
CONCETTI PRELIMINARI GROUP TECNOLOGY COSTO … · 2 RICERCA STATISTICA DELL' OTTIMO OTTIMIZZAZIONE...
61
1 INTRODUZIONE INTRODUZIONE AL LAVORO......................................................................................................... 3 CONCETTI PRELIMINARI CLASSIFICAZIONE E DIMENSIONAMENTO DEI SISTEMI PRODUTTIVI ............................................ 5 INDICI DI PRESTAZIONE ............................................................................................................... 6 GROUP TECNOLOGY DESCRIZIONE GROUP TECHNOLOGY ............................................................................................ 8 ALGORITMO DI RANK ORDER AND CLUSTERING .......................................................................... 8 Esempio (Rank Order and Clustering) .......................................................................................... 9 SUDDIVISIONE CELLULARE ......................................................................................................... 11 APPLICAZIONE DI TROVA_CELLA ALL'ELEMENTO DI COORDINATE (1,1) ..................................... 12 SDOPPIAMENTO DI MACCHINARI .............................................................................................. 13 COSTO CELLULARE DEFINIZIONE DEI PARAMETRI DI COSTO .................................................................................... 15 MINIMIZZAZIONE DEL COSTO DELL’IMPIANTO .......................................................................... 16 EURISTICHE BASATE SU SDOPPIAMENTI DI UNA SINGOLA MACCHINA RICERCA DELL’OTTIMO CON COMPLESSITA’LINEARE ................................................................. 17 Esempio (ricerca dell'ottimo lineare) ......................................................................................... 17 RICERCA DELL’OTTIMO CON COMPLESSITA’ ESPONENZIALE ...................................................... 18 BIPARTIZIONE DI UN INSIEME .................................................................................................... 18 LIMITITI DELLE EURISTICHE ........................................................................................................ 20 RAGGIUNGIMENTO DEL COSTO OTTIMO CALCOLO DELLA COMPLESSITA’COMPUTAZIONALE DEL PROBLEMA.......................................... 21 Esempio..................................................................................................................................... 21 IMPORTANZA DELL’APPLICAZIONE PREVENTIVA DELL’ALGORITMO DI RANK ORDER AND CLUSTERING ........................................................................................................................... 23 BREVE RICHIAMO SULLE PARTIZIONI DI UN INSIEME ................................................................. 23 NUMERI DI STIRLING DI SECONDA SPECIE.................................................................................. 24 NUMERI DI BELL ........................................................................................................................ 25 COMPLESSITA’ COMPUTAZIONALE ............................................................................................ 27 RICERCA ESAUSTIVA PER INSIEMI CON PICCOLA CARDINALITA’ ................................................. 28 Esempio..................................................................................................................................... 28
Transcript of CONCETTI PRELIMINARI GROUP TECNOLOGY COSTO … · 2 RICERCA STATISTICA DELL' OTTIMO OTTIMIZZAZIONE...

1
INTRODUZIONE INTRODUZIONE AL LAVORO ......................................................................................................... 3
CONCETTI PRELIMINARI CLASSIFICAZIONE E DIMENSIONAMENTO DEI SISTEMI PRODUTTIVI ............................................ 5 INDICI DI PRESTAZIONE ............................................................................................................... 6
GROUP TECNOLOGY DESCRIZIONE GROUP TECHNOLOGY ............................................................................................ 8 ALGORITMO DI RANK ORDER AND CLUSTERING .......................................................................... 8 Esempio (Rank Order and Clustering) .......................................................................................... 9 SUDDIVISIONE CELLULARE ......................................................................................................... 11 APPLICAZIONE DI TROVA_CELLA ALL'ELEMENTO DI COORDINATE (1,1) ..................................... 12 SDOPPIAMENTO DI MACCHINARI .............................................................................................. 13
COSTO CELLULARE DEFINIZIONE DEI PARAMETRI DI COSTO .................................................................................... 15 MINIMIZZAZIONE DEL COSTO DELL’IMPIANTO .......................................................................... 16
EURISTICHE BASATE SU SDOPPIAMENTI DI UNA SINGOLA MACCHINA RICERCA DELL’OTTIMO CON COMPLESSITA’LINEARE ................................................................. 17 Esempio (ricerca dell'ottimo lineare) ......................................................................................... 17 RICERCA DELL’OTTIMO CON COMPLESSITA’ ESPONENZIALE ...................................................... 18 BIPARTIZIONE DI UN INSIEME .................................................................................................... 18 LIMITITI DELLE EURISTICHE ........................................................................................................ 20
RAGGIUNGIMENTO DEL COSTO OTTIMO CALCOLO DELLA COMPLESSITA’COMPUTAZIONALE DEL PROBLEMA.......................................... 21 Esempio..................................................................................................................................... 21 IMPORTANZA DELL’APPLICAZIONE PREVENTIVA DELL’ALGORITMO DI RANK ORDER AND
CLUSTERING ........................................................................................................................... 23 BREVE RICHIAMO SULLE PARTIZIONI DI UN INSIEME ................................................................. 23 NUMERI DI STIRLING DI SECONDA SPECIE .................................................................................. 24 NUMERI DI BELL ........................................................................................................................ 25 COMPLESSITA’ COMPUTAZIONALE ............................................................................................ 27 RICERCA ESAUSTIVA PER INSIEMI CON PICCOLA CARDINALITA’ ................................................. 28 Esempio..................................................................................................................................... 28

2
RICERCA STATISTICA DELL' OTTIMO OTTIMIZZAZIONE ORDINALE ...................................................................................................... 31 Esempio..................................................................................................................................... 32 APPLICAZIONE OTTIMIZZAZIONE ORDINALE AL PROBLEMA ....................................................... 34
DISTRIBUZIONE DELLA PROBABILITÀ INTRODUZIONE ......................................................................................................................... 35 PROBABILITÀ EQUIDISTRIBUITA ................................................................................................ 35 ALGORITMO PER L’ESTRAZIONE EQUIPROBABILE DI PARTIZIONI DI ORDINE K ........................... 35 ESTRAZIONE EQUIPROBABILE DI PARTIZIONI ............................................................................ 38 Esempio 1 .................................................................................................................................. 39 Esempio 2 .................................................................................................................................. 40 PROBABILITÀ POLARIZZATA ....................................................................................................... 40 Esempio .................................................................................................................................... 41 DIMOSTRAZIONE ANALITICA DELLA POLARIZZAZIONE ............................................................... 42 Esempio 1 .................................................................................................................................. 43 Esempio 2 .................................................................................................................................. 44 COMPLESSITA'COMPUTAZIONALE:ALGORITMI DI OTTIMIZZAZIONE .......................................... 45
SIMULAZIONI
Simulazione 1 ........................................................................................................................... 46 Simulazione 2 ............................................................................................................................ 50 Simulazione 3 ............................................................................................................................ 56
CONCLUSIONI CONSIDERAZIONI FINALI ............................................................................................................ 60
BIBLIOGRAFIA TESTI E ARTICOLI CONSULTATI ................................................................................................... 61

3
INTRODUZIONE
INTRODUZIONE AL LAVORO
Questo lavoro è stato svolto nell’ambito della Group Technology (GT), un tipo di organizzazione della produzione che ormai da diversi anni è oggetto di numerose ricerche ( [1], [5], [9] ). L'idea fondante del concetto di Group Technology (GT) è quella di suddividere un insieme tecnologico (ad esempio un insieme di parti) in sottoinsiemi tra di loro simili chiamati famiglie, che verranno prodotte in celle distinte, ottenendo vantaggi sia a livello economico che organizzativo. Tra questi si annoverano i miglioramenti di alcuni indici prestazionali dell’impianto come l’aumento della produttività, l’incremento della qualità dei prodotti, la semplificazione del controllo di produzione, la riduzione delle scorte e l’ aumento del coordinamento e della comunicazione. Il nodo centrale di questa trattazione è quello di individuare quale sia la migliore modalità di creazione delle suddette famiglie di parti. A differenza di molte pubblicazioni si cercherà di affrontare il problema dell’ottimizzazione in maniera differente poiché, anziché cercare di ottimizzare il sistema solo da un punto di vista strutturale ( [6] ), si cercherà di configurare il medesimo in modo da rendere minima una certa funzione di costo, capace di tener conto della spesa necessaria all’acquisto dell’impianto e della complessità dello stesso.
Il problema è stato innanzitutto formalizzato introducendo una funzione di costo associata alle celle produttive che tenesse conto degli indici prestazionali precedentemente richiamati. In una prima fase quindi si è affrontata la questione, come similmente fatto da altri autori ( [4], [12] ), utilizzando uno tra gli algoritmi presenti in letteratura già dai primi anni ‘80: il Rank Order and Clustering (ROC), un algoritmo che però fornisce una soluzione euristica generalmente non ottima al problema considerato in questa tesi. La non ottimalità di questo tipo di approccio è dovuta al fatto che la soluzione ottima potrebbe prevedere diverse repliche di alcuni macchinari, cosa non contemplata nell’algoritmo in questione. Si è comunque dimostrato in questo lavoro che l’applicazione del ROC è un passo preliminare che avvicina in qualsiasi caso alla soluzione ottima e che quindi deve sempre essere effettuato. Utilizzando l’algoritmo di Rank Order and Clustering come passo base si è cercato di raggiungere la configurazione ottima mediante varie euristiche basate su sdoppiamenti di singoli macchinari. Dapprima si è provato ad effettuare sdoppiamenti progressivi di macchinari scegliendo di volta in volta tramite algoritmi, di complessità lineare e poi esponenziale, le possibili modalità di sdoppiamento del singolo macchinario. Si è però dimostrato che questo tipo di strategie possono migliorare solo in alcuni casi la configurazione base e che non costituiscono in alcun modo una valida strategia per raggiungere la soluzione ottima. Per risolvere il problema del raggiungimento della configurazione ottima si è avuta l’intuizione di cambiare punto di vista e quindi non cercare di ottimizzare il sistema mediante la scelta dei macchinari da sdoppiare ma far derivare tale scelta dal raggruppamento delle parti nelle varie famiglie.
Al fine di poter creare un metodo di soluzione esaustivo è stato necessario calcolare la complessità computazionale del problema. Poiché la complessità del problema è legata al numero di modi possibili di partizionare l’insieme delle parti ( [14] ), si è potuto constatare che questa è espressa dai numeri di Bell, i quali sono proprio definiti come il numero di sottoinsiemi non vuoti (partizioni) nei quali può essere diviso un insieme di n elementi. Individuata la complessità, si è potuto creare un algoritmo capace di generare tutte le possibili partizioni dell’insieme parti e di creare da queste tutte le possibili configurazioni del sistema. Successivamente si è prodotto un altro algoritmo capace di valutare il costo di ciascuna configurazione e di scegliere quindi in maniera esaustiva quella ottima, risolvendo così in maniera definitiva il problema della tesi.

4
A causa dell’incremento più che esponenziale della complessità computazionale (numeri di Bell) al variare del numero di parti nel sistema, si sono introdotti approcci alternativi. Tramite considerazioni di tipo statistico, sono stati introdotti due approcci probabilistici ([14]), basati sull’ottimizzazione ordinale, e ne è stata proposta una versione pratica mediante l’implementazione di algoritmi. I due approcci, senza tener conto dell’incremento della complessità computazionale, permettono di individuare configurazioni del sistema che, anche non essendo con piena certezza ottime, si trovano in un range di ottimalità precedentemente definito dall’utilizzatore. Le due modalità di ricerca proposte si differenziano da un punto di vista pratico poiché una compie tale ricerca in maniera equiprobabile mentre l’altra in maniera polarizzata. Per garantire l’equiprobabilità è stata utilizzata come sotto-procedura, mediante vari accorgimenti, una funzione creata da Herbert Wilf ( [14] ) che sfruttando delle proprietà derivanti dai numeri di Stirling di seconda specie riesce a garantire l’estrazione equiprobabile di partizioni di una data classe. Un capitolo della trattazione è stato interamente dedicato alle distribuzioni di probabilità dei due algoritmi e alle dimostrazioni relative alle medesime poiché da queste dipendono le previsioni effettuabili in merito ai risultati della ricerca prima menzionata. Al fine di avere una stima della bontà dei risultati ottenuti è stato analizzato il comportamento dei due differenti approcci in termini di guadagno temporale e perdita delle prestazioni. Si è dedicato ampio spazio nel lavoro a simulazioni tabulari capaci di dare una stima dell’efficienza dei medesimi e dei loro margini prestazionali. Nell’ultima parte del lavoro mediante grafici sono stati confrontati i risultati ottenuti dai metodi di ottimizzazione statistica e da quello di ricerca esaustiva (cioè il costo della configurazione ottima del sistema).
Per concludere il lavoro si sono fatte infine delle osservazioni sui risultati ottenuti e si è data una panoramica dei possibili sviluppi futuri facendo riferimento a due diverse possibili metodologie di procedere per affrontare in maniera efficace il problema dell’ ottimizzazione. Si è proposta quindi una prima soluzione richiamante le procedure denominate ‘greedy algorithms’ e una seconda invece facente riferimento agli algoritmi di tipo ‘genetico’ ( [11] ), molto in voga per la soluzione di una discreta varietà di problemi ingegneristici.
Per ragioni di semplicità e agevolezza nella consultazione all’interno del testo verranno raramente riportate le procedure algoritmiche implementate per l’ottimizzazione, si darà invece spazio alle idee su cui esse sono fondate.

5
CONCETTI PRELIMINARI
CLASSIFICAZIONE E DIMENSIONAMENTO DEI SISTEMI PRODUTTIVI
Per classificare un generico impianto di produzione può essere utile, come approccio preliminare, analizzare il rapporto tra la varietà delle parti prodotte e la loro quantità. Generalmente un impianto con un’elevata varietà non sarà in grado di garantire una grande produzione e viceversa. Tale concetto è molto semplice da rappresentare su di un piano cartesiano ove sulle ascisse vi sarà la quantità prodotta e sulle ordinate la varietà di beni prodotti.
Figura 1 Rappresentazione cartesiana del rapporto quantità-varietà di beni prodotti
Come è possibile vedere dal grafico in Figura 1 il piano viene delimitato da una fascia costituita da due rette con pendenza negativa. Tale fascia è divisa a sua volta in tre partizioni rappresentanti rispettivamente la bassa produzione (con quantità nell’ordine delle cento unità all’anno e con elevata varietà), la media produzione (con quantità nell’ordine delle mille unità all’anno e media differenziazione) ed infine l’alta produzione (con una produzione superiore alle diecimila unità all’anno e una limitata varietà di parti prodotte).
A seconda del tipo di produzione l’impianto avrà una differente organizzazione del sistema produttivo. Per la bassa varietà si avrà un sistema di tipo JOB SHOP con un cammino diverso per ogni parte prodotta, per la media varietà vi sarà un’organizzazione a LOTTI o CELLULARE con stessi cammini di lavorazione per lotti di parti simili tra loro, mentre per la bassa varietà vi sarà un assetto di tipo flow-line con lo stesso cammino per tutte le parti prodotte.

6
Per la classificazione dell’impianto oltre al rapporto varietà/quantità di produzione e tipo di organizzazione per la lavorazione delle parti è necessario anche definire il LAYOUT, cioè la disposizione dei vari macchinari all’interno del sistema produttivo.
A seconda del tipo di produzione, come già si è visto nell’organizzazione per la lavorazione delle parti, si avrà un tipo di LAYOUT piuttosto che un altro. I tipi di LAYOUT sono sostanzialmente quattro:
LAYOUT A POSIZIONE FISSA: Viene in genere utilizzato per piccole produzioni. I macchinari sono fissi e lavorano disposti come satelliti intorno al bene in produzione.
LAYOUT A PROCESSO Viene utilizzato per medie e piccole produzioni. L’impianto è suddiviso in piccoli sottoimpianti, ognuno dei quali svolge un tipo di lavorazione diversa. I beni all’interno del sistema produttivo viaggiano di cella in cella subendo ad ogni passaggio una differente lavorazione cosicché a seconda delle celle visitate dalla parte in produzione si avrà un tipo di prodotto finale piuttosto che un altro.
LAYOUT CELLULARE Viene spesso utilizzato per medie produzioni. E’ caratterizzato da una suddivisione dell’impianto in una moltitudine di celle (group technology), similmente al caso precedentemente. La differenza sostanziale risiede nel fatto che ogni cella produce un bene e non si occupa del solo incremento di valore aggiunto; quindi ogni cella si comporta come se fosse un micro impianto che opera un processo completo.
LAYOUT A PRODOTTO Viene utilizzato per grandi produzioni. Questo genere d’impianto si può pensare come una serie di macchine disposte lungo una linea rappresentante idealmente il percorso che dovranno compiere le parti all’interno del sistema. Poiché la linea è unica la varietà in uscita sarà molto bassa.
Come è ovvio notare c’è un legame strettissimo tra il layout del sistema ed il tipo di produzione dello stesso poiché l’uno influenza inevitabilmente l’altro.
INDICI DI PRESTAZIONE
Per modellare un processo è necessario definire delle leggi dipendenti da indici legati alle sue prestazioni. Si potrà così migliorare un processo cercando di migliorare i suoi indici prestazionali. Il vincolo da tenere in considerazione nell’ottimizzazione del processo è il rapporto di correlazione che vi è tra i vari indici; migliorandone uno potrebbe peggiorarne un altro o si potrebbero avere dei valori ottimi per uno e dei valori inaccettabili per un altro. La scelta ottimale si ottiene quindi dall’ottimizzazione combinata dei vari indici. Gli indici da tenere in considerazione sono essenzialmente quattro: il THROUGHPUT o tasso produttivo del sistema, il coefficiente di utilizzazione delle macchine, il WIP (work in progress) e l’ MLT (manifacturing lead time).
Il TROUGHPUT è il numero di parti prodotte dal sistema nell’unità di tempo. Se si conosce la domanda del mercato per massimizzare il profitto risulta utile adeguare questo indice in modo da non avere giacenze di magazzino e avere un rapporto domanda-offerta pari ad uno.

