
Tesi di Laurea - elite.polito.itelite.polito.it/files/thesis/fulltext/pisapia.pdf · La...
108
POLITECNICO DI TORINO Facoltà di Ingegneria dell’Informazione Corso di Laurea in Ingegneria Informatica Tesi di Laurea Integrazione di applicazioni Web con sistemi esistenti mediante un’architettura orientata ai servizi Relatore prof. Fulvio Corno Candidato Pisapia Arturo Luigi Aprile 2004
-
Upload
hoangnguyet -
Category
Documents
-
view
217 -
download
0
Transcript of Tesi di Laurea - elite.polito.itelite.polito.it/files/thesis/fulltext/pisapia.pdf · La...

POLITECNICO DI TORINO
Facoltà di Ingegneria dell’Informazione
Corso di Laurea in Ingegneria Informatica
Tesi di Laurea
Integrazione di applicazioni Web con sistemi esistenti mediante un’architettura orientata ai
servizi Relatore prof. Fulvio Corno
Candidato Pisapia Arturo Luigi
Aprile 2004

RINGRAZIAMENTI Desidero ringraziare tutte le persone che mi hanno aiutato nel mio percorso universitario. In particolare ringrazio i miei genitori per avermi supportato anche nei momenti più difficili; un ringraziamento anche a tutti i miei amici ed in particolare a Valeria. Ringrazio il relatore, Ing. Fulvio Corno, per avermi consigliato ed aiutato durante la stesura della tesi. Ringrazio la Cluster reply S.r.l. per l’ospitalità fornitami, ed in particolare l’Ing. Alessandro Bonaudo per avermi supportato durante lo svolgimento della tesi. Grazie

Sommario
Sommario Capitolo 1 .......................................................................................................................... 5 Introduzione ad Anagrafica Programmi.............................................................................. 5
1.1 Il progetto Anagrafia Programmi ........................................................................ 5 1.2 Il Contesto di utilizzo di Anagrafica programmi................................................. 7 1.3 I principali requisiti progettuali........................................................................... 9 1.4 FFuunnzziioonnaalliittàà ddeell PPrrooddoottttoo .................................................................................... 9 1.5 Architettura ...................................................................................................... 12 1.6 Un caso d’uso ................................................................................................... 15
Capitolo 2 ........................................................................................................................ 20 Introduzione al Framework .NET..................................................................................... 20
2.1 Principi generali................................................................................................ 20 2.2 Il Common Language Runtime (CLR) .............................................................. 22 2.3 Framework Class Library.................................................................................. 30 2.4 Data Services.................................................................................................... 30 2.5 User Interface Services ..................................................................................... 31 2.6 Web Services.................................................................................................... 31
Capitolo 3 ........................................................................................................................ 32 La Programmazione distribuita......................................................................................... 32
3.1 Introduzione ..................................................................................................... 32 3.2 I componenti in una architettura distribuita ....................................................... 33 3.3 Caratteristiche di un sistema distribuito............................................................. 33 3.4 Architetture distribuite multilivello ................................................................... 38
Capitolo 4 ........................................................................................................................ 41 L’Architettura di Anagrafica Programmi .......................................................................... 41
4.1 Dettaglio sulla Three-tiered Architecture di Anagrafica Programmi .................. 41 4.2 Il Data Layer..................................................................................................... 43 4.3 Il Business Layer .............................................................................................. 54 4.4 Il Presentation Layer......................................................................................... 56
Capitolo 5 ........................................................................................................................ 57 Le transazioni distribuite .................................................................................................. 57
5.1 Introduzione ..................................................................................................... 57 5.2 Le Transazione Distribuite................................................................................ 60 5.3 Il protocollo di Two-Phase Commit (2PC) ....................................................... 61 5.4 Le transazioni in Anagrafica Programmi........................................................... 62

Sommario
Capitolo 6 ........................................................................................................................ 63 Gestione delle Eccezioni .................................................................................................. 63
6.1 Introduzione ..................................................................................................... 63 6.2 Gerarchia delle eccezioni FCL .......................................................................... 64 6.3 Meccanismi di gestione delle eccezioni............................................................. 66 6.4 Definizione di eccezioni personalizzate............................................................. 69 6.5 Struttura delle eccezioni in un’applicazione ...................................................... 70 6.6 La struttura delle eccezioni di anagrafica Programmi ........................................ 72
Capitolo 7 ........................................................................................................................ 74 Gestione dei log e la libreria di Logging Log4Net per il tracing degli eventi..................... 74
7.1 Introduzione al logging di eventi....................................................................... 74 7.2 La libreria Log4net ........................................................................................... 74 7.3 Il file di configurazione di Anagrafica Programmi ............................................ 76 7.4 Inserimento dei log all’interno del codice di Anagrafica Programmi ................. 79
Capitolo 8 ........................................................................................................................ 81 I Web services e l’ arricchimento semantico dei file XSD ................................................ 81
8.1 I Web services e .NET ...................................................................................... 81 8.2 La validazione nei WebMethod ASP.NET attraverso l’arricchimento semantico dei file XML Schema ................................................................................................... 83 8.3 Estensione dei WebMethods ............................................................................. 84
Capitolo 9 ........................................................................................................................ 94 Conclusioni ...................................................................................................................... 94 Appendice........................................................................................................................ 96
A.1 Introduzione ai Web services ............................................................................ 96 Bibliografia .................................................................................................................... 107

5
Capitolo 1 Introduzione ad Anagrafica Programmi
1.1 Il progetto Anagrafia Programmi Questo progetto è nato dall’esigenza da parte del cliente RAI di svecchiare i propri sistemi informativi. I sistemi preesistenti in RAI sono molti ed eterogenei, si spazia dalle applicazioni Web sviluppate nelle vecchie tecnologie Microsoft, ad applicazioni data-intensive basate su DB Oracle o SqlServer e alle applicazioni basate su mainframe IBM. Posso affermare che le applicazioni Mainframe basate su transazioni CICS e scritte principalmente in Cobol rappresentano ad oggi la fetta più grande dei sistemi RAI. Quindi questa iniziativa si colloca nell’ambito di una serie di iniziative progettuali e di evoluzione dei sistemi di Core Business a supporto dei processi editoriali e produttivi, con l’obiettivo di migliorare l’efficienza operativa e il grado di automazione dei processi, superando così gli attuali elementi di maggiore criticità. Tramite la realizzazione del sistema “Anagrafica Programmi TV/RF” (la sigla TV/RF sta a significare che il dominio dei programmi di questa anagrafica spazia dai programmi televisivi ai programmi radiofonici ), la RAI si è posta l’obiettivo di migrare dai sistemi di Core Business dall’ambiente Host all’ambiente Open, privilegiando le architetture basate su tecnologie WEB. Si è pensato di passare alla tecnologia Object oriented basate su Microsoft .NET e di far migrare i dati verso un DBMS MS SQL Server; questa tecnologia garantisce una gran semplicità d’integrazione, grazie agli Xml Web services; inoltre sarà garantita una maggior scalabilità e affidabilità del sistema. Il sistema realizzato contiene e integra tutte le informazioni gestite dal vecchio archivio anagrafico; per fare ciò si è deciso di utilizzare un nuovo modello dati completamente relazionale basate sulla piattaforma Microsoft SQLServer. Quando l’applicativo passerà in produzione, non tutti i sistemi esterni che si interfacciano ad esso saranno pronti per staccarsi dal vecchio DataBase perciò si è reso necessario

Capitolo 1 - Introduzione ad Anagrafica Programmi
6
l’utilizzo di uno strumento di allineamento che replica sull’archivio anagrafico legacy tutte le modifiche attuate sul nuovo sistema, in una modalità transazionale (protocollo di two-phase commit ). Il sistema Anagrafia Programmi rappresenta il cuore dei sistemi di RAI, in quanto essa contiene tutti i programmi prodotti o acquisiti da RAI e contiene tutta la storia dei programmi, compresi quelli che sono stati ceduti ad altre cordate editoriali. Un po’ tutti i sistemi principali vanno ad accedere a questa anagrafica, interagendo con essa sia in lettura che in scrittura. È importante porre l’accento sul fatto che il nostro progetto è un rifacimento completo del preesistente sistema anagrafico sviluppato in tecnologia MainFrame OS/390, quindi un ulteriore punto critico sarà quello di sostituire il nodo centrale di un’architettura già esistente senza causare scompensi di alcun genere, ma cercando di migliorare la risposta del sistema complessivo. Il dominio impattato spazia dai sistemi editoriali, della gestione fino agli strumenti di ricerca e analisi dei dati. Quindi il cliente ha deciso per una graduale conversione dei propri sistemi nella nuova tecnologia, tenendo presente che si sarebbe dovuta garantire la trasparenza della transizione vecchio-nuovo per i sistemi periferici al sistema d’anagrafia. Sono state implementate una serie di funzionalità e servizi per la gestione dell’archivio anagrafico accessibili tramite un’applicazione web, sviluppata in tecnologia Microsoft ASP.NET. Oltre alle funzionalità di accesso diretto (tramite interfaccia web) dell’utente al sistema, il sistema mette a disposizione degli applicativi pre-esistenti una parte di queste funzionalità, sfruttando in modo esteso la tecnologia degli XML Web Services, attraverso i quali i sistemi esterni possono accede in lettura o scrittura (secondo il caso) al database interno. Il nuovo sistema sostituisce il vecchio applicativo legacy garantendo le stesse funzionalità preesistenti ma allo stesso tempo semplificando notevolmente le problematiche di integrazione con gli altri sistemi aziendali. La scelta tecnologica fatta ha l’ambizioso obiettivo di guidare l’interazione tra i sistemi aziendali verso lo standard SOAP, rendendo, di fatto, l’accesso alle informazioni indipendente dalla tecnologia che le ospita.

Capitolo 1 - Introduzione ad Anagrafica Programmi
7
1.2 Il Contesto di utilizzo di Anagrafica programmi I sistemi esistenti con cui la nuova Anagrafica Programmi si deve in qualche modo integrare sono i seguenti:
• Archivio anagrafico esistente: deve esistere un meccanismo di allineamento, tale che il vecchio archivio sia mantenuto aggiornato per tutti quei sistemi che continueranno ad accedere a tale archivio; requisito vincolante è che i sistemi in oggetto accedano in sola lettura al vecchio archivio anagrafico.
• Nirvana: scrive dati nel nuovo database in modalità batch • Commesse Editoriali: fornisce dati al nuovo sistema in modalità on-line • STRADA: fornisce dati al nuovo sistema in modalità on-line • Gestione Diritti: scrive dati nel nuovo database in modalità batch • AUDITEL: scrive dati nel nuovo database in modalità batch • OCTOPUS: la nuova applicazione web accede al sistema OCTOPUS mediante una
chiamata diretta (URL parametrica) Nella pagina seguente ho inserito uno schema a blocchi che rappresenta il contesto di utilizzo dell’intero sistema.
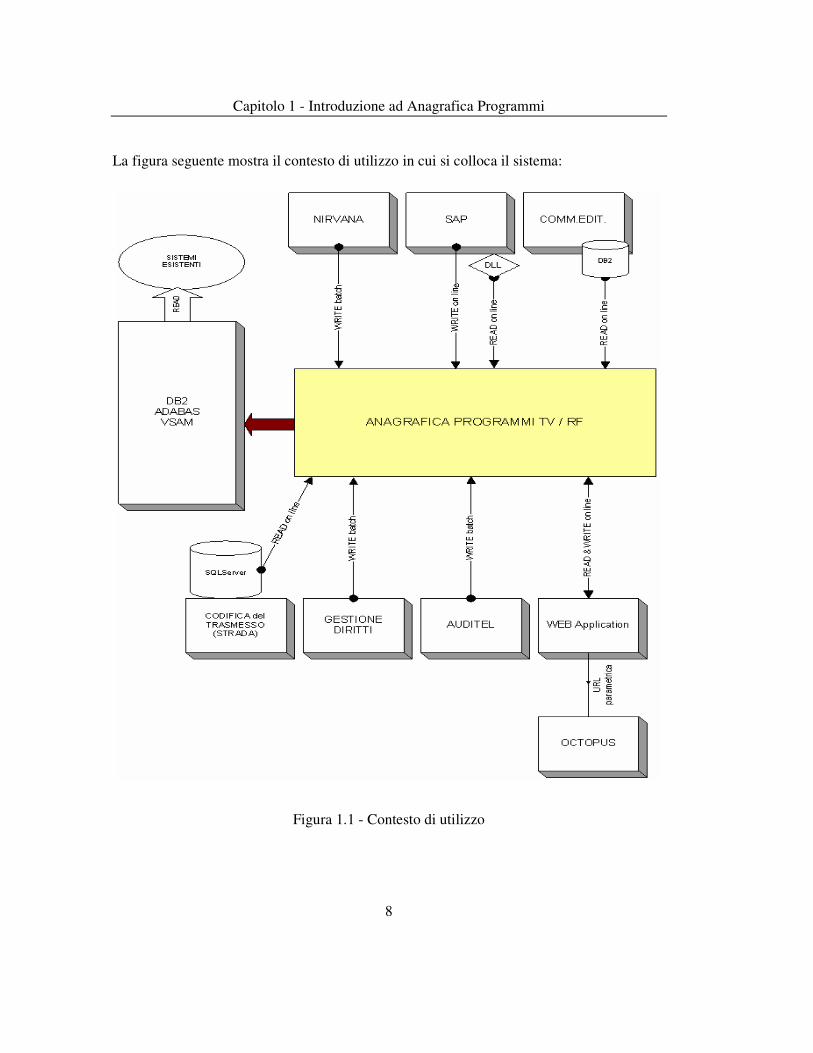
Capitolo 1 - Introduzione ad Anagrafica Programmi
8
La figura seguente mostra il contesto di utilizzo in cui si colloca il sistema:
Figura 1.1 - Contesto di utilizzo

Capitolo 1 - Introduzione ad Anagrafica Programmi
9
1.3 I principali requisiti progettuali • Il sistema anagrafico oggetto del rifacimento consiste in una serie di transazioni
CICS che operano su database DB2, Adabas e VSAM. Nel nuovo sistema, devono essere garantire le funzionalità che gli utenti hanno attualmente a disposizione.
• Una parte dei sistemi collegati all’attuale archivio anagrafico non potranno essere adeguati prima del rilascio in produzione del nuovo sistema. Pertanto, è stato mantenuto l’allineamento dei dati del nuovo sistema e del sistema legacy, al quale continueranno ad accedere quei sistemi che, per motivi tecnologici o impossibilità di adeguamento, non possono accedere al nuovo archivio dipartimentale. L’allineamento, richiesto a fronte di ogni operazione di inserimento, aggiornamento e cancellazione, verrà dismesso quando tutti i sistemi collegati saranno migrati sul nuovo archivio anagrafico. Per rendere possibile tutto ciò l’aggiornamento su mainframe avviene nell’ambito di una transazione.
• Si prevedono 150/200 utenti abilitati in aggiornamento, mentre gli utenti che potranno operare in consultazione potenzialmente sono tutti i dipendenti RAI (per gran parte di essi sarà disponibile la banca dati di ricerca); l’applicazione dovrà supportare l’accesso contemporaneo di circa 20 – 30 utenti
1.4 FFuunnzziioonnaalliittàà ddeell PPrrooddoottttoo • La funzione di login, comune ai contesti TV e RF • La funzione di consultazione delle anagrafie dei codici • L’allineamento con l’archivio mainframe • Le funzioni proprie del contesto televisivo • Le funzioni proprie del contesto radiofonico • I Web services di scrittura dell’anagrafica del contesto televisivo • I Web services di scrittura dell’anagrafica del contesto radiofonico

Capitolo 1 - Introduzione ad Anagrafica Programmi
10
1.4.1 Login Deve essere prevista una funzione di login che consenta all’utente di autenticarsi ed essere abilitato alle funzioni permesse dal proprio profilo.
1.4.2 Consultazione delle anagrafie dei codici Sull’anagrafica sono definite le tabelle dei codici che vengono utilizzati come attributi dell’anagrafia. E’ stata predisposta una funzione che ne permetta la visualizzazione nell’applicativo.
1.4.3 Allineamento con l’archivio mainframe Il nuovo archivio anagrafico deve essere allineato con la banca dati mainframe; per questo tutte le operazioni di inserimento, modifica e cancellazione dovranno essere completate da una operazione analoga effettuata sull’archivio mainframe. L’operazione di allineamento consiste nella replica dei passi che vengono eseguiti sull’archivio dipartimentale, tenendo conto delle differenze determinate dal nuovo disegno della banca dati.
1.4.4 Le funzioni del contesto televisivo L’oggetto cardine del contesto televisivo e’ rappresentato dalla uorg/matricola, della quale possono essere gestiti tutti i dettagli. Poiché il contenuto informativo è attualmente presente sulla banca dati host, occorre predisporre un impianto che consenta il porting dei dati sul database distribuito; inoltre, poiché l’integrazione dei sistemi collegati verrà effettuata in step successivi, sulla base di un disegno generale di priorità, è necessario garantire l’allineamento dell’archivio mainframe ogni volta che saranno effettuate operazioni di aggiornamento. Quando tutti i sistemi editoriali riferiti all’anagrafica saranno migrati sul database distribuito, questa connessione potrà essere eliminata. Nell’ambito del rifacimento dell’anagrafica, sarà definita una nuova banca dati di ricerca, da caricare quotidianamente con modalità incrementale; per effettuare questa operazione e’ necessario che vengano tracciate le operazioni di inserimento, modifica e cancellazione. Le funzioni considerate sono le seguenti:
- Gestione anagrafia - Gestione commessa - Gestione dati descrittivi

Capitolo 1 - Introduzione ad Anagrafica Programmi
11
- Gestione finestre di non trasmettibilità - Gestione produttori - Voltura - Cessione - Sospensione - Scarico - Blocco - Impostazione anno pronto - Ricerca anagrafie - Ricerca utilizzazioni - Analisi del trasmesso
1.4.5 Le funzioni del contesto radiofonico L’oggetto cardine del contesto radiofonico e’ rappresentato dalla uorg/matricola, analogamente al contesto televisivo. Le funzioni considerate sono le seguenti :
- gestione anagrafia - ricerca anagrafia Il sistema inoltre, per realizzare particolari funzioni, richiede informazioni a SAP e Octopus relativamente alla banca dati di ricerca dei contratti.
1.4.6 I Web services di scrittura dell’anagrafica del contesto televisivo Di seguito sono specificate le interfacce di scrittura sull’anagrafica televisiva che sono previste all’atto dell’avvio del nuovo sistema :
- Web service di gestione delle anagrafie dal sistema Nirvana - Web service di gestione delle prenotazioni e assegnazioni dal sistema Nirvana - Web service di gestione delle trasmissioni dal sistema Codifica del Trasmesso - Web service di aggiornamento di ascolto e share dal sistema Auditel - Web service di aggiornamento del contratto dal sistema SAP - Web service di aggiornamento del pacchetto dal sistema Gestione Diritti

Capitolo 1 - Introduzione ad Anagrafica Programmi
12
1.4.7 I Web services di scrittura dell’anagrafica del contesto radiofonico
- Web service Contratto SAP: si tratta della procedura on-line che consente l’inserimento del contratto dal sistema SAP all’atto della firma
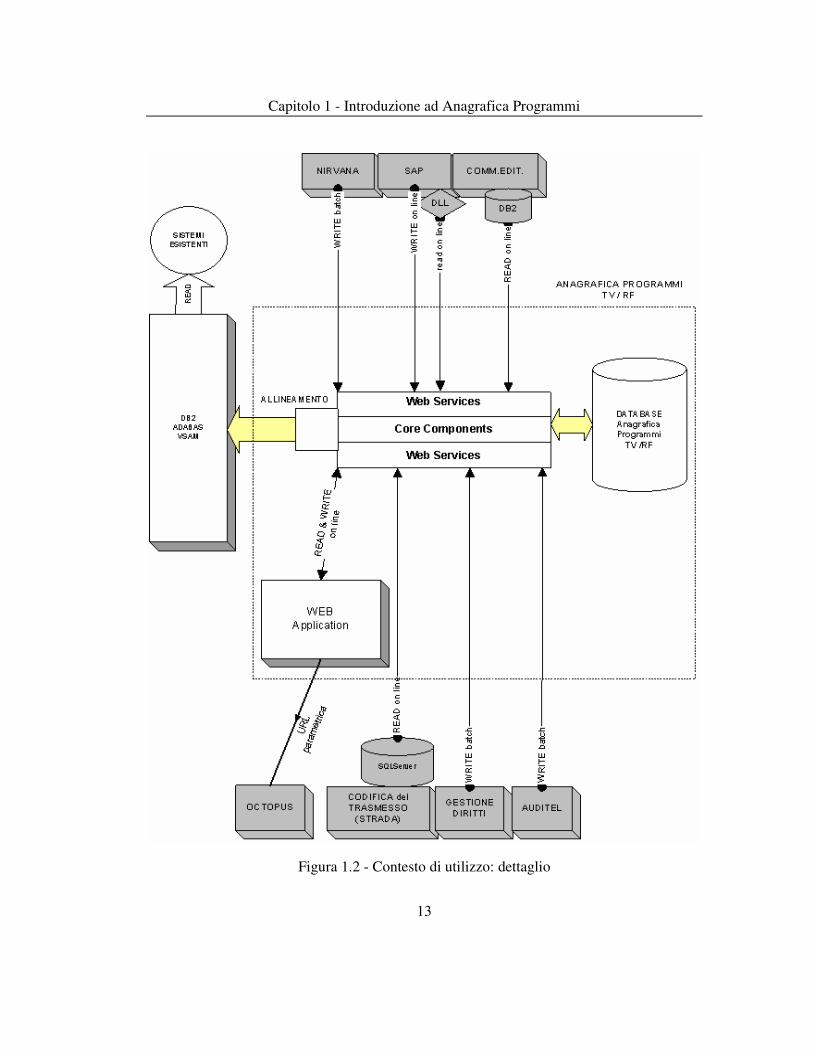
1.5 Architettura Nella figura seguente vengono mostrati in maggior dettaglio i componenti interni del sistema “Anagrafica Programmi TV/RF”. In particolare, si vede come il sistema sia composto sostanzialmente da 5 parti:
1. Database “Anagrafica Programmi TV/RF”: è il contenitore relazionale che integra i dati provenienti dalle varie fonti
2. Web Services: è lo strato di servizio che espone verso il mondo esterno tutte le funzionalità che permettono ai client di lavorare con il database
3. Core components: sono i componenti che implementano tutte le logiche del sistema: profilazione, trattamento dei dati, gestione degli errori, accesso al database, ecc.
4. Allineamento: è il componente che si occupa di mantenere aggiornato l’archivio anagrafico legacy, in una modalità consistente rispetto alle modifiche effettuate sul database
5. Web Application: è l’applicazione che permette agli utenti di accedere al nuovo sistema anagrafico; anch’essa si appoggia sui servizi messi a disposizione dallo strato di Web Services.
Io mi sono occupato principalmente dei livelli dal primo al quarto e dei Web Services. In questa architettura i sistemi che scrivono su Anagrafica Programmi devono adeguarsi alle interfacce esposte dai Web Services, quindi l’eventuale trasformazione e trattamento dei dati è in parte a carico dei sistemi collegati e in parte a carico dei Web Services.
Capitolo 1 - Introduzione ad Anagrafica Programmi
13
Figura 1.2 - Contesto di utilizzo: dettaglio
Capitolo 1 - Introduzione ad Anagrafica Programmi
14
DATABASEAnagraficaProgrammi
TV /RF
WEBApplication
Businesscomponents
Data Accesscomponents
SISTEMI COLLEGATI
DB2ADABAS
VSAM
ALLINEAMENTO
Web Services
External SystemsInterface
Web AppInterface
Core Components
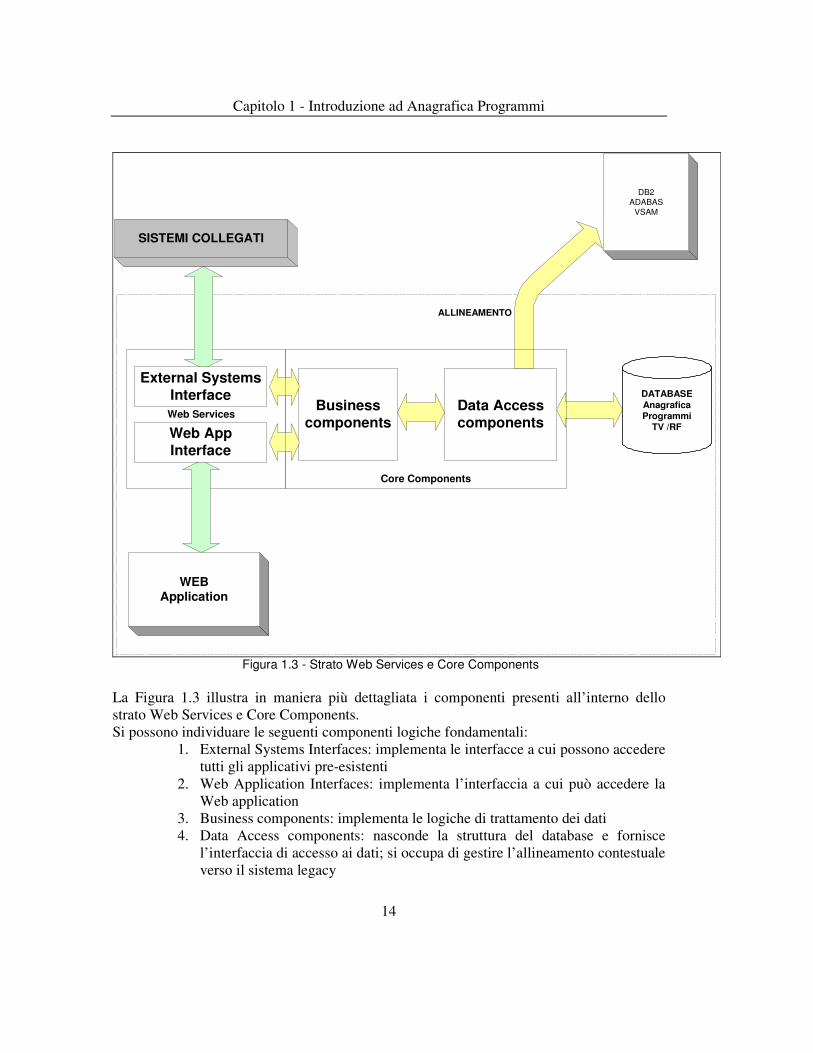
Figura 1.3 - Strato Web Services e Core Components La Figura 1.3 illustra in maniera più dettagliata i componenti presenti all’interno dello strato Web Services e Core Components. Si possono individuare le seguenti componenti logiche fondamentali:
1. External Systems Interfaces: implementa le interfacce a cui possono accedere tutti gli applicativi pre-esistenti
2. Web Application Interfaces: implementa l’interfaccia a cui può accedere la Web application
3. Business components: implementa le logiche di trattamento dei dati 4. Data Access components: nasconde la struttura del database e fornisce
l’interfaccia di accesso ai dati; si occupa di gestire l’allineamento contestuale verso il sistema legacy

