
Modelli di Programmazione Matematica A.A....
129
Modelli di Programmazione Matematica A.A. 2002/2003 Fabio Schoen Dipartimento di Sistemi e Informatica e-mail: [email protected] web: alanine.dsi.unifi.it/users/schoen PL – versione 1.01 - 13.1.2003
Transcript of Modelli di Programmazione Matematica A.A....

Modelli di Programmazione MatematicaA.A. 2002/2003
Fabio Schoen Dipartimento di Sistemi e Informaticae-mail: [email protected]
web: alanine.dsi.unifi.it/users/schoen
PL – versione 1.01 - 13.1.2003

Parte I
Programmazione lineare
1

Capitolo 1
Modelli di programmazionelineare
1.1 Esempi elementari
1.1.1 Modelli di miscelazione
Uno dei piu semplici modelli di ottimizzazione, descritto in qualunque testointroduttivo di Ricerca Operativa, e il cosiddetto modello di miscelazione,presentato a volte sotto forma di modello per la formulazione di una dieta;un modello per la pianificazione di diete di costo minimo con vincoli di ti-po nutrizionale e stato uno dei primi modelli di ottimizzazione risolti conil metodo del simplesso. Tale modello venne risolto a mano da un gruppodi ricercatori, e richiese parecchie ore di calcolo “parallelo”: e forse inutileosservare che quel modello, basato su una proposta del premio Nobel per l’e-conomia del 1982 George Stigler, puo essere risolto in una frazione di secondosu un modesto Personal Computer.
Nella sua forma base, il modello di miscelazione corrisponde al problemadi decidere come comporre una miscela di costo minimo e qualita garantita,ottenuta da diverse materie prime. Uno dei campi industriali nei quali ilmodello di miscelazione trova vasta applicazione e quello della produzionedi alluminio da rottami. Si immagini di poter acquistare, in quantitativilimitati, alcuni rottami costituiti in massima parte da alluminio, ma misce-lati anche ad altri elementi chimici, e di volerli miscelare in modo tale daottenere, tramite fusione, un materiale che contenga quantitativi prefissatidei vari elementi chimici. Naturalmente, per correggere la qualita dei rottami
2

disponibili, e sempre possibile acquistare, in quantita teoricamente illimitate,ma ad un prezzo sensibilmente piu alto, elementi chimici puri. Il problemadiventa quindi quello di stabilire le quantita di rottami e di materiali purida impiegare in una miscela che rispetti i vincoli imposti sulla qualita e cherisulti di costo minimo.
Nella tabella seguente viene riportato il file dati, preparato secondo lasintassi di AMPL, per un ipotetico problema di miscelazione di alluminioda rottami. L’obiettivo e quello di ottenere una miscela secondo specifichequalitative prefissate e note nell’ambiente della produzione di alluminio conil codice “6063”.
file: Al6063.dat
# problema di miscelazione ottimale
set MATERIALI := Scarti_ALMC Scarti_KAC Rottami Al Si Mg;
set ELEMENTI := Si Mg Fe Cu Mn Zn Cr Ti Al Altri;
param qta_rich := 4.5; # tonnellate
param: rich_min rich_max :=
Si 0.2 0.6
Mg 0.45 0.9
Fe . 0.35
Cu . 0.1
Mn . 0.1
Zn . 0.1
Cr . 0.1
Ti . 0.1
Al 96.9 100.0
Altri . 0.15
;
param compos:
Scarti_ALMC Scarti_KAC Rottami Al Si Mg:=
Si 0.50 0.50 0.30 . 100 .
Mg 0.75 0.70 0.50 . . 100
Fe 0.20 0.20 0.35 . . .
Cu 0.01 0.01 0.05 . . .
Mn 0.02 0.02 0.05 . . .
Zn 0.02 0.02 0.05 . . .
Cr 0.02 0.02 0.05 . . .
Ti 0.02 0.02 0.05 . . .
Al 97.00 97.00 90.00 100 . .
Altri 0.06 0.06 0.77 . . .
;
param: dispon costo := # costo in Euro per tonnellata
Scarti_ALMC 0.50 1230
Scarti_KAC 1.20 1230
Rottami 2.20 1230
Al . 2140
3

Si . 1300
Mg . 2442;
La prima parte del file dati contiene la definizione dei nomi dei materia-li disponibili e degli elementi chimici di interesse. Segue la specifica dellaquantita totale di materiale da produrre (in tonnellate) e, per ciascun ele-mento chimico, il valore della percentuale minima e massima richiesta, inbase alle specifiche di definizione della miscela “6063” (il valore di defaultper la richiesta minima e pari a 0). Come si vede dal listato, viene richiestauna miscela di alluminio contenente almeno una piccola frazione di Silicio eManganese. Successivamente, nel file dati vengono riportate le composizionichimiche dei vari materiali ed infine, per ciascun materiale, il quantitativomassimo disponibile ed il costo in Euro per tonnellata.
Per la formalizzazione del problema occorre individuare le variabili di de-cisione, i vincoli, l’obiettivo. Per le variabili di decisione e naturale associareuna incognita matj a ciascun materiale j; il vincolo relativo alla quantitatotale da produrre si puo esprimere mediante l’equazione∑
j∈MATERIALImatj = qta rich.
Per il bilancio chimico, se si indica con composi,j la percentuale di elemen-to chimico i presente nel materiale j, la quantita percentuale dell’elementochimico i presente nella miscela sara data da
∑j∈MATERIALI
composi,j ·matj
qta rich
e, pertanto, i vincoli che esprimono le richieste minime e massime di elementichimici presenti nella miscela assumono la forma
rich mini ≤∑
j∈MATERIALIcomposi,j ·
matj
qta rich≤ rich maxi.
Infine, per ciascun materiale j, dovra essere imposta la non negativita e, peri materiali disponibili in quantita limitata, un limite superiore:
0 ≤ matj ≤ disponj.
4

L’obiettivo, dato un costo unitario costoj associato a ciascun materiale, sara
min∑
j∈MATERIALIcostojmatj.
Riassumendo, il modello completo della miscelazione di costo minimo ha laforma seguente:
minmat
∑j∈MATERIALI
costojmatj
∑j∈MATERIALI
composi,j ·matj
qta rich≤ rich maxi ∀i
∑j∈MATERIALI
composi,j ·matj
qta rich≥ rich mini ∀i
∑j∈MATERIALI
matj = qta rich
matj ≤ disponj ∀jmatj ≤ 0 ∀j.
Il modello, in linguaggio AMPL, puo essere implementato come riporta-to nel file seguente, dove si puo notare la forte somiglianza tra il modellomatematico e la sua implementazione in AMPL.
file: AlBlend.mod
# ----------------------------------------------------------------#
# problema di miscelazione ottimale #
# ----------------------------------------------------------------#
# ----------------------------------------------------------------#
# dichiarazione insiemi
# ----------------------------------------------------------------#
set MATERIALI; # materiali disponibili
set ELEMENTI; # elementi chimici
# ----------------------------------------------------------------#
# dichiarazione parametri
# ----------------------------------------------------------------#
5

param qta_rich >=0 ; # qta’ richiesta
param disponMATERIALI, default Infinity;
# disponibilita’ dei materiali
param compos ELEMENTI, MATERIALI default 0, >=0, <=100;
# composizione chimica dei materiali
param rich_min ELEMENTI >= 0 default 0;
# richieste minime in percentuale
param rich_max el in ELEMENTI <= 100, >= rich_min[el];
# richieste massime
param costo MATERIALI;
# ----------------------------------------------------------------#
# controllo
# ----------------------------------------------------------------#
check mat in MATERIALI: 0 < sum el in ELEMENTI compos[el,mat] <= 100;
# ----------------------------------------------------------------#
# dichiarazione variabili e limiti inferiori e superiori
# ----------------------------------------------------------------#
var qta mat in MATERIALI >= 0, <= dispon[mat];
# ----------------------------------------------------------------#
# definizione obiettivo
# ----------------------------------------------------------------#
minimize costo_tot:
sum mat in MATERIALI costo[mat] * qta[mat];
# ----------------------------------------------------------------#
# definizione vincoli
# ----------------------------------------------------------------#
subject to totale:
sum mat in MATERIALI qta[mat] = qta_rich;
subject to def_qualita el in ELEMENTI:
rich_min[el] <=
sum mat in MATERIALI (qta[mat]/qta_rich) * compos[el,mat]
<=rich_max[el];
# la qta e’ assoluta ==> divisa per qta_rich fornisce qta percentuale;
Con i dati del file sopra riportati, utilizzando un opportuno risolutore, si
6

ottiene la seguente soluzione di costo minimo:
Al 2.04176Mg 0.00438Si 0.00970
Rottami 0.74416Scarti ALMC 0.5Scarti KAC 1.2
ed il costo, in Euro, risulta pari a 7398.988. Per quanto riguarda la qualitadella miscela ottenuta, si puo far riferimento alla tabella seguente:
rich min miscela rich maxAl 96.9 96.9 100Cr 0 0.0158 0.1Cu 0 0.0120 0.1Fe 0 0.1334 0.35Mg 0.45 0.45 0.9Mn 0 0.0158 0.1Si 0.2 0.4542 0.6Ti 0 0.0158 0.1Zn 0 0.0158 0.1
Altri 0 0.15 0.15
1.1.2 Il modello della dieta
Il modello della dieta puo essere visto come una variante del modello di mi-scelazione; il modello classico prevede la determinazione della dieta, o dellamiscela di cibi, di costo minimo soggetta a vincoli sul contenuto nutritivo.Tali vincoli, come nel modello di miscelazione, possono prevedere soglie mi-nime (per gli elementi nutritivi vantaggiosi) e/o soglie massime (per quellinocivi). L’unica differenza sostanziale tra il modello elementare di miscela-zione e quello di dieta consiste nel fatto che in quest’ultimo non ha in generesenso imporre vincoli sulla quantita totale; un’altra differenza e il fatto chenei problemi di dieta i contenuti nutritivi non sono espressi generalmente inpercentuale, ma in unita di misura differenti, quali grammi, ad esempio perle proteine, i grassi ed i carboidrati, o calorie, nel caso del valore energeti-co. Spesso le etichette sulle confezioni di cibo riportano il valore riferito a100g di prodotto, oppure il valore riferito ad una porzione tipica: in questi
7

casi nel formulare il modello occorrera prestare attenzione al significato dellevariabili, che deve essere scelto coerentemente ai dati nutrizionali utilizzati.Spesso, almeno per alcuni componenti nutritivi quali le vitamine, si utilizzaun’unita di misura detta percentuale del fabbisogno medio giornaliero: conquesto termine si usa indicare la quantita che mediamente un individuo adul-to dovrebbe assumere giornalmente in una dieta equilibrata. Quest’ultimaunita di misura, pur avendo il nome di percentuale, deve essere trattata comeuna normale unita di misura: quando si indica ad esempio che una porzionedi un dato cibo fornisce il 30% del fabbisogno giornaliero di ferro, significache 2 porzioni forniranno il 60% e 4 porzioni il 120%. Il modello elementaredella dieta puo quindi essere presentato nel modo seguente, utilizzando unaterminologia che sia la piu vicina possibile a quella utilizzata per il modellodi miscelazione:
minmat
∑j∈CIBI
costojqtaj
∑j∈CIBI
composi,jqtaj ≤ rich maxi ∀i∑
j∈CIBIcomposi,jqtaj ≥ rich mini ∀i
qtaj ≤ 0 ∀j.
In questo modello sono stati omessi anche i limiti superiori alla quantita ac-quistabile per ogni cibo, in quanto si puo immaginare che la disponibilita dicibo sia sostanzialmente illimitata per una dieta singola, cioe che le quan-tita di cibo acquistabili in base ai vincoli nutrizionali siano sempre reperibilisul mercato. In alcuni casi e utile pero inserire tali vincoli non tanto perriprodurre la situazione di cibi difficilmente reperibili sul mercato, quantopiuttosto per limitare la quantita di cibo di un dato tipo presente nella die-ta. Ad esempio, in una dieta pianificata per un’intera giornata, si potrebberichiedere che per molti, o forse tutti, i cibi il numero massimo di porzionisia pari a 1 oppure a 2. A titolo di esempio si riporta un file dati AMPLcon alcune specifiche nutrizionali (naturalmente l’esempio ha il solo scopodi illustrare la metodologia di modellizzazione e non deve essere consideratocome un esempio realistico di modello di dieta, ne si deve considerare la dietarisultante dal modello come consigliabile).
8
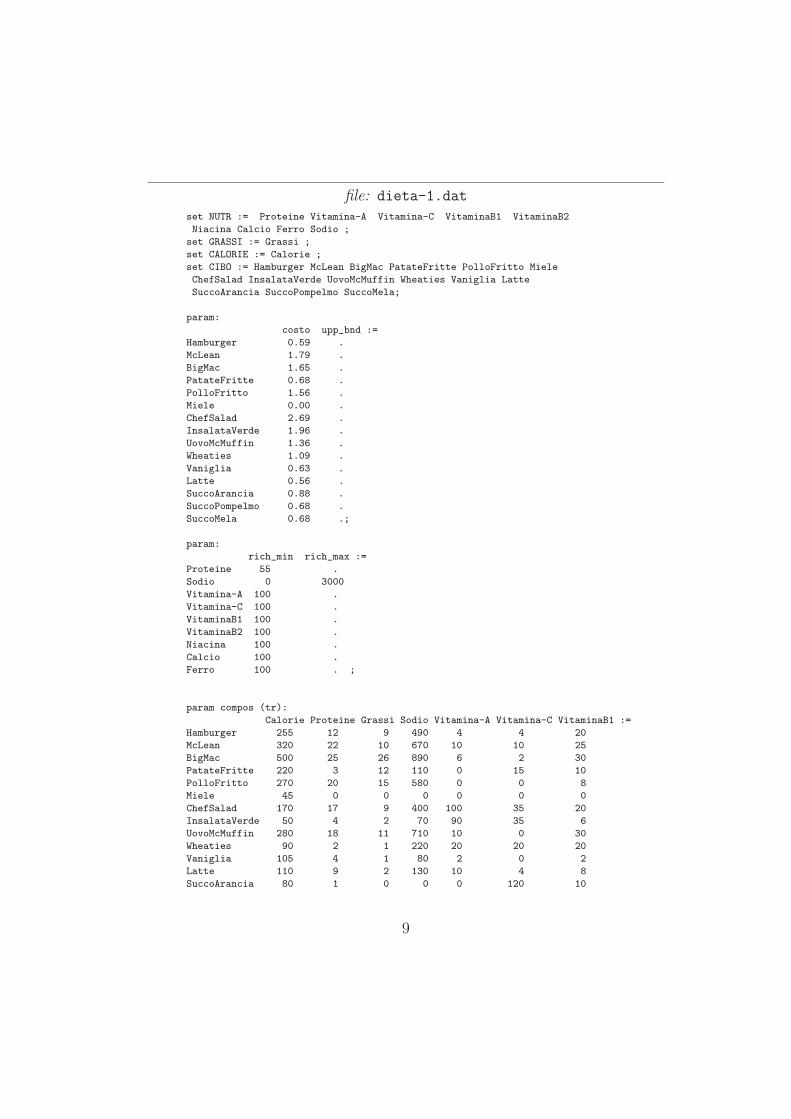
file: dieta-1.dat
set NUTR := Proteine Vitamina-A Vitamina-C VitaminaB1 VitaminaB2
Niacina Calcio Ferro Sodio ;
set GRASSI := Grassi ;
set CALORIE := Calorie ;
set CIBO := Hamburger McLean BigMac PatateFritte PolloFritto Miele
ChefSalad InsalataVerde UovoMcMuffin Wheaties Vaniglia Latte
SuccoArancia SuccoPompelmo SuccoMela;
param:
costo upp_bnd :=
Hamburger 0.59 .
McLean 1.79 .
BigMac 1.65 .
PatateFritte 0.68 .
PolloFritto 1.56 .
Miele 0.00 .
ChefSalad 2.69 .
InsalataVerde 1.96 .
UovoMcMuffin 1.36 .
Wheaties 1.09 .
Vaniglia 0.63 .
Latte 0.56 .
SuccoArancia 0.88 .
SuccoPompelmo 0.68 .
SuccoMela 0.68 .;
param:
rich_min rich_max :=
Proteine 55 .
Sodio 0 3000
Vitamina-A 100 .
Vitamina-C 100 .
VitaminaB1 100 .
VitaminaB2 100 .
Niacina 100 .
Calcio 100 .
Ferro 100 . ;
param compos (tr):
Calorie Proteine Grassi Sodio Vitamina-A Vitamina-C VitaminaB1 :=
Hamburger 255 12 9 490 4 4 20
McLean 320 22 10 670 10 10 25
BigMac 500 25 26 890 6 2 30
PatateFritte 220 3 12 110 0 15 10
PolloFritto 270 20 15 580 0 0 8
Miele 45 0 0 0 0 0 0
ChefSalad 170 17 9 400 100 35 20
InsalataVerde 50 4 2 70 90 35 6
UovoMcMuffin 280 18 11 710 10 0 30
Wheaties 90 2 1 220 20 20 20
Vaniglia 105 4 1 80 2 0 2
Latte 110 9 2 130 10 4 8
SuccoArancia 80 1 0 0 0 120 10
9

SuccoPompelmo 80 1 0 0 0 100 4
SuccoMela 90 0 0 5 0 2 2
: # continuazione tabella
VitaminaB2 Niacina Calcio Ferro :=
Hamburger 10 20 10 15
McLean 20 35 15 20
BigMac 25 35 25 20
PatateFritte 0 10 0 2
PolloFritto 8 40 0 6
Miele 0 0 0 0
ChefSalad 15 20 15 8
InsalataVerde 6 2 4 8
UovoMcMuffin 20 20 25 15
Wheaties 20 20 2 20
Vaniglia 10 2 10 0
Latte 30 0 30 0
SuccoArancia 0 0 0 0
SuccoPompelmo 2 2 0 0
SuccoMela 0 0 0 4 ;
Un modello che rappresenta il problema della dieta sopra descritto e ilseguente:
file: dieta-1.mod
set NUTR; # elementi nutritivi
set CALORIE;
set GRASSI;
# calorie e grassi sono considerati a parte per poter formare vincoli piu’
# complessi o obiettivi diversi dalla minimizzazione del costo.
set CARATT := NUTR union CALORIE union GRASSI;
# l’insieme di tutte le caratteristiche nutrizionali.
set CIBO;
param costo CIBO >= 0;
param low_bnd CIBO >= 0. default 0;
param upp_bnd j in CIBO >= low_bnd[j], default +Infinity;
# quantita’ minime e massime di ciascun cibo nella dieta - default 0 e
# infinito rispettivamente
param rich_min NUTR >= 0, default 0;
param rich_max NUTR >= 0, default +Infinity;
# richieste minime e massime per i singoli elementi nutritivi
param compos CARATT,CIBO >= 0;
var Qta j in CIBO >= low_bnd[j], <= upp_bnd[j];
minimize costo_totale: sum j in CIBO costo[j] * Qta[j];
10

subject to dieta i in NUTR:
rich_min[i] <= sum j in CIBO compos[i,j] * Qta[j] <= rich_max[i];
L’esecuzione di un algoritmo risolutore per questo modello produce ilseguente risultato: la dieta minima risulta avere un costo totale di 6.12605(i costi sono espressi in Euro) e risulterebbe composta come segue:
cibo qtaHamburger 5.299Insalata verde 0.535Latte 1.441Succo Pompelmo 0.381’Wheaties’ 0.812
ed i contenuti nutrizionali risultano i seguenti:
Elemento nutritivo qtaCalcio 100Ferro 100Niacina 124.047Proteine 80.708Sodio 3000Vitamina A 100Vitamina C 100Vitamina B1 138.48Vitamina B2 116.44
Come si vede immediatamente, la dieta ottenuta dal risolutore, sebbenecorretta, non e utilizzabile in pratica, per vari motivi. Ad esempio, appareimproponibile una dieta che presenti un numero di porzioni molto elevate –piu di 5 – per un singolo cibo (ricordando che i dati inseriti corrispondonoalla pianificazione di una dieta per un giorno). Inoltre la varieta di cibi eabbastanza limitata: sono stati scelti dal risolutore solo relativamente pochicibi, rispetto al totale disponibile. Infine, dovendo programmare una dietaper un’unica persona, occorrerebbe evitare la presenza di valori decimali nellasoluzione. Per quanto riguarda la limitazione del numero totale di porzioniassunte nel corso di un’unica giornata, nel modello e sufficiente specificareun dato diverso da quello di default per il parametro upp bnd; imponendoad esempio un limite superiore pari a 2 porzioni per ogni cibo si ottiene lasoluzione seguente:
11

cibo qtaHamburger 2InsalataVerde 0.265823Latte 0.949367SuccoPompelmo 0.388987UovoMcMuffin 1.85823Wheaties 2
con un costo pari a 7.204e - come si puo facilmente intuire, l’aumento divincoli comporta un aumento di prezzo. Si nota anche come l’inserimento delvincolo relativo al numero massimo di porzioni ha portato ad una variazionenon solo nelle quantita dei cibi, ma anche nella composizione della dietaottimale. Aggiungendo il vincolo di interezza sulle variabili, si ottiene lasoluzione
cibo qtaBigMac 1Hamburger 2Insalata Verde 1Latte 2Patate Fritte 1Wheaties 2
di costo 8.77e. Si noti come la soluzione intera non sia un arrotondamentodella soluzione decimale – compaiono cibi nuovi ed alcuni (Latte) assumonovalori molto diversi da quelli ottenuti precedentemente.
Naturalmente il modello qui presentato e talmente elementare da rivelarsidi poca o nessuna utilita pratica; tuttavia esso puo costituire la base per lacostruzione di un modello piu realistico. Ad esempio, uno dei vincoli che gliesperti di nutrizione inseriscono spesso e una limitazione sulla quantita dialcuni tipi di grassi, sia in assoluto, sia in rapporto ad altri grassi. Spesso,in una dieta equilibrata, si richiede che le calorie provenienti dai grassi nonsuperino il 30% delle calorie totali. Avendo a disposizioni i dati sulla quantitadi calorie provenienti dai grassi e quelle totali per ogni cibo, il vincolo siesprime facilmente come disequazione lineare:
∑j∈CIBI
CalorieDalGrassojqtaj ≤30
100
∑j∈CIBI
Caloriejqtaj.
12

Molti altri requisiti nutrizionali possono essere espressi in modo simile a que-sto. Altri richiedono invece una modellazione piu complessa e, spesso, pos-sono essere formulati utilizzando le variabili binarie indicatrici come si vedranella parte dedicata ai modelli di programmazione lineare intera. Vincoli diquesto genere sono spesso posti sotto forma di vincoli logici del tipo: “Sela dieta prevede hamburger, allora devono esserci anche le patatine” oppu-re “Nella dieta devono essere presenti o gli hamburger o i BigMac, ma nonentrambi”, ecc.
Anche nella sua versione elementare, pero, il modello risulta utile, in par-ticolare in campi quali quello della preparazione dei mangimi per animali odei fertilizzanti per terreni, dove non entrano in gioco vincoli particolari sulgusto o sulla varieta della dieta. Infine, come si vedra nella parte dedicataai modelli, l’esempio qui descritto puo essere generalizzato su un orizzontetemporale di piu di una giornata: in questo caso le variabili dovranno avereun secondo indice relativo alla giornata e si potranno prevedere vincoli nutri-zionali relativi a periodi piu lunghi, tipicamente una settimana od un mese.In questi casi il problema si avvicina a quello della pianificazione dei menuper una mensa.
1.1.3 Il modello dell’abbinamento
Un modello piuttosto lontano dai due precedentemente esposti e il seguente:si consideri la situazione in cui un certo numero n di progetti (ad esempio,lo sviluppo di moduli di un progetto software) devono essere affidati ad unugual numero n di progettisti o di sviluppatori. Ogni progettista deve svol-gere esattamente un progetto – si tratta quindi di mettere in corrispondenzabiunivoca i progetti ed i progettisti (esistono varianti del modello nelle qualinon tutti i progetti devono essere svolti o altre nelle quali qualche progettistapuo svolgere piu di un progetto). Per addestrare il progettista i a realizzareil progetto j occorre un periodo di addestramento il cui costo e stimato paria cij. Il problema di abbinamento consiste nel determinare l’accoppiamentoprogetto/progettista che rende minimo il costo totale di addestramento.
Per questo modello e comodo utilizzare delle variabili decisionali di tipobinario, δij, con la convenzione che δij = 1 sta ad indicare che il progettistai svolge il progetto j e 0 altrimenti. Con questa convenzione il costo totale
13

di addestramento si esprime facilmente come∑i,j
cijδij.
Il vincolo che esprime la necessita che ogni progetto sia svolto esattamenteda un progettista, ricordando che le variabili δ sono binarie, si esprime come∑
i
δij = 1 ∀j
(una somma di variabili binarie vale uno se e solo se esattamente una diloro e pari ad 1), mentre il fatto che ogni progettista svolga esattamente unprogetto si esprime simmetricamente come∑
j
δij = 1 ∀i.
Si vedra piu avanti che questo modello, nonostante richieda l’interezza dellevariabili, puo essere risolto trascurando questo vincolo.
In tutti gli esempi presentati in questo paragrafo, si puo vedere comeesistano alcuni elementi comuni. Ogni modello prevede l’identificazione di 3componenti principali: un insieme di variabili di decisione, o incognite, unoo piu vincoli, espressi generalmente sotto forma di equazioni e/o disequa-zione, una funzione obiettivo da massimizzare o minimizzare. La maggiorparte dei vincoli visti nei modelli qui presentati e costituita da equazioni edisequazioni lineari; naturalmente esistono molti modelli nei quali i vincoli siesprimono come equazioni o disequazioni non lineari. Un esempio particolaresi e visto gia nei modelli presentati, quando, ad esempio nel modello delladieta, si e richiesta l’interezza delle variabili: questo e un vincolo complesso,non esprimibile come vincolo lineare (ma, come vedremo, esprimibile comeequazione non lineare), la cui presenza spesso porta ad un enorme crescitadella complessita di risoluzione del problema.
Naturalmente, oltre alle 3 componenti viste, ogni modello prevedera laspecifica di parametri, cioe dei coefficienti che compaiono in tutti i vincolie nell’obiettivo. Sistemi di modellizzazione algebrica quali AMPL o anchesistemi basati su fogli elettronici quali Excel prevedono una separazione trale specifiche descrittive del modello ed i dati. Questa separazione, maggiorenei linguaggi algebrici che nei fogli elettronici, riduce la possibilita di erro-ri, separando la fase di progettazione del modello, da effettuarsi a cura di
14

un esperto nella formulazione di problemi di decisione, dalla fase di specifi-ca dei dati di un esempio particolare (quella che con un orribile neologismoviene detta “istanziazione”), operazione che puo essere effettuata da qual-cuno non particolarmente esperto nella formulazione di modelli. Un terzocomponente, separato sia dal modello che dai dati, e il risolutore, un algo-ritmo in grado di determinare una soluzione ad un problema di decisionerappresentato formalmente mediante modello e dati.
15

Capitolo 2
Problemi di ottimizzazione
2.1 Introduzione e definizioni principali
Un generico problema di ottimizzazione P e dato da una terna
〈Opt, X, f〉e si indica con
P : Optx∈Xf(x) (2.1)
Opt puo indicare l’operatore min oppure l’operatore max, X ⊆ Rn e detto in-sieme ammissibile ed e un sottoinsieme dello spazio euclideo n–dimensionale,con n ∈ N, mentre f e una funzione reale f : X → R detta funzione obiettivo.
Definizione 1 Il problema di ottimizzazione P si dice non ammissibile oinammissibile se X = ∅.Definizione 2 Un vettore x ∈ Rn si dice soluzione ammissibile per il pro-blema P se x ∈ X.
Definizione 3 Un problema di ottimizzazione P di minimo si dice illimi-tato (inferiormente) se esiste almeno una successione xk∞k=1 di soluzioniammissibili tale che
limk→∞
f(xk) = −∞.Un problema di ottimizzazione P di massimo si dice illimitato (superior-mente) se esiste almeno una successione xk∞k=1 di soluzioni ammissibilitale che
limk→∞
f(xk) = +∞.
16

Definizione 4 Un problema di ottimizzazione P di minimo ammette ottimofinito se e solo se
∃x ∈ X : f(x) ≤ f(x) ∀x ∈ X. (2.2)
Analogamente un problema P di massimo ammette ottimo finito se e solo se
∃x ∈ X : f(x) ≥ f(x) ∀x ∈ X. (2.3)
Ogni punto x che soddisfi la (2.2) per un problema di minimo o la (2.3) peruno di massimo, si dice ottimo (globale) per il problema P .
L’insieme degli ottimi di P si indica con
arg optP.
17

