
Architettura e funzionalità del calcolatore - Intranet...
25
Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3 1 / 25 FONDAMENTI DI INFORMATICA Prof. Lorenzo Mezzalira Appunti del corso di Fondamenti di informatica Fascicolo integrativo - 3 - Architettura e funzionalità del calcolatore Problematiche di interfacciamento Acquisizione di informazioni di stato o di evento Emissione di informazioni Meccanismi di sincronizzazione: Polling – Interrupt - DMA Memoria di massa
-
Upload
vuonghuong -
Category
Documents
-
view
214 -
download
0
Transcript of Architettura e funzionalità del calcolatore - Intranet...

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
1 / 25
FONDAMENTI DI INFORMATICA Prof. Lorenzo Mezzalira
Appunti del corso di Fondamenti di informatica
Fascicolo integrativo - 3 -
Architettura e funzionalità del calcolatore
Problematiche di interfacciamento Acquisizione di informazioni di stato o di evento
Emissione di informazioni
Meccanismi di sincronizzazione: Polling – Interrupt - DMA Memoria di massa

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
2 / 25
Problematiche di interfacciamento
Il concetto di interfacciamento entra in gioco in tutti i casi in cui debbano interagire tra loro delle entità diverse. Le interazioni si manifestano con scambi di informazioni (dati e comandi). I confini che individuano le entità interagenti possono essere assunti con larga arbitrarietà ed in particolare dipendono dal livello di astrazione e aggregazione con cui si considera il sistema. Infatti ciò che ad un alto livello di astrazione può essere considerato un sistema unico, a livelli di astrazione più bassi potrà essere scomposto in vari sottosistemi interagenti tra loro. Tra le entità interagenti esistono in generale delle disomogeneità, il cui superamento, con opportune “catene causa-effetto” di fenomeni, costituisce il problema centrale dell'interfacciamento. Causa = produzione di un’informazione da parte di un mittente Effetto = percezione dell’informazione da parte del destinatario Si parla di “catene” perchè tra il mittente primario ed il destinatario finale sono generalmente interposti destinatari e mittenti intermedi, come una specie di “passaparola”. I problemi di interfacciamento sono ovviamente tanto più articolati quanto più marcate sono le disomogeneità da superare, mettendo in gioco diversi fenomeni nelle catene di cause-effetti il cui scopo è che certe cause prime in un sottosistema producano certi effetti finali in un altro sottosistema. Assumiamo quindi affidati ad altre discipline i problemi a livello degli elementi materiali (Fisica), a livello
circuitale (Elettronica) e a livello strutturale (Teorie dei circuiti logici). Concentriamo la nostra attenzione sull'interazione tra calcolatori e mondo esterno vista ad un livello di astrazione relativamente elevato. Ovviamente è essenziale, per l'utilità di un calcolatore, la possibilità che esso possa ricevere dal
mondo esterno informazioni ed emettere verso di esso risultati e comandi in modo corretto e
tempestivo.
Informazione
A
FENOMENO
CALCOLATORE
Catena di interfaccia di acquisizione
Immagine
A’
Catena di interfaccia di emissone
Comando
B
Immagine
B’
Causa prima Effetto finale
Input Acquisizione di informazioni
A = aspetto rilevante del fenomeno = informazione da acquisire
A’ = immagine di A
Output Emissione di comandi
B’ = immagine di B B = aspetto del fenomeno = informazione emessa

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
3 / 25
Nel gergo informatico il calcolatore è considerato il punto di riferimento rispetto alla direzione dei flussi di informazioni; si parla quindi di ingressi ed uscite (I/O = Input / Output) rispetto al calcolatore, salvo che si stia considerando esplicitamente ed isolatamente un altro sottosistema.
Tutto ciò che non è direttamente governabile dall'unità centrale del calcolatore tramite i segnali del bus di sistema, viene in genere chiamato "mondo esterno". Con questa definizione appartengono al mondo esterno anche tutte le unità periferiche e le stesse memorie di massa, indipendentemente dalla loro collocazione fisica eventualmente all'interno dello stesso contenitore del calcolatore. Queste unità periferiche sono infatti sede di fenomeni dotati di una propria dinamica indipendente dai ritmi interni di funzionamento della CPU. Tra il calcolatore (elettronico, digitale binario, programmabile) ed i sistemi del mondo esterno (che possono essere i più disparati, sede di fenomeni elettrici, meccanici, ottici, chimici, ecc.) esistono varie disomogeneità, più o meno accentuate a seconda dei casi.
Si hanno in generale disomogeneità: fisiche formali temporali spaziali attitudinali Un corretto interfacciamento di un calcolatore con il mondo esterno, cioè un corretto trasferimento di informazioni, richiede che vengano superate queste disomogeneità, mediante l'impiego integrato delle tecniche circuitali (HW = hardware) e programmative (SW = software) di volta in volta più opportune. Come si è detto, queste disomogeneità vengono in genere superate con catene di dispositivi interagenti: FENOMENO
sensore - trasduttore - mezzo trasmissivo - trasduttore CALCOLATORE
Queste catene di trasferimenti e trasformazioni di informazioni attraversano diversi strati esterni ed interni al calcolatore (fig. seguente).
Fig. - Elementi dell’interfacciamento

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
4 / 25
Il progetto di un’interfaccia consiste quindi nell’individuazione di una catena di elementi che complessivamente soddisfano i requisiti globali di trasferimento e trasformazione della rappresentazione delle informazioni, preservando il contenuto informativo rilevante attraverso tutte le trasformazioni intermedie. Inoltre il modello di comunicazione delle informazioni tra i vari elementi dipende dal livello di astrazione a cui ci si pone, che a sua volta dipende da dove si collocano i problemi dominanti: così
un’astrazione Fisica ed Elettronica si focalizzerà sulle interazioni tra grandezze fisiche dei fenomeni (trasformazioni operate da sensori e trasduttori),
un'astrazione Informatica si centra sul problema del significato e della rappresentazione delle informazioni (codifiche ed aggregazioni), mentre
un'astrazione di Telecomunicazione si centra sul problema del trasporto delle informazioni. La visione proposta in questa sede per gli elementi delle catene di comunicazione sarà a "scatole nere"
(black box) definite cioè dalla loro funzionalità ai "morsetti", riservandoci di adottare di volta in volta il
livello di astrazione più adatto ai problemi da evidenziare (come scatole cinesi).
Analizziamo ora brevemente i vari tipi di disomogeneità sopra citati.
La disomogeneità FISICA si riferisce al fatto che le grandezze fisiche messe in gioco dai fenomeni del mondo esterno o non sono grandezze elettriche o non sono di valore compatibile con quelle dei circuiti di un calcolatore; non solo, ma anche quando si tratti di grandezze elettriche (in particolare delle tensioni), non sempre esse sono di valore compatibile con quelle dei circuiti di un calcolatore e spesso neppure associate allo stesso riferimento di massa.. Il superamento delle disomogeneità fisiche richiede l’uso di sensori, trasduttori e attuatori che effettuano il trasferimento delle informazioni da un fenomeno ad un altro. Questi dispositivi, per alcuni tipi di fenomeni e grandezze fisiche, possono essere anche molto complessi, così da costituire a loro volta dei sottosistemi composti di numerosi elementi, molti dei quali tipicamente a tecnologia elettronica. Una disomogeneità FORMALE deriva dalle caratteristiche del segnale usate per rappresentare le informazioni, e si ha quando, pur avendo a disposizione delle grandezze elettriche, queste si presentano in una forma diversa da quella che dovrà essere poi utilizzata all'interno di un calcolatore. Per esempio casi tipici sono costituiti dalle grandezze analogiche, oppure da codifiche digitali particolari (codici BCD, Gray, ecc.). Si hanno anche altre disomogeneità formali; per es. un fenomeno esterno può presentarsi sotto forma di impulsi, i quali non corrispondono direttamente a delle informazioni memorizzabili ma per es. dovranno essere contati (mediante totalizzatori) o se ne dovrà rilevare la distanza temporale (misure di frequenza). Rientra in questa categoria di disomogeneità anche quella introdotta dalla "modulazione", che richiede una corrispondente "demodulazione" per estrarre da un segnale le caratteristiche rilevanti agli effetti dell'informazione.
