
Algoritmi e Strutture Dati1 -...
184
Algoritmi e Strutture Dati 1 Corso di Laurea in Ingegneria dell’Informazione Sapienza Universit` a di Roma – sede di Latina Fabio Patrizi Dipartimento di Ingegneria Informatica, Automatica e Gestionale (DIAG) Sapienza Universit` a di Roma – Italy www.dis.uniroma1.it/ ~ patrizi [email protected] 1 Slides prodotte a partire dal materiale didattico fornito con il testo Demetrescu, Finocchi, Italiano: Algoritmi e strutture dati, McGraw-Hill, seconda edizione.
Transcript of Algoritmi e Strutture Dati1 -...

Algoritmi e Strutture Dati1
Corso di Laurea in Ingegneria dell’InformazioneSapienza Universita di Roma – sede di Latina
Fabio Patrizi
Dipartimento di Ingegneria Informatica, Automatica e Gestionale (DIAG)
Sapienza Universita di Roma – Italy
www.dis.uniroma1.it/
~
patrizi
1
Slides prodotte a partire dal materiale didattico fornito con il testo Demetrescu,Finocchi, Italiano: Algoritmi e strutture dati, McGraw-Hill, seconda edizione.

Informazioni Generali
Docente: Fabio Patrizi
email: [email protected]
web: http://www.dis.uniroma1.it/~
patrizi
Libro di testo adottato: Demetrescu, Finocchi, Italiano, Algoritmi estrutture dati, McGraw-Hill, seconda edizione. 2008.
Pagina web del corso: http://www.dis.uniroma1.it/~
patrizi/
sections/teaching/asd-latina-17-18/index.html
Ricevimento: prima/dopo lezione (inviare un’email il giornoprecedente)
Algoritmi e Strutture dati Fabio Patrizi 2

Obiettivi del Corso
Obiettivi principali:
Illustrare le tecniche algoritmiche e le strutture dati fondamentali perrisolvere in modo e�ciente problemi computazionali
Introdurre gli strumenti fondamentali per valutare la qualita deglialgoritmi e delle strutture dati
Impareremo a:
Misurare l’e�cienza di algoritmi e strutture dati
Progettare e selezionare gli algoritmi e le strutture dati piu appropriatiper la soluzione e�ciente di un dato problema
Algoritmi e Strutture dati Fabio Patrizi 3

Introduzione all’Analisi di Algoritmi
Algoritmi e Strutture dati Fabio Patrizi 4

AlgoritmiIntuizione
Un algoritmo e un insieme di passi semplici che, se eseguitimeccanicamente, producono un risultato determinato.
Esempio
Algoritmo preparaCaffe
Svita la ca↵ettieraRiempi d’acqua il serbatoio della ca↵ettieraInserisci il filtroRiempi il filtro con la polvere di ca↵eAvvita la parte superiore della ca↵ettieraMetti la ca↵ettiera sul fornelloAccendi il fornelloSpegni il fornello quando il ca↵e e pronto
Algoritmi e Strutture dati Fabio Patrizi 5

Algoritmi
Algoritmo:
Procedimento per risolvere un problema
Fa uso di strutture dati
Programma:
Implementazione di un algoritmo
Algoritmo 6= Programma
Questo corso introduce gli strumenti di analisi degli algoritmi e dellestrutture dati
Useremo lo pseudocodice per definire gli algoritmi
Algoritmi e Strutture dati Fabio Patrizi 6

Analisi di Algoritmi e Strutture Dati
Analizziamo il procedimento adottato, non il programma che loimplementa
Vantaggi:
Analisi generale, indipendente da:I dettagli implementativiI particolari istanze considerate (per il test del programma)
Stima delle prestazioni di un programma prima dell’implementazione
Obiettivi principali:
Valutare la qualita di un algoritmo
Scegliere tra piu alternative, quando disponibili
Algoritmi e Strutture dati Fabio Patrizi 7

Esempio: i numeri di Fibonacci
Numeri di FibonacciSuccessione di numeri interi F
1
, F2
, . . ., definita come segue:
Fn
=
⇢1, se 1 n 2
Fn�1
+ Fn�2
, se n > 2
ProblemaDato un intero positivo n, calcolare l’n-esimo numero di Fibonacci, F
n
Algoritmi e Strutture dati Fabio Patrizi 8

Fibonacci: soluzione analitica
E possibile dimostrare che:
Formula di Binet, 1843
Fn
=
1p5
(�n � ˆ�n
)
Dove:
� =
1+
p5
2
= 1.6180339887...
ˆ� =
1�p5
2
= �0.6180339887...
Osservazione:
� e ˆ� irrazionali: non rappresentabili finitamente
Algoritmi e Strutture dati Fabio Patrizi 9

L’algoritmo fibonacci 1
Possiamo usare il seguente algoritmo?
Algoritmo fibonacci 1(intero n)! intero
return
1p5
(�n � ˆ�n
)
Purtroppo � e ˆ� sono irrazionaliIl valore restituito approssima F
n
ma non e quello cercato
Con � = 1.618 e
ˆ
� = �0.618, abbiamo:
n fibonacci 1 arrotondamento Fn
3 1.99992 2 2
16 986.698 987 987
18 2583.1 2583 2584
L’algoritmo non e corretto!
Vediamo altre possibili soluzioni...Algoritmi e Strutture dati Fabio Patrizi 10

L’algoritmo fibonacci 2
Sfruttiamo la definizione ricorsiva di Fn
Algoritmo fibonacci 2(intero n)! intero
1: if n 2 then
2: return 13: else
4: return (fibonacci 2(n� 1) + fibonacci 2(n� 2))
fibonacci 2 e corretto
Algoritmi e Strutture dati Fabio Patrizi 11

L’algoritmo fibonacci 3
Generiamo F1
, F2
, . . . , Fn
iterativamente
Algoritmo fibonacci 3(intero n)! intero
1: Fib: array di n interi2: Fib[1] 1
3: Fib[2] 1
4: for i 3, n do
5: Fib[i] Fib[i� 1] + Fib[i� 2]
6: return Fib[n]
Anche fibonacci 3 e corretto
Algoritmi e Strutture dati Fabio Patrizi 12

Confronto di Algoritmi
Sappiamo che fibonacci 2 e fibonacci 3 sono entrambi corretti
Sono equivalenti o preferiamo uno all’altro?
Se anche fibonacci 1 fosse corretto, quale preferiremmo? Perche?
Algoritmi e Strutture dati Fabio Patrizi 13

Costo di un Algoritmo
In presenza di piu soluzioni, e conveniente scegliere quella piu economica,ovvero che usa una quantita inferiore di risorse
Le risorse usate da un algoritmo sono:
Tempo
Spazio (di memoria)
Come misurare tali risorse?
Vogliamo una misura che sia funzione della dimensione dell’input
Algoritmi e Strutture dati Fabio Patrizi 14

Costo di un Algoritmo
Tempo:
Secondi?1 Stiamo valutando l’algoritmo, non il programma: non possiamo
eseguirlo2 Dipenderebbe dal compilatore, dalla macchina, dalle istanze di input
Spazio:
Memoria utilizzata?I Considerazioni simili a quanto detto sopra
Algoritmi e Strutture dati Fabio Patrizi 15

Modello di Costo
Adottiamo le seguenti misure:
Tempo: numero di operazioni elementari eseguite
Spazio: dimensione complessiva delle strutture dati necessarie amemorizzare i valori usati dall’algoritmo
Consideriamo come operazioni elementari (dette anche passi base):
allocazioni di variabile e assegnazioni a variabile
valutazioni di espressione e test di condizioni booleane
restituzione del risultato
Consideriamo come strutture dati:
variabili: dimensione unitaria
insiemi, liste, pile, code, vettori, etc.: dimensione pari alla cardinalita
record di attivazione (per funzioni ricorsive): dimensione pari ad 1 piudimensione delle strutture dati nel record
Algoritmi e Strutture dati Fabio Patrizi 16

Modello di Costo
Le misure adottate trascurano vari dettagli:
Il costo della valutazione delle espressioni dipende dal numero di valorie di operatori coinvolti
I valori hanno un impatto sul costo della valutazione di espressioni
Analoghe considerazioni valgono per le condizioni booleane
Lo spazio necessario a memorizzare un valore dipende dal valore stesso
Bisognerebbe distinguere il caso di valori interi da valori reali
...
Tuttavia, il modello di costo scelto consente un’accuratezza su�ciente avalutare l’andamento di un algoritmo al crescere della dimensione dell’input
Algoritmi e Strutture dati Fabio Patrizi 17

Funzione di Costo
Valutiamo il costo di un algoritmo rispetto ad una risorsa (tempo o spazio)in funzione della dimensione n dell’input
Ovvero, cerchiamo una funzione che, data la dimensione n dell’istanza delproblema, fornisca la quantita di risorsa utilizzata dall’algoritmo
Indichiamo con T (n) il tempo (numero di passi base) richiestodall’algoritmo
Indichiamo con S(n) lo spazio (unita di memoria) usato dall’algoritmo
Algoritmi e Strutture dati Fabio Patrizi 18

Analisi Asintotica
Confronteremo gli algoritmi sulla base del loro costo asintotico, ovvero alcrescere della dimensione dell’input (dettagli in seguito)
Algoritmi e Strutture dati Fabio Patrizi 19

Algoritmo fibonacci 2: Tempo di Esecuzione
Algoritmo fibonacci 2(intero n)! intero
1: if n 2 then
2: return 1
3: else
4: return (fibonacci 2(n� 1) + fibonacci 2(n� 2))
Tempo di esecuzione:
se n 2: test (linea 1) e restituzione del risultato (l.2)
se n > 2: test (l.1), due chiamate ricorsive, somma e restituzione (l.4)
Le chiamate ricorsive non sono operazioni elementari:
costo: T (n� 1) e T (n� 2)
Il tempo d’esecuzione soddisfa la seguente relazione:
T (n) =
⇢2, se n 2
3 + T (n� 1) + T (n� 2), se n > 2
Algoritmi e Strutture dati Fabio Patrizi 20

Relazioni di ricorrenza
L’equazioneT (n) = 3 + T (n� 1) + T (n� 2)
e detta relazione (o equazione) di ricorrenza
Per conoscere T (n) occorre risolvere l’equazione, ovvero trovareun’espressione che, sostituita a T (n), soddisfi la relazione (metodi dirisoluzione in seguito)
E possibile dimostrare che: T (n) = 5Fn
� 3
Quindi, essendo Fn
=
1p5
(�n � ˆ�n
)
T (n) =
5p5
(�n � ˆ�n
)� 3
(Andamento esponenziale in n)
Algoritmi e Strutture dati Fabio Patrizi 21

Algoritmo fibonacci 3: Tempo di Esecuzione
Algoritmo fibonacci 3(intero n)! intero
1: Fib: array di n interi
2: Fib[1] 1
3: Fib[2] 1
4: for i 3, n do
5: Fib[i] Fib[i� 1] + Fib[i� 2]
6: return Fib[n]
T (n) =
⇢n + 5, se n < 3
n + 2 + 4(n� 2) + 1 = 5n� 5, altrimenti
(Andamento lineare)
Algoritmi e Strutture dati Fabio Patrizi 22
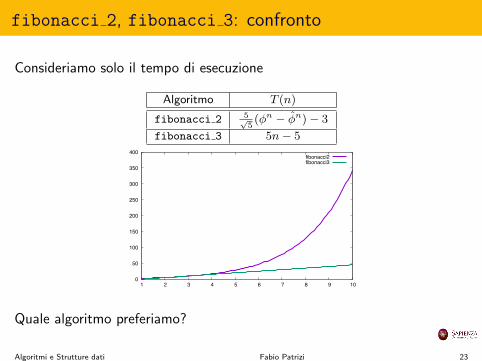
fibonacci 2, fibonacci 3: confronto
Consideriamo solo il tempo di esecuzione
Algoritmo T (n)
fibonacci 2
5p5
(�
n � ˆ
�
n)� 3
fibonacci 3 5n� 5
�
��
���
���
���
���
���
���
���
� � � � � � � � � ��
������������������
Quale algoritmo preferiamo?
Algoritmi e Strutture dati Fabio Patrizi 23

fibonacci 2, fibonacci 3: confronto
L’algoritmo che esegue “meno operazioni” e chiaramente preferibile
Tuttavia, un algoritmo potrebbe andare meglio di un altro solo per alcunivalori di input. Quale scegliere?
Osservazioni:
Per valori piccoli dell’input, le di↵erenze di costo sono pocoapprezzabili
Normalmente, il tempo d’esecuzione cresce con la dimensionedell’input, quindi e preferibile l’algoritmo con funzione di costo acrescita meno rapida
Siamo cioe interessati all’andamento asintotico delle funzioni di costo
Algoritmi e Strutture dati Fabio Patrizi 24

Algoritmo fibonacci 2: Occupazione di Memoria
Valutiamo ora il costo in termini di spazio di fibonacci 2 e fibonacci 3
Si considera solo il costo aggiuntivo rispetto alla dimensione dell’input (inquanto e su questa grandezza che vengono confrontati due algoritmi cheprendono lo stesso input)
Algoritmo fibonacci 2(intero n)! intero
1: if n 2 then
2: return 1
3: else
4: return (fibonacci 2(n� 1) + fibonacci 2(n� 2))
Sembrerebbe che non vengano usate variabili aggiuntive rispetto ad n
Tuttavia, per funzioni ricorsive, occorre considerare lo stack delle chiamate
Algoritmi e Strutture dati Fabio Patrizi 25

Algoritmo fibonacci 2: Occupazione di Memoria
Per un’invocazione di fibonacci 2 su input n, si puo dimostrare (dettagliin seguito) che la dimensione massima dello stack delle chiamate e:
S(n) =
⇢1, se n 2
n� 1, se n > 2
Algoritmi e Strutture dati Fabio Patrizi 26

