
Analisi di Outcome Multipli - simg.it · L' identificazione del cut off 0.05 è una scelta...
23
1 Analisi di Outcome Multipli Saggio a cura di Alessandro Battaggia 2006 Cosa sono le analisi multiple? Si definiscono 'analisi multiple ' tutte le procedure rivolte a saggiare diverse ipotesi statistiche all' interno di uno stesso trial [9]. Nelle Analisi di Outcome Multipli i bracci originali del campione vengono confrontati per i risultati di più di un outcome. Nelle Analisi per Sottogruppi il campione originale viene suddiviso in vari strati e in ciascun strato vengono creati bracci a confronto. Nei Confronti di Bracci Multipli il campione originale viene allocato in diversi bracci di intervento e in un unico braccio di controllo. Nelle Analisi ad Interim oltre all' analisi finale vengono eseguite durante il follow-up varie analisi intermedie. A complicare le cose molte di queste procedure vengono messe in atto in modo crociato entro l' ambito di una stessa ricerca: ad esempio molto frequentemente gli autori confrontano i bracci di diversi sottogruppi per l' incidenza di diversi end- point. Le analisi multiple hanno l' ovvio scopo di aumentare l' efficienza informativa del trial, che coincide con la possibilità di fornire un numero maggiore di informazioni a parità di investimenti di risorse umane e materali. L' utilizzo di queste tecniche può essere lecito quando il ricercatore abbia ben chiari i loro limiti e le loro finalità, che devono sempre essere specificate ex ante nel protocollo. Sfortunatamente invece molte di queste analisi vengono utilizzate per forzare l' interpretazione delle ricerche verso direzioni volute dall' autore, cosicchè i loro risultati -anzichè generare nuove conoscenze- generano spesso solo confusione. Classificazione degli outcome in base alla finalità dell' utilizzo dei loro risultati nelle conclusioni del trial L' analisi di un outcome può avere uno scopo <confirmatory> , <supportive>, <exploratory> (tabella 1) [9]. Tabella 1 - Finalità dell' analisi di un outcome Primary Outcome Secondary Outcome Post-hoc Outcome Confirmatory fornisce una risposta al quesito principale della ricerca si no no Supportive funge da supporto ai risultato delle analisi confirmatory no si no Exploratory fornisce solo ipotesi di lavoro no si si Gli end-point primari sono chiamato così perchè condizionano le potenzialità statistiche del trial. In particolare il calcolo del sample size viene tarato sui risultati che ci si aspetta di ottenere per questi outcome. Sulla analisi di questi end-point viene quindi 'consumata' tutta la quantità di Errore e di Errore programmata dal ricercatore (vedi oltre).
Transcript of Analisi di Outcome Multipli - simg.it · L' identificazione del cut off 0.05 è una scelta...

1
Analisi di Outcome Multipli
Saggio a cura di Alessandro Battaggia 2006
Cosa sono le analisi multiple? Si definiscono 'analisi multiple ' tutte le procedure rivolte a saggiare diverse ipotesi statistiche all' interno di uno stesso trial [9]. Nelle Analisi di Outcome Multipli i bracci originali del campione vengono confrontati per i risultati di più di un outcome. Nelle Analisi per Sottogruppi il campione originale viene suddiviso in vari strati e in ciascun strato vengono creati bracci a confronto. Nei Confronti di Bracci Multipli il campione originale viene allocato in diversi bracci di intervento e in un unico braccio di controllo. Nelle Analisi ad Interim oltre all' analisi finale vengono eseguite durante il follow-up varie analisi intermedie. A complicare le cose molte di queste procedure vengono messe in atto in modo crociato entro l' ambito di una stessa ricerca: ad esempio molto frequentemente gli autori confrontano i bracci di diversi sottogruppi per l' incidenza di diversi end-point. Le analisi multiple hanno l' ovvio scopo di aumentare l' efficienza informativa del trial, che coincide con la possibilità di fornire un numero maggiore di informazioni a parità di investimenti di risorse umane e materali. L' utilizzo di queste tecniche può essere lecito quando il ricercatore abbia ben chiari i loro limiti e le loro finalità, che devono sempre essere specificate ex ante nel protocollo. Sfortunatamente invece molte di queste analisi vengono utilizzate per forzare l' interpretazione delle ricerche verso direzioni volute dall' autore, cosicchè i loro risultati -anzichè generare nuove conoscenze- generano spesso solo confusione.
Classificazione degli outcome in base alla finalità dell' utilizzo dei loro risultati nelle conclusioni del trial L' analisi di un outcome può avere uno scopo <confirmatory> , <supportive>, <exploratory> (tabella 1) [9].
Tabella 1 - Finalità dell' analisi di un outcome
Primary
Outcome
Secondary Outcome
Post-hoc Outcome
Confirmatory
fornisce una risposta al quesito principale della ricerca
si no no
Supportive
funge da supporto ai risultato delle analisi confirmatory
no si no
Exploratory
fornisce solo ipotesi di lavoro no si si
Gli end-point primari sono chiamato così perchè condizionano le potenzialità statistiche del trial. In particolare il calcolo del sample size viene tarato sui risultati che ci si aspetta di ottenere per questi outcome. Sulla analisi di questi end-point viene quindi 'consumata' tutta la quantità di Errore e di Errore programmata dal ricercatore (vedi oltre).