Capitolo 1 - Introduzione ad Anagrafica Programmi
15
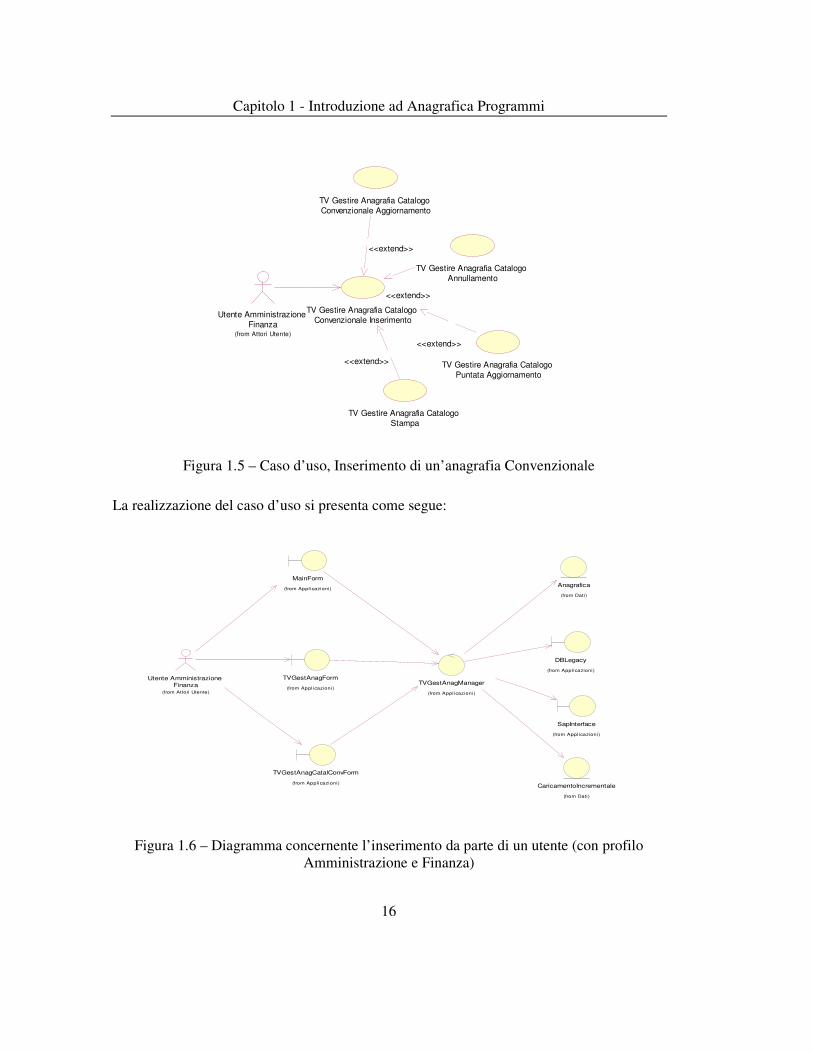
1.6 Un caso d’uso Per chiarire meglio il modo di funzionare di Anagrafica Programmi ho deciso di mostrare un caso d’uso relativo all’inserimento di una nuova anagrafia convenzionale (basti sapere che l’anagrafia Convenzionale è un particolare tipo di anagrafia ). Prima di andare avanti con la spiegazione del caso d’uso ci tengo a chiarire cosa si intende per Programma e quali sono i principali oggetti sui quali la nostra anagrafia si basa.
• PROGRAMMA: Individua il prodotto immatricolato, cioè il Prodotto/Diritto sfruttabile dall’Azienda.
• IDENTIFICATORI: Matricola e Uorg • MATRICOLA: Corrisponde alla matricola aziendale attribuita al singolo
programma • UORG: E’ l'unita organizzativa (la Struttura Aziendale) di chi acquista il
programma È importante notare che l’oggetto cardine dell’anagrafia è la Matricola, all’interno di una matricola possono esistere N serie e a loro volta all’interno della serie possono esistere M puntate.
Figura 1.4 - Struttura di un programma
Capitolo 1 - Introduzione ad Anagrafica Programmi
16
TV Gestire Anagrafia Catalogo Convenzionale Aggiornamento
TV Gestire Anagrafia Catalogo Convenzionale Inserimento
Utente Amministrazione Finanza
(from Attori Utente)
TV Gestire Anagrafia Catalogo Annullamento
TV Gestire Anagrafia Catalogo Puntata Aggiornamento
TV Gestire Anagrafia Catalogo Stampa
<<extend>>
<<extend>>
<<extend>>
<<extend>>
Figura 1.5 – Caso d’uso, Inserimento di un’anagrafia Convenzionale
La realizzazione del caso d’uso si presenta come segue:
Utente Amministrazione Finanza
(from Attori Utente)
TVGestAnagForm
(from Applicazioni)
TVGestAnagCatalConvForm
(from Applicazioni)
MainForm
(from Applicazioni)Anagrafica
(from Dati)
DBLegacy
(from Applicazioni)
CaricamentoIncrementale
(from Dati)
SapInterface
(from Applicazioni)
TVGestAnagManager
(from Applicazioni)
Figura 1.6 – Diagramma concernente l’inserimento da parte di un utente (con profilo Amministrazione e Finanza)

Capitolo 1 - Introduzione ad Anagrafica Programmi
17
L’utente di amministrazione finanza accede alla form principale e richiede la gestione delle anagrafiche.
Successivamente, dalla schermata di gestione anagrafie seleziona il “Catalogo Convenzionale” e procede successivamente alle operazioni di inserimento:
: Utente Amministrazio...
: MainForm : TVGestAnagForm : TVGestAnagCatalConvForm : TVGestAnagManager : Anagrafica : DBLegacy : SapInterface : CaricamentoIncrementale
//richiediGestioneAnagrafie
//richiediGestioneAnagrafie
//crea
//richiediGestioneAnagrafieCatalogo
//richiediGestioneAnagrafieCatalogo
//crea
//presentaMascheraCampiDigitabili
inserisciDati
Obbligatorietà, validità, coerenza.
controlliSuiDati
//inserisciPuntata
//inserisciPuntata
//inserisciPuntata
//inserisciPuntata
//ok
//ok
//ok
//visualizzaDettAnagrConvenzionale
Figura 1.7 - Sequence Diagram

Capitolo 1 - Introduzione ad Anagrafica Programmi
18
Il caso d’uso è poi suddiviso, nelle sue funzionalità, sui vari livelli che costituiscono l’applicazione Anagrafica Programmi ( Presentation Layer, Business Layer e Data Layer – vedi Capitolo sul modello a livelli utilizzato in Anagrafica Programmi).
UtentiHTTP / SSO
Altri SistemiHTTP-SOAP / NTLM-WSSEC
AnagraficaProgrammiWeb<<subsystem>>
(from Modello Subsystems)AnagraficaProgrammiWS
<<subsystem>>
(from Modello Subsystems)
AnagraficaProgrammiBO<<subsystem>>
(from Modello Subsystems)
Aggancio verso sistemi esterni.[Interfacce eterogenee]
AnagraficaProgrammiIO<<subsystem>>
(from Modello Subsystems)
WF_TVGestioneCatalogo
(from WorkFlow)
BO_TVGestioneCatalogo
(from BO)
SapInterface
(from Servizi esterni)
Anagrafica
(from Internal DB)
CaricamentoIncrementale
(from Internal DB)
DBLegacy
(from Servizi esterni )
GestioneSQLServer
(from Internal DB)
MainForm(from Interfaccia Web)
<<Client Page>>TVGestAnagForm(from Interfaccia Web)
<<Client Page>>TVGestAnagCatalConvForm
(from Interfaccia Web)
<<Client Page>>
I_TVGestioneCatalogo
(from Business Facade)
TVGestAnagWebManager(from Interfaccia Web)
<<BehindCode>>
Figura 1.8 – Diagramma attraverso i livelli

Capitolo 1 - Introduzione ad Anagrafica Programmi
19
L’utente interagisce con le pagine web tramite browser. Il subsystem AnagraficaProgrammiWeb (Presentation Layer) gestisce la presentation generando le pagine ed interagendo con il modulo AnagraficaProgrammiBO ( Biz Layer). Quest’ultimo è responsabile del flusso della richiesta ricevuta dai livelli superiori, nonché della interazione con il layer dati delle sezioni di accesso al DB principale e della sincronizzazione con l’esterno (DB legacy e SAP).

20
Capitolo 2 Introduzione al Framework .NET
2.1 Principi generali Microsoft ha impiegato tre anni per sviluppare Microsoft .NET, che è stato lanciato pubblicamente al PDC 2000 ad Orlando, Florida. Non è facile spiegare cosa sia esattamente il Framework.NET in quanto molto è stato scritto su questo argomento e diversi sono gli ambiti che fanno parte di questa nuova tecnologia; per cercare di fare un po' di chiarezza, posso distinguere tre principali famiglie:
• Visione .NET: secondo questa nuova concezione, tutte le periferiche (compresi frigoriferi, orologi, forni...) saranno interconnesse tra loro mediante una Rete Globale a banda larga; la potenza e la flessibilità di .NET consentirà di gestire tutte queste periferiche attraverso un unico ambiente di lavoro.
• Framework .NET: indica la nuova piattaforma di esecuzione ed elaborazione che semplifica lo sviluppo e la distribuzione di applicazioni in ambiente Windows e tutte le tecnologie coinvolte nell'ambiente, come ad esempio: ASP.NET, C#, VisualBasic.NET, JScript.NET.
• .NET Enterprise Server: tutti i prodotti Enterprise Microsoft. I servizi di.NET sono integrati nel sistema operativo e forniscono un supporto comune allo sviluppo delle applicazioni. Ciò è possibile grazie ad un’architettura (vedi figura 2.1) i cui componenti fondamentali sono:
• Common Language Runtime
o Common Type System o Common Language Specification o MSIL e JIT Compiler o Garbage Collector (GC) o Caricamento di CLR
• Framework Class Library • Data Services

Capitolo 2 - Introduzione al Framework .NET
21
• User Interface Services • Web Services
Figura 2.1
Il Framework .NET fornisce le basi sulle quali è nata tutta la “visione .NET” grazie alla quale, in un futuro prossimo, tutti i dispositivi saranno interconnessi tra loro, parlando “linguaggi” comuni, come ad esempio l'XML,ed utilizzando protocolli standard e riconosciuti, come l'HTTP. E' importante sottolineare che altre società hanno sposato questa visione, come ad esempio IBM e SUN. Il Framework .NET si basa su un CRL (Common Language Runtime), un Runtime che compila al volo il codice e lo converte in MSIL (Microsoft Intermediate Language). Tutte le Applicazioni realizzate in VisualBasic.NET, C#, J# e tutti gli altri linguaggi supportati dal Framework, saranno automaticamente convertite in MSIL prima di essere eseguite dal Sistema. Lo sviluppatore non è obbligato a scrivere le proprie applicazioni con un determinato linguaggio siccome sarà il Framework a creare il MSIL indipendentemente dalla scelta di sviluppo. Il vantaggio di usare un linguaggio di programmazione piuttosto che un altro sta nel fatto che i diversi linguaggi di programmazione consentono lo sviluppo mediante sintassi diverse. Ad esempio per le applicazioni matematiche e finanziarie l’utilizzo della sintassi APL piuttosto che della sintassi Perl consentirà di ridurre notevolmente il tempo necessario per lo sviluppo. Uno degli obiettivi principali del DevTeam di Microsoft, in fase di progettazione del Framework, è stato quello di ottenere alti gradi prestazioni in termini di velocità d’esecuzione e scalabilità delle applicazioni. Il CRL compila tutto il codice dell'applicazione in codice macchina nativo, questa conversione è realizzata in fase d’esecuzione dell'applicazione o durante la prima installazione; già nella prima versione del Framework era possibile notare un netto miglioramento di 3/4 volte in termini di velocità

Capitolo 2 - Introduzione al Framework .NET
22
d’esecuzione rispetto alla vecchia versione di ASP. Con le successive versioni del CLR si prevedono ulteriori miglioramenti in termini di velocità ed occupazione della memoria.
2.2 Il Common Language Runtime (CLR) Il Common Language Runtime è un ambiente d’esecuzione delle applicazioni per la piattaforma .NET, indipendente dal linguaggio di programmazione utilizzato per svilupparla. Nella figura seguente si può notare una vista dettagliata dell’intero Framework .NET evidenziando la collocazione del CLR.
Figura 2.2 - Il FrameWork .NET
Qualsiasi applicazione .NET, a prescindere dal linguaggio di programmazione, viene compilata in un linguaggio intermedio,indipendente dall’hardware, chiamato Microsoft Intermediate Language (MSIL). .NET genera un linguaggio IL Intermediate Language (a differenza del codice macchina generato dai vecchi compilatori come ad esempio VisualBasic 6).

Capitolo 2 - Introduzione al Framework .NET
23
Prima dell’effettiva esecuzione, il Common Language Runtime si occuperà della compilazione del codice intermedio nel corrispondente codice nativo tramite uno specifico compilatore (Just In Time compiler) dipendente dalla effettiva architettura hardware sottostante. E’ facile intuire che un eseguibile generato in .NET (quindi in IL) non potrà essere eseguito su sistemi che non presentano il Framework .NET installato in quanto non sarà possibile riconoscere ed interpretare l'IL. Il compilatore JIT si occupa della conversione della pagina in codice nativo solo nel momento in cui si richiede l'utilizzo di una particolare funzione del programma, convertendo solo la porzione di codice presa in considerazione; questo consente di ottimizzare il tempo di compilazione e l'occupazione in Kb del file generato. Il codice risultante da questa compilazione è chiamato managed code, per sottolineare il fatto che il runtime si occuperà di gestire la sua esecuzione prendendosi carico di tutte le operazioni necessarie: allocazione della memoria, creazione di oggetti, garbage collection, ecc. L’esistenza del Common Language Runtime pone le basi per lo sviluppo di applicazioni indipendenti dall’hardware e dal linguaggio di programmazione utilizzato. Questi aspetti hanno richiesto un esame dei linguaggi di programmazione più utilizzati sotto le piattaforme Windows in modo da ottimizzarli per la loro operatività nel .NET Framework. Da questa revisione sono nati Visual Basic.NET, C# e JScript.NET. Altri linguaggi sono in fase di revisione per il loro utilizzo nel .NET Framework. Il CLR è un Runtime unificato e comune che esegue il codice .NET compilato, è quindi in grado di trasformare codice scritto in VisualBasic.NET, C#, J#, Python, Fortran, Cobol, C++, JavaScript, Perl e molti altri ancora, per un totale di circa 30 linguaggi, in un linguaggio intermedio, il MSIL (Microsoft Intermediate Language), che in seguito sarà compilato Just in time (in tempo reale) dal Framework. Il CLR è in grado di gestire funzionalità ed eventi supportati da tutto il Framework. Con il Framework .NET è possibile utilizzare, ad esempio, una classe scritta in VisualBasic .NET da un'applicazione scritta in C#, poiché utilizzano dei tipi di dati comuni (gestiti dal Framework). Nella nuova logica introdotta da .NET, ogni applicazione deve essere considerata come un'insieme di Assembly e da un file "Assembly principale" (il file .exe) necessario per avviare l'applicazione; gli Assembly presentano il vantaggio di essere autodescrittivi in quanto contengono: codice IL, metadati con informazioni su strutture, classi... Lo schema seguente (figura 2.3) illustra le operazioni eseguite durante la fase di compilazione. Avviando il programma, viene caricato il primo Assembly, successivamente vengono caricate le Classi base di .NET; il CLR si occupa invece di controllare i tipi ed i permessi di esecuzione sulla base delle informazioni presenti nei metadati ed alle impostazioni di sicurezza del sistema.
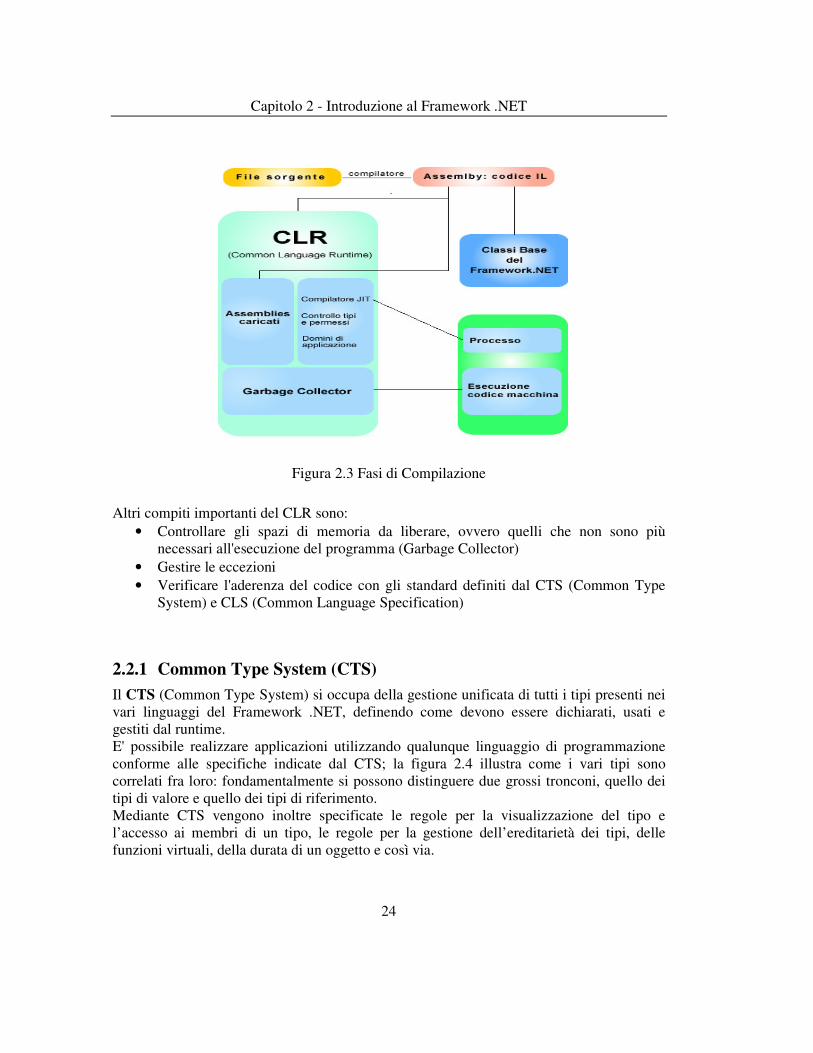
Capitolo 2 - Introduzione al Framework .NET
24
Figura 2.3 Fasi di Compilazione
Altri compiti importanti del CLR sono: • Controllare gli spazi di memoria da liberare, ovvero quelli che non sono più
necessari all'esecuzione del programma (Garbage Collector) • Gestire le eccezioni • Verificare l'aderenza del codice con gli standard definiti dal CTS (Common Type
System) e CLS (Common Language Specification)
2.2.1 Common Type System (CTS) Il CTS (Common Type System) si occupa della gestione unificata di tutti i tipi presenti nei vari linguaggi del Framework .NET, definendo come devono essere dichiarati, usati e gestiti dal runtime. E' possibile realizzare applicazioni utilizzando qualunque linguaggio di programmazione conforme alle specifiche indicate dal CTS; la figura 2.4 illustra come i vari tipi sono correlati fra loro: fondamentalmente si possono distinguere due grossi tronconi, quello dei tipi di valore e quello dei tipi di riferimento. Mediante CTS vengono inoltre specificate le regole per la visualizzazione del tipo e l’accesso ai membri di un tipo, le regole per la gestione dell’ereditarietà dei tipi, delle funzioni virtuali, della durata di un oggetto e così via.
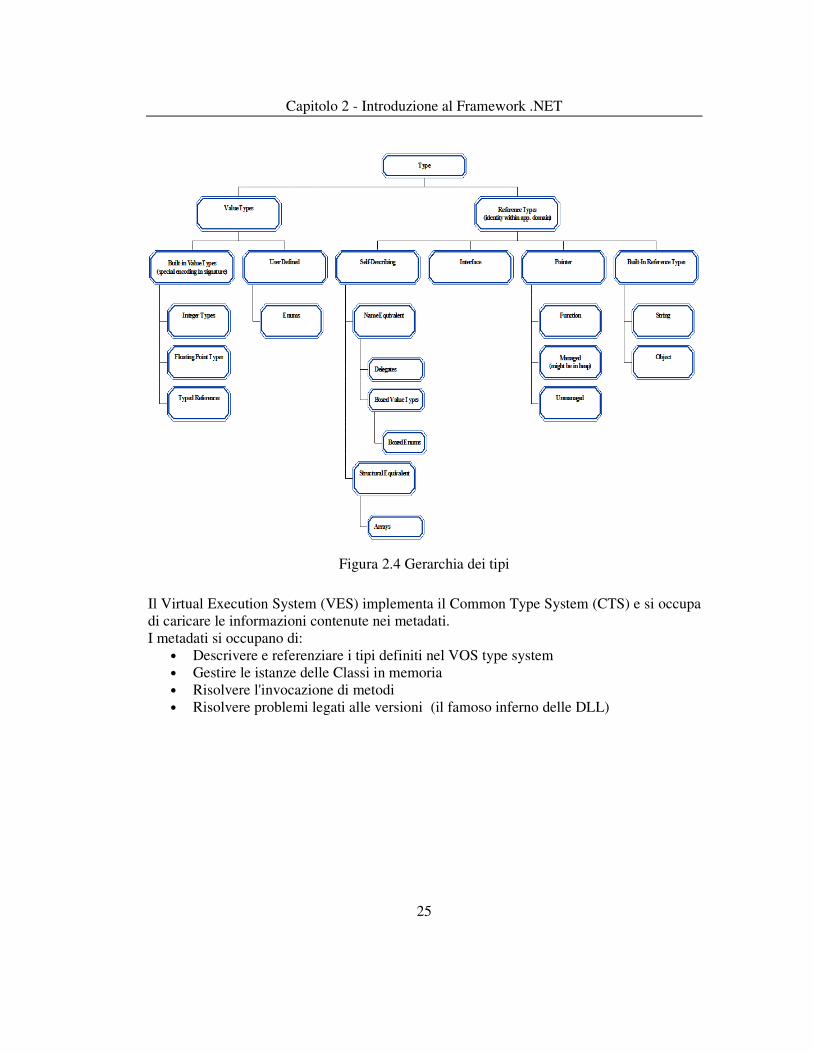
Capitolo 2 - Introduzione al Framework .NET
25
Figura 2.4 Gerarchia dei tipi
Il Virtual Execution System (VES) implementa il Common Type System (CTS) e si occupa di caricare le informazioni contenute nei metadati. I metadati si occupano di:
• Descrivere e referenziare i tipi definiti nel VOS type system • Gestire le istanze delle Classi in memoria • Risolvere l'invocazione di metodi • Risolvere problemi legati alle versioni (il famoso inferno delle DLL)

Capitolo 2 - Introduzione al Framework .NET
26
2.2.2 Microsoft Intermediate Language e il Just In Time Compiler Tutti i compilatori .NET generano lo stesso Intermediate Language (IL: linguaggio intermedio di basso livello) indipendentemente dal linguaggio utilizzato; per questo motivo l'Intermediate Language viene considerato "il linguaggio del CLR". Il compilatore Just in Time, si occupa della conversione dell'IL nel codice della piattaforma/device che eseguirà l'applicazione. In .NET esistono 3 tipi di compilazioni Just in Time:
• Pre - JIT (Compila l’intero codice in formato nativo in un colpo solo) • Ecno - JIT (Compila le singole parti di codice quando necessario) • Normal - JIT (Compila solo la parte di codice quando viene chiamata e messa in
cache) Come è facile intuire è possibile, anche se non propriamente consigliabile, scrivere applicazioni utilizzando direttamente IL. Nell'IL qualunque istruzione che inizia con "." è una direttiva dell'assembler, per eseguire una determinata operazione. Ecco alcune delle più importanti direttive ed istruzioni dell'IL:
• .assembly : Name of the deployment unit • .class : Creates a class • .method : Creates a method • .entrypoint : Shows the compiler the entry point into the program • .module : It could be either .exe file or .dll • .ctor : Constructor of a class • .hash : Algorithm used for hashing • .ver : Major.minor.build.revision number • ret : Return from function • call : Calls a function • hidebysig : In derived class we can't have two methods with the same signature • specialname : To tell that the function is special • auto : Layout memory to be decided at runtime • extends : To inherit from base class • mscorlib : Microsoft core library • ldstr : Loads a string on the stack
Utilizzando queste istruzioni e direttive è possibile scrivere qualunque applicazione, basterà semplicemente salvare i files con l'estensione .IL ed utilizzare il comando ILASM.EXE del Framework .NET.

