
Concetti di base delle Moderne architetturegunetti/DIDATTICA/architettureII/01-risc-2.pdf · come...
58
1 1 Concetti di base delle Moderne architetture • una semplice architettura RISC • esecuzione delle istruzioni in un unico ciclo di clock • esecuzione delle istruzioni in più cicli di clock • introduzione del pipelining • Architetture RISC e architetture CISC 2 Due concetti fondamentali • Microarchitettura: l’architettura interna di un processore, ossia come è fatto dentro il processore, a partire dal suo datapath: il percorso che compiono le istruzioni all’interno del processore per venire eseguite. • Come vedremo, diversi tipi di istruzioni possono dover attraversare diverse parti del datapath per venire eseguite, e in generale una istruzione richiede un maggior tempo di esecuzione se deve compiere un percorso più lungo all’interno del datapath (sostanzialmente perché sono coinvolte più porte logiche, il cui tempo di commutazione è finito)
Transcript of Concetti di base delle Moderne architetturegunetti/DIDATTICA/architettureII/01-risc-2.pdf · come...

1
1
Concetti di base delle Moderne architetture
• una semplice architettura RISC
• esecuzione delle istruzioni in un unico ciclo di clock
• esecuzione delle istruzioni in più cicli di clock
• introduzione del pipelining
• Architetture RISC e architetture CISC
2
Due concetti fondamentali • Microarchitettura: l’architettura interna di un processore, ossia
come è fatto dentro il processore, a partire dal suo datapath: il percorso che compiono le istruzioni all’interno del processore per venire eseguite.
• Come vedremo, diversi tipi di istruzioni possono dover attraversare diverse parti del datapath per venire eseguite, e in generale una istruzione richiede un maggior tempo di esecuzione se deve compiere un percorso più lungo all’interno del datapath (sostanzialmente perché sono coinvolte più porte logiche, il cui tempo di commutazione è finito)

2
3
Due concetti fondamentali • ISA: Instruction Set Architecture. L’insieme di istruzioni macchina
di un processore. Notate che due processori con lo stesso ISA possono avere microarchitetture diverse, ossia modi e tempi diversi di eseguire quelle istruzioni.
• Nel seguito, useremo in maniera intercambiabile i termini “microarchitettura” e “architettura” o “architettura interna” (di un processore)
• Analogamente potremo usare “ISA” o “Instruction Set” in modo intercambiabile.
4
Una semplice architettura RISC • Il nostro punto di partenza è la descrizione di una semplice
microarchitettura RISC su cui vengono eseguite istruzioni con dimensione fissa di 32 bit.
• Ciò che descriveremo è di fatto una versione semplificata della MIPS, la prima macchina RISC, progettata da J. Hennessy all’inizio degli anni ottanta.
• Per semplicità, considereremo solo la “parte intera” dell’architettura, in cui le istruzioni sono operazioni tra registri, (come add, sub, ecc.) load e store e i salti, condizionati e no.

3
5
Una semplice architettura RISC • Ci concentreremo sul datapath della CPU descrivendo solo
superficialmente l’unità di controllo (la control unit): la parte della logica che pilota e sincronizza le varie componenti del datapath nell’esecuzione delle istruzioni.
• Ma cercheremo di dare un’idea di due aspetti fondamentali delle architetture RISC:
1. Le istruzioni macchina sono semplici.
2. Proprio per questa ragione, la control unit è semplice, e non è necessario un sofisticato microprogramma per l’esecuzione delle istruzioni macchina della CPU.
6
Una semplice architettura RISC
• La nostra macchina è dotata di 32 registri general purpose interi a 32 bit. nella MIPS, e in molti altri casi reali, il registro R0 è speciale e contiene sempre il valore 0 (ciò che vedremo vale comunque allo stesso modo anche per le architetture a 64 bit).
• Poiché non consideriamo operazioni floating point, l’architettura che descriveremo non avrà registri floating point né unità funzionali ossia componenti del datapath) per operare su dati floating point.

4
7
I campi delle istruzioni MIPS • Una generica istruzione MIPS ha il seguente formato:
• op: tipo di operazione di base richiesta
• reg_1: registro sorgente 1
• reg_2: registro sorgente 2
• reg_dest: registro destinazione
• shift: per le eventuali operazioni di shift sui registri
• funct: specifica la variante dell’operazione op richiesta.
op reg_1 reg_2 reg_dest shift funct 6 bit 5 bit 5 bit 5 bit 5 bit 6 bit
bit 0 bit 31
8
I campi delle istruzioni MIPS • Con questi campi possiamo descrivere le cosiddette:
• Istruzioni di tipo-R: due registri e restituiscono il risultato in un terzo registro. Ad esempio:
– DADD R1, R20, R30 // R1 = R20 + R30
0 20 30 1 not-used 32
– DSUB R5, R11, R12 // R5 = R11 – R12
0 11 12 5 not-used 34

5
9
I campi delle istruzioni MIPS • Notiamo alcune cose:
• si usa spesso il prefisso “D” per indicare una istruzione che opera sugli interi (useremo F per il floating point).
• Nella notazione simbolica, il primo registro è di solito il registro che deve contenere il risultato dell’operazione.
• Nei due esempi di istruzioni viste, “op = 0” indica in entrambi i casi che si tratta di una operazione che usa la ALU, opera su due registri e restituisce il risultato in un terzo. E’ il campo funct a specificare esattamente di operazione si tratta (una somma piuttosto che una sottrazione o una moltiplicazione, ecc.)
10
I campi delle istruzioni MIPS • Naturalmente, non sempre i campi vengono usati in questo modo.
Nelle istruzioni di tipo-I, che usano cioé un valore immediato (un numero intero), la suddivisione dei campi sarà:
• Ad esempio:
– DADDI R5, R1, 1500 // R5 = R1 + 1500
• notate che op ha un valore diverso rispetto a prima, e il valore immediato è scritto su 16 bit.
op reg_1 reg_dest immediate value
8 1 5 1500

6
11
I campi delle istruzioni MIPS • Questo formato permette anche di esprimere le istruzioni di load
e store. Ad esempio:
• LD R1, 128(R4)
– mette in R1 4 byte di memoria principale che si trovano a partire dall’indirizzo 128 + contenuto di R4
– SD R1, 252(R4)
– mette il contenuto di R1 all’indirizzo 252 + contenuto di R4
35 4 1 128
43 4 1 252
12
I campi delle istruzioni MIPS • E infine abbiamo le istruzioni di salto:
branch (salti condizionati):
• ad esempio: BNE R1, R2, 100 // salta se R1<>R2
• e jump (salti incondizionati):
• ad esempio: JMP 10000
op offset
5 1 2 25
op reg_1 reg_2 offset
4 2500

7
13
I campi delle istruzioni MIPS • Notate che stiamo ignorando molti aspetti. Ad esempio come
specificare indirizzi di salto condizionato superiori a 216 byte (perché questo è importante?)
• Oppure come vengono gestite le chiamate di procedura
– (di solito, un sottoinsieme dei registri – 4 nella MIPS – viene usato per passare i parametri, e altri registri – due nella MIPS – per passare il risultato) Vedremo le chiamate di procedura nella parte sulla programmazione in assembler.
• Oppure come usare costanti a 32 bit.
• Tutte queste cose sono fondamentali e vanno risolte in una implementazione reale, ma non sono necessarie per capire il funzionamento di base di una CPU.
14
Una versione monociclo della MIPS
• L’esecuzione delle istruzioni della MIPS (e in generale di qualsiasi architettura RISC) è simile per qualsiasi tipo di istruzione.
• In particolare, i primi due passi di ogni istruzione sono praticamente sempre identici:
1. usa il PC per prelevare dalla memoria di istruzioni quella da eseguire.
2. Decodifica l’istruzione mentre, contemporaneamente (capiremo meglio fra poco), leggi uno o due registri, usando i campi dell’istruzione per selezionare quale/quali.

8
15
Una versione monociclo della MIPS • Dopo i primi due passi, le azioni richieste dipendono dal tipo di
istruzione:
– accesso alla memoria (load e store)
– operazione logico-aritmetica
– salto (condizionato e incondizionato)
• ma le azioni richieste sono più o meno simili all’interno di ciascun tipo di istruzione, e vi sono forti somiglianze anche tra i diversi tipi.
• Ad esempio tutte le istruzioni (eccetto i jump, perché?) usano la ALU.
16
Una versione monociclo della MIPS
• La parte finale delle istruzioni invece si diversifica:
• Load e Store accedono alla memoria dati, e nel caso della Load aggiornano un registro
• Le istruzioni logico-aritmetiche aggiornano un registro
• Le istruzioni di salto alterano (solo eventualmente, nel caso dei branch) il valore del PC

9
17
Una versione monociclo della MIPS • Uno schema ad alto livello del datapath MIPS, con le principali
unità funzionali e le relative connessioni. Notate che sono presenti memorie separate per le istruzioni e per i dati. Ne riparleremo più avanti. (Patterson-Hennessy, fig. 4.1)
18
Una versione monociclo della MIPS • Nel lucido successivo: uno schema ad alto livello del datapath
MIPS, con l’aggiunta dell’unità di controllo, dei multiplexer necessari per selezionare tra i diversi ingressi quello da mandare in uscita, e dei segnali per il controllo delle unità funzionali e dei multiplexer. (Patterson-Hennessy, fig. 4.2)
• Cercate di famigliarizzarvi con questo schema ad alto livello (e con i successivi, ovviamente), che è sostanzialmente comune a tutte le architetture moderne.