2
Gli end-point secondari sono così chiamati perchè per definizione costituiscono analisi accessorie, che non dovrebbero essere utilizzate per fornire una risposta al quesito del trial ma solo per supportare i risultati rilevati per l' end-point primario o in alternativa per fornire ipotesi di lavoro (tabella 1) [3,9]. Gli end-point primari e secondari devono sempre essere specificati ex ante nel protocollo di ricerca. Gli end-point 'post-hoc' vengono generati dopo la raccolta dei dati (sono outcome data-driven); la loro analisi fornisce molto spesso risultati non riproducibili perchè gravata da selection bias e la loro interpretazione deve essere utilizzata solo per scopi assolutamente marginali (tabella 1).
Primary outcome In base a quanto suggerito dalle 'ICH E9 Guidelines on biostatistical principles in clinical trials' la condizione ideale è che le conclusioni di un trial (confirmatory claims) vengano fondate solo sull' analisi dell' outcome primario [8]. The primary variable (‘target’ variable, primary endpoint) should be the variable capable of providing the most clinically relevant and convincing evidence directly related to the primary objective of the trial [8]. Una ricerca è organizzata infatti per fornire una risposta precisa ad un quesito molto specifico, tipo : <il farmaco A è in grado di ridurre la mortalità generale in modo più rilevante rispetto al farmaco B?> Per fornire questa risposta può essere organizzato uno studio controllato in cui la frequenza dei decessi riscontrata in un gruppo di pazienti a cui viene somministrato il farmaco A (braccio di intervento) viene confrontata con la frequenza dei decessi riscontrata in un gruppo di pazienti a cui viene somministrato il farmaco B (braccio di controllo): l’ outcome primario in questo caso è rappresentato dalla ‘mortalità generale’. Se nello stesso studio viene eseguita anche una analisi di un altro end-point (esempio:se viene paragonata la frequenza di 'infarti non fatali' nei due bracci) , questa viene definita analisi di un outcome secondario. Non si tratta di una definizione accademica in quanto lo strumento in grado di fornire una risposta al quesito della ricerca è costituito dai risultati rilevati per l' outcome 'mortalità' e non dai quelli che si riferiscono all' infarto non fatale. Le conclusioni dello studio dovrebbero essere quindi basate -a rigor di logica- solo sull' analisi dell' end-point primario. L' interpretazione corretta dei risultati di una ricerca implica il rispetto di queste condizioni: a) I ricercatori devono basare la definizione del risultato della sperimentazione (= 'positivo', 'negativo', 'nullo', 'non informativo' --> vedi oltre) sull' analisi dei risultati che si riferiscono all' outcome primario [8,9]. L' outcome primario viene cioè utilizzato con finalità <confirmatory> (tabella 1) [9]. b) Occasionalmente può essere scelto più di un outcome primario ma ciò deve essere esplicitamente dichiarato ex ante dagli autori [9] in quanto la definizione degli outcome primari implica la necessità di distribuire tutto l' Errore del trial su tutto il panorama delle analisi ad essi riferite. Nella maggior parte dei casi gli autori identificano con chiarezza l' outcome 'primario' ma è sconcertante osservare quanto spesso ignorino nelle conclusioni finali le analisi dei risultati che si riferiscono a questo end-point [2, 3,11,13,15]. Ciò avviene in modo particolare quando il trial è caratterizzato da risultati 'nulli' o 'non informativi', quando cioè non è stata dimostrata significatività statistica per i risultati che si riferiscono all' outcome primario. E' quanto Freemantel definisce ' lock the crazy aunt in the attic' , dove l' outcome primario è 'the crazy aunt' [3]. c) Se viene deciso di identificare come 'outcome primario' più di un end-point il valore di P utilizzato per la definizione della significatività statistica di ciascun confronto deve essere aggiustato in modo tale da rispettare il livello generale di Errore accettato per lo studio (vedi oltre: ). In ogni caso gli autori possono decidere di attribuire a ciascun 'outcome primario' un livello di Errore 'tollerabile' identico per tutti o in alternativa diverso per ogni outcome. Non esiste infatti alcun presupposto matematico o statistico che obblighi alla scelta di livelli di Errore identici per ogni outcome a patto che sia rispettato il livello di Errore totalmente programmato per lo studio [9].
3
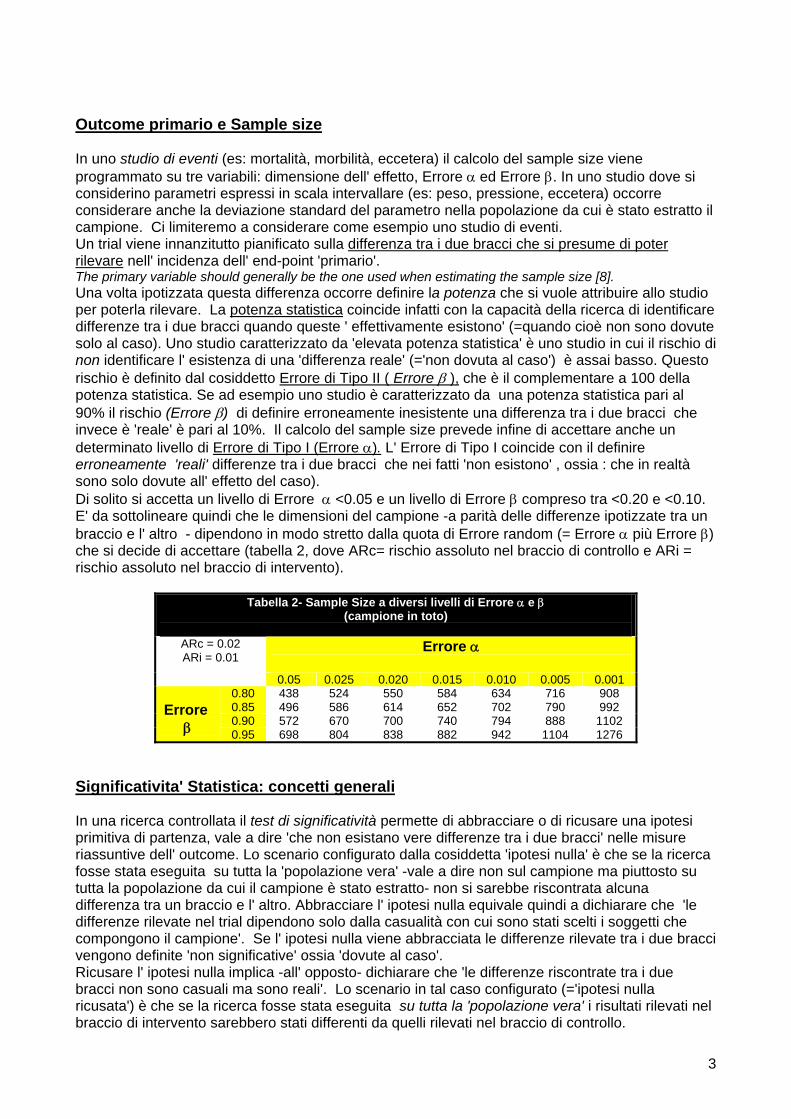
Outcome primario e Sample size In uno studio di eventi (es: mortalità, morbilità, eccetera) il calcolo del sample size viene programmato su tre variabili: dimensione dell' effetto, Errore ed Errore . In uno studio dove si considerino parametri espressi in scala intervallare (es: peso, pressione, eccetera) occorre considerare anche la deviazione standard del parametro nella popolazione da cui è stato estratto il campione. Ci limiteremo a considerare come esempio uno studio di eventi. Un trial viene innanzitutto pianificato sulla differenza tra i due bracci che si presume di poter rilevare nell' incidenza dell' end-point 'primario'. The primary variable should generally be the one used when estimating the sample size [8]. Una volta ipotizzata questa differenza occorre definire la potenza che si vuole attribuire allo studio per poterla rilevare. La potenza statistica coincide infatti con la capacità della ricerca di identificare differenze tra i due bracci quando queste ' effettivamente esistono' (=quando cioè non sono dovute solo al caso). Uno studio caratterizzato da 'elevata potenza statistica' è uno studio in cui il rischio di non identificare l' esistenza di una 'differenza reale' (='non dovuta al caso') è assai basso. Questo rischio è definito dal cosiddetto Errore di Tipo II ( Errore ), che è il complementare a 100 della potenza statistica. Se ad esempio uno studio è caratterizzato da una potenza statistica pari al 90% il rischio (Errore ) di definire erroneamente inesistente una differenza tra i due bracci che invece è 'reale' è pari al 10%. Il calcolo del sample size prevede infine di accettare anche un determinato livello di Errore di Tipo I (Errore ). L' Errore di Tipo I coincide con il definire erroneamente 'reali' differenze tra i due bracci che nei fatti 'non esistono' , ossia : che in realtà sono solo dovute all' effetto del caso). Di solito si accetta un livello di Errore <0.05 e un livello di Errore compreso tra <0.20 e <0.10. E' da sottolineare quindi che le dimensioni del campione -a parità delle differenze ipotizzate tra un braccio e l' altro - dipendono in modo stretto dalla quota di Errore random (= Errore più Errore ) che si decide di accettare (tabella 2, dove ARc= rischio assoluto nel braccio di controllo e ARi = rischio assoluto nel braccio di intervento).
Tabella 2- Sample Size a diversi livelli di Errore e (campione in toto)
ARc = 0.02 ARi = 0.01
Errore
0.05 0.025 0.020 0.015 0.010 0.005 0.001
Errore
0.80 438 524 550 584 634 716 908 0.85 496 586 614 652 702 790 992 0.90 572 670 700 740 794 888 1102 0.95 698 804 838 882 942 1104 1276
Significativita' Statistica: concetti generali In una ricerca controllata il test di significatività permette di abbracciare o di ricusare una ipotesi primitiva di partenza, vale a dire 'che non esistano vere differenze tra i due bracci' nelle misure riassuntive dell' outcome. Lo scenario configurato dalla cosiddetta 'ipotesi nulla' è che se la ricerca fosse stata eseguita su tutta la 'popolazione vera' -vale a dire non sul campione ma piuttosto su tutta la popolazione da cui il campione è stato estratto- non si sarebbe riscontrata alcuna differenza tra un braccio e l' altro. Abbracciare l' ipotesi nulla equivale quindi a dichiarare che 'le differenze rilevate nel trial dipendono solo dalla casualità con cui sono stati scelti i soggetti che compongono il campione'. Se l' ipotesi nulla viene abbracciata le differenze rilevate tra i due bracci vengono definite 'non significative' ossia 'dovute al caso'. Ricusare l' ipotesi nulla implica -all' opposto- dichiarare che 'le differenze riscontrate tra i due bracci non sono casuali ma sono reali'. Lo scenario in tal caso configurato (='ipotesi nulla ricusata') è che se la ricerca fosse stata eseguita su tutta la 'popolazione vera' i risultati rilevati nel braccio di intervento sarebbero stati differenti da quelli rilevati nel braccio di controllo.
4
Se si 'ricusa l' ipotesi nulla' la differenza tra i due bracci del campione viene definita 'significativa' ossia 'non dovuta al caso'. In base a quanto esposto viene però logico pensare che non ci sarà mai la certezza assoluta che una differenza rilevata tra i due bracci di un campione non sia dovuta al caso. Per la casualità del reclutamento infatti i due gruppi di soggetti che in un campione rappresentano il braccio di intervento e il braccio di controllo saranno sicuramente sempre diversi (per quanto poco lo siano) relativamente a caratteristiche potenzialmente in grado di influenzare l'outcome in modo indipendente dall' intervento studiato dal trial. Come si definisce allora 'operativamente' il concetto di 'significatività'? Il famoso valore di P prodotto dal test statistico identifica semplicemente la probabilità che la differenza rilevata tra i due bracci sia dovuta ad un effetto del caso. Le note modalità di interpretazione dei valori di P permettono di definire l' 'assenza' o la 'presenza' di 'significatività' in base al superamento o meno del famoso cut off ' 0.05'. Infatti se P >0.05 il risultato della sperimentazione viene definito 'non significativo' (= 'ipotesi nulla abbracciata'); se invece P<0.05 il risultato della sperimentazione viene definito 'significativo' (= 'ipotesi nulla ricusata'). L' identificazione del cut off 0.05 è una scelta artificiale e convenzionale. La filosofia su cui si basa è che la statistica considera 'non casuale' un fenomeno caratterizzato da una 'bassa probabilità di manifestarsi' (in particolare caratterizzato da una probabilità < 1/20 ossia: P<0.05). Quindi se il test statistico ci dice -attraverso il valore di P da esso generato- che la differenza riscontrata tra braccio di intervento e braccio di controllo ha una probabilità di essere stata 'rilevata solo per caso' inferiore a 1/20 (P<0.05) siamo autorizzati a non accettare l’ ipotesi nulla (secondo cui quanto rilevato rappresenta invece un effetto del caso) . L' ipotesi nulla viene insomma ricusata perchè la differenza riscontrata può essere stata -è vero- 'solo casuale' ma nella fattispecie la probabilità che questo si sia verificato è 'molto bassa' (<1/20) e quindi viene considerata 'trascurabile'. Ricusando l' ipotesi nulla ' in presenza di valori di P<0.05 dichiariamo quindi che la differenza rilevata dal trial è 'significativa' (cioè 'non dovuta al caso'). Viceversa per valori di P > 0.05 la differenza riscontrata viene definita 'non significativa' in quanto la probabilità che il reperto sia solo casuale è considerata 'alta' (ossia superiore a 1/20).
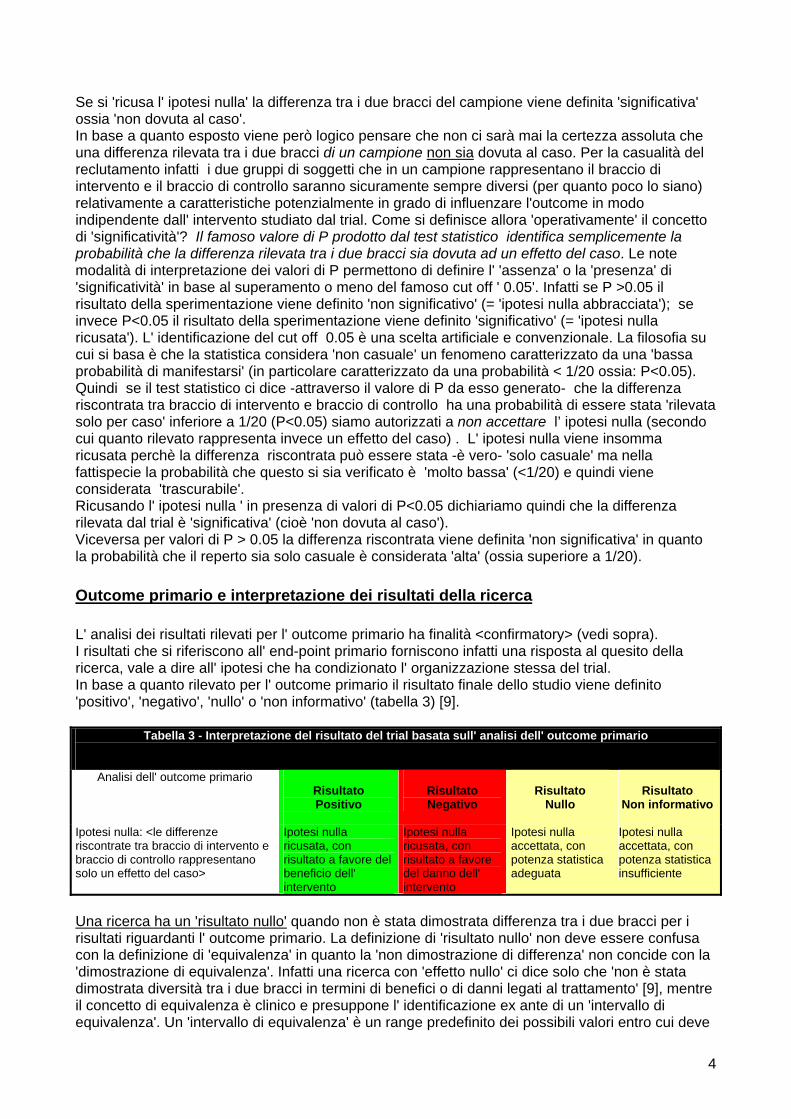
Outcome primario e interpretazione dei risultati della ricerca L' analisi dei risultati rilevati per l' outcome primario ha finalità <confirmatory> (vedi sopra). I risultati che si riferiscono all' end-point primario forniscono infatti una risposta al quesito della ricerca, vale a dire all' ipotesi che ha condizionato l' organizzazione stessa del trial. In base a quanto rilevato per l' outcome primario il risultato finale dello studio viene definito 'positivo', 'negativo', 'nullo' o 'non informativo' (tabella 3) [9].
Tabella 3 - Interpretazione del risultato del trial basata sull' analisi dell' outcome primario
Analisi dell' outcome primario
Risultato Positivo
Risultato Negativo
Risultato
Nullo Risultato
Non informativo
Ipotesi nulla: <le differenze riscontrate tra braccio di intervento e braccio di controllo rappresentano solo un effetto del caso>
Ipotesi nulla ricusata, con risultato a favore del beneficio dell' intervento
Ipotesi nulla ricusata, con risultato a favore del danno dell' intervento
Ipotesi nulla accettata, con potenza statistica adeguata
Ipotesi nulla accettata, con potenza statistica insufficiente
Una ricerca ha un 'risultato nullo' quando non è stata dimostrata differenza tra i due bracci per i risultati riguardanti l' outcome primario. La definizione di 'risultato nullo' non deve essere confusa con la definizione di 'equivalenza' in quanto la 'non dimostrazione di differenza' non concide con la 'dimostrazione di equivalenza'. Infatti una ricerca con 'effetto nullo' ci dice solo che 'non è stata dimostrata diversità tra i due bracci in termini di benefici o di danni legati al trattamento' [9], mentre il concetto di equivalenza è clinico e presuppone l' identificazione ex ante di un 'intervallo di equivalenza'. Un 'intervallo di equivalenza' è un range predefinito dei possibili valori entro cui deve