Capitolo 3
Introduzione allaprogrammazione lineare
3.1 Problemi di programmazione lineare - im-
portanza della linearita
Gran parte dei modelli che verranno studiati in questo volume rientra nellacategoria dei cosiddetti “modelli lineari”. E’ opportuno ricordare che unafunzione lineare definita in Rn puo sempre essere espressa nella forma
f(x1, . . . , xn) = a1x1 + · · ·+ anxn =n∑
i=1
aixi = aTx
dove con a si e indicato il vettore colonna
a =
a1...an
e con a1, . . . , an si sono indicate n costanti reali.I problemi di programmazione lineare sono caratterizzati da una funzione
obiettivo lineare e da un insieme ammissibile rappresentabile esplicitamentemediante un numero finito di equazioni e/o disequazioni lineari. Un gene-rico problema di programmazione lineare potrebbe pertanto avere la formaseguente:
18

Optn∑
j=1
cjxj (3.1)
n∑j=1
aijxj = bi i = 1, . . . ,ml (3.2)
n∑j=1
aijxj ≤ bi i = ml + 1, . . . ,mh (3.3)
n∑j=1
aijxj ≥ bi i = mh + 1, . . . ,mk (3.4)
In questo problema il simbolo Opt rappresenta l’operatore min o l’opera-tore max; sono presentiml ≥ 0 equazioni lineari e (mk−ml) ≥ 0 disequazionilineari, alcune delle quali rappresentate in forma di ≤, altre di ≥.
Nel problema sopra rappresentato sono presenti i principali elementi deigenerici problemi di programmazione lineare e, in particolare:
1. un insieme di variabili di decisione o incognite x1,x2, . . . , xn;
2. una funzione obiettivo o costo da minimizzare o massimizzare;
3. alcune (in certi casi anche nessuna) equazioni lineari o vincoli di egua-glianza ;
4. alcune (a volte nessuna) disequazioni lineari o vincoli di diseguaglianza;
5. alcuni vincoli di segno o di non negativita sulle variabili; questi vin-coli non sono altro che semplici disequazioni lineari, ma in genere sipreferisce mantenerli separati dagli altri vincoli del problema.
Si noti che nel modello appena introdotto non sono presenti vincoli didiseguaglianza stretta, cioe caratterizzati dalla relazione > o <; ne sonopresenti vincoli di diseguaglianza, caratterizzati dalla relazione =.
In un modello lineare, la funzione obiettivo, cioe la funzione da minimiz-zare o massimizzare, e lineare, cosı come i vincoli sono espressi da equazionie/o disequazioni lineari. La funzione obiettivo potrebbe anche essere “affine”,cioe avere la forma aTx+c, con c ∈ R, anche se dal punto di vista algoritmico
19

non vi e alcuna differenza nell’ottimizzare funzioni che differiscono fra loroper una costante.
Il notevole peso dato ai modelli lineari si puo spiegare in vari modi:
1. molti concetti e proprieta relativi ai modelli lineari si possono ritrovare,con opportune varianti, anche in alcuni modelli piu complessi;
2. i modelli lineari possono essere risolti molto efficientemente;
3. moltissimi modelli applicativi sono effettivamente o possono ricondursia modelli lineari;
4. molti modelli non lineari possono essere approssimati efficacementemediante opportuni modelli lineari.
Naturalmente l’ipotesi di linearita e molto forte. Formulare un proble-ma mediante un modello lineare corrisponde ad assumere la validita delleseguenti ipotesi:
1. additivita: il contributo al “costo” (o al membro di sinistra di equazionio disequazioni) e la somma dei contributi dovuti alle singole incognite;
2. proporzionalita marginale: il contributo (ad esempio, al costo) di cia-scuna variabile e di tipo proporzionale: a valori doppi della variabilecorrisponde un contributo doppio. Spesso questa ipotesi non e ragio-nevole – si pensi ad esempio al caso degli sconti per acquisti di grossequantita, oppure ai modelli di imposizione fiscale, nei quali ad impo-nibili via via crescenti corrispondono percentuali di prelievo crescenti.Nel capitolo ?? verra presentata la formulazione dei modelli lineari atratti, utili per formulare problemi di questo genere;
3. divisibilita: le incognite possono assumere qualsiasi valore reale com-patibile con i vincoli. Cioe, se una variabile puo assumere sia il valore3 che il valore 7, allora potra anche assumere ciascuno dei valori del-l’intervallo [3, 7] . Questa e forse l’ipotesi che piu spesso non e verificatanelle applicazioni reali. Molto spesso alcune incognite possono assume-re solo valori interi, a volte soltanto binari. Nel capitolo ?? verrannotrattati in dettaglio i modelli di programmazione lineare intera.
20

Anche se quello appena visto e il piu generale problema di programma-zione lineare che incontreremo in questo libro, e importante definire unaforma “standard”, alla quale sia facile ricondurre altre forme di problemi diprogrammazione lineare. Avendo a disposizione tale forma standard sarapossibile sviluppare un algoritmo risolutivo “standard”, senza dover cioepresentare forme algoritmiche differenti per le diverse tipologie di problemi.
3.1.1 Forma standard di un problema di programma-zione lineare
Useremo la convenzione di definire standard un problema di minimizzazioneche si presenti sotto il seguente aspetto:
min c1x1 + c2x2 + · · · + cnxna11x1 + a12x2 + · · · + a1nxn = b1a21x1 + a22x2 + · · · + a2nxn = b2
......
...am1x1 + am2x2 + · · · + amnxn = bm
x1 ≥ 0, x2 ≥ 0, . . . , xn ≥ 0
(3.5)
Il problema standard consiste quindi nella minimizzazione di una fun-zione, detta funzione obiettivo, lineare nelle n incognite reali x1, . . . , xn; icoefficienti c1, . . . , cn delle incognite sono chiamati coefficienti di costo. Ivincoli sono rappresentati da un sistema di m equazioni lineari e dall’imposi-zione del vincolo di non negativita su tutte le incognite; l’i–esima equazioneha coefficienti ai1, . . . , ain.
Naturalmente lo stesso problema puo anche essere espresso in forma piuconcisa come
[c]lllminn∑
j=1
cjxj
n∑j=1
aijxj = bi, i = 1, . . . ,m
xj ≥ 0, j = 1, . . . , n.
In molti casi sara conveniente utilizzare una rappresentazione ancora piu
21

concisa. Riunendo i coefficienti del sistema di equazioni in una matricem×n:
A =
a11 · · · a1n...
...am1 · · · amn
i costi in un vettore n–dimensionale:
c =
c1...cn
i termini noti in un vettore m–dimensionale
b =
b1...bm
ed, analogamente, le incognite in un vettore n–dimensionale:
x =
x1...xn
si puo scrivere
minxcTx (3.6)
Ax = b (3.7)
x ≥ 0 (3.8)
Con la notazione cT si indica il trasposto del vettore c (quindi, in questocaso, un vettore riga 1 × n) e con cTx si rappresenta il prodotto interno (oprodotto scalare)
∑nj=1 cjxj tra i vettori c ed x.
3.1.2 Trasformazione di programmi lineari in formastandard
Spesso un problema di programmazione lineare si presenta gia nella formastandard precedentemente introdotta. Ad esempio, un semplice problema di
22

abbinamento 3× 3
min3∑
i=1
3∑j=1
cijxij
3∑j=1
xij = 1, i = 1, 2, 3
3∑i=1
xij = 1, j = 1, 2, 3
xij ≥ 0, i = 1, 2, 3; j = 1, 2, 3
e gia scritto in forma standard e puo essere rappresentato in forma matricialeponendo
A =
1 1 1 0 0 0 0 0 00 0 0 1 1 1 0 0 00 0 0 0 0 0 1 1 11 0 0 1 0 0 1 0 00 1 0 0 1 0 0 1 00 0 1 0 0 1 0 0 1
,
b =[1 1 1 1 1 1
]T,
c =[c11 c12 c13 c21 c22 c23 c31 c32 c33
]T,
x =[x11 x12 x13 x21 x22 x23 x31 x32 x33
]T.
In altri casi pero il problema originale non si presenta in forma stan-dard — si pensi, ad esempio, al problema della dieta, nel quale i vincolisono disequazioni lineari che rappresentano richieste minime o massime dielementi nutritivi. Fortunatamente e facile ricondurre un generico problemadi programmazione lineare in forma standard.
Massimizzazione
Se il problema dato richiede la massimizzazione di un obiettivo lineare, cisi puo ricondurre ad un problema standard semplicemente cambiando segnoal vettore dei costi. Questo perche, data una qualunque funzione f ed ungenerico insieme Ω,
maxf(x) : x ∈ Ω = −min−f(x) : x ∈ Ωe se x ∈ Ω e tale che f(x) = maxf(x) : x ∈ Ω, allora e anche vero chelo stesso x e tale che −f(x) = min−f(x) : x ∈ Ω. La dimostrazione diquesta importante proprieta e molto elementare e viene lasciata al lettore.
23

Dovendo ad esempio risolvere un problema di massimizzazione linearecon vincoli lineari di eguaglianza e variabili vincolate in segno, avendo adisposizione un codice di calcolo predisposto per la minimizzazione, basterarisolvere il problema
−min −cTxAx = bx ≥ 0
dove il segno − prima dell’operatore min indica che, al termine, occorrecambiare segno al valore dell’ottimo trovato (solo al valore dell’ottimo, nonall’ottimo stesso).
Vincoli di diseguaglianza
Se in un problema di programmazione lineare compare un vincolo del tipo
n∑j=1
aijxj ≤ bi,
ci si puo ricondurre alla forma standard introducendo una variabile in piu.L’espressione del vincolo puo essere scritta in modo equivalente come
bi −n∑
j=1
aijxj ≥ 0.
Ora, definendo una nuova variabile si come
si = bi −n∑
j=1
aijxj,
il vincolo originale si riduce al vincolo di non negativita si ≥ 0. In altreparole, al posto del vincolo originale scriveremo
n∑j=1
aijxj + si = bi, si ≥ 0,
coerentemente con quanto richiesto dalla forma standard.La variabile si viene detta variabile di slack o di scarto, in quanto rap-
presenta lo scarto esistente fra i due membri della disequazione originale. Se
24

nel problema compaiono diversi vincoli di diseguaglianza, si potra operareuna simile trasformazione per ciascuno di essi, ricordandosi di utilizzare, perciascun vincolo, una diversa variabile di slack.
Se in un problema compaiono disequazioni di tipo “≥”, si utilizza unprocedimento del tutto analogo; in particolare una disequazione del tipo
n∑j=1
aijxj ≥ bi
puo essere portata in forma standard con l’introduzione di una variabileaggiuntiva (detta di surplus o di eccedenza):
n∑j=1
aijxj − si = bi, si ≥ 0.
Vincoli sul segno delle variabili
A volte, anche se nelle applicazioni cio e relativamente raro, un’incognita evincolata ad assumere valori non positivi: xj ≤ 0; ovviamente, in questocaso, sostituendo ogni occorrenza della variabile xj con il suo opposto −xj cisi riporta alla forma standard, con vincoli di non negativita sulle incognite.
In altri casi invece sull’incognita xj non e richiesto alcun vincolo di segno— si pensi ad esempio al caso di un’incognita che rappresenti il livello di unconto corrente bancario: a secondo dei movimenti, l’incognita potra assumeresia valori negativi che positivi. Altre volte, infine, non e noto a priori se sialecito o meno presupporre un segno specifico per una variabile.
Uno dei sistemi piu comunemente utilizzati per trattare questo caso con-siste nel sostituire tale incognita libera con la differenza di due incognite nonnegative:
xj ≡ x+j − x−j dove x+
j ≥ 0, x−j ≥ 0.
Per qualsiasi valore di xj esisteranno infinite coppie di valori x+j ed x−j tali
che xj e uguale a x+j − x−j . In generale x+
j e x−j non coincidono con la partepositiva e la parte negativa di xj; questo avviene se e solo se almeno una delledue variabili x+
j o x−j e nulla – in questo caso l’altra variabile corrispondealla parte positiva (o negativa) di xj.
Grazie alle trasformazioni appena viste, un problema generico di program-mazione lineare puo sempre essere ricondotto ad un problema equivalente informa standard; in alcuni casi tale problema avra un numero di incognitemaggiore del problema originale.
25

3.2 Equivalenza tra problemi di ottimizzazione
L’equivalenza tra diversi problemi di programmazione lineare e stata po-stulata nel paragrafo precedente appoggiandosi su una base intuitiva. Unadefinizione rigorosa di equivalenza tra problemi di ottimizzazione raramenteviene fornita nei libri di testo; poiche pero alcune trasformazioni portanoa problemi abbastanza differenti fra loro (si pensi al caso dell’eliminazionedelle variabili libere in segno appena presentato) pare utile a questo pun-to definire il concetto di equivalenza in modo piu rigoroso e non basare ilconcetto di equivalenza esclusivamente sull’intuizione. Per giungere ad unadefinizione formale che contenga come casi particolari i problemi “evidente-mente” equivalenti, ma che non estenda l’equivalenza a problemi qualsiasi,pare conveniente introdurre una definizione formale di equivalenza non trasingoli problemi ma tra famiglie di problemi di ottimizzazione.
Un problema di ottimizzazione consiste nella minimizzazione oppure nellamassimizzazione di una funzione obiettivo su un insieme ammissibile. Siadata una coppia di famiglie di problemi di ottimizzazione cosı definita:
P (F ,X ) Q(G,Y)
OptPx∈Xf(x), X ∈ X , f ∈ F OptQy∈Y g(y), Y ∈ Y , g ∈ G
dove OptP e OptQ possono indicare indifferentemente l’operatore min o maxe X ⊆ Rn, Y ⊆ Rm. Per formalizzare il concetto di equivalenza occorrestabilire una corrispondenza tra famiglie diverse di problemi di ottimizzazioneche permetta di passare dalla soluzione di un problema di una famiglia allarisoluzione di un problema dell’altra e viceversa.1
Definizione 5 Le famiglie di problemi P e Q si dicono equivalenti se esi-stono quattro trasformazioni
Φ : P → Q φX : X ⊆ Rn → Y ⊆ Rm
Ψ : Q→ P ψY : Y ⊆ Rm → X ⊆ Rn
tali che
1si ringrazia l’ing. B. Addis per le osservazioni che hanno permesso di migliorare lapresentazione di questo capitolo
26

1. se un problema 〈f,X,OptP〉 ∈ P e inammissibile allora Φ 〈f,X,OptP〉 ∈Q e inammissibile e, viceversa, se un problema 〈g, Y,OptQ〉 ∈ Q einammissibile allora Ψ 〈g, Y,OptQ〉 ∈ P e inammissibile
2. se un problema 〈f,X,OptP〉 ∈ P e illimitato allora il problema Φ 〈f,X,OptP〉 ∈Q e illimitato e viceversa;
3. vale inoltre:
∀x ∈ arg opt 〈f,X,OptP〉 =⇒ φX(x) ∈ arg opt Φ 〈f,X,OptP〉
e
∀ y ∈ arg opt 〈g, Y,OptQ〉 =⇒ ψY (y) ∈ arg opt Ψ 〈g, Y,OptQ〉
Possiamo ora verificare formalmente l’equivalenza tra alcune famiglie par-ticolari di problemi di ottimizzazione.
Teorema 3.1 Il problema di ottimizzazione
minx∈X
f(x)
e equivalente al problema di ottimizzazione
−maxx∈X
(−f(x))
Dimostrazione. Le famiglie di problemi
P := 〈f,X,min〉e
Q := 〈−f,X,max〉con X = Rn sono equivalenti. Infatti, considerate le trasformazioni
Φ : Φ (f,X,min) = 〈−f,X,max〉Ψ : Ψ (f,X,max) = 〈−f,X,min〉
φX(x) = x
ψX(x) = x
si ha:
27

1. l’insieme ammissibile di un problema in una delle due famiglie e identicoal corrispondente insieme nell’altra;
2. se un problema in P e illimitato, esiste una successione di soluzioniammissibili xk ⊆ X tale che limk f(xk) = −∞: utilizzando la stessasuccessione si ha che limk(−f(xk)) = +∞, il viceversa si dimostra inmaniera analoga;
3. se x ∈ argminx∈X f(x) allora x = φX(x) ∈ argmaxx∈X −f(x) e
viceversa. Infatti, se x ∈ argminx∈X f(x) significa che
f(x) ≤ f(x) ∀x ∈ Xma, in questo caso,
−f(x) ≥ −f(x) ∀x ∈ Xe l’equivalenza e provata.
Come ulteriore esempio di applicazione formale della nozione di equiva-lenza si consideri il caso dei problemi lineari con vincoli di diseguaglianza.
Teorema 3.2 I problemi:
P : min cTxAx ≤ bx ≥ 0
eQ : min cTxAx+ y = b
x, y ≥ 0
sono equivalenti.
Dimostrazione. Si considerino gli insiemi ammissibili
X = x ∈ Rn : Ax ≤ b, x ≥ 0Y =
(x, y) ∈ Rn+m : Ax+ y = b, x, y ≥ 0
e le trasformazioni
Φ :⟨cTx,X,min
⟩ → ⟨cTx+ 0Ty, Y,min
⟩28

con
φX(x) =
[x
b− Ax]
eΨ :
⟨cTx+ 0Ty, Y,min
⟩ → ⟨cTx,X,min
⟩con
ψY (x, y) = x.
1. occorre dimostrare che se x : Ax ≤ b, x ≥ 0 = ∅ allora (x, y) : Ax+y = b, x, y ≥ 0 = ∅, ovvero che se (x, y) : Ax + y = b, x, y ≥ 0 = ∅allora x : Ax ≤ b, x ≥ 0 = ∅. Infatti se esistesse (x, y) in Y allorax sarebbe tale che Ax ≤ b, x ≥ 0, ovvero x ∈ X e percio X = ∅.Analogamente se x ∈ X, scelto y = b − Ax si ha (x, y) ∈ Y , percioY = ∅.
2. se esiste una successione xk ammissibile per un problema P conlim cTxk = −∞, la successione, xk, yk con yk = b − Axk, forniscela dimostrazione di illimitatezza per il corrispondente problema in Q.Il viceversa si dimostra del tutto analogamente;
3. attraverso le trasformazioni φX e ψY si ottiene la corrispondenza cercataper gli ottimi dei due problemi. Infatti, se x e un ottimo per P , lacoppia
[x b− Ax ]
rappresenta una soluzione ammissibile per Q.Nessuna diversa soluzione ammissibile per Q puo avere costo inferiore aquesta: se per assurdo esistesse una soluzione ammissibile
[x y
]con
cT x < cTx, la soluzione x risulterebbe ammissibile per P e di costoinferiore a cTx; il viceversa e immediato.
Teorema 3.3 Dato un qualunque insieme P ∈ Rn, e due funzioni reali f, gda P in R, i problemi
minx,zz (3.9)
z = max f(x), g(x)x ∈ P
29

e
minx,zz (3.10)
z ≥ f(x)z ≥ g(x)x ∈ P
sono equivalenti.
Dimostrazione. La funzione obiettivo e la direzione dell’ottimizzazionesono le medesime nelle due famiglie di problemi. Una coppia di trasformazioniutilizzabile per la dimostrazione di equivalenza e data da
φX(x, z) = (x, z)
ψY (x, z) = (x,max f(x), g(x))1. Se l’insieme X = x, z : z = max f(x), g(x) , x ∈ P e vuoto, allo-
ra deve essere vuoto anche Y = x, z : z ≥ f(x), z ≥ g(x), x ∈ P eviceversa; infatti se esistesse una coppia (x, z) in X la stessa coppiafornirebbe un punto ammissibile per Y ; viceversa se esistesse una cop-pia ammissibile per Y , poiche la variabile z non compare nel vincolox ∈ P , basterebbe definire z′ = max f(x), g(x) per ottenere unasoluzione ammissibile (x, z′) di X.
2. Se il problema (3.9) e illimitato, esiste una successione xk, zk ammis-sibile con zk → −∞; la medesima successione prova l’illimitatezza delproblema (3.10); viceversa, data una successione xk, zk ammissibi-le per il problema (3.10) e con costo divergente a −∞, la successionexk, z′k = max f(xk), g(xk) risulta ammissibile per il problema (3.9)e con costo illimitato.
3. Infine, per quanto riguarda l’ottimalita, si osservi che, se (x, z) e otti-mo per (3.9), allora e anche ottimo per il secondo problema: se infattiesistesse una soluzione ammissibile (x, z) per il secondo problema, conz < z, si avrebbe anche f(x) < z e g(x) < z e, pertanto, la soluzione(x,max f(x), g(x)) sarebbe ammissibile per il primo problema e concosto inferiore a z; viceversa, data una soluzione ottimale (x, z) peril problema (3.10), sicuramente si avra z = max f(x), g(x), poichealtrimenti, non essendo la variabile z presente nei vincoli che definiscono
30

P , sarebbe possibile costruire soluzioni ammissibili con costo stretta-mente minore a z. La coppia (x, z) risulta dunque ottimale ancheper (3.9).
Grazie a questo teorema e quindi possibile trasformare problemi di mini-max in problemi equivalenti. Ad esempio, il problema non lineare
minx
maxcT1 x, c
T2 x, . . . , c
Tk x
Ax = b
x ≥ 0
risulta equivalente al problema di PL
minz,xz
z ≥ cT1 xz ≥ cT2 x. . .
z ≥ cTk xAx = b
x ≥ 0.
Da questo esempio si puo anche osservare che, affinche due famiglie diproblemi siano equivalenti, non e necessario che esista una trasformazionebiunivoca dell’insieme ammissibile di un problema nell’insieme ammissibiledell’altro: ad esempio, attraverso la trasformazione φX non e possibile otte-nere soluzioni ammissibili (x, z) del problema (3.10) con z > f(x), z > g(x).E’ importante, come si vede in questo caso, che le mappe φ e ψ abbiano co-me dominio un insieme che contiene i possibili punti di ottimo del problematrasformato, ma non necessariamente tutti i punti ammissibili.
Nel seguito le dimostrazioni di equivalenza verranno spesso presentatesottintendendo le trasformazioni tra famiglie di problemi, ma evidenziandosolamente le trasformazioni dell’insieme ammissibile di un problema nell’al-tro e viceversa, oppure le trasformazioni tra le funzioni obiettivo dei dueproblemi. Generalmente inoltre, per non appesantire troppo la notazione,si individuera una famiglia di problemi con un suo generico rappresentante,evitando quindi la presentazione formale della tripla.
31

La verifica di equivalenza puo essere effettuata sfruttando la seguentecondizione sufficiente:
Teorema 3.4 Due famiglie di problemi di minimizzazione P : minx∈X f(x)e Q : miny∈Y g(y) sono equivalenti se X = ∅ ⇒ Y = ∅, Y = ∅ ⇒ X = ∅ e seesistono due funzioni
φ : X → Y e ψ : Y → X
tali che:∀x ∈ X =⇒ g(φ(x)) ≤ f(x)
e∀ y ∈ Y =⇒ f(ψ(y)) ≤ g(y)
Dimostrazione.
1. Se esiste una successione di soluzioni ammissibili xk ⊆ X tale chelimk f(xk) = −∞, considerando la successione yk con yk = φ(xk), siosserva che
g(yk) = g(φ(xk)) ≤ f(xk)→ −∞da cui segue che il problema corrispondente in Q e illimitato. Il vice-versa si dimostra analogamente;
2. se x e un ottimo il problema in P , allora y = φ(x) e un ottimoper il corrispondente problema in Q. Infatti, se esistesse una soluzioneammissibile y ∈ Y per Q con costo g(y) < g(y), si avrebbe anche che
f(ψ(y)) ≤ g(y) < g(y) = g(φ(x)) ≤ f(x)
da cui segue l’assurdo.
Come esempio di applicazione della condizione sufficiente appena dimo-strata si consideri il caso dei problemi con variabili non vincolate in segno.La proprieta verra ora dimostrata in un caso piu generale di quello visto peril caso lineare.
Teorema 3.5 I problemi:P : min
x∈Xf(x)
32

e
Q : min f(u− v)u− v ∈ Xu, v ≥ 0
sono equivalenti.
Dimostrazione.
1. i due problemi sono o entrambi ammissibili o entrambi non ammissibili.Infatti, se ∃ x ∈ X, scegliendo
ui = max0, xi i = 1, . . . , n (3.11)
vi = −min0, xi i = 1, . . . , n (3.12)
si ottiene una soluzione[u v
]ammissibile perQ; viceversa se
[u v
]e ammissibile per Q, si vede immediatamente che x = u− v e ammis-sibile per P .
2. definendo
φ(x) =
[uv
]con u e v definiti tramite le (3.11) e (3.12) e
ψ(u, v) = u− vsi ottengono due mappe tra gli insiemi ammissibili dei due problemiche soddisfano i requisiti del teorema 3.4. Infatti
g(φ(x)) = g
([max(0, x)−min(0, x)
])= f(max(0, x) + min(0, x)) = f(x)
ef(ψ(u, v)) = f(u− v) = g(u, v)
Vale la pena osservare a questo punto che spesso uno stesso problema puoessere trasformato in diversi problemi equivalenti fra loro. Ad esempio si puovedere come e possibile trasformare un problema con variabili libere in segnoin uno equivalente che ha solo una variabile in piu rispetto all’originale. Quiper semplicita ci si limitera a presentare il caso in cui tutte le variabili sianolibere in segno:
33

Teorema 3.6 I problemiP : min
x∈Xf(x)
e
Q : min f(y − v1)y − v1 ∈ Xy ≥ 0 ∈ Rn
v ≥ 0 ∈ R
sono equivalenti.
(con 1 si e indicato un vettore di dimensione opportuna i cui elementi sonotutti pari ad 1)
La trasformazione che permette di dimostrare l’equivalenza e la seguente:
φ : x ∈ X →[yv
]
conv = −min0, min
j=1,...,nxj
eyj = xj + v,
mentreψ(y, v) = x
conxj = yj − v j = 1, . . . , n.
La dimostrazione formale dell’equivalenza viene lasciata come esercizio.
34

