
XML: UNO STANDARD IN...
16
1. UNO STANDARD PER LA RAPPRESENTAZIONE DEI TESTI X ML (eXtensible Markup Language) è uno standard abbastanza recente, nato per la rappresentazione di documenti testuali: ideato da Tim Bray e Jean Pauli, è stato pub- blicato ufficialmente nel febbraio 1998 dal World Wide Web Council (W3C), il consorzio preposto alla definizione degli standard del World Wide Web. 1.1. Struttura logica e presentazione Le componenti elementari di un testo, i carat- teri, sono, com’è noto, rappresentate nel computer mediante il codice ASCII (American Standard Code for Information Interchange). Per rappresentare la qualità grafica con cui i caratteri sono stampati su carta o visualizza- ti sullo schermo (per precisare cioè il tipo e le dimensioni dei font, caratteristiche come ne- retto, corsivo ecc.) sono nati specifici formati di videoscrittura (per esempio Word), formati di stampa (PostScript) e di visualizzazione (PDF, Portable Document Format) e veri e propri linguaggi per la stampa, come TROFF e Tex (molto usato nelle università per la stam- pa di formule matematiche). XML si distingue rispetto a questi formati di visualizzazione e di stampa, non solo in quanto standard documentato e indipen- dente dai produttori di software, ma soprat- tutto perché risponde ad un’esigenza speci- fica, avvertita da editori e studiosi umanisti, quella cioè di rappresentare la struttura lo- gica di un documento (per esempio la sud- divisione in titoli, capitoli, paragrafi ecc.), creando un’astrazione della sua presenta- zione, ovvero dell’aspetto grafico, con cui il documento si presenta sulla pagina stam- pata e sullo schermo di un computer. Al con- trario di TROFF e Tex, linguaggi procedurali, che descrivono le operazioni da fare per stampare le diverse porzioni di un docu- mento, XML è un linguaggio dichiarativo, che definisce le varie parti del testo e le loro rispettive relazioni. Più precisamente XML è un linguaggio di markup mediante il quale, è possibile asso- ciare a ciascuna parte di un testo, un marca- MONDO DIGITALE • n.2 - giugno 2002 XML, inizialmente proposto come standard per la rappresentazione dei documenti testuali, si sta ora imponendo come infrastruttura generale del World Wide Web, per l’interscambio di informazioni tra le diverse applica- zioni. XML stabilisce un insieme di convenzioni per definire diversi linguaggi di codifica, in base alle diverse tipologie di informazioni da rappresentare: associando ai dati di partenza informazioni descrittive (dette “tag” o mar- catori), pone le premesse per la costruzione di inferenze automatiche sulla semantica dei dati (Semantic Web). Ernesto Damiani Paolo Fezzi XML: UNO STANDARD IN ESPANSIONE 50
Transcript of XML: UNO STANDARD IN...

1. UNO STANDARD PERLA RAPPRESENTAZIONEDEI TESTI
X ML (eXtensible Markup Language) è unostandard abbastanza recente, nato per
la rappresentazione di documenti testuali:ideato da Tim Bray e Jean Pauli, è stato pub-blicato ufficialmente nel febbraio 1998 dalWorld Wide Web Council (W3C), il consorziopreposto alla definizione degli standard delWorld Wide Web.
1.1. Struttura logica e presentazioneLe componenti elementari di un testo, i carat-teri, sono, com’è noto, rappresentate nelcomputer mediante il codice ASCII (American
Standard Code for Information Interchange).Per rappresentare la qualità grafica con cui icaratteri sono stampati su carta o visualizza-ti sullo schermo (per precisare cioè il tipo e ledimensioni dei font, caratteristiche come ne-retto, corsivo ecc.) sono nati specifici formatidi videoscrittura (per esempio Word), formatidi stampa (PostScript) e di visualizzazione(PDF, Portable Document Format) e veri e
propri linguaggi per la stampa, come TROFF eTex (molto usato nelle università per la stam-pa di formule matematiche).XML si distingue rispetto a questi formati divisualizzazione e di stampa, non solo inquanto standard documentato e indipen-
dente dai produttori di software, ma soprat-tutto perché risponde ad un’esigenza speci-fica, avvertita da editori e studiosi umanisti,quella cioè di rappresentare la struttura lo-
gica di un documento (per esempio la sud-divisione in titoli, capitoli, paragrafi ecc.),creando un’astrazione della sua presenta-
zione, ovvero dell’aspetto grafico, con cui ildocumento si presenta sulla pagina stam-pata e sullo schermo di un computer. Al con-trario di TROFF e Tex, linguaggi procedurali,che descrivono le operazioni da fare perstampare le diverse porzioni di un docu-mento, XML è un linguaggio dichiarativo,che definisce le varie parti del testo e le lororispettive relazioni.Più precisamente XML è un linguaggio di
markup mediante il quale, è possibile asso-ciare a ciascuna parte di un testo, un marca-
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
XML, inizialmente proposto come standard per la rappresentazione dei
documenti testuali, si sta ora imponendo come infrastruttura generale del
World Wide Web, per l’interscambio di informazioni tra le diverse applica-
zioni. XML stabilisce un insieme di convenzioni per definire diversi linguaggi
di codifica, in base alle diverse tipologie di informazioni da rappresentare:
associando ai dati di partenza informazioni descrittive (dette “tag” o mar-
catori), pone le premesse per la costruzione di inferenze automatiche sulla
semantica dei dati (Semantic Web).
Ernesto DamianiPaolo Fezzi
XML: UNO STANDARDIN ESPANSIONE
50
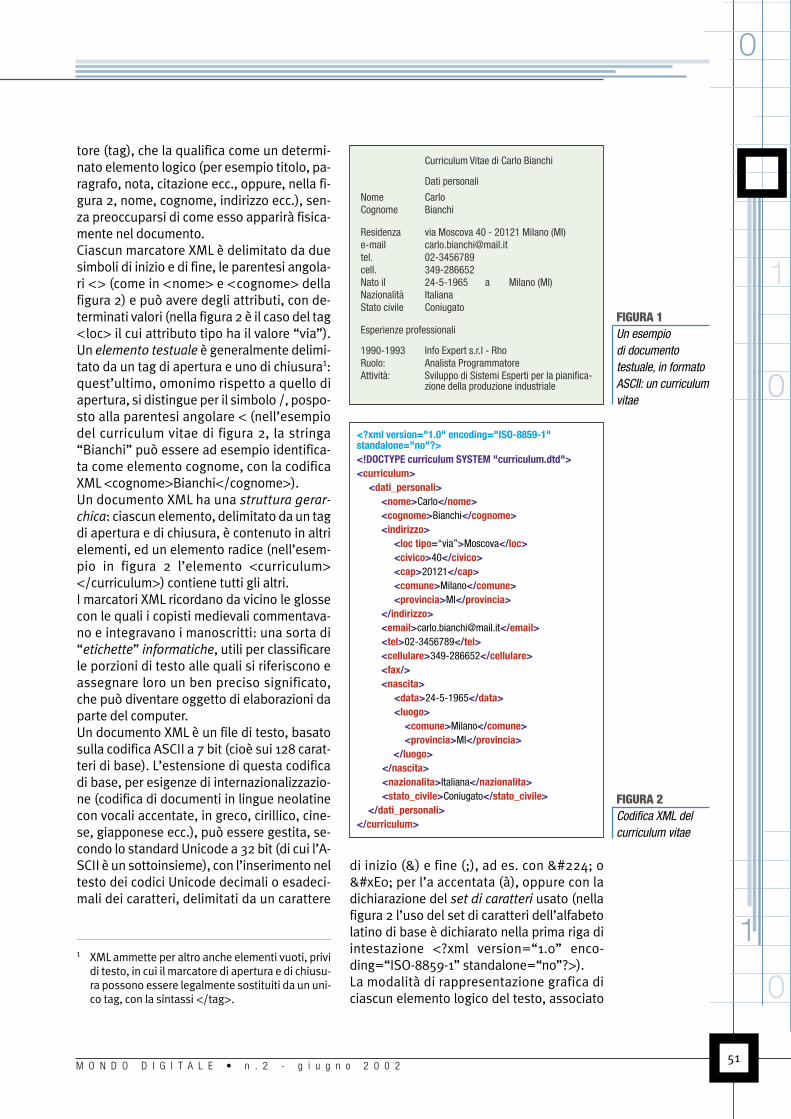
tore (tag), che la qualifica come un determi-nato elemento logico (per esempio titolo, pa-ragrafo, nota, citazione ecc., oppure, nella fi-gura 2, nome, cognome, indirizzo ecc.), sen-za preoccuparsi di come esso apparirà fisica-mente nel documento.Ciascun marcatore XML è delimitato da duesimboli di inizio e di fine, le parentesi angola-ri <> (come in <nome> e <cognome> dellafigura 2) e può avere degli attributi, con de-terminati valori (nella figura 2 è il caso del tag<loc> il cui attributo tipo ha il valore “via”).Un elemento testuale è generalmente delimi-tato da un tag di apertura e uno di chiusura1:quest’ultimo, omonimo rispetto a quello diapertura, si distingue per il simbolo /, pospo-sto alla parentesi angolare < (nell’esempiodel curriculum vitae di figura 2, la stringa“Bianchi” può essere ad esempio identifica-ta come elemento cognome, con la codificaXML <cognome>Bianchi</cognome>).Un documento XML ha una struttura gerar-
