
Appunti di Teoria dell'Informazione e Codici - tti.unipa.itgarbo/Teoria InfeCodici.pdf · Indice v...
213
DIPARTIMENTO DI ENERGIA, INGEGNERIA DELL’INFORMAZIONE E MODELLI MATEMATICI (DEIM) Appunti di Teoria dell'Informazione e Codici Giovanni Garbo, Stefano Mangione 06/09/2013
Transcript of Appunti di Teoria dell'Informazione e Codici - tti.unipa.itgarbo/Teoria InfeCodici.pdf · Indice v...

DIPARTIMENTO DI
ENERGIA, INGEGNERIA DELL’INFORMAZIONE
E MODELLI MATEMATICI
(DEIM)
Appunti di Teoria dell'Informazione e
Codici
Giovanni Garbo, Stefano Mangione 06/09/2013

ii Appunti di Teoria dell’Informazione e Codici

Sommario
7 Capitolo - 1
Le Sorgenti d’Informazione 7
1.1 - Premessa ............................................................................................................ 7
1.2 - Misura dell’Informazione .......................................................................................... 9
1.3 - Sorgenti d’Informazione ......................................................................................... 11 Esempio I.1.1 ....................................................................................................................15
1.4 - Informazione Associata a un Messaggio ........................................................................ 15
17 Capitolo - 2
Sorgenti con Alfabeto Continuo 18
2.1 - Entropia di una Sorgente con Alfabeto Continuo............................................................... 18
2.2 - Sorgenti Gaussiane ............................................................................................... 19
23 Capitolo - 3
La Codifica di Sorgente 23
3.1 - Premessa .......................................................................................................... 23
3.2 - La Regola del Prefisso ........................................................................................... 23
3.3 - Lunghezza Media di un Codice. ................................................................................ 24
3.4 - La Disuguaglianza di Kraft. ..................................................................................... 25 Esempio 3.1 .....................................................................................................................26
3.5 - Limite Inferiore per la Lunghezza di un Codice. ............................................................... 27 Esempio 3.2 .....................................................................................................................28
3.6 - La Proprietà di Equipartizione. ................................................................................. 30
3.7 - Teorema sulla Codifica di una Sorgente DMS. ................................................................. 32 Teorema 3.1 .....................................................................................................................34 Esempio 3.3 .....................................................................................................................34
3.8 - Codifica di Sorgenti con Memoria. .............................................................................. 36 Esempio 3.4 .....................................................................................................................37 Esempio 3.5 .....................................................................................................................37
39 Capitolo - 4
Canali Privi di Memoria 39
4.1 - L’Informazione Mutua. .......................................................................................... 39
4.2 - Concetto di Canale. .............................................................................................. 40
4.3 - L’equivocazione. ................................................................................................. 43
4.4 - La capacità di canale ............................................................................................. 44

ii Appunti di Teoria dell’Informazione e Codici
4.5 - Il Canale Simmetrico Binario. .................................................................................. 45
4.6 - Capacità del Canale AWGN a Banda Limitata. ................................................................ 47
4.7 - Informazione Mutua tra -messaggi. .......................................................................... 50
4.8 - Canali in Cascata................................................................................................. 51
4.9 - L’Inverso del Teorema della Codifica di Canale ............................................................... 53 Teorema 4.1 .....................................................................................................................58
4.10 - Il piano di Shannon ............................................................................................. 59
61 Capitolo - 5
Cenni di Trasmissione Numerica 61
5.1 - Scenario di Riferimento. ......................................................................................... 61
5.2 - Struttura del modulatore e del codificatore di sorgente ........................................................ 61
5.3 - Struttura del Ricevitore. ......................................................................................... 62
5.4 - La Regola di Decisione Ottima. ................................................................................ 63
5.5 - Il Criterio della Massima Verosimiglianza. ..................................................................... 64
5.6 - Funzioni di Verosimiglianza. ................................................................................... 65
5.7 - Le Regioni di Decisione. ........................................................................................ 66
5.8 - L’Union Bound. ................................................................................................. 68
5.9 - Bound di Bhattacharrya. ........................................................................................ 70
5.10 - Bound di Gallager............................................................................................... 75
79 Capitolo - 6
Il Teorema di Shannon sulla Codifica di Canale 79
6.1 - Premessa. ........................................................................................................ 79
6.2 - La Disuguaglianza di Jensen.................................................................................... 80 Definizione 6.1 ..................................................................................................................80 Definizione 6.2 ..................................................................................................................81
6.3 - Il Teorema di Shannon sulla Codifica di Canale. .............................................................. 83 Teorema 6.1: Teorema di Shannon sulla codifica di canale ..................................................................92
95 Capitolo - 7
Strutture Algebriche 95
7.1 - Gruppo ........................................................................................................... 95
7.2 - Anello ............................................................................................................ 95
7.3 - Campo............................................................................................................ 95
7.4 - Spazio vettoriale ................................................................................................. 96

Indice iii
97 Capitolo - 8
Distanza di Hamming 97
8.1 - Lo Spazio ..................................................................................................... 97
8.2 - Generalizzazione della distanza di Hamming .................................................................. 98
101 Capitolo - 9
Codici Binari a Blocchi 101
9.1 - Codificatore, Codice, Decodificatore .......................................................................... 101 Definizione 9.1 - codificatore a blocchi ..................................................................................... 101 Definizione 9.2 - codice binario a blocchi ................................................................................... 101 Definizione 9.3 - decodificatore ............................................................................................. 102
9.2 - Utilità della codifica di canale ................................................................................. 103
9.3 - La decodifica a massima verosimiglianza .................................................................... 105 Regola di decisione a Massima Verosimiglianza ............................................................................ 106
9.4 - Definizioni e teoremi sui codici rivelatori e correttori ........................................................ 106 Definizione 9.4 ................................................................................................................ 107 Definizione 9.5 ................................................................................................................ 107 Teorema 9.1 ................................................................................................................... 107 Definizione 9.6 ................................................................................................................ 108 Teorema 9.2 ................................................................................................................... 108 Teorema 9.3 ................................................................................................................... 109
111 Capitolo - 10
Codici Lineari a Blocchi 111
10.1 - Premessa ....................................................................................................... 111
10.2 - Morfismi ....................................................................................................... 111 Definizione 10.1 - omomorfismo ............................................................................................ 112 Definizione 10.2 - monomorfismo .......................................................................................... 112 Definizione 10.3 - isomorfismo .............................................................................................. 112
10.3 - Schema di principio di un codice lineare a blocco .......................................................... 112
10.4 - Matrice generatrice del codice ............................................................................... 113
10.5 - Distribuzione dei pesi di un codice lineare a blocco ........................................................ 115 Definizione 10.4 –Distribuzione dei pesi di un codice lineare ............................................................. 115
10.6 - Capacità di rivelazione di un codice lineare a blocco ....................................................... 116 Teorema 10.1 .................................................................................................................. 116
10.7 - Probabilità di non rivelazione d’errore di un codice lineare ................................................ 116
10.8 - Laterali di un sottogruppo .................................................................................... 117
10.9 - Decodifica tramite i rappresentanti di laterale ............................................................... 119 Teorema 10.2 .................................................................................................................. 120
10.10 - Probabilità d’errore di un codice lineare a blocchi ......................................................... 120

iv Appunti di Teoria dell’Informazione e Codici
10.11 - Codici perfetti, bound di Hamming ........................................................................ 121
123 Capitolo - 11
Codici Sistematici 123
11.1 - Codici Sistematici ............................................................................................. 123
11.2 - Matrice di controllo di parità ................................................................................. 125
11.3 - Codici duali ................................................................................................... 125
11.4 - Decodifica basata sulla sindrome ............................................................................ 126
129 Capitolo - 12
Codici di Hamming e loro duali 129
12.1 - Codici di Hamming .......................................................................................... 129 Esempio 12.1 .................................................................................................................. 130
12.2 - Duali dei codici di Hamming ................................................................................ 131
12.3 - Codici ortogonali e transortogonali .......................................................................... 132
135 Capitolo - 13
Codici Convoluzionali 135
13.1 - Premessa ...................................................................................................... 135
13.2 - Struttura del codificatore ..................................................................................... 135
13.3 - Matrice generatrice e generatori. ............................................................................ 136
13.4 - Diagramma di stato del codificatore. ........................................................................ 138
13.5 - Codici catastrofici ............................................................................................ 140
13.6 - Trellis degli stati .............................................................................................. 141 Esempio 13.1 .................................................................................................................. 143
145 Capitolo - 14
L’Algoritmo di Viterbi 145
14.1 - Decodifica hard e soft di un codice convoluzionale. ........................................................ 145
14.2 - L’algoritmo di Viterbi ........................................................................................ 148
14.3 - Efficienza dell’algoritmo di Viterbi .......................................................................... 150
153 Capitolo - 15
Prestazioni dei Codici Convoluzionali 153
15.1 - Distanza libera di un codifie convoluzionale. ............................................................... 153
15.2 - Funzione di trasferimento di un codificatore convoluzionale. ............................................. 154
15.3 - Bound sulla probabilità di primo evento d’errore. .......................................................... 157

Indice v
Esempio 15.1 .................................................................................................................. 160
15.4 - Bound sulla probabilità d’errore sul bit informativo. ........................................................ 164
169 Capitolo - 16
Anelli di Polinomi 169
16.1 - Premessa ....................................................................................................... 169
16.2 - L’anello polinomi a coefficienti in ......................................................................... 169
16.3 - Spazi di polinomi.............................................................................................. 171
173 Capitolo - 17
Codici polinomiali 173
175 Capitolo - 18
Ideali di un anello di polinomi 175
18.1 - Premessa ....................................................................................................... 175
18.2 - Ideali di un anello con identità. .............................................................................. 176 Teorema 18.1 .................................................................................................................. 176 Teorema 18.2 .................................................................................................................. 177
179 Capitolo - 19
Codici Ciclici 179
19.1 - Rappresentazione polinomiale di un codice ciclico. ........................................................ 179 Definizione 19.1 ............................................................................................................... 179
19.2 - Teorema sui codici ciclici .................................................................................... 180 Teorema 19.1 .................................................................................................................. 180
19.3 - Polinomio generatore di un codice ciclico ................................................................... 181
19.4 - Polinomio di parità di un codice ciclico ..................................................................... 182 Esempio 19.1 .................................................................................................................. 183
19.5 - Matrice generatrice di un codice ciclico ..................................................................... 184
19.6 - Codici ciclici Sistematici ...................................................................................... 185 Esempio 19.2 .................................................................................................................. 186
19.7 - Duale di un codice ciclico .................................................................................... 187
189 Capitolo - 20
Campi finiti 189
20.1 - Polinomi irriducibili e campi a essi associati ................................................................ 189 Definizione 20.1 ............................................................................................................... 189 Teorema 20.1 .................................................................................................................. 189
20.2 - Ordine degli elementi di un gruppo ......................................................................... 190
20.3 - Ordine degli elementi di un campo finito ................................................................... 191

vi Appunti di Teoria dell’Informazione e Codici
20.4 - Ordine di un campo finito ................................................................................... 192 Teorema 20.2 - Ordine di un campo finito ................................................................................. 192
20.5 - Elementi primitivi di un campo ............................................................................. 193
20.6 - Campi di polinomi ........................................................................................... 194 Esempio 20.1 .................................................................................................................. 194
20.7 - Polinomi irriducibili primitivi................................................................................ 195 Definizione 20.2 ............................................................................................................... 195 Teorema 20.3 .................................................................................................................. 195
20.8 - Alcune proprietà dei campi finiti ............................................................................ 195 Esempio 20.2 .................................................................................................................. 196
20.9 - Il logaritmo di Zech .......................................................................................... 198
20.10 - Elementi algebrici di un campo su un sottocampo ........................................................ 199 Definizione 20.3 ............................................................................................................... 200
201 Capitolo - 21
Codici BCH 201
21.1 - Codici BCH ................................................................................................... 201 Esempio 21.1 - Progetto di un codice BCH ................................................................................ 203
207 Capitolo - 22
La Trasformata di Fourier Discreta 207
22.1 - La Trasformata di Fourier Discreta.......................................................................... 207
22.2 - DFT e codici ciclici .......................................................................................... 210 Definizione 22.1 ............................................................................................................... 210

Capitolo - 1
LE SORGENTI D’INFORMAZIONE
1.1 - Premessa
Uno dei maggiori problemi che s’incontrano nella stesura di
un testo che tratti la teoria dell’informazione è quello della
notazione da adottare, non è affatto semplice trovare il giusto
compromesso tra sinteticità e chiarezza della stessa.
Nel seguito avremo spesso a che fare con variabili aleatorie (V.A.)
che indicheremo con lettere maiuscole. Come è noto ad ogni V.A.
si può associare una distribuzione di probabilità (DDP) ed una densità
di probabilità (ddp) che altro non è se non la derivata della DDP,
intesa eventualmente in senso generalizzato.
Nel caso delle variabili aleatorie discrete che possono cioè
assumere un numero finito di valori è più comodo fare riferi-
mento alla distribuzione di massa di probabilità (dmp) cioè ad una
funzione ( ) che associa ad ogni valore che la V.A. può
assumere la probabilità dell’evento: “ assume il valore ”.
Quando si riterrà che non vi siano possibilità d’equivoci si
ometterà il pedice che individua la V.A. affidando all’argomento
della funzione anche questo compito, cioè ( ) ( ).
Si noti che la notazione che qui si adotta è purtroppo
analoga a quella normalmente utilizzata per indicare la ddp di una
variabile aleatoria, un minimo di attenzione al contesto dovrebbe,
si spera, essere sufficiente ad evitare confusioni. Le ddp verranno
di regola indicate con lettere greche con a pedice la V.A. cui si
riferiscono ad esempio ( ).
Come è noto per le variabili aleatorie discrete è particolarmente
semplice desumere da una qualunque delle tre funzioni di proba-
bilità appena citate le altre. In particolare se è nota la dmp di una
variabile aleatoria discreta che assume valori appartenenti all’in-

0 - Appunti di Teoria dell’Informazione e Codici 8
sieme la corrispondente DDP ( ) sarà una fun-
zione definita su tutto costante a tratti con discontinuità d’am-
piezza ( ) in corrispondenza dei valori che la V.A. può assu-
mere. La ddp ( ) sarà espressa da ( ) ∑ ( ) (
).
Nel calcolo delle sommatorie che s’incontreranno ad ogni
piè sospinto si indicherà il più sinteticamente possibile l’indice su
cui le suddette operano. Ad esempio avendo a che fare con una
V.A. discreta che assuma valori in un insieme , la
condizione di normalizzazione della sua dmp sarà indicata come
segue:
∑ ( )
(1.1.1)
anziché:
∑
( ) (1.1.2)
Analogamente quando si avrà a che fare con variabili alea-
torie multidimensionali, come ad esempio nel caso di una -upla
di simboli emessi consecutivamente, si utilizzeranno distribuzioni
di massa congiunte che saranno caratterizzate scrivendo, ove pos-
sibile, pedice e argomento in grassetto. Ad esempio nel caso di
una coppia di variabili aleatorie che assumono entrambe
valori sull’insieme , la condizione di normalizzazione verrà
sinteticamente scritta:
∑ ( )
(1.1.3)
anziché
∑ ∑ ( )
(1.1.4)

Sorgenti con Alfabeto Continuo 9
Nel caso delle ddm condizionate con
( ) (1.1.5)
si indicherà sinteticamente la seguente probabilità condizionata:
( ) (1.1.6)
anche in questo caso, quando si riterrà che non vi siano possibilità
d’equivoci si ometterà il pedice affidando agli argomenti l’identi-
ficazione delle variabili aleatorie cui si fa riferimento.
1.2 - Misura dell’Informazione
Il concetto d’informazione a livello intuitivo è chiaro. Si
acquisisce un’informazione nel momento in cui si viene a cono-
scenza di qualcosa che prima ci era ignoto. Quantificare l’informa-
zione da un punto di vista matematico richiede invece qualche ri-
flessione.
Per inquadrare meglio il problema facciamo riferimento ad
un esperimento casuale che com’è noto è caratterizzato da un in-
sieme di possibili risultati, da una famiglia d’eventi (insiemi di
risultati) e dalle probabilità associate a ciascuno di essi.
In prima istanza si accetta facilmente l’idea che il contenuto
informativo di un evento sia tanto più grande quanto più esso è
inatteso, ciò ad esempio si riflette nella dimensione del carattere
utilizzato nei titoli di un quotidiano che, di regola, è direttamente
proporzionale alla “sensazionalità” dell’evento di cui il titolo
intende dare notizia. Una notizia è tanto più sensazionale quanto
più essa è inattesa, “un padrone ha morso il suo cane”.
Pertanto, volendo definire una misura per la quantità d’in-
formazione associata ad un evento, minor prevedibilità deve equi-
valere ad un valore maggiore di tale misura.
Inoltre, qualora si verifichino più eventi, per semplicità
prendiamone in considerazione solo due, la misura dell’informa-
zione complessiva dovrebbe essere pari alla somma delle infor-
mazioni acquisite con il manifestarsi dei singoli eventi, sempre che

0 - Appunti di Teoria dell’Informazione e Codici 10
le informazioni acquisite con il manifestarsi di uno di essi non ab-
biano modificato l’incertezza sul secondo.
In conclusione una misura dell’informazione deve essere:
- legata alla probabilità che il generico evento ha di manifestarsi
ed in particolare deve crescere al diminuire di essa e deve
variare con continuità al variare di quest’ultima;
- nel caso di un evento congiunto deve essere pari alla somma
delle informazioni associate ai singoli eventi, se questi sono
tra loro statisticamente indipendenti cioè se il manifestarsi di
uno dei due lascia inalterata l’incertezza sull’altro.
Ricordando che la probabilità che si verifichino più eventi
statisticamente indipendenti è pari al prodotto delle probabilità
dei singoli eventi, si può pensare di quantificare l’informazione
sfruttando la nota proprietà dei logaritmi
( ) ( ) ( ) (1.2.1)
In particolare si assume come informazione (A) associata ad un
evento che si manifesta con probabilità (A) valga:
( ) (
) (1.2.2)
L’informazione associata all’evento non dipende quindi dal-
la natura di quest’ultimo, ma solo dalla probabilità che esso ha di
manifestarsi, pertanto la notazione utilizzata è impropria poiché fa
apparire l’informazione come associata all’evento, non alla sua
probabilità.
La (1.2.2) soddisfa i due requisiti sopra indicati, in partico-
lare cresce al diminuire di . É stato dimostrato che il logaritmo è
l’unica funzione che soddisfa i requisiti sopra elencati.
Osserviamo anche che la base adottata per il logaritmo non
è concettualmente importante, cambiarla equivale ad introdurre
un fattore di scala, come appare ovvio se si ricorda la regola per il
cambiamento di base dei logaritmi:

Sorgenti con Alfabeto Continuo 11
(1.2.3)
In pratica scegliere la base nella (1.2.2) equivale a scegliere una
particolare unità di misura. La potenza di un motore non cambia
se viene misurata in KW o in HP, anche se espressa in cavalli è
più accattivante.
Nella Teoria dell’Informazione si utilizzano tipicamente
due basi per il logaritmo che compare nella (1.2.2) la base se si
intende misurare l’informazione il nat, o la base se la si vuole
misurare in bit (binary information unit non binary digit).
Ad esempio nel caso del lancio di una moneta non truccata al
manifestarsi dell’evento è associata un’informazione pari
a –
o a –
L’utilizzo del bit
come unità di misura è di regola preferito dal momento che la
quasi totalità dei moderni sistemi di informazione utilizza sistemi
di calcolo che lavorano in base e che i dati tra computer vengo-
no scambiati tipicamente sotto forma di parole binarie. In quel
che segue il logaritmo naturale verrà indicato con “ ” ed il loga-
ritmo in base con “ ” omettendo l’indicazione della base.
1.3 - Sorgenti d’Informazione
Una sorgente d’informazione, è un sistema che emette in
modo più o meno casuale sequenze d’elementi appartenenti ad un
assegnato insieme, l’alfabeto della sorgente.
Come vedremo, la natura dei simboli è del tutto inessen-
ziale per lo sviluppo della teoria, potremo quindi sempre pensare
che l’alfabeto sia numerico, cioè che la sorgente emetta una se-
quenza di variabili aleatorie, che, se l’insieme è finito, saranno di
tipo discreto. In alternativa possiamo pensare di definire sull’in-
sieme dei simboli emessi, che costituisce in sostanza l’insieme dei
risultati di un esperimento casuale, una V.A. biettiva.
Un sistema di trasmissione ha il compito di recapitare dei
dati in modo affidabile da un emissario a un destinatario. Il grado

