
Scrivere Un Sistema Operativo
36
1 di 36 Scrivere un sistema operativo di: Antonio Mazzeo pubblicato il: 24-04-2001 Introduzione: In questo corso cercheremo di creare un nostro piccolo sistema operativo, con il solo scopo di capire quanto possa essere difficile progettarne uno e allo stesso tempo renderlo efficiente. Introduzione La realizzazione di un sistema operativo è un’impresa ardua con diversi ostacoli posti sulla strada. Già anni addietro mi ero avviato in questa avventura, ma la quantità irrisoria di informazioni di cui ero in possesso sull’argomento, lo studio, ed altre motivazioni mi fecero abbandonare questo progetto. Oggi sono convinto che giunto il momento di tirare dal cassetto questo vecchio ed arduo progetto, ma per far sì che questa impresa sia condotta a termine scriverò diverse lezioni sull ’argomento, ed accettando in qualsiasi momento eventuali vostri suggerimenti e/o critiche, al fine di poter realizzare un sogno covato sin dall ’età di 15 anni. Lo scenario attuale Chiun que vorrà intra prend ere questa strada insieme con me deve avere conoscenz e indis pensa bili per proseguire lungo questo cammino. I moderni sistemi operativi tendono ad avere kernel di dimensioni a dir poche assurde, che necessitano di svariate decine di megabyte di memoria ram per girare, e come se non bastasse di una buona fetta di spazio su disco fisso per un ’installazione decente. Tutti qua nti hanno ben pres ent e Microso ft Windows, e chi ha buon memoria, ricord erà che all’uscita di Windows 95 sulla scatola del prodotto vi era scritto ‘Requisiti hardware minimi: cpu INTEL 80386DX 33Mhz, 4 Mb di memoria RAM’ e se non ricordo male cir ca 100Mb di spa zio sul vost ro disco fisso, e almeno un’altra fetta per il file di swap. Beh, Microsoft ci aveva visto giusto, il suo sistema operativo poteva girare sui gloriosi 386 che avessero almeno 4Mb di ram, peccato che per farlo funzionare in modo decente di memoria ram come minimo ne serviva 16 MB e...la cpu? Beh..ho avuto modo di usarlo su un P100 in modo decente, su un 486dx2 mi ha dato l’impressione che stava un po’ stretto. Con una cpu del 300% più veloce di quella dichiarata e col 400% di RAM in confronto a ciò che Microsoft andava urlando, il suo sistema operativo girava in modo apprezzabile. L’introduzione delle cosiddette GUI (Graphics Interface User) ha semplificato la vita a chiunque è a digiuno di comput er, facili tando ne l’app roccio e la pos sibili tà di pot er real iz zare qua lcosa di concreto sin dal 1° giorno d’utilizzo, senza dover stare dietro a dei prompt tremendi che non tollerano una sola lettera sbagliata. Ho avuto modo di visionare il BeOS, forse uno dei sistemi operativi che meritino ancora di portare questo nome, gira in modo eccellente sul mio PC, chiede soltanto 40Mb di spazio che poi arriva a circa 100Mb installando i relativi compilatori, ma non mi pare di aver visto qualche altro sistema operativo moderno che si accontenti di così poco spazio su disco fisso. Orientamento di questo corso Per poter proseguire in questa opera, è necessario conoscere bene l ’architettura dove si andrà a scrivere il sistema operativo. Nelle successive lezioni tratteremo lo sviluppo di un sistema operativo per piattaforme INTEL o compatibile, essendo le più diffuse in mercato, pertanto chiunque fosse interessato a seguire il corso, dovrà avere delle conoscenze di base del set di istruzioni di queste CPU, ovvero per dirla breve del linguaggio Assembler. Oltre al linguaggio Assembler sarà utilizzato anche il linguaggio C. La scelta di questo linguaggio è dettata da motivazioni abbastanza semplici, la disponibilità di compilatori ANSI C per quasi tutte le piattaforme e per quasi tutti i vari microprocessori esistenti in commercio, permette la scrittura di un codice facilmente por tat ile, qua lor a il sis tema ope rativo dov esse essere conver tit o nel minor temp o possibile su al tre piattaforme incompatibili. In questo modo cercheremo di realizzare un’astrazione dall’hardware, ricorrendo al linguaggio assembler soltanto nelle poche sezioni dove esso è realmente indispensabile.
-
Upload
massimiliano-ranaldi -
Category
Documents
-
view
225 -
download
0
Transcript of Scrivere Un Sistema Operativo

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 1/36
1 di 36
Scrivere un sistema operativodi: Antonio Mazzeo
pubblicato il: 24-04-2001
Introduzione: In questo corso cercheremo di creare un nostro piccolosistema operativo, con il solo scopo di capire quanto possa esseredifficile progettarne uno e allo stesso tempo renderlo efficiente.
Introduzione
La realizzazione di un sistema operativo è un’impresa ardua con diversi ostacoli posti sulla strada. Già anniaddietro mi ero avviato in questa avventura, ma la quantità irrisoria di informazioni di cui ero in possessosull’argomento, lo studio, ed altre motivazioni mi fecero abbandonare questo progetto. Oggi sono convintoche giunto il momento di tirare dal cassetto questo vecchio ed arduo progetto, ma per far sì che questaimpresa sia condotta a termine scriverò diverse lezioni sull’argomento, ed accettando in qualsiasi momentoeventuali vostri suggerimenti e/o critiche, al fine di poter realizzare un sogno covato sin dall ’età di 15 anni.
Lo scenario attualeChiunque vorrà intraprendere questa strada insieme con me deve avere conoscenze indispensabili perproseguire lungo questo cammino. I moderni sistemi operativi tendono ad avere kernel di dimensioni a dirpoche assurde, che necessitano di svariate decine di megabyte di memoria ram per girare, e come se nonbastasse di una buona fetta di spazio su disco fisso per un’installazione decente.
Tutti quanti hanno ben presente Microsoft Windows, e chi ha buon memoria, ricorderà che all’uscita diWindows 95 sulla scatola del prodotto vi era scritto ‘Requisiti hardware minimi: cpu INTEL 80386DX 33Mhz,4 Mb di memoria RAM’ e se non ricordo male circa 100Mb di spazio sul vostro disco fisso, e almenoun’altra fetta per il file di swap. Beh, Microsoft ci aveva visto giusto, il suo sistema operativo poteva giraresui gloriosi 386 che avessero almeno 4Mb di ram, peccato che per farlo funzionare in modo decente dimemoria ram come minimo ne serviva 16 MB e...la cpu? Beh..ho avuto modo di usarlo su un P100 in mododecente, su un 486dx2 mi ha dato l’impressione che stava un po’ stretto. Con una cpu del 300% più velocedi quella dichiarata e col 400% di RAM in confronto a ciò che Microsoft andava urlando, il suo sistemaoperativo girava in modo apprezzabile.L’introduzione delle cosiddette GUI (Graphics Interface User) ha semplificato la vita a chiunque è a digiunodi computer, facilitandone l’approccio e la possibilità di poter realizzare qualcosa di concreto sin dal 1°giorno d’utilizzo, senza dover stare dietro a dei prompt tremendi che non tollerano una sola lettera sbagliata.Ho avuto modo di visionare il BeOS, forse uno dei sistemi operativi che meritino ancora di portare questo
nome, gira in modo eccellente sul mio PC, chiede soltanto 40Mb di spazio che poi arriva a circa 100Mbinstallando i relativi compilatori, ma non mi pare di aver visto qualche altro sistema operativo moderno chesi accontenti di così poco spazio su disco fisso.
Orientamento di questo corsoPer poter proseguire in questa opera, è necessario conoscere bene l’architettura dove si andrà a scrivere ilsistema operativo.Nelle successive lezioni tratteremo lo sviluppo di un sistema operativo per piattaforme INTEL o compatibile,essendo le più diffuse in mercato, pertanto chiunque fosse interessato a seguire il corso, dovrà avere delleconoscenze di base del set di istruzioni di queste CPU, ovvero per dirla breve del linguaggio Assembler.Oltre al linguaggio Assembler sarà utilizzato anche il linguaggio C. La scelta di questo linguaggio è dettatada motivazioni abbastanza semplici, la disponibilità di compilatori ANSI C per quasi tutte le piattaforme e
per quasi tutti i vari microprocessori esistenti in commercio, permette la scrittura di un codice facilmenteportatile, qualora il sistema operativo dovesse essere convertito nel minor tempo possibile su altrepiattaforme incompatibili. In questo modo cercheremo di realizzare un’astrazione dall’hardware, ricorrendoal linguaggio assembler soltanto nelle poche sezioni dove esso è realmente indispensabile.

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 2/36
2 di 36
I principali compilatori che utilizzeremo per questo corso saranno il Turbo Assembler della Borlandfacilmente reperibile sulla rete [1], ed un compilatore ANSI C che generi codice per piattaforme x86. Almomento la scelta di quest’ultimo compilatore è ricaduta sul CM32, compilatore che ho trovato nelCD-ROM allegato a [2], ma anche scaricabile dall’indirizzo ftp://ftp.nsk.su (ftp://ftp.nsk.su/ ).Oltre a questi due compilatori, è indispensabile avere documentazione completa sul funzionamento dei varicomponenti hardware di un personal computer, in quanto deve essere lo stesso sistema operativo a fornireun’interfaccia comune al software, dando così la possibilità a chi si appresta a sviluppare applicativi per ilnostro sistema operativo di non doversi interfacciare con l’hardware stesso per gestirlo, ma attraverso un
set di specifiche API gestire periferiche a volte totalmente incompatibili tra di loro.Obiettivi indispensabili per il nostro sistema operativo saranno dati da una velocità d ’esecuzione, da unadimensione ridotta, da efficienza, e da un quantitativo irrisorio di memoria.Questa introduzione termina qui. Nella prossima lezione tratteremo due applicativi indispensabili per unsistema operativo, di dimensioni talmente ridotte, ma senza i quali nessun sistema operativo sarebbe ingrado di avviarsi, il BOOT SECTOR e il MASTER BOOT RECORD (MBR).
Bibliografia[1] Developing Your Own 32-Bit Operating System – Richard A. Burgess – Sams Publishing.
Riferimenti[2] http://playtools.cjb.net (http://playtools.cjb.net/ ) contiene nella sezione compilatori un link al TurboAssembler 5 di Borland.
Lezione 1: Il Boot Sector e il Master Boot Record.
IntroduzioneIn questa lezione tratteremo di due piccoli software, delle dimensioni ridotte, ma la cui presenza èessenziale affinché il sistema operativo venga caricato in modo corretto.La maggior parte di voi avrà sicuramente sentito parlare di Boot Sector e Master Boot Record (da ora in poiidentificato col termine di MBR), due termini che identificano due zone ben precise del disco fisso e di unfloppy disk.
Si tende ad identificare come boot sector il 1° settore di un floppy disk o il 1° settore di ogni partizionepresente in un disco fisso, mentre si identifica col termine di MBR il 1°settore di un disco fisso.Perché questa differenza tra boot sector e MBR? Ciò che differenzia questi due settori e il loro contenuto.Nel 1° troviamo un microprogramma avente lo scopo di caricare il sistema operativo, mentre nel 2°troviamo un altro microprogramma avente lo scopo di identificare la partizione attiva su un determinatodisco e di caricare di conseguenza il relativo boot sector in memoria per caricare così il sistema operativo.Tratteremo il contenuto e la codifica dei relativi microprogrammi nei paragrafi successivi, dopo aver trattatoin modo veloce il funzionamento di una CPU in modalità reale
La modalità realeE’ necessario innanzitutto dire che un microprocessore a 32bit che supporta il set di istruzioni x86 puòlavorare principalmente in due modalità differenti: la modalità reale e la modalità protetta.
In questa lezione tratteremo esclusivamente la modalità reale, molto più semplice della modalità protetta,priva di complicazioni derivanti dall’impiego della memoria e soprattutto la modalità con la quale una cpuviene costretta a lavorare dal momento in cui riceve il segnale di #RESET o subito dopo l’accensione.La modalità reale non è altro che un modo per gestire la memoria presente sulla macchina. Una cpu a 32bitin modo reale risulta essere come una vecchia cpu a 16bit più veloce e con un set di istruzioni più ampiorispetto ai predecessori.Preciso comunque che il modo nativo di una CPU a 32bit è la cosiddetta modalità protetta , ma dato ilperiodo in cui venne lanciato sul mercato il primo processore a 32bit (il 386, a metà degli anni ’80), i progettidi INTEL preferirono mantenere la compatibilità con l’architettura precedente, onde garantire che tutto ilsoftware fino ad allora esistente sul commercio potesse girare in modo corretto anche sui nuovi processori.La modalità reale venne introdotta negli anni 70, con i processori a 16bit di INTEL, i quali avevano un limitedi indirizzamento max della memoria di 1Mb, tant ’è vero che lo stesso Bill Gates considerò tale quantitativodi memoria più che sufficiente per qualsiasi tipo di applicazione.
In modalità reale ogni singolo byte viene indirizzato attraverso una coppia di puntatori, chiamatiSEGMENTO ed OFFSET. Questa coppia di puntatori viene combinata dal processore in un particolareregistro interno di 20bit, ottenendo di conseguenza l ’indirizzo lineare del byte da indirizzare in memoria.Per poter indirizzare la memoria vennero creati appositi registri:

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 3/36
3 di 36
CS – Code Segment – Questo registro, combinato insieme al registro IP (Istruction Pointer) forniscel’indirizzo della prossima istruzione che la cpu dovrà eseguire. A differenza di tutti gli altri registri, questacoppia è l’unica che non può essere modificata attraverso le normali istruzioni, ma viene modificataindirettamente dalle istruzioni di salto (condizionale e non), dalle istruzioni per chiamare routine e perterminarle (CALL, RET, RETF) e dalle istruzioni di interrupt. (INT, IRET).DS – Data Segment – Normalmente questo registro viene utilizzato in coppia col registro SI, per indicarequal è il segmento dove sono memorizzati i dati del software in memoria.ES – Extra Segment – normalmente in coppia al registro DI, ed è utilizzato per indirizzare dati in memoria.
SS – Stack Segment – Questo registro, insieme al registro SP (Stack Pointer) fornisce l’indirizzo di stacknella memoria. Lo stack viene normalmente utilizzato per salvare il contenuto di registri, ma col passare deltempo i compilatori incominciarono ad usare lo stack per il passaggio dei parametri ad eventuali routinerichiamate nel codice. La modifica del contenuto dei registri SS ed SP deve essere fatta con particolareattenzione, essendovi in una cpu a 16bit un solo stack. Un esempio di codice vi mostrerà il perché ènecessario porre attenzione alla modifica di questi due registri.
Esempio:Contenuto di SS:SP – 8000:8F00 – Indirizzo assoluto -> 88F000
Interrupt attivi
Istruzione da eseguire:MOV AX, 7000MOV SS, AX - Subito dopo questa istruzione lo stack punta all’indirizzo assoluto 78F000, dal contenuto non meglioidentificato!
MOV SP, 9000
Ipotizziamo che nel momento in cui il processore si accinge ad eseguire l’istruzione MOV SP, 9000 arriva alprocessore un segnale di interrupt proveniente dal TIMER, e dato che i segnali IRQ (Interrupt RequestHardware) hanno priorità assoluta la CPU trasferisca il controllo al relativo indirizzo, salvando tutti i registrinello stack, si potrebbe sovrascrivere dei dati, o nel peggiore dei casi del codice applicativo, bloccando diconseguenza la macchina.
Pertanto, il codice corretto è:CLI > Disabilita gli interrupt hardware
MOV AX, 7000MOV SS, AXMOV SP, 9000STI > Riabilita gli interrupt hardware
Questo ci offre un minimo di sicurezza, garantendoci che per un breve istante il processore ignori lamaggior parte dei segnali di IRQ, ma purtroppo ciò non avviene per i segnali NMI (Non MaskerableInterrupt), aventi una priorità molto più alta dei segnali di IRQ e quindi non vengono ignorati affatto dallaCPU anche se il flag Interrupt è disabilitato tramite l’istruzione CLI. Avremo modo comunque di trattare degliNMI successivamente.
Oltre a queste coppie di registri, in una cpu x86 sono presenti altri registri, che però non vengono trattati inquanto il lettore che si appresti a seguire questo corso deve avere una conoscenza minima del linguaggio
assembler.
La transizione di un indirizzo espresso sottoforma di SEGMENTO:OFFSET ad indirizzo LINEARE puòessere riassunta brevemente come segue:
Ipotizziamo di avere la coppia DS:SI con i seguenti valori, DS = 10h e SI = 1000h
Si divide il contenuto di SI per 10hIl risultato sarà addizionato al registro segmento, e il resto va a costituire l’offset della pagina da indirizzare.Risultato della divisione: 1000h / 10h = 100hResto della divisione: 1000h % 10h = 0h
Il contenuto del registro segmento viene fatto scorrere a sinistra di 4bit, pertanto il nostro 10h diventa di
conseguenza 100h, a cui viene sommato il risultato della divisione, ovvero 100h.
Abbiamo pertanto come indirizzo di segmento 200h, mentre come indirizzo di offset abbiamo 0h.