10
19
Una versione monociclo della MIPS
20
Una versione monociclo della MIPS
• L’esecuzione di ciascuna istruzione in questo datapath può avvenire in un unico ciclo di clock: è sufficiente che il ciclo sia abbastanza lungo da permettere a ciascuna istruzione di percorrere tutta la parte del datapath necessaria per la sua esecuzione.
• Per capirne bene il funzionamento, ricordiamo che il datapath di un qualsiasi processore è composto di due tipi diversi di elementi logici (nel loro insieme chiamati unità funzionali): gli elementi di stato e gli elementi di tipo combinatorio

11
21
Una versione monociclo della MIPS 1. gli elementi di stato sono quelli in grado di memorizzare un valore,
come un flip flop o, nel datapath della MIPS, i registri e le memorie.
• ricordiamo che un elemento di stato possiede almeno due ingressi ed un’uscita. Gli ingressi richiedono: 1) il valore da scrivere nell’elemento e 2) il clock, che determina quando il valore viene scritto (sul fronte di salita o di discesa del clock).
• In qualsiasi istante, il dato disponibile all’uscita di un elemento di stato è quindi quello memorizzatovi in un ciclo di clock precedente
22
Una versione monociclo della MIPS 1. Gli elementi combinatori, sono quelli in cui le cui uscite
dipendono solo dai valori all’ingresso in un dato istante (a meno dei tempi di ritardo nella propagazione del segnale attraverso le porte logiche di cui è fatto l’elemento), come ad esempio le ALU e i multiplexer del datapath MIPS.
• Al livello di astrazione più alto, l’esecuzione di una istruzione in un unico ciclo di clock all’interno del datapath può essere descritta come in questa figura: (Patterson-Hennessy, fig. 4.3)

12
23
Una versione monociclo della MIPS • perché tutto funzioni basta che il ciclo del clock sia
sufficientemente lungo da permettere che i segnali in ingresso ad un elemento di stato si siano stabilizzati prima che il fronte attivo del clock permetta di memorizzarli nell’elemento stesso
• Notate che gli elementi di stato 1 e 2 possono anche coincidere: (Patterson-Hennessy, fig. 4.4).
• In questo caso, nella prima parte del ciclo del clock l’output dell’elemento di stato (memorizzato al suo interno in una qualche fase precedente) costituisce l’input alla logica combinatoria (lettura). Questa produce un output che verrà memorizzato nello stesso elemento di stato (modificando quindi in qualche modo il contenuto precedente) nella seconda parte dello stesso ciclo di clock (scrittura).
• Perché tutto funzioni è sufficiente che il tempo di commutazione della logica combinatoria sia inferiore alla durata del ciclo di clock
24
Una versione monociclo della MIPS • Nel datapath MIPS, un esempio semplice di questa situazione è
l’incremento, ad ogni ciclo di clock, del Program Counter, attraverso una ALU dedicata. Il PC viene utilizzato ad ogni ciclo per estrarre dalla memoria di istruzioni quella da mandare in esecuzione (Patterson-Hennessy, fig. 4.6)

13
25
Il banco di registri • Nel datapath visto, i 32 registri della CPU sono rappresentati da
un’unità funzionale detta register file o banco dei registri.
• Di fatto funziona come un normale banco di memoria, ma interno alla CPU, molto piccolo e molto veloce.
• Il banco di registri comprende le unità vere e proprie di memoria (appunto, i registri) e una logica di controllo che permette di 1) accedere a ciascuno dei registri specificandone il numero e il tipo di operazione (lettura o scrittura), e di 2) controllare se e quando il contenuto di un registro può essere modificato.
26
Digressione: register file • la veduta esterna del register file. Il segnale di controllo RegWrite
proviene dalla control unit. Quando viene asserito permette di scrivere il valore proveniente dalla ALU o dalla Data Memory nel registro di destinazione (DSTaddr) specificato dall’istruzione in esecuzione.
RegWrite or Data Memory

14
27
Digressione: il register file • mentre le scritture nel register file sono controllate da uno specifico
segnale, le letture sono “immediate”: in qualunque momento il register file fornisce in uscita su SRC1data e SRC2data il contenuto dei registri i cui numeri sono specificati sugli ingressi SRC1addr e SRC2addr
RegWrite or Data Memory
28
Una semplice Control Unit • Per realizzare la Control Unit (CU) della macchina MIPS è innanzi
tutto necessario definire i segnali di controllo della ALU, che riceve due valori in input e li combina in output usando la funzione aritmetico-logica specificata dal valore del segnale ALU control. Se assumiamo che siano sufficienti 4 bit per specificare tutte le operazioni possibili, potremmo ad esempio avere:
ALU control Funzione eseguita 0000 AND 0001 OR 0010 somma 0110 sottrazione 0111 set on less than
... ...
15
29
Una semplice Control Unit • Una parte della CU si deve dunque occupare di generare i 4 bit di
controllo della ALU, a seconda del tipo di istruzione in esecuzione. Chiamiamo proprio ALU control questa parte della CU. La ALU control riceverà in input:
– Il campo “funct” dell’istruzione in esecuzione
– due bit di controllo “ALUop” che sono già stati elaborati dalla CU principale e che sostanzialmente permettono di stabilire se l’operazione che deve eseguire la ALU è una somma per calcolare l’indirizzo a cui operano load o store, una sottrazione, o viene deciso dal campo “funct”
• E produrrà in output i 4 bit del segnale ALU control del lucido precedente.
30
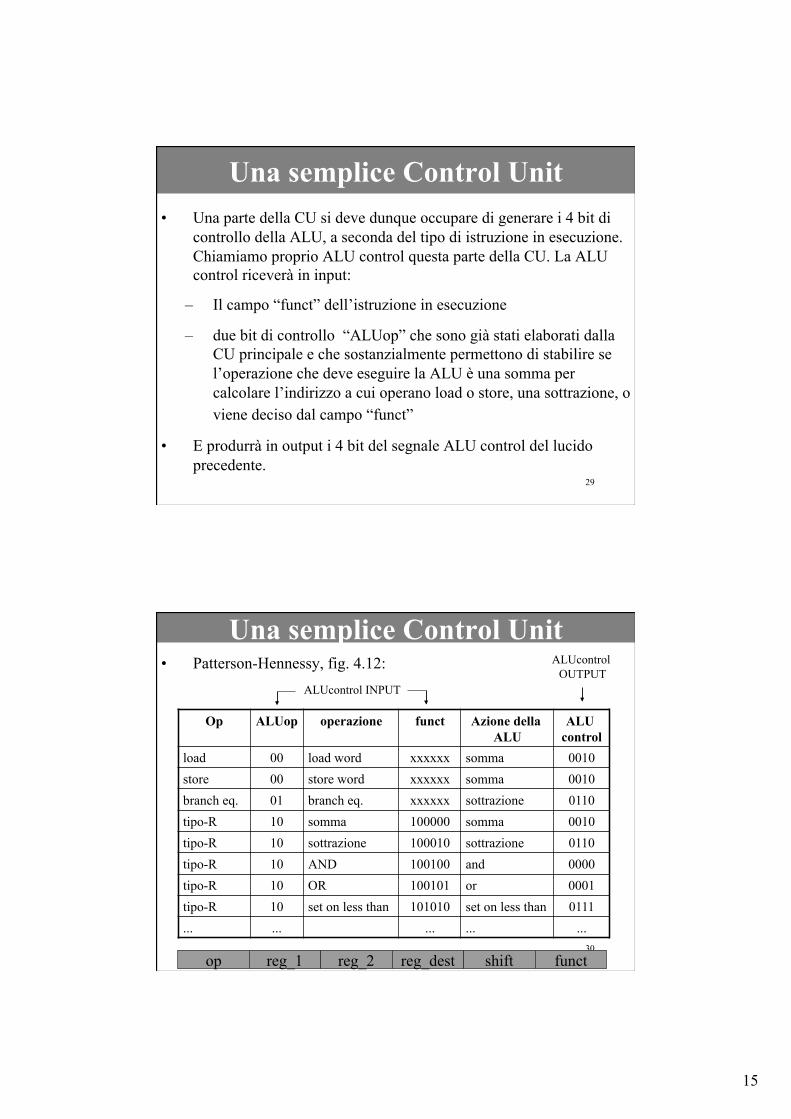
Una semplice Control Unit
Op ALUop operazione funct Azione della ALU
ALU control
load 00 load word xxxxxx somma 0010 store 00 store word xxxxxx somma 0010 branch eq. 01 branch eq. xxxxxx sottrazione 0110 tipo-R 10 somma 100000 somma 0010 tipo-R 10 sottrazione 100010 sottrazione 0110 tipo-R 10 AND 100100 and 0000 tipo-R 10 OR 100101 or 0001 tipo-R 10 set on less than 101010 set on less than 0111 ... ... ... ... ...
op reg_1 reg_2 reg_dest shift funct
• Patterson-Hennessy, fig. 4.12: ALUcontrol INPUT
ALUcontrol OUTPUT

16
31
Una semplice Control Unit
• Dunque, i 2 bit ALUop vengono prodotti dalla CU principale sulla base del campo “op”, e insieme ai bit del campo “funct” costituiscono l’input della ALU control, il cui output sono i 4 bit che dicono alla ALU quale operazione eseguire, a seconda dell’istruzione in esecuzione.
32
Una semplice Control Unit • A questo punto, la ALU control non sarà altro che il circuito logico
che implementa la tabella di verità che mette in corrispondenza gli ingressi della ALU control (ALUop + funct) con le sue uscite, ossia i 4 bit che pilotano la ALU. Le x indicano bit il cui valore è indifferente. (Patterson-Hennessy, fig. 4.13):
ALUop0 ALUop1 F5 F4 F3 F2 F1 F0 ALUcontrol 0 0 x x x x x x 0010 x 1 x x x x x x 0110 1 x x x 0 0 0 0 0010 1 x x x 0 0 1 0 0110 1 x x x 0 1 0 0 0000 1 x x x 0 1 0 1 0001 1 x x x 1 0 1 0 0111 ... ... ... ... ... ... ... ... ...

