Ipotesi di analisi lista twitter
12
SNA TWITTER LIST ipotesi di analisi by: C. Di Tullio aka Dr_Who drwho.it
-
Upload
camillo-di-tullio -
Category
Data & Analytics
-
view
164 -
download
0
Transcript of Ipotesi di analisi lista twitter

“La scienza si fa con i fatti come una casa si fa con i mattoni, ma l’accumulazione dei fatti non è scienza più di quanto un mucchio di mattoni non sia una casa” Henri Poincarè
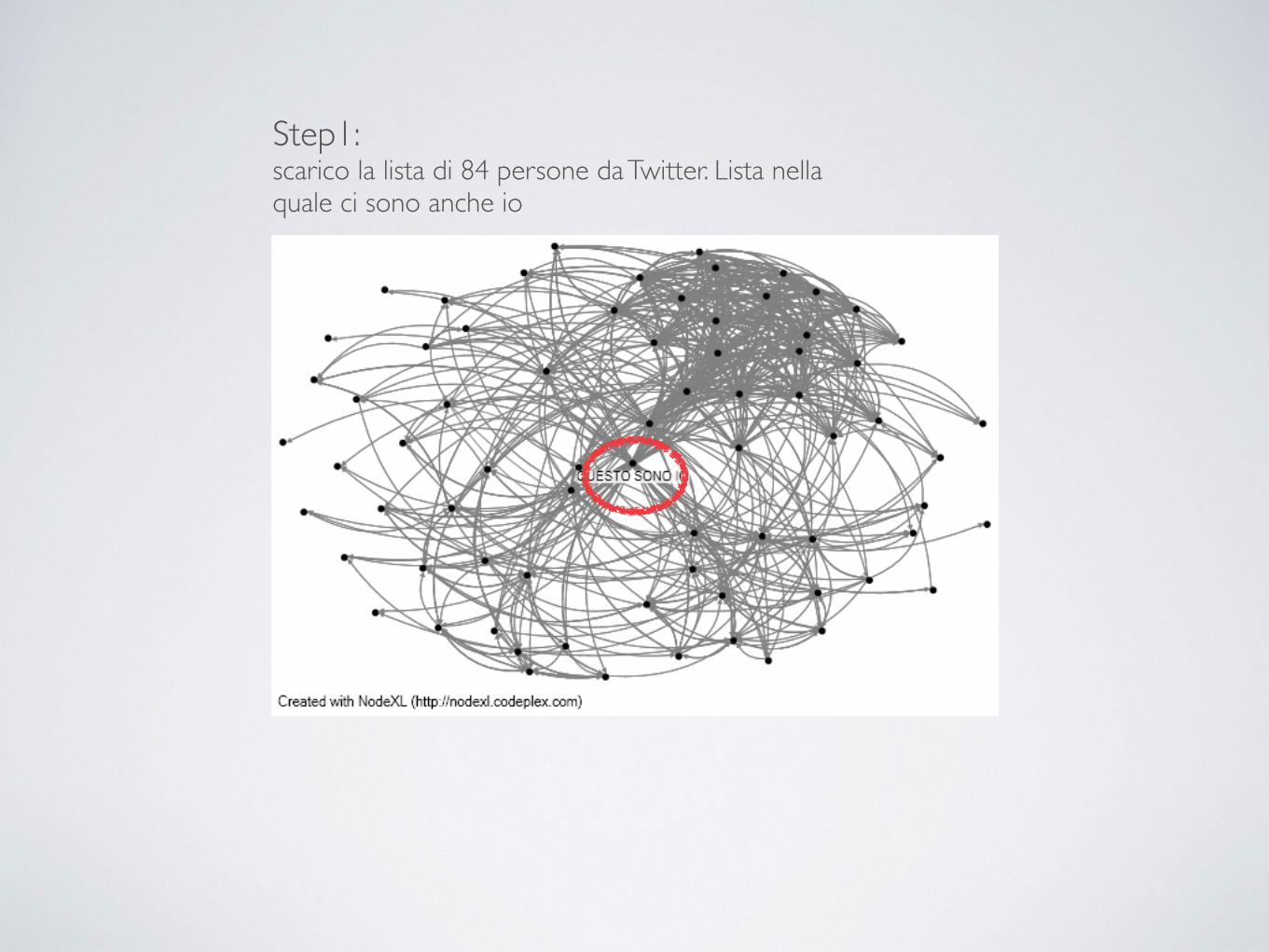
Step1: scarico la lista di 84 persone da Twitter. Lista nella quale ci sono anche io

Step2: la depuro da me: eliminando i miei dati dal foglio vertex e tutti i collegamenti a me relativi dal foglio edges

Step3: domanda: come identificare le persone più influenti da contattare? calcolo le metriche
