







Le lingue
Pagine
Legale


Scuola Politecnica e delle Scienze di BaseCorso di Laurea in Ingegneria Informatica
Elaborato finale in Basi di Dati
Hypergraph Database
Anno Accademico 2014/15
Candidato:
Giampaolo Bovenzi
matr. N46001824

[Dedica]

Indice
Indice ................................................................................................................................................. IIIIntroduzione .......................................................................................................................................... 5Capitolo 1: Grafi e Ipergrafi ................................................................................................................. 6
1.1 Grafi ............................................................................................................................................ 61.1.1 Definizioni ........................................................................................................................... 61.1.2 Collegamenti ........................................................................................................................ 61.1.3 Implementazioni dei grafi .................................................................................................... 71.1.4 Sottografo ............................................................................................................................ 71.1.5 Progressione di archi ........................................................................................................... 71.1.6 Operazioni su grafi .............................................................................................................. 8
1.2 Ipergrafi ...................................................................................................................................... 81.2.1 Definizioni ........................................................................................................................... 8
Capitolo 2: DBMS: Relazionale VS Grafo ........................................................................................ 102.1 Modello Relazionale ................................................................................................................. 10
2.1.1 Struttura ............................................................................................................................. 102.1.2 SQL in breve ...................................................................................................................... 11
2.2 Modello a Grafo ....................................................................................................................... 122.2.1 Definizione ........................................................................................................................ 12
Capitolo 3: Big Data ........................................................................................................................... 133.1 Definizione ............................................................................................................................... 133.2 Caratteristiche ........................................................................................................................... 133.3 Modelli ..................................................................................................................................... 143.4 Architettura ............................................................................................................................... 14
Capitolo 4: HyperGraphDB ................................................................................................................ 154.1 Architettura ............................................................................................................................... 164.2 Tipizzazione ............................................................................................................................. 174.3 Indicizzazione ........................................................................................................................... 184.4 Querying ................................................................................................................................... 184.5 Distribuzione P2P ..................................................................................................................... 194.6 Sguardo all'implementazione .................................................................................................... 204.7 Esempio di applicazione ........................................................................................................... 204.8 Esempi di utilizzo delle API di HyperGraphDB ...................................................................... 20
4.8.1 Creazione di un database ................................................................................................... 214.8.2 Memorizzazione di un oggetto Java .................................................................................. 214.8.3 Memorizzare due oggetti e collegarli ................................................................................ 214.8.4 Utilizzo degli Handle per il recupero ................................................................................ 214.8.5 Esempio per il querying ..................................................................................................... 224.8.6 Esempio di attraversata dell'ipergrafo ............................................................................... 224.8.7 Esempio di transazione ...................................................................................................... 22
Capitolo 5: Analisi dell'Algoritmo di Dijkstra ................................................................................... 235.1 Algoritmo di Dijkstra ............................................................................................................... 23
5.1.1 Algoritmo .......................................................................................................................... 235.1.2 Implementazione (pseudocodice) ...................................................................................... 24
5.2 Implementazione in Java con HyperGraphDB ......................................................................... 25

5.2.1 Esempio di file log ............................................................................................................. 255.2.2 Grafici ................................................................................................................................ 275.2.3 Tool DijkstraAnalysisSoftware ......................................................................................... 28
Conclusioni ......................................................................................................................................... 31Bibliografia ......................................................................................................................................... 32

Introduzione
Questo lavoro di tesi ha l'obiettivo di presentare gli Hypergraph Database, ovvero la teoria
dei grafi generalizzata agli ipergrafi applicata alle basi di dati. In particolare si farà
riferimento alla libreria HyperGraphDB che implementa questo modello di database.
Poiché la Teoria dei Grafi è basilare per questo studio, il primo capitolo ne dà una
spiegazione rigorosa descrivendo Grafi e Ipergrafi e le loro proprietà. Il secondo capitolo
invece descrive due modelli di database, relazionali e basati su grafo, facendone
distinzioni per il tipo di applicazione. Nel Cap.3 si trattano i Big Data, per la cui gestione
viene fatto un largo uso di database di tipo NoSQL, famiglia di cui i database basati su
ipergrafi fanno parte. Il quarto capitolo contiene la spiegazione della struttura della libreria
HyperGraphDB e infine il Cap.5 mostra una applicazione di questa libreria nell'analisi
dell'algoritmo di Dijkstra che è tra quelli che implementa.
5

Capitolo 1: Grafi e Ipergrafi
1.1 Grafi
I grafi sono strutture matematiche discrete che consentono la risoluzione di problemi non
strettamente matematici ma anche riguardanti vari campi tra cui l'informatica, ad esempio
per schematizzare programmi, circuiti, reti di computer, mappe di siti, e l'ingegneria,
essendo alla base di modelli di sistemi e processi.
1.1.1 Definizioni
Un grafo (Fig. 1.1) è costituito da un insieme V di nodi o vertici e da un insieme E di
coppie di vertici ordinate e si usa la notazione G(V , E ) . Una coppia di vertici non
ordinata è detta spigolo, mentre una coppia di vertici ordinata è detta arco. Un grafo
contenente solo spigoli è detto non orientato o indiretto; un grafo contenente solo archi è
detto orientato o diretto. Una coppia di vertici può essere connessa da uno o più archi.
Uno spigolo (arco) può partire e arrivare ad uno stesso vertice e in questo caso è
denominato cappio.
Figura 1.1: esempio di grafo diretto
1.1.2 Collegamenti
Vertici facenti parte di una stessa coppia sono detti adiacenti. Il concetto di adiacenza è
esteso anche ad archi che collegano stessi vertici. Uno spigoli (arco) è detto incidente ai
suoi due vertici. Si dice che uno spigolo {u , v } collega i vertici u e v , mentre un arco
6

