
di un processo produttivo -...
21
Indici di capacità di un processo produttivo
Transcript of di un processo produttivo -...

Indici di capacità
di un processo produttivo

3
1. Introduzione
La norma UNI EN ISO 8402 definisce un processo come “un insiemedi risorse e di attività tra loro interconnesse che trasformano deglielementi in ingresso in elementi in uscita”. La norma chiarisce inoltreche le “risorse” possono comprendere personale, disponibilità finanziaria,mezzi, apparecchiature, tecnologie e metodologie. In generale, qualsiasitipologia di processo si consideri, l’obiettivo è realizzare elementi inuscita (d’ora in poi per comodità li chiameremo prodotti o elementi) chesiano il più possibile conformi a delle specifiche definite in fase diprogetto. Il termine capacità di un processo indica l’abilità dello stesso aprodurre elementi conformi alle specifiche. L’analisi della capacità deiprocessi (Process Capability Analysis) è un insieme di attività che,utilizzando tecniche statistiche, consente di quantificare la capacità efornisce indicazioni per eventuali interventi migliorativi sul processo.L’importanza dell’analisi della capacità dei processi è sottolineata anchenella norma UNI EN ISO 9004-4 che al punto 10.2 afferma quanto segue“Si dovrebbe verificare che i processi siano in grado di realizzareprodotti conformi alle specifiche. Dovrebbero essere identificate leoperazioni associate con le caratteristiche del prodotto o del processoche possono avere un effetto significativo sulla qualità del prodotto.Dovrebbe essere stabilito un controllo appropriato per assicurare chequeste caratteristiche rimangano nei limiti di specifica o che sianoseguite modifiche o cambiamenti appropriati. La verifica dei processidovrebbe comprendere materiali, attrezzature, sistemi di elaborazionedati e software, procedure e personale.”.
2. Capacità, limiti naturali e limiti di specificazione
In un processo solitamente è ben individuabile una grandezzamisurabile, detta caratteristica di qualità, strettamente legata con ilprodotto finale. Di tale caratteristica sono di norma noti il valoreobiettivo (detto anche valore target) ed i limiti di specificazione. In lineagenerale una caratteristica di qualità è caratterizzata da una variabilitàintrinseca al processo produttivo, che si manifesta in oscillazioni rispettoal valore target. Quando il processo si trova in uno stato di controllo
4
statistico questa “variabilità naturale” può spesso essere descritta, almenoin modo approssimativo, dalla distribuzione normale. Indicando conX∼N ( , )µ σ la caratteristica di qualità si possono definire i limitinaturali di tolleranza del processo UNTL e LNTL1 (figura 2.1):
UNTL= +µ σ3 LNTL= −µ σ3
Figura 2.1. Limiti naturali di tolleranza nella distribuzione normale
Nel caso di distribuzione normale i limiti naturali di tolleranza includonoil 99.73% dei valori della variabile, o in altre parole, solo lo 0.27%dell’output del processo cade esternamente all’intervallo naturale ditolleranza: UNTL-LNTL. A differenza dei limiti di tolleranza, chedipendono esclusivamente dalle caratteristiche intrinseche del processo, ilimiti di specificazione sono fissati generalmente su indicazioni derivantidal progetto (in alcuni casi dall’esperienza o da studi empirici). Tali limitivengono indicati con LSL e USL, limite di specificazione inferiore esuperiore. Un elemento è definito non conforme (NC) se la misurariferita alla caratteristica di qualità non rientra nell’intervallo dispecificazione: USL-LSL. Definiti i limiti naturali e di specificazione,per impostare l’analisi della capacità dei processi è opportuno ricordareche una scarsa capacità di un processo è sempre dovuta ad almeno unadelle due cause seguenti (Montgomery, 1997): a) la variabilità delprocesso (σ ) è troppo grande relativamente alla lunghezza dell’intervallodi specificazione (figura 2.2); b) il livello del processo è troppo lontano
1 UNTL (Upper Natural Tolerance Limit) LNTL (Lower Natural Tolerance Limit)

