
Conversione Analogica Digitale: complementi Quantizzazione · Riguardo al primo punto, si può...
19
Bozza Data 17/03/2003 1 Conversione Analogica Digitale: complementi Quantizzazione Generalità sull’errore di quantizzazione e sul rapporto SQNR Si indichi con n x e ˆ n x l’n-esimo valore campionato e il suo corrispondente valore quantizzato. L’errore di quantizzazione risulta dato da: ˆ n n n e x x = - (1.1) L’errore dipende, oltre che dalla legge di quantizzazione q(x), anche dal valore di x n . Di conseguenza, la differenza fra il segnale ricostruito e quello originario, detta “rumore di quantizzazione”, risulta dipendente dal segnale stesso, e quindi intrinsecamente diversa dai tipici rumori additivi dovuto alla rumorosità dei circuiti elettrici. Ad esempio, supponendo che la legge di quantizzazione abbia un intervallo centrato nell’origine, se il segnale si annulla si annulla anche il rumore di quantizzazione. Al contrario un rumore additivo indipendente risulterebbe sempre presente. Le prestazioni di un quantizzatore dipendono dalla legge di quantizzazione e dalla distribuzione statistica dei campioni. Esse vengono valutate sulla base del rapporto segnale rumore di quantizzazione SQNR (Signal to Quantization Noise Ratio) 2 2 n n E x SQNR Ee = (1.2) Un quantizzatore viene progettato per operare nell’intervallo [-M,M], che dovrebbe coincidere (almeno sostanzialmente) con la dinamica del segnale. A questo scopo spesso provvede un circuito AGC (Automatic Gain Control), in quanto un disadattamento della dinamica del segnale rispetto a quella del quantizzatore provoca un rapido degrado delle prestazioni. In particolare, se la dinamica del segnale è troppo piccola, allora gli intervalli esterni di quantizzazione non vengono utilizzati, mentre se è troppo grande il quantizzatore entra in regime di “saturazione”, nel quale per i campioni che cadono all’esterno dell’intervallo [-M,M] il rumore di quantizzazione non è più limitato ad una frazione di un intervallo di quantizzazione, ma cresce linearmente con il modulo del campione stesso, con un rapido degrado dell’ SQNR. La regione [-M,M], in cui l’errore di quantizzazione è limitato, viene detta “granulare”, per distinguerla dalla regione di saturazione, esterna al medesimo. Nel seguito si supporrà di poter trascurare il rumore di saturazione.
Transcript of Conversione Analogica Digitale: complementi Quantizzazione · Riguardo al primo punto, si può...

Bozza Data 17/03/2003
1
Conversione Analogica Digitale: complementi
Quantizzazione
Generalità sull’errore di quantizzazione e sul rapporto SQNR Si indichi con nx e ˆnx l’n-esimo valore campionato e il suo corrispondente valore quantizzato.
L’errore di quantizzazione risulta dato da:
ˆn n ne x x= − (1.1)
L’errore dipende, oltre che dalla legge di quantizzazione q(x), anche dal valore di xn. Di
conseguenza, la differenza fra il segnale ricostruito e quello originario, detta “rumore di
quantizzazione”, risulta dipendente dal segnale stesso, e quindi intrinsecamente diversa dai tipici
rumori additivi dovuto alla rumorosità dei circuiti elettrici. Ad esempio, supponendo che la legge di
quantizzazione abbia un intervallo centrato nell’origine, se il segnale si annulla si annulla anche il
rumore di quantizzazione. Al contrario un rumore additivo indipendente risulterebbe sempre
presente.
Le prestazioni di un quantizzatore dipendono dalla legge di quantizzazione e dalla distribuzione
statistica dei campioni. Esse vengono valutate sulla base del rapporto segnale rumore di
quantizzazione SQNR (Signal to Quantization Noise Ratio)
2
2
n
n
E xSQNR
E e
� �� �=� �� �
(1.2)
Un quantizzatore viene progettato per operare nell’intervallo [-M,M], che dovrebbe coincidere
(almeno sostanzialmente) con la dinamica del segnale. A questo scopo spesso provvede un circuito
AGC (Automatic Gain Control), in quanto un disadattamento della dinamica del segnale rispetto a
quella del quantizzatore provoca un rapido degrado delle prestazioni. In particolare, se la dinamica
del segnale è troppo piccola, allora gli intervalli esterni di quantizzazione non vengono utilizzati,
mentre se è troppo grande il quantizzatore entra in regime di “saturazione”, nel quale per i campioni
che cadono all’esterno dell’intervallo [-M,M] il rumore di quantizzazione non è più limitato ad una
frazione di un intervallo di quantizzazione, ma cresce linearmente con il modulo del campione
stesso, con un rapido degrado dell’ SQNR. La regione [-M,M], in cui l’errore di quantizzazione è
limitato, viene detta “granulare”, per distinguerla dalla regione di saturazione, esterna al medesimo.
Nel seguito si supporrà di poter trascurare il rumore di saturazione.

Bozza Data 17/03/2003
2
Quantizzazione uniforme Se l’intervallo [-M,M] è suddiviso in L intervalli uguali, il quantizzatore si dice uniforme, o,
impropriamente, lineare. La larghezza di un intervallo è legata al numero di bit di quantizzazione b
dalla seguente:
2 22b
M Mq
L= = (1.3)
Le prestazioni di un quantizzatore lineare, fissato L (ovvero b) e supposto il quantizzatore adattato,
dipendono dalla distribuzione statistica dei campioni. In particolare esso risulta ottimo se la densità
di probabilità dei campioni è uniforme, cosa che risulta spesso verificata nella quantizzazione di
segnali relativi alle immagini (ad esempio le componenti R, G e B di un colore), mentre non lo è,
come vedremo, nel caso di segnali audio. Tuttavia, anche quando altre leggi di quantizzazione
potrebbero fornire risultati migliori, la quantizzazione uniforme viene utilizzata lo stesso, con o
senza qualche artificio, perché è la più facile da implementare a livello circuitale.
Calcolo del rapporto segnale rumore L’ipotesi di partenza è che i valori campionati risultino uniformemente distribuiti all’interno di ogni
intervallo di quantizzazione. Ciò è certamente verificato se la densità di priobabilità p(xn) è
uniforme nell’intervalo [-M,M], ma lo è anche, seppure in modo approssimato, se sono soddisfatte
entrambe le condizioni seguenti:
1. gli intervalli sono piccoli (ovvero L è grande);
2. la distribuzione p(xn), è comunque regolare all’interno di [-M,M].
Il rumore di quantizzazione risulta dato da (si omettono i pedici per semplicità formale):
2/ 2 / 22 2
/ 2 / 2
1[ ] ( )
12
q q
q q
qE e e p e de e de
q− −= = =� � (1.4)
Poiché tutti gli intervalli hanno la stessa ampiezza, esso è indipendente dall’intervallo in cui cade
effettivamente il campione.
Il rapporto segnale rumore di picco (ovvero quello massimo) è dato da,
2 2 22
max 222
2
12 123 2
42
b
b
M M MSQNR
MqE e= = = =
� �� � (1.5)
Introducendo quindi il fattore di cresta,
2
2c
MF
E x=
� �� � (1.6)