(u ,v ) parte da u e finisce in v . In seguito si farà uso della dicitura arco
indifferentemente dalla natura del collegamento.
1.1.3 Implementazioni dei grafi
Siano u1 ,…,u i i vertici di G(V , E ) e siano e1 ,… ,e j i suoi archi. Tra i vari modi di
definire un grafo è possibile utilizzare la matrice di adiacenza A=(a i , j) di G , dove
a i , j è uguale al numero di archi che collegano i nodi u i e u j , infatti se a i , j=0 allora
u i e u j non sono adiacenti. Un'altra rappresentazione è quella che fa uso della matrice
di incidenza B=(b i , j) di G , dove se bi , j=1 il vertice u i è incidente all'arco e j e se
bi , j=0 non lo è. Un grafo può quindi essere espresso tramite una lista che contenga o le
coppie di vertici collegate da archi o l'insieme di vertici adiacenti ad ogni vertice.
1.1.4 Sottografo
Si dice G ' (V ' , E ') sottografo di G(V , E ) se V '⊆V ed E '⊆E , se ognuno degli
archi di E ' è incidente a soli vertici contenuti in V ' e se E ' contiene tutti gli archi di
G che connettono i vertici V ' . Si dice scheletro di G il sottografo G ' (V , E ' ) che
contiene tutti i vertici e una partizione degli archi di G , E '⊆E .
1.1.5 Progressione di archi
Una sequenza di archi (u0, u1) , … ,(ur− 1 , ur) è detta progressione di archi e collega i
vertici u0 e ur . Se tutti gli archi di una successione sono diversi, la sequenza è detta
catena. Una catena è semplice se tutti i suoi vertici sono diversi. Un grafo si dice
connesso se tutte le coppie di suoi vertici sono connesse da una progressione di archi. Un
grafo non connesso contiene almeno una coppia di componenti connessi. La lunghezza di
una progressione (catena o catena semplice) è data dal numero di archi che si attraversano.
La lunghezza della più corta catena semplice tra due nodi u i e u j di un grafo G è detta
distanza tra u i e u j e si indica con d (ui , u j) . La quantità minuimaxu j
d (u i , u j) è detta
diametro, mentre il vertice u0 per cui maxu jd (ui , u j) assume il valore più piccolo è
detto centro di G .
7

Il grado di un vertice u i di G si indica con d i ed equivale al numero di archi incidenti
nel vertice stesso. Se d i=0 allora il vertice si dice isolato, se d i=1 allora in vertice si
dice terminale o pendente. Un grafo che contiene tutti vertici di ugual grado k è detto
grafo regolare di grado k . Un grafo si dice completo se non contiene cappi e se ogni
coppia di nodi è collegata da uno ed un solo arco.
1.1.6 Operazioni su grafi
Siano G1=G (V 1, E1) e G2=G(V 2, E2) tali che V 1∩V 2=∅ e E1∩E2=∅ .
L'unione di G1 e G2 è il grafo G=G1∪G2 con insieme di vertici V=V 1∪V 2 e insieme
di archi E=E1∪E2 .
Il prodotto di G1 e G2 è il grafo G=G1× G2 il cui insieme di vertici è dato dal prodotto
cartesiano V=V 1× V 2 , due qualsiasi dei vertici (u1, u2) e (v1, v 2) sono adiacenti se e
solo se u1=v1 e u2 è adiacente a v2 , oppure u2=v2 e u1 è adiacente a v1 .
1.2 Ipergrafi
Gli ipergrafi sono la generalizzazione dei grafi con archi (detti iperarchi) che possono
connettere due o più nodi. Questa caratteristica permette la definizione di relazioni tra più
di due nodi mediante un solo iperarco superando la limitazione dovuta alla
bidimensionalità degli archi dei grafi. Quindi un grafo è un ipergrafo con archi binari.
1.2.1 Definizioni
Un ipergrafo (Fig. 1.2) è definito come una famiglia ε di insiemi, conosciuti come archi
o iperarchi costruita su un insieme V di oggetti detti nodi o vertici. Un ipergrafo si
denota con H (V , ε) .
Due vertici si dicono adiacenti se esiste un arco che li contiene entrambi. Un vertice v e
un arco E si dicono incidenti se v∈E . Un ipergrafo H con n vertici e m archi può
essere definito con una matrice di incidenza ∣∣ai , j∣∣ , di dimensioni n× m dove le
colonne corrispondono agli archi e le righe ai vertici di H , tale che:
8

È possibile, quindi, assegnare ad ogni matrice binaria sparsa M un ipergrafo H per cui
M è matrice di incidenza. H star è il duale dell'ipergrafo H e presenta una matrice di
incidenza uguale alla trasposta di quella di H . Il grado di un vertice è il numero di
iperarchi che sono incidenti al vertice.
H ' (V ' , ε ') è chiamato sottoipergrafo di un ipergrafo H (V , ε) se V '⊆V , se ε⊆ε ' e
se un vertice v∈V ' e un arco ε∈ε ' sono incidenti nell'ipergrafo H ' se e solo se sono
incidenti anche in H . Un ipergrafo può essere rappresentato in maniera planare indicando
i nodi con dei punti e gli archi come insiemi che contengono i nodi a cui sono incidenti.
Un ipergrafo è isomorfo ad un grafo bipartito in cui un gruppo rappresenta i suoi nodi e
l'altro i suoi iperarchi.
Figura 1.2: esempio di rappresentazione planare di un ipergrafo
9
a i , j={10se vi∈E j ,sev i∉E j ,
i=1, ... , n ; j=1, ... ,m.

Capitolo 2: DBMS: Relazionale VS Grafo
Un Database Management System (DBMS) è un sistema software di gestione di dati
strutturati (database). Questo sistema permette quindi la creazione, la manipolazione e
l'interrogazione efficiente di database.
Con il passare del tempo i DBMS hanno subito varie “specializzazioni” a seconda del
campo applicativo. Nei due paragrafi successivi tratteremo il Modello Relazionale e il
Modello a Grafo.
2.1 Modello Relazionale
Un DBMS può adottare, come accennato, il modello relazionale ed in questo caso è detto
Relational DBMS (RDBMS). Il modello relazionale è stato proposto da Edgar Codd agli
inizi degli anni '70 per semplificare il Query Language e per favorire l'indipendenza dei
dati. Questo modello si basa sul concetto matematico di relazione inteso inizialmente
come una tabella, che definisce a tutti gli effetti una relazione tra le colonne. In generale
un database basato su tabelle non è per forza di tipo relazionale.
2.1.1 Struttura
Un RDBMS si basa sulla seguente struttura:
• attributi o campi dato
• tipo di dato sono definiti tipi mappati dal RDBMS
• dominio definito come l'insieme dei valori che può assumere un
determinato attributo di un dato tipo
• valore per ciascun attributo all'interno del dominio o tipo di dato
consentito
• tupla cioè l'insieme non ordinato di valori assunti dagli attributi
Si definisce testata di una relazione l'insieme di attributi, mentre è detto corpo l'insieme
10

delle tuple di valori.
Alla base di questo modello, inoltre, ci sono le relazioni tra tabelle definite mediante un
identificativo univoco per ogni tupla (record) detto chiave primaria (primary key).
Questo tipo di relazione fa in modo da dover unificare i dati relazionati per il querying e,
di conseguenza, è stato implementato un linguaggio apposito che permettesse una agevole
formulazione delle richieste di recupero: SQL.
Il dover ogni volta effettuare una join delle tabelle interessate dalle query è il motivo per
cui questo modello di database non si presta ad analizzare grosse quantità di dati
distribuite come nei Big Data e, inoltre, la relazione definita tramite tabelle è tanto forte da
non garantire la giusta elasticità a fronte di tanti dati velocemente variabili.
2.1.2 SQL in breve
SQL (Structured Query Language) è un linguaggio dichiarativo nato per la gestione dei
DBMS relazionali. Un linguaggio dichiarativo serve a descrivere le proprietà logiche delle
informazioni ricercate.
SQL è diviso in:
• Data Definition Language permette di creare e cancellare database o di
modificarne la struttura
• Data Manipulation Language permette di inserire, cancellare o modificare i
dati
• Data Control Language permette di gestire gli utenti e i permessi
• Query Language permette di interrogare il database
• Device Media Control Language permette di controllare i supporti (memorie di
massa) dove vengono memorizzati i dati
Le istruzioni fondamentali di SQL derivano dalla cosiddetta Tavola CRUD (Create, Read
(Retrieve), Update e Delete (Destroy)), che indica i metodi di accesso alle informazioni.
I comandi SQL corrispondenti alle 4 operazioni, nell'ordine, sono INSERT, SELECT,
UPDATE e DELETE.
11

