
Clustering - Intranet DEIBhome.deib.polimi.it/lanzi/msi/color/Esercitazione_02_Clustering.pdf ·...
139
Ing. Igor Rossini Laurea in Ingegneria Informatica Politecnico di Milano Polo Regionale di Como Metodologie per Sistemi Intelligenti Clustering
Transcript of Clustering - Intranet DEIBhome.deib.polimi.it/lanzi/msi/color/Esercitazione_02_Clustering.pdf ·...

Ing. Igor RossiniLaurea in Ingegneria InformaticaPolitecnico di MilanoPolo Regionale di Como
Metodologie per Sistemi Intelligenti
Clustering

© Igor Rossini
Cos’è il clustering?
• Il processo di raggruppamento di un insieme di oggetti fisici o astratti in classi di oggetti simili (Han 2001).
• Un cluster è una collezione di oggetti “simili” tra loro che sono “dissimili”rispetto agli oggetti degli altri cluster.

© Igor Rossini
Definizione
• Dati un insieme di esempi, descritti da un insieme di attributi, e una misura di similaritàtrovare un insieme di cluster tali che:– Gli esempi appartenenti allo stesso cluster risultino
simili– Gli esempi appartenenti a cluster differenti dissimili
• La misura di similarità è il cuore del problema e ilcuore della soluzione al problema– Distanza Euclidea se gli attributi sono tutti numerici
e se ha senso…– Nella maggior parte dei casi, è specifica al problema

© Igor Rossini
A cosa si applica?
• In biologia può essere utilizzato per derivare tassonomie di animali e piante.
• Nel marketing può essere impiegato per derivare e caratterizzare gruppi di consumatori.
• ...per derivare aree geografiche simili.• Nell’analisi dei dati viene impiegato per
studiare come i dati si distribuiscono nello spazio.

© Igor Rossini
Clustering (1)
• Cerchiamo raggruppamenti interessanti• Alla base c’è l’ipotesi che si possa
definire una distanza o misura di similarità• La distanza deve essere
significativa per il dominio• L’ipotesi implicita è più i dati sono vicini,
più sono simili• Lo scopo generale è trovare
dei cluster tali che– Le distanze intracluster siano minime– Le distanze intercluster siano massime

© Igor Rossini
Clustering (2)
Distance based clustering• Un gruppo di oggetti appartengono allo
stesso cluster se sono “vicini” rispetto ad una determinata distanza.
Conceptual Clustering• Gli oggetti appartengono ad un cluster se
questo definisce un concetto comune ai diversi oggetti.

© Igor Rossini
Applicazioni di Clustering
• Pattern Recognition• Spatial Data Analysis
– Creare mappe tematiche negli strumenti GIS per individuare raggruppamenti simili nello spazio
• Image Processing• Economic Science (especially market
research)• WWW
– Classificazione dei documenti– Analisi dei dati di Weblog per scoprire gruppi
caratterizzati da comuni profili di accesso e navigazione

© Igor Rossini
Esempi di Applicazioni (1)
• Marketing– Aiuta i marketing managers a scoprire segmenti distinti
all’interno della customer base, e quindi ad utilizzarequesta conoscenza per lo sviluppo di campagne miratedi marketing
• Utilizzo del Territorio– Identificare aree territoriali di simile utilizzo mediante
l’analisi di un database di osservazioni sul territorio
• Assicurazioni– Partizionare il portafoglio clienti auto in segmenti a
supporto delle attività di target marketing

© Igor Rossini
Esempi di Applicazioni (2)
• Pianificazione urbana– Identificare gruppi di edifici per tipologia, valore e
localizzazione geografica
• Studi sismici– Formare cluster di epicentri di eventi sismici e
verificare che si trovino lungo le faglie deicontinenti
• Astronomia– Analisi delle immagini del cielo– Analisi delle esplosioni di raggi gamma

© Igor Rossini
Requisiti
• Scalabilità• Possibilità di trattare molteplici tipi di attributi• Minimo numero possibile di parametri• Possibilità di trattare dati affetti da “rumore”• Indipendenza dall’ordine degli esempi• Possibilità di trattare esempi con
molti attributi

© Igor Rossini
Esempio (1)

© Igor Rossini
Esempio (2)

© Igor Rossini
Quali sono i problemi tipici?
• L’efficacia dipende dalla definizione di distanza
• Se non esiste una misura di distanza ovvia, bisogna “inventarla”
• La bontà del risultato dipende completamentedall’adeguatezza della misura rispetto al problema
• L’interpretazione del risultato dipende dalladistanza.
• I risultati in molti casi possono esserearbitrari……come pure la loro interpretazione!

© Igor Rossini
Esempio
• Abbiamo dei dati relativi agli accessiad un sito
• Conosciamo gli IP degli utentiche accedono al sito
• Provare a definire una distanzafra indirizzi IP

© Igor Rossini
Tassonomie
• Tassonomia degli Algoritmi– Gerarchici
viene generata una gerarchia di possibilisuddivisioni
– Partition-Basedviene generata una sola partizione
• Tassonomia delle tecniche– Bottom-up– Top-down

© Igor Rossini
Algoritmi di Clustering
• Partition-based clustering– Dato k, partiziona gli esempi in k cluster di almeno un
elemento; ogni esempio può appartenere solo ad un elemento.
• Hierarchical clustering– Scompone l’insieme degli esempi in una gerarchia di
partizioni di diversa complessità.
• Density-based clustering– Gli esempi vengono suddivisi in cluster via via sempre più
numerosi fino a quando la “densità” di ogni cluster rimaneaccettabile.
• Grid-based e Model-based clustering

© Igor Rossini
Algoritmi Partition-Based
• Scopo: trovare una suddivisionedei dati in k cluster (k fissato all’inizio)
• Strategie Locali– formare i cluster sfruttando la struttura locale dei
dati• Strategie Globali
– ogni cluster viene rappresentato da un prototipo,– ogni esempio viene assegnato al cluster
il cui prototipo è maggiormente simile

© Igor Rossini
Algoritmi Gerarchici
• Si parte– Da un unico cluster contenente tutti gli esempi
(top-down)– Da un cluster per ogni esempio (bottom-up)
• Ad ogni passo, – Si divide un cluster in due (top-down)– Si raggruppano due cluster (bottom-up)
• In questo modo si forma una gerarchiadi suddivisioni, fusioni di cluster
• La gerarchia viene rappresentatacon un dendrogramma

© Igor Rossini
Nearest Neighbor Clustering
• Input– Una soglia t sulla distanza– Un insieme di n esempi x1...xn
– Una misura di distanza• Output
– k cluster in cui la distanza fra elementi appartenenti a cluster distinti è almeno t

© Igor Rossini
Funzionamento del NNINPUT t e gli n esempi {x1...xn}OUTPUT k cluster
C1 = {x1}; i=1; k=1;do {
i=i+1;x’ = elemento più vicino a xi
tra quelli assegnati ai cluster;// assumiamo x’ appartenga al cluster Cm;if (distanza(xi,x’)>t){
k = k + 1;Ck = {xi};
} else {Cm = Cm +{xi};
}} while (i!=n);

© Igor Rossini
NN per Classificazione
• E’ possibile utilizzare il NN come modello di classificazione
• Per ogni nuovo caso da classificare occorre:– Calcolare la similitudine di quest’ultimo
rispetto ai cluster individuati dal modello non supervisionato
– Attribuire al nuovo caso la stessa classificazione del cluster cui risulta più simile
– Aggiungere il nuovo caso classificato alla tabella dei casi noti

© Igor Rossini
Esempio Nearest Neighbor (1.1)
25 30 35 40 45 50
1
2
3
4
?
?
?
Programma televisivo A
Programma televisivo B
Programma televisivo C
Programma televisivo D

© Igor Rossini
Esempio Nearest Neighbor (1.2)
25 30 35 40 45 50
1
2
3
4
Z
X
W
Programma televisivo A
Programma televisivo B
Programma televisivo C
Programma televisivo D

© Igor Rossini
Esempio Nearest Neighbor (2.1)Codice
Paziente Mal di Gola Febbre Ghiandole
Ingrossate Congestione Mal di Testa Diagnosi
1 Si Si Si Si Si Affezione da Streptococco
2 No No No Si Si Allergia
3 Si Si No Si No Raffreddore
4 Si No Si No No Affezione da Streptococco
5 No Si No Si No Raffreddore
6 No No No Si No Allergia
7 No No Si No No Affezione da Streptococco
8 Si No No Si Si Allergia
9 No Si No Si Si Raffreddore
10 Si Si No Si Si Raffreddore

© Igor Rossini
Esempio Nearest Neighbor (2.2)
• Nuovo paziente da classificare
• Similitudine in base al conteggio delle corrispondenze attributo-valore
Codice Paziente
Mal di Gola
Febbre Ghiandole Ingrossate
Congestione Mal di Testa
14 Si No No No No
Corrispondenze 1 2 3 4
Pazienti 1, 9 2, 5, 10 3, 6, 7, 8 4
Affezione da Streptococco

© Igor Rossini
Considerazioni sul NN (1)
• Vantaggi– Per la sua efficacia è necessario un
pretrattamento dei dati per la determinazione degliattributi rilevanti
– Ridotti tempi di calcolo confrontando i casi daclassificare con un sottoinsieme di casi tipici trattida ogni classe rappresentata nei dati
– La descrizione generale di ciascuna classe puòessere ottenuta esaminando gli insiemi dei casipiù tipici delle classi

© Igor Rossini
Considerazioni sul NN (2)
• Svantaggi– Tempi di calcolo elevati nel caso di dataset
di grandi dimensioni– Non effettua distinzioni tra attributi rilevanti
e irrilevanti– Difficoltà nel capire se gli attributi scelti
siano in grado di differenziare le classicontenute nei dati

© Igor Rossini
k-means
• Dati– Un numero k– Un insieme di n esempi– Una misura di distanza– Un criterio di stop (minimo errore quadratico)
• Il k-means partiziona gli n esempi in k cluster• La similarità fra esempi appartenenti
allo stesso cluster deve essere alta• La similarità fra oggetti appartenenti
a cluster diversi deve essere bassa

© Igor Rossini
Funzionamento del k-means?INPUT k e gli n esempiOUTPUT k cluster che minimizzano l’errore quadratico
Dato k e n esempiSeleziona k esempi tra n come centroidi inizialiRepeat
assegna ogni esempio al cluster corrispondente al centroide a cui l’esempio e’ più vicino.
calcola “il valore medio degli elementi del cluster” ovvero calcola i nuovi centroidi.
Until criterio soddisfatto

© Igor Rossini
Come funziona il k-means?
• Come criterio di stop viene solitamente utilizzato l’errore quadratico:
• Dove mi rappresenta il centroide del cluster Ci