Algoritmo fibonacci 3: Occupazione di Memoria
Algoritmo fibonacci 3(intero n)! intero
1: Fib: array di n interi
2: Fib[1] 1
3: Fib[2] 1
4: for i 3, n do
5: Fib[i] Fib[i� 1] + Fib[i� 2]
6: return Fib[n]
Usiamo:
un vettore di dimensione n
una variabile contatore (di dimensione unitaria)
Abbiamo quindi:S(n) = n + 1
Algoritmi e Strutture dati Fabio Patrizi 27
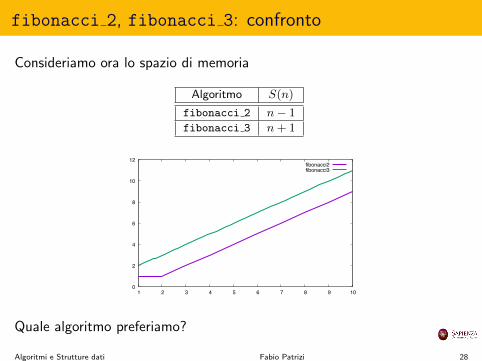
fibonacci 2, fibonacci 3: confronto
Consideriamo ora lo spazio di memoria
Algoritmo S(n)
fibonacci 2 n� 1
fibonacci 3 n+ 1
�
�
�
�
�
��
��
� � � � � � � � � ��
������������������
Quale algoritmo preferiamo?
Algoritmi e Strutture dati Fabio Patrizi 28

fibonacci 2, fibonacci 3: confronto
fibonacci 2 sembra preferibile
Tuttavia:
l’andamento delle funzioni di costo (spaziale) e essenzialmenteidentico a meno di due unita
dobbiamo considerare le semplificazioni del modello di costo, che nonrendono conto di piccole di↵erenze (formalizzeremo questa idea inseguito)
E lecito quindi considerare i due costi spaziali sostanzialmente equivalenti
Concludiamo pertanto che fibonacci 3 e preferibile, in quanto:
ha migliori prestazioni in termini di tempo
e comparabile a fibonacci 2 in termini di occupazione di memoria
Algoritmi e Strutture dati Fabio Patrizi 29

L’algoritmo fibonacci 4
Possiamo ridurre l’occupazione di memoria di fibonacci 3?
Algoritmo fibonacci 4(intero n)! intero
a, b, c: variabili interea 1
b 1
for i 3, n do
c a + ba bb c
return c
Algoritmi e Strutture dati Fabio Patrizi 30

fibonacci 3, fibonacci 4: confronto
fibonacci 4 usa un numero costante di variabili (3), non un numerocrescente con l’input (fibonacci 3: n + 1)
E immediato vedere che fibonacci 4 ha costo temporale T (n) = 6n� 6,essenzialmente analogo a quello di fibonacci 3 (le costanti moltiplicativepossono essere trascurate per le approssimazioni del modello di costo–dettagli in seguito)
fibonacci 4 e pertanto preferibile
Algoritmi e Strutture dati Fabio Patrizi 31

fibonacci 5
Possiamo migliorare il tempo d’esecuzione di fibonacci 4?
Sfruttiamo la seguente proprieta, facilmente dimostrabile per induzione
Proprieta✓
1 1
1 0
◆n
=
✓Fn+1
Fn
Fn
Fn�1
◆
Cioe, moltiplicando la matrice
✓1 1
1 0
◆per se stessa n volte, troviamo
l’(n + 1)-esimo numero di Fibonacci in posizione (0, 0)
Algoritmi e Strutture dati Fabio Patrizi 32

fibonacci 5
Consideriamo il seguente algoritmo
Algoritmo fibonacci 5(intero n)! intero
M : matrice 2⇥ 2 // 4 passi base
M ✓
1 0
0 1
◆// 4 passi base
for i 1, n� 1 do
M M ·✓
1 1
1 0
◆// 8 passi base
return M [0][0] // 1 passo base
Tempo di esecuzione: T (n) = 9 + 8(n� 1) = 9n + 1
Abbiamo un tempo di esecuzione essenzialmente analogo a quello difibonacci 4 (6n� 6)
Algoritmi e Strutture dati Fabio Patrizi 33

Calcolo di potenze
Possiamo ridurre il numero di iterazioni per la potenza di matrice
Quadrati ripetuti
Mn
=
⇢P · P, se n e pari
P · P · M, altrimenti, con P = M bn
2
c
Nota: P viene calcolata una volta sola
Algoritmi e Strutture dati Fabio Patrizi 34

Calcolo di potenze
Possiamo calcolare la potenza di una matrice con la seguente procedura(e↵ettua side-e↵ect su M)
Procedura potenza(matrice 2⇥ 2 M, intero n)
if (n > 1) thenpotenza(M, bn
2
c)M M · M
if (n dispari) then M M ·✓
1 1
1 0
◆
Con tempo d’esecuzione (assumendo 4 operazioni per il prodotto):T (n) = 18 + T (
n
2
) ⇡ 18 log
2
n (metodo di soluzione in seguito)
E occupazione di memoria: S(n) = log
2
n
Algoritmi e Strutture dati Fabio Patrizi 35

fibonacci 6
Algoritmo fibonacci 6(intero n)! intero
M : matrice 2⇥ 2
M I // matrice identitapotenza(M, n� 1)
return M [0][0]
Tempo di esecuzione: T (n) = 9 + 18 log
2
(n� 1)
Occupazione di memoria: S(n) = 4 + log
2
n
Algoritmi e Strutture dati Fabio Patrizi 36
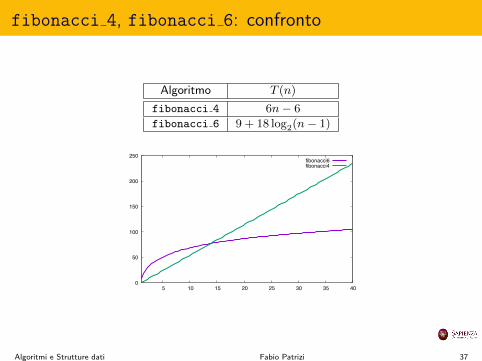
fibonacci 4, fibonacci 6: confronto
Algoritmo T (n)
fibonacci 4 6n� 6
fibonacci 6 9 + 18 log
2
(n� 1)
�
��
���
���
���
���
� �� �� �� �� �� �� ��
������������������
Algoritmi e Strutture dati Fabio Patrizi 37

Algoritmi a Confronto
Algoritmo Tempo di esecuzione Occupazione di memoria
fibonacci 2
5p5
(�n � ˆ�n
)� 3 n� 1
fibonacci 3 5n� 5 n + 1
fibonacci 4 6n� 6 3
fibonacci 5 9n + 1 4
fibonacci 6 9 + 18 log
2
(n� 1) 4 + log
2
n
Concludiamo che fibonacci 6 e (asintoticamente) l’algoritmo piu velocetra quelli considerati
fibonacci 4 e fibonacci 5 sono invece gli algoritmi con minoroccupazione di memoria
Algoritmi e Strutture dati Fabio Patrizi 38

Riepilogo
Le funzioni di costo ottenuto non descrivono fedelmente i costi deglialgoritmi ma l’andamento rispetto alla dimensione dell’input
Causa: i dettagli trascurati dal modello di costo rendono irrilevantidi↵erenze di costo per valori costanti (anche all’interno di cicli)
Pertanto, e ragionevole trascurare costanti additive e moltiplicativenelle funzioni di costo
I tempi d’esecuzione di fibonacci 3, fibonacci 4 e fibonacci 5
sono considerati sostanzialmente analoghi: andamento lineare
fibonacci 2 e invece piu costoso: andamento esponenziale
fibonacci 6 e il piu veloce: andamento logaritmico
Queste intuizioni saranno presto formalizzate
Algoritmi e Strutture dati Fabio Patrizi 39

Modelli di Calcolo e Metodologie diAnalisi
Algoritmi e Strutture dati Fabio Patrizi 40

Modelli di Calcolo
Il modello di calcolo che adottiamo e detto a costo uniforme:
operazioni a costo costante, indipendente dalla dimensione deglioperandi
trascura il fatto che il costo delle operazioni puo dipendere dalladimensione degli operandi
Modello a costo logaritmico:
costo delle operazioni dipendente dalla dimensione degli operandi(logaritmo del valore)
piu accurato ma di maggiore complessita
Entrambi:
forniscono una stima dell’andamento del costo al variare delladimensione dell’input
permettono il confronto tra algoritmi (nello stesso modello)Algoritmi e Strutture dati Fabio Patrizi 41

La Notazione Asintotica
Le approssimazioni che adottiamo nel modello di costo rendono pocointeressanti le di↵erenze di costo dovute a costanti additive o moltiplicative
Ci interessiamo pertanto all’andamento delle funzioni di costo, non aivalori specifici assunti per particolari dimensioni dell’input
La notazione asintotica e lo strumento matematico che permette ilconfronto tra gli andamenti di due funzioni al crescere della dimensionedell’input
Algoritmi e Strutture dati Fabio Patrizi 42
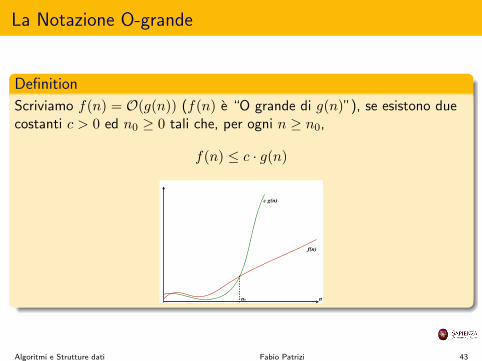
La Notazione O-grande
Definition
Scriviamo f(n) = O(g(n)) (f(n) e “O grande di g(n)”), se esistono duecostanti c > 0 ed n
0
� 0 tali che, per ogni n � n0
,
f(n) c · g(n)
n0
c g(n)
f(n)
n
Algoritmi e Strutture dati Fabio Patrizi 43
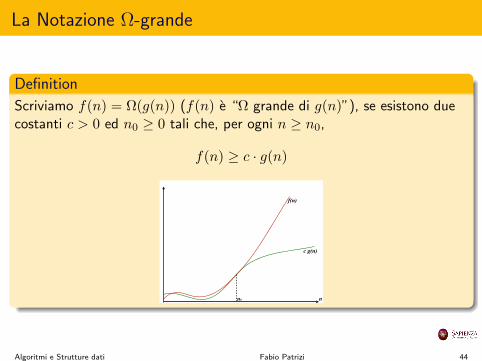
La Notazione ⌦-grande
Definition
Scriviamo f(n) = ⌦(g(n)) (f(n) e “⌦ grande di g(n)”), se esistono duecostanti c > 0 ed n
0
� 0 tali che, per ogni n � n0
,
f(n) � c · g(n)
n0
c g(n)
f(n)
n
Algoritmi e Strutture dati Fabio Patrizi 44
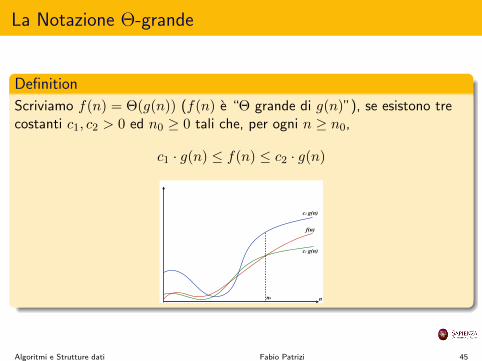
La Notazione ⇥-grande
Definition
Scriviamo f(n) = ⇥(g(n)) (f(n) e “⇥ grande di g(n)”), se esistono trecostanti c
1
, c2
> 0 ed n0
� 0 tali che, per ogni n � n0
,
c1
· g(n) f(n) c2
· g(n)
n0
c1 g(n)
f(n)
n
c2 g(n)
Algoritmi e Strutture dati Fabio Patrizi 45

La Notazione Asintotica
Theorem
Date due funzioni f(n) e g(n), abbiamo che f(n) = ⇥(g(n)) se e solo se:
f(n) = O(g(n))
f(n) = ⌦(g(n))
Algoritmi e Strutture dati Fabio Patrizi 46

La Notazione Asintotica
Theorem
Per ogni polinomio p(n) = a0
+ a1
n + · · · + am
nm, t.c. am
> 0, si ha:P (n) = ⇥(nm
).
Proof.Consideriamo solo n > 0
Per p(n) = O(nm
): p(n) cnm, dove c =
Pm
i=0
|ai
| > 0
Per p(n) = ⌦(nm
): p(n) � am
nm �Nnm�1, dove N =
Pm�1
i=0
|ai
| > 0
Cerchiamo ora c > 0 ed n0
� 0 t.c. am
nm �Nnm�1 � cnm, per n � n0
:a
m
nm �Nnm�1 � cnm , (am
� c)n � N , n � N
a
m
�c
= n0
, con c < am
Quindi, per 0 < c < am
ed n � n0
, abbiamo p(n) � cnm, ovvero p(n) = ⌦(nm
).
Algoritmi e Strutture dati Fabio Patrizi 47

Esempi
Example
Si consideri la funzione f(n) = 3n2
+ 10
Abbiamo:
f(n) = O(n2
) (es., c = 4 e n0
= 10)
f(n) = ⌦(n2
) (es., c = 1 e n0
= 0)
f(n) = ⇥(n2
) (dai punti sopra e dal teorema precedente)
f(n) = O(n3
) ma f(n) 6= ⇥(n3
) (perche f(n) 6= ⌦(n3
))
Algoritmi e Strutture dati Fabio Patrizi 48

