Natural Language Processing - mobilab.unina.it MSTD-Mazzeo/Slide Lezione... · rispetto a una data...
31
Natural Language Natural Language Processing 1 CONCETTI INTRODUTTIVI Argomenti trattati nella lezione: CONCETTI INTRODUTTIVI NATURAL LANGUAGE ANALYSIS ARCHITETTURA SISTEMA NLA STEMMER STEMMER TAGGER PARSER A PPLICAZIONE Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
Transcript of Natural Language Processing - mobilab.unina.it MSTD-Mazzeo/Slide Lezione... · rispetto a una data...

Natural LanguageNatural LanguageProcessing
1
g
C O N C E T T I I N T R O D U T T I V I
Argomenti trattati nella lezione:
C O N C E T T I I N T R O D U T T I V IN A T U R A L L A N G U A G E A N A L Y S I SA R C H I T E T T U R A S I S T E M A N L AS T E M M E RS T E M M E RT A G G E RP A R S E RA P P L I C A Z I O N E
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
Concetti Introduttivi
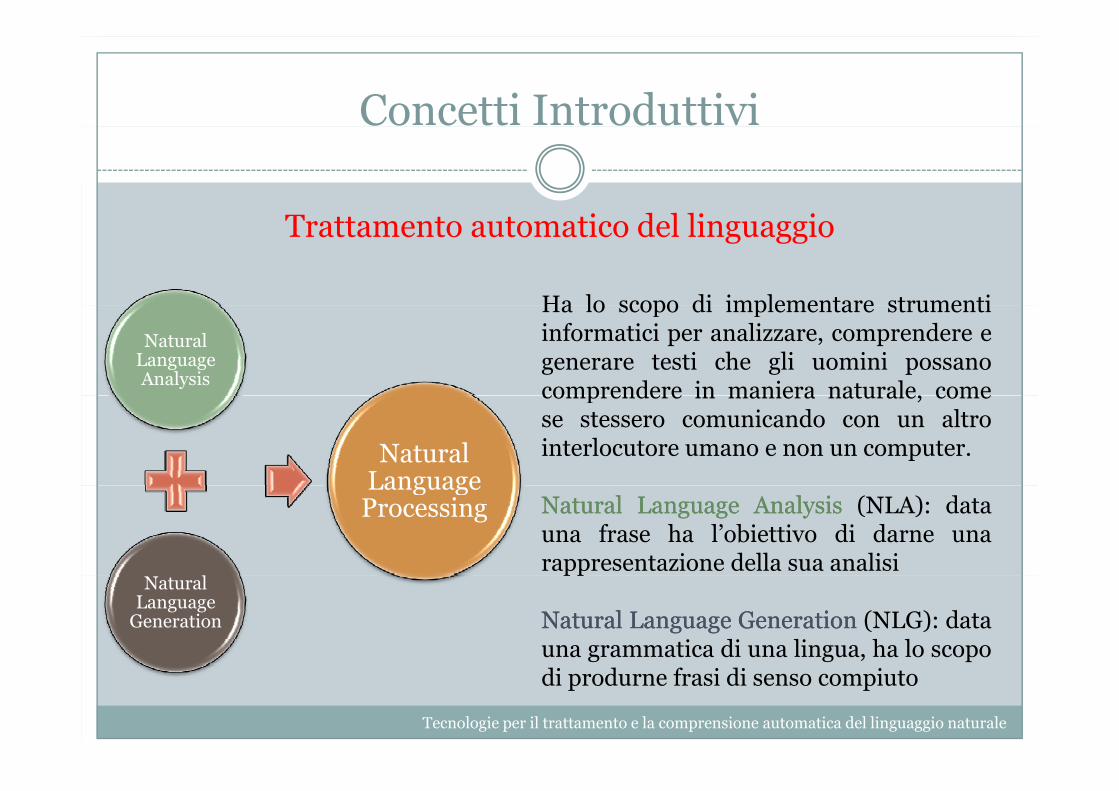
T i d l li iTrattamento automatico del linguaggio
Ha lo scopo di implementare strumentiHa lo scopo di implementare strumentiinformatici per analizzare, comprendere egenerare testi che gli uomini possanocomprendere in maniera naturale, come
NaturalLanguageAnalysis comprendere in maniera naturale, come
se stessero comunicando con un altrointerlocutore umano e non un computer.Natural
LanguageNaturalNatural LanguageLanguage AnalysisAnalysis (NLA): datauna frase ha l’obiettivo di darne unarappresentazione della sua analisi
LanguageProcessing
pp
NaturalNatural LanguageLanguage GenerationGeneration (NLG): datauna grammatica di una lingua, ha lo scopo
NaturalLanguage
Generation
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
di produrne frasi di senso compiuto
Concetti Introduttivi
NLANLA NLGNLG
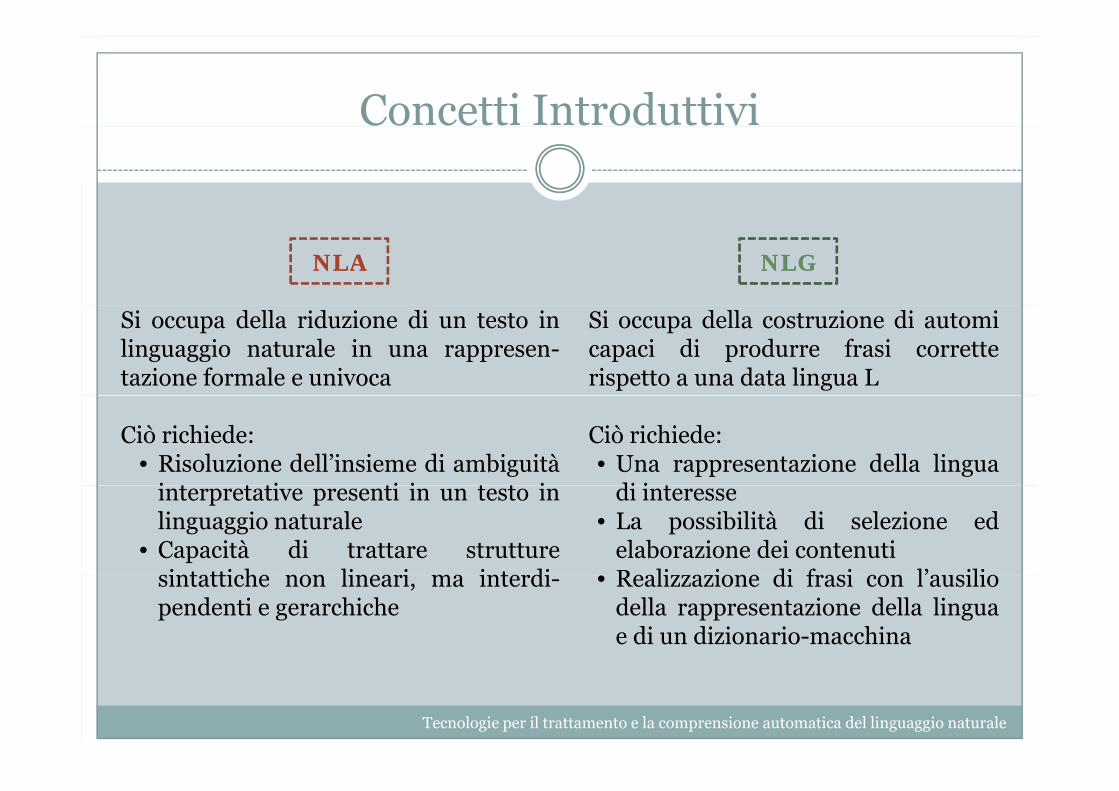
Si occupa della riduzione di un testo inlinguaggio naturale in una rappresen-tazione formale e univoca
Si occupa della costruzione di automicapaci di produrre frasi corretterispetto a una data lingua L
