







Le lingue
Pagine
Legale


Suoni e Lettere Marco Svolacchia
1. Seconda articolazione del significante
Non è necessario essere dei linguisti per rendersi conto
che la caratteristica essenziale del linguaggio consiste
nell’associazione di suoni e significati, quello che i filo-
sofi medievali designavano come la relazione tra signi-
ficans e significatum, ‘significante’ e ‘significato’.
Quello che è meno evidente per i non addetti ai lavori è
quanto la caratterizzazione dei ‘suoni’ di una lingua sia
compito tutt’altro che semplice e immediato. Molti si
renderanno conto di un’interessante proprietà dell’ita-
liano: la forma sonora di ognuna delle parole del lessico
non è un insieme inanalizzabile, ma è composta da uni-
tà ricorrenti e riconoscibili di suono; gli stessi, per ana-
logia e in base all’esperienza di qualche altra lingua, as-
sumeranno implicitamente che questa proprietà si ap-
plichi ad ogni altra lingua umana (a parte quelle volte in
cui si è tentati di dubitarne sentendo parlare una lingua
incomprensibile ad una velocità che sembra inumana).
Il nome che i linguisti danno a questa proprietà è ‘se-
conda articolazione del linguaggio’. Probabilmente ai
più mancherà la parola per riferirsi a queste unità di
suono; molti saranno tentati di ricorrere al termine ‘let-
tera’, più per necessità che per convinzione, in quanto si
parla di suoni e non di scrittura. Per quanto riguarda
noi, utilizzeremo per ora il termine ‘segmento di suo-
no’, o, più semplicemente, ‘segmento’.
Dato che il tema di questa discussione è la compren-
sione dei meccanismi mentali che sottostanno
all’alfabetizzazione e alla pratica del leggere/scrivere, e
dato che la scrittura, qualsiasi tipo di scrittura ma in
particolare quella alfabetica, presuppone un sistema di
suoni, si rende necessario partire dallo studio dei seg-
menti di suono.
Già a questo punto, però, ci si imbatte in una diffi-
coltà apparentemente spiazzante: là dove ci si attende-
rebbe una sola disciplina specifica, ne troviamo due:
‘fonetica’ e ‘fonologia’. Qualsiasi tentativo serio di
spiegare a questo punto della discussione le ragioni di
questa bipartizione non raggiungerebbe molto proba-
bilmente altro scopo che confondere il lettore. Questo
per almeno un paio di ragioni: una è che le relazioni tra
queste due discipline sono molto complesse, tanto da ri-
sultare non del tutto chiare persino agli specialisti;
l’altra è che vi sono aspetti connessi con lo studio del
suono linguistico che, per essere afferrati, richiedono
una notevole intuizione ed esperienza. Pertanto, la
comprensione delle ragioni di questo dualismo e le dif-
ferenze fondamentali tra fonetica e fonologia piuttosto
che una premessa, saranno un risultato di questa di-
scussione. Come si apprezzerà più tardi, questo scopo è
direttamente connesso con la comprensione della feno-
menologia della lettura/scrittura.
Per il momento ci limiteremo a parlare di suoni, o
meglio di segmenti di suono, in modo ingenuo, senza
preoccuparci di approfondire la loro natura. Qui ci si
imbatte, però, in una prima difficoltà: c’è una bella dif-
ferenza tra ‘saper fare qualcosa’ e ‘sapere qualcosa’,
ovvero, sapere come si fa a fare ciò che si fa. Questa è
una tipica situazione in cui ci si imbatte in molte attività
umane; p.e. (quasi) chiunque di noi è in grado di affer-
rare un oggetto che si muove nello spazio, ma quanto a
spiegare come facciamo è un altro discorso. Nessuno di
noi ha idea, meglio: consapevolezza, della complessità
della computazione che questa azione apparentemente
semplice comporta. Ciò implica, tra l’altro, che in base
alla sua direzione, a volte nemmeno lineare, dobbiamo
calcolare la traiettoria dell’oggetto, più il momento in
cui si troverà nel punto che noi scegliamo per intercet-
tare lo stesso.
Per la maggior parte dei fatti connessi al linguaggio
ci si trova nella stessa situazione: sappiamo fare mera-
viglie con la nostra lingua, ma non abbiamo la minima
idea di cosa o come facciamo, in quanto si tratta di co-
noscenza inconsapevole. In realtà, a seconda dei casi,
come in parte vedremo poi, esistono livelli diversi di
(in)consapevolezza. Per quanto riguarda le capacità fo-
nologiche, che è quello che qui ci riguarda direttamente,
ciò che si è appena detto si mostra in modo esemplare.
Ci sembra scontato che si possa articolare e discrimina-
re a velocità supersonica le sequenze di suono del lin-
guaggio, ignorando l’incredibile specializzazione cere-
brale e neuromuscolare che questa attività comporta per
gli esseri umani, i soli in grado di realizzarla. Un bar-
lume della realtà ci sovviene solo quando siamo esposti
ad enunciati in una lingua che non conosciamo o perfi-
no, in una certa misura, che conosciamo ma non come
lingua madre: è esperienza comune che, a seconda dei
casi, non si riesce nemmeno a delimitare i segmenti di
suono, meno che mai ad identificarli con sicurezza.
Si immagini soltanto ciò che la nostra mente deve fa-
re quando è sottoposta ad un messaggio sonoro come in
una normale conversazione: deve computare un’enorme
massa di informazioni sonore che arrivano a grande ve-
locità e in condizioni tutt’altro che ideali (non conver-
siam1o normalmente in un laboratorio insonorizzato; il
parlante spesso e volentieri ‘ipoarticola’, termine tecni-
co per il più corrente ‘si mangia le parole’, ecc.). In re-
altà, è molto più che questo: non è solo l’aspetto quanti-
tativo che stupisce ma anche e soprattutto la complessi-
tà delle informazioni. Oltre alle informazioni connesse
col riconoscimento delle parole (i segmenti di suono)
un ascoltatore deve decodificare tutti quei segnali paral-
leli correlati alla durata, al ritmo, all’intonazione. Ora,
tutti questi segnali sono spesso sovrapposti in modo as-
solutamente intricato (p.e. un tono alto può essere un
segnale tanto di accento, tanto di un elemento intonati-
vo) e hanno per lo più un valore relativo (i.e. una sillaba
è considerata accentata non perché sia associata ad un
valore, di forza e/o durata e/o altezza, assoluto e defini-
to ma perché in quel contesto è contrassegnata da un
valore più alto rispetto ad un’altra sillaba). Non stupisce
il fatto che non esistano macchine che possano compie-
re questa analisi fonetica in modo automatico, anzi, un
risultato del genere è ancora inconcepibile; piuttosto, è
stupefacente come la nostra mente riesca non solo

2
nell’impresa ma anche con quella rapidità, facilità e
precisione che sappiamo.
Il problema, come si diceva, è che non abbiamo idea
di come facciamo e dei risultati di questa analisi. Ma
perché non ne abbiamo consapevolezza? Tutti i lingui-
sti, in genere, danno questo per scontato ma raramente
si prova ad affrontare una domanda del genere. Qua-
lunque sia l’eventuale risposta esatta, due sono gli in-
gredienti di base: uno è il concetto di apprendimento
inconscio, cioè spontaneo, l’altro è quello di innatezza,
relativo a ciò che non deve essere appreso, in quanto
patrimonio speciespecifico già presente alla nascita. Per
quel che riguarda la conoscenza dei suoni di una lingua
madre entrambi i fattori si presentano chiaramente. Il
fatto che si riesca molto più facilmente ad individuare i
segmenti di suono nella propria lingua che non in
un’altra dipende dall’apprendimento spontaneo e pre-
coce delle specificità di una particolare lingua, i.e. quali
segmenti di suono sono utilizzati, come si pronunciano,
come si combinano, ecc. Il fatto che si riesca, invece, ad
effettuare quel tipo di computazione in assoluto, a pre-
scindere dalla lingua specifica a cui si applica, e che si
possa apprendere la grammatica dei suoni di qualsiasi
lingua umana, in presenza di uno stimolo adeguato in
età adeguata (noi e solo noi della nostra specie), dipen-
de appunto da conoscenze innate. A questi due diversi
strati di capacità linguistica corrispondono anche, con
buona evidenza, livelli diversi di consapevolezza; per
quanto entrambi saperi inconsci è evidente che è molto
più facile avere accesso al tipo di informazioni linguo-
specifiche che non a quelle universali innate. In effetti
di questo tipo di capacità introspettiva, dai più chiamata
‘intuizione linguistica’, si fa abbondante ricorso nella
costruzione e convalidazione delle teorie fonologiche (e
linguistiche in generale). Ne faremo ampio uso anche
noi nel corso di questa discussione.
Tornando al problema che qui interessa, come si
debbano rappresentare le sequenze di suono
dell’italiano, è chiaro che in base a quanto appena detto
non è possibile trovare una risposta immediata, proprio
perché non abbiamo accesso diretto a queste informa-
zioni. Si dovrà procedere allora indirettamente, basan-
doci specialmente sulla nostra intuizione linguistica. In
realtà, chiunque di noi ha imparato a leggere/scrivere
l’italiano ha già appreso, per così dire, una teoria dei
segmenti dell’italiano, perché, si ricordi, in linea di
principio in un sistema alfabetico le lettere stanno per
segmenti di suono. Un buon punto di partenza per com-
prendere come è articolato l’italiano è perciò la sua or-
tografia, perché nel bene o nel male questa influenza la
nostra concezione della rappresentazione dei suoni.
2. Come la scrittura rappresenta i suoni
2.1. Il principio alfabetico
Procederemo ora ad un esame critico della scrittura
dell’italiano per capire quanto sia affidabile per i nostri
scopi. Si ricordi in cosa consiste “l’alfabeto perfetto”:
(1) PRINCIPIO ALFABETICO
Un alfabeto è un sistema di scrittura in cui i segni (le ‘lette-
re’) e i segmenti di suono sono in relazione di biunivocità.
Per semplicità la formulazione in (1) può essere distinta
in due parti:
(1a) ciascuna specifica lettera è in relazione con uno speci-
fico segmento;
(1b) ciascuno specifico segmento è in relazione con una
specifica lettera.
Si noti che (a) e (b) seguenti non sono equivalenti. A lo-
ro volta ciascuna delle due formulazioni contiene due
distinte proposizioni (in cui con ‘entità grafica’ si in-
tende qualsiasi lettera o combinazione di lettere, i.e. po-
ligrammi): (1ai) una lettera è in relazione con uno e un solo segmento;
(1aii) una specifica entità grafica è in relazione con un uni-
co specifico segmento;
(1bi) un segmento è in relazione con una e una sola lettera;
(1bii) un unico specifico segmento è in relazione con una
specifica entità grafica.
Per quanto l’insieme di queste formulazioni possa sem-
brare più complicato di quando non si desidererebbe,
esso esplicita l’idea intuitiva di alfabeto, un sistema il
più semplice e coerente possibile, parte nozione quanti-
tativa (un singolo segmento di suono deve essere rap-
presentato da una singola lettera), parte qualitativa (un
segmento di suono deve essere rappresentato sempre
nello stesso modo). È importante sottolineare che que-
ste caratteristiche non derivano da astratti requisiti logi-
ci aprioristici ma derivano da fedeltà ad una caratteristi-
ca fondamentale dei sistemi di suono delle lingue uma-
ne, la già menzionata seconda articolazione.
2.2. Principio alfabetico e ortografia italiana
Quello che segue è un piccolo brano, di seguito in tra-
scrizione ortografica, che sarà utilizzata estesamente nel
corso di questa discussione: (1) L’ho detto a mio figlio, questo libro che sta leggendo è
ignobile, il peggiore che abbia mai visto: solo sesso, violenza
e oscenità. Un giudizio troppo sbrigativo? Ma se l’ho già let-
to tre volte!
È facile rendersi conto che l’ortografia italiana, nono-
stante la communis opinio (‘l’italiano si legge come si
scrive’), è lontana dall’essere un alfabeto perfetto e se a
volte lo considera tale è solo in rapporto a sistemi orto-
grafici ben più incongrui, come quello francese o, ancor
di più, quello inglese, il probabile primatista mondiale
in questo campo. Vediamo in dettaglio quali sono le
violazioni dell’italiano riguardo al principio alfabetico.
2.2.1. Poligrammi
Una prima, evidente deviazione dal principio alfabetico
riguarda la proposizione (1bi) ed ha per soggetto i poli-
grammi, gruppi di lettere che rappresentano un unico
segmento. In italiano ci sono i seguenti tre digrammi,
i.e. gruppi di due lettere (le lettere sono sempre in cor-
sivo; la ragione per cui gl è seguito da i tra parentesi di-
venterà chiara più avanti):

