
Sistemi di raccomandazione
72
Sistemi di Raccomandazione Alfredo Pulvirenti Università degli Studi di Catania
-
Upload
big-data-for-you -
Category
Data & Analytics
-
view
197 -
download
0
Transcript of Sistemi di raccomandazione

Sistemi di Raccomandazione
Alfredo Pulvirenti
Università degli Studi di Catania

Sommario
• Introduzione
• Unapanoramicasulletecniche
• Content-based
• Collabora8veFiltering• Collabora8veFilteringinpra8ca:SVD
• RaccomandazioneGraph-based
• MetodiIbridi
• UnprogeBosviluppatodalnostrogruppo

Parte I Introduzione

Introduzione
• Un sistema di raccomandazione è una classe di
applicazioni (comunemente web-based) che
predicono le risposte degli uten8 sulla base delle
loropreferenze.
• Dueesempi:• Suggerirear8coliaileBorideiquo8dianion-line;
• Offrireaiclien8deisi8die-commercesuggerimen8sucosapotrebbeessere
dilorointeresse.

Esempiodisistemadiraccomandazione
• ClienteX• AcquistaCDMetallica
• AcquistaCDMegadeth
• ClienteY• FaunaricercasuiMetallica• IlsistemadiraccomandazionesuggerisceMegadethinbaseaida8colleziona8sulclienteX

Lemetodologie
• Diverse tecnologie ma due gruppi
principali:• Content-based systems: esaminare le proprietà degli
ar8coliperraccomandarnenuovi.
• Collabora5vefilteringsystems:usaremisuredisimilarità
tra uten8e/oprodoRper raccomandarenuovi prodoR
(oggeRsimiliodiproprietàdiuten8simili).
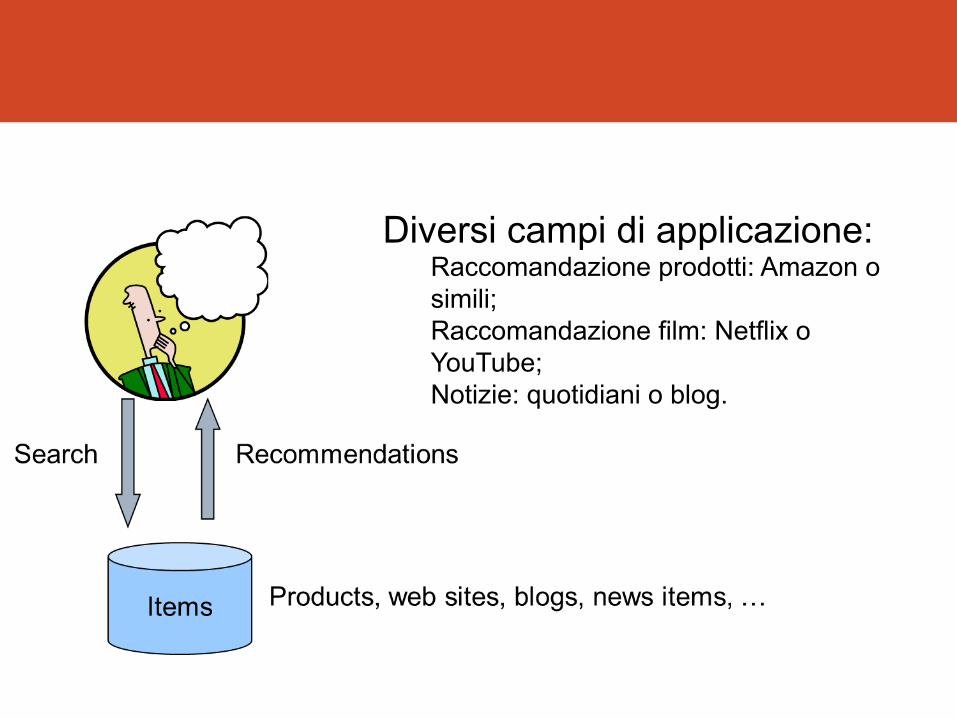
Diversi campi di applicazione: Raccomandazione prodotti: Amazon o simili; Raccomandazione film: Netflix o YouTube; Notizie: quotidiani o blog.

Definizione
• Sistemadiraccomandazionehadueclassidien5tà:
• UninsiemediUten5(U={u1,…,un})
• UninsiemediOgge>(O={o1,…,om})
rappresentateall’internodiunau5litymatrix(Um={duo}nxm)
• matricesparsacheperognicoppiautente-oggeBocalcolaungradodipreferenza
dell’utenteperl’oggeBo.
• ObieRvodel sistemadi raccomandazione:predire leentry
vuotedellamatriceperinferirelepreferenzedell’utente.
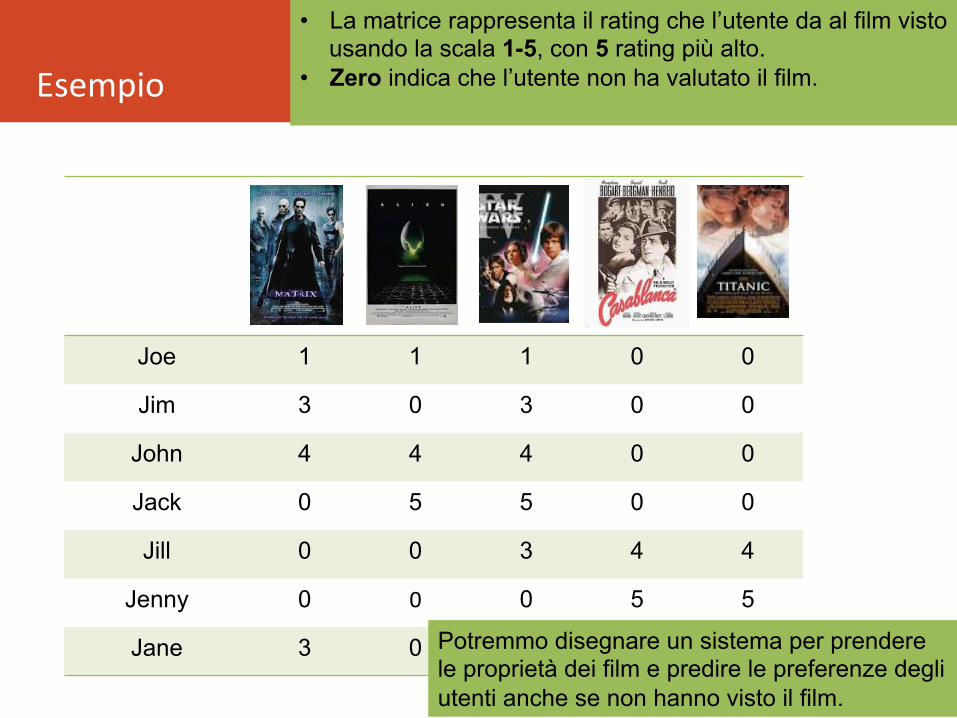
Esempio
Matrix
Alien
Star Wars
Casablanca
Titanic
Joe 1 1 1 0 0
Jim 3 0 3 0 0
John 4 4 4 0 0
Jack 0 5 5 0 0
Jill 0 0 3 4 4
Jenny 0 0 0 5 5
Jane 3 0 0 2 2
• La matrice rappresenta il rating che l’utente da al film visto usando la scala 1-5, con 5 rating più alto.
• Zero indica che l’utente non ha valutato il film.
Potremmo disegnare un sistema per prendere le proprietà dei film e predire le preferenze degli utenti anche se non hanno visto il film.