5
dal punto centrale dell’intervallo di specificazione M USL LSL= +2
(figura 2.3).
Figura 2.2. Processo centrato con elevata variabilità
Figura 2.3. Processo non centrato
Gli studi sulla capacità dei processi possono essere condotti seguendolinee diverse. Per esempio, si può verificare se la caratteristica di qualitàsegue una distribuzione di probabilità con prefissate media e deviazionestandard. Alternativamente, la capacità può essere misurata in termini difrazione di elementi non conformi, cioè la frazione di elementi in uscitache non rispetta le specifiche, oppure si può ricorrere a delle semplicimisure quantitative dette indici di capacità.
6
3. L'indice Cp
Una semplice misura dell’abilità del processo a produrre elementiall’interno dei limiti di specificazione è l’indice di capacità Cp , dettoanche indice di capacità potenziale:
C USL LSLp = −
6σ (3.1)
dove σ denota la deviazione standard di X. L’indice è dato dal rapportotra l’intervallo di specificazione e l’intervallo naturale di tolleranza dellacaratteristica di qualità X. Sono desiderabili valori elevati dell’indice(almeno maggiori di 1) che indicano che il processo, se centrato, produceun’elevata frazione di elementi con misure comprese nell’intervallo di
specificazione. Interessante è anche l’interpretazione di PCp
=�
���
�
���
1 100
che rappresenta la percentuale dell’intervallo di specificazione utilizzato
dal processo. Se X∼N ( , )µ σ e µ = +USL LSL2
-il punto centrale
dell’intervallo di specificazione- allora la proporzione attesa, p, dielementi non conformi (NC) è data da
p d= −���
���2Φ
σ (3.2)
dove dUSL LSL
=−2
e Φ indica la funzione di ripartizione della
normale standard. Segue dalla (3.1) che
Cd
p =3σ
(3.3)
e se µ = +USL LSL2
allora
p Cp= −2 3Φ( ) (3.4)
7
Quindi se Cp = 1 la proporzione attesa di NC è pari a 0.27%, tale valoreè talvolta indicato come il valore minimo accettabile. Spesso nella praticasono richiesti valori dell’indice pari a 1, 1.33, o 1.5, corrispondentirispettivamente a USL-LSL=6σ, 8σ o 9σ.
E’ importante notare che Cp = 1 non garantisce che la proporzione diNC sia effettivamente pari a 0.27%. Infatti quello che è garantito è checon l’assunzione X∼N ( , )µ σ , la proporzione di NC non è inferiore a
0.27%. Solo nel caso in cui µ = +USL LSL2
il valore della proporzione
attesa è del 0.27%. Di conseguenza, si nota che generalmente elevativalori di Cp , in assenza di informazioni sulla media, non garantisconoun’elevata capacità del processo.
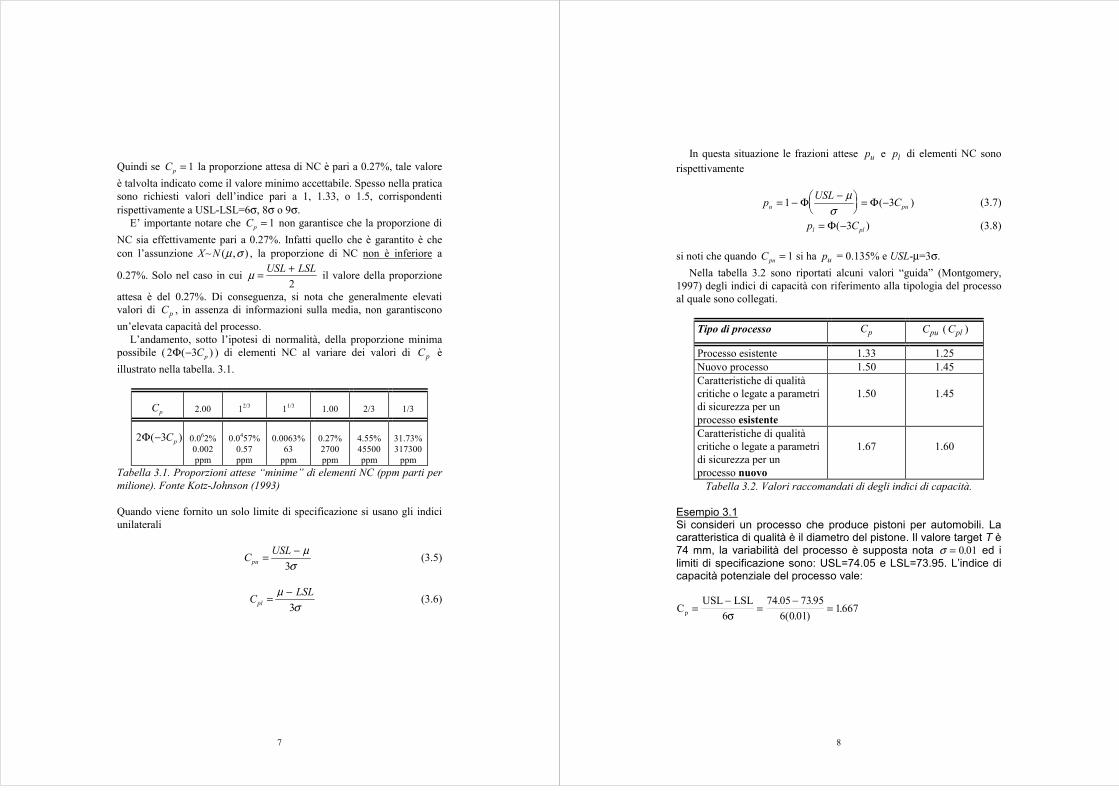
L’andamento, sotto l’ipotesi di normalità, della proporzione minimapossibile ( 2 3Φ( )− Cp ) di elementi NC al variare dei valori di Cp èillustrato nella tabella. 3.1.
Cp 2.00 12/3 11/3 1.00 2/3 1/3
2 3Φ( )− Cp 0.062%0.002ppm
0.0457%0.57ppm
0.0063%63
ppm
0.27%2700ppm
4.55%45500ppm
31.73%317300
ppmTabella 3.1. Proporzioni attese “minime” di elementi NC (ppm parti permilione). Fonte Kotz-Johnson (1993)
Quando viene fornito un solo limite di specificazione si usano gli indiciunilaterali
C USLpu =
− µσ3
(3.5)
C LSLpl =
−µσ3
(3.6)
8
In questa situazione le frazioni attese pu e pl di elementi NC sonorispettivamente
p USL Cu pu= −−�
��
��� = −1 3Φ Φ
µσ
( ) (3.7)
p Cl pl= −Φ( )3 (3.8)
si noti che quando Cpu = 1 si ha pu = 0.135% e USL-µ=3σ.Nella tabella 3.2 sono riportati alcuni valori “guida” (Montgomery,
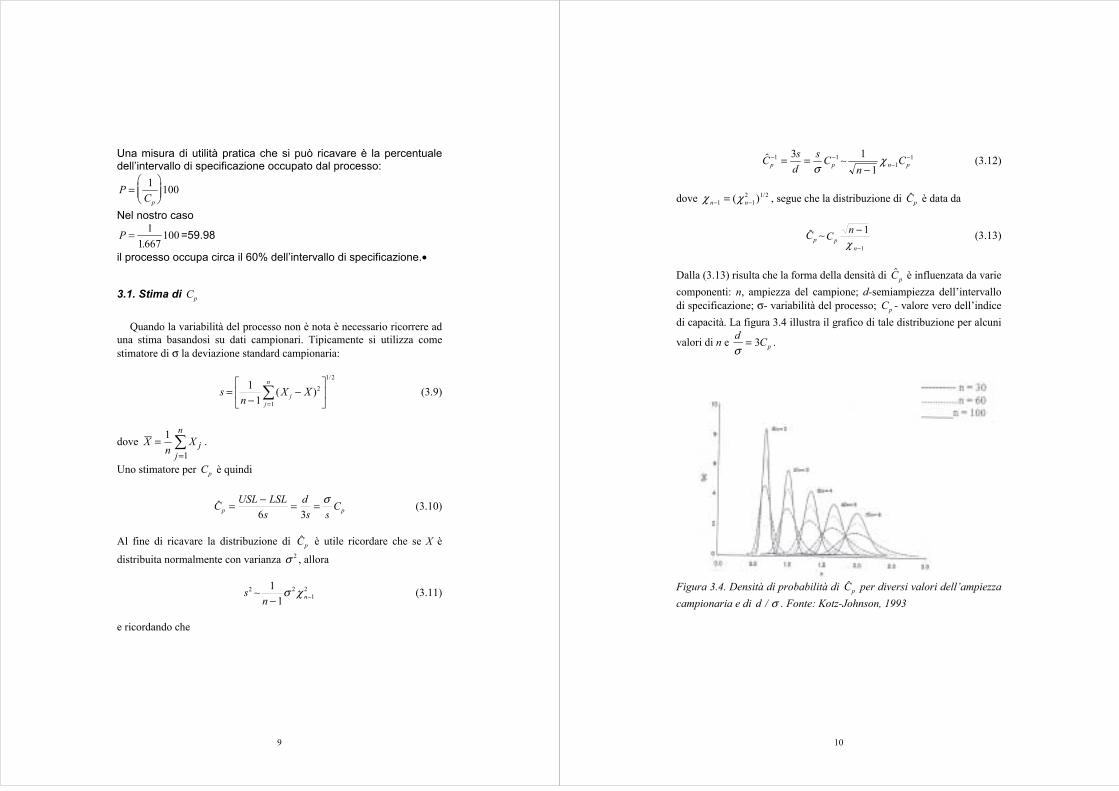
1997) degli indici di capacità con riferimento alla tipologia del processoal quale sono collegati.
Tipo di processo Cp Cpu ( Cpl )
Processo esistente 1.33 1.25Nuovo processo 1.50 1.45Caratteristiche di qualitàcritiche o legate a parametridi sicurezza per unprocesso esistente
1.50 1.45
Caratteristiche di qualitàcritiche o legate a parametridi sicurezza per unprocesso nuovo
1.67 1.60
Tabella 3.2. Valori raccomandati di degli indici di capacità.
Esempio 3.1Si consideri un processo che produce pistoni per automobili. Lacaratteristica di qualità è il diametro del pistone. Il valore target T è74 mm, la variabilità del processo è supposta nota σ = 0 01. ed ilimiti di specificazione sono: USL=74.05 e LSL=73.95. L’indice dicapacità potenziale del processo vale:
CUSL LSL
p =−
=−
=6
74 05 73956 0 01
1667σ
. .( . )
.
9
Una misura di utilità pratica che si può ricavare è la percentualedell’intervallo di specificazione occupato dal processo:
PCp
=�
���
�
���
1 100
Nel nostro caso
P = 11667
100.
=59.98
il processo occupa circa il 60% dell’intervallo di specificazione.•
3.1. Stima di Cp
Quando la variabilità del processo non è nota è necessario ricorrere aduna stima basandosi su dati campionari. Tipicamente si utilizza comestimatore di σ la deviazione standard campionaria:
sn
X Xjj
n
=−
−�
��
�
��
=�
11
2
1
1 2
( )/
(3.9)
dove Xn
X jj
n=
=�
1
1.
Uno stimatore per Cp è quindi
�C USL LSLs
ds s
Cp p= − = =6 3
σ (3.10)
Al fine di ricavare la distribuzione di �Cp è utile ricordare che se X è
distribuita normalmente con varianza σ 2 , allora
s2 ∼ 11
21
2
n n− −σ χ (3.11)
e ricordando che
10
�C sd
s Cp p− −= =1 13
σ∼ 1
1 11
nCn p− −
−χ (3.12)
dove χ χn n− −=1 12 1 2( ) / , segue che la distribuzione di �Cp è data da
�Cp ∼C np
n
−
−
1
1χ (3.13)
Dalla (3.13) risulta che la forma della densità di �Cp è influenzata da variecomponenti: n, ampiezza del campione; d-semiampiezza dell’intervallodi specificazione; σ- variabilità del processo; Cp - valore vero dell’indicedi capacità. La figura 3.4 illustra il grafico di tale distribuzione per alcuni
valori di n e d Cpσ= 3 .
Figura 3.4. Densità di probabilità di �Cp per diversi valori dell’ampiezzacampionaria e di d / σ . Fonte: Kotz-Johnson, 1993