3
sc, gn, gl(i)
Ma come facciamo a sapere che si tratta di digrammi e
non di gruppi di lettere che corrispondono a gruppi di
segmenti? La domanda è meno peregrina di quanto non
possa sembrare, in quanto, se non avessimo alcun ac-
cesso alle conoscenze fonologiche inconsce non sa-
remmo in grado di distanziarci dall’ortografia. Eviden-
temente, come la tradizione grammaticale italiana e
l’intuizione di molti parlanti nativi mostrano, siamo in
grado di renderci conto che il tratto di suono che queste
sequenze di lettere rappresentano è singolo. Vale a dire
che in forme come sci o gnomo le due lettere iniziali (o
le tre iniziali in glielo) corrispondono a livello segmen-
tale alla lettera iniziale di una forma come sì, piuttosto
che alle prime due lettere di una forma come psicologo.
Al contrario, intuiamo che la lettera iniziale di xilofono
corrisponde a livello segmentale alle due lettere iniziali
di psicologo e non alla lettera iniziale di libro. In questo
caso, una lettera ‘doppia’, si tratta di una violazione
della proposizione (1ai), parallela alla precedente.
Possiamo a questo punto emendare l’ortografia ita-
liana sostituendo ai poligrammi e alle lettere doppie ri-
spettivamente una lettera e due lettere, così da avvici-
narci alla rappresentazione mentale dei suoni
dell’italiano. Per questo utilizzeremo l’IPA, l’Alfabeto
Fonetico Internazionale. Pertanto avremo le seguenti
sostituzioni (dove le parentesi quadre indicano che si
tratta di segmenti di suono, non di scrittura):
sc > [ ] gn > [ ] gl(i) > [] x > [ks]
2.2.2. Lettere ‘mute’ e iperspecificazione
La violazione più eclatante di (1ai) è però rappresentata
dalle cosiddette “lettere mute”, in quanto non rappre-
sentano alcun segmento di suono. Sono di due tipi di-
versi; nel primo tipo rientrano quelle lettere che pur non
avendo un’identità fonetica individuale hanno contenu-
to fonetico. Parliamo in questi casi di lettere con fun-
zione ‘diacritica’ (= discriminante). Il caso più cono-
sciuto è quello di h, la ‘lettera muta’ per eccellenza; h
viene utilizzata come diacritico di suono dopo c/g se-
guite da vocali anteriori, i, e (p.e. chiesa, ghiro, boschi),
per indicare una lettura arretrata (“dura”, nella termino-
logia scolastica), contrariamente alla regola generale di
lettura di queste lettere in italiano, che prevede un valo-
re “morbido” (avanzato) prima di vocale avanzata. La
ragione è puramente storica, eredità di un fase antica
dell’italiano in cui le consonanti morbide erano solo
delle varianti prima di vocale morbida delle consonanti
dure, i.e. erano solo un modo diverso di pronunciare lo
stesso segmento di suono prima di vocale avanzata. Si
trattava, cioè, di una semplice alternanza prodotta da
assimilazione. Un riflesso di ciò è visibile in italiano
contemporaneo nell’alternanza che riguarda numerosi
temi (per lo più nominali e verbali), come gli esempi
seguenti mostrano: DURA MORBIDA
farmaco farmaci
psicologo psicologi
intrinseco intrinseci
raggiungo raggiungi
spingono spingiamo
conosco conosci
nascono nascita
In un italiano in cui le consonanti “dure” e quelle “mor-
bide” non sono più tra loro complementari si rende ne-
cessario potere indicare una lettura “dura” anche prima
di una vocale “morbida”. Questo è il caso, p.e., di for-
me come chiesa, ghiro, in cui, appunto, h indica che la
lettura di c/g è, contrariamente alla regola generale,
“dura”. Come mostrano gli ultimi due esempi, questo
uso di h riguarda anche il gruppo grafico sc, che merita
una menzione a parte perché, come si è già visto, prima
di vocale avanzata non corrisponde a due segmenti di-
stinti ma è un digramma col valore di [], anch’esso
suono avanzato.
Analogo è l’uso di i che qui chiameremo diacritica
per distinguerla dalla stessa quando sta per una vera vo-
cale, come p.e. in vino. Il fatto che i, a differenza di h,
possa avere valore fonetico è la ragione per cui essa non
viene tradizionalmente annoverata tra le lettere mute.
L’uso di i diacritica è illustrato di seguito:
arancio,
cialda
giacca,
giullare
sciame,
sciopero
aglio,
paglia
La funzione di i diacritica è speculare a quella di h: se-
gnala che, contrariamente alla regola generale, pur
comparendo le consonanti e il gruppo già visti prima di
vocale “dura” devono essere lette come “morbide”. Per
inciso, alla luce della regola generale che governa la let-
tura di queste lettere, la scelta di i come diacritico di let-
tura “morbida” è ben motivata. Alcune particolarità ag-
giuntive presenta gl(i).
Come dopo sc, il diacritico i serve a segnalare dopo
gl che si tratta di un digramma che rappresenta una
consonante“ morbida” invece che due consonanti di-
stinte, una delle quali “dura”. La differenza sta nel fatto
che non si tratta di un diacritico che si usa solo in de-
terminati contesti (davanti a vocali “dure”) ma che si
usa sempre per indicare la lettura “morbida”, indipen-
dentemente dal contesto; in altre parole, gl ha di per sé
il valore di [gl], non di [á]. Per questa ragione si consi-
dera tradizionalmente gli un trigramma.
Potrebbe sembrare completamente equivalente (e ir-
rilevante) se considerare i un diacritico di gl o l’ultima
lettera del trigramma gli; in realtà ci sono buone ragioni
per preferire la prima interpretazione. Il digramma gl è
parallelo a gn: g segnala in questi poligrammi che la let-
tera seguente deve essere letta come ‘palatale’ invece
che col valore normale, ‘alveolare’. Il digramma gl è
però ambiguo, perché può anche avere il valore del
gruppo consonantico [gl] (p.e. glicine); viceversa in ita-
liano non esiste [gn], pertanto gn non è ambiguo, ma
può solo avere il valore di [ ù]. È questa ambiguità del
digramma gl che rende necessario il diacritico i. È inte-
ressante notare che il gruppo grafico gli risulta ambiguo
per un lettore italiano: data una parola fittizia come
glidda, per molti può essere letto ambiguamente sia

