IL METODO DI RASCH PER L'ANALISI DEI TEST A RISPOSTA …€¦ · 2=0,38 D 2=0,73 B 3=2,54 D 3=5,87...
20
1 IL METODO DI RASCH PER L'ANALISI DEI TEST A RISPOSTA MULTIPLA 1. INTRODUZIONE Vogliamo fornire una semplice esposizione del Metodo di Rasch per facilitare l'interpretazione dei risultati di test standardizzati quali il test PISA (cfr. [7]) e il test di accesso e di verifica delle competenze erogato dalla Conferenza Nazionale dei Presidi delle Facoltà di Scienze (test CNP), cfr. [6]. Un test standardizzato consiste di domande scelte secondo uno standard fissato, procedure standard per la correzione e per l'attribuzione del punteggio, e in un archivio di risultati da confrontare con l’uso di metodi statistici. Tra i vantaggi di un test standardizzato c'è innanzitutto il fatto che sulla base del punteggio ottenuto sono possibili confronti più oggettivi tra sottopopolazioni di vario livello e tra versioni diverse del test basate su set di domande coincidenti solo parzialmente. Inoltre, per il fatto che il punteggio è standardizzato, la distribuzione dei risultati può fornire utili informazioni relative a diverse sotto-popolazioni di interesse. Esistono numerose obiezioni all'uso di test standardizzati. Citiamo, tra le molte, la seguente, che ci sembra riassumere molte delle critiche più significative: “Standardized tests can’t measure initiative, creativity, imagination, conceptual thinking, curiosity, effort, irony, judgment, commitment, nuance, good will, ethical reflection, or a host of other valuable dispositions and attributes. What they can measure and count are isolated skills, specific facts and function, content knowledge, the least interesting and least significant aspects of learning.” 1 Pur condividendo molte di queste obiezioni, riteniamo comunque che l’uso di test standardizzati sia di grande interesse per stabilire indicatori importanti che aiutino a prendere decisioni migliori sia a livello politico (per esempio scelte di politica scolastica), sia a livello individuale (per esempio la scelta del corso di laurea). Inoltre, la possibilità di misurare la difficoltà di domande erogate in momenti diversi su un'unica scala permette di monitorare e verificare la qualità dei test e di comprendere meglio e più analiticamente la natura e l'evoluzione delle difficoltà incontrate dalle popolazioni sottoposte ai test 1 “I test standardizzati non possono misurare l'intraprendenza, la creatività, l'immaginazione, il pensiero concettuale, la curiosità, lo sforzo, l'ironia, il giudizio, l'impegno, le sfumature, la buona volontà, la riflessione etica, o una serie di altre tendenze e attributi preziosi. Ciò che essi misurano e considerano sono abilità isolate, fatti e funzioni specifiche, conoscenza dei contenuti, cioè gli aspetti dell'apprendimento meno interessanti e meno significativi.” cfr. [2] Traduzione a cura degli autori.
Transcript of IL METODO DI RASCH PER L'ANALISI DEI TEST A RISPOSTA …€¦ · 2=0,38 D 2=0,73 B 3=2,54 D 3=5,87...

1
IL METODO DI RASCH PER L'ANALISI
DEI TEST A RISPOSTA MULTIPLA
1. INTRODUZIONE
Vogliamo fornire una semplice esposizione del Metodo di Rasch per facilitare l'interpretazione dei risultati di test standardizzati quali il test PISA (cfr. [7]) e il test di accesso e di verifica delle competenze erogato dalla Conferenza Nazionale dei Presidi delle Facoltà di Scienze (test CNP), cfr. [6].
Un test standardizzato consiste di domande scelte secondo uno standard fissato, procedure standard per la correzione e per l'attribuzione del punteggio, e in un archivio di risultati da confrontare con l’uso di metodi statistici.
Tra i vantaggi di un test standardizzato c'è innanzitutto il fatto che sulla base del punteggio ottenuto sono possibili confronti più oggettivi tra sottopopolazioni di vario livello e tra versioni diverse del test basate su set di domande coincidenti solo parzialmente. Inoltre, per il fatto che il punteggio è standardizzato, la distribuzione dei risultati può fornire utili informazioni relative a diverse sotto-popolazioni di interesse.
Esistono numerose obiezioni all'uso di test standardizzati. Citiamo, tra le molte, la seguente, che ci sembra riassumere molte delle critiche più significative:
“Standardized tests can’t measure initiative, creativity, imagination, conceptual thinking, curiosity, effort, irony, judgment, commitment, nuance, good will, ethical reflection, or a host of other valuable dispositions and attributes. What they can measure and count are isolated skills, specific facts and function, content knowledge, the least interesting and
least significant aspects of learning.”1
Pur condividendo molte di queste obiezioni, riteniamo comunque che l’uso di test standardizzati sia di grande interesse per stabilire indicatori importanti che aiutino a prendere decisioni migliori sia a livello politico (per esempio scelte di politica scolastica), sia a livello individuale (per esempio la scelta del corso di laurea). Inoltre, la possibilità di misurare la difficoltà di domande erogate in momenti diversi su un'unica scala permette di monitorare e verificare la qualità dei test e di comprendere meglio e più analiticamente la natura e l'evoluzione delle difficoltà incontrate dalle popolazioni sottoposte ai test
1 “I test standardizzati non possono misurare l'intraprendenza, la creatività, l'immaginazione, il pensiero concettuale, la curiosità, lo sforzo, l'ironia, il giudizio, l'impegno, le sfumature, la buona volontà, la riflessione etica, o una serie di altre tendenze e attributi preziosi. Ciò che essi misurano e considerano sono abilità isolate, fatti e funzioni specifiche, conoscenza dei contenuti, cioè gli aspetti dell'apprendimento meno interessanti e meno significativi.” cfr. [2] Traduzione a cura degli autori.