© Igor Rossini
Esempio k-means
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
© Igor Rossini
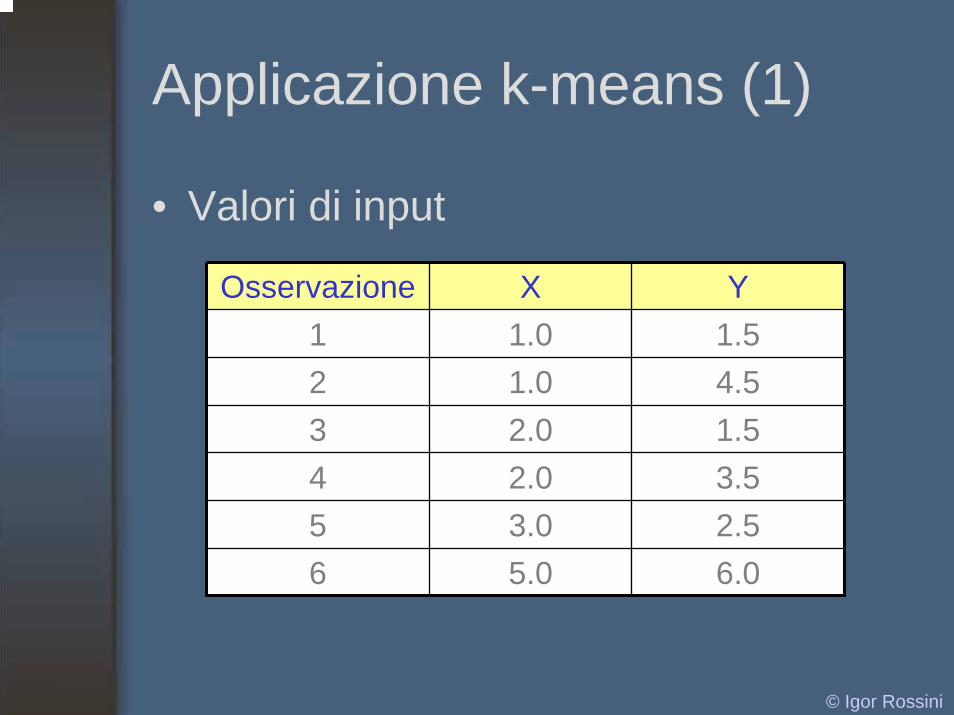
Applicazione k-means (1)
• Valori di input
Osservazione X Y1 1.0 1.52 1.0 4.53 2.0 1.54 2.0 3.55 3.0 2.56 5.0 6.0
© Igor Rossini
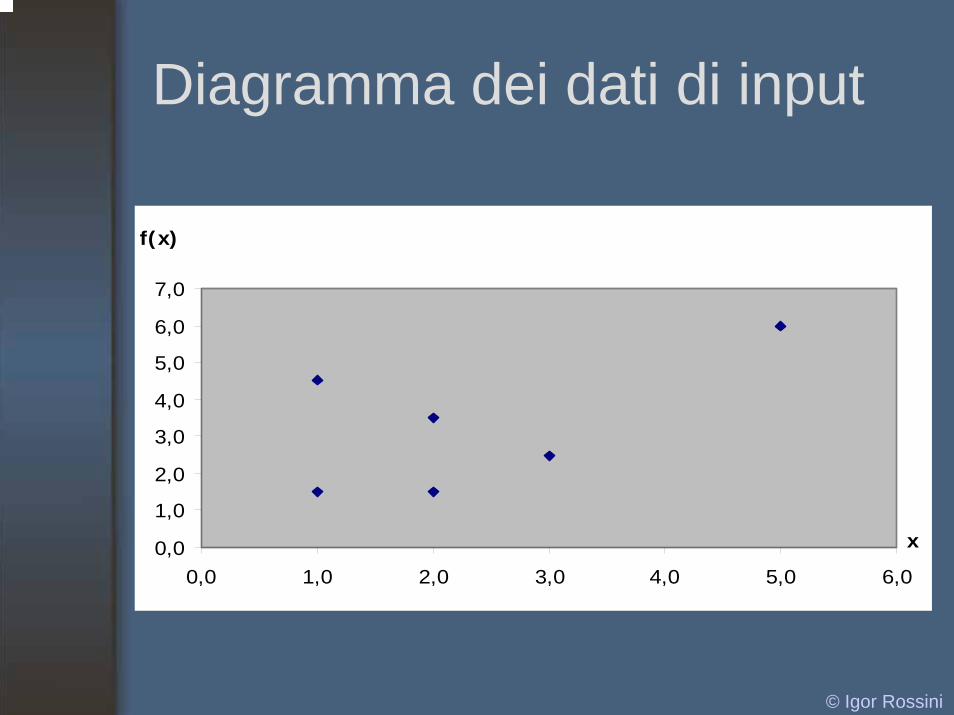
Diagramma dei dati di input
f(x)
0,0
1,0
2,0
3,0
4,0
5,0
6,0
7,0
0,0 1,0 2,0 3,0 4,0 5,0 6,0
x
© Igor Rossini
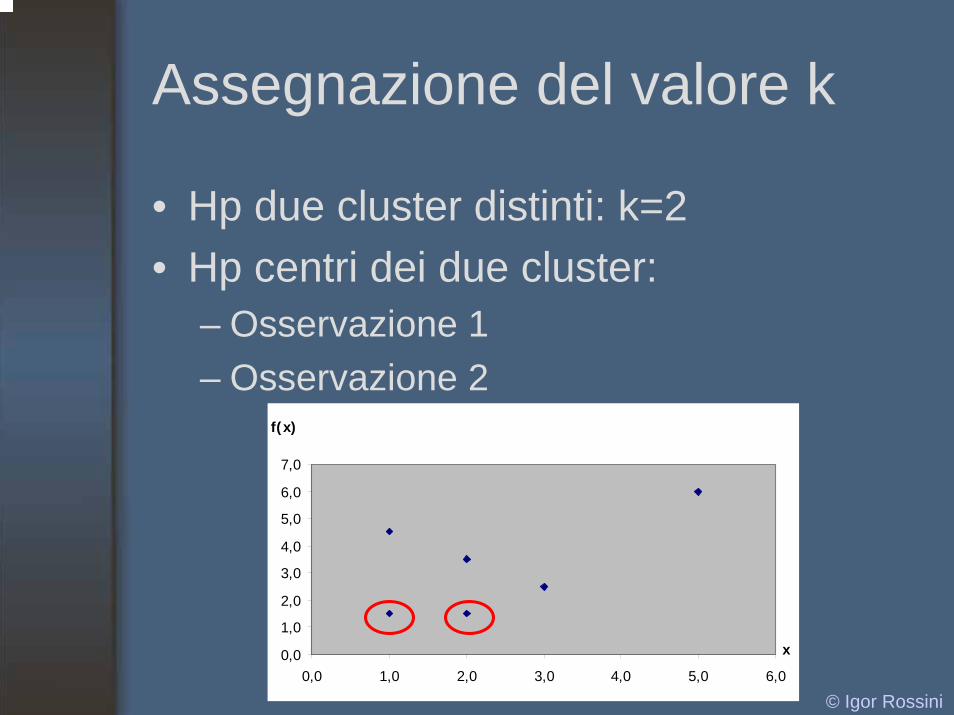
Assegnazione del valore k
• Hp due cluster distinti: k=2• Hp centri dei due cluster:
– Osservazione 1– Osservazione 2
f(x)
0,0
1,0
2,0
3,0
4,0
5,0
6,0
7,0
0,0 1,0 2,0 3,0 4,0 5,0 6,0
x
© Igor Rossini
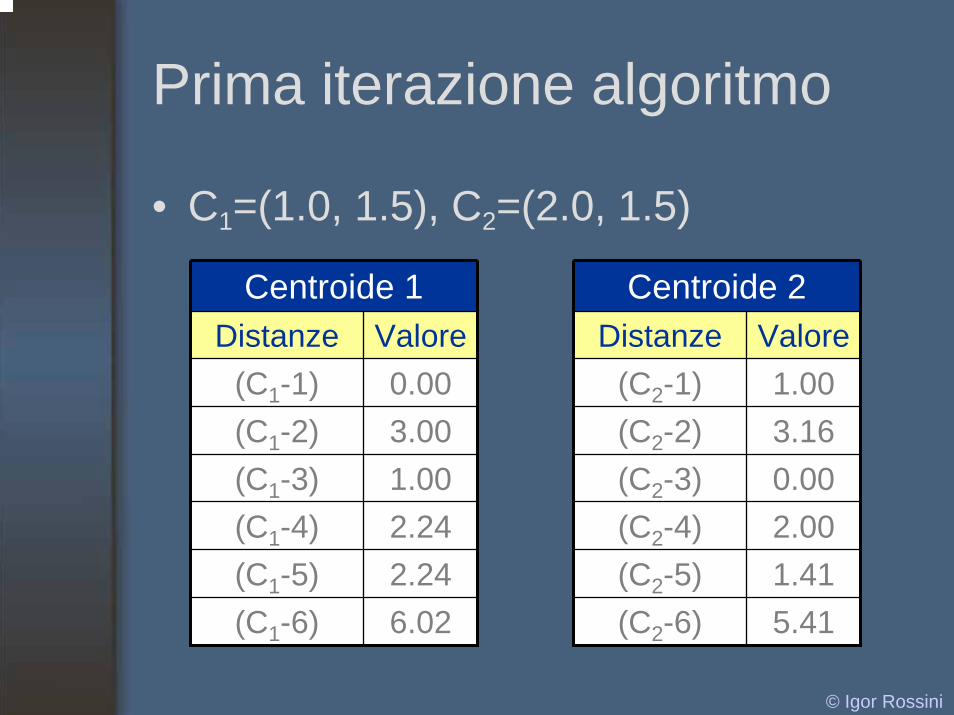
Prima iterazione algoritmo
• C1=(1.0, 1.5), C2=(2.0, 1.5)
Centroide 1Distanze Valore
(C1-1) 0.00(C1-2) 3.00(C1-3) 1.00(C1-4) 2.24(C1-5) 2.24(C1-6) 6.02
Centroide 2Distanze Valore
(C2-1) 1.00(C2-2) 3.16(C2-3) 0.00(C2-4) 2.00(C2-5) 1.41(C2-6) 5.41

© Igor Rossini
• Cluster ottenutiC1 ∈ {1, 2} C2 ∈ {3, 4, 5, 6}
• Calcolo nuovi centroidi– Cluster C1
x=(1.0+1.0)/2=1.0y=(1.5+4.5)/2=3.0
– Cluster C2
x=(2.0+2.0+3.0+5.0)/4=3.0y=(1.5+3.5+2.5+6.0)/4=3.3
Risultati prima iterazione

© Igor Rossini
• C1=(1.0, 3.0), C2=(3.0, 3.375)
Centroide 1Distanze Valore
(C1-1) 1.50(C1-2) 1.50(C1-3) 1.80(C1-4) 1.12(C1-5) 2.06(C1-6) 5.00
Centroide 2Distanze Valore
(C2-1) 2.74(C2-2) 2.29(C2-3) 2.125(C2-4) 1.01(C2-5) 0.875(C2-6) 3.30
Seconda iterazione algoritmo

© Igor Rossini
• Cluster ottenutiC1 ∈ (1, 2, 3) C2 ∈(4, 5, 6)
• Calcolo nuovi centroidi– Cluster C1
x=(1.0+1.0+2.0)/3=1.3y=(1.5+4.5+1.5)/3=2.5
– Cluster C2
x=(2.0+3.0+5.0)/3=3.3y=(3.5+2.5+6.0)/3=4.0
Risultati seconda iterazione

© Igor Rossini
Terza iterazione algoritmo
• C1=(1.3, 2.5) C2=(3.3, 4.0)
Centroide 1Distanze Valore
(C1-1) …(C1-2) …(C1-3) …(C1-4) …(C1-5) …(C1-6) …
Centroide 2Distanze Valore
(C2-1) …(C2-2) …(C2-3) …(C2-4) …(C2-5) …(C2-6) …

© Igor Rossini
Cluster risultanti
Risultato Centri dei Cluster
Punti dei Cluster
(2.6, 4.6) 2, 4, 61, 3, 51, 3
2, 4, 5, 61, 2, 3, 4, 5
6
(2.0, 1.8)(1.5, 1.5)(2.7, 4.1)(1.8, 2.7)(5,0, 6.0)
Errore Quadratico
1 14,5
2 15,9
3 9,6

© Igor Rossini
Visualizzazione risultato 2
f(x)
0,0
1,0
2,0
3,0
4,0
5,0
6,0
7,0
0,0 1,0 2,0 3,0 4,0 5,0 6,0
x

© Igor Rossini
Considerazioni sul k-means (1)
• Vantaggi– Di immediata comprensione e
implementazione– Relativamente efficiente: O(tkn), dove n è
# records, k è # clusters, e t è # di iterazioni. Normalmente, k, t << n
– Spesso si arresta in un ottimo locale. L’ottimo globale può essere determinatoutilizzando altre tecniche di analisi come glialgoritmi genetici

© Igor Rossini
Considerazioni sul k-means (2)
• Svantaggi– Applicabile solo quando la media è definita, quindi
non nel caso di attributi categorici– Occorre specificare a priori il numero dei cluster k– Difficoltà nel trattare dati con rumore e outliers– Non adatto a scoprire clusters con forme
geometriche non convesse– I risultati sono migliori quando i cluster presenti nei
dati hanno la stessa dimensione– Necessità di interpretare i risultati ottenuti

© Igor Rossini
Clustering Gerarchico
• I cluster non vengono creati in un unico passo• Si inizia con una partizione in cui:
– ogni elemento è un potenziale cluster; oppure– tutti gli elementi formano un unico cluster.
• A partire da questa situazione iniziale è possibile– creare agglomerati dai singoli cluster
per formare via via cluster più grandi– dividere i cluster più grandi per
formare cluster via via più piccoli

© Igor Rossini
Clustering Gerarchico
• Supponiamo di avere cinque elementi di cui vogliamotrovare gli agglomerati interessanti.
• Primo Passo: Calcolo della Matrice delle distanze
⎟⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜⎜
⎝
⎛
=
0.00.30.50.80.90.00.40.90.10
0.00.50.60.00.2
0.0
D
• Dij è la distanza fra l’elemento “i” e l’elemento “j”

© Igor Rossini
Clustering Gerarchico
• Secondo Passo– Si trovano i due elementi più “vicini” e si
raggruppano in un singolo cluster.– In questo caso i primi due elementi sono più vicini.
• Terzo Passo: ricalcolo della matrice delle distanze.
• Qual è la distanza fra due cluster?

© Igor Rossini
Qual è la distanza fra due cluster?

