
Dispense di Istituzioni di Probabilità -...
175
Dispense di Istituzioni di Probabilit Franco Flandoli 2013-14
Transcript of Dispense di Istituzioni di Probabilità -...

Dispense di Istituzioni di Probabilità
Franco Flandoli
2013-14

2

Indice
1 Introduzione ai Processi Stocastici 71.1 Prime definizioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.1.1 Processi stocastici . . . . . . . . . . . . . . . . . . . . . . . . . . 71.1.2 Legge di un processo . . . . . . . . . . . . . . . . . . . . . . . . 91.1.3 Legge nello spazio delle funzioni continue . . . . . . . . . . . . . 11
1.2 Teorema di estensione di Kolmogorov . . . . . . . . . . . . . . . . . . . 121.2.1 Processi gaussiani . . . . . . . . . . . . . . . . . . . . . . . . . . 18
1.3 Filtrazioni e tempi d’arresto . . . . . . . . . . . . . . . . . . . . . . . . 261.3.1 Filtrazioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 261.3.2 Tempi d’arresto . . . . . . . . . . . . . . . . . . . . . . . . . . . 291.3.3 La σ-algebra associata ad un tempo d’arresto . . . . . . . . . . 33
1.4 Speranza condizionale e probabilità condizionale . . . . . . . . . . . . . 341.4.1 Speranza condizionale . . . . . . . . . . . . . . . . . . . . . . . 341.4.2 Probabilità condizionale . . . . . . . . . . . . . . . . . . . . . . 37
1.5 Proprietà di Markov . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
2 Il moto browniano 452.1 Definizione, esistenza e proprietà di Markov . . . . . . . . . . . . . . . 45
2.1.1 Una motivazione modellistica . . . . . . . . . . . . . . . . . . . 522.2 Regolarità del moto browniano . . . . . . . . . . . . . . . . . . . . . . . 53
2.2.1 Diffi coltà ad usare il MB come integratore . . . . . . . . . . . . 532.2.2 Commenti sulle funzioni a variazione limitata . . . . . . . . . . 542.2.3 Variazione quadratica del MB e variazione non limitata . . . . . 562.2.4 Non differenziabilità . . . . . . . . . . . . . . . . . . . . . . . . 58
3 Martingale 633.1 Definizioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.1.1 Esempi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 653.1.2 Altri esempi e preliminari . . . . . . . . . . . . . . . . . . . . . 67
3.2 Teoremi d’arresto e disuguaglianze . . . . . . . . . . . . . . . . . . . . 693.2.1 Il caso a tempo discreto . . . . . . . . . . . . . . . . . . . . . . 693.2.2 Il caso a tempo continuo . . . . . . . . . . . . . . . . . . . . . . 74
3

4 INDICE
3.3 Applicazioni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 773.3.1 Disuguaglianza esponenziale per il moto browniano . . . . . . . 773.3.2 Problema della rovina . . . . . . . . . . . . . . . . . . . . . . . 78
3.4 Teorema di decomposizione di Doob per submartingale discrete . . . . 803.5 Teorema di convergenza per super-martingale discrete . . . . . . . . . . 82
3.5.1 Tentativo di euristica . . . . . . . . . . . . . . . . . . . . . . . . 823.5.2 Risultati rigorosi . . . . . . . . . . . . . . . . . . . . . . . . . . 86
3.6 Altri risultati per martingale a tempo continuo . . . . . . . . . . . . . . 893.7 Teoria della variazione quadratica . . . . . . . . . . . . . . . . . . . . . 903.8 Martingale locali e semimartingale . . . . . . . . . . . . . . . . . . . . . 97
4 L’integrale stocastico 994.1 Integrale di processi elementari . . . . . . . . . . . . . . . . . . . . . . 99
4.1.1 Estensione a integratori martingale . . . . . . . . . . . . . . . . 1044.2 Integrale di processi progressivamente misurabili, di quadrato integrabile 1054.3 Integrale di processi progressivamente misurabili più generali . . . . . . 1104.4 Il caso multidimensionale . . . . . . . . . . . . . . . . . . . . . . . . . . 116
4.4.1 Moto browniano in Rd . . . . . . . . . . . . . . . . . . . . . . . 1164.4.2 Integrale stocastico rispetto ad un moto browniano in Rd . . . . 118
5 La formula di Itô 1235.1 La “chain rule”per funzioni poco regolari . . . . . . . . . . . . . . . . 123
5.1.1 Caso multidimensionale e dipendente dal tempo . . . . . . . . . 1285.1.2 Integrale secondo Stratonovich . . . . . . . . . . . . . . . . . . . 133
5.2 Applicazione ai processi stocastici . . . . . . . . . . . . . . . . . . . . . 1345.2.1 Variazione quadratica . . . . . . . . . . . . . . . . . . . . . . . . 1375.2.2 Integrale stocastico rispetto ad un processo di Itô . . . . . . . . 140
5.3 Formula di Itô . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1415.3.1 Notazione differenziale . . . . . . . . . . . . . . . . . . . . . . . 1445.3.2 Esempi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145
6 Applicazioni della formula di Itô 1476.1 Disuguaglianza di Doob per gli integrali stocastici . . . . . . . . . . . . 1476.2 Caratterizzazione del moto browniano secondo Lévy . . . . . . . . . . . 148
6.2.1 Cambio di scala temporale . . . . . . . . . . . . . . . . . . . . . 1516.3 Il teorema di Girsanov . . . . . . . . . . . . . . . . . . . . . . . . . . . 152
6.3.1 Un problema da risolvere . . . . . . . . . . . . . . . . . . . . . . 1526.3.2 Ricerca di ρt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1546.3.3 Versione assiomatica . . . . . . . . . . . . . . . . . . . . . . . . 1576.3.4 Varianti . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1596.3.5 Teorema di Girsanov . . . . . . . . . . . . . . . . . . . . . . . . 1606.3.6 Applicazione . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 161

INDICE 5
7 Equazioni differenziali stocastiche 1637.0.7 Esempio . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 170
7.1 Presentazione informale del legame con le PDE . . . . . . . . . . . . . 172

6 INDICE

Capitolo 1
Introduzione ai Processi Stocastici
1.1 Prime definizioni
1.1.1 Processi stocastici
Ricordiamo che uno spazio di probabilità è una terna (Ω,F , P ) dove Ω è un insieme, Fè una σ-algebra di parti di Ω, P è una misura di probabilità su (Ω,F); la coppia (Ω,F)è chiamata spazio misurabile. In uno spazio topologico E indicheremo con B (E) laσ-algebra dei boreliani (la più piccola σ-algebra che contiene gli aperti). Una variabilealeatoria Y su (Ω,F) a valori in uno spazio misurabile (E, E) è una funzione Y : Ω→ Emisurabile da (Ω,F) in (E, E), cioè tale che ω ∈ Ω : Y (ω) ∈ B ∈ F per ogni B ∈ E .Una variabile aleatoria reale Y su (Ω,F) è una variabile aleatoria su (Ω,F) a valori in(R,B (R)).
Sia T un insieme non vuoto. L’insieme T sarà l’insieme dei parametri del processostocastico. A livello interpretativo, può essere ad esempio un insieme di tempi, oppuredi posizioni spaziali o di spazio-tempo. In alcuni momenti sarà necessario supporre diavere uno spazio misurabile (T, T ) ed in altri uno spazio topologico T , con T = B (T );altrimenti T è del tutto arbitrario. Tutto ciò fino al momento in cui introdurremo lefiltrazioni; con l’introduzione del concetto di filtrazione, restringeremo l’attenzione alcaso in sia T ⊂ [0,∞), T = B (T ) ed interpreteremo T come insieme dei tempi. Tuttigli sviluppi avanzati del corso riguarderanno il caso T = [0,∞) (o T = [0, t0]) percui avrebbe senso restringersi fin da ora a quel caso. Però può essere concettualmenteinteressante osservare che questi primi paragrafi hanno carattere più generale, per cuiper ora supporremo solo che T sia un insieme, non vuoto.
Siano dati, oltre a T , uno spazio di probabilità (Ω,F , P ) ed uno spazio misurabile(E, E) (detto spazio degli stati). Un processo stocastico X = (Xt)t∈T , definito su(Ω,F , P ) a valori in (E, E) è una funzione X definita su Ω× T a valori in E, tale cheper ogni t ∈ T la funzione ω 7−→ Xt (ω) sia misurabile da (Ω,F) in (E, E). Ne segue
7

8 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
che, dati t1 < ... < tn ∈ T , la funzioneω 7−→ (Xt1 (ω) , ..., Xtn (ω))
è misurabile da (Ω,F) in (En,⊗nE). Le leggi di probabilità di questi vettori (leggiimmagine di P rispetto a queste applicazioni) si chiamano distribuzioni di dimensionefinita del processo.Le funzioni t 7−→ Xt (ω) da T in E (ad ω fissato) si dicono realizzazioni o traiettorie
del processo stocastico. Il termine traiettoria va forse riservato al caso in cui sia T ⊂[0,∞).Due processi stocastici X = (Xt)t∈T e Y = (Yt)t∈T si dicono equivalenti se hanno
le stesse distribuzioni di dimensione finita. Si dicono modificazione (o versione) unodell’altro se per ogni t ∈ T vale
P (Xt = Yt) = 1.
Si dicono indistinguibili se
P (Xt = Yt per ogni t ∈ T ) = 1.
Due processi indistinguibili sono modificazione uno dell’altro. Due processi che sonomodificazione uno dell’altro sono equivalenti. Si veda l’esercizio 1. Si noti che, adifferenza delle altre due, la definizione di processi equivalenti non richiede che essisiano definiti sullo stesso spazio (Ω,F , P ).Supponiamo che T ed E siano spazi topologici e siano T = B (T ), E = B (E).
Un processo si dice continuo se le sue realizzazioni sono funzioni continue; si dice q.c.continuo se ciò avviene per P -quasi ogni realizzazione.Quando T ⊂ [0,∞), le definizioni di continuo a destra e/o a sinistra, costante a
tratti ed altre della stessa natura sono simili. Un processo si dice càdlàg (continue àdroite, limite à gauche) se le sue traiettorie sono continue a destra ed hanno limitefinito a sinistra.Se (T, T ) è uno spazio misurabile, possiamo dare la seguente definizione. Un proces-
so si dice misurabile se l’applicazione (t, ω) 7−→ Xt (ω) è misurabile da (T × Ω, T ⊗ F)in (E, E).Elenchiamo anche alcune nozioni che si usano soprattutto nella cosiddetta teoria
della correlazione dei processi stazionari, per noi marginale ma toccata almeno nel casodei processi gaussiani. Supponiamo che sia (E, E) = (R,B (R)). Indichiamo con E [·] lasperanza matematica su (Ω,F , P ) (E [Y ] =
∫ΩY dP , per ogni Y v.a. reale (Ω,F , P ) in-
tegrabile), con V ar [·] la varianza (V ar [Y ] = E[(Y − E [Y ])2] quando Y è di quadrato
integrabile), con Cov (·, ·) la covarianza (Cov (Y, Z) = E [(Y − E [Y ]) (Z − E [Z])] seY e Z sono v.a. di quadrato integrabile). Sia X un processo stocastico a valori in(R,B (R)), su (Ω,F , P ). Se E [|Xt|] < ∞ per ogni t ∈ T , chiamiamo m (t) = E [Xt],t ∈ T , funzione valor medio del processo X. Se E [X2
t ] <∞ per ogni t ∈ T , chiamiamoσ2 (t) = V ar [Xt], t ∈ T , funzione varianza di X e chiamiamo C (t, s) = Cov (Xt, Xs),t, s ∈ T , funzione covarianza di X.
1.1. PRIME DEFINIZIONI 9
Esercizio 1 Costruire due processi equivalenti che non siano modificazione uno del-l’altro e due processi modificazione uno dell’altro che non siano indistinguibili.
1.1.2 Legge di un processo
Sia ET lo spazio di tutte le funzioni f : T → E. Indichiamo con S l’insieme di tuttele n-ple ordinate τ = (t1, ..., tn) di elementi di T tali che ti 6= tj per ogni i 6= j,i, j = 1, ..., n. Indichiamo con En la σ-algebra prodotto di n copie di E .Presa τ = (t1, ..., tn) ∈ S e preso B ∈ En consideriamo l’insieme
C (τ , B) ⊂ ET
di tutte le funzioni f : T → E tali che
(f (t1) , ..., f (tn)) ∈ B.
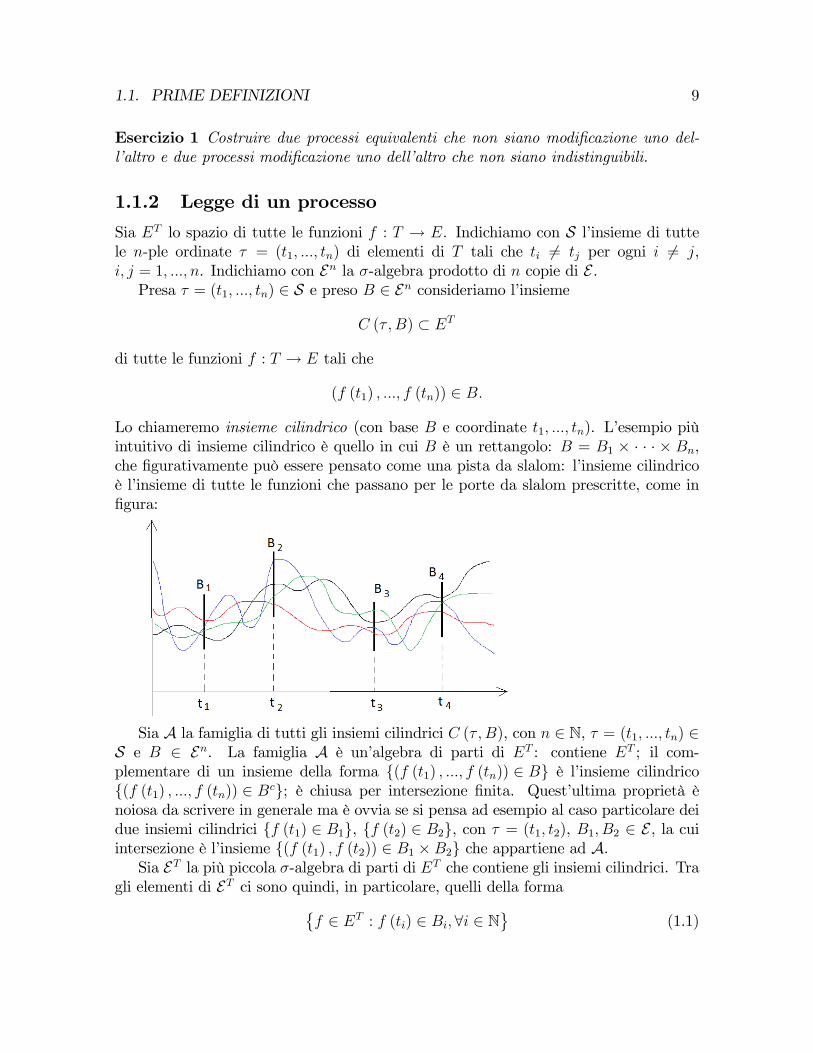
Lo chiameremo insieme cilindrico (con base B e coordinate t1, ..., tn). L’esempio piùintuitivo di insieme cilindrico è quello in cui B è un rettangolo: B = B1 × · · · × Bn,che figurativamente può essere pensato come una pista da slalom: l’insieme cilindricoè l’insieme di tutte le funzioni che passano per le porte da slalom prescritte, come infigura:
Sia A la famiglia di tutti gli insiemi cilindrici C (τ , B), con n ∈ N, τ = (t1, ..., tn) ∈S e B ∈ En. La famiglia A è un’algebra di parti di ET : contiene ET ; il com-plementare di un insieme della forma (f (t1) , ..., f (tn)) ∈ B è l’insieme cilindrico(f (t1) , ..., f (tn)) ∈ Bc; è chiusa per intersezione finita. Quest’ultima proprietà ènoiosa da scrivere in generale ma è ovvia se si pensa ad esempio al caso particolare deidue insiemi cilindrici f (t1) ∈ B1, f (t2) ∈ B2, con τ = (t1, t2), B1, B2 ∈ E , la cuiintersezione è l’insieme (f (t1) , f (t2)) ∈ B1 ×B2 che appartiene ad A.Sia ET la più piccola σ-algebra di parti di ET che contiene gli insiemi cilindrici. Tra
gli elementi di ET ci sono quindi, in particolare, quelli della formaf ∈ ET : f (ti) ∈ Bi,∀i ∈ N
(1.1)

10 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
dove ti è una successione di elementi di T , Bi una successione di elementi di E(sono intersezioni numerabili di insiemi cilindrici).Dato un processo stocastico X = (Xt)t∈T definito su uno spazio di probabilità
(Ω,F , P ) a valori in uno spazio misurabile (E, E), vale la seguente semplice propo-sizione, nel cui enunciato inseriamo il concetto di legge del processo:
Proposizione 1 L’applicazione
ω 7−→ X· (ω) (1.2)
da (Ω,F) in(ET , ET
)è misurabile. La legge immagine di P (probabilità su (Ω,F))
attraverso tale applicazione, che indichiamo con PX (probabilità su(ET , ET
)) verrà
detta legge del processo X. E’ caratterizzata dai suoi valori sugli insiemi cilindrici,dati da
PX (C (τ , B)) = P ((Xt1 , ..., Xtn) ∈ B)
per ogni τ = (t1, ..., tn) ∈ S e B ∈ En.
Proof. Preso un insieme cilindrico C (τ , B), τ = (t1, ..., tn) ∈ S, B ∈ En, la suacontroimmagine è l’insieme
(Xt1 , ..., Xtn) ∈ B
che sappiamo essere misurabile, elemento di F . Rammentiamo che per verificare lamisurabilità di un’applicazione basta farlo su una famiglia generante la σ-algebra inarrivo (in simboli generali, se X : (Ω,F) → (E, E) soddisfa X−1 (B) ∈ F per ogniB ∈ G, dove G ⊂ E ed E =σ (G), allora X è misurabile; infatti, si prenda la famigliaH ⊂ P (E) degli insiemi B ⊂ E tali che X−1 (B) ∈ F ; si verifica che H è una σ-algebra e contiene G, quindi contiene σ (G)). Quindi l’applicazione definita dalla (1.2)è misurabile tra (Ω,F) ed
(ET , ET
).
Essa definisce quindi una legge immagine, che indichiamo con PX ; è una misuradi probabilità su
(ET , ET
). Come tale, per un noto teorema di Caratheodory, se A è
un’algebra che genera ET chiusa per intersezione finita e Q è una misura di probabilitàsu(ET , ET
)che coincide con PX su A, allora Q = PX (su ET ). In questo senso diciamo
che PX è caratterizzata dai suoi valori suA. Nell’enunciato della proposizione, abbiamopreso come A la famiglia degli insiemi cilindrici.
Proposizione 2 Due processiX edX ′, definiti rispettivamente su (Ω,F , P ) e (Ω′,F ′, P ′)a valori in (E, E), sono equivalenti se e solo se hanno la stessa legge su
(ET , ET
).
Proof. Se hanno la stessa legge allora, presi τ = (t1, ..., tn) ∈ S e B ∈ En, vale
P ((Xt1 , ..., Xtn) ∈ B) = PX (C (τ , B)) = P ′X′ (C (τ , B))
= P ′((X ′t1 , ..., X
′tn
)∈ B
)

1.1. PRIME DEFINIZIONI 11
quindi hanno le stesse distribuzioni di dimensione finita.Viceversa, se hanno le stesse distribuzioni di dimensione finita, vale
PX (C (τ , B)) = P ((Xt1 , ..., Xtn) ∈ B) = P ′((X ′t1 , ..., X
′tn
)∈ B
)= P ′X′ (C (τ , B))
quindi le misure di probabilità PX e P ′X′ , misure su(ET , ET
), coincidono sugli insiemi
cilindrici. Come nel caso della dimostrazione precedente, se ne deduce che le due misurecoincidono su tutta ET . La dimostrazione è completa.
1.1.3 Legge nello spazio delle funzioni continue
Esaminiamo adesso un problema più delicato. Supponiamo che X sia continuo. Percapire bene il problema senza complicazioni topologiche collaterali, iniziamo discutendoil caso in cui
T = R+ := [0,∞), E = Rn (1.3)
e le σ-algebre sono quelle dei boreliani. Indichiamo con C0 l’insieme C (R+;Rn) dellefunzioni continue da R+ in Rn, munito della topologia della convergenza uniforme suicompatti.L’insieme Λ (Ω) non è solo un sottoinsieme di ER+ ma anche di C0. E’naturale pen-
sare che Λ definisca una misura immagine su (C0,B (C0)). Purtroppo si può dimostrareche C0 /∈ B (E)R+ (omettiamo la dimostrazione) e questo non permette facilmente di
“restringere” la legge del processo, precedentemente definita su(ER+ ,B (E)R+
), ad
una legge su (C0,B (C0)) (in realtà anche questa strada è percorribile con opportuneconsiderazioni basate sulla misura esterna, applicabili dopo aver verificato che la misuraesterna dell’insieme non misurabile C0 è pari ad 1).Per aggirare questo ostacolo basta dimostrare il risultato seguente.
Proposizione 3 Se X = (Xt)t≥0 è un processo continuo a valori reali, allora Λ è mis-urabile da (Ω,F) in (C0,B (C0)). Possiamo quindi considerare la misura immagine diP attraverso Λ, su (C0,B (C0)), che chiameremo legge del processo X su (C0,B (C0)).
Proof. La σ-algebra B (C0) è generata dagli insiemi della forma
B (f0, T, R) =
f ∈ C0 : max
t∈[0,T ]|f (t)− f0 (t)| ≤ R
al variare di f0 ∈ C0, T ∈ N, R > 0. Basta quindi verificare che la controimmagine diun tale insieme attraverso l’applicazione (1.2) appartiene ad F .Sia quindi T fissato nel seguito e sia tj ⊂ [0, T ] una successione che conta i
razionali di [0, T ]. Vale
B (f0, T, R) =f ∈ C0 : |f (tj)− f0 (tj)| ≤ R, ∀ j ∈ N
=
f ∈ C0 : f (tj) ∈ [f0 (tj)−R, f0 (tj) +R] , ∀ j ∈ N
.

12 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
Questo è un insieme simile a quelli della forma (1.1), ma non lo è esattamente, perchéqui stiamo considerando f ∈ C0 invece che in ET . Quindi dobbiamo ripetere il ra-gionamento che porta a dire che la sua controimmagine, attraverso l’applicazione (1.2),appartenga ad F (altrimenti bastava applicare la Proposizione 1). Vale
B (f0, T, R) =⋂
N∈NB (f0, T, R,N)
doveB (f0, T, R,N) =
f ∈ C0 : |f (tj)− f0 (tj)| ≤ R, ∀ j = 1, ..., N
.
Se la controimmagine di B (f0, T, R,N) sta in F , allora ci sta anche la controimmaginedi B (f0, T, R), essendo F chiusa per intersezione numerabile. Ma la controimmaginedi B (f0, T, R,N) è l’insieme
ω ∈ Ω : |X (ω, tj)− f0 (tj)| ≤ R, ∀ j = 1, ..., N
che appartiene a F . Quindi la dimostrazione è completa.
Osservazione 1 Con ragionamenti non molto diversi si dimostra che due proces-si continui con le stesse distribuzioni di dimensione finita, hanno la stessa legge su(C0,B (C0)).
Se un processo X è solamente q.c. continuo, definisce ugualmente una misura diprobabilità su (C0,B (C0)) del tutto analoga al caso precedente, che continueremo achiamare misura immagine di P attraverso Λ su (C0,B (C0)). Infatti, esiste un insiemeΩ′ ∈ F di P -misura 1 tale che Λ (Ω′) ⊂ C0. Consideriamo lo spazio probabilizzato(Ω′,F ′, P ′) dove F ′ = F ∩ Ω′ e P ′ è la restrizione di P ad F ′. Ora Λ : Ω′ → C0 è bendefinita e induce una misura di probabilità su (C0,B (C0)). Si verifica facilmente cheessa non dipende dalla scelta di Ω′ con le proprietà precedenti.Le considerazioni illustrate sopra si estendono a varie situazioni più generali. Una
molto simile è quella in cui T è uno spazio metrico, unione numerabile di compatti(spazio metrico σ-compatto) ed E è uno spazio metrico separabile.
1.2 Teorema di estensione di Kolmogorov
Abbiamo visto che, dato un processo X = (Xt)t∈T , questo definisce una misura diprobabilità su
(ET , ET
). Quando vale il viceversa, cioè per quali misure µ di probabilità
su(ET , ET
)esiste un processo che ha µ come legge? Per tutte: basta prendere il
processo canonico, Ω = ET , F = ET , Xt (ω) = ω (t). Meno banale è il problema diinversione che ora descriveremo.Data una misura di probabilità µ su
(ET , ET
), definiamo le sue distribuzioni di
dimensione finita nel seguente modo. Presa τ = (t1, ..., tn) ∈ S, indichiamo con πτ :

1.2. TEOREMA DI ESTENSIONE DI KOLMOGOROV 13
ET → En l’applicazione πτ (f) = (f (t1) , ..., f (tn)). E’misurabile, rispetto a ET e En(presoB ∈ En la sua controimmagine è l’insieme cilindrico
f ∈ ET : (f (t1) , ..., f (tn)) ∈ B
,
che appartiene ad ET ). La distribuzione di dimensione n di µ relativa a τ è la leggeimmagine µτ di µ attraverso πτ :
µτ (B) = µ(f ∈ ET : (f (t1) , ..., f (tn)) ∈ B
), B ∈ En.
Se µ = PX , essa è la legge del vettore aleatorio (Xt1 , ..., Xtn) e µτ ; τ ∈ S è la famigliadelle distribuzione di dimensione finita del processo X.Il problema di inversione è il seguente: data una famiglia di misure di probabilità
µτ ; τ ∈ S (si sottintende che se τ = (t1, ..., tn) ∈ S, allora µτ è una misura di proba-bilità su (En, En)), esiste una misura di probabilità µ su
(ET , ET
)di cui µτ ; τ ∈ S sia
la famiglia delle distribuzioni di dimensione finita? Siccome l’esistenza di un processocon legge µ è ovvia, il problema è equivalente a: data una famiglia di misure di prob-abilità µτ ; τ ∈ S, esiste uno spazio probabilizzato (Ω,F , P ) ed un processo X su(Ω,F , P ) che abbia µτ ; τ ∈ S come famiglia delle distribuzioni di dimensione finita?
Osservazione 2 Alla base dei seguenti ragionamenti c’è il fatto che un insieme cilin-drico non ha una sola rappresentazione. Ad esempio, dati t1, ..., tn, tn+1 ∈ T , B ∈ En,valef ∈ ET : (f (t1) , ..., f (tn)) ∈ B
=f ∈ ET : (f (t1) , ..., f (tn) , f (tn+1)) ∈ B × E
oppure, dati t1, t2 ∈ T , B1, B2 ∈ E, vale
f ∈ ET : (f (t1) , f (t2)) ∈ B1 ×B2
=f ∈ ET : (f (t2) , f (t1)) ∈ B2 ×B1
.
Servono due ingredienti: una proprietà di compatibilità tra le µτ ed un po’ diregolarità dello spazio (E, E). La proprietà di compatibilità tra le µτ si intuisce facil-mente a posteriori, quando esse sono le distribuzioni di dimensione finita di µ. Sitratta di due condizioni, che a parole potremmo chiamare “invarianza sotto permu-tazioni degli indici” e “invarianza sotto contrazioni degli indici”. Vediamo la prima.Se τ = (t1, ..., tn) ∈ S e se (i1, ..., in) è una permutazione di (1, ..., n), indicata conP(i1,...,in) : En → En l’applicazione che manda la generica sequenza (x1, ..., xn) nella(xi1 , ..., xin), deve valere (per le distribuzioni di dimensione finita di un processo)
µ(t1,...,tn) (B) = µ(ti1 ,...,tin)(P(i1,...,in) (B)
). (1.4)
Vediamo ora la seconda. Data τ = (t1, ..., tn) ∈ S, indichiamo con τ n la sequen-za τ n = (t1, ..., tn−1) (la sequenza ottenuta omettendo tn dalla τ), le misure µτ eµτ n sono legate dalla proiezione πn : En → En−1 che manda una generica sequenza(x1, ..., xn) ∈ En nella sequenza (x1, ..., xn−1) ∈ En−1 (la sequenza ottenuta omettendol’ultima componente di (x1, ..., xn)). Vale
µτ n = πn (µτ ) (1.5)

14 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
nel senso che µτ n è la legge immagine di µτ attraverso πn, ovvero esplicitamenteµτ n (B) = µτ (πn ∈ B) per ogni B ∈ En−1.Si può verificare facilmente che è equivalente richiedere queste condizioni per insiemi
B di tipo rettangolare, rispetto a cui esse si scrivono più agevolmente. Possiamorichiedere che
µ(t1,...,tn) (B1 × · · · ×Bn) = µ(ti1 ,...,tin) (Bi1 × · · · ×Bin)
µ(t1,...,tn) (B1 × · · · × E) = µ(t1,...,tn−1) (B1 × · · · ×Bn−1)
per ogni n ∈ N, (t1, ..., tn) ∈ S, B1, ..., Bn ∈ E .
Definizione 1 Sia µτ ; τ ∈ S una famiglia di misure di probabilità (sempre sottin-tendendo che se τ = t1, ..., tn ∈ S, µτ sia una misura di probabilità su (En, En)).Quando valgono (1.4)-(1.5) per ogni scelta di n ∈ N, τ = (t1, ..., tn) ∈ S, i = 1, ..., n,diciamo che la famiglia µτ ; τ ∈ S è consistente.
Ricordiamo che uno spazio metrico E si dice σ-compatto se è unione numerabiledi compatti di E. Un risultato di teoria della misura dice che su uno spazio metricoσ-compatto E, se ρ è una misura di probabilità definita sui boreliani B (E), allora perogni B ∈ B (E) ed ε > 0 esiste un compatto K ⊂ B tale che ρ (B\K) < ε. Per chivolesse vedere più in dettaglio questo enunciato, la sua validità sotto opportune ipotesipiù generali (per esempio per una misura non di probabilità) e le dimostrazioni, sisuggerisce la consultazione di W. Rudin, Analisi Reale e Complessa, Boringhieri 1982,teoremi 2.14 e 2.18, definizione 2.15. Useremo questo risultato nella dimostrazione delseguente teorema.
Teorema 1 Se µτ ; τ ∈ S è una famiglia consistente, E è uno spazio metrico σ-compatto, E = B (E), allora esiste una ed una sola misura di probabilità µ su
(ET , ET
)di cui µτ ; τ ∈ S sia la famiglia delle distribuzioni di dimensione finita.
Proof. Passo 1 (preparazione). L’unicità è del tutto analoga a quella della Propo-sizione 2: due misure con le stesse distribuzioni di dimensione finita coincidono su unaclasse chiusa per intersezione finita e generante la σ-algebra ET , quindi coincidono sututta ET .Per l’esistenza, ricordiamo il seguente teorema di Charateodory: dato uno spazio
misurabile (Ω,G) ed un’algebra A che genera G, se µ è una misura finitamente addi-tiva su (Ω,A), continua in ∅ (cioè tale che, se An è una successione di eventi diA decrescente con intersezione vuota allora limn→∞ µ (An) = 0), allora µ si estendeunivocamente ad una misura numerabilmente additiva su (Ω,G).Prendiamo l’algebra A di tutti gli insiemi cilindrici C (τ , B), con n ∈ N, τ =
t1, ..., tn ∈ S e B ∈ En. L’algebra A genera ET . Basta definire una misura µ su

1.2. TEOREMA DI ESTENSIONE DI KOLMOGOROV 15
A con le proprietà del teorema di Charateodory ed avente µτ ; τ ∈ S come famigliadelle distribuzioni di dimensione finita, ed il teorema è dimostrato.Preso un insieme cilindrico C ∈ A, esistono infinite sue rappresentazioni nella forma
C = C (τ , B) con τ = (t1, ..., tn) e B ∈ En. Presa una di tali rappresentazioni, possiamocalcolare µτ (B) e porre
µ (C) = µτ (B) .
Ma la definizione è ben data solo se non dipende dalla rappresentazione di C. Quiinterviene l’ipotesi di consistenza della famiglia. Se C (τ ′, B′) e C (τ ′′, B′′) sono duerappresentazioni dello stesso insieme cilindrico C, abbiamo µτ ′ (B
′) = µτ ′′ (B′′). La
dimostrazione è elementare ma un po’ laboriosa da scrivere, per cui la isoliamo nelLemma 1.La verifica che µ, così definita, è finitamente additiva su A, si esegue nel seguente
modo: presi degli insiemi disgiunti C1, ..., Ck ∈ A, c’è una sequenza τ = (t1, ..., tn)tale che tutti gli insiemi Ci possono essere rappresentati tramite τ , cioè esistonoB1, ..., Bk ∈ En, oltretutto disgiunti, tali che Cj = C (τ , Bj), j = 1, ..., k. Valek⋃j=1
Cj = C
(τ ,
k⋃j=1
Bj
)per cui
µ
(k⋃j=1
Cj
)= µτ
(k⋃j=1
Bj
)=
k∑j=1
µτ (Bj) =k∑j=1
µ (Cj)
dove il passaggio intermedio si basa sull’additività di µτ su En. L’additività su A siriconduce cioè a quella di un’opportuna distribuzione di dimensione finita.Passo 2 (continuità della misura). Dobbiamo infine dimostrare la continuità in ∅.
Sia Cn è una successione di eventi diA decrescente con intersezione vuota. Dobbiamodimostrare che limn→∞ µ (Cn) = 0.Facciamo una piccola digressione che può aiutare a capire la dimostrazione. Ci sono
alcune famiglie di successioni Cn per cui la dimostrazione è facile. Gli esercizi 2 e3 illustrano esempi in cui ci si può ricondurre ad usare una singola distribuzione didimensione finita, un po’come nella verifica fatta sopra dell’additività. In questi casi,la dimostrazione che limn→∞ µ (Cn) = 0 è facile. Se ci si potesse restringere ad insiemicilindrici come quelli descritti agli esercizi 2 e 3, non ci sarebbe bisogno dell’ipotesi diregolarità dello spazio E.Ma le famiglie di insiemi cilindrici descritte da tali esercizi non sono algebre. Tra
le successioni di insiemi cilindrici esistono esempi, come quello dell’esercizio 4, in cuinon si vede come ricondursi ad usare una singola distribuzione di dimensione finita.Facendo però riferimento a concetti topologici, precisamente alla compattezza, c’è
un’altra classe in cui la dimostrazione che limn→∞ µ (Cn) = 0 si riesce a completarefacilmente. Supponiamo che la successione Cn di eventi di A decrescente con inter-sezione vuota abbia la forma Cn = C (τn, Kn) con Kn insieme compatto (per inciso, se

16 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
E non è compatto, questa rappresentazione è unica, quando esiste). Allora gli insiemiKn non possono essere tutti diversi dal vuoto. Rimandiamo la verifica al Lemma 2.Ma allora, se per un certo n0 l’insieme Kn0 è vuoto, vale µ (Cn0) = 0, da cui discende(per monotonia) µ (Cn) = 0 per ogni n ≥ n0 e quindi anche limn→∞ µ (Cn) = 0.L’idea della dimostrazione allora è la seguente: data una rappresentazione Cn =
C (τn, Bn) degli insiemi cilindrici della successione, fissato ε > 0, usando la proprietàdi regolarità dello spazio E si può trovare una successione di compatti Kn, Kn ⊂ Bn
tali che, detto Dn l’insieme cilindrico di base Kn (invece che Bn) e coordinate τn,insieme che verifica Dn ⊂ Cn, vale
µ (Cn)− µ (Dn) = µ (Cn\Dn) ≤ ε.
Se riusciamo a trovare Kn in modo che Dn sia anche decrescente, allora per ilLemma 2, limn→∞ µ (Dn) = 0. Questo implica che esiste n0 ≥ 0 tale che per ognin ≥ n0, µ (Cn) ≤ ε. Per l’arbitrarietà di ε si ottiene limn→∞ µ (Cn) = 0.L’unico punto che richiede un attimo di lavoro è fare in modo che Dn sia decres-
cente. Sia quindi, fissato ε > 0, K01 una successione di compatti, K0
n ⊂ Bn, tali cheµτn (Bn\K0
n) < ε2n(essi esistono per la regolarità di E). Indichiamo con D0
n la succes-sione degli insiemi cilindrici di base K0
n e coordinate τn; D0n ⊂ Cn in quanto K0
n ⊂ Bn,ma non sappiamo se D0
n è decrescente. Poniamo Dn = D01 ∩ ... ∩ D0
n. SicuramenteDn è una successione di insiemi cilindrici decrescente. Mostriamo che esistono deicompatti Kn ⊂ Bn, tali che Dn ha base Kn e coordinate τn; e µ (Cn\Dn) ≤ ε.Gli insiemi Dn hanno la forma
Dn =f |τ1 ∈ K0
1 , ..., f |τn ∈ K0n
.
Si immagini l’esempio D2 =f |(t1,t2) ∈ K0
1 , f |(t2,t3) ∈ K02
. Si può descrivere nella
forma
D2 =f |(t1,t2,t3) ∈ K0
1 × E, f |(t1,t2,t3) ∈ E ×K02
=f |(t1,t2,t3) ∈
(K0
1 × E)∩(E ×K0
2
)e l’insieme (K0
1 × E)∩ (E ×K02) è compatto. Il caso generale si scrive con fatica ma è
identico. Quindi esiste Kn ⊂ Bn, tali che Dn ha base Kn e coordinate τn.Vale poi (si osservi cheD0
k ⊂ Ck ⊂ Cn; si scriva inoltreCn\Dn = Cn∩(D01 ∩ ... ∩D0
n)c)
Cn\Dn =(Cn\D0
1
)∪(Cn\D0
2
)∪ ... ∪
(Cn\D0
n
)⊂(C1\D0
1
)∪(C2\D0
2
)∪ ... ∪
(Cn\D0
n
)da cui
µ (Cn\Dn) ≤n∑k=1
µ(Ck\D0
k
)≤
n∑k=1
ε
2k≤ ε.
La dimostrazione è completa.Nella dimostrazione del seguente lemma usiamo la notazione |τ | per la cardinalità
di τ ∈ S. Se τ = (t1, ..., tn), vale |τ | = n.

1.2. TEOREMA DI ESTENSIONE DI KOLMOGOROV 17
Lemma 1 Se C (τ ′, B′) e C (τ ′′, B′′) sono due rappresentazioni dello stesso insiemecilindrico C, abbiamo µτ ′ (B
′) = µτ ′′ (B′′).
Proof. Se vale τ ′ = τ ′′, si può riconoscere che vale anche B′ = B′′. In questo caso latesi è ovvia. Se τ ′′ è ottenuta da τ ′ tramite una permutazione degli indici (i1, ..., in),allora B′′ = P(i1,...,in) (B′) e l’invarianza della definizione di µ è garantita dalla proprietà(1.4).Se, cosiderando τ ′ e τ ′′ come insiemi non oridinati, vale τ ′ ⊂ τ ′′, a meno di permu-
tazione delle coordinate risulta B′′ è della forma B′×E|τ ′′|−|τ ′|. Quando |τ ′′| − |τ ′| = 1basta applicare la proprietà (1.5); quando |τ ′′| − |τ ′| > 1 si agisce in |τ ′′| − |τ ′| passisempre con la proprietà (1.5).Se τ ′ e τ ′′, cosiderate come insiemi non oridinati, non sono contenute una nell’altra,
si consideri τ = τ ′ ∩ τ ′′. Esiste B tale che C (τ , B) è una terza rappresentazione; B èla proiezione lungo le coordinate τ di B′ o di B′′. Per capire che è così, si pensi al casoτ ′ = (t1, t2), τ ′′ = (t2, t3) (il caso generale è solo notazionalmente più faticoso): vale
f ∈ ET : (f (t1) , f (t2)) ∈ B′
=f ∈ ET : (f (t2) , f (t3)) ∈ B′′
ovvero
(f (t1) , f (t2) , f (t3)) ∈ B′ × E = (f (t1) , f (t2) , f (t3)) ∈ E ×B′′ .
Questo implica che gli insiemi di E3 dati da B′ × E e E × B′′ coincidono. Questo ècompatibile solo con la struttura E ×B × E.Vale allora C (τ ′, B′) = C (τ , B) ma τ ⊂ τ ′, quindi µτ ′ (B
′) = µτ (B). Lo stesso sipuò dire per C (τ ′′, B′′) e quindi µτ ′ (B
′) = µτ ′′ (B′′). La dimostrazione è completa.
Lemma 2 Sia Cn ⊂ A decrescente con intersezione vuota, della forma Cn = C (τn, Kn)con Kn insieme compatto. Allora gli insiemi Kn non possono essere tutti diversi dalvuoto.
Esercizio 2 Sia tn ⊂ T una successione data e sia Cn ⊂ A della forma
Cn = f (t1) ∈ B1,n, ..., f (tn) ∈ Bn,n
dove la famiglia a due indici interi positivi Bk,n ⊂ E soddisfa
Bk,n+1 ⊂ Bk,n
per ogni k, n ∈ N. Quindi Cn è decrescente. Mostrare in questo caso che, se Cnha intersezione vuota, allora limn→∞ µ (Cn) = 0.
Esercizio 3 Sia tn ⊂ T una successione data e sia Cn ⊂ A decrescente. Supponi-amo che esista k0 ∈ N tale che, per n ≥ k0, πk0Cn ⊂ E sia una successione decres-cente con intersezione vuota. Qui πk0 : ET → E è la proiezione f 7−→ πk0 (f) = f (tk0).Allora Cn ha intersezione vuota e limn→∞ µ (Cn) = 0.

18 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
Esercizio 4 Sia tn ⊂ T una successione data. Verificare che gli insiemi
Cn =
f (tk−1) < f (tk) < f (tk−1) +
1
n, k = 2, 3, ..., n
non rientrano nei casi trattati dagli esercizi precedenti ma formano una successionedecrescente con intersezione vuota.
Esercizio 5 Data una misura di probabilità λ sui boreliani di uno spazio metrico(X, d), diciamo che essa è tight se per ogni ε > 0 esiste un compatto Kε tale cheλ (Kε) > 1 − ε. Mostrare che il teorema di costruzione dei processi di Kolmogorovcontinua a valere se, invece di supporre che lo spazio metrico E sia σ-compatto, si sup-pone che sia metrico e che ogni distribuzione di dimensione finita µτ , τ ∈ S, sia tight.[Presa τ ∈ S e la corrispondente misura µτ su En, esiste un boreliano Xn ⊂ En che èuno spazio metrico σ-compatto e µτ può essere ristretta ad una misura di probabilitàsu Xn. Il resto della dimostrazione del teorema di Kolmogorov è inalterata.]
Osservazione 3 Ogni misura di probabilità λ sui boreliani uno spazio metrico com-pleto e separabile (polacco) è tight. La proprietà di essere polacco passa al prodottocartesiano finito. Allora il teorema di Kolmogorov vale se, invece di supporre che lospazio metrico E sia σ-compatto, si suppone che sia polacco.
1.2.1 Processi gaussiani
Vettori gaussiani
Ricordiamo che la densità gaussiana standard è la funzione f (x) = 1√2π
exp (−x2/2) ela densità gaussiana N (µ, σ2) è la funzione
f (x) =1√
2πσ2exp
(−(x− µ)2
2σ2
).
Una v.a. reale X si dice gaussiana di classe N (µ, σ2) se ha quest’ultima come densità(scriviamo X ∼ N (µ, σ2)) e si verifica che µ = E [X], σ2 = V ar [X]. Se X ∼ N (0, 1),la chiamiamo v.a. gaussiana standard. Si verifica che, data X ∼ N (µ, σ2), esisteZ ∼ N (0, 1) tale che
X = σZ + µ
(basta standardizzare X, cioè porre Z = X−µσe verificare che Z ∼ N (0, 1)). Questa
proprietà offre lo spunto per la definizione di vettore gaussiano. Inoltre, viene usata adesempio come nella seguente osservazione, utile in molti esercizi.

1.2. TEOREMA DI ESTENSIONE DI KOLMOGOROV 19
Osservazione 4 SeX è gaussiana, E [|X|p] <∞ per ogni p ≥ 1 (vale anche E[eλX]<
∞ per ogni λ ∈ R e addirittura E[eλX
2]<∞ per ogni λ < σ2
2). Introduciamo i numeri
cp = E [|Z|p]
dove Z ∼ N (0, 1). Allora, se X ∼ N (µ, σ2),
E [|X − µ|p] = cpσp.
Tutti i “momenti centrati”sono calcolabili tramite la deviazione standard σ.
Un vettore aleatorio Z = (Z1, ..., Zn) si dice gaussiano standard se ha densitàcongiunta
f (x1, ..., xn) =n∏i=1
1√2π
exp
(−x
2i
2
)= (2π)−n/2 exp
(−x
21 + ...+ x2
n
2
)(questo equivale a chiedere che le componenti Z1, ..., Zn siano gaussiane standard in-dipendenti), mentre un vettore X = (X1, ..., Xm) si dice gaussiano se si può rappre-sentare nella forma
X = AZ + b
con A matrice n×m, Z = (Z1, ..., Zn) vettore gaussiano standard, b ∈ Rm.Tra le equivalenze con cui si può riscrivere questa definizione, ricordiamo la seguente:
un vettore X = (X1, ..., Xm) è gaussiano se e solo se la v.a.∑m
i=1 λiXi è gaussianaper ogni scelta di (λ1, ..., λm) ∈ Rm. Segue subito da queste definizioni che se X =(X1, ..., Xm) è un vettore gaussiano, B è una matrice m× k e c ∈ Rk, allora il vettorealeatorio BX + c è un vettore gaussiano (in Rk).Ricordiamo inoltre che per matrice di covarianza di un vettore X = (X1, ..., Xm) si
intende la matrice Q ∈ Rm×m definita da
Qij = Cov (Xi, Xj) , i, j = 1, ...,m.
E’simmetrica e semi-definita positiva. La media (o vettore dei valori medi) è il vettoredi coordinate E [Xi], i = 1, ...,m. Un vettore gaussiano standard Z = (Z1, ..., Zn)ha media nulla e covarianza pari all’identità di Rn. Un vettore gaussiano della formaX = AZ+b come sopra, ha media b e matrice di covarianza Q = AAT . Più in generale,ricordiamo la seguente proposizione (che invitiamo a dimostrare per esercizio):
Proposizione 4 Se X = (X1, ..., Xm) è un vettore gaussiano di media µX e covarianzaQX , B è una matrice m × k e c ∈ Rk, allora il vettore aleatorio Y = BX + c è unvettore gaussiano di media µY = BµX + c e covarianza
QY = BQXBT .

20 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
Sia X = (X1, ..., Xm) un vettore gaussiano di media µ e covarianza Q. QuandodetQ 6= 0, X ha densità di probabilità congiunta (la sua legge è assolutamente continuarispetto alla misura di Lebesgue di Rm), data da
f (x) =1√
(2π)n detQexp
(−〈Q
−1 (x− µ) , (x− µ)〉2
)dove x = (x1, ..., xn). Altrimenti, se detQ = 0, la legge di Y è singolare rispetto allamisura di Lebesgue di Rm ed è concentrata su un sottospazio proprio (precisamenteuna varietà affi ne, di codimensione maggiore di zero, della forma b + V , dove V è ilsottospazio di Rm generato dagli autovettori di Q corrispondenti agli autovalori nonnulli).Chiameremo gaussiana ogni misura di probabilità su (Rn,B (Rn)) che sia legge di
un vettore aleatorio gaussiano. Equivalentemente, una misura di probabilità ρ su(Rn,B (Rn)) è gaussiana se la sua legge immagine su (R,B (R)) attraverso qualsiasiproiezione uni-dimensionale è una misura con densità gaussiana o una delta di Dirac.Ricordiamo che vale il seguente risultato:
Proposizione 5 Dati un vettore b ∈ Rn ed una matrice Q ∈ Rn×n simmetrica e semi-definita positiva, esiste una ed una sola misura gaussiana su (Rn,B (R)n) che ha b comevettore delle medie e Q come matrice di covarianza.
Limitiamoci ad un’idea della dimostrazione dell’esistenza, che può essere interes-sante per altri scopi, anche pratici (es. simulativi, se si vuole generare un campionecasuale a partire da una coppia (Q, b)): esiste una matrice ortogonale U ed una matricediagonale D con elementi non negativi tale che Q = UDUT . Si definisce la matrice√D come la matrice diagonale che ha come elementi le radici di quelli di D e poi
si pone√Q := U
√DUT . La matrice
√Q è simmetrica, semidefinita positiva e vale√
Q√Q = Q. Preso un vettore gaussiano standard Z (esso essite facilmente), basta
porre X =√QZ + b e verificare che la sua legge soddisfa le proprietà richieste.
Processi gaussiani
Fatte queste premesse sui vettori gaussiani, possiamo definire ed analizzare i processigaussiani. Osserviamo che anche in questo paragrafo l’insieme T è qualsiasi.
Definizione 2 Un processo a valori reali X = (Xt)t∈T si dice gaussiano se tutte lesue marginali di dimensione finita (Xt1 , ..., Xtn) sono vettori gaussiani. Analogamente,
una misura di probabilità su(RT ,B (R)T
)si dice gaussiana se tutte le sue distribuzioni
di dimensione finita sono gaussiane.
Un processo reale è quindi gaussiano se e solo se la sua legge su(RT ,B (R)T
)è
gaussiana.

1.2. TEOREMA DI ESTENSIONE DI KOLMOGOROV 21
Se T è un sottoinsieme di uno spazio euclideo, unione numerabile di compatti, dici-amo che una misura su (C (T,E) ,B (C (T,E))) è gaussiana se tutte le sue distribuzionidi dimensione finita sono gaussiane.Un processo gaussiano ha la legge caratterizzata da poche funzioni: la funzione
valor medio m (t) = E [Xt], t ∈ T e la funzione di covarianza C (t, s) = Cov (Xt, Xs),t, s ∈ T .
Proposizione 6 Se due processi gaussiani hanno le stesse funzioni m (t) e C (t, s),allora hanno la stessa legge.
Proof. La legge è identificata dalle distribuzioni di dimensione finita. Le leggi deidue processi sono misure gaussiane, con distribuzioni di dimensione finita gaussiane.Tali gaussiane, diciamo in Rn, sono univocamente determinate dai loro vettori medi edalle matrici di covarianza, che però a loro volta hanno come componenti le valutazionidelle funzioni m (t) e C (t, s) in opportuni punti, quindi coincidono (precisamente, conle notazioni delle sezioni precedenti, la distribuzione di dimensione finita µ(t1,...,tn) hamedia (m (t1) , ...,m (tn)) e matrice di covarianza di componenti C (ti, tj)).Vediamo un risultato di esistenza. Vogliamo invertire il procedimento che da un
processo fornisce m (t) e C (t, s). Naturalmente questi ultimi sono solo dei riassun-ti, molto riduttivi, che non esauriscono in generale le caratteristiche di un processo;salvo nel caso gaussiano. Osserviamo preliminarmente che, dato un processo X taleche E [X2
t ] < ∞ (quindi per il quale le funzioni m (t) e C (t, s) siano ben definite) lafunzione C (t, s) è simmetrica (dalla definizione di covarianza) e semi-definita positiva,nel seguente senso: per ogni n ∈ N, (t1, ..., tn) ∈ T n, (ξ1, ..., ξn) ∈ Rn, vale la disug-uaglianza (1.6). Infatti la matrice (C (ti, tj))i,j=1,...,n è la matrice di covarianza di unvettore aleatorio, (Xt1 , ..., Xtn). E’comunque interessante vedere il conto:
n∑i,j=1
C (ti, tj) ξiξj =n∑
i,j=1
Cov(Xti , Xtj
)ξiξj
= Cov
(n∑i=1
ξiXti ,n∑j=1
ξjXtj
)
= V ar
[n∑i=1
ξiXti
]≥ 0
dove abbiamo usato la linearità della covarianza in entrambi gli argomenti.
Proposizione 7 Date due funzioni m (t) e C (t, s), t, s ∈ T , se C (t, s) = C (s, t) e sevale
n∑i,j=1
C (ti, tj) ξiξj ≥ 0 (1.6)

22 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
per ogni n ∈ N, (t1, ..., tn) ∈ T n, (ξ1, ..., ξn) ∈ Rn, allora esiste un processo gaussianoche ha queste funzioni come media e covarianza; ed è unico in legge.
Proof. Applichiamo il teorema di costruzione di Kolmogorov. Lo spazio di arrivo(E, E) = (R,B (R)) soddisfa l’ipotesi topologica del teorema. Basta quindi costruireuna famiglia µτ ; τ ∈ S di distribuzioni di dimensione finita tale che:i) la famiglia sia consistente (questo garantisce che esista un processo X con tali
distribuzioni di dimensione finita)ii) le µτ siano gaussiane (questo garantisce che X sia gaussiano, per definizione di
processo gaussiano)iii) le funzioni media e covarianza di X siano quelle assegnate.Presa τ = (t1, ..., tn) ∈ S, se prendimo come µτ la legge gaussiana di vettore medio
(m (t1) , ...,m (tn)) e matrice di covarianza di componenti C (ti, tj), la proprietà (ii) èovviamente soddisfatta ed anche (iii), perché il processo X, una volta che esista, saràtale che, per ogni t, s, la v.a. Xt ha legge µt di media m (t) ed il vettore (Xt, Xs) halegge µt,s, la cui matrice di covarianza ha come elemento fuori dalla diagonale C (t, s).Resta quindi da verificare (i), con la scelta appena indicata delle µτ . Svolgiamo
la verifica in due modi, il primo più sintetico, l’altro più algebrico. Limitiamoci allaverifica della proprietà
µ(t1,...,tn) (B1 × · · · ×Bn−1 × E) = µ(t1,...,tn−1) (B1 × · · · ×Bn−1)
al variare di tutti gli argomenti, con le solite notazioni. Sia Y = (Y1, ..., Yn) un vettorealeatorio di legge µ(t1,...,tn). Vale
µ(t1,...,tn) (B1 × · · · × E) = P (Y ∈ B1 × · · · ×Bn−1 × E)
= P(Y ∈ B1 × · · · ×Bn−1
)dove Y = (Y1, ..., Yn−1). Se verifichiamo che µ(t1,...,tn−1) è la legge di Y , l’ultimo ter-mine delle precedenti identità è uguale a µ(t1,...,tn−1) (B1 × · · · ×Bn−1), come volevamo
dimostrare. Il vettore Y è trasformazione lineare di Y , quindi gaussiano. Basta quindiverificare che la legge di Y e µ(t1,...,tn−1) hanno lo stesso vettore di valori medi e la stes-sa matrice di covarianza. Ci limitiamo alla seconda verifica. La generica componentedella matrice di covarianza di Y è Cov (Yi, Yj) (con i, j = 1, ..., n− 1), ovvero C (ti, tj),in quanto C (ti, tj) è la generica componente della matrice di covarianza di Y (coni, j = 1, ..., n) che ha le stesse componenti di Y . Ma anche µ(t1,...,tn−1) ha matrice dicovarianza di componenti Cov (Yi, Yj), i, j = 1, ..., n− 1. La dimostrazione è completa.Vediamo come si può verificare la stessa proprietà in modo algebrico. Con le no-
tazioni usate in precedenza, τ = (t1, ..., tn) ∈ S, τ n = (t1, ..., tn−1), πn : En → En−1
che manda la generica sequenza (x1, ..., xn) ∈ En nella sequenza (x1, ..., xn−1) ∈ En−1,dobbiamo dimostrare che
µτ n = πn (µτ ) .

