
Analisi delle prestazioni delle principali soluzioni per ...
138
Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica Tesi di laurea Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe Anno Accademico 2009/2010 Relatore Ch.mo prof. Domenico Cotroneo Correlatore Ing. Christiancarmine Esposito Candidato Vincenzo De Luca matr. 041/002809
Transcript of Analisi delle prestazioni delle principali soluzioni per ...

Facoltà di Ingegneria Corso di Studi in Ingegneria Informatica
Tesi di laurea
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
Anno Accademico 2009/2010 Relatore Ch.mo prof. Domenico Cotroneo Correlatore Ing. Christiancarmine Esposito Candidato Vincenzo De Luca matr. 041/002809

Questa volta lasciate che sia felice, non è successo nulla a nessuno, non sono da nessuna parte, succede solo che sono felice fino all’ultimo profondo angolino del cuore.
Sono più sterminato dell’erba nelle praterie, e l’acqua sotto, gli uccelli in cima, il mare come un anello intorno alla mia vita, l’aria canta come una chitarra.
Il mondo è oggi la mia anima, lasciatemi essere felice, Oggi lasciate che sia felice, io e basta, con o senza tutti essere felice
(Tratto da “Ode al giorno Felice”P.Neruda)
Dedicata ai miei genitori, a mia sorella, a Roberto, a chi mi è sempre stato vicino nel bene e nel male.

III
Indice
Introduzione 8
Capitolo 1. Introduzione ai sistemi publish - subscribe 10
1.1 Introduzione ai Middleware 10
1.2 Service Oriented Architecture (SOA) 12
1.2.1 Enterprise Service Bus 13
1.2.2 Event – Driven Architecture 13
1.2.3 Staged Event – Driven Architecture 14
1.3 Modello Publish/Subscribe 14
1.4 Modello architetturale Publish/Subscribe 18
1.4.1 Infrastruttura di overlay 18
1.4.2 Indirizzamento degli eventi 20
1.4.3 Controllo degli eventi 22
1.5 Altri paradigmi di comunicazione 22
Capitolo 2. Le principali architetture Publish/Subscribe 26
2.1 Middleware Publish/Subscribe DDS 26
2.2 Qualità del servizio nei Middleware DDS 27
2.3 Architettura dei Middleware DDS 30
2.4 Real Time Innovations Data Distribution Service RTI - DDS 32
2.4.1 QoS supportate 35
2.4.2 Discovery 37
2.5 OpenSplice 38
2.5.1 Architettura OpenSplice 39
2.5.2 QoS supportate 42
2.6 Corba 43
2.6.1 I servizi CORBA 46
2.6.2 CORBA EVENT SERVICE 48
2.6.3 CORBA NOTIFICATION SERVICE 50
2.6.4 CORBA TAO 51
2.7 JMS – Java Message Service 54
2.7.1 Apache ActiveMQ - CPP 60
2.8 AMQP 62
2.8.1 AMQP Model Layer 64
2.8.2 Il Layer Session 65
2.8.3 Il layer di trasporto (Transport layer) 67
2.8.4 OpenAMQ 68
2.8.5 QPID 71
2.9 Confronto delle soluzioni middleware 73

IV
Capitolo 3. Valutazione prestazionale 78
3.1 Sistema di Riferimento 78
3.2 I Test 79
3.3 Parametri di confronto 81
3.4 Test RTI - DDS 82
3.5 Test OpenSplice 90
3.6 Test CORBA TAO 95
3.7 Test Apache ActiveMQ - CPP 104
3.8 Test OpenAMQ 111
3.9 Test QPID 118
3.10 Confronto delle prestazioni delle soluzioni publish/subscribe 125
Conclusioni e Sviluppi futuri 129
Ringraziamenti 131
Bibliografia 135

V
Indice delle figure
Figura 1.1 Struttura a livelli per applicazioni di rete distribuite 10
Figura 1.2 Genealogia del Middleware 11
Figura 1.3 Un semplice sistema Publish/Subscribe 15
Figura 1.4 Space, Time e Synchronization decoupling 17
Figura 1.5 Architettura a livelli di un sistema Publish/Subscribe 18
Figura 1.6 Interazione Message Passing 23
Figura 1.7 Interazione RPC 23
Figura 1.8 Interazione Notification 24
Figura 1.9 Interazione Shared spaces 24
Figura 1.10 Interazione Message queue 25
Figura 2.1 Schema concettuale del DCPS 31
Figura 2.2 Architettura di un’applicazione sviluppata su RTI DDS 32
Figura 2.3Architettura RTI DDS 35
Figura 2.4 Architettura OpenSplice DDS 40
Figura 2.5 Architettura OMA (Object Management Architecture) 44
Figura 2.6 Macroblocchi dell'architettura OMA 45
Figura 2.7 Pila ISO-OSI 46
Figura 2.8 Modalità di invio degli eventi: push e pull 49
Figura 2.9 Le interfacce principali il servizio di notifica 51
Figura 2.10 Architettura TAO 53
Figura 2.11 Architettura JMS 55
Figura 2.12 Il modello di programmazione Java Message Service 57
Figura 2.13 Un client-library trasforma messaggi JMS da e per eventi strutturati 59
Figura 2.14 Schema dei protocolli di Apache ActiveMQ – CPP 61
Figura 2.15 Struttura a layer di AMQP 63
Figura 2.16 Semantica AMQP 65
Figura 2.17 Header 68
Figura 3.1 Schema Cluster CINI utilizzato per i test 79
Figura 3.2 Schema di Calcolo Latenza 80
Figura 3.3 Architettura decentralizzata 82
Figura 3.4 Mediana dei tempi di RTT RTI - DDS 87
Figura 3.5 Distanza interquartile dei tempi di RTT RTI - DDS 88
Figura 3.6 Mediana Scalabilità RTI - DDS 89
Figura 3.7 Architettura federata 90
Figura 3.8 Mediana dei tempi di RTT OpenSplice DDS 94
Figura 3.9 Distanza interquartile dei tempi di RTT OpenSplice DDS 95
Figura 3.10 Mediana Scalabilità OpenSplice - DDS 96
Figura 3.11 Architettura centralizzata 97
Figura 3.12 Mediana dei tempi di RTT Corba 101
Figura 3.13 Distanza interquartile dei tempi di RTT Corba 102
Figura 3.14 Mediana Scalabilità Corba 103
Figura 3.15 Mediana dei tempi di RTT Apache ActiveMQ - CPP 108
Figura 3.16 Distanza interquartile dei tempi di RTT Apache ActiveMQ - CPP 109
Figura 3.17 Mediana Scalabilità Apache ActiveMQ - CPP 110
Figura 3.18 Mediana dei tempi di RTT OpenAMQ 115
Figura 3.19 Distanza interquartile dei tempi di RTT OpenAMQ 116
Figura 3.20 Mediana Scalabilità OpenAMQ 117

VI
Figura 3.21 Mediana dei tempi di RTT QPID 122
Figura 3.22 Distanza interquartile dei tempi di RTT QPID 123
Figura 3.23 Mediana Scalabilità QPID 124
Figura 3.24 Mediana dei tempi di RTT 1Pub – 2 Sub 125
Figura 3.25 Distanza interquartile dei tempi di RTT 1Pub – 2 Sub 125
Figura 3.26 Mediana dei tempi di RTT 1Pub – 4 Sub 126
Figura 3.27 Distanza interquartile dei tempi di RTT 1Pub – 4 Sub 126
Figura 3.28 Mediana dei tempi di RTT 1Pub – 6 Sub 127
Figura 3.29 Distanza interquartile dei tempi di RTT 1Pub – 6 Sub 127
Figura 3.30 Mediana scalabilità 2 Sub – 4 Sub 128
Figura 3.31 Mediana scalabilità 2 Sub – 6 Sub 128

VII
Indice delle tabelle
Tabella 2.1 QoS Policy 36
Tabella 2.2 Architettura 76
Tabella 2.3 Quality of Service Policy 77
Tabella 3.1 Valori della mediana RTI - DDS 84
Tabella 3.2 Valori della distanza interquartile RTI DDS 85
Tabella 3.3 Valori della mediana di Scalabilità RTI – DDS 86
Tabella 3.4 Valori della mediana OpenSplice DDS 91
Tabella 3.5 Valori della distanza interquartile OpenSplice DDS 92
Tabella 3.6 Valori della mediana di Scalabilità OpenSplice – DDS 93
Tabella 3.7 Valori della mediana Corba 98 Tabella 3.8 Valori della distanza interquartile Corba 99 Tabella 3.9 Valori della mediana di Scalabilità Corba 100 Tabella 3.10 Valori della mediana Apache ActiveMQ – CPP 105 Tabella 3.11 Valori della distanza interquartile Apache ActiveMQ – CPP 106 Tabella 3.12 Valori della mediana di Scalabilità Apache ActiveMQ – CPP 107 Tabella 3.13 Valori della mediana OpenAMQ 112 Tabella 3.14 Valori della distanza interquartile OpenAMQ 113 Tabella 3.15 Valori della mediana di Scalabilità OpenAMQ 114 Tabella 3.16 Valori della mediana QPID 119
Tabella 3.17 Valori della distanza interquartile QPID 120 Tabella 3.18 Valori della mediana di Scalabilità QPID 121

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
8
Introduzione
L‟esigenza di avere applicazioni distribuite in ambienti di larga scala, scalabili e affidabili,
ha portato alla creazione di nuovi paradigmi di comunicazione. L‟unico in grado di fornire
la disseminazione delle informazioni in forma anonima, in maniera asincrona, garantendo
il totale disaccoppiamento dei partecipanti è il paradigma publish/subscriber. Tali
caratteristiche permettono di ottenere una distribuzione delle informazioni scalabile e
affidabile, in quanto i partecipanti non devono conoscersi reciprocamente, l‟operazione di
invio e ricezione non devono essere sincronizzate e non richiede che le entità interessate
siano “attive” nello stesso tempo. Questo paradigma di comunicazione, grazie a queste
caratteristiche, nell‟ultimo decennio si è guadagnato un ruolo centrale nello sviluppo di
applicazioni su larga scala; esempi di applicazione sono il controllo del traffico aereo, il
controllo dei processi industriali, lo scambio delle quotazioni finanziarie. A seconda del
campo di applicazione, la diffusione delle informazioni deve seguire regole e rispettare
vincoli più o meno restrittivi: si pensi per esempio a quanto sia tollerabile la perdita di una
transazione finanziaria “real-time”. Per cui le problematiche che un sistema di diffusione
delle informazioni si trova ad affrontare sono molteplici: l‟ormai crescente mole di dati che
si vuole trasmettere ad un numero sempre maggiore di partecipanti interessati, i quali
possono essere dislocati su una rete geograficamente vasta, è un altro aspetto da tenere
bene in considerazione, come pure la diversità delle architetture usate per i singoli
partecipanti. Senza contare aspetti dinamici delle reti, guasti, il continuo entrare o uscire
dei partecipanti dalla comunicazione, l‟inaffidabilità dei canali, aspetti che appaiono
evidenti, e maggiormente critici, se si pensa ad una rete di dispositivi mobili. Poichè tali
problematiche sono comuni a molti e diversi campi d‟applicazione, si `e pensato di creare
uno strato software che si occupasse di esse. Uno strato che forma una “terra di mezzo” tra
applicazione e sistema sottostante e per questo chiamato middleware. L‟idea è dunque di
demandare al middleware la gestione delle problematiche, mentre l‟applicazione dovrà
occuparsi solo della propria logica: inviare un dato per l‟applicazione si tradurrà in
un‟istruzione al middleware sottostante, inviarlo affidabilmente potrà essere la stessa

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
9
istruzione con parametri di affidabilità. Il resto del gioco è intrapreso dal middleware, il cui
apporto migliorerà sia l‟interoperabilità con i vari sistemi che l‟efficienza delle
applicazioni. Una soluzione architetturale è costituita dai sistemi middleware di tipo
publish/subscribe. Il modello Publish/Subscribe risulta particolarmente adatto alla
realizzazione di applicazioni distribuite aventi come task principale la distribuzione dei
dati. I middleware basati sul modello Publish/Subscribe offrono infatti un elevato grado di
disaccoppiamento tra le entità comunicanti, rendendo particolarmente agevole la
realizzazione di schemi di comunicazione molti-a-molti anche con requisiti di tempo
stringenti, come nel caso di sistemi real-time e mission critical ed offrendo un elevato
grado di scalabilità al crescere dei partecipanti alla comunicazione
Nel nostro lavoro di tesi abbiamo valutato diverse soluzioni middleware publish/subscribe,
spaziando tra le varie soluzioni attualmente disponibili sul mercato, partendo da soluzioni
middleware già affermate come RTI DDS, OpenSpliceDDS, Corba, e giungere ad
esaminare soluzioni più recenti come AMQP e JMS.
Di seguito riportiamo l‟organizzazione del lavoro in capitoli:
Capitolo 1 - Introduzione ai Sistemi Publish/Subscribe: In questo capitolo si
introduce il paradigma Publish/Subscribe.
Capitolo 2 - Le principali architetture Publish/Subscribe: In questo capitolo ci
soffermiamo ad esaminare le caratteristiche dei middleware presi in esame durante
questo lavoro di tesi per cercare di trarne un confronto.
Capitolo 3 - Valutazione prestazionale: In questo capitolo si introduce la
metodologia e la tipologia dei test di funzionamento eseguiti sui middleware presi
in esame. I risultati di tali test sono stati poi raccolti e utilizzati per effettuare una
valutazione prestazionale delle varie soluzioni da cui si è ricavato un confronto

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
10
Capitolo 1 - Introduzione ai Sistemi Publish/Subscribe
1.1 Introduzione ai Middleware
L'evoluzione di Internet ha cambiato notevolmente la scala dei sistemi distribuiti. Questi
oggi comprendono milioni di entità, distribuite in tutto il mondo, i cui comportamenti
possono variare nel corso del tempo. Il collante tra le differenti entità, in un ambiente di
scala così ampio, deve essere fornito da un sistema middleware dedicato, basato su un
adeguato sistema di comunicazione come illustrato in figura 1.1 [1]. Il middleware è uno
strato software interposto tra il sistema operativo e le applicazioni in grado di fornire
astrazioni e servizi utili per lo sviluppo di applicazioni distribuite, così da consentire loro
di interoperare indipendentemente da possibili eterogeneità.
Figura 1.1 Struttura a livelli per applicazioni di rete distribuite.
Un Middleware può essere catalogato in base ai servizi offerti:
RPC-based system: prevede le infrastrutture necessarie per effettuare le RPC in modo
trasparente al programma, ed in modo uniforme rispetto ai protocolli sottostanti;
TP Monitor: i middleware di questo tipo sono in grado di supportare transazioni
distribuite con proprietà ACIDE per dati distribuiti su più sistemi eterogenei;
Object-Broker: estendono il paradigma RPC con l‟aggiunta di numerosi servizi che

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
11
semplificano lo sviluppo di applicazioni distribuite secondo il paradigma Object-
Oriented [1];
Object monitor: nasce dall‟unione di due tipi di middleware il TP Monitoe e l‟Object
Broker;
Message-oriented: (MOM) sono middleware basati su scambio di messaggi. Per
messaggio si intende un insieme di dati strutturati, caratterizzati da un tipo ed
un‟insieme di parametri del messaggio. La limitazione principale di questo
middleware è l‟indirizzamento punto-punto;
Message-brokers: è un message middleware che si occupa dello scambio di messaggi
in una rete di telecomunicazioni, lo schema di indirizzamento di questa tipologia di
middleware non è più di tipo punto-punto ma è un indirizzamento orientato ai
messaggi. Il paradigma più noto è il Publish/Subscribe;
Nella Fig. 1.2 viene rappresentata la genealogia dei middleware appena descritti.
Figura 1.2 Genealogia del Middleware.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
12
1.2 Service Oriented Architecture (SOA)
Un sistema distribuito è formato da diversi agenti software discreti che devono cooperare
insieme per svolgere determinate funzioni. Inoltre, gli agenti in un sistema distribuito non
operano nello stesso ambiente, quindi devono comunicare affidandosi a protocolli software
e hardware attraverso una rete. Questo implica che le comunicazioni in un sistema
distribuito sono intrinsecamente meno veloci e disponibili di quelle tramite invocazione
diretta nel codice e usando memoria condivisa. Questo ha delle importanti implicazioni
architetturali, poichè i sistemi distribuiti richiedono che gli sviluppatori prendano in
considerazione l‟imprevedibile latenza di una comunicazione remota e gestire le
problematiche derivate dalla concorrenza e dai possibili fallimenti parziali.
I distributed object systems sono sistemi distribuiti nei quali la semantica
dell‟inizializzazione di un oggetto e dei suoi metodi sono esposti a sistemi remoti tramite
meccanismi proprietari o standard per inoltrare la richiesta oltre i confini del sistema,
effettuare marshall o unmarshall degli argomenti dei metodi, etc.
Una Service Oriented Architecture (SOA) [57,58] è una forma d‟architettura di sistemi
distribuiti tipicamente caratterizzata da queste proprietà:
Vista logica: Il servizio è un‟astrazione, vista logica, del programma, database,
processo etc., definito in termini di cosa fa, tipicamente astraendo un‟operazione.
Orientato ai messaggi: Il servizio è formalmente definito in termini dei messaggi
scambiati tra l‟agente fornitore e l‟agente fruitore e non sulle proprietà degli agenti
stessi. La struttura interna degli agenti, compreso ad esempio il linguaggio di
programmazione usato per implementarlo, la struttura dei processi o la struttura delle
basi di dati, sono deliberatamente astratti nella SOA: non deve essere assolutamente
necessario sapere qualcosa dell‟implementazione di un agente per interagirci. Un
beneficio chiave di questa funzionalità interessa i cosiddetti sistemi legacy.
Orientato alla descrizione: Un servizio è descritto da metadati interpretabili da una
macchina. Questa descrizione deve supportare la natura pubblica della SOA: solo

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
13
quei dettagli utili all‟uso del servizio devono essere resi pubblici. La semantica del
servizio deve essere, direttamente o indirettamente, inserita in questa descrizione.
Granulare: I servizi tendono ad usare poche operazioni con messaggi relativamente
grandi e complessi.
Orientato alla rete: I servizi tendono ad essere utilizzati attraverso una rete, anche se
non è un requisito assoluto.
Indipendente dalla piattaforma: I messaggi sono inviati in un formato standard
indipendentemente dalla piattaforma utilizzata.
1.2.1 Enterprise Service Bus
Un Enterprise Service Bus (ESB) è un'infrastruttura software che fornisce servizi di
supporto ad architetture SOA complesse. Un ESB si basa su sistemi disparati, interconnessi
con tecnologie eterogenee, e fornisce in maniera consistente servizi di orchestration,
sicurezza, messaggistica, routing intelligente e trasformazioni, agendo come una dorsale
attraverso la quale viaggiano servizi software e componenti applicativi. Un ESB si
contraddistingue come soluzione migliorativa, rispetto ad altre più classiche di tipo SOA
oriented, in quanto ad esso sono delegati i servizi comuni, denominati core service
(Security, tracking, routing etc..), che andrebbero altrimenti realizzati.
1.2.2 Event – Driven Architecture
Event-driven architecture (EDA) è un paradigma di architettura sofware per la produzione,
gestione, utilizzo e reazione agli eventi.
Per evento s‟intende “una significativa modifica allo stato”. Ad esempio quando un
acquirente compra una macchina, il suo stato cambia in “venduta”. Il sistema di gestione
del venditore può trattare questo cambio di stato come un evento da raccogliere, segnalare
e far processare da varie applicazioni a corredo dell‟architettura.
Questo paradigma architetturale può essere applicato nella specifica e implementazione di
applicazioni e sistemi che trasmettono eventi attraverso componenti software fortemente

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
14
disaccoppiati e servizi. Un sistema orientato agli eventi tipicamente è costituito da
produttori e consumatori di eventi. I consumatori si sottoscrivono a degli intermediari detti
event manager, mentre i produttori pubblicano gli eventi a questi managers (Subscribe and
Publish, S&P). Quando un manager riceve un evento dal produttore, lo notifica al
consumatore. Se questo è indisponibile, lo memorizza e tenta un ulteriore invio in seguito.
Questo metodo di trasmissione degli eventi è riferito nei sistemi orientati ai messaggi come
“store and foward” Costruire applicazioni e sistemi basandosi su questo tipo di architettura
permette di ottenere una maggiore affidabilità, poiché i sistemi basati sugli eventi sono, per
costruzione, più tolleranti ad ambienti imprevedibili ed asincroni.
1.2.3 Staged Event – Driven Architecture
SEDA [31,32] è l‟acronimo di staged event-driven architecture. Questa architettura è stata
ideata da Matt Welsh dell‟Università di Harvard e prevede di decomporre un‟applicazione
complessa, orientata agli eventi, in un set di fasi (stages) connessi da code. Questa
architettura risolve il problema di overhead presente in modelli basati su thread, e
disaccoppia eventi e thread dalla logica applicativa. Questo permette di prevenire che le
risorse siano occupate da un carico di lavoro che eccede le loro capacità, evitando un
approccio thread-based, dove ogni richiesta è associata ad un thread.
1.3 Modello Publish/Subscribe
Sulla base del paradigma publish/subscribe, i subscriber hanno la possibilità di esprimere i
loro interessi verso eventi, o insiemi di eventi. Successivamente, essi vengono informati di
ogni altro evento pubblicato da un'altra entità cruciale del paradigma, detta publisher. Un
evento viene propagato in modo asincrono a tutti i subscriber che hanno dichiarato
interesse per quell'evento.
Il paradigma publish/subscribe o più in generale event-based è spesso usato per:
• Disseminazione delle informazioni a molti consumatori che sottoscrivono il loro
interesse, come ad esempio: disseminazione delle news.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
15
• Monitoraggio della rete per il controllo dei componenti del sistema e per la
protezione da attacchi D.O.S.
• Integrazione di applicazioni aziendali.
• Sistemi Mobili dove la rete sottostante e particolarmente caratterizzata da
dinamicità ed eterogeneità.
L'informazione è tipicamente chiamata “evento” e l'atto di diffonderlo è detto “notifica”.
Un sistema publish/subscribe è composto da un insieme di entità ed è rappresentato in
figura 1.3 [2]:
I Publisher sono i componenti attivi del sistema e producono i messaggi da
diffondere;
I Subscribers sono gli elementi passivi del sistema, ricevono i messaggi di interesse;
L'Event Service è un astrazione che costituisce da collante tra publisher e
subscriber;
Figura 1.3 Un semplice sistema Publish/Subscribe
L'event service fornisce un mediatore neutrale tra publisher e subscriber. I subscriber
sottoscrivono i loro interessi, solitamente attraverso una chiamata subscribe(), senza
curarsi dell'effettivo svolgersi di tale chiamata. Questa informazione rimane memorizzata
nell'event service fino a quando non viene invocata la chiamata unsubscribe(). Per

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
16
generare un evento, un publisher generalmente chiama la funzione notify() o publish().
L'event service si occupa di propagare gli eventi a tutti i subscriber sensibili nei confronti
di quel tema. Una notevole quantità di middleware publish/subscribe sono stati sviluppati
e realizzati, è possibile raggruppare queste implementazioni diverse a seconda
dell'architettura adottata e del modello di sottoscrizione dei messaggi[2]:
Architettura adottata:
Centralizzata, ad esempio un server di posta tra publishers e subscribers;
Distribuita, ad esempio implementando le primitive di comunicazione con
meccanismi store and forward sia sui producer che sui consumer;
Federata, per esempio una rete distribuita di server;
Modello Subscription:
Topic-based [3]: i partecipanti possono pubblicare e iscriversi a singoli
eventi, le notifiche sono raccolte per topic (argomento);
Content-based [3]: gli eventi vengono classificati in base a una funzione
corrispondente sul loro contenuto, i subscriber esprimono il loro interesse
specificando condizioni sul contenuto delle notifiche che essi vorranno
ricevere;
Type-based [3]: gli eventi appartengono ad un tipo specifico, incapsulando
sia attributi che metodi, Gli eventi sono filtrati non più in base al loro topic,
ma al loro tipo. Questo permette di definire gerarchie di tipi di eventi.
Il modello Publish/Subscribe ci permette di creare un disaccoppiamento delle parti
interagenti in quanto né le notifiche né le sottoscrizioni sono dirette ad una specifica
entità. Questo disaccoppiamento può essere osservato sotto tre punti di vista [2] [3]:
Space decoupling: le parti interagenti non necessitano di conoscersi. I publisher
pubblicano i loro eventi e i subscriber li raccolgono attraverso l'event service. Sia
Publishers che Subscribers non sanno quanti di questi partecipano all'interazione.
Come mostrato in figura 1.4 l'event service fornisce l'unico punto di riferimento
unilaterale per subscriber e publisher [2] [3].