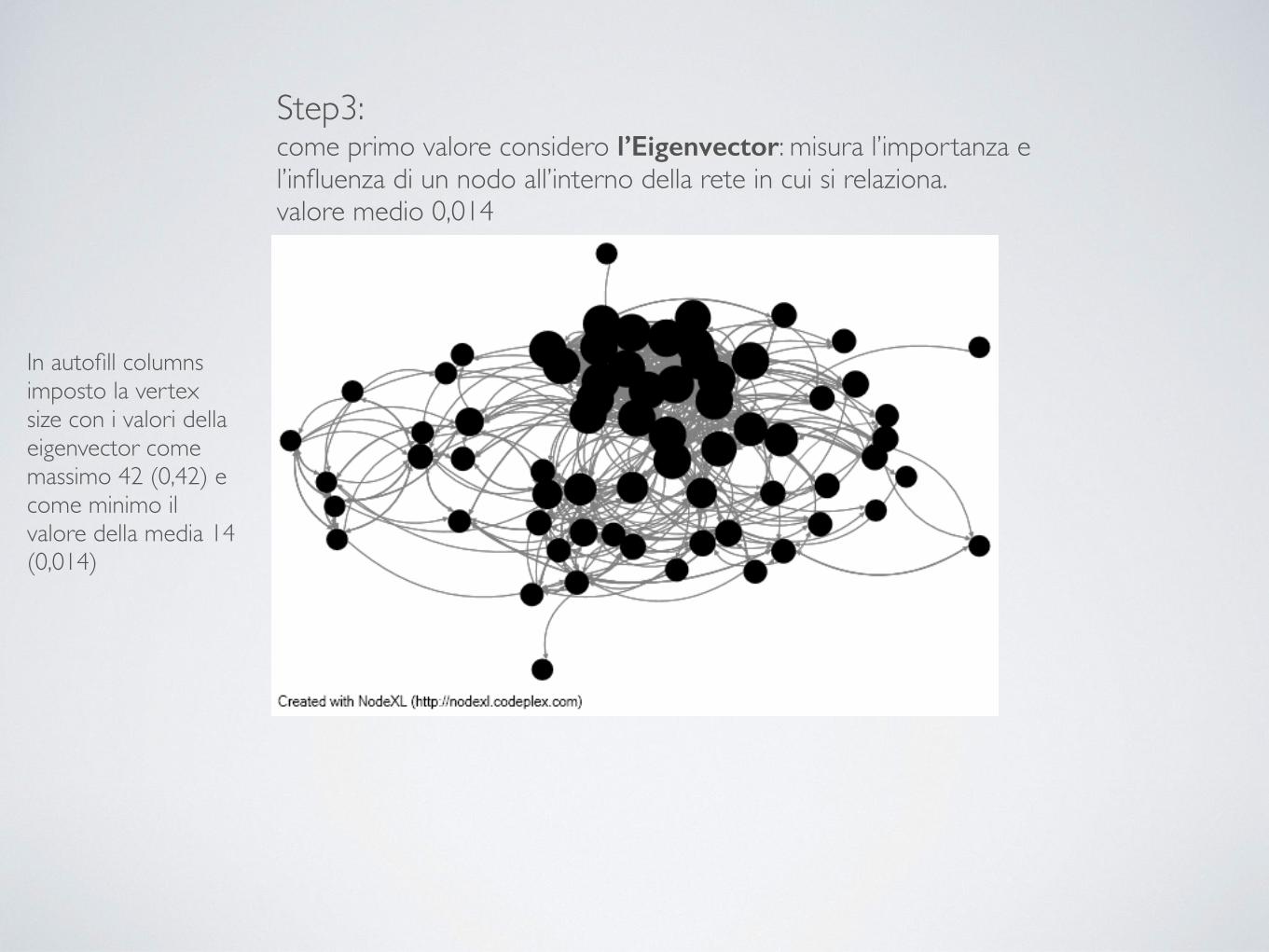
Step3: come primo valore considero l’Eigenvector: misura l’importanza e l’influenza di un nodo all’interno della rete in cui si relaziona. valore medio 0,014
In autofill columns imposto la vertex size con i valori della eigenvector come massimo 42 (0,42) e come minimo il valore della media 14 (0,014)