4
come [gl]idda, sia [á]idda, sebbene il primo risulti pre-
ferenziale.
Un caso diverso dai precedenti è quello di h quando
è usato come diacritico lessicale, cioè senza alcun valo-
re fonetico ma con la funzione di discriminare tra forme
omografe (= scritte nello steso modo). Non indica per-
ciò nessuna particolare lettura ma serve al riconosci-
mento di determinate forme. Di fatto, la convenzione
interessa solo alcune forme del presente indicativo del
verbo avere:
ho hai ha hanno abbiamo, avevo; avrò, ecc.
o ai a anno Ø
Un altro uso di h, simile al precedente, è quello che si
trova nelle interiezioni, dove sembra essere un diacriti-
co di classe, a segnalare che si tratta di forme particola-
ri, non propriamente parte del lessico, come negli e-
sempi che seguono:
ah, ehi,
Una convenzione simile a quella di h diacritico lessicale
si incontra nei monosillabi, in relazione ai quali il segno
dell’accento viene utilizzato per distinguere coppie al-
trimenti omografe, come negli esempi seguenti: né là è sì
ne la e si
La norma è convenzionale in quanto la funzione prima-
ria del segno d’accento è quella di discriminare tra for-
me diverse, non di segnalare l’accento primario di paro-
la, che in italiano, come illustreremo più avanti, è se-
gnalato solo in casi eccezionali, comunque non sui mo-
nosillabi, per ovvi motivi. D’altra parte non è conven-
zionale la scelta di quale delle due forme sia associata
al segno dell’accento. Tutte le forme con accento grafi-
co sono effettivamente accentate fonologicamente,
mentre tutte le forme senza accento grafico sono effet-
tivamente atone, si tratta di ‘clitici’, forme senza auto-
nomia fonologica che vanno a formare gruppi ritmici
(‘parole fonologiche’) con parole adiacenti (precedenti
o seguenti, a seconda dei casi). In questo caso, quindi,
questa norma ortografica riflette una precisa intuizione
fonologica.
Pur rientrando nella rubrica delle lettere ‘mute’, una
funzione diversa è assolta dall’apostrofo. Esso segnale
che del materiale fonologico è stato eliso, cioè non vie-
ne pronunciato. Ciò che viene eliso può andare da una
vocale (a), a una sillaba (b): a b
l’ quest’ fa’ po’ be’
‘sto
lo questa fai poco bene questo
(Forme come be’ e ‘sto sono fortemente colloquiali; le
si incontra tipicamente solo nella trascrizione di dialo-
ghi). Se la norma è ben fondata dal punto di vista fono-
logico, vi è tuttavia qualche eccezione, fonte di ben noti
“errori ortografici”. La norma prescrive che le forme
brevi di uno e quale siano scritte come un e qual (in
forme come un amico, qual è), e non come *un’ e
*qual’. L’analisi che sottintende queste ortografie nor-
mative è che l’apostrofo non vada messo perché non ci
sarebbe elisione, essendo identiche alle forme base,
quelle che si usano prima di una forma cominciante per
consonante semplice: a b
1 qual buon vento qual è
2 un gatto un amico
L’analisi è però errata: l’uso di qual in contesti come in
(1a) è limitato a qualche espressione idiomatica che cri-
stallizza stadi precedenti di italiano; in italiano contem-
poraneo la forma base è quale (p.e. ‘Quale buon citta-
dino non lo farebbe?’, e non ‘*Qual buon cittadino non
lo farebbe?’). Sebbene meno evidente, lo stesso vale per
un, che in realtà deriva da uno, come gli esempi seguen-
ti mostrano: a b c d e
uno studio psicologo sciopero haiku e un solo
giorno
Le forme sopra mostrano che ogni qualvolta in cui la
parola seguente presenta delle particolarità la forma
dell’articolo è uno. In (a–c) si tratta di parole aventi un
elemento non sillabificato (= che non appartiene a nes-
suna sillaba); in (d) abbiamo una parola straniera che
inizia con determinate consonanti non italiane (natu-
ralmente si può utilizzare la forma elisa prima di queste
parole, ma solo se h iniziale non viene pronunciata, p.e.
uno handout o un handout, a seconda se [h] venga o
meno pronunciata); in (e) abbiamo l’articolo in quello
che verrebbe definito ‘uso pronominale’ (in realtà qui
semplicemente separato dalla forma che modifica, co-
me si vede cambiando l’ordine del congiunto: ‘un gior-
no e uno solo’). In conclusione l’elisione non ha luogo
ogni volta in cui o sorgerebbe un problema sillabico o
l’articolo è separato dalla forma che modifica, renden-
dosi impossibile la cliticizzazione. Abbiamo quindi un
caso in cui la norma ortografica va contro l’intuizione
del parlante.
Un ultimo caso di ‘lettere mute’ è quella di i che non
assolve nessuna funzione, né fonetica, né diacritica,
come negli esempi seguenti: a b c
1 cielo scienza ciliegie
2 celeste conoscenza ciliege
Tutte le forme in (1) condividono il fatto che i si trova
tra due lettere che rappresentano segmenti ‘morbidi’ (a-
vanzati). Che effettivamente i in queste forme non ab-
bia valore fonetico si può capire comparandole con le
corrispondenti in (2): celeste deriva da cielo ma non
presenta questa i; le ultime due sillaba di conoscenza
suonano esattamente come scienza pur avendo grafia
diversa; ciliegie suona esattamente come ciliege, sua
variante grafica. Si noti che i in queste forme non ha
nemmeno una funzione diacritica.
In alcuni casi la ragione della i muta è puramente fo-
nologica, dovuta all’‘assorbimento di [i]’ dopo una con-
sonante ‘morbida’, come si verifica tipicamente in al-
cune forme verbali, p.e. mangiamo, in cui i è muta, ri-
spetto a amiamo, dove i è pronunciata. Il parlante nati-
vo non è consapevole del fatto che non pronunci i in

5
questi contesti perché è fuorviato, per così dire, dalla
forma “ideale”, in quanto il suffisso in questione è –
iamo. In altri casi la ragione è solo storica, come nel ca-
so di scienza (da scire ‘sapere’). In altri, infine, come
nel caso di ciliegie, sembra dovuto a fraintendimento
delle convenzioni ortografiche.
Ragionando da un punto di vista molto generale sui
rapporti tra pronuncia e scrittura, gli usi delle cosiddette
‘lettere mute’ possono avere valenze molto diverse. Nel
caso di i e h diacritici fonetici, quando cioè identificano
segmenti di suono diversi, come in cialda e chiesa, essi
vengono ad assumere un ruolo di complemento della
lettera precedente, cioè in ultima analisi vengono a co-
stituire un digramma. Negli altri casi, invece, quelli in
cui delle lettere non hanno effettivamente nessuna va-
lenza fonetica, parliamo di iperspecificazione, il feno-
meno per cui la scrittura è in eccesso rispetto ai suoni
che rappresenta. Qui si tratta di un iperspecificazione
totale, perché riguarda segmenti interi. Un fenomeno
molto più interessante del precedente è
l’iperspecificazione parziale, che tratteremo più avanti.
2.2.3. Segmenti incoerentemente trascritti
Una classe diversa di idiosincrasie dell’ortografia ita-
liana deriva dalla violazione delle proposizioni (1a/bii),
quella che avevamo chiamata ‘parte qualitativa’ del
Principio Alfabetico, che è essenzialmente un requisito
di coerenza: ogni segmento di suono deve essere scritto
sempre nello stesso modo e ogni entità grafica deve
rappresentare un unico segmento. Una violazione di
(1bii) è rappresentata dalle entità grafiche seguenti: DURE MORBIDE
c – ch – q(u) g – gh c – ci g – gi
Ognuna delle entità grafiche nella stessa colonna rap-
presenta lo stesso segmento di suono, come è evidente a
qualsiasi parlante nativo di italiano. <q> presenta delle
idiosincrasie aggiuntive. La lettera q ricorre solo prima
di u non sillabica (i.e. quando u non fa sillaba, come in
quadro, che è scandita qua-dro, non *qu-a-dro). Non
ha nemmeno l’esclusiva di questo contesto: anche c può
ricorrere prima di u asillabica. L’utilizzazione di q o c
dipende fondamentalmente dall’etimologia. La ragione
della presenza nell’alfabeto italiano di q, che non ha al-
cuna specificità fonetica, deriva dal latino, lingua in cui
il digramma qu rappresentava un singolo segmento di
suono distinto [kw], che è arrivato in italiano come
[kw], i due segmenti distinti identici a quelli rappresen-
tati da cu. Inoltre q è l’unica lettera che non si raddop-
pia per segnalare una consonante lunga, ma viene af-
fiancata di norma da una c alla sua sinistra (p.e. acqua).
Nello spirito del compito che ci siamo preposti, ef-
fettueremo le seguenti sostituzioni, avvalendoci
dell’IPA dove necessario: DURE MORBIDE
k g t
La ragione per cui l’IPA utilizza simbolo composto (at-
tenzione, non un digramma!) per queste consonanti di-
venterà chiaro più avanti.
2.2.4. Lettere ambigue e ipospecificazione
Il problema inverso al precedente, una violazione di
(1aii), è rappresentato da quelle entità di suono che non
trascrivono un solo dato segmento di suono, risultando
quindi di lettura ambigua. L’esempio più notevole ri-
guarda le lettere e, o, che corrispondono ciascuna a due
distinti segmenti di suono, come gli esempi seguenti il-
lustrano: “APERTE” “CHIUSE”
terra posto tetto ponte
È fondamentale rendersi conto che non si tratta di ‘mo-
di diversi di pronunciare le stesse parole’, ma di diffe-
renze di suono fondamentali per il riconoscimento delle
parole. Al fine di rendere più chiara questa differenza
può essere utile ricorrere ad alcune coppie minime, una
tecnica utile a fare risaltare singole differenze di suono
che contano per il riconoscimento delle parole: “CHIUSE” “APERTE”
venti
pesca
legge
te
(numero)
(verbo)
(nome)
(pronome)
venti
pesca
legge
tè
(< ‘vento’)
(nome)
(verbo)
(nome)
botte
colto
pose
fosse
(recipiente)
(agg.)
(verbo)
(verbo)
botte
colto
pose
fosse
(< ‘botta’)
(verbo)
(< ‘posa’)
(< ‘fossa’)
Nonostante l’importanza di questa distinzione di suono,
i parlanti italiani tendono ad esserne scarsamente con-
sapevoli. Vi sono diverse ragioni (alcune delle quali di-
venteranno più chiare più avanti) ma la principale sta
con tutta probabilità proprio nel fatto che essa non è in
genere riconosciuta dall’ortografia, che, come si ricor-
derà, fornisce l’input più immediato alla nostra consa-
pevolezza dei suoni della nostra lingua. Un caso in cui
la distinzione viene riconosciuta, ma solo per e aperta –
chiusa, è in fine di parola, dove la norma (peraltro non
tra le più seguite, nemmeno nella pubblicistica, e igno-
rata completamente nell'insegnamento scolastico) pre-
scrive di utilizzare l’accento acuto per la "chiusa" (é),
l’accento "grave" per l’aperta (è). Nell'IPA si utilizzano
i simboli [e, o] per le "chiuse" e [] per le aperte.
Le stesse caratteristiche si trovano anche per la lette-
ra z, che in italiano codifica due segmenti di suono di-
stinti, uno sordo e uno sonoro (rispettivamente [ts] e
[dz] in IPA). Ecco alcuni esempi, il primo dei quali è
una coppia minima: SORDO (ts) SONORO (dz)
razza ‘stirpe’ razza ‘pesce’
pazzo rozzo
canzone bronzo
Come si può vedere dagli esempi, ognuna delle forme
riportate può essere pronunciata solo con uno dei due
segmenti (p.e. *canzone, in cui z è [dz], sarebbe una
pronuncia inaccettabile). Per una trattazione più estesa
di [ts–dz] si veda più avanti.
Possiamo trarre una prima generalizzazione riguardo
alle violazioni appena discusse del principio alfabetico:

6
si tratti di casi in cui la rappresentazione scritta è in di-
fetto rispetto alla rappresentazione mentale sonora, in
quanto ignora alcune caratteristiche di suono di un certo
segmento. Parliamo in questo caso di ipospecificazione
grafica. Per esempio, z è ipospecificato rispetto alla so-
norità, perché non tiene conto di questa caratteristica di
suono che distingue due segmenti di suono diversi in i-
taliano. Le lettere e, o sono ipospecificate rispetto all'a-
pertura, perché possono rappresentare unicamente voca-
li di apertura media (i.e. né chiuse, come [i, u], né aper-
te, come [a]), ma ciò è insufficiente in italiano, che di-
stingue tra due serie diverse di vocali medie: medio-
chiuse e medioaperte (medioalte e mediobasse, come si
dice tra gli addetti ai lavori).
2.2.5. Segmenti “ciechi” e prosodia
Per concludere questa rassegna delle incongruenze della
scrittura rispetto ai segmenti di suoni che essa intende
rappresentare, rimane aperta un'altra possibilità in linea
di principio, quella di ipospecificazione estrema, in cui
un segmento di suono non abbia alcuna rappresentazio-
ne scritta; per analogia con il termine 'lettere mute' use-
remo in questo caso il termine 'segmenti ciechi'. Si veri-
fica questa eventualità in italiano? La risposta è no, non
si dà il caso di un segmento che venga pronunciato e
non riceva alcuna rappresentazione scritta. Tuttavia, se
invece dei segmenti consideriamo altri elementi di suo-
no, i cosiddetti soprasegmentali, allora la risposta non
può che essere affermativa. Con ‘soprasegmentali’ ci si
riferisce a quegli elementi si suono che hanno
un’estensione superiore al segmento: sillaba, durata,
accento e ritmo, intonazione. Un termine più tradizio-
nale ancora utilizzato per abbracciare tutti questi aspetti
è prosodia.
Di questi elementi solo la durata consonantica (del
tipo di penna, tappo) è coerentemente espressa
nell’ortografia italiana, tramite il raddoppiamento della
lettera. Ma su questo punto torneremo estesamente più
avanti.
La sillaba non trova normalmente alcuna realizza-
zione grafica; essa è però presente in potenza nella pra-
tica dell’andare a capo, cioè nella possibilità di spezza-
re le parole tra un rigo e il successivo, che si basa
sull’integrità sillabica: si può spezzare una parola ma
non una sillaba. Quindi la pratica dell’andare a capo si
basa sull’intuizione del parlante riguardo alla divisione
in sillabe. I bambini italiani non mostrano alcun pro-
blema ad apprendere le modalità l’andare a capo, né si
notano comportamenti devianti rispetto alla norma, ap-
punto perché non è convenzionale ma è fonologicamen-
te fondata. C’è però un’importante eccezione: la divi-
sione in sillabe dei nessi consonantici con S preconso-
nantica, la cosiddetta ‘s impura’.
Per questi nessi la norma ortografica prescrive che s
vada a capo, assumendo una divisione in sillabe del tipo
–sC (in cui C sta per qualsiasi tipo di consonante; p.e.
in una parola come pasta la divisione in sillabe grafica
è pa–sta). Tuttavia, il comportamento spontaneo dei
parlanti italiani si mostra divergente: i bambini che im-
parano a scrivere, una volta che hanno intuito il princi-
pio su cui si basa la possibilità dell’andare a capo, divi-
dono s dalla consonante seguente (p.e. *pas–ta;
l’asterisco prima di una forma indica che la stessa è er-
rata rispetto alla norma di riferimento). Questo compor-
tamento si osserva sporadicamente anche tra adulti. La
spiegazione di questa discordanza tra norma grafica e
comportamento sistematico dei parlanti è in questo caso
molto semplice: è la norma grafica che è fonologica-
mente infondata, in quanto la scansione sillabica è esat-
tamente quella implicata dalla divisione in sillaba dei
bambini che imparano a scrivere, [pas–ta] nell’esempio
precedente. Sappiamo questo con sicurezza per una se-
rie di ragioni (a parte l’intuizione di qualunque parlante
che non si lasci condizionare dalla scrittura)
Vi sono diverse ragioni, al di là dell’intuizione dei
parlanti, che dimostrano che i nessi con ‘s impura’ non
appartengono alla stessa sillaba (cioè –sC) ma a due sil-
labe diverse (cioè s–C; dove ‘C’ sta per qualsiasi con-
sonante), sia all’interno di parola (p.e. posto, sillabato
come [pOs–to], non come *[pO–sto]), sia tra parole in
date configurazioni (p.e. uno studente, sillabato come
[u–nos–tudente], non come *[uno–stu–dente]).
1. La vocale che precede la ‘s impura’ è breve anche se
accentata, p.e p[O]sta, non *p[O:]sta, cioè non si verifica
l’Allungamento Vocalico, segno che la ‘s impura’
chiude la sillaba (in italiano si ha Allungamento Vocali-
co in sillaba accentata, aperta (= che non termina in
consonante), non finale di parola: ‘l[i:]-bro, ‘c[a:]-sa;
se la sillaba è accentata ma chiusa, i.e. termina in
consonante, non si ha Allungamento Vocalico: ‘c[a]s-
sa; se la sillaba è accentata e aperta ma è finale di
parola non si ha Allungamento Vocalico: cit-‘t[a]).
2. I nessi con ‘s impura’ non permettono l’elisione della
vocale finale degli elementi prenominali (p.e. lo studio,
non *il studio; grande studioso, non *gran studioso,
ecc.). Ciò si spiega col fatto che l’elisione creerebbe
una sillaba illegittima: *ils–tu-dio, impronunciabile, in-
vece che los–tu-dio, perfettamente pronunciabile;
3. Viene inserita una protesi vocalica in alcune parole
che iniziano per ‘s impura’ (p.e. in [i]Spagna, in
[i]spirito, per [i]scritto). La protesi serve a sillabificare
‘s impura’, che non appartiene a nessuna sillaba (i.e. i–
nis–pagn–gna);
4. ‘s impura’ viene cancellata in forme come pe(r)–
spicace; supe(r)–stite; co(n)–statare; i(n)–stallare: se s
(quella sottolineata) facesse parte dell’attacco perché la
sonorante precedente si dovrebbe elidere, dato che una
sonorante può occupare la coda di sillaba? Se invece la
divisione in sillabe è pers–pi–ca–ce allora diventa chia-
ro perché [r] venga elisa: in italiano non possono ricor-
rere due consonanti in fine di sillaba, quindi una non
viene pronunciata.
5. s viene elisa in parole inizianti per ‘s impura’ dopo
un prefisso terminante in consonante:

7
ad– dis–
ombra ad+ombrare erba dis+erbare
destro ad+destrare sacro dis+sacrare
dritto ad+drizzare sperare dis+(s)perare
Nella tabella si trovano parole derivate tramite un pre-
fisso terminante in consonante, ad– nella colonna a si-
nistra, dis– nella colonna a destra. Nelle parole della co-
lonna a sinistra, con la sillaba iniziale normale, la con-
sonante iniziale del tema non viene mai elisa, nemmeno
quando esso comincia con due consonanti
(ad+drizzare); viceversa, nelle stesse condizioni la ‘s
impura’ viene elisa (in dis+(s)perare [s] iniziale del
tema, qui tra parentesi, non viene pronunciata). La ra-
gione del contrasto è che formazioni a sinistra non dan-
no luogo a problemi sillabici, perché ogni elemento
viene sillabificato (i.e. ad–driz–za–re), mentre in quelle
a destra ‘s impura’ non può essere sillabificata (non può
far parte né della sillaba a destra, né della sillaba a sini-
stra, già completa perché terminante in una consonante;
i.e. dis–s–pe–ra–re) e viene pertanto eliminata.
6. Un'altra prova proviene dalla pronuncia dei bambini
(2-5 anni circa), come i dati seguenti mostrano: ADULTI BAMBINI
a tor-ta tot-ta
b tre-no t-no
c i tre-ni i t-ni
d sport pt (*t)
e lo sport lo p-pt
I nessi consonantici vengono semplificati eliminando
una delle due consonanti adiacenti. Se la consonante e-
liminata è in coda di sillaba; la consonante seguente
prende il suo posto, cioè si allunga (allungamento di
compenso), come in (a); viceversa, se la consonante e-
liminata sta in attacco non c’è allungamento di compen-
so, e la consonante eliminata è quella più vicino al nu-
cleo, come in (b–c). A contrario, se una parola comincia
per ‘s impura’ allora il comportamento rispetto alla
semplificazione è opposto: è la ‘s impura’ che viene e-
liminata, pur essendo apparentemente più esterna ri-
spetto al nucleo della consonante seguente, (d), e dà al-
lungamento di compenso, (e), comportandosi così non
come una consonante in attacco di sillaba ma come una
consonante in coda di sillaba (cf. /r/ di tor-ta).
Nella teoria fonologica corrente elementi come ‘s
impura’ vengono analizzati come marginali, non facenti
parte della sillaba propriamente detta. Questi elementi
aggiuntivi vengono perciò chiamati extrasillabici e pos-
sono ricorrere solo ai limiti della parola (inizio o fine).
L’accento e il ritmo sono notati nell’ortografia ita-
liano solo eccezionalmente, per segnalare l’accento
sull’ultima sillaba (parole ‘tronche’), che è molto mar-
ginale nella regola di accentazione dell’italiano. Facol-
tativamente, si segnala l’accento anche su sillabe diver-
se dall’ultima, per disambiguare parole altrimenti omo-
grafe (p.e. prìncipi, per distinguerlo da princìpi; nòccio-
lo, per distinguerlo da nocciòlo). Ma si tratta di un uso
molto formale (limitato comunque alla carta stampata),
poco sistematico e, probabilmente, démodé.
Intonazione: è opinione comune che la punteg-
giatura sia la rappresentazione grafica dell’intonazione.
In realtà la relazione tra intonazione e punteggiatura è
molto indiretta e le corrispondenze solo approssimative.
Quello che emerge da questa breve discussione è un
contrasto tra i segmenti di suono e gli elementi sopra-
segmentali:
(a) I segmenti di suono sono sempre rappresentati gra-
ficamente in italiano (sporadicamente con ipospecifica-
zione, come abbiamo visto). Del resto questa è una si-
tuazione che si riscontra in generale nei sistemi grafici
del mondo: non si dà il caso (o, al massimo, è estrema-
mente raro) che un segmento di suono di una lingua non
trovi espressione in un sistema grafico di tipo fonetico.
Si incontrano casi di segmenti di suono che non tro-
vano alcuna rappresentazione scritta? La risposta è mol-
to probabilmente negativa se si considerano i sistemi
propriamente alfabetici. Esiste però una classe di siste-
mi grafici, tutti strettamente correlati, che forniscono
molta materia di discussione a questo riguardo. Si tratta
dei cosiddetti “alfabeti semitici”, che hanno un’enorme
importanza per almeno un paio di ragioni:
1. per ragioni storiche: uno di questi sistemi di scrittura
(tradizionalmente si parla del fenicio) è l’antenato di
tutti i sistemi alfabetici esistenti al mondo;
2. per ragioni culturali: questi sistemi di scrittura sono
usati per trascrivere lingue molto importanti dal punto
di vista culturale (vedi ebraico e arabo) o anche per dif-
fusione (vedi arabo). L’“alfabeto arabo”, in particolare,
in virtù della sua importanza culturale, soprattutto reli-
giosa, ha avuto un impatto enorme nella grafizzazione
di numerose lingue e nell’alfabetizzazione di molti po-
poli; di fatto la scrittura araba, insieme a quella greca e,
ancor più, quella latina, è a tutt’oggi uno dei sistemi
grafici maggiormente diffusi al mondo.
La peculiarità di questi sistemi grafici è che si tratta
di ‘scritture consonantiche’, vale a dire che registrano
solo consonanti; le vocali, invece, non trovano alcuna
rappresentazione grafica, in linea di principio. Così,
p.e., una parola araba come [akl] ‘cibo’ (in cui il sim-
bolo è una consonante) si scrive (da destra a sinistra)
nel modo seguente (è una scrittura corsiva, anche nei
testi a stampa):
أ ك ل
l k
Il suono vocalico, qui [a], non ha alcuna rappresenta-
zione grafica. Come logica conseguenza
dell’ipospecificazione grafica, la maggior parte delle
parole grafiche arabe sono ambigue, a volte estrema-
mente ambigue. Così la stessa parola grafica può tra-
scrivere anche [kala] ‘mangiò’, [ukila] ‘fu mangiato’,
ecc. Il recupero della specificazione vocalica avviene
fondamentalmente tramite il contesto linguistico (mor-