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
17
Time decoupling: le parti interagenti non necessitano di partecipare all'interazione
nello stesso istante di tempo. In particolare i publisher possono pubblicare alcuni
eventi, mentre i subscriber sono disconnessi e viceversa. Come si vede dalla
figura 1.4 si ha la completa indipendenza delle operazioni di pubblicazione e
ricezione dell'evento [2] [3].
Synchronization decoupling: la produzione e il consumo di messaggi non
avvengono nello stesso flusso di controllo tra publisher e subscriber. Il
disaccoppiamento della produzione e del consumo aumenta la scalabilità
eliminando tutte le dipendenze tra i partecipanti che interagiscono. Nella figura
1.4 si cerca di mostrare graficamente la mancanza di sincronizzazione tra
publisher e subscriber.[2] [3]
Figura 1.4 Space, Time e Synchronization decoupling

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
18
1.4 Modello architetturale Publish/Subscribe
Un sistema Publish/Subscribe è composto da tre livelli come illustrato nella figura 1.5:
Figura 1.5 Architettura a livelli di un sistema Publish/Subscribe.
Per la diffusione scalabile delle informazioni, i livelli funzionali sono: l‟overlay
Infrastructure, l‟event routing (indirizzamento degli eventi) e l‟algoritmo per il matching
fra eventi e sottoscrizioni. L‟“Overlay Infrastructure” rappresenta l‟organizzazione delle
diverse entità che compongono il sistema, mentre per “Event Routing” si intende il
meccanismo per la disseminazione delle informazioni dai publishers ai subscribers. Esso
sfrutta l‟infrastruttura di overlay e vi integra le proprie informazioni di routing per ottenere
una spedizione degli eventi scalabile. Infine l‟“Algoritmo di Matching” filtra gli eventi
prodotti dai publisher e fa in modo che al subscriber giungano solo quelli che soddisfano
determinati criteri previsti dal modello di sottoscrizione.
1.4.1 Infrastruttura di overlay
Generalmente un sistema Publish/Subscribe si basa su una overlay network, si presentano
diverse possibilità di infrastrutture overlay dipendenti dal modo in cui i nodi della rete
sono organizzati, e dal ruolo che essi ricoprono.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
19
Broker Overlay: I broker server formano una rete di overlay comunicante con i protocolli
di network. Un client che intende connettersi e partecipare alla comunicazione può
accedere al sistema tramite un qualsiasi broker, che in genere memorizza solo un
sottoinsieme delle sottoscrizioni. Le connessioni sono puramente logiche e astratte,
quindi una broker network è statica. La broker network può essere: gerarchica e flat.
Nel primo caso i punti d‟accesso dei publisher risiedono alla radice e quelli dei
subscriber alle foglie (o viceversa) e gli eventi viaggiano solo attraverso i livelli
interessati [12] [13]; nel secondo caso invece non ci sono limitazioni alla connessione,
il che, ha il vantaggio di non sovraccaricare i nodi radice [14].
Peer-to-peer Structured Overlay: Una overlay network peer-to-peer structured è una
rete di livello applicazione composta da un insieme di nodi che si autogestiscono,
formanti un grafo strutturato su uno spazio di chiavi virtuali, dove ad ogni chiave è
associato un nodo. La presenza di questa struttura delle chiavi imposta al grafo,
permette l‟efficiente rilevazione dei partecipanti e dei dati da trasmettere, nonché la
comunicazione attraverso i nodi. Il fatto che la overlay sia strutturata garantisce
quindi che vi sia sempre corrispondenza tra un qualsiasi indirizzo ed un nodo attivo
anche in presenza di nodi che entrano ed escono dalla rete e di guasti sui nodi [20]
[21] [22].
Peer-to-peer Unstructured Overlay: La rete si sforza di organizzare i nodi in una
struttura gerarchica o flat in un piccolo raggio di copertura di rete, contro guasti dei
nodi e frequenza di ingresso/uscita di nodi.Non si suppone che i nodi siano server
dedicati, ma possono includere anche workstations, portatili, dispositivi mobili, ed
essi possono agire sia come client che come parte del pub/sub system. I nodi sono in
grado di autogestirsi. Poiché non vi è una struttura, per reperire i nodi ed i dati esse
sfruttano tecniche di flooding, gossiping o cammini casuali attraverso il grafo per
diffondere e ricevere informazioni associate ai nodi. Il vantaggio risiede nella facilità
con cui vengono gestiti i “join” e “leave” (unione e rilascio) dei nodi. In ogni caso, a
differenza delle reti strutturate, non vi è garanzia che ad ogni indirizzo sia associato

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
20
un nodo attivo.
Unstructured Overlays over Mobile Networks: In un ambiente formato da dispositivi
mobili, il cambiamento di topologia è una caratteristica imprescindibile, dovuta allo
spostamento dei dispositivi nonché ai guasti. E' impossibile in questo caso, agire
creando strutture gerarchiche o flat a piccoli raggi in quanto i nodi sono mobili.
Inoltre sono necessari algoritmi che mantengano connettività e consistenza delle
strutture dati per il routing, altrimenti il routing degli eventi stesso non può avvenire
correttamente [8] [9].
1.4.2 Indirizzamento degli eventi
Il cuore di un sistema Pub/Sub distribuito risiede nel meccanismo di Event Routing. In
poche parole è il processo di consegna degli eventi a tutti i subscribers che abbiano
manifestato la volontà di sottoscrivere una pubblicazione. Questo implica una visita dei
nodi da parte del Notification Service al fine di trovare, per ogni evento pubblicato, tutti i
client la cui sottoscrizione registrata è presente nel sistema al momento della
pubblicazione. Tuttavia, l‟impossibilità di definire un ordine temporale globale tra una
sottoscrizione ed una pubblicazione accadute su due nodi diversi (e quindi con clock
generalmente diverso) rende ambigua questa definizione di event routing. Il problema
principale dell‟event routing è la scalabilità. Le performance dovrebbero degradarsi il
meno possibile all‟aumentare dei nodi, delle sottoscrizioni e delle pubblicazioni. A tal fine
occorre regolare le pubblicazioni in modo che la propagazione degli eventi coinvolga
quanto più possibile solo i brokers che contengono delle sottoscrizioni per essi (Message
overhead). D‟altro canto, ridurre la quantità di informazioni di routing da mantenere sui
brokers al fine di permettere flessibili cambiamenti delle sottoscrizioni (Memory
overhead). Questi due aspetti sono in evidente contrapposizione, bilanciarli è uno dei
primi compiti del progettista di un sistema Pub/Sub. Esistono tre categorie di routing e
sono: flooding algorithm, selective algorithm, event gossiping algorithm.
Flooding algorithm: Gli algoritmi di flooding sono basati su una deterministica e

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
21
completa disseminazione degli eventi sull‟intero sistema. Una soluzione banale
consiste nel propagare ogni evento dal publisher verso tutti i nodi del sistema. Il
vantaggio di questo algoritmo è l‟assenza di limitazioni sulle sottoscrizioni, lo
svantaggio principale è il sovraccarico di messaggi scambiati al crescere della rete
quindi la non scalabilità. Per diminuire il message overhead si è creato il subscription
flooding, in cui ogni sottoscrizione è inviata a tutti i brokers, i quali hanno la
conoscenza dell‟intero sistema [24] [15].
Selective algorithm: Gli algoritmi selettivi tendono a ridurre la disseminazione
dell‟informazione degli algoritmi di flooding con l‟uso di strutture deterministiche
costruite sulle sottoscrizioni. Per ottenere ciò un sottoinsieme dei nodi di broker deve
memorizzare ogni sottoscrizione ed un sottoinsieme dei nodi di broker deve essere
visibile da ogni evento [25]. Il Filtering-based routing ed il Rendezvous-based routing
sono due algoritmi selettivi.
Filtering-based routing: L‟algoritmo riduce il message overlay inoltrando
un evento solo ai nodi che si trovano su un percorso che collega il publisher
ai vari subscriber [26].
Rendezvous-based routing: Questo algoritmo ottimizza le prestazioni
raggruppando tutte le sottoscrizioni di un determinato evento in uno stesso
nodo, evitando l‟esecuzione delle operazioni di matching su più nodi [27].
Event gossiping: Gli algoritmi di gossiping sono algoritmi probabilistici, che non usano
routing strutturati. Nel basic gossiping ogni nodo scambia informazioni con uno o
pochi nodi vicini nella rete, selezionati in modo casuale. In questo modo la
disseminazione dell‟informazione assomiglia molto alla disseminazione
epidemiologica [28]. In Informed gossip protocol si ha un basic gossiping algorithm
nel quale la scelta dei nodi vicini a cui inoltrare l‟evento viene eseguita in base alle
conoscenze acquisite dal nodo durante la sua esistenza. Con questo approccio si tenta
di inoltrare l‟evento solo ai nodi interessati. Ogni nodo mantiene informazioni
riguardanti le sottoscrizioni dei suoi vicini, quindi si introduce un overheard di

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
22
memoria, a vantaggio di un minor overheard di messaggi.
1.4.3 Controllo degli eventi
Con Matching si indica il processo di controllo di un evento che sia adatto ad una
sottoscrizione. Il matching è eseguito dal sistema Pub/Sub al fine di determinare se un
evento debba essere consegnato ad un subscriber o meno. Esso si interfaccia anche con
l‟agoritmo di routing, in quanto spesso decisioni di routing sono prese in base al matching
degli eventi delle sottoscrizioni. Nel contesto di sistemi di larga scala è desiderabile da un
lato avere un un numero di sottoscrizioni elevato e dall‟altro avere alte velocità di
elaborazione degli eventi. Ne segue che in generale il processo di matching viene eseguito
spesso e su grandi quantità di dati. Questo non è un gran problema in un sistema Topic-
based, dove il matching si riduce ad un semplice lookup in tabelle, ma in un sistema
Content-based è un grande scoglio per le performance generali, per cui l‟efficienza
dell‟algoritmo di matching gioca un ruolo fondamentale.
1.5 Altri paradigmi di comunicazione
Esistono altri paradigmi di comunicazione oltre al paradigma Publish/Subscribe appena
introdotto. Tali paradigmi sono Message passing, remote invocations, notifications,
shared spaces e message queuing. Tali paradigmi si differenziano tra loro per livello di
astrazione, per tale motivo non è facile effettuare un‟analisi comparativa. Tutti questi
modelli non disaccoppiano la comunicazione tra i partecipanti come avviene nel modello
Publish/Subscribe, e presentano, un limitato supporto nel tempo e nello spazio.
Message Passing: Il message passing rappresenta una comunicazione distribuita a
basso livello, dove i partecipanti comunicano tramite l‟invio e la ricezione di
messaggi [3]. Come mostrato in figura 1.6 il produttore invia i messaggi in modo
asincrono attraverso un canale di comunicazione ed il consumatore riceve tali
messaggio ascoltando in modo sincrono il canale. Il produttore ed il consumatore
devono essere accoppiati temporalmente e spazialmente e devono conoscersi

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
23
reciprocamente.
Figura 1.6 Interazione Message Passing.
RPC: La Remote Procedure Call è la più diffusa forma d‟interazione distribuita; la
quale è stata poi rafforzata applicandola al contesto object-oriented nella forma di
Remote Method Invocations. Come si vede dalla figura 1.7 [3] la distribuzione non
può essere effettuata in modo completamente trasparente all‟applicazione, in quanto
l‟applicazione si trova a dover gestire potenziali fallimenti che possono derivare da
problemi di trasmissione o fallimenti remoti. Risulta presente un accoppiamento
spaziale (consumatore e produttore si devono conoscere) e temporale (il
consumatore effettua chiamate bloccanti
Figura 1.7 Interazione RPC.
Notification: Questo paradigma consente l‟invocazione remota di metodi in
modalità asincrona. Per consentire ciò si è divisa l‟invocazione sincrona in due
comunicazioni distinte asincrone. Nella prima comunicazione il client invia al
server gli argomenti dell‟invocazione ed un riferimento di call - back necessario al
client per gestire il valore di ritorno. La seconda comunicazione inviata dal server

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
24
verso il client per restituire il valore di ritorno. Visto che la comunicazione avviene
in modo diretto tra client e server si ha il fenomeno dell‟accoppiamento spaziale
[3].
Figura 1.8 Interazione Notification.
Shared Spaces: Il paradigma distributed shared memory DSM prevede che più host
in un sistema distribuito vedano un‟area di memoria condivisa, distaccata dal loro
spazio di indirizzamento locale. La comunicazione tra host viene effettuata tramite
l‟inserimento e rimozione di tuple dal tuple space. Questo modello d‟interazione
consente il disaccoppiamento spaziale e temporale, in quanto gli host consumatori
e produttori possono non conoscersi reciprocamente[3].
Figura 1.9 Interazione Shared spaces.
Message Queuing: Il Message queuing è una recente alternativa per le interazioni
distribuite; questo paradigma di comunicazione è fortemente legato al paradigma

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
25
publish/subscribe, perchè usualmente ne utilizza alcune forme. A livello di
interazione la coda di messaggi assomiglia molto al tuple space; in quanto la coda
può essere vista come uno spazio globale in cui sono memorizzati i messaggi dal
produttore. Dal punto di vista funzionale il sistema a code di messaggi garantisce le
proprietà transazionali e di ordinamento. Produttore e consumatore sono
disaccoppiati temporalmente e spazialmente, e si ha sincronizzazione nella fase di
prelevamento dei messaggi. Sono stati sviluppati sistemi che supportano una
consegna asincrona dei messaggi, ma tali sistemi non supportano un gran numero
di consumatori [3].
Figura 1.10 Interazione Message queue.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
26
Capitolo 2 - Le principali architetture Publish/Subscribe
2.1 Middleware Publish/Subscribe DDS
L‟OMG (Object Management Service) ha redatto uno standard per la comunicazione
publish/subscribe che contenga un forte supporto alla qualità del servizio. Tale standard
prende il nome di Data Distribution Service for Real Time System (DDS). Lo standard
OMG non prevede specifiche riguardanti l‟integrazione tra i diversi prodotti software,
quindi non è possibile attualmente avere interoperabilità tra le varie implementazioni del
DDS. Per sopperire a tale mancanza si sta lavorando per redigere uno standard di
interoperabilità tra diverse implementazioni. L‟obbiettivo del DDS è di agevolare la
distribuzione efficiente dei dati in sistemi distribuiti, ed ha come oggetto i sistemi real-
time; per tale motivo è stata sviluppata un‟architettura completamente decentralizzata e
sono state previste un ricco insieme di qualità del servizio che consentono di bilanciare
l‟efficienza e le prestazioni del software. La specifica del DDS è basata sull‟astrazione di
un Global Data Space GDS, in cui i publisher producono dati ed i subscriber consumano
dati, tale spazio può essere caratterizzato dal concetto di topic, Publisher, Subscriber,
Subscription e Quality of Service;
Quality of Service: con le QoS si indica un concetto generale, utilizzato per
specificare il comportamento del servizio fornito. Con le QoS il protocollo spiega
“cosa” ci si può attendere da una applicazione e non il “come” si ottiene [2] [3].
Topic: definisce un tipo di dato che può essere scritto nel GDS. Il DDS fornisce
anche la capacità di distinguere topic di uno stesso tipo tramite l‟uso di semplici
chiavi. Ad ogni topic si possono associare specifiche qualità del servizio (QoS). Da
un punto di vista applicativo i topic sono utilizzati per definire l‟Application
Information Model, cioè il tipo di informazioni scambiate nel modello. Il DDS
fornisce inoltre le capacità per eseguire semplici aggregazioni di topic, ed il content-
based filtering [2] [3];

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
27
Publisher: definisce una sorgente dati, può dichiarare l‟interesse di generare dati con
determinate caratteristiche di qualità del servizio associate e scrivere il dato nel GDS.
Le qualità definite devono essere compatibili con quelle dichiarate dal topic di
interesse [2] [3]
Subscriber: leggono topic in GDS, per i quali esiste una sottoscrizione correlata. Il
DDS conta su uno specifico DataReade che serve come tipo letto dal GDS. Il
Subscriber incapsula la responsabilità associate alla ricezione dei dati in accordo alle
QoS richieste [2] [3].
Subscription: operazione logica che consente di legare insieme un subscriber ai
publish interessati. La sottoscrizione deve soddisfare due tipi di condizioni. Un tipo
di condizioni sono relative alle caratteristiche concrete del topic, come tipo, nome del
contenuto. L‟altro insieme di condizioni sono relative alle QoS. Per le QoS si segue
un modello di richiesta/offerta, nel quale le QoS richieste devono essere le stesse o
più deboli di quelle offerte [2] [3].
Una caratteristica chiave alla base del DDS è il servizio di discovery. Tale servizio ha il
compito di scoprire e comunicare le proprietà dei partecipanti al GDS. Infatti le
informazioni necessarie per stabilire una sottoscrizione sono completamente distribuite e
vengono scoperte automaticamente.
2.2 Qualità del servizio nei Middleware DDS
Il DDS implementa un insieme molto ricco di Quality Of Service.
Risorse: queste QoS consentono di controllare le risorse usate nella disseminazione
dati, le più rilevanti politiche che consentono di controllare le risorse di calcolo e le
risorse di rete sono la RESOURCE LIMITY e la TIME BASED FILTERED. La
RESOURCE LIMITY permette di controllare la quantità di messaggi memorizzati
in una implementazione del DDS. La TIME BASED FILTERED permette alle
applicazioni di specificare l‟intervallo temporale minimo tra due messaggi di dato; i
messaggi prodotti ad una velocità maggiore non sono consegnati [2] [3].

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
28
Data Timeliness: il DDS prevede un insieme di politiche che consentono di
controllare la proprietà di timeliness della distribuzione dati. Le QoS supportate sono
DEADLINE e LATENCY BUDGET. La DEADLINE permette ad una applicazione
di definire il massimo intervallo di tempo tra i dati; se trascorre tale intervallo senza
l‟arrivo di un messaggio viene effettuata una notifica tramite LISTENER. Il
LATENCY BUDGET consente ad una applicazione di fornire al middleware il
livello d‟urgenza associato ad un dato comunicato, specifica il massimo ammontare
di tempo che dovrebbe trascorrere dall‟istante in cui il dato è scritto, all‟istante in cui
viene posto nella coda di ricezione del ricevente [2] [3].
Data Availability: per controllare la data availability posso usare le politiche di,
LIFESPAN e HISTORY. La DURABILITY fornisce un controllo sul tempo di vita
di un dato scritto nel GDS. Questa caratteristica consente al dato di essere volatile e
dall‟altro permette al dato di avere persistenza. E utile notare che dati transienti e
persistenti consentono di fare Time Decoupling tra lo scrittore ed il lettore; rendendo
il dato disponibile per i successivi lettori inscritti, nel caso di dati transienti oppure
dopo che lo scrittore ha lasciato il GDS, nel caso di dati persistenti. Il LIFESPAN
permette di controllare l‟intervallo di tempo nel quale il dato è considerato valido, il
valore di default è infinito. La HISTORY fornisce un modo per controllare il
numero di dati, cioè la sottosequenza scritta nello stesso topic e tenuta disponibile
per il lettore; i possibili valori attribuibili sono gli ultimi, gli ultimi N oppure tutti i
samples [2] [3].
Data Delivery: permette di controllare come il dato è consegnato, ed a chi è
consentito scrivere su uno specifico topic. Le politiche che si possono usare sono la
RELIABILITY, DESTINATION ORDER e OWNERSHIP. La RELIABILITY
permette di controllare il livello di reliability associato alla diffusione dati, le
possibili scelte sono reliable e best-effort. La DESTINATION ORDER consente di
definire l‟ordine dei cambiamenti eseguiti dal publisher sulla stessa istanza di un dato
topic. Il DDS consente di ordinare i vari cambiamenti in accordo ai time-stamp della

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
29
sorgente o della destinazione. La politica di OWNERSHIP consente di controllare il
numero di scrittori permessi per un dato topic. Se configurato come esclusivo si
indica che il topic può essere posseduto e quindi scritto da un singolo scrittore. E'
possibile inoltre associare una nuova politica, detta OWNER-SHIP STRENGTH
che consente di associare un valore numerico di forza ad ogni scrittore, in questo
caso il topic è posseduto da colui che ha un valore di owneship strength più alto. Un
valore di OWNERSHIP STRENGTH è shared, con questo valore si possono avere
più scrittori che sovrascrivono un topic. I vari cambiamenti devono essere ordinati in
accordo al valore settato nella politica di DESTINATION ORDER [2] [3].
Oltre alle politiche appena definite il DDS fornisce alcuni modi per definire e distribuire
informazioni di bootstrapping, tramite il significato di USER DATA, TOPIC DATA e
GROUP DATA.
La USER DATA permette all‟applicazione di associare informazioni aggiuntive
all‟oggetto entità creato, tale informazione può essere utilizzata dalle applicazioni remote
per uno scopo apposito, ad esempio attribuire credenziali di sicurezza.
Il TOPIC DATA consente di aggiungere informazioni aggiuntive ad un topic creato, tale
informazione può essere prelevata da applicazioni remote.
Il GROUP DATA associa informazioni aggiuntive al Publisher e Subscriber creati, tale
valore è disponibile alle applicazioni nelle entità DataReader e DataWriter, tale valore
viene propagato tramite il topic creato.
Un‟altra politica di QoS prevista è la LIVELINESS, la quale consente di settare i
parametri utilizzati nella determinazione di entità considerate “vive”. Questa politica ha
molti settaggi per consentire una modellazione più consona per le possibili situazioni. Il
settaggio AUTOMATIC consente di determinare i fallimenti al livello di processo ma non
determina i fallimenti a livello logico di processo, questa modalità richiede poco
overheard. Il settagio MANUAL consente di determinare fallimenti logici, richiede
l‟esecuzione dell‟operazione di ASSERT-LIVENESS.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
30
La politica di PARTITION consente l‟introduzione di una partizione logica nella
partizione fisica indotta dal dominio, questa partizione non crea un vero isolamento tra i
partecipanti come un dominio. Questa policy può` essere modificata, ciò causa una
modifica delle relazioni esistenti tra i DataReader ed i DataWriter del dominio, creando
nuove relazioni o rompendo relazioni esistenti [2] [3].
2.3 Architettura dei Middleware DDS
La specifica del DDS definisce due livelli di interfacce, il DCPS (Data Centric Publish-
Subscribe) ed il DLRL (Data Local Reconstruct Layer).
DCPS: Prevede le funzionalità richieste per pubblicare e ricevere data-object, in
modo efficiente;
DLRL: Livello opzionale che permette una semplice integrazione di servizi al livello
applicativo;
Le funzionalità del DCPS sono:
Identificazione dei dati che un publisher intende pubblicare e tipi di valori previsti
per tali dati;
Identificazione dei dati di interesse per un subscriber e come accedere a tali dati;
Applicazioni per definire topic, per associare vari tipi di dato al topic, per creare
publisher e subscriber e per associare caratteristiche di QoS a tali entità.
Per descrivere un DCPS si usano due specifiche, il PIM Platform Independent Model ed il
PSM Platform Specific Model per le piattaforme basate su PIM.
Nel DCPS la comunicazione è effettuata con l‟aiuto delle seguenti entità:
DomainParticipant, DataWriter, DataReader, Publisher, Subscriber e Topic. Lo
schema concettuale del DCPS viene rappresentato nella seguente figura 2.1, nel quale
viene rappresentato il flusso dell‟informazione tra le varie entità [2] [3].

