
Sistemi Operativi: Il kernel linux - Lezione 06
155
1 Modello architetturale di Linux • Kernel monolitico – Esecuzione di tutte le funzionalità critiche in kernel mode – Modello ibrido tramite l'esecuzione di codice critico (device driver) in user mode (fuse) • Kernel stratificato – Diversi livelli di chiamate a funzione (6-10) prima di svolgere concretamente un compito – http://www.linuxdriver.co.il/kernel_map • Kernel modulare – Meccanismo dei moduli per caricare a tempo di esecuzione funzionalità secondarie
-
Upload
majong-devjfu -
Category
Technology
-
view
1.339 -
download
0
Transcript of Sistemi Operativi: Il kernel linux - Lezione 06

1
Modello architetturale di Linux
• Kernel monolitico– Esecuzione di tutte le funzionalità critiche in
kernel mode– Modello ibrido tramite l'esecuzione di codice
critico (device driver) in user mode (fuse)
• Kernel stratificato– Diversi livelli di chiamate a funzione (6-10)
prima di svolgere concretamente un compito– http://www.linuxdriver.co.il/kernel_map
• Kernel modulare– Meccanismo dei moduli per caricare a tempo di
esecuzione funzionalità secondarie

2
Il linguaggio C
• Sviluppato da Ken Thompson e Dennis Ritchie all'inizio degli anni '70
• Concepito per la programmazione del kernel e degli applicativi di sistema UNIX
• Successore del linguaggio BCPL• Duplice scopo:– definire un linguaggio sufficientemente ad alto
livello per poter implementare un SO senza impazzire
– definire un linguaggio sufficientemente a basso livello da poter permettere il colloquio con le periferiche

3
Caratteristiche del linguaggio C
• Linguaggio compilato– traduzione da alto livello (programma C) a
basso livello (codice macchina)– compilatore
• Linguaggio estremamente compatto– funzionalità aggiuntive fornite da librerie
esterne
• Paradigma di programmazione procedurale– programmazione strutturata
• Linguaggio fortemente tipizzato– impedisce operazioni non valide sui dati

4
Caratteristiche del linguaggio C
• Accesso non controllato, a basso livello, alla memoria– meccanismo dei puntatori
• Set di istruzioni minimalistico– solo lo stretto necessario per implementare cicli,
assegnamenti, salti
• Passaggio di parametri per valore/riferimento• Meccanismo di puntatori a funzione– scheletro generico
– funzionalità dipendenti dall'implementazione
• Tipi di dati strutturati– parola chiave struct

5
Manchevolezze del C
• Mancanza di type safety– char -> int, int->char– somma di interi e float produce conversioni
automatiche
• Garbage collection automatica– meccanismo per ripulire automaticamente la
memoria allocata e non più utilizzata
• Meccanismi diretti per l'object oriented programming
• Annidamento di funzioni• Overloading degli operatori– “string1” + “string2” = “string1string2”

6
Un primo programma in C
#include <stdio.h>
int main(void) {
printf(“Hello, world\n”);
return 0;
}
• Editate il file prova.c con il contenuto di cui sopra• Che cosa fa questo programma?– stampa “Hello, world” sullo STDOUT del terminale

7
Un primo programma in C
#include <stdio.h>
• Direttiva di preprocessamento #include• Il preprocessore (primo strumento a toccare il
codice) esamina prova.c e sostituisce #include <stdio.h> con il file /usr/include/stdio.h
• Il file /usr/include/stdio.h contiene le definizioni di costanti e funzioni legate all'I/O

8
Un primo programma in C
#include <stdio.h>
• Le parentesi <> stanno ad indicare che stdio.h è un file include di sistema– distribuito con la libreria del C
– localizzato nel percorso di sistema /usr/include

9
Un primo programma in C
#include <stdio.h>
• Si possono anche utilizzare le virgolette “” per includere un file include
• Le virgolette “” stanno ad indicare un file include non di sistema
• Viene cercato nella directory corrente oppure nelle directory specificate dall'opzione -I del compiler

10
Un primo programma in C
int main(void) {
}
• Definizione di una funzione (in questo caso, la funzione main())– int: tipo di dato ritornato dalla funzione (intero)
– main: nome della funzione
– (...): lista di argomenti forniti alla funzione♦ void: nessun argomento

11
Un primo programma in C
int main(void) {
}
• Definizione di una funzione (in questo caso, la funzione main())– { ... }: delimitatori di inizio/fine funzione
♦ contengono la sequenza di statement (linee di codice) C

12
Un primo programma in C
int main(void) {
}
• La funzione main() è speciale– punto di ingresso dell'esecuzione del programma
– contiene lo “scheletro” del programma
– DEVE essere presente in ciascun programma♦ altrimenti, il programma non si compila

13
Un primo programma in C
printf(“Hello, world\n”);
• Viene invocata la funzione di libreria printf(), con l'argomento “Hello world\n”
• \n: sequenza di escape– si traduce in: “vai all'inizio della prossima riga”

14
Un primo programma in C
printf(“Hello, world\n”);
• Il valore di ritorno di printf è un intero, ma in questo caso, non interessandoci, non viene memorizzato in alcuna variabile– viene scartato automaticamente

15
Un primo programma in C
printf(“Hello, world\n”);
• Se invece avessi voluto memorizzare il valore:ret = printf(“Hello, world\n”);

16
Un primo programma in C
return 0;
• Questo è il codice di ritorno della funzione, ossia il valore ritornato dalla stessa

17
Tipi di dato del C
• Caratteri:– char: singolo carattere
• Interi– unsigned short int: intero da 0 a 65535– short int: intero da -32768 a +32767– unsigned int: intero da 0 a 4294967296– int: intero da -2147483648 a 2147483647
• Virgola mobile– float: da 0.29 * 10-38 a 1.7 * 1038

18
Tipi di dato del C
• Tipi di dato enumerati:– enum: lista di elementi “etichettati”enum stati {
attivo = 1,inattivo,interrotto
}

19
Tipi di dato del C
• Record– struct: tipo di dato complesso, contenente più
datistruct esempio {
int a;char b;
} mio_esempio;
• L'accesso ad un record avviene con l'operatore .:mio_esempio.a = 10;

20
Tipi di dato del C
• Unioni disgiunte di strutture– union: alternativa fra 2 o più struttureunion unione {
int primo_valore;char secondo_carattere;struct mystruct terza_struttura;
} mia_unione;
• L'accesso ad una unione avviene con l'operatore .:mia_unione.primo_valore=10;

21
Tipi di dato del C
• Indirizzamento della memoria– puntatori: indirizzo di una locazione di memoria
♦byte (8 bit), word (16 bit), long word (32 bit)
• Dichiarazione di una variabile puntatore:– int *int_ptr;
• Dereferenziazione (dereference) di un puntatore: ottenimento del valore della variabile a partire dall'indirizzo– int int_var, *int_ptr; int_var = *int_ptr;

22
Tipi di dato del C
• Indirizzamento della memoria– puntatori: indirizzo di una locazione di memoria
♦byte (8 bit), word (16 bit), long word (32 bit)
• Dichiarazione di una variabile puntatore:– int *int_ptr;
• Indirizzamento (addressing) di un puntatore: ottenimento dell'indirizzo di una variabile a partire dalla variabile stessa– int int_var, *int_addr; int_addr= &int_var;

23
Tipi di dato del C
• Casting: conversione esplicita di un puntatore in un altro
• Puntatore nullo: rappresenta l'indirizzo 0, e serve ad indicare che l'indirizzo contenuto dalla variabile puntatore è invalido– costante NULL

24
Tipi di dato del C
• Aritmetica dei puntatori: a seconda della grandezza della variabile puntata, gli operatori + e – assumono il seguente significato:– operatore di somma +: incrementa l'indirizzo
puntato del numero di byte occupato dal tipo di variabile puntata
– operatore di sottrazione -: decrementa l'indirizzo puntato del numero di byte occupato dal tipo di puntatore

25
Tipi di dato del C
• Casting a int pointer:a= (int *) puntatore_ad_altro_tipo;
• Aritmetica: In questo caso, a viene incrementata di 4 * 4 byte (la dimensione di un int) = 16 byteint a=10;
int *int_ptr = &a;
a=a+4;
• Aritmetica: In questo caso, a viene incrementata di 4 * 1 byte (la dimensione di un char) = 4 bytechar a='a';
int *int_ptr = &a;
a=a+4;

26
Tipi di dato del C
• Vettori di elementi– array: vettore di elementi dello stesso tipo, avente
una lunghezza fissaint a[10];
a[0] = 2;
a[1] = 3;
• Il nome di un array è anche l'indirizzo del primo elementoint *int_ptr = a;
• Array multidimensionali: uso di più indiciint a[10][20];
a[1][2] = 4;