7
Il COEFFICIENTE DI UTILIZZAZIONE DELLE MACCHINE rappresenta il rapporto tra il tempo di lavorazione e il tempo di stallo all’interno del sistema produttivo. Spingere al massimo questo indice permette di ottenere il massimo della produttività del sistema nella configurazione data, ma allo stesso tempo incrementa le sue probabilità di guasto e i vari rischi connessi. Risulta quindi necessario trovare un giusto compromesso tra rischi e benefici.
Il WIP rappresenta il numero medio di parti nel sistema a regime. Un aumento di questo indice porta un aumento di complessità del sistema dovuto a difficoltà di gestione e di giacenza di parti tra un macchinario e l’altro, con conseguente costo di magazzino e problemi di sincronizzazione nella lavorazione. Inoltre avere un WIP alto risulta essere pericoloso, poiché si ha un incremento della probabilità di guasto all’interno della stazione e quindi la possibilità d’immobilizzamento di una gran parte del capitale. Inoltre in caso d’incidenti, per esempio incendi, si potrebbe avere addirittura una perdita dello stesso. E’ possibile inoltre che a seguito di un guasto parziale di un macchinario si abbia la produzione di pezzi non conformi alle specifiche tecniche previste e, poiché spesso i controlli sono effettuati sul prodotto finito, si abbia una gran parte della produzione fallata.
L’MLT rappresenta il tempo di permanenza della parte nell’impianto. Minimizzare questo indice porta sicuramente una minore esposizione del capitale a rischi, maggiore controllo nella produzione, semplificazione di sincronizzazione ed aumento dell’efficienza produttiva. L’ottimo per questo indice è costituito dal valore limite zero.
E’ interessante notare come l’MLT e il WIP siano legati da una relazione proporzionale. Con il crescere del numero medio di parti all’interno di un sistema cresce conseguentemente il tempo medio di attraversamento all’interno dello stesso. Questo legame è espresso dalla legge di LITTLE la quale afferma che il numero di entità all’interno del sistema è pari alla frequenza media con cui le entità entrano nel sistema. Tale relazione, come è ovvio notare dalla parola ‘media’, è valida per sistemi a regime.
In questo testo si presterà particolare attenzione alla GROUP TECHNOLOGY (produzione di tipo cellulare) e all’ottimizzazione dei suoi indici prestazionali.

8
GROUP TECHNOLOGY
DESCRIZIONE GROUP TECHNOLOGY
La group tecnology è una produzione di tipo cellulare accompagnata spesso da una discreta varietà e da una moderata quantità di produzione. Questo tipo d’impianto ha un costo abbastanza elevato ma consente di avere ridotti valori di WIP e conseguentemente MLT contenuti. Il sistema complessivo risulta un insieme di tanti sottosistemi ciascuno capace di produrre una famiglia di parti. Per ottenere un impianto di questo tipo è necessaria un’ analisi preliminare delle parti da produrre. A seguito dell’analisi è possibile creare delle famiglie di parti che richiedono lavorazioni simili e poter conseguentemente organizzare il LAYOUT produttivo disponendo i macchinari in celle, ciascuna delle quali dovrà produrre una delle famiglie individuate. Per quanto concerne la classificazione in famiglie, vengono seguiti due criteri cardine: il criterio della classificazione in base al materiale e alla struttura esteriore delle parti e quello della classificazione in base al processo produttivo che essa deve subire . La scelta migliore, come già è avvenuto in precedenza , consiste nell’integrare il più possibile i due criteri poiché il primo consente una più semplice creazione di nuove parti, mentre il secondo una più agevole disposizione dei macchinari. Per la divisione in famiglie risulta molto utile l’utilizzo del CODICE di OPTIZ (1970). Questa notazione assegna ad ogni parte un codice di tredici cifre le quali esprimono, tramite una convenzione, le caratteristiche strutturali della parte e le sue interazioni con il processo produttivo. Utilizzando questo tipo di codifica si ottiene una buona astrazione e una maggior facilità nel raggruppamento cellulare macchine- famiglie di parti.
ALGORITMO DI RANK ORDER AND CLUSTERING
Per trovare un’adeguata divisione cellulare ed aumentare l’efficienza dell’impianto si ricorre ad una tecnica chiamata PFA, production flow analysis. Per applicare questa tecnica, basata su di un algoritmo chiamato “rank order and clustering”, è necessario definire una matrice, detta matrice d’incidenza. Tale matrice è composta da n righe rappresentanti i diversi tipi di macchine e da m colonne corrispondenti ciascuna ad una diversa parte da lavorare. Si crea in tal modo una matrice d’incidenza macchine-parti in cui ciascuno degli n×m elementi può assumere rispettivamente il valore ‘0’, se la parte non è lavorata dalla macchina in questione, ed invece è pari ad ‘1’, se la parte viene lavorata da quest’ultima. Si converte successivamente ciascuna riga della matrice in una stringa decimale, associando ad ogni colonna, partendo dall’ultima verso l’estremo destro, pesi crescenti nell’ordine delle potenze di due (da 20 fino ad arrivare a 2m-1). Si sommano successivamente gli elementi di ciascuna riga moltiplicati rispettivamente per i propri pesi; si ottiene così il valore decimale della stringa binaria considerata. Infine dopo aver compiuto l’operazione di conversione si ordinano le righe in base al loro valore decimale in maniera decrescente. Si compie successivamente la stessa operazione sulle colonne con l’unica differenza costituita dai pesi associati agli elementi, che invece di essere da 20 fino a 2m-1 saranno da 20 a 2n-1. Si procede quindi ordinando le colonne, come si è fatto per le righe, in maniera decrescente. Si itera

9
l’operazione sulle righe e successivamente sulle colonne fino ad arrivare ad un punto in cui non è più possibile effettuare scambi. Il risultato è una matrice diagonalizzata a blocchi in cui ciascun blocco rappresenta una cella produttiva nella quale viene lavorata una famiglia di parti. Tramite dimostrazioni è possibile notare che questo algoritmo assicura la convergenza e che quindi darà comunque luogo a una soluzione in un tempo finito.
Esempio (algoritmo RANK ORDER AND CLUSTERING)
Si abbia una matrice d’incidenza macchine parti definita nel seguente modo:
Figura 2 Rappresentazione tramite matrice d'incidenza del sistema considerato
In primo luogo è necessario convertire ogni riga da binaria a decimale ed associare a ciascuna di queste il suo valore corrispondente, come esplicitato dalla figura sottostante (nella prima riga sono riportati i pesi associati agli elementi di ciascuna colonna, mentre nell’ultima colonna sono rappresentati i pesi totali di ciascuna riga):
Figura 3 Matrice d'incidenza con esplicitati i pesi di ciascuna riga, evidenziati in giallo nell’ultima colonna

10
A seguito dell’ordinamento per righe si ottiene la seguente matrice
Figura 4 Matrice d'incidenza con le righe ordinate, come esplicitato dai pesi evidenziati
Si riportano nella prima colonna i pesi di ciascun elemento appartenente alla riga in questione. Nell’ultima riga sono riportati i pesi totali di ciascuna colonna)
Figura 5 Matrice d'incidenza con colonne da ordinare, come esplicitato dai pesi evidenziati in giallo nell’ultima riga
Si procede quindi in modo del tutto analogo compiendo però un ordinamento per colonne. La matrice ottenuta dopo l’ordinamento per colonne è la seguente
Figura 6 Matrice ottenuta dopo l'applicazione del ROC. In rosso sono evidenziate le nuove celle ottenute

11
Come è evidenziato dai tre rettangoli rossi si è ottenuta una matrice diagonale a blocchi in cui sono evidenti le tre famiglie di parti con le relative macchine necessarie per la loro lavorazione. Arrivando a questo punto l’algoritmo non ha necessità di ripetersi poiché sia le righe che le colonne sono ordinate e quindi una successiva iterazione non creerebbe modifiche all’interno della matrice suddetta. Bisogna tenere in considerazione che colonne o righe di uguale valore possono essere ordinate indifferentemente, poiché apparterranno obbligatoriamente alla stessa famiglia di parti. Le tre famiglie di parti sono quindi {A,H,D} , {B,F,G} , {I,C,E} con le relative divisioni cellulari di macchine necessarie per la loro lavorazione {1,5} , {7,4} , {3,6,2}.
SUDDIVISIONE CELLULARE
Per individuare le celle in maniera algoritmica è stata implementata la procedura ‘trova_celle’. Tale funzione, sfruttando le proprietà della matrice d’incidenza ottenuta a seguito dell’applicazione dell’algoritmo di RANK ORDER AND CLUSTERING, riesce ad individuare la corretta divisione cellulare della matrice data. La funzione ‘trova_celle’ riceve in ingresso una matrice ordinata, secondo l’algoritmo ROC restituisce in uscita, un vettore sub-partito in insiemi di cardinalità pari a quattro: i primi due elementi di ciascun insieme rappresentano rispettivamente la riga e la colonna iniziale della cella in esame, mentre i secondi due la riga e la colonna finale di quest’ultima. I singoli sottoinsiemi sono forniti dalla funzione ‘trova_cella’ la quale ricevendo in ingresso la matrice ordinata secondo ROC e due indici, il primo riferito alla riga e il secondo riferito alla colonna iniziale da considerare, restituisce un vettore di lunghezza pari a quattro con i primi due valori pari agli indici di riga e di colonna ricevuti in ingresso e gli ultimi riferiti rispettivamente agli indici della riga e della colonna dell’ultimo elemento della cella considerata. La ricerca della dimensione della singola cella avviene con complessità lineare: partendo dall’elemento indicato dagli indici in ingresso. si incrementano gli indici in uscita. L’incremento continua fintanto che non vi sia una ‘sottoriga’ nulla e una ‘sottocolonna’ nulla di grandezza pari rispettivamente al numero di colonne occupate dalla cella e al numero di righe occupate dalla medesima. Il funzionamento di tale procedura è garantito dall’applicazione preventiva dell’algoritmo ROC. Tale algoritmo, ordinando la matrice data, fa in modo che vi sia un compattamento degli ‘1’ verso l’angolo in alto a sinistra della matrice, e quindi permette l’individuazione delle celle incrementando solo di una unità l’indice di colonna e riga finale relativo alla cella in esame. Di seguito viene riportata una matrice prima e dopo l’algoritmo di RANK ORDER AND CLUSTERING. Nel paragrafo successivo tale matrice verrà utilizzata per produrre un esempio pratico dell’algoritmo ‘trova_cella’. L’algoritmo verrà utilizzato per trovare solo la prima cella della matrice.
Figura 7 Matrice prima dell'applicazione dell’algoritmo ROC Figura 8 Matrice dopo l'applicazione dell'algoritmo ROC

12
APPLICAZIONE DI ‘TROVA_CELLA’ ALL’ ELEMENTO DI COORDINATE (1,1)
STEP 1: Si inizializzano i valori di riga e colonna iniziali e finali, restitituiti dalla funzione, con i valori delle coordinate fornite in ingresso. Per verificare se la cella definita da tali indici è effettivamente una cella si prova se la sottocolonna di destra e la sottoriga inferiore sono completamente nulle.
STEP 2: Dal momento che né la sottoriga né la sottocolonna sono effettivamente nulle si incrementano entrambi gli indici finali e si ripete la verifica precedente.
STEP 3: Poiché il test fallisce solo sulla sottocolonna di destra si incrementa solo l’indice di colonna finale e si ripete la verifica.
STEP 4: La verifica va a buon fine sia per la sottocolonna che per la sottoriga quindi vengono restituiti gli indici relativi rispettivamente alla riga e alla colonna da cui è iniziato il test e alla riga e alla colonna finali ottenuti mediante lo svolgimento dell’algoritmo. La funzione ‘trova_celle’ richiama la funzione ‘trova_cella’ sulla matrice ordinata mediante ROC e sull’elemento riga_finale+1 e colonna_finale+1.
Figura 9 Dall'angolo alto a sinistro rappresentazione grafica in senso orario dei quattro step dell’algoritmo trova_cella
Da notare inoltre che non è possibile trovare una sottoriga non nulla o una sottocolonna non nulla al di sotto o a destra di una sottoriga nulla o di una sottocolonna nulla. Tale proprietà come è stato detto in precedenza è garantita dall’applicazione preventiva dell’algoritmo di Rank Order and Clustering.

13
SDOPPIAMENTO DI MACCHINARI
Vi sono dei casi in cui dopo aver applicato l’algoritmo di Rank Order and Clustering non si ha una matrice a blocchi perfettamente diagonale. Quindi potrebbe risultare utile apportare delle modifiche all’impianto per ottenere una migliore distribuzione cellulare. Una scelta consigliabile in questo caso potrebbe essere quella di duplicare uno o più macchinari dell’impianto. Con tale scelta è possibile distribuire le parti da lavorare sulle nuove macchine e ridurre la dimensione delle celle precedentemente ottenute. Un esempio di questa eventualità è dato dalla seguente matrice d’incidenza.
Figura 10 Matrice prima dell'applicazione del ROC Figura 11 Matrice dopo il ROC con celle evidenziate
Dalla figura riportata sopra risulta evidente che, con i macchinari dati, è possibile dividere l’impianto in sole due celle produttive. Per ottenere un miglioramento si potrebbe pensare di comprare un duplicato di qualche macchinario.
Figura 12 Matrice d'incidenza con evidenziato il possibile sdoppiamento
In questo caso si nota che scegliendo la macchina uno e distribuendo diversamente le lavorazioni delle parti B e D è possibile creare un’altra cella produttiva.
Figura 13 Matrice d'incidenza con evidenziate le nuove celle a seguito dello sdoppiamento
Dopo lo sdoppiamento si ottiene un impianto a tre celle produttive.

14
In questo esempio si è scelto di sdoppiare solamente una macchina, la macchina numero uno, e di dare così origine ad un impianto a tre celle. La scelta dello sdoppiamento non è assolutamente univoca ed è ancorata a parametri decisionali dipendenti dall’impianto considerato. E’ quindi importante ricordare che la scelta fatta in questo breve esempio non è necessariamente la migliore ma è solo una delle possibili scelte attuabili. Per valutare quale tra le possibili scelte vada effettuata, risulta utile definire una funzione di costo.

15
COSTO CELLULARE
DEFINIZIONE DEI PARAMETRI DI COSTO
Il costo di un impianto cellulare può essere definito come la sommatoria dei costi di ogni singola cella che lo compone, di conseguenza per definirne il costo è sufficiente concentrarsi su di una singola cella ed iterare il ragionamento per tutte le altre. Il costo di una singola cella può essere visto come la somma di due costi: uno derivante dalla complessità introdotta dalla grandezza della singola cella l’altro derivante dal costo dei macchinari che la compongono.
퐶 = ∑ 퐶푚 + 퐶 (eq.1)
dove Ci è il costo totale della cella i-esima, Cmk è il costo del macchinario k-esimo presente nella cella i-esima, Cci è il costo dovuto alla dimensione della cella i-esima e Nmi è il numero di macchinari presenti nella cella i-esima.
Il costo derivante dalle dimensioni della cella potrebbe essere visto come un costo indiretto poiché in prima battuta non sembrerebbe incidere direttamente sul capitale ma, ad un analisi più attenta, si nota una stretta correlazione con il WIP e l’MLT dell’impianto: all’aumentare della complessità, derivante da un aumento delle dimensioni, si ha un aumento di entrambi gli indici. I fattori che influiscono su tale costo sono principalmente due: il numero di macchinari presenti all’interno della cella e il numero di parti lavorate nella medesima (la cella infatti ha una grandezza #parti × #macchine). Per stimare tale complessità è stata scelta una funzione di tipo quadratico, in cui appunto la complessità della singola cella è definita come la somma tra i quadrati rispettivamente del numero delle macchine che la compongono e del numero delle parti che vi vengono lavorate.
퐶 = 훼푁 + 훽푁 (eq.2)
Dove Nmi è il numero di macchine presente nella cella i-esima e Npi è il numero di parti presenti nella stessa. I coefficienti di proporzionalità che moltiplicano entrambi i quadrati servono per penalizzare o agevolare l’aumento o la diminuzione di macchine nell’impianto. Il costo complessivo risulta quindi definito dalla seguente relazione :
퐶 = ∑ 퐶 (eq.3)
Dove 퐶 è il costo totale dell’impianto, i è la cella in esame, n le celle totali, 퐶 il costo della cella i-esima calcolato come definito nell’eq.1.

16
Se si fosse invece deciso di adottare una funzione di costo lineare:
퐶 = 훼푁 + 훽푁
ci si sarebbe accorti che la suddivisione in celle non avrebbe portato alcun benefizio e che sdoppiando i macchinari si andrebbe sempre e comunque incontro ad un aumento del costo. Tale affermazione è giustificata dal fatto che rimanendo costanti le parti nel sistema e aumentando le macchine, data la linearità del costo della cella, il costo non può far altro che aumentare linearmente.
Esempio
Data una cella su cui effettuare lo sdoppiamento composta da 4 macchinari e da 3 parti e considerando la possibilità di formare due celle: composte una da 4 macchinari e da 1 parte e l’altra da 4 macchinari e due parti si nota che il costo totale subisce un incremento:
퐶 = 4 + 3=7
= 퐶 = 4 + 2 + 4 + 1 = 11
MINIMIZZAZIONE DEL COSTO DELL’IMPIANTO
La funzione di costo totale risulta essere una funzione discontinua quindi il problema di minimizzazione non è affrontabile con i canonici strumenti matematici poiché non è possibile studiare le derivate della curva in esame. Per minimizzare il costo totale è necessario quindi trovare una combinazione di fattori per cui la sommatoria dei costi della complessità delle varie celle e quella dei vari macchinari operanti nelle medesime sia minima. Il problema quindi si riduce a trovare quali debbano essere i macchinari da sdoppiare in modo da ottenere una nuova disposizione cellulare capace di abbassare il costo degli indici sopra descritti. Un primo approccio possibile potrebbe essere quindi quello di concentrarsi sui macchinari da sdoppiare cercando il miglior sdoppiamento possibile tra quelli selezionabili e iterando il procedimento fino a che non ci siano più sdoppiamenti convenienti.