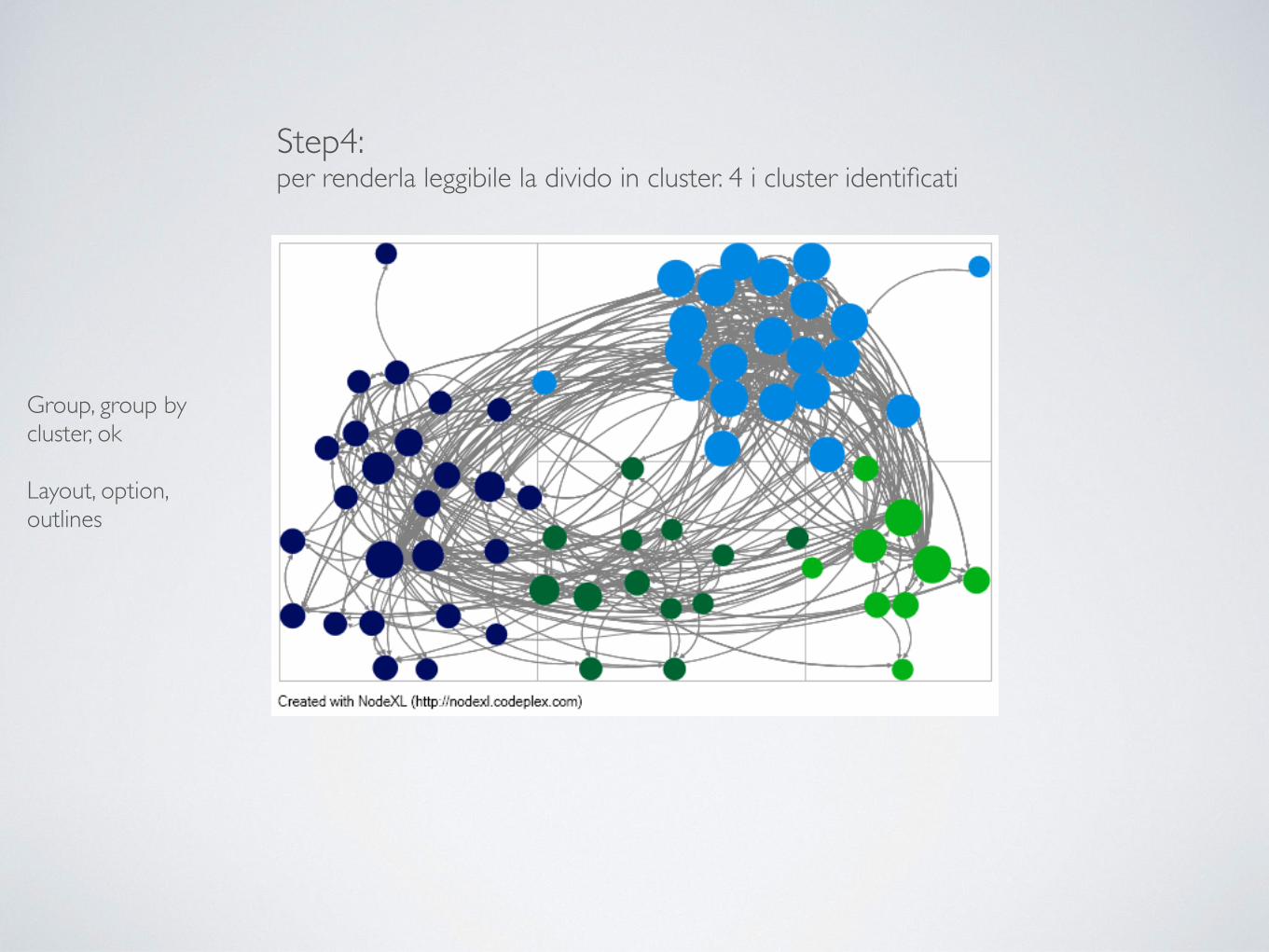
Step4: per renderla leggibile la divido in cluster. 4 i cluster identificati
Group, group by cluster, ok !Layout, option, outlines
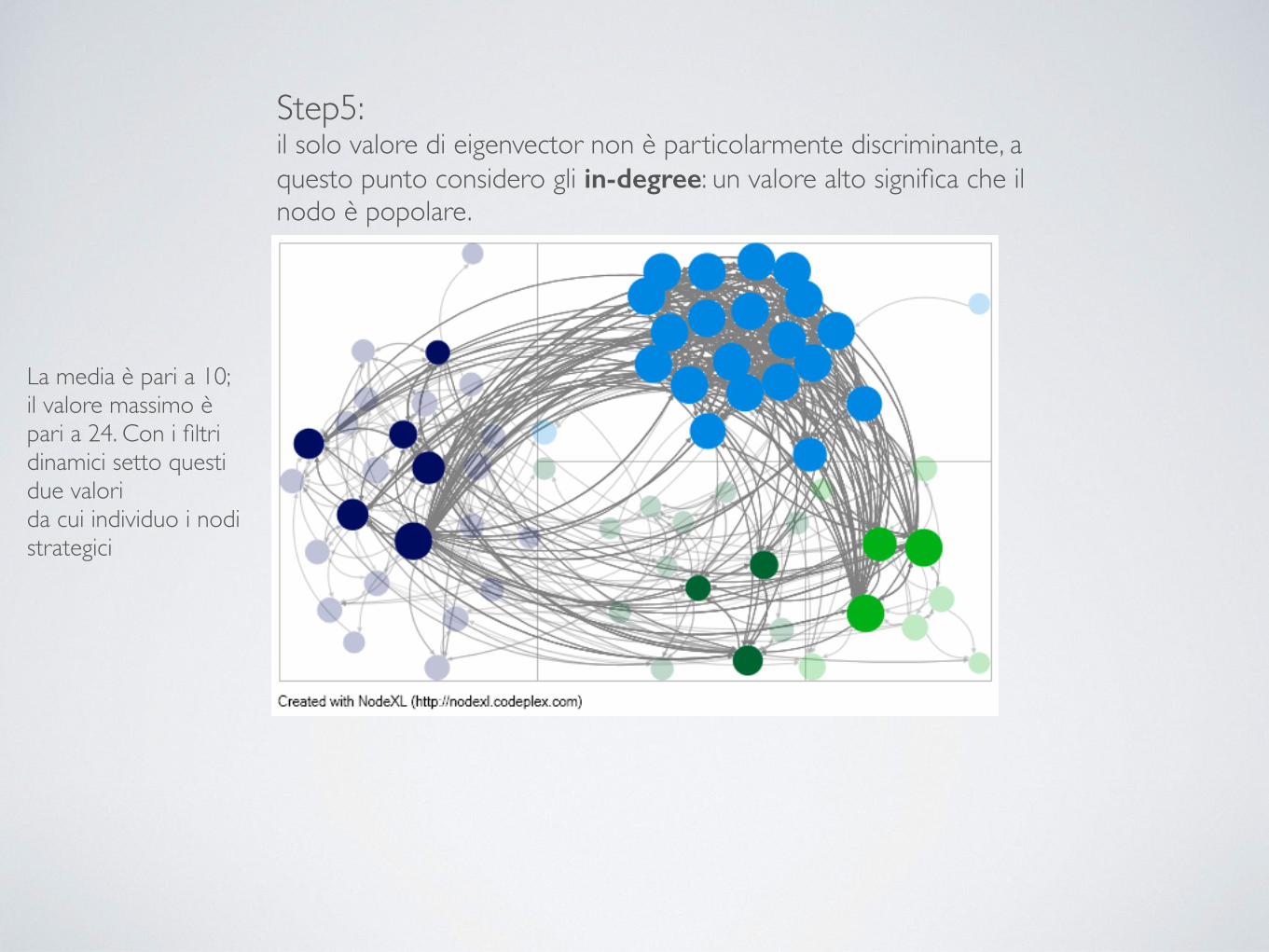
Step5: il solo valore di eigenvector non è particolarmente discriminante, a questo punto considero gli in-degree: un valore alto significa che il nodo è popolare.