IlfenomenodellaLongtail
• Negozifisici:spaziolimitatosugliscaffali,mostrano
piccolafrazionediprodoR(ipiùpopolari).
• Web: non ha questo problema, cos8 per
pubblicizzareiprodoRviciniallozero…
• Piùsceltapergliuten8,ma…vannoaiuta8!
• Ci servono filtri migliori… usiamo i sistemi di
raccomandazione!
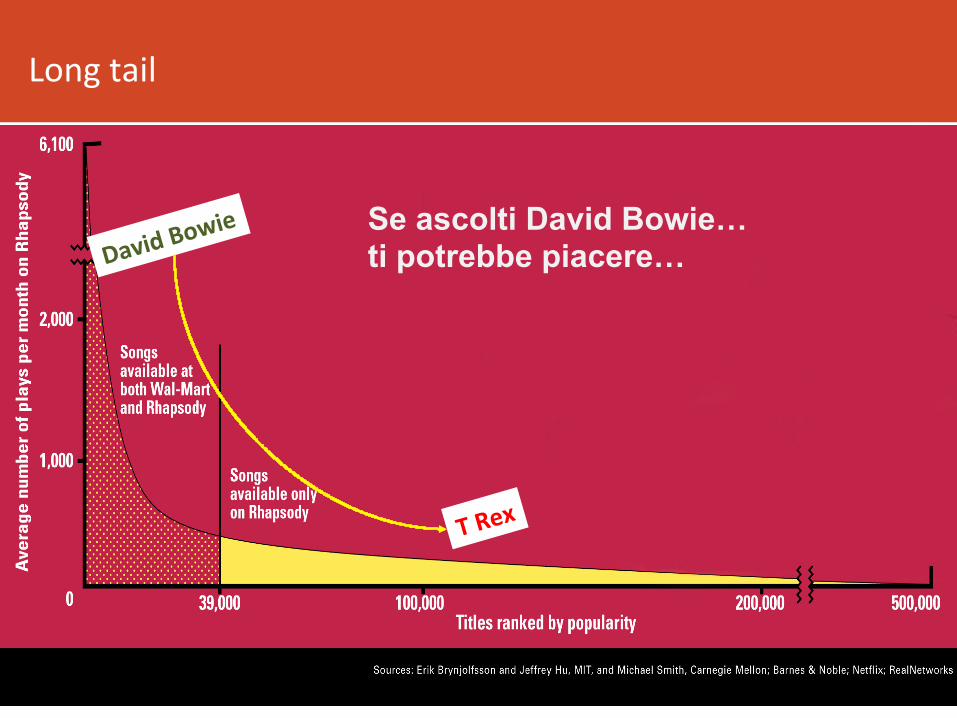
Longtail
DavidBowi
e
TRex
Se ascolti David Bowie… ti potrebbe piacere…

Problemichiave
• Collezionare valutazioni “conosciute” per la u8litymatrix.
• Predirevalutazioninuoveedelevateapar8redallevalutazioniconosciute.

ComeoBenerelevalutazioni(ra8ng)
• Costruire una u8lity matrix è un task complicato, due
approcci per scoprire il valore che un utente da ad un
prodoBo:
• Esplicito:• Chiederedivalutareunitem(es.YouTube).
• Implicito:
• Apprenderedalleazionidell’utente.

Estrapolarelau8litymatrixeraccomandare
• DescriviamoiquaBroapprocciprincipali:• Content-based
• Collabora5veFiltering
• Graph-based
• HybridApproach

Parte II Content-based
recommendation

RaccomandazioniContent-based
• Idea principale: gli oggeR raccomanda8
all’utente U sono simili agli oggeR valuta8
posi8vamentedaU.
• Il sistema focalizza sulle proprietà degli
ogge>.• Lasimilarità tradueoggeRèdeterminatamisurando la
similaritàdelleloroproprietà.
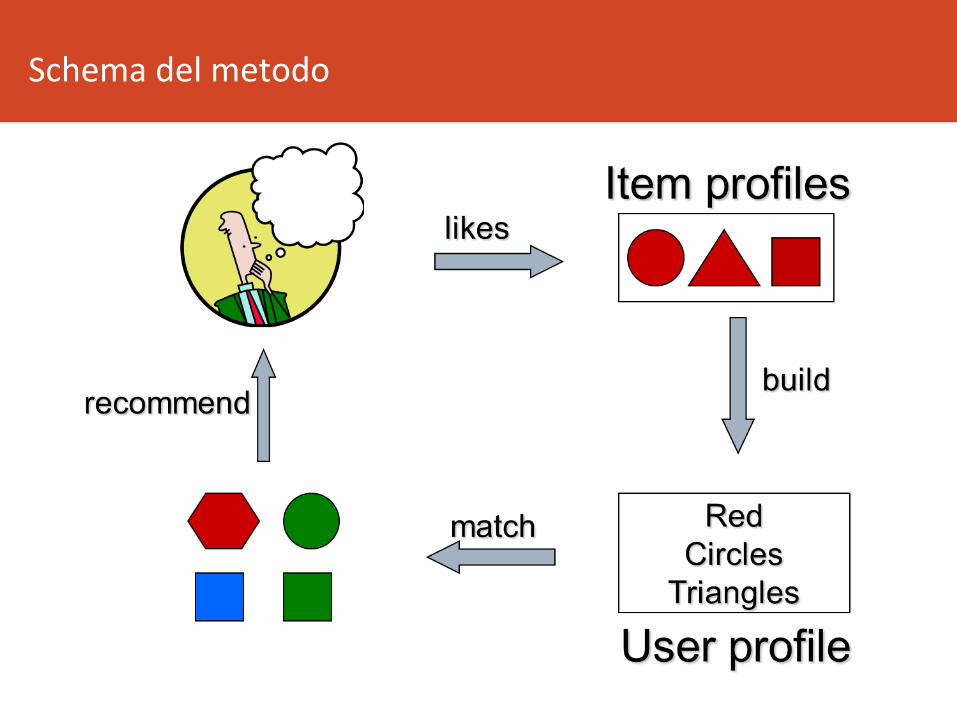
Schemadelmetodo

IlprofilodeglioggeR
• PerognioggeBosicreaunprofilo;
• Un Profilo è un insieme di feature che rappresentano
caraBeris8cheimportan8.
• I Documen5 sono una classe di oggeR per i quali non è
semplicedefinirequalidebbanoesserelefeature.
• Usareleparolepiùimportan5diundocumento.
• Comescegliamoleparoleimportan8?
• Tipicaeuris8caTF.IDF(TermFrequency5mesInverseDocFrequency)

TF.IDF
• “fij”frequenzadideltermine“i”neldocumento“dj”
• “ni”numerodidocumen8chemenzionanoiltermine“i”,
• Nilnumerototaledidocumen8,
TF.IDF:“wij=TFij·IDFi”
• Profilo diundocumento:insiemedelleparolechehannoil
piùaltoTF.IDFscore,assiemeailoroscore.

Profiliutenteepredizione
• Userprofile,diversepossibilità:• MediaponderatadeiprofilideglioggeR;
• ...
• Euris5cadipredizione:• Dato il profilo x dell’utente e il profilo i del prodo.o,s8miamo𝑢(𝒙,𝒊) = cos(𝒙,𝒊) = 𝒙·𝒊/||𝒙||⋅||𝒊||

Proecontro
+:Nonc'èbisognodida5sualtriuten5
+:Ingradodiconsigliareagliuten5congus5unici
+:Ingradodiraccomandarear5colinuovienonpopolari
+:faciledainterpretare
–:Trovarelefeaturegiusteèdifficile
–:Raccomandazionepernuoviuten5
–:Monomodale

Parte III Collaborative Filtering
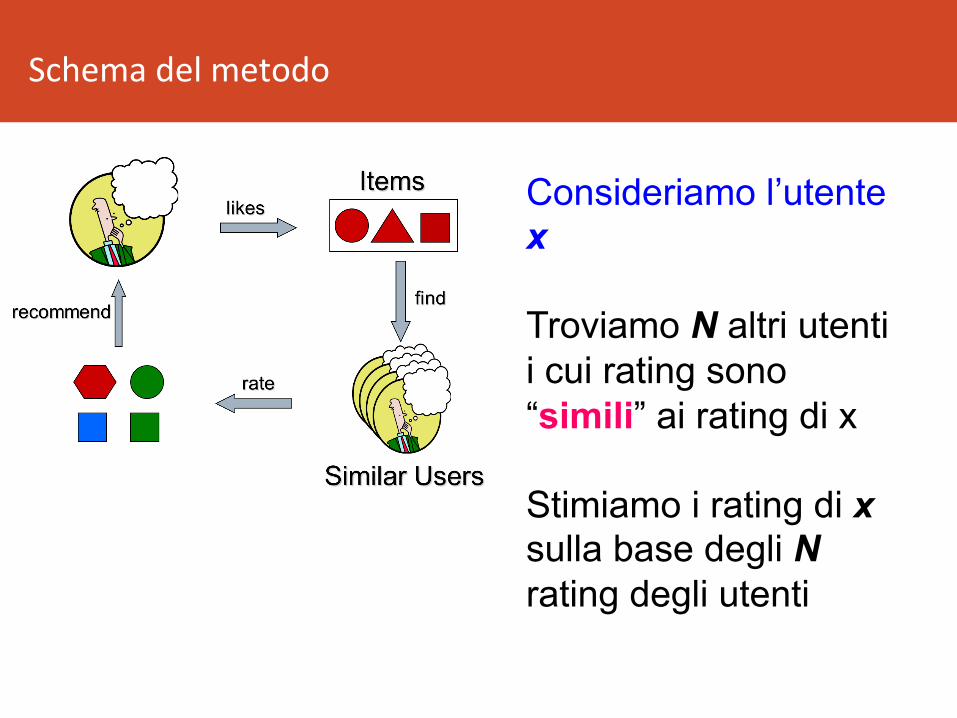
Schemadelmetodo
Consideriamo l’utente x
Troviamo N altri utenti i cui rating sono “simili” ai rating di x
Stimiamo i rating di x sulla base degli N rating degli utenti

