Cache e gerarchia di memoria - uniroma1.italberto/didattica/Calcolatori/cache.pdf · Il miss ratio...
58
Cache e gerarchia di memoria
Transcript of Cache e gerarchia di memoria - uniroma1.italberto/didattica/Calcolatori/cache.pdf · Il miss ratio...

Cache e gerarchia di memoria

Cache e gerarchia di memoria
Gerarchia di Memoria:motivazioni tecnologiche per caching.
Località:perché il caching funziona
Datapath
Memory
Processor
Input
Output
Control

Tecnologie
I vari tipi di memoria sono realizzati con tecnologiediverse e si differenziano per• Costo per bit immagazzinato• Tempo di accesso (o latenza): ritardo fral'istante in cui avviene la richiesta e l'istante incui il dato è disponibile• Modo di accesso (seriale o casuale).
Tecnologie• Memorie a semiconduttore con tecnologia VLSI
(memoria cache e DRAM)• Memorie magnetiche (memoria secondaria).• Memorie ottiche (memoria secondaria).

Memoria interna, principale e secondaria
Registri interni alla CPU° Visibili o no al programmatore° Memorizzano temporaneamente dati e
istruzioni° Dimensioni: centinaia di bytes° Tempo di accesso: tempo CPU
Memoria principale (DRAM)° Memorizza dati e istruzioni dei programmi° La CPU vi accede direttamente
Memoria secondaria (dischi, DVD, ..)° dimensioni: Gbytes, Tbytes° velocità: decine di millisecondi (milioni di
nanosecondi)

1980-2003, CPU più veloce delle DRAM ...
10
DRAM
CPU
Prestazioni(1/ latenza)
100
1000
1980
2000
1990
Anno
Gap grew 50% peryear
D.: come risolvere questa differenza?
R.: utilizzare memorie “cache” tra CPU eDRAM. Create a “memory hierarchy”.
10000
2005
CPU60% per yr2X in 1.5 yrs
DRAM9% per yr2X in 10 yrs 1977: Apple II
CPU 1000 ns
DRAM: 400 ns

Le memorie RAM statiche
La cella elementare ècostituita da 6 transistorimos che formano un FLIP-FLOP.L’informazione permanestabile in presenza dellatensione di alimentazione• Tempi di accesso rapidi.• Costi elevati.

Le memorie RAM dinamiche
° La cella elementare è costituira da uncondensatore che viene caricato (1) oscaricato (0).
° La tensione sul condensatore tende adiminuire (millisecondi) e quindi deve essereripristinata o rinfrescata
° Tempi di accesso altiLa semplicità dellacella consente capacitàmolto elevate in spazi(e costi) contenuti

Velocità CPU e DRAM
La tecnologia consente di realizzare CPU semprepiù veloci e memorie sempre più grandiMA la velocità di accesso delle memorie noncresce così rapidamente come la velocità dellaCPU
Nell’architettura VonNeuman il canale dicomunicazione tra la CPU e la memoria è ilpunto critico (collo di bottiglia) del sistema.

Gerarchia di memoria
La soluzione ottimale per un sistema dimemoria è:
° Costo minimo° Capacità massima° Tempi di accesso minimi
Soluzione approssimata: GERARCHIA° Tecnologie diverse possono soddisfare al
meglio ciascuno dei requisiti.° Una gerarchia cerca di ottimizzare
globalmente i parametri.

Gerarchia di memoria
Più livelli di memoriaAl crescere delladistanza dalla CPUcresce il costo e lacapacità dimemorizzazione.In ogni istante di tempoi dati sono copiatisolamente tra ciascunacoppia di livelliadiacenti, per cui ci sipuò concentrare su duesoli livelli.

Caches: latenza
Small, fastLarge,slow
DaCPU
AllaCPU
Data in uppermemoryreturned withlower latency.
Data in lowerlevel returnedwith higherlatency.
Dati
Indiirizzi

2005 Gerarchia di Memoria: Apple iMac G5
iMac G51.6 GHz
¤1299.00
Reg L1 Inst L1 Data L2 DRAM Disk
Size 1K 64K 32K 512K 256M 80GLatency(cycles) 1 3 3 11 160 10e7
gestitidal
compilatore
gestitida hardware
gestiti dal SistemaOper., da hardware,
applicazione
Obiettivo: creare l’illusione di una grandeeconomica e veloce memoria:cioè che i programmi possano indirizzare unospazio di memoria grande come un disco allavelocità con cui accedono ai registri interni