chica: ciascun elemento, delimitato da un tagdi apertura e di chiusura, è contenuto in altrielementi, ed un elemento radice (nell’esem-pio in figura 2 l’elemento <curriculum></curriculum>) contiene tutti gli altri.I marcatori XML ricordano da vicino le glossecon le quali i copisti medievali commentava-no e integravano i manoscritti: una sorta di“etichette” informatiche, utili per classificarele porzioni di testo alle quali si riferiscono eassegnare loro un ben preciso significato,che può diventare oggetto di elaborazioni daparte del computer.Un documento XML è un file di testo, basatosulla codifica ASCII a 7 bit (cioè sui 128 carat-teri di base). L’estensione di questa codificadi base, per esigenze di internazionalizzazio-ne (codifica di documenti in lingue neolatinecon vocali accentate, in greco, cirillico, cine-se, giapponese ecc.), può essere gestita, se-condo lo standard Unicode a 32 bit (di cui l’A-SCII è un sottoinsieme), con l’inserimento neltesto dei codici Unicode decimali o esadeci-mali dei caratteri, delimitati da un carattere
di inizio (&) e fine (;), ad es. con à oà per l’a accentata (à), oppure con ladichiarazione del set di caratteri usato (nellafigura 2 l’uso del set di caratteri dell’alfabetolatino di base è dichiarato nella prima riga diintestazione <?xml version=“1.0” enco-ding=“ISO-8859-1” standalone=“no”?>).La modalità di rappresentazione grafica diciascun elemento logico del testo, associato
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
51
0
0
0
1
Curriculum Vitae di Carlo Bianchi
Dati personali
Nome CarloCognome Bianchi
Residenza via Moscova 40 - 20121 Milano (MI)e-mail [email protected]. 02-3456789cell. 349-286652Nato il 24-5-1965 a Milano (MI)Nazionalità ItalianaStato civile Coniugato
Esperienze professionali
1990-1993 Info Expert s.r.l - RhoRuolo: Analista ProgrammatoreAttività: Sviluppo di Sistemi Esperti per la pianifica-
zione della produzione industriale
FIGURA 1Un esempiodi documentotestuale, in formatoASCII: un curriculumvitae
<?xml version="1.0" encoding="ISO-8859-1"standalone="no"?><!DOCTYPE curriculum SYSTEM "curriculum.dtd"><curriculum>
<dati_personali><nome>Carlo</nome><cognome>Bianchi</cognome><indirizzo>
<loc tipo=“via”>Moscova</loc><civico>40</civico><cap>20121</cap><comune>Milano</comune><provincia>MI</provincia>
</indirizzo><email>[email protected]</email><tel>02-3456789</tel><cellulare>349-286652</cellulare><fax/><nascita>
<data>24-5-1965</data><luogo>
<comune>Milano</comune><provincia>MI</provincia>
</luogo></nascita><nazionalita>Italiana</nazionalita><stato_civile>Coniugato</stato_civile>
</dati_personali></curriculum>
FIGURA 2Codifica XML delcurriculum vitae
1 XML ammette per altro anche elementi vuoti, prividi testo, in cui il marcatore di apertura e di chiusu-ra possono essere legalmente sostituiti da un uni-co tag, con la sintassi </tag>.

ad una coppia di marcatori, è definita a parteda appositi linguaggi, detti fogli di stile: di-venta così possibile utilizzare uno stesso do-cumento codificato in XML per diverse moda-
lità di pubblicazione (carta, CD-ROM, WorldWide Web, audio), semplicemente cambian-do il foglio di stile associato. Il linguaggio distile più usato e più sofisticato è XSL (eXten-
sible Stylesheet Language) (Paragrafo 6), unvero e proprio linguaggio di programmazionebasato su regole di trasformazione, che con-sentono non solo di decidere il formato grafi-co, ma anche di scegliere quali elementi vi-sualizzare e in che ordine. Sono utilizzati an-che i più semplici fogli di stile CSS (Casca-
ding Style Sheet), che si limitano ad associa-re a ciascun elemento XML determinate ca-ratteristiche di formattazione (tipo e dimen-sione dei font ecc.).
1.2. Tipologie di documenti e DTDXML è un metalinguaggio generico che con-sente di costruire diversi linguaggi di codifi-ca, ciascuno per una diversa tipologia di do-cumenti: XML non prescrive i nomi dei diversimarcatori, ma solo la sintassi generica per la
loro definizione e il loro utilizzo nell’identifi-cazione degli elementi di testo.In XML è possibile definire la peculiare struttu-ra logica che identifica e descrive una tipologiadi documenti nella cosiddetta DTD (Document
Type Definition)2, un insieme di specifiche che,situate in una sezione all’inizio del documentocodificato o in un documento a parte, stabili-scono quali sono i nomi ammissibili per i mar-catori, quali i nomi dei loro attributi e quali re-lazioni di inclusione possono sussistere tra diloro. Ad esempio, una DTD può stabilire cheuna determinata tipologia di documenti possacontenere al suo interno diversi elementi logi-ci, denominati capitoli, che hanno al loro inter-no paragrafi e sottoparagrafi e che ciascun ele-mento sia identificato da un attributo “nume-ro”, con il relativo valore numerico.In una DTD (Figura 3) la dichiarazione <!ELE-MENT associa il nome di un elemento ai suoipossibili contenuti. L’elemento radice coinci-de con il nome associato alla DTD nella di-chiarazione <!DOCTYPE che, all’interno deldocumento, richiama la corrispondente DTD(Figura 2). Nell’esempio del curriculum vitael’elemento radice, curriculum, che identificala DTD, contiene quattro elementi, dati_per-sonali, istruzione, esperienze_professionali,interessi, che a loro volta contengono ulterio-ri elementi, secondo una struttura gerarchicaad albero (Figura 3). Un documento che rispetta la sintassi generi-ca di XML, senza riferirsi a una specifica DTD,è detto ben formato. Un documento XML con-gruente rispetto a una determinata DTD è det-to valido. Il controllo della validità di un docu-mento rispetto a una DTD precedentementedefinita è una garanzia di congruenza forma-le, necessaria per applicare con successo aldocumento stesso procedure automatiche dielaborazione (fogli di stile per la formattazio-ne, istruzioni di information retrieval ecc.).
1.3. Cenni storici: da SGML a XML, via HTMLDall’evoluzione di GML (Generalized Markup
Language), ideato nel 1969 dai ricercatoriGoldfarb, Mosher e Lorris nei laboratori del-
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
0
0
0
1
52
<!ELEMENT curriculum(#PCDATA|dati_personali|istruzione|esperienze_professionali|interessi)*><!ELEMENT dati_personali(#PCDATA|nome|cognome|indirizzo|email|tel|cellulare|fax|nascita|nazionalita|stato_civile)*><!ELEMENT istruzione(#PCDATA|corso|formazione_professionale|lingue)*><!ELEMENT corso(#PCDATA|anno|titolo|votazione|org|periodo)*><!ELEMENT org(#PCDATA|ragione_sociale|comune)*><!ELEMENT ragione_sociale(#PCDATA)><!ELEMENT formazione_professionale(#PCDATA|corso)*><!ELEMENT periodo(#PCDATA|anno|da)*><!ELEMENT lingue (#PCDATA|lingua)*><!ELEMENT lingua (#PCDATA)><!ELEMENT esperienze_professionali(#PCDATA|esperienza)*><!ELEMENT esperienza(#PCDATA|periodo|org|ruolo|attivita|competenze)*><!ELEMENT ruolo (#PCDATA)><!ELEMENT attivita (#PCDATA)><!ELEMENT competenze (#PCDATA)><!ELEMENT interessi (#PCDATA|p)*><!ELEMENT emph (#PCDATA)>
FIGURA 3DTD del curriculum
vitae
2 Una metodologia alternativa alla DTD per definirela struttura di una tipologia di documenti è costi-tuita da XML Schema (Paragrafo 3).