Una disomogeneità TEMPORALE deriva dal fatto che i fenomeni del mondo esterno sono asincroni, evolvono cioè con una loro dinamica indipendente dai tempi di evoluzione dei programmi all'interno del calcolatore.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
5 / 25
C'è quindi un problema di sincronizzazione affinchè le operazioni di acquisizione, elaborazione ed emissione di informazioni da parte del calcolatore avvengano in istanti opportuni rispetto all’evoluzione dei fenomeni esterni. Si noti che la dinamica dei fenomeni dipende spesso da leggi fisiche o eventi casuali su cui non è facile intervenire, ed è quindi in generale il calcolatore a doversi adeguare ai tempi dei fenomeni esterni. Per la sincronizzazione dell’esecuzione di operazioni svolte dal calcolatore con il verificarsi di eventi nel mondo esterno vengono utilizzate varie tecniche:
tecniche circuitali (tipicamente bistabili e registri),
i tre meccanismi di base classici per sincronizzare l’esecuzione di programmi con eventi esterni:
o controllo di programma (polling) o interruzione di programma (interrupt), o DMA (accesso diretto alla memoria)
meccanismi di sincronizzazione e temporizzazione dei processi SW di elaborazione interna al calcolatore (trattati nella seconda parte del corso - Sistemi Operativi).
Un altro aspetto di cui si deve tener conto è il comportamento di dispositivi nel tempo continuo (tipico dei fenomeni della fisica classica) che è diverso dai comportamenti nel funzionamento sequenziale e discreto (tipico dei sistemi digitali e in particolare dei calcolatori).
Il corretto superamento di queste disomogeneità temporali costituisce uno dei problemi centrali della cosiddetta elaborazione in tempo reale.
La disomogeneità SPAZIALE si riferisce alla collocazione nello spazio del calcolatore e dei dispositivi con esso interagenti, che possono essere posti a distanze anche rilevanti. Il superamento di questo aspetto viene realizzato mediante opportune tecniche di trasmissione, in cui gli aspetti di trasporto delle informazioni assumono un'influenza rilevante sulle tecniche di progetto da adottare. Infatti i fenomeni fisici adatti ad un buono sfruttamento dei mezzi trasmissivi a distanza portano ad adottare, nella catena di interfacciamento, elementi specificatamente adatti al trasporto (ad es. modulazione, sequenzializzazione, segnali ottici, onde radio, ecc.), che spesso introducono localmente ulteriori disomogeneità fisiche, formali e temporali che non sarebbero concettualmente necessarie.
La disomogeneità ATTITUDINALE si evidenzia nell’interfacciamento tra elementi attivi, e tipicamente nell'interfacciamento con l'uomo, che ha caratteristiche di comprensione ed elaborazione delle informazioni molto diverse da quelle del calcolatore. I problemi di adattamento a queste diversità attitudinali sono risolti di solito con unità periferiche opportune, ("ergonomiche") e con opportuni algoritmi per la gestione di queste unità in modo "user friendly" (interattività uomo- macchina). Disomogeneità attitudinali, sia pure meno marcate, si riscontrano però anche tra diversi dispositivi più o meno "intelligenti", cioè dalla funzionalità più o meno articolata, caratterizzati da diversi modelli di comportamento, come si riscontra spesso tra i calcolatori collegati in rete. L'adozione di opportuni protocolli, cioè regole che governano lo scambio di informazioni, costituisce il tipico modo di superare queste disomogeneità.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
6 / 25
Interfacce circuitali Si è detto che le interfacce sono costituite dall'insieme di funzionalità HW e SW atte a consentire l'interazione tra elementi, superando le disomogeneità che ne caratterizzano il comportamento. Spesso è necessario, o conveniente, centrare l'attenzione sugli aspetti circuitali, considerando quelli programmativi come se fossero un'estensione dei primi. Nel seguito vengono brevemente riprese alcune considerazioni di architettura dei calcolatori, a partire dalle semplici porte di ingresso o uscita e passando poi ad analizzare una tipica interfaccia generalizzata che può essere assunta come modello unificante di interfacciamento.
Interfacce circuitali elementari Le interfacce elementari, dette generalmente porte, sono costituite da registri o da buffer accessibili dalla CPU mediante apposite istruzioni macchina di lettura (IN) o scrittura (OUT). I buffer sono dei semplici circuiti ripetitori che rigenerano i segnali, seguendone man mano le variazioni, ma portandoli ad un più elevato livello energetico. Spesso i buffer sono del tipo tri-state, attivabili o disattivabili tramite un comando OE (Output Enable). I registri sono circuiti utilizzati per memorizzare in certi istanti le informazioni e renderle disponibili per il tempo necessario. Questi registri sono simili a celle di memoria (e in alcuni calcolatori appartengono allo stesso spazio di indirizzamento, con l'approccio detto "memory mapped I/O") ma presentano, a differenza delle celle di memoria, la caratteristica di essere collegati con elementi del mondo esterno. E’ importante distinguere le informazioni associate a stati e le informazioni associate ad eventi Informazioni associate a STATI
Valori di grandezze fisiche (temperature, velocità, forze, ecc.) o informazioni che possono essere lette in ogni momento perchè sono informazioni sempre presenti. Ad esempio con un sensore digitale di temperatura l’informazione associata allo stato “temperatura attuale” potrà essere costituita da un valore numerico codificato in complemento a due.
Informazioni associate ad EVENTI Informazioni che sono disponibili solo quando si verificano determinati eventi (pressione di un tasto, ecc.) e quindi richiedono meccanismi di sincronizzazione tra il produttore (mittente) di informazioni e il consumatore (ricevente). Ad esempio con una tastiera l’informazione associata all’evento “pressione di un tasto” è costituita dal codice ASCII del carattere corrispondente al tasto premuto.
Acquisizione di informazioni associate a stati Si tratta di informazioni permanenti e quindi sempre disponibili. Per l'acquisizione di informazioni associate a stati, le porte di ingresso sono costituite da "buffer tri-state" che, quando sono attivati dalla corrispondente operazione di lettura, immettono sul BUS DATI, in modo trasparente, i valori binari che sono presenti in quel momento ai loro morsetti esterni. L’operazione di lettura viene effettuata con l’esecuzione da parte della CPU dell’istruzione macchina IN <porta> dove <porta> è l’indirizzo della porta di ingresso.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
7 / 25
Con questo tipo di porte di ingresso l’acquisizione di informazioni è come una
“fotografia” della configurazione di bit presente ai morsetti della porta in quel
momento, scattata dall’istruzione IN PORTA.