17
EURISTICHE BASATE SU SDOPPIAMENTI DI UNA SINGOLA MACCHINA
RICERCA DELL’OTTIMO CON COMPLESSITA’LINEARE
Un primo approccio da considerare potrebbe essere quello di cercare uno sdoppiamento possibile mantenendo una complessità lineare. Per realizzare tale ricerca è stato implementato un algoritmo che, ricevendo in ingresso la matrice ordinata secondo l’algoritmo ROC, calcola il costo dell’impianto dato e lo imposta come costo iniziale. Al passo successivo la procedura scorre tutte le righe della matrice d’incidenza cercando in maniera lineare il miglior sdoppiamento possibile e itera questa procedura finché non sia più conveniente effettuare alcuno sdoppiamento. Un esempio di questo algoritmo è riportato di seguito:
Esempio (ricerca dell’ottimo lineare)
Per semplicità è stata presa in esame una matrice d’incidenza 3 x 3 così da poter mostrare in modo dettagliato l’esecuzione dell’intero algoritmo. In tale esempio i costi dei macchinari sono considerati tutti equivalenti e pari ad uno.
A B C
A B C
A B C
1 1 0 0
1 1 0 0
1 1 1 1 Sdoppiamento 1b 0 1 1 ROC 2 1 1 0 2 1 1 0
2 1 1 0 1b 0 1 1 3 0 0 1 Ciniz=21 3 0 0 1 Ctot=29 3 0 0 1
A B C
A B C
A B C
1 1 1 0
1 1 1 0
1 1 1 1 Sdoppiamento 1b 0 0 1 ROC 2 1 1 0 2 1 1 0
2 1 1 0 1b 0 0 1 3 0 0 1 Ciniz=21 3 0 0 1 Ctot=17 3 0 0 1
A B C
A B C
A B C
1 1 1 1
1 1 1 1
1 1 1 1 Sdoppiamento 2 1 0 0 ROC 2 1 0 0 2 1 1 0
2b 0 1 0 2b 0 1 0 3 0 0 1 Ciniz=21 3 0 0 1 Ctot=29 3 0 0 1
A B C
A B C
1 1 1 1
A B C
1 1 1 1 Sdoppiamento 2 1 1 0 ROC 1 1 1 1 2 1 1 0
2b 0 0 0 2 1 1 0 3 0 0 1 Ciniz=21 3 0 0 1 Ctot=21 3 0 0 1
18
A B C
A B C
1 1 1 1
A B C 1 1 1 1 Sdoppiamento 2 0 1 1 ROC 1 1 1 1 2 1 1 0
3 0 0 0 2 1 1 0 3 0 0 1 Ciniz=21 3b 0 0 1 Ctot=21 3b 0 0 1
A B C
A B C
1 1 1 1
A B C
1 1 1 1 Sdoppiamento 2 0 0 1 ROC 1 1 1 1 2 1 1 0
3 0 0 0 2 1 1 0 3 0 0 1 Ciniz=21 3b 0 0 1 Ctot=21 3b 0 0 1
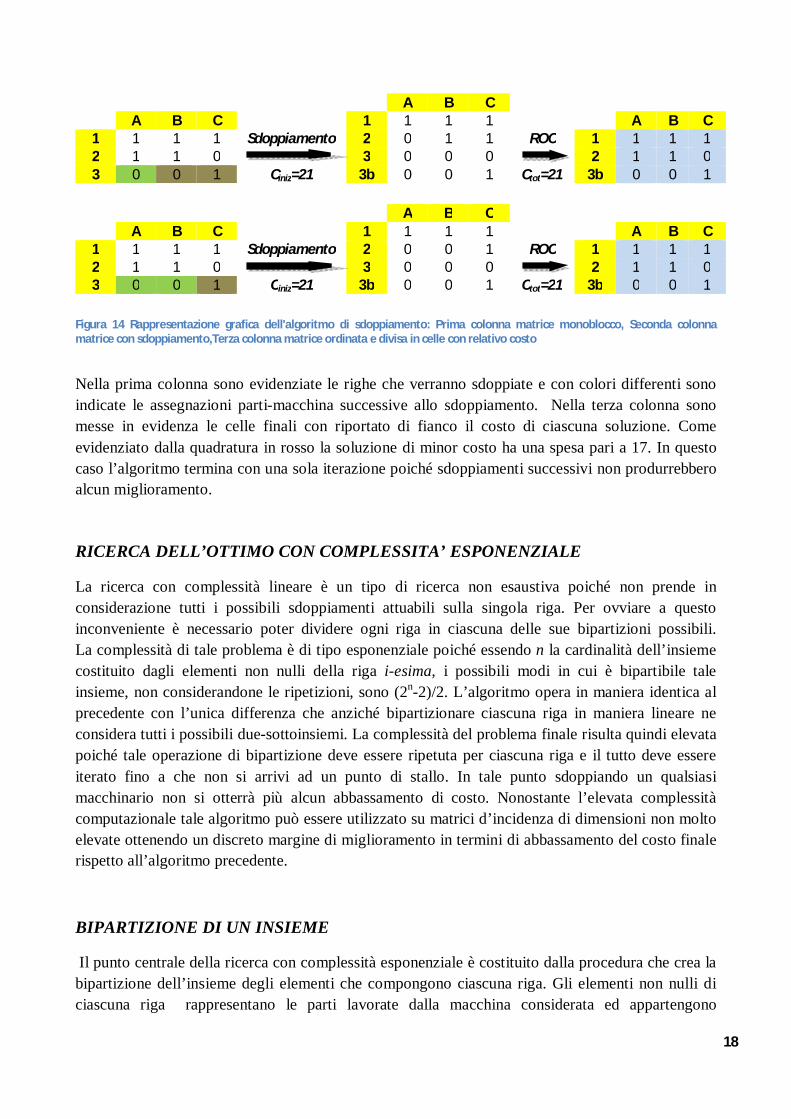
Figura 14 Rappresentazione grafica dell'algoritmo di sdoppiamento: Prima colonna matrice monoblocco, Seconda colonna matrice con sdoppiamento,Terza colonna matrice ordinata e divisa in celle con relativo costo
Nella prima colonna sono evidenziate le righe che verranno sdoppiate e con colori differenti sono indicate le assegnazioni parti-macchina successive allo sdoppiamento. Nella terza colonna sono messe in evidenza le celle finali con riportato di fianco il costo di ciascuna soluzione. Come evidenziato dalla quadratura in rosso la soluzione di minor costo ha una spesa pari a 17. In questo caso l’algoritmo termina con una sola iterazione poiché sdoppiamenti successivi non produrrebbero alcun miglioramento.
RICERCA DELL’OTTIMO CON COMPLESSITA’ ESPONENZIALE
La ricerca con complessità lineare è un tipo di ricerca non esaustiva poiché non prende in considerazione tutti i possibili sdoppiamenti attuabili sulla singola riga. Per ovviare a questo inconveniente è necessario poter dividere ogni riga in ciascuna delle sue bipartizioni possibili. La complessità di tale problema è di tipo esponenziale poiché essendo n la cardinalità dell’insieme costituito dagli elementi non nulli della riga i-esima, i possibili modi in cui è bipartibile tale insieme, non considerandone le ripetizioni, sono (2n-2)/2. L’algoritmo opera in maniera identica al precedente con l’unica differenza che anziché bipartizionare ciascuna riga in maniera lineare ne considera tutti i possibili due-sottoinsiemi. La complessità del problema finale risulta quindi elevata poiché tale operazione di bipartizione deve essere ripetuta per ciascuna riga e il tutto deve essere iterato fino a che non si arrivi ad un punto di stallo. In tale punto sdoppiando un qualsiasi macchinario non si otterrà più alcun abbassamento di costo. Nonostante l’elevata complessità computazionale tale algoritmo può essere utilizzato su matrici d’incidenza di dimensioni non molto elevate ottenendo un discreto margine di miglioramento in termini di abbassamento del costo finale rispetto all’algoritmo precedente.
BIPARTIZIONE DI UN INSIEME
Il punto centrale della ricerca con complessità esponenziale è costituito dalla procedura che crea la bipartizione dell’insieme degli elementi che compongono ciascuna riga. Gli elementi non nulli di ciascuna riga rappresentano le parti lavorate dalla macchina considerata ed appartengono

19
all’insieme da bipartire. Tale insieme contiene quindi gli indici delle colonne rappresentanti le parti lavorate dalla macchina presa in esame. Per ottenere tutte le possibili bipartizioni è sufficiente individuare tutte le combinazioni di parti da inserire nel primo insieme e scrivere il secondo come sottrazione tra l’insieme totale e quello selezionato. Per trovare tutti i possibili modi in cui è riempibile il primo insieme è stato ideato il seguente algoritmo:
Dato ad esempio un insieme costituito da cinque parti tutti i possibili modi di riempire il primo insieme sono:
{1} {2} {3} {4} {5}
{1,2} {2,3} {3,4} {4,5} {1,3} {2,4} {3,5} {1,4} {2,5} {1,5} {1,2,3} {2,3,4} {3,4,5}
{1,2,4} {2,3,5} {1,2,5} {2,4,5} {1,3,4} {1,3,5} {1,4,5} {1,2,3,4} {2,3,4,5}
{1,2,3,5} {1,2,4,5} {1,3,4,5} {1,2,3,4,5}
Figura 15 Esempio grafico di applicazione dell'algoritmo di bipartizione di un insieme su di un insieme costituito da cinque elementi
Partendo dall’insieme costituito dagli n elementi ordinati in maniera crescente si prende ciascuno di essi singolarmente e si creano così i primi n modi diversi di riempire il primo insieme con un solo elemento. Per formare tutti i possibili sottoinsiemi di cardinalità due si considerano uno alla volta tutti i sottoinsiemi di cardinalità uno e si uniscono tra loro in gruppi da due elementi in modo che ciascun elemento si unisca solo con elementi maggiori di lui. I vari sottoinsiemi devono essere ordinati in maniera crescente e divisi a blocchi in modo che tutti i sottoinsiemi, da due elementi, generati dall’elemento più piccolo appartengano allo stesso blocco e così via per gli altri. Per formare i sottoinsiemi di cardinalità tre si procede in modo analogo unendo i sottoinsiemi di cardinalità uno con quelli di cardinalità due.. Il criterio da mantenere nell’unione è lo stesso: il sottoinsieme di cardinalità uno si unisce con i sottoinsiemi di cardinalità due appartenenti ai blocchi di cardinalità due generati da elementi più grandi di lui. Proseguendo con questo algoritmo è possibile ottenere tutti i possibili riempimenti del primo sottoinsieme. Analizzando bene la soluzione finale si nota che manca l’insieme vuoto e che la metà delle soluzioni ottenute è ridondante poiché speculare. Quindi le soluzioni da considerare effettivamente sono (2n-2)/2 poiché è necessario escludere le due soluzioni derivanti dall’insieme totalmente pieno e totalmente vuoto ed eliminare dividendo per due tutte le speculari.

20
LIMITITI DELLE EURISTICHE
Entrambe le euristiche pur talvolta migliorando le prestazioni dell’impianto non possono garantire il raggiungimento dell’ottimo poiché consentono lo sdoppiamento di un solo macchinario alla volta e quindi non riescono a migliorare situazioni in cui c’è necessità di sdoppiare contemporaneamente più macchinari. Per trovare un raffronto di questa affermazione è sufficiente considerare il seguente esempio in cui sempre per semplicità i costi dei macchinari vengono considerati pari all’unità. Nella parte sinistra è presentata una matrice d’incidenza ottimizzata secondo l’algoritmo lineare (quella ottenuta mediante l’algoritmo esponenziale è la stessa) mentre nella parte destra è presentata la stessa matrice con un doppio sdoppiamento.
A B C D Sdoppiamento
A B C D
1 1 1 1 1 simultaneo delle 1 1 1 0 0
2 1 1 1 1 2 1 1 0 0 3 1 0 0 0 macchine 1 e 2 3 1 0 0 0 4 1 0 0 0
4 1 0 0 0
1b 0 0 1 1
2b 0 0 1 1
Figura 16 Rappresentazione grafica del limite delle euristiche basate sullo sdoppiamento di un singolo macchinario. Nella figura di destra si evidenzia lo sdoppiamento cellulare non compendiato dalle euristiche precedentemente citate.
Come si evince dall’esempio il costo totale diminuisce poiché quello di partenza è uguale a 36 mentre quello di arrivo è pari a 34. Si deduce quindi che entrambi gli algoritmi di minimizzazione precedentemente implementati non sono capaci di fornire una soluzione ottima.

21
RAGGIUNGIMENTO DEL COSTO OTTIMO
CALCOLO DELLA COMPLESSITA’COMPUTAZIONALE DEL PROBLEMA
Per risolvere in maniera precisa il problema è necessario fare una stima esatta della sua complessità computazionale. Per fare ciò è necessario guardare la situazione da una diversa angolazione. Nei paragrafi precedenti ci si è concentrati sullo sdoppiamento di un singolo macchinario ma come si è visto tale scelta non risulta essere la migliore. Sembrerebbe quindi che sia necessario riuscire ad individuare di volta in volta quale sia il miglior raggruppamento di macchinari da sdoppiare in modo da raggiungere la soluzione ottima. Questa scelta fatta dal lato delle macchine da sdoppiare potrebbe risultare alquanto complicata poiché non è possibile garantire che lo sdoppiamento ottimo di gruppi di macchinari riesca a raggiungere la configurazione a costo minimo per il sistema. Il modo più semplice di affrontare il problema è invece quello di concentrarsi sul numero di parti in lavorazione, che non sarebbe altro che il numero di colonne della matrice d’incidenza. Riflettendo più attentamente si nota che sdoppiare gruppi di macchinari non significa altro che raggruppare in maniera differente i tipi di parti presenti all’interno del sistema. Per risolvere il problema in maniera definitiva si possono quindi analizzare tutti i vari raggruppamenti generabili con le parti presenti nel sistema (ciascuna legata al suo macchinario di lavorazione) e scegliere tra tutte le configurazioni ottenute quella a costo minimo. La complessità computazionale del problema è quindi data dal numero di raggruppamenti creabili avendo n parti da lavorare. Come noto, il numero di sottoinsiemi diversi generabili da un insieme con cardinalità n è pari a nn, ma tale risultato non è corretto in questo caso, poiché negli nn sottoinsiemi si contempla anche l’ordine reciproco dei vari raggruppamenti, cosa che non influisce minimamente con il costo totale della configurazione finale. Per fissare meglio le idee, di seguito viene proposto un esempio.
Esempio Dato un sistema di tre macchine che lavora tre parti [A,B,C] tutti i possibili diversi raggruppamenti non tenenti conto dell’ordine reciproco tra i vari sottoinsiemi sono:
Configurazione finale con divisione in tre celle {A}; {B}; {C} Configurazione finale con divisione in due celle {A}; {B, C} Configurazione finale con divisione in due celle {B}; {A, C} Configurazione finale con divisione in due celle {C}; {A, B} Configurazione finale con divisione ad una cella .{A, B, C}
Per fare un esempio concreto si potrebbe considerare una matrice d’incidenza con tre parti e tre macchine che le lavorano:
A B C
1 1 1 0 2 1 1 0 3 0 1 1
Figura 17 Matrice d'incidenza di base

22
Nelle seguenti tre colonne sono rappresentate rispettivamente: la matrice d’incidenza data, la matrice d’incidenza costruita seguendo le indicazioni date dagli insiemi sopra elencati e la matrice d’incidenza con le macchine eliminate poiché non compivano alcuna lavorazione. La divisione in celle è evidenziata in celeste:
A B C
A B C
A B C
1 1 1 0
1 1 0 0
1 1 0 0 2 1 1 0
2 1 0 0
2 1 0 0
3 0 1 1
3 0 0 0
1b 0 1 0
1b 0 1 0
2b 0 1 0
2b 0 1 0
3b 0 1 0
3b 0 1 0
3c 0 0 1
1c 0 0 0
2c 0 0 0
3c 0 0 1
A B C
A B C
A B C
1 1 1 0
1 1 0 0
1 1 0 0 2 1 1 0
2 1 0 0
2 1 0 0
3 0 1 1
3 0 0 0
1b 0 1 0
1b 0 1 0
2b 0 1 0
2b 0 1 0
3b 0 1 1
3b 0 1 1
A B C
B A C
B A C
1 1 1 0
1 1 0 0
1 1 0 0 2 1 1 0
2 1 0 0
2 1 0 0
3 0 1 1
3 1 0 0
3 1 0 0
1b 0 1 0
1b 0 1 0
2b 0 1 0
2b 0 1 0
3b 0 0 1
3b 0 0 1
A B C
C A B
C A B 1 1 1 0
1 0 0 0
3 1 0 0
2 1 1 0
2 0 0 0
1b 0 1 1 3 0 1 1
3 1 0 0
2b 0 1 1
1b 0 1 1
3b 0 0 1
2b 0 1 1
3b 0 0 1
A B C
A B C
A B C 1 1 1 0
1 1 1 0
1 1 1 0
2 1 1 0
2 1 1 0
2 1 1 0 3 0 1 1
3 0 1 1
3 0 1 1
Figura 18 Rappresentazione a tre colonne della formazione dei vari insiemi delle parti esplicitati nell’esempio. Nella prima colonna è rappresentata la matrice di partenza, nella seconda colonna vengono formati i nuovi insiemi delle parti e vengono evidenziate le cancellazioni delle macchine non utilizzate ed infine nella terza colonna la matrice ottenuta con la relativa divisione cellulare
Da notare che per esempio un raggruppamento del tipo {A}{B,C} sarebbe stato del tutto equivalente ad un raggruppamento del tipo {B,C}{A}.

23
IMPORTANZA DELL’APPLICAZIONE PREVENTIVA DELL’ALGORITMO DI RANK ORDER AND CLUSTERING
Nel precedente esempio non è stato applicato preventivamente l’algoritmo di RANK ORDER AND CLUSTERING ma solitamente tale applicazione semplifica di molto il problema della ricerca della configurazione ideale per il sistema. Tale algoritmo, riordinando il sistema lo partiziona diminuendo, o al massimo eguagliando, il suo costo di partenza senza introdurre alcun costo derivante dallo sdoppiamento di macchinari. Successivamente è possibile applicare la ricerca dell’ottimo singolarmente sulle nuove celle trovate diminuendo così il numero di parti in gioco. Ciò è vero poiché si dovrà lavorare con una partizione dell’insieme totale delle parti e non con l’intero insieme. Un esempio di tale procedura è mostrato di seguito
A B C D
A D C B
A D C B
1 1 0 0 1
1 1 1 0 0
1 1 1 0 0 2 1 0 0 1 ROC 2 1 1 0 0 Nuove 2 1 1 0 0 3 1 0 1 0 3 1 0 1 0 3 1 0 1 0 4 0 1 0 0 Ctot=21 4 0 0 0 1 celle 4 0 0 0 1
Figura 19 Rappresentazione grafica della semplificazione dovuta all'applicazione preventiva dell'algoritmo di ROC
Dopo il RANK ORDER AND CLUSTERING, senza aver introdotto alcun costo, si deve applicare l’algoritmo per la ricerca dell’ottimo anziché ad un insieme di cardinalità quattro a due insiemi il primo di cardinalità uno e il secondo di cardinalità tre. Il vantaggio in termini di costo computazionale è notevole. Basti pensare che i sottoinsiemi diversi generabili a partire da quattro elementi sono 15, quindi i confronti necessari per ottenere la configurazione ottima sarebbero stati il numero dei sottoinsiemi meno uno. In questo caso invece sono necessari solo quattro confronti poiché come si è visto in precedenza per un insieme di cardinalità tre ne sono necessari solo 4 e l’insieme costituito da un solo elemento non ha bisogno di confronti.
Per calcolare quindi l’esatto numero di sottoinsiemi diversi creabili da un insieme di cardinalità n senza tener conto dell’ordine reciproco dei medesimi è necessario richiamare alcune nozioni di insiemistica con particolare rilievo per i numeri di Stirling di seconda specie e per quelli di Bell.
BREVE RICHIAMO SULLE PARTIZIONI DI UN INSIEME
Si definisce partizione di un insieme A una famiglia di sottoinsiemi non vuoti Ai | i є I che rispettano le due proprietà seguenti:
1. L’intersezione tra ogni coppia di insiemi diversi in A deve generare l’insieme vuoto, quindi tutti gli insiemi di A sono disgiunti e vale la seguente relazione Ai ∩ Ak = 0 per ogni i ≠ k.
2. A è costituito dall’unione di tutti i sottoinsiemi Ai cioè, A = ⋃ A .
Ciascun sottoinsieme Ai prende il nome di parte della partizione. Dalla proprietà sopra esposte è ovvio dedurre quindi, che ogni insieme di cardinalità finita avrà un numero finito di partizioni.