27
Allocazione della memoria
• Tre modalità di allocazione della memoria:– statica: attraverso array– dinamica:
♦prenotazione della memoria attraverso l'uso della funzione di libreria malloc()
int *init_addr=(int *)malloc( 10 * sizeof(int));♦rilascio della memoria prenotata con free()free(init_addr);
– automatica: variabili locali allocate sullo stack dell'applicativo

28
Allocazione della memoria:pregi e difetti
• Allocazione statica:– molto veloce– impossibile a runtime
• Allocazione dinamica:– più lenta rispetto alla statica (overhead malloc()/
free())– utilizzabile a runtime
• Allocazione automatica:– molto veloce– locale alla funzione che la contiene

29
Sintassi del C
• Statement: ciascun statement (singola istruzione) deve terminare con il carattere ;
• Commenti: un commento è delimitato dalla sequenza /* *//* esempio di commento */
• Definizione di variabili: si fa precedere il tipo di dato al nome della variabileint a, b=4;
struct mystruct {int c=4;int *d;
} struttura = { 4, NULL };

30
Sintassi del C
• parola chiave static:– applicata alle variabili locali, permette di salvare il
valore di una variabile automatica fra più chiamate
– applicata alle variabili globali, limita l'accesso alla variabile alle sole funzioni definite nello stesso file
– applicata alle funzioni, limita l'accesso alla funzione alle sole funzioni definite nello stesso file
static int a = 10;
static int f(int b) { return b – 2 };
• Meccanismo per proteggere funzioni private, di implementazione, dall'uso di moduli esterni
• Le funzioni non-static costituiscono l'interfaccia di un modulo di codice

31
Sintassi del C
• Nel caso in cui un programma C sia costituito da più file, è necessario dire al compilatore che alcune funzioni o variabili utilizzati in un file sono definiti in altri file
• Parola chiave externextern int var_esterna;
• In questo esempio, la definizione della variabile var_esterna viene cercata definita in un altro file– se non viene trovata alcuna definizione, il processo
di linking termina con un errore
– abusare di extern è segno di programmazione poco pulita

32
Operatori più comuni
• Aritmetici:– somma, sottrazione, moltiplicazione, divisione: +, -,
*, /
– resto modulo n: %
• Bit:– shift a sinistra: << (divide * 2)
– shift a destra: >> (moltiplica * 2)
– AND bit a bit: &
– OR bit a bit: |
• Logici:
– AND logico: &&
– OR logico: ||

33
Operatori più comuni
• Assegnamento: si usa l'operatore =int a = 10;
• Confronto– Uguaglianza: si usa l'operatore ==
if ( a==b )printf “a uguale a b.\n”;
– Minore di: si usa l'operatore <
– Minore o uguale di: si usa l'operatore <=
– Maggiore di: si usa l'operatore >
– Maggiore o uguale di: si usa l'operatore >=

34
Operatori più comuni
• Alcuni esempi di operazioniint a = 10, b=255, c;
c = a & b; /* c=10 */
c = a | b; /* c=255 */
c= a && b; /* c=1 */
c= a || b; /* c=1 */

35
Controllo di flusso del programma
• Ciclo while: esegue il blocco di codice specificato fintantoché la condizione rimane vera
while ( condizione ) {
<blocco di codice>
}
• Ciclo do-while: esegue il blocco di codice specificato fintantoché la condizione rimane vera
do {
<blocco di codice>
} while ( condizione );
• Il ciclo do-while esegue almeno una volta

36
Controllo di flusso del programma
• Ciclo for: esegue il blocco di codice specificato fintantoché la condizione rimane vera, aggiornando delle variabili nel contempofor ( i=1; i < 10; i++ ) {
<blocco di codice>
}
for (p=list->next; p != NULL; p=p->next) {printf(“P has %s\n”, p->string;
}

37
Particolarità del kernel• Il kernel è una applicazione radicalmente
diversa da quelle che girano in user mode• Elementi di diversità del kernel:– Caratteristiche avanzate del C
– Nessun utilizzo della libreria del C
– File include
– Nessuna protezione della memoria
– Nessun utilizzo (semplice) di virgola mobile
– Dimensione dello stack
– Portabilità
– Allineamento delle strutture dati
– Byte ordering
– Sincronizzazione e concorrenza

38
Caratteristiche avanzate del C
• Il kernel fa ampio uso delle caratteristiche avanzate del C
• Alcune specificate nel primo standard del C (standard K&R)– K&R sta per Kernighan & Ritchie
• Altre specificate negli standard successivi ANSI(1983), ISO/C90 (1990)
• Altre caratteristiche definite come estensioni del compilatore GNU (gcc)

39
Macro
• Talvolta risulta comodo definire con un nome una sequenza di caratteri ripetitiva– una costante di uso frequente
– uno statement di uso frequente
• Direttiva del preprocessore #define(arg1,...,argn): permette di definire una “macro definizione” (o macro)#define DBG(str) printf (”%s\n”, str);
• Il compilatore, prima di compilare il programma, sostituisce ad ogni istanza di DBG(argomento) una istanza di printf(“%s\n”, argomento);
• La sostituzione non è una generazione di codice!

40
Macro
• Si può controllare se una macro è definita oppure no con le direttive del preprocessore #ifdef, #ifndef#ifdef CONFIG_VIDEO
stampa_16mil_colori(msg);
#elsestampa_1_colore(msg);
#endif
• Le direttive #ifdef, #ifndef sono molto comode per:– escludere/includere codice a seconda della
configurazione
– evitare che un file include locale, incluso due volte per errore, generi un messaggio di errore in compilazione

41
Macro
• Una #define particolarmente lunga può essere spezzata in più righe, terminando ciascuna riga con la stringa \ (escape di fine riga)#define FOO(x) \
printf(“arg is %s\n”, x); \do_something_useful(x);
• Le macro definite tramite la direttiva #define su più righe è dichiarata obsoleta nei nuovi compilatori, che consigliano l'utilizzo di:– meccanismi di protezione delle #define
– uso delle funzioni inline

42
Macro
• Che cosa ha di tanto grave la seguente macro?#define FOO(x) \
printf(“arg is %s\n”, x); \do_something_useful(x);
• Supponiamo che tale macro sia richiamata dal seguente codice:if (blah == 2)
FOO(blah);
• Che cosa fa il compilatore, prima di compilare il programma?

43
Macro
• Il compilatore sostituisce#define FOO(x) \
printf(“arg is %s\n”, x); \do_something_useful(x);
nel seguente codice:if (blah == 2)
FOO(blah);
ottenendo:if (blah == 2)
printf(“arg is %s\n”, blah);do_something_useful(blah);;

44
Macro
• Non notate niente di strano?if (blah == 2)
printf(“arg is %s\n”, blah);do_something_useful(blah);;
• Ho 2 errori:1.La macro termina con ;, l'istruzione che
richiama la macro termina con ;, ed alla fine ho ;; (errore sintattico)
2.La macro non è protetta con un blocco di codice { }; dopo l'espansione, se blah==2 viene eseguita solo la printf()

45
Macro
• Come posso correggere questo errore?– Incastro il codice della macro in un ciclo do { }
while(0), che viene eseguito una ed una sola volta
#define FOO(x) \do {
printf(“arg is %s\n”, x); \do_something_useful(x); \
} while (0)

46
Macro
• Cosa risulta dall'espansione?if (blah == 2)
do {printf(“arg is %s\n”, x); \do_something_useful(x); \
} while (0);
che risulta essere codice corretto• OSS.: la protezione di macro tramite do {} while(0);
è molto frequente nel codice del kernel di Linux• Se proprio dovete scrivere macro multiriga,
proteggetele!

47
Puntatori a funzione
• Come dice il nome stesso, un puntatore a funzioneè una variabile puntatore che, se dereferenziata, invoca una funzione
• Come si definisce una variabile puntatore a funzione?int (*ptr_to_function(int));
• Come si dereferenzia un puntatore a funzione?ret_code = (*ptr_to_function) (2);
ret_code =ptr_to_function(2);
• Come si assegna una funzione ad un puntatore?ptr_to_function=&my_func;
ptr_to_function=my_func;

48
Puntatori a funzione
• A cosa servono i puntatori a funzione?– implementazione meccanismo callback
♦ un programma è progettato “per eventi” ed associa un puntatore di funzione a ciascun evento
♦ quando si verifica l'evento, viene invocata la funzione opportuna tramite il function pointer opportuno
♦ scheletro molto semplice: struttura dati con associazione evento-funzione, e loop che invoca la funzione
– polimorfismo (object oriented programming)♦ cambiare modo di operare in funzione del tipo di dato
che viene fornito

49
Puntatori a funzione
• Definizione di struttura contenente puntatori a funzione:include/linux/fs.h:
struct file_operations {loff_t (*llseek) (struct file *, loff_t, int);ssize_t (*read) (struct file *, char __user *, size_t,
loff_t *);ssize_t (*write) (struct file *, const char __user *,
size_t, loff_t *);...int (*setlease)(struct file *, long, struct file_lock **);
};
Questa è la strutturagenerica delle operazioni
su di un file
Q

50
Puntatori a funzione
• Inizializzazione di una struttura puntatrice a blocchi con le operazioni relative ad un dispositivo a blocchi:fs/block_dev.c:
struct file_operations def_blk_fops = {.open = blkdev_open,.release = blkdev_release,....read = do_sync_read,...
};
Qui vengono definite lefunzioni per un devicea blocchi, tramite deipuntatori a funzione

51
Puntatori a funzione
• Funzione vfs_read():fs/read_write.c:
ssize_t vfs_read(struct file *file, char __user *buf, size_t cnt, loff_t *pos) {
ssize_t ret;
<controlli vari>;
if (file->f_op->read) {ret = file->f_op->read(file, buf, count, pos);
}
<aggiorna contatori>
} La semantica di vfs_read()non dipende dal device sucui sarà effettuata la read().