Comemisuriamolasimilarità
• Jaccardsimilarity:
sim(x,y)=|rx∩ry|/|rx∪ry|
• Cosinesimilarity:
sim(x,y)=cos(rx,ry)
• Pearsoncorrela5oncoefficient:
rx = [*, _, _, *, ***] ry = [*, _, **, **, _]

Predizioni
Dallasimilaritàallaraccomandazione:
• SiarxilveBoredira8ngdell’utentex
• SiaNl’insiemedeikuten8piùsimiliaxchehannovalutato
l’oggeBoi
• Predizionedell’oggedoiperl’utentex:• 𝑟↓𝑥𝑖 = 1/𝑘 ∑𝑦∈𝑁↑▒𝑟↓𝑦𝑖
• 𝑟↓𝑥𝑖 = ∑𝑦∈𝑁↑▒𝑠↓𝑥𝑦 ⋅ 𝑟↓𝑦𝑖 /∑𝑦∈𝑁↑▒𝑠↓𝑥𝑦
• Altreopzioni?
• Molte..
𝒔↓𝒙𝒚 =𝒔𝒊𝒎(𝒙,𝒚)

OggeBo-OggeBoCollabora8veFiltering
• Vista:oggedo-oggedo• TroviamoglioggeRsimiliai
• S8miamoilra8ngperiinbaseaira8ngdeglioggeRsimili
∑∑
∈
∈⋅
=);(
);(
xiNj ij
xiNj xjijxi s
rsr
sij… similarità degli oggetti i e j rxj…rating dell’utente x sull’oggetto j N(i;x)… set di oggetti simili a i valutati da x

CF:Approcciocomune
• DefiniamolasimilaritàsijtraglioggeRiej
• SelezioniamoknearestneighborN(i;x)
• OggeRpiùsimiliai,valuta8dall’utentex
• S8miamoilra8ngrxipesatoconlamedia:
Stima baseline per rxi ¡ μ=mediageneraledituRifilm¡ bx=deviazionedelra8ngdallamedia
dell’utentex=(avg.ra1ngutentex)–μ¡ bi=deviazionedelra8ngperl’oggeBoi
∑∑
∈
∈=);(
);(
xiNj ij
xiNj xjijxi s
rsr
∑∑
∈
∈−⋅
+=);(
);()(
xiNj ij
xiNj xjxjijxixi s
brsbr
𝒃↓𝒙𝒊 =𝝁+ 𝒃↓𝒙 + 𝒃↓𝒊

Proecontro
+:Lavoracontu>i5pidiogge>
+:Nonènecessariafeatureselec5on
-:Newuserproblem
-:Newitemproblem
-:Matricedeira5ngsparsa

DimensionalityReduc8on
• Possibile soluzione per il problema dovuto alla
“sparsità”dellamatrice?• DimensionalityReduc5on
• LatentSeman5cIndexing(LSI)• Tecnicaalgoritmicasviluppatatralafinedeglianni‘80primianni‘90
• Risolve problemi di sinonima, “sparsità” e scalabilità per grandi
dataset
• RiduceladimensionalitàecaBuralerelazionilaten8
• Si può mappare facilmente nel Collabora5ve
Filtering!

LSI
• Tecnica di indicizzazione che usa la SingularValue Decomposi5on per iden8ficare
paBernnella relazionetra terminieconceR
contenu8neltesto.
• Si basa sul principio che parole che sono
usatenellostessocontestotendonoadavere
significatosimile.
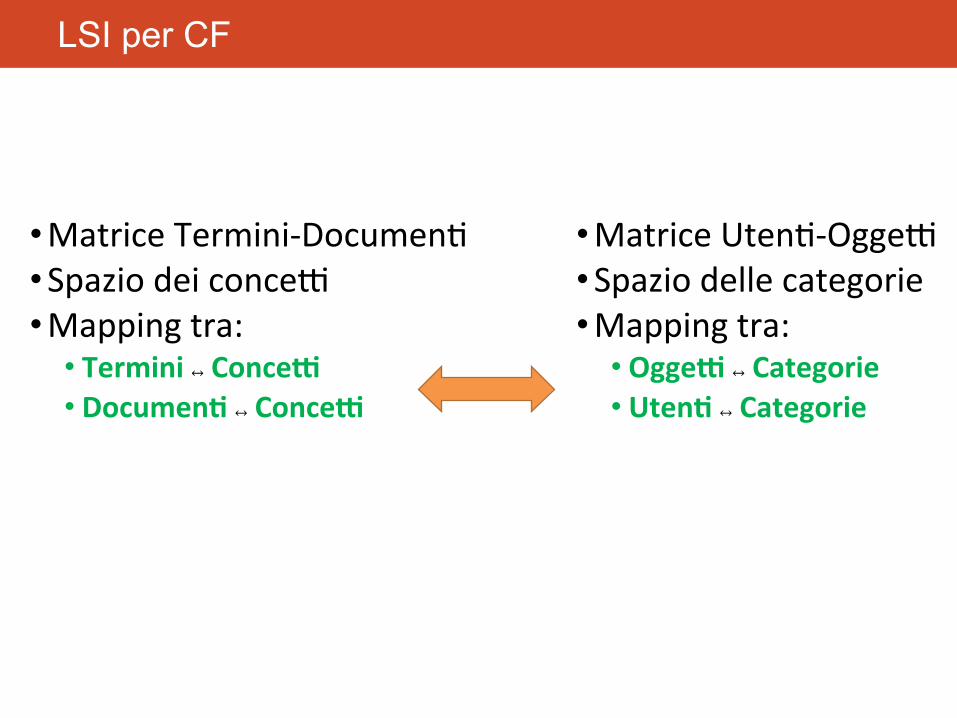
LSI per CF
• MatriceTermini-Documen8• SpaziodeiconceR• Mappingtra:
• Termini↔Conce>• Documen5↔Conce>
• MatriceUten8-OggeR• Spaziodellecategorie• Mappingtra:
• Ogge>↔Categorie• Uten5↔Categorie

NeklixChallenge
• Compe8zione per iden8ficare il migliore algoritmo di CF per predire
ra8ngdegliuten8perIfilm,sullabasedira8ngpreceden8.
• Prize:USD$1,000,000
• Compe8zioneiniziatanel2006
• Unteamhavintolacompe8zionenel2009(habaButol’algoritmousato
daNeklixmigliorandoleprestazionidel10.06%)
• Dataset:
• ~480,000uten8e~18,000film;solo~100milionidira8ng
• U8litymatrixsparsaal99%!(Circa8.5miliardidira5ngpotenziali)

Singular-ValueDecomposi8on(SVD)
• Rappresentazione low-dimensional di una matrice
high-dimensional• RappresentazioneesaBa
• Facilerimuovereledimensionimenosignifica8ve
• Algoritmiefficien8(R,matlab)