Capitolo 2 - Introduzione al Framework .NET
27
Vediamo un semplice esempio: Codice scritto in C#:
using System; class HelloCsharp { public static void Main() { Console.WriteLine("Ciao mondo"); } }
Lo stesso esempio scritto in VisualBasic.NET:
' Esempio di codice scritto in Visual Basic.NET imports System public Module ALL public sub main() Console.WriteLine("Ciao mondo") end sub end Module
Lo stesso codice scritto direttamente in Intermediate Language:
Esempio di codice scritto in IL .assembly snrao{} .class public snr { .method public hidebysig static void surapaneni() cil managed { .entrypoint ldstr " Ciao mondo" call void[mscorlib] [m1] System.Console::WriteLine(class System.String) ret } .method public hidebysig specialname rtspecialname instance void .ctor() il managed { call instance void[mscorlib]System.Object::.ctor() ret } }

Capitolo 2 - Introduzione al Framework .NET
28
2.2.3 Caricamento di Common Language Runtime Gli eseguibili di Microsoft .NET sono diversi dai vecchi eseguibili Windows poiché non trasportano solo codice e dati, ma anche metadati. Quando si genera un Assembly EXE, il compilatore/linker creerà alcune informazioni speciali nell’intestazione del file PE dell’assembly e nella sezione .text del file. Quando il file EXE viene richiamato, mediante queste informazioni verrà caricato e inizializzato CLR. In seguito, CLR individua il metodo del punto di ingresso dell’applicazione e consente l’esecuzione di questa ultima. Adesso approfondirò meglio i concetti di PE files, Assembly e dei Metadati.
2.2.3.1 .NET Portable Executable File Un eseguibile Windows, sia esso un EXE o una libreria DLL, deve essere conforme al formato dei file PE, che è derivato dal Microsoft Common Object File Format (COFF). Il sistema operativo Windows sa come caricare ed eseguire le DLL e gli eseguibili perché comprende il formato dei file PE. I files Windows PE standard sono divisi in due sezioni principali. La prima include gli headers PE/COFF che puntano al contenuto all’interno del file PE. In aggiunta alla sezione degli headers, il file PE possiede un certo numero di sezioni native, incluse le sezioni .data, .rdata, .rsrc , e .text. Queste sono le sezioni tipiche di un eseguibile Windows, ma i compilatori Microsoft C/C++ permettono l’aggiunta di proprie sezioni all’interno del PE file. Ad esempio si può creare la propria sezione per mantenere dei dati criptati. Come si può notare nella figura 2.5, mentre il CLR header detiene le informazione che indicano che il PE file è un eseguibile .NET, la CLR data section contiene i metadati e il codice IL, che determinano come il programma sarà eseguito.
Figura 2.5 – Portable Executable File

Capitolo 2 - Introduzione al Framework .NET
29
2.2.3.2 Metadati Un metadato è una informazione machine-readable su una risorsa o un dato che descrive un’altro dato; queste informazioni possono includere dettagli sul contesto, sul formato,dimensione o altre caratteristiche della sorgente dati. In .NET i metadati racchiudono la definizione dei tipi, informazioni sulla versione, references ad assembly esterni e altre informazioni standard. Sfruttando questa caratteristica Microsoft ha aggiunto qualche nuova sezione al normale PE in modo da supportare le funzionalità di CLR. Ad esempio, il CLR leggerà queste sezione per determinare come caricare le classi ed eseguire il codice a runtime. Per stabilire quali tipi supporta un assembly .NET, si usa un gruppo di classi che permettono di avere una facile interfaccia per esaminare e manipolare i metadati. Queste classi in .NET sono dette Reflection API e includono le classi degli spazi dei nomi System.Reflection e System.Reflection.Emit.
2.2.3.3 Assembly e Manifesto Un assembly consiste in un insieme di uno o più file contenenti definizioni di tipi e file di risorse. Uno dei file dell’assembly viene scelto per contenere un manifesto. Il manifesto è un altro insieme di tabelle di metadati che di base contiene il nome dei file che fanno parte dell’assembly. Questi ultimi, inoltre, descrivono la versione, la lingua, l’editore, i tipi esportati dell’assembly e tutti i file che costruiscono l’assembly. Il manifesto può essere memorizzato sia in un PE file contenente più file e il manifesto o, in alternativa, è possibile creare un file PE separato contenente soltanto il manifesto (figura 2.6). CLR carica sempre per primo il file contenente le tabelle di metadati del manifesto, quindi utilizza il manifesto per ottenere i nomi degli altri file nell’assembly.
Figura 2.6 – Gli Assembly

Capitolo 2 - Introduzione al Framework .NET
30
In breve, un assembly consiste in un’unità di riutilizzo, controllo delle versioni e protezione. L’assembly consente di partizionare i tipi e le risorse in file separati in modo tale che si possa stabilire quali file inserire nel package e distribuire. Una volta caricato il file contenente il manifesto, CLR consente di stabilire quali file dell’assembly contengono i tipi e le risorse a cui fa riferimento l’applicazione.
2.3 Framework Class Library Il .NET Framework prevede una libreria di classi predefinite (Framework Class Library) che fornisce un unico modello di programmazione indipendente dal linguaggio utilizzato. Questa libreria di classi sostituisce funzionalmente l’insieme delle API e dei servizi COM forniti dalle piattaforme Win32 e definisce centinaia di classi organizzate gerarchicamente in namespace. L’uso dei namespace può essere considerato come un meccanismo per organizzare le classi previste dal sistema. I namespace sono analoghi a librerie di classi con funzionalità omogenee. Le funzionalità implementate da queste classi sono diverse: dalla gestione dell’I/O all’accesso ai dati, dalla gestione della sicurezza al supporto dell’interfaccia grafica. L’operatore fondamentale di questa sintassi è il punto (.) che separa i vari namespace secondo il seguente schema: namespace1.namespace2.namespace3 Per esempio, le classi che consentono l’accesso a SQL Server sono contenute nel namespace System.Data.SQL. Poiché FCL contiene migliaia di tipi, allo sviluppatore viene presentato un insieme di tipi correlati all’interno di uno spazio di nomi singolo, il namespace System, che contiene il tipo di base Object da cui derivano tutti gli altri tipi. Inoltre lo spazio dei nomi System contiene tipi per valori interi, caratteri, stringhe, gestione delle eccezioni e I/O di console oltre a un insieme di utilità che consentono la conversione sicura tra i tipi di dato, la formattazione dei tipi di dati, la generazione di numeri casuali e altre funzioni matematiche. Per personalizzare il comportamento dei tipi è possibile ricavare semplicemente il proprio tipo dal tipo FCL desiderato.
2.4 Data Services Nell’architettura del .NET Framework il supporto per l’accesso ai dati è fornito da ADO.NET, l’evoluzione naturale della tecnologia Active Data Objects. ADO.NET è implementato nel .NET Framework da uno dei namespace della Base Class Library, precisamente da System.Data, e fornisce un supporto potenziato per la gestione di ambienti di dati disconnessi e una maggiore integrazione con XML rispetto al suo predecessore ADO. Mentre ADO era stato progettato per supportare la gestione di dati in ambiente client/server tradizionale, ADO.NET è stato pensato ed ottimizzato per fornire supporto alla gestione di dati sul web.

Capitolo 2 - Introduzione al Framework .NET
31
2.5 User Interface Services Il .NET Framework fornisce un supporto unificato per l’implementazione delle interfacce utente per le proprie applicazioni. Tale supporto è unico ed è indipendente dal linguaggio di programmazione utilizzato. L’unica distinzione che viene fatta nell’ambito delle interfacce utente riguarda il tipo di piattaforma di riferimento: applicazioni Windows o applicazioni Web. Nel caso di applicazioni Windows, è necessario utilizzare il namespace System.WinForms. Esso fornisce un supporto di creazione rapida delle interfacce grafiche e, grazie al supporto dell’ereditarietà, la possibilità di creare elementi personalizzati. Le interfacce per il Web si basano sul namespace System.Web.UI che costituisce il supporto per le cosiddette Web Forms. Le Web Forms forniscono un semplice e potente meccanismo per costruire interfacce web dinamiche e compatibili con gli standard HTML, quindi senza richiedere nessun supporto particolare ai browser.
2.6 Web Services I Web Services forniscono il supporto per la realizzazione di applicazioni web distribuite utilizzando XML per la descrizione dei dati e HTTP come protocollo di comunicazione. A differenza delle applicazioni ASP o ASP.NET, che restituiscono codice HTML come risultato dell’elaborazione server side e quindi presuppongono l’interazione con un essere umano, i Web Services restituiscono informazioni leggibili da una macchina (tipicamente XML). All’interno del .NET Framework, i Web Services sono implementati dal namespace System.Web.Service

32
Capitolo 3 La Programmazione distribuita
3.1 Introduzione La parola “architettura” oramai è una buzzword, una delle definizioni che si possono trovare su Internet è: “the structure of the pieces that make up a complete sw installation, including the responsibilities of these pieces, their interconnection, and possible the appropriate technology”. In questi ultimi anni è diventato fondamentale soddisfare alcuni requisiti durante la progettazione dell’architettura logica di un’applicazione Business-oriented. Perciò si deve identificare quali caratteristiche sono prioritarie, per guidare le decisioni di progetto sin dalle fasi iniziali. Il contesto in cui ci troviamo è quello di una complessa enterprise application, composta da un elevato numero di elementi a diversi livelli di astrazione. Come si può progettare l’architettura logica dell’applicazione per garantire che sia mantenibile, scalabile, riutilizzabile, robusta e sicura? L’architettura logica utilizzata nel nostro progetto è l’architettura a tre livelli ( three-tiered architecture); questa architettura garantisce tutti i requisiti a cui ho accennato all’inizio del capitolo. Il mio obiettivo in questo capitolo è quello di fornire una panoramica generale sulla programmazione distribuita ponendo l’enfasi su quali caratteristiche deve soddisfare una piattaforma per poter sviluppare applicazioni distribuite, su quali sono i componenti che la compongono e quali i servizi che deve fornire. Nel prossimo capitolo, invece, sono entrato nel dettaglio di quella che è l’architettura del mio progetto.

Capitolo 3 - La Programmazione distribuita
33
3.2 I componenti in una architettura distribuita Un componente software è una parte di codice che implementa un insieme di interfacce ben definite. Sviluppare “a componenti” significa scomporre il problema in tanti sottoproblemi e successivamente affrontarli tutti in modo indipendente dagli altri. Ogni componente presenterà un’interfaccia che permetterà la comunicazione con il resto del mondo e potrà essere sostituito in qualsiasi momento cambiandone anche radicalmente la logica d’esecuzione ma lasciandone inalterata l’interfaccia; per cui, dati i vari componenti, si risolverà un problema combinando gli stessi in modo opportuno come pezzi di un puzzle. Lo sviluppo di un applicativo a componenti permette di poter usare il paradigma “divide-et-impera”; vi saranno pertanto delle figure che si occuperanno dello sviluppo dei componenti e quindi solo della logica del problema specifico, senza preoccuparsi della gestione della sicurezza delle risorse o della comunicazione tra le parti. Inoltre vi saranno altri soggetti che si occuperanno dei server capaci di poter gestire e istanziare i componenti e poi ci sarà qualcuno che provvederà a fornire gli applicativi per colloquiare con i componenti stessi dal lato client.
3.3 Caratteristiche di un sistema distribuito Intuitivamente, un sistema distribuito è costituito da componenti che possono essere eseguiti su computer differenti e che devono poter interagire con tutti gli altri oggetti che compongono l’applicazione. Una piattaforma di sviluppo, per poter essere considerata un sistema distribuito, deve soddisfare le seguenti caratteristiche non funzionali, non legate cioè alla singola applicazione:
• Scalabilità (Scalability) • Apertura (Openess) • Eterogeneità (Heterogeneity) • Accesso e condivisione delle risorse • Resistenza ai guasti (Fault-tolerance)
Di seguito si descriveranno nel dettaglio queste caratteristiche.
3.3.1 Scalabilità Nella progettazione di una architettura software è molto importante determinare il carico di lavoro a cui sarà sottoposta. Una stima troppo ottimista potrebbe portare allo sviluppo di software non in grado di rispondere alle richieste, mentre un stima troppo pessimista potrebbe tradursi in un inutile spreco di risorse. Per un sistema software, il carico può essere definito come il numero di transazioni che il sistema deve essere in grado di eseguire in un dato periodo. In una banca ad esempio ci

Capitolo 3 - La Programmazione distribuita
34
possono essere fino a due milioni di transazioni al giorno e ci si aspetta che il sistema sia in grado di rispondere in modo adeguato a tale richiesta. Se ad esempio un impiegato della banca deve aspettare più di 2 minuti per la fine della transazione allora si può dire che il sistema riesce a far fronte al carico ma che comunque la qualità del servizio è bassa che si traduce in una sbagliata stima del carico del sistema e quindi in una sbagliata progettazione dello stesso. Invece nel contesto del nostro applicativo Anagrafica Programmi il numero di transazione è di qualche ordine di grandezza più piccolo. Una architettura software quindi deve essere progettata in modo da essere stabile per l’intero tempo di vita del sistema, quindi deve essere in grado di far fronte al carico quando si va in produzione in base a stime fatte in fase di sviluppo, cosa che però è molto difficile. Si pensi soltanto al fenomeno Internet dove non ci si poteva aspettare che il numero di nodi connessi alla rete arrivasse a quello attuale, e il successo di Internet bisogna ricercarlo proprio nel fatto che il sistema è stato in grado di adeguarsi all’aumentare del carico e questo perché la sua architettura è una architettura molto scalabile. Quindi in generale possiamo dire che una architettura è scalabile se è in grado di far fronte ad aumenti di carico del sistema previsti od imprevisti. Per rendere un sistema scalabile è necessario ricorrere ad una architettura distribuita. In questo modo ad un aumento del carico si può rispondere ad esempio aumentando le macchine e i componenti software del sistema.
3.3.2 Apertura Un sistema si dice aperto se può essere facilmente esteso e modificato. Per fare questo un sistema deve avere delle interfacce chiare e documentate. La costruzione del sistema quindi si deve appoggiare a degli standard in modo da rendere i componenti sviluppati interscambiabili svincolando lo sviluppo dell’applicazione da un particolare vendor. L’apertura è richiesta anche nel caso in cui si abbia bisogno di cambi funzionali, chi commissiona il software vuole garantito che il suo investimento sia preservato anche in caso di modifiche al sistema o nuove aggiunte funzionali o integrazioni con altri componenti già esistenti, senza dover di nuovo ricominciare da capo. L’integrazione ad esempio significa che bisogna riuscire a far comunicare tutti i componenti software dell’applicazione con componenti già esistenti, per questo è necessario avvalersi di ben definite interfacce in modo da rendere la comunicazione tra i componenti conforme ad uno standard comune a tutti. Una interfaccia dichiara i servizi che un componente offre. I servizi sono le operazioni che un componente è in grado di eseguire. Un client può, quindi, grazie alle interfacce richiedere l’esecuzione di una operazione ad un componente (server component) il quale a sua volta può richiamare altre operazioni su altri componenti di cui lui sarà il client.

Capitolo 3 - La Programmazione distribuita
35
Da quello che si è detto è facile intuire che esiste una stretta relazione tra il concetto di distribuzione dei componenti e il concetto di apertura. I componenti di un sistema distribuito, infatti, devono dichiarare i servizi che offrono a tutti gli altri componenti che li devono utilizzare. Una richiesta di un servizio può essere eseguita da un componente che si trova su un’altra macchina e la richiesta può essere eseguita in modo sincrono oppure asincrono.
3.3.3 Eterogeneità Un’altra caratteristica che è spesso richiesta per i nuovi sistemi è che possano integrare componenti eterogenei. L’eterogeneità è necessaria per diverse ragioni. I componenti possono essere delle applicazioni legacy già esistenti che bisogna mantenere, oppure possono essere sviluppati da diversi costruttori e in diverse tecnologie. I componenti possono essere tra loro eterogenei perché utilizzano tecnologie di implementazione dei sevizi differenti (un componente scritto in C++ e uno in JAVA), perché gestiscono i dati in maniera differente (Codifica LSB oppure MSB) o perché sono eseguiti su diverse piattaforme hardware. Per integrare componenti eterogenei bisogna sviluppare dei sistemi distribuiti in modo da poter disaccoppiare differenti linguaggi di programmazione, differenti supporti hardware e differenti tipi di comunicazione.
3.3.4 Accesso e condivisione delle risorse Per risorse si intendono risorse hardware, software e di dati. La condivisione delle risorse è spesso richiesta per rendere più veloce e performante l’accesso alle funzionalità del sistema. Ad esempio un database rappresenta una risorsa essenziale all’interno dello sviluppo di una applicazione distribuita diventa indispensabile per la comunicazione e la cooperazione tra gli utenti. Condividere risorse però porta con se diverse problematiche relative alla sicurezza degli accessi, quindi bisogna tener conto che bisogna utilizzare un meccanismo di accesso controllato quindi il sistema deve essere in grado di filtrare le richieste di accesso e di controllarne la pertinenza.
3.3.5 Tolleranza ai guasti Sia componenti hardware che software che componenti che compongono la rete sono soggetti a guasti. I problemi possono essere dovuti a errori software, o a guasti hardware o a usura ecc. Una importante caratteristica non funzionale che è spesso richiesta dal sistema è quindi la tolleranza ai guasti, cioè che il sistema continui a funzionare anche in presenza di guasti. Un sistema distribuito può essere considerato più tollerante ai guasti rispetto ad un sistema centralizzato grazie alla possibilità di avere componenti ridondanti. Un sistema distribuito

Capitolo 3 - La Programmazione distribuita
36
può essere quindi costruito in modo da continuare ad operare in presenza di guasti su alcuni dei suoi componenti individuando il guasto e sostituendo il componente difettoso con un suo clone presente nel sistema.
3.3.6 Trasparenza in un sistema distribuito Progettare un sistema distribuito che rispetti tutte le funzionalità richieste è abbastanza complicato soprattutto perché per l’utente deve sembrare un singolo sistema integrato, cioè il fatto che il sistema sia composto da componenti distribuiti dovrebbe essere trasparente per l’utente. Inoltre nascondere la complessità del sistema distribuito allo sviluppatore stesso ingegnerizzando il più possibile l’architettura che permette la comunicazione tra le parti è praticamente necessario, perché, in questo modo, eseguire le ordinarie manutenzioni e costruire nuove funzionalità non richiede uno sforzo aggiuntivo per la complessità introdotta dalla distribuzione. Esistono diversi criteri di trasparenza che saranno discussi brevemente in seguito essi sono:
• Trasparenza agli accessi • Trasparenza alla locazione • Trasparenza alla migrazione dei componenti • Trasparenza alle repliche • Trasparenza alla concorrenza • Trasparenza alla scalabilità • Trasparenza alle prestazioni • Trasparenza ai guasti
3.3.7 Trasparenza agli accessi La trasparenza degli accessi è una importante caratteristica di un sistema distribuito. Un componente che non ha un accesso trasparente non può essere spostato da un host ad un altro senza dover modificare il codice di tutti gli altri componenti che ne fanno uso. La trasparenza degli accessi permette di mantenere la stessa interfaccia per chiamare i servizi di un componente indipendentemente dalla posizione fisica del componente su una macchina host piuttosto che su un’altra. Per fare un esempio si pensi ad un componente che viene spostato da una macchina con sistema operativo Windows ad una con UNIX. La trasparenza agli accessi assicura che il client potrà accedere agli stessi servizi sul componente spostato senza dover tener conto del diverso sistema operativo.
3.3.8 Trasparenza alla locazione Per fornire un servizio, un dato componente deve essere in grado di indirizzare altri componenti. Per fare ciò deve poter identificare il componente in grado di erogare il

Capitolo 3 - La Programmazione distribuita
37
servizio richiesto. La trasparenza alla locazione è quella caratteristica che permette di identificare il componente richiesto senza conoscerne la sua ubicazione fisica.
3.3.9 Trasparenza alla migrazione dei componenti A volte è necessario dover muovere un componente da un host ad un altro. La trasparenza alla migrazione permette di rilocare il componente senza dover notificare l’azione ai client software e agli utenti. Questa caratteristica è fortemente correlata con la trasparenza alla locazione e con la trasparenza degli accessi, anche se il suo dominio di pertinenza è più rivolto verso componenti di gestione dati. In questa ottica si ha trasparenza alla migrazione quando dei dati vengono spostati da un host ad un altro e il client riesce ad accedervi nello stesso modo di prima.
3.3.10 Trasparenza alle repliche E’ abbastanza vantaggioso mantenere più istanze dello stesso componente su host diversi. L’assunto di base è però che le diverse istanze dovendo fornire lo stesso tipo di servizio, devono necessariamente preservare in ogni momento lo stesso stato, quindi, devono essere sempre sincronizzate tra di loro. Attraverso questo sistema di replica è possibile sia aumentare le performance dell’intero sistema rendendo il tutto scalabile, sia aumentarne la robustezza. Le varie repliche naturalmente devono essere trasparenti al client che non deve tener conto che il componente può essere replicato. Anche questa caratteristica è fortemente dipendente dalla trasparenza alla locazione e agli accessi. Senza un sistema di repliche si può andare in contro ad una architettura poco scalabile e sensibile ai guasti.
3.3.11 Trasparenza alla concorrenza In un sistema distribuito diversi componenti, anche dello stesso tipo, possono essere attivi contemporaneamente nello stesso istante. Si ha trasparenza alla concorrenza quando diversi componenti possono contemporaneamente richiedere servizi ad un componente condiviso preservando l’integrità del componente condiviso senza che il client sappia come la concorrenza sia controllata.
3.3.12 Trasparenza alla scalabilità Una delle ragioni per cui un sistema distribuito è preferibile ad uno centralizzato consiste nel fatto che un sistema distribuito è scalabile.

Capitolo 3 - La Programmazione distribuita
38
La scalabilità è un’altra caratteristica che deve essere trasparente sia agli sviluppatori che agli utenti. La trasparenza alla scalabilità tiene traccia del comportamento del sistema nel suo complesso quando più richieste concorrenti sono eseguite e in modo attivo cerca di mantenere invariata una data qualità del servizio. L’esempio più calzante per spiegare la trasparenza alla scalabilità è data dalla rete Internet. Anche se questa aumenta di dimensione giornalmente e il traffico di rete aumenta in proporzione, non si hanno degradi di prestazione.
3.3.13 Trasparenza alle prestazioni La trasparenza alle prestazioni si ha quando è trasparente sia all’utente che all’applicazione il modo in cui le performance del sistema sono ottenute. Con performance si intende il grado di efficienza con cui il sistema utilizza le risorse a sua disposizione. Ad esempio tecniche come il load-balancing sono utilizzate per migliorare le performance in modo trasparente. In questo modo è il middleware che decide come bilanciare il carico in modo del tutto trasparente sia all’utente che al componete.
3.3.14 Trasparenza ai guasti In un sistema distribuito la probabilità di guasti è elevata. La trasparenza ai guasti è quella caratteristica che svincola sia i client che i server dal doversi effettivamente preoccupare della gestione applicativa di eventuali guasti.
3.4 Architetture distribuite multilivello La caratteristica principale delle architetture distribuite è quella di poter supportare l'esecuzione sicura ed efficace di operazioni simultanee di utenti concorrenti. Costruire oggetti robusti di questo tipo non è sicuramente un compito facile dal momento che vanno affrontati aspetti come scalabilità, sicurezza, tolleranza ai guasti e molti altri ancora. Qualsiasi architettura distribuita prevede una partizione logica delle applicazioni in livelli, ognuno con differenti responsabilità. Un sistema strutturato a livelli indipendenti è progettato in modo appropriato dal momento che ogni livello è responsabile di un lavoro separato. Una partizione logica molto tipica, soprattutto nelle moderne applicazioni commerciali della rete, prevede tre livelli logici:
1. Livello presentazione: contiene componenti responsabili dell'interfaccia verso l'utente e dell’iterazione con lo stesso.
2. Livello della logica business: contiene componenti che costituiscono la logica e il motore dell’applicativo per la risoluzione dei problemi.