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 4/36
4 di 36
Combinando 200h con 0h otteniamo 2000h, che non è altro che l’indirizzo assoluto del nostro byte inmemoria.
La nota più interessante di questo particolare indirizzamento di memoria è data dal fatto che un singolo bytepuò essere indirizzato a volte anche da (2^16)-16 combinazioni di valori di SEGMENTO:OFFSET.
Spiegata semplicemente questa modalità di memoria andiamo ad osservare come si presenta il 1°megabyte di memoria dopo l’accensione.
La coppia di registri CS:IP punta all’indirizzo F000:FFF0, che è anche l’entry point del BIOS. Quest’indirizzodi conseguenza contiene un’istruzione di JUMP al codice effettivo del BIOS.
Il BIOS (Basic Input Output System) non è altro che un insieme di routine software che fornisce supportoper gestire la tastiera, i supporti di massa (siano essi floppy disk che hard disk), porte seriali, porte parallele,tastiera, timer, video e numerosi altri servizi.Oltre a fornire questa interfaccia, compito del BIOS è quello di verificare il corretto funzionamento deidispositivi hardware essenziali in un computer, e di segnalare eventuali errori all’utente. E’ necessarioconoscere inoltre dove tali informazioni vengono registrate in memoria, dato che ci permettono dirisparmiare tempo e di conoscere informazioni quali l ’ammontare della memoria RAM presente sul propriopc, il tipo di scheda video e il tipo di monitor, eventuali porte COM, porte LPT, e molto altro ancora. Unavolta che il diagnostico di sistema termina l’esecuzione viene invocato l’interrupt software 19h, meglio
conosciuto come interrupt di boot-strap.
Compito di questo interrupt è determinare quali sono i dispositivi di boot da controllare, e di trovare il settoredi avvio o di caricare il codice dell ’MBR. Qualora non venga trovato nessun floppy disk nei disk driverpresenti sulla macchina, e non sia presente nessun disco fisso sulla macchina, il controllo viene trasferitoad un applicativo ROM, oramai scomparso da circa 15 anni dai PC e sostituito da un semplice messaggiodi testo che ci avverte dell’assenza di un qualsiasi sistema da cui caricare un eventuale sistema operativo.
Il boot sectorIniziamo col dire che sia il Boot Sector che il Master Boot Record hanno una dimensione standard di 512byte, convenzionalmente la dimensione di un settore.Il boot sector si viene a trovare, come ho già detto prima, nella posizione avente coordinate cilindro 0, faccia0, settore 1. Questo vale per tutti i dischi, ad eccezione del fatto che nei dischi fissi esso prende il nome diMBR, di cui tratteremo al capitolo successivo, ma in un disco fisso noi possiamo trovare fino a 16 settoriidentificati col nome di boot sector.Come lo stesso nome dice, il boot sector è un settore di avvio, ovvero ha il compito di caricare in memoria ilsistema operativo, o nel caso quest’ultimo fosse molto grande, le procedure di inizializzazione del sistemaoperativo, che di solito comprendono il gestore di memoria, un file system, un interprete di comandi e dellesemplici routine per gestire i principali componenti hardware. Il boot sector che andremo ad analizzare inquesto corso, fa parte del progetto Prometeo, ovvero il sistema operativo su cui sto lavorando al momento.Incominciamo subito col dire che quando un boot sector viene caricato, esso viene caricato all’offset0000:7C00 della memoria, ovvero al byte assoluto 7C00. Il contenuto dei registri della CPU sarà di tipoindefinito, ad eccezione dei registri di segmento, che hanno tutti lo stesso valore, 0.
Innanzitutto, come potrete vedere troviamo subito un’istruzione di SHORT JUMP, dato che in un boot sectorvi è definita anche una struttura dati che racchiude le proprietà del disco che si sta leggendo. Questastruttura dati non è necessaria, ma per mantenere una compatibilità con altri sistemi operativi, oramairisulta presente in qualsiasi floppy troviate in circolazione, affinché un qualsiasi sistema operativo non riportiun errore quando va a leggere il floppy disk.
Analizziamo tale struttura:
bsOEM db 'PROMETEO' ; Qui viene inserito il nome del sistema operativo, di una lunghezza max di 8 byte.bsSECTSIZE dw 0200h ; Questa word riporta la dimensione dei settori presenti sul dispositivo, settato a 512 per default.bsCLUSTSIZE db 1 ; Questo valore, che qui viene riportato a 1 indica quanti settori del dispositivo fanno parte di un
; particolare cluster. Il cluster è l’unità minima di allocazione in un file system quali FAT12, FAT16,FAT32
; ed NTFS. In ext2 (il file system di Linux) questa unità prende il nome di blocco.bsRESSECT dw 0 ; Indica il numero di settori riservati prima del file system, di solito settati a 0 ma con un valore
maggiore ; nel remoto caso in cui un boot sector sia molto più grande del solito.bsFACTCNT db 1 ; Indica il numero di copie della tabella d’allocazione dei file presenti sul disco o nella partizione.
; Al momento, non è ancora stato stabilito quale sia il file system utilizzato normalmente da Prometeo,; ma per compatibilità mettiamo 1.

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 5/36
5 di 36
bsROOTSIZE dw ? ; Indica la dimensione della ROOT del disco, in settori. Tale voce fa parte dei file system di Microsoft.bsTOTALSECT dw ? ; Indica il numero totale di settori totali presenti sul disco. Qualora il disco sia superiore a 32mb questo
; valore sarà 0.bsMEDIA db ? ; Indica il tipo di supporto, e il tipo di FILE SYSTEM adottato. Ogni file system viene contrassegnatocon
; un valore di identificazione.bsFATSIZE dw ? ; Indica la dimensione del la FAT.bsTRACKSECT dw ? ; Indica il numero di settori per tracciabsHEADCNT dw ? ; Indica i l numero di faccebsHIDENSECT dd ? ; Indica il numero di settori nascosti.bsHUGESECT dd ? ; Indica il numero di settori qualora l’unità sia superiore a 32mb.bsDRIVENUM db ? ; Questo numero, identi fica l’unità dalla quale é stato caricato il boot sector. Nei floppy disk è posto a0.
; mentre negli hard-disk il 7bit (equivalente all’8, dato che si parte a contare da 0!) viene settato a 1.bsRESERV db ? ; Non usatobsBOOTSIGN db ? ; Indica se il dispositivo é avviabile o meno, cioè se contiene un sistema operativo da caricare o no!bsVOLID dd ? ; Qui viene memorizzato il codice seriale a 32bit del disco, calcolato in base al giorno e all’ora della
; formattazione del dispositivo.; Ora in un sistema operativo tradizionale quale MS-DOS qua andrebbe una stringa di 11 byte
contenente; il nome del volume, ma al momento in Prometeo è stato sostituito con strutture più importanti.
bsCYLTOTAL dw ? ; Indica il numero di traccebsHEADTOTAL db ? ; Indica il numero di faccebsSECTTOTAL db ? ; Indica il numero di settori per tracciabsRESERVED db 7 dup (?) ; 7 byte riservati
bsFILESTYPE db 8 dup (?) ; La stringa contenente il nome del file system.bsCYLSTART dw ? ; Il primo cilindro da dove caricare il codice di loader - PrometeobsHEADSTART db ? ; Prima faccia dove caricare il codice di loader - PrometeobsSECTSTART db ? ; Primo settore dove caricare il codice di loader - PrometeobsCODESIZE dw ? ; Numero di settori da caricare in memoria – Prometeo – Max 32Mb di codice!
_start:db 0eahdw offset _main, 07c0h
Questa prima istruzione, subito la struttura dati ci permette di riallineare il registro CS, in modo daavere il codice di Prometeo iniziante a 0 e non a 7C00h. Semplicemente, come spiegato in alto, un byte puòessere puntato con diversi valori, e CS assumerà il valore di 7C0h
_main:
lea si, Prometeocall PrintString
Stampa una stringa di benvenuto a video. Il codice di PrintString non utilizza altro che il servizio 0Edell’interrupt 10h. Carichiamo in CS:SI la stringa da stampare e la stampiamo. Per maggiori informazioni sutale servizio vi rimandiamo all’Interrupt List di Ralph Brown.
cmp byte ptr cs:[bsBOOTSIGN], 00h ; The disk is bootable ? je not_bootableos jmp bo otableos
Controlliamo se il supporto é avviabile o meno, se non è avviabile andiamo in un frammento di codice che ci
dice che non c’è nessun sistema operativo sul floppy, e che la procedura di boot sarà riavviata, con unwarm-boot attraverso una chiamata all’INT19.
mov ax, 1000h ; Segment to load Prometeo CODE startupmov es, axxor bx, bx
Al momento Prometeo viene caricato all’indirizzo 10000, mentre nei giorni avvenire probabilmente saràspostato all’indirizzo 600 della memoria.Una procedura che qui non riportiamo ha il compito di caricare il numero di settori, attraverso la funzione 02dell’interrupt 13, e una volta che tale codice viene caricato, viene trasferito il codice ad esso inserendo nellostack l’indirizzo ed eseguendo un’istruzione RETF.
Nel caso si verificasse qualche errore durante il caricamento, questa procedura resetta la macchina.
db 0eah ; COLD-RESETdw 0fff0h ;dw 0f000h ;
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 6/36
6 di 36
PrintString:mov ah, 0ehmov bx, 0007h
LoadCharacter:mov al, byte ptr cs:[si]cmp al, 00h
je _endPrintStringint 10hinc si
jmp LoadCharacter
_endPrintString:ret
Ecco qui in alto il codice che stampa a video i relativi messaggi.
Il codice del boot-sector di Prometeo ha una dimensione piuttosto ridotta al momento, tanto è vero chebisogna aggiungere 126 byte per arrivare a scrivere in modo corretto la WORD contenente la SIGNATURE,che non è altro che una coppia di byte che indicano se il settore è o meno avviabile. Tale SIGNATURE almomento viene totalmente ignorata dai BIOS per quanto riguarda un floppy disk, infatti potrete controllarevoi stessi con un vostro boot-sector con e senza SIGNATURE. La SIGNATURE deve trovarsi negli ultimi 2byte del settore, e deve essere AA55. Comunque è un bene inserirla, in quanto se il BIOS la ignora per iboot sector dei floppy, così non avviene per quanto riguarda il MASTER BOOT RECORD e di conseguenzalo stesso MBR ne controlla la presenza nei boot sector delle partizioni.
Il Master Boot RecordCome ho già detto prima, l’MBR é il primo settore assoluto di un disco fisso. Ha lo scopo di memorizzareun’apposita struttura della lunghezza di 64 byte composta da 4 strutture dati identiche, con l’unica differenzache hanno valori differenti. Tale struttura dati è la seguente:
Partition STRUCBoot db ? Indica se questa é la partizione da dove caricare il boot-sector o no!BegHead db ? Indica la prima faccia della partizione.BegSeCyl dw ? Indica la combinazione settore/cilindro che costituisce il contenuto del registro CX
per il servizio 02 dell’interrupt 13. I 6 bit meno significativi identificano il 1. settore,mentre gli altri 10 bit identificano la prima traccia della partizione.
SysCode db ? Codice del file system presente in questa partizione.EndHead db ? Ultima faccia della partizione.EndSeCyl dw ? Ultimo settore e ultimo cilindro.StarSec dd ? Numero assoluto del primo settore.SizeSec dd ? Numero assoluto di settori presenti nella partizione.
Partition ENDS
Come al solito l’MBR viene caricato allo stesso offset del BOOT-SECTOR, quindi è a carico delprogrammatore far si che l’MBR si sposti in un’altra locazione di memoria affinché possa caricare nellalocazione in cui si trova lui al momento il codice del boot sector.
cli
xor ax, axmov ss, axmov sp, 7c00hmov si, sppush axpop dssti
Queste prime righe, modificano il valore dei registri dello stack, come potete vedere durante tale operazionegli interrupt vengono disabilitati.
mov di, 0600hmov es, axmov cx, 100h
repnemovsw

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 7/36
7 di 36
Contiene l’offset dove sarà spostato il codice. Indirizzo assoluto 600 della memoria. Trasferisce 512 byte epoi un bel FAR JUMP ed eccoci al codice vero e proprio.
db 0EAhdw offset continuedw 0060h
Questo semplice ciclo controlla in memoria quale sia la partizione che contiene il sistema operativo. Se tale
partizione non è presente allora stampa a video un messaggio di errore, altrimenti provvede al caricamentodella stessa.
continue:lea si, partition_tablemov cx, 4
@1: cmp byte ptr ds:[si], 80h je fin d_ptableadd si, ax ; AX contiene la lunghezza della struttura… cioè 16loop @1
find_ptable:mov bx, 7c00h
mov ax, 0201hmov dx, word ptr ds:[si]mov cx, word ptr ds:[si+SECYL]
int 13h
jc load_panic
mov ax, 07c0hmov es, ax
lea di, signaturemov ax, word ptr es:[di]cmp ax, word ptr cs:[di]
je valid_boot_sector
Una volta identificata la partizione corretta il sistema provvede a trasferire il controllo all’offset assoluto7C00, dopo essersi accertato che la SIGNATURE sia corretta .
valid_boot_sector:xor ax, axmov es, axmov ax, 07c00hpush espush axretf
Il solito salto attraverso l’uso dello stack. All’indirizzo 1BE della partizione troviamo le 4 strutture contenentile informazioni circa le partizioni, e infine la SIGNATURE.
Table1 Partition <0, 0, 0, 0, 0, 0, 0, 0> ; Partition 1Table2 Partition <0, 0, 0, 0, 0, 0, 0, 0> ; Partition 2Table3 Partition <0, 0, 0, 0, 0, 0, 0, 0> ; Partition 3Table4 Partition <0, 0, 0, 0, 0, 0, 0, 0> ; Partition 4
signature:dw 0AA55h
Nel caso in cui nel campo SYSCODE della struttura dati della partizione si dovesse trovare il valore 05,ovvero Partizione Estesa, noi ritroveremmo nel relativo boot sector un settore simile all’mbr contenenti lesolite informazioni su altre 4 partizioni. Purtroppo, i livelli di annidamento che esistono oggi non cipermettono di avere in un segmento di una partizione estesa ulteriori partizioni estese, quindi il limitemassimo di partizione su un disco fisso è di 4x4, ovvero 16 partizioni.C’è comunque da specificare che i software quali LILO BOOT LOADER, OS/2 BOOT MANAGER, e altrisoftware di questo genere, che permettono il caricamento di più sistemi operativi, vengono inseriti nei settoriche fanno parte della traccia 1 faccia 0, che di norma viene riservata per il MBR, di lunghezza max di 1settore, ma per la struttura dei moderni dischi fissi, a volte può arrivare anche una lunghezza di 32Kb,
spazio più che sufficiente per un software che ha il compito di far scegliere all’utente la partizione da cuieffettuare il boot.
Conclusioni

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 8/36
8 di 36
Spero che questa introduzione del boot sector e del master boot record sia stata più che sufficiente.Qualora avreste dubbi in merito, vi ricordo il mio indirizzo email: [email protected] (mailto:[email protected] ). Vianticipo sin da adesso che la prossima lezione sarà tendenzialmente indirizzata alla modalità protetta, inquanto la conoscenza di questa modalità della cpu è alla base del memory manager che vi permetterà diindirizzare sulla vostra macchina sino a 4 Gb di memoria fisica e la stratosferica cifra di 64 TB (Tera byte,equivalente a 1024 GB!) a patto che abbiate un dispositivo di massa che abbia questa capienza.
Lezione 2: Affronteremo in questa lezione la modalità protetta delle CPU a32bit, indispensabile in un sistema operativo moderno per gestire lamemoria.
IntroduzioneIn questa lezione affronteremo l’argomento modalità protetta, cercando di spiegarne il funzionamento el’utilità di questa modalità, introdotta la prima volta nel 1986 con il rilascio della cpu 80386 da parte diINTEL.Nel libro [1] troviamo subito scritto quanto segue: “L’80386 è un potente microprocessore a 32bit ottimizzatoper i sistemi operativi multitasking e progettato per applicazioni che necessitano di prestazioni moltoelevate. I registri ed i cammini dei dati a 32bit sono in grado di gestire quantità che rappresentano indirizzoo dati a 32bit. Il processore può indirizzare fino a 4 gigabyte di memoria fisica e 64 terabyte (2^46 byte) dimemoria virtuale. I mezzi di gestione della memoria onchip comprendono i registri per la conversionedell’indirizzo, un avanzato hardware multitasking, un meccanismo di protezione e il sistema di paginazionedella memoria virtuale. Speciali registri di debugging forniscono breakpoint di dati e di codice perfino nelsoftware basato su ROM”. Queste poche righe di testo ci fanno subito capire quali siano le reali potenzialitàdi questa cpu, e cosa permette di fare ad un sistema operativo. Iniziamo subito con l’analizzare le novitàintrodotte nelle cpu a 32bit.
Le novità delle cpu a 32bit.Per mantenere una compatibilità con l’intero parco software già disponibile in passato INTEL decide dimantenere l’intera compatibilità col set di istruzioni della famiglia x86, aggiungendo però al nuovoprocessore e ai processori successivi delle nuove istruzioni, cosa che oggi con la velocità con la qualevengono sfornati dai diversi produttori le cpu rende la vita un po’ difficile.
I registriI registri del nuovo processore vengono classificati in diverse categorie, secondo la loro utilità.Registri generali – EAX, EBX, ECX, EDX, EBP, ESP, ESI, EDI. Questi registri sono la versione a 32bit deigià noti registri AX, BX, CX, DX, BP, SP, SI, DI. Infatti é possibile accedere ai primi 16bit del registrosemplicemente usando il vecchio nome e così via anche per le due diverse parti a 8bit.Registri segmento – Sono i soliti registri CS, DS, ES, SS, ma vengono affiancati questa volta da due nuoviregistri: FS e GS. In modalità reale essi contengono il segmento, che combinato assieme all ’offset (comegià visto nella lezione 1) ci permettono di ottenere l’indirizzo lineare del byte interessato entro il 1°megabytedi memoria. Nella modalità protetta essi contengono invece il valore del selettore, che affronteremo piùavanti. Nemmeno l’uso dei registri segmento é cambiato, infatti SS viene combinato insieme al registro ESPper accedere allo stack, e CS insieme al registro EIP per indicare la prossima istruzione in memoria da
eseguire.Registro dei flags – Il registro dei flags controlla certe operazioni ed indica lo stato della CPU nel momentoin cui viene letto tale valore. Discuteremo di questo registro in un paragrafo successivo.Registri di gestione della memoria – Questi registri identificano strutture di dati che controllano lagestione segmentata della memoria. Essi sonoGDTR – Global Descriptor Table RegisterLDTR – Local Descriptor Table RegisterIDTR – Interrupt Descriptor Table RegisterTR – Task RegisterRegistri di controllo – I registri di controllo dell’80386 sono CR0, CR2 e CR3. Il registro CR0 contiene iflags di controllo del sistema, che controllano o indicano le condizioni applicabili al sistema nel suocomplesso e non ad un singolo task. Il registro CR2 viene impiegato per gestire gli errori di pagina qualoravengano utilizzate tabelle di pagine per convertire gli indirizzi. Il registro CR3 consente al processore di
individuare l’elenco di tabelle di pagine per il task corrente.Registri di debugging – Questi registri forniscono un supporto al programmatore per l’esecuzione deldebugging del proprio applicativo. Tratteremo questi registri e il loro impiego al momento opportuno.Registri di test – Questi registri non fanno parte dell’architettura standard del sistema.