11
Per ricavare i momenti di �Cp è sufficiente ricordare che dalla (3.13) siha
�Cp∼Cf
pfχ
(3.14)
dove f=n-1. L’espressione del momento r-esimo risulta quindi
E C f C E
f C E
f Cf r
f
pr
r
pr
fr
r
pr
f
r
r
pr
( � ) ( )
( )
( )
= =
=�
��
�
��
= ��
��
−�
���
��
��
��
−
−
2
2 2 2
2
2
12
2
χ
χ
Γ
Γ
(3.15)
In particolare la media, la media quadratica e la varianza, risultanorispettivamente
E C ff
fC
bCp p
fp( � ) = �
��
���
−���
���
���
���
=2
12
2
112Γ
Γ (3.16)
E C ff
Cp p( � )2 2
2=
− (3.17)
Var C ff
b Cp f p( � ) =−
−�
��
�
��
−
22 2 (3.18)
dove il termine bf , detto fattore di correzione, è pari
12
bf
f
ff = �
��
�
��
���
���
−���
���
2 21
2
12
Γ
Γ (3.19)
Da quando esposto segue che lo stimatore
1� �C b Cp f p= (3.20)
è stimatore corretto per Cp , la cui varianza vale
Var Cfb
fCp
fp( � )1
22
21=
−−
�
���
�
���
(3.21)
A scopo illustrativo, nella tabella 3.3 sono riportati alcuni valori delfattore di correzione bf al variare di f=n-1. Quando f > 14 una sempliceformula approssimata per bf è
b ff ≅ − −1 34
1 (3.22)
f 4 9 14 19 24 29bf 0.798 0.914 0.945 0.960 0.968 0.974f 34 39 44 49 54 59bf 0.978 0.981 0.983 0.985 0.986 0.987
Tabella 3.3. Valori del fattore di correzione bf (Kotz e Johnson, 1993)
Si nota che al crescere della numerosità campionaria il fattore dicorrezione si avvicina all’unità.
Utilizzando l’approssimazione (3.22) è possibile riscrivere le varianze(3.18) e (3.21) utilizzando espressioni più semplici:
Var C f ff f
Cp p( � ) ( )( )( )
≅ +− −
8 92 4 3 2
2 (3.23a)

13
Var C ff f
Cp p( � ) ( )( )1
28 916 2
≅ +−
(3.23b)
Al fine di esaminare alcuni importanti aspetti riguardo alle prestazionidegli stimatori di Cp , nella tabella 3.4 sono riportati i valori attesi e lerelative deviazioni standard (D.S.) dello stimatore �Cp per diversi valori
di f e d Cp/σ = 3 . Si noti che dal momento che E C Cp p( � ) e
Var C Cp p( � ) 2 non dipendono da Cp , tutti i valori della tabella 3.4 sipossono dedurre da quelli relativi alla combinazione Cp =1 ( / )d σ = 3 .
Si può osservare che quando f = 24 (n = 25) si ha che D.S. ( �Cp ) è circa il
14-15% di E( �Cp ). Questo rappresenta ancora una dispersione rilevante,quindi si otterrebbe una stima poco precisa. Se invece Cp = 1.33 (d/σ =4), corrispondente al valore raccomandato dell’indice per un processoesistente (Tab. 3.2), e f = 19 si ha E( �Cp ) = 1.389 con D.S.( �Cp ) = 0.240.Questo significa che è elevato il rischio di sovrastimare Cp , infatti dalla
(3.10) e (3.11) si ha Pr�
Pr[ ]CC
c fcp
pf>
�
���
�
���= < −χ 2 2 e con c = 1
l’espressione precedente diventa: Pr[ � . ] Pr[ ]Cp > = <133 19192χ =53.3%.
d/σ (3Cp) 2 3 4 5 6f=n-1 E D.S E D.S E D.S. E D.S. E D.S.
4 0.836 0.437 1.253 0.655 1.671 0.874 2.089 1.092 2.507 1.3109 0.729 0.198 1.094 0.297 1.459 0.396 1.824 0.496 2.189 0.59414 0.705 0.145 1.058 0.218 1.410 0.291 1.763 0.364 2.116 0.43619 0.694 0.120 1.042 0.180 1.389 0.240 1.736 0.300 2.083 0.36024 0.688 0.104 1.033 0.156 1.377 0.209 1.721 0.261 2.065 0.31329 0.685 0.094 1.027 0.140 1.369 0.187 1.711 0.234 2.054 0.28134 0.682 0.086 1.023 0.128 1.364 0.171 1.705 0.214 2.046 0.25739 0.680 0.079 1.020 0.119 1.360 0.159 1.700 0.198 2.039 0.23844 0.678 0.074 1.017 0.111 1.357 0.148 1.696 0.186 2.035 0.22349 0.677 0.070 1.016 0.105 1.354 0.140 1.693 0.175 2.031 0.21054 0.676 0.067 1.014 0.100 1.352 0.133 1.690 0.166 2.028 0.19959 0.675 0.063 1.013 0.095 1.351 0.127 1.688 0.158 2.026 0.190∞ 0.667 - 1.000 - 1.333 - 1.667 - 2.000 -
Tabella 3.4. Momenti di �Cp :E =E[ �Cp ]; D.S = D.S.( �Cp / Cp ). (Kotz eJohnson, 1993)
14
Se n è piccolo, per esempio n = 5 e Cp = 1.33, D.S.( �Cp ) = 0.87: si notiche questa deviazione standard rappresenta più della metà del valore diCp . Da quanto esposto si può concludere che la stima di Cp per npiccolo non è molto precisa, mentre si può affermare che stime accuratedell’indice si possono ottenere quando n>50.
3.2. Intervalli di confidenza.
In alcuni casi è importante ricavare un intervallo di confidenza perCp . Riprendendo la (3.10) e la (3.11) si può scrivere
Pr�
Pr[ ( ) ]CC
c n cp
pn>
�
���
�
���= < −−
−χ 12 21 (3.24)
Poiché Pr[ ],χ χ εεn n− −≤ =12
12 , si può scrivere
Pr
Pr
Pr � �
, / , /
, / , /
, / , /
σ χ σ χ
χσ
χ
χ χα
α α
α α
α α
2
1 22 2
2
1 1 22
1 2 1 1 2
1 2 1 1 2
1 1
6 1 6 6 1
1 11
ns
n
USL LSLs n
USL LSL USL LSLs n
Cn
C Cn
n n
n n
pn
p pn
−≤ ≤
−�
��
�
�� =
−−
≤ − ≤ −−
�
��
�
�� =
−≤ ≤
−�
��
�
�� = −
− − −
− − −
− − −
quindi
�
( ); �
( )
, / , /Cn
Cn
pn
pnχ χα α− − −
− −
�
�
���
�
�
���
1 212
1 1 2121 1
(3.25)
è un intervallo di confidenza 100(1-α)% per Cp .