Ciò richiede:• Risoluzione dell’insieme di ambiguità
i t t ti ti i t t i
Ciò richiede:• Una rappresentazione della lingua
di i tinterpretative presenti in un testo inlinguaggio naturale
• Capacità di trattare strutturesintattiche non lineari ma interdi
di interesse• La possibilità di selezione ed
elaborazione dei contenutiRealizzazione di frasi con l’ausiliosintattiche non lineari, ma interdi-
pendenti e gerarchiche• Realizzazione di frasi con l ausilio
della rappresentazione della linguae di un dizionario-macchina
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Natural Language Analysisg g y
Paradigmi di RiferimentoParadigmi di RiferimentoPer il Per il NaturalNatural LanguageLanguage AnalysisAnalysis
KnowledgeKnowledge EngineeringEngineering MachineMachine LearningLearning
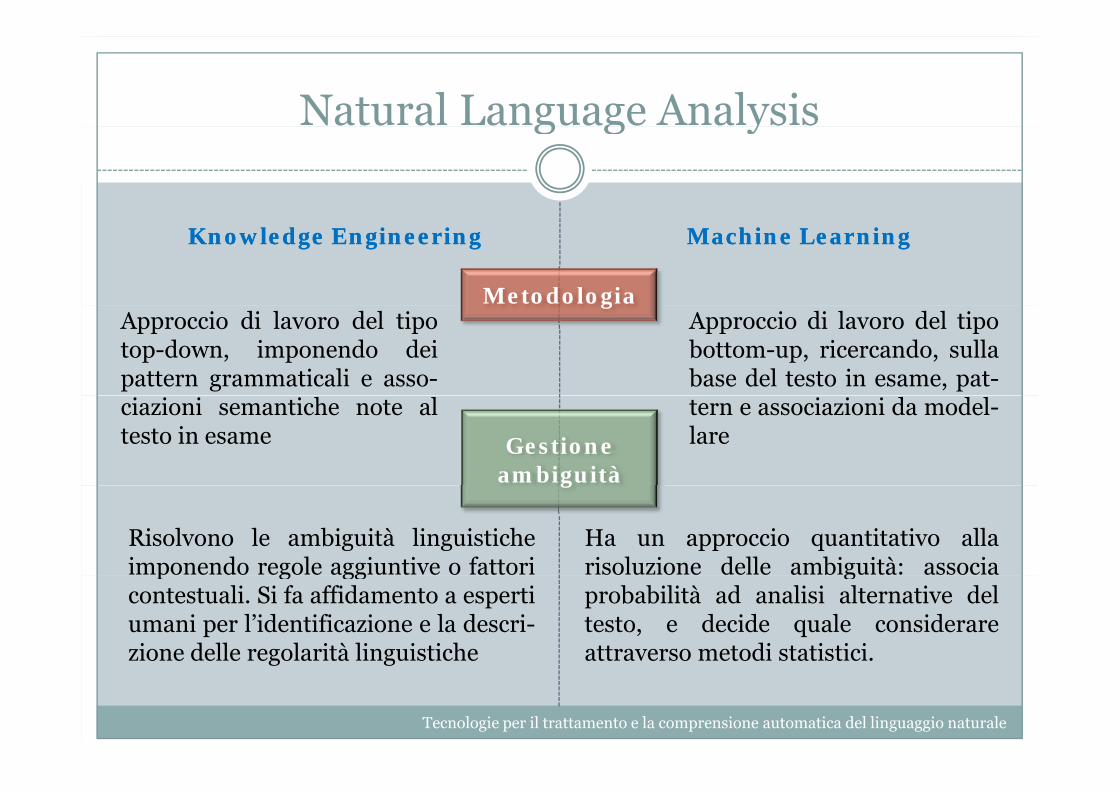
Codifica manuale di grammatiche elessici da parte di esperti. È un tipoesempio di approccio rules-based.
Addestramento di modelli statistici sugrandi quantità di dati (corpora annotatio non annotati)
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
Natural Language Analysisg g y
Metodologia
KnowledgeKnowledge EngineeringEngineering MachineMachine LearningLearning
gApproccio di lavoro del tipotop-down, imponendo deipattern grammaticali e asso-
Approccio di lavoro del tipobottom-up, ricercando, sullabase del testo in esame, pat-
Gestione ambiguità
ciazioni semantiche note altesto in esame
tern e associazioni da model-lare
g
Risolvono le ambiguità linguisticheimponendo regole aggiuntive o fattori
Ha un approccio quantitativo allarisoluzione delle ambiguità: associap g gg
contestuali. Si fa affidamento a espertiumani per l’identificazione e la descri-zione delle regolarità linguistiche
gprobabilità ad analisi alternative deltesto, e decide quale considerareattraverso metodi statistici.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
g g
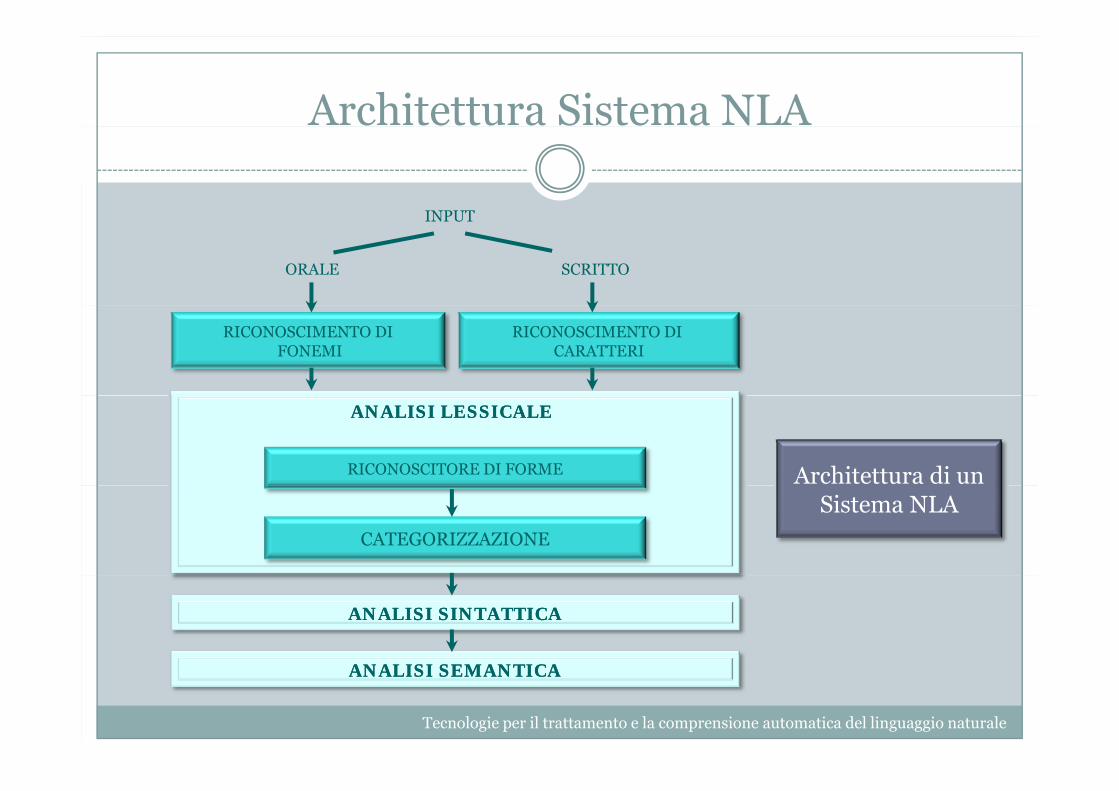
Architettura Sistema NLA