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 9/36
9 di 36
Le nuove istruzioniOvviamente, l’introduzione di queste novità a livello di registro e di memoria sarebbero state inutili se nonfosse stato ampliato il set di istruzioni, in modo da permettere al programmatore di sfruttare appieno lenovità del processore. Le istruzioni della cpu vengono classificate secondo quanto segue:1 – Istruzioni di trasferimento dei dati1.1 – Istruzioni generali di trasferimento dei dati1.2 – Istruzioni di manipolazione dello stack1.3 – Istruzioni di conversione del tipo
2 – Istruzioni di aritmetica binaria2.1 – Istruzioni di addizione e sottrazione2.2 – Istruzioni di confronto e d’inversione di segno2.3 – Istruzioni di moltiplicazione2.4 – Istruzioni di divisione3 – Istruzione di aritmetica decimale3.1 – Istruzioni di correzione BCD impaccato3.2 – Istruzioni di correzione BCD non impaccato4 – Istruzioni logiche4.1 – Istruzioni di operazione booleane4.2 – Istruzioni di test e modifica bit4.3 – Istruzioni di scansione di bit4.4 – Istruzioni di scorrimento e rotazione4.5 – Istruzioni di assegnazione condizionata di byte4.6 – Istruzioni di test5 – Istruzioni di trasferimento del controllo5.1 – Istruzioni di trasferimento incondizionato5.2 – Istruzioni di trasferimento condizionato5.3 – Interruzioni generate dal software6 – Istruzioni di conversione di stringa e di carattere6.1 – Prefissi di ripetizione6.2 – Indicizzazione e controllo dei flags di direzione6.3 – Istruzioni di stringa7 – Istruzioni per linguaggi con struttura a blocchi8 – Istruzioni di controllo dei flags8.1 – Istruzioni di controllo dei flags di riporto e di direzione8.2 – Istruzioni di trasferimento di flags9 – Istruzioni d’interfaccia del coprocessore10 – Istruzioni relative ai registri segmento10.1 – Istruzioni di trasferimento per registri segmento10.2 – Istruzioni di trasferimento del controllo di tipo FAR10.3 – Istruzioni di puntamento ai dati11 – Istruzioni miscelanee11.1 – Istruzioni di calcolo dell’indirizzo11.2 – Istruzioni di nessuna operazione11.3 – Istruzioni di conversione12 – Istruzioni di sistema
Essendo lo scopo di questo corso scrivere un sistema operativo e non imparare il linguaggio assembler,sarà trattato l’uso delle istruzioni qualora esse siano fondamentali per il sistema operativo. I primi 11 blocchidi istruzione vengono utilizzati da colui che scrive un applicativo, mentre il 12° blocco di istruzioni invece èriservato al programmatore di sistema. Infatti, uno dei punti principali di questa nuova architettura è lapossibilità di definire quali siano i privilegi di cui è in possesso un ’applicazione, e di conseguenza dare lapossibilità al sistema operativo di essere informato qualora un’applicazione violi tali privilegi permettendoglidi terminare l’applicazione senza che quest’ultima possa causare danni alle altre applicazioni che sono inesecuzione.
Gestione della memoria in modalità protettaFatta questa introduzione sul processore a 32bit, passiamo a trattare la gestione della memoria in modalitàprotetta.Un vantaggio della modalità protetta è quella di dare ad ogni applicativo sino a 4Gb di memoria RAM, anchese in realtà sulla macchina sono presenti soltanto 4Mb di memoria RAM.Come già detto in precedenza, i registri di segmento in modalità protetta indicano un descrittore, ovvero unadeterminata struttura caricata in una apposita tabella.Incominciamo ad analizzare il contenuto di un descrittore:

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 10/36
10 di 36
Un descrittore è una struttura di 64bit contenente le seguenti informazioni:
Base 31-24 G D 0 Avl LSEG1619 P DPL A0 A1 A2 A3 A4 Base 16-23
Base 15-0 Limite 0-15
Tabella 1
Il bit 0, ovvero il primo bit di questa struttura è contenuto in basso a destra, e fa parte del limite segmento(Limite 0-15). Questo è dovuto al byte order di INTEL usato nei suoi processori.
LIMITE:I due campi Limite 0-15 e Limite 16-19 (LSEG1619 nella tabella) costituiscono il limite segmento. Il limiteindica la dimensione del segmento. Concatenando i due campi contenuti nel descrittore otteniamo unindirizzo a 20bit. Questo indirizzo può assumere un valore da 0 a (2^20 –1).
BIT DI GRANULARITA’:Nel descrittore questo bit è indicato con la lettera G ed indica in che modo deve essere interpretato il campolimite. Qualora questo bit non sia settato, il contenuto di LIMITE viene interpretato come unità in byte, quindisi ha un limite massimo di 1.024.768 – 1, mentre se il bit G è settato il limite sarà considerato come ilnumero di unità da 4kb, ed in tal caso avremo un max di 1.024.768 x 4096 che è uguale a 2^32 –1 byte,
ovvero 4Gb di memoria virtuale.
BASE:Questo valore identifica la locazione del segmento entro lo spazio d’indirizzi lineare da 4Gb. In parolesemplici, identifica l’indirizzo assoluto in memoria dove si trova il 1°byte del segmento.
DPL:Questi 2 bit indicano il livello di privilegio del descrittore e di conseguenza i relativi permessi concessi alcodice o ai dati in esso contenuto. L’accesso a un segmento deve avvenire qualora il CPL sia uguale ominore del DPL.
Bit di presenza del segmento:Questo bit indicato con la lettera P nella tabella 1 identifica un descrittore valido o meno. Qualora un
descrittore con il bit P settato a 0 venga caricato in un registro SEGMENTO viene generata un’eccezione daparte della CPU.
Bit di accesso avvenuto:Questo bit è indicato nella tabella 1 con la sigla A4. Questo bit è settato qualora il descrittore sia caricato inuno dei registri SEGMENTO, e può essere utile ad un sistema operativo per verificare quali siano idescrittori più usati, e quindi da immagazzinare in memoria oppure da tenere salvati su disco. Questo bit havalidità qualora il bit A0 sia settato (indicando di conseguenza un descrittore usato per codice o datiapplicativi), mentre se non è settato esso indica un descrittore speciale.
Default bit:Questo bit identificato con la lettera D nella tabella 1 indica se le istruzioni contenute nel descrittore hannouna dimensione di default da 16 bit (flags D=0) oppure hanno una dimensione per default da 32 bit (flags
D=1).
Bit disponibile:Identificato con la sigla Avl questo bit é a disposizione del sistemista.
Bit CODICE/DATI:Identificato nella tabella 1 con la sigla A1, qualora il bit A0 sia settato, indica un segmento codice (A1 = 1) oun segmento dati (A1 = 0).
Bit conformante:Se il bit A0 è uguale a 1:
Se il bit A1 è settato:A2 = 1 – Segmento ConformanteA2 = 0 – Segmento non conformante
Se il bit A1 non è settato:A2 = 1 - Espansione verso il basso

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 11/36
11 di 36
Un segmento conformante è un segmento nel quale, se viene trasferito il controllo da un altro segmentocon maggiori privilegi, fa si che il CPL non venga modificato, e quindi il codice in esso contenuto ha privilegimaggiori.
Un segmento con espansione verso il basso un qualsiasi offset che non sia compreso tra 0 e LIMITEgenera una eccezione, altrimenti gli indirizzi fuori dal limite sono considerati validi, e modificando neldescrittore il limite si può modificare la quantità di memoria da allocare dinamicamente nel descrittore.
Bit A3:Se il bit A0 é uguale a 1:
Se il bit A1 è settato:A3 = 1 – Il segmento è leggibile
Se il bit A1 non è settato:A3 = 1 – Il segmento è scrivibile.
Una volta descritto il contenuto di un descrittore, passiamo ad analizzare il contenuto della tabella deidescrittori globali e locali (GDT ed LDT).
Queste due tabelle vengono gestite tramite le istruzioni LGDT, SGDT, LLDT, SLDT.Le istruzioni LGDT ed SGDT permettono di accedere alla tabella GDT. LGDT carica nel registro LGDTRl’indirizzo lineare della memoria dove risiede l’elemento 0 della GDT. Per l’esecuzione di questa istruzione èindispensabile avere un CPL uguale a 0. L’istruzione SGDT invece permette di ottenere l’indirizzo linearedel primo elemento della GDT. L’indirizzo lineare caricato nel registro GDTR rappresenta l’offset reale delprimo elemento della GDT.Le istruzioni LLDT ed SLDT forniscono l’accesso alla LDT ed al registro LDTR.
Il primo elemento della GDT (GDT[0]) non viene usato dal processore.Un registro segmento in modalità protetta contiene il numero del descrittore caricato, il livello di privilegio deldescrittore e un bit indicante se tale descrittore fa riferimento alla GDT o alla LDT.
Indice nella GDT o nella LDT (dal bit 3 al bit 15) GDT(0) LDT(1)1 bit
DPL 2 bit
Tabella 3 - Formato del selettore
Il processore, quando deve accedere a un byte situato in memoria compie i seguenti passi.
Ricorreggere la sezione dove viene trattato il selettore, e scriverequanto segue:Copia in un registro interno il valore del descrittore;Verifica quale tabella deve controllare tramite il bit 2 (0 GDT, 1 LDT);Verifica se il descrittore scelto sia un descrittore valido attraverso il bit P del descrittore stesso, se il bit P èposto a 0 genera una eccezione, altrimenti continua;Verifica che vi siano i relativi privilegi per accedere a questo descrittore, confrontando il CPL con il DPL deldescrittore scelto, altrimenti genera un’eccezione;Legge dal descrittore il bit G e il LIMITE, al fine di verificare che l’offset richiesto rientri dentro il valore maxdel LIMITE (correttamente calcolato nel caso in cui vi sia attiva la granularità);
Se l’offset supera il LIMITE viene generata un’eccezione;Aggiunge all’indirizzo BASE l’offset, e nel caso in cui la paginazione sia disattivata richiede il byteBASE+OFFSET alla memoria RAM.
La tabella IDT Il registro IDTR contiene l’indirizzo della tabella vettori di interrupt. In modalità reale questa tabella eracostituita da vettori di 4 byte per un numero massimo di 256 elementi, e si trovava all ’indirizzo 0 dellamemoria. In modalità protetta, ogni task può avere una sua tabella vettori di interrupt. Gli elementi possonoessere fino a un massimo di 256 elementi, ed ognuno di essi è rappresentato da una struttura di 64bit cosìcostituita:
Offset 16-31 P DPL 0 1 1 1 T 0 RES
Selettore Offset 0-15Tabella 2

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 12/36
12 di 36
SELETTORE:Indica il descrittore dove si trova il codice da eseguire.
OFFSET:Combinando insieme i 2 elementi offset otteniamo l’indirizzo del codice da eseguire dentro il selettoreprescelto.
Bit P:Indica se l’interrupt é presente o meno.
DPL:Indica il livello di privilegio dell’interrupt.
T:Indica se si tratta di una trappola (T=1) oppure di una interruzione (T=0).
L’accesso alla IDT avviene tramite le istruzioni LIDTR e SIDTR. Anch’esso contiene un indirizzo lineare inmemoria.
Quando si verifica un errore, la cpu in modo protetto lo comunica al sistema operativo generando una
eccezione. Le eccezioni sono delle interruzioni che mandano in esecuzione i relativi interrupt.Pertanto, i primi 17 interrupt sono riservati al codice di sistema operativo:
IDT[00] Errore di divisioneIDT[01] Eccezione di debuggingIDT[02] Non usatoIDT[03] Breakpoint / DebuggingIDT[04] OverflowIDT[05] Verifica dei confiniIDT[06] Codice operativo non valido (istruzione sconosciuta!)IDT[07] Coprocessore non disponibile (e di conseguenza, qui bisognerebbe agganciare un emulatore)IDT[08] Doppio difettoIDT[09] Superamento del segmento di coprocessore
IDT[0A] TSS non validoIDT[0B] Segmento non presenteIDT[OC] Eccezione di stackIDT[0D] Protezione generaleIDT[0E] Difetto di paginaIDT[0F] Non usatoIDT[10] Errore di processore
I rimanenti interrupt possono essere definiti dal sistemista o dall ’applicativo.
Il registro di controllo CR0, CR2 e CR3Questo è uno dei più importanti registri delle cpu a 32bit. Permette di controllare lo stato del processore
stesso, e di modificarne il funzionamento.E’ utilizzabile attraverso una variante dell’istruzione MOV.Esempio:
; Legge il contenuto di CR0MOV EAX, CR0; Scrive il contenuto di EAX in CR0MOV CR0, EAX
Il contenuto del registro CR0 è il seguente:
Bit 0 – Protection Enable – Se questo bit è settato, la CPU lavora in modalità protetta, altrimenti in modalitàreale.Bit 1 – Math Present – Se questo bit è settato, è presente nel sistema un coprocessore matematico 287,387 o superiore.
Bit 2 – Emulation – Questo bit indica se il coprocessore matematico deve essere emulato.Bit 3 – Task Switched – Questo bit viene attivato ogni qualvolta avviene una commutazione di task.Bit 4 – Extension Type – Questo bit indica il tipo di coprocessore matematico presente.Bit 31 – Paging – Questo bit indica se è attiva la paginazione o meno. Per questo particolare modo di

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 13/36
13 di 36
gestire la memoria si rimanda al relativo paragrafo.
Il registro CR2 contiene l’indirizzo lineare in cui si verifica un errore qualora sia attiva la paginazione. Sirimanda al relativo paragrafo per ulteriori chiarimenti.Il registro CR3 viene utilizzato quando è utilizzata la paginazione. Esso contiene l’indirizzo linearedell’elenco delle tabelle di pagina per il task corrente.
La paginazioneQualora la memoria fisica non fosse sufficiente a contenere tutto il codice in esecuzione e i relativi dati, énecessario trasferire il contenuto della stessa memoria RAM su un dispositivo di massa, e ricaricarlo inmemoria quando lo stesso viene richiesto dall’applicativo. Questo compito é completamente a carico delsistema operativo, come la gestione della memoria stessa in modo efficiente.I processori a 32bit vengono in aiuto ai programmatori di sistema operativo, mettendo a disposizione uninteressante sistema in modalità protetta per gestire la memoria virtuale, dando così la possibilità di metterea disposizione degli applicativi una relativamente infinita di memoria.Questo meccanismo viene chiamato paginazione, e consiste nel suddividere la memoria virtuale inparagrafi da 4Kb ognuno, i quali possono essere situati in memoria, oppure su disco, e quando énecessario accedere a un paragrafo non presente nella memoria, il microprocessore attraverso ilmeccanismo delle eccezioni comunica tale richiesta al sistema operativo, il quale ha la possibilità (seprevista dagli sviluppatori stessi!) di caricare in memoria i dati richiesti, in un’area disponibile, e di rieseguirel’istruzione che ha richiesto tali dati.Per poter usare la paginazione, consultare il paragrafo relativo ai registri di controllo.
La divisione della memoria in pagine da 4Kb avviene attraverso l ’uso di pagine stesse, che hanno il compitodi contenere apposite tabelle che descrivono la memoria stessa.La quantità di memoria indirizzata in un singolo segmento può arrivare fino a 4Gb, quindi la divisione dellastessa memoria in paragrafi da 4Kb porta ad avere 1.048.762 pagine. Non tutte queste pagine però sonoeffettivamente utilizzate, quindi la maggior parte di esse non esisteranno ne in memoria ne su disco. Questepagine vengono indirizzate da 2 voci presenti in 2 tabelle diverse.Una prima tabella primaria contiene l’indirizzo delle relative 1.024 tabelle secondarie, le quali contengono leinformazioni relative ai dati stessi.L’indicizzazione di queste tabelle avviene attraverso il registro CR3.Ogni task può avere le sue tabelle di memoria, oppure si può avere una sola tabella per tutti i task chegirano sulla macchina. Questa scelta ovviamente é da attribuirsi al programmatore di sistema.
Passiamo ora ad analizzare le 2 tabelle. Tutte queste tabelle sono allineate sui confini di pagina, ovvero sitrovano in locazioni di memoria allineate a multipli di 4Kb. Questo fa si che il microprocessore possa gestirein modo più efficace la memoria virtuale.
Gli elementi della tabella primaria sono come già detto 1.024. Ognuno di questi elementi ha una dimensionedi 32bit (DWORD) e contengono l’indirizzo della relativa tabella secondaria.Le tabelle secondarie contengono come le tabelle primarie anch’esse 1.024 elementi, le quali stavolta peròpuntano direttamente al relativo paragrafo.
Le voci di entrambe le tabelle sono così composte:
Gli elementi delle tabelle di livello 1 puntano all'indirizzo effettivodella tabella. Ecco il grafico che ne rappresenta la descrizione.
Indirizzo frame di pagina DISP RIS D A RIS U/S R/W P
Tabella 4 – Elemento che descrive una pagina
Bit 0 – P – Indica se tale pagina esiste. Se il valore del bit è 0 la pagina non esiste, ed il sistemaoperativo genera un’eccezione, indicando nel registro CR2 il relativo indirizzo a cui si è tentato diaccedere.Bit 1 - R/W - Permessi di lettura/scrittura nella pagina. 0 se si hanno solo permessi di lettura, indispensabileper proteggere del codice, mentre se settato si hanno anche permessi di scrittura nella pagina.Bit 2 - U/S - Utente/SupervisoreBit 3, 4 - RiservatiBit 5 - A - Accesso avvenutoBit 6 - D - Scrittura effettuata
5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 14/36
14 di 36
Bit 7, 8 - RiservatiBit 9,10, 11 - Disponibili al sistema operativo per inserire informazioni sulla pagina.Bit 12..31 - Indicano l'indirizzo frame di pagina, allineato su confine da 4Kb.
Il microprocessore, onde evitare di accedere continuamente a queste tabelle, utilizza una cache internadove registra gli indirizzi delle pagine a cui si accede più frequentemente, consultando ed aggiornando talidati quando è costretto a consultare le tabelle di paginazione.
Il multitaskingAltra novità del microprocessore a 32bit è stata l’introduzione del multitasking, ovviamente non nel sensoletterario della parola. Infatti i task continuano ad essere eseguiti singolarmente, data la presenza di unsingolo microprocessore nella quasi totalità dei sistemi in circolazione. Il supporto al multitasking da partedel microprocessore è dato dalla possibilità dello stesso a salvare informazioni relative a un determinatotask in esecuzione, e attraverso un opportuno descrittore, di ripristinare l’esecuzione di un altro task.
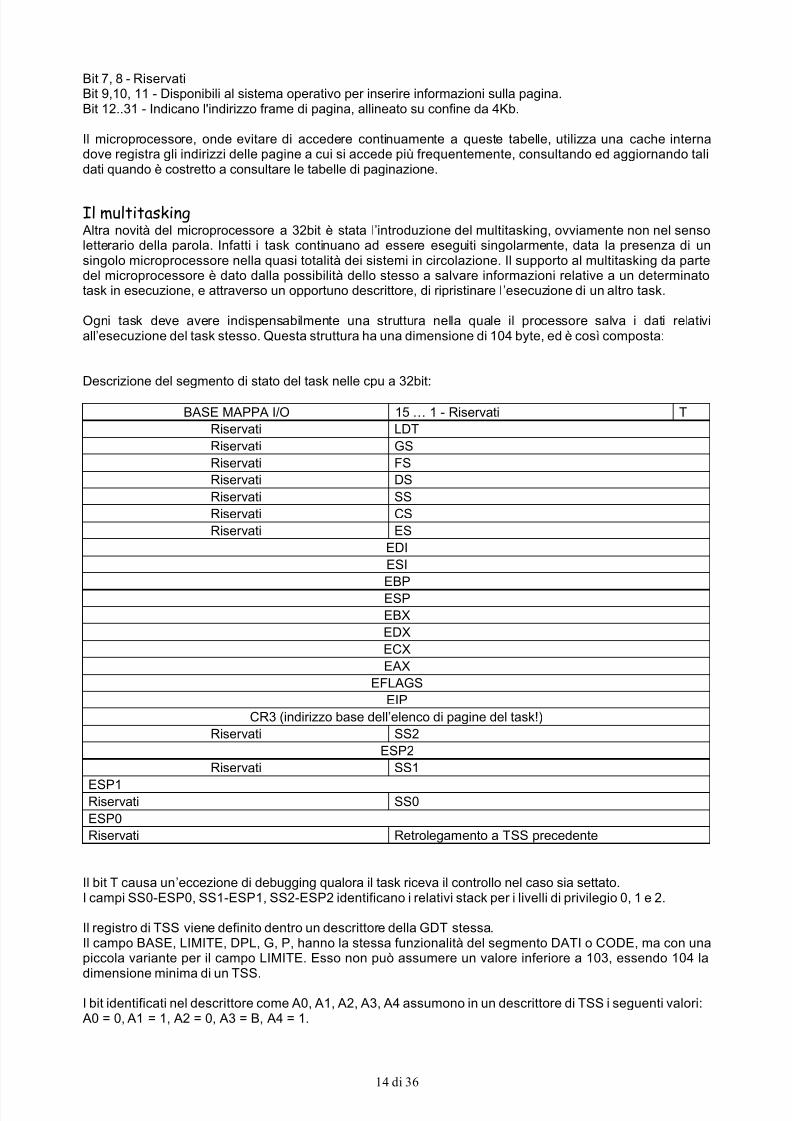
Ogni task deve avere indispensabilmente una struttura nella quale il processore salva i dati relativiall’esecuzione del task stesso. Questa struttura ha una dimensione di 104 byte, ed è così composta:
Descrizione del segmento di stato del task nelle cpu a 32bit:
BASE MAPPA I/O 15 … 1 - Riservati T
Riservati LDT
Riservati GS
Riservati FS
Riservati DS
Riservati SS
Riservati CS
Riservati ES
EDI
ESI
EBPESP
EBX
EDX
ECX
EAX
EFLAGS
EIP
CR3 (indirizzo base dell’elenco di pagine del task!)
Riservati SS2
ESP2
Riservati SS1
ESP1Riservati SS0
ESP0
Riservati Retrolegamento a TSS precedente
Il bit T causa un’eccezione di debugging qualora il task riceva il controllo nel caso sia settato.I campi SS0-ESP0, SS1-ESP1, SS2-ESP2 identificano i relativi stack per i livelli di privilegio 0, 1 e 2.
Il registro di TSS viene definito dentro un descrittore della GDT stessa.Il campo BASE, LIMITE, DPL, G, P, hanno la stessa funzionalità del segmento DATI o CODE, ma con unapiccola variante per il campo LIMITE. Esso non può assumere un valore inferiore a 103, essendo 104 la
dimensione minima di un TSS.
I bit identificati nel descrittore come A0, A1, A2, A3, A4 assumono in un descrittore di TSS i seguenti valori:A0 = 0, A1 = 1, A2 = 0, A3 = B, A4 = 1.