UC Regents Spring 2005 © UCBCS 152 L14: Cache I
(1K)
Registers
L1 (64K Instruction)
L1 (32K Data)
512KL2
90 nm, 58 Mtransistors
PowerPC 970 FX

Latenza: tempi accesso lettura
Reg L1 Inst L1Data L2 DRAM Disk
Size 1K 64K 32K 512K 256M 80GLatency(cycles) 1 3 3 11 160 1e7Latency
(sec) 0.6n 1.9n 1.9n 6.9n 100n 12.5m
Hz 1.6G 533M 533M 145M 10M 80
Nota: tempi di accesso per accedere un dato in modo casualeper accedere ad un blocco di dati in locazioni adiacenti i tempidi accesso per il secondo, il terzo, .. dato sono inferioriAd esempio con N banchi di memoria separati posso accedere aN dati con soli N cicli in più del primo (accesso interleaving)

Principio di località
Un sistema di memoria gerarchico è efficiente sela modalità di accesso ai dati sono prevedibili
Il principio di località : in un dato istante iprogrammi fanno accesso ad una porzionerelativamente piccola del loro spazio diindirizzamento (sia dati che istruzioni)
° Località temporale: è probabile che un oggetto acui si è fatto riferimento venga nuovamente richiestoin tempi brevi (Es: cicli in un programma: le istruzionisono richieste ripetutamente)
° Località spaziale: è probabile che gli oggetti che sitrovano vicini ad un oggetto a cui si è fattoriferimento vengano richiesti in tempi brevi (Es:esecuzione sequenziale in un programma; accessoagli elementi di un vettore)
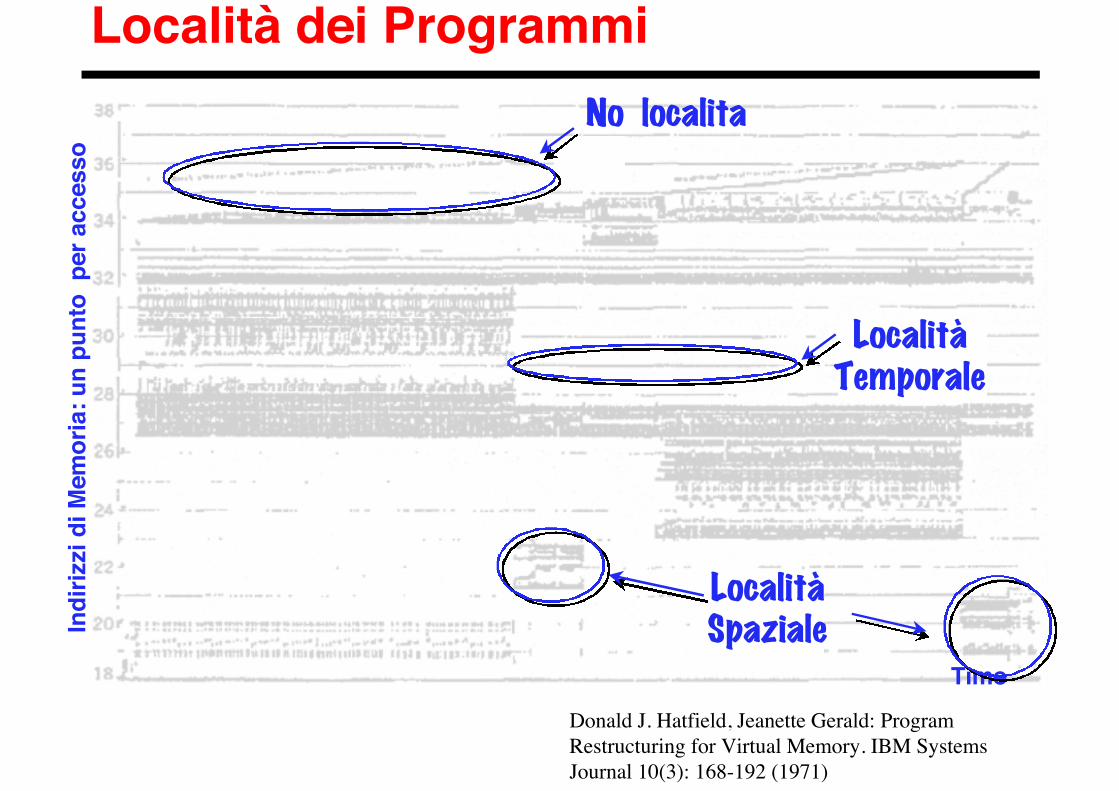
Località dei Programmi
Donald J. Hatfield, Jeanette Gerald: ProgramRestructuring for Virtual Memory. IBM SystemsJournal 10(3): 168-192 (1971)
Time
Indi
rizzi
di M
emor
ia: u
n pu
nto
per
acc
esso
LocalitàSpaziale
LocalitàTemporale
No localita