Capitolo 4
Teoria della ProgrammazioneLineare
4.1 Basi e soluzioni di base nella programma-
zione lineare
Si consideri un problema di programmazione lineare in forma standard:
min cTxAx = bx ≥ 0
E’ possibile, senza perdita di generalita, assumere la validita della seguenteipotesi:
1. Il numero m di righe della matrice A ∈ Rm×n e strettamente minoredel numero di colonne;
2. la matrice A ha rango pari al numero m di righe.
E’ chiaro che in molti casi queste ipotesi non sono verificate. Tuttavia epossibile ridurre l’analisi dei problemi di PL alle sole situazioni nelle quali ledue ipotesi sono valide. Da un punto di vista formale, si hanno i seguenticasi:
1. m > n: in questo caso nel sistema di equazioni Ax = b compaionopiu equazioni che incognite. Segue che o il sistema e privo di soluzioni,
35

nel qual caso il problema di PL sara non ammissibile, oppure, se esistealmeno una soluzione di Ax = b, almeno un’equazione e ridondante epuo essere eliminata. Si puo ripetere l’operazione, eliminando via viale equazioni ridondanti, fino ad ottenere un sistema nel quale m = n;
2. m = n: il sistema di equazioni e quadrato. Se det(A) = 0, esisteun’unica soluzione del sistema Ax = b: se tale unica soluzione ha com-ponenti tutte non negative, essa sara anche ottimale; se invece almenouna componente e negativa, il problema di PL e inammissibile. Seinvece det(A) = 0, di nuovo, o il sistema non ha soluzioni, oppure al-meno un’equazione puo essere eliminata. Ci si riconduce quindi al casom < n;
3. m < n: ancora, eliminando tutte le eventuali equazioni ridondanti, siarriva ad un sistema, equivalente a quello iniziale, caratterizzato dauna matrice dei coefficienti A con rango(A) = m.
Le considerazioni fatte qui sopra ci autorizzano a considerare solo proble-mi di PL che soddisfano alle due condizioni date. Tuttavia occorre ricordareche volendo giungere ad un algoritmo risolutivo, occorrera identificare unmetodo che permetta di trasformare un problema in uno equivalente chesoddisfi le ipotesi. Fortunatamente lo stesso metodo che verra utilizzato perla risoluzione dei problemi di PL, potra essere utilizzato anche per la verificadelle ipotesi, come si vedra piu avanti.
Si ipotizzi quindi che il rango di A sia m, pari al numero delle righe diA; in questo caso e sempre possibile scegliere tra le n colonne della matriceA un sottoinsieme costituito da m colonne fra loro linearmente indipenden-ti. Ammettendo che tali colonne abbiano indici corrispondenti ad un datoinsieme B e che le restanti abbiano indici nell’insieme N = 1, . . . , n \B, sipotra scrivere (a parte un eventuale scambio di colonne)
A = [AB AN ]
dove AB e una matrice (m,m) con determinante non nullo che viene detta
base.
Il nome di “base” deriva dal fatto che le m colonne di AB costituisconouna base per lo spazio euclideo m–dimensionale, cioe ogni elemento di Rm
puo essere espresso in modo univoco tramite una combinazione lineare delle
36

colonne di AB. Ricordando che anche il termine noto b e un vettore m–dimensionale, si ha che il sistema di equazioni
ABx = b
ammettera sempre una (ed una sola) soluzione
xB = A−1B b ∈ Rm.
Se si considera il vettore n−dimensionale x =
[xB0
]si vede immediata-
mente che tale vettore e una soluzione del sistema Ax = b. Infatti
Ax = [AB AN ]
[xBxN
]= ABxB + AN0 = ABA
−1B b+ 0 = b.
Una soluzione x cosı costruita viene chiamata
soluzione di base
corrispondente alla base AB. Le variabili xB si dicono
variabili di base.
Si noti che una soluzione di base possiede sempre almeno n−m compo-nenti uguali a zero. Potrebbe tuttavia averne anche piu di n −m nulle; intal caso la corrispondente soluzione di base si dice
soluzione di base degenere.
Per estensione anche la base si dira degenere.
4.2 Interpretazione del concetto di base
I concetti di base e di soluzione ammissibile di base si prestano a facili inter-pretazioni per alcuni dei problemi presentati nel capitolo 1. Ad esempio, unasoluzione di base nei problemi della dieta od in quelli di miscelazione ottimalecorrisponde ad una ricetta composta da un numero ridotto di elementi. Labase corrisponde ad un insieme di cibi i cui contributi nutritivi, opportuna-mente combinati, possono soddisfare esattamente qualsiasi esigenza. Occorrericordare che, nel problema della dieta, spesso i vincoli sono espressi come
37

disequazioni lineari; per poter parlare di basi e di soluzioni di base, occorreraquindi inserire delle variabili di slack e/o di surplus. Le basi potranno per-tanto essere costituite anche da coefficienti di variabili di slack o di surplus,non solo da quelli di variabili associate a cibi. Puo sembrare a prima vistapiuttosto restrittivo limitarsi a considerare le soluzioni di base, poiche, adesempio, in un problema di dieta ottimale in cui si debba ottenere la ricet-ta ottimale miscelando 100 cibi diversi in modo da soddisfare a 3 richieste(vincoli) sul contenuto nutritivo, le soluzioni di base saranno costituite danon piu di 3 cibi a livello strettamente positivo. Nel prossimo capitolo sivedra come cio non costituisca affatto una restrizione; naturalmente se, pernecessita diverse, quali ad esempio quella di voler garantire una certa varietaalla dieta, si desiderassero ricette con piu elementi non nulli (ad esempio,con almeno un primo, un secondo, un contorno), occorrerebbe modificare ilproblema, inserendo vincoli opportuni; in genere tali vincoli richiedono l’usodi variabili binarie o variabili indicatrici.
4.2.1 Basi e soluzioni di base nei problemi di flusso
Piu complessa, ma di notevole importanza sia teorica che applicativa, e l’in-terpretazione di base nei problemi di ottimizzazione su grafi introdotti nel-l’appendice A. Sia dato un grafo G = 〈V,E〉 con |V | = m e |E| = n, e siaA la matrice di incidenza (nodi–archi). Si consideri un problema di flusso dicosto minimo
min cTfAf = df ≥ 0
(4.1)
in cui si e supposto che la capacita minima di ogni arco sia 0 e quella massimasia +∞; il vettore d rappresenta la differenza tra flusso uscente da ciascunnodo e flusso entrante. Il generico problema con vincoli sul flusso sia inferioriche superiori puo essere trattato con relativa semplicita come estensione delproblema qui considerato. Si ipotizza in genere che
∑i∈V di = 0: infatti,
se cosı non fosse, il sistema sarebbe certamente privo di soluzioni poichesommando i membri di sinistra nella (4.1) si otterrebbe il vettore nullo. Sequindi i termini noti hanno somma paria a zero, segue che sicuramente almenouna delle equazioni Af = d e ridondante e puo essere eliminata senza chel’insieme ammissibile del problema vari. Questo significa anche che, ammessoche esistano soluzioni ammissibili, non potranno certamente esistere soluzionidi base, almeno se si intende il concetto di base in senso stretto, come definito
38

in precedenza. Il rango della matrice di incidenza non puo essere superiorea m− 1. Scelto comunque un nodo v, sia A\v la matrice di incidenza da cuie stata cancellata la riga corrispondente a v e sia d\v il vettore d modificatoin modo analogo. Ricordando che la matrice A ha m = |V | righe ed n = |E|colonne, vale la seguente proprieta fondamentale:
Teorema 4.1 La matrice A di incidenza di un grafo G = 〈V,E〉 ha rangopari a |V | − 1 se e solo se il grafo e connesso (debolmente).
La dimostrazione di questo importante teorema si basa su altre proprieta,altrettanto fondamentali:
Teorema 4.2 Un grafo e connesso se e solo se possiede un albero di suppor-to.
Teorema 4.3 La matrice di incidenza di un albero H = 〈V, T 〉 di supportoper G ha rango |V | − 1; inoltre essa puo essere scritta in forma triangolare,con elementi tutti pari a +1 o a −1 sulla diagonale.
I teoremi 4.2 e 4.3 implicano la condizione sufficiente del teorema 4.1; ilteorema seguente permette invece di dimostrarne la necessita.
Teorema 4.4 Gli archi corrispondenti alle colonne di una base della ma-trice di incidenza di G (privata di una riga qualsiasi) formano un albero disupporto per G.
Dimostrazione. (teorema 4.2): Dato un grafo connesso e possibile elimi-nare un arco alla volta, mantenendo sempre la connessione; dopo un numerofinito di iterazioni si ottiene un grafo connesso nel quale e impossibile eli-minare un arco senza perdere la connessione: questa condizione e necessariae sufficiente perche il grafo risultante sia un albero. La dimostrazione del-l’implicazione in senso opposto e banale: se un grafo contiene un albero disupporto, e certamente connesso.
Dimostrazione. (teorema 4.3) Il rango della matrice di incidenza di unsottografo di G qualsiasi non puo essere superiore a |V | − 1; dimostriamoche, nel caso degli alberi di supporto, e esattamente pari a |V | − 1. Ladimostrazione viene fatta per induzione su |V |. Il lemma vale se |V | = 2poiche in questo caso la matrice di incidenza ha una delle due forme possibili:[
+1−1
],
[ −1+1
]
39

ed eliminando una qualunque delle due righe si ottiene una matrice quadratadi rango |V | − 1 = 1, triangolare con elemento sulla diagonale pari a 1 o a−1.Supponendo valido il teorema per |V | = k, lo si dimostra ora per |V | = k+1.Per una proprieta elementare dei grafi, in ogni albero con almeno un arcoesistono almeno due foglie; sicuramente sara quindi sempre possibile scegliereuna foglia, w ∈ V , non coincidente con il nodo v (non e detto che v sia unafoglia, ma anche se lo fosse se ne potrebbe sempre trovare un’altra). Siae ∈ T l’unico arco dell’albero H incidente su w; eliminando dall’albero H ilnodo w e l’arco e, si ottiene un grafo ancora privo di cicli (poiche lo e H)e connesso (poiche si e eliminata una foglia), cioe si ottiene un albero H ′.H ′ e un albero con k nodi, quindi, per l’ipotesi di induzione, la sua matricedi incidenza, privata della riga associata a v, sara quadrata, invertibile escrivibile in forma triangolare (ad esempio, superiore) con tutti elementi paria ±1 sulla diagonale. Sia T ′ tale matrice. Orlando T ′ in basso con la rigaassociata a w e a destra con la colonna corrispondente a e si ottiene la matriceseguente: [
T ′ u0T ±1
]
dove il vettore u conterra un solo elemento non nullo. Essendo T ′ triangolaresuperiore, anche questa matrice sara triangolare e con elementi pari a ±1sulla diagonale. Da qui segue che la matrice cosı ottenuta e invertibile e ilteorema e dimostrato. Tale matrice corrisponde ad un riordinamento dellerighe e delle colonne della matrice di incidenza, privata di una riga, dell’albero
Si e quindi dimostrato che se un grafo G e connesso, esso possiede unalbero di supporto e, poiche la matrice di incidenza dell’albero di supportoha rango |V | − 1, anche la matrice di incidenza ha rango |V | − 1.
Occorre ora provare che se la matrice di incidenza di G ha rango |V | −1, esso e connesso, cioe possiede un albero di supporto. La dimostrazioneconsiste nel mostrare che le colonne corrispondenti ad una sottomatrice dellamatrice di incidenza di rango |V | − 1 sono associate agli archi di un alberodi supporto per G.
Dimostrazione. (Teorema 4.4) Si consideri una sottomatrice di A dirango |V | − 1 e siano Ae1 , Ae2 , . . . , Ae|V |−1
le sue colonne, corrispondenti adun sottografo di G. In tale sottografo non puo esistere alcun ciclo; infatti, se
40

in un grafo qualsiasi esistesse un ciclo orientato, diciamo
C = v0, v1, . . . , vk, vk+1 = v0,
composto dagli archi (v0, v1), . . . , (vk, v0), ricordando che la colonna dellamatrice di incidenza corrispondente ad un arco (i, j) puo essere scritta comeei − ej, dove ei e l’i–esimo versore, sommando le colonne della matrice diincidenza del ciclo si otterrebbe:
(ev0 − ev1) + (ev1 − ev2) + · · ·+ (evk−1− evk
) + (evk− ev0) = 0
Pertanto le colonne della matrice di incidenza associate ad un ciclo sonolinearmente dipendenti (una loro combinazione lineare con coefficienti pariad 1 fornisce il vettore nullo). Se il ciclo fosse non orientato, (si ricordi che unciclo non orientato e un grafo orientato in cui modificando l’orientamento dialcuni archi si puo ottenere un ciclo orientato) basterebbe scegliere un versodi percorrenza qualsiasi e moltiplicare per +1 gli archi percorsi “in avanti”e per −1 (il che equivale a cambiarne il verso) gli archi percorsi all’indietro.Quindi anche in questo caso si otterrebbe una combinazione non banale chedimostra la dipendenza lineare.
Si e quindi dimostrato che se un sottoinsieme delle colonne di una matricedi incidenza e formato da vettori linearmente indipendenti, il grafo corrispon-dente e aciclico; nel caso di un sottoinsieme di |V |−1 colonne tale grafo saraun albero di supporto, essendo aciclico e composto da |V | − 1 archi.
Dai teoremi appena dimostrati segue quindi che vi e corrispondenza biu-nivoca tra alberi di supporto di un grafo connesso e matrici (|V |− 1, |V |− 1)invertibili.
Il teorema 4.3, assieme al teorema 4.4, implica un’altra importante pro-prieta dei problemi di flusso a costo minimo, e cioe che se il termine noto dnella (4.1) e intero, allora ogni soluzione di base del problema di PL corrispon-dente sara intera. Infatti, poiche ogni soluzione di base si ottiene risolvendoun sistema di equazioni del tipo
ABf = d
e poiche AB puo essere portata in forma triangolare superiore con elementisulla diagonale tutti pari a ±1, risolvendo il sistema partendo dall’ultimaequazione si vede immediatamente che tutte le componenti di f sarannocombinazioni lineari a coefficienti interi di d.
41

Esempio 4.1 Si consideri il problema di flusso a costo minimo caratteriz-zato dal grafo nella figura seguente, in cui la quantita indicata sugli archirappresenta il costo associato all’arco.
A
2
1
B4 C
3
D3
3
E
2
6
4
1
F
1
G
5
2 H
2
6 I
3
Si suppone che il vettore d sia definito da d(A) = +8, d(E) = −3, d(I) = −5e d(v) = 0 per ogni altro nodo v. Il sottografo rappresentato nella prossimafigura e un albero di supporto.
A
2
B C
D
3
E
2
6
4 F
G
5
2 H6 I
La sottomatrice della matrice di incidenza corrispondente a tale albero e datada
AD DG EB EC EF GE GH HIA +1 0 0 0 0 0 0 0B 0 0 −1 0 0 0 0 0C 0 0 0 −1 0 0 0 0D −1 +1 0 0 0 0 0 0E 0 0 +1 +1 +1 −1 0 0F 0 0 0 0 −1 0 0 0G 0 −1 0 0 0 +1 +1 0H 0 0 0 0 0 0 −1 +1I 0 0 0 0 0 0 0 −1
.
Eliminando una riga da questa matrice, ad esempio la riga corrispondentead A, si ottiene una matrice quadrata. Il teorema 4.3 garantisce che questamatrice e una base.Tale teorema afferma che e possibile trasformare in formatriangolare superiore tale sottomatrice. La tecnica per ottenere tale trasfor-mazione, indicata dal procedimento per induzione usato nella dimostrazione,
42

consiste nell’iniziare ad elencare i nodi partendo da una foglia e aggiungendol’unico arco su di essa incidente. E’ possibile iniziare da una qualsiasi fo-glia, purche non coincidente con il nodo associato alla riga che si e eliminatadalla matrice di incidenza. Ad esempio, si puo iniziare con la foglia I e l’ar-co (H, I) incidente su di essa; immaginando di eliminare tale foglia e l’arcocorrispondente si otterrebbe un albero con un nodo in meno. Se si sapesseportare in forma triangolare superiore la matrice di incidenza di tale albe-ro, la si potrebbe orlare con la riga associata ad I e la colonna associata ad(H, I) mantenendo la forma triangolare. A questo punto si prosegue in mo-do ricorsivo, analizzando il sottoalbero privo della foglia I. Anche in questosottoalbero esistera almeno una foglia (non coincidente con A). Proseguendosi potrebbe ottenere la seguente sequenza di foglie: H,F,C,B,E,G,D. Siottiene quindi la matrice riordinata
AD DG GE EB EC EF GH HID −1 +1 0 0 0 0 0 0G 0 −1 +1 0 0 0 +1 0E 0 0 −1 +1 +1 +1 0 0B 0 0 0 −1 0 0 0 0C 0 0 0 0 −1 0 0 0F 0 0 0 0 0 −1 0 0H 0 0 0 0 0 0 −1 +1I 0 0 0 0 0 0 0 −1
Osservando che il vettore richieste, riordinato coerentemente, ha la forma
dT =[0 0 −3 0 0 0 0 −5 ]
si determina immediatamente la soluzione di base corrispondente:
f(HI) = 5
f(GH) = 0 + f(HI) = 5
f(EF ) = 0
f(EC) = 0
f(EB) = 0
f(GE) = 3 + f(EB) + f(EC) + f(EF ) = 3
f(DG) = f(GE) + f(GH) = 8
f(AD) = f(DG) = 8
43

che e una soluzione ammissibile di base. Il costo di questa soluzione e paria 2 · 8 + 3 · 8 + 5 · 3 + 2 · 5 + 6 · 5 = 95. Esistono altre soluzioni di baseammissibili, alcune delle quali con costo inferiore a quello della soluzionequi determinata. Non e detto che un albero di supporto corrisponda sempread una base ammissibile. Ad esempio, sostituendo l’arco (H, I) con l’arco(I, F ), si otterrebbe un nuovo albero, ma non una soluzione ammissibile.
4.3 Il teorema fondamentale della program-
mazione lineare
Un aspetto fondamentale del metodo del simplesso che verra presentato piuavanti e che, nel corso delle iterazioni, esso produce soluzioni ammissibili(cioe soluzioni che soddisfano tutti i vincoli) di base. Il teorema seguentefornisce il necessario supporto teorico:
Teorema 4.5 Si consideri un problema di programmazione lineare in formastandard, con m vincoli, n incognite, m < n e di rango m.
1. esiste una soluzione ammissibile se e solo se esiste almeno una solu-zione ammissibile che e anche di base;
2. esiste una soluzione ottimale se e solo se esiste almeno una soluzioneottimale che e anche di base.
Siamo quindi autorizzati a limitarci all’esplorazione delle soluzioni di base,poiche tra di esse, se il problema ammette ottimo, si trovera la soluzioneottimale; cio non vuol dire che non possano esistere soluzioni ottimali non dibase, ma almeno una delle soluzioni ottimali deve essere di base. Le eventualisoluzioni ottimali alternative avranno, naturalmente, tutte lo stesso costo.Si osservi che questo teorema permette, in un certo senso, di passare da unproblema in cui lo spazio delle soluzioni da analizzare per trovare l’ottimoe un “continuo”, ad un insieme di candidati ottimi discreto, anzi, finito:infatti le soluzioni di base nascono dall’identificazione di una sottomatriceAB invertibile costituita da m colonne della matrice originale A, e pertantoil numero complessivo di possibili basi non potra superare il numero (finito)di modi in cui e possibile scegliere m colonne da un insieme di n, e cioe(
n
m
)=
n!
m!(n−m)!.
44

Naturalmente la finitezza del numero massimo di basi, se da un lato per-mette di pensare ad una procedura finita per la risoluzione di un genericoproblema di programmazione lineare per il quale sia nota l’esistenza di unasoluzione ottima, dall’altro non rappresenta un risultato molto potente. Ilnumero di basi di un problema di programmazione lineare cresce, al cresce-re di n ed m ad una velocita tale da rendere totalmente impraticabile lastrada dell’enumerazione esplicita di tutte le soluzioni di base. Il metododel simplesso si e spesso dimostrato in pratica estremamente efficiente neldeterminare una base ottimale evitando di generare esplicitamente tutte lesoluzioni di base, compiendo cioe un’enumerazione implicita delle basi.
Come ulteriore osservazione si puo far notare che, se da un lato questaproprieta ha fornito la giustificazione teorica del metodo del simplesso, dal-l’altro e stata spesso considerata come una caratteristica irrinunciabile deglialgoritmi per la programmazione lineare: solo recentemente sono stati svilup-pati algoritmi radicalmente diversi dal metodo del simplesso che procedonogenerando via via soluzioni intermedie non di base.
Passiamo ora alla dimostrazione del teorema fondamentale, che contienein nucleo alcuni degli aspetti che caratterizzano il metodo del simplesso.
Dimostrazione.
1. La condizione sufficiente si dimostra banalmente; per quanto riguardala condizione necessaria, si consideri una soluzione ammissibile x delsistema Ax = b. La matrice A puo essere vista come accostamento din vettori colonna:
A = [A1 A2 · · · An ]
e pertanto il sistema di equazioni Ax = b puo essere scritto nella forma
n∑j=1
Ajxj = b;
in altri termini si puo esprimere il vettore b come combinazione linearedelle colonne di A mediante i coefficienti xj. Sia p, (0 ≤ p ≤ n), ilnumero di componenti non nulle nel vettore x. Si puo sempre supporreche le eventuali componenti non nulle occupino i primi p posti nelvettore x: sia cioe
x =[x1 x2 . . . xp 0 . . . 0
]T.
45

Avendo espresso x in questo modo, sara vero che
p∑j=1
Ajxj = b.
Per quel che riguarda le colonne dei coefficienti delle componenti nonnulle di x si possono distinguere due situazioni possibili:
(a) le colonne A1, . . . , Ap sono linearmente indipendenti. In questocaso p e certamente non maggiore di m, poiche non possono esi-stere piu di m colonne linearmente indipendenti in una matricedi rango m. Se p = m la soluzione x e una soluzione di base(la corrispondente sottomatrice AB =
[A1 . . . Am
]di A e in-
vertibile); se invece p < m, per una proprieta elementare dellematrici, sicuramente tra le colonne Ap+1, . . . , An se ne possonoscegliere m− p che, assieme alle prime p colonne, formano un si-stema di m vettori linearmente indipendenti (cioe una base). Sia-no Ai1 , Ai2 , . . . , Aim−p tali colonne. Il vettore x rappresenta unasoluzione di base corrispondente alla base
AB =[A1 A2 · · · Ap Ai1 Ai2 · · · Aim−p
]Infatti, la combinazione lineare
A1x1 + · · ·+ Apxp + Ai10 + · · ·+ Aim−p0 = b
e ancora valida e, dato che i coefficienti formano una matrice in-vertibile, la soluzione x1, . . . , xp, 0, . . . , 0 sara l’unica soluzione (dibase) del sistema ABx = b. In questo caso, in cui sono nulle al-cune delle componenti della soluzione di base (oltre naturalmentea quelle fuori base), la soluzione di base e la base stessa sonodegeneri.
(b) le colonne A1, . . . , Ap sono linearmente dipendenti. La tecnicadimostrativa consiste in questo caso nel generare soluzioni ammis-sibili con un numero decrescente di componenti non nulle, finoa ridursi al caso in cui i coefficienti di tali variabili formino uninsieme di vettori linearmente indipendenti (caso a). Dalla defini-zione di vettori linearmente dipendenti si deduce che sicuramente
46

esistono p coefficienti d1, d2, . . . , dp non tutti nulli tali che
p∑j=1
Ajdj = 0.
Ricordando che vale la relazionep∑
j=1
Ajxj = b
si ottiene immediatamente chep∑
j=1
Aj(xj + εdj) = b ∀ε ∈ R.
Introducendo il vettore n−dimensionale
d =[d1 d2 . . . dp 0 0 . . . 0
]T,
si haA(x+ εd) = b.
Mentre per qualsiasi valore di ε, il vettore x + εd e soluzione delsistema Ax = b, non e detto che in generale tale vettore sia solu-zione ammissibile. L’idea e a questo punto di scegliere ε in modotale da annullare almeno una componente di x+ εd senza perderel’ammissibilita. Si e visto che non tutte le componenti di d sononulle; si consideri ora ciascuna componente del vettore x+ εd, conε ∈ R (ci si puo limitare alle componenti di indice j = 1, . . . , p,essendo tutte le altre pari a 0):
• se dj = 0 allora xj + εdj = xj > 0 ∀ε;• se dj < 0 allora xj + εdj ≥ 0 ∀ε ≤ − xj
dj;
• se dj > 0 allora xj + εdj ≥ 0 ∀ε ≥ − xj
dj.
Dovendo rispettare il vincolo sul segno di ciascuna componentedel vettore xj + εdj, occorrera scegliere per ε la condizione piurestrittiva. Siano:
εl = maxj:dj>0
− xjdj
εu = minj:dj<0
− xjdj
47

Si noti che εl < 0 e che εu > 0 e che almeno uno dei due termini εl,εu e finito, grazie al fatto che non tutti gli elementi dj, j = 1, . . . , psono nulli.Supponendo che ad esempio εu sia finito, allora il vettore
x := x+ εud
e ancora soluzione, ma con al piu p− 1 componenti non nulle. Seinvece εu = +∞, sicuramente si avra −∞ < εl < 0, nel qual casosara il vettore
x := x+ εld
ad avere al piu p− 1 componenti non nulle. Sostituendo al postodi x la nuova soluzione ammissibile x, si puo ripetere il procedi-mento, fino a giungere, in non piu di p iterazioni, ad una soluzionecorrispondente a colonne linearmente indipendenti (caso a), cioead una soluzione di base.
2. Per dimostrare la seconda parte del teorema, cioe che se esiste una solu-zione ottimale, esiste pure una soluzione ottimale di base (il viceversa ebanale), si procede sulla falsariga della dimostrazione della prima par-te. Si ipotizzi di avere a disposizione una soluzione x ammissibile eottimale. Si distinguono ancora i due casi:
(a) le colonne A1, . . . Ap sono linearmente indipendenti. In questo casola soluzione considerata e gia (a parte l’eventuale aggiunta di zeri)una soluzione di base, ed il teorema e dimostrato;
(b) le colonne sono linearmente dipendenti. Procedendo come nellaprima parte della dimostrazione, si osserva che, perturbando ilvettore x, il costo
cT x
viene modificato incT (x+ εd).
Da quanto gia illustrato, si vede immediatamente che x + εd eammissibile per ogni ε ∈ [εl, εu]. Da qui si deduce che cTd deveessere necessariamente nullo: infatti, se cTd fosse strettamente
48

positivo, scegliendo εl ≤ ε < 0 si avrebbe
cT (x+ εd) = cT x+ εcTd
< cT x
che e assurdo essendo x una soluzione ottimale. Analogamente sefosse cTd < 0, scegliendo 0 < ε ≤ εu si avrebbe
cT (x+ εd) = cT x+ εcTd
< cT x
Pertanto, essendo cTd = 0, lo spostamento ammissibile da x a x+εd, con ε ∈ [εl, εu], effettuato come indicato nella prima parte delladimostrazione mantiene, oltre all’ammissibilita, anche l’ottimalita.La nuova soluzione, ancora ottimale, avra al piu p−1 componentinon nulle; iterando il procedimento ci si riconduce in un numerofinito di passi, al caso a.
La dimostrazione precedente e importante da un punto di vista metodo-logico poiche evidenzia una delle tecniche principali su cui e basato il piupopolare algoritmo per la risoluzione di problemi di PL: il metodo del sim-plesso. L’aspetto piu interessante e la tecnica mediante la quale si passa dauna soluzione ammissibile ad un’altra mediante uno spostamento ammissi-bile. L’algoritmo del simplesso, come si vedra nei prossimi paragrafi, sfruttaesattamente lo stesso procedimento, passando da una soluzione ammissibiledi base all’altra mediante spostamenti ammissibili. A questo proposito, siricorda che, considerato un insieme generico S ⊆ Rn ed un punto x ∈ S, sidice che un vettore d ∈ Rn rappresenta direzione ammissibile in x se esisteε > 0 tale che
x+ εd ∈ S ∀ ε ∈ [0, ε].
In base alla definizione la direzione degenere d = 0 e sempre ammissibile: inquesto caso si ammette anche che ε = 0. Nel caso di insiemi ammissibili diproblemi di programmazione lineare in forma standard, si ha
S = x ∈ Rn : Ax = b, x ≥ 0quindi le direzioni ammissibili in x saranno caratterizzate da
A(x+ εd) = b, x+ εd ≥ 0
49

cioe daAd = 0, x+ εd ≥ 0.
Si vede quindi che le direzioni ammissibili sono identificabili con un sot-toinsieme degli elementi del nucleo (Ker) della matrice A; nella dimostra-zione del teorema fondamentale, in particolare nella seconda parte, gioca unruolo fondamentale la possibilita di compiere un passo non nullo sia in dire-zione d che in direzione −d. Questo equivale, nella scelta di una direzioneammissibile d, a poter compiere spostamenti ammissibili caratterizzati daun passo ε sia positivo che negativo; da qui segue immediatamente che, pergarantire la non negativita, per ciascuna componente xj = 0 si avra neces-sariamente dj = 0. Le direzioni utilizzate nella dimostrazione del teoremafondamentale sono quindi “bi–ammissibili” (cioe ammissibili in entrambe ledirezioni). Si e quindi anche implicitamente dimostrato che in corrispon-denza di una soluzione ammissibile non di base, esiste sempre almeno unadirezione bi–ammissibile. Nell’esempio seguente viene mostrata la tecnica diperturbazione ammissibile vista nella dimostrazione del teorema.
Esempio 4.2 Si consideri il seguente insieme dei vincoli di un problema diPL:
1 −1 1 0 2 1 2−1 0 0 1 1 2 10 0 1 1 −1 1 1
x =
3
11
x ≥ 0.
E immediato verificare che il vettore x =[1 1 1 1 1 0 0
]Te una
soluzione ammissibile (cioe verifica i vincoli sopra indicati). Tuttavia sicura-mente non e una soluzione di base, avendo 5 elementi non nulli. Seguendo latecnica usata nella dimostrazione del teorema si individua una perturbazioneammissibile della soluzione x.Le colonne corrispondenti agli elementi non nulli di A sono le prime 5; efacile vedere che una combinazione lineare di tali colonne con coefficienti adesempio pari a: [
1 0 −1 1 0]T
fornisce il vettore nullo. Lo spostamento ammissibile avviene quindi nella
direzione d =[1 0 −1 1 0 0 0
]T. Scegliendo un passo ε si ottiene il
50

nuovo punto
x(ε) =
1111100
+ ε
10−11000
=
1 + ε1
1− ε1 + ε100
Per mantenere l’ammissibilita si dovra scegliere il passo ε ∈ [−1, 1]. Sce-gliendo ad esempio il passo −1 si ottiene la soluzione ammissibile x =[0 1 2 0 1 0 0
]Tche e di base, essendo le colonne numero 2, 3, 5
della matrice originale fra loro linearmente indipendenti; scegliendo invece il
passo ε = 1, si ottiene la soluzione ammissibile x =[2 1 0 2 1 0 0
]Tche non e di base; iterando il procedimento, scegliendo ad esempio come coef-ficienti delle colonne numero 1, 2, 4, 5 i valori 2 4 1 1 si ottiene lo spo-
stamento ammissibile d =[2 4 0 1 1 0 0
]T; applicando il criterio
per la determinazione del passo massimo in entrambe le direzioni si ottieneche, essendo d non negativo, εu = +∞ – come e facile verificare, infatti, tuttii punti
x(ε) =
2 + 2ε1 + 4ε
02 + ε1 + ε00
sono soluzioni ammissibili, per qualunque valore di ε ≥ 0. Per quantoriguarda invece gli spostamenti in direzione negativa, si ha
εl = maxj:dj>0
− xjdj
= max
−2
2;−1
4;−2
1;−1
1
= −1
4
da cui si ottiene la nuova soluzione ammissibile
x =[
32
0 0 74
34
0 0]
E’ facile verificare che la sottomatrice costituita dalla prima, quarta e quintacolonna di A e invertibile; la soluzione trovata e dunque una soluzione di base.
51