2.2 Modello a Grafo
Oltre ai DBMS basati sul modello relazionale è stata sviluppata anche un'altra famiglia
convenzionalmente detta NoSQL di cui fanno parte anche i Graph Database.
Questi ultimi, a differenza di quelli relazionali, garantiscono una maggiore velocità di
associazione e una maggiore scalabilità al crescere della quantità di dati. In particolare
sono utili nel caso si abbia a che fare con schemi che evolvono dinamicamente nel tempo,
poiché garantiscono una minore rigidità di schema. Di contro, per operazioni ripetitive su
tanti dati è preferibile utilizzare il modello relazionale.
I Graph Database si basano sulla Teoria dei Grafi per la memorizzazione, la mappatura e
per il recupero dei dati.
2.2.1 Definizione
Un Graph Database è quindi una collezione di nodi e di archi. Un nodo rappresenta una
entità e un arco rappresenta una relazione tra due nodi. Ogni nodo del grafo è identificato
da un unico id, da un insieme di archi uscenti ed uno di entranti e da un insieme di
proprietà espresse come coppie chiave/valore. Ogni arco ha un id univoco, un nodo di
partenza, un nodo di arrivo e un insieme di proprietà.
12

Capitolo 3: Big Data
Per Big Data si intende una grossa mole di dati che devono essere estrapolati, gestiti e
processati in un tempo ragionevole. Quindi è necessario strutturare i dati in maniera
efficiente ed efficace in base alla specifica applicazione poiché le tradizionali tecniche di
data processing sono inadeguate per lo scopo.
La forte crescita che riguarda i dataset va avanti da oltre un ventennio ed è dovuta sia alla
necessità di aggregare più dati al fine di aumentare la quantità dell'informazione
estrapolabile, sia per il basso costo della generazione e acquisizione di dati.
3.1 Definizione
"Big Data represents the Information assets characterized by such a High Volume,
Velocity and Variety to require specific Technology and Analytical Methods for its
transformation into Value".[3]
(Big Data rappresenta un patrimonio informativo caratterizzato da grande volume, velocità
e varietà, al punto tale da richiedere una specifica tecnologia e metodi analitici per la sua
trasformazione in valore)
3.2 Caratteristiche
Il modello dei Big Data si basa sulle seguenti sei caratteristiche:
• volume riferito alla dimensione del dataset
• velocità riferita alla generazione dei dati
• varietà riferita alle varie tipologie di dati
• variabilità riferita all'inconsistenza dei dati
• veridicità riferita al valore informativo che si riesce ad estrarre dai dati
• complessità riferita alla connessione di dati che migliorano le prestazioni di query
13

3.3 Modelli
Poiché i Big Data sono caratterizzati da volumi di dati di grossa mole e poiché fanno
ampio uso di dati non strutturati non è possibile utilizzare i tradizionali RDBMS (Cap. 2)
perché non rendono possibile un'archiviazione altamente dinamica e una elevata velocità
di analisi. In pratica infatti si utilizzano sistemi con elevata scalabilità e soluzioni basate
sulla NoSQL (Cap. 4).
Nell'ambito della business analytics nascono nuovi modelli di rappresentazione in grado di
gestire tale mole di dati con elaborazioni in parallelo dei database. Architetture di
elaborazione distribuita di grandi insiemi di dati sono offerte da MapReduce [10] di
Google, e dalla controparte open source Apache Hadoop [1]. Con questo sistema le
applicazioni sono separate e distribuite con nodi in parallelo, e quindi eseguite in parallelo
(funzione map). I risultati vengono poi raccolti e restituiti (funzione reduce).
3.4 Architettura
Una architettura a più livelli è una delle migliori opzioni per affrontare i problemi legati ai
Big Data. Una architettura parallela distribuita spalma i dati su più server, migliorando
notevolmente la velocità di elaborazione dei dati. Questo tipo di architettura inserisce i
dati in un DBMS parallelo, che fa uso di modelli di programmazione come MapReduce e
Hadoop prima citati. Questo tipo di framework è trasparente all'utente finale mediante
l'utilizzo di un server front-end. [6]
14

Capitolo 4: HyperGraphDB
HyperGraphDB è un meccanismo general purpose e open-source di memorizzazione dati
basato su un forte formalismo di gestione dell'informazione noto come ipergrafo diretto.
L'ipergrafo diretto è un costrutto molto naturale in quanto permette la costruzione ricorsiva
di relazioni logiche. Il maggiore punto di forza però risiede nel permettere la definizioni di
relazioni n-arie.
Anche se questo modello di memorizzazione persistente è specifico per la gestione delle
conoscenze, dell'IA e dei progetti di web semantico, può comunque essere utilizzato come
un database embedded di qualsivoglia dimensione per applicazioni Java. [9]
Nel modello di dati di HyperGraphDB, l'unità di base di rappresentazione è chiamata
Atom (atomo). Ogni atomo ha una tupla di atomi associata chiamati insieme di
destinazione. La dimensione del gruppo di destinazione si chiama grado dell'atomo. Gli
atomi di grado nullo sono chiamati nodi e gli atomi di grado positivo sono chiamati archi.
L'insieme di incidenza di un atomo x è l'insieme di atomi che hanno x nel proprio insieme
di destinazione. Ogni atomo ha associato un valore fortemente tipizzato. I valori sono di
tipi arbitrari, e i tipi stessi sono atomi. Gli atomi sono le entità semantiche che formano la
struttura ipergrafo, mentre i valori sono dati che possono essere strutturati o meno. Il
valore di un atomo può essere modificato o sostituito con un valore di un tipo differente
mantenendo inalterata la struttura dell'ipergrafo.
Si noti che questo modello impone una semantica particolare ai dati memorizzati. Si tratta
di un modello di uso generale semi-strutturato che incorpora grafi, relazioni e gli aspetti
object-oriented. Lo schema del database HyperGraphDB è un sistema che evolve in modo
dinamico, in cui i vincoli di integrità dei dati possono essere imposti dai tipi implementati.
15