L’algoritmo di caching
Località Temporale: mantieni i datirichiesti recentemente vicino alla CPU
Località Spaziale: Muovi blocchi contiguidi dati nei livelli di memoria più vicini allaCPU
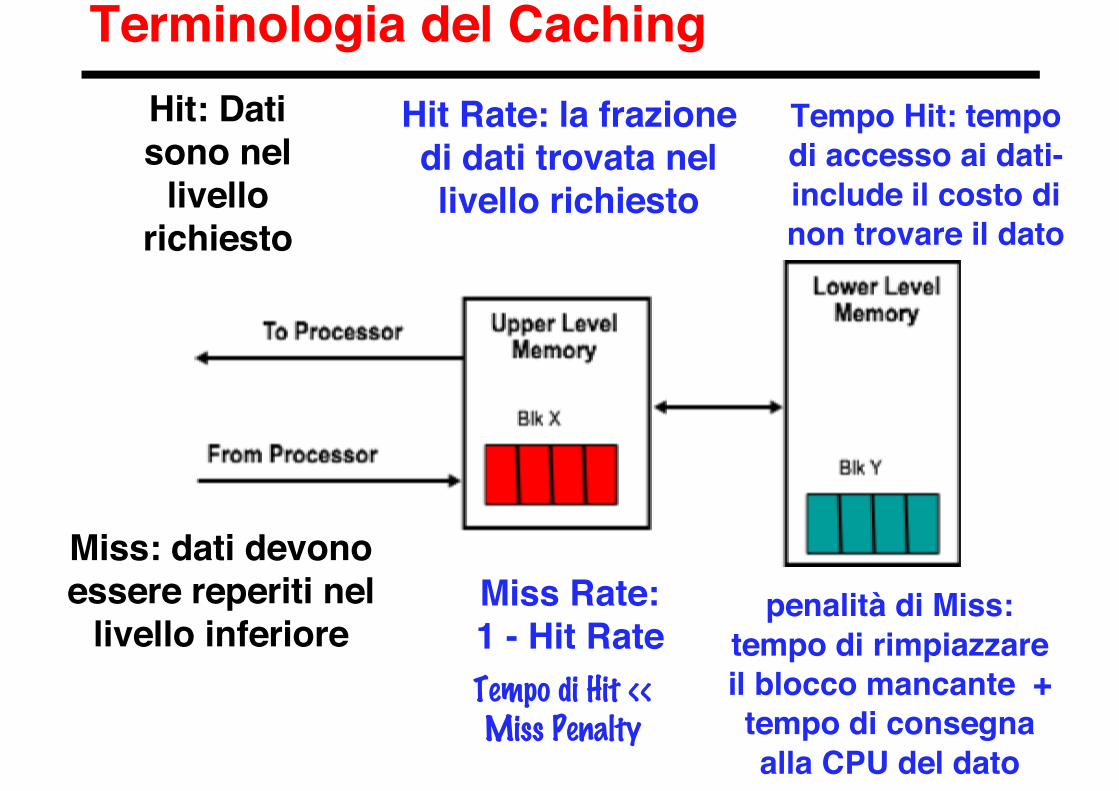
Terminologia del CachingHit: Datisono nel
livellorichiesto
Miss: dati devonoessere reperiti nel
livello inferiore
Hit Rate: la frazionedi dati trovata nellivello richiesto
Miss Rate:1 - Hit Rate
Tempo Hit: tempodi accesso ai dati-include il costo dinon trovare il dato
penalità di Miss:tempo di rimpiazzareil blocco mancante +tempo di consegnaalla CPU del dato
Tempo di Hit <<Miss Penalty