8
fologico, sintattico e semantico). Anche il contesto ex-
tralinguistico gioca a volte un ruolo nel processo.
L’esatta natura di questi sistemi di scrittura è ogget-
to di un vivace dibattito. Qualcuno li ritiene in fondo
scritture sillabiche, benché di un tipo speciale; altri li
considerano a sé stanti, una via di mezzo tra i sillabari e
gli alfabeti, tanto che per denominarli hanno coniato il
termine ‘abjad’ (in cui ‘j’ ha la lettura inglese), dai pri-
mi quattro caratteri dell’“alfabeto” arabo.
(b) Gli elementi soprasegmentali, al contrario, tendono
a essere scarsamente rappresentati graficamente, in ita-
liano, come in altri sistemi scrittori.
Questo contrasto è illuminante per comprendere la
natura dei sistemi di scrittura, siano essi fonetici o me-
no, alfabetici o altro: i sistemi di scrittura hanno come
scopo di essere solo strumenti con una finalità stretta-
mente pratica, quella del riconoscimento, non della
rappresentazione, dei messaggi linguistici. Pertanto,
più un elemento è prevedibile in base al contesto tanto
minori saranno le probabilità che esso trovi rappresen-
tazione scritta. Questo spiega il contrasto tra i segmenti
di suono, la cui predicibilità è generalmente scarsa, e i
soprasegmentali, largamente predicibili in quanto alta-
mente ridondanti.
2.2.6. Conclusioni: dalle lettere ai suoni
A conclusione di questa prima parte possiamo applicare
al nostro mini testo i risultati a cui siamo finora perve-
nuti in direzione della realtà sonora dell’italiano. Per-
tanto, a seguito degli emendamenti necessari esso appa-
rirà nella forma seguente:
(2) l detto a mio fio, kuesto libro ke sta leddndo
ibile, il peddore ke abbia mai visto: solo ssso, violntsa
e oenita. un duditsio trppo sbrigativo? ma se l da ltto
tre vlte!
In aggiunta a quanto già detto, si considerino le seguen-
ti osservazioni:
a. non viene osservata la differenza tra lettere minu-
scole e maiuscole, che è una differenza che non ha al-
cun contenuto fonetico;
b. vengono notati per semplicità solo i segmenti di
suono, astraendo dagli elementi soprasegmentali;
c. sono state mantenute alcune convenzioni come la
divisione in parole grafiche e la punteggiatura perché
rendono più agevole la lettura.
3. Cosa scriviamo quando scriviamo
3.1. Dai ‘segmenti di suono’ alla pronuncia
A questo punto possiamo interrogarci sulla esatta natura
del risultato a cui siamo pervenuti. In altre parole: che
cosa è esattamente la trascrizione in (2)? La domanda
può sembrare a prima vista oziosa, perché la risposta
sembra ovvia: (2) è una trascrizione di come in italiano
standard si pronuncia (si legge) il testo (1). Per quanto
possa sembrare controintuitivo, questa conclusione è si-
curamente sbagliata, ed è facile rendersene conto esa-
minando da vicino alcune parole del nostro mini testo.
3.1.1. Consonanti intrinsecamente doppie
La prima forma che considereremo è figlio. La trascri-
zione, [fio], non è una rappresentazione accurata. Una
rappresentazione più realistica è [fio] (in cui
l’elemento aggiuntivo è evidenziato in rosso). Il
segmento [] è “doppio”, o ‘lungo’; ciò significa che ha
durata doppia rispetto ad una consonante semplice, bre-
ve. È facile constatare questa proprietà, anche senza
strumenti di analisi acustica, tramite la comparazione
tra questa forma e altre simili:
Qualsiasi parlante nativo di italiano intuisce che figlio
non “rima” con filo, ma piuttosto con fillo (che questa
parola non esista in italiano non ha nessuna importan-
za). Chi desidera un esempio più realistico può conside-
rare una forma analoga: paglia non rima con pala ma
con palla; pigna rima con pinna, non con Pina, ecc. Lo
stesso fatto ricorre varie volte nel testo: ignobile
[ibile], oscenità [oenita], giudizio [dudittsio]. Si
tratta di un fenomeno perfettamente regolare in italiano,
che riguarda forme in cui ricorrono specifici segmenti
di suono, le consonanti intrinsecamente doppie.
È fondamentale sottolineare che non si tratta di
‘sfumature’; la lunghezza di queste consonanti è la stes-
sa delle consonanti doppie in forme come cassa (vs. ca-
sa), palla (vs. pala), ecc., di cui nessun italiano si so-
gnerebbe di dire che si tratta di ‘sfumature’.
3.1.2. Allungamento vocalico
La seconda forma che andiamo ad esaminare è libro.
Anche qui la trascrizione data, [libro], non registra la
nostra pronuncia effettiva, che è [li:bro], con una vocale
lunga (nella convenzione IPA i due punti dopo un seg-
mento indicano che lo stesso è lungo, ha durata doppia).
Nel nostro mini testo se ne incontrano molti esempi:
[peddo:re, sbrigati:vo], ecc.
Anche qui non si tratta di ‘sottigliezze fonetiche’: la
durata di queste vocali lunghe in italiano è perfettamen-
te comparabile a quella delle consonanti doppie già vi-
ste (p.e. cassa, palla). Anche in questo caso si tratta di
un fenomeno perfettamente regolare e prevedibile in i-
taliano, l'Allungamento Vocalico.
3.1.3. Raddoppiamento Sintattico
Un’altra forma che considereremo ora è l’ho detto, che
avevamo trascritto come [l detto]. Anche qui è abba-
stanza facile rendersi conto che (in italiano standard)
questa formazione viene pronunciata con un raddop-
piamento, sebbene non venga notato nell’ortografia. La
pronuncia reale è [lddetto], con la consonante iniziale
della seconda parola doppia. Nel testo ricorrono molti
esempi analoghi: [ammio, stalleddndo, trevvlte],
ecc. Sebbene la regola che governa questi raddoppia-
menti sia abbastanza variegata, anche questo fenomeno
figlio filo fillo