5
cadere il risultato di efficacia del trial (con tutto il rispettivo intervallo di confidenza) affinchè l' effetto dell' intervento in un braccio possa essere definito 'clinicamente equivalente' all' effetto rilevato nell' altro braccio (vedi il rispettivo capitolo: Studi di equivalenza). Uno studio con risultato 'nullo' ha mantenuto la potenza statistica programmata ex ante: vale a dire che la probabilità di aver erroneamente definito 'nullo' il risultato della sperimentazione coincide con il rischio di Errore previsto ex ante dal protocollo (vedi sopra). La definizione di 'risultato non informativo' va riservata invece alle situazioni in cui l' ipotesi nulla viene abbracciata in presenza di una potenza statistica inferiore a quella programmata ex ante dal ricercatore. Una situazione del genere si verifica per esempio quando per tutta una serie di circostanze il numero di pazienti considerato nell' analisi finale è inferiore al numero necessario per assicurare la potenza statistica programmata. In tal caso la 'non dimostrazione di differenza' può essere spiegata da un Errore con probabilità molto maggiore di quella tollerata dal protocollo (vedi sopra). Che tipo di outcome primario scegliere? In condizioni ideali si dovrebbe scegliere un unico end-point caratterizzato da un unico componente (esempio: la mortalità). In pratica si utilizza quasi sempre un outcome composito, che riassume cioè molteplici singoli eventi (esempio: mortalità + stroke non fatali + infarti non fatali) . Si tratta di un espediente utile nelle condizioni in cui si è incerti nell' attribuire una priorità all' importanza clinica di outcome su cui potrebbe influire l' intervento studiato. Nella pratica però l' utilizzo di un outcome primario 'composito' rispecchia fondamentalmente la necessità di aumentare l' efficienza statistica del trial. La scelta di un outcome composito aumenta infatti il 'Rischio basale' dei soggetti reclutati per questo end-point e ciò contribuisce ad aumentare le dimensioni dell' effetto che si presume di poter riscontrare tra un braccio e l' altro . Quindi, a parità di potenza statistica e di Errore , ciò significa poter reclutare un numero inferiore di soggetti e/o poter programmare un follow-up più breve, con ovvi vantaggi sui costi di gestione [7]. In un saggio apposito valuteremo i problemi connessi con la scelta di outcome compositi (vedi: Outcome Compositi).
Errore di Tipo II () nelle analisi di outcome multipli Più alta è la numerosità del campione, più basso sarà l' Errore (Errore di Tipo II) e più alta sarà la potenza statistica del confronto. Più piccola è la differenza tra un braccio e l' altro che ci si propone di dimostrare nel confronto, più grande dovrà essere la potenza statistica (e quindi la numerosità del campione) atta a poter dimostrare questa differenza. La numerosità del campione originale dipende -a parità del resto- dalla potenza statistica programmata per l' analisi dell' end-point primario (l' Errore , si ricordi, è il complementare a 100 della potenza statistica). Pertanto in un confronto eseguito nell' ambito del campione originale del trial le differenze tra un braccio e l' altro che il confronto avrà la potenza di rilevare coincideranno con quelle programmate per l' outcome primario nel il calcolo del sample size. Come interpretare la 'non significatività statistica' nelle analisi degli end-point secondari? Nell' analisi degli outcome secondari i confronti riguardano (come per l' outcome primario) i due bracci della casistica originale. In presenza di 'non significatività dei risultati' l' Errore è condizionato dall' entità della differenza riscontrata tra i due bracci nell' incidenza di quel determinato end-point . Se la differenza riscontrata per quell' outcome secondario è minore di quella programmata per l' end-point primario (il numero di soggetti a confronto è ovviamente identico) le probabilità di Errore sarà maggiore di quella tollerata dal protocollo di ricerca (vedi sopra). Come calcolare l' Errore per ciascuno degli outcome secondari?

6
E' estremamente utile per un critical appraisal di una ricerca in cui si eseguono confronti multipli calcolare la potenza statistica di ciascuno di essi ai livelli di Errore e programmati per l' outcome primario . Ciò viene fatto tenendo conto della numerosità dei due bracci e della differenza riscontrata nella incidenza dell' outcome in quel confronto. Ciò è agevolmente consentito da programmi disponibili 'on line' [4]
Errore di Tipo I () nelle analisi di outcome multipli Natura del problema Non esiste ricerca in cui non si eseguano confronti tra i due bracci anche per outcome diversi da quello primario =(outcome secondari). Gli autori dei trial dovrebbero attenersi strettamente alle indicazioni della tabella 4 [9]. Tuttavia ciò viene fatto molto raramente, cosicchè il più delle volte le analisi degli outcome secondari presentano tutti i rischi classici delle analisi multiple eseguite su uno stesso campione.
Tabella 4 - Corretto utilizzo delle analisi degli outcome [9]
Outcome Errore di Tipo I Utilizzo dell' analisi Note
Outcome primario in genere unico; può essere però più di uno
L' Errore di Tipo I programmato ex ante
per il trial () deve essere distribuito su tutte le analisi che riguardano questi outcome (FWER testing)
<Confirmatory use>: fornisce una risposta ai quesiti che la ricerca si propone di risolvere (permette in altri termini di definire 'positivo', 'negativo', 'nullo' o 'non informativo' il risultato della ricerca stessa)
Gli autori dovrebbero specificare ex ante nel protocollo della ricerca il numero di outcome primari, la gerarchia esistente tra gli outcome primari, il grado di dipendenza tra un outcome primario e gli altri (D)
Outcome secondari quasi sempre multipli
Viene eseguito un test di significatività per ogni outcome (nominal testing) ma la sua interpretazione deve essere vincolata alla verifica della frazione di Errore di tipo I programmato ex
ante () ancora disponibile (vedi testo)
<Supportive use>: le analisi di questi outcome vengono utilizzate a rinforzo delle conclusioni ricavate dall' analisi dell' outcome primario. In alternativa: <Exploratory use> . Un uso <Confirmatory > può essere molto pericoloso perchè l’ errore alfa introdotto può portare a superare l' Errore di
Tipo I programmato (vedi testo)
Devono essere specificati ex ante (nel protocollo).
Exploratory endpoints
in genere più di uno
L' analisi formale (nominal testing) di questi end-point produce risultati inaffidabili e spesso assurdi . I risultati inoltre sono spesso distorti da bias di selezione
<Exploratory use>: le analisi ad esse riferite devono essere utilizzate esclusivamente per generare ipotesi di lavoro
Si tratta di analisi 'data driven' ossia si analisi supplementari scelte in base ad un ragionamento dopo aver valutati i risultati finali del trial : non rappresentano 'research' ma solo 'search'