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
31
Figura 2.1 Schema concettuale del DCPS
Il Publisher ed il DataWriter risiedono nel mittente, mentre Subscriber e Data Reader
risiedono nel ricevente. Un Publisher è responsabile della distribuzione dei dati, egli può
pubblicare dati di diverso tipo. Un DataWriter è l‟oggetto dell‟applicazione usato dal
publisher per comunicare l‟esistenza di una nuova istanza di dato per uno specifico tipo di
dato, ed è associato ad un singolo tipo di dato [2] [3].
Un Subscriber è l‟oggetto responsabile della ricezione di dati pubblicati, e della fornitura
di tale dato alle applicazioni interessate, si possono ricevere vari tipi di dati, rispettando le
QoS richieste. Per accedere ai dati ricevuti l‟applicazione usa il modulo DataReader
collegato alla sottoscrizione del dato, con tale modulo si esprime l‟interesse
dell‟applicazione nei confronti dei dati relativi al DataReader [2] [3].
Il Topic è un oggetto concettuale che si interpone tra le pubblicazioni (oggetti
DataWriter) e le sottoscrizioni (oggetti DataReader), con l‟obbiettivo di creare
un‟associazione tra un nome (unico nel sistema), un tipo di dato e le QoS associate al dato
stesso. La definizione del tipo di dato deve fornire le informazioni necessarie per il servizio
di gestione dei dati, come serializzazione e deserializzazione del dato in uno adatto alla
trasmissione. La definizione può essere fatta per mezzo di un linguaggio testuale oppure

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
32
per mezzo di un “plugin” operazionale che fornisce i metodi necessari [2] [3]. Il DCPS può
anche supportare sottoscrizioni CONTENT-BASED con l‟uso di un filtro, questa è una
caratteristica opzionale, in quanto il filtro può essere computazionalmente intensivo e
quindi introdurre un ritardo difficile da predire; comunque recenti ricerche hanno
dimostrato che esistono efficienti algoritmi per affrontare questo problema [2] [3].
2.4 Real Time Innovations Data Distribution Service RTI - DDS
RTI Data Distribution Service è un Network Middleware per applicazioni real-time
distribuite. Fornisce i servizi che sono necessari per sviluppare applicazioni time-critical
distribuite che diffondono dati, fra i vari dispositivi che li richiedono, con il minimo ritardo
possibile. RTI DDS utilizza il modello Publish/Subscribe per la comunicazione,
implementa le DCPS API fornite dall‟OMG nella specifica DDS per le applicazioni Real-
time [29]. RTI Data Distribution Service è indipendente dal sistema operativo e dal
linguaggio di programmazione permettendo a sistemi eterogenei di comunicare tra loro in
maniera piuttosto semplice, come si può vedere dalla seguente figura 2.2 [30]:
Figura 2.2 Architettura di un‟applicazione sviluppata su RTI DDS.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
33
Le applicazioni saranno completamente separate, useranno dal lato mittente oggetti di tipo
Publisher e DataWriter, in ricezione invece saranno di tipo Subscriber e Data-Reader. Ogni
partecipante alla comunicazione può agire nel ruolo di Publisher o Subscriber o entrambi.
Il singolo partecipante alla comunicazione è un oggetto di tipo DomainParticipant ovvero
proprio un partecipante del dominio. I domini servono per discriminare le diverse
applicazioni che si avvalgono di RTI DDS in modo che non interferiscano l‟un l‟altra. Per
cui un Domain rappresenta una rete di comunicazione logica ed isolata che fa in modo che
entità di domini diversi (anche se presenti sulla stessa macchina) non si scambino mai dati.
La piattaforma automaticamente gestisce tutti gli aspetti della consegna dei messaggi,
senza richiedere nessun intervento da parte dell‟applicazione dati, includendo: la
determinazione di chi dovrà ricevere i dati; dove sono ubicati i recipienti; cosa accade se il
messaggio non è consegnato. Tutto questo avviene in accordo ai parametri di QoS settati
nell‟applicazione e forniti dalla piattaforma all‟utente per configurare il meccanismo di
discovery automatico ed il comportamento quando si ricevono o inviano dati. Inoltre RTI
DDS include le seguenti caratteristiche che sono progettate per soddisfare la necessità di
distribuire le applicazioni real-time [29]:
Data-centric publish-subscribe communications: Semplifica la programmazione di
applicazioni distribuite e fornisce un flusso di dati time-critical con latenza
minima;
User-definable data types: Consente la modellazione dell‟informazione inviata;
Reliable Messagging: Consente all‟applicazione subscriber di specificare la consegna
reliable dei messaggi;
Multiple comunication networks: Più domini indipendenti possono essere usati sulla
stessa rete fisica. Le applicazioni sono in grado di partecipare solo nei domini a
cui appartengono. Un applicazione può essere configurata per partecipare in più
domini;

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
34
Symmetric architecture: Rende le applicazioni robuste in quanto non sono presenti
server centrali o nodi privilegiati, i sottoscrittori e i pubblicatori possono essere
aggiunti e rimossi dinamicamente;
Pluggable transports framwework: Include l‟abilità di definire nuovi “plug-in” per il
trasporto su UDP/IP e “shared memory”;
L'architettura del sistema è incentrato sulla RTI DDS Database, così come si può vedere
dalla figura 2.3 che contiene tutti i dati relativi ai gruppi di publisher e dei subscriber.
Questo database è accessibile al RTI DDS Library e ad una serie di RTI DDS Tasks. Il
componente prima fornisce un insieme completo di servizi per le applicazioni utente, in
forma di Application Programming Interface. I compiti RTI DDS Tasks sono quelli di
gestire abbonamenti e servizi, e di inviare e ricevere aggiornamenti di pubblicazione. Il
RTI DDS database è condiviso tra tutti i nodi della rete, fornendo loro una visione olistica
della comunicazione [2]. La conoscenza globale può essere utilizzata per calcolare l'attuale
carico del sistema. Queste informazioni vengono poi rese disponibili alle applicazioni.
Ognuna delle quali ha l'obbligo di stabilire e mantenere le comunicazioni. Lo stato viene
mantenuto in qualsiasi parte del sistema, e decade nel corso del tempo. Nessuna parte del
sistema si basa sull'handshaking tra i nodi. Ogni posizione ha anche la memoria sufficiente
per mantenere una cache locale di publications e di subscriptions. Per supportare i requisiti
di decadimento dello stato, i messaggi di aggiornamento extra vengono inviati per
mantenere le informazioni memorizzate nella cache corrente. Questo design rende la
domanda globale distribuita più robusta, disaccoppiando gli errori di nodo, e rende
semplice la sistemazione dei singoli fallimenti di un nodo. Non vi è alcun altro
meccanismo per sostenere la tempestività del traffico al di fuori del controllo di
ammissione del carico corrente di comunicazione. Tuttavia, in termini di fault-tolerance,
RTI DDS prevede altri meccanismi per sostenere la ridondanza dei publisher. Così, ogni
gruppo può avere più subscribers e molti publishers replicano la stessa entità, producendo
tutto in parallelo. Ogni pubblicazione ha due ulteriori parametri associati: la robustezza e la
persistenza. La robustezza definisce il peso relativo di un publisher per quanto riguarda

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
35
altri publisher dello stesso ente. La persistenza specifica la validità temporale della
pubblicazione. Subscribers considerano una pubblicazione solo se la sua robustezza è
maggiore o uguale alla robustezza di uno degli ultimi che hanno ricevuto da tale soggetto.
Nel caso in cui la finestra temporale della persistenza scade, la prima pubblicazione di tale
entità, dopo quel momento è sempre accettato, indipendentemente dalla sua robustezza.
Questi meccanismi sono integrati con un numero progressivo assegnato ad ogni
pubblicazione e permetteranno di individuare le istanze mancanti. I Publishers
manterranno le loro pubblicazioni in un buffer per un periodo determinato. Durante tale
periodo, i subscribers che perdono una pubblicazione possno chiedere la ritrasmissione [2].
Figura 2.3Architettura RTI DDS
2.4.1 QoS supportate
RTI DDS implementa lo standard della OMG, in ogni caso sussistono delle scelte
architetturali che apportano delle estensioni alla specifica, nonché l‟esistenza di QoS non
supportate. Di seguito sono riportate le QoS di maggior interesse, sono riportate come
previste dallo standard DDS e se implementate o meno da RTI DDS [29].

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
36
QoS Policy Valore Specifica DDS RTI
DURABILITY Un tipo:
VOLATILE,
TRANSIENT-
LOCAL,
TRANSIENT,
PERSISTENT
Indica se i dati debbano essere
disponibili anche dopo che
sono stati inviati al Data-
Writer per permettere che dei
DataReader che si uniscono in
ritardo alla comunicazione li
ricevano
Implementa
VOLATILE e
TRANSIENT-
LOCAL
DEADLINE Una durata
Temporale
Un DataReader si aspetta di
ricevere dati almeno con
periodo di
deadline. Nel Data-
Writer invece, indica
che l‟applicazione
mira a inviare dati almeno con
periodo di deadline
Implementato
OWNERSHIP Un tipo: SHARED,
EXCLUSIVE
Specifica se sia permesso che
più Data-Writer possano
scrivere la stessa istanza di
dato e in caso come ciò debba
essere arbitrato
Implementato
RELIABILITY Un tipo: BEST
EFFORT,
RELIABLE ed una
durata di max
blocking - time
Indica il livello di affidabilità
richiesta/offerta dal servizio ed
il tempo massimo che il
DataWriter può rimanere
bloccato se non ha più spazio
perulteriori campioni
Implementato
LIFESPAN Una durata
temporale
Specifica la massima durata di
validità di un dato scritto dal
Data-Writer
Implementato
HISTORY Un tipo:
KEEP_LAST,
KEEP_ALL, ed un
numero intero di
depth
Questa QoS specifica i
campioni che debbano essere
mantenuti in memoria, nel
caso KEEP_LAST solo gli
ultimi depth campioni saranno
mantenuti.
Implementato
RESOURCE-
LIMITS
Tre numeri interi:
max_samples,
max_instance,
max_samples_pre_
instance
Specifica le risorse che il
servizio può consumare per
offrire le QoS desiderate
Implementato
Tabella 2.1 QoS Policy
Ci sono alcune QoS che non sono implementate nella specifica, bensì estese da RTI DDS:

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
37
TRANSPORT UNICAST - Specifica le interfacce unicast transport network da usare per
la ricezione dei messaggi da parte dell‟entità;
DISCOVERY - Specifica gli attributi necessari a trovare i partecipanti nel dominio;
WIRE PROTOCOL - Specifica gli attributi del wire protocol per il DDS Domain
Participant ;
DATA READER RESOURCE LIMITS - Specifica l‟ammontare delle risorse specifiche
che RTI Data Distribution Service può usare per il DataReader ;
DATA WRITER RESOURCE LIMITS - Specifica l‟ammontare delle risorse specifiche
che RTI Data Distribution Service può usare per il DataWriter ;
DATA READER PROTOCOL - Configura i parametri di QoS specifici del DataReader ;
DATA WRITER PROTOCOL - Configura i parametri di QoS specifici del DataWriter ;
ASYNCHRONOUS PUBLISHER - Specifica la configurazione del Publishing asincrono
per le istanze di DDSPublisher.
2.4.2Discovery
Il modello DCPS fornisce una comunicazione molti-a-molti, trasparente e anonima. Ogni
volta che l‟applicazione invia dei dati in un Topic il middleware li replica a tutti i
Subscriber che hanno sottoscritto quel Topic. L‟applicazione nel lato Publisher non deve
curarsi di quanti siano i subscriber e tanto meno dove siano; lo stesso discorso vale per il
lato Subscriber. Per ottenere ciò, su ogni nodo, RTI DDS deve mantenere una lista di
applicazioni interessate al Topic ed alcune informazioni sulla QoS per l‟invio dei dati. La
propagazione di queste informazioni fra i vari partecipanti interessati è chiamata
Discovery process. La specifica DDS (DCPS) non specifica come tale processo debba
avvenire e RTI DDS lo implementa tramite un protocollo di RTPS (Real Time Publish
Subscribe) opportuno: Quando un DomainParticipant viene creato, il middleware lancia
dei pacchetti sulla rete per annunciarne l‟esistenza. Quando un‟applicazione trova che
un‟altra applicazione appartiene allo stesso dominio (Domain) scambieà` con essa
informazioni sullo stato di pubblicazioni e sottoscrizioni e relative QoS. Quando nuovi

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
38
DataWriter e DataReader sono creati, tale informazione sarà notificata a tutta la lista di
applicazioni conosciute. Una veloce descrizione di come funzioni è la seguente: quando
un DomainParticipant viene avviato, per default invia tre messaggi ad ogni nodo nella sua
PEER LIST. Il numero di tali messaggi può essere configurato nella QoS del
DomainParticipant nel campo
discovery_config.new_remote_participant_announcements. Questi messaggi
vengono inviati ad intervalli casuali tra zero ed un secondo per default. Anche questo
tempo è configurabile nella QoS del DomainParticipant nel campo
discovery_config.new_remote_participant_announcement_period. Esso serve ad
inviare messaggi a ritardi casuali compresi tra zero ed il valore impostato, in modo da
evitare il flooding (inondazione) del nuovo DomainParticipant remoto con tanti messaggi
di discovery assieme. Se tutti i messaggi vengono persi, il DomainParticipant attenderà 30
secondi, e tale valore viene preso anche come periodo di liveliness, configurabile nel
campo discovery_config.participant_liveliness_assert_period [29] [30].
2.5 OpenSplice
PrismTech's OpenSplice DDS, è una seconda generazione, completamente compatibile
con l'implementazione OMG DDS, offre supporto per tutti i profili DCPS, nonché il
Profilo DLRL-object. Lo scopo di OpenSplice DDS è quello di fornire una infrastruttura e
un middleware layer in tempo reale per sistemi distribuiti. Questa è una realizzazione
delle specifiche OMG-DDS-DCPS per un Data Distribution Service basata su una
architettura Data Centric Publish/Subscribe. OpenSplice DDS fornisce un'infrastruttura
per la distribuzione dei dati real-time ed offre servizi middleware alle applicazioni [31].
Per garantire la scalabilità, la flessibilità e l'estensibilità, OpenSplice DDS ha una
architettura interna che utilizza una memoria condivisa di interconnessione, non solo tutte
le applicazioni che risiedono all'interno di un nodo di elaborazione, ma anche un nodo
configurabile ed estensibile di insieme di servizi. Questi servizi costituiscono “la
funzionalità pluggable” come la messa in rete (QoS driven real-time networking è basato

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
39
su più canali multicast affidabile), la durata (fault tolerant storage sono forniti sia ai dati di
stato real-time che alle impostazioni), e il controllo remoto e monitoraggio del servizio
(viene fornito con un accesso remoto basato sul web utilizzando il protocollo SOAP dal
OpenSplice DDS Tuner tools) [31].
2.5.1 Architettura OpenSplice
OpenSplice DDS utilizza una architettura a memoria condivisa, in cui i dati sono
fisicamente presenti solo una volta su qualsiasi macchina, e in cui l'amministrazione Smart
fornisce ancora ad ogni abbonato la propria visione privata su questi dati. Ciò consente agli
abbonati ai dati di percepire quest'ultimi come contenuti in un singolo database, questo
database può essere filtrati, interrogato, ecc (utilizzando il profilo di abbonamento, come
sostenuto da OpenSplice DDS). I risultati di tale architettura di memoria garantisce
eccellente scalabilità e prestazioni ottimali rispetto alle implementazioni in cui ogni
publisher/subscriber comunica ciascuno con la propria storage [31].
Il middleware OpenSplice DDS può essere configurato “on the fly”, ovvero specificando
solo i servizi realmente utilizzati, nonché la configurazione di tali servizi per un ottimale
abbinamento con il dominio di applicazione (i parametri di rete, la durata livelli, ecc.).
OpenSplice DDS è facilmente manutenibile attraverso file XML, attraverso questi si
possono configurare tutti i servizi. La configurazione di OpenSplice è anche supportata
attraverso la MDA strumento che permette di modellare il sistema / rete e la generazione
automatica della opportuno file XML di configurazione [2].

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
40
Figura 2.4 Architettura OpenSplice DDS
Come si può vedere dalla figura 2.4, ogni applicazione collegherà le librerie OpenSplice al
fine di utilizzare le caratteristiche DDS e di comunicare con i servizi inseribili tramite la
memoria comune condivisa.
Il file di configurazione XML definisce e configura i seguenti servizi:
il default service - chiamato anche il domain service, è responsabile per l'avvio e il
monitoraggio tutti gli altri servizi
il durability service - è responsabile per la memorizzazione dei dati non volatili e
mantenerli coerenti all'interno del dominio
il networking service - realizza una comunicazione tra gli user configurati ed i nodi
di un dominio
il tuner service - fornisce una interfaccia SOAP per il sintonizzatore OpenSplice per
connettersi al nodo remoto da qualsiasi altro nodo raggiungibile
La dimensione del database predefinito che viene mappato su un segmento di memoria
condivisa è limitato e la dimensione massima può essere di 10 Megabyte, quindi deve

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
41
essere regolato. La configurazione tramite un file XML esterno è un modo comoda per
eseguire le operazioni di configurazione per i servizi, poiché questo consente all'utente di
modificare facilmente i parametri che influenzano il comportamento del sistema [2].
Domain Service: è responsabile per la creazione e l'inizializzazione di
un'amministrazione condivisa dei nodi nella memoria condivisa, per un dominio
DDS specifico su un nodo di elaborazione. Senza questa amministrazione, nessun
altro servizio o applicazione è in grado di partecipare a un Domain Service [2] [31].
Durability Service: I dati prodotti dalle applicazioni devono rimanere a disposizione
del DataReader fino alla fine della loro adesione. La durabilità dei dati può essere
transitoria o permanente ed è determinata dalla qualità del servizio. Se uno
specifico argomento è stato contrassegnato per essere transitoria, le istanze
corrispondenti ai dati rimangono disponibili nel sistema durante l'intero ciclo di vita
del sistema. Se uno specifico argomento è stato contrassegnato per essere
persistente, le istanze corrispondenti ai dati addirittura sopravvivono dopo l'arresto
del sistema, perché sono scritti in una memoria permanente. Il Durability Service è
il responsabile per la realizzazione di queste proprietà dei dati nel sistema[2] [31].
Networking Service: Quando i terminali di comunicazione sono situati in nodi di
calcolo differenti, i dati ottenuti utilizzando il DDS service locale devono essere
comunicati al DDS service remoto e viceversa. Il Networking Service fornisce un
ponte tra il DDS service locali e di una interfaccia di rete. Networking Service
multiple possono esistere l'uno accanto all'altro, ciascuno al servizio di una o più
interfacce di rete fisica. Il Networking Service è responsabile della trasmissione di
dati alla rete e per la ricezione di dati dalla rete. Può essere configurato in modo da
distinguere i canali di comunicazione multipli con diverse politiche di QoS
assegnate ed essere in grado di pianificare l'invio e la ricezione di messaggi
specifici per fornire prestazioni ottimali per un dominio specifico di applicazione. I
Networking Service possono utilizzare canali separati, ognuno con il proprio nome
e propri parametri; questi canali possono essere affidabili o non affidabili. Il

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
42
Networking Service sceglie il canale più appropriato per ogni DataWriter, ovvero il
canale che garantisce la sua QoS e le impostazioni migliori [2] [31].
Tuner Service: Il Tuner Service fornisce un'interfaccia remota per il monitoraggio e il
controllo delle strutture OpenSplice mediante il protocollo SOAP. Ciò consente al
sintonizzatore OpenSplice in remoto, da qualsiasi luogo raggiungibile, di
monitorare e di controllare i servizi OpenSplice così come le applicazioni che
OpenSplice utilizza per la distribuzione dei loro dati [2] [31].
2.5.2 QoS supportate
La QoS fornisce un meccanismo generico alle applicazione per controllare il
comportamento di un'entità: ogni politica di controllo è rappresentata da un tipo strutturato
contenente gli attributi per tutti i parametri rilevanti. Il modo con cui comunica OpenSplice
DDS è definito dai campi chiave del rispettivo tipo di dato e la Quality of Service (QoS),
del loro topic corrispondente. Ogni topic deve essere creato prima che possa essere
distribuito specificando il tipo di dati e la politica di QoS da associare. Le politiche di QoS
che devono essere associate ad un topic specifico descrivono i diversi aspetti della gestione
dei dati per tale specifico topic [31].
Le politiche di QoS che più importanti sono:
DURABILITY - OpenSplice DDS supporta quattro tipi di durability. La durability
definisce la durata di vita dei dati, classificati in VOLATILE,
TRANSIENT_LOCAL, TRANSIENT e PERSISTENT data. OpenSplice non
realizza alcun copia di backup per i dati volatili. Quando i dati volatili vengono
consegnati, non viene data alcuna garanzia che questi dati si possano ottenere di
nuovo. I dati transient sono registrati da OpenSplice per i lettori che li hanno
sottoscritti, ma per un tempo limitato, ovvero finché l'infrastruttura OpenSplice è
attiva, una copia di tutti i dati transitori sarà conservata e riprodotta. I dati persistent
sopravvive alla durata di vita dell'infrastruttura OpenSplice perché tali dati vengono
salvati su un numero differente di dischi ridondanti a seconda della configurazione.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
43
Quindi una copia dei dati persistenti è sempre disponibile, anche quando
l'infrastruttura OpenSplice viene riavviata. In genere, i dati di configurazione di
sistema sono persistenti, mentre quelli aggiornati di frequente non la saranno perchè i
benefici che si otterranno non saranno superiori all'overhead [31].
RELIABILITY - in OpenSplice possono essere utilizzati due tipi di affidabilità che
sono consegna BEST_EFFORT e consegna AFFIDABILE. I topic che vengono
contrassegnati per una consegna affidabile al fine di garantire il successo della
trasmissione dei messaggi viene garantita una ri-trasmissione automatica dei
campioni persi. I topic che sono contrassegnati per una consegna best effort non
hanno maggiori garanzie di giungere al destinatario rispetto a quello che viene già
implementato dalla rete sottostante: quando un topic si perde sulla sua strada rimane
inosservato [31].
2.6 CORBA
La Common Object Request Broker Architecture (CORBA) è stata definita nel 1991
dall‟OMG (Object Management Group) un consorzio consacrato ad aumentare il grado di
interoperabilità per applicazioni distribuite in ambiente eterogeneo attraverso la tecnologia
orientata agli oggetti (OO). Di fatto è stato preso uno dei principi chiave della
programmazione orientata agli oggetti, l‟incapsulamento, applicandolo all‟abbattimento
delle differenze tra i prodotti usati nell‟infrastruttura hardware, software, di
programmazione e di rete di un sistema distribuito. Pensiamo a due applicazioni
preesistenti che gestiscono due applicazioni non create per cooperare tra loro. Se queste
applicazioni vengono opportunamente incapsulate all‟interno di due oggetti omogenei, è
possibile creare una sinergia dapprima impossibile (una applicazione potrebbe richiedere
delle funzionalità all‟altra attraverso una invocazione di metodo). Tuttavia se le due
applicazioni risiedono su due macchine distinte abbiamo bisogno di un mezzo che metta in
comunicazione i due oggetti ovvero li localizzi e successivamente ne gestisca lo scambio
dati. Prima di entrare in dettaglio nella descrizione della architettura CORBA, mostriamo

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
44
nella figura 2.5 l‟architettura OMA (Object Management Architecture) che rappresenta la
struttura logica su cui le specifiche successive definite dall‟OMG si basano [34] [35].
Figura 2.5 Architettura OMA (Object Management Architecture)
Questa architettura ha quattro componenti: ORB, CORBAservices e CORBAfacilities e
Application Objects. Le CORBAfacilities sono un insieme di servizi che possono essere
condivisi da molte applicazioni ma che non sono vitali come i CORBA services.
L‟Application Object corrisponde alla nozione classica di applicazione prodotta da una
particolare organizzazione. Di conseguenza non è standardizzato da OMG.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
45
Ultimata l‟architettura OMA, OMG ha iniziato un lavoro per la specifica dei macroblocchi
di Figura 2.6. I contributi più importanti emersi dal lavoro dell‟OMG sono stati [34] [35]:
Figura 2.6 Macroblocchi dell'architettura OMA
L‟OMG Interface Definition Language (IDL) utilizzato per circoscrivere all‟interno
di un oggetto le differenze legate al linguaggio di programmazione [32] [33].
L‟Object Request Broker (ORB) utilizzato per nascondere la locazione fisica a due
oggetti interagenti, consentendo pertanto una serie di operazioni (invocazione di
metodo, attivazione ecc.) a prescindere dalla locazione degli oggetti all‟interno
dell‟ORB. Questa funzionalità viene realizzata attraverso una serie di interfacce al
di sopra di un core ORB come l‟Object Adaper, la Dynamic Invocation Interface
(DII), l‟Implementation Repository e l‟Interface Repository (vedi Figura 1.11). La
specifica del componente ORB dell‟OMA è CORBA (Common Object Request
Broker Architecture)[32] [33].
General Inter-ORB protocol (GIOP) utilizzato per nascondere la locazione fisica a
due oggetti interagenti che risiedono in due ORB distinti [32] [33].
I CORBA Object Service (COS) supportano funzioni base per usare ed
implementare oggetti per eseguire delle operazioni sul sistema. Questi servizi sono
forniti di interfaccia specificata dall‟IDL. Attualmente ci sono sedici servizi

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
46
standard tra cui: Naming service, Transaction Service, Concurrency control service,
security e time ecc [32] [33].
Nella figura 2.7 è illustrata la posizione di CORBA rispetto alla pila OSI:
Figura 2.7 Pila ISO-OSI
2.6.1 I servizi CORBA
I servizi CORBA aggiungono funzionalità all‟ORB. Le operazioni messe a disposizione
dal servizio CORBA sono definite da una interfaccia IDL. Tale interfaccia è stata
standardizzata dall‟OMG. Attualmente i servizi standard sono divisi in tre categorie servizi
legati ai sistemi distribuiti, alle applicazioni e di tipo generale [35].
Servizi legati ai sistemi distribuiti:
Naming service. Permette ad un client di trovare un oggetto attraverso il suo nome
e ad un server di registrare i suoi oggetti dandogli un nome. La struttura dei nomi in
CORBA è di tipo gerarchico simile alla struttura del file system di UNIX.
Trading Service. Il trading service è un servizio di locazione di oggetti. Nel
Trading Service si fanno delle richieste per avere una lista di oggetti che soddisfano
certe caratteristiche o proprietà. Il Trading Service contiene dei record chiamati

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
47
offer, formati da un campo tipo di servizio, insieme di proprietà del servizio e
riferimento all‟oggetto.
Event Service. Aggiunge a CORBA la possibilità di utilizzare un paradigma
asincrono simile al publish/subscribe per le comunicazioni tra gli oggetti.
Notification Service. Estensione dell‟Event Service, più flessibile e affidabile. In
particolare il Notification Service definisce un modello dati per i messaggi,
permette di effettuare delle sottoscrizioni basate su query e quindi di filtrare i
messaggi su un canale e aggiunge il supporto per la qualità del servizio nella
trasmissione delle notifiche.
Servizi di tipo generale:
Licensing Service. Questo servizio controlla i diritti di utilizzo di un client di un
determinato servizio CORBA, servizio applicativo o della piattaforma stessa.
Life Cycle Service (LFS). L‟interfaccia di LFS include una serie di operazioni per
copiare, muovere, creare e distruggere un oggetto all‟interno dell‟ORB. Il
componente centrale di un LFS è l‟object factory ovvero un oggetto capace di
creare altri oggetti. Un client che fa una richiesta di creazione di un oggetto avrà
restituito un riferimento all‟oggetto creato.
Servizi legati alle applicazioni:
Transaction Service (OTS). Se un client deve eseguire modifiche su una serie di
oggetti distinti e queste modifiche hanno la caratteristica di atomicità siamo in
presenza di una transazione. Quindi CORBA deve mettere a disposizione un
servizio per la gestione delle transazioni in modo che queste ultime soddisfino la
proprietà ACID (atomicità, consistenza, isolamento e durabilità).
Externalization Service. Questo servizio permette ad oggetti di essere
immagazzinati in una sequenza di byte per essere successivamente ricostruiti. Le
operazioni di questo servizio sono due: externalize e internalize. La prima scrive
l‟oggetto in una sequenza di byte includendo lo stato corrente al momento della