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 15/36
15 di 36
Il bit A3 consente al processore di rilevare un tentativo di commutare a un task già attivato. Infatti A3assume il valore 1 nel caso in cui il task sia attivo.
La modifica dei dati contenuti nel descrittore del TSS deve avvenire tramite un altro descrittore, checondivide la stessa area di memoria, ma che la descrive come una semplice area dati.
Le istruzioni messe a disposizione dal processore per la memoria protetta sono LTR ed STR.LTR è l’istruzione che carica nel registro TR il task da eseguire, puntando al relativo TSS e di conseguenza
Il registro TR identifica il Task Register, e precisamente il task in corso. L’uso di questa istruzione deveavvenire con CPL settato a 0.L’istruzione STR invece permette di leggere il valore contenuto nel registro TR. Non è una istruzioneprivilegiata.
Il registro TR (Task Register) è composto da due porzioni, una parte visibile la quale può essere modificatadalle istruzioni, e una parte invisibile che non è leggibile.
La base mappa I/O è una speciale area dati che contiene riferimenti relativi ai descrittori di porta di task, iquali di solito vengono collocati nello spazio successivo al TSS stesso.
Un descrittore di porta di TASK è così configurato:
Non usato P DPL 0 0 1 0 1
Non usato Selettore Non usato
Il descrittore della porta di task fornisce un riferimento protetto indiretto al TSS.
Il campo DPL controlla il diritto di usare il descrittore per causare una commutazione di task.Per causare una commutazione di task si può usare un descrittore di porta di TASK se si hanno i relativipermessi, oppure tramite istruzioni JMP, CALL, INTERRUPT, ed eccezioni.
Il modo virtuale 8086Il modo virtuale 8086 è una modalità introdotta da INTEL per permettere ad applicativi progettati perl’esecuzione in modalità reale di girare anche in modalità protetta senza generare eccezioni per l’accesso a
locazioni di memoria di cui non si posseggono i relativi diritti. Per accedere al modo virtuale 8086 ènecessario creare un TSS nel quale viene settato nel campo EFLAGS il bit VM. Dovendo creare un sistemaoperativo totalmente nuovo, il problema della modalità virtuale 8086 non si presenta, pertanto rimando iltrattamento di questa modalità a una lezione successiva.
ConclusioniTutti gli argomenti trattati in questa lezione, sono un po ’ difficili, pertanto, nelle lezioni successive, sarannoritrattati quando ci accingeremo ad analizzare il memory manager, lo scheduler e i servizi del sistemaoperativo.
Bibliografia
(1) INTEL CORPORATION - "Il manuale INTEL 80386 per il programmatore ", Intel Corporation, 1986
Lezione 3: PIC8259A, CMOS, DMA, PIT8253.
IntroduzioneTra i principali compiti di un sistema operativo ritroviamo quello di gestire l’hardware presente in un PC alfine di mettere a disposizione un’interfaccia comune per la gestione di qualsiasi componente al softwareche andrà a girare sul s.o. stesso. Questo è quanto accade oggi in sistemi operativi compatibili allostandard POSIX. Ma ovviamente per dare un’interfaccia così comune ad ogni componente è necessarioprima programmarlo nel migliore dei modi. In questa lezione affronteremo la gestione di 4 componentihardware, riservandoci di trattare in lezioni successive altri componenti hardware.
Basic Input Output System (il BIOS)Come è stato già detto nella prima lezione, all’avvio un microprocessore x86, manda in esecuzione le

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 16/36
16 di 36
istruzioni che si trovano all’indirizzo 0FFFF0h. Il caricamento del diagnostico e di tutto ciò che è contenutonella ROM è un compito che spetta al controller. In questa lezione ci limiteremo a trattare alcuni componentiessenziali che si trovano su un pc, e data la loro natura, il codice di gestione degli stessi deve essereintegrato nel kernel del sistema operativo.Tornando al BIOS possiamo dire che data la natura differente dei vari componenti hardware presenti su unpc, e di conseguenza la differente natura nel gestire gli stessi, ha fatto si che fosse necessario un sistemastandard. Il principale compiti di un BIOS, oltre a diagnostico di sistema, è quello di fornire una interfacciafatta di servizi software ad un sistema operativo per la gestione dei diversi componenti. Oltre al BIOS
integrato su una scheda madre è possibile trovare ulteriori estensioni su controller SCSI, schede video,schede di rete ed altri componenti. Il compito che spetta al BIOS di sistema è quello di provvedereall’inizializzazione di tutti gli altri BIOS. Di solito viene riservata una determinata locazione di memoria dentroun PC per caricare i vari firmware, questa locazione si trova tra l’indirizzo 0C0000 e l’indirizzo 0FFFFF. Datal’impossibilità di usufruire dei servizi del BIOS da un sistema operativo che giri in modalità protetta èindispensabile scrivere il codice per gestire i vari componenti hardware presenti su una macchina.
Programmable Interrupt Controller 8259AIn cima alla lista dei componenti da gestire troviamo il PIC8259A, un controller il cui compito è quello dinotificare alla CPU eventi proveniente da dispositivi hardware attraverso linee IRQ. In un pc troviamo duePIC8259A, ognuno dei quali gestisce 8 linee di comunicazione. Ogni linea viene identificata con la dicituraIRQx (dove x assume un valore da 0 a 7). Essendoci 2 controller, i primi 8 vengono identificati come IRQmaster, mentre gli altri 8 vengono identificati come IRQ slave.
Alle linee master troviamo collegati i seguenti dispositivi:IRQ0 – System TimerIRQ1 – KeyboardIRQ2 – Cascade InterruptIRQ3 – COM2/COM4IRQ4 – COM1/COM3IRQ5 – LPT2IRQ6 – FDCIRQ7 – LPT1
Alle linee slave invece troviamo i seguenti dispositivi:IRQ0 – Real Time Clock Chip
IRQ1 – Networking adapterIRQ2 – Non usatoIRQ3 – Non usatoIRQ4 – Non usatoIRQ5 – Floating Processor UnitIRQ6 – HDCIRQ7 – Non usato
Per questione di comodità da ora in poi ci riferiremo alle linee master usando le diciture IRQ0...IRQ7 mentrealle linee slave usando IRQ8..IRQ15.
Ovviamente alcune di queste impostazioni possono essere cambiate. Prendete esempio da una schedaaudio, a volte troverete nelle impostazioni come IRQ utilizzato il 5. Questo perché difficilmente vi è unaseconda porta parallela su una macchina, e quando essa è presente se ne può tramite appositi jumper (o
attraverso il software stesso, dialogando col controller stesso) modificare l’IRQ utilizzato.L’utilizzo da parte di più dispositivi dello stesso IRQ causa dei conflitti a volte non facilmente risolvibili, chedanno l’impressione che il nostro ultimo acquisto non funziona! Spesso questo accade con la famigeratatecnologia Plug & Play (inserisci e vai!). L’ultimo di questi conflitti che ho avuto su una mia macchina è statotra una scheda audio PNP e una scheda ethernet anch ’essa PNP. Entrambe avevano avuto la bella idea diutilizzare l’IRQ10 per comunicare col processore, e nonostante abbia tolto tutti i componenti del PC,bloccato attraverso il BIOS l’impiego di alcuni canali IRQ (il 10 per primo!) ho dovuto optare per unasoluzione poco ortodossa, o la scheda di rete o la scheda audio. Ho tolto quest ’ultima, rimpiazzandola conun vecchio modello ISA.
La comunicazione tra la cpu ed i due controller 8259A avviene attraverso 4 porte di I/O (2 per ogni PIC).Le porte di I/O sono la 20h e la 21h per il controller master, e la A0h e la A1h per il controller slave.
Il PIC8259A accetta due tipi di comandi:ICW – Initialization Command Words;OCW – Operation Command Words.
I comandi ICW sono 4 e vengono spediti uno in coda all’altro seguendo l’ordine numerico.

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 17/36
17 di 36
ICW1 – Porta 20h e A0hBit 0 – Se settato indica al controller che non sarà trasmesso ICW4;Bit 1 – Se settato indica che si tratta del controller master, altrimenti del controller slave;Bit 2 – Se settato indica che i vettori di interrupt hanno dimensione da 8 byte, altrimenti da 4 byte;Bit 3 – Se settato forza setta il modo ‘level triggered’ (PS/2) altrimenti lo imposta sul modo ‘edge triggered’;Bit 4 – Bit settato se si tratta di un comando ICW1;Bit 5, 6, 7 – Non settati;
ICW2 – Porta 21h e A1hBit 0, 1, 2 – Non definiti;Bit 3, 4, 5, 6, 7 – Specifica il vettore di interrupt per ogni IRQ partendo dall ’IRQ0, assegnando l’interruptsuccessivo agli irq successivi;
ICW3 – Porta 21h e A1hBit 0, 1, 2, 3, 4, 5, 6, 7 – Indica a quale IRQ è collegato il canale slave sul canale master. Nell’architetturaAT viene collegato sul canale IRQ2 (si invia il valore 04 sul controller master, mentre si invia il valore 02 sulcontroller slave).
ICW4 – Porta 21h o A1h (se specificato nel bit 0 in ICW1)Bit 0 – Settato;
Bit 1 – Seleziona il metodo per terminare un interrupt:Se settato viene impostato in AUTO MODE, ovvero il PIC imposta il relativo bit dopo aver inviato alprocessore il segnale di INTERRUPT, mentre in NORMAL MODE il processore deve comunicare attraversoOCW2 la fine dell’interrupt;Bit 2, 3 – Buffered mode;Bit 4 – Settato – ‘Special fully neested mode (SFNM)’, non settato SEQUENTIAL MODE;Bit 5, 6, 7 – Impostati a 0
OCW1 – Porta 21h e A1hBit 0, 1, 2, 3, 4, 5, 6, 7 – Ognuno di questi bit corrisponde allo stato del relativo IRQ. Se il bit è azzerato, isegnali proveniente dall’IRQ vengono ignorati, altrimenti se è impostato vengono elaborati.
OCW2 – Porta 20h e A0h
Bit 0, 1, 2 – Determina il livello prioritario;Bit 3, 4 – Azzerati;Bit 5 – Settato se si comunica la terminazione di un interrupt;Bit 6 – Non settato – Priorità ‘Rotate one’, se settato la priorità è impostata nei primi 3 bit;Bit 7 – Se è settato, viene settata la priorità secondo il bit 6, altrimenti non viene modificata.
OCW3 – Porta 20h e A0h inviato al PIC per leggere lo stato dell ’ISR, dell’IRR e della MHI (Mask HardwareInterrupt)Bit 0 – Viene impostato secondo relativa necessità;Bit 1 – Se settato indica che il bit 0 specifica quale registro leggere (0 ISR, 1 IRR);Bit 2 – Se settato il PIC entra in modo POLLING;Bit 3 – Settato;Bit 4 – Non settato;
Bit 5 - Viene impostato secondo relativa necessita;Bit 6 – Se settato il bit 5 controlla la modalità della maschera (1 ON, 0 OFF) e tutte le richieste vengonoelaborate secondo i privilegi;Bit 7 – Non usato.
Ecco delle semplici routine per gestire il PIC8259, sia il canale MASTER, che il canale SLAVE.
Listato 01 –Routine di Prometeo per la gestione dei PIC8259
; Prometeo; Programmable Interrupt Controller 8259; (C) 2001 Mazzeo Antonio; e-mail: [email protected]
.386p
.model flat, stdcall
.CODE

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 18/36
18 di 36
; Initialize the PIC8259; On entry - No param; On exit - No param
__InitIRQHandler proc
push eaxcli
; Set ICW1mov al, 00010101b ; ICW4 PRESENT bit0; Interrupt vector are 8bytes long bit2; level-triggered mode bit3 (not set!); costant bit4
out 20h, al; Set ICW2
mov al, 10h ; IRQ0 -> INT10hout 21h, al
; Set ICW3mov al, 04h ; Slave PIC is connected to IRQ2 in AT architecture!out 21h, al
; Set ICW4mov al, 00001b ; Bit0 - It's always forced!
; Bit1 - 0 Normal End Of Interrupt
; - 1 Auto End Of Interrupt; Bit2 - 0 Buffered mode; B i t 3 - 0 " "; Bit4 - 0 Sequential Mode; - 1 Special Fully Nested Mode; Bit5,6,7 - 0
out 21h, al
; Slave PIC! See Master PIC for other info!mov al, 00010101b ; ICW1out 0a0h, almov al, 18h ; IRQ8 -> INT18h - ICW2out 0a1h, almov al, 02h ; ICW3out 0a1h, al ; Slave PIC is connected to IRQ2
mov al, 01h ; ICW4out 0a1h, al
stipop eaxret
__InitIRQHandler endp
; Enable an IRQ handler!; On entry:; WORD - IRQ To enable; On exit:; E A X - > 0
__EnableIRQHandler procpush ebpmov ebp, esp
push ebxxor eax, eaxmov ax, word ptr ss:[ebp+08h]mov ebx, eax
cmp al, 8h ; Verifica che il bit7 sia attivo o meno!jge _slaveIRQEnable ; Si tratta di un IRQ slave
in al, 021h ; Read the Mask Register!movzx eax, albts eax, ebxout 021h, al
jmp endOfEIH
_slaveIRQEnable:
in al, 0a1h

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 19/36
19 di 36
sub ebx, 8hmovzx eax, albts eax, ebxout 0a1h, al
endOfEIH:pop ebxxor eax, eaxmov esp, ebp
pop ebpret
__EnableIRQHandler endp
; Disable an IRQ handler!; On entry; WORD - IRQ to disable
__DisableIRQHandler procpush ebpmov ebp, esp
push ebxxor eax, eaxmov ax, word ptr ss:[ebp+08h]mov ebx, eax
cmp al, 8h ; Verifica che il bit7 sia attivo o meno!jge _slaveIRQDisable ; Si tratta di un IRQ slave
in al, 021h ; Read the IMRmovzx eax, al ; Clear eaxbtr eax, ebx ; Disable the IRQout 021h, al ; Disable it!
jmp endOfDIH
_slaveIRQDisable:
in al, 0a1hmovzx eax, al ;
sub ebx, 8h ; BL now assume the value of IRQ to disable!btr eax, ebx ;out 0a1h, al ; Disable IT!
endOfDIH:pop ebxxor eax, eaxmov esp, ebppop ebpret
__DisableIRQHandler endp
; Verifica quale sia l'IRQ da terminare e lo termina; On entry; WORD - Irq da terminare
__EndOfIRQ procpush ebpmov ebp, espmov ax, word ptr ss:[ebp+08h]
cmp al, 08hjge _slaveEOImov al, 20hout 20h, aljmp _EndOfIRQProcedure
_slaveEOI:mov al, 20hout 0a0h, al
_EndOfIRQProcedure:mov esp, ebp
pop ebpret
__EndOfIRQ endp
END