7
Uso mistificatorio della <significatività statistica> Non esiste studio di eventi in cui venga considerato un solo outcome: pressochè tutte le ricerche prendono in considerazione più di un end-point. Il braccio di intervento e il braccio di controllo vengono confrontati tante volte quanti sono gli outcome dello studio e per ogni singolo confronto un test statistico nominale genera un valore di P. Uno o più end-point vengono utilizzati nell’ analisi primaria; gli altri dovrebbero servire solo per analisi secondarie , cioè accessorie e/o complementari alla analisi primaria. Si definisce <analisi primaria> quella destinata a fornire una risposta al quesito che ha giustificato l' organizzazione del trial. I risultati dell' analisi primaria sono quindi <confirmatory> in quanto devono fornire una risposta positiva, negativa o nulla a questo quesito (vedi sopra). Il protocollo dello studio dovrebbe sempre indicare in modo esplicito quali outcome siano destinati all' analisi primaria : l’ adozione ex post di strategie <confirmatory > è destinata infatti a produrre risultati ambigui se non addirittura caotici. Il campione della ricerca a parità di altre condizioni (vedi sopra) deve infatti essere tarato su un livello di errore alfa definito ‘ex ante’ e distribuito su tutto il complesso delle analisi <confirmatory>. Il livello ‘programmato’ di questo Errore di Tipo I per l' analisi primaria viene identificato con la lettera . Se l' outcome a cui si riferisce l' analisi primaria è uno solo l' errore viene accorpato alla analisi di questo end-point; se gli outcome utilizzati sono più di uno l' errore viene distribuito sulle analisi riguardanti tutti gli end-point <confirmatory>. L’ errore rappresenta quindi il rischio che si accetta (come limite operativo della stessa ricerca) di ‘dichiarare erroneamente significativi’ i risultati dell' analisi primaria quando invece essi ‘sono solo dovuti al caso’. L' analisi statistica dei risultati rilevati per gli outcome <confirmatory> produrrà un valore di P che esprime la probabilità che i risultati ottenuti siano solo dovuti al caso. Il rischio di dichiarare erroneamente 'reali' le differenze riscontrate tra i due bracci per la quantità di effetto correlata agli end-point <confirmatory> coinciderà quindi con questi valori di P, che esprimono la probabilità di Errore di tipo I calcolata ex post per i risultati dell' analisi primaria . Questo errore viene identificato come Errore E e ovviamente riveste nei confronti dell' insieme degli end-point <confirmatory> lo stesso significato posseduto dai valori di P calcolati a livello dei singoli end-point . La probabilità di Errore E associato ai risultati delle analisi <confirmatory> dovrà essere quindi confrontata con il livello di Errore programmato ex ante per l' analisi primaria. Il livello programmato di Errore (di solito: 0.05) rappresenta infatti il ‘cut off decisionale’ per abbracciare o rifiutare l' ipotesi nulla. Se il rischio di Errore alfa determinato ex post per l' analisi primaria (Errore E) risulterà inferiore all’ errore alfa accettato ex ante per l' analisi primaria (Errore ) l' ipotesi nulla sarà ricusata e il risultato dell' analisi <confirmatory> sarà considerato <significativo> Se invece l' Errore E risulterà superiore all' Errore l' ipotesi nulla sarà abbracciata e il risultato dell' analisi <confirmatory> sarà considerato <non significativo> Probabilità ex post di Errore E inferiori ai livelli programmati di Errore configurano quindi una condizione di <significatività statistica> per i risultati dell' analisi primaria. Da quanto esposto risulta ormai chiaro che le conclusioni del trial devono coincidere esclusivamente con le conclusioni riferite all' analisi primaria. L' analisi primaria è stata infatti tarata sulla ipotesi a cui il trial deve fornire una risposta e le caratteristiche del campione -che esprimono quello che realisticamente si può pretendere dal trial- sono state tarate sui precisi livelli di errore random accettati e programmati ex ante per l' analisi primaria. Gli autori invece mistificano troppo spesso il significato dei valori di P riscontrati nominalmente in molte <analisi secondarie> attribuendo significati particolari ai valori inferiori a 0.05. La <significatività statistica > di un risultato <primario> deve invece considerare, come abbiamo visto, l' errore alfa associato alla globalità delle analisi <confirmatory> in quanto le analisi di molteplici outcome tendono ad espandere enormemente (come in tutti i confronti multipli eseguiti su uno stesso campione) il rischio di Errori di Tipo I a livello individuale.

8
Non è raro ad esempio che in assenza di significatività statistica per l' outcome prmario (vero oggetto della ricerca) gli autori elaborino le conclusioni dei trial solo alla luce dei risultati <significativi> riscontrati per alcuni outcome secondari [12, 14]. I problemi più frequenti delle analisi <confirmatory> pubblicate sono brevemente riassunti nella tabella 5:
Tabella 5 - quello che si osserva nei lavori pubblicati
gli autori non identificano nel protocollo gli outcome primari
A
avviene molto raramente (conseguenza: è impossibile arrivare a conclusioni attendibili)
gli autori identificano nel protocollo gli outcome primari
non programmano ex ante l' errore
B avviene raramente (idem)
programmano ex ante l' errore , utilizzano ad uso confirmatory solo gli outcome primari, calcolano correttamente l' errore E per le analisi confirmatory , confrontano correttamente E con nelle conclusioni del trial
C avviene non frequentemente (situazione ideale)
programmano ex ante l' errore , utilizzano ad uso confirmatory anche outcome secondari, non identificano correttamente l' errore E nelle analisi confirmatory, non confrontano E con nelle conclusioni del trial
D avviene molto frequentemente (conseguenza: errori e incertezze nella interpretazione dei risultati rilevati per gli outcome secondari)
La formula per il calcolo dell' Errore E e la formula per la programmazione dell' errore sono consultabili in Appendice.
tabella 6 - cosa si vede in letteratura
Gli autori utilizzano troppo spesso analisi di outcome secondari per usi <confirmatory>
non programmati ex ante
Inoltre
interpretano troppo spesso i valori di P <0.05 prodotti dai test nominali che riguardano singoli outcome non previsti nella analisi primaria a conferma della 'significatività statistica' dei risultati che si riferiscono a quegli
outcome
Questo si scontra
a) con la necessità di programmare chiaramente nel protocollo quali analisi saranno utilizzate a scopo <confirmatory>
b) con la necessità di definire la <significatività statistica>dei risultati della analisi primaria attraverso il
confronto tra Errore E ed Errore Esempio di un trial il cui risultato è da considerare 'positivo' [9] Una ricerca si propone di dimostrare se un intervento è efficace nel ridurre gli effetti della demenza senile nelle funzioni cognitive. Vengono programmati ex ante tre end-point primari (l' analisi che li riguarda sarà quindi utilizzata <confirmatory use>). Viene programmato per questa analisi un Errore Tipo I complessivo ( pari a 0.05, che viene distribuito equamente sui tre end-point (0.05/3 = 0.0167). I test nominali di significatività producono i valori di P indicati nella tabella 7. Utilizzando per il calcolo la formula in appendice, l' Errore Tipo I (E) che caratterizza ex post l' analisi primaria

9
è dato da : E = min(0.0167,0.044)+min(0.0167,0.100)+ min(0.0167,0.001) = 0.0167+0.0167+0.0010 = 0.034
Tabella 7 - esempio di studio con risultati 'positivi'[9]
Outcome primari
Errore programmato per ogni outcome
Valore di P rilevato per ogni outcome al test nominale di significatività
1 Boston naming task 0.0167 0.044 2 Digit symbol substitution 0.0167 0.100 3 Quality of Life 0.0167 0.001
Quindi: dato che E < (ossia: 0.034 < 0.05) il risultato dello studio è 'positivo', nonostante i valori nominali di P per l' outcome 1 e i valori nominali di P per l' outcome 2 siano risultati maggiori dei livelli di errore programmati per i singoli confronti . I risultati positivi sulla QoL rendono questo studio 'positivo' Qual' è quindi il rischio delle analisi degli Outcome 'Secondari' (riassunto)? Quando le conclusioni della ricerca vengono basate sulla sola analisi dell' outcome primario ( o degli outcome primari ) il rischio di Errore e di Errore corrisponde ai livelli programmati di Errore random nel calcolo delle dimensioni del campione (vedi sopra) : di solito corrisponde ad = 0.05 e = 0.10-0.20. In altri termini con questa scelta si accetta un rischio di Errore random corrispondente 'alle regole del gioco' , ossia ai livelli preordinati ex ante di Errore Tipo I e Errore Tipo II. Invece è osservazione comune che gli autori tendano a basare in modo preminente (o addirittura esclusivo!) la discussione dei propri risultati sulle analisi di uno o più outcome secondari , che vengono pertanto utilizzate con finalità <confirmatory> rispondendo ad ipotesi statistiche il più delle volte non previste dal protocollo. Ciò rappresenta un grave errore di metodo. In primis perchè la conduzione di una ricerca dovrebbe rappresentare un percorso logico che partendo dalla formulazione di una ipotesi viene concluso con la conferma o la smentita di questa ipotesi (l' ipotesi di partenza è sempre quella che riguarda le analisi programmate come 'primarie'). In seconda istanza perchè tale atteggiamento rappresenta una grave violazione dei principi generali della inferenza statistica. Dichiara Moye infatti <to many investigators, the sample becomes the population; they believe that every result in the sample reflects a true finding about the population from whick the sample was obtained, this in a dangerous trap [9]. Eseguendo più di una analisi entro uno stesso campione il livello di Errore Tipo I aumenta in modo proporzionale al numero di confronti eseguiti , rendendo sempre più probabile che il risultato delle analisi per ciascun confronto rappresenti un puro effetto del caso. Non è ammissibile in queste situazioni valutare la presenza di 'significatività statistica' solo attraverso i test di significatività 'nominali', quelli cioè eseguiti per ciascuno dei singoli confronti. Una analisi corretta dei risultati che si riferiscono a multipli end-point non può sottrarsi ad una analisi complessiva del rischio di Errore di Tipo I connesso con l' interpretazione stessa dei risultati. Questa valutazione del rischio di Errore di Tipo I implica una misura accurata di quanto della quantità' iniziale di Errore alfaprevista ex ante () per l' analisi primaria sia stato consumato per l' analisi primaria (E) e quanto quindi resti ancora a disposizione ( -E) per confronti aggiuntivi (come ad esempio analisi di outcome secondari ritenuti ex post importanti dagli autori per interpretare i risultati generali del trial). Errore di Tipo I <programmato ex ante> nelle Analisi di Outcome Multipli () La quantità di Errore alfa programmato ex ante per la analisi primaria ( , vedi sopra) - è uno dei fattori che condizionano la numerosità del campione e le sue potenzialità statistiche. Qualsiasi tipo di confronto multiplo eseguito entro l' ambito dello stesso campione comporta un aumento dell' Errore alfa complessivo (Errore Tipo I) i cui livelli sono proporzionali al numero di confronti eseguiti nel campione.