Bozza Data 17/03/2003
3
si ottiene il rapporto segnale rumore (medio)
2 22
2 2
[ ] 13 2 b
cc
E x MSQNR
FE e F E e= = =
� � � �� � � � (1.7)
Espresso in dB si ha
10 10 10( ) 10log (3) 2 10log (2) 10log ( )
4.77 6 ( )c
c
SQNR dB b F
b F dB
= + + == + −
(1.8)
Sulla base del risultato trovato, si possono fare le seguenti osservazioni:
• le prestazioni dipendono dalla densità di probabilità dei campioni, p(x), attraverso il fattore
di cresta Fc;
• ogni bit di quantizzazione in più o in meno determina una variazione di 6 dB del rapporto
segnale rumore; questa proprietà è spesso comune anche ad altri tipi di quantizzazione.
Riguardo al primo punto, si può facilmente verificare che se la p(x) è uniforme, il suo fattore di
cresta è pari a 3, ovvero a 4.77 dB. Di conseguenza, se i campioni sono uniformemente distribuiti, si
ha semplicemente:
( ) 6SQNR dB b= (1.9)
Riguardo al secondo, si noti che passando da 8 bit di quantizzazione a 16 (due valori spesso
utilizzati in pratica, in quanto corrispondenti ad uno o due byte), si ha un incremento di 48 dB.
Interessante è anche esaminare il caso in cui la dinamica del segnale risulti inferiore a quella del
quantizzatore, per cui un certo numero di intervalli esterni non viene utilizzato. In questo caso il
rumore di quantizzazione non cambia, perché è sempre pari a 2 /12q per ogni intervallo, mentre
risulta ovviamente ridotta la potenza del segnale. La costanza del rumore di quantizzazione fa sì che
un attenuazione di N dB del segnale di ingresso si traduca esattamente in una perdita di N dB nel
rapporto SQNR.
Quantizzazione non uniforme La scelta di suddividere l’intervallo di quantizzazione in intervalli uniformi è ottima nel caso in cui
sia uniforme anche la densità di probabilità dei campioni, p(x). Ciò avviene di norma nel caso di
segnali video, ma non nel caso di segnali audio, dove la p(x) ha tipicamente un andamento a
campana, per il quale conviene, a parità di livelli di quantizzazione, suddividere più finemente la
zona centrale dell’intervallo [–M,M] e più grossolanamente le zone esterne. Il quantizzatore
ottenuto viene detto non uniforme, appunto perché gli intervalli sono di ampiezza diversa. Più in
generale, per ogni possibile andamento della p(x) è possibile individuare un quantizzatore ottimo,

Bozza Data 17/03/2003
4
ovvero “adattato” alla p(x). Tuttavia, si preferisce spesso realizzare, più che un quantizzatore che
garantisca prestazioni ottime per una specifica p(x), e magari scadenti per altri andamenti, un
quantizzatore “robusto”, in grado di operare in modo soddisfacente con diversi tipi di p(x) ed anche
in presenza di forti attenuazioni del segnale di ingresso, una situazione che manda facilmente in
crisi un quantizzatore uniforme, come visto in precedenza.
Prima di procedere, è necessario premettere che i quantizzatori non uniformi non sono facili da
implementare direttamente, per cui in pratica per ottenere la suddivisione voluta si utilizza un
quantizzatore uniforme a più alto numero di intervalli, per poi accorpare gli intervallini ottenuti in
modo opportuno. Anche se questo è l’accorgimento utilizzato ai nostri giorni, lo studio della
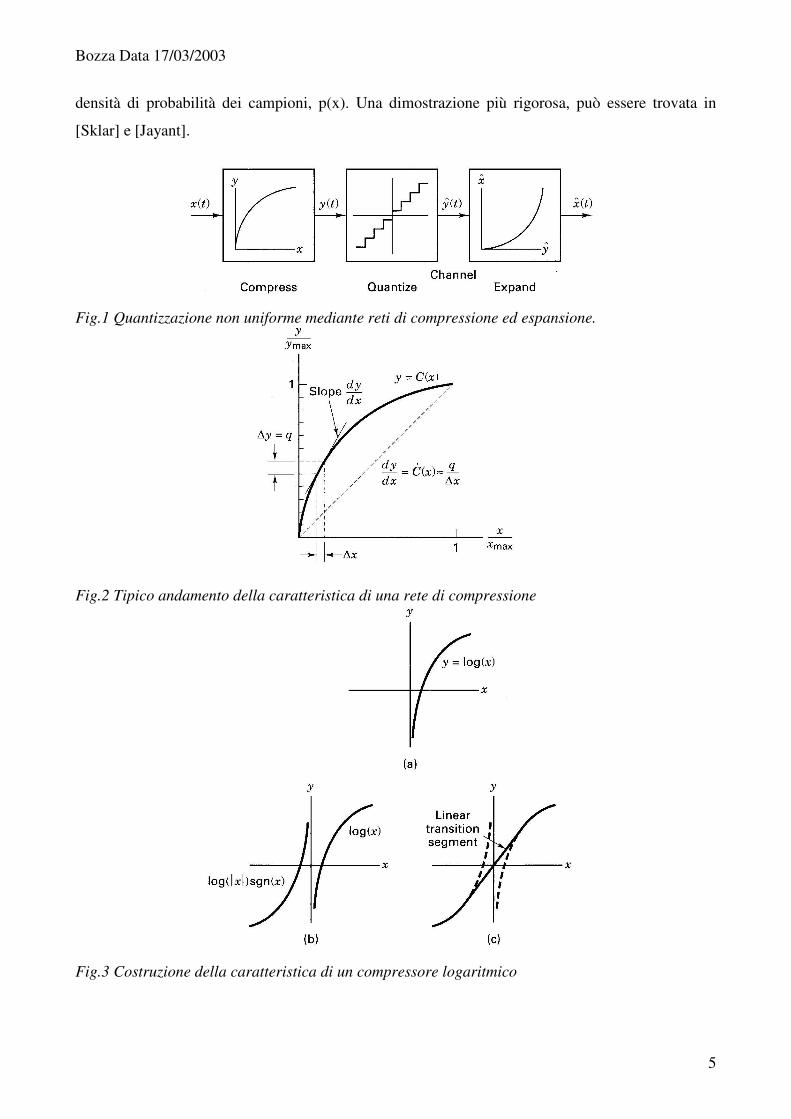
quantizzazione non uniforme si basa sullo schema logico presentato in Fig.1, in passato
corrispondente ad un’implementazione analogica dei dispositivi. In questo schema, il quantizzatore
uniforme, operante al numero di livelli voluto, è preceduto da una rete non lineare non reattiva,
descritta dalla sua caratteristica ingresso uscita, detta compressore, e seguito da una rete con
caratteristica inversa, detta espansore. Un possibile andamento della caratteristica del compressore,
y=C(x), è riportato in Fig.2, dove è riportata per confronto anche la retta y=x (valori normalizzati ai
rispettivi massimi), corrispondente all’assenza del compressore. L’asse delle ordinate è suddiviso in
intervalli uniformi, di ampiezza q, corrispondenti agli intervalli del quantizzatore che segue il
compressore. Il compressore fa corrispondere all’intervallo q un intervallo di ampiezza inferiore
dove la derivata della curva è superiore ad uno, ovvero per valori “piccoli” delle x, mentre il
contrario vale per valori “grandi”. L’effetto finale è quello di suddividere l’asse delle ascisse in
intervalli di ampiezza / ( )x q C x∆ �� , più piccoli di q vicino all’origine e più grandi agli estremi. Il
progetto del quantizzatore non uniforme si riconduce quindi all’individuazione della caratteristica
C(x) voluta. Per realizzare un quantizzatore “robusto”, si può dimostrare che sarebbe necessario
adottare un andamento di tipo logaritmico, il quale però presenta i seguenti problemi:
1) Il logaritmo esiste solo per numeri positivi
2) Il logaritmo non passa per l’origine ma tende velocemente a meno infinito per valori che ad
esso si approssimano
Per questi motivi si estende, con simmetria dispari, la caratteristica logaritmica nel III quadrante,
ovvero per x negativi, quindi si raccordano le due caratteristiche con un tratto lineare passante per
l’origine, ottenendo una specie di curva ad “S”(Fig.3). Il quantizzatore che si ottiene viene detto
“logaritmico”. Il quantizzatore risulta robusto, nel senso prima indicato, perché associa a campioni
piccoli, intervalli piccoli, ovvero poco rumore di quantizzazione, mentre a campioni grandi associa
un rumore elevato. Questa caratteristica fa sì che le prestazioni dipendano in misura limitata dalla
Bozza Data 17/03/2003
5
densità di probabilità dei campioni, p(x). Una dimostrazione più rigorosa, può essere trovata in
[Sklar] e [Jayant].
Fig.1 Quantizzazione non uniforme mediante reti di compressione ed espansione.
Fig.2 Tipico andamento della caratteristica di una rete di compressione
Fig.3 Costruzione della caratteristica di un compressore logaritmico