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 20/36
20 di 36
CMOSLa memoria CMOS è una memoria tampone che contiene alcune importanti informazioni sullaconfigurazione della macchina. Queste informazioni vengono mantenute anche se il PC è spento per unlungo periodo, essendo la memoria alimentata da una batteria che si trova sulla scheda madre.
L’accesso alla memoria CMOS avviene tramite due porte di I/O. La porta 70h utilizzata per indirizzare il byteinteressato, e la porta 71h per leggere o modificare il relativo byte.
Non vi è nessun controllo sul byte indirizzato nella memoria CMOS, infatti la porta 70h è una porta a solascrittura, quindi prima di leggere o modificare qualsiasi byte contenuto nella memoria è importantedisabilitare gli interrupt attraverso l’istruzione CLI e riabilitarli successivamente attraverso l’istruzione STI.Questa coppia di istruzioni purtroppo non ha nessun effetto sulle interrupt NMI (Non Maskerable Interrupt).
La memoria CMOS ha una dimensione standard di 64 byte, ma col passare del tempo i produttori di schedemadri ne hanno aumentato la capacità a 128 byte.
Ecco una tabella riassuntiva del contenuto della CMOS:
Indirizzo Lunghezza Contenuto
00 0E Real Time Clock Information
0E 01 Diagnostic state byte
OF 01 Shutdown state byte10 01 Type of the floppy disk drives
11 01 Reserved
12 01 Type of hard disk drive
13 01 Reserved
14 01 Equipment set byte
15 02 Base memory size
17 02 Extended memory size (above 1M)
19 01 Type of hard disk drive C
1A 01 Type of hard disk drive D
1B 06 Reserved
21 0D Reserved2E 02 CMOS Checksum
30 02 Size of extended memory above 1M
32 01 Current century
33 01 Additional information
34 0C Reserved
40 40 Estensioni della memoria CMOS da parte deiproduttori di scheda madri.
Il contenuto di questi byte che non portano la dicitura ‘Reserved’ é standard, mentre il contenuto degli altribyte di solito varia a secondo del produttore della scheda madre.
Ecco due semplici funzioni per accedere alla memoria CMOS sia in lettura che in scrittura.
Listato 02 – Funzioni per leggere e scrivere nella memoria CMOS
; On entry:; WORD – Byte to read
; On exit:; AL - Byte
__ReadCMOSByte PROCPUSH EBPMOV EBP, ESP
MOV AX, WORD PTR SS:[EBP+08]CLIOUT 70h, AL
IN AL, 71hSTI
MOV ESP, EBPPOP EBP

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 21/36
21 di 36
RET __ReadCMOSByte ENDP
; On entry:; WORD; Low Byte – Byte to write
; High Byte – Value to write; On exit:; A X 0
__WriteCMOSByte PROCPUSH EBPMOV EBP, ESP
MOV AX, WORD PTR SS:[EBP+08]CLIOUT 70h, ALXCHG AH, ALOUT 71h, ALSTI
MOV ESP, EBPPOP EBPXOR AX, AXRET
__WriteCMOSByte ENDP
Direct Memory Access (DMA)Come il nome stesso ci dice, il DMA ha il compito di favorire lo scambio di dati tra un device e la memoriacentrale del sistema, senza sovraccaricare il processore durante queste operazioni. Per fare un esempiopratico di come viene utilizzato il sistema DMA pensate ad una scheda audio, oppure a un modernocontroller EIDE. Una scheda audio è in grado di riprodurre dei suoni senza che il processore invii ognisingolo bit alla scheda, ma semplicemente limitandosi a caricare i dati nella memoria centrale e attraverso ilDMA comunicarli alla scheda audio.Nell’architettura AT noi troviamo due controller DMA, ognuno dei quali è dotato di 27 registri classificati in12 categorie differenti, più sistemi per il controllo del dispositivo stesso.
Principalmente un controller DMA lavora in due fasi, identificate come ciclo idle e ciclo working . Leoperazioni che portano un controller dal ciclo idle al ciclo working generano 7 stati differenti.
Il 1° di questi stati è detto stato idle (SI) ed è uno stato passivo. Il controller in questo stato può essereprogrammato dal processore, impostando i canali da utilizzare per il trasferimento, le modalità ditrasferimento, le operazioni da compiere e gli indirizzi di memoria che coinvolgeranno tali operazioni.Una volta che il dispositivo è stato programmato, entra nello stato S0, dove vengono compiute le seguentioperazioni:Il controller invia un segnale HOLD al processore;Attende un segnale HLDA dal bus di sistema;Ricevuto il segnale il controller provvede a sconnettere il processore dal bus;Il controller incomincia ad eseguire i suoi compiti, entrando così negli stati S1, S2, S3, S4.
Il controller DMA può compiere in automatico le proprie operazioni se viene impostato in modalità di autoinizializzazione. Impostato in tale modalità una volta che vengono trasferiti gli indirizzi dei blocchi di memoriada trasferire, esso può svolgere il proprio compito senza che gli sia comandato.
E’ possibile impostare la priorità con la quale vengono notificati al processore i segnali provenienti daicanali.Le modalità disponibili sono:Fixed Priority – La priorità non viene mai variata, al canale 0 del controller slave viene assegnata lamassima priorità, mentre la più bassa priorità viene assegnata al canale 4 del controller master.Rotating Priority – Ad ogni canale viene assegnata una priorità iniziale, ed ogni volta che esso segnalerà unevento al processore la sua priorità sarà impostata a 0, aumentando di volta in volta quando gli altri canalisaranno impostati a 0. La massima priorità sarà destinata al canale che non segnalerà mai nessun evento.
DMA Channel Modes (Modalità di trasferimento dei dati)Il controller DMA dispone di diverse modalità per il trasferimento dei dati:
Single Transfer Mode – In questa modalità il controller riconnette il processore al bus di sistema ad ogniciclo di trasferimento, e comunicherà la terminazione del suo compito inviando un segnale quando il bit TC

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 22/36
22 di 36
(Termination Counter) sarà settato;Block Transfer Mode – Questa modalità è molto più veloce della precedente, in quanto il controllerriconnette al bus di sistema il processore soltanto quando avrà terminato il proprio compito;Demand Transfer Mode – In questa modalità il controller viene pilotato nelle sue attività attraverso le portedi I/O. E’ molto utile nei trasferimenti di piccoli buffer tra device e memoria centrale. Ad ogni trasferimento ilprocessore prende il controllo per preparare i trasferimenti successivi;Cascade Mode – Questa modalità prevede l’utilizzo di un canale DMA per permettere al 2° controller dicomunicare con il processore, proprio come avviene con i PIC8259A. Il 2°controller DMA prende il nome di
controller MASTER, ed è connesso al processore. Il 4° canale del chip viene utilizzato per connettere ilcontroller SLAVE al processore, ottenendo in questo modo canali DMA separati.
DMA Transfer Type (Tipi di trasferimento dati)Esistono 4 modalità di trasferimento dati:Read type – E’ un trasferimento in modalità lettura, ovvero i dati vengono trasferiti dalla memoria centralead un device attraverso le relative porte di I/O;Write type – I dati vengono trasferiti dal device attraverso le porte di I/O alla memoria centrale;Memory to memory transfer type – Questa modalità viene utilizzata per trasferire blocchi di memoria da unalocazione della memoria centrale ad un’altra locazione;Verify transfer mode – Questa è una modalità utilizzata per verificare che il trasferimento possa avvenire inmodo corretto, infatti il controller eseguirà tutti gli stadi intermedi che danno luogo ad un trasferimento dati,ma nessun dato sarà realmente trasferito.
DMA Register and Commands (Registri del controller e suoi comandi)In questo paragrafo tratteremo i registri di un controller DMA e il suo contenuto:
Current Address Register – Questo registro contiene l’indirizzo corrente del blocco di memoria che saràinteressato nelle operazioni successive;Base Address Register - L’indirizzo base corrisponde ad ogni registro indirizzo corrente. Può essereprogrammato solo via software ed indica il punto da cui iniziare a trasferire i dati. Il contenuto definiscel’indirizzo entro un segmento di 64Kb di memoria;Page Register – La memoria del sistema viene vista dal controller DMA come pagine da 64Kb, quindi èopportuno indicare in questo registro a quale pagina si riferisce il valore da noi indicato nel registro base;Current Word Counter – Questo registro é presente per ogni canale DMA. Il registro contiene il numero di
byte da manipolare meno 1. Quando questo registro raggiunge il valore massimo 0FFFF (65535 + 1 =655336, la dimensione di una pagina) viene generato un segnale TC (Termination Counter);Base Word Counter – Questo registro viene utilizzato per l’inizializzazione del canale, ed ogni volta che unvalore viene scritto nel registro ‘Current Word Counter’ il suo valore viene automaticamente copiatodall’hardware in questo registro;Mode Register – Questo registro viene utilizzato per settare le modalità del controller:Bit 0, 1 – Numero del canale selezionato;Bit 2 – Se settato l’auto-inizializzazione è permessa, altrimenti è negata;Bit 3 – Indica la direzione, se settato il contatore viene decrementato ad ogni ciclo di trasferimento,altrimenti viene incrementato;Bit 4, 5 – Indica il tipo di trasferimento;Bit 6, 7 – Indica la modalità dell’operazione (00 verifica, 01 scrittura, 10 lettura, 11 memoria – memoria);Command Register – Questo registro specifica i comandi per l’operazione da eseguire:
Bit 0 – Trasferimento memoria-memoria, se settato è permesso, altrimenti è negato;Bit 1 – Bloccaggio dell’indirizzo del canale 0, se settato è permesso, altrimenti è negato;Bit 2 – Se settato il controller viene bloccato, altrimenti no;Bit 3 – Indica il tempo da impiegare, se settato viene utilizzato un tempo ristretto (è ignorato se il bit 0 èsettato);Bit 4 – Priorità (0 fissa, 1 rotatoria);Bit 5 – Modo ‘Extended write’ (1 permessa, 0 negata) (ignorata se il bit 3 è settato);Bit 6 – Livello DREQ (0 alto livello, 1 basso livello);Bit 7 – Livello DAC (1 alto livello, 0 basso livello);Status Register – Questo registro riflette lo stato di tutti i canali nel controller;Mask Register – Questo registro fornisce una maschera per l’utilizzo dei canali DMA. I bit impostati a 1 da 0a 3 indicano i servizi per i canali del controller slave, ed i restanti bit indicano i servizi per i canali delcontroller master;
Request Register – Questo registro viene utilizzato per gestire le richieste software o hardware;Temporary Register – Questo registro viene impiegato nei trasferimenti da memoria a memoria comeregistro tampone;
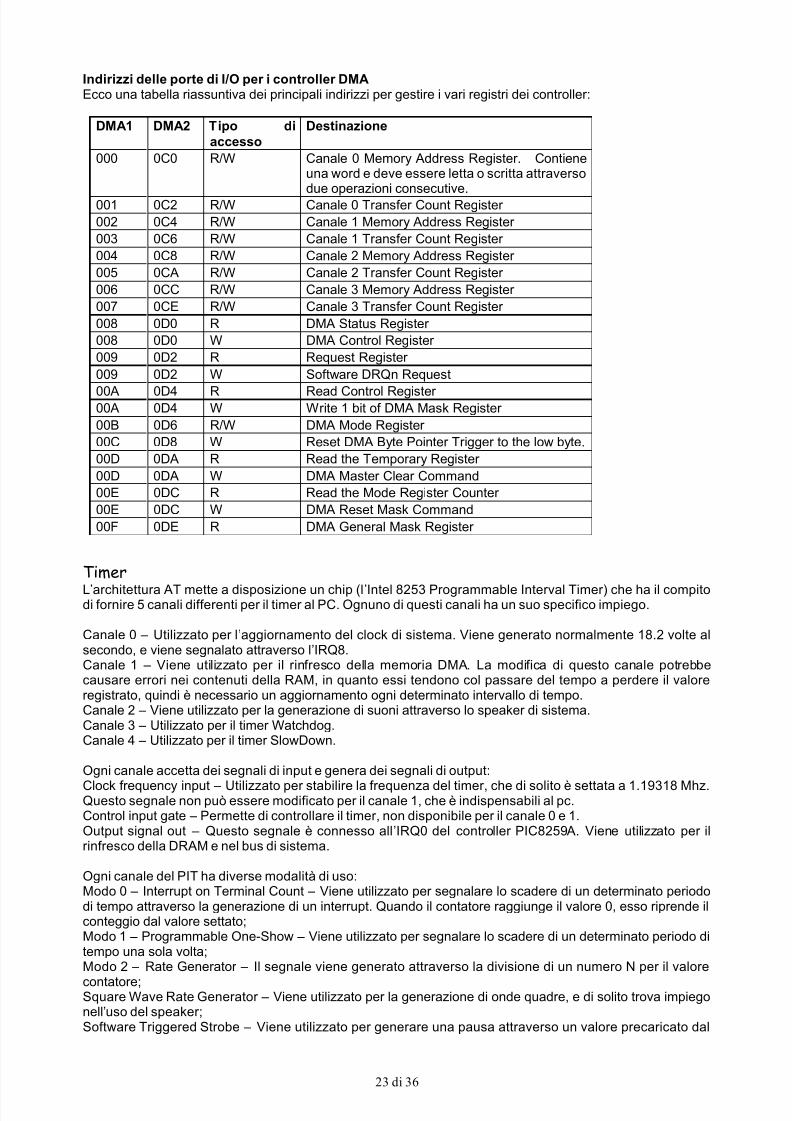
5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 23/36
23 di 36
Indirizzi delle porte di I/O per i controller DMAEcco una tabella riassuntiva dei principali indirizzi per gestire i vari registri dei controller:
DMA1 DMA2 Tipo diaccesso
Destinazione
000 0C0 R/W Canale 0 Memory Address Register. Contieneuna word e deve essere letta o scritta attraverso
due operazioni consecutive.001 0C2 R/W Canale 0 Transfer Count Register
002 0C4 R/W Canale 1 Memory Address Register
003 0C6 R/W Canale 1 Transfer Count Register
004 0C8 R/W Canale 2 Memory Address Register
005 0CA R/W Canale 2 Transfer Count Register
006 0CC R/W Canale 3 Memory Address Register
007 0CE R/W Canale 3 Transfer Count Register
008 0D0 R DMA Status Register
008 0D0 W DMA Control Register
009 0D2 R Request Register
009 0D2 W Software DRQn Request
00A 0D4 R Read Control Register00A 0D4 W Write 1 bit of DMA Mask Register
00B 0D6 R/W DMA Mode Register
00C 0D8 W Reset DMA Byte Pointer Trigger to the low byte.
00D 0DA R Read the Temporary Register
00D 0DA W DMA Master Clear Command
00E 0DC R Read the Mode Register Counter
00E 0DC W DMA Reset Mask Command
00F 0DE R DMA General Mask Register
TimerL’architettura AT mette a disposizione un chip (l’Intel 8253 Programmable Interval Timer) che ha il compitodi fornire 5 canali differenti per il timer al PC. Ognuno di questi canali ha un suo specifico impiego.
Canale 0 – Utilizzato per l’aggiornamento del clock di sistema. Viene generato normalmente 18.2 volte alsecondo, e viene segnalato attraverso l’IRQ8.Canale 1 – Viene utilizzato per il rinfresco della memoria DMA. La modifica di questo canale potrebbecausare errori nei contenuti della RAM, in quanto essi tendono col passare del tempo a perdere il valoreregistrato, quindi è necessario un aggiornamento ogni determinato intervallo di tempo.Canale 2 – Viene utilizzato per la generazione di suoni attraverso lo speaker di sistema.Canale 3 – Utilizzato per il timer Watchdog.Canale 4 – Utilizzato per il timer SlowDown.
Ogni canale accetta dei segnali di input e genera dei segnali di output:
Clock frequency input – Utilizzato per stabilire la frequenza del timer, che di solito è settata a 1.19318 Mhz.Questo segnale non può essere modificato per il canale 1, che è indispensabili al pc.Control input gate – Permette di controllare il timer, non disponibile per il canale 0 e 1.Output signal out – Questo segnale è connesso all’IRQ0 del controller PIC8259A. Viene utilizzato per ilrinfresco della DRAM e nel bus di sistema.
Ogni canale del PIT ha diverse modalità di uso:Modo 0 – Interrupt on Terminal Count – Viene utilizzato per segnalare lo scadere di un determinato periododi tempo attraverso la generazione di un interrupt. Quando il contatore raggiunge il valore 0, esso riprende ilconteggio dal valore settato;Modo 1 – Programmable One-Show – Viene utilizzato per segnalare lo scadere di un determinato periodo ditempo una sola volta;Modo 2 – Rate Generator – Il segnale viene generato attraverso la divisione di un numero N per il valore
contatore;Square Wave Rate Generator – Viene utilizzato per la generazione di onde quadre, e di solito trova impiegonell’uso del speaker;Software Triggered Strobe – Viene utilizzato per generare una pausa attraverso un valore precaricato dal
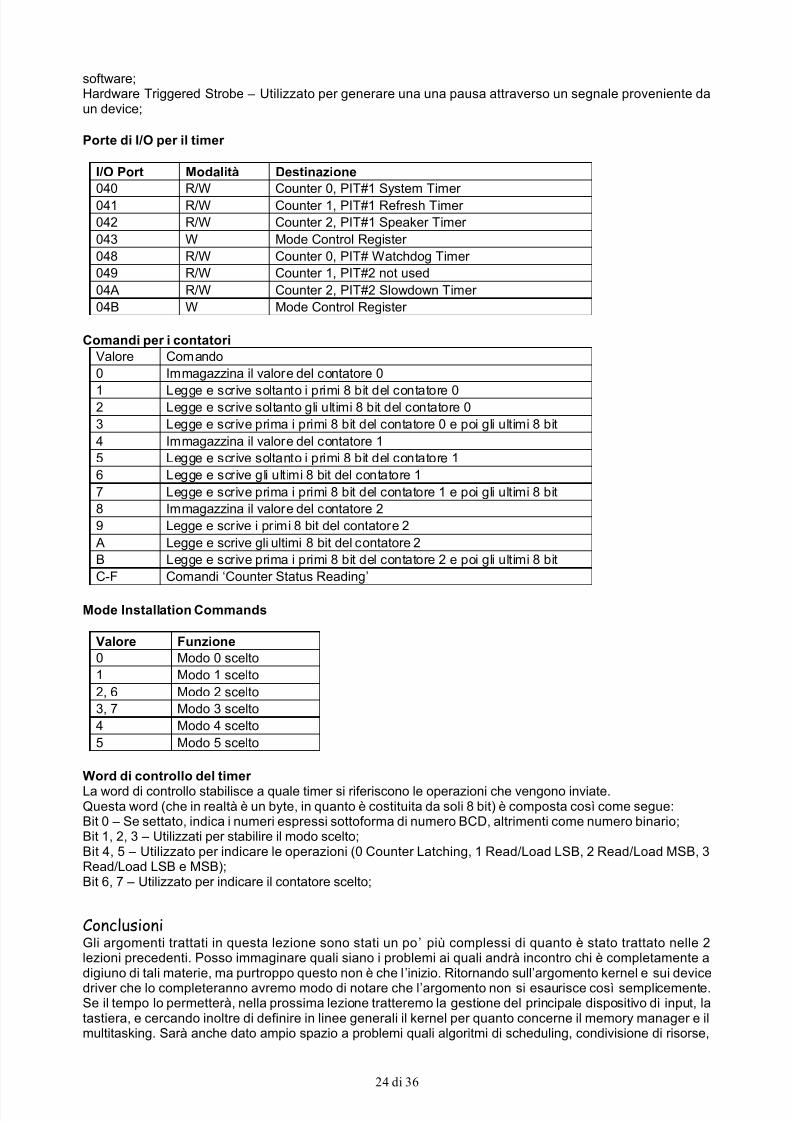
5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 24/36
24 di 36
software;Hardware Triggered Strobe – Utilizzato per generare una una pausa attraverso un segnale proveniente daun device;
Porte di I/O per il timer
I/O Port Modalità Destinazione
040 R/W Counter 0, PIT#1 System Timer041 R/W Counter 1, PIT#1 Refresh Timer
042 R/W Counter 2, PIT#1 Speaker Timer
043 W Mode Control Register
048 R/W Counter 0, PIT# Watchdog Timer
049 R/W Counter 1, PIT#2 not used
04A R/W Counter 2, PIT#2 Slowdown Timer
04B W Mode Control Register
Comandi per i contatori
Valore Comando
0 Immagazzina il valore del contatore 0
1 Legge e scrive soltanto i primi 8 bit del contatore 02 Legge e scrive soltanto gli ultimi 8 bit del contatore 0
3 Legge e scrive prima i primi 8 bit del contatore 0 e poi gli ultimi 8 bit
4 Immagazzina il valore del contatore 1
5 Legge e scrive soltanto i primi 8 bit del contatore 1
6 Legge e scrive gli ultimi 8 bit del contatore 1
7 Legge e scrive prima i primi 8 bit del contatore 1 e poi gli ultimi 8 bit
8 Immagazzina il valore del contatore 2
9 Legge e scrive i primi 8 bit del contatore 2
A Legge e scrive gli ultimi 8 bit del contatore 2
B Legge e scrive prima i primi 8 bit del contatore 2 e poi gli ultimi 8 bit
C-F Comandi ‘Counter Status Reading’
Mode Installation Commands
Valore Funzione
0 Modo 0 scelto
1 Modo 1 scelto
2, 6 Modo 2 scelto
3, 7 Modo 3 scelto
4 Modo 4 scelto
5 Modo 5 scelto
Word di controllo del timerLa word di controllo stabilisce a quale timer si riferiscono le operazioni che vengono inviate.Questa word (che in realtà è un byte, in quanto è costituita da soli 8 bit) è composta così come segue:Bit 0 – Se settato, indica i numeri espressi sottoforma di numero BCD, altrimenti come numero binario;Bit 1, 2, 3 – Utilizzati per stabilire il modo scelto;Bit 4, 5 – Utilizzato per indicare le operazioni (0 Counter Latching, 1 Read/Load LSB, 2 Read/Load MSB, 3Read/Load LSB e MSB);Bit 6, 7 – Utilizzato per indicare il contatore scelto;
ConclusioniGli argomenti trattati in questa lezione sono stati un po’ più complessi di quanto è stato trattato nelle 2lezioni precedenti. Posso immaginare quali siano i problemi ai quali andrà incontro chi è completamente a
digiuno di tali materie, ma purtroppo questo non è che l ’inizio. Ritornando sull’argomento kernel e sui devicedriver che lo completeranno avremo modo di notare che l’argomento non si esaurisce così semplicemente.Se il tempo lo permetterà, nella prossima lezione tratteremo la gestione del principale dispositivo di input, latastiera, e cercando inoltre di definire in linee generali il kernel per quanto concerne il memory manager e ilmultitasking. Sarà anche dato ampio spazio a problemi quali algoritmi di scheduling, condivisione di risorse,