4.1 Architettura
Aspetti chiave dell'architettura di HyperGraphDB sono i due livelli di organizzazione dati
che descrive. Il livello fisico sottostante che gestisce la persistenza è invece implementato
mediante un Berkeley DB [9].
I due livelli definiscono le primitive che permettono di astrarre l'ipergrafo: il primo livello
è detto Primitive Layer e il secondo Model Layer.
Il Primitive Layer si basa su due array associativi, il LinkStore e il DataStore, che
contengono rispettivamente identificatori e dati raw:
• LinkStore : ID → List < ID >
• DataStore : ID → List < byte >
Il Model Layer definisce l'astrazione degli atomi, espone le facilities ed è implementato
formalizzando il layout del Primitive Layer con le seguenti strutture:
• AtomID → [TypeID, ValueID, TargetID,...,TargetID]
• TypeID → AtomID
• TargetID → AtomID
• ValueID → List < ID > | List < byte >
Ogni struttura serve a rappresentare o un atomo dell'ipergrafo o il valore di un atomo. Nel
primo caso l'atomo è memorizzato come una tupla che ha come primo argomento il tipo,
come secondo il valore e nel resto l'insieme di destinazione. Nel secondo caso il valore è
direttamente memorizzato come un array di byte.
Infine gli indici principali che sono necessari per una efficiente implementazione del
modello sono:
• IncidenceIndex : UUID → SortedSet < UUID >
• TypeIndex : UUID → SortedSet < UUID >
• ValueIndex : UUID → SortedSet < UUID >
L'IncidenceIndex mappa gli atomi dell'ipergrafo all'insieme degli archi che gli sono
incidenti. Il TypeIndex mappa un tipo di atomo a tutte le proprie istanze. Il ValueIndex
mappa un valore di una struttura di alto livello all'insieme degli atomi che lo contengono.
16

4.2 Tipizzazione
HyperGraphDB permette di memorizzare dati di tipi arbitrari come atomi comportandosi
da embedded database. La tipizzazione in HyperGraphDB si basa su due definizioni:
• Un tipo è un atomo capace di memorizzare, costruire e rimuove rappresentazioni di
sue istanze a tempo di esecuzione interagendo con il livello di memorizzazione.
• Un tipo è capace, date due sue istanze, di dire se una delle due può essere sostituita
dall'altra.
In altre parole, i tipi sono atomi che hanno un ruolo speciale permettendo al sistema di
mantenere associazioni tra tipi ed istanze. Ogni tipo di atomo deve infatti implementare la
seguente interfaccia Java:
public interface HGAtomType {
Object make(ID valueId, List<ID> targetSet, Set<ID> incidenceSet);
ID store(Object instance); // restituisce valueId per istanze a tempo di esecuzione
void release(ID valueId);
boolean subsumes(Object general, Object specific);
}
Si nota che l'interfaccia definisce i metodi CRUD (Create Read Update Delete) per la
gestione del livello di memorizzazione sottostante.
Strutture simili a record possono essere gestite mediante l'interfaccia astratta
HGCompositeType.
In conclusione, i tipi in HyperGraphDB aggregano molti degli aspetti dei tipi definiti dai
vari linguaggi di programmazione. Giocano un ruolo simile alle classi nei linguaggi
object-oriented e definiscono le proprietà della struttura degli atomi. Infine, essi svolgono
un ruolo semantico nel vincolare l'utilizzo dell'atomo e far rispettare determinate proprietà
di coerenza e l'integrità come usuale nella tipizzazione e nei database.
17

4.3 Indicizzazione
L'indicizzazione implicita degli atomi descritta nel paragrafo 4.1 non è opzionale ma
essenziale per un efficiente supporto al modello semantico. Per esempio, l'insieme di
incidenza è cruciale sia per l'attraversamento del grafo che per le operazioni di querying.
Oltre agli indici definiti nel Primitive Layer è possibile definirne altri dal livello di
memorizzazione gestendoli con tipi. L'implementazione di default dei tipi primitivi
mantiene un indice tra il dato primitivo e il suo valore, rafforzando la condivisione tra
atomi a livello database con una conta dei riferimenti. Questa condivisione non è però
implementata di default per tipi complessi perché non c'è una maniera univoca per farlo
senza un appropriato costruttore che definisca una primary key.
Al livello di modello, gli indici possono lavorare sia sulla struttura del grafo che sulla
struttura dei valori degli atomi.
Gli indici sono registrati con un sistema che implementa l'interfaccia HGIndexer che deve
produrre una chiave dato un atomo. A loro volta le istanze HGIndexer sono memorizzate
come atomi e hanno associati meta-dati persistenti per ottimizzare il querying. Di seguito
un elenco di alcuni indici predefiniti:
• ByPartIndexer Indicizza atomi con tipi composti lungo una data
dimensione
• ByTargetIndexer Indicizza atomi di una specifica tupla di destinazione
• CompositeIndexer Combina due altri indici in uno
• LinkIndexer Indicizza atomi di tutta la loro tupla di destinazione
• TargetToTargetIndexer Dato un arco, indicizza una delle sue destinazioni con
un altro
4.4 Querying
Il querying su database basati su grafi può essere di varie forme. L'attraversamento del
grafo è una query che ritorna una sequenza di atomi. Recuperare atomi non
necessariamente connessi che verificano un predicato è ancora un altro tipo di query.
18

Infine, una terza categoria di basa sul riscontro basato su pattern di strutture nel grafo.
Gli attraversamenti del grafo si traducono nella scelta del percorso da seguire
considerando gli atomi adiacenti ad un dato atomo. Quindi le API di livello devono
semplicemente garantire algoritmi che si basano sulle liste di adiacenza. Si noti che query
di questo tipo dipendono dall'indice di incidenza e da un efficiente caching degli insiemi di
incidenza.
Le query orientate ai predicati si basano su un insieme di primitive come:
• eq(x),lt(x),eq(”name”,x),... Confronta il valore degli atomi.
• type(TypeID) Il tipo dell'atomo è TypeID.
• typePlus(TypeID) Il tipo dell'atomo è un sottotipo di TypeID.
• subsumes(AtomID) L'atomo è più generale di AtomID.
• target(LinkID) L'atomo fa parte dell'insieme di destinazione di
LinkID.
• incident(TargetID) L'atomo punta a TargetID.
• link(ID1,...,IDn) L'insieme di destinazione dell'atomo include
{ID1,...,IDn}.
• orderedLink(ID1,...,IDn) L'atomo è una tupla della forma data.
• arity(n) Il grado dell'atomo è n.
Molte delle attività di querying si basano su operazioni di join tra i vari indici disponibili
per la query.
Data la generalità del modello dei dati di HyperGraphDB, il querying per pattern è
conveniente da fare con un linguaggio special purpose tipo SPARQL [11].
4.5 Distribuzione P2P
La distribuzione dei dati in HyperGraphDB è implementata dal Model Layer usando un
framework peer-to-peer agent-based. Gli algoritmi sono sviluppati utilizzando i protocolli
di comunicazione usando l'Agent Communication Language (ACL) [8]. ACL si basa su un
set di primitive tipo propose, accept, inform, request, query etc. Ogni agente gestisce un
19