INPUTINPUT
ORALE SCRITTO
RICONOSCIMENTO DIFONEMI
RICONOSCIMENTO DICARATTERI
RICONOSCITORE DI FORME
ANALISI LESSICALEANALISI LESSICALE
Architettura di un
CATEGORIZZAZIONE
Sistema NLA
ANALISI SINTATTICAANALISI SINTATTICA
ANALISI SEMANTICAANALISI SEMANTICA
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
ANALISI SEMANTICAANALISI SEMANTICA
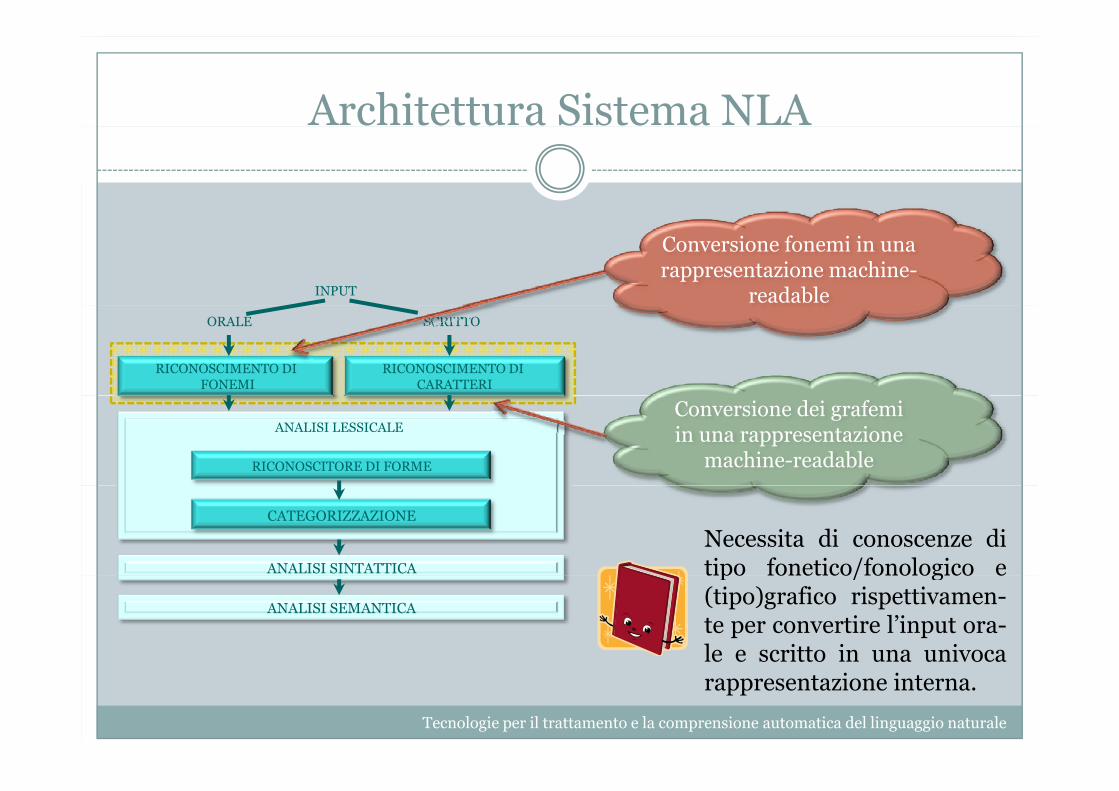
Architettura Sistema NLA
INPUT
Conversione fonemi in una rappresentazione machine-
readableORALE SCRITTO
RICONOSCIMENTO DIFONEMI
RICONOSCIMENTO DICARATTERI
RICONOSCITORE DI FORME
ANALISI LESSICALEConversione dei grafemi in una rappresentazione
machine-readable
CATEGORIZZAZIONE
ANALISI SINTATTICA
Necessita di conoscenze ditipo fonetico/fonologico e
ANALISI SEMANTICA
tipo fonetico/fonologico e(tipo)grafico rispettivamen-te per convertire l’input ora-le e scritto in una univocarappresentazione interna.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Architettura Sistema NLA
Riconoscimento Riconoscimento FonemiFonemi
Il sistema che opera la conversione dei fonemi in una rappresentazione macchinainterna è detto Speech-to-Text System, ed è oggetto del campo della Spokenp y , gg p pLanguage Processing.
waveform
spectrum
words
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Architettura Sistema NLA
Riconoscimento Riconoscimento FonemiFonemi
Il sistema per la conversione dei grafemi in una rappresentazione macchinap g ppinterna realizza uno scanning del documento cartaceo generando un file. Talesistema è detto Optical Character Recognitioner (OCR).
L’OCR può basare la sua azione su una base di conoscenza che contiene tutti ipossibili elementi tipografici per ogni simbolo della lingua naturale. Taleapproccio diventa impraticabile nel caso del riconoscimento della grafia.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
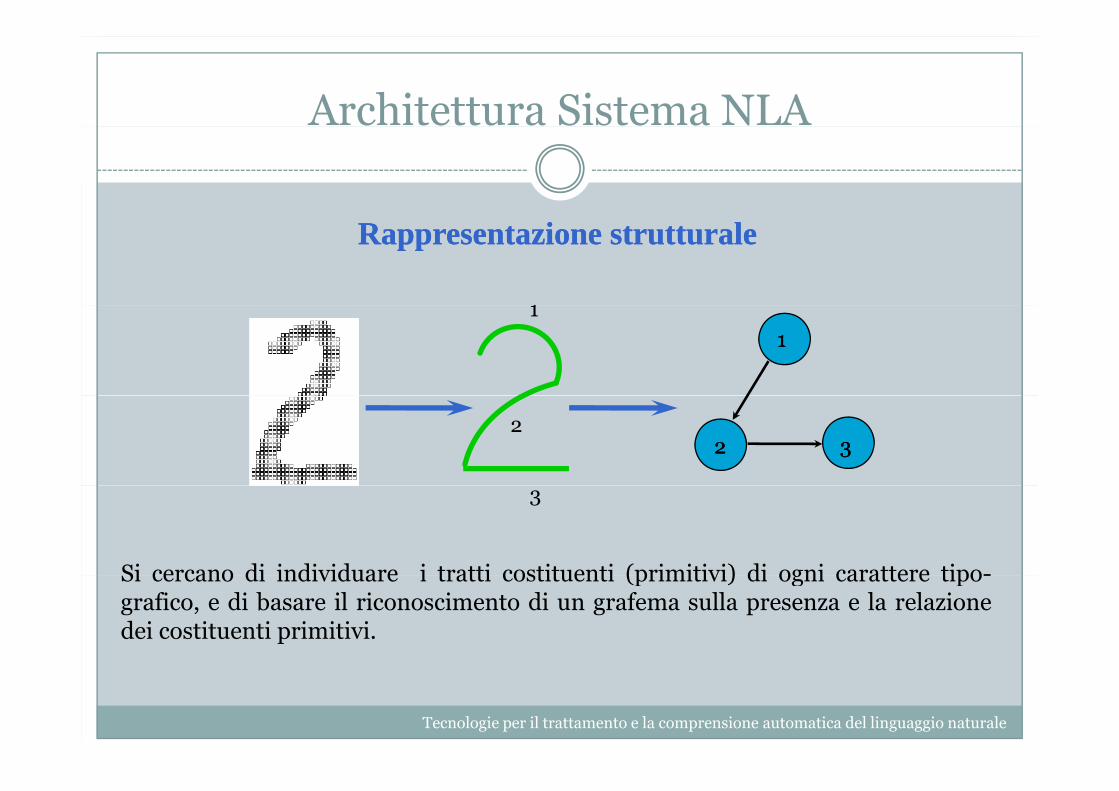
Architettura Sistema NLA
RappresentazioneRappresentazione strutturalestrutturale
1111
222 33
