
Esercizi di Informatica: Shell - DISI, University of...
36
Esercizi di Informatica: Shell Stefano Teso mailto:[email protected] Versione 2015.0 Istruzioni per l’uso • In questo documento, i riferimenti a comandi shell e percorsi sono indicati cos` ı . • Gli esercizi ed i dati necessari si trovano su http://disi.unitn.it/ ~ teso nella sezione “materiale didattico”. Qui si trovano anche i dati necessari. I dati sono nella directory data/ . • Negli esercizi assumeremo di lavorare esclusivamente con file di testo. • Se volete ripetere un comando eseguito in precedenza, usate il tasto “freccia in alto” ↑ . • Per visualizzare gli ultimi comandi eseguiti, usate history . • Se un programma si blocca, potete “ucciderlo” con Control - c . • Per pulire il terminale, usate Control - l . • Per muovervi da una parola all-altra, usate Control e le frecce. • Per muovervi all’inizio/alla fine della riga, usate Home e End , con la tastiera italiana si tratta di - e Fine .
Transcript of Esercizi di Informatica: Shell - DISI, University of...

Esercizi di Informatica: Shell
Stefano Tesomailto:[email protected]
Versione 2015.0
Istruzioni per l’uso
• In questo documento, i riferimenti a comandi shell e percorsi sono indicati cosı .
• Gli esercizi ed i dati necessari si trovano su http://disi.unitn.it/~teso nella sezione “materialedidattico”. Qui si trovano anche i dati necessari. I dati sono nella directory data/ .
• Negli esercizi assumeremo di lavorare esclusivamente con file di testo.
• Se volete ripetere un comando eseguito in precedenza, usate il tasto “freccia in alto” ↑ .
• Per visualizzare gli ultimi comandi eseguiti, usate history .
• Se un programma si blocca, potete “ucciderlo” con Control - c .
• Per pulire il terminale, usate Control - l .
• Per muovervi da una parola all-altra, usate Control e le frecce.
• Per muovervi all’inizio/alla fine della riga, usate Home e End , con la tastiera italiana si tratta di↖ e Fine .

Debugging
Quando costruite un comando complesso, procedete in maniera incrementale!
In caso di errore, spezzate il comando nei suoi elementi fondamentali e controllate che ciascuna parte siacorretta, eseguendola indipendentemente e verificandone la sintassi con man .
Checklist
La checklist per fare debugging (ovviamente incompleta):
1. Controllare la sintassi delle opzioni (spazi, valori, etc.)
2. Le redirezioni sono giuste? (verso dei simboli)
3. Le pipe sono giuste? (i comandi accettano il pipelining?)
4. I file e le directories necessari esistono?
5. I file contengono i dati giusti? O sono vuoti?
Esempi:
• Maiuscolo e minuscolo. X non e equivalente ad x .
• Tipi di apici: destro ‘ e sinistro ’ .
• Tipi di virgolette: singole ’ e doppie " .
• Tipi di parentesi (ma non ne faremo uso).
• La shell non capisce le lettere accentate!

1 Invocare Comandi
Per invocare il comando cmd , e sufficiente scrivere cmd nel terminale e dare invio.
Esempio 1. Per invocare il manuale, scrivo man .
Il comportamento di un comando e specificato con:
• Gli argomenti indicano tipicamente percorsi di file: da dove prendere l’input e/o dove metterel’output:
scanformotifs protein.txt motifs.txt
• Le opzioni alterano il comportamento del comando. Quasi sempre sono facoltative:
cmd -x -y -z --a-long-option
Esempio 2. Per leggere l’aiuto del manuale, scrivo man -? oppure man --help .
Esempio 3. Per leggere l’aiuto di ls , scrivo ls --help .
Esempio 4. Il comando ls stampa a schermo la lista dei file contenuti in una directory. Accetta 1+argomenti, ed 0+ opzioni.
Per vedere la lista dettagliata dei file nella mia home, uso ls con l’opzione -l :
ls -l /home/stefano
Posso usare piu opzioni, ad esempio -l e -t :
ls -l -t /home/stefano oppure ls -lt /home/stefano
Nota. Non c’e uno spazio tra il carattere - e il carattere che specifica l’opzione!