10
Nelle condizioni in cui nell' interpretazione dei risultati del trial gli outcome secondari vengono utilizzati alla stessa stregua di un outcome primario l' Errore alfa inizialmente programmato dal trial può essere come visto rapidamente 'bruciato'. Questo fenomeno viene quantificato dal confronto tra Errore programmato ex ante per l' analisi <confirmatory> ed Errore E che caratterizza ex post l' analisi stessa. Esistono formule statistiche (in appendice) che consentono di calcolare l' Errore previsto per una analisi <confirmatory> . Questo errore viene definito anche 'familywise (type I) error probability' o 'error level' o anche FWER[9] Le formule considerano A. Il numero di confronti eseguiti In pratica corrisponde al numero di outcome utilizzati <confirmatory use>. Gli autori pertanto dovrebbero sempre specificare ex ante nel protocollo la natura e il numero di questi outcome <confirmatory>. B. Il grado di interdipendenza tra un outcome e l' altro (D). Occorre considerare attentamente la natura degli outcome <confirmatory> perchè è importante definire esattamente la correlazione esistente tra un outcome e l' altro. Questa variabile è necessaria al calcolo di nelle formule statistiche e viene identificata dalla lettera D [9]. Occorre valutare in altri termini se gli outcome <confirmatory> siano o meno reciprocamente indipendenti. Due eventi sono 'indipendenti' quando la frequenza del primo evento non può fornire alcuna informazione sulla frequenza del secondo evento e viceversa. Per esempio anche se alcuni pazienti infartuati hanno gli occhi azzurri ciò non consente di prevedere se un paziente con occhi azzurri avrà un infarto. Due eventi sono -all' opposto- 'dipendenti' quando la frequenza del primo è in grado di fornire informazioni sulla frequenza del secondo o viceversa. La dipendenza dipende a propria volta da due fattori: a) la coincidenza (c) ossia il contributo fornito da ciascun paziente al manifestarsi di ciascuno dei due eventi (più i pazienti subiscono più di un outcome più gli outcome sono reciprocamente dipendenti) b) l' omogeneità o meno dell' effetto dell' intervento (h) ossia la misura in cui l' intervento studiato dal trial agisce in modo univoco sul manifestarsi di ciascuno dei due eventi. Ad esempio [9]: immaginiamo un trial in cui venga studiato un farmaco potenzialmente in grado di ridurre l' incidenza di eventi cardiovascolari fatali e in cui due outcome primari siano rappresentati dalla mortalità generale (outcome 1) e dalla mortalità coronarica (outcome 2). E' evidente che esiste in tal caso una sicura interdipendenza tra i due outcome :il numero dei pazienti deceduti per cause coronariche (outcome 2) contribuisce infatti al calcolo del numero dei pazienti deceduti per ogni causa (outcome 1) per cui esiste un certo grado di 'coincidenza' per i due eventi. Se il 75% dei pazienti deceduti è rappresentato dai pazienti deceduti per eventi coronarici la coincidenza può essere espressa da c=0.75. In questa situazione però l' effetto dell' intervento (il farmaco) non influenza in modo omogeneo la frequenza di ciascun outcome :vale a dire che il farmaco potenzialmente in grado di ridurre gli eventi cardiovascolari fatali condiziona sicuramente l' incidenza dell' outcome 2 ma non condiziona in alcun modo l' incidenza di una frazione più o meno consistente dei decessi che rappresentano l' outcome 1 (non influenza infatti l' incidenza di morti da cancro, da incidente stradale, eccetera). Il grado di omogeneità dell' effetto dell' intervento sulla frequenza dei due outcome è espresso allora da h= zero (figura 1). Figura 1
morti non coronariche mortalità generale (1)
mortalità coronarica (2) morti coronariche
morti coronariche
azione del farmaco no azione del farmaco si

11
La tabella 5 illustra chiaramente in che misura il grado di dipendenza tra gli outcome utilizzati con finalità <confirmatory > può influenzare l' Errore previsto per l' analisi. Si immagina in questo esempio una ricerca in cui oltre l' outcome primario vengano utilizzati altri nove outcome <confirmatory use> e in cui sia stato programmato nominalmente (= per ciascuna di queste analisi ) un valore di alfa pari a 0.05. Come si vede, più gli outcome sono indipendenti più aumenta il livello di Errore complessivo. Se per esempio i 10 outcome sono totalmente indipendenti la probabilità che per uno di essi il risultato riscontrato sia dovuto al caso non è P=0.05 ma piuttosto è P =0.401. Se all' estremo opposto esiste una completa interdipendenza tra i dieci outcome la probabilità che per uno di essi il risultato riscontrato sia dovuto al caso è pari a 0.058.
Tabella 8 - Errore in un trial in cui 10 outcome vengono utilizzati
<confirmatory use> : i valori di sono condizionati dal grado di inter- dipendenza tra gli outcome (D).
(valore di attribuiti singolarmente a ciascun outcome = 0.05) Grado di interdipendenza (D)
Errore Tipo I complessivo ()
0
completa indipendenza 0.401
0.1
livello basso di dipendenza 0.398
0.2
livello basso di dipendenza 0.389
0.3
livello medio di dipendenza 0.375
0.4
livello medio di dipendenza 0.354
0.5
livello medio di dipendenza 0.326
0.6
livello medio di dipendenza 0.291
0.7
livello medio di dipendenza 0.247
0.8
livello alto di dipendenza 0.193
0.9
livello alto di dipendenza 0.128
0.99
totale dipendenza 0.058
Gli autori quando decidono di utilizzare più di un outcome <confirmatory use> devono quindi specificare sempre nel protocollo il grado di dipendenza tra un outcome e l' altro (D) [9]. Un livello di dipendenza espresso da valori di D compresi tra 0.3 e 0.7 viene definito 'moderato' [9]. L' esistenza di totale indipendenza reciproca tra gli outcome è espressa da D=0 L' esistenza di una parziale dipendenza reciproca tra gli outcome è espressa da D=0.3-->0.7 L' esistenza di una totale dipendenza reciproca tra gli outcome è espressa da D=0.999999. Nota: in realtà il livello di dipendenza (D) tra un outcome e l' altro non viene praticamente mai specificato dagli autori nel protocollo. Errore di Tipo I <calcolato ex post> nelle Analisi di Outcome Multipli (E) L' errore E che caratterizza ex post nel suo complesso una analisi <confirmatory> è condizionato dai livelli di errore alfa programmati ex ante per ciacun end-point () e dai valori di P prodotti dai

12
test nominali di significatività statistica per i risultati relativi a ciascun end-point (P). La formula per calcolare l' Errore E è visibile in appendice. Come detto, l' Errore E rappresenta per tutta l' analisi <confirmatory> quello che P rappresenta per l' analisi di ciascun end-point. Gli autori confrontano E con ? Da quanto esposto risulta chiaro che le analisi degli outcome secondari portano spesso ad identificare l' esistenza di differenze tra i due bracci quando queste in realtà sono dovute al caso. La probabilità di questo errore è espressa dalla probabilità di Errore Tipo I prodotta dall' analisi <confirmatory> (=E ). Se E supera la conclusione di 'significatività' dei risultati prodotti da una analisi di outcome secondari non ha alcun valore. Il fatto che i test nominali eseguiti dagli autori per i singoli outcome esprimano 'significatività statistica' non deve pertanto portare erroneamente a sottovalutare questa possibilità, che solo il confronto tra E e può quantificare .
Analisi di outcome multipli e linee guida per un critical appraisal Come più volte sottolineato molto spesso gli autori utilizzano le analisi di outcome secondari come base scientifica a supporto delle conclusioni finali delle loro ricerche. Questo approccio è metodologicamente scorretto e il più delle volte mistificante. Nelle conclusioni del documento EMEA , utilizzato come linea guida metodologica ad uso dei Comitati Etici [5] viene infatti esplicitamente affermato che <le analisi di outcome secondari o di sottogruppi possono costituire elementi aggiuntivi per le conclusioni di un trial [che devono essere basate solo sull' analisi dell' outcome primario], solo quando l' ipotesi primaria della ricerca è stata soddisfatta [vale a dire quando l' ipotesi nulla dell' analisi primaria è stata ricusata] , e quando le ipotesi esplorate da queste analisi secondarie costituiscano parte integrante del protocollo dello studio [ossia siano state previste ex ante] e siano state esplorate attraverso idonei strumenti statistici. (Additional claims on statistically significant and clinically relevant findings based on secondary variables or on subgroups are possible only after the primary objective of the clinical trial has been achieved, and if the respective questions were pre-specified, and were part of an appropriately planned statistical analysis strategy [5]) Il presente saggio è stato scritto a sostegno di questa strategia. La revisione della letteratura metodologica da noi proposta ha l' obiettivo di fornire strumenti di critical appraisal utili a quantificare il rischio di Errore random associato ad una lettura incongrua dell' analisi dei risultati che si riferiscono ad outcome secondari. Un approccio razionale per interpretare correttamente la 'significatività statistica' di una analisi secondaria è utilizzare le formule proposte da Moyè per calcolare l' Errore di Tipo I complessivo E) associato all' analisi di multipli outcome primari e per calcolare l’ Errore di Tipo I programmato ex ante per le analisi di multipli outcome primari (in appendice) [9]. Una volta calcolato E, si confronteranno i suoi valori con i livelli di errore alfa programmati ex ante dagli autori (). Se gli autori di una ricerca basano le proprie conclusioni su outcome secondari ciò equivale a dire che hanno utilizzato questi end-point ad uso <confirmatory> e quindi alla stessa stregua di una analisi primaria. Appare quindi logico a fini di critical appraisal calcolare <quanto Errore Tipo I della quantità totale di Errore alfa inizialmente programmata dagli autori sia rimasto a disposizione per le analisi secondarie dopo aver eseguito l' analisi primaria'>