15
Esempio 3.2Si supponga che un processo abbia limiti di specificazionesuperiore ed inferiore rispettivamente a: USL=62 e LSL=38. Uncampione di ampiezza n=20 rivela che il processo è centratoapprossimativamente sul punto centrale dell’intervallo dispecificazione e che la deviazione standard campionaria è pari as=1.75. La stima di Cp è pertanto:
�
( . ).C USL LSL
sp = − = − =6
62 386 175
2 29 .
L’intervallo di confidenza al 95% per Cp è ricavabile come segue:
USL LSLs n
C USL LSLs n
C
np
n
p
−−
≤ ≤ −−
≤ ≤
− − −
6 1 6 1
2 2919
2 2919
2 212
1 12
0 025 192
0 975 192
χ χ
χ χ
α α; ;
. ; . ;. .
essendo χ 0 025 192 8 91. ; .= e χ 0 975 19
2 32 85. ; .= si ricava che157 301. .≤ ≤Cp è l’intervallo di confidenza al 95% per Cp .•
3.3. Verifica di ipotesi su Cp
Una pratica sempre più frequente nelle industrie è richiedere ad unfornitore di dimostrare la capacità dei suoi processi produttivi come parteintegrante degli accordi contrattuali. Questo significa dimostrare chel’indice di capacità è uguale o superiore ad particolare valore targetindicato con Cp0 . Questo problema può essere riformulato in termini diverifica d’ipotesi:
H C Cp p0 0: < (il processo ha scarsa capacità)
H C Cp p1 0: ≥ (il processo ha buona capacità)
16
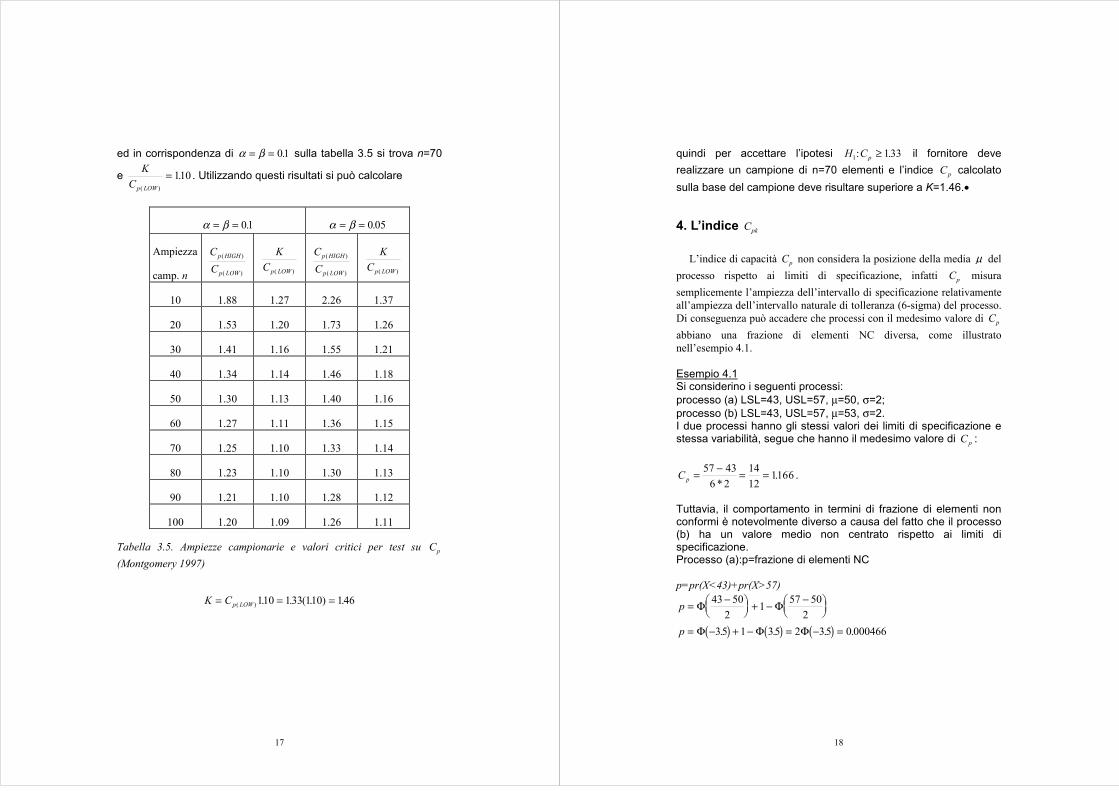
In questo modo rifiutare H0 equivale a dimostrare che il processoraggiunge i requisiti richiesti in termini di capacità. Questo tipo di teststatistico è stato studiato da Kane (1986) il quale determina una serie divalori critici K che consentono di rifiutare H0 se �C Kp > . L’autorecostruisce il test definendo Cp HIGH( ) come il valore di capacità di unprocesso che si desidera accettare con probabilità 1−α e Cp LOW( ) come ilvalore di capacità di un processo che si desidera rifiutare con probabilità1− β . Nella tabella 3.5 sono riportati i valori di C Cp HIGH p LOW( ) ( ) eK Cp LOW( ) per varie ampiezze campionarie e α β= = 0 05. eα β= = 01. . L’esempio 3.3 chiarisce l’uso della tabella 3.5.
Esempio 3.3Un’azienda per concludere un contratto di fornitura richiede alfornitore di dimostrare che la capacità del suo processo èmaggiore di Cp = 133. . Il fornitore è quindi interessato adimplementare una procedura per verificare il seguente sistemad’ipotesi:
H Cp0 133: .<
H Cp1 133: .≥ .
Il fornitore vuole essere sicuro che qualora il processo abbia unacapacità inferiore a 1.33 la probabilità di accettare H0 sia elevata(0.9), mentre se la capacità del processo supera 1.66 laprobabilità di accettare H1 sia elevata (ancora 0.9). Questosignifica definire Cp LOW( ) .= 133 , Cp HIGH( ) .= 166 e α β= = 01. . Pertrovare l’ampiezza campionaria ed il valore critico per il test sicalcola il rapportoCC
p HIGH
p LOW
( )
( )
.
..= =166
133125
17
ed in corrispondenza di α β= = 01. sulla tabella 3.5 si trova n=70
e KCp LOW( )
.= 110 . Utilizzando questi risultati si può calcolare
α β= = 01. α β= = 0 05.
Ampiezza
camp. n
CC
p HIGH
p LOW
( )
( )
KCp LOW( )
CC
p HIGH
p LOW
( )
( )
KCp LOW( )
10 1.88 1.27 2.26 1.37
20 1.53 1.20 1.73 1.26
30 1.41 1.16 1.55 1.21
40 1.34 1.14 1.46 1.18
50 1.30 1.13 1.40 1.16
60 1.27 1.11 1.36 1.15
70 1.25 1.10 1.33 1.14
80 1.23 1.10 1.30 1.13
90 1.21 1.10 1.28 1.12
100 1.20 1.09 1.26 1.11
Tabella 3.5. Ampiezze campionarie e valori critici per test su Cp
(Montgomery 1997)
K Cp LOW= = =( ) . . ( . ) .110 133 110 146
18
quindi per accettare l’ipotesi H Cp1 133: .≥ il fornitore deverealizzare un campione di n=70 elementi e l’indice Cp calcolatosulla base del campione deve risultare superiore a K=1.46.•
4. L’indice Cpk
L’indice di capacità Cp non considera la posizione della media µ delprocesso rispetto ai limiti di specificazione, infatti Cp misurasemplicemente l’ampiezza dell’intervallo di specificazione relativamenteall’ampiezza dell’intervallo naturale di tolleranza (6-sigma) del processo.Di conseguenza può accadere che processi con il medesimo valore di Cp
abbiano una frazione di elementi NC diversa, come illustratonell’esempio 4.1.
Esempio 4.1Si considerino i seguenti processi:processo (a) LSL=43, USL=57, µ=50, σ=2;processo (b) LSL=43, USL=57, µ=53, σ=2.I due processi hanno gli stessi valori dei limiti di specificazione estessa variabilità, segue che hanno il medesimo valore di Cp :
Cp = − = =57 436 2
1412
1166*
. .
Tuttavia, il comportamento in termini di frazione di elementi nonconformi è notevolmente diverso a causa del fatto che il processo(b) ha un valore medio non centrato rispetto ai limiti dispecificazione.Processo (a):p=frazione di elementi NC
p=pr(X<43)+pr(X>57)
( ) ( ) ( )
p
p
= −���
��� + − −�
��
���
= − + − = − =
Φ Φ
Φ Φ Φ
43 502
1 57 502
35 1 35 2 35 0 000466. . . .

