
Learning Machine Come dare senso ai dati Martedì 11 ...cena/materiale/GestioneDB/Laboratorio...
77
Machine Learning Come dare senso ai dati laboratorio Mirko Lai [email protected] Martedì 11/Mercoledì 12 Dicembre 2018
Transcript of Learning Machine Come dare senso ai dati Martedì 11 ...cena/materiale/GestioneDB/Laboratorio...

Machine Learning
Come dare senso ai datilaboratorio
Mirko Lai [email protected]
Martedì 11/Mercoledì 12 Dicembre 2018
Modello
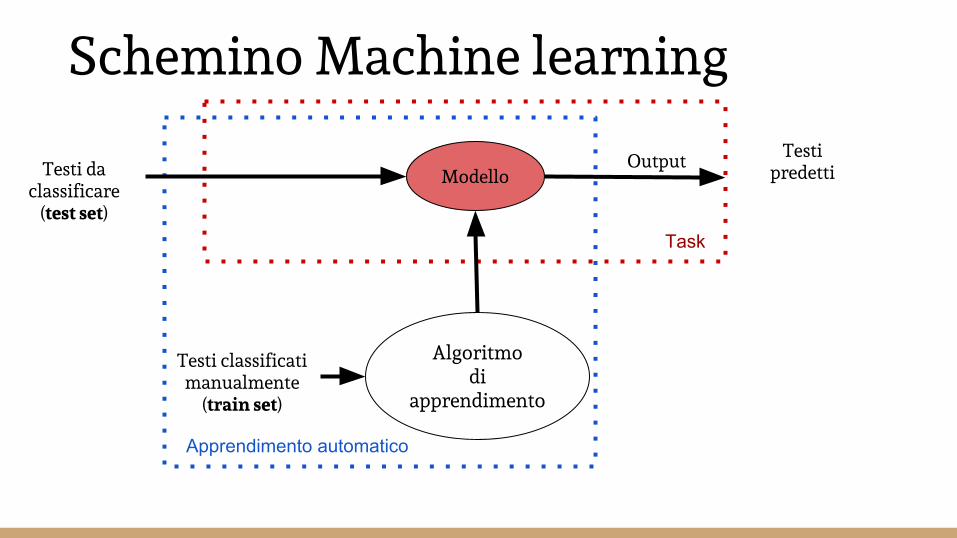
Schemino Machine learning
Testi da classificare
(test set)
Algoritmo di
apprendimento
Testi classificatimanualmente
(train set)
Output
Task
Apprendimento automatico
Testi predetti

Prima fase: Training1047919240848838656
@MaxBastoni @coccaclaudio Riprendiamoci la nostra città ripulita da clandestini ,abusivi, delinquenti, migranti, spacciatori e nigeriani e zingari YES
... …. ...
1055101652557094913
"Sciacallo!" gridano al Ministro dell'Interno, accorso per un omicidio, quelli che vanno in crociera a filmare immigrati. #desiree NO
Modello
Algoritmo di
apprendimento
Apprendimento automatico
train set
1 1 0 ... 1 0
YES
... ... ... ... ... ......
0 0 1 ... 0 1
NO
Rappresentazione vettoriale del train set

Modello
Seconda fase: TestingOutput
Task
1047919240848838656
@MaxBastoni @coccaclaudio Riprendiamoci la nostra città ripulita da clandestini ,abusivi, delinquenti, migranti, spacciatori e nigeriani e zingari
... ….
1055101652557094913
"Sciacallo!" gridano al Ministro dell'Interno, accorso per un omicidio, quelli che vanno in crociera a filmare immigrati. #desiree
1 1 0 ... 1 0
... ... ... ... ... ...
0 0 1 ... 0 1
Rappresentazione vettoriale del test set
1047919240848838656
@MaxBastoni @coccaclaudio Riprendiamoci la nostra città ripulita da clandestini ,abusivi, delinquenti, migranti, spacciatori e nigeriani e zingari YES
... …. ...
1055101652557094913
"Sciacallo!" gridano al Ministro dell'Interno, accorso per un omicidio, quelli che vanno in crociera a filmare immigrati. #desiree NO
test setpredizione

Validazione 20/80La validazione 20/80 divide randomicamente il dataset annotato in due parti. Una consiste nell’80% del dataset e viene usata per addestrare l’algoritmo di apprendimento TRAIN e l’altra, il 20%, viene usata per valutare il modello TEST)
Train set Fase Unica

Validazione 20/80
Modello
Algoritmo di
apprendimento
Dati Output
Task
Apprendimento automatico
Train
Test Predizione Gold
Fase Unica
vs