3
Si cercano di individuare i tratti costituenti (primitivi) di ogni carattere tipo-Si cercano di individuare i tratti costituenti (primitivi) di ogni carattere tipo-grafico, e di basare il riconoscimento di un grafema sulla presenza e la relazionedei costituenti primitivi.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
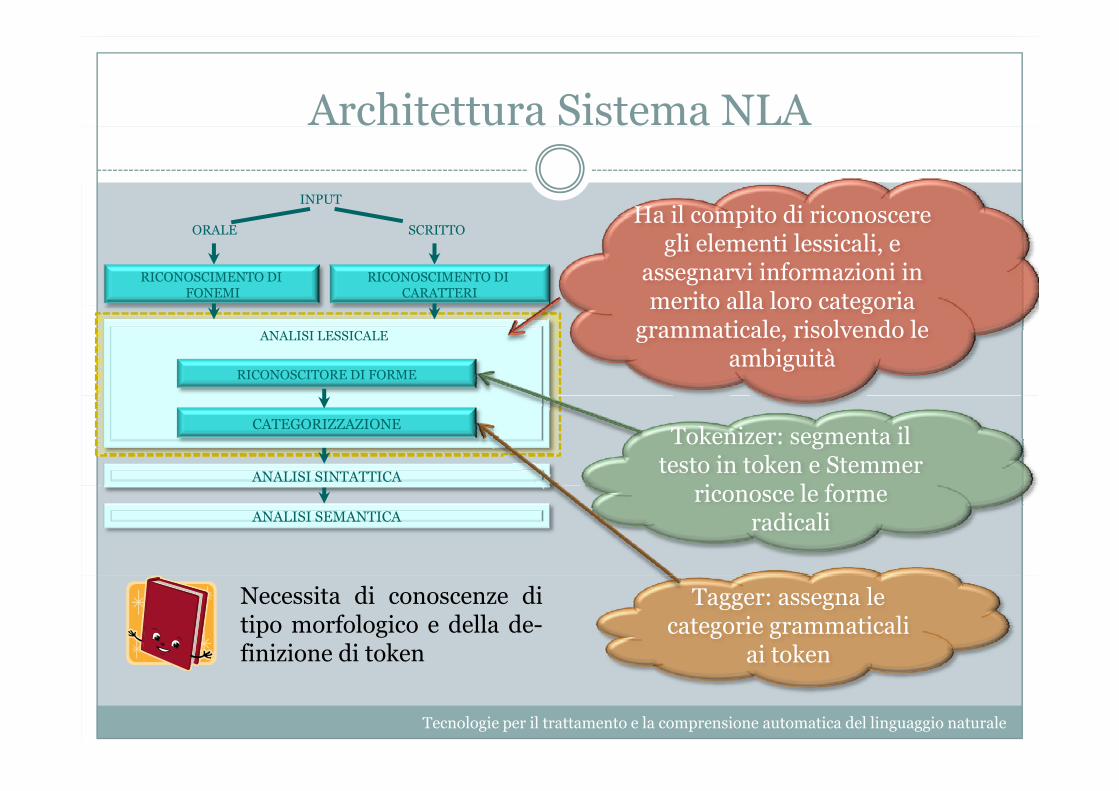
Architettura Sistema NLA
INPUTHa il compito di riconoscere
ORALE SCRITTO
RICONOSCIMENTO DIFONEMI
RICONOSCIMENTO DICARATTERI
Ha il compito di riconoscere gli elementi lessicali, e
assegnarvi informazioni in merito alla loro categoria
RICONOSCITORE DI FORME
ANALISI LESSICALE
merito alla loro categoria grammaticale, risolvendo le
ambiguità
CATEGORIZZAZIONE
ANALISI SINTATTICA
Tokenizer: segmenta il testo in token e Stemmer
i l f ANALISI SEMANTICA
riconosce le forme radicali
Tagger: assegna le categorie grammaticali
ai token
Necessita di conoscenze ditipo morfologico e della de-finizione di token
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Architettura Sistema NLA
TokenizerTokenizer//StemmerStemmer
Il Tokenizer deve individuare gli elementi linguistici atomici all’interno del testoin input. A tale scopo è necessario conoscere gli opportuni delimitatori.
Il problema è dato dalla non determinatezza dei delimitatori:essi dipendono fortemente dalla lingua adoperata nel testo esono presenti irregolarità (unità atomiche composte da unp g ( pinsieme di parole, i.e Polirematiche). Inoltre è possibile che uncarattere di delimitazione non sia adoperato per delimitareparole (ad esempio il punto nelle sigle).p p p g
Lo Stemmer deve operare la lemmatizzazione del testo, aggiungendo delmetalinguaggio che specifica il lemma e il tipo di flessione dell’unità in esame.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Architettura Sistema NLA
TaggerTagger
Il POS-Tagger ha il compito di categorizzare le unità linguistiche all’interno deicluster sintattici delle parti del discorso.
