
Elementi di Econometria - Benvenuto nella Facoltà di Economia … · 2014-10-02 · 1.3.1 Un altro...
69
Elementi di Econometria Riccardo (Jack) Lucchetti 2 ottobre 2014
Transcript of Elementi di Econometria - Benvenuto nella Facoltà di Economia … · 2014-10-02 · 1.3.1 Un altro...

Elementi di Econometria
Riccardo (Jack) Lucchetti
2 ottobre 2014

2

Premessa (per chi è già del mestiere)
Questo non è un vero libro di econometria. È un libro per bambini. Ma è ancheun esercizio di acrobazia.
Se ci fate caso, questa dispensa non contiene le parole “stimatore”, “test”,né alcun altro concetto di tipo probabilistico-inferenziale. Ciò di cui parlere-mo sono solo ed esclusivamente statistiche descrittive, che hanno la proprietàdi fornire una sintesi (ottimale da un certo punto di vista) dei dati. Il proble-ma, tipicamente inferenziale, di usare i dati per parlare del mondo qui non cisfiora. Qui affronteremo soltanto il problema di usare i dati per parlare dei dati,evitando accuratamente le perigliose acque del Mare dell’Induzione.
La scelta ha vari motivi, ma è soprattutto una scelta didattica. Gli studenti acui è rivolta questa dispensa sono persone che spesso dichiarano di non essere aloro agio con gli strumenti dell’inferenza statistica: hanno imparato le proprietàdegli stimatori a memoria, non sono sicuri di saper leggere un test, non hannoben chiaro cosa sia la distribuzione di una statistica (figurarsi quella asintotica),fanno confusione fra lo stimatore di una varianza e la varianza di uno stimatore.E questo, quando va bene. E allora, lasciamo stare; non importa. C’è tanto chesi può dire sull’attrezzo base dell’econometria (l’OLS) anche senza tutto questo,e che fa bene sapere. Una volta che lo studente abbia imparato a maneggiarecon sicurezza l’OLS come puro strumento computazionale, si potrà affrontare ilproblema del suo uso e della sua interpretazione come stimatore e dell’uso dellestatistiche test da esso derivate.
Il neofita tende a far confusione fra proprietà dei minimi quadrati che sonovere per costruzione e proprietà che discendono da qualche assunzione pro-babilistica. Queste ultime, in questa dispensa, non ci sono. In un certo senso,è come una dispensa di geometria assoluta. Forse si sarebbe potuto chiamareEconometria assoluta, ma suppongo che sarebbe sembrata la mia ennesima di-mostrazione di sciocca presunzione. Mi sono baloccato per un po’ con l’idea diintitolarla Econometria improbabile, ma pensandoci bene anche quello sarebbestato vacuo ed esibizionista.
Tenterò, in questo breve testo, di spiegare come si legge una regressione sen-za cadere nell’automatismo dello statistico di professione, che è istintivamenteportato a vedere gli OLS come uno stimatore di parametri incogniti di una distri-buzione condizionata. Certo, l’OLS si può usare come stimatore, ma ha una suaragion d’essere ed una sua dignità anche come semplice, umile, modesta stati-stica descrittiva. Anzi, chi legge gli OLS come stimatori (cioè noi tutti) è spessoportato a dimenticarsi che quello che stiamo stimando non è mai il modello“giusto”, qualsiasi cosa questo voglia dire.
Un automatismo simile ce l’ha l’economista di professione, che è tentato divedere nei risultati di una regressione la quantificazione dei parametri di un suomodello teorico. Da qui, il gioco delle parti che si fa regolarmente fra economistiin cui ci si accapiglia per finta sull’esogeneità dei regressori. Di nuovo: gli OLSpossono essere usati per stimare parametri comportamentali, sotto certe parti-
3

colari condizioni. Ma non è che debbano essere buttati via, se queste condizioninon ricorrono.
Credo che sia molto salutare saper leggere una regressione usando un setminimale di assunzioni, probabilistiche o di teoria economica. Lo studente vo-lonteroso queste le può studiare in seguito; l’economista applicato forse si ri-sparmierebbe qualcuna delle ingenuità che a volte gli escono dalla bocca (magli si vuol bene per questo, in fondo).
Non vorrei che la scelta di non parlare di probabilità venisse fraintesa: è unascelta didattica sperimentale, che magari tra qualche anno abbandonerò, maprima voglio vedere cosa succede. Di sicuro la scelta non deriva da un atteg-giamento snobistico tipo quello di certi statistici francesi che fanno i brillantiparlando male dell’inferenza. Anzi, uno degli scopi di questa dispensa è proprioquello di far venire al lettore la voglia di studiare statistica inferenziale.
Un’altra cosa su cui vorrei evitare equivoci: non mi astengo dal parlare diprobabilità perché penso che il lettore sia troppo scemo per capirla. E infatti,nonostante che questa dispensa sia nata col nome “il libro per bambini”, nonfarò alcuno sforzo per semplificare i problemi se non nei casi in cui spiegazionirigorose implicherebbero digressioni impraticabili. Mi impegno formalmente anon trattare il lettore in modo paternalistico. Certo, banalizzerò, semplificherò,a volte anche in modo irritante per chi le cose le sa già. Ma se uno non fa così,non deve fare didattica. Si accontenti di fare ricerca e basta.
Peraltro, i prerequisiti per leggere fruttuosamente questa dispensa sono po-chi: un minimo di analisi reale, i concetti di vettore e matrice con associate ope-razioni elementari (somma, prodotto, trasposizione, inversione) e una qualchefamiliarità con la statistica descrittiva: media, varianza, frequenza eccetera.
Un’ultima cosa: questa dispensa è rilasciata sotto la licenza Creative Com-mons BY-SA 3.0. Questo significa che tu, lettore, sei libero
• di riprodurre, distribuire, comunicare al pubblico, esporre in pubblico,rappresentare, eseguire e recitare quest’opera;
• di modificare quest’opera;
• di usare quest’opera per fini commerciali;
alle seguenti condizioni:
Attribuzione Devi attribuire la paternità dell’opera nei modi indicati dall’auto-re o da chi ti ha dato l’opera in licenza e in modo tale da non suggerire cheessi avallino te o il modo in cui tu usi l’opera.
Condividi allo stesso modo Se alteri o trasformi quest’opera, o se la usi per crear-ne un’altra, puoi distribuire l’opera risultante solo con una licenza identi-ca o equivalente a questa.
La licenza vera e propria è in fondo al testo.
4

Indice
Premessa (per chi è già del mestiere) . . . . . . . . . . . . . . . . . . . . . . 3
1 La teoria 71.1 La media aritmetica . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.2 Gli OLS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2.1 La regressione su una dummy . . . . . . . . . . . . . . . . . . 101.2.2 Il caso generale . . . . . . . . . . . . . . . . . . . . . . . . . . . 141.2.3 Il problema geometrico . . . . . . . . . . . . . . . . . . . . . . 171.2.4 Le matrici di proiezione . . . . . . . . . . . . . . . . . . . . . . 211.2.5 Misure di bontà del modello . . . . . . . . . . . . . . . . . . . 24
1.3 La scelta dei regressori . . . . . . . . . . . . . . . . . . . . . . . . . . . 251.3.1 Un altro paio di cose sulle matrici di proiezione . . . . . . . . 261.3.2 Un risultato sconfortante (in apparenza) . . . . . . . . . . . . 271.3.3 Modelli e vincoli . . . . . . . . . . . . . . . . . . . . . . . . . . 281.3.4 I minimi quadrati vincolati . . . . . . . . . . . . . . . . . . . . 31
1.4 Misure di perdita di fit . . . . . . . . . . . . . . . . . . . . . . . . . . . 341.4.1 Un interessante caso particolare . . . . . . . . . . . . . . . . . 36
1.5 Come si legge l’output . . . . . . . . . . . . . . . . . . . . . . . . . . . 371.5.1 La lettura dei coefficienti . . . . . . . . . . . . . . . . . . . . . 391.5.2 Il resto dell’output . . . . . . . . . . . . . . . . . . . . . . . . . 411.5.3 Il teorema di Frisch-Waugh . . . . . . . . . . . . . . . . . . . . 421.5.4 L’effetto leva . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
1.6 La regressione dinamica . . . . . . . . . . . . . . . . . . . . . . . . . . 481.6.1 L’operatore ritardo . . . . . . . . . . . . . . . . . . . . . . . . . 501.6.2 Equazioni alle differenze . . . . . . . . . . . . . . . . . . . . . 541.6.3 La rappresentazione ECM . . . . . . . . . . . . . . . . . . . . . 57
1.7 E adesso? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
A La Licenza 64
5

6

Capitolo 1
La teoria
1.1 La media aritmetica
Cos’è una statistica descrittiva? È una funzione dei dati che fornisce una sintesisu un particolare aspetto dei dati che a noi interessa; naturalmente, è auspica-bile che questa sintesi sia quanto più informativa possibile. L’idea che motival’uso delle statistiche descrittive è grosso modo questa: vogliamo studiare un fe-nomeno ed abbiamo dei dati; questi dati, però, sono “tanti”, e non abbiamo tem-po/voglia/modo di guardarli tutti. Cerchiamo allora una funzione di questi datiche, una volta calcolata, ci dica quel che vogliamo sapere, senza appesantircicon dettagli non necessari.
L’esempio più ovvio di statistica descrittiva è la media aritmetica, che ognistudente sa calcolare, se non altro per l’attenzione maniacale che riserva al pro-prio libretto. Dato un vettore colonna y di dimensione n, la media aritmeticanon è che
Y = 1
n
n∑i=1
yi = 1
nι′y (1.1)
La notazione con la sommatoria sarà probabilmente più familiare alla maggiorparte dei lettori; io, però, preferisco la seconda per la sua maggiore concisionee perché, come vedremo, si presta meglio ad essere generalizzata. Per conven-zione, indichiamo con ι un vettore colonna i cui elementi sono tutti pari a 1. Unvettore così fatto si chiama anche vettore somma, perché il suo prodotto internocon un altro vettore x resituisce la somma degli elementi di x.
Vediamo come possiamo motivare l’uso della media aritmetica. Come ho giàdetto, noi vorremmo poter usare una statistica descrittiva, che provvisoriamentechiamerò m, come sintesi dell’informazione contenuta nell’intero campione.
Un’idea interessante l’ha data nel 1929 Oscar Chisini, che ha proposto que-sta definizione: data una funzione di interesse g (·), la media del vettore y è quelnumero m che rappresenta l’unica soluzione di g (y) = g (m · ι). L’idea è potente:per esempio, la media aritmetica emerge come caso particolare se la funzioneg (·) è la somma e altri casi notevoli ve li trovate da soli.
7

OSCAR CHISINI
L’idea di Chisini può essere ulteriormente raffinata: seci mettiamo nell’ottica di usare m — che, a questo stadiodel ragionamento, non è necessariamente la media aritme-tica — come descrizione imperfetta ma parsimoniosa delcampione completo, è naturale chiedersi quanta e qualesia l’informazione che perdiamo. Vediamo: se di un cam-pione conoscessimo solo m, cosa potremmo dire su ognisingolo elemento del campione? In assenza di altre infor-mazioni, la cosa più sensata che possiamo dire è che, perun i generico, yi sarà “più o meno” uguale a m. Se del-lo studente Pinco Pallino sappiamo solo che ha la mediadel 23, alla domanda “Quanto ha preso P.P. in Storia Eco-nomica?”, risponderemmo “Boh? Avrà preso ventitré”. Se poi venisse fuori cheP.P. ha effettivamente preso 23, tutto bene. Se invece ha preso 30, l’abbiamosottovalutato, e possiamo misurare la discrepanza in 7 punti.
Nella situazione ideale, in cui l’uso di m come sintesi dei dati non provo-ca perdita di informazione, la discrepanza è 0 per ogni elemento del campio-ne (Pinco Pallino ha un libretto di tutti 23). Nella situazione non ideale, si puòpensare di misurare la bontà di m tramite la dimensione degli errori, che in ger-go si chiamano residui. Il vettore dei residui, naturalmente, è definito comee = y− ι ·m. Definiamo pertanto una funzione, che chiamiamo funzione di per-dita, che dipende dai residui e misura il costo che noi sosteniamo in seguito allaperdita di informazione.
C (m) = P [e(m)]
In linea di principio, non ci sono molte cose che si possono dare per scontatesulla forma di questa funzione. Una cosa che si può dire è che P (0) = 0: se iresidui sono tutti zero, non ci sono errori di approssimazione e il costo che sisostiene è zero. Un’altra idea ragionevole è che P (e) ≥ 0: non si può guadagnareda un errore.1 Per il resto, c’è poco che si può dire in generale: non è detto chela funzione C (·) abbia particolari caratteristiche di concavità, né di simmetria.Dipende dal problema.
Come che sia fatta questa funzione, comunque, sarà bene scegliere m in mo-do da rendere C (m) più piccolo possibile. Detto più in matematichese: per undato problema, specifichiamo la funzione di perdita e utilizziamo, come indi-catore di sintesi, quella statistica che ha la proprietà di renderla minima. Informule:
m = Argminm∈R
C (m) = Argminm∈R
P (y− ι ·m)
In pratica, trovando il minimo della funzione C (·) per un dato problema, abbia-mo la garanzia di aver usato al meglio i nostri dati. Bene. E adesso? Eh, adesso
1Attenzione, però. Non è detto che valga il converso. Il costo può essere 0 anche presenza diun errore non-zero: in certi contesti, possiamo considerare errori “piccoli” come irrilevanti.
8

comincia il bello, perché la prima cosa che viene in mente ad una persona ra-gionevole è “Ma come faccio a specificare la funzione C (·)? Cioè, chi me lo dicecome è fatta? Che faccio, vado su Google e digito ‘funzione di perdita’? Mi con-siglio col guru, col prete, con lo psicanalista?”. Infatti, a parte casi straordinari incui la funzione di perdita viene suggerita naturalmente dal problema stesso, for-malizzare la forma della funzione può essere un affare complicato. Com’è fattala funzione di perdita per il libretto di Pinco Pallino?
Per di più, spesso abbiamo la necessità di calcolare un indicatore di sintesisenza sapere in anticipo a cosa ci servirà. È ovvio che in questi casi trovare mnon è difficile, bensì impossibile. Dobbiamo accontentarci di una cosa che nonsia troppo sbagliata. Una possibilità allettante è quella di definire
C (m) =n∑
i=1(yi −m)2 = e′e (1.2)
Questo criterio è una funzione di m basato sulla somma dei quadrati dei residui:oltre ad essere semplice da manipolare, è una funzione simmetrica e convessa,così da valutare equanimemente residui in difetto e in eccesso e da penalizzaredi più errori più grandi in valore assoluto. Oltretutto, una funzione così, rispettoalle possibili alternative simmetriche e globalmente convesse, offre il non tra-scurabile vantaggio (come vedremo fra breve) di far sì che la soluzione del pro-blema sia molto facile da calcolare. Non è irragionevole pensare che, in molticasi pratici, una funzione di perdita così sia un compromesso accettabile.
Parliamo, in questo caso, di criterio dei minimi quadrati. Per trovare il mi-nimo della (1.2) rispetto a m non facciamo altro che derivare C rispetto a m;
C ′(m) = dC
dm=
n∑i=1
d(yi −m
)2
dm=−2
n∑t=1
(yi −m
)Nel punto di minimo la derivata dev’essere 0, così che
n∑i=1
(yi −m
)= 0
che a sua volta implica
nm =n∑
t=1yi
e quindi m = Y . In notazione matriciale si faceva ancora prima:
C (m) = (y− ιm)′(y− ιm)
la derivata èC ′(m) =−2ι′(y− ιm) = 0
da cuim = (ι′ι)−1ι′y = Y
9

Il lettore è invitato a controllare che ι′ι= n. Il valore della funzione C nel puntodi minimo, ovvero e′e = ∑n
i=1(yi − Y )2 è una quantità che in questo caso par-ticolare si chiama devianza, ma che conviene abituarsi (per motivi che saran-no chiari più avanti) ad indicare con la sigla SSR, dall’inglese Sum of SquaredResiduals.
L’argomento che porta a scegliere la media aritmetica come indicatore disintesi che ho appena sviluppato è, in realtà, molto più generale di quanto nonappaia a prima vista: infatti, quasi tutte le statistiche descrittive che usiamo so-no casi particolari della media aritmetica, che può essere usata per descriveremolte caratteristiche di y: basta prenderne trasformazioni appropriate.
In pratica: la media aritmetica di z, dove zi = f (yi ) e la funzione f (·) è sceltacon intelligenza, ci racconta un sacco di cose. L’esempio più banale è la varian-za: essa, infatti non è altro che la media aritmetica di una variabile zi = (yi −Y )2,che ovviamente misura quanto yi è diverso da Y ; come si sa, la varianza è unindicatore di dispersione.
Più interessante il caso in cui esprimiamo una frequenza relativa come me-dia aritmetica: definiamo l’evento yi ∈ A, dove A è un qualche sottoinsieme deivalori possibili per yi ; definiamo ora la variabile zi = I(yi ∈ A), dove I(·) è la co-siddetta “funzione indicatrice”, che vale 1 quando il suo argomento è vero e 0quando è falso. Evidentemente, Z è la frequenza relativa dell’evento A. Altriesempi inventateli voi.
1.2 Gli OLS
1.2.1 La regressione su una dummy
Se ci limitiamo a descrivere il mondo per mezzo di una sola variabile, facciamopoca strada. Ovviamente, questo apre il problema di avere un sistema per diredelle cose sensate sulle relazioni fra variabili.
Un possibile approccio è: chiediamoci se yi è “grande” o “piccolo” quandoxi è “grande” o “piccolo”. Definiamo
zi = (yi − Y )(xi − X )
che in pratica è una specie di indicatore della concordanza fra i segni. Vale a dire,zi > 0 quando yi > Y e xi > X oppure quando yi < Y e xi < X . Come è noto, Zsi chiama covarianza, e la covarianza può essere normalizzata per la media geo-metrica delle varianze ottenendo così il cosiddetto coefficiente di correlazione;ma questa è roba da statistica elementare è non è il caso di rivangarla qui.
Il problema con la covarianza/correlazione è che è un concetto simmetrico.Vale a dire, le variabili yi e xi sono trattate allo stesso modo: la covarianza frayi e xi è, per costruzione, la stessa che c’è fra xi e yi . Invece, spesso a noi piacedi più ragionare in termini di yi = m(xi ) perché abbiamo in mente una lettura
10

del mondo in cui yi “dipende” da xi , e non il contrario.2 È per questo che la yi
viene detta variabile dipendente e la xi variabile esplicativa. In questo con-testo, un’idea che sorge piuttosto naturale è quella di esaminare cosa succedesuddividendo il vettore y in diversi sottovettori, ad ognuno dei quali corrispon-de un diverso valore di xi . In un contesto probabilistico, questo si chiamerebbecondizionamento.
Un esempio semplice: supponiamo che il nostro vettore y includa n osser-vazioni, di cui nu riguardano maschi e nd = n −nu riguardano le femmine. Di-ciamo che questa informazione è inclusa in una variabile xi , che vale 1 se l’indi-viduo è maschio e 0 se è femmina. Come si sa, una variabile 0/1 si dice binaria,dicotomica, o più comunemente variabile dummy.
Il buonsenso ci dice che, se diamo per nota la distribuzione per genere, lamedia aritmetica per genere ci fornirà una descrizione dei dati che sarà lieve-mente meno sintetica della semplice media aritmetica (perché usa due numerianziché uno), ma sicuramente non meno accurata. Evidentemente, possiamodefinire
Yu =∑
xi=1 yi
nu= Su
nuYd =
∑xi=0 yi
nd= Sd
nd
dove, cioè, Su è la somma delle yi per i maschi e Sd è la somma delle yi per lefemmine.
Il ragionamento, però, diventa più eccitante se formalizziamo il problema inmodo analogo a quanto abbiamo fatto prima con la media aritmetica. In altreparole, vediamo se possiamo usare al meglio l’informazione (che supponiamodi avere) se l’individuo i -esimo è maschio o femmina. Quindi, anziché adope-rare un numero per sintetizzare i dati, vogliamo usare una funzione, ossia unacosa del tipo
m(xi ) = mu · xi +md · (1−xi )
che ovviamente vale mu per gli uomini (perché xi = 1) e md per le donne (per-ché xi = 0). La nostra sintesi deve essere una regola che ci dia un valore ‘emble-matico’ di yi in funzione di xi . In un contesto probabilistico, un oggetto similesi chiama funzione di regressione; qui non siamo in un contesto probabilisti-co, ma usiamo il termine lo stesso. Parallelamente, la variabile esplicativa vieneanche detta regressore.
A questo punto, riprendiamo la definizione del residuo come errore di ap-prossimazione: chiaramente, in questo caso, si ha che ei ≡ yi −m(xi ), da cui siricava
yi = mu xi +md (1−xi )+ei (1.3)
2Qui sono deliberatamente vago: dire che A dipende da B può voler dire, nel linguaggio corren-te, molte cose, non tutte coerenti fra loro. Per esempio, non è detto che la “dipendenza” implichiun rapporto di causa-effetto. Il problema è molto meno banale di quel che non appaia a pri-ma vista, e lo lasciamo agli epistemologi professionisti; noi, qui, stiamo sul sicuro tenendoci sulgenerico.
11