24
NUMERI DI STIRLING DI SECONDA SPECIE
I numeri di Stirling di seconda specie, espressi matematicamente da S(n,k), definiscono il numero delle possibili k-partizioni attuabili su di un insieme di cardinalità n. Per calcolare il valore di S(n,k) è utile applicare il seguente teorema.
Teorema
Sia S(n,k) il numero di partizioni di un insieme A con n elementi in k parti, con 1 ≤ k ≤ n. Allora:
1. S(n,1) = 1 2. S(n,n) = 1 3. S(n,k) = S(n-1,k-1) + k ∙ S(n-1,k) con 2 ≤ k ≤ n-1.
Dimostrazione
Per dimostrare le prime due asserzioni è sufficiente notare che per partizionare A in un unico sottoinsieme l’unico modo è considerare A stesso, di conseguenza la soluzione possibile è unica. Tale soluzione è unica anche nel caso in cui si volesse n-partizionarlo poiché l’unico modo per farlo risulta essere quello di prendere tutti gli elementi di A disgiuntamente, ciò creare n sottoinsiemi unitari di A.
Detto s un elemento di A , sia A0=A\{s}. Allora una partizione di A in k parti si ottiene in maniera univoca in uno solo dei seguenti modi:
1. Aggiungendo la parte formata dall’insieme unitario s ad una partizione in k-1 blocchi di A0 2. Aggiungendo l’elemento s ad una delle k parti della partizione di A0 e questo è possibile in k
modi diversi.
Da tale teorema è possibile rappresentare i numeri di Stirling di seconda specie mediante una tabella infinita avente sulle colonne il numero delle partizioni desiderate e sulle righe la cardinalità dell’insieme da partizionare.
Come esempio vengono riportate di seguito le prime otto righe della tabella sopra citata:
n \ k 0 1 2 3 4 5 6 7 8
0 1 1 0 1 2 0 1 1 3 0 1 3 1 4 0 1 7 6 1 5 0 1 15 25 10 1 6 0 1 31 90 65 15 1 7 0 1 63 301 350 140 21 1
8 0 1 127 966 1701 1050 266 28 1
Figura 20 Rappresentazione tabulare dei numeri di Stirling di seconda specie. La prima colonna rappresenta la cardinalità dell’insieme considerato mentre la prima riga l’ordine di partizione scelto.

25
E’ interessante notare come i numeri di Stirling di seconda specie abbiano un legame con i coefficienti multinomiali. Tali coefficienti infatti contano il numero di permutazioni con ripetizione di k oggetti in cui il primo è preso n1 volte il secondo n2 volte , il k – esimo nk volte, con n.=.n1.+.n2+……..+. nk e valgono :
… = !! !… !
(eq.4)
Si osservi che i coefficienti multinomiali non sono altro che una generalizzazione dei coefficienti binomiali, infatti nel caso in cui k=2 si ha la loro coincidenza :
푛푛 푛
=푛푛
=푛푛
=푛!
푛 !푛 !
con 푛 = 푛 + 푛 (eq.5)
NUMERI DI BELL
I numeri di Bell, indicati con B(n), rappresentano il numero di sottoinsiemi non vuoti in cui è possibile partizionare un insieme di n elementi. Per il calcolo dei numeri di Bell risulta utile enunciare il seguente teorema:
Teorema
Dato un insieme I di ordine n ≥ 1, siano B(n -i) e B( n) l’ (n-i)-esimo e l’(n)-esimo numero di Bell. Si ha la seguente formula [ FORMULA DI AITKEN ] :
퐵(푛) = ∑ 퐵(푛 − 푖) (eq.6)
Dimostrazione
Si consideri S una partizione dell’insieme I. L’elemento a di I appartiene ad uno ed uno solo dei sottoinsiemi A di S. Ciò significa che ogni partizione di I è individuata univocamente dal sottoinsieme A che contiene a e da una partizione di I – A . L’ordine I dell’insieme A è compreso tra 1 ed n ( i ≠ 0 poiché A ≠ Ø ). A può essere scelto in modi, poiché tanti sono i sottoinsiemi di I

26
che contengono a; le partizioni di I-A, che è un insieme di ordine n-i. risultano invece essere B(n-i). Dunque, per ogni i, 1 ≤ i ≤ n, vi sono esattamente (per il principio delle scelte) ∙ 퐵(n-i) partizioni di I nelle quali a appartiene ad un elemento A di ordine i. Ne segue quindi che le partizioni di I sono quelle evidenziate dalla formula di AITKEN.
Per ricavare i numeri di Bell è inoltre possibile utilizzare altre espressioni matematiche tra cui è possibile annoverare quella dovuta a Dobiński
퐵(푛) = ∑! (eq.7)
oppure quella ricorsiva molto utilizzata per ragioni di compattezza:
퐵(푛 + 1) = ∑ 퐵 (eq.8)
Per l’implementazione algoritmica risulta invece molto utile vedere i numeri di Bell come sommatorie dei numeri di Stirling di seconda specie relativi ad un insieme di cardinalità data
퐵(푛) = ∑ 푆(푛, 푘) (eq.9)
Infatti come si nota dalla formula, per ottenere il numero di Bell ennesimo è sufficiente sommare tra loro tutti gli elementi della riga ennesima della tabella contente i numeri di Stirling di seconda specie.
Per il calcolo grafico dei numeri di Bell si ricorre invece al cosiddetto triangolo di Bell in cui la prima colonna è appunto costituita da tutti numeri di Bell.
1 1 2
2 3 5 5 7 10 15
15 20 27 37 52 52 67 87 114 151 203
203 255 322 409 523 674 877
Figura 21 Rappresentazione tabulare dei numeri di Bell. Sulla prima colonna sono evidenziati in grassetto i primi 6 numeri di Bell
Per compilare il triangolo si inizia mettendo i primi due uno della prima colonna e poi si procede nel seguente modo: gli elementi sulla destra sono ottenuti tramite somma del loro elemento adiacente sinistro e di quello che lo sovrasta, gli elementi della prima colonna eccetto i due uno iniziali sono gli elementi finali di ciascuna riga posti nell’indice riga pari alla colonna che occupano più uno.

27
COMPLESSITA’ COMPUTAZIONALE
Come si è potuto capire dai paragrafi precedenti la complessità computazionale del problema in esame è data da B(n) dove n è appunto la cardinalità dell’insieme costituito dalle parti in lavorazione nel sistema dato. E’ interessante confrontare la complessità reale del problema con quella esponenziale e con quella massima prima descritta:
Figura 22 Confronto tra la complessità esponenziale, nn e quella dovuta ai numeri di Bell
020406080
100120140
1 2 3 4 5 6 7
Com
ples
sità
Cardinalità
Complessità esponenziale 2n
0
200000
400000
600000
800000
1000000
1 2 3 4 5 6 7
Com
ples
sità
Cardinalità
Complessità nn
0
200
400
600
800
1000
1 2 3 4 5 6 7
Com
ples
sità
Cardinalità
Complessità reale B(n)

28
Osservando i tre grafici precedenti si nota che la complessità B(n) è inferiore a quella massima precedentemente descritta, quindi si potrebbe pensare che il problema in questione sia risolvibile in maniera completa. In realtà come si vede confrontando il terzo grafico con il primo si nota che la complessità è sì inferiore a quella di ordine nn, ma è di gran lunga superiore a quella di un esponenziale. Il problema quindi per insiemi con elevata cardinalità risulta irrisolvibile applicando una ricerca di tipo esaustivo.
RICERCA ESAUSTIVA PER INSIEMI CON PICCOLA CARDINALITA’
Come è stato detto nel paragrafo precedente, data la complessità computazionale del problema, è stata implementata una ricerca esaustiva dell’ottimo per insiemi con piccola cardinalità. Un approccio di questo tipo non risulta del tutto inutilizzabile poiché spesso dopo l’applicazione preventiva dell’algoritmo di RANK ORDER AND CLUSTERING si ha un ridimensionamento delle celle base. Il core dell’algoritmo per la ricerca esaustiva è costituito dalla procedura che si occupa, dato un insieme con cardinalità n, di trovare tutte le possibili B(n) partizioni. L’idea di base dell’algoritmo ricalca in un certo senso la formula per il calcolo iterativo dei numeri di Bell :
퐵(푛 + 1) = ∑ 퐵 (eq.10)
Dato un insieme con cardinalità n, per costruire tutte le possibili partizioni, si parte considerando un insieme costituito solo dal primo degli n elementi e poi si incrementa l’insieme aggiungendo il secondo e il terzo elemento, arricchendo in tal modo il numero delle partizioni. Un esempio pratico è riportato di seguito.
Esempio
Dato un insieme A = {1,2,3} con cardinalità pari a 3 per trovare tutte le possibili B(3) = 5 partizioni si procede nel seguente modo: Si considera un insieme formato solo dal primo elemento dei tre, quindi A1={1}. La cardinalità di tale insieme è uno, quindi si alloca uno spazio in memoria Nello spazio allocato viene inserito l’elemento dell’insieme A1:come mostrato nella figura sottostante:
{1}
Si considera il secondo elemento quindi l’insieme A2 sarà formato da {1,2}. La cardinalità dell’insieme è pari a 2. Quindi si allocano due spazi in memoria. Nel primo spazio si inserisce la partizione ottenuta precedentemente lasciando vuoto il secondo spazio. Si ottiene quindi una situazione di questo tipo:

29
{1}{} *
Una procedura conta quanti insiemi pieni vi sono nella riga sopra mostrata e imposta l’ indice d’iterazione con il valore ottenuto più 1. Il valore dell’indice d’iterazione è due. Nella prima iterazione partendo sempre dalla riga * si immette nel primo insieme il secondo elemento di A2 e si lascia vuoto il secondo insieme. Nella seconda iterazione, considerando sempre la riga *, si immette il secondo elemento di A2 nell’insieme con lo stesso indice dell’indice d’iterazione (quindi nell’insieme vuoto). L’indice d’iterazione è arrivato al suo massimo valore e le righe costruite rappresentano tutte le partizioni possibili dell’insieme A2. Il risultato ottenuto è il seguente:
{1,2} {}
{1} {2}
Si considera quindi il terzo elemento di A e si costruisce in modo analogo ad A2 l’insieme A3 = {1,2,3}. Come si nota l’insieme A3 coincide con l’insieme A. Come si è detto precedentemente l’insieme A ha cardinalità pari a tre quindi sarà necessario allocare tre spazi. Dal momento che precedentemente vi erano due righe sarà necessario allocare due righe con tre spazi. La situazione che si andrà a verificare sarà la seguente:
{1,2} {} {} *1*
{1} {2} {} *2*
La stessa procedura utilizzata in precedenza conta nella riga *1* quanti insiemi pieni vi sono e imposta l’indice d’iterazione allo stesso valore più 1. Il valore dell’indice d’iterazione è ancora una volta 2. Nella prima delle due iterazioni dovute alla riga *1* si immette nell’insieme con indice pari all’indice d’iterazione il terso elemento dell’insieme A3 e si lasciano vuoti gli altri due. Come fatto in precedenza si incrementa l’indice d’iterazione e considerando sempre la medesima riga si va a riempire con il terzo elemento di A3 l’insieme con indice pari a quello d’iterazione.
Il risultato che si ottiene dopo le due iterazioni sulla prima riga è il seguente:
{1,2,3}{} {}
{1,2} {3} {}

30
Si ripete la procedura utilizzata sulla riga *1* sulla riga *2*. L’indice d’iterazione in questo caso risulta pari a 3. Alla prima iterazione si inserisce quindi il terzo elemento di A3 nel primo insieme della riga *2*, alla seconda iterazione si inserisce il terzo elemento di A3 nel secondo insieme della medesima riga e alla terza ed ultima iterazione si inserisce il terzo elemento di A3 nel terzo insieme. Finite quindi le iterazioni consentite dalla riga *2* si genera il seguente risultato:
{1,3} {2} {}
{1} {2,3} {}
{1} {2} {3}
Dal momento che le righe di partenza erano due e che le iterazioni previste per ciascuna riga sono state eseguite, l’algoritmo termina restituendo come risultato finale lo sviluppo di entrambe le righe:
{1,2,3}{} {}
{1,2} {3} {}
{1,3} {2} {}
{1} {2,3} {}
{1} {2} {3}
Le righe mostrate sopra rappresentano tutte le possibili partizioni attuabili su A3, e visto che si è detto che A3 coincide con A queste rappresentano il risultato finale desiderato.

31
RICERCA STATISTICA DELL’ OTTIMO
OTTIMIZZAZIONE ORDINALE
Dal momento che non è sempre possibile applicare l’algoritmo per la ricerca esaustiva è necessario introdurre un metodo alternativo di validità più generale. Data la complessità computazionale del problema il miglior modo per garantire una soluzione che si discosti di una quantità controllabile da quella ottimale è quello di affrontarlo da un punto di vista statistico. L’approccio che verrà preso in considerazione in questo paragrafo è quello dell’ottimizzazione ordinale. Le idee base dell’ottimizzazione ordinale sono principalmente due:
1. E’ sufficiente compiere brevi simulazioni per valutare il rapporto reciproco tra due grandezze anziché valutare il valore numerico delle stesse, cioè è più semplice stabilire se un indice è maggiore o inferiore ad un altro piuttosto che ricavare il preciso valore di entrambi. E’ possibile sfruttare tale considerazione notando che la probabilità di trovare la stima di un valore, che sia compresa tra due valori fissati, converge esponenzialmente ad 1 con l’aumentare della durata della simulazione.
2. Quando la cardinalità dell’insieme contenente tutte le possibili scelte è molto grande, la probabilità di pescare in sul colpo la scelta ottima da tale insieme è molto piccola, per esempio se l’insieme ha cardinalità 100000 la probabilità di avere la scelta ottima con una sola estrazione è 1/100000 (praticamente nulla). Se invece si restringe la richiesta di base, e ci si accontenta di pescare dall’insieme considerato una scelta che sia nel primo 10% delle migliori scelte, la probabilità di trovare una scelta con tali caratteristiche è del 10%. Come è semplice constatare tale probabilità è sensibilmente più elevata della precedente, ed inoltre spesso il valore ottenuto non si discosta di molto dall’ottimo reale.
Tenendo conto della seconda considerazione sopra riportata sembra essere abbastanza semplice estrarre un valore sub-ottimo da insiemi di cardinalità molto elevata; infatti la probabilità di non trovare un valore desiderato con l’aumentare delle simulazioni è davvero molto bassa:
푝̅ = 1 − % (eq.11)
Dove 푝̅ è la probabilità di non ottenere un valore desiderato nel range dei valori scelto, x% è la grandezza del range di ottimalità scelto, x è la grandezza totale dell’insieme e n è il numero d’iterazioni. Facendo un esempio numerico, per trovare l’ottimo di un insieme di cardinalità 7 sarebbe necessario calcolare B(7) costi = 877 costi. Per scegliere invece una disposizione dei

32
macchinari il cui costo sia nel primo 10% dei migliori costi ottenibili, già con un numero di confronti pari a 50.
Con tale numero di iterazioni si ottiene una probabilità di non riuscita dell’evento pari allo 0,51%:
푝̅ = 1 −87,7877
= 0,005153
Praticamente con un decimo delle iterazioni si ha la certezza di avere una disposizione dei macchinari sub-ottima che sia nel 10% delle migliori scelte possibili. Per dare un’idea migliore della situazione è riportato di seguito un esempio fatto su di un insieme con cardinalità cinque del tipo {A,B,C,D,E}
Esempio
Data la seguente matrice d’incidenza, rappresentante un sistema in cui vengono lavorate cinque parti da cinque macchinari , e i relativi costi dei macchinari, si effettua un ROC preventivo per verificare se vi è la possibilità di una suddivisione cellulare a priori
A B C D E
A B C D E
1 1 0 1 0 0
1 1 1 0 0 0 2 1 1 0 0 0 ROC 2 1 0 1 0 0 3 0 1 0 1 0
3 0 1 1 0 0 4 0 0 1 0 1
4 0 1 0 1 0
5 0 1 1 0 0
5 0 0 1 0 1
Macchinari Costo macchinari 1 1,4 2 1,3 3 1,6 4 1,1 5 1,2
Figura 23 Rappresentazione del sistema mediante matrice d’incidenza e costo dei macchinari espresso in unità di costo. Nella parte destra vi è La matrice d’incidenza dopo l’algoritmo di RANK ORDER AND CLUSTERING
Come si vede chiaramente nella matrice di destra l’algoritmo di RANK ORDER AND CLUSTERING non riesce a trovare alcuna cella, quindi per abbassare il costo dell’impianto risulta necessario ricorrere a uno dei due metodi sopra descritti ( Ricerca esaustiva o Ottimizzazione ordinale). In questo caso sarebbe molto semplice applicare una ricerca esaustiva poiché la complessità del sistema è bassa poiché B (5) = 52 ma nel nostro esempio verrà applicata la ricerca ordinale per mostrare l’efficacia di questa soluzione.