2
Un limite dei test standardizzati analizzati con il modello di Rasch è la difficoltà da parte di un pubblico esteso di interpretare correttamente i risultati. Questo lavoro, diviso in due parti vuole essere un contributo per superare questa difficoltà.
2. MISURARE UN’ABILITÀ
Per effettuare confronti oggettivi tra i risultati di test differenti è necessario estrarre dai punteggi grezzi ottenuti (per esempio il numero delle risposte esatte) una misura di abilità sulla base della quale effettuare tali confronti.
Una misura deve godere di proprietà formali di invarianza e di indipendenza dallo strumento di misura, in questo caso il test. Perché una misura di abilità possa dirsi invariante è necessario almeno che, se lo stesso studente viene misurato in test diversi, la sua abilità deve risultare la stessa, a meno di errori casuali di misurazione. Perché una misura di abilità possa dirsi indipendente è necessario almeno che la probabilità di rispondere correttamente ad un item è indipendente dalla probabilità di rispondere correttamente agli altri e dipende solo dall’abilità dello studente.
I processi in base ai quali uno studente risponde ad una domanda sono estremamente complessi. Per gestire in maniera accettabile questa complessità è necessario un modello probabilistico, dovendo necessariamente rinunciare ad una descrizione deterministica di questi processi.
Il punteggio di un test non è una misura dell’abilità ma ne è solo una manifestazione. Infatti, per esempio, a seconda della difficoltà degli item di un test, il punteggio varia: studenti con la stessa abilità possono ottenere punteggi diversi: un punteggio basso in un test difficile e un punteggio alto per un test facile. Quindi, il punteggio non gode delle proprietà di invarianza e di indipendenza dallo strumento che caratterizzano una misura.
A partire dal punteggio ottenuto al test, vogliamo stimare una misura di abilità. Per fare ciò abbiamo bisogno di un modello probabilistico che leghi la misura di abilità ad una sua manifestazione (punteggio).
Il modello probabilistico più semplicemente utilizzato a questo scopo è il modello di Rasch, cui ci limitiamo in questa esposizione.
3. IL MODELLO DI RASCH
Nel 1960, il matematico danese Georg Rasch (1901-1980) pubblicò Probabilistic models for some intelligence and attainment tests (cfr. [5]), dove affrontava l’analisi dei test da un punto di vista probabilistico, con l’intento di introdurre un modello che spiegasse l’interazione tra uno studente e un item nel processo di risposta.
Il punto fondamentale dell’approccio di Rasch è quello di formulare il modello in funzione di quantità analoghe alle quantità della geometria e della fisica. L’ipotesi è che esista una certa quantità presente sia nello studente che nell’item e che la risposta, giusta o sbagliata, dipenda dal confronto di queste quantità. Per capire, possiamo ricorrere ad una analogia sia per lo studente che per l’item con una figura geometrica tridimensionale.

3
La loro interazione produce una risposta esatta se il “volume” dello studente è maggiore di quello dell’item e, viceversa, produce una risposta sbagliata se il “volume” dello studente è minore di quello dell’item. Nell’analogia, il “volume” dello studente si identifica con la sua abilità mentre quello dell’item si identifica con la sua difficoltà.
In pratica, la possibilità di determinare una proprietà degli studenti e degli item analoga al volume non è sempre possibile.
Il modello proposto da Rasch per estrarre queste quantità si basa innanzitutto sulla rappresentazione dei risultati di un test, costituito da k item e somministrato a N studenti, con una matrice N×k (Tabella 1).
item studenti 1 2 … j … k-1 k
1 x11 x12 … x1j … x1k-1 x1k r1
2 x21 x22 … x2j … x2k-1 x2k r2 … … … … i xi1 xi2 … xij … xik-1 xik ri
… … … … N-1 xN-11 xN-12 … xN-1j … xN-1k-1 xN-1k rN-1
N xN1 xN2 … xNj … xNk-1 xNk rN s1 s2 … sj … sk-1 sk
Tabella 1: Matrice dei risultati di un test
Nella matrice, xij è la risposta dell’i-esimo studente al j-esimo item: xij=1 se la risposta è corretta, xij=0 se la risposta è sbagliata o se lo studente non ha dato risposta. La riga i-esima si dice vettore delle risposte dello studente i-esimo.
La somma ri degli elementi sulla i-esima riga, !=
=
k
j
iji xr
1
è il punteggio grezzo dello
studente i-esimo, ovvero il numero delle risposte esatte date da tale studente.
La somma sj degli elementi sulla j-esima colonna, !=
=
N
i
ijj xs
1
è il punteggio grezzo
dell’item j-esimo, ovvero il numero delle risposte esatte date a tale item.
Vorremmo riuscire ad estrarre da questi dati, per ogni studente, una misura della quantità di abilità, Bi, che lo studente possiede e, per ogni item, una misura della quantità di difficoltà, Dj, che l’item possiede. Entrambe queste misure devono essere, come il volume utilizzato nell’analogia precedente, positive.
Per illustrare il modello di Rasch consideriamo due esempi. Il primo è un esempio “reale”. I dati sono stati raccolti nel test di verifica delle conoscenze all’ingresso dei corsi di laurea delle Facoltà di Scienze, preparati dalla CNP (Conferenza Nazionale dei Presidi di Scienze). Questo test è stato somministrato a 13312 studenti ed è composto da 25 item

4
di matematica. Gli item proposti al test si possono reperire all’indirizzo web http://www.testingressoscienze.org/ (cfr. [6]).
Il secondo è un esempio “minimale” che utilizzeremo per illustrare esplicitamente le formule generali ed è costituito da un piccolo sottoinsieme dei dati relativi al test sopraindicato. I dati dell’esempio “minimale” sono presentati nella Tabella 2.
Chiara 0 1 0 Marco 1 0 0
Francesca 1 1 0 Giulia 1 1 0 Andrea 1 0 1 Claudio 1 1 1
Tabella 2 Il data-set dell'esempio "minimale".
Nella prima colonna sono riportati nomi di fantasia per i primi 6 studenti del test, nelle restanti tre colonne sono riportate le risposte di questi ai primi 3 item del test.
Da questi dati risulta, per esempio, che lo studente Claudio (sesta riga) ha risposto correttamente a tutte e tre gli item, mentre lo studente Marco (seconda riga) ha risposto correttamente solo al primo item.
Nell’esempio minimale, le stime delle quantità Bi e Dj, secondo le procedure che discuteremo in seguito, sono:
B1=0,38 D1=0,23 B2=0,38 D2=0,73 B3=2,54 D3=5,87 B4=2,54 B5=2,54 B6=16,78
E’ chiaro che la determinazione di queste quantità a partire dal data-set minimale non può che essere affetta da grande indeterminazione, come se cercassimo di pesare un oggetto disponendo di pochissimi (in questo caso tre) pesi di riferimento.
In generale, quanto più grande è il numero di item tanto più precisa è la stima delle abilità dello studente, e tanto più grande è il numero degli studenti quanto più precisa è la stima delle difficoltà degli item.
Tornando ai principi in base ai quali si estraggono le misure, Rasch ipotizza che la probabilità che lo studente i-esimo risponda correttamente all’item j-esimo sia funzione f del rapporto
j
i
D
B , dove Bi e Dj sono le incognite del problema da stimare a partire dai dati.
Questa funzione deve godere di alcune proprietà che sono ovvie visto il contesto cui si riferiscono:

5
i. [ ]1,0: !"+f ;
ii.
0lim0
=!!
"
#
$$
%
&
'j
i
B D
Bf
i
1lim =!!
"
#
$$
%
&
'(j
i
B D
Bf
i
1lim0
=!!
"
#
$$
%
&
'j
i
D D
Bf
j
0lim =!!
"
#
$$
%
&
'(j
i
D D
Bf
j
;
iii. fissato D, f è funzione monotona crescente di B,
fissato B, f è funzione monotona decrescente di D.
Per esempio, il primo limite della proprietà ii. significa che la probabilità che lo studente i-esimo risponda correttamente all’item j-esimo è vicina a zero quando la quantità di abilità dello studente è vicina a zero.
Il modello di Rasch assume come funzione f la funzione:
j
i
j
i
j
i
D
B
D
B
D
Bf
+
=!!
"
#
$$
%
&
1
(1).
Questa scelta è la “più semplice” tra quelle che verificano le proprietà i. ii. e iii., nel senso che non esistono funzioni polinomiali che verificano le tre proprietà e, tra le funzioni razionali, quella proposta ha grado minimo per numeratore e denominatore.
Se
j
i
j
i
D
B
D
B
+1
è la probabilità di risposta corretta allora
j
i
j
i
j
i
D
B
D
B
D
B
+
=
+
!
1
1
1
1 è quella di risposta
sbagliata.
Per uniformità con la famiglia dei modelli della Item Response Theory, della quale il modello di Rasch è un caso particolare, conviene applicare una trasformazione per sostituire Bi e Dj con i nuovi parametri βi e δj.
ieBi
!= e jeD j
!= (2).
βi e δj sono detti semplicemente abilità dello studente i-esimo e difficoltà dell’item j-esimo. Si noti che, a differenza di Bi e Dj, +!<<"!
i# e +!<<"! j# .

6
Nell’esempio minimale, utilizzando la formula inversa per calcolare la stime di abilità (
iiBln=! ) e di difficoltà ( jj Dln=! ), otteniamo le seguenti stime:
98,01 !=" 46,11 !=" 98,02 !=" 31,02 !=" 93,03 =! 77,13 =! 93,04 =! 93,05 =! 82,26 =!
Sostituendo (2) in (1), otteniamo la funzione per il modello di Rasch più comunemente utilizzata:
( )( )
( )ji
jiij
e
eP
x
ji !"
!"
!"#
#
+=1
, .
Riassumendo, il meccanismo probabilistico in base al quale uno studente risponde ad un item è completamente specificato nel modello di Rasch assegnando:
1. ad ogni item un parametro di difficoltà δ;
2. ad ogni studente un parametro di abilità β;
3. la funzione ( )!"
!"
!"#
#
+ e
e
1, a , detta funzione caratteristica (Item characteristic
Function, Figura 1), la quale assegna la probabilità che uno studente risponda correttamente ad un item in funzione di β e δ.
Figura 1 La curva caratteristica di un item
4. STIMA DEI PARAMETRI
Il primo passo per applicare il modello di Rasch ai dati di un test è quello di stimare i parametri del modello (cfr. [1] e [3]).
Abbiamo visto che, nel modello di Rasch, la probabilità di ottenere una risposta corretta è determinata unicamente dal parametro di abilità β dello studente e dal parametro di

7
difficoltà δ dell’item, ma le sole informazioni che si conoscono sono le risposte degli studenti, ovvero la Tabella 1 (cfr. p. 3).
Il problema della “stima dei parametri” consiste nell’assegnare, in base a qualche “ragionevole principio” un valore β per ciascuno studente e un valore δ per ciascun item a partire dalla matrice dei dati.
Il processo di stima della difficoltà di un item, che per il modello di Rasch può anche essere fatto indipendentemente dalla stima delle abilità, prende il nome di calibrazione. Come già detto, nel modello di Rasch si postula che la probabilità P che uno studente di abilità β risponda correttamente ad un item di difficoltà δ è data da:
!"
!"
#
#
+=
e
eP
1
e quindi β e δ sono quantità omogenee che si misurano sulla medesima scala. In particolare, secondo il modello, uno studente di abilità uguale alla difficoltà di un item ha probabilità
2
1 di rispondere correttamente a tale item.
Figura 2 Curva caratteristica di un item.
Le stime delle difficoltà degli item e delle abilità degli studenti, come le stime di ogni parametro statistico, sono affette da errore. E’ possibile stimare, nell’ipotesi che il modello di Rasch sia adeguato a descrivere i dati, anche la grandezza di questo errore con un numero, detto errore standard della stima. Ritorneremo nella seconda parte su questo importante concetto.
Si possono utilizzare diversi principi in base ai quali stimare i parametri del modello di Rasch. Quello più comunemente utilizzato è il principio di massima verosimiglianza (cfr. [1]), che consiste nel calcolare una funzione di verosimiglianza che dipende dai parametri incogniti
N!!! ...,,1= e
k!!! ...,,1= e scegliere i valori dei parametri che massimizzano
tale verosimiglianza. Per esempio, con il metodo della stima di massima verosimiglianza congiunta (Joint Maximum Likelihood, JML), la funzione di verosimiglianza che viene utilizzata è:

8
!!
!!"
"
+=#
i j
i j
x
ji
jiij
e
e
)1()(
)(
$%
$%
%$ (3)
che rappresenta la probabilità di osservare una matrice delle risposte come quella data, nelle ipotesi che il modello di Rasch sia applicabile. Si stimano i parametri andando a considerare quelli che massimizzano la funzione di verosimiglianza. Per fare ciò, avendo a che fare con funzioni derivabili dei parametri, si guarda innanzitutto ai punti stazionari, ovvero soluzioni del sistema di equazioni non lineare ottenuto uguagliando a zero tutte le derivate, o ugualmente, ma più semplicemente, quelle dove consideriamo il suo logaritmo.
Vediamo di spiegare meglio in che consiste il procedimento di stima dei parametri a partire dalla matrice dei dati dell’esempio minimale.
δ1 δ2 δ3 Chiara β1 0 1 0 r1=1 Marco β2 1 0 0 r2=1
Francesca β3 1 1 0 r3=2 Giulia β4 1 1 0 r4=2 Andrea β5 1 0 1 r5=2 Claudio β6 1 1 1 r6=3
s1=5 s2=4 s3=2 Tabella 3 Il data-set dell'esempio "minimale".
La funzione di verosimiglianza (3) è
)1)(1)(1()1)(1)(1)(1)(1)(1( 362616322212312111
3626163515241423131221 )()()()()()()()()()()(
!"!"!"!"!"!"!"!"!"
!"!"!"!"!"!"!"!"!"!"!"
"! #########
###########
+++$$$++++++
$$$$$$$$$$$=%
eeeeeeeee
eeeeeeeeeee
che, riducendo in fattori comuni, diventa
)1)(1)(1()1)(1)(1)(1)(1)(1( 362616322212312111
321654321 2453)(2
!"!"!"!"!"!"!"!"!"
!!!""""""
"! #########
###+++++
+++$$$++++++=%
eeeeeeeee
e
Il sistema delle derivate, rispetto a tutti e nove i parametri, del logaritmo di !"# è