ratori dell’IBM, nel 1980 nasce SGML (Stan-
dard Generalized Markup Language) suspecifiche dell’ANSI (American National
Standards Institute), l’ente deputato negliUSA alla definizione degli standard: adotta-to nel 1983 dal DoD (Department of Defen-se), il Dipartimento della Difesa statuniten-se, e approvato nel 1986 dall’ISO, comestandard ISO 8879.SGML può essere considerato come il direttoprogenitore di XML, con il quale ha in comu-ne la maggior parte delle convenzioni sintat-tiche e semantiche per la costruzione dei tage la possibilità di definire diversi linguaggi dicodifica in base alla tipologia di documento,cioè di definire diverse DTD. La differenzaconsiste nella maggiore complessità sintatti-ca di SGML e in una certa macchinosità deisuoi fogli di stile.Alla fine degli anni ’80, le maggiori organiz-zazioni internazionali degli informatici uma-nisti, ACH (Association for Computers and
the Humanities), ACL (Association for Com-
putational Linguistics) e ALLC (Association
for Literary and Linguistic Computing), han-no deciso di utilizzare SGML per un ambizio-so progetto di codifica dei testi umanistici,denominato TEI (Text Encoding Initiative),che è approdato alla definizione di unaomonima DTD, specificamente dedicata al-l’elaborazione dei testi letterari, storici e fi-losofici: recentemente ne è stata pubblicatauna versione più semplice e ridotta, deno-minata TEI Lite.Usato da alcune case editrici americane, daenti governativi (soprattutto negli USA) e dagrandi aziende per gestire ampie basi di do-cumenti elettronici, per la sua complessitàSGML non è stato, tuttavia, adottato al difuori delle grandi organizzazioni e della ri-stretta cerchia dei ricercatori umanisti.L’applicazione più popolare di SGML, piùpropriamente, la sua più diffusa DTD, è HTML(HyperText Markup Language), apposita-mente pensato per pubblicare documentiipertestuali in Internet. Ideato nel 1989 epubblicato nel 1991 da un ricercatore delCERN (Conseil European pour la Recherché
Nucleaire) di Ginevra, Tim Berners-Lee, per lasua semplicità, HTML è in pochi anni diventa-to il formato standard per la pubblicazione didocumenti in Internet, costituendo la base
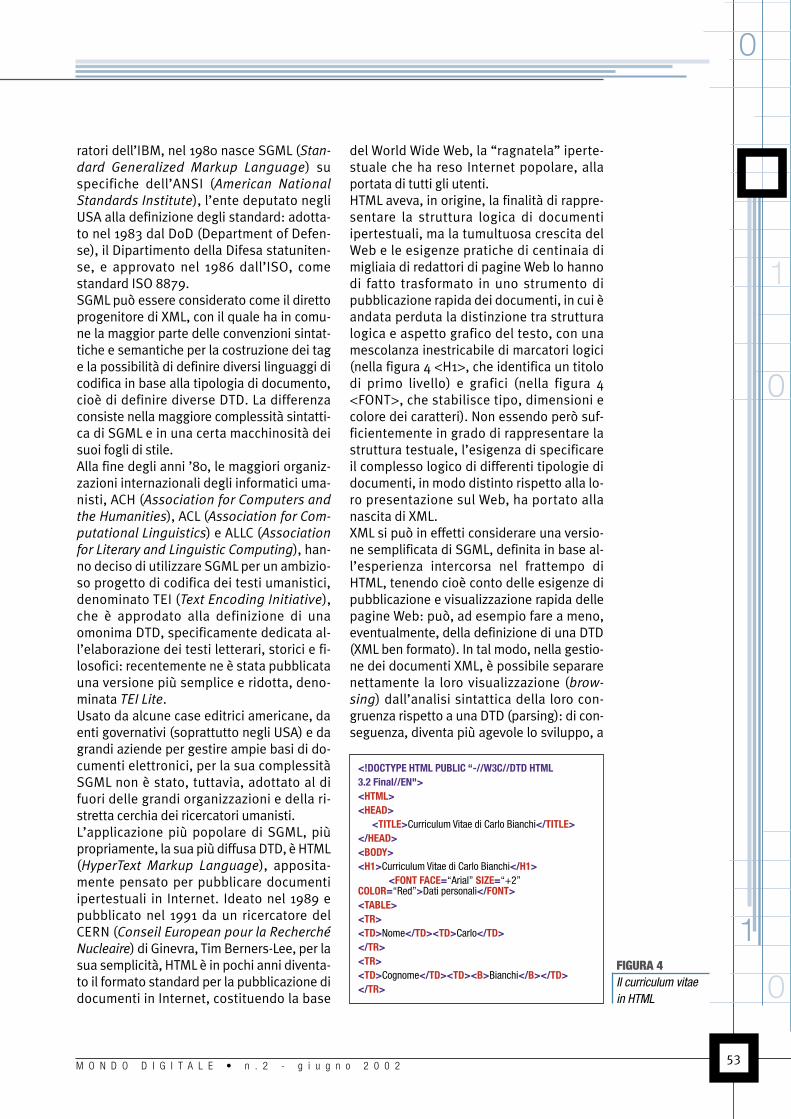
del World Wide Web, la “ragnatela” iperte-stuale che ha reso Internet popolare, allaportata di tutti gli utenti.HTML aveva, in origine, la finalità di rappre-sentare la struttura logica di documentiipertestuali, ma la tumultuosa crescita delWeb e le esigenze pratiche di centinaia dimigliaia di redattori di pagine Web lo hannodi fatto trasformato in uno strumento dipubblicazione rapida dei documenti, in cui èandata perduta la distinzione tra strutturalogica e aspetto grafico del testo, con unamescolanza inestricabile di marcatori logici(nella figura 4 <H1>, che identifica un titolodi primo livello) e grafici (nella figura 4<FONT>, che stabilisce tipo, dimensioni ecolore dei caratteri). Non essendo però suf-ficientemente in grado di rappresentare lastruttura testuale, l’esigenza di specificareil complesso logico di differenti tipologie didocumenti, in modo distinto rispetto alla lo-ro presentazione sul Web, ha portato allanascita di XML.XML si può in effetti considerare una versio-ne semplificata di SGML, definita in base al-l’esperienza intercorsa nel frattempo diHTML, tenendo cioè conto delle esigenze dipubblicazione e visualizzazione rapida dellepagine Web: può, ad esempio fare a meno,eventualmente, della definizione di una DTD(XML ben formato). In tal modo, nella gestio-ne dei documenti XML, è possibile separarenettamente la loro visualizzazione (brow-
sing) dall’analisi sintattica della loro con-gruenza rispetto a una DTD (parsing): di con-seguenza, diventa più agevole lo sviluppo, a
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
53
0
0
0
1
<!DOCTYPE HTML PUBLIC “-//W3C//DTD HTML3.2 Final//EN"><HTML><HEAD>
<TITLE>Curriculum Vitae di Carlo Bianchi</TITLE></HEAD><BODY><H1>Curriculum Vitae di Carlo Bianchi</H1>
<FONT FACE=“Arial” SIZE=“+2”COLOR=“Red”>Dati personali</FONT><TABLE><TR><TD>Nome</TD><TD>Carlo</TD></TR><TR><TD>Cognome</TD><TD><B>Bianchi</B></TD></TR>
FIGURA 4Il curriculum vitaein HTML

basso costo, di strumenti software per la so-la visualizzazione (browser).La maggiore diffusione di XML3 rispetto al suoprogenitore, SGML, è dunque conseguenza diun contesto mutato dalla presenza di HTML,che da un lato ha reso popolari in tutto il mon-do, tramite il Web, le fondamentali convenzio-ni dei linguaggi di markup, dall’altro costitui-sce uno dei possibili output di XML, grazie aifogli di stile XSLT (eXtensible Stylesheet Lan-
guage Transformation) (Paragrafo 6).
1.4. XML e teoria del testoIn generale, non tutte le componenti di unfenomeno sono rappresentate nel suo mo-dello, che è costruito mediante un procedi-mento di astrazione, selezionando gli ele-menti considerati rilevanti per l’indagine:come ogni altro modello, la codifica XML diun testo ha, dunque, un valore euristico edè relativa al punto di vista adottato dall’os-servatore e ai suoi obiettivi. Di conseguen-za, sono possibili molte diverse codificheXML per uno stesso testo, mai identiche altesto stesso, cioè mai in grado di esaurirnetutti gli aspetti.Per porre nei termini corretti la questionemetodologica dell’adeguatezza e pertinenzadella codifica XML rispetto al testo rappre-sentato, giova accennare qui in breve allafondamentale distinzione di Hjelmslev traespressione (il “significante”, ossia l’aspettovisibile del testo) e contenuto (il “significa-to”, cioè la semantica del testo).Non è questa la sede per una trattazione si-stematica delle possibili implicazioni per ilmarkup XML delle teorie strutturaliste deltesto e del linguaggio (De Saussure, Hjelm-slev, Jakobson, Lotman, Propp, Greimasecc.): ci si limita, in questo contesto, ad os-servare che una cooperazione interdiscipli-nare tra l’informatica e le discipline umani-stiche, che studiano i testi, sarebbe notevol-mente feconda per lo sviluppo di XML. Po-trebbe infatti contribuire da un lato a una piùprofonda comprensione dello statuto teori-co del markup; dall’altro potrebbe introdur-re una maggiore consapevolezza nella pras-
si corrente della codifica XML di documentitestuali, che spesso oscilla (confondendolein una stessa DTD) tra codifica dell’espres-sione e del contenuto. Nell’esempio del cur-riculum vitae (Figure 2 e 3) coesistono volu-tamente, a scopo didattico, elementi di tiposemantico, che codificano ciò di cui parla iltesto (per esempio <nome>, <cognome>,<ruolo> ecc.) ed elementi che riguardano in-vece la forma visibile del testo (<emph>,che contrassegna le parti evidenziate del te-sto), ma una mescolanza del genere andreb-be evitata.