La Notazione Asintotica
Definition (Costo temporale di un algoritmo (limitazione superiore))
Un algoritmo ha costo temporale O(f(n)) su istanze di ingresso didimensione n, se il numero T (n) di operazioni elementari da esso eseguiteper risolvere qualsiasi istanza di dimensione n soddisfa la relazioneT (n) = O(f(n)).
Definition (Costo temporale di un algoritmo (limitazione inferiore))
Un algoritmo ha costo temporale ⌦(f(n)) su istanze di ingresso didimensione n, se il numero T (n) di operazioni elementari da esso eseguiteper risolvere qualsiasi istanza di dimensione n soddisfa la relazioneT (n) = ⌦(f(n)).
Analoghe definizioni valgono per lo spazio
Algoritmi e Strutture dati Fabio Patrizi 49

Metodi di Analisi
Algoritmi e Strutture dati Fabio Patrizi 50

Caso Peggiore, Migliore, Medio
Misuriamo le risorse di calcolo usate da un algoritmo in funzione delladimensione n dell’input (ovvero dell’istanza del problema da risolvere)
Input di pari dimensioni possono richiedere quantita di risorse diverse
Vogliamo una misura che non dipenda dalla configurazione dell’input,ma solo dalla sua dimensione
Algoritmi e Strutture dati Fabio Patrizi 51

Caso Peggiore, Migliore, Medio
Example (Ricerca Sequenziale)
Algoritmo RicercaSequenziale(lista L, elem x)! Boolean
for all (y 2 L) doif (y = x) then return true
return false
Se forniamo in input una lista di n elementi, quanti confronti eseguiral’algoritmo prima di terminare?
Chiaramente dipende dalla posizione in lista dell’elemento cercato
Ad esempio, se l’elemento si trova nella posizione favorevole (laprima), bastera un solo confronto
Come eliminare questa dipendenza dalla configurazione dell’input?
Algoritmi e Strutture dati Fabio Patrizi 52

Caso Peggiore, Migliore, Medio
Tre approcci classici all’analisi:
Caso peggiore: quanto impiega l’algoritmo su un’istanza didimensione n se la configurazione e la piu sfavorevole?
Caso migliore: sulla configurazione piu favorevole?
Caso medio: mediamente su tutte le istanze di dimensione n?
Algoritmi e Strutture dati Fabio Patrizi 53

Caso Peggiore
Definition
Indichiamo con tempo(I) il tempo impiegato dall’algoritmo perrisolvere la generica istanza I
Indichiamo con Istanzen
l’insieme delle istanze di dimensione n
Definiamo la misura di costo temporale nel caso peggiore:
Tworst
(n) = max
{Istanzen}{tempo(I)}
Tworst
(n) ci dice quanto tempo impiega l’algoritmo sulle istanze piusfavorevoli di dimensione n
Fornisce un upper bound (“peggio di cosı non puo andare”)
O↵re garanzia sulle prestazioni: se Tworst
(n) e accettabile, lo saraanche tempo(I) per qualsiasi istanza di dimensione n
Considereremo il caso peggiore per l’analisi degli algoritmi
Algoritmi e Strutture dati Fabio Patrizi 54

Caso Migliore
DefinitionDefiniamo la misura di costo temporale nel caso migliore:
Tbest
(n) = min
{Istanzen}{tempo(I)}
Tbest
(n) ci dice quanto tempo impiega l’algoritmo sulle istanze piufavorevoli di dimensione n
Fornisce un lower bound (“meglio di cosı non puo andare”)
Non o↵re nessuna garanzia sulle prestazioni:I Se T
best
(n) non e accettabile, sicuramente non lo sara tempo(I) pernessuna istanza di dimensione n
I Viceversa, se Tbest
(n) e accettabile, non sappiamo se lo sara tempo(I)
(per I di dimensione n)
Algoritmi e Strutture dati Fabio Patrizi 55

Caso Medio
Definition
Indichiamo con Pn
(I) la probabilita che un’istanza I di dimensione nsia fornita in input
Definiamo la misura di costo temporale nel caso medio:
Tavg
(n) =
X
{I2Istanzen}
Pn
(I) · tempo(I)
Tavg
(n) ci dice quanto e il tempo atteso impiegato dall’algoritmo suuna generica istanza di dimensione n
Fornisce indicazioni circa il tempo medio d’esecuzione
Informativa (e utile) ma non sempre applicabile: occorre conoscere ladistribuzione di probabilita P
n
Algoritmi e Strutture dati Fabio Patrizi 56

Esempio: Ricerca Sequenziale
Algoritmo RicercaSequenziale(lista L, elem x)! Boolean
for all (y 2 L) doif (y == x) then return true
return false
Caso migliore: elemento in prima posizione, Tbest
(n) = O(1)
Caso peggiore: elemento assente, Tworst
(n) = O(n)
Caso medio (per elemento in posizione i con probabilita 1/n):
Tavg
(n) =
O(
X
1in
P (pos(x) = i) ·tempo(I)) = O(
X
1in
1/n ·i) = O((n+1)/2)
Algoritmi e Strutture dati Fabio Patrizi 57

Esempio: Ricerca Binaria
Algoritmo RicercaBinaria(lista L, elem x)! Boolean
a 1
b dimensione di Lwhile (L[(a + b)/2] 6= x) do
i (a + b)/2
if (L[i] > x) then b i� 1
else a i + 1
if (a > b) then return false
return true
Caso migliore: elemento in posizione (a + b)/2, Tbest
(n) = O(1)
Caso peggiore: elemento assente, Tworst
(n) = O(log n)
Caso medio (per elemento in posizione i con probabilita 1/n):
Tavg
(n) = O(log n� 1 + 1/n)
Algoritmi e Strutture dati Fabio Patrizi 58

Analisi Asintotica: Spazio
Tutte le definizioni, i risultati e le osservazioni viste fin qui trovano analogaapplicazione al caso dell’analisi di costo spaziale.
Algoritmi e Strutture dati Fabio Patrizi 59

Analisi di Algoritmi Ricorsivi
Algoritmi e Strutture dati Fabio Patrizi 60

Analisi di algoritmi ricorsivi
L’analisi di algoritmi ricorsivi e in generale piu complessa del casoiterativo
Occorre impostare e risolvere un’equazione di ricorrenza
Algoritmi e Strutture dati Fabio Patrizi 61

Equazioni di Ricorrenza
Definition (Equazione di ricorrenza)
Un’equazione di ricorrenza e un’equazione che lega il valore di una funzionef : N! N sull’input n al valore della funzione f su input minori di n:
f(n) = F [f(n� 1), . . . , f(1)]
Risolvere un’equazione di ricorrenza significa trovare una funzione f(n)
che la soddisfa
Come risolverla? Diversi metodi...
Algoritmi e Strutture dati Fabio Patrizi 62
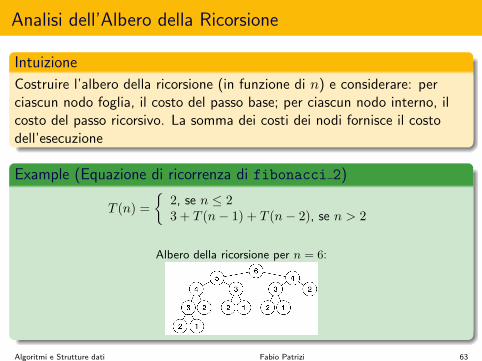
Analisi dell’Albero della Ricorsione
Intuizione
Costruire l’albero della ricorsione (in funzione di n) e considerare: perciascun nodo foglia, il costo del passo base; per ciascun nodo interno, ilcosto del passo ricorsivo. La somma dei costi dei nodi fornisce il costodell’esecuzione
Example (Equazione di ricorrenza di fibonacci 2)
T (n) =
⇢2, se n 2
3 + T (n� 1) + T (n� 2), se n > 2
Albero della ricorsione per n = 6:
Algoritmi e Strutture dati Fabio Patrizi 63

Analisi dell’Albero della Ricorsione
Example (Costo d’esecuzione di fibonacci 2)
Assegniamo a ciascun nodo interno costo 3 (v. eq. ricorrenza)
Assegniamo a ciascun nodo foglia costo 2 (v. eq. ricorrenza)
Abbiamo quindi: T (n) = 3Nnodi interni
+ 2Nnodi foglia
Per un albero binario: Nnodi interni
= Nnodi foglia
� 1
Quindi: T (n) = 3(Nnodi foglia
� 1) + 2Nnodi foglia
= 5Nnodi foglia
� 3
Siccome Nnodi foglia
= Fn
e Fn
=
1p5
(�n � ˆ�n
), otteniamo:
T (n) =
5p5
(�n � ˆ�n
)� 3
Algoritmi e Strutture dati Fabio Patrizi 64

Metodo dell’Iterazione
IntuizioneConsideriamo le chiamate ricorsive passo-passo, ottenendo una sommatoriadipendente dalla dimensione n dell’input iniziale e dal numero k di passi.
Example
Equazione: T (n) =
⇢1, se n = 1c + T (n/2), altrimenti
Per k passi abbiamo:
T (n) = c + T (n/2) = 2c + T (n/4) = · · · = (kc + T (n/2
k
))
Procediamo fino a T (1), ovvero n/2
k
= 1, cioe k = log
2
(n), ottenendo:
T (n) = c log
2
(n) + T (1) = O(log n)
Algoritmi e Strutture dati Fabio Patrizi 65

Metodo della Sostituzione
Intuizione
Scegliere un candidato (ragionevole) per la soluzione e dimostrare lacorrettezza della scelta tramite induzione matematica
Algoritmi e Strutture dati Fabio Patrizi 66

Induzione Matematica
Induzione Matematica
Possiamo dimostrare che una proprieta P vale per ogni intero n 2 [n0
,1),dimostrando che:
(Passo Base) P vale per un intero n0
(Passo Induttivo) Se P vale per tutti i valori [n0
, n� 1] (ipotesiinduttiva), allora P vale anche per n
Example (Formula di Gauss per la somma dei primi n interi)nX
i=1
i =
n(n + 1)
2
(Passo Base)P
1
i=1
i = 1 = 1(1 + 1)/2
(Passo Induttivo) Assumendo cheP
n�1
i=1
i = n(n� 1)/2, abbiamo:Pn
i=1
i = n(n� 1)/2 + n = n(n + 1)/2
Algoritmi e Strutture dati Fabio Patrizi 67

Metodo della Sostituzione
Example
Equazione: T (n) =
⇢1, se n = 1
T (dn/2e) + n, altrimenti
Ipotizziamo che T (n) cn, per qualche c, ovvero che T (n) = O(n)
Dimostriamo per induzione che l’ipotesi e corretta:
Caso base: T (1) = 1 c, per ogni c � 1
Passo induttivo: T (n) = T (dn/2e) + n cn/2 + n = n(c/2 + 1)
Abbiamo che n(c/2 + 1) cn, c/2 + 1 c, c � 2
Abbiamo dimostrato che, per c � 2, T (n) cn
La risoluzione per sostituzione richiede intuito e colpo d’occhio, qualitache si ottengono con un po’ d’esercizio.
Algoritmi e Strutture dati Fabio Patrizi 68

Teorema Mastero Teorema Fondamentale delle Ricorrenze
Theorem (Teorema Master)
Data la seguente equazione di ricorrenza:
T (n) =
⇢1, se n = 1a · T (n/b) + f(n), se n > 1
Abbiamo che:
1 T (n) = ⇥(nlogb a), se f(n) = O(nlogb a�✏
), per ✏ > 0;
2 T (n) = ⇥(nlogb alog n), se f(n) = ⇥(nlogb a
);
3 T (n) = ⇥(f(n)), se f(n) = ⌦(nlogb a+✏
), per ✏ > 0 ea · f(n/b) c · f(n), per c < 1 ed n su�cientemente grande.
Algoritmi e Strutture dati Fabio Patrizi 69
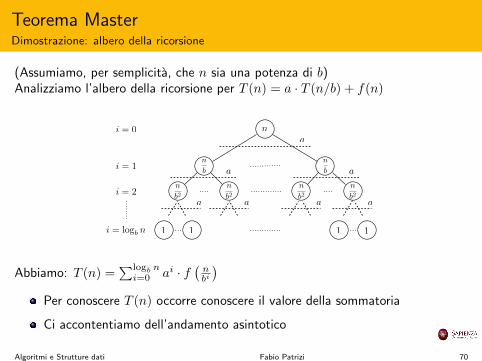
Teorema MasterDimostrazione: albero della ricorsione
(Assumiamo, per semplicita, che n sia una potenza di b)Analizziamo l’albero della ricorsione per T (n) = a · T (n/b) + f(n)
1 1 1
1
na
a a
a a a a
n
b
n
b
n
b2
n
b2
n
b2
n
b2
i = 0
i = 1
i = 2
i = log
b
n
Abbiamo: T (n) =
Plog
b
n
i=0
ai · f�
n
b
i
�
Per conoscere T (n) occorre conoscere il valore della sommatoria
Ci accontentiamo dell’andamento asintotico
Algoritmi e Strutture dati Fabio Patrizi 70

Teorema MasterDimostrazione: caso 1
Se f(n) = O(nlog
b
a�✏
), per il generico termine della sommatoria, abbiamo:
ai · f�
n
b
i
�= O
⇣ai · � n
b
i
�log
b
a�✏
⌘= O
⇣ai · n
log
b
a�✏
b
i(log
b
a�✏)
⌘= O
⇣ai · n
log
b
a�✏
a
i
b
�i✏
⌘=
O �nlog
b
a�✏ · bi✏
�
Quindi: T (n) =
Plog
b
n
i=0
ai · f�
n
b
i
�=
Plog
b
n
i=0
O �nlog
b
a�✏ · bi✏
�=
O⇣nlog
b
a�✏ · Plog
b
n
i=0
(b✏
)
i
⌘= O
⇣nlog
b
a�✏ · (b
✏
)
log
b
n+1�1
b
✏�1
⌘=
O⇣nlog
b
a�✏ · b
✏
n
✏�1
b
✏�1
⌘= O �
nlog
b
a�✏ · n✏
�= O �
nlog
b
a
�
(Si ricordi che:P
k
i=0
xi
=
x
k+1�1
x�1
)
Inoltre, dall’ultimo livello dell’albero: T (n) = ⌦(alog
b
n
) = ⌦(nlog
b
a
)
Pertanto:T (n) = ⇥(nlog
b
a
)
Algoritmi e Strutture dati Fabio Patrizi 71