Bozza Data 17/03/2003
6
Quantizzatori A-law e µµµµ-law Gli esempi più importanti di quantizzazione logaritmica sono rappresentati dai quantizzatori A-law
e µ-law, utilizzati rispettivamente in Europa e negli USA per la telefonia fissa (PCM, 8000 Hz di
campionamento, 8 bit per campione).
La formula generale per la quantizzazione A-law è riportata sotto per completezza. In essa, My
identifica il valore massimo di y, M quello di x, ed A è un parametro legato alla pendenza della
curva nel tratto lineare: più alto A, più piccoli gli intervallini nell’intorno dell’origine. Più alto
questo valore, migliori sono le prestazioni per campioni piccoli, ed al contrario peggiori quelle per
campioni grandi. Il valore di A utilizzato nello standard della telefonia Europea è 87.56.
| || | 1
( ) 01 ln
( )| |
1 ln1 | |
( ) 11 ln
y
y
xA xMM sign x
A M Ay C x
xA
xMM sign xA A M
��
≤ ≤� +�= = �� �� + � � � ≤ ≤�� +
(1.10)
Le prestazioni “asintotiche” per A=87.56 sono le seguenti:
38 segnali "grandi" dB
24.08 segnali "piccoli"uniforme
SQNRSQNR�
= � +�
�
(1.11)
La formula generale per la quantizzazione µ-law, riportata sotto, dipende invece il parametro µ,
anch’esso legato alla pendenza della curva nel tratto lineare. Il valore di µ utilizzato nello standard
della telefonia USA è di 255.
[ ]
| |ln 1
( ) ( )ln 1y
xMy C x M sign x
µ
µ
� �+ � �= =+
(1.12)
Le prestazioni “asintotiche” per µ=255 sono:
38 segnali "grandi" dB
33.25 segnali "piccoli"uniforme
SQNRSQNR�
= � +�
�
(1.13)
Il quantizzatore si rileva robustissimo nei confronti delle attenuazioni del segnale di ingresso: in
pratica i 38 dB di rapporto segnale rumore si mantengono fino a circa 30 dB di attenuazione, mentre
un quantizzatore uniforme avrebbe una perdita di 30 dB sul rapporto SQNR, ovvero prestazioni
pessime.
Le curve corrispondenti sono riportate nella Fig.4. Come si può vedere le differenze sono minime.

Bozza Data 17/03/2003
7
Fig.4 Leggi di quantizzazione A-law e µ-law
Implementazione digitale Come già ricordato, l’implementazione attuale non prevede più, come in passato, la presenza di una
rete di compressione e di una di espansione analogiche, ma semplicemente l’utilizzo di un
quantizzatore uniforme a più grande numero di livelli, seguito da un opportuno accorpamento dei
medesimi, realizzato semplicemente tramite la lettura di una tabella. Per fissare le idee, si descrive
l’implementazione prevista dallo standard µ-law ad 8 bit.
La curva C(x) è approssimata in questo modo:
1) il bit b8 indica il segno, quindi il quadrante in cui cade il campione;
2) ogni quadrante di C(x) è suddiviso in 8 segmenti, indicati da b7, b6, b5;.
3) ogni segmento è suddiviso in 16 intervalli uguali, indicati da b4, b3, b2, b1.
Gli 8 bit di ogni campione vengono ottenuti a partire dai 14 bit di un quantizzatore uniforme,
tramite tabella. I fattori di accorpamento vanno da 1 a 256, all’aumentare dell’indice del segmento.
A titolo di esempio, i 16 intervalli del segmento 8, quello più esterno, avranno dimensione pari a
256 volte l’intervallo più piccolo.
Tabella 1 Implementazione della codifica µ-law ad 8 bit.
-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
0.6
0.8
1
-1 -0.8 -0.6 -0.4 -0.2 0 0.2 0.4 0.6 0.8 1
x/M
y/M
y
m-lawA-law