1.2. TEOREMA DI ESTENSIONE DI KOLMOGOROV 23
La trasformazione πn è lineare e quindi i vettori delle medie mτ n e mτ di µτ n e µτrispettivamente sono legati dalla relazione mτ n = πnmτ , le matrici di covarianza Qτ n
e Qτ di µτ n e µτ rispettivamente sono legate dalla relazione Qτ n = πnQτπTn (us-
ando la notazione πn anche per la matrice associata alla trasformazione nella basecanonica). Il vettore mτ ha componenti m (tk), k = 1, ..., n, quindi πnmτ è il vettore(m (t1) , ...,m (tn−1)) ∈ En−1, che è proprio il vettore delle medie di µτ n .La verifica della proprietà Qτ n = πnQτπ
Tn è elementare ma noiosa da scrivere. Per
completezza la riportiamo. La matrice πn ha componenti (πn)j,α = δj,α, per j =
0, ..., n−1, α = 1, ..., n. Quindi la matrice πTn,i ha componenti(πTn)β,k
= (πn)k,β = δk,β,per k = 0, ..., n− 1, β = 1, ..., n. Quindi, dall’identità
(πnQτπ
Tn
)jk
=
n∑α,β=1
(πn)j,α (Qτ )α,β(πTn)β,k
si deduce, per j, k = 0, ..., n− 1,
=n∑
α,β=1
δj,αC (tα, tβ) δk,β = C (tj, tk) .
Questa è la matrice Qτ n . La dimostrazione è completa.
Processi gaussiani stazionari
Ancor più economica è la descrizione nel caso di processi stazionari. Supponiamo chesull’insieme T sia definita un’operazione di somma +, cioè t + s ∈ T se t, s ∈ T . Adesempio si possono considerare T = Rn o T = [0,∞) con l’usuale somma euclidea.
Definizione 3 Un processo stocasticoX = (Xt)t∈T a valori in (E, E) si dice stazionarioin senso stretto se, per ogni τ = (t1, ..., tn) ∈ S le leggi di (Xt1 , ..., Xtn) e (Xt1+h, ..., Xtn+h)coincidono per ogni h ∈ T .
Definizione 4 Un processo reale X = (Xt)t∈T , con E [X2t ] < ∞ per ogni t ∈ T , si
dice stazionario in senso lato o debole se
m (t+ h) = m (t)
C (t+ h, s+ h) = C (t, s)
per ogni h, s, t ∈ T .
Nel caso di un processo reale, la stazionarietà in senso stretto implica quella insenso lato, ma non viceversa (non possiamo risalire alle leggi dai momenti di ordineuno e due).

24 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
Proposizione 8 Se un processo gaussiano è stazionario in senso lato allora è anchestazionario in senso stretto.
Proof. Dati τ = (t1, ..., tn) ∈ S e h ∈ T , le leggi di (Xt1 , ..., Xtn) e (Xt1+h, ..., Xtn+h),essendo gaussiane, sono identificate dai vettori medi di componenti E [Xtk ] e E [Xtk+h],che coincidono essendom (tk + h) = m (tk), k = 1, ..., n, e dalle matrici di covarianza dicomponenti Cov
(Xti , Xtj
)eCov
(Xti+h, Xtj+h
), che coincidono essendoC (ti + h, tj + h) =
C (ti, tj). Quindi le leggi di (Xt1 , ..., Xtn) e (Xt1+h, ..., Xtn+h) coincidono ed abbiamo lastazionarietà in senso stretto.Supponiamo che T sia un gruppo rispetto alla somma + e sia 0 l’elemento neutro.
In questo caso la stazionarietà in senso lato permette di descrivere la legge del processogaussiano in modo estremamente economico.
Proposizione 9 Se un processo gaussiano è stazionario in senso lato allora la sualegge è identificata dal numero m := E [Xt] e dalla funzione di una variabile
C (t) := Cov (Xt, X0) , t ∈ T.
Proof. Le distribuzioni di dimensione finita sono identificate dalle funzioni m (t) eC (t, s) ma queste, a loro volta, per la stazionarietà in senso lato sono l’una costante,m (t) = m, l’altra identificata dai suoi valori nei punti (t, s) della forma (r, 0), in quanto
C (t− s, 0) = C (t, s)
(h = s nella definizione di stazionarietà).
Corollario 1 Data una costante m ed una funzione C (t) tale che C (−t) = C (t) e
n∑i,j=1
C (ti − tj) ξiξj ≥ 0
per ogni n ∈ N, (t1, ..., tn) ∈ T n, (ξ1, ..., ξn) ∈ Rn, allora esiste un processo gaussianostazionario ad esse associato, unico in legge.
Sulla verifica della condizione di definita positività
Verificare che una data funzione C (t, s) soddisfa la condizione (1.6) appare spessoassai diffi cile, se non si usano opportuni trucchi. Un caso importante e sintomatico èla funzione
C (t, s) = t ∧ s.Si provi a dimostrare algebricamente la (1.6), per rendersi conto di quanto sia diffi cile.Ecco un trucco che spesso semplifica le cose, nel caso in cui sia T = [0, 1] (o un altrointervallo dei numeri reali).

1.2. TEOREMA DI ESTENSIONE DI KOLMOGOROV 25
Invece che verificare la condizione (1.6), esaminiamo quella integrale∫ 1
0
∫ 1
0
C (t, s) f (s) f (t) dsdt ≥ 0
per ogni funzione f : [0, 1]→ R continua (o regolare quanto si vuole, a seconda di cosaserve per svolgere i calcoli). Se verifichiamo questa condizione, non è diffi cile rendersiconto che vale la (1.6), prendendo una famiglia di funzioni fε che tende, per ε→ 0, alladistribuzione
∑ni=1 ξiδti (abbiamo usato un linguaggio avanzato ma si tratta solamente
di applicare regole note di calcolo integrale, simili al fatto che 12ε
∫ ti+εti−ε f (s) ds→ f (ti)).
Non scriviamo i dettagli, non diffi cili da formalizzare.Osserviamo inoltre che, per la simmetria di C (t, s), basta verificare∫ 1
0
(∫ t
0
C (t, s) f (s) ds
)f (t) dt ≥ 0
oppure ∫ 1
0
(∫ 1
t
C (t, s) f (s) ds
)f (t) dt ≥ 0.
Esempio 1 Nel caso C (t, s) = t ∧ s, posto g (t) =∫ 1
tf (s) ds, vale∫ 1
0
(∫ 1
t
C (t, s) f (s) ds
)f (t) dt =
∫ 1
0
tf (t)
∫ 1
t
f (s) dsdt = −∫ 1
0
tg′ (t) g (t) dt
= −∫ 1
0
td
dtg2 (t) dt =
∫ 1
0
g2 (t) dt ≥ 0.
Nel caso stazionario, possiamo invece avvalerci della trasformata di Fourier. Ac-cenniamo solo all’idea. Data una funzione C (t), definita per t ∈ R e simmetrica,supponiamo che abbia senso calcolare la sua trasformata di Fourier C (θ) e che valga(a meno di costante, a seconda delle convenzioni)
C (t) =
∫ +∞
−∞eitθC (θ) dθ.
Proposizione 10 Se C (θ) ≥ 0, allora C (t) è semidefinita positiva.
Proof.n∑
i,j=1
C (ti − tj) ξiξj =
n∑i,j=1
ξiξj
∫ +∞
−∞ei(ti−tj)θC (θ) dθ
=
∫ +∞
−∞
n∑i=1
ξiei(ti)θ
n∑j=1
ξjeitjθC (θ) dθ
=
∫ +∞
−∞
∣∣∣∣∣n∑i=1
ξiei(ti)θ
∣∣∣∣∣2
C (θ) dθ ≥ 0.

26 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
Vale anche un importante teorema di Bochner che afferma, in un certo senso, ilviceversa, facendo ricorso però a misure positive C (dθ); rimandiamo a testi specializ-zati.Con questi strumenti, provare ad esaminare le due funzioni
C (t, s) = t ∧ s− ts, t, s ∈ [0, 1]
C (t, s) = e−|t−s|, t, s ≥ 0.
Osservazione 5 Se in un punto t vale C (t, t) = 0, vuol dire che V ar [Xt] = 0, ovveroche Xt = E [Xt] q.c. (la v.a. Xt è costante). Nell’esempio C (t, s) = t ∧ s − ts, valeC (0, 0) = C (1, 1) = 0, quindi il processo Xt è vincolato, nei punti t = 0, 1, ad assumereun certo valore costante (quello specificato dalla funzione m (t)). Si usa in questo casoil linguaggio suggestivo di “ponte”gaussiano.
1.3 Filtrazioni e tempi d’arresto
1.3.1 Filtrazioni
A partire da questo paragrafo supponiamo che T sia un intervallo di R, o più precisa-mente per fissare le idee
T = [0,∞).
Si intuisce che si possa svolgere una teoria più generale ma gli esempi che tratteremonel corso non la motivano.Chiamiamo filtrazione su (Ω,F , P ) una famiglia (Ft)t∈T di σ-algebre di insiemi di
Ω, Ft ⊂ F per ogni t ∈ T , che sia crescente: Fs ⊂ Ft se s < t ∈ T .Un processo X = (Xt)t∈T definito su (Ω,F , P ) a valori in (E, E) si dice adattato alla
filtrazione (Ft)t∈T se per ogni t ∈ T la funzione Xt è misurabile da (Ω,Ft) in (E, E).Supponiamo T = [0,∞); se T è un intervallo che contiene 0 la definizione è analoga.
Il processo X si dice progressivamente misurabile se per ogni t ≥ 0 l’applicazione(s, ω) 7−→ Xs (ω) da ([0, t]× Ω,B ([0, t])⊗Ft) in (E, E) è misurabile.Se X è progressivamente misurabile, allora è misurabile ed adattato. Viceversa,
vale ad esempio il seguente risultato.
Proposizione 11 Sia E uno spazio topologico, E = B (E). Se X è adattato e q.c.continuo a destra (oppure q.c. continuo a sinistra) allora è progressivamente misurabile.
Proof. Sia G una σ-algebra su Ω. Il seguente criterio di misurabilità è noto: seuna funzione f : [a, b] × Ω → E è continua a destra ed ω 7−→ f (t, ω) è misura-bile da (Ω,G) in (E, E) per ogni t ∈ [a, b], allora (t, ω) 7−→ f (t, ω) è misurabile da

1.3. FILTRAZIONI E TEMPI D’ARRESTO 27
([a, b]× Ω,B ([a, b])⊗ G) in (E, E). La dimostrazione si fa ad esempio approssimandof con funzioni continue a destra e costanti a tratti in t.Basta allora applicare questo criterio ad ogni restrizione di X ad insiemi della forma
[0, t]× Ω. La dimostrazione è completa.Un insiemeN ⊂ Ω è trascurabile rispetto a (Ω,F , P ) se inf P (B) ;B ∈ F , N ⊂ B =
0; ovvero se esiste B ∈ F tale N ⊂ B e P (B) = 0. Indichiamo con N l’insieme degliinsiemi trascurabili rispetto a (Ω,F , P ). Una filtrazione (Ft)t∈T è completa se ogni Ftcontiene N . E’equivalente che F0 contenga N . [I concetti di filtrazione completa eσ-algebra completa differiscono. Una σ-algebra G si dice completa quando contiene gliinsiemi trascurabili rispetto a (Ω,G, P ). In questo senso, fissato t ≥ 0, Ft è completase contiene gli eventi trascurabili rispetto a (Ω,Ft, P ); mentre la filtrazione è completase, per ogni t ≥ 0, Ft contiene gli eventi trascurabili rispetto a (Ω,F , P ), che sono apriori di più.]E’comodo che tutte le σ-algebre di una filtrazione contengano N . Altrimenti si
creano tante piccole complicazioni un po’innaturali; ad esempio se Y è modificazionedi un processo adattato X e la filtrazione non è completa, non si può concludere cheanche Y sia adattato; al contrario:
Proposizione 12 Se (Ft)t∈T è completa, X è un processo adattato e Y è modificazionedi X, allora Y è adattato.
Proof. Preso B ∈ E e t ∈ T , vale
Yt ∈ B = Yt ∈ B,Xt = Yt ∪ Yt ∈ B,Xt 6= Yt= Xt ∈ B,Xt = Yt ∪ Yt ∈ B,Xt 6= Yt .
L’evento Xt 6= Yt è trascurabile rispetto a (Ω,F , P ) (perché X ed Y sono versioni),quindi lo è anche Yt ∈ B,Xt 6= Yt, che pertanto appartiene a Ft essendo comple-ta. L’evento Xt = Yt è il complementare di Xt 6= Yt, quindi appartiene a Ft; an-che Xt ∈ B perché X è adattato, quindi Xt ∈ B,Xt = Yt ∈ Ft. Si conclude cheYt ∈ B ∈ Ft, quindi Y è adattato.Una filtrazione (Ft)t∈T si dice continua a destra se per ogni t ∈ T
Ft =⋂ε>0
Ft+ε.
Questa condizione interviene ogni tanto nei teoremi successivi, e la completezza ancoradi più, per cui spesso per unificare gli enunciati di una teoria si assume sin dall’inizioche la filtrazione di riferimento della teoria sia completa a continua a destra. Diremoche una filtrazione soddisfa le condizioni abituali se è completa e continua a destra.Si ricordi che l’intersezione (arbitraria) di σ-algebre è una σ-algebra, quindi
⋂ε>0
Ft+ε
è sempre una σ-algebra. Invece l’unione no; indicheremo col simbolo F∨G la più piccola

28 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
σ-algebra che contiene F ∪ G; per cui scriveremo ad esempio∨t≥0
Ft per la più piccola
σ-algebra che contiene ogni Ft, denotata con F∞.Dato un processo stocastico X, ad esso è associata la filtrazione generata da X
definita daF00t = σ Xs; s ∈ T, s ≤ t
A livello interpretativo, gli eventi di F00t sono gli eventi conoscibili al tempo t se os-
serviamo il processo X. La notazione F00t non è universale ed è usata qui solo per
distinguere questa filtrazione dalle seguenti.Essendo comodo che la filtrazione di riferimento sia completa, si introduce la fil-
trazione (F0t )t∈T definita da F0
t = σ F00t ∪N. La filtrazione (F0
t )t∈T è il completa-mento della filtrazione (F00
t )t∈T (naturalmente questo procedimento si può applicare aqualsiasi filtrazione).
Osservazione 6 In generale F0t 6= F00
t . Si pensi ad esempio ad un processo stocasticocontinuo e nullo per t = 0 (come sarà il moto browniano). Possiamo definire la sualegge, che indichiamo con P , sullo spazio Ω = C0 ([0,∞);R) delle funzioni continue enulle in zero (munito della convergenza uniforme sui compatti e della relativa famigliadei boreliani F). Consideriamo ora il processo canonico ξt : Ω→ R, t ≥ 0, definito da
ξt (ω) = ω (t) .
La legge di ξ è P . Ora, F000 = ∅,Ω, è la σ-algebra banale, perché dato un boreliamo
B, l’evento ξ0 ∈ B è ∅ se 0 /∈ B, mentre è Ω se 0 ∈ B. Se, come per la legge P delmoto browniano, accade che eventi del tipo ξt = a, a ∈ R, t > 0, hanno probabilitànulla, allora essi sono trascurabili per (Ω,F , P ), ma ovviamente non appartengono aF00
0 . Quindi F000 6= F0
0 (e lo stesso vale ad ogni tempo). L’esempio è un po’estremo (acausa del fatto che F00
0 è banale) ma accade un fenomeno simile nella maggior partedei casi.
Osservazione 7 Si osservi anche che, per completare F000 , abbiamo aggiunto even-
ti che anticipano il futuro! Questo disturba un po’ nell’ottica di voler considerarefiltrazioni che dipendono solo dal passato del processo. Per fortuna si tratta di ag-giungere eventi trascurabili; quindi spesso lo si fà per comodità matematica, anche seconcettualmente non sarebbe molto naturale.
Volendo richiedere che la filtrazione sia anche continua a destra, poniamo
Ft =⋂ε>0
F0t+ε.

1.3. FILTRAZIONI E TEMPI D’ARRESTO 29
Osservazione 8 Questa filtrazione è continua a destra: Ft =⋂ε>0
Ft+ε. Infatti, F0t ⊂
Ft (per ogni t ∈ T ) per monotonia di (F0t )t∈T e definizione di Ft, quindi
⋂ε>0
F0t+ε ⊂⋂
ε>0
Ft+ε, per cui Ft ⊂⋂ε>0
Ft+ε per definizione di Ft. Viceversa, Ft+ε ⊂ F0t+2ε per ogni
t ∈ T ed ε > 0, per definizione di Ft, quindi⋂ε>0
Ft+ε ⊂⋂ε>0
F0t+2ε = Ft.
La filtrazione così costruita è la più piccola che soddisfi le condizioni abituali erispetto a cui il processo sia adattato.
1.3.2 Tempi d’arresto
Genericamente, potremmo chiamare tempo aleatorio (non è una definizione canonica)ogni v.a. a valori in [0,∞), o addirittura a valori in [0,∞]. Un tempo aleatorioτ : Ω → [0,∞] si dirà tempo d’arresto, rispetto ad una filtrazione data (Ft)t≥0, se perogni t ≥ 0 l’evento τ ≤ t appartiene a Ft:
τ ≤ t ∈ Ft ∀t ≥ 0.
Quindi anche τ > t ∈ Ft. Se τ : Ω→ [0,∞), diremo che è un tempo d’arresto finito.Se esiste T > 0 tale che |τ | ≤ T , diremo che è un tempo d’arresto limitato.Per processi a tempo discreto (li useremo unicamente nella teoria delle martingale),
relativamente a filtrazioni (Fn)n∈N, si considerano tempi d’arresto a valori discreti, cioètempi aleatori τ : Ω → N ∪ +∞ tali che τ ≤ n ∈ Fn per ogni n ∈ N. Si verificasubito che questa condizione equivale a τ = n ∈ Fn per ogni n ∈ N. Infatti, se valela prima (τ ≤ n ∈ Fn), allora
τ = n = τ ≤ n \ τ ≤ n− 1 ∈ Fn
perché τ ≤ n ∈ Fn, τ ≤ n− 1 ∈ Fn−1 ⊂ Fn ed Fn è chiusa per differenza.Viceversa, se vale la seconda (τ = n ∈ Fn), allora
τ ≤ n =n⋃k=0
τ = k ∈ Fn
perché τ = k ∈ Fk ⊂ Fn per ogni k = 0, ..., n ed Fn è chiusa per unione finita.Il significato intuitivo di tempo d’arresto è il seguente: fissato t0 ≥ 0 (ad esempio
l’orario di chiusura di un negozio) ci chiediamo se l’istante aleatorio τ (ad esempiol’arrivo di un cliente che deve ritirare della merce) avvenga prima o dopo t0. Tale evento,τ ≤ t0, è conoscibile al tempo t0, se per “conoscibili” intendiamo gli eventi dellafiltrazione data (nell’esempio del negozio, se la filtrazione è associata alle informazioni

30 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
note a chi sta lavorando nel negozio, vale τ ≤ t0 ∈ Ft0 : lo vedono se il cliente èarrivato o no in tempo; se invece è una filtrazione associata alle informazioni note adun gestore a distanza che viene informato il giorno successivo di ciò che è accaduto innegozio, τ ≤ t0 /∈ Ft0).Abbiamo descritto questa nozione nel caso a tempo continuo, ma è identica a tempo
discreto.Un tempo deterministico τ = T è un tempo d’arresto, perché gli eventi della forma
τ ≤ t appartengono a ∅,Ω.Tra le numerose proprietà generali a volte utili segnaliamo la seguente, usata spesso
per ridurre un tempo d’arresto qualsiasi ad uno limitato:
Proposizione 13 Se τ 1, τ 2 sono tempi d’arresto, allora lo è anche τ 1 ∧ τ 2. In parti-colare, lo è τ 1 ∧ T per ogni tempo determinsitico T > 0.
Proof. Dato t ≥ 0,τ 1 ∧ τ 2 ≤ t = τ 1 ≤ t ∪ τ 2 ≤ t
e ciascuno di questi eventi appartiene a Ft.SiaX = (Xt)t≥0 un processo stocastico a valori in uno spazio metricoE (E = B (E)),
adattato alla filtrazione (Ft)t≥0. Sia A ∈ B (E). Introduciamo un tempo aleatorioτA : Ω → [0,∞] ponendo τA (ω) = inf t ≥ 0 : Xt (ω) ∈ A per ogni ω ∈ Ω tale chel’insieme t ≥ 0 : Xt (ω) ∈ A è non vuoto, τA (ω) = ∞ altrimenti. Useremo scriverepiù compattamente
τA = inf t ≥ 0 : Xt ∈ Aintendendo tutte le frasi precedenti. Diciamo che τA è il tempo (o istante) di ingressodel processo nell’insieme A. Chiediamoci se sia un tempo d’arresto.Intanto vediamo il caso a tempo discreto. Definiamo cioè
τA = inf n ≥ 0 : Xn ∈ A
se l’insieme n ≥ 0 : Xn ∈ A è non vuoto, τA = ∞ altrimenti. Fissato n0 ∈ N, cichiediamo se τA ≤ n0 ∈ Fn0 . Vale
τA ≤ n0 = ∃n ≤ n0 : Xn ∈ A =⋃n≤n0
Xn ∈ A ∈ Fn0
dove l’ultima disuguaglianza deriva dal fatto che Xn ∈ A ∈ Fn e che Fn ⊂ Fn0 sen ≤ n0. Quindi è vero: τA è un tempo di arresto. Non serve alcuna altra ipotesi.A tempo continuo non è così. Proviamo a ripetere i passaggi precedenti, relativa-
mente ad un tempo fissato t0 ≥ 0:
τA ≤ t0 = ∀ε > 0,∃t ≤ t0 + ε : Xt ∈ A∀n ∈ N,∃t ≤ t0 +
1
n: Xt ∈ A
=
⋂n∈N
⋃t≤t0+ 1
n
Xt ∈ A .

1.3. FILTRAZIONI E TEMPI D’ARRESTO 31
L’evento Xt ∈ A appartiene a Ft e quindi a Ft0+ 1nse t ≤ t0 + 1
n. Ma prima di tutto
l’unione⋃
t≤t0+ 1n
è (a priori) più che numerabile. Quand’anche potessimo riesprimerla
come unione numerabile, quindi potessimo asserire che⋃
t≤t0+ 1n
Xt ∈ A ∈ Ft0+ 1n, poi
l’intersezione⋂n∈N
starebbe in Ft0 se la filtrazione fosse continua a destra, altrimenti
non potremmo concluderlo.
Proposizione 14 Se X è un processo continuo, A è un aperto e (Ft)t≥0 è continuaa destra, allora τA è un tempo di arresto. Lo stesso vale se X è continuo a destra ocontinuo a sinistra.
Proof. Se X è continuo e A è aperto allora∀n ∈ N, ∃t ≤ t0 +
1
n: Xt ∈ A
=
∀n ∈ N,∃t ≤ t0 +
1
n, t ∈ Q : Xt ∈ A
.
Basta verificare l’inclusione ⊂. Sia ω ∈ Ω tale che ∀n ∈ N, ∃t ≤ t0 + 1ntale che Xt ∈ A.
Se, relativamente ad n e t che verificano questa condizione, prendiamo una successionetn → t, tn ∈ Q, tn ≤ t0 + 1
n, abbiamo Xtn (ω)→ Xt (ω), ma quindi Xtn (ω) ∈ A per n
abbastanza grande, in quanto A è aperto.L’identità precedente permette di scrivere
τA ≤ t0 =⋂n∈N
⋃t≤t0+ 1
n,t∈Q
Xt ∈ A
da cui discende la tesi per i ragionamenti già fatti sopra. Le verifiche nel caso continuoa destra o continuo a sinistra sono simili.Quando A, che ora chiameremo C, è chiuso ed X è continuo, si può modificare la
dimostrazione precedente dall’inizio e concludere che τC è un tempo d’arresto. Nonserve la continuità a destra della filtrazione. Il criterio è quindi anche più semplice delprecedente, ma la dimostrazione è più complicata. Si noti anche la riscrittura di τCcome minimo corrisponde ancor più all’idea di primo istante di ingresso in C.
Proposizione 15 Se X è un processo continuo e C è un chiuso, allora τC è un tempodi arresto e vale
τC = min t ≥ 0 : Xt ∈ C .
Proof. SeX è continuo eC è chiuso allora, preso ω ∈ Ω, se l’insieme t ≥ 0 : Xt (ω) ∈ C 6=∅, vale
τA (ω) = min t ≥ 0 : Xt (ω) ∈ C .

32 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
Infatti, per definizione di τC (ω) come inf t ≥ 0 : Xt (ω) ∈ C, esiste una successionetn (ω) ↓ τC (ω) tale che Xtn(ω) (ω) ∈ C; ma per continuità delle traiettorie Xtn(ω) (ω)→XτC(ω) (ω) e per chiusura di C valeXτA(ω) (ω) ∈ C. Quindi l’insieme t ≥ 0 : Xt (ω) ∈ Cpossiede minimo. Abbiamo dimostrato l’ultima affermazione della proposizione. Vedi-amo la prima.Ora possiamo dire che
τC ≤ t0 = ∃t ≤ t0 : Xt ∈ C =⋃t≤t0
Xt ∈ C .
Non possiamo però ridurre questa unione ad una numerabile perché dobbiamo im-maginare ad esempio il caso in cui C sia un singolo punto, ed il processo lo tocchi acerti istanti (non necessariamente membri di un insieme numerabile prefissato) ma nonpermanga in C.Il caso t0 = 0 però si risolve: τC ≤ 0 = X0 ∈ C ∈ F0. Possiamo restringerci a
t0 > 0.Introduciamo allora l’intorno aperto di raggio ε > 0 di C:
Cε = x ∈ E : d (x,C) < ε .
Vale ⋃t≤t0
Xt ∈ C =⋂n∈N
⋃t≤t0,t∈Q
Xt ∈ C 1
n
∈ Ft0 .
L’appartenenza a Ft0 è ovvia. Verifichiamo l’identità tra i due insiemi. L’inclusione ⊂è concettualmente più facile. Sia ω nell’insieme di sinistra. Se per un certo t ≤ t0 valeXt (ω) ∈ C, allora per ogni n ∈ N esiste un numero razionale tn ≤ t0 tale che Xtn (ω) ∈C 1n, per continuità della traiettoria X· (ω). Quindi l’inclusione ⊂ è dimostrata.Vediamo l’inclusione ⊃. Sia ω nell’insieme di destra. Per ogni n ∈ N esiste un
numero razionale tn ≤ t0 tale che Xtn (ω) ∈ C 1n. Dalla successione limitata tn si può
estrarre una sottosuccessione convergente tnk; sia t il suo limite; vale t ≤ t0. Percontinuità di X· (ω) vale limk→∞Xtnk
(ω) = Xt (ω). Se dimostriamo che Xt (ω) ∈ C,allora ω appartiene anche all’insieme di sinistra.Ma Xtnk
(ω) ∈ C 1nk
. Questo implica che esiste un elemento ek (ω) ∈ C tale che
d(Xtnk
(ω) , ek (ω))≤ 2
nk. Siccome limk→∞ d
(Xtnk
(ω) , Xt (ω))
= 0,
limk→∞
d (Xt (ω) , ek (ω)) ≤ limk→∞
d(Xtnk
(ω) , Xt (ω))
+ limk→∞
d(Xtnk
(ω) , ek (ω))
= 0.
Questo significa ek (ω) → Xt (ω), quindi Xt (ω) ∈ C perché C è chiuso. La di-mostrazione è completa.

1.3. FILTRAZIONI E TEMPI D’ARRESTO 33
1.3.3 La σ-algebra associata ad un tempo d’arresto
Sia (Ω,F , P ) uno spazio probabilizzato e τ : Ω → [0,∞] un tempo d’arresto rispettoad una filtrazione (Ft)t≥0. Sappiamo che se per ogni t ≥ 0 l’evento τ ≤ t appartienea Ft. Prendiamo un evento A ∈ F∞ = ∨tFt. Esaminiamo la condizione
A ∩ τ ≤ t ∈ Ft per ogni t ≥ 0.
La famiglia di tutti gli insiemi A ∈ F∞ che soddisfano questa condizione è una σ-algebra, che indichiamo con Fτ . Infatti Ω ∈ Fτ perché Ω ∩ τ ≤ t = τ ≤ t ∈ Ft; seA ∈ Fτ allora Ac ∈ Fτ perché
Ac ∩ τ ≤ t = τ ≤ t \ (A ∩ τ ≤ t) ;
ed infine, se An ⊂ Fτ allora ∪nAn ∈ Fτ per la proprietà distributiva di unione eintersezione.Si noti che se A ∈ Ft0 per qualche t0 ≥ 0, non è detto che sia A ∈ Fτ , perché la
condizione A ∈ Fτ richiede che sia A ∩ τ ≤ t ∈ Ft per ogni t ≥ 0, non solo al tempot0. Quindi può apparire non è ovvio esibire eventi di Fτ . Invece, ad esempio un eventodel tipo
τ ∈ [0, T ]
con T > 0 ci sta. Infatti
τ ∈ [0, T ] ∩ τ ≤ t = τ ∈ [0, t ∧ T ] ∈ Ft∧T ⊂ Ft.
Quindi τ è Fτ -misurabile. Pertanto, gli eventi della forma τ ∈ B, con B ∈ B (R),sono esempi di eventi di Fτ .Non si deve però pensare che Fτ sia la σ-algebra generata da τ . La seguente
proposizione fornisce ulteriori eventi di Fτ .
Proposizione 16 Sia τ un tempo d’arresto finito. Sia (Xt)t≥0 un processo progressi-vamente misurabile. Allora Xτ (definito da ω 7−→ Xτ(ω) (ω)) è una v.a. Fτ -misurabile.
Proof. Consideriamo l’applicazione misurabile ω 7−→ (τ (ω) , ω) da (Ω,F∞) in ([0,∞)× Ω,B ([0,∞))×F∞)e l’applicazione misurabile (s, ω) 7−→ Xs (ω) da ([0,∞)× Ω,B ([0,∞))×F∞) in (R,B (R)).La loro composizione è l’applicazione ω 7−→ Xτ(ω) (ω) che quindi risulta misurabile da(Ω,F∞) in (R,B (R)). Questo chiarisce che ogni evento della forma Xτ ∈ B conB ∈ B (R) è F∞-misurabile. Preso poi t ≥ 0, esaminiamo la condizione Xτ ∈ B ∩τ ≤ t ∈ Ft; se vale, significa che Xτ ∈ B ∈ Fτ , quindi Xτ è Fτ -misurabile.Osserviamo che
Xτ ∈ B ∩ τ ≤ t = Xτ∧t ∈ B ∩ τ ≤ t
quindi basta verificare che Xτ∧t ∈ B ∈ Ft.

34 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
Consideriamo allora l’applicazione ω 7−→ (τ (ω) ∧ t, ω) da (Ω,Ft) in ([0, t]× Ω,B ([0, t])×Ft)e l’applicazione (s, ω) 7−→ Xs (ω) da ([0, t]× Ω,B ([0, t])×Ft) in (R,B (R)). La lorocomposizione è l’applicazione ω 7−→ Xτ(ω)∧t (ω). Se le due applicazioni che componi-amo sono misurabili, allora lo è la loro composizione, da (Ω,Ft) in (R,B (R)) e questoimplica che Xτ∧t ∈ B ∈ Ft per ogni B ∈ B (R). La seconda delle due applicazioni èmisurabile per l’ipotesi di progressiva misurabilità. Vediamo la prima.L’applicazione ω 7−→ (τ (ω) ∧ t, ω) da (Ω,Ft) in ([0, t]× Ω,B ([0, t])×Ft) è misura-
bile. Basta verificarlo su un insieme di generatori. Prendiamo un insieme della forma[0, t0]×B con t0 ∈ (0, t) e B ∈ Ft. La sua controimmagine è l’insieme
ω ∈ Ω : τ (ω) ∧ t ∈ [0, t0] ∩ ω ∈ B = τ ≤ t0 ∩B
che appartiene a Ft perchéB ∈ Ft e τ ≤ t0 ∈ Ft0 ⊂ Ft. La dimostrazione è completa.
1.4 Speranza condizionale e probabilità condizionale
1.4.1 Speranza condizionale
Teorema 2 Data una v.a. X a valori reali, integrabile su (Ω,F , P ) ed una σ-algebraG ⊂ F , esiste una v.a. G-misurabile X ′ tale che∫
B
XdP =
∫B
X ′dP
per ogni B ∈ G. Inoltre è unica a meno di P -equivalenze.
La dimostrazione dell’esistenza si basa sul teorema di Radon-Nikodym, l’unicità suun semplice argomento prendendo l’evento B = X ′ > X ′′, se X ′, X ′′ soddisfano lestesse condizioni.
Definizione 5 Sia X una v.a. integrabile su (Ω,F , P ) e sia G una σ-algebra, G ⊂F . Chiamiamo speranza condizionale di X rispetto a G ogni variabile aleatoria G-misurabile X ′ tale che ∫
B
XdP =
∫B
X ′dP
per ogni B ∈ G. Chiameremo con lo stesso nome anche la classe di P -equivalenza ditali variabili. La speranza condizionale di X rispetto a G viene indicata con E [X|G].Quando scriveremo uguaglianze tra diverse speranze condizonali o tra una speranza
condizionale ed una v.a., si intenderà sempre l’uguaglianza come classi di equivalenza,o P -q.c.

1.4. SPERANZA CONDIZIONALE E PROBABILITÀ CONDIZIONALE 35
L’intuizione è che, avendo a disposizione il grado di informazione fornito da G, lanostra attesa circa il valore di X è più precisa della semplice E [X] (attesa incon-dizionata), dipende da ciò che si avvera nei limiti della finezza di G, quindi è una v.a.G-misurabile. Inoltre, se B è un atomo di G con P (B) > 0, per cui X ′ deve esserecostante su B, l’identità della definizione dice che
X ′|B =1
P (B)
∫B
XdP
cioèX ′ è una sorta di media locale diX; per un B generale l’identità stabilisce una gen-eralizzazione di tale proprietà. Si risolva il seguente esercizio, per aiutare ulteriormentel’intuizione.
Esercizio 6 Sia G generata da una partizione misurabile B1, ..., Bn. Allora E [X|G] =∑ni=1
(1
P (Bi)
∫BiXdP
)· 1Bi. In altre parole, E [X|G] è costante su ciascun Bi e lì vale
la media di X su Bi, 1P (Bi)
∫BiXdP .
Proof. La v.a. X ′ =∑n
i=1
(1
P (Bi)
∫BiXdP
)· 1Bi è G-misurabile. Prendiamo Y = 1B1 .
Vale
E [XY ] =
∫B1
XdP
E [X ′Y ] =n∑i=1
(1
P (Bi)
∫Bi
XdP
)E [1Bi1B1 ]
=n∑i=1
(1
P (Bi)
∫Bi
XdP
)δi1P (B1) =
∫B1
XdP
e quindi sono uguali.
Osservazione 9 La definizione data sopra equivale a chiedere che X ′ sia G-misurabilee valga
E [XY ] = E [X ′Y ]
per ogni v.a. Y limitata G-misurabile. Un’implicazione è ovvia (prendendo Y dellaforma 1B con B ∈ G). Per l’altra, dalla definizione, che si riscrive E [X1B] = E [X ′1B],discende che E [XY ] = E [X ′Y ] per Y della forma Y =
∑yi1Bi, yi ∈ R, Bi ∈ G. Con
variabili di quel tipo possiamo approssimare dal basso puntualmente ogni Y limitataG-misurabile e passare al limite per convergenza monotona.
Proposizione 17 Siano X, Y , Xn integrabili, G una sotto σ-algebra di F . Valgonole seguenti affermazioni:

36 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
i) Se G ′ ⊂ G ⊂ F allora E [E [X|G] |G ′] = E [X|G ′]; in particolare (G ′ = ∅,Ω),E [E [X|G]] = E [X]ii) Se X è G-misurabile ed XY è integrabile, allora E [XY |G] = XE [Y |G]iii) Se X è indipendente da G allora E [X|G] = E [X]iv) E [aX + bY + c|G] = aE [X|G] + bE [Y |G] + cv) Se Xn è una successione di v.a. monotona non decrescente, con X = limn→∞
Xn integrabile, allora E [Xn|G]→ E [X|G] q.c.
La verifica di queste proprietà è un utile esercizio; rimandiamo comunque ai corsi dibase di Probabilità. Utile tecnicamente è la seguente generalizzazione delle proprietà(ii)-(iii). Si noti che ϕ è G ′-misurabile nel suo secondo argomento, X è G-misurabile, eG, G ′ sono σ-algebre indipendenti.
Proposizione 18 Dato uno spazio probabilizzato (Ω,F , P ) ed uno spazio misurabile(E, E), siano G ⊂ F e G ′⊂ F due σ-algebre indipendenti. Sia ϕ : (E × Ω, E ⊗ G ′) →(R,B (R)) misurabile limitata e sia X : (Ω,G)→ (E, E) misurabile. Allora
E [ϕ (X, ·) |G] = Φ (X)
dove Φ è definita daΦ (x) := E [ϕ (x, ·)] , x ∈ E.
Proof. Supponiamo ϕ a variabili separate, ϕ (x, ω) = ϕ1 (x)ϕ2 (ω), con ϕ1 : (E, E)→(R,B (R)), ϕ2 : (Ω,G ′)→ (R,B (R)) misurabili limitate. Allora
E [ϕ (X, ·) |G] = E [ϕ1 (X)ϕ2 (·) |G] = ϕ1 (X)E [ϕ2 (·)]Φ (X) = E [ϕ (x, ·)]x=X = E [ϕ1 (x)ϕ2 (·)]x=X = ϕ1 (X)E [ϕ2 (·)]
quindi la formula è verificata. Per linearità, vale per combinazioni lineari di funzioniϕ della forma ϕ (x, ω) = ϕ1 (x)ϕ2 (ω). Si passa al caso generale per convergenzamonotona, usando la stabilità della speranza condizionale rispetto a tale convergenza.
Apparentemente potrebbe sembrare che, rimuovendo l’ipotesi che G ′ sia indipen-dente da G, ovvero prendendo una qualsiasi funzione ϕ : (E × Ω, E ⊗ F)→ (R,B (R))misurabile limitata, valga l’identità
E [ϕ (X, ·) |G] = E [ϕ (x, ·) |G] |x=X
di cui quella della proposizione è un caso particolare. Qui però si pone un problema diversioni: per ogni x la speranza condizionale E [ϕ (x, ·) |G] è definita a meno di insiemidi misura nulla e quindi la sostituzione E [ϕ (x, ·) |G] |x=X non ha un senso ovvio.Tra i risultati rilevanti citiamo anche il seguente. Se X è di quadrato integra-
bile, E [X|G] è la proiezione ortogonale di X sul sottospazio chiuso L2 (Ω,G, P ) diL2 (Ω,F , P ) (funzioni di quadrato integrabile misurabili rispetto a G e F rispettiva-mente).

1.4. SPERANZA CONDIZIONALE E PROBABILITÀ CONDIZIONALE 37
1.4.2 Probabilità condizionale
Sia (Ω,F , P ) uno spazio probabilizzato. Dati due eventi A,B ∈ F con P (B) > 0,chiamiamo probabilità condizionale di A sapendo B il numero
P (A|B) :=P (A ∩B)
P (B).
Data una partizione misurabile B1, ..., Bn di Ω, possiamo definire in numeriP (A|Bi) per tutti gli i = 1, ..., n tali che P (Bi) > 0. Potremmo dire che la famiglia dinumeri P (A|Bi) è la probabilità di A condizionata alla partizione B1, ..., Bn. Inanalogia col caso della speranza condizionale, potremmo codificare questa informazionenella funzione
n∑i=1
P (A|Bi) · 1Bi
(se per un certo i vale P (Bi) = 0, la funzione 1Bi è equivalente a quella nulla e quindipossiamo definire P (A|Bi) arbitrariamente). C’è quindi una funzione G-misurabile,P (A|G) :=
∑ni=1 P (A|Bi) · 1Bi , che racchiude le informazioni utili circa la probabilità
condizionale di A rispetto ai vari elementi della partizione B1, ..., Bn e quindi delleinformazioni contenute nella σ-algebra G.Tra l’altro, si noti che, sempre nel caso particolare di G generata da B1, ..., Bn,
valeE [1A|G] = P (A|G)
in quanto∫Bi
1AdP = P (A ∩Bi). Inoltre,
P (A) = E [P (A|G)]
o più in generale
P (A ∩B) =
∫B
P (A|G) dP
per ogni B ∈ G (si verifichino queste due identità). Queste ultime formule sono unariscrittura compatta dell’utilissima formula di fattorizzazione (o delle probabilità totali)
P (A) =n∑i=1
P (A|Bi)P (Bi)
e sua generalizazione a P (A ∩B).Possiamo estendere queste definizioni e proprietà al caso di una σ-algebra G ⊂ F
più generale, raggiungendo due livelli di generalizzazione.Innanzi tutto, data G ⊂ F qualsiasi, poniamo
P (A|G) := E [1A|G]

38 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
detta probabilità condizionale di A rispetto alla σ-algebra G. Quindi P (A|G), definitaa meno di P -equivalenza (o come classe di equivalenza), è una v.a. G-misurabile taleche ∫
B
P (A|G) dP =
∫B
1AdP = P (A ∩B)
per ogni B ∈ G. Questa identità, data ora per definizione, è una versione generalizzatadella formula di fattorizzazione. La probabilità condizionale di A rispetto ad una σ-algebra G è definita tramite la formula di fattorizzazione; o in altre parole, è quellav.a. che fa funzionare la formula di fattorizzazione anche nel caso non finito (cioè diuna σ-algebra generale invece che generata da una partizione finita). Questo è il primolivello.C’è poi un secondo livello, più complesso. Nasce dalla seguente domanda natu-
rale. Per ogni A ∈ F , P (A|G) è una classe di equivalenza, o comunque è definita ameno di insiemi trascurabili. Non ha senso fissare ω ∈ Ω e considerare la funzioneA 7−→ P (A|G) (ω). Possiamo scegliere un rappresentante P (A|G) da ciascuna classe
di equivalenza in modo che la funzione d’insieme A 7−→ P (A|G) (ω) sia una misura diprobabilità? Se prendiamo degli insiemi disgiunti A1, A2, ... ∈ F , nel senso delle classidi equivalenza (oppure quasi certamente per ogni scelta di rappresentanti) vale
P
(⋃i
Ai|G)
=∑i
P (Ai|G) .
Ma non possiamo sperare che valga per P (·|G) (ω), con ω fissato, senza operare unascelta molto oculata e non banale dei rappresentanti.
Definizione 6 Dati (Ω,F , P ) e G ⊂ F , chiamiamo versione regolare della probabilitàcondizionale rispetto a G una funzione (A, ω) 7−→ PG (A, ω), definita su F× Ω, con leseguenti proprietà:i) per P -q.o. ω, la funzione d’insieme A 7−→ PG (A, ω) è una misura di probabilità
su (Ω,F)ii) per ogni A ∈ F , la funzione ω 7−→ PG (A, ω) è misurabile ed appartiene alla
classe di equivalenza P (A|G).
Vale il seguente teorema non banale:
Teorema 3 Se (Ω, d) è uno spazio metrico completo e separabile (spazio polacco) edF = B (Ω), esiste sempre versione regolare della probabilità condizionale rispetto adogni G ⊂ B (Ω).
Per la versione regolare valgono, come sopra,
PG (A, ·) = E [1A|G]

1.5. PROPRIETÀ DI MARKOV 39∫B
PG (A, ·) dP = P (A ∩B)
per ogni A ∈ F , B ∈ G. In più però, possiamo definire integrali del tipo∫Ω
X (ω′)PG (dω′, ω)
con ω fissato ed X ad esempio limitata misurabile. Si può allora dimostrare che vale∫Ω
X (ω′)PG (dω′, ·) = E [X|G]
(nel senso che l’integrale a sinistra è un elemento della classe di equivalenza a destra).Questo inverte il procedimento visto sopra: a livello uno si può definire la probabil-ità condizionale a partire dalla speranza condizionale; a livello due si può definire lasperanza condizionale a partire da una versione regolare della probabilità condizionale.Concludiamo con alcune varianti dei concetti precedenti. Data una v.a. X su
(Ω,F , P ) ed un evento A ∈ F indichiamo con σ (X) la più piccola σ-algebra rispetto acui X è misurabile e con P (A|X) la v.a. P (A|σ (X)). Per un teorema di Doob, esisteuna funzione misurabile gA : R → R tale che P (A|X) = gA (X). A causa di questo,viene anche usata la notazione P (A|X = x) per intendere gA (x):
P (A|X = x) = gA (x) .
Ovviamente in generale P (X = x) non è positivo, per cui non sarebbe lecito definireP (A|X = x) come P (A ∩ X = x) /P (X = x).
1.5 Proprietà di Markov
La proprietà di Markov si può esprimere a vari livelli, sia per un singolo processostocastico, sia per una famiglia di processi, sia per una famiglia di misure di proba-bilità relativamente ad uno stesso processo. Inoltre si può riscrivere in innumerevolimodi. Infine, esiste la proprietà di Markov e quella di Markov forte. Illustriamo quiuna possibilità tra le tante, riservandoci in seguito di descrivere altri casi ed altreformulazioni.Sia X = (Xt)t≥0 un processo stocastico su (Ω,F , P ) a valori nello spazio misurabile
(E, E). Sia (Ft)t≥0 una filtrazione (qualsiasi) in (Ω,F , P ).
Definizione 7 Il processo X si dice di Markov se
E [ϕ (Xt+h) |Ft] = E [ϕ (Xt+h) |Xt] (1.7)
per ogni funzione ϕ : (E, E)→ (R,B (R)) misurabile limitata, ed ogni t ≥ 0, h > 0.

40 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
Proposizione 19 Chiedere l’uguaglianza E [ϕ (Xt+h) |Ft] = E [ϕ (Xt+h) |Xt] equivalesemplicemente a chiedere che E [ϕ (Xt+h) |Ft] sia σ (Xt)-misurabile. Inoltre, equivale achiedere che per ogni A ∈ E valga
P (Xt+h ∈ A|Ft) = P (Xt+h ∈ A|Xt) . (1.8)
Oppure, che per ogni A ∈ E la v.a. P (Xt+h ∈ A|Ft) sia σ (Xt)-misurabile.
Proof. Se vale l’identità (1.7), allora E [ϕ (Xt+h) |Ft] è σ (Xt)-misurabile. Viceversa,supponiamo che Y := E [ϕ (Xt+h) |Ft] sia σ (Xt)-misurabile. Dal momento che Ysoddisfa l’uguaglianza E [Y Z] = E [ϕ (Xt+h)Z] per ogni v.a. Z che sia Ft-misurabile,la soddisfa anche per tutte le v.a. Z che siano σ (Xt)-misurabili. Quindi Y è unasperanza condizionale di ϕ (Xt+h) sapendo Xt, ovvero vale (1.7).Infine, se vale (1.7), allora prendendo ϕ (x) = 1x∈A vale (1.8). Viceversa, se vale
(1.8) per ogni A ∈ E , vale (1.7) per le indicatrici ϕ (x) = 1x∈A e poi per linearità per leloro combinazioni lineari. Si passa alle funzioni misurabili limitate o con un teoremagenerale o con un esplicito passaggio al limite monotono (ogni funzione misurabile limi-tata è limite crescente puntuale di funzioni semplici; poi si usa la convergenza monotonadelle speranze condizionali). L’ultima affermazione si dimostra con ragionamenti simili.
La proprietà di Markov esprime il fatto che ciò che possiamo prevedere del futuroè influenzato in uguale misura dal presente come dal presente incluso il passato. Dettoaltrimenti, il passato non influisce sul futuro, noto il presente. Con un po’di pazienzasi possono dimostrare varie formulazioni equivalenti, alcune delle quali ad esempioenfatizzano il ruolo simmetrico del passato e del futuro. Ad esempio, vale:
Proposizione 20 Il processo X è di Markov se e solo se
E[Φ(X|[t,∞)
)Ψ(X|[0,t]
)|Xt
]= E
[Φ(X|[t,∞)
)]E[Ψ(X|[0,t]
)]per ogni coppia di funzioni Φ :
(E[0,∞), E [0,∞)
)→ (R,B (R)), Ψ :
(E[0,t], E [[0,t]
)→
(R,B (R)), misurabili limitate, ed ogni t ≥ 0.
Il futuro è indipendente dal passato, noto il presente.Una classe interessante di processi di Markov è quella dei processi a incrementi
indipendenti, che contiene processi di fondamentale importanza.
Definizione 8 Sia E uno spazio vettoriale. Diciamo che un processo stocastico X =(Xt)t≥0, rispetto ad una filtrazione (Ft)t≥0, ha incrementi indipendenti, se per ognit, h ≥ 0 la v.a. Xt+h −Xt è indipendente da Ft.
Proposizione 21 Un processo a incrementi indipendenti è di Markov.

1.5. PROPRIETÀ DI MARKOV 41
Proof. Applichiamo la Proposizione 18. Dati t, h ≥ 0, sia G ′=σ Xt+h −Xt, G = Ft.Le σ-algebre G e G ′ sono indipendenti. La v.a. Xt+h − Xt è G-misurabile. Pre-sa una funzione misurabile limitata ψ : (E, E) → (R,B (R)), vogliamo verificare cheE [ψ (Xt+h) |Ft] è σ Xt-misurabile. Scriviamo
E [ψ (Xt+h) |Ft] = E [ψ (Xt +Xt+h −Xt) |Ft]
e consideriamo la funzione ϕ (x, ω) = ψ (x+Xt+h (ω)−Xt (ω)). Essa è E⊗G ′-misurabile.Quindi sono soddisfatte tutte le ipotesi della Proposizione 18 (conX = Xt), che forniscel’identità
E [ψ (Xt +Xt+h −Xt) |Ft] = E [ϕ (x, ·)] |x=Xt .
Quindi E [ψ (Xt+h) |Ft] è σ Xt-misurabile. La dimostrazione è completa.Introduciamo ora un concetto collegato alla proprietà di Markov.
Definizione 9 Su uno spazio misurabile (E, E), diciamo che una funzione p (s, t, x, A),definita per t > s ≥ 0, x ∈ E, A ∈ E, è una funzione di transizione markoviana se:i) per ogni (s, t, A), x 7−→ p (s, t, x, A) è E-misurabileii) per ogni (s, t, x), A 7−→ p (s, t, x, A) è una misura di probabilità su (E, E)iii) vale l’equazione di Chapman-Kolmogorov
p (s, t, x, A) =
∫E
p (u, t, y, A) p (s, u, x, dy)
per ogni t > u > s ≥ 0, x ∈ E, A ∈ E.
Definizione 10 Data una funzione di transizione markoviana p ed una misura di prob-abilità µ0 su (E, E), diciamo che un processo stocastico X = (Xt)t≥0, rispetto ad unafiltrazione (Ft)t≥0 (su uno spazio probabilizzato (Ω,F , P )) è un processo di Markovassociato a p con legge iniziale µ0 se:i) X0 ha legge µ0
ii) per ogni t ≥ 0, h > 0, A ∈ E vale
P (Xt+h ∈ A|Ft) = p (t, t+ h,Xt, A) . (1.9)
Si noti che se un processo soddisfa le condizioni di quest’ultima definizione, alloraè di Markov, per la Proposizione 19. La definizione quindi arricchisce la proprietà diMarkov.Come sopra, la proprietà (1.9) è equivalente a
E [ϕ (Xt+h) |Ft] =
∫ϕ (y) p (t, t+ h,Xt, dy) (1.10)
per ogni ϕ misurabile limitata.