Hit & MissSi ha hit (successo nell’accesso) quando i dati richiesti dal livello
superiore (ad es. il processore) compaiono in qualche blocco nel livelloinferiore.
Si ha un miss (fallimento nell’accesso) se il dato non è presente nellivello immediatamente inferiore ed occorre accedere al livello piùdistante.
Uno dei parametri principali per la valutazione delle prestazioni di unagerarchia di memoria è l’hit ratio (tasso di hit), ovvero la frazionedegli accessi in ram che si sono risolti al livello più vicino. Il miss ratioè definito come 1-hit ratio ed indica la percentuale degli accessi chenon sono stati soddisfatti dal livello più vicino nella gerarchia.
Tempo di hit: tempo necessario a prelevare il dato dal livello più vicino,comprendendo il tempo necessario a determinare se l’accesso è un hito un miss.
Tempo di miss: tempo necessario a sostituire un dato nel livello piùvicino con il blocco corrispondente nel livello inferiore, più il temponecessario per consegnare il dato al livello richiedente (ad es. ilprocessore).

La cache
Il termine cache è stato usato per la prima volta per indicareil livello della gerarchia tra la CPU e la memoriaprincipale, ma è oggi utilizzato per indicare qualsiasi tipodi gestione della memoria che tragga vantaggio dallalocalità degli accessi.
Il meccanismo è semplice: Il processore interagiscedirettamente SOLO con la cache. Quando il processorerichiede una parola non presente nella cache (miss) laparola viene trasferita dalla memoria nella cache
Occorre definire dei meccanismi per:1. Conoscere se un dato è nella cache2. Nel caso in cui il dato sia presente, conoscere la sua
posizione ed accedervi.Queste operazioni devono essere eseguite nel minor tempo
possibile, poiché la velocità con cui si riesce ad accedereai dati nella cache influisce molto sulle prestazionidell’intero sistema di memoria.
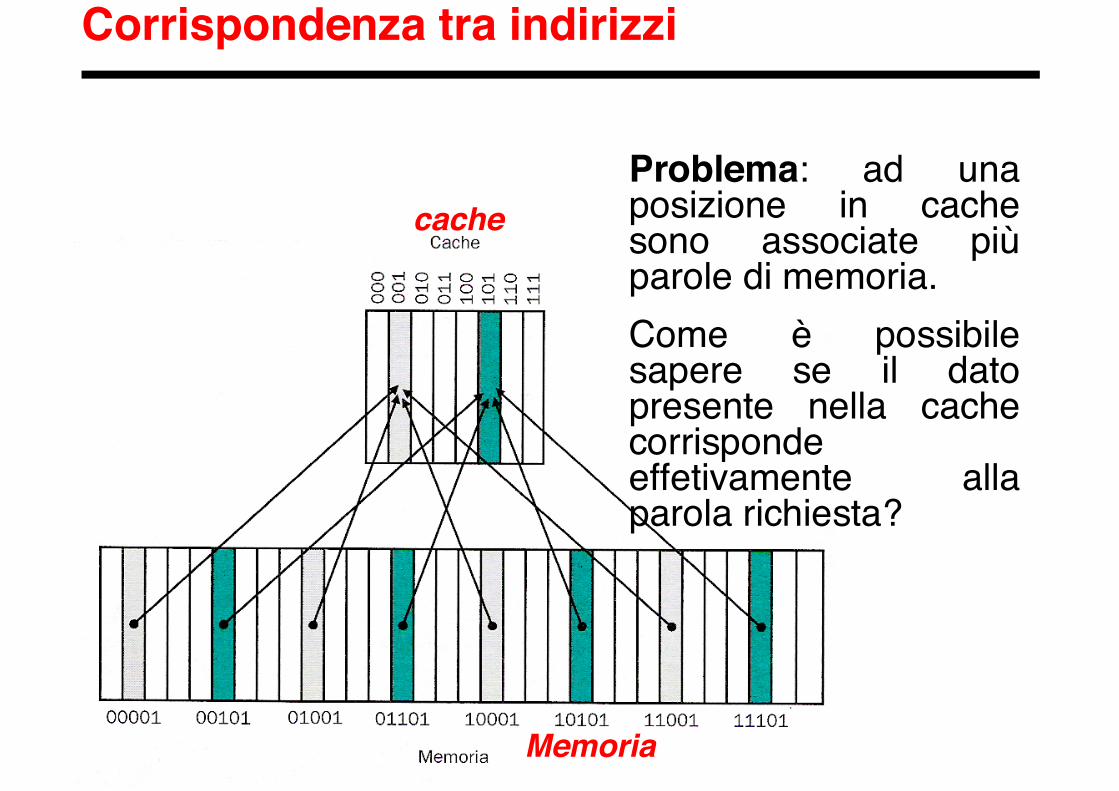
Corrispondenza tra indirizzi
Problema: ad unaposizione in cachesono associate piùparole di memoria.Come è possibilesapere se il datopresente nella cachecorrispondeeffetivamente allaparola richiesta?
Memoria
cache