19
Processo (b):p=frazione di elementi NC
p=pr(X<43)+pr(X>57)
( ) ( )
p
p
= −���
��� + − −�
��
���
= − + − = ≅ + =
Φ Φ
Φ Φ
43 532
1 57 532
5 1 2 0 0 022775 0 02275( ) . .•
Dalle considerazioni precedenti risulta evidente la mancanza di unarelazione diretta tra Cp e la probabilità di ottenere un elemento NC. Inaltre parole, anche con valori Cp > 1 si possono avere delle frazioni dielementi NC elevate, se la media del processo non è centrata rispetto ailimiti USL e LSL. La situazione può essere migliorata definendo unanuova misura di capacità che tenga conto della posizione di µ rispetto aUSL e LSL, in modo da fornire una relazione diretta tra l’indice e lafrazione di NC. Questo indice, denominato Cpk è definito nel modoseguente:
C C C
USL LSL
USL LSL
pk pu pl=
= − −���
���
= − −
min( , )
min ,
min( , )
µσ
µσ
µ µσ
3 3
3
(4.1)
Utilizzando la relazione min( , ) (| | | |)a b a b a b= + − −12
è possibile
esprimere l’indice Cpk secondo un’espressione equivalente:
20
C USL LSL USL LSL
USL LSL USL LSL
d LSL USL
LSL USL
dC
pk
p
= − − + −
=− − − +
=− − +
= −− +�
�
�
����
12
2 3
12 2
312
3
1
12
[| | | |] /
| | | |
| ( )|
| ( )|
µ σ
µ
σ
µ
σ
µ
(4.2)
Inoltre, ricordando che C dp = 3σ
si ha
C CUSL LSL
pk p= −− +| ( )|µ
σ
12
3 (4.3)
Esempio 4.2Per il processo (a) dell’esempio 4.1 C Cp pk= = 1166. , in quanto ilprocesso risulta centrato.Per il processo (b) invece,
( )
C C C
USL LSLpk pu pl=
=− −�
��
���
= − −�
��
�
�� = =
min( , )
min ,
min( )
,( )
min . , . .
µσ
µσ3 3
57 533 2
53 433 2
0 666 1 766 0 666
•L’indice Cpk è una misura della capacità effettiva del processo a
differenza di Cp che misura la capacità potenziale. La capacità delprocesso aumenta al crescere del valore di Cpk ed è interessante farnotare che il numeratore dell’indice è la distanza (con segno) di µ dal

21
più vicino limite di specificazione. Generalmente C Cpk p≤ ,l’uguaglianza vale solo nel caso in cui il processo è centrato
µ = +���
���
USL LSL2
, quindi Cpk se confrontato con Cp fornisce una
misura della non centratura del processo. Valori negativi dell’indiceindicano che il processo è completamente inadeguato, infatti si verificanoquando µ >USL o µ < LSL .
Partendo dal valore dell’indice Cpk è possibile determinare la frazionidi elementi NC associata al processo. Se X è distribuita normalmente, lafrazione, p, di elementi NC è data da
p LSL USL=
−���
��� + −
−���
���Φ Φ
µσ
µσ
1 (4.4)
nel caso in cui 12
( )USL LSL USL+ ≤ ≤µ si ha C USLpk = − µ
σ3 ed
essendo
LSL USL USL LSL C Cpk p− = − − − = −µσ
µσ3 3
2( ) ( )
si ottiene che la frazione di elementi NC risulta
p C C Cp pk pk= − − + −Φ Φ[ ( )] ( )3 2 3 (4.5)
Inoltre, dato che 2C C Cp pk pk− ≥ (perché C Cpk p≤ ), segue che laproporzione attesa di elementi non conformi è contenuta nell’intervallo
Φ Φ( ) ( )− ≤ ≤ −3 2 3C p Cpk pk (4.6)
e p Cpk= −2 3Φ( ) solo quando il processo è centrato, cioè C Cpk p= . In
modo analogo si può trattare il caso in cui LSL USL LSL≤ ≤ +µ 12
( ) .
22
4.1. Stima di Cpk
Nel caso in cui il livello del processo µ e/o la varianza σ 2 non sianonoti occorre stimarli dai dati campionari. Uno stimatore naturale di Cpk è
�
| |C
d X USL LSL
spk =− − −
23
(4.7)
Ricordando che se X∼ N ( , )µ σ 2 segue che X ∼ N n( , / )µ σ 2 ,s∼ χ σf f 1 2/ , con X e s indipendenti. Sfruttando questi risultati è
possibile ricavare i momenti di �Cpk , in particolare il momento r-esimorisulta:
E C E s
rj
d E X LSL USL
d fE
rj d n
En X USL LSL
pkr
rr
j
j
r r jj
r
fr
j
j
rj
j
( � ) ( )
( )
( )
( )( )
= ���
���
−��
���
�� − +�
���
�
���
=�
��
�
��
−��
���
�����
���
− +�
�
�
�
�
�
−
=
−
−
=
13
12
3
1
12
0
0
σχ
σσ
(4.8)
Per r = 1, 2 si ottengono la Media

23
E C ff
fd
n
n USL LSL USL LSL
n USL LSL
pk( � )
exp
= ���
���
−���
���
���
���
− ���
��� ×
�
�
× −− +���
���
�
�
���
�
��
�
��
�
�
��
�
��
−− +���
���
×
× −− +�
�
����
�
�
����
���
���
�
���
���
�
����
13 2
12
2
2
22
2
1 2 2
12
2
2
Γ
Γ
Φ
σ π
µ
σ
µ
σ
µ
σ
(4.9)
e la Varianza
Var C ff
d dn
n USL LSL USL LSL
n USL LSL USL LSL
pk( � )( )
exp
=−
���
��� − �
��
������
���
�
�
�
�
× −− +���
���
�
�
���
�
��
�
��
�
�
��
�
��
+− +���
���
×
× −− − +�
�
����
�
�
����
���
���
�
���
���
�
����
+− +���
���
�
�
��
+
9 22 2
22
2
1 2 2 2
12
2
2
2
2
σ σ π
µ
σ
µ
σ
µ
σ
µ
σΦ
[ ]
1
2
n
E Cpk
�
�����
− ( � )
(4.10)
24
L’aspetto importante che si desidera sottolineare è che lo stimatore risultadistorto: E C Cpk pk( � ) ≠ . Di conseguenza nelle situazioni reali risultanecessario considerare l’entità dell’errore che si può commettere, per noncorrere il rischio di prendere decisioni aziendali sbagliate. Uno studiodettagliato, al quale si rimanda, sul comportamento dello stimatore èriportato in Kotz e Johnson (1993). Qui è sufficiente ricordare che conpiccoli campioni, n < 10, è assolutamente sconsigliato tentare di stimareCpk ed anche quando n è circa 40 non è prudente prendere decisioniaziendali riguardo al processo in esame basandosi solo su �Cpk .
4.2. Intervalli di confidenza per Cpk
Come per Cp , può risultare utile e/o necessario costruire un intervallodi confidenza per Cpk . La costruzione di un intervallo di questo tipo nonè semplice e può essere fatta seguendo due linee:
a) utilizzare la distribuzione esatta di �Cpk
b) ricorrere ad intervalli di confidenza approssimati.
Generalmente, la prima possibilità è poco operativa perché ladistribuzione da esaminare è molto complicata. In via alternativa, peravere un’idea della regione di incertezza per Cpk si possono costruireseparatamente gli intervalli di confidenza, al livello 100(1-α)%, per µ e σ(in quanto C fpk = ( , )µ σ ):
X t s X t sf f
− × ≤ ≤ − ×− −, ,1 2 1 2α αµ intervallo di confidenza per µ
s f s f
f fχ
σχα α, ,1 2 2−
≤ ≤ intervallo di confidenza per σ