L’equazione (1.3) è importante perché è un semplice esempio di ciò che ineconometria chiamiamo un modello. Il numero yi viene scisso in due compo-nenti additive, di cui la prima è la cosiddetta parte sistematica, che dipende dallavariabile xi (per essere precisi, è una funzione lineare di xi ), e l’altra è un di piùche contiene la parte non riconducibile ad una specifica regolarità. In questadispensa, useremo la seguente notazione
yi ' m(xi ),
per indicare che il nostro modello consiste di una funzione che deve approssi-mare meglio che si può il valore della variabile y per tutte le i . Nell’econome-tria “vera” ei = yi −m(xi ) è un oggetto su cui vengono fatte varie ipotesi di ti-po probabilistico che qui però, come promesso, ignoriamo. In questo esempio,m(xi ) = mu xi +md (1−xi ).
Farà comodo riscrivere la (1.3) come
yi = md + (mu −md )xi +ei =[
1 xi][
md
mu −md
]+ei
perché ciò ci permetterà di usare la notazione matriciale, che è decisamente piùcompatta ed elegante
y = Xβ+e, (1.4)
dove
β=[
md
mu −md
]=
[β1
β2
]e X è una matrice di n righe e 2 colonne, in cui la i -esima riga è [1,1] se ilcorrispondente individuo è di sesso maschile e [1,0] altrimenti.
In questo modo, il problema di scegliere in modo ottimale mu e md è ricon-dotto al problema di trovare quel vettore β che minimizza la funzione di perditae′e. La soluzione non è difficile: troviamo quel (o quei) β per cui valga
de′edβ
= d
dβ(y−Xβ)′(y−Xβ) = d
dβ(y′y−2β′X′y+β′X′Xβ) = 0
Usando le note regole di derivazione matriciale,3 si ha che
X′y = X′Xβ (1.5)
Se la matrice X′X è invertibile, la soluzione esiste unica, ed è
Argminβ∈R2
e′e = β= (X′X)−1X′y
3Non sono note? Uffa:da′xdx
= a′ dx′Ax
dx= x′(A+ A′)
12

Il cappello ( ˆ ) sullaβ sta ad indicare che fra tutti i possibili valori diβ, noi stiamoprendendo proprio quello che rende vera la (1.5) e che quindi rende minima lafunzione di perdita. I coefficienti β ottenuti dalla (1.10) hanno il nome di coeffi-cienti OLS, dall’inglese Ordinary Least Squares, ossia minimi quadrati ordinari.4
Il vettorey = Xβ
è la nostra rappresentazione approssimata di y. Convenzionalmente, ci si rife-risce a y come al vettore dei valori fittati, con brutto prestito dall’inglese fitted.Gli orrori linguistici non finiscono qui, peraltro: sovente, scappa anche a me diparlare della capacità del modello di fittare i dati, e di dire che la SSR è una mi-sura del fit del modello. Pertanto, se vi capita di trovare uno che dice “questomodello fitta bene” compiangetelo, perché come dice Nanni Moretti “chi parlamale pensa male e vive male”, ma sappiate che non si è inventato nulla.5
Nell’esempio in questione, bastano un po’ di semplici conti per vedere che
X′X =[
n nu
nu nu
]X′y =
[ ∑ni=1 yi∑
xi=1 yi
]=
[Su +Sd
Su
]dove (ricordo al lettore) Su =∑
xi=1 yi e Sd =∑xi=0 yi cioè le somme delle yi per
maschi e femmine rispettivamente.Usando la regola standard per l’inversione di matrici (2×2), che suppongo
anch’essa nota,6
(X′X)−1 = 1
nund
[nu −nu
−nu n
]da cui
β= 1
nund
[nu −nu
−nu n
][Su +Sd
Su
]= 1
nund
[nuSd
nd Su −nuSd
]e infine
β=[
Sd /nd
Su/nu −Sd /nd
]=
[Yd
Yu − Yd
]per cui mu non è che la media aritmetica dei maschi e md quella delle femmine.Ancora una volta, se usiamo una funzione di perdita quadratica (e′e), gli indica-tori di sintesi che risultano ottimali sono quelli che ci suggerisce il buon senso.La cosa nuova, però, è che in questo caso, per descrivere il vettore y utilizziamouna funzione, che ha come argomento il vettore x, i cui parametri sono i nostriindicatori di sintesi.
4Per inverosimile che possa sembrare, il senso dell’aggettivo “ordinario”, in questo contesto, èsemplicemente l’opposto di “straordinario”. Cioè, minimi quadrati, ma niente di straordinario.
5Per carità, eh, al peggio non c’è mai fine: l’Italia è piena di gente che crede di far bella figuradicendo pèrformans, oppure manàgment o menéigment. Potrei andare avanti, ma mi fermo.
6Non è nota? Ariuffa:
(a bc d
)−1
= (ad −bc)−1(
d −b−c a
).
13

1.2.2 Il caso generale
Nel problema analizzato alla sezione precedente, il lettore attento avrà notatoche, di fatto, l’assunzione che x sia una variabile dummy gioca un ruolo mar-ginalissimo. Non ci sono motivi per i quali l’equazione m(xi ) = β1 +β2xi nondebba valere anche quando xi contiene dati numerici di qualsiasi altro tipo. Sipuò controllare che la soluzione del problema rimane assolutamente invariata;ovvio: il vettore β non conterrà più le medie per sottocampione, ma il fatto cheβ= (X′X)−1X′y minimizzi la funzione di perdita continua ad essere vero.
Esempio 1 Supponiamo che
y =2
34
X =1 1
1 21 0
Il lettore è invitato a controllare che
X′X =[
3 33 5
]⇒ (X′X)−1 =
[5/6 −1/2−1/2 1/2
]X′y =
[98
]
e quindi
β=[
3.5−0.5
]y =
32.53.5
e =−1
0.50.5
0
1
2
3
4
5
6
7
-1 -0.5 0 0.5 1 1.5 2 2.5 3
y
x
m(x) = 1.93 + 1.40 x
Figura 1.1: OLS su sei dati
Nei libri di econometria più attaccati alla tradizione, a questo punto c’è sem-pre un grafico simile a quello mostrato in Figura 1.1, che però a me non sta
14

simpaticissimo, e fra poco spiegherò perché. Comunque, ve lo faccio vedereanch’io: in questo esempio, usiamo
y′ = [4 1 5 1 3 6
]x′ = [
1 0 2 −1 1 3]
Come si può controllare,7 la funzione m(xi ) che minimizza la SSR è m(xi ) =1.93+1.4xi ed il valore di e′e è pari a 26/15. Nel grafico in figura, ogni pallinocorrisponde ad una coppia di valori; la linea tratteggiata è il grafico della fun-zione m(x) e i residui sono le differenze verticali fra ognuno dei pallini e la lineatratteggiata; il criterio dei minimi quadrati consiste nel fatto che la linea trat-teggiata rende minima la somma dei quadrati delle lunghezze di tali segmenti,ossia passa più che può in mezzo ai pallini.
Ciò premesso, si vede bene che il ragionamento fatto fin qui si può gene-ralizzare in varie direzioni: ad esempio, non si vede perché la funzione m(xi )debba per forza essere lineare. E infatti, una tecnica più generale esiste, è bennota e si chiama NLS (Non-linear Least Squares). Non è molto utilizzata, però,per due motivi. In primo luogo, la minimizzazione di una funzione criterio deltipo C (β) = ∑n
i=1
[yi −m(xi ,β)
]2, dove m(·) è una qualche funzione più o me-no fantasiosa può essere un problema spinoso: può avere soluzioni multiple, onon averne nessuna, o magari averne una, ma che non si può scrivere in for-ma chiusa. In secondo luogo, per poter utilizzare la tecnica OLS è sufficienteche il modello sia lineare nei parametri, ma non serve che lo sia nelle variabili.Per essere più chiari, un modello del tipo m(xi ) = β1 +β2 log(xi ) comporta unatrasformazione nonlineare di xi , ma la funzione in sé resta una combinazionelineare di roba osservabile: basta definire zi = log(xi ) e il gioco è fatto.
Un’altra generalizzazione, decisamente più interessante, riguarda il caso incui abbiamo più di una variabile esplicativa. In questo caso, la cosa naturaleda fare è pensare la nostra funzione di regressione come una funzione linearedel vettore di variabili esplicative xi , e cioè m(xi ) = x′iβ. Ad esempio noi sap-piamo, per ogni esame che Pinco Pallino ha dato, non solo quanto ha preso, maanche in quanti giorni l’ha preparato e la percentuale delle lezioni che ha fre-quentato; questi dati per l’i -esimo esame stanno in un vettore x′i , ciò che ricon-duce all’equazione (1.4). Oltretutto, il vantaggio che c’è ad usare una funzionelineare è che i coefficienti β possono essere interpretati come derivate parziali.Nell’esempio precedente, il coefficiente associato al numero di giorni che PincoPallino ha impiegato a preparare l’esame può essere definito come
∂m(x)
∂x j=β j (1.6)
e quindi può essere letto come la derivata della funzione m(·) rispetto al nu-mero di giorni. Ovviamente, su queste grandezze si può ragionare sia tenendo
7Prima di esclamare trionfalmente “Non porta!” ricordatevi di accostare ι a x.
15

presente il loro segno (la funzione “voto” è crescente o decrescente rispetto aigiorni impiegati per la preparazione?) che il loro valore assoluto (che differenzac’è nella funzione m(·) fra due esami che hanno le stessa caratteristiche, a parteil fatto che uno è stato preparato in 10 giorni e un altro in 11?). Evidentemen-te, è forte la tentazione di leggere i coefficienti in forma controfattuale (quantoavrebbe preso Pinco Pallino se avesse studiato un giorno di più?), ma per po-ter far questo in modo epistemologicamente corretto avremmo bisogno di tuttauna serie di assunzioni extra che non sono disposto a fare qui.8
L’algebra per risolvere questo problema è esattamente la stessa del caso cheabbiamo analizzato fino ad ora, e la riespongo qui in forma abbreviata per pu-ra comodità del lettore. Se il residuo in base al quale vogliamo minimizzarela funzione di perdita è ei (β) = yi − x′iβ, allora il vettore dei residui può esserescritto
e(β) = y−Xβ (1.7)
cosicché la funzione criterio da minimizzare sarà C (β) = e(β)′e(β). Poiché laderivata di e(β) non è che−X, la condizione di primo ordine sarà semplicemente
X′e(β) = 0 (1.8)
Mettendo assieme la (1.7) con la (1.8) si ottiene un sistema di equazioni notecome equazioni normali:
X′Xβ= X′y (1.9)
dalle quali si ricava l’espressione per β
β= (X′X
)−1 X′y (1.10)
sempreché la matrice X′X sia invertibile. Si noti, di nuovo, che la media aritme-tica può essere ottenuta come caso particolare ponendo X = ι. Aggiungo ancheche le formule precedenti consentono di calcolare tutte le quantità rilevanti nelproblema senza necessariamente conoscere le matrici X e y: in effetti, basta co-noscere y′y, X′y e (X′X)−1. Date queste quantità, infatti, non solo è immediatotrovare β, ma anche e′e:
e′e = (y−Xβ)′(y−Xβ) = y′y−y′Xβ− β′X′y+ β′(X′X)β
e usando la (1.9) si ha
e′e = y′y− (y′X)β.
Se chiamiamo k il numero di colonne di X, si vede immediatamente che la for-mula qui sopra esprime la SSR come differenza fra uno scalare e il prodotto in-terno di due vettori di k elementi. Il numero di righe di y, cioè n, non entra mai
8Chi è del mestiere sa benissimo di cosa parlo. Chi non sa di cosa parlo, e vorrebbe saperlo, sirassegni a studiare econometria per davvero.
16

in gioco, e potrebbe anche essere immenso senza che il calcolo ne risulti perquesto più difficile.
La mia assenza di entusiasmo per il grafico mostrato in Figura 1.1 dovrebbeavere, a questo punto, una motivazione chiara: nel caso in cui X abbia un nu-mero di colonne superiore a 2, non è ben chiaro come disegnare un grafico delgenere. Anzi, quando le colonne sono più di 3 la strada risulta evidentementeimpercorribile. In più, l’intuizione geometrica che veicola rischia di sovrappor-si ed oscurare un’interpretazione geometrica alternativa del problema che è altempo stesso molto più interessante e molto più utile. Ne parlo al prossimoparagrafo.
1.2.3 Il problema geometrico
Qui conviene partire ricordando in breve un paio di concetti di cui il lettore hagià probabilmente sentito parlare, ma da cui, altrettanto probabilmente, ha giàprovveduto a disinfestare il cervello (spero, senza troppo successo). Il primo èil concetto di distanza (a volte detta anche metrica). Dati due oggetti a e b, ladistanza fra loro è una funzione che deve possedere queste quattro proprietà:
1. d(a,b) = d(b, a)
2. d(a,b) ≥ 0
3. d(a,b) = 0 ⇔ a = b
4. d(a,b)+d(b,c) ≥ d(a,c)
L’unica che val la pena di commentare è la quarta, che si chiama diseguaglianzatriangolare, che dice semplicemente che ad andare dritti si fa prima.9 Gli oggettiin questione possono essere i più svariati, ma noi considereremo solo il caso incui essi sono vettori. La distanza di un vettore dallo zero si chiama norma, e siscrive ||x|| = d(x,0).
L’esempio più comune, nella vita di tutti i giorni, di funzione che ci piacechiamare distanza è la cosiddetta distanza euclidea, che è definita come
d(x,y) =√
(x−y)′(x−y)
di cui dò per note le proprietà. Ovviamente, la norma euclidea è ||x|| =px′x.
Il secondo concetto che vorrei richiamare alla mente del lettore è quello dispazio lineare. Consideriamo k vettori ad n elementi. Coi vettori possiamo fa-re sostanzialmente due cose: moltiplicarli per uno scalare e sommarli fra loro.
9Non sto prendendo in giro il lettore: in certi casi, è utile considerare delle funzioni in cuila diseguaglianza triangolare non vale. Consiglio a chi fosse interessato di partire dalla pagina“Distanza” di Wikipedia.
17

Poiché in ambo i casi il risultato dell’operazione è un vettore, ha senso chiedersiche caratteristiche abbia la combinazione lineare di k vettori:
y =k∑
j=1λ j x j
che, volendo, si poteva scrivere più compattamente y = Xλ, in cui X è una matri-ce le cui colonne sono i vettori x j e λ è un vettore di k elementi.
Il risultato è, naturalmente, un vettore a n elementi, ossia un punto in Rn .Visto che i k vettori x1, . . . ,xk possono essere visti a loro volta come k punti nellospazio Rn , ci chiediamo: quali sono le caratteristiche geometriche di y? Ossia,che posto occupa nello spazio? Dov’è y rispetto ai vettori x1,x2 eccetera?
Cominciamo col considerare il caso particolare k = 1. In questo caso y èun puro e semplice multiplo di x1; più lungo, se |λ1| > 1, più corto altrimenti;rovesciato rispetto all’origine se λ1 < 0, dritto altrimenti. Facile, banale, noioso.A questo punto del discorso, mi basta far notare che, se metto insieme tutti gliy ottenibili con diverse scelte di λ1, ottengo una retta; questo insieme di puntisi chiama Sp(x), che si legge spazio generato da x. Si noti che il giochino smettedi funzionare se x = 0: in questo caso, Sp(x) non è più una retta, ma un punto(l’origine).
Se i vettori x sono due, il caso standard è che non siano allineati rispettoall’origine. In questo caso, Sp(x1,x2) è un piano e y = λ1x1 +λ2x2 è un punto daqualche parte sul piano. Il punto esatto del piano su cui si trova dipende da λ1 eλ2, ma va notato che
• scegliendo opportunamente λ1 e λ2, nessun punto del piano è irraggiun-gibile
• comunque vengano scelti λ1 e λ2, non si può uscire dal piano.
Tuttavia, se x2 è già un multiplo di x1, allora x2 ∈ Sp(x1) e Sp(x1,x2) = Sp(x1),cioè di nuovo una retta. In questo caso, considerare x2 non fa “crescere” didimensione Sp(x1), perché è già contenuto in esso.
Per generalizzare ancora di più il discorso è utile introdurre il concetto diindipendenza lineare: un insieme di k vettori x1, . . . ,xk si dice linearmente in-dipendente se nessuno di essi può essere espresso come combinazione linearedegli altri. Nel caso di prima dei due vettori, quello che ho chiamato “caso stan-dard” è il caso in cui x1 e x2 sono linearmente indipendenti. Chiudo il discorsoricordando al lettore il concetto di rango: se prendiamo k vettori e li usiamo percostruire una matrice (n ×k) (chiamiamola X), il numero massimo di colonnelinearmente indipendenti di X si dice “rango di X”, e si scrive rk(X). La funzio-ne rango ha varie simpatiche proprietà, alcune più semplici da dimostrare, altremeno.
1. 0 ≤ rk(X) ≤ k (dalla definizione)
18

2. rk(X) = rk(X′) (non lo dimostro)
3. 0 ≤ rk(X) ≤ min(k,n) (mettendo insieme le due precedenti)
4. se rk(X) = min(k,n) la matrice si dice “di rango pieno”
5. rk(A ·B) ≤ min(rk(A) , rk(B)); nel caso particolare A′ = B , allora vale l’u-guaglianza, ossia rk
(B ′B
)= rk(B) (non lo dimostro).
6. se A è (n ×n), allora rk(A) = n ⇔ |A| 6= 0, ossia per le matrici quadrate ilrango pieno è sinonimo di invertibilità.
Mi pare che basti con le proprietà; la cosa davvero importante, in questo conte-sto, è che la funzione rango può essere pensata come un misuratore della di-mensione dello spazio generato da X. Cioè, se per esempio rk(X) = 1, alloraSp(X) è una retta, se rk(X) = 2, allora Sp(X) è un piano, e così via.
A questo punto, siamo pronti a discutere il problema che ci interessa dav-vero: consideriamo lo spazio Rn , dove abitano un vettore y e un certo numerodi vettori x j , con j = 1. . .k e k < n. Chiamiamo X la matrice le cui colonne so-no i vari x j . Vogliamo trovare, fra tutti i vettori appartenenti a Sp(X), quello piùvicino ad y. In formule:
y = Argminx∈Sp(X)
||y−x||;
poiché la ricerca del punto ottimale deve avvenire all’interno di Sp(X), il proble-ma si può ri-esprimere come: troviamo quel vettore β tale per cui il vettore Xβ(che è compreso in Sp(X) per definizione) è più vicino possibile a y:
β= Argminβ∈Rk
||y−Xβ|| (1.11)
Se la distanza è quella euclidea, la soluzione è la stessa del problema sta-tistico visto prima alla sezione 1.2.2: dato che la funzione “radice quadrata” èmonotona, il minimo di ||y − Xβ||, se esiste, è lo stesso di (y − Xβ)′(y − Xβ), equindi
Argminβ∈Rk
||y−Xβ|| = β= (X′X)−1X′y
da cui discende
y = Xβ= X(X′X)−1X′y.
Si noti che y è una trasformata lineare di y. In altre parole, il punto y è il ri-sultato della premoltiplicazione di y per la matrice X(X′X)−1X′, che opera unatrasformazione detta “proiezione”. Ne parleremo più avanti.
Perché, parlando della soluzione, ho detto “se esiste”? Perché, se rk(X) < k,la matrice X′X non è invertibile. In tal caso, il minimo c’è ed è unico, ma non èunico il vettore β ad esso associato. Faccio un esempio per farmi capire.
19

Supponiamo di avere un vettore y e che la matrice X sia composta da unasola colonna (non-zero) chiamata x1. Come è chiaro, la soluzione esiste unica, èuno scalare ed è molto semplice da scrivere:
β1 =x′1y
x′1x1,
per cui y = β1x1. Ora, aggiungiamo alla matrice X una seconda colonna x2, cheperò è un multiplo di x1; cioè x2 = kx1. Evidentemente, x2 ∈ Sp(x1), quindiSp(x1,x2) = Sp(x1), quindi y è sempre lo stesso. Si noti, però, che ci sono infinitimodi di scriverlo:
y =β1x1 = 0.5β1x1 +0.5β1
kx2 = 0.01β1x1 +0.99
β1
kx2 = . . .
perché ovviamente β1
k x2 =β1x1.10 In altre parole, esistono infiniti modi di com-binare x1 e x2 fra loro per ottenere y, anche se quest’ultimo è unico e la funzioneobiettivo ha un minimo ben definito.
Questa situazione si chiama collinearità, o anche multicollinearità, ed inteoria è facile da risolvere: basta buttare via le colonne in più, e quindi potareX in modo che abbia rango pieno. Nella pratica, le cose non sempre sono cosìsemplici, perché come è noto gli elaboratori operano con precisione numericafinita. Mi spiego: immaginiamo di avere a che fare con una matrice X fatta così:
X =
1 12 23 34 4+ε
Ovvio che, per ε> 0, la matrice ha rango 2; tuttavia, se ε è un numero molto
piccolo, un software non appositamente costruito per gestire queste situazio-ni11 dà di matto; si parla, tecnicamente, di quasi-collinearità. Per esempio, hofatto fare a gretl12 il prodotto (X′X)−1(X′X) per diversi valori di ε; il risultato ènella Tabella 1.1. Se il problema della precisione macchina non esistesse, nellacolonna a destra della tabella dovremmo vedere tutte matrici identità. Invece,come si vede, già per ε= 1e −05 il risultato è abbastanza insoddisfacente, e piùsi va avanti, peggio è. Tengo a precisare che questo non è un problema di gretl,ma del fatto che in un elaboratore digitale la precisione numerica non è infinita.
In questo esempio è chiaro cosa succede, perché la matrice X ha quattro ri-ghe, e le cose si vedono a occhio. In una situazione in cui la matrice ha decine, o
10Sono sicuro che il lettore volonteroso non faticherà a trovare una generalizzazione dellaformula di cui sopra.
11Ce n’è: si chiama software in precisione arbitraria. I programmi statistico/econometrici, però,non fanno parte di questa categoria per ragioni che sarebbe lungo spiegare, ma che sono ottimeragioni.
12Noto pacchetto statistico-econometrico: vedi alla URL http://gretl.sf.net. Ma qualcosami dice che il lettore sa già di cosa parlo.
20

