
Ottimizzazione di interrogazioni - DB&KB Group - Query Optimization.pdf · Parsing e check...
72
Ottimizzazione di interrogazioni Tecnologie delle Basi di Dati M
Transcript of Ottimizzazione di interrogazioni - DB&KB Group - Query Optimization.pdf · Parsing e check...

Ottimizzazione di interrogazioni
Tecnologie delle Basi di Dati M

Ottimizzazione delle query
� La risoluzione di un’interrogazione (anche semplice) può essere realizzata in diversi modi, con costi differenti
� Per ogni query, il DBMS deve scegliere il modo migliore (più veloce) per risolverla
� A tal fine il query manager dispone di un ottimizzatore e di un valutatore dei piani di accesso
� L’ottimizzazione di una query richiede:� L’enumerazione dei possibili piani di accesso per la sua risoluzione� La stima del costo di ogni piano di accesso, al fine di selezionare il piano
dal costo minore (stimato)
� La stima del costo di ogni piano di accesso viene effettuata dal valutatore dei piani di accesso usando le statistiche fornite dai cataloghi
� In realtà il processo di elaborazione di una query SQL comporta l’esecuzione di più attività…
2
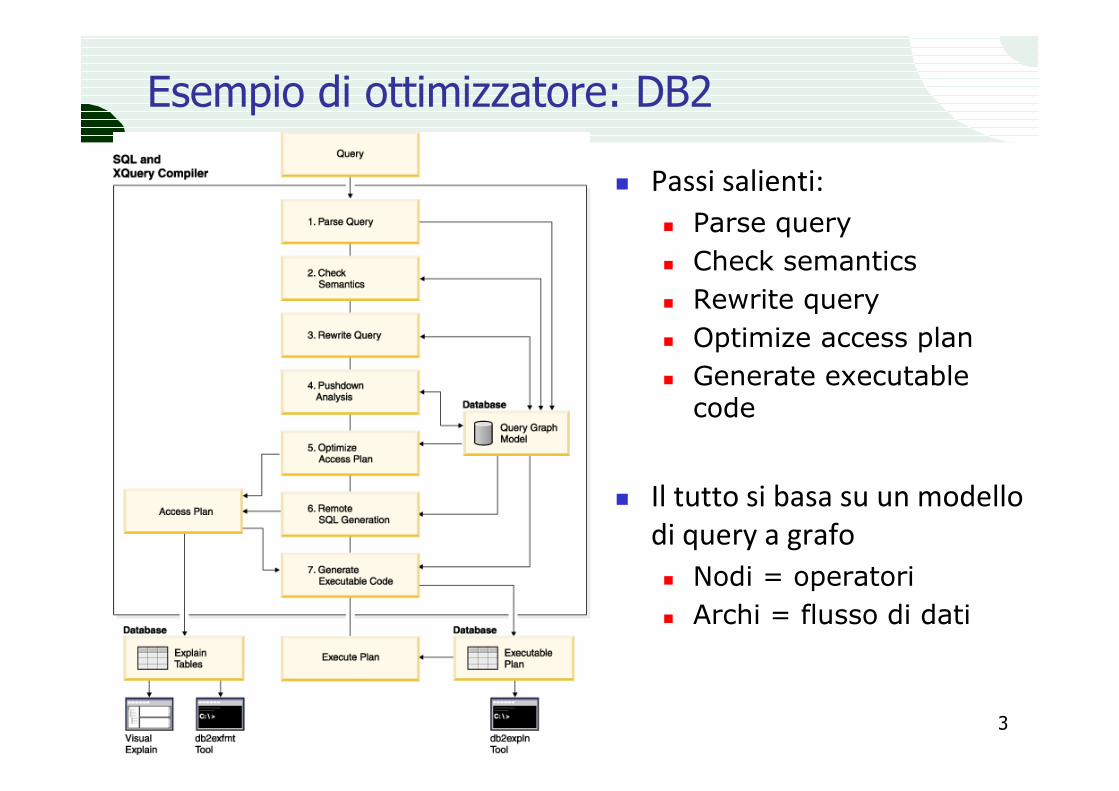
� Passi salienti:
� Parse query� Check semantics� Rewrite query� Optimize access plan� Generate executable
code
� Il tutto si basa su un modello di query a grafo
� Nodi = operatori� Archi = flusso di dati
Esempio di ottimizzatore: DB2
3

Parsing e check semantico
� Il primo passo consiste nel verificare la validità lessicale e sintattica della query (parsing)
� Al termine di questo passo viene prodotta una prima rappresentazione interna, che evidenzia gli oggetti interessati (relazioni, attributi, ecc.)
� La fase di check semantico, facendo uso dei cataloghi, verifica che:� Gli oggetti referenziati esistano� Gli operatori siano applicati a dati di tipo opportuno� L’utente abbia i privilegi necessari per eseguire l’operazione
4

Check semantici e uso dei cataloghi (i)
� Facciamo riferimento ai cataloghi di DB2 nello schema SYSCAT:
5
SQL Catalog SQL attribute Descrizione
TABLES TABSCHEMA Nome dello schema
TABLES TABNAME Nome della table, vista o alias
TABLES DEFINER Userid del creatore
TABLES TYPE T = Table; V = View; A = Alias
COLUMNS TABSCHEMA Nome dello schema
COLUMNS TABNAME Nome della table o vista
COLUMNS COLNAME Nome dell’attributo
VIEWS VIEWSCHEMA Nome dello schema
VIEWS VIEWNAME Nome della view
VIEWS DEFINER Userid del creatore
VIEWS TEXT Definizione SQL della vista