17
33
Una semplice Control Unit
• Ed ecco qui la nostra ALUcontrol (i pallini significano la negazione del segnale in input alle porte OR). Notate che i due bit più significativi di “funct” non sono usati, in quanto sono a x nella tabella precedente. (Patterson-Hennessy 3rd ed., fig. C.2.3).
34
Una semplice Control Unit
• La costruzione del resto della CU procede in modo simile a quanto visto per la ALU control.
• La Control Unit principale riceve in input i 6 bit del campo op dell’istruzione (bit 31-26) e deve generare in output i segnali per:
– pilotare la scrittura dei registri (RegWrite)
– pilotare la lettura e la scrittura della memoria dati (MemRead e MemWrite)
– controllare i multiplexer (RegDst, ALUSrc, MemtoReg, PCsrc)
– pilotare la ALU (ALUop, i due segnali già visti)

18
35
Una semplice Control Unit • Il datapath MIPS con l’aggiunta dei segnali di controllo della CU.
Notate l’aggiunta del multiplexer per l’input in scrittura al register file (Patterson-Hennessy, fig. 4.15)
36
Una semplice Control Unit
• Nel lucido successivo, il significato delle linee di controllo provenienti dalla Control Unit (eccetto che per ALUOp, già visti), insieme con il loro effetto quando asseriti (bit a 1) e quando non asseriti (bit a 0). Patterson-Hennessy, fig. 4.16.
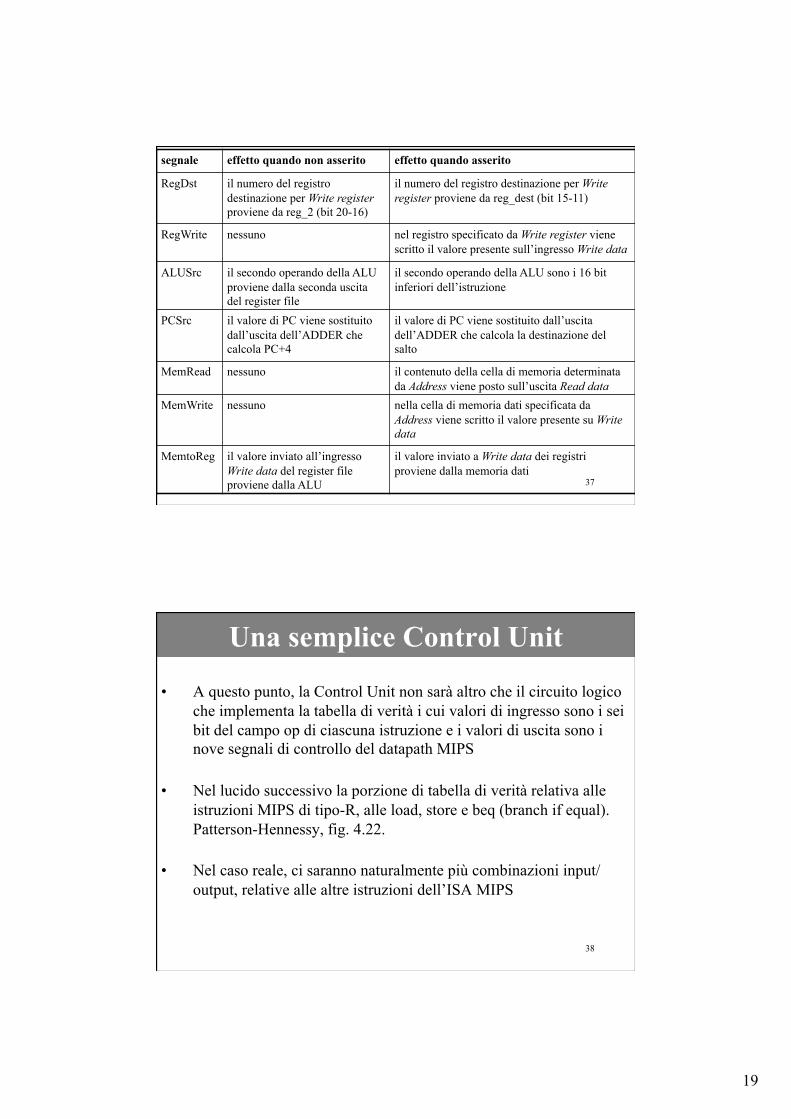
19
37
segnale effetto quando non asserito effetto quando asserito
RegDst il numero del registro destinazione per Write register proviene da reg_2 (bit 20-16)
il numero del registro destinazione per Write register proviene da reg_dest (bit 15-11)
RegWrite nessuno nel registro specificato da Write register viene scritto il valore presente sull’ingresso Write data
ALUSrc il secondo operando della ALU proviene dalla seconda uscita del register file
il secondo operando della ALU sono i 16 bit inferiori dell’istruzione
PCSrc il valore di PC viene sostituito dall’uscita dell’ADDER che calcola PC+4
il valore di PC viene sostituito dall’uscita dell’ADDER che calcola la destinazione del salto
MemRead nessuno il contenuto della cella di memoria determinata da Address viene posto sull’uscita Read data
MemWrite nessuno nella cella di memoria dati specificata da Address viene scritto il valore presente su Write data
MemtoReg il valore inviato all’ingresso Write data del register file proviene dalla ALU
il valore inviato a Write data dei registri proviene dalla memoria dati
38
Una semplice Control Unit
• A questo punto, la Control Unit non sarà altro che il circuito logico che implementa la tabella di verità i cui valori di ingresso sono i sei bit del campo op di ciascuna istruzione e i valori di uscita sono i nove segnali di controllo del datapath MIPS
• Nel lucido successivo la porzione di tabella di verità relativa alle istruzioni MIPS di tipo-R, alle load, store e beq (branch if equal). Patterson-Hennessy, fig. 4.22.
• Nel caso reale, ci saranno naturalmente più combinazioni input/output, relative alle altre istruzioni dell’ISA MIPS
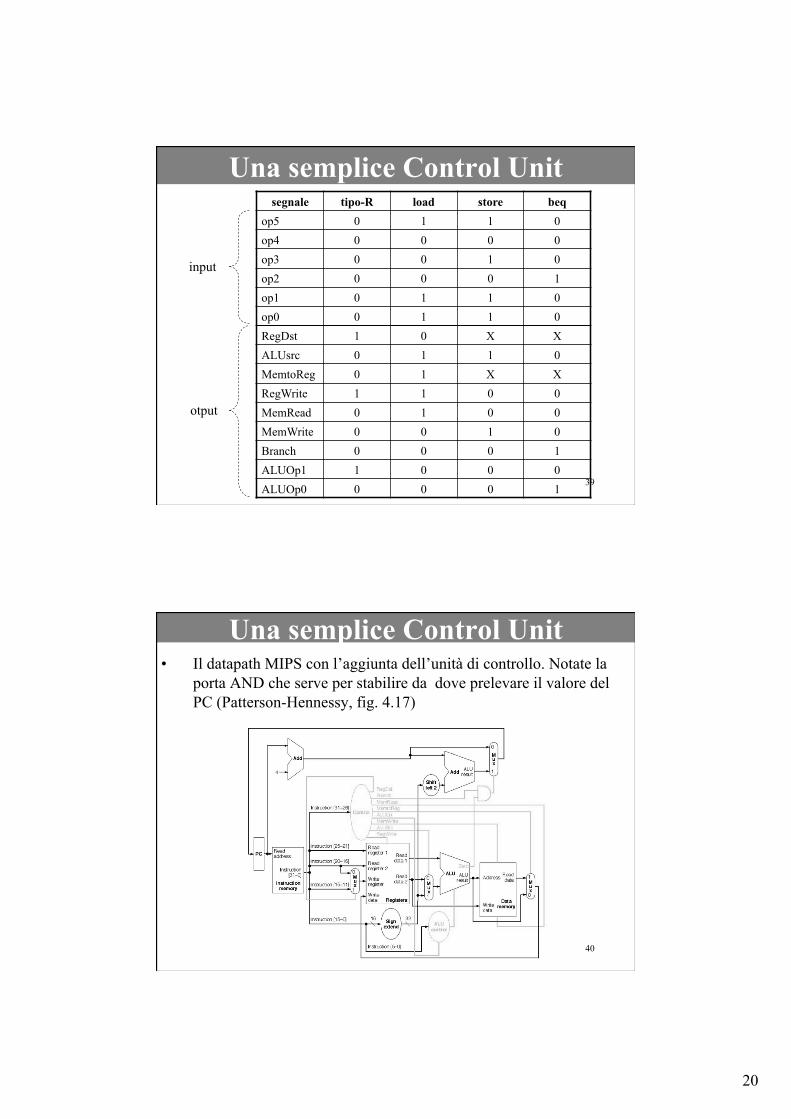
20
39
segnale tipo-R load store beq op5 0 1 1 0 op4 0 0 0 0 op3 0 0 1 0 op2 0 0 0 1 op1 0 1 1 0 op0 0 1 1 0 RegDst 1 0 X X ALUsrc 0 1 1 0 MemtoReg 0 1 X X RegWrite 1 1 0 0 MemRead 0 1 0 0 MemWrite 0 0 1 0 Branch 0 0 0 1 ALUOp1 1 0 0 0 ALUOp0 0 0 0 1
input
otput
Una semplice Control Unit
40
Una semplice Control Unit • Il datapath MIPS con l’aggiunta dell’unità di controllo. Notate la
porta AND che serve per stabilire da dove prelevare il valore del PC (Patterson-Hennessy, fig. 4.17)