42 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
L’introduzione della funzione p (s, t, x, A) è concettualmente (ed anche tecnica-mente) un effettivo arricchimento. Essa corrisponde all’idea intuitiva che, ad ogniistante s ≥ 0, a causa della proprietà di Markov il processo “riparta”dalla posizionex occupata in quell’istante, scordandosi del passato. La posizione x al tempo s iden-tifica la probabilità p (s, t, x, A) di occupare una posizione in A in un generico istantesuccessivo t.Nascono due domande naturali:
1. dato un processo di Markov, esiste una funzione di transizione markoviana p adesso associata?
2. Data una funzione di transizione markoviana p ed una generica probabilità inizialeµ0, esiste un processo di Markov X ad esse associato?
La prima domanda è delicata per cui ci accontenteremo di verificare l’esistenza invari esempi o di supporla in certi teoremi.
Osservazione 10 Mostriamo alcuni passi nella direzione di una costruzione di p par-tendo da un processo di Markov. Se il processo X è definito su uno spazio (Ω,F , P )in cui Ω è metrico completo e separabile, F = B (Ω), presa la sotto-σ-algebra G = F s,esiste una versione regolare della probabilità condizionale di P rispetto a G, che in-dichiamo con Ps (A′, ω), A′ ∈ F , ω ∈ Ω. Essa soddisfa, oltre alla misurabilità rispettoa Fs ed all’essere una misura di probabilità rispetto ad A′,
Ps (A′, ·) = P (A′|Fs) .
Preso A′ della forma A′ = Xt ∈ A con A ∈ E, scriviamo
ρ (s, t, ω, A) := Ps (Xt ∈ A , ω) .
Questo soddisfa
ρ (s, t, ·, A) = P (Xt ∈ A|Fs) = P (Xt ∈ A|Xs)
dove abbiamo usato l’ipotesi di markovianità. La funzione A 7−→ ρ (s, t, ω, A) è unamisura di probabilità. Il problema è passare da ρ (s, t, ω, A), ω ∈ Ω, a p (s, t, x, A),x ∈ E.
La seconda domanda ha risposta affermativa in spazi degli stati σ-compatti. Premet-tiamo una proposizione che illustra come la conoscenza della funzione di transizionemarkoviana e della legge iniziale sono suffi cienti a identificare la legge di un processo,se si suppone che esso sia di Markov.

1.5. PROPRIETÀ DI MARKOV 43
Proposizione 22 Se X è un processo di Markov con funzione di transizione marko-viana p, allora, per ogni τ = (t1, ..., tn) ∈ S, A1, ..., An ∈ E, vale
P (Xtn ∈ A3, · · ·, Xt1 ∈ A1)∫A1
µt1 (dy1)
∫A2
p (t1, t2, y1, dy2) · · ·∫An
p (tn−1, tn, yn−1, dyn)
dove µt1 è la legge di Xt1.
Proof. Il caso n = 3 chiarisce completamente la dimostrazione, che va poi svolta perinduzione. Chi avesse visto la dimostrazione perle catene di Markov ne riconoscerebbela struttura, basata sulla disintegrazione rispetto all’ultimo istante di tempo. Vale
P (Xt3 ∈ A3, Xt2 ∈ A2, Xt1 ∈ A1) = E [1A3 (Xt3) 1A2 (Xt2) 1A1 (Xt1)]
= E [E [1A3 (Xt3) 1A2 (Xt2) 1A1 (Xt1) |Ft2 ]]= E [1A2 (Xt2) 1A1 (Xt1)E [1A3 (Xt3) |Ft2 ]]= E [1A2 (Xt2) 1A1 (Xt1) p (t2, t3, Xt2 , A3)] .
Analogamente, usando (1.9),
E [1A2 (Xt2) 1A1 (Xt1) p (t2, t3, Xt2 , A3)]
= E [E [1A2 (Xt2) 1A1 (Xt1) p (t2, t3, Xt2 , A3) |Ft1 ]]= E [1A1 (Xt1)E [1A2 (Xt2) p (t2, t3, Xt2 , A3) |Ft1 ]]
= E
[1A1 (Xt1)
∫1A2 (y) p (t2, t3, y, A3) p (t1, t2, Xt1 , dy)
]E
[1A1 (Xt1)
∫A2
p (t2, t3, y, A3) p (t1, t2, Xt1 , dy)
].
Infine, quest’ultima espressione si può riscrivere nella forma∫1A1 (y1)
∫A2
p (t2, t3, y2, A3) p (t1, t2, y1, dy2)µt1 (dy1)
=
∫A1
µt1 (dy1)
∫A2
p (t1, t2, y1, dy2)
∫A3
p (t2, t3, y2, dy3) .
Proposizione 23 Supponiamo E metrico σ-compatto. Date una funzione di tran-sizione markoviana p ed una generica probabilità iniziale µ0, esiste un processo diMarkov X ad esse associato, unico in legge.

44 CAPITOLO 1. INTRODUZIONE AI PROCESSI STOCASTICI
Proof. Diamo solo la traccia. Cerchiamo di usare il Teorema di Kolmogorov dicostruzione dei processi. Per far questo, dobbiamo costruire quelle che saranno ledistribuzioni di dimensione finita del processo. Sulla base della proposizione precedente,per ogni τ = (t1, ..., tn) ∈ S indichiamo con µτ la misura di probabilità su (En, En) taleche
µτ (A1 × ...× An) =
∫A1
µt1 (dy1)
∫A2
p (t1, t2, y1, dy2) · · ·∫An
p (tn−1, tn, yn−1, dyn) .
La consistenza si verifica immediatamente usando l’equazione di Chapman-Kolmogorov(si deve prendere Ai = E). Le altre proprietà richiedono un po’di lavoro che nonriportiamo.

Capitolo 2
Il moto browniano
2.1 Definizione, esistenza e proprietà di Markov
Definizione 11 Un moto browniano grossolano è un processo stocastico B = (Bt)t≥0
tale chei) P (Bt = 0) = 1ii) per ogni t > s ≥ 0, Bt −Bs è una gaussiana N (0, t− s)iii) per ogni n ∈ N ed ogni sequenza tn > ... > t1 ≥ 0, le v.a. Btn − Btn−1,
Btn−1 −Btn−2, ... , Bt2 −Bt1 sono indipendenti.Se aggiungiamo che sia continuo, lo chiameremo moto browniano perfezionato o
semplicemente moto browniano. La sua legge su (C[0,∞),B (C[0,∞))) sarà dettamisura di Wiener.
A causa della proprietà (i) si suole dire che è un moto browniano standard. Al-trimenti si può considerare il caso in cui il processo esca da un altro punto iniziale,diverso dallo zero.A volte è utile considerare il concetto di moto browniano rispetto ad una filtrazione
data.
Definizione 12 Un moto browniano, rispetto ad una filtrazione (Ft)t≥0, è un processostocastico B = (Bt)t≥0 tale chei) P (Bt = 0) = 1ii) è adattatoiii) per ogni t > s ≥ 0, Bt −Bs è una gaussiana N (0, t− s) indipendente da Fs.Se non imponiamo che sia continuo, lo diremo moto browniano grossolano, altri-
menti lo chiameremo moto browniano perfezionato o semplicemente moto browniano.
Proposizione 24 Se un processo soddisfa la definizione 12 (rispetto ad una filtrazionequalsiasi) allora soddisfa anche la definizione 11.
45

46 CAPITOLO 2. IL MOTO BROWNIANO
Proof. Supponiamo che valga la definizione 12. Presi tn > ... > t1 ≥ 0, osserviamoche gli incrementi Btn−1 −Btn−2 , ... , Bt2 −Bt1 sono misurabili rispetto a Ftn−1 , quindiBtn −Btn−1 è indipendente da essi:
P(Btn −Btn−1 ∈ An,
(Btn−1 −Btn−2 , ..., Bt2 −Bt1
)∈ A′
)= P
(Btn −Btn−1 ∈ An
)P((Btn−1 −Btn−2 , ..., Bt2 −Bt1
)∈ A′
)per ogni An ∈ B (R) ed A′ ∈ B (Rn−1). Questo vale in particolare per insiemi del tipoA′ = An−1 × · · · × A2 con Ai ∈ B (R). Basta poi iterare il ragionamento per ottenere
P(Btn −Btn−1 ∈ An, ..., Bt2 −Bt1 ∈ A2
)=
n∏i=2
P(Bti −Bti−1 ∈ Ai
)che è la condizione (iii) della definizione 11. Le altre proprietà sono ovvie.Per invertire l’enunciato, cioè per passare dalla definizione 11 alla 12, bisogna speci-
ficare una filtrazione. Iniziamo con quella naturale (F00t )t≥0 (F00
t è la più piccolaσ-algebra che rende misurabili tutte le v.a. Bs, con s ∈ [0, T ]).
Proposizione 25 Se un processo soddisfa la definizione 11 allora soddisfa la definizione12 rispetto alla filtrazione naturale (F00
t )t≥0.
Proof. Che sia adattato e valgano le prime prorietà è ovvio. Dobbiamo solo dimostrareche presi t > s ≥ 0, Bt−Bs è indipendente da F00
s . Ricordando il criterio dell’esercizio7, è suffi ciente dimostrare l’indipendenza tra σ (Bt −Bs) e gli elementi di una base diF00s . Prendiamo la famiglia A ⊂ F00
s degli eventi della forma Bu1 ∈ A1, ..., Bun ∈ Anal variare di u1 ≤ ... ≤ un ∈ [0, s], A1, ..., An ∈ B (R). Questa è una base, in quanto gen-era F00
s , è chiusa per intersezione finita, contiene Ω. Basta allora dimostrare l’indipen-denza tra σ (Bt −Bs) e gli elementi di A. Fissati u1 ≤ ... ≤ un ∈ [0, s], basta quindidimostrare l’indipendenza tra σ (Bt −Bs) e gli elementi di σ (Bu1 , Bu2 , ..., Bun). Le dueσ-algebre σ (Bu1 , Bu2 , ..., Bun) e σ
(Bu1 , Bu2 −Bu1 , ..., Bun −Bun−1
)coincidono (i vet-
tori (Bu1 , Bu2 , ..., Bun) e(Bu1 , Bu2 −Bu1 , ..., Bun −Bun−1
)sono legati da una trasfor-
mazione biunivoca). Quindi basta mostrare l’indipendenza tra σ (Bt −Bs) ed una basedi σ
(Bu1 , Bu2 −Bu1 , ..., Bun −Bun−1
), ad esempio quella formata dagli eventi della for-
maBu1 ∈ A1, Bu2 −Bu1 ∈ A2, ..., Bun −Bun−1 ∈ An
al variare di A1, ..., An ∈ B (R).
A questo punto la verifica è ovvia, basandoci sull’indipendenza delle v.a. Bt − Bs,Bs −Bun , Bun −Bun−1 , ... , Bu2 −Bu1 , Bu1 . La dimostrazione è completa.Facile è passare alla filtrazione completata F0
t :
Corollario 2 Se un processo soddisfa la definizione 11 allora soddisfa la definizione12 rispetto alla filtrazione naturale completata (F0
t )t≥0.
Proof. L’adattamento vale a maggior ragione e le altre prime proprietà sono ovvie. Ilpunto è solo accertarsi, aumentando la filtrazione, che l’indipendenza degli incrementi

2.1. DEFINIZIONE, ESISTENZA E PROPRIETÀ DI MARKOV 47
si mantenga. Dobbiamo verificare che, presi t > s ≥ 0, Bt − Bs è indipendente daF0s . Ma l’indipendenza tra σ-algebre non cambia se ad una si aggiungono gli eventitrascurabili (si verifica ad esempio usando il criterio dell’esercizio 7).Un po’meno ovvio è passare alla filtrazione cotinua a destra Ft:
Corollario 3 Se un processo soddisfa la definizione 11 allora soddisfa la definizione12 rispetto alla filtrazione naturale completata e continua a destra (Ft)t≥0.
Proof. Dobbiamo solo verificare che, presi t > s ≥ 0, Bt − Bs è indipendente da Fs.E’equivalente verificare che, preso A ∈ Fs e ϕ funzione continua e limitata, vale
E [ϕ (Bt −Bs) 1A] = E [ϕ (Bt −Bs)] · P (A) .
Vale A ∈⋂ε>0
F0s+ε. Quindi, fissato ε > 0 tale che s + ε < t, essendo A ∈ F0
s+ε e
Bt −Bs+ε indipendente da F0s+ε, vale
E [ϕ (Bt −Bs+ε) 1A] = E [ϕ (Bt −Bs+ε)] · P (A) .
Basta ora passare al limite per ε → 0, usando la continuità di B, di ϕ, la limitatezzadi ϕ ed il teorema di convergenza dominata.
Osservazione 11 Con più fatica si può dimostrare che
Ft = F0t
(quindi la dimostrazione precedente è superflua). Il completamento, come osservato inprecedenza, ingrandisce la filtrazione, ma (in questo caso) non l’operazione che la rendecontinua a destra.
Esistono numerose formulazioni equivalenti della definizione di moto browniano (siveda anche la sezione 2.1.1). Eccone una utile per la costruzione successiva.
Proposizione 26 Se B = (Bt)t≥0 è un moto browniano standard grossolano, presaτ = (t1, ..., tn) ∈ S, la distribuzione marginale µτ su (Rn,B (R)n) è una gaussiana dimedia nulla e matrice di covarianza Q(τ) di componenti
Q(τ)ij = ti ∧ tj.
Quindi B è un processo gaussiano, con funzione valor medio m (t) = 0 e funzione dicovarianza
C (t, s) = t ∧ s.Viceversa, un processo gaussiano con tali funzioni media e covarianza, è un motobrowniano grossolano.

48 CAPITOLO 2. IL MOTO BROWNIANO
Proof. Il vettore(Btn −Btn−1 , Btn−1 −Btn−2 , ..., Bt2 −Bt1 , Bt1
)è gaussiano (si noti
che possiamo scrivere Bt1 come Bt1 − B0). Infatti, ha componenti indipendenti egaussiane (in generale non sarebbe vero se le componenti non fossero indipendenti),quindi la densità congiunta si può scrivere come prodotto delle marginali, che essendogaussiane conducono con facili calcoli ad una densità congiunta gaussiana.Il vettore (Bt1 , ..., Btn) si ottiene dal precedente con una trasformazione lineare,
quindi è anch’esso gaussiano. La sua media è nulla (per verifica diretta). Calcoliamo lasua matrice di covarianza direttamente, piuttosto che con la regola di trasformazionecitata a suo tempo. Se j > i, quindi tj > ti, vale
Q(µ)ij = Cov
(Bti , Btj
)= Cov
(Bti , Btj −Bti
)+ Cov (Bti , Bti)
= Cov (Bti , Bti) = V ar [Bti ] = ti
per linearità della covarianza nei suoi argomenti, indipendenza tra Btj − Bti e Bti ed
altri fatti ovvi. Quindi Q(µ)ij = ti ∧ tj.
Viceversa, supponiamo che B sia un processo gaussiano con funzioni m (t) = 0 eC (t, s) = t∧s. Al tempo t = 0 abbiamo E [B0] = 0, V ar [B0] = C (0, 0) = 0, quindi B0
è una v.a. che vale 0 quasi certamente (ad esempio si deduce dalla disuguaglianza diChebyshev). Quindi la (i) è verificata. Il vettore (Bt1 , ..., Btn) è gaussiano. Usando latrasformazione inversa di quella usata nella prima parte della dimostrazione, si deduceche il vettore
(Btn −Btn−1 , Btn−1 −Btn−2 , ..., Bt2 −Bt1 , Bt1
)è gaussiano. La sua media
è nulla per verifica diretta. Gli elementi della sua matrice di covarianza valgono
Cov(Btn−i −Btn−i−1 , Btn−j −Btn−j−1
)= Cov
(Btn−i , Btn−j
)− Cov
(Btn−i , Btn−j−1
)− Cov
(Btn−i−1 , Btn−j
)+ Cov
(Btn−i−1 , Btn−j−1
)che, per i > j diventano (tn−i−1 < tn−i ≤ tn−j−1 < tn−j), usando la formulaCov (Bt, Bs) =t ∧ s,
= tn−i − tn−i − tn−i−1 + tn−i−1 = 0
mentre per i = j diventano (tn−i−1 = tn−j−1 < tn−i = tn−j)
= tn−i − tn−i−1 − tn−i−1 + tn−i−1 = tn−i − tn−i−1.
Quindi la covarianza è diagonale, cioè le componenti del vettore aleatorio sono scorre-late e questo implica che sono indipendenti, perché si tratta di un vettore gaussiano.Le componenti sono gli incrementi del moto browniano, che quindi sono indipendenti(proprietà (iii)), oltre che gaussiani. Vale infine la proprietà (ii): abbiamo già stabilitoche il generico incremento è gaussiano e centrato; vale poi, con gli stessi calcoli appenaeseguiti, per t > s ≥ 0,
V ar [Bt −Bs] = Cov (Bt, Bt)− Cov (Bt, Bs)− Cov (Bs, Bt) + Cov (Bs, Bs)
= t− s− s+ s = t− s.

2.1. DEFINIZIONE, ESISTENZA E PROPRIETÀ DI MARKOV 49
La dimostrazione è completa.Esistono numerose costruzioni di un moto browniano grossolano. Fatta la fatica
della proposizione precedente, per noi la strada più breve è basarsi sul teorema dicostruzione di Kolmogorov, nella sua applicazione generale ai processi gaussiani.
Proposizione 27 Un moto browniano grossolano esiste. La legge su(R[0,∞),B (R)[0,∞)
)è univocamente determinata.
Proof. La legge su(R[0,∞),B (R)[0,∞)
)è univocamente determinata dalle marginali,
che sono univocamente note in base al lemma precedente. Veniamo alla costruzione.Per l’esistenza, grazie alla Proposizione 26, basta che mostriamo l’esistenza di un
processo gaussiano conm (t) = 0 e C (t, s) = t∧s. Possiamo usare il criterio di esistenzadi processi gaussiani con funzioni m (t) e C (t, s) date. Per far questo, basta verificareche C (t, s) = t ∧ s sia una funzione semidefinita positiva, nel senso che valga
n∑i,j=1
(ti ∧ tj) ξiξj ≥ 0 (2.1)
per ogni (t1, ..., tn) ∈ [0,∞)n, (ξ1, ..., ξn) ∈ Rn. Il resto della dimostrazione si occupa diquesta verifica. Possiamo ad esempio usare i risultati della Sezione 1.2.1. Per curiositàillustriamo altri due metodi.Ispirandoci a quanto già scoperto sopra (Proposizione 26), possiamo mostrare che
esiste un vettore aleatorio con matrice di covarianza avente componenti ti∧ tj. Siccomeuna matrice di covarianza è semidefinita positiva, la proprietà (2.1) sarà dimostrata.Prendiamo delle v.a. X1, ..., Xn indipendenti, centrate e di varianze t1, t2 − t1, ..., tn −tn−1. Definiamo delle v.a. Y1, ..., Yn tramite le relazioni
X1 = Y1
X2 = Y2 − Y1
...
Xn = Yn − Yn−1
(relazioni chiaramente invertibili). Per ogni i = 2, ..., n, vale
Yi = Yi − Yi−1 + ...+ Y2 − Y1 + Y1 = Xi + ...+X2 +X1
quindi
V ar [Yi] = V ar [Xi] + ...+ V ar [X1] = ti − ti−1 + ...+ t2 − t1 + t1 = ti
ovveroCov (Yi, Yi) = ti = ti ∧ ti.

50 CAPITOLO 2. IL MOTO BROWNIANO
Inoltre, se j > i, per ragioni analoghe (essendo cioè Yi = Xi + ... + X2 + X1), le v.a.Xj, Xj−1..., Xi+1 sono indipendenti da Yi, quindi
Cov (Yj, Yi) = Cov (Yj − Yj−1 + ...+ Yi+1 − Yi + Yi, Yi)
= Cov (Xj + ...+Xi+1 + Yi, Yi)
= Cov (Yi, Yi) = ti = ti ∧ tj.
Quindi la matrice di covarianza di (Y1, ..., Yn) ha le componenti desiderate. Questoconclude la dimostrazione.Volendo si possono perseguire dimostrazioni più algebriche, o ragionando sui minori
della matrice, oppure verificando la condizione (2.1) per n basso e trovando poi unastruttura iterativa. Per n = 2 vale
2∑i,j=1
(ti ∧ tj) ξiξj = t1 (ξ1 + ξ2)2 + (t2 − t1) ξ22
mentre per n = 3 vale
3∑i,j=1
(ti ∧ tj) ξiξj = t1 (ξ1 + ξ2 + ξ3)2
+ (t2 − t1) ξ22 + 2 (t2 − t1) ξ2ξ3 + (t3 − t1) ξ2
3
dove la somma degli ultimi tre termini è simile al punto di partenza del caso n = 2. Civuole però molta pazienza a completare il conto in questo modo. La dimostrazione ècompleta.Esaminiamo ora l’esistenza di un moto browniano continuo. Premettiamo il seguente
teorema che non dimostriamo in quanto ha fatto parte di un corso precedente. E’dettoteorema di regolarità di Kolmogorov.
Teorema 4 Se un processo stocastico X = (Xt)t∈D definito in un aperto D ⊂ Rnsoddisfa
E [|Xt −Xs|p] ≤ C |t− s|n+α
per certe costanti p, C, α > 0, allora esiste una modificazione X ′t di Xt tale che letraiettorie di X ′t sono γ-hölderiane per ogni γ <
αp.
Proposizione 28 Esiste un moto browniano continuo e le sue traiettorie sono α-hölderiane, per ogni α ∈ (0, 1/2). Precisamente, per ogni T > 0 ed ogni α ∈ (0, 1/2)esiste una funzione CT,α : Ω→ (0,∞) tale che
|Bt (ω)−Bs (ω)| ≤ CT,α (ω) |t− s|α per ogni t, s ∈ [0, T ] ed ogni ω ∈ Ω.

2.1. DEFINIZIONE, ESISTENZA E PROPRIETÀ DI MARKOV 51
Proof. Sia B un moto browniano grossolano. La v.a. Bt−Bs√t−s (per t > s) è una normale
standard. Fissiamo n ∈ N, diciamo n > 2. Siccome∫ +∞−∞ |x|
n e−x2/2dx <∞, esiste una
costante Cn > 0 tale che
E
[∣∣∣∣Bt −Bs√t− s
∣∣∣∣n] ≤ Cn
e quindiE [|Bt −Bs|n] ≤ Cn (t− s)n/2 = Cn (t− s)1+n−2
2 .
La costante Cn non dipende da t > s ≥ 0. In base al teorema di regolarità di Kol-mogorov, esiste una modificazione B(n)
t di Bt tale che le traiettorie di B(n)t sono γ-
hölderiane per ogni γ <n−22
n= n−2
2n. Innanzi tutto, preso ad es. n = 3, questo dimostra
l’esistenza di un moto browniano continuo: infatti B(3)t è un processo continuo che
soddisfa le proprietà (i) ed (ii) della definizione 11; anche la (iii) è facile, usando l’e-sercizio 8. Quindi B(3)
t è un moto browniano continuo. Prendiamo ora B(n)t , con n > 3
qualsiasi. E’una modificazione continua di Bt, quindi anche di B(3)t . Ma due processi
X ed Y continui che sono modificazione uno dell’altro sono indistinguibili: numeratii tempi positivi razionali con la successione tn, posto Nn = Xtn 6= Ytn, l’insiemeN = ∪nNn ha misura nulla, per ω ∈ N c vale Xt (ω) = Yt (ω) per ogni t ∈ Q∩ [0,∞), equindi per ogni t ≥ 0 essendo processi continui.Abbiamo così dimostrato che B(n)
t è indistinguibile da B(3)t . Sia Nn l’insieme dove
differiscono, di misura nulla. Sia N = ∪nNn, di misura nulla. Per ω ∈ N c, B(3)t ha la
regolarità delle traiettorie di qualsiasi B(n)t , quindi γ-hölderiane per ogni γ < n−2
2n, con
n qualsiasi, quindi γ-hölderiane per ogni γ < 12. Abbiamo trovato un moto browniano
che quasi certamente ha traiettorie γ-hölderiane per ogni γ < 12. Sull’insieme di misura
nulla in cui questo non accade possiamo porlo identicamente uguale a zero. Il nuovoprocesso soddisfa le condizioni della proposizione.
Proposizione 29 Il moto browniano (anche grossolano) è un processo di Markov.
Proof. Basta applicare una proposizione vista nel paragrafo dei processi di Markov cheasserisce che ogni processo a incrementi indipendenti è di Markov. Il moto brownianoha infatti incrementi indipendenti.
Esercizio 7 Sia (Ω,F , P ) uno spazio probabilizzato. Ricordiamo che un insieme digeneratori di F è una famiglia H ⊂ P (Ω) tale che F =σ (H). Invece una base di F èun insieme di generatori chiuso per intersezione finita e contenente Ω (o almeno taleche l’unione numerabile di opportuni elementi di H sia Ω). Ricordiamo ad esempioche due misure coincidenti su una base coincidono su tutta la σ-algebra. Ricordiamopoi che due sotto σ-algebre G, G ′ di F si dicono indipendenti se vale P (A ∩B) =P (A)P (B) per ogni A ∈ G, B ∈ G ′. Sia H una base di G ′. Mostrare che, se valeP (A ∩B) = P (A)P (B) per ogni A ∈ G, B ∈ H, allora G e G ′, sono indipendenti.

52 CAPITOLO 2. IL MOTO BROWNIANO
[Verificare che l’insieme di tutti gli elementi B ∈ F tali che P (A ∩B) = P (A)P (B)per ogni A ∈ G, è una σ-algebra.]
Esercizio 8 Verificare che se X1, ..., Xn sono v.a. indipendenti, e X ′1, ..., X′n sono P -
equivalenti alle X1, ..., Xn rispettivamente, allora le v.a. X ′1, ..., X′n sono indipendenti.
[Preso A1 ∈ B (R), esistono due insiemi N1, N′1 di misura nulla tali che X ′1 ∈ A1 ∪
N ′1 = X1 ∈ A1 ∪N1.]
2.1.1 Una motivazione modellistica
Brown osservò che particelle molto leggere ma visibili (tipo polline) messe in sospen-sione in un liquido si muovono incessantemente e molto irregolarmente. Chiamiamoleparticelle browniane. La spiegazione del loro moto, così erratico, è che le particellebrowniane risentono degli innumerevoli urti molecolari delle molecole del fluido e sispostano in conseguenza di essi.Alcuni studiosi (Ornstein, Uhlenbeck, Chandrasekar ecc.) hanno dato una de-
scrizione tramite equazioni di Newton, molto realistica. Adottiamo invece una de-scrizione più fenomenologica, basata più su argomenti ragionevoli e semplici piuttostoche su un dettagliato bilancio di forze.Sia Xt la posizione al tempo t della particella browniana. Per semplicità supponi-
amola uni-dimensionale (oppure descriviamo una delle due componenti). La traiettoriat 7−→ Xt è continua. Gli spostamenti Xtn−Xtn−1 , Xtn−1−Xtn−2 , ... , Xt2−Xt1 relativia intervalli temporali disgiunti si possono considerare ragionevolmente indipendenti,visto che gli innumerevoli urti in ciascun intervallo [ti−1, ti] sono relativi a molecole di-verse. Lo spostamento Xt+h −Xt ha ragionevolmente una legge statistica che dipendesolo da h e non da t. Possiamo inoltre supporre che i momenti di Xt+h − Xt sianofiniti, ad esempio fino all’ordine 3 (questa è una condizione puramente tecnica), perh piccolo, senza violare così l’intuizione fisica (non ci aspettiamo spostamenti troppograndi, mediamente); e che abbia media nulla. Infine, poniamo la particella borwniananell’origine, al tempo t = 0.Tra queste, l’unica ipotesi che è un’idealizzazione della realtà è quella di indipen-
denza, ma sembra molto vicina al reale. Si noti che non abbiamo ipotizzato nulla diquantitativo circa la legge (es. gaussiana) e la dipendenza della varianza da h.Supponiamo quindi di avere un processo stocastico Xt tale che:i) P (Xt = 0) = 1, Xt ha traiettorie continueii) Xtn − Xtn−1 , Xtn−1 − Xtn−2 , ... , Xt2 − Xt1 sono v.a. indipendenti, per ogni
tn ≥ tn−1 ≥ ... ≥ t1 ≥ 0
iii) la legge di Xt+h −Xt dipende solo da h, ha media zero, ed esiste una costanteC > 0 tale che E
[|Xh|3
]≤ C per h suffi cientemente piccolo.
Un simile processo è unico, è cioè univocamente identificato da questi requisiti? Sipuò precisare la distribuzione statistica degli incrementi, o si può calcolare quella della

2.2. REGOLARITÀ DEL MOTO BROWNIANO 53
posizione Xt? La risposta è affermativa. Omettiamo la dimostrazione completa delteorema che richiede alcuni argomenti un po’tecnici sulle funzioni caratteristiche.
Teorema 5 La varianza di Xt è finita per ogni t. Supponendo (per fissare un’unità dimisura) che V ar [X1] = 1, X è una moto browniano.
Proof. Fissato t > 0, preso n ∈ N e detto h = tn, vale
Xt =(Xt −Xn−1
nt
)+ ...+
(X 2
nt −X 1
nt
)+(X 1
nt −X0
).
Le v.a. tra parentesi sono indipendenti ed hanno varianza finita (almeno se n è grande)per cui Xt ha varianza finita. Fissiamo la scala ponendo V ar [X1] = 1.Mostriamo che V ar [Xt] = t per ogni t razionale positivo. Se t = n
mcon n,m
interi positivi, vale Xt =(Xn/m −X(n−1)/m
)+ ...+
(X1/m −X0
), quindi V ar
[Xn/m
]=
nV ar[X1/m
]. La relazione vale anche per n = m, quindi 1 = mV ar
[X1/m
]. Vale
quindiV ar
[X n
m
]=
n
m.
Per l’ipotesi sul momento terzo e la continuità delle traiettorie, possiamo applicare ilcriterio di passaggio al limite in valore atteso di Vitali e dedurre V ar [Xt] = t perogni t ≥ 0. Questa dimostrazione si può ripetere per il generico incremento Xt − Xs
provando che V ar [Xt −Xs] = t− s per ogni t > s ≥ 0.Manca solo la gaussianità di Xt − Xs, per aver verificato tutte le condizioni di
un moto browniano. La gaussianità si dimostra nello stesso modo del teorema limitecentrale, ma facendo entrare in gioco la continuità delle traiettorie. Questa parte èpiuttosto tecnica e la omettiamo.
2.2 Regolarità del moto browniano
2.2.1 Diffi coltà ad usare il MB come integratore
Nei capitoli successivi saremo interessati ad integrali del tipo∫ t
0
XsdBs
dove B è un moto browniano. Come potrebbe essere definito questo integrale? Elenchi-amo alcune possibilità (nessuna funzionante), in ordine di diffi coltà.1. Se le traiettorie del MB fossero funzioni differenziabili, e la derivata dBs(ω)
dsavesse
un minimo di integrabilità, potremmo definire l’integrale precedente in modo ovvio,come
∫ t0Xs (ω) dBs(ω)
dsds. Invece il MB ha traiettorie che, q.c., non sono differenziabili
in alcun punto. Questa proprietà è così speciale che la dimostreremo in dettaglio nelseguito del capitolo.

54 CAPITOLO 2. IL MOTO BROWNIANO
2. Un’apparente ancora di salvezza sembra venire da un ragionamento semplicissi-mo. Se X è suffi cientemente regolare, possiamo definire∫ t
0
Xs (ω) dBs (ω) = [Xs (ω)Bs (ω)]s=ts=0 −∫ t
0
Bs (ω) dXs (ω)
cioè scaricare il problema della regolarità su X. Basta ad esempio che X abbia traiet-torie a variazione limitata. Ma questo, pur vero, è troppo restrittivo per i nostri scopi.Infatti, il caso per noi di maggior interesse sarà quello di integrali del tipo∫ t
0
f (Xs) dBs
dove f è regolare ed X risolve un’equazione differenziale contenente B, e fatta in modoche la (poca) regolarità delle traiettorie di X sia simile a quella di B (si immagini adesempio un’equazione della forma Xt = Bt + At, dove A è un processo con traiettoriemolto regolari). Allora X non ha traiettorie a variazione limitata, come non le ha B,e quindi il trucchetto di integrare per parti non si può applicare.3. Se le traiettorie di B fossero funzioni a variazione limitata (ricorderemo tra
poco cosa questo significhi), allora potremmo definire∫ t
0Xs (ω) dBs (ω) per q.o. ω,
per processi X opportuni, come integrale di Lebesgue-Stieltjes. Ma questo non è vero,le traiettorie di B non sono a variazione limitata, come dimostreremo poco sotto nelcapitolo. La derivata delle traiettorie browniane dBs (ω) /ds non è una misura, è solouna distribuzione di classe meno regolare e non utile per effettuare integrazioni.4. Esiste poi un concetto di integrale secondo Young che si applicherebbe se B· (ω)
fosse di classe Cα ([a, b]) con α > 12(funzioni hölderiane di ordine α), cosa non vera,
come vedremo sotto. E’una teoria utile ad esempio per integrare rispetto a variantidel MB come il moto browniano frazionario con indice di Hurst H > 1
2.
5. In conclusione, serve un concetto nuovo di integrale, detto integrale secondo Itô,di cui ci occuperemo in un capitolo successivo. Va detto che in anni recenti è statasviluppata la teoria dell’integrazione dei rough paths, che, entro certi limiti e con molteprecisazioni piuttosto complesse, permette di integrare rispetto a traiettorie browniane,senza bisogno della teoria di Itô. Sia per la complessità, sia per le limitazioni, non harimpiazzato la teoria di Itô, per gli usuali scopi di questa teoria. E’invece risultatautile per scopi particolari ed è attualmente in grande evoluzione.
2.2.2 Commenti sulle funzioni a variazione limitata
Consideriamo funzioni f : [a, b] → R. Usiamo le seguenti notazioni: indichiamouna generica partizione di [a, b] con π = a ≤ t1 < ... < tnπ ≤ b e scriviamo |π| =maxi=1,...,nπ−1 |ti+1 − ti|.

2.2. REGOLARITÀ DEL MOTO BROWNIANO 55
Una funzione f : [a, b]→ R si dice a variazione limitata, e scriviamo f ∈ BV [a, b],se
supπ
nπ−1∑i=1
|f (ti+1)− f (ti)| <∞.
Se f ∈ BV [a, b] e g ∈ C ([a, b]) allora, presa una successione πkk∈N di partizioni di[a, b], con limk→∞ |πk| = 0, della forma πk =
a ≤ tk1 < ... < tknπk
≤ b, esiste il limite
lim|π|→0
nπk−1∑i=1
g (ξi)(f(tki+1
)− f
(tki))
per ogni scelta di ξi ∈[tki , t
ki+1
], indicato con
∫ bagdf e chiamato integrale di Riemann-
Stieltjes. Tale integrale si estende poi ad altre funzioni, in particolare nella direzionedell’integrazione di Lebesgue, ma sostanzialmente serve sempre l’ipotesi che f siaBV [a, b].Useremo poco più tardi la seguente proposizione. A parole, potremmo dire che
se la variazione quadratica è non nulla, allora la funzione non è a variazione limitata.Indichiamo inoltre con Cα ([a, b]) lo spazio delle funzioni hölderiane di ordine α ∈ (0, 1).
Proposizione 30 Sia f una funzione continua e sia πkk∈N una successione di par-tizioni di [a, b], con limk→∞ |πk| = 0, della forma πk =
a ≤ tk1 < ... < tknπk
≤ b.
Se
limk→∞
nπk−1∑i=1
∣∣f (tki+1
)− f
(tki)∣∣2 > 0
allora f non è di classe BV [a, b]. Non è nemmeno di classe Cα ([a, b]) per qualcheα ∈
(12, 1). In altre parole, se f è una funzione continua BV, oppure Cα ([a, b]) per
qualche α ∈(
12, 1), allora limk→∞
∑nπk−1
i=1
∣∣f (tki+1
)− f
(tki)∣∣2 = 0.
Proof. Osserviamo che vale
nπk−1∑i=1
∣∣f (tki+1
)− f
(tki)∣∣2 ≤ nπk−1∑
i=1
∣∣f (tki+1
)− f
(tki)∣∣ ( max
i=1,...,nπk−1
∣∣f (tki+1
)− f
(tki)∣∣)
≤ ω (f, πk) · supπ
nπ−1∑i=1
|f (ti+1)− f (ti)|
dove ω (f, πk), oscillazione di f su πk, è definita da
ω (f, πk) = maxi=1,...,nπk−1
∣∣f (tki+1
)− f
(tki)∣∣ .

56 CAPITOLO 2. IL MOTO BROWNIANO
Vale limk→∞ ω (f, πk) = 0, essendo f uniformemente continua su [a, b]. Se per assurdofosse f ∈ BV [a, b], allora dedurremmo limk→∞
∑nπk−1
i=1
∣∣f (tki+1
)− f
(tki)∣∣2 = 0, in
contraddizione con l’ipotesi. Quindi f /∈ BV [a, b].Se per assurdo fosse f ∈ Cα ([a, b]) per un qualche α ∈
(12, 1), cioè se relativamente
ad una costante C > 0 valesse
|f (t)− f (s)| ≤ C |t− s|α , t, s ∈ [a, b]
alloranπk−1∑i=1
∣∣f (tki+1
)− f
(tki)∣∣2 ≤ C
nπk−1∑i=1
∣∣tki+1 − tki∣∣2α = C
nπk−1∑i=1
∣∣tki+1 − tki∣∣ ∣∣tki+1 − tki
∣∣2α−1
≤ C
nπk−1∑i=1
∣∣tki+1 − tki∣∣ |πk|2α−1 = C (b− a) |πk|2α−1
da cui dedurremmo dedurremmo limk→∞∑nπk−1
i=1
∣∣f (tki+1
)− f
(tki)∣∣2 = 0, in contrad-
dizione con l’ipotesi. La dimostrazione è completa.
2.2.3 Variazione quadratica del MB e variazione non limitata
Teorema 6 Sia B un moto browniano (continuo) e sia T > 0. Sia πkk∈N una succes-sione di partizioni di [0, T ], con limk→∞ |πk| = 0, della forma πk =
0 = tk1 < ... < tknπk
= T.
Allora
limk→∞
E
nπk−1∑i=1
∣∣∣Btki+1−Btki
∣∣∣2 − T2 = 0
e∑nπk−1
i=1
∣∣∣Btki+1−Btki
∣∣∣2 converge a T in probabilità. Ne discende che, q.c., le traiettoriebrowniane non sono di classe BV [0, T ] e non appartengono ad alcun Cα ([a, b]) perα ∈
(12, 1).
Proof. La v.a.Btki+1−B
tki√
tki+1−tkiè N (0, 1), quindi la v.a. Yk,i =
∣∣∣∣Btki+1−B
tki
∣∣∣∣2tki+1−tki
ha legge in-
dipendente da k ed i. Inoltre, fissato k, le v.a. Yk,1, ..., Yk,nπk−1 sono indipendenti.Pertanto
E
nπk−1∑i=1
∣∣∣Btki+1−Btki
∣∣∣2 − T2 = E
nπk−1∑i=1
Yk,i(tki+1 − tki
)− T
2= E
nπk−1∑i=1
(Yk,i − 1)(tki+1 − tki
)2

2.2. REGOLARITÀ DEL MOTO BROWNIANO 57
= E
nπk−1∑i,j=1
(Yk,i − 1) (Yk,j − 1)(tki+1 − tki
) (tkj+1 − tkj
)=
nπk−1∑i,j=1
(tki+1 − tki
) (tkj+1 − tkj
)E [(Yk,i − 1) (Yk,j − 1)] .
I termini con i 6= j sono nulli: per l’indipendenza
E [(Yk,i − 1) (Yk,j − 1)] = E [Yk,i − 1]E [Yk,j − 1]
e ciascun fattore è nullo:
E [Yk,i − 1] = E [Yk,i]− 1 =1
tki+1 − tkiE
[∣∣∣Btki+1−Btki
∣∣∣2]− 1 = 0.
Quindi
E
nπk−1∑i=1
∣∣∣Btki+1−Btki
∣∣∣2 − T2 =
nπk−1∑i=1
(tki+1 − tki
)2E[(Yk,i − 1)2]
= C
nπk−1∑i=1
(tki+1 − tki
)2
dove C = E[(Yk,1 − 1)2] (finita perché le v.a. gaussiane hanno momenti di ogni ordine
finiti)
≤ C |πk|nπk−1∑i=1
(tki+1 − tki
)= C |πk|T
da cui la convergenza in media quadratica, e da essa la convergenza in probabilità per illemma di Chebyshev. Infine, da queste convergenze discende la convergenza quasi certadi una sottosuccessione; ma allora vale (per le partizioni di quella sottosuccessione)l’ipotesi della Proposizione 30, da cui il fatto che le traiettorie non sono BV [0, T ], conprobabilità uno.
Esercizio 9 Semplificare la dimostrazione precedente usando il fatto che la varianzadella somma di v.a. indipendenti è la somma delle varianze.
Esercizio 10 Mostrare che lungo le partizioni diadiche vale la convergenza quasi certa
di∑nπk−1
i=1
∣∣∣Btki+1−Btki
∣∣∣2 a T .

58 CAPITOLO 2. IL MOTO BROWNIANO
2.2.4 Non differenziabilità
Per capire la dimostrazione della non differenziabilità, affrontiamo prima un problemapiù semplice: la non differenziabilità in un punto prefissato.
Proposizione 31 Dato t0 ≥ 0, q.c. le traiettorie di un moto browniano non sonodifferenziabili in t0. Detto più formalmente,
P
(ω ∈ Ω : lim
h→0
Bt0+h (ω)−Bt0 (ω)
hesiste finito
)= 0.
Proof. Per ogni R > 0, sia NR l’evento
NR =
ω ∈ Ω : l (ω) := lim
h→0
Bt0+h (ω)−Bt0 (ω)
hesiste, |l (ω)| ≤ R
.
Vogliamo dimostrare che P (NR) = 0 (dall’arbitrarietà di R segue la tesi della propo-sizione). Come osservazione generale, se per un evento N abbiamo N ⊂ ∪k≥0 ∩n≥k Ane vale limn→∞ P (An) = 0, allora P (N) = 0. Infatti, N ⊂ ∪k≥0Nk con Nk = ∩n≥kAn;quindi Nk ⊂ An per ogni n ≥ k, da cui segue P (Nk) ≤ infn≥k P (An) = 0; questoimplica infine P (N) = 0.Premettiamo un facile fatto di analisi. Se l (ω) := limh→0
Bt0+h(ω)−Bt0 (ω)
hesiste, con
|l (ω)| ≤ R, allora esiste δ (ω) > 0 tale che per ogni h con |h| ≤ δ (ω) vale
|Bt0+h (ω)−Bt0 (ω)| ≤ (R + 1) |h| .
Infatti, per definizione di limite, (preso ε = 1) esiste δ (ω) > 0 tale che per ogni h con|h| ≤ δ (ω) vale l (ω)−1 ≤ Bt0+h(ω)−Bt0 (ω)
h≤ l (ω)+1, da cui −R−1 ≤ Bt0+h(ω)−Bt0 (ω)
h≤
R + 1, da cui |Bt0+h (ω)−Bt0 (ω)| ≤ (R + 1) |h|.In particolare, esiste k (ω) > 0 tale che per ogni n con n ≥ k (ω) vale∣∣∣Bt0+ 1
n(ω)−Bt0 (ω)
∣∣∣ ≤ R + 1
n.
Quindi
NR ⊂ ∪k≥0 ∩n≥k A(R)k,n
A(R)n : =
ω ∈ Ω :
∣∣∣Bt0+ 1n
(ω)−Bt0 (ω)∣∣∣ ≤ R + 1
n
.
Ma
P(A(R)n
)= P
(∣∣∣Bt0+ 1n−Bt0
∣∣∣ ≤ R + 1
n
)= P
(∣∣∣∣∣Bt0+ 1n−Bt0√
1/n
∣∣∣∣∣ ≤ R + 1√n
)= P
(|Z| ≤ R + 1√
n
)

2.2. REGOLARITÀ DEL MOTO BROWNIANO 59
dove Z è unaN (0, 1). Si verifica facilmente che limn→∞ P(A
(R)n
)= 0, quindi P (NR) =
0. La dimostrazione è completa.
Esercizio 11 Compattare la dimostrazione precedente usando il lemma di Borel-Cantelli.
Corollario 4 Dato un insieme numerabile D ⊂ [0,∞), q.c. le traiettorie di un motobrowniano non sono differenziabili in alcun punto di D:
P
(ω ∈ Ω : esiste t0 ∈ D tale che lim
h→0
Bt0+h (ω)−Bt0 (ω)
hesiste finito
)= 0.
Proof. Detto Nt0 l’insieme di misura nulla della proposizione precedente e detto NDquello di questo corollario, vale
ND = ∪t0∈DNt0
da cui discende subito la tesi.
Teorema 7 Sia B un moto browniano. Allora
P
(ω ∈ Ω : esiste t0 ∈ [0,∞) tale che lim
h→0
Bt0+h (ω)−Bt0 (ω)
hesiste finito
)= 0.
Proof. Dati R > 0, k ∈ N, sia NR,k l’insieme degli ω ∈ Ω tali che la funzionet 7−→ Bt (ω) è differenziabile almeno in un punto t0 ∈ [k, k + 1] con derivata in modulonon superiore ad R. Basta verificare che P (NR,k) = 0 per ogni R > 0, k ∈ N. Si capisceche se lo dimostriamo per k = 0, il caso generale sarà uguale. Quindi dimostriamoP (NR) = 0 dove
NR =
ω ∈ Ω : esiste t0 ∈ [0, 1] tale che esiste lim
h→0
Bt0+h (ω)−Bt0 (ω)
h∈ [−R,R]
.
Volendo ricalcare la dimostrazione vista sopra, si deve cercare di esprimere NR
tramite unioni ed intersezioni numerabili riconducendosi ad insiemi più elementariaventi probabilità molto piccola. Ma qui la prima diffi coltà è che la condizione “dif-ferenziabile almeno in un punto” coinvolge a priori l’unione più che numerabile dieventi. Cerchiamo allora di dedurre, dalla condizione che definisce NR, una condizioneesprimibile in modo numerabile.Abbiamo già verificato nella dimostrazione della Proposizione 31 che, se Bt (ω) è
differenziabile in t0 con derivata in modulo non superiore ad R, allora esiste δ (ω) > 0tale che |Bt0+h (ω)−Bt0 (ω)| ≤ (R + 1)h per ogni h ∈ [0, δ (ω)]. Allora, posto
AM,δ := ω ∈ Ω : esiste t0 ∈ [0, 1] tale che |Bt0+h (ω)−Bt0 (ω)| ≤Mh per ogni h ∈ [0, δ]

60 CAPITOLO 2. IL MOTO BROWNIANO
valeNR ⊂
⋃δ>0
AR+1,δ.
Ma vale anche⋃δ>0
AR+1,δ =⋃n∈N
AR+1,1/n, quindi se dimostriamo che P (AM,δ) = 0 per
ogni M > 0, δ > 0, possiamo dedurre P (NR) = 0 per ogni R > 0. Mostriamo quindiche P (AM,δ) = 0.Per inquadrare i calcoli che seguono, può essere utile introdurre anche gli eventi
(fissato t0 ∈ [0, 1])
AM,δ,t0 := ω ∈ Ω : |Bt0+h (ω)−Bt0 (ω)| ≤Mh per ogni h ∈ [0, δ] .
Vale AM,δ =⋃
t0∈[0,1]
AM,δ,t0 ma, come già osservato, si tratta di un’unione più che
numerabile.Tuttavia, per ogni n tale che 2
2n< δ, e per ogni t0 ∈ [0, 1], vale
AM,δ,t0 ⊂ DM,n,k(t0) ⊂⋃
k=0,...,2n
DM,n,k
dove
DM,n,k :=
ω ∈ Ω :
∣∣∣B k+12n
(ω)−B k2n
(ω)∣∣∣ ≤ 3M
2n
e k (t0) è il valore in 0, ..., 2n per cui k(t0)−1
2n< t0 ≤ k(t0)
2n. Infatti, se ω ∈ AM,δ,t0 ,
vale |Bt0+h (ω)−Bt0 (ω)| ≤ Mh per ogni h ∈ [0, δ]; quindi, osservando che grazie allacondizione 2
2n< δ i numeri k(t0)
2ne k+1
2nstanno in [t0, t0 + δ], e che k(t0)
2n− t0 ≤ 1
2ne
k(t0)+12n− t0 ≤ 2
2n, vale∣∣∣B k(t0)+1
2n(ω)−B k(t0)
2n(ω)∣∣∣ ≤ ∣∣∣B k(t0)
2n(ω)−Bt0 (ω)
∣∣∣+∣∣∣B k(t0)+1
2n(ω)−Bt0 (ω)
∣∣∣che per la condizione ω ∈ AM,δ,t0 risulta
≤M
((k (t0)
2n− t0
)+
(k (t0) + 1
2n− t0
))≤ 3M
2n.
L’inclusione AM,δ,t0 ⊂⋃
k=0,...,2n
DM,n,k così dimostrata vale per ogni t0 ∈ [0, 1] e l’evento
di destra non dipende da t0, quindi possiamo dire che AM,δ ⊂⋃
k=0,...,2n
DM,n,k. Siamo
riusciti a tradurre l’unione più che numerabile AM,δ in un’unione numerabile (conun’inclusione, non un’identità).

2.2. REGOLARITÀ DEL MOTO BROWNIANO 61
Purtroppo questa fatica non basta. Infatti
P
( ⋃k=0,...,2n
DM,n,k
)≤
2n∑k=0
P (DM,n,k) ≤2n∑k=0
C
√1
2n
che diverge, dove la disuguaglianza P (DM,n,k) ≤ C√
12nsi dimostra come descritto
sotto. Bisogna allora introdurre l’ultimo elemento non banale della dimostrazione.Per ogni n tale che 4
2n< δ, e per ogni t0 ∈ [0, 1], vale
AM,δ,t0 ⊂ DM,n,k(t0) ⊂⋃
k=0,...,2n
DM,n,k
dove
DM,n,k :=
∣∣∣B k+12n−B k
2n
∣∣∣ ≤ 3M
2n,∣∣∣B k+2
2n−B k+1
2n
∣∣∣ ≤ 5M
2n,∣∣∣B k+3
2n−B k+2
2n
∣∣∣ ≤ 7M
2n
.
Infatti, dalla condizione |Bt0+h −Bt0| ≤ Mh per ogni h ∈ [0, δ], osservando chek(t0)2n, k(t0)+1
2n, k(t0)+2
2n, k(t0)+3
2nstanno in [t0, t0 + δ], e che k(t0)+j
2n−t0 ≤ 1+j
2n, vale
∣∣∣B k(t0)+12n−B k(t0)
2n
∣∣∣ ≤3M2n(già dimostrato),∣∣∣B k(t0)+2
2n−B k(t0)+1
2n
∣∣∣ ≤ ∣∣∣B k(t0)+12n−Bt0
∣∣∣+∣∣∣B k(t0)+2
2n−Bt0
∣∣∣≤ M
((k (t0) + 1
2n− t0
)+
(k (t0) + 2
2n− t0
))≤ 5M
2n
ed analogamente∣∣∣B k(t0)+3
2n−B k(t0)+2
2n
∣∣∣ ≤ 7M2n. Quindi AM,δ ⊂
⋃k=0,...,2n
DM,n,k, per cui
P (AM,δ) ≤2n∑k=0
P(DM,n,k
).
Ora, per l’indipendenza degli incrementi vale
P(DM,n,k
)≤ P
(∣∣∣B k+12n−B k
2n
∣∣∣ ≤ 7M
2n
)P
(∣∣∣B k+22n−B k+1
2n
∣∣∣ ≤ 7M
2n
)P
(∣∣∣B k+32n−B k+2
2n
∣∣∣ ≤ 7M
2n
)= P
(|Z| ≤ 7M
√1
2n
)3
dove Z è una N (0, 1). Quindi
P (AM,δ) ≤2n∑k=0
P
(|Z| ≤ 7M
√1
2n
)3
= (2n + 1)P
(|Z| ≤ 7M
√1
2n
)3
.