13
Un esempio basato su questo approccio è stato descritto da Moyè [9] in una analisi dei risultati dello studio ATLAS , un RCT sulla terapia farmacologica dello scompenso cardiaco [10]. Questo argomento è stato ripreso anche altrove [2,3,5] Esaminiamo di seguito due situazioni opposte ma entrambe caratterizzate dal fatto che gli autori della ricerca hanno basato le conclusioni del trial su analisi di risultati che si riferiscono a outcome secondari:
I) viene riportata dal trial presenza di significatività statistica per i risultati che si riferiscono all' outcome primario
II) viene riportata dal trial assenza di significatività statistica per i risultati che si riferiscono
all' outcome primario
Tabella 9 - Linee guida per l' interpretazione delle analisi di outcome multipli
significatività dei risultati relativi agli outcome:
interpretazione dei risultati del
trial da parte degli autori:
decisioni operativi del revisore (critical appraisal):
I) risultati significativi per l' analisi primaria e risultati significativi per alcune analisi secondarie
A) è stata basata solo sull' analisi dell' outcome primario [<confirmatory use> dell' outcome primario] e i risultati sugli outcome secondari sono stati utilizzati solo per <supportive use> o <exploratory use>
le conclusioni degli autori vanno confermate
B) è stata basata sull' analisi dell' outcome primario [<confirmatory use> dell' outcome primario] ma anche sull' analisi di alcuni outcome secondari [<confirmatory use> di alcuni outcome secondari]
1) le conclusioni degli autori che riguardano l' outcome primario (se ci sono) vanno confermate 2) calcolare l' Errore E dell' analisi <confirmatory> tenendo conto del numero di analisi <confirmatory use> eseguite dagli autori (=quella primaria + quelle secondarie) , considerando i valori di P ricavati dai test di significatività nominali e considerando i livelli di errore programmati ex ante per ciascun end-point
a) quando Enon supera il livello totale di anche dopo aver incluso nel suo calcolo tutti i risultati degli end-point secondari utilizzati per <confirmatory use> le conclusioni degli autori che riguardano gli outcome secondari vanno confermate b) quando Enon supera il livello totale di dopo aver incluso nel suo calcolo alcuni (ma non tutti) i risultati degli end-point secondari utilizzati per <confirmatory use> le conclusioni degli autori che riguardano gli outcome secondari vanno ricusate c) quando E supera il livello totale di dopo aver incluso nel suo calcolo anche un solo risultato degli end-point secondari utilizzati per <confirmatory use> le conclusioni degli autori che riguardano gli outcome secondari vanno ricusate
II) risultati non significativi per l' analisi primaria e risultati significativi per alcune analisi secondarie
A) è stata basata sull' analisi dell' outcome primario [<confirmatory use> dell' outcome primario]; i risultati sugli outcome secondari sono stati utilizzati per <exploratory use>
le conclusioni degli autori vanno confermate

14
B) gli autori hanno ignorato o sottodimensionato i risultati non significativi dell' analisi primaria per enfatizzare risultati significativi di analisi secondarie [<confirmatory use> di outcome secondari>]
le conclusioni degli autori vanno ricusate: la non significatività dei risultati dell' analisi primaria preclude la possibilità di rivalutare il ruolo delle analisi secondarie in quanto i valori di Erisulteranno sempre maggiori del livello di Errore programmato per l' analisi primaria (nella maggior parte dei casi: 0.05)
A) I risultati che si riferiscono all' outcome primario 'sono significativi' In questo caso le conclusioni 'significative' di una analisi secondaria possono essere utilizzate a sostegno dei risultati emersi per l' outcome primario (<supportive use>) o per generare ipotesi di lavoro <exploratory use> . Se pur raramente, queste analisi possono essere anche utilizzate per <confirmatory use> . L' utilizzo <confirmatory use> impone che dopo l' analisi primaria sia rimasta a disposizione una frazione sufficiente dell' Errore programmato dal protocollo della ricerca. Calcoliamo quindi l' Errore E determinato ex post per le analisi <confirmatory> utilizzate dagli autori [9] e confrontiamolo con l' Errore programmato ex ante per la ricerca (quello utilizzato per la definizione del sample size). Una volta calcolato E potremo avere tre situazioni diverse. a) L' Errore E dell' analisi <confirmatory> - una volta inseriti nell’ analisi tutti gli outcome utilizzati dagli autori a scopo <confirmatory>- è inferiore all’ Errore In tal caso le conclusioni degli autori che si riferiscono agli outcome secondari possono essere confermate in quanto non è stata consumata del tutto la quantità di Errore tipo I prevista ex ante per l' analisi primaria (. b) L' Errore E dell' analisi <confirmatory> è superiore all’ Errore quando sia incluso nel suo calcolo - oltre all' outcome primario - anche uno solo degli outcome secondari valorizzati dagli autori. In tal caso le conclusioni degli autori che si riferiscono agli outcome secondari devono essere ricusate perchè i livelli di Errore E complessivo risultano inaccettabili: è stata consumata integralmente la quantità di Errore tipo I prevista ex ante per l' analisi primaria (. c) L' Errore E dell' analisi <confirmatory> è inferiore ai livelli di Errore qualora siano inclusi nel suo calcolo - oltre all' outcome primario- alcuni (ma non tutti!) outcome secondari valorizzati dagli autori. Questa situazione genera molta incertezza. Infatti è ancora a disposizione una certa frazione della quantità totale di Errore alfa programmato ex ante per il trial (. Il problema però è come spendere questa frazione. Possiamo certamente utilizzare a tal fine alcuni outcome secondari : ma non tutti. Come scegliere allora l' outcome secondario da valorizzare? E' chiaro che in qualche modo occorre stabilire una priorità. A volte, anche se raramente, una gerarchia degli outcome secondari può essere stata formulata dagli stessi autori nel protocollo (es: sulla base di criteri clinici). Questa eventualità -per l' esperienza di chi scrive- è alquanto remota . Molto probabilmente , in assenza di qualsiasi riferimento che ci aiuti a formulare una selezione razionale degli outcome secondari, nella condizione a punto c) vale la pena ricusare le conclusioni degli autori sulla 'significatività dei risultati' che si riferiscono a questi outcome. La tabella 7 si basa sulla metodologia suggerita da Moyè per la programmazione dell' errore nelle analisi primarie [9]. E' molto importante sottolineare la necessità che la metodologia adottata dagli autori per questi calcoli sia chiaramente esplicitata nel protocollo dello studio o chiaramente descritta nella sezione 'Analisi Statistica' dell' articolo. Tabella 7 - Il protocollo del trial deve pianificare ex ante l' uso <confirmatory> di una analisi di outcome multipli,
che va inserita come elemento dell' analisi primaria
1 definizione del livello di errore programmato per l' analisi primaria

15
2 elementi
dell' analisi primaria
A) end-point primario 1 a) definizione dell' outcome primario 1 b) rischio basale dell' outcome primario 1 (=rischio basale nel braccio di controllo della coorte originale) c) dimensione ipotizzata dell' effetto dell' intervento sull' outcome primario 1 d) livello di errore alfa accettato per l' outcome primario 1 e) potenza statistica accettata per l' outcome primario 1 f) sample size per l' outcome primario 1(calcolato in base a: c, d, e)
B) Altri outcome inseriti nell' analisi primaria
La pianificazione di tutti gli outcome utlizzati per l' analisi primaria prevede se sono più di uno che essi siano classificati per ranghi di importanza. L' analisi al punto C va ripetuta per ciascuno di essi. Gi autori devono specificare con chiarezza le condizioni in cui gli obiettivi del trial possono essere considerati raggiunti . In particolare devono specificare il numero di outcome utilizzati nella analisi primaria e per quali e/o quanti di essi il risultato dovrà essere <significativo e a favore dell' intervento> affinchè le conclusioni del trial possano essere considerate <a favore dell' intervento>.
C) end point primario 2 a) definizione dell' outcome primario 2 b) rischio basale dell' outcome primario 2 (=rischio basale nel braccio di controllo della coorte originale) c) dimensione dell' effetto prevista per l' outcome primario 2 d) grado di dipendenza dell' outcome primario 2 rispetto all' outcome primario 1 (D2/1) e) livello di Errore per l' outcome primario 2 Errore : va calcolato in base ai valori prestabiliti di Errore tipo I programmato per l' analisi primaria e in base ai valori di Errore 1 (se altri outcome sono stati utilizzati nell' analisi primaria : di Errore 1 3 j ) tenendo conto che 1 2 3 j non deve mai superare l' Errore tipo I programmato per l' analisi primaria f) potenza statistica accettata per l' outcome primario 2 g) sample size per l' outcome primario 2 (calcolato in base a: c, e, f)
Nota: gli indirizzi EMEA [5] Il problema dell' interpretazione della 'significatività statistica' degli outcome secondari è stato affrontato anche da altri autori. Le linee guida EMEA [5] , nella loro interpretazione delle linee guida ICH [8] suggeriscono per esempio un diverso approccio analitico. Le indicazioni EMEA sono sintetizzate nei successivi punti A e B. Punto A) A patto che gli outcome secondari siano stati classificati gerarchicamente dagli autori in base alla rispettiva importanza clinica e a patto che questa classificazione sia stata comunque prevista dal protocollo dello studio si potrà attribuire alla 'significatività statistica' di un outcome secondario un ruolo <confirmatory> anche senza eseguire una analisi formale dell' Errore Tipo I complessivo . Affinchè ciò sia possibile l' outcome secondario dovrà essere collocato in questa scala gerarchica in un rango superiore a quello della prima analisi secondaria per il quale è stata riscontata 'non significatività statistica'. In caso contrario il ruolo attribuito all' analisi dei risultati di questo outcome sarà solo 'exploratory'. La tabella7 esplicita questi scenari. NB: questo approccio non è condiviso da tutti in quanto utilizza un duplice criterio gerarchico: da un lato, una classificazione degli outcome in ranghi prevista ex ante dagli autori (assolutamente accettabile), dall' altro una sottoclassificazione degli outcome in base alla presenza o meno di significatività statistica ai test