33
Rappresentando sulle ascisse di un sistema cartesiano tutte le partizioni possibili e sulle ordinate tutti i costi possibili relativi alle partizioni si ottiene una distribuzione di questo tipo
Figura 24 Esempio di rappresentazione cartesiana della distribuzione dei costi per un sistema composto da cinque parti
Se si pensasse ipoteticamente di poter ordinare i costi ottenuti dal più grande al più piccolo si otterrebbe la distribuzione seguente
Figura 24 Rappresentazione cartesiana della distribuzione dei costi ordinata in maniera decrescente
Come è evidenziato in rosso nella figura, scegliere una soluzione che si trova nel primo 10% delle migliori comporta un errore sul costo ottimo abbastanza piccolo e quindi in casi con una complessità molto elevata un ottimo rapporto tra scelta finale e tempo di risoluzione del problema.

34
APPLICAZIONE OTTIMIZZAZIONE ORDINALE AL PROBLEMA
Applicando l’ottimizzazione ordinale ad un sistema con una complessità di soluzione abbastanza elevata si otterrà sempre un risultato molto simile come configurazione a quello della ‘Figura 24’ poiché generalmente la fascia tra cui oscilla il costo minimo e quello massimo del sistema è molto limitata, mentre quella delle possibili partizioni è molto ampia. Inoltre se si guarda con attenzione l’andamento della parte iniziale e di quella finale della distribuzione, come mostrato nella ‘Figura 25 e 25 bis’, si nota un brusca diminuzione dei costi nella prima parte e un appiattimento degli stessi nella seconda. Questo fa sì che la soluzione che si ottiene dall’ottimizzazione ordinale sia decisamente migliorativa e molto poco lontana da quella ottima.
Figura 25-25 bis A sinistra e a destra rispettivamente zoom della parte iniziale e finale della distribuzione di costo ordinata
Gli andamenti riportati sopra potrebbero sembrare andamenti particolari invece essi risultano comuni ad una discreta varietà di sistemi. Questa similitudine avviene principalmente per due motivi:
1. Come è stato esposto in precedenza, le possibili partizioni occupano un insieme di cardinalità molto più elevato di quello dei possibili costi.
2. Se i costi dei macchinari sono comparabili, come nel caso precedente, con i costi dovuti alla complessità cellulare lo sdoppiamento di macchinari risulta spesso molto migliorativo.
Analizzando i due punti si capisce immediatamente che il punto 1. è il responsabile dello schiacciamento del grafico, mentre dal punto 2. dipende la brusca diminuzione iniziale del costo e, anche se in piccola parte, l’appiattimento della distribuzione delle soluzioni a minor costo.

35
DISTRIBUZIONE DELLA PROBABILITÀ
INTRODUZIONE
Per garantire un corretto funzionamento dell’ottimizzazione ordinale è necessario che le estrazioni casuali delle varie combinazioni di parti con cui costruire le celle del sistema avvengano in maniera equidistribuita, altrimenti si rischia di falsare in modo incontrollabile, almeno apparentemente, la probabilità di non riuscita dell’evento ( quella che è stata definita in precedenza come 푝̅ ). Talvolta potrebbe anche risultare utile cercare di influenzare la scelta delle parti, falsando quindi l’equiprobabilità delle estrazioni, ma i risultati ottenibili variano di caso in caso. Per il nostro problema verranno presi in esame due tipi di approccio, quello equidistribuito e quello con la probabilità di scelta falsata (polarizzata), e verranno messi a confronto i due risultati.
PROBABILITÀ EQUIDISTRIBUITA
Come si è detto in precedenza per garantire le proprietà dell’ottimizzazione ordinale è necessario avere equiprobabilità nella scelta delle varie partizioni possibili. Ottenere una distribuzione uniforme sembrerebbe in prima istanza banale ma in realtà risulta essere molto complicato poiché minimi eventi possono variare la probabilità finale di ciascuna scelta. Per garantire tale proprietà è stata utilizzata l’idea dell’ algoritmo ideato dal matematico Herbert S. Wilf.
ALGORITMO PER L’ESTRAZIONE EQUIPROBABILE DI PARTIZIONI DI ORDINE K
L’algoritmo di Wilf restituisce una delle possibili partizioni di ordine k compiuta su di un iniseme costituito da n elementi. Le partizioni sono restituite in maniera posizionale, cioè se l’insieme è composto ad esempio da 4 elementi {A,B,C,D} e l’ordine di partizione è ad esempio 2, una delle possibili partizioni restituite sarà del tipo {1,2,1,1} cioè gli elementi {A, C, D} appartengono a un sottoinsieme e {B} appartiene all’altro sottoinsieme. Per il corretto funzionamento dell’algoritmo è necessario avvalersi di una procedura capace di calcolare i numeri di Stirling di seconda specie. Wilf nel suo testo “East West” ha proposto un metodo ricorsivo per il calcolo di tali numeri. Ma poiché in linguaggi non precompilati come MATLAB la ricorsione causa enormi rallentamenti, in questo testo, oltre all’implementazione base è presentata una variante che calcola tali numeri mediante un’ approssimazione della distribuzione. Questo metodo crea un grandissimo aumento delle prestazioni ma si rivela poco preciso per il calcolo dei numeri di Stirling di seconda specie per insiemi con cardinalità superiore a 24. Di seguito, scritte in pseudo codice, vengono riportate le due versioni dell’algoritmo:
STIRLING_DIR ( n, k )
ritorna E( n, k ) / k!
dove 퐸(푛, 푘) = ∑ (−1) (푘 − 1)

36
STIRLING_RIC ( n, k )
SE n<1
restituisci 0
ALTRIMENTI
SE n=1
SE k<1 oppure k>1
restituisci 0
ALTRIMENTI
restituisci 1
ALTRIMENTI
restituisci STIRLING_RIC( n-1, k-1 ) + k*STIRLING_RIC( n-1, k )
Come è facile notare, l’algoritmo ricorsivo sopra presentato, ricalca in maniera esplicita l’enunciato del teorema precedentemente riportato riguardante i numeri di Stirling di seconda specie. L’algoritmo, in pseudocodice, che fornisce una possibile partizione di ordine k dell’insieme formato da n elementi è il seguente:
CREA_PARTIZIONE ( n , k )
SE n = 1
SE k > 1 o k < 1
restituisci = [ insieme vuoto ]
ALTRIMENTI
restituisci = [ partizione con dentro 1]
ALTRIMENTI
SE random (numero reale tra 0 e 1) < #Stirling ( n-1, k-1 ) / #Stirling ( n, k )
restituisci [CREA_PARTIZIONE(n-1,k-1), k]
ALTRIMENTI
Restituisci [CREA_PARTIZIONE ( n-1, k ), RANDOM (numero intero tra 1 e k)]

37
L’algoritmo presentato è di tipo ricorsivo, quindi come tale risulta essere ripartito in due parti:
1. La parte verde rappresenta il caso base, cioè quello capace di far terminare la ricorsione.
2. La parte blu rappresenta la ricorsione. Questa parte è a sua volta bipartita e in ciascuna delle sue parti, a seconda del risultato ottenuto dal “se” viene richiamata la procedura con argomenti differenti.
Per analizzare al meglio l’algoritmo risulta quindi utile concentrarsi separatamente su ciascuna delle due parti. Per quanto concerne la prima parte si nota che vi sono due casi: quello possibile in cui si ha un insieme con cardinalità 1 e si vuole fare un unico raggruppamento, quindi k = 1, e quello che rappresenta l’errore, cioè quello in cui si ha un insieme con cardinalità 1 e si desidera fare un numero di raggruppamenti k ≠ 1. La seconda parte, il cuore dell’algoritmo, è a sua volta ripartita in due casi ciascuno dei quali viene preso in considerazione in base al risultato ottenuto dalla condizione espressa dalla prima riga in blu. Per capire a fondo il funzionamento complessivo è quindi necessario prestare attenzione alla condizione precedentemente menzionata:
random (numero reale tra 0 e 1) < #Stirling ( n-1, k-1 ) / #Stirling ( n, k )
A sinistra del segno di minore vi è un generatore di numeri casuali il quale genera, come esplicitato tra parentesi, numeri reali compresi tra 0 ed 1. A destra invece vi è il rapporto, sempre minore o al massimo uguale ad 1, tra il numero di Stirling di seconda specie (n,k-1) e lo stesso calcolato su (n,k). Il perché della scelta di tale rapporto risiede nel fatto che esso tiene conto del numero di scelte possibili che si hanno nel cercare di volta in volta di allocare un elemento in una partizione piuttosto che in un’altra. Tale rapporto confrontato con il generatore di numeri random riesce a bilanciare, grazie alla giusta chiamata ricorsiva, la probabilità d’inserimento di ciascun elemento, in modo che alla fine la probabilità con cui si scelga una possibile partizione di ordine k, sia del tutto analoga a quella con cui si sarebbe scelta un’altra partizione avente lo stesso ordine. Per maggiore chiarezza e semplicità di seguito è riportato uno spaccato della tabella di Stirling riguardante i numeri di seconda specie e una spiegazione pseudo grafica del funzionamento sopra descritto:
n \ k 0 1 2 3 4 5 0 1 1 0 1 2 0 1 1 3 0 1 3 1 4 0 1 7 6 1 5 0 1 15 25 10 1
Figura 26 Spaccato della tabella rappresentante i numeri di Stirling di seconda specie

38
Al fine di comprendere pienamente l’utilizzo del rapporto è utile distinguere tre differenti casistiche:
1. Il rapporto è pari a 1.
2. Il rapporto è compreso tra 0.5 e 1.
3. Il rapporto è compreso tra 0 e 0.5
La situazione numero 1 si verifica quando si cerca di partizionare un insieme di n elementi o in k = 1 partizioni o in k = n partizioni. Con questo risultato l’algoritmo chiama quasi sempre la prima istruzione e di conseguenza le chiamate ricorsive avvengono sempre sulla diagonale della tabella sopra riportata. La prima istruzione non fa altro che creare un vettore in cui inserisce la grandezza della partizione con cui è stata chiamata la funzione ( quindi il sottoinsieme a cui apparterrà il primo elemento dell’insieme base ) e completare il resto del vettore richiamando la procedura su di un insieme più piccolo con un ordine di partizione minore di una unità. Se casualmente venisse chiamata la seconda istruzione, in questo caso, si avrebbe un risultato del tutto simile, con l’unica differenza che l’elemento che si andrebbe ad inserire sarebbe scelto casualmente tra 1 e k. Per quanto concerne le situazioni 2. e 3. si può notare una certa dicotomia poiché entrambe esprimono in maniera opposta situazioni in cui c’è un discostamento dal valore di equiprobabilità 0.5. L’algoritmo in entrambi i casi cerca di penalizzare o favorire l’ inserimento di un elemento in un sottoinsieme piuttosto che in un altro e con l’utilizzo della ricorsione cerca di dirigere le scelte future in modo che al passaggio di ricorsione successivo, il rapporto si avvicini il più possibile al valore di equiprobabilità 0.5.
ESTRAZIONE EQUIPROBABILE DI PARTIZIONI
Per ottenere la soluzione desiderata, cioè un algoritmo che date ‘s’ iterazioni estragga ‘s’ modi diversi di partizionare l’insieme con cardinalità n, è necessario che di volta in volta si passi correttamente alla proceduta, precedentemente descritta, il parametro k. Se si passasse in maniera casuale , scegliendolo tra 1 e k, si otterrebbe una distribuzione polarizzata. Questo avviene poiché attuando una scelta di questo tipo è come se si affermasse che il numero di partizioni di un qualsiasi ordine è identico al numero di partizioni di un qualsiasi altro ordine, mentre come è evidente dalla tabella rappresentata in Figura 26 non è così. Al fine di risolvere questo problema è quindi necessario effettuare la scelta del k adattando il selettore random in modo che tenga conto delle diverse cardinalità di ciascun ordine di partizione. Un modo per risolvere il problema è quello di creare un vettore ‘E’ di dimensione pari alla cardinalità degli elementi dell’insieme più una unità e di riempire progressivamente le posizioni k-esime dello stesso utilizzando la seguente formula:
E ( k+1) = E (k) + S (n,k) / B (n) , E(1) = 0 (eq.12)

39
Successivamente si sfrutta il selettore di numeri random per ottenere un numero reale compreso tra 0 ed 1 e si confronta progressivamente, partendo dalla posizione 0, con gli elementi presenti nel vettore. Quando il numero selezionato risulta maggiore di un elemento del vettore, si blocca il confronto e, si imposta k pari all’indice dell’elemento considerato. Questo confronto con il vettore base deve essere iterato per ciascuna estrazione in modo da pesare opportunamente la scelta dei vari ordini di partizione. Per far si che questo metodo sia funzionale è necessario implementare una procedura in grado di calcolare i numeri di Bell. Anche in questo caso la soluzione ricorsiva risulta poco efficace, per i linguaggi non precompilati come MATLAB. Si potrebbe quindi scegliere di ottenere tali numeri mediante la sommatoria dei numeri di Stirling di seconda specie calcolati seguendo l’algoritmo non ricorsivo (si ricorda che B(n) non è altro che la sommatoria degli elementi presenti nella riga n-esima della tabella di Stirling relativa ai numeri di seconda specie). Allo scopo di avvalorare i risultati ottenuti sono state compiute due simulazioni con 30000 estrazioni su insiemi di cardinalità rispettivamente pari a 4 e a 5 in modo da poter apprezzare la reale equiprobabilità della distribuzione.
Esempio 1
Considerando un insieme di cardinalità quattro del tipo {A,B,C,D} su 30000 estrazioni di possibili partizioni si ottiene la seguente distribuzione:
Figura 27 Distribuzione di probabilità su 3000 campioni del partizionatore equidistribuito su di un insieme di cardinalità pari a 4
18601880190019201940196019802000202020402060
Num
ero
di E
stra
zion
i
Partizioni Possibili
Distribuzione della probabilità su di un insieme con cardinalità pari a 4 del tipo {A,B,C,D}
(simulazione effettuata su 30000 estrazioni)
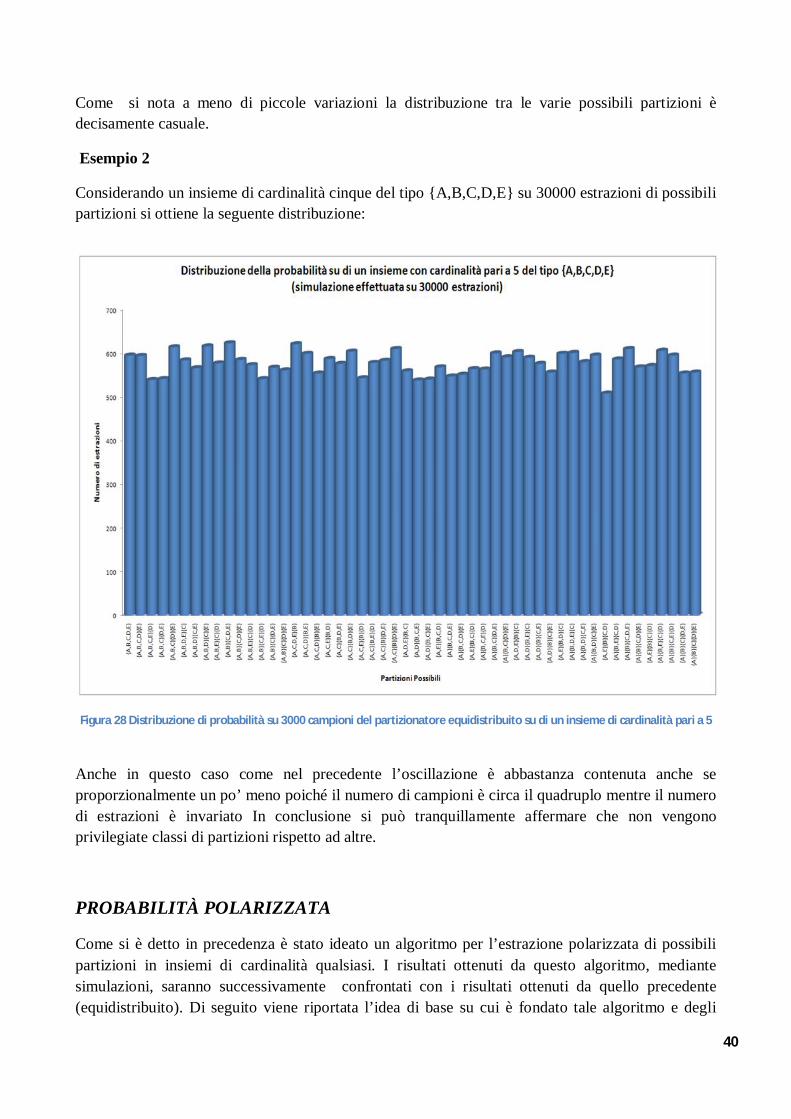
40
Come si nota a meno di piccole variazioni la distribuzione tra le varie possibili partizioni è decisamente casuale.
Esempio 2
Considerando un insieme di cardinalità cinque del tipo {A,B,C,D,E} su 30000 estrazioni di possibili partizioni si ottiene la seguente distribuzione:
Figura 28 Distribuzione di probabilità su 3000 campioni del partizionatore equidistribuito su di un insieme di cardinalità pari a 5
Anche in questo caso come nel precedente l’oscillazione è abbastanza contenuta anche se proporzionalmente un po’ meno poiché il numero di campioni è circa il quadruplo mentre il numero di estrazioni è invariato In conclusione si può tranquillamente affermare che non vengono privilegiate classi di partizioni rispetto ad altre.
PROBABILITÀ POLARIZZATA
Come si è detto in precedenza è stato ideato un algoritmo per l’estrazione polarizzata di possibili partizioni in insiemi di cardinalità qualsiasi. I risultati ottenuti da questo algoritmo, mediante simulazioni, saranno successivamente confrontati con i risultati ottenuti da quello precedente (equidistribuito). Di seguito viene riportata l’idea di base su cui è fondato tale algoritmo e degli

41
esempi esplicativi che consentano di visualizzare la distribuzione di probabilità del medesimo. L’algoritmo per la scelta della partizione si articola in due step:
Step 1: Dato l’insieme delle parti da partizionare si effettua una permutazione casuale su di esso in modo da ottenere un nuovo insieme contenente gli stessi elementi dell’insieme di partenza ma con ordine diverso. Step 2: Si scorre l’insieme permutato e per ogni elemento, tramite un algoritmo generatore di numeri casuali, si simula il lancio di una moneta, generando quindi in maniera equiprobabile i valori 0 ed 1. Se il risultato ottenuto dal ‘lancio’ è 0 l’elemento considerato appartiene allo stesso sottoinsieme dell’ elemento precedente, altrimenti se è 1 appartiene ad un altro sottoinsieme. Naturalmente per il primo elemento si fa un’eccezione poiché obbligatoriamente dovrà appartenere al primo sottoinsieme.
Per maggiore chiarezza espositiva si riporta di seguito un piccolo esempio pratico sul funzionamento di tale algoritmo.
Esempio
Considerato un insieme di cardinalità pari a cinque del tipo {A,B,C,D,E} e considerando una sola iterazione (per n iterazioni è sufficiente replicare la procedura sotto elencata), l’algoritmo agisce nel seguente modo:
Step 1: Si effettua una permutazione casuale sugli elementi dell’insieme. Si potrebbe ottenere ad esempio un risultato del tipo {D,B,C,E,A}. Step 2: si lancia la moneta virtuale per tutti gli elementi tranne che per il primo. Supponendo che la serie di lanci produca una combinazione del tipo [ 0, 1, 1, 0 ] , la partizione dell’insieme permutato che si otterrà sarà quindi:
{D,B}{C}{E,A}
Si potrebbe pensare in prima istanza che un algoritmo così strutturato permetta di generare partizioni equiprobabili ma come si dimostrerà, sia tramite simulazioni che per via analitica, ci sono delle partizioni che vengono privilegiate rispetto ad altre.

