
EQUALIZZAZIONE RMAP PER TRASMISSIONI …infocom.uniroma1.it/~robby/Tesi/Masiello 2003-04.pdf ·...
174
UNIVERSITÀ DEGLI STUDI DI ROMA LA SAPIENZA FACOLTÀ DI INGEGNERIA TESI DI LAUREA IN INGEGNERIA DELLE TELECOMUNICAZIONI EQUALIZZAZIONE RMAP PER TRASMISSIONI NUMERICHE SU CANALI HF CON ELEVATA DISPERSIONE TEMPORALE RELATORE LAUREANDA CH.MO PROF. ROBERTO CUSANI TIZIANA MASIELLO ANNO ACCADEMICO 2003/2004
-
Upload
truongliem -
Category
Documents
-
view
218 -
download
0
Transcript of EQUALIZZAZIONE RMAP PER TRASMISSIONI …infocom.uniroma1.it/~robby/Tesi/Masiello 2003-04.pdf ·...

UNIVERSITÀ DEGLI STUDI DI ROMA
LA SAPIENZA
FACOLTÀ DI INGEGNERIA
TESI DI LAUREA
IN INGEGNERIA DELLE TELECOMUNICAZIONI
EQUALIZZAZIONE RMAP
PER TRASMISSIONI NUMERICHE
SU CANALI HF
CON ELEVATA DISPERSIONE TEMPORALE
RELATORE LAUREANDA
CH.MO PROF. ROBERTO CUSANI TIZIANA MASIELLO
ANNO ACCADEMICO 2003/2004

Indice
I
Indice
INDICE I
INTRODUZIONE 1
CAPITOLO I IL CANALE HF 4
I.1 MULTIPATH E FADING DI CANALE.........................................................................................4
I.2 MODELLO MATEMATICO PER CANALI AFFETTI DA MULTIPATH ...........................................10
I.3 SELETTIVITÀ IN FREQUENZA...............................................................................................13
I.4 FADING VELOCE E FADING LENTO.......................................................................................17
I.5 MODELLO DI CANALE TEMPO VARIANTE DI WATTERSON ...................................................19
CAPITOLO II FORMA D’ONDA PROPOSTA 25
II.1 INTRODUZIONE: STRUTTURA CON TRAMA SECONDO LO STANDARD MIL-STD-188-110 A 25
II.1.1 SINCHRONIZATION (SYNC) PREAMBLE PHASE.................................................................. 28
II.1.2 DATA PHASE....................................................................................................................... 28
II.1.3 EOM PHASE ....................................................................................................................... 29
II.1.4 FLUSH PHASE...................................................................................................................... 29
II.2 FEC ENCODER................................................................................................................29
II.3 INTERLEAVING ...................................................................................................................31
II.3.1 INTERLEAVE LOAD....................................................................................................... 32
II.3.2 INTERLEAVE FETCH ..................................................................................................... 32
II.4 MODIFIED GRAY DECODING ...............................................................................................33
II.5 SYMBOL FORMATION..........................................................................................................35
II.5.1 UNKNOWN DATA ............................................................................................................... 35
II.5.2 KNOWN DATA .................................................................................................................... 36
II.6 PREAMBOLO DI SYNC .......................................................................................................38
II.7 SCRAMBLER… ...................................................................................................................40

Indice
II
II.7.1 GENERATORE DELLA SEQUENZA RANDOM DEI DATI ....................................................... 40
II.7.2 GENERATORE DELLA SEQUENZA RANDOM DI SYNC ...................................................... 41
II.8 MODULAZIONE 8-PSK .......................................................................................................42
II.9 FILTRI SAGOMATORI A COSENO RIALZATO..........................................................................43
CAPITOLO III L’EQUALIZZAZIONE DI CANALE 45
III.1 MODELLO DEI CANALI CON ISI [PRO 95] [3.] .....................................................................45
III.2 EQUALIZZAZIONE LINEARE [PRO95] [3.]............................................................................51
III.3 CANALE AWGN CON RIVELATORE A SOGLIA (SLICER) ......................................................53
CAPITOLO IV EQUALIZZAZIONE BASATA SUL “CONSTANT MODULUS ALGORITHM” 56
IV.1 PRINCIPI DI FUNZIONAMENTO ED APPLICAZIONE SU CANALE TEMPO INVARIANTE ..............56
IV.1.1 CANALE TEMPO INVARIANTE A DUE COEFFICIENTI REALI............................................... 59
IV.1.2 CANALE TEMPO INVARIANTE A DUE COEFFICIENTI GENERALMENTE COMPLESSI ......... 62
IV.1.3 EQUALIZZATORE CMA CON ALGORITMO DI “PHASE RECOVERY” ADATTATIVO ......... 64
IV.1.4 CMA CON STIMATORE DI RITARDO .................................................................................. 66
IV.1.5 RAPIDITÀ DI CONVERGENZA ED INSTABILITÀ NUMERICA DEL CMA ............................. 69
IV.2 EQUALIZZAZIONE ADATTATIVA DI TIPO CMA, SU CANALE TEMPO VARIANTE DI
WATTERSON.......................................................................................................................70
IV.2.1 SIMULAZIONI AL CALCOLATORE E PRESTAZIONI DEL CMA NEL CASO DI CANALE
TEMPO VARIANTE ............................................................................................................... 71
IV.3 CMA CON TRAINING SUI SIMBOLI KNOWN ......................................................................73
IV.3.1 CONFRONTO TRA LE PRESTAZIONI DEL CMA “PURO” E DEL CMA CON TRAINING..... 75
IV.3.2 SOLUZIONE A T/2 DEL CMA CON TRAINING ................................................................... 76
IV.3.3 SOLUZIONE A T/2 DEL CMA CON CICLI SUI TRAINING DA 16 SIMBOLI .......................... 79
IV.3.4 SOLUZIONE A T/2 DEL CMA CON CICLI SU N REPLICHE DA 48 SIMBOLI ........................ 83
IV.4 CMA PERFORMANCE (STANDARD MIL-STD-188-110A) ..................................................87
IV.5 CONCLUSIONI (EQUALIZZATORE CMA).............................................................................89

Indice
III
CAPITOLO V STIMA DI CANALE 90
V.1 INTRODUZIONE (BLIND CHANNEL ESTIMATION) .................................................................90
V.2 STIMATORE DI CANALE PER IL MODEM MIL-STD-188-110A.............................................94
V.2.1 UTILIZZO DEL CMA COME EQUALIZZATORE ................................................................... 94
V.2.1.a Simulazioni al calcolatore nel caso di canale tempo invariante ............ 96
V.2.1.b Simulazioni al calcolatore nel caso canale tempo variante .................... 97
V.2.2 SOLUZIONE ERROR-FREE .................................................................................................... 99
V.2.3 UTILIZZO DI UN CANCELLATORE COME EQUALIZZATORE ............................................ 101
CAPITOLO VI EQUALIZZAZIONE BASATA SULL’ALGORITMO R-MAP 105
VI.1 L’EQUALIZZATORE MAP .................................................................................................105
VI.2 L’EQUALIZZATORE RMAP...............................................................................................109
VI.3 PRESTAZIONI PER CANALE TEMPO INVARIANTE A FASE MINIMA .......................................112
VI.4 FILTRAGGIO PRELIMINARE ...............................................................................................115
VI.4.1 IL FILTRO MATCHED ......................................................................................................... 116
VI.4.2 IL FILTRO WHITENING ...................................................................................................... 118
CAPITOLO VII FILTRO SBIANCANTE (“WHITENING FILTER”) 121
VII.1 REALIZZAZIONE TRAMITE ALGORITMO LMS ....................................................121
VII.1.1.a Simulazioni per canale tempo invariante generico ............................... 122
VII.1.1.b Simulazioni nel caso di canale tempo variante di Watterson .............. 123
VII.1.2 SECONDA STIMA DI CANALE: INTERPOLAZONE LINEARE .......................... 125
VII.1.2.a Prestazioni canale tempo variante. .......................................................... 128
VII.2 REALIZZAZIONE CON CALCOLO ANALITICO .....................................................131
VII.2.1 COSTRUZIONE DELLA MATRICE DEI COEFFICIENTI......................................................... 131
VII.2.2 CALCOLO DELLA MATRICE 1−T : ALGORITMO DI LEVINSON-DURBIN.................... 132
VII.2.3 LEMMA DELL’INVERSIONE DELLA MATRICE PARTIZIONATA A BLOCCHI ...................... 136
VII.3 CONFRONTO TRA I DUE ALGORITMI ..................................................................................138
VII.3.1 PRESTAZIONI PER CANALE TEMPO INVARIANTE ............................................................ 138

Indice
IV
VII.3.2 SIMULAZIONI NEL CASO DI CANALE TEMPO VARIANTE DI WATTERSON...................... 141
VII.4 LIMITI PRESTAZIONALI DELLA SECONDA STIMA DI CANALE..............................................145
CAPITOLO VIII CONCLUSIONI 148
BIBLIOGRAFIA 154
APPENDICE “ANALISI DELLA COMPLESSITÀ DEL WMF “ 156
A.1 ANALISI COMPLESSITÀ NELLA REALIZZAZIONE DEL MATCHED .........................................156
A.2 ANALISI COMPLESSITÀ NELLA REALIZZAZIONE DEL WHITE-FILTER .................................157
A.2.1 CALCOLO AUTOCORRELAZIONE DELLA STIMA DEL CANALE............................................ 157
A.2.2 COSTRUZIONE MATRICE DEI COEFFICENTI Ψ ................................................................... 158
A.2.3 CALCOLO DELLA MATRICE 1−T : ALGORITMO DI LEVINSON-DURBIN....................... 159
A.2.4 LEMMA DELLA INVERSIONE DELLA MATRICE A BLOCCHI ................................................. 164
A.2.5 CALCOLO DEI COEFFICIENTI DEL WHITENING FILTER...................................................... 167
A.3 CONCLUSIONI ...................................................................................................................167

Introduzione
1
INTRODUZIONE
Negli ultimi anni nel mercato delle telecomunicazioni considerevoli sforzi sono
stati rivolti allo studio dei sistemi di trasmissioni numeriche ad elevate prestazioni che
operino nel canale radio. L’obiettivo è quello di progettare sistemi in grado di sfruttare
efficientemente le risorse spettrali a disposizione e garantire una velocità di
trasmissione più alta possibile. Questa esigenza porta all’impiego di algoritmi sempre
più complessi che richiedono molte risorse di calcolo, le quali tuttavia non sono sempre
disponibili. La richiesta di una elevata potenza di elaborazione è dettata dalla necessità
di poter contrastare gli effetti di degradazione prodotti dal canale radio sul segnale
trasmesso.
Tale canale, su cui avviene la trasmissione, ha caratteristiche variabili nel tempo
e quindi il segnale ricevuto non è stazionario. Diversi sono gli effetti negativi connessi:
dispersione temporale, dispersione in frequenza, errori di sincronismo, affievolimenti,
rumore termico.
La dispersione temporale (delay spread) è dovuta al fenomeno dei cammini
multipli, per il quale il segnale trasmesso arriva al ricevitore insieme a sue repliche
traslate nel tempo producendo interferenza tra i simboli adiacenti. Questo fenomeno è
noto come interferenza di intersimbolo (ISI). Inoltre, il medesimo canale presenta la
caratteristica di variare nel tempo a causa delle fluttuazioni degli strati ionosferici,
oppure a causa della velocità di un ricetrasmettitore mobile.
La dispersione in frequenza (frequency spread) è invece un indice della velocità
con la quale variano le caratteristiche del canale. Larghe dispersioni in frequenza
indicano rapide variazioni del canale.

Introduzione
2
Per compensare tali effetti indesiderati, negli apparati ricevitori viene effettuata
un’operazione di equalizzazione adattativa, la quale consente una modifica dei parametri
del ricevitore in base alle mutanti condizioni del canale trasmissivo.
Sono stati sviluppati diversi algoritmi di equalizzazione adattativa tra i quali si
possono citare: “Decision Feedback Equalization” (DFE), “Maximum Likehood
Sequence Extimation” (MLSE), “Constant modulus algorithm” (CMA) e “Maximum A
Posteriori probability “ (MAP). Nel presente lavoro sono stati utilizzati algoritmi
adattativi quali il CMA e l’equalizzatore MAP, il CMA sebbene abbia una complessità
computazionale piuttosto ridotta, presenta tuttavia dei limiti, fra cui principalmente
quello di non riuscire ad invertire canali con raggi ricevuti di egual potenza.
Oltre alle tecniche di equalizzazione è opportuno adottare anche altri tipi di
accorgimenti per migliorare le prestazioni del segnale ricevuto affinché il messaggio
ricevuto sia il più possibile simile a quello trasmesso.
Il canale di trasmissione, in genere variante nel tempo, presenta degli
affievolimenti più o meno pesanti sul segnale trasmesso e ciò può produrre degli errori
a burst (errori a blocchi) pertanto per ridurre e contrastare tale effetto si debbono
adottare varie tecniche di codifica, decodifica e di interleaving.
Indipendentemente dal tipo di equalizzatore utilizzato, è sempre necessario
sfruttare, per un corretto funzionamento del ricevitore, la conoscenza all’interno dei
pacchetti di informazione (trame), di una sequenza nota di simboli, detta training
sequence.
È evidente il fatto che il ricevitore deve conoscere la posizione della sequenza di
sincronizzazione all’interno della trama ricevuta per poter sfruttarne le proprietà.
Tale conoscenza è, però, contrastata da diversi fattori di non idealità. Tra questi
ricordiamo il “jitter” di campionamento, dovuto ad una imperfetta sincronizzazione
dell’oscillatore del trasmettitore con quello del ricevitore, modellabile come un ritardo
aleatorio imposto al pacchetto ricevuto. La presenza di tale ritardo costringe il ricevitore
a lavorare su un insieme di dati distorti, comportando un peggioramento consistente
delle prestazioni.

Introduzione
3
Da quanto detto si intuisce come i sincronismi di trama, in prima battuta, e di
simbolo, successivamente, sono molto importanti ai fini di una corretta ricezione,
soprattutto in presenza di interferenza intersimbolica e canali rapidamente varianti nel
tempo.
Il lavoro presentato è uno sviluppo di un lavoro più ampio all’interno di un
piano di collaborazione tra la Marconi Selenia S.p.a. di Pomezia (Roma) ed il
Dipartimento Infocom dell’Università “La Sapienza” di Roma, avente l’obbiettivo di
studiare la realizzazione software di un ricevitore per trasmissioni numeriche in banda
HF da impiegare nella costruzione di un modem a portante singola che adotti lo
standard di trasmissione MIL-STD-188-110A.
Il modem è impiegato in ambito militare dalla rete del Dipartimento Nazionale
della Difesa (DND) per la comunicazione tra comando base e unità dispiegate sul
territorio (aerei, navi ed elementi di terra).
Benché il modem MIL-STD-188-110A, così come lo Stanag (STAndard Nato
AGreement) 4285, sia stato prodotto in ambito militare, il loro utilizzo è presente anche
in quello civile per comunicazioni navali transoceaniche, ovvero per comunicazioni
avioniche. Vengono altresì utilizzati nell’ambito della protezione civile (polizia,
carabinieri, servizi sanitari, ecc.).
Infine per quanto riguarda la loro realizzazione viene usata l’implementazione
su DSP, essendo questa microprogrammabile e quindi più versatile e flessibile rispetto
alla logica cablata.

Capitolo I Il canale HF
4
Capitolo I
IL CANALE HF
I.1 Multipath e fading di canale
Prima di esaminare alcune delle diverse operazioni che vengono compiute sul
segnale ricevuto per estrarne l'informazione convogliata, è sembrato opportuno
descrivere lo scenario di propagazione del segnale stesso tra le antenne trasmittente e
ricevente; risulterà così più facile comprendere le alterazioni subite dal segnale durante
l’attraversamento di questa distanza e quindi la necessità delle elaborazioni descritte
nei capitoli seguenti.
L'ambiente di propagazione considerato in questo lavoro è costituito dal canale
radio nella banda di frequenze che si estende da 3 MHz a 30 MHz, meglio nota come
banda HF; nel seguito, quindi, sarà brevemente trattata la propagazione ionosferica
delle onde elettromagnetiche, nell’ambito della radiocomunicazione HF digitale.
Nel caso ideale di propagazione nello spazio libero, l’atmosfera è assimilata ad
un mezzo non assorbente perfettamente uniforme ed inoltre qualsiasi ostacolo
(compreso il terreno) è considerato infinitamente distante dal segnale che si propaga,
tanto da non poter esercitare alcuna influenza misurabile sulla trasmissione.
In questo caso l’unico segnale disturbante, che si sovrappone al segnale utile, è
caratterizzato da una statistica Gaussiana a valor medio nullo e densità spettrale di
potenza piatta, ed è noto come rumore Gaussiano bianco additivo ("Additive White Gaussian
Noise", AWGN); l'origine di tale disturbo è l’inevitabile moto d’agitazione termica degli
elettroni nei circuiti interni del ricevitore. Si parlerà quindi di canale Gaussiano o
"AWGN Channel".

Capitolo I Il canale HF
5
Fondamentalmente, in questo modello, l’attenuazione dell’energia fra il
trasmettitore e il ricevitore segue una legge quadratica inversa. La potenza ricevuta
espressa in termini della potenza trasmessa è attenuata da un fattore detto perdita di
cammino ("path loss"), Ls(d).
Quando l’antenna ricevente è isotropa, questo fattore vale:
24( )s
dL d
π
λ
=
(I.1)
dove d è la distanza fra il trasmettitore e il ricevitore e λ è la lunghezza d’onda del
segnale che si propaga.
Nella maggior parte dei casi pratici, però, questo modello risulta inadeguato, dal
momento che la propagazione del segnale ha luogo in atmosfera reale, vicino al terreno,
in presenza di ostacoli di ogni tipo ed è quindi influenzata da diversi fenomeni, quali:
• riflessione: l’onda elettromagnetica urta contro una superficie liscia le cui
dimensioni sono molto grandi se paragonate alla lunghezza d’onda λ e
viene riflessa dalla superficie stessa;
• diffrazione: il cammino dell’onda è ostruito da un corpo solido di
dimensioni comparabili con λ, dando luogo ad onde secondarie che si
propagano oltre l’ostacolo;
• rifrazione: l’onda passa da un mezzo ad un altro e la direzione di
propagazione subisce una variazione;
• scattering o diffusione: l’onda radio incontra una superficie irregolare o le
cui dimensioni sono dell’ordine di λ o più piccole, determinando uno
sparpagliamento dell’energia riflessa in tutte le direzioni.
In un sistema di comunicazione nella banda HF sono di particolare importanza i
fenomeni sopra descritti: essi fanno sì che il segnale viaggi dal trasmettitore al ricevitore
attraverso una molteplicità di cammini dovuta ad un numero molto elevato di
riflessioni che possono verificarsi su vari tipi di superfici (strati ionosferici, terreno); in

Capitolo I Il canale HF
6
letteratura questo fenomeno è noto come propagazione per cammini multipli
("multipath propagation").
Il segnale che giunge al ricevitore è quindi costituito dalla sovrapposizione di più
repliche del segnale trasmesso, ciascuna con una propria ampiezza, fase e tempo di
arrivo; la composizione dei vari contributi dà origine a momentanei affievolimenti,
anche di grossa entità, dell’inviluppo del segnale ricevuto. Tale fenomeno è
comunemente indicato con il nome di fading da cammini multipli ("multipath fading").
Quest’ultimo non è però che una delle manifestazioni del fading di canale, com’è
bene evidenziato in Figura I.1.
Manifestazioni delfading di canale
Fading su larga scaladovuto a movimento su
larghe aree
Fading su scala ridottadovuto a piccoli
cambiamenti di posizione
Attenuazione delvalor medio del
segnale vs distanza
Variazioni intorno alvalor medio
Time spreadingdel segnale
Varianza neltempo delsegnale
Fadingselettivo infrequenza
Fading piatto(Flat fading)
Fadingveloce
Fadinglento
Figura I.1 Manifestazioni del fading di canale [Skl97]

Capitolo I Il canale HF
7
Nella classificazione delle manifestazioni del fading di canale bisogna, quindi,
innanzitutto distinguere tra fading su larga scala ("large-scale fading"), che rappresenta
un’attenuazione della potenza media di segnale dovuta a spostamenti su vaste aree, e
fading su scala ridotta ("small-scale fading"), che si verifica in seguito a piccoli
movimenti relativi (piccoli come mezza lunghezza d’onda) fra trasmettitore e ricevitore.
Il fenomeno del fading su larga scala è strettamente dipendente dal profilo del
terreno tra trasmettitore e ricevitore: sono determinanti a tal riguardo la presenza e la
dislocazione di ostacoli quali colline, foreste e gruppi d’edifici su cui rimbalzano i raggi
ionosferici prima di arrivare al ricevitore.
In questo caso la perdita di cammino media assume la forma più generica:
= 0
( )n
p
dL d
d (I.2)
dove d è la distanza fra trasmettitore e ricevitore, 0d è una distanza di riferimento da un
punto situato nel campo lontano dell’antenna (in modo tale da ipotizzare che il campo
si propaghi su un’onda piana) e l’esponente n dipende dalla frequenza, dall’altezza
dell’antenna e dall’ambiente di propagazione. Come visto nell’equazione (I.1), nello
spazio libero n=2; in presenza di onde fortemente guidate (come nelle strade urbane)
tale esponente può diventare anche più piccolo di 2; quando invece ci si trova in
presenza di ostacoli che ostruiscono la propagazione, si ha n>2.
Misurazioni pratiche mostrano che, per ogni valore di d, la perdita di cammino
Lp(d) è una variabile aleatoria avente distribuzione log-normale intorno al valor medio
espresso dall’equazione (I.2).
Nel caso invece di fading su scala ridotta ("small-scale fading") piccole variazioni
dello spazio che separa trasmettitore e ricevitore, possono provocare notevoli variazioni
dell’ampiezza e della fase del segnale ricevuto. Ѐ questo il caso dei cammini multipli, in
Capitolo I Il canale HF
8
cui spostamenti anche piccoli di un rice-trasmettitore mobile o fluttuazioni degli strati
ionosferici, cambiano notevolmente la qualità di ricezione poiché cambia in maniera
imprevedibile il modo in cui si sovrappongono le varie componenti del segnale in
corrispondenza dell'antenna ricevente.
Com’è noto, il generico segnale ricevuto r(t) si esprime come la convoluzione del
segnale trasmesso s(t) con la risposta impulsiva del canale ( )ch t ; trascurando la
degradazione dovuta al rumore, scriviamo:
= ∗( ) ( ) ( )cr t s t h t (I.3)
Possiamo inoltre considerare r(t) come prodotto di due componenti aleatorie,
cioè:
0( ) ( ) ( )r t m t r t= ⋅ (I.4)
dove m(t) è la componente del fading su larga scala il cui modulo, espresso in dB, ha
una densità di probabilità Gaussiana; ( )0r t è invece la componente del fading su piccola
scala ed è anche detta, per i motivi di cui sopra, multipath fading.
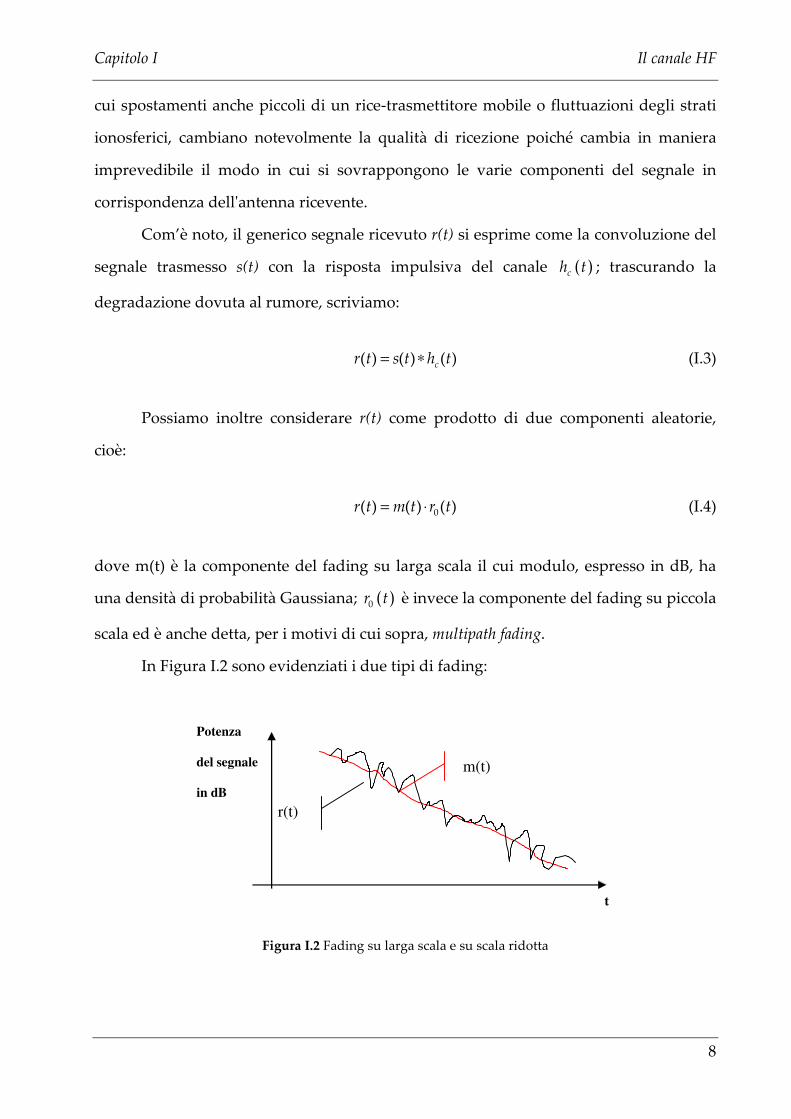
In Figura I.2 sono evidenziati i due tipi di fading:
r(t)
m(t)
Potenza
del segnale
in dB
t
Figura I.2 Fading su larga scala e su scala ridotta

Capitolo I Il canale HF
9
Il fading su scala ridotta può essere di due tipi: fading di Rayleigh quando al
ricevitore giungono diverse repliche del segnale, tutte indipendenti fra loro, ed inoltre
le antenne trasmittente e ricevente non sono in condizioni di visibilità ottica (assenza di
Line Of Sight), per cui non c'è il contributo dominante del raggio diretto; l’inviluppo del
segnale ricevuto è di conseguenza caratterizzato da una funzione densità di probabilità
di Rayleigh:
2
2 2( ) exp 02
r rp r r
σ σ
= − ≥
(I.5)
dove r è l’ampiezza dell’inviluppo del segnale ricevuto, e 2 2σ è la potenza media del
segnale a cammini multipli.
Se invece fra le diverse componenti del segnale ricevuto c’è un cammino
dominante (presenza di LOS) si parla più propriamente di fading di Rice e l’inviluppo
del segnale ricevuto ha una funzione di densità di probabilità di Rice:
2
02 2( ) exp exp( ) 2 02
r r rp r k I k r
σ σ σ
= − − ≥
(I.6)
dove 0I rappresenta la funzione di Bessel modificata d’ordine zero e k è pari al rapporto
tra la potenza del cammino diretto e la potenza complessiva di tutti gli altri cammini
multipli. Come si può osservare, quando k tende a zero (assenza di LOS) si ritrova la
funzione densità di probabilità di Rayleigh, invece per k elevati si trova il caso di canale
Gaussiano, in cui c’è una netta predominanza del cammino diretto.
Come si sarà già intuito, il caso di fading di Rayleigh per un collegamento singolo
rappresenta il caso peggiore, in termini di potenza media di segnale ricevuta.

Capitolo I Il canale HF
10
Come già anticipato in Figura I.1, il fading su piccola scala ha due modi di
manifestarsi:
• dispersione temporale (time-spreading) degli impulsi digitali costituenti il
segnale;
• comportamento tempo variante del canale a causa delle fluttuazioni degli
strati ionosferici.
Se si prova, infatti, a trasmettere un segnale di durata molto breve, idealmente un
impulso, attraverso un canale soggetto al fenomeno dei cammini multipli il segnale
ricevuto potrebbe apparire come un treno d’impulsi: il canale ha cioè “allargato”
l’occupazione temporale del segnale (time-spreading).
Se poi si prova a ripetere più volte l’esperimento precedente, potremmo
osservare dei cambiamenti nel treno d’impulsi ricevuto, ed in particolare nell’ampiezza
dei singoli impulsi, nei ritardi relativi tra essi e, molto frequentemente, nel loro numero.
Tali variazioni, dovute alla natura tempo-variante del canale, sono inoltre del tutto
imprevedibili dal punto di vista dell’utente.
I.2 Modello matematico per canali affetti da multipath
Per quanto detto finora appare del tutto ragionevole caratterizzare un canale
tempo variante soggetto a multipath da un punto di vista statistico.
Indichiamo allora il segnale trasmesso in termini del suo inviluppo complesso
( )s t rispetto alla frequenza fc:
( ) Re[ ( )exp( 2 )]cs t s t j f tπ= (I.7)

Capitolo I Il canale HF
11
Com’è noto, l’inviluppo complesso (in gergo detto "low-pass equivalent") è una
rappresentazione del segnale s(t) che nelle applicazioni si fa coincidere con una sua
traslazione in banda base.
Assumendo che vi sia propagazione tramite cammini multipli, è possibile
associare a ciascun cammino un ritardo di propagazione ed un fattore d’attenuazione,
entrambi variabili nel tempo in maniera aleatoria. Il segnale in banda passante ricevuto
può quindi essere espresso nella forma:
( ) ( ) ( )n nn
x t t s t tα τ= − ∑ (I.8)
dove ( )n tα e ( )n tτ costituiscono, rispettivamente, l’attenuazione ed il ritardo di
propagazione subiti dal path n-esimo del segnale ricevuto. Sostituendo nell’equazione
(I.8) l’espressione di s(t) data dall’equazione (I.7), si ottiene:
( ) Re{[ ( )exp( 2 ( )) ( ( ))]exp( 2 )}n c n n cn
x t t j f t s t t j f tα π τ τ π= − −∑ (I.9)
Ѐ quindi evidente che l’inviluppo complesso (equivalente passa-basso) del
segnale ricevuto è:
( ) ( )exp[ 2 ( )] [ ( )]n c n nn
r t t j f t s t tα π τ τ= − −∑ (I.10)
Essendo il canale in esame lineare ma non permanente, vale l’espressione:
( ) ( ; ) ( )r t c t s t dτ τ τ+∞
−∞
= −∫ (I.11)

Capitolo I Il canale HF
12
Perciò si deduce facilmente che tale canale è descritto dalla risposta impulsiva
tempo-variante:
( ; ) ( )exp[ 2 ( )] ( ( ))n c n nn
c t t j f t tτ α π τ δ τ τ= − −∑ (I.12)
Tale modello fornisce una giustificazione matematica al fenomeno del fading; si
consideri, infatti, la trasmissione di una portante di frequenza fc non modulata, ossia
del segnale:
( ) cos(2 ) ( ) 1cs t f t s t tπ= → = ∀ (I.13)
In questo caso particolare il segnale ricevuto assume la seguente espressione:
( ) ( )exp[ 2 ( )] ( )exp[ ( )]n c n n nn n
r t t j f t t j tα π τ α θ= − = −∑ ∑ (I.14)
dove ( ) ( )2n c nt f tθ π τ= .
Perciò il segnale presente in ricezione consiste nella somma di un certo numero
di vettori tempo-varianti (fasori) caratterizzati da ampiezze ( )n tα e fasi ( )n tθ .
Ѐ da notare che sono necessarie notevoli variazioni dinamiche nel mezzo
trasmissivo affinché ( )n tα cambi talmente tanto da produrre una significativa
variazione nel segnale ricevuto (componente del fading su larga scala). Da parte sua,
( )n tθ varierà di ben 2π radianti (provocando una rotazione completa del fasore) ogni
volta che ( )n tτ cambia di una quantità molto piccola pari a 1/fc; quindi perturbazioni
del mezzo anche in apparenza trascurabili sono in grado di produrre sensibili
modifiche nelle fasi delle componenti di segnale che si sommano in ricezione. In alcuni
istanti tali variazioni di fase possono essere tali che i vettori ( )n tα exp[-j ( )n tθ ] si
sommino distruttivamente; quando ciò accade, il segnale risultante ricevuto è molto
piccolo, se non addirittura nullo. In altri istanti invece i vettori possono sommarsi

Capitolo I Il canale HF
13
costruttivamente, rendendo il segnale ricevuto grande. E’ questo il caso del fading su
scala ridotta.
I.3 Selettività in frequenza
Dopo aver esaminato il modello matematico del canale in presenza di cammini
multipli, è opportuno soffermarsi brevemente sui due modi di manifestarsi del fading
su piccola scala, già menzionati al termine del paragrafo I.1, iniziando, in questo
paragrafo, con il fenomeno del time-spreading.
A tal fine, assumiamo che la risposta impulsiva equivalente passa-basso del
canale, c(τ;t), definita dalla (I.12), possa considerarsi come un processo stocastico
stazionario in senso lato (ipotesi WSS): questo implica fra l’altro che la sua funzione
d’autocorrelazione sia invariante rispetto a traslazioni temporali. Quest’ultima si può
definire come:
1 2 1 2
1( , ; ) [ ( ; ) ( ; )]
2cc t E c t c t tρ τ τ τ τ∗∆ = + ∆ (I.15)
Inoltre, poiché nella maggioranza dei mezzi trasmissivi radio, l’attenuazione e lo
sfasamento subiti dal segnale nel path con ritardo 1τ sono incorrelati con quelli associati
al path con ritardo 2τ , possiamo applicare al nostro canale anche l'ipotesi di scattering
incorrelato (US).
Con queste ipotesi si ottiene:
1 2 1 1 2
1[ ( ; ) ( ; )] ( ; ) ( )
2 ccE c t c t t tτ τ ρ τ δ τ τ∗ + ∆ = ∆ − (I.16)
In generale ( ; )cc tρ τ ∆ fornisce la potenza media in uscita del canale come
funzione sia del ritardo temporale τ che della differenza Δt tra gli istanti d'osservazione.
Se poniamo poi Δt=0, la risultante funzione di autocorrelazione ( )( ; 0)cc ccρ τ ρ τ≡ è

Capitolo I Il canale HF
14
semplicemente la potenza media d'uscita del canale in funzione del ritardo τ del
generico path, rispetto all’istante di arrivo del primo cammino.
Per questo motivo ( )ccρ τ è detta spettro di potenza nel ritardo τ, oppure profilo
d’intensità del multipath.
In genere l'andamento di questo profilo si presenta molto frastagliato, con diversi
picchi, ma mediamente tale funzione tende a scendere con τ ed assume valori
significativi fino ad un valore di τ posto pari a mT , valore noto come ritardo massimo,
inteso relativamente all’istante di arrivo del primo raggio. L’intervallo [0, mT ] è detto
"multipath spread" del canale.
Ragionando invece nel dominio della frequenza, la funzione di trasferimento di
( )ccρ τ è definita nel seguente modo:
( ){ } ( ) ( ) ( )F P exp 2cc cc ccf j f dρ τ ρ τ π τ τ+∞
−∞= ∆ = − ∆∫ (I.17)
Tale funzione può essere caratterizzata dal reciproco del ritardo massimo mT che
ci fornisce una misura della banda di coerenza del canale:
m
1( )
Tcf∆ ≈ (I.18)
Due sinusoidi separate in frequenza di una quantità superiore a ( )c
f∆ saranno
quindi distorte in maniera differente durante l’attraversamento del canale. Perciò,
quando è trasmesso un segnale di banda W che convoglia informazione, si può definire
il fading:
• selettivo in frequenza se (Δf) c <W: in questo caso il segnale risulterà notevolmente
distorto, dato che le sue componenti spettrali non cadono tutte dentro la banda di
coerenza del canale e pertanto saranno soggette a differenti guadagni e sfasamenti;

Capitolo I Il canale HF
15
• non selettivo in frequenza se ( )c
f∆ >W: le componenti frequenziali del segnale
verranno modificate in modo omogeneo, dato che rientrano tutte all'interno della
banda di coerenza del canale.
Dato che si può porre approssimativamente W=1/ sT , dove sT è il tempo di
simbolo, è possibile dare una giustificazione più intuitiva al concetto di selettività in
frequenza, riducendolo al confronto fra sT e mT . Avremo pertanto:
• fading selettivo in frequenza se s mT T< : le componenti del multipath si estendono nel
tempo oltre la durata di ogni simbolo trasmesso. Si ha così il ben noto fenomeno
dell’interferenza intersimbolica indotta dal canale per cui le componenti relative
ad un simbolo di segnale non si sono ancora del tutto smorzate prima dell’arrivo
delle componenti del successivo;
• fading non selettivo in frequenza o flat fading se s mT >T : il flat fading non introduce
interferenza intersimbolica, poiché le componenti di ciascun simbolo si sono
notevolmente attenuate, prima dell'arrivo di quelle relative al simbolo successivo;
si può comunque riscontrare una diminuzione del rapporto segnale-rumore,
poiché le diverse componenti del multipath, come detto, possono sommarsi
distruttivamente in ricezione, dove arrivano con ampiezza e fasi diverse.

Capitolo I Il canale HF
16
In Figura I.3 mostriamo i due tipi di fading:
Den
sità
D
ensi
tà
W ∆fc
frequenza
frequenza
Figura I.3 Confronto fra la funzione di trasferimento del canale ed un segnale con occupazione di banda
W [Skl97]. In alto è mostrato un tipico caso di fading selettivo in frequenza ( )( )cf W∆ < , mentre in
basso un tipico caso di flat fading ( )( )cf W∆ >

Capitolo I Il canale HF
17
I.4 Fading veloce e fading lento
Il secondo fenomeno connesso con il fading su scala ridotta è il comportamento
tempo-variante del canale dovuto alle fluttuazioni degli strati ionosferici le quali
determinano la variazione del punto in cui viene riflessa e/o rifratta l’onda incidente e
quindi il cambiamento dei cammini di propagazione. Le altezze degli strati ionosferici
sono fortemente dipendenti dalla latitudine e dalle condizioni climatiche tanto che per
il loro corretto utilizzo sono state effettuate diverse campagne di misura durante tutto
l’anno solare e a varie ore del giorno.
Per caratterizzare questo tipo di fading occorre introdurre la funzione R(Δt),
detta funzione di correlazione tempo-spaziata, che rappresenta l'autocorrelazione della
risposta del canale ad una sinusoide; questa funzione specifica l'estensione
dell'intervallo temporale all'interno del quale c'è correlazione tra le risposte del canale a
due sinusoidi trasmesse a distanza di tempo Δt. Definiamo inoltre tempo di coerenza
T c l'intervallo temporale in cui si stima essere essenzialmente invariante la risposta del
canale ovvero segnali trasmessi a distanza massima T c non vengono modificati in
modo sostanzialmente diverso.
La trasformata di Fourier di R(Δt), rispetto alla variabile temporale Δt, è indicata
con ( )cS λ ; tale funzione è uno spettro di potenza che fornisce l'intensità del segnale
come funzione della frequenza Doppler λ. Per questo motivo ( )cS λ è detta spettro di
potenza Doppler del canale.
L'intervallo di valori di λ in cui lo spettro di potenza Doppler risulta
essenzialmente diverso da zero, è chiamato banda Doppler del canale, Bd. Dunque il
tempo di coerenza e la banda Doppler sono l'uno l'inverso dell'altro, cioè 1/T c =B d .