Bozza Data 17/03/2003
8
PCM Differenziale (DPCM e ADPCM)
Descrizione La codifica PCM opera quantizzando e codificando separatamente i campioni del segnale, come se
essi fossero indipendenti. In realtà, essi si presentano spesso altamente correlati, per cui si intuisce
che una codifica più efficiente si può ottenere tenendo conto di questa correlazione. Uno dei metodi
possibili consiste nell’utilizzare i campioni precedenti per ottenere una stima del campione
successivo, per poi quantizzare e codificare con tecnica PCM la sola differenza fra il campione
attuale e quello predetto, ovvero l’errore di predizione. In questo caso si parla di PCM differenziale,
o DPCM. Una sua variante, più evoluta, ovvero il DPCM adattativo, viene indicata come ADPCM.
L’esame degli schemi a blocchi del codificatore e del decodificatore, mostrati in Fig.5, aiuta a
comprendere il funzionamento della tecnica in esame.
+ Quant.
Predittore
+
Codificatore Decodificatore
+
Predittore
canale
+
-+
+
++
CalcoloCoefficienti
CalcoloCoefficienti
x̂(n)x∼(n)
δ∼
(n)δ(n) δ∼
(n) x̂(n)
x∼(n)
x(n)
Fig.5: schemi di un codificatore e di un decodificatore ADPCM Sulla base dei campioni precedenti il predittore (in pratica un filtro trasversale presente sia nel
codificatore che nel decodificatore), produce una stima del campione attuale; l’errore di predizione
viene quantizzato, codificato ed inviato sul canale di trasmissione, quindi nel decodificatore viene
decodificato e sommato al valore predetto localmente, per poi essere filtrato con un filtro
passabasso. Il valore riprodotto non è esattamente identico a quello di partenza a causa delle perdite
di informazione legate alla quantizzazione dell’errore di predizione. Si noti che per evitare derive
fra i valori predetti, i campioni in ingresso al filtro di predizione sono sempre quantizzati, sia nel
codificatore che nel decodificatore.
Nell’ADPCM, a differenza di quanto accade nel DPCM, sia il predittore, ovvero i coefficienti del
filtro trasversale, che il quantizzatore, non sono fissi ma cambiano nel tempo, adattandosi alle
caratteristiche del segnale e migliorando così la qualità del segnale riprodotto. Il calcolo dei
coefficienti può avvenire sulla base dei campioni passati (backward adaption) o di quelli futuri
(“forward adaption”). In quest’ultimo caso il calcolo risulta più accurato, ma richiede l’inserimento

Bozza Data 17/03/2003
9
di un buffer nel codificatore e l’invio, come informazione “collaterale” dei valori dei coefficienti
stessi, dato che questi ultimi sono calcolabili solo dal lato del codificatore. Nella figura è riportato
lo schema “backward”.
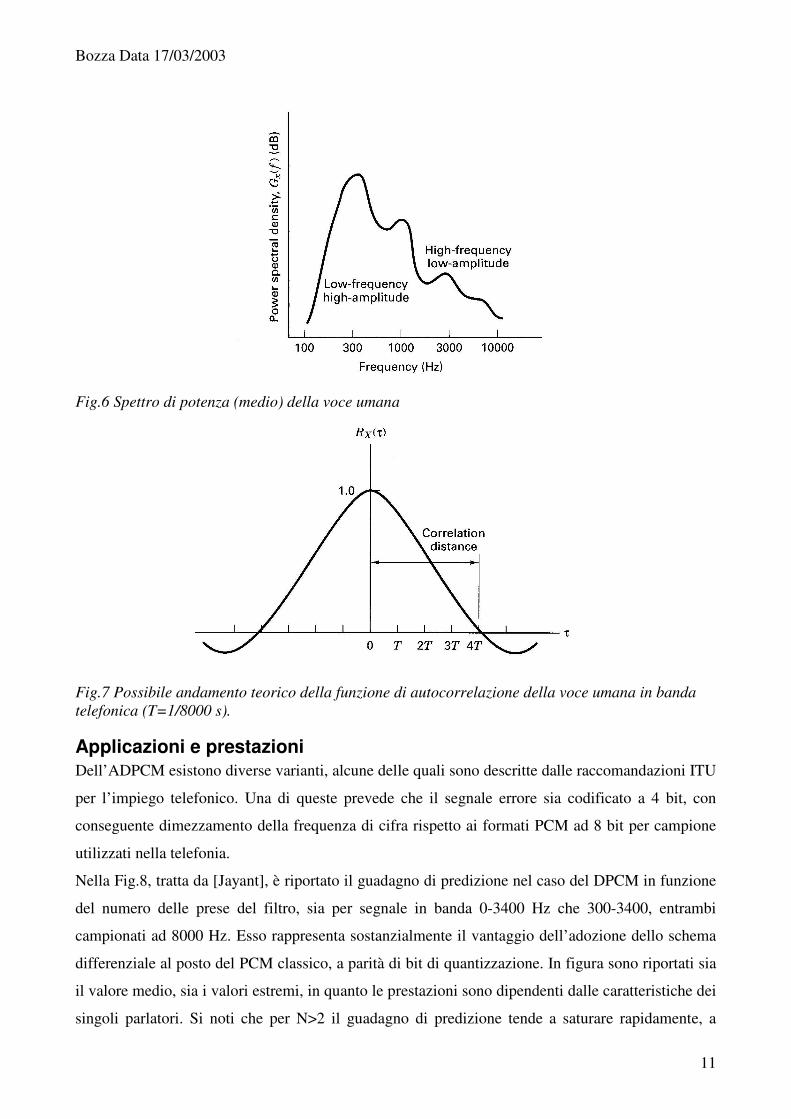
Calcolo dei coefficienti L’efficacia della codifica differenziale è legata al livello di correlazione dei campioni. Questo può
essere esaminato direttamente, nel dominio del tempo, oppure osservando lo spettro di potenza del
segnale, legato alla funzione di autocorrelazione dalla trasformata di Fourier. Più relativamente
importanti sono le basse frequenze dello spettro, più saranno correlati campioni vicini del segnale.
Ciò accade di norma nel caso dei segnali vocali, per i quali un tipico spettro è riportato in Fig.6. Si
noti che le componenti più significative si collocano attorno ai 300 Hz. Di solito il picco si ha sotto
ai 300 Hz per la voce maschile e appena sopra per quella femminile. Un possibile andamento della
funzione di autocorrelazione per un segnale vocale in banda telefonica, campionato a 8000 Hz, è
riportato in Fig.7. Da esso si deduce che i valori di correlazione più alti sono relativi ai primi
campioni, per poi calare rapidamente. Normalmente la lunghezza del filtro FIR non supera la decina
di prese. I valori ottimali dei coefficienti dipendono dalla funzione di autocorrelazione del segnale,
ma, dato che questa cambia nel tempo poiché il segnale vocale non è stazionario, per avere
prestazioni ottime è necessario ricalcolare i coefficienti ogni 100-50 ms, o anche meno, in presenza
di algoritmi subottimi. Il criterio di ottimizzazione delle prese consiste nel minimizzare la potenza
dell’errore di predizione, perché così facendo si possono ridurre i bit di quantizzazione. L’algoritmo
per il calcolo dei coefficienti nel caso generale di N prese può essere facilmente reperito in
letteratura [Sklar], [Jayant], qui verrà esaminato quello per N=1.
L’errore di predizione, supponendo di poter trascurare la differenza fra i campioni ed i
corrispondenti valori quantizzati è dato da
( ) ( ) ( 1)d n x n ax n= − − (1.14)
La sua potenza, quindi è
2 2 2 2
2
2
[ ( )] [ ( ) 2 ( ) ( 1) ( 1)]
(0) 2 (1) (0)
(0)[1 2 (1)]x x x
x x
E d n E x n ax n x n a x n
R aR a R
R a aC
= − − + − == − + =
= + −
(1.15)
Dove ( )xR n rappresenta la funzione di autocorrelazione statistica e ( ) ( ) / (0)x x xC n R n R= la
funzione di autocorrelazione normalizzata alla potenza del segnale. Volendo trovare il coefficiente a
che rende minima la potenza della differenza, occorre calcolare la derivata dell’espressione trovata,