SingularValueDecomposi8on
• Problema:#1:TrovareConceR
#2:Ridurreladimensionalità

SVD-Definizione
A[nxm]=U[nxr]Λ[ rxr](V[mxr])T
• A:matricenxm(es,ndocumen8,mtermini)
• U:matricenxr(ndocumen8,rconceR)
• Λ:matricediagonalerxr(forzadiogni‘conceBo’)(r:rango(*)dellamatrice)
• V:matricemxr(mtermini,rconceR)
*
*Numerodirigheocolonnelinearmenteindipenden8dellamatrice
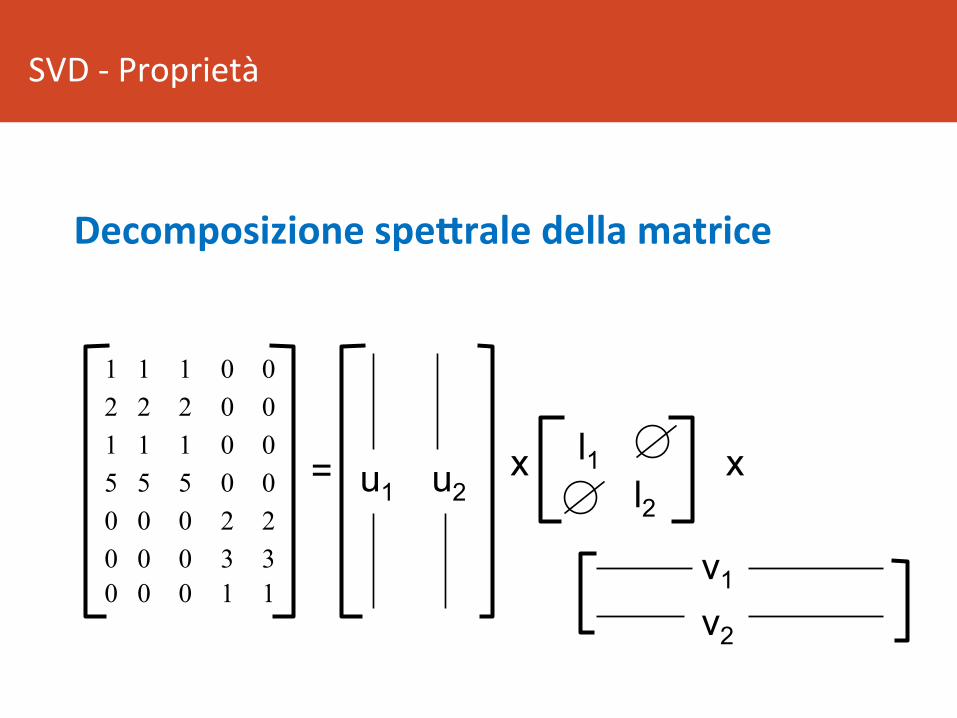
SVD-Proprietà
Decomposizionespedraledellamatrice
1 1 1 0 0 2 2 2 0 0 1 1 1 0 0 5 5 5 0 0 0 0 0 2 2 0 0 0 3 3 0 0 0 1 1
= x x u1 u2 l1
l2
v1 v2
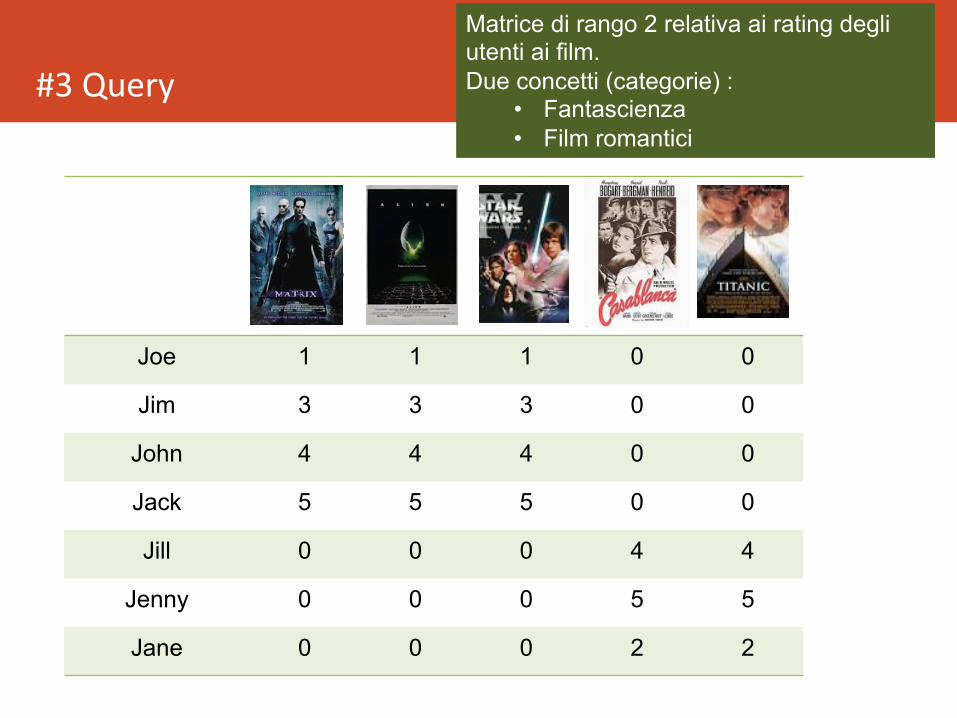
#3Query
Matrix
Alien
Star Wars
Casablanca
Titanic
Joe 1 1 1 0 0
Jim 3 3 3 0 0
John 4 4 4 0 0
Jack 5 5 5 0 0
Jill 0 0 0 4 4
Jenny 0 0 0 5 5
Jane 0 0 0 2 2
Matrice di rango 2 relativa ai rating degli utenti ai film. Due concetti (categorie) :
• Fantascienza • Film romantici

EffeBuareraccomandazioni
• UsalaCosineSimilarity
• Grazie alla SVD, possiamo effeBuare delle
predizioniconunsempliceprodoBoscalare.• Datounutenteelalistadeira8ngdeifilmchehavistoea
zeroquellichenonhavisto(p):• Mappiamo i ra5ng corren5 dell’utente dallo spazio originale a quello
dellecategorie(mol5plichiamoperV,matricefilm-categorie): 𝑝 =𝑝×𝑉
• CalcoliamolaraccomandazioneusandonuovamentelamatriceV:
𝑝 = 𝑝 × 𝑉↑𝑇
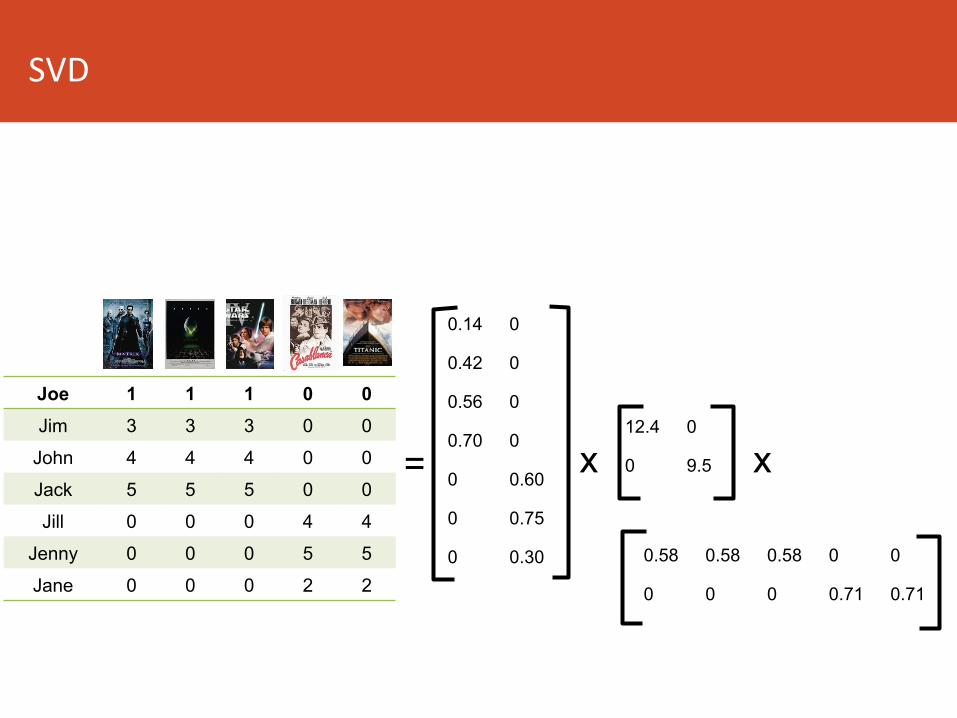
Joe 1 1 1 0 0Jim 3 3 3 0 0
John 4 4 4 0 0
Jack 5 5 5 0 0
Jill 0 0 0 4 4
Jenny 0 0 0 5 5
Jane 0 0 0 2 2
0.14 0
0.42 0
0.56 0
0.70 0
0 0.60
0 0.75
0 0.30
12.4 0
0 9.5 x
0.58 0.58 0.58 0 0
0 0 0 0.71 0.71
x =
SVD