62 CAPITOLO 2. IL MOTO BROWNIANO
Ricordiamo che questa disuguaglianza vale per ogni n tale che 42n
< δ. Usando ladensità gaussiana si verifica subito che
limn→∞
(2n + 1)P
(|Z| ≤ 7M
√1
2n
)3
≤ C limn→∞
(2n + 1)
(1
2n
)3/2
= 0
dove C =(
2π
)3/2(7M)3, in quanto P (|Z| ≤ r) ≤
√2πr per ogni r > 0 (basta osservare
che P (|Z| ≤ r) =∫ r−r
1√2π
exp(−x2
2
)dx ≤
∫ r−r
1√2πdx). Quindi P (AM,δ) = 0. La
dimostrazione è completa.
Osservazione 12 Col linguaggio della misura di Wiener, l’enunciato precedente fa uncerto effetto: l’insieme delle funzioni continue che sono derivabili almeno in un punto,ha misura di Wiener nulla, è un insieme trascurabile. Se immaginassimo la misura diWiener alla stregua della misura di Lebesgue negli spazi Rn, questo enunciato direbbeche le funzioni differenziabili in almeno un punto sono un insieme davvero piccolissimorispetto alla totalità delle funzioni continue!

Capitolo 3
Martingale
3.1 Definizioni
SiaM = (Mt)t≥0 un processo stocastico a valori reali su uno spazio (Ω,F , P ) ed (Ft)t≥0
una filtrazione. Supponiamo che sia E [|Mt|] < ∞ per ogni t ≥ 0 e che sia adattato.Diciamo che M è una martingala rispetto alla filtrazione (Ft)t≥0 se per ogni t > s ≥ 0vale 1
E [Mt|Fs] = Ms.
Se invece vale E [Mt|Fs] ≥ Ms parliamo di submartingala, mentre se vale E [Mt|Fs] ≤Ms parliamo di supermartingala2.Calcolando il valore atteso di ambo i membri della condizione di martingala (risp.
submartigala) si vede che E[Mt] = E[Ms] (risp. E[Mt] ≥ E[Ms]) quindi la funzionevalore atteso m (t) è costante (risp. crescente). Una martingala in media e costante(risp. una supermartingala in media cresce).Le stesse definizioni si applicano al caso di un processo a tempo discreto M =
(Mn)n∈N. In questo caso è suffi ciente che valga la condizione quando i tempi s e t sonoconsecutivi; vediamolo nel caso delle martingale. Se vale
E [Mn+1|Fn] = Mn
per ogni n ∈ N, allora vale
E [Mn+2|Fn] = E [E [Mn+2|Fn+1] |Fn] = E [Mn+1|Fn] = Mn
1Ricordiamo che ogni identità coinvolgente una speranza condizionale va intesa quasi certamenteo come identità tra classi di equivalenza
2I termini sub e super martinagala sono diffi cili da interiorizzare perché sembrano opposti all’in-tuizione: il prefisso sub sembra richiamare la decrescenza, mentre la miglior previsione del futuro(Xt) al momento attuale (Fs) è maggiore del presente (Xs), cioè in un certo senso il processo ha unatendenza a crescere. Se però si associa la parola coda (temporalmente intesa come il passato) a quelladi martingala, si può pensare che una submartingala abbia la coda in ribasso e questo può aiutare lamemoria.
63

64 CAPITOLO 3. MARTINGALE
e quindi iterativamente si verifica che vale E [Mm|Fn] = Mn per ogni m > n ∈ N.La definizione di martingala equivale alla seguente: i) (Mt)t≥0 è integrabile ed
adattato a (Ft)t≥0, ii) per ogni t > s ≥ 0 vale
E [Mt −Ms|Fs] = 0.
Infatti, per l’adattamento, vale E [Ms|Fs] = Xs. Forse da questo punto di vista nonstupisce la seguente proposizione, che stabilisce la vicinanza del concetto di martingalacol concetto di processo a incrementi indipendenti e centrati (valore atteso nullo).Premettiamo due definizioni.Un processoX = (Xt)t≥0 si dice a incrementi indipendenti rispetto ad una filtrazione
(Ft)t≥0 se è adattato e Xt−Xs è indipendente da Fs per ogni t ≥ s ≥ 0. [La condizionedi indipendenza, quando Ft = σ (Xu;u ∈ [0, t]), equivale alla seguente: per ogni n ∈ Ned ogni tn ≥ tn−1 ≥ ... ≥ t1 ≥ 0 le v.a. Xtn−Xtn−1 , ..., Xt2−Xt1 , Xt1 sono indipendenti.La dimostrazione di questa equivalenza è identica a quella svolta ne caso del motobrowniano, Proposizione 25]. Diciamo che un processo X, tale che E [X2
t ] < ∞ perogni t ≥ 0, ha incrementi scorrelati se
Cov (Xt −Xs, Xu −Xv) = 0
per ogni t ≥ s ≥ u ≥ v ≥ 0.
Proposizione 32 Se X è un processo, con E [|Xt|] <∞ per ogni t ≥ 0, ha incrementicentrati e indipendenti rispetto a (Ft)t≥0, allora è una martingala rispetto a (Ft)t≥0.Se X è una martingala rispetto ad una filtrazione (Ft)t≥0, con E [X2
t ] < ∞ perogni t ≥ 0, allora è un processo a incrementi scorrelati e centrati. Se inoltre è unprocesso gaussiano, allora ha incrementi indipendenti rispetto alla filtrazione generatadal processo (F00
t )t≥0.
Proof. La prima affermazione è immediata: presi t ≥ s ≥ 0, per l’indipendenza da Fsed il valore atteso nullo dell’incremento Xt −Xs, vale
E [Xt −Xs|Fs] = E [Xt −Xs] = 0.
Vediamo la seconda. Il valore atteso nullo si vede così: per la proprietàE [Xt −Xs|Fs] =0 ed una proprietà dei valori attesi condizionali (analogo della formula di fattoriz-zazione), vale
0 = E [E [Xt −Xs|Fs]] = E [Xt −Xs] .
Mostriamo che gli incrementi sono scorrelati. Presi t ≥ s ≥ u ≥ v ≥ 0, ed avendo giàstabilito che il valore atteso di ogni incremento è nullo, vale (usando varie proprietàdella speranza condizionale)
Cov (Xt −Xs, Xu −Xv) = E [(Xt −Xs) (Xu −Xv)] = E [E [(Xt −Xs) (Xu −Xv) |Fs]]= E [(Xu −Xv)E [(Xt −Xs) |Fs]] = 0,

3.1. DEFINIZIONI 65
l’ultimo passaggio essendo valido in quanto E [(Xt −Xs) |Fs] = 0. Infine, se il processoè pure gaussiano, presi tn > tn−1 > ... > t1 ≥ 0, il vettore
(Xtn −Xtn−1 , ..., Xt2 −Xt1
)è gaussiano ed ha matrice di covarianza diagonale, per cui ha componenti indipendenti.Da questo discende che, per ogni t ≥ s ≥ 0, Xt−Xs è indipendente da F00
s (lo abbiamogià dimostrato in occasione delle riformulazioni della definizione di moto browniano.La dimostrazione è completa.Il secondo esempio illustrato nella prossima sezione è una martingala ma non ha
incrementi indipendenti (solo scorrelati). Quindi c’è spazio tra queste due categorieapparentemente molto vicine (processi a incrementi indipendenti e scorrelati) e lemartingale si collocano in tale spazio.
3.1.1 Esempi
Vediamo due esempi fondamentali. Per noi le martingale saranno rilevanti princi-palmente per due ragioni (collegate): il moto browniano è una martingala e lo sono(sotto opportune ipotesi) gli integrali stocastici rispetto al moto browniano. E’utilis-simo vedere poi numerosi altri tipi di esempi, soprattutto a tempo discreto, anche piùelementari di questi, ma li rimandiamo agli esercizi.La teoria delle martingale è uno snodo unico nel calcolo stocastico. La proprietà
di martingala è tutto sommato apparentemente scarna, ed ha invece incredibili con-seguenze. Allora è importante sapere che i processi che a noi servono maggiormentesono martingale (o sono collegati a martingale, vedi il teorema di decomposizione diDoob). Questo motiva i due esempi seguenti, anche se il secondo può apparire un po’tecnico.
Esempio 2 Sia B = (Bt)t≥0 un moto browniano rispetto ad una filtrazione (Ft)t≥0.Allora B è una martingala rispetto a (Ft)t≥0, in quanto è un processo centrato aincrementi indipendenti (Proposizione 32).
Veniamo al secondo esempio. Sia B = (Bt)t≥0 un moto browniano rispetto ad unafiltrazione (Ft)t≥0 e siaX = (Xt)t≥0 un processo adattato a (Ft)t≥0 ma costante a trattirelativamente ad una sequenza di tempi tn ≥ tn−1 ≥ ... ≥ t1 = 0, cioè della forma
Xt =n−1∑i=1
Xti1[ti,ti+1) (t) , Xti misurabile rispetto a Fti , E[X2ti
]<∞.
Definiamo, per questo particolare processo3, per ogni b ≥ a ≥ 0,∫ b
a
XsdBs =n−1∑i=1
Xti
(B(a∨ti+1)∧b −B(a∨ti)∧b
).
3Ora ragioniamo su un processo X fissato, di questo tipo. Se si considera invece la classe di tuttiquesti processi, detti elementari, introducendo il simbolo
∫ baXsdBs si deve verificare che la definizione
non dipende dalla rappresentazione di X, che non è univoca.

66 CAPITOLO 3. MARTINGALE
Le espressioni (a ∨ ti+1)∧ b e (a ∨ ti)∧ b sono un po’laboriose da interpretare, per cuipuò convenire l’uso della seguente riscrittura. Osserviamo che, fissati b ≥ a ≥ 0, sipuò arricchire la sequenza di tempi considerando la nuova sequenza t′n+2 ≥ t′n−1 ≥... ≥ t′1 = 0 formata dai tempi ti e da a, b; poi si può scrivere Xt nella formaXt =
∑n+1i=1 X
′t′i
1[t′i,t′i+1) (t) con X ′t′i misurabile rispetto a Ft′i così definiti: se t
′i = tj ∈
t1, ..., tn, poniamo X ′t′i = Xtj ; se t′i = a (risp. t′i = b) e tj ∈ t1, ..., tn è il più grande
con la proprietà tj ≤ a (risp. tj ≤ b), allora poniamo X ′t′i = Xtj . A questo punto∫ b
a
XsdBs =∑
a≤t′i≤t′i+1≤b
Xt′i
(Bt′i+1
−Bt′i
).
Naturalmente i punti t′i dipendono da a, b. Si può verificare che vale∫ baXsdBs +∫ c
bXsdBs =
∫ caXsdBs per ogni c ≥ b ≥ a ≥ 0; se ci si raffi gura la successione di tempi
ti ed i tempi c ≥ b ≥ a ≥ 0, l’idea è evidente, anche se noiosa da scrivere.
Osservazione 13 L’integrale stocastico ora introdotto ha una naturale interpretazionein finanza matematica. Supponiamo di considerare un titolo finanziario (azioni, titolidi stato,...) il cui prezzo cambia nel tempo. Indichiamo con St il prezzo al tempo t.Immaginiamo poi una partizione temporale tn ≥ tn−1 ≥ ... ≥ t1 = 0 corrispondente agliistanti in cui noi eseguiamo operazioni finanziarie. All’istante ti acquistiamo una quan-tità Xti del titolo finanziario suddetto. Paghiamo quindi Xti · Sti. Al tempo Xti+1 ven-diamo la quantità acquistata Xti, incassando Xti ·Sti+1. Complessivamente, con questasingola operazione abbiamo guadagnato (o perso, dipende dal segno) Xti ·
(Sti+1 − Sti
).
Supponiamo di ripetere l’operazione su ogni intervallino. Il guadagno complessivo sarà
n∑i=1
Xti
(Sti+1 − Sti
).
Vediamo quindi che integrali del tipo visto sopra rappresentano il guadagno complessivoin un certo periodo di tempo. Naturalmente, sopra abbiamo definito questo integralenel caso in cui sia S = B, ma tale operazione si potrà generalizzare ad altri casi, unavolta capita nel caso browniano.
Poniamo Mt =∫ t
0XsdBs.
Proposizione 33 M = (Mt)t≥0 è una martingala rispetto a (Ft)t≥0.
Proof. Intanto
E [|Mt|] ≤n−1∑i=1
E[|Xti |
∣∣Bti+1∧t −Bti∧t∣∣]

3.1. DEFINIZIONI 67
e E[|Xti|
∣∣Bti+1∧t −Bti∧t∣∣] < ∞ per ogni i, grazie alla disuguaglianza di Hölder. Poi,
Mt =∫ t
0XudBu è Ft-misurabile, essendo somma e prodotto di variabili tutte Ft-
misurabili. Resta allora da dimostrare cheE [Mt −Ms|Fs] = 0, ovvero cheE[∫ t
sXudBu|Fs
]=
0. Si noti che l’incremento∫ tsXudBu non è indipendente da Fs: contiene (attraver-
so X) alcune delle v.a. Xti , che non sono supposte indipendenti da Fs. Riscriviamo∫ tsXudBu come detto sopra nella forma∫ t
s
XudBu =∑
s≤t′i≤t′i+1≤t
Xt′i
(Bt′i+1
−Bt′i
).
Vale
E
[∫ t
s
XudBu|Fs]
=∑
s≤t′i≤t′i+1≤t
E[Xt′i
(Bt′i+1
−Bt′i
)|Fs].
Mostriamo che ciascun termine E[Xt′i
(Bt′i+1
−Bt′i
)|Fs]è nullo, concludendo così la
dimostrazione. Vale
E[Xt′i
(Bt′i+1
−Bt′i
)|Fs]
= E[E[Xt′i
(Bt′i+1
−Bt′i
)|Ft′i]|Fs]
= E[Xt′i
E[Bt′i+1
−Bt′i
]|Fs]
= 0
avendo usato varie proprietà della speranza condizionale, l’inclusione Fs ⊂ Ft′i (ricor-diamo che nella somma precedente prendiamo solo i t′i ≥ s), l’indipendenza diBt′i+1
−Bt′i
da Ft′i , il fatto che Xt′iè Ft′i-misurabile, ed infine la proprietà E
[Bt′i+1
−Bt′i
]= 0. La
dimostrazione è completa.
Osservazione 14 Come già osservato, abbiamo così costruito un’ampia classe di es-empi che stanno nell’intercapedine (apparentemente molto piccola) tra “scorrelazione”e “indipendenza” (intesa per gli incrementi temporali). Gli integrali stocastici han-no incrementi scorrelati ma non necessariamente indipendenti (perché il processo X lilega).
3.1.2 Altri esempi e preliminari
Esempio 3 Ricordiamo che un processo stocastico (Nt)t≥0 si dice di Poisson di inten-sità λ > 0, rispetto ad una filtrazione (Ft)t≥0, se P (N0 = 0) = 1, è cadlag e per ognit ≥ s ≥ 0 l’incremento Nt−Ns è indipendente da Fs ed ha distribuzione di Poisson diparametro λ (t− s):
P (Nt −Ns = k) = e−λ(t−s) (λ (t− s))k
k!, k ∈ N.
Vale E [Nt −Ns] = λ (t− s). Posto
Mt = Nt − λt

68 CAPITOLO 3. MARTINGALE
il processo (Mt)t≥0 è una martingala rispetto a (Ft)t≥0 (a causa di questo, la funzione λtviene detta compensatore). Infatti la proprietà di indipendenza degli incrementi restavera (non si modifica per addizione di una costante) e gli incrementi ora sono centrati:E [Mt −Ms] = 0. Quindi è una martingala per la Proposizione 32.
Esempio 4 Sia X una v.a. integrabile e (Ft)t≥0 una filtrazione. Allora
Mt = E [X|Ft]
è una martingala. Preliminarmente, osserviamo che E [|Mt|] ≤ E [E [|X| |Ft]] =E [|X|], quindi Mt è integrabile. Inoltre, E [X|Ft] è Ft-misurabile, quindi Mt è adat-tato. Vale poi
E [Mt|Fs] = E [E [X|Ft] |Fs] = E [X|Fs] = Ms
dove abbiamo usato la proprietà di doppia proiezione della speranza condizionale. Quin-diM è una martingala. A volte è detta “martingala chiusa da X”. Il processo E [X|Ft]ha un chiaro significato in varie applicazioni, ad esempio in finanza matematica: X rap-presenta una grandezza incognita del futuro (ammontare di vendite del prossimo mesedi luglio, valore di un titolo finanziario tra sei mesi, ecc.), Ft descrive il grado di in-formazione disponibile al tempo t, E [X|Ft] rappresenta la miglior stima di X fattibileal momento t. La formula E [Mt|Fs] = Ms esprime una coerenza tra le stime.
Proposizione 34 Se (Mt)t≥0 è una martingala, ϕ : R → R una funzione convessa eE [|ϕ (Mt)|] <∞ per ogni t ≥ 0 allora (ϕ (Mt))t≥0 è una submartingala. In particolare,lo sono |Mt| e M2
t (nel secondo caso se M è di quadrato integrabile).Se (Mt)t≥0 è una submartingala, ϕ : R→ R una funzione non decrescente convessa
e E [|ϕ (Mt)|] <∞ per ogni t ≥ 0 allora (ϕ (Mt))t≥0 è una submartingala.
Proof. Grazie alla convessità, per ogni punto x0 ∈ R esiste m (x0) ∈ R tale che
ϕ (x) ≥ ϕ (x0) +m (x0) (x− x0) , x ∈ R.
Per il seguito ci serve che la funzione m sia misurabile; una tale funzione esiste, comesi può verificare prendendo ad es. la derivata destra in x0. Presi t ≥ s ≥ 0, vale allora
ϕ (Mt) ≥ ϕ (Ms) +m (Ms) (Mt −Ms) (3.1)
e quindi (per monotonia e linearità della speranza condizionale)
E [ϕ (Mt) |Fs] ≥ E [ϕ (Ms) |Fs] + E [m (Ms) (Mt −Ms) |Fs]= ϕ (Ms) +m (Ms)E [(Mt −Ms) |Fs]
(per la misurabilità di ϕ (Ms) e m (Ms) rispetto a Fs). A questo punto, se M è unamartingala, E [(Mt −Ms) |Fs] = 0; se invece è una submartingala e ϕ è non decrescente

3.2. TEOREMI D’ARRESTO E DISUGUAGLIANZE 69
(quindim ≥ 0 in ogni punto), E [(Mt −Ms) |Fs] ≥ 0 e quindim (Ms)E [(Mt −Ms) |Fs] ≥0. In entrambi i casi,
E [ϕ (Mt) |Fs] ≥ ϕ (Ms)
ovvero ϕ (Mt) è una submartingala.La dimostrazione ora data è però completa solo se m (Ms) (Mt −Ms) è integrabile.
La funzionem è limitata su intervalli limitati maMs non assume necessariamente valoriin un intervallo limitato, per cui servirebbe una stima della crescita di m all’infinitoed altro ancora. Si risolve tutto con un troncamento: si introduce l’evento AR =|Ms| ≤ R, si moltiplica la disuguaglianza (3.1) per 1AR e si prosegue come sopra (conle stesse motivazioni dei passaggi, più il fatto che ora la v.a. 1ARm (Ms) è limitata):
E [1ARϕ (Mt) |Fs] ≥ E [1ARϕ (Ms) |Fs] + E [1ARm (Ms) (Mt −Ms) |Fs]= 1ARϕ (Ms) + 1ARm (Ms)E [(Mt −Ms) |Fs]
da cui, come sopra,E [1ARϕ (Mt) |Fs] ≥ 1ARϕ (Ms) .
Se R < R′, AR ⊂ AR′ , quindi 1AR ≤ 1AR′ . Basta allora passare al limite, per R → ∞col teorema di convergenza monotona per la speranza condizionale, osservando che
limR→∞
1AR = 1
quasi certamente (in quanto ∪RAR = |Ms| <∞ che ha probabilità 1). La di-mostrazione è completa.
Osservazione 15 Se M è una submartingala, non è detto che lo siano |Mt| e M2t , in
quanto le funzioni x 7−→ |x| e x 7−→ x2 non sono crescenti. Se però M è a valori posi-tivi, si può modificare la dimostrazione e verificare che |Mt| e M2
t sono submartingale(nel secondo caso se M è di quadrato integrabile).
3.2 Teoremi d’arresto e disuguaglianze
La strategia generale che seguiremo sarà di dimostrare prima i teoremi fondamentalinel caso a tempo discreto, poi di dedurre da essi il caso continuo con un passaggio allimite, da tempi diadici a tempi qualsasi (che coinvolgerà qualche ipotesi di continuitàdel processo).
3.2.1 Il caso a tempo discreto
Sia M = (Mn)n∈N una martingala a tempo discreto. I tempi d’arresto di cui si parlerànel seguito sono sempre a valori nei numeri naturali, eventualmente con l’aggiunta di+∞. Un tempo d’arresto si dirà limitato superiormente se esiste una costante (intera

70 CAPITOLO 3. MARTINGALE
nel caso a tempo discreto) N > 0 tale che τ (ω) ≤ N per ogni ω ∈ Ω. Se M è unamartingala (quindi integrabile) e τ è un tempo d’arresto limitato superiormente dallacostante intera N > 0, allora le v.a. Mτ
4 e maxn=1,...,N |Mn| sono integrabili:
E [|Mτ |] ≤ E
[max
n=1,...,N|Mn|
]≤ E
[N∑n=1
|Mn|]
=N∑n=1
E [|Mn|] <∞.
Lo stesso vale per sub e super martingale o per qualsiasi processo discreto integrabile.Questa premessa interviene in molte delle dimostrazioni seguenti e non verrà ripetuta.Nel seguente teorema l’affermazione E [MN ] = E [M0] è ovvia, come abbiamo
osservato subito dopo la definizione di martingala.
Teorema 8 (d’arresto) Se τ è un tempo d’arresto limitato superiormente da unintero N , allora
E [Mτ ] = E [MN ] = E [M0] .
Se M è una submartingala, allora vale E [Mτ ] ≤ E [MN ].
Proof. Con le notazioni precedenti vale
E [Mτ ] =N∑n=0
E [Mτ1τ=n] =N∑n=0
E [Mn1τ=n] .
Per la proprietà di martingala E [Mn1τ=n] = E [MN1τ=n], quindi
E [Mτ ] =N∑n=0
E [MN1τ=n] = E [MN ] .
Ma E [MN ] = E [M0]. La proprietà è dimostrata. Il caso della submartingala è identico,senza il passaggio finale.
Corollario 5 Se τ 1 ≤ τ 2 sono due tempi d’arresto limitati superiormente, allora vale
E [Mτ2|Fτ1 ] = Mτ1 .
Se M è una submartingala e τ 2 = N è costante, allora vale
E [MN |Fτ1 ] ≥Mτ1 .
4Definita da (Mτ ) (ω) =Mτ(ω) (ω)

3.2. TEOREMI D’ARRESTO E DISUGUAGLIANZE 71
Proof. PresoA ∈ Fτ1 dobbiamo dimostrare che∫AMτ2dP =
∫AMτ1dP (risp.
∫AMNdP =∫
AMτ1dP nel caso della submartingala). Consideriamo la funzione τ 3 : Ω → [0,∞)
definita da
τ 3 (ω) =
τ 1 (ω) se ω ∈ Aτ 2 (ω) se ω /∈ A .
Verifichiamo che sia un tempo d’arresto. Preso t ≥ 0, vale
τ 3 ≤ t = (A ∩ τ 1 ≤ t) ∪ (Ac ∩ τ 2 ≤ t) .
L’insieme A ∩ τ 1 ≤ t appartiene a Ft per l’ipotesi su A. Ac ∈ Fτ1 , quindi Ac ∈ Fτ2(si veda l’esercizio 12), pertanto Ac ∩ τ 2 ≤ t ∈ Ft. Quindi τ 3 ≤ t ∈ Ft, cioè τ 3 èun tempo d’arresto. Ovviamente è anch’esso limitato.Per il teorema d’arresto vale allora
E [Mτ3 ] = E [MN ] = E [Mτ2 ]
(risp. E [Mτ3 ] ≤ E [MN ] nel caso della submartingala) cioè, ricordando la definizionedi τ 3,
E [Mτ11A +Mτ21Ac ] = E [Mτ2 ]
da cuiE [Mτ11A] = E [Mτ21A], che è ciò che volevamo dimostrare (risp. E [Mτ11A +MN1Ac ] ≤E [MN ] da cui E [Mτ11A] ≤ E [MN1A] nel caso della submartingala). La dimostrazioneè completa.
Osservazione 16 I due risultati precedenti sono equivalenti. Abbiamo dimostrato ilcorollario a partire dal teorema. Se invece avessimo dimostrato prima il corollario,basterebbe prendere la speranza di ambo i membri delle sue formule per ottenere quelledel teorema.
Osservazione 17 Vedremo più avanti che si può rimuovere l’ipotesi τ 2 = N , nelcorollario.
Teorema 9 (disuguaglianza massimale) Sia M una martingala oppure una sub-martingala positiva. Allora, per ogni N intero positivo e per ogni λ > 0, vale
P
(max
n=1,...,N|Mn| ≥ λ
)≤ 1
λE[|MN | 1maxn=1,...,N |Mn|≥λ
]≤ 1
λE [|MN |] .
Proof. Per capire la naturalezza del primo passaggio della dimostrazione è utile ricor-dare la dimostrazione della disuguaglianza di Chebyshev: essa asserisce che P (|X| ≥ λ) ≤1λE [|X|], per ogni λ > 0 ed ogni v.a. X, e la dimostrazione si svolge semplicementeapplicando la monotonia del valore atteso alla disuguaglianza
λ1|X|≥λ ≤ |X| 1|X|≥λ.

72 CAPITOLO 3. MARTINGALE
Veniamo al caso delle submartingale. Data la submartingala originaria M =(Mn)n∈N e dato N intero positivo, introduciamo una nuova submartingala MN =(MN
n
)n∈N definita da M
Nn = Mn per n ≤ N , MN
n = MN per n > N . E’ equiva-lente dimostrare la tesi del teorema perMN . Quindi possiamo supporre sin dall’inizio,senza restrizione, che M sia costante dal tempo N in poi; facciamo questa ipotesi edusiamo la notazione M per la nostra submartingala.Introduciamo la funzione τN : Ω→ 0, ..., N definita da
τN = min n ≤ N : |Mn| ≥ λ
se tale insieme non è vuoto, τN = N + 1 altrimenti. E’un tempo d’arresto: se n0 ≤ N ,
τN ≤ n0 =⋃n≤n0
|Mn| ≥ λ ∈ Fn0
mentre, se n0 > N ,
τN ≤ n0 = τN = N + 1 =⋂n≤N|Mn| < λ ∈ FN ⊂ Fn0 .
Valeλ1maxn=1,...,N |Mn|≥λ ≤ |MτN | 1maxn=1,...,N |Mn|≥λ.
Infatti, sull’evento maxn=1,...,N |Mn| ≥ λ vale τN ≤ N e MτN ≥ λ.Integrando,
P
(max
n=1,...,N|Mn| ≥ λ
)≤ 1
λE[|MτN | 1maxn=1,...,N |Mn|≥λ
].
Ora, l’evento maxn=1,...,N |Mn| ≥ λ = τN ≤ N appartiene a FτN ed il processo|Mn| è una submartingala (se Mn è una martingala, allora |Mn| è una submartingalacome trasformazione convessa; se Mn è una submartingala positiva, allora |Mn| è unasubmartingala come trasformazione convessa crescente), quindi vale, per il Corollario5,
E[|MτN | 1maxn=1,...,N |Mn|≥λ
]≤ E
[|MN+1| 1maxn=1,...,N |Mn|≥λ
]= E
[|MN | 1maxn=1,...,N |Mn|≥λ
]dove abbiamo usato il fatto che τN ≤ N + 1 e che MN+1 = MN . La dimostrazione ècompleta.
Corollario 6 Dato p ≥ 1, se E [|Mn|p] <∞ per ogni n, allora
P
(max
n=1,...,N|Mn| ≥ λ
)≤ 1
λpE [|MN |p] .
Dato θ > 0, se E[eθ|Mn|
]<∞ per ogni n, allora
P
(max
n=1,...,N|Mn| ≥ λ
)≤ e−θλE
[eθ|MN |
].

3.2. TEOREMI D’ARRESTO E DISUGUAGLIANZE 73
Proof. Il processo |Mn|p è una submartingala, per la Proposizione 34. Per la disug-uaglianza massimale applicata a |Mn|p e λp
P
(max
n=1,...,N|Mn| ≥ λ
)= P
(max
n=1,...,N|Mn|p ≥ λp
)≤ 1
λpE [|MN |p] .
La dimostrazione della seconda disuguaglianza è identica, usando la funzione convessae crescente x 7−→ eθx.Le stime delle code di una v.a. implicano stime sui valori medi. Ricordiamo:
Lemma 3 Se X è una v.a. integrabile non negativa, allora
E [Xp] =
∫ ∞0
pap−1P (X ≥ a) da
per ogni p ≥ 1.
Proof.∫ ∞0
pap−1P (X ≥ a) da =
∫ ∞0
pap−1E [1X≥a] da = E
[∫ ∞0
pap−11X≥ada
]= E
[∫ X
0
pap−1da
]= E [Xp] .
Nell’ambito delle equazioni differenziali stocastiche, il seguente risultato è moltoutile.
Teorema 10 (disuguaglianza di Doob) Se M è una martingala oppure una sub-martingala positiva, per ogni p > 1 vale
E
[max
n=1,...,N|Mn|p
]≤(
p
p− 1
)pE [|MN |p] .
Precisamente, se E [|MN |p] = +∞, la disuguaglianza è ovvia; se E [|MN |p] <∞ alloraanche maxn=1,...,N |Mn|p è integrabile e vale la disuguaglianza.Proof. Poniamo M∗
N = maxn=1,...,N |Mn|. Allora
E
[max
n=1,...,N|Mn|p
]=
∫ ∞0
pap−1P (M∗N ≥ a) da ≤
∫ ∞0
pap−1 1
aE[|MN | 1M∗N≥a
]da
= E
[|MN |
∫ M∗N
0
pap−2da
]=
p
p− 1E[|MN | (M∗
N)p−1] .Per la disuguaglianza di Hölder, ricordando che 1
p+ p−1
p= 1,
E[|MN | (M∗
N)p−1] ≤ E [|MN |p]1p E [(M∗
N)p]p−1p
quindi, dividendo per E [(M∗N)p]
p−1p ,
E [(M∗N)p]
1p ≤ p
p− 1E [|MN |p]
1p
da cui la tesi.
Esercizio 12 Se τ 1 ≤ τ 2 sono due tempi d’arresto, allora Fτ1 ⊂ Fτ2.

74 CAPITOLO 3. MARTINGALE
3.2.2 Il caso a tempo continuo
Le dimostrazioni che seguono sono basate tutte sulla stessa strategia. Data una mar-tingala (resp. submartingala) M = (Mt)t≥0, dato un tempo T > 0, si considerano gliistanti “diadici”della forma kT
2n, con n ∈ N e k = 0, 1, ..., 2n e si introduce, per ogni
n ∈ N, il processo a tempo discreto
M(n,T )k := M kT
2n, k ∈ N.
Esso è una martingala (resp. submartingala) a tempo discreto, rispetto alla filtrazione(F kT
2n
)k∈N. Ad essa si applicano quindi i risultati precedenti. Bisogna poi eseguire un
passaggio al limite per n → ∞ e per controllare il limite di alcune quantità servonodelle ipotesi di continuità di M . I primi due teoremi necessitano solo della seguenteipotesi:
supt∈[0,T ]
|Mt| = limn→∞
maxk=1,...,2n
∣∣∣M (n,T )k
∣∣∣ q.c. (3.2)
Questa vale ad esempio se ogni (o q.o.) traiettoria di M è continua, ma anche più ingenerale.
Teorema 11 (disuguaglianza massimale) SiaM una martingala, oppure una sub-martingala positiva, che soddisfa (3.2). Allora, per ogni T > 0, λ > 0, vale
P
(supt∈[0,T ]
|Mt| ≥ λ
)≤ 1
λE [|MT |] .
Proof. Per ogni n ∈ N, introduciamo l’evento
An =
max
k=1,...,2n
∣∣∣M (n,T )k
∣∣∣ ≥ λ
.
Per la disuguaglianza massimale discreta applicata alla submartingala M (n,T )k , vale
P (An) ≤ 1
λE[∣∣∣M (n,T )
2n
∣∣∣] =1
λE [|MT |]
osservando che M (n,T )2n = MT . Gli eventi An sono non decrescenti, quindi P (∪nAn) =
limn→∞ P (An). Preso ε > 0, grazie all’ipotesi (3.2), se supt∈[0,T ] |Mt| ≥ λ + ε, allora
esiste n tale che maxk=1,...,2n
∣∣∣M (n,T )k
∣∣∣ > λ. Questo dice chesupt∈[0,T ]
|Mt| ≥ λ+ ε
⊂⋃n∈N
An

3.2. TEOREMI D’ARRESTO E DISUGUAGLIANZE 75
quindi
P
(supt∈[0,T ]
|Mt| ≥ λ+ ε
)≤ lim
n→∞P (An) ≤ 1
λE [|MT |] .
I numeri λ, ε > 0 sono arbitrari, quindi abbiamo anche dimostrato che, per ε < λ,
P
(supt∈[0,T ]
|Mt| ≥ λ
)≤ 1
λ− εE [|MT |] .
Pendendo il limite per ε→ 0 si ottiene la tesi. La dimostrazione è completa.
Corollario 7 Dato p ≥ 1, se E [|Mt|p] <∞ per ogni t, allora
P
(supt∈[0,T ]
|Mt| ≥ λ
)≤ 1
λpE [|MT |p] .
Dato θ > 0, se E[eθ|Mt|
]<∞ per ogni t, allora
P
(supt∈[0,T ]
|Mt| ≥ λ
)≤ e−θλE
[eθ|MT |
].
La dimostrazione è identica a quella del Corollario 6.
Teorema 12 (disuguaglianza di Doob) Sia dato p > 1. Se M è una martingala,oppure una submartingala positiva, che soddisfa (3.2) e E [|Mt|p] < ∞ per ogni t,allora, per ogni T > 0, la v.a. supt∈[0,T ] |Mt|p è integrabile e vale
E
[supt∈[0,T ]
|Mt|p]≤(
p
p− 1
)pE [|MT |p] .
Proof. Per ogni n ∈ N, introduciamo la v.a. Xn = maxk=1,...,2n
∣∣∣M (n,T )k
∣∣∣p. Per ladisuguaglianza di Doob discreta applicata alla submartingala M (n,T )
k , vale
E [Xn] ≤(
p
p− 1
)pE [|MT |p] .
La successione di v.a. Xnn∈N è non descrescente e non negativa, quindi, per il teoremadi convergenza monotona,
E[
limn→∞
Xn
]≤(
p
p− 1
)pE [|MT |p] .
Ma la v.a. limn→∞Xn coincide con supt∈[0,T ] |Mt|p per l’ipotesi (3.2). Questo completala dimostrazione.

76 CAPITOLO 3. MARTINGALE
Teorema 13 (d’arresto) Supponiamo che esista p > 1 tale che E [|Mt|p] < ∞ perogni t. Se M è una martingala continua a destra e τ è un tempo d’arresto limitato,allora
E [Mτ ] = E [M0] .
Proof. Per ogni n ∈ N, introduciamo il tempo aleatorio τn : Ω→ [0,∞) così definito:
τn =k + 1
2nse
k
2n< τ ≤ k + 1
2n.
E’un tempo aleatorio:
τn ≤ t =⋃
k, k+12n≤t
τn =
k + 1
2n
=
⋃k, k+1
2n≤t
k
2n< τ ≤ k + 1
2n
∈ Ft.
Inoltre, limn→∞ τn = τ . Infine, esiste un intero N > 0 tale che τn ≤ N per ogni n ∈ N.Per il teorema di arresto discreto,
E [Mτn ] = E [MN ] = E [M0] .
Per la continuità a destra, limn→∞Mτn = Mτ . Inoltre,
|Mτn| ≤ supt∈[0,N ]
|Mt|
che è integrabile per la disuguaglianza di Doob, e quindi, per il teorema di convergenzadominata, limn→∞E [Mτn ] = E [Mτ ]. La dimostrazione è completa.Esistono tante varianti del teorema d’arresto. Ne enunciamo una d’uso pratico nel
caso di processi continui.
Corollario 8 Supponiamo che esista p > 1 tale che E [|Mt|p] <∞ per ogni t. Se M èuna martingala continua, τ è finito e la successione Mτ∧n è uniformemente integrabile(oppure limitata in modulo da una funzione integrabile), allora
E [Mτ ] = E [M0] .
Proof. Consideriamo i tempi d’arresto limitati τ ∧ n al variare di n ∈ N. Vale (per ilteorema di arresto)
E [Mτ∧n] = E [M0]
e limn→∞Mτ∧n = Mτ per la continuità a sinistra. La tesi discende all’uniforme inte-grabilità ed il relativo teorema di passaggio al limite in valore atteso (o dal teoremadi convergenza dominata di Lebesgue, se la successione Mτ∧n è limitata in modulo dauna funzione integrabile). La dimostrazione è completa.

3.3. APPLICAZIONI 77
3.3 Applicazioni
3.3.1 Disuguaglianza esponenziale per il moto browniano
Si possono dimostrare le seguenti disuguaglianze, per λ > 0:(λ+
1
λ
)−1
e−λ2
2 ≤∫ ∞λ
e−x2
2 dx ≤ 1
λe−
λ2
2 .
Da quella di destra si ottiene, per ogni T > 0,
P (BT ≥ λ) ≤
Infatti
P (BT ≥ λ) = P(BT/√T ≥ λ/
√T)≤ 1
2π
√T
λe−
λ2
2T .
Trascurando il fattore di fronte all’esponenziale, possiamo dire che la coda della v.a.
BT decade come e−λ2
2T (in realtà decade un po’più velocemente, grazie al fattore chemoltiplica l’esponenziale). La seguente disuguaglianza esponenziale rafforza questorisultato dal punto di vista dell’uniformità nel tempo, o se si vuole stabilisce un risultatosimile per le traiettorie del moto browniano.
Proposizione 35 Sia B un moto browniano. Allora, per ogni λ > 0, vale
P
(supt∈[0,T ]
Bt ≥ λ
)≤ e−λ
2/2T .
P
(supt∈[0,T ]
|Bt| ≥ λ
)≤ 2e−λ
2/2t.
Proof. Per la Proposizione 34, preso θ > 0, il processoMt := eθBt è una submartingalae quindi, per la disuguaglianza massimale,
P
(supt∈[0,T ]
Bt ≥ λ
)= P
(supt∈[0,T ]
eθBt ≥ eθλ
)≤ e−θλE
[eθBt
].
Se X è una v.a. N (0, σ2) si dimostra con un calcolo elementare che E[eθX]
= eθ2σ2
2 .
Pertanto E[eθBt
]= e
θ2t2 . Otteniamo quindi
P
(supt∈[0,T ]
Bt ≥ λ
)≤ inf
θ>0e−θλ+ θ2t
2 = einfθ>0
(θ2t2−θλ
).

78 CAPITOLO 3. MARTINGALE
Per concludere basta osservare che il punto di minimo della parabola θ2t2− θλ si trova
in θ = λt> 0 e vale −λ2
2t.
Infine, osserviamo che −B è ancora un moto browniano, quindi vale
P
(supt∈[0,T ]
(−Bt) ≥ λ
)≤ e−λ
2/2t.
D’altra partesupt∈[0,T ]
|Bt| ≥ λ
⊂
supt∈[0,T ]
Bt ≥ λ
⋃supt∈[0,T ]
(−Bt) ≥ λ
per cui passando alle probabilità si ottiene la seconda disuguaglianza della proposizione.
3.3.2 Problema della rovina
Sia B un moto browniano (continuo) e, presi a, b > 0, consideriamo il problemadell’uscita di B dall’intervallo [−a, b].
Osservazione 18 Possiamo immaginare, per aiutare l’intuizione, che Bt + a rappre-senti il patrimonio di un giocatore al tempo t, patrimonio che ammonta al valore a > 0al tempo t = 0, e che b sia la quantità che il giocatore si prefissa di vincere: smetteràdi giocare quanto il suo patrimonio sarà pari ad a+ b, ovvero quando Bt = b. Se però,prima di allora, il suo patrimonio si sarà ridotto a zero (Bt = −a), il giocatore saràcaduto in rovina prima di raggiungere il suo scopo. Questo problema serve a mostrareche la strategia di continuare a giocare fino al momento in cui si raggiunge la vincitadesiderata (che in teoria prima o poi accadrà) si scontra col fatto che si dispone di unpatrimonio iniziale limitato e quindi si può cadere in rovina prima di raggiungere ilsuccesso.
Introduciamo il tempo di ingresso in (−a, b)c, detto anche tempo d’uscita da (−a, b),o primo istante in cui B raggiunge il valore a oppure b:
τa,b = min t ≥ 0 : Bt ∈ (−a, b)c .
Essendo B continuo ed (−a, b)c chiuso, τa,b è un tempo d’arresto.Supponiamo di poter stabilire che τa,b sia finito. Siccome B è continuo e Bt ∈ [−a, b]
per t ≤ τa,b (quindi la successione di v.a.∣∣Bτa,b∧n
∣∣n∈N è equilimitata), possiamo
applicare la versione del teorema d’arresto data dal Corollario 8 ed ottenere
E[Bτa,b
]= E [B0] = 0.

3.3. APPLICAZIONI 79
D’altra parte, sempre nell’ipotesi che τa,b sia finito, avremmo
E[Bτa,b
]= E
[Bτa,b1Bτa,b=−a
]+ E
[Bτa,b1Bτa,b=b
]= −E
[a1Bτa,b=−a
]+ E
[b1Bτa,b=b
]= −aP
(Bτa,b = −a
)+ bP
(Bτa,b = b
)ed anche
P(Bτa,b = −a
)+ P
(Bτa,b = b
)= 1.
Quindi avremmo le due relazioni
−aP(Bτa,b = −a
)+ bP
(Bτa,b = b
)= 0
P(Bτa,b = −a
)+ P
(Bτa,b = b
)= 1
da cui dedurremmo
P(Bτa,b = −a
)=
b
a+ b, P
(Bτa,b = b
)=
a
a+ b. (3.3)
Proposizione 36 Vale (3.3). Inoltre,
E [τa,b] = ab.
Proof. Consideriamo il processo
Mt := B2t − t.
E’una martingala (inquadreremo questo fatto più in generale nel seguito):
E [Mt|Fs] = E[B2t |Fs
]− t = E
[(Bt −Bs)
2 |Fs]
+ 2E [BtBs|Fs]− E[B2s |Fs
]− t
= E[(Bt −Bs)
2]+ 2BsE [Bt|Fs]−B2s − t
= t− s+ 2B2s −B2
s − t = B2s − s = Ms.
Preso T > 0, introduciamo il tempo d’arresto limitato τa,b ∧ T . Vale
E[Mτa,b∧T
]= E [M0] = 0
ovveroE [τa,b ∧ T ] = E
[B2τa,b∧T
].
Esiste una costante (il ragionamento è simile a quello fatto sopra) C > 0 tale cheB2τa,b∧T ≤ C, indipendentemente da T , quindi
E [τa,b ∧ T ] ≤ C.

80 CAPITOLO 3. MARTINGALE
Per convergenza monotona, si ottiene E [τa,b] ≤ C e quindi τa,b <∞ quasi certamente.Valgono quindi i calcoli sviluppati sopra, che portano alle formule (3.3).Inoltre, possiamo applicare il Corollario 8 ad M ed ottenere
E[Mτa,b
]= E [M0] = 0.
D’altra parte,
E[Mτa,b
]= E
[Mτa,b1Bτa,b=−a
]+ E
[Mτa,b1Bτa,b=b
]= E
[(a2 − τa,b
)1Bτa,b=−a
]+ E
[(b2 − τa,b
)1Bτa,b=b
]= a2P
(Bτa,b = −a
)+ b2P
(Bτa,b = b
)− E [τa,b] .
da cui
E [τa,b] = a2P(Bτa,b = −a
)+ b2P
(Bτa,b = b
)= a2 b
a+ b+ b2 a
a+ b= ab.
La dimostrazione è completa.
3.4 Teorema di decomposizione di Doob per sub-martingale discrete
Teorema 14 Se X è una submartingala rispetto ad una filtrazione (Fn)n≥0, alloraesistono una martingala M = (Mn)n≥0 ed un processo crescente A = (An)n≥0 tali che
Xn = Mn + An.
Inoltre, An è Fn−1 misurabile, per ogni n.
Proof. Definiamo Mn iterativamente in modo che valga
Mn+1 −Mn = Xn+1 − E [Xn+1|Fn] .
Poniamo ad esempio M0 = 0, M1 = X1 − E [X1|F0], e così via Mn+1 = Mn + Xn+1 −E [Xn+1|Fn].Vale
E [Mn+1 −Mn|Fn] = E [Xn+1 − E [Xn+1|Fn] |Fn]
= E [Xn+1|Fn]− E [Xn+1|Fn] = 0.
Quindi M è una martingala. Il processo
An := Xn −Mn

3.4. TEOREMADI DECOMPOSIZIONEDI DOOBPER SUBMARTINGALEDISCRETE81
soddisfa
An+1 = Xn+1 −Mn+1 = E [Xn+1|Fn]−Mn ≥ Xn −Mn = An
quindi è crescente. Inoltre, sempre da qui si vede che An+1 è Fn misurabile. Ladimostrazione è completa.Possiamo finalmente tornare al teorema d’arresto e svincolarci da una limitazione
antipatica per le submartingale.
Corollario 9 Siano X una submartingala discreta e τ 1 ≤ τ 2 due tempi d’arrestolimitati. Allora
E [Xτ2 |Fτ1 ] ≥ Xτ1
ed in particolareE [Xτ2 ] ≥ E [Xτ1 ] .
Proof. Scriviamo X nella forma
Xn = Mn + An
come nel teorema di decomposizione. Allora
E [Xτ2|Fτ1 ] = E [Mτ2|Fτ1 ] + E [Aτ2|Fτ1 ] .
Siccome A è crescente, Aτ2 ≥ Aτ1 (q.c.) e quindi, per la monotonia della speranzacondizionale, E [Aτ2|Fτ1 ] ≥ E [Aτ1 |Fτ1 ]. Essendo poi Aτ1 misurabile rispetto a Fτ1(esercizio 13), vale
E [Aτ2|Fτ1 ] ≥ Aτ1 .
Inoltre,E [Mτ2 |Fτ1 ] = Mτ1
per il risultato d’arresto delle martingale. Quindi
E [Xτ2|Fτ1 ] ≥Mτ1 + Aτ1 = Xτ1 .
L’affermazione E [Xτ2 ] ≥ E [Xτ1 ] discende dalla precedente calcolando il valore attesodi ambo i membri. La dimostrazione è completa.
Esercizio 13 Se X è un processo a tempo discreto e τ un tempo d’arresto finito, alloraXτ misurabile rispetto a Fτ .

82 CAPITOLO 3. MARTINGALE
3.5 Teorema di convergenza per super-martingalediscrete
Proviamo ad apprezzare intuitivamente il problema ragionando sulle traiettorie di unamartingala. Abbiamo visto all’inizio del capitolo che gli incrementi sono indipendenti oquasi, e centrati. L’immagine che ci facciamo è quindi di traiettorie altamente oscillanti,con oscillazioni ugualmente distribuite verso l’alto e verso il basso (qui usiamo le parolein modo molto intuitivo); si pensi ad esempio al moto browniano. Il teorema chevedremo in questo paragrafo afferma che, sotto certe ipotesi, esiste finito il limite pert→∞, delle traiettorie (q.c.). Come può questo essere compatibile con le oscillazionisuddette? Le traiettorie browniane sono illimitate sia dall’alto sia dal basso, per t→∞.Ciò che forse ci inganna pensando al moto browniano è la stazionarietà dei suoi
incrementi. Una martingala, invece, può avere incrementi sempre più “piccoli”, alcrescere del tempo. Essi continueranno ad essere quasi indipendenti dal passato, mase sono sempre più piccoli non è assurdo immaginare che le traiettorie abbiano limite;un po’come per la funzione f (t) = 1
tsin t.
3.5.1 Tentativo di euristica
Il teorema che stiamo per esporre è davvero inaspettato, rispetto alla media dei nostriteoremi e la sua dimostrazione non è affatto concettualmente semplice, pur moltosintetica. Proviamo allora ad avvicinarci per gradi con ragionamenti il più possibileplausibili (pur costruiti a posteriori).Prendiamo una submartingala a tempo discreto M = (Mn)n≥0, rispetto ad una
filtrazione (Fn)n≥0:E [Mn+1 −Mn|Fn] ≥ 0
per ogni n ∈ N. L’immagine intuitiva, almeno nel caso delle martingale (che vogliamoincludere nel teorema), è che le sue traiettorie oscillino continuamente, per n → ∞.Un modo di esplorare se abbia limite o meno, per n → ∞, è quello di prendere duegeneriche soglie a < b ed esplorare se le traiettorie “attraversano” l’intervallo [a, b]infinite volte oppure no.
Osservazione 19 Spieghiamo cosa si intende per attraversamento di [a, b] dal bassoverso l’alto, per una successione numerica (xn)n≥0. Analogamente a quanto vedremosotto, poniamo
σ1 = inf n ≥ 0 : xn < a , τ 1 = inf n > σ1 : xn > b
σi+1 = inf n > τn : xn < a , τ i+1 = inf n > σn+1 : xn > b , i ≥ 1
con la convenzione che questi numeri sono infiniti se il corrispondente insieme è vuoto.Se τ 1 <∞, diremo che tra gli istanti σ1 e τ 1 c’è un attraversamento di [a, b] dal basso

3.5. TEOREMA DI CONVERGENZA PER SUPER-MARTINGALE DISCRETE83
verso l’alto; e così via se τ i+1 <∞. La quantità (eventualmente infinita)
γa,b = Card i ≥ 1 : τ i <∞
rappresenta il numero di attraversamenti di [a, b] dal basso verso l’alto.
Osservazione 20 Se il numero di questi attraversamenti è finito, qualsiasi siano a <b, allora esiste limn→∞ xn (finito o infinito). Infatti, il limite limn→∞ xn esiste se esolo se i limiti superiore e inferiore coincidono (eventualmente infiniti); se questo nonè verificato, allora si possono trovare (partendo da due sottosuccessioni che tendonoai limiti estremi) due numeri reali a < b (basta prenderli strettamente contenuti trai due limiti estremi) e due sottosuccessioni nak,
nbktali che xnak < a, xnbk > a,
nak < nbk < nak+1 per ogni k.
Torniamo alla submartingala. Vogliamo capire se gli attraversamenti di un genericointervallo [a, b], dal basso verso l’alto, delle sue traiettorie, sono finiti o infiniti. Poniamo
σ1 (ω) = inf n ≥ 0 : Mn (ω) < aτ 1 (ω) = inf n > σ1 (ω) : Mn (ω) > b
ponendo σ1 (ω) =∞ o τ 1 (ω) =∞ se i relativi insiemi sono vuoti. Poi iterativamenteintroduciamo, per i ≥ 1,
σi+1 (ω) = inf n > τn (ω) : Mn (ω) < aτ i+1 (ω) = inf n > σn+1 (ω) : Mn (ω) > b
sempre con la convenzione suddetta se gli insiemi sono vuoti. La quantità aleatoria, avalori interi non negativi o +∞,
γa,b (ω) = Card i ≥ 1 : τ i (ω) <∞
è il numero di attraversamenti di [a, b] in modo ascendente. Come detto sopra, se èfinita, allora c’è limite, per la realizzazione (Mn (ω))n≥0.Gli istanti σi e τ i sono tempi d’arresto (sono simili agli istanti di primo ingresso,
solo con un vincolo dal basso (es. n > τn nella definizione di σi+1, ma la verifica èidentica, per ricorrenza).
Osservazione 21 Se fossero limitati, avremmo (per il teorema d’arresto)
E [Mτ i ] ≤ E[Mσi+1
].
Questo è impossibile: Mσi+1 < a e Mτ i > b (se σi e τ i sono finiti) quindi
E[Mσi+1
]≤ a < b ≤ E [Mτ i ] .