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 25/36
25 di 36
e quanto altro sarà ritenuto necessario trattare. Spero comunque che troviate queste lezioni interessanti.
Bibliografia(1) Autori Vari - "Assembler Language Master Class", Wrox, 1995.
Lezione 4: Gestione della memoria.
IntroduzioneL’argomento sul quale ci soffermeremo in questa lezione è la gestione della memoria. Nelle prime 2 lezioniè stato trattato questo argomento, introducendo le principali modalità che un processore della famiglia x86mette a disposizione del sistema operativo per gestire la memoria. L’argomento non si esauriscecertamente lì, essendo stata quella soltanto un’analisi del processore, quindi in questa lezione cercheremodi analizzare quali sono i compiti di un memory manager , analizzando i diversi schemi per gestire lamemoria tramite un softwarePrincipalmente possiamo classificare in 2 famiglie:
1) Sistemi che gestiscono soltanto la memoria fisica;2) Sistemi a paginazione con l’uso di swapping.
La prima famiglia comprende i gestori di memoria di più semplice realizzazione, mentre la seconda famigliacomprende tutti i gestori di memoria che vengono utilizzati nei moderni sistemi operativi, i quali necessitanodi una parte del disco fisso per simulare e mettere a disposizione del software una memoria virtualmenteinfinita.Analizzeremo ovviamente entrambi i modelli di gestione della memoria, trattando i vari schemi che vengonoimpegnati in queste due classi.
Gestione della memoriaIn questa famiglia troviamo i primi gestori di memoria, realizzati ed impiegati nei primi computer. Nei
personal computer questi gestori di memoria sono utilizzati in quei sistemi operativi di fascia bassa, chenecessitano di pochi requisiti per poter funzionare correttamente.
Monoprogrammazione senza swapping o paginazioneQuesto a mio avviso è il modello più semplice per gestire la memoria di un calcolatore. La sua semplicità èdovuta al fatto che tutta la memoria fisica presente viene utilizzata per eseguire un solo applicativo allavolta, al quale viene riservata tutta la memoria disponibile sul sistema.In questo modello di memoria spesso viene utilizzata una tabella come indice per tenere traccia dellamemoria disponibile e di quella allocata. Ad ogni elemento della tabella viene assegnato un blocco didimensioni fisse della memoria (es. in ms-dos corrisponde a 16byte).Quando un applicativo viene caricato in memoria il gestore provvede a trovare un blocco di memoriasufficiente a tenere l’applicativo.Possiamo inoltre riscontrare spesso che alcuni blocchi di memoria sono riservati, tipo la cima della memoria
oppure la base, occupata dal kernel del s.o. oppure da un eventuali firmware presente sulle macchine (tipo iBIOS, oppure eventuali blocchi di memoria riservati come i 128Kb riservati per la memoria video).Questo metodo è stato impiegato in gestori di memoria all’inizio in CP/M e DOS. Purtroppo l’evoluzione deimicroprocessori e la crescente quantità di memoria disponibile lo rendono praticamente inutilizzabile in queisistemi operativi dove spesso vengono caricati più applicativi in memoria. Personalmente credo comunqueche sia utile in architetture proprietarie, dove la memoria disponibile è relativamente piccola e non vi è lapossibilità di disporre di unità dove effettuare lo swapping dei dati presenti nella memoria.
Multiprogrammazione con partizioniIn alcune macchine negli anni passati, era necessario avere più processi caricati contemporaneamente inmemoria, affinché non venisse perso inutilmente del tempo di elaborazione in attesa di un qualche segnaledi I/O da parte di un processo. Lo schema più semplice per permettere di avere più processicontemporaneamente caricati in memoria consiste nel suddividere la memoria fisica presente sulla
macchina in partizioni aventi dimensioni identiche. Ovviamente, eventuali processi che richiedono unaquantità di memoria più grande di quella messa a disposizione del sistema non potrebbero essere eseguiti,onde evitare questo inconveniente la memoria viene divisa in partizioni avente dimensione variabili. Unaeventuale coda in cui vengono inseriti i processi da eseguire provvede ad assegnare ad ogni processo una

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 26/36
26 di 36
partizione disponibile. Anche questa ultima soluzione però può presentare eventuali inconvenienti.Ipotizziamo di avere una memoria di 1Mb divisa in 4 partizioni da 100Kb, 250Kb, 500Kb, 150Kb. I processida caricare in memoria sono p(n, x) dove n identifica il numero del processo ed x il quantitativo espresso inKb di memoria richiesta. I processi presenti nella coda sono p(1, 80), p(2, 140), p(3, 90), p(4, 180), p(5,400).Il sistema viene avviato, i processi p(1), p(2), p(3) vengono caricati correttamente in memoria in quanto leprime 3 partizioni sono sufficientemente grandi per contenerle. Il processo p(4) invece viene scartato inquanto richiede una quantità di memoria che non è disponibile, e quindi si salta al caricamento di p(5) il
quale viene anche scartato di conseguenza per insufficienza di memoria. Bisogna pertanto far attendere ilprocesso p(4) e p(5) affinché le 2 partizioni in grado di contenerle vengono liberate (la 2°e la 4°partizione).Ciò è controproducente, in quanto il processo p(2) viene caricato in un blocco che supera di ben 90Kb lamemoria da lui richiesta, ed il processo p(3) addirittura in un blocco avente una dimensione ancora piùmaggiore con una perdita di memoria di 410Kb.L’ideale sarebbe quello di creare più code di processi, dove vengono stabilite le dimensioni massime per unprocesso. Pertanto la distribuzione dei processi verrebbe così fatta:
- 1 partizione: p(1), p(3);- 2 partizione: p(2), p(4);- 3 partizione: p(5);- 4 partizione: nessun processo.
Questo sistema è ancora controproducente, in quanto la 4° partizione è rimasta libera, mentre si puòcaricare il processo p(4) nella partizione vuota, occupando quindi il processore per la maggior parte del suotempo di attività.Ipotizziamo comunque di avere in ingresso altri 6 processi numerati da 5 a 10 aventi tutta una dimensionetalmente piccola da poter essere caricati nella 1° partizione. Le partizioni 2 e 3, quando i relativi processihanno terminato l’elaborazione, vengono inutilizzate.Questo problema viene risolto aggiungendo una 3°informazione nella coda, un numero k che indica quantevolte il processo è stato scartato per l’elaborazione. Quando il processo è stato scartato un numero max divolte gli viene assegnata una delle partizioni attualmente disponibile sul sistema.Anche questo modello di memoria oggi è stato prevalentemente abbandonato dai programmatori di sistemioperativi.
Rilocazione e protezioneI problemi derivanti dall’impiego del modello sopra esposto sono molto comuni. Ogni software non puòsapere in quale partizione verrà eseguito, in quanto non tutte le macchine hanno lo stesso quantitativo dimemoria e non tutte le partizioni hanno le stesse dimensioni. Pertanto, quando un processo viene creatodal programmatore, viene sviluppato con indirizzi relativi, cioè il processo stesso viene implementatopresupponendo che sarà eseguito nella partizione 1 avente inizio all’indirizzo di memoria 0. Sarà compitodel linker quello di creare una tabella delle istruzioni relative, e sarà compito del loader ricorreggere tuttequelle istruzioni che fanno riferimento a locazioni relative, inserendo il corretto valore.
Listato 1 – Scansione di una stringa
ScanString procpush ebpmov ebp, esp
mov ax, [ebp+08] ; Carica il selettore d’originemov esi, [ebp+0a] ; Carica l’offset d’origine
push axpop ds
mov ecx, -1xor eax, eax
cldrep scasb ; Termina l’elaborazione della stringa finché non
; DS:[ESI] non è uguale a 0
neg ecxsub ecx, 1
mov eax, ecx
mov esp, ebppop ebp

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 27/36
27 di 36
retScanString endp
mov ds, @datamov esi, offset Nomecall ScanString
Questo piccolo processo dovrà essere modificato in 2 punti. Il 1. è identificato dall’istruzione mov ds,@data, in quanto non è possibile conoscere il segmento dove sarà eseguito, e il secondo punto èl’istruzione mov esi, offset Nome in quanto non si può conoscere quale partizione sarà assegnata.Prima dell’esecuzione, il software che si preoccuperà di caricare l’applicativo correggerà le due istruzionisostituendo i relativi indirizzi con quelli effettivi. Questo sistema viene utilizzato nei file eseguibilidell’MS-DOS, dove è presente una tabella di elementi da rilocare data la dimensione dei segmenti inmodalità reale nei processori x86 e la dimensione degli applicativi.Comunque, ciò non risolve il problema principale, ovvero impedire al processo p(3) di accedere allamemoria del processo p(1) affinché ne sovrascriva le istruzioni e i dati causando danni irreparabili (in alcunis.o. che non sto qui ad elencare equivale al blocco della macchina), quindi viene aggiunta un ulteriorecampo nelle informazioni del processo, un numero identificativo. Il processore quando accede in memoriaper compito di un processo verifica che questo numero sia identico a quello assegnato alla partizione, e nelcaso ciò non sia vero viene generata una eccezione. In alcune CPU il processo di rilocazione venivaeseguito dal processore stesso, senza l’intervento del loader. Venivano memorizzate nelle informazionidella partizione l’indirizzo BASE della partizione stessa e un indirizzo LIMITE. Per qualsiasi accesso allamemoria viene sommato l’indirizzo BASE e verificato il tutto con l’indirizzo LIMITE, se questo controllo vienesuperato una eccezione viene sollevata dal processore ed elaborata dal s.o.Questo modello ci ricorda il comportamento dei processori x86 a 32bit operanti in modalità protetta. A titoloinformativo la prima CPU ad adottare uno schema simile a questo è stata impiegata nel CDC 6600, il primosuper computer prodotto.
SwappingSi fa ricorso all’uso dello swapping quando la memoria fisica presente su una macchina non è sufficienteper poter tenere caricati in memoria tutti i processi che sono stati mandati in esecuzione. Per rimediare aquesto problema si è pensato di utilizzare la memoria dei dischi come supporto alla memoria RAM.Purtroppo l’impiego del disco per contenere quei dati che non possono essere caricati in memoria causa ilrallentamento dell’esecuzione dei processi.Il più semplice schema di swapping consiste nel caricare un processo dal disco in memoria, eseguirlo perun dato periodo di tempo, salvarlo sul disco e procedere con i processi successivi. Questo schema nonsembra essere utilizzato nei sistemi operativi, ed ovviamente vi sono tutte le ragioni per non farlo. Unsistema del genere venne integrato in una distribuzione DOS della Digital Research (DR-DOS 6) e venivautilizzato per avere a disposizione un ambiente multi-tasking, con risultati assai sgradevoli.Il principale sistema di swapping oggi adoperato è costituito dalla memoria virtuale. Grazie ai supporti fornitidal microprocessore è possibile eseguire un applicativo caricando solo una parte del codice che locompone.Riprenderemo lo swapping nei paragrafi successivi.
Meccanismi per gestire la memoriaCompito del memory manager come già illustrato è quello di fornire la memoria all’applicativo che larichiede, ed allo stesso tempo tenere traccia di quali blocchi di memoria sono occupati e di quali sono liberi.Per svolgere questo compito vengono utilizzati due meccanismi diversi:
- Gestione della memoria con le bit map- Gestione della memoria con le liste
Procediamo ad esaminare questi due meccanismi.
Gestione della memoria con le bit mapLa gestione della memoria attraverso le bit map viene adoperata quando la memoria presente sul sistemaviene suddivisa in blocchi uguali. Ad ognuno di questi blocchi corrisponde un determinato flag diidentificazione nella tabella delle bit map. Il valore del flag indica lo stato del blocco di memoria, se èdisponibile o è stato assegnato.Ipotizziamo di avere la seguente bit map:
1111 000 0101 0011 0111 1100 0000 1110Bit0 Bit4 Bit8 Bit12 Bit16 Bit20 Bit24 Bit28
Ognuno di questi elementi rappresenta una pagina di 32Kb. In tutto abbiamo 32 elementi per un totale di1Mb di memoria indirizzata.

