
Database NewAGE
61
1 Database Database NewAge NewAge CLIMAWARE 23 settembre 2016
-
Upload
riccardo-rigon -
Category
Education
-
view
81 -
download
0
Transcript of Database NewAGE

1
DatabaseDatabase NewAgeNewAge
CLIMAWARE 23 settembre 2016

2
Database NewAGE
Database originariamente creato nell'ambito del progetto “Nuovo Adige” per l'autorità di Bacino dell'Adige.
www.bacino-adige.it
Gran parte dei dati è stata raccolta nell’ambito del progetto europeo “GLOBAQUA”.
www.globaqua-project.eu
Il database è stato infine riorganizzato da HydroloGIS secondo una struttura di tipo DBMS.
www.hydrologis.com
Stefano Tasin

3
Database NewAGE
DBMSDataBase Management System
Sistema software progettato per gestire la creazione, la manipolazione e l'interrogazione efficiente di base di dati.
Stefano Tasin
Perché usare un DBMS?● Accesso ai dati tramite un linguaggio universale ● Accesso efficiente ai dati ● Indipendenza dei dati ● Controllo della ridondanza dei dati ● Imposizione di vincoli di integrità sui dati ● Atomicità delle operazioni● Accesso concorrente ai dati ● Privatezza dei dati● Affidabilità dei dati

4
Tipo di database
Stefano Tasin
Il database è stato realizzato grazie alla libreria SQLite ed alla sua estensione SpatiaLite che consente di trattare tabelle con informazioni di tipo geometrico (selezioni spaziali, operazioni di tipo vettoriale, ecc.).
Il database è memorizzato in un unico file con estensione “.sqlite” autoesplicativo e facilmente trasportabile.
● SQLite:– https://sqlite.org
● Spatialite:– https://www.gaia-gis.it/fossil/libspatialite/index

5
SQLite
Stefano Tasin
SQLite è una libreria software scritta in linguaggio C che implementa un DBMS SQL incorporabile all'interno di applicazioni.
Limiti:
● Non ha una vera gestione della concorrenza
● Non offre le stored procedure
● Ecc.
Caratteristiche:
● Compatta
● Veloce
● Open source
● Multipiattaforma
● Ecc.

6
Database NewAGE: contenuto
Stefano Tasin
I dati relativi al bacino dell’Adige sono organizzati secondo due tipologie di tabella:
● Dati raccolgono dati relativi a grandezze meteorologiche, idrometriche e legate alla gestione della risorsa idrica...
● Geometrichedescrivono il bacino idrografico, il territorio…Queste tabelle sono caratterizzate dalla presenza di una colonna di tipo “geometria”.
NewAge_DB
7
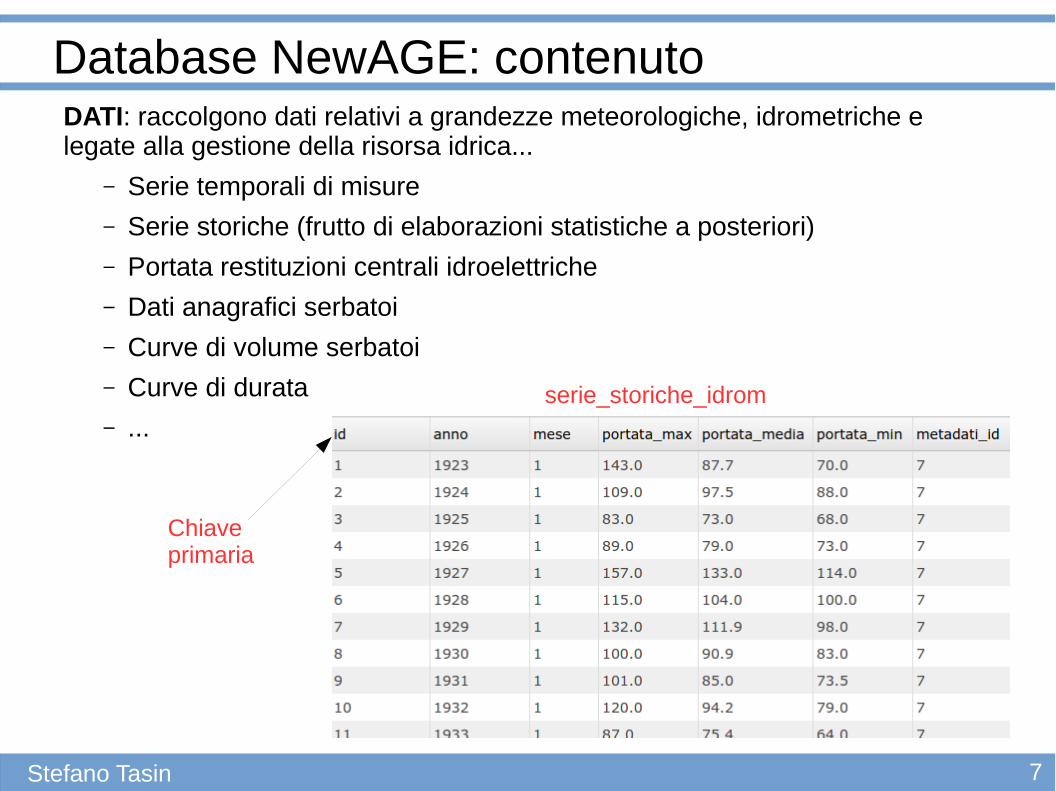
Database NewAGE: contenuto
Stefano Tasin
DATI: raccolgono dati relativi a grandezze meteorologiche, idrometriche e legate alla gestione della risorsa idrica...
– Serie temporali di misure
– Serie storiche (frutto di elaborazioni statistiche a posteriori)
– Portata restituzioni centrali idroelettriche
– Dati anagrafici serbatoi
– Curve di volume serbatoi
– Curve di durata
– ...serie_storiche_idrom
Chiave primaria
8
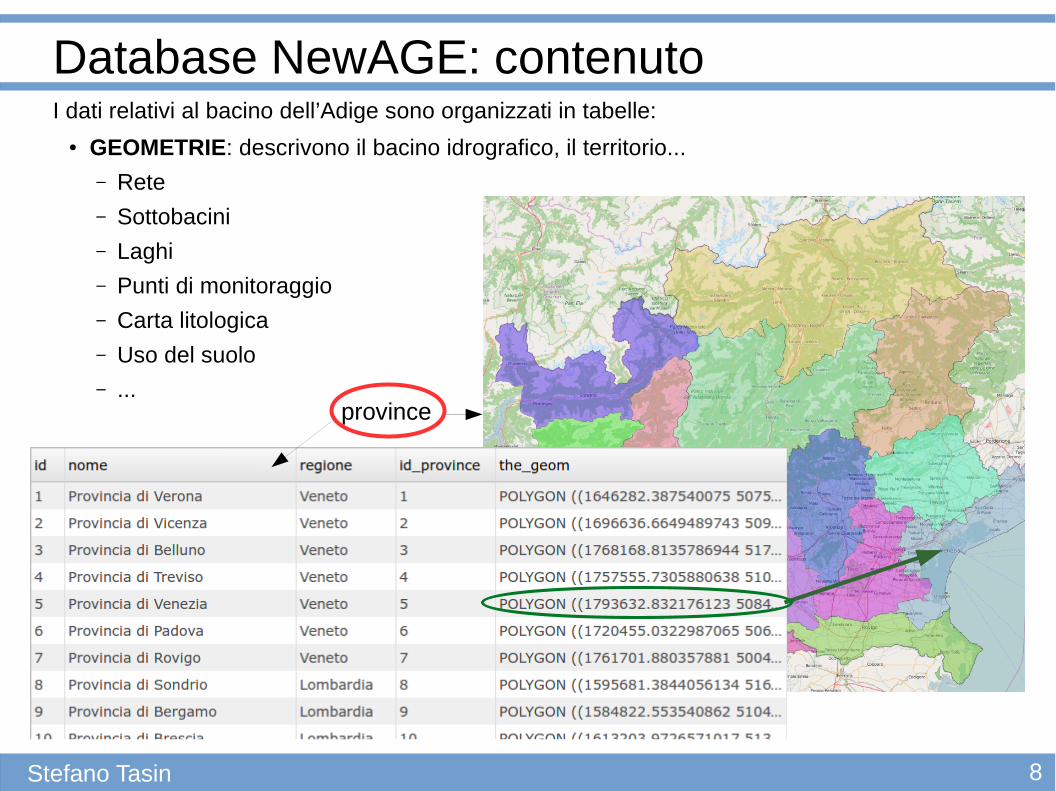
Database NewAGE: contenuto
Stefano Tasin
I dati relativi al bacino dell’Adige sono organizzati in tabelle:
● GEOMETRIE: descrivono il bacino idrografico, il territorio... – Rete– Sottobacini– Laghi– Punti di monitoraggio
– Carta litologica
– Uso del suolo– ...
province

9
Database NewAGE: contenuto
Stefano Tasin
Tipi di colonna geometrica secondo lo standard WKT (Well-Known Text):● POINT ● LINESTRING● POLYGON
● MULTIPOINT● MULTILINESTRING● MULTIPOLYGON
10Stefano Tasin
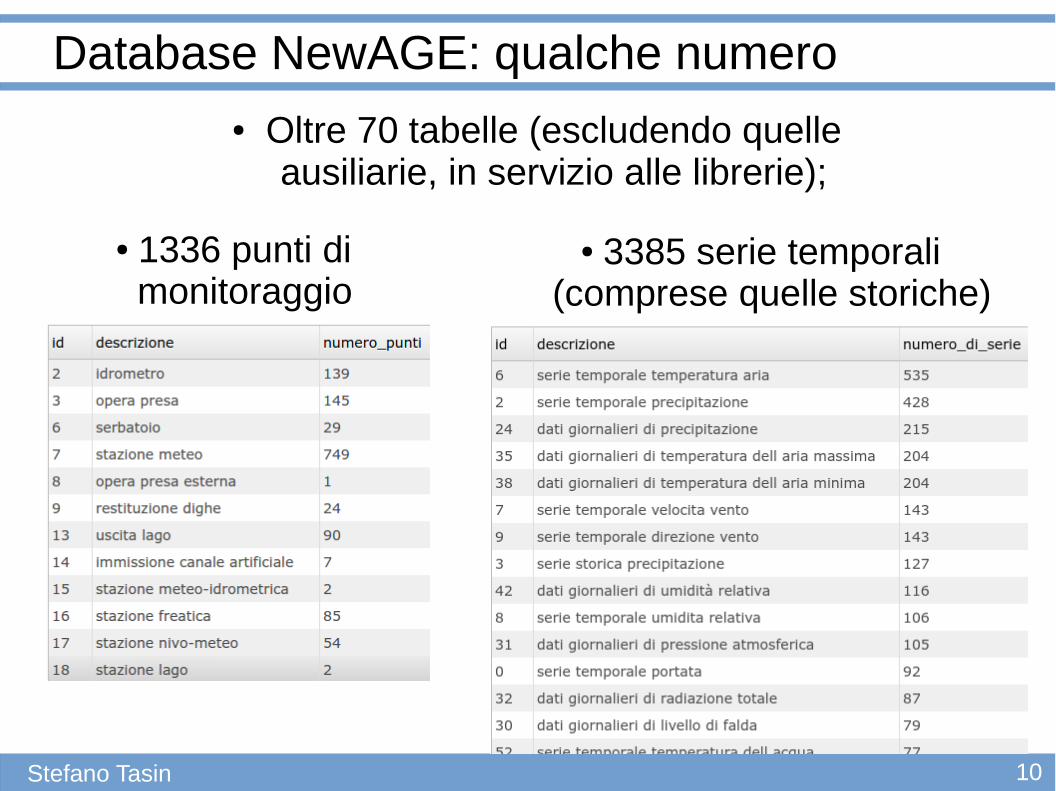
Database NewAGE: qualche numero● Oltre 70 tabelle (escludendo quelle
ausiliarie, in servizio alle librerie);
● 1336 punti di monitoraggio
● 3385 serie temporali (comprese quelle storiche)

