
ANCHELEAPPLICAZIONI CONSUMANOENERGIA -...
16
MONDO DIGITALE •n.1 - marzo 2011 1. INTRODUZIONE AL GREEN SOFTWARE I l Green IT, che nella sua accezione più pro- pria è la disciplina che studia l’efficienza energetica dell’IT, è ormai al centro dell’at- tenzione a livello sia accademico che indu- striale da alcuni anni. Nell’ambito del Green IT è possibile distinguere diversi campi di azione, tra i quali i più importanti sono: ❑ Postazioni di lavoro; ❑ Data center; ❑ Green hardware; ❑ Green software; Il consumo energetico dell’IT distribuito (pri- ncipalmente PC, monitor, laptop, stampanti) raccoglie sempre più attenzione in quanto il suo campo di applicazione è molto vasto, poiché la maggior parte delle aziende è or- mai informatizzata o comunque dispone di postazioni di lavoro informatizzate. Tuttavia, le leve principali di ottimizzazione dell’effi- cienza energetica dell’IT distribuito non sono informatiche, ma di tipo gestionale: politiche di acquisto, politiche comportamentali, poli- tiche di gestione e assegnazione delle risor- se informatiche in base al reale fabbisogno. L’efficienza energetica dei data center è un te- ma di ricerca e innovazione su cui diverse aziende e centri di ricerca stanno ormai lavo- rando da anni, [5, 7, 8, 15]. Un data center di medie dimensioni può consumare anche 300 kW, l’equivalente di 100 appartamenti, men- tre un data center di una grande banca o di un operatore Telecom può arrivare a consumare diversi MW. Le riduzioni di consumo e di costo ottenibili sono quindi rilevanti, anche se ri- guardano un numero relativamente ristretto di enti e aziende (in Italia si contano circa 3.000 data center con più di 5 rack). La mag- gior parte dell’energia assorbita da un data center viene dissipata dai componenti infra- strutturali [9, 2] come gli impianti di condizio- namento, gli UPS (Uninterruptible Power Sup- ply) e i sistemi di distribuzione dell’energia. Un indicatore comunemente utilizzato per mi- surare l’efficienza energetica di un data center è il PUE (Power Usage Effectiveness), calcola- to come la potenza elettrica entrante nel data center divisa per la potenza elettrica che effet- tivamente arriva ai macchinari IT. Benché al- Ormai da qualche anno si parla diffusamente dell’efficienza energetica del- l’IT, ma raramente si affronta il problema del ruolo rivestito dal software nel determinare il consumo energetico dell’IT. È infatti il software a “guidare” il funzionamento dell’hardware e quindi ad essere il primo responsabile del consumo. L’articolo presenta i risultati di alcune ricerche sperimentali che mostrano l’impatto del software sui consumi e propone una panoramica sulle linee di ricerca attualmente in corso per ottimizzarne l’efficienza. Giovanni Agosta Eugenio Capra GREEN SOFTWARE ANCHE LE APPLICAZIONI CONSUMANO ENERGIA 9 3.2
Transcript of ANCHELEAPPLICAZIONI CONSUMANOENERGIA -...

M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1. INTRODUZIONEAL GREEN SOFTWARE
I l Green IT, che nella sua accezione più pro-pria è la disciplina che studia l’efficienza
energetica dell’IT, è ormai al centro dell’at-tenzione a livello sia accademico che indu-striale da alcuni anni. Nell’ambito del GreenIT è possibile distinguere diversi campi diazione, tra i quali i più importanti sono:� Postazioni di lavoro;� Data center;� Green hardware;� Green software;Il consumo energetico dell’IT distribuito (pri-ncipalmente PC, monitor, laptop, stampanti)raccoglie sempre più attenzione in quanto ilsuo campo di applicazione è molto vasto,poiché la maggior parte delle aziende è or-mai informatizzata o comunque dispone dipostazioni di lavoro informatizzate. Tuttavia,le leve principali di ottimizzazione dell’effi-cienza energetica dell’IT distribuito non sonoinformatiche,ma di tipo gestionale: politichedi acquisto, politiche comportamentali, poli-tiche di gestione e assegnazione delle risor-
se informatiche in base al reale fabbisogno.L’efficienza energetica dei data center è un te-ma di ricerca e innovazione su cui diverseaziende e centri di ricerca stanno ormai lavo-rando da anni, [5, 7, 8, 15]. Un data center dimedie dimensioni può consumare anche 300kW, l’equivalente di 100 appartamenti, men-tre un data center di una grande banca o di unoperatore Telecom può arrivare a consumarediversiMW. Le riduzioni di consumoedi costoottenibili sono quindi rilevanti, anche se ri-guardano un numero relativamente ristrettodi enti e aziende (in Italia si contano circa3.000 data center con più di 5 rack). La mag-gior parte dell’energia assorbita da un datacenter viene dissipata dai componenti infra-strutturali [9, 2] come gli impianti di condizio-namento, gli UPS (Uninterruptible Power Sup-ply) e i sistemi di distribuzione dell’energia.Un indicatore comunemente utilizzato permi-surare l’efficienza energeticadi undata centerè il PUE (Power Usage Effectiveness), calcola-to come la potenza elettrica entrante nel datacenterdivisa per la potenza elettrica che effet-tivamente arriva ai macchinari IT. Benché al-
Ormai da qualche anno si parla diffusamente dell’efficienza energetica del-
l’IT, ma raramente si affronta il problema del ruolo rivestito dal software nel
determinare il consumo energetico dell’IT. È infatti il software a “guidare” il
funzionamento dell’hardware e quindi ad essere il primo responsabile del
consumo. L’articolo presenta i risultati di alcune ricerche sperimentali che
mostrano l’impatto del software sui consumi e propone una panoramica
sulle linee di ricerca attualmente in corso per ottimizzarne l’efficienza.
Giovanni AgostaEugenio Capra
GREEN SOFTWAREANCHE LE APPLICAZIONICONSUMANO ENERGIA
9
3.2
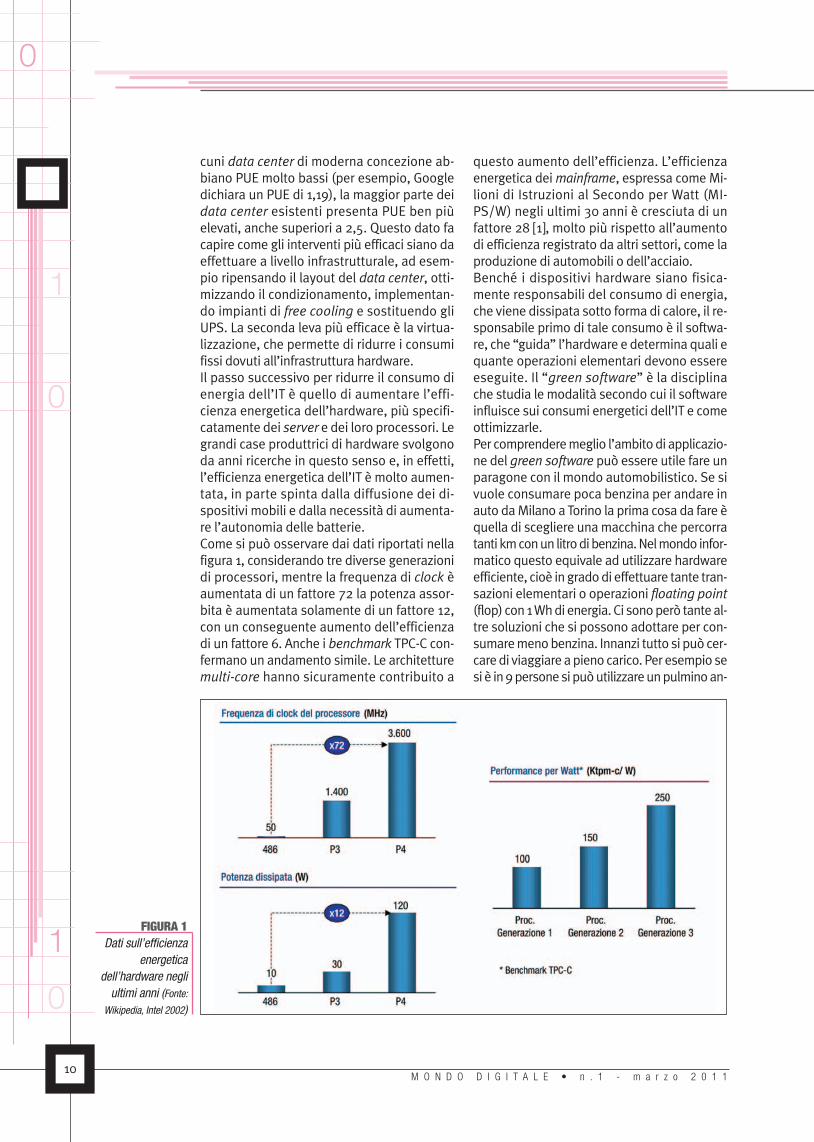
cuni data center di moderna concezione ab-biano PUE molto bassi (per esempio, Googledichiara un PUE di 1,19), la maggior parte deidata center esistenti presenta PUE ben piùelevati, anche superiori a 2,5. Questo dato facapire come gli interventi più efficaci siano daeffettuare a livello infrastrutturale, ad esem-pio ripensando il layout del data center, otti-mizzando il condizionamento, implementan-do impianti di free cooling e sostituendo gliUPS. La seconda leva più efficace è la virtua-lizzazione, che permette di ridurre i consumifissi dovuti all’infrastruttura hardware.Il passo successivo per ridurre il consumo dienergia dell’IT è quello di aumentare l’effi-cienza energetica dell’hardware, più specifi-catamente dei server e dei loro processori. Legrandi case produttrici di hardware svolgonoda anni ricerche in questo senso e, in effetti,l’efficienza energetica dell’IT è molto aumen-tata, in parte spinta dalla diffusione dei di-spositivi mobili e dalla necessità di aumenta-re l’autonomia delle batterie.Come si può osservare dai dati riportati nellafigura 1, considerando tre diverse generazionidi processori, mentre la frequenza di clock èaumentata di un fattore 72 la potenza assor-bita è aumentata solamente di un fattore 12,con un conseguente aumento dell’efficienzadi un fattore 6. Anche i benchmark TPC-C con-fermano un andamento simile. Le architetturemulti-core hanno sicuramente contribuito a