Un forte problema è rappresentato da una elevata ambiguitàpresenti nelle lingue. Un esempio sono gli omografi: adesempio “porta” funge sia da nome che da voce verbale.p p g bTale problema può essere risolto con un lavoro sinergico deltagger con il tokenizer, e da approcci che non si limitano adanalizzare singolarmente la specifica voce linguistica, mag p g ,contestualizzandola. (il 40% delle ambiguità di una lingua èrisolvibile analizzandone il contesto d’uso)
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
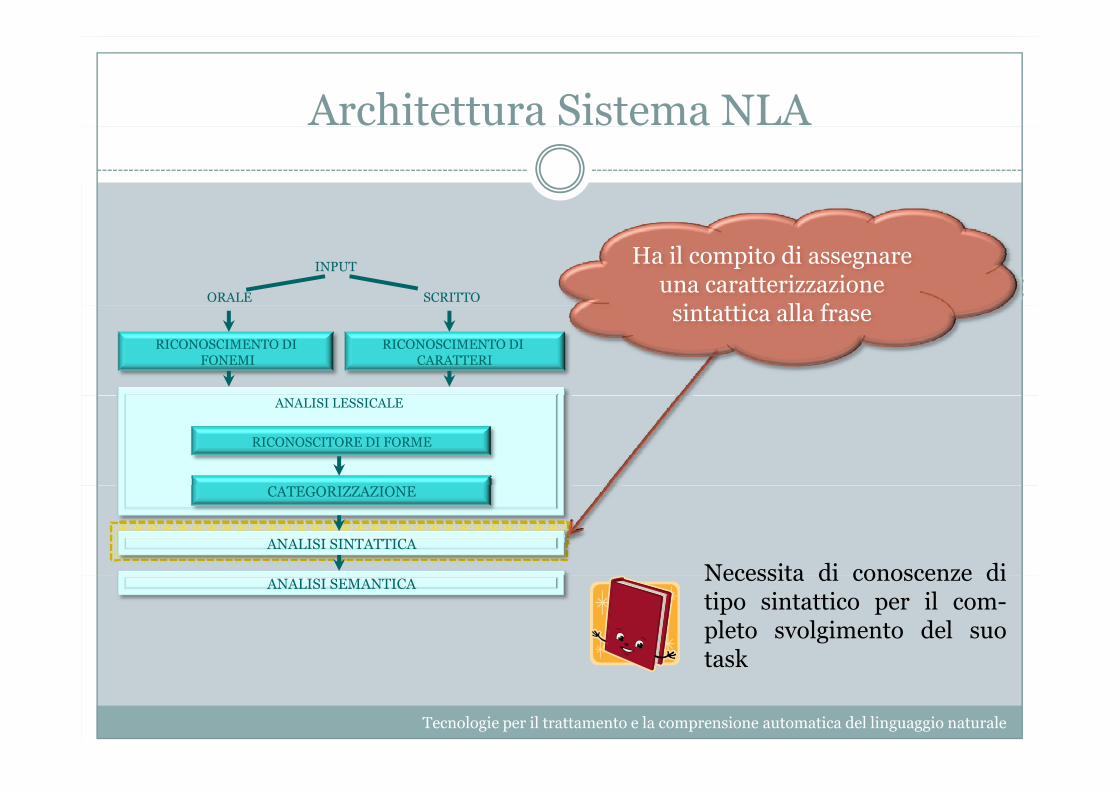
Architettura Sistema NLA
INPUT
ORALE SCRITTO
Ha il compito di assegnare una caratterizzazione
i i ll fRICONOSCIMENTO DI
FONEMIRICONOSCIMENTO DI
CARATTERI
sintattica alla frase
RICONOSCITORE DI FORME
ANALISI LESSICALE
CATEGORIZZAZIONE
ANALISI SINTATTICA
Necessita di conoscenze diANALISI SEMANTICA Necessita di conoscenze ditipo sintattico per il com-pleto svolgimento del suotasktask
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
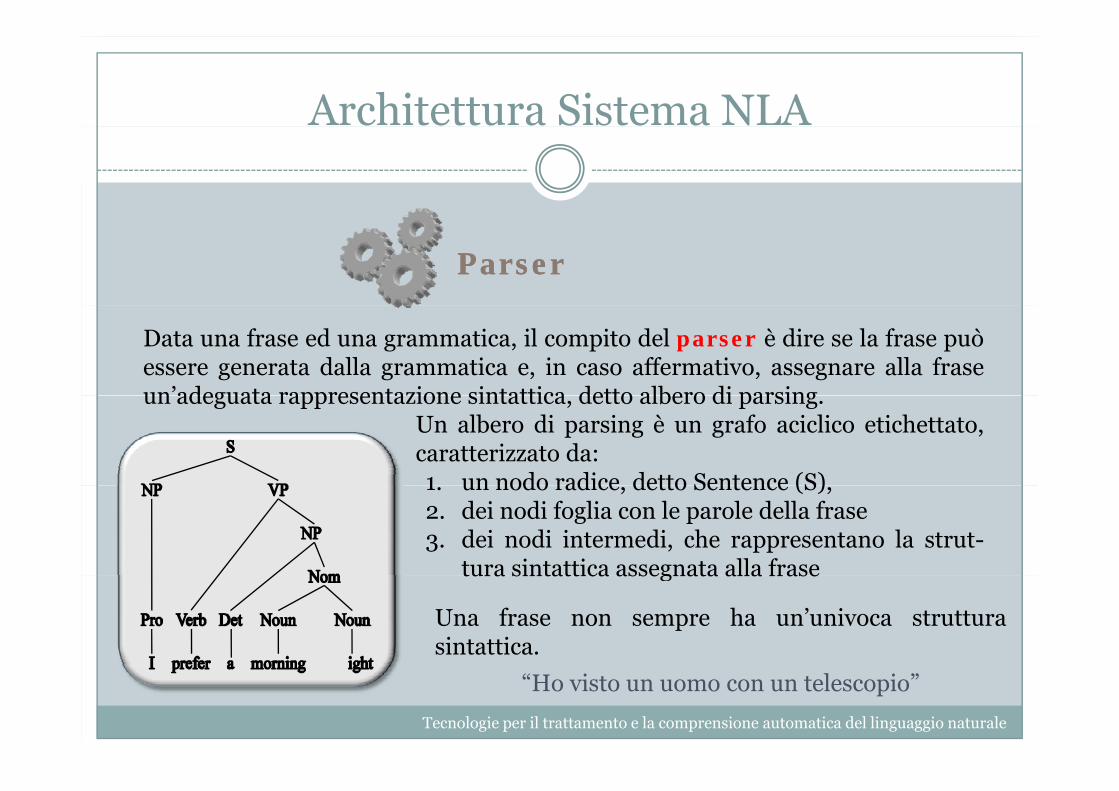
Architettura Sistema NLA
ParserParser
Data una frase ed una grammatica, il compito del parser è dire se la frase puòessere generata dalla grammatica e, in caso affermativo, assegnare alla fraseun’adeguata rappresentazione sintattica detto albero di parsingun adeguata rappresentazione sintattica, detto albero di parsing.
Un albero di parsing è un grafo aciclico etichettato,caratterizzato da:1 un nodo radice detto Sentence (S)1. un nodo radice, detto Sentence (S),2. dei nodi foglia con le parole della frase3. dei nodi intermedi, che rappresentano la strut-
tura sintattica assegnata alla frasetura sintattica assegnata alla frase
Una frase non sempre ha un’univoca strutturasintattica.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
“Ho visto un uomo con un telescopio”
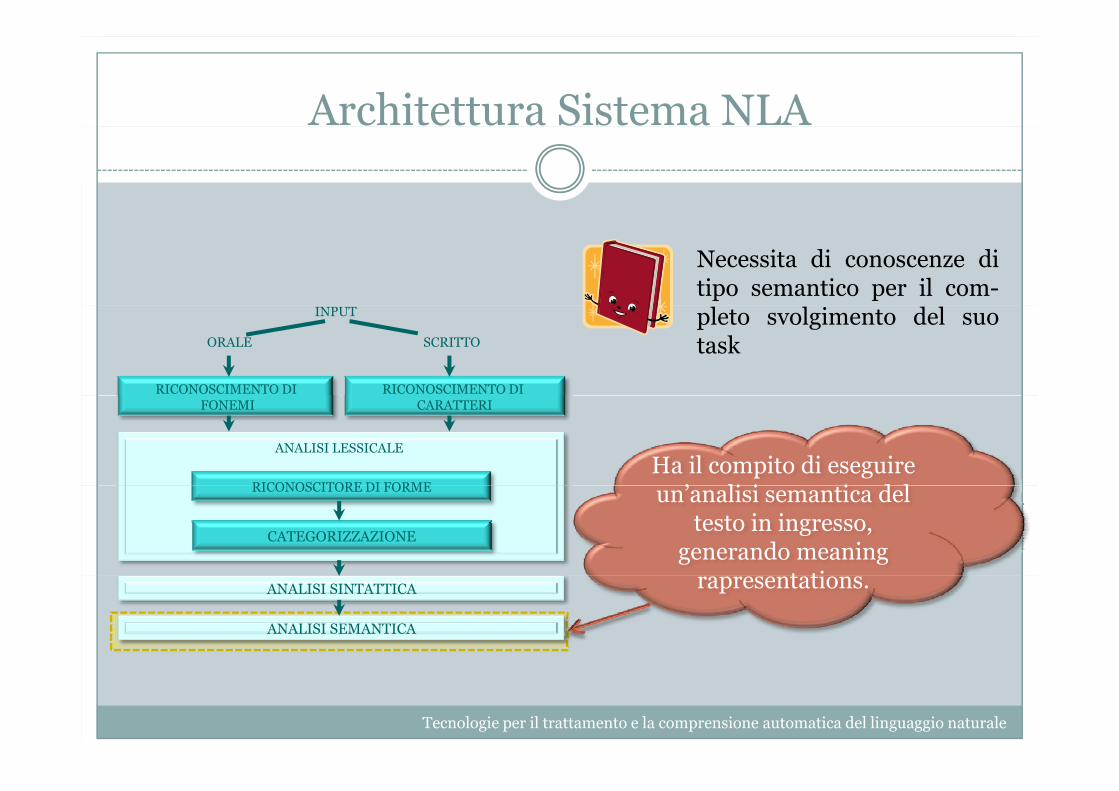
Architettura Sistema NLA
Necessita di conoscenze ditipo semantico per il com-
INPUT
ORALE SCRITTO
RICONOSCIMENTO DI RICONOSCIMENTO DI
pleto svolgimento del suotask
FONEMI
RICONOSCITORE DI FORME
ANALISI LESSICALE
CARATTERI
Ha il compito di eseguire ’ li i i d l RICONOSCITORE DI FORME
CATEGORIZZAZIONE
un’analisi semantica del testo in ingresso,
generando meaningt tiANALISI SINTATTICA
ANALISI SEMANTICA
rapresentations.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
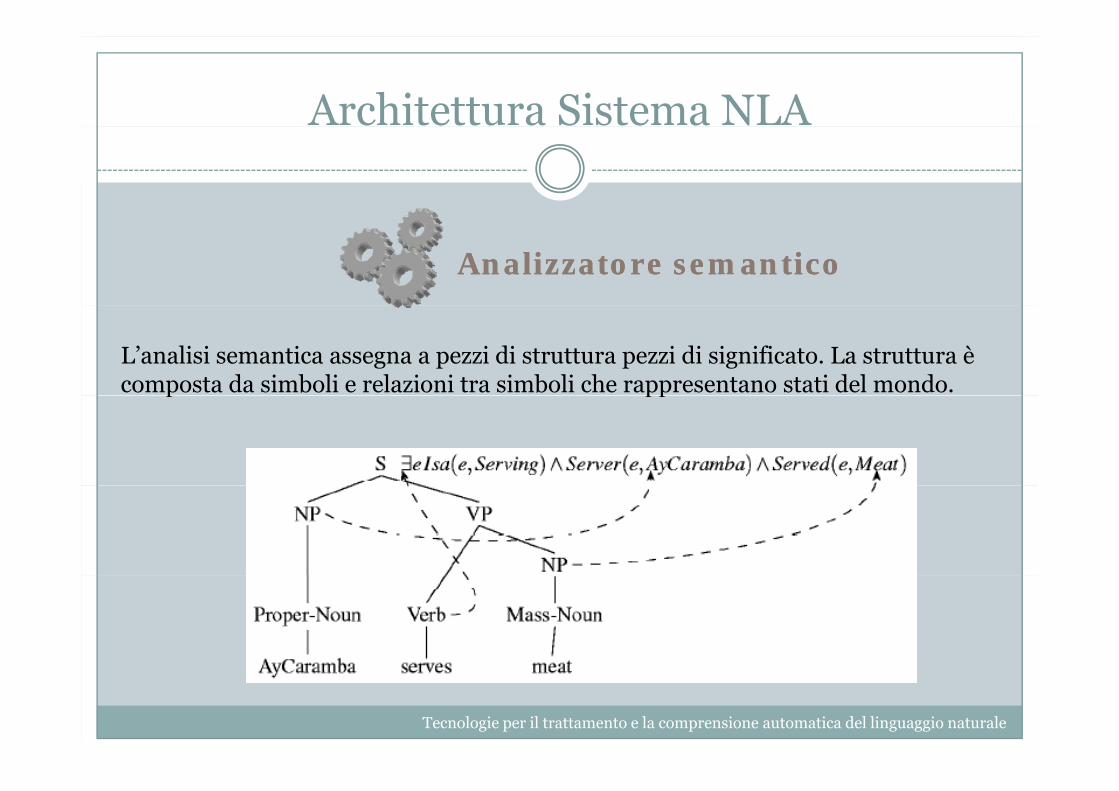
Architettura Sistema NLA
Analizzatore semanticoAnalizzatore semantico
L’analisi semantica assegna a pezzi di struttura pezzi di significato. La struttura è composta da simboli e relazioni tra simboli che rappresentano stati del mondo.p pp
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Stemmer