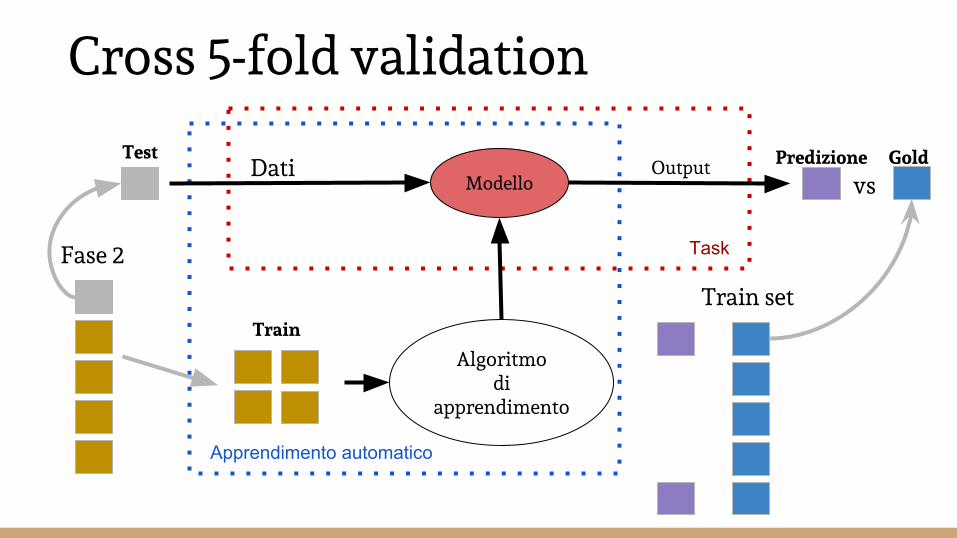
Cross 5-fold validationK-fold validation
5-fold validation (in ogni fase uso 4 parti per addestrare l’algoritmo di apprendimento TRAIN e 1 parte per valutare il modello TEST)Train set Fase 1 Fase 2 Fase 3 Fase 4 Fase 5

Cross 5-fold validation
Modello
Algoritmo di
apprendimento
Dati Output
Task
Apprendimento automatico
Train
Test
Train set
Predizione Gold
Fase 1
vs
Cross 5-fold validation
Modello
Algoritmo di
apprendimento
Dati Output
Task
Apprendimento automatico
Train
Test
Train set
Predizione Gold
Fase 2
vs
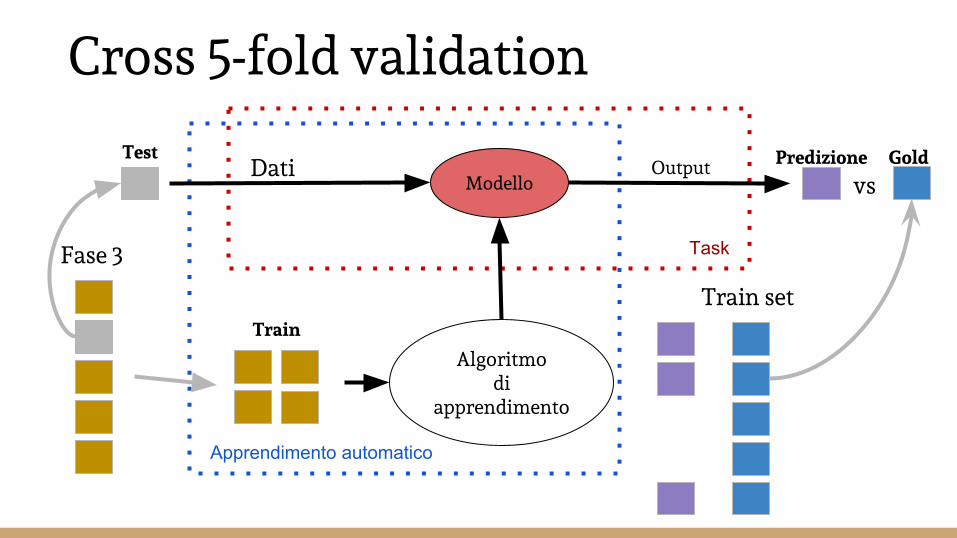
Cross 5-fold validation
Modello
Algoritmo di
apprendimento
Dati Output
Task
Apprendimento automatico
Train
Test
Train set
Predizione Gold
Fase 3
vs

Cross 5-fold validation
Modello
Algoritmo di
apprendimento
Dati Output
Task
Apprendimento automatico
Train
Test
Train set
Predizione Gold
Fase 4
vs
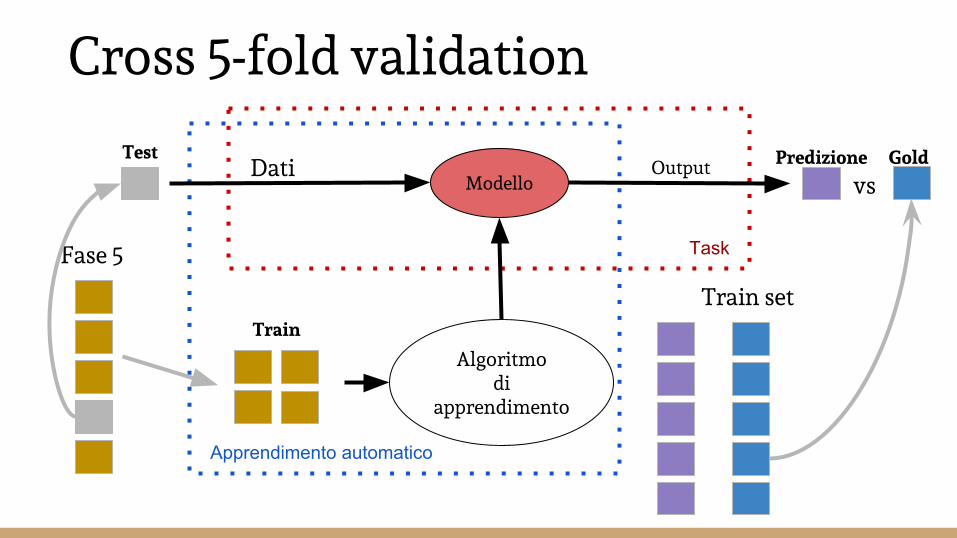
Cross 5-fold validation
Modello
Algoritmo di
apprendimento
Dati Output
Task
Apprendimento automatico
Train
Test
Train set
Predizione Gold
Fase 5
vs