I tag
Oltre ai dati richiesti, la cache deve permettere lamemorizzazione di informazioni aggiuntive (tags)che permettano la corretta gestione della gerarchiadi memorie.
Per associare univocamente una parola di memoriaad una posizione in una cache direct mapped èsufficiente memorizzare, assieme al dato,anche la parte più significativa dell’indirizzo,quella che non corrisponde ai bit utilizzati comeindice nella cache.
Per distinguere le posizioni della cache contenentidati validi (es.all’avvio del processore la cache èvuota ed il suo contenuto non è significativo), ilmetodo più comune è aggiungere un bit divalidità.

Sfruttare la località spaziale
Per trarre vantaggio del principio di località spaziale,è opportuno prevedere che i blocchi della cachesiano più ampi di una sola parola. In caso di misssaranno così caricate diverse parole adiacenti chehanno un’elevata probabilità di essere richieste nelprossimo futuro.
Ogni linea di cache memorizza più parole e si usa ilcampo “Offset del blocco” per selezionare laparola richiesta tra quelle presenti nella linea
Nota: una linea della cache contiene più dati ma i bitdi indirizzo e i tag non sono replicati. Perché?

CPU spazio indirizzi: vettore di “blocchi”Block #
7
123456
0
227
- 1
...
32-byte blocks
27 bits 5 bits
Il compito di unacache è di
memorizzare lepagine “piùpopolari”
Nel seguito assumiamoindirizzo di memoria 32-bitblocco di memoria: 32 byte
Numero del blocco Byte #031
mem
oria

Cache a corrispondenza diretta-direct mapped
A ciascuna parola di memoria corrispondeesattamente una locazione della cache.posizione nella cache=(indir. parola) mod (numero di posizioni in cache)
Se il numero di blocchi nella cache e’ 2N allorala posizione corrispondente della parola in cache èdata dai N bits meno significativi dell’indirizzo
Esempio:Numero di elementi nella cache: 4Bit per indirizzare una locazione della cache:log2(8)=2Indirizzo della parola di memoria=
0111 01010 0010 0100Posizione in cache: 00 (posizione 0)

Cache direct mappedBlock #
7
123456
0
227
- 1
...
32-byte blocksBlocchi di un dato colorepossono comparire SOLOnella stessa linea di cache
32-bit Memory Address
Numero del blcoo Colore Byte #
031 4567
25 bits 2 bits 5 bits
Indica la riga dellacache: sono sufficiente2 bit per specificareun colore fra quattro

Cache Direct Mapped: esempio
Cache Tag (25 bit) Indice No. Byte
531 04
=
Hit: si verifica sei 25 bit
significatividell’indirizzo
sono uguali a tagmemorizzato in
cache
Ex: 0x01
Se si verifica Hit ildato viene fornito
alla CPU
Ex: 0x00
67
BitValidità
Byte31 ... Byte
1Byte
0
Byte31 ... Byte
1Byte
0
Cache Tag 024 DATI Cache
indirizzo memoria (32 bit)

Dimensione di una cache direct mapped
Calcolo della dimensione totale di unacache a corrispondenza diretta
Il numero totale di bit in una cache acorrispondenza diretta con 2n blocchi èmaggiore di: 2n x dim.blocco= 2n x 32 bits
InfattiAssumendo che la cache abbia una capacità di 2n
parole, e blocchi di 32 bit (4 bytes) il campo tagha dimensione: 32 – (n+2) bit, (2 bit sono usatiper l’offset del byte, indir. su byte), ladimensione è pari a
2n x (dim.blocco+dim.tag+dim.bit validità)=2n x (32+32-(n+2)+1)= 2n x (63-n) bits

I limiti di cache direct-mapped...
Donald J. Hatfield, Jeanette Gerald: ProgramRestructuring for Virtual Memory. IBM SystemsJournal 10(3): 168-192 (1971)
TimeIndi
rizzo
i di
mem
oria
: un
pun
to p
er a
cces
so)
Cosa succede se i blocchihanno lo stesso colore?

