
Giuseppe Rodriguez - bugs.unica.itbugs.unica.it/~gppe/did/ca/dispense.pdf · Dipartimento di...
24
Università degli Studi di Cagliari Dipartimento di Matematica Dispense di Calcolo Numerico Giuseppe Rodriguez
Transcript of Giuseppe Rodriguez - bugs.unica.itbugs.unica.it/~gppe/did/ca/dispense.pdf · Dipartimento di...

Università degli Studi di CagliariDipartimento di Matematica
Dispense di Calcolo NumericoGiuseppe Rodriguez

2

Capitolo 1
Introduzione
L’Analisi Numerica è lo studio degli algoritmiper i problemi della matematica del continuo.
Questa definizione, data da L.N. Trefethen chiarisce quali sono gli obiettivi del-l’Analisi Numerica, cioè sviluppare ed analizzare algoritmi (chiariremo in seguitoil significato esatto di questo ed altri termini) per risolvere una particolare classedi problemi, e precisamente quelli che coinvolgono variabili reali o complesse.
La particolarità della risoluzione di questi problemi consiste nel fatto che,nella generalità dei casi, è necessario operare su dati affetti da errori. Questipossono essere dovuti alla misurazione dei dati (errori sperimentali) o semplice-mente al fatto che essi devono essere memorizzati con un numero finito di cifre(errori di arrotondamento).
Se un problema è risolubile con un algoritmo finito, l’analisi si limita allo studiodella propagazione degli errori. In molti casi, però, per necessità o convenienzasi ricorre ad un algoritmo infinito, in cui la soluzione è ricavata come limite di unasuccessione, o si discretizza un modello continuo, dando origine ad altri tipi dierrori sui risultati: gli errori di troncamento e di discretizzazione.
Cominciamo con l’introdurre alcuni concetti fondamentali.
1.1 Buona posizione e condizionamento
Sempre più spesso la Matematica viene utilizzata per risolvere problemi di inte-resse per le scienze applicate. Talvolta si ha la necessità di prevedere l’esito diun fenomeno, in altri casi si vuole simulare l’andamento di un processo che, perqualche motivo, non si può osservare sperimentalmente.
In ogni caso, il primo passo consiste nel costruire un modello matematicodel fenomeno sotto studio, vale a dire un complesso di formule che descrivano
1–1

1–2 CAPITOLO 1. INTRODUZIONE
il suo comportamento. Questo compito è tutt’altro che semplice e richiede unaconoscenza profonda della Fisica che governa il fenomeno.
Spesso le equazioni così ottenute sono troppo complicate per poter essererisolte direttamente. In questi casi si associa al modello matematico un proble-ma numerico in cui viene introdotta qualche semplificazione o approssimazione,allo scopo di renderlo risolubile numericamente su un calcolatore.
Nel 1924 J. Hadamard diede la seguente definizione di problema ben posto
Definizione 1.1 Un problema è ben posto se esso possiede, in un prefissatocampo di definizione, una e una sola soluzione e questa dipende con continuitàdai dati. In caso contrario, viene detto mal posto.
Esempio 1.1 Esempi di problemi mal posti:
1. Trovare x ∈ R che soddisfa l’equazione x2 + 1 = 0 (la soluzione non esiste).
2. Trovare x, y ∈ R che soddisfano l’equazione x + y = 1 (manca l’unicità).
Quando il terzo requisito viene violato, quando cioè il problema è instabile, puòaccadere che una piccolissima perturbazione sui dati possa portare ad unasoluzione molto differente da quella corrispondente ai dati esatti.
Quest’ultima proprietà è particolarmente importante nelle applicazioni reali,in cui si ha che fare con dati misurati sperimentalmente e quindi affetti da errore.Per questo motivo, anche quando il problema è stabile si cerca di dare una misu-ra quantitativa di come la sua soluzione venga influenzata da una perturbazionedei dati. Questa caratterizzazione viene detta condizionamento del problema.
Definizione 1.2 Sia δd una perturbazione dei dati d di un problema e sia δx lacorrispondente perturbazione sulla sua soluzione x. Sia inoltre ‖ · ‖ una qual-siasi norma vettoriale. Il numero di condizionamento assoluto K = K(d) èdefinito dalla relazione
‖δx‖ ≤ K‖δd‖,
mentre il numero di condizionamento relativo (o, semplicemente, numero dicondizionamento) κ = κ(d) verifica la diseguaglianza
‖δx‖‖x‖ ≤ κ
‖δd‖‖d‖ .
Il condizionamento misura, quindi, quanto un errore sui dati possa essere am-plificato nei risultati. Osserviamo che la propagazione dell’errore dovuta ad unelevato condizionamento non dipende dal metodo utilizzato per la risoluzione delproblema e quindi non è legata all’utilizzazione di un calcolatore elettronico, masi verificherebbe anche se i calcoli venissero effettuati a mano.