7.4. Valutare il modelloPredizione Gold
vsSi tratta di valutare quanto la predizione del modello sia “simile” all’annotazione manuale
Due misure comuni sono:
● Accuracy
● F-measure

Valutare il modelloPredizione Gold
vsL’accuracy misura il numero di volte che il modello ha azzeccatoPredizione
YES
NO
Gold
+
Accuracy
7/(7+3)=0,7

Valutare il modelloPredizione Gold
vsL’F-Measure è invece una misura più complessa e si calcola come rapporto (media armonica) tra precision e recall
F_YES= 2 (precision_YES*recall_YES)/(precision_YES+recall_YES)
F_NO= 2 (precision_NO*recall_NO)/(precision_NO+recall_NO)
F_AVG= (F_YES+F_NO)/2
Tutti i valori sono compresi tra 0 e 1

Valutare il modelloPredizione Gold
vs
La recall sulla classe YES misura il numero di volte che il modello ha “azzeccato” la classe YES diviso il numero di volte che il modello avrebbe dovuto predire YES
PredizioneYES
NO
Gold
+
Precision_YES
1/(1+2)=0,3

Valutare il modelloPredizione Gold
vs
La precision sulla classe YES misura il numero di volte che il modello ha “azzeccato” la classe YES diviso il numero di volte che il modello ha predetto YES
PredizioneYES
NO
Gold
+
Precision_YES
1/(1+1)=0,5

Valutare il modelloPrecision = quante anatre ho colpito/quanti colpi ho sparato
Recall = quante anatre ho colpito/quante anatre hanno sorvolato il prato
F-measure = media armonica tra precision e recall

Valutare il modelloPredizione Gold
vsPredizione
YES
NO
Gold
+
F_YES/2=0,1875
*Precision_YES Recall_YES
Precision_YES Recall_YES
+
*0,5 0,3
0,5 0,3
F_YES=0,375

Machine Learning MethodsLe tre principali categorie dell’apprendimento automatico
1. Apprendimento supervisionato
2. Apprendimento non supervisionato
3. Apprendimento per rinforzo

Machine Learning MethodsLe tre principali categorie dell’apprendimento automatico
1. Apprendimento supervisionato
2. Apprendimento non supervisionato
3. Apprendimento per rinforzo

Machine Learning MethodsApprendimento supervisionatoIl sistema riceve degli esempi etichettati in base all’output che si vuole
ottenere e, a partire da questi dati di training, deve estrarre una regola
generale che associ ad ogni nuovo input l’etichetta corretta.

Machine Learning MethodsFrom: Profolan Object: Il miglior rimedio contro le calvizie
From: 7Slim Object: Come perdere peso?
From: News-info Object: Pubblicazione bandi
From: EasyChair Object: CLiC-it 2018 submission
From: Nicoin Object: Il modo più semplice di smettere di fumare
Spam o E-mail?
Es. Classificazione tramite l’utilizzo degli alberi decisionali
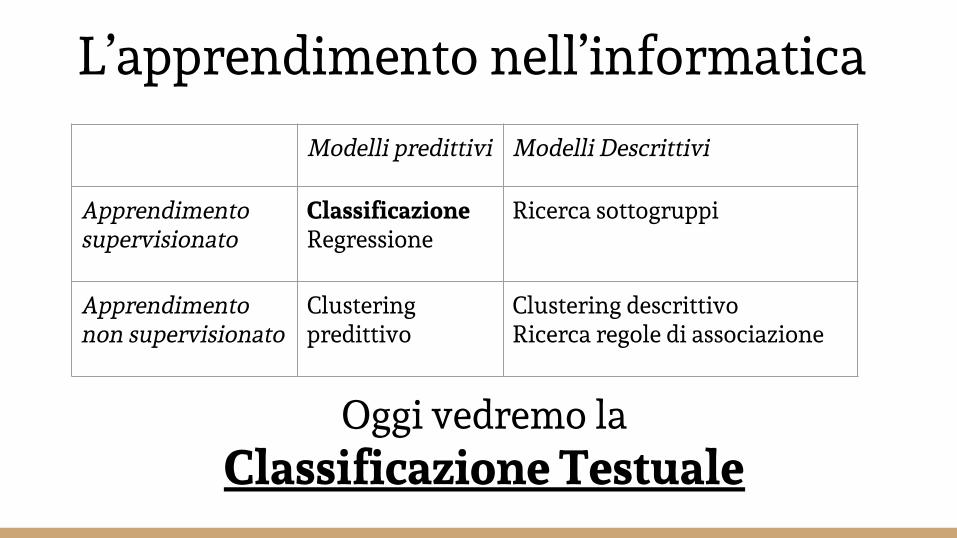
L’apprendimento nell’informaticaModelli predittivi Modelli Descrittivi
Apprendimento supervisionato
ClassificazioneRegressione
Ricerca sottogruppi
Apprendimento non supervisionato
Clustering predittivo
Clustering descrittivoRicerca regole di associazione
Oggi vedremo laClassificazione Testuale