SVD–Queryconl’usodeiconceR
• Abbiamo l’utente (Alfredo) nuovo, non presente
nellamatrice.
• Possiamocapirecosaglipotrebbepiacere?
• HavistosoloMatrix,rate4
• Rappresen8amoAlfredocome:
p=[40000]
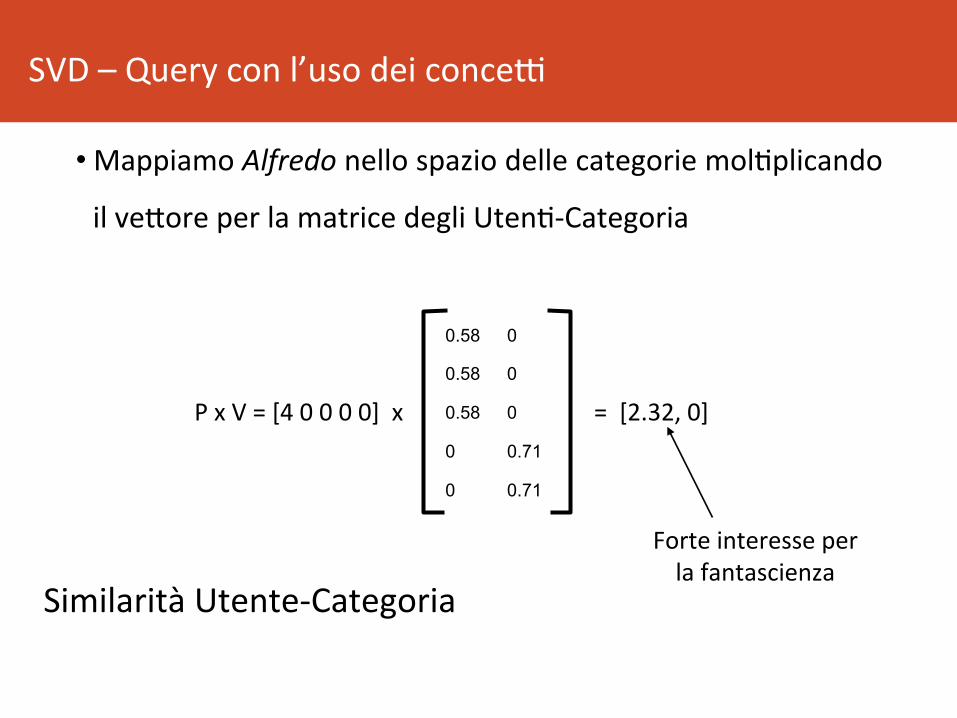
SVD–Queryconl’usodeiconceR
• MappiamoAlfredonellospaziodellecategoriemol8plicando
ilveBoreperlamatricedegliUten8-Categoria
0.58 0
0.58 0
0.58 0
0 0.71
0 0.71
Forteinteresseperlafantascienza
SimilaritàUtente-Categoria
PxV=[40000]x =[2.32,0]

SVD–Queryconl’usodeiconceR
• RimappiamoAlfredonellospaziodeifilmmol8plicando[2.32,0]per
VT.
0.58 0.58 0.58 0 0
0 0 0 0.71 0.71 [2.32,0]x =[1.35,1.35,1.35,0,0]

Part IV Metodi Graph-based

MetodiGraph-based
• Simile al Collabora8ve Filtering ma usa un grafo bipar5to per
immagazzinareleinformazioni.
• Le raccomandazioni sono oBenute a par8re dalla struBura della rete
bipar8ta.
• Dueclassidiiden8tà:Uten5(U)eOgge>(O).
• Definiamoilgrafobipar8tocomesegue:
• G(U,O,E,W)
• E={eij:uilikesoj)
• W:E→ℜ
• “E”insiemedegliarchie “W”èunafunzionecherappresentaildegreedi
preferenzacheunutentehaperilpar8colareoggeBo.

Lau8litymatrixcomegrafobipar8to
Joe
Jim
John
Jack
Jill
Jenny
Jane
1 3
4
4 5
2 4 5
2
5
5 5
1
1 3 3
5
4 4
Schemadelmetodo
NBI
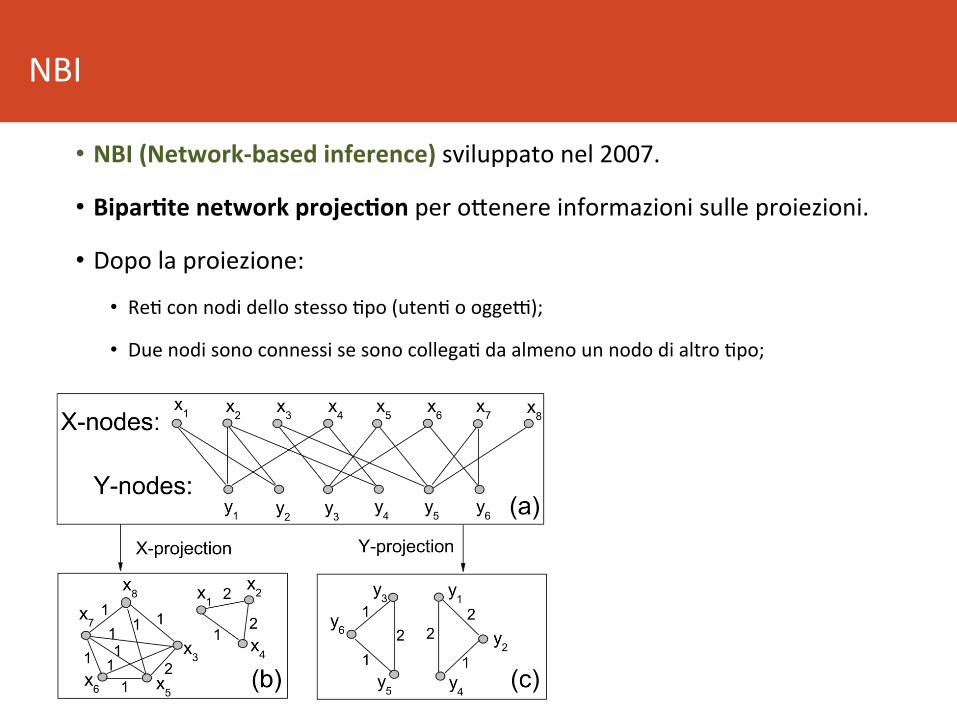
• NBI(Network-basedinference)sviluppatonel2007.
• Bipar5tenetworkprojec5onperoBenereinformazionisulleproiezioni.
• Dopolaproiezione:• Re8connodidellostesso8po(uten8ooggeR);
• Duenodisonoconnessisesonocollega8daalmenounnododialtro8po;

NBI
• Idea base dell’algoritmo: flusso delle risorse sulla
retebipar8ta:• aglioggeRvieneassegnataunaquan8tàinizialedirisorse;
• inunprocessoadue fasi le risorse sono trasferitedaglioggeRagli
uten8esuccessivamentetrasferi8indietroaglioggeR;
• questo processo, con una fase di normalizzazione consente di
oBeneredegliscoreperlecoppieuten8-oggeR.
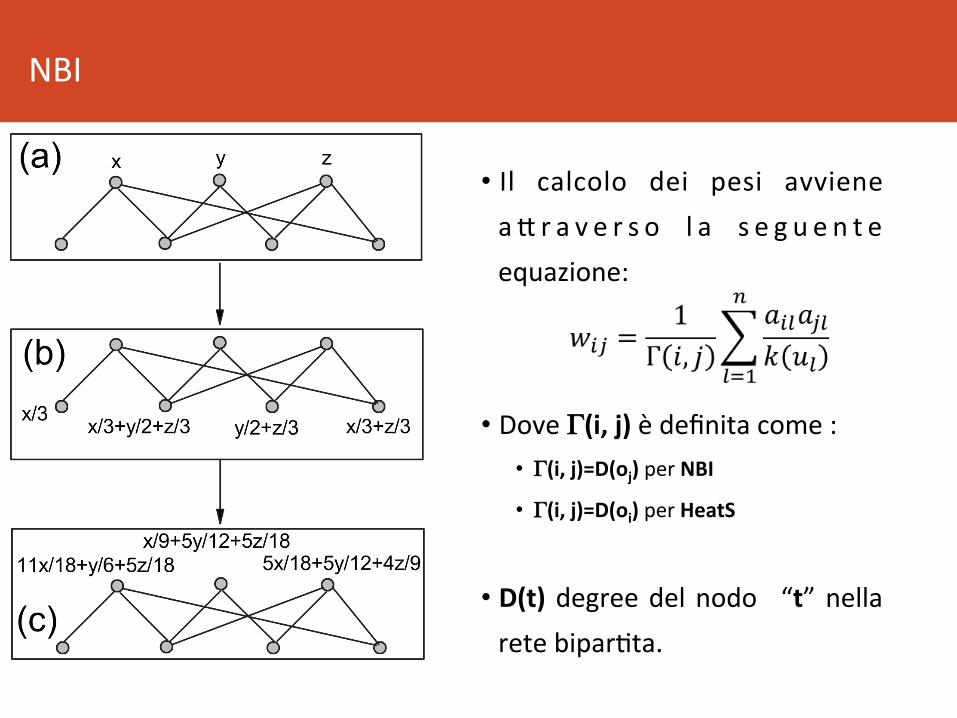
NBI
• Il calcolo dei pesi avvienea B r a v e r s o l a s e g u e n t eequazione:
• DoveΓ(i,j)èdefinitacome:• Γ(i,j)=D(oj)perNBI
• Γ(i,j)=D(oi)perHeatS
• D(t) degreedelnodo “t”nellaretebipar8ta.