9
è assolutamente regolare e prevedibile, e va sotto il no-
me di Raddoppiamento Sintattico.
3.1.4. Arrotondamento
Un altro fatto di pronuncia che andiamo a considerare è
rappresentato nel nostro testo dall’esempio questo, pre-
cedentemente trascritto come [kuesto]; in realtà una
rappresentazione più realistica della nostra pronuncia
sarebbe [kwuest
wo], in cui il simbolo in apice indica che
la consonante precedente è arrotondata (un termine e-
quivalente è ‘labializzata’), cioè pronunciata con le lab-
bra sporgenti e arrotondate, come quando pronunciamo,
p.e., la vocale [u]. È possibile rendersene conto osser-
vando il movimento delle labbra mentre viene pronun-
ciata questa parola in modo più evidente per [kw] che
per [tw]. Tuttavia, mentre abbiamo qualche consapevo-
lezza del movimento delle labbra quando pronunciamo
suoni come [u], non ne abbiamo affatto quando pronun-
ciamo queste consonanti arrotondate.
Nel nostro mini testo compaiono numerosi casi di
consonante arrotondata: in tutti i casi, però, si può veri-
ficare che essi precedono una vocale arrotondata ([u, o,
]), cioè un segmento che viene pronunciato sempre
con questa caratteristica di suono. Per esempio, [kw] e
[tw] sono arrotondati perché precedono, rispettivamente,
[u] e [o]. Il fenomeno che produce queste caratteristiche
di suono è quindi l’Assimilazione, cioè l’adattamento di
un segmento di suono alle caratteristiche di un altro
segmento adiacente.
3.1.5. Vocali alte asillabiche
Forme come questo o violenza, già trascritte come
[kuesto] e [violntsa], esemplificano un altro aspetto
della pronuncia dell’italiano (e di moltissime altre lin-
gue, in verità): la pronuncia variabile delle vocali alte
(‘chiuse’) i e u. Le vocali alte, a seconda della posizione
che occupano nella sillaba, vengono pronunciate più o
meno lunghe, più o meno alte. In particolare, nelle for-
me che stiamo considerando esse hanno una pronuncia
“consonantica”, nel senso che sono ‘asillabiche’, cioè
non fanno sillaba. Così una forma come questo, pur in-
cludendo tre vocali, ha solo due sillabe: ques-to, non
*qu-es-to. Nell’IPA queste forme vengono trascritte
come, rispettivamente [kwesto] e [vjoltsa], in cui i
segmenti in causa sono evidenziati per comodità, e
vengono denominate semiconsonanti. Un'altra forma
del testo, mai, esemplifica un altro tipo di vocale asilla-
bica, che nell’IPA è trascritta come [maĭ] (o, per u
[flaŭto]), e che viene da qualcuno denominata
semiconsonante. Anche qui la caratteristica fondamen-
tale è che si tratta di una vocale che non fa sillaba (mai
è monosillabico, fla-uto è bisillabico).
3.1.6. N e S preconsonantici
L’ultimo aspetto che andiamo a considerare comprende
due casi per molti aspetti simili: S e N preconsonantici.
Questi due segmenti di suono hanno in comune la
caratteristica che hanno una pronuncia variabile prima
di un’altra consonante. Il testo ci offre qualche spunto.
In un giudizio la nasale è stata trascritta come [n]; in
realtà la reale pronuncia è qualcosa di molto vicino a
[], il suono corrispondente a gn ortografico. Questo
non significa però che N venga pronunciato così prima
di ogni consonante; al contrario, la sua pronuncia varia
in funzione della consonante seguente, come la tabella
seguente mostra: [ ] LESSEMA LUOGO D’ARTICOLAZIONE
iN– m possibile BILABIALE
fallibile LABIODENTALE
n tentato DENTALE
civile PALATOALVEOLARE
credibile VELARE
In altre parole, in coda di sillaba (in quanto una nasale
preconsonantica si trova necessariamente in coda di sil-
laba) N non ha una propria definizione di Luogo di Ar-
ticolazione (cioè l’articolatore attivato) ma lo riceve
dalla consonante seguente. Si tratta, cioè, di un feno-
meno analogo all’assimilazione.
Una situazione analoga, sebbene più semplice, è
quella di S preconsonantica. Una forma come sbriga-
tivo è stata trascritta come [sbrigativo]; non è però dif-
ficile rendersi conto che la reale pronuncia è piuttosto [
zbrigativo], in cui il simbolo IPA [z] sta per il corrispet-
tivo sonoro di [s], come quello che si sente in forme
come casa, pronunciata da molti parlanti italiani, specie
settentrionali.
Anche in questo caso non è che S si pronunci sempre
sonora prima di un’altra consonante, piuttosto essa si
accorda in sonorità alla consonante che segue, come la
tabella seguente evidenzia: [s] [z]
sparire
stonare
sconto
sbarra
sdentato
sgridare
smilzo
snaturato
slavata
sregolato
Il senso del fenomeno è che in italiano S preconsonan-
tica non ha una propria definizione di sonorità ma si ac-
corda con la consonante che segue. Come per N prece-
dente, si tratta di assimilazione, seppure di un tipo par-
ticolare.
3.1.7. Conclusioni: come pronunciamo l’italiano
A conclusione di questa discussione, i risultati a cui
siamo pervenuti riguardo alla pronuncia del nostro mini
testo italiano sono i seguenti (gli elementi di pronuncia
aggiuntivi rispetto alla trascrizione in (2) sono in rosso;
quelli diversi sono evidenziati in giallo; non si è tenuto
conto delle parole grafiche, ma grosso modo dei gruppi
ritmici):
(3) lwddett
wo ammiofiw
o, kwwest
wo l:ibr
wo
kestalleddn:dwo iw:bile, ilpeddo:re keabbja
maĭvis:two: s
wol
wo sss
wo, vjoln:tsa eoenita. ududittsjo
trwppozbrigati:vo? massell
wddallttow tre vvl:te!

10
3.1.2. Segmenti di suono, foni e fonemi
A questo punto si pone una domanda: se (3) rappresenta
come noi pronunciamo l’italiano (o, meglio, gli aspetti
più importanti della pronuncia dell’italiano) cosa rap-
presenta la trascrizione in (2)? Alla luce della discus-
sione sulla pronuncia dell’italiano si potrebbe essere
portati a dedurre che (2) sia una versione approssimati-
va di (3), in quanto non è né una rappresentazione gra-
fica dell’italiano, né fonetica, nel senso che non illustra
effettivamente i movimenti salienti del nostro apparato
fonatorio. Questa conclusione, però, sarebbe sbagliata.
In realtà, una rappresentazione come quella in (2) coin-
cide sostanzialmente con quella che la gran parte dei
linguisti definirebbe una ‘trascrizione fonematica’, vale
a dire che consiste nei cosiddetti ‘fonemi’. Si ricorderà
che all’inizio della nostra discussione avevamo accen-
nato alla bipartizione della scienza del suono linguistico
in due discipline, la fonetica e la fonologia. È venuto il
momento di spiegare in cosa consista la differenza. I
fonemi attengono alla fonologia, così come i foni atten-
gono alla fonetica. Quella in (3) è appunto una trascri-
zione fonetica, cioè in foni, che sono appunto elementi
di pronuncia. Ma cosa sono i fonemi? In prima appros-
simazione possiamo dire che sono unità di suono men-
tali. In quanto tali sono astrazioni, nel senso che non si
possono osservare fisicamente, come è invece possibile
per più concreti i foni, elaborati sulla base
dell’osservazione dei movimenti dell’apparato fonatorio
e delle emissioni acustiche. Nonostante ciò le prove
della loro esistenza mentale sono incontrovertibili. La
fonologia, quindi, si interessa dell’aspetto mentale del
suono linguistico, mentre la fonetica si interessa
dell’aspetto fisico, osservabile esternamente.
È importante rendersi conto che questa distinzione
non è solo disciplinare–metodologica; in realtà ci sono
ottime ragioni per ritenere che nella nostra mente ci
siano due componenti con funzioni distinte che corri-
spondono grosso modo alle due sottodiscipline. Ma
quali sono queste diverse funzioni? La risposta può
sembrare abbastanza evidente per il componente foneti-
co: si può pensare, magari un po’ semplificando, che si
occupi della pronuncia dei segmenti di suono, vale a di-
re che istruisce i vari articolatori dell’apparato fonatorio
riguardo ai movimenti da effettuare; in una parola della
fonazione. Ma perché un componente fonologico? Eb-
bene la risposta è che il componente fonologico ha la
funzione di interpretare linguisticamente i suoni lingui-
stici. L’interpretazione dei suoni linguistici consiste es-
senzialmente nel loro riconoscimento. Quando noi a-
scoltiamo un enunciato linguistico l’aspetto fondamen-
tale non è di ascoltare come i singoli segmenti di suono
siano effettivamente pronunciati ma semplicemente di
riconoscerli. Senza questo riconoscimento non sarebbe
possibile la comunicazione, in quanto non sarebbe pos-
sibile identificare gli elementi dotati di senso, morfemi,
parole e costituenti. Questa è la ragione per cui la fono-
logia, e non la fonetica, è direttamente correlata alla
grammatica e al lessico.
Tradotto in termini più analitici, la competenza di
base del componente fonologico (e quindi di una tra-
scrizione in fonemi, che simula la nostra rappresenta-
zione mentale fonologica) è quello della discriminazio-
ne dei segmenti di suono. Ciò significa che un parlante,
quando viene esposto ad un messaggio, deve identifica-
re le unità di suono con cui vengono costruite le parole
della sua lingua sulla base della sua conoscenza
dell’inventario dei fonemi della propria lingua. In altre
parole, non si tratta di un’operazione di ascolto passivo
e neutro, ma di un esercizio di identificazione. Ciò che
conta in questa operazione, quindi, non è di registrare
tutte le sottigliezze di suono, che pure siamo perfetta-
mente in grado di sentire, ma di astrarre solo quelle
proprietà di suono che servono per distinguere un fo-
nema da tutti gli altri, in breve i tratti distintivi.
Alla luce di quanto abbiamo appena detto la rappre-
sentazione (2) comincia ad avere senso. Si noterà che in
tutti i casi si tratta di segmenti di suono distintivi; per
meglio dire la rappresentazione (2) contiene (salvo al-
cune parziali eccezioni che verranno discusse più avan-
ti) solo proprietà di suono che sono potenzialmente in
grado di costruire parole diverse. Si può capire facil-
mente questo confrontando la trascrizione fonologica
con quella fonetica (ripetute qui di seguito per comodi-
tà):
(2) TRASCRIZIONE FONOLOGICA
l detto a mio fio, kuesto libro ke sta leddndo ibile,
il peddore ke abbia mai visto: solo ssso, violntsa e
oenita. un duditsio trppo sbrigativo? ma se l da ltto tre
vlte!
(3) TRASCRIZIONE FONETICA
lwddett
wo ammiofiw
o, kwwest
wo l:ibr
wo kestalleddn:d
wo
iw:bile, ilpedo:re keabbja maĭvis:two: s
wol
wo sss
wo,
vjoln:tsa eoenita. ududittsjo trwppozbrigati:vo?
massellwddalltto
w tre vvl:te!
Una delle differenze più evidenti tra le due trascrizioni
è che in (3) sono presenti molti casi di segmenti lunghi
(doppi) non registrati invece in (2), sebbene anche in
(2) compaiano segmenti lunghi. Allora la domanda è:
perché la trascrizione fonologica registra alcuni casi di
lunghezza e ne ignora altri? Si noti che ciò non dipende
da fattori fisici, nel senso che i casi di lunghezza regi-
strati nella trascrizione fonologica non differiscono in
nulla dagli altri. È forse un fatto arbitrario, magari lega-
to a corrispondenti arbitrarietà del nostro sistema orto-
grafico? La risposta è no, il diverso trattamento non è
affatto arbitrario ma obbedisce al criterio di distintività,
che, come si è detto, è fondamentale in fonologia. Così,
tutti i casi di segmenti doppi in (2) rientrano nella cate-
goria della lunghezza consonantica contrastiva che ca-
ratterizza un gran numero di morfemi grammaticali e,
soprattutto, lessicali dell’italiano. Ecco alcuni esempi di
coppie minime: cane – canne casa – cassa pala – palla vedremo –
vedremmo