16
nominali (che obbedisce quindi ad un principio data-driven, che alcuni non considerano accettabile [6]) Punto B Qualora gli autori abbiano stabilito che i risultati del trial potranno essere considerati <a favore dell' intervento> solo in presenza di <significatività dei risultati a favore dell' intervento> per tutti gli outcome considerati nell' analisi primaria, per l' interpretazione della significatività dei risultati di ciascun outcome utilizzato nell' analisi primaria potranno essere utilizzati i valori di P calcolati nominalmente (cioè senza aggiustamenti statistici per l' errore ). Il risultato finale della ricerca sarà allora <a favore dell' intervento> solo se la direzione dei risultati per tutti gli outcome utilizzati nell' analisi primaria sarà <a favore dell' intervento> e solo se per tutti gli outcome utilizzati nell' analisi primaria il valore di P ai test nominale indicherà <significatività statistica> [5].
tabella 7 - EMEA [5]
Interpretazione della significatività statistica per i risultati rilevati per un Outcome secondario in presenza di significatività per l' Outcome
primario (scenario esemplificativo) gerarchia
Outcome confronto tra i due bracci
confirmatory claims
exploratory claims
I Outcome primario P<0.05 si - II Outcome secondario 1 P<0.05 si no III Outcome secondario 2 P<0.05 si no IV Outcome secondario 3 P>0.05 no si V Outcome secondario 4 P<0.05 no si VI Outcome secondario 5 P<0.05 no si VII Outcome secondario 6 P<0.05 no si
Secondo il parere di chi scrive le indicazioni EMEA [5] sono ancora più restrittive , ai fini di un critical appraisal, delle indicazioni fornite da Moyè [6]. Infatti la verifica del soddisfacimento delle condizioni previste al punto A prevede -assolutamente- la gerarchizzazione degli outcome secondari in ranghi e la verifica del soddisfacimento delle condizioni previste sia al punto A che al punto B prevede una chiara ed esplicita pianificazione della analisi primaria da parte degli autori nel protocollo dello studio e alla voce 'Analisi satistica'. Tutto ciò non viene praticamente mai fatto (vedi oltre per alcuni esempi della letteratura recente) B) I risultati che si riferiscono all' outcome primario 'non sono significativi' In questo caso le conclusioni 'significative' di una analisi secondaria dovrebbero essere utilizzate solo per generare ipotesi di lavoro [2,3]. L' Errore inizialmente 'tollerato' nel calcolo del sample size è stato infatti 'speso' integralmente per l' analisi primaria [2]. La presenza di 'significatività statistica per una analisi secondaria rappresenta qui una situazione fortemente viziata. Pertanto un risultato 'significativo' per un outcome secondario deve essere considerato 'exploratory and hypothesis generating' piuttosto che 'confirmatory and hypothesis testing' [2]. In realtà si notano sempre più di frequente nella letteratura biomedica gravi mistificazioni nell' interpretazione dei risultati della ricerca soprattutto quando gli autori non siano stati in grado di dimostrare 'significatività statistica' per l' analisi che si riferisce all' outcome primario. Ciò risulta ancor più sorprendente se si considera che questi concetti metodologici dovrebbero essere ormai assodati da tempo. Il fatto che gli autori tentino sempre più frequentemente di 'nascondere in soffitta la vecchia zia scema' (dove 'zia scema' rappresenta la libera traduzione di 'crazy aunt' [6] e coincide con l' ignorare deliberatamente le conclusioni emerse per l' end-point primario) è stato per esempio già messo in luce da Moyé nel 1999 [6].
Alcuni esempi di analisi di Outcome Secondari tratti dalla letteratura recente I) I Trial sulla terapia farmacologica dell' ipertensione [11]

17
Una recente analisi EQM [11] della letteratura internazionale ha dimostrato che gli autori dei trial che confrontano due o più trattamenti attivi contro l' ipertensione hanno fondato nel 60% circa dei casi le proprie conclusioni -in modo parziale o totale- sull' interpretazione di analisi secondarie. I messaggi di queste ricerche risultano spesso confusi e contrastanti. Se invece le conclusioni dei trial vengono basate solo sui dati che si riferiscono alle analisi primarie i risultati appaiono straordinariamente omogenei e risultano tra l' altro coerenti con quelli forniti dalle metanalisi degli stessi trial. Il nostro critical appraisal è stato pubblicato nel sito ww.farmacovigilanza.org dell' Università di Messina, il cui link è riportato anche dal nostro sito www.evidenzaqualitametodo.it
II) Lo studio ASCOT-BPLA Il critical appraisal EQM [13] di questo articolo [12] è reperibile on line al sito ww.farmacovigilanza.org il cui link è riportato anche dal nostro sito www.evidenzaqualitametodo.it L' ipotesi testata dallo studio ASCOT-BPLA era < l' amlodipina (eventualmente associata a perindopril) è più efficace dell' atenololo (eventualmente associato a bendrofumethiazide-potassio) nel ridurre l' incidenza di morti coronariche + infarti non fatali (=outcome primario)>? Il Sample size era stato calcolato prevedendo una potenza statistica dell' 80% nel rilevare per l' outcome primario (= morti coronariche + infarti non fatali) un Hazard Ratio pari a 0.84 con livelli di errore alfa pari a 0.05. La casistica era rappresentata da 19257 pazienti randomizzati (9639 assegnati al braccio amlodipina; 9618 assegnati al braccio atenololo). Risultati in Hazard Ratio (con rispettivi intervalli di confidenza al 95%) : HR per 'outcome primario' = 0.90 (0.79-1.02) (non significativo) ; HR per 'stroke' = 0.77 (0.66-0.89) (significativo) ; HR per 'tutti gli eventi e le procedure cardiovascolari' =0.84 (0.78-0.90) (significativo); HR per 'mortalità da tutte le cause' =0.89 (0.81-0.99) (significativo); HR per 'sviluppo di diabete' = 0.70 (0.63-0.78) (significativo) Conclusioni degli autori: il trattamento con amlodipina previene un maggior numero di eventi cardiovascolari e induce meno casi di diabete rispetto al trattamento basato sull' atenololo (..) Questi risultati sono importanti nel suggerire la combinazione ideale di farmaci antiipertensivi. Critical appraisal Gli autori in presenza di mancata significatività dei risultati per l' outcome primario hanno basato le proprie conclusioni solo sulle analisi secondarie. Questa situazione è classificabile al punto II della tabella 6. Le conclusioni andrebbero quindi immediatamente ricusate in quanto l' errore che gli autori dichiarano di aver programmato (0.05) è stato palesemente speso tutto per l' analisi primaria. Per esemplificare la metodica illustrata in questo saggio riportiamo comunque tutti i passaggi matematici per l' analisi di relativi ai risultati dei <confirmatory endpoints> a) Potenza statistica dello studio (calcolata con il tool disponibile all' indirizzo http://newton.stat.ubc.ca/~rollin/stats/ssize/b2.html) in base a questi dati (figura 4 del lavoro originale [12]): ARi (outcome primario) = 429/9639 = 0.044506692 ARc (outcome primario) = 474/9618 = 0.049282595 Sample size = (9639+9618)/2 = 9628 Errore Tipo I programmato = 0.05 Potenza statistica = 0.35 (molto più bassa di quella prevista nel calcolo del sample size che corrisponde a 0.8). Gli autori riconoscono, correttamente, la bassa potenza della loro analisi che attribuiscono al sottocampionamento dovuto alla precoce interruzione dello studio. B) Calcolo dell' Errore reale (vedi formula in appendice) Gli autori utilizzano <confirmatory use> oltre all'outcome primario altri 4 outcome (ossia 4 end-point secondari - tabella A). L’ Errore dichiarato programmato per l’ analisi primaria (0.05) avrebbe pertanto dovuto essere distribuito -correttamente- sulle analisi dei risultati rilevati per questi cinque outcome. Gli autori hanno invece definito la 'significatività statistica' dei risultati che si riferiscono a ciascuno dei 4 outcome secondari considerando i valori di P calcolati nominalmente sui risultati riportati per ciascun outcome. Ciò equivale a dire che nella analisi <confirmatory> a tutti gli effetti allestita dagli autori il valore di tollerato per ciascun outcome corrispondeva a 0.05!. Calcoliamo in base a questo assunto il reale valore di di questa analisi. Non avendo a disposizione i dati

