 1990. Varetto F. “Alberi decisionali ed algoritmi genetici nell’analisi del rischio di insolvenza” Documento 5, Centrale dei Bilanci, Torino, aprile, 1998(a) Varetto F. “Genetic algorithms applications in the analysis of insolvency risk” sul Journal of Banking and Finance, ottobre, 1998(b) Varetto F. – Marco G. “Diagnosi delle insolvenze e reti neurali” ed. Bancaria Editrice, Roma, 1994 Vinso J. “A determination of the risk of ruin” sul Journal of Financial and Quantitative Analysis”, marzo, 1979 Vitali O. “Statistica per le scienze applicate” Volume II, ed. Cacucci, Bari, 1993 Von Stein J. – Ziegler W. “The prognosis and surveillance of risk from commercial credit borrowers” sul Journal of Banking and Finance, giugno, 1984 Ward T. “An empirical study of the incremental predictive ability of Beaver’s naive operating flow measure using four-state ordinal models of financial distress” sul Journal of Business Finance & Accounting, giugno, 1994 Ward T. – Foster B. “A note on selecting response measure for financial distress” su The Journal of Business Finance & Accounting, luglio 1997 West R. “A factor-analytic approach to bank condition” sul Journal of Banking and Finance, giugno, 1985 Wiginton J. “A note on the comparison of logit and discriminant models of consumer credit behavior” su The Journal of Financial and Quantitative Analysis”, settembre, 1980 Wilcox J. “A simple theory of financial ratios a predictors of failure” sul Journal of Accounting Research, autunno, 1971 Wilcox J. “A prediction of business failure us ing accounting data” su Empirical Research in Accounting, Selected Studios, 1973 Wilkins M. “Technical default, auditor decisions and future financial distress” su Accounting Horizon, dicembre, 1997 Wilson T. “Portfolio credit risk (1)", su Risk, settembre, 1997 Wolf M. “New technologies for customer rating” su International Journal of Intelligent Systems in Accounting, Finance and Management, dicembre, 1995

118
Wood D. – Piesse J. “The information value of MDA based financial indicators” sul Journal of Business Finance & Accounting, primavera, 1987 Zavgren C. “The prediction of corporate failure: the state of the art” sul Journal of Accounting Literature, vol. 2, 1983 Zavgren C. “Assessing the vulnerability to failure of American industrial firms” sul Journal of Business Finance & Accounting, primavera, 1985 Zavgren C. – Dugan M. – Reeve J. “The association between probabilities of bankruptcy and market response” su Journal of Business Finance & Accounting, primavera, 1988 Zmijewski M. “Methodological issues related to the estimation of financial distress prediction models” sul Journal of Accounting Research, supplemento al vol. 22, 1984 Zopounidis C. “Évaluation du risque de défaillance de l’entreprise” ed. Economica, Parigi, 1995 Zopounidis C. – Dimitras A. “Multicriteria decision aid methods for the prediction of business failure” ed Kluwer A.P., Dordrecht, 1998 Zopounidis C. – Dimitras A. – Le Rudulier L. “A multicriteria approach for the analysis and prediction of business failure in Greece”, compreso in Zopounidis C. (ed.) “Operational tools in the management of financial risk” ed . Kluwer A.P., Dordrecht, 1998 Zopounidis C. – Doumpos M. “FINCLAS: a multicriteria decision support system for financial classification problems”, compreso in Zopounidis C. “Operational tools in the management of financial risks” ed. Kluwer, Dordrecht, 1998 Principio di revisione n. 21 “Continuità Aziendale”, a cura del Consiglio Nazionale dei Dottori Commercialisti e Consiglio Nazionale dei Ragionieri, ed. Giuffré, Milano, gennaio, 1995

119


