DATEN
WRITE
AB7 AB6 AB5 AB4
ADPER
AB3
AB0 Morsetti dal mondo esterno D7 - - - - - D0
DB7
DB0
OE
Comparatore
tra indirizzi e contatti di selezione
Se eguali uscita = 1
+5 V - VCC
Contatti di selezione indirizzo del modulo APERTO = 1 CHIUSO = 0
AB1 AB2
Buffer “trasparente” tri-state
BUS INDIRIZZI
BUS DATI
BUS di CONTROLLO
0 V - GND
Fig. – Schema semplificato di porta di ingresso per informazioni di stato con buffer trasparente tri-state. Il buffer che costituisce la porta di ingresso, quando il suo segnale di comando OE = Output Enable viene attivato (a livello basso, nell’esempio), riporta sui segnali del bus dati i valori dei bit presenti agli ingressi, cioè i morsetti dal mondo esterno. L’esecuzione da parte della CPU dell’istruzione IN <porta> provoca l’attivazione di OE della porta indirizzata. Poi la CPU memorizzerà al suo interno, tipicamente nel registro accumulatore, i bit così ricevuti tramite il bus dati. Al termine del trasferimento di lettura della porta di ingresso il segnale OE ritorna a livello alto (cioè inattivo) e il buffer tri-state si porta nello stato ad alta impedenza che quindi non impone alcun valore sui segnali del bus dati lasciandoli disponibili per altri trasferimenti.
Acquisizione di informazioni associate ad eventi Le informazioni associate ad eventi sono transienti Quando si debbano acquisire informazioni associate ad eventi, occorre utilizzare come porte di ingresso dei registri che siano in grado di memorizzare il valore associato all'evento quando esso accade, mantenendo tale valore "congelato" fino a quando sarà letto dal processore. E’ come una fotografia scattata dal verificarsi dell’evento che produce i dati e non dall’esecuzione dell’operazione di INPUT che verrà eseguita in seguito.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
8 / 25
La successiva operazione di IN PORTA trasferirà nella CPU i valori dei bit memorizzati nel registro della porta che saranno eventualmente diversi da quelli presenti ai morsetti di ingresso in quel momento che potranno essere variati nel frattempo se il dato esterno non è più presente. In questo caso occorrono anche bit ausiliari per la gestione del rapporto di sincronizzazione:
Produttore (mondo esterno) --> Consumatore (calcolatore). Con questo tipo di porte di ingresso il verificarsi di un certo evento del mondo esterno (ad esempio la pressione di un tasto di una tastiera, il “click” del mouse, ecc.) provoca la memorizzazione nel registro dell’informazione associata all’evento (ad es. il codice ASCII del tasto premuto). Tale valore rimane memorizzato nella porta e quando la CPU eseguirà l’operazione di INPUT riceverà, tramite il bus dati, questo valore memorizzato a suo tempo e non la configurazione di bit presente in quel momento ai morsetti della porta.
Sincronizzazione dell’acquisizione Occorrono meccanismi ausiliari per consentire alla CPU di sapere se nella porta è contenuta un’informazione associata ad un nuovo evento. Questi meccanismi, nel caso più semplice si riducono ad un flip-flop tipo RS. Il verificarsi dell’evento agisce sul comando Set del FF, portandolo nello stato 1. La CPU quando trova FF = 1 legge la porta che contiene una nuova informazione e poi con il comando Reset riporta il FF = 0 per indicare che non ci sono informazioni nuove. Il FF assume il significato di “nuovo dato pronto” Dopo l’acquisizione il contenuto della porta non viene generalmente cancellato, ma è comunque considerato consumato (= usato) e quindi non ulteriormente significativo. In altri termini il FF così gestito funge da elemento di sincronizzazione tra l’acquisizione di dati e gli eventi esterni che li producono.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
9 / 25
Porta di ingresso per informazione di evento con registro di memorizzazione
DATEN
WRITE
AB7 AB6 AB5 AB4
ADPER
AB3
AB0 Morsetti dal mondo esterno D7 - - - - - D0
Load
OE
DB7
DB0
Comparatore
tra indirizzi e contatti di selezione
Se eguali uscita = 1
+5 V - VCC
Contatti di selezione indirizzo del modulo APERTO = 1 CHIUSO = 0
AB1 AB2
Registro “latch” tri-state
BUS INDIRIZZI
BUS DATI
BUS di CONTROLLO
0 V - GND
R S FF
Q
Evento
Dato pronto
Porte di uscita Le porte di uscita sono viste dalla CPU come celle di memoria a "sola scrittura" che rendono disponibile, su opportuni morsetti, il loro contenuto al mondo esterno. Eseguendo l’istruzione macchina OUT PORTA la CPU emette sul bus indirizzi la codifica dell’indirizzo di PORTA e sul bus dati il valore da emettere, che verrà scritto nella porta. Queste porte devono essere sempre realizzate mediante registri in cui le informazioni vengono prelevate dal bus dati e memorizzate nel registro, all’interno del breve intervallo temporale corrispondente al ciclo di bus dell'operazione di scrittura sulla porta d’uscita. Il registro presenta all'esterno con continuità il suo contenuto (generalmente con pilotaggio totem-pole), che rimane immutato fino alla successiva operazione di scrittura su quella porta. Se si tratta di informazioni di stato questo registro è sufficiente. Per le porte destinate a fornire informazioni in uscita associate ad eventi occorrono ulteriori indicatori (FF) che consentano al calcolatore e ai dispositivi del mondo esterno di riconoscere le varie situazioni dell'evento, per la gestione del rapporto: Produttore (calcolatore) –> Consumatore (mondo esterno). In particolare il produttore (calcolatore) dopo aver scritto nella porta d’uscita il valore dell’informazione, dovrà segnalare che l’evento si è verificato portando (con comando Set) a TRUE il FF di sincronizzazione associato a quella porta. Il dispositivo esterno che funge da consumatore di queste informazioni deduce dal valore del FF che c’è un dato pronto da consumare e quindi lo utilizza e poi riporta (con il comando Reset) il FF al valore FALSE, di riposo, segnalando così che il dato è stato consumato.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
10 / 25
Un esempio di informazioni di uscita, del tipo ad eventi, è costituito dalle trasmissioni di caratteri al video o alla stampante o verso altri dispositivi.
Funzionalità dei registri di stato e di comando nelle interfacce complesse Per alcuni tipi di interfacce si hanno funzionalità più complesse, che non si riducono a semplici porte di ingresso e uscita. Esempi di interfacce complesse sono
USART (Universal Synchronous Asynchronous Receiver Transmitter) per comunicazioni digitali seriali,
interfacce verso memorie di massa come hard disk,
circuiti di conteggio o di temporizzazione
circuiti di generazione di impulsi programmabili (PWM = Pulse Width Modulation)
circuiti di acquisizione di misure analogiche con convertitori Analogico/Digitali (ADC). Le funzioni di queste interfacce sono realizzate mediante una serie di circuiti, anche molto complessi e talvolta corredati persino di propri appositi microcontrollori. Per consentire alla CPU di gestire il funzionamento di questi dispositivi sono in genere previsti, accanto alle porte dati di ingresso e dati di uscita, anche ulteriori registri di stato e di comando. Registri di stato
Una o più porte di ingresso consentono alla CPU di acquisire vari bit dei registri di stato, che con il loro valore forniscono informazioni sullo stato dell’interfaccia e della periferica. Esempi: spento/acceso – on-line/off-line – dato pronto/dato non pronto – ecc. Si noti che il FF di sincronizzazione per le informazioni in ingresso associate ad eventi, costituisce un caso molto semplice di registro di stato di 1 bit. Registri di comando
Una o più porte di uscita consentono alla CPU di scrivere negli appositi registri dell’interfaccia dei bit che con il loro valore producono dei comandi specifici (eventi) o impostano le modalità di funzionamento volute (stati).
Esempi: Comandi ad eventi:
azzera una segnalazione di errore
lancia le operazioni di conversione Analogico/Digitale
carica il valore su un temporizzatore
ecc. Si noti che il FF di sincronizzazione per le informazioni in uscita associate ad eventi, costituisce un caso molto semplice di registro di comando di 1 bit. Comandi di stati:
imposta la velocità di trasmissione (baud rate) di una USART
abilita/disabilita la generazione di richieste di interruzione da una periferica
imposta il numero della traccia su cui posizionare la testina magnetica del disco
ecc.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
11 / 25
Interfaccia circuitale generalizzata Nella fig. è rappresentata in forma molto schematica la struttura di un’interfaccia circuitale generale, cui possono ricondursi molti dispositivi di corredo per realizzare le funzioni di I/O dei calcolatori.