1.2. ALGORITMI 1–3
Esempio 1.2 Calcoliamo il numero di condizionamento del prodotto tra due numeri x ey, introducendo una perturbazione su ciascuno di essi e studiandone la propagazione.Siano εx e εy tali che |εx|, |εy| ≤ τ. Tralasciando gli infinitesimi di ordine superiore, siha
x(1 + εx) · y(1 + εy) ' xy(1 + εx + εy).
La perturbazione relativa εxy = εx + εy sul prodotto verifica la diseguaglianza εxy ≤ 2τ,di conseguenza il numero di condizionamento è 2. Questo valore è decisamente soddi-sfacente perché indica che nel peggiore dei casi gli errori presenti sugli operandi si som-meranno tra loro. Potrebbe quindi verificarsi un accumulo eccessivo solo nel prodotto dimolti fattori.
1.2 Algoritmi
Definizione 1.3 Un algoritmo è una sequenza univoca di un numero finito dioperazioni elementari che stabilisce come calcolare la soluzione di un problema,assegnati certi dati iniziali.
Sottolineiamo l’importanza di alcune parole presenti nella definizione:
sequenza univoca non è sufficiente dare una formula, deve essere chiaro an-che in che ordine bisogna eseguire le operazioni;
operazioni elementari si tratta di una nozione relativa, devono essere elemen-tari, cioè di semplice comprensione, per chi leggerà l’algoritmo;
numero finito se l’algoritmo è iterativo deve essere fornito un criterio di arresto;
input/output deve essere chiaro il numero ed il tipo dei dati richiesti dall’algorit-mo e di quelli da esso generati.
Gli algoritmi vengono generalmente rappresentati mediante mappe struttura-li, una sorta di programmi scritti utilizzando uno pseudo-codice molto simile allinguaggio di programmazione Pascal. Non è necessario utilizzare regole sin-tattiche ferree per la loro stesura, è sufficiente essere chiari e precisi. È ancheconsigliabile utilizzare solo le più comuni strutture di controllo del flusso (if , for ,while e repeat) e non costrutti presenti solo in determinati linguaggi di program-mazione, allo scopo di rendere possibile la comprensione dell’algoritmo anche achi non conosce quel particolare linguaggio. In fase di effettiva implementazione,si potrà poi ottimizzare il codice per trarre vantaggio dalla sintassi del linguaggioche si è deciso di usare. Gli esempi che seguono illustrano un possibile stile perla descrizione degli algoritmi.

1–4 CAPITOLO 1. INTRODUZIONE
Esempio 1.3 Calcolo del prodotto matrice per vettore
y = Ax, A ∈ Rm×n, x ∈ Rn, y ∈ Rm.
Segue la mappa strutturale dell’algoritmo:
1. input A, x, m, n2. for i = 1, . . . , m
1. yi = 02. for j = 1, . . . , n
1. yi = yi + aij ∗ xj3. output y
Esempio 1.4 Approssimare il valore del numero di Nepero mediante lo sviluppo
e =∞
∑k=0
1k!
,
troncando la sommatoria quando il termine generico risulta essere minore di 10−8. Unodei possibili algoritmi è il seguente:
1. k = 02. a = 13. e = a4. while a ≥ 10−8
1. k = k + 12. a = a/k3. e = e + a
5. output e, k
In uscita vengono forniti l’approssimazione di e, insieme al numero di iterazioni effettuate.Sarebbe stato possibile conoscere in anticipo il numero delle iterazioni necessarie perraggiungere la precisione richiesta?
Un algoritmo serve a risolvere problemi, ma non tutti i problemi matematicisono effettivamente risolubili.
La Definizione 1.1 potrebbe indurci a pensare che un problema risolubilecoincida necessariamente con un problema ben posto e che questo sia l’unicotipo di problemi di nostro interesse. La realtà è molto più articolata.
In primo luogo, esistono moltissimi problemi applicativi che vengono model-lizzati mediante problemi mal posti e che esigono, comunque, un qualche tipo disoluzione.
In secondo luogo, non è detto che un problema ben posto si possa risolve-re in pratica, almeno quando assume determinate caratteristiche (dati imprecisio dimensioni elevate). Per illustrare questo punto è necessario introdurre trecaratterizzazioni comunemente attribuite agli algoritmi numerici.

1.3. CARATTERIZZAZIONI DEGLI ALGORITMI 1–5
1.3 Caratterizzazioni degli algoritmi
Abbiamo già detto che gli errori da cui sono affetti i dati possono subire un’am-plificazione a causa del cattivo condizionamento di un problema. Ebbene, glialgoritmi hanno essi stessi la caratteristica di propagare in vario modo gli errori.
Definizione 1.4 Definiamo stabile (risp. instabile) un algoritmo nel quale lasuccessione delle operazioni non amplifica (risp. amplifica) eccessivamente glierrori presenti sui dati.
Da questo punto di vista non avrebbe senso considerare risolubile un problemaal quale, a causa della propagazione degli errori, siamo in grado di dare solo unasoluzione inaccurata, o addirittura errata. Risulta cruciale, quindi, lo studio dellapropagazione degli errori e la ricerca di algoritmi stabili.
Osserviamo che sviluppare un algoritmo stabile è possibile solo in presenzadi problemi ben condizionati. In caso contrario è necessario prima stabilire seè possibile riformulare il problema in modo da ridurre il condizionamento e, diconseguenza, la propagazione degli errori da esso causata.
Esempio 1.5 Spesso si verificano errori inaspettati anche in operazioni molto semplici.Provate, con una qualsiasi calcolatrice tascabile, a calcolare la quantità 3( 4
3 − 1)− 1. Ilrisultato dovrebbe essere 0, quello che troverete sarà un numero piccolo, ma non nullo(a meno che la vostra calcolatrice non “bari”!). Riuscite ad immaginare perché?
Esercizio 1.1 Valutate su un computer il limite notevole
limx→0
1− cos xx2
calcolando la funzione per valori sempre più piccoli della variabile, ad es. x = 10−1, 10−2, . . .,e dite se il risultato che otterrete è in accordo col valore del limite che avete studiato inAnalisi Matematica. Riuscite a pensare a qualche altro modo di effettuare il calcolo?Ottenete risultati differenti?
Definizione 1.5 La complessità computazionale di un algoritmo, per gli ana-listi numerici, è il numero delle operazioni in virgola mobile necessarie per risol-vere un problema mediante l’algoritmo dato.
Il fatto che questa definizione non coincida con quella generalmente utilizzatain Informatica, che invece tiene conto di tutte le operazioni effettuate, deriva dalfatto che l’Analisi Numerica studia algoritmi che coinvolgono variabili reali o com-plesse, e che in genere il tempo di calcolo richiesto dalle operazioni su questevariabili supera di gran lunga quello richiesto dalle altre istruzioni (operazioni suvariabili intere, spostamento di blocchi di memoria, etc.).