2 Il Manuale
Il manuale descrive la sintassi di un dato comando, inclusi gli argomenti e le opzioni accettati dal comando.
Per visualizzare il manuale di ls , scrivete:man ls
Per navigare il manuale, usate le frecce. Per chiuderlo, premete q .
Per cercare nel testo (es, cosa vuol dire l’opzione -l di ls ?) scrivete / e il testo che volete cercare.Per saltare da un’occorrenza all’altra, usate n e p . Per annullare la ricerca, scrivete q .
Nota. In caso di panico, usate man !
Nota. Oppure Google/Yahoo/StackOverflow/etc.
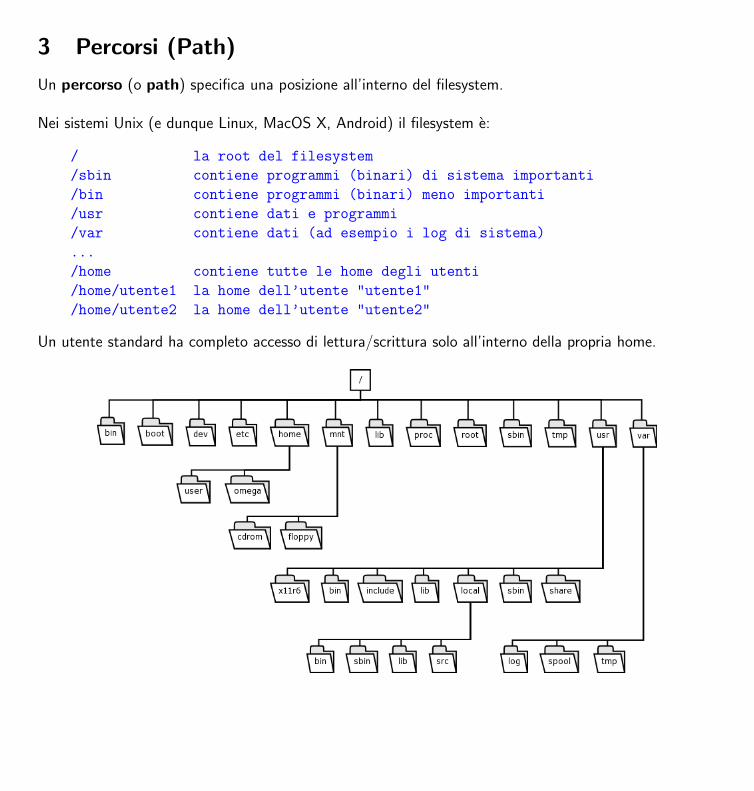
3 Percorsi (Path)
Un percorso (o path) specifica una posizione all’interno del filesystem.
Nei sistemi Unix (e dunque Linux, MacOS X, Android) il filesystem e:
/ la root del filesystem
/sbin contiene programmi (binari) di sistema importanti
/bin contiene programmi (binari) meno importanti
/usr contiene dati e programmi
/var contiene dati (ad esempio i log di sistema)
...
/home contiene tutte le home degli utenti
/home/utente1 la home dell’utente "utente1"
/home/utente2 la home dell’utente "utente2"
Un utente standard ha completo accesso di lettura/scrittura solo all’interno della propria home.

Per visualizzare il path della directory corrente (detta working directory), usate il comando pwd .
Alcuni percorsi speciali sono:
• / e la root del filesystem.
• . e la directory corrente.
• .. e la directory che contiene la directory corrente.
• ~ e la vostra home.
Quando invocate un comando, potete passagli un percorso:
• assoluto, cioe relativo alla root del filesystem.
• relativo rispetto alla directory corrente.
Esempio 5. Il percorso /home/stefano/Informatica e assoluto. Se mi trovo nella mia home (che e
/home/stefano ), il percorso relativo equivalente e Informatica .

Esercizi
1. Cosa significa l’opzione -l di ls ?
2. Cosa significa l’opzione -n di cat ?
3. I comandi cat e tac accettano le stesse opzioni?
4. Come si invoca il manuale di man ?
5. Dire se i seguenti path sono validi, e in tale caso se sono assoluti o relativi:
(a) ../bio/info
(b) /home/luca/data
(c) ../..
(d) /usr/../home/
(e) ././here/there/
(f) ..////..//./.../
(g) ..////..//./../
(h) /../home
6. Qual’e il path assoluto della tua home?
7. Qual’e il path relativo di x se la directory corrente e y?
(a) x = ~/data , y = ~
(b) x = ~/foo/bar/ , y = ~/bee/muu
8. Qual’e il path assoluto di x se la directory corrente e y?
(a) x= . , y = ~/bio-data
(b) x= .. , y = ~/personal
(c) x= ./../temp/. , y = ~/personal
(d) x= .././temp/.. , y = ~/personal
(e) x= .. , y = /

9. Qual’e il path assoluto di ../proteins ?
10. Il path relativo di una directory rispetto ad un’altra e unico?

4 Spostarsi nel FS, Manipolare file
I comandi per spostarsi nel filesystem e manipolare file (ma non i loro contenuti) sono:
Comando Opzioni Operazionels -l, -h, -t Elenca i contenuti di una directorycd - Cambia la directory correntemv -i, -f Sposta o rinomina oggetticp -R, -i, -f Copia oggetti
rm -R, -i, -f Rimuove oggettimkdir -p Crea una directory
La shell esegue quello che si chiama wildcard expansion. Questo vuol dire che ogni volta che incontrail carattere * , lo sostituisce con la lista dei contenuti della directory corrente. Idem con ~ .
Esempio 6. Se eseguo il comando ls * , la shell come prima cosa sostituisce la * con la lista dei filenella directory corrente, poi esegue ls con la lista come argomento.
Esempio 7. Lo stesso accade se utilizzando un percorso come prefisso. Ad esempio:
ls /home/stefano/informatica/*
prima sostituisce * con la lista dei file in /home/stefano/informatica/ , poi esegue ls .
Per impedire che avvenga la wildcard expansion, e sufficiente posizionare la * tra apici singoli o doppi,ad esempio ls ’*’ .
Nota. In caso di panico, usate cd (senza opzioni): vi riportera dritti alla vostra home.
Nota. Se vi trovate in~/sono/una/directory/molto/profonda
e fate per per sbagliocd ~/sono/da/tutta/un/altra/parte
per tornare indietro, usate cd - .

Esercizi
1. Cosa fa ls data/prot-fasta data/prot-pdb ? Confrontatelo con ls data/prot-fasta e
ls data/prot-pdb separatamente.
2. Cosa fa ls se gli si passa un path a file piuttosto che ad una directory?
3. Cosa fa ls se gli si passa path misti a file e directory?
4. Che differenza c’e tra cd . e cd .. ?
5. Che differenza c’e tra ls e ls . ?
6. Che differenza c’e tra ls e ls * ?
7. Che differenza c’e tra ls -l e ls -lh ?
8. Il risultato di ls ../* “include” il risultato di ls . ?
9. Che differenza c’e tra ls /home/luca/bio e ls ../luca/bio se pwd e /home ?
10. Il file data/empty1 e vuoto? E il file data/empty2 ?
(a) Si puo fare con almeno tre comandi diversi.
11. Cosa fa il comando mkdir muu/bee ?
12. Cosa fa il comando mkdir -p muu/bee/grr; rm muu/bee/grr ?
13. Cosa fa il comando mkdir -p muu/bee/grr; rm -R muu/bee ?
14. Cosa fa il comando mkdir muu; cd .; mkdir muu ?
15. Cosa fa il comando mkdir muu; cd .; mkdir -p muu ? Perche?
16. Il comando rm -R muu/bee rimuove anche la directory muu ?
17. Stampare a schermo la lista dei file contenuti nelle directory:
(a) data/deep0
(b) data/deep1

(c) . . .
(d) data/deep4
(e) Stampare tutti i file, inclusi quelli nelle sotto-directory
(f) Stampare solo i file, non le sotto-directory
18. Che differenza c’e tra cd.. e cd .. ?
19. Cosa fa il comando ls - l ?