0 - Appunti di Teoria dell’Informazione e Codici 12
d’affidabilità del sistema può essere caratterizzato dal numero
d’errori da cui è mediamente afflitto.
Si osservi che emissario e destinatario possono anche trovarsi nel-
lo stesso luogo ed essere addirittura lo stesso soggetto, come ad
esempio avviene nel caso della memorizzazione di dati, che si au-
spica possano essere utili in futuro, su un supporto fisico.
L’emissario in sostanza è una sorgente d’informazione che
può generare segnali a tempo continuo o discreto.
Le sorgenti di tipo discreto sono quelle che emettono dei
simboli, o lettere, appartenenti ad un assegnato insieme, al più
numerabile, che chiameremo alfabeto di sorgente.
Se la probabilità che in un dato istante la sorgente emetta
una qualunque lettera non dipende dai simboli emessi negli altri
istanti si dice che la sorgente è priva di memoria.
Una sorgente discreta priva di memoria (Discrete Memoryless Source,
DMS) potrebbe ad esempio essere quella che emette la sequenza
dei risultati ottenuti lanciando ripetutamente un dado, l’alfabeto
utilizzato sarebbe in questo caso costituito da sei simboli che si
potrebbero etichettare con i primi sei numeri naturali.
Viceversa una sorgente discreta dotata di memoria potreb-
be essere una sorgente che trasmette testi in lingua italiana. Esiste-
rebbero pochi dubbi su quale sarà il simbolo emesso successiva-
mente alla sequenza “p r e c i p i t e v o l i s s i m e v o l m e n t”,
almeno per quelli che hanno visto Mary Poppins, o sul fatto che
dopo l’emissione della lettera q verrà emessa una u, a meno che i
due simboli precedenti non siano stati s o, fatti salvi, ovviamente,
gli errori, sempre in agguato malgrado e, talvolta, a causa dei cor-
rettori ortografici.
Come anticipato nella premessa, non si perde generalità
ipotizzando che la sorgente emetta una sequenza di variabili
aleatorie che assumono valori appartenenti ad un sotto-
insieme di che si può porre in corrispondenza biunivoca con
l’insieme delle lettere che costituiscono l’alfabeto della sorgente

Sorgenti con Alfabeto Continuo 13
che supporremo finito.
In sostanza quanto detto equivale ad
associare un’etichetta numerica ad ogni lettera dell’alfabeto della
sorgente.
In quel che segue supporremo che la sia stazionaria
cioè che la sua statistica a qualunque ordine dipenda esclusiva-
mente dalla posizione relativa degli istanti di osservazione, non
dall’origine dei tempi. L’ipotesi appena fatta implica, tra l’altro,
che l’alfabeto utilizzato non vari al variare dell’indice temporale .
Detta la V.A. emessa dalla sorgente all’istante , ad ogni
simbolo dell’alfabeto si può associare una probabilità d’emis-
sione:
( ) (1.3.1)
L’informazione che si acquisirebbe rilevando l’emissione
della lettera senza nulla sapere sulle lettere precedentemente
emesse varrebbe quindi:
( ) ( ) (1.3.2)
assumendo ove necessario (
) , alla sorgente si può asso-
ciare la sua entropia:
( ) ∑ ( )
( )
∑
(1.3.3)
L’entropia ( ) appena definita, è la media statistica
dell’informazione associata all’emissione dell’ -esimo simbolo.
Essa rappresenta pertanto l’informazione che mediamente si
acquisisce per effetto dell’emissione di un simbolo da parte della
sorgente all’istante . Osserviamo che la stazionarietà della sequen-
za comporta che ( ) sia indipendente da , tale indice può
quindi essere omesso.
Si noti che anche l’entropia dipende esclusivamente dalla
distribuzione di probabilità dei simboli emessi e non dalla loro na-
tura.
0 - Appunti di Teoria dell’Informazione e Codici 14
L’entropia di una sorgente, è non negativa ed è limitata
superiormente. In particolare se l’alfabeto ha cardinalità si ha:
∑
(1.3.4)
Per verificare la precedente disuguaglianza consideriamo
due possibili dmp:
∑
∑
(1.3.5)
vale la seguente catena di disuguaglianze:
∑
∑
∑
∑
∑ (
)
(1.3.6)
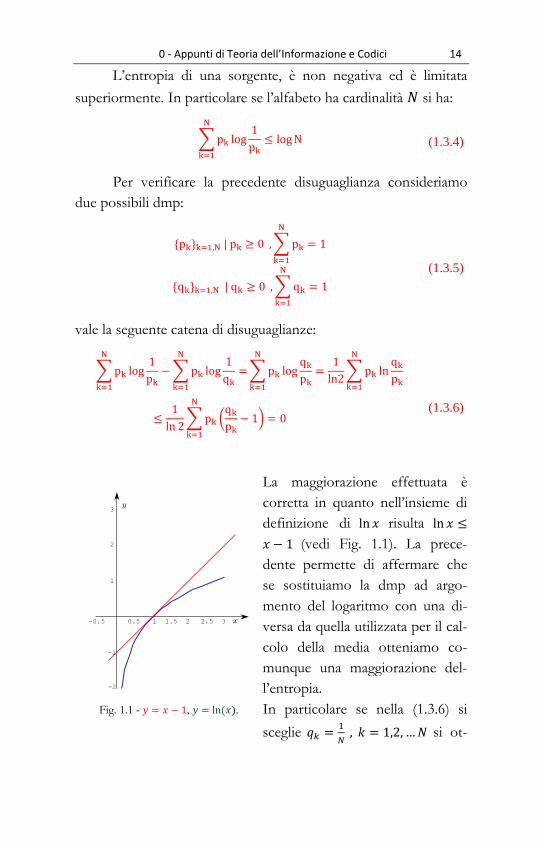
La maggiorazione effettuata è
corretta in quanto nell’insieme di
definizione di risulta
(vedi Fig. 1.1). La prece-
dente permette di affermare che
se sostituiamo la dmp ad argo-
mento del logaritmo con una di-
versa da quella utilizzata per il cal-
colo della media otteniamo co-
munque una maggiorazione del-
l’entropia.
In particolare se nella (1.3.6) si
sceglie
si ot-
Fig. 1.1 - , ( ).
x-0.5 0.5 1 1.5 2 2.5 3
-2
-1
1
2
3y
Sorgenti con Alfabeto Continuo 15
tiene:
∑
∑
( ) ∑
(1.3.7)
da cui la (1.3.4).
Esempio I.1.1
Si consideri una sorgente che emette simboli appartenenti a un alfabeto
binario costituito quindi da due soli simboli ad esempio, , detta la
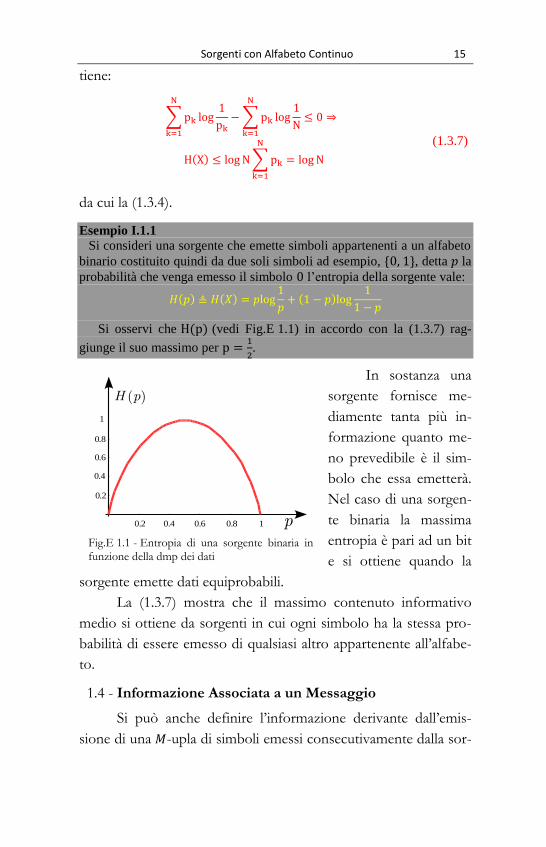
probabilità che venga emesso il simbolo l’entropia della sorgente vale:
( ) ( )
( )
Si osservi che ( ) (vedi Fig.E 1.1) in accordo con la (1.3.7) rag-
giunge il suo massimo per
.
In sostanza una
sorgente fornisce me-
diamente tanta più in-
formazione quanto me-
no prevedibile è il sim-
bolo che essa emetterà.
Nel caso di una sorgen-
te binaria la massima
entropia è pari ad un bit
e si ottiene quando la
sorgente emette dati equiprobabili.
La (1.3.7) mostra che il massimo contenuto informativo
medio si ottiene da sorgenti in cui ogni simbolo ha la stessa pro-
babilità di essere emesso di qualsiasi altro appartenente all’alfabe-
to.
1.4 - Informazione Associata a un Messaggio
Si può anche definire l’informazione derivante dall’emis-
sione di una -upla di simboli emessi consecutivamente dalla sor-
Fig.E 1.1 - Entropia di una sorgente binaria in
funzione della dmp dei dati
0.2 0.4 0.6 0.8 1
0.2
0.4
0.6
0.8
1
p
H p

0 - Appunti di Teoria dell’Informazione e Codici 16
gente. In questo caso parleremo di -messaggio emesso dalla sor-
gente, che possiamo pensare come la realizzazione di una V.A. -
dimensionale . Se l’alfabeto della sorgente ha
cardinalità allora esisteranno al più possibili messaggi. Indi-
cando con A , il generico -messaggio e con
( ) la probabilità che sia emesso, l’informazione ad esso
associata è data da:
( )
( ) (1.4.1)
mediando sui possibili messaggi otteniamo l’entropia associata
all’ -messaggio:
( ) ∑ ( )
( )
(1.4.2)
Se i simboli emessi dalla sorgente sono i.i.d. allora risulta:
( ) ∏ ( )
(1.4.3)
sostituendo la precedente nella (1.4.2):
( ) ∑ ( )
( )
∑ ( )
∏ ( )
∑ ( )∑
( )
∑ ∑ ( )
( )
∑∑ ( )
( )
( )
(1.4.4)
pertanto, se la sorgente è stazionaria e priva di memoria, l’entropia
associata ad un messaggio di lunghezza è volte l’entropia
associata al singolo simbolo.
Assumiamo adesso:

Sorgenti con Alfabeto Continuo 17
( ) ∏ ( )
(1.4.5)
( ) soddisfa ovviamente le condizioni necessarie per essere una
possibile dmp di una V.A.multidimensionale. Seguendo la falsa-
riga della (1.3.6) si può scrivere:
∑ ( )
( ) ∑ ( )
( )
∑ ( ) ( )
( )
∑ ( )
( ( )
( ) )
(1.4.6)
d’altro canto risulta:
∑ ( )
( )
∑ ( )
∏ ( )
∑ ( )
∑
( )
∑ ∑ ( )
( ) ∑ ∑ ( )
( )
∑ ( )
( )
(1.4.7)
dove l’ultima uguaglianza vale solo nel caso in cui i simboli emessi
dalla sorgente siano identicamente distribuiti, cioè nel caso in cui
la sorgente sia stazionaria, pur non essendo necessariamente priva
di memoria.
Dalle (1.4.6) e (1.4.7) deduciamo che in generale per sor-
genti stazionarie risulta
( ) ( ) (1.4.8)
cioè a parità di cardinalità dell’alfabeto e di lunghezza del mes-
saggio la massima informazione media è fornita da sorgenti prive
di memoria che emettono simboli equiprobabili.

0 - Appunti di Teoria dell’Informazione e Codici 18
SORGENTI CON ALFABETO CONTINUO
1.5 - Entropia di una Sorgente con Alfabeto Continuo
Consideriamo adesso una sorgente che emette con cadenza
regolare simboli appartenenti ad un insieme non numerabile.
Potremo cioè pensare che la sorgente emetta una sequenza
di variabili aleatorie di tipo continuo. La sorgente sarà per-
tanto equivalente da un processo aleatorio a tempo discreto conti-
nuo in ampiezza, che è completamente caratterizzato qualora sia
nota la sua statistica a qualunque ordine.
Per definire l’entropia ( ) di una tale sorgente, cioè l’in-
formazione che mediamente acquisiremmo in seguito all’emis-
sione di un singolo simbolo, senza nulla sapere dei simboli emessi
precedentemente da una tale sorgente, dovremo fare riferimento
alla densità di probabilità ( ) della variabile aleatoria che essa
genera in un dato istante. Se supponiamo che la sorgente sia
stazionaria tale densità di probabilità sarà indipendente dall’istante
di osservazione.
Basandoci su quanto detto per le sorgenti con alfabeto
discreto, sorge spontaneo definire tale entropia come segue:
( ) ∫ ( )
( )
(1.5.1)
assumendo che
. Tale definizione non gode di tutte le
proprietà di cui godeva l’entropia di una sorgente con alfabeto
finito, essa ad esempio può assumere anche valori negativi e può
non essere limitata.
Anche per le sorgenti ad alfabeto continuo possiamo defi-
nire l’entropia associata a più simboli emessi. Nel caso di due soli
simboli si ha:

Sorgenti con Alfabeto Continuo 19
( ) ∫ ∫ ( )
( )
∫ ∫ ( )
( )
∫ ∫ ( )
( )
( ) ( ) ( ) ( )
(1.5.2)
se e sono statisticamente indipendenti dalla precedente si
ottiene:
( ) ( ) ( ) (1.5.3)
Si può provare che in generale risulta:
( ) ( ) ( ) (1.5.4)
1.6 - Sorgenti Gaussiane
Osserviamo che:
( ) ∫ ( ) ( ( ))
∫ ( )( ( ) )
∫ ( ( ))
( ) ∫ ( ( ))
(1.6.1)
ne segue che se ∫ ( ( ))
la ( ) è limitata inferior-
mente. Ciò avviene certamente se la ( ) è limitata. La somma-
bilità di ( ) garantisce in questo caso anche quella di ( ( )) . La
( ) è certamente limitata inferiormente anche quando la ( )
non si mantiene limitata, purchè in corrispondenza ai valori di
in cui diverge lo faccia più lentamente di
con
per
. Consideriamo adesso una generica ddp ( ) risulta:

0 - Appunti di Teoria dell’Informazione e Codici 20
∫ ( )
( )
∫ ( )
( ) ∫ ( )
( )
( )
∫ ( ) (
( )
( ) )
(1.6.2)
La precedente può essere pensata come una generalizzazione della
(1.4.6).
Supponiamo che la sorgente emetta una variabile aleatoria
con varianza finita , ponendo nella (1.6.2) ( )
√
( )
,
cioè scegliendo una ddp Gaussiana con varianza otteniamo:
∫ ( )
( )
∫ ( ) (√
( )
)
√ ∫ ( )
∫ ( ) ( ( )
)
(
) ∫ ( )( )
(
)
(
)
(1.6.3)
d’altro canto si verifica facilmente che
(
) è anche
l’entropia di una variabile aleatoria Gaussiana, con varianza .
Quanto appena esposto ci porta a concludere che a parità
di varianza le sorgenti continue Gaussiane generano la massima
informazione media.
È opportuno osservare che l’entropia di una sorgente sta-
zionaria continua è indipendente dal valor medio della variabile
aleatoria emessa. Un valor medio non nullo incide solo sul valor
quadratico medio della sequenza emessa aumentandolo. Il che in
altri termine vale a dire che un valor medio diverso da zero au-

Sorgenti con Alfabeto Continuo 21
menta la potenza media del processo senza offrire alcun beneficio
in termini d’informazione media a esso associata.


Capitolo - 2
LA CODIFICA DI SORGENTE
2.1 - Premessa
Gli attuali sistemi di trasmissione sono spesso basati su un
mezzo trasmissivo di capacità limitata che viene condiviso tra più
utenti, diventa quindi essenziale cercare di ottimizzarne l’utilizzo
al fine di consentire l’accesso alla risorsa ad un maggior numero di
soggetti. È quindi auspicabile mettere in atto dei metodi che
consentano di “compattare” le informazioni da trasmettere in
modo da utilizzare il sistema per il minor tempo possibile, ovvero
da occupare una minore quantità di banda, senza pregiudicare il
contenuto informativo del messaggio. Lo stesso discorso ovvia-
mente vale nel caso dell’immagazzinamento delle informazioni,
“zippare” un file serve a sfruttare meglio la memoria dell’hard
disk.
La quasi totalità dei sistemi di trasmissione oggigiorno è
numerica, e fa uso di sistemi d’elaborazione digitale che lavorano
in base due, pertanto ci occuperemo di analizzare delle tecniche di
codifica di sorgente che associno alle singole lettere o a interi mes-
saggi emessi da quest’ultima delle parole binarie cioè delle stringhe
di lunghezza non necessariamente costante costituite utilizzando
un alfabeto di due sole lettere.
Una sorgente che utilizza un alfabeto di cardinalità può
emettere al più M-messaggi distinti, se a ciascuno di essi si
associa una parola binaria si dice che si è definito un codice.
2.2 - La Regola del Prefisso
Il codice citato nel precedente paragrafo può essere costru-
ito utilizzando parole binarie tutte con lo stesso numero di bit, nel
qual caso la lunghezza minima di tali parole non potrà essere infe-
riore a:

24 Capitolo - 2 - Appunti di Teoria dell’Informazione e Codici
( ) (2.2.1)
dove indica il primo intero non minore.
Si possono anche utilizzare parole di codice di lunghezza
variabile, in questo caso, però, occorrerà prestare attenzione al
fatto che se s’invia un file costituito da più -messaggi consecu-
tivi i singoli messaggi dovranno essere decodificabili in modo uni-
voco, dovremo in altri termini essere certi del fatto che a coppie
distinte di sequenze finite di messaggi il codice non associ la stessa
stringa binaria (da qui in poi con stringa indicheremo una sequen-
za di lunghezza finita di parole di codice).
Tale requisito è certamente soddisfatto se nessuna delle pa-
role del codice è identica alla parte iniziale di un’altra parola di
codice. In questo caso diciamo che il codice rispetta la regola del
prefisso.
È opportuno sottolineare che la regola del prefisso è solo
sufficiente, si potrebbero cioè individuare dei codici che pur non
rispettandola, sono decodificabili in modo univoco. Tali codici
tuttavia ci obbligherebbero per effettuare la decodifica ad atten-
dere la ricezione se non dell’intera sequenza di -messaggi certa-
mente di più di un messaggio. Viceversa, se il codice soddisfa la
regola del prefisso la decodifica può essere effettuata istanta-
neamente cioè ogniqualvolta una parola binaria coincide con una
parola di codice l’ -messaggio corrispondente si può dare per
identificato, non essendo possibile alcuna ambiguità.
2.3 - Lunghezza Media di un Codice.
Note le caratteristiche della sorgente e fissata la lunghezza
del messaggio da codificare e detto ( ) il numero di bit che co-
stituiscono la parola binaria ( ) che il codice associa all’ -mes-
saggio , ad ogni codice si può associare una lunghezza media del-
la parola di codice:
∑ ( ) ( )
(2.3.1)

La Codifica di Sorgente 25
ne discende che il numero medio di bit utilizzati per ciascun sim-
bolo emesso dalla sorgente è pari a
.
La conoscenza di tale dato è importante in quanto ci per-
mette ad esempio di stimare con buona approssimazione lo spa-
zio di memoria necessario per archiviare un file “tipico” costituito
da un numero sufficientemente grande di simboli emessi dalla
sorgente .
Dal nostro punto di vista un codice di sorgente è tanto mi-
gliore quanto minore è la sua lunghezza media a patto che ovvia-
mente la sua decodifica non risulti troppo onerosa.
Esiste un importante teorema che, nel caso di sorgenti
DMS stazionarie da un lato pone un limite inferiore alla lunghezza
media ottenibile al variare del codice scelto e dall’altro garantisce
che, se si è disposti ad accettare una maggiore complessità nei
processi di codifica/decodifica è possibile approssimare tale limite
bene quanto si vuole.
Per dimostrare tale teorema ci serviremo di una condizione
necessaria alla decodificabilità di un codice di sorgente, a differen-
za di quella del prefisso che, come già detto, è invece una condi-
zione sufficiente.
2.4 - La Disuguaglianza di Kraft.
Consideriamo una sorgente DMS con alfabeto di cardina-
lità ed un generico codice per gli -messaggi emessi da essa.
Comunque scelto vale l’identità:
( ∑ ( )
)
∑ ∑
∑ ( ( ) ( ) ( ))
(2.4.1)
la sommatoria ad ultimo membro della precedente può anche es-
sere calcolata “accorpando” i termini con uguale esponente. A tale
scopo indichiamo con la massima lunghezza raggiunta dalle
parole di codice. Il massimo esponente che può comparire nel-

26 Capitolo - 2 - Appunti di Teoria dell’Informazione e Codici
l’ultimo membro della (2.4.1) vale quindi . Ciò premesso,
possiamo scrivere:
( ∑ ( )
)
∑
(2.4.2)
essendo il numero di stringhe di bit che si possono ottenere
giustapponendo parole di codice.
Se pretendiamo che il codice sia univocamente decodifi-
cabile, dovrà necessariamente essere , se così non fosse,
esisterebbero certamente almeno due sequenze di -messaggi
codificate con la stessa stringa binaria di bit.
La considerazione fatta suggerisce per la (2.4.2) la seguente
maggiorazione:
( ∑ ( )
)
∑
∑
(2.4.3)
Osserviamo che la precedente deve valere per ogni e, vi-
sto che il primo membro, se crescesse con lo farebbe esponen-
zialmente, non può essere soddisfatta a meno che non risulti
∑ ( )
(2.4.4)
La precedente va sotto il nome di Disuguaglianza di Kraft ed
in quanto condizione necessaria all’univoca decodificabilità costi-
tuisce un vincolo sulla distribuzione delle lunghezze delle parole
di un codice.
Esempio 2.1
Premesso che:un grafo è definito da una coppia d’insiemi ( );
- l’insieme è detto insieme dei vertici ;
- l’insieme è detto insieme dei lati e definisce una
relazione (detta di adiacenza) su
- a ciascun vertice di un grafo si può associare un grado definito
come il numero di lati in cui esso appare;
- un percorso di lunghezza è definito come una sequenza di
vertici , tali che ( ) , ;