25
Utilizzando tali intervalli è possibile quindi individuare una regione diconfidenza, R, per la coppia (µ σ) del tipo visualizzato in figura 4.1 e diconseguenza scegliere come estremi dell’intervallo di confidenza perCpk :
min( ) ( , )C fpk = µ σ
max( ) ( , )C fpk = µ σcon (µ σ)∈R.
Figura 4.1
E’ importante sottolineare che la probabilità che l’intervallo per Cpk ,individuato seguendo la procedura sopra illustrata, includa effettivamenteil valore vero è minore di 1− α . Ad esempio, se ciascun intervalloseparato è al livello di confidenza 100 1( )%− α e i due eventi sonoindipendenti, allora la probabilità complessivaè:100 1 100 12( ) % ( )%− < −α α . Inoltre, possono esistere coppie di valori(µ σ)∉R. che portano a valori di Cpk entro l’intervallo.Alcuni autori hanno studiato formule approssimate per ricavare gliintervalli di confidenza per Cpk ad esempio:
26
�
( )�
( )C z n
n nC
n npk pk± −−
+−
+−
���
���
��
��
−12
12
2
19 3
12 3
1 61α
(Heavlin,1998)
� ��
( )C z
nC
Cnpk pk
pk± +−
���
��
���
��−1
22
12
2
19 2 1α per n≥30
(Franklin e Wasserman, 1992)
5. L’indice Cpm
L’indice Cpk considera la posizione della media del processo rispettoai limiti di specificazione, quindi costituisce un miglioramentodell’indice Cp . Tuttavia, Cpk utilizzato senza ulteriori integrazioni èancora una misura inadeguata della centratura del processo, in particolaredella posizione della media del processo rispetto al valore target. Inoltre,Cpk dipende inversamente da σ diventando sempre più grande perσ →0, pertanto un valore elevato dell’indice non è molto informativosulla posizione di µ all’interno dell’intervallo di specificazione.
Esempio 5.1LSL=35 USL=65 Valore target T=50Processo A: µ A = 50 , σ A = 5 , Cp = 1, Cpk = 1Processo B: µ B = 57 5. , σ B = 2 5. , Cp = 2 , Cpk = 1Il processo B, pur non essendo centrato, ha lo stesso indice Cpk
di A. Tale risultato dipende dal fatto che B presenta una variabilitàridotta rispetto ad A.•
Una strada per superare i problemi illustrati è quella di utilizzare unanuova misura di capacità: l’indice Cpm (Chan, Cheng e Spring 1988).L’indice è definito come segue
27
C USL LSLT
USL LSL dpm = −
+ −= − =
6 6 32 2 12[ ( ) ]σ µ τ τ
(5.1)
dove T è il valore target, che molto spesso coincide con il punto centraledell’intervallo di specificazione, e τ σ µ2 2 2= + −( )T . Le figure 5.1 e5.2 illustrano il diverso comportamento di Cpk e Cpm al variare di µ eσ : si può notare che l’indice Cpm tende ad essere meno sensibile di Cpk
a variazioni di σ .
Figura 5.1. Indice Cpk come funzione di µ e σ (LSL=5.5, USL=8.5)Fonte: Mittag e Rinne (1993)
28
Figura 5.2. Indice Cpm come funzione di µ e σ (LSL=5.5, USL=8.5).Fonte: Mittag e Rinne (1993)
E’ interessante notare che τ 2 si può esprimere come somma di duecomponenti che esprimono la “variabilità totale” del processo attorno alvalore target:
τ σ µ µ µ2 2 2 2 2 2= + − = − = − + −( ) ( ) ( ) ( )T E X T E X T (5.2)
Anche l’indice Cpm può essere scritto come funzione di Cp , infatti dalla
(5.1) e ricordando che C dp =
3σ segue che:
C C CT
C
pm p p
p
= =+ −
=
= + −
στ σ µ
σ
ζ
1
1
2 2
2
2 12
( )
( )
(5.3)

29
dove ζ µσ
= − T , risulta quindi che C Cpm p≤ con C Cpm p= solo se
µ = T .
Esempio 5.2LSL=35 USL=65 Valore target T=50Si considerino 3 processiProcesso A: µ A = 50 , σ A = 5 , Cp = 1, Cpk = 1, Cpm = 1Processo B: µ B = 57 5. , σ B = 2 5. , Cp = 2 , Cpk = 1, Cpm = 0 63.Processo C: µ c = 6125. , σ c = 125. , Cp = 4 , Cpk = 1, Cpm = 0 44.In questo esempio si nota che all’allontanarsi della media delprocesso dal valore target Cpm tende a ridursi, mentre risultainsensibile a questo aspetto, l’indice Cp . Infatti, l’indice Cp
aumenta essenzialmente perché si riduce la variabilità delprocesso. L’indice Cpk invece, rimane costante nonostante i treprocessi presentino caratteristiche completamente differenti. •
E’ utile sottolineare che l’indice Cpm è una misura adeguata di capacità diun processo solo quando il valore target coincide con il punto centraledell’intervallo di specificazione: T m USL LSL= = +1
2 ( ) . Infatti, si puònotare che Cpm rimane inalterato se E X T( ) = − δ o E X T( ) = + δ(δ>0):
C dT
dpm =
+ −=
+3 32 2 2 212
12[ ( ) ] [ ]σ µ σ δ
mentre la proporzione attesa di elementi non conformi può cambiare,anche consistentemente, se T m≠ .
Per esempio, supponendo che X abbia una distribuzione simmetrica, seT USL LSL= +3
414 e δ = − =1
412( )USL LSL d , quando
E X T USL( ) = + =δ , ci si attende almeno il 50% di elementi NC.Mentre, se E X T m( ) = − =δ la proporzione di NC risulta molto piùpiccola, pertanto le proprietà di Cpm valgono quando T m= .
30
6. Relazioni tra Cp , Cpm , Cpk
Tra gli indici di capacità esaminati intercorrono relazioni2 utilizzabiliper ricavare ulteriori informazioni sulla capacità del processo.Ricordando le definizioni di Cp (3.1), Cpk (4.2) e Cpm (5.1) si ha
C md
C Cpk p p= − −�
���
��≤1 | |µ (6.1)
C m C Cpm p p= + −���
���
�
�
���
≤−
12
12µ
σ (6.2)
da cui segue che: max( Cpm , Cpk )≤Cp e Cp = Cpm = Cpk quando µ = m .Combinando la (6.1) e la (6.2) si può scrivere
C C md
mpk pm= − −�
���
��+ −��
��
�
���
�
���
1 12
12| |µ µ
σ(6.3)
da cui risulta:
Cpk ≥ Cpm se 1 12
12
− −�
���
��+ −��
��
�
���
�
���
| |µ µσ
md
m ≥ 1 (6.4a)
Cpk ≤ Cpm se 1 12
12
− −�
���
��+ −��
��
�
���
�
���
| |µ µσ
md
m ≤ 1 (6.4b)
Partendo dalla relazione precedente, (6.4), è possibile ricavare espressioni
più semplici ed utili, infatti ponendo3 km
d=
−µ segue che
2 Le relazioni ricavate nel seguito valgono nel caso in cui il valore target coincide con ilpunto centrale dell’intervallo di specificazione3 Usualmente k<1, altrimenti µ sarebbe oltre i limiti di specificazione