ε (X′X)−1(X′X)
0.1
[1 4.36984e −13
5.59552e −13 1
]0.01
[1 −8.82778e −11
6.25278e −13 1
]0.001
[1 8.44739e −09
2.06783e −08 1
]0.0001
[0.999999 1.50409e −07
8.47504e −07 1
]1e-05
[0.999791 1.85966e −05
6.01411e −05 0.999926
]1e-06
[0.996029 0.00340652
0.00341797 0.991581
]1e-07
[0.499512 −0.0007324220.28125 0.78125
]1e-08
[0.859863 0.845215
1 1
]Tabella 1.1: Precisione numerica
centinaia, o migliaia di righe, una situazione così rischia di non essere evidente,e bisogna capirlo dai risultati che ci restituisce il software, che possono esseredel tutto farlocchi: ci possono essere dei casi in cui la matrice X è collineare, mail software non se ne accorge, e spara dei numeri a caso. Oppure, dei casi in cuila matrice X non è collineare, ma il software dice che lo è. In questi casi, di solitoil problema è la precisione macchina. Mi piacerebbe parlare ancora di questoargomento, ma la digressione è durata già troppo a lungo.
1.2.4 Le matrici di proiezione
Nella sottosezione precedente abbiamo visto che la soluzione y è una trasfor-mata lineare di y. La matrice che opera tale trasformazione è detta matrice diproiezione. Per spiegare il perché, l’esempio che faccio sempre è quello dellamosca nel cinema. Immaginate che ci sia una mosca in un cinema. Sullo scher-mo appare un puntino: l’ombra della mosca. La posizione della mosca è y, lospazio generato dalle X è lo schermo e l’ombra della mosca è y.
La matrice che trasforma la posizione della mosca nella posizione della suaombra è la matrice X(X′X)−1X′. Per essere più precisi, questa matrice proiet-ta sullo spazio generato dalle X qualsiasi vettore per cui viene postmoltiplicata.Come vedremo, tale matrice è abbastanza utile ed importante da meritare unnome (matrice di proiezione)13 e un’abbreviazione: PX.
PX = X(X′X)−1X′
13Ad essere pignoli, bisognerebbe dire proiezione ortogonale, perché esiste anche un altroattrezzo che si chiama proiezione obliqua. Ma noi non lo useremo mai.
21
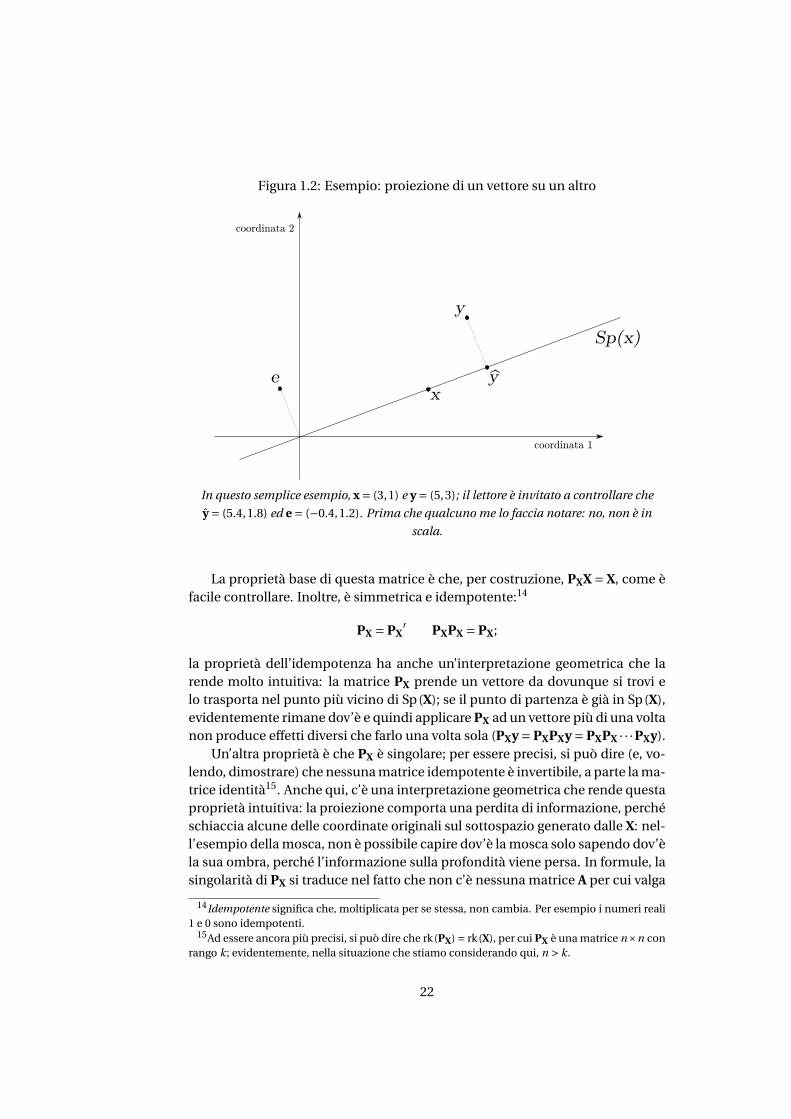
Figura 1.2: Esempio: proiezione di un vettore su un altro
x
ySp(x)
ye
coordinata 1
coordinata 2
In questo semplice esempio, x = (3,1) e y = (5,3); il lettore è invitato a controllare che
y = (5.4,1.8) ed e = (−0.4,1.2). Prima che qualcuno me lo faccia notare: no, non è in
scala.
La proprietà base di questa matrice è che, per costruzione, PXX = X, come èfacile controllare. Inoltre, è simmetrica e idempotente:14
PX = PX′ PXPX = PX;
la proprietà dell’idempotenza ha anche un’interpretazione geometrica che larende molto intuitiva: la matrice PX prende un vettore da dovunque si trovi elo trasporta nel punto più vicino di Sp(X); se il punto di partenza è già in Sp(X),evidentemente rimane dov’è e quindi applicare PX ad un vettore più di una voltanon produce effetti diversi che farlo una volta sola (PXy = PXPXy = PXPX · · ·PXy).
Un’altra proprietà è che PX è singolare; per essere precisi, si può dire (e, vo-lendo, dimostrare) che nessuna matrice idempotente è invertibile, a parte la ma-trice identità15. Anche qui, c’è una interpretazione geometrica che rende questaproprietà intuitiva: la proiezione comporta una perdita di informazione, perchéschiaccia alcune delle coordinate originali sul sottospazio generato dalle X: nel-l’esempio della mosca, non è possibile capire dov’è la mosca solo sapendo dov’èla sua ombra, perché l’informazione sulla profondità viene persa. In formule, lasingolarità di PX si traduce nel fatto che non c’è nessuna matrice A per cui valga
14Idempotente significa che, moltiplicata per se stessa, non cambia. Per esempio i numeri reali1 e 0 sono idempotenti.
15Ad essere ancora più precisi, si può dire che rk(PX) = rk(X), per cui PX è una matrice n×n conrango k; evidentemente, nella situazione che stiamo considerando qui, n > k.
22

A ·PX = I, e quindi non esiste nessuna matrice che permette di scrivere Ay = y,cioè di ricostruire la posizione originale di y partendo dalla sua proiezione.
Un’altra matrice interessante che possiamo costruire partendo da PX è
MX = I−PX.
Evidentemente, MXy = y− y = e. Questa matrice, in un certo senso, fa un lavo-ro opposto e complementare a quello di PX: applicata ad un vettore, ritorna loscarto fra il punto originale ed il punto proiettato. Si può controllare facilmen-te che MX ha la proprietà fondamentale per cui MXX = 0; ciò implica che ognivettore del tipo MXy è ortogonale a Sp(X), ossia forma un angolo retto con qual-siasi vettore Xλ.16 Altre proprietà degne di nota: MX è anch’essa simmetrica,idempotente e singolare17. Inoltre,
MXPX = PXMX = [0].
Esempio 2 Il lettore è invitato a controllare (facendo i conti a mano o col softwareche preferisce) che, usando gli stessi dati dell’esempio 1, si ha
PX =1/3 1/3 1/3
1/3 5/6 −1/61/3 −1/6 5/6
MX = 2/3 −1/3 −1/3−1/3 1/6 1/6−1/3 1/6 1/6
E la varie proprietà di tali matrici (ad esempio l’idempotenza).
Nel contesto che ci interessa, il vantaggio di aver definito le matrici di pro-iezione in rapporto al problema geometrico è che diventa facile esprimere inmodo semplice, compatto ed intuitivo le principali grandezze inerenti al pro-blema statistico di approssimare la variabile y per mezzo di un modello linearecostruito con le variabili che formano le colonne di X:
Grandezza Simbolo FormulaCoefficienti OLS β (X′X)−1X′y
Valori fittati y PXyResidui e MXy
Somma dei quadrati dei residui SSR e′e = y′MXy
Consideriamo ad esempio il caso particolare in cui X = ι. Come abbiamovisto, questo conduce a risolvere il problema per mezzo della media aritmetica,cosicché β = Y : il vettore dei valori fittati18 è Pιy = ι · Y e i residui sono sempli-cemente gli scarti dalla media: e = Mιy = y− ι · Y . Infine, la devianza può esserescritta come y′Mιy (e quindi, volendo, la varianza come V (y) = n−1y′Mιy).
16Ricordo che due vettori si dicono ortogonali fra loro se il loro prodotto interno è 0. In formule:x ⊥ y ⇔ x′y = 0. Un vettore si dice ortogonale ad uno spazio se è ortogonale a tutti i punti di quellospazio: y ⊥ Sp(X) ⇔ y′X = 0 e quindi y ⊥ Xλ per qualsiasi λ.
17In effetti, MX è anch’essa una matrice di proiezione, ma lasciamo stare.18Ecco, l’ho detto.
23

1.2.5 Misure di bontà del modello
A questo punto, è piuttosto naturale porsi il problema della bontà dell’appros-simazione a cui il nostro modello statistico perviene. In un certo senso, il pro-blema è già stato parzialmente risolto con l’adozione di una funzione criterio.Quando usiamo β come approssimatore in yi ' x′iβ, sappiamo che stiamo fa-cendo del nostro meglio, cioè stiamo scegliendo il valore di β che ottimizza lafunzione criterio.
Come spesso accade, però, può darsi che fare del nostro meglio non sia ab-bastanza. Sarebbe interessante avere un’idea di quanto il modello riesce a cattu-rare il fenomeno di nostro interesse, ossia quanta informazione perdiamo nellasintesi.
La misura più immediata da definire emerge in modo molto naturale daqueste due disuguaglianze:
0 ≤ y′y = y′PXy ≤ y′y;
la prima è abbastanza ovvia considerando che y′y è una somma di quadrati, equindi è non-negativa. La seconda è appena meno evidente: infatti, y′PXy =y′y−y′MXy = y′y−e′e; poiché anche e′e è una somma di quadrati, ovviamentey′PXy ≤ y′y. Dividendo il tutto per y′y, si ha
0 ≤ y′yy′y
= R2u ≤ 1 (1.12)
Questo indice si chiama R2u (che si legge “erre-quadro non centrato”), e gli si
può dare un’interpretazione molto intuitiva nel problema geometrico. Eviden-temente, nello spazio Rn i punti y, y e l’origine formano un triangolo rettangolo(vedi anche la figura 1.2) in cui c’è un cateto “buono”, che è y, e uno “cattivo”,che è congruente a e: vogliamo che il cateto cattivo sia più corto possibile. Datoil teorema di Pitagora, l’indice R2
u ci dà semplicemente il rapporto (al quadrato)fra cateto buono e ipotenusa. Naturalmente, più questo indice è vicino ad 1, piùsiamo contenti.
L’indice R2u testè definito è perfettamente appropriato al problema geome-
trico, ma un tantino meno a quello statistico. Infatti, in molte circostanze noivorremmo poter dare per scontata l’informazione contenuta nella media arit-metica, che però nell’indice R2
u viene computata nel cateto “buono”. In altritermini, non ha molto senso che un modello in cui sintetizziamo y con la solamedia, e cioè via ι · Y ci possa dare un R2
u arbitrariamente vicino ad uno; in quelcaso, avremmo semplicemente l’indicazione che la dispersione dei dati intornoalla media è piccola in rapporto alla media stessa.
Una modifica all’indice che lo rende più vicino alle esigenze statistiche èquella di usare, come fattore di normalizzazione, y′Mιy anziché y′y. Infatti, seι ∈ Sp(X), si ha
0 ≤ y′MXy = e′e ≤ y′Mιy ≤ y′y,
24

ciò che rende possibile definire il cosiddetto R2 centrato, noto anche come indi-ce di determinazione:
R2 = 1− e′ey′Mιy
. (1.13)
Quando si parla di R2 senza specificare, di solito si intende quest’ultimo, e que-sto è il motivo per cui la versione dell’indice definita nella (1.12) aveva una “u”in pedice (dall’inglese uncentred).
Forse il lettore distratto non si è accorto di niente, ma in modo del tutto sur-rettizio ho introdotto un’idea travolgente. Dicendo che l’R2 centrato è più adattoa quantificare la bontà del modello sotto il profilo statistico, ho implicitamentedetto che la bontà del modello statistico è una cosa che va misurata confrontan-do due modelli fra loro. In effetti, la (1.13) può essere letta come un numero chedipende dal confronto fra due funzioni di perdita: una, quella relativa al model-lo, per così dire, base (quello basato sulla sola media aritmetica); l’altra, quellache risulta del modello, per così dire, completo.
Il proseguimento naturale di questa idea è quella di capire esattamente se,ed in che misura, possiamo usare una valutazione di questo tipo (il confronto frafunzioni di perdita) per guidarci in una scelta che, fino ad ora, abbiamo dato perscontata, e cioè: come si costruisce la matrice X? Quali variabili è giusto, pro-duttivo, utile, istruttivo, eccetera, includere nella nostra funzione m(xi )? Tuttequelle che abbiamo? Solo alcune? E quali?
1.3 La scelta dei regressori
In questa sezione, ci porremo il problema di trovare dei criteri per capire qualisono le variabili migliori per costruire la matrice X. Per cominciare, conside-riamo il problema di scegliere se è “meglio” (in qualche senso da decidere) unmodello del tipo
yi ' x′iβ (1.14)
(chiamiamolo modello A) oppure un modello del tipo
yi ' x′iβ+z′iγ (1.15)
(chiamiamolo modello B).Diciamo che sul potere esplicativo delle xi siamo sicuri; sulle zi , un po’ me-
no, e vorremmo decidere sulla base dei dati se è il caso di includerle nel nostromodello o no. Chiaramente, il modello B è più articolato, ma il modello A è piùleggero. Potrebbe darsi che B sia ridondante, oppure che A sia troppo succinto.
Un esempio estremo di questa situazione è: cerchiamo di capire se c’è qual-che regolarità che ci possa aiutare a descrivere il libretto di Pinco Pallino. Il vet-tore xi contiene delle variabili più o meno ragionevoli: quanti giorni ha studiatoper quell’esame, e così via. Il vettore zi , invece, contiene delle variabili che nonpossono essere legate al voto preso in quell’esame se non per qualche sciocca
25

superstizione: che so, se la data in cui si è svolto l’esame è un multiplo di 9, se ilprof porta gli occhiali, o se la seconda lettera del nome dell’esame è “a”.
Ragionevolezza vorrebbe che, qualunque sia il criterio che usiamo, noi sifinisca per optare per il modello A. Purtroppo, però, se usiamo un criterio basatopuramente sulla funzione di perdita, finiremo sempre per scegliere il modello B(lo dimostrerò fra poco). Il lettore superficiale concluderà, a questo punto, chel’econometria è tutta una truffa e smetterà di leggere. Al lettore più intelligente,invece, chiedo di portare pazienza per qualche pagina ancora. Prima di capirecome stanno le cose, abbiamo bisogno di qualche nozione in più.
1.3.1 Un altro paio di cose sulle matrici di proiezione
Consideriamo il caso di uno spazio ad n dimensioni e di una matrice X, di nrighe, k colonne e rango pieno. Come si diceva poche pagine fa, le colonnedi questa matrice definiscono un sottospazio a k dimensioni che chiamiamoSp(X).
Definiamo ora una matrice W, che possa essere scritta come come X·A, doveA è una qualche matrice di rango minore di k. È evidente che ogni combinazio-ne lineare delle colonne di W è anche combinazione delle colonne di X, e perciòha la proprietà di essere compresa in Sp(X). Ne segue che ogni vettore compresoin Sp(W) è anche un elemento di Sp(X).
Tuttavia, il converso non è vero: ci sono degli elementi di Sp(X) che nonpossono essere scritti come combinazione delle colonne di Sp(W) (la dimostra-zione è un po’ più complicatuccia e non ve la faccio). In breve, Sp(W) è unsottoinsieme di Sp(X) o, come si scrive, Sp(W) ⊂ Sp(X).
Un caso tipico di questa situazione lo si ha quando consideriamo una matri-ce W che contiene alcune colonne di X, ma non tutte. Diciamo, senza perdita digeneralità, che W è formato dalle prime k −p colonne di X o, equivalentemen-te, che cancellando le p colonne più a destra di X otteniamo W. In questo caso,infatti, la matrice che prima ho chiamato A può essere scritta
A =[
I0
]dove la matrice identità che sta sopra ha k−p righe e colonne, e la matrice 0 chesta sotto ha p righe e, naturalmente, k −p colonne.
In questa situazione, la proprietà PXW = PXXA = XA = W comporta alcuneinteressanti conseguenze sulle matrici di proiezione legate agli spazi Sp(W) eSp(X), che elenco qui di seguito:
PWPX = PXPW = PW
MWMX = MXMW = MX
MWPX = PXMW = PX −PW = MW −MX
PWMX = MXPW = 0
Invito il lettore a dimostrarle per esercizio. Non dovrebbe volerci molto.
26

1.3.2 Un risultato sconfortante (in apparenza)
Riprendiamo i due modelli A e B di cui parlavo prima, alle equazioni (1.14) e(1.15). A questo punto, è facile dimostrare che la SSR per il modello B è sempreminore che per il modello A.
SSRA = e′aea SSRB = e′beb
dove ea = MXy e eb = MX,Zy. Visto che Sp(X) ⊂ Sp(X,Z), si ha che
MX,ZMX = MX,Z
e perciò MX,Zea = eb ; ne consegue che
SSRB = e′beb = e′aMX,Zea = e′aea −e′aPX,Zea ≤ e′aea = SSRA
In pratica, se giudichiamo il risultato finale in termini di funzione di perdita, ilmodello B (quello assurdo) è sempre almeno tanto buono quanto il modello A(quello ragionevole), e forse di più. Neanche l’indice R2 ci può essere d’aiuto:dimostrare che
SSRB ≤ SSRA ⇒ R2B ≥ R2
A .
è un giochino da terza media.Ne consegue che aggiungendo variabili esplicative ad un modello preesisten-
te, l’indice R2 non può peggiorare, per quanto insensata sia la scelta dei regressori.Che scandalo. Che schifo. Qui è tutto un magna magna. Ah, signora mia, la penadi morte ci vorrebbe.
Se cerchiamo di essere ragionevoli, però, notiamo una cosa. Questa pro-prietà per cui più regressori usiamo, più la SSR diminuisce è una conseguenzainevitabile dell’aver scelto di impostare il problema dell’approssimazione comeproblema di ottimo. Infatti, l’equazione (1.14) è un caso particolare della (1.15),che si ottiene ponendo γ = 0. Consideriamo ora la soluzione del problema diottimo per la (1.15): se la soluzione ottima per γ è il vettore zero, allora la fun-zione obiettivo risulta minimizzata sia per la (1.14) che per la (1.15). Altrimenti,il vettore 0 non è l’ottimo per la (1.15), e quindi la funzione obiettivo può essereulteriormente decrementata. Come che sia, è impossibile che la funzione obiet-tivo risulti migliore per il modello A che per il modello B. Al massimo, può esserenon peggiore, cioè uguale.19
Detto in termini più tecnici, si può pensare che l’OLS applicato al model-lo B restituisca la soluzione di un problema di ottimo libero, mentre applicatoal modello A restituisce la soluzione di un problema di ottimo vincolato, doveil vincolo è appunto γ = 0. Che il punto di ottimo del problema vincolato siapeggiore di quello libero è soltanto ovvio.
19I più astuti fra i miei lettori avranno già capito che questo punto è assolutamente generale enon dipende in alcun modo dalla forma della funzione di perdita.
27

A questo punto, comincia a profilarsi una possibile soluzione: la decisionesu quale modello scegliere fra A e B non può essere basata sul puro e sempliceconfronto fra le funzioni di perdita (perché è ovvio che la perdita diminuisce nelmodello non vincolato), bensì su un qualche tipo di criterio che misuri di quantola funzione di perdita cambia fra l’uno e l’altro. Se il guadagno è trascurabile,allora tanto vale optare per il modello più parsimonioso.
Una prima soluzione a questo problema è quella fornita dal cosiddetto indi-ce R2 aggiustato, o barrato, o anche corretto:
R2 = 1− e′ey′Mιy
n −1
n −k, (1.16)
dove n è il numero di righe di y, cioè il numero di osservazioni di cui disponia-mo, e k è il numero di colonne di X, ovvero il numero di parametri della nostrafunzione m(xi ) (compresa l’intercetta). Come si vede facilmente, aggiungere almodello variabili esplicative senza senso può non produrre un miglioramentonell’indice: infatti, è vero che la SSR scende, ma è anche vero che questo effettopuò essere controbilanciato dal fattore n −k che sta al denominatore.
Non è difficile dimostrare che, se nell’esempio dei modelli A e B visto soprachiamiamo k e p il numero di elementi nei vettori xi e zi rispettivamente, valela seguente relazione:
R2B ≥ R2
A ⇔ SSRB
SSRA< 1− p
n −k(1.17)
e quindi, per far migliorare l’indice R2 è necessario che SSRB sia sostanzialmenteminore di SSRA .
Vedremo che questa idea, adeguatamente sviluppata, ci darà la soluzioneche cerchiamo. Dobbiamo formalizzare esattamente la relazione che intercorrefra il vincolo sul modello e il connesso peggioramento nella funzione di perdita,così da stabilire dei criteri per decidere quando è meglio usare il modello liberoanziché quello vincolato. Per dare una soluzione generale, bisogna sviluppareun po’ l’algebra per il confronto fra modelli liberi e vincolati.
1.3.3 Modelli e vincoli
Come ho detto sopra, vogliamo analizzare cosa succede ad un modello di re-gressione se minimizziamo la funzione di perdita sotto un qualche vincolo econfrontare le proprietà della soluzione con quella trovata in assenza di vincolo.
Per fissare le idee, conviene partire da un’osservazione: se prendiamo unmodello lineare del tipo che abbiamo analizzato finora
m(xi ) = xi ,1β1 +xi ,2β2 +·· ·+xi ,kβk =k∑
j=1xi , jβ j = x′iβ,
dove tipicamente xi ,1 = 1, l’idea di imporre dei vincoli sugli elementi di β si puòtradurre in una forma vincolata del modello.
28