52
Utilizzo estensioni GCC• Il kernel è, in larga parte, scritto in C• Per motivi di efficienza spaziale e temporale, il
kernel fa uso massiccio di estensioni del C– Estensioni del compilatore GNU gcc– Estensioni dello standard C99
• Estensioni più comuni:– Inline functions– Inline assembly– Asmlinkage– Branch annotation– Volatile

53
Estensioni GCC: inline functions• Solitamente, quando una funzione viene
tradotta in linguaggio macchina, il compilatore inserisce del codice per:– Passare gli argomenti sullo stack– Creare spazio per variabili locali– Ritornare il risultato attraverso lo stack
• Quando tale funzione viene invocata, si mettono i parametri sullo stack e si chiama (call) la funzione
• Una funzione inline cerca di ovviare agli aggravi computazionali legati a tale procedura
• Una funzione si dichiara inline con la parola chiave inline

54
Estensioni GCC: inline functions• Per una funzione inline, il compilatore non
genera il codice di gestione dei parametri attraverso lo stack
• La chiamata alla funzione viene sostituita al codice oggetto della funzione stessa
• La funzione viene eseguita più velocemente (non c'è più il codice di gestione dello stack)
• La dimensione del codice prodotto aumenta considerevolmente– Per ogni chiamata, al posto della call ho l'intero
codice oggetto della funzione
• Non posso avere più definizioni identiche di una stessa funzione inline

55
Estensioni GCC: inline functionsint funzione(int a) {
return (a + 2);
}
...
int b = funzione(10);
...
pushl %ebp
movl %esp, ebp
subl $N, %esp
movl 8(%ebp), %eax
addl $2, %eax
leave
ret
...
pushl 10
call funzione
...

56
Estensioni GCC: inline functionsInline int funzione(int a) {
return (a + 2);
}
...
int b = funzione(10);
...
...
movl $1, %eax
addl $2, %eax
...

57
Estensioni GCC: inline functions• Non tutte le funzioni dichiarate inline possono
essere effettivamente sostituite con il loro codice oggetto– Le funzioni ricorsive– Le funzioni che utilizzano l'indirizzo iniziale
della funzione– Le funzioni che sono invocate prima della loro
definizione
• “inline” è un suggerimento al compilatore– Il suggerimento può essere applicato oppure no

58
Estensioni GCC: inline functions• Il comportamento di inlining può essere
ulteriormente raffinato con le parole chiave static ed extern
• static inline:– Il compilatore può generare oppure no il codice
oggetto per la funzione
– Se tutte le chiamate a funzione sono inlined, non viene generato codice per la funzione, bensì viene copiato il codice oggetto al posto della chiamata
– Se almeno una chiamata non può essere inlined, allora viene creata una versione static della funzione, col proprio codice oggetto
– Si possono avere più definizioni di una funzione senza avere errori di ridefinizione

59
Estensioni GCC: inline functions• Il comportamento di inlining può essere
ulteriormente raffinato con le parole chiave static ed extern
• extern inline:– Il compilatore non genera mai codice oggetto per la
funzione
– La funzione viene considerata alla stregua di una macro con parametri
– Si possono avere più definizioni di una funzione senza avere errori di ridefinizione
– Se l'inlining non può essere applicato, deve essere presente una definizione non-inline della funzione che possa essere invocata, altrimenti il compilatore genera un errore di linker

60
Estensioni GCC: inline functions• Quando e dove vengono utilizzate static inline
ed extern inline?• static inline:– Viene utilizzata per le funzioni interne, che non
si vogliono esportare pubblicamente– Utilizzata nei file *.c e file *.h
• extern inline:– Viene utilizzata per le funzioni pubbliche, che
rappresentano l'interfaccia con altri moduli– interfaccia popolari definite nei file include– Utilizzata nei file *.h

61
Estensioni GCC: Assembler inline• Il GCC permette l'inserimento di istruzioni
assembler all'interno di codice scritto in C• Utilizzato per implementare porzioni del kernel
dipendenti dall'architettura• Si utilizza la parola chiave asm (oppure
__asm__ se asm è già definita)• Due varianti:– Basic inlining: inserimento di un gruppo di
istruzioni fisse, senza operandi– Extended Asm: inserimento di un gruppo di
operazioni con passaggio di valori

62
Estensioni GCC: Assembler inline• Basic inlining:
asm("movl %ecx, %eax");asm( "movl %eax, %ebx\n\t"
"movl $56, %esi\n\t""movl %ecx, $label(%edx,%ebx,$4)\n\t""movb %ah, (%ebx)");

63
Estensioni GCC: Assembler inline• Extended asm: formato
asm( assembler template: output operands (opzionali): input operands (opzionali): list of clobbered registers (opzionali)
);
• Extended asm: esempioint a=10, b;
asm( "movl %1, %%eax;movl %%eax, %0;": “=r”(b) /* b è l'output (%0) */: =”r”(a) /* a è l'input (%1) */: “%eax” ); /* %eax modificato */

64
Estensioni GCC: Assembler inline• Formato operandi:– L'operando di output viene contrassegnato con
uno %0– Gli operandi di input vengono contrassegnati
con %1, %2, ...
• Register constraints:– “=r(x)”: l'operando è memorizzato nel registro x
♦x=a: %eax, x=b: %ebx, x=c: %ecx, x=d: %edx, x=S: %esi, x=D: %edi
– “m(y)”: l'operando è memorizzato nella locazione di memoria y
• Clobber list: specificihiamo i registri modificati nell'operazione (il gcc non li usa per il caching)

65
Estensioni GCC: Asmlinkage• Alcune funzioni sono marcate con la parola
chiave asmlinkage• La parola chiave asmlinkage istruisce il
compilatore a non prelevare i parametri attraverso registri, bensì solo sullo stack
• Usato nelle system call (ed in tante altre funzioni)

66
Estensioni GCC: Branch annotation• Il compilatore GNU gcc mette a disposizione
una direttiva (__builtin__expect()) che si può applicare a funzioni
• Il kernel di Linux mette a disposizione due macro (likely() ed unlikely()) che sfruttano in maniera semplice tale direttiva
• Se il risultato di una espressione è quasi sempre vero, si può ottimizzare il codice generato in modo tale da renderlo molto veloce per il caso frequente (vero)– Idem se il risultato è una espressione quasi
sempre falsa

67
Estensioni GCC: Branch annotation• Se foo è una espressione quasi sempre vera, si
può scrivere:if (likely(foo)) {
...
}
che risulta in un codice molto più veloce diif (foo) {
...
}
• Analogamente, se foo è una espressione quasi sempre falsa, si può scrivere:if (unlikely(foo)) {
...
}
Il confronto è molto piùlento del normale se
foo è falso
Il confronto è molto piùlento del normale se
foo è vero

68
Estensioni GCC: volatile• Supponiamo che il compilatore debba
compilare queste linee di codice:static int foo;
void bar(void) {foo = 0;while (foo != 255) ;
}
• La variabile foo non sembra valere mai 255• Il compilatore vede questo fatto, e prova ad
ottimizzare le cose– Perché mantenere quel controllo foo!=255?– Non è equivalente a while(true)?