Teorema MasterDimostrazione: caso 2
Se f(n) = ⇥(nlogb a), per il generico termine della sommatoria, abbiamo:
ai · f�n
b
i
�= ⇥
⇣ai · � n
b
i
�logb a
⌘= ⇥
⇣ai · n
logb a
b
i logb a
⌘= ⇥
⇣ai · n
logb a
a
i
⌘=
⇥
�nlogb a
�
Quindi: T (n) =
Plogb n
i=0
ai · f�n
b
i
�=
Plogb n
i=0
⇥
�nlogb a
�=
⇥
�nlogb a
log
b
n�
= ⇥
�nlogb a
log n�
Algoritmi e Strutture dati Fabio Patrizi 72

Teorema MasterDimostrazione: caso 3
Se a · f�
n
b
� c · f(n), per il generico termine della sommatoria abbiamo:
ai · f�
n
b
i
�= ai�1 · a · f
⇣n
b
i�1
b
⌘ c · ai�1 · f
�n
b
i�1
� · · · ci · f(n)
Quindi: T (n) =
Plog
b
n
i=0
ai · f�
n
b
i
� Plog
b
n
i=0
ci · f(n) f(n) · P1i=0
ci
=
f(n) · 1
1�c
= O(f(n))
Inoltre, e immediato vedere che: T (n) = ⌦(f(n))
Pertanto: T (n) = ⇥(f(n))
Osservazione: l’ipotesi f(n) = ⌦
�nlog
b
a+✏
�non e utilizzata, in quanto implicata
da a · f�
n
b
� c · f(n):
a · f�
n
b
� c · f(n)) f(n) � a
c
· f�
n
b
�) · · ·) f(n) � �a
c
�i · f
�n
b
i
�) · · ·)f(n) � �
a
c
�log
b
n · f(1)) f(n) = ⌦
⇣�a
c
�log
b
n
⌘= ⌦
⇣�a
c
�log a
c
n·logb
a
c
⌘=
⌦
⇣nlog
b
a+log
b
1
c
⌘= ⌦
�nlog
b
a+✏
�(con ✏ = log
b
1
c
> 0, essendo c < 1)
Algoritmi e Strutture dati Fabio Patrizi 73

Teorema MasterEsempi
Consideriamo la relazione di ricorrenza: T (n) = 9T (n/3) + n
Applichiamo il Teorema Master:
a = 9
b = 3
f(n) = n = ⇥(n)
Poiche nlogb a= 2, siamo nel caso 1 del teorema: f(n) = O(nlogb a�✏
), con✏ = 1
Pertanto:T (n) = ⇥(nlogb a
) = ⇥(n2
)
Algoritmi e Strutture dati Fabio Patrizi 74

Teorema MasterEsempi
Relazione di ricorrenza di RicercaBinaria: T (n) = T (n/2) + c
Applichiamo il Teorema Master:
a = 1
b = 2
f(n) = c = ⇥(1)
Poiche nlogb a= 1, siamo nel caso 2 del teorema: f(n) = ⇥(nlogb a
)
Pertanto:T (n) = ⇥(log n)
Algoritmi e Strutture dati Fabio Patrizi 75

Teorema MasterEsempi
Relazione di ricorrenza: T (n) = 3T (n/9) + n
Applichiamo il Teorema Master:a = 3
b = 9
f(n) = n
Si ha nlogb a= n1/2, quindi: f(n) = ⌦(nlogb a+✏
), per ✏ = 1/2
Dimostriamo che, per c < 1, si ha a · f�n
b
� c · f(n):
a · f�n
b
� c · f(n), 3n/9 cn, c � 1/3
Pertanto siamo nel caso 3 del teorema:
T (n) = ⇥(n)
Algoritmi e Strutture dati Fabio Patrizi 76

Strutture Dati Elementari
Algoritmi e Strutture dati Fabio Patrizi 77

Tipi di Dato Astratto e Strutture Dati
Definition (Tipo di Dato Astratto)
Un tipo di dato (astratto) e una specifica formale dei dati d’interesse edelle operazioni ad essi associate.
Definition (Struttura Dati)
Una struttura dati e una specifica organizzazione implementativa dei datiche ne supporta le operazioni.
Il tipo di dato astratto ci dice cosa fare, non come, ne comeorganizzare i dati
La struttura dati ci dice come organizzare i dati su cuiimplementeremo le operazioni
Algoritmi e Strutture dati Fabio Patrizi 78

Tipo di Dato Astratto Dizionario
tipo Dizionario:dati: insieme finito S ✓ Chiave⇥ Elemento (Chiave e totalmente ordinato)operazioni:
insert(Chiave c, Elemento e):Se ¬9e0.(c, e0) 2 S, aggiunge (c, e) ad S
delete(Chiave c):Se 9e0.(c, e0) 2 S, rimuove (c, e0) da S
search(Chiave c)! E :Se 9e.(c, e) 2 S, restituisce e, altrimenti restituisce null
Algoritmi e Strutture dati Fabio Patrizi 79

Il Tipo di Dato Astratto Pila
tipo Pila:dati: Sequenza S di n elementi e 2 Elementooperazioni:
isEmpty()! Boolean:Restituisce true se S e vuota, false altrimenti
push(Elemento e):Inserisce e come elemento a�orante di S
pop()! Elemento:Estrae l’elemento a�orante da S e lo restituisce
top()! Elemento:Restituisce l’elemento a�orante da S (senza estrarlo)
Politica di accesso LIFO (last-in-first-out)
Algoritmi e Strutture dati Fabio Patrizi 80

Il Tipo di Dato Astratto Coda
tipo Coda:dati: Sequenza S di n elementi e 2 Elementooperazioni:
isEmpty()! Boolean:Restituisce true se S e vuota, false altrimenti
enqueue(Elemento e):Inserisce e in S come elemento in ultima posizione
dequeue()! Elemento:Estrae da S l’elemento in prima posizione e lo restituisce
first()! Elemento:Restituisce l’elemento di S in prima posizione (senza estrarlo)
Politica di accesso FIFO (first-in-first-out)
Algoritmi e Strutture dati Fabio Patrizi 81

Tecniche di Rappresentazione dei Dati
Vogliamo implementare un dizionario
Il primo problema che si presenta e: come rappresentare l’insieme S?
Due approcci:
Rappresentazione indicizzata: dati contenuti in un arrayI Vantaggio: accesso indicizzato (tempo costante)I Svantaggio: dimensione fissa (riallocazione in tempo lineare)
Rappresentazione collegata: dati contenuti in record collegati dapuntatori
I Vantaggio: dimensione variabile (tempo costante)I Svantaggio: accesso sequenziale (tempo lineare)
La scelta della rappresentazione puo influenzare il costo delle operazioni!
Algoritmi e Strutture dati Fabio Patrizi 82

Implementazione Indicizzata di Dizionario
Classe DizionarioIndicizzato implementa Dizionario:dati: array S di dimensione n contenente coppie (c, e) 2 Chiave⇥ Elementooperazioni:
insert(Chiave c, Elemento e): se S contiene una coppia con chiave ctermina; altrimenti, alloca un nuovo array S0 con dimensione n + 1 e vicopia, in ordine, tutte le coppie di S con chiave minore di c; inserisce lacoppia c, e in S0; copia, in ordine, tutte le coppie di S con chiave maggioredi c in S0; rimpiazza S con S0. T (n) = O(n).
delete(Chiave c): se S non contiene una coppia con chiave c, termina;altrimenti alloca array S0 con dimensione n� 1 e vi copia, in ordine, tutti glielementi di S saltando la coppia con chiave c; rimpiazza S con S0.T (n) = O(n).
search(Chiave c)! E: esegue RicercaBinaria(S, c). Se S contiene unacoppia con indice c, restituisce il relativo elemento e, altrimenti restituiscenull. T (n) = log(n).
Algoritmi e Strutture dati Fabio Patrizi 83

Strutture Collegate Lineari (SCL)
Una struttura collegata e una struttura dati formata da un insieme direcord, in cui:
I dati d’interesse sono contenuti nei campi dei record
Ciascun record contiene uno o piu riferimenti ad altri record
Esiste un record da cui tutti i record della struttura sono accessibili
Una struttura collegata e detta lineare se i suoi riferimenti permettono didefinire un ordine totale sui suoi elementi
Example (Lista Semplice)
L I S T
Algoritmi e Strutture dati Fabio Patrizi 84

Implementazione di Dizionario con SCL
Classe DizionarioCollegato implementa Dizionario:dati:
collezione D di n record (c, e, next) 2 Chiave⇥ Elemento⇥Riferimento
riferimento dizionario al primo record (null se dizionario vuoto)
operazioni:
insert(Chiave c, Elemento e): partendo dal primo record, scorre Dseguendo il campo next; se trova un record con chiave c termina, altrimentiinserisce un nuovo record (c, e, null) in fondo alla struttura. T (n) = O(n).
delete(Chiave c): partendo dal primo record, scorre D seguendo il camponext; se trova un record r con chiave c aggiorna il riferimento del recordprecedente ad r, da r ad r.next. T (n) = O(n).
search(Chiave c)! E: partendo dal primo record, scorre D seguendo ilcampo next; se trova un record r con chiave c ne restituisce il campo e.T (n) = O(n).
Algoritmi e Strutture dati Fabio Patrizi 85

Alberi
Spesso e utile organizzare i dati in maniera gerarchica (esempio: file system)
Alberi: strutture matematiche che astraggono il concetto di gerarchia
Definition (Albero)
Albero T = (N, A):
N e l’insieme finito dei nodi
A ✓ N ⇥N e l’insieme degli archi
tale che:
Esiste un solo nodo r, detto radice, che non ha padre (non esiste nessunarco (n, r) 2 A)
Tutti i nodi n diversi da r hanno esattamente un padre n0 (esiste l’arco(n0, n) 2 A)
Nessun nodo n puo essere padre di se stesso (non esiste l’arco (n, n) 2 A)
Algoritmi e Strutture dati Fabio Patrizi 86
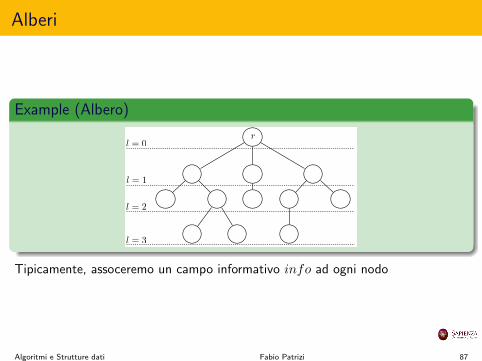
Alberi
Example (Albero)
l = 0
l = 1
l = 2
l = 3
r
Tipicamente, assoceremo un campo informativo info ad ogni nodo
Algoritmi e Strutture dati Fabio Patrizi 87

Il Tipo di Dato Astratto Albero
tipo Albero:dati: Insieme N ✓ Nodo di nodi, Insieme A ✓ N ⇥N di archioperazioni:
numNodi! Intero: Restituisce |N |grado(Nodo n)! Intero: Restituisce il numero di archi uscenti da n
padre(Nodo n)! Nodo: Restituisce il padre di n
figli(Nodo n)! Insieme[Nodo]: Restituisce l’insieme dei figli di n
aggiungiNodo(Nodo n)! Nodo: Crea un nuovo nodo v, lo inserisce comefiglio di n e lo restituisce. Se l’albero e vuoto, v ne diventa la radice (ed nviene ignorato)
aggiungiSottoalbero(Albero a, Nodo n): Inserisce l’albero a comesottoalbero, rendendo la radice di a figlio di n. Se l’albero e vuoto, adiventa l’albero
rimuoviSottoalbero(Nodo n)! Albero: Disconnette il sottoalbero conradice in n (compresa) dall’albero e lo restituisce.
Algoritmi e Strutture dati Fabio Patrizi 88

Rappresentazione di Alberi
Anche per gli alberi si pone il problema della loro implementazione, inparticolare di come organizzare i dati
Anche in questo caso, abbiamo due possibili alternative:
Rappresentazione indicizzata
Rappresentazione mediante struttura collegata (non lineare)
Algoritmi e Strutture dati Fabio Patrizi 89

Rappresentazioni Indicizzate di Alberi
Vettore Padri
Le componenti di ciascun vettore contengono un record (info, padre):
info e il contenuto informativo del nodo
padre e l’indice della componente corrispondente al nodo padre
Costo delle operazioni base:
padre(n): O(1)
figli(n): O(|N |)
Algoritmi e Strutture dati Fabio Patrizi 90

Rappresentazioni Indicizzate di Alberi
Vettore Posizionale (per alberi d-ari completi, con d � 2
Il nodo radice e in posizione 0
Ciascuna componente contiene l’informazione relativa ad un nodo
I figli del nodo in posizione v si trovano in posizione d · v + i, peri = 1, . . . , d
Costo delle operazioni base:
padre(n): O(1)
figli(n): O(grado(n))
Algoritmi e Strutture dati Fabio Patrizi 91

Rappresentazioni Collegate di Alberi
Puntatori ai Figli (solo per alberi con grado limitato d)
Ciascun nodo e un record di tipo (info, figlio1
, . . . , figliom
):
info: contenuto informativo del nodo
figlioi
: riferimento al figlio i-esimo (null se assente)
Spazio occupato: O(n)
Costo delle operazioni base:
padre(n): O(n)
figli(n): O(grado(n))
Algoritmi e Strutture dati Fabio Patrizi 92

Rappresentazioni Collegate di Alberi
Lista dei Figli
Ciascun nodo e un record di tipo (info, figli):
info: contenuto informativo del nodo
figli: riferimento ad una lista di riferimenti ai figli
Spazio occupato: O(n)
Costo delle operazioni base:
padre(n): O(n)
figli(n): O(1)
Variante: ogni record contiene un riferimento al primo figlio ed al fratellosuccessivo.
Algoritmi e Strutture dati Fabio Patrizi 93