Gli stemmer sono analizzatori morfologici di due tipi:Inflectional morphology, esprime relazioni sintattiche tra le parole tra leparole della stessa parte del discorso.Derivational Morphology, esprime la creazione di nuove parole da partireda quelle conosciute, e cerca di collegare le differenti parole con la formaradicale. La derivazione solitamente coinvolge un cambiamento nellacategoria grammaticale della parola, e può implicare un cambiamento del suosignificato.
Gli analizzatori morfologici fanno un intenso uso di regole e dizionari lessicali, chepossono essere temporalmente dispendiosipossono essere temporalmente dispendiosi.Molte applicazioni non richiedono analizzatori linguisticamente corretti, in talicasi si ha analizzatori euristici, che usano regola empirica approssimativa.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Stemmer
Un algoritmo di stemming molto adoperato è l’Algoritmo di Potter, costituitoda una serie in cascata di regole di riscrittura delle parole. Le regole hanno unaforma del tipo:
(condizione) S1 -> S2
ovvero, se la forma flessa finisce con il suffisso S1 e la forma radicale soddisfa lacondizione, allora S1 è sostituito da S2.
(m > 0) ATIONAL -> ATE | relational -> relate(m > 0) FUL -> ε | hopeful -> hope
Se la forma flessa ha parte radicale di misura positiva, il suffisso ATIONAL o FULsono sostituiti da ATE o la stringa vuota, cosicché il termine “relational” diventa“relate” e “hopeful” invece è “hope”
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
relate e hopeful , invece, è hope .

Taggergg
Un Tagset di Tagging èl’i i d ll l il’insieme delle classi mor-fologiche di appartenenzadelle parole.
Classi chiuse, elementicon appartenenza relati-vamente fissatavamente fissata
Classi aperte, col tempovengono affiliati nuovi
Penn Termbank Parto-of-Speech Tags
vengono affiliati nuovitermini, ovvero parole direcente conio
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
Penn Termbank Parto of Speech Tags

Taggergg
Tipi di Tipi di TaggingTagging
Rule-based tagger, posseggono un grande database di regole dideterminazione della parte del discorso di una unità linguistica
Stochastic tagger, adoperano un corpus di riferimento per determinare laprobabilità che una data unità linguistica abbia un tag morfologico in unpreciso cotesto
Trasformation-based tagger, è un approccio ibrido, e ha un insieme diregole per l’assegnazione dei tag alle unità linguistiche, e anche le regole
i d i l icomputate a partire da un corpus appositamente annotato per la correzionedi eventuali errori di assegnazioni di tag
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Parser
Il i ò i t diIl parsing può essere visto come un processo diricerca, all’interno dello spazio di tutti i possibilialberi di parsing generabili dalla grammatica iningresso, dell’albero più adatto alla frase in esame.