RaccomandazioniconNBI
• Il peso “wij” della proiezione corrisponde a quante risorse
vengono trasferitedall’oggeBo“j”all’oggeBo“i”,oquanto
piaceràl’oggeBo“j”adunutenteacuipiacel’oggeBo“i”.
• Data la matrice di adiacenza “A” del grafo bipar8to e la
matrice“W”,lamatricediraccomandazione“R”pertuRgli
uten8puòesserecalcolatainununicostep:
𝑅=𝑊×𝐴

Proecontro
+:Funzionasutu>i5pidiogge>
+: Risolve il problema della sparsità della u5lity
matrix.
-:Newuserproblem
-:Newitemproblem
-:Richiedeimportan5risorsecomputazionali

Metodiibridi
• Usare in combinazione diversi metodi di
raccomandazione
• Supponiamodiavereimetodi“X”e“Y”chedanno
rispeRvamentegliscore“xa”e“ya”.Loscorediun
modelloibridopuòessereoBenutocome:
• λ∈[0;1]

Proecontro
+: Efficace nel migliorare la qualità delle
raccomandazioni
-:Computazionalmentepesante

Part V Predizione di annotazioni su
una banca dati di articoli
scientifici

Mo8vazioni
InseBoricomelabiomedicina
• LeBeraturascien8ficaenorme;
• Cen8naia di database con risulta8 di analisi
sperimentali;
• Può essere difficile a volte iden8ficare risulta8 già
conosciu8..Pocominingsuques8da8..

Mo8vazioni
• Problema:
An8cipare l’informazione di cui l’utente ha bisogno (ma
nonlosa!!).
Definizione:
Dato un insieme di termini che l’utente ha oBenuto per un
ar8colo, interrogando un search engine, vogliamo
raccomandare un insiemepiccolo, significa5vo edifferente,
diterminirilevan=perl’ar8colomanoncontenu8inesso.

Abstractannota8on:unmodoperinferirenuoveipotesi
E2F3 senescence
mir-499 microRNA
EZH2 PDGFB CTGF SOX4
microRNA Cancer