Capitolo I Il canale HF
18
Concludendo, diciamo che la natura tempo-variante del canale viene allora così
definita:
• si ha fading veloce se T c <T s o equivalentemente B d >W; in tal caso ci si può
aspettare che le caratteristiche del fading cambino notevolmente durante
l'intervallo di simbolo, generando così una distorsione della forma dell'impulso in
banda base, distorsione che può dar origine ad errori non correggibili.
• si ha fading lento se T c >T s o equivalentemente B d <W; in tal caso la forma
dell'impulso in banda base non è alterata e il canale può essere considerato tempo-
invariante per la durata di diversi simboli.
Antitrasformata di Fourier
fc-fd fd fc+fd λ
∆t
Tc
Figura I.4 Relazione fra spettro di potenza Doppler (in alto) e funzione di correlazione tempo-spaziata (in basso)

Capitolo I Il canale HF
19
I.5 Modello di canale tempo variante di Watterson
Nel presente simulatore si implementa un modello di canale tempo variante di
Watterson a due cammini multipli.
S(k)
FILTRO SAGOMATORE
A COSENO RIALZATO
CANALE TEMPO VARIANTE
DI WATTERSON
R(k)
AWGN
Figura I.5 Modello numerico del canale di forma d’onda simulato
Il blocco che in Figura I.5 viene sommariamente indicato come “CANALE
TEMPO VARIANTE DI WATTERSON” è in realtà descritto più in dettaglio dallo
schema in Figura I.6, ove si nota che l’uscita del canale è data dalla combinazione di un
raggio a ritardo nullo con un raggio ritardato di Δ secondi; i coefficienti della
combinazione sono tuttavia tempo varianti e costituiscono il vero e proprio Spettro
Doppler del canale.
Nel modello da noi considerato i guadagni dei raggi hanno distribuzione
gaussiana complessa, con componenti indipendenti ed identicamente distribuite ed
indipendenti anche fra loro. Inoltre, per ciascuno dei due guadagni si è assunto uno
Spettro di densità di potenza Gaussiano con larghezza di banda pari alla banda doppler
del canale.

Capitolo I Il canale HF
20
Σ
X X
ritardo teta
S(t)
r(t)
g2(t) g1(t)
Ts
r(k)
Figura I.6 Schema a blocchi del canale tempo variante secondo il modello Watterson.; è stato incluso nello
schema anche il campionamento in ricezione
Indicati con r 1 (t) e r 2 (t) l’evoluzione temporale rispettivamente della
componente riflessa dallo strato ionosferico che arriva per prima a destinazione e della
componente riflessa che arriva con un ritardo di Δτ rispetto alla prima, il segnale in
uscita dal canale avrà un’evoluzione temporale data da:
( ) ( ) ( )1 2r t r t r t= + (I.19)
Entrambi i processi sono complessi:
1 1,Re 1,Im( ) ( ) ( )r t r t jr t= + (I.20)
( ) ( ) ( )2 2 ,Re 2 ,Imr t r t r t= + (I.21)
r(n) è la sequenza di campioni complessi derivante dal campionamento con
frequenza di campionamento fs =1/Ts del segnale r(t) in uscita dal canale.

Capitolo I Il canale HF
21
Ovviamente sussiste la seguente relazione:
( ) ( ) ( )1 2r n r n r n= + (I.22)
dove: ( )1r n è la sequenza di campioni complessi derivata dal campionamento del
segnale ( )1r t ; ( )2r n è la sequenza di campioni complessi derivata dal campionamento
del segnale ( )2r t (sempre con la stessa frequenza di simbolo fs).
S(n) è la sequenza di campioni complessi derivante dal campionamento, sempre
con la stessa frequenza di simbolo, del segnale in ingresso al canale. La potenza
complessiva è pari all’unità, cioè:
( ) ( ) ( ) ( ) ( ) ( )2 2 2 2 2 2 2
1 2 1,Re 1,Im 2,Re 2,Im 4 1gr t r t r t r t r t r t σ+ = + + + = = (I.23)
Indicando con ( )1g n i campioni complessi che definiscono il comportamento del
canale rispetto al primo raggio (che derivano dal campionamento del segnale ( )1g t che
descrive l’evoluzione temporale del canale rispetto al primo raggio) e ( )2g n i campioni
complessi che definiscono il comportamento del canale rispetto al secondo raggio, si ha:
( ) ( ) ( )1 1 1r n g n s n= ∗ (I.24)
dove ( )1s n è la sequenza di campioni derivanti dal campionamento del segnale di
ingresso, non ritardata, ed inoltre:
( ) ( ) ( )2 2 2r n g n s n= ∗ (I.25)
dove ( )2s n è la sequenza di campioni derivanti dal campionamento del segnale di
ingresso, ritardata di Δτ rispetto alla sequenza di ingresso.
Per ottenere le sequenze di campioni complessi ( )1g n e ( )1g n che descrivono il
canale rispettivamente con riferimento al primo e al secondo raggio,tenendo anche

Capitolo I Il canale HF
22
conto della rotazione di fase introdotta dalla presenza di una banda doppler, si è
proceduto nel seguente modo.
Come primo passo sono stati generati i campioni che definiscono lo spettro
Doppler nel dominio della frequenza, secondo un andamento Gaussiano definito dalla
relazione:
( )
2
exp
2
s
d
k f
NH kB
⋅
= −
(I.26)
ove è indicato in tabella a seguire il significato di B d , f s , N.
fs
frequenza di
simbolo:
10.500
N
numero dei
campioni della
FFT:
220= 1.048.576
Bd
banda
Doppler:
1Hz
È da rimarcare che il valore di N utilizzato nelle simulazioni deve essere sempre
una potenza di 2 e deve essere dimensionato in funzione della risoluzione spettrale
richiesta alla FFT; processi doppler più lenti richiedono un N più elevato.

Capitolo I Il canale HF
23
L’ andamento degli H(k) viene mostrato nella figura seguente, ed è noto come
Spettro doppler del canale di Watterson:
Figura I.7 Spettro doppler del canale di Watterson
Si osservi come la banda Doppler coincida col doppio della deviazione standard,
ovvero con l’intervallo tra i due punti di flesso della curva.
Dato che da un punto di vista numerico è più conveniente operare con funzioni
di trasferimento i cui campioni nel dominio della DFT vadano da 0 a N-1,la funzione di
trasferimento del filtro sagomatore che utilizziamo nel nostro programma ha
l’andamento mostrato in Figura I.8. È evidente che la sequenza mostrata in questo
grafico è ottenuta da una finestratura da 0 a N-1 dell’estensione periodica a periodo N
della sequenza mostrata di seguito.
Figura I.8 Spettro doppler con estensione monolatera
Sono poi state generate due sequenze gaussiane bianche, per la componente reale
ed immaginaria, con deviazione standard ( )1 4 1g Kσ = • + dove K è il fattore di Rice
che nel caso da noi considerato di fading di Rayleigh tende a zero per cui gσ =0.5.

Capitolo I Il canale HF
24
Di tali sequenze è stata fatta la trasformata di fourier secondo l’algoritmo della
FFT, per poi effettuare il filtraggio in frequenza con la funzione sagomatrice H(k) di cui
sopra. I campioni così filtrati sono stati trasformati nuovamente nel dominio del
tempo(vedi Fig. I.9 ). Questo procedimento viene eseguito due volte, una per ogni
cammino in modo da ottenere ( )1g n e ( )2g n .
generazione dei
campioni gaussiani
FFT
FFT inversa
Filtraggio in
frequenza
Sequenza dei campioni
complessi che
definiscono il canale
FFT
Filtraggio in
frequenza
FFT inversa
generazione dei
campioni gaussiani
ramo componente immaginaria
ramo componente reale
Figura I.9 Schema del modello funzionale adoperato per la generazione dei campioni complessi che
definiscono il comportamento del canale

Capitolo II Forma d’onda proposta
25
Capitolo II
FORMA D’ONDA
PROPOSTA
II.1 Introduzione: struttura della trama secondo lo standard
MIL-STD-188-110 A
In questo capitolo si descrivono le forme d’onda di un modem per dati operante
in banda HF ad un symbol rate di 2400 simboli al secondo. Le forme d’onda single-tone
specificate in questo capitolo usano la tecnica di modulazione 8-PSK.
È possibile operare con un bit_rate di partenza di 75,150,300,600,1200,2400,4800
bps. È previsto anche un codificatore convoluzionale seguito da un interleaver, capace
di processare blocchi la cui lunghezza può essere scelta in un insieme discreto di due
valori.
È poi prevista la presenza di un modified Gray decoder, di un formatore di
simbolo, di uno scrambler e infine del modulatore.
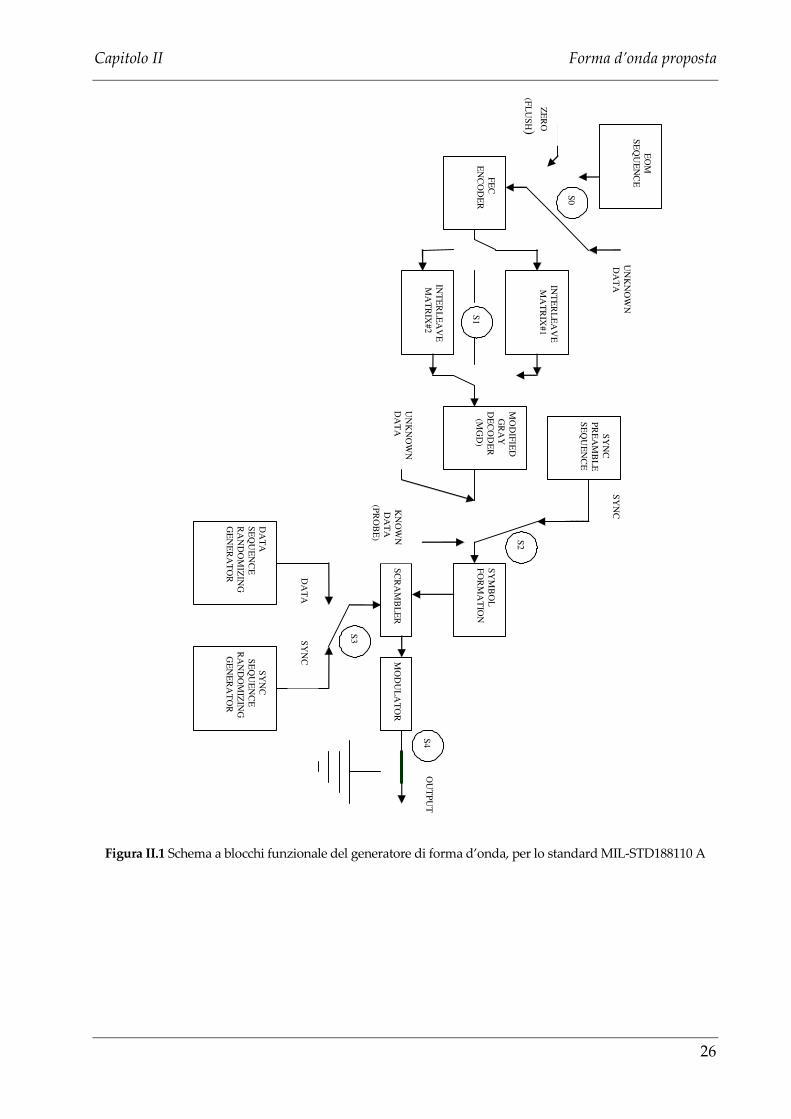
La Figura II.1 illustra lo schema a blocchi funzionale del generatore di foma
d’onda secondo lo standard MIL_STD_188_110 A, dove è stato tralasciato quanto
attiene ai meccanismi protocollari con lo strato di collegamento.
Capitolo II Forma d’onda proposta
26
EO
M
SEQ
UE
NC
E
FEC
E
NC
OD
ER
UN
KN
OW
N
DA
TA
INT
ER
LE
AV
E
MA
TR
IX#1
S0
INT
ER
LE
AV
E
MA
TR
IX#2
MO
DIFIE
D
GR
AY
D
EC
OD
ER
(M
GD
)
UN
KN
OW
N
DA
TA
SYN
C
PRE
AM
BL
E
SEQ
UE
NC
E
S2
SYM
BO
L
FOR
MA
TIO
N
SCR
AM
BL
ER
SYN
C
SEQ
UE
NC
E
RA
ND
OM
IZIN
G
GE
NE
RA
TO
R
DA
TA
SE
QU
EN
CE
R
AN
DO
MIZ
ING
G
EN
ER
AT
OR
S3 SYN
C
DA
TA
MO
DU
LA
TO
R
KN
OW
N
DA
TA
(PR
OB
E)
SYN
C
ZE
RO
(FL
USH )
OU
TPU
T
S4
S1
Figura II.1 Schema a blocchi funzionale del generatore di forma d’onda, per lo standard MIL-STD188110 A

Capitolo II Forma d’onda proposta
27
SYNC DATI#1 M DATI#2 ……
DATI#239
DATI#240
PM UM
SYNC: preambolo di sincronizzazione composto da 11520 simboli per il long interleaving e da 1440 simboli per lo short interleaving
DATI
BLOCCO 0 BLOCCO 1
DATI : blocco dati di 32 simboli nei casi di bit_rate 2400 e 4800, di 20 simboli nei casi di bit_rate 150,300,600,1200
M : minipreambolo composto da 16 simboli nulli nel caso di bit_rate 2400 e 4800 , composto da 20 simboli nulli nel caso di bit_rate 150,300,600,1200
PM : il penultimo minipreambolo del singolo blocco interlivato . UM : l’ultimo minipreamolo del singolo blocco interlivato. Essi avranno la stessa dimensione dei preamboli M ma non saranno composti da simboli nulli.
Figura II.2 Struttura della trama per lo standard MIL-STD-188-110 A
Il bit rate e la lunghezza di interleaving sono entrambe trasmesse esplicitamente
come parte della forma d’onda, in particolare come parte del preambolo iniziale e poi
periodicamente negli ultimi due minipreamboli del singolo blocco interlivato i quali
precedono per l’appunto il blocco successivo.
Come evidenzia la Figura II.1 la forma d’onda specificata dallo standard in
questione ha 4 fasi temporali funzionalmente distinte:
a.Synchronization preamble phase.
b.Data phase.
c.End-of-message (EOM) phase.
d.Coder and interleaver flush phase.

Capitolo II Forma d’onda proposta
28
II.1.1 Sinchronization (sync) preamble phase
La durata di questa fase coincide esattamente con l’intervallo di tempo richiesto
per caricare la matrice di interleaving con un blocco di dati. Durante questa fase,
l’interruttore S0 della Figura II.1, sarà nella posizione UNKNOWN DATA e le funzioni
di codifica e di interleaver saranno attive dal momento che il modem comincia ad
accettare dati dal DTE (Data Terminal Equipment). Gli interruttori S2 e S3 saranno nella
posizione SYNC. Il modem comincerà quindi a trasmettere il preambolo di
sincronizzazione che permette la sincronizzazione nel tempo e in frequenza con il
ricevitore.
La durata temporale della sync sarà di 0.6 sec per lo zero e lo short interleaver,
4.8 sec per il long interleaver.
II.1.2 Data Phase
Durante questa fase la forma d’onda trasmessa conterrà sia dati informativi
(UNKNOWN DATA)che KNOWN DATA che sono delle sequenze di simboli utilizzati
in ricezione per l’equalizzazione del canale.
Gli interruttori S0 ed S3 sono nelle rispettive posizioni UNKNOWN DATA e
DATA, mentre S2 commuta periodicamente tra le posizioni UNKNOWN DATA
(l’uscita del modified Gray decoder (MGD)) e KNOWN DATA.
Per i bit rate 2400 e 4800 la durata dell’intervallo in cui S2 rimarrà nella posizione
UNKNOWN DATA è pari a quella corrispondente a 32 simboli,subito dopo S2
commuta nella posizione KNOWN DATA e vi rimane per una durata corrispondente a
16 simboli.
Per i bit rate 150,300,600,1200 S2 manterrà la stessa posizione prima di
commutare nell’altra posizione per una durata di 20 simboli in entrambi i casi.
Per il bit rate 75 S2 rimarrà sempre nella posizione UNKNOWN DATA.

Capitolo II Forma d’onda proposta
29
II.1.3 EOM Phase
Non appena l’ultimo bit della sequenza di dati informativi che precede l’assenza
del segnale RTS (Request To Send) entra nell’encoder, S0 commuta nella posizione
EOM. Questo determina l’invio all’encoder di una sequenza di 32 bits che indicano la
fine della trasmissione .
II.1.4 Flush Phase
Subito dopo la EOM PHASE , S0 commuterà nella posizione FLUSH e si avrà
l’ingresso nell’encoder dei bits di flush.
II.2 FEC ENCODER
Il coder di trasmissione riceve in ingresso una sequenza binaria { }kb e ne
fornisce, in uscita, una { }2 kb avente un ritmo binario doppio. Possiamo supporre che la
sequenza di ingresso sia il risultato di una conversione analogico-digitale (A/D)
effettuata su un segnale di qualunque natura (voce, immagini,…) eseguita a monte del
codificatore, oppure una vera e propria sequenza di bit proveniente da un computer o
da una qualunque altra sorgente binaria.
I dati in ingresso subiscono una codifica convoluzionale tale da raddoppiarne il
ritmo binario, per tale scopo la sequenza viene suddivisa in N blocchi, tali blocchi
vengono codificati singolarmente con codifica convoluzionale; infine all’uscita del
codificatore vengono riassemblati per ricostruire la sequenza.
Lo schema di principio del codificatore convoluzionale è rappresentato in Figura II.3.
Il bit rate 4800 non viene codificato , per i bit rate 2400,1200 e 600 si ottengono in
uscita dal codificatore dei coded bit streams a 4800,2400,1200 bps rispettivamente.
Per i bit rate 300 e 150 la coppia di bit in uscita dal codificatore in corrispondenza
ad ogni singolo bit in ingresso vengono ripetuti rispettivamente 2 e 4 volte in modo da
ottenere un bit rate codificato di 1200 bps.

Capitolo II Forma d’onda proposta
30
x5 x6 x4 x3 x2 x 1
+
+
OUTPUT INPUT
FREQUENZA DELLO SWITCH PARI AL DOPPIO DELLA
FREQUENZA DEI BIT IN INGRESSO
T1(x)
T2(x)
Polinomi generatori: T1(x)= x6+x4+x3+x+1 T2(x)= x6+x5+x4+x3+1
Figura II.3 Codificatore convoluzionale
Per il bit rate 75 viene utilizzato un formato diverso ottenendo un bit rate
codificato di 150 bps.
Quanto detto viene riassunto nella Tabella II.1.
Data rate (bps) Effective code rate Metodo per ottenere il
code rate
4800 (no coding) (no coding)
2400 1/2 (4800) Rate ½ code
1200 1/2 (2400) Rate ½ code
600 1/2 (1200) Rate ½ code
300 1/4 (1200) Rate ½ code ripetuto per 2
150 1/8 (1200) Rate ½ code ripetuto per 4
75 1/2 (150) Rate ½
Tabella II.1 Effective code rate per i vari bit-rate di ingresso

Capitolo II Forma d’onda proposta
31
II.3 Interleaving
La tecnica dell’interleaving permette una correzione di errori a burst in ricezione
secondo i limiti del codice, errori che altrimenti non potrebbero essere corretti e
comprometterebbero il trasferimento dell’informazione..
L’interleaver farà uso di due matrici, le cui dimensioni saranno funzione del bit
rate, queste matrici verranno di volta in volta caricate con il singolo blocco da
interlivare le cui dimensioni saranno compatibili con la dimensione delle matrici.
La dimensione delle matrici sarà calibrata in base al bit rate in modo tale che la
durata della fase di immagazzinamento dei dati nella singola matrice abbia sempre la
durata di 0.0, 0.6, 4.8 s rispettivamente per lo zero, short e long interleave.
Sono necessarie due matrici di interleave dal momento che i bit vengono caricati
e prelevati in momenti diversi. Questo permette che una matrice venga caricata mentre
l’altra viene scaricata.
La Tabella II.2 riporta le dimensioni delle matrici al variare del bit rate per le
varie tipologie di interleave.Per il bit rate 4800 l’interleaver viene bypassato.
Long interleaver Short interleaver
Bit rate (bps) Numero di
righe
Numero di
colonne
Numero di
righe
Numero di
colonne
2400 40 576 40 72
1200 40 288 40 36
600 40 144 40 18
300 40 144 40 18
150 40 144 40 18
75 20 36 10 9
Tabella II.2 Dimensione della matrice di interleave al variare del bit rate e del tipo di interleave

Capitolo II Forma d’onda proposta
32
II.3.1 INTERLEAVE LOAD
I dati vengono caricati nella matrice di interleave in base al seguente algoritmo:
partendo dalla colonna numero zero , il primo bit viene caricato nella riga numero zero,
il successivo bit nella riga numero 9, il terzo nella riga numero 18 e il quarto nella riga
numero 27. L’indice di riga nell’ambito della stessa colonna dunque viene di volta in
volta incrementato di 9 modulo 40.
Il procedimento continua fino a quando vengono caricate tutte le 40 righe.
A questo punto il caricamento procede con la colonna numero 1 e cosi via fino a che la
matrice risulta completamente riempita. Questo algoritmo di caricamento è valido sia
per lo short che per il long interleave.
Fa eccezione il bit rate 75 per il quale, nel caso di long interleave , il
procedimento è lo stesso ma il numero di riga viene di volta in volta incrementato di 7
modulo 20. Nel caso di short interleave il numero di riga viene incrementato di 7
modulo 10.
II.3.2 INTERLEAVE FETCH
La sequenza di bit prelevati dalla matrice di interleave inizia dall’elemento di
indice sia di riga che di colonna pari a zero. La locazione del successivo bit da prelevare
viene determinata incrementando di uno l’indice di riga e decrementando di 17
(modulo il numero di colonne della matrice di interleave) l’indice di colonna. Questo
procedimento continua fino a quando il numero di riga raggiunge il suo valore
massimo. A questo punto, l’indice di riga viene reinizializzato a zero e il numero di
colonna viene incrementato di uno rispetto al valore che aveva l’ultima volta che
l’indice di riga aveva assunto il valore zero. L’intero procedimento continua finché
l’intera matrice viene scaricata. Fa al solito eccezione il bit rate 75 per il quale il
decremento dell’indice di colonna sarà pari a 7 anziché 17.

Capitolo II Forma d’onda proposta
33
I bit prelevati dalla matrice di interleave vengono a questo punto raggruppati
insieme come entità di uno, due o tre bit (asseconda del bit rate) le quali entità
prendono il nome di channel symbols. La Tabella II.3 illustra il modo in cui vengono
raggruppati i bits per formare i channel symbols, al variare del bit rate.
Data rate (bps) Numero di bit prelevati per channel
symbol
2400 3
1200 2
600 1
300 1
150 1
75 2
Tabella II.3 Numero di bits per channel symbol al variare del bit rate
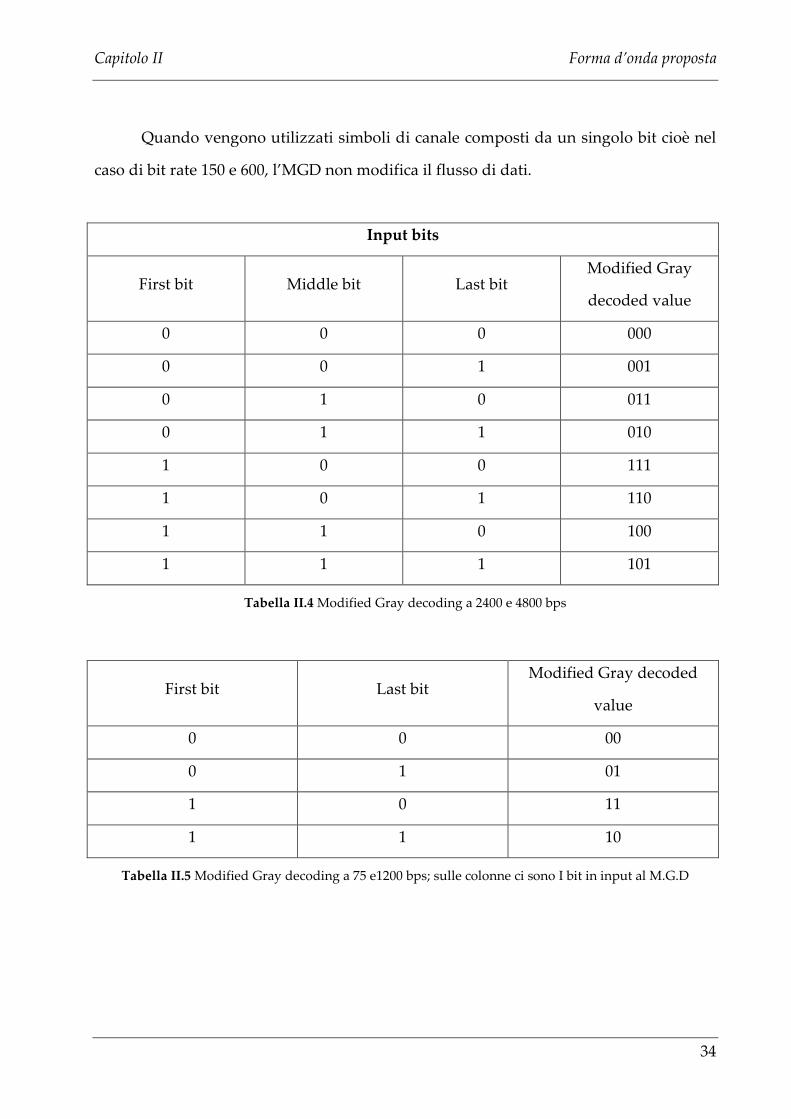
II.4 Modified Gray decoding
Lo scopo di effettuare una decodifica dei bit provenienti dalla matrice di
interleave mediante il modified gray decoder è di garantire che gli errori che
coinvolgono simboli con fasi adiacenti al ricevitore corrispondono all’errore su un
singolo bit del simbolo.
Per i bit rate 4800 e 2400 i bit di canale vengono effettivamente trasmessi
utilizzando 8-ary channnel symbols. Per 1200 e 75 bps i bit vengono effettivamente
trasmessi utilizzando 4-ary channel symbols.
Il modified gray decoding dei bit rate 2400,4800 (tribit channel symbol) e 75,1200
(dibit channel symbol) è illustrato rispettivamente in Tabella II.4 e in Tabella II.5.
Capitolo II Forma d’onda proposta
34
Quando vengono utilizzati simboli di canale composti da un singolo bit cioè nel
caso di bit rate 150 e 600, l’MGD non modifica il flusso di dati.
Input bits
First bit Middle bit Last bit Modified Gray
decoded value
0 0 0 000
0 0 1 001
0 1 0 011
0 1 1 010
1 0 0 111
1 0 1 110
1 1 0 100
1 1 1 101
Tabella II.4 Modified Gray decoding a 2400 e 4800 bps
First bit Last bit Modified Gray decoded
value
0 0 00
0 1 01
1 0 11
1 1 10
Tabella II.5 Modified Gray decoding a 75 e1200 bps; sulle colonne ci sono I bit in input al M.G.D

Capitolo II Forma d’onda proposta
35
II.5 Symbol formation
La funzione di symbol formation effettua il mapping dei simboli di canale
formati da uno, due , oppure tre bit in uscita dall’ MGD o dal preambolo di sync in
simboli formati da tre bit , compatibili con lo schema di modulazione 8-PSK.
II.5.1 Unknown data
A tutti i bit rate ad eccezione del 75 bps ciascun channel symbol sia esso
composto da uno, due, tre bit, verrà mappato direttamente in uno degli 8-ary tribit
numbers cioè in uno degli 8 simboli della costellazione 8-PSK, a modulo unitario.
Quando vengono utilizzati channel symbol da un bit (per i bit rate 600 e 150),
l’uscita del symbol formation sarà composta dai tribit numbers 0 e 4 (caso BPSK).
A 1200 bps, i dibit channel symbol saranno mappati nei simboli della
costellazione 8-PSK 0, 2, 4, e 6.
I bit rate 4800 e 2400 verranno mappati nei simboli da 0 a 7.
Questi valori verranno successivamente scramblati ai fini di poter assumere il
valore di uno tra tutti i possibili simboli della costellazione 8-PSK.
A 75 bps i simboli di canale sono formati da 2 bit e vengono mappati nei simboli
0, 2, 4, e 6. Però in questo caso non vengono inseriti miniprobe di simboli noti, ma viene
utilizzato un formato diverso: ogni simbolo 4-PSK viene mappato in 32 tribit numbers,
secondo la Tabella II.6.
Verrà utilizzato il mapping della Tabella II.6 (la parte a. ) per tutti i sets di 32
tribit numbers ad eccezione di ogni 45-esimo set di ogni blocco interlivato nel caso di
shot interleave e ad eccezione di ogni 360-esimo set nel caso di long interleave. Cioè
fanno eccezione gli ultimi 32 tribit numbers di ogni blocco che in questo modo
segnalano al ricevitore la fine di un blocco e l’inizio del successivo. In questi casi viene
utilizzato il mapping illustrato nella Tabella II.6 (parte b).

Capitolo II Forma d’onda proposta
36
Anche in questo caso i simboli verranno sottoposti ad uno scrambling. All’uscita
dello scrambler i simboli della trama apparterranno all’insieme dei simboli della
costellazione 8-PSK.
Channel symbol Tribit numbers
a. Mapping per i sets normali
00 (0) (0000) ripetuto 8 volte
01 (2) (0404) ripetuto 8 volte
10 (4) (0044) ripetuto 8 volte
11 (6) (0440) ripetuto 8 volte
b.Mapping per i sets che fanno eccezione
00 (0) (0000 4444) ripetuto 4 volte
01 (2) (0404 4040) ripetuto 4 volte
10 (4) (0044 4400) ripetuto 4 volte
11 (6) (0440 4004) ripetuto 4 volte
Tabella II.6 Mapping dei channel symbols per il bit rate 75 bps
II.5.2 Known data
Durante il periodo in cui i simboli noti vengono trasmessi, l’uscita del formatore
di simbolo viene posta a 0 (000) ad eccezione del caso in cui vengono trasmessi gli
ultimi due miniprobe del singolo blocco interlivato, ossia i due miniprobe che
precedono la trasmissione del successivo blocco interlivato.
La lunghezza del singolo blocco interlivato sarà pari a 1440 tribit channel
symbols nel caso di short interleave e 11520 tribit channel symbols per il caso di long
interleave.
Nel caso in cui vengono trasmesse le ultime due sequenze di simboli noti del
singolo blocco i 16 simboli di queste sequenze saranno ottenuti dal mapping dei simboli

Capitolo II Forma d’onda proposta
37
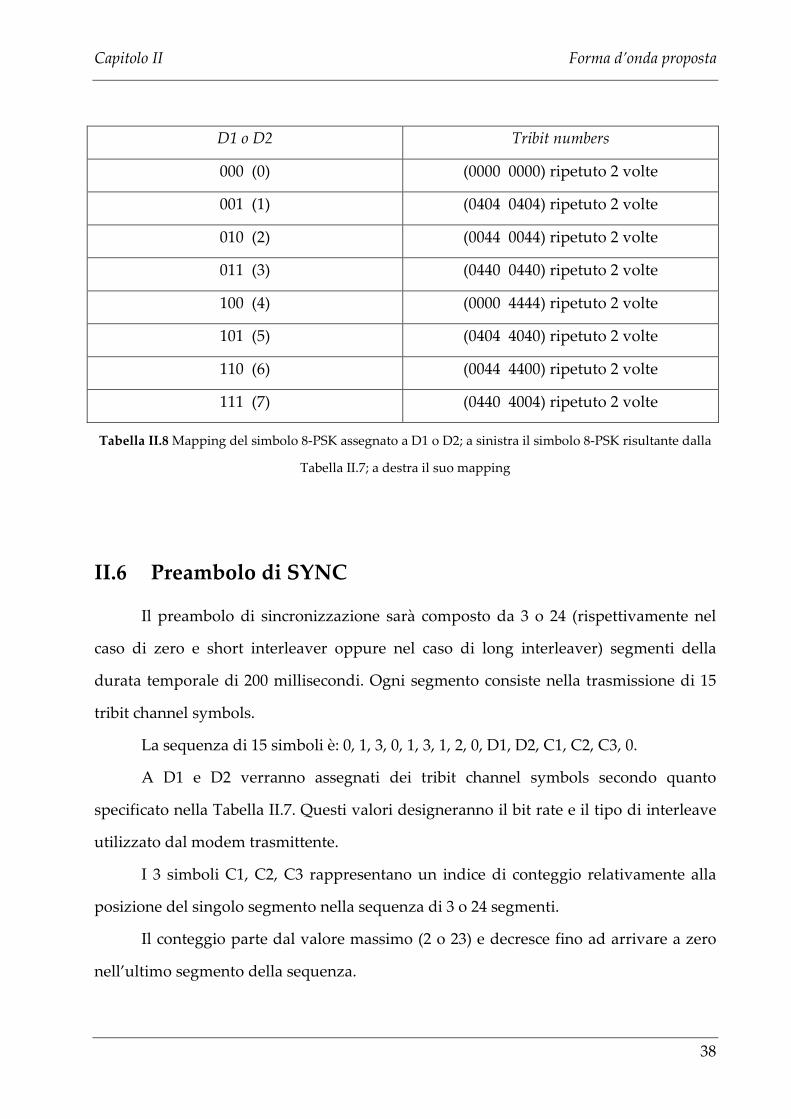
di designazione D1 e D2 rispettivamente per il penultimo e per l’ultimo miniprobe,
secondo la Tabella II.8.
Dapprima però ai simboli D1 e D2 verranno assegnati dei valori in relazione al
bit rate e al tipo di interleaver come descritto nella Tabella II.7.
Nel caso di zero interleaver viene utilizzata la sequenza valida per lo short
interleaver.
Short interleave Long interleave Bit rate
D1 D2 D1 D2
4800 7 6 - -
2400
(Secure Voice) 7 7 - -
2400
(Data) 6 4 4 4
1200 6 5 4 5
600 6 6 4 6
300 6 7 4 7
150 7 4 5 4
75 7 5 5 5
Tabella II.7 Assegnazione di un simbolo della costellazione 8-PSK ai simboli di designazione D1 e D2
Capitolo II Forma d’onda proposta
38
D1 o D2 Tribit numbers
000 (0) (0000 0000) ripetuto 2 volte
001 (1) (0404 0404) ripetuto 2 volte
010 (2) (0044 0044) ripetuto 2 volte
011 (3) (0440 0440) ripetuto 2 volte
100 (4) (0000 4444) ripetuto 2 volte
101 (5) (0404 4040) ripetuto 2 volte
110 (6) (0044 4400) ripetuto 2 volte
111 (7) (0440 4004) ripetuto 2 volte
Tabella II.8 Mapping del simbolo 8-PSK assegnato a D1 o D2; a sinistra il simbolo 8-PSK risultante dalla
Tabella II.7; a destra il suo mapping
II.6 Preambolo di SYNC
Il preambolo di sincronizzazione sarà composto da 3 o 24 (rispettivamente nel
caso di zero e short interleaver oppure nel caso di long interleaver) segmenti della
durata temporale di 200 millisecondi. Ogni segmento consiste nella trasmissione di 15
tribit channel symbols.
La sequenza di 15 simboli è: 0, 1, 3, 0, 1, 3, 1, 2, 0, D1, D2, C1, C2, C3, 0.
A D1 e D2 verranno assegnati dei tribit channel symbols secondo quanto
specificato nella Tabella II.7. Questi valori designeranno il bit rate e il tipo di interleave
utilizzato dal modem trasmittente.
I 3 simboli C1, C2, C3 rappresentano un indice di conteggio relativamente alla
posizione del singolo segmento nella sequenza di 3 o 24 segmenti.
Il conteggio parte dal valore massimo (2 o 23) e decresce fino ad arrivare a zero
nell’ultimo segmento della sequenza.
Capitolo II Forma d’onda proposta
39
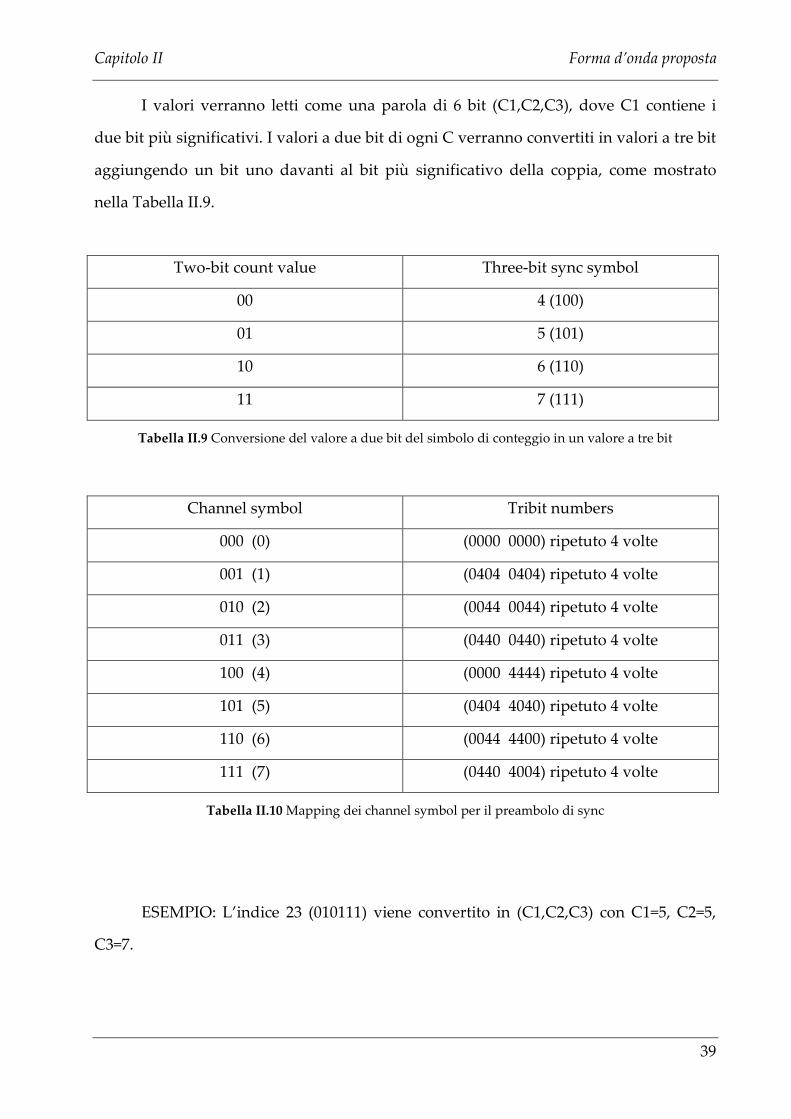
I valori verranno letti come una parola di 6 bit (C1,C2,C3), dove C1 contiene i
due bit più significativi. I valori a due bit di ogni C verranno convertiti in valori a tre bit
aggiungendo un bit uno davanti al bit più significativo della coppia, come mostrato
nella Tabella II.9.
Two-bit count value Three-bit sync symbol
00 4 (100)
01 5 (101)
10 6 (110)
11 7 (111)
Tabella II.9 Conversione del valore a due bit del simbolo di conteggio in un valore a tre bit
Channel symbol Tribit numbers
000 (0) (0000 0000) ripetuto 4 volte
001 (1) (0404 0404) ripetuto 4 volte
010 (2) (0044 0044) ripetuto 4 volte
011 (3) (0440 0440) ripetuto 4 volte
100 (4) (0000 4444) ripetuto 4 volte
101 (5) (0404 4040) ripetuto 4 volte
110 (6) (0044 4400) ripetuto 4 volte
111 (7) (0440 4004) ripetuto 4 volte
Tabella II.10 Mapping dei channel symbol per il preambolo di sync
ESEMPIO: L’indice 23 (010111) viene convertito in (C1,C2,C3) con C1=5, C2=5,
C3=7.