2. EVOLUZIONE DI XML
Nei paragrafi precedenti, XML è stato presen-tato come formato per la definizione, attra-verso la marcatura, della struttura e della se-mantica di documenti di testo.Questa descrizione, benché didatticamenteutile e perfettamente coerente con la storiadi XML, non rispecchia però lo stato attualedello standard, che si rivolge alla rappresen-tazione di qualsiasi tipo di informazione chepossa essere scambiata tra sistemi software.
2.1. XML Infoset e i modelli di contenutoLa parte oggi considerata più importante del-l’intero standard XML, il cosiddetto Infoset,descrive i documenti XML come insiemi dioggetti astratti, che hanno una o più pro-prietà dotate di nomi convenzionali, senzafare alcuna ipotesi sul loro formato di memo-rizzazione a basso livello (detto anche forma-
to di serializzazione) che può essere o menoquello canonico basato sui caratteri.Anche la modellazione di Infoset segue lastruttura gerarchica dei testi (Sottoparagra-fi 1.1. e 1.2.); l’intero documento XML costi-tuisce, infatti, un oggetto-documento para-gonabile alla radice di un albero multi-
sorte, cioè composto da oggetti di vario ti-po: gli elementi XML, il loro contenuto, leistruzioni di elaborazione ed i commenti. Glioggetti-contenuto (assieme ai commenti ele istruzioni di elaborazione) costituiscono inodi terminali (le foglie) dell'albero Infoset,mentre gli oggetti-elementi fungono da no-di intermedi.Ogni sistema software che deve manipolaredati XML è libero di definirne una propria rap-
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
0
0
0
1
54
3 Ora è adottato come standard anche nel proget-to TEI.

presentazione interna di basso livello, pur-ché rispetti lo standard Infoset. Il fatto che il formato prescelto sia quasi sem-pre quello basato sul testo risolve senza dub-bio i problemi di chi (come gli autori di que-st’articolo) deve scrivere esempi di dati XML;in molte applicazioni, però, risulta consiglia-bile usare rappresentazioni XML non testuali,ad esempio, per ridurre le dimensioni di mes-saggi XML inviati su una rete congestionatao a banda stretta.Se queste rappresentazioni non testuali ri-spettano lo standard Infoset, i sistemi che le uti-lizzano possono interoperare traducendo, quan-do necessario, l’informazione in un formato diserializzazione canonico basato sul testo.La parte centrale di Infoset, detta nucleo oXML Information Set Core, elenca i blocchi ele proprietà fondamentali che devono esserericonosciuti e gestiti da tutte le implementa-zioni di XML4.Spesso, gli elementi di un documento XMLnon contengono direttamente dei dati, maservono a racchiudere e a correlare uno o piùelementi figlio.L’esempio, <dati_personali> non contienedati ma ha lo scopo di tenere insieme altrimarcatori, che a loro volta contengono leinformazioni anagrafiche sul candidato. Nella terminologia di Infoset, la struttura in-terna di un elemento XML viene chiamatamodello di contenuto; nel caso di <dati_per-sonali>, si parla di modello di contenuto di
soli elementi, mentre per gli elementi checontengono solo dati e non hanno elementifiglio (come <comune> o <e-mail>) si parladi modello di contenuto di soli dati.Quando si usa XML per rappresentare datida manipolare via software, questi due mo-delli di contenuto sono del tutto sufficienti;ma nei sistemi di gestione dei documenti èpratica comune intercalare elementi figliocon dati in forma di caratteri. Questo model-lo di contenuto, noto come modello a conte-
nuto misto, sta per essere progressivamen-te abbandonato.
3. XML SCHEMA
Anche se a prima vista può sembrare che leDTD forniscano tutte le funzionalità neces-sarie per definire la struttura dei documentiXML, ad uno sguardo più attento esse pre-sentano anche numerosi svantaggi, chehanno suggerito l’adozione di soluzioni al-ternative.In primo luogo, esiste il problema della man-canza di uniformità tra i dati (il contenuto deidocumenti XML) e i corrispondenti metadati,cioè le DTD usate per descriverne la struttu-ra. In altre parole, poiché la sintassi usata perscrivere le DTD non è essa stessa una marca-tura XML valida, non è possibile elaborare imetadati con gli stessi strumenti softwareusati per manipolare i dati.Oltre ad essere sintatticamente nonuniformi ai dati che descrivono, le DTD so-no carenti anche dal punto di vista dei tipi
di dati elementari, cioè dei valori che pos-sono assumere gli elementi e gli attributi.Nella DTD del curriculum, ad esempio, nonsarebbe possibile limitare il contenuto de-gli elementi <da> e <a> in modo che sipossa trattare solo di numeri interi nell’in-tervallo da 1960 a 2100, anche se questovincolo risulterebbe prezioso per la valida-zione dei dati.In generale, ci si è resi conto che quando sidefinisce la struttura di dati in formato XMLsarebbe utile disporre dello stesso reperto-rio di tipi di dati elementari incorporati, co-munemente a disposizione dei progettisti didatabase relazionali; ma le DTD richiedonoun’obbligata definizione manuale anche di ti-pi di uso molto comune come le date.Inoltre, la tecnica con cui sono definiti gli ele-menti delle DTD (Sottoparagrafo 2.1) non èadatta a complessi progetti di sistemi di tipi
di dati, in cui possono esistere più tipi con si-gnificative parti comuni.Se nell’esempio fosse stato necessario di-sporre di due elementi <indirizzo>, uno informato europeo (<indirizzoEU>) e uno sta-tunitense (<indirizzoUSA>) sarebbe statoindispensabile definirli in maniera del tuttoindipendente, benché le differenze sianomarginali.I linguaggi di programmazione a oggetti, ri-solvono situazioni del genere attraverso la
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
55
0
0
0
1
4 È importante notare che la definizione di interfac-ce per accedere da programma ai dati XML non èparte di Infoset, ma è oggetto di standard separa-ti (Paragrafo 4).

fattorizzazione degli elementi comuni a piùtipi in appositi tipi di dati astratti, a partiredai quali vengono definiti per differenza i tipidi dati concreti effettivamente stanziati, cioèusati, nei programmi. Purtroppo, le DTD XMLnon permettono di definire elementi per dif-ferenza rispetto ad altri.Lo standard XML Schema del W3C è nato pro-prio per risolvere questi problemi. Si tratta diuna sintassi XML che distingue tra tipi di dati
ed elementi XML appartenenti a quei tipi. Ol-tre ad includere una quarantina di tipi ele-mentari incorporati, XML Schema fornisce alprogettista più o meno lo stesso potereespressivo degli attuali linguaggi di program-mazione ad oggetti. In altri termini, XMLSchema è un completo Data Definition Lan-
guage (DDL) basato su XML che incoraggia(anche se non impone) il classico modo diprocedere dei progettisti software: partiredalla definizione di tipi di dati per eseguireuna successiva dichiarazione di elementiXML appartenenti a quei tipi.Nel modello di XML Schema, le DTD sono deltutto assenti: ogni documento XML fa usodegli elementi definiti da un certo SchemaXML. Ciò corrisponde all’orientamento, piùvolte ribadito dal W3C, di considerare strate-gica la tecnologia degli Schemi rispetto aquella delle DTD.Uno schema definisce uno spazio di deno-minazione, o target namespace, che è com-posto dai nomi dei tipi e degli elementi, ap-partenenti a quei tipi, definiti al suo interno(Figura 5). Uno schema può utilizzare al suointerno anche elementi o tipi definiti in altrinamespace (source namespace), qualifican-
doli con un prefisso che corrisponde alloUniform Resource Identifier (URI) che ne
identifica la provenienza. Un URI identificaunivocamente una risorsa sulla Rete; il tipomaggiormente conosciuto di URI è la URLabitualmente utilizzata per le pagine Web,che oltre a identificare univocamente le pa-gine permette ai browser Web di recuperar-le su Internet. Il prefisso xsd: è solitamenteusato per qualificare gli elementi del lin-guaggio XML Schema stesso, che sono usa-ti per scrivere gli altri schemi e costituisco-no lo “schema degli schemi” messo a puntodal W3C.La figura 6 mostra la tecnica di validazione
in due fasi dei documenti XML usando glischemi.All’interno degli schemi XML, i tipi di datipossono essere definiti per restrizione oestensione di tipi già esistenti, mentre tra ti-pi completamente diversi possono esserestabilite sofisticate relazioni di sostituibilità
(per esempio, è possibile permettere l’inter-scambiabilità di un tipo di dati “metropoli-tana” con un tipo di dati “treno” che purenon hanno in comune alcuna parte della lo-ro struttura). La seguente definizione di tipo
complesso (ComplexType) XML Schemaspecifica la struttura interna di un tipo Curri-culumItem:
<xsd:complexType name=“CurriculumItemType”>