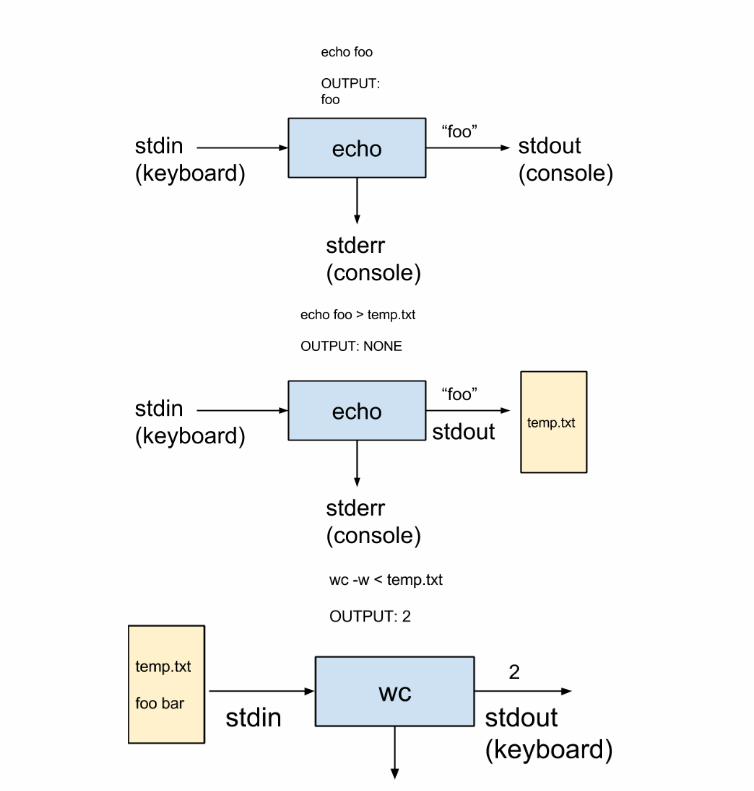
5 Redirezione
Tutti i comandi standard lavorano su tre “file speciali”:
• stdin, da dove leggono l’input. Di default e il terminale.
• stdout, dove scrivono il loro output. Di default e il terminale.
• stderr, dove scrivono i messaggi di errore. Di default e il terminale.
Questi sono nomi simbolici: non vi troverete mai a scrivere “ stdin ” o “ stdout ” da nessuna parte.
E possibile manipolare questi tre file speciali usando gli operatori di redirezione:
• cmd < file legge lo stdin di cmd da file .
• cmd > file scrive lo stdout di cmd in file , sovrascrivendo il file (se esiste).
• cmd >> file scrive lo stdout di cmd in file , appendendo al file (se esiste).
Nota. Non tutti i comandi permettono di redirigere lo stdin, ad esempio ls e cat .
Esempio 8. Il comando ls prende il path della directory da scansionare sempre dall’input utente (quindiper ls , lo stdin e fisso) e scrive la lista dei file contenuti sullo stdout, che puo essere il terminale oppureun file. Confrontate:
ls e ls > lista.txt

6 Pipes e Pipelines
La shell diventa improvvisamente utile quando concateniamo piu comandi in sequenza con l’operatoredi concatenamento (pipelining), scritto | :
cmd1 | cmd2 | . . . | cmdn
Lo stdout del comando cmdi diventa lo stdin del comando cmdi+1
Se vogliamo lanciare piu comandi in sequenza, senza che questi comunichino attraverso pipes, possiamoscrivere:
cmd1 ; cmd2 ; . . . ; cmdn
Questo dice alla shell di eseguire prima cmd1 , poi cmd2 , etc., ed e equivalente a dare i comandi insequenza, su righe diverse. Si noti che in questo caso lo stdin e stdout di ogni comando restano invariati.
Esempio 9. Anticipando un po i tempi, se lancio:
ls | tac
ottengo che l’output di ls venga poi stampato in ordine inverso da tac , mentre se lancio:
ls ; tac
prima viene eseguito ls , che stampera a schermo una lista di file; poi viene eseguito tac , che nonavendo input si piantera.
Esempio 10. Per stampare su stdout la lista dei file nella mia home con ls e poi contare le righe conwc (vedremo sotto), scrivo:
ls ~ | wc -l
Il modo di passare opzioni resta invariato.