questo aumento dell’efficienza. L’efficienzaenergetica dei mainframe, espressa comeMi-lioni di Istruzioni al Secondo per Watt (MI-PS/W) negli ultimi 30 anni è cresciuta di unfattore 28 [1], molto più rispetto all’aumentodi efficienza registrato da altri settori, come laproduzione di automobili o dell’acciaio.Benché i dispositivi hardware siano fisica-mente responsabili del consumo di energia,che viene dissipata sotto forma di calore, il re-sponsabile primo di tale consumo è il softwa-re, che “guida” l’hardware e determina quali equante operazioni elementari devono essereeseguite. Il “green software” è la disciplinache studia le modalità secondo cui il softwareinfluisce sui consumi energetici dell’IT e comeottimizzarle.Per comprenderemeglio l’ambitodi applicazio-ne del green software può essere utile fare unparagone con il mondo automobilistico. Se sivuole consumare poca benzina per andare inauto daMilano aTorino la prima cosa da fare èquella di scegliere unamacchina che percorratanti kmconun litrodibenzina.Nelmondo infor-matico questo equivale ad utilizzare hardwareefficiente, cioè ingradodi effettuare tante tran-sazioni elementari o operazioni floating point(flop) con1Whdi energia. Ci sonoperò tanteal-tre soluzioni che si possono adottare per con-sumaremenobenzina. Innanzi tutto si puòcer-caredi viaggiareapienocarico. Per esempiosesi è in9personesipuòutilizzareunpulminoan-
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
0
0
0
1
10
FIGURA 1Dati sull’efficienza
energeticadell’hardware negliultimi anni (Fonte:
Wikipedia, Intel 2002)

ziché 2 automobili. Questo equivale a bilancia-re i carichi di lavoro e a virtualizzare i sistemi,praticheche rientranonell’ambitodelgreen da-ta center. Dopodiché si può viaggiare alla velo-citàcheminimizza il consumodi carburante, chesolitamente non coincide con lamassima velo-cità raggiungibiledal veicolo. Infine, si puòsce-gliere la strada cheminimizza il numero di kmpercorsi. Queste due ultime tipologie di azionicorrispondononelmondo informatico algreensoftware. Un’applicazione può essere valutatain base alla sua efficienza energetica, oltre cheinbaseagli altri classici parametri dimerito, co-me il tempodi risposta. Inoltre, un’applicazionescritta “bene” permetterà di soddisfare i requi-siti funzionali tramite ilminornumeropossibiledi operazioni elementari e quindi di energia.Mentre diverse ricerche sono state svolte sul-l’hardware, sui sistemi embedded [4] e sui da-ta center, il tema dell’efficienza energetica delsoftware applicativo è relativamente nuovo einesplorato. Il ciclodi sviluppodel softwaree lerelative metodologie non prendono pratica-mentemai in considerazione l’efficienza ener-getica come obiettivo. D’altro canto, è la stes-sa crescentedisponibilità di hardware efficien-te e a basso costo che induce i programmatoria non occuparsi dell’efficienza energetica delcodice. La letteraturaattuale sull’ingegneriadelsoftwarenon fornisceneppuremetrichepermi-surare l’efficienzaenergeticadel software.Nep-pure le 50metriche di qualità del software de-finitedall’International Standards Organization(ISO/IECTR9126:2003andTR25000:2005) in-cludono l’efficienza energetica.Lamaggior parte degli ITmanager sembra cre-dere che il software di per sé abbia un impattomolto limitato sui consumi, specialmente nel-l’ambito dei sistemi transazionali classici, co-me i softwarebancari o gliEnterprise ResorucePlanning (ERP) [6]. È generalmente accettatoche i sistemi operativi influenzino le prestazio-ni e i consumi di energia [10], ma non le appli-cazioni. Queste convinzioni raramente sonosupportate da un approccio scientifico e damisure sperimentali.In realtà il potenzialedi risparmioottenibiledalgreen software è elevato. Infatti, come accen-nato sopra, nellamaggiorpartedeidata centerla percentuale di energia entrante, effettiva-mente utilizzata per il calcolo, è molto bassa acausa delle inefficienze dei diversi livelli infra-
strutturali. Questi dati possono essere inter-pretati al contrario: per ogni Watt di energiautilizzato per il calcolo sono necessari almeno5 o piùWatt totali. Quindi i risparmi ottenuti alivello software vengono amplificati da tutti i li-velli infrastrutturali soprastanti: se vengonoeseguitemenooperazioni elementari saràpro-dottomeno calore, quindi sarà necessariame-no energia per il condizionamento, e così via.Questoarticolo si focalizzerà sulgreen softwa-re, dapprima discutendo alcuni risultati speri-mentali che mostrano come il consumo ener-getico del software sia effettivamente signifi-cativo, e in seguitoproponendoalcune lineediricerche sul tema, attualmente in corso di ese-cuzione presso il Dipartimento di Elettronica eInformazione del Politecnico diMilano.
2. IL CONSUMO ENERGETICODEL SOFTWARE È SIGNIFICATIVO
2.1. Il sistema per la misura sperimentaledel consumoPer poter affrontare in modo scientifico il pro-blema del consumo energetico indotto dalsoftware è opportuno innanzi tutto analizzarequalche dato sperimentale. La figura 2 illustral’architettura del sistema adottato per misura-re empiricamente il consumo di energia. Il si-stema comprende un kit hardware permisura-re l’energia assorbita dal server basato su pin-ze amperometriche e uno strumento softwareper generare carichi di lavoro di benchmarkper diverse categorie di applicazioni. Per averemisure significative rispetto alle realtà azien-dali, si è sceltodi confrontare applicazioni di ti-po Management Information Systems (MIS)con caratteristiche funzionali e parametri con-frontabili anziché utilizzare benchmark più dif-fusi in letteratura come gli SPEC o i TPC.In particolare sono stati confrontati:� 2 sistemi Enterprise Resource Planning(ERP): Adempiere e Openbravo;� 2 sistemi Customer Relationship Manage-ment (CRM): SugarCRM e vTiger;� 4 Database Management Systems (DBMS):MySQL, PostgreSQL, Ingres eOracle.Tutte lemisuresonostateeffettuatesulla stes-sapiattaformahardwaree leapplicazioni sonostate configurate in modo tale da essere il piùpossibili confrontabili. Per esempio, i DBMSsono stati configurati con la stessa dimensio-
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
11
0
0
0
1

nedi pagina, bloccoe cachee congli stessi pa-rametri relativi al buffering, alla memoria tota-le di sistema e al numero di connessioni (si ve-da [3] per ulteriori dettagli).Le applicazioni vengono eseguite sul server,cheè lamacchinadi cui simisura il consumodienergia. Per ogni applicazione sono stati rea-lizzati diversi esperimenti con un numero diclient variabile da 1 a 10. È stato sviluppato untool Java, chiamato Workload Simulator, ingrado di simulare per ciascuna applicazioneun flusso di operazioni e di eseguirlo per uncerto numero di volte simulando una certaquantità di utenti simultanei e generando inquesto modo un carico di lavoro di bench-mark. Per gli ERP i carichi di lavoro consideratisono stati l’inserimento di un nuovo businesspartner, di unnuovoprodottoediunnuovoor-dine. Per i CRMsono stati simulati la creazionedi un nuovo account e di una nuova campa-gna. Infine, per i DBMS è stata implementatauna versione ad-hoc del benchmark TPC-C,che è comunemente utilizzato per confrontareleperformance di sistemi transazionali.Il segnale analogico acquisito dalle pinze am-perometriche viene processato da un Data Ac-quisition Board (DAQ) NI USB-6210, che è col-legato via USB con un altro PC, la Virtual In-strument machine. L’analisi dei dati è effettua-
ta tramite un tool software sviluppato tramiteLabVIEW (www.ni.com/labview/), che acquisi-sce e campiona i valori della potenza assorbitaogni 4 microsecondi (quindi con una frequen-za di campionamento di 250MHz) e infine cal-cola il valore totale dell’energia consumata in-terpolando i valori della potenza. Per non in-fluenzare la misura sia il Workload Simulatorche i software per l’acquisizione delle misurerisiedevano sumacchine diverse dal server.