Sarebbe più interessante, nonché più elegante, discutere il problema in ter-mini generali. Per amor di semplicità, però, noi ci concentreremo sul caso divincoli lineari. Il caso più semplice in assoluto è quello di vincolare uno o piùcoefficienti ad essere 0. Ad esempio, il modello
m(xi ) = xi ,1β1 +xi ,2β2 +x3,1β3, (1.18)
se sottoposto al vincolo β2 = 0 diventa, banalmente,
m(xi ) = xi ,1β1 +xi ,3β3.
Questa era davvero semplice, ma seguendo questo principio noi possiamo tra-sformare un modello di partenza in una cosa apparentemente del tutto diversa,solo usando in modo sapiente la funzione (o le funzioni) vincolo. Per esempio,il modello (1.18), se sottoposto al vincolo β1 = 1, diventa
m(xi ) = xi ,2β2 +xi ,3β3,
dove abbiamo sostituito al problema di approssimare la variabile yi per mez-zo di una funzione m(·) il problema di approssimare la variabile (yi − xi ,1) permezzo di una funzione m(·); in altre parole, l’imposizione del vincolo modificanon solo la forma della funzione m(·), ma anche la definizione della variabiledipendente.
Altro esempio: supponiamo di voler sottoporre la (1.18) al vincoloβ2+β3 = 0(o, in forma equivalente, β2 =−β3): questo conduce a riscrivere tale equazionecome
m(xi ) = xi ,1β1 + (xi ,2 −xi ,3)β2.
Nauturalmente, i vincoli possono essere combinati fra loro. Ad esempio,imponendo il sistema di vincoli {
β1 = 1β2 +β3 = 0
di nuovo all’equazione (1.18), quest’ultima si trasforma in
yi −xi ,1 ' m(xi ) = (xi ,2 −xi ,3)β2.
È chiaro che il modo più generale, ed al tempo stesso efficiente, di rappresen-tare un sistema di vincoli come quelli che abbiamo visto sin qui è quello dirappresentarli per mezzo dell’equazione matriciale
Rβ= d ,
dove la matrice R ed il vettore d sono scelti da noi in modo tale da riprodurrela funzione vincolo. Per esempio, se il modello libero è quello dell’equazione(1.18), la seguente tabella fornisce alcuni esempi che dovrebbero illuminare illettore sul principio generale:
29

Vincolo R d Modello vincolatoβ3 = 0
[0 0 1
]0 yi ' xi ,1β1 +xi ,2β2
β1 = 1[1 0 0
]1 yi −xi ,1 ' xi ,2β2 +xi ,3β3
β2 +β3 = 0[0 1 1
]0 yi ' xi ,1β1 + (xi ,2 −xi ,3)β2{
β1 = 1β2 =β3
[1 0 00 1 −1
] [10
]yi −xi ,1 ' (xi ,2 +xi ,3)β2
La domanda che a questo punto dovrebbe venire spontanea è: ma perchédovremmo imporre dei vincoli, se questi fanno sicuramente peggiorare la nostrafunzione di perdita? Ci possono essere vari motivi, ognuno dei quali non escludegli altri:
• Uno potrebbe voler confutare una qualche teoria, mostrando che l’esclu-sione di alcune variabili esplicative da un modello non produce un peg-gioramento apprezzabile della capacità, da parte del modello stesso, disintetizzare i dati.
• Uno potrebbe voler confrontare il modello libero con uno vincolato per-ché il vincolo esprime indirettamente un’ipotesi sul mondo ed è interes-sante capire se e quanto accettare incondizionatamente tale ipotesi pre-giudica la nostra capacità di sintetizzare i dati.
• Spesso, i modelli econometrici sono scritti in termini di parametri che so-no passibili di interpretazione diretta nella teoria economica. Consideria-mo ad esempio una funzione di produzione Cobb-Douglas Q = AKα1 Lα2 .È noto dalla teoria microeconomica (o almeno, dovrebbe) che la Cobb-Douglas ha rendimenti di scala costanti se e solo se α+α2 = 1. Scrivendola funzione in logaritmi si ha
q = a +α1k +α2l
Supponiamo di condurre un esperimento in cui facciamo variare a no-stro piacimento k e l , e osserviamo i cambiamenti in q . In questo caso, ènaturale pensare di quantificare il vettore di parametri
β= aα1
α2
con i minimi quadrati. Se però sapessimo — o congetturassimo — che lafunzione è a rendimenti di scala costanti, vorremmo che la nostra stimadi β incorporasse l’informazione α1 +α2 = 1. Ovviamente, non c’è alcunagaranzia che β rispetti questa condizione.
30

Nella sezione che segue, svilupperemo l’algebra che serve per mettere in re-lazione il sistema dei vincoli Rβ= d con il peggioramento nella funzione criterioad esso associato, così che potremo discutere con cognizione di causa sulla de-cisione da prendere quando ci chiediamo se sia “migliore” il modello libero oquello vincolato.
1.3.4 I minimi quadrati vincolati
Nel modello vincolato, vogliamo una statistica che soddisfi a priori un insiemedi p restrizioni che possiamo scrivere come Rβ = d . In altre parole, cerchiamouna soluzione al problema di trovare un vettore β che minimizzi la SSR ma checontemporaneamente rispetti un dato insieme di vincoli lineari:
β= ArgminRβ=d
||y−Xβ||; (1.19)
si confronti la (1.19) con la (1.11), che definisce la statistica ottimale per il mo-dello non vincolato. Così come la soluzione del problema non vincolato si chia-ma OLS (Ordinary Least Squares), la soluzione del problema vincolato si chiamaRLS (Restricted Least Squares).
Figura 1.3: Esempio: vettore di due parametri
β2
β1
β2
β1β1
β2^
^
~
~
Le ellissi sono le curve di livello della funzione e′e. Il vincolo è β1 = 3β2. Il numero di
parametri k è uguale a 2 e il numero di vincoli p è pari a 1. Il punto di minimo non
vincolato è β1, β2; Il punto di minimo vincolato è β1, β2.
Per trovare tale statistica, minimizziamo la somma dei quadrati dei residuisotto vincolo. Definendo i residui come e(β) = y−Xβ il lagrangiano sarà
L = 1
2e′e+λ′(Rβ−d).
31

Poiché la derivata di e rispetto aβ è−X, la condizione di primo ordine può esserescritta
X′e = R ′λ, (1.20)
dove indichiamo con β il vettore che rende vera la (1.20) e con e il vettore y−Xβ.L’equazione (1.20) può essere riscritta in modo tale da rendere evidenti le
relazioni che esistono fra il problema di minimo vincolato (e la sua soluzione) eil problema di minimo libero (e la sua soluzione, che è ovviamente la statisticaOLS). In particolare, possiamo considerare le implicazioni della (1.20)
1. nello spazio dei parametri (Rk )
2. nello spazio dei vincoli (Rp )
3. nello spazio delle osservazioni (Rn)
4. nello spazio della funzione obiettivo (R).
Cominciamo coi parametri: premoltiplicando la (1.20) per (X′X)−1 si ottieneuna relazione interessante fra la soluzione vincolata e quella libera:
β= β− (X′X)−1R ′λ (1.21)
La soluzione vincolata, quindi, è uguale a quella libera più un “fattore di corre-zione” proporzionale a λ.
La seconda cosa che si può dire riguarda lo spazio dei vincoli, e quindi ilvalore di λ: premoltiplicando la (1.21) per R si ha che
λ= [R(X′X)−1R ′]−1
(Rβ−d) (1.22)
perché Rβ= d per costruzione.Dovrebbe essere chiaro dalla (1.22) che, se la statistica non vincolata rispet-
ta già di per sé il vincolo (Rβ = d), allora λ = 0 e quindi la statistica vincolatacoincide con quella libera. In questo senso, si può dire che il vettore λ ci dà unamisura di quanto la soluzione del problema vincolato sia diversa da quella delproblema libero; sarò più preciso fra poco. La formula che si trova di solito neilibri di testo la si ottiene combinando le equazioni (1.21) e (1.22):
β= β− (X′X)−1R ′ [R(X′X)−1R ′]−1(Rβ−d) (1.23)
Possiamo esaminare cosa succede nello spazio delle osservazioni premolti-plicando la (1.21) per X:
Xβ= y = y−X(X′X)−1R ′λ
da cui discendee = e+X(X′X)−1R ′λ
32

Consideriamo ora lo spazio della funzione obiettivo: la somma dei quadratidei residui vincolati (cioè il minimo vincolato) e′e può essere scritta nel seguentemodo:
e′e = e′e+λ′R(X′X)−1R ′λ (1.24)
dove abbiamo sfruttato il fatto che e = MXy e quindi, per costruzione, X′e = 0.Ora, la (1.24) ci dice una cosa importante: la differenza che c’è fra il minimovincolato e il minimo libero (che è evidentemente sempre positiva) può esserescritta come una forma quadratica in λ.20
Mettendo assieme le equazioni (1.21), (1.22) e (1.24) si arriva alle seguentiuguaglianze:
e′e− e′e =λ′R(X′X)−1R ′λ= (β− β)′(X′X)(β− β) =
(Rβ−d)′[R(X′X)−1R ′]−1
(Rβ−d)
(1.25)
L’espressione (1.25) è molto interessante, perché ci dice che la stessa quan-tità può essere interpretata in tre modi diversi ed equivalenti:
1. e′e− e′e è la differenza che c’è fra la funzione obiettivo vincolata e non.Maggiore è questa differenza, maggiore è la perdita di capacità che il mo-dello vincolato ha di accostarsi ai dati empiricamente osservati;
2. λ′R(X′X)−1R ′λ è una forma quadratica che vale 0 solo se λ = 0.21 Poi-ché abbiamo già visto che λ = 0 solo se la statistica vincolata coincidecon quella libera, questa grandezza varia sostanzialmente con la distan-za ||β− β|| (una volta definita opportunamente la metrica); si può anchenotare che, usando la (1.20), la quantità in questione può essere scrittacome e′PXe;
3. la grandezza (Rβ−d)′[R(X′X)−1R ′]−1
(Rβ−d) è una forma quadratica (de-finita positiva) in (Rβ− d), ossia in un vettore che è pari a 0 solo se lostimatore libero rispetta già di per sé il vincolo.
La morale della storia è: la stessa quantità può essere letta in vari modi, mail messaggio veramente importante è che la differenza nella funzione obiettivoche si ha fra modello vincolato e modello libero può essere vista come una mi-sura di quanto β e β sono diversi fra loro. Questa molteplicità di approcci, oltre
20Ricordo che una forma quadratica è un’espressione del tipo f (x) = x′Ax, dove A è una matricesimmetrica e x è un vettore conformabile. Se A è tale per cui f (x) > 0 per qualsiasi x 6= 0, allorala matrice A si dice definita positiva; se f (x) ≥ 0 per qualsiasi x 6= 0, allora la matrice A si dicesemidefinita positiva. Se una matrice è semidefinita positiva e invertibile, allora è anche definitapositiva.
21Poiché λ è il vettore dei moltiplicatori di Lagrange del problema di minimo vincolato è pos-sibile — come è noto — darne una lettura in termini di prezzo ombra: l’i -esimo elemento delvettore λ ci dice quanto migliora la funzione obiettivo ad una variazione ‘piccola’ del vincolocorrispondente. Formalmente, si può dimostrare che λ è il vettore di derivate parziali di e′e/2rispetto a d .
33

ad essere piuttosto intrigante dal punto di vista puramente estetico (ma questa,ammetto, è una questione di gusti) è utile perché ci permette di ragionare suisingoli elementi di β ragionando su quanto la loro distanza da un qualsiasi valo-re prefissato farebbe peggiorare il modello in termini di capacità interpretativadei dati.
1.4 Misure di perdita di fit
A questo punto, siamo nella condizione di poter dire qualcosa di preciso, comepromesso, sulla relazione che c’è fra funzione obiettivo e vincoli.
Un buon punto da cui partire è la statistica σ2, che è semplicemente la va-rianza delle ei per il modello libero. Questa statistica ha una variante alternativa,che risulta dall’uso al denominatore di n −k anziché n, e si chiama s2:
σ2 = e′en
; s2 = e′en −k
;
la motivazione primaria per usare s2 anziché σ2 è di tipo statistico-inferenzialeper cui, fedele al mio proposito, non ne parlo. Mi limito a far notare che in unmodello in cui k sia uguale ad n la SSR è zero per costruzione (dimostrarlo èmolto semplice) e quindi può avere senso normalizzare la SSR per n−k anzichén. È evidente che in una condizione standard n è molto maggiore di k, cosicchéle due statistiche sono di fatto interscambiabili.
Il secondo ingrediente che ci serve è la differenza e′e− e′e, che è ovviamen-te sempre non-negativa, perché (come abbiamo ampiamente discusso) e′e ≥e′e. Evidentemente, tanto più è grande questa differenza, tanto grande è ladiscrepanza, in termini di fit, fra il modello libero e quello vincolato.
Si noti che il valore assoluto delle statistiche e′e e e′e dipende dall’unità dimisura che scegliamo per misurare la nostra variabile dipendente. Dato chequesta unità di misura è, evidentemente, arbitraria, possiamo ottenere una pri-ma indicazione della perdita normalizzando la differenza fra le due per unamisura della varianza. Un primo indicatore è la cosiddetta statistica W
W = e′e− e′eσ2 = n · e′e− e′e
e′e
che usa σ2; un’alternativa è la cosiddetta statistica F , che è data da
F = e′e− e′es2
1
p= e′e− e′e
e′e· n −k
p,
e, rispetto alla statistica W , presenta due differenze: è basata su s2 anziché σ2 edè normalizzata per il numero dei vincoli (W non lo è). La relazione che intercorrefra le due è davvero molto facile da scrivere
W = p ·Fn
n −k
34

cosicché in una situazione standard, in cui n è molto più grande di k, si ha cheW ' pF .
Ovviamente, c’è un legame molto stretto fra le statistiche W ed F e l’indiceR2: se indichiamo con R2
L e R2V gli indici R2 dei modelli libero e vincolato, è
semplice dimostrare chee′e− e′e
e′e= R2
L −R2V
1−R2L
per cui, ad esempio,
W = nR2
L −R2V
1−R2L
.
Un’altra cosa che val la pena di notare è che, poiché e′e− e′e = e′PXe, le duestatistiche W ed F possono anche essere scritte in termini di
R2aux =
e′e− e′ee′e
,
che non è altro che l’indice R2 è della cosiddetta regressione ausiliaria,22in cui lavariabile dipendente è e e le variabili esplicative sono X.
Il lettore sarà, dopo questa sarabanda di modi alternativi di scrivere semprela stessa cosa o quasi, colto da una leggera vertigine. È normale. La cosa dav-vero importante è che vi abbia convinto del fatto che usare la statistica W o lastatistica F per confrontare il modello libero con quello vincolato è una buonaidea. Quale delle due sia quella che scegliamo di usare, il criterio non può essereche questo: se la statistica è “piccola”, il modello vincolato è preferibile, perchéla perdita di fit è compensata dalla maggior sintesi; se invece è “grande”, andràpreferito il modello libero, perché il peggioramento nella funzione di perdita chesegue all’imposizione del vincolo è troppo oneroso.
Il problema che si pone a questo punto è: qual è il valore soglia che devo usa-re per decidere se W o F sono “piccole” o “grandi”? In ultima analisi, si usanodelle convenzioni, più o meno facili da motivare in un contesto inferenziale, chenoi qui prendiamo per buone giustificandole semplicemente come una prassitradizionale. La prassi consiste nel trasformare le statistiche F e W (che, ricor-do, sono comprese fra 0 e infinito) in un numero fra 0 e 1 che si chiama p-value
22Una regressione ausiliaria è una tecnica computazionale: per calcolare certe statistiche, a vol-te conviene applicare l’OLS ad un modello che in realtà non è quello di nostro interesse, ma usan-do il quale la statistica che ci interessa diventa facile da calcolare. In questo caso, la sequenzadelle operazioni sarebbe:
1. applico l’OLS al modello vincolato;
2. calcolo i residui e;
3. applico l’OLS ad un modello in cui la variabile dipendente è e e i regressori sono quelli delmodello non vincolato;
4. prendo l’R2 di quest’ultima regressione e la moltiplico per n.
In questo contensto, l’uso della regressione ausiliaria è forse un po’ forzato, ma il principio tornaveramente comodo quando si fa sul serio, e cioè quando si usa l’OLS come stumento inferenziale.
35
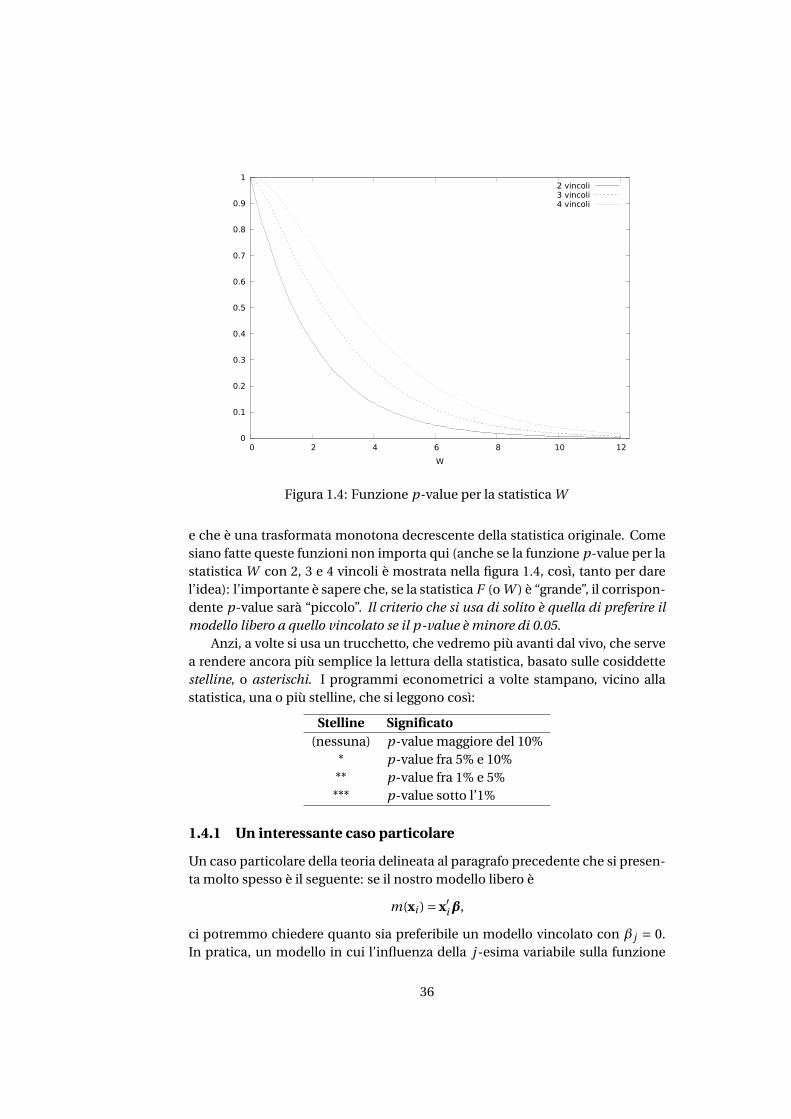
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 2 4 6 8 10 12
W
2 vincoli3 vincoli4 vincoli
Figura 1.4: Funzione p-value per la statistica W
e che è una trasformata monotona decrescente della statistica originale. Comesiano fatte queste funzioni non importa qui (anche se la funzione p-value per lastatistica W con 2, 3 e 4 vincoli è mostrata nella figura 1.4, così, tanto per darel’idea): l’importante è sapere che, se la statistica F (o W ) è “grande”, il corrispon-dente p-value sarà “piccolo”. Il criterio che si usa di solito è quella di preferire ilmodello libero a quello vincolato se il p-value è minore di 0.05.
Anzi, a volte si usa un trucchetto, che vedremo più avanti dal vivo, che servea rendere ancora più semplice la lettura della statistica, basato sulle cosiddettestelline, o asterischi. I programmi econometrici a volte stampano, vicino allastatistica, una o più stelline, che si leggono così:
Stelline Significato(nessuna) p-value maggiore del 10%
* p-value fra 5% e 10%** p-value fra 1% e 5%*** p-value sotto l’1%
1.4.1 Un interessante caso particolare
Un caso particolare della teoria delineata al paragrafo precedente che si presen-ta molto spesso è il seguente: se il nostro modello libero è
m(xi ) = x′iβ,
ci potremmo chiedere quanto sia preferibile un modello vincolato con β j = 0.In pratica, un modello in cui l’influenza della j -esima variabile sulla funzione
36