Fig. - Schema di interfaccia generalizzata. CS = chip select abilita i trasferimenti sul bus quando il decodificatore riconosce l’indirizzo presente sul bus indirizzi come uno degli indirizzi dell’interfaccia. AD = address sono i bit di indirizzo meno significativi che selezionano il registro interno interessato dal trasferimento. I vari indirizzi dell’interfaccia sono ognuno identificativo di un registro dati o di stato o di comando. R/W = read / write determina la direzione del trasferimento. Dal bus di controllo si deduce se si tratta di un’operazione di lettura di uno dei registri o di scrittura su uno dei registri. In molti casi è previsto che l’interfaccia possa generare richieste di interruzione per segnalare il verificarsi di eventi. Ciò avviene tramite dei flip-flop (FF) che inoltrano nel segnale INTREQ (Interrupt Request) la richiesta, in genere con circuito di pilotaggio di tipo open collector.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
12 / 25
Temporizzazione e sincronizzazione di acquisizione ed emissione di informazioni Cioè come superare le “disomogeneità temporali”.
La funzionalità e le temporizzazioni all'interno del calcolatore sono determinate dall'esecuzione
delle istruzioni, mentre nel mondo esterno i fenomeni fisici evolvono con una loro dinamica
dettata dalle leggi della fisica o dalla volontà degli operatori umani. Si tratta cioè di due mondi
asincroni tra loro.
Se l’esecuzione di operazioni di I/O e di elaborazione devono essere correlate con degli eventi del
mondo esterno occorre effettuare delle opportune sincronizzazioni
Le sincronizzazioni riguardano eventi ed azioni (solitamente acquisizioni o emissioni di dati) che
sarebbero spontaneamente scorrelati, ma cui si vuole imporre una relazione di causa-effetto
tramite un’opportuna catena di eventi-azioni intermedi. Cioè si vuole far in modo che un
determinato evento agisca come causa che produce come effetto l’esecuzione di una determinata
azione (esecuzione di una parte di programma) che può essere considerata come servizio di
risposta all’evento.
Nei normali calcolatori sono disponibili meccanismi di sincronizzazione generalmente noti come
meccanismi di interrupt e di DMA.
Si noti che si può distinguere tra due diverse esigenze di sincronizzazione:
Sincronizzazione dell’acquisizione di informazioni relative ad un evento esterno con il verificarsi di tale evento. L’evento in questo caso è considerato come indicatore di “valore significativo” dell’informazione da acquisire.
Sincronizzazione dell’acquisizione di informazioni di uno stato esterno con il verificarsi di eventi temporali. Si parla in questo caso più specificamente di temporizzazioni, come è il caso del campionamento, in opportuni istanti temporali, di misure di grandezze fisiche.
In entrambi i casi ci si riconduce in genere agli stessi meccanismi che fanno in modo che un
evento, esterno o temporale che sia, produca l’attivazione di specifiche azioni.
Si noti inoltre che nella catena di sincronizzazioni in genere sono significativi almeno due diversi
livelli di sincronizzazione, corrispondenti a due diverse scadenze temporali:
Sincronizzazione di primo livello tra evento e trasferimento dei dati associati. Per questa operazione la deadline (scadenza temporale) è dipendente da quanto tempo i dati generati dall’evento restano disponibili e validi. Talora questa scadenza è piuttosto stretta, nel senso che i dati possono restare validi per un breve periodo di tempo dopo l’evento.
Sincronizzazione di secondo livello tra trasferimento dei dati e loro elaborazione. La deadline per questo secondo livello si riferisce alla generazione, mediante opportuna elaborazione, della risposta allo stimolo costituito dall’evento. La scadenza per le elaborazioni e generazione delle

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
13 / 25
risposte è in genere meno stringente di quella per acquisire i dati, e in alcuni casi può essere anche relativamente lasca.
Scopo di un'interfaccia è quello di effettuare trasferimenti di informazioni, che per essere
significativi devono avvenire con il rispetto di precisi vincoli temporali e con la corretta gestione di
rapporti produttore-consumatore tra il sottosistema che genera eventi ed il sottosistema che li
deve recepire.
Esempio di sincronizzazione dell’acquisizione e dell’elaborazione di informazioni
xxxxxx DATO VALIDO xxxx Dato non più valido xxxxx
Scadenza1 acquis. dato
Scadenza2 emissione risultato di risposta
xxxxxxxxxxxxxxxx Elaborazione corretta temporalmente Risposta tardiva
acquisizione dato
emissione
risposta
T
T
evento produzione
di un dato
Sync 1° livello
Sync 2° livello
ISR
Programma applicativo
In questo diagramma si colloca l’origine dell’asse dei tempi sull’istante in cui si verifica l’evento
che produce un’informazione da acquisire ed elaborare per produrre una risposta.
Vengono riportate sul diagramma temporale le due scadenze:
Tra il verificarsi dell’evento e l’acquisizione del dato si ha la sincronizzazione di 1° livello con la
Scadenza 1 – generalmente breve – prima della quale il dato prodotto dall’evento è valido
e quindi va acquisito entro tale scadenza, pena la perdita del dato.
Tra l’acquisizione del dato e l’elaborazione si ha la sincronizzazione di 2° livello con la Scadenza
2 – generalmente più lunga – entro la quale si deve emettere il risultato di elaborazioni,
come risposta allo “stimolo” costituito dall’evento.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
14 / 25
Realizzazione delle funzioni di interfaccia con HW o SW
E’ importante notare che le funzioni di interfaccia nei calcolatori sono affidate in parte ad appositi
circuiti (HW) ed in parte all’esecuzione di programmi (SW). Una buona suddivisione dei compiti
tra HW e SW in base alle loro caratteristiche peculiari e complementari, consente di rispettare le
specifiche di progetto e minimizzare i costi complessivi.
Si noti che l’hardware ha le caratteristiche:
veloce nell’esecuzione
presenta funzionalità semplice e rigida
occupa spazio e consuma energia
ha un costo di produzione e di collaudo che si ripete per ogni esemplare
Il software ha le caratteristiche complementari:
più lento dell’HW
è in grado di realizzare funzioni complesse e flessibili
ha un costo di sviluppo iniziale (non trascurabile) ma un costo di duplicazione quasi nullo.
Parametri di valutazione dei meccanismi di I/O
- Tempo di reazione (Latenza)
E' il tempo che intercorre tra l'istante in cui si verifica un evento significativo e l'istante in cui il
calcolatore è in grado di acquisire e trattare le informazioni associate.
- Velocità di trasferimento (Transfer rate)
E' la massima frequenza di trasferimento di informazioni (numero di informazioni trasferibili per
unità di tempo) e prescinde da latenze e operazioni ausiliarie di servizio (overhead) iniziali.
- Flusso di informazioni (Throughput)
E' la frequenza media (sul lungo periodo) con cui possono essere effettuati trasferimenti e tiene
conto delle latenze e overhead , delle pause e dei tempi di elaborazione delle informazioni.
- Efficienza complessiva
Dà un'idea di quanto le operazioni di acquisizione ed emissione di dati degradano le prestazioni
relative all'esecuzione dei programmi di elaborazione interna, cioè del carico imposto alla CPU
dalle operazioni di sincronizzazione e trasferimento.
- Complessità e costo
Si tende ovviamente a minimizzare questi aspetti, nel rispetto delle specifiche del progetto.
Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
15 / 25
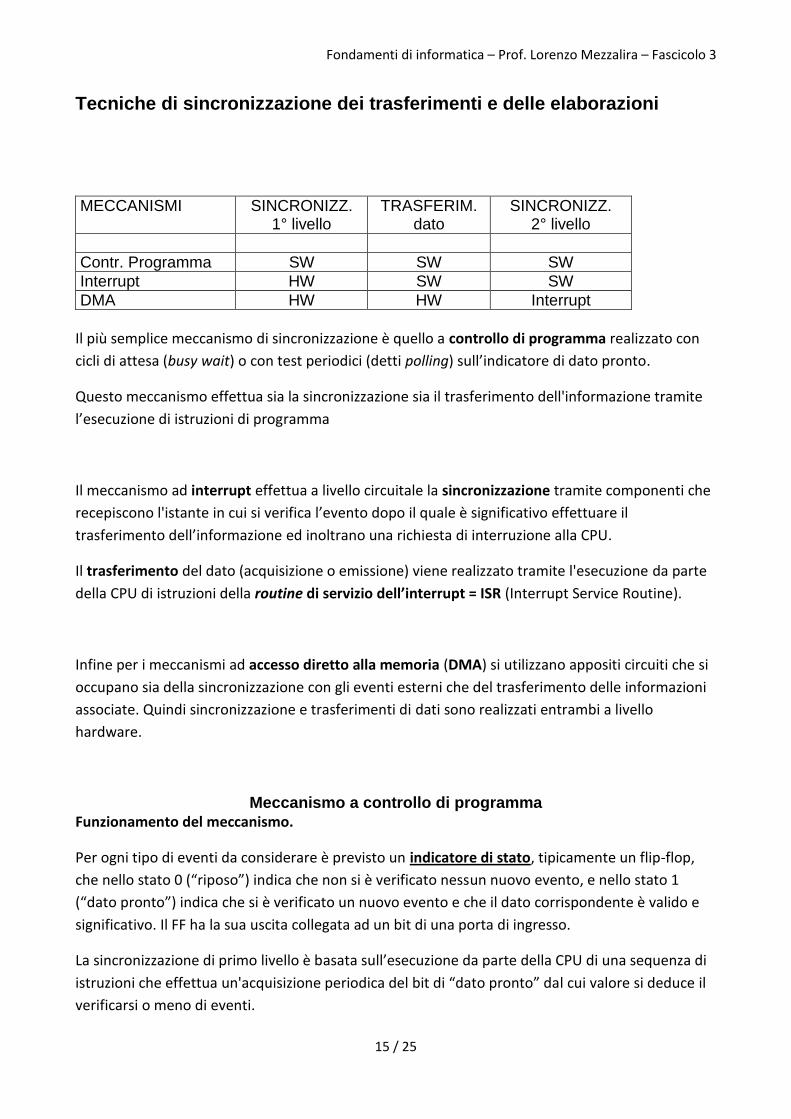
Tecniche di sincronizzazione dei trasferimenti e delle elaborazioni
MECCANISMI SINCRONIZZ. 1° livello
TRASFERIM. dato
SINCRONIZZ. 2° livello
Contr. Programma SW SW SW
Interrupt HW SW SW
DMA HW HW Interrupt
Il più semplice meccanismo di sincronizzazione è quello a controllo di programma realizzato con
cicli di attesa (busy wait) o con test periodici (detti polling) sull’indicatore di dato pronto.
Questo meccanismo effettua sia la sincronizzazione sia il trasferimento dell'informazione tramite
l’esecuzione di istruzioni di programma
Il meccanismo ad interrupt effettua a livello circuitale la sincronizzazione tramite componenti che
recepiscono l'istante in cui si verifica l’evento dopo il quale è significativo effettuare il
trasferimento dell’informazione ed inoltrano una richiesta di interruzione alla CPU.
Il trasferimento del dato (acquisizione o emissione) viene realizzato tramite l'esecuzione da parte
della CPU di istruzioni della routine di servizio dell’interrupt = ISR (Interrupt Service Routine).
Infine per i meccanismi ad accesso diretto alla memoria (DMA) si utilizzano appositi circuiti che si
occupano sia della sincronizzazione con gli eventi esterni che del trasferimento delle informazioni
associate. Quindi sincronizzazione e trasferimenti di dati sono realizzati entrambi a livello
hardware.
Meccanismo a controllo di programma
Funzionamento del meccanismo.
Per ogni tipo di eventi da considerare è previsto un indicatore di stato, tipicamente un flip-flop,
che nello stato 0 (“riposo”) indica che non si è verificato nessun nuovo evento, e nello stato 1
(“dato pronto”) indica che si è verificato un nuovo evento e che il dato corrispondente è valido e
significativo. Il FF ha la sua uscita collegata ad un bit di una porta di ingresso.
La sincronizzazione di primo livello è basata sull’esecuzione da parte della CPU di una sequenza di
istruzioni che effettua un'acquisizione periodica del bit di “dato pronto” dal cui valore si deduce il
verificarsi o meno di eventi.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
16 / 25
L’acquisizione periodica può assumere la forma di un ciclo di attesa (busy-wait) che si ripete fino a
quando la verifica dà esito positivo (cioè “dato pronto”), se si può dedicare completamente la CPU
a questo scopo, altrimenti si adotta la soluzione di eseguire a cadenza temporizzata una sequenza
di test (polling) sui bit di stato che indicano quali nuovi eventi si sono verificati e richiedono il
relativo servizio.
La catena cause-effetti che si realizza è a grandi linee la seguente.
HW - L’evento esterno porta appositi circuiti (ad esempio un flip-flop) in uno stato che indica “dato pronto”.
SW - Il programma esegue delle istruzioni di lettura dello stato. Ad esempio legge il bit del flip-flop tramite una porta di ingresso.
SW - Il programma deduce dallo stato l’avvenuto verificarsi dell’evento.
SW - Il programma esegue l’azione (ad es. lettura di un valore da una porta di IN).
SW - Il programma esegue le elaborazioni del valore acquisito.
busy wait – comportamento sequenziale – per ogni evento atteso si rimane in
attesa senza fare altro fino a quando l’evento si verifica
polling – comportamento “parallelo” (virtualmente) – per ogni potenziale
evento si verifica se si è verificato. Se l’evento si è verificato si esegue acquisizione
ed elaborazione, mentre se l’evento non si è verificato si procede a verifiche su altri
eventi o ad altre elaborazioni.
busy wait wait C1 // attendi la condizione C1
do A1 // esegui l’azione A1
wait C2 // attendi la condizione C2
do A2 // esegui l’azione A2
…
polling // se C1 è vera esegui A1 altrimenti procedi
if C1 then A1
// se C2 è vera esegui A2 altrimenti procedi
if C2 then A2
...
Questo meccanismo è detto “a controllo di programma” perchè è la successione delle istruzioni
del programma che determina il procedere e i tempi di esecuzione
Un pregio di questa tecnica è la innegabile semplicità del meccanismo elementare
I difetti sono tipicamente i seguenti.
Scarso sfruttamento del tempo macchina.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
17 / 25
Deriva dal fatto che si dedica ripetutamente il tempo della CPU a valutare se si sono
verificati eventi. Questo tempo è speso anche quando non si verificano eventi.
Rischio di non rispettare le specifiche temporali e perdere eventi.
La latenza di rilievo degli eventi, cioè il massimo tempo che può intercorrere dal verificarsi
di un evento e le sua percezione, è data dalla distanza temporale tra l’effettuazione dei test
su “dato pronto”. Si riduce la latenza aumentando la frequenza dei test e assegnando così
un maggior carico di lavoro alla CPU, a scapito di altre elaborazioni. Se si vuole ridurre il
carico di lavoro della CPU rallentando la cadenza di rilievo degli eventi, si introduce una
maggiore latenza di rilievo che può portare alla perdita di eventi.