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 28/36
28 di 36
Al momento in cui viene inoltrata una richiesta di allocazione di memoria il gestore deve effettuare lascansione dell’intera bit map per cercare il blocco in grado di soddisfare la richiesta. Qualora sia richiestauna quantità di 128Kb di memoria, abbiamo due possibilità. Utilizzare l’elemento 22, 23, 24, 25 oppure i 4elementi successivi al 24.Il dover effettuare la scansione dell’intera tabella e la possibilità che il blocco che soddisfi la richiesta sipossa trovare a cavallo di 2 byte rappresenta un punto a svantaggio di questo metodo, ma nonostante ciò èutilizzato da alcuni gestori di memoria.Altro problema che deriva dall’impiego delle bit map riguarda la dimensione stessa della bit map. In questo
esempio per comodità ogni elemento della bit map rappresenta un blocco da 32Kb, quindi se fosserichiesta anche solo 1300 byte si sarebbe costretti ad assegnare un intero blocco, perché non vi è modo disapere quanti dati effettivamente siano utilizzati nel blocco. Una soluzione sarebbe quello di aumentare glielementi della bit map in modo da diminuire la dimensione di un blocco di memoria stesso. Ma questoaumenterebbe il consumo della memoria per la bit map. Infatti se nel nostro esempio la memoria richiestadalle bit map è di soli 4byte, se si scendesse ad un kb per ogni blocco si arriverebbe ad occupare già128byte. Non è una grande dimensione, però comunque si arriverebbe a sprecare sino a un max di 1023byte per ogni richiesta di allocazioni dati. Se scendiamo addirittura ad un paragrafo di memoria (riducendola dimensione di un blocco a soli 16byte) la perdita sarebbe minima, ma la bit map automaticamenteoccuperebbe 8Kb di memoria.
Gestione della memoria con le listeUn’alternativa all’impiego delle bit map per la gestione della memoria è data dalle liste. Ogni elemento dellalista rappresenta una porzione di memoria, indicando la dimensione del blocco, lo stato e i collegamenti aglielementi successivi e precedenti.Un esempio di un elemento della lista è il seguente:
typedef struct memlink {bool status; // 0 free, 1 usedunsigned long address;
unsigned long size;struct memlink *prev, *next;
} MEMLINK;
Un solo elemento della lista può gestire tutta la memoria del calcolatore, considerando che il membro sizepuò avere un valore max di 2^32 (equivale a 4gb di memoria).Trovare un nuovo blocco di memoria si riduce ad una semplice scansione della lista. Le operazioni perallocare una quantità di memoria da un blocco più grande senza sprecare un solo byte sono le seguenti:
- Si crea un elemento di tipo MEMLINK all’indirizzo address del blocco più grande;- Il membro address del nuovo MEMLINK assume il valore del vecchio elemento MEMLINK;- Il membro size del nuovo MEMLINK assume il valore del blocco di memoria da allocare più la
dimensione dell’oggetto MEMLINK;- Il membro prev punta all’oggetto MEMLINK contenuto in prev del vecchio elemento MEMLINK;- Il membro next punta al vecchio elemento MEMLINK;- Il vecchio elemento MEMLINK viene aggiornato nel campo prev, size ed address e viene collocato
al nuovo indirizzo address.
Ovviamente per migliorare l’efficienza delle liste si può memorizzare in due liste separate la memoria liberae quella allocata.
Gli algoritmi utilizzati per la scansione della lista sono i seguenti:- first fit – Scandisce la lista finché non viene trovato il primo elemento in grado di soddisfare larichiesta, ma a lungo andare questo algoritmo genera blocchi di memoria sempre più piccoli,rischiando di non poter soddisfare le richieste successive. Nonostante ciò esso è il più semplice daimplementare ed anche il più veloce;
- next fit – Questo algoritmo invece tiene memorizzata la posizione dell’ultimo elemento che hasoddisfatto una richiesta per l’allocazione di un dato blocco, in modo da effettuare la ricerca solo neiblocchi successivi;
- best fit – Questo algoritmo prevede una scansione dell’intera lista alla ricerca del blocco che siadatta a soddisfare in modo migliore la richiesta;
- worst fit – Questo algoritmo prevede la scansione dell’intera lista alla ricerca del blocco più grandeche ci sia, in modo che spezzando tale blocco in 2 parti si generi un blocco libero che possa essereimpiegato successivamente per altre richieste di memoria;
- quick fit – Questo algoritmo invece prevede la memorizzazione di diverse liste dove gli elementihanno una dimensione pressoché identica, in modo da velocizzare la ricerca. Ciò che penalizzal’impiego di questo algoritmo è dovuto alla compattazione della memoria. Quando della memoriaallocata viene rilasciata, se essa è confinante con un blocco disponibile, si deve prevedere

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 29/36
29 di 36
all’unione dei 2 blocchi, rimovendoli dalle rispettive liste ed inserendo il nuovo elemento nella listaappropriata.
La memoria virtualeL’impiego della memoria virtuale, come è stato già detto, è dovuto alla necessità di poter utilizzare unaquantità relativamente grande di memoria, senza che però essa sia necessariamente presente sullamacchina. Immaginate un processo che per la sua corretta esecuzione richieda 2Mb di memoria fisica,mentre la macchina ne può mettere a disposizione soltanto uno. L ’unica alternativa che lo sviluppatore haconsiste nel suddividere il proprio processo in più frammenti, chiamati overlay, i quali venivano caricatiaccuratamente dal sistema operativo ogni qualvolta era necessario, ma assicurarsi che tutti i dati di cui undeterminato overlay avesse bisogno era un compito che spettava al programmatore stesso, e taleoperazione era lunga e noiosa. Tutto questo si è risolto introducendo la memoria virtuale. L ’utilizzo dellamemoria virtuale permette di eseguire un processo anche con una minima porzione di dati e di codice,garantendo l’eventuale caricamento in memoria degli stessi all’occorrenza. Purtroppo, l’impiego dellamemoria virtuale richiede automaticamente l’impiego di un disco dove memorizzare i dati non presenti nellamemoria.
La paginazioneLa maggior parte dei sistemi con memoria virtuale utilizza la tecnica della paginazione. Nella lezione 2abbiamo trattato la paginazione di un processore x86 a 32bit, mentre in questa approfondiremo l’argomentodella paginazione.La memoria fisica del computer viene divisa in opportuni blocchi aventi tutti una dimensione uguale,chiamate pagine , come accade con la gestione delle bit map, ma ad ogni pagina può corrispondere unindirizzo virtuale di memoria che non è identico al suo indirizzo fisico. Infatti in presenza di paginazione tuttigli indirizzi virtuali utilizzati dalla CPU per accedere alla memoria fisica vengono tradotti da un appositodispositivo chiamato MMU (Memory Manager Unità). Nel caso in cui ad un indirizzo virtuale noncorrisponda nessun indirizzo fisico, l’MMU avverte il sistema operativo generando l’eccezione page fault dando così la possibilità al sistema stesso di provvedere al caricamento dei dati stessi in una pagina libera,oppure attraverso determinate procedure al rimpiazzamento della pagina con una nuova, garantendo alprocesso una corretta esecuzione.La gestione della memoria virtuale necessita dell’utilizzo di tabelle che descrivono le pagine stesse. Ognielemento di queste tabelle descrive lo stato di ogni pagina presente sul sistema. Le tabelle che descrivonola memoria possono essere a un solo livello o a più livelli.Nei sistemi in cui viene adoperato un solo livello per le tabelle di pagine, è necessario avere in memoria unacopia dell’intera tabella, e questo ci obbliga ad occupare una quantità non indifferente di memoria solo perla tabella (un esempio pratico è dato dai processori a 32bit INTEL, dove per tenere tutte le tabelle di paginein memoria è necessario dedicare 4100Kb di memoria!). L’adozione di questo meccanismo è un grossoproblema, in quanto se la tabella ha dimensioni non indifferenti, viene posizionata in memoria, causando unrallentamento non indifferente all’esecuzione dell’applicativo.Nei sistemi in cui vengono adoperate tabelle a più livelli, ogni elemento della tabella di livello inferiorepermette di puntare a più elementi. Ciò permette inoltre di poter stabilire solo quali tabelle di livello superiorecaricare fisicamente in memoria, dandoci così la possibilità di risparmiare una quantità non indifferente dimemoria. Tale meccanismo come abbiamo visto viene adoperato dalle cpu x86 a 32bit (per accedereall’indirizzo virtuale 00400200 tale CPU carica dalla tabella di primo livello il 2° elemento, e se esso ècaricato in memoria carica dalla stessa tabella il primo elemento dato che 0200 rientra nell ’offset della
prima pagina).Per aumentare la velocità d’accesso alla tabella di pagine viene adoperato una particolare unità chiamataTLB (Translation Lookaside Buffer o memoria associativa) che ha il compito di mantenere in appositiregistri hardware un elenco delle pagine a cui si accede molto più frequentemente. Quando il processoredeve accedere a una locazione di memoria, l’MMU controlla in parallelo tutti gli elementi della TLB, e nelcaso in cui tali elementi non hanno memorizzate le informazioni relative alla pagina consulta la tabellacaricata in memoria, scartando un elemento della TLB per rimpiazzarlo col nuovo elemento caricato dallamemoria. In alcune architetture il caricamento degli elementi nella TLB avviene in modo trasparente al s.o.mentre in altre architetture, gli elementi della TLB devono essere caricati dal s.o. via software. Ovviamente,questo compito deve essere fatto nel minor numero possibile di cicli di clock, dato che le eccezioni dovutealla mancanza di un elemento nella TLB avvengono più spesso delle eccezioni di pagina.Una soluzione alle tabelle di pagine è data dalle tabelle di pagine inverse adoperate spesso in quellearchitetture dove la quantità di memoria fisicamente indirizzabile è talmente vasta che la suddivisione in
pagine darebbe vita a tabelle di pagina molto grandi. Le tabelle di pagine inverse sono delle tabelle in cui gliunici elementi che figurano non sono altro che quelli effettivamente presenti, quindi non si può utilizzarel’indirizzo virtuale come indice per identificare l’elemento ma bensì deve essere effettuata una scansionedegli elementi alla ricerca di quello corretto. Questa procedura mediante l’impiego della TLB può esserevelocizzata, e attraverso appositi algoritmi di ricerca una eventuale scansione della tabella può essere

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 30/36
30 di 36
effettuata in un tempo più che ragionevole.La dimensione delle pagine è un parametro che spesso ricade sul s.o. nonostante l’architettura dellamacchina preveda pagine di dimensione differente. Onde evitare di sprecare della memoria inutilmente,spesso si tende a scegliere una dimensione di pagine ridotta. Comunque per ottenere la protezione a livellodi pagine da parte dell’hardware è consigliato avere una dimensione di pagina logica identica alla stessadimensione di una pagina fisica, e di scegliere sempre un multiplo di 2 per sfruttare al meglio l ’architetturadel processore.
Algoritmi per il rimpiazzamento delle pagineQuando non vi è in memoria più nessuna pagina disponibile, si pone il dubbio di determinare quale sia lapagina da eliminare dalla memoria per rimpiazzarla con quella necessaria. A questo proposito, esistonodiversi algoritmi, quindi andiamo ad esaminarne alcuni:
- Algoritmo ottimo per il rimpiazzamento delle pagine – Questo algoritmo è il miglior algoritmoche possa esistere, ma è impossibile da realizzare. Esso prevede una scansione dell ’applicativoalla ricerca delle pagine utilizzate e della frequenza dell’accesso, in modo da stabilirestatisticamente quale siano le pagine che si possono togliere evitando un page fault per il maggiortempo possibile. Tale algoritmo purtroppo può essere applicato a un processo analizzando primadel caricamento il flusso stesso del codice. Dato che è specifico a un determinato processo, talealgoritmo non viene implementato da nessun sistema;
- Algoritmo di rimpiazzamento delle pagine Not-Recently-Used – I vari sistemi che utilizzano lepagine per la memoria virtuale, permettono di utilizzare alcuni bit negli elementi che descrivono lepagine per indicare un eventuale accesso alla pagina ed eventuali modifiche apportate alla stessa.Quando si verifica un’eccezione, il sistema operativo effettua una scansione degli elementi nelletabelle al fine di cercare quali pagine non siano mai utilizzate, e sceglie una di queste pagine perprovvedere al rimpiazzamento. Qualora non vi siano pagine mai utilizzate, il s.o. può scegliereinvece tra quelle pagine modificate ma mai utilizzate in lettura;
- Algoritmo di rimpiazzamento delle pagine FIFO – Questo algoritmo prevede il rimpiazzamentodelle pagine attraverso una coda FIFO. Il primo elemento inserito nella coda (e in tal caso la paginache risiede in memoria da un maggior numero di tempo) viene estratto per essere rimpiazzato incima alla coda dal nuovo elemento. Ciò però non è buono, in quanto la pagina che si trova allabase della coda può essere anche la pagina più utilizzata dal sistema;
- Algoritmo di rimpiazzamento delle pagine Second Chance – Questo algoritmo si rifàsull’algoritmo FIFO, ma dando la possibilità alle pagine utilizzate di essere conservate nel sistema.
Al verificarsi di un PAGE FAULT l’algoritmo verifica che l’elemento base della coda non sia statoutilizzato, se invece è stato utilizzato la pagina viene spostata in cima alla coda come se fosse stataappena caricata e si provvede ad esaminare l’elemento successivo della coda;
- Algoritmo dell’orologio per il rimpiazzamento delle pagine – Tale algoritmo è identicoall’algoritmo ‘Second Chance’ con l’unica differenza che le pagine non vengono mai spostate nellalista, ma bensì viene conservato il puntatore all’ultimo elemento controllato, provvedendo adeffettuare la ricerca dall’elemento puntato. Quando viene individuata nella coda una pagina nonadoperata di recente, essa viene rimpiazzata con la nuova pagina da caricare e il puntatore avanzaall’elemento successivo della coda;
- Algoritmo di rimpiazzamento delle pagine Least Recently Used – Questo algoritmo riprendel’algoritmo ottimo per il rimpiazzamento delle pagine. Consiste nel cercare la pagina meno utilizzatarecentemente attraverso un riferimento di tipo cronologico o in base al numero di accessi effettuatiin una determinata pagina prima del verificarsi di un’eccezione di pagina. Dato che la maggior parte
delle istruzioni usano un operando che spesso è localizzato in memoria diventa inefficientedovendo mantenere aggiornata la tabella dei riferimenti per la ricerca della pagina da rimuovere.
In alcune forme di paginazione, quando un processo è caricato non ha nessuna pagina in memoria, quindiman mano che esso sarà in esecuzione attraverso i page fault il s.o. provvederà a caricare tutte le pagine dicui ha bisogno in memoria. Normalmente un processo necessita di un numero molto piccolo e spesso benidentificato di pagine in memoria per un corretto funzionamento. Il numero di pagine caricate in memoria inun dato istante che appartengono ad un determinato processo prendono il nome di working set. Finchél’intero working set di un processo non viene caricato correttamente in memoria il processo genererà pagefault. Una soluzione ideale negli algoritmi di rimpiazzamento delle pagine è quella di evitare di rimpiazzare lepagine che appartengono al working set del processo in modo da ridurre il numero di page fault provocati.
La segmentazioneOltre alla paginazione, la memoria virtuale può essere gestita attraverso la segmentazione, che ci permettedi creare spazi di indirizzamento virtuali e di tenere separati blocchi quali codice, dati, stack per diversiprocessi. Mantenere separati questi blocchi ci permette di far crescere la dimensione dei segmenti senza

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 31/36
31 di 36
mai rischiare di entrare in collisione con altri blocchi di memoria, inoltre ciò ci permette di tenere del codicecondiviso fra più processi, quali il codice del s.o. che altrimenti dovrebbe essere caricato nella memoriavirtuale del processo stesso. Nonostante si possano tenere separati in segmenti diversi blocchi di memorianon si deve dimenticare che essi sono fisicamente presenti nella stessa memoria, quindi è possibileaccedere alla memoria di un processo semplicemente ridefinendo un nuovo segmento che la comprendautilizzando privilegi differenti. Un esempio reale ci può essere dato dai processori x86.Nella GDT viene definito un segmento alias che comprende l’intera memoria fisica del processore, mentrein altri segmenti viene incapsulato il processo. Attraverso il segmento alias nessuno ci impedisce di
accedere al contenuto di tutta la memoria fisica contenuta nella macchina, in quanto nello stesso segmentola stessa memoria viene vista come un unico banco DATI con gli attributi R/W settati, con base uguale a 0e LIMITE equivalente al corrispettivo della memoria fisica.Spesso in molte architetture si fa ricorso alla segmentazione combinata alla paginazione onde evitare che ilcontenuto di tutto il segmento sia realmente presente in memoria. Una delle architetture più importanti adadottare questo sistema fu MULTICS (girava su macchine Honeywell 6000) mentre uno dei più diffusi neinostri giorni è il processore Pentium di INTEL del quale ne abbiamo trattato il funzionamento sia in modalitàreale (Lezione 1) che in modalità protetta (Lezione 2).
ConclusioniAbbiamo analizzato in questa lezione un argomento abbastanza interessante. Come avete avuto modo dileggere, esistono diversi sistemi per gestire la memoria, e l’uso di concetti quali paginazione esegmentazione riducono le architetture verso il quale è possibile fare il porting del proprio s.o.Per chiunque fosse interessato ad approfondire questo argomento, si rimanda alla lettura di (1).
Bibliografia(1) Andrew S. Tanenbaum, Albert S. Woodhull - "Sistemi operativi - Progetto e implementazione ",Prentice Hall International, 2001.
Lezione 5: I processi
IntroduzioneIn questo appuntamento tratteremo i processi, ovvero il modo in cui un sistema operativo affronta lagestione di più applicativi in esecuzione su una macchina facendo credere all’utente che si stannoeseguendo tutti contemporaneamente. Ci tengo a dire innanzitutto che non esiste nessun sistema operativoin grado di effettuare il multitasking in presenza di un singolo processore. Oggi il termine multitasking vieneutilizzato senza rispettare affatto il suo significato. Multitasking significa poter eseguire nello stesso istantepiù processi, non condividere il processore tra più task caricati contemporaneamente nella memoria, comeavviene oggi in tutti quei s.o. che vengono eseguiti su macchine con un solo processore.L’esecuzione di più processi su una macchina, in presenza di uno o più processori, genera problemi inerentialla risorsa più importante, il tempo di utilizzo della CPU. Nessun programmatore sarebbe disposto arichiamare dal suo applicativo una fantomatica API di sistema avente lo scopo di sospendere l ’esecuzionedel processo per dare la possibilità ad altri processi di essere eseguiti.Questo compito spetta allo scheduler di sistema, che stabilisce il tempo da dedicare ad un dato processo,la priorità di esecuzione degli stessi processi e l’utilizzo delle risorse di sistema nel modo più efficiente ondeevitare blocchi di sistema a causa di due processi che lottano per acquisire una singola risorsa.Spesso negli applicativi che attendono un evento troviamo una simile forma di codice:
while(1) {ioctl(handle, FIONBIO, &data); // Controlla se sono disponibili byte..if (data) break;
}
.... continua la normale esecuzione del processo, i dati attesi sono finalmentedisponibili.
Sarete tutti d’accordo che forme di codice del genere dovrebbero essere evitate quanto più è possibile, main quei s.o. che non permettono ad un software di sospendere l’esecuzione finché un dato evento non si
verifichi, da qualche parte bisogna pur bloccare l’esecuzione, altrimenti si rischierebbe di giungere alla finedel processo stesso senza che nessun dato sia stato elaborato.Un’alternativa al codice riportato sopra sarebbe quella di farci inviare dal kernel un segnale, qualora vi sianodei dati disponibili per l’handle utilizzato, ma resta sempre il problema che il nostro software deve eseguire