La Codifica di Sorgente 27
- un grafo è detto connesso se comunque scelti due vertici distinti
esiste un percorso tra essi;
- un ciclo è un percorso in cui il primo e l’ultimo vertice coinci-
dono;
- un albero è un grafo connesso senza cicli;
- in un albero i nodi di grado uno sono detti foglie;
- un albero ha radice se uno dei vertici viene etichettato come tale;
- un albero binario è un albero con radice in cui nessun vertice ha
grado maggiore di tre e la radice ha grado non maggiore di due;
- per ordine di un vertice si intende la lunghezza del percorso che
lo connette alla radice, i vertici di ordine adiacenti ad un
nodo di ordine sono detti figli ed il vertice che li connette è
detto padre.
Un metodo per costruire un codice che soddisfi la regola del prefisso
è definire un albero binario avente foglie ed associare ai vertici
stringhe binarie di lunghezza pari al loro ordine secondo le seguenti
regole:
- alla radice si associa la stringa vuota
- ai vertici figli si associano stringhe distinte ottenute a partire da
quelle associate ai vertici padri, giustapponendovi rispettiva-
mente i simboli ‘0’ ed ‘1’.
Al termine della costruzione, le foglie dell’albero hanno associate pa-
role di codice che soddisfano la regola del prefisso. È utile notare che la
diseguaglianza di Kraft è soddisfatta per costruzione. In particolare lo è
come uguaglianza nel caso in cui il numero di vertici dell’albero sia
.
2.5 - Limite Inferiore per la Lunghezza di un Codice.
Forti del precedente risultato consideriamo la seguente
funzione del generico -messaggio
( ) ( )
∑ ( )
(2.5.1)
( ) soddisfa tutte le condizioni per poter essere la dmp di una
-upla di variabili aleatorie discrete che assumono valori apparte-
nenti all’alfabeto , pertanto, tenendo conto della (1.3.6), si può
scrivere:

28 Capitolo - 2 - Appunti di Teoria dell’Informazione e Codici
( ) ∑ ( )
( )
∑ ( )
( )
∑ ( )
( )
∑ ( ) ( ∑ ( )
)
∑ ( ) ( )
( ∑ ( )
) ( ∑ ( )
)
(2.5.2)
La disuguaglianza di Kraft ci garantisce che il logaritmo al-
l’ultimo membro della precedente non è positivo, se ne conclude
che vale la disuguaglianza
( ) (2.5.3)
che, se la sorgente è stazionaria, comporta:
( )
(2.5.4)
La precedente ci fa capire che, non possono esistere codici
univocamente decodificabili che utilizzano un numero medio di
bit per simbolo minore dell’entropia della sorgente da codificare.
Esiste quindi un limite inferiore alla possibilità di “comprimere”,
senza perdite, le informazioni emesse dalla sorgente, a prescindere
dalla complessità del codificatore, che come s’intuisce, tipicamen-
te cresce al crescere di . La (2.5.4) ha anche il merito di chiarire
meglio l’importanza dell’entropia nell’ambito della Teoria dell’In-
formazione.
Esempio 2.2
Un algoritmo ricorsivo per la costruzione di un codice di sorgente
ottimo nel senso della lunghezza media delle parole è dovuto ad Huffman
(1952).
L’algoritmo di Huffman consiste nella costruzione ricorsiva di un
albero binario. Ricordando che l’obiettivo è ottenere la minore lunghezza
media possibile, si intuisce che a simboli meno probabili devono corri-
spondere parole di codice aventi lunghezza maggiore, ovvero foglie
aventi ordine maggiore.
Per costruire l’albero si deve disporre delle probabilità di mani-
festazione degli -messaggi . L’albero costruito dall’algoritmo di
Huffman ha vertici: i primi sono associati alle probabilità

La Codifica di Sorgente 29
, mentre i restanti vengono determinati ricorsivamente. A
ciascun vertice viene associata una variabile booleana che ne indica
l’utilizzo da parte dell’algoritmo.
Al passo -esimo, si procede come segue:
si scelgono tra i vertici non ancora marcati come utilizzati i due
vertici e aventi le probabilità associate minori, si marcano e
come utilizzati e si introduce un nuovo vertice avente probabilità
associata pari a si aggiungono all’insieme dei lati i due elementi
( ) e ( ).
Sostanzialmente l’algoritmo può essere riassunto come segue:
“inizialmente tutti i vertici sono orfani; a ciascun passo si scelgono i due
orfani aventi probabilità associata minima e li si dota di un vertice padre
(a sua volta orfano) avente probabilità pari alla somma delle probabilità
dei figli”.
Al termine dell’algoritmo resta un unico vertice non ancora utilizzato,
e lo si denota radice dell’albero. Una volta costruito l’albero, il codice di
Huffman è definito dalla procedura dell’Esempio 2.1.
Come esempio, consideriamo la costruzione di un codice di Huffman
per una sorgente DMS stazionaria avente alfabeto e
probabilità di emissione e .
Essendo la sorgente binaria, con il codice contiene due sole
stringhe ‘0’ ed ‘1’; la lunghezza media del codice risulta:
mentre l’entropia è data da:
( )
Con , gli M-messaggi possibili sono quattro, caratterizzati dalle
probabilità di emissione , , e ; l’albero costruito secondo l’algoritmo di Huffman è riportato in
Fig.E 2.1.
La lunghezza media del codice risulta:
( )
AA
BB
BA
AB
M-messaggio Parola di codice
AA 111
AB 110
BA 10
BB 0
1.00
0.51
0.09
0.21
0.49
0.21
0.30
Fig.E 2.1 - Albero e codice di Huffman associato al codice con M = 2

30 Capitolo - 2 - Appunti di Teoria dell’Informazione e Codici
ed il numero medio di bit utilizzati per simbolo ( ),
in accordo con la (2.5.4).
2.6 - La Proprietà di Equipartizione.
Occupiamoci adesso di un’importante proprietà delle
sorgenti d’informazione.
Consideriamo una DMS stazionaria con entropia ( ) ,
fissiamo un e, nell’insieme di tutti gli -messaggi, prendia-
mo in considerazione il sottoinsieme S così definito
{ ( ( ) )
( ) ( ( ) )} (2.6.1)
dalla precedente discende innanzi tutto che:
∑ ( ( ) )
∑ ( )
(2.6.2)
quest’ultima implica che la cardinalità di S non può essere mag-
giore di ( ( ) ) quindi tutti i messaggi appartenenti ad S pos-
sono essere codificati utilizzando parole di codice di lunghezza
fissa con un numero di bit non superiore a:
( ( ) ) (2.6.3)
Tenendo conto del fatto che la sorgente è per ipotesi priva di me-
moria si può anche scrivere:
{ ( ( ) ) ∑
( )
( ( ) )}
{ ( ) ∑ ( ( ))
}
(2.6.4)
Dall’ultimo membro della precedente si può facilmente
dedurre la definizione, del complementare di S rispetto
all’insieme degli -messaggi, precisamente:
{ |∑ ( ( ))
( )| } (2.6.5)

La Codifica di Sorgente 31
Ci proponiamo di maggiorare la probabilità dell’evento: “la
sorgente ha emesso un messaggio appartenete a ”. A tal fine ricordiamo
che la disuguaglianza di Chebyshev garantisce che la probabilità
che una V.A. con varianza disti dal suo valore medio per più di
è non maggiore di
.
Notiamo che ∑ ( ( ))
può essere interpretata
come una V.A. ottenuta sommando le variabili aleatorie statisti-
camente indipendenti ( ( )) tutte identicamente distri-
buite. Il valor medio di ciascuna di esse vale ( ) quindi il valor
medio di vale:
(∑ ( ( ))
) ( ) (2.6.6)
Anche la varianza di è volte la varianza di ( ( )) e vale:
∑( ( ( )) ( ))
( )
(2.6.7)
In conclusione, ponendo , la probabilità che un -
messaggio appartenga ad sarà non maggiore di
( )
∑ ( ( ( )) ( )) ( ( ))
(2.6.8)
La disuguaglianza appena scritta ci dice che la probabilità
che un -messaggio non appartenga a S tende a zero al tendere
di all’infinito.
In altri termini abbiamo appena mostrato che “asintoticam-
ente” i messaggi emessi da una sorgente possono essere suddivisi
in due classi la prima contiene messaggi sostanzialmente equipro-
babili con probabilità di manifestarsi ( ) , la seconda
contenente messaggi che si presentano con probabilità prossima a
zero.

32 Capitolo - 2 - Appunti di Teoria dell’Informazione e Codici
La proprietà appena descritta, che vale anche per sorgenti
dotate di memoria, va sotto il nome di proprietà di equipartizione
(equipartition property). Essa in sostanza ci dice che, pur di conside-
rare messaggi sufficientemente lunghi, il numero di messaggi di-
stinti che una sorgente emette è approssimativamente pari a
( ) che rappresenta solo una frazione degli teori-
camente generabili.
Il fatto che esista un sottoinsieme di messaggi aventi un’e-
sigua probabilità di manifestarsi può essere utilmente sfruttato nel
caso in cui si vogliano mettere a punto dei sistemi di codifica che
accettino una qualche perdita nel contenuto informativo. Si po-
trebbe ad esempio pensare di progettare un codificatore di sor-
gente che ignori i messaggi poco probabili. Ciò porterebbe a una
perdita d’informazione che potrebbe però essere trascurabile ri-
spetto a quella che si perderebbe comunque a causa ad esempio
degli errori introdotti dal sistema di trasmissione.
2.7 - Teorema sulla Codifica di una Sorgente DMS.
Abbiamo visto che la (2.5.4) impone un limite inferiore alla
lunghezza media del codice, ma, la stessa, nulla ci dice su quanto a
detto limite ci si possa avvicinare.
Per rispondere a questo quesito utilizzeremo la proprietà di
equipartizione introdotta nel paragrafo precedente al fine di co-
struire un codice univocamente decodificabile per gli M-messaggi
emessi dalla sorgente.
Fissiamo ad arbitrio un , possiamo utilizzare il primo
bit (binary digit) della parola del costruendo codice per classifi-
carla come appartenente o meno all’insieme S definito nel prece-
dente paragrafo. Osserviamo quindi che, per identificare univoca-
mente tutti gli elementi di S , sulla base della (2.6.3), saranno suf-
ficienti ulteriori S ( ( ) ) bit. Restano da codificare
gli elementi appartenenti ad . A tal fine ricordiamo che tali ele-
menti hanno una probabilità molto piccola di manifestarsi, quindi

La Codifica di Sorgente 33
incidono poco sulla lunghezza media del codice che è la quantità
che ci interessa limitare. Ciò premesso possiamo utilizzare per co-
dificarli un numero di bit , laddove bit
sarebbero sufficienti a codificare tutti gli M-messaggi.
In sostanza la generica parola di codice avrà lunghezza S o
, e non vi è nessuna ambiguità per il decodificatore che osser-
vando il primo bit di ogni parola saprebbe quale è la sua lunghez-
za. Ciò ovviamente è vero solo se il codificatore e il decodificatore
sono esenti da errori.
Calcoliamo adesso lunghezza media per simbolo emesso
dalla sorgente del codice che abbiamo appena costruito:
(
( ) ( )) (2.7.1)
che, tenuto conto della (2.6.8), si può maggiorare come segue:
(
( ) ( ))
(
( ))
(
)
( ( ( ) ) ) ( )
( ( ) ) ( )
( )
(2.7.2)
Si osservi che può essere scelto arbitrariamente, in parti-
colare possiamo scegliere
ottenendo:
( )
(
) (2.7.3)
Nella (2.7.3) tutti gli addendi a secondo membro eccetto il primo
tendono a zero al crescere di , possiamo quindi scriverla nella
forma:

34 Capitolo - 2 - Appunti di Teoria dell’Informazione e Codici
( ) ( ) (2.7.4)
La precedente ci permette di affermare che per una DMS,
accettando una maggiore complessità di codifica/decodifica, si
può costruire un codice con un numero medio di bit per simbolo
prossimo quanto si vuole alla sua entropia.
In conclusione mettendo insieme la (2.5.3) e la (2.7.4)
abbiamo dimostrato il seguente
Teorema 2.1 Data una DMS stazionaria con entropia ( ) e comunque scelto
, esiste un intero in corrispondenza al quale si può costruire un
codice univocamente decodificabile che esibisce una lunghezza media per
simbolo di sorgente che soddisfa la seguente disuguaglianza:
( )
( ) (2.7.5)
Inoltre, qualunque sia , non è possibile costruire codici per i quali
risulti:
( ) (2.7.6)
***********
Vale la pena di osservare che il codice che abbiamo co-
struito, se da un lato c’è stato utile per ottenere la (2.7.5), dal
punto di vista pratico sarebbe difficilmente applicabile perché
presuppone la conoscenza della dmp della sorgente, dato questo
di cui in pratica difficilmente si dispone. Esistono algoritmi di
codifica che tendono al limite inferiore imposto dalla (2.7.5) pur
non presupponendo la conoscenza della dmp in parola, e che
quindi si rivelano molto più utili in pratica.
Esempio 2.3
L’algoritmo di Huffman descritto nell’Esempio 2.2 richiede la cono-
scenza a priori delle probabilità dei simboli di sorgente. Descriviamo
brevemente un possibile metodo per ottenere una versione adattativa
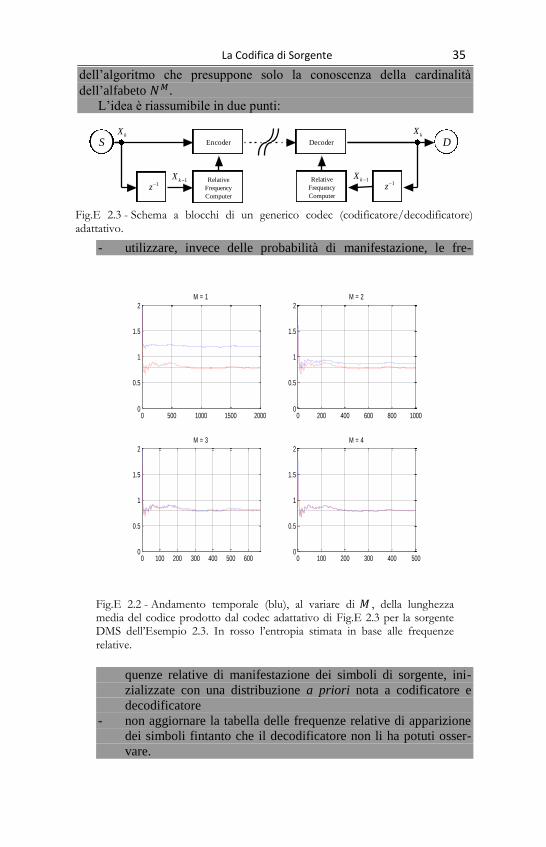
La Codifica di Sorgente 35
dell’algoritmo che presuppone solo la conoscenza della cardinalità
dell’alfabeto .
L’idea è riassumibile in due punti:
- utilizzare, invece delle probabilità di manifestazione, le fre-
quenze relative di manifestazione dei simboli di sorgente, ini-
zializzate con una distribuzione a priori nota a codificatore e
decodificatore
- non aggiornare la tabella delle frequenze relative di apparizione
dei simboli fintanto che il decodificatore non li ha potuti osser-
vare.
Fig.E 2.2 - Andamento temporale (blu), al variare di , della lunghezza media del codice prodotto dal codec adattativo di Fig.E 2.3 per la sorgente DMS dell’Esempio 2.3. In rosso l’entropia stimata in base alle frequenze
relative.
0 500 1000 1500 20000
0.5
1
1.5
2M = 1
0 200 400 600 800 10000
0.5
1
1.5
2M = 2
0 100 200 300 400 500 6000
0.5
1
1.5
2M = 3
0 100 200 300 400 5000
0.5
1
1.5
2M = 4
S Encoder
Relative
Frequency
Computer
kX
1kX
Decoder D
Relative
Frequency
Computer
kX
1kX
1z
1z
Fig.E 2.3 - Schema a blocchi di un generico codec (codificatore/decodificatore) adattativo.

36 Capitolo - 2 - Appunti di Teoria dell’Informazione e Codici
Lo schema di riferimento dell’algoritmo adattativo (che è di carattere
generale) è riportato in Fig.E 2.3Si noti che così descritto, questo metodo
richiede nella peggiore delle ipotesi la ricostruzione (previa verifica di
consistenza) dell’albero di Huffman per ogni simbolo trasmesso, il che
può essere impraticabile. Inoltre, l’algoritmo adattativo così formulato è
basato sull’assunzione che le frequenze relative convergano in tempi
brevi alle probabilità di manifestazione dei simboli; per “brevi” si in-
tende rispetto al tempo durante il quale si può assumere che la sorgente
sia effettivamente stazionaria.
In Fig.E 2.2 è mostrato l’andamento temporale della lunghezza
(media) del codice per un codificatore adattativo che elabora simboli
quaternari caratterizzati dalle probabilità di manifestazione ,
, e , al variare della lunghezza degli
M-messaggi; l’entropia della sorgente è pari a ( ) .
2.8 - Codifica di Sorgenti con Memoria.
Una sorgente è detta con memoria quando la probabilità di
emissione di un simbolo dipende dalla sequenza di simboli emessa
in precedenza:
( ) ( ) (2.8.1)
Come puntualizzato al termine del capitolo precedente, per
una sorgente discreta con memoria l’entropia di un M-messaggio è
minore dell’entropia della sorgente riguardata come senza memo-
ria. Ciò implica che codificare una sorgente con memoria con
metodi che possono essere ottimi nel caso di sorgenti DMS può
risultare ben lontano dall’ottimo.
Si potrebbe osservare che la proprietà di equipartizione,
valida anche per sorgenti con memoria, permette di affermare che
la codifica senza memoria di -messaggi è, asintoticamente per
, ottima; d’altra parte l’impiego di valori di maggiori di
qualche unità è quasi sempre proibitivo.
L’approccio utilizzato in pratica per la codifica di sorgenti
con memoria consiste nell’operare una forma di pre-codifica allo
scopo di rendere il più possibile incorrelata la sorgente. Riportia-
mo di seguito alcuni esempi didattici che s’ispirano a metodi im-
piegati nella pratica.

La Codifica di Sorgente 37
Esempio 2.4
Nel caso di sorgenti discrete ottenute tramite campionamento di
segnali a valori discreti (si pensi ad esempio ad una scansione FAX), si
può impiegare la codifica run-length (RLE).
L’idea alla base della RLE è sostituire sequenze costituite da simboli
identici con una indicazione di quale simbolo viene ripetuto quante volte.
Ad esempio, la codifica run-length della sequenza:
A, A, A, A, A, B, B, B, B, B, B, C, C, C, C, A, A, B, B, B, B, B, C, C, C
è data da:
(A,5), (B,6), (C,4), (A,2), (B,5), (C,3).
Per valutare l’efficienza della codifica run-length si deve tenere conto
dell’overhead richiesto per codificare la lunghezza dei run. Per ottenere
qualche numero tangibile, consideriamo la piccola immagine in bianco e
nero (32 righe, 128 colonne) in Fig.E 2.4
Questa immagine, riguardata come una sequenza di simboli binari
emessi da una sorgente DMS, ha una entropia di 0.5871 bit/simbolo (578
pixel neri, 3518 pixel bianchi), ovvero un contenuto informativo stimato
di 2405 bit.
Se codificata RLE per colonne con lunghezza massima dei run pari a
511, è rappresentata da 313 run aventi una entropia stimata di 4.582
bit/run ovvero un contenuto informativo complessivo non inferiore a
1435 bit (con un guadagno potenziale del 65% rispetto alla dimensione
non codificata di 4096 bit).
Si deve però notare che la lunghezza massima dei run è un parametro
problematico da impostare, in quanto se, da una parte, incrementandolo il
numero complessivo di run diminuisce, dall’altra il numero di bit
necessario a codificare la lunghezza di un singolo run aumenta, sicché
per immagini di piccola dimensione come questa l’effettivo guadagno
può risultare marginale.
Da segnalare che per la codifica di immagini in bianco e nero (ad.
esempio FAX), esistono generalizzazioni bidimensionali della codifica
run length, che sfruttano le correlazioni esistenti tra le righe.
Esempio 2.5
Nel caso di sorgenti discrete generiche esistono molti metodi, nes-
suno dei quali ottimo. Un approccio utilizzato nella codifica di sorgente
Fig.E 2.4 - Immagine (ingrandita in modo da evidenziare i singoli pixel) per l’esempio di codifica run-length (32x128x1).

38 Capitolo - 2 - Appunti di Teoria dell’Informazione e Codici
di dati correlati è quello a dizionario. Il più diffuso algoritmo di codifica
di sorgente a dizionario è il Lempel-Ziv (del 1977, LZ77), implementato
in molte utility “zip” (pkzip, winzip, infozip, gzip, compress e altre).
L’idea della codifica LZ77 è sostituire, nella sequenza originaria, a
sequenze di simboli già incontrate una indicazione di “a partire da dove”
e “per quanti simboli” è possibile copiarle. Per chiarire, consideriamo la
codifica LZ77 della sequenza dell’Esempio 2.4
(A,1,4), (B,1,5), (C,1,3), (A,11,6), (C,1,2).
Il primo blocco, (A,1,4), viene decodificato come: “dopo un simbolo
A, torna indietro di un passo e copia per quattro volte”, ovvero una
sequenza di cinque simboli A. Il secondo blocco ed il terzo blocco sono
analoghi al primo. Per comprendere come viene interpretato il quarto
blocco, notiamo che dopo i primi tre blocchi il decodificatore avrà
prodotto la sequenza:
A, A, A, A, A, B, B, B, B, B, B, C, C, C, C.
A questo punto, aggiungere un simbolo A, tornare indietro di undici
passi e copiare per sei volte corrisponde ad aggiungere la sequenza A, B,
B, B, B, B, C in coda. L’ultimo blocco è di tipo run-length come i primi
tre.
La codifica LZ77 dell’immagine in bianco e nero di Fig.E 2.4 è una
sequenza di solo 60 triplette aventi una entropia stimata di 11.52 bit
ciascuna, per un contenuto informativo complessivo non minore di 692
bit (con un guadagno potenziale dell’83% sulla dimensione non
codificata di 4096 bit).