Meccanismo ad interruzione
Questa tecnica prevede dei dispositivi di interfaccia che comunicano a livello circuitale (segnale
INTREQ) al processore (CPU) che si è verificato un evento da acquisire e servire. Un bit di stato
nella CPU indica se essa è abilitata a recepire e servire le richieste di interruzioni.
Funzionamento del meccanismo di interruzione.
E’ previsto un circuito (tipicamente un flip-flop) che al verificarsi dell’evento atteso viene posto
nello stato “attivo” nel quale attiva un segnale di richiesta di interruzione che, se la CPU è abilitata
a recepire le interruzioni, ha l'effetto di
interrompere l'esecuzione del programma che il processore sta svolgendo, e di
attivare l'esecuzione di un sottoprogramma di servizio (Interrupt Service Routine - ISR).
Terminata l’esecuzione della ISR si riprende l’esecuzione del programma interrotto
All'interno della ISR vi saranno delle istruzioni (SW), tipicamente trasferimenti di informazioni, che
il meccanismo hardware permette di attivare in modo sincronizzato (primo livello) con il verificarsi
dell'evento esterno.
E’ indispensabile che la ISR salvi e alla fine ripristini il contesto di esecuzione in corso ed in
particolare il contenuto dei registri della CPU. Ciò è fondamentale affinchè il programma interrotto
possa riprendere correttamente l’esecuzione senza aver subito interferenze dall’esecuzione della
ISR che, ovviamente utilizza i registri della CPU modificandone il contenuto.
È inoltre necessario prevedere dei meccanismi mediante i quali comunicare l’avvenuto
trasferimento di informazioni (sincronizzazione di secondo livello con i processi di elaborazione)
mediante posizionamento di indicatori SW (flag) oppure mediante chiamate di primitive del
sistema operativo di tipo "signal". Nota: gli indicatori SW sono tipicamente variabili logiche.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
18 / 25
Il meccanismo dell’interruzione ha analogie con l’esecuzione di istruzioni macchina
CALL <sottoprogramma>
La differenza fondamentale è che tale istruzione non è inserita in punti determinati del
programma, ma viene “forzata” in modo asincrono, tramite un segnale HW esterno, mentre le
chiamate a sottoprogramma sono inserite dal programmatore in ben precisi punti del programma.
Altra differenza: la ISR tipicamente non ha correlazione col programma in esecuzione al momento
dell’interruzione. Il programma in esecuzione sta probabilmente elaborando informazioni già
disponibili, mentre i nuovi dati ricevuti tramite interruzione dovranno probabilmente essere
elaborati da un altro programma che nel frattempo era in attesa.
I diversi tipi di processori sono dotati al loro interno, oppure con circuiti controllori di interrupt
esterni, di meccanismi di gestione delle interruzioni con diversi gradi di complessità.
I controllori di interrupt sono dotati di registri di stato e di comando, accessibili mediante
operazioni di I/O.
Caratteristiche dei meccanismi di interruzione
Vettorizzazione.
La vettorizzazione è il meccanismo con cui per ogni causa (canale) di interrupt si genera
l’indirizzo di una sua specifica routine di servizio. La vettorizzazione può essere fissa o
programmabile.
Mascherabilità.
Si possono abilitare o disabilitare (mascherare) selettivamente i singoli canali di interrupt,
scrivendo i bit corrispondenti sugli appositi registri di comando del controllore di
interruzioni.
Priorità.
I vari canali di interruzione possono tipicamente avere diverse priorità. Le priorità hanno lo
scopo principale di risolvere i conflitti dovuti a contemporanee richieste di interruzione da
parte di diversi canali.
Alcuni controllori di interrupt prevedono priorità modificabili da programma.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
19 / 25
Annidamento.
Spesso i circuiti di gestione delle richieste di interruzione sono in grado di mascherare
automaticamente le richieste di livello di priorità inferiore o uguale a quello in servizio in un
certo momento.
Con questi controllori è possibile consentire che una richiesta di interruzione più prioritaria
possa interrompere il servizio di una meno prioritaria.
Cambiamento di contesto.
Il salvataggio del contesto di esecuzione da interrompere, per adottare quello della ISR,
richiede di salvare in opportune aree di memoria di lavoro il contenuto dei registri della
CPU ed in particolare del Program Counter (PC) e, nel caso di diversi processi, anche dello
Stack Pointer (SP).
Si noti che i vari registri, incluso il PC possono essere utilmente salvati nello stack (pila),
mentre lo SP va salvato (ovviamente) in un’apposita struttura dati.
La tipica catena cause-effetti che si realizza nella gestione di un interrupt è a grandi
linee la seguente.
a livello HW si succedono le seguenti operazioni
l’evento pone a TRUE lo stato di un indicatore di richiesta nell'interfaccia (set FF Dato pronto)
un meccanismo di arbitraggio tra le diverse priorità inoltra la richiesta alla CPU – Segnale INTREQ sul bus
la CPU se il suo FF Enable Interrupt è abilitato campiona prima di ogni fetch lo stato di richiesta di interruzione.
Se trova attiva la richiesta di interruzione:
la CPU emette un segnale di conferma INTACK sul bus
la CPU disabilita la sensibilità ad ulteriori richieste – Disable Interrupt (reset FF EI)
la CPU salva (sullo stack) il contenuto del Program Counter (e di PSW= Program Status Word)
la CPU riconosce l'eventuale vettore di interrupt Indirizzo della procedura ISR
la CPU carica nel Program Counter l'indirizzo della routine di servizio (vettore)
a livello SW (routine di servizio) vengono svolte dalla CPU le seguenti operazioni
salvataggio dei registri della CPU + contesto (tipicamente sullo stack)
individuazione della causa dell'interrupt (cioè da quale canale e flusso di eventi proviene la richiesta)
azione (gestione dell’evento e trasferimenti delle informazioni associate)
rimozione della richiesta – Reset del FF indicatore di dato pronto
impostazione degli indicatori o invocazione della primitiva signal (per sincr. di 2° livello) conclusione SW
ripristino dei registri della CPU + contesto
riabilitazione dell'interrupt (set FF EI)
ritorno al programma in esecuzione

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
20 / 25
Sincronizzazione di secondo livello SW
La sincronizzazione di secondo livello, cioè tra l’acquisizione dell’informazione e l’attivazione del
programma di elaborazione può svolgersi in uno dei seguenti modi.
Il processo interessato ad elaborare le informazioni associate all’evento, trova gli indicatori impostati (flag di “dato acquisito”), e da ciò deduce di poter procedere con le elaborazioni del caso.
Oppure, nel caso di Sistema Operativo multiprogrammato (multitasking), in seguito alla
chiamata della primitiva Signal da parte della ISR il sistema operativo mette in stato di
“pronto” il processo destinatario del dato da elaborare e lo manderà in esecuzione quando
sarà il suo turno.
Un classico (in alcuni sistemi l'unico) utilizzo dell'interrupt è correlato con l'uso di temporizzatori
detti RTC (Real Time Clock). Questi generatori di richieste periodiche di interruzione servono per
tener conto del passare del tempo e per attivare, con opportuna periodicità, l’esecuzione di
operazioni come
mantenere aggiornato il valore di una variabile “tempo corrente”.
campionamenti di informazioni di stato
Si noti che l'attivazione periodica di una routine (o meglio di un processo), mediante interrupt
generato da timer, costituisce in molti casi un interessante compromesso e connubio tra i vantaggi
dell'approccio ad interrupt e quelli del controllo di programma. Si realizza cioè un polling time-
driven (cioè guidato dal tempo) invece che execution-driven.