Algoritmi di Machine LearningGli algoritmi di machine learning che possono essere utilizzati per classificare possono essere divisi in base ai loro output:
● Modelli probabilistici (per esempio Naïve Bayes)● Modelli geometrici (per esempio Support Vector Machine)● Modelli logici (per esempio gli alberi decisionali)● Basati su reti neurali
Nella lezione di laboratorio entreremo più in dettaglio su questo punto.

Modelli probabilistici: Naïve BayesSi basano su assunzioni probabilistiche ed in particolare sul teorema di Bayes.
P(Y|X) = P(X|Y) P(Y)
P(X)

Modelli probabilistici: Naïve BayesDiciamo che conosciamo la variabile X e vogliamo conoscere la variabile Y.La variabile X rappresenta le feature (es. Bag of Words).La variabile Y rappresenta le classi (es. Spam o E-mail).
Noi siamo interessati a trovare P(Y|X) =
dato che conosciamo X (es. le parole contenute nel testo).Y può invece assumere i valori Spam o E-mail.
P(X|Y)P(Y)
P(X)

Modelli probabilistici: Naïve Bayes
P(Y|X) =P(X|Y)P(Y)
P(X)
P(Y|X): Probabilità condizionata (anche detta probabilità a posteriori. Probabilità che si verifichi Y se è avvenuto X).
P(X|Y): Probabilità condizionata (probabilità che si verifichi X data l’evidenza Y).
P(Y): Probabilità a priori della proposizione (probability of proposition)
P(X): Probabilità a priori dell’evidenza (perché è l’informazione che conosco)

Modelli probabilistici: Naïve Bayes
P(Y|X) =P(X|Y)P(Y)
P(X)
A noi interessa calcolare se P(Y= Spam |X) > P(Y= E-Mail|X) o se P(Y= Spam |X) < P(Y= E-Mail|X). La probabilità maggiore ci indicherà quale classe associare al nuovo tweet che vogliamo annotare.
P(X) è uguale sia per P(Y= Spam |X) che perP(Y= E-Mail|X). Quindi possiamo non considerare P(X)

Modelli probabilistici: Naïve Bayes
P(Y|X) = P(X|Y)P(Y)
A noi interessa calcolare se P(Y= Spam |X) >P(Y= E-Mail|X). La probabilità maggiore ci indicherà quale classe associare al nuovo tweet che vogliamo annotare.
Supponiamo che P(Y= Spam) e P(Y= E-Mail) siano uguali.Significa assumere che le classi siano distribuite in egualmisura sul train set.Quindi possiamo non considerare P(Y).

Modelli probabilistici: Naïve Bayes
P(Y|X) = P(X|Y)
Abbiamo semplificato un pò le cose no?
Vediamo un esempio pratico...

Modelli probabilistici: Naïve Bayes
Qual è la probabilità che il messaggio ricevuto sia Spam se contiene le parole criptovalute, pillola e bitcoin?
In notazione probabilistica P(Y=Spam|X=criptovalute,pillola,bitcoin)
Ma gli eventi X che conosciamo sono dipendenti o INdipendenti?
P(X=criptovalute,pillola,bitcoin): Probabilità congiunta: La probabilità che gli eventi si verifichino insieme e siano dipendenti DIFFICILE DA CALCOLARE
P(X=criptovalute) P(X=pillola) P(X=bitcoin): Probabilità congiunta: La probabilità che gli eventi si verifichino insieme e siano INdipendenti FACILE DA CALCOLARE

Modelli probabilistici: Naïve BayesP(Y=Spam|X=criptovalute,pillola,bitcoin) =
Semplificazione vista prima: rimuoviamo P(Y=Spam) e P(X=criptovalute,pillola,bitcoin)
P(Y=Spam|X=criptovalute,pillola,bitcoin) = P(X=criptovalute,pillola,bitcoin|Y=Spam)
P(X=criptovalute,pillola,bitcoin|Y=Spam)P(Y=Spam)
P(X=criptovalute,pillola,bitcoin)

Modelli probabilistici: Naïve Bayes
Altra Assunzione (questa volta ufficiale): gli eventi criptovalute, pillola e bitcoin vengono considerati eventi indipendenti. Da qui l’appellativo Naïve.
P(Y=Spam|X=criptovalute,pillola,bitcoin) = P(X=criptovalute|Y=Spam) P(X=pillola|Y=Spam) P(X=bitcoin|Y=Spam)
P(Y=Spam|X=criptovalute,pillola,bitcoin) =P(X=criptovalute,pillola,bitcoin|Y=Spam)

Modelli probabilistici: Naïve BayesA noi servono questo valori
P(X=criptovalute|Y=Spam) P(X=pillola|Y=Spam) P(X=bitcoin|Y=Spam)
Il train set ci consente di trovare tutte probabilità condizionate.
Quante volte la parola X è contenuta in un testo etichettato come Y?
P(X|Y=Spam) e P(X|Y=E-Mail)Più questi valori sono diversi tra di loro, più la feature X è “buona” per classificare.