Nei prossimi capitoli si vedra come questa tecnica di spostamento lungodirezioni ammissibili possa essere sfruttata per mettere a punto efficientialgoritmi risolutivi per problemi di PL.
52

Capitolo 5
Il metodo del simplesso
5.1 Un esempio d’uso del metodo del simples-
so
Si consideri un problema di programmazione lineare caratterizzato solamenteda vincoli di “≤” e variabili vincolate in segno; si ipotizzi anche che tutti itermini noti bi siano non negativi:
minn∑
j=1
cjxj
n∑j=1
aijxj ≤ bi i = 1, . . . ,m
xj ≥ 0 j = 1, . . . , n.
Introducendo m variabili di slack per portare il sistema in forma standardsi arriva alla forma
minn∑
j=1
cjxj
n∑j=1
aijxj + si = bi i = 1, . . . ,m
xj ≥ 0 j = 1, . . . , nsi ≥ 0 i = 1, . . . ,m.
(5.1)
Grazie alla presenza delle variabili di slack e facile scrivere la soluzione
53

generale del sistema di equazioni (5.1):
si = bi −n∑
j=1
aijxj i = 1, . . . ,m. (5.2)
In questo caso si vede immediatamente come il sistema che, in formastandard, contiene m equazioni ed n +m incognite, possa essere risolto as-segnando valore arbitrario a n variabili (si osservi che n = (n + m) − m,cioe e pari al numero delle incognite meno il rango del sistema). La rap-presentazione (5.2) viene a volte detta “dizionario”, poiche corrisponde alladefinizione di un simbolo (si) mediante altri simboli. Nella terminologia dellaprogrammazione lineare si dice anche che mediante la (5.2) le variabili di bases1, . . . , sm sono esplicitate in funzione delle variabili non di base x1, . . . , xn.Nel caso dell’esempio qui riportato, la matrice dei coefficienti delle variabili dislack e certamente una matrice invertibile, cioe una base, essendo la matriceidentica.
Per introdurre il metodo del simplesso utilizziamo un semplice esempionumerico. Si consideri il problema
minx− 4y
x+ y ≤ 1
x− 2y ≤ 0
−x+ y ≤ 1
2x, y ≥ 0
Inserendo le opportune variabili di slack ed introducendo una variabile ausi-liaria z per rappresentare la funzione obiettivo, il problema precedente puoessere scritto come
min z = x− 4y
s = 1− x− yt = −x+ 2y
u =1
2+ x− y
x, y, s, t, u ≥ 0
Si dice che la forma precedente corrisponde alla rappresentazione del pro-blema originale in funzione della base costituita dalle variabili s, t, u; sarebbe
54

piu corretto dire che la base e costituita dalla matrice dei coefficienti di talivariabili, ma spesso si usera indifferentemente il termine “base” anche per in-dicare un insieme di variabili i cui coefficienti formano una base. Le variabilix ed y sono “fuori base”. Assegnando ad x ed y valori arbitrari, si ottengonotutte le soluzioni del sistema di equazioni appena scritto. Occorre ricordarsipero che qui stiamo trattando il caso di problemi con disequazioni – anche nelcaso standard compaiono delle disequazioni: sono i vincoli di non negativita– anche se apparentemente semplici, queste disequazioni rappresentate daivincoli di segno costituiscono la vera novita della programmazione lineare,rispetto al classico trattamento dei sistemi di equazioni lineari.
Quando un sistema e scritto nella forma del dizionario visto sopra, e pos-sibile ottenere immediatamente una soluzione particolare assegnando valore0 a tutte le variabili fuori base: il vettore di valori cosı ottenuto si dice so-luzione di base. Nel caso del sistema in esame, ponendo uguali a 0 le duevariabili fuori base x ed y si ottiene la soluzione di base
x = 0, y = 0, s = 1, t = 0, u =1
2;
il costo associato a questa soluzione di base e z = 0.Il nucleo dell’algoritmo del simplesso e l’operazione che ora stiamo per
descrivere, detta operazione di pivot o di cardine, mediante la quale si pas-sa dal dizionario corrispondente ad una base ad un dizionario relativo aduna base diversa, tramite semplici operazioni di trasformazione del sistemalineare. Lo scopo e quello di ottenere cosı facendo una soluzione di base conobiettivo inferiore.
Il ragionamento su cui si fonda l’operazione di pivot e piuttosto elementa-re: nell’attuale soluzione di base tutte le incognite fuori base hanno valore 0:si cerca, se e possibile, di incrementare il valore di una delle incognite fuoribase in modo tale da
1. generare un nuovo dizionario (associato ad una nuova base);
2. garantire che la soluzione di base associata al nuovo dizionario siaancora ammissibile;
3. migliorare l’obiettivo.
Consideriamo l’esempio: in corrispondenza della soluzione di base cor-rente sia x che y valgono 0. Se si provasse ad incrementare la sola variabile
55

x non si otterrebbe un miglioramento dell’obiettivo: infatti, essendo il costoz = x− 4y, mantenendo y = 0 e rendendo positivo, se possibile, x, si otter-rebbe un aumento di z, l’esatto opposto di cio che desidereremmo. Questonon significa che nessuna soluzione con x positivo sia conveniente – significasoltanto che non e conveniente incrementare x in questo momento. Al con-trario, un incremento di y, lasciando x a 0, porterebbe ad una diminuzionedel costo – una diminuzione di 4 unita per ogni unita di incremento di y. Diquanto e possibile incrementare y, lasciando invariato x = 0? Per quantoriguarda il sistema di equazioni, non esistono vincoli ai valori assumibili day; tuttavia occorre rispettare i vincoli di non negativita per tutte le variabili.Esaminandoli singolarmente, si osserva che:
• x resta fissato a 0;
• y e scelto non negativo per costruzione;
• s resta non negativo se e solo se 1− y ≥ 0, cioe se y ≤ 1;
• la non negativita di t e assicurata per qualsiasi valore di y ≥ 0;
• quella di u solo per y ≤ 12.
Pertanto, mentre per soddisfare il sistema di equazioni avremmo potutoscegliere y liberamente, per tener conto dei vincoli sul segno siamo costretti alimitare la scelta ai valori 0 ≤ y ≤ 1
2. Poiche maggiore e il valore di y, minore
sara il valore dell’obiettivo, la scelta piu conveniente pare essere y = 12.
Per costruzione, solo le variabili di base possono assumere valore non nul-lo; pertanto per ottenere una soluzione di base con y = 1
2dovremo scrivere
un dizionario nel quale y compaia fra le variabili di base; ma il numero divariabili nella base e fissato e pari ad m, pertanto una variabile che attual-mente fa parte della base dovra lasciare il posto ad y. Poiche si e sceltodi dare ad y il massimo valore possibile, compatibilmente con i vincoli sulsegno, tale scelta avra l’effetto di rendere nulla una (in genere, almeno una)delle attuali variabili di base. Nel caso in esame, sara u ad annullarsi quandoy = 1
2. Questa variabile e la candidata naturale per lasciare il posto in base
ad y. Riscriviamo quindi il dizionario esplicitando le equazioni rispetto alleincognite s, t, y: dalla terza equazione ricaviamo y = 1
2+x−u che, sostituita
56

nelle prime due e nell’obiettivo, porta al dizionario seguente:
z = −2− 3x+ 4u
s =1
2− 2x+ u
t = 1 + x− 2u
y =1
2+ x− u.
Si noti che in questo dizionario si sono tralasciate sia l’indicazione delladirezione dell’ottimizzazione (min) che i vincoli di non negativita su tutte levariabili: adottando la convenzione di associare un dizionario solo a problemidi programmazione lineare standard, sara sempre sottinteso che i problemisaranno di minimo e con tutte le variabili non negative.
Il dizionario appena ricavato e, naturalmente, una rappresentazione esat-tamente equivalente alla precedente, ottenuta con operazioni standard di tra-sformazione di sistemi lineari (si tratta del metodo di eliminazione di Gauss).Tuttavia questa rappresentazione permette una lettura piu agevole ed indicala strada verso la soluzione ottimale. In particolare, questo dizionario e as-sociato ad una nuova soluzione di base, facilmente leggibile ponendo ugualia zero le variabili fuori base, corrispondente ai valori
x = 0, y =1
2, s =
1
2, t = 1, u = 0
e caratterizzata da un costo z = −2 (leggibile anche direttamente dalla primaequazione, ponendo x = u = 0).
I coefficienti delle variabili non di base nell’espressione dell’obiettivo sidicono coefficienti di costo ridotto o anche prezzi ombra. Come gia vistoprecedentemente, il segno dei coefficienti di costo ridotto e particolarmen-te utile nella determinazione della variabile entrante in base, cioe di quellavariabile, attualmente fuori base – e quindi a valore nullo nella soluzione dibase corrente – che conviene rendere positiva. Si vede immediatamente checoefficienti di costo ridotto positivi corrispondono a variabili il cui ingresso inbase porterebbe tendenzialmente ad un peggioramento del costo; le variabiliche possono entrare a far parte della base con profitto (cioe con diminuzionetendenziale del costo) sono quelle alle quali e associato un coefficiente di costoridotto negativo. Quelle con coefficiente di costo ridotto 0 non comportanoalcuna variazione nell’obiettivo. Queste considerazioni hanno solo valore lo-cale, nel senso che una variabile con coefficiente di costo ridotto positivo ad
57

un’iterazione, e quindi non conveniente rispetto alla base corrente, potrebberisultare conveniente in un’iterazione successiva.
Nell’esempio, il coefficiente di costo ridotto di x e pari a −3: cio significache per ogni unita di incremento assegnato ad x il costo diminuira di 3 unita.Il coefficiente di costo ridotto di u e invece positivo, pari a 4: un eventualeinnalzamento del livello di u provocherebbe un aumento del costo. Si notiche la positivita del coefficiente di costo ridotto della variabile appena uscitadi base non e casuale, ma e conseguenza del fatto che un eventuale ingressoin base di u riporterebbe il dizionario ad assumere la forma iniziale, conconseguente aumento del costo.
Ripetendo il ragionamento svolto in precedenza, analizziamo l’effetto cheun innalzamento del livello di x potrebbe avere sui vincoli di segno: dallaprima equazione otteniamo che la condizione di non negativita di s e x ≤ 1
4;
dalla seconda non abbiamo vincoli (un incremento di x non puo renderenegativa t) e cosı pure dalla terza. Quindi la scelta sara quella di far entrarex in base a livello 1
4, facendo uscire nel frattempo la variabile s (divenuta
pari a 0).Ricavando x dalla prima equazione e sostituendola nelle rimanenti, si
ottiene
z = −11
4+
3
2s+
5
2u
x =1
4− 1
2s+
1
2u
t =5
4− 1
2s− 3
2u
y =3
4− 1
2s− 1
2u.
Questo dizionario corrisponde ad una base costituita da x, y, t e rappre-senta una soluzione di base con
x =1
4, y =
3
4, s = 0, t =
5
4, u = 0
e costo pari a −11/4. In teoria si potrebbero scrivere dizionari diversi; tutta-via si puo osservare che i coefficienti di costo ridotto di entrambe le variabilinon di base sono positivi (basterebbe in realta che fossero non negativi).Poiche le soluzioni ammissibili sono un sottoinsieme delle soluzioni ottenuteassegnando valore arbitrario, ma non negativo, alle due variabili fuori base
58

(t, y), dall’espressione z = −114+ 3
2s + 5
2u si deduce che nessuna soluzione
ammissibile puo avere obiettivo inferiore a −11/4. Pertanto la soluzione dibase corrente e ottimale: abbiamo risolto il problema dato.
Vale la pena di sottolineare quanto appena visto:
Teorema 5.1 Se ad una soluzione ammissibile di base sono associati coeffi-cienti di costo ridotto non negativi, tale soluzione e ottimale.
5.2 Presentazione dell’algoritmo del simples-
so mediante dizionario.
Lo schema computazionale visto nel paragrafo precedente puo essere facil-mente generalizzato a problemi generici di programmazione lineare. Occorrericordare pero che nell’esempio visto sono state introdotte varie ipotesi sem-plificatrici e che nulla e stato detto circa la teoria del metodo. Inoltre i codicidi calcolo disponibili in commercio non utilizzano la forma del “dizionario”,ma usano raffinamenti del metodo e strutture dati particolari sia per evitarei problemi derivanti dagli errori di arrotondamento, sia per poter gestire inmodo efficiente problemi di grande dimensione – si pensi che attualmente epossibile risolvere, con macchine di normali capacita di calcolo, problemi conmigliaia di incognite e vincoli e che, su macchine potenti, si arriva anche aproblemi con milioni di variabili e centinaia di migliaia di vincoli.
Ricordiamo innanzitutto lo sviluppo del metodo cosı come esemplificatonel precedente paragrafo. Si e ipotizzato di avere un dizionario iniziale – che,nell’esempio, era costituito dalle variabili di slack, ma, in genere, puo essere
59

composto da m variabili qualsiasi, purche formino una base – nella forma:
z = z +n∑
j=m+1
cjxj
x1 = b1 +n∑
j=m+1
a1jxj
x2 = b2 +n∑
j=m+1
a2jxj
...
xm = bm +n∑
j=m+1
amjxj
dove b1, . . . , bm sono costanti non negative – l’ipotesi di non negativita elegata alla necessita di avere una base iniziale ammissibile.
Si tratta quindi di un problema con n incognite, m vincoli di eguaglianza,il vincolo di non negativita (sottointeso per tutte le incognite), un obiettivo zda minimizzare. I coefficienti cj nell’equazione dell’obiettivo sono i coefficientidi costo ridotto; la base e formata dalle incognite x1, . . . , xm, mentre fuoribase abbiamo le incognite xm+1, . . . , xn.
Se tutti i coefficienti di costo ridotto sono non negativi, allora questa basee ottimale e la soluzione ottimale del problema e data da
x1 = b1, x2 = b2, . . . , xm = bm, xm+1, . . . , xn = 0
con costo pari a z.Altrimenti certamente esistera almeno un coefficiente di costo ridotto
strettamente minore di 0. Sia l’indice di un simile coefficiente: c < 0.L’incognita (fuori base) x e “competitiva” rispetto a quelle attualmente inbase: un suo eventuale ingresso in base, ad un livello strettamente positi-vo, porterebbe ad un miglioramento del costo; in particolare, per ogni unitadi x in base si avrebbe una variazione pari a c del costo. Per capire se epossibile fare entrare in base tale variabile e, in caso affermativo, poter co-struire il nuovo dizionario, occorre considerare i vincoli ed analizzare l’effettoche l’eventuale ingresso di tale variabile in base avrebbe sul segno delle altreincognite.
60

Consideriamo una generica equazione del dizionario, evidenziando il ter-mine contenente la variabile x:
xk = bk + akx + · · ·
(non sono stati scritti esplicitamente gli altri addendi in quanto, nel corsodelle operazioni di pivot, le variabili non di base con indice diverso da restano fissate a 0).
Si vede che se ak ≥ 0, all’aumentare di x anche xk non diminuira,mantenendo quindi la positivita – si ricordi che si e supposto che bk ≥ 0.Se al contrario il segno del coefficiente della variabile entrante in base fossenegativo, allora per non violare il vincolo sul segno di xk si dovrebbe scegliere
x ≤ − bkak
(che e una quantita non negativa). Analizzando la situazione di tutte leequazioni del dizionario, si dovra scegliere x in modo tale da rispettare lapiu restrittiva di tutte le condizioni, cioe
x ≤ − bkak
∀ k : ak < 0
da cui si ottiene
x ≤ mink
− bkak
: ak < 0
.
Per quanto gia visto, poiche tanto maggiore e il valore della variabile entrantein base, tanto maggiore sara la diminuzione del costo, si scegliera
x = mink
− bkak
: ak < 0
.
Questa scelta provoca l’azzeramento di almeno una tra le variabili dibase. Sia k l’indice di tale variabile: sara questa la variabile uscente di base.L’operazione di pivot puo essere ora effettuata “risolvendo” l’equazione che,nel dizionario, corrisponde alla definizione di xk, rispetto a x e sostituendoogni occorrenza di x nelle altre equazioni e nell’espressione dell’obiettivo.
61

Capitolo 6
Cenni sull’interpretazionegeometrica dellaprogrammazione lineare
In questo capitolo verranno fornite alcune definizioni e proprieta elementarirelative alla geometria della PL. Le considerazioni geometriche che verrannopresentata in questo capitolo saranno di tipo elementare e saranno orientateal miglioramento della comprensione di alcuni aspetti della programmazionelineare e del funzionamento del metodo del simplesso. L’argomento, trattatoin modo rigoroso, richiederebbe una trattazione ben piu estesa; si e ritenutoqui di fornire solo alcune nozioni elementari per facilitare la comprensione dialcuni aspetti della programmazione lineare, rimandando a testi specializzatiper approfondimenti e per estensioni.
Si consideri lo spazio vettoriale n−dimensionale Rn;
Definizione 6 Un sottoinsieme S ⊆ Rn chiuso rispetto alla somma vetto-riale ed al prodotto scalare si dice sottospazio di Rn.
Ogni sottospazio S di Rn puo essere rappresentato come l’insieme deipunti dello spazio che soddisfano ad un sistema di equazioni lineari omogenee,cioe
S = x ∈ Rn : Ax = 0dove A e una matrice (m,n); senza perdere di generalita, si supporra chem ≤ n.
62

Definizione 7 La dimensione di un sottospazio S, e il massimo numero divettori linearmente indipendenti contenuti in S.
Esempio 6.1 In R3 l’insieme
S = (x, y, z) : x+ y + z = 0rappresenta un sottospazio (con m = 1, n = 3). E’ facile vedere che i vettorilinearmente indipendenti
v1 =[1 −1 0
], v21 =
[1 0 −1 ]
appartengono ad S; quindi la dimensione di questo sottospazio e almeno 2.Si puo anche dimostrare che non e possibile trovare tre vettori indipendentiin S.
Vale una proprieta che rende piu semplice il calcolo della dimensione diun sottospazio.
Teorema 6.1 La dimensione di un sottospazio S = x ∈ Rn : Ax = 0 epari a
n− rango(A)
Nell’esempio precedente, il rango della matrice dei coefficienti
A =[1 1 1
]e pari ad 1 e, pertanto, la dimensione di S e 2.
Definizione 8 Un sottospazio affine e un sottoinsieme di Rn ottenuto tra-slando un sottospazio.
Equivalentemente un sottospazio affine e rappresentabile come un sot-toinsieme S di Rn che soddisfa un sistema di equazioni lineari (non necessa-riamente omogenee):
S = x ∈ Rn : Ax = b.La dimensione di un sottospazio affine e quella del sottospazio corrispon-
dente (cioe quella del sottospazio ottenuto ponendo b = 0).
Definizione 9 La dimensione di un qualunque insieme E ⊆ Rn e la minimadimensione di un sottospazio affine che contenga E.
63

Ad esempio, un insieme costituito da due punti distinti in Rn, con n ≥ 1,ha dimensione 1, come pure ha dimensione 1 un segmento; un cerchio conraggio strettamente positivo ha dimensione 2, e cosi via.
L’insieme ammissibile di un problema di PL
Ax = b
x ≥ 0
e un sottoinsieme dello spazio affine x : Ax = b e pertanto avra dimensionenon superiore a n− rango(A).
Sia α ∈ Rn un vettore non nullo e β un numero reale.
Definizione 10 Si definisce iperpiano il sottospazio affine di dimensionen− 1:
H =x ∈ Rn : αTx = β
Il vettore α si dice normale ad H. Un iperpiano suddivide lo spazio in
due regioni convesse dette semispazi affini la cui espressione analitica e:
H≤ = x ∈ Rn : αTx ≤ βH≥ = x ∈ Rn : αTx ≥ β.
Si puo vedere facilmente che l’orientamento del vettore α e verso l’internodel semispazio affine H≥. Un sistema di disequazioni lineari
Ax ≤ brappresenta quindi l’intersezione di un numero finito di semispazi.
Definizione 11 L’intersezione di un numero finito di semispazi affini e unafigura convessa detta poliedro.
Si ricorda che un insieme convesso e caratterizzato dal fatto che dati duesuoi punti qualsiasi il segmento che li unisce e tutto contenuto nell’insiemestesso. I semispazi affini, gli iperpiani ed i poliedri sopra definiti sono insiemiconvessi. Poiche come si e visto nei capitoli precedenti, un qualunque sistemadi equazioni e disequazioni lineari puo essere ricondotto ad un sistema di di-sequazioni lineari, segue che l’insieme ammissibile di un qualunque problemadi PL e un poliedro ed e, pertanto, un insieme convesso.
Definizione 12 Un poliedro limitato e non vuoto e detto politopo.
64
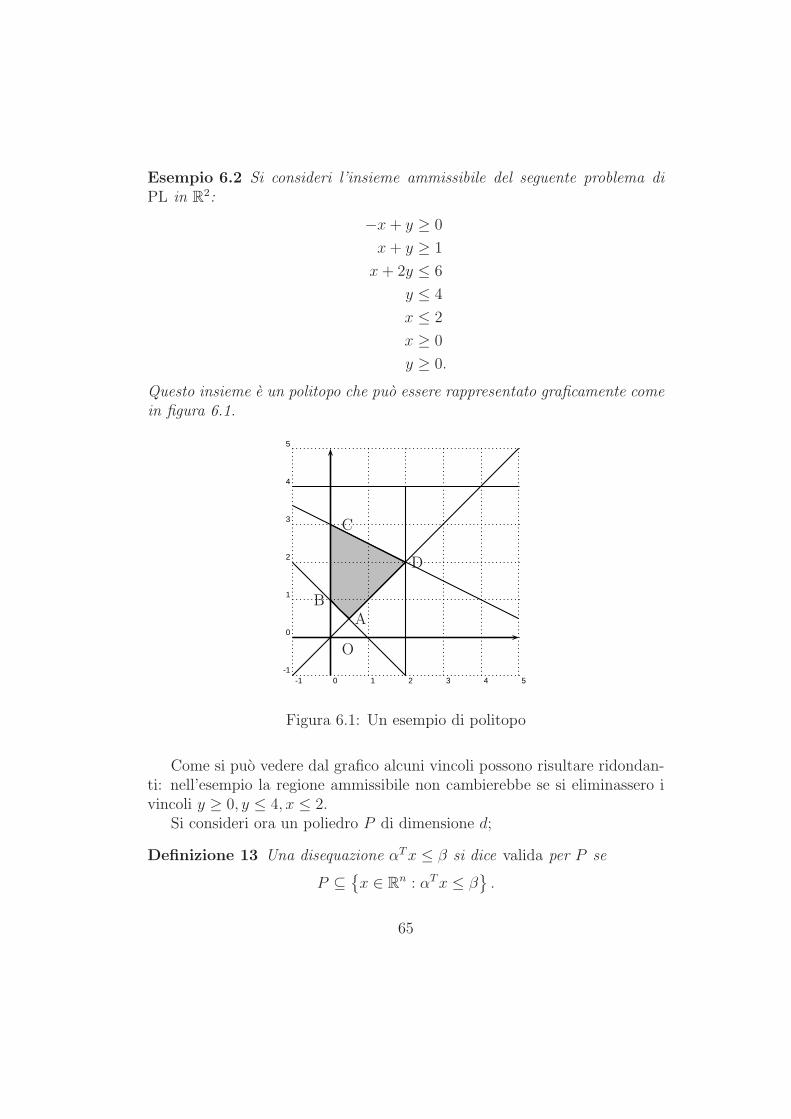
Esempio 6.2 Si consideri l’insieme ammissibile del seguente problema diPL in R2:
−x+ y ≥ 0
x+ y ≥ 1
x+ 2y ≤ 6
y ≤ 4
x ≤ 2
x ≥ 0
y ≥ 0.
Questo insieme e un politopo che puo essere rappresentato graficamente comein figura 6.1.
-1 0 1 2 3 4 5-1
0
1
2
3
4
5
AB
C
D
O
Figura 6.1: Un esempio di politopo
Come si puo vedere dal grafico alcuni vincoli possono risultare ridondan-ti: nell’esempio la regione ammissibile non cambierebbe se si eliminassero ivincoli y ≥ 0, y ≤ 4, x ≤ 2.
Si consideri ora un poliedro P di dimensione d;
Definizione 13 Una disequazione αTx ≤ β si dice valida per P se
P ⊆ x ∈ Rn : αTx ≤ β
.
65

Definizione 14 Data una disequazione
αTx ≤ βvalida per P , l’iperpiano
H =x ∈ Rn : αTx = β
si dice iperpiano di supporto per P se e solo se
P ∩H = ∅.
L’insiemeP ∩H
si chiama faccia del poliedro.
I vincoli che definiscono un generico poliedro sono ovviamente disegua-glianze valide. Se con aTi e bi si indicano rispettivamente i coefficienti dell’i−esimovincolo ed il corrispondente termine noto, si ha che l’intersezione di ogniiperpiano della forma
aTi x = bi
con il poliedro P , se non vuota, costituisce una faccia; inoltre l’intersezionedi piu facce di P e una faccia.
Una faccia di dimensione zero (cioe un punto) si dice vertice mentre unafaccia di dimensione 1 si dice spigolo .
Una faccia di dimensione n− 1 e detta faccetta oppure faccia massimale
Esempio 6.3 Con riferimento al precedente esempio 6.2, si osservi che isegmenti AB,BC,CD,DA sono spigoli (e anche facce massimali) del polie-dro i cui vertici sono A,B,C,D. In particolare lo spigolo AB puo esseregenerato dalla disequazione valida
x+ y ≥ 1.
Infatti la retta x + y = 1 interseca il poliedro lungo lo spigolo AB. L’in-tersezione fra la faccia AB e la faccia AD corrisponde al vertice A. Talevertice e una faccia di dimensione 0; puo ad esempio essere generato dalladisequazione valida
2y ≥ 1
66