Proposta
• BioTAGMEo Un sistemaper l’estrazione di informazioni nella formadi termini
seman5camentecorrela5:tag/ancoredaPubMed.
o Duetecnologie:ü TAGME:Sistemaperl’estrazionediannotazionidates8;
ü DT-Hybrid:Algoritmodiraccomandazione.
o Ilcontesto Circa 25 milioni di citazioni dalla letteratura biomedica
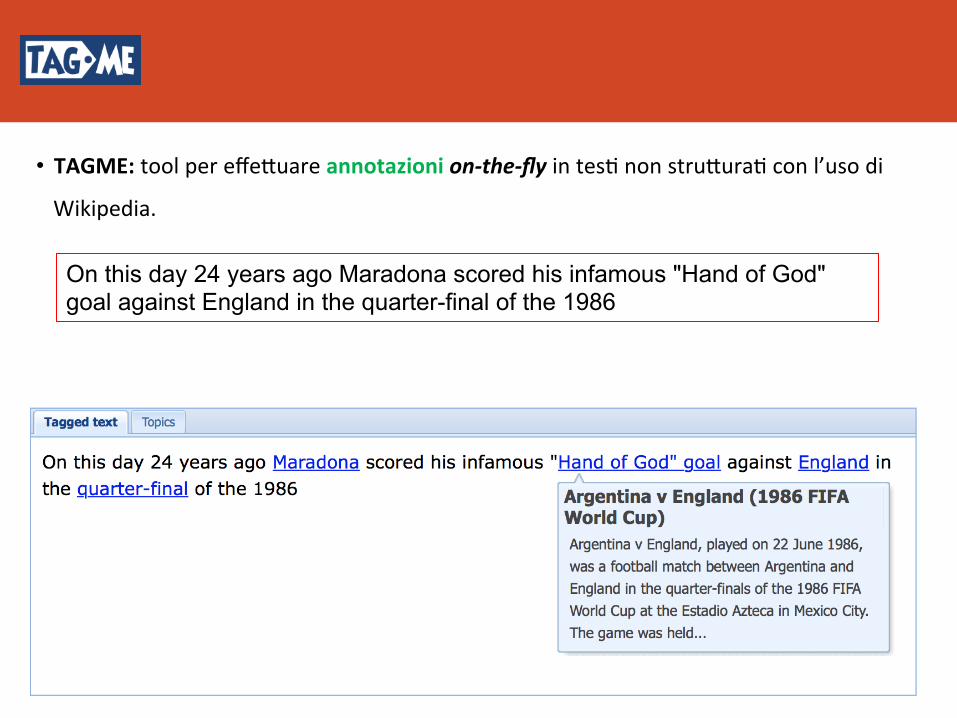
• TAGME:toolpereffeBuareannotazionion-the-flyintes8nonstruBura8conl’usodi
Wikipedia.
On this day 24 years ago Maradona scored his infamous "Hand of God" goal against England in the quarter-final of the 1986
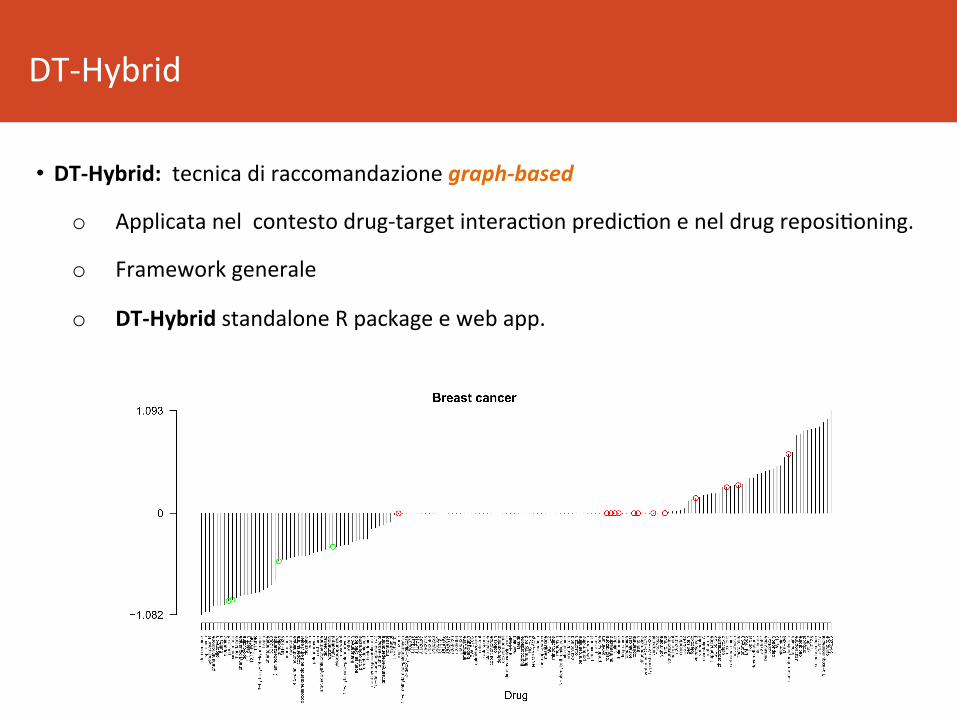
DT-Hybrid
• DT-Hybrid:tecnicadiraccomandazionegraph-based
o Applicatanelcontestodrug-targetinterac8onpredic8oneneldrugreposi8oning.
o Frameworkgenerale
o DT-HybridstandaloneRpackageewebapp.
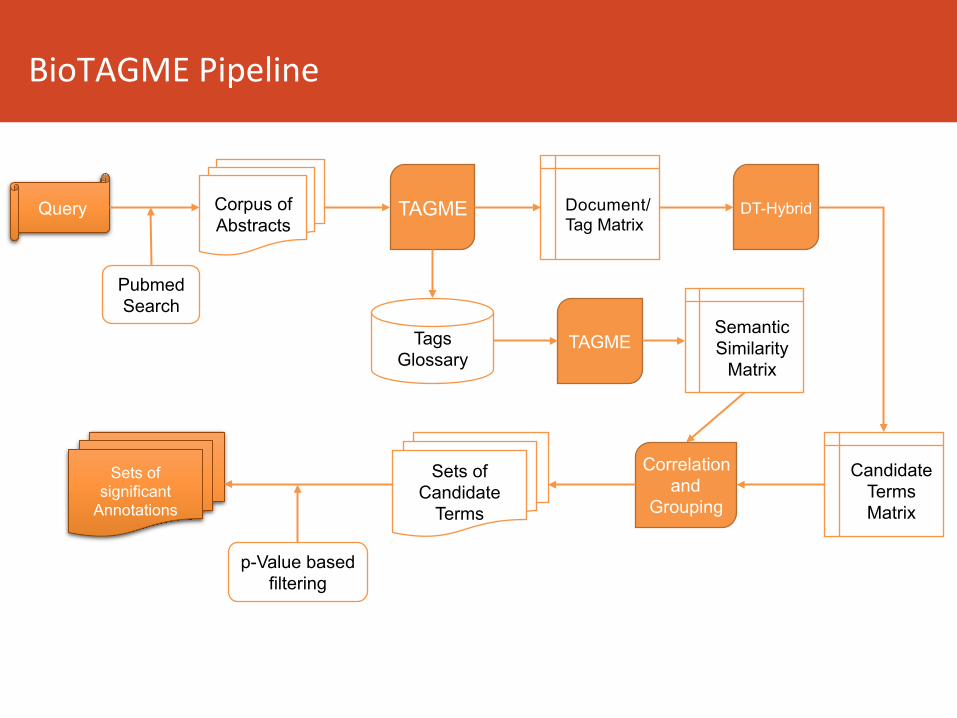
Query TAGME Document/Tag Matrix
Candidate Terms Matrix
DT-Hybrid
TAGME Semantic Similarity
Matrix
Sets of Candidate
Terms
Sets of significant
Annotations
Corpus of Abstracts
Pubmed Search
BioTAGMEPipeline
p-Value based filtering
Correlation and
Grouping
Tags Glossary
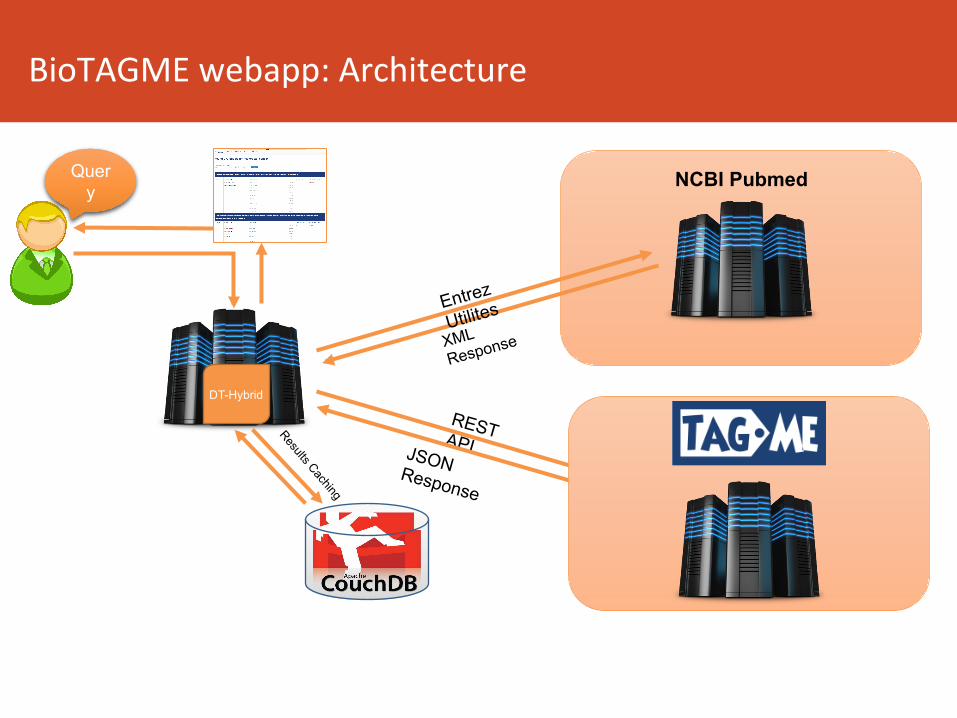
BioTAGMEwebapp:Architecture
Query
REST API JSON Response
NCBI Pubmed
Entrez
Utilites
XML
Response
DT-Hybrid
BioTAGMEwebapp
http://alpha.dmi.unict.it/biotagme/
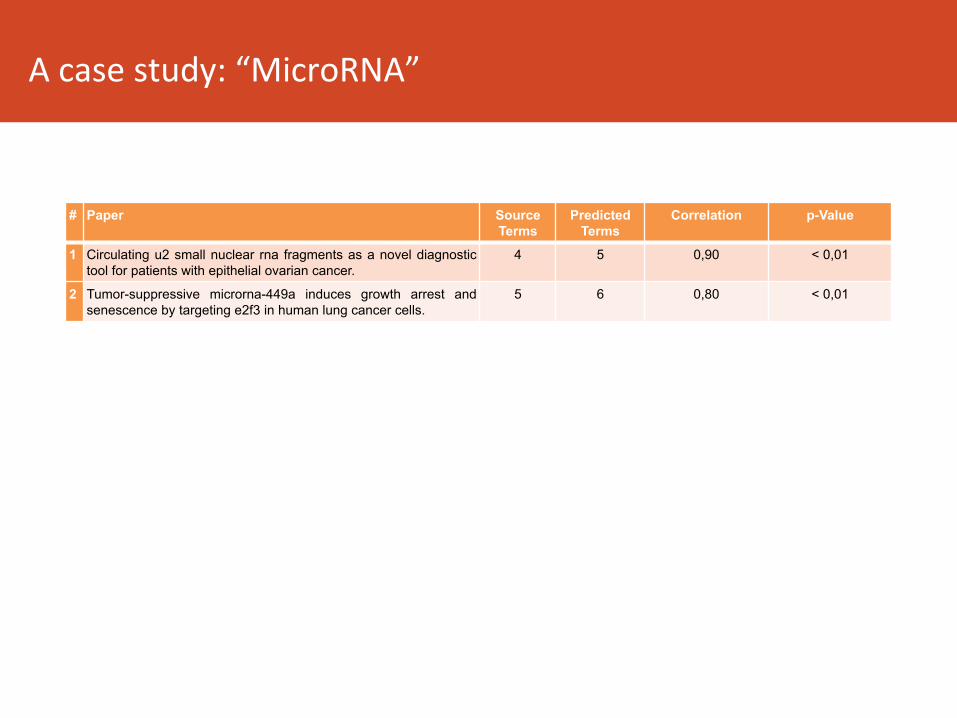
Acasestudy:“MicroRNA”
# Paper Source Terms
Predicted Terms
Correlation p-Value
1 Circulating u2 small nuclear rna fragments as a novel diagnostic tool for patients with epithelial ovarian cancer.
4 5 0,90 < 0,01
2 Tumor-suppressive microrna-449a induces growth arrest and senescence by targeting e2f3 in human lung cancer cells.
5 6 0,80 < 0,01
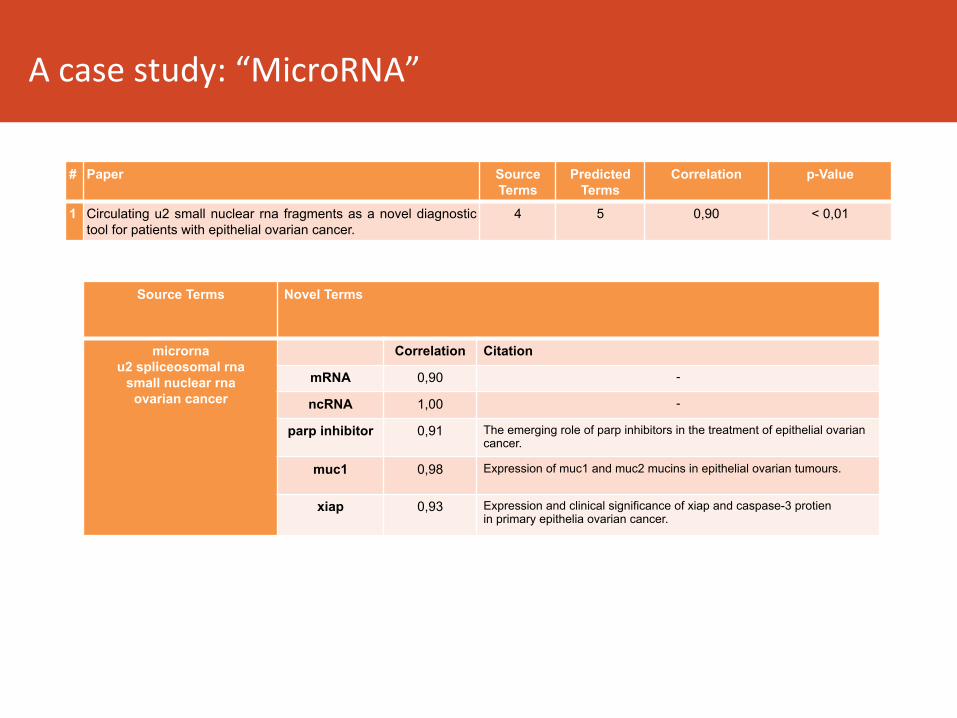
Acasestudy:“MicroRNA”
Source Terms Novel Terms
microrna u2 spliceosomal rna
small nuclear rna ovarian cancer
Correlation Citation
mRNA 0,90 -
ncRNA 1,00 -
parp inhibitor 0,91 The emerging role of parp inhibitors in the treatment of epithelial ovarian cancer.
muc1 0,98 Expression of muc1 and muc2 mucins in epithelial ovarian tumours.
xiap 0,93 Expression and clinical significance of xiap and caspase-3 protien in primary epithelia ovarian cancer.
# Paper Source Terms
Predicted Terms
Correlation p-Value
1 Circulating u2 small nuclear rna fragments as a novel diagnostic tool for patients with epithelial ovarian cancer.
4 5 0,90 < 0,01
Acasestudy:“MicroRNA”
Source Terms Novel Terms
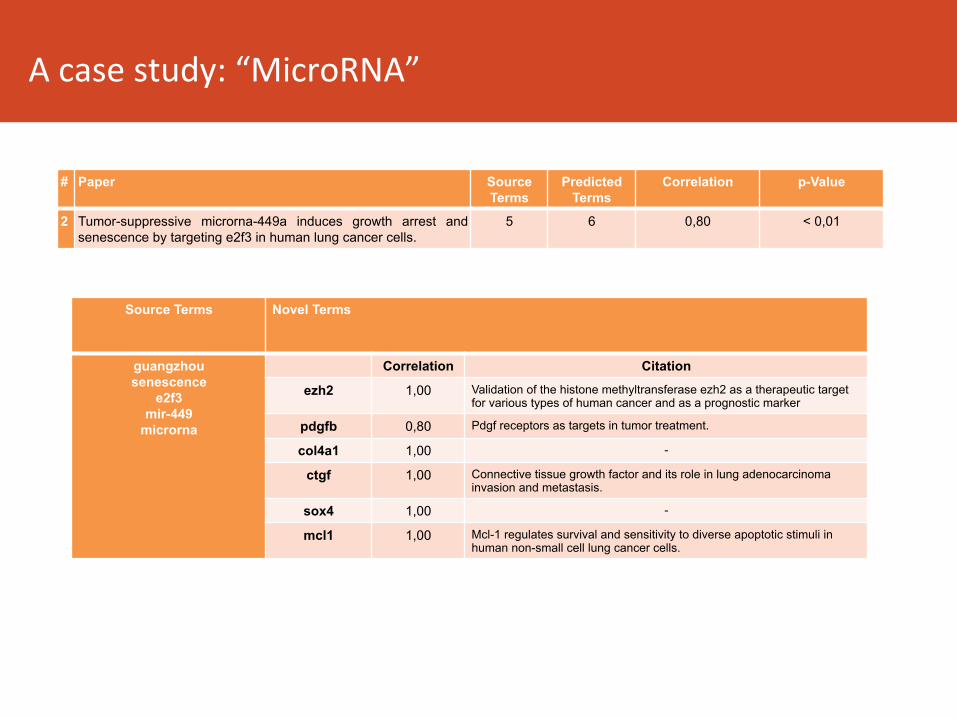
guangzhou senescence
e2f3 mir-449
microrna
Correlation Citation
ezh2 1,00 Validation of the histone methyltransferase ezh2 as a therapeutic target for various types of human cancer and as a prognostic marker
pdgfb 0,80 Pdgf receptors as targets in tumor treatment.
col4a1 1,00 -
ctgf 1,00 Connective tissue growth factor and its role in lung adenocarcinoma invasion and metastasis.
sox4 1,00 -
mcl1 1,00 Mcl-1 regulates survival and sensitivity to diverse apoptotic stimuli in human non-small cell lung cancer cells.
# Paper Source Terms
Predicted Terms
Correlation p-Value
2 Tumor-suppressive microrna-449a induces growth arrest and senescence by targeting e2f3 in human lung cancer cells.
5 6 0,80 < 0,01
Wisdomofcrowds