Modelli probabilistici: Naïve BayesIl train set ci consente di calcolare tutti i P(X|Y=Spam) e P(X|Y=E-Mail)
P(X=criptovalute|Y=Spam) P(X=criptovalute|Y=E-Mail)
P(X=pillola|Y=Spam) P(X=pillola|Y=E-Mail)
P(X=bitcoin|Y=Spam) P(X=bitcoin|Y=E-Mail)
Quanto è frequente la parola X negli Spam?
Quanto è invece frequente la parola X nelle E-mail?
Come calcolare questi valori???

Modelli probabilistici: Naïve BayesFortunatamente è molto semplice!
Supponiamo di avere 200 tweet. 100 etichettati come E-Mail e 100 etichettati come Spam.
La parola criptovalute è presente in 67 tweet etichettati come E-Mail.
La parola criptovalute è presente in 50 tweet etichettati come Spam.
P(X=criptovalute|Y=E-Mail) = 67/100=0,67
P(X=criptovalute|Y=Spam) = 50/100=0,5

Modelli probabilistici: Naïve BayesPoniamo che il nostro spazio vettoriale è lungo tre (un indice per ogni parola considerata). Poniamo che le distribuzioni delle probabilità condizionate nel train set siano le seguenti. Questo è la rappresentazione del nostro modello generato dall’algoritmo di machine learning Naïve Bayes con uno specifico train set.
Spam
criptovalute pillola bitcoin
0,5 0,67 0,33
criptovalute pillola bitcoin
0,67 0,33 0,33

Modelli probabilistici: Naïve BayesPer ogni nuovo messaggio che riceviamo, noi conosciamo X perché possiamo verificare la presenza delle parole criptovalute, pillola e bitcoin creando una rappresentazione vettoriale del messaggio.
Il vettore è normalmente molto più lungo. Lungo quanto le parole del nostro dizionario. Qui utilizziamo solo tre parole per semplificare il discorso.
Pillola per dimagrire super efficace. Comprala con i bitcoin.….Seminario sulle criptovalute. Cosa sono Bitcoin e criptovalute?
criptovalute
pillola bitcoin
0 1 1... ... ...
1 0 1

Modelli probabilistici: Naïve BayesArriva un nuovo testo da classificare. Che si fa?
Rappresentazione vettoriale del nuovo testo
Pillola per dimagrire super efficace. Comprala con i bitcoin.
criptovalute
pillola bitcoin
0 1 1

Modelli probabilistici: Naïve Bayes
RICORDIAMOCI: Noi vogliamo verificare che la probabilità
P(Y=Spam|X=criptovalute=0, pillola=1, bitcoin=1)
Sia maggiore o minore di
P(Y=E-mail|X=criptovalute=0, pillola=1, bitcoin=1)
Pillola per dimagrire super efficace. Comprala con i bitcoin.
criptovalute
pillola bitcoin
0 1 1

Modelli probabilistici: Naïve BayesP(Y=Spam|criptovalute=0,pillola=1,bitcoin=1)=(1-0,5)*(0,67)*(0,33)=0,110
Spam
criptovalute
pillola bitcoin
0,5 0,67 0,33
criptovalute
pillola bitcoin
0,67 0,33 0,33
criptovalute
pillola bitcoin
0 1 1
(1-0,5) perchè criptovalute ha il valore 0

Modelli probabilistici: Naïve BayesP(Y=E-mail|criptovalute=0,pillola=1,bitcoin=1)=(1-0,67)*(0,33)*(0,33)=0,035
Spam
criptovalute
pillola bitcoin
0,5 0,67 0,33
criptovalute
pillola bitcoin
0,67 0,33 0,33
criptovalute
pillola bitcoin
0 1 1
(1-0,5) perchè criptovalute ha il valore 0

Modelli probabilistici: Naïve BayesP(Y=E-mail|criptovalute=0,pillola=1,bitcoin=1)=(1-0,67)*(0,33)*(0,33)=0,035
P(Y=Spam|criptovalute=0,pillola=1,bitcoin=1)=(1-0,5)*(0,67)*(0,33)=0,110
Pillola per dimagrire super efficace. Comprala con i bitcoin. Spam
P(Y=Spam|criptovalute=0,pillola=1,bitcoin=1)
P(Y=E-mail|criptovalute=0,pillola=1,bitcoin=1)= 3,14 > 1
Vedendola invece come rapporto spam sta ad e-mail 3,14 a 1