<xsd:sequence><xsd:element name=“periodo”type=“TimeIntervalType”/><xsd:element name=“organizzazione”type=“OrganizationType”/>
</xsd:sequence></xsd:complexType>
Come si vede, in XML Schema la struttura diun tipo complesso dotato di nome può esse-re definita in termini di una sequenza di ele-menti di altri tipi (le cui definizioni sono quiomesse per brevità). Possiamo usare il con-sueto stile di programmazione a due livelli(definizione di tipo e dichiarazione di variabi-le) per dichiarare l’elemento <esperienza> inmodo che abbia la struttura precedentemen-te definita. Basterà scrivere:
<xsd:element name=“esperienza” type=“CurriculumItemType”/>
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
0
0
0
1
56
schemaLocation=“schema1.xsd”
documento .xm1
- usa elementidel namespace A
schema .xsd
- definisce gli elementidel namespace A
targetNamespace=“A”
FIGURA 5Schema e target
namespace

Ovviamente, è anche possibile dichiararel’elemento <esperienza> e definirne con-testualmente la struttura senza far riferi-mento ad alcun tipo denominato, comesegue:
<xsd:element name=“esperienza”><xsd:sequence>
<xsd:element name=“periodo” type=“TimeIntervalType”/><xsd:element name=“organizzazione”type=“OrganizationType”/>
</xsd:sequence></xsd:element>
Ma in questo modo uno dei motivi fonda-mentali per usare gli schemi viene meno: lastruttura interna di <esperienza> non potràinfatti essere ereditata da altri tipi o comun-que riutilizzata per definirli.Lo stile di definizione/dichiarazione a duelivelli, appena descritto, costituisce un ap-proccio semplice, ma molto efficace, allamodellazione di dominio usando gli Sche-mi XML.Questa tecnica consiste nell’usare le defini-zioni ComplexType di XML Schema per pro-gettare il completo repertorio informativo ditipi relativo a un dominio applicativo oppuread un’organizzazione. Ai tipi di questo Sche-ma principale saranno riferiti gli elementiusati di volta in volta nei documenti o mes-saggi XML che circolano all’interno dell’orga-nizzazione stessa. Per dichiarare gli elementiXML si usano spesso altri schemi, gestiti indi-pendentemente da quello principale. Tecni-camente, però, le dichiarazioni di elementi inessi contenute faranno tutte riferimento alnamespace sorgente dello schema principa-le (per esempio, definendo e usando un pre-fisso come orgtypes:) oltre, naturalmente, ariferirsi al namespace di XML Schema, quali-ficandolo come xsd: .A livello più basso, lo standard comprende lanozione di tipo semplice o SimpleType, checonsente la definizione di nuovi tipi per enu-merazione o restrizione dei 40 tipi elementa-ri, oppure specificando espressioni regolari.Viene mostrata, di seguito, la definizione diun tipo per l’elemento <da> del nostro esem-pio, operando una restrizione sul tipo ele-mentare incorporato date.
<xs:simpleType name=“sinceType”><xs:restriction base="xs:date"/>
</xs:simpleType>
4. PARSING E VALIDAZIONEDEI DOCUMENTI: I FORMATI SAXE DOM
Il risultato della validazione di un documentoXML rispetto a una DTD o ad uno Schema(operazione spesso chiamata parsing) è unarappresentazione dell’Infoset del documentoin un formato più adatto all’elaborazione daparte di programmi informatici, rispetto alformato di serializzazione.Le due rappresentazioni più comuni di XMLsono il Document Object Model (DOM) Level2 e la Simple API (Application Program(ming)Interface) for XML (SAX). Entrambe questetecniche si basano sulla traduzione delleastrazioni di Infoset in un modello a oggettiche evita ai programmatori di dover manipo-lare direttamente i caratteri del formato di se-rializzazione di XML. Sia SAX che DOM defini-scono un insieme di interfacce che permetto-no ai programmi di accedere all'insieme delleinformazioni XML, ma differiscono in alcuniaspetti fondamentali. SAX traduce l’alberoInfoset di un documento XML in una sequen-za lineare di eventi. Leggendo un file XML, unparser SAX genera un evento ogni volta cheincontra uno degli oggetti Infoset; l’applica-zione che deve accedere ai dati gestisce que-sti eventi con altrettante chiamate di funzio-ne. Un parser DOM traduce l’Infoset del file inun albero di oggetti. DOM è particolarmenteadatto alle applicazioni che devono rappre-sentare interamente in memoria un docu-
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
57
0
0
0
1curriculum.xml currischema .xsd XMLschema .xsd
(schema-degli-schemi)
Valida il documento rispettoalle dichiarazioni di currischema .xsd
Valida il currischema .xsd rispettoalle dichiarazioni dello “schemadegli schemi” definito dal W3C
FIGURA 6Validazione di undocumento rispettoa uno schema

mento XML, mentre le applicazioni basate suSAX non hanno bisogno di tenere in memorial’intera rappresentazione dell’Infoset.Una seconda non trascurabile differenza de-riva dal fatto che DOM è una Raccomandazio-ne del W3C e ha dietro di sé il peso istituzio-nale di questa organizzazione, mentre SAX èuno standard di fatto sviluppato da un grup-po di progettisti che facevano capo alla mai-ling list XML-DEV, supervisionato da DavidMegginson. La mancanza di un’approvazione“ufficiale” di SAX non ha tuttavia impeditoche la maggior parte dei prodotti softwareper XML supporti sia SAX che DOM. Poichésia il formato SAX che DOM sono conformi aInfoset, possono interoperare senza proble-mi (infatti, molte implementazioni di DOMsono state scritte sulla base di codice SAX).
5. SELEZIONE DI INFORMAZIONIXML: LO STANDARD XPATH
La struttura gerarchica di Infoset può essereusata per individuare sottoinsiemi dei nodi diun documento attraverso un semplice linguag-gio che descrive l'attraversamento dell’albero.In questo modo, invece di scrivere le routinedi estrazione e di attraversamento in un lin-guaggio di programmazione, gli sviluppatoripossono ricorrere a semplici espressioni e la-sciar fare tutto il lavoro al parser XML.Il linguaggio proposto dal W3C per estrarre sot-toinsiemi di nodi dell’albero dei documenti XMLè chiamato XPath (XML Path Language 1.0).Il costrutto più importante usato nelle espres-sioni XPath è chiamato percorso di posiziona-
mento. Proprio come i percorsi dei file sy-stem, i percorsi di posizionamento XPath pos-sono essere assoluti o relativi; quelli assolutiiniziano con una barra obliqua (/) e indicanoche la navigazione deve incominciare dal no-do radice nel modello ad albero. Un percorsodi posizionamento relativo non inizia con unabarra obliqua: ciò significa che l’attraversa-mento dell’albero deve iniziare dal nodo concui inizia il percorso di posizionamento.Ecco l’espressione XPath che individua tuttigli elementi <nome> che sono figli di ele-menti <dati_personali>, i quali a loro voltadiscendono dal nodo radice <curriculum> :
/curriculum/dati_personali/nome
Nel caso di questo semplice esempio, nonsarebbe difficile scrivere un programma cheesegue lo stesso compito usando le API SAXo DOM, ma nel caso di espressioni più com-plicate che includano caratteri jolly e condi-zioni logiche, aumentano i vantaggi di dele-gare il codice di attraversamento al parserXML. L’espressione che segue estrae i nodiInfoset <località> discendenti dalla radice<curriculum> e dotati di un attributo tipo ilcui contenuto sia piazza.
curriculum/*/località/[@tipo=‘piazza’]
Oltre ad essere utilizzato direttamente XPathviene presupposto dallo standard XSLT 1.0per le trasformazioni di documenti XML e dalnuovo linguaggio di interrogazione XQueryproposto dal W3C. XSLT usa XPath per identi-ficare i sottoinsiemi di nodi di un documentodi origine che saranno tradotti in parti del do-cumento di output.
6. I LINGUAGGI DI STILE:XSL E LE REGOLEDI TRASFORMAZIONE
Nel sottoparagrafo 1.1 è stato brevemente in-trodotto XSL , come standard per la presenta-zione dei documenti XML, per visualizzarlicioè su schermo, su carta o riprodurli via au-dio. Nella definizione di questo standard di-venne chiaro che si trattava di un processo indue fasi: prima vi fu una trasformazionestrutturale, e poi subentrò il processo di for-mattazione vero e proprio. Per questo, il lin-guaggio XSL fu diviso in: XSL-T per definire letrasformazioni e XSL-FO (XSL Formatting
Objects) per definire la fase di formattazione.XSL-FO è un namespace XML in cui i marcato-ri descrivono aree della schermata o della pa-gina stampata e le loro proprietà. Poiché sitratta di marcatori XML, XSL-T non ha proble-mi per generarli come suo output. La defini-zione di XSL-FO è però un’impresa di difficoltàparagonabile alla creazione dello standardPostScript e i prodotti che implementanoXSL-FO sono in una fase, ancora primitiva, disviluppo. Per questo, i documenti XML vengo-no di solito tradotti usando XSLT per produrreoutput in HTML, visualizzabili attraverso unbrowser standard per la navigazione del Web.