m(xi ) sia 0 per ipotesi. In questo caso, d è lo scalare 0, e la matrice R è un vet-tore riga fatto in modo particolare, che si chiama la j -esima base canonica: unvettore fatto tutto di zeri a parte la j -esima posizione, dove c’è 1.
La particolarità di una base canonica è che estrae una riga o una colonna diciò per cui viene moltiplicata (è per questo che una base canonica a volte vieneanche chiamata vettore estrattore). Per esempio, se b2 è la seconda base canoni-ca, il prodotto A ·b2 ha come risultato la seconda colonna di A, e il prodotto b′
2 Aha come risultato la seconda riga.23 Evidentemente,
b′i Ab j = Ai j
Torniamo a noi: usando l’equazione (1.25), si nota che, nel caso in esame,
e′e− e′e = (Rβ−d)′[R(X′X)−1R ′]−1
(Rβ−d) =(b′
j β)2
b′j (X′X)−1b j
=β2
j
δ j,
dove δ j è l’i -esimo elemento sulla diagonale di (X′X)−1. Poiché in questo ca-so p = 1, le corrispondenti statistiche W ed F possono essere ottenute sempli-cemente dividendo il rapporto nell’equazione precedente per σ2 o s2 rispetti-vamente. In questo secondo caso, anzi, possiamo definire una statistica, dettastatistica t , o t-ratio, come
β j
s ·√δ j
(1.26)
che ha la proprietà di fornire immediatamente la statistica F se elevata al qua-drato. Il denominatore del rapporto si chiama errore standard del coefficienteβ j . Di nuovo: se mi fossi concesso il lusso di parlare di inferenza, vi spiegherei ilperché, ma in questa dispensa è un nome come un altro.24
In questo caso, non c’è nemmeno bisogno di guardare il p-value: la regolaa occhio che si segue fra economisti applicati è quella di rifiutare il vincolo se ilt-ratio è, in valore assoluto, maggiore di 2. Poiché il vincolo equivale in pratica,all’irrilevanza della variabile esplicativa in questione, si dice che tale regressoreè significativo nel modello, il che vuol dire in pratica che il suo influsso sullafunzione m(·) non può essere trascurato senza che il modello peggiori in modosostanziale. Naturalmente, nessuno impedisce di usare anche in questo caso iltrucchetto delle stelline (che anzi, sono la prima cosa che molti guardano).
1.5 Come si legge l’output
Vediamo ora come le cose che vi ho raccontato fin a qui funzionano in un ca-so pratico: la Tabella 1.2 contiene un regressione effettuata su un dataset di 549
23Come sempre, il lettore è invitato a controllare, anziché fidarsi.24Uno si potrebbe chiedere: c’è un motivo per usare s2 anziché σ2, e cioè la statistica F anziché
la W ? Risposta: in realtà, no, se non la tradizione. E comunque, per un valore di n tale per cuiabbia senso porsi il problema di voler sintetizzare i dati davvero non fa alcuna differenza.
37

studenti della facoltà di Economia di Ancona che hanno sostenuto l’esame diEconomia Politica I (d’ora in poi, EP1) nell’anno accademico 2008/2009; la va-riabile dipendente è il voto che hanno preso.25 Il software usato è, come al solito,gretl, ma qualsiasi altro pacchetto econometrico restituisce un output che nonè troppo diverso. Le variabili esplicative usate sono:
Legenda variabilisesso 1 = maschio, 0 = femminaeta Età in anni
votomg Voto di Matematica Generalevotomat Voto di maturità (in 100esimi)
Dependent variable: votoep1
coefficient std. error t-ratio p-value
--------------------------------------------------------
const 14.2526 2.33784 6.096 2.06e-09 ***
sesso 0.265843 0.297672 0.8931 0.3722
eta -0.0546321 0.0631395 -0.8653 0.3873
votomg 0.297902 0.0421685 7.065 4.95e-12 ***
votomat 0.0612471 0.0134888 4.541 6.91e-06 ***
Mean dependent var 25.60291 S.D. dependent var 3.623583
Sum squared resid 5981.851 S.E. of regression 3.316029
R-squared 0.168660 Adjusted R-squared 0.162548
F(4, 544) 27.59138 P-value(F) 7.09e-21
Log-likelihood -1434.609 Akaike criterion 2879.219
Schwarz criterion 2900.759 Hannan-Quinn 2887.637
Tabella 1.2: Esempio: il voto di Economia Politica I
Cominciamo con le cose facili: sulla prima riga della parte inferiore della ta-bella trovate delle statistiche descrittive della variabile dipendente: media (circa25.6) e scarto quadratico medio (circa 3.6). Qui c’è poco da interpretare e passoavanti. La riga seguente riporta la ESS del modello (pari a 5981.851) con, accan-to, la radice quadrata di s2, che risulta in questo caso di circa 3.3. Ricordo, infatti,che s2 = e′e/(n−k). In questo caso, n = 549 e k = 5, per cui il conto è presto fatto.Insomma, la dimensione “tipica” degli errori di approssimazione a cui pervienequesto modello è di circa 3 punti; considerando che il voto è in trentesimi, nonun gran che.
Nella riga ancora sotto, trovate l’indice R2 e la sua variante aggiustata (vedieq. 1.16). In entrambi i casi, siamo intorno al 16%-17%. Di nuovo, non un granche, ma insomma meglio che niente.
A questo punto, cominciamo a chiederci: come possiamo leggere il model-lo? Che informazioni ci ritorna sulle relazioni che intercorrono fra caratteristi-
25Il 30 e lode è, piuttosto arbitrariamente, codificato come 31.
38

che del singolo studente e voto di EP1? Come cambierebbe il fit del modello semodificassimo la composizione dei regressori?
1.5.1 La lettura dei coefficienti
È il momento di dare un’occhiata alla parte superiore della tabella, quella orga-nizzata in colonne. Per ciascuno dei regressori abbiamo:
1. il corrispondente elemento di β, ossia βi ;
2. il relativo errore standard, ossia s ·√δi ;
3. il loro rapporto, ossia il t-ratio (vedi eq. 1.26);
4. il p-value relativo, con tanto di stelline.
Prendiamo ad esempio la variabile eta: la prima cosa da notare è che il coef-ficiente è negativo, per cui la funzione m(·) è decrescente nell’età dell’individuo.In pratica, a parità di altre condizioni, persone più in là negli anni tendono aprendere voti più bassi; peraltro, l’effetto è piuttosto lieve: un ventesimo di pun-to circa all’anno. Insomma, il voto medio dei quarantenni (di nuovo, ceteris pa-ribus) è circa di un punto inferiore a quello dei ventenni. Ciò detto, ci sono tredomande che vengono in mente:
1. Perché succede questo?
2. Quanto è significativo questo fenomeno?
3. È corretto dire che questo vale in generale?
La risposta alla prima domanda non ce l’ho: forse, quelli più vecchi sonopiù somari; forse, quelli più vecchi sono gente che lavora e ha meno tempo difrequentare e studiare; forse, semplicemente quelli che lavorano non si posso-no permettere di rifiutare un voto basso; forse, un quarantenne non ha amiciche si siedono vicino a lui allo scritto e non può copiare da nessuno; forse, idocenti hanno una preferenza per gli studenti giovani; forse, è soltanto un ca-so. I dati non ci dicono quale di queste congetture è corretta: ci dicono che nelnostro dataset succede questo, punto. E peraltro, vale la pena di considerare larisposta alla domanda numero 2: cosa succederebbe se specificassimo una ver-sione alternativa di questo modello, in cui l’età dell’individuo non viene presain considerazione? È presto detto: la SSR, naturalmente, salirebbe, ma non dimolto. Infatti, la statistica t relativa a questo coefficiente ammonta ad un mise-ro -0.8653, il cui valore assoluto è ben al di sotto della soglia magica del 2; tant’èvero che il p-value è circa del 39%, degno di neanche una stellina. In pratica:l’omissione di questa variabile dal modello non fa peggiorare di molto la sua ca-pacità di sintetizzare i dati. Come direbbe un economista applicato, la variabileetà non è significativa.
39

La domanda numero 3 è davvero un coltello nella carne viva: abbiamo stabi-lito che, mediamente, gli studenti anagraficamente più anziani nel nostro cam-pione prendono dei voti un pochino più bassi. Peraltro, l’effetto non sembramolto forte, tant’è che potremmo ignorare l’età dello studente e trovarci con unmodello il cui potere descrittivo rimane grosso modo invariato. È assolutamen-te naturale interpretare il risultato come indicazione che l’età dello studente è,in generale, irrilevante per il voto di EP1: i docenti non fanno parzialità, i giova-ni non copiano più dei vecchi eccetera. In altre parole, la debolezza dell’effettoche l’età ha sul voto è una conseguenza del fatto che ciò che vediamo nel nostrocampione è un caso, un volgare scherzo del destino quando invece in generalel’età di un candidato all’esame di EP1 non ha effetto sul voto. Il debole effettoche vediamo nel nostro campione non è più che un episodio.
La conclusione di cui sopra è del tutto naturale e del tutto ingiustificata. Al-meno, usando l’interpretazione dell’OLS che abbiamo usato fino ad ora. Infatti,tale conclusione sarebbe un esempio da manuale di ragionamento induttivo,ossia:
1. Ho visto la tal cosa succedere in passato.
2. Il futuro si ripeterà come il passato.
3. Di conseguenza, la tal cosa accadrà anche in futuro.
DAVID HUME
Come notoriamente argomentò il filosofo scozzese Da-vid Hume, l’affermazione numero 2 è un puro e sempli-ce atto di fede. Uno può scegliere di crederci, ma non hanessun argomento razionale per convincerne chiunque al-tro. Eppure, a tutti noi piacerebbe poter ragionare dandoper ovvio che la 2 valga: la nostra vita è piena di situa-zioni nelle quali noi ci comportiamo prendendo per cer-te delle cose che, a rigor di logica, non lo sono affatto. Senon lo facessimo, diventeremmo matti. Hume, addirittu-ra, sosteneva che la tendenza all’induzione è un dato bio-logico dell’essere umano, argomento che io trovo moltopersuasivo.
L’inferenza statistica, che abbiamo bandito da questa dispensa, è appuntoun modo per rendere passabilmente rigoroso un ragionamento di tipo indutti-vo, e si fonda sulla sostituzione dell’affermazione numero 2 fatta poc’anzi conuna serie di assunzioni (e cioè affermazioni indimostrabili che scegliamo arbi-trariamente di considerare come vere) che traducono in linguaggio formalizzatola nostra (naturale, direbbe Hume) tendenza a generalizzare.
E quindi: a rigor di logica, l’evidenza empirica mostrata nella Tabella 1.2 nonci autorizza a dire che l’età è irrilevante anche al di fuori del nostro dataset, perquanto ragionevole questo ci sembri. Per poterlo fare, dovremmo fare delle op-portune ipotesi sui motivi per cui abbiamo osservato i dati che abbiamo osser-vato (e non altri) e su quanto sarebbe stato diverso un dataset raccolto in un altro
40

anno accademico, o in un altro ateneo, o su un altro pianeta. Come ho ripetutofino alla noia, noi qui non lo facciamo, ma l’econometria “vera” si fonda sull’i-dea di poterlo e doverlo fare, ed ecco perché per fare le cose sul serio bisognastudiare bene la teoria della probabilità. Ma mi fermo qui.
Per controllare di aver capito bene, consideriamo il coefficiente associato adun’altra variabile, e cioè votomg, il voto preso dallo studente in Matematica Ge-nerale. Il coefficiente vale circa 0.3, ciò che si traduce in: se due studenti conle stesse caratteristiche hanno preso 21 e 28 di Matematica Generale rispetti-vamente, il nostro modello ci suggerisce che il voto che il secondo studente hapreso di EP1 sarà di circa 2 punti superiore a quello del primo. Il conto dellaserva sarebbe: (28−21)×0.297902 ' 2.09.
Inoltre, il coefficiente è significativo: il t-ratio è un roboante 7.065, equiva-lente ad un p-value di circa 5 ·10−12, che si merita tre stelline.26 Come direbbeun economista applicato, la variabile “voto di matematica” è molto significativa.
Ciò premesso, possiamo dire che l’esclusione di questa variabile dal nostromodello produrrebbe un suo forte peggioramento? Assolutamente sì. Possiamodire che quelli che prendono buoni voti in Matematica Generale prendono vo-ti mediamente più alti degli altri in EP1? Nel nostro campione, assolutamentesì. Fuori dal nostro campione, no.27 Possiamo dire che, se gli studenti studias-sero meglio matematica, andrebbero meglio di economia? Ci piacerebbe po-terlo fare, ma non è un’affermazione che possiamo motivare in modo rigoroso.Possiamo dire che, se i docenti di Matematica Generale abbassassero le loro va-lutazioni di 2 punti, questo condurrebbe ad un abbassamento dei voti di EP1intorno a 0.6? Certamente no.
1.5.2 Il resto dell’output
Non restano molte cose da commentare, e sono tutte nelle ultime tre righe dellaTabella 1.2. La statistica F alla quarta riga è semplicemente il confronto fra il mo-dello e un modello assolutamente minimale, basato sulla sola media aritmetica,cioè un confronto fra e′e e y′Mιy. In pratica, il vincolo consiste nell’azzeramentocontemporaneo di tutti i coefficienti ad esclusione del primo. In questo caso, ilp-value è talmente infinitesimale da autorizzarci a preferire il modello libero.28
La riga seguente contiene il valore della log-verosimiglianza (in inglese, log-likelihood), che è calcolato come
L =−n
2
[1+ ln(2π)+ ln(σ2)
]26Per dare l’idea: 5 · 10−12 è circa il rapporto che c’è fra il prezzo di una pizza e una birra e il
debito pubblico dello Stato italiano.27Anche se non possiamo neanche dire che non sia vero; su questo argomento, non possiamo
dire niente.28Il lettore entusiasta non tarderà a scoprire una semplice relazione, che dimostra che questa
statistica è una funzione crescente dell’indice R2, e in pratica contiene la stessa informazione.
41

Nel nostro contesto, non si vede quale informazione questo numero aggiungaessendo, di nuovo, una trasformazione monotona della SSR. La sua utilità emer-ge soprattutto in un contesto probabilistico-inferenziale. Per noi, qui, è utile so-lo in quanto fornisce l’ingrediente di base per il calcolo dei cosiddetti criteri diinformazione, che sono delle statistiche utili a confrontare modelli non annidati.
Cosa vuol dire “modelli non annidati”? Sono modelli che non si possonoesprimere in modo tale che uno dei due sia un caso particolare dell’altro. Peresempio, i due modelli visti alle equazioni (1.14) e (1.15) sono annidati per-ché, come abbiamo ampiamente argomentato, la (1.15) assieme al vincoloγ= 0diventa la (1.14).
Consideriamo però la situazione in cui dobbiamo scegliere fra
yi ' x′iβyi ' z′iγ
Di nuovo, vorremmo trovare un accettabile compromesso fra l’esigenza di ap-prossimare le yi meglio che si può e quella di farlo usando un numero di para-metri abbastanza piccolo da rendere la nostra approssimazione compatta e ma-neggevole. L’idea, pertanto, è di definire delle statistiche che bilancino questedue esigenze in modo ragionevole. Un primo esempio l’abbiamo già visto, edè l’indice R2 (vedi eq. 1.16 nella sezione 1.3.2). I criteri di informazione pren-dono come base la log-verosimiglianza (moltiplicata per -2) e ci aggiungonouna funzione (detta di penalizzazione) che è crescente nel numero di parame-tri del modello, e talvolta anche nel numero di osservazioni. I criteri che gretl
riporta sono quelli di Akaike (AIC), quello di Schwartz (BIC) e quello di Hannan-Quinn (HQC), che , come si vede, si differenziano fra loro solo per la forma dellafunzione di penalizzazione.
AIC = −2L+2k (1.27)
BIC = −2L+k logn (1.28)
HQC = −2L+2k loglogn (1.29)
Dovrebbe essere ovvio che ognuno di questi criteri dovrebbe essere, idealmen-te, più basso possibile. Per cui, fra due modelli non annidati tendenzialmentesceglieremo quello che presenta il criterio più basso.
Forse potrei fare un esempio e rendere più chiaro il tutto, ma magari a questopunto se lo può anche inventare il lettore.
1.5.3 Il teorema di Frisch-Waugh
Un’altra cosa che si vede molto bene usando le matrici di proiezione è il teoremadi Frisch-Waugh: supponiamo di dividere le colonne di X in due gruppi, chechiamiamo X1 e X2. Naturalmente, viene diviso di conseguenza anche il vettore
42

β, così che possiamo scrivere
y = [X1 X2
][β1
β2
]L’applicazione della (1.10) produce la seguente espressione:[
β1
β2
]=
[X′
1X1 X′1X2
X′2X1 X′
2X2
]−1 [X′
1yX′
2y
]Si possono, a questo punto, ricavareβ1 eβ2 in funzione di X1, X2 e y andando
a vedere che forma ha l’inversa della matrice X′X; la cosa presenta anche uncerto interesse didattico, ma c’è un modo più conciso ed elegante di recuperareil risultato che ci interessa. Consideriamo che
y = y+e = X1β1 +X2β2 +e
e premoltiplichiamo l’espressione sopra per MX2 ; si ha
MX2 y = MX2 X1β1 +e
perché MX2 X2 = 0 (per costruzione) e MX2 e = e (perché e = MXy, ma Sp(X2) ⊂Sp(X), e quindi MX2 MX = MX). Premoltiplicando ancora per X′
1 otteniamo
X′1MX2 y = X′
1MX2 X1β1
perché X′1e = 0. Di conseguenza,
β1 =(X′
1MX2 X1)−1 X′
1MX2 y (1.30)
Si noti che la (1.30) potrebbe anche essere scritta
β1 =[(X′
1MX2 )(MX2 X1)]−1 (X′
1MX2 )(MX2 y)
e quindi β1 è il vettore dei coefficienti della regressione che approssima i residuidi y rispetto a X2 sui residui di X1 rispetto a X2. Per ragioni di simmetria, è deltutto ovvio che risulta
β2 =(X′
2MX1 X2)−1 X′
2MX1 y
Cosa ci dice questo risultato? Ci dice che i coefficienti relativi ad un gruppodi regressori misurano la risposta di y al netto degli altri. L’esempio che si fa ingenere è: l’inclusione del vettore ι fra i regressori fa sì che i coefficienti associatiagli altri regressori (chiamiamoli X1) sono quelli che si otterebbero facendo laregressione degli scarti dalla media di y sugli scarti di X1 dalla propria media.Dimostrazione: immediata, ponendo X2 = ι (e quindi, MX2 = Mι).
Un esempio più articolato, che forse aiuta un po’ di più la comprensione, è:immaginiamo che y contenga dati sui redditi di n individui, che X1 sia il loro li-vello di istruzione e che X2 contenga la costante e una dummy che vale 0 se gli
43

individui abitano al Nord e 1 se al Sud. Naturalmente MX2 y contiene gli scarti dalreddito medio della propria regione, così come MX2 X1 contiene gli scarti deglianni di istruzione dalla media della propria regione. In pratica, stiamo pulen-do i dati dell’effetto Nord-Sud, e quindi stiamo implicitamente tenendo contoche differenze di reddito fra regioni posso dipendere da differenze nel livello diistruzione medio fra una regione e l’altra. Di conseguenza, stimando un modelloche contiene sia la variabile “istruzione” che la dummy “regione”, il coefficien-te relativo all’istruzione misura l’effetto dell’istruzione sul reddito al netto deglieffetti territoriali. In gergo, si direbbe in questo caso che “stiamo controllandoper la dummy regione”, il che significa che gli effetti delle altre variabili sono daconsiderarsi depurati dall’effetto di eventuali disparità geografiche.
Un esempio pratico lo fornisce la coppia di modelli mostrata nella Tabel-la 1.3, in cui sono usati dati provenienti dal database dei World DevelopmentIndicators, curato dalla Banca Mondiale. Le variabili usate sono:
Legenda variabilil_inet Logaritmo della quota di popolazione che usa Internet
(var. dipendente)l_wpoll Logaritmo dell’indice di inquinamento delle acque (var.
esplicativa)l_gdp Logaritmo del PIL pro capite (var. esplicativa)
Variabile dipendente: l_inet(Errori Standard in parentesi)
(a) (b)const 5.100∗∗ −5.748∗∗
(0.8758) (1.176)
l_wpoll −0.7967∗∗ −0.1388(0.3026) (0.1923)
l_gdp 0.9451∗∗(0.09169)
n 61 61R2 0.1051 0.6840R2 0.0900 0.6731SSR 100.7983 35.5991
Tabella 1.3: Uso di Internet
Il modello (a) ci informa che usare il dato dell’inquinamento delle acque perapprossimare i diversi livelli di uso di Internet fra i paesi produce risultati nondisprezzabili: i paesi con le acque più pulite sono quelli in cui più persone usanoInternet. Il coefficiente dell’inquinamento nel modello (a) si pavoneggia, fortedelle sue due stelline.
Ora, non è che buttare diossina in un fiume provochi una diminuzione deivostri contatti Facebook. È che i paesi più ricchi sono anche quelli che si posso-
44

no permettere la tecnologia anti-inquinamento (che costa un sacco di soldi). Einfatti, guardando il modello (b) si vede che, una volta che si è controllato per ilreddito pro capite, le stelline sull’inquinamento scomapiono. Fra l’altro, come sivede, la SSR diminuisce sensibilmente. Questo non vuol dire che il modello (a)sia sbagliato; è un modello parziale, se volete incompleto, in cui il dato statisticodella correlazione negativa fra inquinamento e uso della rete produce il risultatoovvio di un coefficiente negativo e significativo.
Non è che la correlazione fra inquinamento e uso di Internet non esista. Èsemplicemente che tale correlazione dipende da una causa a monte di ambe-due, che è il livello di sviluppo economico. Una volta che introduciamo nel mo-dello una variabile che spiega il perché di questa correlazione (a cui, evidente-mente, non si può dare alcuna connotazione causale), l’effetto sparisce. Questoci consente di dire che il modello (b) è “giusto”? Per me, in assoluto no. Tutta-via, ci consente di dire che è più giusto del modello (a) o, meglio ancora, menosbagliato.
1.5.4 L’effetto leva
I patiti della finanza non si eccitino anzitempo: parliamo di una cosa diversa.Supponiamo di voler ricalcolare l’OLS senza la i -esima osservazione e chia-
miamo β(−i ) la statistica corrispondente. Anzi, usiamo la convenzione di usareil pedice “(−i )” per intendere “esclusa la i -esima osservazione”; quindi, con uncerto qual abuso di notazione, X(−i ) è una matrice di n−1 righe e k colonne, datadalla matrice X alla quale abbiamo tolto la i -esima riga.
Il motivo per cui lo facciamo è per vedere cosa succede al nostro model-lo se una certa osservazione, che in realtà abbiamo, non fosse stata disponi-bile. È chiaro che, se i risultati cambiassero drasticamente omettendo questaosservazione dal nostro dataset, quella osservazione merita di essere studia-ta in modo approfondito, perché rappresenta, per così dire, un caso a parte, equindi potrebbe anche venirci il dubbio che stiamo sbagliando qualcosa: ma-gari i dati sono sbagliati, magari il nostro modello è inapplicabile a quel certoindividuo29, magari ci siamo dimenticati di includere nel modello un qualcheregressore importante, o non ce l’abbiamo.
Come che sia, un modo elegante per vedere cosa succede è quello di consi-derare un modello in cui alla matrice dei regressori viene aggiunta una colonnad, che contiene tutti zeri, a parte la i -esima riga, che contiene 1. Senza perditadi generalità, supponiamo che i = n; quindi, d è un vettore di zeri con un 1 infondo. In pratica, il modello diventa
y = Xβ+dα+e = Wγ+e (1.31)
dove
y =[
y(−i )
yi
]W =
[X(−i ) 0
x′i 1
]γ=
[β
α
]29Aaaaaaahhhh! La legge ad personam!
45