ProgeBoinprogress:what’snext
• PubMedofflineCrawling;
• Automa8cbibliographyconstruc8on;
• Sviluppo versione custom di BioTAGME con le
ontologiebiomediche(OMIM,GO).
• Integrazionedibancheda8esterne:raccomandazione
domain-tuned.

Takehomemessage
• ModelliLatentFactoregraphbasedmolto
efficaci.
• Spazio di applicazione dei sistemi di
raccomandazionemoltoampio.
• Moltelibrerieesisten8.

Bibliografiaeringraziamen8
• Alcunicontenu8sonoriadaBa8daMiningMassiveData:hBp://www.mmds.org/
• MetodiGraph-based:
• Zhou, T., Ren, J., Medo, M., and Zhang, Y. (2007). Bipar5te network projec5on and personal recommenda5on. Physical
ReviewE,76(4),046115–22.
• Zhou, T., Kuscsik, Z., Liu, J.-G.,Medo,M.,Wakeling, J. R., and Zhang, Y.-C. (2010).Solving theapparentdiversity-accuracy
dilemmaofrecommendersystems.ProceedingsoftheNa8onalAcademyofSciences,107(10),4511–4515.
• AlgoritmoDT-Hybrid:
• Alaimo S, Pulviren8 A, Giugno R, Ferro A.Drug–target interac5on predic5on through domain-tuned network-
basedinference.Bioinforma8cs201329:2004-2008.
• AlaimoS,GiugnoR,Pulviren8A."ncPred:ncRNA-DiseaseAssocia8onPredic8onthroughTripar8te
Network-BasedInference."Fron1ersinbioengineeringandbiotechnology2(2014).
• TAGME
• Ferragina, P., Scaiella, U. (2012). Fast and Accurate Annota5on of Short Texts withWikipedia
Pages.IEEESo�ware29(1):70-75.AlsoappearedinProcsACMCIKM(2010,pp.1625-1628).
• BioTAGME
• Alaimo S, Ferragina P, Ferro A, Giugno R, Pulviren8 A. An algorithm for the predic5on of
annota5onsonPubmed(submided)

Ilteam!
AlfredoFerro,FullProfessor,UniversitàdiCatania
SalvatoreAlaimo,Post-Doc,UniversitàdiCatania
RosalbaGiugno,AssociateProfessor,UniversitàdiVerona
PaoloFerragina,FullProfessor,UniversitàdiPisa

Grazie!


