21
41
Una semplice Control Unit • Vediamo, come esempio, come avviene l’esecuzione di una
istruzione di tipo-R.
1. il contenuto del PC viene usato per indirizzare la Instruction Memory e produrre in output l’istruzione da eseguire.
2. il campo op dell’istruzione viene mandato in input alla Control Unit, mentre i campi reg_1 e reg_2 vengono usati per indirizzare il register file.
• In realtà, notate che a questo punto non sappiamo ancora che l’istruzione da eseguire è di tipo-R, ossia che ci servano effettivamente i valori dei registri reg_1 e reg_2, ma ci torneremo più avanti...
42
Una semplice Control Unit 3. la CU produce in output i nove segnali di controllo relativi ad una
operazione di tipo-R, ed in particolare ALUOp=10, che, dati in input alla ALU control insieme al campo funct dell’istruzione stabiliscono l’effettiva operazione di tipo-R che deve eseguire la ALU
4. Nel frattempo, il register file produce in output i valori dei due registri reg_1 e reg_2, mentre il segnale ALUSrc=0 stabilisce che il secondo input della ALU deve provenire dal secondo output del register file.
5. La ALU produce in output il risultato della computazione, che attraverso il segnale MemtoReg viene presentato in input al register file (Write data)

22
43
Una semplice Control Unit • Notate che tutti questi passi possono essere eseguiti all’interno dello
stesso ciclo di clock, purché questo abbia una durata maggiore dei tempi di ritardo con cui i segnali si propagano tra le varie unità funzionali.
• Notate anche che fino a questo punto gli elementi di stato del datapath coinvolti nell’esecuzione (PC, instruction memory e register file) non hanno dovuto cambiare il proprio stato (cioé non hanno dovuto memorizzare un nuovo valore).
• Si sono quindi di fatto comportati come elementi combinatori, fornendo “immediatamente” in output il dato memorizzato al loro interno (nel caso del register file, l’output è il valore contenuto nei registri il cui numero è specificato nei campi SRC addr 1/2)
44
Una semplice Control Unit 6. ma a questo punto il valore presente sull’ingresso Write data del
register file deve essere memorizzato nel registro il cui numero è specificato nel campo reg_dest dell’istruzione, e la scrittura avviene nel momento in cui si presenta il fronte del clock a cui il register file è sensibile.
• Notate che il segnale di controllo RegWrite è asserito, proprio per permettere la scrittura del registro di destinazione dell’istruzione.
• Provate, per esercizio, a ripetere il ragionamento appena visto per gli altri tipi di istruzione (load, store, beq), verificando l’effetto dei vari segnali di controllo.

23
45
Una semplice Control Unit
• Ed ecco qui la Control Unit della nostra architettura monociclo. I pallini significano la negazione del segnale in input alle porte AND. (Patterson-Hennessy 3rd ed., fig. C.2.5.)
46
Una versione multiciclo della MIPS • Sebbene le macchine a ciclo singolo possano funzionare
correttamente, non vengono usati nelle implementazioni moderne, poiché sono inefficienti.
• Infatti, le diverse istruzioni di un processore hanno tempi di esecuzione diversi, a seconda della quantità di lavoro necessario all’interno del datapath (ossia a seconda della porzione di datapath da attraversare).
• Ma dato che il ciclo del clock deve ovviamente essere stabilito a priori, dovrà avere una durata sufficiente a permettere l’esecuzione dell’istruzione con la durata maggiore, facendo sprecare tempo quando viene eseguita una istruzione che richiede meno tempo.

24
47
Una versione multiciclo della MIPS • Per trasformare la macchina monociclo in multiciclo, il progettista
scompone l’esecuzione di ciascuna istruzione in un insieme di passi, ognuno dei quali sia eseguibile in un singolo ciclo di clock (Nota: nel seguito, useremo indifferentemente il termine passo, fase, stadio, stage come sinonimi)
• E’ opportuno che ogni passo richieda più o meno lo stesso tempo di esecuzione. Infatti, se un passo è più lungo degli altri, la durata del clock dovrà necessariamente essere sufficiente all’esecuzione del passo più lungo.
• E a questo punto, il ciclo di clock può essere ridimensionato sulla base del tempo necessario ad attraversare la singola fase del datapath, e non più il datapath completo. Dunque se il datapath è stato suddiviso in N fasi, il nuovo ciclo di clock dovrà essere lungo all’incirca un N-esimo della lunghezza del ciclo di clock della macchina monociclo.
48
Una semplice architettura RISC • Ogni passo dovrà contenere al più una operazione su ciascuna unità
funzionale.
• Ad esempio, se nella CPU c’è una sola ALU non possiamo usarla nello stesso passo per incrementare il PC e per sommare due registri
• Incominciamo a mostrare il datapath completo del processore MIPS multiciclo, in modo da poterne commentare il suo funzionamento passo passo rispetto all’esecuzione delle istruzioni che abbiamo visto. Notate i nomi delle 5 fasi in cui è stato scomposto il datapath.
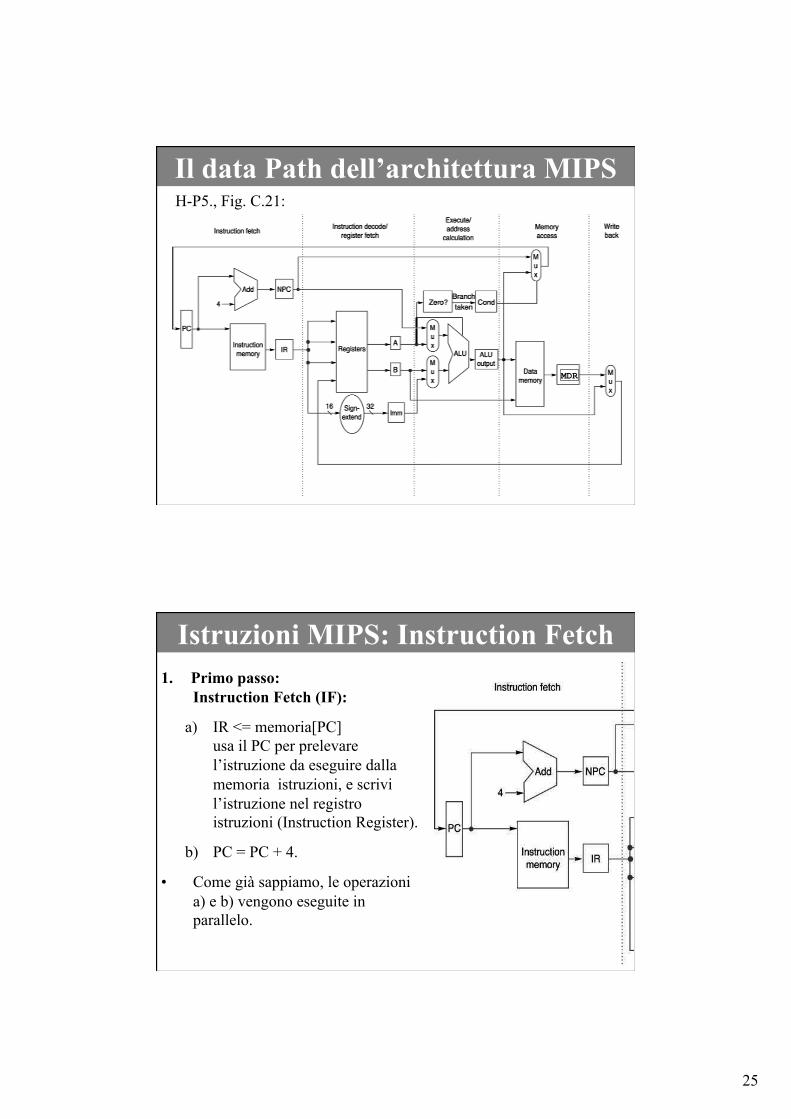
25
49
Il data Path dell’architettura MIPS H-P5., Fig. C.21:
MDR
50
Istruzioni MIPS: Instruction Fetch 1. Primo passo:
Instruction Fetch (IF):
a) IR <= memoria[PC] usa il PC per prelevare l’istruzione da eseguire dalla memoria istruzioni, e scrivi l’istruzione nel registro istruzioni (Instruction Register).
b) PC = PC + 4.
• Come già sappiamo, le operazioni a) e b) vengono eseguite in parallelo.