Nota. Con la tastiera italiana la barra verticale | si scrive premendo Shift -\ (il tasto sotto Esc ).
Nota. Il simbolo | rappresenta un tubo (pipe).
Per creare pipe complesse, e saggio partire dal primo comando ed aggiungere volta per volta un comandoin pipe, controllando ad ogni passaggio l’output.
Esempio 11. Per visualizzare in modo comodo l’output di una pipeline:
cmd1 | cmd2 | . . . | cmdn | less

7 Leggere e Scrivere il Contenuto dei Files
I comandi standard per leggere il testo contenuto nei file sono:
Comando Opzioni Operazioneecho -n Stampa una stringacat -n Stampa un file per interotac Stampa un file al rovesciohead -n Stampa l’inizio di un filetail -n Stampa la fine di un fileless Visualizza un file interattivamente

Esercizi
1. Partendo da ~ , controllare dopo ogni passaggio il risultato:
(a) Creare una directory Informatica . E vuota?
(b) Creare una directory Eserc .
(c) Spostarsi in Informatica .
(d) Rinominare Eserc in EsShell .
(e) Copiare EsShell in Informatica .
(f) Rimuovere la copia originale di EsShell .
(g) Creare, in Informatica/EsShell , un file README , contenente la stringa” Esercitazioni di Informatica ”
(h) Aggiungere a README una seconda riga: ” Parte 1, Introduzione alla Shell ”
(i) Tornare nella propria home.
2. Cosa fa il comando ls -e | head -n +25 ? Perche?
3. Cosa fa il comando cat | head | tail ?
4. Cosa fa il comando cat . ?
5. Cosa fa il comando echo cat ?
6. Sempre partendo da ~ :
(a) Creare un file di testo A in una nuova directory temp
• Il contenuto deve essere la stringa “ * ”
(b) Fare una copia di sicurezza di temp , chiamata backup
(c) Dopo ciascuno dei punti successivi, rimuovere temp e rimpiazzarla con una copia di backup
i. Creare in temp due copie di A , chiamate B e C
ii. Che differenza c’e tra echo A , ls A , e cat A ?
iii. Che differenza c’e tra mv A B e cp A B; rm A ?
iv. Che differenza c’e tra cp A B; cp A C e mv A B; mv B C ?
v. Che differenza c’e tra mv A Z e mkdir Z; mv A Z ?

vi. Che differenza c’e tra cp A Z e mkdir Z; cp A Z ?
vii. Che differenza c’e tra echo A Z e mkdir Z; echo A Z ?
viii. Creare dieci file A0 ,. . . , A9 . Rimuoverli con una sola invocazione di rm .
7. Cosa fa il comando cat A > B ?
8. Che differenza c’e tra:
(a) head < A > B
(b) cat A | head > B
(c) cat < A | head > B
(d) tac < A | tac | head > B
(e) tac < A | head | tac > B
9. Che differenza c’e tra:
(a) head < IN | tail > OUT
(b) head < OUT | tail > IN
10. Cosa significa head > A | tail > B ?
11. Cosa significa cat << A ?
12. Che differenza c’e tra:
(a) tac A | head -n 25 > B
(b) cat A | tail -n 25 > B
13. Che differenza c’e tra head A | tail e head A > temp; tail A ?
14. Cosa fa il comando: ls | cat ? E ls | cat | cat ?
15. Cosa fa la sequenza di comandi: ls > A; rm < A ? Perche?
16. Cosa fa il comando echo KrustyIlKlown > A ?
17. Cosa fa il comando tac < FILE1 | tac > FILE2 ?

18. Che differenza c’e tra cat FILE | head e cat | head FILE ?
19. Come si fa a leggere l’nesima riga di un file?
20. Come si possono leggere le righe dalla n alla n+m di un file?
21. Cosa fa il comando tail -n n FILE | head -n m se m > n?
22. (a) Creare un file data/B che contenga le stesse righe di data/A , ordinate dalla 26 alla 50, dalla1 alla 25, dalla 51 alla 100.
(b) Creare un file data/C che contenga le stesse righe di data/A , ordinate dalla 26 alla 50, dalla25 alla 1, dalla 51 alla 100.

8 Wildcards
Le wildcards sono caratteri speciali (elencati qui sotto) che specificano determinati insiemi di caratteri:
Wildcard Significato* Una qualunque stringa di caratteri (anche vuota)? Esattamente un carattere qualunque
[akz] Esattamente un carattere tra a , k , e z
[0-9] Esattamente un carattere tra 0 , 1 , . . . , 9
[!123] Esattamente un carattere che non sia 1 , 2 o 3
[!a-e] Esattamente un carattere che non sia a , b ,. . . , e
{fasta,pdb} Esattamente una tra le due stringhe fasta e pdb
Nota. Le wildcards sono simili a, ma non vanno confuse con, le espressioni regolari. Le prime si applicanosolo all’espansione di paths e filenames da parte della shell, mentre le seconde sono usate da grep .
Quando la shell incontra un comando del tipo:
cmd arg1 arg2 ...argN
dove uno o piu degli argomenti contiene delle wildcards, esegue (come gia anticipato) la wildcard ex-pansion, e cioe sostituisce all’argomento incriminato tutti i file che combaciano con la wildcard.
Esempio 12. La wildcard:le rose sono *se
combacera con le rose sono rosse ma anche le rose sono grosse e le rose sono costose :
la * “cattura” rispettivamente ros , gros , e costo . Lo stesso vale per le rose sono fahrenheit451se .
La wildcard:le rose sono [!0-9]
combacera con le rose sono rosse e le rose sono x ma non con le rose sono 7 .
Nella pratica, la shell opera in questo modo. Quando trova un comando con una wildcard, ad esempio:
cat data/dna-fasta/*.[12]

cerca nella directory indicata ( data/dna-fasta/ ) tutti i file che soddisfano la wildcard; in questo casofasta.1 e fasta.2 . Quindi la shell sostituisce all’argomento originale i percorsi dei file trovati.
Questo vuol dire che il comando precedente e del tutto equivalente a:
cat data/dna-fasta/fasta.1 data/dna-fasta/fasta.2
che stampa i contenuti dei due file, in sequenza.
Esempio 13. Se voglio stampare a schermo i contenuti della directory data , scrivo:
ls data
Se voglio stampare il contenuto delle directory che stanno in data , scrivo:
ls data/*
Qui la wildcard * viene espansa in
aatable deep0 deep1 deep2 deep3 deep4 dna-fasta empty1 empty2 prot-fasta prot-pdb simple1
perche tutti questi file combaciano con la wildcard * , per definizione. Se voglio invece stampare aschermo solo il contenuto delle directory deep1 , deep2 , etc., allora posso scrivere:
ls data/deep*
Restringendo ancora di piu il filtro, posso stampare i contenuti solo di deep1 e deep2 , ma non di
deep3 , deep4 :
ls data/deep[12]
Piu complesso: posso combinare le wildcards per ottenere effetti ancora piu imprevedibili, come stamparei contenuti di tutte le directory deep* tranne deep4 :
ls data/deep[!4]/*