Il modello di partenza è, ovviamente, il modello vincolato con α = 0. Alcunirisultati che ci faranno comodo nel prosieguo:30
X′Md =[
X′(−i ) 0
]X′MdX = X′
(−i )X(−i ) =∑j 6=i
x j x′j
X′Mdy = X′(−i )y(−i ) =
∑j 6=i
x j y ′j
d′MXd = mi
d′MXy = d′e = ei
Dove e sono i residui dell’OLS sul modello di partenza, che poi altro non è cheil modello nell’equazione (1.31), vincolato ad α = 0; mi è l’i -esimo elementosulla diagonale di MX, ossia 1−x′i (X′X)−1xi . È anche utile introdurre la quantitàhi = 1−mi = x′i (X′X)−1xi , l’i -esimo elemento sulla diagonale di PX.
I risultati dell’OLS applicato all’equazione (1.31) sono facili da trovare trami-te il teorema di Frisch-Waugh:
β= (X′MdX)−1X′Mdy = (X′−1X−1)−1X′
−1y−1
α= (d′MXd)−1d′MXy = ei /mi
Il vettore β non è altro che la statistica OLS ottenuta omettendo l’i -esimaosservzione. Per quanto invece riguarda α, invece, consideriamo il vettore deiresidui e = MWy; notiamo in primo luogo che d′MW = 0′ (vero per costruzione,visto che d ∈ Sp(W)) implica d′e = ei = 0. Di conseguenza, α= yi−x′i β, che si puòvedere come l’errore commesso usando tutte le altre osservazioni per predire lai -esima. Chiamiamolo “errore di previsione”.
Inoltre, dalla definizione di e si ha
y = Xβ+dα+ e,
che, premoltiplicata per MX, dà
MXy = e = MXdα+ e
e quindi
e′e = d′MXdα2 + e′e
e infine
e′e = e′e− e2i /mi
che mostra come la SSR del modello senza la i -esima osservazione sia ugualealla SSR del modello completo meno e2
i /mi .
30Sono facili da dimostrare. Anzi: è un esercizio carino, sapete? Fatelo.
46

Si noti che tutte queste quantità possono essere calcolate senza ricalcolarel’OLS sull’equazione (1.31), ma semplicemente riutilizzando i risultati dell’OLSsul dataset completo. Si può dimostrare che
β= β+ (X′X)xiei
mi
di conseguenza,
x′i β= x′i β+ eihi
mi
Sembra chiaro che la grandezza ei /mi è suscettibile di un’interpretazioneparticolare: più è grande, più la i -esima osservazione impatta sulla stima com-plessiva. Ovviamente, questo succede tanto più è grande (in valore assoluto)ei , ma ovviamente questo dipende anche da quanto è piccolo mi , e quindi daquanto è grande hi . Per dare un’ordine di grandezza, si può mostrare che lamedia aritmetica delle hi è uguale a k/n.
Più precisamente: si chiama traccia di una matrice quadrata la somma deglielementi lungo la sua diagonale, e si scrive
tr(A) =n∑
i=1ai ,i ,
in cui naturalmente immaginiamo che A sia una matrice n × n. La funzionetraccia ha un sacco di proprietà divertenti: in primo luogo, è lineare (ma questoè piuttosto ovvio), per cui tr(A+B) = tr(A)+ tr(B); per di più, se A = BC , allora
tr(A) = tr(BC ) = tr(C B)
in cui la prima uguaglianza è ovvia, ma la seconda lo è molto meno. Più in gene-rale, vale quella che io chiamo “proprietà del trenino”, per cui dentro la funzionetraccia si può staccare un vagone dalla cima e attaccarlo in testa e viceversa,cosicché
tr(ABC ) = tr(BC A) = tr(C AB)
Questo risultato ci consente di dimostrare facilmente che tr(PX) = k: infatti
tr(PX) = tr(X(X′X)−1X′)= tr
((X′X)−1X′X
)= tr(I ) = k
Poiché hi non è che l’i -esimo elemento sulla diagonale di PX e quasta matriceha n righe, chiaramente la media delle hi è k/n e mi è, in media 1−k/n.
Il criterio di cross-validation è un criterio che misura la “stabilità” del nostromodello misurando quanto grandi sarebbero gli errori di previsione per tutte leosservazioni.
n∑i=1
e2(−i ) =
n∑i=1
(ei
mi
)2
47

1.6 La regressione dinamica
Finora, abbiamo dato per scontato che le informazioni utili per costruire un’ap-prossimazione del dato di nostro interesse yi fossero reperibili solo nel corri-spondente elemento xi ; in certi casi, questa assunzione è del tutto naturale. Inun dataset di tipo cross-section, ad esempio, questa è la norma. Perché mai le ca-ratteristiche del signor Rossi dovrebbero essere utili nel sintetizzare il dato rela-tivo al signor Bianchi? Certo, in alcuni frangenti non saremmo così sicuri. Forseil tasso di disoccupazione in Emilia-Romagna può avere degli effetti sui salari inToscana. Forse nel libretto di Pinco Pallino il voto di Statistica I ha qualche cosaa che fare con il numero di ore passate a studiare Matematica Generale.
Se proprio volessimo trattare questo punto in modo generale, allora potrem-mo dire che, in astratto, nessuno ci vieta di pensare a modelli in cui la funzionem(·), che usiamo per approssimare l’i -esimo elemento del vettore y, possa di-pendere dall’intera matrice X. Ma, come spesso accade, perseguire la generalitàporta rapidamente a porsi dei problemi che non hanno soluzione.
Perché si possa dire qualcosa di sensato, il problema va delimitato in qualchemodo. Nell’econometria “per davvero”, la soluzione più generale ed eleganteporta ai cosiddetti modelli spaziali, che oggi godono di una certa popolarità e dicui però non parlo. Un caso che, invece, è ben noto da lungo tempo è quello deicampioni di serie storiche. In questo caso, il problema risulta molto semplificatoper via di due caratteristiche:
1. I dati hanno un ordinamento naturale.
2. In un dato istante di tempo, possiamo ritenere noto ciò che accade nelpresente e che è accaduto nel passato, ma non quello che accadrà nelfuturo.
Facendo violenza a ciò che c’è di più sacro nell’analisi probabilistica delleserie storiche, a questo punto introduco una definizione: chiamiamo set infor-mativo al tempo t l’insieme delle informazioni note al tempo t e usiamo perindicarlo il simbolo ℑt . In pratica, se usiamo, come di consueto, il vettore yper raccogliere i dati sulla variabile dipendente e la matrice X per le variabiliesplicative, possiamo dire che il set informativo al tempo t è l’insieme
ℑt ={
x1,x2, . . .xt , y1, y2, . . . , yt−1}
Si noti che non solo, come è ovvio, l’insieme ℑt contiene le prime t righe di X, macontiene anche i dati sulla y fino al tempo t −1. Questo perché il problema del-l’approssimazione viene visto implicitamente in chiave sequenziale: vogliamoapprossimare yt sulla base delle informazioni che abbiamo al tempo t .
È evidente che, per definizione, ℑt−1 ⊂ ℑt ⊂ ℑt+1, per cui, in linea di prin-cipio, ad ogni istante la funzione che usiamo per approssimare yt può essere
48

diversa da tutte le precedenti; più passa il tempo, più cose sappiamo. Tutta-via, potremmo anche decidere di ignorare per semplicità le informazioni pro-venienti da un passato “troppo” remoto, ed autolimitarci a considerare solo unsottoinsieme di ℑp
t dato da tutto ciò che è avvenuto nel passato recente:
ℑpt = {
xt−p ,xy−p+1, . . .xt , yt−p , yt−p+1, . . . , yt−1}
dove lo scalare p è la traduzione del nostro concetto di “recente”.Se aggiungiamo un piccolo livello di flessibilità nell’ammettere che il limite
all’indietro per la yt non deve necessariamente essere uguale a quello per la xt , ilproblema è abbastanza delimitato da permetterci di approssimare yt per mezzodella funzione
yt 'p∑
i=1αi yt−i +
q∑i=0
β′i xt−i (1.32)
così che possiamo scrivere una cosa del tipo
yp+1
yp+2
yp+3...
=
yp yp−1 . . . y1 x′p+1 x′p . . . x′p−q+1
yp+1 yp . . . y2 x′p+2 x′p+1 . . . x′p−q+2
yp+2 yp+1 . . . y3 x′p+3 x′p+2 . . . x′p−q+3...
α1
α2...αp
β0
β1...βq
+
ep+1
ep+2
ep+3...
e rientrare così nello schema analitico che abbiamo seguito fino a qui, con laconseguenza che possiamo continuare ad usare l’OLS.
Un modello così si chiama modello ADL(p,q), dove ADL sta per Autoregressi-ve Distributed Lags. Spiegare perché è pedante e noioso e probabilmente inutile,per cui non lo faccio. Dico invece che il calcolo di parametri avviene, di nuovo,per mezzo della tecnica OLS, e quindi non c’è molto da dire in più di quantoabbiamo già detto.
È interessante, invece, porsi un’altra domanda, che deriva dal fatto che stia-mo usando come approssimazione della variabile dipendente una funzione chenon è più una semplice funzione lineare, ma è un oggetto più complesso notocome equazione alle differenze. Ciò apre un problema di interpretazione: senel modello statico il coefficiente β j ha un’interpretazione naturale in terminidi derivata parziale (vedi (1.6) a pag. 15), un’operazione analoga è un po’ piùdifficile per un’equazione alle differenze. Come vedremo, dovremo estendere ilconcetto da statico a dinamico, ossia chiederci, per un’equazione del tipo
yt =p∑
i=1αi yt−i +
q∑i=0
β′i xt−i
49

quale sia l’effetto della x sulla yt dopo un dato lasso di tempo. In pratica, la do-manda da porsi è: che effetto ha un movimento nella xt su yt+ j ? Che poi, dalmomento che i coefficientiαi eβi non dipendono da t , è la stessa cosa che chie-dersi: che effetto ha avuto su yt un evento avvenuto j periodi fa, ossia xt− j ? Ov-vio che, per j = 0, questa domanda comprende come caso particolare il modellostatico, ossia l’equazione lineare, ma consente anche di descrivere meccanismipiù complessi, in cui le cose non succedono necessariamente all’istante.
Dobbiamo trovare un modo, pertanto, di calcolare delle grandezze del tipo
di = ∂yt
∂xt−i= ∂yt+i
∂xt, (1.33)
che si chiamano moltiplicatori dinamici, o anche semplicemente moltiplicato-ri. Il primo, cioè d0 si chiama anche moltiplicatore d’impatto.
Per risolvere il problema dobbiamo imparare a manipolare le equazioni alledifferenze. Coraggio e rimbocchiamoci le maniche.
1.6.1 L’operatore ritardo
In fin dei conti, le serie storiche non sono altro che sequenze di numeri, ordinateattraverso il tempo. In molti casi, è comodo poter manipolare le sequenze condegli appositi attrezzi, detti operatori. L’operatore ritardo viene generalmenteindicato con la lettera L nella letteratura econometrica (gli statistici preferisco-no la B); è un operatore che si applica a sequenze di oggetti, e trasforma una se-quenza xt in un altra sequenza che ha la curiosa caratteristica di avere gli stessivalori di xt , ma sfalsati di un periodo.31 Se applicato ad una grandezza costantenel tempo, la lascia invariata. In formule,
Lxt = xt−1
L’applicazione ripetuta n volte di L viene indicata con la scrittura Ln , e quindi siha Ln xt = xt−n . Per convenzione si pone L0 = 1. L’operatore L è un operatore li-neare, nel senso che, se a e b sono costanti, si ha L(axt +b) = aLxt +b = axt−1+b. La caratteristica più graziosa dell’operatore L è che le sue proprietà appe-na enunciate permettono, in molte circostanze, di manipolarlo algebricamentecome se fosse un numero. Questo avviene soprattutto quando si consideranopolinomi nell’operatore L. Facciamo un paio di esempi semplici.
Esempio 3 Una squadra di calcio ha in classifica tanti punti quanti ne aveva allagiornata precedente, più quelli che ha guadagnato nell’ultimo turno. Chiamandorispettivamente queste sequenze ct e ut , si avrà
ct = ct−1 +ut
31In certi contesti, si utilizza anche il cosiddetto operatore anticipo, usualmente indicato conla lettera F e definito come l’inverso dell’operatore ritardo (F xt = xt+1). Noi non lo useremo mai,ma è bello sapere che c’è.
50

La stessa cosa si sarebbe potuta scrivere adoperando l’operatore ritardo:
ct = Lct +ut → ct −Lct = (1−L)ct =∆ct = ut
L’operatore ∆, che dovrebbe essere una vecchia conoscenza, è definito come (1−L), ossia un polinomio di primo grado in L. L’espressione precedente non dicealtro che la variazione dei punti in classifica è data dai punti guadagnati in ognigiornata.
Esempio 4 Chiamiamo qt il saldo demografico trimestrale per il comune di Roc-ca Cannuccia. È evidente che il saldo demografico annuale (cioè le nascite degliultimi 12 mesi meno le morti nello stesso periodo) sono date da
at = qt +qt−1 +qt−2 +qt−3 = (1+L+L2 +L3)qt
Poiché (1+L +L2 +L3)(1−L) = (1−L4) (moltiplicare per credere), “moltipli-cando” l’espressione precedente32 per (1−L) si ha
∆at = (1−L4)qt = qt −qt−4
la variazione del saldo demografico annuale tra un trimestre ed il successivo nonè che la differenza fra il saldo dell’ultimo trimestre e il corrispondente trimestredell’anno precedente.
Le manipolazioni possono essere anche più complesse; in particolare ci so-no due risultati di routine: il primo è che
n∑i=0
ai = 1−an+1
1−a
per a 6= 1. Se poi |a| < 1, si ha che an → 0 e quindi∑∞
i=0 ai = 11−a . Ponendo
a =αL, si può dire che, per |α| < 1, i due operatori (1−αL) e (1+αL+α2L2+·· · )sono uno l’inverso dell’altro. In pratica, se |a| < 1, vale
(1−αL)(1+αL+α2L2 +·· · ) = 1,
da cui l’espressione
(1−αL)−1 =∞∑
i=0αi Li ,
che spesso si abbrevia anche in
∞∑i=0
αi Li = 1
1−αL.
32Ad essere precisi, si dovrebbe dire: ‘applicando all’espressione precedente l’operatore (1−L)’.
51

Il secondo risultato riguarda i polinomi. Prendiamo un polinomio di n-esimo grado, e chiamiamolo P (x). Per definizione, si ha
P (x) =n∑
j=0p j x j
Se P (0) = p0 = 1, allora è possibile esprimere il polinomio di n-esimo gradocome il prodotto di n polinomi di primo grado:
P (x) =n∏
j=1(1−λ j x) (1.34)
i coefficienti λ j non sono altro che i reciproci delle radici di P (x), ossia quei va-lori per cui P ( 1
λ j) = 0. Nessuno assicura che queste radici siano reali (per n > 1
possono anche essere numeri complessi), ma dal punto di vista teorico questonon ha alcuna rilevanza. Questo risultato è importante perché, unito al prece-dente, permette di stabilire le condizioni di invertibilità per polinomi di qualun-que grado. In particolare, si vede facilmente che il polinomio P (x) è invertibilese e solo se ognuno degli elementi della produttoria nell’equazione (1.34) lo è.Di conseguenza, P (x) è invertibile se e solo se |λ j | < 1 per ogni j , ciò che, a suavolta, è vero se e solo se tutte le radici del polinomio sono maggiori di 1 in valoreassoluto.
In pratica: se una sequenza è at è definita come trasformazione di un’altrasequenza ut attraverso il polinomio P (L), ciò che in formule si scrive
at = P (L)ut ,
allora è possibile ritrovare la sequenza ut partendo da at solo se l’operatore P (L)ha un’inverso, cioè se i valori z che rendono vera P (z) = 0 sono tutti numerimaggiori di 1 in modulo. In questo caso, si può scrivere
ut = P (L)−1at = 1
P (L)at .
Un altro trucchetto di uso comune è quello di valutare un polinomio P (L) inL = 1. Evidentemente, l’espressione P (1) è uguale a
P (1) =n∑
j=0p j 1 j =
n∑j=0
p j
e quindi è semplicemente uguale ad un numero, dato dalla somma dei coeffi-cienti del polinomio. Questo torna comodo quando si applica un polinomio aduna costante, visto che
P (L)µ=n∑
j=0p jµ=µ
n∑j=0
p j = P (1)µ.
Vediamo un altro esempio:
52

Esempio 5 (Il moltiplicatore keynesiano) Supponiamo che
Yt = Ct + It
Ct = αYt−1
Dove α è la propensione marginale al consumo, compresa fra 0 e 1. Combinandole due equazioni si ha
Yt =αYt−1 + It → (1−αL)Yt = It ;
in questo modello, quindi, applicando alla sequenza Yt (la serie storica del red-dito) il polinomio di primo grado A(L) = (1−αL) si ottiene la serie storica degliinvestimenti, semplicemente perché It = Yt −Ct = Yt −αYt−1.
Un risultato più interessante si ha invertendo l’operatore A(L) = (1−αL):
Yt = (1+αL+α2L2 +·· · )It =∞∑
i=0αi It−i :
la domanda aggregata al tempo t può essere vista come una somma ponderatadei valori presenti e passati dell’investimento. Se poi il flusso di investimenti ècostante nel tempo, allora It = I può essere tirato fuori dalla sommatoria, e siottiene il risultato standard da libro di macro elementare:
Yt = I∞∑
i=0αi = I
1−α .
In questo ultimo caso si sarebbe anche potuto scrivere
A(1)Yt = I =⇒ Yt = I
1−α .
Il fatto che spesso si può maneggiare l’operatore L come se fosse un numeronon vuol dire che lo si possa far sempre: bisogna sempre ricordare che Lxt nonè ‘L per xt ’, ma ‘L applicato a xt ’. L’esempio seguente dovrebbe servire a metterein guardia.
Esempio 6 Date due sequenze xt e yt , definiamo una terza sequenza zt = xt yt .È del tutto chiaro che zt−1 = xt−1 yt−1. Tuttavia, potremmo essere tentati di fare ilseguente ragionamento:
zt−1 = xt−1 yt−1 = Lxt Lyt = L2xt yt = L2zt = zt−2
che è evidentemente assurdo.
L’operatore L può essere applicato in modo del tutto analogo anche nel casoin cui xt sia un vettore: Lxt = xt−1 . Le cose si fanno più articolate se consideria-mo espressioni del tipo
xt + Axt−1 = (I + AL)xt
dove A è una matrice. In questo caso l’espressione (I + AL) è un operatore— funzione dell’operatore L — matriciale. Esso può essere visto in due modiequivalenti:
53

Polinomio matriciale L’operatore (I + AL) è la somma di due matrici, ognunadelle quali “moltiplica” l’operatore L per una potenza diversa. Si può pen-sare a (I + AL) come ad un polinomio di ordine 1 nell’operatore L in cui ilprimo coefficiente è la matrice identità ed il secondo è la matrice A.
Matrice di polinomi L’operatore (I + AL) è una matrice i cui elementi sono po-linomi di ordine 1; ad esempio, l’elemento i j di (I + AL) è di j +ai j L, do-ve di j è il cosiddetto ‘delta di Kronecker’, che è uguale a 1 per i = j e 0altrimenti.
La generalizzazione al caso di polinomi di ordine p dovrebbe essere immediata,così che un’espressione del tipo
yt =C (L)xt =C0xt +C1xt−1 +·· ·+Cp xt−p
non dovrebbe destare alcuno stupore. Se il vettore xt ha n elementi e le Ci sonomatrici (r ×n), allora yt è una sequenza di vettori di r elementi. Il problemadell’invertibilità in questo contesto è però un tantino più complicato, per cuiglisso.
1.6.2 Equazioni alle differenze
Ora che i polinomi in L non hanno per noi più segreti, possiamo passare al pro-blema che davvero ci interessa. Partiamo da un’equazione alle differenze, chepossiamo scivere come
A(L)yt = B(L)xt
dove A(L) e B(L) sono polinomi in L di ordine p e q rispettivamente. In generale,yt e xt possono essere vettori, nel qual caso A(L) e B(L) sono polinomi matricia-li. Qui, per far le cose semplici, assumerò che siano scalari. Se il polinomio A(L)è invertibile, possiamo definire D(L) = B(L)/A(L), che per A(L) 6= A(0) è infinitoe quindi
yt = D(L)xt =∞∑
i=0di xt−i
A questo punto, il problema da cui eravamo partiti, e cioè quello di dareun’interpretazione ai parametri di un’equazione alle differenze, è risolto: infatti,i moltiplicatori dinamici definiti all’equazione (1.33), che riporto qui sotto
di = ∂yt
∂xt−i= ∂yt+i
∂xt,
sono semplicemente i coefficienti del polinomio D(L). Questi, volendo, si pos-sono calcolare analiticamente invertendo il polinomio A(L), ma non è né in-teressante né divertente. Invece, si può fare la stessa cosa in modo rapido edistruttivo usando un algoritmo ricorsivo, e ora vi spiego come.
Cominciamo col dire che il moltiplicatore di impatto è facile da trovare, per-ché è semplicemente d0, ossia D(0), ossia B(0)/A(0), ossia β0 (visto che A(0) =
54