69
Estensioni GCC: volatile• Detto fatto, il compilatore decide di
“ottimizzare” il codice in:static int foo;
void bar(void) {foo = 0;while (true) ;
}
• Il codice risultante è molto più veloce (non si deve valutare l'espressione foo != 255)
• Supponiamo che qualcuno (ad es., una interruzione) scriva un valore nell'indirizzo di foo
• Il valore di foo può cambiare “al di fuori” del file C ora descritto

70
Estensioni GCC: volatile• Il compilatore, preso dal desiderio di
ottimizzare, ha generato un codice non corretto!
• Come si elimina la brama di ottimizzazione?• Parola chiave volatile– Dice al compilatore di non fare alcun tipo di
ottimizzazione riguardante una variabilestatic volatile int foo;
void bar(void) {foo = 0;while (true) ;
}

71
Estensioni GCC: volatile• La parola chiave volatile viene utilizzata per
proteggere variabili che possono essere cambiate da una interruzione o da un altro processore
• La parola chiave volatile viene anche usata spesso in congiunzione con la parola chiave asm (inline assembly): asm volatile– In tal modo, vengono impedite ottimizzazioni
sulle istruzioni assembler

72
Nessun accesso alla libreria del C• Le applicazioni normali vengono “fuse” con I
codici oggetto della libreria C, che provvedono a dare le necessarie funzionalità– Gestione file, gestione memoria, I/O
• Uno dei compiti principali del kernel è quello di implementare tali funzionalità correttamente, efficientemente, in maniera portabile
• Di conseguenza, il kernel non può utilizzare alcuna funzione della libreria del C!– Scordatevi printf(), malloc(), open(), close(),
read(), write()

73
Nessun accesso alla libreria del C• In realtà, nel kernel è implementato un piccolo
insieme di funzioni “di libreria”– printk(): analogo della funzione printf(); stampa
stringhe su una console/log– kmalloc(): analogo della funzione malloc();
alloca memoria dinamicamente– kfree(): analogo della funzione free(); libera
memoria dinamicamente– Str...(): anloghe delle funzioni str...(); gestione di
stringhe
• Per una descrizione non esaustiva dell'API di Linux, si consulti:– http://www.gelato.unsw.edu.au/~dsw/public-
files/kernel-docs/kernel-api/

74
File include• I file include (detti anche header) sono utilizzati
come meccanismo di definizione dell'API– strutture dati– prototipi di funzioni (API)
• La libreria del C definisce la propria API tramite i suoi file include– directory /usr/include
• Il kernel definisce la propria API tramite I suoi file include– sottodirectory include di un qualunque albero
sorgente del kernel

75
File include• La libreria del C invoca le chiamate di sistema del
kernel, passando gli opportuni parametri e ricevendo gli opportuni valori di ritorno
• Il kernel deve conoscere il formato sia delle strutture dati passate come parametri, sia delle strutture dati passate come valore di ritorno
• D'altro canto, il kernel implementa una sua API interna (non utilizzabile dagli applicativi user mode) per ciascun strato interno
• Due API diverse definite nel kernel:– API interna: strutture dati e prototipi delle funzioni
usate negli strati interni del kernel
– API di raccordo: strutture dati e prototipi delle funzioni usate dalla libreria del C

76
File include• L'API di raccordo del kernel deve essere
coerente con l'API definita dalla libreria del C– Condizione solitamente garantita dal gestore
dei pacchetti del sistema– Durante il processo di compilazione della
libreria del C, viene fatto esplicito riferimento ai file include del kernel (API di raccordo)
– Se si compila il kernel a mano, bisogna stare attenti alla compatibilità fra le due API!
– Non è necessario che le due versioni dei file include (libreria C e kernel) siano identiche

77
File include• La libreria del C cerca di essere compatibile
all'indietro con l'API di raccordo del kernel– Una libreria C compilata con una data versione
dei file include del kernel funziona con tutti i kernel aventi file include “più vecchi”
– Se si compila una libreria del C con file include del kernel vecchi e poi si usa un kernel con file include più recenti, le nuove funzionalità introdotte a livello di kernel potrebbero non essere supportate (o, peggio, introdurre bachi)
• Si consulti la FAQ della libreria del C per ulteriori approfondimenti:– http://www.gnu.org/software/libc/FAQ.html

78
File include• Solitamente, la libreria del C messa a
disposizione dalla distribuzioni più popolari è compilata con i file include di un kernel abbastanza recente
• Il problema della compatibilità non dovrebbe porsi anche se si compila l'ultimissima versione del kernel

79
File include• Un file include del kernel può essere incluso
da molteplici file• Una inclusione doppia può portare a
ridefinizioni di variabili/funzioni, con conseguente errore da parte del compilatore
• I file include del kernel sono inclusi una sola volta tramite l'utilizzo di una costante#ifndef COSTANTE#define COSTANTE 1...#endif

80
Nessuna protezione della memoria• Quando una applicazione in user mode accede
ad indirizzo invalido, il kernel intercetta tale errore ed uccide il processo relativo
• Il kernel non ha un meccanismo analogo!• Un accesso ad una area di memoria illegale (ad
es., l'indirizzo 0x00000000) causa un blocco istantaneo ed irreversibile del sistema (panic)
• La memoria del kernel non può essere gestita in modalità virtuale, per motivi di efficienza– Niente swap, solo memoria fisica– Occorre allocare solo lo stretto necessario

81
Nessun (semplice) uso di floating point• L'uso di aritmetica in virgola mobile (floating
point) richiede l'uso di registri speciali• Tali registri non vengono salvati durante un
cambio di contesto, per motivi di efficienza• Non si può usare artimetica floating point in
punti nei quali lo scheduler oppure una interruzione ci possono interrompere!
• Morale: non usiamo aritmetica floating point nel kernel!

82
Dimensione dello stack• Gli applicativi eseguiti in user mode hanno uno
stack di dimensione variabile• Lo stack del kernel è piccolo e di dimensione
fissa– 4KB su architetture a 32 bit– 8KB su architetture a 64 bit
• Non si può sprecare tale stack con:– chiamate ricorsive– Passaggio di strutture grandi (meglio passare
puntatori a tali strutture)– Ritorno di strutture grandi (meglio passare
puntatori a tali strutture)– Variabili locali di grandi dimensioni

83
Portabilità• Il kernel è scritto per poter essere eseguito su
una miriade di architetture diverse• Architetture diverse hanno formati e
dimensioni diverse di rappresentazione dei dati– Architetture a 16, 32, 64 bit– Alcuni tipi di dato (int, long) possono avere
dimensioni diverse
• La parte architecture-independent del kernel deve essere scritta in modo tale che funzioni su ciascuna di tali architetture– Non si possono fare assunzioni sulle
dimensioni dei tipi di dato

84
Portabilità• Si definisce “parola” la quantità di dati che una
architettura è in grado di elaborare in un colpo di clock
• Una architettura a n bit è una architettura in cui la parola ha dimensione n bit– I registri general purpose hanno la stessa
dimensione di una parola– La dimensione del bus di memoria ha almeno la
stessa dimensione di una parola– Per le architetture supportate da Linux,
l'”almeno” si traduce in “uguale”– Ne consegue che la dimensione di un puntatore
è pari alla dimensione della parola– Il tipo di dato long è equivalente alla parola

85
Portabilità• Un esempio: nelle architetture a 64 bit– Registri, puntatori, long sono a 64 bit– Il tipo di dato int è a 32 bit– puntatore != intero (come invece è nelle
architetture a 32 bit)
• Sarebbe un grosso errore supporre, in generale, puntatori di 32 bit
• Il kernel definisce il numero di bit in un tipo di dato long:– macro BITS_PER_LONG, in <asm/types.h>

86
Portabilità• Alcune regole da ricordare quando si usano i
tipi di dato– Il tipo di dato char è sempre lungo 8 bit– Il tipo di dato int vale 32 bit su tutte le
architetture supportate da Linux– Il tipo di dato short vale 16 bit su tutte le
architetture supportate da Linux– Mai fare assunzioni sulla lunghezza di long o di
un puntatore– Mai assumere che int e long abbiano la stessa
lunghezza– Mai assumere che int e puntatore abbiano la
stessa lunghezza

87
Portabilità• Il kernel fa ampio uso di tipi di dato opachi• Un tipo di dato opaco è un tipo di dato
generico definito tramite l'operatore C typedef• Architetture diverse possono definire il tipo di
dato opaco in modi diversi• Obiettivi:– Permettere dimensioni più grandi su
architetture più potenti (es.: offset di seek dei file)
– Forzare un tipo di dato ad avere la stessa dimensione su tutte le architetture(es.: indirizzi IP)

88
Portabilità• Il kernel fa ampio uso di tipi di dato espliciti• Un tipo di dato esplicito è l'esatto contrario di
un tipo di dato opaco• Il tipo di dato esplicito è definito tramite
l'operatore typedef– File include/asm/types.h
• Il tipo di dato esplicito ha sempre la stessa dimensione, su tutte le architetture
• Alcuni esempi:– s8, u8: signed/unsigned 16 bit integer– s16, u16: signed/unsigned 16 bit integer– s32, u32: signed/unsigned 32 bit integer– s64, u64: signed/unsigned 64 bit integer