Capitolo II Forma d’onda proposta
40
Abbiamo a questo punto ottenuto una sequenza di tribit channel symbols
ciascuno dei quali verrà mappato in 32 tribit numbers appartenenti alla costellazione
8-PSK cosi come specificato nella Tabella II.10.
II.7 Scrambler
Ai tribit numbers in uscita al formatore di simbolo vengono sommati modulo 8 i
tribit numbers forniti o dal generatore della sequenza random di dati o dal generatore
della sequenza random di sync.
II.7.1 Generatore della sequenza random dei dati
Il generatore della sequenza random di dati è un registro a scorrimento il cui
schema funzionale è mostrato nella Figura II.4.
All’inizio del data phase lo shift register viene caricato con la sequenza iniziale
(101110101101) mostrata in Figura II.4 e fatto scorrere in avanti 8 volte.
Il simbolo formato dai 3 bit evidenziati in Figura II.4 costituisce il primo simbolo
(un numero tra 0 e 7) della sequenza generata dallo scrambler. Il secondo simbolo della
sequenza viene generato facendo scorrere in avanti il registro per 8 volte e così via per
ogni nuovo simbolo.
Quindi lo scorrimento di 8 posizioni in avanti avviene con cadenza pari al
periodo di simbolo. Dopo i primi 160 simboli generati dal registro, esso viene resettato e
reinizializzato con i valori che conteneva prima dell’ultimo scorrimento in avanti di 8
posizioni.
Questo procedimento produce una sequenza periodica di 160 simboli.

Capitolo II Forma d’onda proposta
41
1
0
1
1
1
0 +
1
0
1 +
1
0 +
1
MSB
Middle Bit
LSB
Figura II.4 Diagramma funzionale del randomizing shift register
II.7.2 Generatore della sequenza random di SYNC
Viene ripetuta periodicamente la stessa sequenza di 32 simboli: 7 4 3 0 5 1 5 0 2 2
1 1 5 7 4 3 5 0 2 6 2 1 6 2 0 0 5 0 5 2 6 6.
Le sequenze generate dallo scrambler verranno sommate modulo 8 alla sequenza
in uscita dal formatore di simbolo.

Capitolo II Forma d’onda proposta
42
II.8 Modulazione 8-PSK
La modulazione usata è la 8-PSK; la mappatura dei simboli è mostrata in
Tabella II.11.
Simbolo Fase In fase In quadratura
0 0 1.000000 0.000000
1 π/4 0.707107 0.707107
2 π/2 0.000000 1.000000
3 3π/4 -0.707107 0.707107
4 π -1.000000 0.000000
5 5π/4 -0.707107 -0.707107
6 3π/2 0.000000 -1.000000
7 7π/4 0.707107 -0.707107
Tabella II.11 Mappatura dei simboli 8PSK
Nella tabella di Tabella II.12 sono mostrate sinteticamente le principali
caratteristiche della forma d’onda generata.

Capitolo II Forma d’onda proposta
43
INFORMATION RATE
CODING RATE
CHANNEL RATE
BITS/CHANNEL SYMBOL
8 PHASE SYMBOL PER
CHANNEL SYMBOL
UNKNOWN SYMBOLS
KNOWN SYMBOLS
4800 bps --- 4800 3 1 32 16
2400 bps 1/2 4800 3 1 32 16
1200 bps 1/2 2400 2 1 20 20
600 bps 1/2 1200 1 1 20 20
300 bps 1/4 1200 1 1 20 20
150 bps 1/8 1200 1 1 20 20
75 bps 1/2 150 2 32 all 0
Tabella II.12 Caratteristiche della forma d’onda
Da notare, infine, che il tempo per trasmettere i simboli di dati appartenenti ad
un singolo blocco interlivato è (32*240)/2400=3,2 secondi mentre quello per trasmettere
l’intera trama è di 11520/2400= 4,8 secondi .
Definito il throughput come payload
payload overheadρ =
+, in cui i simboli di
overhead sono costituiti dai minipreamboli ciascuno lungo Lpre, si ha per la trama
proposta: Lpre =16 e Ldata =32: ρ=0,66.
II.9 Filtri sagomatori a coseno rialzato
Il ruolo dei filtri di modulazione è quello di costringere la forma d’onda ad
occupare una banda predeterminata. Attualmente, viene usato un filtro sagomatore a
radice di coseno rialzato con un fattore di roll-off (banda in eccesso) del 35%.
Utilizzando questo filtro sia in trasmissione che in ricezione si ottiene la
massimizzazione del rapporto segnale-rumore e la minimizzazione dell’interferenza
intersimbolica.

Capitolo II Forma d’onda proposta
44
Questo filtro ha la seguente risposta in frequenza:
( )
( ) ( ) ( ){ }( )
1
0.5 1 sin / 2
0
n n
n n n n n n
H f f f pf
H f f f pf f pf f f pf
H f altrove
π
= ≤ −
= − − − ≤ ≤ +
=
(II.1)
dove nf è la frequenza di Nyquist ( nf = 1/2T) = 1200 Hz e p è il fattore di roll-off.
I filtri di mo-demodulazione sono realizzati effettuando semplicemente la
radice quadrata della risposta in frequenza precedentemente definita.

Capitolo III L’equalizzazione di canale
45
Capitolo III
L’EQUALIZZAZIONE
DI CANALE
III.1 Modello dei canali con ISI [Pro 95] [3.]
L’inviluppo complesso di segnale per qualunque tecnica di modulazione digitale
ha la forma
0
( ) ( )nn
v t I g t nT+∞
=
= −∑ (III.1)
dove { nI } rappresenta la sequenza di informazione discreta dei simboli e g(t) è un
impulso che, per i propositi di questa discussione, è assunto che abbia una risposta in
frequenza G(f) limitata in banda, i.e., G(f)=0 per|f|>W. Questo segnale è trasmesso su
un canale che ha una risposta in frequenza C(f), anche essa limitata a |f| ≤ W.
Conseguentemente, il segnale ricevuto può essere rappresentato come
0
( ) ( ) ( )l nn
r t I h t nT z t+∞
=
= − +∑ (III.2)
dove,
( ) ( ) ( )h t g c t dτ τ τ+∞
−∞
= −∫ (III.3)
e z(t) rappresenta il rumore Gaussiano bianco additivo.

Capitolo III L’equalizzazione di canale
46
Si supponga che il segnale ricevuto sia passato precedentemente in un filtro e poi
campionato ad una frequenza di 1/T campioni/sec. Sappiamo che il filtro ottimo dal
punto di vista della rivelazione del segnale è quello adattato all’impulso ricevuto. La
risposta in frequenza del filtro in ricezione è H*(f). L’uscita del filtro di ricezione quindi
è:
0
( ) ( ) ( )nn
y t I x t nT tν+∞
=
= − +∑ (III.4)
dove x(t) è l’impulso rappresentante la risposta del filtro ricevente all’impulso di
ingresso h(t) e ν(t) è la risposta del filtro ricevente al rumore z(t).
Adesso, se y(t) è campionato al tempo t = kT + 0τ , k = 0,1,…, abbiamo
0 0 00
( ) ( ) ( )k nn
y kT y I x kT nT kTτ τ ν τ+∞
=
+ ≡ = − + + +∑ (III.5)
oppure, equivalentemente,
0
0,1,...k n k n kn
y I x kν+∞
−=
= + =∑ (III.6)
dove 0τ è il ritardo di trasmissione attraverso il canale.
I valori campionati possono essere espressi come
( )00,0
1k k n k n k
n n k
y x I I xx
ν+∞
−= ≠
= + +∑ (III.7)

Capitolo III L’equalizzazione di canale
47
Consideriamo x 0 come un arbitrario fattore di scala, che arbitrariamente
settiamo ad uno per convenienza.
Quindi
0,0
1k k n k n k
n n k
y I I xx
ν+∞
−= ≠
= + +∑ (III.8)
Il termine kI rappresenta il simbolo di informazione desiderato al k-mo istante di
campionamento, il termine
0,
n k nn n k
I x+∞
−= ≠
∑ (III.9)
rappresenta l’interferenza di intersimbolo (ISI), e kν è la variabile di rumore gaussiano
additivo al k-mo istante di campionamento.
L’ISI causa la chiusura del diagramma ad occhio con una conseguente riduzione
del margine d’errore per il rumore additivo. Noto che l’ISI distorce la posizione degli
attraversamenti dello zero e riduce l’apertura dell’occhio, ciò porta il sistema ad essere
più sensibile ad errori di sincronizzazione e al rumore.
Nel trattare con canali limitati in banda che presentano ISI è conveniente
sviluppare un modello tempo-discreto equivalente per il sistema analogico (tempo
continuo). Dal momento che il trasmettitore invia simboli a tempo-discreto alla
frequenza di 1/T simboli/sec e che anche l’uscita campionata del filtro adattato al
ricevitore è un segnale tempo-discreto con campioni ottenuti ad un tasso di 1/T simboli
per secondo, ne segue che la cascata del filtro analogico al trasmettitore con risposta
impulsiva g(t), del canale con risposta impulsiva c(t), del filtro adattato al ricevitore con
risposta impulsiva h*(-t), e del campionatore può essere rappresentata tramite un filtro
trasversale tempo-discreto equivalente avendo per coefficienti di guadagno dei tappi
{x k }.
Capitolo III L’equalizzazione di canale
48
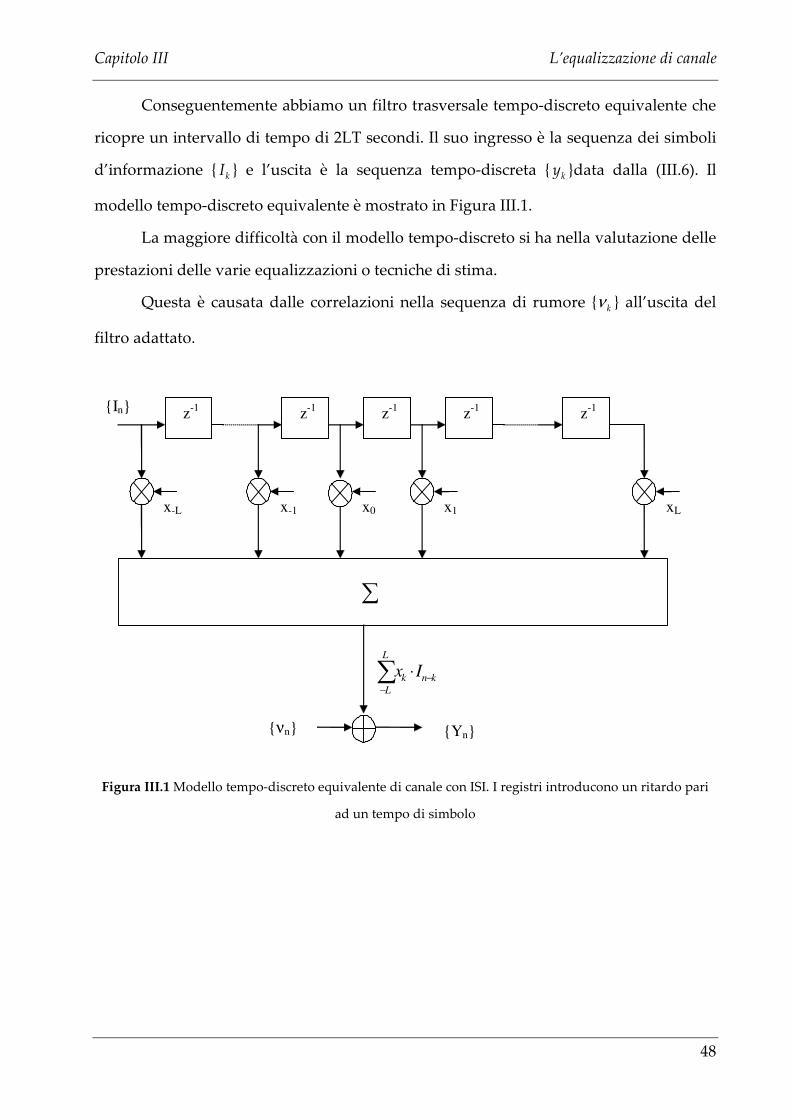
Conseguentemente abbiamo un filtro trasversale tempo-discreto equivalente che
ricopre un intervallo di tempo di 2LT secondi. Il suo ingresso è la sequenza dei simboli
d’informazione { kI } e l’uscita è la sequenza tempo-discreta { ky }data dalla (III.6). Il
modello tempo-discreto equivalente è mostrato in Figura III.1.
La maggiore difficoltà con il modello tempo-discreto si ha nella valutazione delle
prestazioni delle varie equalizzazioni o tecniche di stima.
Questa è causata dalle correlazioni nella sequenza di rumore { kν } all’uscita del
filtro adattato.
{In}
{Yn}
xL x1 x0 x-1 x-L
∑
z-1 z-1 z-1 z-1 z-1
{νn}
∑−
−⋅L
L
knk Ix
Figura III.1 Modello tempo-discreto equivalente di canale con ISI. I registri introducono un ritardo pari
ad un tempo di simbolo

Capitolo III L’equalizzazione di canale
49
L’insieme delle variabili di rumore { kν } è una sequenza con distribuzione
gaussiana con media nulla e funzione di autocorrelazione
( )( )
( )
012 0
k j
k j
N x k j LE
altrimentiν ν
−∗ − ≤
=
(III.10)
Adesso la sequenza di rumore è correlata eccetto kx =0, k ≠ 0.
Dato che è più conveniente trattare con la sequenza di rumore bianco quando si
sta calcolando la prestazione del tasso d’errore, è desiderabile sbiancare la sequenza di
rumore con un ulteriore filtraggio della sequenza { ky }. Il filtro sbiancante tempo-
discreto è determinato come segue.
Consideriamo con X(z) la trasformata z (bilatera) della funzione di
autocorrelazione campionata { kx }, i.e.,
( )L
kk
k L
X z x z−
=−
= ∑ (III.11)
Dato che k kx x∗−= , ne segue che X(z)=X*(z 1− ) e le 2L radici di X(z) hanno la
simmetria tale che se ρ è una radice anche 1/ρ* lo è. Adesso X(z) può essere fattorizzata
ed espressa come
* 1( ) ( ) ( )X z F z F z−= (III.12)
dove F(z) è un polinomio di grado L con radici 1ρ , 2ρ ,…, Lρ e F*(z 1− ) è un polinomio di
grado L con radici 1/ 1ρ *, 1/ 2ρ *,…,1/ Lρ *. Poi un filtro sbiancante appropriato ha per
trasformata z 1/F*(z 1− ). Dato che ci sono 2L possibili scelte di radici per F*(z 1− ), ogni
scelta corrisponde ad una caratteristica di filtro che è identica in modulo ma differente
in fase dalle altre scelte di radici, proponiamo di scegliere l’unica F*(z 1− ) avente fase
minima, i.e., il polinomio avente tutte le sue radici nel cerchio unitario. Così, quando
tutte le radici di F*(z 1− ) sono nel cerchio unitario, 1/F*(z 1− ) è un filtro tempo-discreto,
Capitolo III L’equalizzazione di canale
50
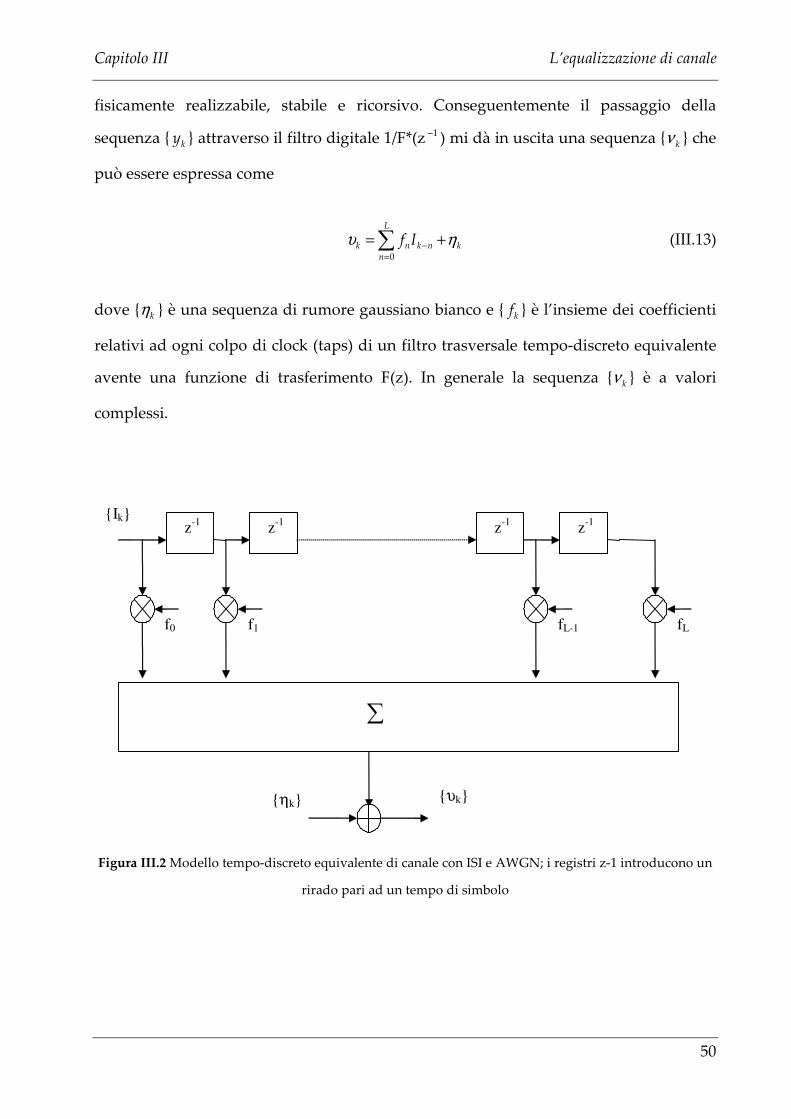
fisicamente realizzabile, stabile e ricorsivo. Conseguentemente il passaggio della
sequenza { ky } attraverso il filtro digitale 1/F*(z 1− ) mi dà in uscita una sequenza { kν } che
può essere espressa come
0
L
k n k n kn
f Iυ η−
=
= +∑ (III.13)
dove { kη } è una sequenza di rumore gaussiano bianco e { kf } è l’insieme dei coefficienti
relativi ad ogni colpo di clock (taps) di un filtro trasversale tempo-discreto equivalente
avente una funzione di trasferimento F(z). In generale la sequenza { kν } è a valori
complessi.
{Ik}
fL fL-1 f1 f0
∑
z-1 z-1 z-1 z-1
{υk} {ηk}
Figura III.2 Modello tempo-discreto equivalente di canale con ISI e AWGN; i registri z-1 introducono un
rirado pari ad un tempo di simbolo

Capitolo III L’equalizzazione di canale
51
In conclusione, la cascata del filtro di trasmissione g(t), il canale c(t), il filtro
adattato h*(-t), il campionatore ed il filtro sbiancante tempo-discreto 1/ F*(z 1− ) può
essere rappresentato come un filtro trasversale tempo-discreto equivalente avente
l’insieme { kf } come “taps coefficients” (detti brutalmente tappi).
La sequenza di rumore additivo { kη } che corrompe l’uscita del filtro trasversale
tempo-discreto è una sequenza di rumore gaussiana bianca avente media nulla e
varianza N 0 . La Figura III.2 illustra il modello del sistema tempo-discreto equivalente
con rumore bianco (AWGN).
III.2 Equalizzazione lineare [Pro95] [3.]
È il metodo più semplice per compensare l’ISI introdotta da un canale. Un tipo di
approccio impiega un filtro trasversale lineare la cui struttura ha una complessità che è
una funzione lineare della lunghezza di dispersione del canale L.
Il filtro lineare più usato per l’equalizzazione è il filtro trasversale mostrato in
Figura III.3. Il suo ingresso è la sequenza { kυ } data in (III.13) e la sua uscita è la stima
della sequenza d’informazione { kI }. La stima del k-mo simbolo può essere espressa
come
ˆk
k j k jj k
I c υ −=−
= ∑ (III.14)
dove { jc } sono i 2K+1 tappi complessi del filtro.
La stima ˆkI è quantizzata (in distanza) al simbolo di informazione più vicino per
formare la decisione kI% . Se kI% non è identico al simbolo di informazione trasmesso kI
vuol dire che è stato commesso un errore.
Una ricerca considerevole è stata fatta sul criterio per l’ottimizzazione dei
coefficienti dei filtri { jc }.

Capitolo III L’equalizzazione di canale
52
Dato che la misura di prestazione più significativa per un sistema di
comunicazioni digitale è la probabilità d’errore media, è desiderabile scegliere i
coefficienti per minimizzare questo indice di prestazione.
{υk}
∑
z-1 z-1 z-1 z-1
Algoritmo per la regolazione del
guadagno dei “taps”
c-2 c-1 c0 c1 c2
+
Uscita equalizzata
{Îk}
Figura III.3 Filtro trasversale lineare
Comunque, la probabilità d’errore è una funzione di { jc } altamente non lineare e
conseguentemente impraticabile come indice di prestazione per l’ottimizzazione dei
coefficienti di peso dei tappi.

Capitolo III L’equalizzazione di canale
53
III.3 Canale AWGN con rivelatore a soglia (slicer)
Le simulazioni effettuate e quindi le relative curve e tabelle di prestazioni per i
vari formati di modulazione fanno riferimento ad un canale di tipo AWGN. In queste
curve l’SNR è espresso come rapporto tra l’energia del bit media Eb e la varianza del
rumore N 0 ; si è ottenuto poi dal simulatore il SER (Simbol Error Rate) relativo ad ogni
valore di Eb/N 0 .
Lo schema a blocchi del modem usato nelle simulazioni è rappresentato dalla
Figura III.4.
Essendo il canale supposto di tipo AWGN e dato che i segnali sono modulati il
rumore sarà descritto da un segnale complesso, ciò significa che occorre generare due
sorgenti di rumore in modo indipendente fra di loro. Le prestazioni sono calcolate al
variare dell’ SNR che, essendo i segnali normalizzati in energia, si può scrivere come
10N − ; di conseguenza fissato il rapporto segnale/rumore in dB si calcola la varianza del
rumore come 100 10
SNR
N−
= . Il valore ( )12
00.5 N è usato per pesare i valori reali distribuiti
secondo una gaussiana a varianza unitaria generati da una funzione della libreria del
linguaggio C. In questo modo si generano le due componenti analogiche di bassa
frequenza del rumore a potenza 0N .
Nelle ipotesi semplificative dell’ambiente di simulazione di Figura III.4, il
demodulatore, che ha lo scopo di estrarre dalle componenti analogiche di bassa
frequenza il simbolo trasmesso, si riduce ad un decisore che lavora simbolo a simbolo.
Per le modulazioni QPSK e 8-PSK il decisore deve estrarre, a partire dalle
componenti in fase ed in quadratura del segnale ricevuto, la fase di questo numero
complesso e poi decidere a quale settore circolare appartenga, quindi associargli il
punto di costellazione. Fare ciò equivale a trovare il punto di costellazione a minima
distanza da quello ricevuto. Per le QAM si è proceduto, invece, adottando direttamente

Capitolo III L’equalizzazione di canale
54
il metodo della minima distanza calcolando la distanza del punto ricevuto da tutti i
punti di costellazione e associandogli il più vicino.
si+jsj
wi+jwj
ri+jrj
S Mappatore
Demodulatore
Calcolo del SER
si+jsj
bits simb
simb
Modulatore
Generatore della trama
Figura III.4 Schema a blocchi del modem software con AWGN
Questo modo di agire obbliga a eseguire tutti i confronti ed in particolare per la
64-QAM si nota un certo aumento del tempo di simulazione che si può ridurre
scegliendo prima il quadrante di appartenenza del punto ricevuto per poi al suo interno
applicare il metodo della minima distanza, riducendo così il numero di confronti medio
di un fattore 4.
Per le simulazioni si è proceduto nel seguente modo: per ogni tipo di
modulazione si è fatto variare l’SNR in un certo intervallo ed è stato misurato il SER
(Symbol Error Rate), cioè il numero dei simboli errati diviso il numero totale dei simboli
relativi ai dati d’utente.
Il secondo passo è stato quello di verificare la bontà delle prestazioni misurate.
Per fare ciò viene effettuata una comparazione tra i grafici ottenuti e quelli già riportati
nei testi di telecomunicazioni per le modulazioni previste e per il canale AWGN. I testi
considerati sono stati [Pro95] [3.]e [Ben90] [2.].

Capitolo III L’equalizzazione di canale
55
Il grafico di Figura III.5 e la Tabella III.1 sono stati ottenuti simulando 10 trame
per un equivalente di 184320 simboli relativi ai dati di utente.
Eb/ 0N
(dB) SER
Q-PSK SER
8-PSK SER
16-QAM SER
32-QAM SER
64-QAM -4 3,39E-01 5,47E-01 6,82E-01 7,89E-01 8,72E-01 0 1,52E-01 3,48E-01 4,88E-01 6,34E-01 7,63E-01 4 2,51E-02 1,38E-01 2,29E-01 3,86E-01 5,64E-01 8 4,83E-04 1,84E-02 4,20E-02 1,23E-01 2,78E-01
12 - 1,30E-04 1,06E-03 9,29E-03 5,41E-02 16 - - - 1,63E-05 1,29E-03
Tabella III.1 Ser per canale AWGN con slicer per diverse modulazioni
1,E-05
1,E-04
1,E-03
1,E-02
1,E-01
1,E+00
-4,00 0,00 4,00 8,00 12,0 16,0Eb/No
Ser
serqpsk
ser8psk
ser16qam
ser32qam
ser64qam
Figura III.5 SER per canale AWGN con slicer per diverse modulazioni

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
56
Capitolo IV
EQUALIZZAZIONE BASATA SUL
“CONSTANT MODULUS
ALGORITHM”
IV.1 Principi di funzionamento ed applicazione su canale
tempo invariante
Si considerino in prima istanza canali descritti da risposta impulsiva di tipo FIR a
2 coefficienti, come descritto in Figura IV.1.
C(0)=1
C(1)=α
Figura IV.1 Canale tempo invariante, con α che nelle simulazioni ha assunto valori 0.2,0.5, 0.8
Nelle simulazioni si è considerata la trasmissione di 70 long interleaver blocks al
rate di 2400 bps, con tramatura appartenente allo standard MIL-STD-188-110A. In totale
quindi, fra preambolo di sincronizzazione iniziale, miniprobe di canale e miniblocchi

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
57
informativi, sono stati trasmessi nel canale 818 Ksimboli appartenenti ad una
costellazione 8-PSK.
Come è mostrato in Figura IV.2, in ricezione è stato introdotto un blocco AGC
che effettua una normalizzazione in potenza del segnale ricevuto. Infatti dalle
simulazioni è risultato che l’equalizzatore basato sul CMA è molto sensibile a variazioni
di ampiezza nel segnale di ingresso, nel senso che rapidamente gli aggiornamenti dei
coefficienti del FF portano a una situazione di overflow non appena la potenza ricevuta
cresce. Adattando il δ di aggiornamento alla potenza di ingresso non si è riuscito a
rendere superflua la presenza dell’AGC. A valle dell’AGC c’è il filtro FIR che equalizza
il canale.
AGC FF filter
Calcolo
ky2
+
-
+ 1
errore
r(k)
uscita
Figura IV.2 Schema del ricevitore: AGC ed equalizzatore CMA
L’uscita del FF viene poi utilizzata per il calcolo di un termine di errore che è
tanto più alto quanto più il modulo dell’uscita del FF è diverso dall’unità. Tale errore è
utilizzato per il calcolo della configurazione successiva dei coefficienti del FF filter,
secondo la relazione vettoriale (Rif. [JCS] [7.]):

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
58
( ) ( )2* 1k ky yδ+ = + ⋅ ⋅ ⋅ −k 1 k kf f r (IV.1)
Nelle simulazioni viene indicato con SER il Symbol Error Rate definito come
_
7680 * _n errori
sern blocchi
= (IV.2)
dove 7680 è il numero di simboli 8-PSK che portano informazione in ogni blocco. Tali
simboli non sono però trasmessi consecutivamente, ma sono intervallati con simboli di
training come mostrato in Figura IV.3
sync (11520) 32 16 32 16 32 16… …… . 32 16 32 16 32 16… … … .…… .
Blocco
# ( Nb locchi-1 )
B locco
#0
Figura IV.3 Struttura della trama in trasmissione. In celeste si denotano i simboli che portano
informazione, in verde i simboli di training

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
59
IV.1.1 Canale tempo invariante a due coefficienti reali
Canale (1; 0.2)
Parametri della simulazione Figura IV.4:
• Dimensione del filtro FF 3
• Delta di aggiornamento 0.002
• Numero di blocchi informativi della simulazione 70
1,0E-07
1,0E-06
1,0E-05
1,0E-04
1,0E-03
1,0E-02
1,0E-01
1,0E+00
0 5 10 15 20 25
snr(dB)
se
r
Figura IV.4 Risultati per canale 1-0,2; Lunghezza FF=3; delta=0.002. Validi anche in presenza di Phase
recovery e di stimatore di ritardo
Commenti ai risultati di Figura IV.4:
i. aumentando il numero di registri di FF, non c’è miglioramento del SER;
ii. cambiando δ non si ha miglioramento.
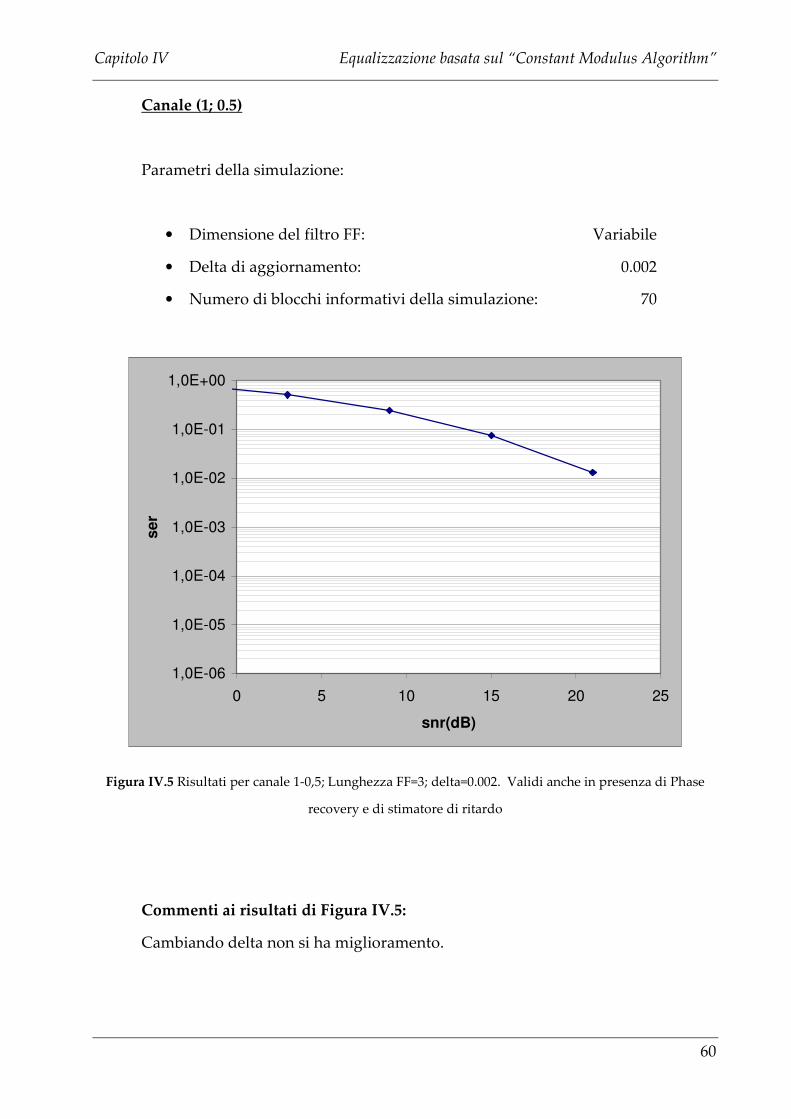
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
60
Canale (1; 0.5)
Parametri della simulazione:
• Dimensione del filtro FF: Variabile
• Delta di aggiornamento: 0.002
• Numero di blocchi informativi della simulazione: 70
1,0E-06
1,0E-05
1,0E-04
1,0E-03
1,0E-02
1,0E-01
1,0E+00
0 5 10 15 20 25
snr(dB)
ser
Figura IV.5 Risultati per canale 1-0,5; Lunghezza FF=3; delta=0.002. Validi anche in presenza di Phase
recovery e di stimatore di ritardo
Commenti ai risultati di Figura IV.5:
Cambiando delta non si ha miglioramento.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
61
Ser per canale tempo invariante 1-0.5; AGC+CMA a 9
coeff.; delta=0.002
1,0E-07
1,0E-06
1,0E-05
1,0E-04
1,0E-03
1,0E-02
1,0E-01
1,0E+00
0 5 10 15 20 25
snr(dB)
se
r
CMA
dim_FF=9
CMA
dim_FF=3
DFE 5,3;
delta 0.002
AWGN
Figura IV.6 Risultati per canale 1-0,5; Lunghezza FF=9; FF=3; delta=0.002
Commenti ai risultati di Figura IV.6:
i. aumentando il numero di registri di FF, c’è miglioramento del Ser;
ii. cambiando delta non si ha miglioramento.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
62
IV.1.2 Canale tempo invariante a due coefficienti
generalmente complessi
Parametri della simulazione:
• Dimensione del filtro FF: Variabile
• Delta di aggiornamento: 0.002
• Numero di blocchi informativi della simulazione: 70
• I coefficienti del canale simulato sono : g0: 0.15 +j*0.66
g1:-0.05+j*(-0.2)
Lo schema proposto in Figura IV.2 ha mostrato di non essere adeguato ad evitare
la convergenza del filtro ad una configurazione che ruota la costellazione trasmessa,
come evidenziato in Figura IV.7.
-1,5
-1
-0,5
0
0,5
1
1,5
-1,5 -1 -0,5 0 0,5 1 1,5
Figura IV.7 Costellazione trasmessa ed uscita della TDL (Tapped Delay Line). La rotazione di fase fa
varcare il confine di decisione ai simboli in uscita all’equalizzatore. Dim_ff=5; delta di
aggiornamento=0.002

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
63
Altre simulazioni sono state effettuate considerando altri canali sempre a due
coefficienti non reali e si è evidenziato lo stesso problema. Non si esclude che,
cambiando opportunamente la inizializzazione della TDL (Tapped Delay Line), anche
con questo canale l’equalizzatore CMA di Figura IV.2 possa portare alla inversione MSE
(Mean Square Error) del canale. Tuttavia si è ritenuto più semplice ovviare a questa
problematica adottando uno schema CMA del tipo di quello in Figura IV.8.
AGC FF filter
Calcolo
ky
+
-
+ 1
errore
r(k) ej*φ
Figura IV.8 Schema del CMA, con rotatore di fase per allineare l’uscita della TDL alla costellazione 8-PSK trasmessa
La fase di cui ruota l’uscita del filtro FIR è calcolata alla fine del training iniziale,
confrontando la fase dell’ultimo simbolo della sequenza di SYNC trasmesso con la fase
dell’uscita della TDL alla fine del training iniziale. Essendo il canale tempo invariante
non è necessario aggiornare il blocco rotatore di fase adattativamente. Tale modo di
operare ha tuttavia un limite ; perché tutto funzioni correttamente è necessario che al
momento del “phase recovery” la TDL sia arrivata alla convergenza e che il canale non
vari più in modo consistente. Se tali ipotesi sussistessero, le curve del SER
coinciderebbero con quelle relative al canale a due coeff. reali, mostrate in Figura IV.4,
Figura IV.5, Figura IV.6.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
64
IV.1.3 Equalizzatore CMA con algoritmo di “Phase
recovery” adattativo
Come già visto, l’algoritmo di equalizzazione adattativo CMA può portare i
coefficienti del filtro FF a convergere ad una configurazione ruotata rispetto a quella che
inverte il canale secondo il criterio MSE. Allo scopo di compensare tale rotazione di fase
si è introdotto nello schema di Figura 9 un anello di “phase recovery”.
AGC FF filter
Calcolo
ky2
+
-
+ 1
errore
r(k) ky
φje
∑∞−
⋅k
)(16
1
+
training seq.
-
Φ(k)
0
TRAINING_FLAG
Figura IV.9 Schema concettuale dell’equalizzatore CMA con anello di phase recovery