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 32/36
32 di 36
operazioni inutili perché non vi è modo di arrestare la sua esecuzione.Oltre alla gestione dei processi e al coordinamento delle risorse hardware presenti sulla macchina, il kerneldeve anche mettere a disposizione mezzi di comunicazione a tali processi e permettere la condivisione dimemoria.
I processiNei sistemi in cui è disponibile un solo processore, come è già stato detto, il multitasking viene realizzatograzie alla possibilità della CPU di commutare da un processo a un altro in un tempo relativamente breve.Ovviamente la quantità di tempo dedicata ad un processo influenza la velocità di elaborazione dei processistessi, dato che il continuo scambio da un processo ad un altro e il passaggio attraverso lo scheduler (cheha il compito di decidere quale processo eseguire successivamente) ridurrà il tempo di elaborazionedisponibile per i processi stessi.In un sistema dove vi è la possibilità di eseguire più processi, ognuno di questi processi ha sempre unprocesso padre che lo ha generato, il quale dispone di tutti i permessi per farlo terminare in qualsiasiistante, e a sua volta ogni processo figlio può creare altri processi.I principali stati in cui si può trovare un processo sono i seguenti:
- In esecuzione – Quando il controllo sarà trasferito al processo, esso sarà in grado di continuarel’elaborazione;
- Pronto – Il processo non è in elaborazione, in quanto la cpu sta elaborando un altro processo;
- Bloccato – Il processo non può essere eseguito, in quanto non si è verificato un dato evento.Quest’ultimo stato ci porta alle considerazioni fatte prima; se il processo è in attesa dei suoi dati si devebloccare, quindi le possibilità sono o il blocco automatico del processo, oppure una chiamata allo schedulerper chiedere di bloccare il processo.Ora però la possibilità di bloccare in modo automatico il processo (ad esempio quando tenta di leggere daun dispositivo seriale, ed i dati non sono ancora presenti, il processo viene bloccato) ci impedisce dieseguire ulteriori operazioni (tipo l’aggiornamento di un orologio che viene visualizzato a video); attendereun segnale dallo scheduler ci obbliga a scrivere una apposita procedura che faccia da destinatario ad unospecifico messaggio.
Gestione dei processiPer la gestione dei processi il sistema deve tenere un elenco dei processi stessi da gestire, attraversoun’apposita tabella dei processi. Gli elementi che figurano in questa tabella sono lo stato del processo, il
valore di tutti i registri e quant’altro possa essere utile a ripristinare la situazione del processo al momento incui il controllo gli sarà di nuovo trasferito.Naturalmente, oltre a queste informazioni nei s.o. che implementano un modello multiprocesso gestendo lamemoria tramite la paginazione, è importante, prima di trasferire il controllo al processo, caricare quelminimo indispensabile di pagine affinché non provochi continui page-fault.Oltre ad una tabella per gestire un processo è necessario che un s.o. fornisca anche delle strutture primitiveper permettere la gestione dei thread . Il thread non è altro che un piccolo processo, che gira nello spazio diindirizzamento di un processo padre che lo ha generato.Immaginate per un attimo ad un server http quale APACHE oppure IIS. Nel momento in cui l’utenteprovvede ad effettuare una connessione al web-server, questo provvede a soddisfare la richiesta nel minortempo possibile (banda permettendo), ma se tutte le richieste http dovessero essere effettuate da unsingolo processo, il risultato sarebbe pessimo. Ecco che in questo caso l’utilizzo dei thread è la sceltaottimale, in quanto istanziare un nuovo processo per soddisfare una richiesta sarebbe troppo dispendioso.
Ad ogni richiesta che giunge al server, la richiesta viene passata ad un thread affinché venga soddisfatta.Ovviamente, se un numero di thread fossero già creati, ma in attesa di un compito (e quindi bloccati)l’efficienza del web-server aumenterebbe. Spesso i thread possono essere gestiti al pari di un processo,mettendo a disposizione dello sviluppatore routine per la creazione, la cancellazione, l’assegnazione dipriorità, la modifica dello stato di un thread stesso.Tra le più importanti librerie in circolazione per la gestione dei thread troviamo la P-thread POSIX e laC-thread di Mach.I thread POSIX sono molto conosciuti da coloro che sviluppano sotto l’ambiente Linux, in quanto è unasemplice alternativa all’impiego della fork per gestire più operazioni contemporaneamente.La gestione dei thread a livello pratico, come ovviamente dei processi, sarà affrontata in una lezionesuccessiva.Dato atto che ogni processo può dare vita ad un numero non meglio precisato di processi, quanti threadpossono essere presenti su una macchina in un dato istante? E soprattutto, qual è la soluzione più efficace
per gestire i thread, permettendo loro qualsiasi azione ma allo stesso tempo negando loro la possibilità diapportare modifiche al processo stesso al fine di provocarne un malfunzionamento?

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 33/36
33 di 36
Comunicazione interprocessoNei sistemi in cui vi sono più processi in esecuzione è indispensabile che due o più processi possanocomunicare tra loro per uno scambio di informazioni.Perché è necessario che i processi comunichino tra di loro? Innanzitutto per evitare che più processipossano tentare di accedere in un dato istante ad una determinata risorsa e quindi evitare che l’unodanneggi l’altro. La gestione di alcune risorse deve essere affidata a determinati processi (tipo lo spooler distampa) e far sì che il software che desideri effettuare una tale operazione debba per forza comunicare col
processo piuttosto che dare lui la possibilità di accedere alla risorsa. Cosa succederebbe se due softwarecontemporaneamente decidessero di stampare un file e non vi è nessun processo che gestisca taleoperazione? Uno dei due software si vedrebbe negata la propria richiesta, o nel peggiore dei casi entrambi idocumenti sarebbero stampanti senza nessuna distinzione, combinando i dati di uno con i dati dell ’altrosulla carta! Questo genere di problemi prende il nome di corsa critica, e cercare di risolvere questo generedi problemi (che si presentano seguendo la famosa legge di Murphy (vedi Listato1)) è un’operazioneabbastanza complessa data la manifestazione del problema in modo casuale.Una soluzione per evitare le “corse critiche” è data dalla mutua esclusione, ovvero impedire ad ogniprocesso di accedere ad una determinata risorsa che è stata già impegnata da un altro processo.Evitare le corse critiche comporta conoscere quando un processo entra in una sezione critica, econoscere la sezione critica di un processo significa evitare che un altro processo possa entrare nellapropria sezione critica quando lo è già uno, e per poter fare ciò bisogna che lo sviluppatore notifichi alsistema che la sezione in esecuzione è da considerarsi una sezione critica.
Per poter ottenere la muta esclusione è necessario garantire che durante l’impiego di una data risorsanessun altro processo la possa utilizzare. Esistono diverse possibili soluzioni a questo problema.
- Interruzioni disabilitate – Molti scheduler utilizzano le interruzioni del timer per effettuare il saltoda un processo ad un altro, quindi disabilitandole si garantisce che durante una sezione criticanessun processo possa prendere il controllo del sistema;
- Variabili di lock – Questa soluzione prevede l’impiego di una variabile di stato nella quale simemorizzi se il processo è in una sezione critica o meno. Quando un nuovo processo tenta dientrare in una sezione critica, se tale variabile è già posta a 1 un errore verrà notificato, altrimenti lavariabile sarà posta a 1 ed il processo continuerà la propria esecuzione nella sezione critica. Siveda il listato 1 alla fine di questa lezione per ulteriori commenti;
- Alternanza stretta - L’alternanza stretta consiste nel far si che due o più processi che debbanolavorare in una sezione critica si diano il cambio tramite una variabile di stato, quando uno dei
processi sta lavorando, l’altro processo attende che il valore della variabile di stato cambi, eviceversa;
- La soluzione di Peterson – G. L. Peterson nel 1981 scoprì un metodo più semplice per ottenerela mutua esclusione. Prima di utilizzare delle variabile condivise ogni processo chiama una funzioneenter_region. Questa chiamata lo blocca finché non gli viene dato l’accesso alla sezione critica.Una chiamata alla funzione leave_region lo farà uscire dalla sezione critica. Il listato 2 riportainsieme ad un commento la soluzione di Peterson;
- Istruzioni TSL – Nei sistemi multiprocessore, quando una cpu accede alla memoria esegueun’istruzione TSL (Test and Set Lock) vietando alle altre cpu l ’uso del bus per accedere allamemoria. Questa soluzione, insieme alla soluzione di Peterson, ha però il problema di dare vita adegli enormi cicli di attesa, sprecando il tempo macchina di elaborazione;
- Sleep e wakeup – sleep è una chiamata di sistema che fa sì che il chiamante si blocchi e restiquindi sospeso fino a che un altro processo non lo risveglia, mentre wakeup è una chiamata di
sistema che richiede come parametro il processo da svegliare. Questo permette di bloccare unprocesso e di dare la possibilità ad un altro, alla fine della sua sezione critica di richiamarne unaltro.
- Semafori – Nel 1965 E. Dijkstra suggerì l’uso di una variabile intera per contare il numero disegnali di risveglio. Questo tipo di variabile prendeva il nome di semaforo, ed indica il numero diwakeup che sono rimasti in attesa di essere elaborati. L ’insieme di quelle azioni che hanno comefine il controllo del semaforo, e una sua eventuale modifica devono essere raggruppati all ’interno diuna singola operazione, indivisibile o atomica. Le principali azioni di un semaforo sono UP (ha ilcompito di incrementare il valore del semaforo, ed è lo stesso valore di wakeup) e DOWN (ha ilcompito di controllare se il semaforo non ha un valore pari a 0, ed ha le funzioni di sleep).
La maggior parte dei s. o. oggi permettono ai processi di comunicare tra loro attraverso i messaggi. Leprincipali funzioni per garantire lo scambio dei messaggi sono due:
- SEND – Invia un messaggio;- RECEIVE – Riceve un messaggio.
Entrambe queste funzioni naturalmente richiedono il destinatario e il mittente del messaggio, ed un buffer

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 34/36
34 di 36
contenente il messaggio da ricevere o inviare. Unico inconveniente di questo sistema è costituito dalmittente e dal destinatario, che normalmente vengono espressi sottoforma di valore numerico(corrispondente all’il del processo, perciò ogni volta differente), il quale deve essere conosciuto a priori dalprocesso. Una probabile soluzione potrebbe essere data da una famigerata funzione chiamataRegisterProcess che registra una coda per lo scambio dei messaggi con un eventuale nome. Unaeventuale funzione a sua volta chiamata FindProcess otterrà l’eventuale id del processo, favorendo loscambio. Questa possibile soluzione presenta un solo piccolo difetto, se 2 processi completamentedifferenti hanno in comune il nome, chi ci assicura che il destinatario dei messaggi sia quello corretto? Unaeventuale procedura di autenticazione potrebbe risolvere il problema, ma a questo punto lo scambio deimessaggi sta diventando sempre più complesso.
Problemi di comunicazione interprocesso
Problema dei filosofi affamatiLo stesso Dijkstra formulò e risolse un problema di sincronizzazione chiamato problema dei filosofiaffamati.Esponiamo questo problema:
- 5 filosofi sono seduti attorno a un tavolo circolare;- Ogni filosofo ha un piatto di spaghetti tanto scivolosi, che necessitano di 2 forchette per poter
essere mangiati;- Sul tavolo vi sono in totale 5 forchette.
La vita di ogni filosofo è scandita da due momenti distinti, un momento in cui esso pensa, ed un momento incui esso mangia.Quando un filosofo ha fame, prende la forchetta che sta a sinistra e quella che sta a destra del suo piatto,mangia per un po’ e poi mette sul tavolo le due forchette. Questa soluzione sarebbe fattibile se gli altri 4filosofi stanno pensando, ma se in un dato istante tutti i filosofi decidessero di mangiare prendendo tutti laforchetta a sinistra del loro piatto, e non trovando la forchetta a destra si avrebbe un blocco del sistema(deadlock).Un altro metodo sarebbe quello di prendere la forchetta a sinistra, e controllare se la forchetta a destra èdisponibile, quindi se non lo è il filosofo mette giù la forchetta a sinistra, attendendo per un tempo casualeprima di ripetere l’operazione. Questa soluzione è anche inefficace, perché se i 5 filosofi decidessero nello
stesso istante di prendere la forchetta a sinistra, essi non troverebbero la forchetta a destra, e nessuno diloro mangerebbe. L’attesa casuale potrebbe risolvere il problema, ma è una soluzione inefficace, non si puòpretendere che un fattore casuale determini il funzionamento di un sistema.Risolvere questo problema attraverso l’impiego dei semafori è molto più semplice. Ad ogni filosofo vieneassegnato un semaforo, e ogni qualvolta che esso deciderà di mangiare, viene controllato lo stato deisemafori che lo circondano. Se entrambe le forchette non sono disponibili, il filosofo viene bloccato, e nonpuò continuare la sua operazione.
Problema dei lettori e degli scrittoriA differenza del problema espresso precedentemente, forse questo problema è più comune a coloro chehanno a che fare con architetture client/server per la condivisione di dati.Immaginiamo la seguente situazione:
- In piena stagione un villaggio turistico può ancora ospitare una famiglia;- Due famiglie, situate in due città completamente differenti, si recano contemporaneamente in due
agenzie diverse, venendo a conoscenza del posto libero nel villaggio turistico;- Decidono entrambe di prenotare, così vengono inviate dai terminali delle agenzie le due richieste,
dato che il posto risultava ancora disponibile al momento dell’interrogazione del database remoto;- Le due richieste vengono accodate in una pila dal database, che provvede ad elaborare i due
segnali;- Essendo entrambe richieste di scrittura sul database, il software blocca il record elaborando la
prima richiesta;- Il thread che ha il compito di effettuare la seconda richiesta, all ’accesso al record del database
viene bloccato dal semaforo, essendo sotto elaborazione un altro processo;- Il primo thread termina l’elaborazione, invia un segnale DOWN al semaforo, che così permetterà
l’elaborazione al secondo thread;
- Il secondo thread, trovando occupato il record ritornerà un errore.
Cosa sarebbe successo se non vi fosse stato un semaforo a regolare questa operazione ? Entrambi ithread

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 35/36
35 di 36
avrebbero soddisfatto la richiesta, mentre solo una delle due famiglie ha realmente prenotato il posto.
Problema del barbiere addormentatoUn altro problema è il seguente:In una bottega un barbiere serve i proprio clienti. Nella bottega vi sono un numero N di sedie, ed un unicobarbiere. Se nessun cliente è nella bottega, il barbiere si mette a dormire sulla poltrona.Quando entra il cliente, la prima cosa che controlla è se il barbiere sta dormendo oppure no. Se il barbieresta dormendo, il cliente lo sveglia e viene servito. Altrimenti, se un altro cliente viene servito, il clienteappena entrato controlla che vi sia una sedia libera e si siede in attesa del suo turno, altrimenti abbandonala bottega senza essere stato servito.Dato che è impossibile conoscere lo stato di un semaforo (una eventuale chiamata al semaforo perrichiedere una particolare risorsa può bloccare il processo nel caso questa risorsa sia già impegnata) inquesto problema viene utilizzata una variabile alternativa, che viene aggiornata dal semaforo e che contieneil numero di clienti in attesa, in modo da sapere a priori se vi è disponibile un posto oppure no.
Scheduling dei processiIn un sistema operativo dove più processi sono eseguibili, la parte del sistema che ha il compito di sceglierequale processo deve essere mandato in esecuzione prende il nome di scheduler e l’algoritmo usato perprendere questa decisione prende il nome di algoritmo di scheduling.I criteri che stabiliscono cosa costituisce un buon algoritmo di scheduling sono i seguenti:
1) Equità – Assicurarsi che ogni processo riceva una parte del tempo della CPU;2) Efficienza – Mantenere la CPU impegnata per il 100% del tempo;3) Tempo di risposta – Minimizzare il tempo di risposta per gli utenti interattivi;4) Turnaround – Minimizzare il tempo di risposta che gli utenti di processi batch devono attendere
per il risultato;5) Throughput – Massimizzare il numero di job elaborati in ogni ora.
Ovviamente, qualsiasi algoritmo si impieghi a favore di una particolare classe di job (punto 3, risposta agliutenti interattivi) danneggia un’altra classe di job (in questo caso la 4, o viceversa).Gli algoritmi di scheduling in cui l’esecuzione di un processo (job) viene interrotta per favorirne un altroprendono il nome di scheduling preemptive (con prerilascio, come accade in tutti i s. o. di oggi che girano
su una singola cpu) mentre invece l’algoritmo che provvederà a soddisfare le richieste di un processosuccessivo soltanto quando il processo che è in elaborazione finirà il suo compito prende il nome dinonpreemptive scheduling. Questi ultimi algoritmi sono di più facile implementazione, ma nell’ipotesi che idue processi fossero due software per la generazione di un frattale, il secondo processo sarebbe avviatocon un ritardo molto enorme da quando il processo stesso viene avviato.Analizzeremo adesso diversi algoritmi di scheduling.
Scheduling round robinQuesto algoritmo è uno dei più vecchi, ed è uno degli algoritmi di scheduling preemptive di più facileimplementazione. Questo algoritmo consiste nel suddividere il tempo a disposizione della CPU in quanti ofrazione di tempo da dedicare ad un processo. Lo scambio del processo prende il nome di context switch,e richiede un determinato periodo di tempo per essere effettuato. Se la durata di un quanto viene fissata inun periodo di tempo molto basso, si violerebbe il 2° punto esposto in alto (efficienza) perché lo scheduler
arriverebbe a richiedere più tempo di quanto non ne rilasci ai processi. Aumentare la durata di un quanto,invece diminuirebbe la quantità di tempo dedicata al context switch, ma allo stesso tempo violerebbe ilpunto 3 (tempo di risposta). La durata di un quanto deve essere stabilita in un determinato intervallo ditempo in modo che non si violi nessuno dei punti sopra esposti.
Scheduling prioritarioQuesto algoritmo riprendere l’algoritmo precedente, ma con una piccola differenza. Introduce oltre alconcetto di quanto il concetto di priorità, dando così la possibilità allo scheduler di eseguire a priori semprequei processi con priorità maggiore, e di dedicare meno quanti ai processi con priorità inferiore. Ondeevitare di dedicare il 100% del tempo ai processi più importanti, allo scadere di ogni quanto lo schedulerpuò aggiornare la priorità, in modo che dopo un certo numero di quanti i processi meno importanti abbianola possibilità di essere eseguiti. Ogni qualvolta che un processo ha raggiunto la minima priorità assoluta, loscheduler ripristina il suo livello a quello originale. Questa soluzione evita le attese a tempo indeterminato
da parte di alcuni processi (starvation).
Code multipleL‘adozione da parte degli scheduler di livelli di priorità danno vita a diverse classi, ognuna delle quali

5/17/2018 Scrivere Un Sistema Operativo - slidepdf.com
http://slidepdf.com/reader/full/scrivere-un-sistema-operativo 36/36
36 di 36
raggruppa tutti i processi aventi la stessa priorità. Man mano che l ’esecuzione va avanti, i processi vengonodeclassati, fino a ritrovarsi nella classe più bassa (o più alta, a secondo delle regole di scheduling) e il suocompito non si è esaurito. Ovviamente, l’adozione di questo modello non può essere rispettata per queiprocessi che hanno bisogno di interagire con l’utente. In alcuni sistemi, questi processi vengono side-classificati, ma un input proveniente dal terminale dove sono in esecuzione li riportano nella classe amaggior priorità di esecuzione. Questo modello, se adottato in sistemi distribuiti penalizzerebbe tutti quegliutenti che non stanno davanti al terminale, e soprattutto quei processi che forniscono soltanto un output,senza richiedere alcuna forma di input dopo il caricamento in memoria.
Shortest job first


