42
DIMOSTRAZIONE ANALITICA DELLA POLARIZZAZIONE
Per dimostrare la polarizzazione della probabilità è necessario dimostrare che esiste almeno una scelta effettuata dall’algoritmo, tale che abbia una probabilità diversa da quella che si avrebbe nel caso equamente distribuito (cioè quella che si avrebbe per una qualsiasi scelta):
⁆ 푖 | 푝 ( ) =( )
≠ 푝 ( ) (eq.13)
Dove pequa(i) rappresenta la probabilità equidistribuita di estrarre la i-esima partizione, B(n) il numero di Bell di ordine n e ppolarizzata(i) la probabilità di estrazione della partizione i-esima mediante l’algoritmo considerato.
Per trovare una partizione per cui non venga rispettata l’equiprobabilità è sufficiente concentrarsi sulla partizione di ordine k = n, la quale essendo unica non subisce variazioni di probabilità neanche a seguito della permutazione iniziale. La probabilità che essa venga estratta da un insieme con cardinalità n è la seguente:
푝 ( ) = (eq.14)
Tale formula è giustificata dal fatto che per avere una partizione di ordine n è necessario che la moneta virtuale nei suoi successivi lanci generi una combinazione di questo tipo [11 12 13 1n-2 1n-1]. La probabilità che questo avvenga è quindi:
푝[ … ] = = (eq.15)
Come si può notare dalle dimostrazioni fatte in precedenza (Figura 22) è ben lontana dall’inverso della complessità del problema. Facendo un breve esempio si potrebbe pensare ad un insieme con cardinalità 5. La probabilità equidistribuita di ottenere una partizione di ordine k = n è uguale, come è stato precedentemente detto 1/ B(n) = 1/52 mentre nel caso della probabilità polarizzata si otterrebbe 1/16 ben diverso da 1/52.
Per fissare maggiormente le idee proposte in questa dimostrazione sono state compiute due simulazioni, come nel caso di probabilità di estrazione equidistribuita, su due insiemi di cardinalità rispettivamente quattro e cinque.

43
Esempio 1
Considerando un insieme di cardinalità quattro del tipo {A,B,C,D} su 30000 estrazioni di possibili partizioni si ottiene la seguente distribuzione:
Figura 29 Distribuzione di probabilità su 3000 campioni del partizionatore polarizzato su di un insieme di cardinalità pari a 4
Si può notare, come già annunciato dalla dimostrazione precedente, che vengono privilegiate le partizioni di classe k = n e per analogo ragionamento quelle di classe k = 1 (entrambe uniche in tutti i casi non degeneri possibili). Come fatto anche nel caso precedente risulta interessante ripetere la simulazione su di un esempio di cardinalità maggiore. Per avvalorare ciò che è stato detto nella precedente dimostrazione anche in questo caso dovrebbe esserci un privilegiamento delle partizioni dovute a combinazioni testa-croce monovalore. Naturalmente con grande probabilità le combinazioni precedentemente citate non saranno le uniche ad essere privilegiate ma vi sarà come nel caso equidistribuito un’oscillazione di fondo nella parte centrale, decisamente meno attenuata, dal momento che il metodo in questione non è equiprobabile.
0
500
1000
1500
2000
2500
3000
3500
4000
Num
ero
di e
stra
zion
i
Partizioni Possibili
Distribuzione della probabilità su di un insieme con cardinalità pari a 4 del tipo {A,B,C,D}
(simulazione effettuata su 30000 estrazioni)

44
Esempio 2
Considerando un insieme di cardinalità quattro del tipo {A,B,C,D,E} su 30000 estrazioni di possibili partizioni si ottiene la seguente distribuzione:
Figura 30 Distribuzione di probabilità su 3000 campioni del partizionatore polarizzato su di un insieme di cardinalità pari a 5
Come è stato preannunciato il risultato ottenuto è molto simile alle aspettative. Le due sovra-elongazioni laterali simmetriche esprimono esattamente ciò che è stato dimostrato in precedenza e l’ondulazione centrale rafforza la non equiprobabilità del metodo in questione. Bisogna tener però presente che un metodo di questo genere, pur essendo polarizzato e non pienamente equiprobabile, non esclude in maniera categorica classi di scelte; potrebbe essere visto quindi, come un compromesso tra l’equiprobabilità e la polarizzazione totale.
COMPLESSITA’ COMPUTAZIONALE : ALGORITMI DI OTTIMIZZAZIONE
Per analizzare i metodi precedentemente presentati, oltre ad un’analisi da un punto di vista di distribuzione probabilistica è interessante, come fatto per l’analisi esaustiva, valutare il loro costo computazionale. Tale analisi risulta molto importante ai fini dell’applicazione pratica poiché da questa dipende il tempo di esecuzione di ciascun algoritmo. Per quanto concerne l’ottimizzazione ordinale equidistribuita è necessario considerare due fattori : la scelta dell’ordine di partizione k e la

45
ricorsione all’interno della procedura. La complessità dei due fattori precedentemente esposti è rispettivamente n e 2n : il primo deriva dalla necessità di compiere al più n confronti per capire l’ordine di partizione da scegliere , il secondo dalla ricorsione e dallo srotolamento della medesima che al più ha lunghezza n (quindi il totale al massimo è 2n). L’ordine di complessità di tale procedura è quindi O(n), per la precisione 3n. Per quanto concerne invece l’algoritmo polarizzato il fattore da considerare è uno solo, poiché data la permutazione di base è necessario scegliere solamente l’appartenenza o la non appartenenza di ciascun elemento a un dato sottoinsieme. Tale procedura è effettuabile con un costo computazionale non superiore ad n. Anche questo algoritmo ha quindi una complessità nell’ordine di O(n), per la precisione n. Di seguito si riporta un grafico rappresentante i tempi di simulazione su sistemi con insiemi di parti con cardinalità crescente da 1 a 9, ottenuti considerando l’algoritmo di ottimizzazione polarizzato con complessità n, quello equidistribuito con complessità 3n e quello esaustivo con complessità B(n)
Figura Andamenti temporali dei vari algoritmi per la ricerca dell’ottimo
Come si nota dalla figura gli andamenti temporali rispecchiano bene le considerazioni fatte sulla complessità computazionale dei singoli algoritmi.

46
SIMULAZIONI
Simulazione 1
Per effettuare questa simulazione si è preso in esame un sistema produttivo costituito da 9 parti lavorate da 9 macchinari, ognuno dei quali ha un costo di acquisto. Si richiede di trovare la configurazione macchine- parti che permetta di minimizzare il costo del sistema, considerando che il suo costo base è di 176,2. Di seguito è riportata la matrice d’incidenza che esprime i mutui rapporti macchine-parti affiancata alla matrice dei costi esprimente appunto i costi dei singoli macchinari.
A B C D E F G H I
Macchinari Costo macchinari 1 1 0 1 0 0 0 0 0 0
1 1,4
2 1 0 0 0 1 1 0 0 0
2 1,3 3 0 0 0 0 0 0 1 1 1
3 1,8
4 0 0 1 0 1 0 0 1 0
4 1,6 5 0 0 1 0 1 0 0 1 1
5 1,8
6 1 1 0 0 0 1 0 0 1
6 1,5 7 0 1 0 1 0 1 0 0 0
7 1,2
8 1 0 1 0 1 0 0 1 1
8 1,7 9 0 0 1 1 0 0 1 0 0
9 1,9
Figura 31 Matrice d’incidenza rappresentante il sistema con relativa tabella inerente ai costi dei macchinari
Come si è già visto in precedenza un problema di questo tipo ha una complessità data dal numero di Bell della cardinalità degli elementi che costituiscono l’insieme parti. Si può quindi affermare che la complessità di questo problema è data da B (9) = 21147. Dal momento che i casi da analizzare non sono moltissimi si può compiere un’analisi esaustiva per trovare la soluzione ottima al problema. Come precedentemente descritto si procede applicando alla matrice l’algoritmo di RANK ORDER AND CLUSTERING per cercare di diminuire preventivamente la complessità da affrontare. Di seguito è riportata la matrice, e i relativi costi dei macchinari, dopo l’applicazione dell’algoritmo d’ordinamento.
A I E B H C G F D
Macchinari Costo macchinari
6 1 1 1 1 0 0 0 0 0
6 1,5 8 1 1 0 0 1 1 1 0 0
8 1,7
2 1 0 1 0 1 0 0 0 0
2 1,3 1 1 0 0 0 0 1 0 0 0
1 1,4
5 0 1 0 0 1 1 1 0 0
5 1,8 3 0 1 0 0 0 0 1 1 0
3 1,8
7 0 0 1 1 0 0 0 0 1
7 1,2 4 0 0 0 0 1 1 1 0 0
4 1,6
9 0 0 0 0 0 1 0 1 1
9 1,9
Figura 32 Matrice d’incidenza e tabella dei costi dei macchinari ordinate a seguito dell’applicazione del ROC

47
Come si può notare dalla figura sovrastante l’algoritmo non ha prodotto alcun risultato, di conseguente si deve procedere creando tutte le partizioni possibili ed analizzando il costo di ciascuna. Tramite l’algoritmo implementato per l’analisi esaustiva si ottiene il seguente risultato:
H C E I A H F B D
Macchinari Costo macchinari
8 1 1 1 1 1 0 0 0 0
8 1,7 5 1 1 1 1 0 0 0 0 0
5 1,8
4 1 1 1 0 0 0 0 0 0
4 1,6 3 1 0 0 1 0 0 0 0 0
3 1,8
1 0 1 0 0 1 0 0 0 0
1 1,4 9 0 1 0 0 0 0 0 0 0
9 1,9
2 0 0 1 0 1 0 0 0 0
2 1,3 6 0 0 0 1 1 0 0 0 0
6 1,5
3 0 0 0 0 0 1 0 0 0
3 1,8 9 0 0 0 0 0 1 0 0 0
9 1,9
6 0 0 0 0 0 0 1 1 0
6 1,5 7 0 0 0 0 0 0 1 1 0
7 1,2
2 0 0 0 0 0 0 1 0 0
2 1,3 7 0 0 0 0 0 0 0 0 1
7 1,2
9 0 0 0 0 0 0 0 0 1
9 1,9
Figura 33 Matrice d’incidenza rappresentante la soluzione ottima e relativa tabella costi dei macchinari
Il costo della soluzione ottenuta è di 135,8 quindi come è facile notare facendo un semplicissimo calcolo si è ottenuta una riduzione del costo di circa il 23%. Il tempo impiegato dall’algoritmo per risolvere un problema di tale dimensioni è di 3 minuti e 34 secondi, un tempo ancora ragionevole ma dovuto ad una cardinalità non eccessivamente elevata dell’insieme di parti. Come si è detto in precedenza la complessità aumenta più che esponenzialmente e quindi l’unico approccio attuabile è un approccio di tipo statistico. In questo caso, in cui si è trovata una soluzione esaustiva potrebbe essere interessante confrontarla con quella ottenibile dai metodi precedentemente esposti in modo da poter valutare la bontà di questi per la risoluzione di problemi ben più complessi. Si inizierà quindi il confronto prendendo in considerazione la soluzione ottenuta mediante l’utilizzo della probabilità equidistribuita. Una richiesta che potrebbe essere molto performante potrebbe essere quella di fissare il valore di costo richiesto nel migliore 0.1%. Per ottenere quasi con certezza che questo avvenga è necessario compiere un numero di simulazioni pari a 10000. Di seguito si calcolerà la probabilità che si verifichi l’evento con il numero di estrazioni scelto:
푝 = 100%− 푝̅ = 1 − (1 − 0.01) = 0.99995 = 99,995%
Come si vede dal calcolo sopra riportato l’evento desiderato avverrà quasi con certezza assoluta.

48
Bisogna tenere inoltre presente che avendo una probabilità così elevata, con ottime speranze si avrà un risultato ancora migliore di quello desiderato. L’algoritmo per l’ottimizzazione ordinale equidistribuita, come fatto in precedenza, comincia l’analisi applicando l’algoritmo di RANK ORDER AND CLUSTERING. Dal momento che l’applicazione dell’algoritmo non produce nuove celle la procedura inizia a creare, analizzandone il costo, le 10000 partizioni richieste. Il risultato ottenuto da tale metodo è il seguente:
11 15 13 19 18 16 12 17 14
Macchinari Costo macchinari
18 1 1 1 0 0 0 0 0 0
18 1,7 12 1 1 0 0 0 0 0 0 0
12 1,3
11 1 0 1 0 0 0 0 0 0
11 1,4 16 1 0 0 0 0 0 0 0 0
16 1,5
15 0 1 1 0 0 0 0 0 0
15 1,8 14 0 1 1 0 0 0 0 0 0
14 1,6
19 0 0 1 0 0 0 0 0 0
19 1,9 18 0 0 0 1 1 0 0 0 0
18 1,7
15 0 0 0 1 1 0 0 0 0
15 1,8 13 0 0 0 1 1 0 0 0 0
13 1,8
16 0 0 0 1 0 0 0 0 0
16 1,5 14 0 0 0 0 1 0 0 0 0
14 1,6
16 0 0 0 0 0 1 1 0 0
16 1,5 17 0 0 0 0 0 1 1 0 0
17 1,2
12 0 0 0 0 0 1 0 0 0
12 1,3 13 0 0 0 0 0 0 0 1 0
13 1,8
19 0 0 0 0 0 0 0 1 0
19 1,9 17 0 0 0 0 0 0 0 0 1
17 1,2
19 0 0 0 0 0 0 0 0 1
19 1,9
Figura 34 Miglior matrice d’incidenza ottenuta a seguito di 10000 iterazioni tramite l’algoritmo di ottimizzazione ordinale equidistribuita
Il costo di questa configurazione è di 140,4 e il tempo di esecuzione impiegato per trovarla è di 2 minuti e 5 secondi. Come si nota si ha una diminuzione del tempo di esecuzione di circa il 30% e una perdita percentuale di ottimalità pari a circa il 2,5%. Il risultato ottenuto è quindi abbastanza buono, soprattutto perché bisogna tener presente che il tempo impiegato dall’algoritmo è in gran parte dovuto al numero di confronti e non alla cardinalità del sistema considerato. Di conseguenza per problemi più complessi la diminuzione percentuale relativa al tempo di soluzione aumenterà costantemente conservando però invariata la richiesta di ottimalità espressa dalla formula precedente. Per verificare che l’algoritmo abbia agito rispettando le aspettative precedentemente esposte è utile confrontare il valore di costo ottenuto con i costi presenti nel ‘best’ 0,1%. La cardinalità di questo insieme ‘best’ è data dalla seguente formula
#푒푙푒푚푒푛푡푖 푏푒푠푡 = 퐵푒푙푙(푛) ∗ (%푑푒푠푖푑푒푟푎푡푎) = 21147 ∗ 0.1% = 21,147 ≅ 21
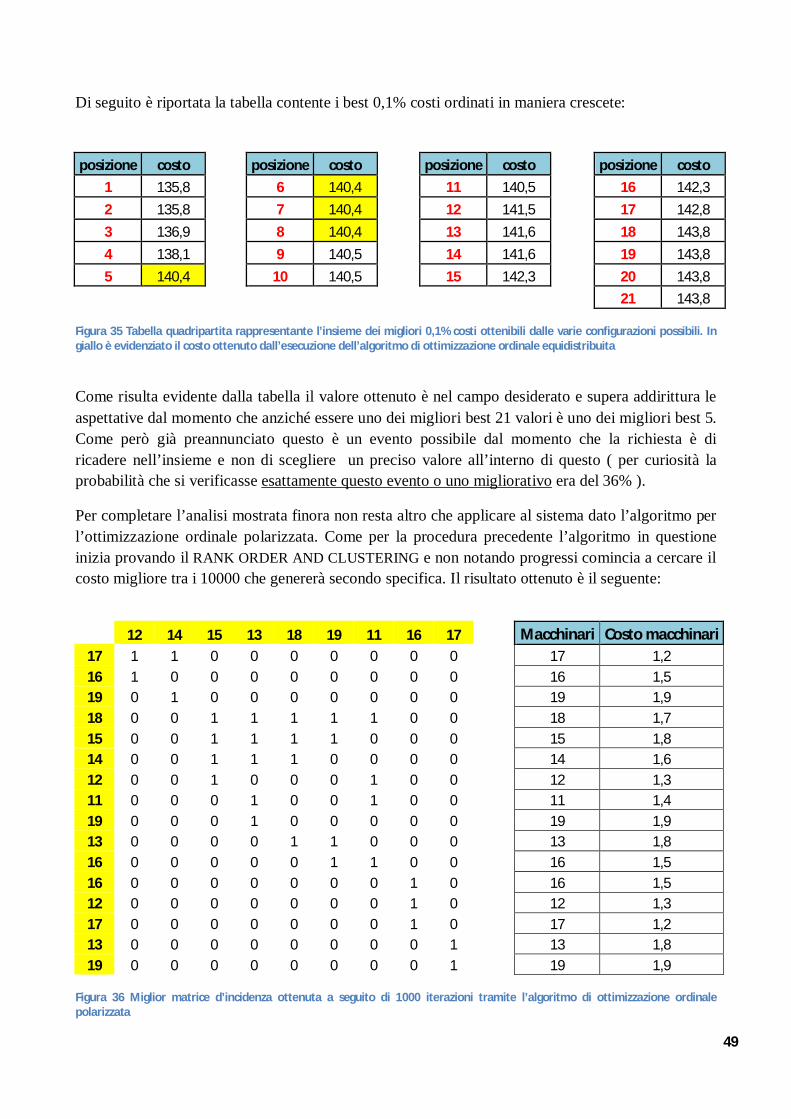
49
Di seguito è riportata la tabella contente i best 0,1% costi ordinati in maniera crescete:
posizione costo posizione costo posizione costo posizione costo
1 135,8
6 140,4
11 140,5
16 142,3
2 135,8
7 140,4
12 141,5
17 142,8
3 136,9
8 140,4
13 141,6
18 143,8
4 138,1
9 140,5
14 141,6
19 143,8
5 140,4
10 140,5
15 142,3
20 143,8
21 143,8
Figura 35 Tabella quadripartita rappresentante l’insieme dei migliori 0,1% costi ottenibili dalle varie configurazioni possibili. In giallo è evidenziato il costo ottenuto dall’esecuzione dell’algoritmo di ottimizzazione ordinale equidistribuita
Come risulta evidente dalla tabella il valore ottenuto è nel campo desiderato e supera addirittura le aspettative dal momento che anziché essere uno dei migliori best 21 valori è uno dei migliori best 5. Come però già preannunciato questo è un evento possibile dal momento che la richiesta è di ricadere nell’insieme e non di scegliere un preciso valore all’interno di questo ( per curiosità la probabilità che si verificasse esattamente questo evento o uno migliorativo era del 36% ).
Per completare l’analisi mostrata finora non resta altro che applicare al sistema dato l’algoritmo per l’ottimizzazione ordinale polarizzata. Come per la procedura precedente l’algoritmo in questione inizia provando il RANK ORDER AND CLUSTERING e non notando progressi comincia a cercare il costo migliore tra i 10000 che genererà secondo specifica. Il risultato ottenuto è il seguente:
12 14 15 13 18 19 11 16 17
Macchinari Costo macchinari
17 1 1 0 0 0 0 0 0 0
17 1,2 16 1 0 0 0 0 0 0 0 0
16 1,5
19 0 1 0 0 0 0 0 0 0
19 1,9 18 0 0 1 1 1 1 1 0 0
18 1,7
15 0 0 1 1 1 1 0 0 0
15 1,8 14 0 0 1 1 1 0 0 0 0
14 1,6
12 0 0 1 0 0 0 1 0 0
12 1,3 11 0 0 0 1 0 0 1 0 0
11 1,4
19 0 0 0 1 0 0 0 0 0
19 1,9 13 0 0 0 0 1 1 0 0 0
13 1,8
16 0 0 0 0 0 1 1 0 0
16 1,5 16 0 0 0 0 0 0 0 1 0
16 1,5
12 0 0 0 0 0 0 0 1 0
12 1,3 17 0 0 0 0 0 0 0 1 0
17 1,2
13 0 0 0 0 0 0 0 0 1
13 1,8 19 0 0 0 0 0 0 0 0 1
19 1,9
Figura 36 Miglior matrice d’incidenza ottenuta a seguito di 1000 iterazioni tramite l’algoritmo di ottimizzazione ordinale polarizzata