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
65
La parte superiore mette in evidenza l’anello di reazione che effettua il vero e
proprio phase recovery, cioè la stima della rotazione di fase introdotta dal canale
convoluto col filtro FF, stima effettuata sulla base della sequenza in ingresso al decisore
8-PSK. Durante i periodi relativi alla ricezione del training (sia esso training iniziale di
SYNC che training di CHANNEL PROBE, vedi Figura IV.3), viene confrontata la fase di
ciò che si presenta all’ingresso del decisore con la fase che avrebbe dovuto avere tale
ingresso che per ipotesi è nota in quanto il training si suppone noto a chi riceve. Tale
confronto viene effettuato a tempo di simbolo per tutta la durata del training che, data
la forma d’onda utilizzata è di 16 intervalli di simbolo. Il risultato di ogni confronto
viene diviso per il numero di confronti effettuati ad ogni training e quindi accumulato
nel blocco accumulatore. Durante le fasi informative l’accumulatore non cambia il suo
stato, e ciò nello schema è messo in evidenza dall’interruttore che commuta all’ingresso
zero. Infatti non è possibile fare phase recovery durante le fasi informative, in quanto
non è noto ciò che è stato trasmesso.
Indicando con ( )kϕ , ( )1kϕ + , rispettivamente le uscite dell’ accumulatore alla fine
del k-mo e del (k+1)-mo intervallo di training (che rappresentano le stime della
rotazione di fase introdotta dal canale convoluto col filtro FF), sussiste quindi la
seguente relazione:
( 1) ( ) ( )1
16φ φ φ+ = + ⋅ ∆∑k k j
j
(IV.3)
ove la sommatoria degli scarti di fase è estesa a tutto il training (k+1)-mo. La
moltiplicazione per 1/16 è fatta per mediare gli scarti di fase calcolati, onde rendere più
affidabile la stima della rotazione di fase. Lo stato iniziale dell’ accumulatore è posto a
zero.
Nella Figura IV.10 sono graficate le prestazioni di tale sistema in presenza di
rumore AWGN, per il momento ferma restando l’ipotesi di canale con raggio ritardato
più piccolo del raggio principale (risposta a fase minima).
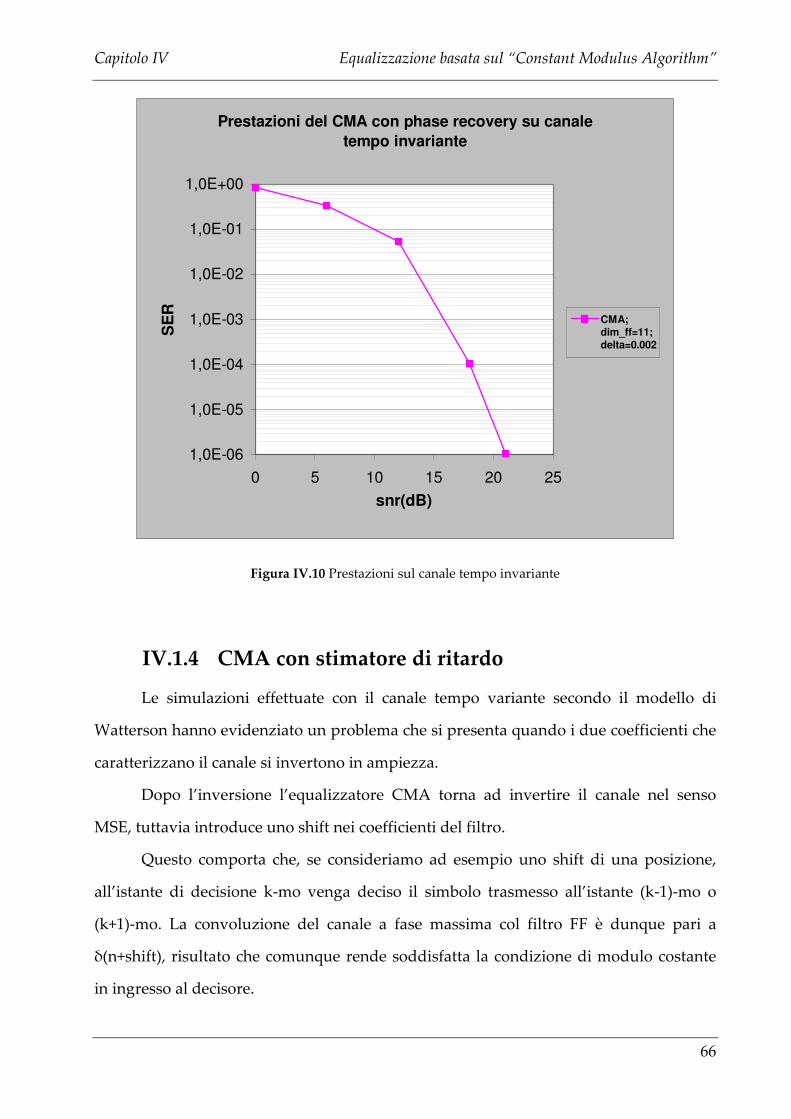
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
66
Prestazioni del CMA con phase recovery su canale
tempo invariante
1,0E-06
1,0E-05
1,0E-04
1,0E-03
1,0E-02
1,0E-01
1,0E+00
0 5 10 15 20 25
snr(dB)
SE
R
CMA;dim_ff=11;
delta=0.002
Figura IV.10 Prestazioni sul canale tempo invariante
IV.1.4 CMA con stimatore di ritardo
Le simulazioni effettuate con il canale tempo variante secondo il modello di
Watterson hanno evidenziato un problema che si presenta quando i due coefficienti che
caratterizzano il canale si invertono in ampiezza.
Dopo l’inversione l’equalizzatore CMA torna ad invertire il canale nel senso
MSE, tuttavia introduce uno shift nei coefficienti del filtro.
Questo comporta che, se consideriamo ad esempio uno shift di una posizione,
all’istante di decisione k-mo venga deciso il simbolo trasmesso all’istante (k-1)-mo o
(k+1)-mo. La convoluzione del canale a fase massima col filtro FF è dunque pari a
δ(n+shift), risultato che comunque rende soddisfatta la condizione di modulo costante
in ingresso al decisore.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
67
Per far fronte a tale evenienza si adopera uno stimatore di tale offset temporale
ed un elemento di ritardo pilotato con la stima effettuata. Da notare che nel software gli
anticipi della TDL sono stati considerati come ritardi negativi.
Lo schema a blocchi complessivo viene presentato in Figura 11, ove si
evidenziano in rosso i blocchi deputati al recupero del ritardo.
SEQUENZA DI TRAINING TRASMESSA (MIL-A)
……
10 2 15 ……
3 4
11
…… ……
PARTE UTILIZZATA PER LA STIMA DEL RITARDO
1 0 2 15 ……
3 4
11 …
… ……
SEQUENZA DI TRAINING ALL’USCITA DELLA
T.D.L.
OFFSET=1
5
……
Figura IV.11: Processo di correlazione fra la sequenza trasmessa e la sequenza in uscita alla T.D.L. In tale
caso il picco di correlazione si ottiene moltiplicando scalarmente l’ingresso con l’uscita anticipata di 1
campione a tempo di simbolo
Funzionamento
Lo stimatore del ritardo entra in funzione durante intervalli di training
equispaziati di 10 miniblocchi (32+16) sulla trama MIL-A. La scelta di tale valore deriva
dall’esigenza di far fronte a canali con tempo di coerenza minimo di 0.2 secondi che a
2400 baud/sec è pari alla durata di 10 miniblocchi. Per il momento è sufficiente

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
68
effettuare una stima di ritardo una volta ogni intervallo di coerenza, dato che in tale
periodo il canale non presenterà più di un inversione.
La correlazione è effettuata considerando solo la parte centrale del training di 16
simboli, dalle posizione 4 a 11. La selezione del picco di cross-correlazione conduce alla
stima dell’offset temporale, come evidenziato in Figura IV.11.
Nella figura successiva (Figura IV.12) è mostrato infine lo schema complessivo
dell’equalizzatore CMA, comprensivo di anello di “phase recovery” e di stimatore di
ritardo.
- + 1
errore
AGC FF
filter
r(k)
+
training seq.
- Φ(k)
0
TRAINING_FLAG
φje
ky
+
2
ky
Training seq.
( )∑16
1
∆
Ritardo ∆
stimatore di offset temporale
kr
Figura IV.12 Schema a blocchi dell’equalizzatore CMA, con “phase recovery” e stimatore
di offset temporale
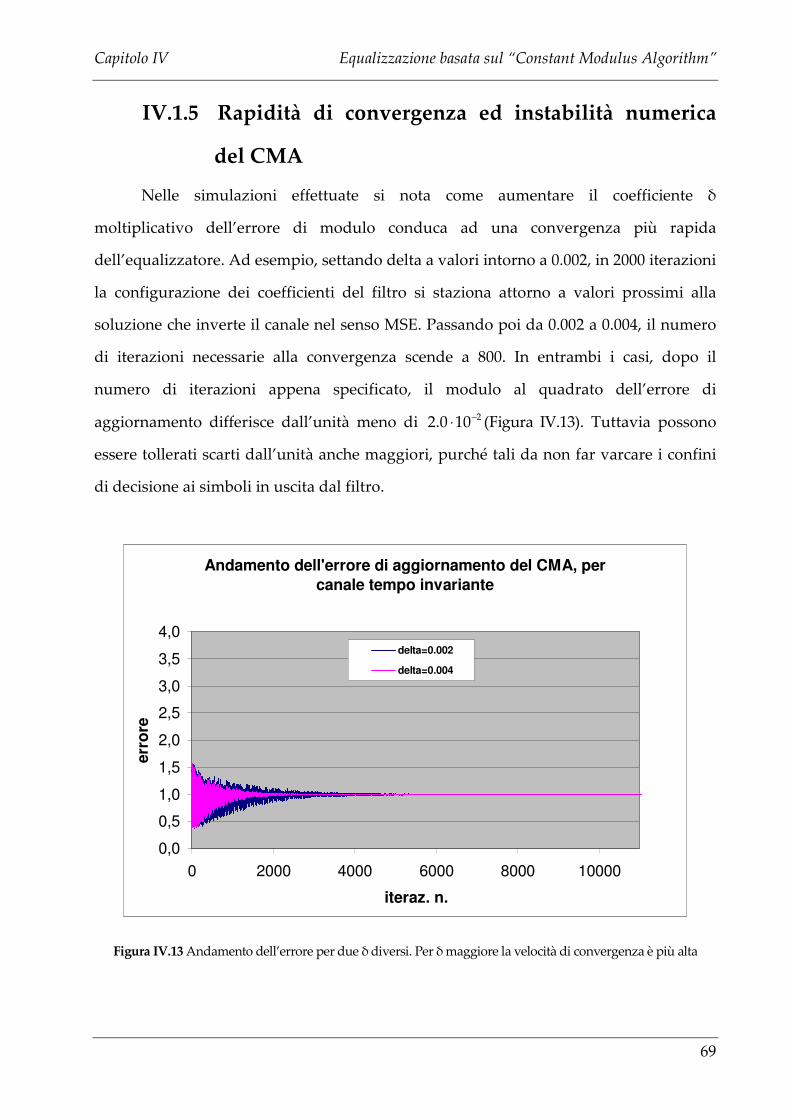
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
69
IV.1.5 Rapidità di convergenza ed instabilità numerica
del CMA
Nelle simulazioni effettuate si nota come aumentare il coefficiente δ
moltiplicativo dell’errore di modulo conduca ad una convergenza più rapida
dell’equalizzatore. Ad esempio, settando delta a valori intorno a 0.002, in 2000 iterazioni
la configurazione dei coefficienti del filtro si staziona attorno a valori prossimi alla
soluzione che inverte il canale nel senso MSE. Passando poi da 0.002 a 0.004, il numero
di iterazioni necessarie alla convergenza scende a 800. In entrambi i casi, dopo il
numero di iterazioni appena specificato, il modulo al quadrato dell’errore di
aggiornamento differisce dall’unità meno di 22.0 10−⋅ (Figura IV.13). Tuttavia possono
essere tollerati scarti dall’unità anche maggiori, purché tali da non far varcare i confini
di decisione ai simboli in uscita dal filtro.
Andamento dell'errore di aggiornamento del CMA, per
canale tempo invariante
0,0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
0 2000 4000 6000 8000 10000
iteraz. n.
err
ore
delta=0.002
delta=0.004
Figura IV.13 Andamento dell’errore per due δ diversi. Per δ maggiore la velocità di convergenza è più alta

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
70
Tuttavia valori di delta più elevati conducono prima e più facilmente a situazioni
di instabilità numerica dell’errore. Questo fenomeno è spiegabile osservando
l’equazione di aggiornamento dei coefficienti del filtro FF, che viene qui riproposta:
( ) ( )* 21δ+ = + ⋅ ⋅ ⋅ −k ky yk 1 k kf f r (IV.4)
Da tale equazione si può notare come il ruolo di δ sia analogo a quello di un
guadagno in un sistema reazionato; aumentandolo oltre una certa soglia si può
innescare un meccanismo di reazione positiva che produce instabilità. Se infatti, per
ipotesi, ad un dato istante ky dovesse diventare maggiore dell’unità il contributo del
secondo termine dell’aggiornamento crescerebbe, aumenterebbero di conseguenza i
valori dei coefficienti e ciò porterebbe l’uscita 1ky + ad essere ancora più alta (in modulo)
di ky . Iterando il ragionamento si spiega quindi l’instabilità. Dalle simulazioni emerge
come la crescita del modulo dell’errore sia di tipo esponenziale, passando in 5-6
iterazioni da valori dell’ordine di 10 0 a valori come 10 2 .
Volendo evitare fenomeni di instabilità, non rinunciando tuttavia ad avere
convergenze piuttosto rapide, si potrebbe abbassare la potenza di ingresso al filtro FF,
magari adattativamente. Tuttavia c’è da aspettarsi che tale soluzione dia prestazioni
peggiori in termini d SNR, dato che elimina parte dell’energia del segnale ricevuto.
IV.2 Equalizzazione adattativa di tipo CMA, su canale tempo
variante di Watterson
La Figura IV.14 mostra lo schema del canale utilizzato per le simulazioni, noto
come modello di Watterson semplificato. In breve, sono considerati solo due raggi
ionosferici caratterizzati ognuno da un processo di guadagno gaussiano complesso, a
valor medio nullo e di nota banda doppler. I due raggi sono ritardati fra loro di teta
secondi. Sia il ritardo che la banda doppler sono deterministici, mentre il
campionamento in ricezione è effettuato a frequenza di simbolo.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
71
Σ
X X
ritardo teta
S(t)
r(t)
g2(t) g1(t)
Ts
r(k)
Figura IV.14 Schema a blocchi del canale tempo variante utilizzato nelle simulazioni
IV.2.1 Simulazioni al calcolatore e prestazioni del CMA
nel caso di canale tempo variante
Sono state effettuate varie simulazioni, allo scopo di evidenziare il
comportamento e le prestazioni del CMA su vari canali tempo-varianti. Dapprima si è
considerato il caso di canale con banda doppler 0.5 Hz e ritardo del secondo raggio pari
ad un tempo di simbolo ( nella MIL-A è di 416 μsec.), come riassunto nella Tabella IV.1.
In si nota come il CMA riesca ad equalizzare canali a fase minima e massima, ma
non riesca ad invertire (nel senso MSE) nei momenti in cui i coefficienti del canale sono
circa uguali. Ciò è dovuto al troncamento della risposta IIR che inverte il canale,
inevitabile dal momento che si dispone di un numero finito di registri ( 11 in queste
simulazioni ).
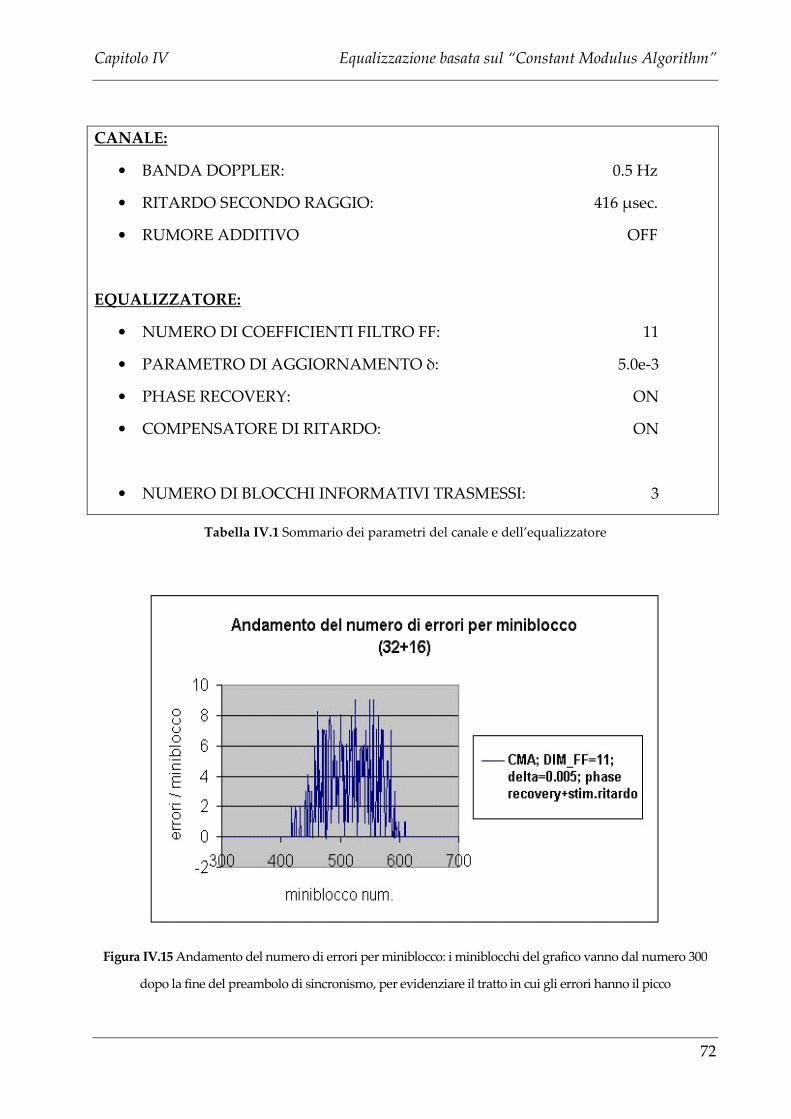
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
72
CANALE:
• BANDA DOPPLER: 0.5 Hz
• RITARDO SECONDO RAGGIO: 416 μsec.
• RUMORE ADDITIVO OFF
EQUALIZZATORE:
• NUMERO DI COEFFICIENTI FILTRO FF: 11
• PARAMETRO DI AGGIORNAMENTO δ: 5.0e-3
• PHASE RECOVERY: ON
• COMPENSATORE DI RITARDO: ON
• NUMERO DI BLOCCHI INFORMATIVI TRASMESSI: 3
Tabella IV.1 Sommario dei parametri del canale e dell’equalizzatore
Figura IV.15 Andamento del numero di errori per miniblocco: i miniblocchi del grafico vanno dal numero 300
dopo la fine del preambolo di sincronismo, per evidenziare il tratto in cui gli errori hanno il picco

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
73
Figura IV.16 Andamento del canale: è graficato dal miniblocco (32+16) numero 300, in corrispondenza
d’ascissa con la Figura IV.15
SER OTTENUTO CON SNR 18 dB: 4.0 E-02
IV.3 CMA con training sui simboli KNOWN
I risultati ottenuti col sistema CMA “puro” non sono ritenuti soddisfacenti dallo
standard, ovvero i SER ottenuti nelle ultime simulazioni sul CMA, sfruttando anche il
recupero di fase e lo stimatore di ritardo, sono comunque troppo alti per le esigenze
richieste. Tale carenza di prestazioni viene in parte imputata al fatto che il sistema CMA
“puro” non sfrutta appieno la conoscenza trasportata nella trama dai simboli KNOWN.
Infatti, anche nel preambolo di sincronizzazione e durante la ricezione dei 16 simboli
noti in ogni replica, l’aggiornamento dei coefficienti del filtro FIR che equalizza il canale
avviene tramite il sistema CMA che, come sottolinea il nome (Constant Modulus
Algorithm) utilizza il modulo unitario del simbolo ricevuto come unica nozione per
aggiornare i coefficienti del FIR. Durante la trasmissione dei simboli noti possiamo però
sfruttare la conoscenza completa dei simboli stessi, migliorando così le prestazioni
dell’equalizzatore.
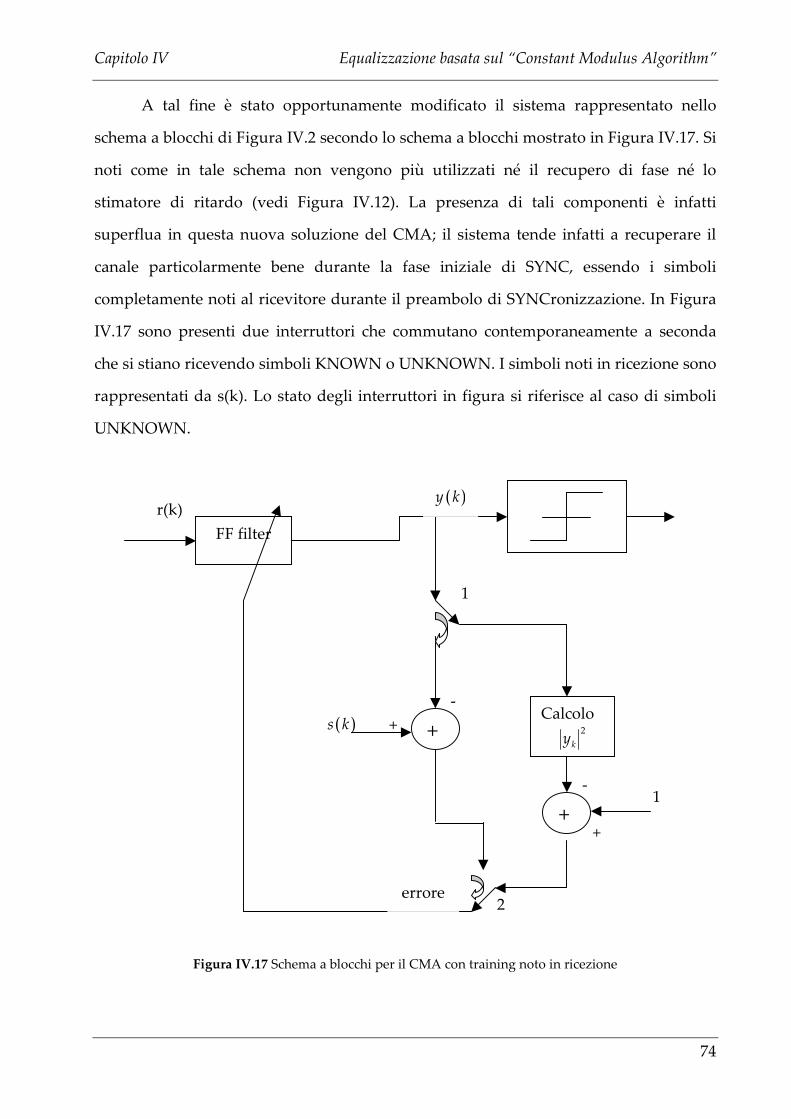
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
74
A tal fine è stato opportunamente modificato il sistema rappresentato nello
schema a blocchi di Figura IV.2 secondo lo schema a blocchi mostrato in Figura IV.17. Si
noti come in tale schema non vengono più utilizzati né il recupero di fase né lo
stimatore di ritardo (vedi Figura IV.12). La presenza di tali componenti è infatti
superflua in questa nuova soluzione del CMA; il sistema tende infatti a recuperare il
canale particolarmente bene durante la fase iniziale di SYNC, essendo i simboli
completamente noti al ricevitore durante il preambolo di SYNCronizzazione. In Figura
IV.17 sono presenti due interruttori che commutano contemporaneamente a seconda
che si stiano ricevendo simboli KNOWN o UNKNOWN. I simboli noti in ricezione sono
rappresentati da s(k). Lo stato degli interruttori in figura si riferisce al caso di simboli
UNKNOWN.
Figura IV.17 Schema a blocchi per il CMA con training noto in ricezione
1
( )s k + -
2
1
-
+
r(k)
FF filter
Calcolo 2
ky
+
errore
+
( )y k

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
75
Nel caso in cui gli interruttori siano posizionati come in figura la formula
ricorsiva che consente l’aggiornamento del FF filter è la (IV.1). Quando gli interruttori
commutano l’errore utilizzato per l’aggiornamento del FIR cambia, per cui la nuova
formula di aggiornamento sarà:
( )*
( )δ+ = + ⋅ ⋅ −train k k
s yk 1 k kf f r (IV.5)
dove kr è la sequenza ricevuta, ky il simbolo stimato dal FIR e ks il simbolo trasmesso
noto anche in ricezione. Si noti che il coefficiente di aggiornamento della (IV.5) è
chiamato trainδ (δ training) per distinguerlo dal trackδ (δ tracking) utilizzato
nell’aggiornamento dei simboli UNKNOWN secondo la (IV.1). L’avere due gradi di
libertà nel nostro sistema ( trainδ e trackδ ) aiuterà ad ottimizzare in maniera più efficiente
le prestazioni del CMA con training.
IV.3.1 Confronto tra le prestazioni del CMA “puro” e del
CMA con training
Varie simulazioni hanno evidenziato un miglioramento del SER utilizzando il
nuovo equalizzatore piuttosto che il “vecchio”. Qui di seguito vengono riportati alcuni
risultati, viene considerato sia il caso di canale tempo invariante che il modello di canale
tempo variante di Watterson.
In Figura IV.10 sono stati riportati i SER ottenuti col CMA “puro” in funzione del
SNR. In Figura IV.18 è stato sovrapposto il grafico di Figura IV.10 con il nuovo grafico
indicante le prestazioni del CMA con training.
Il miglioramento introdotto da questa nuova versine è evidente.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
76
Confronto CMA e CMA con training. dim_ff=11. Canale 1-0,5
time invariant. Time spread=416 µsec
1,00E-06
1,00E-05
1,00E-04
1,00E-03
1,00E-02
1,00E-01
1,00E+00
0 5 12 18 21
SNR
Se
r
CMA "puro" delta=0,002
CMA con training delta
train=0,008 delta
track=0,001
Figura IV.18 Confronto tra i Ser ottenuti con Cma "puro" e Cma con training
IV.3.2 Soluzione a T/2 del CMA con training
Il progetto del CMA con training ha dunque abbassato il SER rispetto al classico
CMA, almeno nel caso di canale time invariant. Tuttavia le simulazioni hanno
evidenziato che non vi sono migliorie sensibili se consideriamo un modello di canale
tempo variante di Watterson. Si è deciso quindi di modificare ulteriormente il sistema
CMA con training operando un sovracampionamento di ordine 2 a valle del canale di
Watterson. Per comprendere meglio la modifica apportata al sistema si consideri la
Figura IV.14, in sostanza in ricezione il segnale analogico viene ora campionato al
doppio della frequenza di simbolo, vedi Figura IV.19.
Il simulatore è stato modificato in maniera opportuna al fine di supportare il
sovracampionamento del segnale ricevuto. Tra le altre cose l’equalizzatore adattativo
dovrà preoccuparsi di effettuare un sottocampionamento di un fattore 2 sul segnale
equalizzato, al fine di presentare in uscita la trama di uscita di dimensioni pari a quella
di ingresso. Il software di simulazione compie automaticamente tale
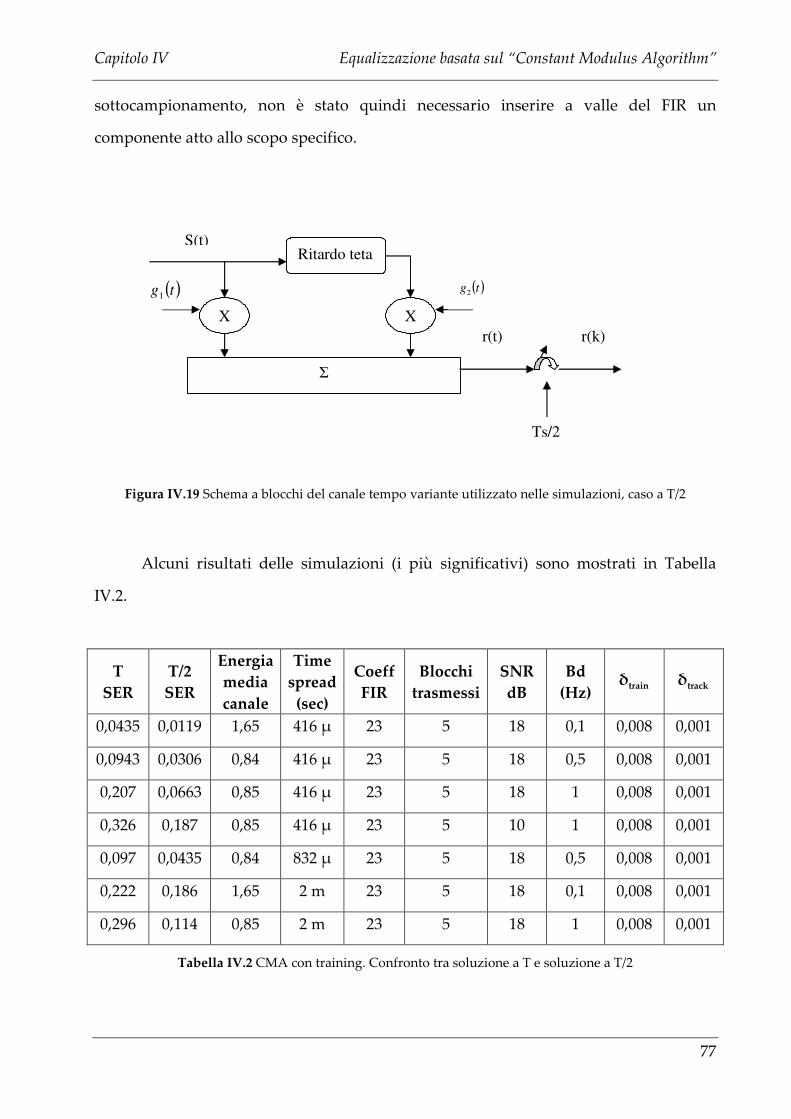
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
77
sottocampionamento, non è stato quindi necessario inserire a valle del FIR un
componente atto allo scopo specifico.
S(t) Ritardo teta
X X
( )tg1 ( )tg2
Σ
r(t)
Ts/2
r(k)
Figura IV.19 Schema a blocchi del canale tempo variante utilizzato nelle simulazioni, caso a T/2
Alcuni risultati delle simulazioni (i più significativi) sono mostrati in Tabella
IV.2.
T SER
T/2 SER
Energia media canale
Time spread
(sec)
Coeff FIR
Blocchi trasmessi
SNR dB
Bd (Hz) trainδ trackδ
0,0435 0,0119 1,65 416 μ 23 5 18 0,1 0,008 0,001
0,0943 0,0306 0,84 416 μ 23 5 18 0,5 0,008 0,001
0,207 0,0663 0,85 416 μ 23 5 18 1 0,008 0,001
0,326 0,187 0,85 416 μ 23 5 10 1 0,008 0,001
0,097 0,0435 0,84 832 μ 23 5 18 0,5 0,008 0,001
0,222 0,186 1,65 2 m 23 5 18 0,1 0,008 0,001
0,296 0,114 0,85 2 m 23 5 18 1 0,008 0,001
Tabella IV.2 CMA con training. Confronto tra soluzione a T e soluzione a T/2

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
78
Commenti alla Tabella IV.2:
I dati presentati in Tabella IV.2 si riferiscono alla trasmissione di una trama a
2400 baud/sec, secondo lo standard della MIL-A. L’emissione di bit della sorgente
avviene sempre a velocità 2400 bit/sec (ricordiamo che la MIL-A prevede vari rate di
sorgente). Successivamente i simboli 8-PSK della trama attraversano un canale di
Watterson con parametri mostrati in Tabella IV.2. δ train e δ track sono i coefficienti già
definiti in precedenza; i valori 0,008 e 0,001 si riferiscono al caso ottimo, cioè i valori per
cui, a parità di condizioni, il SER risulta essere minimo.
Dalle colonne dei SER si nota un evidente miglioramento del CMA con training a
T/2 rispetto a quello a T. Miglioramento che risulta più marcato per time spread bassi
del canale (il SER diminuisce di un fattore � 3). Per time spread più alti, 2 msec,
l’abbassamento del SER è meno evidente, tuttavia il fattore di improvement 2 garantisce
una più alta efficienza della soluzione a T/2 rispetto a quella a T.
Confronto dell’andamento del Ser
La seguente Figura IV.20 mostra l’andamento del SER in funzione di vari SNR per
la soluzione a T e a T/2 del CMA con training.
CMA con training
1,00E-03
1,00E-02
1,00E-01
1,00E+00
0 5 12 18 21
SNR
Ser CMA con
training a T
CMA con
training a T/2
Figura IV.20 SER messi a confronto in funzione del SNR per la soluzione a T e a T/2 del CMA con training

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
79
Note per la Figura 20:
I SER ottenuti in figura si riferiscono a una simulazione con i seguenti parametri:
• time spread 416 μsec
• coefficienti del FIR 23
• blocchi lanciati 5
• Bd 0,5 Hz
• δ train 0,008
• δ track 0,001
Ricordiamo che per “blocchi lanciati” si intende il numero di blocchi da
240*(32+16) simboli 8-PSK trasmessi nella simulazione. Il numero di simboli per blocco
(11520) è quello previsto dallo standard della MIL-A per trasmissioni a 2400 bit/sec con
long interleaving.
IV.3.3 Soluzione a T/2 del CMA con cicli sui training da
16 simboli
Un’ulteriore modifica del sistema ha portato il SER a scendere ulteriormente
rispetto ai valori (peraltro già abbastanza buoni) ottenuti con il CMA con training a T/2
semplice. In pratica il CMA è stato modificato in modo da aggiornare il filtro
equalizzatore non una sola volta per ogni miniblocco da 16 simboli di training, ma n
volte, con n ottimizzato opportunamente. Quindi il filtro FIR, durante ogni replica da
16+32 simboli, viene aggiornato mediante la (IV.1) durante i 32 simboli UNKNOWN,
mediante la (IV.5) durante i 16 simboli KNOWN; tuttavia dopo il 16esimo simbolo non
si passa direttamente ai 32 simboli UNKNOWN della replica successiva per aggiornare
il FIR, ma si ricaricano in maniera opportuna i buffer che contengono l’uscita del canale
di Watterson e il simulatore riprende ad aggiornare il FIR sugli stessi 16 simboli
KNOWN poco prima utilizzati per portare l’equalizzatore a convergenza.
Per meglio comprendere il funzionamento del sistema si faccia riferimento alla
Figura IV.17. Nel nostro caso quindi, quando gli interruttori 1 e 2 commutano dalla
posizione in figura (simboli UNKNOWN) al caso di aggiornamento per simboli