2.2. Alcuni risultati sperimentaliLe figure 3, 4 e 5 mostrano il valore della po-tenza consumata rispetto al tempo per le trecategorie di applicazioni considerate esegui-te su sistemaWindows (graficiA) e Linux (gra-fici B). La linea dritta in ciascun grafico rap-presenta il valore di potenza assorbito in idledal sistema, mentre nel riquadro in alto a de-stra vengono indicati i valori dell’energia tota-le aggiuntiva rispetto all’idle assorbita da cia-scuna applicazione per completare l’esecu-zione del carico di lavoro. L’energia consuma-ta è calcolata integrando i valori della potenzaassorbita nel tempo impiegato.Il primo importante risultato che emerge daquesti grafici è che la potenza consumata dalserver quando esegue l’applicazione è signifi-cativamente più alta rispetto a quella assorbi-
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
0
0
0
1
12
2x IntelXeon 2.40 GHz
Internal data cache 2 × 8 kb
On-board cache 2 × 512 kb
RAM 1 GB DIMM
Memory bus 4 × 100 MHz
68 GB SCSI Hard Disk
Ms Windows 2003 Server EnterpriseEditions
Linux CentOS
Virtual Instrument
Workload Simulator Server
Comandidi controllo
Client
Comandi diesecuzione
Creazionee popolame
nto
database
Macchina server
Acquisizione datitramite il kitdi misura
FIGURA 2Architettura
sperimentaleper misurareil consumo
energetico indottodal software
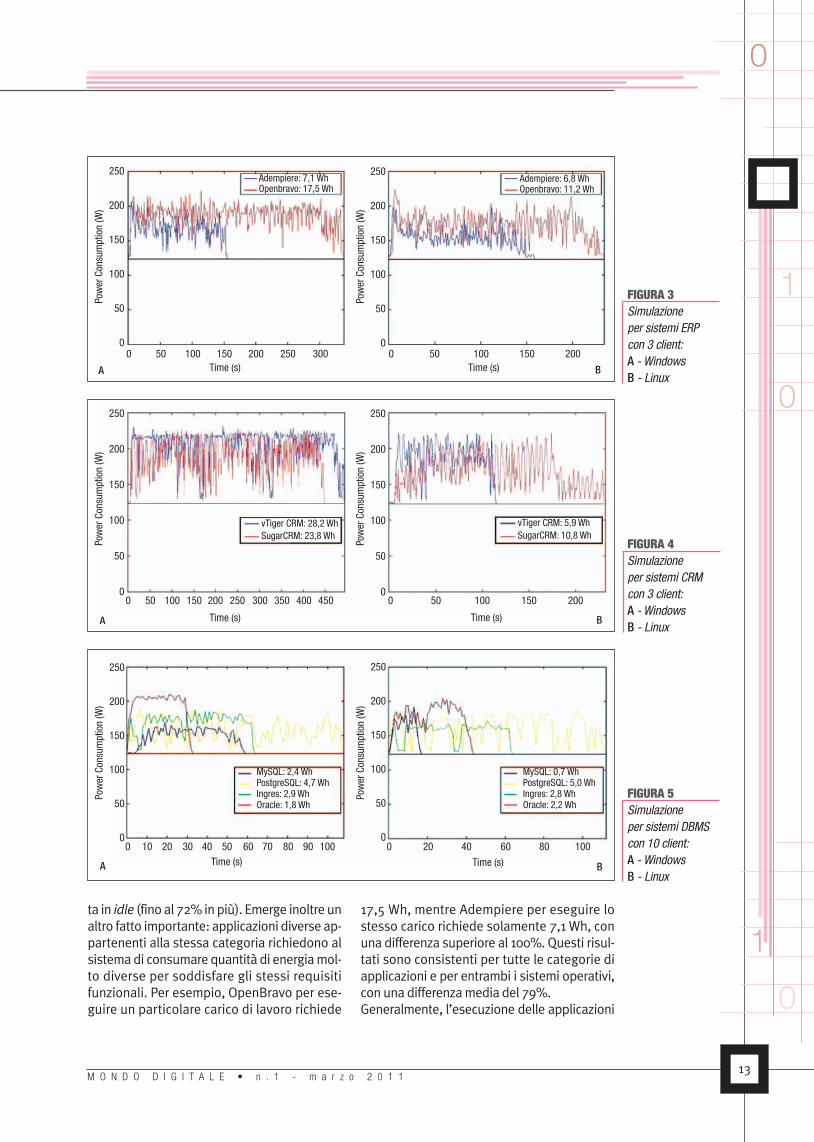
ta in idle (fino al 72% inpiù). Emerge inoltre unaltro fatto importante: applicazioni diverse ap-partenenti alla stessa categoria richiedono alsistemadi consumare quantità di energiamol-to diverse per soddisfare gli stessi requisitifunzionali. Per esempio, OpenBravo per ese-guire un particolare carico di lavoro richiede
17,5 Wh, mentre Adempiere per eseguire lostesso carico richiede solamente 7,1 Wh, conuna differenza superiore al 100%. Questi risul-tati sono consistenti per tutte le categorie diapplicazioni e per entrambi i sistemi operativi,con una differenzamedia del 79%.Generalmente, l’esecuzione delle applicazioni
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
13
0
0
0
1
250
200
150
100
50
0
PowerConsum
ption(W)
250
200
150
100
50
0
PowerConsum
ption(W)
Time (s) Time (s)
Adempiere: 7,1 WhOpenbravo: 17,5 Wh
Adempiere: 6,8 WhOpenbravo: 11,2 Wh
0 50 100 150 200 250 300 0 50 100 150 200
250
200
150
100
50
0
PowerConsum
ption(W)
250
200
150
100
50
0
PowerConsum
ption(W)
Time (s) Time (s)
vTiger CRM: 28,2 WhSugarCRM: 23,8 Wh
vTiger CRM: 5,9 WhSugarCRM: 10,8 Wh
0 50 100 150 200 250 300 350 400 450 0 50 100 150 200
FIGURA 3Simulazioneper sistemi ERPcon 3 client:A - WindowsB - Linux
A B
A B
250
200
150
100
50
0
PowerConsum
ption(W)
250
200
150
100
50
0
PowerConsum
ption(W)
Time (s) Time (s)
MySQL: 2,4 WhPostgreSQL: 4,7 WhIngres: 2,9 WhOracle: 1,8 Wh
MySQL: 0,7 WhPostgreSQL: 5,0 WhIngres: 2,8 WhOracle: 2,2 Wh
0 10 20 30 40 50 60 70 80 90 100 0 20 40 60 80 100
A B
FIGURA 4Simulazioneper sistemi CRMcon 3 client:A - WindowsB - Linux
FIGURA 5Simulazioneper sistemi DBMScon 10 client:A - WindowsB - Linux

in ambiente Linux risulta più efficiente rispettoall’ambiente Windows. Per esempio, comeemergedalla figura3, il consumodiAdempieree di Openbravo si riduce rispettivamente del4% e del 36% quando sono eseguiti su Linux.In media, le applicazioni eseguite in ambienteLinux consumano il 50% inmenodi energia.È tuttavia interessante notare che l’effetto delsistema operativo sul consumo energeticononèdel tutto prevedibile. Per esempio, comesi può notare dalla figura 4, mentre su Win-dows,SugarCRMèpiùefficientedi vTiger, la si-tuazione si inverte sotto Linux, anche se il con-sumomedio due delle applicazioni in ambien-te Linux è comunque inferiore rispetto aquelloin ambiente Windows. L’impatto del sistemaoperativo sul consumo di energia delle appli-cazioniMISèquindimolto forte,mavariabileedipendente dall’applicazione stessa.Un’osservazione critica dei dati proposti sug-gerisce inoltre il fatto che l’efficienza energeti-ca debba essere considerata come un nuovoparametro di merito di un’applicazionesoftware, in aggiunta alla performance. La re-lazione tra tempo di esecuzione ed energiaconsumata non è sempre lineare. Per esem-pio, Oracle è il DBMS più veloce e che consu-ma meno energia nel campione considerato.Ingres richiede un tempo doppio per eseguirelo stesso carico di lavoro, ma solo il 60% dienergia in più. Analizzando le misure effettua-te su tutto il campione, emerge che dimezzareil tempo di esecuzione in media riduce il con-sumodi energia solamentedel 30%. Laperfor-mance temporale non è quindi sufficiente agiustificare la diversità di efficienza energeticadelle applicazioni software.
3. LA RICERCA IN AMBITOGREEN SOFTWARE
Le osservazioni sperimentali presentate nellasezione precedente dimostrano che il consu-mo energetico indotto dal software è signifi-cativo e lasciano intuire ampi margini di ri-sparmio potenzialmente derivabile dall’otti-mizzazione delle applicazioni.Volendo proporre un programma di ricercache affronti inmodo scientifico questa temati-ca sono almeno tre i filoni da considerare.Innanzi tutto, occorre misurare l’efficienzaenergetica del software tramite opportune
metriche, esigenza che emerge anche soloper voler presentare inmodopiù rigoroso i da-ti proposti nella sezione precedente. Si notiche il concetto di efficienza è diverso da quel-lo di consumo, in quanto rapporta l’energiaconsumata alla quantità di lavoro che ha per-messo di svolgere. Un insiemedimetriche perl’efficienza energetica del software può esse-re utile sia per selezionare il software che vie-ne adottato, complimentando i parametri dimerito attualmente utilizzati, sia per valutareil software prodotto inhouse e quindi il teamdi sviluppo. Esse costituiscono lo strumentoessenziale per poter confrontare tra loro siste-mi diversi e quindi fare benchmarking.Ponendosi invece l’obiettivo di migliorare l’ef-ficienza energetica, gli approcci perseguibilipossono essere raggruppati in due grandi ca-tegorie. Un primo approccio è quello di otti-mizzare il codice: scrivere meglio il codicepuò avere un effetto sulle performance ener-getiche dell’applicazione. Ovviamente, que-ste tecniche sono applicabili solamente alsoftware sviluppato inhouse e possono tra-dursi sia inmetodologie, lineeguidae toolperlo sviluppo, che in linee guida a livello orga-nizzativo e relative alle competenze e al per-corso di formazione degli sviluppatori.Migliorare l’efficienza energetica ottimizzandoil codicepotrebbeperònonessere sempre fat-tibileoppurenonessereconveniente.Sedaunaparte potrebbe essere sensato riscrivere e ot-timizzare le routinepiù energivore opiù comu-nemente eseguite in un sistema, dall’altra nonsarebbe pensabile realizzare l’analisi e l’otti-mizzazione di tutto il codice del sistema infor-mativo di una banca e, in ogni caso, lo sforzonecessario per questa operazione difficilmen-te sarebbe ripagato dai risparmi ottenuti.Per questomotivo è opportuno sviluppare an-che strumenti di ottimizzazione a livello di si-stema, applicabili cioè in modo trasversale esenza chesia richiestooperarea livellodi codi-ce.Molti sonogli strumenti e le azioni chepos-sono essere sviluppati a questo livello e la ri-cercaèquantomaiaperta.Unesempiodi azio-ne, riprendendo le evidenze empiriche discus-se nella sezione precedente, potrebbe essereuna scelta oculata dello stack, considerandol’impatto che l’interazione fra sistema operati-vo e applicazione ha sul consumo complessi-vo. Nel seguito di questo articolo saranno pre-
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
0
0
0
1
14

sentati i primi risultati di due ricerche condottedal Dipartimento di Elettronica e InformazionedelPolitecnicodiMilano riguardanti rispettiva-mente la gestione green della memoria e delgarbage collector e l’utilizzo della tabulazionedinamicaperaumentare l’efficienzadi applica-zioni computation intensive.Il paragrafo 4 sintetizza le linee di ricerca pro-poste individuandoper ciascunadi esse i pos-sibili ambiti di applicazione. Nelle sezioni se-guenti sarà presentata una panoramica dellericerche possibili e in corso nei vari filoni.