Esercizi
1. Cosa fa il comando echo * ?
2. Cosa fa il comando echo ’*’ ?
3. Cosa fa il comando cat data/simple1/*.txt ?
4. Stampare il contenuto dei file .txt in data/simple1 .
5. Concatenare il contenuto dei file .txt in data/simple1 in un nuovo file temp .
6. Stampare il contenuto dei file .abc in data/simple1 . Sono file di testo?
7. Concatenare il contenuto dei file .abc in data/simple1 ed aggiungerlo in coda a temp .
8. Tra i nomi dei file in /usr/bin :
(a) Quali iniziano per una cifra?
(b) Quali iniziano o finiscono per x ?
(c) Quali iniziano e finiscono per x ?

9 Filtri
I filtri sono comandi che prendono righe di testo dallo stdin e le filtrano, contano, sostituiscono caratteri,etc., restituendo il risultato su stdout. Possono essere combinati con in pipeline.
Comando Opzioni Operazionewc -m , -w , -l Stampa il numero di caratteri/parole/lineesort -f , -g , -r Stampa le righe in ordine lessicografico
uniq -c , -d Stampa od omette le righe ripetute
cut -d , -f Ritaglia le colonne specificatetr -d , -s Traduce o cancella caratterigrep -i , -v Seleziona righe che soddisfano una regex
Esempio 14. Creo un file con due righe di testo:
echo uno > file; echo due >> file
Voglio controllare quante righe effettivamente sono state scritte nel file:
wc -l file
Esempio 15. Concateniamo i file in data/dna-fasta :
cat data/dna-fasta/* > fastas
Vogliamo stampare le righe di fastas in ordine alfanumerico:
sort fastas
Ed ora vogliamo stamparle in un file:
sort fastas > sorted-fastas
Avremmo potuto anche costruire il file sorted-fastas in un solo passaggio:
cat data/dna-fasta/* | sort > sorted-fastas
Esempio 16. Dati i due file data/numbers.1 e data/numbers.2 , che contengono liste di numeri,vogliamo innanzitutto controllare se ci sono doppioni. L’idea e di usare uniq a questo scopo.
C’e pero un problema: uniq trova solo righe sequenziali ripetute, cioe, se applicato al testo seguente:

aaaa
bbbb
bbbb
aaaa
riesce a capire che bbbb e ripetuto due volte, ma non aaaa .
Questo vuol dire che se vogliamo applicarlo ai file data/numbers.[12] dobbiamo prima ordinarli, e poiusare uniq .
sort data/numbers.1 > temp1
sort data/numbers.2 > temp2
Ora possiamo controllare se ci sono numeri ripetuti nei due file:
uniq -d temp1; uniq -d temp2
Non ci sono ripetizioni nei file presi singolarente.
Ci sono forse doppioni nei due file presi assieme? Veniamo tentati dal comando:
cat temp[12] | uniq -d
su cui pero uniq non funziona, perche non e detto che il concatenamento di due file ordinati producaun output ordinato. Quindi usiamo:
cat temp[12] | sort | uniq -d
Il numero 3 appare piu volte. Quante?
cat temp[12] | sort | uniq -c -d
Due volte.
Esempio 17. Il comando wc conta il numero di caratteri, parole, o righe all’interno di un file — o meglio,dello stdin. Posso usarlo per sapere quante righe ha il file data/numbers.1 :
wc data/numbers.1
oppure per contare quanti file ci sono in /home/ :
ls /home | wc -l

Guardando l’esempio precedente, noto che uniq -d stampa a schermo le righe ripetute. Se voglio anche
sapere quante sono le ripetizioni, un’alternativa a wc -d -c e usare wc :
cat data/numbers.[12] | uniq -d | wc -l
Nota. Spesso un problema di programmazione ammette piu di una soluzione corretta.
Esempio 18. Il comando tr serve per sostituire caratteri con altri. Se ad esempio, data una sequenzanucleotidica, voglio sostituire tutte le citosine con una X , allora posso scrivere:
echo ’TGTTCTTCTA’ | tr ’C’ ’X’
Un uso molto comune di tr e passare da maiuscolo a minuscolo o viceversa:
echo ’oh! minuscolo!’ | tr ’a-z’ ’A-Z’
Un’altro impiego comune e la sostituzione dei caratteri “a capo” ’\n’ con altri tipi di delimitatore.Confrontate ad esempio:
ls data/ e ls data/ | tr’\n’ ’,’
tr puo essere usato anche per rimuovere ripetizioni continue di caratteri con l’opzione s (da squeezerepeats, spremi le ripetizioni), ad esempio per rimuovere spazi multipli tra parole:
echo "voglio uno spazio solo!" | tr -s " "
Infine, tr pouo essere usato per rimuovere particolari caratteri, ripetuti o meno, con l’opzione d , adesempio per cancellare caratteri estranei:
echo "oxrax vix dxxxxic uxxxxn pxoexxxsixa" | tr -d "x"
Esempio 19. Il comando cut serve per estrarre alcune colonne da un file. Ha due opzioni fondamentali(senza specificarle e essenzialmente inutile):
• d specifica il delimitatore, cioe il carattere che separa le colonne.
• f (da “fields”, campi) specifica quali colonne estrarre.
Ad esempio, per un file che contenga il seguente testo (colonne separate da spazi):