Capitolo - 3
CANALI PRIVI DI MEMORIA
3.1 - L’Informazione Mutua.
Consideriamo un generico esperimento casuale. Abbiamo
detto che al manifestarsi di un dato evento è associata una
quantità d’informazione
( ); la stessa quantità può essere in-
terpretata come la nostra incertezza sull’evento . Ad esempio se
( ) allora sul fatto che si manifesti non abbiamo nes-
suna incertezza ed in questo caso si avrebbe
( ) nel caso
in cui ( ) fosse molto piccola avremmo una grande incertezza
sul fatto che si possa manifestare, ed acquisiremmo quindi una
grande informazione qualora si manifestasse.
Consideriamo adesso una coppia d’eventi , , il manife-
starsi di può variare la nostra incertezza su se ad esempio
il manifestarsi di rimuoverebbe tutta l’incertezza
( ) che a priori avevamo su . Se, viceversa, i due eventi
fossero statisticamente indipendenti il manifestarsi di lascereb-
be immutata l’incertezza che a priori avevamo su .
In altri termini se sapessimo che è verificato il manife-
starsi di ci fornirebbe un’informazione in genere diversa da
quella che avremmo avuto a priori (cioè senza saper nulla circa ).
In particolare l’informazione fornita a posteriori (cioè sapendo che
è verificato) dal manifestarsi di varrebbe
( ).
Si definisce informazione mutua ( ) tra due eventi, l’incer-
tezza che rimossa sull’evento per effetto del manifestarsi di
In formule:
( )
( )
( )
( )
( ) (3.1.1)

40 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
Alla luce della definizione appena data la scelta del nome
informazione mutua può apparire infelice, esso probabilmente
trae origine dal fatto che ricordando la regola di Bayes possiamo
scrivere:
( ) ( )
( ) ( )
( )
( ) ( ) (3.1.2)
Osserviamo che, nel caso in cui , ( ) varrebbe
( ) cioè ci fornisce su tutta l’informazione che ci po-
trebbe fornire stesso. cioè rimuoverebbe ogni incertezza su
. Se ( ) ( ) ( ) allora ( ) che sta a
significare che il manifestarsi di non modificherebbe la nostra
l’incertezza su .
È anche opportuno sottolineare che ( ) può assumere
anche valori negativi, ciò da conto del fatto che il manifestarsi di
potrebbe rendere molto più incerto, se non impossibile il ma-
nifestarsi di , ad esempio qualora si avrebbe
( ) ( )
( ) (3.1.3)
3.2 - Concetto di Canale.
Come già detto, un sistema di trasmissione serve a inviare
un messaggio da un emissario a un destinatario in luoghi e/o
tempi diversi. Per recapitare il messaggio, il sistema si giova di un
mezzo trasmissivo che viene abitualmente chiamato canale.
Il concetto di canale è piuttosto ampio, nel senso che esso
può includere, a seconda delle necessità, o solo il mezzo fisico, ad
esempio il solo doppino telefonico o un nastro magnetico, o an-
che tutto ciò che è compreso tra un microfono e un altoparlante.
Nel caso di un sistema di trasmissione numerico modulato
linearmente basato su di una costellazione bidimensionale, si può
pensare che il canale includa, modulatore, amplificatore RF, mez-
zo fisico, amplificatore d’ingresso, eventuale demodulatore a fre-
quenza intermedia, demodulatore, filtri adattati e campionatori. In

Canali Discreti Privi di Memoria 41
questo caso il canale accetta in ingresso un numero complesso
associato ad un punto della costellazione e fornisce in uscita un
numero complesso che in genere differisce da quello inviato per
effetto del rumore e dei disturbi introdotti dal mezzo e dagli appa-
rati. Se decidessimo di includere nel canale anche il decisore, l’u-
scita del canale sarebbe sì un punto della costellazione, ma, come
ben sappiamo, non sempre lo stesso che si era inviato.
Qui ci limitiamo a considerare canali di tipo discreto che
sono caratterizzati da un alfabeto d’ingresso e da uno d’uscita ,
legati da un mapping aleatorio.
In pratica non si lede la generalità se si pensano ingresso e
uscita come una coppia di variabili aleatorie definite sullo stesso
esperimento casuale.
Se l’alfabeto d’ingresso e quello d’uscita hanno rispettiva-
mente cardinalità ed e se e
sono i
rispettivi alfabeti, il canale è univocamente individuato quando
sono note le seguenti dmp condizionate:
( | ) ( | )
(3.2.1)
Risulta spontaneo pensare alle come agli elementi di una
matrice con un numero di righe pari alla cardinalità dell’alfa-
beto di ingresso e un numero di colonne uguale alla cardinalità di
quello d’uscita. Chiameremo matrice di transizione di canale.
Nel caso in cui l’alfabeto d’ingresso è finito e quello d’uscita
ha la potenza del continuo il canale è caratterizzato se si cono-
scono le seguenti densità di probabilità condizionate:
( | ) ( | ) (3.2.2)
Si dice che il canale è privo di memoria se, la pro-
babilità di rivelare un data sequenza di simboli d’uscita in
corrispondenza ad un dato -messaggio di ingresso è data da

42 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
( [ ] | [ ]) ∏ ( )
(3.2.3)
se l’alfabeto d’uscita è finito.
Ovvero la densità di probabilità della sequenza d’uscita
condizionata ad una sequenza d’ingresso è data da:
( )( ) ∏ ( | )
(3.2.4)
nel caso in cui l’alfabeto d’uscita ha la potenza del continuo.
Se in ingresso al canale è connessa una sorgente che emette
simboli compatibili con il canale, e se sono note le probabilità d’e-
missione ( ) di ciascun simbolo dell’alfabeto di sorgente
dalle (3.2.1) e (3.2.2) possiamo dedurre la distribuzione di massa
di probabilità dell’alfabeto d’uscita del canale, cioè dei simboli
:
( ) ∑
(3.2.5)
ovvero la densità di probabilità della V.A. d’uscita:
( ) ∑ ( )
(3.2.6)
Consideriamo un canale discreto e privo di memoria (DMC
- Discrete Memoryless Channel).
Se in uscita rilevassimo il simbolo l’incertezza residua
sull’emissione del generico simbolo d’ingresso varrebbe:
( )
(3.2.7)
che ricordando la (3.1.2) è uguale a
( )
( )
(3.2.8)

Canali Discreti Privi di Memoria 43
mediando su tutte le possibili coppie ingresso uscita otteniamo
una misura dell’incertezza che mediamente rimane sul simbolo in
ingresso dopo aver osservato il corrispondente simbolo in uscita:
( ) ∑ ∑ ( ) ( )
( )
∑ ∑ ( ) ( | )
( )
∑ ∑ ( )
(3.2.9)
Abbiamo appena definito l’informazione mutua media. Sostituendo
nella precedente la (3.2.5) otteniamo ancora:
( ) ∑ ∑
∑
(3.2.10)
Sebbene l’informazione mutua (3.2.8) possa assumere an-
che valori negativi così non è per l’informazione mutua media
(3.2.9), risulta infatti:
( )
∑ ∑
∑ ∑ (
)
∑ ∑ ( )
[∑ ∑
∑ ∑ ( )
]
(3.2.11)
3.3 - L’equivocazione.
La ( ) si può anche scrivere:

44 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
( ) ∑ ∑ ( ) ( )
( )
∑ ( )
( )
∑ ∑ ( )
( )
(3.3.1)
Il primo addendo ad ultimo membro della precedente rappresenta
l’entropia della sorgente ( ), il secondo la cosiddetta equivocazione
( ) ∑ ∑ ( )
( ) . Si costata che ( )
Utilizzando l’equivocazione possiamo scrivere:
( ) ( ) ( ) ( ) (3.3.2)
La ( ) deve il suo nome al fatto che essa rappresenta la
quantità l’informazione che viene mediamente dispersa dal canale.
Essa risulta infatti nulla nel caso di canale ideale, cioè nel caso in
cui il simbolo in uscita dal canale determina con certezza il sim-
bolo emesso dalla sorgente. In questo caso avremmo cioè
( ) ( ). Nel caso di canale inutile, cioè nel caso in cui l’u-
scita del canale sia statisticamente indipendente dal suo ingresso,
avremmo ( ) ( ) e, conseguentemente, ( ) . Tutta
l’informazione della sorgente verrebbe pertanto dispersa dal
canale.
3.4 - La capacità di canale
Osservando la (3.2.10) ci rendiamo conto che l’informa-
zione mutua non dipende solo dal canale, ma anche dalla dmp
della sorgente. Al fine di fornire una grandezza caratteristica del
solo canale si procede alla ricerca del massimo della (3.2.10) al va-
riare delle distribuzioni di massa di probabilità
della sorgente. Otteniamo così la capacità di canale:
( )
(3.4.1)

Canali Discreti Privi di Memoria 45
che, come vedremo, gioca un ruolo fondamentale nel dimensiona-
mento di un sistema di trasmissione. La ricerca del suddetto
massimo, dato il tipo di dipendenza da non è in genere sem-
plice.
Ricordando la (1.3.7) e la (3.3.2) per un canale con alfabeto
di ingresso di cardinalità possiamo scrivere:
( ) ( ) (3.4.2)
La precedente vale per ogni possibile informazione mutua, quindi
anche per quella in corrispondenza alla quale si raggiunge la capa-
cità del canale. Ne concludiamo che la capacità di un canale dis-
creto è limitata superiormente dal logaritmo della cardinalità del-
l’alfabeto d’ingresso.
3.5 - Il Canale Simmetrico Binario.
Si consideri un canale
schematizzato in Fig. 3.1 che
accetta ed emette simboli ap-
partenenti a un alfabeto bi-
nario costituiti cioè rispetti-
vamente da due soli simboli,
, .
La matrice di transizio-
ne ad esso associata è quindi
una che se risulta è simmetrica. La matrice di
transizione di canale in questo caso vale:
|
| (3.5.1)
Un canale caratterizzato dalla matrice appena scritta è detto Canale
simmetrico binario (BSC, Binary Simmetric Channel).
Se il canale è connesso a una sorgente che emette simboli
con probabilità , risulta:
Fig. 3.1 - Canale Simmetrico Binario

46 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
( ) ( ) ( )( )
(3.5.2)
L’informazione mutua media di un BSC varrà quindi:
( ) ∑ ∑
∑ ∑
∑ ∑
∑ ∑
∑
( ) ( ) ( )
( )( ) ( ) ∑
( ) ( ) ∑
( ) ( )
(3.5.3)
Dalla precedente si evince che la
capacità di canale si ottiene massimiz-
zando l’entropia dell’uscita ( ), che,
come già visto, raggiunge il suo mas-
simo quando i simboli d’uscita sono e-
quiprobabili, cosa che, data la simme-
tria del canale, avviene quando lo sono
quelli emessi dalla sorgente.
Concludiamo che la capacità di un
BSC vale:
( ) (3.5.4)
(vedi Fig. 3.2).
È interessante osservare che
implicherebbe che
da conto del fatto che in questo caso il canale sarebbe ovviamente
del tutto inutile ai fini del trasferimento d’informazione.
Fig. 3.2 - Capacità del canale sim-metrico binario

Canali Discreti Privi di Memoria 47
3.6 - Capacità del Canale AWGN a Banda Limitata.
Consideriamo adesso il canale
con ingresso e uscita ad alfabeto
continuo rappresentato in Fig. 3.3
esso aggiunge alla variabile aleatoria
generata dalla sorgente un disturbo
costituito da una variabile aleatoria
, Gaussiana a media nulla e varianza , statisticamente indipen-
dente dalla variabile aleatoria in ingresso.
L’informazione mutua associata al canale in questione è da-
ta da:
( ) ( ) ( )
∫ ( )
( )
∫ ∫ ( )
( )
∫ ( )
( )
∫ ( )∫ ( )
( )
(3.6.1)
Osserviamo che ( )
√
( )
in quanto differisce da
per il solo disturbo che abbiamo detto essere Gaussiano. So-
stituendo nella (3.6.1) e ricordando la (1.6.3) otteniamo:
( ) ∫ ( )
( )
∫ ( ) (
)
∫ ( )
( )
(
)
(3.6.2)
Per ottenere la capacità del canale dobbiamo massimizzare
l’integrale ad ultimo membro, cioè l’entropia dell’uscita. Sappiamo
(vedi § 1.6 - ) che il massimo dell’entropia, a parità di varianza, si
ottiene da una sorgente Gaussiana.
SX
n
Y
Fig. 3.3 - Canale Gaussiano

48 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
Affinché la ( ) sia Gaussiana, tale deve essere la variabile
aleatoria in ingresso Indicata con la sua varianza, in virtù
della supposta indipendenza tra ed si ha:
(3.6.3)
La capacità del canale Gaussiano è quindi data da:
( )
( )
(
)
(
)
(
)
(3.6.4)
Consideriamo adesso il ca-
nale AWGN (Addittive White
Gaussian Noise) (vedi Fig. 3.4)
cioè un canale con ingresso e u-
scita a tempo continuo che agisce
sul segnale d’ingresso sommando
a quest’ultimo un segnale stazionario Gaussiano a media nulla e
densità spettrale di potenza bilatera costante pari ad
Come sappiamo ogni sistema di trasmissione è affetto quan-
tomeno dal rumore termico che si può modellare proprio con un
processo Gaussiano bianco.
Ogni sistema d’interesse pratico tratta di fatto segnali a banda
limitata. Pertanto, per ridurre la potenza di rumore introdotta il
canale viene sempre limitato in banda tramite un apposito filtro
passabasso o passabanda posto tipicamente in ingresso al ricevito-
re. Se indichiamo con la banda del segnale sappiamo che esso
può essere ricostruito a partire dai suoi campioni purché ne ven-
gano prelevati almeno al secondo. Il canale AWGN equivale
quindi a un canale Gaussiano utilizzato con la stessa cadenza. La
varianza dei campioni del segnale coinciderà con la potenza media
del segnale, e quella del rumore con la frazione di potenza di
quest’ultimo contenuta nella banda del segnale risulta quindi:
Fig. 3.4 - Canale AWGN

Canali Discreti Privi di Memoria 49
( )
(3.6.5)
dove ( ) rappresenta la potenza del segnale e indica la densi-
tà spettrale di potenza monolatera del rumore. Sostituendo nella
(3.6.4) otteniamo:
(
( )
) (3.6.6)
La precedente indica la capacità del canale AWGN limitato
in banda per uso del canale, espressa quindi in bit. In pratica è più
utile esprimere la capacità in termini di bit al secondo, in questo
caso a partire dalla precedente è sufficiente osservare che il canale
viene utilizzato volte al secondo. La capacità espressa in
del canale in questione vale quindi:
( ( )
) (3.6.7)
Osserviamo che nella (3.6.7) appare il rapporto segnale ru-
more. Essa ci dice che per aumentare la capacità di un canale a
tempo continuo possiamo aumentarne il rapporto segnale rumore
o aumentarne la banda. Occorre però tener presente che un
aumento del rapporto segnale rumore comporta sì un aumento
della capacità, ma detto aumento non segue una legge lineare
bensì una legge logaritmica. In sostanza, affinché la capacità del
canale aumenti di un bit al secondo, la potenza del segnale do-
vrebbe approssimativamente raddoppiare quindi parrebbe molto
più efficace agire sulla banda del segnale, osserviamo però che, a
parità di potenza del segnale, un aumento della banda comporta
un deterioramento del rapporto segnale rumore. Per meglio capire
come tali effetti si combinino, mantenendo costante la potenza
del segnale e la densità spettrale monolatera del rumore, fac-
ciamo tendere nella precedente la banda ad infinito. Otteniamo:

50 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
( ( )
)
( ( )
)
( )
( )
(3.6.8)
La precedente ci fa capire che un aumento della banda a parità di
potenza del segnale comporta oltre certi limiti effetti trascurabili
sulla capacità del canale, viceversa, a parità di banda aumentando
la potenza trasmessa si può aumentare, almeno in linea di princi-
pio, la capacità del canale indefinitamente. Ciò, come abbiamo
mostrato nel § - 3.4 - non accade nei canale con alfabeto di
ingresso e di uscita finiti la cui capacità è limitata dal logaritmo
della cardinalità dell’alfabeto di ingresso.
3.7 - Informazione Mutua tra -messaggi.
Consideriamo un DMC. Utilizzando le dmp congiunte,
possiamo facilmente definire l’informazione mutua tra -messag-
gi in ingresso e in uscita.
( ) ∑ ∑ ( )
( )
( )
(3.7.1)
la precedente può anche essere riscritta:
( ) ∑ ( )
( )
∑ ∑ ( )
( )
(3.7.2)
e, ricordando la (1.3.6), può essere maggiorata come segue:
( ) ∑ ( )
∏ ( )
∑ ∑ ( )
( )
∑ ∑ ( ) ( ) ∏ ( )
( )
∑ ∑ ∑ ( ) ( ) ( )
( )
∑ ( )
(3.7.3)

Canali Discreti Privi di Memoria 51
L’uguaglianza vale se i simboli d’uscita sono mutuamente statisti-
camente indipendenti perché in questo caso si avrebbe ( )
∏ ( )
. Questa condizione è certamente soddisfatta se la
sorgente è priva di memoria.
Se la sorgente ed il canale sono stazionari tenuto conto del-
la (3.4.1) possiamo ulteriormente scrivere:
( ) ∑ ( )
( ) (3.7.4)
3.8 - Canali in Cascata.
Consideriamo adesso il caso di due canali in cascata (vedi
Fig. 3.5). Supponiamo che l’alfabeto d’uscita del primo canale
coincida con quello d’ingresso del secondo, e che l’uscita di cia-
scun canale dipenda esclusivamente dal suo ingresso. Ciò significa
che
( ) ( ) (3.8.1)
Facendo sempre riferimento alla figura, consideriamo la dif-
ferenza tra le informazioni mutue ( )ed ( ). Si ha:
( ) ( ) ∑ ( ) ( )
( )
∑ ( ) ( )
( )
∑ ( ) ( ) ( )
( ) ( )
(3.8.2)
Fig. 3.5 - Canali in cascata

52 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
∑ ( ) (
( ) ( )
( ) ( ) )
(∑
( ) ( ) ( )
( ) ( )
∑ ( )
)
(∑
( ) ( ) ( ) ( )
( ) ( )
)
(∑
( ) ( ) ( )
( )
)
(∑ ( ) ( ) ( )
)
(∑ ( )∑ ( )
)
(∑ ( )
)
In definitiva abbiamo mostrato che se si collegano due, o,
ovviamente, più canali in cascata l’informazione mutua tra ingres-
so e uscita può solo diminuire. Il risultato appena ottenuto vale
anche nel caso in cui si colleghino in cascata al canale dei sistemi
deterministici, come ad esempio un codificatore in ingresso e\o
un decodificatore d’uscita.
Consideriamo (vedi Fig. 3.6) il caso di una DMS connessa a
un codificatore che opera in modo deterministico su M-messaggi
emessi dalla sorgente per generare sequenze di lettere compati-
bili con un DMC con alfabeti d’ingresso e d’uscita della stessa car-
Fig. 3.6
Codificatore Canale DecodificatoreS
1 MX XX 1 MV VV 1 LY YY 1 LZ ZZ

Canali Discreti Privi di Memoria 53
dinalità . L’uscita del canale è poi connessa a un decodificatore
che opera in modo deterministico sugli -messaggi emessi dal
canale per “cercare” di ricostruire gli -messaggi emessi dalla sor-
gente. Ovviamente una condizione sufficiente affinché in uscita
venga ricostruito correttamente il messaggio è che il canale non
abbia introdotto disturbi tali da indurre il decodificatore in errore.
Assumiamo inoltre che le durate dell’ -messaggio emesso
dalla sorgente e del corrispondente -messaggio in uscita al codifi-
catore siano uguali, pertanto se la sorgente emette lettere con una
cadenza regolare la cadenza dei simboli in ingresso al canale
sarà data da:
(3.8.3)
Con riferimento alla Fig. 3.6 considerando l’informazione
mutua ( ), tenuto conto della (3.8.2) possiamo scrivere:
( ) ( ) ( ) (3.8.4)
dove è la capacità relativa ad una coppia di simboli ingres-
so/uscita del canale.
3.9 - L’Inverso del Teorema della Codifica di Canale
Il nostro obiettivo nella progettazione di un sistema di tra-
smissione è ottenere la minore probabilità d’errore compatibil-
mente con dei prefissati vincoli di potenza impiegabile e/o di
banda, senza tralasciare ovviamente la complessità del sistema
che, anche quando non si scontra con barriere tecnologiche, ha
comunque un impatto sui costi.
Facendo sempre riferimento alla Fig. 3.6 considerando ad
esempio la -esima lettera dell’ -messaggio emesso dalla sorgente,
il sistema commette un errore se la -esima lettera del corrispon-
dente -messaggio in uscita dal decodificatore non coincide con
quella emessa.