Capitolo 3 - La Programmazione distribuita
39
3. Livello dati: usato dalla logica del business per mantenere uno stato in modo permanente.
Il vantaggio principale di dividere logicamente un applicativo in questo modo è appunto quello di isolare tra loro i vari livelli in modo da rendere possibili modifiche di uno di essi senza avere il minimo impatto sugli altri, per esempio modificare la logica dell'applicativo senza doversi preoccupare di modificare la sua interfaccia utente. In un'architettura server "two-tier", solo due di questi livelli logici sono separati fisicamente dall’altro, mentre un'architettura server "N-tier" separa ognuno dei tre livelli astratti e logici dell'applicazione in tre livelli fisici separati. Vediamo brevemente le caratteristiche delle due architetture elencandone vantaggi e svantaggi in modo da capire come la seconda soluzione risulta essere migliore rispetto la prima.
3.4.1 Architetture Two-Tier Quest’architettura combina la logica dell'applicazione con uno dei due livelli rimanenti in due combinazioni possibili. La prima soluzione combina il livello presentazione con la logica dell'applicativo separandoli dal sottostante livello dati da cui prelevano le informazioni di cui hanno bisogno (secondo un approccio client- server). Il primo livello comunica con il sottostante attraverso delle API di programmazione che fungono da ponte tra l'applicazione e il Data Base sottostante, quali Open Data Base Connectivity o Java Data Base Connectivity in modo da rendere l'applicativo staccato dal particolare Data Base Management System utilizzato. Questa soluzione ha tuttavia notevoli lati negativi. Primo fra tutti essa richiede che i driver del particolare Data Base utilizzato siano contenuti nell'applicativo, questo comporta alti costi sia di installazione (deployment) dello stesso sia di aggiornamento nel caso di cambiamento del Data Base utilizzato o di una nuova versione dei driver. Dal momento che i componenti della logica sono installati nell’applicazione una modifica della stessa costringe una nuova compilazione e quindi una installazione della stessa. Ogni applicazione ha inoltre la necessità di aprire e mantenere una connessione propria verso la base di dati, anche nei momenti di non utilizzo della stessa e, dato che queste ultime sono limitate in numero, ciò limita fortemente la scalabilità dell'applicativo. Ogni volta che i componenti della logica effettuano un'istruzione al Data Base ciò comporta un numero di operazioni lungo la frontiera fisica dei due livelli. Se quest'ultima è costituita da una rete, ciò fa soffrire molto le sue performance tecnologiche. La seconda soluzione prevede invece di posizionare tutta o parte della logica nel Data Base utilizzando le cosiddette "stored procedure", dei veri e propri programmi memorizzati all'interno del Data Base ed eseguiti su esplicita richiesta del client. Questa soluzione, che poi è quella che abbiamo scelto, non solo diminuisce il volume di

Capitolo 3 - La Programmazione distribuita
40
traffico della rete dalla logica al Data Base, ma anche la velocità di esecuzione delle stesse query. L’aspetto negativo di questa soluzione è il fatto di non poter sviluppare dei componenti della logica portabili, dato che si utilizzano delle procedure scritte spesso in linguaggi proprietari dei produttori di DBMS.
3.4.2 Architetture N-Tier Un’architettura N-tier aggiunge uno o più livelli all'architettura precedente. Un esempio concreto di tale architettura è quello che prevede tre livelli:
• Livello presentazione(Web Tier): Eseguito nel contesto di un web server e consistente in Servlet o script lato server (come ASP.NET o JSP).
• Livello della logica Business: Eseguito nel contesto di un Application Server, necessario per fornire un ambiente di esecuzione nel quale far eseguire i componenti della logica del Business.
• Livello Data: Consistente in uno o più Data Base. Un’architettura a N livelli possiede molte caratteristiche positive:
• Basso costo del deployment delle applicazioni: i driver dei DBMS sono installati e configurati sul lato server e non sul lato client. Questo permette non solo la riduzione dei costi di installazione e configurazione del software, dal momento che avviene solamente dal lato server ma anche, dato che i client non accedono direttamente al Data Base, la riduzione dei costi di aggiornamento di quest'ultimi.
• Basso costo di migrazione delle logica del Business: cambiare la logica Business dei componenti non significa necessariamente compilare nuovamente e reinstallare il livello client.
• Possibilità di utilizzo di firewall per proteggere parte delle applicazioni. • Le risorse possono essere efficacemente condivise e riutilizzate tra i vari
componenti (pooling delle risorse). • Ogni livello è indipendente dall’altro. Ciò permette di localizzare più facilmente a
che livello le performance sono minime e facilita la localizzazione di eventuali errori.
Tuttavia essa presenta anche aspetti negativi come il sovraccarico di lavoro per la comunicazione tra i livelli logici. Dal momento che i tre livelli sono fisicamente separati, essi devono comunicare attraverso processi, domini o dispositivi che rappresentano appunto il confine fisico tra questi.

41
Capitolo 4 L’Architettura di Anagrafica Programmi
4.1 Dettaglio sulla Three-tiered Architecture di Anagrafica Programmi
Figura 4.1 Architettura a tre livelli (generale)
L’architettura a tre livelli garantisce una netta separazione tre le funzioni dell’applicazione. Ecco un’altra immagine che mostra con maggior chiarezza le funzionalità dei vari livelli:
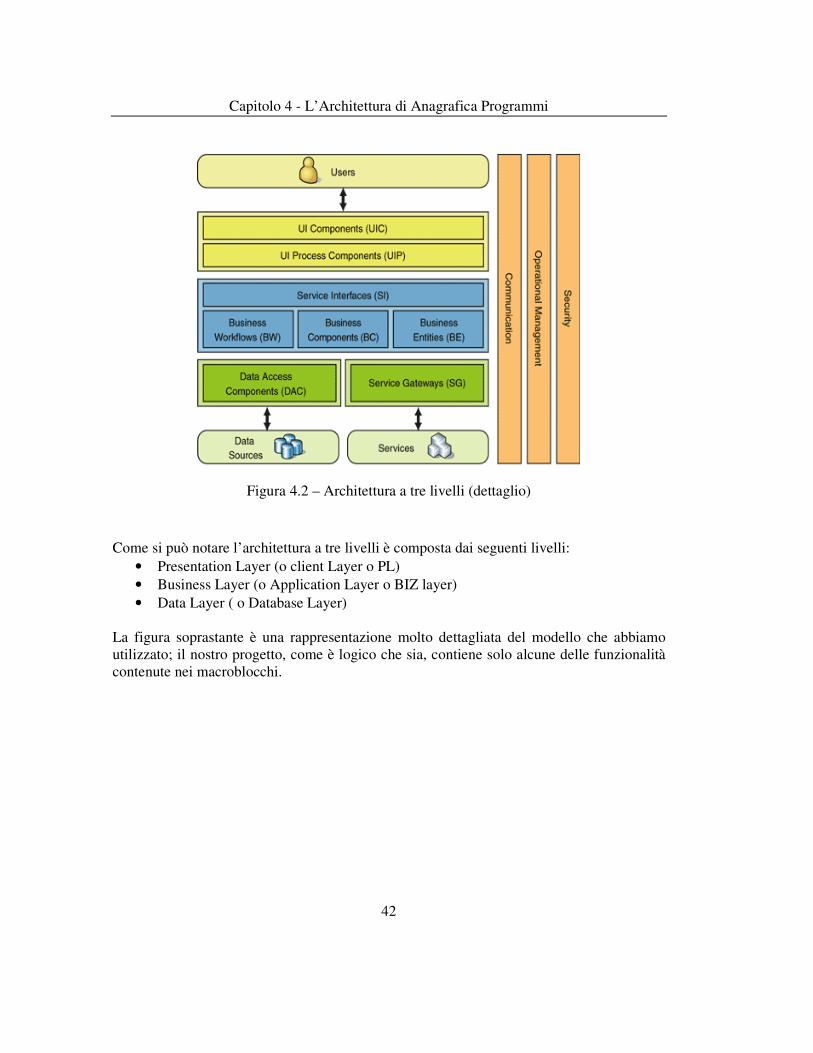
Capitolo 4 - L’Architettura di Anagrafica Programmi
42
Figura 4.2 – Architettura a tre livelli (dettaglio)
Come si può notare l’architettura a tre livelli è composta dai seguenti livelli:
• Presentation Layer (o client Layer o PL) • Business Layer (o Application Layer o BIZ layer) • Data Layer ( o Database Layer)
La figura soprastante è una rappresentazione molto dettagliata del modello che abbiamo utilizzato; il nostro progetto, come è logico che sia, contiene solo alcune delle funzionalità contenute nei macroblocchi.
Capitolo 4 - L’Architettura di Anagrafica Programmi
43
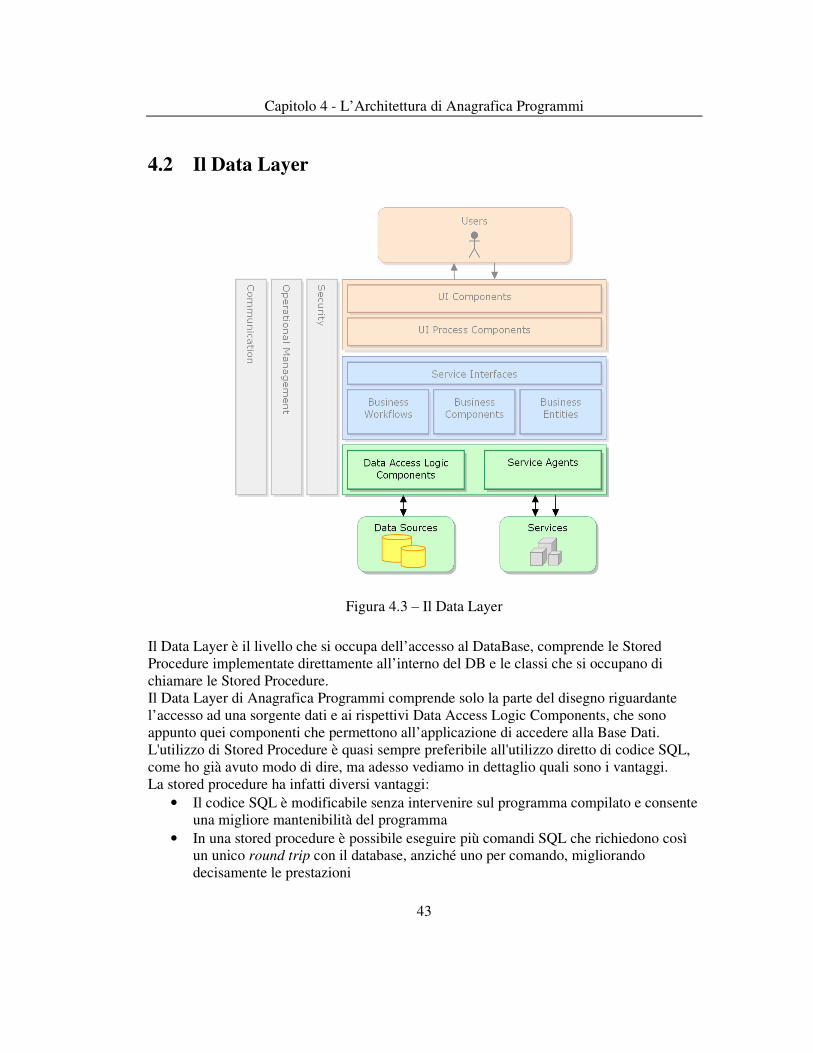
4.2 Il Data Layer
Figura 4.3 – Il Data Layer
Il Data Layer è il livello che si occupa dell’accesso al DataBase, comprende le Stored Procedure implementate direttamente all’interno del DB e le classi che si occupano di chiamare le Stored Procedure. Il Data Layer di Anagrafica Programmi comprende solo la parte del disegno riguardante l’accesso ad una sorgente dati e ai rispettivi Data Access Logic Components, che sono appunto quei componenti che permettono all’applicazione di accedere alla Base Dati. L'utilizzo di Stored Procedure è quasi sempre preferibile all'utilizzo diretto di codice SQL, come ho già avuto modo di dire, ma adesso vediamo in dettaglio quali sono i vantaggi. La stored procedure ha infatti diversi vantaggi:
• Il codice SQL è modificabile senza intervenire sul programma compilato e consente una migliore mantenibilità del programma
• In una stored procedure è possibile eseguire più comandi SQL che richiedono così un unico round trip con il database, anziché uno per comando, migliorando decisamente le prestazioni

Capitolo 4 - L’Architettura di Anagrafica Programmi
44
• Nelle stored procedures il codice è generalmente precompilato e questo migliora la performance
• E' possibile gestire la sicurezza a livello di stored procedure rendendo il Database più sicuro.
Ognuna di queste classi segue il modello Object Oriented ed è il risultato di un’astrazione su una tabella del DB. Queste classi si occuperanno di gestire tutte le richieste di accesso alla Base di Dati dando così una protezione ai dati dell’applicazione. Le classi del Data Layer iniziano nel nostro progetto col prefisso “Dat”, ad indicare che si trattano delle classi del Data Layer. Tutte le richieste che passeranno da questo livello saranno gestite attraverso transazioni distribuite. Attraverso il Data Layer si potrà perciò garantire che nessun altro riuscirà ad accedere alla Base di Dati, garantendo perciò l’integrità dei dati. Inoltre se il DataBase cambia per qualsiasi ragioni sarà più facile andare a modificare il Data Layer, senza che queste modifiche si ripercuotano sugli altri livelli.
���������
������������������� ����
���������������������������� ���������������������������������������������������������� ����!����������"����#�� �����������$%&#�� ����������������!��� ����������'�������� �����
��������� �
�����'�������������������� ������������� ������������� �'������������������ �'������������������� �'������������������ �'���� �%������������ �'���� ������
�����������
�������!!� ������������� �����������(�����!!� ������
�������� ���
��������������������������������������!��������� (�#��������� �������#����������������������)*��#����������� �" �+#�������
���������
������ ������������������������� ������������� ��������� ������� ���#���������� ������ ���#�������
��������
���������������������������� ������������� ������
���������� �
Figura 4.4 Gerarchia delle Classi del Data Layer

Capitolo 4 - L’Architettura di Anagrafica Programmi
45
Come si può notare dal Class Diagram soprastante tutte le classi del Data Layer ereditano dalla classe DataLayer, la quale contiene tutti i metodi comuni per l’accesso al DB, in particolare questa classe contiene il metodo executeTransactionalQuery che si occupa di richiamare la logica per la gestione delle transazioni distribuite. Altri metodi importanti nella logica del Data Layer sono i metodi createOleDbParameter che si occupano delle creazione dei parametri da passare alla libreria che gestisce le transazioni distribuite per quanto riguarda le operazioni sul DB legacy.
DB2 Adapter
VSAM Adapter
Message Queue System<<role>>
Data layer<<role>>
Host update service<<role>>
Main DBMS(from Persistenza)
<<role>>
Allineamento DB Legacy<<mechanism>>
Figura 4.5 Data Layer e allineamento DB legacy
Il Data Layer incapsula la gestione dell’allineamento, rendendo tale operazione transitoria trasparente ai layer; in particolare, è stato implementato un servizio di Host Update che provvede alla propagazione nel DB legacy di tutte le modifiche che avvengono nel database principale, tramite le interfacce di accesso rese disponibili dall’infrastruttura. L’Host Update Service garantirà la gestione delle transazioni la cui propagazione non dovesse andare a buon fine.

Capitolo 4 - L’Architettura di Anagrafica Programmi
46
Anagrafica Programmi : Data layer
SQL Server : Main DBMS
: Message Queue System : DB2 Adapter : VSAM
Adapter
: Host update service
sql statements
commit transaction
Disaccoppiati temporalmente dalla coda di messaggi.
ok: transaz. chiusa
Solo se OK
sql statements
sql statements
Figura 4.6 Time Diagram delle transazioni su SqlServer e il DB legacy
4.2.1 La rappresentazione dei dati Il miglior modo per evitare la latenza quando si inviano dei dati è di fare poche chiamate ai metodi e di passare molti dati; un modo per farlo sarebbe di passare una lunga lista di parametri, ma questo approccio è molto sensibile agli errori, poiché se si dovessero passare 10 stringhe sarebbe facile per lo sviluppatore passarle nell’ordine sbagliato. Allora conviene creare un “data transfer object” che contiene tutti i dati necessari nella chiamata al metodo. Quando i componenti che gestiscono l’accesso ai dati ( vedi capitolo che parla dell’architettura a tre livelli) devono restituire dei dati o quando devono essere passati loro, ci sono diverse strade possibili in .NET:
• Xml • DataReader • DataSet • DataSet tipizzati

Capitolo 4 - L’Architettura di Anagrafica Programmi
47
• Oggetti ad-hoc ( Business entities) che hanno un mapping con i campi della base dati che essi rappresentano
Nel progetto “Anagrafica Programmi” abbiamo deciso di rappresentare le entità logiche di accesso ai dati con degli oggetti ad-hoc, tenendo conto delle seguenti liste di vantaggi e svantaggi:
• Vantaggi � Leggibilità del codice � Incapsulamento, poiché gli oggetti di Business possono contenere
semplici metodi che implementano regole di Business elementari � Nei casi in cui si debbano modellare sistemi complessi potrebbe
essere comodo definire oggetti di Business che assorbono un po’ della complessità
� Validazione localizzata; gli oggetti creati possono contenere semplici regole di validazione per rilevare inserimenti di dati errati
� Con i campi privati si possono nascondere al chiamante le informazioni che non si ritiene opportuno esporre
• Svantaggi � Le collezioni di entità di Business vanno create � La serializzazione dell’oggetto deve essere implementata � Nella ricerca e nell’ordinamento di dati si dovrà implementare, se
necessario, l’interfaccia IComparable � Si dovrà fare il deploy su tutti i livelli dell’applicazione
dell’assembly contenente la definizione di tali oggetti di Business � Per supportare COM+ si dovrà installare l’assembly nella Global
Assembly Cache � Se lo schema del DataBase cambia, si dovranno cambiare
necessariamente gli oggetti creati
Una volta analizzati tutti i pro e i contro si è deciso di usare quest’approccio, in quanto nel nostro caso gli aspetti positivi superavano di gran lunga quelli negativi. Si è deciso perciò di creare una classe per rappresentare ogni entità di Business, definendo campi per la memorizzazione dei dati e definendo proprietà per esporre i dati all’applicazione client. Abbiamo poi definito metodi che incapsulano la più semplice logica di Business, facendo uso dei campi dell’oggetto creato.
4.2.2 La rappresentazione di dati relazionali attraverso entità di Business Spesso i database contengono molte tabelle, ad esempio in Anagrafica Programmi vi sono tutte le tabelle che si vedono nella figura sottostante, le quali hanno molte relazioni fra loro ( tramite l’utilizzo di chiavi primarie e chiavi esterne).

Capitolo 4 - L’Architettura di Anagrafica Programmi
48
���������
,$-��'(-.�$�'
���������������
,$-���.��-$�,/.$0)11
'$�.'/.$0)���'0'�-'".'�2��)0(-$��.��$($
����������������� �����!�
����������"����������������
,$-��'(-.�$�',$-���.��-$�,/.$0)3�$��$��'(.�'0'�-'".�.3�$��$��'�)0/)3�$��$��.'0.".�'/.$0)3�$��$�3,��)(3�$��$��$0('3.�.//'/.$0)�-$�-).#$
�����
,$-��'(-.�$�')-.)
�#�����
,$-��'(-.�$�')-.)�,0('('
��������
�$�.�)��$��)4445446 6441
1
6
6 1
6
1
����#�����
�$�.�)��-$�,(($-)
'$�.'/.$0)�'0'�-'".'�2��-$�,(($-)
1
1
��������
,$-��'(-.�$�')-.)�,0('('�''��.$
������������
,$-��'(-.�$�')-.)�,0('('�''��.$�$�.�)��'-()
���������
�'(-.�$�')-.)�,0('('
1
6
6 1
6
6441
��������$��������
�'(-.�$�',$-�
6
6
��������������$�
�'(-.�$�'
6441
5446
��������������
�$�.�)��$��)'
6441
1
'$�.'/.$0)�'0'�-'".'�2��$��))��.()
$���#��
,$-���.��'-()0/'�'(-.�$�'��.��'-()0/',$-��3')��.�'--.#$�'(-.�$�'��.�'--.#$
6
1
����������������� �����!�
����������"�����#�����
�'(-.�$�'�$�.�)��-$�,(($-)"�'��.0�.�)0�)0()�-$�-).#$
5446
6
�������������������������%�����&
�'(-.�$�')-.)�-$�-).#$
1
6441
1
6441
����������������� �����'''
,$-��'(-.�$�'�$�.�)��$��)'�-$�-).#$
0����������� ����� �����!!� ����� ��������6�����!�������7�!����� ���!����������� ������5���6� ������!!� ������+�����6�����7��������!!� �� �����������������!� ��4���0����� ����*����������� ���!�������� ������ ���������8���!!� ������+�����������7���� � ������9 � ���:� �����!!� ��!� ��4�������+������������!������������!!� ��!� ���:�����++������������%�����'0'�()�(4������%�����'0'�(�-���������������� ������� ���������!!� ��!� ��������4
Figura 4.7 Modello logico del DataBase di Anagrafica Programmi
Nella definizione delle entità di Business che modellano le entità del DB abbiamo analizzato con cura e deciso quali potessero essere le entità di Business che rappresentano meglio le funzionalità dell’applicazione, piuttosto che definire un’entità di Business per ogni tabella. Ecco le principali caratteristiche delle entità di Business:
• Le entità di Business forniscono accesso ai dati ed, in alcuni casi, ad altre funzionalità relative ai dati
• Le entità di Business possono essere costruite da dati con schemi complessi. I dati spesso si riferiscono a diverse tabelle che hanno delle relazioni
• Le entità di Business possono essere serializzate • In ogni caso le entità di Business non accedono direttamente al DB, ma mediante il
loro associato Data Access Logic Component • Le entità di Business non avviano, in nessun caso, una transazione. Le transazioni
vengono fatte dalle regole di Business che usano gli oggetti di Business

Capitolo 4 - L’Architettura di Anagrafica Programmi
49
4.2.3 La definizione di classi personalizzate per le Business Entities In Anagrafica Programmi abbiamo definito diverse classi che modellano le nostre entità di Business; ecco una lista delle principali classi:
• ObjMatricola • ObjSerie • ObjPuntata • ObjCommessa • ObjCessione • ObjDatiDescrittivi • ObjFinestraNonTrasmettibilità • ObjProduttore • ObjVoltura • ObjDatiPrevisionali
Ecco lo pseudocodice di BizCommessa, una delle entità di Business principali, poiché si riferisce ad una Commessa di un Programma : using System; using System.Runtime.Serialization; using RAI.AP.APCore; namespace RAI.AP.DataObject { [Serializable] public class ObjCommessa:ICloneable { public const string APDBtablename="ANAGTPRD"; public string COMMESSA; public string TIPO_COMMESSA; public DateTime DATA_ORA_IMM; public DateTime DATA_ORA_VAR; public string TITOLO; public string UTENTE_IMM; public string UTENTE_VAR; public ObjCommessa() { this.COMMESSA = APCoreCommon.starString; this.TIPO_COMMESSA = APCoreCommon.starString; this.TITOLO = APCoreCommon.starString;

Capitolo 4 - L’Architettura di Anagrafica Programmi
50
this.UTENTE_IMM = APCoreCommon.starString; this.UTENTE_VAR = APCoreCommon.starString; } //override di Equals //override del metodo GetHashCode //override di Clone() }
}
Quando si è trattato di definire queste strutture dati, ci siamo trovati di fronte alla scelta tra l’uso di una struct o di una classe; la nostra scelta è ricaduta sull’uso di classi poiché nel nostro caso si trattava di costruire entità di Business complesse. Inoltre ci siamo trovati di fronte alla scelta dei nomi dei campi pubblici che alla fine abbiamo definito uguali ai nomi delle medesime colonne sul DataBase; questa scelta permette un’immediata associazione dei campi, inoltre nel nostro caso è particolarmente comoda in quanto ci permette di attuare la Reflection nel modo più semplice possibile (parlerò più avanti in questo capitolo di questa tecnica). Abbiamo anche fatto l’override del metodo Equals (e del metodo GetHashCode, che calcola il codice hash di un’istanza di un oggetto), tenendo conto di quali siano realmente i campi public da confrontare tra due oggetti, ad esempio nel codice precedente riguardo all’oggetto ObjCommessa non sono stati confrontati i campi UTENTE_IMM e UTENTE_VAR poiché non rappresentano campi logici dell’oggetto Commessa ma solo l’identificativo dell’utente che ha immesso la commessa e quello che eventualmente l’ha modificata. Inoltre si è reso anche utile un override del metodo Clone che si occupa della copia di un oggetto. I metodi Equals e Clone si sono resi molto utili in tutta la logica di Business e spesso anche a livello di Data Layer per molte operazioni; un esempio banale potrebbe essere quello dell’aggiornamento di una Matricola: se i dati di quest’oggetto non sono cambiati (utilizzo del metodo Equals personalizzato), è inutile fare un update sul DB. L’oggetto principale dell’applicativo Anagrafica Programmi, cioè l’oggetto che si riferisce ad una Matricola, ha dei puntatori a tutti gli altri oggetti; in questo modo siccome spesso

Capitolo 4 - L’Architettura di Anagrafica Programmi
51
nelle operazioni si fa riferimento ad una matricola, anche se si opera su molti altri dati, si riesce a inglobare tutti i parametri nel passaggio di un unico parametro ObjMatricola (ovviamente la logica di questo oggetto si complica leggermente rispetto agli altri, soprattutto per quanto riguarda la Clone e il metodo Equals poiché si dovrà tenere conto degli oggetti aggregati ad esso). Inoltre nello pseudo-codice soprastante si può notare la label: [Serializable] , questa label C# ha che fare con la Serializzazione dell’oggetto.
4.2.4 La Serializzazione degli oggetti La serializzazione è il processo di runtime per la conversione di un oggetto o di un grafo di oggetti in una sequenza lineare di byte. Il blocco di memoria che risulta può essere utilizzato per la memorizzazione o la trasmissione in rete tramite un particolare protocollo. In Microsoft .NET la serializzazione degli oggetti può avere tre forme diverse di output: binario, SOAP ( Simple Object Access Protocol) e XML. Le serializzazione di runtime degli oggetti ( Binaria, SOAP e XML) rappresentano tecnologie sostanzialmente diverse con implementazioni diverse e, soprattutto, con obiettivi diversi. Il processo di serializzazione XML converte l’interfaccia pubblica di un oggetto in un particolare schema XML. Questo meccanismo è utilizzato ampiamente in .NET Framework come metodo per salvare lo stato di un oggetto in un flusso. In .NET sono le classi dello spazio dei nomi System.Runtime.Serialization che si occupano della serializzazione degli oggetti; queste classi forniscono la congruenza dei tipi e forniscono la deserializzazione. La deserializzazione è il processo inverso alla serializzazione, ovvero la deserializzazione raccoglie le informazioni memorizzate e ricrea gli oggetti in base a tali informazioni. La serializzazione può generare dati di output in più formati tramite moduli di formattazione personalizzati diversi. Le classi possono essere serializzate tramite formattatori in due modi: possono supportare l’attributo [Serializable] o implementare l’interfaccia Iserializable Attraverso l’uso dell’attributo [Serializable] non abbiamo bisogno, per la nostra classe, di eseguire altre operazioni, in quanto la serializzazione viene gestita dalle applicazioni chiamanti e i dati della classe sono ottenuti tramite reflection. In alcuni casi particolari, inoltre la FCL mette a disposizione un modo per controllare completamente il processo di serializzazione. Si può fare implementando l’interfaccia ISerializable e fornendo un’altro costruttore per la serializzazione. In questo momento non mi soffermerò su questa tecnica poiché ne parlo già in modo dettagliato nel capitolo dedicato ai Web services.