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
48
“esternalizzazione”, la seconda ricostruisce l‟oggetto da una data sequenza di byte
includendo lo stato “esternalizzato”.
Relationship Service. All‟interno di una piattaforma distribuita, gli oggetti
stabiliscono delle relazioni. Nel caso in cui si vogliano esplicitarle, l‟OMG ha
introdotto la possibilità di definire relazioni all‟interno dell‟IDL attraverso un
servizio apposito.
Concurrency Control Service. Questo servizio permette a client o transazioni di
mettere lock sugli oggetti in lettura ed in scrittura, esclusivi e condivisi. Questo
servizio permette di implementare algoritmi complessi di controllo della
concorrenza tra le transazioni all‟interno dell‟ORB.
Query Service. Questo servizio permette di interrogare collezioni di oggetti. Esso
riceve delle stringhe di caratteri che rappresentano l‟interrogazione in un dato
linguaggio. L‟OMG ha per ora specificato un servizo di query in grado di
interpretare interrogazioni in SQL e QQL.
Persistence Service. Questo servizio mette a disposizione un insieme di strumenti
per il salvataggio su memoria stabile dei dati che rappresentano lo stato di un
oggetto. Questo stato può essere ad esempio reinstallato a seguito di un guasto che
causa la morte dell‟oggetto.
2.6.2 CORBA EVENT SERVICE
La comunicazione CORBA attraverso l‟invocazione di richieste si basa su un paradigma
client/server sincrono. In molte applicazioni questo potrebbe non essere sufficiente [37]. Il
tipico esempio è la notifica asincrona di eventi: un produttore di eventi comunica l‟evento
a uno o più consumatori. Realizzare questo meccanismo attraverso le richieste CORBA
prevede la realizzazione di callback, cioè di chiamate inverse dal server al client, che
dovrebbe essere quindi esso stesso un server. L‟Event Service OMG offre il supporto per
questo tipo di comunicazione tra gli oggetti, permettendo ad un produttore di notificare
eventi a uno o più consumatori inviando ad essi dei messaggi. Il modello dell‟Event

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
49
Service prevede che produttori e consumatori di eventi si connettano ad un event channel
comune. I consumatori non devono essere a conoscenza dei produttori e viceversa, perché
è l‟event channel il responsabile della consegna dei messaggi a tutti i consumatori
interessati. Nell‟Event Service sono previste due modalità di invio degli eventi: push e
pull. Nel modello push, i produttori inviano gli eventi ai consumatori, mentre nel pull sono
i consumatori a richiedere gli eventi ai produttori. Gli event channel permettono di
connettere più produttori e più consumatori, ognuno dei quali può usare un modello
diverso [37].
Figura 2.8 Modalità di invio degli eventi: push e pull
Le interfacce per l‟interazione con gli event channel sono definite nel modulo
CosEventComm. Tutte le interfacce si basano sulla distinzione tra produttore e
consumatore: l‟event channel stesso è sia un produttore che un consumatore. Queste
interfacce sono chiamate proxy perché sono una rappresentazione di tutti gli effettivi
produttori o consumatori. In altre parole, danno l‟illusione ad un produttore di interagire
con il vero consumatore e viceversa.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
50
2.6.3 CORBA NOTIFICATION SERVICE
Il notification service è uno standard OMG che permette a fornitori di eventi multipli di
inviare questi per i vari consumers. Il notification service può essere utilizzato in una vasta
gamma di scenari, come il meccanismo di integrazione per le apparecchiature di
telecomunicazione, all'interno di reti di grandi dimensioni sul router di backbone Internet,
sui portali di e-commerce per grandi banche, sull'infrastruttura di messaggistica per
collegare i satelliti e le loro stazioni di terra [38].
In Corba notification service i producers sono disaccopiati dai consumers per mezzo di un
canale, che si occupa della registrazione e de-registrazione del client, e la diffusione degli
eventi per più consumers. Il canale ospita anche i consumers lenti o non disponibili.
Il Notification Service supporta sia il modello push che pull, e l'architettura consente
l'invio degli eventi e l'uso di intermediari. L' event service si può estendere con un servizio
di filtraggio degli eventi e di qualità del servizio (QoS). Alcune delle più importanti
caratteristiche QoS includono:
Gli eventi e le connessioni persistenti a sostegno di una garanzia di consegna.
La gestione delle code con politiche di ordimento e scarto di eventi.
Ritardare l'inizio e la fine di un evento con un meccanismo di time out.
Il Notification Service supporta anche il concetto di un event strutturati, che si qualifica
come un messaggio "corretto" in termini di sistemi di message middleware. Le interfacce
principali del Notification Service sono rappresentate nella figura 2.9, che mostra anche
che il Notification Service supporta un dato strutturato, e tipi di client per l'invio e la
ricezione di eventi in sequenza.
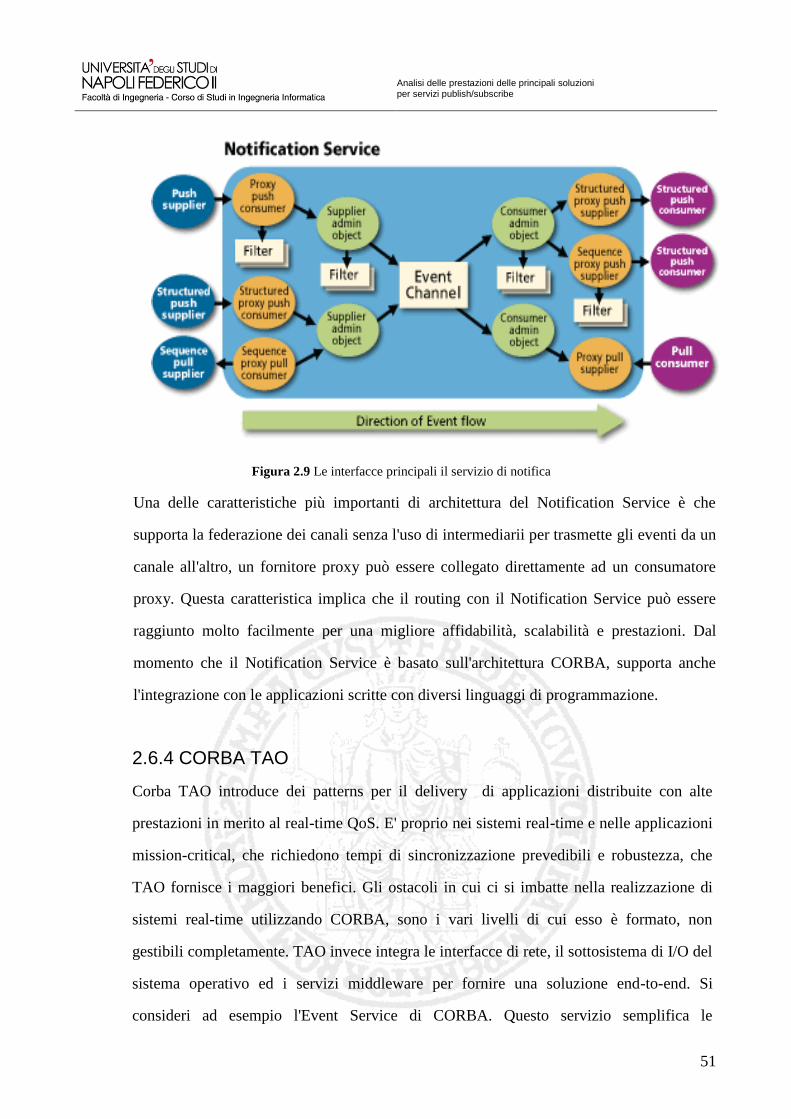
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
51
Figura 2.9 Le interfacce principali il servizio di notifica
Una delle caratteristiche più importanti di architettura del Notification Service è che
supporta la federazione dei canali senza l'uso di intermediarii per trasmette gli eventi da un
canale all'altro, un fornitore proxy può essere collegato direttamente ad un consumatore
proxy. Questa caratteristica implica che il routing con il Notification Service può essere
raggiunto molto facilmente per una migliore affidabilità, scalabilità e prestazioni. Dal
momento che il Notification Service è basato sull'architettura CORBA, supporta anche
l'integrazione con le applicazioni scritte con diversi linguaggi di programmazione.
2.6.4 CORBA TAO
Corba TAO introduce dei patterns per il delivery di applicazioni distribuite con alte
prestazioni in merito al real-time QoS. E' proprio nei sistemi real-time e nelle applicazioni
mission-critical, che richiedono tempi di sincronizzazione prevedibili e robustezza, che
TAO fornisce i maggiori benefici. Gli ostacoli in cui ci si imbatte nella realizzazione di
sistemi real-time utilizzando CORBA, sono i vari livelli di cui esso è formato, non
gestibili completamente. TAO invece integra le interfacce di rete, il sottosistema di I/O del
sistema operativo ed i servizi middleware per fornire una soluzione end-to-end. Si
consideri ad esempio l'Event Service di CORBA. Questo servizio semplifica le

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
52
applicazioni software disaccoppiando producers e consumers garantendo la possibilità di
una comunicazione di gruppo grazie ad un sistema asincrono di event delivery. TAO
migliora l'Event Service di CORBA inserendo caratteristiche importanti, quali il
dispatching e lo scheduling real-time degli eventi, il loro processamento periodico e il loro
filtering ed un protocollo multicast necessario per le applicazioni real-time [34] [35].
Le modifiche rispetto alle normali versioni di CORBA sono:
Threading: sia a singolo thread, sia controllate dall'ORB;
Lifespan: specifica quali objects sono transienti e quali persistenti;
ObjectId Uniqueness: specifica se una o più entità sono implementate;
Servant Retention: specifica se le associazioni tra servant e CORBA object
sonomantenute oppure stabilite ad ogni richiesta;
Request Processing: specifica come le richieste devono essere processate dal POA;
Implicit activation: utilizzando questo servizio si può registrare un servant e creare
un object reference in una singola operazione.
Oltre ai servizi OMG CORBA services e alle caratteristiche peculiari di CORBA TAO
introduce altre caratteristiche:
CORBA Messaging: Asynchronous Method Invocation (callback), ed un
Framework per la gestione del QoS;

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
53
Figura 2.10 Architettura TAO
Portable Interceptors: ovvero oggetti che l'ORB invoca in un determinato punto
durante il request ed il reply (request interceptor), o durante la generazione dello
IOR (IOR interceptors);
Interface Repository: che provvede allo storage, alla distribuzione ed alla gestione
di un insieme di interfacce di object correlati;
Implementation Repository: che consente il binding indiretto tra le richieste del
client e le implementazioni del server per soddisfare tali richieste. In alternativa,
prevede l'avvio automatico del server quando un client effettua una invocazione;
Bi-Directional GIOP: che consente alle richieste e alle risposte di viaggiare bi-
direzionalmente attraverso una singola connessione tra due processi, che sono
l'invio e la ricezione delle domande e delle risposte. Questa capacità aiuta a
risolvere il problema di invocare callbacks sui clienti situati dietro un firewall.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
54
Object by Value: che parzialmente attua la CORBA OBV, che combina la
semantica delle strutture e delle interfacce, consentendo in tal modo agli oggetti di
essere passati per valore (cioè copiati) attraverso interfacce IDL fintanto che
l'implementazione esiste a livello locale sul lato di ricezione.
Object Reference Template (ORT): TAO implementa l'Object Reference
Template (ORT) definito in CORBA 3.0 Core per l'implementazione di un
interfaccia per la generazione di un object reference da parte di un object adapters.
TAO, inoltre, è conforme a Real-Time CORBA versione 1.1 e offre i seguenti servizi che
consentono di apprezzare le capacità di TAO in vari ambienti real-time deterministici o
statistici:
TAO Real-Time Event Service: aumenta le funzionalità fornite da CORBA Event
Service standard fornendo l'event correlations ed il real-time dispatching;
Pluggable Protocols: permette agli sviluppatori di inserire un modello
personalizzato di trasporto sotto GIOP senza modificare l'applicazione a livello di
codice.
2.7 JMS – Java Message Service
Java Message Service o JMS è un insieme di API che consentono lo scambio di messaggi
tra applicazoni Java distribuite nella rete. In sostanza JMS fornisce un metodo standard
tramite il quale le applicazioni possono creare, inviare e ricevere i messaggi usando un
message oriented middleware [44]. Un sistema architettato con JMS è costituito dai
seguenti elementi [45]:
Client JMS: programma in linguaggio Java che invia o riceve messaggi JMS.
Messaggio: raggruppamento di dati che viene inviato da un client a un altro.
JMS Provider: sistema di messaggistica che implementa la specifica JMS e realizza
funzionalità aggiuntive per l‟amministrazione e il controllo della comunicazione
attraverso messaggi.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
55
Administered objects: sono oggetti preconfigurati da un amministratore ad uso dei
client. Incapsulano la logica specifica del JMS provider nascondendola ai client,
garantendo maggiore portabilita al sistema complessivo.
ConnectionFactory : è un administered object utilizzato da un client per realizzare
la connessione con il provider.
Destination (queue/topic): è un administered object che svolge il ruolo di
“deposito” in cui i mittenti possono lasciare i messaggi che creano, e da cui i
destinatari possono recuperare i messaggi. Le destinazioni possono essere usate
contemporaneamente da più mittenti e da più destinatari. A seconda del tipo di
destinazione usato (queue o topic), la consegna dei messaggi avviene secondo
modalità diverse (point to point o publish/subscribe).
Figura 2.11 Architettura JMS
Le applicazioni JMS hanno qualità intrinseche che sono sintetizzabili in:
Asincronicità della comunicazione: il provider JMS consegna i messaggi al client
appena quest‟ultimo si è reso disponibile. Il provider li consegna senza che il
receiver abbia effettuato una richiesta specifica.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
56
Affidabilità della comunicazione: JMS può assicurare che un messagio sia
consegnato una ed una sola volta.
Disaccopiamento spaziale: grazie all‟uso del sistema di naming di Java (JNDI)
non è necessario avere un riferimento diretto ad oggetti remoti, ma ci si affiderà alla
presenza degli administered object: la creazione di connection factory e destination
è compito dell‟ amministratore JMS che deve inserirli all‟interno di un contesto
JNDI in un opportuno namespace in modo che possano essere recuperati da
qualsiasi client mediante le API JNDI
Quality of Service configurabile: le API JMS prevedono differenti livelli
diaffidabilità per considerare molteplici scenari applicativi.
Robustezza ai cambiamenti: sono presenti tipologie differenti di messaggi e
features personalizzabili.
JMS fornisce un approccio semplificato e comune ai client Java per accedere ai message-
oriented middleware. Con l'introduzione del Message-Driven Beans (MDB), JMS è
diventato ancora più strettamente integrato in J2EE. Questa integrazione fornisce un
metodo asincrono all‟Enterprise Java Beans (EJB) per comunicare con gli altri elementi in
una architettura distribuita. JMS è stato progettato come un'astrazione degli esistenti
prodotti di messaggistica. Questa astrazione ha portato anche le seguenti
caratteristiche[46]:
JMS è puramente una interfaccia. Per il trasporto e il routing dei messaggi è
necessario una qualche forma di motore di messaggistica. JMS non specifica nulla
ne sul motore, ne sulla sua architettura, o sul trasporto
Le specifiche JMS non facilita l'interoperabilità tra le diverse implementazioni. Se
la specifica non si occupa di un protocollo di trasporto non ci sarà mai
l'interoperabilità.
Rispetto ai prodotti proprietari MOM, JMS ha un insieme relativamente semplice
dei formati dei messaggi, ne esistono solo sei tipi.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
57
JMS supporta un modello punto-punto (o coda) e un modello publish/subscribe, e definisce
una serie di tipi di messaggi che i publisher ed i subscribers possono scambiarsi. Le
proprietà di un messaggio definiscono il modo in cui dovrebbero essere trattati con il
sistema di messaggistica. I subscribers possono filtrare i messaggi utilizzando una
grammatica SQL. I Client possono essere transient o durable, e messaggi possono essere
inviati o ricevuti nel contesto di una transazione. La Figura 2.12 mostra le principali
nozioni di JMS. Anche se il modello di comunicazione publish/subscribe ed il modello
point-to-point sono molto diversi da un punto di vista concettuale, gli autori di JMS si
resero conto che i modelli hanno molto in comune. JMS è quindi centrata su un modello
generico di messaggistica, ed il modello publish/subscribe e point-to-point sono derivate
nel senso di ereditarietà di interfaccia dal modello generico [38].
Figura 2.12 Il modello di programmazione Java Message Service.
Le caselle nella Figura 2.12 rappresentano l'interfaccia con il point-to-point sulla sinistra e
l'interfaccia publish/subscribe a destra. Le frecce che conducono da cima a fondo nella
figura rappresentano le fasi tipiche che uno sviluppatore JMS esegue per lo sviluppo di
applicazioni client:

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
58
Risolvere una factory di connessione e una destinazione da JNDI. Una destinazione
è una coda o un topic.
Creare una connessione utilizzando la factory di connessione.
Creare una sessione con le proprietà desiderate dalla connessione.
Se l'applicazione è un fornitore, creare un MessageProducer se la domanda è
un consumatore, creare un MessageConsumer dalla sessione.
Iniziare a inviare o ricevere messaggi utilizzando il produttore o l'oggetto di
consumo. Il produttore utilizzerà la sessione per creare diversi tipi di messaggi.
JMS supporta sei diversi tipi di messaggi, che vengono utilizzati per effettuare i diversi tipi
di carico utile. L'intestazione di un messaggio è lo stesso indipendentemente dal carico, il
che significa che il filtraggio è la stessa per tutti e sei i tipi di messaggi. Un messaggio
supporta una serie di proprietà per impostare la priorità, l'affidabilità e altre proprietà di
QoS, che sarà interpretato e gestito dal server JMS. Al fine di supportare correttamente i
messaggi durevoli, JMS utilizza la nozione di un subscriber durevole. Ciò è necessario
soltanto nel modello publish/subscribe, i messaggi memorizzati in una coda saranno
consumati da qualsiasi ricevitore che si connette alla coda in questione. Il subscriber
durevole è identificato da un nome, e la stessa operazione è convenientemente utilizzata
per la creazione e ri-creare il subscriber. Oltre alle interfacce illustrate nella figura 2.12,
JMS supporta una serie di interfacce per il recapito di messaggi di natura commerciale e di
consumo. La factory di connessione, la connessione, e le interfacce di ogni sessione hanno
un interfaccia con il prefisso XA, che supporta il Java Transaction API (JTA) per le
transazioni distribuite. Questo è in genere supportata quando JMS è integrata in un
application server. La specifica JMS definisce cinque diversi messaggi che derivano tutte
le funzionalità comuni dall'interfaccia base del messaggio. I messaggi JMS sono
concettualmente trasmessi utilizzando il servizio di notifica, come illustrato nella Figura
2.13 [38]. Poiché JMS non definisce un protocollo di rete, un qualche tipo di mappatura
del messaggio è necessario.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
59
Figura 2.13 Un client-library trasforma messaggi JMS da e per eventi strutturati.
JMS supporta due modi di ricevere gli eventi: un modello pull o un modello push. Nel
modello pull, un client JMS richiama un metodo per il consumatore del messaggio al fine
di ricevere un evento. Nel modello push, i registri dei consumatori richiamano un oggetto
con il consumatore o di sessione ed i messaggi vengono ricevuti in modo asincrono dalle
invocazioni del metodo onMessage nell'interfaccia di callback. Entrambi i modelli per
la ricezione di eventi hanno una mappa per il servizio di notifica dei modelli push e pull.
Non è possibile, tuttavia, per un consumatore del servizio di notifica essere sia un
consumatore push che un consumatore pull, pertanto, il servizio di notifica dovrà essere
esteso per supportare una nuova consegna. Il messaggio di interfaccia è un messaggio di
base per tutti i messaggi JMS. Dal momento che tutti i messaggi JMS sono interfacce, la
responsabilità è dei fornitori delle librerie JMS client fornire implementazioni dei
messaggi. Un messaggio JMS è costituito da una intestazione, un insieme di proprietà e di
un corpo. La parte del corpo è diverso per ciascuno dei cinque diversi tipi di messaggi
JMS. L'intestazione e le proprietà sono le stesse per tutti i tipi di messaggi. JMS consente
solo ai clienti di filtrare le proprietà del messaggio. Per garantire che solo le intestazioni
dei messaggi possono essere filtrati, queste informazioni devono essere confezionati

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
60
all'interno di un corpo filtrabile di un evento strutturato. Questa è l'unica informazione dai
messaggi JMS che diventa parte filtrabile del corpo. Il messaggio di interfaccia supporta
tre attributi che hanno un significato ben definito nel servizio di notifica:
DeliveryMode: Abbiamo due modalità di consegna PERSISTENT e
NON_PERSISTENT in base alla modalità di consegna nella variabile di intestazione
possiamo trovare il valore Persistent oppure BestEffort
Expiration: La scadenza JMS in millisecondi si trova nel QoS Timeout nella
variabile di intestazione di eventi strutturati. I messaggi scaduti non sono visibili ai
clienti.
Priority: La priorità del messaggio si associa al notification Priority QoS nella
variabile di intestazione di eventi strutturati. La modalità di consegna con priorità
viene utilizzata per garantire che i messaggi con priorità più alta vengono consegnati
prima di messaggi con priorità più bassa.
2.7.1 Apache ActiveMQ - CPP
CMS, acronimo di C++ Messaging Service è un JMS API per C++ per l'interfacciamento
con i broker del tipo Apache ActiveMQ. ActiveMQ - CPP è un client, ed un message
broker come Apache ActiveMQ è necessario per far comunicare i vari client [47].
ActiveMQ-CPP ha un'architettura che consente diversi protocolli di connessione per
formati diversi di trasporto. ActiveMQ-CPP fornisce anche una serie di classi per il
threading, per le operazioni di I/O [48].