Cache Fully associative
Nelle cache direct mapped a ciascun blocco della memoriacorrisponde una specifica locazione nella cache
Cache fully associative (completamente associativa):ogni blocco può essere collocato in qualsiasi locazionedella cache
Vantaggio: massima utilizzazione della cacheContro: per ricercare un blocco nella cache è necessario
cercarlo in tutte le linee della cache.° La ricerca sequenziale è troppo lenta° Per velocizzare la ricerca è necessario effettuarla in
parallelo, associando un comparatore a ciascunaposizione della cache. COSTO MOLTO ELEVATO

Cache Fully Associative
Cache Tag (27 bit) No. Byte
531 04
Ex: 0x04
BitValidità
Byte31 ... Byte
1Byte
0
Byte31 ... Byte
1Byte
0
Cache DataHolds 4 blocks
=
=
=
=
Hit: esiste una linea dellacache in cui tag indirizzo=
tag in cache
Se si verifica Hit ildato viene fornito
alla CPU
Block # (”Tags”)026
Ideali ma costose...

Cache set associative
Nelle cache direct mapped a ciascun blocco della memoriacorrisponde una specifica locazione nella cache.
In una cache fully associative ogni blocco può esserecollocato in qualsiasi locazione della cache.
Un buon compromesso è costituito dalle cache set-associative (anche n-way set associative) : ciascunblocco di memoria ha a disposizione un numero fisso n(>=2) di locazioni in cache. In questo caso la ricerca diun blocco richiede di confrontare il tag in n posizioni
In questo modo si trae vantaggio della possibilità senzaaumentare il costo di ricerca in modo inaccettabile

Cache 2-Set Associative
Cache Tag (26 bits) Index(2 bits)
Byte Select(4 bits)
NOTA: in esempio la dim. blocco è lametà per mantenere costante ilnumero di bit dati in cache
Valid
Cache Block
Cache Block
Cache Tags Cache Data
Cache Block
Cache Block
Cache TagsValidCache Data
Ex: 0x01
=
HitRight
=
HitLeft
Hit: il dato ètrovato nel
blocco a destrao in quello a
sinistra
“N-way” set associative -- N è il numero di blocchi di ciascun colore (in fig. 2)
16 bytes16 bytes
PowerPC 970: 32K 2-wayset associative L1 D-cache

Cache 4-set associative

Politiche di rimpiazzamento in cache
Dopo un miss in cache se non ci sono blocchidisponibili, quale blocco bisogna rimuoveredalla cahce (per fare posto al blocco chiesto)?
Blocco scelto a caso (random)?Facile da realizzare;
MA è efficiente?
L’ultimo blocco richiesto (LRU)?Auspicabile MA difficile daimplementare in cache complet.associat.
Dimens. Random LRU16 KB 5.7% 5.2%64 KB 2.0% 1.9%
256 KB 1.17% 1.15%
Miss Rate per cache 2-way Set Associative
Nota: nel caso 2-way è faciel realizzare LRU

Gestione delle operazioni di scrittura
Le operazioni di scrittura devono essere gestite inmaniera più complessa rispetto alle letture. Se lescritture alterassero solo lo stato della cache e nonvenissero propagate fino alla memoria principale sicreerebbero situazioni di incoerenza
Due modalità:write-through: assicurare la coerenza di cache ememoria scrivendo sempre i dati sia nella memoriache nella cache.write back: scrivere solo quando necessario

Write through1. Accedere alla cache usando come indice i bit meno
significativi dell’indirizzo2. Scrivere i rimanenti bit dell’indirizzo nel campo tag,
scrivere la parola di dato e settare il bit di validità3. Scrivere la parola nella memoria principale
utilizzando l’indirizzo completoSvantaggi: tutte le operazioni di scrittura implicano
scrittura nella memoria principale, durante le quali ilprocessore rimane in fase di stallo.
Possibile soluzione: buffer delle scritture. Limiti:processore può generare richieste di scritture ad untasso maggiore di quello con cui la memoria porta atermine le scritture
Nota: per scrivere non è necessario effettuare accessi inlettura alla memoria principale.