insieme di conversazioni implementando un dialogo con un gruppo di peer. Tutte le
attività sono asincrone e i messaggi in ingresso sono smistati da uno scheduler e processati
in un pool di thread.
L'utilizzo di una architettura distribuita P2P deriva dall'assunzione che la totale
disponibilità di tutta la conoscenza concentrata in una sola locazione non è sempre
possibile né desiderabile.
4.6 Sguardo all'implementazione
Dal livello applicativo l'entry point per utilizzare HyperGraphDB è fornito dalle API della
classe HyperGraph. Questa classe opera a livello di ipergrafo, permettendo operazioni
come l'inserimento e la rimozione di nodi e archi (iperarchi), gestione di indici predefiniti
e gestione di query. La classe HGTypeSystem definisce corrispondenze tra tipi
dell'ipergrafo e tipi Java. La classe HGStore gestisce operazioni di persistenza dei dati
(memorizzazione e indicizzazione) interagendo direttamente con un Berkeley DB. Il
sistema di query implementa operazioni di querying di basso livello, cioè a livello del
Berkeley DB.
4.7 Esempio di applicazione
Un settore in cui HyperGraphDB è stato applicato con successo è di Natural Language
Processing (NLP). Per esempio Disko è un sistema di elaborazione distribuita NLP che
utilizza una pipeline standard NLP in cui un documento è suddiviso in paragrafi e frasi,
poi ogni frase viene analizzata in un insieme di relazioni di dipendenza sintattiche. Infine
una analisi semantica viene applicata al frutto della precedente analisi producendo una
rappresentazione logica del loro significato.
4.8 Esempi di utilizzo delle API di HyperGraphDB
Di seguito sono riportati alcuni esempi in codice Java per la gestione di un HyperGraph
Database mediante le API fornite dalla libreria HyperGraphDB.
20

4.8.1 Creazione di un database
import org.hypergraphdb.*; // le API di alto livello sono contenute in questo package
public class HGDBEsempioCreazione { public static void main(String [] args) { String locazioneDatabase = args[0]; HyperGraph grafo = null; try { grafo = new HyperGraph(databaseLocation); //operazioni sul grafo } catch (Exception e) { e.printStackTrace(); } finally { if(grafo != null) grafo.close(); } }}
4.8.2 Memorizzazione di un oggetto Java
HyperGraph grafo = HGEnvironment.get("./test_hgdb");String x = "Ciao Mondo";Libro mioLibro = new Libro("Il Capitale", "K. Marx"); grafo.add(x);HGHandle libroHandle = grafo.add(mioLibro);grafo.add(new double [] {0.9, 0.1, 4.3434});
// Aggiornamento di un atomo già inseritomioLibro.setAnnoPubblicazione(1867);grafo.update(mioLibro);
// Eliminazione di un atomo tramite Handlegrafo.remove(libroHandle);
4.8.3 Memorizzare due oggetti e collegarli
HyperGraph grafo = HGEnvironment.get("./test_hgdb");Libro mioLibro = new Libro("Il Capitale", "K. Marx");HGHandle libroHandle = grafo.add(mioLibro);HGHandle prezzoHandle = grafo.add(9.95);HGValueLink arco = new HGValueLink("prezzo_libro", libroHandle, prezzoHandle);
4.8.4 Utilizzo degli Handle per il recupero
HGHandle handle = ...// qualcosa che ottenga l'handle di un atomo (tipo query)Libro libro = (Libro)grafo.get(handle);
21

4.8.5 Esempio per il querying
HGQueryCondition condizione = new And( new AtomTypeCondition(Libro.class), new AtomPartCondition(new String[]{"autore"}, "K. Marx", ComparisonOperator.EQ));
HGSearchResult<HGHandle> rs = grafo.find(condizione);try { while (rs.hasNext()) { HGHandle corrente = rs.next(); Book libro = grafo.get(corrente); System.out.println(libro.getTitolo()); }} finally { rs.close();}
4.8.6 Esempio di attraversata dell'ipergrafo
HGHandle mioLibro = ...// qualcosa che ottenga l'handle di un atomo (tipo query)
HGDepthFirstTraversal traversal = new HGDepthFirstTraversal(mioLibro, new SimpleALGenerator(grafo));
while (traversal.hasNext()) { Pair<HGHandle, HGHandle> corrente = traversal.next(); HGLink arco = (HGLink)grafo.get(corrente.getFirst()); Object atomo = grafo.get(corrente.getSecond()); System.out.println("Attraversando l'atomo " + atomo + " puntato da " + arco);}
4.8.7 Esempio di transazione
HyperGraph grafo = HGEnvironment.get("./test_hgdb");
grafo.getTransactionManager().beginTransaction();try { // esegui comandi… // … // fine comandi
grafo.getTransactionManager().commit();} catch (Exception e) { // la transazione non è stata completata grafo.getTransactionManager().abort();}
22

Capitolo 5: Analisi dell'Algoritmo di Dijkstra
In questo capitolo è presentata l'analisi prestazionale dell'Algoritmo di Dijkstra mediante
l'utilizzo delle librerie HypergraphDB.
L'esperimento si basa sulla misurazione della durata dell'esecuzione dell'implementazione
di questo algoritmo fornita dalla classe GraphClassics, al crescere della dimensione del
problema.
5.1 Algoritmo di Dijkstra
L'algoritmo di Dijkstra è stato ideato per risolve il problema legato alla ricerca del
percorso minimo tra due nodi di un grafo orientato nel caso di costi degli archi non unitari
ma variabili. L'algoritmo può essere esteso anche a ipergrafi considerando gli iperarchi
come nodi di un grafo e i nodi comuni a più iperarchi come archi tra questi ultimi. Questo
algoritmo, inoltre, è utilizzato nell'Interior Gateway Protocol OSPF (Open Short Path
First) per il calcolo da parte di ogni router/nodo dei percorsi minimi, permesso dal fatto
che OSPF è di tipo Link-State e quindi ogni router/nodo ha una conoscenza totale della
sua rete. L'algoritmo presenta un tempo di esecuzione T V =O(∣V∣2) che nel nel worst
case diventa O(∣E∣+∣V∣log∣V∣) .
5.1.1 Algoritmo
Dato un grafo G(V , E) costruito in modo che il costo dell'arco tra due nodi qualsiasi
i∈V e j∈V soddisfino la condizione c i , j≥0 e siano n=card (V ) e
m=card (E ) allora ad ogni nodo si associano due etichette, πi che indica il costo
totale del cammino fino a quel nodo e p i che indica il nodo che precede il nodo i nel
cammino e inoltre si definiscono due insiemi A e B , il primo contenente i nodi
ancora non etichettati e il secondo contenente i nodi etichettati.
I passi sono i seguenti:
1. Inizializzazione.
23