50
Il costo della configurazione ottenuta è 142,3 e il tempo impiegato dall’algoritmo per la soluzione del problema è 5,6 secondi. Come si può notare dai risultati il valore ottenuto è sempre contenuto nell’insieme dei ‘best’ 0,1% e la diminuzione del tempo di calcolo è di oltre il 97%. In prima approssimazione questo risultato è davvero molto buono e sembra discostarsi abbastanza dalla linea teorica tracciata fino a questo momento. Per confermare o per smentire questo risultato è necessario quindi effettuare altre simulazioni, mantenendo invariate le iterazioni e il sistema produttivo considerato. Di seguito, per brevità, viene riportata una tabella con i costi ottenuti nelle varie simulazioni ed il tempo di esecuzione delle medesime:
# simulazione costo tempo (s)
1 140,4 5,75 2 146,2 5,43 3 141,6 5,54 4 135,8 5,75 5 140,5 5,85 6 140,5 5,56 7 144,3 5,64 8 148,3 5,62 9 145,1 5,6
10 135,8 5,5
Figura 37 Tabella rappresentante i costi ottenuti da 10 esecuzioni dell’algoritmo di ottimizzazione ordinale polarizzata. Ciascuna esecuzione è stata effettuata compiendo 10000 iterazioni. In rosso sono rappresentati i costi fuori dal campo dei best 0.1% costi
Come evidenziato dalla tabella l’algoritmo polarizzato offre risultati in tempi molto brevi ma non riesce a dare garanzie sul risultato finale: il 40% delle simulazioni danno un valore che esce fuori dal range di ottimalità precedentemente definito. Bisogna però notare che nel complesso la totalità dei risultati ottenuti, anche non corrispondendo pienamente alle aspettative, non è del tutto disastrosa poiché vi sono valori decisamente ‘buoni’ misti a valori ‘cattivi’ che, tranne eccezioni, non sono eccessivamente distanti dall’insieme desiderato. Questo fenomeno è giustificato dal fatto che la distribuzione di probabilità di questo tipo di algoritmo pur non essendo pienamente equa non esclude totalmente classi di partizioni ma ne agevola o disagevola l’estrazione. L’effetto finale di questo tipo di politica è quello di poter ottenere risultati molto buoni ma senza avere garanzie sull’avverarsi degli stessi.
Simulazione 2
Dopo aver testato gli algoritmi per insiemi che permettano l’analisi esaustiva potrebbe essere interessante confrontare gli algoritmi statistici su di un sistema avente un insieme delle parti con una cardinalità abbastanza superiore a quella del precedente. Scegliendo un sistema con un numero di parti pari a 14 si avrebbe una complessità B (14) = 190899322. Come si nota immediatamente il numero di confronti necessario per l’analisi esaustiva in questo caso sarebbe quasi ingestibile, di conseguenza l’approccio da preferire è sicuramente quello statistico. Bisogna ricordare che il

51
calcolo compiuto in precedenza per ottenere un costo che fosse nei ‘best’ 0.1% possibili costi resta valido anche in questo caso. Tale considerazione è vera poiché, come si può vedere dalla formula, la probabilità di scegliere un elemento che sia nell’insieme ‘best’ 0.1% non dipende dalla cardinalità delle parti del sistema considerato ma solo dalle richieste dell’utilizzatore. Si considera quindi la seguente matrice d’incidenza con un costo base di 412 e i rispettivi costi dei macchianari:
A B C D E F G H I L M N O P
macchine
Costo macchine
11 0 0 1 0 0 0 0 0 0 0 0 0 1 1
11 1,2 12 1 0 0 0 1 1 0 0 0 0 0 0 1 0
12 1,5
13 0 0 0 0 0 0 1 0 1 0 1 0 0 1
13 1,7 14 0 0 1 0 1 0 0 1 0 0 0 1 0 0
14 1,9
15 0 0 0 0 1 0 0 0 1 0 1 0 1 0
15 1,1 16 0 1 0 1 0 1 0 0 0 1 0 1 0 1
16 1,2
17 0 1 0 1 0 0 0 0 0 1 0 0 1 0
17 1,6 18 1 0 1 0 1 0 0 1 0 1 0 1 0 0
18 1,1
19 0 0 1 1 0 0 0 0 0 1 0 0 1 0
19 1,2 20 0 0 0 1 0 0 0 0 0 1 0 0 1 0
20 1,5
21 0 1 1 0 0 0 0 0 0 0 0 1 0 0
21 1,7 22 0 0 0 1 0 0 1 0 0 0 0 0 0 0
22 1,3
23 0 0 0 1 0 0 1 0 0 1 0 1 0 0
23 1,2 24 0 0 1 0 1 0 0 0 0 1 0 1 0 0
24 1,8
Figura 38 Matrice d’incidenza rappresentante il sistema con relativa tabella inerente ai costi dei macchinari
La matrice dopo l’applicazione preventiva dell’algoritmo di RANK ORDER AND CLUSTERING compiuta da entrambi gli algoritmi è la seguente:
E A N C L H O F I M B D P G
18 1 1 1 1 1 1 0 0 0 0 0 0 0 0 12 1 1 0 0 0 0 1 1 0 0 0 0 0 0 24 1 0 1 1 1 0 0 0 0 0 0 0 0 0 14 1 0 1 1 0 1 0 0 0 0 0 0 0 0 15 1 0 0 0 0 0 1 0 1 1 0 0 0 0 21 0 0 1 1 0 0 0 0 0 0 1 0 0 0 16 0 0 1 0 1 0 0 1 0 0 1 1 1 0 23 0 0 1 0 1 0 0 0 0 0 0 1 0 1 19 0 0 0 1 1 0 1 0 0 0 0 1 0 0 11 0 0 0 1 0 0 1 0 0 0 0 0 1 0 17 0 0 0 0 1 0 1 0 0 0 1 1 0 0 20 0 0 0 0 1 0 1 0 0 0 0 1 0 0 13 0 0 0 0 0 0 0 0 1 1 0 0 1 1 22 0 0 0 0 0 0 0 0 0 0 0 1 0 1
Figura 39 Matrice d’incidenza rappresentante il sistema dopo l’applicazione dell’algoritmo ROC
La matrice ottenuta dopo l’ottimizzazione ordinale equidistribuita è la seguente:

52
E A G N L B C H F O I M D P
18 1 1 0 0 0 0 0 0 0 0 0 0 0 0 12 1 1 0 0 0 0 0 0 0 0 0 0 0 0 24 1 0 0 0 0 0 0 0 0 0 0 0 0 0 14 1 0 0 0 0 0 0 0 0 0 0 0 0 0 15 1 0 0 0 0 0 0 0 0 0 0 0 0 0 23 0 0 1 0 0 0 0 0 0 0 0 0 0 0 13 0 0 1 0 0 0 0 0 0 0 0 0 0 0 22 0 0 1 0 0 0 0 0 0 0 0 0 0 0 16 0 0 0 1 1 1 0 0 0 0 0 0 0 0 18 0 0 0 1 1 0 0 0 0 0 0 0 0 0 24 0 0 0 1 1 0 0 0 0 0 0 0 0 0 23 0 0 0 1 1 0 0 0 0 0 0 0 0 0 21 0 0 0 1 0 1 0 0 0 0 0 0 0 0 14 0 0 0 1 0 0 0 0 0 0 0 0 0 0 17 0 0 0 0 1 1 0 0 0 0 0 0 0 0 19 0 0 0 0 1 0 0 0 0 0 0 0 0 0 20 0 0 0 0 1 0 0 0 0 0 0 0 0 0 18 0 0 0 0 0 0 1 1 0 0 0 0 0 0 14 0 0 0 0 0 0 1 1 0 0 0 0 0 0 24 0 0 0 0 0 0 1 0 0 0 0 0 0 0 21 0 0 0 0 0 0 1 0 0 0 0 0 0 0 19 0 0 0 0 0 0 1 0 0 0 0 0 0 0 11 0 0 0 0 0 0 1 0 0 0 0 0 0 0 12 0 0 0 0 0 0 0 0 1 0 0 0 0 0 16 0 0 0 0 0 0 0 0 1 0 0 0 0 0 12 0 0 0 0 0 0 0 0 0 1 0 0 0 0 15 0 0 0 0 0 0 0 0 0 1 0 0 0 0 19 0 0 0 0 0 0 0 0 0 1 0 0 0 0 11 0 0 0 0 0 0 0 0 0 1 0 0 0 0 17 0 0 0 0 0 0 0 0 0 1 0 0 0 0 20 0 0 0 0 0 0 0 0 0 1 0 0 0 0 15 0 0 0 0 0 0 0 0 0 0 1 1 0 0 13 0 0 0 0 0 0 0 0 0 0 1 1 0 0 16 0 0 0 0 0 0 0 0 0 0 0 0 1 0 23 0 0 0 0 0 0 0 0 0 0 0 0 1 0 19 0 0 0 0 0 0 0 0 0 0 0 0 1 0 17 0 0 0 0 0 0 0 0 0 0 0 0 1 0 20 0 0 0 0 0 0 0 0 0 0 0 0 1 0 22 0 0 0 0 0 0 0 0 0 0 0 0 1 0 16 0 0 0 0 0 0 0 0 0 0 0 0 0 1 11 0 0 0 0 0 0 0 0 0 0 0 0 0 1 13 0 0 0 0 0 0 0 0 0 0 0 0 0 1
Figura 40 Matrice d’incidenza ottenuta con l’ottimizzazione ordinale equidistribuita a seguito di 1000 iterazioni
Il costo di questa configurazione è di 325,4 con una diminuzione del costo base superiore al 20%. Questa volta però, il tempo necessario per l’elaborazione è stato di 37.9 secondi. Come si può constatare il tempo impiegato dall’algoritmo è decisamente ragionevole e di molto inferiore al tempo che si sarebbe impiegato per compiere un’analisi esaustiva ( almeno 3 ordini di grandezza in più).

53
Un buon metro di paragone è dato dall’applicazione dell’ottimizzazione ordinale polarizzata:
G P B C N I M F O L D H A E
23 1 0 0 0 0 0 0 0 0 0 0 0 0 0 13 1 0 0 0 0 0 0 0 0 0 0 0 0 0 22 1 0 0 0 0 0 0 0 0 0 0 0 0 0 16 0 1 0 0 0 0 0 0 0 0 0 0 0 0 11 0 1 0 0 0 0 0 0 0 0 0 0 0 0 13 0 1 0 0 0 0 0 0 0 0 0 0 0 0 21 0 0 1 0 0 0 0 0 0 0 0 0 0 0 16 0 0 1 0 0 0 0 0 0 0 0 0 0 0 17 0 0 1 0 0 0 0 0 0 0 0 0 0 0 18 0 0 0 1 1 0 0 0 0 0 0 0 0 0 24 0 0 0 1 1 0 0 0 0 0 0 0 0 0 14 0 0 0 1 1 0 0 0 0 0 0 0 0 0 21 0 0 0 1 1 0 0 0 0 0 0 0 0 0 19 0 0 0 1 0 0 0 0 0 0 0 0 0 0 11 0 0 0 1 0 0 0 0 0 0 0 0 0 0 16 0 0 0 0 1 0 0 0 0 0 0 0 0 0 23 0 0 0 0 1 0 0 0 0 0 0 0 0 0 15 0 0 0 0 0 1 0 0 0 0 0 0 0 0 13 0 0 0 0 0 1 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 1 0 0 0 0 0 0 0 13 0 0 0 0 0 0 1 0 0 0 0 0 0 0 12 0 0 0 0 0 0 0 1 0 0 0 0 0 0 16 0 0 0 0 0 0 0 1 0 0 0 0 0 0 12 0 0 0 0 0 0 0 0 1 0 0 0 0 0 15 0 0 0 0 0 0 0 0 1 0 0 0 0 0 19 0 0 0 0 0 0 0 0 1 0 0 0 0 0 11 0 0 0 0 0 0 0 0 1 0 0 0 0 0 17 0 0 0 0 0 0 0 0 1 0 0 0 0 0 20 0 0 0 0 0 0 0 0 1 0 0 0 0 0 16 0 0 0 0 0 0 0 0 0 1 1 0 0 0 23 0 0 0 0 0 0 0 0 0 1 1 0 0 0 19 0 0 0 0 0 0 0 0 0 1 1 0 0 0 17 0 0 0 0 0 0 0 0 0 1 1 0 0 0 20 0 0 0 0 0 0 0 0 0 1 1 0 0 0 18 0 0 0 0 0 0 0 0 0 1 0 0 0 0 24 0 0 0 0 0 0 0 0 0 1 0 0 0 0 22 0 0 0 0 0 0 0 0 0 0 1 0 0 0 18 0 0 0 0 0 0 0 0 0 0 0 1 0 0 14 0 0 0 0 0 0 0 0 0 0 0 1 0 0 18 0 0 0 0 0 0 0 0 0 0 0 0 1 0 12 0 0 0 0 0 0 0 0 0 0 0 0 1 0 18 0 0 0 0 0 0 0 0 0 0 0 0 0 1 12 0 0 0 0 0 0 0 0 0 0 0 0 0 1 24 0 0 0 0 0 0 0 0 0 0 0 0 0 1 14 0 0 0 0 0 0 0 0 0 0 0 0 0 1 15 0 0 0 0 0 0 0 0 0 0 0 0 0 1
Figura 41 Matrice d’incidenza ottenuta con l’ottimizzazione ordinale polarizzata a seguito di 1000 iterazioni
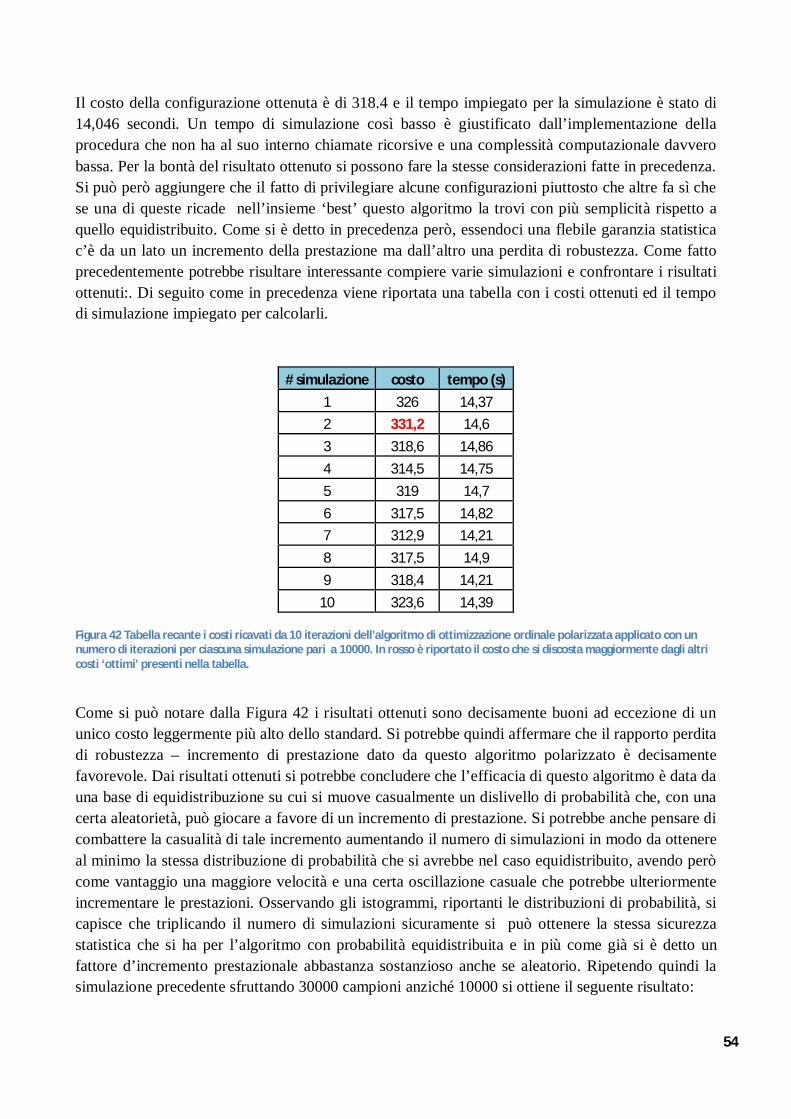
54
Il costo della configurazione ottenuta è di 318.4 e il tempo impiegato per la simulazione è stato di 14,046 secondi. Un tempo di simulazione così basso è giustificato dall’implementazione della procedura che non ha al suo interno chiamate ricorsive e una complessità computazionale davvero bassa. Per la bontà del risultato ottenuto si possono fare la stesse considerazioni fatte in precedenza. Si può però aggiungere che il fatto di privilegiare alcune configurazioni piuttosto che altre fa sì che se una di queste ricade nell’insieme ‘best’ questo algoritmo la trovi con più semplicità rispetto a quello equidistribuito. Come si è detto in precedenza però, essendoci una flebile garanzia statistica c’è da un lato un incremento della prestazione ma dall’altro una perdita di robustezza. Come fatto precedentemente potrebbe risultare interessante compiere varie simulazioni e confrontare i risultati ottenuti:. Di seguito come in precedenza viene riportata una tabella con i costi ottenuti ed il tempo di simulazione impiegato per calcolarli.
# simulazione costo tempo (s)
1 326 14,37
2 331,2 14,6
3 318,6 14,86
4 314,5 14,75
5 319 14,7
6 317,5 14,82
7 312,9 14,21
8 317,5 14,9
9 318,4 14,21
10 323,6 14,39
Figura 42 Tabella recante i costi ricavati da 10 iterazioni dell’algoritmo di ottimizzazione ordinale polarizzata applicato con un numero di iterazioni per ciascuna simulazione pari a 10000. In rosso è riportato il costo che si discosta maggiormente dagli altri costi ‘ottimi’ presenti nella tabella.
Come si può notare dalla Figura 42 i risultati ottenuti sono decisamente buoni ad eccezione di un unico costo leggermente più alto dello standard. Si potrebbe quindi affermare che il rapporto perdita di robustezza – incremento di prestazione dato da questo algoritmo polarizzato è decisamente favorevole. Dai risultati ottenuti si potrebbe concludere che l’efficacia di questo algoritmo è data da una base di equidistribuzione su cui si muove casualmente un dislivello di probabilità che, con una certa aleatorietà, può giocare a favore di un incremento di prestazione. Si potrebbe anche pensare di combattere la casualità di tale incremento aumentando il numero di simulazioni in modo da ottenere al minimo la stessa distribuzione di probabilità che si avrebbe nel caso equidistribuito, avendo però come vantaggio una maggiore velocità e una certa oscillazione casuale che potrebbe ulteriormente incrementare le prestazioni. Osservando gli istogrammi, riportanti le distribuzioni di probabilità, si capisce che triplicando il numero di simulazioni sicuramente si può ottenere la stessa sicurezza statistica che si ha per l’algoritmo con probabilità equidistribuita e in più come già si è detto un fattore d’incremento prestazionale abbastanza sostanzioso anche se aleatorio. Ripetendo quindi la simulazione precedente sfruttando 30000 campioni anziché 10000 si ottiene il seguente risultato:

55
B O F O G E H A M I C N L D
21 1 0 0 0 0 0 0 0 0 0 0 0 0 0 16 1 0 0 0 0 0 0 0 0 0 0 0 0 0 17 1 0 0 0 0 0 0 0 0 0 0 0 0 0 16 0 1 0 0 0 0 0 0 0 0 0 0 0 0 11 0 1 0 0 0 0 0 0 0 0 0 0 0 0 13 0 1 0 0 0 0 0 0 0 0 0 0 0 0 12 0 0 1 0 0 0 0 0 0 0 0 0 0 0 16 0 0 1 0 0 0 0 0 0 0 0 0 0 0 12 0 0 0 1 0 0 0 0 0 0 0 0 0 0 15 0 0 0 1 0 0 0 0 0 0 0 0 0 0 19 0 0 0 1 0 0 0 0 0 0 0 0 0 0 11 0 0 0 1 0 0 0 0 0 0 0 0 0 0 17 0 0 0 1 0 0 0 0 0 0 0 0 0 0 20 0 0 0 1 0 0 0 0 0 0 0 0 0 0 23 0 0 0 0 1 0 0 0 0 0 0 0 0 0 13 0 0 0 0 1 0 0 0 0 0 0 0 0 0 22 0 0 0 0 1 0 0 0 0 0 0 0 0 0 18 0 0 0 0 0 1 1 1 0 0 0 0 0 0 14 0 0 0 0 0 1 1 0 0 0 0 0 0 0 12 0 0 0 0 0 1 0 1 0 0 0 0 0 0 24 0 0 0 0 0 1 0 0 0 0 0 0 0 0 15 0 0 0 0 0 1 0 0 0 0 0 0 0 0 15 0 0 0 0 0 0 0 0 1 1 0 0 0 0 13 0 0 0 0 0 0 0 0 1 1 0 0 0 0 18 0 0 0 0 0 0 0 0 0 0 1 1 1 0 24 0 0 0 0 0 0 0 0 0 0 1 1 1 0 14 0 0 0 0 0 0 0 0 0 0 1 1 0 0 21 0 0 0 0 0 0 0 0 0 0 1 1 0 0 19 0 0 0 0 0 0 0 0 0 0 1 0 1 1 11 0 0 0 0 0 0 0 0 0 0 1 0 0 0 16 0 0 0 0 0 0 0 0 0 0 0 1 1 1 23 0 0 0 0 0 0 0 0 0 0 0 1 1 1 17 0 0 0 0 0 0 0 0 0 0 0 0 1 1 20 0 0 0 0 0 0 0 0 0 0 0 0 1 1 22 0 0 0 0 0 0 0 0 0 0 0 0 0 1
Figura 43 Matrice d’incidenza rappresentante la miglior soluzione ottenuta a seguito di 3000 iterazioni dell’algoritmo polarizzato
Il costo della configurazione così ottenuta è di 300,5 e il tempo di simulazione è di circa 39 secondi. Il risultato ottenuto è molto buono poiché, rispetto all’algoritmo equidistribuito, si ha a parità di tempo impiegato un miglioramento del costo finale di circa il 6%. Formalizzando ciò che si è detto precedentemente per la probabilità polarizzata, si può affermare empiricamente che: la probabilità di ottenere un certo costo con i iterazioni da un insieme ‘best’ di cardinalità B(n)% che appartiene ad un insieme padre di cardinalità B(n) sia:
푝 = 1 − 1 − ( )%( )
(eq.16)

56
Simulazione 3
Per maggiore completezza e rapidità di rappresentazione in questa sezione verranno rappresentati graficamente gli abbassamenti di costo prodotti dai diversi algoritmi su sistemi aventi una cardinalità dell’insieme diversa. Dal momento che, come precedentemente dimostrato, il numero dei macchinari non influenza la complessità nella ricerca della ‘configurazione ottimale’ (od ottima a seconda del metodo utilizzato) per semplicità ed uniformità si sceglierà sempre un numero di macchine uguale a quello delle parti. Per iniziare si è scelto un insieme con cardinalità bassa in modo da poter confrontare i costi ottenuti con il costo ottimo: L’esempio in questione rappresenta un sistema composto da 8 macchinari e 8 parti con un numero di iterazioni pari a 600:
Figura 44 Confronto tra gli andamenti dei fronti di costo dei vari metodi di ottimizzazione considerati. Complessità B(8)
Di seguito viene proposto uno zoom della parte più movimentata del grafico in cui si nota una maggior velocità di convergenza all’ottimo dell’algoritmo polarizzato.
Figura 45 Zoom con relativo resize della figura 44
0 100 200 300 400 500 600 700 800 900 100070
80
90
100
110
120
130
140
150
160
170
iterazioni
cost
o de
lla c
onfig
uraz
ione
Andamenti dei costi in un sistema 8 macchine - 8 parti. (Simulazione effettuata su 1000 iterazioni)
Ottimizzazione PolarizzataOttimizzazione OrdinaleCosto OttimoCosto Massimo
0 50 100 150 200
80
85
90
95
100
105
iterazioni
cost
o de
lla c
onfig
uraz
ione
ZOOM Andamenti dei costi in un sistema 8 macchine - 8 parti. (Simulazione effettuata su 1000 iterazioni)
Ottimizzazione PolarizzataOttimizzazione OrdinaleCosto OttimoCosto Massimo

57
Continuando con la serie di esempi preannunciati si passa ad un esempio costituito da un sistema 9 macchine- 9 parti, quindi ancora trattabile in maniera esaustiva:
Figura 46 Confronto tra gli andamenti dei fronti di costo dei vari metodi di ottimizzazione considerati. Complessità B(9)
Come fatto in precedenza viene proposto uno zoom della parte ‘interessante’ del grafico. Questa volta si evince un’inversione di tendenza :l’ottimizzazione ordinale converge prima all’ottimo di quella polarizzata.
Figura 47 Zoom con relativo resize della figura 46
0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000110
120
130
140
150
160
170
Iterazioni
cost
o de
lla c
onfig
uraz
ione
Andamenti dei costi in un sistema 9 macchine - 9 parti.(Simulazione effettuata su 5000 iterazioni )
Ottimizzazione PolarizzataOttimizzazione OrdinaleCosto OttimoCosto di base
0 500 1000 1500 2000 2500 3000
110
115
120
125
130
135
140
Iterazioni
cost
o de
lla c
onfig
uraz
ione
ZOOM Andamenti dei costi in un sistema 9 macchine - 9 parti.(Simulazione effettuata su 5000 iterazioni )
Ottimizzazione PolarizzataOttimizzazione OrdinaleCosto OttimoCosto di base

58
Per continuare la trattazione si è pensato interessante trattare dei casi in cui l’analisi esaustiva sarebbe stata troppo onerosa. Si è scelto quindi di iniziare trattando un sistema composto da 10 macchini e 10 parti:
Figura 48 Confronto tra gli andamenti dei fronti di costo dei vari metodi di ottimizzazione considerati. Complessità B(10)
Dato il notevole incremento dei fronti di costo si è pensato di proporre un altro test aumentando ulteriormente il numero di parti e di macchinari presenti nel sistema. Il sistema in esame è un sistema 12 macchine-12 parti:
Figura 49 Confronto tra gli andamenti dei fronti di costo dei vari metodi di ottimizzazione considerati. Complessità B(12)

59
Come è facile notare dalla figura si è avuto un’inversione di tendenza: L’ottimizzazione ordinale che sembrava convergere con grande rapidità nella figura in questo caso dà risultati alquanto deludenti. Al fine di completare l’analisi risulta utile compiere un’ultima simulazione aumentando ancora il numero di macchine e di macchinari presenti nel sistema per osservare se la tendenza mostrata dalla figura è confermata. L’esempio proposto rappresenta un sistema costituito da 14 macchine e 14 parti.
Figura 50 Confronto tra gli andamenti dei fronti di costo dei vari metodi di ottimizzazione considerati. Complessità B(14)
Dalla figura si evince facilmente che l’ottimizzazione ordinale all’aumentare della cardinalità dell’insieme parti non produce risultati migliorativi mentre quella polarizzata, anche se con margini non troppo elevati, riesce ancora a migliorare il costo totale del sistema. Tale risultato è giustificato dal fatto che essendo l’ottimizzazione ordinale un metodo di scelta totalmente equo ed essendo l’insieme delle possibili partizioni molto grande, è possibile che il sistema nella configurazione data si trovi già nello 0,01% delle migliori configurazioni e che quindi non si riesca ad avere un miglioramento in termini di costo. Per quanto concerne l’algoritmo polarizzato non essendo equo esso si dirige casualmente verso classi di partizioni che come si è detto in precedenza potrebbero portare un miglioramento. Per avere una maggiore garanzia statistica a parità di tempo impiegato si potrebbe utilizzare l’accorgimento descritto nell’eq.16.
0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000375
380
385
390
395
400
iterazione
cost
o de
lla c
onfig
uraz
ione
Andamenti dei costi in un sistema 14 parti -14 macchine.(Simulazione effettuata su 10000 iterazioni)
Ottimizzazione PolarizzataOttimizzazione OrdinaleCosto Base

60
CONCLUSIONI
CONSIDERAZIONI FINALI
Lo scopo di questo lavoro è stato quello di trovare, mediante l’utilizzo di varie strategie un metodo capace di ottimizzare la configurazione cellulare di un sistema produttivo. Dal momento che il problema non è sempre risolubile compiutamente si è proposto oltre all’approccio di tipo esaustivo un approccio di tipo statistico che, come si è visto dalle simulazioni effettuate, offre un buon compromesso in termini di tempo speso e prestazione ottenuta. Nel testo si sono confrontati due metodi: uno totalmente equo, quindi ‘miope’ ed uno polarizzato , con una ‘lungimiranza’ però abbastanza aleatoria. La miopia del primo metodo permette di dare delle garanzie dal punto di vista statistico ma, come si è visto dagli esempi precedentemente esposti, spesso è più prestante un metodo di ottimizzazione di tipo polarizzato; soprattutto se rafforzato da un numero maggiore di iterazioni (si è detto in precedenza che ciò non è strano poiché la complessità del metodo equamente distribuito è 3n mentre quella di quello polarizzato è n). Dati i risultati ottenuti si possono ricavare due importanti direttrici che potrebbero condurre a interessanti sviluppi futuri:
1) Riduzione delle dimensioni del problema
2) Incremento della lungimiranza nelle scelte delle varie partizioni
Per quanto concerne il punto 1. si potrebbero applicare i metodi di ottimizzazione statistica mediante una struttura propria dei ‘greedy algorithms’, cioè quella di riapplicare le procedure di ottimizzazione su partizioni ottenute tramite un primo sgrossamento iniziale. Si potrebbe iterare il metodo cercando di semplificare il problema al punto di arrivare ad una cardinalità delle singole sub-partizioni trattabile da un punto di vista esaustivo. Metodi di questo tipo generalmente offrono un avvicinamento asintotico alla soluzione ottima con un’ottima diminuzione del tempo di processo.
Al fine di incrementare la lungimiranza della procedura si potrebbe invece pensare ad un algoritmo di tipo genetico che selezionando dalla totalità degli individui (insieme delle partizioni) campioni degli stessi possa mediante procedure di accoppiamento, basate su regole dedotte da simulazioni, generare una prole (quindi direzionare la scelta) sempre più performante in termini di costo.
L’algoritmo di scelta polarizzato e l’applicazione preventiva dell’algoritmo di RANKORDER AND CLUSTERIND hanno rappresentato, anche se in piccola dose, la base per l’applicazione degli sviluppi futuri. Per quanto concerne l’applicazione che si è fatta dell’algoritmo di RANK ORDER AND CLUSTERING preventivo esso non ha rappresentato altro che un banale esempio di ‘greedy algorithms’ mentre l’ottimizzazione polarizzata è servita per dare un’idea del concetto di lungimiranza nelle scelte. Partendo quindi dai risultati ottenuti in questo testo si potrebbero sviluppare metodi di ottimizzazione più efficienti e performanti capaci di dare risultati e garanzie migliori di quelle raggiunte finora.

61
BIBLIOGRAFIA
TESTI E ARTICOLI CONSULTATI
[1] H.M. Chan, D.A. Miller, Direct clustering algorithm for group formation in cellular manufacturing, Journal of Manufacturing Systems 1 (1982) 64–75
[2] A. Kusiak, Generalized group technology concept, International Journal of Production Research 25 (1987) 561–569.
[3] K. Shanker, A.K. Agrawal, Models and solution meth- odologies for the generalized grouping problem in cellular manufacturing, International Journal of Production Research 35 (2) (1997) 513-538.
[4] G. Srinivasan, A clustering algorithm for machine cell formation in group technology using minimum spanning trees, International Journal of Production Research 32 (9) (1994) 2149–2158
[5] Burbidge, J. L., Change to Group Technology: Process Organization is Obsolete International Journal of Production Research, Volume 30 (1992), pp1209–1219.
[6] Kumar, C. S., & Chandrasekharan, M. P. (1990). Grouping e0cacy: A quantitative criterion for goodness of diagonal forms of binary matrices in group technology. International Journal of Production Research, 28, 233–243.
[7] Goncalves, J., & Resende, M. (2004). An evolutionary algorithm for manufacturing cell formation. Computers and Industrial Engineering, 47, 247–273.
[8] Chu, C. H. & Tsai, C. C. (2001). A heuristic algorithm for grouping manufacturing cells. In Proceedings of the 2001 IEEE Congress on Evolutionary Computation, Seoul, Korea (pp. 310–317).
[9] Wang, J. (2003). Formation of machine cells and part families in cellular manufacturing systems using a linear assignment algorithm. Automatica, 39(9), 1607–1615.
[10] T. H., Chang, C. C., & Chung, S. H. (2008). A simulated annealing algorithm for manufacturing cell formation problems. Expert Systems with Applications, 34, 1609–1617.
[11] D.E. Goldberg, Computer-aided pipe line operation using genetic algorithms rule learning, API Pipeline Cybernetics Symposium, Houston, TX, 1984.
[12] S. Sankaran, K.G. Kassilingam, An integrated approach to cell formation and part routing in group technology, Engineering Optimization 16 (3) (1990) 235–245.
[13] Mikell P.Groover, Automation, Production System and Computer- Integrated Manufacturing (Second Edition), Prentice Hall International INC (2001).
[14] Herbert Wilf, East West, University of Pennsylvania Philadelphia, PA, USA (1999).


