9
!!!!!!!!!!!!
"
!!!!!!!!!!!!
#
$
=%
&%
=%
&%
=%
&%
=%
&%
=%
&%
=%
&%
=%
&%
=%
&%
=%
&%
0log
0log
0log
0log
0log
0log
0log
0log
0log
6
5
4
3
2
1
3
2
1
'
'
'
'
'
'
(
(
(
'(
'(
'(
'(
'(
'(
'(
'(
'(
(4),
!!!!!!!!!!!!
"
!!!!!!!!!!!!
#
$
=+
%+
%+
%
=+
%+
%+
%
=+
%+
%+
%
=+
%+
%+
%
=+
%+
%+
%
=+
%+
%+
%
=+
+++
++
++
++
+%
=+
+++
++
++
++
+%
=+
+++
++
++
++
+%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
0
111
3
0
111
2
0
111
2
0
111
2
0
111
1
0
111
1
0
111111
2
0
111111
4
0
111111
5
36
36
26
26
16
16
35
35
25
25
15
15
34
34
24
24
14
14
33
33
23
23
13
13
32
32
22
22
12
12
31
31
21
21
11
11
36
36
35
35
34
34
33
33
32
32
31
31
26
26
25
25
24
24
23
23
22
22
21
21
16
16
15
15
14
14
13
13
12
12
11
11
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
(4’)
Poiché si osserva dalla Tabella 3 che Chiara e Marco hanno ottenuto lo stesso punteggio (r1=r2=1) e lo stesso possiamo dire per Francesca, Giulia e Andrea (r3=r4=r5=2), le stime delle loro abilità coincideranno: β1=β2 e β3=β4=β5. Inoltre, con questo metodo, non si stimano le abilità degli studenti che hanno ottenuto punteggio nullo (nell’esempio non vi sono) e degli studenti che hanno ottenuto punteggio massimo (come Claudio, r6=3). Possiamo allora ridurre il sistema (4), e quindi il sistema (4’), in un uno in sole cinque equazioni. Infatti, la quarta e la quinta risultano uguali (poiché β1=β2) e ugualmente la sesta, la settima e l’ottava (β3=β4=β5), mentre la nona non è necessaria. Chiamiamo con β1 il parametro di abilità degli studenti che hanno ottenuto punteggio r pari a 1 e con β2 il parametro di abilità degli studenti che hanno ottenuto punteggio r pari a 22. Decidendo, quindi, di voler stimare solo β1 e β2, possiamo effettuare un’ulteriore riduzione, in particolare per le prima tre equazioni, ottenendo infine il seguente sistema definitivo:
!!!!!!
"
!!!!!!
#
$
=%
&%
=%
&%
=%
&%
=%
&%
=%
&%
0log
0log
0log
0log
0log
2
1
3
2
1
'
'
(
(
(
'(
'(
'(
'(
'(
(5),
!!!!!!
"
!!!!!!
#
$
=+
%+
%+
%
=+
%+
%+
%
=+
++
+%
=+
++
+%
=+
++
+%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
%
0
111
2
0
111
1
0
1
3
1
22
0
1
3
1
24
0
1
3
1
25
32
32
22
22
12
12
31
31
21
21
11
11
32
32
31
31
22
22
21
21
12
12
11
11
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
&'
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
e
(5’)
2 Quindi, β2 non sta più ad indicare il parametro di abilità del secondo studente, Marco. In generale, per non fare confusione con gli indici, indicheremo il parametro di abilità dello studente che ha ottenuto punteggio r al test con βr dove r è il punteggio, r=1, …, k-1 e dove k è il numero di item e quindi il punteggio massimo possibile.

10
In generale,
!!
"
!!
#
$
=%
&%
=%
&%
0log
0log
r
j
'
(
('
('
(6),
!!
"
!!
#
$
%==+
%
==+
+%
&
&
=%
%
%
=%
%
k
j
k
r
rj
kre
er
kje
eis
jr
jr
jr
jr
1
1
1
1...,,1,01
...,,1,01
'(
'(
'(
'(
(6’),
dove j=1, …, k (nell’esempio minimale, j=1,2,3), βr sono le stime delle abilità di tutti gli studenti per ogni punteggio totale r=1, …, k-1 (nell’esempio minimale, r=1,2) e ir è il numero degli studenti che hanno ottenuto lo stesso punteggio r (nell’esempio minimale, 2 studenti con punteggio r=1 e 3 studenti con punteggio r=2).
Il procedimento è lo stesso impiegato in molte applicazioni di modelli statistici e le difficoltà di calcolo sono superate utilizzando opportune tecniche iterative con il calcolatore.
Nell’esempio minimale, utilizzando il software MATHEMATICA (cfr. [10]), abbiamo ottenuto le seguenti stime dei parametri di abilità e di difficoltà.
β1= -1,52 δ1= -1,99 β2= -1,52 δ2= -0,80 β3= 0,47 δ3= 1,33 β4= 0,47 β5= 0,47
Osserviamo che i valori ottenuti non sono gli stessi (cfr. p. 4) che abbiamo calcolato con il software WINSTEPS (cfr. [8]), ma sono statisticamente uguali, a meno di una costante. (spiegare meglio)
Abbiamo già accennato che tale principio non stima le abilità degli studenti che hanno ottenuto punteggio massimo o minimo al test (nel caso dell’esempio minimale, non è stata stimata l’abilità di Claudio che ha ottenuto punteggio massimo). Per tali stime si ricorre ad un approccio Bayesiano (cfr. [11]).
5. PROPRIETA’
Osserviamo che nei coefficienti del sistema (6’) non appaiono i valori xij dei dati ma solo i valori marginali, cioè la somma per righe r (punteggi grezzi degli studenti) e la somma per colonne sj (punteggi grezzi degli item). Quindi, per stimare i βi e i δj è sufficiente usare i punteggi grezzi. Questa proprietà prende il nome di sufficienza dei punteggi grezzi.
Osserviamo anche che per ogni studente viene stimato un valore di abilità che dipende soltanto dal suo punteggio grezzo. La trasformazione del punteggio grezzo in misura di abilità è quindi monotona , ma non lineare. Le proprietà delle misure di Rasch sono migliori rispetto a quelle del punteggio grezzo. Innanzi tutto, tali misure sono indipendenti, a meno di una costante, dagli item che vengono usati per stimarle (così