Bozza Data 17/03/2003
10
2[ ( )]2 (0)[ (1)]x x
E d nR a C
a∂ = −
∂ (1.16)
ed annullarla, trovando così che la soluzione ottima è la seguente
(1)opt xa C= (1.17)
Utilizzando il coefficiente ottimo si trova quindi il valore minimo della potenza dell’errore di
predizione,
2,min (0) (0)[1 (1)]d x xR R C= − (1.18)
Il rapporto fra la potenza del segnale e quella del valore predetto viene detto guadagno di
predizione,
2,min
(0) 1(0) 1 (1)
xp
d x
RG
R C= =
− (1.19)
e risulta tanto maggiore quanto più alta la correlazione fra un campione e quello successivo. Il
guadagno di predizione individua il miglioramento del rapporto segnale rumore di quantizzazione, a
parità di livelli di quantizzazione, ovvero permette di ricavare, a parità di tale rapporto, quanti bit di
quantizzazione possono essere risparmiati. Per campioni incorrelati si verifica l’inutilità dello
schema differenziale.
Può essere anche interessante chiedersi per quale valore della funzione di autocorrelazione il più
semplice dei predittori possibili, ovvero quello che fornisce come predizione il campione
precedente (a=1), fornisce un guadagno di predizione maggiore di uno. Allo scopo è sufficiente
riscrivere l’equazione (1.15)
(0) 1(0) 2[1 (1)]
dp
x x
RG
R C= =
− (1.20)
per ottenere
1
1 2[1 (1)]
(1) 0.5
p
x
x
G
C
C
>
> −>
(1.21)
Per valori di autocorrelazione (normalizzata) superiori a 0.5, quindi anche un semplice ritardo può
portare a dei vantaggi rispetto al semplice PCM. Questa osservazione è alla base della codifica detta
“modulazione delta”, molto utilizzata nelle implementazioni pratiche, per la quale si rimanda alla
letteratura [Jayant].
Bozza Data 17/03/2003
11
Fig.6 Spettro di potenza (medio) della voce umana
Fig.7 Possibile andamento teorico della funzione di autocorrelazione della voce umana in banda telefonica (T=1/8000 s).
Applicazioni e prestazioni Dell’ADPCM esistono diverse varianti, alcune delle quali sono descritte dalle raccomandazioni ITU
per l’impiego telefonico. Una di queste prevede che il segnale errore sia codificato a 4 bit, con
conseguente dimezzamento della frequenza di cifra rispetto ai formati PCM ad 8 bit per campione
utilizzati nella telefonia.
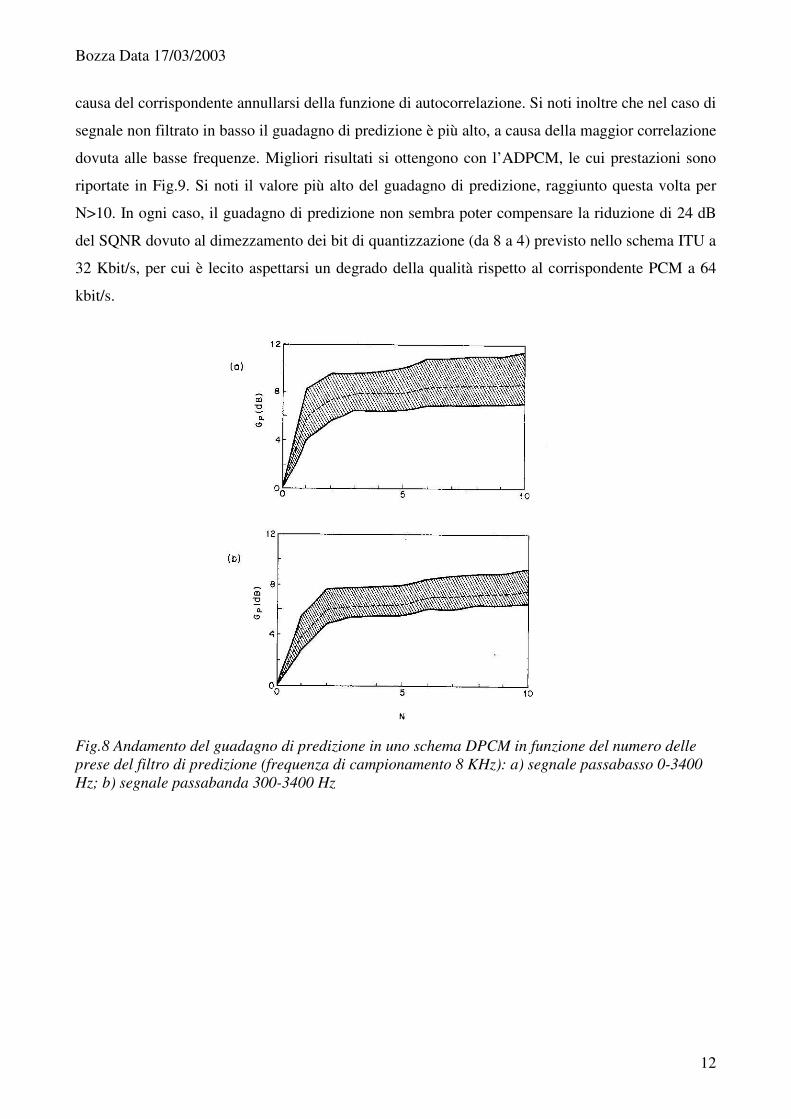
Nella Fig.8, tratta da [Jayant], è riportato il guadagno di predizione nel caso del DPCM in funzione
del numero delle prese del filtro, sia per segnale in banda 0-3400 Hz che 300-3400, entrambi
campionati ad 8000 Hz. Esso rappresenta sostanzialmente il vantaggio dell’adozione dello schema
differenziale al posto del PCM classico, a parità di bit di quantizzazione. In figura sono riportati sia
il valore medio, sia i valori estremi, in quanto le prestazioni sono dipendenti dalle caratteristiche dei
singoli parlatori. Si noti che per N>2 il guadagno di predizione tende a saturare rapidamente, a
Bozza Data 17/03/2003
12
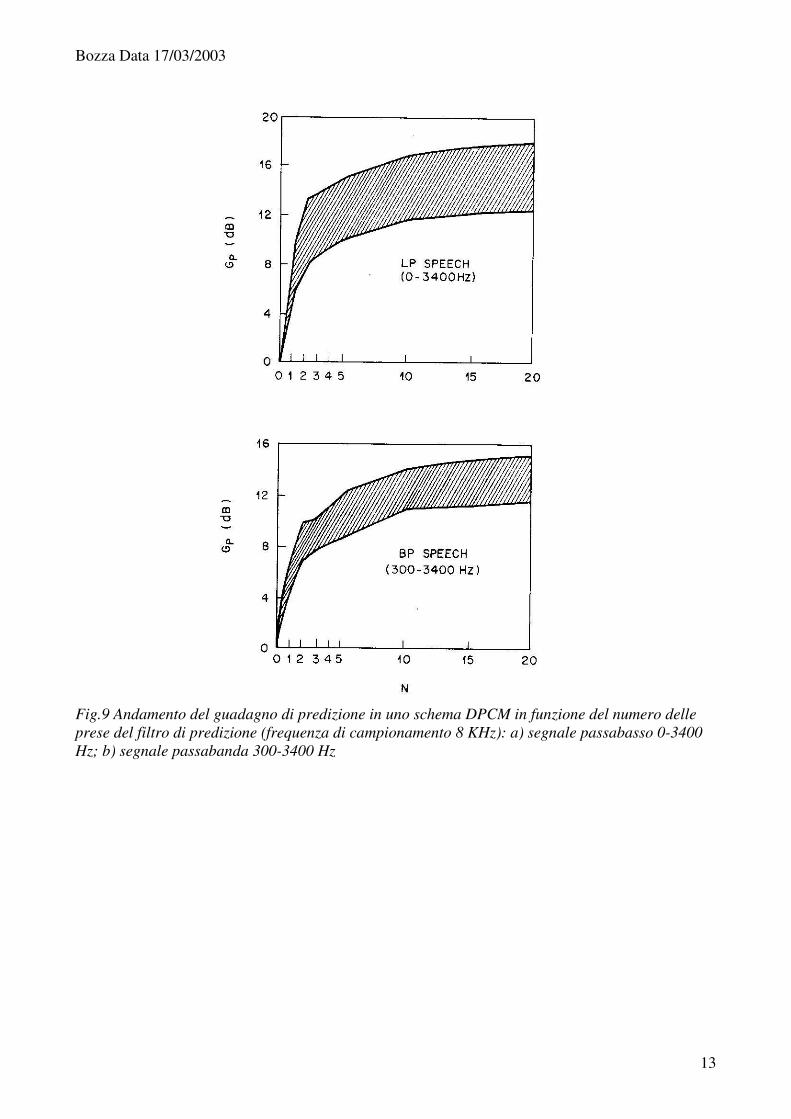
causa del corrispondente annullarsi della funzione di autocorrelazione. Si noti inoltre che nel caso di
segnale non filtrato in basso il guadagno di predizione è più alto, a causa della maggior correlazione
dovuta alle basse frequenze. Migliori risultati si ottengono con l’ADPCM, le cui prestazioni sono
riportate in Fig.9. Si noti il valore più alto del guadagno di predizione, raggiunto questa volta per
N>10. In ogni caso, il guadagno di predizione non sembra poter compensare la riduzione di 24 dB
del SQNR dovuto al dimezzamento dei bit di quantizzazione (da 8 a 4) previsto nello schema ITU a
32 Kbit/s, per cui è lecito aspettarsi un degrado della qualità rispetto al corrispondente PCM a 64
kbit/s.
Fig.8 Andamento del guadagno di predizione in uno schema DPCM in funzione del numero delle prese del filtro di predizione (frequenza di campionamento 8 KHz): a) segnale passabasso 0-3400 Hz; b) segnale passabanda 300-3400 Hz
Bozza Data 17/03/2003
13
Fig.9 Andamento del guadagno di predizione in uno schema DPCM in funzione del numero delle prese del filtro di predizione (frequenza di campionamento 8 KHz): a) segnale passabasso 0-3400 Hz; b) segnale passabanda 300-3400 Hz