Modelli probabilistici: Naïve Bayes
Altre varianti di questo approccio probabilistico usano invece la probabilità a posteriori (quella vista nella prima slides di questa brutta storia).Ciò è molto utile se il train set è molto sbilanciato a favore di una classe rispetto che all’altra (es. ci sono molte più spam che e-mail).P(Y=E-mail) e P(Y=Spam) sono facilmente calcolabili.
P(Y=E-mail | criptovalute=0,pillola=1,bitcoin=1|)=0,035*P(Y=E-mail)
P(Y=Spam | criptovalute=0,pillola=1,bitcoin=1|)=0,110*P(Y=Spam)

Dataset EVALITAHate Speech Detection: http://www.di.unito.it/~tutreeb/haspeede-evalita18/data.html
Problemi di importazione
● I campi devono essere separati dal carattere ,● I campi testuali devono essere delimitati dal carattere "● Se il campo è numerico, utilizzare il . (e non la ,) per separare la parte decimale ● Se dentro il testo è presente il carattere ", sostituirlo con la stringa ‘ QUOTATIONMARK ‘● I campi testuali non devono contenere i caratteri \n o \r, sostituirli con la stringa ‘ NEWLINE ‘
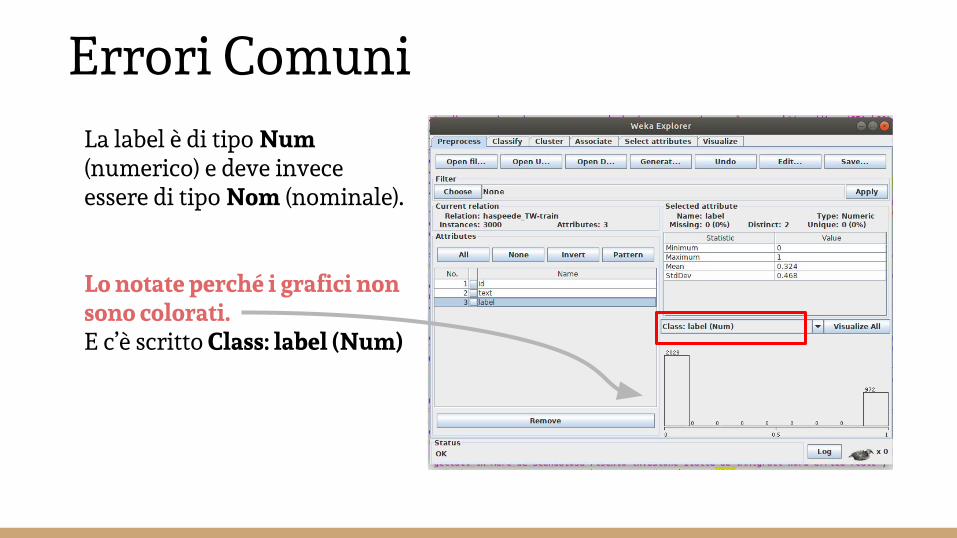
Errori ComuniLa label è di tipo Num (numerico) e deve invece essere di tipo Nom (nominale).
Lo notate perché i grafici non sono colorati.E c’è scritto Class: label (Num)

Errori ComuniSoluzioni
● Sostituire i valori numerici delle label con valori testuali (es “0” -> “NO”)

Errori ComuniOppure
● Modificare la tipologia del campo label da Num a Nom

Errori ComuniFilter->Unsupervised->NumerictoNominal
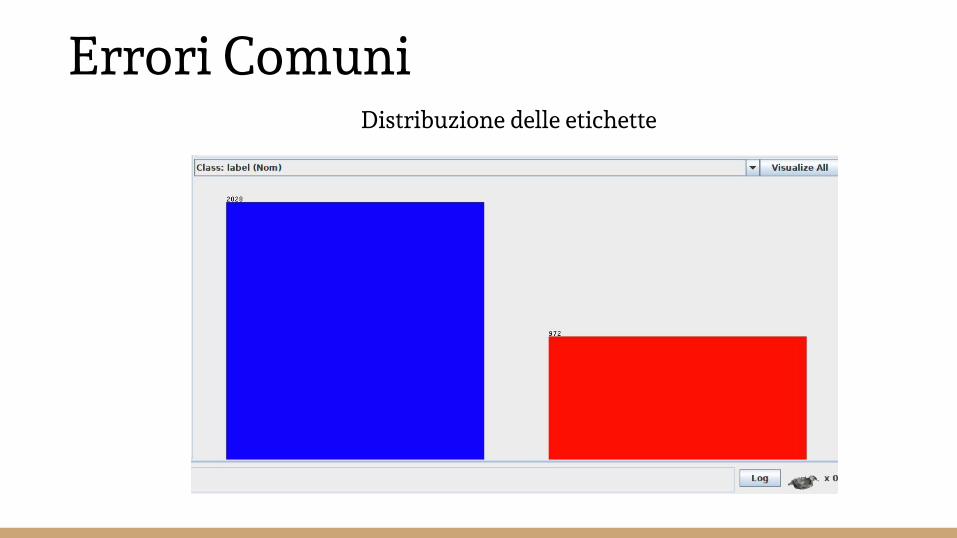
Errori ComuniDistribuzione delle etichette

Ultimo passaggioRimuovere le colonne che non ci servono

Pronti a vettorizzare?