Check semantici e uso dei cataloghi (ii)
� … e supponiamo di avere la seguente query:
SELECT EmpNo
FROM MySchema.Employee
� In fase di check semantico vengono eseguite query del tipo:
SELECT *
FROM SYSCAT.TABLES
WHERE TABSCHEMA = ‘MySchema’
AND TABNAME = ‘Employee’ ;
SELECT *
FROM SYSCAT.COLUMNS
WHERE TABSCHEMA = ‘MySchema’
AND TABNAME = ‘Employee’
AND COLNAME = ‘EmpNo’ ;
6

Riscrittura di query
� Prima di procedere alla fase vera e propria di ottimizzazione della query, il DBMS esegue un passo di “rewriting” della stessa
� Lo scopo della fase di riscrittura è semplificare la query e pervenire a una forma più semplice da analizzare e quindi ottimizzare
� Tra le operazioni tipiche che hanno luogo in questa fase vi sono:� Risoluzione delle viste: si esegue il merge della query in input con le
query che definiscono le viste referenziate� Unnesting: se la query include delle subquery si prova a trasformarla in
una forma senza innestamenti� Uso dei vincoli: vengono sfruttati i vincoli definiti sugli schemi al fine di
semplificare la query
� Il modo con cui vengono eseguite queste operazioni varia da sistema a sistema, e quindi non è possibile fornire soluzioni di validità generale (il modo cambia anche per uno stesso DBMS se si scelgono “livelli di ottimizzazione” differenti!)
7

Risoluzione di viste
� Per un semplice esempio, si consideri la vista:
CREATE VIEW EmpSalaries(EmpNo,Last,First,Salary)
AS SELECT EmpNo,LastName,FirstName,Salary
FROM Employee
WHERE Salary > 20000
e la query:
SELECT Last, First
FROM EmpSalaries
WHERE Last LIKE ‘B%’
� La risoluzione della vista porta a riscrivere la query come:
SELECT LastName,FirstName
FROM Employee
WHERE Salary > 20000
AND LastName LIKE ‘B%’
8

Query innestate
� Le subquery sono query SELECT usate nella clausola WHERE di un’altra query
� Una subquery si dice correlata se fa riferimento ad attributi (“variabili”) delle relazioni nel blocco “esterno”, altrimenti è detta costante
� In genere, si producono piani di accesso per le subquery come se fossero query a parte
� Per evitare però di “perdere” dei piani di accesso a basso costo, l’ottimizzatore cerca di riscrivere la query senza usare subquery
9

Unnesting: esempio I
� Il passaggio a una forma senza subqueryalle volte è immediato; ad esempio la seguente query:
SELECT EmpNo, PhoneNo
FROM Employee
WHERE WorkDept IN ( SELECT DeptNo
FROM Department
WHERE DeptName = ‘Operations’ )
viene riscritta come:
SELECT E.EmpNo, E.PhoneNo
FROM Employee E, Department D
WHERE E.WorkDept = D.DeptNo
AND D.DeptName = ‘Operations’
10

Unnesting: esempio II
� La query:
SELECT E.EmpNo
FROM Employee EWHERE E.EmpNo NOT IN ( SELECT EA.EmpNo
FROM Emp_Act EA )
viene riscritta usando un outer join:
SELECT Q.EmpNo
FROM ( SELECT E.EmpNo, EA.EmpNoFROM Emp_Act EA RIGHT OUTER JOIN Employee E ON (E.EmpNo = EA.EmpNo) ) AS Q(EmpNo,EmpNo1)
WHERE Q.EmpNo1 IS NULL
11

Uso dei vincoli (i)
� Il DBMS “ragiona” sfruttando la presenza di vincoli per semplificare le query
� Ad esempio, se EmpNo è una chiave:
SELECT DISTINCT EmpNo
FROM Employee
la query si riscrive più semplicemente come:
SELECT EmpNo
FROM Employee
12

Uso dei vincoli (ii)
� Per un esempio di semplificazione basata sul vincolo di Foreign Key, si consideri:
SELECT EA.EmpNo -- EA.EmpNo è FK
FROM Emp_Act EAWHERE EA.EmpNo IN (SELECT EmpNo FROM Employee)
che viene riscritta come:
SELECT EA.EmpNo FROM Emp_Act EA
� Se EA.EmpNo ammettesse valori nulli, la riscrittura aggiungerebbe
WHERE EA.EmpNo IS NOT NULL
� In questo esempio potrebbe essere l’utente stesso scrivere a la query in forma semplificata; nel prossimo esempio ciò non è possibile, ma può farlo solo il DBMS
13

Uso dei vincoli (iii)
� Si supponga di avere la vista:
CREATE VIEW People
AS SELECT FirstName,LastName,DeptNo,MgrNo
FROM Employee E, Department D
WHERE E.WorkDept = D.DeptNo
e la query:
SELECT LastName,FirstName FROM People
in cui chi esegue la query non ha privilegio di SELECT né su Employee né su Department
� Il DBMS può però semplificare la query:
SELECT LastName,FirstName FROM Employee
eventualmente aggiungendo (se WorkDept ammette valori nulli)
WHERE WorkDept IS NOT NULL
14

Modello interno della query
� Il punto di partenza per il processo di ottimizzazione è dato da una rappresentazione ad albero della query:
� Foglie = relazioni� Nodi interni = operatori logici� Rami = flussi di dati� Radice = risultato dell’interrogazione
SELECT S.snomeFROM Recensioni R, Sommelier SWHERE R.sid=S.sidAND R.vid=100 AND S.val>4
πsnome(σvid=100∧val>4(Recensioni��Sommelier))
15
πsnome
σvid=100∧val>4
��sid=sid
Recensioni Sommelier

Piano di accesso
� L’ottimizzatore deve trasformare l’albero della query in un access plan, ovvero un albero di operatori fisici, ognuno dei quali è
� un algoritmo che realizza un operatore logico� un metodo di accesso alle relazioni
16
πsnome
σvid=100∧val>4
��sid=sid
Recensioni Sommelier
πsnome
σvid=100∧val>4
��sid=sid
Recensioni Sommelier
Page nested loops
Sul momento (in RAM)
Sul momento (in RAM)
Table scan Table scan