nome cognome anno-di-nascita
Marco Rossi 1989
Luisa Bianchi 1981
Dante Alighieri 1265
Posso estrarre la colonna dei nomi usando il comando:
cut -d’ ’ -f1 file
e quella delle date con:cut -d’ ’ -f3 file
Notate come per istruire cut che il delimitatore e il carattere spazio, debba usare -d’ ’ , con le virgo-lette (destre).
Se volessi estrarre solo il campo dei nomi, saltando la prima riga potrei scrivere:
tail -n +2 file | cut -d’ ’ -f1
oppure, equivalentemente:cut -d’ ’ -f1 file | tail -n +2
o ancora:cat file | cut ... | tail ...
Se il file contenesse invece le righe:
nome,cognome,anno-di-nascita,impatto-sui-posteri
Dante,Alighieri,1265,10
Marcel,Proust,1871,8
Qualunque,Boh,2013,0
dove le colonne sono separate da virgole, per estrarre la colonna dei cognomi, potrei scrivere:
tail -n +2 file | cut -d’,’ -f2
Il comando cut permette di estrarre colonne multiple. Infatti, se volessi estrarre dal file di cui soprasolamente nome, cognome e data di nascita, ma non l’impatto sui posteri, potrei scrivere:
tail -n +2 file | cut -d’,’ -f1,2,3
oppuretail -n +2 file | cut -d’,’ -f1-3
Per estrarre nome, cognome e impatto:
tail -n +2 file | cut -d’,’ -f1,2,4

Simbolo Combacia con. un carattere qualunquea il carattere alfabetico a
abc la stringa abc
[abc] un qualunque carattere tra a , b e c
[a-z] un qualunque carattere nell’intervallo
[^abc] un qualunque carattere che non sia a , b ne c
^ l’inizio della riga
$ la fine della rigaregex* almeno zero ripetizioni di regex
regex+ almeno una ripetizione di regex
regex{n} esattamente n ripetizioni di regex
regex{n+} almeno n ripetizioni di regex
regex{n,m} almeno n , ma non piu di m , ripetizioni si regex
regex1|regex2 regex1 oppure regex2
Le regex (espressioni regolari, usate da grep ) sono combinazioni dei seguenti caratteri:Nota. La differenza tra regex e wildcards e che:
• Le wildcards sono usate dalla shell per effettuare la wildcard expansion, e cioe vengono sostituitecoi percorsi a tutti i file che combaciano.
• Le regex sono usate da grep per identificare quali righe tenere e quali scartare.
Esempio 20. Il comando grep serve per estrarre righe che combaciano con una data espressione regolare.Viene utilizzato frequentemente per filtrare le righe di un file o dello stdin alle quali siamo interessati. Lasintassi e:
grep regex file oppure cat file | grep regex
Ad esempio, supponiamo di avere un file 1A34.fasta , preso dalla Protein Data Bank, http://www.rcsb.org/pdb/explore/explore.do?structureId=1a34, che contiene la sequenza aminoacidica delletre catene della proteina 1A34:
>1A34:A|PDBID|CHAIN|SEQUENCE
MGRGKVKPNRKSTGDNSNVVTMIRAGSYPKVNPTPT
WVRAIPFEVSVQSGIAFKVPVGSLFSANFRTDSFTS
VTVMSVRAWTQLTPPVNEYSFVRLKPLFKTGDSTEE

FEGRASNINTRASVGYRIPTNLRQNTVAADNVCEVR
SNCRQVALVISCCFN
>1A34:B|PDBID|CHAIN|SEQUENCE
AAAAAAAAAA
>1A34:C|PDBID|CHAIN|SEQUENCE
UUUUUUUUUU
Ogni catena e identificata da un’intestazione (o header) che comincia col carattere > , seguita dalla se-quenza primaria.
Sono interessato ad estrarre dal file solo le intestazioni. Posso sfruttare il loro formato (cominciano per> ) ed usare grep :
grep ’>’ 1A34.fasta
Cosı stampero a schermo solo le righe che combaciano con l’espressione regolare, cioe le intestazioni:
>1A34:A|PDBID|CHAIN|SEQUENCE
>1A34:B|PDBID|CHAIN|SEQUENCE
>1A34:C|PDBID|CHAIN|SEQUENCE
Se al contrario voglio stampare tutto tranne le intestazioni, posso usare l’opzione v (da “invert”):
grep -v ’>’ 1A34.fasta
Esempio 21. Le seguenti regex, ad esempio, combaciano con:
• .* , con tutte le stringhe, anche la stringa vuota.
• .+ , con tutte le stringhe tranne la stringa vuota.
• abc , con tutte le stringhe che contengono abc .
• [abc] con tutte le stringhe che contengono almeno uno tra a , b e c .
• ^abc ,con tutte le stringhe che iniziano per abc .
• abc$ , con tutte le stringhe che finiscono per abc .
• ^abc$ , con la sola stringa abc .
• ^.*$ , con tutte le stringhe, anche vuote, che terminano con un a capo.