© Igor Rossini
Single Linkage Clustering
• d(12)3 = min[d13,d23] = d23 = 5.0• d(12)4 = min[d14,d24] = d24 = 9.0• d(12)5 = min[d15,d25] = d25 = 8.0

© Igor Rossini
Clustering Gerarchico
• La nuova matrice D2 è:
⎟⎟⎟⎟⎟
⎠
⎞
⎜⎜⎜⎜⎜
⎝
⎛
=
0.00.30.50.80.00.40.9
0.00.50.0
2D
• Il processo continua fino a trovare un solo cluster
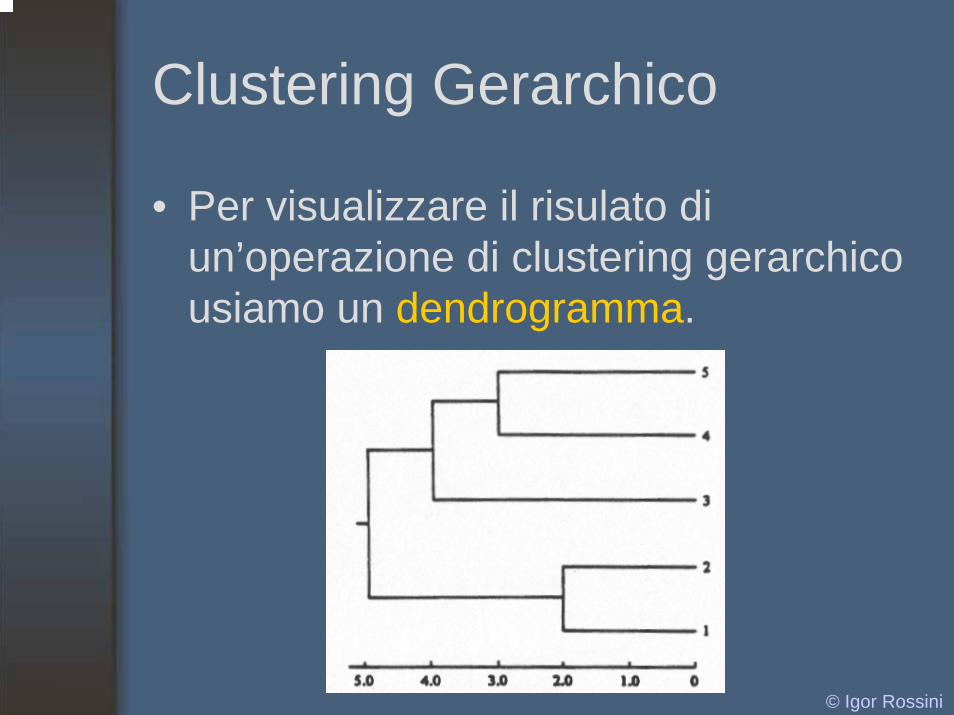
© Igor Rossini
Clustering Gerarchico
• Per visualizzare il risulato di un’operazione di clustering gerarchicousiamo un dendrogramma.

© Igor Rossini
Complete Linkage Clustering
• d(12)3 = max[d13,d23] = d23 = 6.• d(12)4 = max[d14,d24] = d24 = 10.0• d(12)5 = max[d15,d25] = d25 = 9.0

© Igor Rossini
Complete Linkage Clustering

© Igor Rossini
Average Linkage Clustering
• dAB = (d13+ d14+ d15+ d23+ d24+ d25)/6

© Igor Rossini
Clustering Gerarchico

© Igor Rossini
AGNES (Agglomerative Nesting)• Introdotto da Kaufmann e Rousseeuw (1990)• Implementato in tool di analisi statistica
(es. Splus)• Utilizza il metodo del Single-Linkage e la
matrice di dissimilarità• Crea i cluster unendo i nodi con il più basso
valore di dissimilarità• I cluster sono creati secondo una modalità di
tipo “bottom-up”• Eventualmente tutti i nodi sono raggruppati in
un unico cluster

© Igor Rossini
Esempio AGNES
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10

© Igor Rossini
DIANA (Divisive Analysis)
• Introdotto da Kaufmann e Rousseeuw(1990)
• Implementato in tool di analisi statistica(es. Splus)
• Formazione dei cluster in ordine inversorispetto all’algoritmo AGNES
• Eventualmente ogni nodo forma un singolo cluster
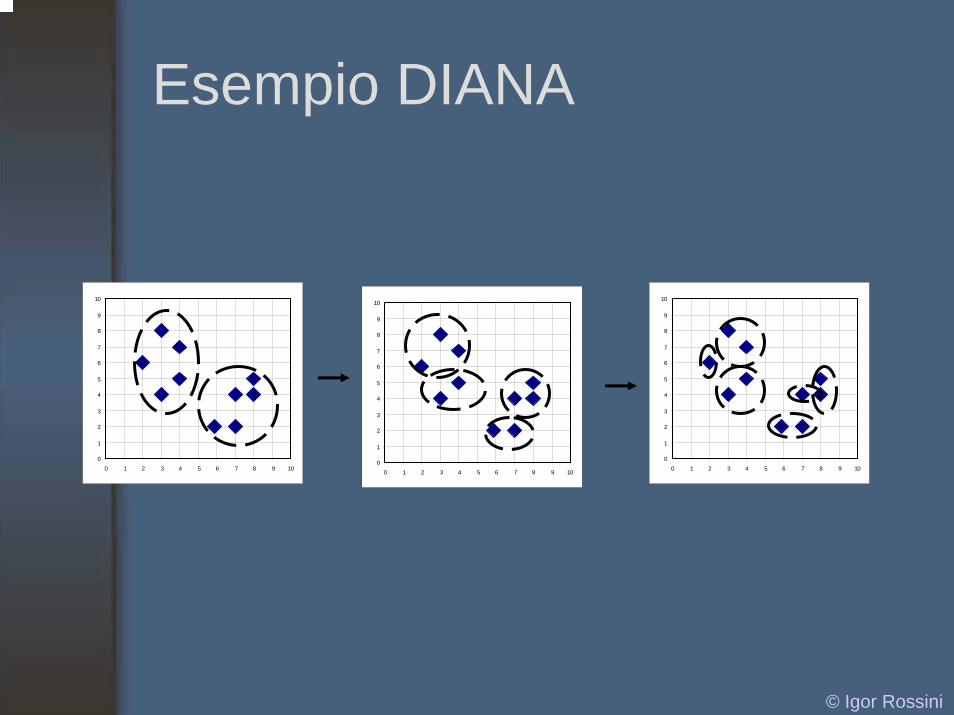
© Igor Rossini
Esempio DIANA
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 100
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10
0
1
2
3
4
5
6
7
8
9
10
0 1 2 3 4 5 6 7 8 9 10

© Igor Rossini
Considerazioni
• Non necessitano della definizione a priori del numero di gruppi
• Onerosi dal punto di vista computazionale
• Scarsamente efficienti con grandi moli di dati
• Fortemente influenzati dalla presenza di outliers

© Igor Rossini
Analisi Fattoriale
• E’ una tecnica statistica per lo studio dell’interdipendenza tra variabili di tipo quantitativo
• Lo scopo è condensare l’informazione contenuta in un numero elevato di variabili in un numero esiguo di nuove variabili (fattori latenti)
• I fattori latenti sono ottenuti come combinazione lineare delle variabili di partenza con una perdita minima di informazione
© Igor Rossini
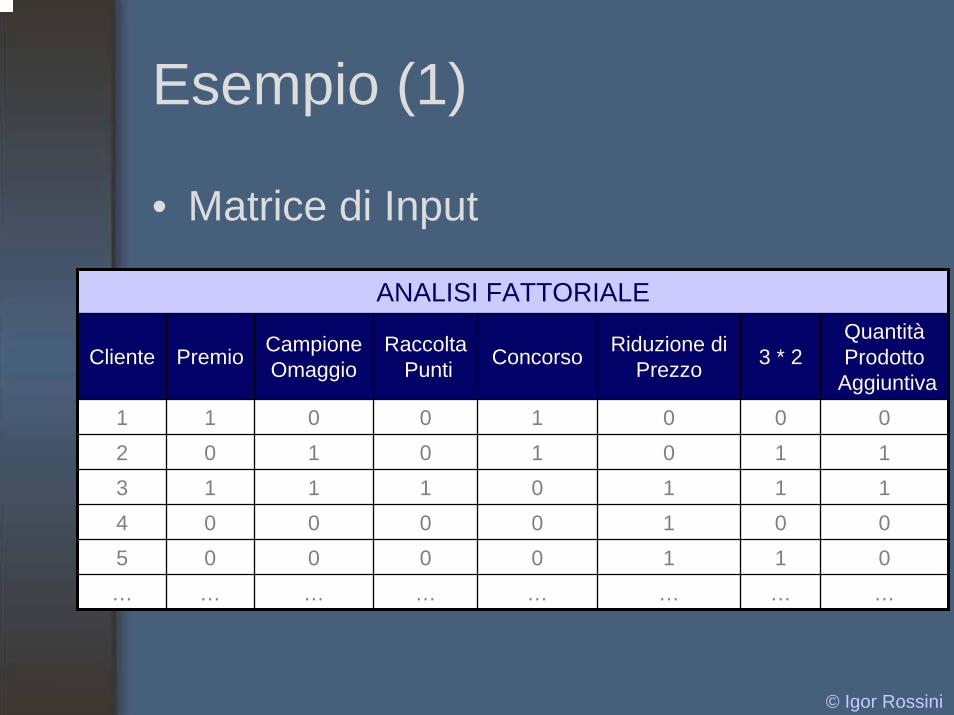
Esempio (1)
• Matrice di Input
ANALISI FATTORIALE
Cliente Premio CampioneOmaggio
Riduzione diPrezzo 3 * 2
0 0110
5 0 0 0 0 1 1 0…
011
…
4 0 0 0 0 0
RaccoltaPunti Concorso
Quantità Prodotto
Aggiuntiva1 1 0 0 1 02 0 1 0 1 13 1 1 1 0 1
… … … … … …
© Igor Rossini
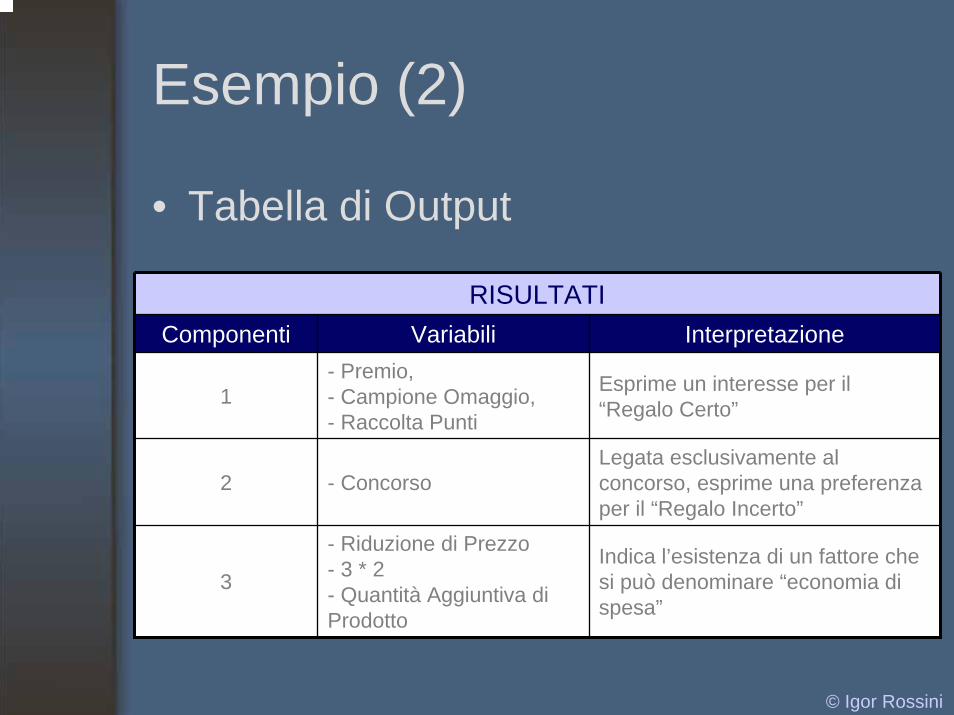
Esempio (2)
• Tabella di Output
RISULTATIComponenti Variabili Interpretazione
1- Premio,- Campione Omaggio,- Raccolta Punti
- Concorso
- Riduzione di Prezzo- 3 * 2- Quantità Aggiuntiva di Prodotto
2
Esprime un interesse per il “Regalo Certo”
Legata esclusivamente al concorso, esprime una preferenza per il “Regalo Incerto”
3Indica l’esistenza di un fattore che si può denominare “economia di spesa”

© Igor Rossini
• Criterio più comune di estrazione dei fattori da un insieme di dati
• Consiste nella trasformazione del set di dati originale in un nuovo insieme di variabili composite definite componenti principali
Analisi delle Componenti Principali (1)