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
0
0
0
1
58

6.1. Introduzione a XSLTXSLT è un linguaggio standard progettatoper trasformare documenti XML. Le sue ap-plicazioni sono molteplici: per esempio, leorganizzazioni che hanno investito nellacreazione di fonti d’informazioni in formatoXML standard devono essere in grado ditrasformarle per inviarle non solo al tradi-zionale browser web, ma anche ai terminalimobili e ai televisori. Inoltre, può esserenecessario trasformare dati XML, inviati co-me messaggio, in modo che rispettino laDTD o lo Schema adottati dal destinatario.Poiché il commercio elettronico interazien-dale è sempre più diffuso, la quantità di da-ti scambiati tra aziende aumenta giornal-mente e questa esigenza diventa semprepiù pressante.Quando XSLT non era ancora disponibile,per eseguire queste trasformazioni era ne-cessario scrivere applicazioni software inlinguaggi complessi come C++ o Java: conXSLT diventa possibile (e molto più como-do) descrivere le trasformazioni desiderateusando un linguaggio dichiarativo cheesprima le trasformazioni come una serie diregole che definiscano l’output che deve es-sere prodotto. Inoltre, XSLT si basa su unparser DOM per convertire il documentoXML nella struttura ad albero corrisponden-te: è l’Infoset del documento che XSLT mani-pola, non il documento stesso. Un foglio distile XSLT è un programma dichiarativo checontiene un insieme di regole che permetto-no di navigare nell’albero Infoset, che rap-presenta un documento, di scegliere nodispecifici e di eseguire elaborazioni anchecomplesse su questi nodi.
6.2. Modalità di trasformazioneL’elaborazione di un foglio di stile XSLT consi-ste di due fasi distinte:❙ la trasformazione strutturale: i dati XML iningresso sono convertiti in una struttura cheriflette l’output desiderato;❙ la formattazione: la nuova struttura è con-vertita nel formato di uscita richiesto, peresempio HTML o PDF.La trasformazione strutturale consiste inoperazioni come la selezione dei dati (cioè lascelta di alcuni degli elementi e attributi neldocumento XML in ingresso), il loro ordina-
mento e l’esecuzione di conversioni aritmeti-che (per esempio la trasformazione di centi-metri in pollici). La figura 7 mostra il flusso didati della trasformazione XSLT.
6.3. XSLT e i linguaggi d’interrogazioneper basi di datiXSLT presenta alcune somiglianze con i lin-guaggi di interrogazione usati per i databaserelazionali. In un database relazionale, i daticonsistono in una serie di tabelle; usando illinguaggio di interrogazione SQL (Structured
Query Language), è facile definire operazionidi estrazione e aggregazione dei dati delle ta-belle, per poi convertire il risultato in HTML.Come si vedrà in seguito, molti database re-lazionali oggi consentono di estrarre infor-mazioni anche in formato XML; ma che van-taggio c’è nel delegare a XSLT i compiti di tra-sformazione su queste informazioni? La ri-sposta sta nel fatto che le trasformazioniXSLT sono adatte anche a sorgenti di dati
eterogenee, perché funzionano per qualun-que sorgente di dati che esporti XML e nonsolo per i database relazionali. Naturalmen-te, XSLT e SQL sono destinati a coesistere: idati saranno memorizzati in database rela-zionali e trasmessi tra i sistemi in formatoXML, personalizzandoli a seconda delle esi-genze del ricevente.
6.4. La sintassi di XSLTIn genere, un linguaggio di trasformazionedefinisce una sintassi per selezionare i datiche devono essere elaborati, siano essi me-morizzati in un database relazionale o in undocumento XML. Per questo scopo in SQL viè la clausola SELECT; in XSLT l’equivalentesono le espressioni XPath di cui ci si è occu-pati in precedenza (Paragrafo 5).I percorsi di attraversamento di XPath sono
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
59
0
0
0
1
Foglio di stile
Albero del foglio di stile
Testo
Documento Albero Albero
sorgente sorgente Processo di trasformazione risultato XML
HTML
FIGURA 7Flusso di dati dellatrasformazione

usati per identificare i nodi desiderati all’in-terno di un documento XML, in base ad unpercorso attraverso il documento XML (par-tendo dalla radice o dalla posizione corren-te) o in base al contesto in cui il nodo appa-re. XSLT viene usato poi per manipolare i ri-sultati di queste selezioni (modificando inodi selezionati, costruendo nuovi nodi ecosì via).Un’altra importante proprietà concettualecomune a XSLT e SQL è la chiusura, la pro-prietà per cui l’output di una trasformazioneha la stessa struttura dati dell’input. In SQLquesta struttura (cioè, l’ambiente rispetto acui il linguaggio è chiuso) è definita dalle ta-belle relazionali, nel caso di XSLT si tratta de-gli alberi Infoset dei documenti XML.La proprietà di chiusura implica che le opera-zioni eseguite usando il linguaggio possonoessere composte per definire operazionimolto più complesse: si può prendere l’out-put di un’operazione e renderlo l’input dell’o-perazione successiva. In SQL è possibile ese-guire ciò definendo viste o interrogazioni se-condarie (sub-query), mentre in XSLT è possi-bile filtrare i dati d’ingresso attraverso unaserie di fogli di stile.
6.5. Esempi di trasformazioniIl seguente frammento di foglio di stile mo-stra una versione semplificata della trasfor-mazione necessaria per tradurre, in HTML, ilnostro curriculum di esempio:
<?xml version=“1.0” encoding=“UTF-8”?><xsl:stylesheet version=“1.0” xmlns:xsl=
“http://www.w3.org/1999/XSL/Transform”
xmlns:fo=“http://www.w3.org/1999/XSL/
Format”>
<xsl:template match=“curriculum”><HTML>
<HEAD><TITLE>
Curriculum vitae
</TITLE></HEAD><BODY><xsl:apply-templates/></BODY>
</HTML></xsl:template>
<xsl:template match=“dati_personali”><H1>Riepilogo dati personali</H1><TABLE Border=“1” width=“100%”>
<TR><TD>nome</TD><TD>cognome</TD><TD>via</TD><TD>civico</TD><TD>cap</TD><TD>comune</TD><TD>provincia</TD><TD>mail</TD><TD>tel</TD><TD>cellulare</TD><TD>fax</TD><TD>datanascita</TD><TD>comunenascita</TD><TD>provincianascita</TD><TD>cittadinanza</TD><TD>statocivile</TD>
</TR><xsl:apply-templates/>
</TABLE><br/>
</xsl:template>
<xsl:template match=“nome”><TD><xsl:apply-templates/></TD></xsl:template>
<xsl:template match=“cognome”><TD><xsl:apply-templates/></TD></xsl:template>
………
</xsl:stylesheet>
È interessante notare che il foglio di stile XSLT èesso stesso un documento XML. Non potendotrattare qui in modo esauriente il linguaggio ditrasformazione5, ci si limiterà a fare qualche com-mento, seguendo passo per passo l’esempioproposto. Il foglio di trasformazione inizia con:
<xsl:stylesheet version=“1.0”xmlns:xsl=“http://www.w3.org/2000/XSL/Transform”xmlns:fo=“http://www.w3.org/2000/XSL/Format”>
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
0
0
0
1
60
5 Il file del foglio di stile è comunque disponibile co-sì come gli altri esempi menzionati nell’articolo al-la url http://beserker.crema.unimi.it/xml

Si tratta dell'intestazione standard XSLT. L’at-tributo xmlns:xsl è una dichiarazione di XMLNa-mespace, che indica che verrà usato il prefissoxsl per contrassegnare i nomi degli elementi de-finiti nello schema dello standard XSLT rilasciatodal W3C, in modo da non confonderli con gli al-tri elementi utilizzati nel documento di input edefiniti in uno Schema o DTD dell’utente.