1–6 CAPITOLO 1. INTRODUZIONE
La complessità computazionale è proporzionale al tempo di calcolo, ma, adifferenza da questo, non dipende dal particolare computer utilizzato. L’unità dimisura è il flop (floating point operation = operazione in virgola mobile), ma spes-so vengono utilizzati i suoi multipli (Kflop, Mflop, Gflop). In genere non interessaconoscere con esattezza la complessità computazionale di un algoritmo, ma ci siaccontenta del suo ordine di grandezza rispetto alla dimensione n del problema,ad es. O(1
3 n3) in luogo di 13 n3 + 2n2 + · · · .
Esercizio 1.2 Determinare la complessità computazionale di alcuni dei più comuni cal-coli che coinvolgono vettori e matrici: somma delle componenti, norma, prodotto scalare,prodotto matrice per vettore e matrice per matrice, etc.
Talvolta il flop è utilizzato nella misura della velocità di elaborazione, spes-so intesa nel calcolo scientifico come numero di operazioni in virgola mobileper secondo (flop/s, o semplicemente flops). Un moderno personal computerraggiunge velocità dell’ordine delle centinaia di Mflops.
Per capire come la complessità computazionale di un algoritmo influenzi l’ef-fettiva risolubilità di un problema, osserviamo la Tabella 1.1, dove sono riportatii tempi di calcolo, stimati su un calcolatore con la velocità di 100 Mflops, per larisoluzione di un sistema di n equazioni lineari in n incognite con il classico me-todo di Cramer, calcolando i determinanti con la regola di Laplace, e mediantel’algoritmo di Gauss, che studieremo nei prossimi capitoli. È evidente che anche
Tabella 1.1 Tempi di calcolo per la risoluzione di un sistema linearen Cramer + Laplace Gauss12 23 minuti 1.2 10−5 secondi13 6 ore 1.5 10−5 secondi14 4 giorni 1.8 10−5 secondi20 617175 anni 5.3 10−5 secondi30 1.5 1020 anni 1.8 10−4 secondi40 8.3 1035 anni 4.3 10−4 secondi50 4.8 1052 anni 8.3 10−4 secondi
un incremento di un fattore 1000 nella velocità del calcolatore non renderebbel’algoritmo di Cramer praticamente utilizzabile, specie se si tiene conto che i si-stemi lineari che si incontrano nelle applicazioni hanno dimensioni ben superioria 50 (talvolta sono dell’ordine delle decine di migliaia di equazioni) e soprattuttoche l’Universo ha un’età di 1010 anni!
Esercizio 1.3 Vedremo che l’algoritmo di Gauss richiede O( 13 n3) addizioni ed altrettan-
te moltiplicazioni per la risoluzione di un sistema di n equazioni. Qual’è la complessitàdel metodo di Cramer accoppiato alla regola di Laplace per il calcolo dei determinanti?

1.3. CARATTERIZZAZIONI DEGLI ALGORITMI 1–7
Un’altra caratteristica degli algoritmi, di fondamentale importanza per pro-blemi di dimensione elevata, è l’occupazione di memoria da essi richiesta.Determinati problemi, in situazioni estreme, possono portare all’elaborazione diuna tale mole di dati da rendere indispensabile l’uso di tecniche di memoriz-zazione particolarmente raffinate e, conseguentemente, l’adozione di algoritmispecializzati per la loro risoluzione.
Quanto detto ci induce a considerare risolubile un problema ben posto eben condizionato per il quale esista un algoritmo con caratteristiche di stabilità,complessità ed occupazione di memoria compatibili con la precisione richiesta, ladimensione del problema, le caratteristiche del calcolatore utilizzato ed il tempodi calcolo ammissibile per la sua soluzione.
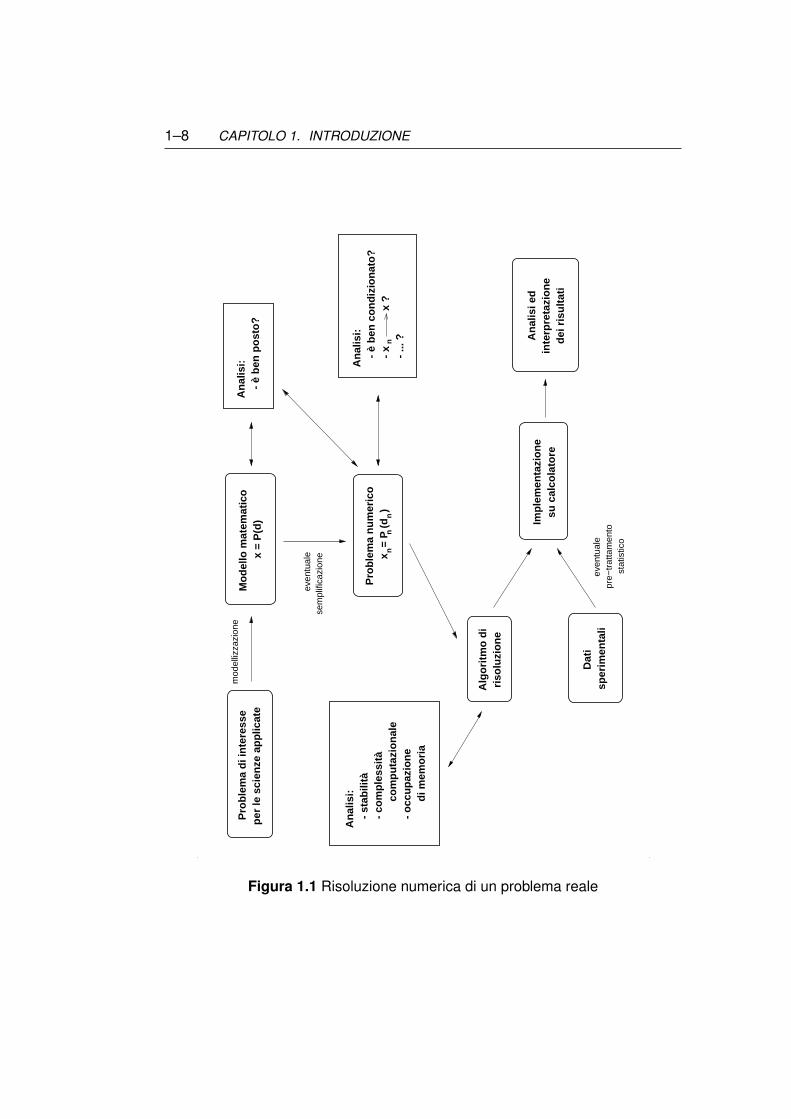
La Figura 1.1 riassume i vari passi che conducono dalla modellizzazione diun problema reale alla risoluzione del problema numerico ad esso associato edall’analisi dei risultati ottenuti.
1–8 CAPITOLO 1. INTRODUZIONE
co
mpu
tazi
onal
e
di
mem
oria
Ana
lisi:
-
stab
ilità
-
com
ples
sità
-
occu
pazi
one
Ana
lisi:
-
è be
n po
sto?
Ana
lisi:
-
è be
n co
ndiz
iona
to?
-
x
x ?
-
... ?n
Alg
oritm
o di
risol
uzio
ne
Dat
i sp
erim
enta
li
Impl
emen
tazi
one
su c
alco
lato
re
Ana
lisi e
din
terp
reta
zion
ede
i ris
ulta
ti
even
tual
epr
e−tr
atta
men
tost
atis
tico
even
tual
ese
mpl
ifica
zion
e
Pro
blem
a di
inte
ress
epe
r le
sci
enze
app
licat
eM
odel
lo m
atem
atic
ox
= P
(d)
Pro
blem
a nu
mer
ico
nn
x =
P (
d ) n
mod
elliz
zazi
one
Figura 1.1 Risoluzione numerica di un problema reale