26
51
Istruzioni MIPS: Instruction Fetch • Notiamo subito alcune cose, che ci permetteranno anche di chiarire
meglio il funzionamento dell’intera architettura
• L’incremento del PC potrebbe essere fatto direttamente dalla ALU, che in questa fase dell’esecuzione dell’istruzione non è usata.
• Ma quando aggiungeremo il pipelining delle istruzioni, vedremo che (sperabilmente) anche in questa fase la ALU è impegnata, ma da un’altra istruzione.
• Ci conviene quindi avere un ADDER separato per il PC
• Notate anche che il nuovo PC (NPC) viene instradato anche verso la ALU (perché?)
52
Istruzioni MIPS: Instruction Fetch • Notate che, alla fine di questa fase,
il nuovo PC e l’istruzione saranno memorizzati in due registri interni (NPC e IR).
• Questi registri sono invisibili al livello ISA (e quindi al programmatore) ma, in una implementazione multiciclo, sono necessari per memorizzare le informazioni che devono essere rese disponibili alla fase successiva

27
53
istruzioni MIPS: Instruction Decode 2. Instruction decode/register fetch
(ID)
• All’inizio di questa fase non si sa ancora quale sia l’istruzione da eseguire, ma si possono comunque compiere operazioni che non siano dannose, nel caso in cui l’istruzione da eseguire non sia quella ipotizzata.
54
istruzioni MIPS: Instruction Decode
a) A <= reg[IR[25-21]] B <= reg [IR[20-16]]
• lettura dei registri sorgente. Notate che non si sa ancora se i registri andranno usati, cioé se questa è un’istruzione di tipo-R, ma non è dannoso leggerli, e potrebbero servire ai passi successivi, per cui vengono letti dal register file e memorizzati nei registri temporanei A e B (invisibili al livello ISA).
• Il register file viene quindi letto ad ogni ciclo, e i registri temporanei A e B vengono sovrascritti ad ogni ciclo

28
55
istruzioni MIPS: Instruction Decode b) ALUout <= PC + IR[15-0]
• Viene calcolato l’eventuale indirizzo di destinazione dei branch, e memorizzato nel registro interno ALUoutput, da cui verrà prelevato al ciclo di clock successivo se l’istruzione è effettivamente di branch (Patterson-Hennessy, fig. 4.9).
Nota (1): in questa figura vedete un ADDER dedicato al calcolo di PC+IR[15]. In realtà, si può far fare la cosa alla ALU (tornate allo schema completo del datapath)
Nota (2): In realtà, l’istruzione di incremento è: ALUout <= PC + + (sign-extended (IR[15-0]) << 2
56
istruzioni MIPS: Instruction Decode • Se le istruzioni non hanno una struttura regolare (come nel caso
dell’IA-32), fino a che non si sa qual è l’istruzione in esecuzione non è possibile sapere in quali bit si trovano i suoi operandi, e quindi recuperarli (Patterson-Hennessy, fig. 2.41)
• Come conseguenza, le istruzioni vanno prima decodificate e poi si possono prelevare i loro argomenti.
• Per mandare in esecuzione una istruzione ci vuole dunque più tempo.

29
57
istruzioni MIPS: EXecution 3. Execution (EX): La Control Unit pilota la ALU
usando l’op-code dell’instruction register, e la ALU opera sugli operandi (preparati al ciclo precedente) eseguendo una di quattro possibili operazioni a seconda del tipo di istruzione:
a) Istruzione di tipo-I, o accesso alla memoria (load e store)
b) Istruzione di tipo-R (registro-registro)
c) salto condizionato (branch)
d) salto incondizionato (jump)
58
istruzioni MIPS: EXecution
a) Istruzione di tipo-I o accesso alla memoria (load/store)
• ALUout <= A + IR[15-0]
• la ALU somma al registro temporaneo A il valore immediato (in caso di load/store questo è l’indirizzo di RAM su cui operare)
b) Istruzione tipo-R (Registro-Registro)
• ALUout <= A op B
• la ALU esegue l’operazione specificata sui valori contenuti nei registri temporanei A e B

30
59
istruzioni MIPS: EXecution c) Salto condizionato (branch)
• if (A == B) PC <= ALUoutput
• La ALU viene usata per confrontare i due registri sorgente, e il segnale Zero della ALU, se viene asserito, serve per scrivere il PC con il contenuto di ALUoutput.
d) Salto incondizionato (jump)
• PC <= Indirizzo del salto
• Notate che in caso di istruzione di salto effettuato, il PC viene scritto due volte: viene prima scritto nella fase IF, e poi sovrascritto nella fase EX
60
istruzioni MIPS: MEMory access 4. Memory access (MEM/WriteReg):
a) load/store • MDR <= memoria[ALUoutput] (load) • memoria[ALUoutput] <= B (store)
b) istruzione logico/aritmetica (tipo-I o tipo-R)
• Reg[IR[15-11]] <= ALUoutput MDR

31
61
istruzioni MIPS: MEMory access • Come abbiamo visto, nel datapath dell’architettura MIPS sembrano
essere presenti due memorie, una di istruzioni acceduta al passo “Instruction Fetch” e una di dati acceduta al passo “MEMory access”.
• In pratica, potrebbero anche essere un’unica memoria, in quanto le due memorie vengono accedute in fasi diverse dell’esecuzione di una istruzione (ossia, in diversi cicli del clock).
• Del resto, questo è un principio dei moderni computer che conosciamo bene: la RAM contiene sia istruzioni che dati.
62
istruzioni MIPS: MEMory access • Tuttavia, quando introdurremo il pipelining delle istruzioni,
vedremo che le due memorie vengono accedute entrambe nello stesso ciclo di clock, a causa di due istruzioni contemporaneamente in esecuzione in fasi diverse: se non fossero memorie distinte l’accesso contemporaneo non sarebbe possibile.
• E difatti, nel caso reale, la Instruction Memory e la Data Memory del datapath MIPS, e di qualsiasi moderna CPU, sono due memorie distinte.
• E devone essere in grado di lavorare alla stessa velocità degli altri componenti del datapath (cosa che non sarebbe certamente possibile se queste memorie fossero della comune RAM)

32
63
istruzioni MIPS: MEMory access • Come vedremo meglio quando parleremo della cache,
corrispondono alla cache di primo livello della CPU, che è appunto divisa in una cache di dati e una di istruzioni, con indirizzamento e uscite separate.
• Questa doppia memoria, che è fisicamente all’interno della CPU, è in grado di lavorare alla stessa velocità della CPU, e quindi non introduce rallentamenti nell’esecuzione delle istruzioni.
• Ovviamente, le cose peggiorano un po’ se il dato o l’istruzione indirizzati non si trovano nella cache...
64
istruzioni MIPS: Write Back 5. Write back Register (WB/REG):
• Reg[IR[20-16]] <= MDR
• Viene completata l’operazione di load, scrivendo il contenuto dell’MDR nel registro di destinazione dell’istruzione in esecuzione.
• Notate che in questa fase, la control unit deve asserire il segnale RegWrite (WE) del register file, per permettere la scrittura del registro IR[20-16]

33
65
Il data Path dell’architettura MIPS H-P5, Fig. C.21:
MDR
66
Esecuzione delle istruzioni MIPS • Quindi, in questa implementazione, un branch richiede 3 cicli di
clock, una operazione logico aritmetica di tipo-I o di tipo-R, o uno store richiedono 4 cicli, e una load richiede 5 cicli di clock per essere portate a termine.
• Se assumiamo (sono valori ragionevoli, ottenuti statisticamente campionando varie architetture RISC), che la frequenza di una istruzione branch sia del 12%, e di una load sia del 10%, il numero medio di cicli di clock necessari per eseguire una istruzione è CPI = 3,98 (provate a verificare questo valore per conto vostro).
• Abbiamo ottenuto un vantaggio rispetto ad una ipotetica implementazione monociclo?
• Ovviamente si, se assumiamo che il ciclo di clock della macchina multiciclo abbia una durata di circa 1/5 di quello della corrispondente macchina monociclo.