11Stefano Tasin
Si possono raggruppare in base alle relazioni che intercorrono tra di esse:
● Geometrie del bacino (bacini, rete, nodi rete)● Rete e Laghi● Rete e sezioni trasversali (Fiume Adige)● Punti di monitoraggio e informazioni relative alle concessioni
● Serie dati (serie temporali grandezze meteo e idrologiche)
● Caratteristiche del suolo
Struttura del database
12Stefano Tasin
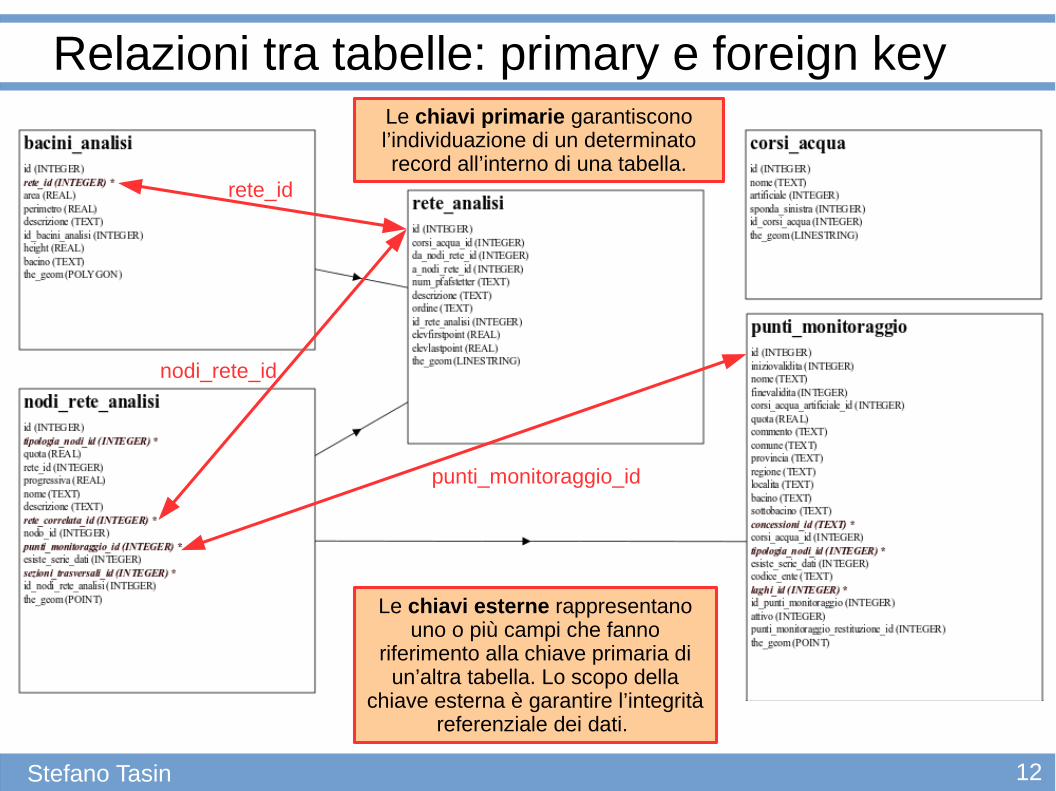
Relazioni tra tabelle: primary e foreign key
rete_id
nodi_rete_id
punti_monitoraggio_id
Le chiavi esterne rappresentano uno o più campi che fanno
riferimento alla chiave primaria di un’altra tabella. Lo scopo della
chiave esterna è garantire l’integrità referenziale dei dati.
Le chiavi primarie garantiscono l’individuazione di un determinato record all’interno di una tabella.
13Stefano Tasin
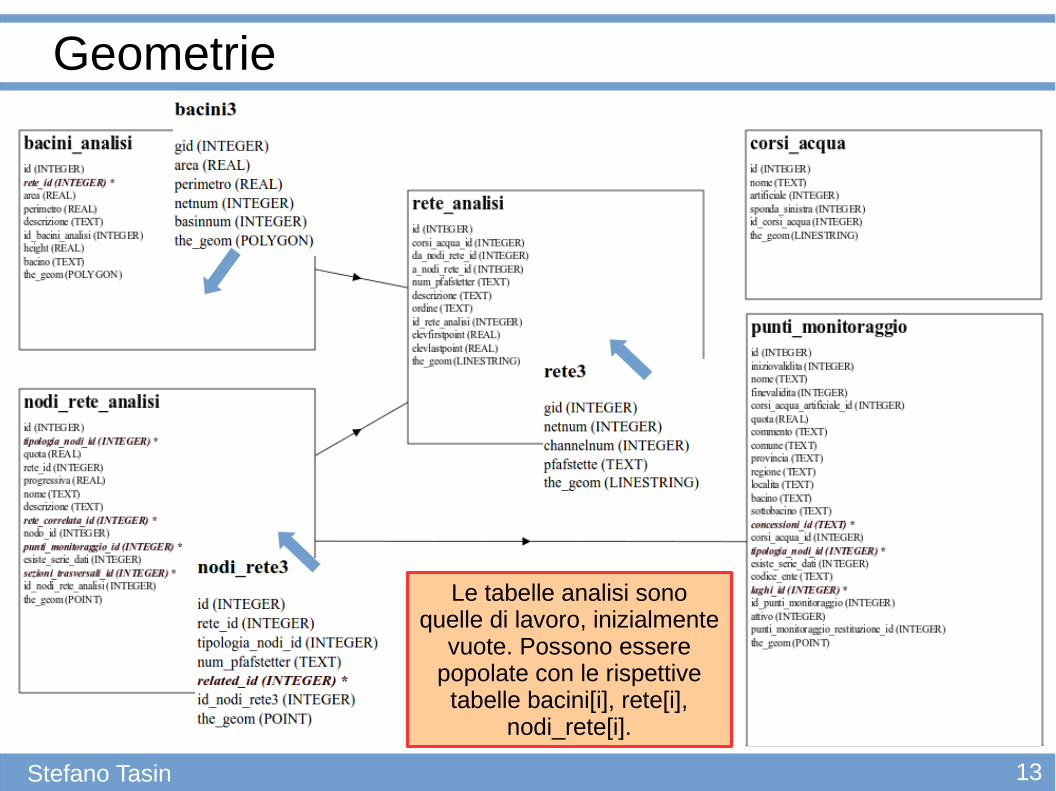
Geometrie
Le tabelle analisi sono quelle di lavoro, inizialmente
vuote. Possono essere popolate con le rispettive tabelle bacini[i], rete[i],
nodi_rete[i].
14Stefano Tasin
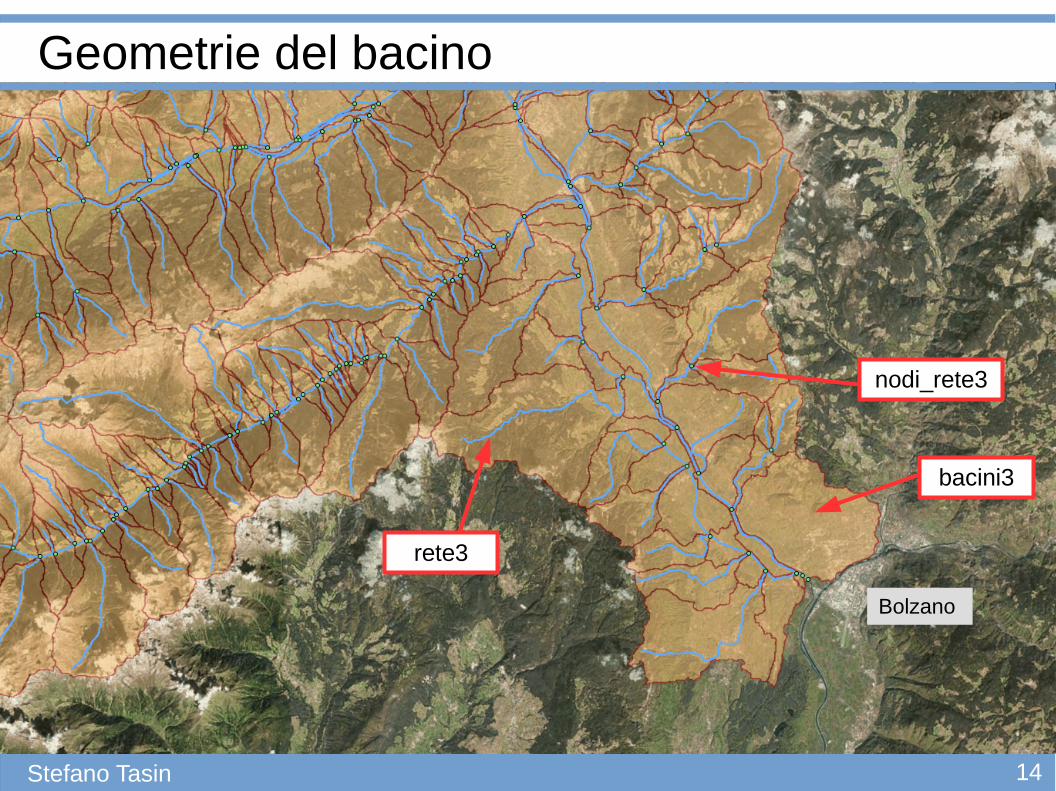
Geometrie del bacino
bacini3
rete3
nodi_rete3
Bolzano
15Stefano Tasin
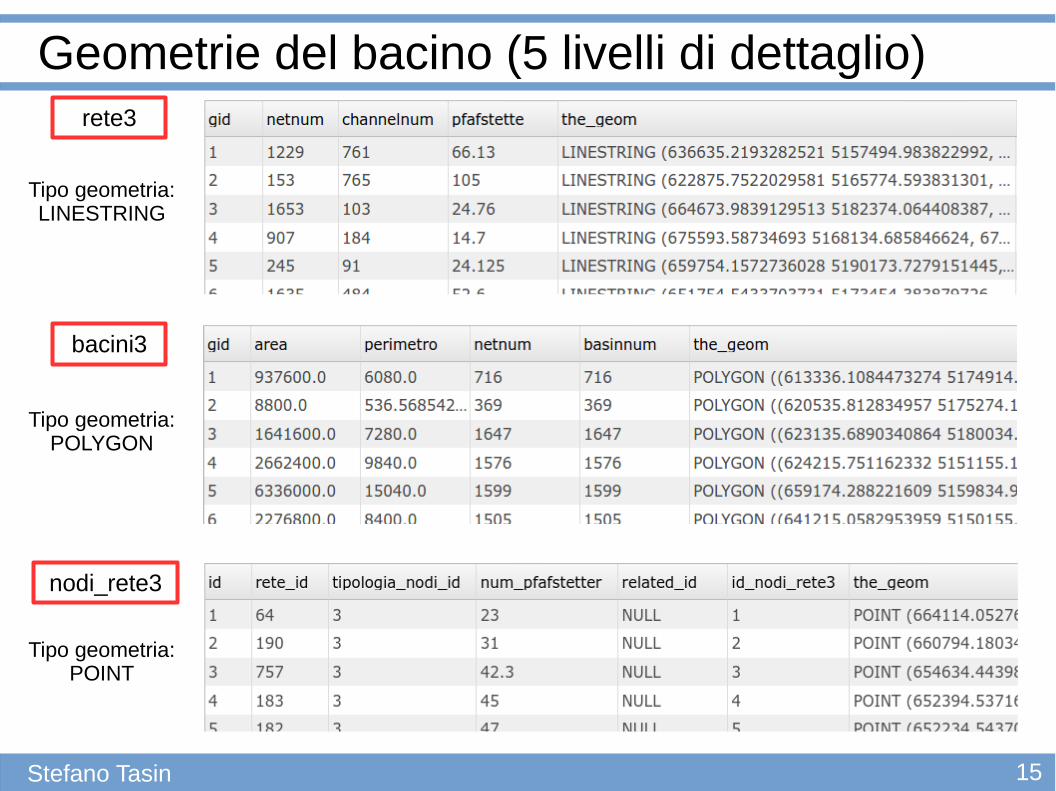
Geometrie del bacino (5 livelli di dettaglio)
bacini3
rete3
nodi_rete3
Tipo geometria:LINESTRING
Tipo geometria:POLYGON
Tipo geometria:POINT