11
come le misure di difficoltà degli item sono indipendenti dagli studenti ai quali sono stati sottoposti). Questo non significa che sottoponendo a due test distinti si ottengono per gli stessi studenti gli stessi valori di abilità, ma che tali valori sono statisticamente uguali, cioè la probabilità di avere una deviazione significativa è bassa e misurabile, nell’ipotesi che il modello di Rasch sia adeguato a descrivere i dati.
Per dimostrare questa proprietà di indipendenza delle misure di abilità degli studenti dagli item utilizzati e delle misure di difficoltà degli item dagli studenti cui è stato somministrato il test si deve procedere presentando un particolare approccio alla stima dei parametri: quello di massima verosimiglianza condizionata che fa intervenire la nozione di probabilità condizionata. (da sistemare)
Calcolata la probabilità ( )!,XP che uno studente di abilità β fornisca il vettore di risposta X , vogliamo considerare ora tale probabilità condizionata al punteggio r:
( )( )( )
!!
!
"
"
==
rX
x
x
j
jj
j
jj
e
e
rP
XPrXP
|
,
,|,
#
#
$
$$ , dove !
rX |
sono le somme su tutti i possibili vettori X che
hanno come punteggio grezzo totale r.
La funzione di verosimiglianza è data dal prodotto
( )!!="
=
"#
==$N
ik
r
ir
s
r
j
jj
erXP
11
1
|,
%
&
'
(7),
dove !!"
=
rX
x
rj
jij
e
|
#
$ e ir è il numero di studenti con punteggio grezzo r.
Consideriamo, nuovamente, la matrice dei dati dell’esempio minimale:
δ1 δ2 δ3 Chiara β1 0 1 0 r1=1 Marco β2 1 0 0 r2=1
Francesca β3 1 1 0 r3=2 Giulia β4 1 1 0 r4=2 Andrea β5 1 0 1 r5=2 Claudio β6 1 1 1 r6=3
s1=5 s2=4 s3=2 Tabella 4 Il data-set dell'esempio "minimale".
La funzione di verosimiglianza (7) nell’esempio minimale, quindi, sarà:

12
( )( )32
245
3
2
2
1
245
31212112
321321
!!!!!!!!
!!!!!!
"" ########
######
+++
==$
eeeee
ee .
Per il principio di massima verosimiglianza, si stimano i parametri andando a considerare quelli che massimizzano la funzione di verosimiglianza, ovvero si risolve il sistema:
!"
!#$
=%
&%0
log
j'
'( (8), cioè !"
!#$
=+% &%
=
%0
1
1
1
k
r r
rrj is'
' (8’), dove γr-1 e γr sono le probabilità che uno
studente, con un punteggio rispettivamente pari a r-1 e r, risponda correttamente all’item j-esimo.
Osserviamo che il sistema (8’) per stimare i δ è diverso da quello utilizzato nel principio di massima verosimiglianza congiunta (6’). In particolare, il sistema (8’) non accoppia le stime dei δj con quelle dei βi. Questo significa appunto che le stime dei δj sono indipendenti dalle abilità degli studenti che vengono utilizzati per stimarle e, analogamente, che le stime delle βi sono indipendenti dalle difficoltà degli item.
Si osservi che non abbiamo ancora dimostrato che il sistema di equazioni ottenuto in base al metodo di massima verosimiglianza congiunta è equivalente a quello ottenuto in base al principio di massima verosimiglianza condizionata. In effetti, non è così difficile. Basta moltiplicare le stime delle difficoltà ottenute in base al metodo di massima verosimiglianza congiunta per la costante
k
k 1! per poterle confrontare con quelle
ottenute con il metodo di massima verosimiglianza condizionata.
Ricapitolando, abbiamo introdotto due diversi principi in base ai quali stimare i parametri del modello di Rasch.
Guardando al sistema di equazioni (6’) prodotto in base al primo principio abbiamo immediatamente riconosciuto la proprietà di sufficienza dei punteggi grezzi. Guardando al secondo metodo (8’) abbiamo riconosciuto la proprietà di indipendenza delle stime di abilità da quelle di difficoltà e viceversa.
6. CONCLUSIONI
Presentiamo la Tabella delle stime delle difficoltà degli item, calcolate con WINSTEPS (cfr. [8]), per l’esempio reale (il Test Nazionale composto da 25 item somministrati a 13312 studenti) per anticipare il significato dei parametri, presenti in essa, che serviranno per fare l’analisi dell’adattamento dei dati al modello di Rasch (cfr. [9]).
13
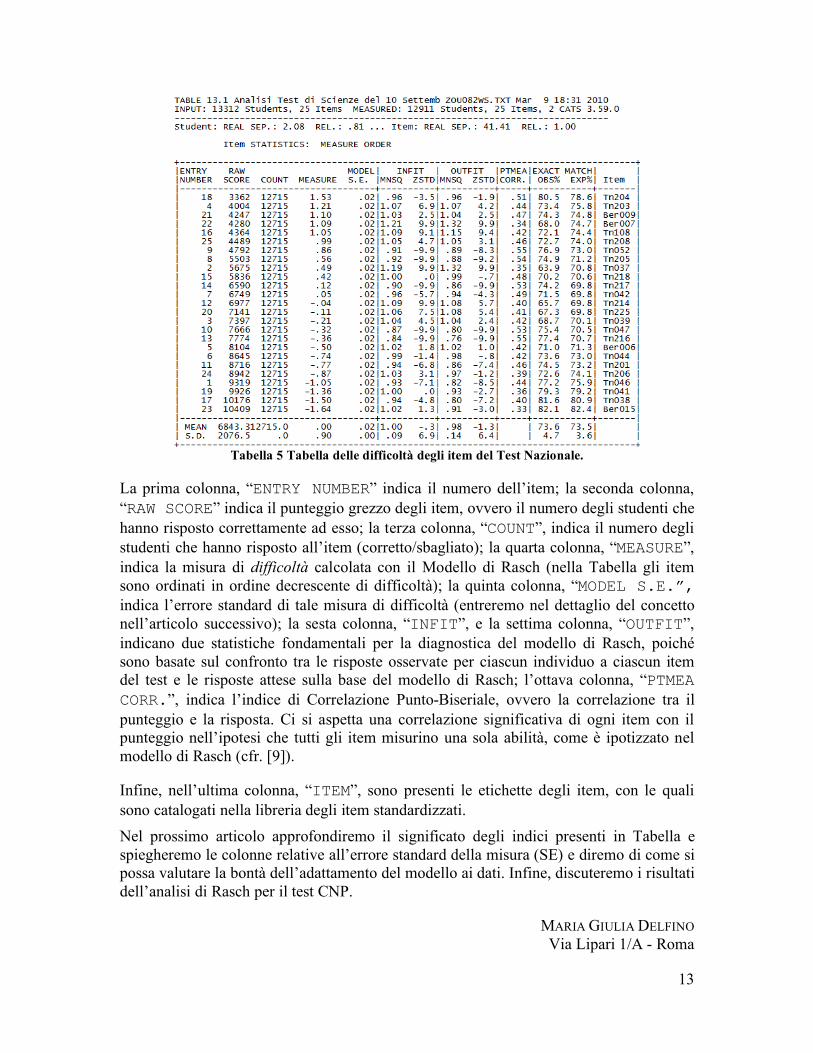
Tabella 5 Tabella delle difficoltà degli item del Test Nazionale.
La prima colonna, “ENTRY NUMBER” indica il numero dell’item; la seconda colonna, “RAW SCORE” indica il punteggio grezzo degli item, ovvero il numero degli studenti che hanno risposto correttamente ad esso; la terza colonna, “COUNT”, indica il numero degli studenti che hanno risposto all’item (corretto/sbagliato); la quarta colonna, “MEASURE”, indica la misura di difficoltà calcolata con il Modello di Rasch (nella Tabella gli item sono ordinati in ordine decrescente di difficoltà); la quinta colonna, “MODEL S.E.”, indica l’errore standard di tale misura di difficoltà (entreremo nel dettaglio del concetto nell’articolo successivo); la sesta colonna, “INFIT”, e la settima colonna, “OUTFIT”, indicano due statistiche fondamentali per la diagnostica del modello di Rasch, poiché sono basate sul confronto tra le risposte osservate per ciascun individuo a ciascun item del test e le risposte attese sulla base del modello di Rasch; l’ottava colonna, “PTMEA CORR.”, indica l’indice di Correlazione Punto-Biseriale, ovvero la correlazione tra il punteggio e la risposta. Ci si aspetta una correlazione significativa di ogni item con il punteggio nell’ipotesi che tutti gli item misurino una sola abilità, come è ipotizzato nel modello di Rasch (cfr. [9]).
Infine, nell’ultima colonna, “ITEM”, sono presenti le etichette degli item, con le quali sono catalogati nella libreria degli item standardizzati. Nel prossimo articolo approfondiremo il significato degli indici presenti in Tabella e spiegheremo le colonne relative all’errore standard della misura (SE) e diremo di come si possa valutare la bontà dell’adattamento del modello ai dati. Infine, discuteremo i risultati dell’analisi di Rasch per il test CNP.
MARIA GIULIA DELFINO Via Lipari 1/A - Roma