1). Tutti gli altri moltiplicatori possono essere trovati da lì in funzione di quel-li già disponibili semplicemente sfruttando la definizione (1.33); per essere piùchiari, la (1.33) permette di esprimere di per mezzo di di−1,di−2 eccetera. Unavolta trovato il primo, gli altri seguono.
Faccio un esempio che mi sa che è meglio. Nel caso dell’ADL(1,1),
yt =αyt−1 +β0xt +β1xt−1, (1.35)
usando il fatto che un moltiplicatore non è che una derivata, si ha
d0 = ∂yt
∂xt= ∂
∂xt
(αyt−1 +β0xt +β1xt−1
)=β0
d1 = ∂yt
∂xt−1= ∂
∂xt−1
(αyt−1 +β0xt +β1xt−1
)=α∂yt−1
∂xt−1+β1 =αd0 +β1
d2 = ∂yt
∂xt−2= ∂
∂xt−2
(αyt−1 +β0xt +β1xt−1
)=α∂yt−1
∂xt−2=αd1
eccetera, eccetera, eccetera, eccetera, eccetera, . . .
Esempio 7 (Inversione di polinomi) Supponiamo che
yt = 0.2yt−1 +0.4xt +0.3xt−2.
In questo caso A(L) = 1−0.2L e B(L) = 0.4+0.3L2. L’inverso di A(L) è
A(L)−1 = 1+0.2L+0.04L2 +0.008L3 +·· ·
per cuiB(L)
A(L)= (0.4+0.3L2)× (1+0.2L+0.04L2 +0.008L3 +·· · )
È evidente che il calcolo a mano si può fare, e risulta
B(L)
A(L)= 0.4× (1+0.2L+0.04L2 +0.008L3 +·· · )+
+0.3L2 × (1+0.2L+0.04L2 +0.008L3 +·· · ) == 0.4+0.08L+0.016L2 +0.0032L3 +·· ·+
+0.3L2 +0.06L3 +0.012L4 +0.0024L5 · · · == 0.4+0.08L+0.316L2 +0.0632L3 +·· ·
Ma si fa prima a fare il calcolo ricorsivo:
d0 = B(0)/A(0) = 0.4/1 = 0.4
d1 = 0.2 ·d0 = 0.08
d2 = 0.2 ·d1 +0.03 = 0.016+0.3 = 0.316
d3 = 0.2 ·d2 = 0.0632
e così via.
55

In molte circostanze, è interessante applicare i moltiplicatori per risponderead una domanda ben specifica: cosa succede a yt se si verifica una variazionepermanente in xt . Chiaramente, al tempo zero l’effetto sarà dato dal moltipli-catore d’impatto d0, ma dopo un periodo bisognerà sommare l’effetto istanta-neo con quello derivante dal periodo precedente, e quindi l’effetto sarà dato dad0 +d1. Procedendo per induzione, è naturale definire una nuova sequenza dimoltiplicatori come
c j = d0 +d1 +·· ·+d j =j∑
i=0di .
La grandezza c j si chiama moltiplicatore interinale e misura l’effetto su yt diuna variazione permanente di xt avvenuta j periodi fa. Naturalmente, è interes-sante calcolare c = lim j→∞ c j , che è noto come moltiplicatore di lungo periodo.La cosa è più semplice di quanto sembri, visto che
c j =∞∑
i=0di = D(1)
ossia c è il valore del polinomio D(z) valutato in z = 1; ma poiché D(z) = B(z)/A(z),se ne deduce che c = B(1)
A(1) .
Esempio 8 (Moltiplicatori interinali) Riprendiamo l’esempio precedente in cui
yt = 0.2yt−1 +0.4xt +0.3xt−2.
I moltiplicatori interinali si calcolano facilmente partendo da quelli dinamici:
c0 = d0 = 0.4
c1 = d0 +d1 = c0 +d1 = 0.48
c2 = d0 +d1 +d2 = c1 +d2 = 0.796
eccetera. Il limite di questa sequenza sembra difficile da calcolare, ma in realtà èdavvero molto semplice:
c = D(1) = B(1)
A(1)= 0.7/0.8 = 0.875
Et voilà.
Il moltiplicatore di lungo periodo c è molto importante, perché dice la pro-porzionalità che c’è fra yt e xt in stato stazionario: immaginiamo di fissare xt adun dato valore e di fare modo che rimanga fisso a quel valore per sempre. Esisteun valore limite per yt ? Se la risposta è affermativa, allora il sistema ammet-te uno stato stazionario (anche noto come steady state), che si può considerarecome equilibrio di lungo periodo, nel senso che se il sistema si trova in statostazionario, allora cessa di muoversi finché non arrivano shock dall’esterno aturbare l’equilibrio.
56

Per vedere il motivo per cui c è il parametro di stato stazionario, immaginia-mo che il sistema sia in tale condizione: ambedue le variabili restano ferme neltempo, e possiamo scrivere yt = Y e xt = X ; per conseguenza,
A(L)yt = B(L)xt ⇒ A(L)Y = B(L)X ⇒ A(1)Y = B(1)X ⇒ Y = B(1)
A(1)X = c X
e il sistema non è in equilibrio ogni qual volta che yt 6= c X . Come vedremo,questa banale osservazione sarà piuttosto importante in seguito.
1.6.3 La rappresentazione ECM
Come si è visto, il modo più efficace di leggere i parametri di un’equazione alledifferenze è quello di trasformarli in una sequenza di moltiplicatori (ed even-tualmente cumularli).
DAVID HENDRY
Fra tutti i moltiplicatori, quelli che presumibilmenteinteressano di più sono il moltiplicatore d’impatto (per-ché dice cosa succede istantaneamente) e quello di lun-go periodo (perché dice cosa succede una volta che tuttigli aggiustamenti sono terminati). Ambedue sono piutto-sto semplici da calcolare, essendo pari, rispettivamente, aB(0)/A(0) e B(1)/A(1). Tuttavia, c’è un modo di riscrivereun modello ADL che rende il tutto ancora più evidente, edè la cosiddetta rappresentazione ECM.
La sigla ECM può significare varie cose:33 quello cheper consenso pressoché unanime è considerato il papàdell’ECM, e cioè Sir David Hendry, insiste nel dire che significa EquilibriumCorrection Mechanism. Peccato però che questa sia una trovata posteriore al-la sua introduzione in econometria, avvenuta ad opera dello stesso Hendry conun manipolo di sodali tutti provenienti dalla London School of Economics, nel1978. All’epoca, l’avevano chiamato Error Correction Model, e molti continuanoa chiamarlo così.
Per far vedere come funziona, partiamo dal caso più semplice di tutti, e cioèun ADL(1,1), e cioè l’equazione (1.35), che ripropongo qui in forma un tantinopiù generale, e cioè con xt vettore:
yt =αyt−1 +β′0xt +β′
1xt−1
è evidente che si può riscrivere yt = yt−1 +∆yt e xt = xt−1 +∆xt . Sostituendo, siha
∆yt = (α−1)yt−1 +β′0∆xt + (β0 +β1)′xt−1
che può essere a sua volta riscritto come
∆yt =β′0∆xt + (α−1)
[yt−1 − (β0 +β1)′
1−α xt−1
](1.36)
33Niente a che vedere con Pat Metheny o Keith Jarrett.
57

Il senso è: la variazione di yt nel tempo può essere provocata da un movi-mento della xt , nel qual caso la risposta è β0, il moltiplicatore di impatto; tut-tavia, può anche darsi che la xt resti ferma (e quindi ∆xt = 0), ma il termine fraparentesi quadre sia diverso da 0, ciò che evidentemente provoca ugualmenteun movimento nella yt . Il termine fra parentesi quadre può essere anche scrittocome
yt−1 −c′xt−1
dove c = β0+β1
1−α , ossia il vettore dei moltiplicatori di lungo periodo. In pratica,tale termine, noto come termine ECM, misura se c’era, al tempo t −1, uno sco-stamento tra il valore effettivo di yt−1 ed il valore che, data la xt−1, sarebbe statonecessario affinché il sistema si trovasse in equilibrio.
Posto che |α| < 1, allora (α−1) è un numero negativo: se il termine ECM èpositivo (e quindi la yt−1 era più grande del suo valore di equilibrio), allora ∆yt
sarà negativo (e quindi la yt tende a riavvicinarsi verso la situazione di equi-librio). Evidentemente, tale situazione è simmetrica nel caso in cui il termineECM sia negativo, per cui si può dire che in ogni caso, se (α−1) < 0, il sistematende a tornare verso uno stato di quiete. Anzi, il numero 1−α può essere vistocome la frazione di disequilibrio che viene riassorbita in un periodo, e quindil’aggiustamento verso l’equilibrio sarà tanto più rapido tanto più α è vicino a 0.
La trasformazione da ADL ad ECM può essere effettuata sempre, qualsiasisiano gli ordini dei polinomi A(L) e B(L); ora ve lo dimostro. Cominciamo da unrisultato preliminare (che non dimostro):
Teorema 1 Se P (x) è un polinomio qualsiasi di grado n > 0, allora si può sempretrovare un polinomio Q(x) di grado (n −1) tale per cui valga
P (x) = P (a)+Q(x)(a −x);
quando n = 0, ovviamente Q(x) = 0.
Forti di questo risultato preliminare, consideriamo un polinomio nell’ope-ratore ritardo di grado n ≥ 1, che chiamiamo P (L), e applichiamo due volte di filail teorema appena enunciato, una volta con a = 0 e la seconda volta con a = 1:
P (L) = P (0)−Q(L) ·L (1.37)
Q(L) = Q(1)+P∗(L)(1−L) (1.38)
Nel caso n = 1, evidentemente P∗(L) = 0. Altimenti, Q(L) è un polinomio diordine (n − 1) e P∗(L) è un polinomio di ordine (n − 2). Valutando la (1.37) inL = 1, si ha P (1) = P (0)−Q(1), cosicché la (1.38) diventa
Q(L) = P (0)−P (1)+P∗(L)(1−L)
e quindi, usando di nuovo la (1.37),
P (L) = P (0)− [P (0)−P (1)+P∗(L)(1−L)
] ·L = P (0)∆+P (1)L−P∗(L)∆ ·L.
58

Non ci interessa particolarmente come sia fatto il polinomio P∗(L): ci basta sa-pere che esiste, ovvero che la scomposizione di P (L) effettuata sopra non dipen-de da ipotesi particolari, ma è valida in generale.
Queste manipolazioni apparentemente insensate ci permettono di scrivereogni sequenza del tipo P (L)zt come segue:
P (L)zt = P (0)∆zt +P (1)zt−1 −P∗(L)∆zt−1.
Applichiamo ora questo risultato alla nostra equazione alle differenze A(L)yt =B(L)xt ; si ha
∆yt + A(1)yt−1 − A∗(L)∆yt−1 = B(0)∆xt +B∗(L)∆xt−1 +B(1)xt−1.
Con un sapiente riarrangiamento dei vari termini, si perviene all’ECM vero eproprio:
∆yt = B(0)∆xt + A∗(L)∆yt−1 +B∗(L)∆xt−1 − A(1)[
yt−1 −c′xt−1]
dove naturalmente c′ = B(1)A(1) contiene i moltiplicatori di lungo periodo. In pra-
tica, il movimento nella variabile dipendente viene scomposto in un impattoistantaneo, altre componenti di breve periodo ed una componente di lungo pe-riodo in cui l’ingrediente base è il moltiplicatore di stato stazionario c. Nientemale, eh?
Esempio 9 (Rappresentazione ECM) Usiamo di nuovo l’equazione alle differen-ze
yt = 0.2yt−1 +0.4xt +0.3xt−2
e calcoliamone la rappresentazione ECM. Il modo più rapido è quello di ri-esprimeretutto in funzione del periodo (t −1), e cioè:
yt = yt−1 +∆yt
xt = xt−1 +∆xt
xt−2 = xt−1 −∆xt−1
da cuiyt−1 +∆yt = 0.2yt−1 +0.4(xt−1 +∆xt )+0.3(xt−1 −∆xt−1)
e quindi∆yt =−0.8yt−1 +0.7xt−1 +0.4∆xt −0.3∆xt−1
e infine∆yt = 0.4∆xt −0.3∆xt−1 −0.8
[yt−1 −0.875xt−1
];
il moltiplicatore d’impatto è 0.4, quello di lungo periodo è 0.875; la frazione disquilibrio che si riaggiusta in ogni periodo è 0.8. E non venitemi a dire che eradifficile.
59
È importante notare che l’ADL e l’ECM non sono due modelli diversi, ma sol-tanto due modi diversi di scrivere la stessa equazione alle differenze, tant’è chepossono essere usati indifferentemente come modelli empirici senza che unorisulti migliore dell’altro in termini di fit (seguirà esempio). La differenza fra idue sta solo nel fatto che l’ECM rende più immediato all’occhio umano valutarei parametri di più notevole interesse interpretativo, cioè i moltiplicatori d’im-patto e di lungo periodo, mentre l’ADL consente di calcolare in modo semplicee meccanico l’intera sequenza dei moltiplicatori dinamici.
13
13.2
13.4
13.6
13.8
14
14.2
14.4
14.6
1980 1985 1990 1995 2000 2005 2010
yc
Figura 1.5: Reddito e consumo nell’area Euro (in logaritmi)
Esempio 10 (ADL-ECM su dati veri) La figura 1.5 rappresenta le serie storiche(in logaritmi) del PIL reale e dei consumi privati, indicati con y e c rispettivamen-te, dal primo trimestre 1976 al quarto trimestre 2009.34 Decidiamo di modellareil consumo attraverso il reddito usando un modello ADL(1,3). In pratica, si avrà
ct ' k +αct−1 +β0 yt +β1 yt−1 +β2 yt−2 +β3 yt−3
e il risultato dell’OLS su questo modello lo trovate nella Tabella 1.4.
Ne consegue che α= 0.882, β0 = 0.638, eccetera. Con un po’ di buona volontàsi può anche calcolare che la sequenza dei moltiplicatori, che risulta
34Fonte: EACBN, Area Wide Model database, vers. 16 update 10.
60

adl: OLS, using observations 1976:1-2009:4 (T = 136)
Dependent variable: c
coefficient std. error t-ratio p-value
--------------------------------------------------------
const 0.0138955 0.0220090 0.6314 0.5289
c_1 0.882331 0.0452090 19.52 1.87e-40 ***
y 0.637865 0.0606835 10.51 4.41e-19 ***
y_1 -0.678971 0.0998675 -6.799 3.45e-10 ***
y_2 0.271915 0.0985160 2.760 0.0066 ***
y_3 -0.118637 0.0614148 -1.932 0.0556 *
Mean dependent var 13.52360 S.D. dependent var 0.207026
Sum squared resid 0.001742 S.E. of regression 0.003661
R-squared 0.999699 Adjusted R-squared 0.999687
F(5, 130) 86327.74 P-value(F) 5.3e-227
Log-likelihood 573.0659 Akaike criterion -1134.132
Schwarz criterion -1116.656 Hannan-Quinn -1127.030
Tabella 1.4: Esempio di regressione dinamica
i di ci
0 0.63787 0.637871 -0.11616 0.521702 0.16942 0.691123 0.03085 0.721974 0.02722 0.749195 0.02401 0.773206 0.02119 0.794397 0.01870 0.813098 0.01650 0.82958...
......
Inoltre, si ha che A(1) = 1−0.882331 = 0.117669, B(1) = 0.112171, e quindi il mol-tiplicatore di lungo periodo risulta uguale a c = 0.953273. La rappresentazioneECM di questa equazione alle differenze si calcola facilmente una volta fatte leseguenti sostituzioni:
ct = ct−1 +∆ct
yt = yt−1 +∆yt
yt−2 = yt−1 −∆yt−1
yt−3 = yt−1 −∆yt−1 −∆yt−2
da cui
∆ct ' k + (α−1)ct−1 +β0∆yt + (3∑
i=0βi )yt−1 − (β2 +β3)∆yt−1 −β3∆yt−2
61

ossia
∆ct ' k +β0∆yt − A(1)[ct−1 −cyt−1
]− (β2 +β3)∆yt−1 −β3∆yt−2
Si noti, peraltro, che questa rappresentazione avrebbe potuto benissimo esserecalcolata direttamente applicando l’OLS alla rappresentazione ECM: consideran-do la Tabella 1.5, si vede bene che quello che viene calcolato è lo stesso modelloscritto in altra forma. Infatti, non solo i valori dei parametri di una rappresen-tazione possono essere ricavati esattamente a partire dai parametri dell’altra, maanche la funzione obiettivo (la SSR) è del tutto identica (in ambedue i modelli, èpari a 0.001742), e così tutte le statistiche da essa derivate. Le uniche differenzesono una conseguenza del fatto che il modello è trasformato in modo tale che lavariabile dipendente non è la stessa fra ADL (dove è il livello di ct ) ed ECM (doveè la sequenza ∆ct ).
ecm: OLS, using observations 1976:1-2009:4 (T = 136)
Dependent variable: d_c
coefficient std. error t-ratio p-value
--------------------------------------------------------
const 0.0138955 0.0220090 0.6314 0.5289
d_y 0.637865 0.0606835 10.51 4.41e-19 ***
d_y_1 -0.153277 0.0618298 -2.479 0.0145 **
d_y_2 0.118637 0.0614148 1.932 0.0556 *
c_1 -0.117669 0.0452090 -2.603 0.0103 **
y_1 0.112171 0.0437532 2.564 0.0115 **
Mean dependent var 0.004970 S.D. dependent var 0.005291
Sum squared resid 0.001742 S.E. of regression 0.003661
R-squared 0.538954 Adjusted R-squared 0.521221
F(5, 130) 30.39349 P-value(F) 2.28e-20
Log-likelihood 573.0659 Akaike criterion -1134.132
Schwarz criterion -1116.656 Hannan-Quinn -1127.030
Tabella 1.5: Esempio di regressione dinamica in forma ECM
1.7 E adesso?
E adesso, sarebbe il caso di cominciare la parte più interessante, cioè quella incui ricominciamo tutto da capo, ma usiamo i metodi della statistica inferenziale.
Se vogliamo che i dati ci parlino non solo del mondo che abbiamo già vi-sto, ma anche di tutto quel che non abbiamo visto ancora, dobbiamo fare delleipotesi sul processo generatore dei dati, e quindi dobbiamo studiare probabili-tà e statistica inferenziale per dire qualcosa di sensato. Ma alla fine andremo, inmoltissimi casi, ad usare le stesse statistiche che qui abbiamo imparato a leggerecome statistiche descrittive e a dar loro una nuova interpretazione molto, molto
62

più interessante. Il vettore β, la statistica W e tutte le altre quantità che qui ab-biamo usato per parlare dei dati verranno utilizzate per parlare della macchinache li ha generati (e che magari ne genererà di nuovi).
E dopo, sarebbe il caso anche di parlare di econometria in senso stretto, ecioè: una volta che ho descritto non solo i miei dati, ma anche il processo che ligenera, come posso fare a dire qualcosa di sensato sulle relazioni che intercor-rono fra il mondo che c’è nei libri di micro e di macro e il mondo in cui abitoio? Posso usare i miei modelli per validare/confutare i miei modelli economiciastratti? Posso usare i miei dati per fare previsioni sul futuro? Posso usare i mieidati per misurare l’effetto delle politiche economiche? Posso usare i miei datiper chiedermi cosa avrebbe fatto quel certo individuo se le condizioni sotto lequali ha fatto la sua scelta fossero state diverse?
La risposta in molti casi è affermativa ma, come scrisse Évariste Galois, “jen’ai pas le temps” (io, però, dai duelli mi guardo bene).
63