Esecuzione di un piano di accesso
� Per eseguire un piano di accesso occorre valutare gli operatori dell’albero a partire dal basso
� Esistono due possibilità di esecuzione� Per materializzazione
� Ogni operatore memorizza il proprio risultato in una tabella temporanea
� Un operatore deve attendere che tutti gli operatori di input da cui dipende abbiano terminato l’esecuzione per iniziare a produrre il proprio risultato
� In pipeline (tramite iteratori)� Ogni operatore richiede un risultato agli operatori di input
(demand-driven evaluation)
� Non è “bloccante”
� Non sempre è possibile (es. sort)
� La valutazione per materializzazione è altamente inefficiente, in quanto comporta la creazione, scrittura e lettura di molte relazioni temporanee, relazioni che, se la dimensione dei risultati intermedi eccede lo spazio disponibile in memoria centrale, devono essere gestite su disco
17

Esecuzione per materializzazione (i)
18
SELECT P.ProjNo, E.EmpNo, D.*
FROM Department D, Employee E,Project P
WHERE E.WorkDept = D.DeptNo
AND E.EmpNo = P.RespEmp
E.EmpNo = P.RespEmp
E.WorkDept = D.DeptNo

Esecuzione per materializzazione (ii)
� L’esecuzione per materializzazione produrrebbe come risultato del primo Join:
19
A partire da tale risultato intermedio si può poi calcolare il secondo join

Esecuzione in pipeline
� Un modo alternativo di eseguire un piano di accesso è quello di eseguire più operatori in pipeline, ovvero non aspettare che termini l’esecuzione di un operatore per iniziare l’esecuzione di un altro
� Nell’esempio visto, si inizia a eseguire il primo join (E.EmpNo = P.RespEmp). Appena viene prodotta la prima tupla:
questa viene subito passata in input al secondo join, (E.WorkDept =
D.DeptNo), che può quindi iniziare la ricerca di matching tuples e quindi produrre la prima tupla del risultato finale della query:
� L’esecuzione prosegue cercando eventuali altri match per la tupla prodotta dal primo join; quando è terminata la scansione della relazione interna (Department), il secondo join richiede al primo di produrre un’altra tupla
20

Operatori: interfaccia a iteratore
� Per semplificare il codice di coordinamento dell’esecuzione dei piani di accesso si usa un’interfaccia standardizzata per gli operatori:
� Metodi:� open: inizializza, alloca buffer, passa parametri e richiama
ricorsivamente pen sui figli� hasNext: verifica se ci sono altre tuple� next: richiede la prossima tupla� reset: riparte dalla prima tupla (es. nested loops)� close: termina e rilascia le risorse
21
open
next
close
<op_type>
buffer pool
hasNext
reset

Pipeline con iteratori
� L’interfaccia a iteratore supporta naturalmente un’esecuzione in pipeline degli operatori, in quanto la decisione se lavorare in pipeline o materializzare è incapsulata nel codice specifico dell’operatore
� Se l’algoritmo dell’operatore permette di elaborare completamente una tuplain input appena questa viene ricevuta, allora l’input non viene materializzato e si può procedere in pipeline
� E’ questo il caso del Nested Loops Join
� Se, viceversa, la logica dell’algoritmo richiede di esaminare la stessa tupla in input più volte, allora si rende necessario materializzare
� E’ questo il caso del Sort, che non può produrre in output una tupla senza prima aver esaminato tutte le altre
� E’ importante osservare che l’interfaccia a iteratore viene usata anche per incapsulare i metodi di accesso quali i B+-tree, che esternamente vengono quindi visti semplicemente come operatori che producono un insieme (stream) di tuple
22

Piani di accesso alternativi: esempio (i)
� Supponiamo di eseguire l’albero visto in precedenza:
� Il costo risulta quello del join: 501000 I/O, ovvero circa 1.4 ore!
� Si può fare di peggio!� Prodotto Cartesiano tra le relazioni
seguito dalla selezione sull’attributo di join
� L’obiettivo è cercare di ridurre il costo evitando di valutare tutte le possibili alternative
23
πsnome
σvid=100∧val>4
��sid=sid
Recensioni Sommelier
Page nested loop
Sul momento
Sul momento
Table scan

Piani di accesso alternativi: esempio (ii)
� Poiché il join è un’operazione costosa, una prima soluzione è diminuire la dimensione degli input
� Una possibilità è quella di applicare le selezioni prima di effettuare il join (push-down)
� Es.: vid=100 si applica solo a Recensioni� Creiamo relazioni temporanee T1 e T2 e le ordiniamo� Costo
= P(R) + P(T1) + P(S) + P(T2) + sort(T1) + sort(T2) + P(T1) + P(T2) =1000 + 10 + 500 + 250 + 40 + 1500 + 10 + 250 = 3560 (35 sec)
24
πsnome
��sid=sid Merge-scan
Sul momento
σvid=100 σval>4
Recensioni SommelierTable scanTable scan
Sort Sort
Sul momentoSul momento