• Poniamo B={0 } , A= {1,2 ,... , n} , π0=0 , p0=0 .
• Poniamo πi=c0, i , p i=1 per tutti i nodi adiacenti a 0 .
• Poniamo πi=∞ , per tutti gli altri nodi.
2. Assegnazione etichetta permanente
• Se πi=∞ per ogni i∈ A FINE
• Troviamo j∈A tale che π j=min [ci] con i∈ A
• Poniamo A=A−{ j } e B=B∪{ j }
• Se A=Ø FINE
3. Assegnazione etichetta provvisoria
• Per ogni i∈ A , adiacente a j e tale che πi>π j+c j , i poniamo: πi=π j+c j , i
• p i= j
• Torniamo al passo 2.
5.1.2 Implementazione (pseudocodice)
funzione Dijkstra(Grafo, sorgente): per ogni vertice v nel Grafo: // Inizializzazione dist[v] := infinito // La distanza iniziale tra il vertice sorgente e
// v è posta ad infinito precedente[v] := non_definito // Il nodo precedente non è definito dist[source] := 0 // Distanza dalla sorgente alla sorgente Q := l'insieme di tutti i vertici del grafo // Tutti i nodi del grafo non sono
// ottimizzati, quindi sono in Q finché Q non è vuoto: // loop principale u := nodo in Q con la più piccola dist[ ] rimuovi u da Q per ogni vicino v di u: // dove v non è ancora stato rimosso da Q alt := dist[u] + dist_tra(u, v) if alt < dist[v] // rilascia (u,v) dist[v] := alt precedente[v] := u ritorna precedente[ ]
24

5.2 Implementazione in Java con HyperGraphDB
L'applicazione Java che effettua le misurazioni del tempo di esecuzione dell'algoritmo di
Dijkstra genera ipergrafi completi di dimensione crescente ai quali applica l'algoritmo
scegliendo i nodi più lontani. Sono generati un numero di atomi che va da 100 a 200'000,
di cui il 10% sono salvati come iperarchi e il 90% come nodi. Ogni iperarco contiene 10
nodi, meno l'ultimo che ne contiene 9. La struttura dell'ipergrafo in analisi è descritta in
Fig. 5.1 e può essere vista come un grafo a catena semplice (§1.1.5).
Figura 5.1: struttura di un generico ipergrafo in analisi, i numeri indicano
la quantità dei nodi facenti parte dell'iperarco e sovrapposizioni
di iperarchi contengono un nodo di collegamento tra i due.
La creazione dell'ipergrafo è gestita mediante un pool di 50 thread, dove ogni thread è
incaricato di produrre un iperarco. La gestione multi-thread serve per velocizzare la parte
di configurazione del database precedente alla raccolta dati.
Per ogni sessione sono salvati due file .txt:
• log_aaaammgg_hhmmss.txt che contiene informazioni “prolisse”
• data_aaaammgg_hhmmss.txt che contiene dati strutturati da processare
5.2.1 Esempio di file log
log_201618_19357.txt8/1/2016 19:3:57Dijkstra Algorithm Analysis***************************
total numb: 100 total dijkstra time: 42 ms path_cost: 10.0.
total numb: 200 total dijkstra time: 47 ms path_cost: 20.0.
total numb: 300 total dijkstra time: 54 ms path_cost: 30.0.
25