• [a-z] , con tutte le stringhe che contengono almeno un carattere minuscolo.
• ^[A-Z]$ , con tutte le stringhe che contengono esclusivamente caratteri maiuscoli.
• ^[01 ]{3+}$ , con tutte le stringhe di almeno 3 caratteri che contengono esclusivamente i caratteri
0 , 1 , o lo spazio.
• ant(onio|idiluviano) , con tutte le stringhe che contengono antonio oppure antidiluviano .
• ^[ ,](X{10}|Y{10})[ ,] , combacia tutte le stringhe che iniziano con: (1) uno spazio o una
virgola, seguito da (2) dieci X oppure dieci Y , seguiti da (3) uno spazio o una virgola.
Esempio 22. Per costruire una regex che interpreti alcuni caratteri speciali, come ad esempio . , in modoletterale, posso inserirli tra parentesi quadre. Se infatti l’esperessione:
grep ’.’ data/aatable
significa “filtra tutte le righe che contengono almeno un carattere”, l’espressione:
grep ’[.]’ data/aatable
significa “filtra tutte le righe che contengono il carattere . ”.
Esempio 23. Riprendiamo l’esempio precedente, ed assumiamo di avere un file 1A34.fasta . Per estrarrele intestazioni, possiamo usare, come suggerito sopra:
grep ’>’ 1A34.fasta
Se pero vogliamo essere piu cauti, ed evitare di stampare erroneamente anche righe che contengono ilcarattere > non all’inizio, possiamo usare:
grep ’^>’ 1A34.fasta
Supponiamo di essere invece interessati a scoprire se, tra le catene in formato fasta contenute in data/prot-fasta/ ,
alcune contengano la sequenza DP (acido aspartico seguito da prolina):
grep DP data/prot-fasta/*.fasta
La risposta e sı, grep stampa:

data/prot-fasta/3J00.fasta:FVIDADHEHIAIKEANNLGIPV...
data/prot-fasta/3J00.fasta:PRRRVIGQRKILPDPKFGSELL...
data/prot-fasta/3J00.fasta:SMQDPIADMLTRIRNGQAANKA...
data/prot-fasta/3J01.fasta:AKGIREKIKLVSSAGTGHFYTT...
data/prot-fasta/3J01.fasta:EYDPNRSANIALVLYKDGERRY...
data/prot-fasta/3J01.fasta:ARNLHKVDVRDATGIDPVSLIA...
Posso usare l’opzione --color per fare in modo che grep colori la parte della stringa che ha fatto match.
In generale pero il comando e rischioso: potrebbe fare il match con le intestazioni! Per stare sul sicuro,posso usare:
grep DP data/prot-fasta/*.fasta | grep -v ’^>’
Esempio 24. Proviamo a costruire una pipeline complessa.
Riferendoci all’esempio precedente, dato l’output di grep DP ... , voglio stampare il nome delle proteine
che contengono la sequenza DP . L’output di grep e il seguente:
data/prot-fasta/3J00.fasta:FVIDADHEHIAIKEANNLGIPV...
data/prot-fasta/3J00.fasta:PRRRVIGQRKILPDPKFGSELL...
data/prot-fasta/3J00.fasta:SMQDPIADMLTRIRNGQAANKA...
data/prot-fasta/3J01.fasta:AKGIREKIKLVSSAGTGHFYTT...
data/prot-fasta/3J01.fasta:EYDPNRSANIALVLYKDGERRY...
data/prot-fasta/3J01.fasta:ARNLHKVDVRDATGIDPVSLIA...
L’idea e quella di usare cut per tagliare la colonna dei nomi, quella che contiene 3J00 e 3J01 , senzail suffisso .fasta .
Il problema e che cut accetta un solo delimitatore, mentre nel nostro caso il nome delle proteine epreceduto da / e seguito da . , due caratteri diversi.
Possiamo ovviare a questo problema trasformando i due caratteri in uno solo, ad esempio il caratterespazio, con tr :
grep DP data/prot-fasta/*.fasta | tr ’/.’ ’ ’
ed ottenere:
data prot-fasta 3J00 fasta:FVIDADHEHIAIKEANNLGIPV...
data prot-fasta 3J00 fasta:PRRRVIGQRKILPDPKFGSELL...

data prot-fasta 3J00 fasta:SMQDPIADMLTRIRNGQAANKA...
data prot-fasta 3J01 fasta:AKGIREKIKLVSSAGTGHFYTT...
data prot-fasta 3J01 fasta:EYDPNRSANIALVLYKDGERRY...
data prot-fasta 3J01 fasta:ARNLHKVDVRDATGIDPVSLIA...
Ora posso usare cut per ritagliare la colonna giusta:
grep DP data/prot-fasta/*.fasta | tr ’/.’ ’ ’ | cut -d’ ’ -f3
ed ottenere:
3J00
3J00
3J00
3J01
3J01
3J01
A questo punto posso usare sort e uniq per completare il comando:
grep ... | tr ’/.’ ’ ’ | cut -d’ ’ -f3 | sort | uniq
ed ottenere:
3J00
3J01
Se voglio posso usare wc -l per contare le proteine.
Esempio 25. Un’alternativa ad usare tr e quella di invocare cut due volte, come segue:
grep DP ... | cut -d’/’ -f3 | cut -d’.’ -f1 | ...
Nota. I comandi presentati nel corso non sono i soli. A puro scopo informativo, ecco altri comandiutili:
• paste , il contrario di cut .
• rev , stampa una stringa dalla fine all’inizio.
• sed , permette di rimuovere/sostituire intere stringhe — simile a tr , che pero e limitato a rimuo-vere/sostituire singoli caratteri.
• awk , permette manipolazioni arbitrariamente complesse.
Non siete assolutamente tenuti a conoscerli ai fini di questo corso.