16
Tabelle geometriche
Stefano Tasin
ATTENZIONE!
Attualmente alcune tabelle geometriche non coprono l’intero bacino del fiume Adige!
(Adige chiuso a Bolzano)
Naturalmente il database può essere integrato, ma mantenendo però la coerenza con la struttura dati esistente. Altrimenti conviene ripensare la struttura di queste tabelle e popolarle con le nuove geometriche.
17Stefano Tasin
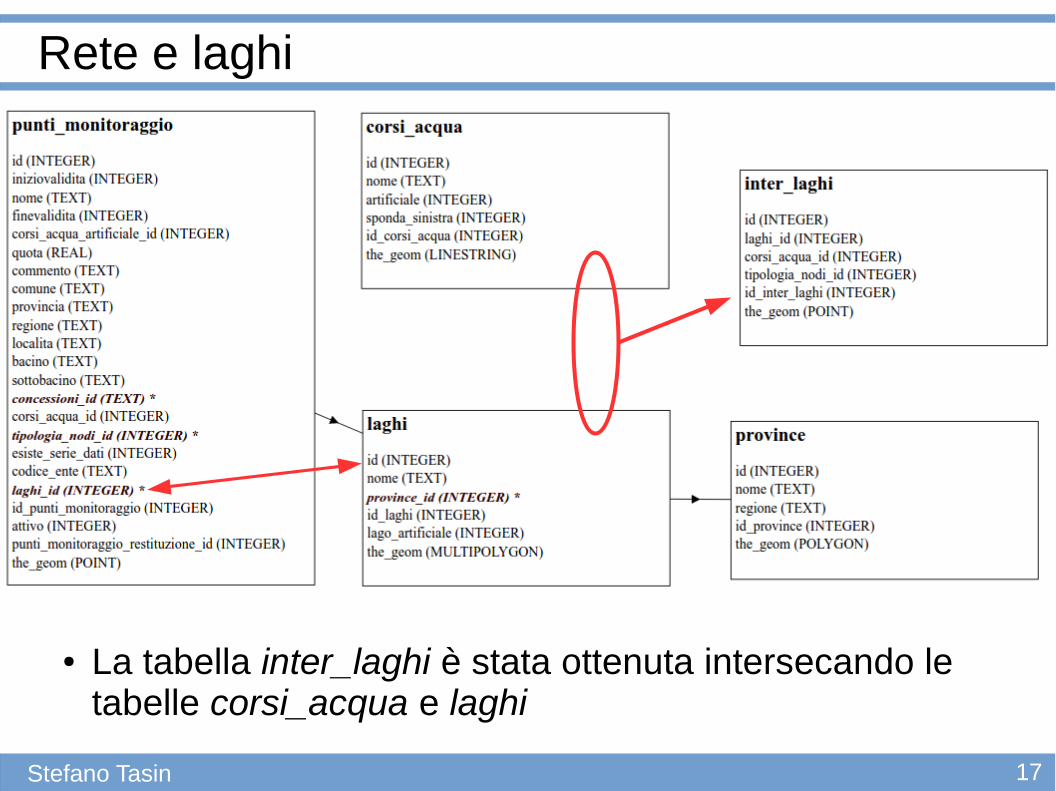
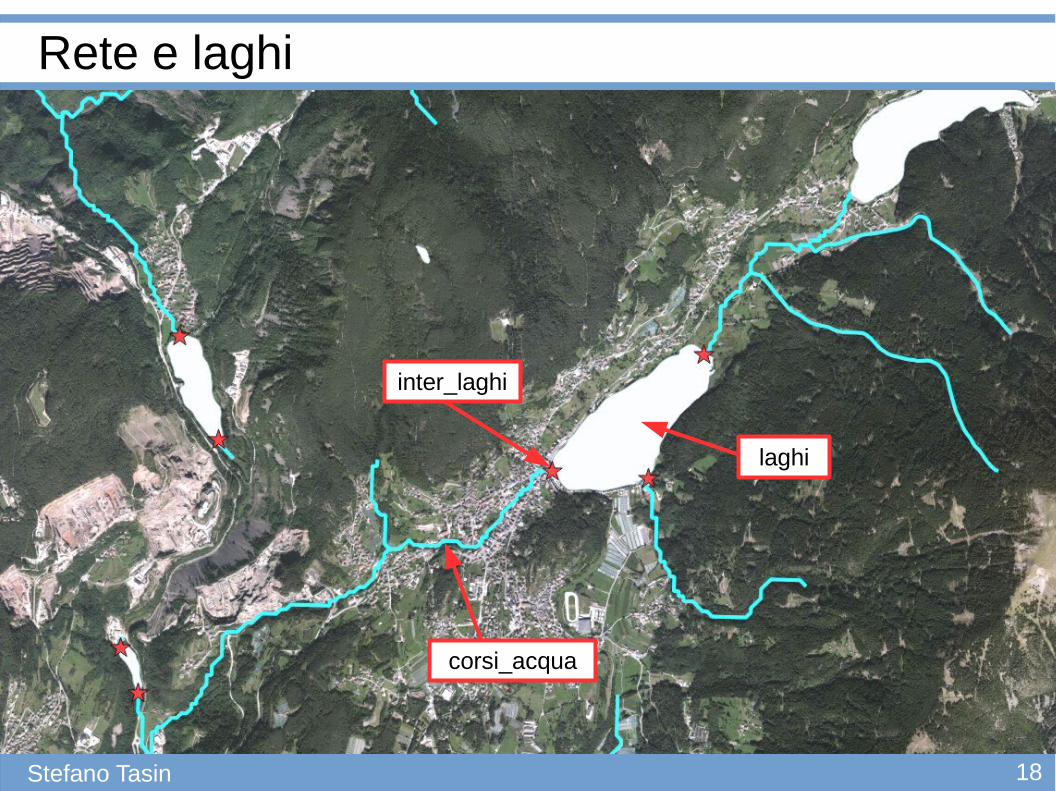
Rete e laghi
● La tabella inter_laghi è stata ottenuta intersecando le tabelle corsi_acqua e laghi
18Stefano Tasin
Rete e laghi
corsi_acqua
inter_laghi
laghi

19Stefano Tasin
Rete e sezioni trasversali
(attualmente solo per il fiume Adige)● selezionare i punti di una sezione trasversale:
0 100 200 300 400 500 600 700 8001444
1446
1448
1450
1452
1454
1456
1458
1460
SELECT pst.progressiva, pst.quotaFROM sezioni_trasversali st, punti_sezioni_trasversali pstWHERE st.id=pst.sezioni_trasversali_idAND st.id=5
20Stefano Tasin
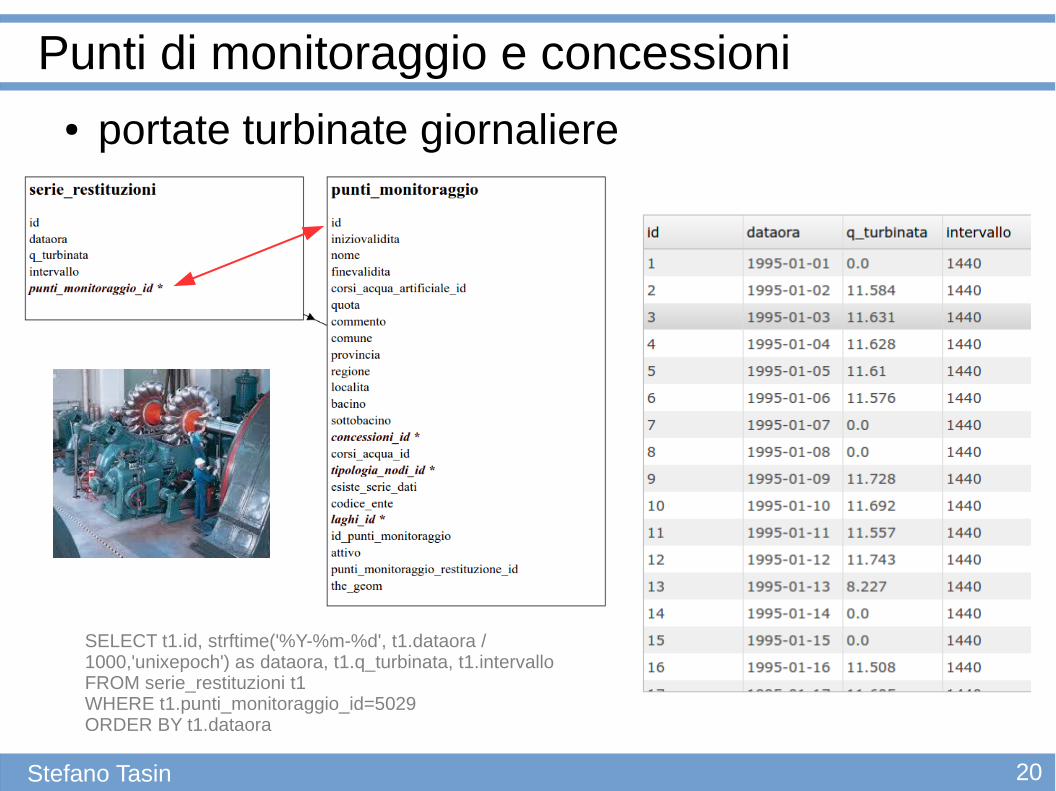
Punti di monitoraggio e concessioni● portate turbinate giornaliere
SELECT t1.id, strftime('%Y-%m-%d', t1.dataora / 1000,'unixepoch') as dataora, t1.q_turbinata, t1.intervalloFROM serie_restituzioni t1WHERE t1.punti_monitoraggio_id=5029ORDER BY t1.dataora

21
Serie temporali
Stefano Tasin
Le chiavi primarie sono denominate “id”.
Le chiavi esterne (indicate in grassetto e dall'asterisco) sono denominate in base alla tabella a cui si riferiscono, con:“nome_tabella_id”
Campo che contiene l'informazione geometrica.
22
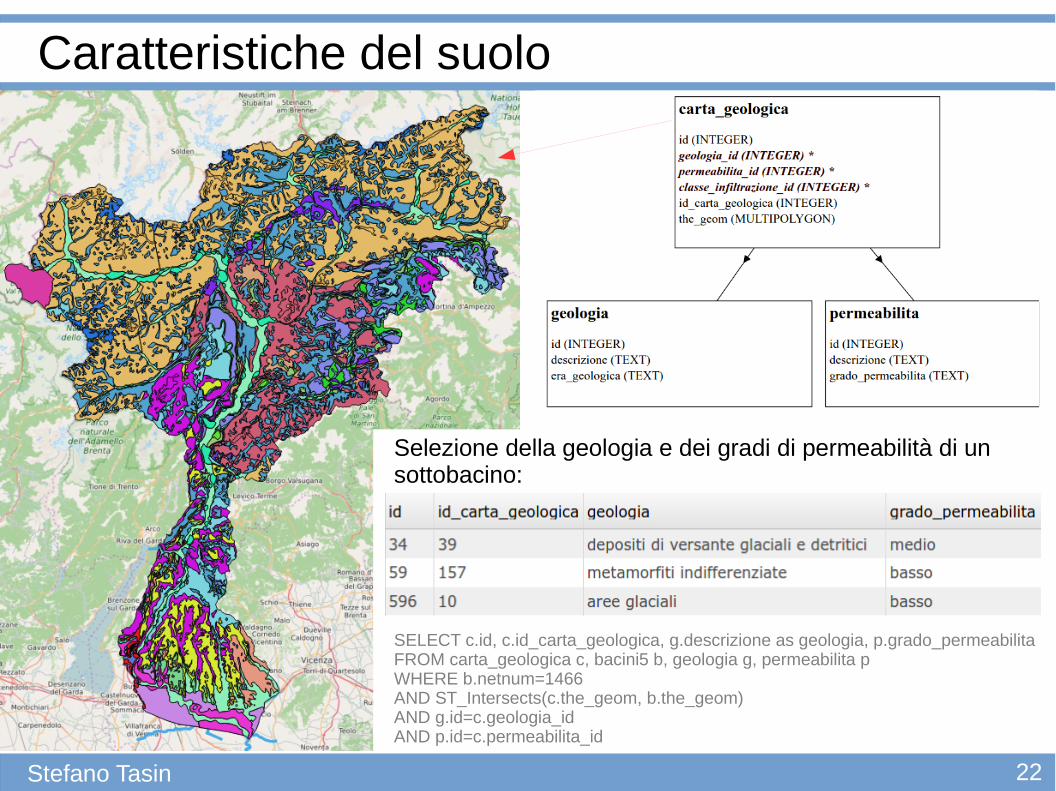
Caratteristiche del suolo
Stefano Tasin
SELECT c.id, c.id_carta_geologica, g.descrizione as geologia, p.grado_permeabilitaFROM carta_geologica c, bacini5 b, geologia g, permeabilita pWHERE b.netnum=1466AND ST_Intersects(c.the_geom, b.the_geom)AND g.id=c.geologia_idAND p.id=c.permeabilita_id
Selezione della geologia e dei gradi di permeabilità di un sottobacino:

23
SQL Istruzioni fondamentali
S. Franceschi, A. Antonello
● Structured Query Language (SQL):– non è un linguaggio di programmazione
– linguaggio di interazione con il DBMS
● permette di definire lo schema di un database, popolare le tabelle, aggiornare i dati, eseguire query, definire vincoli ed autorizzazioni
● Nota: la libreria SQLite utilizza una sintassi molto simile a quella SQL, ma più compatta.