total numb: 400 total dijkstra time: 56 ms path_cost: 40.0.
total numb: 500 total dijkstra time: 60 ms path_cost: 50.0.
total numb: 600 total dijkstra time: 66 ms path_cost: 60.0.
total numb: 700 total dijkstra time: 84 ms path_cost: 70.0.
total numb: 800 total dijkstra time: 74 ms path_cost: 80.0.
total numb: 900 total dijkstra time: 77 ms path_cost: 90.0.
total numb: 1000 total dijkstra time: 85 ms path_cost: 100.0.
total numb: 2000 total dijkstra time: 147 ms path_cost: 200.0.
total numb: 3000 total dijkstra time: 170 ms path_cost: 300.0.
total numb: 4000 total dijkstra time: 227 ms path_cost: 400.0.
total numb: 5000 total dijkstra time: 274 ms path_cost: 500.0.
total numb: 6000 total dijkstra time: 238 ms path_cost: 600.0.
total numb: 7000 total dijkstra time: 227 ms path_cost: 700.0.
total numb: 8000 total dijkstra time: 260 ms path_cost: 800.0.
total numb: 9000 total dijkstra time: 300 ms path_cost: 900.0.
total numb: 10000 total dijkstra time: 385 ms path_cost: 1000.0.
total numb: 20000 total dijkstra time: 1551 ms path_cost: 2000.0.
total numb: 30000 total dijkstra time: 2364 ms path_cost: 3000.0.
total numb: 40000 total dijkstra time: 3920 ms path_cost: 4000.0.
total numb: 50000 total dijkstra time: 6306 ms path_cost: 5000.0.
total numb: 60000 total dijkstra time: 10665 ms path_cost: 6000.0.
total numb: 70000 total dijkstra time: 12779 ms path_cost: 7000.0.
total numb: 80000 total dijkstra time: 14821 ms path_cost: 8000.0.
total numb: 90000 total dijkstra time: 18393 ms path_cost: 9000.0.
total numb: 100000 total dijkstra time: 25461 ms path_cost: 10000.0.
total numb: 110000 total dijkstra time: 30459 ms path_cost: 11000.0.
total numb: 120000 total dijkstra time: 34737 ms path_cost: 12000.0.26
total numb: 130000 total dijkstra time: 44719 ms path_cost: 13000.0.
total numb: 140000 total dijkstra time: 57503 ms path_cost: 14000.0.
total numb: 150000 total dijkstra time: 57475 ms path_cost: 15000.0.
total numb: 160000 total dijkstra time: 62193 ms path_cost: 16000.0.
total numb: 170000 total dijkstra time: 73605 ms path_cost: 17000.0.
total numb: 180000 total dijkstra time: 85151 ms path_cost: 18000.0.
total numb: 190000 total dijkstra time: 102003 ms path_cost: 19000.0.
total numb: 200000 total dijkstra time: 109681 ms path_cost: 20000.0.
“total numb” corrisponde al numero totale di atomi (nodi e iperarchi) che compongono
l'ipergrafo, quindi il numero reale di nodi(iperarchi) in gioco è “total numb / 10”.
5.2.2 Grafici
I seguenti grafici sono stati generati con OpenOffice Calc a partire dai dati raccolti.
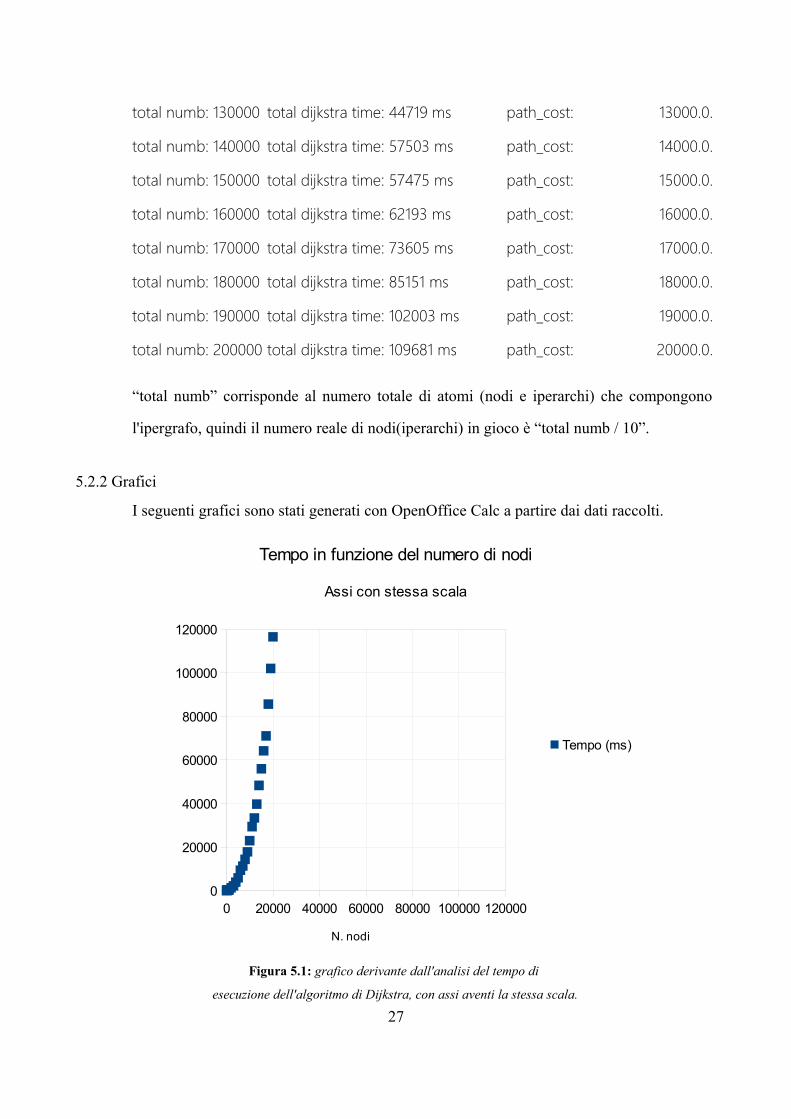
Figura 5.1: grafico derivante dall'analisi del tempo di
esecuzione dell'algoritmo di Dijkstra, con assi aventi la stessa scala.
27
0 20000 40000 60000 80000 100000 1200000
20000
40000
60000
80000
100000
120000
Tempo in funzione del numero di nodi
Assi con stessa scala
Tempo (ms)
N. nodi
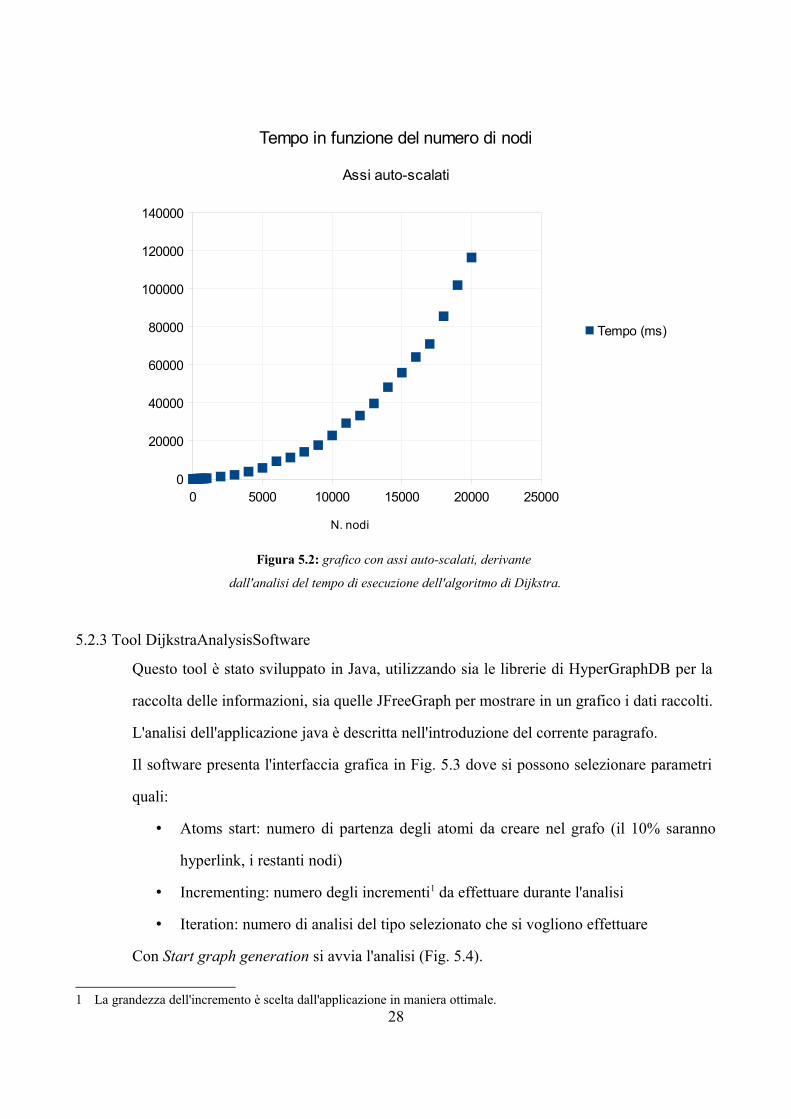
Figura 5.2: grafico con assi auto-scalati, derivante
dall'analisi del tempo di esecuzione dell'algoritmo di Dijkstra.
5.2.3 Tool DijkstraAnalysisSoftware
Questo tool è stato sviluppato in Java, utilizzando sia le librerie di HyperGraphDB per la
raccolta delle informazioni, sia quelle JFreeGraph per mostrare in un grafico i dati raccolti.
L'analisi dell'applicazione java è descritta nell'introduzione del corrente paragrafo.
Il software presenta l'interfaccia grafica in Fig. 5.3 dove si possono selezionare parametri
quali:
• Atoms start: numero di partenza degli atomi da creare nel grafo (il 10% saranno
hyperlink, i restanti nodi)
• Incrementing: numero degli incrementi1 da effettuare durante l'analisi
• Iteration: numero di analisi del tipo selezionato che si vogliono effettuare
Con Start graph generation si avvia l'analisi (Fig. 5.4).
1 La grandezza dell'incremento è scelta dall'applicazione in maniera ottimale.28
0 5000 10000 15000 20000 250000
20000
40000
60000
80000
100000
120000
140000
Tempo in funzione del numero di nodi
Assi auto-scalati
Tempo (ms)
N. nodi