31
Cpk ≥ Cpm se ( )1 12
2
12
− + ���
���
�
�
���
k d kσ
≥ 1 (6.5a)
Cpk ≤ Cpm se ( )1 12
2
12
− + ���
���
�
�
���
k d kσ
≤ 1 (6.5b)
da cui con semplici passaggi si ricava
Cpk ≥ Cpm se d kk kσ
���
��� ≥ −
−
2
2
21( )
Cpk ≤ Cpm se d kk kσ
���
��� ≤ −
−
2
2
21( )
e ricordando che C dp =
3σ l’espressione precedente diventa
Cpk ≥ Cpm se C kk kp
22
29 1
≥ −−( )
(6.6a)
Cpk ≤ Cpm se C kk kp
22
29 1
≤ −−( )
(6.6b)
Si può notare, Tab. 6.1, che la funzione 29 1 2
−−
kk k( )
raggiunge un minimo
di 1.23 per k≈0.4.
k 0 0.2 0.4 0.5 0.6 0.8 12
9 1 2
−−
kk k( )
∞ 1.56 1.23 1.33 1.62 4.17 ∞
Tabella 6.1. Alcuni valori della funzione 29 1 2
−−
kk k( )
Pertanto se
• Cp ≤ 1 allora Cpk ≤ Cpm
32
• Cp2 123> . ( Cp > 111. ) allora si può avere Cpk > Cpm , purché k non sia
troppo vicino a 0 o 1.
• k=0, ( )µ = m allora C C Cpk pm p= = .
7. Indici di capacità e non-normalità
Un'operazione necessaria prima del calcolo degli indici di capacità, ècontrollare che la caratteristica di qualità X relativa al processo segua ladistribuzione Normale. Questo perché le proprietà enunciate nelle pagineprecedenti, riguardanti gli indici di capacità, rimangono valide solo senon si rifiuta l’ipotesi di normalità. Quando si presenta unallontanamento significativo dalla distribuzione Gaussiana si possonoseguire due strade: la prima consiste nello studiare le proprietà degliindici di capacità e dei relativi stimatori quando la distribuzione assumespecifiche forme distributive; la seconda prevede di svilupparemetodologie che consentono di trattare la non normalità, giungendo allacostruzione di indici di capacità robusti cioè non troppo influenzati dallaforma distributiva.
7.1 Effetti della non normalità
Si considerino, a titolo esemplificativo, le seguenti distribuzioni peruna caratteristica di qualità X (Gunter, 1989):
1. un chi-quadrato con 4.5 gradi di libertà ( χ 4 52
. ) (distribuzioneasimmetrica con limite inferiore finito)
2. una t con 8 gradi di libertà (distribuzione con code pesanti)
3. una distribuzione uniforme.
4 una distribuzione normale X∼ N ( , )µ σ 2

33
I grafici delle distribuzioni standardizzate sono riportati nella figura 7.1.
Figura 7.1: Fonte: Kotz e Johnson (1993)
Per costruzione le distribuzioni hanno la stessa media µ e la stessadeviazione standard σ, di conseguenza hanno gli stessi valori per Cpk eCp . Tuttavia, le proporzioni (in parti per milione ppm) di elementi NC aldi fuori dei limiti ±3σ sono notevolmente diverse:
nel caso 1) 14000 (tutti al di sopra di 3σ );nel caso 2) 4000 (metà sopra 3σ e metà sotto −3σ );nel caso 3) 0;nel caso 4) 2700 (metà sopra 3σ e metà sotto −3σ ).
Dall’esempio si comprende che si corre il rischio di giungere aconclusioni errate se si valuta la capacità di un processo con gli indicitradizionali quando la caratteristica di qualità non segue la distribuzionenormale.
34
Sempre a scopo illustrativo si consideri la seguente situazione. Sia( )ϕ µ σx; ; la funzione di densità di una variabile casuale normalmente
distribuita, con media µ e scarto σ , e si consideri il processo“contaminato” con funzione di densità data da
( ) ( )p x p xϕ µ σ ϕ µ σ; ; ( ) ; ;1 1 2 21+ − (7.1)
con 0<p<1, ( ) ( )µ σ µ σ1 1 2 2, ,≠ .Se p è prossimo a 1, 1-p è piccolo e la seconda componente della (7.1)
rappresenta la contaminazione della distribuzione base rappresentatadalla prima componente. Il risultato è che con i test convenzionali èspesso difficile distinguere questo tipo di non normalità, tuttavia ilcomportamento di Cpk può variare anche sostanzialmente (Gunter, 1989).
7.2 Il metodo di Clements
Un metodo per costruire gli indici Cp e Cpk , basato sull’assunzioneche la distribuzione del processo possa essere adeguatamenterappresentata da una variabile casuale appartenente al sistema delledistribuzione di Pearson è stato proposto da Clements (1989).
Il sistema di distribuzioni di Pearson è definito per funzioni di densità,f(x), che soddisfano l’equazione differenziale:
d f xdx
a xc c x c x
(log ( )) ( )= − ++ +0 1 2
2 (7.2)
Il valore dei parametri c0 , c1 , c2 , determina la forma del grafico di f(x).La forma delle curve può variare sensibilmente e dipende dalle radicidell’equazione di secondo grado:
c c x c x0 1 22 0+ + = (7.3)
Alcune distribuzioni appartenenti al sistema di curve di Pearson sono:

35
- c c c0 1 20 0> = =; (distribuzione Normale)
- ; ;c c1 20 0≠ = (distribuzione Gamma)
- radici reali, ma di segno opposto (distribuzione Beta)
- c c c1 0 20 0= >; , (distribuzione t-Student).
Ricordando che
C USL LSL dp = − =
6 3σ σ
dove 6σ rappresenta l’intervallo naturale di tolleranza,µ σ µ σ+ − −3 3( ) che nel caso di X∼ N ( , )µ σ 2 è tale che
( ){ }Pr , .X ∉ + − =µ σ µ σ3 3 0 0027 , Clements propone come intervallodi tolleranza naturale
U Lp p− (7.4)
Dove U p è il percentile U99 865. , cioè { }Pr .X U p≥ = 0 00135 , e Lp è il
percentile L0 135. ( { }Pr .X Lp≤ = 0 00135) della distribuzione dellaconsiderata.
L’indice di capacità calcolato secondo il metodo di Clements risultaquindi
C USL LSLU Lp
p p
= −−
(7.5)
Se si considerano i percentili standardizzati,
θµ
σupU
=−
e θµ
σlpL
=−
si ha
36
U p u= +µ θ σ e Lp l= +µ θ σ
e quindi ( )U Lp p u l− = − =θ θ σ θσ con θ θ θu l− =
per cui
C USL LSLp = −
θσ(7.6)
Il metodo ha i seguenti meriti: quando la distribuzione è Normale gliindici sono esattamente gli stessi di quelli ottenuti con il metodotradizionale (θ u = 3 θ l = −3 e θ = 6); è relativamente facile da calcolaremanualmente o con un calcolatore; non richiede una trasformazionematematica dei dati.
Nella tabella 7.1 (Kotz e Johnson 1993) sono riportati i percentilistandardizzati θ U e θ l per distribuzioni appartenenti alla famiglia dellacurve di Pearson. I percentili sono tabulati in funzione dei valoridell’indice di asimmetria 1β , e del coefficiente di Kurtosi4
2β .Riguardo a Cpk Clements propone di calcolarlo nel seguente modo
( )C C Cpk pl pu= min , (7.7)
dove
4 L’indice di asimmetria è dato dall’espressione:
β µ σ1 33= dove [ ]µ3
3 3
1
1= − = −
=�M x x n x xii
n
( ) ( )
mentre l’indice di Kurtosi si determina in questo modo:
β2 = µ σ44
dove µ4 è calcolato in maniera analoga a µ3 .