<xsl:template match=“curriculum”>
Un elemento <xsl:template> definisce il mo-dello da cercare nel documento sorgente.L’attributo match=“curriculum” indica che laregola viene applicata all’elemento-radicedel documento XML sorgente, <curriculum>.È importante rilevare che qui, curriculum,non è un nome di tag, ma un'espressione diattraversamento Xpath, che identifica un in-sieme di nodi (composto in questo caso dalsolo nodo radice del documento d’esempio). Una volta che la condizione di applicazione del-la regola è stata selezionata, il corpo della re-gola dice al foglio di stile quale output generare.Per questa prima regola, si tratta di una se-quenza di elementi HTML (compresa l’inte-stazione di una tabella) che deve essere co-piata nel file di output. Segue poi un elemen-
to cruciale, <xsl:apply-templates/>, che cau-sa una chiamata ricorsiva dell’intero foglio distile, all’insieme cioè delle regole XSLT quicontenute, a cui viene dato in input il sottoal-bero del documento originale che corrispon-de al punto fin qui raggiunto.Il foglio prosegue, quindi, elaborando i nodi fi-gli di curriculum e seguendo sue semplici stra-tegie: nel caso di nodi interni (con modello dicontenuto a soli elementi) si limita ad esegui-re una chiamata ricorsiva, mentre, nel caso dinodi foglia, aggiunge una semplice formatta-zione HTML e i marcatori <TD> necessari peraggiungere una riga alla tabella HTML. La figu-ra 8 mostra il risultato dell’applicazione del fo-glio di stile al documento d’esempio.Benché questo semplice esempio ha riguar-dato la sola traduzione in HTML, a tecnica ditrasformazione dichiarativa basata su XSLTpresentata in questo paragrafo, si prestamolto bene alla realizzazione di servizi
informativi multi protocollo, in grado di ri-spondere alle richieste degli utenti trasfor-mando sul momento dati in formato XMLper ottenere documenti formattati nel mo-do più adatto al profilo d’interessi dell’uten-te e soprattutto al tipo di terminale che stautilizzando.
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
61
0
0
0
1
FIGURA 8Il risultatodell’applicazionedel foglio di stileal nostro curriculumd’esempio

7. APPLICAZIONI
7.1. EditoriaUna delle tante potenzialità delle tecnologieXML e XSLT, tra loro combinate, nella pubbli-cazione dinamica dei contenuti, è l’utilizzodel codice XSL parametrico per la realizzazio-ne di servizi multiprotocollo. Ma XML, per lasua capacità di rappresentare la struttura lo-gica di un documento in modo distinto ri-spetto alla modalità di rappresentazione gra-fica, ha molte altre utili applicazioni in campoeditoriale. Con XML diventa infatti possibile ilriutilizzo di uno stesso documento codificato
in XML per diversi tipi di stampa (per esem-pio in bianco e nero o in quadricromia), diver-
si formati (HTML, PFD, PostScript) e diverse
modalità di pubblicazione (carta, CD-ROM,World Wide Web), senza dover apportare al-cuna modifica alla codifica XML, ma sempli-cemente cambiando i fogli di stile associati.XML facilita inoltre la gestione delle riedizio-
ni e, grazie alle potenzialità di XSLT, rendepossibile la personalizzazione delle edizioni,in base alle esigenze del committente: è pos-sibile, per esempio, da una collezione di ope-re estrarre facilmente un’antologia.
7.2. Interoperabilità e integrazioneQuasi tutti i principali produttori di softwarehanno incorporato nel progetto delle loropiattaforme di servizi basate sul Web la no-zione di trasformazione in linea di dati XML.La figura 9 rappresenta una classica soluzio-ne strutturale di questo tipo, che prevedeuna base documentale (che può essere sosti-tuita da un’interfaccia verso un database re-lazionale) da cui l’informazione XML vieneprelevata all’atto di una richiesta. I dati XMLvengono sottoposti a parsing per ricavare
l’albero DOM, su cui si applica poi la trasfor-
mazione XSL lato server necessaria per ri-spondere alla richiesta remota. I nodi dell’al-bero DOM selezionati vengono resi persi-
stenti e salvati in una memoria cache (dettaanche persistence manager) per essere recu-perati più velocemente nel caso in cui arrivi-no altre richieste che li riguardano.Questa visione trasformazionale dei serverWeb si è recentemente evoluta nell’idea deiWeb services, servizi remoti che ricevono ri-chieste o invocazioni sotto forma di messag-gi XML e inviano risposte parimenti codifica-te come XML.Un campo applicativo di particolare interes-se per l’integrazione via XML è quello relativoall'accesso via Internet ai database aziendalie alle operazioni di commercio elettronico.Le principali applicazioni riguardano lo scam-bio di dati tra varie attività aziendali nell’am-bito di una catena di approvvigionamento(Electronic Data Interchange o EDI), secondoil ben noto modello del commercio elettroni-co B2B (Business to Business), e nelle tran-sazioni su Internet che coinvolgono clienti fi-nali (commercio elettronico Business to Con-sumer o B2C).La figura 10 mostra una tipica transazione in-teraziendale basata sull’interscambio di do-cumenti in formato XML.La tecnologia XML viene sfruttata a due li-velli ben distinti tra loro. In primo luogo, lacomunicazione tra applicazioni software in-dispensabile per queste applicazioni è stataottenuta mediante tecnologie software d’in-tegrazione basate su protocolli proprietaricome Microsoft COM/DCOM (Component
Object Model/ Distribuited COM) o standardcome CORBA (Common Object Request
Broker Architecture). I protocolli “leggeri”per l’esecuzione remota di servizi attraver-so HTTP (Hyper Text Transfer Protocol) eXML hanno guadagnato consensi tra gli svi-luppatori di servizi interoperabili per il lorocosto computazionale limitato e per la loroflessibilità.I protocolli “leggeri” basati su XML comeSOAP (Simple Object Access Protocol), che èalla base dell’architettura Microsoft .NET,permettono di eseguire l’integrazione tra ap-plicazioni remote attraverso l’interscambiodi dati standardizzati in formato XML.
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
0
0
0
1
62
Eventmanager
Richieste
XML trasformato
XML parserXSL transformer
Persistancemanager
Docbase
FIGURA 9Architettura con
trasformazione XSLlato server

7.3. Semantic Web e RDFUno degli aspetti più interessanti della mar-catura XML è la possibilità di usarla per deno-tare la semantica dei dati, rendendo così piùfacile la loro selezione e classificazione.Le usuali pagine Web non contengono alcunaesplicita rappresentazione del loro significa-to, a parte quella fornita dai marcatori HML<META>, usata dai motori di ricerca per l'in-dicizzazione delle pagine.Questa situazione rappresenta un proble-ma soprattutto per chi deve scrivere degliagenti software in grado di raccogliere edelaborare senza intervento dell’utentel’informazione presente sui siti Web dellaRete. I metadati XML (sotto forma, peresempio, di XML Schema) offrono solo unasoluzione molto parziale a questo proble-ma, prima di tutto perché, come abbiamo vi-sto, la semantica dei marcatori definiti dalnamespace XML di un’organizzazione ètutt’altro che ovvia per altre organizzazioni.In secondo luogo, uno Schema XML descri-ve soltanto dati in formato XML nativo. Que-sto apparente vicolo cieco tecnologico èstato affrontato dal W3C proponendo unostandard internazionale basato su XML perla rappresentazione astratta dei contenutidelle risorse di rete, siano o meno espressiin XML, che può essere usato dagli agentisoftware per le loro ricerche. Questo stan-dard prende il nome di Resource Descrip-
tion Format o RDF.
7.4. RDF in breveIl concetto principale su cui si basa lo stan-dard RDF è che i dati sono descritti da asser-zioni, relative a risorse identificate in modounivoco tramite un Uniform Resource Identi-
fier o URI6 (file XML o sottoalberi individuatida un XPath, pagine HTML, interi siti Web). Leasserzioni RDF specificano una proprietà del-la risorsa (per esempio il titolo, la data dicreazione o il tipo) e un valore, che può esse-re una stringa, numero, un frammento XML oun’altra risorsa.L’asserzione RDF che segue, specifica che
l’autore della risorsa del nostro curriculumd’esempio, si chiama Carlo Bianchi:
<?xml version=“1.0” encoding=“UTF-8”?><rdf:statement xmlns:rdf=“http://www.w3.org/1999/02/22-rdf-syntax-ns#” xmlns:rdfs=“http://www.w3.org/2000/01/rdf-schema#”>
<rdf:subject resource=“http://www.cer-calavoro.org/Curricula/curriculum.xml”/><rdf:predicate resource=“http://www.purl.org/dublin-core#author”/><rdf:object>Carlo Bianchi</rdf:object>
</rdf:statement>
La cosa più interessante di questa sintassi RDF,che per il resto dovrebbe essere largamente au-to-esplicativa, è l’associazione esplicita (ese-guita mediante concatenazione di stringhe) sta-bilita dal marcatore <rdf:predicate>.Questa associazione lega il nome della pro-prietà (author) e la URI che contiene la defini-zione di tutte le proprietà utilizzabili per ladescrizione e delle relazioni tra loro (in que-sto caso si fa riferimento allo standard Dublin
Core, un ben noto standard di bibliotecono-mia che elenca le principali proprietà che puòavere un testo scritto).In generale, l’elenco delle proprietà predi-cabili in RDF sulle risorse di un certo domi-nio applicativo e le relazioni che esistonotra queste proprietà costituiscono un mo-dello concettuale del dominio stesso, di po-tere espressivo più o meno equivalente aquello di una rete semantica. Il linguaggioche si usa per specificare proprietà e rela-zioni tra loro è anch’esso basato su XML eprende il nome di RDF Schema (RDFS). Glischemi RDFS, su cui non è il caso di soffer-marsi, organizzano i concetti del dominio in
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
63
0
0
0
1
Richiesta
Conferma
Elabora l’ordinee genera la conferma
d’ordine
Elabora la confermad’ordine
e.g. Ordine di merce (in XML)
e.g. Conferma d’ordine in XML
FIGURA 10Transazioneinteraziendale viaRete con scambiodi documenti XML
6 Un indirizzo logico per l’identificazione di risorsesul Web, analogo all’URL, di cui è una generaliz-zazione.

modo elaborabile da agenti software e co-stituiscono un primo passo verso l’elabora-zione di ontologie di dominio e verso l’indi-cizzazione delle risorse del dominio stessousando questi concetti piuttosto che sem-plici parole-chiave7.Ecco un frammento di uno schema RDF cheesprime il fatto che un Operatore Sanitario èuna sottoclasse di Persona:
<?xml version=“1.0” encoding=“UTF-8”?><rdf:RDF xmlns:rdf=“http://www.w3.