La retta 2y = 1 e di supporto al poliedro, e la sua intersezione con il poliedroe il vertice A. Il vincolo y ≤ 4 e naturalmente una disequazione valida, mala retta y = 4 non interseca il poliedro: non costituisce pertanto un supportoe non definisce una faccia.
Un punto x di un insieme convesso C si dice estremo se non e rappresen-tabile come combinazione convessa in senso stretto di alcuna coppia di puntidistinti di C. In altri termini, x e un estremo di C se e solo se
y, z ∈ C, y = z :x = λy + (1− λ)z,λ ∈ (0, 1)
Per i poliedri, che sono insiemi convessi particolari, e possibile ottenereuna caratterizzazione piu precisa dei punti estremi. Dato un poliedro P =Ax ≤ b ed un punto x, si indichi con I=(x) l’insieme degli indici dei vincolidi P attivi in x, cioe sia
aTi x = bi ∀i ∈ I=(x)
aTi x < bi ∀i /∈ I=(x)
Sia A= la sottomatrice di A costituita dalle righe il cui indice sia in I=(x) eanalogamente si definisca b=; sia quindi A=x = b=. Vale il seguente
Teorema 6.2 Un punto x appartenente ad un poliedro P = x ∈ Rn : Ax ≤b e un estremo per P se e solo se rango(A=) = n.
Dimostrazione. Sia x un estremo di P e si supponga per assurdo cherango(A=) < n; allora il sistema di equazioni
A=x = 0
ammette almeno una soluzione y = 0. I vettori
z = x+ εy
w = x− εy
sono tali che, per qualsiasi valore di ε, A=z = b= e A=w = b=. Inoltre, poicheper i vincoli con indice i /∈ I(x) vale
aTi x < bi
67

e poiche tali vincoli sono in numero finito, esistera una perturbazione εsufficientemente piccola ma strettamente positiva tale che
aTi z = aTi x+ εy ≤ bi
aTi w = aTi x+ εw ≤ biper i /∈ I(x). Ne segue che z e w appartengono al poliedro P . Pero vale
x =1
2z +
1
2w
che e assurdo, essendo x un punto estremo.Per dimostrare il viceversa, si supponga che rango(A=) = n e che, per assur-do, x non sia un punto estremo per P . Devono quindi esistere due punti z ew, con z = w, in P ed un numero reale λ ∈ (0, 1) tali che
x = λz + (1− λ)w.Si consideri ora il sistema A=x = b=; sostituendo si ha che
λA=z + (1− λ)A=w = b=.
Pertanto deve essere
A=z = b=
A=w = b=
poiche, se per una delle due soluzioni valesse il vincolo con il segno di < l’altrarisulterebbe non ammissibile. Si e giunti all’assurdo, poiche in questo caso ilsistema di equazioni A=x = b= avrebbe piu di una soluzione, contraddicendol’ipotesi rango(A=) = n.
Esistono poliedri privi di punti estremi: ogni poliedro Ax ≤ b con Amatrice di rango minore di n non puo avere punti estremi.
Esempio 6.4 Il poliedro
(x, y) ∈ R2 : x+ y ≤ 1e privo di punti estremi.
Teorema 6.3 In un poliedro P vertici e punti estremi coincidono.
68

Dimostrazione. Sia x un vertice di P = Ax ≤ b; se x non fosse unestremo, dovrebbero esistere due elementi z, w ∈ P tali che
x = λz + (1− λ)wcon λ ∈ (0, 1). Essendo x un vertice, deve esistere un iperpiano di supporto
H = x : αTx = βtale che
P ⊆ αTx ≤ βe
H ∩ P = x.
Poiche z e w sono in P deve valere αT z < β e αTw < β (la diseguaglianzadeve essere stretta poiche x e l’unico punto di P che appartiene ad H). Maquesto e assurdo perche, se fosse vero, si avrebbe
αT x = λαT z + (1− λ)αTw < β.
Viceversa, se x e un punto estremo, vale
A=x = b=
con A= matrice di rango n. L’iperpiano
H = x ∈ Rn : αTx = βcon α = 1TA= e β = 1T b= e di supporto per P . Infatti per ogni punto x ∈ Pvale Ax ≤ b e, conseguentemente,
1TA=x ≤ 1T b=.
L’iperpiano H e quindi di supporto per P e vale x ∈ H ∩ P ; resta da dimo-strare che x e l’unico punto in H ∩ P . Se y ∈ H ∩ P deve valere A=y ≤ b= eαTy = β; queste relazioni sono equivalenti a
bi − aTi y ≥ 0 ∀i ∈ I(x)∑i∈I(x)
(bi − aTi y) = 0;
69

ma la somma di quantita non negative puo essere nulla solo se ciascunaddendo e pari a 0. Pertanto vale
A=y = b.
Questo e assurdo, poiche x e l’unica soluzione del sistema A=x = b.Per i poliedri si possono quindi usare indifferentemente i termini di vertice
e di punto estremo. I vertici hanno anche una corrispondenza con le soluzioniammissibili di base dei problemi di PL. Vale infatti:
Teorema 6.4 Ogni soluzione ammissibile di base di un problema di PLstandard
min cTx
Ax = b
x ≥ 0
e un vertice del poliedro
P = x ∈ Rn : Ax = b, x ≥ 0.
Dimostrazione. Una soluzione di base ammissibile e soluzione unica diun sistema
ABx = b
con A matrice (m,m). Almeno n −m componenti di una soluzione di basesono nulle e, pertanto, almeno n−m vincoli x ≥ 0 sono attivi in corrispon-denza della soluzione di base. Si puo quindi determinare la soluzione di basecome unica soluzione di un sistema di n equazioni[
AB 00 I
]x =
[b0
].
Si e quindi dimostrato che la soluzione di base corrisponde ad un vertice diP , in base al teorema 6.2.
Il teorema appena dimostrato afferma che ad ogni soluzione di base cor-risponde un vertice del poliedro P ; non e detto pero che a soluzioni associatea basi differenti corrispondano vertici differenti: piu soluzioni di base potreb-bero essere rappresentate come un unico vertice. Questo avviene nel caso disoluzioni di base degeneri.
70

6.1 Soluzione grafica di problemi di PL
I problemi di PL in R2 o in R3 possono essere rappresentati e risolti pervia grafica. Naturalmente la risoluzione grafica di tali problemi ha esclusiva-mente interesse didattico e nessuna reale utilita pratica. Per poter risolvereper via grafica un problema di PL in R2 si puo iniziare dalla rappresentazio-ne grafica dell’insieme ammissibile; successivamente si possono aggiungere algrafico alcune curve di livello della funzione obiettivo. Per i problemi di PLla funzione obiettivo ha curve di livello esprimibili come
H = x ∈ Rn : cTx = :.
Tali curve sono quindi iperpiani, tutti paralleli fra loro, aventi il vettore deicosti c come normale. Si ricorda che il vettore normale c e orientato nelladirezione del semispazio cTx ≥ :, cioe in direzione crescente della funzio-ne obiettivo. Per risolvere graficamente un problema di PL si puo quindirappresentare il vettore dei costi c e disegnare una retta che abbia c comenormale. Facendo “scivolare” tale retta parallelamente a se stessa fino adincontrare l’ultimo punto di P in direzione opposta a quella indicata da c siottiene l’ottimo del problema di PL.
Esempio 6.5 Si consideri il problema
min−x− 1
2y
−x+ y ≥ 0
x+ y ≥ 1
x+ 2y ≤ 6
y ≤ 4
x ≤ 2
x, y ≥ 0
che ammette la rappresentazione grafica di figura 6.2. Nel disegno sono rap-presentate, a titolo di esempio, le curve di livello a livello 0,−1,−2,−3. Sivede come la curva a livello −3 sia quella di livello minimo tra quelle cheintersecano P . Si deduce quindi che il punto D e la soluzione ottimale delproblema di PL dato.
71
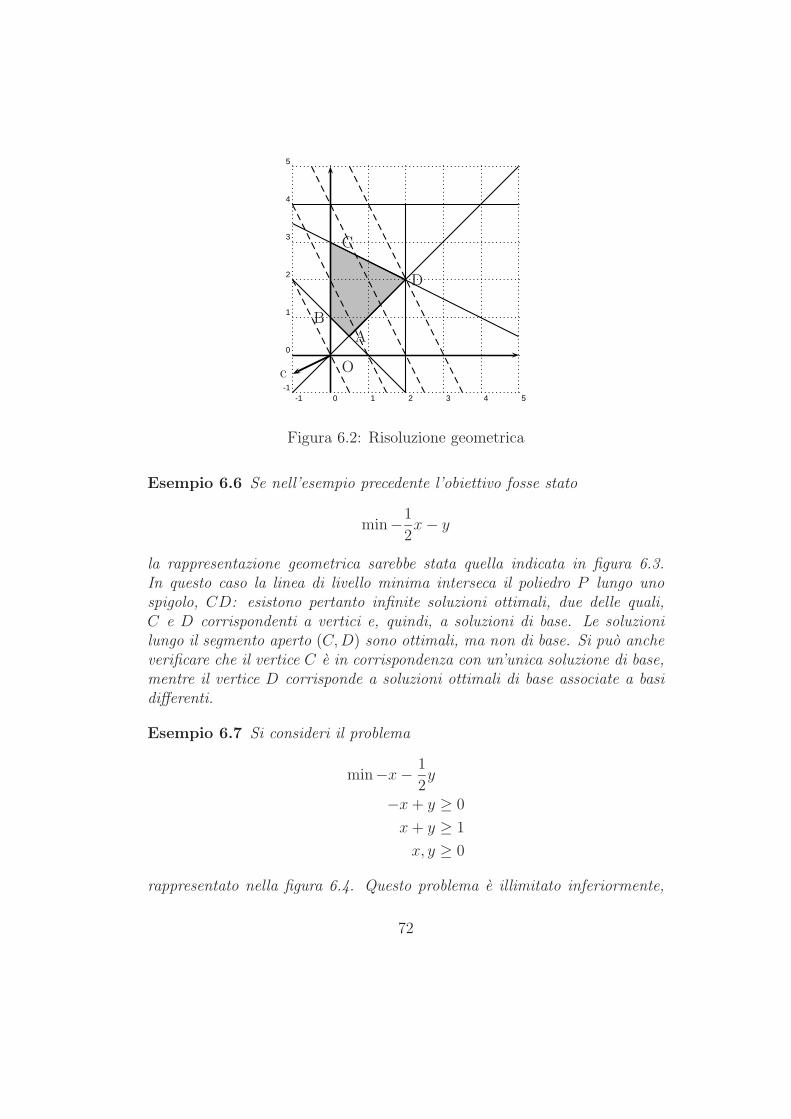
-1 0 1 2 3 4 5-1
0
1
2
3
4
5
AB
C
D
Oc
Figura 6.2: Risoluzione geometrica
Esempio 6.6 Se nell’esempio precedente l’obiettivo fosse stato
min−1
2x− y
la rappresentazione geometrica sarebbe stata quella indicata in figura 6.3.In questo caso la linea di livello minima interseca il poliedro P lungo unospigolo, CD: esistono pertanto infinite soluzioni ottimali, due delle quali,C e D corrispondenti a vertici e, quindi, a soluzioni di base. Le soluzionilungo il segmento aperto (C,D) sono ottimali, ma non di base. Si puo ancheverificare che il vertice C e in corrispondenza con un’unica soluzione di base,mentre il vertice D corrisponde a soluzioni ottimali di base associate a basidifferenti.
Esempio 6.7 Si consideri il problema
min−x− 1
2y
−x+ y ≥ 0
x+ y ≥ 1
x, y ≥ 0
rappresentato nella figura 6.4. Questo problema e illimitato inferiormente,
72
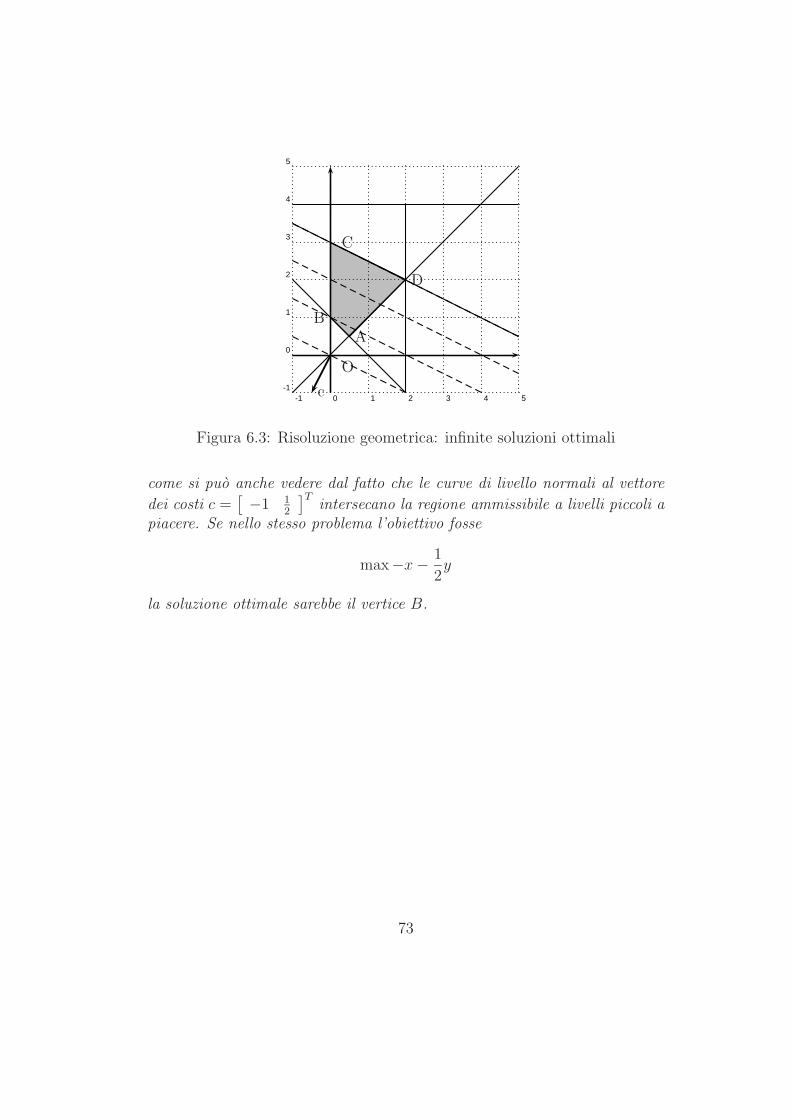
-1 0 1 2 3 4 5-1
0
1
2
3
4
5
AB
C
D
O
c
Figura 6.3: Risoluzione geometrica: infinite soluzioni ottimali
come si puo anche vedere dal fatto che le curve di livello normali al vettore
dei costi c =[ −1 1
2
]Tintersecano la regione ammissibile a livelli piccoli a
piacere. Se nello stesso problema l’obiettivo fosse
max−x− 1
2y
la soluzione ottimale sarebbe il vertice B.
73
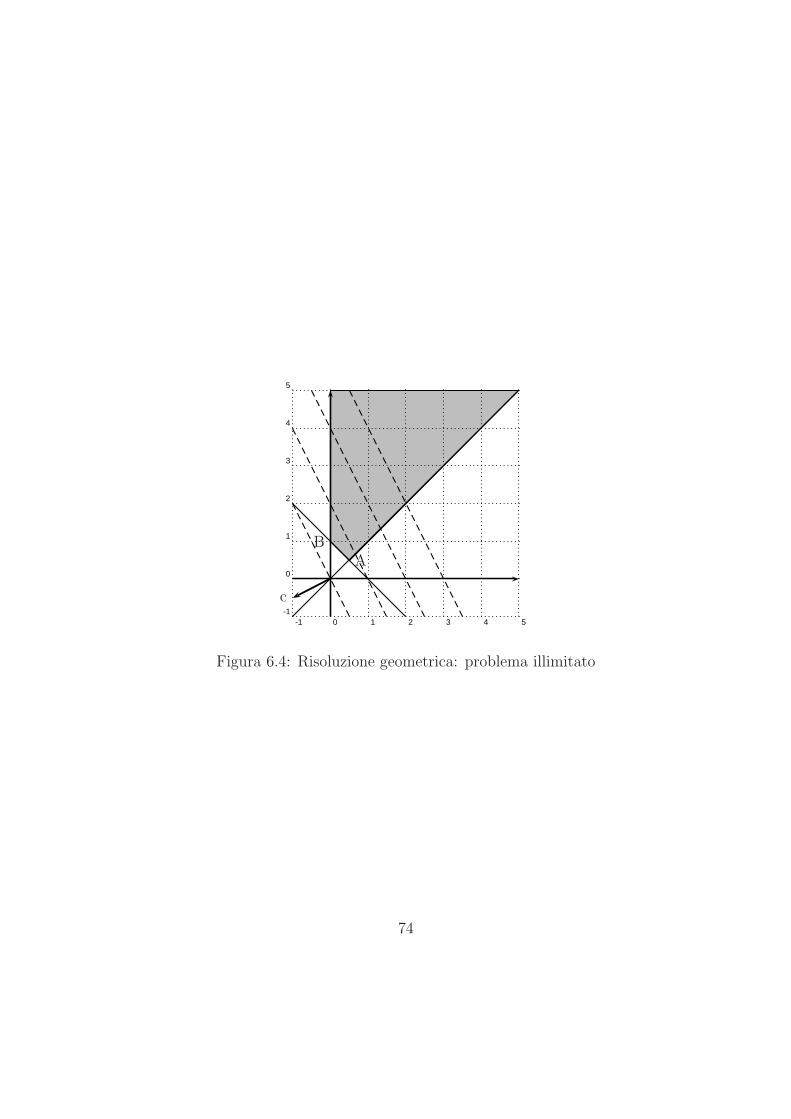
-1 0 1 2 3 4 5-1
0
1
2
3
4
5
AB
c
Figura 6.4: Risoluzione geometrica: problema illimitato
74

Capitolo 7
Formulazione matriciale delmetodo del simplesso
7.1 Presentazione dell’algoritmo
Il metodo del simplesso costituisce uno dei piu diffusi ed efficienti algorit-mi per la risoluzione di problemi di PL anche di notevoli dimensioni. Inquesto paragrafo verra analizzato l’algoritmo nella cosiddetta formulazionematriciale.
Il criterio di base dell’algoritmo consiste nell’analizzare i vertici della re-gione ammissibile (cioe le soluzioni ammissibili di base) procedendo da unvertice ad un vertice adiacente caratterizzato da un valore della funzioneobiettivo non superiore a quello del vertice di partenza.
La struttura dell’algoritmo puo essere scomposta in modo naturale nelleseguenti fasi:
1. scelta di una soluzione ammissibile di base iniziale;
2. controllo di ottimalita della soluzione di base corrente;
3. scelta di una nuova soluzione di base.
Il primo punto, cioe la determinazione di una soluzione ammissibile dibase con cui iniziare l’algoritmo, viene per il momento lasciato in sospeso everra trattato solo come ultimo punto, nel paragrafo 7.2: per determinareuna soluzione ammissibile di base con cui iniziare il metodo del simplesso, oc-correra eseguire il metodo del simplesso stesso su un problema ausiliario, con
75

una tecnica che, in altri contesti, viene detta di bootstrap. Per ora quindi sisupporra di conoscere una base AB ammissibile e la corrispondente soluzioneammissibile di base x per il problema di PL in forma standard
min cTx
Ax = b
x ≥ 0.
Si supporra, al solito, che A sia una matrice m × n di rango m, conm < n. Si ricorda che una sottomatrice AB di A di dimensioni m × mcostituisce una base ammissibile per il problema se e solo se AB e invertibilee xB = A−1
B b ≥ 0.
7.1.1 Ottimalita di una soluzione ammissibile di base
Per comodita di notazione, ma ovviamente senza che cio sia in pratica neces-sario, si supporra che le colonne della matrice dei coefficienti A, le componentidel vettore dei costi c, quelle della generica soluzione x e quelle della soluzio-ne particolare x siano state permutate in modo tale che le prime m colonnecorrispondano alla base AB, cioe:
A =[AB AN
]x =
[xBxN
]
x =
[xB0
]dove AB e una matrice m ×m invertibile, AN e una matrice m × n −m exB = A−1
B b.Nel punto x la funzione obiettivo ha valore z = cT x, che e esprimibile
anche come
z =[cTB cTN
] [xB0
]= cTBxB
Affinche la soluzione x sia ottimale, non deve esistere alcuna altra solu-zione ammissibile con valore funzionale strettamente minore di cTBxB. Ognisoluzione ammissibile deve soddisfare al sistema di equazioni
Ax = b
76

che, espresso in funzione della base corrente B, si puo scrivere come
ABxB + ANxN = b
cioe
xB = A−1B b− A−1
B ANxN
= xB − A−1B ANxN
e, in corrispondenza di una generica soluzione x, la funzione obiettivo havalore
cTx = cTBxB + cTNxN (7.1)
= cTBA−1B b+ (cTN − cTBA−1
B AN)xN
= cT x+ cTNxN . (7.2)
Gli elementi del vettore
cTN = cTN − cTBA−1B AN
sono i
coefficienti di costo ridotto.
Si ha quindi:
z = cT x+ cTNxN
xB = xB − A−1B ANxN
e si vede facilmente che la rappresentazione matriciale non e altro che ildizionario del metodo del simplesso visto in precedenza.
Poiche ogni soluzione ammissibile deve soddisfare la condizione xN ≥ 0,e evidente che la soluzione di base corrente x sara ottimale se nessuno deicoefficienti di xN e negativo. Si e quindi dimostrato, utilizzando la formamatriciale, il criterio sufficiente di ottimalita gia presentato nel teorema 5.1.
Esempio 7.1 Si consideri il problema di PL seguente:
min[2 −1 3 1 0 0
]x[
1 1 −2 1 1 02 −1 1 1 0 1
]x =
[12
]x ≥ 0
77

La soluzione corrispondente alla base A5,6 e data da
x5,6 = A−15,6b =
[1 00 1
]−1 [12
]=
[12
]
ed e caratterizzata da un costo pari a 0 e da coefficienti di costo ridotto
cT1,2,3,4 = cT1,2,3,4 − cT5,6A−15,6A1,2,3,4
=[2 −1 3 1
]− [0 0
] [1 00 1
]−1 [1 1 −2 12 −1 1 1
]=
[2 −1 3 1
].
Tale soluzione ammissibile di base non soddisfa la condizione sufficiente diottimalita, essendo il coefficiente di costo ridotto della variabile x2 negativo.Si puo cercare di costruire qualche soluzione di base nella quale la variabilex2 sia di base. Ad esempio, considerando la base A1,2 si ottiene
x1,2 =
[1 12 −1
]−1 [12
]=
[10
]
alla quale sono associati i coefficienti di costo ridotto
cT3,4,5,6 =[3 1 0 0
]− [2 −1 ] [
1 12 −1
]−1 [ −2 1 1 01 1 0 1
]=
[2 0 0 −1 ]
che ancora non soddisfa la condizione sufficiente di ottimalita. Questa solu-zione di base ha costo pari a 2, ed e degenere. Provando a costruire una basecomprendente sia la variabile x2 che la variabile x6, si ottiene la soluzione dibase
x2,6 =
[1 0−1 1
]−1 [12
]=
[13
]alla quale sono associati i coefficienti di costo ridotto
cT1,3,4,5 =[2 3 1 0
]− [ −1 0] [
1 0−1 1
]−1 [1 −2 1 12 1 1 0
]=
[3 1 2 1
].
78

Questa soluzione ammissibile di base soddisfa il criterio sufficiente di ot-timalita; si puo pertanto affermare che, nel problema in esame, una soluzioneottimale e costituita dal vettore
x =
010003
ed il costo ottimale e pari a −1.E’ importante ricordare che la condizione di ottimalita e sufficiente, ma
non necessaria.
Esempio 7.2 Si consideri un problema ottenuto dal precedente tramite unavariazione del termine noto:
min[2 −1 3 1 0 0
]x[
1 1 −2 1 1 02 −1 1 1 0 1
]x =
[01
]x ≥ 0;
se si considera di nuovo la soluzione di base associata ad A2,6, si ottiene
x2,6 =
[1 0−1 1
]−1 [01
]=
[01
]
e i coefficienti di costo ridotto risultano, come nell’esempio precedente, paria
cT1,3,4,5 =[3 1 2 1
].
Il costo della soluzione ottimale e quindi pari a 0. Se ora si riprende inconsiderazione la prima soluzione ammissibile di base individuata nel prece-dente esempio, e cioe quella associata alla base A5,6, si vede immediatamenteche tale soluzione di base e ammissibile:
x5,6 = A−15,6b =
[1 00 1
]−1 [01
]=
[01
]
79

e, poiche la formula dei coefficienti di costo ridotto non dipende dal terminenoto b, ma solo dal vettore dei costi e dalla ripartizione della matrice deicoefficienti in matrice di base e non, i coefficienti di costo ridotto sarannoidentici a quelli gia calcolati:
cT1,2,3,4 =[2 −1 3 1
].
Questa soluzione di base quindi non soddisfa la condizione sufficiente diottimalita; tuttavia, valutando il costo associato a questa soluzione di base,che e pari a 0, ci si accorge che essa ha lo stesso costo della soluzione ottimaleed e, pertanto, ottimale. Tra l’altro, si puo vedere immediatamente che inrealta non si tratta di una diversa soluzione ottimale, ma sempre della stessa,sebbene ottenuta tramite una diversa rappresentazione della base. Si noti chein questo caso la soluzione ottimale di base e degenere.
La presenza in un problema di PL, di soluzioni ottimali con alcuni coeffi-cienti di costo ridotto negativi non e assolutamente rara – anzi, nei problemiincontrati nella pratica, si puo dire che costituisca la norma, non l’eccezione.Tuttavia, piu avanti si dimostreranno le seguenti fondamentali proprieta:
Teorema 7.1 Se in un problema di PL tutte le soluzioni di base ottimalisono non degeneri, allora ogni soluzione ottimale di base avra coefficienti dicosto ridotto non negativi. La condizione di non negativita dei coefficienti dicosto ridotto e, in questo caso, necessaria e sufficiente per l’ottimalita.
Teorema 7.2 In ogni problema di PL che ammette almeno una soluzioneottimale di base, esiste almeno una base ottimale alla quale sono associaticoefficienti di costo ridotto tutti non negativi.
In base a queste proprieta e, in particolare, all’ultima, si puo pensare di co-struire un algoritmo che utilizzi la condizione di non negativita dei coefficientidi costo ridotto come regola d’arresto. Naturalmente se si potesse riconoscerel’ottimalita di una soluzione di base anche in presenza di coefficienti di costoridotto negativi, la velocita di esecuzione dell’algoritmo sarebbe maggiore;in certi casi questo e possibile: a volte, ad esempio, e noto a priori il valoredell’ottimo, ma non l’ottimo stesso. In questi casi si puo arrestare l’algoritmoappena si incontra una soluzione ammissibile con costo pari all’ottimo. Piuspesso e nota una limitazione inferiore al valore dell’ottimo: anche in questicasi ci si puo arrestare se si incontra una soluzione ammissibile il cui costo epari a tale limitazione inferiore. In generale tuttavia gli algoritmi del tipo del
80

metodo del simplesso attendono di aver determinato una soluzione di basecon tutti i coefficienti di costo ridotto non negativi (o di aver dimostrato chetale soluzione non puo esistere).
7.1.2 Scelta di una nuova soluzione ammissibile di base- operazione di pivot
Se, come supporremo in questo capitolo, si dispone di una soluzione ammis-sibile di base con almeno un coefficiente di costo ridotto negativo, occorreun metodo per modificare, se possibile, la base corrente in una nuova cuicorrisponda una soluzione “migliore” di quella attuale. Questo criterio sicompone di due fasi: la scelta di una direzione e la successiva scelta di unospostamento lungo tale direzione. In genere si cerchera di determinare unadirezione ammissibile, che come si e gia visto in precedenza, rappresenta unadirezione lungo la quale sia possibile effettuare uno spostamento non nullosenza violare alcun vincolo. Sia
x =
[xB0
]
la soluzione di base corrente. L’obiettivo di questo paragrafo e la determina-zione di una nuova soluzione ammissibile
x =
[xBxN
]
che sia ancora di base e non peggiore di x, nel senso che cT x ≤ cT x. Sinoti che la suddivisione di x nelle componenti xB ed xN e fatta, in questomomento, rispetto agli indici della base B corrispondente ad x, non agli indicidella nuova base associata ad x.
Come si e visto, per mantenere l’ammissibilita, le componenti xB e xNdella nuova soluzione x devono soddisfare le relazioni:
xB = A−1B b− A−1
B AN xN
= xB − A−1B AN xN
x ≥ 0
cioe [xB − A−1
B AN xNxN
]≥ 0,
81

ovvero [xB0
]+
[ −A−1B AN
I
]xN ≥ 0.
La scelta xN = 0 corrisponde alla soluzione di base corrente, cioe a x = x.Ricordando che, dalla definizione dei coefficienti di costo ridotto, si ha
cT x = cT x+ cTN xN ,
se la soluzione x non e ottimale esistera certamente almeno una componente,ad esempio quella di indice j ∈ N , del vettore dei coefficienti di costo ridottostrettamente negativa, cj < 0. Incrementando (se possibile) la corrisponden-te componente del vettore xN , il valore della funzione obiettivo diminuira.Indicando con δ l’incremento della variabile xj, si ha
x = x(δ) =
[xB0
]+
[ −A−1B AN
In−m
]ejδ
dove In−m rappresenta una matrice identica di dimensione (n−m)× (n−m)ed ej rappresenta il versore di Rn−m le cui componenti sono tutte nulle adeccezione di quella corrispondente a xj che vale 1. Ponendo
y = −A−1B ANej ∈ Rm
si ottiene
x(δ) = x+
[yej
]δ.
Per costruzione, qualunque sia il valore di δ, il punto x(δ) e soluzione delproblema di PL, cioe soddisfa i vincoli di eguaglianza. Per essere ammissibiledeve inoltre soddisfare la condizione di non negativita x ≥ 0. Scegliendoδ ≥ 0 le componenti di xN sono non negative (anzi, ne esiste soltanto una,quella di indice j, che potrebbe divenire strettamente positiva). Per quantoriguarda le componenti di xB, si ha invece
xi = xi + yiδ i ∈ B (7.3)
Ricordando che si suppone che la soluzione di base corrente sia ammissi-bile, e che pertanto xi sia non negativo, si ha, analizzando i casi possibili:
• se yi ≥ 0, per qualunque valore di δ la corrispondente variabile xi saranon negativa;
82