Bag of Word (BoW)Filter->Unsupervised->NominaltoString

Bag of Word (BoW)Filter->Unsupervised->StringtoWordVector

Bag of Word (BoW)

E finalmente Classifichiamo!!bayes->NaiveBayes

Analizziamo i risultati
Il token #genova è presente5 volte nel training set. Tutte le volte in tweet di classe NO
Quindi P(X=#genova|Y=NO)=5/2028=0,0024eP(X=#genova|Y=YES)=0/972=0
0 sta per la classe NO1 sta per la classe YES
P(Y=NO)=2028/3000=0,68P(Y=YES)=972/3000 =0,32
In questo caso indica il valore della parola più frequente.Ma poco ci interessa...

Analizziamo i risultati
Accuracy
F-Measure

Support Vector MachineMultidimensional Space

Support Vector MachineIniziamo con 2 dimensioni
A
B
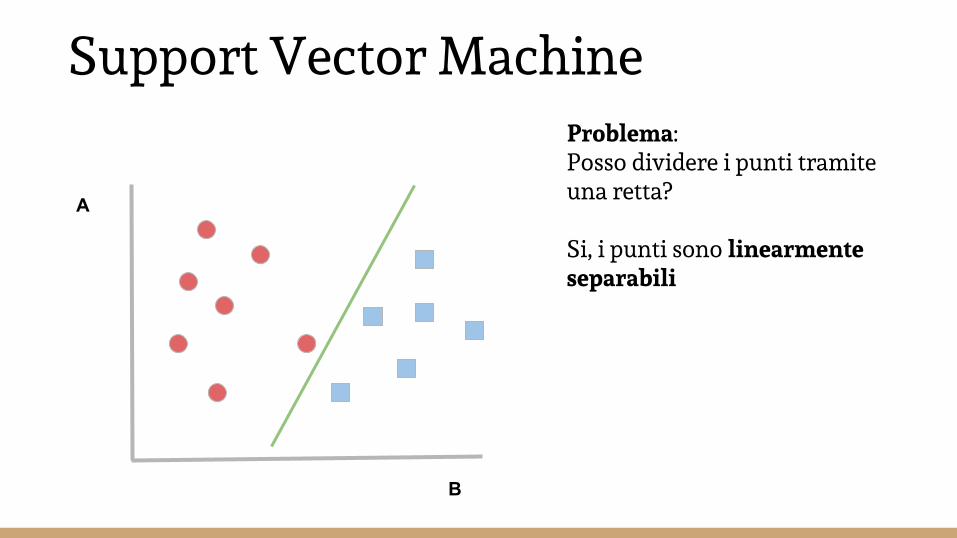
Due variabili note A e BDue classi e
Ogni punto e si trova in coordinatax=(a,b)
Obiettivo:trovare una retta che separi le due classi
Support Vector Machine
A
B
Problema:Posso dividere i punti tramite una retta?
Si, i punti sono linearmente separabili
Support Vector Machine
A
B
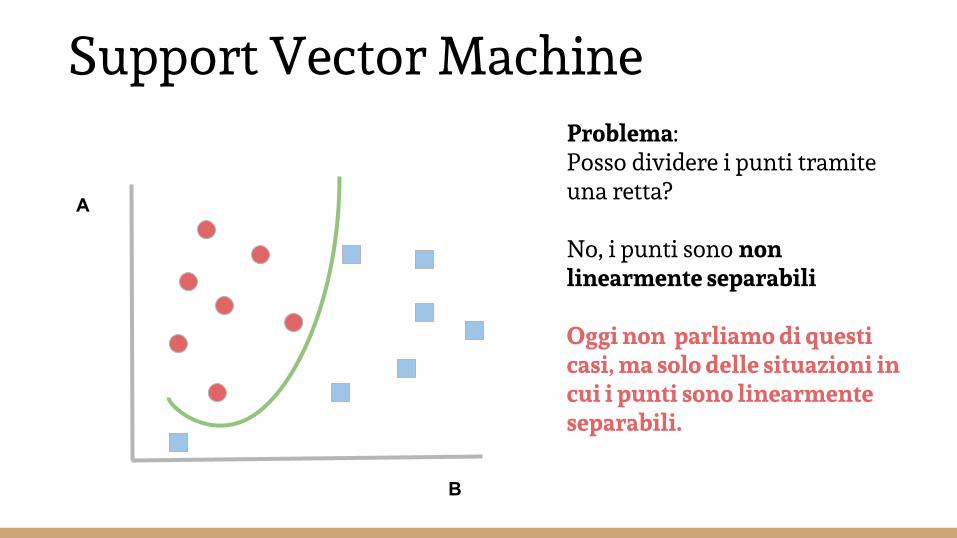
Problema:Posso dividere i punti tramite una retta?
No, i punti sono non linearmente separabili
Oggi non parliamo di questi casi, ma solo delle situazioni in cui i punti sono linearmente separabili.