Piani di accesso alternativi: esempio (iii)
� Un’altra possibilità è quella di introdurre una proiezione in quanto, per il join e in output, solo sid e snome sono richiesti
� Si riducono le dimensioni delle tabelle temporanee� Es.: usando page nested loops e supponendo che la tabella temporanea T2’
creata a partire da Sommelier si possa mantenere tutta in memoria:� Costo
= P(R) + P(T1’) + P(S) + P(T2’) + P(T1’) + P(T2’) = 1000 + 3 + 500 + 250 + 3 + 250 = 2006 (20 sec)
25
πsnome
��sid=sid Page nested loops
Sul momento
σvid=100 σval>4
Recensioni Sommelier Table scanTable scan
πsid πsid,snome Sul momentoSul momento
Sul momentoSul momento
NB: per semplicità il piano di accessonon mostra i nodi di creazione eaccesso alle temporanee
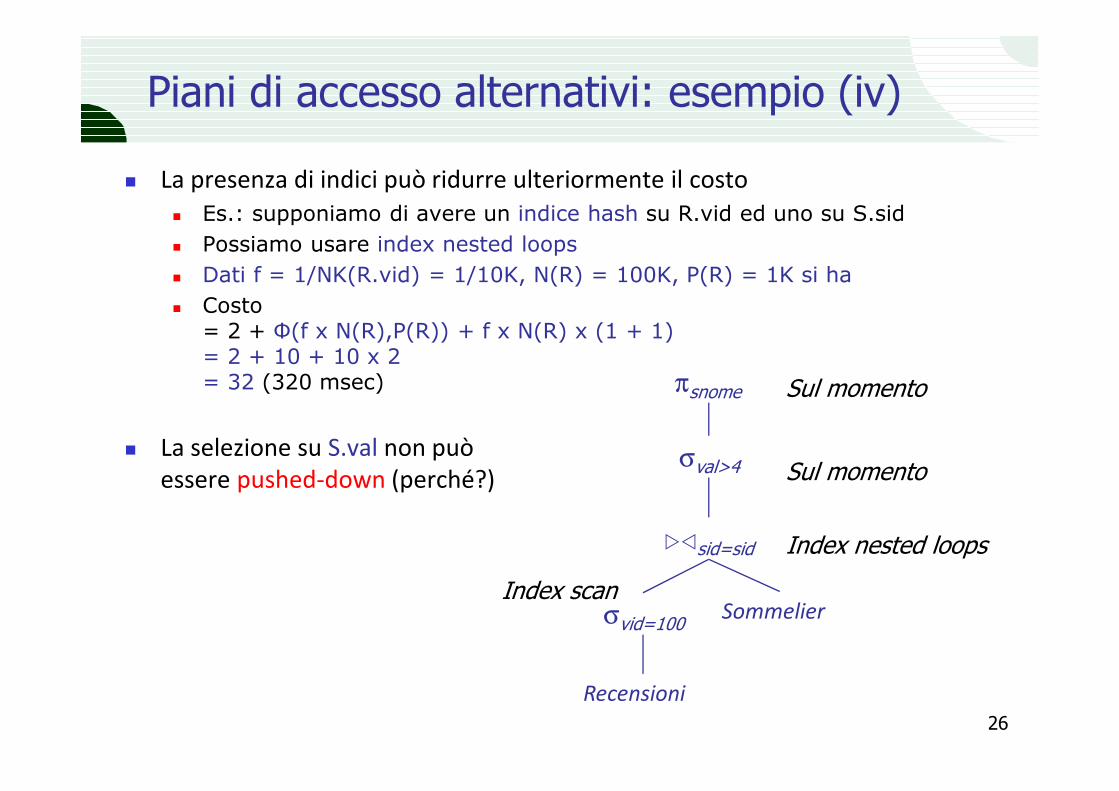
Piani di accesso alternativi: esempio (iv)
� La presenza di indici può ridurre ulteriormente il costo� Es.: supponiamo di avere un indice hash su R.vid ed uno su S.sid� Possiamo usare index nested loops� Dati f = 1/NK(R.vid) = 1/10K, N(R) = 100K, P(R) = 1K si ha� Costo
= 2 + Φ(f x N(R),P(R)) + f x N(R) x (1 + 1) = 2 + 10 + 10 x 2= 32 (320 msec)
� La selezione su S.val non può essere pushed-down (perché?)
26
��sid=sid Index nested loops
Sul momento
σvid=100
Recensioni
SommelierIndex scan
πsnome
σval>4
Sul momento

Modifica dei piani di accesso
� È evidente che, nella generazione di piano di accesso alternativi, occorre che l’ottimizzatore non modifichi la semantica della query originale
� Occorre conoscere l’equivalenza di espressioni in algebra relazionale (con NULL e duplicati)
� Raggruppamento e commutatività della selezione� Raggruppamento e commutatività della proiezione� Commutatività e associatività del join� Push-down della selezione sul join� …
� Va precisato che l’enumerazione dei piani di accesso può avvenire con diverse modalità, alcune delle quali procedono per successive modifiche, altre invece in cui i piani di accesso vengono costruiti incrementalmente aggiungendo man mano i diversi operatori necessari
27

Stima del costo di un piano di accesso
� Per ogni nodo dell’albero fisico occorre stimare:� Il costo
� Si usano le stime già viste, tenendo conto che il pipelining permette di risparmiare il costo di scrittura delle relazioni temporanee in uscita
� La dimensione del risultato� Se il risultato è ordinato o meno
� Il tutto si basa su statistiche che vengono mantenute aggiornate (dal DBMS/DB admin)
28

Esempio: le statistiche di DB2
� Come sappiamo, le statistiche di DB2 vengono mantenute all’interno dei cataloghi
� Schema SYSSTAT
� Le statistiche vengono aggiornate tramite il comando RUNSTATS
� È possibile iniziare l’aggiornamento delle statistiche sia manualmente che automaticamente
� Vengono mantenute statistiche su tabelle, indici, colonne, distribuzioni, gruppi di colonne
29

Esempio: statistiche su tabelle
� FPAGES� Pagine usate da una tabella
� NPAGES� Pagine contenenti record (≤ FPAGES)
� CARD� Record in una tabella (cardinalità)
30