24
SQL Istruzioni fondamentali
S. Franceschi, A. Antonello
● due sezioni di SQL:– Data Definition Language (DDL): definizione dello
schema e degli oggetti del DB● creazione della base dati: CREATE DATABASE● creazione delle tabelle: CREATE TABLE● ecc.
– Data Manipulation Language (DML): utilizzo dei dati del DB (interrogazioni ed aggiornamenti)
● inserimento dei dati: INSERT INTO● interrogazioni: SELECT● eliminazione di dati: DELETE● modifica dei dati: UPDATE● ecc.

25
Interrogare il DB: SELECT
● tre parole chiave per leggere i dati nel DB:SELECT, FROM, WHERE
– SELECT: applicare gli operatori corrispondenti alle tabelle della FROM (proiezioni, ridenominazioni, eliminazione duplicati, AVG)
– FROM: specifica le tabelle da cui prelevare i dati
– WHERE: specifica le selezioni anche multiple legate con connettivi booleani (AND, OR, NOT)
– ORDER BY: specifica gli ordinamenti finali (DESC)
S. Franceschi, A. Antonello

26
Interrogare il DB
Esempio:● visualizzare il contenuto di una tabella
SELECT * FROM tipologia_serie_temporali
● L’operatore “*” preleva tutte le colonne della tabella “tipologia_serie_temporali”● Non specificando la clausola “WHERE” sono riportati tutti i record
S. Tasin

27
Interrogare il DB: condizioni
S. Franceschi, S. Tasin
● WHERE <condizione di ricerca>– contiene una condizione di una espressione booleana che potrà
essere TRUE (vera) o FALSE (falsa)– consentono di effettuare query selettive: solitamente includono una
variabile, una costante e un operatore di confronto.
esempio:SELECT p.id, p.nome, p.quota, p.comune, p.provincia, p.regioneFROM punti_monitoraggio pWHERE p.quota > 2000;
variabile
costante
operatoredi cofronto

28
Interrogare il DB: condizioni
S. Franceschi, S. Tasin
● utilizzo degli operatori: sono gli elementi necessari per specificare le condizioni necessarie a caricare i dati
● possono essere divisi in sei gruppi:– aritmetici (+, -, /, *, %)– di confronto (=, <, >, <=, >=, !=)– di caratteri (LIKE)– logici (AND, OR, NOT, IN, LIKE)– di insieme– vari

29
Interrogare il DB: colonne derivate
S. Franceschi, S. Tasin
● SQL consente di creare colonne virtuali o derivate combinando o modificando le colonne esistenti
● l’argomento della SELECT ammette l’uso degli operatori appena visti
● è buona norma rinominare la colonna derivata con la parola chiave “AS”
esempio:SELECT col_a, col_b, col_a+col_b AS col_c FROM tabella
operazione nome colonna derivata

30Stefano Tasin
● permettono di svolgere operazioni sui dati– Aggregate: COUNT, AVG, MIN, MAX, SUM, VAR, ...
– Temporali: LAST_DAY, ADD_MONTH, ...
– Aritmetiche: ABS, CEIL, FLOOR, COS, TAN, EXP, ...
– Di caratteri: SUBSTR, LENGTH, CHR, ...
– Di conversione– Varie
esempio:
COUNT: restituisce il numero di righe che soddisfano la condizione specificata nella clausola WHERE (senza la clausola WHERE la query fornisce il numero di record della tabella)
SELECT COUNT(*) FROM serie_temporali; SELECT COUNT(*) FROM serie_temporali sWHERE s.valore > 200
Interrogare il DB: Funzioni
5*10^8 righe!

31S. Franceschi, S. Tasin
● funzioni temporali: è possibile lavorare con le date (aggiungere mesi ad una data specifica, individuare l’ultimo giorno del mese indicato nella data, conoscere la data del sistema, sapere quanti mesi separano due date, …)
● NB! Il database adotta il sistema “unix time” (millisecondi dal 1º gennaio 1970 alle 0:00):– da unix-epoch a human date:
strftime('%Y-%m-%d %H:%M:%S', timestampcolumn / 1000, 'unixepoch')
– da human date a unix-epoch:strftime('%s','YYYY-MM-YY HH:mm:ss')*1000
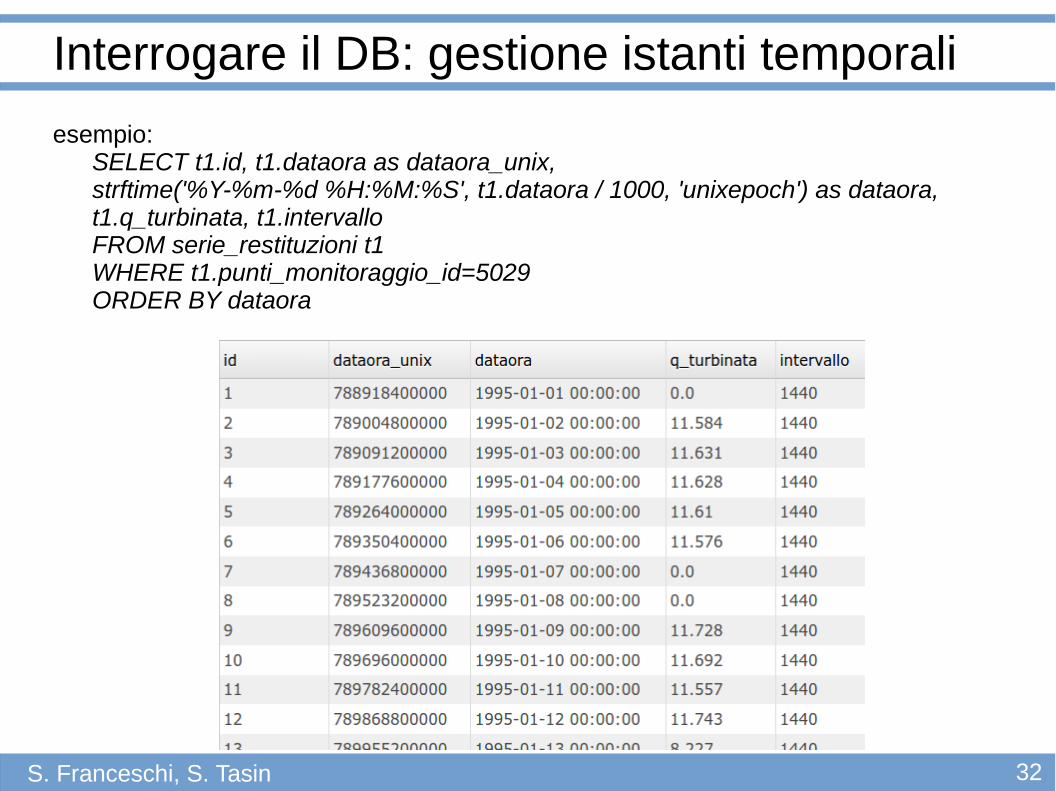
Interrogare il DB: gestione istanti temporali
820454400000 1996-01-01 00:00:00
8204544000001996-01-01 00:00:00
NB. Le date antecedenti al 1° gennaio 1970 hanno tempi unix negativi:
-12341655370001930-11-22 16:14:23
32S. Franceschi, S. Tasin
esempio:SELECT t1.id, t1.dataora as dataora_unix, strftime('%Y-%m-%d %H:%M:%S', t1.dataora / 1000, 'unixepoch') as dataora, t1.q_turbinata, t1.intervalloFROM serie_restituzioni t1WHERE t1.punti_monitoraggio_id=5029ORDER BY dataora
Interrogare il DB: gestione istanti temporali
33S. Franceschi, S. Tasin
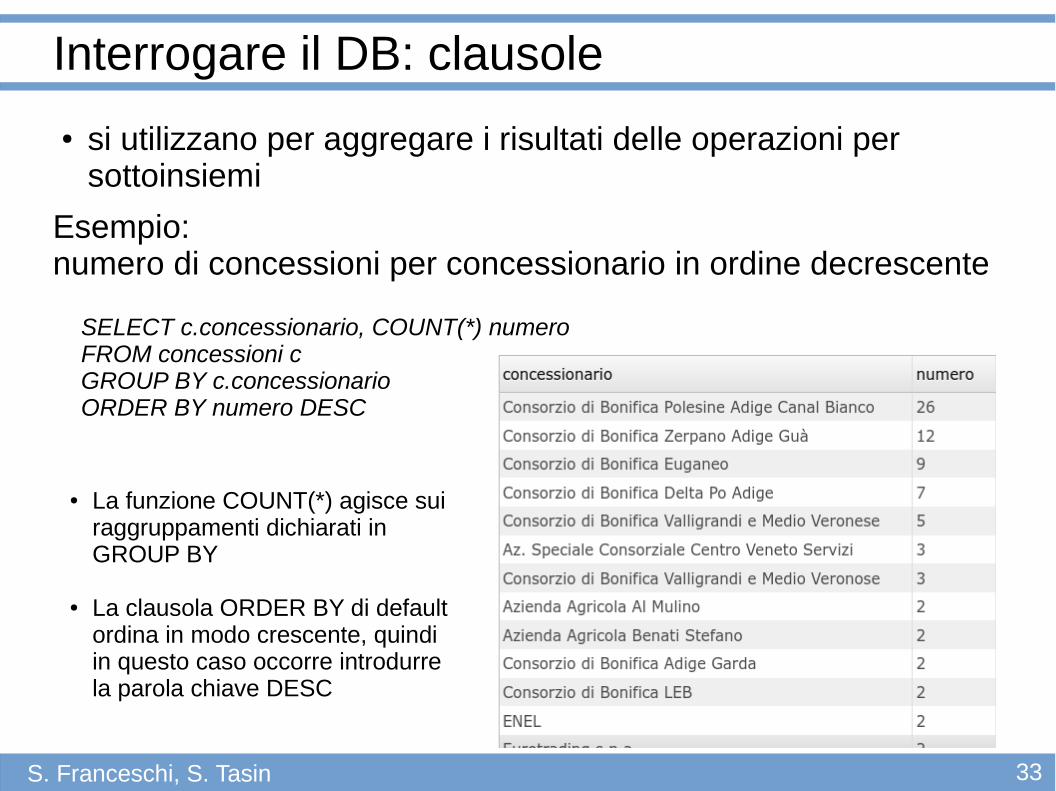
● si utilizzano per aggregare i risultati delle operazioni per sottoinsiemi
Esempio: numero di concessioni per concessionario in ordine decrescente
Interrogare il DB: clausole
SELECT c.concessionario, COUNT(*) numero FROM concessioni cGROUP BY c.concessionarioORDER BY numero DESC
● La funzione COUNT(*) agisce sui raggruppamenti dichiarati in GROUP BY
● La clausola ORDER BY di default ordina in modo crescente, quindi in questo caso occorre introdurre la parola chiave DESC

34S. Franceschi, A. Antonello
● si possono interrogare più tabelle contemporaneamente (cross-join)● attenzione ad effettuare il collegamento tra le colonne che rappresentano gli
stessi elementi● nella FROM si possono definire degli alias per le tabelle:
nome_tab1 alias1, nome_tab2 alias2● le colonne vengono poi richiamate con la sintassi:
alias1.col1
esempio:SELECT s.id, s.num_concessione, s.data_concessione, s.q_media_turb, p.id, p.nome, p.provincia FROM serbatoi s, punti_monitoraggio pWHERE s.punti_monitoraggio_id=p.id
Interrogare il DB: più tabelle
cross-joinalias
Se la clausola WHERE viene omessa,
implicitamente vengono selezionate tutte le
combinazioni possibili. La tabella risultante avrà un numero di
record pari alla moltiplicazione dei
record presenti nelle due tabelle.