54 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
La probabilità che il sistema commetta un errore sulla -
esima lettera del messaggio è quindi uguale alla ( ), che, in
termini della dmp congiunta delle variabili vale:
∑
( )
(3.9.1)
La probabilità d’errore appena calcolata dipende in genere
dall’indice . Se volessimo farci un’idea della probabilità d’errore
media, , su un generico simbolo dell’ -messaggio potremmo
calcolare la media aritmetica delle ottenendo:
∑
(3.9.2)
Consideriamo la catena di disuguaglianze:
( ) ( )
∑ ( )
( )
∑ ∑ ( ) ( )
( )
∑ ∑ ( )
( )
∑ ( ( ) ∑ ( )
( )
)
∑
(
( ) ∑ ( )
∏ ( | )
)
∑ ∑ ∑ ( )
( | )
∑ ∑ ∑ ( )
( | )
(3.9.3)
Il nostro scopo è quello di esplicitare il legame tra le gran-
dezze associate all’informazione e la probabilità d’errore espressa

Canali Discreti Privi di Memoria 55
dalla (3.9.1), appare pertanto opportuno riscrivere la (3.9.3) nella
forma:
( ) ( )
∑
(
∑ ( )
( )
∑ ( )
( )
)
(3.9.4)
Introducendo la probabilità di corretta decisione
sul -esimo simbolo possiamo maggiorare la seconda somma-
toria in parentesi nella precedente come segue:
∑ ( )
( | )
∑ ( )
( | )
∑ ( )
( | )
∑ ( )
∑ ( ) (
( ) )
∑( ( ) ( ))
( )
( )
(3.9.5)
Procedendo in modo analogo sulla prima sommatoria in
parentesi nella (3.9.4) si ottiene anche:
∑ ( )
( | )
∑ ( ) ( )
( | )( )
(3.9.6)

56 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
∑ ( )
( | )( )
∑ ( ) ( )
∑ ( ) (
( | )( ) )
( )
(
∑ ( )
( | )( )
)
( )
(
∑ ( ) ∑
( )
)
( )
( )
(ricordiamo che rappresenta la cardinalità dell’alfabeto ).
Tenuto conto delle (3.9.5) e (3.9.6) il primo membro della
(3.9.4) può essere ulteriormente maggiorato:
( ) ( ) ∑[ ( )
( )
]
∑[ ( )
( )
]
∑ ( ) ( )
( ) ∑ ( )
(3.9.7)

Canali Discreti Privi di Memoria 57
Nella precedente ( ) può essere interpretata come l’entropia di
una sorgente binaria con probabilità e .
Ricordando la (1.3.6) possiamo ancora scrivere:
( ) ( )
( )
∑[
( )
]
( )
( )
( ) ( )
(3.9.8)
Sfruttando il fatto che, per ipotesi, la sorgente è priva di
memoria e tenendo in conto la (3.8.4) abbiamo ancora:
( ) ( ) ( ) ( ) ( ) ( )
( ) (3.9.9)
che, in virtù della (3.8.3), conduce alla:
( ) ( ) ( )
( )
(3.9.10)
Per assegnata cardinalità dell’alfabeto di sorgente possiamo
tracciare il grafico della funzione: ( ) ( ) ( ).
Come si può notare (vedi Fig. 3.7) la ( ) pertanto la
limitazione imposta dalla (3.9.10), che per comodità riscriviamo
nella forma:
( ) ( )
(3.9.11)
non avrà alcun effetto fintanto che risulta ( )
o, che è
lo stesso, quando
( )
(3.9.12)

58 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
cioè fintantoché l’entropia
della sorgente espressa in bit
al secondo si mantiene mi-
nore della capacità di canale,
anch’essa espressa in bit al
secondo.
Quando viceversa la
(3.9.12) non è soddisfatta la
(3.9.11) pone un limite infe-
riore alla probabilità d’errore
ottenibile; saranno compati-
bili con la (3.9.11) solo va-
lori di che fanno si che il valore assunto dalla ( ) resti al di
sopra della quantità ( )
.
Nel piano di Fig. 3.7, ( )
è una retta parallela all’asse
delle ascisse. Saranno dunque compatibili con la (3.9.11) soltanto
valori di probabilità d’errore che restino alla destra dell’ascissa
dell’intersezione di detta retta con la curva ( ).
Quello che abbiamo appena dimostrato è noto come: inverso
del teorema della codifica di canale.
Teorema 3.1 Non è possibile ottenere una probabilità d’errore piccola a piacere
all’uscita di un canale che ha una capacità
[
] se quest’ultima è minore
dell’entropia (espressa in [
]) della sorgente ad esso connessa.
**********
Purtroppo il teorema appena enunciato nulla ci dice circa la
probabilità di errore effettivamente ottenibile nel caso in cui la ca-
pacità del canale sia maggiore dell’entropia della sorgente.
Fig. 3.7 - ( ) ( ) ( )
Pe
eF P
1N
N
logN
1

Canali Discreti Privi di Memoria 59
3.10 - Il piano di Shannon
Riprendiamo in considerazione il canale AWGN, abbiamo
calcolato la sua capacità ( ( )
) [
].
Alla luce del teorema appena dimostrato l’entropia di una
sorgente ad esso connessa dovrà essere inferiore a tale capacità se
non vogliamo porre un limite inferiore alla probabilità d’errore ot-
tenibile. Dovremo quindi avere
( )
(
( )
) (3.10.1)
Il primo membro può essere interpretato come il numero medio
di bit che la sorgente emette ogni secondo, lo chiameremo velocità
di informazione . Detto il tempo impiegato dalla sorgente per
emettere un bit di informazione avremo:
(3.10.2)
Sostituendo nella (3.10.1) abbiamo:
(
( )
) (3.10.3)
Vogliamo utilizzare quest’ultima per confrontare l’efficienza di
sistemi di trasmissione numerica diversi. È utile a tal fine fare
riferimento all’energia ( ) che il sistema di trasmissione
utilizzato mediamente assegna ad ogni bit. Utilizzando la (3.10.2)
otteniamo:
(
)
(3.10.4)
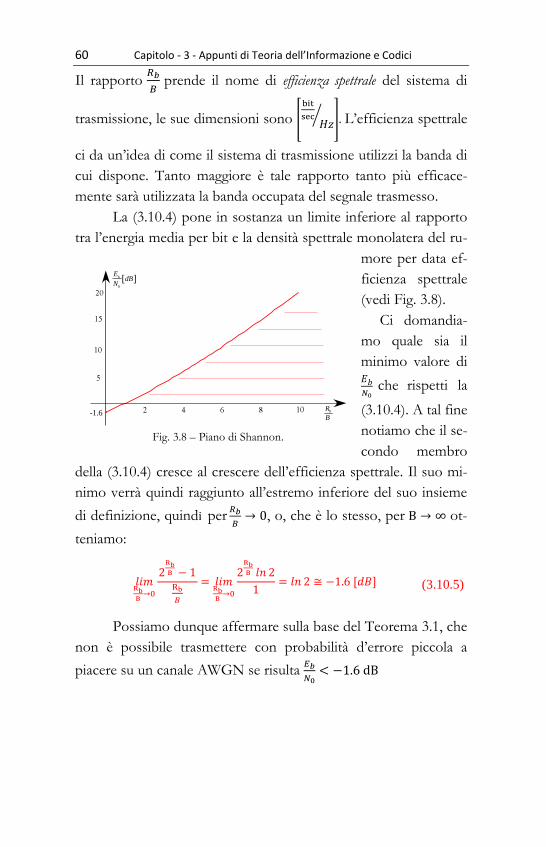
60 Capitolo - 3 - Appunti di Teoria dell’Informazione e Codici
Il rapporto
prende il nome di efficienza spettrale del sistema di
trasmissione, le sue dimensioni sono [
⁄ ] L’efficienza spettrale
ci da un’idea di come il sistema di trasmissione utilizzi la banda di
cui dispone. Tanto maggiore è tale rapporto tanto più efficace-
mente sarà utilizzata la banda occupata del segnale trasmesso.
La (3.10.4) pone in sostanza un limite inferiore al rapporto
tra l’energia media per bit e la densità spettrale monolatera del ru-
more per data ef-
ficienza spettrale
(vedi Fig. 3.8).
Ci domandia-
mo quale sia il
minimo valore di
che rispetti la
(3.10.4). A tal fine
notiamo che il se-
condo membro
della (3.10.4) cresce al crescere dell’efficienza spettrale. Il suo mi-
nimo verrà quindi raggiunto all’estremo inferiore del suo insieme
di definizione, quindi per
, o, che è lo stesso, per ot-
teniamo:
(3.10.5)
Possiamo dunque affermare sulla base del Teorema 3.1, che
non è possibile trasmettere con probabilità d’errore piccola a
piacere su un canale AWGN se risulta
Fig. 3.8 – Piano di Shannon.
0
bE
dBN
bR
B-1.6

Capitolo - 4
CENNI DI TRASMISSIONE NUMERICA
4.1 - Scenario di Riferimento.
Al fine di introdurre il teorema di Shannon sulla codifica di
canale, è opportuno introdurre alcuni concetti di trasmissione
numerica.
Come schema di principio del nostro sistema consideriamo
una sorgente che emette lettere appartenenti ad un alfabeto
di cardinalità finita N con una cadenza di lettere al secondo. La
suddetta sorgente è connessa a un codificatore di sorgente che
ogni secondi emette un -messaggio ( ) (
) che potremo pensare come il risultato di un
esperimento casuale . ( ) piloterà un codificatore di canale.
Il codificatore di canale, o modulatore, ha il compito di
associare ad ogni ( ) un segnale ( ) ad energia finita,
individuato da una funzione reale ( )( ), di durata non maggiore
di , che verrà inviato sul canale, che qui supporremo AWGN,
cioè un canale che si limita a sommare al segnale un processo
stazionario Gaussiano bianco ( ), con densità spettrale di poten-
za bilatera costante , o, che è lo stesso, con funzione di autocor-
relazione ( ) ( ).
Il ricevitore è chiamato, a fornire una stima dell’ -
messaggio trasmesso, basandosi sul segnale ricevuto e, ove pos-
sibile, sulla conoscenza della statistica di sorgente.
4.2 - Struttura del modulatore e del codificatore di sorgente
Il set di segnali utilizzato dal codificatore di canale
sopra citato ha cardinalità finita. Esso sarà pertanto contenuto in
un sottospazio S di dimensione dello spazio dei segnali a
energia finita.

62 Capitolo - 4 - Appunti di Teoria dell’Informazione e Codici
Tramite la procedura di ortonormalizzazione di Gram-
Smith potremo costruire quindi una base ortonormale per
S . Ogni segnale emesso dal modulatore si può quindi esprimere
nella forma:
∑
(4.2.1)
La precedente suggerisce anche uno schema di principio
per il codificatore di sorgente che in sostanza associa a ogni se-
quenza di lettere emesse dalla sorgente il vettore
che consente al codificatore di canale di gene-
rare a sua volta tramite la (4.2.1) il segnale da inviare sul ca-
nale.
4.3 - Struttura del Ricevitore.
Trascurando il ritardo introdotto dal canale, nell’intervallo
), il ricevitore vede al suo ingresso il segnale
(4.3.1)
a energia finita che possiamo pensare come una manifestazione di
un segnale aleatorio .
Il segnale ricevuto può essere scomposto in due segnali: il
primo, S , appartenente al sottospazio S il secondo, ,
ortogonale a detto sottospazio.
In particolare avremo
∑
(4.3.2)
dove
∫ ( ( ) ( )) ( )
(4.3.3)
Teniamo presente che tutte le funzioni in gioco sono reali
e, a parte il rumore, nulle al di fuori dell’intervallo , quindi

Cenni di Trasmissione Numerica 63
tali sono anche le funzioni che rappresentano i componenti della
base ortonormale utilizzata. La (4.3.3) esprime pertanto il
prodotto scalare tra il segnale ricevuto e l’ -esimo elemento .
Le sono variabili aleatorie Gaussiane a media nulla con
varianza , l’ortonormalità della base garantisce anche che
esse sono mutuamente statisticamente indipendenti. Osserviamo
che il segnale S non contiene nessuna informazione cir-
ca il segnale trasmesso in quanto non appartiene per costruzione
allo spazio S dei segnali trasmessi. La nostra strategia di decisio-
ne si può quindi basare esclusivamente su S , o, che è lo stesso,
sul vettore delle sue componenti rispetto alla base .
In sostanza il vettore costituisce la cosiddetta statistica suf-
ficiente su cui deve operare il ricevitore per fornire una stima del
messaggio trasmesso.
Possiamo pensare il ricevitore costituito da due sistemi in
cascata, un demodulatore che ha il compito di calcolare il vettore
ed un decisore che sulla base di quest’ultimo provvede a stimare
il messaggio trasmesso.
In pratica si può pensare al vettore come alla realizzazio-
ne di un vettore di variabili aleatorie definito sull’esperimento
casuale innescato dall’emissione di un messaggio e dal suo invio
sul canale AWGN.
4.4 - La Regola di Decisione Ottima.
Vogliamo che la strategia seguita dal ricevitore nel suo com-
plesso conduca alla minima probabilità d’errore media. In altri ter-
mini vogliamo che sia minima la probabilità di prendere decisioni
sbagliate sul messaggio trasmesso, noto il segnale ricevuto e la
probabilità di emissione di ciascun messaggio.
Ovviamente la minimizzazione della probabilità d’errore
equivale alla massimizzazione della probabilità di corretta decisio-
ne. La regola di decisione ottima sarà quindi quella che ci fa sce-
gliere per il messaggio se risulta:

64 Capitolo - 4 - Appunti di Teoria dell’Informazione e Codici
( | ) ( | ) (4.4.1)
La regola di decisione appena descritta si esprime sintetica-
mente scrivendo:
( )
(4.4.2)
Nell’ipotesi, in questo contesto remota, in cui due o più messaggi
massimizzino la precedente sceglieremo a caso tra essi.
Quando si adotta la regola di decisione (4.4.2) si sta
applicando il criterio della massima probabilità a posteriori (MAP
Maximum A posteriori Probability).
4.5 - Il Criterio della Massima Verosimiglianza.
Detto un intorno di e ( ) la sua misura possiamo
scrivere:
( )
( ) ( )
(4.5.1)
indicando con ( ) la densità di probabilità di , la probabilità
che vale ∫ ( )
Scegliendo opportunamente e in
.possiamo ulteriormente elaborare la (4.5.1) come segue:
( ) ( )
( )
( )
( ) ∫ ( )
∫ ( )
( )
∫ ( )
( )
( ) ( )
( )
( ) ( ) ( )
( ) ( )
( ) ( )
( )
(4.5.2)
sostituendo la (4.5.2) nella (4.4.2) otteniamo:

Cenni di Trasmissione Numerica 65
{ ( ) ( )
( )} (4.5.3)
Appare chiaro che la densità di probabilità marginale di al de-
nominatore della precedente non ha alcuna influenza sull’argo-
mento che lo rende massimo, pertanto possiamo ulteriormente
scrivere:
( ) ( )
(4.5.4)
4.6 - Funzioni di Verosimiglianza.
Un’ulteriore semplificazione della (4.5.3), si ottiene infine se
i messaggi sono tutti equiprobabili. In questo caso, sem-
plificando ulteriormente la notazione, ponendo cioè (
) ( ), la regola di decisione ottima diventa:
decidi per se:
( )
(4.6.1)
La densità di probabilità ( ) prende il nome di funzio-
ne di verosimiglianza. Essa, come si può notare, dipende sostanzial-
mente dal canale, che in questo caso pensiamo costituito dalla
cascata del modulatore, del canale AWGN e del demodulatore.
Un ricevitore che adotta la regola di decisione (4.6.1) appli-
ca il criterio della Massima Verosimiglianza MV, o ML (Maximum
Likelihood), se si preferisce l’acronimo inglese.
È opportuno precisare che il criterio MV viene di regola
adottato, anche quando la statistica della sorgente non è nota, in
questo caso il criterio non è ottimo, non conduce cioè alla minima
probabilità d’errore media, ma spesso non si può fare altrimenti
non conoscendo la statistica della sorgente, in ogni caso, in gene-
re, la perdita in termini di prestazioni adottando il criterio MV
anziché il MAP è accettabile.

66 Capitolo - 4 - Appunti di Teoria dell’Informazione e Codici
4.7 - Le Regioni di Decisione.
Ricordiamo che ad ogni messaggio corrisponde trami-
te la (4.2.1) un punto nello spazio S . Quindi, se è stato tra-
smesso , all’uscita del demodulatore sarà presente il vettore
, dove è la realizzazione di un vet-
tore di variabili aleatorie Gaussiane a media nulla e matrice di co-
varianza cioè di variabili tra loro mutuamente statisticamente
indipendenti, ne segue che , per fissato , è anch’esso un
vettore di variabili aleatorie Gaussiane mutuamente indipendenti
con matrice di covarianza e media .
Si ha pertanto:
( | ) ∏
√
(
)
( )
∏
(
)
( )
∑ (
)
( )
(4.7.1)
ad ogni si può quindi associare l’insieme dei punti di S
( ) ( ) (4.7.2)
che è denominato regione di decisione di .
Se abbiamo cura di assegnare a caso all’una o all’altra regio-
ne i punti di S che si trovano al confine tra due o più regioni di
decisione, ci si convince facilmente che
∪
(4.7.3)
Per il canale AWGN possiamo ancora scrivere:
{ ( )
‖ ‖
( )
‖ ‖
}
{ }
(4.7.4)

Cenni di Trasmissione Numerica 67
dalla precedente s’intuisce facilmente che le frontiere delle regioni
di decisione sono iperpiani di S , e che la probabilità che cada
sulla frontiera di una regione di decisione è in questo caso nulla,
essendo nulla la misura di tali frontiere.
Il concetto di regione di decisione è applicabile anche in un
contesto più generale, basandosi direttamente sulla (4.5.3) nel caso
di messaggi non equiprobabili.
Anche nel caso in cui lo spazio d’osservazione S sia dis-
creto si possono definire le regioni di decisione, tenendo però
presente che tutte le ddp che compaiono nelle (4.5.3) e (4.6.1)
vanno intese come dmp e che, in questo caso, l’eventualità che il
vettore cada su un punto di S appartenente alla frontiera di una
regione di decisione può essere diversa da zero.
Indichiamo con la probabilità che il ricevitore stimi
in modo errato il messaggio atteso che sia stato trasmesso il
messaggio . Detto il complementare di rispetto allo
spazio di osservazione S , ( ) si potrà esprimere come segue:
( ) ( ( )) (4.7.5)
La probabilità d’errore media del sistema sarà espressa dalla media
statistica delle ( ). Avremo quindi:
∑ ( ) ( )
(4.7.6)
che nel caso di equiprobabilità dei messaggi trasmessi varrà:
∑ ( )
(4.7.7)
Sebbene la precedente sia concettualmente semplice, calco-
larne il valore può essere complicato. La sua valutazione com-
porta generalmente il calcolo d’integrali su domini multidimensio-

68 Capitolo - 4 - Appunti di Teoria dell’Informazione e Codici
nali che difficilmente si risolvono in forma chiusa, e che anche ap-
procciati per via numerica possono presentare delle criticità.
È pertanto utile, in generale, e in particolare per i nostri
scopi, introdurre dei metodi che permettano di maggiorare la pro-
babilità d’errore:
4.8 - L’Union Bound.
L’union bound è una maggiorazione della che si basa sul
fatto che la probabilità dell’unione di due eventi è minore o uguale
della somma delle probabilità di ciascuno di essi.
In particolare si osservi che se il decisore dovesse scegliere
soltanto tra due alternative, ad esempio tra il messaggio e il
messaggio , vi sarebbero solo due regioni di decisione quella
associata a e la sua complementare rispetto a S ,
.
Ovviamente , risulta inoltre:
⋂
⋃
(4.8.1)
avremo pertanto:
( ∪
)
∑ ( )
(4.8.2)
Nel caso in esame:
{ } (4.8.3)
la ( ) è data da:

Cenni di Trasmissione Numerica 69
( )
∫ ( )
∫ ( )
∏
(
)
(4.8.4)
Al fine di calcolare la (4.8.4) è utile riformulare la disugua-
glianza che definisce la nel modo seguente:
( )
∑(
)
(4.8.5)
Osserviamo che ∑ (
)
può interpretarsi
come il valore assunto da una variabile aleatoria ottenuta combi-
nando linearmente le componenti di che, se è stato trasmesso
( ) , costituiscono una -upla di variabili aleatorie Gaussiane
statisticamente indipendenti. è quindi una variabile aleatoria
Gaussiana con valor medio:
∑(
)
(4.8.6)
e varianza:
∑(
)
(4.8.7)
Ricordando che ( )
√ ∫
potremo scrivere:
( | ) ( ‖ ‖
‖ ‖
) (4.8.8)

70 Capitolo - 4 - Appunti di Teoria dell’Informazione e Codici
√
∫
( )
‖ ‖ ‖ ‖
( )
√ ∫
(
)
(
√ ( ) ( ) )
(
√ )
(
√ )
L’ultimo membro della precedente può essere sostituito
nella (4.8.2) che tenuto conto della (4.7.6) e dell’ipotesi di equipro-
babilità dei simboli trasmissibili, ci permette di scrivere:
∑ ( ) ( )
∑ ( ) ∑ (‖ ‖
√ )
( )
∑ (
√ )
(4.8.9)
4.9 - Bound di Bhattacharrya.
L’union bound può essere applicato anche al caso in cui lo
spazio di osservazione sia discreto. Consideriamo ad esempio il
caso di una sorgente binaria priva di memoria che emetta una
parola di bit. Vogliamo trasmettere la parola in questione
utilizzando un BSC volte con . Il compito del codificatore