Capitolo 4 - L’Architettura di Anagrafica Programmi
52
4.2.5 Il concetto di Reflection Come ho già avuto modo di dire nel capitolo introduttivo a .NET, i metadati consistono in un insieme di tabelle di definizione dei tipi , dei campi, dei metodi e di tutto ciò che viene creato al momento della generazione di un assembly o di un modulo. Lo spazio dei nomi System.Reflection di FCL contiene diversi tipi di modelli a oggetto che consentono di scrivere codice in grado di analizzare queste tabelle di metadati. Utilizzando tali tipi è possibile enumerare in modo semplice tutti i tipi presenti in una tabella di metadati di definizione dei tipi.
4.2.6 Il metodo getObjValue internal bool getObjValue(Object o,SqlDataReader dr,string prefix)
{ Object valueObj=System.DBNull.Value; Type theType = o.GetType(); FieldInfo [] fields=theType.GetFields(); bool next=dr.Read(); foreach(FieldInfo field in fields) { if(!field.Name.StartsWith("APDB") && !field.FieldType.Name.StartsWith("Obj")) { try { valueObj=dr[prefix+field.Name];}
catch(System.IndexOutOfRangeException) {valueObj=null;}
catch(System.InvalidOperationException) {valueObj=null;} catch(Exception ex) {throw new TechnicalException("Errore
critico nel metodo GetObjValue "+ex.GetType()+":"+ex.Message,ex);
} if((valueObj!=null) && (è String)) { field.SetValue(o, valueObj.Trim()); } //…continua…poiché per differenti tipi vi sono regole di formattazione diverse

Capitolo 4 - L’Architettura di Anagrafica Programmi
53
} } return next; }
Al fine di dare una spiegazione il più possibile concreta, ho pensato di mostrare una parte di una classe del Data Layer (lo strato applicativo che si occupa di gestire l’accesso alla base dati), che riceve un oggetto di tipo Object ( quindi siamo nel caso più generale possibile) e un SqlDataReader aperto sul DB si occupa del corretto caricamento dell’oggetto. Se supponiamo di aver aperto, ad esempio, un SqlDataReader su un record della tabella delle “Commesse” e di aver passato un oggetto ObjCommessa, allora questo metodo andrà a caricare tutti i campi dell’oggetto. Questo avviene grazie all’uso di:
• Metodo getType() che ritorna il tipo dell’oggetto • Metodo GetFields() che ritorna un array di FieldInfo, contenenti tutte le
informazioni ad ogni campo dell’oggetto • Il tipo FieldInfo attraverso i membri GetValue e SetValue permette di ottenere o
impostare il valore del campo puntato dal tipo FieldInfo. • Il membro field.Name, field.FieldType di FieldInfo permettono di risalire al nome
del campo o al tipo ( ma ci sono molte altre possibilità) Date queste premesse sui metodi e le proprietà utilizzate nell’esempio, è facile capire quale è la sua logica: in effetti non fa altro che scorrere i campi dell’oggetto e individuare la corrispondenza 1 a 1 con i campi del SqlDataReader; quando ci sarà match fra di essi, carica il campo del Reader nell’oggetto, in un secondo momento si andrà a formattare il campo del Reader secondo le nostre esigenze, ad esempio nel caso scritto nello pseudocodice di prima si carica una stringa nell’oggetto solo dopo averne fatto il Trim, attraverso il membro setValue di FieldInfo. Com’è logico che sia, questo esempio è solo una piccola parte di quello che è stato fatto nel progetto con la Reflection ed è stato solo dimostrativo di quali ne sono le potenzialità, che si spingono ben oltre questo semplice metodo getObjValue.
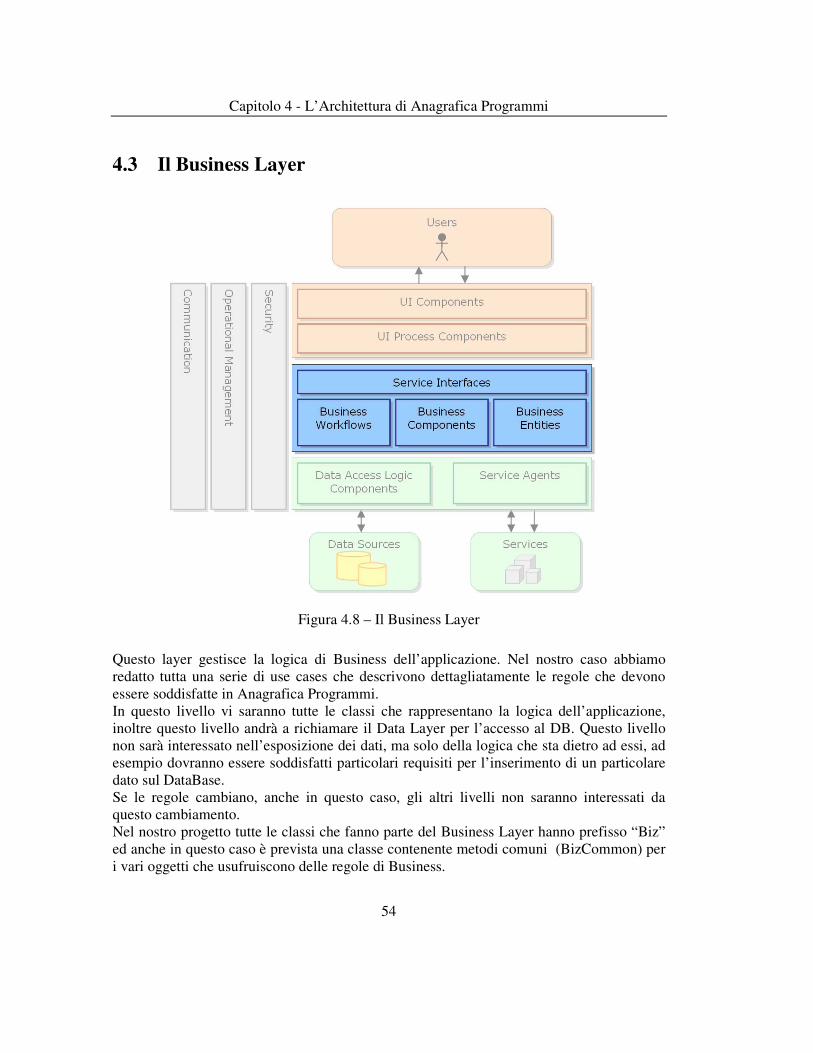
Capitolo 4 - L’Architettura di Anagrafica Programmi
54
4.3 Il Business Layer
Figura 4.8 – Il Business Layer
Questo layer gestisce la logica di Business dell’applicazione. Nel nostro caso abbiamo redatto tutta una serie di use cases che descrivono dettagliatamente le regole che devono essere soddisfatte in Anagrafica Programmi. In questo livello vi saranno tutte le classi che rappresentano la logica dell’applicazione, inoltre questo livello andrà a richiamare il Data Layer per l’accesso al DB. Questo livello non sarà interessato nell’esposizione dei dati, ma solo della logica che sta dietro ad essi, ad esempio dovranno essere soddisfatti particolari requisiti per l’inserimento di un particolare dato sul DataBase. Se le regole cambiano, anche in questo caso, gli altri livelli non saranno interessati da questo cambiamento. Nel nostro progetto tutte le classi che fanno parte del Business Layer hanno prefisso “Biz” ed anche in questo caso è prevista una classe contenente metodi comuni (BizCommon) per i vari oggetti che usufruiscono delle regole di Business.

Capitolo 4 - L’Architettura di Anagrafica Programmi
55
%�(����� ���
�� ��������� �����;�3�+��!!��4 �������� ������� �����;�3�+��!!��4 ������ ����.���������;�3�+��!!��4 ����.���� ��.���������;�3�+��!!��4 ��.�������<��� �����;�3�+��!!��4���<�����=��� �����;�3�+��!!��4���=�����5��� �����;�3�+��!!��4���5
��3�+���������������3�+���������������������(�����������������������"�!�������������*��6�������������*��>��������*'�����������!!�,�������������*'�����������!!�.� ����������*'�����������������������*'���������������'�� ���!������������*'����������*��+������.� ����������*'����������*��+������,�������������*'�������� ��������������?��!!� ��� ����+�������������?�� ����+����" �+���������������?(���������������������?(���������������?(������� ��������������?(���������������?(���������������?�����!!� ����������?��������������?����������������$��#�� ��������!�������(�������#���������!�������0 !���#���������!�������0 !� �����#�������
%�(������
��3�+� ����������������� ��������������������� ������
%�(�����
��3�+��������������� ��������������������� ������
�%�(����� ����)%�
%�(��������
��3�+��!!� ������������� ������
%�(�����
Figura 4.9 Gerarchia delle Classi del Business Layer
Ad esempio, il metodo tvAnagrafiaCatalogo della classe BizMatricola contiene la logica per decidere se una data anagrafia inserita dall’utente rappresenta un’anagrafia “valida” e stabilisce se andare in modalità di Inserimento di una nuova anagrafia oppure in modalità di Aggiornamento di un’anagrafia preesistente.

Capitolo 4 - L’Architettura di Anagrafica Programmi
56
4.4 Il Presentation Layer
Figura 4.10 Il Presentation Layer
In questa architettura, il presentation layer ha a che fare solo con la USER INTERFACE, nel nostro caso WEB, non con i Web Services. I Web Services si agganciano direttamente al Business Layer. Questo layer ha a che fare con tutto quello che riguarda “l’esposizione” dell’applicazione all’esterno; questo livello non contiene solo l’interfaccia utente ma bensì contiene tutte le classi che permettono la presentazione dei dati. Questo layer si interfaccia solo con il layer di Business e in nessun modo accede direttamente al livello Dati.Il presentation layer di anagrafica programmi è composto dall’applicativo Web che espone tutte le funzionalità agli utente. Parallelamente alla UI vi sono i Web services che si interfacciano in modo autonomo alla logica di Business e permettono ad alcuni applicativi di accedere all’archivio anagrafico. Vista la complessità dell’interfaccia grafica di Anagrafica Programmi, è stato adottato il pattern più complesso tra quelli elencati e descritti da Microsoft: Application Controller pattern, sul quale non mi soffermerò in quanto la parte di Presentation Layer è quella sulla quale meno mi sono soffermato.

57
Capitolo 5 Le transazioni distribuite
5.1 Introduzione Una transazione è vista come un'unità logica di elaborazione : per consentire transazioni concorrenti e per garantire la base di dati da malfunzionamenti sono necessari opportuni moduli di gestione. Una transazione raggruppa una sequenza di richieste in modo che la loro esecuzione soddisfi le proprietà ACID:
• Atomicità • Consistenza • Isolamento • Durevolezza
Una transazione può essere eseguita completamente, se tutte le proprietà sono soddisfatte, oppure non viene eseguita affatto; ciò porta il sistema da una stato di consistenza ad un altro, tutto ciò è eseguito in modo completamente isolato da un’altra transazione e, una volta completata, siamo in una situazione durevole. Adesso passerò alla spiegazione, in maggior dettaglio, delle quattro proprietà denominate ACID.

Capitolo 5 - Le transazioni distribuite
58
5.1.1 Atomicità L’atomicità indica la proprietà di una transazione di essere eseguita completamente oppure di non essere eseguita affatto. Quando c’è un errore nel mezzo di una sequenza di richieste, le richieste precedente all’errore vengono eseguite, mentre quelle successive non saranno eseguite. Se la sequenza di richieste è eseguita all’interno di una transazione il transaction manager si assicurerà di disfare le operazioni precedentemente eseguite, in modo da riportare lo stato del Data Base nella situazione in cui era prima della transazione. L’ atomicità è un concetto molto importante perché permette a chi sviluppa le applicazioni di usare le transazioni per definire dei punti in cui il sistema gestisce in modo trasparente eventuali errori.
5.1.2 Consistenza In qualunque applicazione vi sono degli stati inconsistenti che non devono essere violati. Le transazioni permettono di mantenere lo stato di consistenza di un’applicazione passando da uno stato consistente ad un altro stato anch’esso consistente. Questo non significa che non si possono verificare stati inconsistenti, ma bensì che questi stati occorrono solo all’interno della transazione. Se in una transazione non si raggiunge uno stato consistente non si può fare il commit e quindi la transazione sarà abortita e tutti i cambiamenti già fatti al suo interno saranno disfatti. La consistenza è molto importante in una transazione poiché da agli sviluppatori la sicurezza che una transazione, una volta completata con successo, lascerà il sistema in uno stato consistente.
5.1.3 Isolamento L’isolamento garantisce che non vi potranno essere interferenze tra due transazioni concorrenti. Questo significa che i cambiamenti che una transazione attua sulla Base di Dati saranno visibile alle altre transazioni solo al termine della transazione stessa. Perciò il transaction manager si assicura che due transazioni che provano ad accedere alle stesse risorse sono forzate ad un’esecuzione sequenziale in modo da escludere la violazioni dell’integrità (ad esempio il problema dei lost update) del DB.
5.1.4 Durevolezza La durevolezza rappresenta il fatto che una volta che una transazione è andata a buon fine, i cambiamenti che ha fatto sono persistenti e non possono essere disfatti; gli effetti sulla base

Capitolo 5 - Le transazioni distribuite
59
di dati prodotti da una transazione terminata con successo sono permanenti, ovvero non sono alterati da eventuali malfunzionamenti.
Figura 5.1 Stati di una transazione
• commit : segnala al transaction manager che la transazione è andata a buon fine e richiede che gli effetti prodotti sul database vengano resi permanenti.
• rollback (abort) : segnala che si è verificato qualche problema durante l'esecuzione e che il database può essere in uno stato inconsistente; si devono dunque attivare opportune procedure per annullare gli effetti prodotti e riportare il database in uno stato consistente (UNDO). Per gestire in modo corretto le conseguenze derivanti da una transazione che abortisce, il DBMS gestisce un log dove vengono memorizzati dettagli circa le operazioni di aggiornamento effettuate (in particolare vengono gestiti before values e after values). In generale si definisce before image lo stato del database prima di una modifica e after image lo stato raggiunto dopo aver effettuato la modifica.

Capitolo 5 - Le transazioni distribuite
60
5.2 Le Transazione Distribuite Una transazione e’ distribuita quando e’ costituita da sottotransazioni eseguite concorrentemente da processi diversi. O meglio, in una architettura client-server una transazione coinvolge al più un server; quando invece le transazioni coinvolgono più server, parliamo di basi di dati distribuita. Le motivazioni che portano allo sviluppo di soluzioni distribuite sono svariate, ad esempio si può rispondere all’esigenza di adeguare la gestione dei dati alla gestione dell’imprese, che è strutturalmente distribuita. Nel caso di Anagrafica Programmi non siamo di fronte all’utilizzo di una vera e propria Base di Dati distribuita, che ha svariate motivazioni nell’utilizzo tra cui la maggior flessibilità, modularità e resistenza ai guasti. Il caso del nostro applicativo invece richiede semplicemente che i dati vengono replicati su due DBMS diversi (SqlServer 2000 e DB2) per far fronte alla necessità di continuare ad usare le vecchie applicazioni in ambienti MainFrame che hanno bisogno di accedere all’anagrafica. Poi gradualmente si andranno a sostituire tutti i sistemi, passando definitivamente a SqlServer. Nel caso di DBMS distribuiti le sottotransazioni sono eseguite su nodi diversi di una rete.

Capitolo 5 - Le transazioni distribuite
61
5.3 Il protocollo di Two-Phase Commit (2PC)
Figura 5.2 Il 2PC, esempio di transazione
Il protocollo utilizzato nel progetto Anagrafica Programmi è il protocollo di Two-Phase Commit. In questo protocollo vi sono due principali attori: il coordinatore della transazione e i partecipanti alla transazione; il coordinatore è unico, invece i partecipanti possono variare da due ad N. Nel caso di Anagrafica Programmi premetto che gli attori sono solo due, ovvero le operazioni su DB2 e le operazione su SqlServer Microsoft. I partecipanti, chiamati anche transactional clients o resource managers emettono dei comandi al coordinatore della transazione; il transaction manager (in ambienti Microsoft vi è la figura del DTC distributed transaction coordinator) conosce l’identità di tutti i clients partecipanti alla transazione. Il coordinatore della transazione si occupa dunque di controllare l’esecuzione della transazione; il gestore delle transazioni (transaction manager) deve pertanto garantire che la transazione sia considerata atomica anche se in realtà è composta da più operazioni. La terminazione di una transazione distribuita T avviene in due fasi: • tutte le sottotransazioni Ti prendono una decisione comune sul modo di terminare • vengono eseguite le operazioni corrispondenti alla decisione presa

Capitolo 5 - Le transazioni distribuite
62
Il coordinatore si occupa di: • prepara "precommit" sul log • fissa un tempo massimo di attesa • invia un messaggio "prepare" a tutti i partecipanti • se scade il tempo massimo senza avere ricevuto pronto da tutte le transazioni,
registra abort sul log e invia il messaggio "abort" a tutti i partecipanti • se ha ricevuto commit da tutte in tempo utile registra commit sul log e invia il
messaggio "commit" a tutti i partecipanti Il partecipante invece:
• esegue le operazioni e rimane in attesa del messaggio "prepare" • quando riceve "prepare" se può terminare registra sul suo log "pronto" e invia tale
messaggio al coordinatore. Se non può terminare registra sul log "non pronto" e invia al coordinatore tale messaggio (fase di precommit)
• quando riceve dal coordinatore il messaggio "commit" o "abort" registra sul log il messaggio, esegue il comando e invia al coordinatore il messaggio "eseguito" (fase di commit)
I fallimenti vengono gestisti nel seguente modo:
• se fallisce uno degli N partecipanti prima del precommit si ha un abort globale, altrimenti se fallisce dopo il precommit richiederà al coordinatore di prendere una decisione
• Se fallisce il Coordinatore tra precommit e commit. La procedura di ripristino riavvia il protocollo dall’inizio; se invece fallisce dopo aver registrato "commit" o "abort" e prima di "end commit" invia di nuovo il messaggio
5.4 Le transazioni in Anagrafica Programmi Come ho già avuto modo di dire in Anagrafica programmi si attua il 2PC solo al fine di mantenere aggiornati in tempo reale i due DBMS (SqlServer e DB2); il tutto viene fatto attraverso delle replicazioni Sincrone. Nelle replicazioni sincrone tutte le copie devono essere aggiornate al momento del commit della transazione che ha effettuato l’aggiornamento; in ogni istante la replica dei dati su DB2 è identica ai dati originali su SQLServer (Tight Consistency). La replicazioni sincrona ha i seguenti pregi e difetti:
Vantaggi: • Si mantiene l’integrità dei dati • Bassa complessità • Uso del protocollo 2PC, di cui ho già parlato in dettaglio • Trasparenza sulla località

63
Capitolo 6 Gestione delle Eccezioni
6.1 Introduzione Al fine di realizzare applicazioni flessibili, funzionali e facili da manutenere, è necessario adottare una appropriata strategia per la gestione delle eccezioni. È pertanto necessario progettare sistemi che assicurino la cattura delle eccezioni, il logging e il reporting delle informazioni. Molti sviluppatori vengono ingannati dal termine gestione delle eccezioni e credono che la parola eccezione sia correlata alla frequenza di avvenimento di un evento, o meglio credono che sia dovuta al fatto che si tratti di un evento molto raro. In realtà non è così, un’eccezione rappresenta la violazione dei presupposti impliciti di un’interfaccia di programmazione. Quando si progetta un tipo, ad esempio, si immagineranno innanzitutto le varie circostanze di utilizzo e in seguito verranno definiti i relativi campi, le proprietà, i metodi, gli eventi e così via. Il modo di definizione di tali membri diviene l’interfaccia di programmazione del tipo. In definitiva, si verificherà un’eccezione quando un presupposto dell’interfaccia viene violato. Occorre comprendere che la violazione di un presupposto di un’interfaccia di programmazione non è necessariamente un evento negativo, anzi potrebbe essere un evento positivo, in quanto che la gestione delle eccezioni consente di intercettare le eccezioni e di proseguire regolarmente con l’esecuzione. La gestione delle eccezioni comprende la cattura delle eccezioni, lo scatenare le eccezioni e la pubblicazione delle eccezioni ai diversi utenti. Di seguito riporto solo alcuni dei vantaggi offerti dalla gestione delle eccezioni:
• La possibilità di mantenere il codice di pulitura in una posizione localizzata e certezza della sua esecuzione; se si sposta tale codice dalla logica principale di un’applicazione a una posizione localizzata, sarà possibile semplificare la scrittura, la comprensione e la gestione dell’applicazione. La certezza che il codice di pulitura venga eseguito significa che è più probabile che l’applicazione rimanga in uno stato coerente. Se, ad esempio, la scrittura del codice nel file non può più continuare per un motivo qualsiasi, i file saranno chiusi.