35S. Franceschi, A. Antonello
● si possono annidare più query● è possibile usare nella subquery tutte le funzioni che ritornano un valore coerente con la
clausola principale WHERE● sintassi:
SELECT x, y FROM z WHERE a = ( SELECT a FROM b WHERE c = condizione)
● Esempio: estrarre dalla serie storica i mesi con piovosità sopra la mediaSELECT s.id,s.anno,s.mese,s.altezza_prec,s.num_giorni_piovosiFROM serie_storiche_pluv sWHERE metadati_id=115AND s.altezza_prec > ( SELECT AVG(s.altezza_prec) FROM serie_storiche_pluv s)ORDER BY s.anno,s.mese
Interrogare il DB: subquery
AVG(s.altezza_prec)
75.66836
Attenzione!
SQL non permette il confronto diretto
s.altezza_prec > AVG(s.altezza_prec)
36S. Franceschi, A. Antonello
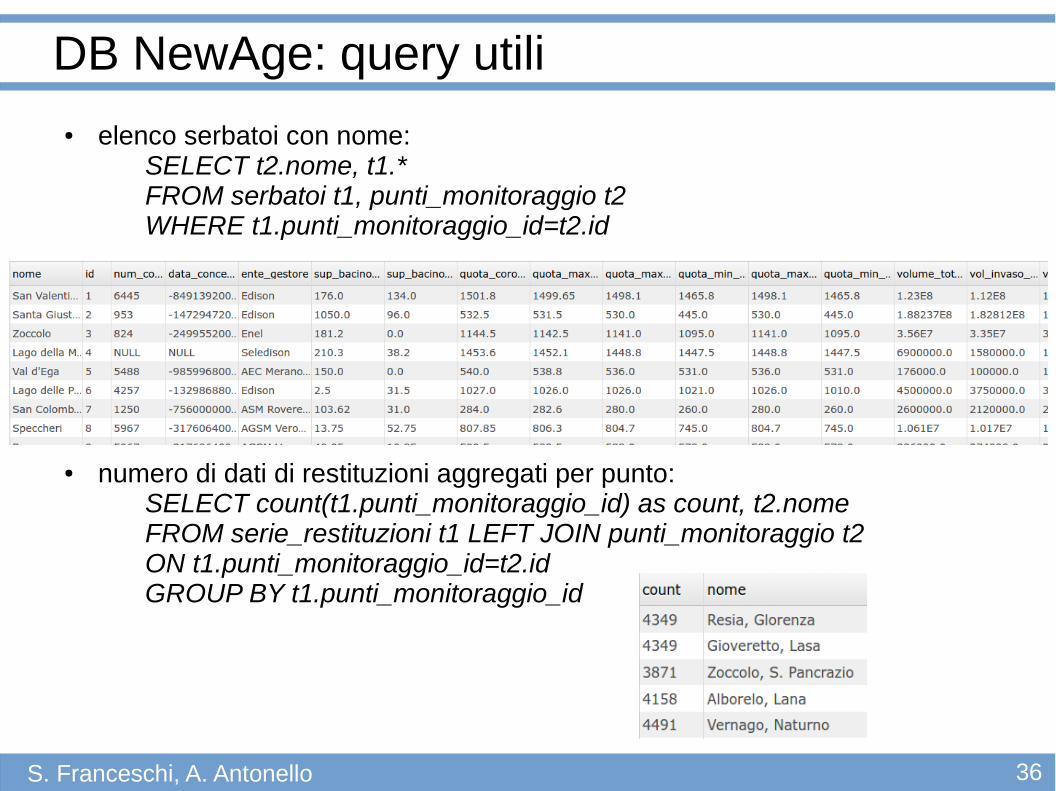
● elenco serbatoi con nome:SELECT t2.nome, t1.* FROM serbatoi t1, punti_monitoraggio t2WHERE t1.punti_monitoraggio_id=t2.id
● numero di dati di restituzioni aggregati per punto:SELECT count(t1.punti_monitoraggio_id) as count, t2.nomeFROM serie_restituzioni t1 LEFT JOIN punti_monitoraggio t2ON t1.punti_monitoraggio_id=t2.idGROUP BY t1.punti_monitoraggio_id
DB NewAge: query utili
37S. Franceschi, A. Antonello
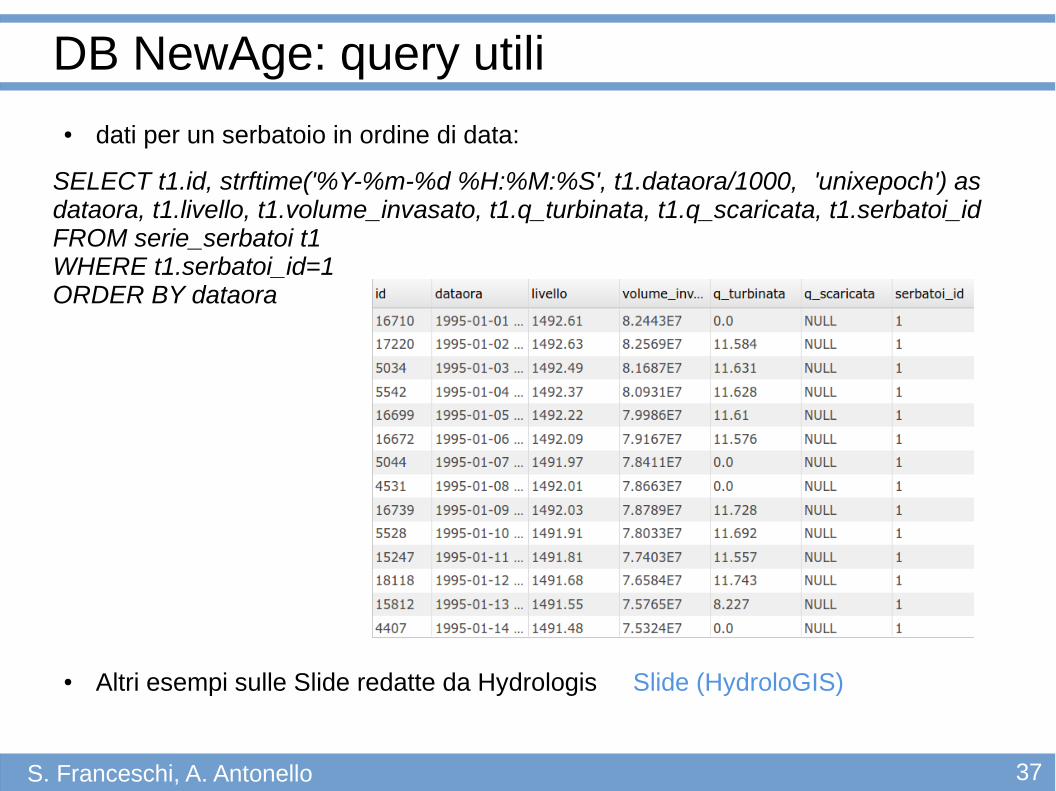
● dati per un serbatoio in ordine di data:
SELECT t1.id, strftime('%Y-%m-%d %H:%M:%S', t1.dataora/1000, 'unixepoch') as dataora, t1.livello, t1.volume_invasato, t1.q_turbinata, t1.q_scaricata, t1.serbatoi_id FROM serie_serbatoi t1 WHERE t1.serbatoi_id=1ORDER BY dataora
● Altri esempi sulle Slide redatte da Hydrologis Slide (HydroloGIS)
DB NewAge: query utili

38Stefano Tasin
● importare uno shape come tabella geometrica (EPSG: 32632)NB: questa funzione è disabilitata per dafault. Per abilitarla è necessario settare la variabile d'ambiente "SPATIALITE_SECURITY=relaxed":
SELECT ImportSHP('path2shp/shape_name','tab_name','UTF-8',32632,'the_geom');
● seleziona gli ID delle stazioni meteo contenute nella maschera "Isarco":
SELECT p.idFROM a_mask a, punti_monitoraggio pWHERE ST_Contains(a.the_geom, p.the_geom)AND p.tipologia_nodi_id=7AND a.name='Isarco'
DB NewAge: query spaziali
Stazioni meteoIsarco
NB! In questo modo non si selezionano le stazioni nivo-meteo, meteo-idrometriche, ecc..

39Stefano Tasin
● seleziona le stazioni meteo con un buffer di 1km (più efficiente operare il buffer sulle stazioni puntuali anziché sul poligono della maschera)
SELECT p.idFROM a_mask a, punti_monitoraggio pWHERE ST_Intersects(a.the_geom, ST_Buffer(p.the_geom,1000.0))AND p.tipologia_nodi_id=7AND a.name='Isarco'
DB NewAge: query preselezione serie dati
Questa query restituisce solo gli ID dei punti selezionati.
In questo modo può essere annidata in un’altra query per
estrarre le serie dati d’interesse.
Si deve passare un solo campo!

40Stefano Tasin
● Pre-selezione delle serie temporali (utile prima di estrarre dalla tabella "serie_temporali", viste le dimensioni). Seleziona tutte le serie di precipitazione disponibili per il bacino dell'Isarco con un buffer di 5km:
SELECT * FROM metadati mWHERE m.tipologia_serie_temporali_id=2AND m.punti_monitoraggio_id IN ( SELECT p.id FROM a_mask a, punti_monitoraggio p WHERE ST_Intersects(a.the_geom, ST_Buffer(p.the_geom, 5000)) AND a.name='Isarco')ORDER BY m.punti_monitoraggio_id
DB NewAge: query preselezione serie dati
Seleziono tutti i punti di monitoraggio che hanno una serie di precipitazione
NB. Ogni punto di monitoraggio può avere più serie temporali di precipitazione nel caso di intervalli di campionamento diversi, origine dati diversa, ecc...
41Stefano Tasin
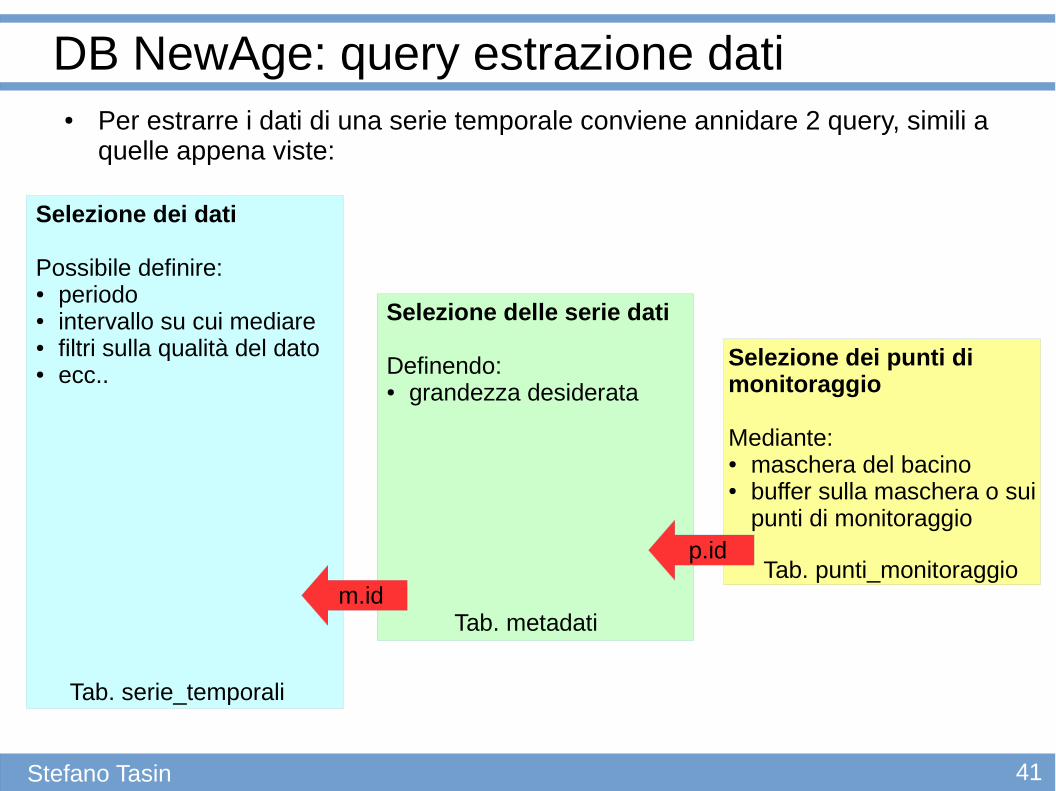
● Per estrarre i dati di una serie temporale conviene annidare 2 query, simili a quelle appena viste:
DB NewAge: query estrazione dati
Selezione dei dati
Possibile definire:● periodo● intervallo su cui mediare● filtri sulla qualità del dato● ecc..
Selezione delle serie dati
Definendo:● grandezza desiderata
Selezione dei punti di monitoraggio
Mediante:● maschera del bacino● buffer sulla maschera o sui
punti di monitoraggio p.id
m.idTab. punti_monitoraggio
Tab. metadati
Tab. serie_temporali