14
ENRICO ROGORA Dip. di Matematica
Sapienza, Univ. di Roma, p.le A. Moro 5
00185 Roma
BIBLIOGRAFIA
[1] D. Andrich, Rasch models for measurements (1988), Newbury Park: Sage Publications, Inc.
[2] W. Ayers, To teach: the journey of a teacher (1993), Columbia University, New York: Teachers College Press.
[3] F. B. Baker – S. Kim, Item response theory. Parameter Estimation Techniques (2004), 2 ed., Statistics: Textbooks and monographs.
[4] M.G. Delfino, Tesi di Laurea, Roma (2010).
[5] G. Rasch, Probabilistic models for some intelligence and attainment test (1960), Copenhagen: Danish Institute for Educational Research.
[6] www.testingressoscienze.org
[7] www.pisa.oecd.org
[8] Linacre J., Winsteps ® Rasch Measurement (2005), Versione: 3.59.0, Winsteps and Facets Rasch Software, pagina web: http://www.winsteps.com/index.htm.
[9] Linacre, J. M., Winsteps ® Program Manual (2010), distribuito on line alla pagina web: http://www.winsteps.com/winman/index.htm?principalcomponents.htm.
[10] Software di MATHEMATICA
[11] Approccio Bayesiano (…)

15
IL METODO DI RASCH PER L'ANALISI
DEI TEST A RISPOSTA MULTIPLA
PARTE II: Analisi dell’adattamento del modello ai dati
1. ANALISI DEL FITTING
La calibrazione degli item e la stima delle abilità degli studenti sono solo una parte dell’analisi che bisogna fare per applicare il modello di Rasch ai dati ottenuti in un test.
Abbiamo anche bisogno di verificare l’adeguatezza del modello di Rasch facendo un’analisi della bontà dell’adattamento dei dati al modello. Tale analisi prende il nome di analisi del fitting. Per fare ciò abbiamo bisogno i controllare alcuni indici. I più comunemente utilizzati sono: l’indice di correlazione degli item con i punteggi e gli indici di misfit. Inoltre, conviene effettuare l’Analisi delle Componenti Principali (ACP) e un controllo di tipo grafico sulle Curve Caratteristiche.
Indice di correlazione degli item con i punteggi. La correlazione tra la variabile punteggio P e la variabile dicotomica Cj relativa al punteggio ottenuto al j-esimo item si calcola con la formula della Correlazione Punto-Biseriale (PBC):
2
0101
N
NNMM
P!
" ,
dove N è la numerosità della popolazione, N0 (e rispettivamente N1) il numero degli individui che hanno dato risposta errata (e rispettivamente risposta esatta) all’item; M0 (e risp. M1) la media del punteggio totale tra gli individui che hanno dato risposta errata (e risp. risposta esatta) all’item e σP la deviazione standard del punteggio sull’intera popolazione:
( )!=
"=
n
i
iPPP
n1
21# .
Il modello di Rasch prevede che il meccanismo in base al quale uno studente risponde ad un item si possa modellare in maniera sufficientemente accurata ipotizzando una sola grandezza che caratterizza lo studente (la sua abilità) e una sola grandezza che caratterizza l’item (la sua difficoltà). In queste ipotesi, ci aspettiamo una correlazione significativa di ogni item con il punteggio, perché tutti gli item misurano un’unica abilità.
Questo non succederebbe se ci fossero diverse abilità che concorrono al punteggio di uno studente. Per esempio, se in un test ci sono item di lingua e item di matematica sarebbe sbagliato ipotizzare che il risultato dipenda da un’unica abilità e osserveremmo correlazioni tra P e Cj sono maggiori di 0.25.