Visita di un Albero
Esplorazione esaustiva dei nodi di un albero
Visita generica
Algoritmo visitaGenerica(nodo r)
S {r}while (S 6= ;) do
estrai un nodo u 2 Svisita uS = S [ {figli(u)}
Struttura dati non lineare: visita possibile seguendo vari ordini
La visita generica non impone un ordine specifico di visita
La politica di gestione di S condiziona il tipo di visita
Algoritmi e Strutture dati Fabio Patrizi 94

Visita di un Albero
Theorem
L’algoritmo visitaGenerica(r) termina in al piu O(n) passi, usa al piuO(n) unita di memoria e visita tutti i nodi dell’albero con radice r.
Proof.Ad ogni iterazione, viene estratto un nodo dall’insieme S e ne vengono inseriti ifigli in S. Poiche l’albero non ha cicli, un nodo estratto non viene mai reinseritoin S. Pertanto, dopo al piu O(n) passi, S e vuoto e l’algoritmo termina.
Per l’occupazione di memoria, si noti che S contiene al piu tutti gli n nodidell’albero.
Mostriamo per contraddizione che tutti i nodi sono visitati, assumendo che unnodo u non lo sia. In tal caso, padre(u) non sarebbe visitato, in quanto sappiamoche ogni volta che un nodo viene visitato, tutti i suoi figli sono inseriti in S (equindi visitati). Ma allora anche padre(padre(u)) non lo sarebbe, e cosı via finoalla radice r che, invece, sappiamo essere visitata alla prima iterazione. L’assurdonasce dall’aver supposto l’esistenza di un nodo non visitato.Algoritmi e Strutture dati Fabio Patrizi 95

Visita in profondita (DFT: depth-first traversal)
S viene gestito come una pila: si procede dalla radice verso le foglie,scendendo di livello appena possibile
Visita in profondita
Algoritmo visitaDF (nodo r)
Pila vuota SS.push(r)while (not S.isEmpty()) do
u = S.pop()
visita ufor all (v 2 figli(u)) do
S.push(v)
Algoritmi e Strutture dati Fabio Patrizi 96
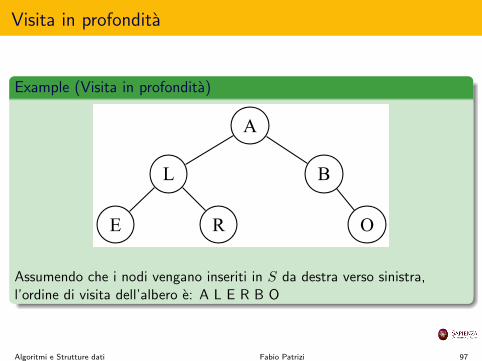
Visita in profondita
Example (Visita in profondita)
A
ORE
BL
Assumendo che i nodi vengano inseriti in S da destra verso sinistra,l’ordine di visita dell’albero e: A L E R B O
Algoritmi e Strutture dati Fabio Patrizi 97

Visita in profondita ricorsiva
La visita in profondita puo essere implementata ricorsivamente, senza l’usodella pila S (che viene costruita implicitamente nello stack)
Visita in profondita ricorsiva
Algoritmo visitaDFRicorsiva(nodo r)
if (r == null) thenreturn
visita rfor all (u 2 figli(r)) do
visitaDFRicorsiva(u)
Implementazioni ricorsive naturali ed eleganti
Algoritmi e Strutture dati Fabio Patrizi 98
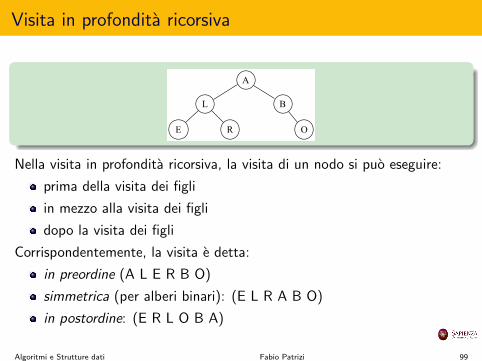
Visita in profondita ricorsiva
A
ORE
BL
Nella visita in profondita ricorsiva, la visita di un nodo si puo eseguire:
prima della visita dei figli
in mezzo alla visita dei figli
dopo la visita dei figli
Corrispondentemente, la visita e detta:
in preordine (A L E R B O)
simmetrica (per alberi binari): (E L R A B O)
in postordine: (E R L O B A)
Algoritmi e Strutture dati Fabio Patrizi 99

Visita in ampiezza (BFT: breadth-first traversal)
S viene gestito come una coda: si procede per livelli, partendo dalla radicee scendendo solo quando il livello corrente e stato completato
Visita in ampiezza
Algoritmo visitaBF (nodo r)
Coda vuota SS.enqueue(r)while (not S.isEmpty()) do
u = S.dequeue()visita ufor all (v 2 figli(u)) do
S.enqueue(v)
Implementazioni ricorsive possibili ma artificiose e inutilmente complesse
Algoritmi e Strutture dati Fabio Patrizi 100
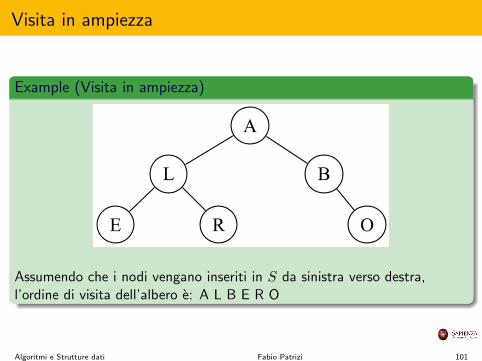
Visita in ampiezza
Example (Visita in ampiezza)
A
ORE
BL
Assumendo che i nodi vengano inseriti in S da sinistra verso destra,l’ordine di visita dell’albero e: A L B E R O
Algoritmi e Strutture dati Fabio Patrizi 101

Ricerca di un Nodo in un albero
La visita di un albero si presta a vari scopi, ad es.:
Ricerca: per ogni nodo visitato, verifica se corrisponde al criterio diricerca
Conteggio: ogni volta che trovo un nodo che corrisponde al criterio diricerca, incremento il risultato
Puo essere conveniente procedere in ampiezza o in profondita
Ricerca: breadth-first search (BFS) o depth-first search (DFS)
Algoritmi e Strutture dati Fabio Patrizi 102

Esercizi
Esercizio 1 (d’esame)
1 Specificare un algoritmo (pseudocodice) con segnatura:quantiNodi(Albero T )! Intero che, preso in input un albero T , nerestituisce il numero di nodi.
2 Indicare, motivando la risposta, il costo temporale dell’algoritmo definito.
Esercizio 2 (d’esame)1 Specificare un algoritmo (pseudocodice) con segnatura:
presente(Albero T, Intero i)! Boolean che, preso in input unalbero T con nodi contenenti valori interi, ed un valore intero i,restituisce il valore true se e solo T contiene un nodo con valore i.
2 Indicare, motivando la risposta, il costo temporale dell’algoritmodefinito.
Algoritmi e Strutture dati Fabio Patrizi 103

Algoritmi di Ordinamento
Algoritmi e Strutture dati Fabio Patrizi 104

Problema dell’Ordinamento
Il Problema dell’Ordinamento e un problema fondamentale:
Si presenta in innumerevoli situazioni
La sua soluzione permette di semplificare altri algoritmi, tra cui laricerca, con significativo risparmio sui tempi di esecuzione (es., ricercabinaria)
Problema dell’Ordinamento
Input: Insieme finito S = {x0
, . . . , xn�1
} di elementi provenienti daun insieme totalmente ordinato
Output: Sequenza L = l0
, . . . , ln�1
t.c.:
{l0
, . . . , ln�1
} = Sli
< li+1
, i 2 [0, n� 1)
Algoritmi e Strutture dati Fabio Patrizi 105

Algoritmi Basati su Approccio Incrementale
Tre algoritmi:
SelectionSort
InsertionSort
BubbleSort
IDEA: se i primi k elementi sono ordinati, estendo l’ordinamento al(k + 1)-esimo elemento (o al contrario, dall’ultimo al primo)
Algoritmi e Strutture dati Fabio Patrizi 106

SelectionSort
Seleziona l’elemento minimo tra quelli rimanenti e lo scambia con quello inposizione k + 1
SelectionSort
Algoritmo SelectionSort(Lista l)
for (k = 0, . . . , |l|� 2) domin = k + 1;
for (j = k + 2, . . . , |l|) doif (l[j] < l[min]) then
min = j;
scambia(l[k + 1], l[min]);
Ordinamento in loco: usa una quantita costante di memoria aggiuntivarispetto a quella usata per l’input
Algoritmi e Strutture dati Fabio Patrizi 107

SelectionSort
Theorem
SelectionSort ordina in loco n elementi in tempo T (n) = ⇥(n2
).
Proof.L’algoritmo esegue
T (n) = ⇥(
n�2X
k=0
n� k � 1) = ⇥(
n�1X
i=1
i) = ⇥((n� 1)n/2) = ⇥(n2
)
operazioni.
Algoritmi e Strutture dati Fabio Patrizi 108

InsertionSort
Inserisce l’elemento in posizione k + 1 nella posizione corretta tra i primi k(gia ordinati)
InsertionSort
Algoritmo InsertionSort(Lista l)
for (k = 1, . . . , |l|� 1) dox l[k + 1];
j 1;while (l[j] x and j k) do
j + +;
if (j < k + 1) thenfor (t = k, . . . , j) do
l[t + 1] = l[t];
l[j] = x;
Algoritmi e Strutture dati Fabio Patrizi 109

InsertionSort
Theorem
InsertionSort ordina in loco n elementi in tempo T (n) = ⇥(n2
).
Proof.L’algoritmo esegue
T (n) = ⇥(
n�1X
i=1
k) = ⇥(n(n� 1)/2) = ⇥(n2
)
operazioni.
Algoritmi e Strutture dati Fabio Patrizi 110

BubbleSort
Esegue n scansioni della lista, scambiando gli elementi adiacenti che nonsono in ordine crescente
BubbleSort
Algoritmo BubbleSort(Lista l)
scambiato true;k 0;while (scambiato and k < |l|� 1) do
scambiato false;for (j = 1, . . . , |l|� k � 1) do
if (l[j] > l[j + 1]) thenscambia(l[j], l[j + 1]);scambiato true;
k + +;
Algoritmi e Strutture dati Fabio Patrizi 111

BubbleSort
Theorem
BubbleSort ordina in loco n elementi in tempo T (n) = ⇥(n2
).
Proof.L’algoritmo esegue
T (n) = ⇥(
n�2X
k=0
n� k � 1) = ⇥(n2
)
operazioni.
Algoritmi e Strutture dati Fabio Patrizi 112

HeapSort
Variante di SelectionSort
Ricerca e�ciente del minimo (massimo) tra i restanti n� k elementi
Usa una nuova struttura dati: Heap
Algoritmi e Strutture dati Fabio Patrizi 113

Heap
Definition (Struttura dati Heap)
Un Heap H associato ad un insieme finito L di elementi (su cui e definitauna relazione di ordine totale <) e un albero binario tale che:
H e completo (almeno) fino al penultimo livello
Ciascun nodo v contiene un elemento di L, indicato con chiave(v),ed ogni elemento e presente in un solo nodo
Per ogni nodo v e per ogni suo figlio w 2 figli(v), si hachiave(v) > chiave(w)
Example
23
14
9
12 6 8
Algoritmi e Strutture dati Fabio Patrizi 114

HeapSort
HeapSort procede essenzialmente come SelectionSort, ordinandodall’ultimo al primo elemento, usando un heap per individuare facilmente ilvalore massimo tra quelli non ancora considerati
HeapSort: intuizione
crea un heap H con gli elementi da ordinare come chiavi;X coda vuota;while (H non vuoto) do
m = massimo di H;elimina m da H;rendi H nuovamente un heap;X.enqueue(m);
return X;
Nota: gli elementi in X occorrono in ordine crescente
Tutte le operazioni possono essere implementate e�cientemente (v. sotto)
Algoritmi e Strutture dati Fabio Patrizi 115

Heap: proprieta notevoli
Theorem
Un heap H contenente n nodi ha altezza ⇥(log n):
Proof.
Un albero binario di altezza h contiene 2
h � 1 nodi interni
Essendo H completo fino al penultimo livello: 2
h � 1 n 2
h+1 � 1
Ovviamente: 2
h�1 2
h � 1 n 2
h+1 � 1 2
h+1
Applicando log
2
a tutti i membri: h� 1 log
2
n h + 1
Pertanto: h = O(log n) e h = ⌦(log n), ovvero: h = ⇥(log n)
Algoritmi e Strutture dati Fabio Patrizi 116