4. COSA VUOL DIRE EFFICIENZAENERGETICA DEL SOFTWARE
Esistono già diverse metriche consolidate permisurare l’efficienza energetica dell’IT a vari li-velli. Il Power Usage Effectiveness (PUE), cal-colato come la potenza entrante in un datacenter divisa per la potenza effettivamente as-sorbita dal carico IT, è comunemente utilizzatoper valutare l’efficienza dei livelli infrastruttu-rali, includendo quindi sistemi di condiziona-mento e UPS. Per valutare il bilanciamento deicarichi e il livello di virtualizzazione si possonoadottare metriche come la percentuale mediadi utilizzo dei processori, sia fisici che virtuali.Vi sono poi diverse metriche utilizzabili a livel-lo di server e di processore per valutare l’effi-cienza energetica dell’hardware, per esempioW/tpm (Watt per transazioni al minuto),FLOP/Wh (operazioni floating point per Wh)oppureMIPS/W (Milioni di istruzioni al secon-do perWatt) per gli ambientimainframe.Tuttavia non vi sono ancorametriche consoli-date e sufficientemente generali per misura-re l’efficienza energetica del software.È importante analizzare l’efficienza energeticadi un sistema informativo a tutti i suoi livelli, inquanto gli attori coinvolti possono esseremol-to diversi. Se consideriamo un data center in-fatti, il PUEpuòessere influenzatoda chi gesti-sce il data center, così come il livello medio diutilizzo dei processori. Le prestazioni a livellodi hardware dipendono esclusivamente daifornitori di tecnologia e quindi possonoessereinfluenzate solo in fase di acquisto. Infine, l’ef-ficienza energetica del software dipende dai“clienti”deldata center, cioèdachi scriveose-leziona le applicazioni software da acquisire.La difficoltà nella definizione delle metriche di
efficienza energetica del software risiede nellaquantificazione del “lavoro” svolto da un’ap-plicazione con una quantità unitaria di ener-gia. Riprendendo il paragone presentato ini-zialmente relativo al mondo automobilistico,se l’efficienza di un’automobile può esseremi-surata in chilometri percorsi con un litro dibenzina, nell’ambito del green software non èfacile misurare i chilometri, mentre, come si èdimostrato nel paragrafo 2, è relativamentesemplicemisurare i litri di benzina consumata,ovvero l’energia.Questo sposta il problema alla definizione diconcetti di transazioneodi carichidi lavorostan-dard, il piùpossibilegenerali, da fareseguireadun’applicazioneper effettuare lemisure.Alcuniistituti come il TPC hanno definito dei carichi dilavoro standard che possono essere utilizzatiaquestoscopo,anchesemoltospesso taliben-chmark sono finalizzati più a testare un interosistema che non l’applicazione finale. Per alcu-ne applicazioni la definizione di transazione èabbastanza intuitiva (peresempio,per iDBMS),mentre per altre, come gli ERP, occorre consi-deraredifferenti tipologiedi transazioneequin-didiversemetrichediefficienza. Lediverse tran-sazioni (per esempio, inserimento di un nuovoordine oppure inserimento di una nuova ana-grafica prodotto nei sistemi ERP) corrispondo-no a differenti moduli e porzioni di codice del-l’applicazione,quindi è sensatoadottaremetri-chediverse, ancheseèauspicabilegiungereadunametrica unica per ciascuna applicazione,derivata da unamedia degli indicatori rispettoalla frequenza di utilizzo. Nella definizione diquestemetriche occorre anche tenere presen-te i dati forniti come input e le dimensioni deidatabase sottostanti (per esempio, a livello diconsumodi energiaè la stessa cosamodificarelagiacenzaamagazzinodiunprodottoquandoci sono 10 tipologiedi prodotti presenti oquan-do ce ne sono 1.000?).È evidente come la definizione e il calcolo diqueste metriche sia più complicata che pergli altri livelli infrastrutturali.Una soluzione alternativa potrebbe esserequella di identificare altremetriche basate sulcodice, in qualche modo correlate all’efficien-za energetica eutilizzarle comeproxy. Talime-triche risulterebberomolto comode in quantosarebbero misurabili tramite opportuni stru-menti software semplicemente analizzando il
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
15
0
0
0
1
codice dell’applicazione, senza bisogno dieseguirla. Tuttavia le ricerche in questo sensonon hanno fino ad ora portato a risultati ap-prezzabili. Il consumodi energia delle applica-zioni analizzate e descritte nel paragrafo 2, equindi l’efficienza energetica, sono risultatescorrelate da tutte le metriche tradizionali diqualità del design del codice (per esempio,coupling, ereditarietà, modularità ecc.).
5. SCRIVERE SOFTWAREPIÙ EFFICIENTE DAL PUNTODI VISTA ENERGETICO
Come visto nel paragrafo 2, applicazioni chesoddisfano gli stessi requisiti funzionali, mastrutturalmente diverse, possono indurreconsumi significativamente differenti. Per ca-pire più in dettaglio quali siano le cause di
questa diversità di comportamento e quindiidentificare possibili strategie di ottimizza-zione è necessario analizzare in modo ap-profondito le applicazioni considerate. Nelprossimo paragrafo sono riportati i risultatirelativi ad un’analisi più dettagliata del com-portamento dei due ERP Adempiere e Open-Bravo.
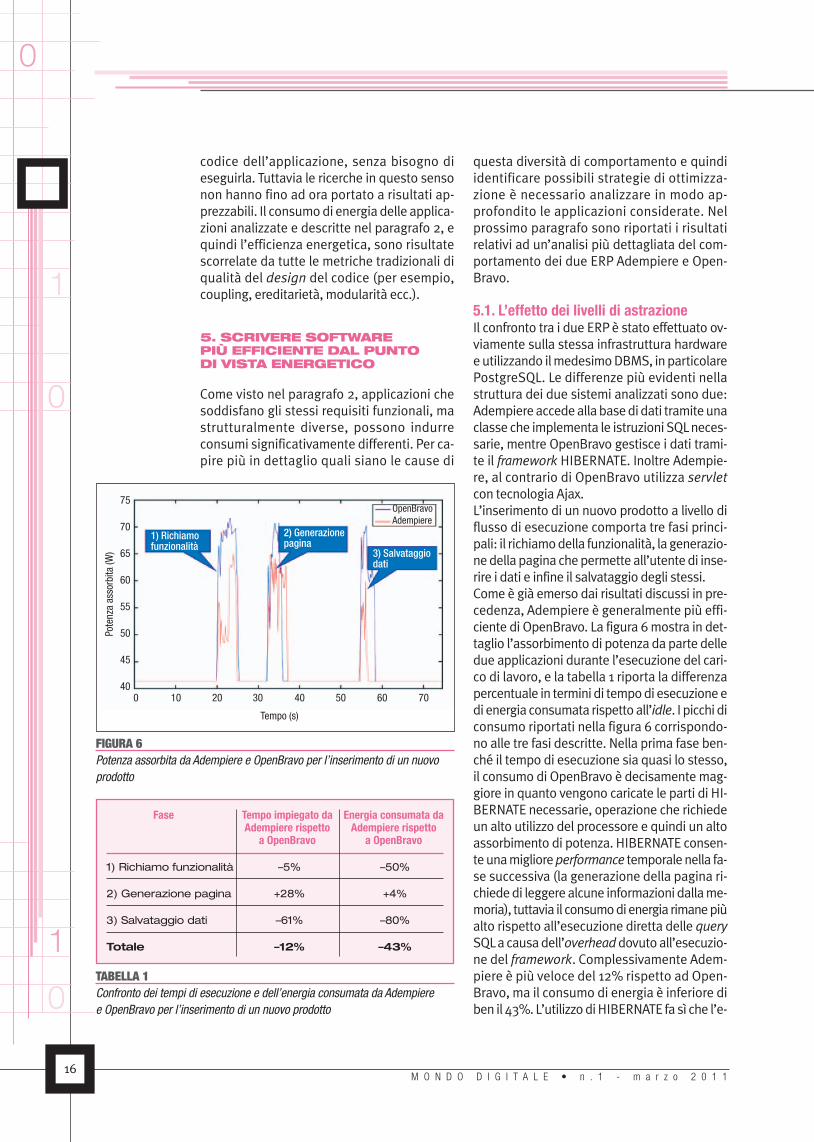
5.1. L’effetto dei livelli di astrazioneIl confronto tra i due ERP è stato effettuato ov-viamente sulla stessa infrastruttura hardwareeutilizzando ilmedesimoDBMS, inparticolarePostgreSQL. Le differenze più evidenti nellastruttura dei due sistemi analizzati sono due:Adempiereaccedeallabasedidati tramiteunaclasse che implementa le istruzioni SQLneces-sarie, mentre OpenBravo gestisce i dati trami-te il framework HIBERNATE. Inoltre Adempie-re, al contrario di OpenBravo utilizza servletcon tecnologia Ajax.L’inserimento di un nuovo prodotto a livello diflusso di esecuzione comporta tre fasi princi-pali: il richiamodella funzionalità, lagenerazio-nedellapagina chepermetteall’utentedi inse-rire i dati e infine il salvataggio degli stessi.Come è già emerso dai risultati discussi in pre-cedenza, Adempiere è generalmente più effi-ciente di OpenBravo. La figura 6mostra in det-taglio l’assorbimento di potenza daparte delledue applicazioni durante l’esecuzione del cari-co di lavoro, e la tabella 1 riporta la differenzapercentuale in termini di tempodi esecuzioneedi energia consumata rispettoall’idle. I picchi diconsumo riportati nella figura 6 corrispondo-no alle tre fasi descritte. Nella prima fase ben-ché il tempo di esecuzione sia quasi lo stesso,il consumo di OpenBravo è decisamentemag-giore in quanto vengono caricate le parti di HI-BERNATE necessarie, operazione che richiedeun alto utilizzo del processore e quindi un altoassorbimento di potenza. HIBERNATE consen-teunamiglioreperformance temporalenella fa-se successiva (la generazione della pagina ri-chiededi leggerealcune informazioni dallame-moria), tuttavia il consumodienergia rimanepiùalto rispetto all’esecuzione diretta delle querySQLacausadell’overheaddovutoall’esecuzio-ne del framework. Complessivamente Adem-piere è più veloce del 12% rispetto ad Open-Bravo, ma il consumo di energia è inferiore diben il 43%.L’utilizzodiHIBERNATE fa sì che l’e-
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
0
0
0
1
16
Fase Tempo impiegato da Energia consumata daAdempiere rispetto Adempiere rispetto
a OpenBravo a OpenBravo
1) Richiamo funzionalità –5% –50%
2) Generazione pagina +28% +4%
3) Salvataggio dati –61% –80%
Totale –12% –43%
TABELLA 1Confronto dei tempi di esecuzione e dell’energia consumata da Adempieree OpenBravo per l’inserimento di un nuovo prodotto
FIGURA 6Potenza assorbita da Adempiere e OpenBravo per l’inserimento di un nuovoprodotto
75
70
65
60
55
50
45
40
Potenzaassorbita
(W)
Tempo (s)
OpenBravoAdempiere
3) Salvataggiodati
2) Generazionepagina
1) Richiamofunzionalità
0 10 20 30 40 50 60 70

secuzione sia più CPU-intensive, con un impat-to negativo sull’efficienza.In generale l’utilizzo di livelli di astrazione e diapplication development environment è mol-to diffuso nei moderni approcci allo sviluppodel software in quanto semplifica la program-mazione. Questi risultati empirici suggerisco-no tuttavia che il loroutilizzoabbiaun impattonon trascurabile sull’efficienza energetica delsoftware.