• se yi < 0, incrementando δ la corrispondente componente di xi di-minuisce; per imporre l’ammissibilita si deve pertanto richiedere chexi + yiδ ≥ 0 e cioe che
δ ≤ −xiyi
∀i : yi < 0.
L’ammissibilita della nuova soluzione e quindi garantita per ogni sceltadi δ tale da soddisfare
0 ≤ δ ≤ δ = mini:yi<0
−xiyi
. (7.4)
Poiche maggiore e il valore di δ, maggiore sara il decremento nel valoredella funzione obiettivo (si veda la (7.2)), ponendo
δ = δ
si ottiene il massimo decremento possibile per la funzione obiettivo lungo ladirezione [
yej
](7.5)
7.1.3 Problemi illimitati
Esiste un caso in cui non e possibile determinare δ e cioe il caso in cui nonesiste nessun indice i ∈ B : yi < 0. In questo caso ciascuna componente delvettore
xi = xi + yiδ i ∈ Bresta non negativa per qualsiasi scelta di δ ≥ 0. Poiche ad uno spostamentoδ > 0 corrisponde una variazione della funzione obiettivo pari a cjδ < 0, sivede, in questo caso, che il problema risulta illimitato.
Esempio 7.3 Si consideri il problema
min[1 0 1 2 −1 −1 ]
x[1 0 2 −1 1 −10 1 −1 1 −1 −1
]x =
[12
]x ≥ 0.
83

Utilizzando come base iniziale la matrice identica A1,2, corrispondente
alla soluzione di base x1,2 =
[12
], si ha
c3,4,5,6 =[1 2 −1 −1 ]− [
1 0] [
2 −1 1 −1−1 1 −1 −1
]=
[ −1 3 −2 0].
Si puo scegliere, come variabile entrante, sia x3 che x5. Si vedra piuavanti che entrambe queste scelte sono corrette. Si scelga, ad esempio, x5.Per la scelta della variabile uscente, si ha
y = −A−11,2A5 =
[ −11
].
L’unica possibilita per la variabile uscente e x1. Lo scambio avvienedunque tra x1 e x5; la nuova base diventa
A2,5 =
[0 11 −1
]
e la soluzione di base ad essa associata e
x2,5 =
[0 11 −1
]−1 [12
]=
[31
].
I coefficienti di costo ridotto associati a questa base sono
c1,3,4,6 =[1 1 2 −1 ]− [
0 −1 ] [0 11 −1
]−1 [1 2 −1 −10 −1 1 −1
]=
[2 3 1 −2 ]
La variabile entrante e quindi x6. Per determinare la variabile uscente, sicerca, al solito, il vettore direzione
y = −A−12,5A6 = −
[0 11 −1
]−1 [ −1−1
]=
[21
].
Nessuna delle componenti di y e negativa. Pertanto il problema e illimi-tato. Per confermare questo fatto, si osservi che la soluzione di base corrente
84

corrisponde al vettore
x =
030010
e che, attraverso lo spostamento individuato dal vettore y appena calcolato,sono ammissibili tutte le soluzioni
x(δ) =
030010
+
020011
δ =
03 + 2δ
00
1 + δδ
,
il cui costo e z(δ) = −(1 + δ)− δ = −1− 2δ → −∞ per δ → +∞.
La (7.3) fornisce una prova costruttiva dell’illimitatezza del problema e,in alcuni casi, puo aiutare a indicarne il motivo; in un problema applicativo,in genere l’illimitatezza e causata da vincoli troppo deboli o assenti. L’indi-viduazione di una direzione di spostamento illimitata in discesa puo aiutarenella scelta di un vincolo da aggiungere al problema in modo da ottenere unottimo finito.
7.1.4 Determinazione della variabile uscente di base
Se il valore δ cosı individuato e strettamente positivo, la (7.4) individua unospostamento non nullo lungo la direzione (7.5). Indicando con i ∈ B unindice in corrispondenza del quale viene raggiunto il minimo nella (7.4), cioequell’indice (o uno di quegli indici) tale che
δ = −xiyi≤ −xi
yi∀ i ∈ B : yi < 0
cioe
i ∈ arg mini∈B:yi<0
−xiyi
85

si vede immediatamente che la variabile di base xi assume valore nullo eche, se δ > 0, la variabile di indice j ∈ N acquista un valore strettamentepositivo. Si dimostrera ora che la matrice ottenuta sostituendo la colonna deicoefficienti Ai con quella dei coefficienti di Aj e ancora una base ammissibile.Si suole dire in questo caso che la variabile di base xi “esce” dalla base,mentre la variabile xj “entra” nella nuova base. L’operazione consistentenello scambio tra queste due variabili, di cui una in base e l’altra fuori base,si chiama operazione di
pivot
o di “cardine”; tale operazione corrisponde, nell’interpretazione geometricadella PL, ad uno spostamento da un vertice ad un vertice adiacente lungouno spigolo del poliedro. L’operazione di pivot puo anche essere effettuataqualora si abbia δ = 0 – cosa che puo accadere solamente nel caso di basidegeneri – nel qual caso il passo effettuato e nullo. La soluzione di base restainvariata, ma cambia la composizione della matrice di base.
Nello scambio tra il vettore dei coefficienti di xi (variabile uscente di ba-se) e quelli di xj (variabile entrante in base), non si perde l’invertibilita dellamatrice AB. Vale infatti un’importante proprieta generale sulla sostituzionedi vettori in matrici invertibili (cioe in basi): sia AB = A1, A2, . . . , Am ∈Rm×m una base di Rm e sia v ∈ Rm un vettore generico. Grazie alla defini-zione di base, esiste un’unica combinazione lineare delle colonne di AB chegenera v:
v =m∑i=1
Aiλi
dove λi sono coefficienti opportuni, univocamente determinati. Vale la pro-prieta seguente:
Teorema 7.3 La matrice AB′ = AB \ Aj ∪ v (ottenuta scambiando v conuna colonna Aj di AB) e ancora una base se e solo se λj = 0.
Dimostrazione. La condizione λj = 0 e sufficiente. Infatti, si consideri-no le colonne
AB′ = A1, A2, . . . , Aj−1, v, Aj+1, . . . , Ame se ne effettui una combinazione lineare con coefficienti µ1, . . . , µm:∑
i=j
Aiµi + vµj (7.6)
86

Sfruttando la rappresentazione di v mediante le colonne di AB questa eequivalente a ∑
i=j
Aiµi + µj∑i
Aiλi
cioe a ∑i=j
(µi + µjλi)Ai + µjλjAj
Poiche AB e una base l’unica combinazione lineare delle sue colonne cheproduce il vettore nullo e quella banale. Per annullare la combinazione (7.6)occorre avere
µjλj = 0
µi + µjλi = 0 i = 1, . . . ,m, i = jed, essendo per ipotesi λj = 0, dovra essere µj = 0. Ma, essendo µj =0, dovranno essere nulli anche tutti i coefficienti µi, i ∈ 1, . . . ,m , i = j.Pertanto l’unica combinazione lineare che annulla le colonne di AB′ e quellabanale tutta nulla: AB′ e quindi una base.
La condizione e anche necessaria. Infatti, se si avesse λj = 0, allora nellarappresentazione di v mediante AB si avrebbe
v =∑i=j
Aiλi
Quindi v sarebbe dipendente linearmente dai vettori Ai, i = j. Non potrebbepertanto formare, con loro, una base.
Questa proprieta pertanto ci permette di caratterizzare tutti e soli gliscambi possibili tra un vettore in base ed uno esterno alla base stessa. Per po-ter applicare quanto visto all’operazione di scambio nel simplesso, osserviamoche la scelta del vettore uscente di base avviene tramite il criterio
i ∈ arg mini∈B:yi<0
−xiyi
(7.7)
con y = −A−1B Aj, dove j e l’indice della variabile entrante in base.
Il vettore y non e altro che (a meno di un cambio di segno) il vettore deicoefficienti nella rappresentazione di Aj tramite le colonne di AB. Infatti siosservi che ∑
i∈BAiyi = ABy = AB(−A−1
B Aj) = −Aj.
87

Il vettore al posto del quale v = Aj viene inserito in base compare esplici-tamente in questa rappresentazione (in base al criterio (7.7) il coefficiente yie sicuramente non nullo, anzi, strettamente negativo). Quindi l’operazionedi pivot e valida, nel senso che trasforma basi in basi. In particolare, data lascelta del segno di yi, in realta tale operazione trasforma basi ammissibili inbasi ammissibili.
L’operazione di pivot appena descritta viene eseguita in modo tale che lafunzione obiettivo non aumenti; in particolare, se δ > 0, la funzione obiettivonel nuovo vertice avra valore strettamente minore di cTBxB.
Esistono due casi in cui non e possibile ottenere un valore δ > 0 finito:
1. yi ≥ 0 ∀i ∈ B: in questo caso la componente di indice j di x puoessere incrementata a piacere senza che alcun vincolo sia violato; cioimplica che il costo cTx puo essere diminuito a piacere incrementandoxj (si veda la (7.2)); pertanto in questo caso si dimostra, come gia visto,che il problema di PL e
illimitato.
2. ∃i ∈ B : xi = 0, yi < 0; in questo caso (ovviamente possibile solo inpresenza di una soluzione di base degenere), lo spostamento δ saranecessariamente pari a zero; ne il vettore soluzione x ne il valore dellafunzione obiettivo quindi varieranno. Tuttavia sara ancora possibileeffettuare l’operazione di “pivot”: in questo caso l’operazione avra comeeffetto semplicemente quello di cambiare la composizione delle colonneche formano la base AB. Si dice che in questo caso la variabile xj entranella nuova base “a livello zero”.
Il trattamento del caso degenere e particolarmente importante sia dalpunto di vista dell’analisi teorica del metodo del simplesso che dal punto divista della realizzazione di algoritmi efficienti e delle implementazioni del me-todo stesso: la presenza di soluzioni degeneri, come si e accennato, potrebbefar ciclare l’algoritmo. Vale un’importante, elementare, proprieta:
Teorema 7.4 Si consideri una versione deterministica del metodo del sim-plesso, implementato in modo tale che le decisioni relative alle variabili en-tranti ed uscenti di base ad ogni iterazione dipendano esclusivamente dallacomposizione della base corrente. Se tale algoritmo non termina, allora deveciclare all’infinito.
88

Dimostrazione. La dimostrazione segue banalmente dal fatto che lebasi di un problema di PL sono in numero finito; pertanto un metodo delsimplesso che non terminasse dovrebbe visitarne almeno una piu volte. Sel’evoluzione del metodo e completamente determinata dalla base corrente,allora l’algoritmo ripetera ciclicamente all’infinito una stessa sequenza di basi.
La richiesta che il metodo sia deterministico nasce dal fatto che se inqualche fase del metodo, come ad esempio la scelta della variabile entranteo uscente di base, si inserisse una decisione di tipo randomizzato, allorasarebbe possibile il ripetersi non ciclico di un insieme di basi. In ogni caso,deterministico o non, dato l’andamento monotono dei valori delle funzioniobiettivo nelle basi successivamente generate dal metodo, la non terminazionee possibile esclusivamente nel caso in cui nel problema vi siano delle basidegeneri. Solo in tale caso infatti e possibile una ripetizione di basi. Valecioe la seguente proprieta elementare:
Teorema 7.5 Se nessuna base incontrata nel corso dell’esecuzione del me-todo del simplesso e degenere, allora il metodo termina in un numero finitodi iterazioni.
Soluzioni di base e vertici degeneri
Si consideri il sistema di equazioni che permette di determinare la soluzionedi base, ABxB = b, equivalente a
∑i∈B Aixi = b. Nel caso di una base AB
degenere, se B′ ⊂ B e l’insieme di indici delle componenti non nulle dellasoluzione di base, si vede che il sistema si riduce a AB′xB′ = b. Esistonoin genere diversi insiemi di colonne della matrice A che, accostate ad AB′
formano una base. Si vede quindi che, nel caso degenere, una stessa soluzionedi base puo essere ottenuta attraverso basi differenti.
Dal punto di vista geometrico, nel caso non degenere una soluzione dibase si trova all’intersezione degli m iperpiani con n − m vincoli del tipoxj = 0 e, pertanto, e l’unica soluzione di un sistema quadrato di equazionilineari: [
AB AN
0n−m,m In−m
]x =
[b0
],
dove 0h,k ed Ihrappresentano rispettivamente una matrice nulla h×k ed unamatrice identica h× h.
89

Nel caso degenere invece la soluzione di base corrente si puo ottenerecome soluzione di un sistema non piu quadrato; indicando con N ′ l’insiemedelle colonne di A con l’eccezione di B′, si ha[
AB AN
0|N ′|,|B′| I|N ′|
]x =
[b0
];
il sistema sopra scritto contiene piu equazioni che incognite (|m+N ′| > n).Poiche si sa che il sistema ammette soluzione (la soluzione di base corrente),se ne deduce che almeno una di tali equazioni e ridondante. Cio significa,geometricamente, che il vertice corrispondente alla base si trova all’interse-zione di un numero superiore ad n di iperpiani. Risulta quindi che, per ladeterminazione del vertice in questione, almeno un vincolo e ridondante. Siosservi che questo non significa che nel problema originale esistono vincolieliminabili. Immaginando ad esempio una piramide a base pentagonale inR3, si vede che un vertice di tale piramide si trova all’intersezione di ben 5piani, mentre tutti gli altri si trovano all’intersezione di 3 piani. Il primovertice e degenere – le sue coordinate potrebbero essere individuate in modounivoco come intersezione di 3 qualunque (purche indipendenti) dei pianiche definiscono le facce della piramide. Tuttavia nessuna delle 5 facce puoessere eliminata senza modificare la forma dell’insieme. Nel caso di una basedegenere e possibile che un’operazione di pivot avvenga “a livello 0”, cioecon spostamento nullo e senza variazione della funzione obiettivo. In questocaso l’operazione di pivot non porta ad un nuovo vertice, ma semplicementeall’individuazione del vertice corrente mediante l’intersezione di un diversoinsieme di iperpiani di supporto, cioe di una diversa base.
Esempio 7.4 Si consideri l’esempio 7.1 di pag. 77:
min[2 −1 3 1 0 0
]x[
1 1 −2 1 1 02 −1 1 1 0 1
]x =
[12
]x ≥ 0
Si e visto che la soluzione
[12
]corrispondente alla base A5,6 e caratterizzata
da un costo pari a 0 e da coefficienti di costo ridotto
cT1,2,3,4 =[2 −1 3 1
]90

Poiche il coefficiente di costo ridotto corrispondente alla seconda variabilenon di base, cioe alla variabile x2, e negativo, e possibile effettuare un’opera-zione di pivot per cercare, se possibile, di diminuire il valore della funzioneobiettivo. Per determinare qual e la variabile uscente dalla base si opera comesegue:
y = −A−1B ANe2
= −[1 00 1
]−1 [1 1 −2 12 −1 1 1
]
0100
=
[ −1+1
]
δ = mini∈B:yi<0
−xiyi
= − 1
−1 = 1
La variabile uscente di base e dunque la prima di base, cioe x5. La nuovabase sara quindi B = 2, 6. La variabile entrante in base (x2) entrera alivello δ = 1.Si vede facilmente (riferendosi all’esempio 7.1) che questa soluzione di basee ottimale.
Esempio 7.5 Riprendendo l’esempio 7.2
min[2 −1 3 1 0 0
]x[
1 1 −2 1 1 02 −1 1 1 0 1
]x =
[01
]x ≥ 0
si considerino la soluzione di base associata a A5,6, con x5,6 =
[01
]ed i
coefficienti di costo ridotto cT1,2,3,4 =[2 −1 3 1
]. E’ possibile effettuare
un’operazione di pivot facendo entrare in base la variabile x2. Per la deter-minazione della variabile uscente, si procede in modo simile a quanto vistonell’esempio precedente:
91

y = −A−15,6A2
=
[ −1+1
]
δ = mini∈B:yi<0
−xiyi
= − 0
−1 = 0
In questo caso il passo di pivot e degenere. Tuttavia lo scambio tra lavariabile entrante in base e quella uscente, x5, viene comunque effettuato.La nuova base B = 2, 6, pur corrispondendo alla stessa soluzione (x1 =x2 = x3 = x4 = x5 = 0, x6 = 1), permette di certificarne l’ottimalita, avendotutti i coefficienti di costo ridotto non negativi.
Scelta della variabile entrante in base
Nel caso in cui piu coefficienti di costo ridotto siano negativi, si pone ilproblema di determinare quale sara l’indice del vettore entrante in base.Esistono varı metodi per compiere questa scelta. Sia l’indice della variabileentrante in base;
1. uno dei metodi piu semplici, ma relativamente poco utilizzati, e lascelta casuale dell’indice nell’insieme N
⋂ j : cj < 0.2. = minj ∈ N : cj < 0, che corrisponde alla scelta del primo
coefficiente di costo ridotto negativo osservato scandendo gli elementidell’insieme N .
3. ∈ argminj∈Ncj. Questo criterio, consistente nella scelta della va-riabile cui e associato il coefficiente di costo ridotto minimo, e utilizzatoin molte implementazioni. Il criterio e anche noto con il nome di “me-todo del gradiente nello spazio delle variabili non di base”, in quanto,osservando la (7.2), si vede come il gradiente della funzione obiettivorispetto alle variabili non di base sia proprio il vettore c; un incrementodella componente della soluzione cui e associato il coefficiente di costoridotto minimo equivale quindi alla scelta della direzione di piu ripidadiscesa, tra le direzioni del tipo (7.5), della funzione obiettivo rappre-sentata in funzione delle variabili con indice in N . Si noti tuttavia cheil solo fatto di “scendere” lungo la direzione piu ripida non e garanzia
92

di efficienza, in quanto il decremento effettivo della funzione obiettivoe funzione non solo della direzione, ma anche dello spostamento possi-bile lungo tale direzione. Addirittura, nel caso di soluzione degenere,lo spostamento potrebbe essere nullo. Inoltre non e detto che un passodi discesa ripida porti necessariamente ad una terminazione piu rapidadell’algoritmo.
4. Uno dei metodi piu utilizzati nelle implementazioni attuali e un com-promesso tra i due metodi precedenti – si sceglie cioe la variabile en-trante tra quelle che possiedono il coefficiente di costo minimo in unsottoinsieme costituito da un certo numero, k, degli indici diN associatia coefficienti di costo ridotto negativo.
E da sottolineare il fatto che nessuno dei metodi sopra illustrati si confi-gura come “ottimale”; e possibile costruire esempi in cui ciascuno dei criterisopra esposti porta all’esplorazione di un numero eccessivo di soluzioni dibase. Il problema dell’esistenza o meno di strategie di pivoting efficienti eun problema tuttora aperto (si veda in proposito la discussione sull’efficienzadel metodo del simplesso nel paragrafo 7.2.2).
In tutti questi metodi, nel caso di ulteriore incertezza nella scelta, siadotta un qualunque criterio di “tie breaking”, ad esempio scegliendo ilcoefficiente di indice minimo oppure estraendo a caso.
E opportuno precisare che, nonostante i metodi suesposti richiedano costicomputazionali differenti, il vantaggio in termini di tempi globali di esecuzio-ne non sempre presenta significative differenze. Se pero il problema di PL edotato di particolare struttura, alcune scelte diventano vantaggiose rispettoad altre: nel caso del problema del cammino minimo, ad esempio, si puodimostrare che, mentre il criterio 2 puo comportare un numero esponenzialedi passi di pivot, il criterio del gradiente richiede l’esecuzione di un numerodi passi di pivot polinomiale rispetto al numero di archi del grafo.
7.1.5 Scelta del vettore uscente dalla base
La scelta della variabile uscente di base non e molto critica nel caso di soluzio-ni di base non degeneri; il caso in cui puo esistere incertezza nella scelta dellavariabile uscente di base corrisponde alla situazione in cui esistono almenodue variabili di base, xl, xk tali che
δ = − xlyl
= − xkyk.
93

In questo caso in genere si puo scegliere indifferentemente l’una o l’altracome variabile uscente di base. Si puo pero vedere che, in ogni caso, lasoluzione di base che si ottiene al termine dell’operazione di pivot, e degenere.
Se la soluzione di base corrente e degenere, e possibile che l’operazione dipivot avvenga a livello 0, cioe con δ = 0. In questo caso, e solo in questocaso, e necessario utilizzare accorgimenti opportuni per evitare i cicli infinitidi operazioni di pivot e, quindi, la non terminazione del metodo.
Si puo dimostrare che, nel caso di soluzioni di base degeneri, e possibileun ciclo infinito di iterazioni solo se almeno 2 variabili sono in base a livellozero e corrispondono a elementi negativi del vettore y. In questo caso occorreun criterio per decidere quale delle variabili a livello zero deve uscire di base.Il metodo piu semplice, anche se non molto utilizzato nella pratica, e quellodi scegliere a caso (uniformemente): il metodo garantisce l’uscita dal ciclocon probabilita uno in un numero finito di iterazioni.
Una tecnica piu usata e la cosiddetta
regola di Bland,
che prescrive sia la scelta del vettore entrante che quella del vettore uscentedi base. Per il vettore entrante si sceglie il primo vettore il cui coefficientedi costo ridotto sia negativo (e il criterio 2 visto nel precedente paragrafo);analogamente, per il vettore uscente, la scelta corrisponde al primo tra gliindici che realizzano il minimo nella (7.4). Cioe si sceglie come variabileuscente la variabile di indice i caratterizzata da:
i = min i ∈ B : yi < 0, xi = 0 .Naturalmente niente vieta di usare la regola di Bland anche nel caso di
basi non degeneri: basta in questo caso scegliere la variabile uscente con indiceminimo tra quelle che determinano il valore δ; tuttavia nella pratica si usageneralmente una regola differente (soprattutto per la scelta della variabileentrante) e si passa alla regola di Bland solamente quando si incontra unpivot degenere.
Questo algoritmo garantisce l’impossibilita di cicli infiniti e, come conse-guenza, la finitezza dell’algoritmo del simplesso.
7.1.6 Finitezza del metodo del simplesso
Teorema 7.6 Il metodo del simplesso, equipaggiato con la regola di Bland,termina sempre in un numero finito di iterazioni.
94

Dimostrazione. Per la dimostrazione e sufficiente mostrare che, graziealla regola di Bland, il metodo del simplesso non entra in ciclo; si ipotizzi,per assurdo, che l’algoritmo non termini. Dovra quindi esistere una sequenzaciclica finita di basi generata dal metodo; siano
B0, B1, . . . , Bk−1, B0
gli insiemi di indici corrispondenti a tali basi. Sia
t = max
i ∈
k−1⋃r=0
Br : i /∈k−1⋂r=0
Br
. (7.8)
In altre parole, t e il massimo tra tutti gli indici che compaiono in almenouna, ma non in tutte le basi della sequenza. Nel corso delle operazioni dipivot che portano in successione alle basi B0, B1, . . . , Bk−1, ad un certo puntola variabile t uscira di base. Si puo sempre immaginare, data la ciclicita dellasequenza, che t esca di base nel passaggio da B0 a B1. Si indichi con s lavariabile che, nel corso di questa operazione di pivot, entra in base.
Il dizionario corrispondente alla base B0 e il seguente:
xB0 =b0 − A−1B0AN0xN0
z =z + cTN0xN0
dove b0 e z indicano rispettivamente la soluzione di base corrente ed il suovalore. In base alle ipotesi fatte t ∈ B0, s ∈ N0. Per come e stato definito t,esistera un altro dizionario, corrispondente ad esempio alla base Bk, in cuila variabile xt, dopo essere uscita di base, rientrera. Si consideri il dizionarioassociato a tale base:
xBk=bk − A−1
BkANk
xNk
z =z + cTNkxNk
.
Poiche le operazioni di pivot considerate sono tutte degeneri, entrambii dizionari hanno lo stesso valore z. Per quanto riguarda la soluzione dibase, il vettore bk non sara necessariamente identico a b0, ma conterra unapermutazione degli elementi di b0.
Associando un coefficiente di costo ridotto nullo alle variabili di base, edindicando con c0 e ck rispettivamente i vettori dei coefficienti di costo ridotto
95

associati alle basi B0 e Bk, si puo scrivere
z = z +n∑
j=0
c0jxj = z +n∑
j=0
ckjxj.
Si immagini ora di incrementare la variabile xs nel dizionario associato aB0, mantenendo fissate a zero tutte le altre variabili fuori base:
xN0 = esδ
xB0 = b0 + yδ
z = z + c0sδ
dove con y si e indicato il vettore −A−1B0As. L’obiettivo puo anche essere
scritto in funzione dei coefficienti di costo ridotto associati alla base Bk:
z = z +n∑
j=0
ckjxj
= z + cksδ + ckT
B0(b0 + yδ).
Uguagliando le due espressioni del costo si ottiene
z + c0sδ = z + cksδ + c
kT
B0(b0 + yδ)
da cuic0sδ = c
ksδ + c
kT
B0(b0 + yδ)
ovvero, raccogliendo δ a fattor comune,
(c0s − cks − ckT
B0y)δ = ck
T
B0b0.
Questa relazione deve essere valida per qualunque valore di δ, e, pertanto,deve risultare
c0s − cks − ckT
B0y = 0
ckT
B0b0 = 0.
A questo punto viene effettivamente utilizzata la regola di Bland: poichela variabile di indice s entra in base, certamente c0s < 0. La variabile diindice s, al pari di quella di indice t, compare in qualcuno dei dizionari del
96

ciclo, ma non in tutti. Si e ipotizzato che t sia l’indice massimo tra quelliche corrispondono a variabili presenti in alcuni, ma non tutti, i dizionari (siveda la 7.8). Quindi s < t e sicuramente cks ≥ 0, perche in caso contrario,per la regola di Bland, nel dizionario k sarebbe stata scelta la variabile xscome variabile entrante. Da queste considerazioni scende che
ckT
B0y < 0,
cioe ∑i∈B0
cki yi < 0,
da cui segue che deve esistere almeno un indice r ∈ B0 tale che ckryr < 0.Questo puo succedere solo se ckr = 0; ricordando che r ∈ B0, si osserva
che anche la variabile xr appartiene a qualcuna, ma non a tutte, le basi delciclo ed, essendo t il massimo indice delle variabili di questo tipo, si avrar < t oppure r = t. Si vede facilmente che in realta non puo essere r = t.Infatti, poiche la variabile di indice t e la variabile entrante nel dizionarioassociato a Bk, c
kt < 0 e yt < 0 poiche la variabile di indice t esce di base nel
dizionario associato a B0. Si ha quindi ckt yt > 0 e, pertanto, non puo esserer = t, essendo ckryr < 0.
Quindi r < t; deve essere allora ckr ≥ 0, altrimenti, per la regola di Bland,al passo k entrerebbe in base la variabile di indice r e non quella di indice t,come si e ipotizzato. Di conseguenza si avra yr < 0.
Ad ogni dizionario del ciclo, essendo ogni pivot degenere, nessuna variabilecambia valore e, pertanto, tutte le variabili che a volte sono in base e a volteno, avranno valore 0; ne segue che in particolare b0r = 0. Questo e assurdo;infatti la scelta della variabile uscente di base, quando il dizionario e quelloassociato a B0, avviene mediante la regola usuale (7.7):
i ∈ arg mini∈B0:yi<0
−b
0i
yi
e, nel caso in esame, si avrebbe, per i = r, yr < 0 e b0r = 0; il pivot sarebbedunque degenere (e questo e possibile), ma poiche r < t, dalla regola di Blandsi sarebbe scelta la variabile r piuttosto che, come ipotizzato, la variabile t,da cui l’assurdo.
La dimostrazione della correttezza della regola di Bland e piuttosto labo-riosa, ma non priva di eleganza. La regola stessa e estremamente semplice,
97