Cenni di Trasmissione Numerica 71
di canale consiste quindi nell’associare a ciascuno dei possibili
messaggi di sorgente una tra le possibili parole da affidare al
canale. Chiameremo codice il sottoinsieme delle parole scelte.
Osserviamo che per effetto del canale la parola ricevuta
potrebbe non appartenere al codice, ma in ogni caso sarebbe una
tra le . In sostanza lo spazio d’osservazione è in questo caso
finito.
La probabilità ( ) che venga rivelata la parola quan-
do è stata trasmessa la parola di codice è data da
( ) ( ) ( ) (
)
(4.9.1)
in cui rappresenta il numero di simboli in cui differisce da
e la probabilità di crossover del BSC. Osserviamo che, se
,
, ( ) è quindi una funzione decrescente di che, co-
me vedremo in seguito, è detta distanza di Hamming. Ciò ci permet-
te di associare a ogni parola di codice una regione di decisione,
che conterrà i punti dello spazio d’osservazione, cioè le parole di
bit aventi da essa una distanza minore rispetto a quella che
hanno dalle altre parole di codice, convenendo di assegnare in
modo puramente casuale a una sola delle regioni interessate i pun-
ti dello spazio d’osservazione che dovessero trovarsi a uguale di-
stanza tra due o più parole di codice.
Ciò premesso, il calcolo della probabilità d’errore condizio-
nata all’emissione di una data parola di codice vale:
∑ ( )
(4.9.2)
e la probabilità d’errore media:
∑ ( ) ∑ ( )
(4.9.3)

72 Capitolo - 4 - Appunti di Teoria dell’Informazione e Codici
dove ( ) rappresenta la probabilità di emissione della parola
da parte del codificatore di canale, che equivale, essendo il
codificatore deterministico, a quella di emissione della corrispon-
dente parola di bit dalla sorgente.
Anche in questo contesto è possibile applicare l’union
bound. Individuando le associate alle coppie di parole di co-
dice possiamo infatti scrivere:
( ) ∑ ( )
(4.9.4)
tramite la funzione ausiliaria
( ) {
(4.9.5)
possiamo riformulare la (4.9.4) come segue
( ) ∑ ( ) ( )
(4.9.6)
Osserviamo che S risulta:
( ) ( ( )
( ))
(4.9.7)
possiamo pertanto maggiorare la (4.9.6) ottenendo:
( ) ∑( ( )
( ))
( )
∑( ( )) ( ))
∑[∏( (
) (
))
]
∏ ∑ ( (
) (
))
(4.9.8)

Cenni di Trasmissione Numerica 73
in cui abbiamo anche tenuto conto del fatto che il canale è privo
di memoria.
La sommatoria a ultimo membro della precedente può as-
sumere solo due valori a seconda che risulti o meno uguale a
nel primo caso la somma varrà nell’altro √ ( ). Potre-
mo finalmente scrivere:
( ) ∏ ∑ ( (
) (
))
( √ ( ))
(4.9.9)
essendo la distanza di Hamming tra e .
Quella appena ottenuta è la maggiorazione di Bhattacharyya.
Che utilizzata nello union bound ci permette di scrivere:
∑ ( ) ∑( √ ( ))
(4.9.10)
Il bound di Bhattacharyya sulla probabilità d’errore può es-
sere applicato anche nel caso di spazio d’osservazione continuo.
Per mostrarlo prendiamo nuovamente in considerazione la
(4.8.4), possiamo scrivere:
( | ) ∫ ( | )
∫ √ ( | )
( | ) ( | )
∫ √ ( | ) ( | )
(4.9.11)
la quale sostituendo alle ddp condizionate che vi compaiono le
loro espressioni fornisce:

74 Capitolo - 4 - Appunti di Teoria dell’Informazione e Codici
( | ) ∫ √ ( | ) ( | )
( )
∫
∑ (
) (
)
( )
∫
∑ ( (
)
)
∏∫
√
(
)
)
∏∫
√
(
)
(
)
∏
(
)
∏
∑ (
)
(4.9.12)
La precedente può essere utilizzata nell’union bound
∑ ( ) ( )
∑ (
√ )
∑
‖ ‖
(4.9.13)
La (4.9.13), a ben vedere, si poteva ottenere direttamente
utilizzando una ben nota catena di disuguaglianze relative alla
( ), risulta infatti (vedi Fig. 4.1):
√ (
)
( )
√
(4.9.14)
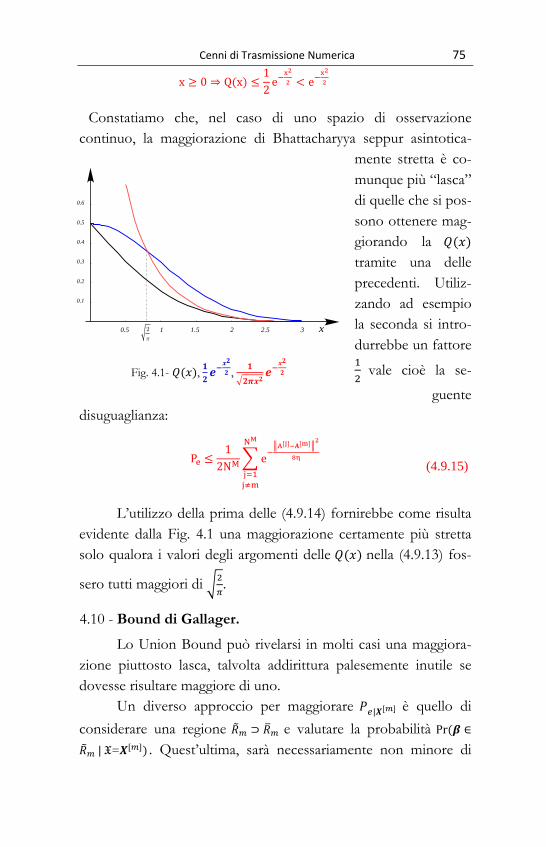
Cenni di Trasmissione Numerica 75
( )
Constatiamo che, nel caso di uno spazio di osservazione
continuo, la maggiorazione di Bhattacharyya seppur asintotica-
mente stretta è co-
munque più “lasca”
di quelle che si pos-
sono ottenere mag-
giorando la ( )
tramite una delle
precedenti. Utiliz-
zando ad esempio
la seconda si intro-
durrebbe un fattore
vale cioè la se-
guente
disuguaglianza:
∑
‖ ‖
(4.9.15)
L’utilizzo della prima delle (4.9.14) fornirebbe come risulta
evidente dalla Fig. 4.1 una maggiorazione certamente più stretta
solo qualora i valori degli argomenti delle ( ) nella (4.9.13) fos-
sero tutti maggiori di √
.
4.10 - Bound di Gallager.
Lo Union Bound può rivelarsi in molti casi una maggiora-
zione piuttosto lasca, talvolta addirittura palesemente inutile se
dovesse risultare maggiore di uno.
Un diverso approccio per maggiorare è quello di
considerare una regione e valutare la probabilità (
) . Quest’ultima, sarà necessariamente non minore di
Fig. 4.1- ( ),
,
√
0.5 1 1.5 2 2.5 3
0.1
0.2
0.3
0.4
0.5
0.6
2
x

76 Capitolo - 4 - Appunti di Teoria dell’Informazione e Codici
. A tale scopo, scelto ad arbitrio , consideriamo il
sottoinsieme dello spazio d’osservazione S :
{ ∑ ( ( )
( ))
} (4.10.1)
, infatti se deve esistere almeno un in corri-
spondenza al quale risulti ( ) ( ), ciò, ricordando
che , comporta che almeno un addendo, e quindi tutta la
sommatoria nella (4.10.1) che è a termini positivi, assuma un va-
lore maggiore di in ogni punto di . Introducendo la funzione
ausiliaria:
( ) {
(4.10.2)
possiamo scrivere:
( ) ∫ ( )
∫ ( ) ( )
(4.10.3)
È facile verificare che per ogni risulta:
( ) [∑ ( ( )
( ))
]
(4.10.4)
la (4.10.3) può quindi essere ulteriormente maggiorata ottenendo:
( ) ∫[∑ ( ( )
( ))
]
( )
∫[∑( ( ))
]
( )( )
(4.10.5)
Ponendo
, nella precedente otteniamo il bound di Gallager:

Cenni di Trasmissione Numerica 77
( ) ∫[∑( ( ))
]
( )
(4.10.6)
La maggiorazione della probabilità d’errore che si ottiene
dalla (4.10.6), mediando su tutti i messaggi , è applicabile
anche a spazi d’osservazione discreti, a patto di sostituire l’integra-
le con una sommatoria estesa all’intero spazio d’osservazione e di
interpretare le densità di probabilità che vi compaiono come di-
stribuzioni di massa di probabilità:
( ) ∑[∑( ( ))
]
( )
(4.10.7)
L’utilizzo del bound di Gallager, tuttavia, rimane ristretto
ad un limitato insieme di sistemi di trasmissione in quanto esso
comporta comunque il calcolo di integrali o sommatorie multidi-
mensionali la cui complessità cresce con legge esponenziale al
crescere delle dimensioni dello spazio d’osservazione.
Va anche sottolineato che il valore di al secondo membro
delle (4.10.6) e (4.10.7) deve essere ottimizzato se si vuole rendere
la maggiorazione più stretta possibile.
In questo contesto il bound appena introdotto è propedeu-
tico alla dimostrazione del teorema di Shannon sulla codifica di
canale che dimostreremo nel prossimo capitolo.


Capitolo - 5
IL TEOREMA DI SHANNON SULLA CODIFICA
DI CANALE
5.1 - Premessa.
Shannon, nel suo pionieristico lavoro del 1948, individuò
una maggiorazione della probabilità d’errore che, anziché cercare
di maggiorare la probabilità d’errore associata alla scelta di uno
specifico insieme di segnali, si propone di maggiorare la probabi-
lità di errore media tra tutti i possibili insiemi costituiti da un nu-
mero fissato di segnali, contenuti in un sottospazio di dimen-
sione assegnata . Le componenti di ciascun segnale possono
assumere valori appartenenti al medesimo alfabeto di cardinalità
finita .
Sotto queste ipotesi si possono effettuare un numero finito
di scelte per la -upla di segnali da impiegare, esistono infatti solo
( ) possibili -uple di segnali, molte delle quali peraltro pale-
semente “infelici” quali ad esempio quelle che, utilizzando due o
più volte uno stesso segnale per messaggi diversi, darebbero luogo
a probabilità d’errore particolarmente elevate.
Shannon, per dimostrare il suo teorema, sfruttò il fatto che
una qualsiasi funzione di variabili aleatorie assume certamente
almeno un valore non maggiore del suo valor medio.
Tale considerazione, applicata al caso in esame, comporta il
fatto che deve esistere almeno una -upla di segnali, anche se non
sappiamo necessariamente quale, che da luogo ad una probabilità
d’errore non maggiore della media tra le probabilità d’errore di
tutte le possibili -uple.
È interessante osservare che quest’affermazione resta valida
quale che sia la distribuzione di massa di probabilità che si sceglie
per calcolare la media citata. Utilizzando, ad esempio una ddm

80 Capitolo - 5 - Appunti di Teoria dell’Informazione e Codici
uniforme (media aritmetica) daremmo peso uguale a ogni -upla.
Potremmo ritenere più sensato scegliere di attribuire peso nullo a
tutte le -uple in cui uno stesso segnale è utilizzato più di una
volta. Con questa scelta otterremo un valor medio delle probabi-
lità d’errore che sarebbe indubbiamente una maggiorazione più
stretta.
In sostanza esistono infinite possibili scelte, ciascuna delle
quali potrebbe rivelarsi più meno felice, ma costituirebbe co-
munque una maggiorazione per la probabilità d’errore di almeno
una - upla.
5.2 - La Disuguaglianza di Jensen
Per dimostrare il teorema di Shannon è utile impiegare la
disuguaglianza di Jensen che trova applicazione anche nella tratta-
zione di molti altri argomenti legati alla Teoria dell’Informazione.
Per provare tale disuguaglianza, cominciamo con il definire
un sottoinsieme convesso di uno spazio vettoriale:
Definizione 5.1 Un sottoinsieme di uno spazio vettoriale su o su è convesso se
comunque presi due suoi elementi e un reale non negativo non
maggiore di risulta:
( ) (5.2.1)
***********
La precedente in sostanza ci dice che un insieme è con-
vesso se contiene tutte le corde che uniscono coppie di suoi
elementi. Un esempio di regione convessa in è l’insieme di
tutte le possibili distribuzioni di massa di probabilità di una
variabile aleatoria discreta che assume valori appartenenti ad un
insieme di cardinalità . Ad esempio in tale regione è
costituita dalla della retta appartenente al primo
quadrante. Nel caso di (vedi Fig. 5.1) da tutti i punti del piano
di coordinate non negative.

Il Teorema di Shannon sulla Codifica di Canale 81
È facile convincersi del fatto che:
- l’intersezione (anche infini-
ta) d’insiemi convessi e convessa
- l’insieme ottenuto moltipli-
cando tutti gli elementi di un
convesso per uno stesso scalare è
convesso.
- è convesso l’insieme che
ha per elementi tutte le possibili
somme tra elementi appartenenti
a due insiemi convessi.
Definizione 5.2 Una funzione ( ) a valori in si dice concava su un sottoinsieme
convesso del suo dominio se comunque presi due elementi apparte-
nenti ad e un reale non negativo risulta:
( ) ( ) ( ) ( ( ) ) (5.2.2)
Se risulta
( ) ( ) ( ) ( ( ) ) (5.2.3)
la funzione si dice strettamente concava.
***********
Le definizioni di funzione convessa e strettamente convessa
sono rispettivamente uguali alle (5.2.2) e (5.2.3) salvo il fatto che
le diseguaglianze cambiano di verso.
Nel caso di funzioni definite su sottoinsiemi di la (5.2.2)
caratterizza le funzioni con concavità rivolta verso il basso in tutti
i punti di un intervallo, di misura non necessariamente finita, che
è l’unico possibile sottoinsieme convesso di .
È noto che, laddove esiste, la derivata seconda di una fun-
zione concava è non positiva.
Inoltre, la combinazione lineare di funzioni concave è
concava, lo è strettamente se anche una sola delle funzioni lo è.
Fig. 5.1
1
1
1

82 Capitolo - 5 - Appunti di Teoria dell’Informazione e Codici
Per verificarlo è sufficiente sommare termine a termine le (5.2.2)
scritte per ciascuno degli addendi della combinazione lineare.
Osservando la (5.2.2) notiamo che se si interpretano ed
come i valori che può assumere una V.A. generalmente multidi-
mensionali e con ed rispettivamente le probabilità che
essa li assuma, potremo affermare che per una funzione concava
su un convesso che contenga tutti i valori che la V.A. può assu-
mere ed una V.A. del tipo citato vale la proprietà:
( ) ( ) (5.2.4)
Vogliamo mostrare che la precedente è valida in generale
cioè per variabili aleatorie discrete generalmente multidimensio-
nali che possano assumere valori.
Abbiamo mostrato che la (5.2.4) è vera per , per
lo è banalmente supponiamo quindi che lo sia per e mo-
striamo che allora lo è anche per .
Se la (5.2.4) è vera per quale che sia la dmp di si ha:
∑ ( )
(∑( )
) (5.2.5)
dove rappresenta la probabilità che la variabile aleatoria
assuma il valore .
Risulta:
∑ ( )
∑
(
∑
∑
( )
)
( ) (5.2.6)
Osserviamo che ∑
∑
soddisfa tutte le proprietà di una
dmp quindi in virtù della (5.2.5) possiamo scrivere:

Il Teorema di Shannon sulla Codifica di Canale 83
∑ ( )
∑
(
(
∑
∑
)
)
( )
∑
( ( )) ( )
(5.2.7)
dove è certamente un punto appartenente al convesso su cui è
definita la funzione.
All’ultimo membro della precedente potremo applicare la
(5.2.2) ottenendo:
∑ ( )
∑
( ( )) ( ) (∑
)
(
∑ ∑
∑
)
(∑
)
( )
(5.2.8)
ovviamente la (5.2.5) diventa
∑ ( )
(∑( )
) (5.2.9)
se la ( ) anziché essere concava è convessa.
5.3 - Il Teorema di Shannon sulla Codifica di Canale.
Consideriamo la probabilità d’errore condizionata
all’emissione dello -esimo segnale di una data -upla. è in
realtà una funzione della -upla nel suo complesso, in quanto il
cambiamento anche di un solo segnale nella -upla potrebbe com-
portare la modifica della regione di decisione associata ad .
Per rimarcare questo fatto, porremo in quel che segue
( ).

84 Capitolo - 5 - Appunti di Teoria dell’Informazione e Codici
Dovendo calcolare la media citata nel precedente paragrafo,
e tenuto conto delle considerazioni fatte in merito, possiamo sce-
gliere ad arbitrio una dmp ( ) per le -uple di
possibili segnali. Per semplicità supponiamo che
( ) ∏ ( )
(5.3.1)
e che tutte le dmp marginali che compaiono nella produttoria
siano identiche.
Per non appesantire troppo la notazione calcoliamo la
tale scelta non lede la generalità dei calcoli in quanto come vedre-
mo il risultato finale è indipendente dall’indice . Avremo quindi:
∑ ∑ ∑ ∏ ( ) (
)
(5.3.2)
utilizzando il bound di Gallager otteniamo:
∑ ∑ ∏ (
)
∫ [∑( (
))
]
(
)
(5.3.3)
che, portando la media all’interno dell’integrale, fornisce:
∫ ∑ (
) (
)
{∑ ∑ ∏ (
) [∑ ( (
))
]
}
(5.3.4)
Osserviamo che la quantità ∑ ( (
))
, è reale
positiva e può intendersi come il valore assunto dalla funzione
( ) (5.3.5)

Il Teorema di Shannon sulla Codifica di Canale 85
dei messaggi .
Nel derivare il bound di Gallager avevamo supposto
se lo limitiamo all’intervallo , è una funzione concava di
A possiamo quindi applicare la disuguaglianza di Jensen
(vedi § precedente). Maggiorando così il contenuto delle parentesi
graffe della (5.3.4)
∑ ∑ ∏ (
) [∑ ( ( |
))
]
( )
[∑ ∑ ∏ (
) ∑ ( ( |
))
]
[∑ ∑ ∑ ∏ (
) ( ( |
))
]
[∑ ∑ (
) ( ( |
))
]
[( ) ∑ (
) ( (
))
]
(5.3.6)
Abbiamo potuto scrivere l’ultimo membro della precedente
in quanto la quantità ∑ (
) ( ( |
))
, come ci si con-
vince facilmente, non dipende dall’indice .
La precedente ci consente di maggiorare ulteriormente la
ottenendo:
∫ ∑ (
) (
)
[( ) ∑ (
) ( ( |
))
]
(5.3.7)

86 Capitolo - 5 - Appunti di Teoria dell’Informazione e Codici
( ) ∫
[∑ ( )( ( ))
]
Ulteriori elaborazioni si possono ottenere osservando che il
contenuto delle parentesi quadre può intendersi come il valor
medio della ( ( ))
pensata come funzione della V.A.
multidimensionale .
Ciò premesso, ipotizziamo che: ( ) ∏ ( )
,
cioè che il canale sia privo di memoria, se utilizzato in tempi
diversi per inviare le componenti del segnale, ovvero che, per in-
viare dette componenti, si utilizzino contemporaneamente
canali identici mutuamente indipendenti.
Sotto tale ipotesi, ricordando che la media di un prodotto è
uguale al prodotto delle medie, la (5.3.7) si può riscrivere come
segue:
∫[ ∑ ∑ ∑ (
)
∏( ( | ))
]
∫[∏ ∑ (
) ( ( | ))
]
(5.3.8)
la quale limitandoci a considerare delle ( ) ∏ ( )
forni-
sce ancora:
∫ [∏ ∑ ( ) ( ( |
))
]
(5.3.9)

Il Teorema di Shannon sulla Codifica di Canale 87
∫ ∏[∑ ( )( ( ))
]
{∫ [∑ ( )( ( ))
]
}
È opportuno ribadire che la maggiorazione appena ricavata,
essendo basata sul bound di Gallager, è del tutto generale quindi
si può applica con semplici modifiche anche a canali discreti.
Pertanto, prima di procedere oltre, provvediamo a riscrive-
re la (5.3.9) per spazi d’uscita discreti.
Per farlo dobbiamo sostituire l’integrale con una sommato-
ria estesa a tutti i possibili simboli dell’alfabeto d’uscita che
supporremo di cardinalità , e la densità di probabilità condizio-
nata che caratterizza il canale con uscita nel continuo con le dmp
condizionate del DMC ottenendo:
[∑(∑ ( )( ( ))
)
]
(5.3.10)
è utile riscrivere la precedente nella forma:
{ [∑ (∑ ( )( ( ))
)
]
}
{ [∑ (∑ ( )( ( ))
)
]}
{
[∑ (∑ ( )( ( ))
)
]}
(5.3.11)
che ne rende esplicita la dipendenza dal rapporto
.
Ricordiamo che è il numero di segnali utilizzati e la di-
mensione del sottospazio in cui detti segnali sono contenuti, si
può quindi interpretate come la massima quantità d’informazio-
ne, espressa in nat, che i parametri fissati per il sistema consenti-
rebbero di affidare a ogni dimensione del sottospazio. rappre-
senta quindi il data rate del sistema.