Write back
Una tecnica alternativa che offre prestazioni ingenere superiori è il write-back.
I blocchi sono effettivamente scritti in memoriaprincipale solo quando è necessario rimpiazzarlinella cache
Svantaggio: maggiore complessità implementativarispetto al write-through
Vantaggio: minore numero di accessi alla memoriaprincipale e quindi maggiore efficienza. Infatti, seuna variabile viene modificata più volte mentre è incache si accede alla memoria una sola volta(quando esce dalla cache)

Gestione delle scritture
Quando si scrive è necessario verificare sempreoffset.
All’atto della scrittura si confronta il tag in cache conquello associato all’indirizzo in cui scrivere. Se sonouguali è sufficiente aggiornare la parola in cache.Altrimenti è necessario caricare l’intero blocco incache e quindi riscrivere la parola che ha causato ilmiss.

Politiche di scrittura
Write-Through Write-Back
PoliticaI dati scritti in
cache sono anchescritti nella
memoria di livelloinferiore
I dati sonoscritti solo incacheSi aggiorna la
memoria dilivello infer.solo quando siha miss
I miss inscrittura
produconooperazioni di
lettura?No Sì
Scrittureripetute sullostesso dato
provocano piùscritture inmemoria di
livelloinferiore?
Sì No
Altraquestione:le scritturedi blocchi
NON in cacheimplicano
l’aggiornamento della
cache o solola scritturadei dati in
memoria dilivello
inferiore?

Prestazioni di cache
Tempo esecuz.programma(sec.)
Numeroistruz. progr.=
Secondiper ciclo
Cicliclockper istr.
NOTA: il numero di cicli diclock per istr. dipende dal
Tempo Medio di Accesso inMemoria per istr. e dati (TMAM)
TMAM = Hit Time +(Miss Rate x Miss Penalty)
Obiettivo: Ridurre TMAM
NOTA: migliorare un fattore puòimlicare l’aumento di altri
fattori!
* *
Cause di miss
• miss obbligatori
• miss di conlfitto
• miss di capacità
Tipicamente miss ratevaria da
1% a 15%

Cause di miss in cache: Miss di conflitto cache M-way assoc.: N blocchi sono usati che
sono in conflitto ma M < N
Soluzione: aumentare M(Associatività)
cache associative
MissRate
Dimens. Cache (KB)
Miss rateimprovementequivalent todoublingcache size.
Altre soluzioniAumenta la dimensioneblocco. (perché funziona?)
.
NOTA: aumentare associativitàpuò aumentare hit timeaumentare dimensione delblocco (a parità di dimensionedella cache può aumentare altritipi di conflitto
TMAM = Hit Time + (Miss Rate x Miss Penalty)Se aumenta Hit time aumenta TMAM
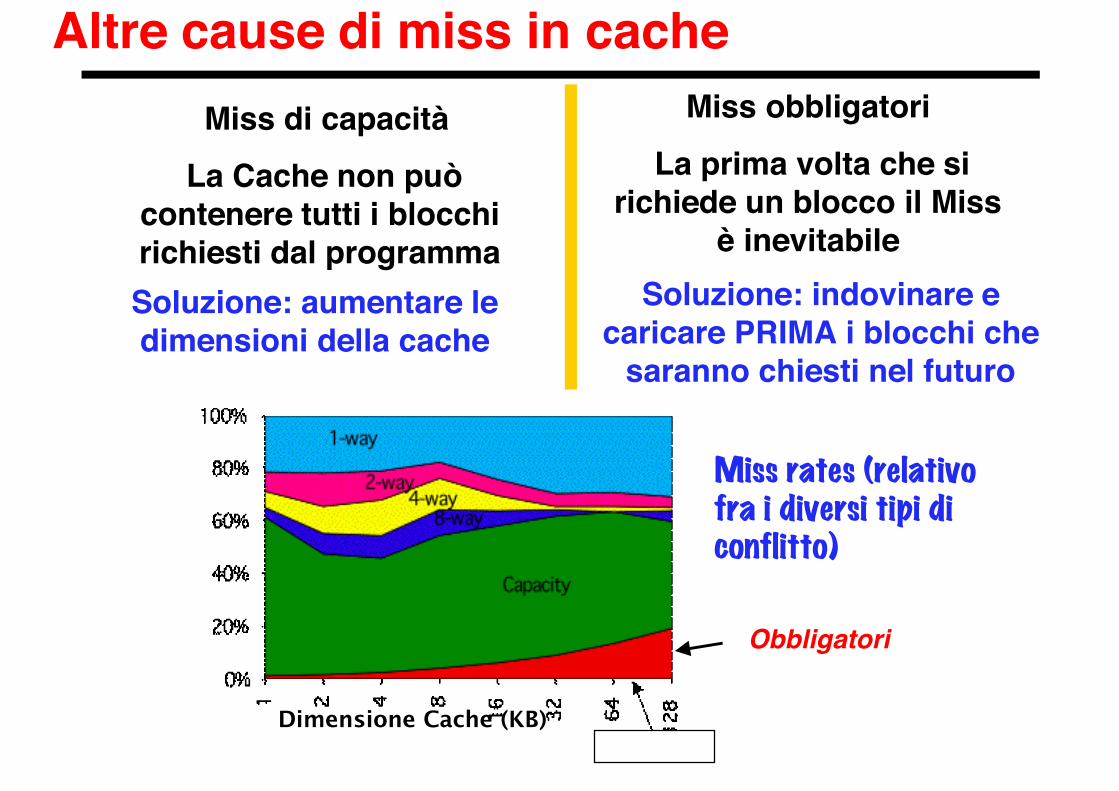
Altre cause di miss in cache
Soluzione: indovinare ecaricare PRIMA i blocchi che
saranno chiesti nel futuro
Miss di capacità La Cache non può
contenere tutti i blocchirichiesti dal programmaSoluzione: aumentare ledimensioni della cache
Miss obbligatori La prima volta che si
richiede un blocco il Missè inevitabile
Miss rates (relativofra i diversi tipi diconflitto)
Dimensione Cache (KB)
Obbligatori