Esercizi
1. Compara wc A e cat A | wc
2. Compara wc -l A e cat A | tr ’\n’ ’ ’ | wc -w
3. Quanti file sono contenuti in /usr/bin ?
4. Visualizzare i file in /usr/bin ordinati per dimensione.
5. Visualizzare il file piu’ piccolo in /usr/bin
6. Stampare a schermo le righe in data/numbers.1 e data/numbers.2 .
7. Sono ordinate per grandezza? Se no, usare man per capire come fare.
8. Stampare a schermo le righe in data/numbers.1 e data/numbers.2 , ordinate in senso opposto.
9. Stampare a schermo le righe in data/numbers.1 e data/numbers.2 , ordinate in senso opposto.Fare la stessa cosa senza l’opzione -r di sort .
10. Ci sono file doppi in usr/bin ?
11. Scrivere in listn.txt la lista di tutti i file in data/deepn , per n = 1, . . . , 4.
12. Scrivere in datan.txt i contenuti di tutti i file in data/deepn , per n = 1, . . . , 3.
13. Quante repliche dispari di Krusty il Klown ci sono in data/deep1 ?
14. Cosa fa echo ACAB | cut -dC -f2 ? E echo BACA | cut -dA -f1,2 ?
15. Compara wc -m A e cat A | wc | tr -s ’ ’ | cut -d’ ’ -f4
16. Visualizzare i file in /usr/bin ordinati per owner. (Si veda -k nel manuale di sort ).
17. Come sopra, ma in ordine inverso.
(a) (E necessario tac ? E necessario sort ?)
18. Visualizzare solo la dim. del file piu’ piccolo in /usr/bin

19. Visualizzare solo il nome del file piu’ grande in /usr/bin
20. Ci sono file di dimensioni identiche in /usr/bin ? Quanti?
21. Ci sono directory di dimensioni identiche in /usr/share/doc ? Quante?
22. Che differenza c’e tra grep MatchMe e grep ^MatchMe ?
23. Cosa significano le seguenti espressioni regolari? (se valide)
(a) .
(b) .*
(c) [09]{2}
(d) [0-9]{2}
(e) *
(f) [
(g) [[]
(h) ^.3
(i) ^.{3}
(j) .{3}$
(k) ^>
(l) AA
(m) ^AA$
(n) aA
(o) [aA]
(p) word
(q) w..d
(r) ^$
(s) [}{]
(t) [0-9]+

24. Scrivere un’espressione regolare per:
(a) Tutti i caratteri alfanumerici, maiuscoli e minuscoli
(b) Le righe contenenti solo spazi
(c) Le righe che contengono punti esclamativi o punti interrogativi
(d) I giorni della settimana (nel modo piu compatto possibile)1
(e) Le parole di radice frazion- (frazione, frazionario, etc.)
(f) I multipli di 10, i multipli di 5, i numeri dispari
(g) I numeri razionali come frazione (e.g., p/q)
(h) I numeri razionali in notazione decimale (e.g., 1.34, .99, 17., 3)
(i) I numeri razionali in notazione scientifica (e.g., 1.34e10, 1.34e− 10)
(j) Le somme (e.g., a+ b+ c+ d) di lunghezza arbitraria, con a, b, c, . . . numeri interi
(k) Le somme di due moltiplicazioni (e.g., (a× b× c) + (d× e))
25. Quante identita corrette ci sono nei file in data/deep2 ?
(a) Esaminare data2.txt prima di cominciare.
26. Quanti mutipli di 5 ci sono in data/deep3 ? Quanti di 2 cifre?
1Senza lettere accentate. La shell non le digerisce.

Esercizi su file FASTA
I file fasta contengono la struttura primaria delle catene di ogni proteina. Ogni catena consta di unheader che comincia per > , e contiene il nome della proteina:catena, seguito dalla struttura primaria.
1. Quante catene ci sono in data/prot-fasta/1A3A.fasta ?
2. Stampare a schermo gli header delle catene.
3. Stampare la struttura primaria della seconda catena (con head , tail )
4. Stampare la struttura primaria di ogni catena in un file col nome della catena stessa. Il file devecontenere una sola riga.
5. Ci sono due A consecutive in qualche catena? Tre?
6. Quante triple- A ci sono? Non consecutive? Al piu tre?
7. Concatenare le catene in un solo file ALL.aa .
8. Contare quante volte appare in ALL.aa ogni tipo di aminoacido.
9. Quali aminoacidi appaiono piu’ di una volta?
10. Quanti aminoacidi in data/aatable cominciano per a ?
11. Quanti aminoacidi in aatable finiscono per ine ?
12. Quali aminoacidi in aatable hanno almeno due a nel nome? Tre?
13. Dati i file fasta in data/prot-fasta :
(a) Quante catene ci sono in totale?
(b) Quanti aminoacidi ci sono in totale?
(c) Quante proline ci sono in totale?
(d) Quante ripetizioni di ” AA , D ,( V oppure F )” ci sono?(Le lettere non devono essere necessariamente consecutive).
(e) Quali proteine non contengono uno di A , V o F ? Nessuno dei tre?
(f) Qual’e l’aminoacido piu abbondante?

Esercizi su file PDB
Nota. Questi esercizi sono difficili.
I file pdb sono organizzati per righe: all’inizio di ogni riga c’e una parola che descrive la funzione della
riga. Ad esempio ATOM indica che la riga descrive un atomo della proteina, SEQRES indica che descrive
la sequenza primaria, HELIX una α-elica.
Nota. Leggere il file pdb brevemente per farsi un’idea di come sia strutturato, prima di eseguire gliesercizi.
In data/prot-pdb/1A3A.pdb :
1. Quanti atomi ci sono?
2. Quante α-eliche ci sono?
3. Quali sono gli aminoacidi all’inizio delle α-eliche?
4. Nella proteina ci sono piu alanine o piu serine?
5. Quanti atomi fanno parte di alanine?
6. Estrarre la sequenza primaria e scriverla in un file
7. Estrarre le coordinate (x, y, z) degli atomi e scriverle in un file
8. Ordinare gli atomi per y crescente (vedi le opzioni g e k di sort )


