Heap: proprieta notevoli
TheoremIl massimo valore tra le chiavi di un heap H e la chiave della radice di H
Proof.Conseguenza immediata della definizione di heap
Algoritmi e Strutture dati Fabio Patrizi 117
Proprieta notevoli
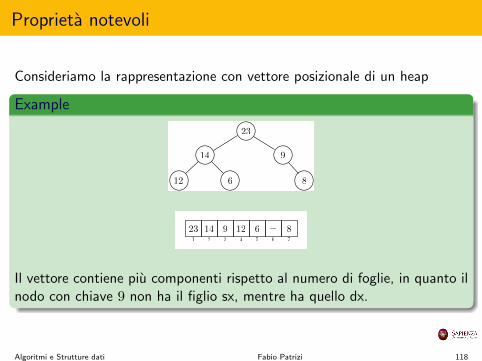
Consideriamo la rappresentazione con vettore posizionale di un heap
Example
23
14
9
12 6 8
23 14 9 12 6 8
�1 2
3
4
5 6 7
Il vettore contiene piu componenti rispetto al numero di foglie, in quanto ilnodo con chiave 9 non ha il figlio sx, mentre ha quello dx.
Algoritmi e Strutture dati Fabio Patrizi 118
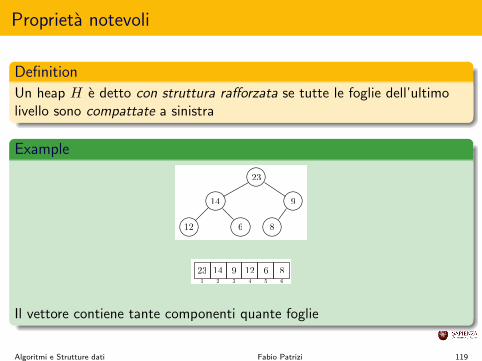
Proprieta notevoli
DefinitionUn heap H e detto con struttura ra↵orzata se tutte le foglie dell’ultimolivello sono compattate a sinistra
Example
23
14
9
12 6 8
23 14 9 12 6 8
1 2
3
4
5 6
Il vettore contiene tante componenti quante foglie
Algoritmi e Strutture dati Fabio Patrizi 119

Proprieta notevoli
TheoremIl vettore posizionale associato ad un heap H con struttura ra↵orzatacontiene un numero di componenti pari al numero di foglie di H
Proof.Conseguenza del fatto che, nel vettore posizionale, le foglie dell’ultimolivello occupano posizioni contigue da sx verso dx in fondo al vettore
Algoritmi e Strutture dati Fabio Patrizi 120

Proprieta notevoli
Riassumendo:
Un heap con n foglie ha altezza ⇥(log n)
La chiave massima di un heap e contenuta nella radice
Un heap con struttura ra↵orzata contenente n foglie puo essererappresentato con un vettore di dimensione n
Queste proprieta permetteranno di implementare e�cientementel’algoritmo e di e↵ettuare l’ordinamento in loco
Algoritmi e Strutture dati Fabio Patrizi 121

HeapSort: rappresentazione dei dati
Rappresentiamo l’input mediante un vettore di Elem
(Assumiamo che il vettore di input contenga elementi distinti)
Per gli alberi (e per l’heap) usiamo una rappresentazione mediantevettore posizionale:
I radice in posizione 1
I figlio sinistro del nodo i in posizione i + 1
I figlio destro del nodo i in posizione 2i + 1
Per gli heap garantiamo sempre la struttura ra↵orzata
Algoritmi e Strutture dati Fabio Patrizi 122

La procedura fixHeap
DefinitionChiamiamo pre-heap un albero che soddisfa tutte le proprieta di un heapeccetto per la chiave di uno dei suoi nodi, che potrebbe non contenere ilvalore massimo
Example (pre heap)
14
9
12 6
8
Algoritmi e Strutture dati Fabio Patrizi 123

La procedura fixHeap
La seguente procedura trasforma in heap un pre-heap in cui un nodo v hachiave minore di qualcuno dei suoi figli
fixHeap
Procedura fixHeap(Nodo v, preHeap H)
if (H vuoto o v foglia) thenreturn ;
w figlio di v con chiave massima;if (chiave(v) > chiave(w)) then
scambia le chiavi di v e w;fixHeap(w, H);
Nota: Poiche fixHeap non modifica la struttura di H (ma interviene solosulle chiavi), se H ha una struttura ra↵orzata prima dell’esecuzione difixHeap, la avra anche dopo
Algoritmi e Strutture dati Fabio Patrizi 124
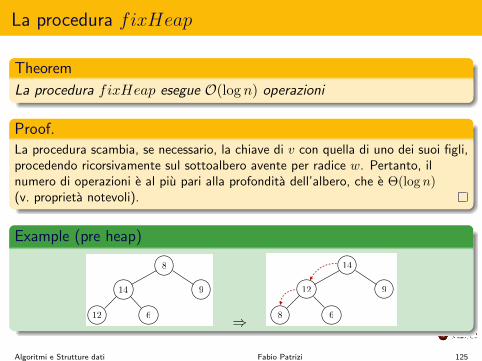
La procedura fixHeap
Theorem
La procedura fixHeap esegue O(log n) operazioni
Proof.La procedura scambia, se necessario, la chiave di v con quella di uno dei suoi figli,procedendo ricorsivamente sul sottoalbero avente per radice w. Pertanto, ilnumero di operazioni e al piu pari alla profondita dell’albero, che e ⇥(log n)
(v. proprieta notevoli).
Example (pre heap)
14
9
12 6
8
)
14
9
12
68
Algoritmi e Strutture dati Fabio Patrizi 125

La procedura fixHeap
Si puo sfruttare fixHeap per:
costruire un heap a partire da un albero
estrarre il massimo dall’heap H e riorganizzare H rendendolonuovamente un heap
Algoritmi e Strutture dati Fabio Patrizi 126

Costruzione dell’heap
heapify
Procedura heapify(Albero T )
if (T e vuoto) then return ;
heapify(sottoalbero sx di T );heapify(sottoalbero dx di T );fixHeap(T );
Theorem
La procedura heapify esegue O(n) operazioni
Proof.
Poiche fixHeap ha costo temporale O(log n), per heapify abbiamo:
T (n) = 2T (n/2) + O(log n)
Dal teorema Master (caso 1): T (n) = O(n)
Algoritmi e Strutture dati Fabio Patrizi 127

Estrazione del massimo e riorganizzazione dell’albero
getMax
Algoritmo getMax(Heap H)! Elem
r radice di H;max chiave(r);v foglia di H piu a destra;Sovrascrivi chiave(r) con chiave(v);Elimina v;fixHeap(H);return max;
Nota: Poiche getMax rimuove sempre la foglia piu a destra, la suainvocazione preserva la struttura ra↵orzata di H
Algoritmi e Strutture dati Fabio Patrizi 128

Estrazione del massimo e riorganizzazione dell’albero
Theorem
L’algoritmo getMax esegue O(log n) operazioni
Proof.Poiche H e rappresentato con vettore posizionale, la foglia piu a destra el’ultimo elemento del vettore. Pertanto la sua estrazione ha costo costante.Anche tutte le altre operazioni hanno costo costante, eccetto fixHeapche ha costo O(log n).
Algoritmi e Strutture dati Fabio Patrizi 129

HeapSort
HeapSort
Algoritmo HeapSort(Array[Elem] A)! Array[Elem]
costruisci un albero H con gli elementi di A;heapify(radice di H,H);X coda vuota; //Coda rappresentata come array di n elementiwhile (H non vuoto) do
m getMax(H);X.enqueue(m);
return X;
Algoritmi e Strutture dati Fabio Patrizi 130

HeapSort
Theorem
L’algoritmo heapSort ha costo temporale O(n log n)
Proof.Conseguenza delle seguenti osservazioni:
La costruzione di H ha costo O(n)
heapify ha costo O(n)
La costruzione di X ha costo O(n)
Il ciclo while esegue n iterazioni
getMax ha costo O(log n)
enqueue ha costo costante
Algoritmi e Strutture dati Fabio Patrizi 131

HeapSort
Notiamo che
HeapSort ha costo temporale O(n log n), chiaramente preferibile adO(n2
) (algoritmi con approccio incrementale)
Tuttavia, HeapSort utilizza spazio O(n), dovuto alle struttureausiliarie H ed X, di dimensione lineare rispetto all’input, mentre glialtri algoritmi ordinano in loco
E pero possible ordinare in loco anche con HeapSort, operandodirettamente sull’array di input ed adottando particolari accorgimenti
Algoritmi e Strutture dati Fabio Patrizi 132

MergeSort
Approccio Divide et Impera:
(Divide) Dividi l’array in due sottoarray di dimensione bilanciata edordinali separatamente
(Impera) Fondi i due array ordinati in un nuovo array ordinato
MergeSort
Algoritmo MergeSort(Array A)! Array
n = |A|;if (n <= 1) then return A;
A1
MergeSort(A[1, n/2]);A
2
MergeSort(A[n/2 + 1, n]);return merge(A
1
, A2
);
Algoritmi e Strutture dati Fabio Patrizi 133

MergeSort
merge
Algoritmo merge(ArrayA, B)! ArrayOrdinato
X : array di dimensione |A| + |B|;n |A|,m |B|;i 1, j 1, k 1;while (i n and j m) do
if (A[i] < B[j]) thenX[k] A[i];i + +;
else
X[k] B[j];j + +;
k + +;if (i > n) then
appendi B[j, m] in fondo ad X;else
appendi A[i, n] in fondo ad X;
return X;Algoritmi e Strutture dati Fabio Patrizi 134

MergeSort
Theorem
MergeSort ordina n elementi in tempo T (n) = ⇥(n log n).
Proof.
merge esegue la fusione in tempo ⇥(|A| + |B|) (si ricordi che A e B sonoordinati)Pertanto MergeSort ha costo temporale: T (n) = 2T (n/2) + ⇥(n)
Dal teorema Master (caso 2), abbiamo: T (n) = ⇥(n log n)
Algoritmi e Strutture dati Fabio Patrizi 135

QuickSort
Approccio Divide et Impera:
(Divide) Scegli un elemento p (pivot) nell’array di input A e crea duearray A
1
e A2
contenenti, rispettivamente, i valori minori o uguali dip e maggiori di p
(Impera) Ordina A1
e A2
ricorsivamente e inserisci in A l’array A1
pA2
QuickSort
Algoritmo QuickSort(Array A)
scegli un elemento p di A;A
1
= {y 2 A : y < p};A
2
= {y 2 A : y > p};if (|A
1
| > 1) then quickSort(A1
);
if (|A2
| > 1) then quickSort(A2
);
copia la concatenazione < A1
, p, A2
> in A;
Algoritmi e Strutture dati Fabio Patrizi 136

QuickSort
Caso peggiore: ad ogni invocazione, il pivot e il minimo o il massimo tra ivalori dell’array da ordinare.
Nota: consideriamo solo il numero di confronti e↵ettuati dall’algoritmo.
Theorem (Complessita nel caso peggiore)
QuickSort ordina, nel caso peggiore, n elementi in tempo T (n) = O(n2
).
Proof.
Abbiamo: T (n) = n� 1 + T (n� 1), ovvero, risolvendo per iterazione:T (n) = O(n2
).
Pertanto, analizzando la complessita nel caso peggiore, QuickSort non emigliore di HeapSort o di MergeSort.
Algoritmi e Strutture dati Fabio Patrizi 137

QuickSort
Scegliendo randomicamente il pivot ad ogni chiamata, riduciamo laprobabilita di essere nel caso peggiore.
Theorem (Complessita nel caso medio)
QuickSort ordina n elementi in un numero atteso di operazioniT (n) = O(n log n).
Proof.Assumendo che il perno sia scelto con probabilita uniforme, abbiamo cheogni partizione ha probablita 1/n di verificarsi. Il valore atteso del numerodi confronti e quindi: T (n) = 1/n
Pn
i=1
n� 1 + T (n� i) + T (i� 1), dacui: T (n) = n� 1 + 1/n
Pn
i=1
+T (n� i) + T (i� 1) =
n� 1 +
Pn
i=1
2/nT (i� 1) = n� 1 +
Pn�1
i=0
2/nT (i)
L’equazione T (n) = n� 1 +
Pn�1
i=0
2/nT (i) ha soluzioneT (n) = O(n log n) (dimostrazione omessa).
Algoritmi e Strutture dati Fabio Patrizi 138

QuickSort
Nella pratica, QuickSort mostra prestazioni migliori di MergeSort eHeapSort in quanto evita scambi non necessari (tra elementi giaordinati), con significativa riduzione del tempo d’esecuzione
Algoritmi e Strutture dati Fabio Patrizi 139

Delimitazione inferiore al costo dell’ordinamento
E possibile migliorare la complessita degli algoritmi visti finora?
In particolare, e possibile ordinare n oggetti in meno di O(n log n)?
Algoritmi e Strutture dati Fabio Patrizi 140

Modello basato su confronti
Gli algoritmi visti finora non sfruttano nessuna informazione suldominio di provenienza degli elementi
L’unica operazione disponibile e il confronto tra due elementi
Pertanto, tali algoritmi e↵ettuano l’ordinamento eseguendo ilconfronto come unica operazione di dominio
Stabiliremo un limite inferiore al costo per gli algoritmi basati suconfronti
Algoritmi e Strutture dati Fabio Patrizi 141

Alberi di decisione
Definition (Albero di decisione)
Un albero di decisione e un albero binario in cui:
Ogni nodo contiene una coppia hv, wi di elementi da confrontare
Il figlio sx di un nodo n contiene i prossimi elementi da confrontarenel caso in cui v w
Il figlio dx di un nodo n contiene i prossimi elementi da confrontarenel caso in cui v > w
La strategia seguita da un algoritmo di ordinamento (basato su confronti)puo essere catturata da un albero di decisione
Algoritmi e Strutture dati Fabio Patrizi 142
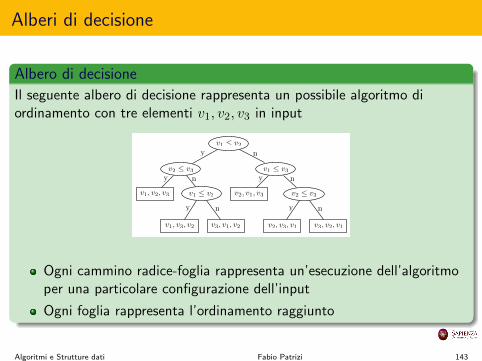
Alberi di decisione
Albero di decisioneIl seguente albero di decisione rappresenta un possibile algoritmo diordinamento con tre elementi v
1
, v2
, v3
in input
n
y
v2
v3
v1
v2
v2
v3
v1
v3
v1
v3
y
y
y
y
n
n n
n
v1
, v2
, v3
v1
, v3
, v2
v3
, v1
, v2
v2
, v1
, v3
v2
, v3
, v1
v3
, v2
, v1
Ogni cammino radice-foglia rappresenta un’esecuzione dell’algoritmoper una particolare configurazione dell’input
Ogni foglia rappresenta l’ordinamento raggiunto
Algoritmi e Strutture dati Fabio Patrizi 143