89
Allineamento• L'allineamento è il posizionamento di una
variabile in un indirizzo multiplo della sua dimensione
• Esempio: un tipo di dato a 32 bit è allineato se è memorizzato in un indirizzo di memoria multiplo di 4 (gli ultimi 2 bit sono a zero)
• In generale, un tipo di dato di 2n byte è allineato se è memorizzato in un indirizzo di memoria avente gli ultimi n bit impostati a 0
• In alcuni sistemi (Intel), l'accesso a dati non allineati è possibile ma lento
• In altri sistemi (RISC), l'accesso a dati non allineati provoca una eccezione

90
Allineamento• Tutte le strutture dati devono essere allineate• Di solito, il compilatore pensa ad allineare
automaticamente le strutture dati– Gli array sono allineati automaticamente ad un
multiplo della dimensione del tipo– Le union sono allineate al tipo di dato più
grande incluso– Le strutture sono allineate al tipo di dato più
grande incluso– Le strutture dati sono soggette a padding

91
Allineamento: padding delle strutture• Padding: gli elementi di una struttura dati sono
allineati• Consideriamo la seguente struttura su una
macchina a 32 bit:struct foo_struct {
char dog; /* 1 byte */unsigned long cat; /* 4 byte */unsigned short pig; /* 2 byte */char fox; /* 1 byte */
};
• Il compilatore inserisce degli zeri in modo tale da allineare ciascun elemento a 4 byte

92
Allineamento: padding delle strutture• Padding: gli elementi di una struttura dati sono
allineati• Ecco la struttura dati in memoria risultante dal
processo di padding:struct foo_struct {
char dog; /* 1 byte */u8 __pad0[3]; /* 3 byte */unsigned long cat; /* 4 byte */unsigned short pig; /* 2 byte */char fox; /* 1 byte */u8 __pad1; /* 1 byte */
};
4 byte
4 byte

93
Byte ordering• Il byte ordering definisce il posizionamento dei
byte all'interno di una parola• Due possibili ordinamenti:– Big endian: il byte più significativo della parola
è memorizzato per primo– Little endian: il byte più significativo della
parola è memorizzato per ultimo
Byte
B
0
0
1 2 3
OrdinamentoBig Endian
Byte
3 2 1 0
OrdinamentoLittle Endian
Piùsignificativo
Menosignificativo
Menosignificativo
Piùsignificativo

94
Byte ordering• Curiosità: I nome Big Endian e Little Endian
vengono dal romanzo “I viaggi di Gulliver” di Jonathan Swift
• Architetture Big Endian:– PowerPC, System/370, SPARC
• Architetture Little Endian:– 6502, z80, x86, VAX, PDP-11
B0

95
Byte ordering• Un esempio: memorizziamo il numero 1027 nei
formati Big Endian e Little Endian
B0
1027 in binario: 00000000 00000000 00000100 00000011
Indirizzo Big Endian Little Endian0 00000000 000000111 00000000 000001002 00000100 000000003 00000011 00000000

96
Sincronizzazione e concorrenza• Il kernel è un software interrompibile in
maniera sincrona ed asincrona– Sincrona: scadenza quanto di tempo, eccezioni
di vario genere– Asincrona: interruzioni
• Che cosa succede se il codice eseguito in seguito all'interruzione modifica il codice che stava eseguendo precedentemente?– Inconsistenza dei dati– Crash

97
Sincronizzazione e concorrenza• Il kernel è un software che può gestire
l'esecuzione concorrente di più processi• I processi possono condividere informazioni,
strutture dati, altre risorse• Che cosa succede se le risorse possono
essere accedute senza alcun meccanismo di protezione/arbitrio/accesso?– Inconsistenza dei dati– Crash

98
Contesti di esecuzione• In ogni istante, il processore può trovarsi in
una di queste condizioni– User mode: esecuzione di codice di un
processo in user mode– Kernel mode: esecuzione di codice di un
processo in kernel mode (system call)– Gestione interruzioni: esecuzione di codice
legato ad una interruzione hardware, per conto di nessun processo

99
Contesti di esecuzione
Applicazione
C
User space
Kernel space
Hardware
Una applicazione vuoleleggere un blocco giàbufferizzato del disco

100
Contesti di esecuzione
Applicazione
C
User space
Kernel spacen=fread(...)
vfs_read()
Hardware
Lista blocchibufferizzati
Il processo invoca la fread(),che a sua volta invoca la vfs_read()

101
Contesti di esecuzione
Applicazione
C
User space
Kernel spacen=fread(...)
vfs_read()
Hardware
Lista blocchibufferizzati
Ad un certo punto, arriva una interruzione,in seguito alla quale un blocco vuoleessere inserito nella posizione da cuivuole leggere il processo

102
Contesti di esecuzione
Applicazione
C
User space
Kernel spacen=fread(...)
vfs_read()
Hardware
Lista blocchibufferizzati
Si ha un accesso simultaneo alla stessastruttura dati (corsa critica)

103
Contesti di esecuzione• La corsa critica, nella “migliore” delle ipotesi,
riesce a sovrascrivere velocemente il buffer, facendo leggere fischi per fiaschi al processo
• Nella peggiore delle ipotesi, l'interruzione arriva nel momento in cui il processo stava estraendo il buffer dalla lista– Il gestore delle interruzioni si trova una lista
mozzata a metà– Viene provata la scansione della lista– Ad un certo punto si prova a saltare ad un
elemento NULL della lista– Accesso illegale -> la macchina si pianta

104
Contesti di esecuzione• Questo problema può essere impedito tramite
due meccanismi– Un gestore veloce di interruzioni, che opera su
un buffer locale, e successivamente copia il buffer locale nel buffer condiviso coi processi
♦Upper half/bottom half– Un meccanismo di prenotazione/rilascio delle
strutture dati (non del codice!)♦Locking/semafori

105
Contesti di esecuzione
Applicazione
C
User space
Kernel space
Hardware
Una applicazione vuoleleggere un blocco giàbufferizzato del disco

106
Contesti di esecuzione
Applicazione
C
User space
Kernel spacen=fread(...)
vfs_read()
Hardware
Lista blocchibufferizzati
Il processo invoca la fread(),che a sua volta invoca la vfs_read()La vfs_read() blocca l'uso dellastruttura dati “lista”
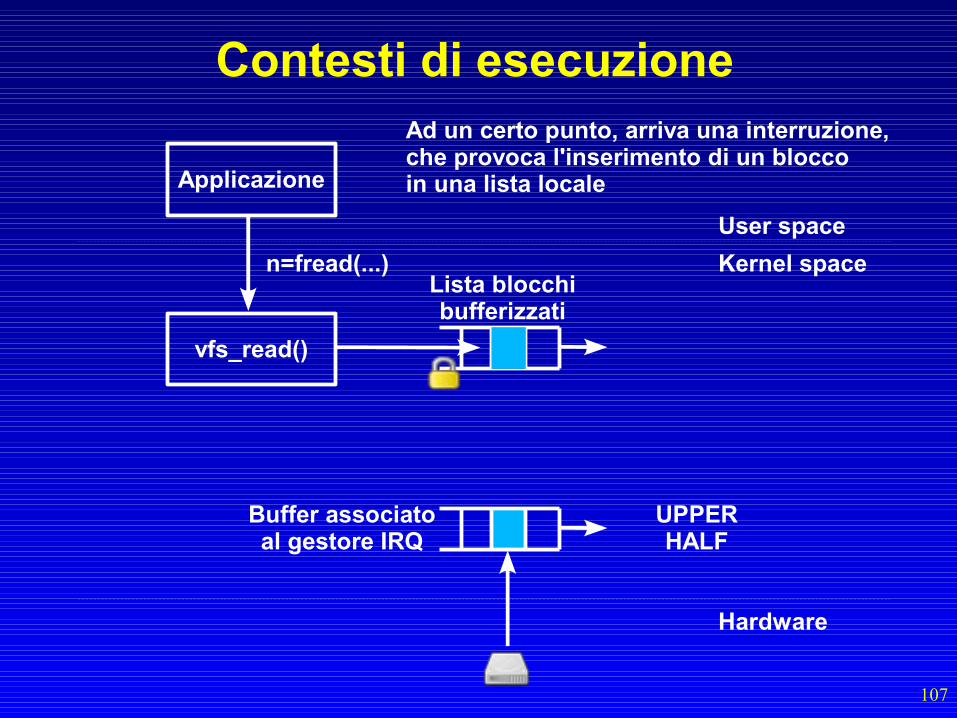
107
Contesti di esecuzione
Applicazione
C
User space
Kernel spacen=fread(...)
vfs_read()
Hardware
Lista blocchibufferizzati
Ad un certo punto, arriva una interruzione,che provoca l'inserimento di un bloccoin una lista locale
Buffer associatoal gestore IRQ
UPPERHALF