84 CAPITOLO 3. MARTINGALE
Quindi σi+1 e τ i non sono limitati. Per avere il primo attraversamento, per certi ωsi deve aspettare moltissimo. Questo però non è (come invece si potrebbe pensare) unprimo indizio di convergenza: vale anche per il moto browniano, dove la convergenzasicuramente non vale (non basta la proprietà di martingala per garantire la convergenzae per ora abbiamo usato solo questa).
Tronchiamo questi tempi aleatori per poter applicare i risultati d’arresto. Dato unintero positivo T (lo si immagini molto grande), introduciamo i tempi aleatori σi ∧ T ,τ i ∧ T . Fissato T , essi sono tempi d’arresto e sono limitati: i tempi deterministicisono tempi d’arresto, il minimo di due tempi d’arresto è un tempo d’arresto, e sonoovviamente limitati da T . Allora, per il Corollario 9,
E [Mτ i∧T ] ≤ E[Mσi+1∧T
](3.4)
per ogni i. Questo è il primo ingrediente cruciale della dimostrazione.Il secondo parte da una stima per γa,b in termini della martingala. La disuguaglianza
più facile da capire è (non la dimostriamo perché non verrà usata)
γa,b (b− a) ≤∞∑i=1
(Mτ i −Mσi) 1τ i<∞.
Tuttavia, come sopra, dobbiamo lavorare con tempi troncati. Introduciamo allora ilnumero di attraversamenti precedenti a T
γTa,b (ω) = Card i ≥ 1 : τ i (ω) < T
ed osserviamo che
γTa,b (b− a) ≤T∑i=1
(Mτ i∧T −Mσi∧T ) 1τ i<T .
Infatti, se (relativamente ad un certo ω) ci sono esattamente k attraversamenti prece-denti a T , cioè γTa,b = k, per un qualche k = 0, 1, ..., T (si noti che il numero diattraversamenti prima di T è limitato almeno da T , ed in realtà da un numero minoreo uguale a T/2), significa che σ1 < τ 1 < σ2 < ... < τ k < T ≤ τ k+1 (non sappiamoperò dove sta σk+1 rispetto a T ), e quindi (il caso k = 0 va fatto separatamente; loomettiamo)
T∑i=1
(Mτ i∧T −Mσi∧T ) 1τ i<T =k∑i=1
(Mτ i −Mσi) + (MT −Mσi∧T ) 1τk+1<T
≥ k (b− a) = γTa,b (b− a) .
Purtroppo però il termine 1τ i<T produce delle complicazioni più tardi (si pensi al fattoche volgiamo usare la (3.4)). Eppure questo termine è cruciale per cancellare l’addendo

3.5. TEOREMA DI CONVERGENZA PER SUPER-MARTINGALE DISCRETE85
(MT −Mσi∧T ) 1τk+1<T . Un’alternativa è la disuguaglianza
γTa,b (b− a) ≤T∑i=1
(Mτ i∧T −Mσi∧T )− infi=1,...,T
(MT −Mσi∧T )
che si dimostra esattamente come la precedente. Si noti che, se sapessimo che Mn ≥ aper ogni n, allora sarebbe
infi=1,...,T
(MT −Mσi∧T ) ≥ 0
perché, se σi < T allora Mσi∧T < a ≤ MT , mentre se σi ≥ T allora Mσi∧T = MT . Inquesto caso allora avremmo
γTa,b (b− a) ≤T∑i=1
(Mτ i∧T −Mσi∧T ) .
Pertanto, se riusciamo a ricondurci al caso di una submartingala tale che Mn ≥ a perogni n, allora una delle disuguaglianze cruciali si semplifica enormemente. Ma questoè sempre possibile: data una submartingala M e dati a < b, basta introdurre
Man = (Mn − a)+ + a.
Il processo Mn− a è ovviamente una submartingala e quindi lo è anche (Mn − a)+ peril teorema sulle trasformazioni convesse crescenti e quindi anche Ma
n . la submartin-gala Ma
n soddisfa Man ≥ a per ogni n. Inoltre, la quantità γTa,b non varia con queste
trasformazioni. Vale quindi
γTa,b (b− a) ≤T∑i=1
(Ma
τ i∧T −Maσi∧T
). (3.5)
Il terzo ingrediente, che ora forse si può immaginare mettendo insieme i due prece-denti, è la semplice identità
MT −Mσ1∧T =T∑i=1
(Mσi+1∧T −Mτ i∧T +Mτ i∧T −Mσi∧T
)=
T∑i=1
(Mσi+1∧T −Mτ i∧T
)+
T∑i=1
(Mτ i∧T −Mσi∧T ) .
Osserviamo solo, circa la sua validità, cheMσT+1∧T = MT perché non ci possono essereT attraversamenti entro il tempo T . In realtà, vista la (3.5), utilizzeremo l’analogaidentità per il processo Ma.

86 CAPITOLO 3. MARTINGALE
Mettendo insieme i tre ingredienti, abbiamo
MaT −Ma
σ1∧T ≥T∑i=1
(Ma
σi+1∧T −Maτ i∧T
)+ γTa,b (b− a)
da cui, ricordando (3.4) (che vale ovviamente anche per Ma),
E [MaT ]− E
[Ma
σ1∧T]≥ E
[γTa,b]
(b− a) .
Non si scordi cheMa non è una martingala, altrimenti avremmo E [MaT ]−E
[Ma
σ1∧T]
=0 che implicherebbe E
[γTa,b]
= 0 (assurdo negli esempi).Possiamo proseguire la dimostrazione così: vale E
[Ma
σ1∧T]≥ E [Ma
0 ] per il teoremadi arresto per submartingale, quindi
E[γTa,b]≤ 1
b− a (E [MaT ]− E [Ma
0 ]) =1
b− a(E[(MT − a)+]− E [(M0 − a)+])
≤ 1
b− aE[(MT − a)+] .
Si arriva alla stessa conclusione senza il teorema di arresto, con la seguente osservazione:
MaT −Ma
σ1∧T ≤ (MT − a)+ .
Questa disuguaglianza è ovvia se σ1 ≥ T , mentre se σ1 < T vale perché
MaT −Ma
σ1∧T = MaT −Ma
σ1= (MT − a)+ + a− (Mσ1 − a)+ + a ≤ (MT − a)+ .
A questo punto abbiamo dimostrato una stima per il numero medio di attraversa-menti, prima di un tempo T qualsiasi. La stima non dipende da T e quindi è intu-itivamente plausibile che si deduca che il numero di attraversamenti è finito. Bisognapoi escludere la possibilità di limite infinito, se vogliamo un teorema sulla convergenza.Nel prossimo paragrafo sistemiamo tutti questi i dettagli.
3.5.2 Risultati rigorosi
Siano γa,b e γTa,b le grandezze aleatorie definite nella sottosezione precedente: numero
di attraversamenti in salita di [a, b] e numero prima del tempo T .
Lemma 4 Se M = (Mn)n≥0 è una submartingala a tempo discreto, allora per ognia < b e T > 0 intero vale
E[γTa,b]≤ 1
b− aE[(MT − a)+]
E[γa,b]≤ 1
b− a supn∈N
E[(Mn − a)+] .

3.5. TEOREMA DI CONVERGENZA PER SUPER-MARTINGALE DISCRETE87
Proof. La dimostrazione della prima disuguaglianza illustrata al paragrafo prece-dente è completa. Volendo sintetizzare a posteriori i suoi passi, senza le discussioniintermedie:
• si introduce la submartingala ausiliariaMa = (Mn − a)+ +a e si verifica che vale
γTa,b (b− a) ≤T∑i=1
(Ma
τ i∧T −Maσi∧T
)• si osserva che vale la semplice l’identità
MaT −Ma
σ1∧T =T∑i=1
(Ma
σi+1∧T −Maτ i∧T
)+
T∑i=1
(Ma
τ i∧T −Maσi∧T
)da cui si deduce
MaT −Ma
σ1∧T ≥T∑i=1
(Ma
σi+1∧T −Maτ i∧T
)+ γTa,b (b− a)
• usando il teorema d’arresto si deduce
E[γTa,b]≤ 1
b− a(E [Ma
T ]− E[Ma
σ1∧T])
• ed infine si conclude osservando che MaT −Ma
σ1∧T ≤ (MT − a)+.
La stima perE[γa,b]discende dalla precedente e dal teorema di convergenza monotona,
visto che γa,b = limn→∞ γna,b, e che E
[γTa,b]≤ 1
b−a supn∈N E[(Mn − a)+] per ogni T > 0.
La dimostrazione è completa.
Teorema 15 Se M = (Mn)n≥0 è una submartingala a tempo discreto tale che
supn∈N
E[M+
n
]<∞
allora la successione (Mn (ω))n≥0 converge q.c., per n→∞.
Proof. Per il lemma, γa,b <∞ q.c., per ogni a < b prefissati. Ne discende subito che
P(γa,b <∞,∀a < b, a, b ∈ Q
)= 1.
E’un facile esercizio verificare che l’affermazione γa,b < ∞, ∀a < b, a, b ∈ Q implical’affermazione γa,b <∞, ∀a < b, a, b ∈ R. Quindi
P(γa,b <∞,∀a < b
)= 1.

88 CAPITOLO 3. MARTINGALE
Abbiamo già dimostrato (osservazione 20) che se vale γa,b (ω) < ∞, ∀a < b, alloraesiste limn→∞ Mn (ω). Resta quindi solo da dimostrare che tale limite è finito, q.c.
Ricordiamo il lemma di Fatou: E[lim infn→∞
Xn
]≤ lim inf
n→∞E [Xn], ad esempio se le v.a.
Xn sono non negative (si accetta il caso di valori infiniti, ad esempio di lim infn→∞
Xn).
AlloraE[
limn→∞
|Mn|]≤ lim inf
n→∞E [|Mn|] ≤ sup
n∈NE [|Mn|] .
Se avessimo ipotizzato supn∈NE [|Mn|] <∞, concluderemmo subito: dedurremmo chelimn→∞ |Mn| < ∞ q.c., come volevamo. Questa condizione però discende dall’ipotesidel teorema, usando nuovamente la proprietà di submartingala: siccome |x| = 2x+− xper ogni numero reale x, abbiamo
E [|Mn|] = 2E[M+
n
]− E [Mn] ≤ 2E
[M+
n
]− E [M0] ≤ 2 sup
n∈NE[M+
n
]− E [M0]
da cui supn∈NE [|Mn|] <∞. La dimostrazione è completa.I seguenti corollari sono immediati.
Corollario 10 Se per una martingala (o sub o super martingala)M esiste una costanteC > 0 tale che E [|Mn|] ≤ C per ogni n, allora Mn converge.
Corollario 11 Una martingala (o super martingala) positiva converge.
Vediamo un teorema sulle martingale chiuse a tempo discreto.
Corollario 12 Teorema 16 Data una v.a. X integrabile ed una filtrazione (Fn)n≥0,il processo Mn = E [X|Fn] è una martingala, vale E [|Mn|] ≤ E [|X|] e quindi Mn
converge. Inoltre, il limite è E [X|F∞] dove F∞ = ∨nFn. In particolare E [X|Fn]converge ad X se X è F∞-misurabile.
Proof. Abbiamo già dimostrato che M è una martingala, esempio 4. Lì avevamo giàosservato che
E [|Mn|] ≤ E [E [|X| |Fn]] = E [|X|]quindi l’ipotesi del Corollario 10 è soddisfatta. Ne discende che Mn converge q.c.Indichiamo con Z il suo limite.Per dimostrare in totale generalità che Z = E [X|F∞] dovremmo usare il concetto
di uniforme integrabilità ed alcune verifiche supplementari, che omettiamo. Per sem-plicità, limitiamoci a dimostrare l’ultima parte del teorema nel caso in cui X sia diquadrato integrabile: E [X2] <∞. Vale come sopra
E[M2
n
]≤ E
[E[X2|Fn
]]= E
[X2]
fatto che useremo tra un momento.

3.6. ALTRI RISULTATI PER MARTINGALE A TEMPO CONTINUO 89
Dobbiamo dimostrare che Z = E [X|F∞]. Usiamo la definizione di speranza con-dizionale. Innanzi tutto, Z è F∞-misurabile. Infatti, Mn è Fn e quindi F∞-misurabile,e Z è limite quasi certo di Mn. Ora basta verificare che E [Z1A] = E [X1A] perogni A ∈ F∞. E’ suffi ciente dimostrarlo per ogni A appartenente ad una base diF∞. Il fatto che basti verificarlo per una base è molto simile al ragionamento fattoin un’altra occasione, per l’indipendenza tra σ-algebre, che non riportiamo (l’idea èconsiderare l’insieme degli eventi A ∈ F tali che E [Z1A] = E [X1A] e mostrare che èuna σ-algebra).Sia A la famiglia
⋃n
Fn, che non è una σ-algebra (non è F∞). E’però una base di
F∞. Prendiamo A ∈ A, precisamente A ∈ Fn0 per un certo n0. Vale E[(Mn1A)2] ≤
E [M2n] ≤ E [X2], e Mn1A → Z1A q.c., quindi per un teorema di Vitali possiamo
passare al limite sotto il segno di valore atteso: E [Mn1A]→ E [Z1A]. Pertanto
E [Z1A] = limn→∞
E [Mn1A] = limn→∞
E [E [X|Fn] 1A] = limn→∞
E [E [1AX|Fn]]
= limn→∞
E [1AX] = E [1AX] .
Abbiamo usato, al terzo passaggio, il fatto che nel calcolo del limite bastano i valoridi n maggiori di n0 e per essi 1A è Fn-misurabile (in quanto Fn0-misurabile). Ladimostrazione è completa.
3.6 Altri risultati per martingale a tempo continuo
Avendo dimostrato in grande dettaglio le affermazioni precedenti, per non appesantirela trattazione ci limitiamo qui ad un elenco di enunciati. Alcuni sono facili esercizi,altri meno. Supponiamo completo lo spazio di probabilità (Ω,F , P ).
Teorema 17 Sia D ⊂ [0,∞) un insieme numerabile denso. Sia M = (Mt)t∈D unasubmartingala rispetto ad una filtrazione (Ft)t∈D. Supponiamo
supt∈D
E [|Mt|] <∞.
Allora, su un insieme di probabilità uno, esistono finiti il limite per t→∞ ed i limitidestro e sinistro per t→ t0 in ogni punto t0 (t ∈ D).
Teorema 18 Sia M = (Mt)t≥0 una submartingala continua a destra. Supponiamo
supt∈D
E [|Mt|] <∞.
Allora, q.c., esistono finiti il limite per t→∞ ed i limiti sinistri in ogni punto t0.

90 CAPITOLO 3. MARTINGALE
Teorema 19 Sia M = (Mt)t≥0 una martingala rispetto ad una filtrazione (Ft)t≥0 chesoddisfi le condizioni abituali. Allora esiste una modificazione càdlàg diM , che è ancorauna martingala.
Teorema 20 Sia M = (Mt)t≥0 una martingala continua a destra, rispetto ad unafiltrazione (Ft)t≥0, e τ 1 ≤ τ 2 due tempi d’arresto limitati. Allora
E [Mτ2|Fτ1 ] = Mτ1 .
Se τ è un tempo d’arresto q.c. finito (non necessariamente limitato), allora (Mt∧τ )t≥0
è una martingala rispetto a (Ft)t≥0.
3.7 Teoria della variazione quadratica
Ricordiamo che, se (Mt)t≥0 una martingala continua e di quadrato integrabile, allora(M2
t )t≥0 è una submartingala. Nell’ottica del teorema di decomposizione di Doob vistosopra nel caso discreto, ci chiediamo seM2
t si decomponga in somma di una martingalaed un processo crescente. Il processo crescente At che emergerà è di fondamentaleimportanza per il legame col concetto di variazione quadratica.Premettiamo vari lemmi dalla dimostrazione molto tecnica ma anche appassionante.
Al termine enunceremo il risultato forndamentale.SiaX = (Xt)t∈[0,T ] un processo stocastico. Sia∆ la partizione 0 = t0 ≤ ... ≤ tn = T .
Per ogni t ∈ [0, T ], detto k l’intero tale che tk ≤ t < tk+1, poniamo
[X]∆t :=k−1∑i=0
(Xti+1 −Xti
)2+ (Xt −Xtk)
2 .
La chiamiamo variazione quadratica di X relativa alla partizione ∆, su [0, t].Il seguente lemma è una versione rozza di teorema di decomposizione: manca la
proprietà che [M ]∆t sia crescente (non lo è, salvo casi molto particolari).
Lemma 5 Se M è una martingala di quadrato integrabile, allora M2t − [M ]∆t è una
martingala.
Proof. Passo 1. Presi t ≥ s in [0, T ], siano l, k gli interi tali che
tl ≤ s < tl+1 ≤ ... ≤ tk ≤ t < tk+1.
Vale
[M ]∆t − [M ]∆s = (Mt −Mtk)2 +
k−1∑i=l+1
(Mti+1 −Mti
)2+(Mtl+1 −Ms
)2
+2(Mtl+1 −Ms
)(Ms −Mtl) .

3.7. TEORIA DELLA VARIAZIONE QUADRATICA 91
Infatti
[M ]∆t − [M ]∆s =
k−1∑i=0
(Mti+1 −Mti
)2+ (Mt −Mtk)
2
−l−1∑i=0
(Mti+1 −Mti
)2 − (Ms −Mtl)2
= (Mt −Mtk)2 +
k−1∑i=l
(Mti+1 −Mti
)2 − (Ms −Mtl)2
= (Mt −Mtk)2 +
k−1∑i=l+1
(Mti+1 −Mti
)2+(Mtl+1 −Ms
)2
+(Mtl+1 −Mtl
)2 −(Mtl+1 −Ms
)2 − (Ms −Mtl)2
= (Mt −Mtk)2 +
k−1∑i=l+1
(Mti+1 −Mti
)2+(Mtl+1 −Ms
)2
−2Mtl+1Mtl + 2Mtl+1Ms − 2M2s + 2MsMtl
= (Mt −Mtk)2 +
k−1∑i=l+1
(Mti+1 −Mti
)2+(Mtl+1 −Ms
)2
+2(Mtl+1 −Ms
)(Ms −Mtl) .
Passo 2. Presi t ≥ s in [0, T ], vale
E[(Mt −Ms)
2 |Fs]
= E
[(Mt −Mtk)
2 +k−1∑i=l+1
(Mti+1 −Mti
)2+(Mtl+1 −Ms
)2 |Fs
].
Infatti
(Mt −Ms)2 =
(Mt −Mtk +
k−1∑i=l+1
(Mti+1 −Mti
)+(Mtl+1 −Ms
))2
= (Mt −Mtk)2 +
k−1∑i=l+1
(Mti+1 −Mti
)2+(Mtl+1 −Ms
)2
+R

92 CAPITOLO 3. MARTINGALE
dove R è composto da vari doppi prodotti, tutti fatti di incrementi su intervalini dis-giunti. Condizionatamente a Fs, la speranza di tali prodotti è nulla: ad esempio peri < j, con s ≤ ti+1,
E[(Mti+1 −Mti
) (Mtj+1 −Mtj
)|Fs]
= E[E[(Mti+1 −Mti
) (Mtj+1 −Mtj
)|Fti+1
]|Fs]
= E[(Mti+1 −Mti
)E[Mtj+1 −Mtj |Fti+1
]|Fs]
= 0
essendo E[Mtj+1 −Mtj |Fti+1
]= Mti+1 −Mti+1 = 0; e lo stesso vale per gli altri. In
definitiva
E[(Mt −Ms)
2 |Fs]
= E
[(Mt −Mtk)
2 +k−1∑i=l+1
(Mti+1 −Mti
)2+(Mtl+1 −Ms
)2 |Fs
].
Passo 3. Riconoscendo le espressioni uguali negli ennciati dei due passi, abbiamo
E[(Mt −Ms)
2 |Fs]
= E[[M ]∆t − [M ]∆s − 2
(Mtl+1 −Ms
)(Ms −Mtl) |Fs
]= E
[[M ]∆t − [M ]∆s |Fs
]= E
[[M ]∆t |Fs
]− [M ]∆s
perché di nuovo(Mtl+1 −Ms
)(Ms −Mtl) ha speranza condizionale nulla rispetto a Fs
(come nel passo 2). Ma
E[(Mt −Ms)
2 |Fs]
= E[M2
t |Fs]
+ E[M2
s |Fs]− 2E [MtMs|Fs]
= E[M2
t |Fs]−M2
s
(essendo E [M2s |Fs] = M2
s e E [MtMs|Fs] = MsE [Mt|Fs] = M2s ). Pertanto
E[M2
t |Fs]−M2
s = E[[M ]∆t |Fs
]− [M ]∆s
da cui discende la tesi.Vogliamo dimostrare che [M ]∆T converge in media quadratica quando∆ converge. E’
quindi naturale dimostrare innanzi tutto che [M ]∆T è equilimitata in media quadratica,rispetto a ∆. Questi risultati richiedono che M sia anche limitata.
Lemma 6 Sia M una martingala limitata: esiste C > 0 tale che |Mt| ≤ C per ogni
t ∈ [0, T ], con probabilità uno. Allora esiste E[(
[M ]∆T
)2]è limitato indipendentemente
dalla partizione ∆:
E
[([M ]∆T
)2]≤(2C + 2C2
)2.

3.7. TEORIA DELLA VARIAZIONE QUADRATICA 93
Proof. Osserviamo che
[M ]∆T :=
n−1∑i=0
(Mti+1 −Mti
)2.
Quindi, anche se M è limitata, non si può concludere subito che [M ]∆T sia limitata,perché c’è una sommatoria arbitraria. Vale
([M ]∆T
)2
: =
n−1∑i=0
(Mti+1 −Mti
)4+ 2
∑i<j
(Mti+1 −Mti
)2 (Mtj+1 −Mtj
)2
=n−1∑i=0
(Mti+1 −Mti
)4+ 2
n−1∑i=0
(Mti+1 −Mti
)2(
[M ]∆T − [M ]∆ti+1
)≤ sup
j
(Mtj+1 −Mtj
)[M ]∆T + 2
n−1∑i=0
(Mti+1 −Mti
)2(
[M ]∆T − [M ]∆ti+1
)≤ 2C [M ]∆T + 2
n−1∑i=0
(Mti+1 −Mti
)2(
[M ]∆T − [M ]∆ti+1
).
Questo conto rivela l’idea: trovare una relazione ricorsiva per [M ]∆T . Per farlo sulsecondo termine bisogna integrare:
n−1∑i=0
E[(Mti+1 −Mti
)2(
[M ]∆T − [M ]∆ti+1
)]=
n−1∑i=0
E[(Mti+1 −Mti
)2E[[M ]∆T − [M ]∆ti+1 |Fti+1
]]=
n−1∑i=0
E[(Mti+1 −Mti
)2E[M2
T −M2ti+1|Fti+1
]]=
n−1∑i=0
E[(Mti+1 −Mti
)2(M2
T −M2ti+1
)]≤ E
[supj
(M2
T −M2tj+1
)[M ]∆T
]≤ 2C2E
[[M ]∆T
]dove abbiamo usato il lemma precedente. Pertanto
E
[([M ]∆T
)2]≤(2C + 2C2
)E[[M ]∆T
]≤(2C + 2C2
)E
[([M ]∆T
)2]1/2

94 CAPITOLO 3. MARTINGALE
da cui E[(
[M ]∆T
)2]1/2
≤ (2C + 2C2).
Sia ∆n una successione di partizioni di [0, T ] con |∆n| → 0. Diremo che è unasuccessione di partizioni incapsulate se vale∆n+1 ⊂ ∆n. Il seguente lemma ed i risultatiche seguono valgono anche senza questa condizione, ma la dimostrazione è ancora unpo’più laboriosa e meno meccanica.
Lemma 7 Sia ∆n una successione di partizioni incapsulate di [0, T ] con |∆n| → 0. SeM è una martingala continua e limitata, allora [M ]∆n
T converge in media quadratica.
Proof. Vale
[M ]∆n
T :=
Nn−1∑i=0
(Mtni+1
−Mtni
)2
dove implicitamente abbiamo indicato le notazioni che useremo. Preso m > n, preso i,l’intervallo
[tni , t
ni+1
]è scomposto dalla partizione ∆m nella forma
tni = tmk ≤ ... ≤ tmk+l = tni+1 (3.6)
e di conseguenza
Mtni+1−Mtni
=k+l−1∑j=k
(Mtmj+1
−Mtmj
)(Mtni+1
−Mtni
)2
=k+l−1∑j=k
(Mtmj+1
−Mtmj
)2
+Ri
dove Ri è somma di prodotti del tipo(Mtmj+1
−Mtmj
)(Mtm
j′+1−Mtm
j′
)con j 6= j′, che
scriviamo espressivamente come
Ri =∑
j(i)6=j′(i)
∆mj(i)∆
mj′(i)
intendendo che gli indici j (i) , j′ (i) sono tutti e soli quelli che soddisfano le relazionitni ≤ tmj , t
mj′ , t
mj+1, t
mj′+1 ≤ tni+1. Pertanto
[M ]∆n
T − [M ]∆m
T =
Nn−1∑i=0
Ri =
Nn−1∑i=0
∑j(i)6=j′(i)
∆mj(i)∆
mj′(i)
([M ]∆n
T − [M ]∆m
T
)2
=Nn−1∑i=0
∑j(i) 6=j′(i)
(∆mj(i)∆
mj′(i)
)2+ S

3.7. TEORIA DELLA VARIAZIONE QUADRATICA 95
dove S è somma di prodotti del tipo(
∆mj(i)∆
mj′(i)
)(∆mj(k)∆
mj′(k)
). Si vede subito, col
solito trucco, cheE[(
∆mj(i)∆
mj′(i)
) (∆mj(k)∆
mj′(k)
)]= 0
isolando tramite una speranza condizionale interna il fattore con gli indici più grossi.Pertanto E [S] = 0. Vale quindi
E
[([M ]∆n
T − [M ]∆m
T
)2]
= E
Nn−1∑i=0
∑j(i) 6=j′(i)
(∆mj(i)∆
mj′(i)
)2
= 2E
Nn−1∑i=0
∑j(i)
(∆mj(i)
)2∑
j′(i)>j(i)
(∆mj′(i)
)2
= 2E
Nn−1∑i=0
∑j(i)
(∆mj(i)
)2(
[M ]∆m
tni+1− [M ]∆m
tmj(i)+1
)= 2E
Nn−1∑i=0
∑j(i)
(∆mj(i)
)2(M2
tni+1−M2
tmj(i)+1
)dove abbiamo usato il solito trucco
E[(
∆mj(i)
)2(
[M ]∆m
tni+1− [M ]∆m
tmj(i)+1
)]= E
[(∆mj(i)
)2E[[M ]∆m
tni+1− [M ]∆m
tmj(i)+1
|Ftmj(i)+1
]]= E
[(∆mj(i)
)2E[M2
tni+1−M2
tmj(i)+1|Ftm
j(i)+1
]]= E
[(∆mj(i)
)2(M2
tni+1−M2
tmj(i)+1
)]basato sulla proprietà di martingala del primo lemma. Pertanto
E
[([M ]∆n
T − [M ]∆m
T
)2]≤ 2E
supi,j(i)
(M2
tni+1−M2
tmj(i)+1
)Nn−1∑i=0
∑j(i)
(∆mj(i)
)2
= 2E
[supi,j(i)
(M2
tni+1−M2
tmj(i)+1
)[M ]∆m
T
]
≤ 2E
[supi,j(i)
(M2
tni+1−M2
tmj(i)+1
)2]1/2
E
[([M ]∆m
T
)2]1/2
quindi, per un’opportuna costante C ′ > 0, vale
E
[([M ]∆n
T − [M ]∆m
T
)2]≤ C ′E
[supi,j(i)
(M2
tni+1−M2
tmj(i)+1
)2]1/2
.

96 CAPITOLO 3. MARTINGALE
Siccome M è continuo e |∆m| → 0, supi,j(i)
(M2
tni+1−M2
tmj(i)+1
)2
→ 0 q.c.; essendoM limitata, si può applicare il teorema di convergenza dominata e concludere che
E
[supi,j(i)
(M2
tni+1−M2
tmj(i)+1
)2]→ 0. Quindi la successione [M ]∆n
T è di Cauchy in L2 e
pertanto converge.
Teorema 21 Sia ∆n una successione di partizioni incapsulate di [0, T ] con |∆n| → 0.Sia M è una martingala continua e limitata. Allora [M ]∆n
t converge uniformemente int, in media quadratica, ad un processo continuo e non decrescente At:
limn→∞
E
[supt∈[0,T ]
∣∣∣[M ]∆n
t − At∣∣∣2] = 0.
Proof. Sappiamo che [M ]∆n
t − M2t è una martingala, quindi per differenza anche
[M ]∆n
t − [M ]∆m
t è una martingala, quindi per il teorema di Doob abbiamo
E
[supt∈[0,T ]
∣∣∣[M ]∆n
t − [M ]∆m
t
∣∣∣2] ≤ 4E
[∣∣∣[M ]∆n
T − [M ]∆m
T
∣∣∣2]da cui discende (per il lemma precedente) che [M ]∆n
t è una successione di Cauchy nellospazio completo L2 (Ω, C ([0, T ])), quindi converge (nel senso detto dall’enunciato delteorema) ad un processo continuo A tale che E
[supt∈[0,T ] |At|
2] <∞.Passando ad una sottosuccessione, possiamo assumere che la convergenza sia quasi
certa. Preso un ω per cui c’è convergenza e presi t > s appartenenti a⋃n
∆n, esiste
sicuramente n0 tale che per ogni n ≥ n0 risulta [M ]∆n
t ≥ [M ]∆n
s . Quindi, al limite,At ≥ As. Siccome A è continuo e
⋃n
∆n è denso, ne discende At ≥ As per ogni t > s.
Quanto illustrato fino ad ora è la parte diffi cile della teoria della variazione quadrat-ica di martingale continue. Con poco ma noioso sforzo in più, effetturato tramite l’usodi tempi di arresto (che rendono limitata una martingala generica) ed alcuni argomenticomplementari, si arriva al seguente risultato.
Teorema 22 Sia ∆n una successione di partizioni incapsulate di [0, T ] con |∆n| →0. Sia M una martingala continua. Allora [M ]∆n
t converge uniformemente in t, inprobabilità, ad un processo continuo e non decrescente At:
limn→∞
P
(supt∈[0,T ]
∣∣∣[M ]∆n
t − At∣∣∣2 > ε
)= 0
per ogni ε > 0. Il processo At non dipende (nel senso dell’indistinguibilità) dallasuccessione di partizioni. Verrà detto variazione quadratica di M ed indicato con [M ]t.Inoltre, il processo M2
t − [M ]t è una martingala. Viceversa, se A è un processocontinuo crescente con A0 = 0, tale che M2
t − At sia una martingala, allora A = [M ].

3.8. MARTINGALE LOCALI E SEMIMARTINGALE 97
3.8 Martingale locali e semimartingale
Abbiamo visto sopra che se M = (Mt)t≥0 è una martingala continua a destra, rispettoad una filtrazione (Ft)t≥0, e τ è un tempo d’arresto q.c. finito, allora (Mt∧τ )t≥0 è unamartingala rispetto a (Ft)t≥0. Questo risultato dà lo spunto per una nuova definizione.Diciamo che un processo (Mt)t≥0 è una martingala locale rispetto a (Ft)t≥0 se esiste
una successione crescente τnn∈N di tempi d’arresto, con limn→∞ τn = +∞, tale che(Mt∧τn)t≥0 è una martingala rispetto a (Ft)t≥0, per ogni n ∈ N. Diciamo che i tempiτn riducono M .Una martingala è una martingala locale (τn = +∞ per ogni n). Per noi l’interesse
maggiore per questo concetto risiederà nel fatto che gli integrali stocastici di processiabbastanza generali sono martingale locali, ma non sempre martingale. Un esempiomolto particolare di questa situazione è il seguente, che comunque illustra un’ideagenerale, quella di troncamento o localizzazione.
Esempio 5 Sia B un moto browniano rispetto a (Ft)t≥0 e sia X0 una v.a. F0-misurabile. Poniamo
Mt = X0Wt.
Se ipotizziamo che X0 sia di quadrato integrabile, o in questo semplice esempio anchesolo integrabile, allora Mt è integrabile perché prodotto di v.a. indipendenti integrabili,e vale
E [X0Wt|Fs] = X0E [Wt|Fs] = X0Ws
cioè Mt è una martingala. Se invece non supponiamo alcuna integrabilità di X0, Mt
non sarà in generale integrabile e quindi non possiamo porci il problema se sia o menouna martingala. Introduciamo però il tempo aleatorio
τn =
∞ se |X0| ≤ n0 se |X0| > n
.
E’un tempo d’arresto:
τn ≤ t = (τn ≤ t ∩ |X0| ≤ n) ∪ (τn ≤ t ∩ |X0| > n)= ∅ ∪ |X0| > n ∈ F0 ⊂ Ft
per ogni t ≥ 0. Inoltre, τn →∞ q.c. Infine,
Mt∧τn = X0Wt∧τn =
X0Wt se |X0| ≤ n
0 se |X0| > n
quindiMt∧τn = X01|X0|≤nWt.
Il processo Mt∧τn è quindi una martingala, perché della forma Y0Wt con Y0 integrabile.

98 CAPITOLO 3. MARTINGALE
Diciamo per brevità che un processo è a variazione limitata se q.c. le sue traiettoriehanno variazione limitata su ogni intervallo finito.Diciamo infine che un processo (Xt)t≥0 è una semimartingala rispetto a (Ft)t≥0 se è
la somma di una martingala locale e di un processo adattato a variazione limitata. Inbase ad uno dei risultati precedenti, un importante esempio di semimartingala è M2
t ,dove M è una martingala continua. Vedremo più in generale nel seguito che anchef (Mt) con f ∈ C2 è una semimartingala, ed ancor più in generale vedremo che se Xè una semimartingala continua, allora lo è anche f (Xt) con f ∈ C2. Per questa edaltre ragioni, la classe delle semimartingale è in un certo senso chiusa per il cosiddettocalcolo stocastico, contiene gli oggetti di maggior interesse (moto browniano, integralistocastici) e quindi è la classe privilegiata in cui svolgere il calcolo.Si può dimostrare che il Teorema 22 si generalizza a tutte le semimartingale con-
tinue, ovvero somma di una martingala locale continua e di un processo continuo avariazione limitata.
Teorema 23 Sia (Xt)t≥0 una semimartingala continua. Valgono le affermazioni delTeorema 22 sia per X sia per la sua parte M di martingala locale, e risulta [X] = [M ].
Pur non vedendo la dimostrazione nel suo complesso ed in totale generalità, esaminer-emo alcune classi di processi (definiti tramite integrali stocastici) per cui alcune diqueste affermazioni saranno dimostrate. Già conosciamo una prima classe: i processidella forma
Xt = Bt + Vt
dove B è un moto browniano e V è un processo continuo a variazione limitata. Infatti,per B abbiamo dimostrato che esiste la variazione quadratica (anche come limite in me-dia quadratica) e, sempre nel capitolo del moto browniano, abbiamo visto che una fun-zione f continua a variazione limitata ha la proprietà lim|πk|→0
∑nk−1i=0 |f (ti+1)− f (ti)|2 =
0, quindi per V esiste lim|πk|→0
∑nk−1i=0
∣∣Vti+1 − Vti∣∣2 quasi certamente (quindi anche inprobabilità), e vale zero.Per la stessa ragione, la coincidenza dei due limiti nel teorema è un fatto ovvio, non
appena uno dei due esiste. Quello che è un po’laborioso è mostrare che esiste [M ]tper ogni martingala locale continua, ma il grosso della dimostrazione è stato illustratonella sezione precedente.

Capitolo 4
L’integrale stocastico
4.1 Integrale di processi elementari
Lo scopo di questo capitolo è quello di definire ed esaminare un integrale del tipo∫ b
a
XtdBt
dove B è un moto browniano ed X un processo, soggetto ad opportune ipotesi (manon più regolare di B, altrimenti la teoria non sarebbe applicabile alle equazionistocastiche).Nel capitolo sul moto browniano abbiamo già discusso le diffi coltà che si incontrano
a tentare di definire tale integrale usando concetti classici, come l’integrale di Lebesgue-Stieltjes. Vediamo come K. Itô, nei primi anni quaranta, ha risolto questo problema.Usiamo le notazioni già introdotte nel capitolo delle martingale. Sia B = (Bt)t≥0 un
moto browniano rispetto ad una filtrazione (Ft)t≥0. Chiamiamo processo elementareogni processo stocastico X = (Xt)t≥0 adattato a (Ft)t≥0 ma costante a tratti relati-vamente ad una sequenza di tempi tn ≥ tn−1 ≥ ... ≥ t1 = 0, cioè ogni processo dellaforma
Xt =
n−1∑i=1
Xti1[ti,ti+1) (t) , Xti misurabile rispetto a Fti .
Se in più richiediamoE[X2ti
]<∞ per ogni i = 1, ..., n
allora lo diremo di quadrato integrabile.Per ogni b ≥ a ≥ 0, poniamo∫ b
a
XsdBs =n−1∑i=1
Xti
(B(a∨ti+1)∧b −B(a∨ti)∧b
).
99

100 CAPITOLO 4. L’INTEGRALE STOCASTICO
Come già osservato in quel capitolo, siccome le espressioni (a ∨ ti+1)∧b e (a ∨ ti)∧bsono troppo laboriose, si può adottare la seguente convenzione. Fissati b ≥ a ≥ 0, si puòarricchire la sequenza di tempi considerando la nuova sequenza t′n+2 ≥ t′n−1 ≥ ... ≥ t′1 =
0 formata dai tempi ti e da a, b, e riscrivendo Xt nella forma Xt =∑n+1
i=1 X′t′i
1[t′i,t′i+1) (t)
con le v.a. X ′t′i misurabili rispetto a Ft′i così definite: se t′i = tj ∈ t1, ..., tn, poniamo
X ′t′i= Xtj ; se t
′i = a (risp. t′i = b) e tj ∈ t1, ..., tn è il più grande con la proprietà
tj ≤ a (risp. tj ≤ b), allora poniamo X ′t′i = Xtj .Qui, per semplicità di notazione, indichiamo la nuova sequenza ancora con tn ≥
tn−1 ≥ ... ≥ t1 = 0; oppure, se si vuole, fissati b ≥ a ≥ 0, si considerano solo quellesequenze tn ≥ tn−1 ≥ ... ≥ t1 = 0 che contengono a e b (una terza strategia è diconsiderare suddivisioni dell’intervallo [a, b] solamente, invece che processi definiti pertutti i t ≥ 0).Poniamo allora ∫ b
a
XsdBs =∑
a≤ti≤ti+1≤b
Xti
(Bti+1 −Bti
).
Con un po’di pazienza si può riconoscere che le due definizioni ora scritte di∫ baXsdBs
coincidono. Possiamo anche introdurre l’insieme di indici
Ja,b = i = 1, ..., n : a ≤ ti ≤ ti+1 ≤ b
e scrivere ∫ b
a
XsdBs =∑i∈Ja,b
Xti
(Bti+1 −Bti
).
Dati c ≥ b ≥ a, si può verificare con pazienza che vale∫ c
a
XsdBs =
∫ b
a
XsdBs +
∫ c
b
XsdBs
(omettiamo i dettagli). Il risultato forse più importante di questo inizio di teoria è ilseguente. La seconda identità è detta a volte formula di isometria.
Proposizione 37 Sia X un processo elementare di quadrato integrabile. Allora la v.a.∫ baXsdBs ha media e varianza finite e vale
E
[∫ b
a
XsdBs
]= 0
E
[(∫ b
a
XsdBs
)2]
=
∫ b
a
E[X2s
]ds.

4.1. INTEGRALE DI PROCESSI ELEMENTARI 101
Proof. Ricordiamo che, date due v.a. X, Y indipendenti e integrabili, il loro prodottoXY è integrabile e vale E [XY ] = E [X]E [Y ]. Ciascun addendo Xti
(Bti+1 −Bti
)che
compone∫ baXsdBs è di tale forma, perché Bti+1 − Bti è indipendente da Fti ed Xti è
Fti-misurabile, quindi∫ baXsdBs è integrabile, e vale
E
[∫ b
a
XsdBs
]=∑i∈Ja,b
E[Xti
(Bti+1 −Bti
)]=∑i∈Ja,b
E [Xti ]E[Bti+1 −Bti
]= 0
in quanto gli incrementi browniani hanno attesa nulla.Vale poi, con la notazione ∆iB = Bti+1 −Bti ,(∫ b
a
XsdBs
)2
=∑i∈Ja,b
∑j∈Ja,b
XtiXtj∆iB∆jB =∑i∈Ja,b
X2ti
(∆iB)2+2∑
i,j∈Ja,b,i<jXtiXtj∆iB∆jB.
Gli addendi X2ti
(∆iB)2 sono integrabili perché X2tie (∆iB)2 sono indipendenti (trasfor-
mazioni di v.a. indipendenti) ed integrabili (X2tiper ipotesi, (∆iB)2 perché gli in-
crementi browniani hanno tutti i momenti finiti). Esaminiamo l’integrabilità degliaddendi XtiXtj∆iB∆jB. Le v.a. Xti e ∆iB sono indipendenti, quindi anche X2
tie
(∆iB)2, che sono integrabili, quindi Xti∆iB è di quadrato integrabile. Anche Xtj èdi quadrato integrabile, quindi XtiXtj∆iB è integrabile, essendo prodotto di v.a. diquadrato integrabile. Siccome XtiXtj∆iB è indipendente da ∆jB (come spiegheremotra un attimo), allora XtiXtj∆iB∆jB è integrabile. Questo completa la verifica che(∫ b
aXsdBs
)2
è integrabile. L’indipendenza tra XtiXtj∆iB e ∆jB si spiega così: la v.a.
∆jB è indipendente da Ftj ed XtiXtj∆iB è Ftj -misurabile (Xti è Fti-misurabile, quin-di Ftj -misurabile perché i < j, ∆iB è Fti+1-misurabile, quindi Ftj -misurabile perchéi+ 1 ≤ j).Usando questi stessi fatti, vale
E
[(∫ b
a
XsdBs
)2]
=∑i∈Ja,b
E[X2ti
]E[(∆iB)2]+ 2
∑i,j∈Ja,b,i<j
E[XtiXtj∆iB
]E [∆jB]
=∑i∈Ja,b
E[X2ti
](ti+1 − ti) =
∫ b
a
E[X2s
]ds.
Abbiamo usato anche le proprietà E[(∆iB)2] = ti+1 − ti, E [∆jB] = 0. Si osservi che∫ b
a
E[X2s
]ds =
∑i∈Ja,b
∫ ti+1
ti
E[X2s
]ds =
∑i∈Ja,b
E[X2ti
](ti+1 − ti) .
La dimostrazione è completa.Vale in realtà una versione rafforzata del risultato precedente:

102 CAPITOLO 4. L’INTEGRALE STOCASTICO
Proposizione 38 Sia X un processo elementare di quadrato integrabile. Allora
E
[∫ t
s
XudBu|Fs]
= 0
E
[(∫ t
s
XudBu
)2∣∣∣∣∣Fs
]= E
[∫ t
s
X2udu
∣∣∣∣Fs] .Proof. Sappiamo già che
∫ tsXudBu e
(∫ tsXudBu
)2
sono integrabili. Vale
E
[∫ t
s
XudBu|Fs]
=∑i∈Js,t
E [Xti∆iB|Fs]
ma, contrariamente a varie situazioni apparentemente simili, non possiamo ad esempioportare Xti fuori dalla speranza condizionale, perché ti è più grande di s. Se peròriscriviamo
E [Xti∆iB|Fs] = E [E [Xti∆iB|Fti ] |Fs]allora vale
E [Xti∆iB|Fs] = E [XtiE [∆iB|Fti ] |Fs] = E [XtiE [∆iB] |Fs] = 0
dove abbiamo usato il fatto che ∆iB è indipendente da Fti ed è centrato. QuindiE[∫ t
sXudBu|Fs
]= 0.
Sappiamo poi già che vale(∫ t
s
XudBu
)2
=∑i∈Js,t
X2ti
(∆iB)2 + 2∑
i,j∈Js,t,i<jXtiXtj∆iB∆jB.
Allora, usando lo stesso trucco e le solite proprietà si ottiene
E
[(∫ t
s
XudBu
)2∣∣∣∣∣Fs
]=
∑i∈Js,t
E[X2ti
(∆iB)2 |Fs]
+ 2∑
i,j∈Js,t,i<jE[XtiXtj∆iB∆jB|Fs
]=
∑i∈Js,t
E[E[X2ti
(∆iB)2 |Fti]|Fs]
+ 2∑
i,j∈Js,t,i<jE[E[XtiXtj∆iB∆jB|Ftj
]|Fs]
=∑i∈Js,t
E[X2tiE[(∆iB)2] |Fs]+ 2
∑i,j∈Js,t,i<j
E[XtiXtj∆iBE [∆jB] |Fs
]=
∑i∈Js,t
E[X2ti|Fs]
(ti+1 − ti) = E
∑i∈Js,t
X2ti
(ti+1 − ti) |Fs
da cui la tesi. La dimostrazione è completa.La prima parte del seguente corollario era già stata dimostrata, in modo un po’
diverso, nel capitolo delle martingale.

4.1. INTEGRALE DI PROCESSI ELEMENTARI 103
Corollario 13 Sia X un processo elementare di quadrato integrabile. Allora Mt =∫ t0XsdBs è una martingala rispetto a (Ft)t≥0. Inoltre, M
2t −∫ t
0X2udu è una martingala
rispetto a (Ft)t≥0.
Proof. E’adattato perché, ad ogni istante t ≥ 0,∫ t
0XsdBs è somma di v.a. Ft-
misurabili. E’integrabile. Vale poi, ricordando che per t ≥ s ≥ 0 abbiamo∫ t
0XudBu =∫ s
0XudBu +
∫ tsXudBu,
E [Mt −Ms|Fs] = E
[∫ t
s
XudBu, |Fs]
= 0.
Quindi M è una martingala.Per ragioni simili, anche M2
t −∫ t
0X2udu è adattato. M
2t è integrabile.
∫ t0X2udu è
integrabile perché (per il teorema di Fubini)
E
[∫ t
0
X2udu
]=
∫ t
0
E[X2u
]du <∞.
Vale poi
E
[M2
t −∫ t
0
X2udu|Fs
]= E
[(Mt −Ms)
2 −∫ t
s
X2udu|Fs
]+E
[2MtMs −M2
s −∫ s
0
X2udu|Fs
]= 2MsE [Mt|Fs]−M2
s −∫ s
0
X2udu = M2
s −∫ s
0
X2udu
quindi M2t −
∫ t0X2udu è una martingala. La dimostrazione è completa.
Con un linguaggio introdotto al termine del capitolo sulle martingale, si può direche
∫ t0X2udu è il processo crescente associato alla submartigala M
2t . Elenchiamo a
questo proposito alcune situazioni viste fino ad ora.
1. Se Mn è una martingala a tempo discreto, di quadrato integrabile, allora perla sub-martigala M2
n vale la decomposizione di Doob M2n = Nn + An, dove An
è crescente. Quindi esiste un processo crescente An tale che M2n − An è una
martingala.
2. Se B è un moto browniano, allora B2t −t è una martingala (facile esercizio oppure
caso particolare del Corollario 13). Il processo At = t è crescente.
3. Se X è un processo elementare di quadrato integrabile ed introduciamo la mar-tingala Mt =
∫ t0XsdBs, allora M2
t −∫ t
0X2udu è una martingala (e At =
∫ t0X2udu
è un processo crescente).
4. In generale abbiamo enunciato un teorema che afferma che, seM è una martingalacontinua, di quadrato integrabile, allora esiste un processo crescente At tale cheM2
t − At è una martingala.

104 CAPITOLO 4. L’INTEGRALE STOCASTICO
4.1.1 Estensione a integratori martingale
Proviamo ad estendere la teoria precedente al caso dell’integrale del tipo∫ baXtdMt
dove M è una martingala rispetto ad una filtrazione (Ft)t≥0.Supponiamo che X sia una processo elementare limitato, cioè della forma Xt =∑n−1i=1 Xti1[ti,ti+1) (t) dove le v.a. Xti , Fti-misurabili, sono limitate. Supponiamo che la
sequenza tn ≥ tn−1 ≥ ... ≥ t1 = 0 contenga b ≥ a ≥ 0 e poniamo∫ b
a
XtdMt =∑i∈Ja,b
Xti
(Mti+1 −Mti
).
Supponiamo inoltre che la martingala sia continua e di quadrato integrabile. Pertantoesiste uno ed un solo processo crescente At tale che M2
t − At sia una martingala (senon si vuole usare tale teorema, dal momento che non è stato dimostrato, si prendal’esistenza di At come un’ipotesi sulla martingala M). Vale quindi
E[(Mt −Ms)
2 − (At − As) |Fs]
= E[M2
t − At|Fs]− 2MsE [Mt|Fs] +M2
s + As
= M2s − As − 2M2
s +M2s + As = 0
ovveroE[(Mt −Ms)
2 |Fs]
= E [(At − As) |Fs] .
Proposizione 39 La v.a.∫ tsXudMu è di quadrato integrabile e vale
E
[∫ t
s
XudMu
∣∣∣∣Fs] = 0
E
[(∫ t
s
XudMu
)2∣∣∣∣∣Fs
]= E
[∫ t
s
X2udAu
∣∣∣∣Fs] .Proof. Dalla formula(∫ t
s
XudMu
)2
=∑i∈Js,t
X2ti
(∆iM)2 + 2∑
i,j∈Js,t,i<jXtiXtj∆iM∆jM
si vede che(∫ t
sXudMu
)2
è integrabile (le Xti sono limitate). Allora, usando le soliteproprietà della speranza condizionale e la proprietà di martingala per M , vale
E
[∫ t
s
XudMu
∣∣∣∣Fs] =∑i∈Js,t
E [Xti∆iM |Fs] =∑i∈Js,t
E [E [Xti∆iM |Fti ] |Fs]
=∑i∈Js,t
E [XtiE [∆iM |Fti ] |Fs] = 0

4.2. INTEGRALEDI PROCESSI PROGRESSIVAMENTEMISURABILI, DI QUADRATO INTEGRABILE105
(in quanto E [∆iM |Fti ] = 0) ed analogamente
E
[(∫ t
s
XudMu
)2∣∣∣∣∣Fs
]=
∑i∈Js,t
E[X2ti
(∆iM)2 |Fs]
+ 2∑
i,j∈Js,t,i<jE[XtiXtj∆iM∆jM |Fs
]=
∑i∈Js,t
E[E[X2ti
(∆iM)2 |Fti]|Fs]
+ 2∑
i,j∈Js,t,i<jE[E[XtiXtj∆iM∆jM |Ftj
]|Fs]
=∑i∈Js,t
E[X2tiE[(∆iM)2 |Fti
]|Fs]
+ 2∑
i,j∈Js,t,i<jE[XtiXtj∆iME
[∆jM |Ftj
]|Fs]
=∑i∈Js,t
E[X2ti|Fs] (Ati+1 − Ati
)= E
∑i∈Js,t
X2ti
(Ati+1 − Ati
)|Fs
da cui la tesi. La dimostrazione è completa.
4.2 Integrale di processi progressivamente misura-bili, di quadrato integrabile
Sia B = (Bt)t≥0 un moto browniano rispetto ad una filtrazione (Ft)t≥0. Dati b ≥ a ≥0, diciamo che un processo X = (Xt)t≥0 è di classe M
2B (a, b) se è progressivamente
misurabile e vale
E
[∫ b
a
X2t dt
]<∞.
Per dare questa definizione basterebbe che il processo fosse definito e progressivamentemisurabile su [a, b]. I processi elementari, cioè della formaXt =
∑n−1i=1 Xti1[ti,ti+1) (t) con
Xti misurabile rispetto a Fti , sono progressivamente misurabili; sono di classeM2B (a, b)
se e solo se sono di quadrato integrabile su [a, b], cioè E[X2ti
]< ∞ per ogni i ∈ Ja,b,
in quanto
E
[∫ b
a
X2t dt
]=∑i∈Ja,b
E[X2ti
](ti+1 − ti) .
Si potrebbe anche dire che M2B (a, b) è la famiglia delle classi di equivalenza dei
processi suddetti, identificando processi X,X ′ tali che E[∫ b
a(Xt −X ′t)
2 dt]
= 0; lo
spazio M2B (a, b) con il prodotto scalare 〈X,X ′〉 = E
[∫ baXtX
′tdt]risulterebbe uno
spazio di Hilbert. Non useremo esplicitamente queste convenzioni e questi fatti.Diremo che X è di classe M2
B se è di classe M2B (0, T ) per ogni T > 0.
Teorema 24 Se X è di classe M2B (a, b), allora esiste una successione di processi
elementari X(n), anch’essi di classe M2B (a, b), tale che
limn→∞
E
[∫ b
a
(Xt −X(n)
t
)2
dt
]= 0. (4.1)

106 CAPITOLO 4. L’INTEGRALE STOCASTICO
Esiste anche una successione di processi continui X(n), di classeM2B (a, b), che converge
ad X nel senso (4.1).
La dimostrazione è piuttosto laboriosa anche se sostanzialmente elementare. Bisognaprima dimostrare che X si può approssimare con processi continui adattati, poi che unprocesso continuo e adattato si può approssimare con processi costanti a tratti adattati.La prima cosa si fa tramite convoluzione con mollificatori unilaterali (cioè che integra-no solo la parte di processo precedente all’istante in cui si calcola la convoluzione).La seconda si fa semplicemente prendendo il valore del processo continuo nell’estremosinistro di ogni intervallino di una partizione, sempre più fine. Vanno però verificatenumerose proprietà, anche un po’laboriose, per cui omettiamo i dettagli, anche perchésimili a quelli di tante dimostrazioni di Analisi relative ai più svariati spazi di funzioni.Vediamo invece le conseguenze di questo teorema.
Proposizione 40 Se X(n) è una successione di processi elementari di classe M2B (a, b)
che converge ad un processo X di classe M2B (a, b) nel senso (4.1), allora la successione
di v.a. ∫ b
a
X(n)t dBt
è di Cauchy in L2 (Ω,F , P ). Il suo limite, elemento di L2 (Ω,F , P ), dipende solo daX (non dalla successione scelta) e verrà indicato con
∫ baXtdBt, detto integrale di Itô
di X.
Proof. Per la formula di isometria dimostrata per i processi elementari, vale
E
[(∫ b
a
(X
(n)t −X
(m)t
)dBt
)2]
=
∫ b
a
E
[(X
(n)t −X
(m)t
)2]dt
da cui discende subito che∫ baX
(n)t dBt è una successione di Cauchy in L2 (Ω,F , P ),
quindi ha limite, essendo questo spazio completo. Se X(n) è un’altra successione con lestesse caratteristiche convergente adX, allora la successione Y (n) data da Y (2n) = X(n),Y (2n+1) = X(n) ha le stesse caratteristiche e converge ad X, nel senso (4.1). Quindi∫ baY
(n)t dBt è una successione di Cauchy in L2 (Ω,F , P ). Il suo limite deve essere lo
stesso delle due sottosuccessioni di indici pari e dispari, limiti che quindi coincidono.La dimostrazione è completa.
Osservazione 22 L’integrale stocastico∫ baXtdBt è, per definizione, una classe di
equivalenza, o se si preferisce è una v.a. definita a meno di modificazioni su insie-mi di misura nulla. Non ha senso, fissato un certo ω ∈ Ω, chiedersi quanto valga(∫ b
aXtdBt
)(ω). In particolare, non ha senso scrivere cose del tipo
(∫ baXtdBt
)(ω) =∫ b
aXt (ω) dBt (ω) (per i processi elementari invece ha senso e vale l’identità). L’unica

4.2. INTEGRALEDI PROCESSI PROGRESSIVAMENTEMISURABILI, DI QUADRATO INTEGRABILE107
teoria che, al momento attuale, è in grado di dare un significato a questo tipo di scrit-ture, per particolari processi X, è quella dei rough paths, però molto più laboriosa diquella ora sviluppata.
Teorema 25 Sia X di classe M2B (0, T ), per un certo T > 0. Allora
E
[∫ T
0
XsdBs
]= 0
E
[(∫ T
0
XsdBs
)2]
=
∫ T
0
E[X2s
]ds
Più in generale, per ogni 0 ≤ s ≤ t ≤ T vale
E
[∫ t
s
XudBu|Fs]
= 0
E
[(∫ t
s
XudBu
)2∣∣∣∣∣Fs
]= E
[∫ t
s
X2udu
∣∣∣∣Fs] .Inoltre, Mt =
∫ t0XsdBs e M2
t −∫ t
0X2udu sono martingale rispetto a (Ft)t≥0, quindi∫ t
0X2udu è il processo crescente associato alla submartigala M
2t .
Proof. Sia X(n) è una successione di processi elementari di classe M2B (0, T ) che con-
verge ad X nel senso (4.1) (con a = 0, b = T ). Allora∫ T
0X
(n)s dBs converge a
∫ T0XsdBs
in L2 (Ω,F , P ), quindi (tramite semplici disuguaglianze) E[∫ T
0X
(n)s dBs
]converge a
E[∫ T
0XsdBs
], E[(∫ T
0X
(n)s dBs
)2]converge a E
[(∫ T0XsdBs
)2]e∫ T
0E
[(X
(n)s
)2]ds
converge a∫ T
0E [X2
s ] ds. Da questo si deducono le prime due identità.Per mostrare le altre, si prendano (senza restrizione) i processi X(n) aventi t ed
s come nodi, e convergenti ad X su [0, T ] nel senso (4.1); ne segue che convergonoad X anche su [s, t], nello stesso senso. Quindi
∫ tsX
(n)u dBu converge a
∫ tsXudBu in
L2 (Ω,F , P ). Inoltre, a causa di (4.1),∫ ts
(X
(n)u
)2
du converge a∫ tsX2udu in L
2 (Ω,F , P ).Grazie a questi fatti si può passare al limite nelle speranze condizionali e verificare le dueidentità. Infatti, ricordiamo che se Zn → Z in L1 (Ω,F , P ), allora E [Zn|G]→ E [Z|G]in L1 (Ω,F , P ):
E [|E [Zn|G]− E [Z|G]|] = E [|E [Zn − Z|G]|] ≤ E [E [|Zn − Z| |G]] = E [|Zn − Z|]→ 0.
Le affermazioni finali sulle proprietà di martingala sono ovvie conseguenze delleidentità precedenti, come nel caso dei processi elementari. La dimostrazione è completa.