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
61
Figura 2.14 Schema dei protocolli di Apache ActiveMQ – CPP
ActiveMQ supporta i messaggi di consulenza che permette di vedere il sistema che
utilizza regolarmente i messaggi CMS. Con i messaggi di consulenza si possono fare le
seguenti operazioni:
Vedere i consumatori, i produttori e le connessioni di partenza e arresto
Vedere le destinazioni temporanee create e distrutte
Ottenere una notifica dei messaggi che scadono, gli argomenti e le code
Osservare il broker durante l'invio dei messaggi alle destinazioni senza i
consumatori
Vedere le connessioni di partenza e l'arresto
I messaggi di consulenza possono essere pensati come una sorta di canali di
amministrazione, dove si ricevono le informazioni su quanto sta accadendo sul provider
JMS con quello che sta succedendo con i produttori, i consumatori e le destinazioni.
Se da un lato JMS offre la possibilità di specificare l‟esatta Quality of Service di ogni
scambio di messaggi in termini di guaranted delivery e di consegna tramite semantica
once-and-only-once, ActiveMQ mette a disposizione altre funzionalità per ottenere
affidabilità del sistema, high availability e tolleranza ai guasti. ActiveMQ è un message

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
62
broker. Un broker è la parte di una soluzione JMS lato server che si occupa di routing,
recovery, persistenza e cosi‟ via. Per quanto riguarda la persistenza, come detto
precedentemente il provider JMS memorizza i messaggi su un persistent storage se il
delivery mode è stato settato a persistent, di modo che sopravvivano a un riavvio del
broker. Inoltre per sopperire alla mancanza del servizio e permetterne la successiva
riattivazione, il provider JMS memorizza anche le durable subscriptions: se così non fosse
il message server, in caso di fallimento, non sarebbe capace di consegnare i messaggi ai
durable subscribers stessi. Per effettuare le operazioni di recovery il provider JMS:
ricrea le destinazioni
recupera la lista di “durable subscriptions” per ogni topic
recupera la lista dei messaggi
recupera la lista di acknowledge per ogni messaggio
È possibile configurare ActiveMQ perché gestisca la persistenza tramite file (AMQ
message store) o tramite database esterno al provider JMS. È stata scelta quest'ultima
opzione perché ha come vantaggio un più facile recupero e interpretazione dei dati
rispetto al caso in cui si utilizzi l‟ AMQ message store, un sistema di gestione della
persistenza basato su file utilizzato di default da ActiveMQ. Le operazioni di accesso e
scrittura su un DB sono sicuramente più pesanti dal punto di vista computazionale, ma
questo approccio è sensato perché la nostra applicazione non ha requisiti particolari di
high performance. All‟avvio il broker creerà automaticamente due tabelle,
ACTIVEMQ_ACKS e ACTIVEMQ_MSGS: la prima tabella mantiene in memoria
informazioni relative ai subscribers e informazioni relative ai messaggi acknowledged, la
seconda contiene al suo interno informazioni relative ai messaggi [48].
2.8 AMQP
Advanced Message Queuing Protocol (AMQP) permette la piena interoperabilità
funzionale tra client e messaging middleware server. L‟obiettivo è di consentire lo
sviluppo e l'uso di una tecnologia standardizzata per middleware di messaggistica. Il fine

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
63
ultimo è che attraverso AMQP, le capacità dei middleware di messaggistica possano essere
portati nella rete stessa, e che attraverso la pervasività della disponibilità di middleware di
messaggistica, possano essere sviluppati nuovi tipi di applicazioni di utilità [53].
Per consentire l'interoperabilità completa, il middleware di messaggistica richiede che sia il
protocollo di rete e sia la semantica dei servizi del broker siano sufficientemente
specificati. AMQP, pertanto, definisce sia il protocollo di rete sia i servizi del broker
attraverso:
1. "Advanced Message Queuing Protocol Model" (AMQP Model), l„AMQP Model
consiste in un insieme di componenti che instradano e memorizzano messaggi
all‟interno del broker e in più un insieme di regole per collegare questi componenti
insieme.
2. Un protocollo di rete wire-level, AMQP permette ai client di comunicare con il
broker e interagire con l‟AMQP Model che esso implementa.
AMQP è un protocollo di tipo binario con caratteristiche quali: multi-canale, asincrono,
portabile, neutrale, sicuro ed efficiente.AMQP è usualmente diviso in tre layer:
Figura 2.15 Struttura a layer di AMQP

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
64
Il layer “Model” offre un insieme di comandi incapsulati in classi e funzionalità che fanno
lavoro utile su richiesta dell„applicazione.
Il layer “Session” offre trasporto affidabile di comandi dall‟applicazione al server e
all‟indietro, sincronizzazione e gestione degli errori.
Il layer “Transport” offre framing, codifica dei dati, rilevamento dei fallimenti e canne
multiplexing [51].
2.8.1 AMQP Model Layer
L‟AMQP Model specifica un insieme modulare di componenti e di regole per connettere
questi componenti tra di loro. Ci sono tre principali tipi di componenti, che sono collegati
in catene di processi all‟interno del server per creare la funzionalità desiderata [51]:
“Exchange” riceve i messaggi dall‟applicazione publisher e instrada questi verso
una coda di messaggi basata su un criterio arbitrario, usualmente proprietà del
messaggio o contenuti.
“Message queue” che memorizza i messaggi finchè essi non possono essere
finalmente processati dall‟applicazione che li consuma o da applicazioni multiple.
“Binding” definisce la relazione tra l‟Exchange e la coda e offre i criteri di routing.
Usando questo modello possiamo emulare i concetti classici di middleware di code “store
and forward” o a sottoscrizione per argomento (topic). In linea di principio, un server
AMQP è analogo a un server di posta elettronica, con ogni Exchange che agisce da agente
di trasferimento messaggi e ogni coda come una mailbox, mentre il binding definisce le
tabelle di routing in ogni agente di trasferimento. I Publisher spediscono messaggi ad un
singolo agente di trasferimento il quale poi instrada i messaggi in una mailbox. I
consumatori infine prendono i messaggi dalle mailbox [54].
Il diagramma che segue mostra la semantica del server che deve essere standardizzata con
l‟intento di garantire la interoperabilità tra le implementazioni AMQP [51]:

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
65
Figura 2.16 Semantica AMQP.
Un middleware server è un server di dati che accetta messaggi e fa due cose significative
con questi:
Li instrada verso differenti consumatori in dipendenza di criteri arbitrari.
Li mette in buffer in memoria o su disco quando i consumatori non sono abili ad
accettarli abbastanza velocemente.
Il modello AMQP divide i compiti sopra citati in due distinti ruoli:
L‟EXCHANGE che accetta i messaggi dai produttori e li instrada verso code di
messaggi.
La MESSAGE QUEUE che immagazzina i messaggi e li inoltra ai consumatori.
C‟è inoltre un' interfaccia tra Exchange e Message Queue chiamata “BINDING”.
2.8.2 Il Layer Session
Il layer Session offre tutte le funzionalità necessarie all‟interno della sessione. Le sessioni
sono interazioni nominate tra peer AMQP. Dal punto di vista strutturale, una sessione è
l‟interfaccia tra il protocollo di rete e il layer dell‟AMQP model; essa costituisce un

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
66
ambito di esistenza per le entità del modello quali, code, Exchange e sottoscrizioni e per
l‟identificazione dei comandi [51].
Le sessioni non sono esplicitamente create o distrutte. Piuttosto che creare una sessione,
un peer deve attendere per “attaccarsi” ad una sessione del suo partner. Il ricevitore di
questa “richiesta di “attacco” può poi cercare di mantenere lo stato per questa sessione. Lo
stato relativo ad una sessione deve essere conservato da entrambi i peer, mentre essi sono
“attaccati”; la sessione può essere interrotta o attraverso un‟esplicita richiesta e tramite
un‟interruzione di connessione di rete tra i peer, ma in ogni caso lo stato della sessione
può essere mantenuto per un determinato periodo di tempo che è stato concordato tra i
peer prima. La sessione può essere definita attraverso più punti di vista:
La Sessione come un mezzo di trasporto per i comandi: Il modello AMQP
interagisce attraverso l‟invio di comandi tra due peer. Questi comandi sono spediti
“sulla” sessione. Appena un comando è tramandato dal layer model alla sessione, a
esso è assegnato un identificatore. Questi identificatori possono poi essere usati per
correlare i comandi con i risultati.
La sessione come layer di interfaccia: La Sessione agisce come un‟interfaccia tra il
protocollo di rete e lo strato riferito al modello AMQP. Lo stato della sessione
consiste in: un buffer di comandi di cui un peer non ha ancora avuto conferma che
il suo partner ha ricevuto e un insieme di identificatori che il peer sa che ha
ricevuto ma non può essere sicuro che il suo partner non aspetterà il re-invio.
Il layer Sessione offre una serie di servizi cruciali al modello costruito sopra di esso:
Identificazione sequenziale dei comandi:Ogni comando pubblicato da un peer
deve essere necessariamente identificato all‟interno della sessione affinchè il
sistema nella sua totalità sia capace di garantire l‟esecuzione esattamente una volta.
Lo strato session a tal fine usa una numerazione sequenziale che permette la
correlazione tra comandi e risultati ritornati asincronamente; l‟identificatore è reso
visibile attraverso il layer model e quando un risultato è ritornato da un comando,
esso è usato per correlare il comando che gli ha dato vita.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
67
Conferme che i comandi saranno eseguiti: Affinchè un peer abbia la capacità di
scartare lo stato in relazione ad un comando, esso deve avere la garanzia che il
comando sia stato eseguito, o che la sua consegna è stata conservata per un tempo
deciso a priori. In pratica ci sono due tipi di messaggi che si può desiderare di
inviare attraverso un sistema di messaggistica: Messaggi durevoli e messaggi
transitori. Per un messaggio transitorio, il contratto generale tra applicazione e
sistema di messaggistica e che i messaggi possono essere persi se il sistema di
messaggistica stesso perde stati transitori. Per un messaggio durevole, invece, il
sistema deve dare la garanzia che il messaggio sarà conservato nella memoria più
durevole disponibile. Il layer session gestisce l‟invio e la ricezione delle conferme;
questo permette di tenere sotto controllo gli stati in caso di fallimenti.
Re-invii e Recuperi: Il layer session offre i tools necessari per identificare i
comandi che sono “in dubbio” o “sospesi” per un fallimento e di replicarli per
ridurre il rischio di un‟accidentale consegna duplicata.
Il layer Session opera sopra la sottostante infrastruttura di rete. Session richiede che il layer
sottostante offra le seguenti funzionalità:
Consegna ordinata, cioè nessun sorpasso tra pacchetti.
Trasmissioni atomiche di unità di controllo e dati.
Rilevamento dei fallimenti della rete.
2.8.3 Il layer di trasporto (Transport layer)
Questo è il layer più basso che si occupa di preparare i messaggi ad essere trasmessi sulla
rete. Il numero di port standard di AMQP è stato assegnato da IANA ed è 5672 per TCP,
UDP e SCTP. Prima di inviare un qualunque frame su una connessione, ogni peer deve
iniziare mandando un header di protocollo che indichi la versione del protocollo usata
sulla connessione. Tale header è costituito da una sequenza di 8-ottetti come mostrato in
figura [51]:

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
68
Figura 2.17 Header.
L‟header protocol è composto dalle lettere maiuscole “AMQP” seguite da:
La classe del protocollo, che è uno per tutti i protocolli AMQP.
L’istanza del protocollo, che è: AMQP over TCP/IP con valore uno e AMQP over
SCTP/IP con valore due.
La maggiore versione del protocollo.
La minore versione del protocollo.
Il modello di negoziazione del protocollo è compatibile con i protocolli esistenti come http
che inizializza una connessione con una stringa di testo costante ed è anche compatibile
con i firewall che analizzano l‟inizio di un protocollo, per decidere quali regole applicare.
In fase di negoziazione client e server AMQP si accordano per la versione di protocollo da
usare.
2.8.4 OpenAMQ
OpenAMQ è un message middleware bastato sulle specifiche AMQP. OpenAMQ fornisce
un framework su cui costruire applicazioni distribuite che comunicano utilizzando
messaggi. Tali applicazioni distribuite sono a volte chiamati "loosely connected". In
genere il flusso dei messaggi è asincrona, ciò significa che il flusso dei messaggi tra le
parti avviene senza una logica complessiva di sincronizzazione o di controllo [55].
OpenAMQ aggiunge ulteriori specifiche allo standard AMQP:
1. Un API standard per le applicazioni, chiamato WireAPI.
2. Un API standard per l'amministrazione remota, chiamata CML.
3. Un modello standard per l'adesione broker insieme in federazione.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
69
AMQP ha caratteristiche utili che migliorano in alcuni casi message middleware come ad
esempio JMS o Stomp queste caratteristiche posso essere così riassunte:
AMQP a differenza di JMS è un wire-level protocol, come HTTP. Ciò significa che
qualsiasi software che si preoccupa per l'attuazione del protocollo può parlare con
un server AMQP.
Funziona con diversi linguaggi di programmazione, i tipi di dati o costrutti non
dipendono dal linguaggio specifico..
Funziona su tutte le piattaforme, non dipende da Windows, Linux o qualsiasi altro
sistema operativo specifico.
Message routing: Implementa il modello di routing AMQP
Implementa fanout, diretto, e cambio di intestazione dei tipi.
Implementa lo scambio di default.
Consente alle applicazioni di creare e gestire gli scambi in fase di runtime.
Supporta temi gerarchica di qualsiasi complessità.
Message Queuing: Implementa il modello della coda AMQP l'utente può definire code di
messaggi flessibili
Crea e gestisce il nome o le code senza nome.
Messaggio di base il cui contenuto va dai zero byte fino a 4 GB.
Code multiple per i readers con servizio round-robin.
Messaggi asynchronous di publishing.
Code condivise e code private ed esclusive
Gestione delle risorse: Fornisce all'operatore il controllo sull'uso delle risorse di sistema
Configurare i limiti sulle dimensioni della coda.
Rallentamento automatico dei publishers quando vengono superati i limiti sulla
dimensione della coda
Clustering: Supporta il failover e la scalabilità grazie al clustering
Creare coppie di server ad alta disponibilità.
Connettere i server e le coppie di server in cluster.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
70
Fanout publish / subscribe tra vari server.
Configurabile client-server
Sicurezza: Supporta le opzioni di sicurezza estensibile e configurabile
Definizioni configurabile dall'utente.
SASL authentication (PLAIN mechanism)
Amministrazione: È facile da gestire tramite Secure Shell remota o la riga di comando
Configurazione tramite file di configurazione XML o da riga di comando.
Amministrazione remota e la configurazione (amq_shell).
Interfaccia client WireAPI: Fornisce una API standard per lo sviluppo di applicazioni
Il supporto per tutti i metodi definiti nella norma AMQP.
Consegna del messaggio in modo asincrono.
Segnalazione degli errori per le applicazioni.
Il WireAPI OpenAMQ è stato progettato per fornire ai programmatori di applicazioni nei
diversi linguaggi la stessa semantica. Ogni linguaggio di programmazione ha la propria
sintassi, ma con una sola semantica, è molto facile per gli sviluppatori stessi cambiare
linguaggio di programmazione e è più facile mantenere il codice in diverse lingue, e
riutilizzare i designs fatti in un solo linguaggio, con ltri.Le WireAPI OpenAMQ seguono
la semantica del protocollo AMQP utilizzando gli stessi nomi e parametri.
WireAPI ha diversi vantaggi rispetto alle API standard di AMQP che possiamo
riassumenre:
Qualsiasi versione di AMQP viene implementata ha una semantica identica nelle
WireAPI di OpenAMQ.
La Semantica WireAPI è portabile in tutti i linguaggi di programmazioni.
Gli aspetti negativi della WireAPI sono:
Obbliga gli sviluppatori a comprendere il protocollo.
Alcune astrazioni utili che sono implementate in AMQP mancano nelle WireAPI
OpenAMQ.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
71
Affidabilità
Una differenza fondamentale tra OpenAMQ e altri prodotti AMQP è l'approccio alla
affidabilità. Ogni messaggio deve essere parte di una transazione in modo che un eventuale
fallimento può essere recuperato. L'affidabilità è centralizzato, il recapito dei messaggi è
meticoloso, e il protocollo per la consegna affidabile è molto complesso. Quando abbiamo
un mix di questo modello con un clustering per l'alta disponibilità (cioè di essere in grado
di passare a un server di backup se si blocca il primo server) si ottiene in un territorio
ancora più complessa. La complessità crea inaffidabilità e il rischio di incidenti e la perdita
di dati aumenta. L'affidabilità centralizzata è incompatibile con il clustering dei mediatori,
e va contro la moderna progettazione di rete. Consideriamo la rete AMQP idealmente
costruita da apparati a basso costo. Questi possono essere organizzati in modo che un nodo
può essere uno o due AMQP server. Questi nodi possono essere uniti insieme. Tali reti,
essendo più semplice di classici messagge broker, risolvono parte del problema della
reliabity. Per ottenere la piena affidabilità implementiamo un protocollo end-to-end nelle
API per ottenere una maggiore affidabilità. Si noti però che le WireAPI non implementano
ciò, questo è stato fatto dalle applicazioni AMQP piuttosto che da OpenAMQ. Il design è
molto semplice. Costruire messaggistica affidabile come richiesta coppie di messaggio di
risposta. Il mittente di una richiesta detiene la richiesta in memoria o sul disco, fino ad
ottenere una risposta. Se non ottiene una risposta in tempi brevi, invia nuovamente la
richiesta. L'altra estremità ignora le richieste di duplicato. In questo modello l'affidabilità è
invisibile per il protocollo (che poi può essere più semplice e quindi migliore), e non ha
bisogno di sostegno da parte del server (che può essere più semplice e più affidabile). E
funziona con qualsiasi rete AMQP, non importa quanto grande o quanto molti server sono
coinvolti.
2.8.5 QPID
Apache Qpid è un message middleware bastato sulle ultime specifiche AMQP fornendo la
gestione delle transizioni, la coda dei messaggi, la distribuzione dei messaggi, la sicurezza,

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
72
la gestione, il clustering, e multi-supporto di piattaforme eterogenee. Anche Qpid supporta
diversi client API per linguaggi di programmazione differenti [56].
Qpid permette lo scambio di messaggi Point-to-Point, Peer-to-Peer, Pub-Sub, ed Eventing.
Point-to-point: AMQP consente di scambiare i messaggi in due modi:
a.) Un client può creare una coda di chiamata che consente al produttore di pubblicare il
messaggio per lo scambio diretto inserendo il nome della coda.
b.) Si può specificare un indirizzo di risposta nei messaggi pubblicati in modo da
consentire al consumatore di rispondere al produttore senza sapere da chi è stato
inviato il messaggio prima di averlo ricevuto.
One-to-many: ci sono alcuni modelli che possono essere utilizzati.
a.) AMQP fornisce un 'fan-out' per l'exchange ed invierà un messaggio a tutte le code
che sono legati ad essa. Domini differenti o argomenti vengono creati con 'fanout'
di exchange diversi.
b.) Si può anche utilizzare l'exchange di intestazioni in questo caso il pattern match
viene utilizzato per inviare il messaggio a tutte le code vincolati. Esso può essere
pensato come un filtro che consente di creare praticamente un modello di routing
uno a molti.
Pub-Sub: Un Topic può essere creato con il 'topic exchange' o il 'direct exchange' per
consentire al consumatore di associare in flussi di dati quelli a cui sono interessati.
FAST Reliable Messaging: Qpid consente trasferimenti affidabili tra due coetanei. Ciò
significa che è possibile pubblicare o iscriversi al broker affidabile senza richiedere la
necessità per le transazioni. Tutto questo può essere fatto in modalità asincrona con il C+ +
Broker permettendo un throughput elevato durante l'esecuzione.
Transient message delivery: i messaggi di default sono transient. Un messagio Transient
può essere inviato a code che sono durevoli. Non saranno sicuri conservati o recuperati, e
si esibirà come qualsiasi altro messaggio transitoria – fast.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
73
Durable message delivery: C'è una intestazione di ogni messaggio in cui vengono
specificate le proprietà del messaggio, uno di questi è la durata. Messaggi che vengono
contrassegnati come durevoli e pubblicati in una coda lunga sarà sicuro memorizzato.
Messaggio Durable sopravviverà il riavvio del broker o cluster.
Federation (Hub-spoke, Trees, graphs): Come AMQP è simmetrica per le
comunicazioni peer-to-peer tutti i building block sono in atto per la creazione di reti di
intermediari. Il C+ + broker ti permette di collegare il broker insieme usando 'qpid-route' e
quindi creare collegamenti tra i broker staticamente o con percorsi dinamici. Questo
permette di avere un messaggio da pubblicare su un broker ed essere consumato da un altro
broker nella rete federata di broker. Questa funzione è ideale per creare data-center, o
isolare la rete consente
2.9 Confronto delle soluzioni middleware
Il crescente interesse in ambito commerciale per le applicazioni che permettono una
distribuzione delle informazioni su sistemi distribuiti in LAN, in grado di fornire soluzioni
scalabili per sistemi real-time ha portato alla creazione di diversi prodotti software.
L‟unico modello di comunicazione in grado di essere scalabile è il modello
Publish/Subscriber, per adattare tale modello alle applicazioni real-time è stato sviluppato
un protocollo di comunicazione noto come RTPS (Real-Time Publish/Subscribe). Questo
protocollo non è in grado di fornire una comunicazione che implementi molte qualità del
servizio, è in grado di fornire un controllo sulle risorse utilizzate nella comunicazione, è
tollerante ai fallimenti e permette di controllare il livello di affidabilità del protocollo
implementato. Vista la difficoltà nel produrre software che implementi molte qualità del
servizio offerto, l‟OMG (Object Management Group) ha deciso di creare uno standard in
grado di garantire un modello di comunicazione di tipo Publish/Subscriber in cui lo
scambio di informazione è di tipo Data-Centric con un‟insieme ampio di qualità del
servizio supportate. Questo standard è stato adottato da molte aziende. L‟attuale interesse

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
74
del mercato è capire se le soluzioni attualmente sviluppate sono adatte ad un ambiente
distribuito. L‟obiettivo di questa tesi è stato lo studio e la valutazione di alcuni prodotti
software: RTI DDS, OpenSpliceDDS, JMS Apache ActiveMQ - CPP, AMQP
OPENAMQ, AMQP QPID, CORBA.
RTI DDS ed OpenSpliceDDS seguono lo standard OMG nella specifica DDS, entrambi
implementano le DCPS API, ma solo OpenSplice implementa la DLRL. RTI DDS e
OpenSpliceDDS benché sviluppando lo stesso standard lo implementano in modi
differenti. RTI DDS ha un architettura decentralizzata che gli conferisce il vantaggio di
non aver bisogno di un demone per lo scambio di messaggi, facendo risultare così ogni
applicazione autonoma. Uno svantaggio di questo middleware è che alcuni dettagli della
configurazione come l‟indirizzo di multicast, il numero di porta, i parametri relativi ai
differenti tipi di trasporto e il modello reliability devono essere definiti nel livello
applicativo e, ciò comporta un sovraccarico del lavoro da parte dello sviluppatore e una
maggiore probabilità di commettere errori. OpenSplice DDS utilizza invece un architettura
federata in cui c‟è un processo demone distinto per ogni interfaccia di rete, una shared-
memory per collegare le applicazioni, che risiedono in un nodo computazionale, ma anche
gli hosts con un insieme di servizi configurabili ed estendibili; utilizzando un‟architettura
di tipo shared-memory, i dati sono fisicamente presenti una sola volta su ogni macchina,
usando un demone si disaccoppiano le applicazioni dai dettagli di comunicazione e di
configurazione del DCPS. Inoltre, in caso di presenza di più partecipanti DDS sullo stesso
nodo, la scalabilità risulta maggiore rispetto agli altri modelli di architettura, infatti è
possibile semplificare la configurazione delle policy per un gruppo di partecipanti aventi la
stessa interfaccia di rete. Uno svantaggio di quest‟architettura è sicuramente la presenza di
un unico point of failure e la necessità di eseguire ulteriori configurazioni. JMS Apache
ActiveMQ è un message middleware implementa lo standard Java Message Service 1.1.
L‟architettura di JMS Apache ActiveMQ può essere sia di tipo centralizzato che di tipo
federato. Secondo l‟architettura centralizzata usa un singolo demone operante su un nodo
designato per la gestione delle informazioni necessarie per creare e gestire le connessioni

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
75
tra i partecipanti in un dominio. I dati passano direttamente dai Publisher ai Subscriber,
mentre è necessaria la comunicazione con il processo demone per il controllo e
l‟inizializzazione delle attività. Il vantaggio di quest‟architettura sta nella semplicità
dell‟implementazione e della configurazione poiché tutte le informazioni di controllo
risiedono in un'unica locazione. Lo svantaggio è senza dubbio, la presenza di un solo
demone che costituisce un unico point of failure. Seguendo invece l‟architettura federata,
per la comunicazione tra i vari client CMS si ha bisogno di un message broker per lo
scambio dei messaggi su rete. Il broker utilizzato è Apache ActiveMQ e per interfacciare i
vari client CMS a quest‟ultimo serve un API C++, per il trasporto dei messaggi viene
utilizzato un protocollo di connessione come Stomp, JMS Apache ActiveMQ garantisce la
possibilità di specificare QoS per ogni messaggio scambiato tra i vari client. CORBA TAO
si differenzia da JMS in quanto i pubblishers sono disaccoppiati dai subscribers per mezzo
di un canale l‟event channel che si occupa della diffusione degli eventi per più consumers.
Una caratteristica importante di questo middleware è che supporta la federazione dei canali
senza l‟uso di intermediari per trasmettere gli eventi da un canale all‟altro. E‟ possibile
specificare per lo scambio di messaggi delle Qos stringenti utili proprio per applicazioni
real-time e mission-critical. OpenAMQ e QPID sono entrambi message middleware basate
sulle specifiche AMQP. L‟architettura di entrambi i middleware può essere assimilata ad
una di tipo federata per la presenza di un demone che mette in comunicazione i vari client
per lo scambio dei messaggi, ne deriva che assimilano vantaggi e svantaggi di questa
architettura. Entrambi i middleware implementano QoS per lo scambio di messaggi in
modo da rendere robusta la comunicazione.
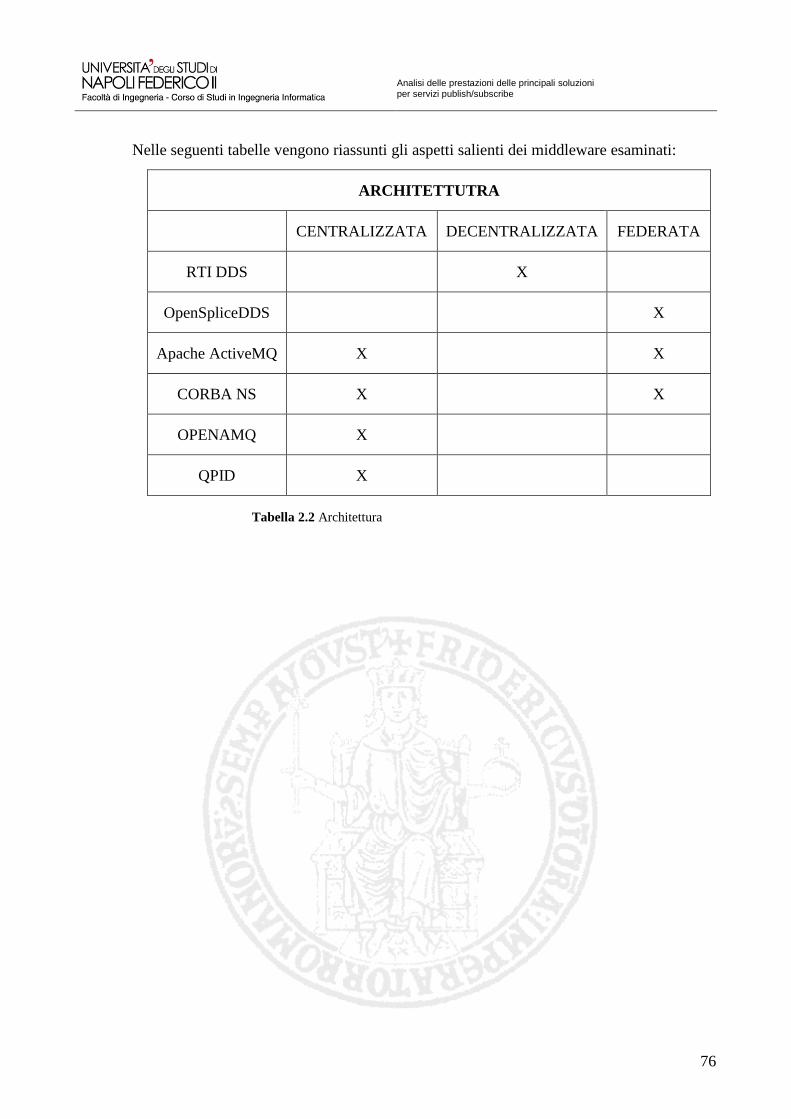
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
76
Nelle seguenti tabelle vengono riassunti gli aspetti salienti dei middleware esaminati:
ARCHITETTUTRA
CENTRALIZZATA DECENTRALIZZATA FEDERATA
RTI DDS X
OpenSpliceDDS X
Apache ActiveMQ X X
CORBA NS X X
OPENAMQ X
QPID X
Tabella 2.2 Architettura