Capitolo 2
Complementi diAlgebra Lineare
Nella Sezione 2.1 verranno richiamati alcuni concetti che dovrebbero essere giàacquisiti dallo studente, e che comunque è indispensabile conoscere. Sarannoinvece trattati con maggiore dettaglio alcuni argomenti che probabilmente nonsono ancora stati introdotti in altri corsi.
2.1 Richiami
In questa sezione vengono richiamate definizioni e proprietà che dovrebbero giàfar parte del bagaglio culturale del lettore.
2.1.1 Spazi
Definizione 2.1 Uno spazio lineare (o vettoriale) reale è un insieme V su cuisono definite due operazioni di somma e prodotto per uno scalare
+ : V ×V −→ V(x, y) 7−→ x + y e
· : R×V −→ V(α, x) 7−→ αx
che, per ogni α, β ∈ R e x, y, z ∈ V, godono delle seguenti proprietà
1. x + y ∈ V (chiusura risp. somma)
2. αx ∈ V (chiusura risp. prodotto)
3. x + y = y + x (pr. commutativa)
4. (x + y) + z = x + (y + z) (pr. associativa)
2–1

2–2 CAPITOLO 2. COMPLEMENTI DI ALGEBRA LINEARE
5. esiste 0 ∈ V tale che x + 0 = x (elemento neutro)
6. esiste −x ∈ V tale che x + (−x) = 0 (inverso additivo)
7. α(βx) = (αβ)x (pr. associativa)
8. α(x + y) = αx + αy (pr. distributiva in V)
9. (α + β)x = αx + βx (pr. distributiva in R)
10. 1x = x (elemento neutro)
In uno spazio lineare complesso il campo degli scalari è costituito dall’insieme deinumeri complessi C. Chiameremo vettori gli elementi di uno spazio lineare. Unsottospazio è un sottoinsieme W ⊂ V che sia esso stesso un spazio lineare.
Esempio 2.1 Seguono alcuni esempi di spazi lineari:
1. gli spazi Rn e Cn delle n-uple di numeri reali o complessi, con le consueteoperazioni di somma componente per componente e di prodotto per uno scalare;
2. lo spazio C[a, b] delle funzioni continue in un intervallo [a, b];
3. lo spazio L2[a, b] delle funzioni il cui quadrato è integrabile in [a, b];
4. lo spazio Πn dei polinomi di grado minore o uguale ad n.
Osserviamo che Πn è un sottospazio di C[a, b], che a sua volta è sottospazio di L2[a, b].
Esempio 2.2 L’insieme dei polinomi di grado pari a n non è uno spazio lineare. Perché?
Si dice combinazione lineare dei vettori {x1, . . . , xk} con coefficienti αi ∈R, i = 1, . . . , k, il vettore x ∈ V dato da
x =k
∑i=1
αixi,
e il sottospazio generato dai vettori {x1, . . . , xk} è costituito da tutte le lorocombinazioni lineari
span(x1, . . . , xk) :=
{x ∈ V : x =
k
∑i=1
αixi
}.
I vettori {x1, . . . , xk} sono linearmente indipendenti se
k
∑i=1
αixi = 0 ⇒ αi = 0, i = 1, . . . , k.