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
80
KNOWN, non tornano poi subito nella posizione iniziale alla fine del training, ma
permangono nella stessa posizione per altri 16 tempi di simbolo. La Figura IV.21 aiuta a
capire meglio la temporizzazione delle operazioni.
11520 32 16 32 16 32 16 ……….
SYNC
n volte n volte n volte
Figura IV.21 Temporizzazione della trama per il CMA a T/2 con cicli sui 16 simboli KNOWN
Risultati delle simulazioni
Sono state effettuate varie simulazioni per testare l’efficacia della nuova
soluzione.
I risultati sono riportati in Tabella IV.3.
Note e commenti alla Tabella IV.3:
La sorgente trasmette sempre a 2400 bit/sec. Il canale è sempre 2 fading. Per ogni
riga della tabella le simulazioni sono state lanciate con trainδ =0,008 e trackδ =0,001, valori
che ottimizzano il SER.
Le prove effettuate sono, per ora, quasi tutte in assenza di rumore. È comunque
evidente, specie per time spread bassi, il miglioramento ottenuto utilizzando il CMA a
T/2 con cicli sui training. Particolarmente significativo è il risultato raggiunto per time
spread=416 μsec, dove anche con Bd elevata (1 Hz) il SER viene circa 2* 210− , dopo
decodifica il BER (Bit Error Rate) sarebbe di circa 410− .
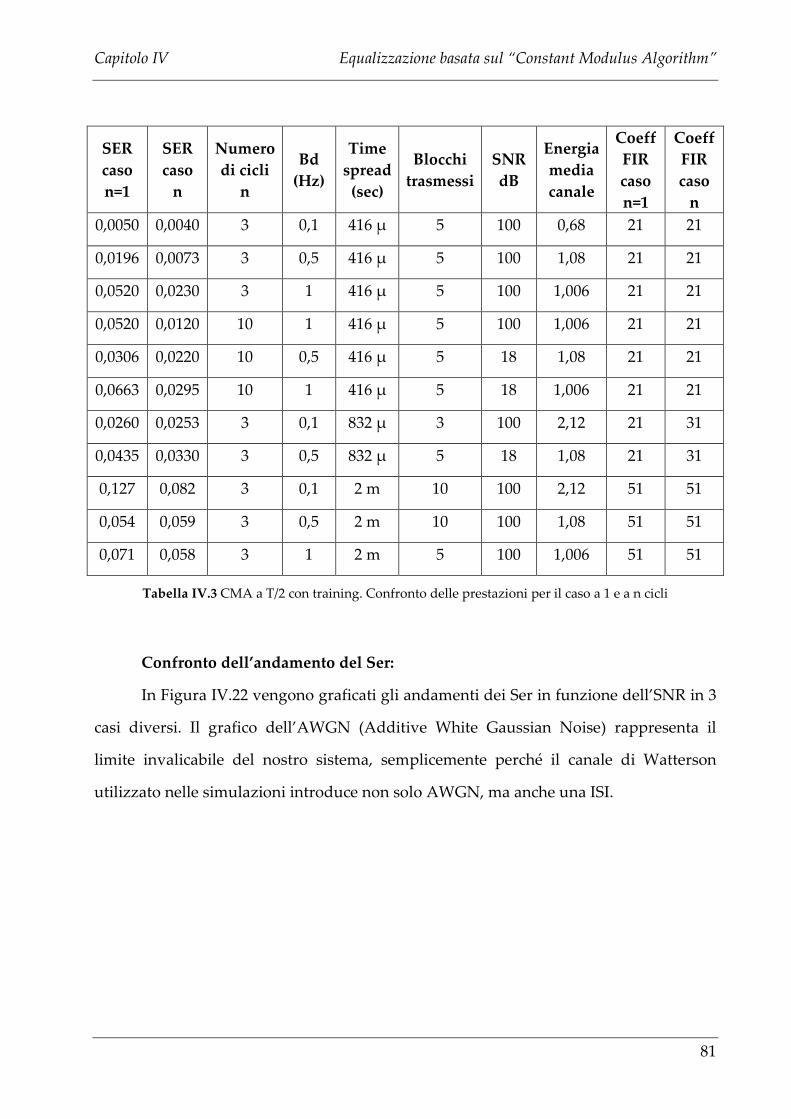
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
81
SER caso n=1
SER caso
n
Numero di cicli
n
Bd (Hz)
Time spread
(sec)
Blocchi trasmessi
SNR dB
Energia media canale
Coeff FIR caso n=1
Coeff FIR caso
n 0,0050 0,0040 3 0,1 416 μ 5 100 0,68 21 21
0,0196 0,0073 3 0,5 416 μ 5 100 1,08 21 21
0,0520 0,0230 3 1 416 μ 5 100 1,006 21 21
0,0520 0,0120 10 1 416 μ 5 100 1,006 21 21
0,0306 0,0220 10 0,5 416 μ 5 18 1,08 21 21
0,0663 0,0295 10 1 416 μ 5 18 1,006 21 21
0,0260 0,0253 3 0,1 832 μ 3 100 2,12 21 31
0,0435 0,0330 3 0,5 832 μ 5 18 1,08 21 31
0,127 0,082 3 0,1 2 m 10 100 2,12 51 51
0,054 0,059 3 0,5 2 m 10 100 1,08 51 51
0,071 0,058 3 1 2 m 5 100 1,006 51 51
Tabella IV.3 CMA a T/2 con training. Confronto delle prestazioni per il caso a 1 e a n cicli
Confronto dell’andamento del Ser:
In Figura IV.22 vengono graficati gli andamenti dei Ser in funzione dell’SNR in 3
casi diversi. Il grafico dell’AWGN (Additive White Gaussian Noise) rappresenta il
limite invalicabile del nostro sistema, semplicemente perché il canale di Watterson
utilizzato nelle simulazioni introduce non solo AWGN, ma anche una ISI.
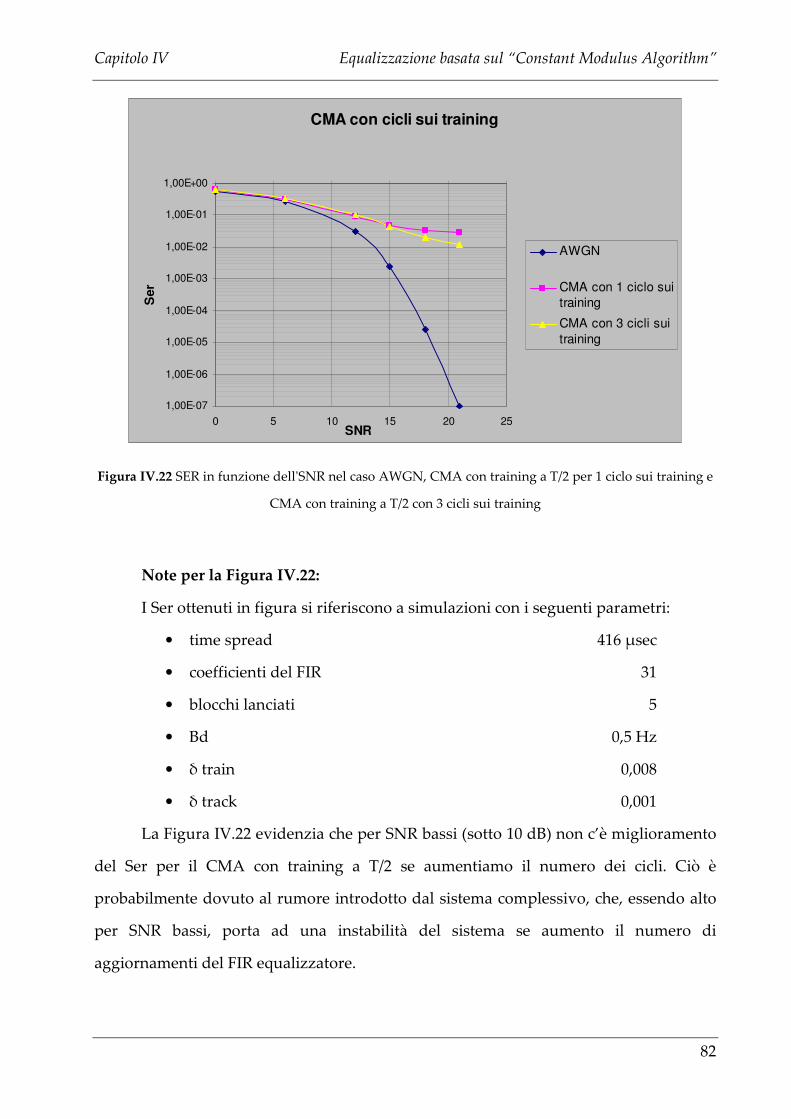
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
82
CMA con cicli sui training
1,00E-07
1,00E-06
1,00E-05
1,00E-04
1,00E-03
1,00E-02
1,00E-01
1,00E+00
0 5 10 15 20 25SNR
Ser
AWGN
CMA con 1 ciclo sui
training
CMA con 3 cicli sui
training
Figura IV.22 SER in funzione dell'SNR nel caso AWGN, CMA con training a T/2 per 1 ciclo sui training e
CMA con training a T/2 con 3 cicli sui training
Note per la Figura IV.22:
I Ser ottenuti in figura si riferiscono a simulazioni con i seguenti parametri:
• time spread 416 μsec
• coefficienti del FIR 31
• blocchi lanciati 5
• Bd 0,5 Hz
• δ train 0,008
• δ track 0,001
La Figura IV.22 evidenzia che per SNR bassi (sotto 10 dB) non c’è miglioramento
del Ser per il CMA con training a T/2 se aumentiamo il numero dei cicli. Ciò è
probabilmente dovuto al rumore introdotto dal sistema complessivo, che, essendo alto
per SNR bassi, porta ad una instabilità del sistema se aumento il numero di
aggiornamenti del FIR equalizzatore.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
83
Si noti inoltre che in questo caso i risultati ottenuti tramite il CMA si discostano
notevolmente dai SER dell’AWGN. Ciò è ovvio, visto che il grafico relativo all’AWGN
si riferisce al caso di canale fisso, quindi con Banda Doppler nulla, mentre i grafici
relativi al CMA sono stati tracciati considerando una Banda Doppler = 0,5 Hz.
IV.3.4 Soluzione a T/2 del CMA con cicli su n repliche
da 48 simboli
La Tabella IV.3 denota che la soluzione del CMA a T/2 con cicli sul training porta
a SER accettabili nel caso in cui il time spread del canale è sufficientemente basso (416
μsec o 832 μsec); se però consideriamo un time spread del canale di 2 msec o maggiore i
miglioramenti ottenuti rispetto al caso del CMA a T/2 “semplice” sono di poco conto,
nel caso di banda Doppler di 0,5 Hz si ha addirittura un peggioramento (vedi Tabella
IV.3). Tale mancanza di precisione del SER è imputabile al fatto che per time-spread=2
msec la risposta impulsiva del canale ha una lunghezza tale che i 16 simboli di training
su cui si cicla non sono sufficienti a invertire adeguatamente il canale,
indipendentemente dal numero di cicli che si applica su ogni training. Tale problema ha
indotto a sperimentare una nuova soluzione in cui i cicli su cui si aggiornano i
coefficienti dell’equalizzatore non avvengono più solamente solo sui 16 simboli noti di
training(vedi anche Par IV.3.3), ma su un certo numero di repliche da 48 simboli,
repliche comprensive quindi di parte KNOWN e UNKNOWN. Il numero di repliche su
cui si cicla dipende dal time-spread del canale, varie simulazioni hanno portato a
considerare come ottimo il numero di 5 repliche da 48 per un time-spread=2 msec.
Per meglio comprendere il funzionamento del nuovo sistema si faccia
riferimento alla Figura IV.23, dove è mostrato il caso di n cicli operanti su un burst di 2
repliche. In pratica il simulatore, terminato l’aggiornamento del filtro equalizzatore
dopo gli 11520 simboli noti della SYNC, passa all’utilizzo del CMA puro nei 32 simboli
UNKNOWN, poi aggiorna il FIR dell’equalizzatore con i 16 simboli KNOWN; continua
poi ad operare anche per il successivo miniblocco, arrivato al 16 simbolo KNOWN del
secondo miniblocco il simulatore non sfrutta il primo simbolo UNKNOWN della

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
84
replica successiva, ma, riportati adeguatamente i vettori e i contatori del caso nella
posizione iniziale, continua ad aggiornare i coefficienti del FIR equalizzatore “ciclando”
sulle 2 repliche per n volte.
11520 32 16 32 16 32 16 ……….
SYNC
n volte n volte
Figura IV.23 Temporizzazione della trama per il CMA a T/2 con cicli su 2 repliche da 48 simboli
Risultati delle simulazioni
Sono state effettuate varie simulazioni per testare l’efficacia della nuova
soluzione.
I risultati sono riportati in Tabella IV.4.
Note e commenti alla Tabella IV.4:
Le simulazioni si riferiscono al caso di bit rate di sorgente= 2400 bit/sec con
canale 2 fading. Facendo riferimento alle formule (IV.5) e (IV.1) sono stati utilizzanti
trainδ =0,008 e trackδ =0,001.
Le prime 2 colonne presentano il SER ottenuto con CMA a T/2 con cicli sul
training, la seconda colonna indica il numero di cicli sui 16 simboli KNOWN. Il SER
della nuova soluzione si trova nella terza colonna, nella quarta colonna ci sono
rispettivamente il numero di repliche su cui si cicla e il numero di cicli effettuati sulle
stesse.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
85
SER n cicli sui 16
n
SER m cicli
su k repliche
k;m Bd
(Hz)
Time spread
(sec)
Blocchi trasmessi
SNR dB
Coeff FIR caso n=1
Coeff FIR caso
n 0,0040 3 0,0022 5; 3 0,1 416 μ 5 100 21 21
0,0073 3 0,0064 5; 3 0,5 416 μ 5 100 21 21
0,0230 3 0,0150 5; 3 1 416 μ 5 100 21 21
0,0120 10 0,0040 5; 10 1 416 μ 5 100 21 21
0,0220 10 0,0100 5; 10 0,5 416 μ 5 18 21 21
0,0295 10 0,0140 5; 10 1 416 μ 5 18 21 21
0,0226 3 0,0160 5; 3 0,1 832 μ 10 100 21 31
0,0330 3 0,0300 5; 3 0,5 832 μ 5 18 21 31
0,054 3 0,044 5; 3 0,1 2 m 20 100 51 51
0,059 3 0,032 9; 3 0,5 2 m 10 100 51 51
0,058 3 0,037 5; 3 1 2 m 5 100 51 51
Tabella IV.4 CMA a T/2 con training. Confronto delle prestazioni per il caso a n cicli sul training e il caso
di m cicli su k repliche
Si noti come il SER sia diminuito di un fattore 2 in tutti i casi presentati in
tabella. La novità rispetto ai dati in Tabella IV.3 è rappresentata dai risultati ottenuti con
time_spread=2 msec, dove in questo caso si riesce a raggiungere un SER di 3*10 2− circa.
Confronto dell’andamento del SER:
La seguente Figura 24 mostra l’andamento del SER per 3 casi, uno dei quali si
riferisce al canale AWGN, limite invalicabile delle prestazioni del nostro sistema.
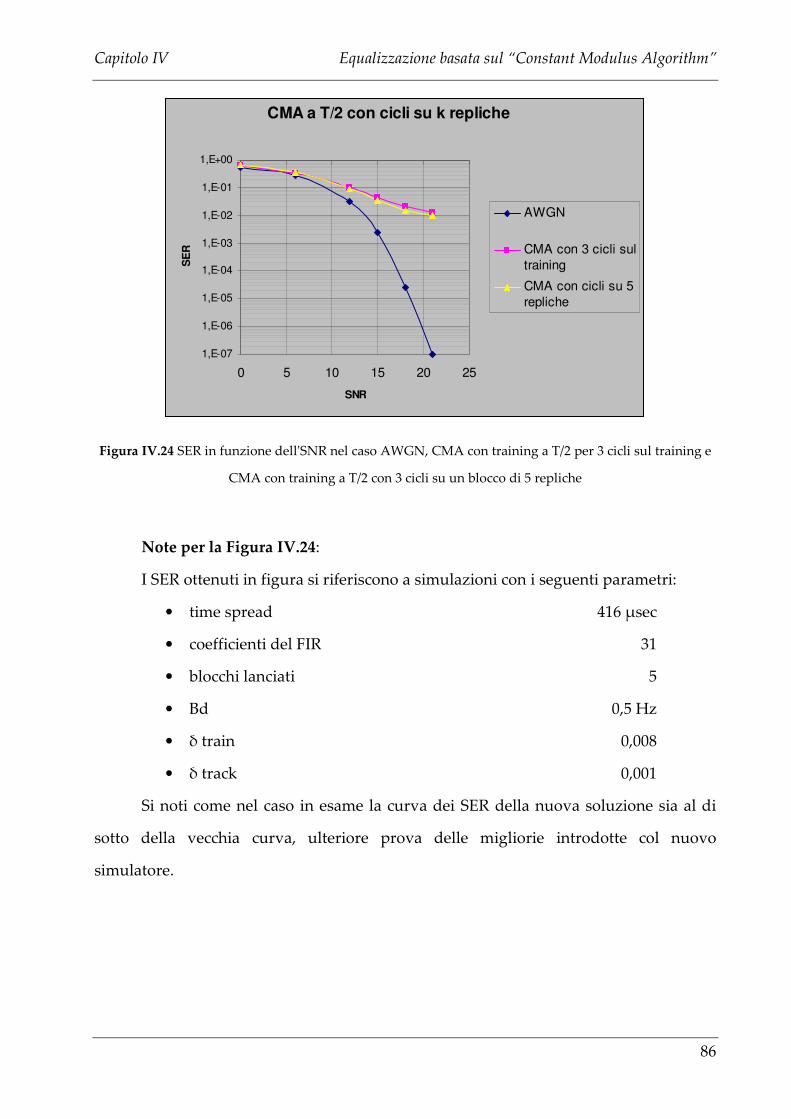
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
86
CMA a T/2 con cicli su k repliche
1,E-07
1,E-06
1,E-05
1,E-04
1,E-03
1,E-02
1,E-01
1,E+00
0 5 10 15 20 25
SNR
SE
R
AWGN
CMA con 3 cicli sul
training
CMA con cicli su 5
repliche
Figura IV.24 SER in funzione dell'SNR nel caso AWGN, CMA con training a T/2 per 3 cicli sul training e
CMA con training a T/2 con 3 cicli su un blocco di 5 repliche
Note per la Figura IV.24:
I SER ottenuti in figura si riferiscono a simulazioni con i seguenti parametri:
• time spread 416 μsec
• coefficienti del FIR 31
• blocchi lanciati 5
• Bd 0,5 Hz
• δ train 0,008
• δ track 0,001
Si noti come nel caso in esame la curva dei SER della nuova soluzione sia al di
sotto della vecchia curva, ulteriore prova delle migliorie introdotte col nuovo
simulatore.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
87
IV.4 CMA performance (standard MIL-STD-188-110A)
In Tabella IV.5 sono indicate le prestazioni richieste dallo standard MIL-A, a
seconda del bit/rate di sorgente e del tipo di canale.
User bit rate Channel
Paths Multipath
(msec) Fading Bd(Hz)
SNR dB Coded BER
4800 1 Fixed - - 17 1,0 E-3
4800 2 Fading 2 0,5 27 1,0 E-3
2400 1 Fixed - - 10 1,0 E-5
2400 2 Fading 2 1 18 1,0 E-5
2400 2 Fading 2 5 30 1,0 E-3
2400 2 Fading 5 1 30 1,0 E-5
1200 2 Fading 2 1 11 1,0 E-5
600 2 Fading 2 1 7 1,0 E-5
300 2 Fading 5 5 7 1,0 E-5
150 2 Fading 5 5 5 1,0 E-5
75 2 Fading 5 5 2 1,0 E-5
Tabella IV.5 Serial (single-tone) mode minimum performance
L’ultima colonna si riferisce al Coded BER, cioè al Bit Error Rate dopo le
opportune codifiche previste dallo standard. Il simulatore CMA fin qui sviluppato
calcola solamente l’Uncoded SER, il BER teorico corrispondente a ogni valore di SER
risulterà più basso di 3 ordini di grandezza, o al peggio 2, del SER stesso.
Facendo riferimento alla Tabella IV.5 viene qui di seguito riportata la Tabella IV.6.
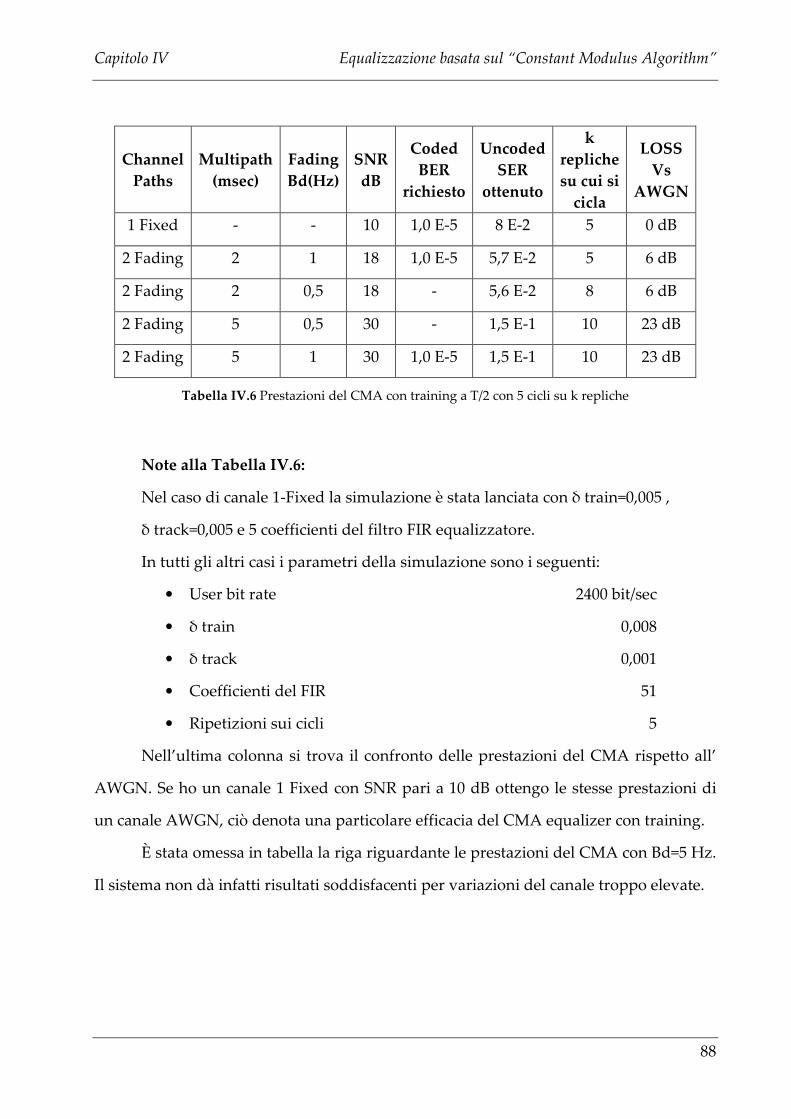
Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
88
Channel Paths
Multipath (msec)
Fading Bd(Hz)
SNR dB
Coded BER
richiesto
Uncoded SER
ottenuto
k repliche su cui si
cicla
LOSS Vs
AWGN
1 Fixed - - 10 1,0 E-5 8 E-2 5 0 dB
2 Fading 2 1 18 1,0 E-5 5,7 E-2 5 6 dB
2 Fading 2 0,5 18 - 5,6 E-2 8 6 dB
2 Fading 5 0,5 30 - 1,5 E-1 10 23 dB
2 Fading 5 1 30 1,0 E-5 1,5 E-1 10 23 dB
Tabella IV.6 Prestazioni del CMA con training a T/2 con 5 cicli su k repliche
Note alla Tabella IV.6:
Nel caso di canale 1-Fixed la simulazione è stata lanciata con δ train=0,005 ,
δ track=0,005 e 5 coefficienti del filtro FIR equalizzatore.
In tutti gli altri casi i parametri della simulazione sono i seguenti:
• User bit rate 2400 bit/sec
• δ train 0,008
• δ track 0,001
• Coefficienti del FIR 51
• Ripetizioni sui cicli 5
Nell’ultima colonna si trova il confronto delle prestazioni del CMA rispetto all’
AWGN. Se ho un canale 1 Fixed con SNR pari a 10 dB ottengo le stesse prestazioni di
un canale AWGN, ciò denota una particolare efficacia del CMA equalizer con training.
È stata omessa in tabella la riga riguardante le prestazioni del CMA con Bd=5 Hz.
Il sistema non dà infatti risultati soddisfacenti per variazioni del canale troppo elevate.

Capitolo IV Equalizzazione basata sul “Constant Modulus Algorithm”
89
IV.5 Conclusioni (Equalizzatore CMA)
L’equalizzatore CMA a T/2 con training raggiunge quindi convergenza esatta nel
caso di canale tempo invariante e criterio di stima MSE (Mean Square Error), per lo
standard MIL-A a 2400 bps. Per il canale tempo variante (Watterson), l’equalizzatore
CMA non riesce a raggiungere l’ottimo richiesto dalle specifiche del progetto; tuttavia
per un ritardo del secondo raggio pari al tempo di simbolo e per un SNR
sufficientemente alto il sistema è stato adeguatamente testato e si rivelano prestazioni
molto buone, anche per Bd elevate.
Si sottolinea che, nonostante le modifiche effettuate e i miglioramenti introdotti,
la causa principale degli errori risiede nel fatto che l’equalizzatore perde comunque
l’aggancio del canale ogni qual volta i coefficienti del canale tempo variante assumono
valori circa uguali in modulo. In tali condizioni il filtro ottimo che equalizza il canale
dovrebbe avere infiniti coefficienti significativi, lavorando con un FIR la perdita che si
presenta nel troncamento è considerevole e le prestazioni del sistema risultano
fortemente degradate. L’aggancio del canale viene però poi puntualmente recuperato,
con velocità di recupero dipendente dal valore di δ (δ più elevati aumentano la velocità
di convergenza).

Capitolo V Stima di canale
90
Capitolo V
STIMA DI CANALE
V.1 Introduzione (Blind channel estimation)
La blind channel estimation (letteralmente “stima cieca di canale” ) può essere
usata nell’ambito della blind channel equalization.
La blind channel equalization equalizza il canale senza l’aiuto di una sequenza di
training nota in ricezione. Tra le varie soluzioni proposte è per noi adatta quella che
sfrutta la blind channel estimation per stimare il canale senza l’aiuto di un training, e
poi utilizza l’algoritmo di RMAP (Reduced Maximum A Posteriori Probability) per
completare l’equalizzazione. Tale soluzione viene mostrata in Figura V.1.
Viterbi algorithm
Blind channel estimation
H
Input y Output x
Figura V.1 Schema generale di un blind channel equalizer che sfrutta la blind channel estimation e
l'algoritmo di Viterbi
Concentrandoci per il momento solo sulla blind channel estimation, esaminando
la soluzione proposta da J. Proakis ( [Pro95][3.]).

Capitolo V Stima di canale
91
È conveniente considerare il modello di canale a tempo discreto con ISI (Inter
Symbol Interference) ,la cui uscita è descritta da:
0
L
n k n k nk
f Iυ η−
=
= +∑ (V.1)
dove { kf } sono i coefficienti del canale tempo discreto, { nI } è la sequenza informativa, e
{ nη } è una sequenza di rumore Gaussiano bianco.
Consideriamo un blocco di N simboli ricevuti, la densità di probabilità congiunta
del vettore di simboli ricevuti 1 2
t
nυ υ υ= v K , condizionata dalla conoscenza del
vettore dei coefficienti del canale 0 1 2
t
Lf f f f= f K e del vettore di simboli informativi
1 2
t
NI I IΙ = K è:
( )( )
2
221 0
1 1, exp
22
N L
n k n kn k
p f Iυσπσ
−= =
= − −
∑ ∑v f I (V.2)
Le stime di f e di I che soddisfano il criterio di massima verosimiglianza sono i
valori dei vettori f e I che massimizzano la densità di probabilità congiunta p(v| f,I) , o,
equivalentemente, i valori di f e I che minimizzano l’esponente della (V.2). Quindi, si
cercano f ed I che minimizzano la norma DM(I,f) così definita:
( )2
2
1 0
,N L
n k n kn k
DM f Iυ −= =
= − = −∑ ∑I f v Af (V.3)
dove la matrice dei dati A è così definita:

Capitolo V Stima di canale
92
1
2 1
3 2 1
1 2
0 0 00 0
0
N N N N L
I
I I
I I I
I I I I− − −
=
A
L
L
L
M M M M
L
(V.4)
È opportuno ora fare alcune osservazioni, anche per comprendere meglio cosa è
richiesto dall’equalizzatore e dallo stimatore di canale quando operiamo in modalità
“blind”. Per prima cosa notiamo che se il vettore I è noto, come nel caso vi sia un
training disponibile al ricevitore, la stima di Massima Verosimiglianza (MV) del canale
ottenuta minimizzando la (V.3) sarà:
( ) ( )1t t
ML
−=f I A A A v (V.5)
D’altro canto, se il vettore dei coefficienti del canale f fosse noto (come ci si
propone di fare mediante la blind channel estimation) si potrebbe trovare l’ottimo per la
sequenza informativa I con l’algoritmo di RMAP.
Nel nostro caso non abbiamo quindi a disposizione una sequenza di training per
stimare il canale, si può però stimare il canale f dalla densità di probabilità condizionata
p(v | f), che può essere ottenuta mediando la p(v,f | I) su tutte le possibili sequenze
informative. Per ottenere la p(v | f) si sfrutta la ben nota proprietà:
( ) ( )( ) ( )( ) ( )( ), ,m m m
m m
p p p P= =∑ ∑v f v I f v I f I (V.6)
dove ( )( )mP I è la probabilità a priori che la sequenza informativa I = I ( )m ha di
presentarsi. Potendo l’indice m assumere valori discreti tra 1 e M N , dove M è la
dimensione dell’alfabeto di sorgente, viene spontaneo assumere le sequenze
informative equiprobabili e porre, ∀ m, P(I ( )m ) = 1/ M N .

Capitolo V Stima di canale
93
Inserendo allora la (V.3) nella (V.2), e quest’ultima nella (V.6) si ottiene:
( ) ( )( ) ( )( )( )
( )
( )( )2
22
1, exp
22
m
m m m
Nm m
p p P Pσπσ
− = = −
∑ ∑v A f
v f v I f I I (V.7)
Ora, la stima di f che massimizza p(v | f) sarà la soluzione dell’equazione
( ) ( )( ) ( ) ( ) ( )( )
( ) 2
2exp 02
m
m m t m m t
m
pP
σ
−∂ = − − = ∂
∑v A fv f
I A A f A vf
(V.8)
Di conseguenza, la stima di f può essere espressa come
( )( ) ( ) ( ) ( )( ) ( )( ) ( )( ) ( )
1
, , , ,m m t m m m m m t
m m
P g P g
−
= ⋅ ∑ ∑f I A A v A f I v A f A v (V.9)
dove la funzione ( )( ), ,mg v A f è così definita
( )( )( ) 2
2, , exp2
m
mgσ
− = −
v A fv A f (V.10)
La (V.9) è un’equazione non lineare per la stima del canale, conoscendo solo il
vettore dei simboli ricevuti v. Risolvere la (V.9) in maniera diretta è molto difficile.
È possibile tuttavia ideare un metodo numerico che ricavi la soluzione ottima MVf della
(V.9) in maniera ricorsiva. Ad esempio possiamo scrivere
( ) ( )( ) ( ) ( ) ( ) ( )( ) ( )( ) ( ) ( )( ) ( )
11 , , , ,k k km m t m m m m m t
m m
P g P g
−
+ = ⋅ ∑ ∑f I A A v A f I v A f A v (V.11)
Una volta trovato MVf si può trovare MVI soddisfacente la (V.3). L’algoritmo
RMAP è molto efficiente per effettuare la minimizzazione voluta.

Capitolo V Stima di canale
94
Bisogna sottolineare che la stima MVf così ottenuta ,ovviamente, è peggiore di
quella che si otterrebbe utilizzando comunque il criterio della massima verosimiglianza
(MV), ma con la sequenza I nota (utilizzo di un training).
Nella bibliografia sono indicati alcuni riferimenti per lo studio di algoritmi che
permettano la Blind channel estimation ([8.][9.]).
V.2 Stimatore di canale per il modem MIL-STD-188-110A
Viene proposta nel presente documento la realizzazione di uno stimatore di
canale da utilizzare per il modem MIL-STD-188-110A. Sfruttando la conoscenza del
canale stimato si può infatti equalizzare in maniera più efficiente il segnale ricevuto. Il
sistema è stato simulato sia per canale tempo invariante che per canale tempo variante
di Watterson.
V.2.1 Utilizzo del CMA come equalizzatore
Come prima istanza è stato sfruttato il CMA per equalizzare il canale. Infatti è
necessario avere nel nostro stimatore un equalizzatore che possa rendere disponibili
allo stimatore di canale una decisione dei simboli UNKNOWN il più possibile accurata.
La disponibilità del CMA ha indotto a optare per questo equalizzatore, anche se il CMA
stesso non necessita di alcuna stima di canale per il suo corretto funzionamento.
Mediante il confronto tra l’uscita del canale di Watterson e l’uscita del canale
stimato si aggiornano i coefficienti della stima della risposta impulsiva del canale
tramite la seguente formula:
$ $ ( )1 k kk k agg ks r rδ∗
+ = + −c c $ $ (V.12)
dove c$ rappresenta il vettore della risposta impulsiva del canale stimato; aggδ è un
coefficiente che nel nostro caso è stato ottimizzato a 0,008; ks∗$ è il simbolo complesso
(coniugato) fatto passare attraverso il canale stimato per avere così in uscita il simbolo

Capitolo V Stima di canale
95
kr$ presunta uscita del canale, da confrontare poi con l’uscita reale kr del canale di
Watterson.
La seguente Figura V.2 aiuta a comprendere meglio il funzionamento del channel
estimator:
Canale di Watterson
Canale stimato
CMA a T/2
ks
k
s
kr
kr$
kε
ks
ks$
2
1
+
-
Figura V.2 Channel estimator utilizzante l'equalizzatore CMA
Note alla Figura V.2:
ks indica il simbolo trasmesso che attraversa il canale di Watterson diventando il
simbolo ricevuto kr . In ingresso al canale stimato si presenta: il simbolo ks noto in
ricezione, nel caso di simboli KNOWN della trama; il simbolo stimato dal CMA ks$ nel
caso di simboli UNKNOWN. La situazione in Figura V.2 (interruttore in posizione 1)
mostra il momento in cui l’ingresso del canale stimato è ks$ , mentre con lo switch in
posizione 2 l’ingresso del canale stimato è ks . kε rappresenta la differenza tra il simbolo
ricevuto kr e quello stimato kr$ , utilizzato nella formula (V.12) per l’aggiornamento dei
coefficienti dello stimatore di canale.

Capitolo V Stima di canale
96
V.2.1.a Simulazioni al calcolatore nel caso di canale tempo
invariante
Forzando il canale ad avere guadagni bloccati a valori 1 per il raggio diretto e 0.2
per quello riflesso, è stato simulato il comportamento per diversi valori di SNR.
Riportiamo alcuni risultati:
Canale tempo invariante 1-0,2
SNR=30. Time-spread=0,416 msec
0
0,2
0,4
0,6
0,8
1
1,2
1 2501 5001 7501 10001 12501 15001 17501 20001 22501 25001 27501
simboli
err
or
Figura V.3 Valutazione del modulo kε nel caso tempo invariante in assenza di rumore (SNR=30 dB)
Canale tempo invariante 1-0,2
SNR=20.Time_spread=0,416 msec
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1 2114 4227 6340 8453 10566 12679 14792 16905 19018 21131
simbolo
err
or
Figura V.4 Valutazione del modulo kε nel caso tempo invariante con SNR=20 dB
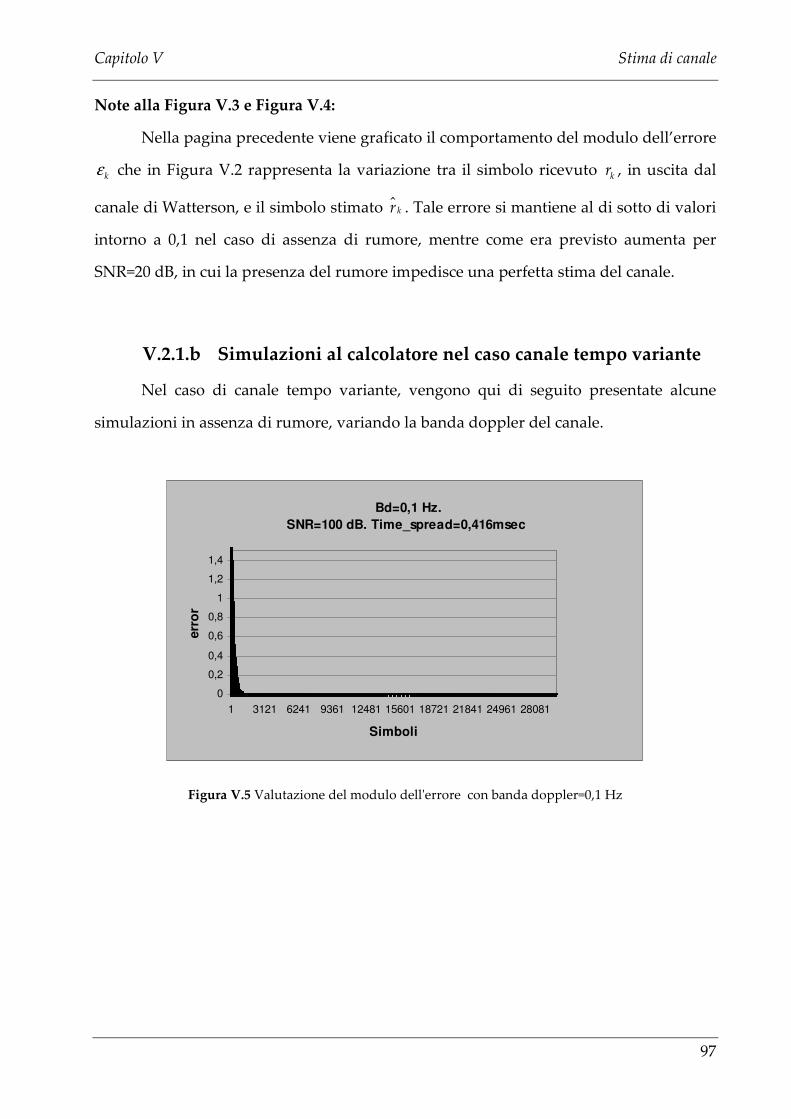
Capitolo V Stima di canale
97
Note alla Figura V.3 e Figura V.4:
Nella pagina precedente viene graficato il comportamento del modulo dell’errore
kε che in Figura V.2 rappresenta la variazione tra il simbolo ricevuto kr , in uscita dal
canale di Watterson, e il simbolo stimato kr$ . Tale errore si mantiene al di sotto di valori
intorno a 0,1 nel caso di assenza di rumore, mentre come era previsto aumenta per
SNR=20 dB, in cui la presenza del rumore impedisce una perfetta stima del canale.
V.2.1.b Simulazioni al calcolatore nel caso canale tempo variante
Nel caso di canale tempo variante, vengono qui di seguito presentate alcune
simulazioni in assenza di rumore, variando la banda doppler del canale.
Bd=0,1 Hz.
SNR=100 dB. Time_spread=0,416msec
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1 3121 6241 9361 12481 15601 18721 21841 24961 28081
Simboli
err
or
Figura V.5 Valutazione del modulo dell'errore con banda doppler=0,1 Hz
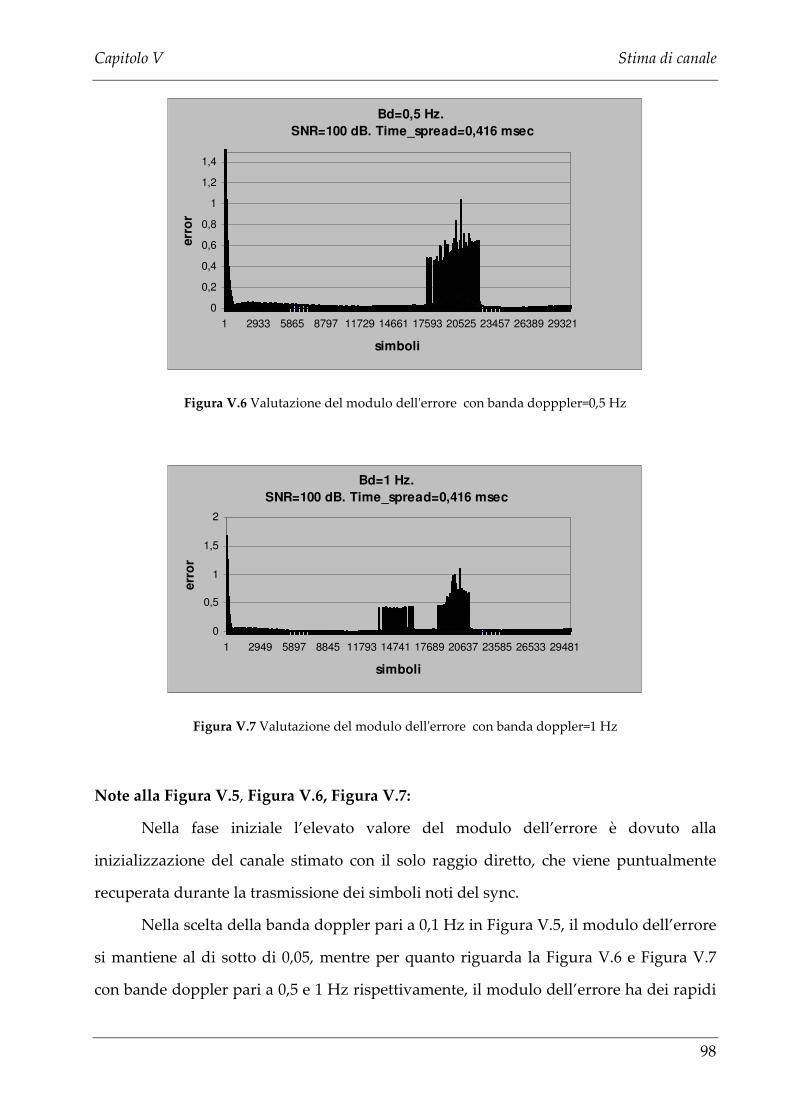
Capitolo V Stima di canale
98
Bd=0,5 Hz.
SNR=100 dB. Time_spread=0,416 msec
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1 2933 5865 8797 11729 14661 17593 20525 23457 26389 29321
simboli
err
or
Figura V.6 Valutazione del modulo dell'errore con banda dopppler=0,5 Hz
Bd=1 Hz.
SNR=100 dB. Time_spread=0,416 msec
0
0,5
1
1,5
2
1 2949 5897 8845 11793 14741 17689 20637 23585 26533 29481
simboli
err
or
Figura V.7 Valutazione del modulo dell'errore con banda doppler=1 Hz
Note alla Figura V.5, Figura V.6, Figura V.7:
Nella fase iniziale l’elevato valore del modulo dell’errore è dovuto alla
inizializzazione del canale stimato con il solo raggio diretto, che viene puntualmente
recuperata durante la trasmissione dei simboli noti del sync.
Nella scelta della banda doppler pari a 0,1 Hz in Figura V.5, il modulo dell’errore
si mantiene al di sotto di 0,05, mentre per quanto riguarda la Figura V.6 e Figura V.7
con bande doppler pari a 0,5 e 1 Hz rispettivamente, il modulo dell’errore ha dei rapidi

Capitolo V Stima di canale
99
incrementi in corrispondenza di particolari posizioni della trama. Tali posizioni sono
coincidenti con gli istanti in cui i guadagni del canale di Watterson sono circa uguali in
modulo, infatti in tali istanti il filtro equalizzatore teorico di tipo IIR ha infiniti campioni
non trascurabili, l’inevitabile utilizzo di un filtro FIR nel nostro sistema comporta un
errore di troncamento considerevole, errore che si ripercuote sulla stima di canale.
V.2.2 Soluzione error-free
È stata adottata una soluzione error-free per analizzare la validità del
comportamento del channel estimator. Eliminando la presenza del CMA vengono
introdotti nel canale stimato direttamente i simboli trasmessi secondo lo standard della
MIL-A. In pratica si suppone che lo stimatore di canale conosca tutta la trama inviata.
Tramite quest’ultima e la conoscenza dei simboli ricevuti attraverso il canale di
Watterson reale vengono aggiornati i coefficienti dello stimatore di canale tramite la ben
nota formula (V.12). In pratica è stata modificata la Figura V.2 in maniera opportuna:
Canale di Watterson
Canale stimato
CMA a T/2
ks
k
s
kr
kr$
kε
+
-
Figura V.8 Channel estimator con soluzione error-free

Capitolo V Stima di canale
100
Risultati delle simulazioni:
Bd=0,5 Hz.
SNR=100 dB. Time_spread=0,416 msec
0
0,2
0,4
0,6
0,8
1
1,2
1,4
1 2949 5897 8845 11793 14741 17689 20637 23585 26533 29481
simboli
err
or
Figura V.9 Valutazione del modulo dell’errore nel caso di soluzione error-free con
banda doppler=0,5 Hz
Bd=1 Hz.
SNR=100 dB. Time_spread=0,416 msec
0
0,5
1
1,5
2
1 2501 5001 7501 10001 12501 15001 17501 20001 22501 25001 27501
simboli
err
or
Figura V.10 Valutazione del modulo dell'errore nel caso di soluzione error-free con banda doppler=1 Hz
Note alla Figura V.9 e Figura V.10:
Come ci si aspettava non si presentano i problemi introdotti dalla presenza del
CMA. Il modulo dell’errore kε si mantiene al di sotto di 0,05 nel caso di banda doppler
di 0,5 Hz di Figura V.9, mentre si mantiene al di sotto di 0,1 nel caso di banda doppler

Capitolo V Stima di canale
101
di 1 Hz di Figura V.10. In sostanza non si presentano i picchi del modulo dell’errore kε
riscontrati in Figura V.6 e in Figura V.7, dovuti ad una equalizzazione del canale da
parte del CMA con dei limiti realizzativi, per il troncamento del filtro IIR teorico.
V.2.3 Utilizzo di un cancellatore come equalizzatore
Un’ulteriore riprova del funzionamento corretto del Channel estimator viene
effettuata attraverso l’utilizzo di un cancellatore. Tuttavia anche questa rappresenta una
soluzione error-free, poiché la cancellazione dell’ISI presuppone la conoscenza dei
simboli futuri, che nella realtà non sono noti a priori.
Il simbolo ricevuto può essere scritto come segue:
1 1 2 2 0 1 1 2 2( ...) ( ...)− − − + − += + + + + + +k n n k n n
r c s c s c s c s c s (V.13)
dove viene messa in evidenza la presenza dell’interferenza dei simboli antecedenti ks
(da 1ns − in poi) e quelli seguenti (da 1ns + in poi). Nelle simulazioni l’estrazione del
simbolo ks trasmesso viene quindi realizzata tramite tale formula:
1 2 1 21 2 1
0
( ... )− +− − +− + + + +=
$ $ $ $$
$nk n n n
k
r c s c s c s cs
c (V.14)
dove i $ kc , rappresentano i coefficienti di volta in volta stimati dal Channel estimator e la
parte tra parentesi rappresenta il contributo ISI da eliminare tramite cancellazione.
Poiché la codifica 8-PSK adottata vincola i simboli a valori in modulo unitari, la
divisione per 0$c ha interesse solo per l’informazione introdotta sulla fase, tanto più che
per modulo prossimo a zero si potrebbero presentare dei problemi.