Esempio: statistiche su colonne
� COLCARD� Cardinalità dell’attributo
� AVGCOLLEN� Dimensione media dell’attributo
� HIGH2KEY, LOW2KEY� Secondo valore maggiore/minore dell’attributo
� NUMNULLS� Numero di valori null
� … e altro ancora
31

Esempio: statistiche su indici
� NLEAF� Foglie
� NLEVELS� Livelli (altezza)
� CLUSTERRATIO� Grado di clusterizzazione dei dati rispetto all’indice
� DENSITY� Percentuale di foglie memorizzate sequenzialmente
� NUMRIDS� RID memorizzate nell’albero
32

Stima del numero di valori distinti
� E’ spesso necessario conoscere il numero di valori distinti di un attributo (o combinazione di attributi)
� L’approccio basato su sorting richiede O(P log P) per ogni attributo
� Esiste un metodo (molto) più veloce basato su hashing, noto come linear counting, che ha complessità O(P)
33

Linear counting
� Si predispone in RAM un array LC di B bit, inizialmente tutti a 0
� Si scandisce la relazione R e, per ogni tupla r, si applica una funzione hash Ha valori in [0,B-1] al valore dell’attributo A di interesse
� Si pone LC[H(r.A)] = 1
� Al termine si conta il numero Z di bit rimasti a 0
� Si stima il numero di valori distinti di A, NK(R.A):
NK(R.A) ≈ B ln (B/Z)
34

Linear counting: analisi
� Basata sullo stesso modello della formula di Cardenas
� Poiché il numero di duplicati di ogni valore non ha influenza su Z, si ha che in media vale la relazione:
B – Z = B (1-(1-1/B)NK) ≈ B – B e-NK/B
e quindi: Z ≈ B e-NK/B ⇒ ln(Z/B) ≈ - NK/B
⇒ NK ≈ B ln (B/Z)
� Perché il metodo funzioni occorre garantire Z > 0� Ad es., ponendo B = N
� Il metodo è ovviamente applicabile a più attributi, o combinazioni, in parallelo
35

Istogrammi
� Il solo numero di valori distinti può portare a stime poco accurate, che possono quindi influenzare in modo impredicibile il processo di ottimizzazione
� Es.: Dati N dipendenti e NK(ruolo) ruoli:� quanti dipendenti hanno il ruolo ‘operaio’? N/NK(ruolo) (?)� quanti ‘direttore di filiale’? N/NK(ruolo) (?)
� La distribuzione uniforme è spesso (molto) lontana dalla realtà dei dati� Vale anche per domini numerici
� Praticamente tutti i DBMS si basano su istogrammi per ottenere stime più accurate
36

Tipi di istogrammi
� Equi-width: il dominio viene suddiviso in B intervalli della stessa ampiezza� Non offrono garanzie sull’errore che si può commettere
� Equi-depth: il dominio viene suddiviso in B intervalli, in modo che il numero di tuple in ogni intervallo sia (circa) lo stesso
� Migliori, ma sensibili ai valori molto frequenti
� Compressed: come equi-depth, ma per ognuno dei V valori più frequenti viene mantenuto un contatore separato
� Spesso usati nei DBMS (anche in DB2)
37

Tipi di istogrammi: esempio
� La distribuzione di N=45 tuple, con NK=15 valori distinti, è:
Equi-width (B=5):Equi-depth (B=5):
Compressed (B=3, V=2)
38
23 3
12
13
8
42
01
24
9
0
2
4
6
8
10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
84
15
3
15
0
5
10
15
20
1-3 4-6 7-9 10-12 13-15
96
129 9
0
5
10
15
1-4 5-7 8-9 10-14 15-15
9 10 9 8 9
0
2
4
6
8
10
12
1-4 5-9 10-14 8 15

Query su singola relazione
� Se la query contiene un’unica relazione nella clausola FROM dobbiamo valutare solo proiezioni e selezioni (+ eventuali raggruppamenti ed operazioni aggregate)
� Ci sono 4 possibili soluzioni� Scansione sequenziale� Uso di un solo indice (eventualmente clustered)� Uso di più indici� Uso solo di un indice (index-only plan = non si accede ai dati)
39

Esempio
SELECT rivistaFROM RecensioniWHERE vid=417 and anno>2005
� Esistono un indice hash su vid, un B+-tree su anno e uno su (vid, anno, rivista)
Scansione sequenziale� Si effettuano selezione e proiezione sul momento� Costo = P(R)
Uso di un solo indice� L’indice più selettivo è quello su vid� Si leggono i record tramite le RID fornite dall’indice� Viene valutato il predicato su anno ed effettuata la proiezione su rivista
Uso di più indici� Si usano sia l’indice su vid che quello su anno� Le RID ottenute vengono intersecate� Si leggono i record e si effettua la proiezione
Uso solo di un indice� Si usa l’indice composto 40

L’ottimizzatore DB2: predicati (i)
� I predicati nell’ottimizzatore DB2 sono di 4 tipi (in ordine di efficienza decrescente):
� Range-delimiting� Delimitano il range di foglie dell’indice cui accedere
� Index SARGable� Non delimitano il range di foglie, ma sono utilizzabili se si accede tramite indice
Es: indice: A,B,C; A=5 ∧ C>10: C>10 è index SARGable
� Data SARGable� Utilizzabili all’istante dell’accesso ai dati
� Residual� Es.: subquery correlate, ANY, ALL, …
41

L’ottimizzatore DB2: predicati (ii)
� La tabella riassume gli effetti dei 4 tipi di predicati
42
Range-
delimiting
Index
SARGable
Data
SARGable
Residual
Riduzione
Index I/OSì NO NO NO
Riduzione
Data I/OSì Sì NO NO
Riduzione
num. tupleSì Sì Sì NO
Riduzione
output finaleSì Sì Sì Sì