37
Tabella 7.1. Per ogni combinazione ( , )β β1 2 la prima riga contiene ilpercentile θ l , la seconda θ u . Se β 1 0< invertire θ l con θ u . FonteKotz e Johnson (1993).
38
C Mediana LSLMediana Lpl
p
= −−
C USL MedianaU Medianapu
p
= −−
(7.8)
Nel caso di normalità Cpl Cpu e Cpk calcolati con il metodo di Clementscoincidono con gli indici calcolati nel caso generale
Esempio 7.1Si supponga che β 1 1= e β 2 5= . Sulle tavola si trovaθ l = −2 023. e θ u = 4 539. , quindi θ = + =2 023 4 539 6 572. . . . L’indicevarrà quindi
C USL LSLp = −
6 572.. σ•
A fini operativi per il calcolo degli indici di capacità l’autore propone unutile foglio di lavoro (Clements 1989), facilmente implementabile in unqualsiasi foglio elettronico. Nella tabella 7.2 è descritto il foglio di lavoroe nell’esempio 7.2 si illustra il suo utilizzo. Per le tabelle necessarie alsuo utilizzo si rimanda al lavoro originale.
Esempio 7.2Relativamente ad un processo produttivo sono dati i seguenti limitidi specificazione: USL=32, LSL=4. Utilizzando un campione sicalcolano le seguenti statistiche relative al processo:
media X =10.5scarto quadratico medio s=3.142indice di asimmetria β1 =1.14indice di Kurtosi β 2 =2.58
Utilizzando la tavola 1a (in quanto β1 è positivo) si determina ilpercentile 0.135 standardizzato:θ l = 2.026 (mentre effettuando la doppia interpolazione lineare diricaverebbe θ l = 1.911).

39
FOGLIO DI LAVORO PER IL CALCOLO DEGLI INDICI DICAPACITA’ CON IL METODO DI CLEMENTS. ( 5)
(1) Inserire i limiti di specificazione. Specifica superiore Specifica inferiore
USLLSL
(2) Inserire le statistiche del processo. Media Deviazione Standard Skewness Kurtosi
xs
SKKU
(3) Percentile 0,135 standardizzato. Per Skewness positivo usa tabella 1a Per Skewness negativo usa tabella 1b
θl
(4) Percentile 99,865 standardizzato. Per Skewness positivo usa tabella 1b Per Skewness negativo usa tabella 1a
θu
(5) Mediana standardizzata (tabella 2). Per Skewness positivo cambia segno Per Skewness negativo lascia uguale
M’
(6) Calcolo del percentile 0,135 stimato.x s l− θ Lp
(7) Calcolo del percentile 99,865stimato.
x s u+ θ
Up
(8) Calcolo della mediana stimata.x sM+ ' M
(9) Calcolo degli indici di capacità delprocesso.
(USL-LSL)/(Up-Lp)(M-LSL)/(M-Lp)(USL-M)/(Up-M)
MINIMO TRA Cpu E Cpl
CpCplCpuCpk
Tabella 7.2. Successione delle operazioni nel metodo di Clements.
5 Nel foglio di lavoro si fa riferimento alle tabelle 1a, 1b e 2. Per consultarle vedereQuality Progress/ September 1989.
40
Utilizzando la tavola 1b (in quanto β1 è positivo) si determina ilpercentile 99.865 standardizzato:θu =4.736 (mentre effettuando la doppia interpolazione lineare diricaverebbe θu =4.739).Utilizzando la tavola 2 si determina la mediana standardizzata:M’=-0.148 (mentre effettuando la doppia interpolazione lineare diricaverebbe M’=-0.159).
Calcolo della stima del percentile 0.135:Lp= 10.5-(3.142)(2.026)=4.134 (con i valori interpolati 4.496)Calcolo della stima del percentile 99.865:Up= 10.5+(3.142)(4.736)=25.381 (con i valori interp. 25.390)Calcolo della stima della mediana:Lp= 10.5+(3.142)(0.026)=4.134 (con i valori interpolati 4.496)Calcolo di Cp :Cp=(32-4)/(25.381-4.13)=1.32 (con i valori interpolati 1.34)Calcolo di Cpl :Cpl=(10.035-4)/(10.035-4.134)=1.02 (con i valori interpolati1.09)Calcolo di Cpu :Cpu =(32-10.035)/(25.381-10.035)=1.43 (con i valori interpolati1.43)Calcolo di Cpk :minimo tra Cpl e Cpu
Cpk =1.02 (con i valori interpolati 1.02)
Riferimenti Bibliografici
A. F. Bissell (1990), How is reliable your capability index? Appl.Statist.,vol.39, 331-340
L. K. Chan, S. W. Cheng, F.A. Spiring (1988), A New Measure ofProcess Capability: Cpm Journal of Quality Technology, vol.20, No.3

41
L. K. Chen, Z. Xiong, D. Zhang (1990) On asymptotic distribution ofsome process capability indices, Commun. Statist-Theor. Meth., vol.19,11-18
J. A. Clements (1989), Process capability calculations for non-normaldistributions, Quality Progress, Vol.22 (2) 49-55.
L. A. Franklin, G. S. Wasserman (1992), A note on the conservativenature of the tables of lower confidence limits for Cpk with a suggestedcorrection, Commun. Statist. Simul. Comp.
E. L. Grant, R. S. Leavenworth (1996) Statistical Quality Control, 7° ed.McGraw-Hill, New York.
B. H. Gunter (1989) The use and abuse of Cpk , Quality Progress,Vol.22 (3), 108-109.
W. D. Heavelin (1988) Statistical properties of capability indices,Technical Report No. 320, Tech. Library, Advanced Micro Devices, Inc.Sunnyvale, California
V. E. Kane (1986), Process Capability Indices, Journal of QualityTechnology, Vol.18, No.1
S. Kotz, N. L. Johnson (1993), Process Capability Indices, Chapman& Hall, London.
H. J. Mittag, H.Rinne (1993) Statistical Methods of Quality AssuranceChapman & Hall, London.
D. C. Montgomery (1997), Introduction to Statistical Quality Control,Third Edition, John Wiley & Sons, New York.
UNI EN ISO 8402 (1995) “ Gestione per la qualità ed assicurazionedella qualità- Termini e definizioni” UNI Milano.
42
UNI EN ISO 9000-1 (1994) “Norme di gestione per la qualità e diassiscurazione della qualità- Guida per la scelta e l’utilizzazione” UNI,Milano
UNI EN ISO 9004-1 (1994) “Gestione per la qualità ed elementi delsistema qualità- Guida generale” UNI, Milano
UNI EN ISO 9004-4 (1995) “Gestione per la qualità ed elementi delsistema qualità- Guida per il miglioramento della qualità” UNI, Milano


