Bozza Data 17/03/2003
14
Codifica Parametrica (Vocoder)
Introduzione Le tecniche di conversione A/D esaminate finora (PCM uniforme e non uniforme, DPCM e
ADPCM) vengono anche classificate come tecniche di codifica della forma d’onda (Waveform
Coding), in quanto mirano ad una riproduzione fedele, per quanto possibile, della forma d’onda
originaria. Volendo però limitarsi alla riproduzione della voce in banda telefonica, per la quale
l’obiettivo di qualità è l’intelligibilità del parlato, piuttosto che la fedele riproduzione del suono, e
desiderando scendere a valori molto più bassi dei 64 o 32 kbit/s tipici del PCM e dell’ADPCM, è
necessario abbandonare l’obiettivo di codificare fedelmente la forma d’onda, per limitarsi a estrarre
dal parlato originario alcuni parametri che ne permettono una riproduzione intelleggibile,
possibilmente non troppo lontana dal “suono” del parlato originario. Si parla in questo caso di
codifica parametrica.
Per capire meglio il cambiamento di prospettiva, si consideri una situazione limite. Volendo
assicurare solo ed esclusivamente l’intelleggibilità del parlato, il mezzo di codifica più efficiente
sarebbe la trascrizione del parlato stesso, seguita dalla sintesi vocale del testo, lato utilizzatore.
Anche utilizzando una codifica dei caratteri ASCII ad otto bit, assolutamente inefficiente, la
codifica di un parlato trascritto richiederebbe una frequenza di bit piccolissima, pari a qualche byte
per secondo, rispetto a quella necessaria alla codifica della forma d’onda, seppur limitata in banda.
Programmi che effettuano la trascrizione automatica del parlato esistono già, seppure operanti con
alcuni limitazioni (parlato non continuo, necessità di addestramento del programma per adattarlo
alle caratteristiche vocali del parlatore), così come esistono programmi in grado di fare la sintesi
vocale di un testo, seppure anche qui con qualche limitazione dal punto di vista della qualità. La
maggior efficienza nella codifica risulterebbe pagata dalla maggior complessità dei codificatori e
decodificatori, in quanto i programmi che effettuano la trascrizione e la sintesi del parlato sono
molto complessi e richiedono elevata potenza di calcolo. Tuttavia, questo non sarebbe l’unico
limite. Infatti, è necessario considerare che andrebbe persa completamente l’informazione
“collaterale” rappresentata dall’identità del parlatore e in parte anche dall’intonazione (ad esempio,
un’intonazione ironica può fare cambiare completamente il significato di quanto viene detto). Nella
quasi totalità delle applicazioni, questo limite non potrebbe essere tollerato, per cui risulta
necessario trovare un compromesso fra l’esigenza di una codifica il più possibile efficiente, ed una
qualità di riproduzione che non può limitarsi alla pura intelligibilità del parlato. Questo è il campo
della codifica parametrica, o dei “vocoder” (codificatori vocali) che si trovano sostanzialmente a
metà strada fra la codifica di forma d’onda e la trascrizione-sintesi del parlato. Essi si basano sulla