L’ottimizzatore DB2: metodi di accesso
� DB2 considera 3 modi per accedere a una tabella:� Scansione sequenziale� Scansione tramite indice (B+-tree)� Scansione tramite lista di RID ottenuta per unione o intersezione
da 2 o più indici
� L’accesso tramite indice può avvenire per:� Test di: IS (NOT) NULL, disuguaglianza, uguaglianza con una costante,
…� Ordinamento
43

Query su più relazioni
� In questo caso è necessario effettuare join delle N relazioni coinvolte
� Esistono
modi diversi di effettuare il join (includendo i prodotti cartesiani) tra N relazioni (= permutazioni x num. modi di “mettere le parentesi”)
� 2 su 2 relazioni 12 su 3 relazioni� 120 su 4 relazioni 1680 su 5 relazioni� 30240 su 6 relazioni 665280 su 7 relazioni� 17297280 su 8 relazioni
44
( )( )
( )
( )
( ) NN
NN
N
N 1
1
12!
!1
!12
−
−=
−
−

Query su più relazioni: N = 3
� I 12 possibili modi sono
� (R1 �� R2) �� R3� (R2 �� R1) �� R3� (R1 �� R3) �� R2� (R3 �� R1) �� R2� (R2 �� R3) �� R1� (R3 �� R2) �� R1
� R1 �� (R2 �� R3)� R2 �� (R1 �� R3)� R1 �� (R3 �� R2)� R3 �� (R1 �� R2)� R2 �� (R3 �� R1)� R3 �� (R2 �� R1)
45

Determinazione del piano ottimale
� L’ottimizzatore dispone di una strategia di enumerazione dei piani di accesso, i cui compiti principali sono:
� Enumerare tutti i piani che, potenzialmente, possono risultare ottimali� Non generare piani di accesso che sicuramente non possono risultare
ottimali
� Lo spazio dei possibili piani di accesso è, tipicamente, molto vasto (esponenziale in N):
� Ogni operatore può essere realizzato in più modi� Ogni query può essere riscritta in più modi diversi� Possono esistere diverse strutture che agevolano l’accesso ai dati
� Per questo motivo, in genere vengono applicate regole euristiche per ridurre lo spazio di ricerca
� L’ottimo non è garantito ma si trova una soluzione valida in tempo ragionevole
� Diversi DBMS permettono di controllare esplicitamente i tipi di pianiconsiderati
46

Left-deep trees
� Una scelta comune è usare solamente left-deep trees, ovvero alberi di join in cui il figlio destro di un nodo è sempre una relazione del DB
� Gli altri alberi si chiamano bushy
� Si scartano gli alberi che comportano l’esecuzione di prodotti cartesiani� Il figlio destro è la relazione interna (che è obbligatoriamente
materializzata)� In questo modo è sempre possibile generare piani in pipeline
� Soluzione comunemente adottata a partire da System R
47

Esempio
SELECT S.snome, V.vnome, R.annoFROM Sommelier S, Recensioni R, Vini VWHERE S.sid=R.sid AND R.vid=V.vid AND R.rivista=‘Sapore DiVino’
� Le possibili sequenze di join ora sono solo 4(= 12 – 6 bushy -2 con prodotti cartesiani):
� (R �� S) �� V
� (S �� R) �� V
� (R �� V) �� S
� (V �� R) �� S
48

Proprietà di piani di accesso
� Una semplice (ma importante!) osservazione è che ogni nodo di un piano di accesso può anche essere visto come la radice di un piano di accesso(“parziale” o “completo”)
� Ogni piano di accesso (ovvero ogni nodo) ha quindi delle proprietà:� Costo � Cardinalità� Schema (set di attributi)� Relazioni � Predicati applicati� Ordine� ….
Proprietà di un nodo = f(proprietà dei figli, operatore del nodo)
49

Ordini significativi
� L’ordine delle tuple di un nodo è detto significativo se può influenzare le operazioni ancora da compiere (o il risultato finale)
SELECT S.snome, R.rivista, V.cantinaFROM Recensioni R, Sommelier S, Vini VWHERE R.sid=S.sid AND R.vid=V.vidAND V.vnome=‘Merlot’ORDER BY S.snome,V.cantina
� Dopo il join tra V e R, gli ordini significativi sono:� sid (può influenzare il join con S)� snome (semplifica l’ORDER BY)� snome, cantina (risolve l’ORDER BY)
ma non cantina o vid
50

Programmazione dinamica
� Una comune tecnica adottata dagli ottimizzatori per ridurre il numero di piani di accesso da enumerare si basa sul principio di ottimalità, che è alla base degli algoritmi di programmazione dinamica
� E’ la tecnica usata, ad esempio, per trovare il percorso di costo minimo in un grafo da un nodo sorgente S a un nodo target T
� Con riferimento alla terminologia usata nei grafi, il principio di ottimalitàasserisce che
dati 2 percorsi parziali P1 e P2 che hanno origine in S e arrivano entrambi in
un nodo V, se costo(P1) < costo(P2), allora P2 non può essere esteso in modo
tale da generare un percorso di costo minimo da S a T
� Quindi percorsi parziali come P2 possono essere ignorati…
51

Pruning di piani parziali
� La seguente osservazione è alla base della determinazione efficiente del piano ottimale:
Un piano di accesso (parziale) AP per i relazioni R1, R2, …, Ri, il cui risultato è
ordinato secondo un ordine O e il cui costo è maggiore di quello di un piano
AP’ per le stesse relazioni e con lo stesso ordine (o più significativo), non può
essere esteso in un piano di accesso a costo minimo
� Si dice che AP’ “domina” AP� Le proprietà di AP’ dominano quelle di AP
52