Support Vector MachineIn due dimensioni, i punti appartenenti a classi diverse linearmente separabili sono separabili tramite una retta, ma in tre dimensioni abbiamo bisogno di un piano.Siccome SVM lavora con un numero elevato di dimensioni, il piano che
separa i punti viene chiamato iperpiano.
Support Vector Machine
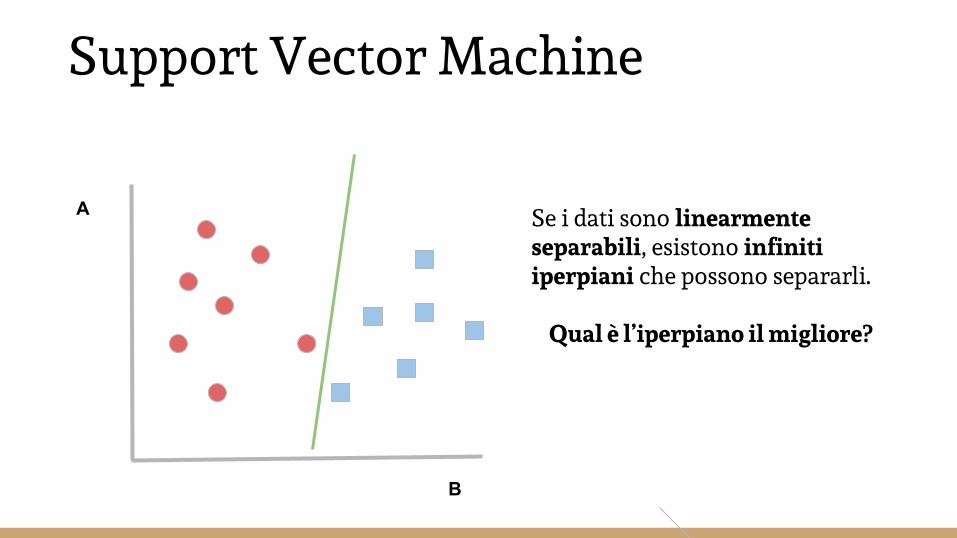
A Se i dati sono linearmente separabili, esistono infiniti iperpiani che possono separarli.
Qual è l’iperpiano il migliore?
B

Support Vector Machine
A Dobbiamo trovare l’iperpiano che abbia la distanza massima tra tutti i punti.
Lo spazio che separa l’iperpiano dai punti viene chiamato margine.
E l’iperpiano migliore è quello che giace in mezzo alla delimitazione dei due margini.
B

Support Vector Machine
A W⋅X-b=1 (Tutto ciò che sta sotto i margini è della classe )
W⋅X-b=-1 (Tutto ciò che sta sopra i margini è della classe )
Dove W è un vettore ortogonale all’iperpiano.
E b è l’intercetta dell’iperpiano all’origine.
B
W
b

E finalmente Classifichiamo!!functions>SMO
ATTENZIONE
Potrebbe non bastare la memoria RAM a cui Java può accedere.In quel caso fate una 5-fold cross validation.
Io ho usato la 5-fold cross validation come per l’esperimento che ho fatto con Naïve Bayes

Analizziamo i risultati0 sta per la classe NO1 sta per la classe YES
Per approfondire: J. Platt: Fast Training of Support Vector Machines using Sequential Minimal Optimization. In B. Schoelkopf and C. Burges and A. Smola, editors, Advances in Kernel Methods - Support Vector Learning, 1998.

Analizziamo i risultati
Accuracy
F-MeasureF-AVG (0,791) è leggermente superiore a quello ottenuto con Naïve Bayes (0,738)

Opzioni StringtoWordVector

Opzioni StringtoWordVectorLista Stop word: https://raw.githubusercontent.com/stopwords-iso/stopwords-it/master/stopwords-it.txt

Opzioni StringtoWordVectorTF term frequency
La frequenza di una parola in un tweet
IDF inverse term frequency
Considera la frequenza della parola nel set di tweet (tweets, tutto il set)

Opzioni StringtoWordVectorStemmer
La funzione che si occupa di trovare la radice di una termine.
mangio -> mangiare
Tokenizer
La funzione che si occupa di dividere il testo in tokenLa Nasa registra per la prima volta il suono del vento su MarteLa, Nasa, registra, per, la, prima, volta, il, suono, del, vento, su, MarteLa Nasa, Nasa registra, registra per, per la, la prima, prima volta,volta il….La Nasa registra, Nasa registra per, registra per la, per la prima...La, a , N, Na, as, sa, a , r, re, eg, gi, is, st, tr, ra...….

Progetto in corso

Anteprima del sito controlodio.it

Versione beta: http://beta.controlodio.it/
Questionario sull’usabità: https://docs.google.com/forms/d/10V6dJN771SqL6jLlq53tvS6HFEsNf-WM
Fc7DzwDgmlA/edit?ts=5c01261d














![FLG5143 - Bioclimatologia Machine Learning€¦ · – No entanto, esse método requer variáveis que nem sempre podem ser obtidas [Majidi el at 2015] – Outros requerem menos variáveis](https://static.fdocumenti.com/doc/165x107/5f0638f67e708231d416e90b/flg5143-bioclimatologia-machine-learning-a-no-entanto-esse-mtodo-requer-variveis.jpg)