Capitolo 6 - Gestione delle Eccezioni
64
• La possibilità di mantenere il codice relativo a situazioni eccezionali in una posizione centrale; le ragioni per cui da una riga di codice possono essere generati errori sono molteplici: overflow aritmetico, overflow dello stack, stato di memoria insufficiente, indice di accesso ad una matrice maggiore della sua dimensione. Senza il supporto della gestione delle eccezioni risulta molto difficile scrivere codice mediante cui individuare gli errori ed eseguire il ripristino. La frammentazione del codice per rilevare questi errori potenziali nella logica principale dell’applicazione complica la scrittura, la comprensione e la gestione del codice stesso. Se si utilizza la gestione delle eccezioni non occorrerà scrivere codice per il rilevamento di potenziali errori.
• La possibilità di individuare e correggere bug nel codice; quando si verifica un errore, CLR esaminerà lo stack di chiamate del thread ricercando il codice in grado di gestire l’eccezione. Se non esiste codice in grado di gestire l’eccezione, si riceve una notifica di eccezione non gestita. È possibile quindi individuare facilmente il codice sorgente che ha generato l’errore, determinare la causa dell’errore e modificare il codice in modo da correggere il bug. I bug saranno pertanto rilevati durante le fasi di sviluppo e test di un’applicazione e corretti prima della distribuzione di quest’ultima.
Se utilizzate correttamente le eccezioni rappresentano un valido strumento che semplifica l’attività di sviluppo del software.
6.2 Gerarchia delle eccezioni FCL Tutte le classi di eccezioni devono derivare dalla classe di base Exception contenuta nel namespace System. I tipi di eccezioni derivati da System.Exception sono compatibili con CLS e C# consente di generare solo eccezioni compatibili con CLS. L’idea di Microsoft prevedeva che Exception fosse il tipo di base per tutte le eccezioni e che altri due tipi, SystemException e ApplicationException derivassero da lei.

Capitolo 6 - Gestione delle Eccezioni
65
Figura 6.1 – Gerarchia delle Eccezioni
Come si può notare nella figura 6.1 CLR genera tipi derivati da SystemException e la maggior parte di essi (come DivideByZeroException, InvalidCastException e IndexOutOfRangeException ) segnalano spesso situazioni non irreversibili da cui è possibile ripristinare un’applicazione, anche se vi sono alcune eccezioni quali StackOverflowException o ExecutionEngineException dalle quali è estremamente improbabile che il ripristino riesca. Sarebbe opportuno che queste eccezioni particolari si trovino in una gerarchia speciale. Il tipo ApplicationException è utilizzato invece come classe di base per tutte le eccezioni specifiche dell’applicazione.

Capitolo 6 - Gestione delle Eccezioni
66
6.3 Meccanismi di gestione delle eccezioni La gestione delle eccezioni fa uso di due meccanismi molto importanti: la propagazione e la cattura (attraverso i blocchi try, catch e finally). Il flowchart in figura 6.2 illustra i passi principali nella gestione delle eccezioni .
Figura 6.2 - Processo di gestione delle eccezioni
Come si può notare il flowchart è molto chiaro, se l’eccezione propagata al metodo in cui ci si trova attualmente non viene cattura (catch dell’eccezione), allora essa si propaga al chiamante del metodo attuale, altrimenti se l’eccezione viene rilevata si può provare a ripristinare l’applicazione, se non vi si riesce vengono aggiunte le informazioni contestuali opportune e si propaga l’eccezione al chiamante, altrimenti, in caso positivo, avviene il ripristino dell’eccezione.

Capitolo 6 - Gestione delle Eccezioni
67
6.3.1 Strategia di propagazione delle eccezioni Vi sono tre metodi principali utilizzati per la propagazione delle eccezioni:
• Lasciare che le eccezioni risalgano: mediante quest’approccio il metodo ignora l’eccezione, lasciandola salire attraverso le chiamate nello stack finché l’eccezione non incontra un blocco catch che contiene un filtro per l’eccezione trovata
• Catturare e ripropagare le eccezioni: in questo caso si prova a catturare l’eccezione e a gestirla, nel caso in cui non ci si riesca l’eccezione risale così com’è
• Catturare, “impacchettare” e ripropagare le eccezioni: questo è il caso più interessante, poiché generalmente quando l’eccezione viene generata il suo tipo di solito non porta informazioni rilevanti per lo sviluppatore o per l’utente dell’applicativo; ad esempio si supponga di avere il seguente codice:
public int metodoProva(int x) { try { return 100/x; } catch(DivideByZeroException e) { throw new ArgumentOutOfRangeException("x",x,"valore 0 non valido",e); } }
Quando viene chiamato metodoProva se il valore di x è zero verrà intercettata l’eccezione specifica DivideByZeroException e generata un’eccezione ArgumentOutOfRangeException; questa tecnica consente di migliorare e di arricchire di significato la generazione dell’eccezione. Ovviamente questo discorso vale anche per un’eccezione che mi sono creato io in prima persona per gestire un particolare evento. Si immagini un tipo Rubrica in cui viene definito un metodo che ottiene un numero telefonico da un nome, come illustrato nello pseudo-codice riportato di seguito:
public class Rubrica { string path; //percorso per il file contenente gli //indirizzi public string getNumeroTelefonico(string nome) { string tel;

Capitolo 6 - Gestione delle Eccezioni
68
FileStream fs=null; try { fs= new FileStream(path,FileMode.Open); /* qui dovrebbe esserci il codice per leggere dal file finché il nome non viene trovato */ tel= /* il numero telefonico trovato */ } Catch(FileNotFoundException e) { /* sollevo una mia eccezione che contiene il nome non Trovato */ Throw new NameNotFoundException(name,e); } finally { if(fs != null) fs.Close();} } Return tel;
} } Il codice riportato di sopra permette di capire quale sia l’importanza nel fornire una visualizzazione astratta del presupposto implicito violato, ovvero del fatto che il file non è stato trovato. In conclusione è sempre utile applicare una strategia di questo tipo in quanto si può contestualizzare meglio un evento associando ad esso tutte le informazioni rilevanti.
Figura 6.3 – Propagazione delle eccezioni
È importante notare che le informazioni dell’eccezione interna (InnerException) non vengono perso ma preservate assieme alla nuova eccezione che fa da “Wrapper”.

Capitolo 6 - Gestione delle Eccezioni
69
6.4 Definizione di eccezioni personalizzate In .NET tutte le eccezioni proprie di un’applicazione dovrebbero ereditare dalla classe ApplicationException (anche se in pratica si potrebbe farle ereditare direttamente da Exception), come illustrato in figura 6.4:
Figura 6.4 Definizione di eccezioni personalizzate
Quando si definisce un nuovo tipo di eccezione, sarà opportuno considerare con attenzione in che modo il codice dell’applicazione intercetterà il tipo di base, quindi conviene scegliere un tipo di base che comporti l’effetto meno negativo possibile. Mi spiego meglio, se intercetto il tipo di base quasi sicuramente potrei avere un comportamento indesiderato per quanto riguarda il tipo di base stesso, poiché al momento della definizione del tipo di base non era stata prevista la definizione della nostra eccezione personalizzata. Durante la definizione dei tipi di eccezioni, è possibile definire liberamente le sottogerarchie, se applicabili all’operazione in corso; è necessario che lo sottogerarchia siano ampie e superficiali, ovvero non presentino più di due o tre livelli.
6.4.1 Creare una classe di Base per le eccezioni In ogni caso un’applicazione dovrebbe derivare da un’unica classe tutte le sue eccezioni, la quale a sua volta deriva da ApplicationException.

Capitolo 6 - Gestione delle Eccezioni
70
Lo sviluppatore poi dovrebbe aggiungere campi e informazioni rilevanti nell’applicativo alla classe di Base, in modo così che poi tutte le classi di eccezione definite possano ereditare queste informazioni aggiuntive.
6.5 Struttura delle eccezioni in un’applicazione L’utilizzo delle eccezioni richiede spesso la cattura di eccezioni ritornate dalla logica di Core-Business e l’astrazione degli errori dei business objects in una forma comprensibile al chiamante. In quest’ottica si può pensare fondamentalmente a due tipi di eccezione che ereditano dal nostro tipo di base (Base Exception) :
• Eccezioni di tipo Technical (ad esempio una connessione a DB fallita) • Eccezioni di tipo Business (ad esempio l’inserimento nel nostro applicativo di una
matricola inesistente) Devo anche porre l’accento sul fatto che ai vari livelli di astrazione dell’applicazione, nel mio caso posso parlare di 3 livelli logici (Presentation Layer, Biz Layer, Data Layer - vedere capitolo precedente, modello Three-layered Services), l’approccio alle eccezioni è fondamentalmente diverso, posso perciò distinguere 3 casi:
• Gestione delle eccezioni nel livello di presentazione • Gestione delle eccezioni nei componenti di Business • Gestione delle eccezioni nei componenti di accesso ai dati
6.5.1 Gestione delle eccezioni nel livello di presentazione Il livello di presentazione avrà a che fare con le eccezioni scatenate dai due livelli sottostanti, vale a dire con le eccezioni del livello Business e con le eccezioni del livello Dati e dovrà decidere, secondo la circostanza, se:
• Ritentare l’operazione • Esporre il risultato all’utente • Fermare, riavviare o continuare col normale flusso dell’applicazione user interface
Voglio subito sottolineare che in “Anagrafica Programmi” si è deciso di esporre semplicemente il problema avvenuto all’utente, così eventualmente potrà ritentare l’operazione o in caso di errori gravi nell’accesso al DB visualizzare una pagina d’errore particolare che sollecita l’utente a contattare gli amministratori del sistema.

Capitolo 6 - Gestione delle Eccezioni
71
6.5.2 Gestione delle eccezioni nei componenti di Business La logica di Business deve avere a che fare con gli errori provenienti dal livello sottostante, il Data Layer o con errori scatenati dal livello Business stesso. La logica dell’applicazione non dovrebbe nascondere le eccezioni dei livelli inferiori al codice chiamante ma propagare le eccezioni che ricevono (nel nostro caso devono essere propagate al livello soprastante, siano essi Web Services o l’applicazione Web). Il livello di Business dovrebbe sollevare le eccezioni (BusinessException) quando:
• Il chiamante prova a fare un’operazione con dati insufficienti o errati ( ad esempio in Anagrafica programmi non è possibile aggiornare dei particolari dati relativi a matricole appartenenti al settore Rai Cinema)
• Avviene un errore all’interno del BIZ Layer La logica di Business deve necessariamente propagare gli errori avvenuti a livello del data access component, ad esempio se ci sono problemi nell’accesso ai dati o errori nelle procedure di accesso ai dati ( in quest’ultimo caso tramite l’utilizzo delle eccezioni sarà più semplice e immediato per lo sviluppatore andare a correggere eventuali errori) . In quasi tutti i casi le eccezioni del livello Data non devono essere nuovamente impacchettate in un’altra eccezione. In generale il livello di Business non deve nascondere nessuna delle eccezioni dei livelli sottostanti che esso chiama poiché nascondere tali eccezioni potrebbe indurre in errore la logica di Business in termini transazionali e perciò potrebbe indurre l’utente a pensare che alcune operazioni siano avvenute con successo.
6.5.3 Gestione delle eccezioni nei componenti di accesso ai dati Il livello dei dati avrà principalmente a che fare con due tipi principali d’eccezioni:
• Eccezioni causate da errori tecnici, come ad esempio un errore di connessione • Altri tipi di errori causati da query data–intensive come delle Stored Procedure
L’exception handling nel livello di accesso ai dati consiste principalmente nella cattura delle eccezioni riguardanti gli errori scatenati dalle sottostanti API (ad esempio, in .NET spesso avvengono delle SqlException) di accesso ai dati e nella loro trasposizione in quelle definite nell’applicazione. Il Data Layer nel nostro applicativo cattura queste eccezioni e le trasforma in TechnicalException, mantenendo le informazioni necessarie dell’eccezione interna e aggiungendo le informazioni che contestualizzano il problema nell’ambito del nostro progetto. Queste eccezioni, siccome rappresentano spesso i “veri” errori o problemi dell’applicazione, vanno in qualche modo salvate; il logging è in questo caso significativo, nella nostra applicazione facciamo logging a diversi livelli ma in ogni caso gli errori del livello dati saranno sempre salvati in un file di Log e nell’EventLog di Windows del Server.

Capitolo 6 - Gestione delle Eccezioni
72
6.6 La struttura delle eccezioni di anagrafica Programmi Non è il caso di ripetere le strategie appena descritte che ho applicato, nel nostro caso, in modo calzante nel progetto Anagrafica Programmi. Infatti, vista l’architettura a tre livelli dell’applicazione, è particolarmente efficace la strategia di gestione delle eccezioni appena descritta.
6.6.1 Gerarchia delle eccezioni di Anagrafica Programmi
Figura 6.5 – Gerarchia delle eccezioni di Anagrafica Programmi
Ecco il diagramma delle classi delle eccezioni di Anagrafica Programmi, come si può notare le foglie (BusinessException e TechnicalException) del diagramma derivano da BaseApplicationException che a sua volta deriva da ApplicationException. Come ho già avuto modo di sottolineare la classe BaseApplicationException arricchisce l’eccezione Application con informazioni aggiuntive; a loro volta l’idea è che le due classi che ereditano da quest’ultima arricchiscano l’eccezione con altre informazioni più vicine al contesto in cui questo tipo di eccezione è utilizzato. Inoltre è da sottolineare il fatto che le eccezioni Business e Technical, come si è capito anche nella mia descrizione generale, vengono gestite in modo diverso in quanto

Capitolo 6 - Gestione delle Eccezioni
73
rappresentano, nel nostro progetto, non è detto in generale, due eccezioni che si propongono su diversi Layer dell’applicazione.
6.6.2 BaseApplicationException Nella classe di base per le eccezioni dell’applicazione viene implementata l’interfaccia ISerializable di CLS e quindi si fa l’override del metodo GetObjectData, nel quale si definisce la serializzazione dei parametri aggiuntivi. La serializzazione, come ho già avuto modo di dire nei capitoli precedenti, è il processo di runtime per la conversione di un oggetto o di un grafo di oggetti in una sequenza lineare di byte. Il blocco di memoria risultante può essere utilizzato per la memorizzazione o la trasmissione in rete tramite un protocollo particolare. Ritornando alla classe di base per le eccezioni dell’applicazione, inizialmente ho pensato di aggiungere informazioni contestuali come il nome della macchina, la data e ora, il nome del thread, il dominio Windows ed altre informazioni aggiuntive di utilità. Le eccezioni che ereditano da BaseApplication ereditano tutte queste informazioni. Inoltre nella BaseApplicationException è presente un metodo che permette di risalire a partire dal un codice d’errore ad un messaggio opportuno da visualizzare a video; questo metodo legge da un file di Risorse (fondamentalmente è un file Xml, la cui peculiarità principale è di essere Embedded nell’Assembly perciò viene caricato in memoria all’atto del caricamento della libreria e perciò permette di essere letto con estrema velocità) i vari messaggi associati ai codici d’errore passati come parametro. Ecco il codice del costruttore che va a richiamare il metodo di caricamento dei messaggi da file di risorse:
public BaseApplicationException(string root,string assemblyName,string errorCode) : this(LoadErrorType(root,assemblyName,errorCode)) { }
La peculiarità di questo costruttore sta nella chiamata di un altro costruttore di BaseApplicationException, passandogli come parametro la stringa ritornata dal metodo LoadErrorType.

74
�
Capitolo 7 Gestione dei log e la libreria di Logging Log4Net per il tracing degli eventi
7.1 Introduzione al logging di eventi La possibilità di tenere un log di ciò che accade all’interno di un’applicazione è di fondamentale importanza durante lo sviluppo della stessa, in quanto facilita la correzione di eventuali errori ed aiuta a prevenire la creazione di bug. Questa funzionalità però ha una notevole importanza anche in fase di produzione, quando il prodotto è messo sul mercato o consegnato al cliente: grazie ad un log è possibile tenere traccia di come gli utenti interagiscono con il sistema, e quindi si possono eventualmente tracciare eventuali tentativi di violazione dei sistemi di sicurezza; più semplicemente, può essere utile registrare informazioni sull’uso a fini statistici, oppure, infine, è semplicemente comodo tenere una traccia di alcune informazioni in modo da poter sapere, in caso di bisogno, cosa è successo in un preciso momento.
7.2 La libreria Log4net Log4net permette agli sviluppatori di non doversi preoccupare di dover scrivere un layer per la gestione del log, ed inoltra li assicura che, così come riporta il sito, le funzionalità offerte sono pensate per essere veloci e flessibili. Log4net è il porting di log4j, nata per Java nel 1996 e re-implementate in ben 12 linguaggi. Il perché di tanto successo balza subito agli occhi: è possibile scrivere log su praticamente qualsiasi supporto, ed inoltre, tramite un file XML di configurazione, il logging può essere abilitato o disabilitato senza dover ricompilare il tutto. Ecco alcuni dei supporti accettati da log4net:
1. ADO.NET: permette di scrivere log su database 2. ASP.NET Trace: scrive nel trace di ASP.Net 3. Event Log: Scrive nell’Event Log di Windows 4. File: scrive su un file

Capitolo 7 - Gestione dei log e la libreria di Logging Log4Net per il tracing degli eventi
75
5. Net Send: dialoga con il servizio Messenger di Windows, per l’invio di messaggi tipo "Net Send"
Questi sono solo alcuni, probabilmente i più usati, ma il totale ammonta a ben 13 supporti e vi sono in fase di sviluppo “Appender” nuovi in continuazione. Questo significa che, in pratica, chiunque potrà trovare quello che meglio si adatta alle sue esigenze. Un’altra caratteristica importante è la possibilità di poter avere un ottimo controllo sulla quantità delle informazioni inserite nel log: se ad esempio è necessario focalizzare l’attenzione su un precisa funzione di cui si sta effettuando il debug, grazie a log4net è possibile far si che il log prodotto della funzione in questione sia il più dettagliato possibile, mentre quello creato da altri oggetti lo sia di meno; il tutto si può, come per le altre funzionalità, attivare molto semplicemente nel file XML di configurazione di Log4net. Si riesce quindi ad ottenere un file di log molto "pulito", focalizzato perfettamente sulle necessità del momento. Questo prodotto ci è servito molto durante lo sviluppo di Anagrafica Programmi e siamo riusciti ad apprezzare molte delle possibilità di integrazione che offre all’interno della nostra applicazione.
7.2.1 Loggers, Appenders e Layouts: breve introduzione Mi appresto a dare una rapida spiegazione di quali sono gli strumenti principali di Log4net, in modo poi da capire meglio come sono stati utilizzati all’interno della nostra applicazione. Log4net ha tre componenti principali: loggers, appenders e layouts. Questi tre tipi di componenti lavorano assieme al fine di permettere il logging dei messaggi a seconda del loro tipo e del loro livello e per controllare a runtime il formato dei messaggi e dove vengono inseriti. I loggers rappresentano in un qualche modo i vari tipi di log che si vogliono fare nell’applicazione; essi hanno una gerarchia, perciò se si stabiliscono determinate caratteristiche per il logger padre, saranno ereditate dai figli. Ad esempio, il logger root è la radice di tutti i logger e dovrà essere sempre dichiarato nel file di configurazione. La caratteristica principale dei loggers è che contengono un livello di log :
• ALL • DEBUG • INFO • WARN • ERROR • FATAL • OFF

Capitolo 7 - Gestione dei log e la libreria di Logging Log4Net per il tracing degli eventi
76
Se il livello di log non è assegnato il logger erediterà il livello dal progenitore più vicino; i livelli sono strutturati in modo molto semplice, ad esempio se nella mia applicazione ho tutti log di livello Debug, questi ultimi saranno tracciati solo se il livello è Debug o All ( un livello superiore), perciò tutti i log di livello Debug quando l’applicazione entrerà in fase di Produzione saranno semplicemente disattivati impostando un nuovo livello. Passando agli Appenders, posso dire che sono quelli che realmente fanno il log all’interno della destinazione desiderata, sia esso un file, l’event log di Windows o altro. Le chiamate ai vari Appenders vanno inserite nei Loggers. I Layouts sono invece responsabile di come sarà visualizzato il log; vi sono tutta una serie di Layouts già definiti, altrimenti è possibile definire un proprio Layout a seconda delle necessità.
7.3 Il file di configurazione di Anagrafica Programmi Al fine di dare una panoramica delle funzionalità di logging introdotte nella nostra applicazione ho deciso di mostrare e analizzare il file XML di configurazione della libreria di logging Log4net che ho realizzato: <?xml version="1.0" encoding="utf-8" ?>
<log4net debug="true"> <appender name="LogFileAppender" type="log4net.Appender.FileAppender"> <param name="File" value="c:\\log\\APWebLog.txt" /> <param name="AppendToFile" value="true" /> <layout type="log4net.Layout.PatternLayout"> <param name="ConversionPattern" value="Timestamp:%d{ISO8601} [%t] %nLoggingLevel:%p%n%c{1}-%C{1} %nMetodo:%M%nFilename:%F [%x]%n%m%n" /> </layout> </appender> <appender name="EventLogAppender" type="log4net.Appender.EventLogAppender"> <param name="ApplicationName" value="APWEB" /> <layout type="log4net.Layout.PatternLayout"> <param name="ConversionPattern" value="Timestamp:%d{ISO8601} [%t] %nLoggingLevel:%p%n%c{1}-%C{1} %nMetodo:%M%nFilename:%F [%x]%n%m%n" /> </layout> </appender> <appender name="LogFileAppenderAPCore"

Capitolo 7 - Gestione dei log e la libreria di Logging Log4Net per il tracing degli eventi
77
type="log4net.Appender.FileAppender"> <param name="File" value="c:\\log\\APCoreLog.txt" /> <param name="AppendToFile" value="true" /> <layout type="log4net.Layout.PatternLayout"> <param name="ConversionPattern" value="Timestamp:%d{ISO8601} [%t] %nLoggingLevel:%p%n%c{1}-%C{1} %nMetodo:%M%nFilename:%F [%x]%n%m%n" /> </layout> <layout type="log4net.Layout.ExceptionLayout"> </layout> </appender> <appender name="RollingLogFileAppender" type="log4net.Appender.RollingFileAppender"> <param name="File" value="c:\\log\\QueryLog.txt" /> <param name="AppendToFile" value="true" /> <param name="MaxSizeRollBackups" value="10" /> <param name="MaximumFileSize" value="5MB" /> <param name="RollingStyle" value="Size" /> <param name="StaticLogFileName" value="true" /> <layout type="log4net.Layout.PatternLayout"> <param name="ConversionPattern" value="%n%m%n"/> </layout> </appender> <!-- Continua dopo il commento -->
Questa prima parte del file di configurazione contiene gli Appenders e il tag log4net con l’attributo debug impostato a True, ciò sta a significare che abbiamo abilitato l’internal debugging di Log4net. L’internal debugging di Log4net ci permette di analizzare tutte le operazioni fatte dalla libreria in fase di Debug (questo tag sarà impostato a false quando sarà ultimata la fase di Debug di Anagrafica Programmi). Passiamo adesso alla spiegazione dei 4 appenders che ho creato per l’applicazione:
• LogFileAppender • EventLogAppender • LogFileAppenderAPCore • RollingLogFileAppender
Innanzitutto ci tengo a sottolineare che il LogFileAppender e LogFileAppenderAPCore sono, in sostanza, molto simili, in quanto utilizzano entrambi l’appender predefinito FileAppender; questo appender accetta come parametri il path del file (parametro “File”) sul quale fare il log e un flag che permette di stabilire se il log va aggiunto al file oppure se il file va ogni volta cancellato e riscritto con il log in questione (parametro

Capitolo 7 - Gestione dei log e la libreria di Logging Log4Net per il tracing degli eventi
78
“AppendToFile”, se impostato a true vuol dire che si aggiunge il log al contenuto precedente). Il tag layout può essere definito solo come figlio del tag appender, nel caso del log su file ci siamo costruiti un layout opportuno, con tutte le informazioni di cui avevamo bisogno. Ecco la stringa utilizzata per la formattazione del log su file:
"Timestamp:%d{ISO8601} [%t] %nLoggingLevel:%p%n%c{1}-%C{1} %nMetodo:%M%nFilename:%F [%x]%n%m%n"
La sintassi è molto simile a quella della printf in C, perciò non mi soffermo sulla spiegazione del significato di ogni singolo parametro. Il risultato di tale stringa di stampa, sul file di log, è il seguente:
“Timestamp:2003-12-24 12:32:41,465 [3836] LoggingLevel:DEBUG BizCommon-BizMatricola Metodo:tvGestireScarico Filename:c:\documents and settings\a.pisapia\my documents\visual studio projects\anagraficaprogrammi\anagrafica programmi\apcore\bizlayer\bizmatricola.cs [] UserName:NT AUTHORITY\NETWORK SERVICE- MachineName:ORAZIO Exception: RAI.AP.ExceptionManagement.BusinessException Message: La uorg/matricola non esiste “
I rimanenti appender EventLogAppender e RollingFileAppender vengono utilizzati, invece rispettivamente per il logging degli eventi sull’EventLog di Windows e per il log su un file particolare che viene reinizializzato quando raggiunge una dimensione massima pari a 5Mb. Ecco la seconda parte del file XML di configurazione:
<root> <level value="DEBUG" /> <appender-ref ref="LogFileAppender" /> <appender-ref ref="EventLogAppender" /> </root> <logger name="APCoreLogger" additivity="false"> <!-- per il momento il level value è a DEBUG, poi sarà abbassato nelle fasi successive --> <level value="DEBUG" />

Capitolo 7 - Gestione dei log e la libreria di Logging Log4Net per il tracing degli eventi
79
<appender-ref ref="LogFileAppenderAPCore" /> </logger> <logger name="testLogger" additivity="false"> <level value="DEBUG" /> <appender-ref ref="RollingLogFileAppender" /> </logger> </log4net>
Questa seconda suddivisione logica del file di configurazione racchiude tutti i logger che ho utilizzato. Il tag “root” sta ad indicare il logger radice dal quale tutti gli altri logger dovrebbero ereditare; si può definire, come è logico che sia, un solo root logger e questo tag deve essere figlio del tag principale log4net. Si può notare che agli appenders LogFileAppender e EventLogAppender si fa riferimento all’interno del tag root, invece per i rimanenti appenders sono stati definiti loggers appositi. I loggers APCoreLogger e testLogger hanno il parametro di additivity impostato a false, ovvero non ereditano il comportamento del logger radice. Come si nota, inoltre, allo stato attuale dello sviluppo dell’applicazione, i loggers sono tutti impostati con un livello di log pari a DEBUG, questo vuol dire che l’applicazione fa il log di tutto.
7.4 Inserimento dei log all’interno del codice di Anagrafica Programmi
In questo paragrafo spiego il motivo per cui ho realizzato nel file di configurazione quattro logger diversi e due appenders a file che, almeno in prima analisi, fanno le stesse operazioni. Innanzitutto si deve notare che i due appenders a file vengono utilizzati in loggers diversi, perciò saranno chiamati in punti diversi del codice e quindi ha senso avere due file per i log distinti; nel file di log di APCore (ovvero nella libreria che contiene il BizLayer,il DataLayer e i Business Objects) ha senso inserire dei log anche nelle fasi successive a quelle dello sviluppo dell’applicazione, in quanto un errore grave, ad esempio nell’accesso al DB, deve essere tracciato per dar modo a chi di dovere di risolvere il problema. Invece nel file di log dell’applicazione WEB è utile inserire dei messaggi solo in questa fase di sviluppo, poiché gli errori che vi saranno inseriti non sono errori non previsti ma piuttosto messaggi di errore all’utente, in ogni caso gestiti dalla logica dell’applicazione. Anche i log sull’EventLog di Windows, i quali permettono una più rapida correzione dei bachi in fase di sviluppo, sono stati inseriti nel logger di Root poiché questi log potrebbero essere eliminati in fase di produzione del prodotto.