2.1. RICHIAMI 2–3
Questa condizione è equivalente al fatto che nessuno dei vettori sia combinazio-ne lineare degli altri. Una base è un insieme di vettori linearmente indipendentitali che ogni vettore dello spazio possa essere espresso come loro combinazionelineare. La dimensione di uno spazio lineare è la cardinalità di una base. Unospazio è a dimensione finita se esiste per esso una base finita.
Esempio 2.3 Lo spazio Πn ha dimensione n + 1, dato che una base per esso è datadai monomi 1, x, x2, . . . , xn (viene detta base canonica). Lo spazio C[a, b], invece, è adimensione infinita.
Definizione 2.2 Uno spazio normato è uno spazio lineare su cui è definita unafunzione
‖ · ‖ : V −→ R
x 7−→ ‖x‖detta norma, tale che per ogni x, y ∈ V e α ∈ R si abbia
1. ‖x‖ ≥ 0 e ‖x‖ = 0 ⇔ x = 0 (positività)
2. ‖αx‖ = |α| ‖x‖ (omogeneità)
3. ‖x + y‖ ≤ ‖x‖+ ‖y‖ (diseguaglianza triangolare)
È immediato dimostrare che una norma verifica la seguente proprietà
‖x− y‖ ≥∣∣‖x‖ − ‖y‖
∣∣, ∀x, y ∈ V. (2.1)
Uno spazio normato è anche uno spazio metrico, in cui la distanza tra duevettori è misurata mediante la funzione
d(x, y) := ‖x− y‖.
Esempio 2.4 Lo spazio Rn può essere dotato di infinite norme. Tre delle più frequente-mente utilizzate sono
‖x‖2 =
(n
∑i=1
x2i
) 12
, ‖x‖1 =n
∑i=1|xi|, ‖x‖∞ = max
i=1,...,n|xi|.
La Figura 2.1 mostra la forma della sfera unitaria di R2
S :={
x ∈ R2 : ‖x‖ = 1}
relativamente alle tre norme introdotte.Gli spazi funzionali C[a, b] e L2[a, b] vengono usualmente dotati delle norme
‖ f ‖∞ = maxx∈[a,b]
| f (x)|, f ∈ C[a, b],
‖g‖2 =(∫ b
a|g(x)|2 dx
) 12
, g ∈ L2[a, b].

2–4 CAPITOLO 2. COMPLEMENTI DI ALGEBRA LINEARE
||x|| 2 ||x|| 1 ||x|| ∞
Figura 2.1 Sfere unitarie in R2 rispetto alle norme con indice 2, 1 e ∞
Teorema 2.1 Tutte le norme di Rn sono equivalenti, nel senso che per ognicoppia di norme ‖ · ‖α, ‖ · ‖β esistono due costanti positive m e M tali che, perogni x ∈ Rn, si ha
m‖x‖β ≤ ‖x‖α ≤ M‖x‖β.
Il risultato precedente è valido anche in Cn e, in generale, negli spazi a dimensio-ne finita. Esso consente, in particolare, di utilizzare indifferentemente qualsiasinorma per studiare la convergenza di una successione di vettori.
Definizione 2.3 Diremo che una successione di vettori xn converge al limite xquando la successione xn − x converge in norma a zero
limn→∞
xn = x ⇔ limn→∞
‖xn − x‖ = 0.
Definizione 2.4 Una successione si dice di Cauchy se
limm,n→∞
‖xm − xn‖ = 0.
Quando tutte le successioni di Cauchy hanno un limite in un dato spazio,esso viene detto completo. Uno spazio normato completo viene detto spaziodi Banach.
Definizione 2.5 Uno spazio di Hilbert è uno spazio lineare su cui è definito unprodotto scalare (o prodotto interno)
〈·, ·〉 : V ×V −→ R
(x, y) 7−→ 〈x, y〉
tale che per ogni x, y, z ∈ V e α ∈ R
1. 〈x, x〉 ≥ 0 e 〈x, x〉 = 0 ⇔ x = 0 (positività)
2. 〈x, y〉 = 〈y, x〉 (pr. commutativa)

2.1. RICHIAMI 2–5
3. 〈αx, y〉 = α〈x, y〉 (omogeneità)
4. 〈x + y, z〉 = 〈x, z〉+ 〈y, z〉 (linearità)
Tale spazio deve inoltre essere completo rispetto alla norma indotta dal prodottointerno
‖x‖ := 〈x, x〉 12 . (2.2)
Due vettori vengono detti ortogonali quando il loro prodotto scalare è nullo.
Esempio 2.5 Il prodotto scalare comunemente utilizzato in Rn è il seguente
〈x, y〉 =n
∑i=1
xiyi. (2.3)
Esso induce la norma euclidea ‖x‖2.Lo spazio L2[a, b] dotato del prodotto interno
〈 f , g〉 =∫ b
af (x)g(x)dx
è uno spazio di Hilbert. La norma indotta è quella definita nell’Esempio 2.4.
Per la norma indotta vale la diseguaglianza di Schwartz
|〈x, y〉| ≤ ‖x‖ · ‖y‖.
Esercizio 2.1 Dimostrare che la (2.2) è una norma.
2.1.2 Matrici
Una matrice m × n è un quadro di mn numeri reali o complessi disposti in mrighe e n colonne
A =
a11 a12 · · · a1na21 a22 · · · a2n...
......
am1 am2 · · · amn
.
Una matrice è quadrata se m = n, in caso contrario viene detta rettangolare.Indicheremo con Mm×n l’insieme di tutte le matrici m × n; scriveremo Rm×n
o Cm×n per evidenziare che ci stiamo riferendo a matrici reali o complesse,rispettivamente.
Sia A ∈ Cm×n. La matrice aggiunta A∗ si ottiene scambiando le righe di Acon le sue colonne e coniugandone gli elementi
(A∗)ij = aji.