La media è pari a 10; il valore massimo è pari a 24. Con i filtri dinamici setto questi due valori da cui individuo i nodi strategici
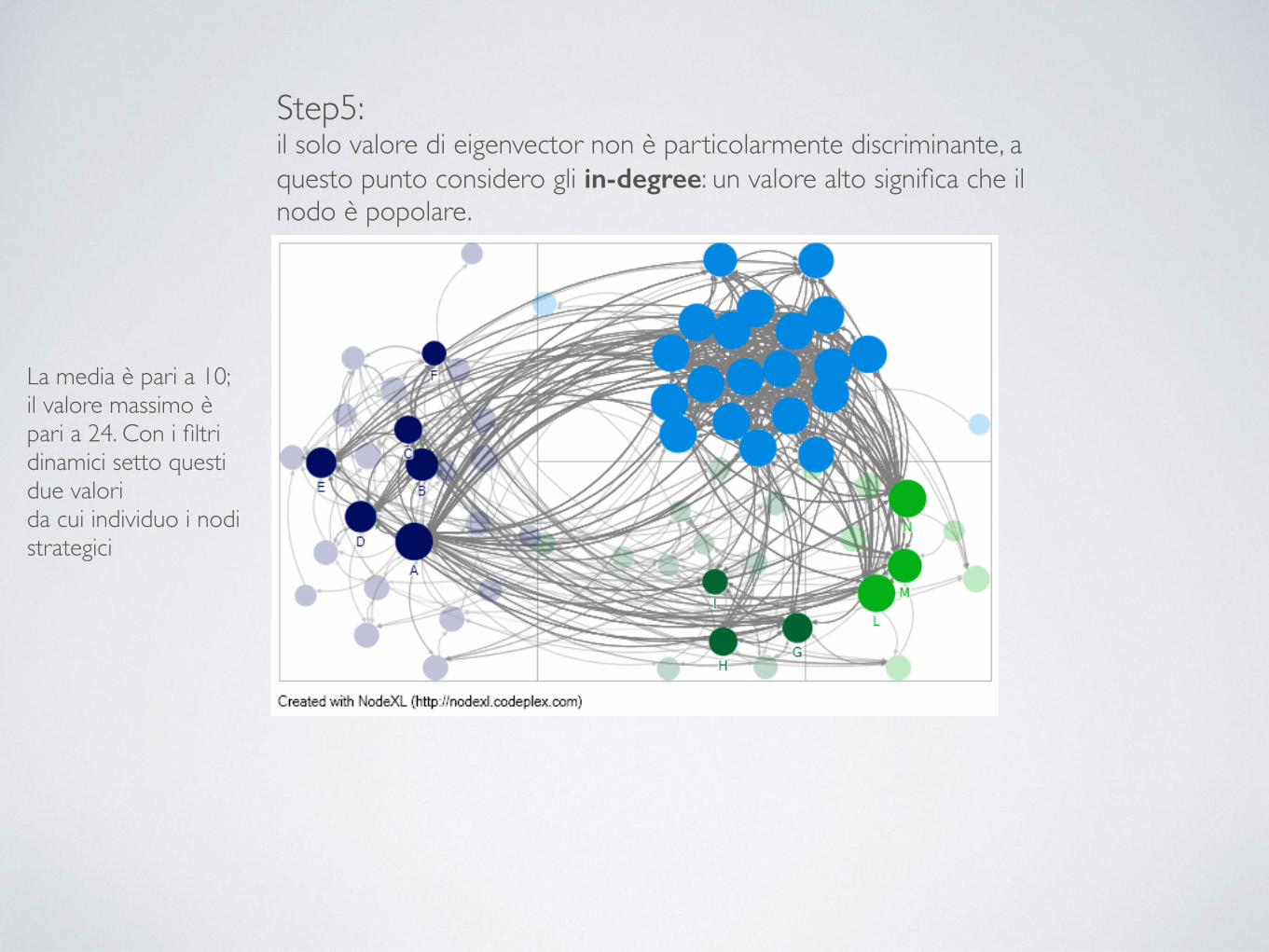
Step5: il solo valore di eigenvector non è particolarmente discriminante, a questo punto considero gli in-degree: un valore alto significa che il nodo è popolare.