Capitolo V Stima di canale
102
Un grafico può aiutare a comprenderne il funzionamento:
Figura V.11 Channel estimator con cancellatore
Note alla Figura V.11:
ks rappresenta il simbolo trasmesso e attraversa il canale di Watterson e il
Channel estimator (nel caso di simboli KNOWN). Inoltre ks viene usato dal cancellatore
per l’eliminazione dell’interferenza introdotta dai simboli futuri. In sostanza, il
cancellatore ha in ingresso sia ks (simbolo trasmesso) che kr (simbolo ricevuto), come
previsto dalla formula (V.14). L’uscita del cancellatore $ ks è il simbolo stimato che viene
usato (nel caso di interruttore in posizione 1) per l’aggiornamento dei coefficienti del
Channel estimator. L’interruttore in posizione 2 invece, si riferisce all’introduzione nel
canale stimato di simboli ks già noti al ricevitore, ma in entrambi i casi per
l’aggiornamento dei coefficienti si fa sempre riferimento alla (V.12).
Alcuni grafici sul comportamento dei simboli 8-PSK stimati possono dare
un’idea della validità dello stimatore di canale con cancellatore.
ks
ks
kr
Canale di Watterson
Canale stimato
Cancellatore
kr$
kε
ks$
ks
+
-2
1

Capitolo V Stima di canale
103
Bd=0,1 Hz SNR=20 dB
-1,5
-1
-0,5
0
0,5
1
1,5
-2 -1 0 1 2
Re Simb
Im S
imb
Simboli 8-PSK
Simboli equalizzati
Figura V.12 Comportamento dei simboli stimati 8-PSK nel caso di SNR=20 e banda doppler pari a 0,1 Hz
Bd=0,5 Hz SNR=20 dB
-1,5
-1
-0,5
0
0,5
1
1,5
-2 -1 0 1 2
Re simb
Im s
imb
Simboli 8-PSK
Simboli equalizzati
Figura V.13 Comportamento dei simboli stimati 8-PSK nel caso di SNR=20 e banda doppler pari a 0,5 Hz
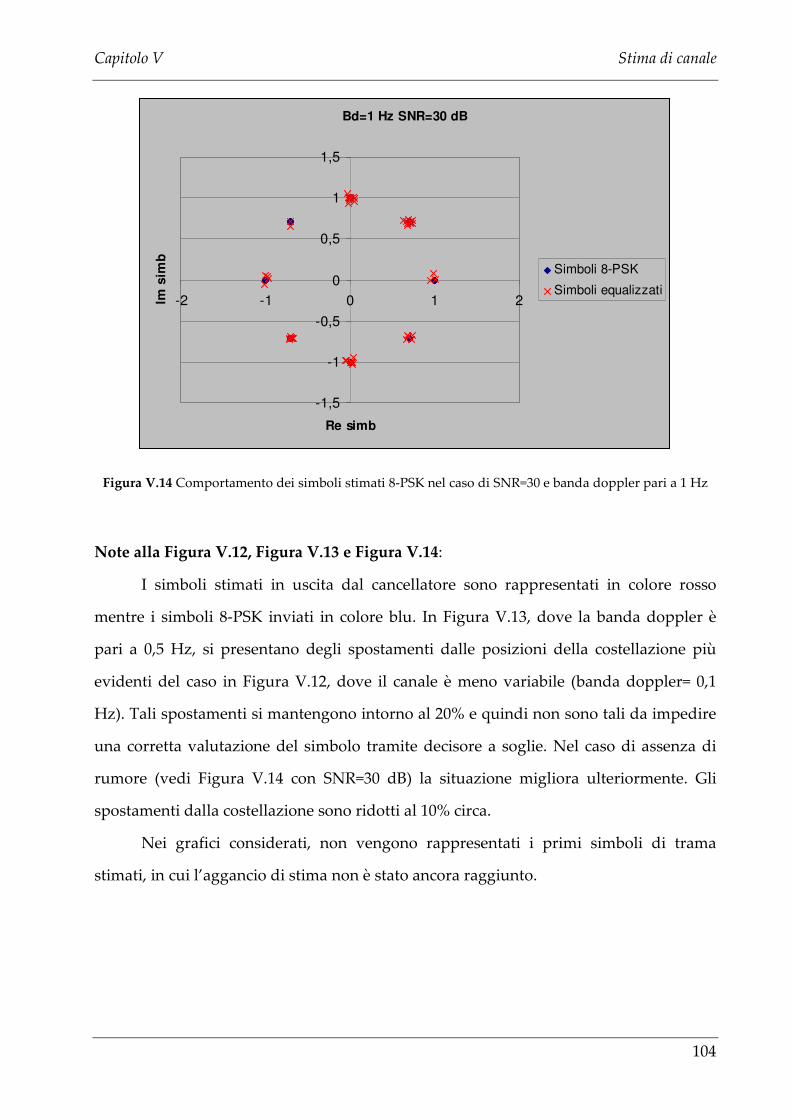
Capitolo V Stima di canale
104
Bd=1 Hz SNR=30 dB
-1,5
-1
-0,5
0
0,5
1
1,5
-2 -1 0 1 2
Re simb
Im s
imb
Simboli 8-PSK
Simboli equalizzati
Figura V.14 Comportamento dei simboli stimati 8-PSK nel caso di SNR=30 e banda doppler pari a 1 Hz
Note alla Figura V.12, Figura V.13 e Figura V.14:
I simboli stimati in uscita dal cancellatore sono rappresentati in colore rosso
mentre i simboli 8-PSK inviati in colore blu. In Figura V.13, dove la banda doppler è
pari a 0,5 Hz, si presentano degli spostamenti dalle posizioni della costellazione più
evidenti del caso in Figura V.12, dove il canale è meno variabile (banda doppler= 0,1
Hz). Tali spostamenti si mantengono intorno al 20% e quindi non sono tali da impedire
una corretta valutazione del simbolo tramite decisore a soglie. Nel caso di assenza di
rumore (vedi Figura V.14 con SNR=30 dB) la situazione migliora ulteriormente. Gli
spostamenti dalla costellazione sono ridotti al 10% circa.
Nei grafici considerati, non vengono rappresentati i primi simboli di trama
stimati, in cui l’aggancio di stima non è stato ancora raggiunto.

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
105
Capitolo VI
EQUALIZZAZIONE BASATA
SULL’ALGORITMO R-MAP
VI.1 L’equalizzatore MAP
Il sistema che effettua la stima di canale descritto nel Capitolo V può essere
utilizzato per costruire un altro tipo di equalizzatore. Il CMA infatti, (Capitolo IV) è un
equalizzatore adattativo che non ha bisogno di conoscere del canale per aggiornare i
suoi coefficienti. L’equalizzatore MAP necessita invece della conoscenza del canale per
funzionare correttamente, conoscenza che ovviamente non è direttamente disponibile in
ricezione; ecco che si rende necessario stimare il canale secondo, ad esempio, le tecniche
presentate nel Capitolo V.
Il MAP è un equalizzatore non lineare, il cui algoritmo di rivelazione simbolo a
simbolo è basato sul criterio della massima probabilità a posteriori (MAP – Maximum A
Posteriori Probability). Esso minimizza la probabilità di errore sul simbolo, scegliendo
la sequenza di simboli trasmessi nI in maniera tale che la densità di probabilità
[ ]( )nP I r n sia massima, dove [ ]r n è la sequenza ricevuta. Come già detto questa
tecnica, per essere implementata, richiede la conoscenza, o comunque la stima, del
canale e della statistica del rumore che corrompe il segnale.

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
106
Al passo n+D, l’equalizzatore MAP calcola la probabilità a posteriori del simbolo
[ ]b n , condizionata alla sequenza ricevuta dall’istante n all’istante n+D:
{ } ( ), D , D [ ] [ D][ ] conn n n n r n r nP b n + ++=r r L (VI.1)
Si decide, quindi, per il simbolo is della costellazione per cui vale:
{ } { }, D, D [ ][ ] n nn n ji b n sP b n s P j i++ == > ∀ ≠rr (VI.2)
Al contrario di un equalizzatore MLSE (Maximum Likelihood Sequence Estimation),
che individua come trasmessa la sequenza che ha la massima probabilità fra tutte le
possibili sequenze, l’equalizzatore MAP decide sul simbolo che ha la massima
probabilità tra tutti i possibili simboli trasmessi.
Un esempio può chiarire meglio la differenza tra le due tecniche. Supponiamo di
disporre delle probabilità delle quattro possibili sequenze di 2 bit:
Sequenza Probabilità
0 0 0,22
0 1 0,27
1 0 0,25
1 1 0,26
Tabella VI.1 Probabilità di una possibile sequenza
L’equalizzatore MLSE individua come sequenza trasmessa quella che ha maggior
probabilità, ovvero la sequenza 0 1.
L’equalizzatore MAP, invece, calcola simbolo a simbolo la probabilità che esso
sia stato trasmesso. Quindi, per il primo simbolo della sequenza si avrebbe
( )0 0,22 0,27 0,49P = + = e ( )1 0, 25 0, 26 0,51P = + = , e deciderebbe per il simbolo 1.

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
107
Analogamente, per il secondo simbolo si avrebbe ( )0 0,22 0, 25 0,47P = + = e
( )1 0, 27 0, 26 0,53P = + = . Pertanto, in questo caso, al contrario del MLSE, il MAP
avrebbe individuato come trasmessa la sequenza 1 1.
Il blocco funzionale che implementa l’equalizzazione MAP, riceve in ingresso la
stima [ ]ch k′′ della risposta impulsiva del canale HF, effettuata mediante il metodo del
gradiente stocastico descritto nel Capitolo V, e la sequenza ricevuta [ ]r n :
L-1
T
0
[ ] [ ] [ ] [ ] ( ) [ ] [ ]c ck
n h k b n k n h n n=
= − + = +∑r n b n (VI.3)
dove [ ] [ ] [ ]( )0 1 1c c c ch h h L= −h K e [ ] [ ] [ ]( )1 1c c c cb n b n b n L= − − +b K sono i vettori
contenenti, rispettivamente, i coefficienti del canale reale e gli ultimi L simboli trasmessi
(stato del canale). Il parametro L è la lunghezza del filtro FIR che rappresenta il canale,
ma regola anche il ritardo D=L-1 della decisione rispetto alla ricezione del simbolo. In
ogni istante i possibili stati del canale sono LN S= , dove S è pari al numero di simboli
della costellazione (ad es.: 8 8PSK S→ = , 16 16QAM S→ = ).
A partire da questi due input, viene calcolato il vettore contenente le probabilità
a posteriori degli stati di canale (APPs di canale):
{ } { }( )-D, -D,[ ] [ ] [ ]n n n nn P n P n= = =1 Nr rp b m b mL (VI.4)
dove i vettori im corrispondono agli N possibili stati di canale. A partire dal vettore
[ ]np è possibile calcolare, con un ritardo pari a D=L-1, il vettore delle probabilità a
posteriori di simbolo (APPs di simbolo):
{ } { }( ), D , D1 S[ ] b[ ] s b[ ] sn n n nn P n P n+ += = =r rs L (VI.5)
Tale operazione può essere eseguita sommando opportunamente gli elementi del
vettore [ ]np .

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
108
Ad esempio, supponendo un canale di lunghezza L=3, ed utilizzando una
modulazione BPSK (S=2), si avrà un vettore [ ]np di 32 8= elementi. Il vettore [ ]np
potrebbe essere pari a:
[ ] ( )0,02 0,01 0,90 0,01 0,00 0,05 0,00 0,01n =p
dove gli 8 possibili stati sono ordinati nel seguente modo:
000 001 010 011 100 101 110 111
In questo caso, le probabilità a posteriori dei simboli 0 e 1 sono pari a:
{ }2,[ 2] 0 | 0,02 0,01 0,90 0,01 0,94n n
P b n −− = = + + + =r
{ }2,[ 2] 1| 0,00 0,05 0,00 0,01 0,06n n
P b n −− = = + + + =r
Pertanto il vettore delle APPs di simbolo sarà:
[ 2] (0,94 0,06)n − =s
Si può pensare di calcolare il vettore [ ]np ricorsivamente, attraverso la matrice F:
1,1 1,
,1 ,
N
N N N
F F
F F
=
F
L
M O M
L
(VI.6)
dove il generico elemento ,i jF rappresenta la probabilità di passaggio di stato:
{ }, [ 1]F P [ ]i jnn − == = ji b mb m (VI.7)

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
109
Si può così ricavare [ ]np semplicemente:
[ ] [ 1]n n= −p F p (VI.8)
Nella Figura III.7 è rappresentato lo schema a blocchi dell’equalizzatore MAP.
Calcolo delle APPs di canale
Calcolo delle APPs di simbolo
One-step delay
F
Decisore MAP
s[n-D] p[n]
p[n-1]
r[n]
Figura VI.1 Equalizzatore MAP
È facilmente intuibile come la soluzione di equalizzazione MAP, seppur
operando con un basso ritardo di decisione, implichi un costo computazionale che
cresce esponenzialmente con la lunghezza del canale (il numero degli stati di canale è
LS ). Per questo motivo si è rivolta l’attenzione verso tecniche di equalizzazione MAP
con un numero ridotto di stati di canale.
VI.2 L’equalizzatore RMAP
La strategia adottata dall’equalizzatore RMAP (Reduced-complexity MAP), per
ridurre la complessità computazionale, consiste nel selezionare, ad ogni passo, solo gli
H elementi maggiori del vettore [ ]1n −p , necessario per calcolare le APPs di canale.
Questa operazione, che equivale ad escludere gli stati di canale meno probabili,
consente una notevole riduzione del costo computazionale (generalmente si sceglie
LH S� ) a fronte di un peggioramento accettabile delle prestazioni del ricevitore in
termini di SER (Symbol Error Rate).

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
110
Di seguito vengono riportati i passi fondamentali dell’equalizzatore RMAP:
1° Passo: A partire dal vettore delle APPs di canale, al passo n-1,
{ } { }( )1 D, 1 1 D, 1[ 1] P [ 1] P [ 1]n n n nn n n− − − − − −− = − = − =1 Hr rp b m b mL di dimensione H×1, si
ricava, tramite la matrice F delle probabilità dei possibili passaggi di stato, di
dimensione SH×H, il vettore [ ]n′p di dimensione SH×1 che contiene le probabilità degli
SH possibili stati di canale, al passo n:
[ ] [ 1]n n′ = −p F p (VI.9)
2° Passo: Nel vettore [ ]n′′p di dimensione H×1, si riportano le probabilità degli H
stati più probabili contenuti in [ ]n′p :
{ }max [ ][ ] H nn ′′′ = pp (VI.10)
3° Passo: Si calcola il vettore [ ]nd , di dimensione H×1, che rappresenta una
funzione di costo di tipo esponenziale, così definita:
T2 2T T
0 0
r[ ] ( ) r[ ] ( )[ ] exp exp
N Nn n
n ′′ ′′− − = − −
c 1 c Hh m h md L (VI.11)
4° Passo: Si pesano le probabilità di stato contenute in [ ]n′′p con la funzione di
costo [ ]nd ; le nuove probabilità di stato vengono messe nel vettore [ ]n′′′p di dimensione
H×1:
{ }[ ] Diag [ ][ ]n nn′′′ ′′=p pd (VI.12)

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
111
5° Passo: Si normalizzano le probabilità di stato contenute in [ ]n′′′p , e si mettono
nel vettore [ ]np delle APPs di canale, al passo n, di dimensione H×1:
{ }[ ][ ] Norm nn ′′′= pp (VI.13)
6° Passo: Dal vettore [ ]np delle APPs di canale, si calcola il vettore [ - D]ns delle
APPs di simbolo, di dimensione S×1, utilizzando la matrice maschera B, di dimensione
S×H, il cui generico elemento Bij è uguale a 1 se lo stato j-esimo (tra gli H sopravvissuti)
contiene il simbolo i-esimo nell’ultima posizione della sua configurazione, mentre è
uguale a 0 altrove:
[ - D] [ ]n n=s B p (VI.14)
7° Passo: Si decide per il simbolo si per cui vale:
$ { } { }D,-D, b[ - D] sb[ - D] s tale che P b[ - D] s P n nn n ji i nn n j i−== = > ∀ ≠rr (VI.15)
In ogni passo bisogna, inoltre, tener memoria delle configurazioni degli H stati
sopravvissuti.
Implementazione softwer:
Si è scelto di mantenere informazione degli H stati sopravvissuti tramite un
vettore di indici CFp di dimensione Hx1, più facile da gestire della corrispondente
matrice TabStates di HxL elementi della costellazione 8-PSK, (dove L rappresenta la
lunghezza del canale). La corrispondenza viene gestita tramite una rappresentazione
ottale dell’indice CFp che qui di seguito riportiamo per maggior chiarezza:

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
112
1 1
2 2
3 3
8 8 0 0 1 0
16 16 0 0 2 0
15 15 0 0 1 7
67 67 0 1 0 3H H
α α
α α
α α
α α
= = →
= = → = == = →
→ = = →
CFp TabStates
L
L
L
M M L L L L L
L
Il 1° e 2° Passo vengono gestiti contemporaneamente: viene innanzittutto
effettuato un’ordinamento (in senso decrescente), dei vettori delle APPs di canale
[ 1]n −p chiamato Xf e quindi del corrispondente indice di stato del canale CFp. Solo i
primi H/S stati saranno considerati per generarne altri S successivi, in questo modo si
ottengono, in maniera immediata, gli H stati successivi più probabili. Data
l’equiprobabilità degli S simboli successori risulta inutile oltre che dispendiosa dal
punto di vista dell’occupazione di memoria, l’utilizzo di una matrice di transizione di
stato F. Per gestire il calcolo delle H probabilità di stati del canale più probabili '[ ]np ,
contenute nel vettore Xp (Hx1), è quindi sufficiente associare una probabilità di 1/S agli
stati successori.
Per quanto riguarda il 6° e 7° Passo (di decisione sul simbolo), viene effettuato
con un ritardo pari a D e vengono implementati tramite l’utilizzo di un vettore s di
dimensione Sx1, in cui in posizione i=0..7 è inserita la probabilità relativa al simbolo 8-
PSK all’istante n-D. La scelta sul simbolo trasmesso è effettuata in favore dell’indice del
vettore s con maggior probabilità.
VI.3 Prestazioni per canale tempo invariante a fase minima
Al fine di testare l’efficacia dell’algoritmo RMAP si è deciso di studiare in prima
istanza il suo funzionamento su un canale tempo invariante secondo il modello di
Watterson (vedi Par. I.5). La Figura IV.1 fornisce un esempio del tipo di canale
utilizzato nelle simulazioni. Tale canale va in ogni caso stimato secondo le tecniche del

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
113
gradiente stocastico studiate nel Capitolo V. La formula ricorsiva utilizzata è la (V.12)
che riportiamo qui di seguito per comodità:
$ $ ( )1 k kk k agg ks r rδ∗
+ = + −c c $ $ (VI.16)
Per un canale tempo invariante, come quello qui utilizzato, si è ritenuto
sufficiente applicare la (VI.16) e quindi aggiornare i coefficienti del canale stimato solo
durante i simboli KNOWN della trama trasmessa (esplicitata in Figura IV.3). Così
facendo la stima della risposta impulsiva del canale si aggiorna durante il preambolo di
SYNC e durante i 16 simboli KNOWN e rimane fissa durante i 32 simboli UNKNOWN.
Vale la pena rimarcare che i risultati delle simulazioni riportati qui di seguito si
riferiscono solo a canali a fase minima ,cioè con il primo coefficiente maggiore del
secondo, se viene a mancare questa ipotesi l’algoritmo RMAP perde molto della sua
efficienza. In seguito verrà presentata una soluzione per ovviare a questo problema.
Canale (1; 0.2):
Parametri della simulazione:
• aggδ dello stimatore di canale: 0,008
• blocchi trasmessi: 3
• time spread: 416 μsec
• H (parametro dell’ RMAP): 16

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
114
Confronto RMAP-AWGN
1,00E-07
1,00E-06
1,00E-05
1,00E-04
1,00E-03
1,00E-02
1,00E-01
1,00E+00
0 3 6 9 12 15 18 21
SNR
SE
R
AWGN
RMAP
Figura VI.2 Prestazioni dell’RMAP per canale fisso (1;0.2)
Note alla Figura VI.2:
Si noti la particolare efficienza dell’ RMAP nell’eliminazione dell’ISI; infatti per
ogni SNR il sistema raggiunge un SER di poco superiore a quello ottenuto con un canale
di tipo AWGN che, come già detto, rappresenta un limite invalicabile nei nostri studi.
Il parametro H=16 è in questo caso particolarmente basso, in pratica gli stati
sopravviventi sono molto pochi rispetto alla totalità degli stati possibili pari a L 11S 8= ;
11 è la lunghezza sia della risposta impulsiva del canale che del parametro D
esprimente il ritardo di decisione introdotto dall’algoritmo RMAP (vedi Parr. VI.1 e
VI.2).
Sono state effettuate simulazioni anche con diversi tipi di canale a fase minima,
come (1; 0.5), (1; 0.8). Le prestazioni ottenute rispecchiano quelle graficate in Figura VI.2.

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
115
VI.4 Filtraggio preliminare
Nel Capitolo I sono state mostrate le caratteristiche del canale HF, e si è visto
come esso possa essere rappresentato da una risposta impulsiva tempo variante con
una durata finita.
Se la risposta impulsiva del canale (CIR – Channel Impulse Response) ha un
andamento temporale come in Figura VI.3, la funzione di trasferimento del canale gode
della proprietà di essere a fase minima, e l’energia del canale è massimamente
concentrata intorno allo zero; è il caso considerato nel precedente Par. VI.3
0 1 2 3 4 n
Figura VI.3 CIR a fase minima
Viceversa se si considera la risposta impulsiva mostrata in Figura VI.4, la
funzione di trasferimento del canale non è a fase minima, e la sequenza ricevuta dipende
fortemente dai simboli precedentemente trasmessi, ovvero è maggiore il contributo
dell’ISI.

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
116
0 1 2 3 4 n
Figura VI.4 CIR non a fase minima
In questo secondo caso l’equalizzatore RMAP, che ricerca tra le possibili
sequenze quella che più probabilmente è stata trasmessa, si trova nella situazione di
ricevere una sequenza che non dipende strettamente dall’ultimo simbolo trasmesso, che
lo porta a prendere decisioni sbagliate sul simbolo.
Per ovviare a tale situazione, si rende necessaria un’elaborazione della sequenza
ricevuta. Il sistema di trasmissione equivalente dovrà soddisfare le seguenti specifiche:
• avere una lunghezza della risposta impulsiva equivalente non maggiore
di quella del canale (in modo da non aumentare il numero di stati
dell’equalizzatore);
• essere causale;
• essere a fase minima;
• non enfatizzare il rumore, e lasciarlo bianco.
Il filtraggio che soddisfa tali requisiti è dato dalla cascata di un filtro matched ed
un filtro whitening.
VI.4.1 Il filtro matched
Indicata con [ ]ch n la risposta impulsiva del canale di lunghezza pari ad L, il
filtro matched (MF – Matched Filter) normalizzato è anticausale, con coefficienti dati
dalla seguente espressione:

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
117
*c
1m[ ] h [ ]
En n= − (VI.17)
dove −
=
∑L 1
2c
k 0
h [k]E = rappresenta l’energia istantanea del canale e ( )= − KL-1 , ,0n .
Indicata con [ ]a n la sequenza trasmessa, il segnale in uscita al filtro matched
risulta essere:
[ ] [ ]( )
[ ] [ ]=−
= − +∑L-1
L-1
y x a nn
n k n k n (VI.18)
dove con [ ]x k è stata indicata la sequenza di autocorrelazione del canale così definita:
( )
=
+ = −
= =
= −
∑ KL-
*c c
q 0
*
1 h [q ]h [q] 1, ,L 1E
x[ ]1 0x [- ] - L 1 ,…,-1
n
n n
nn
n n
(VI.19)
Il filtro matched normalizzato effettua sia un controllo di guadagno sia una
soppressione ottima del rumore. Inoltre, poiché il filtraggio matched non comporta
perdita di informazione, il segnale [ ]y n è una statistica sufficiente per la rivelazione del
segnale.
Il filtro matched va inserito all’uscita del canale reale del nostro sistema di
trasmissione. Dalla formula (VI.17) è evidente che si rende necessaria una stima di
canale simbolo a simbolo. Possiamo a tal fine utilizzare lo stimatore di canale tramite il
CMA studiato nel Par. V.2.1.
Il filtro matched non rimuove l’ISI, ed inoltre il rumore [ ]n n risulta colorato con
potenza tempo variante 0N / E e funzione di autocorrelazione [ ] ( ) [ ]n 0R N / E xn n= . Si
rende così necessario l’utilizzo di un filtro whitening (WF – Whitening Filter) che ha sia il
compito di cancellare i precursori anticausali dell’ISI, sia quello di rendere i campioni di
rumore incorrelati.

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
118
VI.4.2 Il filtro whitening
Le caratteristiche del filtro whitening sono legate alle specifiche che il canale
equivalente deve soddisfare. Indicando con [ ]w n i coefficienti del filtro whitening e
con [ ] [ ] [ ]f x wn n n= ∗ quelli del canale equivalente, in Figura Figura VI.5 è riportato lo
schema a blocchi del sistema di trasmissione equivalente.
Canale HF
Filtro matched m[n]
Filtro whitening w[n]
y[n] r[n] a[n] v[n]
x[n]
f[n]
Figura VI.5 Sistema di trasmissione equivalente
Passando nel dominio della trasformata z, la funzione di autocorrelazione del
canale ( )X z può essere fattorizzata come:
( ) ( )1
X F Fz zz
∗
∗
=
(VI.20)
Scegliendo ( )F z causale e a fase minima e ( ) ( )W 1/ F 1/z z∗ ∗= , si ha che la risposta
del canale equivalente è proprio pari a ( )F z . Tutto ciò è rappresentato nello schema a
blocchi in Figura VI.6.

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
119
Canale HF
Filtro matched M(z)
Filtro whitening W(z)
y[n] r[n] a[n] v[n]
F(z)
Figura VI.6 Sistema di trasmissione con filtraggio ideale
Avendo assunto ( )F z a fase minima e stabile, si ha che i suoi poli e i suoi zeri
giacciono all’interno del cerchio unitario, e quindi che i poli e gli zeri di ( )1/ F 1/ z∗ ∗
giacciono al di fuori del cerchio unitario. Dunque ( )W z , affinché sia stabile, deve essere
anticausale e la sua antitrasformata [ ]w n deve avere lunghezza infinita; non si può
perciò determinare agevolmente la risposta impulsiva del filtro whitening nel dominio
della variabile z.
Per risolvere tale problema si ricorre all’utilizzo di un Decision-Feedback Equalizer
(DFE), infatti la letteratura ci dice che la parte anticausale del FeedForward Filter (FF) del
DFE, ottimizzato con il criterio Zero-Forcing (ZF), coincide con il filtro whitening ideale.
I coefficienti del DFE sono determinati seguendo il criterio della minimizzazione
dell’errore quadratico medio (MMSE – Minimum Mean Square Error) tra la sequenza
stimata e quella ricevuta. In particolare i coefficienti del FF sono la soluzione del
seguente sistema di equazioni:
[ ]
[ ]
[ ]
[ ]
0,0 0,w
w,0 w,w
w 0 x 0
w W x W
Ψ Ψ
= Ψ Ψ
L
M O M M M
L
(VI.21)
dove i coefficienti ,i jΨ della matrice hanno la seguente espressione:

Capitolo VI Equalizzazione basata sull’algoritmo R-MAP
120
[ ] [ ] [ ],L
1x x x
j
i jl
l l i j i jγ
∗
=−
Ψ = + − + −∑ (VI.22)
dove gli [ ]x n sono i campioni della sequenza di autocorrelazione del canale, γ è il
rapporto segnale rumore istantaneo, W+1 è la lunghezza del filtro whitening e
, 0, ,Wi j = K . Per la risoluzione di tale sistema sono possibili due alternative: l’utilizzo
di un DFE con algoritmo LMS (Least Mean Square), oppure la soluzione analitica. I due
algoritmi permettono di ottenere i medesimi risultati, ma con costi computazionali
diversi.

Capitolo VII Filtro sbiancante (“Whitening Filter”)
121
Capitolo VII
FILTRO SBIANCANTE
(“WHITENING FILTER”)
VII.1 REALIZZAZIONE TRAMITE ALGORITMO LMS
L’immediata disponibilità dell’equalizzatore DFE ha portato, in prima
istanza,alla scelta dell’algoritmo LMS per implementare il filtro whitening.
L’equalizzatore DFE è composto da due filtri trasversali numerici. Il filtro
trasversale in avanti FF (feedforward) viene alimentato dalla sequenza dei campioni
ricevuti, mentre il filtro trasversale nel ramo di retroazione FB (feedback), dalla
sequenza dei simboli noti, ovvero dai simboli decisi a seconda che si ricevano simboli
KNOWN o UNKNOWN della trama (vedi Figura IV.3). Ovviamente i simboli KNOWN
sono noti al ricevitore, per quanto riguarda i simboli UNKNOWN si è utilizzato l’
equalizzatore CMA per stimarli (Capitolo IV).
filtro FF
preambolo
Equalizzatore CMA
filtro FB � Simboli KNOWN
� Simboli UNKNOWN decisi
ingresso dei campioni all’uscita
del MATCHED
r(k)
errore
e(k)
uscita filtro FF
(k)r~
Trama ricevuta
Figura VII.1 Schema a blocchi del DFE utilizzato nel calcolo del filtro Whitening
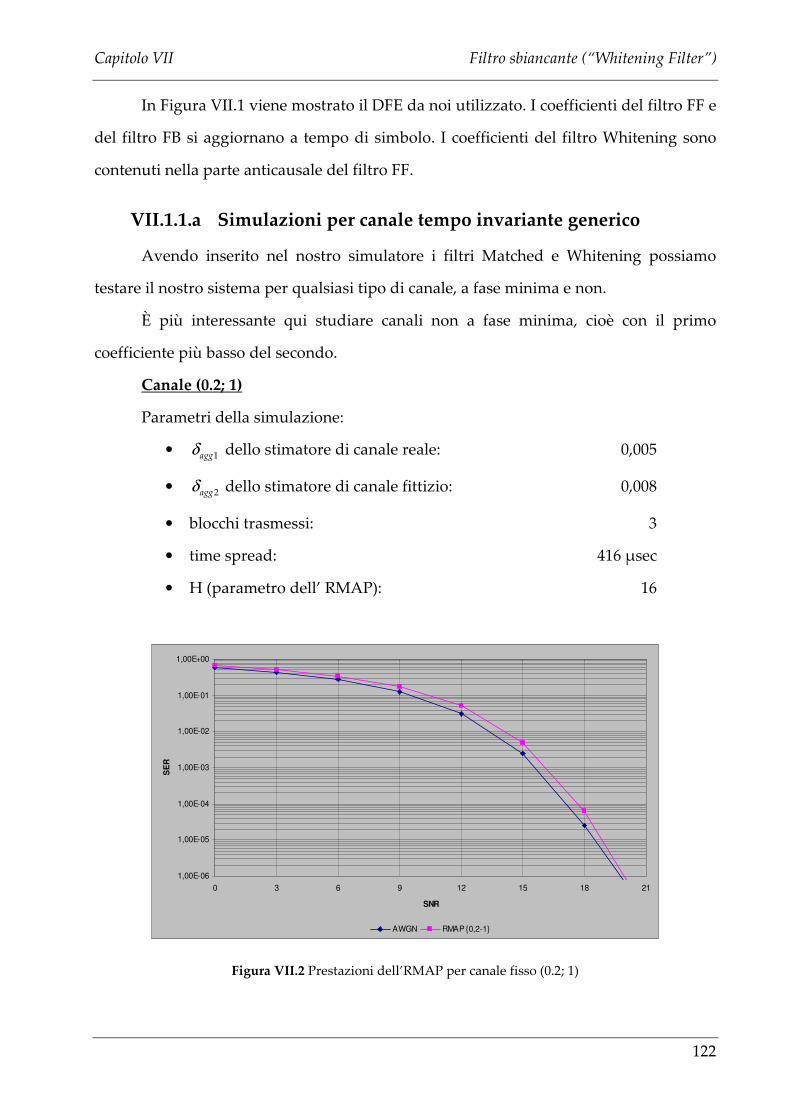
Capitolo VII Filtro sbiancante (“Whitening Filter”)
122
In Figura VII.1 viene mostrato il DFE da noi utilizzato. I coefficienti del filtro FF e
del filtro FB si aggiornano a tempo di simbolo. I coefficienti del filtro Whitening sono
contenuti nella parte anticausale del filtro FF.
VII.1.1.a Simulazioni per canale tempo invariante generico
Avendo inserito nel nostro simulatore i filtri Matched e Whitening possiamo
testare il nostro sistema per qualsiasi tipo di canale, a fase minima e non.
È più interessante qui studiare canali non a fase minima, cioè con il primo
coefficiente più basso del secondo.
Canale (0.2; 1)
Parametri della simulazione:
• 1aggδ dello stimatore di canale reale: 0,005
• 2aggδ dello stimatore di canale fittizio: 0,008
• blocchi trasmessi: 3
• time spread: 416 μsec
• H (parametro dell’ RMAP): 16
1,00E-06
1,00E-05
1,00E-04
1,00E-03
1,00E-02
1,00E-01
1,00E+00
0 3 6 9 12 15 18 21
SNR
SE
R
AWGN RMAP {0,2-1}
Figura VII.2 Prestazioni dell’RMAP per canale fisso (0.2; 1)

Capitolo VII Filtro sbiancante (“Whitening Filter”)
123
Note alla Figura VII.2:
Nella voce “Parametri della simulazione” vengono indicati due tipi di aggδ : 1aggδ si
riferisce al parametro utilizzato nella stima del canale reale, prima della cascata dei filtri
Matched e Whitening; tale stima servirà alla costruzione del filtro Matched stesso. 2aggδ
è invece il parametro della stima del canale fittizio comprendente la cascata del canale
vero + il filtro Matched + il filtro Whitening, stima necessaria per implementare
l’algoritmo RMAP (Par. VI.2).
Il SER prossimo a quello dell’AWGN denota la correttezza e l’efficienza dei filtri
Matched e Whitening costruiti. In sostanza il canale virtuale visto dall’RMAP viene reso
a fase minima dalla cascata dei filtri, indipendentemente che il canale effettivo sia a fase
minima o meno.
Il parametro H=16 dell’RMAP è sufficiente a garantire ottime prestazioni per
canale tempo invariante, utilizzato nella presente simulazione.
Sono state effettuate simulazioni con canali a fasi minima e filtri Matched e
Whitening attivati. I risultati raggiunti sono sostanzialmente analoghi a quelli del Par.
VI.3.
VII.1.1.b Simulazioni nel caso di canale tempo variante di
Watterson
Il sistema complessivo, formato dalla cascata dei filtri Matched e Whitening e
dall’equalizzatore RMAP è ora pronto per essere testato su canale tempo variante
secondo il modello di Watterson (Par. I.5).
A tal fine nella seguente Tabella VII.1 vengono presentati i SER ottenuti tramite
le simulazioni, messi a confronto con i corrispondenti SER dell’equalizzatore CMA a
T/2 (Par. IV.3.4).
Per la stima di canale il coefficiente aggδ vale 0,005 per lo stimatore del canale
vero utilizzato per costruire il filtro Matched, e 0,008 per lo stimatore del canale fittizio
visto dall’RMAP.