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
77
Quality of Service Policy
DURABILITY DEADLINE OWNERSHIP RELIABILITY LIFESPAN HISTORY RESOURCE
- LIMITS
VO
LA
TIL
E
TR
AN
SIE
NT
LO
CA
L
TR
AN
SIE
NT
PE
RS
IST
EN
T
DU
RA
TIO
N
SH
AR
ED
EX
CL
US
IVE
RE
LIA
BL
E
BE
ST
EF
FO
RT
DU
RA
TIO
N
KE
EP
_A
LL
KE
EP
_L
AS
T
RTI DDS X X X X X X X X X X X
OpenSplice
DDS
X X X X X X X X X X
Apache
ActiveMQ
X X X X X X X
CORBA X X X X X X X X X
OPEN AMQ X X X X X X X X X
QPID X X X X X X X X X
Tabella 2.3 Quality of Service Policy

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
78
Capitolo 3 – Valutazione prestazionale
Nei capitoli precedenti abbiamo presentato i diversi middleware da noi utilizzati,
rispettivamente RTI DDS, OpenSpliceDDS, Corba TAO, Apache ActiveMQ – CPP,
OpenAMQ, Apache QPIDI. Abbiamo mostrato le loro caratteristiche generali ed illustrato
le rispettive architetture di funzionamento. Lo scopo di questo capitolo è, invece,
introdurre la metodologia e la tipologia dei test di funzionamento eseguiti sui middleware
presi in esame. I risultati di tali test sono stati poi raccolti e utilizzati per effettuare una
valutazione prestazionale delle varie soluzioni da cui si è ricavato un confronto che ha
portato a conclusioni che saranno espresse in seguito.
3.1 Sistema di Riferimento
Per effetturare i test delle prestazioni abbiamo utilizzato i calcolatori del laboratorio CINI
“CARLO SAVY”. Sugli host interessati per i test si è provveduto ad installare localmente i
middleware che abbiamo esaminato in questo lavoro di tesi, in modo da avere una
configurazione perfettamente omogenea non solo dal punto di vista hardware. Gli host
hanno tutte la medesima configurazione ed hanno le seguenti specifiche tecniche:
HOST: N. 2 CPU Xeon 2.8 Ghz con Hyperthreading per il sistema operativo sono
visibili 4 CPU, 5 GB di memoria RAM, Disco fisso SCSI di 36 GB, N. 2 interfacce
Gigabit Ethernet, N. 1 interfaccia Myrinet(2+2Gbit), Linux RedHat Enterprise con
Kernel version 2.6.25.
Gli host sono collegati tra loro mediante una rete Gigabit Ethernet, l'host server è collegato
mediante un'interfaccia Gigabit Ethernet alla rete privata del CINI e quest'ultima mediante
l'interfaccia GALILEO è collegata verso Internet permettendo così l'accesso da remoto agli
host, secondo lo schema di figura 3.1:

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
79
Figura 3.1 Schema Cluster CINI utilizzato per i test.
3.2 I Test
Stabilire quali dovessero essere la grandezza o le grandezze da misurare per effettuare uno
studio delle prestazioni del sistema, è stato il primo passo svolto nella fase di analisi delle
attività da svolgere.
A valle di tale fase, la scelta dell‟indice di prestazione è ricaduta sulla misura del tempo di
RTT (Round Trip Time) impiegato dal sistema per l'invio e la ricezione di messaggi di
dimensione diversa.
In particolare si è provveduto alla creazione di un benchmark che ha il compito di calcolare
il tempo di invio e ricezione dei messaggi scambiati tra Publisher e Subscriber. In

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
80
particolare il benchmark memorizza sul Publisher due timestamp T1 T2, e sul Subscriber
due timestamp T3 e T4 secondo la seguente metodologia:
il Publisher invia un messaggio registriamo il tempo T1
il Subscriber alla ricezione del messaggio del Publisher registra il tempo T3
il Subscriber manda indietro il messaggio di risposta registra il tempo T4
il Publisher alla ricezione del messaggio di risposta del Subscriber registra il
tempo T2
la latenza è data da T3-T1+T2-T4
Nello schema di figura 3.2 viene schematizzato il funzionamento del benchmark appena
descritto:
Figura 3.2 Schema di Calcolo Latenza

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
81
I tempi di inizio e fine che vengono rilevati durante i test sono memorizzati sia dal
Publisher che dal Subscriber in file di testo differenti. Tali valori verranno poi elaborati con
l‟ausilio di EXCEL per effettuare una rappresentazione grafica dei dati.
Vengono di seguito riportati i frammenti di codice nei quali sono rilevati i tempi T1, T2,
T3, T4.
Sono state eseguite prove differenti con le seguenti caratteristiche:
Test1: 1 Publisher 2 Subscriber: ciclo di scambio di messaggi di dimensione
progressivamente crescente
Test2: 1 Publisher 4 Subscriber: ciclo di scambio di messaggi di dimensione
progressivamente crescente
Test3: 1 Publisher 6 Subscriber: ciclo di scambio di messaggi di dimensione
progressivamente crescente
Tutti i test si riferiscono ad un numero di 1000 messaggi scambiati, i messaggi sono di
dimensione crescente si parte da un minimo di 4B fino ad arrivare ad un massimo di 4096B
con un incremento di 4B per volta, per l‟invio dei messaggi non abbiamo usato una
particolare frequenza di invio, ma questa è stata conseguenza solo dell‟utilizzo e del livello
di congestione della rete interna al CINI al momento dell‟esecuzione dei test.
3.3 Parametri di confronto
Il confronto tra le diverse soluzioni middleware publish/subscribe è stato condotto dal
punto di vista prestazionale. I parametri che abbiamo ritenuto opportuno scegliere a tale
scopo sono:
MEDIANA
DISTANZA INTERQUARTILE
SCALABILITA‟
La Mediana dei tempi, calcolata per ciascun test, ci da informazioni riguardanti le
prestazioni in termini di tempo.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
82
La definizione stretta è: La mediana è il valore che occupa la posizione centrale quando le
osservazioni di un campione sono ordinate in base al loro valore.
La Distanza Interquartile, calcolata per ciascun test, ci da informazioni riguardanti la
prevedibilità di consegna (prevedibilità, in termini di prevedibilità della distribuzione dei
tempi). E‟ un indice di dispersione che ci permette di conoscere la tendenza delle singole
osservazioni di una distribuzione ad allontanarsi dal valore centrale e quindi, è un indice
della variabilità dei dati.
La definizione stretta è: la differenza tra il terzo quartile (pari al 75% dei valori osservati) e
il primo quartile (pari al 25% dei valori osservati). Infine, in termini di analisi prestazionale
possiamo dire che: a distanza interquartile minore corrisponde maggiore prevedibilità di
consegna.
La Scalabilità è la capacità di un sistema di incrementare le proprie prestazioni, il proprio
throughput nel caso di sistemi trasmissivi, se a tale sistema vengono fornite nuove risorse
nel caso del software, maggiore potenza di processore o processori aggiuntivi, nel caso dei
sistemi distribuiti aumentando il numero di client il sistema non deve perdere le proprie
prestazioni. Dalla nostra analisi ricaviamo due curve di scalabilità, una è ottenuta mediante
la differenza tra il tempo di RTT ottenuto con 4 Subscriber in esecuzione ed il tempo di
RTT ottenuto con 2 Subscriber, l‟altra è ottenuta mediande la differenza tra il tempo di
RTT ottenuto con 6 Subscriber ed il tempo di RTT ottenuto con 2 Subscirber.
3.4 Test RTI - DDS
L‟implementazione RTI DDS, da noi usata per fare i test, ha una architettura
decentralizzata e di tipo simmetrico, come si nota dalla figura 3.3. Quest‟architettura pone
la relativa capacità di comunicazione e la relativa capacità di configurazione all‟interno
dello stesso processo utente. Queste capacità svolgono il loro compito in thread separati
che poi la libreria del middleware DCPS usa per gestire comunicazioni e QoS.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
83
Figura 3.3 Architettura decentralizzata
Per testare il funzionamento di RTI DDS è stato prodotto un applicativo Publish/Subscribe
costituito da due programmi:
Un programma che implementa il comportamento del publisher
Un programma che implementa il comportamento del subscriber
Ogni volta che l‟applicazione publisher invia dei dati in un Topic il middleware li replica a
tutti i Subscriber che hanno sottoscritto quel Topic. L‟applicazione nel lato Publisher non
deve curarsi di quanti siano i subscriber e tanto meno dove siano; lo stesso discorso vale
per il lato Subscriber, è lo stesso middleware RTI DDS a mantenere una lista di
applicazioni interessate al Topic ed alcune informazioni sulla QoS per l‟invio dei dati.
Ogni applicazione è autosufficiente, senza la necessità di un demone separato per la
comunicazione ra i partecipanti così come si evince dalla figura 3.3. Quando un nuovo
partecipante viene creato è lo stesso middleware che annuncia l'esistenza agli altri
partecipanti del nuovo subscriber lanciando dei pacchetti sulla rete.
Per ciascuno dei messaggi scambiati si e misurato il RTT e tali misurazioni sono state poi
raccolte in un file EXCEL.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
84
Nella seguente tabella vengono riportati i valori di mediana ottenuti per ognuno dei diversi
test effettuati:
RTI -DDS
Dim. Messaggi Test1 Test2 Test3
4 202021
240249,5 280665,5
8 202302,5
241127 280966
16 203722
244066 282158
32 207330,5
246877 283911
64 212326
253479 294539
128 220439,5
263676 313639,5
256 237466
280694 338933
512 254223
300967 367708
1024 301462
350700,5 427109,5
2048 378459
447118 534575,5
4096 505204
600083 721783
Tabella 3.1 Valori della mediana RTI - DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
85
Nella seguente tabella vengono riportati i valori della distanza interquartile ottenuti per
ognuna delle tipologie di test effettuati:
RTI -DDS
Dim. Messaggi Test1 Test2 Test3
4 267 43,5 253,5
8 83 1236 196
16 300 442 460
32 1063 568,5 2318,75
64 1908 4145 8073
128 7402,75 10061,25 12393,25
256 7566 8598 11506
512 12128 16507 22165
1024 24735,75 31124,25 31529,5
2048 47428,25 63431 85382,5
4096 76328,75 85961 94572
Tabella 3.2 Valori della distanza interquartile RTI - DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
86
Nella seguente tabella vengono riportati i valori della mediana di scalabilità.
RTI -DDS
Dim. Messaggi 2 Sub – 4 Sub 2 Sub – 6 Sub
4 38228,5 78644,5
8 39048 78677
16 40227 78081
32 39546,5 76624
64 40811 82213
128 43316 93106,5
256 44037 102067
512 46997 113665
1024 48285 126016
2048 67718 156077
4096 94031,5 218011
Tabella 3.3 Valori della mediana di Scalabilità RTI - DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
87
Come è possibile notare dalla figura 3.4 dai valori della mediana, possiamo dedurre che i
tempi di RTT aumentano con il crescere della dimensione del messaggio scambiato tra
publisher e subscribe, inoltre si nota che all‟aumentare del numero dei partecipanti allo
scambio dei messaggi si ha un salto verso l‟alto del tempo di RTT e ciò è dovuto al numero
maggiore di richieste che il publisher deve soddisfare.
Figura 3.4 Mediana dei tempi di RTT RTI - DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
88
Invece come è possibile notare dalla figura 3.5 per quanto riguarda l‟analisi visiva del
grafico della distanza interquartile si può dedurre che per messaggi di piccole dimensioni si
ha una maggiore prevedibilità di consegna anche all‟aumentare del numero di partecipanti
allo scambio di messaggi.
Figura 3.5 Distanza interquartile dei tempi di RTT RTI - DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
89
Nella figura 3.6 viene riportato il grafico della mediana di scalabilità, come si può notare
da questo grafico nel passaggio da 2 a 4 subscriber per messaggi di dimensioni inferiori ai
1024B le prestazioni della soluzione RTI – DDS subiscono piccole variazioni mentre per
messaggi di dimensioni superiori ai 1024B si ha un peggioramento delle prestazioni con
l‟aumento del tempo di RTT. Invece nel passaggio da 2 a 6 subscriber si ha un andamento
pressocchè crescente lungo tutta la curva di scalabilità.
Figura 3.6 Mediana Scalabilità RTI - DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
90
3.5 Test OpenSplice
L‟implementazione OpenSplice DDS, da noi usata per fare i test, ha una architettura
interna che utilizza una memoria condivisa di interconnessione, ovvero come si nota dalla
figura 3.7 utilizza un processo demone distinto per ogni interfaccia di rete. Il demone
dovrebbe essere inizializzato su ogni nodo prima dell‟instaurazione della connessione tra i
vari partecipanti. Una volta attivato, comunica con i demoni DCPS presenti sugli altri nodi
per istaurare un canale di comunicazione.
Figura 3.7 Architettura federata
Usando un demone si disaccoppiano le applicazioni dai dettagli di comunicazione e di
configurazione del DCPS. Inoltre, in caso di presenza di più partecipanti DDS sullo stesso
nodo, la scalabilità risulta maggiore rispetto agli altri modelli di architettura, infatti è
possibile semplificare la configurazione delle policy per un gruppo di partecipanti aventi la
stessa interfaccia di rete.
Per testare il funzionamento di OpenSplice DDS è stato prodotto un applicativo
Publish/Subscribe costituito da due programmi:
Un programma che implementa il comportamento del publisher
Un programma che implementa il comportamento del subscriber
Ogni applicazione si collegherà alle librerie OpenSplice al fine di utilizzare le
caratteristiche del DDS. Dato che i terminali di comunicazione sono situati su host
differenti i dati ottenuti utilizzando il DDS service locale devono essere comunicati al

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
91
DDS service remoto e viceversa, il demone ospl fornisce un ponte tra il DDS service
locale e quello remoto, quindi prima di avviare i due applicativi sugli host si deve
provvedere ad avviare il demone.
Per ciascuno dei messaggi scambiati si e misurato il tempo di RTT e tali misurazioni sono
state poi raccolte in un file EXCEL.
Nella seguente tabella vengono riportati i valori di mediana ottenuti per ognuna delle
tipologie di test effettuati:
OpenSplice DDS
Dim. Messaggi Test1 Test2 Test3
4 220750 276234,5 325591
8 221701 277080,5 325737
16 224132 277874 329164
32 226818 280888 334204
64 234285 287596 344573
128 246028 302867,5 366187,5
256 271172 321469 397353
512 298808 349964 437277
1024 352732 403703 511085
2048 446850 520851,5 636697
4096 602313 695167 847714,5
Tabella 3.4 Valori della mediana OpenSplice DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
92
Nella seguente tabella vengono riportati i valori della distanza interquartile ottenuti per
ognuna delle tipologie di test effettuati:
OpenSplice DDS
Dim. Messaggi Test1 Test2 Test3
4 23 650,5 75
8 1380 210,5 1307,5
16 619 1100 1373
32 1438,5 2054,25 1904,75
64 2979 4147 8950
128 8540,25 11195,75 17761,25
256 10698 11166 15164
512 20383 11779 27123
1024 35460,75 33697,5 38872,5
2048 59236 78160,5 82882,25
4096 96309 101345 135991,25
Tabella 3.5 Valori della distanza interquartile OpenSplice DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
93
Nella seguente tabella vengono riportati i valori della mediana di scalabilità.
OpenSplice DDS
Dim. Messaggi 2 Sub – 4 Sub 2 Sub – 6 Sub
4 55484,5 104841
8 54752 104768,5
16 53885 105231
32 54390,5 106985,5
64 53150 110147
128 55359 120297,55
256 49248 126334
512 49842 134690
1024 52516 157340,5
2048 70989,5 189068
4096 99842 251466,5
Tabella 3.6 Valori della mediana di Scalabilità OpenSplice - DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
94
Come è possibile notare dalla figura 3.8 dai valori della mediana, possiamo dedurre che i
tempi di RTT aumentano con il crescere della dimensione del messaggio scambiato tra
pubblisher e subscribe, inoltre si nota che all‟aumentare del numero dei partecipanti allo
scambio dei messaggi si ha un salto verso l‟alto del tempo di RTT e ciò è dovuto al numero
maggiore di richieste che il publisher deve soddisfare.
Figura 3.8 Mediana dei tempi di RTT OpenSplice DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
95
Invece come è possibile notare dalla figura 3.9 per quanto riguarda l‟analisi visiva del
grafico della distanza interquartile si può dedurre che per messaggi di piccole dimensioni si
ha una maggiore prevedibilità di consegna anche all‟aumentare del numero di partecipanti
allo scambio di messaggi.
Figura 3.9 Distanza interquartile dei tempi di RTT OpenSplice DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
96
Nella figura 3.10 viene riportato il grafico della mediana di scalabilità, come si può notare
da questo grafico nel passaggio da 2 a 4 subscriber per messaggi di dimensioni inferiori ai
1024B la soluzione OpenSplice – DDS ha un andamento pressocchè costante della curva di
scalabilità ciò sta ad indicare che pure aumentando il numero dei subscriber le prestazioni
della soluzione non subiscono variazioni percettibili mentre per messaggi di dimensioni
superiori ai 1024B si ha un peggioramento delle prestazioni con l‟aumento del tempo di
RTT secondo un andamento esponenziale. Nel passaggio da 2 a 6 subscriber questo
comportamento si ha fino a messaggi di dimensione pari a 64B, aumentando la dimensione
del messaggio da questo valore in poi si ha un andamento pressocchè crescente lungo tutta
la curva di scalabilità.
Figura 3.10 Mediana Scalabilità OpenSplice - DDS

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
97
3.6 Test CORBA TAO
L‟implementazione CorbaTAO, da noi utilizzata per i test segue l‟architettura
centralizzata, in cui usa un singolo demone operante su un nodo designato per la gestione
delle informazioni necessarie per creare e gestire le connessioni tra i partecipanti DDS in
un dominio. I dati passano direttamente dai Publisher ai Subscriber, mentre è necessaria la
comunicazione con il processo demone per il controllo e l‟inizializzazione delle attività.
Figura 3.11 Architettura centralizzata
Il vantaggio di quest‟architettura sta nella semplicità dell‟implementazione e della
configurazione poiché tutte le informazioni di controllo risiedono in un'unica locazione.
Per testare il funzionamento di CorbaTAO è stato prodotto un applicativo
Publish/Subscribe costituito da due programmi:
Un programma che implementa il comportamento del publisher
Un programma che implementa il comportamento del subscriber
Publisher e subscriber di eventi si connettono ad un event channel comune che risiede su
un host diverso da quelli su cui girano i due applicativi. I subscriber non devono essere a
conoscenza dei publisher e viceversa, perché è l‟event channel responsabile della consegna
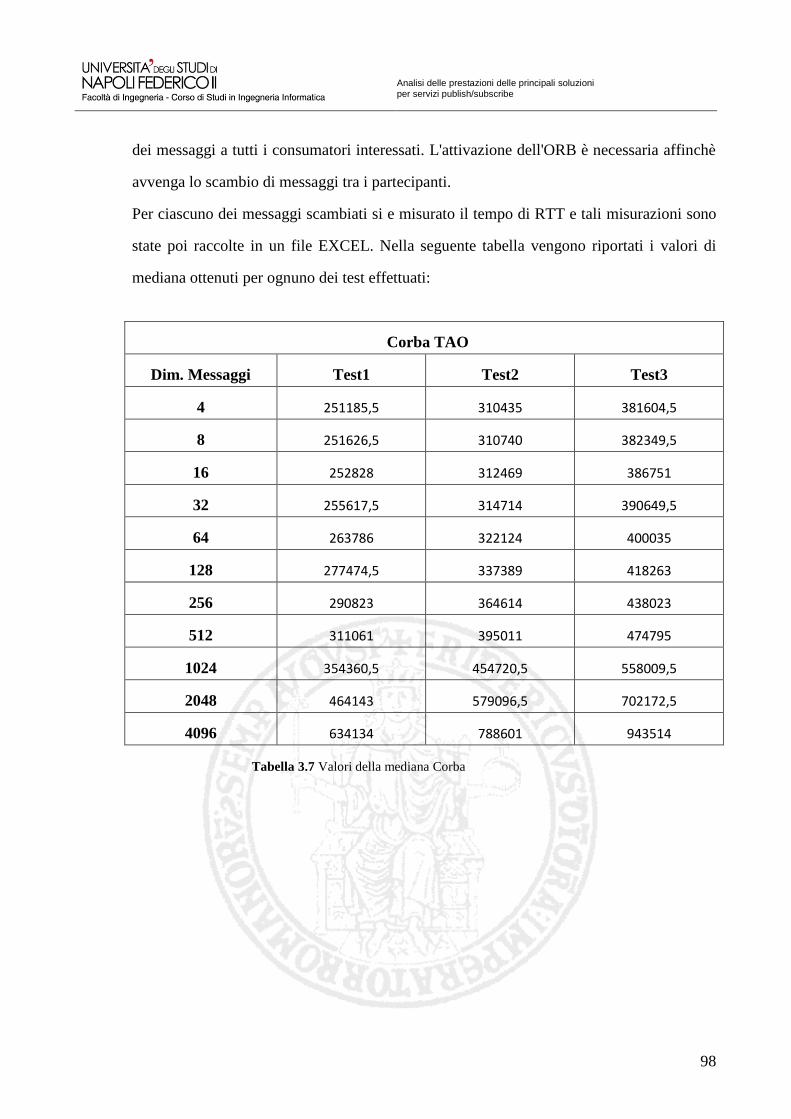
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
98
dei messaggi a tutti i consumatori interessati. L'attivazione dell'ORB è necessaria affinchè
avvenga lo scambio di messaggi tra i partecipanti.
Per ciascuno dei messaggi scambiati si e misurato il tempo di RTT e tali misurazioni sono
state poi raccolte in un file EXCEL. Nella seguente tabella vengono riportati i valori di
mediana ottenuti per ognuno dei test effettuati:
Corba TAO
Dim. Messaggi Test1 Test2 Test3
4 251185,5 310435 381604,5
8 251626,5 310740 382349,5
16 252828 312469 386751
32 255617,5 314714 390649,5
64 263786 322124 400035
128 277474,5 337389 418263
256 290823 364614 438023
512 311061 395011 474795
1024 354360,5 454720,5 558009,5
2048 464143 579096,5 702172,5
4096 634134 788601 943514
Tabella 3.7 Valori della mediana Corba

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
99
Nella seguente tabella vengono riportati i valori della distanza interquartile ottenuti per
ognuna delle tipologie di test effettuati:
Corba TAO
Dim. Messaggi Test1 Test2 Test3
4 323,5 88 693,5
8 243,5 269 1002,5
16 901 681 1139
32 2982,5 677,5 4402,5
64 3660 5630 6863
128 6625,25 11993,5 11632
256 4569 14321 6575
512 14880 19310 27530
1024 34176,5 33799,5 52885,25
2048 61794 74597,25 109471,25
4096 98820 130160 151537,5
Tabella 3.8 Valori della distanza interquartile Corba
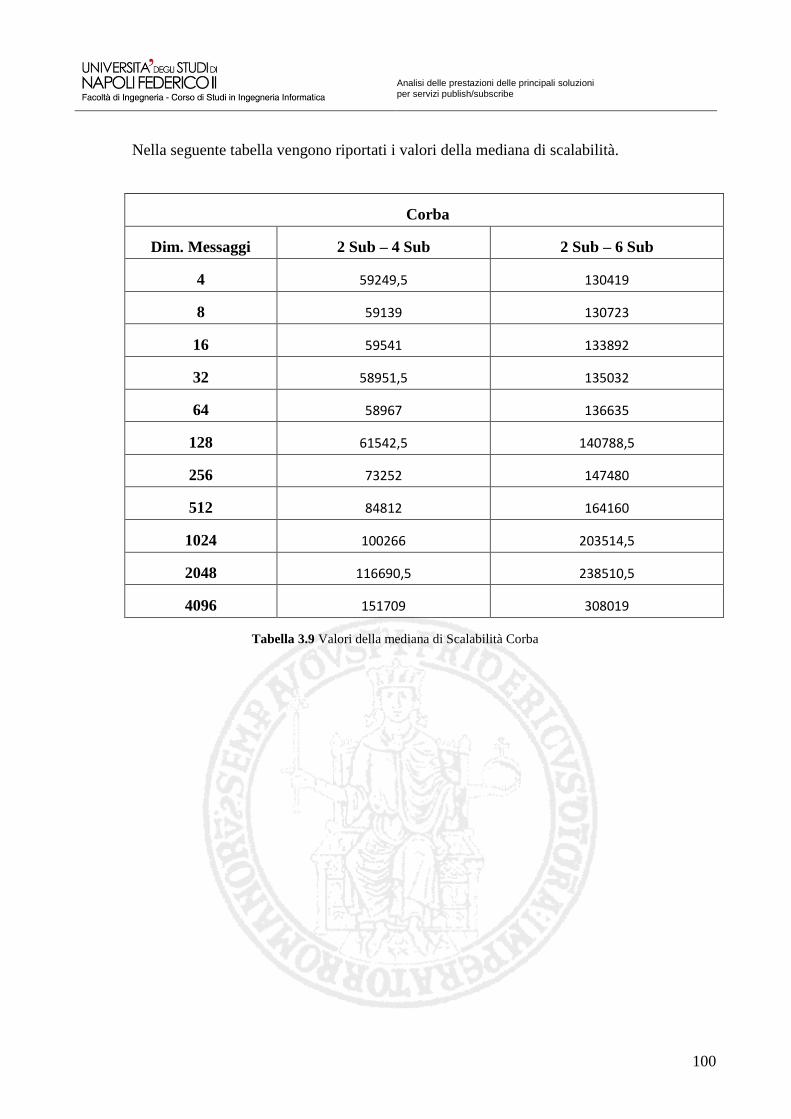
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
100
Nella seguente tabella vengono riportati i valori della mediana di scalabilità.
Corba
Dim. Messaggi 2 Sub – 4 Sub 2 Sub – 6 Sub
4 59249,5 130419
8 59139 130723
16 59541 133892
32 58951,5 135032
64 58967 136635
128 61542,5 140788,5
256 73252 147480
512 84812 164160
1024 100266 203514,5
2048 116690,5 238510,5
4096 151709 308019
Tabella 3.9 Valori della mediana di Scalabilità Corba