La media è pari a 10; il valore massimo è pari a 24. Con i filtri dinamici setto questi due valori da cui individuo i nodi strategici
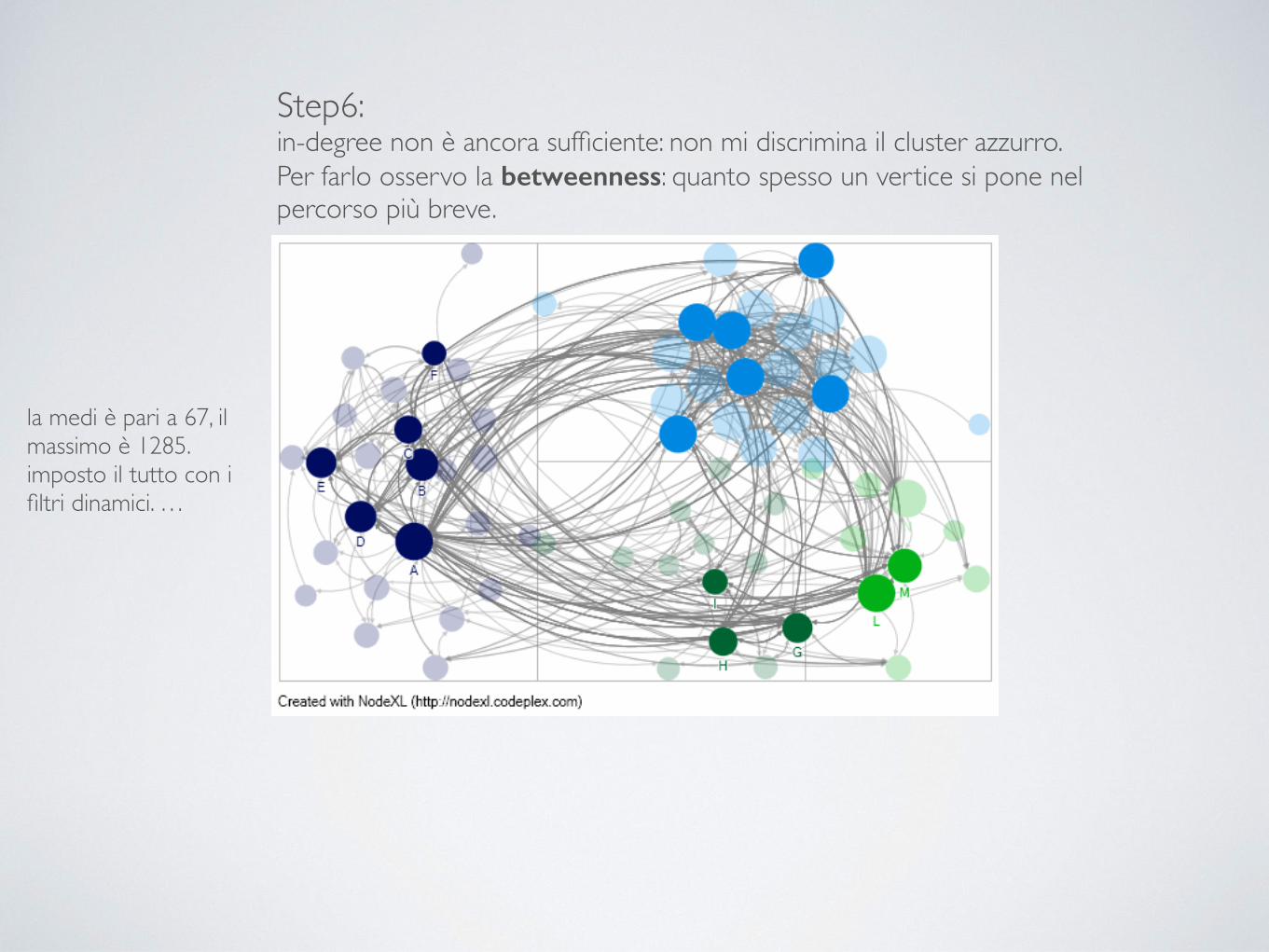
Step6: in-degree non è ancora sufficiente: non mi discrimina il cluster azzurro. Per farlo osservo la betweenness: quanto spesso un vertice si pone nel percorso più breve.
la medi è pari a 67, il massimo è 1285. imposto il tutto con i filtri dinamici. … !