Capitolo VII Filtro sbiancante (“Whitening Filter”)
124
Bd (Hz)
SNR dB
Time spread
(sec)
Blocchi trasmessi
SER (RMAP) H=512
SER CMA a T/2
0,1 100 416 μ 5 2,6 E-05 2,2 E-03
0,15 100 416 μ 20 5,8 E-04 4,3 E-03
0,5 100 416 μ 5 2,3 E-03 6,4 E-03
0,1 100 832 μ 5 4,2 E-04 1,5 E-02
0,5 100 832 μ 5 4,4 E-04 1,2 E-02
0,5 18 832 μ 5 3,0 E-02 3,0 E-02
0,5 21 832 μ 5 1,4 E-02 5,6 E-02
0,1 100 2 m 20 2,8 E-03 4,4 E-02
0,5 100 2 m 10 1,1 E-02 3,2 E-02
0,5 21 2 m 10 2,0 E-02 5,6 E-02
Tabella VII.1 Confronto di prestazioni tra RMAP e CMA a T/2
Note alla Tabella VII.1:
Al fine di confrontare i risultati dell’RMAP con quelli dell’equalizzatore CMA a
T/2 il sistema è stato testato con SNR molto elevati. Per bande doppler basse (� 0,1 Hz)
l’equalizzatore RMAP introduce delle migliorie notevoli rispetto al CMA a T/2, di 1 o
(vedi prima riga di Tabella VII.1) di 2 ordini di grandezza. Ciò avviene per ogni time
spread considerato (ritardo tra primo e secondo raggio del canale). Anche per bande
doppler medie ( � 0,5 Hz) il miglioramento rispetto al CMA a T/2 è evidente anche se è,
in questo caso, “solo” di un fattore 2 o 3. Per bande doppler elevate l’equalizzatore che
sfrutta l’algoritmo RMAP non migliora sostanzialmente le prestazioni del CMA a T/2;
per time spread alti i risultati sono addirittura peggiori! La causa di ciò può essere
imputabile a due fattori:
i. la stima del canale fittizio cascata di: canale vero + filtro Matched + filtro Whitening
rimane bloccata durante la trasmissione dei simboli UNKNOWN. Un possibile

Capitolo VII Filtro sbiancante (“Whitening Filter”)
125
miglioramento si può apportare effettuando un’interpolazione lineare dei
coefficienti della stima di canale tra 2 miniblocchi consecutivi da 16 simboli
KNOWN per avere un aggiornamento della stima di canale anche durante la
trasmissione di simboli UNKNOWN;
ii. il DFE utilizzato per il calcolo del Whitening non è adatto a inseguire un canale
troppo veloce, come quello a banda doppler=1 Hz. Per ovviare a questo problema si
può aggiornare l’FF filter del DFE più volte ogni replica da 48 simboli, “ciclando”
sulla stessa; oppure si può ricorrere alla via analitica per il calcolo dei coefficienti del
filtro Whitening, come accennato nel Par. VI.4.2.
VII.1.2 SECONDA STIMA DI CANALE:
INTERPOLAZONE LINEARE
Nell’implementazione dell’equalizzazione adattativa mediante algoritmo RMAP
(Reduced-complexity MAP) descritta nel Par.VI.2 , è necessario effettuare una seconda
stima del canale fittizio ''c
h , cascata di: canale vero + filtro Matched + filtro Whitening.
Tale stima calcola il vettore [ ]nd definito dalla (VI.11), di dimensione H×1, che
riportiamo di seguito per maggior chiarezza.
( ) ( )
2 2'' ''
0 0
[ ] [ ][ ] exp ...exp
TT T
c cr n r n
nN N
− −
= − −
1 Hh m h md (VII.1)
[ ]nd rappresenta una funzione di peso di tipo esponenziale, adoperata per la
valutazione delle probabilità degli H stati sopravvissuti, [ ]r n rappresenta il simbolo
ricevuto all’istante n , ...1 Hm m sono gli H stati più probabili, mentre 0N è il rapporto
segnale-rumore. ''c
h rappresenta proprio la stima della risposta impulsiva del canale HF,
effettuata mediante il metodo del gradiente stocastico di canale descritto tramite la
oramai nota formula di aggiornamento dei coefficienti:

Capitolo VII Filtro sbiancante (“Whitening Filter”)
126
( )*
1 kk k kagg kc c s r rδ+ = + −$ $ $ $ (VII.2)
sviluppato e quindi già disponibile, dal CMA.
In una prima realizzazione, tale aggiornamento (dei coefficienti del canale) viene
effettuato simbolo a simbolo, per i simboli KNOWN, mentre rimane bloccato durante i
simboli UNKNOWN. Un possibile miglioramento si può apportare effettuando
un’interpolazione lineare dei coefficienti della stima di canale tra 2 miniblocchi
consecutivi da 16 simboli KNOWN per avere un aggiornamento della stima di canale
anche durante la trasmissione di simboli UNKNOWN.
La trama valida che si presenta in ricezione , viene manipolata per unità
elaborativa.
Prendendo in considerazione la struttura della trama trasmessa nello standard
MIL-STD-188-110 A, ( a parte il SYNC iniziale ) , una unità elaborativa è rappresentata
dai 16 simboli KNOWN del probe , con i rispettivi 32 simboli di dati UNKNOWN, più i
16 simboli sempre KNOWN del probe del blocco immediatamente successivo , come
mostrato in Figura VII.3:
Figura VII.3 Unità elaborativa ( UE ) relativa alla trama.
1UE
3UE
2UE
PROBE UNKNOWN PROBE UNKNOWN PROBE
PROBE
UNKNOWN
PROBE
PROBE
UNKNOWN
PROBE
PROBE PROBE
PROBE
UNKNOWN
UNKNOWN

Capitolo VII Filtro sbiancante (“Whitening Filter”)
127
Fissata l’attenzione sull’aggiornamento del canale al termine del primo probe
della singola unità elaborativa , si effettua una stima “ anticipata ” per il secondo probe
della stessa UE.
In questo modo, si ha a disposizione una stima nelle due posizioni A e B
mostrate in Figura VII.4, che può essere sfruttata opportunamente per
un’interpolazione lineare, che permetta un’aggiornamento simbolo a simbolo anche sui
simboli UNKNOWN.
Figura VII.4 Stima di canale su unità elaborativa
Note alla Figura VII.4:
In posizione A si ha una rappresentazione del valore assunto da uno degli L
coefficienti del canale, raggiunto in tal istante dalla seconda stima di canale , in B, la
valutazione dello stesso coefficiente tramite una stima di canale “anticipata”. La
differente altezza delle linee in neretto danno un’idea del diverso valore che nelle due
posizioni può assumere la stima del singolo coefficiente. La linea che unisce i due punti
, riporta l’andamento dell’interpolazione lineare che viene applicata simbolo a simbolo
sul singolo coefficiente di stima.
Analoga implementazione sarà adottata per i restanti L-1 coefficienti.
16 simboli KNOWNal termine del quale si ha la
stima di canale
32 simboli UNKNOWNche sfruttano come stima di canale i
valori interpolati linearmente
A
B
16 simboli KNOWNsui quali si effettua una
stima di canale “anticipata”
PROBE UNKNOWN PROBE
A
KUE

Capitolo VII Filtro sbiancante (“Whitening Filter”)
128
Implementazione softwer:
Per quanto riguarda i coefficienti di canale stimati alla fine del primo probe
dell’unità elaborativa , vengono memorizzati in un buffer , co_ch , di lunghezza l_ch ,
mentre la seconda stima di canale “anticipata”, ( al termine del secondo probe ) , viene
posta in un vettore delta2_ch sempre di lunghezza l_ch. Per ogni coefficiente della
risposta impulsiva di canale i , viene calcolato il valore di incremento a cadenza di
simbolo , da applicare secondo la formula:
_ [ ] _ [ ]_ [ ] 0, , _ 1
i ii i l ch
−= = −
delta2 ch co chdelta ch
REPLL
delta_ch tiene memoria della variazione , mentre REPL risulta pari a 48 , cioè la
dimensione di una replica , come mostrato in Figura VII.4. In questo modo la risposta
impulsiva di canale a cui i simboli UNKNOWN fanno riferimento , non è più fissata da
co_ch , ma subisce una modifica che ne migliora la stima . Infatti l’interpolazione non fa
altro che ammortizzare la variazione percepibile tra le stime co_ch e delta2_ch, come
mostrato:
0, , __ _ [ ] _ [ ] _ [ ]*( _ inf 1)
_ inf 0, ,31
i l ch
i i i j o
j o
=
= + +
=
co ch interp co ch delta ch
L
L
co_ch_interp è la stima di canale a cui i simboli di dati informativi faranno
riferimento . L’incremento da applicare a cadenza di simbolo viene gestito tramite
l’indice j_info che scandisce proprio i 32 simboli UNKNOWN.
VII.1.2.a Prestazioni canale tempo variante.
Le variazioni riscontrate con l’introduzione per i simboli informativi, di
un’interpolazione lineare sulla seconda stima di canale, nel caso di canale fisso sono
risultati quasi inesistenti, si è quindi preferito analizzare le prestazioni nel caso di
canale tempo variante.Per avere una valutazione più completa, sono messe a confronto
con i risultati dell’equalizzatore CMA a T/2.
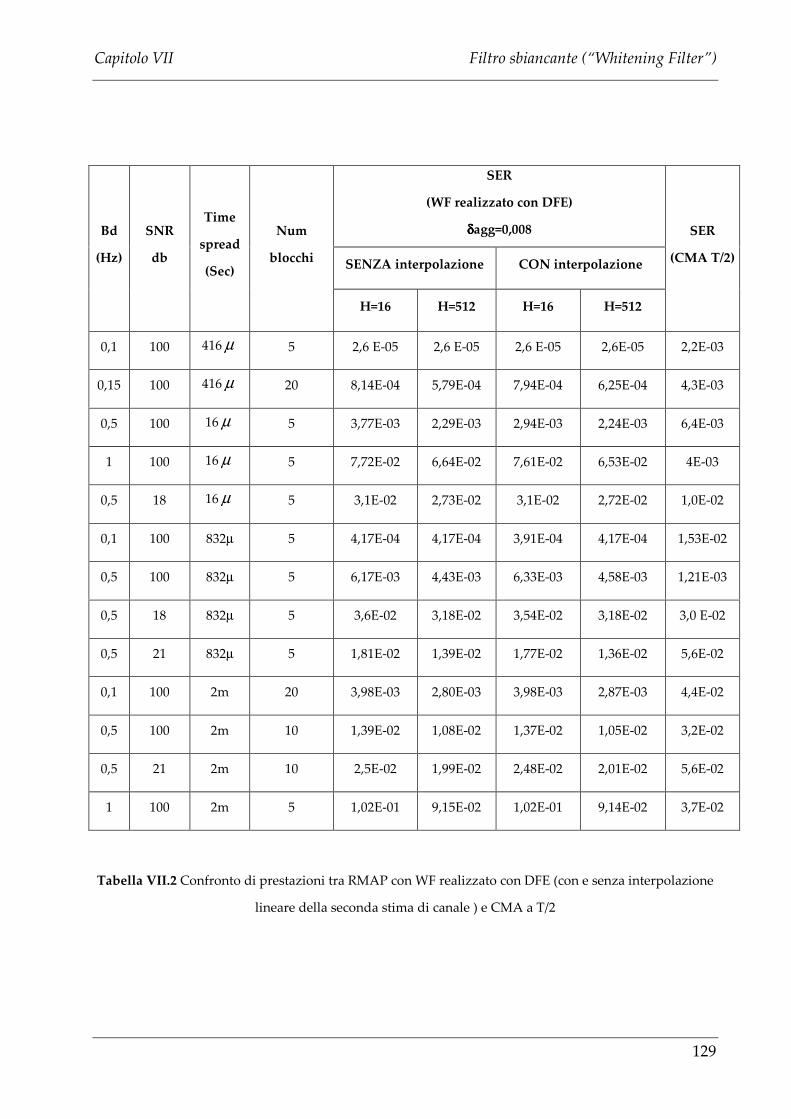
Capitolo VII Filtro sbiancante (“Whitening Filter”)
129
Tabella VII.2 Confronto di prestazioni tra RMAP con WF realizzato con DFE (con e senza interpolazione
lineare della seconda stima di canale ) e CMA a T/2
SER
(WF realizzato con DFE)
δδδδagg=0,008
SENZA interpolazione CON interpolazione
Bd
(Hz)
SNR
db
Time
spread
(Sec)
Num
blocchi
H=16 H=512 H=16 H=512
SER
(CMA T/2)
0,1 100 416 µ 5 2,6 E-05 2,6 E-05 2,6 E-05 2,6E-05 2,2E-03
0,15 100 416 µ 20 8,14E-04 5,79E-04 7,94E-04 6,25E-04 4,3E-03
0,5 100 16 µ 5 3,77E-03 2,29E-03 2,94E-03 2,24E-03 6,4E-03
1 100 16 µ 5 7,72E-02 6,64E-02 7,61E-02 6,53E-02 4E-03
0,5 18 16 µ 5 3,1E-02 2,73E-02 3,1E-02 2,72E-02 1,0E-02
0,1 100 832µ 5 4,17E-04 4,17E-04 3,91E-04 4,17E-04 1,53E-02
0,5 100 832µ 5 6,17E-03 4,43E-03 6,33E-03 4,58E-03 1,21E-03
0,5 18 832µ 5 3,6E-02 3,18E-02 3,54E-02 3,18E-02 3,0 E-02
0,5 21 832µ 5 1,81E-02 1,39E-02 1,77E-02 1,36E-02 5,6E-02
0,1 100 2m 20 3,98E-03 2,80E-03 3,98E-03 2,87E-03 4,4E-02
0,5 100 2m 10 1,39E-02 1,08E-02 1,37E-02 1,05E-02 3,2E-02
0,5 21 2m 10 2,5E-02 1,99E-02 2,48E-02 2,01E-02 5,6E-02
1 100 2m 5 1,02E-01 9,15E-02 1,02E-01 9,14E-02 3,7E-02

Capitolo VII Filtro sbiancante (“Whitening Filter”)
130
Note alla Tabella VII.2:
Per la stima del canale HF utilizzato per costruire il filtro Matched ed il
Whitening ,il coefficiente agg
δ , presente nella (VII.2) per l’implementazione
dell’algoritmo LMS (Least Mean Square) vale 0.005, e 0.008 per lo stimatore del canale
fittizio visto dall’RMAP.
Per avere una visione più completa del comportamento , si è testato l’ RMAP sia
per un numero di stati sopravvissuti relativamente basso (H=16), che per un valore più
elevato (H=512). Ricordiamo infatti , che nel caso considerato, con numero dei
coefficienti di canale l_ch=11 e modulazione 8PSK , il numero degli stati possibili è pari
a _ 118l chS = , quindi aumentare il numero degli stati più probabili considerati ,
aumenta l’efficacia del MAP a stati ridotti.
I miglioramenti sul SER introdotti dall’interpolazione lineare sulla stima di
canale , seppur presenti in maniera uniforme in tutte le simulazioni, non sono tali da
apportare un netto cambiamento in presenza di elevata variabilità del canale: situazione
già testata come critica per l’ RMAP , in cui le prestazioni raggiunte dal CMA sono
migliori.
Per bande doppler basse (0,1 Hz) l’equalizzatore RMAP introduce delle migliorie
notevoli rispetto al CMA a T/2, di 1 o (vedi prima e sesta riga di Tabella VII.2) di 2
ordini di grandezza, per ogni time spread considerato (ritardo tra primo e secondo
raggio del canale). Anche per bande doppler medie ( 0,5 Hz) il miglioramento rispetto
al CMA a T/2 è evidente anche se, in questo caso, è “solo” di un fattore 2 o 3. Per bande
doppler elevate (1 Hz) l’equalizzatore che sfrutta l’algoritmo RMAP non migliora
sostanzialmente le prestazioni del CMA a T/2 (vedi quarta e ultima riga di Tabella VII.2,
in cui i risultati sono addirittura peggiori).

Capitolo VII Filtro sbiancante (“Whitening Filter”)
131
VII.2 REALIZZAZIONE CON CALCOLO ANALITICO
Come constatato da precedenti simulazioni, il DFE utilizzato per il calcolo del
Whitening non è adatto a inseguire un canale troppo veloce, come quello a banda
doppler=1 Hz. Per ovviare a questo problema si può ricorrere alla via analitica, come
accennato nel Par.VI.4.2.
VII.2.1 Costruzione della matrice dei coefficienti
La matrice dei coefficienti del sistema (VI.21) è una matrice Hermitiana di
dimensioni (W+1)×(W+1), contiene, inoltre, una sottomatrice di Toeplitz di dimensioni
(W-L+1)×(W-L+1), dove con L si intende il numero di coefficienti di cui è costituita la
risposta impulsiva del canale.Tale matrice può essere pensata così composta:
=E F
ΨG T
(VII.3)
dove T è la sottomatrice Toeplitz e ( )* T=F G cioè HG .
Implementazione software
La creazione della matrice Ψ chiamata mat_white , viene implementata tramite
la funzione Psi in cui compare la funzione Coeff di generazione effettiva degli elementi
della stessa, secondo la (VI.22) . Per una realizzazione ottimizzata si sono sfruttate le
conoscenze su tale matrice . Il fatto che la matrice risultante debba essere Hermitiana ha
permesso una riduzione dei calcoli dei coefficienti alla sola parte triangolare inferiore,
per quella superiore si considera la corrispondenza dei coefficienti con i trasposti e
coniugati della precedente parte.

Capitolo VII Filtro sbiancante (“Whitening Filter”)
132
Come da struttura (VII.3) le proprietà precedentemente esposte permettono una
inversione agevole della matrice mediante il seguente algoritmo:
• Si applica l’ algoritmo di Levinson –Durbin alla matrice T così calcolando 1−T
• Si aggiunge una riga ed una colonna in modo da ottenere una nuova matrice
quadrata di dimensioni (W-L+2)×(W-L+2), di tale matrice si calcola l’inversa
utilizzando il lemma dell’inversione della matrice partizionata a blocchi .
• Si itera il passo precedente fino ad invertire completamente la matrice.
• Infine si determina la soluzione del sistema moltiplicando la matrice inversa per
il vettore dei termini noti.
Va considerato il caso in cui la matrice risulta singolare, nell’algoritmo di
Levinson Durbin tale evento è rilevato dal fatto che il valore assunto da un parametro,
detto varianza dell’errore di predizione in avanti NE risulta prossimo allo zero; in tal caso
l’algoritmo di Levinson Durbin viene arrestato e si realizza un filtro di lunghezza
minore.
VII.2.2 Calcolo della matrice 1−T : algoritmo di LEVINSON-
DURBIN
L’algoritmo di Levinson – Durbin permette di calcolare in modo efficiente
l’inversa di una matrice Hermitiana e di Toeplitz.
Si consideri una generica matrice Hermitiana e di Toeplitz NxR di dimensioni (N
+1)×(N+1), che possiamo pensare ripartita nella seguente forma:
2 Hx NN
N 1xN
xσ −
=r
Rr R
(VII.4)

Capitolo VII Filtro sbiancante (“Whitening Filter”)
133
dove 2xσ è la varianza del processo cioè l’autocorrelazione calcolata in zero 0xR
,
N 1 Nx xT
R R
=r L rappresenta il vettore delle autocorrelazioni del canale di
dimensioni (Nx1), mentre HNr è il trasposto coniugato di Nr .
HN
* *x x
N*x
0 1 x
x0 11 xx
1 0x x x
R R R N
R RR
R N R R
=
r
R
64444744448
L
L
L M O M
L
(VII.5)
per ottenere la matrice inversa si devono risolvere i seguenti sistemi:
. N N
0
0.
0
0
N
N
E
E
= =
N Nx xR a R p
M
M (VII.6)
dove i coefficienti Na e quelli Np sono legati dalla seguente relazione:
*N N=p Ja (VII.7)
0 0 1
1 0
0 1
1 0 0
=
J
L
M N
N M
L
indica la matrice di scambio. I coefficienti Np si ottengono cioè,
come complessi coniugati e invertiti di Na .
La recursione di Levinson è stata sviluppata originariamente per la soluzione
dell’equazioni normali per la predizione lineare di un processo tempo discreto
stazionario, in tale ambito Na è il vettore dei coefficienti di predizione in avanti e Np il
vettore dei coefficienti di predizione all’indietro.

Capitolo VII Filtro sbiancante (“Whitening Filter”)
134
Le relazioni di ricorrenza sono le seguenti :
N 1N N
N-1
* N 1N
N-1
0K0
0K0N
−
−
= +
= +
aa
p
ap
p
(VII.8)
2N NN-1= (1-| | )E E K (VII.9)
dove l’elemento reale NE indica la varianza dell’errore di predizione al passo N.
Queste necessitano solo della conoscenza al passo (N-1) del coefficiente di
riflessione,che ha la seguente espressione :
N N N-1N-1
1 TKE
= − ⋅ ⋅r J a (VII.10)
e dell’ inizializzazione
2x x0
x1
x
[0]
10
E R
RK
R
σ=
=
= −
(VII.11)
Per la determinazione della matrice inversa ( )1N
x−
R si fa riferimento alla
fattorizzazione LU :
( )1N 1
x−
−= ⋅ ⋅HR L E L (VII.12)

Capitolo VII Filtro sbiancante (“Whitening Filter”)
135
Dove la coniugata della matrice L , è la matrice triangolare inferiore dei
coefficienti di predizione all’indietro come mostrato in (VII.13) :
1,1
*2,2 2,1
N,N N,N-1 N,N-2
1 0 0 0
p 1 0 0
p p 1 0
0
p p p 1
=L
L
L
L
M M M O
L
(VII.13)
e indicando con E la matrice diagonale delle varianze degli errori di predizione in
avanti ai vari passi:
0
1
2
N
0 0 0
0 0 0
0 0 0
0 0 0
E
E
E
E
=E
L
L
L
M M M O M
L
(VII.14)
Implementazione software
L’implementazione dell’algoritmo di Levinson – Durbin viene gestito tramite una
chiamata alla funzione LD2 in cui si inizializza 0E e 1K tramite le (VII.11) e il vettore
An di dimensione (W-L+1) con 1 in prima posizione e tutti zeri . La recursione viene
implementata tramite la funzione Aggiornacoeff che aggiorna al passo N, il coefficiente
di riflessione NK tramite la (VII.10), il vettore An con la (VII.8) e la varianza dell’errore
di predizione NE con la (VII.9).
In questo modo ad ogni iterazione il vettore An rappresenta la riga i-esima della
matrice L

Capitolo VII Filtro sbiancante (“Whitening Filter”)
136
1,1
2,1 2,2
N,1 N,2 N,3
1 0 0 0
1 0 0
1 0
0
1
a
a a
a a a
=L
L
L
L
M M M O
L
(VII.15)
ed iE , l’elemento i-esimo della diagonale della (VII.14), tramite cui si costruisce invE:
10
11
1 12
1N
0 0 0
0 0 0
0 0 0
0 0 0
E
E
E
E
−
=E
L
L
L
M M M O M
L
(VII.16)
Al termine di un numero di iterazioni W-L+1, pari alla dimensione della matrice
di Toepliz , si hanno a disposizione tutti i termini della (VII.12) che permettono il
calcolo di ( )1N
x−
R , matrice che viene memorizzata in invRxn.
VII.2.3 Lemma dell’inversione della matrice partizionata
a blocchi
Si consideri una matrice Y di dimensioni l×l che possiamo pensare partizionata in
sottomatrici A,B,C,D nel modo seguente
A DY =
C B (VII.17)

Capitolo VII Filtro sbiancante (“Whitening Filter”)
137
dove A è una matrice q×q, B è una matrice (l-q)×(l-q), C è una matrice (l-q)×q, D è
una matrice q×(l-q). L’inversa di Y è data da :
-1 -1 -1
-1
-1 -1 -1 -1 -1 -1
Λ -Λ DBY =
-B CΛ B + B CΛ DB (VII.18)
con -1Λ = A - DB C
Implementazione software
L’inversione di matrice, viene gestito dalle funzioni Inv_matrix2 a cui è nota la
matrice inversa di Toeplitz e l’intera matrice mat_white corrispondente alla Ψ di (VII.3)
e Inv_matrix3 che implementa a livello effettivo il lemma dell’inversione di matrice
partizionata a blocchi. Inv_matrix2 itera la chiamata della funzione Inv_matrix3 per un
numero di volte pari a (W+1)-(W-L+1), infatti L-1 è proprio la dimensione del numero di
righe e di colonne, da aggiungere alla matrice di Toeplitz per ricostruire la matrice Ψ di
partenza.
Il lemma viene infatti applicato iterativamente ad una matrice quadrata Y ,
(M+1)x(M+1), di cui di volta in volta, Inv_matrix3 calcola l’inversa invY , conoscendo ,
dall’iterazione precedente, la sottomatrice inversa invB di dimensione M x M
1xM
MxM
=
A D
YC B
6447448
1442443
(VII.19)
Si ricorda che il vettore D 1xM risulta pari ( )* TC1 corrispondente a C della
(VII.17), inoltre data la struttura della matrice, il blocco della (VII.18)

Capitolo VII Filtro sbiancante (“Whitening Filter”)
138
( )*1 1 1 1− − − −
Λ DB = B CΛ , mentre ( )*1 1− −DB = B C caratteristiche sfruttate opportunamente
nell’implementazione software.
VII.3 Confronto tra i due algoritmi
Per un’analisi completa dell’implementazione tramite whitening analitico, si
sono testate le prestazioni sia nel caso canale tempo invariante che variante,
confrontandole con le medesime nel caso di una realizzazione del WF con algoritmo
LMS.
VII.3.1 Prestazioni per canale tempo invariante
Faremo un confronto tra i risultati ottenuti con una realizzazione con algoritmo
LMS e con una realizzazione analitica del filtro Whitening migliorata da una seconda
stima di canale tramite interpolazione lineare. Questo sia nel caso di canale a fase
minima cioè con il primo tappo più alto del secondo, che non .
In entrambe le situazioni i parametri della simulazione adottati sono:
· 1aggδ dello stimatore di canale reale: 0,005
· 2aggδ dello stimatore di canale fittizio: 0,008
· blocchi trasmessi: 3
· time spread: 416 μsec
· H (parametro dell’ RMAP): 16

Capitolo VII Filtro sbiancante (“Whitening Filter”)
139
1,00E-07
1,00E-06
1,00E-05
1,00E-04
1,00E-03
1,00E-02
1,00E-01
1,00E+00
0 3 6 9 12 15 18 21
SNR
SE
R
AWGN RMAP (w hitening con DFE) RMAP (w hitening analitico)
Figura VII.5 Prestazioni dell’RMAP per canale fisso (1;0.2)
1,00E-07
1,00E-06
1,00E-05
1,00E-04
1,00E-03
1,00E-02
1,00E-01
1,00E+00
0 3 6 9 12 15 18 21
SNR
SE
R
AWGN RMAP (w hitening con DFE) RMAP (w hitening analitico)
Figura VII.6 Prestazioni dell’RMAP per canale fisso (0.2; 1)

Capitolo VII Filtro sbiancante (“Whitening Filter”)
140
Note alle Figura VII.5 e Figura VII.6 :
Nella voce “Parametri della simulazione” vengono indicati due tipi di agg
δ : 1aggδ si
riferisce al parametro utilizzato nella stima del canale reale, prima della cascata dei filtri
Matched e Whitening; tale stima servirà alla costruzione del filtro Matched stesso. 2aggδ
è invece il parametro della stima del canale fittizio comprendente la cascata del canale
vero + il filtro Matched + il filtro Whitening, stima necessaria per implementare
l’algoritmo RMAP .
Il SER prossimo a quello dell’AWGN denota la correttezza e l’efficienza dei filtri
Matched e Whitening costruiti. In sostanza il canale virtuale visto dall’RMAP viene reso
a fase minima dalla cascata dei filtri, indipendentemente che il canale effettivo sia a fase
minima o meno.
Il parametro H=16 dell’RMAP è sufficiente a garantire ottime prestazioni per
canale tempo invariante, utilizzato nella presente simulazione.
In entrambe le situazioni, sia di canale (1, 0.2) che (0.2 , 1) , la realizzazione del
WF in forma analitica mostra dei miglioramenti rispetto al caso di una generazione
tramite LMS, dovuta alla necessità di un raggiungimento della convergenza della
procedura iterativa , tutto questo a scapito di un tempo elaborativo superiore al
precedente.
Per maggior chiarezza si è pensato di confrontare in Figura VII.7 , i risultati di
tale nuova implementazione con quelli di uno stesso canale fisso con l’equalizzatore
CMA a T/2 che rappresentava le migliori prestazioni che siamo riusciti ad ottenere
fin’ora.

Capitolo VII Filtro sbiancante (“Whitening Filter”)
141
1,00E-07
1,00E-06
1,00E-05
1,00E-04
1,00E-03
1,00E-02
1,00E-01
1,00E+00
0 3 6 9 12 15 18 21
SNR
SE
R
AWGN RMAP (w hitening ANALITICO) CMA T/2
Figura VII.7 Confronto tra le prestazioni dell’ equalizzatore RMAP e il CMA a T/2 per canale fisso
Il miglioramento rispetto al CMA a T/2 è netto, almeno per quanto riguarda il
canale fisso il SER risulta prossimo a quello dell’AWGN.
VII.3.2 Simulazioni nel caso di canale tempo variante di
Watterson
Il sistema complessivo, formato dalla cascata dei filtri Matched e Whitening e
dall’equalizzatore RMAP è ora pronto per essere testato su canale tempo variante
secondo il modello di Watterson .
In Tabella VII.3 viene mostrato un confronto tra una prima implementazione del
Whitening che sfrutta l’ algoritmo LMS ed una seconda che adotta invece
l’implementazione analitica.
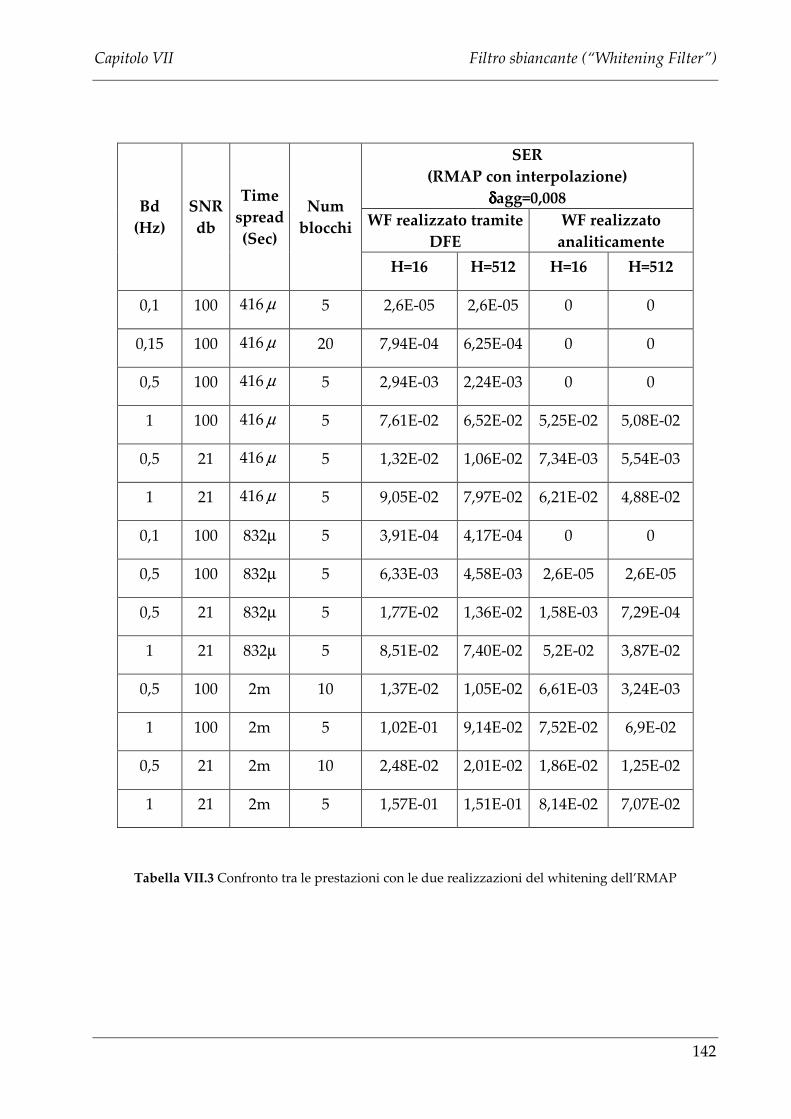
Capitolo VII Filtro sbiancante (“Whitening Filter”)
142
Tabella VII.3 Confronto tra le prestazioni con le due realizzazioni del whitening dell’RMAP
SER (RMAP con interpolazione)
δδδδagg=0,008 WF realizzato tramite
DFE WF realizzato analiticamente
Bd (Hz)
SNR db
Time spread (Sec)
Num blocchi
H=16 H=512 H=16 H=512
0,1 100 416 µ 5 2,6E-05 2,6E-05 0 0
0,15 100 416 µ 20 7,94E-04 6,25E-04 0 0
0,5 100 416 µ 5 2,94E-03 2,24E-03 0 0
1 100 416 µ 5 7,61E-02 6,52E-02 5,25E-02 5,08E-02
0,5 21 416 µ 5 1,32E-02 1,06E-02 7,34E-03 5,54E-03
1 21 416 µ 5 9,05E-02 7,97E-02 6,21E-02 4,88E-02
0,1 100 832µ 5 3,91E-04 4,17E-04 0 0
0,5 100 832µ 5 6,33E-03 4,58E-03 2,6E-05 2,6E-05
0,5 21 832µ 5 1,77E-02 1,36E-02 1,58E-03 7,29E-04
1 21 832µ 5 8,51E-02 7,40E-02 5,2E-02 3,87E-02
0,5 100 2m 10 1,37E-02 1,05E-02 6,61E-03 3,24E-03
1 100 2m 5 1,02E-01 9,14E-02 7,52E-02 6,9E-02
0,5 21 2m 10 2,48E-02 2,01E-02 1,86E-02 1,25E-02
1 21 2m 5 1,57E-01 1,51E-01 8,14E-02 7,07E-02

Capitolo VII Filtro sbiancante (“Whitening Filter”)
143
Note alla Tabella VII.3:
In entrambe le implementazioni per la stima di canale, il coefficiente agg
δ vale
0,005 per lo stimatore del canale vero utilizzato per costruire il filtro Matched, e 0,008
per la seconda stima di canale interpolata vista dall’RMAP.
Fino a Bd di 0.5 Hz, si ottengono dei miglioramenti di uno o addirittura due
ordini di grandezza, per time spread pari a 416μ , raggiungendo un abbattimento a zero
del SER , nel caso di assenza di rumore (vedi prime tre e settima riga della Tabella
VII.3).Nel caso di time spread a 2msec, i miglioramenti si riducono ad un ordine di
grandezza in assenza di rumore, e a circa un fattore due per SNR=21dB.Infine per Bd
pari ad 1Hz, seppur presenti, i miglioramenti risultano meno evidenti per tutti times
spread testati. Tali migliorie, risultano rimarcate incrementando il del numero di stati
sopravvissuti da H= 16 a 512.
Nella seguente Tabella VII.4 vengono presentati invece, i SER ottenuti tramite le
simulazioni di quest’ultima versione, messi a confronto con i corrispondenti SER
dell’equalizzatore CMA a T/2 .
Per la stima di canale il coefficiente agg
δ vale sempre 0,005 per lo stimatore del
canale vero utilizzato per costruire il filtro Matched, e 0,008 per lo stimatore del canale
fittizio visto dall’RMAP.
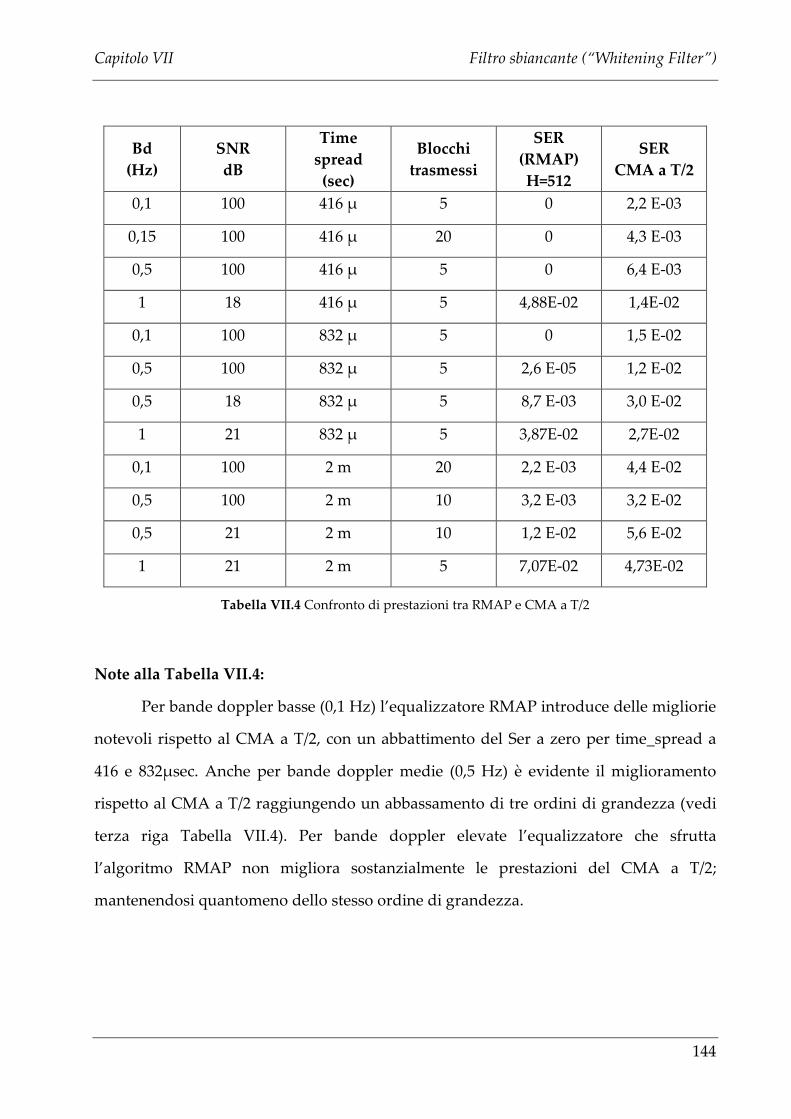
Capitolo VII Filtro sbiancante (“Whitening Filter”)
144
Bd (Hz)
SNR dB
Time spread
(sec)
Blocchi trasmessi
SER (RMAP) H=512
SER CMA a T/2
0,1 100 416 μ 5 0 2,2 E-03
0,15 100 416 μ 20 0 4,3 E-03
0,5 100 416 μ 5 0 6,4 E-03
1 18 416 μ 5 4,88E-02 1,4E-02
0,1 100 832 μ 5 0 1,5 E-02
0,5 100 832 μ 5 2,6 E-05 1,2 E-02
0,5 18 832 μ 5 8,7 E-03 3,0 E-02
1 21 832 μ 5 3,87E-02 2,7E-02
0,1 100 2 m 20 2,2 E-03 4,4 E-02
0,5 100 2 m 10 3,2 E-03 3,2 E-02
0,5 21 2 m 10 1,2 E-02 5,6 E-02
1 21 2 m 5 7,07E-02 4,73E-02
Tabella VII.4 Confronto di prestazioni tra RMAP e CMA a T/2
Note alla Tabella VII.4:
Per bande doppler basse (0,1 Hz) l’equalizzatore RMAP introduce delle migliorie
notevoli rispetto al CMA a T/2, con un abbattimento del Ser a zero per time_spread a
416 e 832μsec. Anche per bande doppler medie (0,5 Hz) è evidente il miglioramento
rispetto al CMA a T/2 raggiungendo un abbassamento di tre ordini di grandezza (vedi
terza riga Tabella VII.4). Per bande doppler elevate l’equalizzatore che sfrutta
l’algoritmo RMAP non migliora sostanzialmente le prestazioni del CMA a T/2;
mantenendosi quantomeno dello stesso ordine di grandezza.