Bozza Data 17/03/2003
15
individuazione dei parametri necessari a riprodurre, ovvero a sintetizzare il parlato, preservando
sostanzialmente l’andamento dello spettro di potenza della voce originaria (quindi non il semplice
contenuto linguistico) senza curarsi della forma d’onda (in particolare ammettendo la perdita delle
informazioni legate alla fase). Per comprendere meglio i principi di funzionamento di un vocoder, è
necessario individuare un modello di produzione del segnale vocale.
Cenni sui modelli di produzione del parlato Facendo riferimento alla Fig.10 a, possiamo distinguere una sorgente di potenza, rappresentata dal
diaframma e dai polmoni che spingono l’aria verso l’esterno, una zona di eccitazione, rappresentata
dalla trachea, dalla laringe e soprattutto dalle corde vocali, ed infine una zona di “risonanza”,
comprendente la cavità nasale e quella orale (lingua, denti e labbra). I componenti elementari del
parlato vengono detti fonemi e corrispondono ai simboli fonetici che si possono trovare su ogni
buon vocabolario di lingua straniera. Il loro numero, in una data lingua, è un po’ superiore al
numero dei caratteri del rispettivo alfabeto. Ad esempio nella lingua italiana la lettera “e”, può
essere pronunciata aperta o chiusa come in “Pepsi” e “pepe”, così come la “z”, può essere sonora o
sorda, come in “pazzo” e “zoo” (a titolo di pura curiosità, si noti che a Bologna la “z” sonora ha
maggior diritto di cittadinanza, per cui esempi di “z” sorda, come “zio”, “zucca”, “zucchero” sono
tutti pronunciati come “zoo”; allo stesso modo gli Imolesi prediligono le “e” chiuse). Se le corde
vocali vengono fatte vibrare, l’aria in uscita è compressa e rarefatta in modo quasi periodico, e si è
in presenza di un fonema vocalico (“voiced”, tutte le vocali ed alcune consonanti, ad esempio, ma
non solo la “l” e la “b”), altrimenti si ha semplicemente un flusso turbolento, fonema non vocalico
(“unvoiced”). Infine la cavità nasale e quella orale agiscono come la cassa di risonanza di uno
strumento, esaltando alcune frequenze dette formanti. Si noti che cambiando la posizione della
lingua, delle labbra e l’apertura della bocca, cambiano le caratteristiche della cavità orale, e quindi
anche la posizione delle formanti e del suono. Molto maggiori dettagli possono essere trovati in
letteratura [Rabiner], [Sereno], ma quelli dati sono sufficienti per introdurre il modello elettrico
rappresentato in Fig.10b. In esso si distingue una sorgente di segnale con due tipi di uscite per il
segnale di eccitazione, di tipo periodico (spettro a righe in Fig.10c), per i fonemi vocalici, di tipo
rumore (spettro bianco in Fig.10c) per i fonemi non vocalici. Il segnale di eccitazione viene quindi
fatto passare attraverso un filtro tempo variante (tipicamente un IIR) avente dei poli in
corrispondenza delle frequenze formanti (le frequenze per le quali si hanno i picchi della
caratteristica di ampiezza riportata in Fig.10c). Prima di passare ad esaminare lo schema a blocchi
di un possibile vocoder, ricordiamo che la frequenza fondamentale del segnale periodico di
eccitazione viene detta “pitch” e varia da persona a persona, con differenze accentuate fra voci
maschili (attorno ai 125 Hz) e femminili (attorno ai 250 Hz), e, per il medesimo parlatore, a seconda

Bozza Data 17/03/2003
16
dell’intonazione (ad esempio, la frequenza è crescente quando si formula una domanda). Si noti
infine che non è il “pitch” a distinguere una vocale dall’altra, ma la posizione delle prime due
formanti, f1 ed f2. A titolo di esempio nella Fig.11 è riportata una possibile classificazione, tratta da
[Sereno]
Fig.10 Modelli di produzione del segnale parlato