5.2. Programmatori ninja o bravi operai?L’utilizzo di livelli di astrazione permette disemplificare la scrittura e la manutenzione delcodice, equindi riduce il costodi sviluppo. È si-curamente più facile sviluppare o modificareun’applicazione che accede ai dati tramite unframework comeHIBERNATE, chemaschera lacomplessità della struttura dati e della gestio-ne del data base, rispetto ad avere a che faread una classe Java che incorpora il codice SQLper lequerynecessarie. I livelli di astrazione, lelibrerie e i componenti standard e i frameworkdi sviluppopermettonodi impiegareper lo svi-luppo delle applicazioni programmatori nonspecializzati, ossia “bravi operai” chepossonoessere formatiper l’usodiqueiparticolari stru-menti e componenti preconfezionati in pocotempo e con un investimento ridotto. Questeapplicazioni soddisfano i requisiti funzionali,ma la generalità che deve caratterizzare glistrumenti utilizzati non può che inficiarne leprestazioni. Se le stesse applicazioni fosserosviluppate da programmatori “ninja”, capacidi scrivere codice ottimizzato specifico per ilcontesto di utilizzo, l’efficienza risultante sa-rebbe probabilmentemaggiore.Un’ulteriore confermadel fatto chescriverebe-ne il codice influisce pesantemente sull’effi-cienza, emerge anche da un’analisi empiricaeffettuata su diverse implementazioni dellafunzione XIRR utilizzate da alcune banche ita-liane. La funzione XIRR calcola il tasso di rendi-mento di un investimento e richiede l’identifi-cazionedegli zeri di unpolinomio.Questaope-razione può essere svolta utilizzando diversialgoritmi, con un impatto devastante sul con-sumodi energia, come si evince dalla figura 7.Ottimizzare l’implementazione della funzio-ne utilizzando l’algoritmo più efficiente ridu-ce il consumo di energia di 3 ordini di gran-dezza, ma richiede programmatori con una
profonda esperienza del dominio e degli al-goritmi di programmazione.Ovviamente l’impiegodiprogrammatori “ninja”fa aumentare considerevolmente i costi di svi-luppo, e potrebbe alzare anche i costi di ma-nutenzione in quanto il codice potrebbe esse-re più difficile da interpretare emodificare.Oc-corre quindi valutare il TCO esteso di un’appli-cazione e bilanciare i vari fattori per determi-nare la strategia di sviluppo ottima. Ad oggi laricercanonhaancoraprodotto indicazioni chia-re in questo senso, ma èmolto probabile cheun approccio 80-20 si possa rivelare vincente:ottimizzare tramiteprogrammatori specializzatiil 20%del codice responsabiledell’80%dei con-sumi, puntando invece sulla facilità di sviluppodella restante parte.
5.3. Ricerche futureL’aumento dell’efficienza energetica tramitel’ottimizzazione del codice rimane un campoaperto per la ricerca. Come discusso in pre-cedenza è probabile che le skill e la formazio-ne dei programmatori abbiano un impattosull’efficienza del codice prodotto, anche senon è ancora chiaro in che misura questo av-venga e quali siano le skill con un impatto piùdiretto sull’efficienza energetica.Occorre inoltre identificare i costrutti, i designpattern e le metodologie di programmazioneche permettono di ridurre i consumi indottidalle applicazioni. Il metodo più immediatoper far progredire la ricerca in questo senso èla realizzazione di esperimenti di comparazio-ne tra porzioni di codice che effettuano le stes-se operazioni, utilizzando costrutti e strutture
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
17
0
0
0
1
FIGURA 7Consumo di energia della funzione XIRR implementata secondo diversialgoritmi

diverse. L’analisi dettagliata del flusso di ese-cuzione permette di identificare in che misurale diverse parti sono responsabili dei consumie quindi di definire best practice di sviluppo.Tali best practice potrebbero confluire in stru-menti di ausilio allo sviluppo, in grado di gui-dare il programmatoreanchemenoespertoaduna programmazione “green oriented”.Queste analisi possono essere complementa-te dallo studio dei profili e dei percorsi forma-tivi degli sviluppatori, per poter arrivare alladefinizione complessiva di strategie per lo svi-luppo “green”.
6. OTTIMIZZARE IL CONSUMOA LIVELLO DI SISTEMA
I risultati riportati nel paragrafo 5 evidenzianocome, per ottenere una base di codice che ga-rantisca l’efficienza energetica, si possa fareleva sul livello di astrazione adottato nellaprogrammazione delle applicazioni – riducen-do il peso dello stack applicativo si liberano ri-sorse e si ottiene un controllo a granularitàpiù fine di quelle effettivamente utilizzate.Questo tipo di azione richiede, rispetto a basidi codice esistente sviluppato senza tenercontodei problemi di consumo, sostanziali re-visioni. Ciò implica un considerevole costo disviluppo, dato che la revisione deve essere af-fidata a programmatori abili e dotati di espe-rienza specifica, ma anche un potenziale in-cremento nei costi di manutenzione, dato chela leva impiegata sposta inevitabilmente ilrapporto fra software “off the shelf” e softwa-re sviluppato internamente o quantomeno adhoc a vantaggio di quest’ultimo.Di conseguenza, queste tecniche sono utiliz-zabili principalmente nella scrittura di nuovocodice e in particolare per applicazioni criti-che, in cui il costoaggiuntivodi sviluppoema-nutenzione sia più che bilanciato dai beneficiottenuti in termini di risparmio energetico, in
mododagarantire nel complessounadiminu-zione del TCO.Al contrario, per grandi basi di codice preesi-stenti, in cui il costo di manutenzione può ri-sultare il fattore critico, è necessario trovareleve diverse. Sono desiderabili in questo ca-so metodologie di ottimizzazione almeno se-miautomatica, applicabili a livello di sistemasull’intera base di codice da personale cheabbia competenze di tipo sistemistico, e chenon richiedano quindi modifiche manuali alcodice, ma piuttosto la regolazione di para-metri di ottimizzazione.Le sezioni seguenti sonodedicate ad illustraredue tipi di intervento a livelli diversi: la regola-zione della gestione della memoria e la me-moizzazione semiautomatica al livello dell’ap-plicazione.
6.1. L’impatto del garbage collector e dellagestione della memoriaUno dei contributi principali alla complessitàdi sviluppo dei sistemi software e nello stessotempo alle prestazioni dei sistemi sviluppati èdato dalla gestione della memoria. Nella mag-gior parte degli ambienti di sviluppo e dei lin-guaggi di livello medio-alto (per esempio JavaSEoPython), tale gestioneèautomatizzataat-traverso un livello software intermedio che, atempo di esecuzione, fornisce un’ulterioreastrazione sopra la memoria virtuale offertadal sistema operativo. Al contrario, nello svi-luppoabasso livello (per esempio nel linguag-gio C o in certe specializzazioni di Java per si-stemi real-time), la gestione della memoria èsovente demandata al programmatore1.Sono evidenti i vantaggi della gestione auto-matica in termini di facilità di sviluppo: la ge-stione automatica della memoria attraversoun garbage collector riduce i problemi dovutiad oggetti non deallocati correttamente, inquanto il sistema si prende carico della deal-locazione di oggetti non più raggiungibili2.
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
0
0
0
1
18
1 Non è sempre così, in quanto la gestione automatica della memoria può essere aggiunta a qualsiasi linguaggio di programma-zione che non ne disponga in modo nativo attraverso librerie e una opportuna disciplina di programmazione. Nel caso del lin-guaggio C, la libreria di garbage collection più nota è il Boehm GC.
2 Sebbene ilgarbage collectorsia ingradodigestiregli errori più comunidovuti apuntatori contenenti indirizzi di areedeallocate (dan-gling pointer) o aree allocate ma non più raggiungibili in quanto non vi sono più puntatori che nemantengano gli indirizzi (memoryleak), è comunque infondata l'idea che esso sia in grado di risolvere tutti gli errori relativi allamemoria. In realtà, oggetti non più uti-lizzatima raggiungibili attraverso riferimenti da altri oggetti ancora utili possono portare a situazioni non dissimili dai più tradiziona-limemory leak, e persino più difficili da identificare, in quanto non immediatamente distinguibili dalla situazione corretta [11].