34
67
L’unità di controllo multiciclo
• Come cambia l’unità di controllo della versione multiciclo della MIPS?
• Sicuramente è più complessa, perché la CU deve specificare quali segnali devono essere asseriti in ciascuna delle fasi della pipeline, e anche quale sia la fase successiva della sequenza, per l’istruzione in esecuzione.
• Ogni fase sarà quindi descritta da una tabella di verità i cui input sono:
– il tipo di istruzione in esecuzione (ossia il solito campo op)
– La fase corrente nella sequenza di esecuzione dell’istruzione
68
L’unità di controllo multiciclo
• L’output della tabella di verità di ciascuna fase sarà invece:
– l’insieme dei segnali da asserire
– La fase successiva nella sequenza di esecuzione dell’istruzione
• Ma questa non è altro che la descrizione informale di una Macchina di Moore: un tipo automa a stati finiti in cui:
– ad ogni stato è associato un output che dipende solo da quello stato (nel nostro caso i segnali da asserire)
– la transizione nello stato successivo dipende solo dallo stato corrente e dall’input (come in ogni automa a stati finiti)

35
69
L’unità di controllo multiciclo • Ed ecco la macchina a stati
finiti che descrive la CU della versione multiciclo della MIPS.
• Notate come i vari stati corrispondano alle fase che abbiamo descritto nei lucidi precedenti.
• Ad esempio, è necessario passare attraverso 4 stati (0, 1, 6, 7) per eseguire una istruzione di tipo-R. Poi si torna allo stato iniziale (Patterson-Hennessy 3rd ed., fig. 5.38).
70
L’unità di controllo multiciclo • E una UC a stati finiti può essere
realizzata semplicemente combinando un blocco di logica combinatoria e un registro per memorizzare lo stato corrente della macchina.
• Notate come lo stato successivo dipenda solo dal precedente. (Patterson-Hennessy 3rd ed., fig. C.3.2).
• Domanda: il registro di stato è a quattro bit. Perché? (guardate il lucido precedente).

36
71
Macchine a Stati Finiti e Microprogrammi
• Ma che differenza c’è tra un datapath controllato da una macchina a stati finiti e uno controllato da un microprogramma? Sostanzialmente, nessuna
• La tecnica della microprogrammazione usa, per descrivere il funzionamento della CU, una rappresentazione simbolica del controllo in forma di microistruzioni, controllate da un micro program counter
• (Esercizio: andate a vedere come, nel Tanenbaum, viene descritta la Instruction Fetch Unit. Cosa viene usato?...)
72
Macchine a Stati Finiti e Microprogrammi
• ma in realtà, il microprogramma non è altro che una rappresentazione testuale di una macchina di Moore a stati finiti, e ogni microistruzione corrisponde ad uno stato della macchina (e a che cosa corrisponde lo “state register”?).
• Perché allora esiste questa doppia rappresentazione (automa a stati finiti o microprogramma) della funzione di controllo del datapath?
• E’ una questione di complessità della funzione stessa, che a sua volta dipende dal numero e dalla complessità delle istruzioni del livello ISA.

37
73
Macchine a Stati Finiti e Microprogrammi
• Una architettura RISC reale ha molte più istruzioni macchina di quelle che abbiamo visto, e queste possono richiedere più cicli di clock per essere eseguite.
• La funzione di controllo per queste architetture sarà evidentemente molto più complessa di quella del nostro esempio, e quindi anche l’automa a stati finiti che la implementa.
• Vengono allora usati dei linguaggi di progettazione hardware (il più usato è il “verilog”) per descrivere la funzione e sintetizzarla in un automa a stati finiti.
74
Macchine a Stati Finiti e Microprogrammi
• Ma oltre una certa complessità dell’automa, questa forma di rappresentazione della funzione di controllo non è più ragionevole.
• Le architetture CISC avevano ISA composti da molte centinaia di istruzioni, alcune delle quali assai espressive e complesse, perché combinavano operazioni di tipo logico-aritmetico con l’accesso alla memoria.
• Inoltre permettevano spesso la completa ortogonalità dell’ISA: ogni argomento di ogni istruzione poteva indirizzare la memoria usando una qualsiasi delle modalità di indirizzamento disponibili

38
75
Macchine a Stati Finiti e Microprogrammi
• Il numero di passi necessari per eseguire istruzioni così complesse è molto alto, e descrivere la funzione di controllo mediante una macchina a stati finiti richiede un automa composto da migliaia di stati e centinaia di sequenze di stati diverse per le varie istruzioni
• Descrivere un automa così complesso, analizzarne la correttezza, e identificare possibili migliorie nel datapath per ottimizzare l’esecuzione delle istruzioni diventa un compito quasi impossibile.
• Invece, la descrizione di una funzione di controllo così complessa mediante microprogramma semplifica la progettazione e l’analisi del datapath del processore controllato da quella funzione.
76
Macchine a Stati Finiti e Microprogrammi
• Per una serie di ragioni tecniche che analizziamo nei prossimi lucidi, la microprogrammazione fu la scelta naturale per le architetture degli anni ‘50, ‘60 e ‘70, nelle quali si tendeva ad avere un insieme molto diversificato di istruzioni macchina molto potenti.
• Le eccezioni a questa tendenza furono pochissime. Vale la pena di menzionare il CDC 6600 progettato da Symour Cray a inizio anni ’60 che anticipava di circa 20 anni l’idea alla base delle architetture RISC.

39
77
Complex Instruction Set Computer • L’idea di descrivere la funzione di controllo del datapath di un
processore mediante un microprogramma viene sviluppata all’inizio degli anni ‘50 da Maurice Wilkes, il quale propone una descrizione dell’esecuzione delle istruzioni macchina mediante microcodice.
• L’idea era di introdurre un ulteriore livello di traduzione tra le istruzioni macchina (il livello ISA) e la loro esecuzione, che veniva scomposta in passi (le microistruzioni) ancora più semplici.
• Inoltre in quel periodo, la formalizzazione della teoria degli automi a stati finiti era ancora in fase di sviluppo, e si concluderà solo intorno alla metà degli anni ’50 grazie ai lavori di G. Mealy e E. Moore.
• E infine, le tecniche di progettazione al computer (CAD) erano ancora ben al di là da venire, per cui descrivere e progettare una CU nei termini di un complesso automa a stati finiti sarebbe stato molto più complicato che farlo nei termini di microprogrammi.
78
Complex Instruction Set Computer • Per tutti gli anni ‘50 e ‘60 l’uso di istruzioni macchina molto
complesse era ampiamente giustificato dalla tecnologia disponibile in quegli anni:
1. Il tempo di accesso alla RAM era molto superiore al tempo di accesso alla ROM che conteneva i microprogrammi e che era posizionata fisicamente più vicino alla CPU (notate che in quegli anni le CPU non erano circuiti integrati miniaturizzati, ma occupavano lo spazio di più circuiti stampati montati all’interno di armadi della dimensione di qualche metro cubo).
2. Non esistevano ancora CPU dotate di cache, che furono introdotte solo a partire dal 1968 con l’IBM 360/85.

40
79
Complex Instruction Set Computer • Aveva quindi senso, ogni volta che si doveva accedere alla RAM
per leggere la successiva istruzione da eseguire cercare di fare in modo che questa istruzione esprimesse una gran quantità di lavoro.
• Ad esempio, l’IBM 370 aveva una istruzione macchina estremamente potente:
– MVC 15 (100, 5), 50 (8)
• Ossia: sposta 100 byte consecutivi che trovi a partire dall’indirizzo in memoria dato da 50 + [R8] all’indirizzo 15 + [R5]
• L’istruzione quindi specifica in modo molto sintetico l’equivalente di due addizioni, 100 LOAD e 100 STORE!
80
Complex Instruction Set Computer 3. Le tecniche di progettazione dei compilatori erano ancora in fase di
sviluppo, e avere a disposizione istruzioni macchina molto espressive permetteva di semplificare il lavoro del compilatore.
In questo modo infatti, una parte del lavoro di traduzione veniva “nascosto” nel microprogramma che permetteva l’esecuzione delle istruzioni macchina prodotte dal compilatore (in altre parole, ISA complessi permettevano di ridurre il gap semantico tra il linguaggio ad alto livello e il linguaggio macchina)
4. La RAM era costosa e scarseggiava, e i processori di quegli anni non erano in ogni caso in grado di gestire grandi spazi di indirizzamento. Dunque l’uso di istruzioni macchina molto espressive permetteva di generare eseguibili più corti.

41
81
Complex Instruction Set Computer 5. Infine, l’uso di microprogrammi per descrivere la funzione di
controllo rendeva semplice arricchire l’ISA di una CPU con nuove istruzioni.
• bastava infatti cambiare il microprogramma aggiungendo il microcodice delle nuove istruzioni all’interno della ROM che ospitava il microcodice.
• Poiché la ROM era solitamente montata su zoccolo (non era cioé parte integrante del chip che conteneva il resto della CPU), era facile dotare il computer di un nuovo (di solito più ampio) Instruction Set sostituendo solo la ROM, e non l’intera CPU.
82
Complex Instruction Set Computer • In particolare, la facilità con cui era possibile aggiungere nuove
istruzioni macchina ad un processore lasciava liberi i progettisti di introdurre nuove istruzioni macchina all’interno di un certo ISA non appena sembrava manifestarsi la necessità.
• Nuove istruzioni macchina sempre più esotiche venivano escogitate e inserite in un ISA esistente, e l’uso di istruzioni così complesse giustificava ulteriormente il ricorso alla microprogrammazione.
• Oltre ai mainframe IBM, esempi eclatanti di questa tendenza sono sicuramente l’ISA della famiglia del VAX e PDP della Digital Equipment Corporation e l’ISA della famiglia 80x86 Intel, che nel tempo si sono arricchiti di un enorme insieme di istruzioni.
• Purtroppo questa tendenza a progettare ISA complessi e molto espressivi si rivelò un’arma a doppio taglio...