© Igor Rossini
• Le componenti principali sono:– una combinazione lineare del set iniziale di dati– non correlate fra di loro– ordinate in maniera decrescente rispetto alla
variabilità spiegata del set di dati di input • Le varianze delle componenti principali,
indicate con λi, sono chiamate autovalori• Gli autovettori identificano la direzione di ogni
componente principale
Analisi delle Componenti Principali (2)
© Igor Rossini
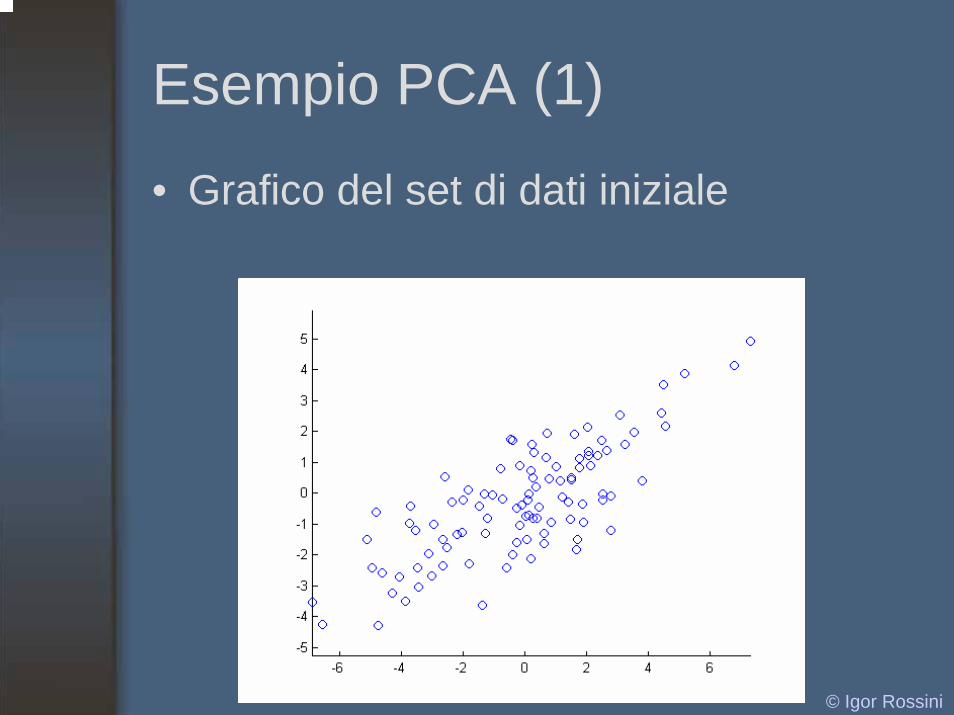
Esempio PCA (1)
• Grafico del set di dati iniziale
© Igor Rossini
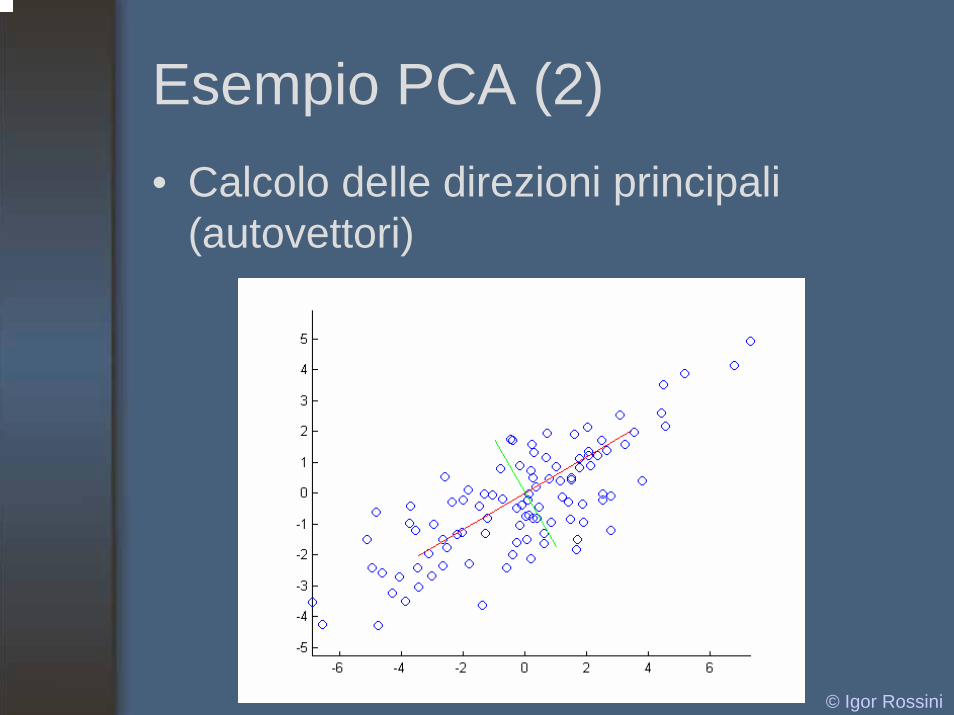
Esempio PCA (2)• Calcolo delle direzioni principali
(autovettori)

© Igor Rossini
Esempio PCA (3)
• Proiezione del set di dati secondo le direzioni principali

© Igor Rossini
Principal Direction Divisive Partitioning• Algoritmo gerarchico divisivo• Opera su valori numerici (anche con
valori missing)• Lo split non è basato su alcuna misura
di distanza o similarità ma sul calcolodelle Componenti Principali

© Igor Rossini
PDDP
• Inizia con un cluster iniziale contenente l’intero set di dati
• Divide inizialmente il cluster iniziale in due cluster figli
• Divide ricorsivamente i due cluster figli in ulteriori due cluster
• L’algoritmo termina quando un criterio di stop è soddisfatto
• Le partizioni generate sono visualizzate in un albero binario (“PDDP tree”)

© Igor Rossini
“PDDP tree”

© Igor Rossini
Esempio: clustering di documenti• Abbiamo un insieme di documenti• Ogni documento è caratterizzato da un
vettore di frequenze, che ci dice quanto una parola compare in un documento
• Vogliamo applicare il clustering per ottenere raggruppamenti interessanti di documenti

© Igor Rossini
Set di Dati di Ingresso
• Ogni esempio è rappresentato da un vettore d n-dimensionale– d documento di testo
• La componente di rappresenta la frequenza relativa della componente i-esima– di frequenza relativa della i-esima parola del
documento• Ogni esempio è standardizzato al fine di
avere uno stesso ordine di grandezza– ⎮⎮d⎮⎮=1

© Igor Rossini
Matrice di Frequenza
Quake Risk High
Closes For
Snow
Rose Bowl
Result
Big 10 Sanctions
Housing Crunch
2200
Ucla 1 0 0 0 11
Wisconsin 0 2 2 1
Berkeley 1 0 0 0Stantofrd 3 0 2 0Minnesota 0 2 0 1
Caltech 1 0 1 0
• I vettori sono raggruppati nella Matrice di Frequenza M=(d1, d2, …, dn,)

© Igor Rossini
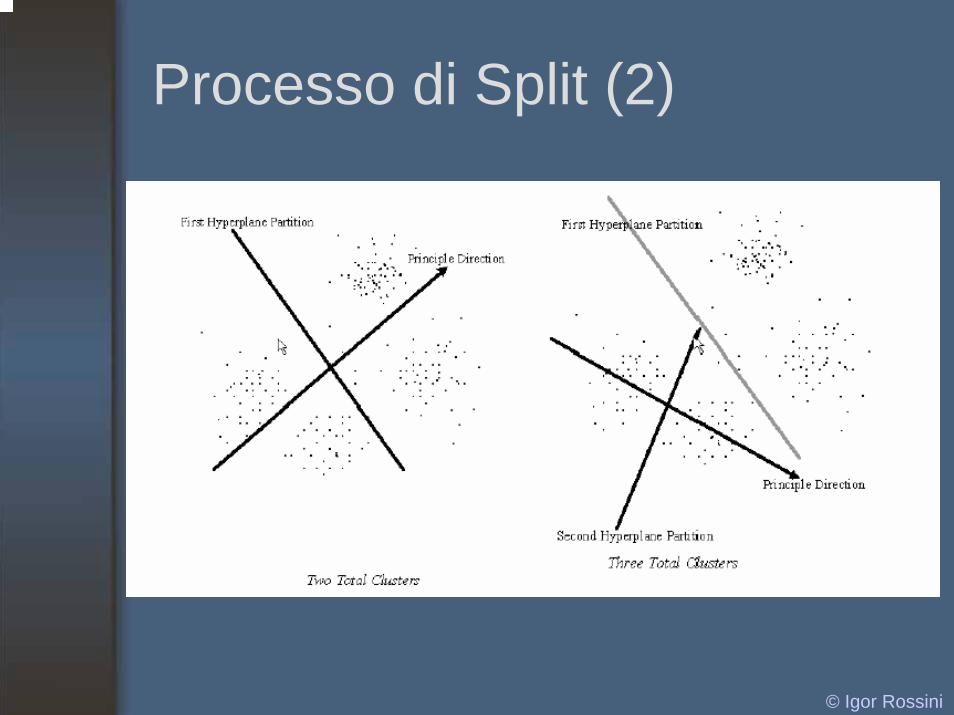
Processo di Split (1)
• A partire dalla matrice M si calcolano le Direzioni Principali
• Lo split avviene in base ai valori ottenuti dalla proiezione dei vettori d sulle Direzioni Principali
• Il processo si ripete sull’intero set di dati
© Igor Rossini
Processo di Split (2)

© Igor Rossini
Funzionamento del PDDP?INPUTmatrice M (n × m) contenente gli n esempi e un numero desiderato
di cluster pari a cmaxOUTPUT un albero binario con cmax nodi foglie formanti una partizione
dell’intero set di dati
Inizializzazione dell’albero binario con un singolo nodo radice (contenente tutto il set di dati)
Repeat for c=2, 3, …, cmaxseleziona il nodo con il più alto valore di “dissimilarità”
calcolo del centroide e della direzione principale
proiezione degli esempi del nodo secondo la direzione principale
split degli esempi nel nodo di sinistra o di destra dell’albero a seconda che il segno della proiezione sia positivo o negativo (se coincidente con il centroide lo split dell’esempio è per convenzione a sinistra)
Until sono ottenuti cmax cluster

© Igor Rossini
Considerazioni
• Necessita della definizione a priori del numero di gruppi
• Veloce, Scalabile, Efficiente con grandi moli di dati
• Riducendo la dimensionalità del set di dati iniziale risulta poco sensibile agli outliers

Ing. Igor RossiniLaurea in Ingegneria InformaticaPolitecnico di MilanoPolo Regionale di Como
Metodologie per Sistemi Intelligenti
Clustering – Metodologia di Analisi

© Igor Rossini
Fasi della Cluster AnalysisScelta delle VARIABILI Scelta delle VARIABILI Eventuale riduzione in Componenti
Principali
Eventuale riduzione in Componenti Principali
Selezione della Misura di Prossimità tra le variabili
Selezione della Misura di Prossimità tra le variabili
Selezione dell’Algoritmo di Classificazione
Selezione dell’Algoritmo di Classificazione
Identificazione del numero dei gruppi entro i quali ripartire le entità
Identificazione del numero dei gruppi entro i quali ripartire le entità
Valutazione della soluzione ottenutaValutazione della soluzione ottenuta
Analisi della soluzione più appropriataAnalisi della soluzione più appropriataEventuale riciclo del processo di analisi
Eventuale riciclo del processo di analisi

© Igor Rossini
• Data la matrice di dati relativa ad n osservazioni e p variabili…
• …occorre decidere quali variabili inserire e le opportune trasformazioni da effettuare (standardizzazione, analisi fattoriale)
⎥⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢⎢
⎣
⎡
npx...nfx...n1x...............ipx...ifx...i1x...............1px...1fx...11x
Scelta delle Variabili

© Igor Rossini
Selezione della Misura di Prossimità• Indici di Similarità
– forniscono informazioni preliminari indispensabili per poter individuare gruppi di unità omogenee
– sono definiti come funzione dei vettori riga della matrice di datiIPij=f(x’i, x’j) i, j=1,2,…,nx’i, x’j vettori riga
– Differiscono a seconda che i dati considerati siano quantitativi, categorici, binari o misti

© Igor Rossini
Tipi di dati nel clustering
• Scala per Intervallo• Binarie• Nominali, Ordinali, Scala per Rapporto• Miste

© Igor Rossini
Scala per Intervallo
• Standardizzazione dei dati– Calcolare la deviazione media assoluta:
where
– Calcolare il valore standardizzato (z-score)
• La deviazione media assoluta è più “robusta” della deviazione standard
|)|...|||(|121 fnffffff mxmxmxns −++−+−=
.)...211
nffff xx(xn m +++=
f
fifif s
mx z
−=

© Igor Rossini
Indici di Similarità (1)
• Le distanze sono utilizzate per misurare il grado di similarità e dissimilarità tra coppie di dati
• La distanza tra due vettori riga x, y gode deleseguenti proprietà– d(x,y) ≥ 0 non negatività– d(x,x) = 0 identità– d(x,y) = d(y,x) simmetria– d(x,y) ≤ d(x,k) + d(k,y) disuguaglianza
triangolare

© Igor Rossini
Indici di Similarità (2)
• Per raggruppare le diverse unità statistiche si calcola la distanza tra tutte le coppie di dati presenti nella matrice dei dati
• L’insieme di tali distanze definisce la matrice delle distanze
⎥⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢⎢
⎣
⎡
0...)2,()1,(:::
)2,3()
...ndnd
0dd(3,10d(2,1)
0