Capitolo 7 - Gestione dei log e la libreria di Logging Log4Net per il tracing degli eventi
80
Il logger “testLogger” è stato anch’esso utilizzato durante le fasi di sviluppo del progetto per fare il log delle Query, in modo da poter testare tutte le query lanciate durante la transazione distribuita e correggere immediatamente gli errori. Ecco la definizione di due variabili statiche di log usate per il logging in Anagrafica Programmi, la prima carica il logger radice , mentre la seconda utilizza il log specificato.
internal static readonly ILog log = log4net.LogManager.GetLogger(System.Reflection.MethodBase.GetCurrentMethod().DeclaringType); internal static readonly ILog log1= log4net.LogManager.GetLogger("testLogger", System.Reflection.MethodBase.GetCurrentMethod().DeclaringType);
Il risultato della dichiarazione di queste variabili sarà nella possibilità di utilizzarle per fare i log in tutti i punti del codice in cui ne abbiamo bisogno. I log perciò sono stati inseriti seguendo questa sintassi per un log a livello Debug:
log.Debug(“Messaggio da mettere nel log”); altrimenti a livello Error:
log.Error(“Messaggio da mettere nel log”);
Secondo le nostre necessità, dunque, abbiamo previsto:
• I log con livello Error per il livello DataLayer ; questi errori saranno sempre messi in un file di log
• I log a livello Debug di tutte le eccezioni scatenate a livello Business, che nella fase successiva allo sviluppo saranno eliminati, semplicemente attraverso la modifica del file di configurazione, alzando il livello nel logger
• I log a livello Debug durante la costruzione delle Query Sql, per la fase di Test delle Query
Grazie alla gestione centralizzata attraverso il file di configurazione, è possibile senza andare a ritoccare il codice dell’applicazione modificare in relazione alla fase di sviluppo il comportamento della libreria di Log. L’idea fondamentale è di andare via via ad eliminare tutte quelle informazioni aggiuntive, utilissime in fase di sviluppo e per la correzione dei bug applicativi, che non servono più con l’avanzare dello sviluppo.

81
Capitolo 8 I Web services e l’ arricchimento semantico dei file XSD
8.1 I Web services e .NET In questo capitolo ho deciso di parlare direttamente dei dettagli implementativi dei Web services che ho curato, invece per un ’introduzione ai Web services ho deciso di rimandare il lettore all’appendice. Attraverso il framework .NET vi sono due modi per implementare Web services che utilizzano come protocollo di trasporto HTTP. Il modo di più basso livello consiste nell’implementare direttamente l’interfaccia IHttpHandler, la quale va direttamente a specificare il contratto che ASP.NET implementa durante le richieste HTTP. La scrittura di un handler personalizzato richiede l’implementazione diretta da parte dello sviluppatore di tutto, ad esempio si dovrà scrivere a mano il documento WSDL oppure andare a scrivere i messaggi SOAP. Un metodo più semplice per implementare i Web services consiste nell’utilizzare i WebMethods resi disponibili dal FrameWork. I WebMethods forniscono un’implementazione di tutti i protocolli utilizzati nei Web services prefatta che permettono allo sviluppatore di realizzare dei Web services con estrema facilità. Ovviamente il tradeoff principale dei WebMethods sta nel fatto che non si possono realizzare Web services che si discostano molto dal modello fornito dal FrameWork; in molti casi può andar bene utilizzare i Web services già precotti di .NET ma in casi particolari, come nel progetto a cui ho partecipato, è necessario personalizzarne il comportamento, cercando di utilizzare il più possibile i WebMethods, visto che altrimenti i tempi di sviluppo e la produttività ne avrebbero risentito enormemente.

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
82
Per dare un’idea del tradeoff tra produttività e flessibilità dei Web services in .NET ripropongo un grafico di Microsoft:
Figura 8.1 Tradeoff tra produttività e flessibilità
I WebMethods permettono il mapping dei messaggi SOAP in metodi contenuti all’interno di classi di .NET. Questo viene realizzato in modo molto semplice inserendo l’etichetta [WebMethod] come cappello al metodo che si desidera rendere un servizio. Ecco un esempio, tratto da un primo scheletro dei miei Web services:
using System.Web.Services.Protocols; using it.reply.cluster.webservices.validation; using it.reply.cluster.ExceptionManagement; namespace Commessa { [WebService(Namespace="http://www.rai.it/anagraficaprogrammi")] [ValidationUri("http://localhost/Schemas/RaiXmlSchema.xsd",true)] [SoapDocumentService(RoutingStyle=SoapServiceRoutingStyle. RequestElement)] public class WsCommessa : System.Web.Services.WebService { [Validation(SchemaValidation=true,CheckAssertions=false)] [WebMethod] public void VariazTitoloCommessa(Commessa Commessa) {
...Codice del metodo...
}

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
83
[Validation(SchemaValidation=true,CheckAssertions=false)] [WebMethod] public void AggregaCommessa(Commessa Commessa1,
Commessa Commessa2) { if(Commessa1.PrdCommessa.Equals(Commessa2.PrdCommessa)) { throw new SoapException(
ExceptionManager.LoadErrorType(err0002), SoapException.ServerFaultCode, HttpContext.Current.Request.Url.AbsoluteUri;
} ...Codice del metodo...
} } }
Quando un messaggio che si riferisce a un file con estensione asmx ( ovvero un Web service .NET) entra nella pipeline HTTP di .NET, quest’ultima chiama la classe WebServiceHandlerFactory che a sua volta istanzia un nuovo oggetto WebServiceHandler che viene utilizzato per attuare la richiesta (attraverso la chiamata del metodo IHttpHandler ProcessRequest). L’handler che si occupa dei Web services si occupa fondamentalmente di altre tre cose:
• Il message dispatching • Il mapping dell’Xml in oggetti • La generazione automatica dei documenti WSDL e della documentazione
Non voglio in ogni modo entrare nei dettagli dell’implementazione dei Web services di .NET ma solo dei componenti che sono andato a toccare, mano a mano che andrò ad illustrare nel dettaglio lo scheletro di codice inserito di sopra. Nel codice soprastante si nota l’utilizzo di una libreria chiamata it.reply.cluster.webservices.validation utilizzata per la validazione dei dati in ingresso al Web service e i vari attributi [Validation] che non sono predefiniti ma contenuti nella libreria in questione; adesso cercherò di spiegare dall’inizio per quale motivo abbiamo realizzato questa libreria.
8.2 La validazione nei WebMethod ASP.NET attraverso l’arricchimento semantico dei file XML Schema
�
Come ho già avuto modo di dire, i WebMethods ASP.NET hanno una scarsa flessibilità; mi spiego meglio, ad esempio i WebMethods non si occupano della validazione dei messaggi sulla base di un XML Schema: questo è quello che intendo fare con l’introduzione della libreria di Validazione, per la realizzazione della quale ho tratto un ottimo spunto da un lavoro di Aaron Skonnard e Dan Sullivan.

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
84
Per fare ciò mi sono occupato di estendere le capacità di validazione dei WebMethods con l’aggiunta di una validazione più sofisticata basata su XML Schema, utilizzando la classe SoapExtension. Ad esempio, con i WebMethods può accadere che, al posto di produrre un SoapFault, quando si tenta di fare dei calcoli con dati non coerenti, il sistema ritorni semplicemente uno zero in ogni caso; questo comportamento, come tanti altri problemi dello stesso tipo, è inaccettabile, poiché i Web services del progetto “Anagrafica Programmi” sono responsabili di una prima validazione “grossolana” e meno fine dei dati; per grossolana intendo che non sarà il Web service a verificare le relazioni di dipendenza tra dati accedendo al DB, ma sarà la logica di Business sottostante; il Web service si occuperà di validare dati palesemente errati, che ci porterebbero ad errori immediati nelle nostre computazioni. La mancanza di controlli formali sui dati in ingresso ad un WebMethod, può causare dunque l’accettazione di dati errati da parte del WebMethod. La ragione di tale comportamento è dovuta al funzionamento della classe XmlSerializer, che i WebMethods utilizzano durante la serializzazione e deserializzazione dei dati Xml. La classe XmlSerializer non esegue nessuna forma di validazione attraverso XML Schema e la conseguenza di ciò è che particolari strutture dati, il loro ordinamento e semplicemente le limitazioni sui dati non sono prese in considerazione durante la serializzazione. Adesso vediamo come fare invece tale validazione attraverso le estensioni dei WebMethods.
8.3 Estensione dei WebMethods L’idea di base è di sfruttare le caratteristiche di estendibilità dei WebMethods per introdurre la validazione. Ci sono due principali meccanismi che permettono l’estensione dei WebMethods:
• Moduli http • Classe SoapExtension
Un modulo http è semplicemente una classe derivata dall’interfaccia IHttpModule che viene configurata per girare in una particolare virtual root utilizzando il file di configurazione web.config. I moduli http possono essere utilizzati per estendere qualunque tipo di applicazione http e rendono possibile il pre- e post-processing sui messaggi http che viaggiano attraverso la pipeline http (vedi figura seguente).

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
85
Figura 8.2 Moduli http
I moduli http ci obbligano a lavorare a livello di messaggi, tuttavia questo è un approccio di basso livello che richiederebbe l’implementazione manuale dei messaggi SOAP. Inoltre, dal momento in cui i moduli http sono configurati per lavorare su un’intera directory virtuale, è abbastanza difficile abilitare o meno tali funzionalità a livello di classi .NET, ancora di meno per quanto riguarda i metodi. L’altra tecnica per estendere le funzionalità dei WebMethods viene chiamata SoapExtension; in questo approccio essenzialmente si tratta di derivare una nuova classe dalla classe SoapExtension e fare l’override di alcuni dei suoi membri. La SoapExtension sarà chiamata prima e dopo ogni chiamata al WebMethod, come si può vedere nella figura sottostante.
Figura 8.3 Le SoapExtensions
Le possibilità di utilizzo delle SoapExtensions sono svariate, io mi soffermerò solo su come utilizzarle per la validazione dei messaggi associati a dei metodi richiamati.

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
86
Le SoapExtensions andranno a validare i messaggi entranti attraverso l’uso di un XML Schema corrispondente (XSD). In base al risultato della validazione sarà permesso al metodo di procedere con le sue operazioni oppure sarà inviato al client un “SOAP fault message” opportuno che descrive la condizione verificatasi. La prossima figura mostra il flow chart di base seguito da questa implementazione:
Figura 8.4 La validazione dei messaggi
Le SoapExtensions sono il metodo che è stato scelto poiché danno un maggior controllo sulla configurazione e hanno granularità di utilizzo riferita ai singoli metodi.
8.3.1 Le Estensioni SOAP Si può configurare le SoapExtensions affinché controllino un’intera directory virtuale, ma non è quello che vogliamo poiché otterremo un comportamento simile ai moduli http, oppure abilitarle su un singolo metodo. Ecco il codice da inserire nel file di configurazione web.config che a sua volta è contenuto all’interno dell’elemento <webServices> :
<soapExtensionTypes> <add type=
"it.reply.cluster.webservices.ValidationExtension, it.reply.cluster.webservices" priority="1" group="0" />
</soapExtensionTypes> Per configurare la SoapExtension su un singolo metodo c’è la necessità di realizzare un attributo (ovvero quello che io ho già chiamato cappello o intestazione al metodo di questo tipo: [attributo] ) che deriva dalla classe SOAPExtensionAttribute. Ecco una parte del codice della classe ValidationAttribute contenuta nella nostra libreria di Validazione:
[AttributeUsage(AttributeTargets.Method,

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
87
AllowMultiple = false)] public class ValidationAttribute : SoapExtensionAttribute {
int priority = 0; bool _schemaValidation = true; bool _checkAssertions = true;
// abilito schema validation? public bool SchemaValidation { get { return _schemaValidation; } set { _schemaValidation = value; } } // abilito assertion processing? public bool CheckAssertions { get { return _checkAssertions; } set { _checkAssertions = value; } } //resto del codice della classe... }
Inoltre ho deciso di inserire degli attributi particolari che si sono resi necessari nello sviluppo del progetto Anagrafica Programmi. Ecco la lista di tutti gli attributi definiti nella libreria di Validazione con una breve descrizione:
• ValidationAttribute: è l’attributo principale, permette di attivare la validazione mediante Schema validation o la validazione mediante Assertion XPath
• ValidationUriAttribute: questo attributo specifica come sorgente degli XmlSchema una URI remota, in modo da mettere gli XML Schema in un repository remoto situato in un qualsiasi punto della rete; permette di fare l’autenticazione Kerberos, NTLM oppure Semplice (l’accesso al repository è definito nel metodo LoadSchemaFromExternalUri, il quale si occupa anche di verificare l’autenticazione)
• ValidationSchemaCache, ValidationSchema sono due attributi meno generali del precedente che sono stati mantenuti perché contenuti nella precedente versione della libreria e si occupano di recuperare lo Schema in locale
• AssertNamespaceBinding: specifica il namespace al quale vengono applicate le XPath assertions
Non voglio entrare nel merito della spiegazione di ogni singola funzionalità della libreria di Validazione, ma mi basta che il lettore abbia ben chiaro che i due attributi che principalmente sono stati usati per la costruzione dei Web services in Anagrafica Programmi sono quello che abilita la validazione e l’attributo che permette di recupera gli Xml Schema da URI.

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
88
Nella Figura sottostante invece è rappresentato il dettaglio dei passi del funzionamento delle estensioni SOAP, facendo una distinzione fra la prima chiamata e tutte le successive chiamate del metodo.
Figura 8.5 I meccanismi di funzionamento delle SOAP Extensions
La classe ValidationExtension che deriva dalla classe di base .NET SoapExtension fa l’override dei metodi necessari, descritti rapidamente nella seguente tabella. Metodo Descrizione GetInitializer(serviceType) Chiamato una volta per la directory virtuale la prima volta
che ogni Webmethod viene chiamato e memorizza gli oggetti ritornati
GetInitializer(methodInfo, attribute)
Viene chiamato una volta per ogni WebMethod (se configurato con un SoapExtensionAttribute
Initialize(object) Chiamato all’invocazione dei WebMethods
ProcessMessage(...) Chiamata 4 volte ad ogni chiamata di un WebMethod (si occupa del pre e post processing)
Ogni volta che un WebMethod viene chiamato, l’applicazione crea una nuova istanza della classe SoapExtension . Il framework delle SoapExtensions fornisce un GetInizializer e inizializza i metodi. La prima volta che ogni WebMethod viene invocato, l’infrastruttura verifica se qualche SoapExtension è stata inserita nel file di configurazione dell’applicazione; se vi sono delle estensioni inserite l’infrastruttura crea un’istanza di ognuna di esse e chiama il metodo GetInizializer nella quale vengono fatte tutte le inizializzazioni e raccolte tutte le informazioni in un oggetto che viene ritornato al sistema.

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
89
L’infrastruttura memorizza l’oggetto ritornato e lo passa al metodo Initialize, che viene poi chiamato ad ogni chiamata del WebMethod. Inoltre durante la prima chiamata vengono passati al GetInizializer anche gli attributi specificati nel WebMethod. Come si può notare nella figura 8.5 ci sono due parti dell’inizializzazione, una viene fatta alla prima chiamata quando il GetInizializer viene chiamato e ritorna un oggetto che viene memorizzato dal runtime per gli accessi futuri; l’altra fase avviene passando l’oggetto di inizializzazione alla funzione ProcessMessagge. Il metodo ProcessMessagge viene poi chiamato quattro volte per ogni messaggi, abbiamo la fasi: BeforeSerialize,AfterSerialize,BeforeDeserialize,AfterDeserialize��L’estensione della libreria di validazione si occupa solo di validare i messaggi prima della deserializzazione (perciò nel codice della ProcessMessage vi sarà solo quest’ultima, le altre fasi non saranno toccate dall’estensione). Questa implementazione carica il messaggio in un oggetto XmlTextReader e poi lo incapsula dentro un XmlValidatingReader che, dopo aver caricato l’Xml Schema, si occupa di leggere lo stream di dati, e di validarlo; nel caso in cui la validazione non andasse a buon fine scatenerà un’eccezione con la descrizione del problema. Tale eccezione sarà poi rimpacchettata in un SOAP fault response message per il client. Fondamentalmente questo metodo si basa sull’utilizzo della classe XmlValidatingReader piuttosto dell’XmlReader che avrebbe usato per default. Il repository di XML Schema Adesso ci tengo a dire qualcosa riguardo alla collocazione degli XML Schema, di cui non ho ancora parlato dettagliatamente. Probabilmente la soluzione più semplice e meno dispendiosa in termini di “sviluppo” sarebbe di metterli in una sottodirectory della directory virtuale e caricarli ogni volta che se ne presenta la necessità; anche se sembra la soluzione più ovvia è poco efficiente in quanto costa molto caricare gli XML Schema dalla directory virtuale quando ne abbiamo bisogno. La soluzione migliore sta nel caricarli in una struttura apposita facendo uso del metodo GetInizializer all’avvio dell’applicazione. Gli XML Schema di cui avremo bisogno saranno quindi in una XMLSchemaCollection .NET che sarà caricata all’atto della chiamato del metodo GetInizializer. Adesso però ci tengo a illustrare la classe WsCommessa, che ho già precedentemente mostrato, attraverso qualche esempio di scenari di colloquio.
8.3.2 Scenari di colloquio con i Web services di Anagrafica Programmi Per realizzare questi test ho dovuto creare un paio messaggi SOAP da inviare ai Web services; in questa prima fase di test ho utilizzato un javascript che invia mediante Post la richiesta ai Web services, eccone il comando:

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
90
• post "http://localhost:8080/ProvaWS/Commessa.asmx" -h content-type "text/xml" -h soapAction "''" -f %1
Come si può notare la richiesta è inviata sulla porta 8080 poichè su quella porta ho opportunamente messo in ascolto la Trace Utility del SOAP Toolkit di Microsoft che non fa altro che intercettare lo scambio di messaggi SOAP tra Web Server e il client. Ecco un primo esempio in cui cerco di richiamare il WebMethod AggregaCommessa che si occupa appunto di unire due commesse in una sola, secondo un particolare algoritmo.
<soap:Envelope xmlns:xsi= "http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body> <AggregaCommessa xmlns= "http://www.rai.it/anagraficaprogrammi"> <Commessa1> <PrdTitolo>Arturo Pisapia Tesi di Laurea </PrdTitolo> <PrdCommessa>A02233</PrdCommessa> <PrdTipoCommessa>A</PrdTipoCommessa> </Commessa1> <Commessa2> <PrdTitolo>Arturo Pisapia
Tesi di Laurea </PrdTitolo> <PrdCommessa>A03133</PrdCommessa> <PrdTipoCommessa>A</PrdTipoCommessa> </Commessa2> </AggregaCommessa> </soap:Body>
</soap:Envelope> Come si può facilmente notare nell’Envelope SOAP è presente un Body che contiene l’elemento AggregaCommessa e le due commesse da aggregare. Questo messaggio è ben formato in quanto segue l’ XML Schema che viene caricato all’atto dell’avvio della libreria di validazione, eccone un estratto che riguarda la sola validazione degli oggetti che rappresentano una commessa:
<!-- dati riguardanti la Commessa --> <s:simpleType name="PrdCommessaT"> <s:restriction base="s:string"> <s:pattern value="([0-9]|[A|T])\c{5}" />

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
91
</s:restriction> </s:simpleType> <s:simpleType name="PrdTipoCommessaT"> <s:restriction base="s:string"> <s:pattern value="[A|E]" /> </s:restriction> </s:simpleType> <s:complexType name="Commessa"> <s:sequence>
<s:element minOccurs="0" maxOccurs="1" name="PrdUtenteVar" type="s:string"/> <s:element minOccurs="0" maxOccurs="1" name="PrdDataOraVar" type="s:dateTime"/> <s:element minOccurs="0" maxOccurs="1" name="PrdUtenteImm" type="s:string"/> <s:element minOccurs="0" maxOccurs="1" name="PrdDataOraImm" type="s:dateTime"/> <s:element minOccurs="1" maxOccurs="1" name="PrdTitolo" type="s0:Titolo40T"/> <s:element minOccurs="1" maxOccurs="1" name="PrdCommessa" type="s0:PrdCommessaT"/> <s:element minOccurs="1" maxOccurs="1" name="PrdTipoCommessa" type="s0:PrdTipoCommessaT" />
</s:sequence> </s:complexType>
Se diamo un’occhiata a questo scorcio di XML Schema si nota che il tipo semplice PrdCommessaT è una stringa che deve iniziare con un numero o una delle due lettere A o T e la sua lunghezza deve essere pari a 6 caratteri; invece il tipo PrdTipoCommessaT deve essere necessariamente un solo carattere tra A o E. Se passiamo poi alla definizione del tipo complesso Commessa si potrà notare che è composto da alcuni tipi semplici e dai tipi che abbiamo dichiarato precedentemente; alcuni elementi poi possono esserci o meno, mentre altri sono obbligatori, perciò sono stati impostati minOccurs e maxOccurs opportunamente a seconda dell’elemento. Analizzando l’XML Schema ci aspettiamo che tutto, per quanto riguarda la validità dei dati dal punto di vista semantico, è corretto. Infatti, ecco la SOAP Response che riceviamo, senza alcun SOAP fault: <?xml version="1.0" encoding="utf-8" ?> <soap:Envelope
xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
92
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<soap:Body> <AggregaCommessaResponse xmlns=
"http://www.rai.it/anagraficaprogrammi" /> </soap:Body> </soap:Envelope> Se invece costruiamo un SOAP message che contiene dati che non rispettano l’XML Schema che ho sviluppato, come il seguente:
<soap:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/"> <soap:Body>
<AggregaCommessa xmlns="http://www.rai.it/anagraficaprogrammi">
<Commessa1> <PrdTitolo>Prova errore</PrdTitolo>
<PrdCommessa>A999BB</PrdCommessa> <PrdTipoCommessa>A</PrdTipoCommessa> </Commessa1> <Commessa2> <PrdTitolo>Prova errore</PrdTitolo> <PrdCommessa>A99999</PrdCommessa> <PrdTipoCommessa>A</PrdTipoCommessa> </Commessa2> </AggregaCommessa> </soap:Body> </soap:Envelope>

Capitolo 8 - I Web services e l’ arricchimento semantico dei file XSD
93
Ecco invece il messaggio contenuto nel SOAP Fault della risposta del Server:
System.Xml.Schema.XmlSchemaException: The 'http://www.rai.it/anagraficaprogrammi:PrdCommessa' element has an invalid value according to its data type. An error occurred at , (12, 25)
La risposta ottenuta è quello che mi aspettavo poiché indica che si è verificata una XmlSchemaException alla riga 12 del messaggio inviato, ovvero nel punto in cui inseriamo il codice della commessa 1 con gli ultimi campi con due caratteri alfabetici e non numerici, come lo Schema si aspetta. Si noti che l’XML Schema che ho creato non può fare tutte le verifiche dei dati, ma solo quelle semantiche che rappresentano gli errori formali nell’inserimento dei dati; altri controlli di coerenza dei dati, come il test fatto nel codice d’esempio nel metodo di aggregazione delle commesse, dove si verifica se il codice delle due commesse non è uguale; oppure ci sono verifiche che vengono fatte sul DataBase, che si devono fare successivamente nel Business Layer. Il messaggio d’errore che restituisce l’eccezione di XmlSchema purtroppo non è molto significativo, credo infatti che chi ha sviluppato questa classe di eccezione avesse in mente di dare un messaggio leggibile dall’utente finale, ma in realtà non è molto utile per lo sviluppatore che vuole dare dettagli ulteriori relativi all’errore avvenuto; in ogni caso nei Web services mi è sufficiente avere a disposizione il nome dell’elemento in cui si è verificato un errore formale.