Miss rate e dimensione dei blocchi
D: Perché al crescere della dim.del blocco il miss rate primadiminuisce e poi cresce?

Altre domande su cacheQuali tipi di miss si verificano in cacheassociative di dimensioni infinite?R. miss obbligatori: bisogna portare un blcoo in memoria .
In una cache associtaiva di dimensionefinita, quali tipi di miss si verificano (oltreagli obbligatori)?
R. miss di capacità. I programmi possonoi usare piùblocchi di quanto entrino in cache.
Inoltre quali tipi di miss asi verificano in unacache set-associative o direct-mapped?R. miss di conflitto.
Calcola il numero di bit richiesto da cache k-set associative.

Esempio di accesso ad una cache a corrispondenzadiretta

La sequenza di accessi considerata

Stato Iniziale

Primo accesso: 22=MISS

Secondo Accesso: 26=MISS

Terzo Accesso: 22 = HIT!

Quarto Accesso: 26 = HIT!

Quinto Accesso: 16 = MISS

Sesto Accesso: 3 = MISS

Settimo Accesso: 16 = HIT

Ottavo Accesso: 18 = Miss + Sovrascrittura

Cache multi livello
Aggiunta di un secondo livelo di cache:spesso la cache primaria è nello stesso chip del processoresi introduce un altro cache basato su tecnologia SRAM tra la
cache primaria e la memoria principale (DRAM)La penalità di miss è ridotta sensibilmente se il dato è trovato
sulla cache di secondo livelloEsempio:
CPI di 1.0 con elaboratore a 500Mhz con 5% miss rate, 200ns DRAMaccesso
Aggiungendo 2nd level cache con tempo di accesso di 20ns timeilmiss rate si abbassa a 2%
Utilizzo di multilevel caches:Si tenta di ottimizzare il tempo di hit sulla cache di primo livelloSi tenta di ottimizzare il tasso di miss sulla cache di secondo
livello.

Prestazioni delle cache a più livelli
Dato un Processore a 2 GHZ (tempo di clock 0.5 ns) conCPIideale=1,0 (se tutti gli accessi sono risolti nella L1cache).
Tempo di accesso a RAM=50ns; Miss-rate L1 cache=5%Miss penalty = 50 ns/ 0,5 ns/cicli di clock = 100 cicli di clockCPIeffettivo=CPIideale+cicli di stallo per istruzione dovuti ad
accesso a RAMCPIeffettivo=1+5%*100=6
Supponiamo di introdurre una cache di secondo livello con :° Tempo di accesso= 5 ns ed° grande abbastanza da avere: Miss-rate L2 cache=2%
Miss penalty L2 cache= 5 ns/0,5 ns/cicli di clock = 10 cicli diclock
CPIeffettivo=CPIideale+cicli di stallo per istruzione dovuti adaccesso a RAM+cicli di stallo per istruzione dovuti adaccesso a L2 cache
CPIeffettivo=1+5%*10+2%*100=3,5