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
101
Come è possibile notare dalla figura 3.12 dai valori della mediana, possiamo dedurre che i
tempi di RTT aumentano con il crescere della dimensione del messaggio scambiato tra
pubblisher e subscribe, inoltre si nota che all‟aumentare del numero dei partecipanti allo
scambio dei messaggi si ha un salto verso l‟alto del tempo di RTT e ciò è dovuto al numero
maggiore di richieste che il publisher deve soddisfare
Figura 3.12 Mediana dei tempi di RTT Corba

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
102
Invece come è possibile notare dalla figura 3.13 per quanto riguarda l‟analisi visiva del
grafico della distanza interquartile si può dedurre che per messaggi di piccole dimensioni si
ha una maggiore prevedibilità di consegna anche all‟aumentare del numero di partecipanti
allo scambio di messaggi.
Figura 3.13 Distanza interquartile dei tempi di RTT Corba

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
103
Nella figura 3.14 viene riportato il grafico della mediana di scalabilità, come si può notare
da questo grafico nel passaggio da 2 a 4 subscriber per messaggi di dimensioni inferiori ai
128B la curva di scalabilità della soluzione Corba ha un andamento pressocchè costante,
ciò sta ad indicare che pure aumentando il numero dei subscriber le prestazioni della
soluzione non subiscono variazioni percettibili mentre per messaggi di dimensioni
superiori ai 128B si ha un peggioramento delle prestazioni con l‟aumento del tempo di
RTT secondo un andamento sempre crescente. Nel passaggio da 2 a 6 subscriber le
prestazioni si mantengono costanti per messaggi inviati fino alla dimensione di 256B,
aumentando la dimensione del messaggio da questo valore in poi si ha un andamento
pressocchè crescente lungo tutta la curva di scalabilità.
Figura 3.14 Mediana Scalabilità Corba

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
104
3.7 Test Apache ActiveMQ - CPP
L‟implementazione Apache ActiveMQ – CPP da noi utilizzata per i test segue
l‟architettura centralizzata, descritta nei paragrafi precedenti.
Per testare il funzionamento di Apache ActiveMQ – CPP è stato prodotto un applicativo
Publish/Subscribe costituito da due programmi:
Un programma che implementa il comportamento del publisher
Un programma che implementa il comportamento del subscriber
Il publisher ed il subcriber prima di iniziare lo scambio di messaggi devono creare una
factory di connessione con il JMS Event connection e successivamente tramite questo
registrarsi presso l‟event channel Apache ActiveMQ comune che risiede su un host diverso
da quelli su cui girano i due applicativi. Sull‟host deputato ad essere l‟event channel, viene
attivato il broker Apache ActiveMQ che si occupa di instradare i messaggi pubblicati dal
publisher verso i subscribe che hanno fatto richiesta di partecipare alla comunicazione.
Per ciascuno dei messaggi scambiati si e misurato il RTT e tali misurazioni sono state poi
raccolte in un file EXCEL.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
105
Nella seguente tabella vengono riportati i valori di mediana ottenuti per ognuna delle
tipologie di test effettuati:
Apache ActiveMQ – CPP
Dim. Messaggi Test1 Test2 Test3
4 180673 220928,5 332218,5
8 181625 221476 333778,5
16 184556 225242 335789
32 189234,5 228901 339304
64 194771 235711 355829
128 209354,5 250950 374439,5
256 223021 275797 413009
512 250775 310366 458408
1024 311671,5 364926,5 540213,5
2048 417873 525532,5 728006,5
4096 611272,5 764517 989378
Tabella 3.10 Valori della mediana Apache ActiveMQ - CPP
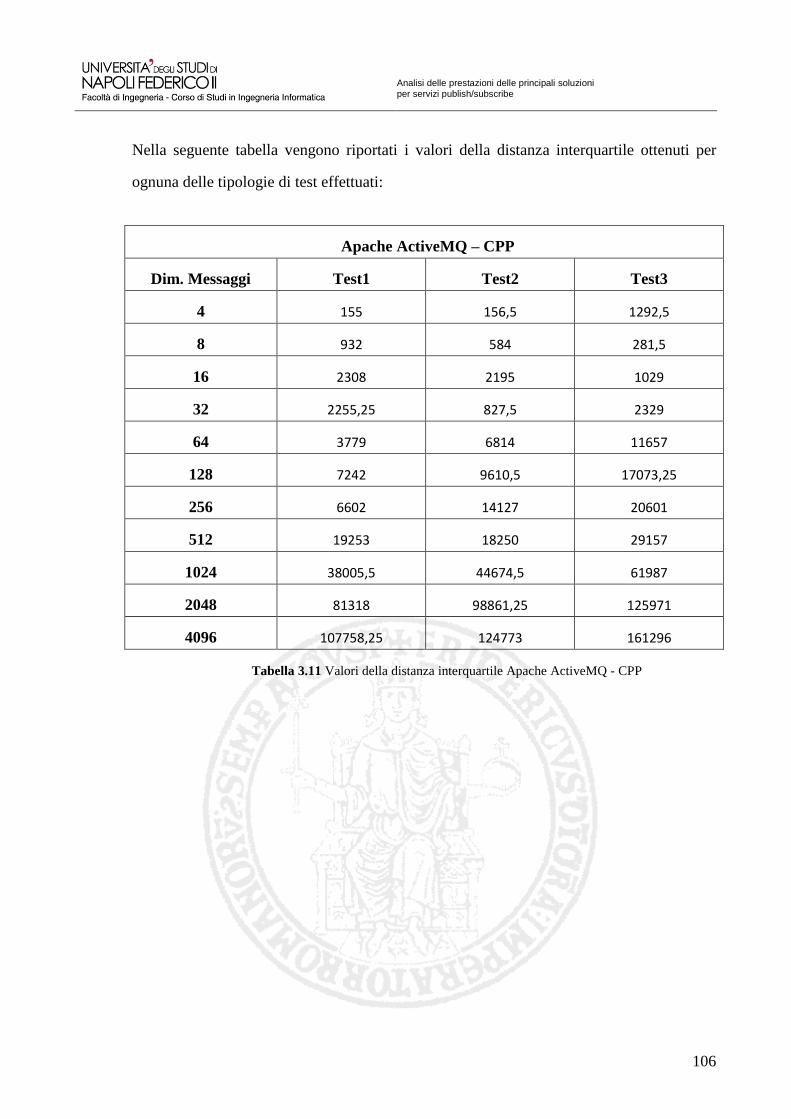
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
106
Nella seguente tabella vengono riportati i valori della distanza interquartile ottenuti per
ognuna delle tipologie di test effettuati:
Apache ActiveMQ – CPP
Dim. Messaggi Test1 Test2 Test3
4 155 156,5 1292,5
8 932 584 281,5
16 2308 2195 1029
32 2255,25 827,5 2329
64 3779 6814 11657
128 7242 9610,5 17073,25
256 6602 14127 20601
512 19253 18250 29157
1024 38005,5 44674,5 61987
2048 81318 98861,25 125971
4096 107758,25 124773 161296
Tabella 3.11 Valori della distanza interquartile Apache ActiveMQ - CPP
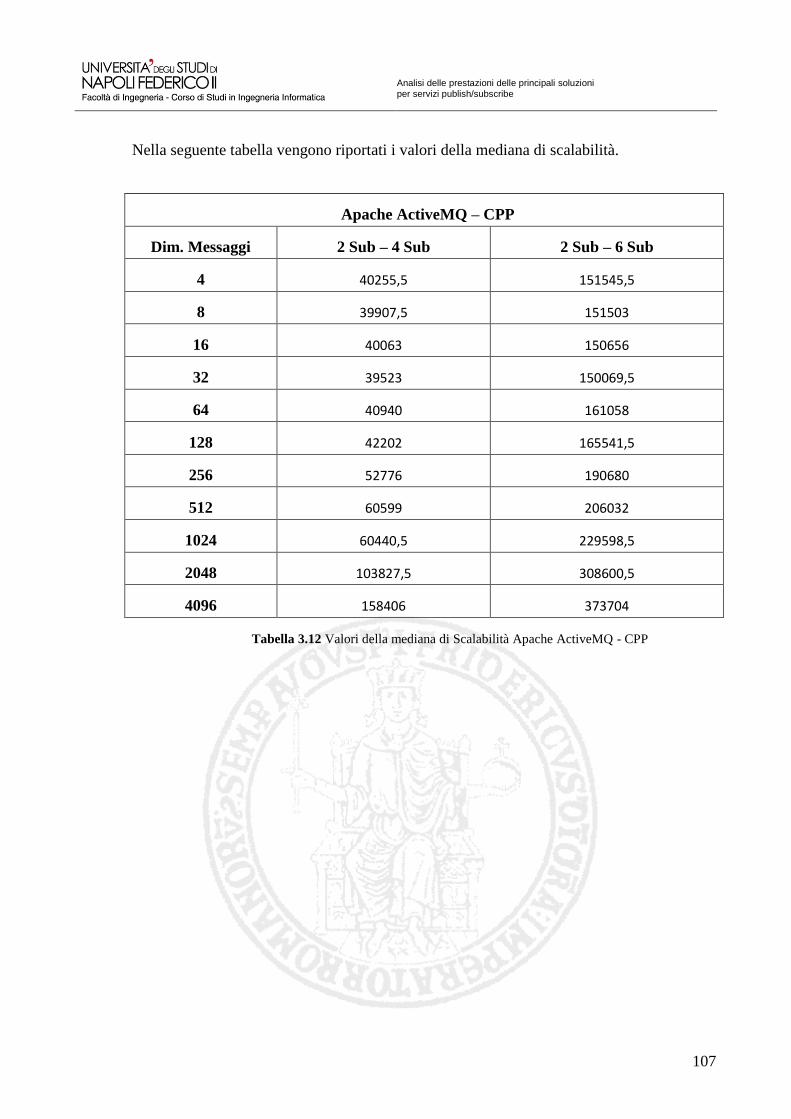
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
107
Nella seguente tabella vengono riportati i valori della mediana di scalabilità.
Apache ActiveMQ – CPP
Dim. Messaggi 2 Sub – 4 Sub 2 Sub – 6 Sub
4 40255,5 151545,5
8 39907,5 151503
16 40063 150656
32 39523 150069,5
64 40940 161058
128 42202 165541,5
256 52776 190680
512 60599 206032
1024 60440,5 229598,5
2048 103827,5 308600,5
4096 158406 373704
Tabella 3.12 Valori della mediana di Scalabilità Apache ActiveMQ - CPP
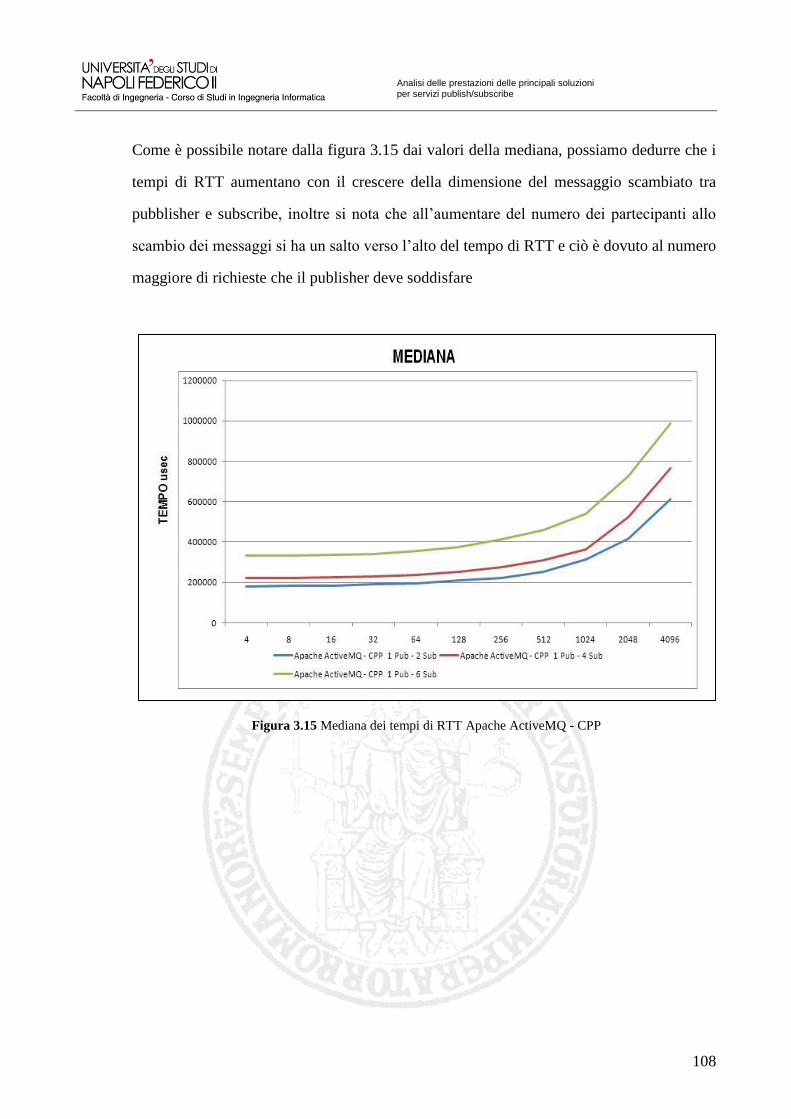
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
108
Come è possibile notare dalla figura 3.15 dai valori della mediana, possiamo dedurre che i
tempi di RTT aumentano con il crescere della dimensione del messaggio scambiato tra
pubblisher e subscribe, inoltre si nota che all‟aumentare del numero dei partecipanti allo
scambio dei messaggi si ha un salto verso l‟alto del tempo di RTT e ciò è dovuto al numero
maggiore di richieste che il publisher deve soddisfare
Figura 3.15 Mediana dei tempi di RTT Apache ActiveMQ - CPP

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
109
Invece come è possibile notare dalla figura 3.16 per quanto riguarda l‟analisi visiva del
grafico della distanza interquartile si può dedurre che per messaggi di piccole dimensioni si
ha una maggiore prevedibilità di consegna anche all‟aumentare del numero di partecipanti
allo scambio di messaggi.
Figura 3.16 Distanza interquartile dei tempi di RTT Apache ActiveMQ - CPP

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
110
Nella figura 3.17 viene riportato il grafico della mediana di scalabilità, come si può notare
da questo grafico nel passaggio da 2 a 4 subscriber per messaggi di dimensioni inferiori ai
128B la soluzione Apache ActiveMQ - CPP ha un andamento pressocchè costante della
curva di scalabilità ciò sta ad indicare che pure aumentando il numero dei subscriber le
prestazioni della soluzione non subiscono variazioni percettibili, per messaggi di
dimensioni comprese tra i 128B ed i 1024B si ha un piccolo scarto verso l‟alto mantendo
prestazioni accettabili, mentre per messaggi di dimensione superiore ai 1024B si ha un
peggioramento delle prestazioni con l‟aumento del tempo di RTT secondo un andamento
sempre crescente. Nel passaggio da 2 a 6 subscriber le prestazioni si mantengono costanti
per messaggi inviati fino alla dimensione di 32B, aumentando la dimensione del messaggio
da questo valore in poi si ha un andamento pressocchè crescente lungo tutta la curva di
scalabilità.
Figura 3.17 Mediana Scalabilità Apache ActiveMQ - CPP

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
111
3.8 Test OpenAMQ
OpenAMQ è un message middleware bastato sulle specifiche AMQP utilizzato per
costruire applicazioni distribuite che comunicano utilizzando messaggi. Il flusso dei
messaggi è asincrona, ciò significa che il flusso dei messaggi tra le parti avviene senza una
logica complessiva di sincronizzazione o di controllo.
L‟implementazione C++ che abbiamo utilizzato è in pratica un broker C++ che
implementa AMQP. Essenzialmente, AMQP è un middleware robusto che può gestire il
traffico di messaggi all‟interno di una rete di client collegati a degli intermediari chiamati
appunto broker.
OpenAMQ utilizza un‟architettura centralizzata e per testare le prestazioni di OpenAMQ è
stato prodotto un applicativo Publish/Subscribe costituito da due programmi:
Un programma che implementa il comportamento del publisher
Un programma che implementa il comportamento del subscriber
I due programmi comunicano tra di loro utilizzando il broker amqserver messo a
disposizione da OpenAMQ, il broker è attivato su un terzo host differente dagli host dove
vengono lanciati i due applicativi, il quale si occupa di instradare i messaggi pubblicati dal
publisher verso i subscribe che hanno fatto richiesta di partecipare alla comunicazione.
Quindi per il corretto svolgimento dei test si è provveduto ad installare su ogni macchina lo
strato middleware ed all‟attivazione del broker sulla macchina candidata ad essere il centro
per la comunicazione dei partecipanti ai test.
Per ciascuno dei messaggi scambiati si e misurato il RTT e tali misurazioni sono state poi
raccolte in un file EXCEL.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
112
Nella seguente tabella vengono riportati i valori della mediana ottenuti per ognuna delle
tipologie di test effettuati:
OpenAMQ
Dim. Messaggi Test1 Test2 Test3
4 241906,5 361647 412033,5
8 242145 362366 414125
16 243555 365575 417886
32 247997,5 371059,5 425322
64 258361 388449 440221
128 271287 411146,5 470094
256 294911 437807 503896
512 331682 484815 558306
1024 398560,5 561372,5 654650,5
2048 540987 754389 856821
4096 743316 1051373 1188383,5
Tabella 3.13 Valori della mediana OpenAMQ

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
113
Nella seguente tabella vengono riportati i valori della distanza interquartile ottenuti per
ognuna delle tipologie di test effettuati:
OpenAMQ
Dim. Messaggi Test1 Test2 Test3
4 137,5 49 309,5
8 163,5 1129,5 2086,5
16 952 2112 2030
32 959,5 3804,25 4309,75
64 5355 14099 7336
128 11691,5 14030,25 20318,25
256 10601 13328 12486
512 19022 32028 27454
1024 50184,75 59156 77434
2048 90226 132807,25 131255,75
4096 102711,5 185233 216051,25
Tabella 3.14 Valori della distanza interquartile OpenAMQ
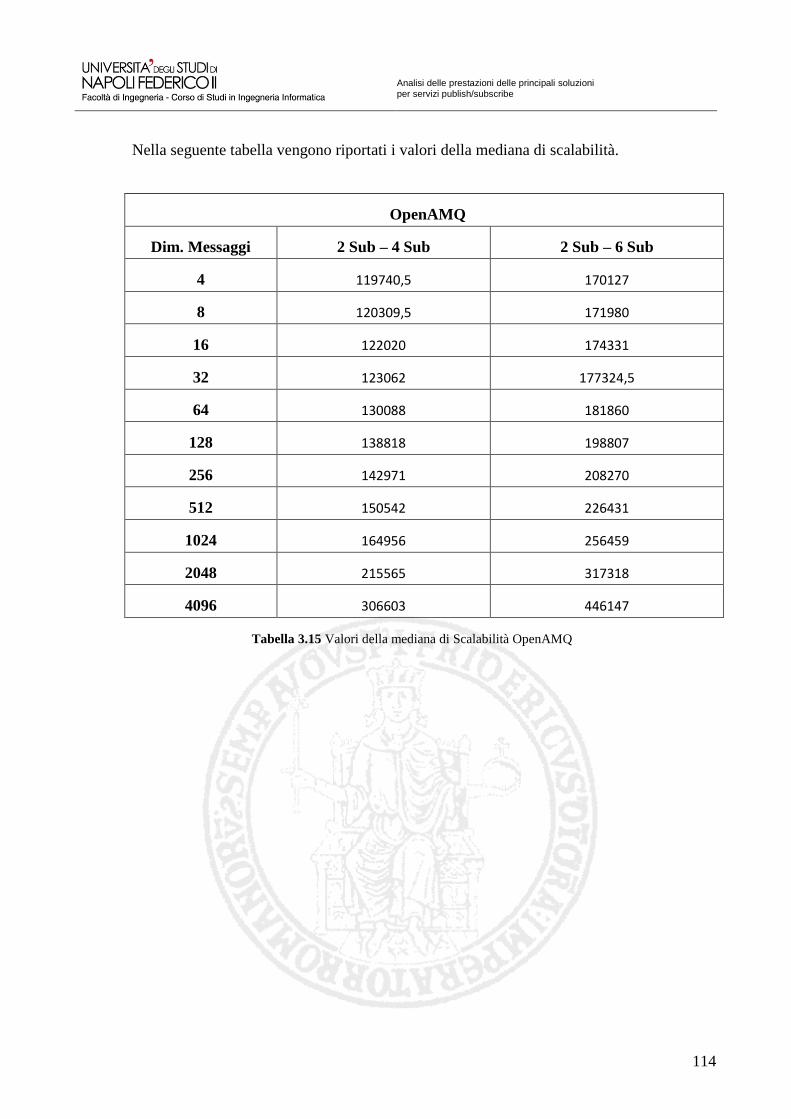
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
114
Nella seguente tabella vengono riportati i valori della mediana di scalabilità.
OpenAMQ
Dim. Messaggi 2 Sub – 4 Sub 2 Sub – 6 Sub
4 119740,5 170127
8 120309,5 171980
16 122020 174331
32 123062 177324,5
64 130088 181860
128 138818 198807
256 142971 208270
512 150542 226431
1024 164956 256459
2048 215565 317318
4096 306603 446147
Tabella 3.15 Valori della mediana di Scalabilità OpenAMQ

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
115
Come è possibile notare dalla figura 3.18 dai valori della mediana, possiamo dedurre che i
tempi di RTT aumentano con il crescere della dimensione del messaggio scambiato tra
pubblisher e subscribe, inoltre si nota che all‟aumentare del numero dei partecipanti allo
scambio dei messaggi si ha un salto verso l‟alto del tempo di RTT e ciò è dovuto al numero
maggiore di richieste che il publisher deve soddisfare
Figura 3.18 Mediana dei tempi di RTT OpenAMQ

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
116
Invece come è possibile notare dalla figura 3.19 per quanto riguarda l‟analisi visiva del
grafico della distanza interquartile si può dedurre che per messaggi di piccole dimensioni si
ha una maggiore prevedibilità di consegna anche all‟aumentare del numero di partecipanti
allo scambio di messaggi.
Figura 3.19 Distanza interquartile dei tempi di RTT OpenAMQ

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
117
Nella figura 3.20 viene riportato il grafico della mediana di scalabilità, come si può notare
da questo grafico nel passaggio da 2 a 4 subscriber per messaggi di dimensioni inferiori ai
32B la soluzione OpenAMQ ha un andamento pressocchè costante della curva di
scalabilità in cui le variazioni del tempo di RTT sono impercettibili, questo è a vantaggio
dei subscriber che pur aumentando di numero le prestazioni della soluzione non subiscono
variazioni eccessive, per messaggi di dimensioni comprese tra i 32B ed i 1024B si ha un
andamento crescente della curva di scalabilità con variazioni non eccessive, mentre per
messaggi di dimensione superiore ai 1024B si ha un netto peggioramento delle prestazioni.
Nel passaggio da 2 a 6 subscriber le prestazioni si mantengono costanti per messaggi
inviati fino alla dimensione di 64B, aumentando la dimensione del messaggio da questo
valore in poi si ha un andamento pressocchè crescente lungo tutta la curva di scalabilità.
Figura 3.20 Mediana Scalabilità OpenAMQ