42Stefano Tasin
● Selezione dei punti di monitoraggio compresi nel bacino con buffer:
SELECT m.punti_monitoraggio_id, s.metadati_id,strftime('%Y-%m-%d %H', s.dataora / 1000, 'unixepoch') || ":00" as dataora, round(avg(s.valore),1) as valore,s.affidabilitaFROM serie_temporali s, metadati mWHERE s.metadati_id IN (
SELECT m.id FROM metadati mWHERE m.tipologia_serie_temporali_id=2AND m.intervallo<=60AND m.punti_monitoraggio_id IN (
SELECT p.id FROM a_mask a, punti_monitoraggio p WHERE ST_Intersects(a.the_geom, ST_Buffer(p.the_geom, 5000))AND a.name='Isarco'
))AND s.dataora>=strftime('%s','2003-01-01 00:00:00')*1000AND s.dataora<strftime('%s','2013-01-01 00:00:00')*1000AND s.metadati_id=m.idGROUP BY m.punti_monitoraggio_id, strftime('%Y-%m-%d %H', s.dataora / 1000, 'unixepoch')
DB NewAge: query estrazione dati

43Stefano Tasin
● Selezione delle "serie_temporali" di precipitazione, orarie o suborarie:
SELECT m.punti_monitoraggio_id, s.metadati_id,strftime('%Y-%m-%d %H', s.dataora / 1000, 'unixepoch') || ":00" as dataora, round(avg(s.valore),1) as valore,s.affidabilitaFROM serie_temporali s, metadati mWHERE s.metadati_id IN (
SELECT m.id FROM metadati mWHERE m.tipologia_serie_temporali_id=2AND m.intervallo<=60AND m.punti_monitoraggio_id IN (
SELECT p.id FROM a_mask a, punti_monitoraggio p WHERE ST_Intersects(a.the_geom, ST_Buffer(p.the_geom, 5000))AND a.name='Isarco'
))AND s.dataora>=strftime('%s','2003-01-01 00:00:00')*1000AND s.dataora<strftime('%s','2013-01-01 00:00:00')*1000AND s.metadati_id=m.idGROUP BY m.punti_monitoraggio_id, strftime('%Y-%m-%d %H', s.dataora / 1000, 'unixepoch')
DB NewAge: query estrazione dati
La tabella metadati contiene tutte le informazioni sulle serie di dati
Serie di precipitazione

44Stefano Tasin
● Selezione dei dati orari dalla tabella "serie_temporali":
SELECT m.punti_monitoraggio_id, s.metadati_id,strftime('%Y-%m-%d %H', s.dataora / 1000, 'unixepoch') || ":00" as dataora, round(avg(s.valore),1) as valore,s.affidabilitaFROM serie_temporali s, metadati mWHERE s.metadati_id IN (
SELECT m.id FROM metadati mWHERE m.tipologia_serie_temporali_id=2AND m.intervallo<=60AND m.punti_monitoraggio_id IN (
SELECT p.id FROM a_mask a, punti_monitoraggio p WHERE ST_Intersects(a.the_geom, ST_Buffer(p.the_geom, 5000))AND a.name='Isarco'
))AND s.dataora>=strftime('%s','2003-01-01 00:00:00')*1000AND s.dataora<strftime('%s','2013-01-01 00:00:00')*1000AND s.metadati_id=m.idGROUP BY m.punti_monitoraggio_id, strftime('%Y-%m-%d %H', s.dataora / 1000, 'unixepoch')
DB NewAge: query estrazione dati

45Stefano Tasin
● Uno sguardo alla query principale
SELECT m.punti_monitoraggio_id, s.metadati_id,strftime('%Y-%m-%d %H', s.dataora / 1000, 'unixepoch') || ":00" as dataora,
round(avg(s.valore),1) as valore, s.affidabilita
FROM serie_temporali s, metadati mWHERE s.metadati_id IN (
...)AND s.dataora>=strftime('%s','2003-01-01 00:00:00')*1000AND s.dataora<strftime('%s','2013-01-01 00:00:00')*1000
AND s.metadati_id=m.idGROUP BY m.punti_monitoraggio_id, strftime('%Y-%m-%d %H', s.dataora / 1000, 'unixepoch')
DB NewAge: query estrazione dati
Raggruppa i dati per ora in modo da poter essere mediati
Converte il tempo da formato unix a human date
Composizione della funzione che media i dati sull’ora e della funzione che arrotonda il dato alla prima cifra decimale
Selezione del periodo d’interesse trasformando le date in epoche unix
Raggruppa i dati per stazione
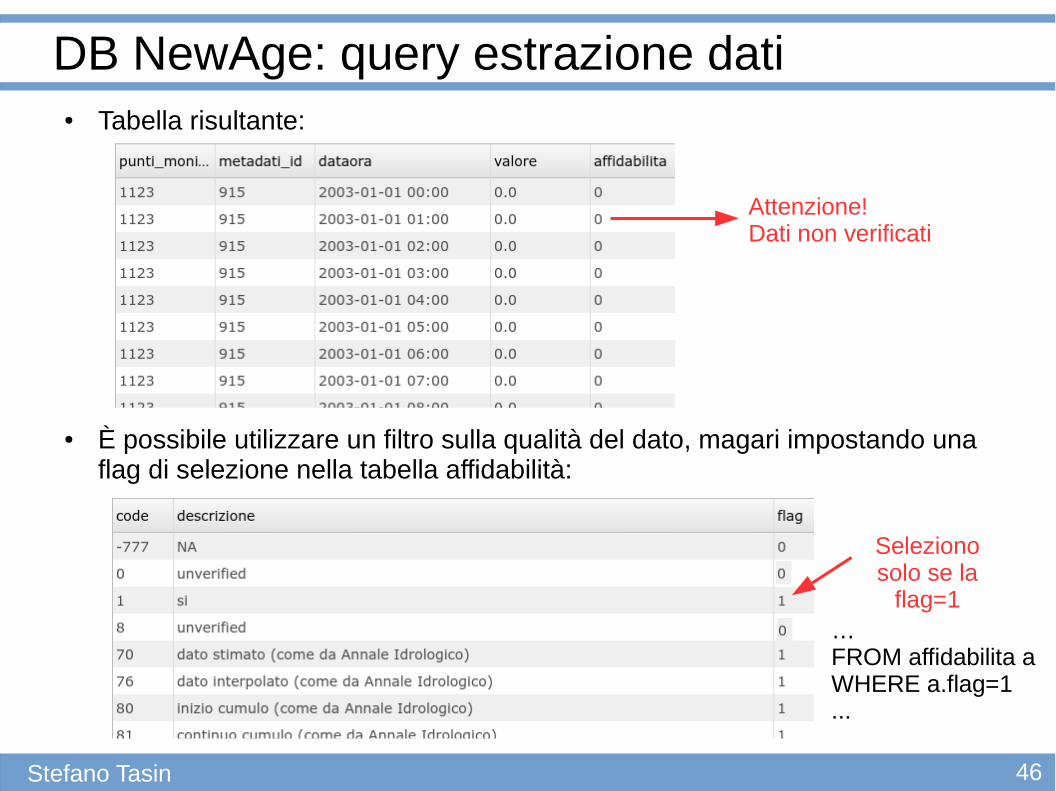
46Stefano Tasin
● Tabella risultante:
● È possibile utilizzare un filtro sulla qualità del dato, magari impostando una flag di selezione nella tabella affidabilità:
DB NewAge: query estrazione dati
Seleziono solo se la
flag=1
Attenzione!Dati non verificati
… FROM affidabilita a WHERE a.flag=1...