Due parametri fondamentali:Due parametri fondamentali:1. le regole grammaticali che predicono come da un nodo radice S ci
siano solo alcune vie di scomposizione possibili per ottenere i nodit i literminali;
2. le parole della frase, che ricordano come la (s)composizione di Sdebba terminare
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
Parser
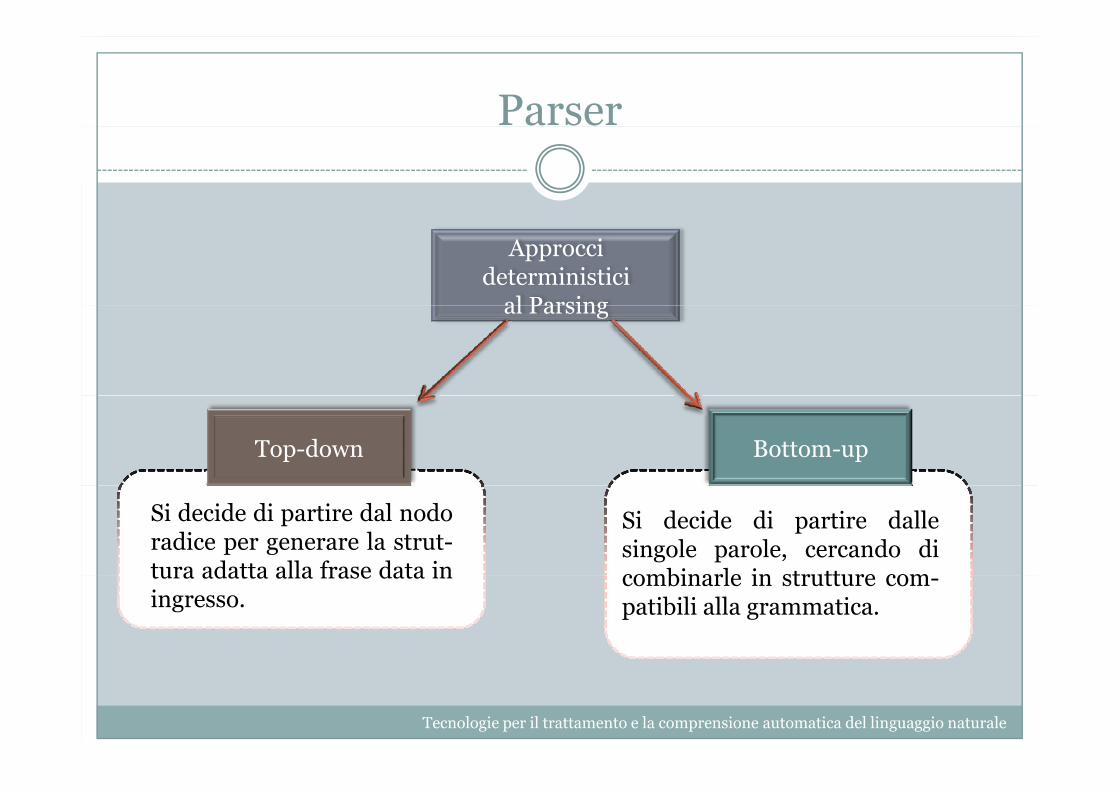
Approcci deterministici
al Parsingal Parsing
Top-down Bottom-up
Si decide di partire dal nodoradice per generare la strut-tura adatta alla frase data in
Si decide di partire dallesingole parole, cercando dicombinarle in strutture comtura adatta alla frase data in
ingresso.combinarle in strutture com-patibili alla grammatica.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Parser
La strategia Top-Down non perde tempo cercando di costruire alberi nonconsistenti con la grammatica, ma genererà tutte le alternative possibiliprescindendo dall’input.
i à i ( l l l ) l’i f iLa strategia Bottom-Up, sarà consistente (almeno localmente) con l’input fornito,ma potrà generare per molti livelli sotto-alberi, che alla fine si rivelerannoincombinabili per ottenere S.
Questo tipo di ricerche sono comunque cieche:non esistono euristiche che suggeriscono la scelta migliorenon si rendono conto dell’errore finché l’espansione non è statanon si rendono conto dell errore finché l espansione non è statacompletamente effettuata.
Perché non combinare i dueapprocci, introducendo un filtro aglialberi generati?alberi generati?
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Parser
Al it d l Al it d l L ftL ft CCAlgoritmo del Algoritmo del LeftLeft CornerCorner
idea di basebi t t i T D l i di t tt filt d lcombinare una strategia Top-Down per la generazione di strutture filtrando le
soluzioni con considerazioni di natura Bottom-Up.
regola dell’angolo sinistro (left corner)regola dell angolo sinistro (left-corner)ogni categoria alla fine verrà riscritta come una serie di parole linearmenteordinate e conoscere la prima parola della serie aiuterà a prevedere la categoria oalmeno ad escludere soluzioni inconsistenti con questa parolaalmeno ad escludere soluzioni inconsistenti con questa parola
Da tale strategia si ottengono i risultati migliori se preliminarmente vienecompilata una tabella che direttamente associa alle categoria un loro possibilecompilata una tabella che direttamente associa alle categoria un loro possibileleft-corner:
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
Parser
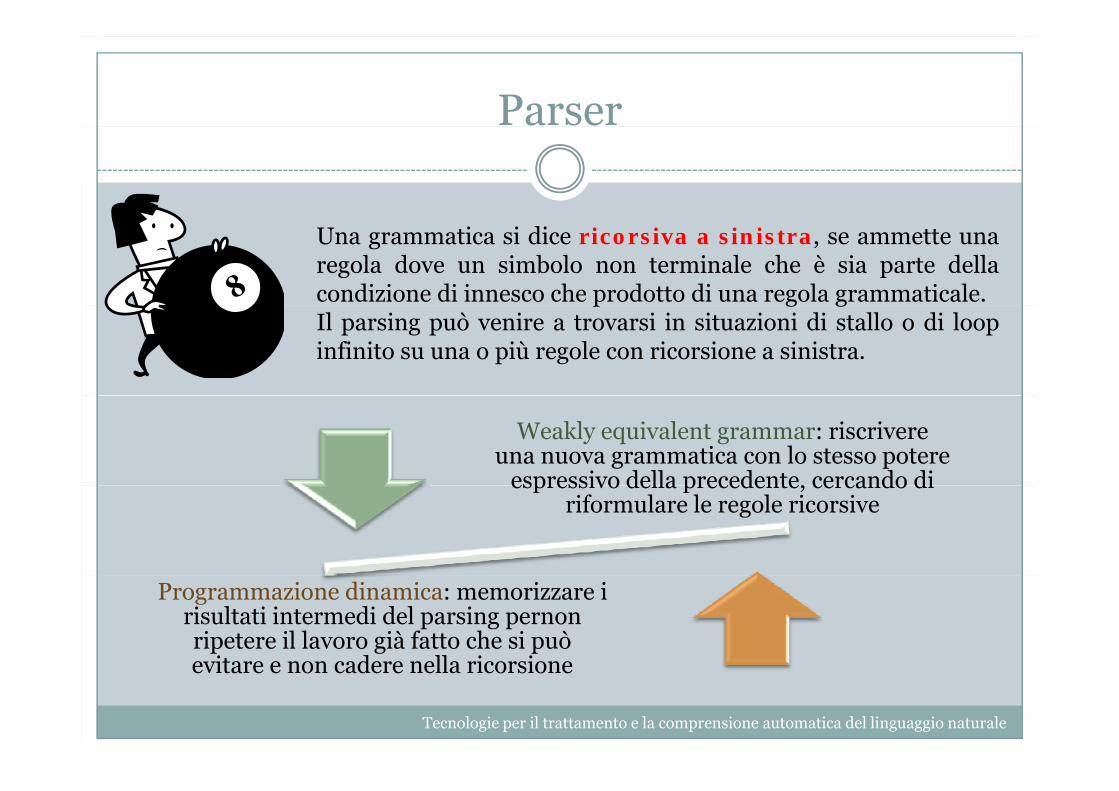
Una grammatica si dice ricorsiva a sinistra, se ammette unaregola dove un simbolo non terminale che è sia parte dellacondizione di innesco che prodotto di una regola grammaticale.p g gIl parsing può venire a trovarsi in situazioni di stallo o di loopinfinito su una o più regole con ricorsione a sinistra.