108 CAPITOLO 4. L’INTEGRALE STOCASTICO
Osservazione 23 Se X, Y ∈M2B (0, T ) allora
E
[(∫ T
0
XsdBs
)(∫ T
0
YsdBs
)]=
∫ T
0
E [XsYs] ds.
Lo si dimostra usando l’identità
(X + Y )2 − (X − Y )2 = 4XY
e la formula di isometria. Si conserva proprio il prodotto scalare (è un fatto generalesulle isometrie tra spazi di Hilbert).
Proposizione 41 Se (Xn) è una successione di processi in M2B (0, T ) che converge ad
X ∈M2B (0, T ) nel senso (4.1), allora
∫ T0Xns dBs →
∫ T0XsdBs in L2 (Ω).
Proof. Basta applicare la formula di isometria per processi di classe M2B (0, T ), alla
differenza Xn −X.Esaminiamo ora la dipendenza dell’integrale
∫ t0XsdBs dal suo estremo di inte-
grazione t. Facciamo preliminarmente un paragone con moto browniano. A suo tempoabbiamo prima costruito un moto browniano grossolano B e poi, tramite il teorema diKolmogorov, abbiamo trovato una sua versione continua. Qui, l’oggetto di partenzanon è un processo nel senso usuale del termine (potenzialmente grossolano, non con-
tinuo) ma una famiglia∫ t
0XsdBs; t ∈ [0, T ]
di classi di equivalenza. Infatti, per ogni
t ∈ [0, T ] fissato, l’integrale stocastico∫ t
0XsdBs nasce come limite in L2 (Ω) di una
successione di Cauchy ed L2 (Ω), per essere considerato completo, va pensato comespazio di classi di equivalenza. Pertanto, il modo giusto di vedere il problema dellaversione continua è il seguente. Chiamiamo selezione ogni processo stocastico (ora insenso usuale) Mt; t ∈ [0, T ] tale che per ogni t ∈ [0, T ] la v.a. Mt sia un rappre-sentante della classe di equivalenza
∫ t0XsdBs. Dobbiamo allora dimostrare che esiste
una selezione Mt; t ∈ [0, T ] che sia un processo continuo. Siccome però tale processosarebbe una versione di una qualsiasi altra selezione, non è così assurdo mantenere ilsolito linguaggio, cioè dire che cerchiamo una versione continua di t 7→
∫ t0XsdBs.
Teorema 26 SiaX di classeM2B (0, T ). Allora esiste una versione continua Mt; t ∈ [0, T ]
di∫ t
0XsdBs, t ∈ [0, T ].
Proof. Sia X(n) è una successione di processi elementari di classe M2B (0, T ) che
converge ad X nel senso (4.1) (con a = 0, b = T ). I processi M (n)t =
∫ t0X
(n)s dBs
sono martingale continue (la continuità si vede subito dalla definizione: se Xt =∑n−1i=1 Xti1[ti,ti+1) (t),
∫ t0XsdBs =
∑n−1i=1 XtiBti+1∧t − Bti∧t). Quindi, dati n,m, vale
la disuguaglianza di Doob, per la martingala M (n)t −M
(m)t :
E
[supt∈[0,T ]
∣∣∣M (n)t −M
(m)t
∣∣∣2] ≤ 4E
[∣∣∣M (n)T −M
(m)T
∣∣∣2] .

4.2. INTEGRALEDI PROCESSI PROGRESSIVAMENTEMISURABILI, DI QUADRATO INTEGRABILE109
Per la formula di isometria,
= E
∫ T
0
∣∣X(n)s −X(m)
s
∣∣2 ds.Pertanto, dal fatto che
(X(n)
)è una successione di Cauchy in L2 (Ω× [0, T ]), discende
che(M (n)
)è una successione di Cauchy in L2 (Ω;C ([0, T ] ;R)). Accettando il fat-
to (probabilmente non dimostrato in corsi precedenti) che L2 (Ω;C ([0, T ] ;R)) è unospazio di Banach, concludiamo cheM (n) converge ad un elementoM ∈ L2 (Ω;C ([0, T ] ;R)),ovvero ad un processo continuo tale che E
[supt∈[0,T ] |Mt|2
]< ∞. Dalla convergenza
ora detta discende che, per ogni t ∈ [0, T ] fissato, M (n)t converge ad Mt in L2 (Ω). Ma
già sappiamo che M (n)t converge ad
∫ t0XsdBs in L2 (Ω). Quindi Mt =
∫ t0XsdBs.
Osservazione 24 Osserviamo che il processo M costruito nella dimostrazione prece-dente è pur sempre una classe di equivalenza, essendo in L2 (Ω;C ([0, T ] ;R)), ma uni-formemente nel tempo: due rappresentanti possono differire su un insieme di misuranulla di Ω, ma fuori da esso coincidono uniformemente in t; quindi sono processi in-distinguibili. In questo senso M è un processo univocamente definito, a differenza dit 7→
∫ t0XsdBs che deve essere visto come famiglia di classi di equivalenza.
Osservazione 25 La dimostrazione precedente è basata sulla completezza dello spazioL2 (Ω;C ([0, T ] ;R)). Se non si vuole usare tale proprietà, si può procedere così. Intan-
to, ricordiamo la disuguaglianza massimale per la submartingala∣∣∣M (n)
t −M(m)t
∣∣∣2:P
(supt∈[0,T ]
∣∣∣M (n)t −M
(m)t
∣∣∣ > ε
)= P
(supt∈[0,T ]
∣∣∣M (n)t −M
(m)t
∣∣∣2 > ε2
)
≤ 1
ε2E
[∣∣∣M (n)T −M
(m)T
∣∣∣2]=
1
ε2
∫ T
0
E[∣∣X(n)
s −X(m)s
∣∣2] dsdove all’ultimo passaggio abbiamo usato la proprietà di isometria. Da questa disug-uaglianza, deduciamo la seguente affermazione: esiste una sottosuccessione M (nk)
t checonverge q.c. ad un processo continuo Nt, uniformemente in t:
P
(limk→∞
supt∈[0,T ]
∣∣∣M (nk)t −Nt
∣∣∣ = 0
)= 1. (4.2)
Lasciamo al lettore il fatto elementare di costruire una successione nk tale che
P
(supt∈[0,T ]
∣∣∣M (nk)t −M (nk+1)
t
∣∣∣ > 1
2k
)≤ 1
k2.

110 CAPITOLO 4. L’INTEGRALE STOCASTICO
Da questo discende che
∞∑k=1
P
(supt∈[0,T ]
∣∣∣M (nk)t −M (nk+1)
t
∣∣∣ > 1
2k
)<∞
e quindi, per il lemma di Borel-Cantelli (prima parte), esiste un evento Ω0 ∈ F diprobabilità uno tale che, per ogni ω ∈ Ω0, vale
supt∈[0,T ]
∣∣∣M (nk)t (ω)−M (nk+1)
t (ω)∣∣∣ ≤ 1
2k
definitivamente in k. QuindiM
(nk)t (ω)
k∈N
è di Cauchy in C ([0, T ] ;R) munito della
topologia della convergenza uniforme; quindi converge ad una funzione continua Nt (ω).Fissato, t, la convergenza q.c. di v.a. implica che il limite è misurabile, è una v.a.,quindi Nt è un processo stocastico; continuo (q.c.; in realtà va definito per ω /∈ Ω0
e possiamo definirlo identicamente nullo, quindi è continuo per ogni ω). Abbiamodimostrato l’asserzione (4.2). Basta ora ricordare che, fissato t ∈ [0, T ], la v.a. M (nk)
t
converge in L2 (Ω,F , P ) a Mt. Siccome converge q.c. a Nt, vale P (Nt = Mt) = 1(entrambe le convergenze implicano quella in probabilità, ed il limite in probabilità èunico, come classe di equivalenza). Quindi N , che è un processo continuo, è unamodificazione di M . La dimostrazione è completa.
Osservazione 26 Sia f ∈ L2 (0, T ) (funzione deterministica). Allora∫ t
0f (s) dBs è
una v.a. gaussiana. Infatti, presa una successione fn ∈ L2 (0, T ) di funzioni costantia tratti che converge in L2 (0, T ) ad f , le v.a.
∫ t0fn (s) dBs sono gaussiane (trasfor-
mazioni lineari di vettori gaussiani) e convergono in L2 (Ω), per la formula di isometria,a∫ t
0f (s) dBs; il limite L2 (Ω) di v.a. gaussiane è una v.a. gaussiana (lo stesso vale
per vettori gaussiani). L’integrale∫ t
0f (s) dBs è detto integrale di Wiener.
4.3 Integrale di processi progressivamente misura-bili più generali
Sia B = (Bt)t≥0 un moto browniano rispetto ad una filtrazione (Ft)t≥0. Dati b ≥ a ≥0, diciamo che un processo X = (Xt)t≥0 è di classe Λ2
B (a, b) se è progressivamentemisurabile e vale
P
(∫ b
a
X2t dt <∞
)= 1
I processi elementari, cioè della forma Xt =∑n−1
i=1 Xti1[ti,ti+1) (t) con Xti misurabilerispetto a Fti , sono progressivamente misurabili e di classe Λ2
B (a, b), senza bisogno dialcuna ipotesi di integrabilità sulle Xti .

4.3. INTEGRALEDI PROCESSI PROGRESSIVAMENTEMISURABILI PIÙGENERALI111
Si potrebbe anche dire che Λ2B (a, b) è la famiglia delle classi di equivalenza dei
processi suddetti, identificando processi X,X ′ tali che P(∫ b
a(Xt −X ′t)
2 dt <∞)
= 1.Non useremo esplicitamente questa convenzione.
Teorema 27 Se X è di classe Λ2B (a, b), allora esiste una successione di processi
elementari X(n) tale che
limn→∞
∫ b
a
(Xt −X(n)
t
)2
dt = 0 (4.3)
quasi certamente. Esiste anche una successione di processi continui X(n), di classeΛ2B (a, b), che converge ad X nel senso (4.3).
La dimostrazione è simile a quella dei processi di classe M2B (a, b), forse un po’più
facile perché non bisogna tenere sotto controllo certe integrabilità rispetto ad ω. E’comunque molto lunga e di moderato interesse probabilistico, per cui la omettiamo.Vogliamo ora definire l’integrale stocastico
∫ baXtdBt, usando questo teorema. Un
modo è quello di basarsi sul seguente lemma molto interessante.
Lemma 8 Sia X un processo elementare. Allora, per ogni ε, ρ > 0, vale
P
(∣∣∣∣∫ b
a
XtdBt
∣∣∣∣ > ε
)≤ P
(∫ b
a
X2t dt > ρ
)+ρ
ε2.
Proof. Separiamo Ω nei due eventi A =∫ b
aX2t dt > ρ
ed Ac =
∫ baX2t dt ≤ ρ
:
P
(∣∣∣∣∫ b
a
XtdBt
∣∣∣∣ > ε
)= P
(∣∣∣∣∫ b
a
XtdBt
∣∣∣∣ > ε
∩ A
)+ P
(∣∣∣∣∫ b
a
XtdBt
∣∣∣∣ > ε
∩ Ac
)e maggioriamo il primo termine con P (A):
P
(∣∣∣∣∫ b
a
XtdBt
∣∣∣∣ > ε
)= P
(∫ b
a
X2t dt > ρ
)+ P
(∣∣∣∣∫ b
a
XtdBt
∣∣∣∣ > ε
∩ Ac
).
Resta da verificare che
P
(∣∣∣∣∫ b
a
XtdBt
∣∣∣∣ > ε,
∫ b
a
X2t dt ≤ ρ
)≤ ρ
ε2.
Introduciamo il processo Yt definito così (con la solita notazioneXt =∑n−1
i=1 Xti1[ti,ti+1) (t)):
Yt =
Xt per t ≤ ti+1 ∈ [ti, ti+1) se
∫ ti+1a
X2t dt ≤ ρ
0 altrimenti

112 CAPITOLO 4. L’INTEGRALE STOCASTICO
(per i ∈ Ja,b). Vale∫ baY 2t dt ≤ ρ. Inoltre, se∫ b
a
X2t dt ≤ ρ
⊂ Y = X su [a, b] ⊂
∫ b
a
XtdBt =
∫ b
a
YtdBt
(per la verifica dell’ultima inclusione si pensi alla definizione di integrale stocastico perprocessi elementari). Quindi
P
(∣∣∣∣∫ b
a
XtdBt
∣∣∣∣ > ε,
∫ b
a
X2t dt ≤ ρ
)≤ P
(∣∣∣∣∫ b
a
YtdBt
∣∣∣∣ > ε,
∫ b
a
X2t dt ≤ ρ
)
≤ P
(∣∣∣∣∫ b
a
YtdBt
∣∣∣∣ > ε
)≤E
[∣∣∣∫ ba YtdBt
∣∣∣2]ε2
=E[∫ b
aY 2t dt]
ε2≤ ρ
ε2.
La dimostrazione è completa.
Corollario 14 Se X(n) è una successione di processi elementari che converge ad unprocesso X di classe Λ2
B (a, b) nel senso (4.3), allora la successione di v.a.∫ b
a
X(n)t dBt
è di Cauchy in probabilità. Il suo limite in probabilità dipende solo da X (non dallasuccessione scelta) e verrà indicato con
∫ baXtdBt, detto integrale di Itô di X.
Proof. Abbiamo
P
(∣∣∣∣∫ b
a
(X
(n)t −X
(m)t
)dBt
∣∣∣∣ > ε
)≤ P
(∫ b
a
(X
(n)t −X
(m)t
)2
dt > ρ
)+ρ
ε2.
La convergenza quasi certa (4.3), implica che, preso ρ > 0, esiste nρ ∈ N tale che
P
(∫ b
a
(X
(n)t −X
(m)t
)2
dt > ρ
)≤ ρ
per ogni n,m ≥ nρ (si pensi ad una delle varie ragioni). Quindi, fissato ε > 0,
P
(∣∣∣∣∫ b
a
(X
(n)t −X
(m)t
)dBt
∣∣∣∣ > ε
)≤ ρ+
ρ
ε2
per ogni n,m ≥ nρ. Relativamente al valore scelto di ε, prendiamo ρε = ε3:
P
(∣∣∣∣∫ b
a
(X
(n)t −X
(m)t
)dBt
∣∣∣∣ > ε
)≤ ε3 + ε

4.3. INTEGRALEDI PROCESSI PROGRESSIVAMENTEMISURABILI PIÙGENERALI113
per ogni n,m ≥ nρε . Questo significa che∫ baX
(n)t dBt è di Cauchy in probabilità. La
dimostrazione è completa.Si può dimostrare facilmente (omettiamo i dettagli):
Proposizione 42 Sia X un processo di classe Λ2B (a, b),. Allora, per ogni ε, ρ > 0,
vale
P
(∣∣∣∣∫ b
a
XtdBt
∣∣∣∣ > ε
)≤ P
(∫ b
a
X2t dt > ρ
)+ρ
ε2.
In particolare, seXnt è una successione di processi di classe Λ2
B (a, b) tale che∫ ba
(Xnt −Xt)
2 dt
tende a zero in probabilità, allora∫ baXnt dBt converge a
∫ baXtdBt in probabilità.
Nel seguito diremo che X è di classe Λ2B se è di classe Λ2
B (0, T ) per ogni T > 0.Ricordiamo che un processoM = (Mt)t≥0 è una martingala locale se c’è una successionedi tempi d’arresto τn, crescente a +∞, tale che Mt∧τn è una martingala per ogni n;diremo che una tale successione di tempi d’arresto riduce la martingala locale.
Teorema 28 Sia X di classe Λ2B. Allora il processo Mt =
∫ t0XsdBs, t ≥ 0, ha una
versione continua ed è una martingala locale. Una successione di tempi d’arresto cheriduce la martingala locale è data da
τn = inf
t > 0 :
∫ t
0
X2sds ≥ n
se l’insieme non è vuoto, altrimenti τn = +∞.
Proof. Diamo solo alcuni elementi della dimostrazione. Le v.a. τn sono tempi diarresto (basta considerare il processo Yt =
∫ t0X2sds e il suo istante di ingresso in [n,∞)),
sono crescenti (Yt è crescente) e tendono a +∞. Infatti, per ogni T > 0, esiste n0 (ω)tale che per ogni n ≥ n0 (ω) vale τn (ω) ≥ T , quasi certamente. Questo perché
An,T :=
∫ T
0
X2sds ≤ n
= τn ≥ T
e l’evento
AT :=⋃n∈N
An,T =
∫ T
0
X2sds <∞
ha probabilità uno per la proprietà Λ2
B.Il processo Yn,t = Xt1t≤τn (simile a quello usato nella dimostrazione del Lemma 8)
è di classe M2B: ∫ T
0
Y 2n,tds =
∫ T
0
X2s 1s≤τnds =
∫ T∧τn
0
X2sds ≤ n

114 CAPITOLO 4. L’INTEGRALE STOCASTICO
quindi E[∫ T
0Y 2n,tds
]≤ n (si verifica anche la progressiva misurabilità di Yt). Allora
Mn,t =∫ t
0Yn,sdBs è una martingala continua (applichiamo la convenzione che il simbolo
indichi la versione continua).Su An,T , Yn,t = Xt per ogni t ∈ [0, T ]. Per il Lemma 9 esposto poco sotto, applicato
su ogni intervallo [0, t], vale
Mt =
∫ t
0
XsdBs =
∫ t
0
Yn,sdBs = Mn,t
su An,T quasi certamente, per ogni t ∈ [0, T ]. Si noti che in questa affermazione, il“quasi certamente”dipende da t. Se An,T avesse probabilità uno, avremmo finito:Mn,t
sarebbe una versione continua di Mt.Se m > n, siccome Ym,t = Yn,t per ogni t ∈ [0, T ] su An,T , per il Lemma 9, applicato
su ogni intervallo [0, t], vale
Mm,t =
∫ t
0
Ym,sdBs =
∫ t
0
Yn,sdBs = Mn,t
su An,T quasi certamente, per ogni t ∈ [0, T ]; con un ragionamento basato sui razionali,si vede che vale
Mm,t = Mn,t per ogni t ∈ [0, T ]
quasi certamente su An,T . E che la proprietà si può rendere uniforme in m. Pertanto,intersecando su ambo gli indici n ed m, esiste un insieme misurabile N di probabilitànulla tale che per ogni n, per ogni ω ∈ An,T\N ,
Mm,t (ω) = Mn,t (ω) per ogni t ∈ [0, T ] ed m ≥ n.
Su AT\N definiamo un processo (M∞,t)t∈[0,T ] nel seguente modo: preso ω ∈ AT\N ,poniamo
M∞,t (ω) = Mn,t (ω)
dove n è un qualsiasi indice tale che ω ∈ An,T\N (per quanto visto poco sopra, questadefinizione non dipende da n). Per le cose osservate precedentemente, M∞,t è unprocesso continuo. Inoltre, è una versione di Mt. Infatti, fissato t ∈ [0, T ], vale
P (M∞,t = Mt) = limn→∞
P (M∞,t = Mt ∩ An,T\N)
= limn→∞
P (Mn,t = Mt ∩ An,T\N) = limn→∞
P (An,T\N) = 1.
Questo dimostra la prima affermazione del teorema, cioè che M ha una versionecontinua.Sapere che la famiglia di classi di equivalenza (M0
t )t∈[0,T ], M0t :=
∫ t0XsdBs, ha una
versione continua Mt, aiuta a dare un significato univoco al processo stoppato Mt∧τn .

4.3. INTEGRALEDI PROCESSI PROGRESSIVAMENTEMISURABILI PIÙGENERALI115
Infatti, Mt, continuo, diventa ora definito univocamente a meno di indistinguibilità,quindi la posizione (Mt∧τn) (ω) := Mt∧τn(ω) (ω) non pone interrogativi di significato.Usando allora la versione continua, vale (omettiamo la verifica dettagliata della
seconda uguaglianza)
Mt∧τn =
∫ t∧τn
0
XsdBs =
∫ t
0
Xs1s≤τndBs =
∫ t
0
Yn,sdBs
e questa è una martingala in quanto Yn,t è un processo di classeM2B. La dimostrazione
è completa.Abbiamo usato il seguente fatto, di interesse indipendente.
Lemma 9 SianoX, Y di classe Λ2B ed A ∈ F tali cheXt (ω) = Yt (ω) per ogni t ∈ [0, T ]
e ω ∈ A. Allora∫ T
0XsdBs =
∫ T0YsdBs su A quasi certamente (cioè esiste un insieme
di misura nulla N tale che∫ T
0XsdBs =
∫ T0YsdBs per ogni ω ∈ A\N).
Non possiamo dare la dimostrazione completa perché poggia sul metodo di approssi-mazione di processi di classe Λ2
B con processi elementari, ma almeno vediamo l’idea.Vale, a proposito di tale approssimazione, che si possano prendere due successioni diprocessi elementariXn, Y n che convergono aX, Y nel modo richiesto, tali cheXn
t (ω) =
Y nt (ω) per ogni t ∈ [0, T ] e ω ∈ A. Da ciò discende che
∫ T0Xns dBs =
∫ T0Y ns dBs su
A. La convergenza in probabilità implica quella quasi certa, quindi dall’identità prece-dente e dalla convergenza quasi certa di
∫ T0Xns dBs e
∫ T0Y ns dBs a
∫ T0XsdBs e
∫ T0YsdBs
rispettivamente, si ottiene∫ T
0XsdBs =
∫ T0YsdBs su A.
Il lemma dice che, se pur l’integrale stocastico non è definito ω per ω ma solo conun procedimento globale in ω, tuttavia rispetta una certa forma di dipendenza localeda ω.Concludiamo con un risultato nello stile delle somme di Riemann.
Proposizione 43 SeX è un processo continuo di classe Λ2B e (πn) è una successione di
partizioni di [0, T ], con |πn| → 0, con πn = tni , i = 0, ..., Nn allora vale in probabilità
limn→∞
Nn−1∑i=0
Xtni
(Btni+1
−Btni
)=
∫ T
0
XsdBs.
Proof. Si denoti con X(n)t il processo elementare
∑Xtni
1[tni ,tni+1). Vale
Nn−1∑i=0
Xtni
(Btni+1
−Btni
)=
∫ T
0
Xns dBs.
Inoltre, per la continuità di X, quasi certamente accade che X(n)t converge ad Xt
uniformemente in t, quindi vale l’ipotesi dell’affermazione di convergenza della Propo-sizione 42, che garantisce pertanto che
∫ T0Xns dBs →
∫ T0XsdBs in probabilità. La
dimostrazione è completa.

116 CAPITOLO 4. L’INTEGRALE STOCASTICO
4.4 Il caso multidimensionale
4.4.1 Moto browniano in Rd
Definizione 13 Un moto browniano in Rd, definito su uno spazio probabilizzato (Ω,F , P ),
rispetto ad una filtrazione (Ft)t≥0 è un vettore di processi stocastici Bt =(B
(1)t , ..., B
(d)t
)tale che ciascuna componente B(i)
t è un moto browniano in R rispetto ad (Ft)t≥0 e lecomponenti sono indipendenti.
Si possono dare varie formulazioni equivalenti, ad esempio:
Definizione 14 Un moto browniano in Rd, definito su uno spazio probabilizzato (Ω,F , P ),rispetto ad una filtrazione (Ft)t≥0 è un processo stocastico (Bt)t≥0 su (Ω,F , P ) a valoriin(Rd,B
(Rd))tale che:
i) P (B0 = 0) = 1ii) è adattato a (Ft)t≥0 e continuoiii) per ogni t ≥ s ≥ 0, l’incremento Bt −Bs è un vettore gaussiano in Rd a media
nulla e matrice di covarianza pari a (t− s) Id, indipendente da Fs.
L’indipendenza di Bt−Bs da Fs, con t ≥ s ≥ 0 arbitrari, si può riformulare dicendoche per ogni tn ≥ tn−1 ≥ ... ≥ t1 ≥ 0 i vettori aleatori Btn − Btn−1 , ... , Bt2 − Bt1 , Bt1
sono indipendenti.Essendo particolarmente elegante, mostriamo una realizzazione (approssimata) di
un moto browniano in R2, ottenuta col software R, basata sulla formula
B(i)nh = B
(i)h +
(B
(i)2h −B
(i)h
)+ ...+
(B
(i)nh −B
(i)(n−1)h
), i = 1, 2
dove gli incrementi sono indipendenti (anche da una componente all’altra) e sono tuttegaussiane a media nulla e varianza h. Basta chiedere al software di generare tantinumeri gaussiani centrati aventi deviazione standard
√h, tramite i comandi:
h=0.01W1=rnorm(10000,0,sqrt(h))W2=rnorm(10000,0,sqrt(h))B1=cumsum(W1)B2=cumsum(W2)plot(B1,B2,type=lines)A titolo di confronto, disegnamo la sua prima componente:ts.plot(B1)
Osservazione 27 Se U è una matrice ortogonale di Rd, allora UBt è ancora un motobrowniano in Rd. Lo si può vedere usando la seconda definizione.
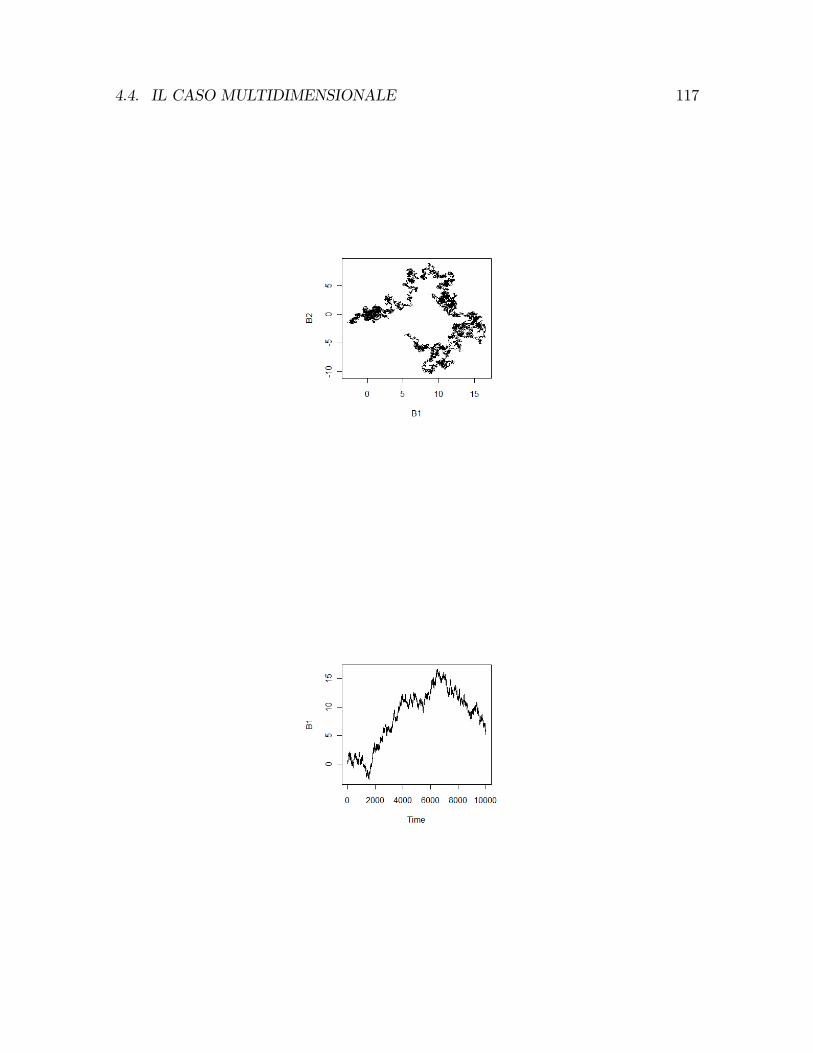
4.4. IL CASO MULTIDIMENSIONALE 117

118 CAPITOLO 4. L’INTEGRALE STOCASTICO
4.4.2 Integrale stocastico rispetto ad un moto browniano inRd
Dato un moto browniano Bt =(B
(1)t , ..., B
(d)t
)in Rd rispetto ad una filtrazione (Ft)t≥0
ed un processo stocastico Xt di classe Λ2 (qui omettiamo l’indicazione B in quantofuorviante), progressivamente misurabile rispetto a (Ft)t≥0, sono ben definiti tutti gliintegrali di Itô ∫ t
0
XsdB(i)s
per i = 1, ..., d. [Si noti che qui è importante essere svincolati dalla filtrazione naturaledel moto browniano rispetto a cui si integra.] Se consideriamo un processo stocastico
Xt =(X
(1)t , ..., X
(d)t
)a valori in Rd avente tutte le componenti di classe Λ2 (diremo
che il processo è di classe Λ2; analogamente per la classe M2), è ben definita la sommadi integrali stocastici ∫ t
0
Xs · dBs :=d∑i=1
∫ t
0
X(i)s dB(i)
s .
E’una martingala locale continua e, se X è di classe M2, è anche una martingala,centrata. Vediamo che forma assume la formula di isometria. Intanto si noti il seguentefatto, forse apparentemente innaturale: gli integrali
∫ t0X
(i)s dB
(i)s e
∫ t0X
(j)s dB
(j)s sono
scorrelati, nonostante contengano processi X(i)s e X(j)
s che possono anche coincidere(gli integrali non sono però indipendenti). Ricordiamo anche l’osservazione 23, chetratta il prodotto di integrali rispetto allo stesso moto browniano; il seguente lemmatratta il caso di due moti browniani indipendenti.
Lemma 10 Se X è di classe M2, allora
E
[∫ t
0
X(i)s dB(i)
s
∫ t
0
X(j)s dB(j)
s
]= 0
per i 6= j.
Proof. Per evitare troppi indici, supponiamo i = 1, j = 2. Supponiamo X(1)s , X
(2)s
processi elementari e, senza restrizione, basati sulla stessa partizione tn ≥ tn−1 ≥ ... ≥t1 ≥ t0 = 0:
X(i)s =
n−1∑k=0
X(i)k 1[tk,tk+1) per i = 1, 2.
Allora, con la notazione ∆kB(i) = B
(i)tk+1−B(i)
tk, abbiamo
E
[∫ t
0
X(i)s dB(i)
s
∫ t
0
X(j)s dB(j)
s
]=
n−1∑k,h=0
E[X
(1)k X
(2)h ∆kB
(1)∆hB(2)].

4.4. IL CASO MULTIDIMENSIONALE 119
Se h = k abbiamo
E[X
(1)k X
(2)k ∆kB
(1)∆kB(2)]
= E[X
(1)k X
(2)k
]E[∆kB
(1)]E[∆kB
(2)]
= 0
perché X(1)k X
(2)k è Ftk misurabile, e gli incrementi ∆kB
(i) sono indipendenti da Ftk equindi da X(1)
k X(2)k ed anche tra loro perché componenti diverse del moto browniano
in Rd.Se h > k (il caso h < k è identico) abbiamo
E[X
(1)k X
(2)h ∆kB
(1)∆hB(2)]
= E[X
(1)k X
(2)h ∆kB
(1)]E[∆hB
(2)]
= 0
perché X(1)k X
(2)h ∆kB
(1) è Fth misurabile, ∆hB(2) è indipendente da Fth e quindi da
X(1)k X
(2)h ∆kB
(1). La dimostrazione nel caso di processi elementari è completa e da essisi passa al caso generale con argomenti di approssimazione simili a quelli usati già altrevolte, che omettiamo.
Proposizione 44 Se X è di classe M2, allora
E
[(∫ t
0
Xs · dBs
)2]
= E
[∫ t
0
|Xs|2 ds]
dove |x| indica la norma euclidea del vettore x ∈ Rd.
Proof. Abbiamo
E
[(∫ t
0
Xs · dBs
)2]
= E
( d∑i=1
∫ t
0
X(i)s dB(i)
s
)2
=d∑
i,j=1
E
[∫ t
0
X(i)s dB(i)
s
∫ t
0
X(j)s dB(j)
s
].
I termini con i 6= j sono nulli per il lemma precedente. La somma per i = j produce ilrisultato della formula, in quanto
E
[(∫ t
0
X(i)s dB(i)
s
)2]
= E
[∫ t
0
(X(i)s
)2ds
].
La dimostrazione è completa.Ragionando componente per componente, sono definiti anche gli integrali stocastici
della forma∫ t
0XsdBs dove X è un processo a valori matrici d× k, con componenti X ij

120 CAPITOLO 4. L’INTEGRALE STOCASTICO
tutte di classe almeno Λ2. Il risultato Yt =∫ t
0XsdBs è un processo a valori in Rk, di
componenti
Y it =
d∑j=1
∫ t
0
X ijs dB
js .
Se le componentiX ij sono di classeM2, la formula di isometria in questo caso assume laseguente forma. Ora con |·| indicheremo la norma euclidea in Rk (o altra dimensione)e con ‖A‖HS la norma Hilbert-Schmidt di una matrice A ∈ Rd×k, ovvero la normaeuclidea in Rd×k, definita da
‖A‖2HS =
k∑i=1
d∑j=1
A2ij.
Proposizione 45 Se le componenti X ij sono di classe M2, allora
E
[∣∣∣∣∫ T
0
XsdBs
∣∣∣∣2]
= E
[∫ T
0
‖Xs‖2HS ds
].
Proof. Infatti, essendo E[|YT |2
]=∑k
i=1E[(Y i
T )2],
E
[∣∣∣∣∫ T
0
XsdBs
∣∣∣∣2]
=k∑i=1
E
( d∑j=1
∫ T
0
X ijs dB
js
)2
=k∑i=1
E
[d∑j=1
∫ T
0
(X ijs
)2ds
]= E
[∫ T
0
‖Xs‖2HS ds
]dove abbiamo usato la Proposizione 44.Anche le disuguaglianze per le martingale si trasportano al caso vettoriale. A titolo
di esempio, vediamo la disuguaglianza di Doob per p = 2.
Proposizione 46 Se le componenti X ij sono di classe M2, allora
E
[supt∈[0,T ]
∣∣∣∣∫ t
0
XsdBs
∣∣∣∣2]≤ 4E
[∫ T
0
‖Xs‖2HS ds
].
Proof.
E
[supt∈[0,T ]
∣∣∣∣∫ t
0
XsdBs
∣∣∣∣2]
= E
supt∈[0,T ]
k∑i=1
(d∑j=1
∫ t
0
X ijs dB
js
)2
≤k∑i=1
E
supt∈[0,T ]
(d∑j=1
∫ t
0
X ijs dB
js
)2 .

4.4. IL CASO MULTIDIMENSIONALE 121
Ciascun processo∑d
j=1
∫ t0X ijs dB
js è una martingala di quadrato integrabile e quindi,
per la disuguaglianza di Doob,
≤ 4k∑i=1
E
( d∑j=1
∫ T
0
X ijs dB
js
)2
= 4k∑i=1
E
[d∑j=1
∫ T
0
(X ijs
)2ds
]= 4E
[∫ T
0
‖Xs‖2HS ds
]avendo usato nuovamente la Proposizione 44.Valgono tanti altri fatti simili al caso uni-dimensionale, che non descriviamo in
dettaglio.

122 CAPITOLO 4. L’INTEGRALE STOCASTICO

Capitolo 5
La formula di Itô
Seguiamo un approccio a questo tema non completamente tradizionale ma estrema-mente istruttivo, dovuto a Hans Föllmer. In sintesi, esso sviluppa prima una formuladi Itô per funzioni deterministiche, che poi viene applicata traiettoria per traiettoriaad alcune classi di processi stocastici.
5.1 La “chain rule”per funzioni poco regolari
Vogliamo dimostrare una formula della catena (chain rule) per una composizione deltipo f (xt) dove f : R → R è regolare, anzi di classe C2, ma (xt)t∈[0,T ] è una funzionenon necessariamente differenziabile (e nemmeno a variazione limitata), con una propri-età speciale di “variazione quadratica”. Per non approfondire alcuni dettagli tecnici,supponiamo T fissato e finito, ma si potrebbe riscrivere tutto per funzioni (xt)t≥0.Indichiamo con π una generica partizione di [0, T ] della forma 0 = t0 ≤ t1 ≤ ... ≤
tn = T , con |π| il numero maxi=0,...,n−1 |ti+1 − ti|, con [x]πt il numero
[x]πt =∑π3ti≤t
(xti+1 − xti
)2, t ∈ [0, T ]
con la convenzione che tn+1 = tn, quindi xtn+1−xtn = 0. Questa convenzione, che servesemplicemente a cancellare un ultimo termine spurio nella somma precedente, verràsempre adottata tacitamente in questi paragrafi. Oppure, quando questo semplifichi lascrittura, useremo la notazione
Jπt = i = 0, ..., n− 1 : tni ≤ t
con la quale scriveremo
[x]πt =∑i∈Jπt
(xti+1 − xti
)2, t ∈ [0, T ]
123

124 CAPITOLO 5. LA FORMULA DI ITÔ
Osservazione 28 Si osservi che, con questa convenzione, la funzione t 7→ [x]πt ènon-decrescente. In precedenza, nel capitolo sulle martingale, avevamo introdotto unconcetto analogo usando però la somma∑
π3ti+1≤t
(xti+1 − xti
)2+ (xt − xtk)
2 (5.1)
dove k è tale che tk ≤ t < tk+1. Questa somma non è crescente in t e questoprovocherebbe delle diffi coltà in questo capitolo. Invece, nel capitolo sulle martingale,era essenziale usare la (5.1), in modo che se M era una martingala, M2 meno talesomma fosse ancora una martingala (uno dei lemmi base della teoria).
Osservazione 29 La differenza tra la grandezza [x]πt =∑
π3ti≤t(xti+1 − xti
)2introdot-
ta ora e la (5.1) è infinitesima, se x è una funzione continua: tale differenza è, semprecon la convenzione tk ≤ t < tk+1,(
xtk+1 − xtk)2 − (xt − xtk)
2
che risulta infinitesima, anche uniformemente in t ∈ [0, T ], quando si prenda unasuccessione di partizioni di ampiezza tendente a zero. Siccome applicheremo la teoriasempre a funzioni x continue, potremo ogni volta verificare facilmente che i risultatilimite, per partizioni di ampiezza tendente a zero, non dipendono dalla definizionescelta.
Introduciamo inoltre la misura su ([0, T ] ,B ([0, T ]))
µπ =n−1∑i=0
(xti+1 − xti
)2δxti
di cui t 7→ [x]πt è la funzione di ripartizione.
Definizione 15 Sia (πn)n∈N una successione di partizioni con |πn| → 0 per n→∞ edx : [0, T ]→ R una funzione continua. Diciamo che x ha variazione quadratica lungo lasuccessione πn se esiste una funzione continua, indicata nel seguito con [x]t, t ∈ [0, T ],tale che
limn→∞
[x]πnt = [x]t (5.2)
per ogni t ∈ [0, T ].
Osservazione 30 Siccome [x]πnt è non decrescente, anche [x]t è non decrescente.
Osservazione 31 Il simbolo [x]t non è completamente appropriato perché dipende an-che dalla successione (πn)n∈N, oltre che da x. In tutti i nostri esempi, però, dipenderàsolo da x, per cui non ci sembra utile appesantire la notazione tramite una dipendenzaesplicita dalla successione.

5.1. LA “CHAIN RULE”PER FUNZIONI POCO REGOLARI 125
Osservazione 32 Se x è di classe Cα con α > 12allora la variazione quadratica (esiste
ed) è pari a zero (lo abbiamo visto nel capitolo del moto browniano). Per avere unavariazione quadratica non nulla, x dev’essere meno regolare.
La funzione continua non decrescente [x]t, t ∈ [0, T ], definisce una misura finitad [x]t su ([0, T ] ,B ([0, T ])). Vale ∫ b
a
d [x]s = [x]b − [x]a
per ogni 0 ≤ a ≤ b ≤ T . La funzione [x]t è la funzione di ripartizione di questamisura. Gli integrali del tipo
∫ t0ϕ (s) d [x]s che scriveremo nel seguito, con ϕ : [0, t]→ R
continua, sono da intendersi rispetto a tale misura.
Proposizione 47 i) Sia D ⊂ [0, T ] un insieme denso tale che T ∈ D. Se esiste unafunzione uniformemente continua t 7−→ [x]t, definita su D, tale che vale (5.2) per ognit ∈ D, allora x ha variazione quadratica lungo la successione πn.ii) Se x ha variazione quadratica lungo la successione πn, allora per ogni t ∈ [0, T ]
limn→∞
∑i∈Jπnt
ϕ (tni )(xtni+1 − xtni
)2
=
∫ t
0
ϕ (s) d [x]s (5.3)
per ogni funzione ϕ : [0, t] → R continua. Abbiamo indicato con tni , i = 0, 1, ..., Nn, ipunti della partizione πn.
Proof. Ricordiamo preliminarmente alcuni fatti sulla convergenza di misure sullaretta reale. Sia (µn) una successione di misure finite, µ una misura finita, Fn (x) =µn ((−∞, x]) e F (x) = µ ((−∞, x]) le loro funzioni di ripartizione. Ricordiamo che:a) la convergenza vaga (cioè contro le funzioni continue a supporto compatto) implicala stretta (cioè contro le funzioni continue limitate) se µn (R) → µ (R); b) se vale laconvergenza stretta allora Fn (x) → F (x) in tutti i punti in cui F è continua; c) seFn (x)→ F (x) in tutti i punti di un insieme denso allora vale la convergenza vaga.Siano ora (µn) e µ delle misure finite aventi supporto in [0, T ] (cioè che danno massa
nulla a [0, T ]c). Dai fatti precedenti si deduce il seguente criterio: se esiste un insiemedenso D ⊂ [0, T ] con T ∈ D, per cui vale Fn (x) → F (x) per ogni x ∈ D, alloraFn (x)→ F (x) in tutti i punti in cui F è continua. Infatti:
• dalle ipotesi discende la convergenza vaga, perché usando il fatto che il supportodelle misure è [0, T ] si verifica che Fn (x)→ F (x) in D∪ [0, T ]c che è denso in R;
• la convergenza vaga e la stretta coincidono (perché il differente requisito sullefunzioni continue contro cui si scontrano diventa irrilevante, dal momento che lemisure danno massa nulla a [0, T ]c); quindi abbiamo anche la convergenza stretta;

126 CAPITOLO 5. LA FORMULA DI ITÔ
• avendo la convergenza stretta, basta applicare il punto (b) precedente.
Dimostriamo l’affermazione (i) della proposizione. La funzione t 7→ [x]t ha esten-sione unica ad una funzione continua su tutto [0, T ], inoltre non decrescente (perchélimite su un denso di funzioni non decrescenti), che continuiamo a indicare con t 7→ [x]t.Introduciamo la misura µ su ([0, T ] ,B ([0, T ])) avente t 7→ [x]t come funzione di ripar-tizione e ricordiamo che t 7→ [x]πnt è la funzione di ripartizione di µπn . Poniamo perchiarezza espositiva Fn (t) = [x]πnt , F (t) = [x]t, funzioni di ripartizione di µ
πn e µrispettivamente. Si tratta di misure a supporto in [0, T ]. Siccome Fn (t) → F (t) pert in un insieme denso di [0, T ] con T ∈ D, Fn (t) → F (t) per tutti i t in cui F (t) ècontinua, quindi per ogni t ∈ [0, T ].Dimostriamo (ii). Si osservi preliminarmente che, presa una funzione continua
ϕ : [0, t]→ R, la si può estendere in modo ovvio ad una funzione continua ϕ : R→ R.Mostriamo allora l’affermazione (ii) per t = T . Dalla proprietà di avere variazionequadratica discende (come sopra) la convergenza vaga delle µπn a µ e da questa (comesopra) discende la convergenza stretta, ovvero
limn→∞
∫ T
0
ϕ (t)µπn (dt) =
∫ T
0
ϕ (t)µ (dt) (5.4)
per ogni funzione continua ϕ : R → R, quindi anche per ogni funzione continua ϕ :[0, T ]→ R.Per t ∈ [0, T ], dobbiamo analogamente dimostrare che la successione di misure
µπn|[0,t] converge strettamente a µ|[0,t], dove le restrizioni sono definite nel seguentemodo: preso A ∈ B ([0, t]), lo si vede come elemento di B ([0, T ]), e si applica la misura.Le funzioni di ripartizione di queste restrizioni sono le restrizioni delle funzioni diripartizione originarie. Per esse vale la convergenza in ogni punto di [0, t], quindi (comesopra) vale la convergenza stretta di µπn|[0,t] a µ|[0,t]. La dimostrazione è completa.
Teorema 29 Sia x : [0, T ] → R una funzione continua avente variazione quadratica[x]t lungo una successione πn. Sia f : R→ R di classe C2. Allora esiste finito il limite
limn→∞∑
i∈Jπntf ′(xtni) (xtni+1 − xtni
), che indichiamo con
∫ t0f ′ (xs) dxs, e vale
f (xt) = f (x0) +
∫ t
0
f ′ (xs) dxs +1
2
∫ t
0
f ′′ (xs) d [x]s
Abbiamo indicato con tni , i = 0, 1, ..., Nn, i punti della partizione πn.
Proof. Abbreviamo Jnt = Jπnt . Vale
f (xt)− f (x0) = limn→∞
∑i∈Jnt
(f(xtni+1
)− f
(xtni))

5.1. LA “CHAIN RULE”PER FUNZIONI POCO REGOLARI 127
essendo x continua. Cerchiamo di esprimere f(xtni+1
)− f
(xtni)opportunamente.
Ricordiamo la formula di Taylor, in un generico punto x0:
f (x) = f (x0) + f ′ (x0) (x− x0) +1
2f ′′(ξx,x0
)(x− x0)2
dove ξx,x0 è un punto intermedio tra x ed x0. Possiamo riscriverla nella forma
f (x) = f (x0) + f ′ (x0) (x− x0) +1
2f ′′ (x0) (x− x0)2 + r (x, x0)
dove r (x, x0) = 12
(f ′′(ξx,x0
)− f ′′ (x0)
)(x− x0)2. Per x, x0 appartenenti all’immagine
di t 7→ xt (o a qualsiasi compatto, da cui dipenderà la funzione a), r (x, x0) soddisfa
|r (x, x0)| ≤ a (|x− x0|) (x− x0)2
dove r 7−→ a (r), r ≥ 0, è una funzione crescente e infinitesima nell’origine, con a(0) =0. Basta porre, relativamente ad un compatto K fissato,
a (r) = supx,x0∈K|x−x0|≤r
1
2
∣∣f ′′ (ξx,x0)− f ′′ (x0)∣∣
che è finito per ogni r grazie alla continuità di f ′′, e verifica limr→0 a (r) = 0 perl’uniforme continuità di f ′′.Usiamo questa versione della formula di Taylor:∑
i∈Jnt
(f(xtni+1
)− f
(xtni))
=∑i∈Jnt
f ′(xtni) (xtni+1 − xtni
)+
1
2
∑i∈Jnt
f ′′(xtni) (xtni+1 − xtni
)2
+∑i∈Jnt
r(xtni+1 , xtni
).
Il secondo termine a destra dell’uguale converge a 12
∫ t0f ′′ (xs) d [x]s. Il terzo termine
tende a zero, essendo∑i∈Jnt
r(xtni+1 , xtni
)≤
∑i∈Jnt
a(∣∣∣xtni+1 − xtni ∣∣∣) (xtni+1 − xtni )2
≤ maxi∈Jnt
a(∣∣∣xtni+1 − xtni ∣∣∣)∑
i∈Jnt
(xtni+1 − xtni
)2
≤ a
(maxi∈Jnt
∣∣∣xtni+1 − xtni ∣∣∣) [x]πnt
ed usando il fatto che maxi∈Jnt
∣∣∣xtni+1 − xtni ∣∣∣→ 0 per n→∞ (essendo x uniformemente
continua e |πn| → 0), a è infinitesima e [x]πnt è limitato perché converge. Il terminea sinistra dell’uguale converge a f (xt) − f (x0). Quindi anche il primo termine adestra dell’uguale converge e vale la formula enunciata dal teorema. La dimostrazioneè completa.