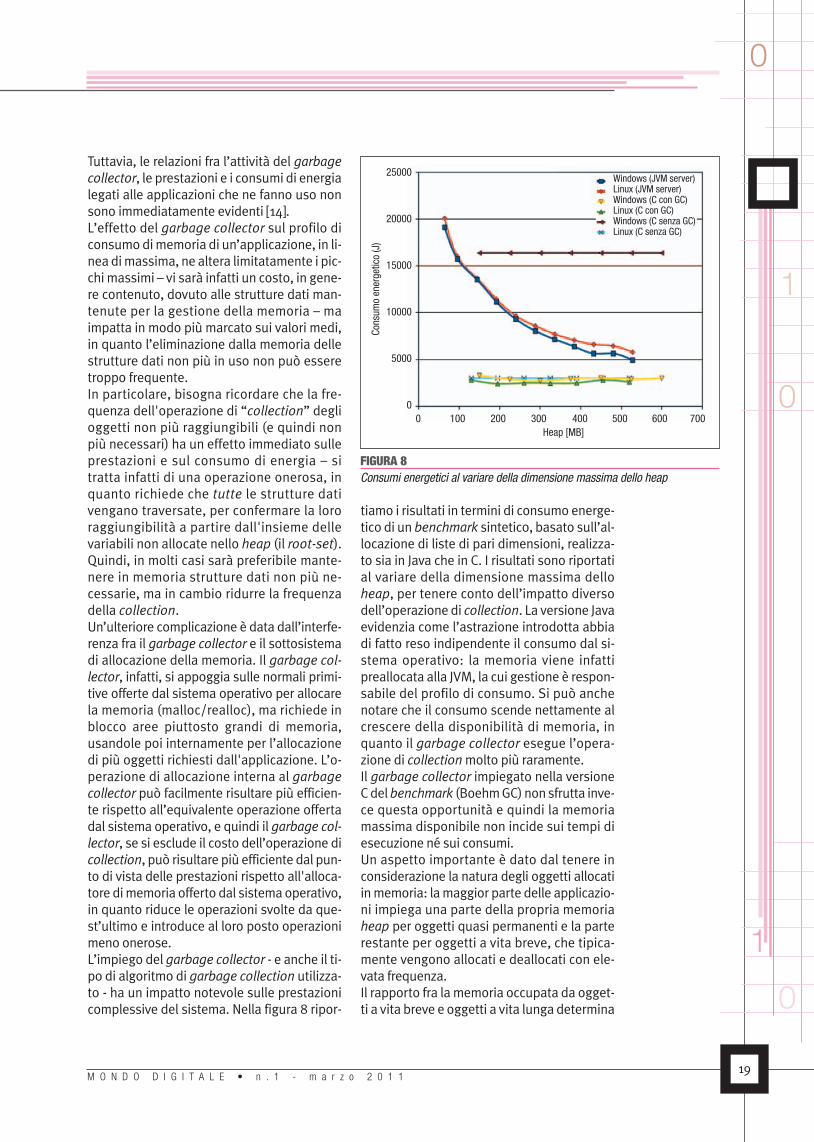
Tuttavia, le relazioni fra l’attività del garbagecollector, le prestazioni e i consumi di energialegati alle applicazioni che ne fanno uso nonsono immediatamente evidenti [14].L’effetto del garbage collector sul profilo diconsumodimemoria di un’applicazione, in li-nea dimassima, ne altera limitatamente i pic-chi massimi – vi sarà infatti un costo, in gene-re contenuto, dovuto alle strutture dati man-tenute per la gestione della memoria – maimpatta in modo più marcato sui valori medi,in quanto l’eliminazione dalla memoria dellestrutture dati non più in uso non può esseretroppo frequente.In particolare, bisogna ricordare che la fre-quenza dell'operazione di “collection” deglioggetti non più raggiungibili (e quindi nonpiù necessari) ha un effetto immediato sulleprestazioni e sul consumo di energia – sitratta infatti di una operazione onerosa, inquanto richiede che tutte le strutture dativengano traversate, per confermare la lororaggiungibilità a partire dall'insieme dellevariabili non allocate nello heap (il root-set).Quindi, in molti casi sarà preferibile mante-nere in memoria strutture dati non più ne-cessarie, ma in cambio ridurre la frequenzadella collection.Un’ulteriore complicazione è data dall’interfe-renza fra il garbage collector e il sottosistemadi allocazione della memoria. Il garbage col-lector, infatti, si appoggia sulle normali primi-tive offerte dal sistema operativo per allocarela memoria (malloc/realloc), ma richiede inblocco aree piuttosto grandi di memoria,usandole poi internamente per l’allocazionedi più oggetti richiesti dall'applicazione. L’o-perazione di allocazione interna al garbagecollector può facilmente risultare più efficien-te rispetto all’equivalente operazione offertadal sistema operativo, e quindi il garbage col-lector, se si esclude il costo dell’operazione dicollection, può risultare più efficiente dal pun-to di vista delle prestazioni rispetto all'alloca-tore dimemoria offerto dal sistemaoperativo,in quanto riduce le operazioni svolte da que-st’ultimo e introduce al loro posto operazionimeno onerose.L’impiego del garbage collector - e anche il ti-po di algoritmo di garbage collection utilizza-to - ha un impatto notevole sulle prestazionicomplessive del sistema. Nella figura 8 ripor-
tiamo i risultati in termini di consumo energe-tico di unbenchmark sintetico, basato sull’al-locazione di liste di pari dimensioni, realizza-to sia in Java che in C. I risultati sono riportatial variare della dimensione massima delloheap, per tenere conto dell’impatto diversodell’operazione di collection. La versione Javaevidenzia come l’astrazione introdotta abbiadi fatto reso indipendente il consumo dal si-stema operativo: la memoria viene infattipreallocata alla JVM, la cui gestione è respon-sabile del profilo di consumo. Si può anchenotare che il consumo scende nettamente alcrescere della disponibilità di memoria, inquanto il garbage collector esegue l’opera-zione di collection molto più raramente.Il garbage collector impiegato nella versioneCdelbenchmark (BoehmGC)nonsfrutta inve-ce questa opportunità e quindi la memoriamassima disponibile non incide sui tempi diesecuzione né sui consumi.Un aspetto importante è dato dal tenere inconsiderazione la natura degli oggetti allocatiinmemoria: lamaggior parte delle applicazio-ni impiega una parte della propria memoriaheap per oggetti quasi permanenti e la parterestante per oggetti a vita breve, che tipica-mente vengono allocati e deallocati con ele-vata frequenza.Il rapporto fra lamemoria occupata da ogget-ti a vita breve e oggetti a vita lunga determina
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
19
0
0
0
1
25000
20000
15000
10000
5000
00 100 200 300 400 500 600 700
Heap [MB]
Windows (JVM server)Linux (JVM server)Windows (C con GC)Linux (C con GC)Windows (C senza GC)Linux (C senza GC)
Consum
oenergetico(J)
FIGURA 8Consumi energetici al variare della dimensione massima dello heap
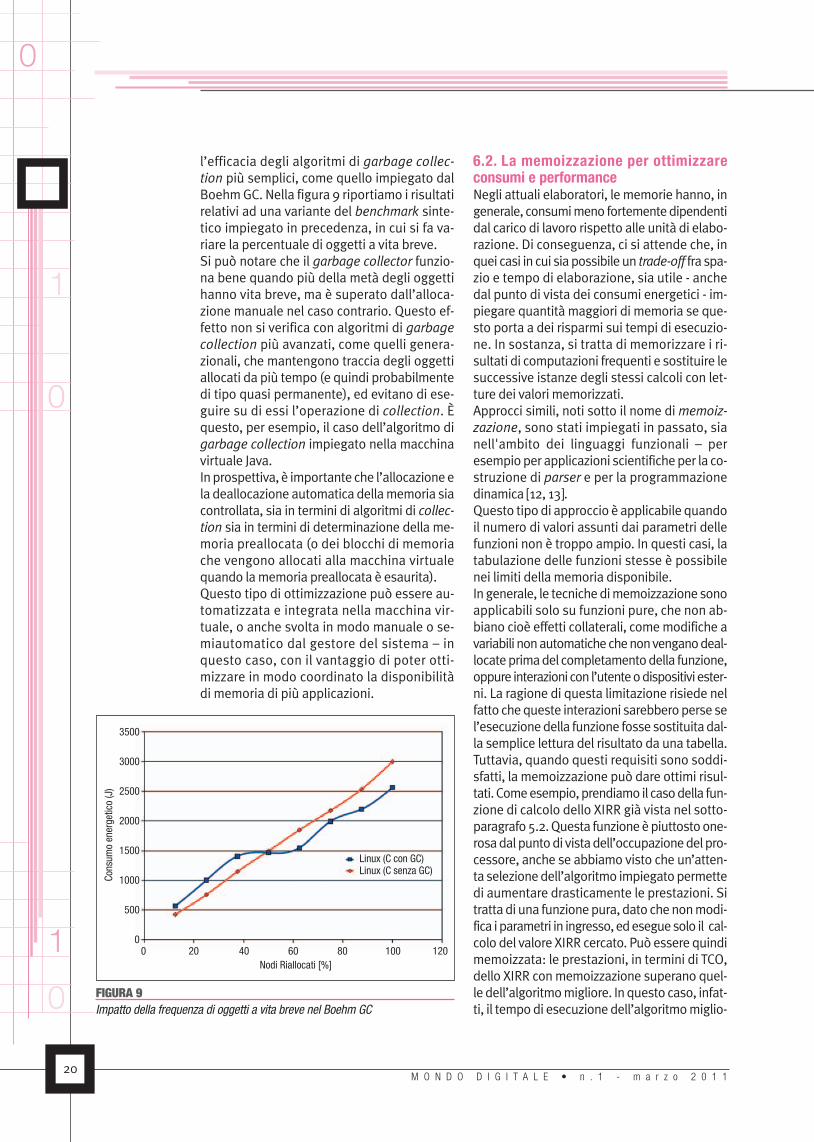
l’efficacia degli algoritmi di garbage collec-tion più semplici, come quello impiegato dalBoehmGC. Nella figura 9 riportiamo i risultatirelativi ad una variante del benchmark sinte-tico impiegato in precedenza, in cui si fa va-riare la percentuale di oggetti a vita breve.Si può notare che il garbage collector funzio-na bene quando più della metà degli oggettihanno vita breve, ma è superato dall’alloca-zione manuale nel caso contrario. Questo ef-fetto non si verifica con algoritmi di garbagecollection più avanzati, come quelli genera-zionali, che mantengono traccia degli oggettiallocati da più tempo (e quindi probabilmentedi tipo quasi permanente), ed evitano di ese-guire su di essi l’operazione di collection. Èquesto, per esempio, il caso dell’algoritmo digarbage collection impiegato nella macchinavirtuale Java.Inprospettiva, è importante che l’allocazioneela deallocazione automatica dellamemoria siacontrollata, sia in termini di algoritmi di collec-tion sia in termini di determinazione della me-moria preallocata (o dei blocchi di memoriache vengono allocati alla macchina virtualequando lamemoria preallocata è esaurita).Questo tipo di ottimizzazione può essere au-tomatizzata e integrata nella macchina vir-tuale, o anche svolta in modo manuale o se-miautomatico dal gestore del sistema – inquesto caso, con il vantaggio di poter otti-mizzare in modo coordinato la disponibilitàdi memoria di più applicazioni.