I tempi da considerare con il meccanismo di interrupt sono:
latenza = tempo tra il verificarsi dell’evento ed il momento in cui la richiesta può essere
recepita. La latenza dipende dalla durata delle disabilitazioni dell'interrupt dovute a:
- disabilitazione volontaria da SW per protezione (mutua esclusione). Eseguendo l’apposita
istruzione macchina DI (Disable Interrupt) la CPU disabilita la percezione delle richieste di
interruzione, che quindi rimangono pendenti fino a quando si avrà la riabilitazione con
l’istruzione EI (Enable Interrupt). Durante questo periodo l’esecuzione di operazioni non
interrompibili è protetta da interferenze.
- disabilitazione automatica da HW per altro servizio di interrupt in corso
tempo di attivazione = tempo necessario per le operazioni preliminari HW e SW (salvare
contesto, individuare la causa)
tempo di servizio = tempo per l'esecuzione del SW specifico di servizio (trasferimenti di
informazioni)
latenza di segnalazione = tempo che trascorre prima che il processo interessato recepisca
l'indicazione che si è verificato l'interrupt (sincronizzazione di secondo livello).

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
21 / 25
Il tempo di attivazione di un interrupt è dell'ordine di 1..50 microsecondi; il tempo di esecuzione di
una routine di risposta all'interrupt può essere anche dell'ordine delle centinaia di microsecondi.
In genere è conveniente effettuare nella routine di risposta solo le operazioni urgenti
(trasferimenti delle informazioni, verifiche di validità, accodamenti di eventi) per minimizzare i
tempi di latenza di altre interruzioni.
Le vere e proprie elaborazioni, talora complesse, sono opportunamente demandate ai processi
attivati con la sincronizzazione di 2° livello.
DMA – Direct Memory Access Consideriamo qui, molto sinteticamente, solo il caso di DMA con funzionalità elementare Il metodo ad accesso diretto alla memoria si usa quando i trasferimenti da effettuare avvengono a
burst, cioè con rapide successioni di eventi intervallate da periodi di pausa. Queste successioni
possono avere anche brevi durate (millisecondi), ma richiedere un’alta frequenza di trasferimento
(elevato transfer rate),
oppure quando è necessario un brevissimo tempo di ritardo nel trasferimento (nel caso di dati
disponibili solo per brevi – microsecondi – intervalli di tempo).
Applicazioni tipiche sono
le linee di trasmissione dati seriali ad alta velocità (collegamenti in rete con velocità dell'ordine di 1-10 Mbit/s) – un burst di dati (in questo caso sono caratteri) corrisponde ad un messaggio
i trasferimenti di informazioni tra memoria operativa e memoria di massa – un burst corrisponde al trasferimento di tutti i byte contenuti in un settore del disco.
campionamento di misure in rapida successione e per limitata durata nel tempo, per analisi di fenomeni rapidi. Ad es. andamento della pressione durante lo scoppio in un cilindro.
Funzionamento del meccanismo di DMA.
Il calcolatore deve essere dotato di un dispositivo DMA controller che ha il compito di sostituirsi
alla CPU nella gestione dei trasferimenti di dati assumendo il ruolo di master del Bus.
Questo DMA controller gioca normalmente il ruolo di circuito slave e come tale viene
“programmato”, per impostare i prossimi trasferimenti, mediante il caricamento nei suoi registri di
comando dei valori relativi a:
indirizzo iniziale dell’area di memoria di lavoro destinata ai dati da trasferire (Start Address)
numero di byte da trasferire (Terminal Count)
modalità operative con cui effettuare i trasferimenti. (Mode)

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
22 / 25
La catena cause-effetti che si realizza è a grandi linee la seguente:
Il controllore di DMA recepisce la richiesta di servizio a seguito di un evento (flip-flop di “dato pronto”).
Il controllore di DMA chiede alla CPU, (segnale HOLDREQ del BUS) e ottiene (HOLDACK) al termine del ciclo di bus in corso, di assumere il ruolo di master del bus del calcolatore.
Il controllore di DMA comanda (agendo sul bus indirizzi e sul bus di controllo) le operazioni di lettura della porta di ingresso e scrittura nell’opportuno indirizzo di memoria (o viceversa, nel caso di emissione di dati).
Il controllore di DMA dopo ogni trasferimento incrementa il suo registro di indirizzo di memoria e il contatore dei trasferimenti.
A conteggio finale raggiunto (Terminal Count) il controllore genera una richiesta di interruzione per indicare la fine del trasferimento. Il servizio a questa interruzione consiste nel riattivare eventualmente il controllore di DMA per il prossimo trasferimento, e segnalare il completamento di un trasferimento di dati al processo interessato (sincronizzazione di secondo livello).
Pregi del DMA
Elevato transfer rate. I tempi in gioco nel DMA sono molto brevi: dell'ordine del microsecondo per
richiesta e conferma ed il trasferimento vero e proprio delle informazioni.
L'efficienza è molto elevata; la CPU non perde tempo per tutte queste operazioni e non deve
salvare il contesto, ma vede solo una sospensione delle sue attività sul bus per un paio di
microsecondi ad ogni trasferimento.
Difetti del DMA
Il costo delle maggiori prestazioni è costituito dal costo del controllore di DMA e dei circuiti
ausiliari necessari.
Inoltre il DMA presenta una notevole rigidità, nel senso che non consente elaborazioni "on-line"
delle informazioni, ma solo semplici trasferimenti a conteggio prefissato.
Le caratteristiche del DMA consentono prestazioni ottimali per gli accessi alle memorie di massa.
per trasferimenti di immagini e per le comunicazioni ad elevata velocità.
Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
23 / 25
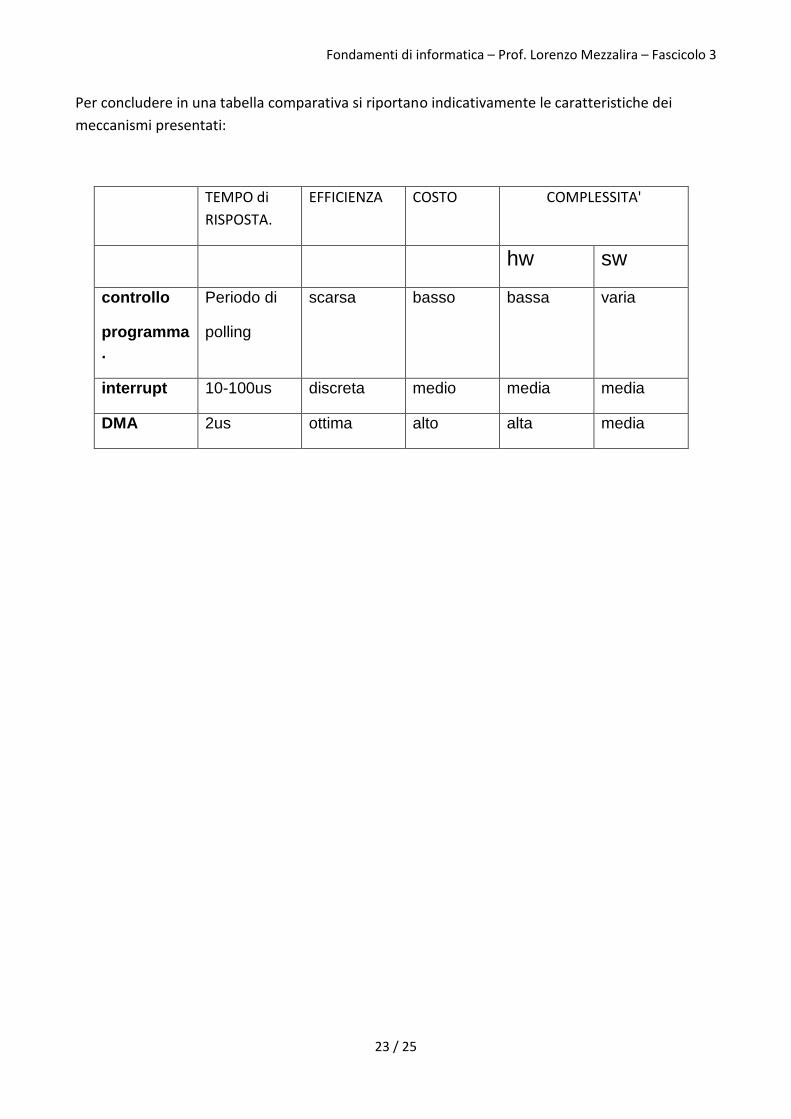
Per concludere in una tabella comparativa si riportano indicativamente le caratteristiche dei
meccanismi presentati:
TEMPO di
RISPOSTA.