11
La lunghezza che caratterizza queste forme è impreve-
dibile perché non può essere ricavata tramite
l’applicazione di una regola, infatti è lessicale, nel sen-
so che deve essere specificamente appresa per ogni
forma in cui compare. È da notare che la lunghezza
consonantica lessicale, pur non essendo rara in assoluto
tra le lingue del mondo, si trova unicamente in italiano
tra le lingue nazionali dell’Europa occidentale.
Viceversa, tutti casi di lunghezza registrati in (3)
ma non registrati in (2) rientrano nella rubrica della
lunghezza non contrastiva. Infatti, come si ricorderà, sia
la Lunghezza Consonantica Intrinseca sia l’Allunga-
mento Vocalico sia il Raddoppiamento Sintattico sono
automatismi governati da regole, come tali non sono in
grado di identificare parole diverse.
Le stesse considerazioni valgono per le altre proprie-
tà di suono considerate in (3) ma trascurate in (2), come
l’arrotondamento consonantico, che non è una proprie-
tà distintiva in italiano. Come si ricorderà, il fatto che
una consonante sia o meno arrotondata in italiano non è
una proprietà autonoma della stessa ma deriva dalla vo-
cale seguente; più precisamente una consonante sarà ar-
rotondata solo se nella stessa sillaba è presente una vo-
cale arrotondata.
3.2. Foni, fonemi e lettere
3.2.1. Scrittura e consapevolezza
A questo punto della nostra discussione siamo in grado
di tirare qualche conclusione. Abbiamo visto che vi so-
no due modi diversi per rappresentare i suoni del lin-
guaggio:
a. quello fonologico, che registra gli elementi di suono
distintivi, perché correlato con il riconoscimento dei fo-
nemi, gli elementi costitutivi della forma fonetica delle
parole;
b. quello fonetico, che registra tutti gli elementi di
suono apprezzabili, distintivi e non distintivi, perché
correlato alla pronuncia effettiva dei suoni linguistici.
Al posto di quello che avevamo chiamato generica-
mente ‘segmenti di suono’ ora distinguiamo tra foni e
fonemi. Abbiamo anche suggerito che questa biparti-
zione corrisponde a due componenti o modalità di fun-
zionamento diversi della nostra mente. Ora è il momen-
to di rendere conto di questa affermazione.
Una differenza fondamentale tra le due modalità ri-
guarda la consapevolezza. Come sarà evidente per chi-
unque abbia seguito fino qui questa discussione, mentre
i parlanti mostrano di avere qualche consapevolezza,
magari non immediata ma comunque solida, degli ele-
menti fonologici, non sembrano averne affatto degli a-
spetti fonetici. Non è perciò sorprendente che ciò che la
scrittura “legge”, il tipo di conoscenze su cui si basa, sia
la fonologia e non la fonetica. In effetti, questo è quasi
ovvio dal momento che, come si ricorderà, avevamo ri-
cavato la rappresentazione fonologica proprio
dall’ortografia, una volta emendata dalle sue idiosincra-
sie. Questo risultato, appunto, non è casuale ma è una
diretta conseguenza della derivazione della scrittura
dalla fonologia.
Vale però la pena di approfondire la relazione tra
consapevolezza e scrittura, che è meno ovvia di quanto
possa sembrare. Si è detto che la scrittura legge la fono-
logia perché è il livello di conoscenza dei suoni di cui si
ha maggiore consapevolezza (ovvero, forse, il solo li-
vello di conoscenza dei suoni di cui si abbia qualche
consapevolezza). Ma perché è necessaria la consapevo-
lezza per scrivere? In fondo, come si è visto, non si ha
bisogno di consapevolezza per pronunciare i suoni del
linguaggio. La risposta è che, cognitivamente parlando,
scrivere/leggere è un’operazione completamente diver-
sa dal parlare/ascoltare. Le principali differenze tra par-
lato e scritto sono presentate schematicamente di segui-
to:
a. Il parlato è naturale; lo scritto artificiale.
b. La scrittura è un successo di biologia applicata, par-
te scoperta (le parole non differiscono olisticamente,
ma per la disposizione di un piccolissimo inventario di
unità, i fonemi), parte invenzione (come codificare le
unità di suono con unità visive).
c. Il parlato è supportato da un modulo specializzato,
in forma di atteggiamenti articolatori astratti e in forma
di capacità percettiva. I due aspetti sono strettamente
coordinati. Non abbiamo invece alcuna specializzazione
per lo scritto.
Il parlato è precategoriale, precognitivo, come tale,
è al di sotto della soglia della consapevolezza e non
comporta consapevolezza fonologica; l’apprendimento
dello scritto comporta invece consapevolezza fonologi-
ca; in particolare, l’apprendimento di un sistema alfabe-
tico comporta crucialmente la consapevolezza dei fo-
nemi. È stato infatti evidenziato in diversi studi quanto
sia cruciale la consapevolezza fonologica, dei fonemi in
particolare, per l’apprendimento di un sistema alfabeti-
co.
Liberman, noto studioso di produzione e ricezione
del parlato, espone una tesi fondamentale sulla relazio-
ne tra parlato e scritto. Nelle sue parole, ‘legge-
re/scrivere è difficile perché parlare/ascoltare è facile’,
vale a dire che le difficoltà nell’apprendimento dello
scritto emergono dal confronto con l’apprendimento del
parlato, che si attua con una facilità sbalorditiva in
quanto l’apparato articolatorio–uditivo dell’uomo ha
un’innata relazione privilegiata col linguaggio, tale che
la vista e l’apparato motorio implicato nello scrivere
non hanno. Una conseguenza è che la scrittura, partico-
larmente un sistema alfabetico, si deve interfacciare con
conoscenze fonologiche di cui il parlante ha normal-
mente scarsa consapevolezza, proprio perché per parla-
re non serve consapevolezza fonologica. Pertanto, im-
parare a leggere/scrivere implica prendere consapevo-
lezza delle conoscenze fonologiche implicate,
un’operazione che è evidentemente possibile, ma né fa-
cile, né immediata; per qualcuno, poi, i bambini ‘disles-
sici’, difficilissima.
Queste tesi sono di immediato interesse per gli edu-
catori di qualunque ambito. Dal punto di vista applica-