47
Interfacce
Stefano Tasin
Esistono molte interfacce per la gestione di database SQLite, ma poche gestiscono l'aspetto geometrico.
Interfacce che supportano i DB SpatiaLite:● DB Manager plugin di Qgis: molto pratico e ben integrato in Qgis,
tuttavia non riesce a sostenere operazioni onerose su database molto grandi. http://docs.qgis.org/2.0/en/docs/user_manual/plugins/plugins_db_manager.html
● Spatilite-gui: messa a disposizione sul sito di riferimento della libreria SpatiaLite stessa: https://www.gaia-gis.it/fossil/spatialite_gui/indexMa anche questa non riesce a trattare database grandi.
● Spatilite da shell: consente di trattare database anche grandi (con Ubuntu 15.10 è presente nel repository ufficiale).
● STAGE: messa a disposizione una versione provvisoria da HydroloGIS come servizio usufruibile da browser web su “localhost” o server in remoto. Consente di gestiere il database di NewAGE senza grossi problemi. Dispone inoltre di una sezione dedicata ai Jgrasstools.
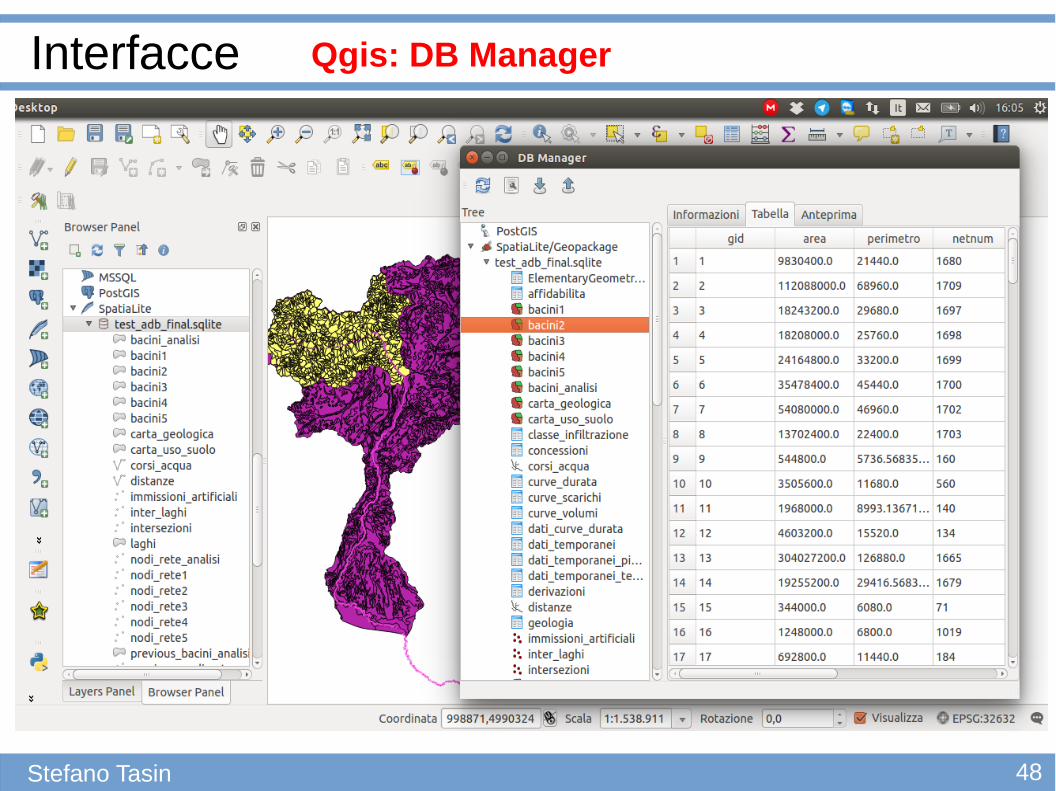
48
Interfacce
Stefano Tasin
Qgis: DB Manager
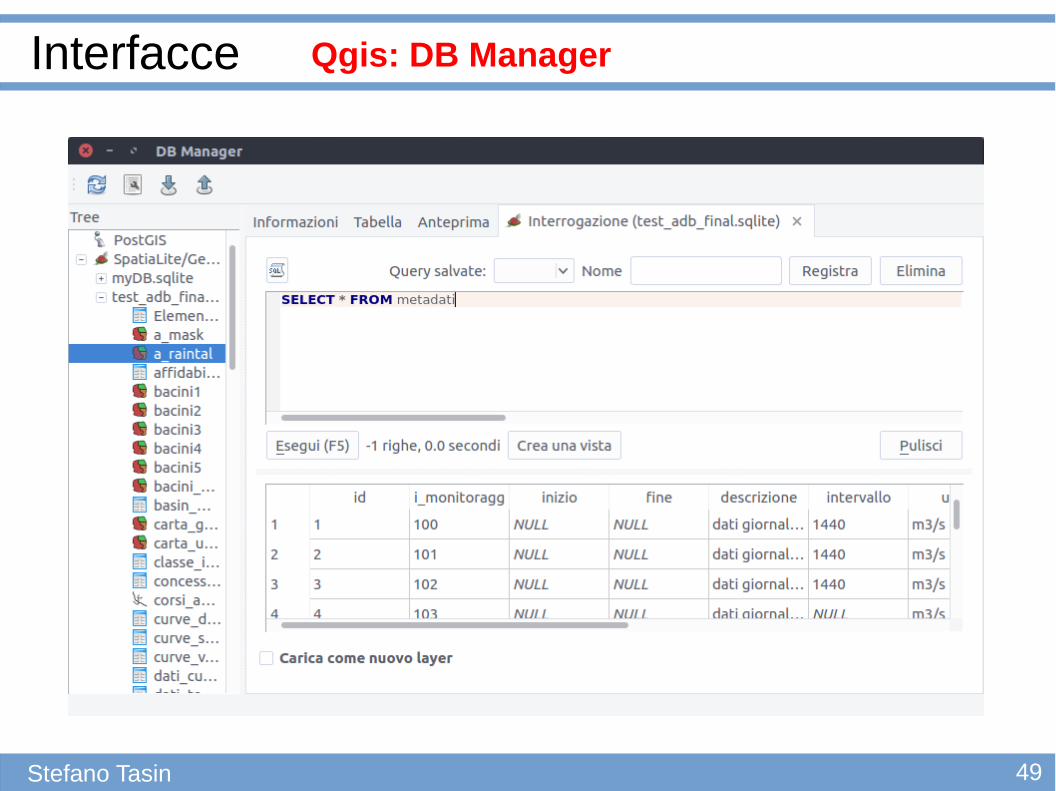
49
Interfacce
Stefano Tasin
Qgis: DB Manager
50
Interfacce
Stefano Tasin
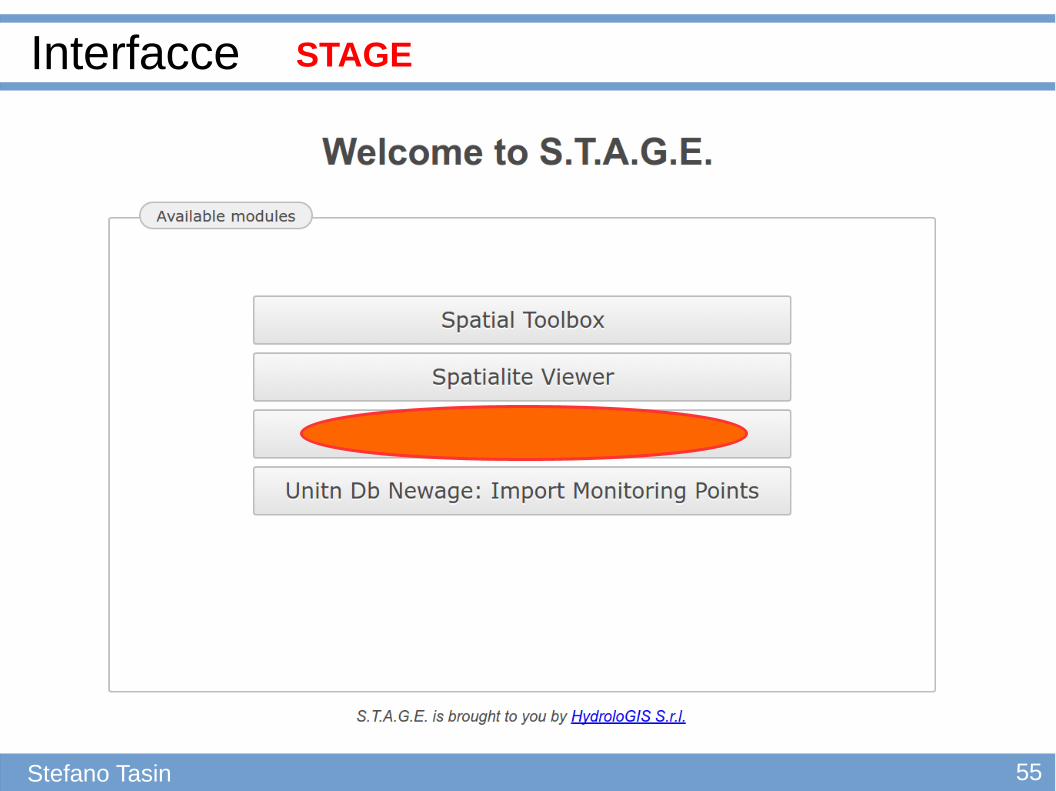
STAGE
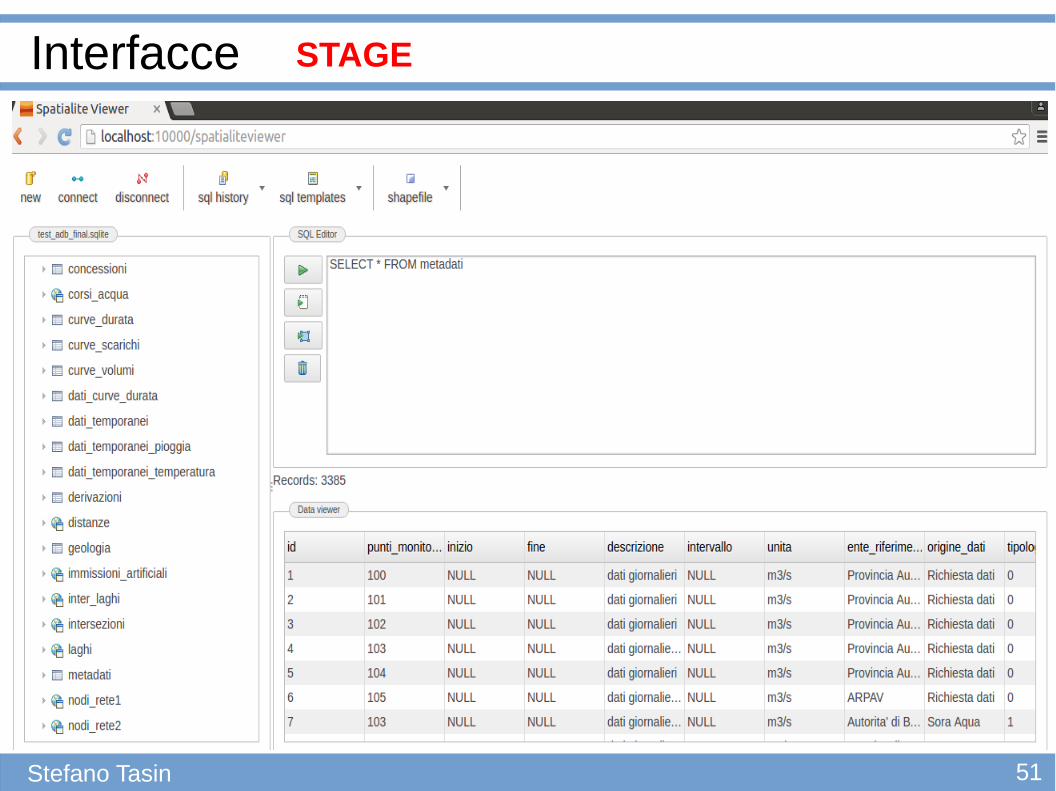
51
Interfacce
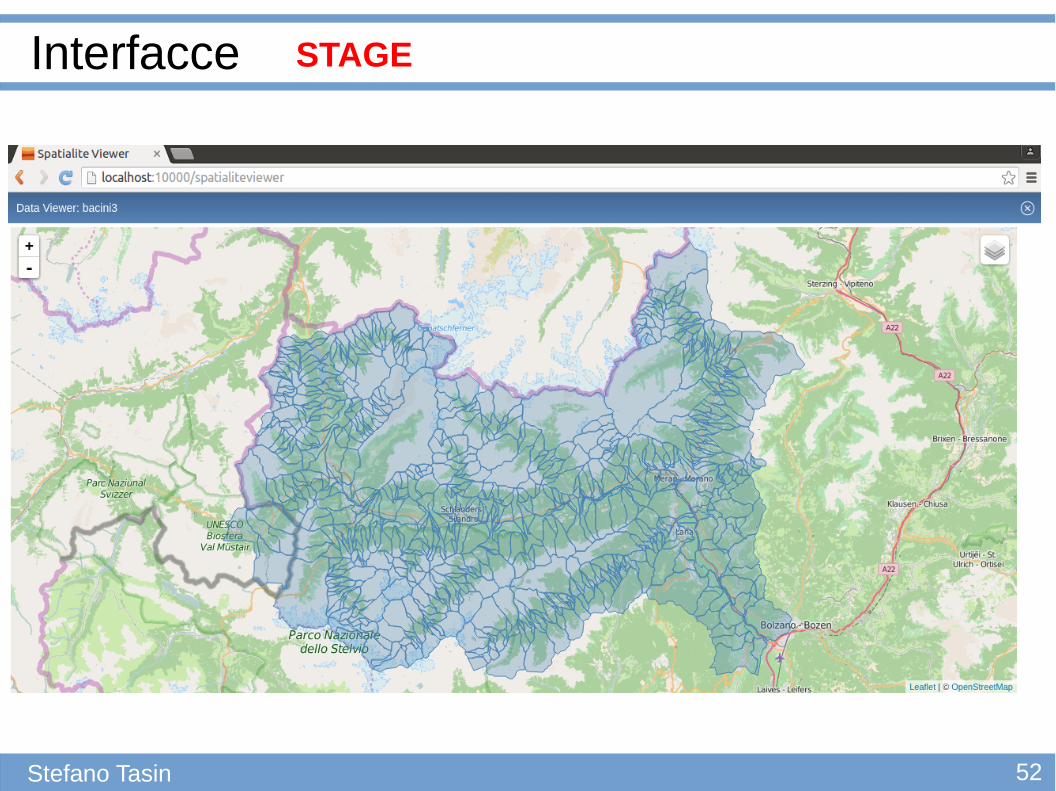
Stefano Tasin
STAGE
52
Interfacce
Stefano Tasin
STAGE
53Stefano Tasin
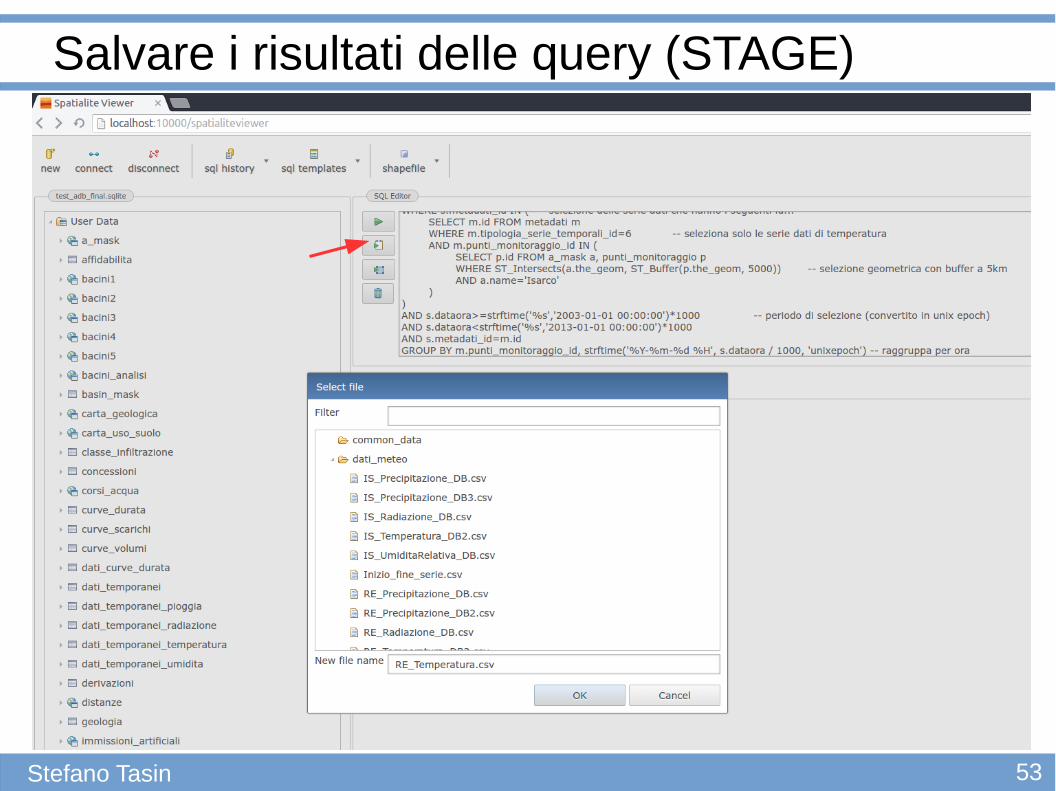
Salvare i risultati delle query (STAGE)
54Stefano Tasin
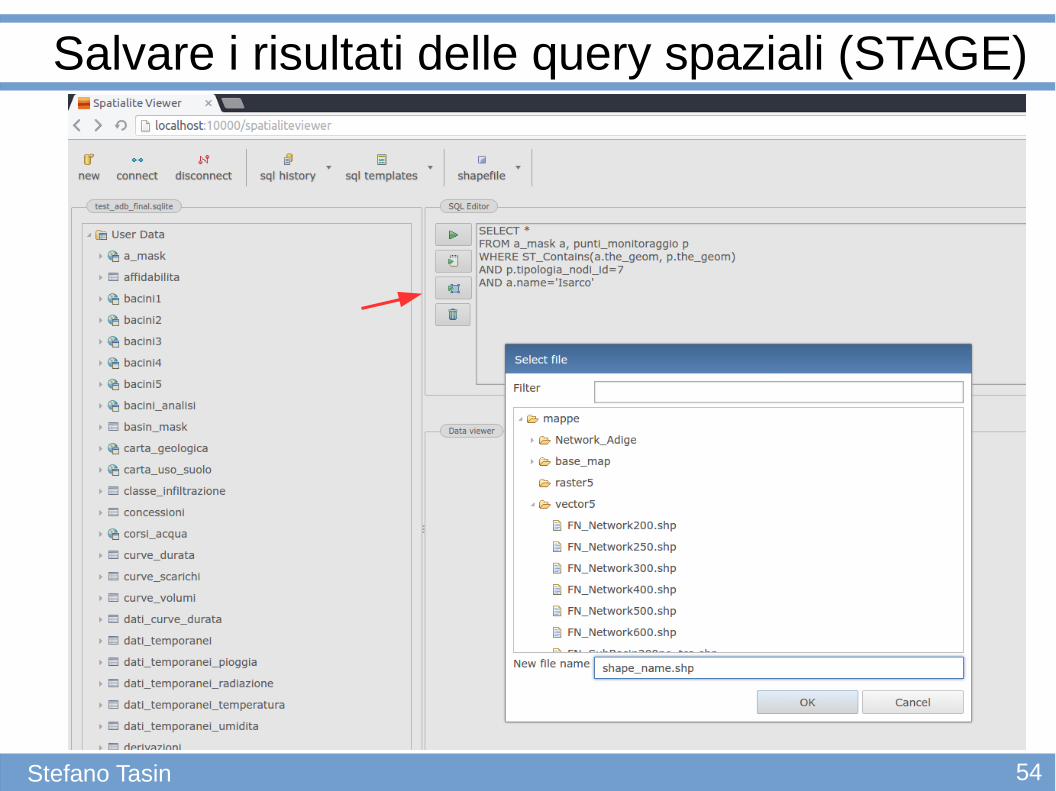
Salvare i risultati delle query spaziali (STAGE)
55
Interfacce
Stefano Tasin
STAGE
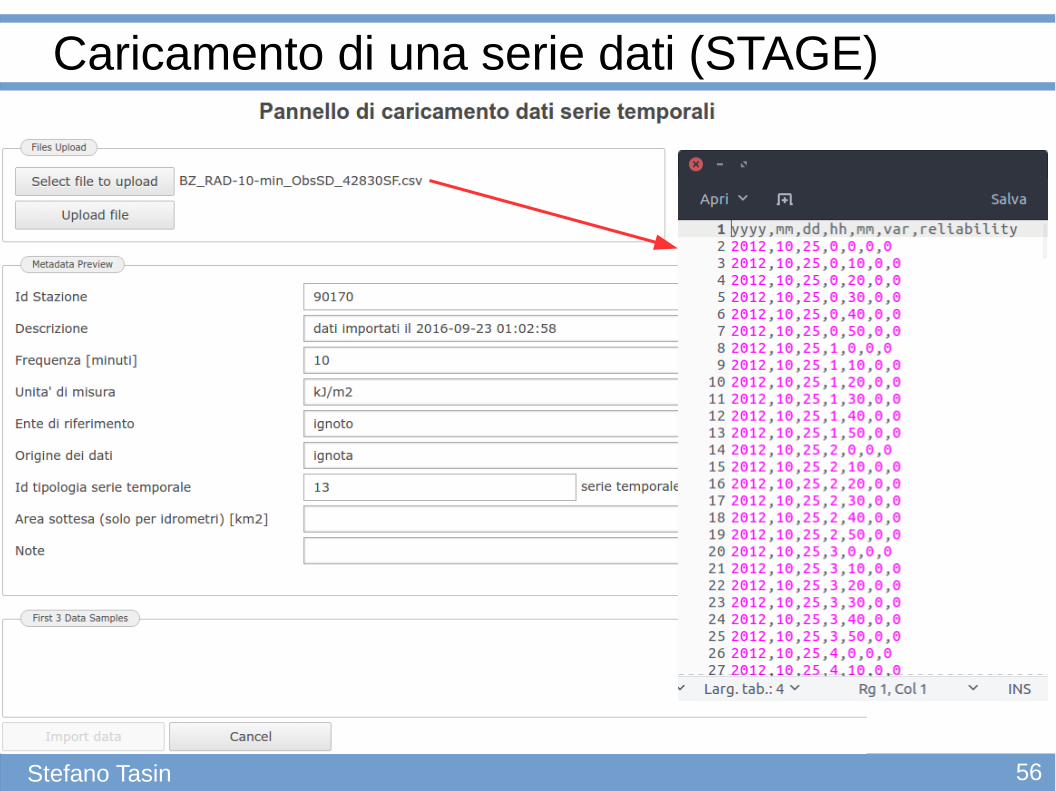
56Stefano Tasin
Caricamento di una serie dati (STAGE)