108
Contesti di esecuzione
Applicazione
C
User space
Kernel spacen=fread(...)
vfs_read()
Hardware
Lista blocchibufferizzati
Successivamente, una proceduradilazionata nel tempo prova ad inserirel'elemento dal buffer locale al bufferdei blocchi
Buffer associatoal gestore IRQ
BOTTOMHALF
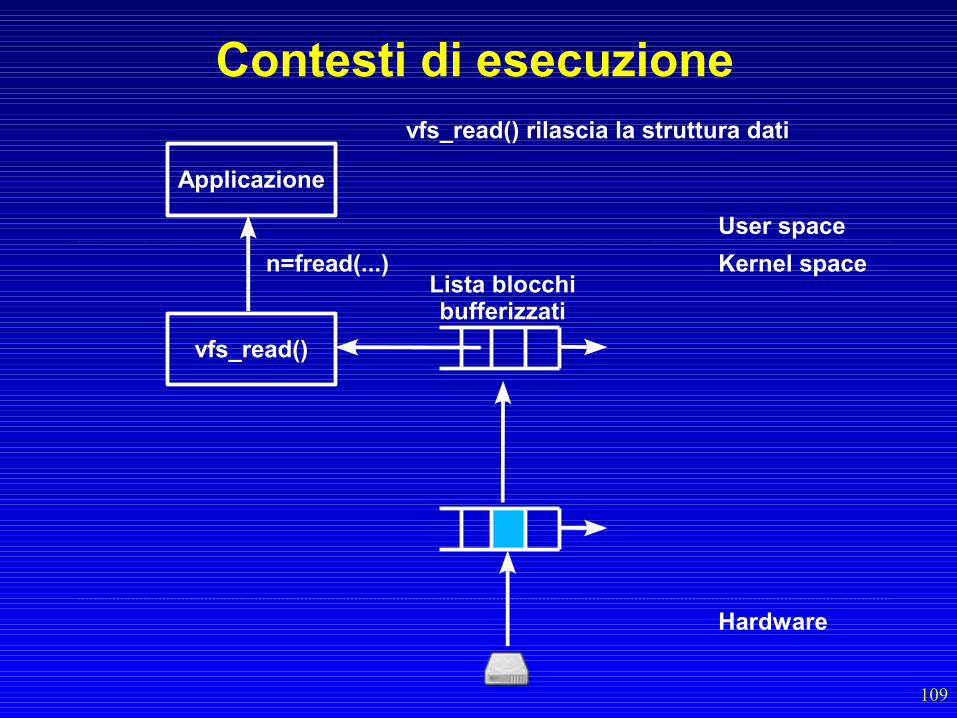
109
Contesti di esecuzione
Applicazione
C
User space
Kernel spacen=fread(...)
vfs_read()
Hardware
Lista blocchibufferizzati
vfs_read() rilascia la struttura dati
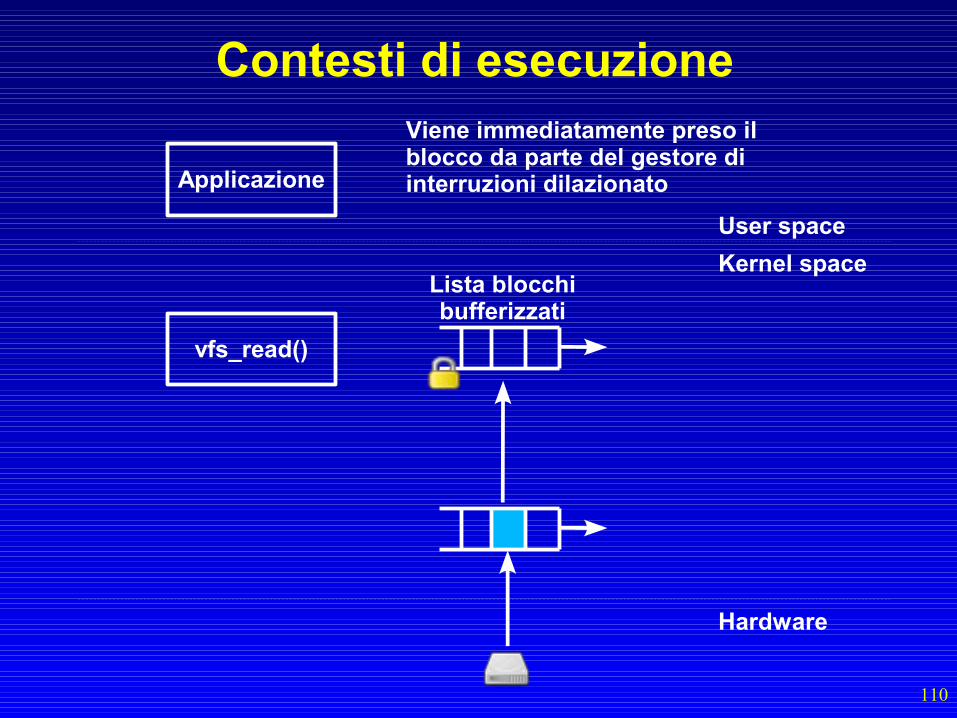
110
Contesti di esecuzione
Applicazione
C
User space
Kernel space
vfs_read()
Hardware
Lista blocchibufferizzati
Viene immediatamente preso ilblocco da parte del gestore diinterruzioni dilazionato

111
Contesti di esecuzione
Applicazione
C
User space
Kernel space
vfs_read()
Hardware
Lista blocchibufferizzati
Avviene l'inserimentodell'elemento nella lista

112
Contesti di esecuzione
Applicazione
C
User space
Kernel space
vfs_read()
Hardware
Lista blocchibufferizzati
Il gestore dilazionato rilasciail blocco sulla lista

113
Anatomia di una funzione del kernel• Una funzione del kernel segue uno scheletro
ben preciso– Dal punto di vista della forma (commenti,
indentazione, coding style in generale)– Dal punto di vista strutturale (prologo,
prenotazione/rilascio risorse, corpo, epilogo, gestione degli errori)

114
Funzione del kernel: Forma• Definita nel file Documentation/CodingStyle• Obiettivi: fare in modo che una funzione sia
leggibile e ben commentata• Indentazione:– 8 spazi (tab) per riconoscere agevolmente I
blocchi di controllo– Limitazione del numero di livelli di indentazione
• Larghezza delle linee di codice:– Non dovrebbe mai superare gli 80 caratteri– Entra in uno schermo
• Lunghezza delle funzioni:– Mai più di 1-2 schermate video

115
Funzione del kernel: Forma• Commenti:– Solo prima dell'intestazione di una funzione– Mai commentare i singoli statement, a meno
che non sia necessario
• Piazzamento delle parentesi:– Stile Kernighan & Richie: il blocco inizia sulla
stessa linea dello statementif ( x is true ) {
do y
}
• Nomi delle variabili:– I più semplici ed intuitivi possibili– ThisVarIsATempCounter: NO, cnt: SI

116
Funzione del kernel: Struttura• Quanto segue è soggetto a 1000 eccezioni! Non
prenderlo come regola aurea!• In generale, una funzione del kernel ha il seguente
scheletro:int funzione(int, char *, ...) {
error = ERROR_CODE;
if ( !valid_check)
goto out;
prenota_risorsa();
if ( !valid_thing )
goto out_rilascia;
...
ret = 0;
out_rilascia:
rilascia_risorsa();
out:
return error;
}

117
Funzione del kernel: Struttura• Le funzioni ritornano, solitamente, un valore < 0
oppure un puntatore NULL per indicare un errore oppure l'incapacità di svolgere il compito assegnato
• La prima fase della funzione consiste in alcuni controlli generici; se i controlli falliscono, si esce direttamente
• Successivamente, si prenota una risorsa e si cerca di portare a termine il compito richiesto; se si fallisce, si salta al percorso di uscita che sblocca la risorsa
• Se tutto va bene, si imposta un valore di uscita opportuno e si segue l'intero percorso di uscita (che sblocca le risorse e ritorna il valore)

118
Gestione delle liste• Una lista concatenata è una struttura dati che
collega un certo numero di elementi (nodi)• Diverse implementazioni:– Lista statica (array)– Lista dinamica (collegamento puntatori)
• Il kernel fa ampio uso di liste dinamiche– Le dimensioni delle liste sono spesso ignote– Si può ottimizzare il consumo di memoria
• Diverse tipologie di collegamento:– Collegamento singolo– Collegamento doppio– Collegamento circolare

119
Gestione delle liste
next
n
...
.
next
n
...
.
next
n
...
.
null
Lista a collegamento singolo
null prev ... next prev ... next prev ... next null
Lista a collegamento doppio

120
Gestione delle liste
next
n
...
.
next
n
...
.
next
n
...
.
Lista circolare a collegamento singolo
prev ... next prev ... next prev ... next
Lista circolare a collegamento doppio

121
Gestione delle liste• Il problema principale di tale struttura è che
risulta essere definita insieme al tipo di dato che essa ospitastruct my_list {
void *my_item;struct my_list *next;struct my_list *prev;
}
• E' impossibile astrarre la definizione di lista in una libreria
• Ogni struttura dati ha la sua libreria per la gestione delle liste
• Duplicazione inutile di codice, con tutti gli svantaggi che ne derivano

122
Gestione delle liste• Il kernel di Linux mette a disposizione una
funzionalità generica di liste, indipendente dal tipo di dato (type oblivious)– Codice riutilizzabile per qualunque tipo di dato/
struttura
• Definizione in include/linux/list.h• Implementazione di lista doppia concatenata• Utilizzo di un primo elemento sentinella
(dummy)– Non rappresenta un elemento– Serve a collegare primo ed ultimo elemento

123
Gestione delle liste• L'elemento chiave delle liste è una
concatenatore (struct list_head), definito come una coppia di puntatori al prossimo concatenatore ed precedente concatenatore:struct list_head {
struct list_head *next;struct list_head *prev;
}
• Come potete vedere, non c'è alcun riferimento diretto ad alcun tipo di struttura dati– Solo puntatori in avanti ed indietro, sempre ad
un'altro concatenatore di lista
• Dove $#%?!&#*! sono i dati?