© Igor Rossini
Misure di Distanza (1)
• Distanza Euclidea
dove i = (xi1, xi2, …, xip) e j = (xj1, xj2, …, xjp) sono due vettori riga p-dimensionali con i, j=1,2,…,n
• Distanza Euclidea Quadratica
)||...|||(|),( 22
22
2
11 pp jxixjxixjxixjid −++−+−=
)||...|||(|),( 22
22
2
11 pp jxixjxixjxixjid −++−+−=

© Igor Rossini
Misure di Distanza (2)
• Esempio della distanza Euclidea su un sistema cartesiano di due generiche entità i,j
b
a
Distanza euclideai (xi1, yi1)
J (xj2, yj2)
© Igor Rossini
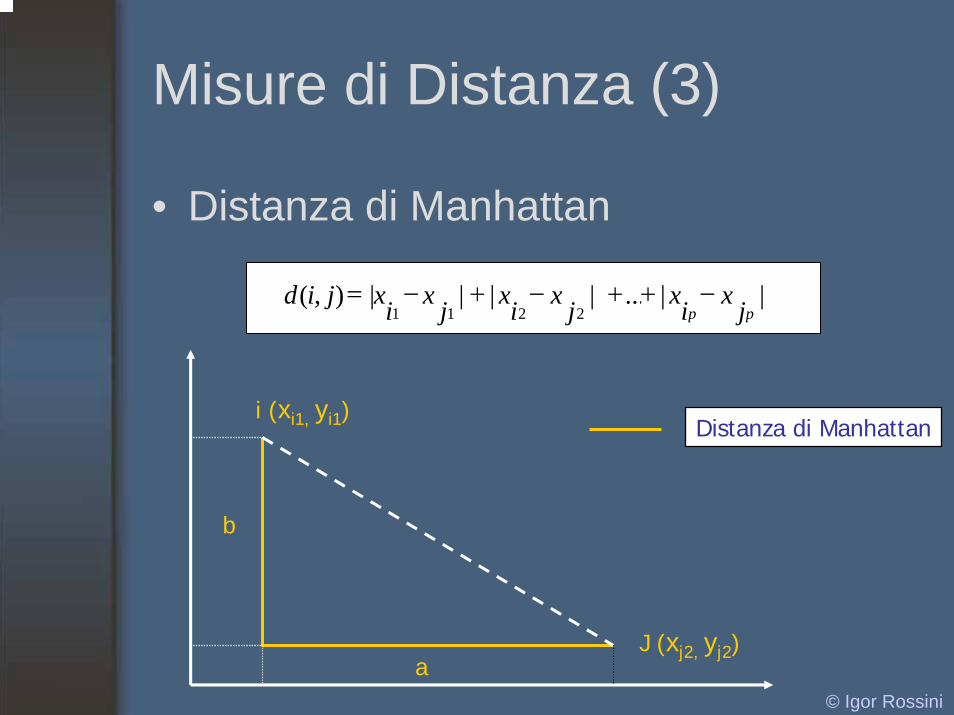
Misure di Distanza (3)
• Distanza di Manhattan
||...||||),(2211 pp jxixjxixjxixjid −++−+−=
b
a
i (xi1, yi1)
J (xj2, yj2)
Distanza di Manhattan

© Igor Rossini
Misure di Distanza (4)
• Distanza di Lagrange-Tchebychev
| )|...||||),(2211 pp jxixjxixjxixjid −,,−,−= Maxp (
b
a
i (xi1, yi1)
J (xj2, yj2)
Distanza di Lagrange

© Igor Rossini
Misure di Distanza (5)
• Distanza di Minkowski
dove q è un intero positivo
q q
pp
jxixjxixjxixjid )||...|||(|),(2211
−++−+−=

© Igor Rossini
Considerazioni (1)
• Distanza Euclidea:– Invariante rispetto a traslazioni o rotazioni degli
assi
• Distanza di Manhattan:– Particolarmente indicata per variabili su scala
ordinale– Non invariante rispetto a traslazioni o rotazioni
degli assi– Pone meno enfasi sulle variabili con distanze
maggiori non elevando al quadrato le differenze

© Igor Rossini
Considerazioni (2)
• Distanza di Minkowski:– E’ la generalizzazione delle altre distanze:
q=1 Manhattanq=2 Euclideaq=∞ Lagrange-Tchebychev
• Standardizzazione:– Necessaria per eliminare distorsioni nel caso di
fenomeni con unità di misura e ordini di grandezza diversi

© Igor Rossini
Binary Variables (1)
• Rappresentati con una tabella di contingenza
pdbcasumdcdcbaba
sum
++++
01
01
Obj
ect
iObject j

© Igor Rossini
Binary Variables (2)
• Simple matching (invariante se la variabile binaria è simmetrica)
• Coefficiente di Jaccard (non-invariantese la variabile binaria è asimmetrica):
dcbacb jid+++
+=),(
cbacb jid++
+=),(

© Igor Rossini
Esempio
• gender è un attributo simmetrico• i rimanenti attributi sono asimmetrici• assumiamo i valori Y e P uguali ad 1, il valore N a 0
Name Gender Fever Cough Test-1 Test-2 Test-3 Test-4Jack M Y N P N N
P
N
Mary F Y N P N
N
N
Jim M Y P N N N
75.0211
21),(
67.0111
11),(
33.0102
10),(
=++
+=
=++
+=
=++
+=
maryjimd
jimjackd
maryjackd

© Igor Rossini
Variabili Nominali
• Generalizzazioni delle variabili binarie (possono assumere molteplici etichette es. giallo, verde, rosso, ecc.)
• Metodo 1: Simple Matching– m: # of matches, p: total # of variables
• Metodo 2: utilizzo di un set di variabili binarie– Creazione di una nuova variabile per ciascuna
delle M etichette
pmpjid −=),(

© Igor Rossini
Variabili Ordinali
• Possono essere discrete o continue• L’ordine è importante (es. rank) • Possono essere trattate come le variabili a
scala per intervallo– Sostituendo xif con il rank corrispondente
– Scalando i valori nel range [0, 1] sostituendo l’i-esimo valore nell’ f-esima variabile da
– Calcolo degli indici di similarità con i metodi delle variabili a scala per intervallo
},...,1{ fif Mr ∈
11−−
=f
ifif M
rz

© Igor Rossini
Variabili a Scala per rapporto
• Valori positivi su una scala non lineare come ad esempio l’esponenziale AeBt or Ae-Bt
• Metodi:– trattarle come variabili a scala per intervallo
– applicare una trasformazione logaritmica
yif = log(xif)– trattarle come variabili ordinali continue e trattare i
loro rank come variabili a scala per intervallo

© Igor Rossini
Variabili di Tipo Misto
• Un set di dati può contenere qualsiasi tipo di variabili binarie (simmetriche e asimmetriche),nominali, ordinalia scala per intervallo, a scala per rapporto
• La seguente misura di prossimità pesata tiene conto degli effetti delle diverse variabili
– f is binary or nominal:dij
(f) = 0 if xif = xjf , or dij(f) = 1 o.w.
– f is interval-based: use the normalized distance– f is ordinal or ratio-scaled
• compute ranks rif and • and treat zif as interval-scaled
)(1
)()(1),(
fij
pf
fij
fij
pf d
jidδ
δ
=
=
ΣΣ
=

© Igor Rossini
Selezione dell’algoritmo
• Gerarchici– Scissori– Agglomerativi
• Non Gerarchici– Generazione di Partizioni– Con Sovrapposizione

© Igor Rossini
Metodi per il calcolo delle distanze
• Richiedono come input la matrice delle distanze:– Single Linkage (Metodo del Legame Singolo)– Complete Linkage (Metodo del Legame Completo)– Average Linkage (Metodo del Legame Medio)
• Richiedono come input la matrice dei dati:– Metodo di Ward
• Richiedono come input la matrice dei dati e lamatrice delle distanze:– Metodo del Centroide

© Igor Rossini
Single Linkage Clustering
• La distanza tra due gruppi è definita come il minimo delle n1n2 distanze tra ciascuna unità di un gruppo A e ciascuna unità dell’altro gruppo B
d(A,B)=min(dij)
i∈A, j∈B
A
B
A
B

© Igor Rossini
Complete Linkage
• La distanza tra due gruppi è definita come il massimo delle n1n2 distanze tra ciascuna delle unità di un gruppo e ciascuna delle unità dell’altro gruppo
d(A,B)=max(dij)
i∈A, j∈B
A
B

© Igor Rossini
Average Linkage
• La distanza tra due gruppi è definita come la media aritmetica delle n1n2 distanze tra ciascuna delle unità di un gruppo e ciascuna delle unità dell’altro gruppo
d(A,B)=
i∈A, j∈B
∑∑= =
1 2n
1i
n
1j21dijnn
1
A
B

© Igor Rossini
x1
Metodo del Centroide
• La distanza tra due gruppi A e B di numerosità n1 e n2 è definita come la distanza dei rispettivi centroidi (medie aritmetiche) x1 e x2
d(A,B)=d( , )x2

© Igor Rossini
Metodo di Ward
• Questo metodo crea gruppi con la massima coesione interna e la massima separazione esterna
• La creazione dei gruppi avviene minimizzando la seguente funzione obiettivo:
T=W+BT=devianza totaleW=devianza nei gruppi (within groups)B=devianza fra i gruppi (between groups)
• Ad ogni passo della procedura si aggregano i gruppi che comportano il minor incremento We il maggior incremento in B

© Igor Rossini
Valutazione del Risultato
• Per ogni livello gerarchico dell’algoritmo di classificazione si calcolano degli indicatori statistici
• Tali indicatori statistici misurano la variabilità:– tra i cluster, ovvero il livello di eterogeneità tra un
gruppo e l’altro (separazione esterna)– entro i cluster, ovvero il livello di omogeneità
all’interno dei gruppi (coesione interna) • Il valore di tali indicatori fornisce una misura
della qualità della clusterizzazione

© Igor Rossini
Indicatori Statistici (1)
• R2 = rapporto tra la varianza tra i cluster e la varianza totale
R2=1-(W/T)=B/T• RSQ = valore di R2 per ogni livello gerarchico
• Caratteristiche dell’indicatore:– R2 ∈[0,1]– Valori prossimi ad 1 indicano partizioni ottimali– R2=0 in presenza di un solo gruppo
• La sola massimizzazione dell’R2 porta a gruppi costituiti da una sola unità (necessario l’uso congiunto di altri criteri)

© Igor Rossini
Indicatori Statistici (2)
• PSF (Pseudo F Statistic) = misura del grado di separazione tra i cluster ad ogni livello gerarchico
• Diminuisce al diminuire del numero di cluster che originano dal processo di classificazione gerarchica
• Brusche variazioni indicano raggruppamenti di cluster molto diversi fra loro
c)W/(n1)B/(cPSF−−
=c=numero di gruppi
n=numero di osservazioni

© Igor Rossini
Indicatori Statistici (3)
• RMSSTD = indica la devianza fra i gruppi “aggiuntiva” che si forma al corrispondente passo della procedura di classificazione
• Un forte incremento rispetto al passo precedente indica l’unione di due gruppi fortemente eterogenei
h=passo h-esimo della proceduraWh=devianza del gruppo del passo hnh=numerosità del gruppo del passo h
p=numero di variabili considerate1)p(n
WRMSSTDh
h
−=

© Igor Rossini
Indicatori Statistici (4)
• SPRSQ (Semipartial R2) = misura l’incremento della devianza all’interno del gruppo ottenuto unendo i gruppi r e s
• Un forte incremento rispetto al passo precedente indica l’unione di due gruppi fortemente eterogenei
T)WW(WSPRSQ srh −−
=
h=nuovo gruppo ottenuto al passo h come fusione dei gruppi r e s
Wh=varianza interna al gruppo h
Wr=varianza interna al gruppo r
Ws=varianza interna al gruppo s