88 Capitolo - 5 - Appunti di Teoria dell’Informazione e Codici
La (5.3.11) si può esprimere in forma più compatta po-
nendo:
( ( )) [∑(∑ ( )( ( ))
)
] (5.3.12)
Sostituendo la precedente nella (5.3.11) otteniamo:
( ( ( )) ) (5.3.13)
Il minimo al variare di e ( ) del secondo membro della prece-
dente fornisce la maggiorazione più stretta.
La minimizzazione citata equivale alla ricerca di:
( )
( ( )) ( ) (5.3.14)
Ovviamente tale ricerca deve tener conto delle limitazioni
poste su , che deve appartenere all’intervallo e del fatto che
la ( ) è una dmp.
Osserviamo infine che la maggiorazione appena ricavata
non dipende da quindi essa è anche una maggiorazione per la
probabilità d’errore media del sistema. Tutto ciò considerato pos-
siamo scrivere:
( ) (5.3.15)
Appare chiaro quanto siano importanti le proprietà della
( ( )). In quel che segue per semplificare la notazione porre-
mo ( ) , ( ) , e indicheremo la distribuzione di
massa ( ) con
Osserviamo che, indipendentemente dalla ( ), risulta:
( ) [∑(∑ ( )
)
]
[∑ ∑
]
(5.3.16)
si ha inoltre:

Il Teorema di Shannon sulla Codifica di Canale 89
( )
|
{ [∑ (∑ ( )
)
]}
||
∑ (∑ ( )
)
||
∑ [∑ ( )
]
||
∑
{( ) [∑ ( )
]}
|
|
∑
{
(∑ )
)
{
[∑ ( )
]
( )∑ ( )
( )
∑ ( )
|
}
}
∑ ( ∑
)
∑
∑∑ ∑∑
( ) ( )
(5.3.17)
Pertanto la pendenza della ( ) , valutata per , è
pari all’informazione mutua del canale connesso ad una sorgente
che emette simboli distribuiti secondo la . Abbiamo indicato la
suddetta informazione mutua come una ( ) proprio per eviden-
ziarne la dipendenza dalla distribuzione sotto il nostro controllo.
Abbiamo già visto che ( ) , se risulta ( ) allora la
( ) che, come abbiamo visto attraversa l’asse delle nell’ori-
gine, assume certamente valori positivi in un intorno destro di
quest’ultima.
Si può anche verificare che la ( ), se ( ) , è una
funzione strettamente crescente e che la sua derivata seconda è
non positiva per . Essa ha quindi la concavità rivolta verso

90 Capitolo - 5 - Appunti di Teoria dell’Informazione e Codici
il basso, salvo alcune eccezioni in cui la derivata seconda è nulla,
ma tali casi non hanno interesse pratico.
Il nostro scopo è quello di massimizzare la ( ) ,
consideriamo per il momento solo la dipendenza da , la derivata
parziale rispetto a della funzione in parola vale:
( )
(5.3.18)
affinché si annulli deve risultare ( )
. Sappiamo che
( )
non è crescente poiché sua derivata è non positiva, pertanto la
(5.3.18) non può annullarsi per se:
( )
|
(5.3.19)
Ovvero se
( )
|
( ) (5.3.20)
per i valori di che soddisfano la (5.3.19) risulta, ( )
quindi ( ) è strettamente crescente nell’intervallo
ed assume il suo massimo valore nell’estremo destro dell’interval-
lo; avremo cioè:
( ) ( ) ( )
|
(5.3.21)
per
( )
|
( ) (5.3.22)
la (5.3.18) si annulla certamente per un valore di appartenente
all’intervallo che risolve l’equazione ( )
. Tale zero
corrisponde certamente a un massimo come si constata facil-

Il Teorema di Shannon sulla Codifica di Canale 91
mente analizzando il segno della (5.3.18). La ( ) nel range di
valori di dato dalla (5.3.22) è implicitamente definita dalle:
{
( ) ( )
( )
( )
(5.3.23)
dalle quali si ottiene:
( )
( ( ) ( )
)
( )
( )
( )
( )
(5.3.24)
che comporta:
( )
( ( )
)
( )
(5.3.25)
Nelle ultime due equazioni il secondo membro è una fun-
zione di essendo la soluzione della seconda delle (5.3.23) che
è unica in quanto nell’intervallo di interesse abbiamo visto che la ( )
è una funzione monotona di .
Per i valori di ( ) la (5.3.18) assumerebbe valori nega-
tivi quindi la ( ) sarebbe una funzione decrescente di
quindi il suo massimo lo raggiungerebbe per , ma ( )
indipendentemente da ne seguirebbe ( ) e la (5.3.15) si
rivelerebbe del tutto inutile.
In conclusione la ( ) per valori di appartenenti al-
l’intervallo [ ( )
|
] è un tratto di retta parallela alla secon-
da bisettrice che tocca l’asse delle ordinate in ( ( )) alla
quale si raccorda un tratto di curva con concavità rivolta verso
l’alto che tocca l’asse delle ascisse in I( ), come si verifica

92 Capitolo - 5 - Appunti di Teoria dell’Informazione e Codici
facilmente valutando le (5.3.23) per . A questo punto non
resta che massimizzare la ( ( )) rispetto alla ( ).
La che massimizza la ( ) dipende dal canale che si sta
utilizzando, e, per fissato canale può dipendere dal rate , in
particolare esistono canali per cui la ( ) è massimizzata da
un'unica , canali per i quali esistono delle distinte che massi-
mizzano la funzione in parola in intervalli di disgiunti e canali
per cui la ( ) che massimizza la ( ) varia con continuità con
. In ogni caso il fatto che la ( ) sia una funzione limitata
convessa per I( ) , assicura che la massimizzazione
desiderata è in pratica l’inviluppo superiore di tutte le ( ), si
può dimostrare che detta funzione è anch’essa convessa,
decrescente e non negativa per , dove
( ( )) è la
capacità di canale e che in questo contesto assume un ruolo fon-
damentale.
In sostanza abbiamo appena dimostrato il:
Teorema 5.1: Teorema di Shannon sulla codifica di canale Dato un qualsiasi canale discreto privo di memoria, esiste un codice
con un rate [
], con parole di simboli per il quale risulta:
( ) (5.3.26)
dove è la probabilità d’errore ottenuta tramite un ricevitore a massima
verosimiglianza ed ( ) una funzione decrescente, convessa e maggiore di
zero nell’intervallo .
***********
Il precedente teorema in pratica mostra che se aumentiamo
mantenendo costante possiamo individuare codici con proba-
bilità d’errore piccola a piacere purché risulti . È opportuno
tuttavia osservare che al crescere di il numero di parole di
codice necessario per mantenere costante il rate cresce anch’esso,
“purtroppo” con legge esponenziale, portando così, spesso a livel-
li improponibili, la complessità di decodifica. Da qui la necessità
di individuare dei codici su spazi dotati di strutture algebriche

Il Teorema di Shannon sulla Codifica di Canale 93
molto ricche che permettano operazioni di codifica e decodifica
relativamente semplici, malgrado l’elevato numero di parole che li
costituiscono.
Potrebbe sorgere una perplessità circa il risultato appena ot-
tenuto, si potrebbe infatti sospettare che il bound ottenuto per la
probabilità d’errore media del codice nasconda delle probabilità
d’errore condizionate all’emissione di una specifica parola del co-
dice molto maggiore del bound relativo alla probabilità d’errore
media.
Per fugare questa, legittima, perplessità consideriamo uno
spazio di dimensione , o che è lo stesso un codice costituito da
parole di simboli emessi consecutivamente da un codificatore di
canale. Il teorema di Shannon ci garantisce che esiste almeno un
set di parole tra le possibili scelte, che esibisce una pro-
babilità d’errore media non maggiore di:
(
( )
) (5.3.27)
Se assumiamo che le parole che costituiscono il codice abbiano
uguale probabilità di essere emesse, allora avremo:
∑
(5.3.28)
Scartando gli segnali cui corrispondono le probabilità d’errore
più grandi, ci rendiamo conto che la probabilità d’errore associata
ad uno qualsiasi dei segnali sopravvissuti non può essere maggiore
di ( ( )
). Se così non fosse, almeno ad un termine dei so-
pravvissuti corrisponderebbe una ( ( )
) vi sarebbero
quindi almeno segnali, quelli scartati più quello appena
citato, con ( ( )
) e potremmo scrivere:
( )
( ( )
)
(
( )
)
( ( )
) (5.3.29)
contro l’ipotesi che il codice soddisfa la (5.3.27).

94 Capitolo - 5 - Appunti di Teoria dell’Informazione e Codici
Per ogni del gruppo dei sopravvissuti potremo allora
scrivere:
(
( )
)
(
( ( ) ( )
))
( ( ) ( )
)
(
( ( )
( )
))
(
( )
)
(5.3.30)
Pertanto esiste certamente un codice costituito da parole di K
simboli per il quale la peggiore delle probabilità d’errore condizio-
nata supera il bound sulla probabilità d’errore media per al più un
fattore .

Capitolo - 6
STRUTTURE ALGEBRICHE
Al fine di introdurre il concetto di codice è opportuno
ricordare alcune definizioni:
6.1 - Gruppo
Un insieme non vuoto in cui si è definita una legge di
composizione interna che indicheremo con è un gruppo rispetto
a tale legge se valgono le seguenti proprietà:
( ) ( )
(6.1.1)
Se la legge di composizione interna è anche commutativa
è un gruppo commutativo o abeliano.
6.2 - Anello
Un insieme nel quale siano state individuate due leggi di
composizione interna che chiameremo addizione e moltiplicazio-
ne è un anello se:
- è un gruppo commutativo rispetto all’addizione;
- la moltiplicazione gode della proprietà associativa;
- vale la legge distributiva della moltiplicazione rispetto all’addi-
zione sia a destra che a sinistra.
Se la moltiplicazione gode anche della proprietà commutati-
va diremo che è un anello commutativo, se esiste in l’elemento
neutro per la moltiplicazione diremo che è un anello con identità.
6.3 - Campo
Un insieme che sia un anello commutativo con identità è
anche un campo se privato dell’elemento neutro rispetto all’addi-
zione è un gruppo commutativo rispetto alla moltiplicazione.

96 Capitolo - 6 - Appunti di Teoria dell’Informazione e Codici
L’insieme dei numeri razionali, l’insieme dei reali e l’in-
sieme dei complessi sono campi. Si verifica facilmente che an-
che l’insieme , effettuando l’addizione senza riporto, cioè po-
nendo e con la usuale moltiplicazione in è un campo
che indicheremo con .
6.4 - Spazio vettoriale
Dato un gruppo abeliano ed un campo si dice che è
uno spazio vettoriale sul campo se si è individuata una legge di
composizione esterna, detta prodotto per scalari, che associa ad
ogni elemento di un elemento di e che comunque scelti
e goda delle proprietà:
{
( ) ( )
(6.4.1)
dove e indicano rispettivamente gli elementi neutri dell’addi-
zione e della moltiplicazione del campo, quello del gruppo, che
chiameremo anche origine dello spazio.

Capitolo - 7
DISTANZA DI HAMMING
7.1 - Lo Spazio
Fissato un naturale consideriamo l’insieme di tutte
le -uple ordinate d’elementi di . Ci si rende conto facilmente
che è un gruppo rispetto alla legge di composizione interna
che associa ad ogni coppia di elementi di quello ottenuto com-
ponendo termine a termine tramite l’addizione in gli elementi
omologhi delle due -uple. Si constata che ogni -upla è l’opposta
di se stessa e che l’elemento neutro del gruppo è la -upla
identicamente nulla.
è anche uno spazio vettoriale di dimensione sopra il
campo , potremo quindi pensare gli elementi di come vettori
riga con componenti che assumono valori in . In quel che se-
gue indicheremo gli elementi di con lettere corsive minuscole
in grassetto e li chiameremo parole di , o semplicemente parole,
le componenti della generica parola saranno chiamate bit (nel sen-
so di Binary digIT, non di Binary Informationn uniT).
È opportuno tenere presente che:
- è uno spazio metrico, possiamo infatti assumere come di-
stanza tra due parole di la somma in delle somme in
delle componenti omologhe;
- è uno spazio normato potendosi assumere come norma
del generico elemento di la distanza di detto elemento dal-
l’origine di , cioè dalla parola identicamente nulla.
In quel che segue indicheremo l’addizione in con .
La distanza sopra introdotta è detta distanza di Hamming.
Essa in pratica è espressa dal numero di bit corrispondenti diversi
delle due parole; in formule:

98 Capitolo - 7 - Appunti di Teoria dell’Informazione e Codici
( ) ∑
(7.1.1)
Che la distanza di Hamming sia effettivamente una metrica
si verifica facilmente, essa infatti è non negativa ed è nulla se e
solo se le parole sono uguali, inoltre si può facilmente verificare
che vale la disuguaglianza triangolare, cioè che date tre parole
di risulta:
( ) ( ) ( ) (7.1.2)
per sincerarsene basta esplicitare la precedente:
∑
∑
∑
(7.1.3)
ed osservare che tutti gli addendi delle sommatorie che compaio-
no nella precedente sono non negativi, pertanto è sufficiente veri-
ficare che la (7.1.3) sia soddisfatta addendo per addendo, fatto
questo facilmente verificabile effettuando prove esaustive.
La massima distanza possibile tra due parole di vale e
si ottiene in corrispondenza a coppie di parole che siano una la
negata dell’altra, cioè ottenute mutando tutti i bit uno in zero e vi-
ceversa.
La norma di un elemento di viene denominato peso della
parola e coincide con il numero di bit uno presenti nella parola.
La norma e la metrica appena introdotte sono tra loro
coerenti, infatti la distanza tra due elementi coincide con la norma
della differenza tra di essi. Ricordiamo che in addizione e sot-
trazione coincidono, in quanto ogni elemento è l’opposto di se
stesso.
7.2 - Generalizzazione della distanza di Hamming
Dato un insieme di cardinalità consideriamo l’insieme
A . Anche su detto insieme si può introdurre la distanza di Ham-
ming tra due suoi elementi, che anche in questo caso è espressa

Codici Lineari a Blocchi 99
dal numero di simboli corrispondenti diversi tra loro. La distanza
tra due elementi di A è quindi al più .
Si può verificare che la distanza di Hamming è una metrica
su A . Essa è non negativa, nulla se e solo se i due elementi sono
lo stesso elemento, la verifica della validità della disuguaglianza
triangolare può essere effettuata analizzando tutti i casi possibili.
Fissato un elemento di A ed un naturale esistono
( )( ) elementi di A a distanza da . Potremmo dire che
detti elementi giacciono sulla superficie di una sfera di raggio
centrata in . Detta sfera contiene esattamente ∑ ( )( )
elementi, il numero di tali elementi, per analogia, ne costituisce il
“volume”.
Qualora A fosse anche uno spazio vettoriale, tramite la
distanza di Hamming si potrebbe individuare un “peso” per ogni
elemento di A espresso dalla distanza dell’elemento dall’origine
dello spazio, tale peso costituirebbe una possibile norma per A .


Capitolo - 8
CODICI BINARI A BLOCCHI
8.1 - Codificatore, Codice, Decodificatore
Cominciamo con alcune definizioni:
Definizione 8.1 - codificatore a blocchi Un codificatore binario a blocchi è un’applicazione da a , se
è iniettiva il codificatore è non ambiguo.
***********
Definizione 8.2 - codice binario a blocchi Dato un codificatore da a chiameremo codice binario a
blocchi l’insieme ( ) . Gli elementi di sono denominati
parole di codice.
***********
In altri termini per codice binario a blocchi intenderemo
l’insieme delle parole di che sono immagine secondo il codifi-
catore di almeno un elemento di , uno solo se il codificatore
è non ambiguo.
In questo contesto la finalità di un codice è quella di com-
battere l’effetto dei disturbi introdotti dal canale nel segnale rice-
vuto, tali disturbi potrebbero infatti dar luogo ad errori nella rice-
zione. Compito del sistema di codifica è ridurre la frequenza di
tali errori seguendo una delle seguenti strategie:
- individuare e segnalare gli errori che si verificano con mag-
giore probabilità.
Ciò è utile qualora:
o sia disponibile un canale di ritorno;
o non sia necessario trasmettere in tempo reale e sia quin-
di possibile la ritrasmissione del messaggio senza pregiu-
dicare la qualità del servizio.

102 Capitolo - 8 - Appunti di Teoria dell’Informazione e Codici
In questo caso si parla di tecniche di tipo ARQ (Automatic
Repeat-reQuest);
- tentare, qualora la ritrasmissione non sia possibile, di correg-
gere gli errori che più verosimilmente sono presenti nella pa-
rola ricevuta in questo caso si fa riferimento a strategie di tipo
FEC (Forward Error Correction).
In alcuni casi sono previste entrambe le strategie, cioè alcu-
ni errori vengono rivelati e corretti, altri semplicemente segnalati.
In quel che segue ci occuperemo principalmente di sistemi
di codifica finalizzati alla FEC. La funzione di correzione sopra
citata è affidata a un’applicazione che chiameremo decodifi-
catore.
Definizione 8.3 - decodificatore Dato un codice binario a blocchi , il decodificatore è un’appli-
cazione
che sulla base di un criterio prefissato, ha il compito di as-
sociare ad ogni elemento di che si presenti all’uscita del canale l’elemento
di che verosimilmente era stato immesso nel codificatore posto all’ingresso
del canale stesso.
***********
Quanto appena detto rende chiaro che più che di codici bi-
sognerebbe parlare di sistemi di codifica-decodifica, sia perché uno
stesso codice (in quanto sottoinsieme di ) potrebbe essere
ottenuto con codificatori diversi, sia perché potrebbe essere deco-
dificato con decodificatori basati su criteri diversi.
Nella pratica in effetti quando si parla di codice ci si rife-
risce indifferentemente, lo faremo anche noi, sia a che a ,
lasciando al contesto l’onere di rendere chiaro a cosa si stia effetti-
vamente facendo riferimento.
Appare in conclusione chiaro che un sistema di codifica è
in realtà completamente definito solo dalla terna .
La capacità di correzione di un codice è in pratica affidata
alla ridondanza più o meno oculatamente introdotta dal codifica-

Codici Binari a Blocchi 103
tore, ne discende che di regola e che il codificatore è una
applicazione iniettiva.
Altrettanto evidente è che, se il codice è non ambiguo, il
criterio adottato per la scelta del decodificatore deve necessaria-
mente essere tale che la restrizione di a coincida con
l’applicazione inversa della restrizione di a .
8.2 - Utilità della codifica di canale
La scelta del codice, e quella del decodificatore possono
avere un considerevole impatto sulle prestazioni del sistema di
trasmissione in termini di probabilità d’errore e di complessità del
sistema.
Va anche sottolineato che, per fissato codice, possono
essere individuati diversi decodificatori. Per taluni sistemi può
essere più qualificante ottimizzare la probabilità d’errore sul
singolo bit informativo, per altri quella sul simbolo trasmesso,
nella scelta del decodificatore se ne dovrebbe tener conto. Un
altro elemento da considerare nella scelta del sistema di codifica è
il tipo di canale, che può essere il classico AWGN, un canale
dotato di memoria, con conseguente presenza d’interferenza
intersimbolica, o un canale che introduce disturbi di tipo burst,
cioè disturbi che seppur di breve durata tendono a coinvolgere
più simboli consecutivi.
Non si può nemmeno trascurare tra i parametri da tenere in
considerazione la complessità della decodifica. Scegliere ad esem-
pio un algoritmo di decodifica sub-ottimo, comporta in genere un
degrado delle prestazioni, detto degrado, però, potrebbe essere
ampiamente ripagato da una significativa riduzione della comples-
sità e quindi dei costi, ovvero potrebbe essere una scelta obbligata
da limiti tecnologici contingenti.
In particolare per il momento faremo riferimento a un si-
stema che trasmette su un BSC (Binary Symmetric Channel) privo
di memoria. I simboli che costituiscono la generica parola di codi-

104 Capitolo - 8 - Appunti di Teoria dell’Informazione e Codici
ce vengono quindi inviati indipendentemente sul canale e ciascu-
no di essi avrà una probabilità
di essere rivelato in modo er-
rato, pertanto in uscita al canale avremo un elemento di che
non è certo corrisponda all’elemento inviato.
La probabilità di ricevere una parola di correttamente
sarà data da ( ) ad esempio con e avremo
conseguentemente la probabilità di ricevere una paro-
la non corretta vale , tale probabilità è in realtà scom-
ponibile nella somma di tante probabilità d’eventi disgiunti, preci-
samente eventi del tipo: “nella parola ricevuta sono presenti esat-
tamente errori”.
La probabilità che la parola ricevuta non sia corretta si può
quindi anche scrivere nella forma:
∑( ) ( )
(8.2.1)
dove il - esimo addendo esprime la probabilità che nella parola
ricevuta siano presenti esattamente errori. La probabilità che la
parola contenga almeno due errori si può pertanto scrivere anche
nella forma:
∑( ) ( )
(8.2.2)
nel nostro esempio tale probabilità si ridurrebbe a .
Quanto detto mostra come il contributo alla probabilità
dell’errore singolo sia di fatto dominante essendo gli addendi della
(8.2.1) rapidamente decrescenti al crescere di 1.
1 Per verificarlo è sufficiente esprimere ( ) nella forma (
⁄ )
(
) ed osservare che se
risulta (
) , pertanto (
) è una funzione
decrescente di t .