128 CAPITOLO 5. LA FORMULA DI ITÔ
Osservazione 33 Se x è differenziabile con continuità, vale
f (xt) = f (x0) +
∫ t
0
f ′ (xs) dxs
dove∫ t
0f ′ (xs) dxs va inteso come
∫ t0f ′ (xs)x
′sds. Il correttore
1
2
∫ t
0
f ′′ (xs) d [x]s
è la novità di questa formula, nel caso di x meno regolare ma avente variazionequadratica.
5.1.1 Caso multidimensionale e dipendente dal tempo
Definizione 16 Date due funzione continue x1, x2 : [0, T ]→ R ed una successione dipartizioni (πn)n∈N con |πn| → 0 per n → ∞, diciamo che x1 e x2 hanno variazionemutua [x1, x2]t, t ∈ [0, T ], lungo πn, se per ogni t ∈ [0, T ] esiste finito il limite
limn→∞
∑k∈Jπnt
(x1tnk+1− x1
tnk
)(x2tnk+1− x2
tnk
)e definisce una funzione continua, che indichiamo appunto con [xi, xj]t, t ∈ [0, T ]. Sex1 = x2, il concetto si riduce a quello di variazione quadratica lungo πn e per semplicitàverrà anche indicato con [x1]t oltre che con [x1, x1]t.
Consideriamo ora una funzione x : [0, T ]→ Rd di componenti xi, i = 1, ..., d.
Definizione 17 Sia (πn)n∈N una successione di partizioni con |πn| → 0 per n → ∞.Diciamo che una funzione continua x : [0, T ]→ Rd ha variazione quadratica congiuntalungo la successione πn se per ogni i, j = 1, ..., d (anche i = j) le componenti xi e xj
hanno variazione mutua [xi, xj]t, t ∈ [0, T ], lungo πn, ovvero[xi, xj
]t
= limn→∞
∑k∈Jπnt
(xitnk+1 − x
itnk
)(xjtnk+1 − x
jtnk
). (5.5)
Lemma 11 La funzione continua x : [0, T ] → Rd ha variazione quadratica congiuntalungo πn se e solo se per ogni i, j = 1, ..., d (anche i = j) le funzioni xi + xj hannovariazione quadratica lungo πn. Le variazioni suddette sono legate dalle formule[
xi, xj]t
=1
2
([xi + xj, xi + xj
]t−[xi, xi
]t−[xj, xj
]t
)[xi + xj, xi + xj
]t
=[xi, xi
]t+[xj, xj
]t+ 2
[xi, xj
]t.

5.1. LA “CHAIN RULE”PER FUNZIONI POCO REGOLARI 129
Proof. Supponiamo che valga la condizione della definizione. Dall’indentità((xitnk+1 + xjtnk+1
)−(xitnk + xjtnk
))2
=(xitnk+1 − x
itnk
)2
+(xjtnk+1 − x
jtnk
)2
+ 2(xitnk+1 − x
itnk
)(xjtnk+1 − x
jtnk
)deduciamo che xi + xj ha variazione quadratica lungo πn. Viceversa, se vale la con-dizione del lemma, dall’indentità(
xitnk+1 − xitnk
)(xjtnk+1 − x
jtnk
)=
1
2
(((xitnk+1 + xjtnk+1
)−(xitnk + xjtnk
))2
−(xitnk+1 − x
itnk
)2
−(xjtnk+1 − x
jtnk
)2)
deduciamo che xi e xj hanno variazione mutua lungo πn.L’utilità del lemma è quella di riportare il problema della variazione mutua a quello
della variazione quadratica, a cui possiamo applicare la Proposizione 47. Ne discendesubito la variante in dimensione d:
Proposizione 48 i) Sia D ⊂ [0, T ] un insieme denso tale che T ∈ D. Se, per ognii, j = 1, ..., d, esiste una funzione uniformemente continua t 7−→ [xi, xj]t, definita suD, tale che vale (5.5) per ogni t ∈ D, allora x ha variazione quadratica congiunta lungoπn.ii) Se x : [0, T ]→ Rd ha variazione quadratica lungo πn allora, per ogni i, j = 1, ..., d
ed ogni t ∈ [0, T ] esiste il seguente limite
limn→∞
∑k∈Jπnt
ϕ (tni )(xitnk+1 − x
itnk
)(xjtnk+1 − x
jtnk
)=
∫ t
0
ϕ (s) d[xi, xj
]s
per ogni funzione ϕ : [0, t] → R continua e limitata. L’integrale∫ t
0ϕ (s) d [xi, xj]s può
essere inteso per differenza, secondo la definizione di [xi, xj]t.
Teorema 30 Sia x : [0, T ] → Rd una funzione continua avente variazione quadraticacongiunta lungo una successione πn. Sia f : [0, T ] × Rd → R una funzione continuaavente le derivate ∂f
∂t, ∂f∂xi, ∂2f∂xi∂xj
continue (diremo di classe C1,2). Allora esiste finitoil limite
limn→∞
∑k∈Jπnt
d∑i=1
∂f
∂xi(tnk , xtnk
) (xitnk+1 − x
itnk
)che indichiamo con ∫ t
0
∇f (s, xs) · dxs

130 CAPITOLO 5. LA FORMULA DI ITÔ
e vale
f (t, xt) = f (0, x0) +
∫ t
0
∂f
∂t(s, xs) ds+
∫ t
0
∇f (s, xs) · dxs
+1
2
d∑i,j=1
∫ t
0
∂2f
∂xi∂xj(s, xs) d
[xi, xj
]s.
Osservazione 34 Gli integrali∫ t
0∂f∂xi
(s, xs) dxis non sono autonomamente definiti, so-
lo la loro somma. Questo è il difetto principale di questa teoria “deterministica” delcalcolo di Itô. Il problema sparisce nel caso di processi stocastici, in quanto questiintegrali saranno definiti nel senso di Itô.
Proof. Passo 1. Vale
f (t, xt)− f (0, x0) = limn→∞
∑k∈Jnt
(f(tnk+1, xtnk+1
)− f
(tnk , xtnk
))
essendo x, f continue. Cerchiamo di esprimere f(tnk+1, xtnk+1
)− f
(tnk , xtnk
)opportuna-
mente.Per funzioni f di classe C1,2, scriviamo la seguente versione asimmetrica della
formula di Taylor, in un generico punto (t0, x0):
f (t, x) = f (t0, x0) +∂f
∂t(t0, x0) (t− t0) +
d∑i=1
∂f
∂xi(t0, x0)
(xi − xi0
)+
1
2
d∑i,j=1
∂2f
∂xi∂xj(t0, x0)
(xi − xi0
) (xj − xj0
)+r (t, t0, x, x0)
dove r (t, t0, x, x0) è definito dall’identità stessa; il punto da chiarire sono le proprietàdi infinitesimo di tale resto. Vale il seguente fatto: per ogni R > 0, esiste una funzionecrescente e infinitesima nell’origine aR : [0,∞)→ R, tale che
|r (t, t0, x, x0)| ≤ aR (‖(t, x)− (t0, x0)‖)(|t− t0|+ |x− x0|2
)per ogni t, t0 ∈ [0, T ], x, x0 ∈ B (0, R). Nel caso di f indipendente da t, la verifica èidentica al caso in d = 1 fatto in precedenza. Nel Passo 2 scriveremo i dettagli nel casogenerale.Usando questa formula abbiamo∑
k∈Jnt
(f(tnk+1, xtnk+1
)− f
(tnk , xtnk
))

5.1. LA “CHAIN RULE”PER FUNZIONI POCO REGOLARI 131
=∑k∈Jnt
∂f
∂t
(tnk , xtnk
) (tnk+1 − tnk
)+∑k∈Jnt
d∑i=1
∂f
∂xi(tnk , xtnk
) (xitnk+1 − x
itnk
)
+1
2
∑k∈Jnt
d∑i,j=1
∂2f
∂xi∂xj(tnk , xtnk
) (xitnk+1 − x
itnk
)(xjtnk+1 − x
jtnk
)+∑k∈Jnt
r(tnk+1, t
nk , xtnk+1 , xtnk
).
Il primo termine a destra dell’uguale converge a∫ t
0∂f∂t
(s, xs) ds per un noto teoremasulla convergenza delle somme di Riemann all’integrale di Riemann. Il terzo termine adestra dell’uguale converge a 1
2
∑di,j=1
∫ t0
∂2f∂xi∂xj
(xs) d [xi, xj]s, grazie al lemma. Il quartotermine tende a zero, essendo ∑
k∈Jnt
r(tnk+1, t
nk , xtnk+1 , xtnk
)
≤∑k∈Jnt
aR
(∥∥∥(tnk+1, xtnk+1
)−(tnk , xtnk
)∥∥∥)(∣∣tnk+1 − tnk∣∣+∣∣∣xtnk+1 − xtnk ∣∣∣2)
≤ maxkaR
(∥∥∥(tnk+1, xtnk+1
)−(tnk , xtnk
)∥∥∥) ∑k∈Jnt
(∣∣tnk+1 − tnk∣∣+
d∑i=1
∣∣∣xitnk+1 − xitnk ∣∣∣2).
Ora (come nel caso unidimensionale), la serie∑
k∈Jnt
∣∣tnk+1 − tnk∣∣ converge a t, la serie∑
k∈Jnt
∑di=1
∣∣∣xitnk+1 − xitnk ∣∣∣2 converge a∑di=1 [xi]t, ed il termine
maxkaR
(∥∥∥(tnk+1, xtnk+1
)−(tnk , xtnk
)∥∥∥)≤ aR
(maxk
∥∥∥(tnk+1, xtnk+1
)−(tnk , xtnk
)∥∥∥)tende a zero perché maxk
∥∥∥(tnk+1, xtnk+1
)−(tnk , xtnk
)∥∥∥→ 0 (ricordiamo l’uniforme conti-
nuità di x).Il termine a sinistra dell’uguale converge a f (xt)− f (x0). Quindi anche il secondo
termine a destra dell’uguale converge e vale la formula enunciata dal teorema.Passo 2. Fissato (t0, x0) e preso un generico (t, x), vale
f (t, x)− f (t0, x0) = (f (t, x)− f (t0, x)) + (f (t0, x)− f (t0, x0)) .

132 CAPITOLO 5. LA FORMULA DI ITÔ
Al secondo addendo applichiamo ragionamenti classici, ovvero
f (t0, x)− f (t0, x0) =d∑i=1
∂f
∂xi(t0, x0)
(xi − xi0
)+
1
2
d∑i,j=1
∂2f
∂xi∂xj(t0, x0)
(xi − xi0
) (xj − xj0
)+ rt0 (x, x0)
dove
rt0 (x, x0) =1
2
d∑i,j=1
(∂2f
∂xi∂xj(t0, ξt0,x,x0
)− ∂2f
∂xi∂xj(t0, x0)
)(xi − xi0
) (xj − xj0
)e dove ξt0,x,x0 è un punto intermedio tra x ed x0. Se ne deduce
|rt0 (x, x0)| ≤ C
(max
z∈B(x0,|x−x0|)
∥∥D2f (t0, z)−D2f (t0, x0)∥∥) |x− x0|2
≤ a′R (|x− x0|) |x− x0|2
dovea′R (r) = C max
t0∈[0,T ]max
x0∈B(0,R)max
z∈B(x0,r)
∥∥D2f (t0, z)−D2f (t0, x0)∥∥ .
Usando l’uniforme continuità di D2f sui compatti, si verifica subito che a′R (nondecrescente) è infinitesima in zero.Per il primo addendo f (t, x)− f (t0, x) vale invece
f (t, x)− f (t0, x) =∂f
∂t(t0, x0) (t− t0) + ρ (t, t0, x, x0)
dove, per ogni R > 0, esiste una funzione crescente e infinitesima nell’origine a′′R, taleche
|ρ (t, t0, x, x0)| ≤ a′′R (‖(t, x)− (t0, x0)‖) |t− t0| (5.6)
per ogni x, x0 ∈ B (0, R). Basta infatti osservare che, per un opportuno α ∈ [0, 1]dipendende dai punti in gioco,
ρ (t, t0, x, x0) =
(∂f
∂t(αt+ (1− α) t0, x)− ∂f
∂t(t0, x0)
)(t− t0)
da cui la (5.6) con
a′′R (r) = maxt0∈[0,T ]
maxx0∈B(0,R)
max(s,z):‖(s,z)−(t0,x0)‖≤r
∣∣∣∣∂f∂t (s, z)− ∂f
∂t(t0, x0)
∣∣∣∣che è di nuovo (non decrescente e) infinitesima in zero, per l’uniforme continuità di ∂f
∂t
sui compatti. La dimostrazione è completa.

5.1. LA “CHAIN RULE”PER FUNZIONI POCO REGOLARI 133
5.1.2 Integrale secondo Stratonovich
Nella teoria precedente il termine del secondo ordine della formula di Taylor gioca unruolo essenziale. Esiste però un modo alternativo di definire gli integrali che perme-tte di ottenere formule più somiglianti al caso classico dell’analisi matematica. Sonodetti integrali secondo Stratonovich. Hanno un innegabile vantaggio in contesti dove lecomposizioni sono frequentissime, come nel caso di processi stocastici su varietà in cuitutto è sempre definito tramite composizione con carte. Hanno però anche dei difetti,che descriveremo al momento buono.Introduciamo il seguente simbolo, ove definito:∫ t
0
ys dxs =
∫ t
0
ysdxs +1
2[y, x]t
dove [y, x]t è la variazione mutua sopra introdotta e∫ t
0ysdxs indica, se esiste, il limite∫ t
0
ysdxs = limn→∞
∑i∈Jπnt
ytni
(xtni+1 − xtni
).
Vale (quando esiste il limite)∫ t
0
ys dxs = limn→∞
∑i∈Jπnt
ytni+1 + ytni2
(xtni+1 − xtni
)in quanto
[y, x]t = limn→∞
∑i∈Jπnt
(ytni+1 − ytni
)(xtni+1 − xtni
).
Teorema 31 Sia x : [0, T ] → R una funzione continua avente variazione quadraticalungo una successione πn. Sia f : R → R una funzione di classe C2. Allora esiste lavariazione mutua [f ′ (x) , x]t e vale
f (xt) = f (x0) +
∫ t
0
f ′ (xs) dxs.
Proof. Sappiamo che vale
f (xt) = f (x0) +
∫ t
0
f ′ (xs) dxs +1
2
∫ t
0
f ′′ (xs) d [x]s .
Dobbiamo dimostrare che [f ′ (x) , x]t esiste e vale
[f ′ (x) , x]t =
∫ t
0
f ′′ (xs) d [x]s .

134 CAPITOLO 5. LA FORMULA DI ITÔ
Abbiamo, se esiste,
[f ′ (x) , x]t = limn→∞
∑i∈Jπnt
(f ′(xtni+1
)− f ′
(xtni))(
xtni+1 − xtni)
mentre sappiamo che∫ t
0
f ′′ (xs) d [x]s = limn→∞
∑i∈Jπnt
f ′′(xtni) (xtni+1 − xtni
)2
.
Inoltre sappiamo che
f ′(xtni+1
)− f ′
(xtni)
= f ′′(xtni) (xtni+1 − xtni
)+ r
(xtni , xtni+1
)con
|r (x, x0)| ≤ a (|x− x0|) (x− x0)2
dove a è una funzione crescente e infinitesima nell’origine. Quindi basta dimostrareche
limn→∞
∑i∈Jπnt
r(xtni , xtni+1
)= 0.
Ma questo segue facilmente dalla proprietà suddetta di r.
5.2 Applicazione ai processi stocastici
In questa sezione vediamo come si può applicare la chain rule nell’ambito dei processistocastici. Da un lato, dobbiamo superare una diffi coltà: che per gli usuali processistocastici non si riesce ad esaminare direttamente la variazione quadratica delle lorosingole traiettorie, ma solo secondo una definizione con la convergenza in probabilità(salvo casi particolarissimi come il moto browiano con le partizioni diadiche). Dall’al-tro però, nel caso dei processi stocastici, gli integrali stocastici sono autonomamentedefiniti, non solo come sottoprodotto della chain rule stessa; dobbiamo però verificareche la definizione autonoma coincide col la formula data dalla chain rule. Iniziamodiscutendo il problema della variazione quadratica. Formuliamo il risultato su [0, T ]ma vale anche per t ≥ 0 (intendendo che vale su [0, T ] per ogni T > 0, con il risultatoche non dipende da T ). Sia (πn) una successione di partizioni di [0, T ] con |πn| → 0;scriviamo πn =
0 = tn0 ≤ ... ≤ tnNn = T
.
Definizione 18 i) Diciamo che un processo stocastico continuo X = (Xt)t∈[0,T ] in Rd
ha variazione quadratica congiunta in probabilità [X i, Xj]t, i, j = 1, ..., d, lungo (πn),

5.2. APPLICAZIONE AI PROCESSI STOCASTICI 135
se per ogni i, j = 1, ..., d, esiste un processo stocastico continuo, che indichiamo con[X i, Xj]t, tale che per ogni t ∈ [0, T ] valga[X i, Xj
]t
= P − limn→∞
∑tni+1≤t
(X itni+1−X i
tni
)(Xjtni+1−Xj
tni
)+(X it −X i
tnk
)(Xjt −Xj
tnk
)(limite in probabilità) dove usiamo la convenzione tnk ≤ t < tnk+1. Chiamiamo [X i, Xj]tvariazione mutua tra X i e Xj, o variazione quadratica quando i = j.ii) Diciamo che un processo stocastico continuo X = (Xt)t∈[0,T ] in Rd ha variazione
quadratica congiunta traiettoria per traiettoria, lungo (πn), se q.c. le sue traiettoriehanno variazione quadratica congiunta lungo (πn), nel senso della Definizione 17.
Osservazione 35 Con riferimento alle osservazioni 28, 29, il punto (i) della definizioneutilizza la convenzione adottata nel capitolo delle martingale; il punto (ii) quella adot-tata nel capitolo della formula di Itô pathwise.
Si può verificare facilmente, per processi continui, che la condizione (ii) implica la(i). Ciò che serve a noi è il viceversa, anche a patto di modificare la successione dipartizioni.
Proposizione 49 Sia X = (Xt)t∈[0,T ] un processo stocastico continuo in Rd che havariazione quadratica congiunta in probabilità [X i, Xj]t, i, j = 1, ..., d, lungo una suc-cessione di partizioni infinitesime (πn). Allora esiste una sottosuccessione (π′n) lungocui ha variazione quadratica congiunta traiettoria per traiettoria. Vale inoltre, per q.o.ω, [X i (ω) , Xj (ω)]t = [X i, X i]t (ω) per ogni i, j = 1, ..., d.
Proof. Scriviamo la dimostrazione in dimensione uno per minimizzare gli indici; ilcaso generale è identico. Supponiamo T ∈ Q, altrimenti basta considerare l’insieme(Q ∩ [0, T ]) ∪ T al posto di Q ∩ [0, T ].Sia t ∈ Q ∩ [0, T ]. Per il noto legame tra convergenza in probabilità e convergenza
quasi certa, esiste una sottosuccessione(π
(t)n
)di partizioni di [0, T ] (che dipende dal t
scelto) per cui valga la convergenza quasi certa:
[X]t = q.c.− limn→∞
∑tni+1≤t
(Xtni+1
−Xtni
)2
+(Xt −Xtnk
)2.
Dalla continuità delle traiettorie di X discende subito
[X]t = q.c.− limn→∞
∑tni ≤t
(Xtni+1
−Xtni
)2
che collega [X]t alla definizione di variazione quadratica data per le singole funzioni (sivedano le osservazioni 28, 29). Però t è fissato e da esso dipendono la sottosuccessionee l’evento trascurabile in cui eventualmente non vale la convergenza puntuale.

136 CAPITOLO 5. LA FORMULA DI ITÔ
Con un procedimento diagonale (numerando gli elementi diQ∩[0, T ]), si può trovareun’unica sottosuccessione, che indichiamo con (π′n), tale che
P
limn→∞
∑i∈Jπ
′n
t
(Xtni+1
−Xtni
)2
= [X]t
= 1 per ogni t ∈ Q ∩ [0, T ] .
Siccome l’intersezione numerabile di insiemi di probabilità uno ha probabilità uno,l’insieme
A =
ω ∈ Ω : limn→∞
∑i∈Jπ
′n
t
(Xtni+1
(ω)−Xtni(ω))2
= [X,X]t (ω) ,∀t ∈ Q ∩ [0, T ]
ha la proprietà P (A) = 1. Per la Proposizione 47, parte (i) (ricordiamo che T ∈Q ∩ [0, T ]) vale
A =
ω ∈ Ω : limn→∞
∑i∈Jπ
′n
t
(Xtni+1
(ω)−Xtni(ω))2
= [X,X]t (ω) ,∀t ∈ [0, T ]
.
La dimostrazione è completa.
Corollario 15 Sia X = (Xt)t∈[0,T ] un processo stocastico continuo in Rd avente vari-azione quadratica congiunta lungo una successione di partizioni; indichiamo poi con(πn) una successione per cui sia vera la tesi della proposizione precedente. Sia f :[0, T ]× R → R una funzione di classe C1,2. Allora, per ogni t ∈ [0, T ], esiste il limitein probabilità e q.c.
limn→∞
∑k∈Jπnt
d∑i=1
∂f
∂xi(tnk , Xtnk
) (X itnk+1−X i
tnk
)che indichiamo con ∫ t
0
∇f (s,Xs) · dXs
e vale q.c.
f (t,Xt) = f (0, X0) +
∫ t
0
∂f
∂t(s,Xs) ds+
∫ t
0
∇f (s,Xs) · dXs
+1
2
d∑i,j=1
∫ t
0
∂2f
∂xi∂xj(s,Xs) d
[X i, Xj
]s.

5.2. APPLICAZIONE AI PROCESSI STOCASTICI 137
Per rendere ancor più operativa questa formula servono due ingredienti. Da un lato,avere un’ampia classe di processi X aventi variazione quadratica congiunta [X i, Xj]te che questa sia calcolabile. Dall’altro, sapere che la v.a.
∫ t0∇f (s,Xs) · dXs si può
riscrivere tramite integrali noti (di Itô o di Lebesgue). Affrontiamo i due problemi nelleprossime due sezioni.Si noti che, per risolvere il secondo problema, non basta riferirsi in modo ovvio
al teorema limite sulle somme di Riemann dimostrato per gli integrali di Itô, per lasemplice ragione che lì si trattava di integrali di Itô rispetto al moto browniano, mentrequi abbiamo un integrale rispetto al processo X.
5.2.1 Variazione quadratica
Martingale locali in dimensione uno
Per le martingale locali continue M abbiamo visto nel capitolo sulle martingale che illimite in probabilità
[M ]t = P − limn→∞
∑tni+1≤t
(Mtni+1
−Mtni
)2
+(Mt −Mtnk
)2
esiste, anche uniformemente su [0, T ] (basta prendere successioni di partizioni incapsu-late, visto che la nostra dimostrazione era ristretta ad esse; ma il risultato vale anchein generale). Ne discende subito che esiste la variazione quadratica traiettoria pertraiettoria, lungo un’opportuna sottosuccessione di partizioni.Ricordiamo anche che il risultato in probabilità non dipendeva dalla successione di
partizioni, quindi il risultato che si ottiene ha un ragionevole grado di indipendenza.Non stiamo però affermando che, data una singola traiettoria di M , il risultato sia lostesso al variare di ogni possibile partizione, anche perché questo in generale non è vero(i controesempi richiedono però un po’di lavoro).
Processi a variazione limitata e continui, dimensione uno
Lemma 12 Sia V un processo a traiettorie continue ed a variazione limitata. Allora,rispetto a qualsiasi successione infinitesima di partizioni, ha variazione quadratica siain probabilità (come processo) sia traiettoria per traiettoria e [V ]t = 0.
La dimostrazione per traiettorie è un’ovvia conseguenza della Proposizione 30, acui va operato un piccolo aggiustamento per lo sfasamento tra le partizioni ed il pun-to t considerato, sfasamento che tende a zero per la continuità delle traiettorie. Laconvergenza in probabilità come processo discende da quella quasi certa.In particolare, questo lemma si applica agli integrali che compariranno nei processi
di Itô:

138 CAPITOLO 5. LA FORMULA DI ITÔ
Corollario 16 Dato un processo b di classe Λ1B, il processo Vt :=
∫ t0bsds ha vari-
azione quadratica nulla (nei due sensi del lemma precedente) lungo ogni successioneinfinitesima di partizioni.
Osserviamo solamente che V è continuo per l’assoluta continuità dell’integrale diLebesgue ed è a variazione limitata perché, per ogni partizione π,
∑ti∈π
∣∣Vti+1 − Vti∣∣ ≤∑ti∈π
∫ ti+1
ti
|bs| ds =
∫ T
0
|bs| ds <∞ q.c.
Il lemma precedente è un caso particolare del seguente fatto, che useremo:
Lemma 13 Sia V un processo a traiettorie continue ed a variazione limitata e siaX un processo continuo. Allora, rispetto ad una successione infinitesima qualsiasi(πn), esiste la variazione mutua [X, V ] in probabilità e traiettoria per traiettoria ed èidenticamente nulla.
Proof. Ragioniamo traiettorie per traiettorie; l’altro caso ne è conseguenza. Fissiamoω q.c., che non scriviamo. Vale∣∣∣∣∣∣
∑tni ≤t
(Xtni+1
−Xtni
)(Vtni+1 − Vtni
)∣∣∣∣∣∣ ≤∑tni ≤t
∣∣∣Xtni+1−Xtni
∣∣∣ ∣∣∣Vtni+1 − Vtni ∣∣∣≤ max
j
∣∣∣Xtnj+1−Xtnj
∣∣∣∑tni
∣∣∣Vtni+1 − Vtni ∣∣∣≤ ω (X, πn) sup
π
∑ti
∣∣Vti+1 − Vti∣∣dove ω (X, πn) è l’oscillazione della traiettoria X su πn. Ora supπ
∑ti
∣∣Vti+1 − Vti∣∣ <∞q.c. e ω (X, πn)→ 0 per l’uniforme continuità della traiettoria X su [0, T ].
Semimartingale continue in dimensione uno e qualsiasi
Ricordiamo che un processoX si dice semimartingala continua se si può esprimere comesomma di due processiM e V conM martingala locale continua e V processo adaattatoa traiettorie continue ed a variazione limitata. Dai risultati precedenti discende subito:
Corollario 17 Se X è una semimartingala continua, allora esiste una successionedi partizioni lungo cui ha variazione quadratica sia in probabilità sia traiettoria pertraiettoria. Inoltre coincide con la variazione di M .

5.2. APPLICAZIONE AI PROCESSI STOCASTICI 139
Proof. Sia (πn) una successione lungo cui esiste la variazione quadratica di M (ilragionamento vale in ciascuno dei due sensi). Siccome
[X]πnt = [M ]πnt + [V ]πnt + 2 [M,V ]πnt
e [M ]πnt converge, [V ]πnt → 0, [M,V ]πnt → 0 (per i lemmi dei paragrafi precedenti),allora [X]πnt converge, allo stesso limite di [M ]πnt .Un processo vettoriale X =
(X1, ..., Xd
)si dice semimartingala continua se lo sono
le sue componenti. Ovviamente il risultato precedente si applica alle singole componentima vorremmo anche avere le variazioni mutue tra le componenti.
Proposizione 50 Se X =(X1, ..., Xd
)è una semimartingala continua in Rd, allora
esiste una successione di partizioni lungo cui X ha variazione quadratica congiunta,sia in probabilità sia traiettoria per traiettoria.Inoltre, se scriviamo X come somma di due processiM e V conM martingala locale
continua in Rd e V processo adattato a traiettorie continue ed a variazione limitata inRd, le variazioni suddette di X coincidono con quelle di M .
Proof. Si ricordi la formula di polarità (a, b ∈ R)
ab =1
4
((a+ b)2 − (a− b)2) .
Presi i, j, i due processi X i +Xj e X i −Xj sono semimartingale, dal momento che losono X i e Xj. Quindi hanno variazione quadratica (nei due sensi). Per la formula dipolarità applicata ai quadrati degli incrementi, esiste la variazione mutua [X i, Xj] (neidue sensi). Questo significa che X ha variazione quadratica congiunta.La seconda affermazione si dimostra come il corollario precedente.
Processi di Itô
Definizione 19 Chiamiamo processo di Itô in Rd un processo X = (Xt)t∈[0,T ] a valoriin Rd della forma
Xt = X0 +
∫ t
0
bsds+
∫ t
0
σsdBs
con X0 misurabile rispetto a F0, b un processo vettoriale in Rd di classe Λ1B (cioè
progressivamente misurabile e tale che∫ T
0|bs| ds < ∞ q.c.), σ processo matriciale in
Rn×d di classe Λ2B. Per componenti,
X it = X i
0 +
∫ t
0
bisds+n∑k=1
∫ t
0
σiks dBks .
Scriveremo anchedXt = btdt+ σtdBt.

140 CAPITOLO 5. LA FORMULA DI ITÔ
Le componenti dei processi di Itô sono somma di processi continui a variazionelimitata (il termine X i
0 +∫ t
0bisds) e di martingale locali, quindi sono semimartingale.
Pertanto X ha variazione quadratica congiunta, nei due sensi. Qui vogliamo inoltrecalcolarla, in termini di b e σ. Sia (πn) una successione di partizioni di [0, T ], con|πn| → 0, lungo cui esiste la variazione suddetta. Come già osservato nella proposizioneprecedente, basta calcolare la variazione della parte di martingala locale, ovvero di
Mt :=
∫ t
0
σsdBs.
Per non appesantre la trattazione con tempi d’arresto, limitiamoci al caso σ ∈M2B, in
cui M è una martingala, continua e di quadrato integrabile. Inoltre, anche se questoin effetti non mostra tutte le piccole diffi coltà tecniche, limitiamoci alla dimostrazionenel caso d = 1. Sappiamo che M2
t −∫ t
0σ2sds è una martingala. Il Teorema 22 dice che
se A è un processo continuo crescente con A0 = 0, tale cheM2t −At sia una martingala,
allora A = [M ]. Quindi∫ t
0σ2sds = [M ]t. Enunciamo il risultato generale.
Teorema 32 Sia X = (Xt)t∈[0,T ] un processo di Itô in Rd della forma
Xt = X0 +
∫ t
0
bsds+
∫ t
0
σsdBs
con b in Rd di classe Λ1B e σ in Rn×d di classe Λ2
B. Allora X ha variazione quadraticacongiunta (nei due sensi) e, per ogni i, j = 1, ..., d e per ogni t, vale q.c.
[X i, Xj
]t
=
∫ t
0
σiks σjks ds =
∫ t
0
(σsσ
Ts
)ijds.
Osservazione 36 Osserviamo che la traccia della matrice ([X i, Xj]t)ij vale
Tr([X i, Xj
]t
)ij
=
∫ t
0
‖σs‖2HS ds.
C’è una forte somiglianza tra le formule in valore atteso quadratico e quelle in vari-
azione quadratica (si ricordi la formula di isometria E[∣∣∣∫ t0 σsdBs
∣∣∣2] = E[∫ t
0‖σs‖2
HS ds]).
5.2.2 Integrale stocastico rispetto ad un processo di Itô
Sia X = (Xt)t∈[0,T ] un processo di Itô in Rd della forma
Xt = X0 +
∫ t
0
bsds+
∫ t
0
σsdBs

5.3. FORMULA DI ITÔ 141
con b in Rd di classe Λ1B e σ in Rn×d di classe Λ2
B. Per componenti,
X it = X i
0 +
∫ t
0
bisds+
n∑k=1
∫ t
0
σiks dBks .
Sia Y un processo di classe Λ2B. Allora, per ogni i = 1, ..., d, poniamo∫ t
0
YsdXis =
∫ t
0
Ysbisds+
n∑k=1
∫ t
0
Ysσiks dB
ks .
Proposizione 51 Se Y è continuo,∫ t
0
YsdXis = lim
n→∞
∑k∈Jπnt
Ytnk
(X itnk+1−X i
tnk
).
Proof. Vale ∑k∈Jπnt
Ytnk
(X itnk+1−X i
tnk
)=
∑k∈Jπnt
Ytnk
∫ tnk+1
tnk
bisds+n∑j=1
∑k∈Jπnt
Ytnk
∫ tnk+1
tnk
σijs dBjs
=∑k∈Jπnt
∫ tnk+1
tnk
Ytnk bisds+
n∑j=1
∑k∈Jπnt
∫ tnk+1
tnk
Ytnkσijs dB
js
(l’ultimo passaggio richiederebbe una dimostrazione che omettiamo)
=
∫ t
0
Y ns b
isds+
n∑j=1
∫ t
0
Y ns σ
ijs dB
js
dove Y ns è il processo che vale Ytnk su [tnk , t
nk+1). Basta ora usare la continuità di Y ed
alcuni argomenti di passaggio al limite tradizionali.
5.3 Formula di Itô
Teorema 33 Sia f : [0, T ] × Rd → R una funzione di classe C1,2 ed X = (Xt)t∈[0,T ]
un processo di Itô in Rd, della forma
Xt = X0 +
∫ t
0
bsds+
∫ t
0
σsdBs

142 CAPITOLO 5. LA FORMULA DI ITÔ
con b in Rd di classe Λ1B e σ in Rn×d di classe Λ2
B. Allora
f (t,Xt) = f (0, X0) +
∫ t
0
∂f
∂s(s,Xs) ds+
d∑i=1
∫ t
0
∂f
∂xi(s,Xs) b
isds
+d∑i=1
n∑k=1
∫ t
0
∂f
∂xi(s,Xs)σ
iks dB
ks
+1
2
d∑i,j=1
n∑k=1
∫ t
0
∂2f
∂xi∂xj(s,Xs)σ
iks σ
jks ds.
In particolare, f (t,Xt) è un processo di Itô.
Osservazione 37 Spesso si semplifica un po’ la scrittura precedente introducendo lanotazione
aijs =n∑k=1
σiks σjks
ovveroas = σsσ
Ts .
Osservazione 38 Si noti che
d∑i,j=1
n∑k=1
∂2f
∂xi∂xj(s,Xs)σ
iks σ
jks = Tr
(asD
2f (s,Xs)).
Osservazione 39 Scriveremo quindi a volte, più concisamente (usando anche altreovvie notazioni vettoriali)
f (t,Xt) = f (0, X0) +
∫ t
0
∂f
∂s(s,Xs) ds+
∫ t
0
〈∇f (s,Xs) , bs〉 ds+
∫ t
0
〈∇f (s,Xs) , σsdBs〉
+1
2
∫ t
0
Tr(asD
2f (s,Xs))ds.
Osservazione 40 Per certi scopi è naturale o utile raggruppare i termini in ds rispettoall’integrale di Itô e scrivere
f (t,Xt) = f (0, X0) +
∫ t
0
(∂f
∂s(s,Xs) + 〈∇f (s,Xs) , bs〉+
1
2Tr(asD
2f (s,Xs)))
ds
+
∫ t
0
〈∇f (s,Xs) , σsdBs〉 .

5.3. FORMULA DI ITÔ 143
Proof. Partiamo dal risultato del Corollario 15. L’ipotesi, che X = (Xt)t∈[0,T ] abbiavariazione quadratica congiunta lungo una successione di partizioni, è verificata peril Teorema 32. Indichiamo poi con (πn) una successione lungo cui abbiano variazionequadratica congiunta quasi tutte le traiettorie di X. Per il Corollario 15, sappiamo cheper ogni t ∈ [0, T ], esiste il limite in probabilità e q.c.
limn→∞
∑k∈Jπnt
d∑i=1
∂f
∂xi(tnk , Xtnk
) (X itnk+1−X i
tnk
)
che abbiamo indicato con∫ t
0∇f (s,Xs) ·dXs. Ma per la Proposizione 51, esiste il limite
in probabilità di ciascun addendo∑
k∈Jπnt∂f∂xi
(tnk , Xtnk
) (X itnk+1−X i
tnk
)della precedente
somma e vale∫ t
0
∂f
∂xi(s,Xs) dX
is =
∫ t
0
∂f
∂xi(s,Xs) b
isds+
n∑k=1
∫ t
0
∂f
∂xi(s,Xs)σ
iks dB
ks .
Pertanto, possiamo riscrivere la formula dimostrata nel Corollario 15 nella forma
f (t,Xt) = f (0, X0) +
∫ t
0
∂f
∂t(s,Xs) ds
+d∑i=1
∫ t
0
∂f
∂xi(s,Xs) b
isds+
d∑i=1
n∑k=1
∫ t
0
∂f
∂xi(s,Xs)σ
iks dB
ks
+1
2
d∑i,j=1
∫ t
0
∂2f
∂xi∂xj(s,Xs) d
[X i, Xj
]s.
Infine, dal Teorema 32 sappiamo che
[X i, Xj
]t
=
∫ t
0
σiks σjks ds
Basta allora usare il fatto che∫ t
0∂2f
∂xi∂xj(s,Xs) d [X i, Xj]s∫ t
0
∂2f
∂xi∂xj(s,Xs) d
[X i, Xj
]s
=
∫ t
0
∂2f
∂xi∂xj(s,Xs)σ
iks σ
jks ds
che si può dimostrare prima nel caso in cui σ è continuo (in tal caso [X i, Xj]t è differen-
ziabile e la misura d [X i, Xj]s èd[Xi,Xj]
s
dsds), poi nel caso generale per approssimazione.
La dimostrazione è completa.

144 CAPITOLO 5. LA FORMULA DI ITÔ
5.3.1 Notazione differenziale
E’uso scrivere molte delle equazioni precedenti in forma differenziale, pur intendendocon questo la forma integrale corrispondente. Ad esempio, un processo di Itô in Rd èun processo X = (Xt)t∈[0,T ] a valori in Rd che ha differenziale stocastico della forma
dXt = btdt+ σtdBt
e a formula di Itô corrispondente, per f ∈ C1,2, è
df (t,Xt) =∂f
∂t(t,Xt) dt+
d∑i=1
∂f
∂xi(t,Xt) b
itdt
+d∑i=1
n∑k=1
∂f
∂xi(t,Xt)σ
ikt dB
kt
+1
2
d∑i,j=1
n∑k=1
∂2f
∂xi∂xj(t,Xt)σ
ikt σ
jkt dt.
Si tratta chiaramente di una notazione, ma è utile per sveltire i calcoli. Anche utile ècontrarre il termine bitdt+
∑nk=1 σ
ikt dB
kt in dX
it per cui scriveremo
df (t,Xt) =∂f
∂t(t,Xt) dt+
d∑i=1
∂f
∂xi(t,Xt) dX
it
+1
2
d∑i,j=1
n∑k=1
∂2f
∂xi∂xj(t,Xt)σ
ikt σ
jkt dt.
Infine, può essere utile sostituire∑n
k=1 σikt σ
jkt dt con d [X i, Xj]t e scrivere
df (t,Xt) =∂f
∂t(t,Xt) dt+
d∑i=1
∂f
∂xi(t,Xt) dX
it
+1
2
d∑i,j=1
∂2f
∂xi∂xj(t,Xt) d
[X i, Xj
]t.
Se poi, infine (ma questo è un molto informale) scriviamo
d[X i, Xj
]t
= dX itdX
jt
la formula assume una forma facilissima da ricordare:
df (t,Xt) =∂f
∂t(t,Xt) dt+
d∑i=1
∂f
∂xi(t,Xt) dX
it +
1
2
d∑i,j=1
∂2f
∂xi∂xj(t,Xt) dX
itdX
jt

5.3. FORMULA DI ITÔ 145
in quanto sembra la riscrittura della formula di Taylor. Possiamo anche scrivere
df (t,Xt) =∂f
∂t(t,Xt) dt+∇f (t,Xt) · dXt +
1
2
⟨D2f (t,Xt) dXt, dXt
⟩.
Abbiamo un po’ rifatto il passaggio all’indietro, dai coeffi cienti espliciti b e σ delprocesso di Itô alla notazione con dX e d [X i, Xj]t. Ogni volta si può scegliere lapiù conveniente per svolgere i calcoli.
Osservazione 41 Può essere utile dal punto di vista mnemonico usare la seguentetavola formale di regole
dt · dt = 0
dt · dBit = 0
dBkt · dBk′
t = δkk′dt.
Così facendo, siccome
dX it = bitdt+
∑k
σikt dBkt
dXjt = bjtdt+
∑k′
σjk′
t dBk′
t
valedX i
tdXjt = bitb
jtdt · dt+ ...
somma in cui tuti i termini sono zero salvo∑k
σikt σjkt dB
kt · dBk
t =∑k
σikt σjkt dt.
In questo modo si ritrova la formula corretta. Questi passaggi, anche se formali, por-tano al risultato corretto e quindi vengono comunemente usati per ricostruire rapida-mente il risultato giusto, cioè er applicare più in fretta la formula di Itô nei casi pratici,invece che sostituire pedantemente i coeffi cienti dell’esempio particolare nella formulagenerale.
5.3.2 Esempi
Esempio 1. Sia Bt un moto browniano reale. Vogliamo calcolare dB2t . Interpretiamo
B2t come f (Bt) con f (x) = x2, per cui
dB2t = f ′ (Bt) dBt +
1
2f ′′ (Bt) dt

146 CAPITOLO 5. LA FORMULA DI ITÔ
dove, nell’ultimo termine, abbiamo già usato il fatto che dBtdBt = dt (o più formal-mente il fatto che d [B]t = dt). Sostituendo f ′ (x) = 2x, f ′′ (x) = 2, troviamo
dB2t = 2BtdBt + dt.
In forma integrale, questo significa che
B2t = B2
0 +
∫ t
0
2BsdBs + t.
Si noti che, se ignorassimo che B è un moto browniano invece che una funzione regolare,questo risultato sembrerebbe banalmente sbagliato (in termine +t sarebbe insensato).Esempio 2. Se
dX it = bitdt+ σitdBt, i = 1, 2
allora
d(X1tX
2t
)= X1
t dX2t +X2
t dX1t + d
[X1, X2
]t
avendo usato la funzione
f(x1, x2
)= x1x2
∇f(x1, x2
)=
(x2, x1
)D2f
(x1, x2
)=
(0 11 0
).
Siccome d [X1, X2]t = σ1tσ
2tdt, troviamo
d(X1tX
2t
)= X1
t dX2t +X2
t dX1t + σ1
tσ2tdt.
Si può anche esplicitare nella forma
d(X1tX
2t
)= X1
t b2tdt+X1
t σ2tdBt +X2
t b1tdt+X2
t σ1tdBt + σ1
tσ2tdt
che però risulta meno interpretabile.Esempio 3. Se (in Rd)
dXt = btdt+ σtdBt,
allora
d |Xt|2 = 2XtdXt +
d∑i=1
n∑k=1
σikt σikt dt
avendo usato la funzione
f (x) = |x|2
∇f (x) = 2x
D2f (x) = 2
(1 00 1
).

Capitolo 6
Applicazioni della formula di Itô
6.1 Disuguaglianza di Doob per gli integrali stocas-tici
Teorema 34 Per ogni p ≥ 2 esiste una costante Cp > 0 tale
E
[supt∈[0,T ]
∣∣∣∣∫ t
0
Xs · dBs
∣∣∣∣p]≤ CpE
[∫ T
0
|Xs|p ds]
per ogni T > 0 e dimensione d, ogni moto browniano B in Rd ed ogni processo stocasticoX ∈Mp
B in Rd.
Proof. Vale X ∈M2B quindiMt :=
∫ t0Xs ·dBs è una martingala. Per la disuguaglianza
di Doob per le martingale vale, per un’opportuna costante Cp > 0,
E
[supt∈[0,T ]
∣∣∣∣∫ t
0
Xs · dBs
∣∣∣∣p]≤ CpE
[∣∣∣∣∫ T
0
Xs · dBs
∣∣∣∣p] .Il problema è maggiorare il termine di destra con E
[∫ T0|Xs|p ds
](a meno di costante
indipendente da X). La dimostrazione che stimamo per svolgere è un po’informale;andrebbe svolta arrestando i processi in modo da poter svolgere i conti intermedi epoi rimuovendo l’arresto tramite il teorema di Fatou; abbiamo già illustrato una voltaquesto procedimento per cui qui, per chiarire altre idee, non ripetiamo quei dettagli.Applichiamo la formula di Itô per f (Mt), con f (x) = |x|p, x ∈ R, p ≥ 2, che è una
funzione di classe C2 avente derivate
f ′ (x) = p |x|p−2 x
f ′′ (x) = p (p− 2) |x|p−2 + p |x|p−2 = p (p− 1) |x|p−2 .
147

148 CAPITOLO 6. APPLICAZIONI DELLA FORMULA DI ITÔ
Troviamo
|Mt|p =
∫ t
0
p |Ms|p−2MsdMs +1
2p (p− 1)
∫ t
0
|Ms|p−2 d [M ]s
dove poid [M ]s = |Xs|2 ds.
Immaginando che se usassimo i tempi di arresto l’integrale stocastico sarebbe unamartingala, deduciamo
E [|MT |p] ≤1
2p (p− 1)
∫ T
0
E[|Ms|p−2 |Xs|2
]ds.
(il ≤ invece dell’= è l’eredità di Fatou nell’immaginazione della metodologia rigorosa).Applicando la disuguaglianza di Hölder rispetto alla doppia integrazione
∫ T0E [...] ds
troviamo
E [|MT |p] ≤1
2p (p− 1)
(∫ T
0
E [|Ms|p] ds) p−2
p(∫ T
0
E [|Xs|p] ds) 2
p
.
Per la già citata disuguaglianza di Doob per le martingale, abbiamo∫ T
0
E [|Ms|p] ds ≤ E
[sups∈[0,T ]
|Ms|p]≤ CpE [|MT |p] .
Quindi
E [|MT |p] ≤1
2p (p− 1)C
p−2p
p E [|MT |p]p−2p
(∫ T
0
E [|Xs|p] ds) 2
p
.
Se E [|MT |p] = 0 abbiamo finito, altrimenti dividendo per E [|MT |p]p−2p troviamo
E [|MT |p]2p ≤ 1
2p (p− 1)C
p−2p
p
(∫ T
0
E [|Xs|p] ds) 2
p
che completa la dimostrazione, rinominando la costante.
6.2 Caratterizzazione del moto browniano secondoLévy
Ricordiamo che un moto browniano B =(B1, ..., Bd
)in Rd è una martingala continua e
vale [Bi, Bj]t = t ·δij. Il teorema di questa sezione dice che vale il viceversa. Vale anchese si suppone solamente la proprietà di martingala locale. Premettiamo un criterio diindipendenza.

6.2. CARATTERIZZAZIONE DEL MOTO BROWNIANO SECONDO LÉVY 149
Lemma 14 Dato (Ω,F , P ), sia G una sotto σ-algebra di F . Se un vettore aleatorioX in Rd ha la proprietà che E
[eiλ·X |G
]= E
[eiλ·X
]per ogni λ ∈ Rd, allora X è
indipendente da G.
Proof. Presa W v.a. G-misurabile limitata, vale, per ogni λ ∈ Rd, µ ∈ R,
E[ei(λ,µ)·(X,W )
]= E
[eiλ·Xeiµ·W
]= E
[E[eiλ·Xeiµ·W |G
]]= E
[eiµ·WE
[eiλ·X |G
]]= E
[eiµ·WE
[eiλ·X
]]= E
[eiλ·X
]E[eiµ·W
].
Quindi la funzione caratteristica di (X,W ) è uguale al prodotto delle funzioni carat-teristiche di X e W . Questo implica l’indipendenza, per un noto criterio. Ma allorale v.a. 1X∈A e 1B sono indipendenti, se A ∈ B
(Rd)e B ∈ G, quindi P (X ∈ A,B) =
P (X ∈ A)P (B). Questo implica l’indipendenza di X da G.
Lemma 15 Sia B =(B1, ..., Bd
)un processo adattato ad una filtrazione (Ft)t≥0 tale
che, per ogni λ ∈ Rd, il processo
Y λt := eiλ·Bt+
12|λ|2t
sia una Ft-martingala. Allora B è un Ft-moto browniano in Rd.
Proof. Per la relazione di martingala, abbiamo
E[eiλ·Bt+
12|λ|2t|Fs
]= eiλ·Bs+
12|λ|2s
quindiE[eiλ·(Bt−Bs)|Fs
]= e
12|λ|2(s−t)
da cui E[eiλ·(Bt−Bs)
]= e
12|λ|2(s−t) e quindi anche
E[eiλ·(Bt−Bs)|Fs
]= E
[eiλ·(Bt−Bs)
].
Per il lemma precedente, Bt − Bs è indipendente da Fs. Inoltre, da E[eiλ·(Bt−Bs)
]=
e12|λ|2(s−t) si può dedurre che è N
(0, |λ|2 (t− s)
). Quindi Bt è un moto browniano in
Rd.
Teorema 35 (caratterizzazione di P. Lévy) Sia M =(M1, ...,Md
)una martin-
gala continua vettoriale, rispetto alla filtrazione (Ft)t≥0, nulla in zero. Se [M i,M j]t =δijt allora M è un moto browniano vettoriale, rispetto a (Ft)t≥0.
Proof. Passo 1. Basta mostrare che, per ogni λ ∈ Rd, il processo
Y λt := eiλ·Mt+
12|λ|2t

150 CAPITOLO 6. APPLICAZIONI DELLA FORMULA DI ITÔ
è una Ft-martingala. Per la formula di Itô pathwise (rispetto ad un’opportuna succes-sione di partizioni) vale
dY λt =
1
2|λ|2 Y λ
t dt+ Y λt iλ · dMt −
1
2Y λt
d∑i,j=1
λiλjd[M i,M j
]t
=1
2|λ|2 Y λ
t dt+ Y λt iλ · dMt −
1
2Y λt
d∑i=1
λ2i dt
= Y λt iλ · dMt
ovvero
Y λt =
∫ t
0
Y λs iλ · dMs.
Qui abbiamo preso f (t, x) = eiλ·x+ 12|λ|2t (∂f
∂t= 1
2|λ|2 f , ∇f = iλf , D2f = −λ ⊗ λf),
Y λt = f (t,Mt) ed abbiamo usato in modo cruciale l’ipotesi [M i,M j]t = δijt.Si verifica con un po’di calcoli (si veda il Passo 2) che
∫ t0Y λs iλ·dMs è una martingala
(si osservi in particolare che Y λs iλ è limitato), e questo implica che Y
λt è una martingala,
come si desiderava.Passo 2. Spieghiamo in grandi linee come si verifica che
∫ t0XsdMs è una martin-
gala, per ogni processo reale continuo adattato e limitato X ed ogni martingala realeM tale che, per semplicità, [M ]t = t (è il caso che interessa a noi ora, ma il risultatovale in maggior generalità). Se X è anche un processo elementare, della forma Xt =∑
iXti1[ti,ti+1), dove la partizione è di [0, t], posto∫ t
0XsdMs =
∑iXti
(Mti+1 −Mti
),
vale la formula di isometria
E
[(∫ t
0
XsdMs
)2]
= E
[∫ t
0
X2sds
]
(in generale compare l’espressione E[∫ t
0X2sd [M ]s
]). Da qui si vede che, approssimando
un processo continuo adattato e limitato X con processi elementari Xn, in modo cheE[∫ t
0(Xs −Xn
s )2 ds]→ 0, allora la successione di v.a.
∫ t0Xns dMs è di Cauchy in
L2 (Ω) e quindi converge ad una v.a. che indichiamo con∫ t
0XsdMs; si verifica poi
che l’integrale∫ t
0Y λs iλ · dMs è somma di integrali di questo tipo. A questo punto,
come per gli integrali rispetto al moto browniano, basta verificare che∫ t
0ZsdMs è una
martingala, per Z processo elementare. Con facili ragionamenti, ci si riconduce allaseguente proprietà: dati t ≥ s ed una partizione di [s, t], verificare che
E
[∫ t
s
ZudMu|Fs]
= 0.

6.2. CARATTERIZZAZIONE DEL MOTO BROWNIANO SECONDO LÉVY 151
Verifichiamo questo fatto. Vale
E
[∫ t
s
ZudMu|Fs]
= E
[∑i
Zti(Mti+1 −Mti
)|Fs
]=
∑i
E[E[Zti(Mti+1 −Mti
)|Fti]|Fs]
=∑i
E[ZtiE
[(Mti+1 −Mti
)|Fti]|Fs]
= 0.
6.2.1 Cambio di scala temporale
Enunciamo come esercizio, basato sul Teorema di Lévy, un fatto molto utile in certicontesti.
Esercizio 14 Sia B un moro browniano reale su(Ω,F , (Ft)t≥0 , P
), σ un processo di
classe M2B tale che
σ2 ≥ ε > 0
ed M la martingala definita da
Mt =
∫ t
0
σsdBs.
Posto τ t = infu ≥ 0 :
∫ u0σ2sds = t
, dimostrare che il processo (Mτ t)t≥0 è un moto
browniano rispetto alla filtrazione (Fτ t)t≥0.Dimostrare quindi che esiste un moto browniano (Wt)t≥0 tale che
Mt = W[M ]t
dove [M ]t =∫ t
0σ2sds.
La famiglia di tempi d’arresto τ tt≥0 è crescente. Siccome σ2 ≥ ε > 0,
∫ u0σ2sds ≥
εu, quindi∫ u
0σ2sds ≥ t se u ≥ t
ε; da questo discende che ciascun tempo τ t è limitato
superiormente. Allora (Mτ t)t≥0 è una martingala rispetto a (Fτ t)t≥0: per il teoremad’arresto vale
E [Mτ t|Fτs ] = Mτs
per ogni s ≤ t (si verifichino anche le altre condizioni).Inoltre, dalla definizione di variazione quadratica, come limite di somme di quadrati,
si vede che[Mτ ]t = [M ]τ t .