6.2. La memoizzazione per ottimizzareconsumi e performanceNegli attuali elaboratori, lememorie hanno, ingenerale, consumimeno fortementedipendentidal carico di lavoro rispetto alle unità di elabo-razione. Di conseguenza, ci si attende che, inquei casi in cui siapossibileun trade-off fra spa-zio e tempo di elaborazione, sia utile - anchedal punto di vista dei consumi energetici - im-piegare quantità maggiori di memoria se que-sto porta a dei risparmi sui tempi di esecuzio-ne. In sostanza, si tratta di memorizzare i ri-sultati di computazioni frequenti e sostituire lesuccessive istanze degli stessi calcoli con let-ture dei valori memorizzati.Approcci simili, noti sotto il nome di memoiz-zazione, sono stati impiegati in passato, sianell'ambito dei linguaggi funzionali – peresempioper applicazioni scientificheper la co-struzione di parser e per la programmazionedinamica [12, 13].Questo tipodi approccio è applicabile quandoil numero di valori assunti dai parametri dellefunzioni non è troppo ampio. In questi casi, latabulazione delle funzioni stesse è possibilenei limiti dellamemoria disponibile.Ingenerale, le tecnichedimemoizzazionesonoapplicabili solo su funzioni pure, che non ab-biano cioè effetti collaterali, comemodifiche avariabili nonautomatichechenonvenganodeal-locateprimadel completamentodella funzione,oppure interazionicon l’utenteodispositiviester-ni. La ragione di questa limitazione risiede nelfatto chequeste interazioni sarebberoperse sel’esecuzionedella funzione fossesostituitadal-la semplice lettura del risultato da una tabella.Tuttavia, quando questi requisiti sono soddi-sfatti, la memoizzazione può dare ottimi risul-tati. Comeesempio,prendiamo il casodella fun-zione di calcolo dello XIRR già vista nel sotto-paragrafo5.2.Questa funzioneèpiuttostoone-rosadalpuntodi vistadell’occupazionedelpro-cessore, anche se abbiamo visto che un’atten-ta selezionedell’algoritmo impiegatopermettedi aumentare drasticamente le prestazioni. Sitrattadi una funzionepura, dato chenonmodi-fica iparametri in ingresso,edeseguesolo il cal-colo del valore XIRR cercato. Può essere quindimemoizzata: le prestazioni, in termini di TCO,dello XIRR conmemoizzazione superano quel-ledell’algoritmomigliore. Inquesto caso, infat-ti, il tempodi esecuzionedell’algoritmomiglio-
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
0
0
0
1
20
3500
3000
2500
2000
1500
1000
500
00 20 40 60 80 100 120
Nodi Riallocati [%]
Linux (C con GC)Linux (C senza GC)
Consum
oenergetico(J)
FIGURA 9Impatto della frequenza di oggetti a vita breve nel Boehm GC

re per lo XIRR è superiore rispetto al tempo diaccesso alla tabella in cui sonomemoizzati i ri-sultati dello XIRR. In termini generali, la conve-nienza della memoizzazione per una data fun-zionepura fdipendedalla frequenza di succes-so α, ovvero il rapporto fra il numero di invoca-zioni di fper cui èpossibile trovare il risultato inmemoriae il numero totaledi invocazionidi f. Inmodopiùpreciso, il tempodicalcolodi fconme-moizzazione è espresso, in funzione di α, deltempo di esecuzione dell'algoritmo originaleTcomp, edei tempidi accessoallamemoria in ca-so di successo (Thit) e fallimento (Tmiss):
Tmemo = α Thit + (1 – α)(Tmiss + Tcomp)
Si raggiunge il punto di break even quandoTmemo = Tcomp.Se la differenza nei tempi di accesso alla me-moria in caso di successo e fallimento è circauguale, ne risulta che, per ottenere un guada-gno, deve essere vera la seguente relazione:
α > Tmiss/Tcomp
La conclusione è che, da una parte, è necessa-rio scegliere funzioni computazionalmenteonerose e che, allo stesso tempo, vengano in-
vocate frequentemente con gli stessi parame-tri, e dall’altra implementare tabelle di me-moizzazione con tempi di accesso rapidi.Di conseguenza, l’impiego della tecnica dime-moizzazione richiede l’impiego di programma-tori e progettisti esperti – non solo perché so-no necessarie la modifica del codice e l’imple-mentazione di strutture di memoizzazionemolto efficienti,ma soprattutto perché l’indivi-duazione delle funzioni che devono esserememoizzate non èbanale, ed è cruciale per ot-tenere un effetto significativo sui consumi esulle prestazioni. Inoltre, modifiche al codicecome quelle richieste per lamemoizzazione ri-chiedono l’accessoal codicesorgente, che,nelcaso di codice sviluppato da terze parti, po-trebbe non essere disponibile.Per ovviare a questi problemi, si può cercare diautomatizzarealmeno inparte il processodiot-timizzazione del codice attraverso la memoiz-zazione.Aquestoscopo,èstatosviluppatopres-so il Politecnico di Milano un prototipo di stru-mento per lamemoizzazione semiautomatica.Lo strumento opera su codice bytecode Java,quindi senza richiedere l’accessoal codicesor-gente, ed è costituito dai componenti illustratinella figura 10:� analisi statica del codice: permette di deter-
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
21
0
0
0
1
Analysis and Code Modification
BytecodeWrite PureFunction Info
Pure FunctionInformation
FunctionsFrequency
FunctionResults
Report
Read
Read
Read
Trade-OffJVMFunctionRequests
F1 (p1,...,pn)
F1 (p1,...,pn)
Green Core
Result
Write WriteLookup
F1 (p1,...,pn), x
BusinessIntelligence
MemoryManagement
Memory
TimeExecutions
Lookup
Static PureFunction Retrieval
BytercodeModification for Static
Pure Function
Decision Maker[Function Code F1]
Bytecode
FIGURA 10Schema dell’architettura per la memoizzazione
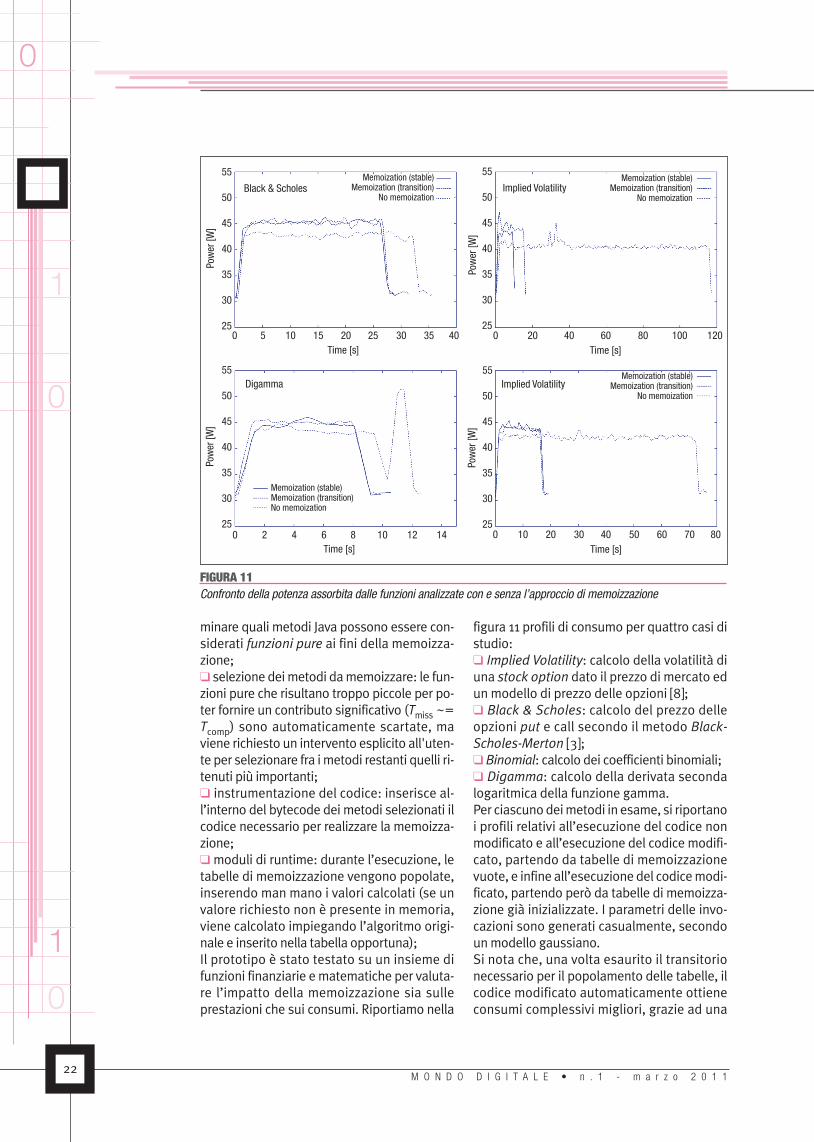
minare quali metodi Java possono essere con-siderati funzioni pure ai fini della memoizza-zione;� selezione deimetodi damemoizzare: le fun-zioni pure che risultano troppo piccole per po-ter fornire un contributo significativo (Tmiss ~=Tcomp) sono automaticamente scartate, maviene richiesto un intervento esplicito all'uten-te per selezionare fra imetodi restanti quelli ri-tenuti più importanti;� instrumentazione del codice: inserisce al-l’interno del bytecode dei metodi selezionati ilcodice necessario per realizzare la memoizza-zione;� moduli di runtime: durante l’esecuzione, letabelle di memoizzazione vengono popolate,inserendo man mano i valori calcolati (se unvalore richiesto non è presente in memoria,viene calcolato impiegando l’algoritmo origi-nale e inserito nella tabella opportuna);Il prototipo è stato testato su un insieme difunzioni finanziarie ematematiche per valuta-re l’impatto della memoizzazione sia sulleprestazioni che sui consumi. Riportiamo nella
figura 11 profili di consumo per quattro casi distudio:� Implied Volatility: calcolo della volatilità diuna stock option dato il prezzo di mercato edunmodello di prezzo delle opzioni [8];� Black & Scholes: calcolo del prezzo delleopzioni put e call secondo il metodo Black-Scholes-Merton [3];� Binomial: calcolo dei coefficienti binomiali;� Digamma: calcolo della derivata secondalogaritmica della funzione gamma.Per ciascunodeimetodi in esame, si riportanoi profili relativi all’esecuzione del codice nonmodificato e all’esecuzione del codice modifi-cato, partendo da tabelle di memoizzazionevuote, e infine all’esecuzionedel codicemodi-ficato, partendo però da tabelle di memoizza-zione già inizializzate. I parametri delle invo-cazioni sono generati casualmente, secondounmodello gaussiano.Si nota che, una volta esaurito il transitorionecessario per il popolamento delle tabelle, ilcodice modificato automaticamente ottieneconsumi complessivi migliori, grazie ad una
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
0
0
0
1
22
55
50
45
40
35
30
250 5 10 15 20 25 30 35 40
Time [s]
Black & ScholesMemoization (stable)
Memoization (transition)No memoization