Capitolo VII Filtro sbiancante (“Whitening Filter”)
145
VII.4 Limiti prestazionali della seconda stima di canale
Si è proposto di analizzare quali siano i limiti prestazionali raggiungibili,
adottando l’algoritmo del gradiente stocastico che secondo la (VI.16) aggiornano i
coefficienti del canale vero + Matched + Whitening filter utilizzata per lo sviluppo
dell’equalizzazione R-MAP.
Come dal Par.VI.3 la seconda stima di canale adottata per l’implementazione di
tale equalizzatore, sfrutta per l’aggiornamento dei coefficienti una conoscenza parziale
sui simboli trasmessi (il SYNC iniziale ed i PROBE’s), che viene fissata per l’intera
durata dei simboli UNKNOWN, permettendo il raggiungimento di prestazioni tabulate
in Tabella VII.1, nel caso di una realizzazione del WF tramite DFE.
In seguito si è reputato opportuno migliorare tale stima introducendo
un’interpolazione lineare che permettesse una variazione della stima del canale simbolo
a simbolo anche per la parte UNKNOWN della trama come da Par.VII.1.2. Si sono così
raggiunti dei miglioramenti visibili dalla Tabella VII.2.
Dopo aver introdotto l’implementazione analitica del WF se ne sono testate le
prestazioni raggiunte sfruttando una seconda stima di canale con interpolazione lineare
come da Tabella VII.4. A questo punto, supponendo una conoscenza completa della
trama trasmessa si è testato il comportamento dell’algoritmo LMS, ottenendo una
valutazione dei limiti raggiungibili con una implementazione di tale tecnica di stima.
Effettuando un’aggiornamento simbolo a simbolo dei coefficienti di stima secondo la
nota formula (VI.16), riportata per maggior chiarezza di seguito:
$ $ ( )1 kkk k agg ks r rδ∗
+ = + −c c $ $
si ottengono le seguenti prestazioni che vengono messe a confronto con i risultati
ottenuti dalla precedente implementazione, (WF realizzato analiticamente con
interpolazione lineare sui simboli UNKNOWN).

Capitolo VII Filtro sbiancante (“Whitening Filter”)
146
SER
δδδδagg=0,008
RMAP
(WF analitico con
interpolazione
lineare)
Soluzione
error_free
(TEORICA)
Bd
(Hz)
SNR
(db)
Time
spread
(Sec)
Num.
blocchi
H=16 H=512 H=16 H=512
0,5 100 416μ 5 0 0 0 0
1 100 416μ 5 5,25E-02 5,08E-02 3,8E-02 2,61E-02
0,5 18 416μ 5 7,34E-03 5,54E-03 2,5E-03 1,77E-03
1 18 416μ 5 6,21E-02 4,88E-02 4,73E-02 3,18E-02
0,5 100 832µ 5 2,6E-05 2,6E-05 0 0
1 100 832µ 5 5,44E-02 5,21E-02 4,4E-02 3,5E-02
0,5 21 832µ 5 1,58E-03 7,29E-04 0 0
1 21 832μ 5 5,20E-02 3,87E-02 4,34E-02 2,36E-02
0,5 100 2m 10 6,61E-03 3,24E-03 7,55E-04 2,47E-04
1 100 2m 5 7,52E-02 6,93E-02 4,29E-02 4,64E-02
0,5 21 2m 10 1,86E-02 1,25E-02 4,19E-02 1,92E-03
1 21 2m 5 8,14E-02 7,07E-02 5,60E-02 4,91E-02
Tabella VII.5 Analisi dei limiti prestazionali dovuti all’algoritmo LMS per la stima di canale
Note allaTabella VII.5:
Ovviamente nel caso di SER nullo non ci si aspettano miglioramenti (caso di time
spread a 416μsec e bande doppler inferiori a 0,5Hz).
Nel caso di bande doppler medie (0,5 Hz) la Tabella VII.5 mostra come sia
possibile un’abbattimento del SER nel caso di time spread pari a 816μsec mentre si

Capitolo VII Filtro sbiancante (“Whitening Filter”)
147
potrebbe raggiungere un miglioramento di un ordine di grandezza per time spread a
2msec.
Per quanto riguarda bande doppler elevate, si può aspirare a miglioramenti di un
fattore due. Nonostante si sia supposta una conoscenza completa della trama, che
permette un aggiornamento simbolo a simbolo dei coefficienti di stima del canale, sono
pur sempre presenti dei limiti prestazionali dovuti all’algoritmo del gradiente
stocastico. Questo infatti ha una ridotta velocità d’inseguimento del canale e quindi
risulta limitativa per canali rapidamente variabili.

Capitolo VIII Conclusioni
148
Capitolo VIII
CONCLUSIONI
A conclusine del lavoro svolto, viene riportata una breve descrizione realizzativa
dell’equalizzatore R_MAP da utilizzare per il modem MIL-STD-188-110A.
In Figura VIII.1 viene mostrato lo schema a blocchi del ricevitore.
Figura VIII.1 Schema a blocchi del ricevitore
La prima stima di canale, utilizzata per la realizzazione del WMF, sfrutta il CMA
per equalizzare il canale. Come descritto nel Par.V.2.1 è necessario avere un
equalizzatore che renda disponibili allo stimatore di canale una decisione sui simboli
UNKNOWN il più possibile accurata. Mediante il confronto tra l’uscita del canale di
Watterson e l’uscita del canale stimato si aggiornano i coefficienti della stima tramite la
seguente formula:
$ $ ( )δ∗
+ = + −$ $1 kk k agg k ks r rc c (VIII.1)
dove c$ rappresenta il vettore della risposta impulsiva del canale stimato; aggδ è un
coefficiente che nel nostro caso è stato ottimizzato a 0.005; ∗$ks è il vettore dei simboli
CANALE HF
2ª STIMADI CANALE
2ª STIMADI CANALE
1ª STIMADI CANALE
1ª STIMADI CANALE
FILTROMATCHED
FILTROWHITENING
EQUALIZZATORERMAP D
S(t)MIL-STD-188-110A
a b

Capitolo VIII Conclusioni
149
complessi (coniugati) fatti passare attraverso il canale stimato fino al punto a, per avere
così in uscita il simbolo kr$ , presunta uscita del canale, da confrontare poi con l’uscita
reale kr del canale di Watterson.
La seconda stima di canale utilizzata per l’implementazione dell’equalizzatore
R-MAP adotta lo stesso algoritmo del gradiente stocastico descritto dalla (VIII.1) per
l’aggiornamento dei coefficienti, dove però aggδ è stato ottimizzato a 0.008 mentre ∗$ks è il
vettore dei simboli fatti passare attraverso il nuovo canale stimato fino al punto b, per
avere così in uscita il simbolo kr$ , presunta uscita, da confrontare poi con l’uscita reale
kr del canale vero + Matched + Whitening. La conoscenza dei simboli KNOWN (il
SYNC e i PROBEs), permette un’aggiornamento dei coefficienti della seconda stima di
canale durante questi ultimi. Come descritto dal Par.VII.1.2, invece di fissare la stima
(per i simboli UNKNOWN), al valore raggiunto al termine di ogni blocco KNOWN, si è
suddivisa la trama in unità elaborative, come in Figura VIII.2 e si è introdotta
un’interpolazione lineare durante quelli UNKNOWN come da Figura VIII.3.
Figura VIII.2 Suddivisione della trama in unità elaborative ( UE ).
PROBE UNKNOWN PROBE UNKNOWN PROBE
PROBE
UNKNOWN
PROBE
PROBE
UNKNOWN
PROBE
PROBE PROBE
PROBE
UNKNOWN
UNKNOWN
1UE
2UE
3UE
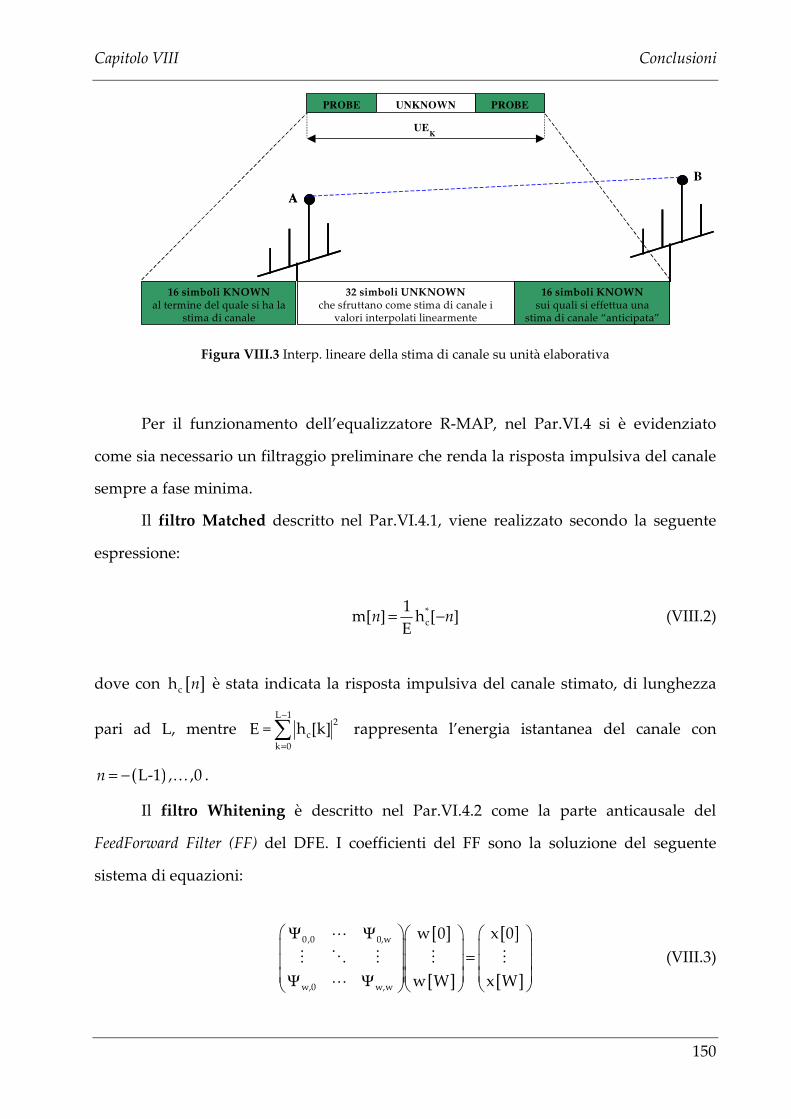
Capitolo VIII Conclusioni
150
16 simboli KNOWNal termine del quale si ha la
stima di canale
32 simboli UNKNOWNche sfruttano come stima di canale i
valori interpolati linearmente
A
B
16 simboli KNOWNsui quali si effettua una
stima di canale “anticipata”
PROBE UNKNOWN PROBE
A
KUE
Figura VIII.3 Interp. lineare della stima di canale su unità elaborativa
Per il funzionamento dell’equalizzatore R-MAP, nel Par.VI.4 si è evidenziato
come sia necessario un filtraggio preliminare che renda la risposta impulsiva del canale
sempre a fase minima.
Il filtro Matched descritto nel Par.VI.4.1, viene realizzato secondo la seguente
espressione:
= −*c
1m[ ] h [ ]
En n (VIII.2)
dove con [ ]ch n è stata indicata la risposta impulsiva del canale stimato, di lunghezza
pari ad L, mentre −
=
∑L 1
2c
k 0
h [k]E = rappresenta l’energia istantanea del canale con
( )= − KL-1 , ,0n .
Il filtro Whitening è descritto nel Par.VI.4.2 come la parte anticausale del
FeedForward Filter (FF) del DFE. I coefficienti del FF sono la soluzione del seguente
sistema di equazioni:
[ ]
[ ]
[ ]
[ ]
Ψ Ψ
= Ψ Ψ
L
M O M M M
L
0,0 0,w
w,0 w,w
w 0 x 0
w W x W (VIII.3)

Capitolo VIII Conclusioni
151
dove i coefficienti ,i jΨ della matrice hanno la seguente espressione:
[ ] [ ] [ ]γ
∗
=−
Ψ = + − + −∑,L
1x x x
j
i jl
l l i j i j (VIII.4)
gli [ ]x n sono i campioni della sequenza di autocorrelazione del canale, γ è il rapporto
segnale rumore istantaneo, W+1 è la lunghezza del filtro whitening e , 0, ,Wi j = K . La
soluzione analitica descritta nel Par. VII.2. prevede l’inversione della matrice Ψ dei
coefficienti del sistema (VIII.3). Ψ è una matrice Hermitiana di dimensioni
(W+1)×(W+1), divisibile nei seguenti blocchi:
=E F
ΨG T
(VIII.5)
T è una sottomatrice di Toeplitz di dimensioni (W-L+1)×(W-L+1), mentre = HF G .
Queste proprietà hanno permesso una inversione agevole della matrice mediante il
seguente algoritmo:
• Si applica l’ algoritmo di Levinson –Durbin, descritto nel Par. VII.2.2, alla matrice T
• Si aggiunge una riga ed una colonna in modo da ottenere una nuova matrice
quadrata di dimensioni (W-L+2)×(W-L+2), di tale matrice si calcola l’inversa
utilizzando il lemma dell’inversione della matrice partizionata a blocchi, descritto nel
Par. VII.2.3 .
• Si itera il passo precedente fino ad invertire completamente la matrice.
• Infine si determina la soluzione del sistema moltiplicando la matrice inversa per il
vettore dei termini noti.
Si ricordi che con L si intende il numero di coefficienti di cui è costituita la risposta
impulsiva del canale e nell’implementazione sviluppata è stata fissata ad 11, mentre la
lunghezza del whitening W+1=2L-1 risulta pari a 21.
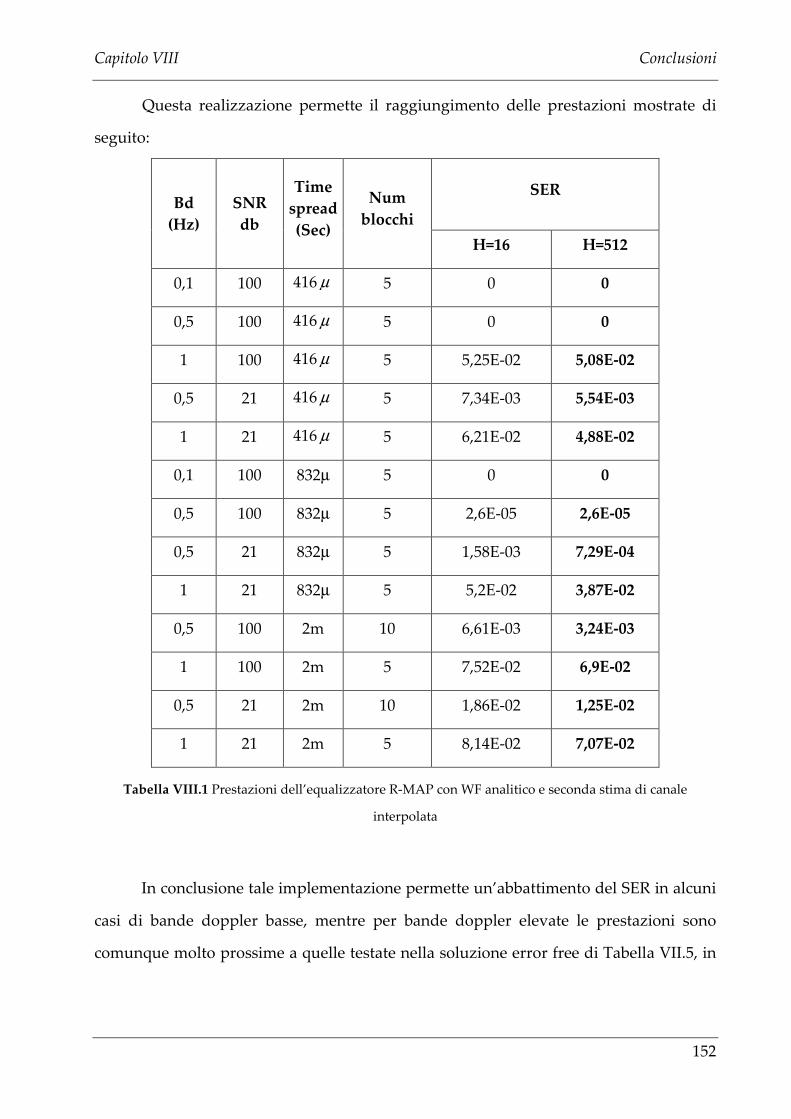
Capitolo VIII Conclusioni
152
Questa realizzazione permette il raggiungimento delle prestazioni mostrate di
seguito:
Tabella VIII.1 Prestazioni dell’equalizzatore R-MAP con WF analitico e seconda stima di canale
interpolata
In conclusione tale implementazione permette un’abbattimento del SER in alcuni
casi di bande doppler basse, mentre per bande doppler elevate le prestazioni sono
comunque molto prossime a quelle testate nella soluzione error free di Tabella VII.5, in
SER Bd
(Hz) SNR db
Time spread (Sec)
Num blocchi
H=16 H=512
0,1 100 416 µ 5 0 0
0,5 100 416 µ 5 0 0
1 100 416 µ 5 5,25E-02 5,08E-02
0,5 21 416 µ 5 7,34E-03 5,54E-03
1 21 416 µ 5 6,21E-02 4,88E-02
0,1 100 832µ 5 0 0
0,5 100 832µ 5 2,6E-05 2,6E-05
0,5 21 832µ 5 1,58E-03 7,29E-04
1 21 832µ 5 5,2E-02 3,87E-02
0,5 100 2m 10 6,61E-03 3,24E-03
1 100 2m 5 7,52E-02 6,9E-02
0,5 21 2m 10 1,86E-02 1,25E-02
1 21 2m 5 8,14E-02 7,07E-02

Capitolo VIII Conclusioni
153
cui l’aggiornamento dei coefficienti della seconda stima di canale, viene effettuato
supponendo nota l’intera trama trasmessa.

Bibliografia
154
BIBLIOGRAFIA
[1.] [Abe70] K. Abend e B.D.Fritchman, “Statistical detection for communication
channels with intersymbol interference”, Proc. IEEE, vol.58.n° 5 pp779-785,
Maggio 1970.
[2.] [Ben90] Benedetto Biglieri Castellani, “Teoria della trasmissione numerica”,
Jackson Edition 1990.
[3.] [Pro95] J. G. Proakis, “Digital Communication”, 3rd ed. New York: McGraw-
Hill International Edition, 1995.
[4.] [Skl97] B. Sklar, “Rayleigh fading channel in mobile digital communication
systems” Part I e II, IEEE Communication Magazine, pp. 90-109, Luglio 1997.
[5.] [EF] E. Eleftheriou and D. Falconer, “Adaptive Equalization Techniques for HF
channels”, IEEE J. On Selected Areas in Comm., vol. SAC-5, pp. 238-256,
February 1987.
[6.] [CJ] G. Jacovitti e R. Cusani, “A two stage Bayesian approach for complex blind
equalization”, INFOCOM Dpt, University of Rome, Italy.
[7.] [JCS] C. R. Johnson and R. Casas, “Blind equalization using the Constant
Modulus Criterion: A Review”, Proceedings of IE
[8.] [CCO] Cao L., Chang Wen Chen, Orlik P., Zhang J., and Gu D. “Blind
channel estimation and Equalization using Viterbi algorithms“, IEEE 2002
[9.] [FUN] Frikel M., Utschick W., and Nossek J. “Blind noise and channel
estimation” IEEE Statistical Signal and Array Processing, 2000. Proceeding of
the Tenth IEEE Workshop on, 14-16 Aug. 2000, pagg. 141-145
[10.] [CPR] R. Cusani, M. Proia, G. Razzano, “A Reduced Complexity MAP Receiver
for Digital ISI Channels, with Application to HF Radio Links”, SPAWC 2002.

Bibliografia
155
[11.] [WJB] C. Watterson, J. Juroshek, W. Bensema, “Experimental Confirmation of
an HF Channel Model”, IEEE Transactions on Communication Technology,
vol. 18, n. 6, Dicembre 1970, pagg. 792-803.
[12.] [Sch03] H. Schildt, “La Guida Completa C++”, 4ª ed., McGraw-Hill, 2003

Appendice “Analisi della complessità del WMF“
156
APPENDICE
“Analisi della complessità
del WMF”
A.1 Analisi complessità nella realizzazione del matched
Come evidente dalla formula (VI.17) che riportiamo per maggior chiarezza di
seguito, i coefficienti del filtro Matched si calcolano come:
= − = − − L*c
1m[ ] h [ ] ( 1) 0
En n n L
dove E rappresenta l’energia istantanea del canale calcolata come il valore
dell’autocorrelazione nell’ origine e viene utilizzata nel calcolo del whitening.
Il filtro si limita a “ribaltare” l’asse delle ascisse ed a calcolare il valore coniugato
del k-esimo coefficiente di ch [ ]n , (la risposta impulsiva stimata del canale di lunghezza
pari ad L). Sono quindi necessarie le seguenti operazioni:
• L-1 scambi
• L coniugazioni
• L divisioni per un valore reale (E)
TOTALE operazioni: 3L-1

Appendice “Analisi della complessità del WMF“
157
A.2 Analisi complessità nella realizzazione del White-filter
Il cuore dell’algoritmo di “sbiancamento” implementato nel simulatore prevede
l’inversione della matrice quadrata (nxn) di (VI.21) ed il prodotto di tale matrice per un
vettore (nx1), avendo indicato con n il numero degli elementi.
In generale, la complessità di un algoritmo per l’inversione di una matrice
generica (che non goda cioè di particolari proprietà) è pari a O(n3). Se vengono adottati
sofisticati algoritmi si può ridurre fino a O(n2log(n)),che è stato dimostrato essere il
limite inferiore.
Nel nostro caso la matrice che deve essere invertita è una descrizione
bidimensionale dello stato del canale ed evolve con una certa continuità, simbolo per
simbolo.
A.2.1 Calcolo autocorrelazione della stima del canale
Si suppone la presenza di un opportuno stimatore di canale in grado di fornire
simbolo a simbolo la stima di canale ( )nh lunga L campioni. Il calcolo della
autocorrelazione della parte causale viene effettuata con la nota formula:
( )−
=
= + = −∑L- 1
*c c
q 0
h [q ]h [q] 0..( 1)n
n n n Lz ( .1)
La parte anticausale non viene calcolata ma ottenuta da quella causale per
semplice ribaltamento e coniugazione. Sono necessarie pertanto le seguenti operazioni:
• 1
0
( )L
k
L k−
=
−∑ prodotti complessi
• 1
( )L
k
L k=
−∑ somme complesse
• L-1 scambi
• L-1 coniugazioni

Appendice “Analisi della complessità del WMF“
158
TOTALE operazioni: 3L-2+21
( )L
k
L k=
−∑
NB: Si noti che il calcolo di *ch [q] viene effettuato nel calcolo del matched e
quindi non considerato.
A.2.2 Costruzione matrice dei coefficenti ΨΨΨΨ
Per la matrice dei coefficienti del sistema (VI.21) si ricordi che si tatta di una
matrice Hermitiana di dimensioni (W+1)×(W+1), contenente una sottomatrice di
Toeplitz di dimensioni (W-L+1)×(W-L+1), dove con L si intende il numero di coefficienti
di cui è costituita la risposta impulsiva del canale. Come da (VII.3) la matrice può
essere pensata così composta:
=E F
ΨG T
( .2)
dove T è la sottomatrice Toeplitz e ( )* T=F G cioè HG .
La matrice dei coefficienti viene costruita a partire dall’espressione (VI.22) che
riportiamo per maggior chiarezza:
*,
1[ ] [ ] [ ] , 0, ,
j
i j
l
x l x l i j x i j i j Wγ=−
Ψ = + − + − =∑L
L
Dove con [ ]x l è indicata l’ autocorrelazione ( .1) normalizzata per il suo valore
nell’ origine (ovvero per l’ energia del canale).
Calcolo della complessità :
• 2 1L − divisioni complesse (per la normalizzazione della autocorrelazione)
• 0
( 1 )W
k
L W k=
+ + −∑ prodotti complessi

Appendice “Analisi della complessità del WMF“
159
• 0
( )W
k
L W k=
+ −∑ +1
1
W
k
k+
=
∑ somme complesse
• 1
1
W
k
k+
=
∑ divisioni per valore reale
• 1
W
k
k=
∑ + (2L-1)coniugazioni
TOTALE operazioni: 2(2L-1)+0
3( 1) 2 ( )W
k
W L W k=
+ + + −∑ +31
W
k
k=
∑
NB: Per l’ottimizzazione dei calcoli si generano solo i coefficienti della parte
superiore della matrice ΨΨΨΨ , i restanti sono trasposti coniugati dei precedenti.
A.2.3 Calcolo della matrice 1−T : algoritmo di LEVINSON-
DURBIN
L’algoritmo di Levinson – Durbin permette di calcolare in modo efficiente
l’inversa di una matrice Hermitiana e di Toeplitz di ( .2).
Per la determinazione della matrice inversa ( )1−
T si fa riferimento alla
fattorizzazione LU di:
( )1 1− −= ⋅ ⋅HT L E L ( .3)
Dove la matrice L è la matrice triangolare inferiore dei coefficienti di predizione
in avanti , HL la sua hermitiana,
1,1
2,2 2,1
N,N N,N-1 N,N-2
1 0 0 0
1 0 0
1 0
0
1
a
a a
a a a
=L
L
L
L
M M M O
L
( .4)

Appendice “Analisi della complessità del WMF“
160
E è la matrice diagonale delle varianze degli errori di predizione in avanti ai vari
passi:
10
11
1 12
1N
0 0 0
0 0 0
0 0 0
0 0 0
E
E
E
E
−
=E
L
L
L
M M M O M
L
( .5)
Per l’implementazione dell’algoritmo di Levinson Durbin è necessaria
innanzittutto l’inizializzazione dei seguenti valori:
2x x0
x1
x
[0]
10
E R
RK
R
σ=
=
= −
( .6)
dove 0E è la varianza dell’errore di predizione e 1K il coefficiente di riflessione al
primo passo.
A partire da questi, è possibile calcolare in maniera ricorsiva i successivi termini
secondo le seguenti formule:
N N N-1N-1
1 TKE
= − ⋅ ⋅r J a ( .7)
N 1N N
N-1
0K0
−
= +a
ap
( .8)
2N NN-1= (1-| | )E E K ( .9)

Appendice “Analisi della complessità del WMF“
161
Dove J indica la matrice di scambio, Na è il vettore dei coefficienti di
predizione in avanti e Np il vettore dei coefficienti di predizione all’indietro, i quali
sono legati dalla seguente relazione:
*N N=p Ja ( .10)
NK rappresenta il coefficiente di riflessione e NE è la varianza dell’errore di predizione al
passo N.
Calcolo della complessità :
inizializzazione:
- 0E di ( .6) non comporta calcolo in quanto si tratta di una semplice
assegnazione;
- 1K di ( .6) , comporta una divisione complessa;
ricorsione:
-il calcolo di NK della ( .7) comporta le seguenti operazioni:
• N scambi
• N prodotti complessi
• N-1 somme complesse
• 1 divisione complessa
• 1 cambio di segno
-il calcolo di Na della ( .8) comporta le seguenti operazioni:
• N scambi
• N coniugazioni
• N prodotti complessi
• N-2 somme complesse
-il calcolo di NE ( .9) comporta le seguenti operazioni:
• 1 coniugazione

Appendice “Analisi della complessità del WMF“
162
• 1 prodotto complesso
• 1 prodotto reale
• 1 sottrazione reale
Matrice L:
per la determinazione dei coefficienti della matrice L viene effettuata la
ricorsione della ( .7) e ( .8) per un numero di volte pari a W-L (cioè N=1…W-L)
per un totale di :
• ( )1
2W L
N
N−
=
∑ scambi
• ( )1
2W L
N
N−
=
∑ prodotti complessi
• ( )1
2 3W L
N
N−
=
−∑ somme complesse
• ( )1
W L
N
N−
=
∑ coniugazioni
• (W-L) divisioni complesse +1 (per il calcolo di 1K )
• (W-L) cambi di segno
TOTALE operazioni: 1
1 ( ) 7W L
N
W L N−
=
− − + ∑
Matrice 1−E :
per la determinazione dei coefficienti della matrice E viene effettuata la
ricorsione della ( .9) per un numero di volte pari a W-L (N=1..W-L). Come è
evidente dalla ( .9) sono necessarie le seguenti operazioni:
• (W-L) coniugazioni
• (W-L) prodotti complessi
• (W-L) prodotto reale
• (W-L) sottrazione reale
• (W-L+1) divisioni reali

Appendice “Analisi della complessità del WMF“
163
Quest’ ultime sono necessarie per il calcolo dell‘inversione della matrice
diagonale E
TOTALE operazioni: 5(W-L)+1
Matrice HL :
Essendo la matrice L di tipo triangolare inferiore con la diagonale principale tutti
1, per costruire la sua hermitiana è sufficente coniugare opportunamente i suoi
termini:
TOTALE operazioni: 1
W L
k
k−
=
∑ coniugazioni.
Prodotto HL 1−E L:
Tenendo presente il fatto che 1−E è una matrice diagonale, ed L è di tipo
triangolare inferiore con diagonale principale di tutti 1, per effettuare il calcolo di
1−E L sono sufficienti:
• 1
W L
k
k−
=
∑ prodotti di numeri complessi per reale
Per l’altro prodotto HL ( 1−E L) non sono previsti particolari accorgimenti e
richiede:
• 3( 1)W L− + prodotti complessi
• 2( 1) ( )W L W L− + − somme complesse
TOTALE operazioni: 2( 1) (2 2 1)W L W L− + − + +1
W L
k
k−
=
∑
Conclusione
Dalle considerazioni precedenti possiamo dedurre che il costo computazionale
dell’intero algoritmo di LEVINSON-DURBIN prevede in totale le seguenti operazioni:
• ( ) 3
1
2 ( ) ( 1)W L
N
N W L W L−
=
+ − + − +∑ moltiplicazioni complesse
• ( ) 2
1
2 3 ( 1) ( )W L
N
N W L W L−
=
− + − + −∑ somme complesse
• ( )1
2 ( )W L
N
N W L−
=
+ −∑ coniugazioni

Appendice “Analisi della complessità del WMF“
164
• ( )1
2W L
N
N−
=
∑ scambi
• ( 1)W L− + divisioni complesse
• ( )W L− cambi di segno
• ( 1)W L− + divisioni reali
• ( )W L− prodotti reali
• ( )W L− sottrazioni reale
• 1
W L
k
k−
=
∑ moltiplicazioni numero complesso per reale
TOTALE operazioni: ( )1
2W L
N
N−
=
∑ +5(W-L)+ + ( )1
2 3W L
N
N−
=
−∑ + ( )1
W L
N
N−
=
∑ +21
W L
N
N−
=
∑ + ( )1
2W L
N
N−
=
∑ + (W-
L+1)+ 2( 1) (2 2 1)W L W L− + − +
A.2.4 Lemma della inversione della matrice a blocchi
Come da (VII.17) la matrice Y di dimensioni l×l la si può pensare partizionata in
sottomatrici A,B,C,D che riportiamo per maggior chiarezza qui di seguito nel modo
seguente
A DY =
C B
dove A è una matrice q×q, B è una matrice (l-q)×(l-q), C è una matrice (l-q)×q, D è
una matrice q×(l-q). Mentre l’inversa di Y è data da (VII.18):
-1 -1 -1
-1
-1 -1 -1 -1 -1 -1
Λ -Λ DBY =
-B CΛ B + B CΛ DB

Appendice “Analisi della complessità del WMF“
165
con -1Λ = A - DB C
A livello realizzativo, il lemma viene gestito aggiungendo di volta in volta alla
matrice B di dimensione MxM, di cui dal precedente passo si conosce la sua inversa,
una riga e una colonna della matrice ΨΨΨΨ di partenza. Quindi la matrice Y all’iterazione
N-esima risulta essere strutturata come da (VII.19):
1xM
MxM
=
A D
YC B
6447448
1442443
e risulta avere dimensione (M+1)x(M+1) . La prima volta che si utilizza tale
tecnica B coincide con la matrice di Toeplitz , di cui l’inversa è stata calcolata con
l’algoritmo di Levinson Durbin descritto nel precedente Par. Quindi il lemma viene
iterato per un numero di volte pari a (W+1)-(W-L+2)= L-1 che è proprio la dimensione
del numero di righe , e quindi di colonne, da aggiungere alla matrice di Toeplitz per
ricostruire la matrice Ψ di partenza.
Calcolo della complessità :
Facendo riferimento al passo N in cui la matrice Y ha dimensioni (M+1)x(M+1) (e
conseguentemente B di dimensioni MxM):
termine 1−Λ :
-per il prodotto della matrice -1B per il vettoreC sono previsti:
• 2M prodotti complessi
• ( 1)M M − somme complesse
-per il prodotto del vettore D per il vettore ( )-1B C :
• M prodotti complessi
• ( 1)M − somme comlpesse

Appendice “Analisi della complessità del WMF“
166
-per la differenza tra lo scalare A e lo scalare ( )-1DB C :
• 1 somma complessa
-per il calcolo dello scalare 1−Λ :
• 1 divisione complessa
vettore -1 -1-B CΛ :
-il vettore ( )-1B C è già stato calcolato in precedenza
-per il prodotto del vettore ( )− -1B C per 1−Λ sono previsti:
• M prodotti complessi
vettore -1 -1-Λ DB :
-poiché risulta essere ( )*1 1 1 1− − − −
Λ DB = B CΛ sono previsti:
• M coniugazioni
matrice -1 -1 -1 -1B + B CΛ DB :
-poiché risulta essere ( )*1 1− −DB = B C e il vettore -1 -1B CΛ è stato calcolato in
precedenza sono necesssari:
• M coniugazioni
• 2M prodotti complessi
• 2M somme complesse
Conclusione:
Il lemma viene iterato per un numero di volte pari a L-1 , con M=(W-L+2)…(W+1).
Il costo computazionale complessivo risulta pari:
• 1
2
2 ( 1)W
M W L
M M+
= − +
+∑ prodotti complessi
• 1
2
2
2W
M W L
M+
= − +
∑ somme complesse
• 1
2
2W
M W L
M+
= − +
∑ coniugazioni
• L-1 divisioni complesse

Appendice “Analisi della complessità del WMF“
167
TOTALE operazioni: L-1+1
2
2
4 ( )W
M W L
M M+
= − +
+∑
A.2.5 Calcolo dei coefficienti del Whitening Filter
Per il calcolo dei coefficenti del filtro occorre effettuare il prodotto della matrice
-1Ψ per il vettore [ ]x l dell’ autocorrelazione del canale stimato normalizzata. Sono
previste, quindi , le seguenti operazioni:
• 2( 1)W + prodotti complessi
• ( )1W W+ somme complesse
TOTALE operazioni: 22 3 1W W+ +
A.3 Conclusioni
Per maggior chiarezza riportiamo in forma tabellare l’analisi della complessità
per la realizzazione dei due filtri, matched e whitening.
Operaz. Scambi Coniug. Sottr.
Real
Prodotti
Real
Div.
Real
Somme
Complex
Div./Moltipl
xReal
L-1 L L
Totale 3L-1
Tabella A.1 Analisi della complessità del Matched filter

Appendice “Analisi della complessità del WMF“
168
Tabella A.2 Analisi della complessità del Whitening filter
Operaz. Scambi Coniug. Sottr.
Real
Prodotti
Real
Div.
Real
Cambi
di
segno
Somme
Complex
Div./Moltipl
xReal
Prodotti
Complex
Div.
Complex
(1.) L-1 L-1 1( )
L
k
L k=
−∑ 1
0( )
L
k
L k
−
=
−∑
(2.) 1
W
k
k=∑ +(2L-1)
1
0 1( )
W W
k k
L W k k
+
= =
+ − +∑ ∑ 1
W L
k
k
−
=∑
0( 1 )
W
k
L W k=
+ + −∑ 2L-1
(3.) 1
2W L
N
N
−
=∑
1
2 ( )W L
N
N W L
−
=
+ −∑ W-L W-L L+1 W-L ( ) 2
1
2 3 ( 1) ( )W L
N
N W L W L
−
=
− + − + −∑ 1
W L
k
k
−
=∑ 3
1
( ) ( 1)2W L
N
W L W LN
−
=
+ − + − +∑ 1W L− +
(4.) 1
2
2W
M W L
M
+
= − +∑
12
2
2W
M W L
M
+
= − +∑
1
2
2 ( 1)W
M W L
M M
+
= − +
+∑ L-1
(5.) (W+1)W 2( 1)W +
Totale
3L-2+2∑L
k=1
(L - k) +2(2L-1)+ ∑W
k=0
3(W + 1) + 2 (L + W - k) +3∑W
k=1
k + ( )∑W-L
N=1
2N +5(W-L)+ ( )∑W-L
N=1
2N - 3 + ∑W-L
N=1
N +2 ∑W-L
N=1
N + ∑W-L
N=1
2N +
+(W-L+1)+ 2(W - L + 1) (2W - 2L + 1) +L-1+ ∑
W+12
M=W-L+2
4 (M +M) + 22W + 3W + 1

Appendice “Analisi della complessità del WMF“
169
Note alla Tabella A.2:
Nella tabella vengono messe in evidenza le diverse fasi di elaborazioni che portano alla
determinazione del whitening filter, riportate di seguito:
(1.) Calcolo dell’autocorrelazione della stima del canale
(2.) Costruzione matrice dei coefficienti Ψ
(3.) Algoritmo di Levinson – Durbin
(4.) Lemma della inversione della matrice a blocchi
(5.) Calcolo dei coefficienti del Whitening filter
In tabella si evidenzia il numero e il tipo di operazioni svolte in ognuna di esse, spiegate
in maniera dettagliata nei precedenti paragrafi.


