152 CAPITOLO 6. APPLICAZIONI DELLA FORMULA DI ITÔ
Infatti, presa una successione infinitesima di partizioni con punti tni , vale
[Mτ ]t = limn→∞
∑tni ≤t
(Mτ tn
i+1−Mτ tn
i
)2
= limn→∞
∑τ tni≤τ t
(Mτ tn
i+1−Mτ tn
i
)2
= [M ]τ t .
Quindi, per il Teorema di Lévy, (Mτ t)t≥0 è un moto browniano, rispetto allafiltrazione (Fτ t)t≥0. Chiamiamolo W .ValeMτ t = Wt. La funzione τ t è inversa di [M ]t:
∫ τ t0σ2sds = t. Quindi, preso a ≥ 0,
Mτa = W[M ]a
come volevamo dimostrare.
6.3 Il teorema di Girsanov
6.3.1 Un problema da risolvere
Dati uno spazio probabilizzato (Ω,F , P ), una filtrazione (Ft)t∈[0,T ] ed un processoX = (Xt)t∈[0,T ], possiamo fare in modo che X sia una martingala? Se così, potremmoapplicare ad X tutti i teoremi sulle martingale.Fare in modo può significare varie cose. Che modifichiamo X, ad esempio compo-
nendolo con una funzione ϕ (t, x): in effetti, sotto opportune ipotesi suX (es. soluzionedi opportune equazioni differenziali stocastiche), si può trovare una funzione ϕ (t, x) (es.soluzione di opportune equazioni equazioni alle derivate parziali) tale che il processoϕ (t,Xt) sia una martingala.Oppure può significare che cerchiamo una nuova filtrazione (Gt)t∈[0,T ] rispetto a cui
X sia una martingala. Cosruire filtrazioni però è meno elementare.Infine, può significare che cerchiamo una nuova misura di probabilità Q, al posto di
P , rispetto a cui X sia una martingala. Ricordiamo che la condizione di martingala è
E [Xt1A] = E [Xs1A]
per ogni t ≥ s, A ∈ Fs; il simbolo E è la speranza matematica intesa rispetto allamisura P ; scriviamo EP per maggior chiarezza e parliamo di P -martingala se (oltrealle condizioni di P -integrabilità ed adattamento) vale
EP [Xt1A] = EP [Xs1A]
per ogni t ≥ s, A ∈ Fs.La domanda allora è (qualora X non sia già una P -martingala): possiamo costruire
una misura di probabilità Q su (Ω,F) tale che X sia una Q-martingala, ovvero valga
EQ [Xt1A] = EQ [Xs1A]

6.3. IL TEOREMA DI GIRSANOV 153
per ogni t ≥ s, A ∈ Fs?Avendo già P a disposizione, il modo più naturale di costruire altre misure Q è
quello di prendere Q della forma dQ = ρdP , magari con ρ > 0, così P e Q sonoaddirittura equivalenti. Cerchiamo quindi ρ, densità di probabilità rispetto a P , taleche
EP [ρXt1A] = EP [ρXs1A]
per ogni t ≥ s, A ∈ Fs (infatti EQ [Xt1A] = EP [ρXt1A] e EQ [Xs1A] = EP [ρXs1A]). Inaltre parole, cerchiamo una densità di probabilità ρ, rispetto a P , tale che il processoρXt sia una P -martingala.Posto così, è un’impresa disperata. Si scopre che un modo più conveniente di porre
il problema è il seguente: cerchiamo un processo stocastico ρ = (ρt)t∈[0,T ] tale che ρTsia una densità di probabilità rispetto a P e tale che, posto dQ = ρTdP , il processoX sia una Q-martingala. Riformuliamo questa condizione, più flessibile. Deve valere(con t ≥ s, A ∈ Fs come sopra)
EP [ρTXt1A] = EP [ρTXs1A] .
Ma ora cerchiamo (ρt)t∈[0,T ] che sia una P -martingala. In questo caso, sotto opportuneipotesi di integrabilità, la condizione precedente si rifomula così:
EP [ρtXt1A] = EP [ρsXs1A] .
Infatti EP [ρTXt1A] = EP [ρtXt1A] (ed analogamente al tempo s) o appellandosi alladefinizione di speranza condizionale (ed alla condizione di martigala per ρt) oppure colcalcolo
EP [ρTXt1A] = EP[EP [ρTXt1A|Ft]
]= EP
[Xt1AE
P [ρT |Ft]]
= EP [ρtXt1A] .
Vediamo quindi che ora, invece che richiedere che ρXt fosse una P -martingala (caso ρindipendente dal tempo), dobbiamo richiedere che ρtXt sia una P -martingala. Vedremotra un momento che questo problema è risolubile.
Appendice: Cambi di misura
Abbiamo nominato sopra un’operazione non comune fino ad ora: modificare la prob-abilità P su (Ω,F) tramite una densità. discutiamo quindi alcune semplici idee perinquadrare il problema.Sia (Ω,F) uno spazio probabilizzabile. Fino ad ora abbiamo sempre fissato una
misura di probabilità P su di esso ed indicato con E il valore atteso corrispondente.D’ora in poi, quando servirà, lo indicheremo con EP per evidenziare che si tratta delvalore atteso calcolato tramite la misura P .

154 CAPITOLO 6. APPLICAZIONI DELLA FORMULA DI ITÔ
Supponiamo di avere due diverse misure di probabilità P eQ, su (Ω,F). Ricordiamoche Q << P (Q assolutamente continua rispetto a P ) se P (A) = 0 implica Q (A) = 0,A ∈ F , e questo equivale all’esistenza di una densità di probabilità ρ = ∂Q
∂P, ovvero una
funzione non negativa misurabile ρ : Ω→ [0,∞) tale che
Q (A) =
∫A
ρdP
per ogni A ∈ F . OppureEQ [X] = EP [ρX]
per ogni v.a. X limitata (ed altre). Scriviamo anche dQ = ρdP .Le misure P e Q si dicono equivalenti se Q << P e P << Q. Se Q << P e ρ = ∂Q
∂P
è strettamente positiva q.c., allora sono equivalenti: ρ−1 è ∂P∂Q:
EQ[ρ−1X
]= EP
[ρρ−1X
]= EP [X]
per ogni v.a. X limitata.Il concetto di martingala cambia a seconda della misura: un processo può essere
una martingala rispetto a P e non rispetto a Q (il valore atteso, che dipende dallamisura scelta, entra in gioco nella definizione di martingala).Invece il concetto di convergenza in probabilità non dipende dalla misura, se si
considerano misure equivalenti. Infatti, se XnP→ X allora per ogni ε > 0
limn→∞
P (|Xn −X| > ε) = 0
e quindi
Q (|Xn −X| > ε) =
∫|Xn−X|>ε
ρdP → 0
per l’assoluta continuità dell’integrale. E viceversa.Pertanto il concetto di variazione quadratica di un processo stocastico non dipende
dalla misura, se si considerano misure equivalenti, essendo legato alla misura soloattraverso una condizione di convergenza in probabilità.Circa le classi per cui definiamo integrali stocastici, la classe M2 dipende dalla
misura P di riferimento, mentre la classe Λ2 no se si considerano misure equivalenti.
6.3.2 Ricerca di ρtTorniamo al problema descritto sopra e ripetiamo cosa cerchiamo: dati uno spazioprobabilizzato (Ω,F , P ), una filtrazione (Ft)t∈[0,T ] ed un processo X = (Xt)t∈[0,T ],cerchiamo una P -martingala ρ = (ρt)t∈[0,T ] tale che ρT sia una densità di probabilitàrispetto a P e tale che ρtXt sia una P -martingala.Anzi, siccome per le martingale con valore iniziale costante vale EP [ρT ] = ρ0,
traduciamo la condizione EP [ρT ] = 1 in ρ0 = 1. Ecco allora la richiesta definitiva (unpo’sovrabbondante):

6.3. IL TEOREMA DI GIRSANOV 155
Problema 1 Trovare una P -martingala ρ = (ρt)t∈[0,T ] tale che ρt > 0 per ogni t ∈[0, T ], ρ0 = 1 e tale che ρtXt sia anch’essa una P -martingala.
Proposizione 52 Se ρ = (ρt)t∈[0,T ] ha le proprietà suddette, posto dQ = ρTdP , ilprocesso X è una Q-martingala.
Proof. In sostanza abbiamo già dimostrato quest’affermazione ma ripercorriamo i pas-saggi per accertarci che le integrabilità siano state rispettate (ed anche per permettereuno studio più assiomatico e meno costruttivo). Intanto, essendo ρT > 0 e EP [ρT ] = 1,Q è una misura di probabilità. Il processo X è adattato. E’Q-integrabile:
EQ [|Xt|] = EP [ρT |Xt|] = EP [ρt |Xt|]
(abbiamo usato la proprietà che ρ è una P -martingala, da cui discendeEP [ρT (|Xt| ∧ n)] =EP [ρt (|Xt| ∧ n)], dalla quale si passa all’identità voluta per convergenza monotona).Ma ρtXt è una P -martingala per ipotesi, quindi in particolare è P -integrabile, ovvero
EP [ρt |Xt|] = EP [|ρtXt|] <∞
e quindi EQ [|Xt|] < ∞. Strada facendo abbiamo anche verificato che ρTXt è P -integrabile.Vale poi, per ogni t ≥ s, A ∈ Fs (nel primo passaggio si usa il fatto che ρTXt è
P -integrabile)EQ [Xt1A] = EP [ρTXt1A] = EP [ρtXt1A]
(come sopra, per la la proprietà che ρ è una P -martingala),
= EP [ρsXs1A]
(per la la proprietà che ρX è una P -martingala),
= EP [ρTXs1A] = EQ [Xs1A]
(come sopra a ritroso). Quindi X è una Q-martingala.Cerchiamo di risolvere il Problema 1 col calcolo stocastico di Itô, quindi ambien-
tiamoci nei processi di Itô ed anzi, per il processo dato X, supponiamo la seguenteforma semplice:
Xt = Bt −∫ t
0
bsds
dove B = (Bt)t∈[0,T ] è uno moto browniano in Rd su (Ω,F , P ) rispetto a (Ft)t∈[0,T ] e bè un processo di classe Λ1
B (tra un attimo richiederemo di più). E, per poter applicareil calcolo di Itô, cerchiamo la martingala ρt della forma particolare
ρt = 1 +
∫ t
0
σs · dBs

156 CAPITOLO 6. APPLICAZIONI DELLA FORMULA DI ITÔ
dove σ è un processo di classe M2B. Dobbiamo trovare σ ∈ M2
B tale che sia ρt > 0 eρtXt sia una P -martingala.Per la formula di Itô (X i
t è la componente i-esima di Xt)
d(ρtX
it
)= X i
tσt · dBt + ρtdBit − ρtbitdt+ σitdt.
(si deve applicare la formula di Itô alla funzione f (x, y) = xy applicata al processo(ρt, X
it); inizialmente il risultato è quello classico più un termine del second’ordine:
d(ρtX
it
)= X i
tdρt + ρtdXit +
1
2· 2 · 1 · d
[ρ,X i
]t
dove la ragione dell’ultimo termine è che le derivate seconde non miste di f sono nulle,mentre ∂2f
∂x∂y= 1 e quindi la semisomma delle derivate miste vale 1
2·2 ·1; inoltre, usando
al posto di d [ρ,X i]t il formalismo più espressivo dρtdXit , abbiamo
dρtdXit =
d∑j=1
σjtdBjt
(dBi
t − bitdt)
= σitdt
da cui la formula detta sopra).Per avere una martingala dev’essere necessariamente σit = ρtb
it per ogni i, ovvero
σt = ρtbt.
Questo però non basta: dovremo ripercorrere i calcoli per vedere se certe integrabilitàsono rispettate, ad esempioX i
tσt, ρt ∈M2B. Ma per ora completiamo il calcolo algebrico.
Abbiamo trovato che ρt deve risolvere l’equazione differenziale stocastica
ρt = 1 +
∫ t
0
ρsbs · dBs (6.1)
ovvero
dρt = ρtbt · dBt
ρ0 = 1.
Se B fosse differenziabile, la soluzione sarebbe ρt = exp(∫ t
0bs · dBs
). Applicando ad
essa la formula di Itô (come faremo nel lemma seguente) si scopre che il risultato èsbagliato e si capisce quindi la corezione che va apportata.
Lemma 16 Se b è un processo di classe Λ2B, il processo stocastico
ρt = exp
(∫ t
0
bs · dBs −1
2
∫ t
0
‖bs‖2 ds
)è soluzione dell’equazione differenziale stocastica (6.1).

6.3. IL TEOREMA DI GIRSANOV 157
Proof. Applichiamo la formula di Itô alla funzione f (x) = ex ed al processo Yt =∫ t0bs · dBs − 1
2
∫ t0‖bs‖2 ds, ovvero dYt = bt · dBt − 1
2‖bt‖2 dt. Troviamo, osservando che
f ′ (Yt) = f ′′ (Yt) = f (Yt) = ρt,
dρt = ρtdYt +1
2ρtd [Y ]t
dove, informalmente,
d [Y ]t = dYtdYt =
(d∑i=1
bitdBit −
1
2‖bt‖2 dt
)2
=d∑i=1
(bit)2dt = ‖bt‖2 dt.
Sostituendo si trova l’equazione desiderata.Abbiamo quindi trovato il processo ρ e dalla sua formula è evidente la proprietà
ρt > 0, che a priori poteva sembrare molto diffi cile da realizzare! Restano solo dacurare le proprietà di integrabilità.
Osservazione 42 Il lemma precedente si generalizza, con la stessa dimostrazione, allaseguente affermazione: se a ∈ Λ1
B, b ∈ Λ2B, il processo stocastico
ρt = ρ0 exp
(∫ t
0
bs · dBs +
∫ t
0
(as −
1
2‖bs‖2
)ds
)è soluzione dell’equazione differenziale stocastica
dρt = ρt (atdt+ bt · dBt) .
Si noti che il termine −12
∫ t0‖bs‖2 ds serve a cancellare il termine del second’ordine
nella formula di Itô.
6.3.3 Versione assiomatica
Siano dati uno spazio probabilizzato (Ω,F , P ), una filtrazione (Ft)t∈[0,T ] ed un processoX = (Xt)t∈[0,T ] in Rd della forma
Xt = Bt −∫ t
0
bsds
dove B = (Bt)t∈[0,T ] è uno moto browniano in Rd su (Ω,F , P ) rispetto a (Ft)t∈[0,T ] e bè un processo in Rd di classe Λ2
B. Sia ρ = (ρt)t∈[0,T ] il processo stocastico
ρt = exp
(∫ t
0
bs · dBs −1
2
∫ t
0
‖bs‖2 ds
).

158 CAPITOLO 6. APPLICAZIONI DELLA FORMULA DI ITÔ
Allora ovviamente ρt > 0 per ogni t ∈ [0, T ] e vale
ρt = 1 +
∫ t
0
ρsbs · dBs
(Lemma 16). Se ρb ∈ M2B, ρt è una P -martingala (dall’equazione soddisfatta da ρt,
per i teoremi sugli integrali stocatici). Vale inoltre ρ0 = 1. Se inoltre anche ρtXt èuna P -martingala, abbiamo risolto il Problema 1 e quindi per la Proposizione 52 ilprocesso X è una Q-martingala rispetto a dQ = ρTdP . Siccome, per i calcoli dellasezione precedente,
d(ρtX
it
)= X i
tσt · dBt + ρtdBit
(abbiamo già imposto σt = ρtbt), richiediamo che sia Xiσ = X iρb ∈ M2
B per ognii = 1, ..., d e ρ ∈ M2
B; questo garantisce che ρtXt sia una P -martingala. Raccogliendotutti questi fatti, abbiamo dimostrato:
Lemma 17 Se ρ ∈M2B, ρb ∈M2
B e Xiρb ∈M2
B per ogni i = 1, ..., d, allora il processoX è una Q-martingala rispetto a dQ = ρTdP .
Vediamo una semplice condizione suffi ciente.
Proposizione 53 Se b è un processo progressivamente misurabile e limitato, alloravalgono le ipotesi del lemma precedente.
Proof. Basta verificare che ρ ∈ M2B e Xρ ∈ M2
B, essendo b limitato. Siccome, dalladefinizione di X,
‖Xt‖4 ≤ C ‖Bt‖4 + CT 4
per un’opportuna costante C > 0, vediamo subito che supt∈[0,T ] E[‖Xt‖4] < ∞.
EssendoE[‖Xtρt‖
2] ≤ E[‖Xt‖4]1/2E [ρ4
t
]1/2e E [ρ2
t ] ≤ E [ρ4t ]
1/2, se dimostriamo che supt∈[0,T ] E [ρ4t ] < ∞, discendono tutte le
integrabilità richieste.Dall’equazione soddisfatta da ρt, per la formula di Itô (per f (x) = x4), troviamo
dρ4t = 4ρ3
tdρt +1
212ρ2
td [ρ]t
= 4ρ4t bt · dBt + 6ρ4
t ‖bt‖2 dt
ovvero
ρ4t = 1 +
∫ t
0
4ρ4sbs · dBs +
∫ t
0
6ρ4s ‖bs‖
2 ds.

6.3. IL TEOREMA DI GIRSANOV 159
Introduciamo il tempo d’arresto τn = inf t ∈ [0, T ] : ρ4t > n∧T (pari a T se l’insieme
è vuoto). Vale
ρ4t∧τn = 1 +
∫ t
0
1s≤τn4ρ4s∧τnbs · dBs +
∫ t
0
1s≤τn6ρ4s∧τn ‖bs‖
2 ds
da cui (essendo 1s≤τn4ρ4sbs di classe M
2B, questa è la ragione del tempo d’arresto, oltre
al fatto di poter dire che E[ρ4t∧τn
]<∞)
E[ρ4t∧τn
]= 1 +
∫ t
0
1s≤τn6E[ρ4s∧τn ‖bs‖
2] ds≤ 1 + C
∫ t
0
E[ρ4s∧τn
]ds
tenendo conto che b è limitato. Per il lemma di Gronwall,
E[ρ4t∧τn
]≤ eCT .
Per la continuità di ρ ed il lemma di Fatou
E[ρ4t
]≤ lim inf
n→∞E[ρ4t∧τn
]≤ eCT .
La dimostrazione è completa.
Corollario 18 Se b è un processo progressivamente misurabile e limitato, allora ilprocesso Xt = Bt−
∫ t0bsds, t ∈ [0, T ], è una Q-martingala rispetto a dQ = ρTdP , dove
ρT = exp
(∫ T
0
bs · dBs −1
2
∫ T
0
‖bs‖2 ds
).
6.3.4 Varianti
Si possono dimostrare vari fatti maggiori o minori legati alle cose appena dette. Eccoalcuni esempi.
Lemma 18 Se b è un processo di classe Λ2B, allora
E [ρT ] ≤ 1.
Proof. Ricordiamo che ρt = 1+∫ t
0ρsbs ·dBs. Poniamo τn = inf t ∈ [0, T ] : ρt > n∧T
(pari a T se l’insieme è vuoto). Vale
ρt∧τn =
∫ t
0
1s≤τnρsbs · dBs

160 CAPITOLO 6. APPLICAZIONI DELLA FORMULA DI ITÔ
quindi ρt∧τn è una martingala e vale E[ρt∧τn
]= E [ρ0] = 1. Per Fatou, usando la
continuità delle traiettorie di ρt,
E [ρt] = E[
limn→∞
ρt∧τn
]≤ 1.
Non c’è bisogno che b sia limitato affi nché ρt sia una martingala.
Teorema 36 (criterio di Novikov) Se
E[eλ∫ T0 ‖bs‖
2ds]<∞
per qualche λ > 12allora ρt è una martingala.
Omettiamo la dimostrazione. Abbiamo sempre preso i processi su un certo intervallo[0, T ] e cambiato misura ponendo dQT = ρTdP (qui enfatizziamo la dipendenza da T ).Se i processi erano definiti su [0,∞), quindi anche ρ, potevamo eseguire un cambio dimisura indipendente da T?
Proposizione 54 Esiste (unica) una funzione Q :∨T≥0
FT → [0, 1], σ-additiva su ogni
FT , tale cheQ = QT su FT
per ogni T . Quindi, data X misurabile rispetto a qualche FT , vale
EQ [X] = EP [ρTX] .
Proof. Fissato T ≥ 0, definiamo Q su FT ponendo Q = QT . Per dire che questodefinisce una funzioneQ :
∨T≥0
FT → [0, 1] dobbiamo verificare che, se T ′ > T , QT ′ = QT
su FT . Ma questo discende subito dalla proprietà di martingala di ρ.
6.3.5 Teorema di Girsanov
Il risultato che stiamo per esporre vale più in generale (ad esempio sotto l’ipotesi delcriterio di Novikov) ma lo formuliamo e dimostriamo in un caso particolare per evitaretroppi dettagli tecnici.Sia (Ω,F , P ) uno spazio probabilizzato, (Ft)t≥0 una filtrazione, B un moto brow-
niano in Rd. Sia (bt)t∈[0,T ] un processo in Rd di classe Λ2. Supponiamo per semplicitàche sia limitato. Sia
dQ = ρTdP
con le notazioni delle sezioni precedenti.

6.3. IL TEOREMA DI GIRSANOV 161
Teorema 37 (Girsanov) Il processo stocastico
Xt := Bt −∫ t
0
Xsds.
è un moto browniano rispetto a Q ed (Ft)t≥0.
Proof. Già sappiamo che Xt è una Q-martingala. Nel calcolo della sua variazionequadratica congiunta, il processo
∫ t0Xsds non gioca alcun ruolo; essa equivale a quella
di Bt. Come già osservato, il concetto di variazione quadratica di un processo, essendoun limite in probabilità non dipende da P a meno di misure equivalenti, quindi ancherispetto a Q esiste ed è la stessa. Quindi [X] = [B] e possiamo applicale il teorema diLévy.
6.3.6 Applicazione
Sia b : [0, T ] × Rd → Rd una funzione misurabile limitata. Si consideri l’equazioneintegrale
Xt = x0 +
∫ t
0
b (s,Xs) ds+Bt
dove x0 ∈ Rd, B è un moto browniano in Rd su (Ω,F , P ) rispetto ad una filtrazione(Ft)t∈[0,T ] e l’incognita X è un processo stocastico in Rd.Se non ci fosse il moto browniano, questa equazione potrebbe non avere alcuna
soluzione continua. Ad esempio, se d = 1, x0 = 0, b (x) =
−1 per x ≥ 01 per x < 0
, una
funzione continua x (t) tale che
x (t) =
∫ t
0
b (x (s)) ds
se esistesse avrebbe la seguente proprietà: se I ⊂ [0,∞) è un intervallo aperto mas-simale in cui x (t) > 0, lì x è derivabile e vale x′ (t) = −1, cioè x è strettamentedecrescente; ma dev’essere x (t0) = 0 in t0 = inf I, altrimenti I non è massimale.Quindi I = ∅. Lo stesso vale per intervalli in cui x sia negativa. Se ne deduce xidenticamente nulla ma in tal caso b (x (s)) = −1 identicamente, violando l’equazione.Questo dimostra che non esistono soluzioni continue.
Teorema 38 Dati (Ω,F , P ) ed una filtrazione (Ft)t∈[0,T ] come sopra (cioè tali cherispetto ad essi ci sia un moto browniano B) esistono un moto browniano W in Rd,rispetto a questa filtrazione ed un processo adattato continuo X tali che
Xt = x0 +
∫ t
0
b (s,Xs) ds+Wt.

162 CAPITOLO 6. APPLICAZIONI DELLA FORMULA DI ITÔ
Proof. Sia B il P -moto browniano rispetto a (Ft)t∈[0,T ] che c’è per ipotesi. Poniamo
Wt = Bt −∫ t
0
b (s, Bs + x0) ds
bt : = b (t, Bt + x0) .
Allora, con la solita notazione
ρt = exp
(∫ t
0
bs · dBs −1
2
∫ t
0
‖bs‖2 ds
)posto dQ = ρTdP , il processo W è un Q-moto browniano. Posto poi Xt = Bt + x0,abbiamo
Xt = Bt −∫ t
0
b (s, Bs − x0) ds+
∫ t
0
b (s, Bs + x0) ds+ x0
= Wt +
∫ t
0
b (s,Xs) ds+ x0.
Osservazione 43 Si noti ovviamente che il moto browniano W che compare nell’e-quazione non è specificato a priori. Più sottilmente, si potrebne osservare che il processoX non è adattato al moto browniano W .
Osservazione 44 Con un po’più di fatica si potrebbe dimostrare anche un teoremadi unicità.

Capitolo 7
Equazioni differenziali stocastiche
Sia (Ω,F , P ) uno spazio probabilizzato, (Ft)t≥0 una filtrazione, B un moto brownianoinRn rispetto a (Ft)t≥0. Chiameremo base stocastica la famiglia
(Ω,F , (Ft)t≥0 , P, (Bt)t≥0
).
In questa sezione studiamo equazioni della forma
Xt = X0 +
∫ t
0
b (s,Xs) ds+
∫ t
0
σ (s,Xs) dBs, t ∈ [0, T ] (7.1)
che scriveremo anche nella forma
dXt = b (t,Xt) dt+ σ (t,Xt) dBt, X|t=0 = X0.
QuiX0 è una v.a. in Rd misurabile rispetto a F0 e b : [0, T ]×Rd → Rd, σ : [0, T ]×Rd →Rn×d sono funzioni continue (in genere con qualche ragionamento ed ipotesi in più bastasupporre che siano misurabili).Le soluzioni che si cercano sono processi a valori in Rd, continui e adattati (questo
garantisce che s 7→ b (s,Xs) sia un processo continuo, di classe Λ1B e s 7→ σ (s,Xs) sia
un processo continuo, di classe Λ2B, per cui gli integrali sono entrambi ben definiti), che
risolvano l’equazione integrale uniformemente in t, quasi certamente.
Definizione 20 Se(Ω,F , (Ft)t≥0 , P, (Bt)t≥0
)è una base stocastica ed X = (Xt)t∈[0,T ]
è un processo stocastico definito su (Ω,F , P ), continuo, adattato alla filtrazione (Ft)t≥0,che soddisfa l’equazione (7.1) uniformemente in t ∈ [0, T ] con probabilità uno:
P
(Xt = X0 +
∫ t
0
b (s,Xs) ds+
∫ t
0
σ (s,Xs) dBs,∀t ∈ [0, T ]
)= 1
allora diciamo che X (o più estesamente(Ω,F , (Ft)t≥0 , P, (Bt)t≥0 , X
)) è una soluzione
dell’equazione (7.1).
E’opportuno fare distinzione tra due possibilità.
163

164 CAPITOLO 7. EQUAZIONI DIFFERENZIALI STOCASTICHE
Definizione 21 Diciamo che c’è esistenza forte per l’equazione (7.1) se, fissata unaqualsiasi base stocastica
(Ω,F , (Ft)t≥0 , P, (Bt)t≥0
)ed una v.a. F0-misurabile X0, esiste
una soluzione X.
Quando invece(Ω,F , (Ft)t≥0 , P, (Bt)t≥0 , X
)è una soluzione dell’equazione (7.1)
ma non abbiamo potuto specificare(Ω,F , (Ft)t≥0 , P, (Bt)t≥0
)a priori, parleremo solo
di soluzione debole. Più precisamente:
Definizione 22 Diciamo che c’è esistenza debole per l’equazione (7.1) se, per ognix0 ∈ Rd, esiste una base stocastica
(Ω,F , (Ft)t≥0 , P, (Bt)t≥0
)ed una soluzione X con
X0 = x0.
Osservazione 45 Quando c’è esistenza forte, c’è esistenza di soluzioni adattate almoto browniano di partenza. Infatti, potendo scegliere arbitrariamente a priori labase stocastica, possiamo prendere come (Ft)t≥0 la filtrazione associata a (Bt)t≥0, cheindichiamo con
(FBt)t≥0; se c’è esistenza forte, c’è una soluzione adattata a
(FBt)t≥0.
Da qui nasce anche la seguente definizione. Indichiamo ora con(FBt)t≥0
la fil-trazione completata, associata a B (così da dare più chances all’esistenza di soluzioniad essa adattate).
Definizione 23 Una soluzione(Ω,F , (Ft)t≥0 , P, (Bt)t≥0 , X
)si dice forte seX è
(FBt)t≥0-
adattata.
Nella sezione della formula di Girsanov, come sua applicazione, abbiamo dimostatoil seguente:
Teorema 39 Per l’equazione
dXt = b (t,Xt) dt+ dBt, X0 = x0.
con b misurabile e limitato, c’è esistenza debole.
Descriviamo ora un teorema di esistenza forte. Corrediamolo di un’affermazione diunicità.
Definizione 24 Diciamo che vale l’unicità forte (o per traiettorie) se, data una qual-siasi base stocastica
(Ω,F , (Ft)t≥0 , P, (Bt)t≥0
)ed una qualsiasi v.a. F0-misurabile X0,
prese due soluzioni X1 e X2, esse sono processi indistinguibili.

165
C’è poi un altro concetto (che non tratteremo), di unicità in legge, che dice quantosegue: vale l’unicità in legge se, date due soluzioni
(Ωi,F i, (F it )t≥0 , P
i, (Bit)t≥0 , X
i),
i = 1, 2 (definite quindi anche su basi diverse), le leggi di X1 e X2 coincidono.Su b e σ imponiamo:
b continua, esiste Lb > 0 tale che
|b (t, x)− b (t, y)| ≤ Lb |x− y| per ogni t ∈ [0, T ] e x, y ∈ Rd
σ continua, esiste Lσ > 0 tale che
‖σ (t, x)− σ (t, y)‖HS ≤ Lσ |x− y| per ogni t ∈ [0, T ] e x, y ∈ Rd
dove ricordiamo che ‖A‖2HS =
∑ij A
2ij. Osserviamo che esiste C > 0 tale che (si veda
(??))|b (t, x)|2 ≤ C
(1 + |x|2
)ed analogamente (eventualmente rinominando C)
‖σ (t, x)‖2HS ≤ C
(1 + |x|2
)in quanto
‖σ (t, x)‖2HS ≤ 2 ‖σ (t, x)− σ (t, 0)‖2
HS + 2 ‖σ (t, 0)‖2HS
≤ 2L2σ |x|
2 + 2 maxt∈[0,T ]
‖σ (t, 0)‖2HS .
Teorema 40 Sotto queste ipotesi su b e σ, c’è esistenza e unicità forte per l’equazione(7.1). Se inoltre E
[|X0|2
]<∞, la soluzione forte verifica anche
E
[supt∈[0,T ]
|Xt|2]<∞.
Diamo per brevità la dimostrazione solamente delle seguenti due affermazioni: i) c’è
unicità forte nella classe dei processi che verificano la condizione E[∫ T
0|Xs|2 ds
]<∞
(un po’più generale di E[supt∈[0,T ] |Xt|2
]< ∞); ii) se (oltre alle altre ipotesi) vale
E[|X0|2
]< ∞, allora esiste una soluzione forte con la proprietà E
[supt∈[0,T ] |Xt|2
]<
∞.Proof. Passo 1. Vediamo l’unicità forte. Data una base stocastica
(Ω,F , (Ft)t≥0 , P, (Bt)t≥0
),
una v.a. F0-misurabile X0 e due soluzioni X1 e X2 tali che E[∫ T
0|X i
s|2ds]< ∞,
i = 1, 2, dobbiamo dimostrare che esse sono indistinguibili. Vale
X1t −X2
t =
∫ t
0
(b(s,X1
s
)− b(s,X2
s
))ds+
∫ t
0
(σ(s,X1
s
)− σ
(s,X2
s
))dBs

166 CAPITOLO 7. EQUAZIONI DIFFERENZIALI STOCASTICHE
da cui∣∣X1t −X2
t
∣∣2 ≤ 2
∣∣∣∣∫ t
0
b(s,X1
s
)− b(s,X2
s
)ds
∣∣∣∣2 + 2
∣∣∣∣∫ t
0
(σ(s,X1
s
)− σ
(s,X2
s
))dBs
∣∣∣∣2 .Da un lato, vale∣∣∣∣∫ t
0
b(s,X1
s
)− b(s,X2
s
)ds
∣∣∣∣2 ≤ (∫ t
0
∣∣b (s,X1s
)− b(s,X2
s
)∣∣ ds)2
≤ t
∫ t
0
∣∣b (s,X1s
)− b(s,X2
s
)∣∣2 dsusando la disuguaglianza di Hölder. Dall’altro, osservando che s 7→ (σ (s,X1
s )− σ (s,X2s ))
è un processo di classeM2B (spiegato poco oltre), per la formula di isometria vettoriale,
Proposizione 45, abbiamo
E
[∣∣∣∣∫ t
0
(σ(s,X1
s
)− σ
(s,X2
s
))dBs
∣∣∣∣2]
= E
[∫ t
0
∥∥σ (s,X1s
)− σ
(s,X2
s
)∥∥2
HSds
].
Pertanto,
E[∣∣X1
t −X2t
∣∣2] ≤ 2T
∫ t
0
E[∣∣b (s,X1
s
)− b(s,X2
s
)∣∣2] ds+ 2E
[∫ t
0
∥∥σ (s,X1s
)− σ
(s,X2
s
)∥∥2
HSds
]≤ 2TL2
b
∫ t
0
E[∣∣X1
s −X2s
∣∣2] ds+ 2L2σ
∫ t
0
E[∣∣X1
s −X2s
∣∣2] ds=
(2TL2
b + 2L2σ
) ∫ t
0
E[∣∣X1
s −X2s
∣∣2] dse quindi, per il lemma di Gronwall applicato alla funzione t 7→ E
[|X1
t −X2t |
2], abbiamo
E[∣∣X1
t −X2t
∣∣2] = 0
per ogni t ∈ [0, T ]. Da questo discende che X1t = X2
t q.c., per ogni t ∈ [0, T ],ovvero che i due processi sono modificazione uno dell’altro; ma essendo continui, sonoindistinguibili.Resta da verificare che s 7→ σ (s,X i
s), i = 1, 2, sono processi di classe M2B. Questo
deriva dalle disuguaglianze (ricordando che ‖σ (t, x)‖2HS ≤ C
(1 + |x|2
))
E
[∫ T
0
∥∥σ (s,X is
)∥∥2
HSds
]≤ E
[∫ T
0
(C +
∣∣X is
∣∣2) ds] = CT + E
[∫ T
0
∣∣X is
∣∣2 ds] <∞per ipotesi.

167
Passo 2. Dimostriamo l’esistenza forte, come abbiamo già detto limitatamente alcaso in cui valga E
[|X0|2
]< ∞. Per dimostrarla, usiamo il metodo delle approssi-
mazioni successive. Poniamo X0t = X0, t ∈ [0, T ] e
Xn+1t = X0 +
∫ t
0
b (s,Xns ) ds+
∫ t
0
σ (s,Xns ) dWs, t ∈ [0, T ]
per ogni n ≥ 0.Vediamo innanzi tutto che l’iterazione è ben definita in un opportuno spazio di
processi. Prendiamo lo spazio C dei processi continui adattati X tali che
E
[supt∈[0,T ]
|Xt|2]<∞.
Si può verificare che esso è uno spazio di Banach, con la norma ‖X‖C =√E[supt∈[0,T ] |Xt|2
].
Verifichiamo che la ricorsione resta in C. La proprietà X0 ∈ C è ovvia (qui si usa perla prima volta l’ipotesi supplementare E
[|X0|2
]< ∞). Supponiamo di sapere che
Xn ∈ C. Allora b (s,Xns ) e σ (s,Xn
s ) sono processi continui e adattati, per cui, per lomeno,
∫ t0b (s,Xn
s ) ds e∫ t
0σ (s,Xn
s )Ws sono processi ben definiti, continui e adattati.Ma, più precisamente, valendo
|b (s,Xns )|2 ≤ C
(1 + |Xn
s |2)
troviamo∣∣∣∣∫ t
0
b (s,Xns ) ds
∣∣∣∣2 ≤ t1/2∫ t
0
|b (s,Xns )|2 ds ≤ T 1/2C
∫ t
0
(1 + |Xn
s |2) ds
da cui discende che
E
[supt∈[0,T ]
∣∣∣∣∫ t
0
b (s,Xns ) ds
∣∣∣∣2]<∞.
Inoltre vale‖σ (s,Xn
s )‖2HS ≤ C
(1 + |Xn
s |2)
per cui σ (s,Xns ) è un processo (matriciale) di classe M2,
∫ t0σ (s,Xn
s )Ws è una mar-tingala (vettoriale), e vale (disuguaglianza di Doob)
E
[supt∈[0,T ]
∣∣∣∣∫ t
0
σ (s,Xns )Ws
∣∣∣∣2]≤ CE
[∫ T
0
‖σ (s,Xns )‖2
HS ds
]<∞
da cui si conclude come sopra per b. Abbiamo così verificato che Xn ∈ C implicaXn+1 ∈ C.

168 CAPITOLO 7. EQUAZIONI DIFFERENZIALI STOCASTICHE
Passo 3. Dimostriamo che, per ogni λ > 0, vale
supt∈[0,T ]
E[e−λt
∣∣Xn+1t −Xn
t
∣∣2] ≤ (Cλ
)nsupt∈[0,T ]
E[e−λt
∣∣X1t −X0
t
∣∣2] (7.2)
dove C = 2T 1/2L2b + 2L2
σ. Sappiamo che
∣∣Xn+1t −Xn
t
∣∣ ≤ ∫ t
0
∣∣b (s,Xns )− b
(s,Xn−1
s
)∣∣ ds+
∣∣∣∣∫ t
0
(σ (s,Xn
s )− σ(s,Xn−1
s
))dWs
∣∣∣∣ .Quindi
∣∣Xn+1t −Xn
t
∣∣2 ≤ 2
(∫ t
0
∣∣b (s,Xns )− b
(s,Xn−1
s
)∣∣ ds)2
+ 2
∣∣∣∣∫ t
0
(σ (s,Xn
s )− σ(s,Xn−1
s
))dWs
∣∣∣∣2 .Da questo, per la disuguaglianza di Hölder e le proprietà dei vari coeffi cienti, troviamo
∣∣Xn+1t −Xn
t
∣∣2 ≤ 2T 1/2
∫ t
0
∣∣b (s,Xns )− b
(s,Xn−1
s
)∣∣2 ds+ 2
∣∣∣∣∫ t
0
(σ (s,Xn
s )− σ(s,Xn−1
s
))dWs
∣∣∣∣2
≤ 2T 1/2L2b
∫ t
0
∣∣Xns −Xn−1
s
∣∣2 ds+ 2
∣∣∣∣∫ t
0
(σ (s,Xn
s )− σ(s,Xn−1
s
))dWs
∣∣∣∣2 .Dalla disuguaglianza precedente discende che, in valore atteso,
E[∣∣Xn+1
t −Xnt
∣∣2] ≤ 2T 1/2L2b
∫ t
0
E[∣∣Xn
s −Xn−1s
∣∣2] ds+ 2L2σ
∫ t
0
E[∣∣Xn
s −Xn−1s
∣∣2] ds= C
∫ t
0
E[∣∣Xn
s −Xn−1s
∣∣2] dsper C = 2T 1/2L2
b + 2L2σ, dove abbiamo usato
E
[∣∣∣∣∫ t
0
(σ (s,Xn
s )− σ(s,Xn−1
s
))dWs
∣∣∣∣2]
= E
[∫ t
0
∥∥σ (s,Xns )− σ
(s,Xn−1
s
)∥∥2
HSds
]≤ L2
σ
∫ t
0
E[∣∣Xn
s −Xn−1s
∣∣2] ds.

169
Moltiplicando per e−λt troviamo
E[e−λt
∣∣Xn+1t −Xn
t
∣∣2] ≤ C
∫ t
0
e−λ(t−s)E[e−λs
∣∣Xns −Xn−1
s
∣∣2] ds≤ C
λsupt∈[0,T ]
E[e−λt
∣∣Xnt −Xn−1
t
∣∣2](essendo
∫ t0e−λ(t−s)ds = 1−e−λt
λ≤ 1
λ) da cui
supt∈[0,T ]
E[e−λt
∣∣Xn+1t −Xn
t
∣∣2] ≤ C
λsupt∈[0,T ]
E[e−λt
∣∣Xnt −Xn−1
t
∣∣2] .Basta ora iterare questa disuguaglianza.Passo 4. Vale poi
E
[supt∈[0,T ]
∣∣Xn+1t −Xn
t
∣∣2] ≤ C ′(C
λ
)n(7.3)
per un’opportuna constante C ′ > 0. Infatti, abbiamo dimostrato sopra che∣∣Xn+1t −Xn
t
∣∣2 ≤ 2T 1/2
∫ t
0
∣∣b (s,Xns )− b
(s,Xn−1
s
)∣∣2 ds+ 2
∣∣∣∣∫ t
0
(σ (s,Xn
s )− σ(s,Xn−1
s
))dWs
∣∣∣∣2quindi
supt∈[0,T ]
∣∣Xn+1t −Xn
t
∣∣2 ≤ 2T 1/2L2b
∫ T
0
∣∣Xns −Xn−1
s
∣∣2 ds+ 2 sup
t∈[0,T ]
∣∣∣∣∫ t
0
(σ (s,Xn
s )− σ(s,Xn−1
s
))dWs
∣∣∣∣2da cui
E
[supt∈[0,T ]
∣∣Xn+1t −Xn
t
∣∣2] ≤ C
∫ T
0
E[∣∣Xn
s −Xn−1s
∣∣2] dsavendo usato i soliti ragionamenti basati sulla disuguaglianza di Doob. Usando la stima(??) otteniamo
E
[supt∈[0,T ]
∣∣Xn+1t −Xn
t
∣∣2] ≤ CeλTT
(C
λ
)nsupt∈[0,T ]
E[e−λt
∣∣X1t −X0
t
∣∣2] .Basta ora rinominare CeλTT supt∈[0,T ] E
[e−λt |X1
t −X0t |
2]con C ′.

170 CAPITOLO 7. EQUAZIONI DIFFERENZIALI STOCASTICHE
Passo 5. Dalla stima (7.3) discende (prendendo λ tale che Cλ< 1) che Xn
· n∈N èuna successione di Cauchy in C che, ricordiamo, è uno spazio di Banach. Esiste quindiun processo (Xt)t∈[0,T ] ∈ C tale che
limn→∞
E
[supt∈[0,T ]
|Xnt −Xt|2
]= 0.
Usando la continuità dei coeffi cienti ed alcuni argomenti elementari sulla dipendenzacontinua degli integrali in gioco, si verifica che Xt soddisfa l’equazione integrale (??).
Facendo un uso più accurato delle disuguaglianze per le martingale si può studiareil caso in cui E [|X0|p] <∞ per un p ≥ 2 qualsiasi, dimostrando il risultato seguente.
Teorema 41 Nelle ipotesi precedenti, se per un certo p ≥ 2 vale E [|X0|p] <∞, allora
E
[supt∈[0,T ]
|Xt|p]<∞.
7.0.7 Esempio
Si consideri l’equazione differenziale in R2
dxtdt
= Axt
dove
A =
(0 1−1 0
).
Posto xt =
(qtpt
), vale
dqtdt
= pt,dptdt
= −qte quindi
d2qtdt2
= −qtche è l’equazione di un oscillatore armonico di massa unitaria. Le soluzioni xt ruotanonel piano R2; in particolare conservano l’energia, se con questo nome intendiamol’espressione
Et :=1
2|xt|2 =
1
2
(q2t + p2
t
)(conservano anche |xt|, la distanza dall’origine). Infatti
d
dt|xt|2 = 2
⟨xt,
dxtdt
⟩= 2 〈xt, Axt〉 = 0

171
ovvero |xt|2 è costante. Abbiamo usato le notazioni |·| e 〈·, ·〉 per norma e prodottoscalare euclideo e la proprietà 〈x,Ax〉 = 0 valida per matrici antisimmetriche.Veniamo al caso stocastico. Consideriamo l’equazione
dXt = AXtdt+ σdBt
dove B è un moto browniano unidimensionale e σ è il vettore (σ0 ∈ R)
σ =
(0σ0
).
Per componenti, si tratta del sistema
dqtdt
= pt, dpt = −qtdt+ σ0dBt
o, più informalmente,d2qtdt2
= −qt + σ0dBt
dt.
Chiediamoci: cosa accade ora all’energia? Il termine aggiuntivo σ0dBtdtintroduce, sot-
trae energia oppure è neutrale? Dobbiamo capire come cambia Et = 12|Xt|2. Ma per
far questo serve la formula di Itô, ed in essa compaiono automaticamente degli inte-grali di Itô, anche se non c’erano nell’equazione originaria. Vediamo il calcolo. Vale(f (x) = |x|2, ∇f (x) = x, D2f (x) = Id)
d|Xt|2
2= 〈Xt, dXt〉+
σ20
2dt
= 〈Xt, AXt〉 dt+ 〈Xt, σdBt〉+σ2
0
2dt
= 〈Xt, σdBt〉+σ2
0
2dt
perché 〈Xt, AXt〉 = 0. Non è chiaro cosa accada all’energia delle singole traiettorie, daquesta identità, ma scrivendola in forma integrale
Et = E0 +
∫ t
0
〈Xs, σdBs〉+σ2
0
2t
ed usando il fatto che il processo X è di classe M2 (per quanto dice il teorema di
esistenza e unicità) possiamo usare il fatto che E[∫ t
0〈Xs, σdBs〉
]= 0 e concludere
E [Et] = E [E0] +σ2
0
2t
cioè l’energia media aumenta linearmente nel tempo. Il disturbo casuale introducesistematicamente energia nel sistema, mediamente parlando.

172 CAPITOLO 7. EQUAZIONI DIFFERENZIALI STOCASTICHE
Osservazione 46 Si noti che un disturbo deterministico εt può anche introdurre en-ergia ma lo fa in modo meno chiaro e controllato. Consideriamo l’equazione determin-istica
dxtdt
= Axt + εt.
Con calcoli identici ai precedenti si dimostra che
Et = E0 +
∫ t
0
〈Xs, εs〉 ds
Non è chiaro a priori se il termine∫ t
0〈Xs, εs〉 ds sia positivo o negativo (dipende dal-
la soluzione, non solo direttamente dal disturbo assegnato) e come cresca nel tempo.Vediamo quindi che il modo di immettere energia in un sistema proprio del moto brow-niano è assai speciale e conveniente per avere sotto controllo con precisione il bilanciodell’energia del sistema.
7.1 Presentazione informale del legame con le PDE
L’equazione differenziale stocastica (SDE)
dXt = b (t,Xt) dt+ σ (t,Xt) dBt
si lega a varie equazioni differenziali alle derivate parziali. Per semplicità di esposizione,limitiamoci al caso σ (t,Xt) = Id, quindi all’equazione con noise additivo
dXt = b (t,Xt) dt+ dBt (7.4)
dove supponiamo che B sia un moto browniano in Rd, b : [0, T ]×Rd → Rd sia suffi cien-temente regolare (se si vuole fissare un’ipotesi unica che vada bene per tutti i teoremi,si prenda ad esempio per semplicità C∞ con derivate limitate; ma caso per caso bastamolto meno) e la soluzione sia un processo continuo adattato in Rd.Oltre ad alcune altre varianti, le tre equazioni di base a cui leghiamo la SDE sono:
1. l’equazione parabolica, scritta in forma retrograda nel tempo, detta equazione diKolmogorov :
∂u
∂t+
1
2∆u+ b · ∇u = 0 su [0, T ]× Rd
u|t=T = uT
dove la soluzione u = u (t, x) è una funzione u : [0, T ]× Rd → R,
∆u =
d∑i=1
∂2u
∂x2i
, b · ∇u =
d∑i=1
bi∂u
∂xi
e si impone la condizione al tempo finale T , u (T, x) = uT (x);

7.1. PRESENTAZIONE INFORMALE DEL LEGAME CON LE PDE 173
2. l’equazione parabolica (in forma di equazione di continuità con viscosità), dettaequazione di Fokker-Planck :
∂p
∂t=
1
2∆p− div (bp) su [0, T ]× Rd
p|t=0 = p0
dove la soluzione p = p (t, x) è una funzione p : [0, T ]× Rd → R+, in genere unadensità di probabilità (ad ogni istante t fissato), e
div (bp) =d∑i=1
∂
∂xi(bip)
e si impone la condizione al tempo iniziale, p (0, x) = p0 (x), anch’essa densità diprobabilità;
3. il problema di Dirichlet
1
2∆u+ b · ∇u = 0 su D
u|∂D = g
dove D ⊂ Rd è un insieme limitato regolare, e la funzione g assegnata al bordo èpure suffi cientemente regolare.
I legami sono i seguenti. Fissato un qualsiasi t0 ∈ [0, T ], risolviamo l’equazione(7.4) sull’intervallo [t0, T ] con dato iniziale x ∈ Rd al tempo t0:
dXt = b (t,Xt) dt+ dBt per t ∈ [t0, T ]
Xt0 = x
ovvero in forma integrale
Xt = x+
∫ t
t0
b (s,Xs) ds+Bt per t ∈ [t0, T ] .
Indichiamo con X (t; t0, x) la soluzione forte, unica. Allora vale:
1. per l’equazione di Kolmogorov:
u (t, x) = E [uT (X (T ; t, x))] (7.5)
per ogni (t, x) ∈ [0, T ]× Rd

174 CAPITOLO 7. EQUAZIONI DIFFERENZIALI STOCASTICHE
2. per l’equazione di Fokker-Planck: se si prende la soluzione Xt dell’equazione (7.4)con dato iniziale aleatorio X0 avente densità di probabilità p0 (x), allora ad ogniistante t ∈ [0, T ] la v.a. Xt ha densità di probabilità, data da p (t, x), soluzionedell’equazione di Fokker-Planck
3. per il problema di Dirichlet: detto τD il tempo di uscita da D (primo istante diingresso in Dc), vale
u (x) = E [g (XτD)] .
Osservazione 47 L’equazione di Fokker-Planck ha notevole utilità pratica nelle appli-cazioni perché offre un modo di calcolare (magari anche solo numericamente) la densitàdi probabilità della soluzione Xt, da cui si possono calcolare valori attesi e probabilità diinteresse applicativo. Inoltre, è di un certo interesse fisico il legame tra le due equazioni(per questo se ne sono interessati Fokker e Planck).
Osservazione 48 I legami invece tra l’equazione (7.4) e le altre due equazioni allederivate parziali vengono di solito usati per scopi interni alla matematica, o per stu-diare le SDE tramite risultati e metodi della teoria delle PDE (equazioni alle derivateparziali), o viceversa.
Osservazione 49 Circa il legame con l’equazione di Kolmogorov, si può notare cheesso è una variante probabilistica del noto legame tra PDE del prim’ordine di tipotrasporto e le loro curve caratteristiche associate. Infatti, è noto che se si vuole studiarela PDE
∂u
∂t+ b · ∇u = 0 su [0, T ]× Rd
u|t=T = uT
si può dare una formula esplicita della soluzione in termini di caratteristiche, cioèrisolvendo l’equazione ordinaria associata
dXt
dt= b (t,Xt) dt per t ∈ [t0, T ]
Xt0 = x
ed il legame è (usando la notazione X (t; t0, x) come sopra)
u (t, x) = uT (X (T ; t, x)) .
Concludiamo con un cenno alla dimostrazione della prima formula, quella per l’e-quazione di Kolmogorov. Se volessimo partire dalla (7.4) e mostrare che la funzioneu (t, x) definita dalla formula (7.5) è soluzione dell’equazione di Kolmogorov, dovrem-mo svolgere molti calcoli (es. dovremmo derivare due volte X (t; t0, x) rispetto ad x).Non esponiamo questo tipo di calcoli. Invece, è moto semplice mostrare il seguenterisultato.

7.1. PRESENTAZIONE INFORMALE DEL LEGAME CON LE PDE 175
Proposizione 55 Se u è una soluzione di classe C1,2 dell’equazione di Kolmogorov,con derivate ∂u
∂xilimitate, allora vale (7.5).
Proof. Per la regolarità di u possiamo applicare la formula di Itô:
du (t,X (t; t0, x)) =∂u
∂tdt+∇u · (dX) +
1
2
∑ij
∂2u
∂xi∂xjd[X i, Xj
]ma d [X i, Xj]t = d [Bi, Bj]t = δijdt, quindi
du (t,X (t; t0, x)) =∂u
∂tdt+∇u · bdt+∇u · dB +
1
2∆udt.
Siccome vale ∂u∂t
+ 12∆u+ b · ∇u = 0, rimane
du (t,X (t; t0, x)) = ∇u (t,X (t; t0, x)) · dBt
ovvero, scrivendo in forma integrale su [t0, T ],
u (T,X (T ; t0, x)) = u (t0, X (t0; t0, x)) +
∫ T
t0
∇u (s,X (s; t0, x)) · dBs.
Per l’ipotesi di limitatezza delle derivate di u, vale E[∫ T
t0∇u (s,X (s; t0, x)) · dBs
]= 0.
Inoltre, X (t0; t0, x) = x, u (T,X (T ; t0, x)) = uT (X (T ; t0, x)), quindi
E [uT (X (T ; t0, x))] = u (t0, x) .
La dimostrazione è completa.


