16
Indicativamente, se le ipotesi del modello sono verificate, allora le correlazioni tra P e Cj piuttosto
Indici di misfit. Gli indici di correlazione offrono una misura molto cruda di adeguatezza. Esistono vari altri metodi per valutare l’adeguatezza del modello, tra questi vi è un test di adeguatezza globale, che si basa sul test del Chi-quadro χ2. Operiamo nel modo seguente.
Sia β uno de valori stimati di abilità degli studenti.
Sia j uno degli item aventi difficoltà stimata pari a δj.
Sia nβ il numero degli studenti aventi abilità stimata pari a β e sia Nβ l’insieme dei loro indici.
Fβj la variabile aleatoria che conta il numero degli studenti di abilità β che rispondono correttamente all’item j.
Il residuo standardizzato di Fβj è j
j
jj
j ZFV
FEFFRS !
!
!!
! ="
=)(
)()( .
Assumendo che Fβj sia normalmente distribuita, allora Zβj ~ N(0,1) e, quindi,
!!"
"
j
jZ2 ~ χ2
(G-1)×(k-1)
dove le somme a sinistra sono su tutti i valori di β stimati, che sono in numero G uguale ai valori distinti dei punteggi osservati, e su tutti i k item.
Il valore osservato per Fβj sia fβj.
Poiché !"
=
#
#
Ni
ijj XF , allora otteniamo le stime E(Fβj) = nβ Pβj e V(Fβj) = nβ Pβj (1-Pβj ).
Quindi, il valore osservato nei nostri dati per Zβj è
)1( jj
jj
PPn
Pnf
!!!
!!!
"
".
Confrontando il valore osservato di !!"
"
j
jZ2 con χ2
(G-1)×(k-1) otteniamo una misura
globale di adeguatezza del modello (esempio).
È possibile, utilizzando un approccio analogo, misurare l’adattamento del singolo studente e del singolo item al modello di Rasch. Si introduce allo scopo una statistica di misfit (in realtà ne esistono due, dette rispettivamente di infit e di outfit, ma che ai fini del nostro discorso non è conveniente distinguere, negli esempi i dati che riportiamo per le statistiche di misfit sono quelli di outfit).

17
Il modo di procedere nell’analisi di Rasch di un test, consiste nell’individuare gli studenti e gli item con statistiche di misfit elevate.
È normale aspettarsi studenti con misfit elevato. Infatti, studenti distratti, oppure studenti che decidono di rispondere a caso, oppure studenti che hanno una preparazione scolastica essenzialmente diversa da quella della maggioranza, rispondono alle domande con un meccanismo diverso da quello ipotizzato da Rasch. Per esempio, se una parte degli studenti ha un background essenzialmente diverso dagli altri, l’ipotesi che la risposta ad una domanda dipenda solo dall’abilità è inadeguata.
Quando lo scopo dell’analisi di Rasch di un test è quello di monitorare la distribuzione dell’abilità nella popolazione degli studenti cui è erogato il test, la presenza di piccole popolazioni con caratteristiche non omogenee a quelle della maggioranza possono disturbare la comprensione del fenomeno e vanno scorporate dalla popolazione.
Questa eliminazione di una parte piccola di dati non va vista come un trucco per “far tornare i conti”, ma come il riconoscimento e l’individuazione di popolazioni non omogenee.
È quindi ammesso nell’analisi di Rasch eliminare una piccola percentuale (< 5%) degli studenti con misfit elevato pur di verificare l’adeguatezza del modello ai dati restanti.
Analoga procedura viene utilizzata per gli item. Si individuano eventuali item con misfit elevato e si cerca di capire perché per questi item il modello di Rasch non è adeguato (per esempio sono item che misurano abilità diverse da quella prevista, oppure sono item troppo difficili per la popolazione cui sono stati erogati, oppure sono item che riguardano abilità che solo una parte della popolazione prevede).
Dopo questa analisi si eliminano gli eventuali item in questione (che per un test ben preparato non dovrebbero presentarsi) e si verifica se il modello di Rasch è applicabile agli item rimanenti. Queste individuazione degli item che non funzionano come ci aspettiamo è particolarmente importante al fine della costruzione di banche di item calibrati da utilizzare per test standardizzati.
Analisi delle Componenti Principali. Il metodo dell’Analisi delle Componenti Principali viene applicato ad un insieme di osservazioni iniziali (le risposte date al test), ed hanno l’obbiettivo di ridurre tali osservazioni ad un numero piccolo di componenti principali che sintetizzino i dati cogliendone l’essenza.
Oggetto dell’Analisi delle Componenti Principali è la “variabilità” dei dati che, nell’ipotesi di applicabilità del modello di Rasch, è dovuta a diversi contributi:
1. la “variabilità” dovuta alle diverse difficoltà degli item e alle diverse abilità degli studenti;
2. la “variabilità” rispetto al valore che ci aspettiamo secondo il modello di Rasch;