2–6 CAPITOLO 2. COMPLEMENTI DI ALGEBRA LINEARE
Se la matrice A è reale (aij ∈ R), si parla di matrice trasposta
(AT)ij = aji.
Un vettore colonna x è una matrice n× 1; un vettore riga xT è una matrice 1× n.Assumeremo convenzionalmente che ogni x ∈ Rn sia un vettore colonna. Avolte è utile considerare una matrice come l’insieme delle sue colonne o dellesue righe, cioè
A =
a11 · · · a1n...
...am1 · · · amn
=[a1 · · · an
]=
a1
...am
, (2.4)
con ai vettore colonna e aj vettore riga.Le matrici costituiscono uno spazio lineare di dimensione mn con somma e
prodotto per uno scalare definiti da
(A + B)ij = aij + bij, (αA)ij = αaij.
Se A ∈ Rm×n e B ∈ Rn×p, il loro prodotto “righe per colonne” (o, semplice-mente, prodotto) è la matrice C = AB ∈ Rm×p definita da
cij =n
∑k=1
aikbkj, i = 1, . . . , m, j = 1, . . . , p.
Il prodotto matriciale è distributivo rispetto alla somma, associativo, ma noncommutativo. L’elemento neutro è la matrice identità
I = diag(1, . . . , 1) =
1 0. . .
0 1
.
La potenza p-esima di una matrice è definita come
Ap = A · A · · · A︸ ︷︷ ︸p volte
.
Ricordiamo che una matrice reale m× n rappresenta la generica trasforma-zione lineare tra gli spazi lineari Rn e Rm. Il prodotto matriciale corrispondeallora alla composizione di due trasformazioni lineari.
Esercizio 2.2 Dati A ∈ Rn×n e x, y ∈ Rn, dite che dimensioni hanno i prodotti
Ax, xT A, xTy, xyT
ed esprimete esplicitamente le loro componenti.

2.1. RICHIAMI 2–7
Osserviamo che il prodotto scalare di Rn definito in (2.3) e la norma da essoindotta possono essere espressi nella forma
〈x, y〉 = xTy, ‖x‖2 =√
xTx.
Una matrice quadrata A si dice invertibile o non singolare se esiste una matri-ce A−1, detta matrice inversa, tale che AA−1 = A−1A = I.
Alcune proprietà:
• (AB)T = BT AT;
• (AB)−1 = B−1A−1;
• (AT)−1 = (A−1)T (scriveremo per brevità A−T);
• A è invertibile se e solo se ha righe (e colonne) linarmente indipendenti.
Il determinante è una funzione che associa a ciascuna matrice quadrata unnumero reale. Tralasciando la sua definizione formale, ricordiamo che, fissatauna riga i, esso può essere calcolato mediante la formula di Laplace
det(A) =n
∑j=1
(−1)i+jaij det(Aij),
essendo Aij la sottomatrice che si ottiene da A eliminando la i-esima riga e laj-esima colonna. Richiamiamo, inoltre, alcune sue proprietà:
• det(AT) = det(A), det(A∗) = det(A), det(A−1) = det(A)−1;
• det(AB) = det(A) det(B), det(αA) = αn det(A);
• uno scambio di due righe di una matrice produce un cambio di segno deldeterminante;
• A è non singolare se e solo se det(A) 6= 0.
Il rango rank(A) di una matrice può essere definito indifferentemente comeil massimo numero di righe (o colonne) linearmente indipendenti o come l’ordinedella più grande sottomatrice con determinante non nullo.

2–8 CAPITOLO 2. COMPLEMENTI DI ALGEBRA LINEARE
2.1.3 Autovalori e autovettori
Definizione 2.6 Si dicono autovalore ed autovettore di una matrice A unoscalare λ ed un vettore x 6= 0 che verifichino la relazione
Ax = λx. (2.5)
Riscriviamo l’equazione (2.5) nella forma
(A− λI)x = 0.
Perché questo sistema lineare omogeneo ammetta una soluzione non nulla ènecessario che il suo determinante
pA(λ) = det(A− λI)
si annulli. Dal momento che pA(λ) è un polinomio di grado n in λ, detto poli-nomio caratteristico di A, il Teorema fondamentale dell’Algebra assicura l’esi-stenza di n autovalori (non necessariamente reali e distinti) che possono esseredeterminati calcolando gli zeri di pA(λ).
Per ciascun autovalore λk, k = 1, . . . , n, una soluzione non nulla del sistemasingolare
(A− λk I)x = 0
fornisce il corrispondente autovettore, che, nel caso in cui la matrice A− λk I ab-bia rango n− 1, resta quindi determinato a meno di una costante moltiplicativa.
Definiamo spettro di una matrice l’insieme dei suoi autovalori
σ(A) = {λ1, . . . , λn}
e raggio spettrale il massimo dei moduli degli autovalori
ρ(A) = maxk=1,...,n
|λk|.
Alcune proprietà:
• det(A) = ∏nk=1 λk;
• σ(AT) = σ(A), σ(A−1) = {λ−11 , . . . , λ−1
n }, σ(Ap) = {λp1 , . . . , λ
pn};
• ad autovalori distinti corrispondono autovettori indipendenti;
• se un autovettore x è noto, il quoziente di Rayleigh xT AxxTx fornisce il corri-
spondente autovalore.