efficace, anche se, a volte, non molto efficiente; esistono altri metodi perevitare i cicli nel metodo del simplesso, ma generalmente non hanno la sem-plicita della regola di Bland. Una di queste regole, usata fino ad alcuni annifa, nasce dall’idea che la degenerazione puo essere eliminata spostando leg-germente i vincoli in modo da impedire che piu di n iperpiani si intersechinonello stesso punto.
Grazie alla correttezza delle regole anti-ciclaggio, come la regola di Bland,si possono dimostrare immediatamente due importantissime proprieta deiproblemi di PL:
Teorema 7.7 Per ogni problema di PL in forma standard che ammettauna soluzione di base ottimale, esiste sempre almeno una soluzione di baseottimale alla quale sono associati coefficienti di costo ridotto non negativi.
Dimostrazione. Se cosı non fosse, eseguendo il metodo del simplessoa partire da una base ottimale, ad ogni passo di pivot si troverebbe semprealmeno un coefficiente di costo ridotto negativo e l’algoritmo prima o poientrerebbe in un ciclo.
Teorema 7.8 Per ogni problema di PL vale una ed una sola delle seguenti:
1. il problema non e ammissibile;
2. il problema ammette ottimo finito;
3. il problema e illimitato.
Dimostrazione. Se il problema e ammissibile, e possibile eseguire l’al-goritmo del simplesso equipaggiato con la regola di Bland. Data la finitezzadelle basi e l’impossibilita di cicli, in un numero finito di passi di pivot osi arriva ad una soluzione di base ottimale con tutti i coefficienti di costoridotto non negativi, oppure si arriva all’individuazione di una direzione didecrescita illimitata dell’obiettivo.
7.2 Inizializzazione del metodo del simplesso
- Il metodo due fasi
Abbiamo visto finora alcune proprieta dei problemi di PL ammissibili e, inparticolare, dei problemi di PL per i quali sia nota una base iniziale ammis-sibile. In questo paragrafo si vedra come verificare se un problema di PL e
98

ammissibile o no ed, in caso affermativo, come trovare, se esiste, una solu-zione ammissibile di base. Infatti, non e detto che un problema ammissibileammetta soluzioni ammissibili di base – il sistema di equazioni potrebbe nonessere ridotto al rango.
Tra i vari metodi esistenti per la ricerca di una soluzione ammissibile dibase, viene qui presentato il piu noto e diffuso, il cosiddetto metodo duefasi. Il nome deriva dal fatto che alla fase di ottimizzazione vera e propriaviene fatta precedere una prima fase il cui scopo e unicamente determinare,se esiste, una base ammissibile iniziale. L’idea di questa prima fase nascedall’osservazione che in alcuni problemi di PL la determinazione di una baseiniziale ammissibile e un problema banale. Si consideri infatti il problema:
min cTx
Ax ≤ bx ≥ 0.
Se il termine noto b e non negativo, allora aggiungendo le variabili di slacksi ottiene immediatamente una base ammissibile:
min[cT 0T
] [xs
][A I
] [xs
]= b
x, s ≥ 0,
costituita dalla matrice identica. Quindi in un problema con variabili dislack e termine noto non negativo, le variabili di slack costituiscono unabase ammissibile. In un problema generico, che supponiamo essere in formastandard, possiamo sempre ricondurci al caso in cui il termine noto sia nonnegativo (al massimo si trattera di moltiplicare per −1 entrambi i membri dialcune equazioni). La prima fase del metodo due fasi consiste nella risoluzionedel seguente problema (detto “problema prima fase”):
min 1Txa
Ax+ xa = b
x, xa ≥ 0,
99

con b ≥ 0.Come si vede il problema prima fase ha alcune variabili, xa dette “variabi-
li artificiali”, che appaiono come variabili di slack. In realta esse sono diversedalle variabili di slack, in quanto queste ultime sono vere e proprie variabili,introdotte per scrivere in forma standard un problema di PL, mentre quelleartificiali sono variabili che provocano una perturbazione del problema origi-nale. L’obiettivo del problema prima fase e la minimizzazione della sommadi tali perturbazioni.
Si vede immediatamente che il problema prima fase non e ne inammissi-bile, ne puo essere illimitato. Infatti una soluzione ammissibile (a patto checi si sia ricondotti al caso b ≥ 0) esiste sempre, ed e data da x = 0, xa = b.Anzi, questa e una soluzione ammissibile di base; inoltre, poiche il costo euna combinazione non negativa di variabili non negative, il problema non po-tra essere illimitato inferiormente. Quindi, per quanto gia visto, il problemaprima fase ammette sempre soluzione ottimale. In base al valore dell’ottimopossiamo dedurre se il problema originale ammette soluzioni ammissibili. Siaz il valore dell’ottimo del problema prima fase e siano x e xa
le componenti
di una soluzione ottimale. Vale il seguente
Teorema 7.9 Esiste almeno una soluzione ammissibile per il sistema Ax =b, x ≥ 0 se e solo se z = 0.
Dimostrazione. Se l’ottimo della prima fase e 0 allora, essendo l’obietti-vo della prima fase pari alla somma delle variabili artificiali, e, poiche questeultime sono non negative, esse dovranno essere tutte nulle. Quindi si avra
Ax + 0 = b
x ≥ 0
e pertanto x sara ammissibile per il problema originario.Se invece z > 0, non e possibile che esista una soluzione ammissibile per il
problema originale. Infatti, se per assurdo esistesse una soluzione ammissibilex tale che Ax = b, x ≥ 0, allora ponendo xa = 0 si otterrebbe una soluzioneammissibile per il problema prima fase il cui costo 1T xa sarebbe 0. Ma questoe assurdo se, come ipotizzato, l’ottimo del problema e strettamente positivo.
Il valore ottimo del problema prima fase ci permette dunque di distingueretra problemi ammissibili e non e, nel caso di problemi ammissibili, fornisceuna soluzione particolare ammissibile. Tuttavia non e detto che tale soluzione
100

sia di base. Il teorema fondamentale garantisce che, nel caso di problemi neiquali il sistema di equazioni lineari sia ridotto al rango, se esiste una soluzioneammissibile ne esiste una ammissibile di base. La prima fase del metodo delsimplesso ci permette anche di determinare una soluzione di base ammissibile.Infatti si indichi con B l’insieme degli indici di una soluzione ottimale di basedel problema prima fase, nel caso in cui la prima fase sia terminata con costopari a 0. Si possono dare i seguenti casi:
1. nessuna variabile artificiale xa appartiene alla base B; in questo casoB e una base ammissibile per il problema originario;
2. almeno una variabile artificiale compare nella base ottimale B; sicu-ramente tale variabile sara nulla, in quanto, essendo l’obiettivo dellaprima fase pari alla somma delle variabili artificiali, nessuna di questepotra essere diversa da zero se l’ottimo e zero. Se e possibile, occorre ef-fettuare un’operazione di pivot per far uscire di base tale variabile. Siaxai una variabile artificiale in base a livello 0. Si consideri una variabilenon artificiale xj fuori base. Sia
A′ = A I
la matrice dei coefficienti del problema prima fase. Si e visto (teore-ma 7.3) che condizione necessaria e sufficiente per poter effettuare loscambio tra la colonna A′
j di coefficienti di xj e quella dei coefficienti di
xai e che l’i–esima componente del vettore d = −A′−1B A′
j sia non nulla.Quindi se (e solo se) esiste una variabile fuori base xj tale che
yi = −eTi A′−1B A′
j = 0
allora sara possibile scambiare le colonne dei coefficienti di xj e di xai .Poiche la variabile artificiale xai e a livello 0, tale operazione cambiasolo la composizione della base, non la soluzione di base (si effettua unpasso di lunghezza 0). Pertanto in questo caso e possibile effettuareun’operazione di pivot sia se yi < 0 che se yi > 0. Si osservi che, ingenerale un’operazione di pivot che faccia uscire di base una variabilecui e associato un coefficiente yi > 0, nel metodo del simplesso none ammessa, poiche il risultato sarebbe una perdita di ammissibilita.Anche nel metodo del simplesso pero, se la variabile entrante in baseha valore 0, l’operazione e in teoria possibile, dato che un passo di
101

lunghezza 0 non modifica la soluzione corrente. Tuttavia nel metododel simplesso, sebbene possibile, questa operazione non ha interessealcuno e, pertanto, non viene mai effettuata. Nella prima fase delmetodo due fasi invece tale operazione di pivot puo servire a far usciredi base la variabile artificiale yi. L’unico caso in cui l’operazione dipivot non e possibile e quello in cui per nessuna variabile xj fuori basesi ha −eTi A′−1
B A′j = 0. Ma questo significa che −eTi A′−1
B AN = 0, doveAN , al solito, rappresenta la matrice delle colonne dei coefficienti dellevariabili x fuori base. Si ha anche
eTi A′−1B A′
B = eTi
e quindi, essendo yi artificiale,
eTi A′−1B A′
Bx= 0
dove con A′Bx
si sono indicate le colonne della matrice di base associatea variabili x non artificiali. Si e quindi dimostrato che
eTi A′−1B A = 0
Il vettore eTi A′−1B fornisce quindi una combinazione lineare nulla non
banale delle righe di A. La matrice A quindi in questo caso non harango massimo. Poiche il sistema Ax = b era ammissibile, significa cheun’equazione, in questo caso quella di indice i, e ridondante e puo essereeliminata dal dizionario finale del problema, al termine della prima fase.
Quindi si potranno fare uscire di base, attraverso operazioni di pivot,tutte e sole le variabili artificiali presenti in base e associate ad equazionidel sistema Ax = b fra loro linearmente indipendenti.
Una volta terminata la prima fase del metodo due fasi, nel caso in cui sisia determinata una base ammissibile, si puo iniziare con il normale metododel simplesso e determinare, se esiste, una soluzione ottimale del problemaoriginario.
Esempio 7.6 Si consideri il problema di PL seguente
min[1 −1 0 1 2
]x
1 −1 −1 1 2−1 −1 0 2 12 0 −1 −1 1
x =
2
12
x ≥ 0.
102

Poiche non e evidente una base iniziale si imposta il problema prima fase:
min[1 1 1
]xa
1 −1 −1 1 2−1 −1 0 2 12 0 −1 −1 1
x+ xa =
2
12
x, xa ≥ 0.
Utilizzando il dizionario per questo problema, si ha:
z = 5− 2x1 + 2x2 + 2x3 − 2x4 − 4x5
xa1 = 2− x1 + x2 + x3 − x4 − 2x5
xa2 = 1 + x1 + x2 − 2x4 − x5
xa3 = 2− 2x1 + x3 + x4 − x5
Facendo entrare in base la variabile x5 (regola del coefficiente di costo ridottominimo), si ottiene
z = 1 + 2xa1 + 2x4
x5 = 1− 1
2xa1 −
1
2x1 +
1
2x2 +
1
2x3 − 1
2x4
xa2 =3
2x1 +
1
2x2 − 1
2x3 − 3
2x4 +
1
2xa1
xa3 = 1− 3
2x1 − 1
2x2 +
1
2x3 +
3
2x4 +
1
2xa1
In questo caso si puo concludere che il problema dato e privo di soluzioniammissibili, in quanto la prima fase e terminata con valore strettamente
positivo. Se il termine noto del problema iniziale fosse stato
2
11
, si sarebbe
invece ottenuto il dizionario seguente:
z = 0 + 2xa1 + 2x4
x5 = 1− 1
2xa1 −
1
2x1 +
1
2x2 +
1
2x3 − 1
2x4
xa2 =3
2x1 +
1
2x2 − 1
2x3 − 3
2x4 +
1
2xa1
xa3 = 0− 3
2x1 − 1
2x2 +
1
2x3 +
3
2x4 +
1
2xa1
103

Da questo dizionario si deduce che il problema originario ammette soluzioni:ad esempio la scelta x5 = 1, con tutte le altre variabili nulle, soddisfa ilsistema dei vincoli, come e facile vedere per sostituzione diretta. Quindi enota una soluzione ammissibile, non pero una soluzione ammissibile di base.Per determinare una base occorre, se possibile, far uscire di base tutte levariabili artificiali, effettuando pivot degeneri. Ad esempio, e possibile faruscire di base la variabile artificiale xa2 facendo un’operazione di pivot conuna qualsiasi delle quattro variabili x presenti nell’equazione che definiscexa2, indipendentemente dal segno del coefficiente. Ad esempio, scambiandoxa2 con x2 si ottiene il dizionario:
z = 2xa1 + 2x4
x2 = 2xa2 − 3x1 + 3x4 − xa1 + x3
x5 = 1− xa1 − 2x1 + xa2 + x4 + x3
xa3 = −xa2 + xa1,che ancora non rappresenta una soluzione di base; volendo far uscire di basela variabile xa3, si scopre che non e possibile, in quanto nell’equazione che de-finisce tale variabile non compare nessuna incognita del problema originario.Ricordando che il problema iniziale non conteneva le variabili artificiali, sipuo anche considerare che la terza equazione sia stata trasformata nell’equi-valente equazione ridondante 0Tx = 0, che puo essere eliminata dal problema.Il problema dato puo pertanto essere risolto partendo dal dizionario seguen-te (seconda fase), nel quale e stata inserita l’equazione del costo, sono stateeliminate le variabili artificiali della prima fase ed e stata eliminata la terzaequazione, combinazione lineare delle prime due:
z = 2 + x3
x2 = −3x1 + 3x4 + x3
x5 = 1− 2x1 + x4 + x3.
Per coincidenza, il dizionario iniziale e gia ottimale. Si conclude pertantoche la soluzione x5 = 1 e ottima per il problema dato.
7.2.1 Problemi con infiniti ottimi
Se, al termine del metodo del simplesso, esistono dei coefficienti di costoridotto nulli, possono esistere infinite soluzioni ottimali; infatti incrementan-do, se possibile, la componente non di base associata ad un coefficiente di
104

costo ridotto nullo, la funzione obiettivo non variera. Se l’incremento δ sarastrettamente positivo e finito, si otterra un nuovo vertice ottimale; e imme-diato verificare che, se x ed y sono due soluzioni ottimali per un problemadi PL, anche ogni soluzione ottenuta come loro combinazione convessa saraammissibile ed ottimale. In particolare, se si compie un’operazione di pivotper portare in base la variabile corrispondente al coefficiente di costo ridottonullo, se esiste almeno una componente negativa nel corrispondente vettoredirezione y, l’operazione di pivot puo essere eseguita e si determina cosı unanuova base ottimale; se invece le componenti di y sono tutte positive o nul-le allora non esistera una corrispondente soluzione di base, ma esisterannocomunque infinite soluzioni ottimali. In altri termini, se x e una soluzioneottimale associata ad una base AB ed esiste un coefficiente di costo ridotto,ad esempio cj, nullo, allora per ogni valore di 0 ≤ δ ≤ δ dove
δ =
min−xi
yi: yi < 0 se ∃ i ∈ B : yi < 0
+∞ altrimenti(7.9)
il vettore
x(δ) =
[A−1
B b0
]+
[yej
]δ
e soluzione ottimale del problema di PL. Naturalmente se nella (7.9) risultaδ = 0, in corrispondenza di ogni coefficiente di costo ridotto nullo, allora lasoluzione ottimale sara ancora unica, pur esistendo diverse basi ottimali. Unproblema di PL (in forma standard e ridotto al rango), se ammette ottimofinito, puo dunque avere una e una sola soluzione ottimale (e, in questo caso,sara sicuramente una soluzione ottimale di base), oppure infinite soluzioniottimali (almeno una delle quali di base). Un problema di PL con uno o infi-niti ottimi puo ammettere diverse basi ottimali; una stessa soluzione ottimalepuo, nel caso degenere, corrispondere a diverse basi ottimali. Un problemadi PL puo avere infinite soluzioni ottimali, tra cui anche una sola potreb-be essere di base. Si noti che, in un caso degenere, un’operazione di pivotdegenere non porta ad un cambiamento della soluzione (δ = 0); in questocaso e possibile anche effettuare un’operazione di pivot corrispondente ad unelemento positivo di y senza perdere l’ammissibilita e l’ottimalita – si trattain sostanza di un passo in una direzione non ammissibile, ma di lunghezza 0e, pertanto, non si perde l’ammissibilita.
Per comprendere meglio la struttura dei problemi di PL e delle lorosoluzioni ottimali, e utile tenere presente le seguenti proprieta:
105

Teorema 7.10 L’insieme ammissibile di un problema di PL e convesso.
Dimostrazione. Si ricordi che un insieme S e convesso se e solo secomunque scelti due suoi elementi u ∈ S, v ∈ S, ciascuna loro combinazioneconvessa appartiene ad S, cioe
λu+ (1− λ)v ∈ S ∀λ ∈ [0, 1].
Scegliendo due soluzioni u e v, ammissibili per un problema in cui S =x ∈ Rn : Ax = b, x ≥ 0 si ha che la combinazione convessa λu+ (1− λ)v enon negativa (essendo combinazione non negativa di due vettori non negativi)e inoltre
A(λu+ (1− λ)v) = λAu+ (1− λ)Av= λb+ (1− λ)b = b,
pertanto λu+ (1− λ)v e soluzione ammissibile per ogni λ ∈ [0, 1].
Teorema 7.11 L’insieme delle soluzioni ottimali di un problema di PL cheammette ottimo finito e convesso.
Dimostrazione. E’ sufficiente dimostrare che il costo della combinazioneconvessa di due soluzioni ottimali e ancora ottimale. In effetti, se u e v sonosoluzioni ottimali, di valore z, si ha
cT (λu+ (1− λ)v) = λcTu+ (1− λ)cTv= λz + (1− λ)z = z.
Il seguente teorema fornisce una rappresentazione finita dei poliedri.
Teorema 7.12 (Minkoswski) Dato un qualsiasi poliedro S = x ∈ Rn : Ax = b, x ≥ 0esiste un numero finito di elementi v1, v2, . . . , vk ∈ S ed un insieme fini-to di vettori y1, y2, . . . , yh ∈ Rn tale che ogni elemento x di S puo essererappresentato come
x =k∑
i=1
λivi +h∑
j=1
µjyj
con
µj ≥ 0 ∀jk∑
i=1
λi = 1, λi ≥ 0 ∀i.
106

Il teorema di Minkowski permette di generare ogni poliedro attraversola somma di una combinazione convessa (cioe effettuata con coefficienti nonnegativi a somma unitaria) di un numero finito di suoi elementi (l’insiememinimale di tali elementi e costituito dai vertici del poliedro) e di una com-binazione a coefficienti non negativi di un numero finito di vettori; in questocaso l’insieme minimale e costituito dai cosiddetti raggi estremi del poliedro.Un raggio r in un poliedro S e un vettore di Rn tale che, se u ∈ S, allora
u+ λr ∈ S ∀λ ≥ 0.
I raggi sono dunque direzioni ammissibili che permettono uno sposta-mento illimitato in un verso, senza mai uscire dall’insieme ammissibile, apartire da un qualunque punto ammissibile. I raggi estremi sono raggi chenon e possibile rappresentare come combinazione convessa non banale (cioea coefficienti non 0 ne 1) di altri due raggi.
Esempio 7.7 Si consideri il problema
min[0 0 0 1
]x[
1 0 1 10 1 −1 2
]x =
[21
]x ≥ 0
che possiede la soluzione ottimale x =[0 3 2 0
]T, corrispondente alla
base A2,3. Per confermare che questa e la base ottimale basta calcolare icoefficienti di costo ridotto:
c1,4 =[0 1
]− [0 0
]A−1
2,3A1,4
=[0 1
].
Il coefficiente di costo ridotto della variabile x1 e nullo; e possibile per-tanto che esistano infinite soluzioni ottimali. Per determinarle si cerca sepossibile di fare entrare in base la variabile x1:
y = −A−12,3A1 = −
[0 11 −1
]−1 [10
]=
[ −1−1
].
107

La variabile uscente di base viene determinata con la regola usuale:
min
− x2
y2,− x3
y3
= min
− 3
−1 ,−2
−1
= 2 = − x3
y3.
La variabile uscente di base e quindi la x3; la nuova base diviene B =1, 2. La soluzione associata a questa base e
x1,2 =
[1 00 1
]−1 [21
]=
[21
]
ed i coefficienti di costo ridotto ad essa associati sono
cT3,4 =[0 1
]− [0 0
] [1 00 1
]−1 [1 1−1 2
]=
[0 1
].
Questa verifica non e in realta necessaria per dimostrare l’ottimalita dellasoluzione corrente, dato che avendo fatto entrare in base una variabile concoefficiente di costo ridotto nullo, sicuramente non si avra un cambio del-la funzione obiettivo. Pero dai coefficienti di costo ridotto di quest’ultimasoluzione di base si vede che per trovare altre soluzioni di base ottimali sidovrebbe fare rientrare in base la variabile x3, che ne e appena uscita. Si puoquindi concludere che le due soluzioni di base trovate sono le uniche soluzio-ni ottimali di base. Non esistono raggi nel poliedro delle soluzioni ottimali(altrimenti si sarebbero trovati in corrispondenza di un coefficiente di costoridotto nullo). Quindi tutte e sole le soluzioni ottimali sono ottenibili da unacombinazione convessa delle due appena trovate:
x(λ) = λ
0320
+ (1− λ)
2100
=
2− 2λ2λ+ 12λ0
con λ ∈ [0, 1].
108

Esempio 7.8 Se si considera il problema seguente, ottenuto modificando inparte il precedente,
min[0 0 0 1
]x[
1 0 −1 10 1 −1 2
]x =
[21
]x ≥ 0
si vede facilmente che la base B = 1, 2 e, come nell’esempio precedente,ottimale. I coefficienti di costo ridotto associati a questa base sono anco-ra cT3,4 =
[0 1
]. Cercando di fare entrare in base la variabile x3, con
coefficiente di costo ridotto nullo, si ottiene:
y = −A−11,2A3 =
[11
].
Lungo la direzione individuata dal vettore y per le variabili di base e possi-bile compiere uno spostamento illimitato senza perdere l’ammissibilita; lungoquesta direzione inoltre il costo non cambia e, pertanto, si e determinato unraggio (estremo) ottimale:
x∗(δ) =[x1,2
0
]+
[ye1
]δ
=
2100
+
1110
δ
=
2 + δ1 + δδ0
.
Le soluzioni x(δ) sono ottimali per ogni scelta di δ ≥ 0. Di queste infinitesoluzioni, una sola, caratterizzata da δ = 0, e di base.
Esempio 7.9 Il problema
min[0 0 0 1
]x[
1 0 1 10 1 −1 2
]x =
[1−1
]x ≥ 0
109

e ancora una variante dei precedenti, e possiede la soluzione ottimale x =[0 0 1 0
]T, degenere, ancora associata alla base A2,3. La conferma e
banale, in quanto la soluzione e ammissibile (come e facile controllare sosti-tuendo il vettore x nel sistema di equazioni) e i coefficienti di costo ridotto,essendo indipendenti dal vettore dei termini noti, sono ancora pari a
cT1,4 =[0 1
].
Cercando di fare entrare in base la variabile di costo ridotto nullo x1, siottiene
y = −A−12,3A1 =
[ −1−1
];
il passo di lunghezza massima possibile in questa direzione e dato da
δ = min
− 0
−1 ,−1
−1
= 0.
Si puo dire, in questo caso, che le infinite soluzioni ottimali sono degene-rate in un solo punto, la soluzione di base corrente. Si osservi che, in questocaso, la soluzione di base e degenere: se in una soluzione ottimale di base nondegenere esiste almeno un coefficiente di costo ridotto nullo, allora esistonosempre infiniti ottimi. Naturalmente, in questo caso, e possibile fare entrarein base la variabile x1 al posto della variabile x2: la nuova base A1,3 e ancoraottimale e corrisponde alla soluzione di base
x1,3 =
[1 10 −1
]−1 [1−1
]=
[01
]
che rappresenta sempre la stessa soluzione, x3 = 1. Esistono pertanto piubasi ottimali, ma una sola soluzione ottimale (si puo verificare che le basiottimali in questo esempio sono 3).
Esempio 7.10 (continuazione).I tre esempi appena visti possono essere facilmente rappresentati grafica-
mente: infatti le prime due variabili, associate alla matrice identica, possonoessere viste come variabili di slack e i tre esempi assumono dunque le seguenti
110
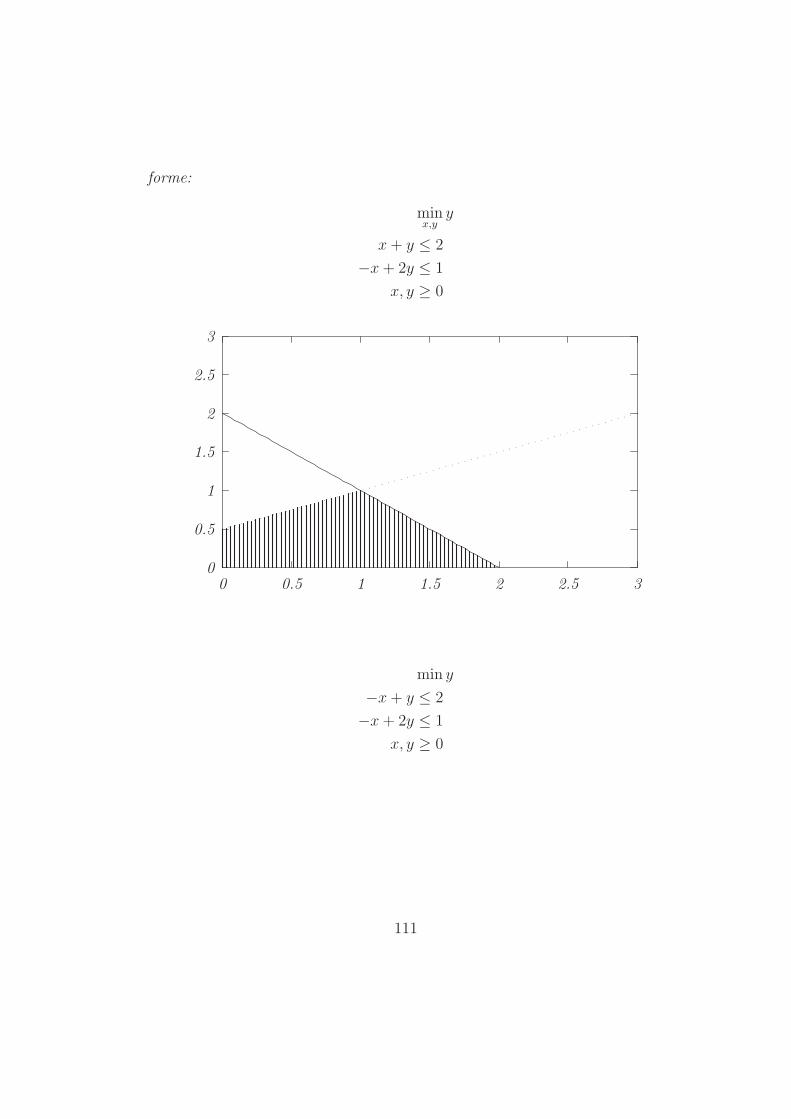
forme:
minx,yy
x+ y ≤ 2
−x+ 2y ≤ 1
x, y ≥ 0
0
0.5
1
1.5
2
2.5
3
0 0.5 1 1.5 2 2.5 3
min y
−x+ y ≤ 2
−x+ 2y ≤ 1
x, y ≥ 0
111
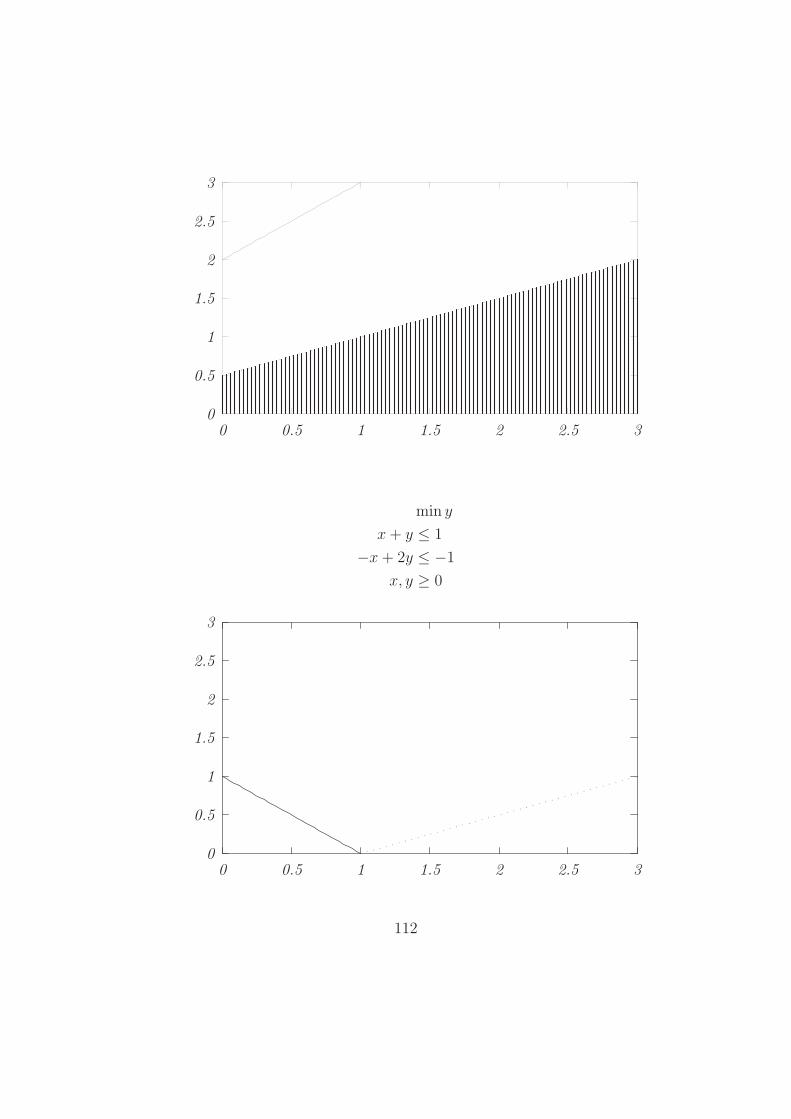
0
0.5
1
1.5
2
2.5
3
0 0.5 1 1.5 2 2.5 3
min y
x+ y ≤ 1
−x+ 2y ≤ −1x, y ≥ 0
0
0.5
1
1.5
2
2.5
3
0 0.5 1 1.5 2 2.5 3
112