12
tivo si è proposto che lo sviluppo della consapevolezza
fonologica, tramite esercizi, giochi fonologici o
quant’altro, faciliti l’alfabetizzazione.
Considerazioni simili sembrano valere anche per la
dislessia, o almeno per la cosiddetta ‘dislessia fonologi-
ca’, come viene denominata da alcuni specialisti, e per
alcuni tipi di deficit di percezione linguistica, che, pur
nelle loro differenze, sembrano entrambi derivare da
qualche tipo di deficit relativi al componente fonologi-
co. Non è intenzione di questa trattazione che il lettore
ricavi la falsa impressione che ‘il problema è compreso
e risolto’. Trattare la dislessia è un compito che va oltre
i nostri scopi e le nostre competenze. Del resto, il pro-
blema è troppo vasto e complesso perché persino uno
specialista ne possa rendicontare in breve. D’altra parte,
può essere di qualche utilità condividere poche rifles-
sioni:
► L’impressione che si ricava (almeno i ‘non ad-
detti ai lavori’) solo curiosando tra la sterminata biblio-
grafia e soprattutto tra l’oceanico numero di siti Internet
dedicati, è che le diverse opinioni riguardo alla dislessia
siano troppo radicalmente diverse per derivare solo da
diverse formazioni e scuole di pensiero. Sembra che ci
sia un problema terminologico-concettuale: non tutti gli
studiosi, e soprattutto educatori e operatori terapeutici
del settore, sembrano rendersi conto che la dislessia è
un epifenomeno, e che non è una specifica patologia,
nel senso medico del termine, più di quanto non lo sia il
mal di testa. Il termine si riferisce solo alla difficoltà di
apprendimento e utilizzazione della lettura/scrittura. Da
questo punto di vista appaiono poco sostanziali le in-
terminabili discussioni su ciò che veramente è dislessia.
È verosimile, quindi, che ci siano cause anche molto
diverse dietro il difficile rapporto tra alcune persone e
la lettura/scrittura, esattamente come ci possono essere
cause molto diverse che determinano un ‘mal di testa’.
Di conseguenza, non sarebbe fondato proporsi una teo-
ria olistica della dislessia. Il tipo a cui si riferiscono gli
studi menzionati (in particolare quello di Liberman) è
quella che alcuni chiamano ‘dislessia fonologica’, per
distinguerla da altri tipi di dislessia che presentano ca-
ratteristiche diverse, in particolare quel tipo di dislessia
che si incontra frequentemente nella letteratura e che
sembra correlata a disturbi psicologici di tipo compor-
tamentale. Quale sia l’incidenza della dislessia fonolo-
gica è difficile dirlo, ma sembra comunque molto rile-
vante, se non la più rilevante.
► Ci sono dei dati molto interessanti che sembrano
confermare questa direzione di ricerca. Come si ricava
da alcuni studi comparativi, l’incidenza della dislessia è
molto diversificata tra i diversi paesi. In particolare, è
massima nei paesi anglosassoni (negli Stati Uniti si cal-
cola intorno al 20%), scarsa in Italia (meno del 5%),
virtualmente assente in Giappone. Come si può rendere
conto di questi dati così sorprendenti? Non sembra ra-
gionevole attribuire queste notevoli differenze ad ana-
loghe differenze nelle condizioni affettive o, peggio, a
differenze endogene attinenti alla visione o al controllo
degli arti superiori. Il sistema scolastico giapponese è
sicuramente più severo e meno tollerante di quello ame-
ricano, ed imparare a leggere/scrivere il giapponese non
è certo più facile che imparare a leggere/scrivere
l’inglese. Ci sono però dei dati linguistici, tendenzial-
mente poco considerati in questo campo, che gettano
una diversa luce sul problema. È una coincidenza che
l’inglese utilizzi uno dei sistemi alfabetici peggiori al
mondo (nel senso, ovviamente, del Principio Alfabeti-
co), certo molto meno efficiente di quello italiano, e che
il giapponese utilizzi un sistema di scrittura non alfabe-
tico (che perciò non necessita di attivare la consapevo-
lezza dei fonemi, ma solo quella delle sillabe e delle pa-
role, ben più intuitive)?
Siamo ora in grado di riesaminare il rapporto tra suoni e
lettere; possiamo, quindi, riformulare in modo più accu-
rato il Principio Alfabetico:
(1i) PRINCIPIO ALFABETICO
Un alfabeto è un sistema di scrittura in cui lettere e fo-
nemi sono in relazione biunivoca.
4. Conclusioni
Al termine di questa discussione sulla relazione tra
scrittura, ortografia italiana in particolare, e suoni pos-
siamo tirare qualche conclusione. I risultati più impor-
tanti sembrano essere i seguenti:
1. Il componente che si occupa della codifica, memo-
rizzazione e decodifica dei suoni del linguaggio è arti-
colato in due sottocomponenti distinti, il componente
fonologico, che ha la funzione di identificare le unità
linguistiche, e il componente fonetico, che ha la funzio-
ne di realizzare concretamente le informazioni del
componente fonologico.
2. La scrittura si interfaccia con la fonologia, il com-
ponente a cui la coscienza dei parlanti riesce ad avere
accesso.
3. In un sistema alfabetico le lettere rappresentano in
linea di principio i fonemi, segmenti di suono caratte-
rizzati da tutte e solo le proprietà di suono distintive.
4. La scrittura non legge invece il componente foneti-
co, troppo al di sotto della soglia della consapevolezza.
5. L’apprendimento della lettura/scrittura è
un’operazione lenta e difficile perché implica un pro-
cesso di autoconsapevolizzazione del componente fono-
logico della propria lingua; l’apprendimento del parla-
re/ascoltare, invece, è rapido e indolore perché non ne-
cessita di alcuna consapevolezza.
6. I dati sulla distribuzione areale della dislessia sug-
geriscono che il grado di congruenza rispetto al Princi-
pio Alfabetico abbia conseguenze sulla facilità e proba-
bilità di successo dell’apprendimento di un sistema al-
fabetico da parte di un parlante, verosimilmente perché
influenza la capacità da parte di chi apprende di inter-
facciare efficacemente la scrittura con le informazioni
del componente fonologico, in altri termini, di com-
prendere ‘per cosa stanno le lettere’.
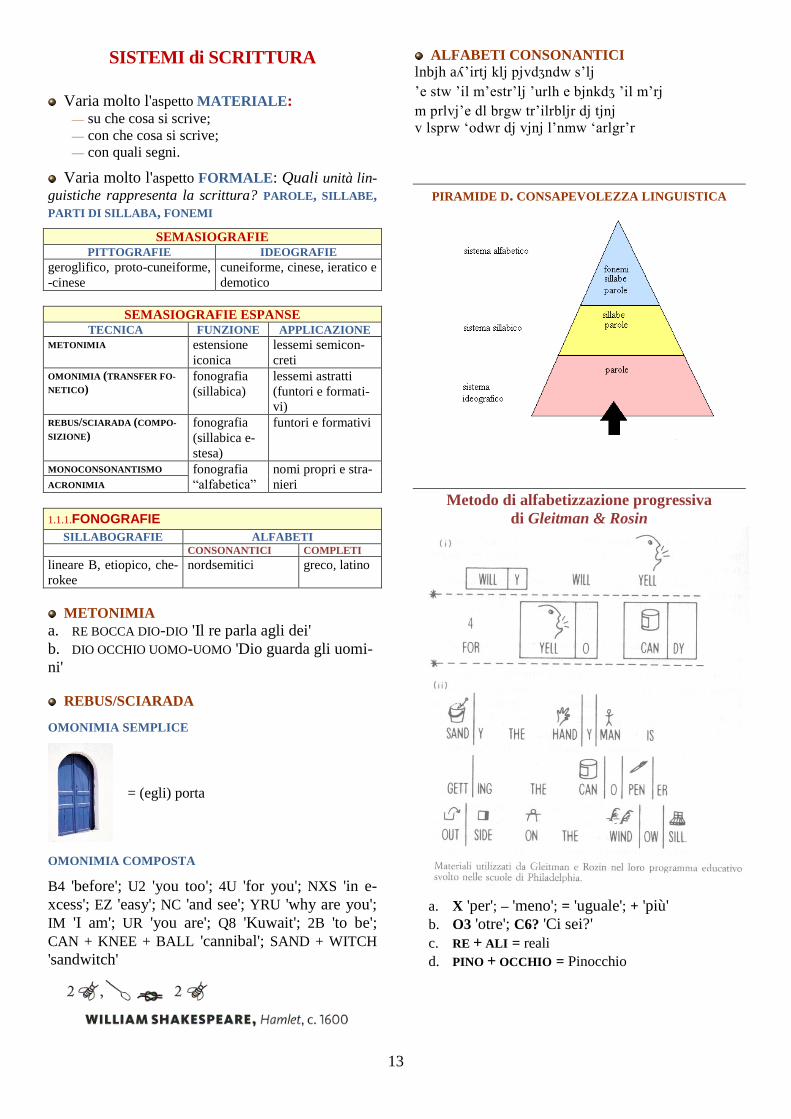
13
SISTEMI di SCRITTURA
Varia molto l'aspetto MATERIALE: — su che cosa si scrive;
— con che cosa si scrive;
— con quali segni.
Varia molto l'aspetto FORMALE: Quali unità lin-
guistiche rappresenta la scrittura? PAROLE, SILLABE,
PARTI DI SILLABA, FONEMI
SEMASIOGRAFIE
PITTOGRAFIE IDEOGRAFIE
geroglifico, proto-cuneiforme,
-cinese
cuneiforme, cinese, ieratico e
demotico
SEMASIOGRAFIE ESPANSE
TECNICA FUNZIONE APPLICAZIONE
METONIMIA estensione
iconica
lessemi semicon-
creti
OMONIMIA (TRANSFER FO-
NETICO) fonografia
(sillabica)
lessemi astratti
(funtori e formati-
vi)
REBUS/SCIARADA (COMPO-
SIZIONE) fonografia
(sillabica e-
stesa)
funtori e formativi
MONOCONSONANTISMO fonografia
“alfabetica”
nomi propri e stra-
nieri ACRONIMIA
1.1.1.FONOGRAFIE
SILLABOGRAFIE ALFABETI CONSONANTICI COMPLETI
lineare B, etiopico, che-
rokee
nordsemitici greco, latino
METONIMIA
a. RE BOCCA DIO-DIO 'Il re parla agli dei'
b. DIO OCCHIO UOMO-UOMO 'Dio guarda gli uomi-
ni'
REBUS/SCIARADA
OMONIMIA SEMPLICE
= (egli) porta
OMONIMIA COMPOSTA
B4 'before'; U2 'you too'; 4U 'for you'; NXS 'in e-
xcess'; EZ 'easy'; NC 'and see'; YRU 'why are you';
IM 'I am'; UR 'you are'; Q8 'Kuwait'; 2B 'to be';
CAN + KNEE + BALL 'cannibal'; SAND + WITCH
'sandwitch'
ALFABETI CONSONANTICI
lnbjh aá’irtj klj pjvdJndw s’lj
’e stw ’il m’estr’lj ’urlh e bjnkdJ ’il m’rj
m prlvj’e dl brgw tr’ilrbljr dj tjnj
v lsprw ‘odwr dj vjnj l’nmw ‘arlgr’r
PIRAMIDE D. CONSAPEVOLEZZA LINGUISTICA
Metodo di alfabetizzazione progressiva
di Gleitman & Rosin
a. X 'per'; – 'meno'; = 'uguale'; + 'più'
b. O3 'otre'; C6? 'Ci sei?'
c. RE + ALI = reali
d. PINO + OCCHIO = Pinocchio

14
E. FERREIRO – A. TEBEROSKY SCRITTURA SPONTANEA NEI BAMBINI
LIVELLO PRESILLABICO
a. Corrispondenza tra nome e segno (m per ‘mela’);
b. Quantità minima (3/4 segni);
c. Varietà interna dei segni (loa-ola);
d. Relazione iconica tra parola scritta e referente; (tre-
no ha più caratteri di formichina).
C A x D I L o
rondini L E ε
sole
LIVELLO SILLABICO
A B R
albero B L N
balena
LIVELLO SILLABICO-ALFABETICO
INTERMEDIO TRA SILLABICO E ALFABETICO
Valore instabile; migliore corrispondenza tra lettera e
fonema.
I S L A
isola I D O
nido
LIVELLO ALFABETICO
Corrispondenza biunivoca tra suoni e lettere; la scrittura
non è ortografica ma comprensibile.
M A N O T E L E F N O

Tipologia degli errori ortografici sistematici
ACCESSO FONOLOGICO1 CONVENZIONI
2 ORTOGRAFIE INNATURALI
3
DIALETTALISMI
E FORESTIERISMI4
ATTACCO MULTIPLO
RIPENDERE
TENO (treno)
CODA
GIROTODO
GIRAFA
IPERCORRETTISMI
?*
* Non sembrano ricorrere.
DIACRITICI
FONETICI
MACCINA (macchina)
GOSTRA (giostra)
LESSICALI
ANNO (hanno)
E (è), FÀ
POLIGRAMMI
DICESA (discesa)
ACCENTO POLISILLABI
CAFFE
PAROLA ORTOGRAFICA
DIPPIÙ
AVVOLTE (a volte)
LETTERE OMOFONE
CUANDO
IPERCORRETTISMI
HABBIAMO
IN SIEME
IPOSPECIFICAZIONE
INPORTANTE
i RIDONDANTE
CELO (cielo)
ELISIONE
UN’ALBERO
QUAL’È
CONSONANTE DOPPIA
NAZZIONE
IPERCORRETTISMI
FACCIE
POLZO
CUBBO
OGLIO
IPERCORRETTISMI
GILIO (giglio)
DANSA (danza)
BIBIA (bibbia)
1 Imperfetto accesso fonologico: spariscono in genere dopo qualche mese dall’inizio dell’alfabetizzazione. Se per-
mangono in modo sistematico in 2° elementare sono un indizio di difficoltà di apprendimento; se permangono dopo
qualche anno, sono un probabile sintomo di dislessia.
2 Imperfetto apprendimento delle convenzioni ortografiche, dalle più generali (p.e. diacritici fonetici e poligram-
mi) a quelle più specifiche (p.e. diacritici lessicali e lettere omofone). Se permane dopo il 1° ciclo è un segno di pro-
blemi di apprendimento. Non è correlato con la dislessia, sebbene le convenzioni ortografiche rendano più arduo a tut-
ti il compito di apprendere l’alfabetizzazione, per i dislessici a maggior ragione.
3 Convenzioni ortografiche controintuitive (sono in conflitto con la rappresentazione mentale del parlante). Possono
essere regolari (‘m’ prima di una consonante bilabiale, l’accento nei monosillabi ambigui) o lessicali (‘i’ ridondante,
‘z’ vs. ‘zz’).
4 Derivano dal fatto che la rappresentazione mentale del parlante non corrisponde in pieno all’italiano standard,
che sottintende l’ortografia italiana, a prescindere dal fatto che si tratti di influenze dialettali o straniere. I forestieri-
smi, però, sono in generale più invasivi e meno facili da isolare.
Top Related