Appendice A
La Licenza
L’OPERA (COME SOTTO DEFINITA) È MESSA A DISPOSIZIONE SULLA BASE DEI TERMINI DEL-LA PRESENTE LICENZA “CREATIVE COMMONS PUBLIC LICENCE” ("CCPL" O "LICENZA"). L’O-PERA È PROTETTA DAL DIRITTO D’AUTORE, DAGLI ALTRI DIRITTI ATTRIBUITI DALLA LEGGESUL DIRITTO D’AUTORE (DIRITTI CONNESSI, DIRITTI SULLE BANCHE DATI, ECC.) E/O DALLEALTRE LEGGI APPLICABILI. OGNI UTILIZZAZIONE DELL’OPERA CHE NON SIA AUTORIZZATAAI SENSI DELLA PRESENTE LICENZA E/O DELLE ALTRE LEGGI APPLICABILI È PROIBITA.
CON IL SEMPLICE ESERCIZIO SULL’OPERA DI UNO QUALUNQUE DEI DIRITTI QUI DISEGUITO ELENCATI, TU ACCETTI E TI OBBLIGHI A RISPETTARE INTEGRALMENTE I TERMI-NI DELLA PRESENTE LICENZA. IL LICENZIANTE CONCEDE A TE I DIRITTI QUI DI SEGUITOELENCATI A CONDIZIONE CHE TU ACCETTI DI RISPETTARE I TERMINI E LE CONDIZIONI DICUI ALLA PRESENTE LICENZA.
Art. 1 - Definizioni
Ai fini e per gli effetti della presente licenza, si intende per
a. “Collezione di Opere”, un’opera, come un numero di un periodico, un’antologia o un’enciclo-pedia, nella quale l’Opera nella sua interezza e forma originale, unitamente ad altri contributicostituenti loro stessi opere distinte ed autonome, sono raccolti in un’unità collettiva. Un’o-pera che costituisce Collezione di Opere non verrà considerata Opera Derivata (come sottodefinita) ai fini della presente Licenza;
b. “Opera Derivata”, un’opera basata sull’Opera ovvero sull’Opera insieme con altre opere preesi-stenti, come una traduzione, un arrangiamento musicale, un adattamento teatrale, narrativo,cinematografico, una registrazione di suoni, una riproduzione d’arte, un digesto, una sintesi, oogni altra forma in cui l’Opera possa essere riproposta, trasformata o adattata. Nel caso in cuiun’Opera tra quelle qui descritte costituisca già Collezione di Opere, essa non sarà considerataOpera Derivata ai fini della presente Licenza. Al fine di evitare dubbi è inteso che, quando l’O-pera sia una composizione musicale o registrazione di suoni, la sincronizzazione dell’Operain relazione con un’immagine in movimento (“synching”) sarà considerata Opera Derivata aifini di questa Licenza;
c. “Licenziante”, l’individuo, gli individui, l’ente o gli enti che offre o offrono l’Opera secondo itermini e le condizioni della presente Licenza;
d. “Autore Originario”, il soggetto o i soggetti che ha o hanno creato l’Opera;
e. “Opera”, l’opera dell’ingegno o, comunque, qualsiasi bene o prestazione suscettibile di prote-zione in forza delle leggi sul diritto d’autore (diritto d’autore, diritti connessi, diritto sui gene-ris sulle banche dati, ecc.), la cui utilizzazione è offerta nel rispetto dei termini della presenteLicenza;
64

f. “Tu"/"Te”, l’individuo o l’ente che esercita i diritti derivanti dalla presente Licenza e che nonabbia precedentemente violato i termini della presente Licenza relativi all’Opera o che, no-nostante una precedente violazione degli stessi, abbia ricevuto espressa autorizzazione dalLicenziante all’esercizio dei diritti derivanti dalla presente Licenza;
g. “Elementi della Licenza”, gli attributi fondamentali della Licenza scelti dal Licenziante ed in-dicati nel titolo della Licenza: Attribuzione, Condividi allo stesso modo;
h. “Licenza Compatibile con Creative Commons”, una licenza elencata pressohttp://creativecommons.org/compatiblelicenses, che Creative Commons abbia riconosciuto come essenzialmenteequivalente a questa Licenza, poiché tale licenza presenta almeno le seguenti caratteristiche:(i) le sue condizioni hanno lo stesso scopo, significato ed effetto degli Elementi della Licenzadi questa Licenza; e (ii) tale licenza permette esplicitamente di licenziare le Opere Derivatedalle opere, che sono state rese disponibili tramite tale licenza, nei termini di questa Licenza odi una licenza Creative Commons “Unported” (non adattata) con gli stessi Elementi della Li-cenza di questa Licenza o di una licenza nazionale Creative Commons con gli stessi Elementidella Licenza di questa Licenza.
Art. 2 - Libere Utilizzazioni
La presente Licenza non intende in alcun modo ridurre, limitare o restringere alcuna utilizza-zione non protetta dal diritto d’autore o alcun diritto di libera utilizzazione o l’operare dellaregola dell’esaurimento del diritto o altre limitazioni dei diritti sull’Opera derivanti dalle leggiapplicabili.
Art. 3 - Concessione della Licenza
Nel rispetto dei termini e delle condizioni contenute nella presente Licenza, il Licenziante conce-de a Te una licenza per tutto il mondo, gratuita, non esclusiva e perpetua (per la durata del dirittod’autore applicabile) che autorizza ad esercitare i diritti sull’Opera qui di seguito elencati:
a. riproduzione dell’Opera, incorporazione dell’Opera in una o più Collezioni di Opere e ripro-duzione dell’Opera come incorporata nelle Collezioni di Opere;
b. creazione e riproduzione di un’Opera Derivata, a condizione che l’Opera Derivata (ivi inclu-se le traduzioni, con qualsiasi mezzo esse siano realizzate) contenga, nei modi appropriatialla forma dell’Opera Derivata, una chiara indicazione del fatto che sono state effettuate del-le modifiche rispetto all’Opera originaria. Per esempio, una traduzione potrebbe contenerel’indicazione “questa è la traduzione in spagnolo dell’opera originaria, scritta in inglese”; unamodifica potrebbe contenere l’indicazione “l’opera originaria è stata modificata”;
c. distribuzione di copie dell’Opera o di supporti fonografici su cui l’Opera è registrata, noleggioe prestito di copie dell’Opera o di supporti fonografici su cui l’Opera è registrata, comuni-cazione al pubblico, rappresentazione, esecuzione, recitazione o esposizione in pubblico, iviinclusa la trasmissione audio digitale dell’Opera, e ciò anche quando l’Opera sia incorporatain Collezioni di Opere;
d. distribuzione di copie dell’Opera Derivata o di supporti fonografici su cui l’Opera Derivataè registrata, noleggio e prestito di copie dell’Opera Derivata o di supporti fonografici su cuil’Opera Derivata è registrata, comunicazione al pubblico, rappresentazione, esecuzione, reci-tazione o esposizione in pubblico, ivi inclusa la trasmissione audio digitale di Opere Derivate.
e. Al fine di evitare dubbi è inteso che, se l’Opera sia di tipo musicale:
(i) Compensi per la comunicazione al pubblico o la rappresentazione o esecuzione di ope-re incluse in repertori. Il Licenziante rinuncia al diritto esclusivo di riscuotere compensi,
65

personalmente o per il tramite di un ente di gestione collettiva (ad es. SIAE), per la co-municazione al pubblico o la rappresentazione o esecuzione, anche in forma digitale (ades. tramite webcast) dell’Opera.
(ii) Compensi per versioni cover. Il Licenziante rinuncia al diritto esclusivo di riscuoterecompensi, personalmente o per il tramite di un ente di gestione collettiva (ad es. SIAE),per ogni disco che Tu crei e distribuisci a partire dall’Opera (versione cover).
f. Compensi per la comunicazione al pubblico dell’Opera mediante fonogrammi. Al fine di evi-tare dubbi, è inteso che se l’Opera è una registrazione di suoni, il Licenziante rinuncia al di-ritto esclusivo di riscuotere compensi, personalmente o per il tramite di un ente di gestionecollettiva (ad es. IMAIE), per la comunicazione al pubblico dell’Opera, anche in forma digitale.
g. Altri compensi previsti dalla legge italiana. Al fine di evitare dubbi, è inteso che il Licenzian-te rinuncia al diritto esclusivo di riscuotere i compensi a lui attribuiti dalla legge italiana suldiritto d’autore (ad es. per l’inserimento dell’Opera in un’antologia ad uso scolastico ex art.70 l. 633/1941). Al Licenziante spettano in ogni caso i compensi irrinunciabili a lui attribuitidalla medesima legge (ad es. l’equo compenso spettante all’autore di opere musicali, cinema-tografiche, audiovisive o di sequenze di immagini in movimento nel caso di noleggio ai sensidell’art. 18-bis l. 633/1941).
I diritti sopra descritti potranno essere esercitati con ogni mezzo di comunicazione e in tuttii formati. Tra i diritti di cui sopra si intende compreso il diritto di apportare all’Opera le modificheche si rendessero tecnicamente necessarie per l’esercizio di detti diritti tramite altri mezzi di co-municazione o su altri formati. Tutti i diritti non espressamente concessi dal Licenziante riman-gono riservati. Tutti i diritti morali irrinunciabili riconosciuti dalla legge applicabile rimangonoriservati.
Qualora l’Opera concessa in licenza includa una o più banche dati sulle quali il Licenzian-te è titolare di un diritto sui generis ai sensi delle norme nazionali di attuazione della Direttiva96/9/CE sulle banche dati, il Licenziante rinuncia a far valere il diritto corrispondente.
Art. 4 - Restrizioni
La Licenza concessa in conformità al precedente punto 3 è espressamente assoggettata a, e limi-tata da, le seguenti restrizioni:
a. Tu puoi distribuire, comunicare al pubblico, rappresentare, eseguire, recitare o esporre in pub-blico l’Opera, anche in forma digitale, solo alle condizioni della presente Licenza e, insiemead ogni copia dell’Opera (o supporto fonografico su cui è registrata l’Opera) che distribuisci,comunichi al pubblico o rappresenti, esegui, reciti o esponi in pubblico, anche in forma di-gitale, devi includere una copia della presente Licenza o il suo Uniform Resource Identifier.Non puoi proporre o imporre alcuna condizione relativa all’Opera che restringa i termini del-la presente Licenza o la capacità da parte di chi riceve l’Opera di esercitare gli stessi diritticoncessi a Te con la presente Licenza. Non puoi concedere l’Opera in sublicenza. Devi mante-nere intatte tutte le informative che si riferiscono alla presente Licenza ed all’esclusione dellegaranzie. Quando distribuisci, comunichi al pubblico, rappresenti, esegui, reciti o esponi inpubblico l’Opera, non puoi utilizzare alcuna misura tecnologica tale da limitare la capacità dichiunque riceva l’Opera da Te di esercitare gli stessi diritti concessi a Te con la presente licen-za. Questo art. 4.a si applica all’Opera anche quando questa faccia parte di una Collezione diOpere, anche se ciò non comporta che la Collezione di Opere di per sé ed indipendentementedall’Opera stessa debba essere soggetta ai termini ed alle condizioni della presente Licenza.Qualora Tu crei una Collezione di Opere, su richiesta di qualsiasi Licenziante, devi rimuoveredalla Collezione di Opere stessa, ove materialmente possibile, ogni riferimento in accordo conquanto previsto dall’art. 4.c, come da richiesta. Qualora Tu crei un’Opera Derivata, su richie-sta di qualsiasi Licenziante devi rimuovere dall’Opera Derivata stessa, nella misura in cui ciòsia possibile, ogni riferimento in accordo con quanto previsto dall’art. 4.c, come da richiesta.
66

b. Tu puoi distribuire, comunicare al pubblico, rappresentare, eseguire, recitare o esporre inpubblico un’Opera Derivata, anche in forma digitale, solo alle condizioni
(i) della presente Licenza,
(ii) di una versione successiva di questa Licenza dotata degli stessi Elementi della Licenza diquesta Licenza,
(iii) della licenza Creative Commons “Unported” (non adattata) o di una licenza CreativeCommons di un’altra giurisdizione (sia la presente versione 3.0 che una successiva) checontenga gli stessi Elementi della Licenza di questa Licenza (ad es. Attribuzione-Condividiallo stesso modo 3.0 “Unported”) (la “Licenza Applicabile”),
(iv) di una Licenza Compatibile con Creative Commons.
Se Tu concedi in licenza un’Opera Derivata con una delle licenze di cui a questo punto (iv) devirispettare i termini di tale licenza. Se Tu concedi in licenza un’Opera Derivata con una dellelicenze di cui ai punti (i), (ii) o (iii) (la “Licenza Applicabile”) Tu devi rispettare tutte le condi-zioni della Licenza Applicabile oltre alle seguenti condizioni. Insieme ad ogni copia dell’OperaDerivata (o supporto fonografico su cui è registrata l’Opera Derivata) che distribuisci, comu-nichi al pubblico o rappresenti, esegui, reciti o esponi in pubblico, anche in forma digitale, Tudevi includere una copia della Licenza Applicabile, o il suo Uniform Resource Identifier. Nonpuoi proporre o imporre alcuna condizione relativa all’Opera Derivata che restringa i terminidella Licenza Applicabile o la capacità di chiunque riceva l’Opera Derivata da Te di esercitaregli stessi diritti concessi a Te con la Licenza Applicabile. Devi mantenere intatte tutte le in-formative che si riferiscono alla Licenza Applicabile ed all’esclusione delle garanzie. QuandoTu distribuisci, comunichi al pubblico, rappresenti, esegui, reciti o esponi in pubblico l’OperaDerivata, non puoi utilizzare sull’Opera Derivata alcuna misura tecnologica tale da limitare lacapacità di chiunque riceva l’Opera Derivata da Te di esercitare i diritti concessi a tale soggettoin forza della Licenza Applicabile. Questo art.4.b si applica all’Opera Derivata anche quandoquesta faccia parte di una Collezione di Opere, ma ciò non comporta che la Collezione di Ope-re di per sé ed indipendentemente dall’Opera Derivata debba esser soggetta ai termini ed allecondizioni della Licenza Applicabile.
c. Qualora Tu distribuisca, comunichi al pubblico, rappresenti, esegua, reciti o esponga in pub-blico, anche in forma digitale, l’Opera (come definita dal succitato art. 1) o qualsiasi OperaDerivata (come definita dal succitato art. 1) o Collezione di Opere (come definita dal succitatoart. 1), a meno che sia stata avanzata una richiesta ai sensi dell’art. 4.a, devi mantenere intattetutte le informative sul diritto d’autore sull’Opera. Devi riconoscere una menzione adeguatarispetto al mezzo di comunicazione o supporto che utilizzi:
(i) all’Autore Originario citando il suo nome (o lo pseudonimo, se del caso), ove fornito; e/o
(ii) alle terze parti designate, se l’Autore Originario e/o il Licenziante hanno designato una opiù terze parti (ad esempio, una istituzione finanziatrice, un ente editoriale, un giornale)(“Parti Designate”) perché siano citate nell’informativa sul diritto d’autore del Licenzian-te o nei termini di servizio o con altri mezzi ragionevoli;
(iii) il titolo dell’Opera, se indicato;
(iv) nella misura in cui sia ragionevolmente possibile, l’Uniform Resource Identifier, che ilLicenziante specifichi dover essere associato con l’Opera, salvo che tale URI non fac-cia alcun riferimento alla informativa sul diritto d’autore o non dia informazioni sullalicenza dell’Opera;
(v) inoltre, in conformità a quanto previsto dall’art. 3.b, in caso di Opera Derivata, devimenzionare l’uso dell’Opera nell’Opera Derivata (ad esempio, “traduzione francese del-l’Opera dell’Autore Originario”, o “sceneggiatura basata sull’Opera originaria dell’AutoreOriginario”).
67

La menzione richiesta dal presente art. 4.c può essere realizzata in qualsiasi maniera ragione-vole possibile; in ogni caso, in ipotesi di Opera Derivata o Collezione di Opere, qualora compa-ia una menzione di tutti i coautori dell’Opera Derivata o della Collezione di Opere, allora essadeve essere parte di tale menzione e deve apparire con lo stesso risalto concesso alla menzionedegli altri coautori. Al fine di evitare dubbi, è inteso che la menzione di cui al presente articoloha lo scopo di riconoscere la paternità dell’Opera nei modi sopra indicati e che, esercitandoi Tuoi diritti ai sensi della presente Licenza, Tu non puoi implicitamente o esplicitamente af-fermare o fare intendere un qualsiasi collegamento con l’Autore Originario, il Licenziante e/ole Parti Designate, o che l’Autore Originario, il Licenziante e/o le Parti Designate sponsorizzi-no o avallino Te o il Tuo utilizzo dell’Opera, a meno che non sussista un apposito, espresso epreventivo consenso scritto dell’Autore Originario, del Licenziante e/o delle Parti Designate.
d. Al fine di evitare dubbi, è inteso che le restrizioni di cui ai precedenti punti 4.a, 4.b e 4.c nonsi applicano a quelle parti dell’opera che siano da considerarsi Opera ai sensi della presen-te Licenza solo in quanto protette dal diritto sui generis su banca dati ai sensi delle normenazionali di attuazione della Direttiva 96/9/CE sulle banche dati.
Art. 5 - Dichiarazioni, Garanzie ed Esonero da responsabi-lità
SALVO CHE SIA ESPRESSAMENTE CONVENUTO ALTRIMENTI PER ISCRITTO FRA LE PARTI, ILLICENZIANTE OFFRE L’OPERA IN LICENZA “COSÌ COM’È” E NON FORNISCE ALCUNA DICHIA-RAZIONE O GARANZIA DI QUALSIASI TIPO CON RIGUARDO ALL’OPERA, SIA ESSA ESPRESSAOD IMPLICITA, DI FONTE LEGALE O DI ALTRO TIPO, ESSENDO QUINDI ESCLUSE, FRA LE AL-TRE, LE GARANZIE RELATIVE AL TITOLO, ALLA COMMERCIABILITÀ, ALL’IDONEITÀ PER UNFINE SPECIFICO E ALLA NON VIOLAZIONE DI DIRITTI DI TERZI O ALLA MANCANZA DI DI-FETTI LATENTI O DI ALTRO TIPO, ALL’ESATTEZZA OD ALLA PRESENZA DI ERRORI, SIANOESSI ACCERTABILI O MENO. ALCUNE GIURISDIZIONI NON CONSENTONO L’ESCLUSIONE DIGARANZIE IMPLICITE E QUINDI TALE ESCLUSIONE PUÒ NON APPLICARSI A TE.
Art. 6 - Limitazione di Responsabilità
SALVI I LIMITI STABILITI DALLA LEGGE APPLICABILE, IL LICENZIANTE NON SARÀ IN ALCUNCASO RESPONSABILE NEI TUOI CONFRONTI A QUALUNQUE TITOLO PER ALCUN TIPO DIDANNO, SIA ESSO SPECIALE, INCIDENTALE, CONSEQUENZIALE, PUNITIVO OD ESEMPLARE,DERIVANTE DALLA PRESENTE LICENZA O DALL’USO DELL’OPERA, ANCHE NEL CASO IN CUIIL LICENZIANTE SIA STATO EDOTTO SULLA POSSIBILITÀ DI TALI DANNI. NESSUNA CLAUSO-LA DI QUESTA LICENZA ESCLUDE O LIMITA LA RESPONSABILITÀ NEL CASO IN CUI QUESTADIPENDA DA DOLO O COLPA GRAVE.
Art. 7 - Risoluzione
La presente Licenza si intenderà risolta di diritto e i diritti con essa concessi cesseranno automa-ticamente, senza necessità di alcuna comunicazione in tal senso da parte del Licenziante, in casodi qualsivoglia inadempimento dei termini della presente Licenza da parte Tua, ed in particolaredelle disposizioni di cui ai punti 4.a, 4.b e/o 4.c, essendo la presente Licenza condizionata risolu-tivamente al verificarsi di tali inadempimenti. In ogni caso, la risoluzione della presente Licenzanon pregiudicherà i diritti acquistati da individui o enti che abbiano acquistato da Te Opere De-rivate o Collezioni di Opere, ai sensi della presente Licenza, a condizione che tali individui o enticontinuino a rispettare integralmente le licenze di cui sono parte. Le sezioni 1, 2, 5, 6, 7 e 8 ri-mangono valide in presenza di qualsiasi risoluzione della presente Licenza. Sempre che venganorispettati i termini e le condizioni di cui sopra, la presente Licenza è perpetua (e concessa per
68

tutta la durata del diritto d’autore applicabile sull’Opera). Nonostante ciò, il Licenziante si riservail diritto di rilasciare l’Opera sulla base dei termini di una differente licenza o di cessare la distri-buzione dell’Opera in qualsiasi momento; fermo restando che, in ogni caso, tali decisioni noncomporteranno recesso dalla presente Licenza (o da qualsiasi altra licenza che sia stata concessa,o che sia richiesto che venga concessa, ai termini della presente Licenza), e la presente Licenzacontinuerà ad avere piena efficacia, salvo che vi sia risoluzione come sopra indicato.
Art. 8 - Varie
Ogni volta che Tu distribuisci, o rappresenti, esegui o reciti pubblicamente in forma digitale l’O-pera o una Collezione di Opere, il Licenziante offre al destinatario una licenza per l’Opera neimedesimi termini e condizioni che a Te sono stati concessi tramite la presente Licenza. Ognivolta che Tu distribuisci, o rappresenti, esegui o reciti pubblicamente in forma digitale un’Ope-ra Derivata, il Licenziante offre al destinatario una licenza per l’Opera originaria nei medesimitermini e condizioni che a Te sono stati concessi tramite la presente Licenza. L’invalidità o l’inef-ficacia, secondo la legge applicabile, di una o più fra le disposizioni della presente Licenza, noncomporterà l’invalidità o l’inefficacia dei restanti termini e, senza bisogno di ulteriori azioni delleparti, le disposizioni invalide o inefficaci saranno da intendersi rettificate nei limiti della misurache sia indispensabile per renderle valide ed efficaci. In nessun caso i termini e le disposizioni dicui alla presente Licenza possono essere considerati rinunciati, né alcuna violazione può essereconsiderata consentita, salvo che tale rinuncia o consenso risultino per iscritto da una dichiara-zione firmata dalla parte contro cui operi tale rinuncia o consenso. La presente Licenza costi-tuisce l’intero accordo tra le parti relativamente all’Opera qui data in licenza. Non esistono altreintese, accordi o dichiarazioni relative all’Opera che non siano quelle qui specificate. Il Licen-ziante non sarà vincolato ad alcuna altra disposizione addizionale che possa apparire in alcunacomunicazione da Te proveniente. La presente Licenza non può essere modificata senza il mutuoconsenso scritto del Licenziante e Tuo. La presente licenza è stata redatta sulla base della leggeitaliana, in particolare del Codice Civile del 1942 e della legge 22 Aprile 1941, n. 633 e successivemodificazioni sulla protezione del diritto d’autore e di altri diritti connessi al suo esercizio.
Nota Finale
Creative Commons non è parte della presente Licenza e non dà alcuna garanzia connessa al-l’Opera. Creative Commons non è responsabile nei Tuoi confronti o nei confronti di altre partiad alcun titolo per alcun danno, incluso, senza limitazioni, qualsiasi danno generale, speciale,incidentale o consequenziale che sorga in connessione alla presente Licenza. Nonostante quan-to previsto nelle due precedenti frasi, qualora Creative Commons espressamente identificasse sestesso quale Licenziante nei termini di cui al presente accordo, avrà tutti i diritti e tutti gli obblighidel Licenziante.
Salvo che per il solo scopo di indicare al pubblico che l’Opera è data in licenza secondo itermini di una CCPL, nessuna parte potrà utilizzare il marchio “Creative Commons” o qualsiasialtro marchio correlato, o il logo di Creative Commons, senza il preventivo consenso scritto diCreative Commons. Ogni uso consentito sarà realizzato in osservanza delle linee guida per l’usodel marchio Creative Commons, in forza in quel momento, come di volta in volta pubblicate sulsito Internet di Creative Commons o altrimenti messe a disposizione a richiesta. Al fine di evitaredubbi, è inteso che questa restrizione all’uso del marchio non fa parte della Licenza.
Creative Commons può essere contattata al sito http://creativecommons.org/.
69


