Weakly equivalent grammar: riscrivere una nuova grammatica con lo stesso potere
espressivo della precedente, cercando di espressivo della precedente, cercando di riformulare le regole ricorsive
Programmazione dinamica: memorizzare i risultati intermedi del parsing pernonripetere il lavoro già fatto che si può evitare e non cadere nella ricorsione
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
evitare e non cadere nella ricorsione
Parser
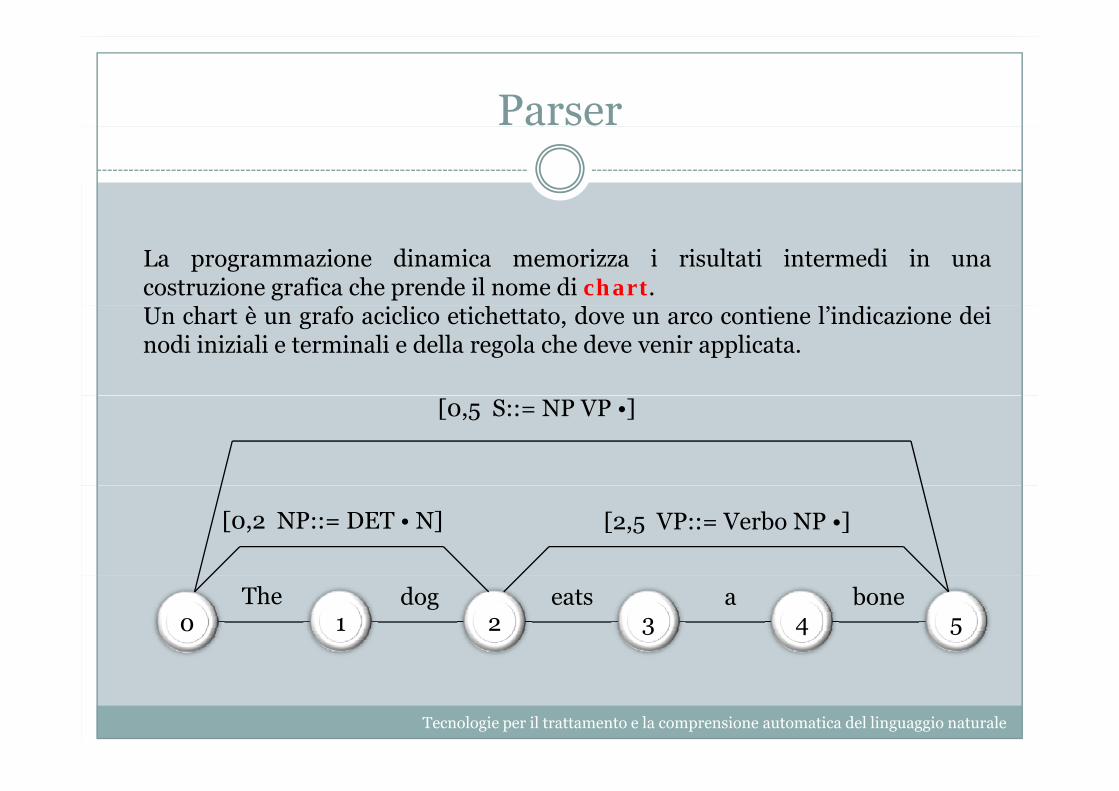
La programmazione dinamica memorizza i risultati intermedi in unacostruzione grafica che prende il nome di chart.Un chart è un grafo aciclico etichettato, dove un arco contiene l’indicazione deinodi iniziali e terminali e della regola che deve venir applicata.
[0,5 S::= NP VP •]
[0,2 NP::= DET • N] [2,5 VP::= Verbo NP •]
0 1 2 3 4 5The dog eats a bone
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Parser
Algoritmo di Algoritmo di EarleyEarley
L’algoritmo inizia con una fase di inizializzazione applicando la regola γ -> S. Adogni passo, uno dei seguenti tre operatori viene applicato al chart corrente:
Previsione: crea nuovi stati nell’entrata corrente del chart,rappresentando le aspettative top-down della grammatica;S i ifi ll’i i l l i iScansione: verifica se nell’input esiste, una parola la cui categoriacombacia con quella prevista dallo stato a cui la regola si trova. Se ilconfronto è positivo, la scansione produce un nuovo stato in cui l’indice di
i i i t t d l l i i tposizione viene spostato dopo la parola riconosciuta.Completamento: determina che un sintagma significativo è statoriconosciuto e verifica se l’ avvenuto riconoscimento è utile per completarequalche altra regola rimasta in attesa di quella categoriaqualche altra regola rimasta in attesa di quella categoria.
Una volta costruito il chart, è possibile ottenere un albero di parsing, estraendol’arco o l’insieme di archi che dal primo nodo portano all’ultimo
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
l arco o l insieme di archi che dal primo nodo portano all ultimo.

Parser
Approcciostatisticoal Parsing
Nel Parsing statistico si scelgono le regole da espandere in base a probabilitàl l t ti d i il i ibil d ’ li i
al Parsing
calcolate a partire da un corpus, per arrivare il prima possibile ad un’analisi erestituirla come “più probabile”. Dato un insieme di regole, fornite sia da espertiche definite a partire da un analisi empirica di un insieme di testi, si definisce laprobabilità di applicazione della regola come:probabilità di applicazione della regola come:
ovvero, la probabilità nota la parte di innesto è pari al numero di volte in cui la regola è applicata nel corpus, diviso il numero di occorrenze della parte di regola è applicata nel corpus, diviso il numero di occorrenze della parte di innesco.
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale

Applicazionepp
Suggeri-tore della
Ricono-scitore di
Corret-tore tore della
forma corretta
scitore di forme
scorrette
tore ortogra-
fico
Il riconoscitore di forme scorrette funziona mediante la comparazione conpun dizionario di riferimento con tutte le possibili flessioni di ogni parola. Perridurre la complessità spaziale, si preferisce memorizzare solo la parte radicaledelle parole, e corredare il dizionario di un insieme di regole di scomposizionemorfologica o di flessione.A fronte dell’immissione di alcune parole, lo strumento opera per prima cosa lostemming con le regole di scomposizione, ottenendo la forma radicale, e
i ll l di ’ l i l di i i
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
successivamente controlla la presenza di quest’ultima nel dizionario.

Applicazionepp
Gli approcci per un suggeritore di forme correte sono:
Basato sugli n-grammi: il sistema ha un insieme di sequenze di caratteriBasato sugli n grammi: il sistema ha un insieme di sequenze di caratteriplausibili, e quando in un testo si riscontra una sequenza non consentita, la sisegnala come errore., e lo sostituisce con una delle sequenze affini.
Basato sulla distanza minima: i candidati per la correzione sono ottenutiapplicando alla parola erronea gli operazioni di cancellazione, inserimento ealterazione di una lettera, secondo il principio della minimizzazione della, p pdistanza della nuova parola con quella erronea.
Per distanza tra due parole, si intende il numero di lettere difformi tra leparole, a parità di lunghezza. Se due parole sono di lunghezza differente, a quellapiù breve si aggiungono in coda tanti caratteri nulli, quanti ne bastano per
i ll l h d ll’ l l d l f
Tecnologie per il trattamento e la comprensione automatica del linguaggio naturale
arrivare alla lunghezza dell’altra parola del confronto.