2.2. MATRICI DI FORMA PARTICOLARE 2–9
La molteplicità algebrica di un autovalore è la sua molteplicità come zerodel polinomio caratteristico. Si definisce, invece, molteplicità geometrica di unautovalore il massimo numero di autovettori indipendenti ad esso corrispondenti.In generale per ogni autovalore si ha sempre
molteplicità geometrica ≤ molteplicità algebrica.
Se per un autovalore vale il minore stretto, la matrice viene detta difettiva.
Esempio 2.6 Calcolate autovalori ed autovettori delle tre matrici22
2
,
22 1
2
,
2 12 1
2
.
2.2 Matrici di forma particolare
Una matrice possiede una struttura (o è strutturata) quando ha delle proprietàche rendono più agevole la risoluzione di un problema che la coinvolge (inversio-ne, risoluzione di un sistema lineare, calcolo di autovalori, etc.). Elenchiamo diseguito alcuni tipi di matrici strutturate.
Matrici Hermitiane Una matrice quadrata è Hermitiana se coincide con la suaaggiunta (A = A∗). Una matrice reale A si dice simmetrica se A = AT. Unamatrice Hermitiana A è definita positiva se
x∗Ax > 0, ∀x ∈ Cn.
La stessa definizione è valida per matrici simmetriche reali, sostituendo Cn conRn.
Il seguente teorema enuncia la principale proprietà delle matrici Hermitiane.
Teorema 2.2 Se A è Hermitiana, i suoi autovalori sono reali ed esiste per Cn
una base di autovettori ortonormali. Se A è anche definita positiva, gli autovalorisono positivi.
Matrici unitarie Una matrice è unitaria se la sua inversa coincide con l’ag-giunta
Q∗Q = QQ∗ = I.
Una matrice reale è ortogonale se l’inversa coincide con la trasposta
QTQ = QQT = I.

2–10 CAPITOLO 2. COMPLEMENTI DI ALGEBRA LINEARE
Ovviamente, dal punto di vista computazionale il maggior vantaggio di una ma-trice unitaria è quello di poter essere invertita senza alcun calcolo, il che con-sente di risolvere immediatamente un sistema lineare. Ricordiamo anche alcuneproprietà, altre verranno richiamate in seguito.
Teorema 2.3 Se Q è unitaria, allora
1. |det(Q)| = 1, (se Q è reale det(Q) = ±1);
2. ‖Qx‖2 = ‖x‖2, per ogni vettore x ∈ Cn.
Dimostrazione. Si ottiene applicando le proprietà dei determinanti e la defi-nizione di norma 2 (da fare per esercizio). �
Matrici triangolari Una matrice U è detta triangolare superiore se i suoi ele-menti verificano la condizione
uij = 0, per i > j.
Una matrice L viene detta triangolare inferiore se
`ij = 0, per i < j.
Il nome di queste matrici deriva dalla disposizione degli elementi non nulli alloro interno. Infatti, se indichiamo tali elementi con degli asterischi, è immediatoosservare che
U =
∗ ∗ · · · ∗∗ · · · ∗
. . ....∗
e L =
∗∗ ∗...
.... . .
∗ ∗ · · · ∗
.
Una matrice diagonale è simultaneamente triangolare superiore ed inferiore
D = diag(d1, . . . , dn) =
d1. . .
dn
.
I sistemi lineari con matrice triangolare o diagonale sono particolarmente sem-plici da risolvere, come vedremo. Un’altra proprietà importante è la seguente.
Teorema 2.4 Se T è triangolare (e quindi anche se è diagonale) il suo de-terminante è dato dal prodotto degli elementi diagonali. Inoltre gli autovaloricoincidono con gli elementi diagonali.

2.3. NORME MATRICIALI 2–11
Dimostrazione. Si ottiene sviluppando il determinante di T (e di T − λI)mediante la regola di Laplace. �
Ricordiamo che le matrici triangolari inferiori (o superiori) formano un’alge-bra. Questo significa che l’inversa di una matrice triangolare, quando esiste, eil prodotto di due matrici triangolari sono ancora matrici triangolari dello stessotipo. La stessa proprietà vale per le matrici unitarie, ma in questo caso non sipuò parlare di algebra dato che l’unitarietà non si trasmette attraverso la sommadi matrici ed il prodotto per uno scalare.
Matrici a banda Gli elementi di una matrice a banda-(k, m) verificano la rela-zione
aij = 0, se i− j ≥ k oppure i− j ≤ −m,
la matrice assume quindi la forma
A =
a1,1 · · · a1,m...
. . . . . . . . .
ak,1. . . . . . . . . an−m+1,n. . . . . . . . .
...an,n−k+1 · · · an,n
.
Le matrici a banda-(1,1), (2,2), (3,3) vengono dette diagonali, tridiagonali, penta-diagonali, etc.
Le matrici a banda possono portare ad un significativo vantaggio in terminidi complessità computazionale nella risoluzione di sistemi lineari e nel calcolodegli autovalori, in quanto alcuni algoritmi consentono di sfruttare in manieraopportuna la loro struttura.
2.3 Norme matriciali
Lo spazio lineare Mm×n, cui appartengono le matrici, può essere dotato dellastruttura di spazio normato definendo una qualsiasi norma ‖ · ‖ che verifichigli assiomi richiesti. In realtà per le norme di matrici si richiedono spesso dueulteriori proprietà.
Definizione 2.7 Una norma matriciale è submoltiplicativa se per ogni coppiadi matrici di dimensioni compatibili si ha
‖AB‖ ≤ ‖A‖ · ‖B‖.