42
83
Complex Instruction Set Computer • All’inizio degli anni ‘80, macchine come il DEC VAX o i mainframes
IBM avevano anche 300 istruzioni macchina diverse e fino a 200 modi diversi di specificare gli operandi delle istruzioni. (il loro tipo e come erano indirizzati). Un livello ISA molto versatile e complesso significava:
– necessità di usare un gran numero di bit in alcune istruzioni, per specificare il tipo di operazione, il numero, il tipo e l’indirizzo degli operandi.
– Impossibilità di usare un numero identico e prefissato di bit per tutte le istruzioni, altrimenti in molti casi la maggior parte dei bit veniva sprecata (nella serie 80x86 le istruzioni variano da 1 a 17 bytes).
84
Complex Instruction Set Computer • Istruzioni fatte così hanno elevati tempi di esecuzione. Infatti:
• La memoria di istruzioni viene letta a blocchi di byte di dimensione fissa, e una volta prelevati, non si sa ancora se contengono la parte centrale di un’istruzione, o la parte finale di un’istruzione e la parte iniziale dell’istruzione successiva, o due istruzioni intere, e così via.
• Poiché le istruzioni hanno dimensione e struttura variabile, gli operandi non sono sempre specificati negli stessi bit. Quindi una volta individuata una istruzione, prima di poterne prelevare gli operandi occorre aver decodificato il suo codice operativo, per sapere in quali bit sono specificati gli operandi stessi.
• Istruzioni complesse richiedono datapath e control unit più complesse, (ossia fatti di più porte logiche) e quindi tempi di commutazione più lunghi (ossia un ciclo di clock più lungo) o pipeline più profonde.

43
85
Complex Instruction Set Computer • ma nell’ISA complessi di quegli anni si nascondeva un problema
anche più grave. Era normale che le istruzioni usassero come operandi non solo i registri della macchina:
ad esempio: ADD R1, R2, R3 // R1 = R2 + R3
• ma anche una combinazione di registri e locazioni di memoria:
ad esempio (VAX instruction): ADDL3 42 (R1), 56 (R2), 0 (R3)
(ossia: prendi la word all’indirizzo dato da 56 + il contenuto di R2, prendi la word all’indirizzo 0 + contenuto di R3, somma i due valori e metti il risultato nella cella di memoria all’indirizzo 42 + contenuto di R1)
86
Complex Instruction Set Computer • E’ quindi vero che istruzioni che usavano esplicitamente locazioni di
memoria permettevano di generare in modo semplice codice molto compatto
– ad esempio, non era necessario scrivere codice esplicito per portare nei registri della CPU gli operandi specificati, ci pensava il microcodice
• Ma potevano facilmente generare dei terribili colli di bottiglia verso la memoria principale, oltretutto più lenta della CPU
– potenzialmente infatti, ogni istruzione poteva specificare uno o più operandi che dovevano essere prelevati in memoria principale.

44
87
Un esempio: l’ISA del Pentium 4: • E’ il risultato dell’evoluzione dell’architettura 80x86 attraverso molti
modelli, e della necessità di di mantenere la compatibilità backward.
• E’ complesso ed irregolare, con fino a 6 campi, ciascuno dei quali di lunghezza variabile. Dei 6 campi, 5 sono opzionali.
• Uno dei due operandi (ma non entrambi – è già qualcosa) di (quasi) ogni istruzione può essere in mem. principale (Tanenbaum, Fig. 5-14)
88
L’ISA del Pentium 4: • Una piccola selezione
delle più comuni istruzioni intere usate nel Pentium 4 (Tanenbaum, Fig. 5-34)

45
89
Restricted Instruction Set Computer • Mentre la produzione di macchine basate su architetture CISC va
avanti, all’inizio degli anni 80 prende il via la progettazione di processori con una concezione architetturale significativamente diversa.
• Nel 1980, a Berkeley, D. Patterson e C. Sequin progettano una CPU in cui la CU non è descritta da un microprogramma, e coniano il termine RISC (e coniano anche il termine CISC, in contrapposizione ovviamente a RISC)
• Il loro progetto evolverà poi nelle architetture SPARC (Scalable Processor ARChitecture) usate nelle macchine della SUN microsystems.
90
Restricted Instruction Set Computer
• Quasi contemporaneamente, nel 1981, a Stanford, J. Hennessy lavora ad una architettura simile, progettata esplicitamente per cercare di sfruttare al meglio il pipelining, che chiama MIPS: Microprocessor without Interlocked Pipeline Stages (ma ovviamente qui c’era anche un gioco di parole con l’acronimo: Millions of Instructions Per Second) e che verrà poi utilizzata in vari processori commerciali.
• Sostanzialmente, è la macchina MIPS che abbiamo visto.
• Entrambi i progetti affondano le radici nella architettura del CDC6600 e nell’IBM 801 (una architettura rimasta a livello solo sperimentale) degli anni ‘60 e ‘70.

46
91
Restricted Instruction Set Computer • In effetti, i lavori di Patterson e Hennessy non nascevano dal nulla:
già a metà degli anni ‘70, vari ricercatori (in particolare J. Cocke dell’IBM) avevano mostrato come i programmatori (e i compilatori) usassero solo una piccola parte di tutte le modalità di indirizzamento messe a disposizione dalle ISA del tempo.
• A. Tanenbaum aveva dimostrato statisticamente che la quasi totalità delle istruzioni che usava valori immediati, usava valori piccoli, che potevano essere memorizzati in al massimo 13 bit, mentre le istruzioni macchina mettevano a disposizione 16 o 32 bit per memorizzare un “immediate value”. Quasi sempre, la maggior parte di quei bit rimaneva inutilizzata
92
Restricted Instruction Set Computer • In altre parole, la maggior parte dei programmi spendeva la maggior
parte del tempo di esecuzione eseguendo istruzioni semplici.
• Era quindi inutile avere a disposizione istruzioni macchina complesse e lunghe (e di lunghezza variabile), che:
– richiedevano molto tempo per essere prelevate dalla RAM (la loro lunghezza poteva richiedere più accessi in RAM)
– Richiedevano molto lavoro per essere decodificate.
– Richiedevano datapath complessi.

47
93
Restricted Instruction Set Computer • Qual è quindi l’idea alla base delle architetture RISC?
1. La CPU deve eseguire un numero limitato di instruzioni macchina semplici che, almeno in linea di principio, possano essere portate a termine in un ciclo di clock di lunghezza limitata.
• Istruzioni semplici richiedono datapath più corti, e una CU semplice, con bassi tempi di calcolo della funzione di controllo (ossia il tempo che intercorre tra quando i campi op e funct vengono forniti in input alla CU e la produzione in output dei segnali di controllo per il datapath).
• Per queste ragioni, possiamo usare un ciclo di clock corto. Se poi risuciamo a sfruttare efficacemente il pipelining (cosa che è favorita da un datapath semplice) tanto meglio.
94
Restricted Instruction Set Computer 2. L’accesso alla RAM va limitato il più possibile (anche in presenza
di cache), ad esempio usando solo opportune istruzioni, come la load e la store.
Questo permette di (e in un certo senso constringe ad) avere istruzioni più semplici e di limitare i colli di bottiglia verso la RAM
3. Come conseguenza, le istruzioni devono principalmente usare argomenti contenuti in registri (quindi interni alla CPU) e mettere il risultato dell’esecuzione di una istruzione in un registro.
Questo impone però di dotare la macchina di molti registri.

48
95
Un esempio: l’ISA dell’architettura SPARC
• Tutte le istruzioni sono a 32 bit. • Tipicamente usano 3 registri come operandi • Nel tempo, il formato delle istruzioni si è arricchito con le varie
versioni SPARC, ma le istruzioni hanno mantenuto dimensione fissa e regolarità nella suddivisione dei campi (Tanenbaum, fig. 5-15)
96
L’ISA dell’UltraSPARC III
• Tutte le istruzioni intere della UltraSPARC III. Notate le uniche istruzioni che possono accedere alla memoria principale (Tanenbaum, Fig. 5-35)

49
97
Restricted Instruction Set Computer • Più in dettaglio, i principi di buona progettazione di una CPU
moderna si possono così riassumere:
• Rinunciare ad un sofisticato livello di microcodice – Infatti una CU semplice ha tempi di commutazione più bassi, e può
usare clock più corti (ossia frequenze di clock più elevate).
– Le istruzioni RISC sono più semplici di quelle CISC, e per ottenere il risultato di una istruzione CISC ci possono volere 4 o 5 istruzioni RISC.
– Questo è accettabile se il maggior spazio occupato in RAM non è più un problema, e in effetti negli anni ‘80 e successivi la tecnologia ha permesso ai computer di dotarsi di sempre più RAM (e cache) a costi sempre più contenuti.
98
Restricted Instruction Set Computer
• Definire istruzioni di lunghezza fissa e facili da decodificare
– perché una istruzione possa essere avviata alla fase EX, deve essere decodificata per determinare quale è l’operazione da compiere e quali risorse usa (quale unità funzionale impegna, quali sono gli operandi, e dove verrà messo il risultato dell’esecuzione dell’istruzione).
– Istruzioni di lunghezza fissa, con pochi operandi e pochi metodi di indirizzamento rendono il prelievo dell’istruzione stessa dalla memoria e la sua decodifica più semplice e veloce.