© Igor Rossini
Esempio (1)
• Clusterizzazione gerarchica con il metodo della MEDIA DI GRUPPO
CLUSTER HISTORY
NCL Cluster Joined FREQ SPRQS RSQ PSF PST2 Norm RMS
Dist10 CL18 OB250 13 0.0047 .707 6.3
62.0
51.8
57.9
38.0
34.2
32.6
27.6
38.7
-
9 CL15 CL12 43 0.0441 .663
0.85987.9
40.4
63.2
10.0
90.7
34.8
28.4
35.3
8 CL16 CL14 190 0.0740 .589
14.4
0.8981
0.9253
0.945
1.0139
1.0961
1.4506
1.9538
2.5363
7 CL10 CL13 16 0.0112 .578
6 CL8 CL9 233 0.1505 .427
5 CL6 CL7 249 0.0790 .348
4 CL5 CL17 255 0.0726 .276
3 CL4 CL11 259 0.0996 .176
2 CL3 OB178 260 0.0461 .130
38.7 4.16981 CL2 OB177 261 0.1299 .000
© Igor Rossini
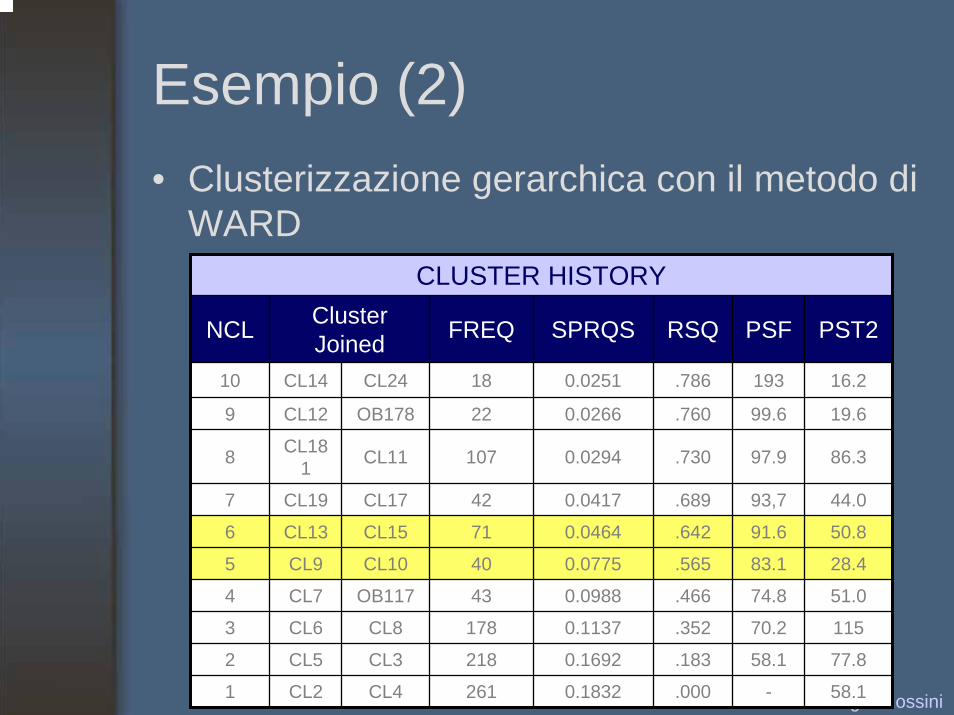
Esempio (2)• Clusterizzazione gerarchica con il metodo di
WARDCLUSTER HISTORY
NCL Cluster Joined FREQ SPRQS RSQ PSF PST2
10 CL14 CL24 18 0.0251 .786 193
99.6
97.9
93,7
91.6
83.1
74.8
70.2
58.1
-
9 CL12 OB178 22 0.0266 .760
16.2
19.6
86.3
44.0
50.8
28.4
51.0
115
77.8
8 CL181 CL11 107 0.0294 .730
7 CL19 CL17 42 0.0417 .689
6 CL13 CL15 71 0.0464 .642
5 CL9 CL10 40 0.0775 .565
4 CL7 OB117 43 0.0988 .466
3 CL6 CL8 178 0.1137 .352
2 CL5 CL3 218 0.1692 .183
58.11 CL2 CL4 261 0.1832 .000

© Igor Rossini
Indicatori Statistici
• Frequency = numero di unità statistiche appartenenti a ciascun cluster
• Max Distance from Seed to Observation = indica la distanza massima tra il centroide di ciascun cluster e la relativa osservazione maggiormente distante
• Distance between Cluster Centroids = indica la distanza tra i centroidi dei cluster individuati
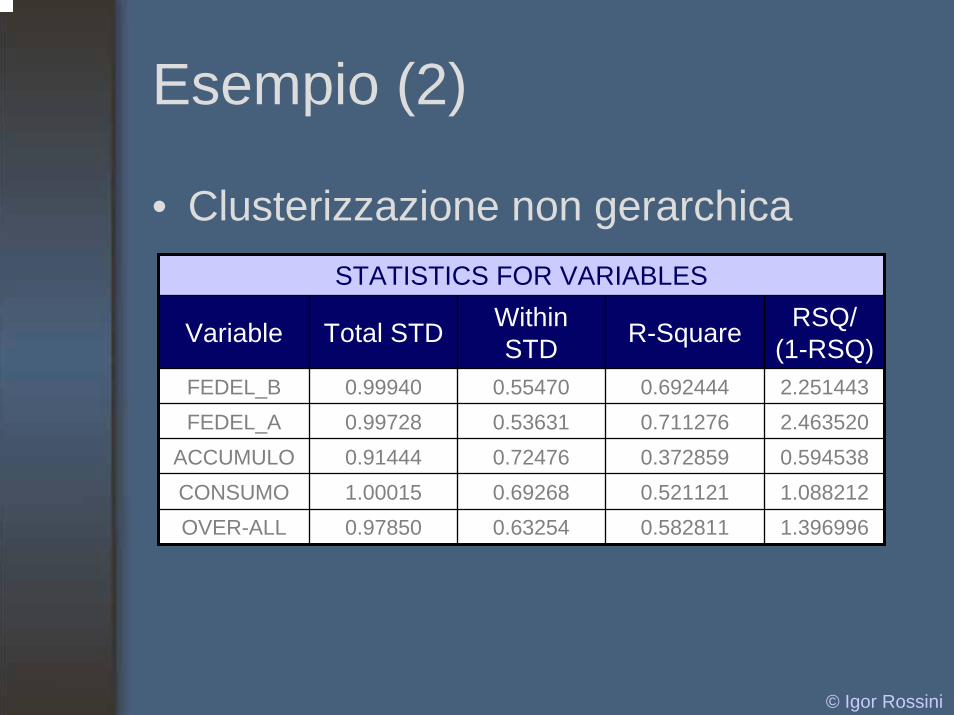
• R_Squared = quota di varianza spiegata dall’analisi a livello totale e relativamente a ciascuna delle variabili di input

© Igor Rossini
Esempio (1)
• Clusterizzazione non gerarchicaCLUSTER SUMMARY
Cluster Frequency RMS Std Deviation
4 403 0.6773 8.0782 2 1.9482
Maximum Distance
from seed toObservation
Nearest Cluster
Distance between Cluster
Centroids
1 227 0.9695 7.7149 2 2.31512 1278 0.4339 1.7844 4 1.94823 241 0.7706 9.4041 2 2.7283
5 276 0.8279 6.0403 2 2.7081
© Igor Rossini
Esempio (2)
• Clusterizzazione non gerarchicaSTATISTICS FOR VARIABLES
Variable Total STD Within STD
CONSUMO 1.00015 0.69268 0.521121 1.088212
R-Square RSQ/(1-RSQ)
FEDEL_B 0.99940 0.55470 0.692444 2.251443FEDEL_A 0.99728 0.53631 0.711276 2.463520
ACCUMULO 0.91444 0.72476 0.372859 0.594538
OVER-ALL 0.97850 0.63254 0.582811 1.396996

© Igor Rossini
Esempio (3)
• Statistiche descrittive per i clusterindividuati
CLUSTER MEANS
Cluster FEDEL_B FEDEL_A
4 -0.618030 -0.607266 0.175172 1.363207
ACCUMULO
CONSUMO
1 1.035574 -0.077365 1.613325 -0.6642002 -0.341784 -0.263096 -0.230027 -0.4904473 2.150274 -0.174211 -0.588238 0.556859
5 -0.237153 2.307065 -0.076983 0.342491
© Igor Rossini
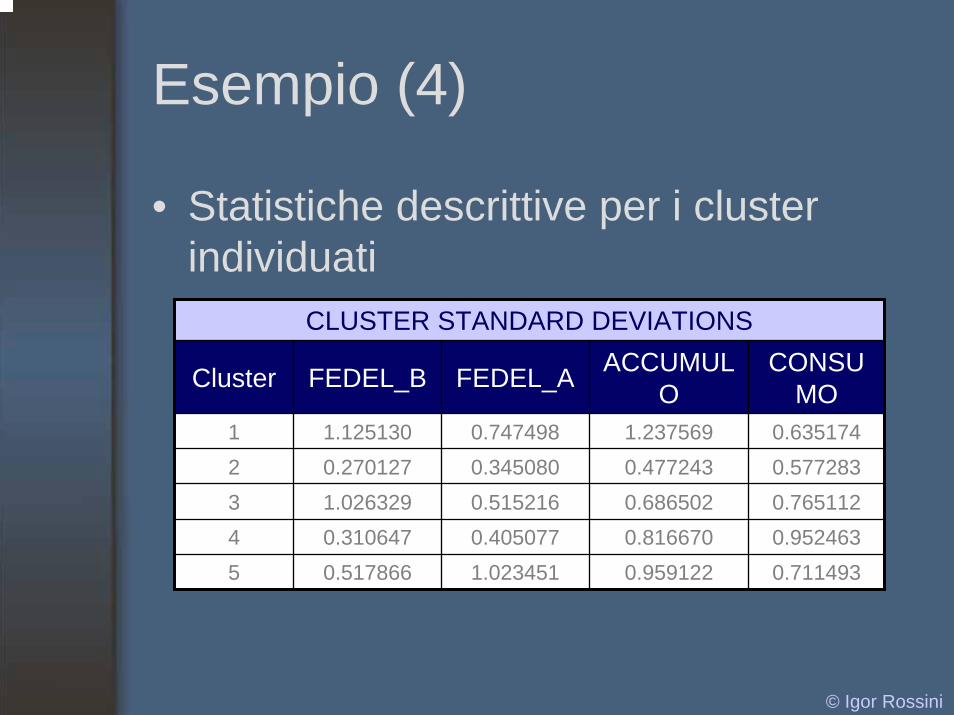
Esempio (4)
• Statistiche descrittive per i clusterindividuati
CLUSTER STANDARD DEVIATIONS
Cluster FEDEL_B FEDEL_A
4 0.310647 0.405077 0.816670 0.952463
ACCUMULO
CONSUMO
1 1.125130 0.747498 1.237569 0.6351742 0.270127 0.345080 0.477243 0.5772833 1.026329 0.515216 0.686502 0.765112
5 0.517866 1.023451 0.959122 0.711493

Ing. Igor RossiniLaurea in Ingegneria InformaticaPolitecnico di MilanoPolo Regionale di Como
Metodologie per Sistemi Intelligenti
Clustering – Esempi Applicativi

© Igor Rossini
Summary
• Hierarchical Clustering• K-means

© Igor Rossini
Summary
• Hierarchical Clustering• K-means

© Igor Rossini
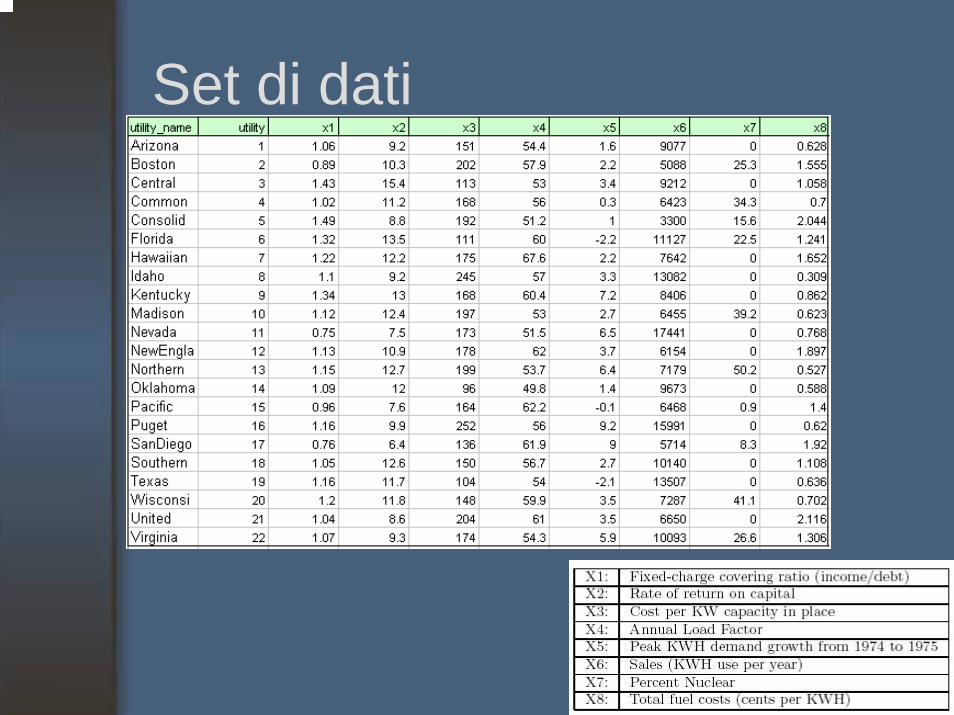
Hierarchical Clustering Case
• A study to classify the cost impact of deregulation
• Need to build a detailed cost model of the various utilities
• The objects to be clustered are the utilities and there are 8 measurements on each utility
• Use of XLMinerTM tool
© Igor Rossini
Set di dati
© Igor Rossini
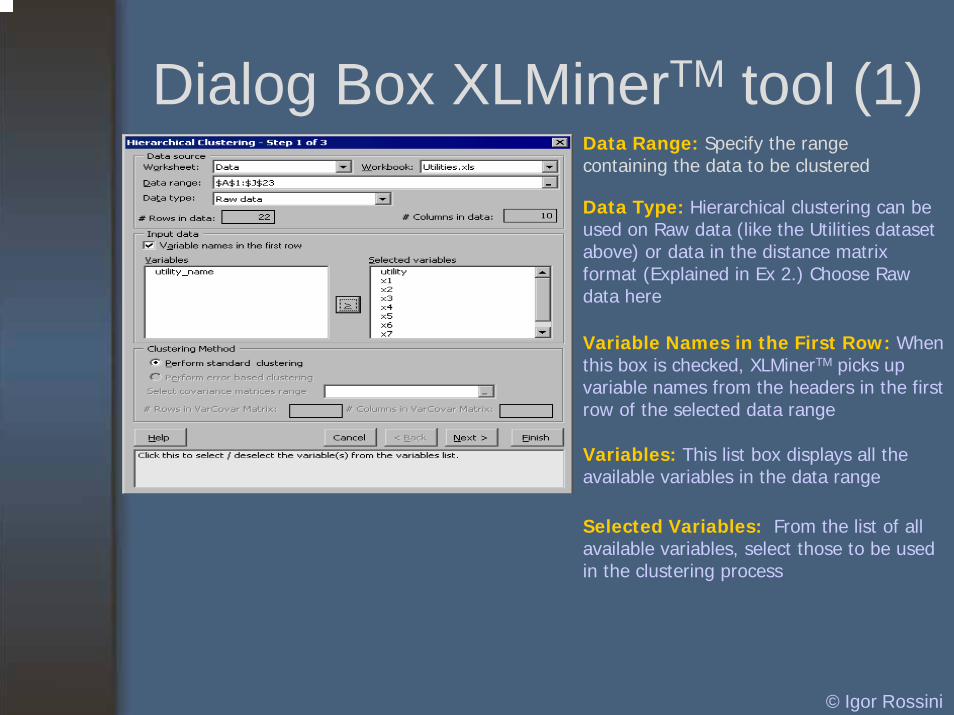
Dialog Box XLMinerTM tool (1)Data Range: Specify the range containing the data to be clustered
Data Type: Hierarchical clustering can be used on Raw data (like the Utilities dataset above) or data in the distance matrix format (Explained in Ex 2.) Choose Raw data here
Variable Names in the First Row: When this box is checked, XLMinerTM picks up variable names from the headers in the first row of the selected data range
Variables: This list box displays all the available variables in the data range
Selected Variables: From the list of all available variables, select those to be used in the clustering process