Power[W]
55
50
45
40
35
30
250 20 40 60 80 100 120
Time [s]
Implied VolatilityMemoization (stable)
Memoization (transition)No memoization
Power[W]
55
50
45
40
35
30
250 2 4 6 8 10 12 14
Time [s]
Digamma
Memoization (stable)Memoization (transition)No memoization
Power[W]
55
50
45
40
35
30
250 10 20 30 40 50 60 70 80
Time [s]
Implied VolatilityMemoization (stable)
Memoization (transition)No memoization
Power[W]
FIGURA 11Confronto della potenza assorbita dalle funzioni analizzate con e senza l’approccio di memoizzazione
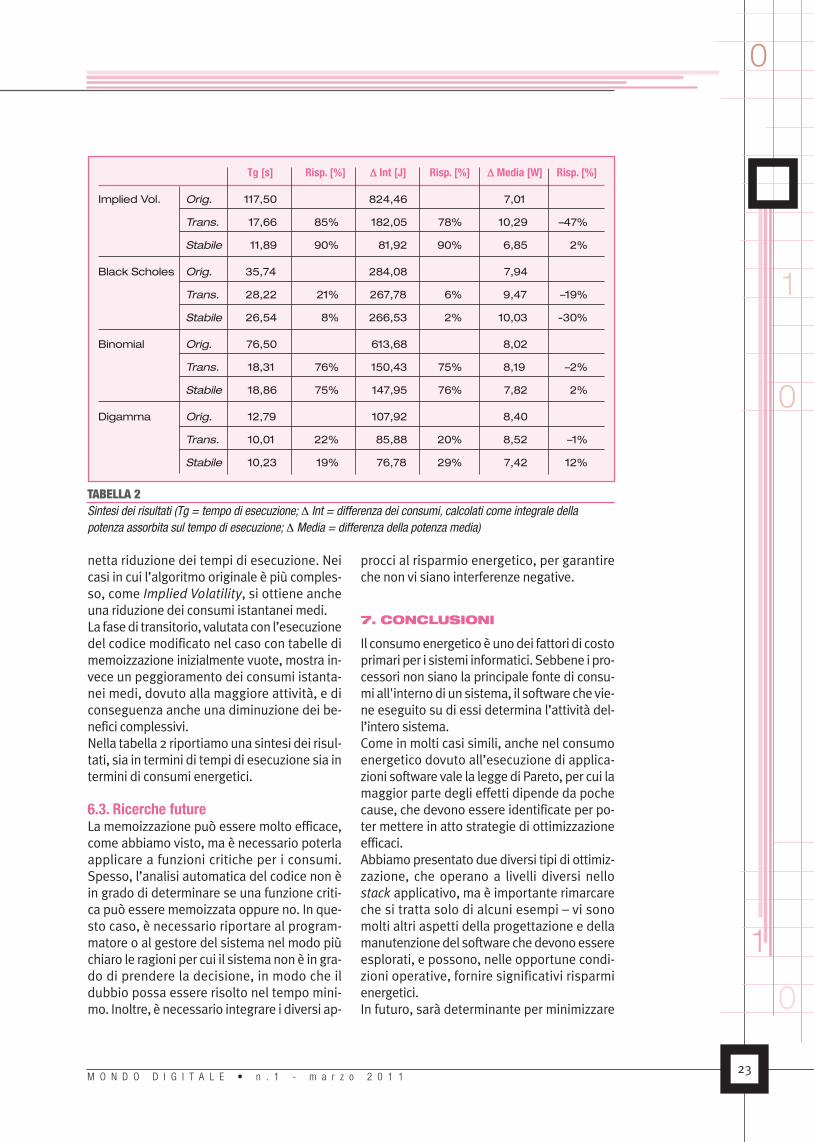
netta riduzione dei tempi di esecuzione. Neicasi in cui l’algoritmo originale è più comples-so, come Implied Volatility, si ottiene ancheuna riduzione dei consumi istantanei medi.La fasedi transitorio, valutatacon l’esecuzionedel codice modificato nel caso con tabelle dimemoizzazione inizialmente vuote, mostra in-vece un peggioramento dei consumi istanta-nei medi, dovuto alla maggiore attività, e diconseguenza anche una diminuzione dei be-nefici complessivi.Nella tabella 2 riportiamouna sintesi dei risul-tati, sia in termini di tempi di esecuzione sia intermini di consumi energetici.
6.3. Ricerche futureLa memoizzazione può essere molto efficace,come abbiamo visto, ma è necessario poterlaapplicare a funzioni critiche per i consumi.Spesso, l’analisi automatica del codice non èin grado di determinare se una funzione criti-ca può essere memoizzata oppure no. In que-sto caso, è necessario riportare al program-matore o al gestore del sistema nel modo piùchiaro le ragioni per cui il sistemanonè in gra-do di prendere la decisione, in modo che ildubbio possa essere risolto nel tempo mini-mo. Inoltre, è necessario integrare i diversi ap-
procci al risparmio energetico, per garantireche non vi siano interferenze negative.
7. CONCLUSIONI
Il consumoenergeticoèunodei fattori di costoprimari per i sistemi informatici. Sebbene ipro-cessori non siano la principale fonte di consu-miall'internodiunsistema, il software chevie-ne eseguito su di essi determina l’attività del-l’intero sistema.Come in molti casi simili, anche nel consumoenergetico dovuto all’esecuzione di applica-zioni software vale la leggedi Pareto, per cui lamaggior parte degli effetti dipende da pochecause, che devono essere identificate per po-ter mettere in atto strategie di ottimizzazioneefficaci.Abbiamopresentato due diversi tipi di ottimiz-zazione, che operano a livelli diversi nellostack applicativo, ma è importante rimarcareche si tratta solo di alcuni esempi – vi sonomolti altri aspetti della progettazione e dellamanutenzionedel software chedevonoessereesplorati, e possono, nelle opportune condi-zioni operative, fornire significativi risparmienergetici.In futuro, sarà determinante per minimizzare
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
23
0
0
0
1
Tg [s] Risp. [%] ∆∆ Int [J] Risp. [%] � ∆∆ Media [W] Risp. [%]
Implied Vol. Orig. 117,50 824,46 7,01
Trans. 17,66 85% 182,05 78% 10,29 –47%
Stabile 11,89 90% 81,92 90% 6,85 2%
Black Scholes Orig. 35,74 284,08 7,94
Trans. 28,22 21% 267,78 6% 9,47 –19%
Stabile 26,54 8% 266,53 2% 10,03 -30%
Binomial Orig. 76,50 613,68 8,02
Trans. 18,31 76% 150,43 75% 8,19 –2%
Stabile 18,86 75% 147,95 76% 7,82 2%
Digamma Orig. 12,79 107,92 8,40
Trans. 10,01 22% 85,88 20% 8,52 –1%
Stabile 10,23 19% 76,78 29% 7,42 12%
TABELLA 2Sintesi dei risultati (Tg = tempo di esecuzione; ∆ Int = differenza dei consumi, calcolati come integrale dellapotenza assorbita sul tempo di esecuzione; ∆ Media = differenza della potenza media)

i consumi la capacità di coordinare queste ot-timizzazioni sull’intero stack applicativo.
RingraziamentiGli autori ringraziano la Prof. Chiara Francalanci el’Ing. Marco Bessi per il prezioso contributo. Siringrazia inoltre Accenture Italia per aver suppor-tato le fasi iniziali della ricerca.
Bibliografia[1] ACEEE: A Smarter Shade of Green. ACEEE Re-
port for the Technology CEO Council, 2008.
[2] Barroso L.A., Hölzle U.: The Datacenter as aComputer: An Introduction to the Design of Wa-rehouse-Scale Machines. Ed. Morgan & Clay-pool, Madison, 2009.
[3] Capra E., Formenti G., Francalanci C., Gallazzi S.:The impact of MIS software on IT energy con-sumption. European Conference of InformationSystems, 2010.
[4] Fornaciari W., Gubian P., Sciuto D., Silvano C.: Powerestimation of embedded systems: A hardwa-re/software codesign approach. IEEE Trans. on VL-SI Systems, Vol.6, n. 2, 1998, p. 266-275.
[5] Lee C., Brown E.G.: Topic overview: Green it. Tech-nical report, Forrester Research, Novembre 2007.
[6] Katz D.M.: CIOs called clueless about extra co-sts. CFO.com, 27 settembre 2010.
[7] Kumar R.: Important power, cooling and greenit concerns. Technical report, Gartner, Gennaio2007.
[8] Saxena A., Chung D.: Optimizing the datacenterfor cost and Efficiency. IDC White Paper, 2009.
[9] Stanford E.: Environmental trends and opportu-nity for computer system power delivery. 20-thInt’l Symposiumon Power Semiconductor Devi-ces and IC’s, 2008.
[10] Vahdat A., Lebeck A., Ellis C.S.: Every joule isprecious: the case for revisiting operating sy-stem design for energy efficiency. ACM SIGOPSEuropean Workshop, 2000, p. 31-36.
[11] Xu G.Q., Rountev A.: Precise memory leak de-tection for java software using container profi-ling. ACM/IEEE 30-th International Conferenceon Software Engineering, 2008. ICSE ‘08, May2008, p.151-160.
[12] Acar Umut A., Blelloch Guy E., Harper R.: Selec-tive memoization. In: Proceedings of the 30-thACM SIGPLAN-SIGACT symposium on Princi-ples of programming languages, POPL ’03, NewYork, NY, USA, 2003. ACM, p. 14-25.
[13] Norvig P.: Techniques for automatic memoiza-tion with applications to context-free parsing.Comput. Linguist., Vol. 17, March 1991, p. 91-98.
[14] Berger E.D., Hertz M.: Quantifying the perfor-mance of garbage collection vs. explicit me-mory management. 2005.
[15] Sissa G.: Green Software. Mondo Digitale, set-tembre 2009.
M O N D O D I G I T A L E • n . 1 - m a r z o 2 0 1 1
1
0
0
0
1
24
GIOVANNI AGOSTA è ricercatore confermato di Sistemi di Elaborazione dell'Informazione presso il Politecnico diMilano, dove ha conseguito la laurea in Ingegneria Informatica nel 2000 e il Dottorato in Ingegneria dell'Infor-mazione nel 2004 e dove è docente di Algoritmi e Principi dell'Informatica e Piattaforme Software per la Rete.La sua attività di ricerca verte principalmente sulle interazioni tra architetture di elaborazione e compilatori,spaziando dalla compilazione dinamica alle metodologie di progetto e implementazione di applicazioni persistemi dedicati, ai modelli di programmazione per architetture parallele e alla sintesi logica. È autore di più ditrenta articoli su riviste e conferenze internazionali.E-mail: [email protected]
EUGENIO CAPRA è professore a contratto di Sistemi Informativi al Politecnico di Milano, presso cui ha consegui-to il Dottorato di Ricerca in Ingegneria dell’Informazione, nel 2008, e la laurea in Ingegneria Elettronica nel2003. È stato Visiting Researcher presso la Carnegie Mellon West University (NASA Ames Research Park, CA)da settembre 2006 a marzo 2007. Ha lavorato come business analyst per McKinsey & Co. dal 2004 fino al2005, svolge attività di consulenza nell’ambito di gestione e innovazione dei processi IT. Le sue attività di ri-cerca principali riguardano il Green ICT, i modelli manageriali in ambiente open source e l’impatto dell’IT suiprocessi di business. Su questi temi ha scritto diversi articoli a livello sia nazionale che internazionale.E-mail: [email protected]


