Bozza Data 17/03/2003
17
Fig.11 Classificazione dei suoni vocalici (vocali della lingua italiana) sulla base delle prime due formanti
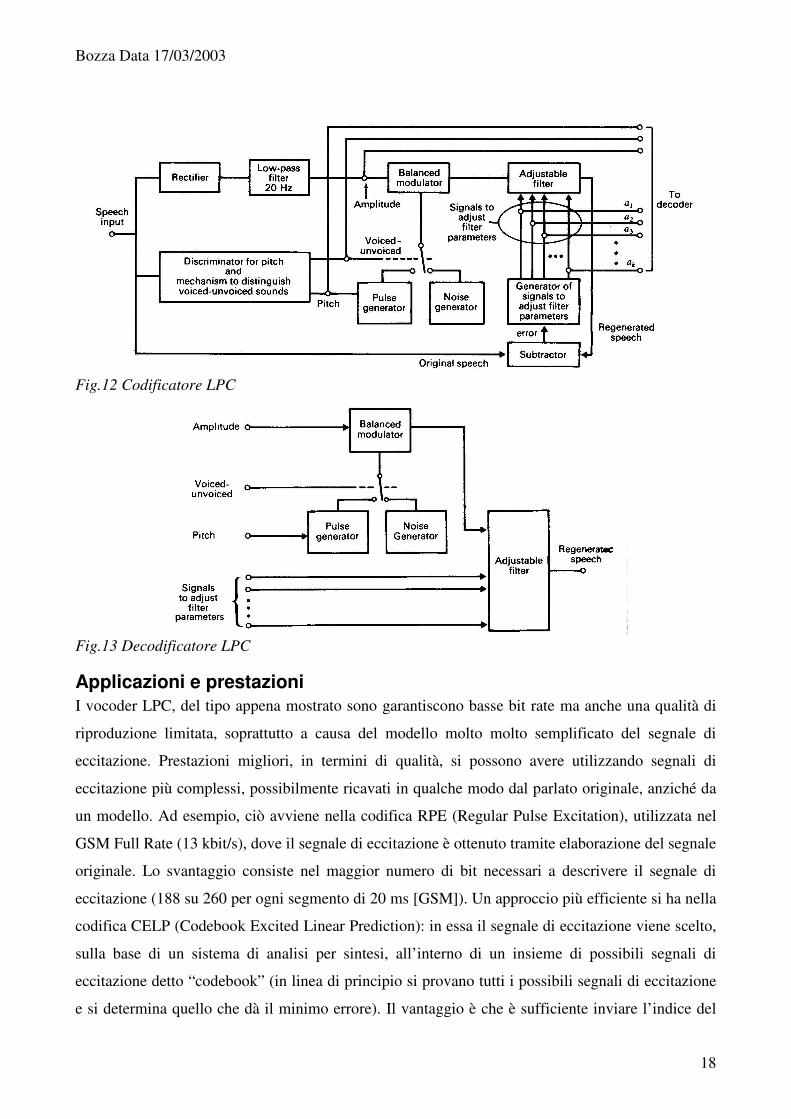
Schema a blocchi di un vocoder LPC In Fig.12 è riportato lo schema a blocchi semplificato di un codificatore LPC (Linear, Predictive
Coefficients), tratto da [Taub], [Jayant]. Il segnale in ingresso viene suddiviso in segmenti temporali
di alcune decine di millisecondi, durante li quali il segnale può essere considerato quasi stazionario.
Quindi ogni segmento viene posto in ingresso al codificatore. In particolare da esso risulta
necessario estrarre le informazioni di:
• ampiezza (per definire il volume)
• vocalico o non vocalico
• il pitch (solo se vocalico)
• i coefficienti del filtro (LPC)
Nell’esempio la ricerca dei coefficienti LPC è del tipo “analysis by synthesis”, ovvero dopo aver
estratto i primi tre parametri, il segnale di eccitazione viene sintetizzato localmente e fatto passare
attraverso il filtro (sintesi). Quindi, tramite il confronto fra il parlato rigenerato e quello originario,
si determinano i coefficienti LPC ottimi (analisi), come quelli che minimizzano la differenza,
ovvero il segnale errore. La comprensione dello schema a blocchi del decodificatore, riportato in
Fig.13, non richiede altri commenti.
Bozza Data 17/03/2003
18
Fig.12 Codificatore LPC
Fig.13 Decodificatore LPC
Applicazioni e prestazioni I vocoder LPC, del tipo appena mostrato sono garantiscono basse bit rate ma anche una qualità di
riproduzione limitata, soprattutto a causa del modello molto molto semplificato del segnale di
eccitazione. Prestazioni migliori, in termini di qualità, si possono avere utilizzando segnali di
eccitazione più complessi, possibilmente ricavati in qualche modo dal parlato originale, anziché da
un modello. Ad esempio, ciò avviene nella codifica RPE (Regular Pulse Excitation), utilizzata nel
GSM Full Rate (13 kbit/s), dove il segnale di eccitazione è ottenuto tramite elaborazione del segnale
originale. Lo svantaggio consiste nel maggior numero di bit necessari a descrivere il segnale di
eccitazione (188 su 260 per ogni segmento di 20 ms [GSM]). Un approccio più efficiente si ha nella
codifica CELP (Codebook Excited Linear Prediction): in essa il segnale di eccitazione viene scelto,
sulla base di un sistema di analisi per sintesi, all’interno di un insieme di possibili segnali di
eccitazione detto “codebook” (in linea di principio si provano tutti i possibili segnali di eccitazione
e si determina quello che dà il minimo errore). Il vantaggio è che è sufficiente inviare l’indice del

Bozza Data 17/03/2003
19
segnale prescelto e non la sua descrizione. A questa categoria appartengono il GSM Enhanced Full-
Rate e l’ Half-Rate (5.6Kbit/s), ed il sistema utilizzato nei cellulari CDMA IS-95 (9.6 kbit/s o
sottomultipli). Frequenze di bit inferiori [2-6 kbit/s], sempre con tecnica CELP, sono previste nei
“tool” di MPEG-4 e nei vocoder utilizzati su Internet [Sereno]. Ovviamente la riduzione della bit
rate comporta di norma una perdita di qualità.
A proposito di questa, occorre considerare che, avendo abbandonato la codifica di forma d’onda, il
rapporto segnale di rumore di quantizzazione SQNR perde sostanzialmente di significato. Per
valutare pertanto la qualità di un vocoder, risulta necessario verificare se esso riproduce bene o
meno il parlato rispetto ad un ascoltatore umano. E’ quindi necessario ricorrere a test soggettivi di
qualità, condotti però con regole strettissime definite dagli stessi standard ITU, in cui un certo
numero di ascoltatori deve esprimere un giudizio da 1 a 5. Il punteggio medio prende il nome di
MOS (Medium Opinion Score).
Bibliografia [Sklar], B. Sklar, “Digital Communications”, second edition”, Prentice Hall
[Jayant], N.S. Jayant, P. Noll, “Digital Coding of Waveforms”, Prentice Hall
[Taub] H.Taub, D.L. Schilling, “Principles of Communication Systems”, McGraw Hill
[Sereno] D. Sereno, P. Valacchi, “Codifica numerica del segnale audio”, Scuola Superiore
Reiss Romoli, ISBN 88 85280 55 2
[Rabiner] L.R.Rabiner, R.W. Schafer, “Digital Processing of Speech Signals”, Prentice Hall
[GSM] M.Mouly, M. Pautet, “The GSM System for Mobile Communications”, Cell & Sys


![ELETTRONICA ANALOGICA... ELETTRONICA ANALOGICA [Formulario Esame] A CURA DI ALESSANDRO PAGHI PROFESSORE: Massimo Macucci ( ...](https://static.fdocumenti.com/doc/165x107/6079539b69cabd414f64ef22/elettronica-elettronica-analogica-formulario-esame-a-cura-di-alessandro-paghi.jpg)