Alberi di decisione
Il cammino radice-foglia piu lungo rappresenta l’esecuzione nel casopeggiore
Pertanto, la profondita di un albero di decisione corrisponde al costodell’algoritmo nel caso peggiore
Determiniamo tale profondita
Algoritmi e Strutture dati Fabio Patrizi 144

Profondita di un albero di decisione
TheoremUn albero di decisione associato ad un algoritmo di ordinamento basato suconfronti ha profondita ⌦(n log n).
Proof.Consideriamo un generico algoritmo di ordinamento A basato su confronti
Per input di n elementi esistono n! possibili ordinamenti
Quindi l’albero di decisione associato ad A dovra contenere almeno n! foglie
Un albero di profondita h contiene al piu 2
h�1 foglie, quindi deve essere:
2
h�1 � n!
Poiche n ⇡ (n/e)n (approssimazione di Stirling), passando ai logaritmi,abbiamo: h� 1 � log
2
(n/e)n, da cui: h � 1 + n log
2
n� n log
2
e, ovveroh = ⌦(n log n).
Algoritmi e Strutture dati Fabio Patrizi 145

Delimitazione inferiore al costo dell’ordinamento
Il teorema precedente ci dice che
Ogni algoritmo di ordinamento basato su confronti esegue, nelcaso peggiore, ⌦(n log n) confronti
Concludiamo pertanto che
Il costo di un algoritmo di ordinamento e ⌦(n log n)
(Nota: risultato valido solo nel caso del modello basato su confronti)
Come importante conseguenza, abbiamo che gli algoritmi HeapSort eMergeSort sono ottimali dal punto di vista della complessita nel casopeggiore
Algoritmi e Strutture dati Fabio Patrizi 146

Algoritmi di ordinamento che sfruttano operazioni didominio
Example
Supponiamo di dover ordinare n interi distinti nell’intervallo [1, n]
Poiche conosciamo il dominio degli interi, sappiamo che l’unicasequenza possible e 1, 2, . . . , n
Possiamo quindi realizzare un algoritmo che determina l’ordinamentoin tempo costante (escludendo il tempo per costruire l’output), senzanemmeno considerare l’ordine degli elementi in input
Questo algoritmo non e basato su confronti (sfrutta proprieta degliinteri e non esegue confronti), per cui la delimitazione inferiore alcosto stabilita precedentemente non e applicabile
Algoritmi e Strutture dati Fabio Patrizi 147

IntegerSort
Ordinamento di n interi nell’intervallo [1, k]
Algoritmo IntegerSort(Intero k, Array[Intero] X)
Y : array di Intero di dimensione k;for (i = 0, . . . , k) do Y [i] 0;
for (i = 0, . . . , n) do Y [X[i]] Y [X[i]] + 1;
j 1;for (i = 1, . . . , k) do
while (Y [i] > 0) doX[j] i;j = j + 1; Y [i] = Y [i]� 1;
Y [i] rappresenta il numero di occorrenze di i nell’input X
Algoritmi e Strutture dati Fabio Patrizi 148

IntegerSort
Theorem
L’algoritmo IntegerSort ordina n interi nell’intervallo [1, k] in tempoT (n) = O(n + k)
Proof.
O(k) per creare ed inizializzare Y
O(n) per scandire X e popolare Y
O(n + k) per scandire Y e popolare X con gli elementi in ordine
Se k = O(n), l’algoritmo e lineare
Se k cresce piu rapidamente di n, ad es., k = ⇥(2
n
), il costo segue k
(In generale, non e possibile dire nulla a priori)
Algoritmi e Strutture dati Fabio Patrizi 149

BucketSort
IntegerSort puo essere facilmente adattato all’ordinamento di nrecord con chiavi intere nell’intervallo [1, k]
E su�ciente usare, al posto di un array di k interi, un array Y di kliste di record
Y [i] conterra la lista dei record che hanno chiave i
Algoritmi e Strutture dati Fabio Patrizi 150

BucketSort
Algoritmo BucketSort(Intero k, Array[Intero] X)
Y : array di liste di Record di dimensione k;for (i = 0, . . . , k) do Y [i] lista vuota;
for (i = 0, . . . , n) do appendi il record X[i] alla lista Y [chiave(X[i])];
for (i = 1, . . . , k) do
copia gli elementi di Y [i] in X, sequenzialmente e mantenendonel’ordine
Dall’analisi di costo di IntegerSort segue immediatamente il seguenterisultato
TheoremL’algoritmo BucketSort ordina n record con chiavi intere nell’intervallo[1, k] in tempo T (n) = O(n + k)
Algoritmi e Strutture dati Fabio Patrizi 151

Proprieta di Stabilita
Definition (Stabilita di un algoritmo di ordinamento)
Un algoritmo di ordinamento e detto stabile se preserva l’ordine iniziale traelementi con lo stesso valore (o chiave)
La stabilita di BucketSort puo essere garantita gestendo le liste in Ycome code
Molti algoritmi di ordinamento posso essere resi stabili con opportuniaccorgimenti
Sfrutteremo questa proprieta a breve
Algoritmi e Strutture dati Fabio Patrizi 152

RadixSort
IntegerSort (e BucketSort) hanno costo temporale O(n + k)
Se k e molto piu grande di n, il vettore Y sara sparso, ovveroconterra numerose componenti con il valore 0 (o vuote)
In tal caso, la scansione di Y richiedera un grande numero di visite acomponenti non significative
Possiamo ridurre il numero di componenti non significative?
Example
Vogliamo ordinare il seguente array: h4368, 2397, 5924iOrdiniamo ripetutamente con IntegerSort dalla cifra menosignificativa verso quella piu significativa
h4368, 2397, 5924i ) h5924, 2397, 4368i ) h5924, 4368, 2397i )h4368, 2397, 5924i ) h2397,4368,5924i
Algoritmi e Strutture dati Fabio Patrizi 153

RadixSort: correttezza
TheoremRadixSort ordina correttamente n valori interi
Proof.Alla i-esima passata:
Se due elementi x ed y hanno cifre diverse in posizione i, alloravengono ordinati secondo la i-esima cifra
Se due elementi x ed y hanno stessa cifra in posizione i, il loro ordineviene mantenuto, grazie alla stabilita di IntegerSort
Pertanto, dopo la i-esima passata, i numeri sono correttamente ordinatisecondo le i cifre meno significative
Algoritmi e Strutture dati Fabio Patrizi 154

RadixSort: tempo di esecuzione
Il tempo di esecuzione di RadixSort dipende dal numero ` di cifrecontenute nell’elemento massimo tra quelli da ordinare, cioe k
Se n e il numero di elementi da ordinare, allora RadixSort esegue `volte BucketSort, ciascuna volta su n elementi nell’intervallo [0, 9],ottenendo quindi T (n) = O(`(n + 10))
E facile vedere che ` log
10
k + 1, quindiT (n) = O((log
10
k + 1)(n + 10)) = O(n log k)
Ma allora, quando k � n, conviene usare un algoritmo ottimalebasato su confronti (O(n log n))
Possiamo migliorare?
Algoritmi e Strutture dati Fabio Patrizi 155

RadixSort: tempo di esecuzione
La dimensione ` della rappresentazione di un numero dipende dallabase adottata:
` log
b
k + 1
Con una rappresentazione in base b le cifre variano nell’intervallo[0, b� 1], quindi ogni esecuzione di BucketSort impiega tempoO(n + b)
In totale, abbiamo: T (n) = O((log
b
k +1)(n+ b)) = O(log
b
k(n+ b))
Scegliendo b = ⇥(n), abbiamo allora:T (n) = O(log
b
k(n + b)) = O(2n log
n
k) = O(n log
n
k) =
O✓
nlog k
log n
◆
Algoritmi e Strutture dati Fabio Patrizi 156

RadixSort: tempo di esecuzione
Theorem
RadixSort ordina n numeri nell’intervallo [0, k] in tempo O(n(1 +
log k
logn
))
Proof.
Per il caso k � n, dall’analisi precedente, abbiamo T (n) = O⇣n log k
logn
⌘.
Per il caso k < n, osserviamo che si devono eseguire almeno n passi per lalettura dell’input. Aggiungendo pertanto n al risultato precedente,otteniamo
T (n) = O✓
n
✓1 +
log k
log n
◆◆
Algoritmi e Strutture dati Fabio Patrizi 157

Alberi di binari ricerca
Algoritmi e Strutture dati Fabio Patrizi 158

Il tipo astratto Dizionario
Riprendiamo il tipo di dato astratto Dizionario
tipo Dizionario:dati: insieme finito S ✓ Chiave⇥ Elemento (Chiave e totalmente ordinato)operazioni:
insert(Chiave c, Elemento e):Se ¬9e0.(c, e0) 2 S, aggiunge (c, e) ad S
delete(Chiave c):Se 9e0.(c, e0) 2 S, rimuove (c, e0) da S
search(Chiave c)! E :Se 9e.(c, e) 2 S, restituisce e, altrimenti restituisce null
Rappresentazione insert delete search
Collegata O(1) O(n) O(n)
Indicizzata O(n) O(n) O(n)
Indicizzata Ordinata O(n) O(n) O(log n)
Esistono implementazioni piu e�cienti?Algoritmi e Strutture dati Fabio Patrizi 159

Alberi binari di ricerca (BST)
Definition
Un Albero Binario di Ricerca (Binary Search Tree, BST), e un alberobinario tale che:
1 Ogni nodo v contiene una chiave, indicata con chiave(v), provenienteda un dominio Chiave totalmente ordinato, ed un elemento, indicatocon elem(v), proveniente da un insieme Elem
2 Per ogni nodo v e ogni nodo w del sottoalbero sinistro di v, si hachiave(w) chiave(v)
3 Per ogni nodo v e ogni nodo w del sottoalbero destro di v, si hachiave(w) > chiave(v)
Le proprieta 2. e 3. sono dette “proprieta di ricerca”
Algoritmi e Strutture dati Fabio Patrizi 160

Ricerca di un elemento in un BST
Grazie alle proprieta di ricerca possiamo eseguire la ricerca in manieraconcettualmente analoga a BinarySearch
Algoritmo search(chiave k)! Elem
v radice dell’albero;while (v 6= null) do
if (chiave(v) == k) then return elem(v);
if (chiave(v) � k) thenv figlio sinistro di v;
else
v figlio destro di v;
return null;
Algoritmi e Strutture dati Fabio Patrizi 161

Ricerca di un elemento in un BST
TheoremL’algoritmo search per la ricerca di un elemento in un BST ha costotemporale O(h) = O(n), dove h e l’altezza del BST.
Proof.Ad ogni iterazione v si sposta in basso di un livello. Poiche sono presenti hlivelli, possono esserci al piu h iterazioni. Inoltre, nel caso peggiore, ogninodo ha un solo figlio, pertanto h = n.
Algoritmi e Strutture dati Fabio Patrizi 162

Inserimento di un elemento in un BST
Nuovi nodi vengono inseriti come foglie
Si procede cercando l’elemento da inserire, fino a raggiungere il nodo che nedovrebbe essere padre
Il nodo raggiunto diventa padre del nuovo elemento
Algoritmo insert(chiave k, Elem e)
Crea un nuovo nodo w con chiave(w) = k e elem(w) = e;if (L’albero e vuoto) then
rendi w radice dell’albero;return ;
v radice dell’alberoif (k chiave(v)) then
if (v non ha figlio sx) then rendi w figlio sx di v;else esegui insert(k, e) sul sottoalbero sx di v;
else
if (v non ha figlio dx) then rendi w figlio dx di v;else esegui insert(k, e) sul sottoalbero dx di v;
Algoritmi e Strutture dati Fabio Patrizi 163

Inserimento di un elemento in un BST
TheoremL’algoritmo insert per l’inserimento di un elemento in un BST ha costotemporale O(h) = O(n), dove h e l’altezza del BST.
Proof.Ogni chiamata ricorsiva viene e↵ettuata su un albero con dimensione paria quella dell’albero di input, ridotta di 1. Sono su�cienti pertanto hchiamate, ciascuna di costo costante.
Algoritmi e Strutture dati Fabio Patrizi 164