© Igor Rossini
Dialog Box XLMinerTM tool (1)Normalize input data: Normalizing the data (subtracting the mean and dividing by the standard deviation) is important to ensure that the distance measure accords equal weight to each variable
Similarity Measure: The option Euclidean distance is automatically chosen as explained in "Using Hierarchical Clustering"
Clustering Method: Select average group linkage method
© Igor Rossini
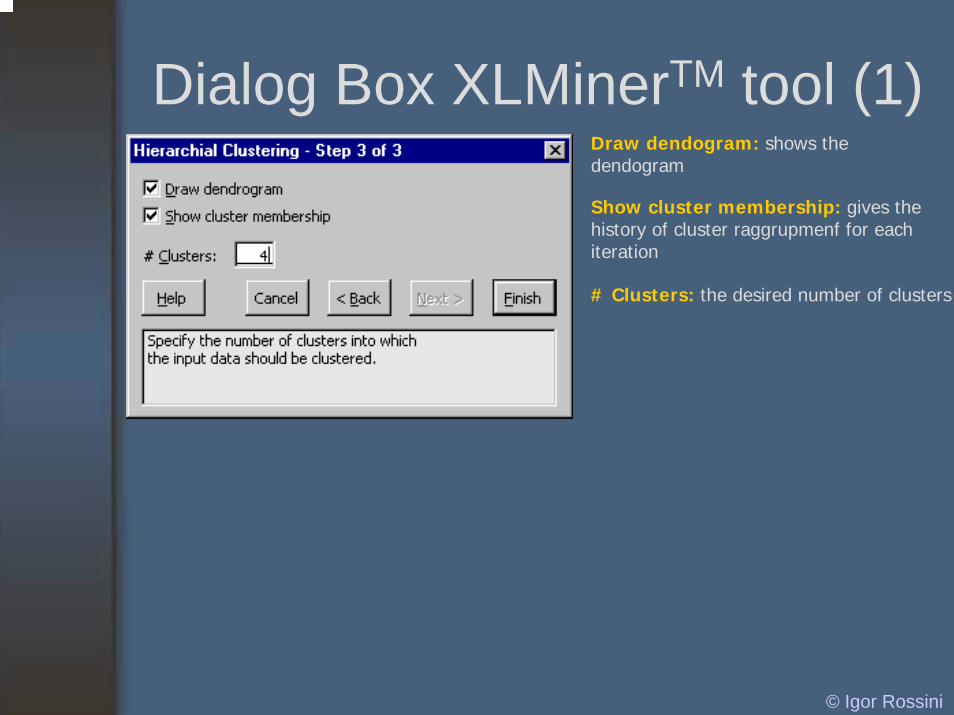
Dialog Box XLMinerTM tool (1)Draw dendogram: shows the dendogram
Show cluster membership: gives the history of cluster raggrupmenf for each iteration
# Clusters: the desired number of clusters
© Igor Rossini
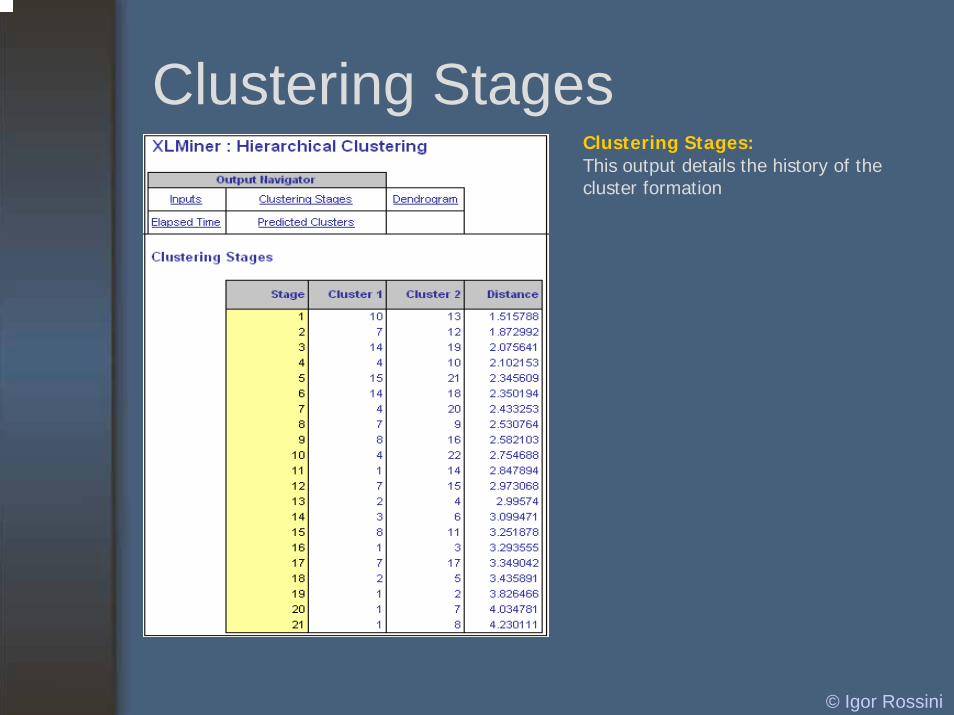
Clustering StagesClustering Stages:This output details the history of the cluster formation
© Igor Rossini
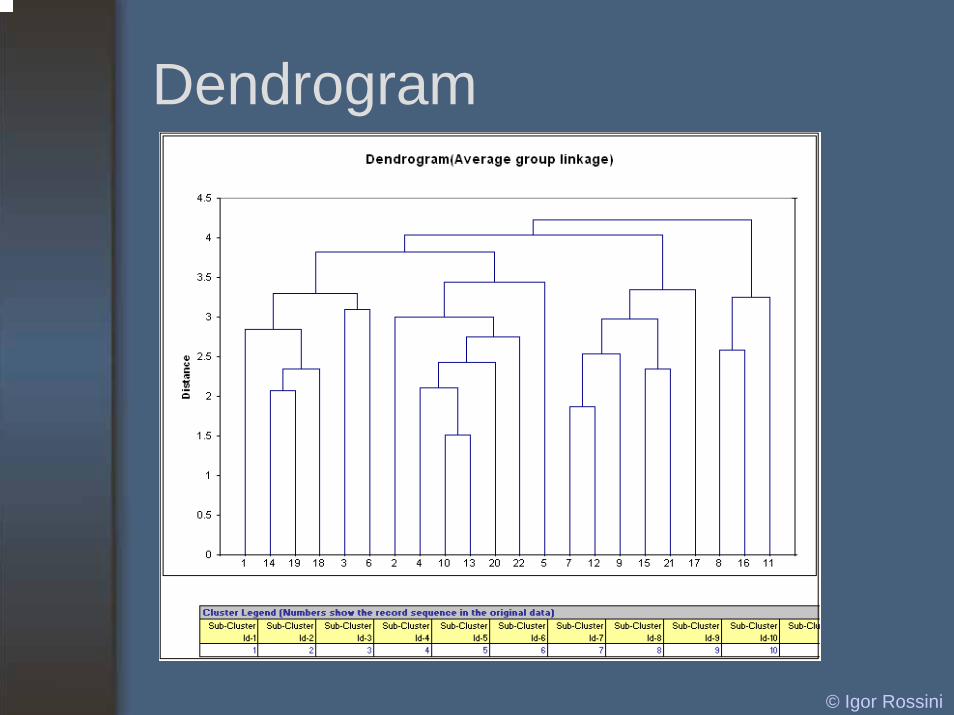
Dendrogram

© Igor Rossini
Summary
• Hierarchical Clustering• K-means

© Igor Rossini
K-mean Case
• A telecommunications provider wants to segment its customer base by service usage patterns
• Need to build a model to classify customers in order to offer more attractive packages
• The objects to be clustered are the client and there are 42 measurements on each client
• Use of SPSS tool

© Igor Rossini
Dialog Box SPSS tool (1)Variables: displays the variables you have chosen for the anaysis
Method: updates initial cluster centers in an iterative process
Label Cases By: optionally you can use the values of a string variables to identify cases

© Igor Rossini
Dialog Box SPSS tool (2)Maximum iterations: limits the number of iterations in the k-means algorithm.
Convergence criterion:determines when iteration ceases
Use running means: allows you to request that cluster centers be updated after eachcase is assigned