EFFICIENZA COSTO COMPLESSITA'
hw sw
controllo
programma
.
Periodo di
polling
scarsa basso bassa varia
interrupt 10-100us discreta medio media media
DMA 2us ottima alto alta media

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
24 / 25
La memoria di massa In molti sistemi di calcolo oltre alla indispensabile memoria di lavoro è prevista anche una memoria ausiliaria detta memoria di massa. Le caratteristiche tipiche delle memorie di massa sono:
persistenza delle informazioni (archivio a lungo termine)
elevata capacità (grande quantità di dati e programmi) E’ accettabile che l’accesso sia sequenziale e non casuale. Si accetta quindi che il tempo di accesso sia relativamente lungo (alcuni ms) purchè poi il ritmo di trasferimento (transfer rate) sia elevato (Mbit/s). Infatti lo scopo della memoria di massa non è quello di fornire accesso a singole informazioni, ma piuttosto di consentire rapidi trasferimenti di blocchi di informazioni verso la memoria di lavoro, dove tali informazioni verranno poi utilizzate dai programmi in esecuzione. Le memorie di massa sono considerabili come unità periferiche. La CPU non è in grado di accedere direttamente, come per la memoria di lavoro, alle informazioni della memoria di massa, ma deve gestire tale memoria tramite interfacce corredate di registri dati, registri di comando e registri di stato, come avviene per le unità gestite tramite interfacce a funzionalità complessa. La memoria di massa utilizza generalmente un supporto magnetico per la memorizzazione delle informazioni. L’informazione binaria (bit) viene memorizzata tramite i due stati di magnetizzazione di un materiale ferromagnetico in grado di mantenere un magnetismo residuo. E’ quindi una memoria permanente. Le tipiche memorie di massa di un calcolatore sono i dischi magnetici. I dischi rigidi (hard disk) hanno tempi di accesso alle informazioni dell’ordine delle poche decine di millisecondi e le capacità dell’ordine dei Gigabyte e Terabyte. Come supporto di memoria rimovibile, e quindi trasportabile, sono utilizzati anche dischi CD e DVD e le “chiavette” con memorie “flash”. I dischi sono fisicamente suddivisi in tracce (corone circolari) e settori (porzioni di traccia), e la lettura/scrittura fisica delle informazioni avviene posizionando la testina di lettura/scrittura sulla traccia e aspettando che con la rotazione si presenti il settore voluto, quindi con accesso sequenziale+ciclico. Accesso sequenziale con il movimento radiale della testina per raggiungere la traccia indirizzata. Questo accesso richiede tempi variabili in dipendenza della posizione iniziale della testina e della posizione della traccia di destinazione. Mediamente sono tempi dell’ordine di alcuni ms. Accesso ciclico per attendere che la rotazione del disco porti sotto la testina il settore indirizzato. Anche questa parte dell’accesso presenta tempi variabili in dipendenza della posizione del disco nella sua rotazione. Un disco che ruoti a 6000 giri/min impiega 10 ms per compiere un intero giro, quindi mediamente il tempo di accesso ciclico sarà di 5 ms. Per motivi di efficienza, dopo l’accesso si trasferiscono in sequenza tutti i byte di un “blocco” costituito da un numero intero di settori contigui. Questo trasferimento avviene con un elevato transfer rate, quindi tipicamente utilizzando il meccanismo dell’accesso diretto alla memoria (DMA). L’interfaccia e la gestione di un disco (drive) è realizzata mediante un dispositivo complesso che risolve i problemi di accesso fisico al disco.

Fondamenti di informatica – Prof. Lorenzo Mezzalira – Fascicolo 3
25 / 25
Le informazioni su disco sono logicamente organizzate in file. Un file rappresenta l’unità logica di informazione su disco, è identificato mediante un nome e al suo interno contiene una sequenza di informazioni. Per poter utilizzare le informazioni su file, è necessario che queste vengano prima ricopiate nella memoria di lavoro tramite un’opportuna sequenza di accessi in lettura alla memoria di massa. Il Sistema Operativo fornisce le funzioni (File system) necessarie all’accesso ai file I file possono contenere informazioni qualsiasi: documenti (file di testo), programmi in codice sorgente (file di testo), programmi in codice macchina (file binario eseguibile), immagini (ad esempio mappa di bit), suoni, ecc.. Delle tracce in posizione prefissata contengono generalmente una parte iniziale di sistema operativo che nella fase cosiddetta di bootstrap all’accensione del sistema viene ricopiata nella memoria di lavoro ed eseguita per attivare la funzionalità di base del calcolatore. Una memoria di massa può essere vista come una collezione di settori collocati nelle varie tracce. Quali settori sono liberi e quali sono allocati ai vari file presenti nel disco è descritto da appositi descrittori contenuti nel disco stesso in posizioni prefissate. Questi descrittori sono detti FAT = File Allocation Table, e sono utilizzati e mantenuti aggiornati dal File System del sistema operativo, che li gestisce in occasione di ogni operazione di apertura, lettura, scrittura e chiusura dei file. I descrittori FAT rappresentano quindi la descrizione di corrispondenza tra la struttura logica delle informazioni organizzate a file e la collocazione fisica (topologica) dei settori in cui tali informazioni sono contenute. Infatti i settori appartenenti ad un file presentano una sequenza logica, ma possono essere collocati su diverse tracce ed in posizioni non consecutive. Ciò è dovuto al fatto che la scrittura di un file avviene andando ad utilizzare i settori liberi laddove questi sono disponibili, eventualmente lasciati liberi in seguito alle precedenti cancellazioni di file. Si intuisce che dopo una certa attività di scritture (creazioni) e cancellazioni (rilascio) di file i settori liberi ed occupati assumano una configurazione “a macchie di leopardo”. Il rallentamento dovuto agli accessi “sparsi” dei vari settori può suggerire di effettuare periodicamente una ristrutturazione, cioè un riordino sequenziale dei settori che contengono le informazioni appartenenti ai file. Queste operazioni di deframmentazione possono richiedere tempi anche piuttosto lunghi (decine di minuti). Altri tipi di memorie di massa I nastri magnetici sono memorie di massa ad accesso sequenziale con tempi di accesso più lunghi e capacità di memorizzazione generalmente superiori ai dischi, e di solito vengono utilizzati per memorizzare informazioni “storiche” o di back-up (copia di sicurezza) e comunque di uso molto poco frequente. Sono estraibili e quindi archiviabili. I CD-ROM sono memorie di massa generalmente utilizzate a sola lettura. La memorizzazione delle informazioni, e la lettura, utilizzano i principi di funzionamento dei dischi ottici.


