57Stefano Tasin
Caricamento dati (shell)
● Serie datisqlite> .mode csvsqlite> .import path/file.csv tabella
● Dati geometricispatialite> .loadshp shape_name spatialite> SELECT * FROM table_name LIMIT 5;
Accedere con il comando:sqlite3 pathToDB/database.sqlite
Oppure accedere direttamente a sqlite con l’estensione spatialite:spatialite pathToDB/database.sqlite
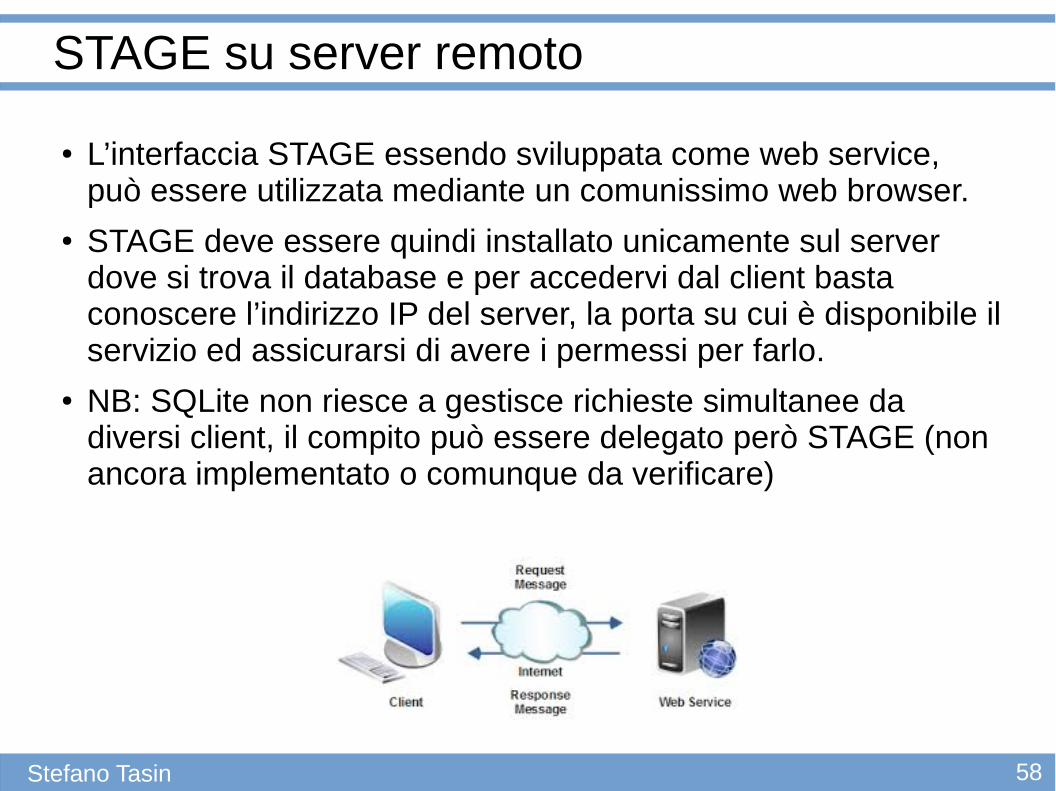
58Stefano Tasin
STAGE su server remoto
● L’interfaccia STAGE essendo sviluppata come web service, può essere utilizzata mediante un comunissimo web browser.
● STAGE deve essere quindi installato unicamente sul server dove si trova il database e per accedervi dal client basta conoscere l’indirizzo IP del server, la porta su cui è disponibile il servizio ed assicurarsi di avere i permessi per farlo.
● NB: SQLite non riesce a gestisce richieste simultanee da diversi client, il compito può essere delegato però STAGE (non ancora implementato o comunque da verificare)

59Stefano Tasin
Plugin SQLite
La gestione di database SQLite può essere integrata in R attraverso il pacchetto “RSQLite”.
https://cran.r-project.org/package=RSQLite
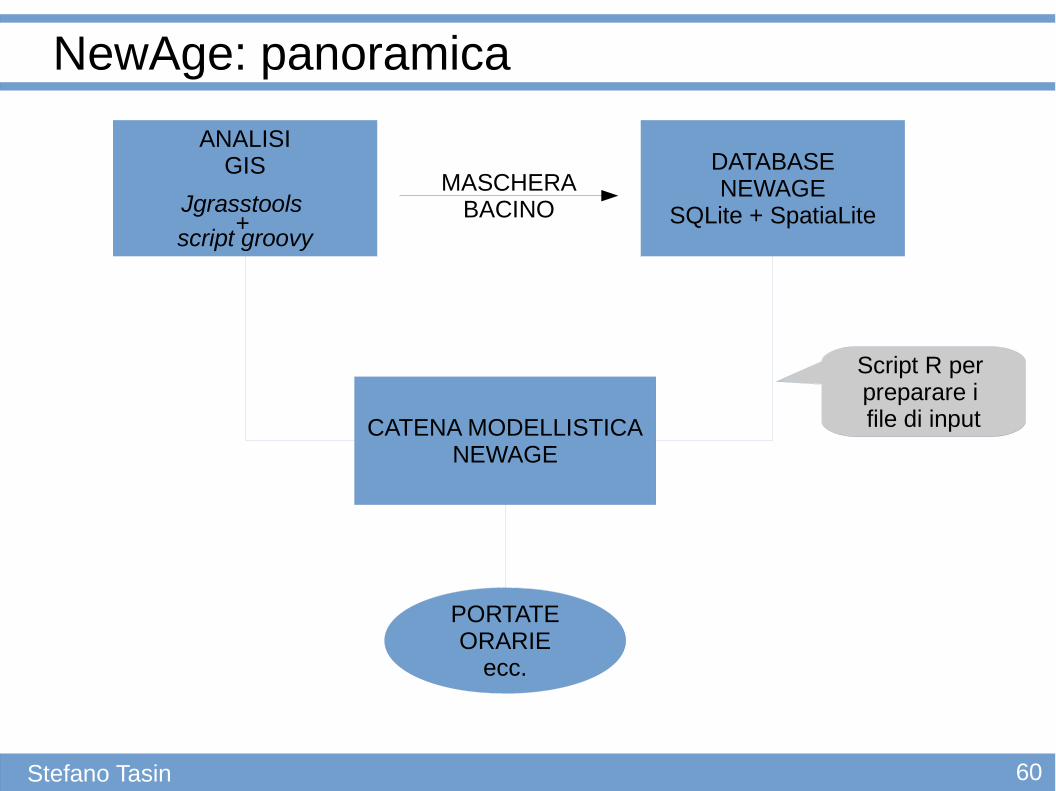
60Stefano Tasin
NewAge: panoramica
ANALISIGIS
Jgrasstools
script groovy
DATABASENEWAGE
SQLite + SpatiaLiteMASCHERA
BACINO
CATENA MODELLISTICANEWAGE
PORTATEORARIE
ecc.
Script R per preparare i file di input
+
61Stefano Tasin
Materiale utile
● DB NewAge:– Slide (HydroloGIS)
– Descrizione tabelle (HydroloGIS)
● SQLite:– https://sqlite.org
● Spatialite:– https://www.gaia-gis.it/fossil/libspatialite/index
– http://www.gaia-gis.it/gaia-sins/spatialite-sql-4.3.0.html
● RSQLite:– https://cran.r-project.org/package=RSQLite


