Cancellazione di un elemento da un BST
Sia u il nodo da eliminare, abbiamo tre casi:
1 Se u e una foglia, si procede alla cancellazione
2 Se u ha un solo figlio, si connette il padre di u al figlio di u
3 Se u ha entrambi i figli, si procede come segue:I si individua il nodo v con chiave massima del sottoalbero sxI si copiano chiave(v) ed elem(v) in uI si elimina v (applicando i casi 1 o 2)
Algoritmi e Strutture dati Fabio Patrizi 165
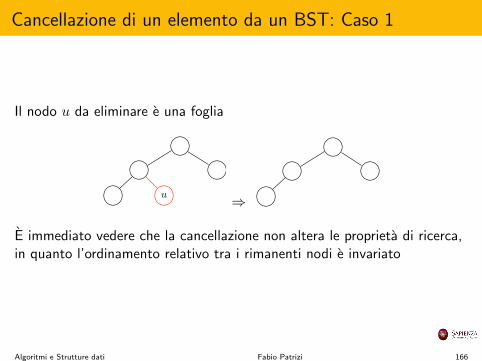
Cancellazione di un elemento da un BST: Caso 1
Il nodo u da eliminare e una foglia
u )
E immediato vedere che la cancellazione non altera le proprieta di ricerca,in quanto l’ordinamento relativo tra i rimanenti nodi e invariato
Algoritmi e Strutture dati Fabio Patrizi 166
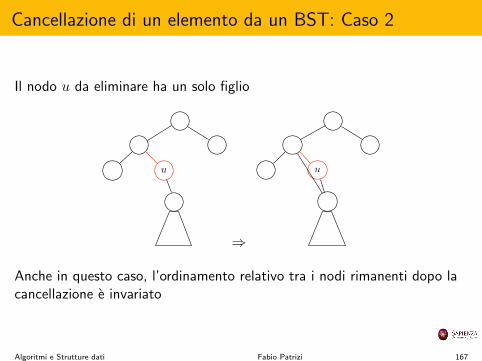
Cancellazione di un elemento da un BST: Caso 2
Il nodo u da eliminare ha un solo figlio
u
)
u
Anche in questo caso, l’ordinamento relativo tra i nodi rimanenti dopo lacancellazione e invariato
Algoritmi e Strutture dati Fabio Patrizi 167
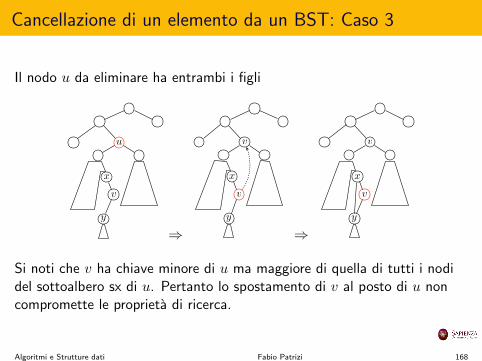
Cancellazione di un elemento da un BST: Caso 3
Il nodo u da eliminare ha entrambi i figli
u
v
x
y
)
v
x
y
v
)
v
x
y
v
Si noti che v ha chiave minore di u ma maggiore di quella di tutti i nodidel sottoalbero sx di u. Pertanto lo spostamento di v al posto di u noncompromette le proprieta di ricerca.
Algoritmi e Strutture dati Fabio Patrizi 168

Cancellazione di un elemento da un BST
Assumiamo che ci sia un solo nodo con chiave k
Algoritmo delete(chiave k)
individua il nodo u con chiave k;if (u e una foglia) then
elimina u dall’albero;return ;
if (u ha un solo figlio w) thenindividua il padre z di u e rendi z padre di w, al posto di u;return ;
individua il nodo v con chiave massima tra i nodi del sottoalbero sx di u;assegna al nodo u chiave(v) ed elem(v);rimuovi il nodo v applicando uno dei casi precedenti;
Algoritmi e Strutture dati Fabio Patrizi 169

Cancellazione di un elemento da un BST
TheoremL’algoritmo delete per la cancellazione di un elemento in un BST ha costotemporale O(h) = O(n), dove h e l’altezza del BST.
Proof.
Individua nodo u con chiave k (e memorizzane nodo padre): O(h)
Elimina foglia (a partire da nodo padre): O(1)
Elimina nodo con un solo figlio (a partire dal nodo padre): O(1)
Individua nodo v con chiave max nel sottoalbero sx di u: O(h)
Assegna campi al nodo u: O(1)
Rimuovi nodo v: O(h)
Complessivamente: numero costante di operazioni di costo O(h).
Algoritmi e Strutture dati Fabio Patrizi 170

Implementazione Dizionario tramite BST
Nell’implementazione di un Dizionario tramite BST, tutte leoperazioni hanno costo O(h), ovvero O(n), potendo essere il BSTarrangiato arbitrariamente
Sembrerebbe pertanto che un’implementazione indicizzata ed ordinatapossa addirittura essere piu conveniente, in quanto tutte le operazionihanno costo O(n) eccetto search, che ha costo O(log n)
Se riuscissimo a limitare l’altezza dell’albero che ospita il Dizionario,ad esempio garantendo h = O(log n) potremmo pero ottenereun’implementazione significativamente piu e�ciente
Algoritmi e Strutture dati Fabio Patrizi 171

Alberi AVL (Adelson-Velsky, Landis)
Algoritmi e Strutture dati Fabio Patrizi 172

Fattore di bilanciamento di un nodo
Definition
Dato un albero T = (N, A) ed un nodo n 2 N , si definisce fattore dibilanciamento di n il valore
�(n) = altezza(sx(n))� altezza(dx(n)),
ovvero la di↵erenza tra l’altezza del sottoalbero sx del nodo n e l’altezzadel sottoalbero dx del nodo n
Definition
Un albero T = (N, A) e detto bilanciato se per ogni nodo n 2 N , si ha:
|�(n)| 1
DefinitionChiamiamo albero AVL un albero binario di ricerca bilanciato
Algoritmi e Strutture dati Fabio Patrizi 173

Altezza di un albero AVL
Theorem
Un albero AVL con n nodi ha altezza h = O(log n).
Per dimostrare questo risultato, dimostriamo innanzitutto il seguenteLemma:
Lemma
Il numero minimo di nodi N(h) per costruire un albero AVL di altezza h,soddisfa la seguente relazione di ricorrenza:
N(h) =
⇢h, se h = 0, 11 + N(h� 1) + N(h� 2), se h � 2
Algoritmi e Strutture dati Fabio Patrizi 174

Altezza di un albero AVL
Per h = 0, 1, e immediato vedere che N(0) = 0 ed N(1) = 1, in quantol’albero vuoto e l’albero con la sola radice sono entrambi alberi AVL.
Per h � 2, indichiamo con Th
un generico albero di altezza h contenenteN(h) nodi.
Poiche Th
contiene il minimo numero di nodi con cui si puo costruire unalbero AVL di altezza h, esso sara necessariamente costituito dalla radice rcon sottoalberi gli alberi AVL con numero minimo di nodi T
h�1
e Th�2
.
Da cio segue il Lemma: N(h) = 1 + N(h� 1) + N(h� 2).
Algoritmi e Strutture dati Fabio Patrizi 175

Altezza di un albero AVL
Dal Lemma precedente, essendo N(h� 2) < N(h� 1), abbiamo che:N(h) = 1 + N(h� 1) + N(h� 2) > N(h� 1) + N(h� 2) > 2N(h� 2), ovvero:
N(h) > 2N(h� 2)
Svolgendo per iterazione, abbiamo:
N(h) > 2N(h� 2) > 2 · 2 · N(h� 4) > . . . > 2
i · N(h� 2i) > 2
h/2�1 · N(2)
Pertanto N(h) > 2
h/2�1 · N(2) ovvero, passando ai logaritmi:log
2
N(h) > log
2
2
h/2�1 · N(2) = (h/2� 1) + log
2
·N(2), da cui:h < 2 log
2
N(h)� 2 log
2
·N(2) + 2, ovvero:
h = O(log N(h))
Osserviamo infine che l’altezza massima h di un albero AVL contenente n nodi etale che: N(h) n < N(h + 1)
Quindi, essendo h = O(log N(h)) ed n � N(h), segue che h = O(log n).
Algoritmi e Strutture dati Fabio Patrizi 176

Operazioni su alberi AVL
Gli alberi AVL hanno altezza h = O(log n) quindi le operazioni insert,search e delete descritte per i BST hanno costo T (n) = O(log n)
Tuttavia, partendo da un albero AVL ed eseguendo un inserimento o unacancellazione potremmo ottenere un albero sbilanciato
Come possiamo garantire che inserimenti e cancellazioni preservino ilbilanciamento?
Algoritmi e Strutture dati Fabio Patrizi 177

Rotazioni
Una rotazione e un’operazione che permette di riconfigurare i nodi di unBST, modificandone i fattori di bilanciamento
Dopo aver eseguito un inserimento o una cancellazione da un albero AVL,se questo risulta sbilanciato, il bilanciamento dei suoi nodi puo essereripristinato tramite opportune rotazioni
Osservazione: se una cancellazione o inserimento sbilanciano un nodoprecedentemente bilanciato, tale nodo avra fattore di bilanciamento pari,in modulo, a 2
Algoritmi e Strutture dati Fabio Patrizi 178

Rotazioni
Per bilanciare un nodo occorre individuare la causa dello sbilanciamento
Sia v un nodo tale che |�(v)| = 2
I sottoalberi di v di↵eriscono in altezza per un valore pari a 2 (quindialmeno uno dei suoi due sottoalberi ha altezza pari a 2)
Distinguiamo 4 casi:(SS) il sottoalbero sx di sx(v) e piu alto del sottoalbero dx di sx(v)
(DD) il sottoalbero dx di dx(v) e piu alto del sottoalbero sx di dx(v)
(SD) il sottoalbero dx di sx(v) e piu alto del sottoalbero sx di sx(v)
(DS) il sottoalbero sx di dx(v) e piu alto del sottoalbero dx di dx(v)
Algoritmi e Strutture dati Fabio Patrizi 179
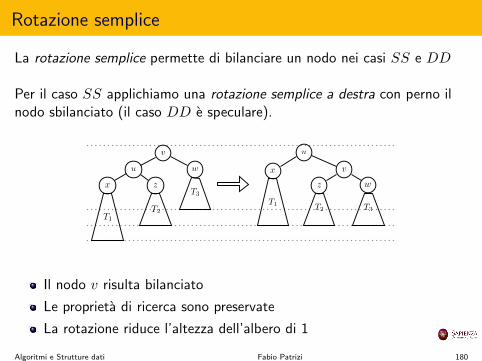
Rotazione semplice
La rotazione semplice permette di bilanciare un nodo nei casi SS e DD
Per il caso SS applichiamo una rotazione semplice a destra con perno ilnodo sbilanciato (il caso DD e speculare).
v
u w
x z
T1
T2
T3
v
u
w
x
z
T1 T
2
T3
Il nodo v risulta bilanciato
Le proprieta di ricerca sono preservate
La rotazione riduce l’altezza dell’albero di 1
Algoritmi e Strutture dati Fabio Patrizi 180
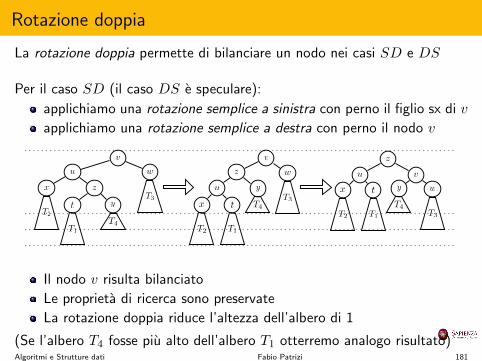
Rotazione doppia
La rotazione doppia permette di bilanciare un nodo nei casi SD e DS
Per il caso SD (il caso DS e speculare):
applichiamo una rotazione semplice a sinistra con perno il figlio sx di vapplichiamo una rotazione semplice a destra con perno il nodo v
v
u w
x z
T1
T2
T3
yt
T4
v
u
w
x
z
T1
T2
T3
y
t T4
vu
wx
z
T1
T2
T3
yt
T4
Il nodo v risulta bilanciatoLe proprieta di ricerca sono preservateLa rotazione doppia riduce l’altezza dell’albero di 1
(Se l’albero T4
fosse piu alto dell’albero T1
otterremo analogo risultato)Algoritmi e Strutture dati Fabio Patrizi 181

Inserimento
Per l’inserimento procediamo come segue:
Inseriamo un nuovo nodo come in un BST
Calcoliamo i fattori di bilanciamento nel cammino dalla radice alnuovo nodo
Se esiste qualche nodo sbilanciato lungo il cammino, e su�cientebilanciare il nodo piu profondo v per bilanciare l’intero albero
Per l’ultimo punto, e su�ciente ricordare che il bilanciamento riduce di 1l’altezza dell’albero con radice v (oltre a cambiarne la radice). Seinizialmente l’altezza e h, dopo l’inserimento diventera h + 1 manuovamente h, a seguito del bilanciamento. Pertanto, al termine delbilanciamento, il fattore di bilanciamento degli antenati di v non saracambiato.
Algoritmi e Strutture dati Fabio Patrizi 182

Cancellazione
Per la cancellazione procediamo come segue:
Cancelliamo il nodo come in un BST
Calcoliamo i fattori di bilanciamento nel cammino dalla radice alnuovo nodo. Si noti che solo i nodi lungo tale cammino possonocambiare fattore di bilanciamento
Se esiste qualche nodo sbilanciato lungo il cammino, occorre bilanciarei nodi, partendo dal nodo piu profondo v tra quelli sbilanciati
Per l’ultimo punto, si noti che la cancellazione non modifica l’altezzadell’albero con radice in v (in quanto abbassa il sottoalbero piu basso).Pertanto, se inizialmente la sua altezza e h, dopo la cancellazione saraancora h ma diventera h� 1, a seguito del bilanciamento. Pertanto, ilfattore di bilanciamento degli antenati di v sara cambiato e cio potrebbecausare uno sbilanciamento.
Algoritmi e Strutture dati Fabio Patrizi 183

Costo delle operazioni in un albero AVL
TheoremLe operazioni di inserimento, cancellazione e ricerca in un albero AVLhanno costo O(log n).
Proof.Per la ricerca, il risultato e conseguenza del fatto che la ricerca in un BST hacosto O(h) e che in un albero AVL h = O(log n).
Per l’inserimento, basta osservare che l’inserimento di un nuovo nodo come fogliaha costo O(h) = O(log n) ed il bilanciamento ha costo costante.
Per la cancellazione, osserviamo che la cancellazione come in un BST ha costoO(h) = O(log n) e che questa deve essere seguita da O(h) = O(log n)
bilanciamenti, ciascuno di costo costante. Si ricordi infatti che occorre bilanciaresolo i nodi lungo il cammino radice-v, che sono, al piu, h = O(log n).
Algoritmi e Strutture dati Fabio Patrizi 184

















![Algoritmi e Strutture Dati - computerscience.unicam.itcomputerscience.unicam.it/merelli/algoritmi11/[05]TabelleHash.pdf · Tabelle Algoritmi e Strutture Dati Tabelle Hash Maria Rita](https://static.fdocumenti.com/doc/165x107/5c66807b09d3f2d0218c6134/algoritmi-e-strutture-dati-05tabellehashpdf-tabelle-algoritmi-e-strutture.jpg)