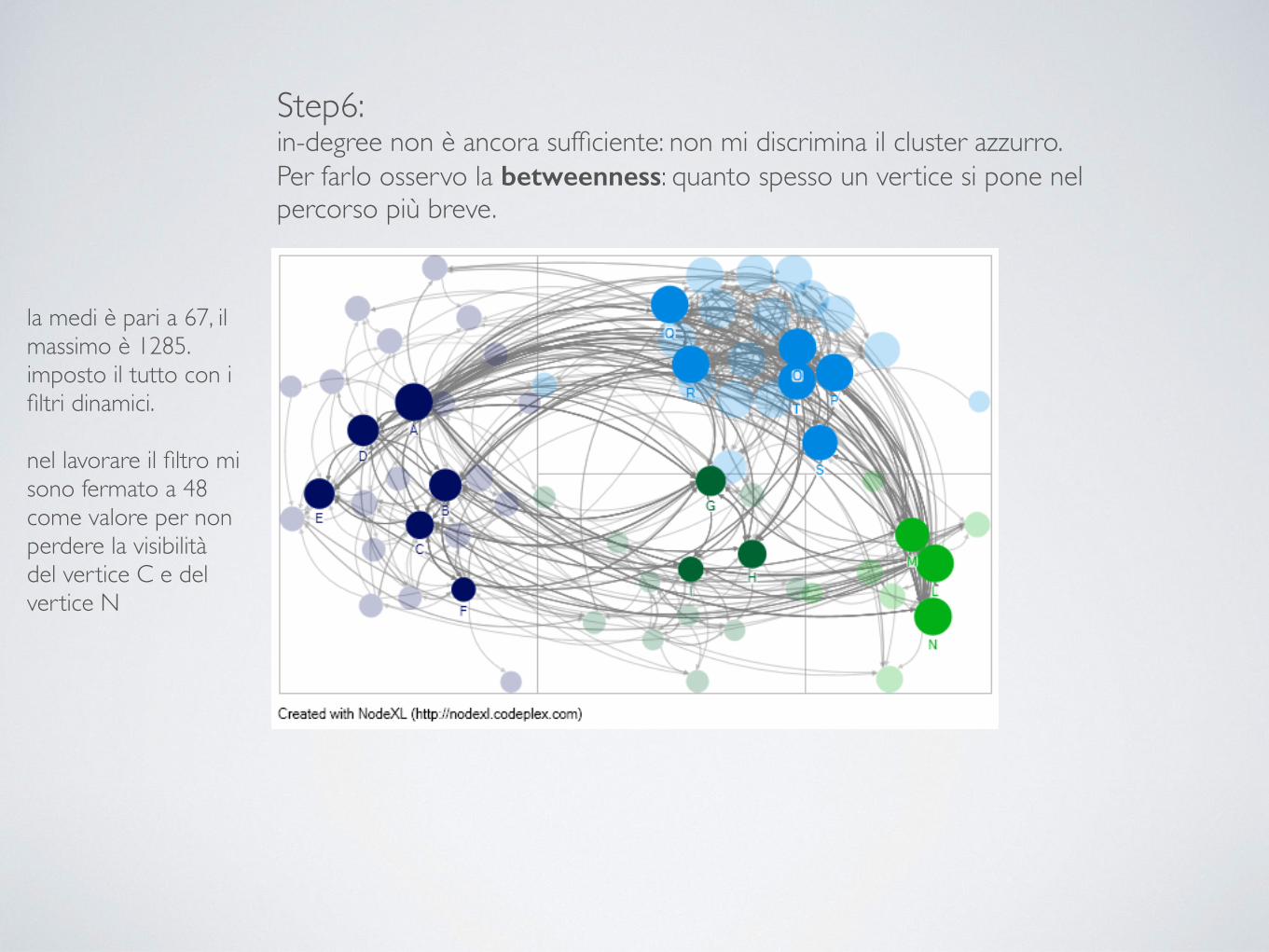
Step6: in-degree non è ancora sufficiente: non mi discrimina il cluster azzurro. Per farlo osservo la betweenness: quanto spesso un vertice si pone nel percorso più breve.
la medi è pari a 67, il massimo è 1285. imposto il tutto con i filtri dinamici. !nel lavorare il filtro mi sono fermato a 48 come valore per non perdere la visibilità del vertice C e del vertice N !