50
99
Restricted Instruction Set Computer • La memoria RAM deve essere indirizzata solo da operazioni di
LOAD e STORE
– Dato che nei processori l’accesso alla memoria RAM richiede molto più tempo dell’accesso ai registri della CPU (e notate che questo era meno vero negli anni 60 e 70, però mancava la cache), è meglio usarla il meno possibile.
– Per quanto possibile, tutte le istruzioni macchina devono lavorare con registri, e accedere la RAM solo quando degli operandi devono essere prelevati dalla, o rimessi nella, RAM stessa.
– naturalmente, l’uso di memorie cache limita il problema della lentezza della RAM, ma l’accesso alla RAM va in ogni caso minimizzato.
100
Restricted Instruction Set Computer • Avere registri general-purpose in abbondanza
– Dato che la RAM è lenta, avere molti registri permette di tenere il risultato intermedio delle computazioni dentro la CPU, evitando di ricorrere alla RAM.
– Infatti, se tutti i registri sono in uso, il risultato di una computazione intermedia deve essere memorizzato in RAM, e questo fa perdere tempo.
– In tutte le architetture più moderne, una attenzione particolare è dedicata a fornire un numero quanto più alto possibile di registri general purpose.

51
101
Restricted Instruction Set Computer • Riassumiamo i punti precedenti con un esempio: l’istruzione CISC del
VAX che abbiamo visto prima:
– ADDL3 42 (R1), 56 (R2), 0 (R3)
• in una architettura RISC corrisponderebbe a una sequenza di istruzioni simile a questa:
– LD R4, 56 (R2) – LD R5, 0 (R3) – ADD R6, R4, R5 – SD R6, 42 (R1)
• Quindi, abbiamo una porzione di programma più lunga, usiamo più registri, e operiamo sulla RAM solo tramite operazioni di load e store
102
Restricted Instruction Set Computer
• E infine: Sfruttare il più possibile il pipelining
– Se l’architettura di una CPU è semplice, è più facile suddividere l’esecuzione di ogni istruzione in tante fasi separate.
– E allora (ma ci torneremo più avanti), ogni fase di una certa istruzione può essere eseguita in parallelo con una fase diversa di un’altra istruzione: è il principio della pipeline

52
103
Restricted Instruction Set Computer
• Sfruttare per quanto possibile il pipelining (Tanenbaum, Fig. 2-4 – adattata alla MIPS)
Instruction execution
unit
Memory Access
unit
104
Restricted Instruction Set Computer • Sfruttare per quanto possibile il pipelining
– Se una pipeline è suddivisa in 5 fasi, e ci vuole un ciclo di clock (diciamo della durata di 2 nanosec.) per passare da una fase all’altra, una istruzione viene eseguita in 10 nanosecondi. MIPS del processore = 100.
– Ma se il pipelining è sfruttato in modo perfetto, ogni 2 nanosecondi possiamo far partire una nuova istruzione, e di fatto ogni 2 nanosecondi un’istruzione viene completata, e quindi il MIPS virtuale della macchina è 500.
– In pratica le cose non funzionano così bene, a causa dei rischi di stalling della pipeline (vedremo in dettaglio queste cose più avanti), e del fatto che una architettura pipelined è leggermente più complessa, e quindi più lenta, di una non pipelined.

53
105
Restricted Instruction Set Computer • Sfruttare per quanto possibile il pipelining
– Il pipelining è una tecnica che si integra in modo naturale nelle architetture RISC. Ricordiamo che MIPS (il nome del processore) voleva dire Microprocessor without Interlocked Pipelines Stages, ad indicare una architettura che permetteva di evitare il più possibile dipendenze tra le istruzioni e sfruttare al massimo il parallelismo a livello di istruzione (ILP) insito nel pipelining
– Nella famiglia 80X86 il pipelining è comparso solo col 486, e due pipeline sono state utilizzate nel Pentium. (col Pentium II si è tornati ad una sola pipeline ma con architettura superscalare)
106
Restricted Instruction Set Computer • Come è continuata la vicenda RISC vs CISC?
• In un articolo del 1980, Clark e Strecker (progettisti dell’architettura VAX) criticano pesantemente la possibilità che una architettura RISC possa mai competere con le architetture complesse di tipo CISC
• Nel 1986 alcune compagnie (HP, IBM) incominciano a produrre processori RISC
• Nel 1987 la Sun Microsystems incomincia a produrre computer con architettura SPARC, basata sul progetto RISC sviluppato a Berkeley da Patterson.

54
107
Restricted Instruction Set Computer • Nel 1990 IBM annuncia la prima architettura RISC superscalare
(RS6000), basata sulle idee del IBM 801 (mai entrato in produzione)
• Alla fine degli anni 80, gli stessi progettisti del VAX si convincono della bontà dell’architettura RISC in conseguenza del confronto tra le prestazioni di due dei processori più potenti di quel periodo (e dalle caratteristiche tecniche comparabili): il VAX 8700 e il MIPS M2000.
• La macchina MIPS risultò circa 3 volte più veloce del VAX nell’eseguire vari benchmark.
• Agli inizi degli anni ‘90, la Digital abbandona la produzione del VAX e incomincia a produrre processori basati sull’architettura Alpha, simile all’architettura MIPS.
108
Restricted Instruction Set Computer • In media, una MIPS esegue il doppio di istruzioni del VAX, ma il CPI
del VAX è circa 6 volte quello della macchina MIPS (Hennessy – Patterson, Fig. 2.41)

55
109
CISC vs RISC • La rivoluzione RISC si è completata nel giro di una decina di anni, e
tutte le compagnie produttrici di computer/CPU si sono spostate verso la produzione di architetture RISC
• Ad esempio, già nel 2000, nel mercato delle CPU embedded a 32 bit (usate in foto e videocamere, e altri congegni elettronici sofisticati) il 90% del mercato era coperto da architetture RISC. Questi numeri sono ulteriormente cresciuti negli anni successivi.
• Solo una architettura dell’era CISC sembra essere sopravvissuta alla guerra, e molto bene, apparentemente...
110
CISC vs RISC • la famiglia Intel 80x86 (che va dal 8086 fino al Pentium 4) e i suoi
successori multicore coprono ancora una buona fetta del mercato desktop/laptop. Perché?
– Una ragione fondamentale è la compatibilità backward delle CPU della famiglia: sui moderni processori Intel potete ancora fare girare programmi scritti per l’8086, il primo processore ad 16 bit su chip singolo (1978). A ciò si aggiunga la scelta iniziale dell’IBM nei primissimi anni 80 di usare l’8086 (e poi l’80286) nella sua linea di PC.
– Siccome miliardi di $ sono stati spesi per lo sviluppo di software che gira sulle macchine 80x86, la compatibilità backward garantisce che tutto quel software non debba essere buttato.

56
111
CISC vs RISC • Ma soprattutto, i progettisti Intel sono riusciti nel tempo ad integrare i
principi di progettazione RISC nei loro processori.
• Una pipeline viene introdotta nel 486. Il “586” ha due pipeline, mentre con il Pentium II si passa ad una struttura superscalare, un’idea che risale addirittura a 40 anni fa col CDC 6600, che come abbiamo già visto si può considerare l’antenato delle prime architetture RISC.
• Come vedremo in dettaglio più avanti, a partire dal 486 le CPU Intel contengono un cuore RISC che permette di eseguire le istruzioni più semplici e di uso più frequente in pochi cicli di clock. Le istruzioni più complesse sono invece ancora interpretate da microcodice in classico stile CISC.
112
CISC vs RISC • Intel si è anche imbarcata (con successo incerto) nel progetto e
commercializzazione di una architettura completamente RISC, che rappresenta una rottura completa rispetto alla linea dei processori 80x86 / core duo / i7-i5-i3, l’ITANIUM 2: una architettura RISC a 64 bit, che vedremo nella sezione sull’ILP statico.

57
113
CISC vs RISC • Va osservato che ormai la distinzione CISC – RISC non ha più molto
senso.
• Da una parte, i principi di progettazione universalmente adottati sono quelli propri delle architetture RISC.
• D’altra parte, una delle caratteristiche RISC, la semplicità delle istruzioni, è un po’ venuta meno, ma sono rimaste le altre: istruzioni di lunghezza fissa e struttura regolare, accesso limitato alla RAM, sfruttamento facilitato del pipelining.
114
l’albero genealogico delle prime architetture RISC
• Le freccie tratteggiate indicano famiglie di processori embedded, mentre i processori indicati in grassetto sono macchine rimaste a livello di ricerca. (Patterson-Hennessy 3rd ed., fig. D.17.2)

58
115
Clock Cycles Per Instruction • CPI = Clock cycles Per Instruction
• Ossia, il numero di cicli di clock necessari ad eseguire una istruzione.
• Questa misura indica la velocità alla quale una CPU è in grado di “sfornare” le istruzioni che esegue.
• In un qualsiasi ISA, diverse istruzioni hanno bisogno di un numero diverso di cicli di clock per essere completate. Data una generica CPU, come potrebbe essere calcolato il suo CPI, e quale valore ragionevole potrebbe avere?
• E quale potrebbe essere il CPI ideale per una CPU?


