In tutti e tre gli esempi, sono ottimali tutte le soluzioni ammissibili cheappartengono all’asse delle x.
7.2.2 Efficienza del metodo del simplesso
Esiste un’importante teoria, detta teoria della complessita computazionale, icui scopi sono l’analisi e la classificazione dei problemi in classi di difficoltadifferente. Non ci vogliamo addentrare qui in una discussione specialisticasull’argomento. Con molta approssimazione si puo dire che una classe di pro-blemi e considerata computazionalmente facile se esiste un algoritmo in gradodi risolvere qualsiasi esempio di tale classe compiendo un numero di operazio-ni elementari che e asintoticamente limitato da un polinomio di grado finitonella dimensione di tale esempio. La definizione di “dimensione” di un pro-blema non e banale: per la programmazione lineare dimensioni naturali sonom ed n, ma questo non basta a caratterizzare in modo soddisfacente la realedimensione del problema. Esistono, ad esempio, molte implementazioni delmetodo del simplesso che sfruttano la sparsita della matrice dei coefficienti.E’ ragionevole pensare quindi che i problemi di PL siano in genere tanto piudifficili quanto meno sparsa e la matrice dei coefficienti. La definizione comu-nemente accettata di dimensione di un problema corrisponde alla lunghezzadi una codifica efficiente dell’intero insieme dei coefficienti
A =
[A bcT 0
]
del problema di PL. Ad esempio, volendo memorizzare i dati di un problemadi PL (con coefficienti interi o razionali) in forma binaria, ed utilizzando ilminimo numero possibile di bit per ogni dato ed un separatore tra un dato el’altro, si vede che occorreranno
L = O(mn+∑
i,j:Aij =0
log(|Aij|))
bit (il simbolo O(f(k)) indica una quantita tale che lim supk→∞O(f(k))f(k)
≤∞). Un algoritmo polinomiale per la PL dovrebbe poter risolvere qualsiasiproblema di PL in un tempo O(Lr), con r costante opportuna.
La questione se la PL fosse o meno una classe di problemi risolvibili inmodo efficiente, al di la della notevole efficienza pratica del metodo del sim-plesso, e rimasta aperta fino agli anni ’80, quando e stato definitivamente
113

dimostrato che esistono algoritmi polinomiali per la PL. Curiosamente, ilmetodo del simplesso non e un algoritmo polinomiale. Per tutte le imple-mentazioni note del metodo si e potuta trovare una successione di problemiparticolari, a lunghezza crescente, per il quale il metodo richiede un numeroesponenziale di passi di pivot.
Per l’implementazione basata sulla scelta della variabile entrante con coef-ficiente di costo ridotto minimo, il seguente esempio fornisce il caso peggioreper il metodo del simplesso:
maxn∑
j=1
10n−jxj
2i−1∑j=1
10i−jxj + xi ≤ 100i−1 i = 1, . . . , n
xj ≥ 0 j = 1, . . . n
Esempio 7.11 Per n = 4 il problema diventa
max[1000 100 10 1 0 0 0 0
]x
1 0 0 0 1 0 0 020 1 0 0 0 1 0 0200 20 1 0 0 0 1 02000 200 20 1 0 0 0 1
x =
1100
10 0001 000 000
x ≥ 0
Si nota subito come questo sia un problema mal scalato, cioe con coef-ficienti il cui ordine di grandezza e molto diverso. A causa della diver-sa grandezza dei termini noti, l’insieme ammissibile non e molto diversodall’iperrettangolo
0 ≤ x1 ≤ 1
0 ≤ x2 ≤ 100
0 ≤ x3 ≤ 10 000
0 ≤ x4 ≤ 1 000 000.
Eseguendo il metodo del simplesso a partire dalla base A5,6,7,8, corrispon-dente all’origine nello spazio delle prime 4 incognite, scegliendo la variabileentrante con coefficiente di costo ridotto minimo, vengono visitati tutti i 24
vertici dell’iperrettangolo deformato.
114

L’algoritmo del simplesso ha rappresentato, e rappresenta tuttora, uncampo di ricerca estremamente ricco ed aperto. Non e ancora stata fornita,ad esempio, una soddisfacente giustificazione teorica del fatto che, nonostantei risultati fortemente negativi della teoria della complessita, l’algoritmo delsimplesso sia in pratica, un metodo estremamente efficiente, utilizzato perrisolvere problemi con centinaia di migliaia di variabili. Esistono studi sullacomplessita media del metodo, ma in genere i modelli stocastici su cui sonobasati non sono sufficientemente vicini ai problemi reali. Studi sia empiriciche teorici tendono a sostenere che il metodo del simplesso termina con unnumero di passi di pivot O(m), in genere compresi tra 3m e 4m.
Un’altra questione tuttora aperta e la seguente: per ogni tipo di strategiadi pivoting finora tentata, si e potuto determinare un controesempio per ilquale il metodo richiede un numero esponenziale di pivot. Ma questo non esufficiente per concludere che non puo esistere una strategia di pivoting cherenda il metodo polinomiale. A tutt’oggi non e ancora chiaro se tale strategiapossa esistere o meno.
115

Appendice A
Introduzione alla teoria deigrafi ed alle reti di flusso
In questo capitolo verranno presentati alcune definizioni e proprieta trattedalla teoria algoritmica dei grafi; non verranno presentate analisi astratteapprofondite sulla teoria vera e propria dei grafi, ma verranno semplicemen-te introdotti alcuni concetti e proprieta importanti per comprendere l’uti-lita della rappresentazione mediante grafo, con particolare riferimento allamodellizzazione di problemi di flusso su rete.
A.1 Terminologia e definizioni principali
Si definisce grafo una coppia di insiemi
G = 〈V,E〉
dove V e un insieme qualsiasi, purche di cardinalita finita, detto insieme deivertici o nodi del grafo e
E ⊆ V × Ve un insieme, detto degli archi, i cui elementi sono coppie di nodi. Un grafoquindi viene definito elencando l’insieme dei nodi e un insieme di coppie dinodi, detti archi.
116

Esempio A.1 Un esempio di grafo e il seguente:
V = FI, PI,MS,LI,GR, SI,AR, PO, PT, LUE =
(FI, PO), (FI,AR), (FI, SI), (PO,PT ), (PT, PI),(PT, LU), (LU,MS), (PI, LI), (PI, LU), (PI,MS)
i cui nodi rappresentano alcune citta della Toscana, mentre gli archi sonoassociati a collegamenti autostradali diretti tra coppie di citta.
Uno dei motivi per i quali i grafi sono diventati un importantissimo stru-mento di modellazione e il fatto che essi ammettono una rappresentazionegrafica (da cui il nome) molto intuitiva. Ad ogni nodo si associa un simbo-lo (tipicamente un cerchio o un quadrato) ed ogni arco viene rappresentatocollegando con una linea i due nodi che lo rappresentano.
Esempio A.2 (cont.) Nell’esempio precedente, una possibile rappresenta-zione grafica e la seguente:
MS
PI
PT
PO
LU FI
LI SI AR GR Nell’esempio appena fatto e nella definizione di grafo si identificano gli
archi con coppie di nodi: un arco e un sottoinsieme di nodi di cardinalita2. In questo senso, l’arco (FI, PO) e l’arco (PO,FI) sono lo stesso arco.Nei modelli di flusso e invece molto piu frequente il caso in cui gli archisiano orientati: in un arco orientato e importante distinguere tra il primoed il secondo nodo. In altri termini (FI, PO) = (PO,FI). Si puo pensareagli archi orientati come a strade a senso unico, in cui e ben evidente ilnodo di partenza ed il nodo di arrivo. La definizione di grafo orientato, odigrafo, differisce da quella di grafo solo per il fatto che gli archi sono coppieordinate di nodi. In tutto questo volume verranno considerati esclusivamentegrafi orientati e, pertanto, per brevita si parlera semplicemente di grafo,intendendo in realta un digrafo. Per rappresentare graficamente un grafo(orientato) si raffigureranno gli archi mediante frecce che vanno dal nodoorigine dell’arco al nodo destinazione.
117

Esempio A.3 Viene qui riportato un esempio di grafo orientato, una por-zione di albero genealogico. Gli archi connettono un genitore con i figli.
@ @ Giovanni@ di Bicci
@ @ Cosimo@ il Vecchio
@ @ Lorenzo@ il Vecchio
@ @ Piero@ il Gottoso
@ @ Pier@ Francesco
@ @ Lorenzo@ il Magnifico
@ @ Giuliano@ @ Lorenzo
@ il Popolano@ @ Giovanni
@ il Popolano
I grafi (orientati) che serviranno come base per la trattazione dei problemidi flusso saranno grafi semplici, dove il termine semplice sta ad indicare grafiprivi di archi multipli e di cappi. Archi multipli sono archi distinti fra loro checonnettono la stessa coppia di nodi; i cappi invece sono archi del tipo (a, a),dove a e un nodo. Graficamente, gli archi multipli si possono rappresentarecome i jmentre i cappi sono rappresentabili nel modo seguente:
i
Si osservi che questi i j
non sono archi multipli. La restrizione ai grafi semplici porta ad alcune sem-plificazioni nel trattamento dei problemi di flusso e nella notazione; d’altraparte, anche se si potrebbe eliminare questa restrizione, essa non e parti-colarmente svantaggiosa, dal momento che sia gli archi multipli che i cappipossono essere trasformati in grafi equivalenti semplici mediante l’aggiunta
118

di nodi e archi: i1 i
j
i2
e i i1
Dato un grafo si dice che un suo arco (i, j) incide sui nodi i e j. I nodi ie j si dicono adiacenti se sono connessi direttamente da un arco.
Per rappresentare un grafo si possono usare molte strutture dati differenti– uno stesso algoritmo puo avere tempi di esecuzione notevolmente differentiin funzione del tipo di struttura dati utilizzata nella memorizzazione di ungrafo. Una struttura elementare e quella vista nella definizione di grafo, unalista di archi e nodi. Altre strutture sono, ad esempio, le liste di adiacenza,in cui ad ogni nodo viene associata la lista degli archi uscenti dal nodo e lalista degli archi entranti. Una rappresentazione molto utile sia nella praticache nell’analisi teorica degli algoritmi su grafi e quella basata sulla matrice diincidenza del grafo. Tale matrice e costituita da |V | righe e |E| colonne: ogniriga corrisponde ad un nodo ed ogni colonna e associata ad un arco. Dato unnodo v ed un arco e, l’elemento della matrice A di incidenza, corrispondentealla riga v ed alla colonna e e cosi definito:
Av,e =
+1 se e = (v, w) per qualche w ∈ V−1 se e = (u, v) per qualche u ∈ V0 altrimenti.
Quindi nella matrice di incidenza, considerata una colonna associata ad unarco e = (i, j), in tale colonna si trovera un elemento pari a +1 in corrispon-denza della riga associata al nodo i, −1 in corrispondenza della riga associataal nodo j e 0 in tutte le altre posizioni.
119

Esempio A.4 La matrice di incidenza del grafo seguente:
a
b
c
de data da
A =abcd
(a, b) (a, c) (b, c) (b, d) (c, b) (c, d) (a, d)+1 +1 0 0 0 0 +1−1 0 +1 +1 −1 0 00 −1 −1 0 +1 +1 00 0 0 −1 0 −1 −1
Come si vede, in ogni colonna della matrice di incidenza esistono un unicoelemento pari ad 1 ed un unico elemento pari a−1. Sommando le righe di unamatrice di incidenza si ottiene quindi il vettore nullo: le righe della matrice diincidenza quindi non sono linearmente indipendenti fra loro. In particolareuna riga qualunque puo essere cancellata senza che il contenuto informativodella matrice venga alterato.
Come da un grafo si puo passare alla matrice di incidenza, cosı da unamatrice di incidenza si puo ricostruire il grafo.
A.2 Flussi su reti – reti di flusso
Una rete di flusso e una struttura basata su un grafo orientato che permette lamodellazione di flussi a regime stazionario. Si puo pensare, come esempio diapplicazione, allo studio di reti di flusso di veicoli in un’area urbana, al flussodell’acqua potabile nella rete idrica di una citta, al flusso di informazionelungo una rete di telecomunicazione, al flusso di materiali in un impianto diproduzione; modelli di flusso vengono anche usati per rappresentare problemidi connessione, problemi di copertura di servizi, ecc. Nelle reti di flussogeneralmente si associa ad ogni arco una quantita variabile che rappresenta ilflusso sull’arco; ai nodi e associata una quantita che rappresenta la domandanetta di flusso o l’offerta netta di flusso (un nodo puo essere produttore,consumatore o semplicemente di transito per il flusso). Sugli archi e spesso
120

definita una quantita positiva che rappresenta il massimo flusso passantelungo l’arco stesso. Formalmente, si definisce rete di flusso una struttura deltipo
N = 〈V,E, b, cap〉dove:
• 〈V,E〉 e un grafo orientato;
• b : V → R : ad ogni nodo della rete v ∈ V viene associata una quantitabv che rappresenta la differenza fra flusso uscente dal nodo e flussoentrante;
• cap : E → R+: ad ogni arco della rete e associata una capacita massi-ma, una quantita cioe pari al massimo flusso che, nell’unita di tempo,puo attraversare l’arco.
Se su ogni arco e definito un costo c : E → R, allora il problema del flussodi costo minimo si definisce nel modo seguente:
minf∈R|E|
∑(i,j)∈E
cijfij
∑k:(i,k)∈E
fik −∑
h:(h,i)∈Efhi = bi ∀i ∈ V (A.1)
fij ≤ capij ∀(i, j) ∈ Efij ≥ 0 ∀(i, j) ∈ E.
La (A.1) rappresenta la legge di conservazione del flusso (o legge di Kirchoff ):la differenza fra flusso uscente e flusso entrante in ogni nodo i deve essere pariad una quantita prefissata bi. Il problema del flusso di costo minimo e dunqueun problema di programmazione lineare. Per rappresentare il problema informa matriciale, si osservi che la matrice di incidenza contiene, nella rigaassociata ad un generico nodo i, elementi pari a +1 associati agli archi uscentie pari a −1 per gli archi entranti. Il vincolo di conservazione del flusso puopertanto essere espresso come
Af = b
121

dove A e la matrice di incidenza del grafo ed f e il vettore dei flussi. L’interoproblema puo quindi essere rappresentato come
min cTf
Af = b
f ≤ capf ≥ 0.
A.3 Alberi
In un grafo orientato, si dice cammino dal nodo i0 al nodo ik una successionefinita di archi
(i0, i1), (i1, i2), . . . , (ik−1, ik)
tale che il nodo terminale di un arco coincide con il nodo iniziale dell’arcosuccessivo. Si dice invece catena una successione finita di archi che puo esseretrasformata in un cammino cambiando eventualmente il verso a qualche arco,cioe invertendo il nodo terminale dell’arco con il nodo iniziale.
B
A
D
C
B
A
D
C
Un cammino Una catena
Un cammino od una catena si dicono semplici se nessun nodo o arco vieneripetuto. Un esempio di cammino non semplice e il seguente:
A B
C
E
D
122

Un circuito e un cammino costituito da almeno due archi distinti nel qualeil nodo iniziale i0 coincide con quello finale ik:
A B C E
D
mentre un ciclo e simile ad un circuito, ma l’orientamento degli archi nonsegue necessariamente un unico verso:
A
B C
E D
Una catena e quindi costituita da un insieme di archi orientati caratterizzatidal fatto che modificando l’orientamento di alcuni di essi si ottiene un cam-mino orientato. Un grafo si dice connesso quando tra ogni coppia di nodiesiste almeno una catena; si dice fortemente connesso se tra ogni coppia dinodi esiste almeno un cammino.
Dato un grafo G = 〈V,E〉, un sottografo di G e un grafo G′ =⟨V
′, E ′⟩
con
V ′ ⊆ VE ′ ⊆ E.
Una componente connessa G′di un grafo G e un sottografo di G connesso e
massimale, cioe e un sottografo di G connesso e tale che non esista nessunsottografo connesso contenente propriamente G
′. Chiaramente se un grafo
e connesso esso contiene un’unica componente connessa, cioe il grafo stesso.Un grafo con n nodi e nessun arco ha invece n componenti connesse. Il grafo
A
B
C
D
E F G
ha due componenti connesse, associate ai nodi A,B,E e C,D, F,G rispetti-vamente.
123

Un albero e un grafo connesso e aciclico.
A B
C
D
E
F
G H
I
Un albero si dice albero di supporto ad un grafo G o albero ricoprente di ungrafoG quando i suoi nodi coincidono con quelli diG. Dato un grafo orientatosi dice grado di un nodo il numero di archi incidenti su quel nodo. In un grafosi chiama foglia un nodo di grado 0 oppure 1. Nell’albero disegnato sopra, inodi A,C,D, F,G,H, I sono foglie, tutte di grado 1.
Alcune proprieta degli alberi risulteranno utili per ulteriori caratterizza-zioni:
Teorema A.1 Si consideri un albero T = 〈V,E〉 con almeno 2 nodi. Il grafoottenuto eliminando un qualsiasi arco (i, j) e composto da due componenticonnesse, ciascuna delle quali e un albero.
Dimostrazione. Se da un albero si elimina un arco qualsiasi (i, j), l’al-bero si sconnette: infatti se rimanesse connesso dovrebbe esistere una catenatar i e j diversa dall’arco (i, j); ma in questo caso, rimettendo l’arco al suoposto si genererebbe un ciclo, cosa impossibile essendo T un albero. Quindila rimozione di un arco provoca la formazione di almeno due componenticonnesse. Le componenti connesse sono in realta esattamente due, poiche,nuovamente, la reinserzione dell’arco (i, j) genera un grafo connesso; mal’inserzione di un arco puo al massimo connettere fra loro due componen-ti. Quindi si e dimostrato che eliminando un arco da un albero si generanosempre esattamente due componenti connesse. Il fatto che siano entrambeacicliche, e quindi alberi, e banale, essendo aciclico ogni sottografo di ungrafo aciclico.
Teorema A.2 Un albero T = 〈V,E〉 con almeno 2 nodi ha almeno duefoglie.
Dimostrazione. Un albero con m = 2 nodi ha evidentemente due foglie.Ipotizziamo che la proprieta valga per un generico grafo con m ≥ 2 nodi e
124

dimostriamolo per un grafo con m + 1 nodi. Si scelga un arco qualunque esi elimini dal grafo. Per quanto appena visto, il grafo risultante ha due com-ponenti connesse, entrambe alberi. Se una delle due componenti ha un solonodo, questo e una foglia; l’altra componente avra, per ipotesi di induzione,almeno due foglie. Rimettendo al suo posto l’arco eliminato si perde al piuuna foglia e quindi il teorema vale. Se invece entrambe le componenti con-nesse hanno piu di un nodo, dopo l’eliminazione dell’arco si hanno in totalealmeno 4 foglie. Di nuovo, la reimmissione dell’arco tolto puo al massimoprovocare la perdita di due foglie.
Teorema A.3 Un albero con m nodi ha m− 1 archi.
Dimostrazione. Il teorema vale banalmente per m = 1 e per m = 2.Si ipotizzi il teorema valido per un generico albero con m − 1 nodi. Siconsideri un albero con m nodi. Grazie alla proprieta precedente, questoalbero ha sicuramente almeno una foglia. Esistera un unico arco dell’alberoincidente sulla foglia. Disconnettendo tale arco, l’albero si sconnette in duecomponenti, una delle quali e un albero con m− 1 nodi e l’altra e un alberoridotto ad 1 nodo. L’albero con m−1 nodi per ipotesi di induzione ha m−2archi; la componente costituita da un solo nodo non ha archi. Rimettendoa posto l’arco eliminato si rigenera l’albero e si possono contare in totale(m− 2) + 1 = m− 1 archi.
E’ possibile caratterizzare gli alberi in molti modi diversi:
Teorema A.4 Si consideri un grafo T = 〈V,E〉 e sia |V | = m, |E| = n. Leseguenti affermazioni sono equivalenti:
1. T e un albero, cioe e connesso e privo di cicli;
2. T e connesso ed ha n = m− 1 archi;
3. T e privo di cicli ed ha n = m− 1 archi;
4. T e connesso, ma l’eliminazione di un suo arco qualsiasi provoca lasconnessione in due componenti;
5. T e aciclico, ma l’aggiunta di un qualsiasi arco provoca la formazionedi uno ed un solo ciclo;
6. Esiste una ed una sola catena che connette ciascuna coppia di nodi diT .
125

Dimostrazione. Si puo iniziare mostrando che 1, 2 e 3 sono equivalenti:1 =⇒ 2: deriva immediatamente dal teorema A.3;2 =⇒ 3: se per assurdo T , connesso con m − 1 archi, possedesse un ciclo,allora sarebbe possibile eliminare un arco appartenente al ciclo senza perderela connessione. Si genererebbe cosi un grafo connesso, aciclico, con m − 2archi. Ma questo e in contrasto con il teorema A.3;3 =⇒ 1: infatti se T non fosse connesso, allora si potrebbero aggiungerearchi che connettono a due a due le componenti del grafo, senza creare cicli,fino ad arrivare ad un’unica componente. A questo punto si avrebbe un grafoconnesso e aciclico, cioe un albero, ma con piu di m−1 archi, il che e assurdo.Quindi le proposizioni 1, 2, 3 sono equivalenti.1 =⇒ 4: e il teorema A.14 =⇒ 5: se esistesse un ciclo, l’eliminazione di un arco appartenente al ciclonon provocherebbe la sconnessione; aggiungendo un arco qualunque sicura-mente si perde l’aciclicita, dato che i due nodi connessi dall’arco aggiuntipossono essere raggiunti attraverso due catene diverse. Il fatto che si gene-ri un unico ciclo e dovuto al fatto che se se ne generassero due, i due cicliavrebbero in comune l’arco aggiunto. Eliminando l’arco aggiunto, restereb-bero due diverse catene che connettono gli estremi di tale arco: il grafo quindirisulterebbe ciclico;5 =⇒ 6: si supponga che T sia aciclico: nessuna coppia di nodi puo essereconnessa da piu di una catena. Infatti se una coppia di nodi fosse connessada due catene, queste formerebbero un ciclo. Inoltre, tra ogni coppia di nodiesiste certamente una catena (e quindi il grafo e connesso): infatti se tra duenodi i e j non esistesse una catena, l’aggiunta di un arco (i, j) al grafo nonprovocherebbe la nascita di un ciclo, contrariamente all’ipotesi.6 =⇒ 1: Se tra ogni coppia di nodi esiste una catena, per definizione il grafoe connesso; se inoltre tale catena e unica, il grafo e anche aciclico.Si e quindi dimostrato che 1, 4, 5, 6 sono equivalenti fra loro, e questocompleta la dimostrazione del teorema.
Le prime tre caratterizzazioni si possono interpretare dicendo che date duedelle tre proprieta: connessione, aciclicita, numero di archi pari al numero dinodi meno uno, la terza e una conseguenza.
126

Indice
I Programmazione lineare 1
1 Modelli di programmazione lineare 21.1 Esempi elementari . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1.1 Modelli di miscelazione . . . . . . . . . . . . . . . . . . 21.1.2 Il modello della dieta . . . . . . . . . . . . . . . . . . . 71.1.3 Il modello dell’abbinamento . . . . . . . . . . . . . . . 13
2 Problemi di ottimizzazione 162.1 Introduzione e definizioni principali . . . . . . . . . . . . . . . 16
3 Introduzione alla programmazione lineare 183.1 Problemi di programmazione lineare - importanza della linearita 18
3.1.1 Forma standard di un problema di programmazionelineare . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.1.2 Trasformazione di programmi lineari in forma standard 223.2 Equivalenza tra problemi di ottimizzazione . . . . . . . . . . 26
4 Teoria della Programmazione Lineare 354.1 Basi e soluzioni di base nella programmazione lineare . . . . . 354.2 Interpretazione del concetto di base . . . . . . . . . . . . . . . 37
4.2.1 Basi e soluzioni di base nei problemi di flusso . . . . . 384.3 Il teorema fondamentale della programmazione lineare . . . . 44
5 Il metodo del simplesso 535.1 Un esempio d’uso del metodo del simplesso . . . . . . . . . . . 535.2 Presentazione dell’algoritmo del simplesso mediante dizionario. 59
127

6 Cenni sull’interpretazione geometrica della programmazionelineare 626.1 Soluzione grafica di problemi di PL . . . . . . . . . . . . . . . 71
7 Formulazione matriciale del metodo del simplesso 757.1 Presentazione dell’algoritmo . . . . . . . . . . . . . . . . . . . 75
7.1.1 Ottimalita di una soluzione ammissibile di base . . . . 767.1.2 Scelta di una nuova soluzione ammissibile di base -
operazione di pivot . . . . . . . . . . . . . . . . . . . . 817.1.3 Problemi illimitati . . . . . . . . . . . . . . . . . . . . 837.1.4 Determinazione della variabile uscente di base . . . . . 857.1.5 Scelta del vettore uscente dalla base . . . . . . . . . . . 937.1.6 Finitezza del metodo del simplesso . . . . . . . . . . . 94
7.2 Inizializzazione del metodo del simplesso - Il metodo due fasi . 987.2.1 Problemi con infiniti ottimi . . . . . . . . . . . . . . . 1047.2.2 Efficienza del metodo del simplesso . . . . . . . . . . . 113
A Introduzione alla teoria dei grafi ed alle reti di flusso 116A.1 Terminologia e definizioni principali . . . . . . . . . . . . . . . 116A.2 Flussi su reti – reti di flusso . . . . . . . . . . . . . . . . . . . 120A.3 Alberi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
128

![Parte xxix Schemeappunti.linux.it/a2/scheme.p4.pdf1 ]=> (cf "ciao_mondo.scm")[Invio] L’esempio mostra la compilazione del sorgente ‘ciao_mondo. scm’, per generare il file ‘ciao_mondo.com’.](https://static.fdocumenti.com/doc/165x107/61171c2c4e216a4142707b4b/parte-xxix-1-cf-ciaomondoscminvio-laesempio-mostra-la.jpg)









![L’Epidemiologia · 2008-12-06 · Scopi dell’Epidemiologia [1] • Studio della distribuzione e dei determinanti di condizioni ed eventi legati alla salute in popolazioni specifiche](https://static.fdocumenti.com/doc/165x107/5e7cd8508c725171d8538108/laepidemiologia-2008-12-06-scopi-dellaepidemiologia-1-a-studio-della-distribuzione.jpg)