© Igor Rossini
Dialog Box SPSS tool (3)Initial cluster centers: first estimate of the variable means for each of the clusters
ANOVA table: displays an analysis-of-variance table wich includes univariate F test for each clustering variable
Cluster information for eachcase: displays for each case the final cluster assignment and the euclidean distance between the case and the cluster center
Exclude cases listwise:escludes cases with missingvalues for any clusteringvariable from the analysis
Exclude cases pairwise:assigns cases to clusters based on distances computed from all variable with no missing values
© Igor Rossini
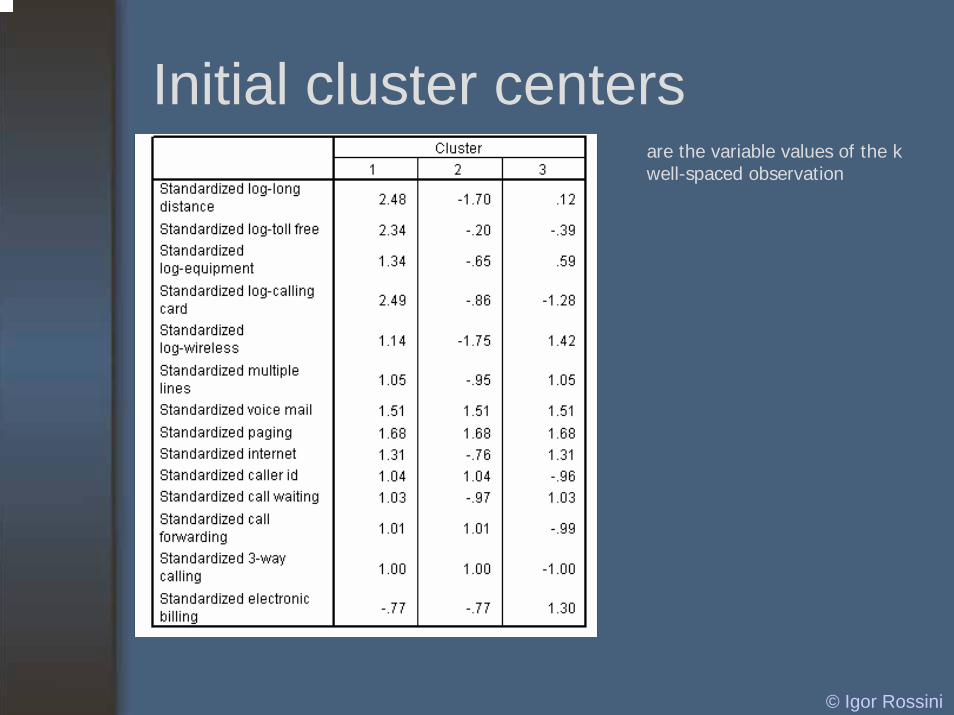
Initial cluster centersare the variable values of the k well-spaced observation
© Igor Rossini
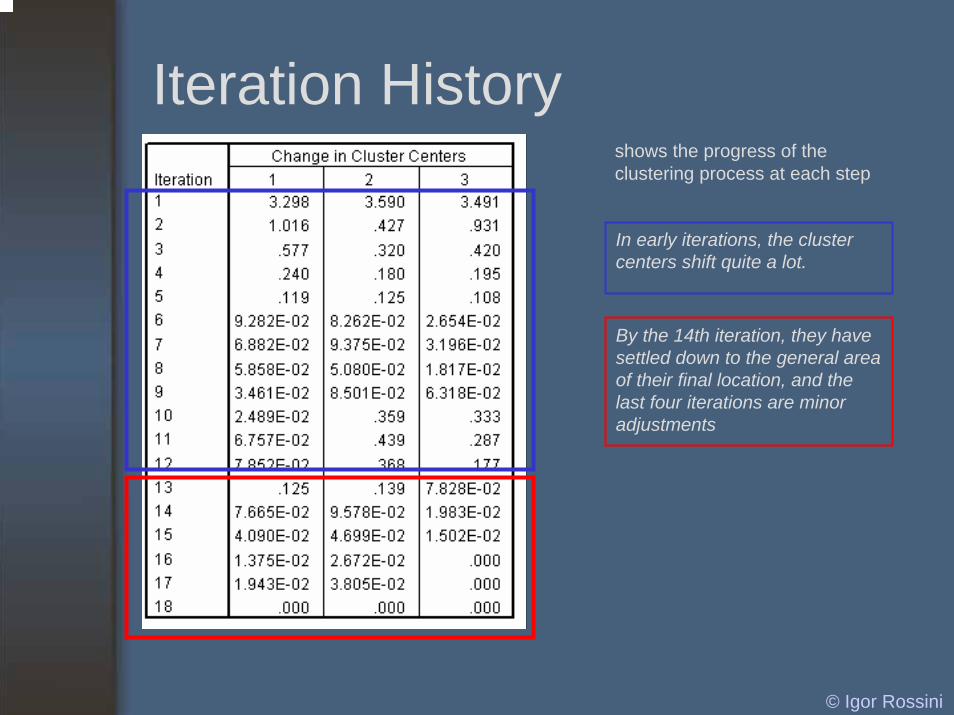
Iteration Historyshows the progress of the clustering process at each step
In early iterations, the cluster centers shift quite a lot.
By the 14th iteration, they have settled down to the general area of their final location, and the last four iterations are minor adjustments
© Igor Rossini
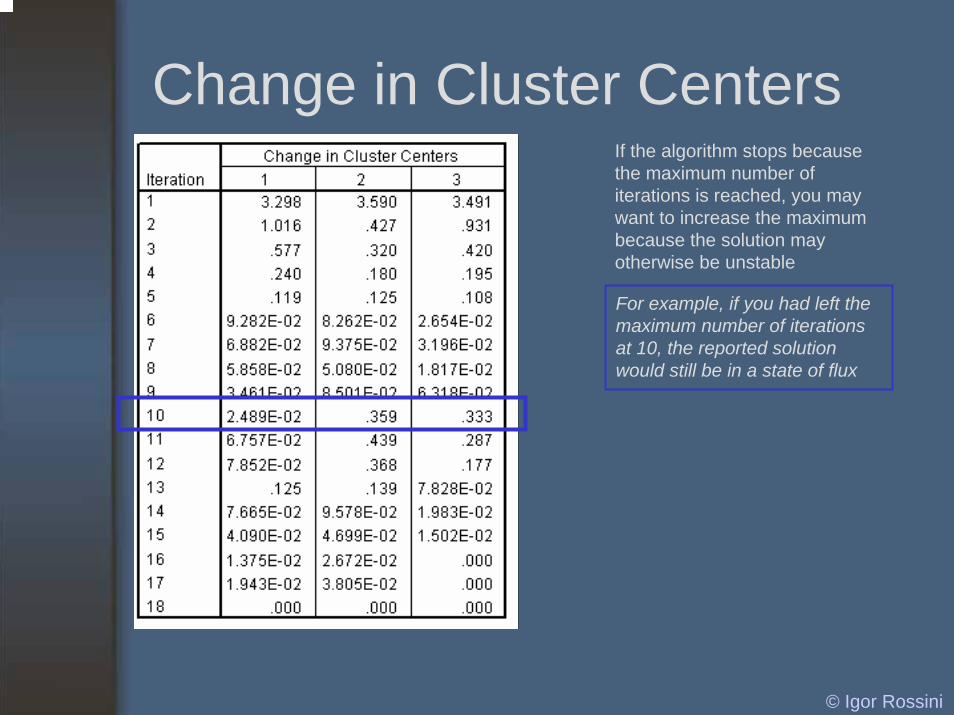
Change in Cluster CentersIf the algorithm stops becausethe maximum number of iterations is reached, you may want to increase the maximum because the solution may otherwise be unstable
For example, if you had left the maximum number of iterationsat 10, the reported solution would still be in a state of flux
© Igor Rossini
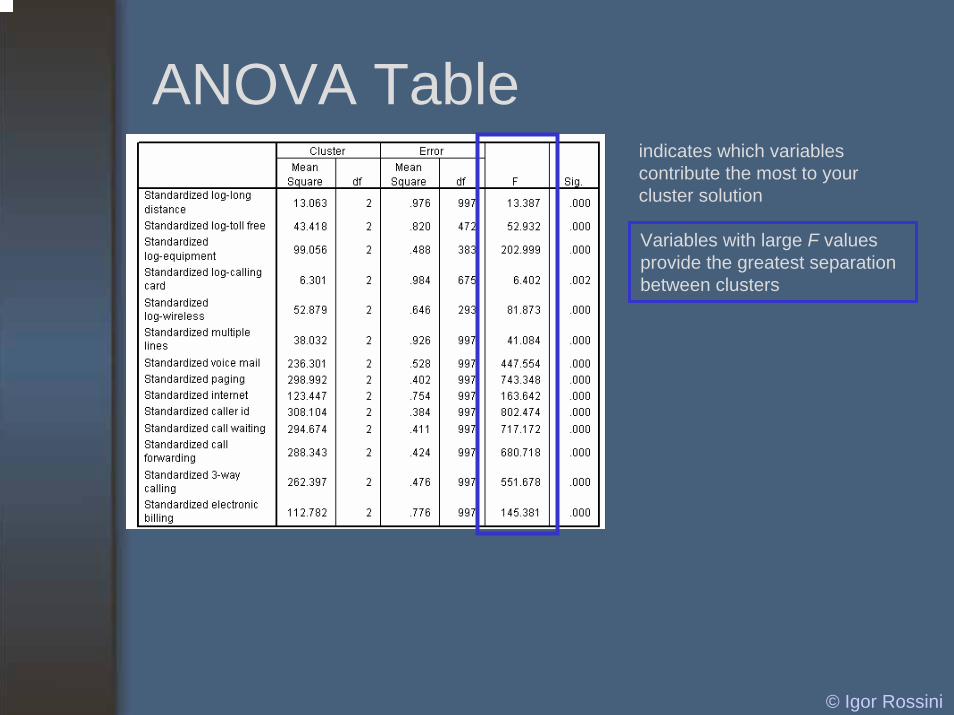
ANOVA Tableindicates which variables contribute the most to your cluster solution
Variables with large F values provide the greatest separation between clusters
© Igor Rossini
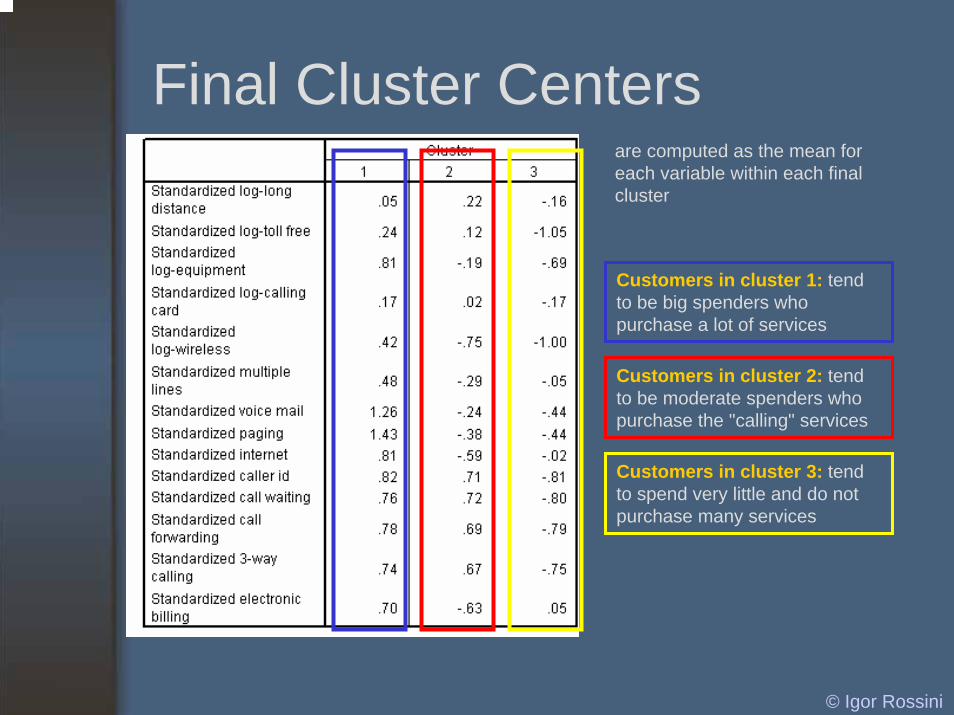
Final Cluster Centersare computed as the mean for each variable within each final cluster
Customers in cluster 1: tend to be big spenders who purchase a lot of services
Customers in cluster 2: tend to be moderate spenders who purchase the "calling" services
Customers in cluster 3: tend to spend very little and do not purchase many services
© Igor Rossini
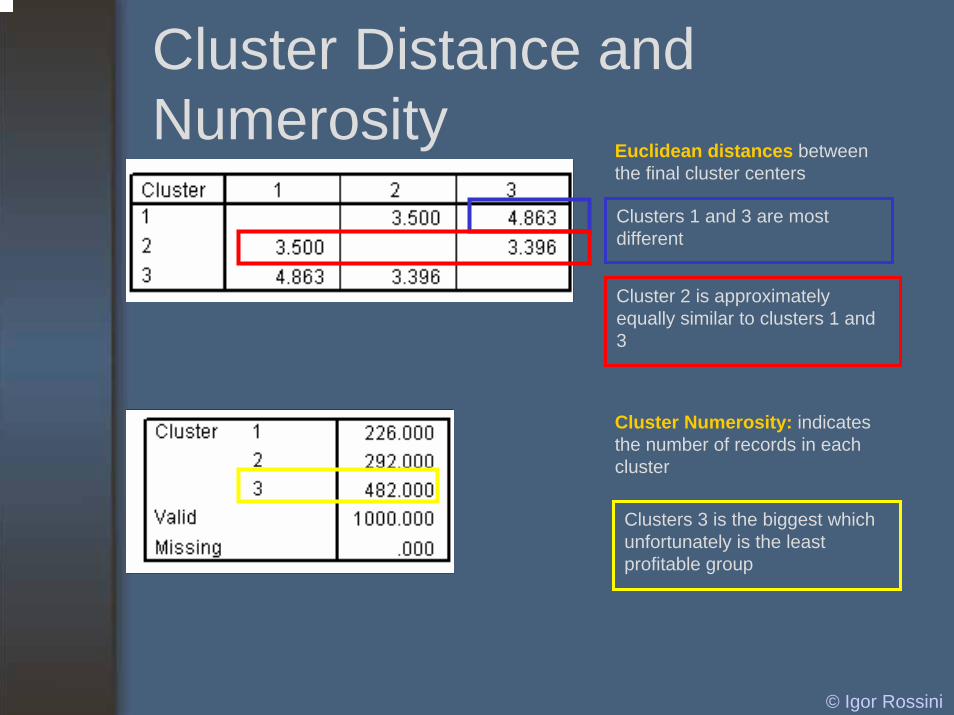
Cluster Distance and Numerosity
Euclidean distances betweenthe final cluster centers
Clusters 1 and 3 are most different
Cluster 2 is approximately equally similar to clusters 1 and 3
Cluster Numerosity: indicatesthe number of records in eachcluster
Clusters 3 is the biggest which unfortunately is the least profitable group


