124
Gestione delle liste• Un passo alla volta :-)• Il concatenatore viene inserito all'interno della
struttura dati che si vuole concatenarestruct kool_list {
int to;struct list_head list;int from;
} my_kool_list;
• Posso inserire il concatenatore dove voglio, all'interno della struttura kool_list
• Posso chiamare il concatenatore come mi pare (list, lista, pinco pallino)
• Posso avere multipli concatenatori

125
Gestione delle liste
int to;
struct list_headlist;
Int from;
struct list_headlist;
int to;
struct list_headlist;
Int from;
ElementosentinellaElementosentinella
Elementolista
Elementolista
structkool_list
structkool_list

126
Gestione delle liste: operazioni• Come posso utilizzare la mia lista nei
programmi?• Devo definire meccanismi per:– Inizializzare la lista– Aggiungere elementi alla lista– Cancellare elementi dalla lista– Controllare se la lista è vuota– Estrarre, dal concatenatore, l'elemento (qui
avviene una vera e propria magia)– Scorrere una lista

127
Gestione delle liste: inizializzazione• Avviene tramite l'utilizzo di apposite macro• Macro diverse a seconda di dove, nel codice,
effettuo l'inizializzazione• Inizializzazione tramite comando:– INIT_LIST_HEAD(&my_kool_list.list);– Vuole un puntatore al concatenatore– INIT_LIST_HEAD(list) effettua le operazioni:
list->next = list;list->prev = list;

128
Gestione delle liste: inizializzazione• Avviene tramite l'utilizzo di apposite macro• Macro diverse a seconda di dove, nel codice,
effettuo l'inizializzazione• Inizializzazione tramite assegnazione:– Vuole una variabile concatenatore (non
puntatore!)– LIST_HEAD_init(list_head_var);struct kool_list my_kool_list = {
.to = ...,
.list = LIST_HEAD_INIT(list_head_var)
.from = ...
}
– LIST_HEAD_INIT(name) si espande in:{ &(name), &(name) }

129
Gestione delle liste: inizializzazione• Avviene tramite l'utilizzo di apposite macro• Macro diverse a seconda di dove, nel codice,
effettuo l'inizializzazione• Inizializzazione tramite assegnazione
automatica:– Vuole un nome di variabile– Alloca un concatenatore con quel nome– LIST_HEAD(my_kool_list);– LIST_HEAD(name) si espande in:
struct list_head_name = LIST_HEAD_INIT( name )

130
Gestione delle liste: inizializzazione
struct list_head list;
prev
next

131
Gestione delle liste: inserimento• Si utilizza la funzione list_add()– list_add(struct list_head *new, struct list_head *
head)– new è il puntatore al concatenatore
dell'elemento che voglio inserire– head è il puntatore al concatenatore sentinella
della lista– Viene inserito l'elemento in cima alla lista
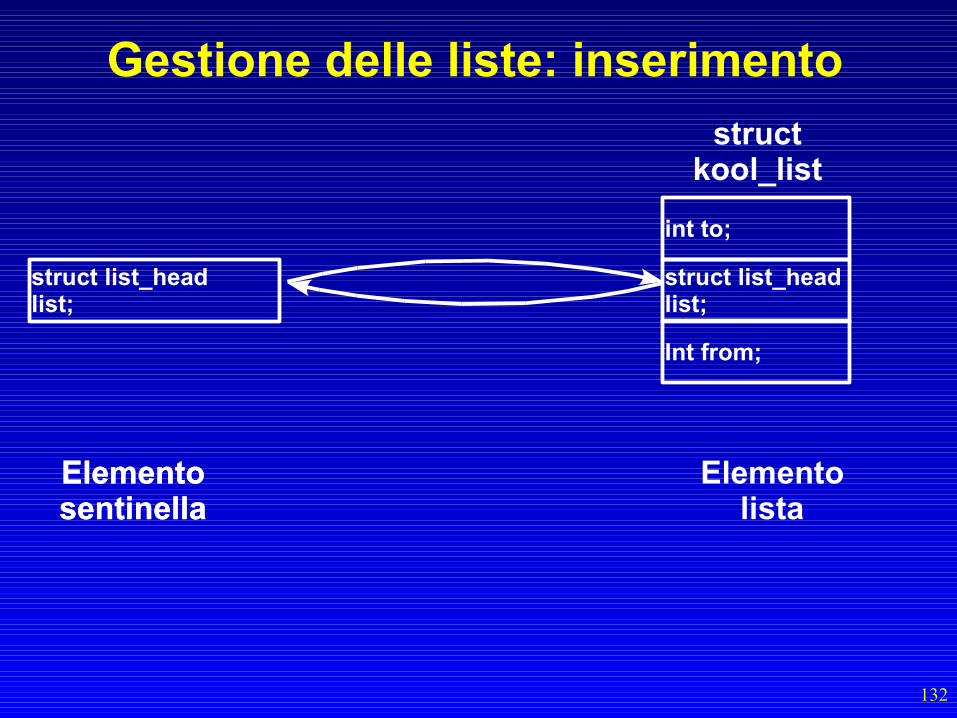
132
Gestione delle liste: inserimento
struct list_headlist;
int to;
struct list_headlist;
Int from;
ElementosentinellaElementosentinella
Elementolista
structkool_list
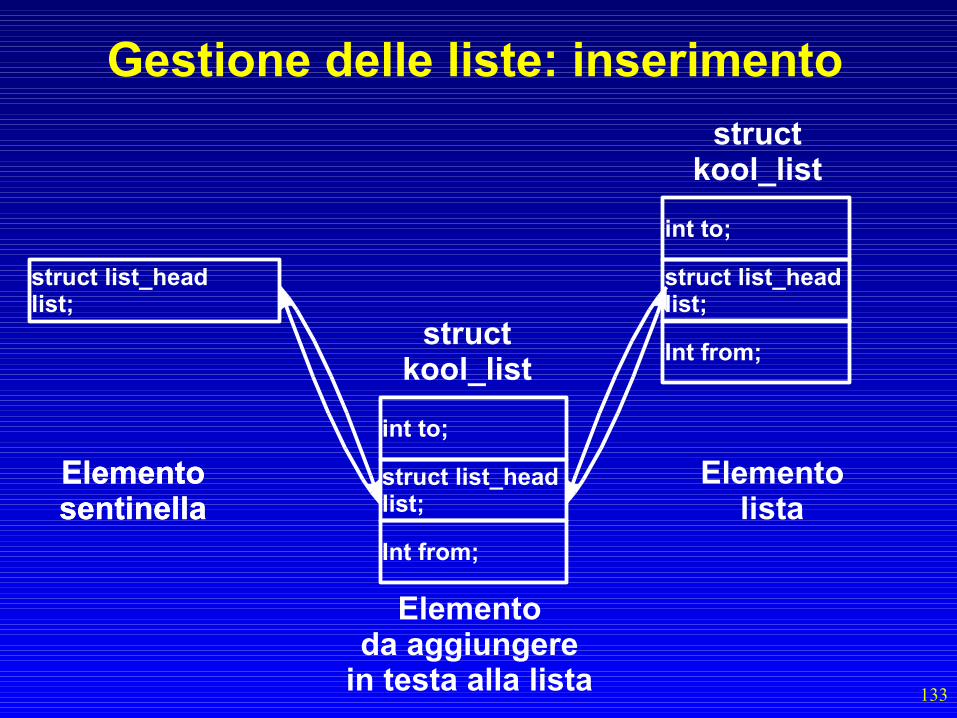
133
Gestione delle liste: inserimento
int to;
struct list_headlist;
Int from;
struct list_headlist;
int to;
struct list_headlist;
Int from;
ElementosentinellaElementosentinella
Elementoda aggiungere
in testa alla lista
Elementolista
structkool_list
structkool_list