2–12 CAPITOLO 2. COMPLEMENTI DI ALGEBRA LINEARE
Definizione 2.8 Una norma di matrice è consistente con le norme vettoriali‖ · ‖a di Rn e ‖ · ‖b di Rm se
‖Ax‖b ≤ ‖A‖ · ‖x‖a, ∀A ∈ Rm×n, ∀x ∈ Rn.
Spesso le norme ‖ · ‖a e ‖ · ‖b coincidono, in tal caso il pedice si trascura.
Ricordiamo che tutte le norme matriciali, essendo definite su spazi lineari adimensione finita, sono equivalenti.
Esempio 2.7 La norma di Frobenius è definita da
‖A‖F =
(m
∑i=1
n
∑j=1|aij|2
)1/2
.
Tale norma è submoltiplicativa.
Definizione 2.9 Una norma matriciale si dice indotta da una norma vettoriale‖ · ‖, se
‖A‖ = supx 6=0
‖Ax‖‖x‖
o se, equivalentemente,‖A‖ = max
‖x‖=1‖Ax‖.
Una norma così definita viene anche detta naturale, o subordinata.
Una norma naturale misura, in una data norma vettoriale, il massimo allunga-mento relativo che un vettore può subire in seguito al prodotto per la matrice A.Essa è consistente con la norma che la induce, in quanto la definizione implicache, qualunque sia x, si abbia
‖Ax‖ ≤ ‖A‖ · ‖x‖.
In particolare, è la più piccola norma consistente con quella particolare normavettoriale.
Teorema 2.5 Ogni norma indotta è submoltiplicativa.
Dimostrazione. Date A e B di dimensioni compatibili, si ha
‖AB‖ = supx 6=0
‖ABx‖‖x‖ = sup
x 6=0
‖ABx‖‖Bx‖ · ‖Bx‖
‖x‖
≤ supy 6=0
‖Ay‖‖y‖ · sup
x 6=0
‖Bx‖‖x‖ = ‖A‖ · ‖B‖,
dove la maggiorazione dipende dal fatto che non è detto che tutti i vettori y nelcodominio di B si possano esprimere nella forma Bx. �

2.3. NORME MATRICIALI 2–13
È immediato osservare che per una norma indotta si ha ‖I‖ = 1, da cui sideduce che la norma di Frobenius non è una norma naturale, dal momento che‖I‖F =
√n.
Vediamo ora le principali norme indotte.
Teorema 2.6 La norma matriciale indotta dalla norma vettoriale ∞ è la seguente
‖A‖∞ = maxi=1,...,m
n
∑j=1|aij|.
Dimostrazione. Per definizione si ha
‖A‖∞ = max‖x‖∞=1
‖Ax‖∞.
Maggiorando l’argomento si ottiene
‖Ax‖∞ = maxi=1,...,m
|(Ax)i| = maxi=1,...,m
∣∣∣∣∣ n
∑j=1
aijxj
∣∣∣∣∣ ≤ maxi=1,...,m
n
∑j=1
∣∣aij∣∣ ∣∣xj
∣∣≤ max
i=1,...,m|xi| · max
i=1,...,m
n
∑j=1|aij| = max
i=1,...,m
n
∑j=1|aij|,
in quanto ‖x‖∞ = maxi=1,...,m |xi| = 1 per ipotesi.Per concludere la dimostrazione è sufficiente mostrare che esiste un vettore
per cui viene raggiunta l’uguaglianza. Tale vettore è x = (s1, . . . , sn)T, dove
sj = sign(aij)
con i indice del massimo delle somme-riga (la funzione sign(z) vale 1 se z ≥ 0e −1 se z < 0). �
In modo analogo si può dimostrare il seguente risultato.
Teorema 2.7 La norma matriciale indotta dalla norma 1 è data da
‖A‖1 = maxj=1,...,n
m
∑i=1|aij|.
Si dice anche che la norma ∞ è il massimo delle somme-riga e la norma 1 è ilmassimo delle somme-colonna della matrice A.
Teorema 2.8 La norma matriciale indotta dalla norma 2 è data da
‖A‖2 =√
ρ(A∗A),
dove ρ(B) indica il raggio spettrale della matrice B.

2–14 CAPITOLO 2. COMPLEMENTI DI ALGEBRA LINEARE
Corollario 2.9 Se A è Hermitiana
‖A‖2 = ρ(A).
Dimostrazione. Immediata, a partire dal Teorema 2.8, dal momento che
ρ(A2) = (ρ(A))2.
�
Dato il suo legame con gli autovalori di una matrice, la norma 2 viene anchedetta norma spettrale.
Tutte le norme consistenti hanno una relazione forte col raggio spettrale diuna matrice, il che consente di utilizzarle per la localizzazione degli autovalori.Il seguente teorema mostra che una norma consistente definisce il raggio diun cerchio sul piano complesso che contiene tutti gli autovalori di A. L’utilitàdi questo risultato deriva dalla maggiore semplicità di calcolo di alcune normematriciali rispetto al raggio spettrale.
Teorema 2.10 Sia ‖ · ‖ una norma consistente. Allora per ogni matrice quadrataA si ha
ρ(A) ≤ ‖A‖.
Dimostrazione. Per ogni autovalore λ di A esiste un autovettore v tale cheAv = λv. Sfruttando la consistenza e le proprietà delle norme, si ottiene
|λ| · ‖v‖ = ‖λv‖ = ‖Av‖ ≤ ‖A‖ · ‖v‖,
da cui, essendo v 6= 0 per definizione, segue |λ| ≤ ‖A‖ per ogni autovalore λe quindi la tesi. �
Si può inoltre dimostrare il seguente risultato, complementare, in un certo senso,del precedente.
Teorema 2.11 Per ogni matrice quadrata A e per ogni ε > 0 esiste una normamatriciale naturale ‖ · ‖ tale che
‖A‖ ≤ ρ(A) + ε.
Sotto opportune ipotesi sugli autovalori di A (molteplicità algebrica e geometri-ca coincidente per ciascun autovalore) esiste una norma naturale per cui si hal’uguaglianza
‖A‖ = ρ(A).
Sottolineiamo la differenza tra questi due enunciati: il Teorema 2.10 è valido perogni norma consistente, mentre il Teorema 2.11 afferma che esiste almeno unanorma che verifica la tesi, ma non chiarisce come ottenerla (la dimostrazione,anzi, mostra che è molto difficile costruirla in pratica).


