18
necessari al calcolo dei rapporti di interdipendenza dei 5 outcome <confirmatory> possiamo eseguire una sensitivity analysis immaginando 4 scenari : 1-completa indipendenza (D=0) 2-completa interdipendenza (D=0.99999) 3-limite inferiore 'media dipendenza'(D= 0.30) 4- limite superiore ‘media dipendenza’ (D=0.70)
Tabella A End-point utilizzati per <confirmatory use>
[12]
P nominal test
Primary endpoint 0.1052 Total cardiovascular events and procedures 0.0001 All cause mortality 0.0247 Fatal and non fatal stroke 0.0003 Development of diabetes 0.0001
Tabella B
Grado di interdipendenza tra gli endpoint (sensitivity Analysis)
valori di D
D=0 completa indipendenza 0.2262 D=0.30 parziale dipendenza 0.2114 D=0.70 parziale dipendenza 0.1432 D=0.9999999 completa dipendenza 0.050
L' Errore reale della analisi <confirmatory> potrebbe coincidere con i livelli di errore alfa programmato dagli autori (0.05 = Errore dichiarato) solo nell’ inverosimile situazione di ‘completa dipendenza’ tra i cinque outcome, vale a dire solo se tutti pazienti che hanno subito un outcome <confirmatory> avessero subito anche tutti gli altri oitcome. In presenza di tali livelli di Errore reale ogni altro calcolo è superfluo: tali livelli stravolgono il cut off normalmente accettato per ricusare l' ipotesi nulla (0.05). Qundi la risposta corretta all' ipotesi testata dallo studio ASCOT deve essere <non è stato provato per insufficiente potenza statistica che l' amlodipina (eventualmente associata a perindopril) sia più efficace dell' atenololo (eventualmente associato a bendrofumethiazide-potassio) nel ridurre l' incidenza di morti coronariche + infarti non fatali (=outcome primario)>.
III) Lo studio WHS [14] Il critical appraisal EQM di questo articolo è reperibile on line al sito ww.farmacovigilanza.org il cui link è riportato anche dal nostro sito www.evidenzaqualitametodo.it ed è stato anche pubblicato sulla rivista SIMG [15] Ipotesi testata <la somministrazione di ASA alla dose di 100 mg a giorni alterni è in grado di ridurre l' incidenza di infarti non fatali + stroke non fatali + morti cardiovascolari nelle donne di 45 anni di età e oltre?> Lo studio non ha dimostrato significatività statistica per la differenza riscontrata tra i due bracci nell’incidenza dell’outcome primario (RR 0.91 P=0.13). E’ emersa invece significatività statistica per le differenze riscontrate tra i due bracci per i seguenti outcome secondari: stroke (RR 0.83 P 0.04); stroke ischemico (RR0.76 P 0.009); stroke non fatale (RR 0.81 P 0.02), TIA (RR 0.78 P 0.01). Conclusioni degli autori: nella casistica esaminata dallo studio la somministrazione di ASA 100 mg a giorni alterni ha abbassato il rischio di stroke senza esercitare influenza sul rischio di infarto miocardio o di morte cardiovascolare (..) Critical appraisal Gli autori in presenza di mancata significatività dei risultati per l' outcome primario hanno basato le proprie conclusioni solo sulle analisi secondarie. Questa situazione è classificabile al punto II della tabella 6. Le conclusioni andrebbero quindi immediatamente ricusate in quanto l' Errore programmato per la analisi primaria (non riportato dagli autori ma con ogni probabilità corrispondente al default 0.05) è stato palesemente speso tutto per l' analisi primaria. Per esemplificare la metodica illustrata in questo saggio riportiamo comunque ancora una volta i passaggi matematici per il calcolo di relativi ai risultati dei <confirmatory endpoints>.

19
a) Potenza statistica dello studio (calcolata con il tool disponibile all' indirizzo http://newton.stat.ubc.ca/~rollin/stats/ssize/b2.html) in base a questi dati (figura 4 del lavoro originale [14]): ARi (outcome primario) = 477/19934 = 0,023928966 ARc (outcome primario) = 522/19942 = 0,02617591 Sample size = (19934+19942)/2 = 19938 Errore Tipo I programmato per l' analisi primaria= non riportato dagli autori: abbiamo utilizzato il default 0.05 Potenza statistica = 0.30 B) Calcolo dell' Errore reale (vedi formula in appendice). La procedura è identica a quella considerata per lo studio ASCOT (vedi sopra). In questo caso gli outcome secondari valorizzati dagli autori sono due; pertanto l’ analisi <confirmatory> è estesa a tre outcome: i due secondari e quello primario.
Tabella A End-point utilizzati per <confirmatory use>
[14]
P nominal test
Primary endpoint 0.13 Stroke 0.04 TIA 0.01
Tabella B Grado di interdipendenza tra gli endpoint
(sensitivity Analysis) valori di D
D=0 completa indipendenza 0.1426 D=0.30 parziale dipendenza 0.1344 D=0.70 parziale dipendenza 0.0978 D=0.99 completa dipendenza 0.050
Anche in questo caso i valori di che si adottano di solito per default (0.05) potrebbero coincidere con quelli calcolati solo nell’ improbabile ipotesi di una completa interdipendenza tra i 3 outcome. Riteniamo che le conclusioni degli autori debbano essere pertanto ricusate a sostegno della definizione della 'nullità' o in alternativa della 'non informatività' dei loro risultati (vedi tabella 3). Vale a dire che la risposta corretta all' ipotesi testata deve essere: <non è stato dimostrato che la somministrazione di ASA alla dose di 100 mg a giorni alterni sia in grado di ridurre l' incidenza di infarti non fatali + stroke non fatali + morti cardiovascolari nelle donne di 45 anni di età e oltre>
Bibliografia [1] Feise RJ Do multiple outcome measures require p-value adjyustment? BMC Medical research Methodology 2002 2:8 [2] Freemantle N How well does the evidence on pioglitazone back up researchers' claims for a reduction in macrovascular events? BMJ 2005 331:836 [3] Freemantle N Interpreting the results of secondary endpoints and subgroup analyses in clinical trial: should we lock the crazy aunt in the attic? BMJ 2001 322:989

20
[4] http://newton.stat.ubc.ca/~rollin/stats/ssize/b1.html [5] EMEA The European Agengy for the Evaluation of Medicinal Products - Evaluation of medicines for human use London 19 september 2002 CPMP/EWP/908/99 [6] Moyé LA Endpoint interpretation in clinical trials: the caso for discipline Control Clin Trials 1999 20:40 [7] Sackett DL Why randomized controlled trial fail but needn't: 2. Failure to employ physiological statistics, or the only formula a clinician-trialist is ever lickely to need (or understand!) JAMC 2001 165:1226 [8] ICH Harmonised Tripartite Guideline - Statistical principles for Clinical trials International conference on harmonisation of technical requirements for registration of pharmaceutical for human use Recommended for Adoption at Step 4 of the ICH Process on 5 February 1998 by the ICH Steering Committee http://www.ich.org/cache/compo/475-272-1.html [9] Moyé LA Multiple Analyses in Clinical Trials - Fundamentals for Investigators Springer - Verlag New York 2003 ISBN 10918937 [10] Packer M et al Comparative effects of low and high doses of the Angiotensin-Converting Enzyme Inibithor, Lisinopril, on morbidity and mortality in Chronic Heart Failure Circulation 1999 100:2312 [11] Battaggia A, Vaona A, Giustini SA <Liberare la zia scema dalla soffitta rende inutili le metanalisi?> Come gli autori dei trial interpretano i risultati delle proprie ricerche http://www.farmacovigilanza.org 15/01/2006 [12] Björn Dahlöf et al. Prevention of cardiovascular events with an antihypertensive regimen of amlodipine adding perindopril as required versus atenolol adding bendromethiazide as required, in the Anglo-Scandinavian Cardiac Outcomes Trial-Blood Pressure Lowering Arm (ASCOT-BPLA): a multicentre randomised controlled trial' Lancet 2005; 366: 895–906 [13] Battaggia A, Vaona A , Rigon G, Giustini SE Old or new drugs for hypertension? No problem: the result is the same Critical Appraisal dello studio ASCOT-BPLA La Farmacovogilanza- Università di Messina [15/01/06] http://www.farmacovigilanza.org [14] Ridker PM et al A randomized trial of low dose aspirin in the primary prevention of cardiovascular disease in women NEJM 2005:352

21
[15] Battaggia A et al (Gruppo EQM) Asa in prevenzione primaria nelle donne. Critical appraisal sull' articolo [ A randomized trial of low dose aspirin in the primary prevention of cardiovascular disease in women Ridker PM et al NEJM 2005:352] Rivista SIMG - Giugno 2005 http://www.simg.it/servizi/servizi_riviste2005/03_2005/8.pdf [16] Battaggia A et al (Gruppo EQM) Liberare la zia scema dalla soffitta rende inutili le metanalisi? La Farmacovigilanza Università di Messina, gennaio 2006 http://www.farmacovigilanza.org

22
APPENDICE
Formula per il calcolo di dove = Errore di tipo I complessivo delle analisi confirmatory use programmato ex ante k = numero di outcome utilizzati in un' analisi confirmatory use = Errore alfa programmato per i singoli confronti (1 = Errore alfa dell' analisi primaria) D = grado di dipendenza di un outcome rispetto agli altri (es: D3/2,1 = grado di dipendenza dell' outcome 3 rispetto all' outcome 2 e alll' oucome 1)
Formula per il calcolo di Ddove D = grado di dipendenza tra due outcome (0= tot. indipendenti 0.999999 = tot. dipendenti) c = grado di coincidenza (0 = nessuna coincidenza 1= completa coincidenza) h = grado di omogeneità dell' effetto dell' intervento (0= nessuna omogeneità 1= perfetta omogeneità)

23
Formula per il calcolo di E dove E = Errore di tipo I rilevato ex post nell' analisi confirmatory use = Errore alfa programmato per i singoli confronti p = Probabilità di errore alfa rilevata per i singoli confronti


