org/1999/02/22-rdf-syntax-ns#"xmlns:rdfs=“http://www.w3.org/2000/01/rdf-schema#”>
<rdfs:Class rdf:ID=“Operatore Sanitario”><rdfs:subClassOf rdf:resource=“#Persona”/></rdfs:Class></rdf:RDF>
La corrispondente gerarchia di concetti, cherisulterà familiare a chi conosce la program-mazione orientata agli oggetti, è riportatanella figura 11.In realtà RDFS ha un potere espressivo analo-go a quello dei Data Definition Language deidatabase ad oggetti, ed è ben più limitato di al-tri linguaggi esistenti per la descrizione di on-tologie. Esistono numerose proposte per la suaestensione, soprattutto da parte di chi si occu-pa di sistemi per la gestione della conoscenza.
8. STRUMENTI SOFTWARE
8.1. Software di basePer la diffusione di XML molto importante è ladisponibilità gratuita di browser XML, cioè diprogrammi che consentono la semplice lettu-ra di documenti XML. Oltre ai molti browserOpen Source (per lo più scritti in Java), traquelli commerciali segnaliamo in particolareMicrosoft Internet Explorer e Netscape 6.Per ragioni di ottimizzazione della velocità divisualizzazione dei documenti XML, non so-no invece generalmente inclusi nei browserparser di validazione del documento rispet-to alla DTD o allo Schema associato. Parserdi validazione e XSLT sono disponibili comeprodotti Open Source, a se stanti, o comecomponenti di complesse piattaformesoftware lato server (sottoparagrafo 7.2.):l’elaborazione del parsing è infatti molto piùveloce se effettuata sul lato server, piuttostoche da browser o altri prodotti sul lato client.I file XML, essendo file di testo, possono esse-re editati e modificati con comuni editor ASCII.Tuttavia, per facilitare il compito ai redattori didocumenti XML, sono nati specifici editor XML
che, pur garantendo all’utente il controllo e lavisibilità sulla codifica XML, forniscono utili fun-zionalità, quali l’evidenziazione con colori di-versi dei tag XML, il controllo sulla coerenza sin-tattica (cioè sull’essere il documento ben for-mato), la validazione rispetto alla DTD o alloXML Schema di riferimento e la visualizzazionedella struttura ad albero degli elementi XML.Tra i vari editor in commercio (ricordiamo qui,tra gli altri, Microsoft XML Notepad, XML Pro,CLIP! XML Editor, CUESoft EXml, XMetal), mol-to popolare qui in Italia è XML Spy, distribuitoda una software house austriaca.Questi editor sono professionali e si rivolgo-no ad utenti esperti, competenti di informati-ca. Un territorio ancora relativamente ine-splorato è quello dei cosiddetti editor visuali
per XML, che semplificano al massimo la ge-stione dei tag, avvicinando XML agli utenti dibase, non specialisti8.
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
0
0
0
1
64
7 Lo scenario, proposto dal W3C, secondo cui le risorse del WWW saranno indicizzate mediante concetti pre-si da ontologie elaborate in modo consortile prende il nome di Semantic Web Initiative.
8 Un editor sperimentale di questo tipo (Visual XML Editor) è stato recentemente prodotto come tesi di lau-rea al Dipartimento di Tecnologie dell’Informazione dell’Università degli Studi di Milano – Polo di Crema.
Risorse
Persona
Paziente Sanitario
Medico
Infermiere
FIGURA 11La gerarchia
d’ereditarietà a cuisi riferisce
lo schema RDFSd’esempio

8.2. XML e database Molti prodotti per la gestione di basi di datirelazionali sono oggi in grado di esportare informato XML il risultato delle interrogazioni.La codifica di una tabella relazionale in XML èun’operazione molto semplice, anche se nonesiste uno standard preciso per farlo.L’esempio che segue riporta la tecnica di co-difica usata dai database Oracle (il sempliceschema XML che esprime la struttura di que-sta codifica in XML dei dati relazionali èomesso per brevità):
<?xml version=“1.0”?> <ROOTDOC><DBROW id=“1”><EMPNO>7876</EMPNO><ENAME>BIANCHI</ENAME> </DBROW><DBROW id=“2”><EMPNO>7499</EMPNO><ENAME>ROSSI</ENAME> </DBROW></ROOTDOC>
La codifica in XML del risultato di un’interro-gazione di una base di dati può essere richie-sta utilizzando un apposito parametro del-l’ambiente applicativo attraverso il quale sicolloquia con il database oppure attraversoclausole che estendono (in modo non stan-dard) il linguaggio SQL comunemente usatoper interrogare le basi di dati. Il database Microsoft SQL Server, ad esem-pio, permette di richiedere la codifica in XMLdel risultato di una qualsiasi interrogazione,semplicemente aggiungendo all’interroga-zione stessa la clausola FOR XML.Ovviamente, è possibile (anzi, è consigliabi-le) usare un foglio di stile XSL per passare daldocumento XML puro e semplice restituitodal database relazionale a un documento piùstrutturato, composto da elementi che ri-spettano il repertorio di tipi aziendali espres-so da uno Schema; sono disponibili vari stru-menti visuali che possono aiutare il program-matore in questa operazione.L’aggiornamento di un database relazionalepartendo da dati in formato XML è inveceun’operazione meno agevole soprattuttoperché il modello dei dati gerarchico del-l’Infoset XML deve essere “appiattito” (un’o-perazione chiamata flattening) prima che undocumento XML possa essere usato per ag-giornare una tabella.Quasi tutti i database relazionali offrono a que-sto scopo dei programmi d’utilità che visitanol’albero DOM dei messaggi XMLin ingresso per
generare gli aggiornamenti alle tabelle relazio-nali; le prestazioni di strumenti di questo tipoin ambienti ad alta intensità di aggiornamentisono ancora oggetto di investigazione.Completamente diversa è la natura dei pro-dotti database XML nativi. Si tratta di sistemiche memorizzano, indicizzano e recuperanoinformazioni usando direttamente XML Info-set come modello dei dati. Questi sistemi, lecui tecniche di gestione devono parecchio aquelle in uso per i vecchi database gerarchi-ci, trovano applicazione soprattutto in am-bienti aziendali dove i flussi informativi sonofortemente orientati ai documenti e hannosorgenti eterogenee (società di consulenza,redazioni, editoria etc.).
Ringraziamenti Gli autori desiderano ringraziare Gianni Degli Antoni,fonte di preziosi suggerimenti e stimolanti scambi diidee su XMLe sulle sue applicazioni, e Dino Buzzetti, peril suo interessante contributo a una teoria del markup,nell’ambito di una più generale teoria del testo.
Bibliografia[1] Biztalk: http://www.biztalk.org
[2] Box D, Lam A, Skinnard A: XML: Beyond
Markup, Addison-Wesley pubblicato in Italia
con il titolo XML: Oltre il Markup.
[3] Xmlbooks: http://www.xmlbooks.com/
[4] Xmledi: http://www.xmledi.com
[5] Xmlsoftware: http://www.xmlsoftware.com
[6] W3C: www.w3.org
ERNESTO DAMIANI è Professore Associato presso il Di-partimento di Tecnologie dell'Informazione dell'Uni-versità di Milano. È stato Visiting Professor presso laGeorge Mason University, VA, US e presso la LaTrobeUniversity, Melbourne, Australia. Tra i suoi interessidi ricerca vi sono i formati semi-strutturati basati suXML per la rappresentazione dell'informazione e ilsoft-computing.e-mail: [email protected]
PAOLO FEZZI laureato in Lettere, è in AICA Responsa-bile della Qualità nel Progetto ECDL. Ha collaboratocon il Dipartimento di Filosofia dell’Università degliStudi di Bologna in progetti di digitalizzazione e co-difica XML di testi di storia della scienza.Ha scritto articoli come redattore di Sistemi e Impre-sa e contributi per De Agostini e Motta.e-mail: [email protected]
M O N D O D I G I T A L E • n . 2 - g i u g n o 2 0 0 2
1
65
0
0
0
1


