Al termine dell'analisi vengono visualizzati i risultati nella sezione sottostante e viene
abilitato il pulsante Generate graphic che alla pressione mostra a schermo il grafico che
descrive i dati raccolti (Fig. 5.5).
Figura 5.3: interfaccia grafica dell'applicazione sviluppata.
Figura 5.4: screenshot dell'applicazione alla fine dell'esecuzione
29
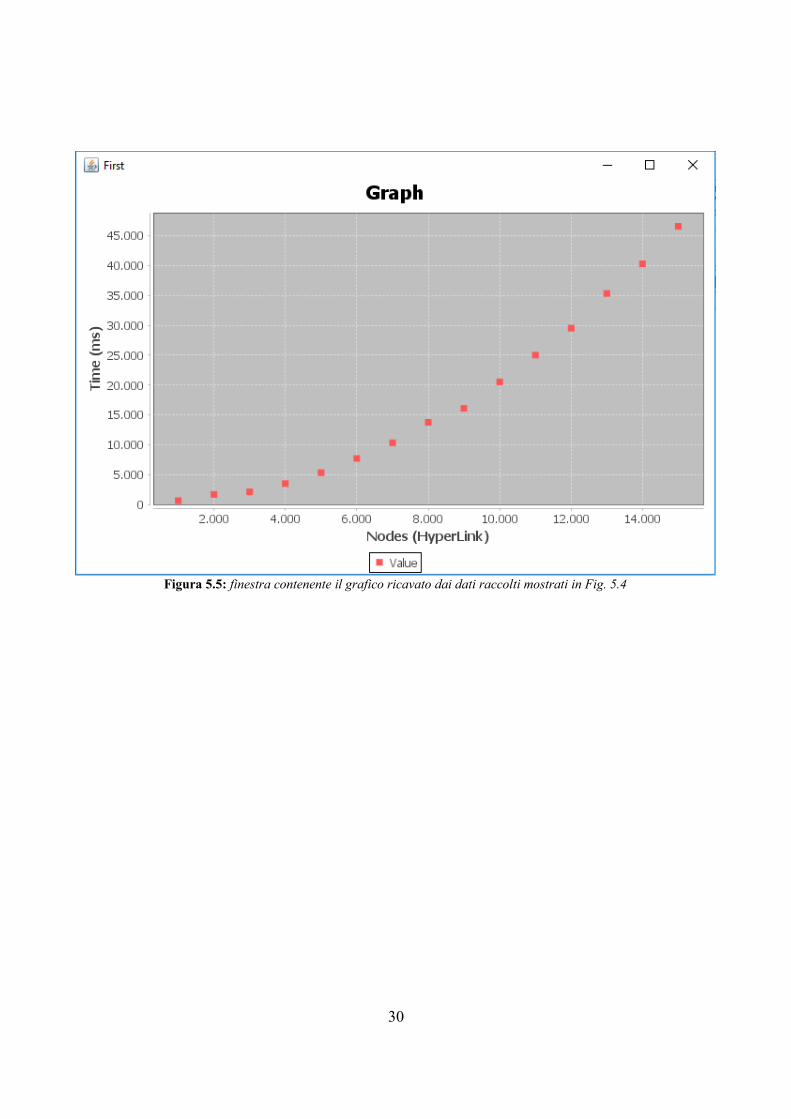
Figura 5.5: finestra contenente il grafico ricavato dai dati raccolti mostrati in Fig. 5.4
30

Conclusioni
La struttura matematica del grafo è molto versatile per la gestione di collezioni di dati non
strutturati di grandi dimensioni ad alta dinamicità come i Big Data. Le strutture ad
ipergrafo, invece, oltre ad avere le stesse potenzialità di quelle basate su grafo vanno oltre.
Infatti la presenza di iperarchi permette la realizzazione di relazioni multidimensionali
proprie dei database relazionali (tuple), permettendone una gestione di tipo NoSQL
mediante un linguaggio non descrittivo ma procedurale. Inoltre la struttura ad ipergrafo è
applicabile a molteplici campi, garantendo eterogeneità nell'applicazione delle librerie che
ne implementano la logica ai fini di data storage e di information retrieval.
HyperGraphDB è una di queste librerie che oltre alla gestione delle conoscenze, dell'IA e
dei progetti di web semantico, può essere utilizzata per costruire un database embedded
per applicazioni Java. Questi database embedded possono implementare sia il modello
Graph Database, sia un modello relazionale NoSQL. La forza di database basati sul
modello a ipergrafo è quindi quella di poter assumere, a discrezione del programmatore,
tutti i comportamenti desiderati. Basti pensare che per creare un database relazionale basta
creare un tipo strutturato (tipo record o classe), assegnare una istanza di questo tipo per
ogni nodo e collegare tutti questi nodi con un iperarco: quest'ultimo svolgerà il compito di
tabella mentre ogni nodo corrisponderà ad una tupla. Un altro punto di forza della libreria
HyperGraphDB è quello di poter distribuire i dati mediante una struttura peer-to-peer,
operazione che velocizza di molto l'analisi di grosse quantità di dati parallelizzandola.
Questa funzione è molto simile a quella offerta da MapReduce di Google e da Apache
Hadoop.
31

Bibliografia
[1] Apache Hadoop, https://hadoop.apache.org/, 08/01/2016
[2] B. Iordanov, "HyperGraphDB: A Generalized Graph Database”
[3] Boja, C; Pocovnicu, A; Bătăgan, L. "Distributed Parallel Architecture for Big
Data", Informatica Economica (2012).
[4] C. Berge, "Graphs and hypergraphs" , North-Holland (1973)
[5] C. Berge, "The theory of graphs and their applications" , Wiley (1962)
[6] De Mauro, Andrea; Greco, Marco; Grimaldi, Michele (2015). "What is big data? A
consensual definition and a review of key research topics"
[7] Encyclopedia of math, https://www.encyclopediaofmath.org/, 09/12/2015
[8] FIPA ACL, http://www.fipa.org/repository/aclspecs.html, 07/01/2016
[9] HyperGraphDB, http://hypergraphdb.org/, 09/12/2015
[10] MapReduce, http://www.mapreduce.it/, 08/01/2016
[11] SPARQL Query Language for RDF, http://www.w3.org/TR/rdf-sparql-query/,
07/01/2016
32
Top Related