134
Gestione delle liste: cancellazione• Si utilizza la funzione list_del()– list_del(struct list_head *entry)– entry è il puntatore al concatenatore
dell'elemento che voglio rimuovere– Il concatenatore viene staccato dalla lista– Non viene distrutto l'elemento puntato dal
concatenatore!
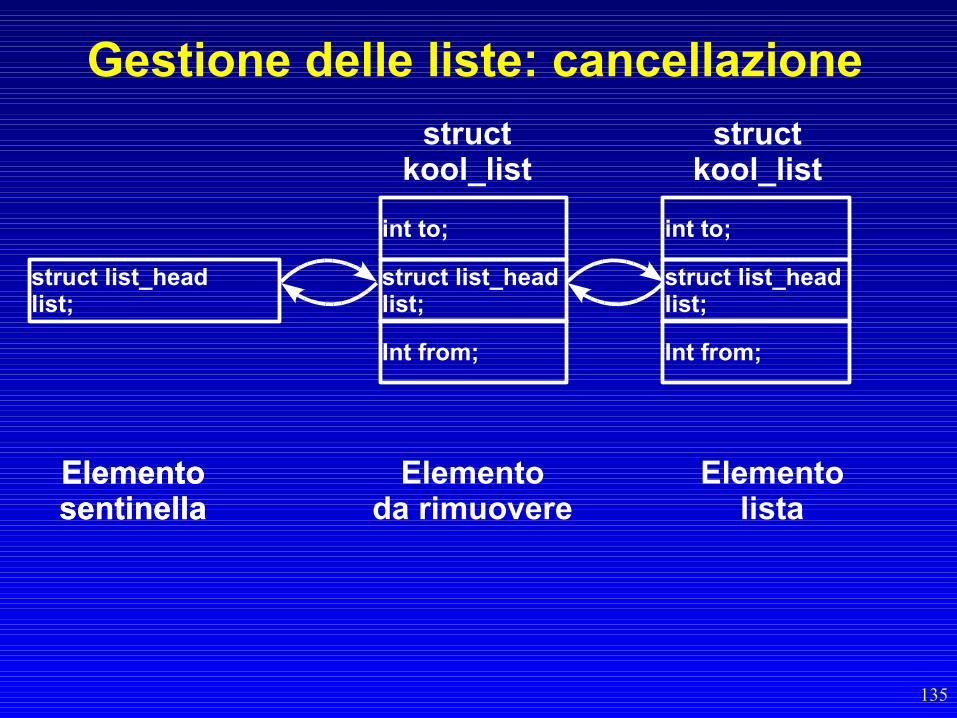
135
Gestione delle liste: cancellazione
int to;
struct list_headlist;
Int from;
struct list_headlist;
int to;
struct list_headlist;
Int from;
ElementosentinellaElementosentinella
Elementoda rimuovere
Elementolista
structkool_list
structkool_list

136
Gestione delle liste: cancellazione
int to;
struct list_headlist;
Int from;
struct list_headlist;
int to;
struct list_headlist;
Int from;
ElementosentinellaElementosentinella
Elementorimosso
Elementolista
structkool_list
structkool_list
prev
next
=0
=0

137
Gestione delle liste: lista vuota• Si utilizza la funzione list_empty()– int list_empty(struct list_head *head)– head è il puntatore al concatenatore sentinella
della lista che voglio controllare– Ritorna 1 se la lista è vuota, 0 altrimenti

138
Gestione delle liste: elemento• Si utilizza la macro list_entry()– list_entry(ptr, type, member)– ptr è il puntatore al concatenatore dell'elemento– type è il tipo di dato dell'elemento (struct ...)– member è il nome della variabile concatenatore
all'interno dell'elemento– struct my_kool_list *element =
list_entry( &my_kool_list.list,struct kool_list, list );
• Fa uso della macro container_of (include/linux/kernel.h)
• Si basa su un trucco ben noto:– ftp://rtfm.mit.edu/pub/usenet-by-
group/news.answers/C-faq/faq (2.14)

139
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;

140
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;

141
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
Prendo l'indirizzo 0 e lovedo (cast) come puntatorealla struttura kool_list.Posso farlo perché non stoscrivendo in memoria.

142
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
Con la dereferenziazione(->)ottengo una variabiledi tipo “member” alloindirizzo 4 (parto da 0!).Non la sto scrivendo; ilsistema non crasha.

143
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
Quale è il tipo dellavariabile di tipo memberche ho appena derefe-renziato? Ovviamente,member!

144
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
Definiamo una variabilepuntatore di tipo member,di nome __mptr. Il doppiounderscore “__” si usaper nomi di variabiliinterne (per convenzione).

145
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
Const indica che ilpuntatore punta ad unaarea di memoria chenon deve essere maimodificata. Se provo ascriverci, il compilatoreemette un errore.E' una misura di protezionecontro codice che scrivail contenuto di __mptraccidentalmente.

146
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
Assegniamo il puntatore__mptr di tipo member,protetto contro la scritturaaccidentale, al valore ptr,che rappresenta l'indirizzoiniziale di list.

147
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
Prendiamo il puntatore__mptr e vediamolo (cast)come un puntatore acaratteri. In questo modo,l'aritmetica sui puntatoridiventa l'aritmetica suibyte.

148
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
L'operatore offsetofcalcola l'offset (in byte)di member all'internodella struttura kool_list(4 byte).

149
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
La differenza dei duevalori (indirizzo di list,offset di list all'internodi kool_list), interpretatain aritmetica dei char *,mi fornisce il valorerichiesto, ossial'indirizzo iniziale dimy_kool_list.

150
Gestione delle liste: elemento• Macro container_of(ptr, type, member):
#define container_of(ptr, type, member) ({ \const typeof( ((type *)0)->member ) *__mptr = (ptr); \(type *)( (char *)__mptr - offsetof(type,member) ); \
})
Indirizzo1000100410121016
struct kool_list {int to;struct list_head list;int from;
} my_kool_list;
L'indirizzo finale vieneconvertito ad un puntatoredi tipo “type” (kool_list).

151
Gestione delle liste: scorrimento• Si utilizza la macro list_for_each()– list_for_each(pos, head)– pos è un puntatore a concatenatore generico,
contiene i vari concatenatori della lista– head è il puntatore al concatenatore sentinella
della lista– Viene scorso l'elenco dei concatenatori di una
listastruct list_head *pos;
struct kool_list my_kool_list;
list_for_each(pos, &my_kool_list.list) {tmp = list_entry( pos, struct kool_list, list );...
}

152
Gestione delle liste: scorrimento
struct list_headlist;
Elementosentinella
Primaiterazione
...
structkool_list
Secondaiterazione
Ultimaiterazione
pos:tmp:
pos:tmp:
pos:tmp:

153
Gestione delle liste: scorrimento• Variante list_for_each_entry()– list_for_each_entry(pos, head, member)– pos è un puntatore al tipo di dato– head è il puntatore al concatenatore sentinella
della lista– member il nome del concatenatore sentinella
nella lista– Scorre la lista assegnando a pos i puntatori
degli elementistruct kool_list pos, my_kool_list;
list_for_each_entry(pos, &my_kool_list.list, list) {# pos punta ad un elemento di tipo kool_list...
}

154
Gestione delle liste: scorrimento• Variante list_for_each_entry()– list_for_each_entry(pos, head, member)– pos è un puntatore al tipo di dato– head è il puntatore al concatenatore sentinella
della lista– member il nome del concatenatore sentinella
nella lista– Scorre la lista assegnando a pos i puntatori
degli elementistruct kool_list pos, my_kool_list;
list_for_each(pos, &my_kool_list.list, list) {# pos punta ad un elemento di tipo kool_list...
}

155
Gestione delle liste: scorrimento• Variante list_for_each_safe()– list_for_each_safe(pos, n, head)– pos è un puntatore a concatenatore generico,
contiene i vari concatenatori della lista– n un puntatore a concatenatore generico, viene
usato come variabile di appoggio– head il nome del concatenatore sentinella nella
lista– Scorre la lista in modalità sicura per permettere
la cancellazione di elementilist_for_each_safe(pos, q, &my_kool_list.list) {
tmp = list_entry(pos, struct kool_list, list);
list_del(pos);
kfree(pos); /* o free(pos) */
}
















![ImoLUG [ Corso Linux ] · ImoLUG [ Corso Linux: Lezione 4 ] [ OTTENERE NOTIZIE SULL'HARDWARE DEL PC: ] dmesg Visualizza i messaggi del kernel [ 8812.744076] usb 1-2: new high speed](https://static.fdocumenti.com/doc/165x107/60a612e8d9448c5e1b20a5f4/imolug-corso-linux-imolug-corso-linux-lezione-4-ottenere-notizie-sullhardware.jpg)