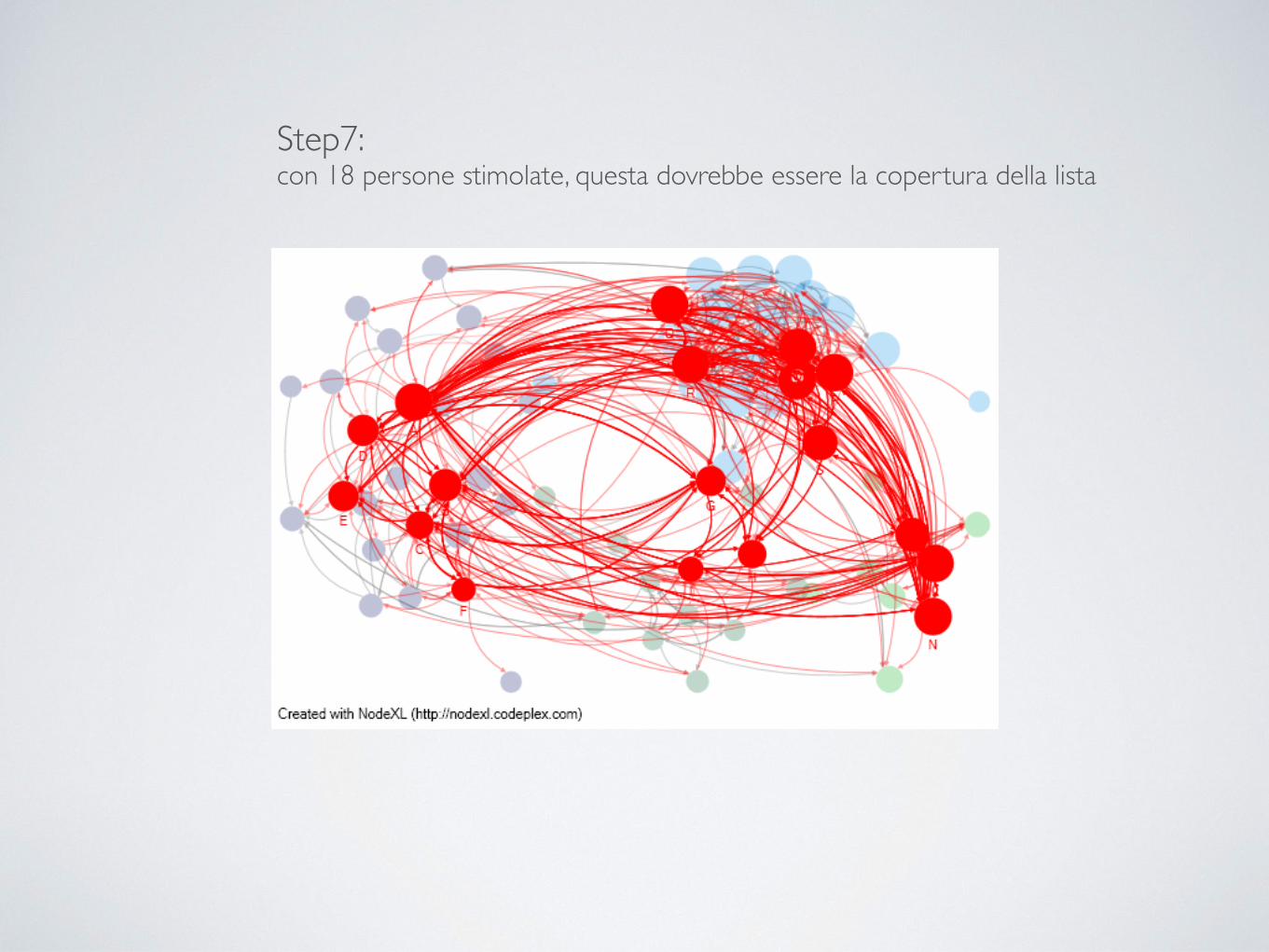
Step7: con 18 persone stimolate, questa dovrebbe essere la copertura della lista