94
Capitolo 9 Conclusioni Nello sviluppo di questa anagrafica, come si evince dalle trattazioni del mio documento di tesi, sono stati fatti diversi sforzi al fine di realizzare un’applicazione realmente mantenibile, scalabile e in grado di sfruttare le potenzialità del framework .NET. Per quanto riguarda i test dell’applicazione, siamo in un’avanzata fase di collaudo; posso affermare che tutti i test svolti sono andati a buon fine. Il nodo critico della nostra applicazione è dato dal collo di bottiglia che inevitabilmente ci pone il protocollo di two-phase commit. È impensabile fare una transazione sincrona, al fine di replicare i dati del nostro DB su un altro, senza avere una rilevante diminuzione delle prestazioni. In ogni modo dopo diversi test e affinamenti successivi siamo arrivati ad ottenere prestazioni del tutto comparabili con quelle del vecchio sistema. Si tenga presente che entro qualche mese, quando tutti i sistemi saranno aggiornati, sarà possibile disattivare la transazione distribuita utilizzando solo il nuovo DBMS, ottenendo così un aumento delle prestazioni notevole. Per quanto riguarda i Web services abbiamo già fatto dei test di dialogo con i sistemi principali, ottenendo buoni risultati. Grazie alla validazione dei dati a livello formale evitiamo, in caso di errori nei dati, inutili chiamate alla logica di Business; possiamo oltremodo affermare che grazie alla pubblicazione di un apposito XmlSchema che caratterizza tutti gli oggetti di Business passati al Web services gli errori più grossolani saranno solo appannaggio di questa prima fase di test, poiché quando l’applicazione entrerà in fase di produzione tutti i sistemi si adegueranno ad esso. Si noti che in una prima fase d’analisi si intendeva riutilizzare completamente, a meno di qualche piccola modifica, i metodi del livello di Business e Dati per i Web services. La nuova necessità del cliente di lavorare su N aggiornamenti o inserimenti sul DB per volta, ci ha portati ad estendere il comportamento delle transazioni, portandole ad un livello più alto di quello che era stato previsto precedentemente. Inoltre ho potuto notare che la gerarchia di eccezioni introdotta nel capitolo 6 permette di gestire le eccezioni in modo calzante con le necessità del progetto, anzi ho anche esteso la BusinessException con una nuova proprietà che permette di trasportare una collezione di

Capitolo 9 - Conclusioni
95
errori al suo interno; questa miglioria ci permette di creare messaggi di errore particolari per i Web services, che necessitano di maggiori informazioni rispetto alla Web application. Infatti, è possibile attraverso i Web services aggiornare N puntate di una data matricola e non una sola come nel caso Web, perciò è necessario aggiungere queste informazioni al messaggio d’errore. Queste modifiche alla classe di BusinessException sono state semplici da realizzare, soprattutto grazie al lavoro architetturale di cui ho già parlato nel sesto capitolo.

96
Appendice
A.1 Introduzione ai Web services Ci sono diversi sistemi che vengono, propriamente o meno, chiamati Web Services; per evitare di fuorviare il lettore ecco la definizione di Web Services proposta dell’ente di standardizzazione W3C: [A Web service is a software system designed to support interoperable machine-to-machine interaction over a network. It has an interface described in a machine-processable format (specifically WSDL). Other systems interact with the Web service in a manner prescribed by its description using SOAP-messages, typically conveyed using HTTP with an XML serialization in conjunction with other Web-related standards.] Un Web Service è dunque un programma attraverso il quale un sistema può fare delle richieste ad un altro sistema, siano essi dei programmi, degli oggetti o l’accesso ad una base di dati, attraverso l’uso di messaggi XML.
Figura A.1 I Web services
Inoltre la parola chiave nella definizione precedente è interoperabilità, siccome i Web services spesso sono usati per permettere a sistemi che non si comprendono di dialogare attraverso la rete. I Web services sono una piattaforma sulla quale lo sviluppatore può costruire le stesse applicazioni distribuite del passato, ma in questo caso l’interoperabilità è elevata ai massimi livelli. Un programma invia una richiesta XML ad un Web service attraverso la rete e, secondo l’esito della richiesta, riceve una risposta, anch’essa utilizzando un messaggio XML. In questo modo i Web services non sono vincolati ad un particolare sistema operativo o ad un linguaggio di programmazione; gli standard definiscono il formato dei messaggi, le
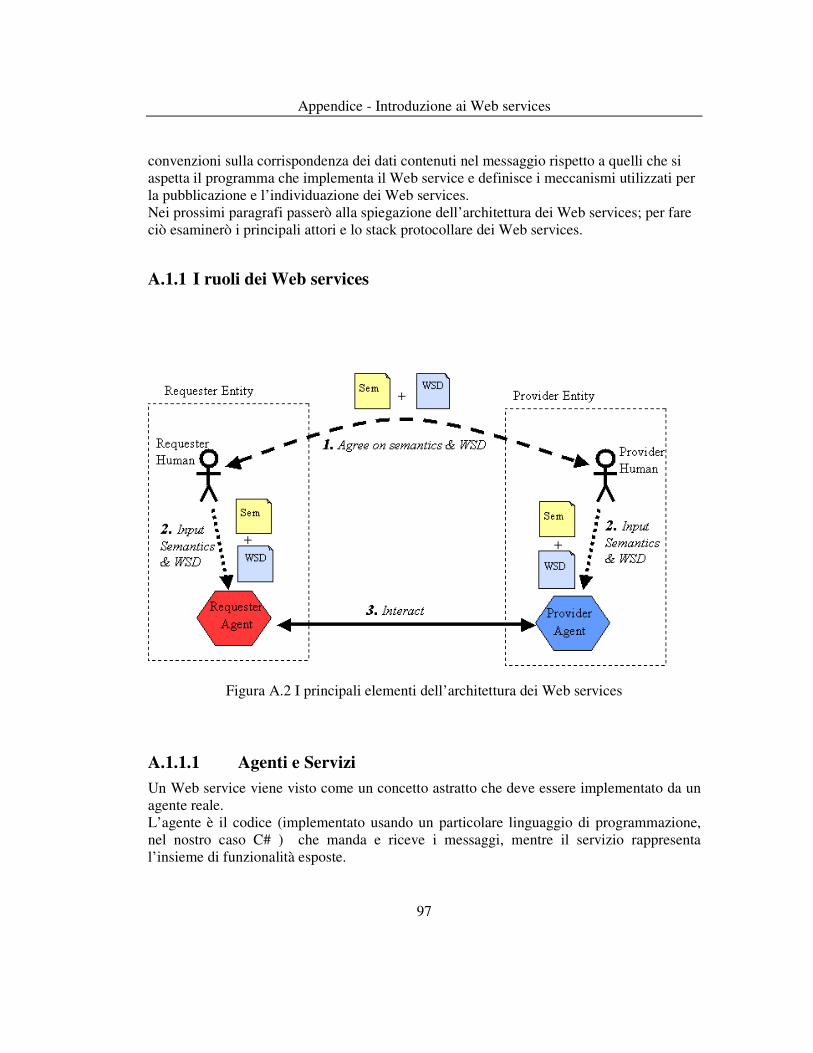
Appendice - Introduzione ai Web services
97
convenzioni sulla corrispondenza dei dati contenuti nel messaggio rispetto a quelli che si aspetta il programma che implementa il Web service e definisce i meccanismi utilizzati per la pubblicazione e l’individuazione dei Web services. Nei prossimi paragrafi passerò alla spiegazione dell’architettura dei Web services; per fare ciò esaminerò i principali attori e lo stack protocollare dei Web services.
A.1.1 I ruoli dei Web services
Figura A.2 I principali elementi dell’architettura dei Web services
A.1.1.1 Agenti e Servizi Un Web service viene visto come un concetto astratto che deve essere implementato da un agente reale. L’agente è il codice (implementato usando un particolare linguaggio di programmazione, nel nostro caso C# ) che manda e riceve i messaggi, mentre il servizio rappresenta l’insieme di funzionalità esposte.

Appendice - Introduzione ai Web services
98
A.1.1.2 Requester e Provider Il fine di un Web service è quello di fornire alcune funzionalità a beneficio di chi lo utilizza; la provider entity è la persona o l’organizzazione che espone un apposito agent ( agente) che implementa un particolare servizio (vedi figura A.2). Un richiedente (requester entity) è la persona o l’organizzazione che vorrebbe usare un Web service. Il richiedente farà uso di un requester agent per scambiare messaggi col provider agent della provider entity. Per fare in modo che lo scambio di messaggi vada a buon fine, le due entità coinvolte nel dialogo devono essere d’accordo sulla semantica e sui meccanismi di scambio del messaggio.
A.1.1.3 La descrizione del servizio (Web service description) Il meccanismo sulla quale si basa lo scambio dei messaggi viene documentato nella descrizione del Web service (WSD). Il WSD è una specifica machine-processable dell’interfaccia del Web service. Questo file definisce il formato dei messaggi, i datatypes, il protocollo di trasporto, il formato per la serializzazione dei dati e stabilisce una o più collocazioni sulla rete alle quali un provider agent può essere interrogato.
A.1.1.4 La Semantica La semantica nello scambio dei messaggi rappresenta il contratto tra il richiedente e il provider e tiene conto dello scopo e dei risultati ottenibili in seguito all’interazione fra le due parti. La semantica contiene anche tutti i dettagli sui meccanismi di scambio dei messaggi che non sono esplicitamente definiti nella WSD. Mentre la WSD rappresenta un contratto che governa tutti i meccanismi d’interazione con un servizio, la semantica raffigura le convenzioni sul significato e lo scopo dell’interazione.
A.1.1.5 Il ruolo dell’uomo • Dovrà essere d’accordo sulla WSD e sulla semantica, spesso parlandone • Si dovrà assicurare che un agent implementi un particolare servizio definito a priori
oppure definito di volta in volta in modo dinamico

Appendice - Introduzione ai Web services
99
A.1.2 Lo stack protocollare di un Web service
Figura A.3 – Stack protocollare dei Web services
Prima di tutto è essenziale dire che il linguaggio XML è la base fondamentale su cui si basa l’architettura dei Web services, poiché rappresenta l’artefice dell’interoperabilità su cui essi si basano. Inoltre l’XML ci permette di distinguere il payload dai dati protocollari, cosa necessaria in molte infrastrutture IT che sono realizzate su componenti proprietari. Quindi la tecnologia di base di un WS è composta da XML 1.x, XML Schema Description Language e XML Base specification. I servizi sono invocati e forniscono un risultato attraverso messaggi che devono essere scambiati attraverso l’utilizzo di un particolare mezzo di comunicazione; i WS abbracciano una gran varietà di protocolli di comunicazione: HTTP, SMTP, FTP e molti altri. I messaggi inoltre sono trasmessi attraverso il protocollo SOAP; mentre è possibile trasferire messaggi molto semplici senza farne uso, diventa difficile trasferire massaggi

Appendice - Introduzione ai Web services
100
sicuri, attendibili, composti da diversi parti. SOAP è uno standard per il packaging delle informazioni nei messaggi, molto robusto e potente. Inoltre per attuare l’interoperabilità in sistemi eterogenei è necessario un meccanismo che permette di comprendere la struttura dei messaggi del Web service al produttore ed al consumatore del servizio. Il WSDL è utilizzato proprio a tale fine. Inoltre se il richiedente non conosce quale provider agent potrà fornirgli il servizio richiesto allora avrà bisogno di utilizzare una funzionalità di discovery che gli permetta di trovare una WSD che corrisponda al servizio di cui ha bisogno, al tal fine viene utilizzato UDDI. Adesso passerò alla spiegazione di tutte le tecnologie contenute nei livelli all’interno del riquadro verde della figura soprastante, tralasciando le specifiche sull’XML che sono ad oggi universalmente note.
A.1.2.1 SOAP L’acronimo SOAP significa “Simple Object Access Protocol”, in passato gli autori di questo protocollo si sono concentrati sullo sviluppo di un protocollo per l’accesso ad oggetti, ma ad oggi si è pensato di utilizzarlo per fini più generali. Quindi l’obiettivo della specifica si è spostata velocemente dagli oggetti a messaggi XML generici, ed il nome SOAP è rimasto tale per non fuorviare gli sviluppatori. La definizione di SOAP che si trova nella più recente specifica è la seguente: SOAP is a lightweight protocol intended for exchanging structured information in a decentralized, distributed environment. SOAP uses XML technologies to define an extensible messaging framework, which provides a message construct that can be exchanged over a variety of underlying protocols. The framework has been designed to be independent of any particular programming model and other implementation specific semantics. Questa definizione rappresenta fedelmente SOAP, si noti come all’interno della definizione non compare nessun riferimento ad oggetti. SOAP definisce un modo di inviare messaggi XML da un punto A ad un punto B. Tutto ciò viene fatto attraverso un framework che deve essere:
1. Estensibile 2. Utilizzabile su diversi protocolli di rete sottostanti 3. Indipendente dal modello di programmazione utilizzato

Appendice - Introduzione ai Web services
101
Figura A.4 – messaggio SOAP
L’estensibilità è un requisito fondamentale di SOAP; per rendere SOAP realmente estensibile si è deciso di lasciarlo molto semplice e privo di molte delle funzionalità che uno sviluppatore si aspetterebbe da un protocollo che riguarda i sistemi distribuiti, quali la sicurezza e l’instradamento. Tutte le caratteristiche che mancano saranno poi aggiunte, a discrezione dello sviluppatore, in base alle necessità di progetto attraverso delle SOAP extensions. SOAP può inoltre essere utilizzato su TCP, HTTP, SMTP e altri protocolli; tutto ciò facilità l’interoperabilità soprattutto quando si desidera utilizzare un protocollo che è al di fuori di quelli comunemente usati. SOAP inoltre permette di utilizzare qualsiasi paradigma di programmazione e non è legato necessariamente all’RPC. Vi è la possibilità di spedire messaggi in un solo verso dove chi invia il messaggio non riceve nessuna risposta oppure è possibile avere una comunicazione in entrambe le direzioni, come mostrato nella figura seguente.
Figura A.5 Messaggio SOAP e risposta

Appendice - Introduzione ai Web services
102
I messaggi SOAP
Figura A.6 Messaggio SOAP
I messaggi SOAP contengono due elementi sottostanti all’elemento principale Envelope: • Header, è l’intestazione, si tratta di un elemento opzionale e contiene diverse
informazioni che si collocano nel contesto dei messaggi • Body, è obbligatorio e contiene le informazioni principali che si desidera inviare; il
Body è un contenitore generico e può contenere qualsiasi tipo di informazione È evidente che in relazione ai punti a favore di SOAP si è scelto di utilizzarlo per lo scambio dei messaggi per i Web services.

Appendice - Introduzione ai Web services
103
A.1.2.2 WSDL Uno scambio di messaggi viene riferito ad un’operazione con la quale chi usufruirà del servizio interagisce; tuttavia quando si interroga un nuovo Web service, si dovrà prima di tutto esaminare una lista delle azioni supportate in modo di sapere cosa offre il servizio. Un XML Schema dice semplicemente come il messaggio XML viene usato ma non come viene riferito rispetto a tutto il resto. Per esempio se vi sono due elementi XML chiamati Add a AddResponse è ovvio che avranno una qualche correlazione ma non c’è modo di indicare tale relazione nello Schema. Quindi gli utenti del servizio dovranno essere consapevoli della possibile interazione dei messaggi da parte del Web service, ad esempio se io mando un messaggio Add allora riceverò come risposta un AddResponse message. Uno scambio di messaggi viene chiamato operazione (operation), le operazioni sono quello che maggiormente interessa ai fruitori del servizio visto che rappresentano il punto cardine dell’interazione che si avrà col Web service. Ogni volta che contatto un nuovo Web service la prima cosa da fare sarà di leggere la lista di tutte le operazioni supportate per avere un’idea di quali sono le sue funzionalità.
Figura A.7 messaggi e operazioni
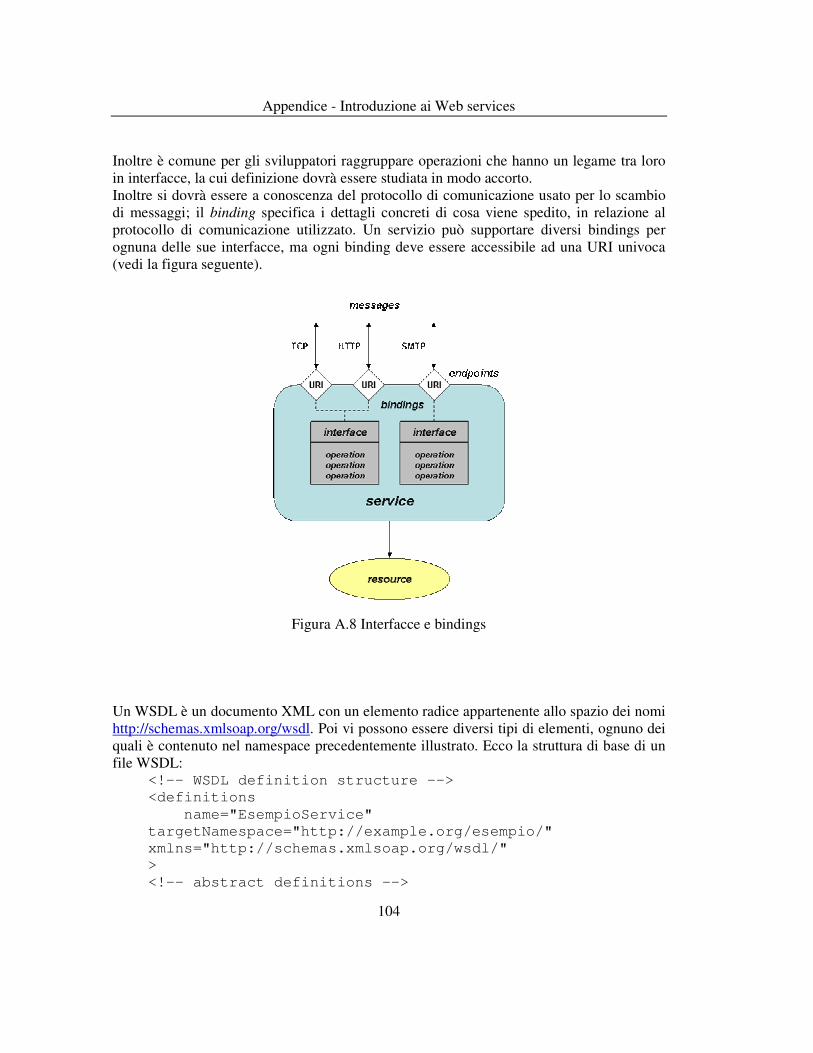
Appendice - Introduzione ai Web services
104
Inoltre è comune per gli sviluppatori raggruppare operazioni che hanno un legame tra loro in interfacce, la cui definizione dovrà essere studiata in modo accorto. Inoltre si dovrà essere a conoscenza del protocollo di comunicazione usato per lo scambio di messaggi; il binding specifica i dettagli concreti di cosa viene spedito, in relazione al protocollo di comunicazione utilizzato. Un servizio può supportare diversi bindings per ognuna delle sue interfacce, ma ogni binding deve essere accessibile ad una URI univoca (vedi la figura seguente).
Figura A.8 Interfacce e bindings
Un WSDL è un documento XML con un elemento radice appartenente allo spazio dei nomi http://schemas.xmlsoap.org/wsdl. Poi vi possono essere diversi tipi di elementi, ognuno dei quali è contenuto nel namespace precedentemente illustrato. Ecco la struttura di base di un file WSDL:
<!-- WSDL definition structure --> <definitions name="EsempioService" targetNamespace="http://example.org/esempio/" xmlns="http://schemas.xmlsoap.org/wsdl/" > <!-- abstract definitions -->

Appendice - Introduzione ai Web services
105
<types> ... <message> ... <portType> ... <!-- concrete definitions --> <binding> ... <service> ... </definition>
Ecco le spiegazioni di ogni elemento contenuto nella struttura di base del WSDL:
Nome dell’elemento
Descrizione
types Un contenitore per la definizione di dati astratti attraverso un XML Schema
message Una definizione che può essere composta da diverse porzioni, ognuna delle quali potrebbe essere diversa
portType Un insieme di operazione supportate da una o diverse interfacce; ogni operazione si riferisce ad un messaggio in ingresso e ad uno in uscita
binding Specifica il protocollo utilizzato e il formato dei dati da utilizzare per ogni portType
service Rappresenta una collezione di interfacce, dove ognuna di esse è definite come combinazione di bindings con un indirizzo URI univoco
Tabella A.9 Elementi del WSDL
A.1.2.3 UDDI Il termine UDDI significa Universal Description, Discovery and Integration e rappresenta una specifica che definisce un modo per pubblicare e “scoprire” informazioni su Web services. Il componente principale di UDDI è la business registration, un file XML utilizzato per descrivere una business entity ed i suoi Web services.

Appendice - Introduzione ai Web services
106
Concettualmente le informazioni fornite da una UDDI business registration consistono di tre componenti: la “white pages” che contengono l’indirizzo, la lista di contatti, ecc; la “yellow pages” che contengono il settore di cui fa parte la compagnia; le informazioni tecniche sui servizi esposti contenute nelle “green pages”. Non voglio entrare nel merito del funzionamento tecnico di UDDI, ma ne ho fatto solo un breve cenno, poiché è un elemento di rilievo dell’architettura di un Web service, ma non è stato utilizzato nel mio progetto.

107
Bibliografia
[1] Jeffrey Richter, “Advanced Programming for Microsoft .NET”, Prima edizione, Microsoft Press, 2002
[2] Tom Archer, “Inside C#”, Seconda edizione, Microsoft Press, 2002
[3] Adrian Turtshci et al., “C# .NET. Web Developer's Guide”, Prima edizione, Syngress, Dicembre 2001
[4] Jesse Liberty & Dan Hurwitz, “Programming ASP.NET”, O'Reilly & Associates, Settembre 2003,�ISBN: 0596004877
[5] Emmerich, W. Engineering Distributed Objects. New York: John Wiley & Sons, 2000, ISBN: 0471986577
[6] Dino Esposito, ”Applied XML Programming for Microsoft .NET”, Prima Edizione, Microsoft Press, Ottobre 2002, ISBN: 0735618011
[7] Microsoft Patterns and Practices, “Microsoft Exception Management Pattern”
[8] Microsoft Patterns and Practices, “Application Architecture for .NET: Designing Applications and Services”
[9] Microsoft Patterns and Practices, “Designing Data Tier Components
[10] and Passing Data Through Tiers”
[11] Microsoft Patterns and Practices, “Enterprise Solution Patterns Using Microsoft .NET”
[12] Microsoft Patterns and Practices, “Building Interoperable Web Services”
[13] Davide Mauri, “.NET Tools”, http://www.davidemauri.it/
[14] Ceki Gülcü, “Short introduction to log4j”

Bibliografia
108
[15] Ceki Gülcü, “Introduction to log4net”, http://log4net.sourceforge.net/release/1.2.0.30507/doc/manual/introduction.html
[16] Aaron Skonnard, “The Birth of Web Services”
[17] Aaron Skonnard, “Understanding SOAP”
[18] Aaron Skonnard, “How ASP.NET Web Services Work”
[19] Aaron Skonnard e Dan Sullivan, “Extend the ASP.NET WebMethod Framework by adding XML Schema Validation”
[20] David Booth,Hugo Haas,Francis McCabe,Eric Newcomer, “Web Services Architecture”
[21] Hugo Haas,David Orchard, “Web Services Architecture Usage Scenarios”
[22] Roger Wolfer, “XML Web Services Basics”
[23] Erik Christensen, Francisco Curbera, “Web Services Description Language (WSDL) 1.1”
[24] Nilo Mitra, “SOAP Version 1.2 Part 0: Primer ”
[25] Martin Gudgin, Marc Hadley, Noah Mendelsohn, “SOAP Version 1.2 Part 1: Messaging Framework”
[26] Karsten Januszewski, “The Importance of Metadata: Reification,Categorization, and UDDI”
[27] UDDI.org, “UDDI Technical White Paper”
[28] Marcel van Brakel, “Binary Serialization with the Microsoft .NET framework”
[29] Sonia Bergamaschi, “Le transazioni distribuite”
[30] Atzeni,Ceri ,Paraboschi, “Basi di Dati”
[31] A. Gori, “Basi di Dati distribuite”


