18
3. la “variabilità” dovuta alla presenza di studenti o item che non “funzionano” secondo quanto previsto dal modello.
Quindi, in generale, le componenti principali sono scelte in modo da spiegare una frazione rilevante della “variabilità” dei dati. Tutta la “variabilità” dei dati che non viene spiegata è detta residuo.
Nell’ipotesi di applicabilità del modello di Rasch, la “variabilità” dei punteggi, come abbiamo già anticipato, è dovuta principalmente all’abilità degli studenti e alla difficoltà degli item.
I residui rappresentano la componente di variabilità che dipende da fattori diversi da quelli previsti dal modello di Rasch. In questo caso è lecito assumere che i residui si distribuiscano in modo casuale secondo una distribuzione approssimativamente normale. Inoltre se il modello di Rasch descrive bene i dati, i residui delle diverse risposte devono essere poco correlati fra loro. Una correlazione elevata dei residui fra più item (o studenti) indica che essi non sono localmente indipendenti e suggeriscono l’esistenza di dimensioni diverse dalla variabile d’interesse, in contrasto con l’ipotesi di unidimensionalità del modello di Rasch.
Quindi, una Analisi delle Componenti Principali dei residui valuta la correlazione dei residui tra gli item (o gli studenti) allo scopo di identificare sottogruppi di item (o studenti) i cui residui dipendano da fattori comuni.
In sostanza, l’analisi permette di identificare la presenza di variabili o di dimensioni secondarie da cui dipendano i risultati degli studenti 3 e, analogamente, l’analisi della correlazione dei residui tra studenti permette di identificare la presenza di sottogruppi di studenti con caratteristiche di risposta simili4.
Analisi grafica sulle Curve Caratteristiche degli Item. Supponiamo che il campione di studenti sia suddiviso in h gruppi, che denoteremo Bh, ciascuno composto da fh=|Bh| soggetti, per ogni punteggio h che si possa ottenere al test. Poiché il punteggio grezzo è una statistica sufficiente per stimare le misure di Rasch, tutti i soggetti appartenenti al medesimo gruppo Bh hanno la stessa abilità stimata
h!̂ .
Consideriamo un item j alla volta, j=1, …, k. Sia )( jhr il numero degli studenti appartenenti
al gruppo Bh, con abilità stimata h
!̂ , che rispondono correttamente all’item j-esimo; quindi, )( j
hh rf ! è il numero degli studenti appartenenti allo stesso gruppo, e con medesima abilità, ma che rispondono in maniera errata.
3 Per esempio, nel caso dei dati della CNP, stiamo ipotizzando che il risultato di uno studente ad un test dipenda dall’abilità matematica generica e non esistano abilità distinte, per esempio, in geometria e in logica per cui ci siano molti studenti bravi nell’una ma non nell’altra. 4 Per esempio determinati dal sesso, lingua materna, livello di istruzione, … .
19
La proporzione osservata di risposte corrette date agli studenti appartenenti al gruppo Bh
è: h
jhj
hf
rp
)()(= .
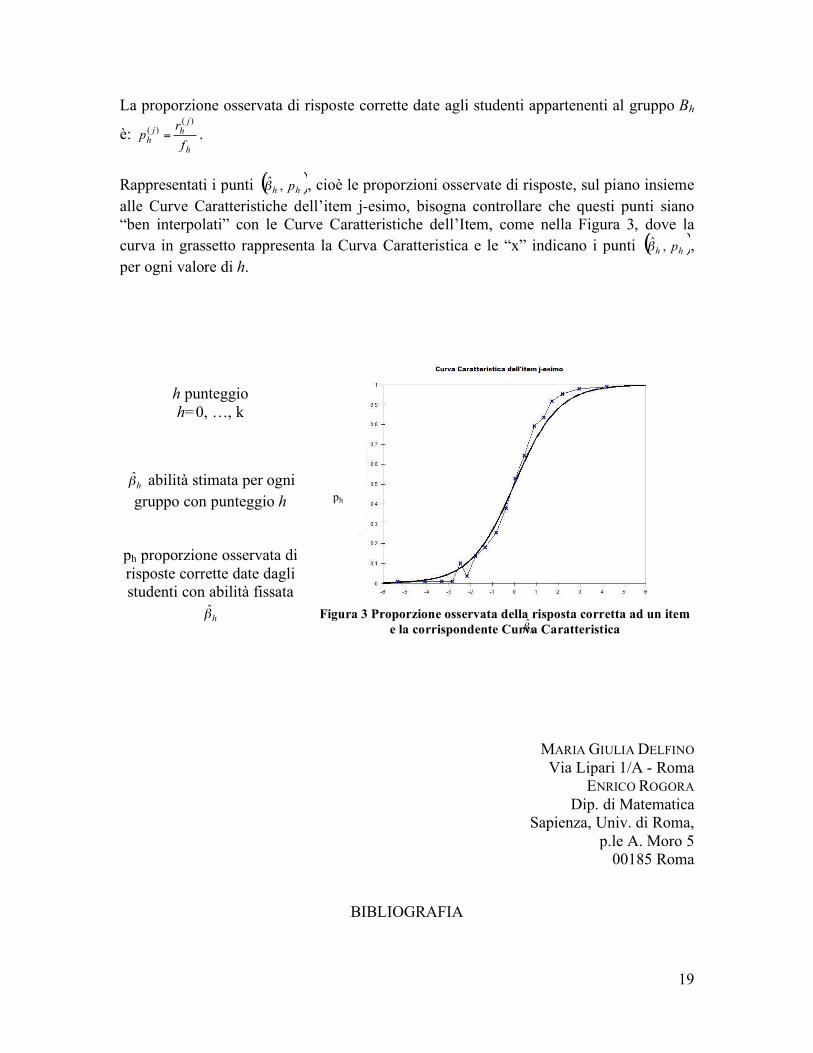
Rappresentati i punti ( )hh p,!̂ , cioè le proporzioni osservate di risposte, sul piano insieme alle Curve Caratteristiche dell’item j-esimo, bisogna controllare che questi punti siano “ben interpolati” con le Curve Caratteristiche dell’Item, come nella Figura 3, dove la curva in grassetto rappresenta la Curva Caratteristica e le “x” indicano i punti ( )hh p,!̂ , per ogni valore di h.
h punteggio h=0, …, k
h!̂ abilità stimata per ogni gruppo con punteggio h
ph proporzione osservata di risposte corrette date dagli studenti con abilità fissata
h!̂
Figura 3 Proporzione osservata della risposta corretta ad un item
e la corrispondente Curva Caratteristica
MARIA GIULIA DELFINO Via Lipari 1/A - Roma
ENRICO ROGORA Dip. di Matematica
Sapienza, Univ. di Roma, p.le A. Moro 5
00185 Roma
BIBLIOGRAFIA
ph
h!̂

20
[1] D. Andrich, Rasch models for measurements (1988), Newbury Park: Sage Publications, Inc.
[2] W. Ayers, To teach: the journey of a teacher (1993), Columbia University, New York: Teachers College Press.
[3] F. B. Baker – S. Kim, Item response theory. Parameter Estimation Techniques (2004), 2 ed., Statistics: Textbooks and monographs.
[4] M.G. Delfino, Tesi di Laurea, Roma (2010).
[5] G. Rasch, Probabilistic models for some intelligence and attainment test (1960), Copenhagen: Danish Institute for Educational Research.
[6] www.testingressoscienze.org
[7] www.pisa.oecd.org