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
118
3.9 Test QPID
Qpid è un incubator middleware, fornito da apache, è nato da un progetto in
collaborazione con red-hat riguardante un sistema di messaggistica open-source che
garantisca l‟interoperabilità tra le varie piattaforme esistenti all‟interno di un patchwork di
sistemi; tale protocollo di messaggistica è appunto AMQP. Qpid è stato installato e
utilizzato per realizzare i test riguardanti AMQP.
L‟implementazione C++ che abbiamo utilizzato è in pratica un broker C++ che
implementa AMQP. Essenzialmente, AMQP è un middleware robusto che può gestire il
traffico di messaggi all‟interno di una rete di client collegati a degli intermediari chiamati
appunto broker.
Qpid utilizza un'architettura di tipo centralizzato e per testare le prestazioni di Qpid è stato
prodotto un applicativo Publish/Subscribe costituito da due programmi:
Un programma che implementa il comportamento del publisher
Un programma che implementa il comportamento del subscriber
I due programmi comunicano tra di loro utilizzando il broker qpidd messo a disposizione
da Qpid, il broker è attivato su un terzo host differente dagli host dove vengono lanciati i
due applicativ, il quale si occupa di instradare i messaggi pubblicati dal publisher verso i
subscribe che hanno fatto richiesta di partecipare alla comunicazione. Quindi per il corretto
svolgimento dei test si è provveduto ad installare su ogni macchina lo strato middleware ed
all‟attivazione del broker sulla macchina candidata ad essere il centro per la comunicazione
dei partecipanti ai test.
Per ciascuno dei messaggi scambiati si e misurato il RTT e tali misurazioni sono state poi
raccolte in un file EXCEL.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
119
Nella seguente tabella vengono riportati i valori della mediana ottenuti per ognuna delle
tipologie di test effettuati:
QPID
Dim. Messaggi Test1 Test2 Test3
4 261924 321213,5 391743,5
8 261994,5 322066 394650,5
16 265203 324997 402312
32 267033,5 333590 408540
64 278681 349445 424717
128 291477 384779 461207,5
256 314706 419547 499377
512 352352 475535 557782
1024 408466,5 548248,5 671612,5
2048 543454 717455,5 860605,5
4096 732806 998251 1184010
Tabella 3.16 Valori della mediana QPID

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
120
Nella seguente tabella vengono riportati i valori della distanza interquartile ottenuti per
ognuna delle tipologie di test effettuati:
QPID
Dim. Messaggi Test1 Test2 Test3
4 48 761,5 1265,5
8 273 502 1736
16 784 1818 914
32 1864,75 1275 6473,5
64 5065 10435 9420
128 11640,75 16732,25 20855,25
256 12100 13057 25782
512 25535 36310 25970
1024 38621,5 46803,25 73202,5
2048 79075,25 113900,75 132916
4096 129904,5 175994,75 173874,75
Tabella 3.17 Valori della distanza interquartile QPID

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
121
Nella seguente tabella vengono riportati i valori della mediana di scalabilità.
QPID
Dim. Messaggi 2 Sub – 4 Sub 2 Sub – 6 Sub
4 59289,5 150109,5
8 60071,5 152130,5
16 59794 152683
32 66039,5 156948
64 70764 161540
128 93175 178438,5
256 106778 190393
512 122587 205119
1024 141634 246714
2048 175587 313367
4096 265605 462602
Tabella 3.18 Valori della mediana di Scalabilità QPID

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
122
Come è possibile notare dalla figura 3.21 dai valori della mediana, possiamo dedurre che i
tempi di RTT aumentano con il crescere della dimensione del messaggio scambiato tra
pubblisher e subscribe, inoltre si nota che all‟aumentare del numero dei partecipanti allo
scambio dei messaggi si ha un salto verso l‟alto del tempo di RTT e ciò è dovuto al numero
maggiore di richieste che il publisher deve soddisfare
Figura 3.21 Mediana dei tempi di RTT QPID

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
123
Invece come è possibile notare dalla figura 3.22 per quanto riguarda l‟analisi visiva del
grafico della distanza interquartile si può dedurre che per messaggi di piccole dimensioni si
ha una maggiore prevedibilità di consegna anche all‟aumentare del numero di partecipanti
allo scambio di messaggi.
Figura 3.22 Distanza interquartile dei tempi di RTT QPID

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
124
Nella figura 3.23 viene riportato il grafico della mediana di scalabilità, come si può notare
da questo grafico nel passaggio da 2 a 4 subscriber per messaggi di dimensioni inferiori ai
16B la soluzione QPID ha un andamento pressocchè costante della curva di scalabilità in
cui le variazioni del tempo di RTT sono impercettibili, questo è a vantaggio dei subscriber
che pur aumentando di numero le prestazioni della soluzione non subiscono variazioni
eccessive, per messaggi di dimensioni comprese tra i 16B ed i 64B la curva cresce ma
molto lentamente tanto che le variazioni non sono percettibili, mentre per dimensioni
superiori ai 64B si ha un andamento sempre crescente della curva con un netto
peggioramento delle prestazioni. Nel passaggio da 2 a 6 subscriber le prestazioni si
mantengono costanti per messaggi inviati fino alla dimensione di 64B, aumentando la
dimensione del messaggio da questo valore in poi si ha un andamento pressocchè crescente
lungo tutta la curva di scalabilità.
Figura 3.23 Mediana Scalabilità QPID

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
125
3.10 Confronto delle prestazioni delle soluzioni publish/subscribe
Di seguito riportiamo i grafici ottenuti utilizzando i valori di mediana, distanza
interquartile e scalabilità per le 3 tipologie di test effettuate. Ciascuno mette a confronto le
diverse soluzioni middleware esaminate in questo lavoro di tesi
Figura 3.24 Mediana dei tempi di RTT 1Pub – 2 Sub
Figura 3.25 Distanza interquartile dei tempi di RTT 1Pub – 2 Sub

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
126
Figura 3.26 Mediana dei tempi di RTT 1Pub – 4 Sub
Figura 3.27 Distanza interquartile dei tempi di RTT 1Pub – 4 Sub

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
127
Figura 3.28 Mediana dei tempi di RTT 1Pub – 6 Sub
Figura 3.29 Distanza interquartile dei tempi di RTT 1Pub – 6 Sub
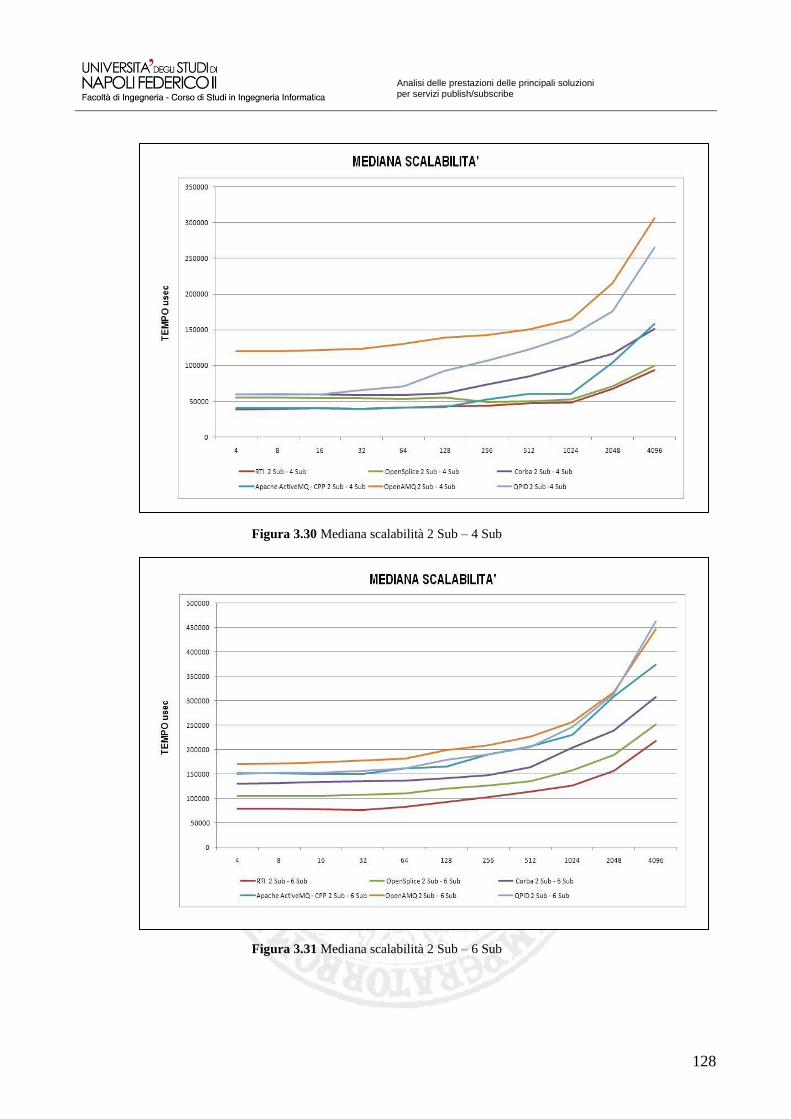
Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
128
Figura 3.30 Mediana scalabilità 2 Sub – 4 Sub
Figura 3.31 Mediana scalabilità 2 Sub – 6 Sub

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
129
Conclusioni e Sviluppi Futuri
La qualità dei risultati ottenuti dalle analisi sono fortemente dipendenti dall‟architettura
delle soluzioni esaminate e dai parametri di qualità del servizio definiti, vi è infatti una
stretta dipendenza delle prestazioni del sistema e delfunzionamento complessivo. dai
parametri di qualità del servizio definiti.
Il middleware RTI DDS, avendo un‟architettura decentralizzata, ha il vantaggio di non
aver bisogno di un demone o broker per lo scambio di messaggi, facendo risultare così
ogni applicazione autonoma. In termini prestazionali questo si traduce in un minore tempo
di consegna dei messaggi scambiati tra i partecipanti. Infatti dall‟analisi dei grafici riportati
nel paragrafo precedente è l‟unica soluzione che garantisce un tempo di RTT minore.
Questa soluzione garantisce, sia all‟aumentare della dimensione dei messaggi scambiati
che del numero dei subscriber, una migliore prevedibilità di consegna infatti come si
evince dai grafici della distanza interquartile si notano bassi valori di quest‟ultima. Per
quanto rigurada la scalabilità questa è l‟unica soluzione che riesce pur aumentando il
numero dei subscriber a mantere prestazioni ottimali.
Il middleware OpenSplice DDS, avendo un‟architettura federata, ha un processo demone
distinto su ogni host, ciò permette un maggiore disaccoppiamento delle parti, ma in termini
prestazionali si traduce in un tempo di RTT di poco superiore a quello del middleware RTI
DDS in quanto i messaggi devono attraversare il demone prima di essere consegnati al
destinatario. Anche questa soluzione riesce a garantire una buona prevedibilità di
consegna, ma non ai livelli di RTI, ed in termini di scalabilità risulta essere la seconda
soluzione che riesce a mantenere buone prestazioni all‟aumentare del numero dei
subscriber.
In fine middleware come Corba, Apache ActiveMQ, OpenAMQ, QPID, avendo un
architettura centralizzata, forniscono delle forti capacità d'interoperabilità tra sistemi
eterogenei, sfruttando la caratteristica d'intermediazione del broker. In termini prestazionali

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
130
questo si traduce in un tempo di RTT maggiore dovuta proprio al fatto che i messaggi
scambiati devo attraversare l‟host su cui risiede il broker. Anche queste soluzioni risultano
avere una buona prevedibilità di consegna con andamenti della curva della distanza
interquartile molto simili. In termini di scalabilità Corba si pone un gradino sopra la
soluzione RTI – DDS ed OpenSplice – DDS, mentre le altre sono nettamente distaccate
dalle altre e le prestazioni decadono con l‟aumentare dei partecipanti allo scambio dei
messagi.
Per le applicazioni real time e mission critical la soluzione middleware RTI DDS è
preferibile alle altre perché garantisce un tempo minore di RTT per il vantaggio di avere
uno scambio diretto tra le parti e una maggiore prevedibilità di consegna.
Un ulteriore sviluppo di questo lavoro può procedere nella direzione di estendere gli
scenari di comunicazione sia unicast che multi cast in una rete reale quale internet, caso
quest‟ultimo non considerato in questo lavoro. Inoltre sarebbe opportuno determinare il
comportamento delle diverse soluzioni middleware per un numero ancora crescente di nodi
e quindi valutare in modo approfondito le caratteristiche intrinseche di scalabilità delle
diverse soluzioni.
Per concludere è necessario sottolineare come la qualità dei risultati ottenuti dalle analisi
sulle diverse soluzioni siano dipendenti dalla tipologia architetturale e dalle qualità del
servizio definite.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
131
Ringraziamenti
Dopo anni di intenso studio e sacrifici, ci si guarda dentro e ci si rende conto che la più
grande forza, per andare avanti, nasce dal desiderio di far felici le persone che ti sono state
accanto e che hanno “scommesso” sulle tue capacità e giunto alla fine di questo intenso
lavoro penso sia più che giusto spendere due parole anche verso coloro che mi hanno
aiutato e sostenuto in questo lungo e faticoso percorso.
In assoluto le singole persone che piú di ogni altre meritano che questo lavoro fosse loro
dedicato sono certamente i miei genitori, mia sorella, ed il mio carissimo amico di sempre
Roberto, a tutti loro dedico un ringraziamento sincero per aver avuto una grande pazienza,
per aver aspettato, per aver atteso così a lungo questo traguardo che mi accingo a
raggiungere, per avermi sopportato e supportato cosí a lungo. Ad essi vanno tutta la mia
stima, il mio rispetto e la mia riconoscenza, senza di loro non sarei mai potuto arrivare fino
a qui.
Un ringraziamento particolare è rivolto al Prof. Domenico Cotroneo, che ha saputo
suscitare interesse nella materia, che ha dimostrato di essere, innanzitutto, una grande
persona prima che un professore, dando conforto ai suoi tesisti nei momenti di difficoltà,
che grazie a lui ho portato a termine due esperienze uniche, la prima senza ombra di
dubbio questo lavoro di tesi, le seconda è l‟opportunità lavorativa presso la System
Management, svolta in questi ultimi mesi di tesi.
Un doppio ringraziamento è rivolto al Dott. Ing. Christian Esposito, doppio perché ancor
prima di essere il mio correlatore per questa tesi, è stato, è e sarà un amico fidato su cui
poter contare sempre, come “Correlatore” è stato impeccabile, mi ha seguito con grande
attenzione dimostrandosi sempre “risolutivo” e “disponibile”, consigliandomi la strada
giusta da seguire durante lo sviluppo e la stesura, come “Amico” mi è stato vicino in un
momento particolare della mia vita, e come pochi è rimasto ad ascoltarmi e consigliarmi in
tante lunghe chiacchierate.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
132
Ora passiamo ai ringraziamenti più spensierati!!! Un grazie va a tutti i miei compagni di
avventura ed in particolare:
A Ettore per avermi spronato a dare il meglio negli ultimi esami, per aver rallegrato le
giornate di studi di questi ultimi anni nell‟aula studio c2a, per la bellissima amicizia che mi
ha regalato e per avermi saputo ascoltare e consigliare. Sicuramente un punto fermo di
questi anni sia per quanto riguarda il percorso di studi sia per quanto riguarda ai valori in
cui credere, un amico sincero sempre presente, pronto a sostenermi nel momento di
bisogno.
A Roberto Fulgido ricordo ancora quando insieme ci immatricolammo, quando i primi
anni insieme seguivamo i corsi e ci facevamo coraggio a vicenda per superare gli esami di
questo lungo percorso, dapprima sinceri compagni di studi e poi il tempo ha contribuito a
consolidare una forte amicizia di quelle che non finiscono con un percorso, ma che
continua al di là degli impegni della vita privata e lavorativa.
A Peppe Di Meo, alias “The pezzott‟ man”, è stata una delle prime persone che ho
conosciuto all‟università insieme a Roberto, lo ringrazio per il supporto che mi ha concesso
nei primi anni di studi, ricordo ancora le ore trascorse insieme allo C.S.I.F. facendo tanti
programmi di esempio per l‟esame di Fondamenti II, e le pause pranzo trascorse a giocare
con una pseudo palla di carta stagnola presso le aule T di Monte Sant‟Angelo quelli erano
anni spensierati, il punto di partenza di quello che siamo oggi, due buoni amici che hanno
condiviso tanto durante il percorso di studi che condividono oggi un‟amicizia sincera fatta
di scorribande serali.
Il mio sogno è quello di poter un giorno lavorare insieme a loro tre, magari in un‟azienda
di consulenza tutta nostra.
Alla compagnia del pezzotto di cui sono membri Arcangelo De Micco, Peppe Ardizio,
Davide Di Mare, Maria Esposito, Iolanda Pennino che hanno saputo rallegrare questi anni
di studi, che si sono sempre interessati sugli esami che sostenevo, per avermi fornito
appunti e materiali.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
133
A tutti gli amici e colleghi di università che ho incontrato lungo il mio cammino e chi più
chi meno mi ha dato un aiuto a proseguire verso il mio traguardo.
Agli amici di laboratorio Antonio, Berniero, Giuseppe che hanno rallegrato un laboratorio
quello del Cini altrimenti solitario ed austero, che hanno reso indimenticabile le pause
pranzo.
Desidero inoltre ringraziare una serie di persone che in circostanze spesso diverse mi
hanno dato serenità, amicizia e supporto morale nell‟arco di quest‟ultimo anno: Maria che
mi ha saputo ascoltare e consigliare in momenti difficili, sempre presente e con parole che
sono sempre riuscite a donarmi conforto, Daniele ragazzo leale sincero, spero il tempo mi
dirà vero amico, che nonostante i miei modi di fare è stato sempre pronto a sostenermi ed
ascoltarmi, specialmente quest‟estate durante il viaggio a Madrid, Eleonora che ogni volta
che uscivamo la sera era sempre pronta a riempirmi la testa di chiacchiere, ma anche a
lasciarsela riempire, Felicia per essere riuscita ad ascoltarmi sempre e comunque, che
nonostante tutto è un‟amica sincera come poche, Manferino “m‟ schiaffiass san‟ san‟” con
questo ho detto tutto sempre pronto a narrare eventi quasi leggendari delle sue vacanze
trascorse qua e là in giro per il mondo, Emilia e Antonio che hanno saputo darmi ottimi
consigli in questo ultimo periodo, Anita compagna di bevute e per avermi fatto ascoltare
buona musica, Paola e Mauro per aver rallegrato le serate in piazzetta San Pelato, Pina per
aver avuto sempre una parola di conforto, Giuseppina pur non essendo vicini, pur divisi da
tanti chilometri siamo riusciti confortarci a vicenda in un periodo particolare delle nostre
vite da lì è nata un‟amicizia che va oltre le distanze, oltre ogni immaginazione.
Infine voglio ringraziare gli amici nonché colleghi della System Management che mi
hanno sopportato e supportato in questi ultimi due mesi, ringrazio Antonino, Lina,
Antonella, Grazia, Anna, Marianna, Fulvio, Valentina, ed un ringraziamento particolare va
ad Annalisa, le sue idee sono state illuminanti per gli ultimi sviluppi di questo lavoro di
tesi.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
134
Un ringraziamento va anche a tutte quelle persone che sicuramente avrò dimenticato,
quindi un grazie sincero a tutti ognuno di voi mi ha dato qualcosa.
Grazie a tutti di tutto
Vincenzo

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
135
Bibliografia
[1] S.Russo, C. Savy, D. Cotroneo, A. Sergio 2003 “Introduzione a corba”
[2] Christian Esposito “DDS‐ related material for beginners”
[3] EUGSTER, FELBER, GUERRAOUI, KERMARREC “The Many Faces of
Publish/Subscribe”
[4] R. Baldoni, R. Beraldi, S. Tucci Piergiovanni, A. Virgillito, 2004 “Measuring
notification loss in publish/subscribe communication systems”.
[5] I. Dionysiou, D. Frincke, D. E. Bakken, Hauser, 2005 “Actor-oriented trust.
Technical Report EECS-GS-006”.
[6] Diot, C., Levine, B., Lyles, B., Kassem, H., Balensiefen, 2000 “Deployment issues
for the ip multicast service”.
[7] Shi, Y.S. 2002 “Design of Overlay Networks for Internet Multicast”
[8] Haung, Y., Garcia-Molina, 2001“Publish/Subscribe in a Mobile Environment”.
[9] Anceaume, E., Datta, A.K., Gradinariu, M., Simon, G. 2002 “Publish/Subscribe
scheme for mobile networks”. 74-81.
[10] Caporuscio, M., Carzaniga, A., Wolf, A.L. 2003 “Design and evalutation of a
support service for mobile, wireless publish/subscribe applications”. 1059-1071.
[11] Muthusamy, V., Petrovic, M., Jacobsen, H.A. 2005 “Effects of routing
computations in content-based routing network with mobile data sources”. 103-116.
[12] Sun Microsystems Inc. “Java messagge serviceapi” rev 1.1, 2002.
[13] Oki B., Pfluegel M., Siegel A., Skeen, D. 1993 “The information bus an architecture
for extensive distributed system”.
[14] Baehni S., Eugster P.T., Guerraoui R. 2004 “Data-aware multicast” 233-242.
[15] Segall B., Arnold D., J. Henderson M., Phelps T. 2000 “Content Based Routing
with Elvin”.
[16] Fabret F., Jacobsen A., Lirbat F., Pereira J., Ross K., Shasha D. 2001 “Filtering
algorithms and implementation for very fast publish/subscribe”. 115-126.

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
136
[17] Muhl G., 2001 “Generic Constraints for Content-Based Publish/Subscribe”
[18] Eugster P., 2001 Guerraoui R., Damm C. 2001 “On Objects and Events”
[19] Eugster P. 2001 Type-based publish/subscribe.
[20] Rowstron A., Druschel P. 2001 “Pastry: Scalable, decentralized object location, and
routing for large-scale peer-to-peer system”. 329-350.
[21] Stoica I., Morris R., Karger D., Kaashoek M.F., Balakrishnan H. 2001 “Chord: A
scalable peer-to-peer lookup service for internet application”.
[22] Ratnasamy S., Handley M., Karp, R. Shenker S. 2001 “Application-level multicast
using content-addressable networks”. 14-34.
[23] Baldoni R., Beraldi R., Cugola G., Migliavacca M. Querzoni, L. 2005 “Structure-
less Content-Based Routing in Mobile Ad Hoc Networks”.
[24] Carzaniga A., Rosenblum D., Wolf A., 2001 “Design and Evalutation of a Wide-
Area Notification Service”. 332-383
[25] Carzaniga a., Rutherford M.J., Wolf A.L. 2005 “A routing scheme for content-based
networking”.
[26] Bittner S., Hinze A. 2005 “A classification of filtering algorithms in content-based
publish/subscribe system”.
[27] Baldoni R., Marchetti C., Virgillito A., Vitenberg, R., 2005 “Content-based publish-
subscribe over structured overlay networks”.
[28] Birman K.P., Hayden M., Ozkasap O., Xiao Z., Budiu M., Minsky Y. 1999
“Bimodal multicast”. 41-88.
[29] RTI “The Real-Time Publish-Subscribe Middleware – User‟s Manual”, Version 4.1
[30] http://www.omg.org/technology/documents/dds_spec_catalog.htm “Data
Distribution Service (DDS) for Real-Time” Systems, OMG Specification version 1.2
[31] PrismTech “OpenSplice Version 2.2 C Tutorial Guide”
[32] M.Henning, S.Vinoski – “Advanced CORBA Programming with C++”- 1999
[33] Alan L. Pope. The CORBA Reference Guide

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
137
[34] Object Management Group. “The Common Object Request Broker Architecture
and Specification”. Revision 2.6 December 2001
[35] Object Management Group. Web site. http://www.omg.org
[36] Cetus Links, “Distributed Objects and components: CORBA”. http://www.cetus-
links.org/oo_corba.html
[37] IBM “CORBA notification services”
http://www.ibm.com/developerworks/library/co-cjct7/
[38] http://onjava.com/onjava/2001/12/12/jms_not.html
[39] C.O‟Ryan, D.C.Schmidt et alter – “The Design and Performance of a Scalable ORB
Architecture for CORBA Asynchronous Messaging” – 2000
[40] D.C.Schmidt, S.Vinosky – “An Overview of the CORBA Messaging QoS
Framework” – 2000
[41] OMG - “CORBA Messaging Specification” - http://www.omg.org/cgi-
bin/doc?formal/04-03-09
[42] OMG - “FT CORBA” - http://www.omg.org/cgi-bin/doc?formal/04-03-10
[43] OMG – “Data Distribution Service Specification”
http://www.omg.org/technology/documents/formal/data_distribution.htm
[44] http://it.wikipedia.org/wiki/Java_Message_Service
[45] http://java.sun.com/products/jms/
[46] http://www.codemesh.com/products/junction/examples/jms.html
[47] http://en.wikipedia.org/wiki/Apache_ActiveMQ
[48] http://activemq.apache.org/articles.html
[49] Apache ActiveMQ User Manual
[50] JMS User Manul
[51] IEEE Advanced Message Queueing Protocol – 0-10 Specification.
[52] QPID User Manual.
[53] http://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol

Analisi delle prestazioni delle principali soluzioni per servizi publish/subscribe
138
[54]
http://www.amqp.org/confluence/display/AMQP/Advanced+Message+Queuing+Protocol
[55] http://www.openamq.org/doc:rfc-cml
[56] http://qpid.apache.org/documentation.html
[57] “Service-Oriented Architecture and Web Service: Concepts, Technologies, and
tools.” Ed Ort http://java.sun.com/developer/technicalArticles/WebServices/soa2/
[58] “What‟s new in SOA and Web Service” Ed Ort
http://java.sun.com/developer/technicalArticles/WebServices/soa2/WhatsNewArticle.html
[59] “SEDA: An Architecture for Scalable, Well Conditioned Internet Services” Matt
Welsh, David Culler, and Eric Brewer http://www.eecs.harvard.edu/~mdw/talks/seda-
sosp01-talk.pdf
[60] “SEDA: An Architecture for Scalable, Well Conditioned Internet Services” Matt
Welsh, David Culler, and Eric Brewer http://www.eecs.harvard.edu/~mdw/papers/seda-
sosp01.pdf


