Pruning: esempio I
� La query include ORDER BY R.B
� AP1127 domina AP224, che viene eliminato
� AP546 non domina AP1127, perché non è ordinato (mentre AP 1127 lo è)
53
AP 1127
Cost 234
Cardinality 25
Schema {R.A,R.B,S.C}
Tables {R,S}
Predicates R.J=S.J, R.A > 5
Order R.B
AP 224
Cost 345
Cardinality 25
Schema {R.A,R.B,S.C}
Tables {R,S}
Predicates R.J=S.J, R.A > 5
Order R.B
AP 546
Cost 216
Cardinality 25
Schema {R.A,R.B,S.C}
Tables {R,S}
Predicates R.J=S.J, R.A > 5
Order none

Pruning: esempio II
� Ipotesi: si usa solo nested loops e non c’è nessun ordine significativo� no ORDER BY, no GROUP BY, no DISTINCT, …
� Per una query sulle relazioni R1, R2 e R3, supponiamo che per eseguire il join tra R1 e R2 sia più conveniente avere R1 esterna
� Nessun piano con la sequenza (R2 �� R1) �� R3 può essere ottimale
54

Ottimizzazione con programmazione dinamica
Livello 1: determina per ogni Ri e ogni ordine significativo O (incluso il caso non ordinato) il piano parziale migliore
Livello i (2..N): Per ogni O e ogni sottoinsieme di i relazioni determina il piano parziale migliore, a partire dal risultato del passo i-1
Livello N+1: determina il piano di accesso ottimale, aggiungendo se necessario il costo di ordinamento finale del risultato
� Il numero di piani valutati è O(2N)
55

Generazione di piani di accesso
� L’algoritmo descritto opera in modo breadth-first (per “livelli” = num. relazioni considerate)
� In pratica la generazione di nuovi piani procede in maniera più efficace, tipicamente espandendo i piani di accesso parziali più “promettenti” (tipicamente: costo minore)
� Questo normalmente permette di eliminare un maggior numero di piani parziali
� Si estende di conseguenza il concetto di dominazione:� Perché AP’ domini AP va anche verificato che le relazioni elaborate da
AP’ includano quelle elaborate da APeguaglianza ⇒ inclusione
56

Esempio di generazione PdA (i)
SELECT S.snome, R.rivistaFROM Recensioni R, Sommelier SWHERE R.sid=S.sidAND R.vid=100 AND S.val=4
� Sono disponibili indici B+-tree unclustered su R.vid, R.sid, S.val e S.sid
� Gli unici algoritmi di join disponibili sono il nested loop e l’index nested loop
� N(R)=2000, P(R)=400, NK(R.vid)=100, L(R.vid)=20, NK(R.sid)=200, L(R.sid)=25
� N(S)=200, P(S)=100, NK(S.val)=20, L(S.val)=3, NK(S.sid)=200, L(S.sid)=5
57

Esempio di generazione PdA (ii)
� Passo 1: si valuta il metodo di accesso di costo minimo per ogni relazione
� Non vi sono ordini significativi
� Relazione R:� Cardinalità risultato = 2000/100 = 20
(AP1) Costo sequenziale = 400
(AP2) Costo indice R.vid = 20/100 + Φ(2000/100,400)=1+20=21
� Relazione S:� Cardinalità risultato = 200/20 = 10
(AP3) Costo sequenziale = 100
(AP4) Costo indice S.val = 3/20 + Φ(200/20,100)=1+10=11
58

Esempio di generazione PdA (iii)
� Passo 2: si espande AP4 (costo 11) considerando il join con R
� Nested loop:� Costo di partenza = 11
� Costo per ogni loop = 21 (indice R.vid)
(AP5) Costo = 11 + 10 x 21 = 221
� Index nested loop (indice R.sid):� Costo di partenza = 11
� Costo per ogni loop = 25/200 + Φ(2000/200,400)=1+10 = 11
(AP6) Costo = 11 + 10 x 11 = 121
59

Esempio di generazione PdA (iv)
� Passo 3: si espande AP2 (costo 21) considerando il join con S
� Nested loop:� Costo di partenza = 21
� Costo per ogni loop = 11 (indice S.val)
(AP7) Costo = 21 + 20 x 11 = 241
� Index nested loop (indice S.sid):� Costo di partenza = 21
� Costo per ogni loop = 1 + 1 = 2 (sid chiave di S)
(AP8) Costo = 21 + 20 x 2 = 61
60

Esempio di generazione PdA (v)
� Passo 4: si cerca di espandere AP8 (costo 61)� Tutti i join sono stati effettuati� AP8 è il piano di costo minimo
61
��sid=sid Index nested loops
Sul momento
σvid=100
Recensioni
SommelierIndex scan
πsnome
σval>4
Sul momento

Esempio (i)
SELECT S.snome, R.rivista, V.cantinaFROM Recensioni R, Sommelier S, Vini VWHERE R.sid=S.sid AND R.vid=V.vid AND S.val=4 AND V.vnome=‘Merlot’
� Esistono indici B+-tree unclustered su R.sid e R.vid
� Esistono indici B+-tree clustered su S.sid e V.vid
� Si ignorano i costi di accesso agli indici� N(R)=5000, P(R)=1000, NK(R.sid)=200, NK(R.vid)=100� N(S)=200, P(S)=100, NK(S.val)=10, NK(S.sid)=200� N(V)=100, P(V)=20, NK(V.vid)=100, NK(V.vnome)=20
� Ordini significativi: sid, vid
62

Esempio (ii)
� Passo 1: si trovano i metodi di accesso di costo minimo alle relazioni, conservando anche quelli che generano ordinamenti utili
(AP1) Scansione di R:� Costo = 1000, risultati = 5000, ordine: nessuno
(AP2) Indice su R.sid:� Costo = 5000, risultati = 5000, ordine: sid
(AP3) Indice su R.vid:� Costo = 5000, risultati = 5000, ordine: vid
(AP4) Scansione di S (con selezione su val):� Costo = 100, risultati = 200/10 = 20, ordine: sid
(AP5) Scansione di V (con selezione su vnome):� Costo = 20, risultati = 100/20 = 5, ordine: vid
63

Esempio (iii)
� Passo 2: si espande AP5 (costo 20) considerando solo il join V �� R (V �� S è prodotto cartesiano)
� Index nested loop:� Costo di partenza = 20
� Costo per ogni loop = 5000/100 = 50
(AP6) Costo = 20 + 5 x 50 = 270
� Ordine: vid
� Merge-scan:� Costo di partenza = 20
� Costo di merge = 5000 (indice unclustered su R.vid)
(AP7) Costo = 20 + 5000 = 5020
� Ordine: vid
� Dimensione risultato = 5000/20 = 250
64

Esempio (iv)
� Passo 3: si espande AP4 (costo 100) considerando solo il join S �� R
� Index nested loop:� Costo di partenza = 100
� Costo per ogni loop = 5000/200 = 25
(AP8) Costo = 100 + 20 x 25 = 600
� Ordine: sid
� Merge-scan:� Costo di partenza = 100
� Costo di merge = 5000 (indice unclustered su R.sid)
(AP9) Costo = 100 + 5000 = 5100
� Ordine: sid
� Dimensione risultato = 5000/10 = 500
65

Esempio (v)
� Passo 4: si espande AP6 (costo 270) considerando il join con S (sequenza: (V �� R ) �� S )
� Index nested loop:� Costo di partenza = 270
� Costo per ogni loop = 1 (sid chiave di S)
(AP10) Costo = 270 + 250 x 1 = 520
� Merge-scan (con sort dell’esterna su sid):� Costo di partenza = 270
� Costo di sort = 4 x P(temp) (sorting su sid della rel. temporanea)
� Costo di merge = P(temp) + P(temp) + 100
(AP11) Costo = 270 + 4 x 10 + 10 + 10 + 100 = 430
� Dimensione risultato = 250/10 = 25
66

Esempio (vi)
� Passo 5: si cerca di espandere AP11 (costo 430)� Tutti i join sono stati effettuati� Questo è il piano di costo minimo, in quanto tutti i piani parziali sono
dominati da AP11
67
πsnome,rivista,cantina
��sid=sid Merge-scan
Sul momento
σsid=?
Sommelier
σval=4 Sul momento
IndexScan
��vid=vid
Vini
σvnome=‘Merlot’Sul momento
Index nested loop
RecensioniTable scan
NB: per semplicità il piano di accessonon mostra i nodi di creazione eaccesso alla temporanea

Ricerca greedy
� Talvolta, per diminuire ulteriormente lo spazio di ricerca, si mantiene per ogni livello solamente la soluzione a costo minimo o, a parità di costo, quella che produce il minor numero di record
� Il costo di ricerca diventa lineare nel numero delle relazioni coinvolte� Evidentemente, può portare a perdere la soluzione migliore
� Attenzione! Per query ad hoc dobbiamo minimizzare il tempo totale = ottimizzazione + soluzione
68

Esercizio
� Date le relazioni
Medici(cod, nome, spec)Pazienti(pid, nome, indirizzo, anno, med)
� N(M)=100, P(M)=5, N(P)=2000, P(P)=100
� Si calcoli il miglior piano di accesso per la query
SELECT P.nomeFROM Medici M JOIN Pazienti P ON (M.cod=P.med)WHERE M.spec=‘cardiologia’ AND P.anno<1930
� Si supponga di avere indici unclustered su:� M.spec (L=1, NK=20), M.cod (L=2, NK=100)� P.anno (L=13, NK=100), P.med (L=13, NK=100)
69

Soluzione (i)
� Fattore di selettività dei predicati:� M.cod=valore, P.med=valore = 1/100� M.spec=‘cardiologia’ = 1/20� P.anno<1930 = 20/100 = 1/5
� Gli ordini da considerare sono
� Medici �� Pazienti
� Pazienti �� Medici
� La cardinalità del risultato è 2000/(20 x 5) = 20
70

Soluzione (ii)
� Accesso a Medici (esterna):� Senza indice:
� Costo = P(M) = 5
� Indice su specializzazione:� Costo = f x L(M.spec) + Φ(f x N(M),P(M))
= 1/20 + Φ(100/20,5) = 1 + 4 = 5
� In entrambi i casi la dimensione del risultato è f x N(M) = 100/20 = 5
� Accesso a Pazienti (interna):� Senza indice:
� Costo = P(P) = 100
� Indice su anno:� Costo = f x L(P.anno) + Φ(f x N(P),P(P))
= 13/5 + Φ(2000/5,100) = 3 + 99 = 102
� Indice su med:� Costo = f xL(P.med) + Φ(f x N(P),P(P))
= 13/100 + Φ(2000/100,100) = 1 + 19 = 20
� Costo totale = 5 + 5 x 20 = 105
71

Soluzione (iii)
� Accesso a Pazienti (esterna):� Senza indice:
� Costo = P(P) = 100
� Indice su anno:� Costo = f x L(P.anno) + Φ(f x N(P),P(P))
= 13/5 + Φ(2000/5,100) = 3 + 99 = 102
� In entrambi i casi la dimensione del risultato è f x N(P) = 2000/5 = 400
� Accesso a Medici (interna):� Senza indice:
� Costo = P(M) = 5
� Indice su specializzazione:� Costo = f x L(M.spec) + Φ(f x N(M),P(M))
= 1/20 + Φ(100/20,5) = 1 + 4 = 5
� Indice su cod:� Costo = 1 + 1 = 2 (cod chiave di M)
� Costo totale = 100 + 400 x 2 = 900� Il piano migliore è quello con accesso sequenziale a Medici seguito da un
index nested loop join72


