Codici Binari a Blocchi 105
Disporre di un codice in grado di correggere anche un nu-
mero limitato di errori in una parola ricevuta sembrerebbe per-
tanto essere una scelta quasi obbligata, in realtà bisogna anche
tener presente che le capacità correttive di un codice comportano
l’introduzione di una ridondanza cioè l’introduzione di bit non de-
stinati a trasportare informazione, ciò, a parità di tempo destinato
all’invio di una parola, comporta un aumento della banda, a meno
di non voler rallentare il flusso informativo.
Bisogna anche considerare che il confronto tra assenza e
presenza di codice andrebbe fatto a parità d’energia associata al
bit informativo, cioè tenendo conto che parte dell’energia dei bit
di informazione non codificati, in presenza di un codice, deve
essere dedicata ai bit di ridondanza, in quanto, a parità di densità
spettrale di potenza del rumore, la sul bit cresce al diminuire
della energia ad esso associata, il calcolo della (8.2.2) andrebbe
quindi effettuato introducendo un valore di che tiene conto di
ciò.
Malgrado le considerazioni appena fatte, fin quando è ac-
cettabile l’aumento della banda, l’introduzione di un codice a cor-
rezione d’errore è comunque vantaggiosa rispetto alla trasmis-
sione non codificata.
8.3 - La decodifica a massima verosimiglianza
In quel che segue ci riferiremo a canali BSC ed adotteremo
la tecnica di decodifica a massima verosimiglianza (MV), nel caso
in cui i bit informativi emessi dalla sorgente siano equiprobabili,
che, com’è noto, equivale alla maximum a posteriori probability
(MAP). Osserviamo che in questo caso sono equiprobabili anche
tutte le parole di e quindi, in virtù dell’iniettività del codificato-
re , lo saranno anche tutte le parole del codice .
Sotto quest’ipotesi, indicando con la generica parola di
codice, con la parola ricevuta e con la parola di codice
scelta dal decodificatore, la regola di decisione sarà:

106 Capitolo - 8 - Appunti di Teoria dell’Informazione e Codici
Regola di decisione a Massima Verosimiglianza Scegli la parola di codice per la quale è massima la probabilità di
ricevere , atteso che sia la parola trasmessa, in simboli:
( ( ))
(8.3.1)
Qualora il massimo non dovesse essere unico, scegli a caso, tra le parole di
codice che lo raggiungono.
***********
Nella precedente e rappresentano VV.AA. multidimen-
sionali che assumono rispettivamente valori in ed in .
Considerato che nel nostro caso risulta:
( ) ( ) ( )
(
)
( ) (8.3.2)
dove rappresenta il numero di bit in cui differisce da Se
il massimo della (8.3.2) si raggiunge per tutti i valori di che
rendono minimo. Qualora ciò avvenga in corrispondenza ad
un'unica parola di codice, si sceglie quella. Se dovessero esservi
più parole per le quali ciò avviene, il decodificatore, o, in armonia
con la regola MV, sceglie a caso, o segnala al trasmettitore la
presenza di errori nella parola ricevuta. Va da se che l’ultima op-
zione è praticabile solo se si dispone di un canale di ritorno e se la
trasmissione non deve necessariamente avvenire in tempo reale.
Osserviamo che , è la distanza di Hamming tra e ,
quindi il criterio di decisione a massima verosimiglianza su canale
BSC consiste in pratica nello scegliere a caso, tra le parole del co-
dice a minima distanza di Hamming dalla parola ricevuta.
8.4 - Definizioni e teoremi sui codici rivelatori e correttori
Supponiamo che il trasmettitore invii una parola e che per
effetto dei disturbi venga ricevuta una parola diversa da . Si
constata che esiste certamente che ci permette di scrivere
. Chiameremo evento o pattern d’errore.

Codici Binari a Blocchi 107
Definizione 8.4 Un pattern di errore è rilevabile se risulta:
(8.4.1)
essendo il complementare di rispetto a .
Viceversa diremo che non è rilevabile se:
(8.4.2)
***********
Ad ogni pattern d’errore corrisponde un peso. sistono
( ) eventi d’errore di peso Osserviamo che le posizioni dei bit
uno nel pattern d’errore identificano i bit errati nella parola rice-
vuta.
Si dice che un codice è in grado di rivelare errori se rivela
tutti i pattern di errore di peso indipendentemente dalla parola
di codice trasmessa.
Definizione 8.5 Siano e due parole di . Si definisce distanza minima ( ) di
un codice:
( ( ) ( ))
(8.4.3)
***********
Teorema 8.1 Un codice binario a blocchi, rivela tutti gli errori di peso se e solo se
.
Dimostrazione:
Necessarietà:
Se il codice rivela tutti gli errori di peso non superiore a ,
allora, comunque scelta una parola di codice ed un pattern
d’errore di peso , la parola non può essere una parola di
codice.
Ammettiamo per assurdo che esisterebbero allora
almeno due parole di codice, siano e , tali che ( ) .

108 Capitolo - 8 - Appunti di Teoria dell’Informazione e Codici
Consideriamo il pattern d’errore , risulta:
(8.4.4)
esisterebbe quindi un evento d’errore di peso che non può es-
sere rivelato in quanto composto con una parola di codice ne
genera un’altra.
Sufficienza:
Se e viene ricevuta la parola , con
risulta:
( ) ( ) (8.4.5)
non può quindi essere una parola di codice poiché ,
l’errore viene pertanto rilevato.
***********
Definizione 8.6 Diciamo che un decodificatore è in grado di correggere un pattern
d’errore se, quale che sia la parola di codice c , risulta:
( ) ( ) (8.4.6)
Diciamo che un decodificatore è in grado di correggere errori di peso
se la precedente è vera per ogni pattern d’errore di peso .
***********
Teorema 8.2 Affinché un decodificatore MV possa correggere tutti i pattern d’errore
di peso non superiore a , il codice deve avere una .
Dimostrazione:
Supponiamo, per assurdo, che esista un codice in grado di
correggere tutti gli errori di peso non superiore a con
. Per detto codice esisterà quindi almeno una coppia di pa-
role di codice, e , la cui distanza è . Esistono anche
certamente due pattern d’errore, siano ed , entrambi di peso
non maggiore di , tali che:
(8.4.7)

Codici Binari a Blocchi 109
Nel caso in cui potremo scegliere un pattern d’errore
tale che ed un tale che che soddisfino la
precedente.
Supponiamo adesso che venga ricevuta la parola , la
sua distanza da vale quella da vale:
( ) ( ) (8.4.8)
pertanto il decodificatore a massima verosimiglianza decide per ,
o per una qualsiasi altra parola di codice che disti non più di da
.
Se potremo scegliere due pattern d’errore ed
entrambi di peso che soddisfano la (8.4.7). Supponiamo ancora
una volta che venga ricevuta la parola , la sua distanza da
vale come pure la sua distanza da pertanto, o il decodificatore
sceglie a caso tra e , ovvero decide a favore di un’altra parola
di codice che disti da , meno di .
***********
Teorema 8.3 Un decodificatore MV è in grado di correggere tutti i pattern d’errore
di peso non superiore a
.
Dimostrazione:
Supponiamo che il canale modifichi una parola di codice
aggiungendovi un pattern d’errore di peso non superiore a .
All’ingresso del decodificatore si presenta quindi la parola
. Quale che sia risulta , in quanto ,
poiché dista da meno di , inoltre:
( ) (8.4.9)
Il peso di e quello del pattern d’errore è non
superiore a , pertanto, , ( ) , mentre ( )

110 Capitolo - 8 - Appunti di Teoria dell’Informazione e Codici
, quindi il decodificatore MV in corrispondenza a restituirà
( ) ( ), l’errore verrà quindi corretto.
***********

Capitolo - 9
CODICI LINEARI A BLOCCHI
9.1 - Premessa
Abbiamo visto che un codice a blocco è sostanzialmente
un’applicazione iniettiva tra e con gli bit ag-
giunti consentono in pratica di migliorare le prestazioni del siste-
ma introducendo un’opportuna ridondanza ai bit informativi.
Osserviamo che al crescere di cresce, con legge esponen-
ziale, il numero delle parole di codice. Ci si rende conto che in
queste condizioni la tecnica di decodifica, consistente in una ri-
cerca esaustiva su una tabella (in pratica un banco di memoria)
che associa ad ogni possibile elemento di l’elemento di che
più “verosimilmente” è stato trasmesso diventa in breve imprati-
cabile a causa delle eccessive dimensioni della succitata tabella, ov-
vero perché si preferisce utilizzare la memoria del sistema per altri
scopi.
Queste considerazioni inducono alla progettazione di codici
che permettano di adottare delle tecniche di decodifica di tipo al-
goritmico, o che quantomeno limitino la quantità di memoria ne-
cessaria per effettuare la ricerca sopra citata.
Tale risultato può essere ottenuto ad esempio se si progetta
un codice in modo da individuare nel sottoinsieme una qualche
struttura algebrica. Tanto più ricca sarà tale struttura, tanto mag-
giore sarà la possibilità di individuare algoritmi di decodifica effi-
cienti.
9.2 - Morfismi
È utile introdurre alcune definizioni

112 Capitolo - 9 - Appunti di Teoria dell’Informazione e Codici
Definizione 9.1 - omomorfismo Un omomorfismo è un’applicazione avente come dominio un gruppo
e come codominio un gruppo tale che
( ) ( ) ( ) (9.2.1)
***********
Nella precedente il segno indica la legge di composizione
interna relativa al gruppo in cui si opera.
Definizione 9.2 - monomorfismo Un monomorfismo è un omomorfismo iniettivo.
***********
Definizione 9.3 - isomorfismo Un monomorfismo suriettivo è un isomorfismo.
***********
Si può dimostrare che l’insieme immagine del dominio di
un omomorfismo ( ) è un sottogruppo del gruppo
d’arrivo. Per sottogruppo s’intende un sottoinsieme di un gruppo
che ha la struttura di gruppo rispetto alla stessa legge di composi-
zione interna del gruppo in cui è contenuto.
9.3 - Schema di principio di un codice lineare a blocco
Un’importante classe di codici a blocco è quella dei codici
lineari. Un codificatore lineare è concettualmente costituito da
(vedi Fig. 9.1) un registro d’ingresso dotato di celle, da un banco
di sommatori ciascuno dei quali con un numero di ingressi
compreso tra e e da un registro di uscita costituito da celle
connesse alle uscite dei sommatori corrispondenti. Questi ultimi,
nel caso dei codici binari, effettuano le somme in . Conveniamo
che un sommatore con un solo ingresso equivale ad una connes-
sione diretta tra la cella d’ingresso e quella di uscita corrispon-
dente al sommatore.

Codici Lineari a Blocchi 113
I registri sopra citati possono essere in pratica registri a
scorrimento (shift register), in questo caso la sorgente emette una
sequenza di bit, non appena il registro d’ingresso è carico, cioè
dopo periodi del suo clock, l’uscita dei sommatori, che potreb-
bero essere realizzati con delle porte logiche di tipo XOR, viene
utilizzata per settare le celle del registro di uscita che verrà
quindi completamente scaricato nel tempo necessario a ricaricare
con i successivi bit il registro di ingresso.
In sostanza, se e indicano rispettivamente i pe-
riodi di clock del registro d’ingresso e di quello d’uscita, deve ri-
sultare .
9.4 - Matrice generatrice del codice
I codici lineari a blocco sono anche chiamati codici a con-
trollo di parità (parity check code) in quanto il generico elemento
del registro d’uscita, vale uno ogniqualvolta la somma in senso
ordinario dei valori delle celle di ingresso a cui è connesso è un
numero dispari e vale zero altrimenti.
Se indichiamo con una parola di e con ( ) la
corrispondente parola di in uscita dal codificatore, l’ esimo
bit della parola d’uscita può esprimersi nella forma:
(9.4.1)
Fig. 9.1 - Schema di principio di un codice di Hamming 15,11
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
clkoutT
1 2 3 4 5 6 7 8 9 10 11S
clk inT

114 Capitolo - 9 - Appunti di Teoria dell’Informazione e Codici
dove il generico è un coefficiente che vale se un ingresso
del -esimo sommatore è connesso alla -esima cella del registro di
ingresso e vale altrimenti.
Ricordiamoci che tutte le operazioni delle (9.4.1) sono
effettuate secondo le regole del campo .
Un codice definito tramite le (9.4.1) si dice lineare in quan-
to, come si verifica facilmente, la parola di codice ottenuta in cor-
rispondenza alla somma di due qualsiasi parole di è la somma
in delle rispettive parole di codice.
e sono gruppi, ed un codificatore lineare è un omo-
morfismo, ovviamente, è auspicabile che sia anche un monomor-
fismo, onde evitare che a due parole distinte di corrisponda la
stessa parola di codice in .
Il codice è pertanto un sottogruppo di .
Se pensiamo e come vettori riga le (9.4.1) si possono
rappresentare sotto forma matriciale:
(9.4.2)
dove è una matrice il cui generico elemento è . è
detta matrice generatrice del codice.
Si osservi che le righe della matrice , sono le parole di
codice che vengono generate in corrispondenza agli elementi che
costituiscono la base canonica di . Ci si convince anche abba-
stanza facilmente del fatto che le righe di generano mediante
tutte le loro possibili combinazioni lineari , che oltre ad essere
un sottogruppo di ne è anche un sottospazio. Ovviamente af-
finché il codice non sia ambiguo deve essere un monomor-
fismo.
Una condizione necessaria e sufficiente affinché sia un
monomorfismo è che le righe della sua matrice generatrice siano
linearmente indipendenti.

Codici Lineari a Blocchi 115
9.5 - Distribuzione dei pesi di un codice lineare a blocco
Abbiamo detto che la somma di due parole di un codice
lineare è una parola di codice, ciò comporta che la parola identica-
mente nulla in un codice lineare è sempre una parola di codice, in
quanto ottenibile sommando ad una qualunque parola del codice
se stessa, indicando con la parola identicamente nulla per un
codice lineare avremo:
( ) ( ) (9.5.1)
ma, per fissato , al variare di in si ottengono tutte le parole
di codice, in sostanza fissata una distanza di Hamming ogni parola
di un codice lineare vedrà lo stesso numero di parole di codice a
quella distanza. Tale proprietà si rivela utile ad esempio nel calco-
lo della probabilità d’errore in quanto la probabilità d’errore con-
dizionata all’invio di una parola di codice non dipende dalla par-
ticolare parola inviata, ed è quindi uguale alla probabilità d’errore
non condizionata.
Dalla (9.5.1) si deduce inoltre facilmente che per calcolare
la distanza minima del codice è sufficiente individuare la parola
non nulla di peso minimo, che è evidentemente la parola a mini-
ma distanza di Hamming dalla parola nulla, ovviamente non è
detto che tale parola sia unica.
La (9.5.1) ci suggerisce di introdurre la cosiddetta distribu-
zione dei pesi del codice.
Definizione 9.4 –Distribuzione dei pesi di un codice lineare
Dato un codice lineare per distribuzione dei pesi s’intende una
applicazione ( ), definita sull’insieme dei naturali non maggiori di , a
valori in ; che associa ad ogni elemento del suo dominio il numero di parole
di codice che hanno peso pari ad esso.
***********
È facile intuire che le prestazioni di un codice sono in pri-
ma istanza influenzate dalla sua distanza minima, che coincide con

116 Capitolo - 9 - Appunti di Teoria dell’Informazione e Codici
il più piccolo elemento non nullo del dominio di ( ) cui corri-
sponde un’immagine diversa da zero, ma dipendono anche dalla
( ) nel suo insieme.
9.6 - Capacità di rivelazione di un codice lineare a blocco
Per la capacità di rivelazione di un codice lineare a blocco
vale il seguente teorema:
Teorema 9.1 Un decodificatore a massima verosimiglianza per un codice lineare non
è in grado di rivelare tutti e soli gli eventi d’errore che coincidono con una
parola di codice.
Dimostrazione:
Se il canale fa sì che ad una parola di codice venga ag-
giunto un pattern d’errore che coincide con una parola di codice
in ingresso al decodificatore si presenterà la parola , ma il
codice è lineare quindi è una parola di codice pertanto
l’errore non sarà rivelato.
Viceversa se un pattern d’errore non viene rivelato, allora
deve esistere una parola di codice tale che essendo
la parola trasmessa. L’eguaglianza appena scritta comporta:
(9.6.1)
pertanto è una parola di codice.
***********
9.7 - Probabilità di non rivelazione d’errore di un codice lineare
Ci proponiamo di calcolare la probabilità che un codice
lineare, impiegato per la sola rivelazione d’errore, non ne riveli la
presenza nella parola ricevuta, sotto l’ipotesi che il codice venga
utilizzato su un canale BSC e che il decodificatore sia a MV.
Sappiamo che (vedi Teorema 9.1) gli unici pattern d’errore
non rivelati sono quelli che coincidono con una parola di codice.

Codici Lineari a Blocchi 117
La probabilità che si presenti un dato pattern d’errore dipende
esclusivamente dal suo peso e vale in particolare:
( ) (9.7.1)
Tra tutti gli ( ) possibili pattern d’errore di peso non verranno
rivelati soltanto quelli che coincidono con una parola di codice,
cioè tanti quante sono le parole di codice di quel peso. Poiché i
pattern d’errore sono tra loro indipendenti, la probabilità ( )
che un errore non venga rivelato dal codice vale:
( ) ∑ ( )
( ) (9.7.2)
La precedente presuppone la conoscenza della distribuzio-
ne dei pesi. Purtroppo detta funzione non è nota per molti dei co-
dici d’uso comune, in questo caso può essere utile una maggiora-
zione della (9.7.2) che si basa sulla considerazione che in ogni
caso deve essere:
( ) (
) (9.7.3)
non possono cioè esservi più pattern d’errore di peso di quante
non siano le parole di aventi quel peso. Potremo quindi certa-
mente scrivere:
( ) ∑ (
)
( ) (9.7.4)
9.8 - Laterali di un sottogruppo
In questo paragrafo utilizzeremo la notazione moltiplicativa
per indicare la legge di composizione di un gruppo e indicheremo
con l’elemento neutro rispetto ad essa.
Consideriamo un gruppo abeliano ed un suo sottogruppo
è quindi chiuso rispetto alla legge di composizione di .

118 Capitolo - 9 - Appunti di Teoria dell’Informazione e Codici
Consideriamo un generico elemento non appartenente a
. Se componiamo con gli elementi di otteniamo un sottoin-
sieme di disgiunto da . Se, infatti, risultasse che, per un qual-
che elemento di , , ciò implicherebbe che
, quindi
, ma se allora, es-
sendo un gruppo, vi appartiene anche , contro l’ipotesi.
viene denominato laterale, coinsieme o coset di .
Consideriamo adesso, se esiste, un elemento che non ap-
partiene né a né a , sia . Anche , composto con gli ele-
menti di , genera un sottoinsieme di disgiunto da , ma an
che da ; se infatti esistesse tale che , ciò
implicherebbe quindi contraddi-
cendo l’ipotesi. Possiamo quindi concludere che i laterali di un
sottogruppo se non sono disgiunti sono coincidenti.
Ogni sottogruppo induce quindi nel gruppo una partizione
in laterali. Si può facilmente verificare che tutti i laterali hanno la
stessa cardinalità del sottogruppo cui sono associati e che ogni
elemento di un laterale, composto con gli elementi del sotto-
gruppo, è in grado di generare il laterale cui appartiene. È quindi
legittimo scegliere in corrispondenza a ogni laterale un suo ele-
mento, che viene denominato rappresentante di laterale o di coinsieme,
o ancora coset leader. Il criterio di scelta può essere qualsiasi.
Ricordiamoci che stiamo considerando gruppi abeliani, se
rimuovessimo questa ipotesi ad ogni sottogruppo potrebbero es-
sere associati dei laterali destri e sinistri, generalmente distinti,
qualora tali laterali dovessero coincidere si direbbe che il sotto-
gruppo considerato è un sottogruppo normale.
Il fatto che tutti i laterali di un sottogruppo hanno la stessa
cardinalità consente di affermare, nel caso di gruppi finiti, che
ogni sottogruppo ha un numero d’elementi sottomultiplo di quel-
lo del gruppo in cui è contenuto.

Codici Lineari a Blocchi 119
9.9 - Decodifica tramite i rappresentanti di laterale
Tornando ai codici lineari a blocco ( ), ricordiamo che
l’insieme delle parole di un tale codice costituisce un sottogruppo
. Abbiamo anche mostrato che un codice lineare a blocco è
in grado di rivelare tutti i pattern d’errore che non coincidono con
parole di codice.
Occupiamoci adesso delle sue capacità correttive. A tal
proposito osserviamo che ogni parola ricevuta appartiene ad un
solo laterale di rispetto a , intendendo ovviamente stesso
come un laterale. Risulta inoltre , il pattern d’errore in-
trodotto dal canale appartiene quindi certamente allo stesso late-
rale cui appartiene .
Visto che la probabilità che il canale introduca un pattern
d’errore di un dato peso decresce al crescere di quest’ultimo, l’ipo-
tesi più verosimile è che il pattern d’errore introdotto coincida
con una parola di peso minimo appartenente allo stesso laterale
della parola ricevuta.
Dato un codice scegliamo quindi in ogni suo laterale una
parola di peso minimo. Qualora in un laterale vi siano più parole
di peso minimo ne sceglieremo una a caso fra esse. Osserviamo
che, quale che sia la parola ricevuta, esisterà una sola parola di
codice che permette di scrivere: essendo il coset leader
del laterale a cui appartiene.
Comunque scelta una parola di codice risulta:
( ) ( ) (9.9.1)
in quanto è una parola di che appartiene allo stesso
laterale di , visto che è una parola di codice, ed è per ipo-
tesi una parola di peso minimo di quel laterale, pertanto se adot-
tiamo la decodifica ML dobbiamo necessariamente scegliere la pa-
rola .
Se nello stesso laterale più di una parola ha peso minimo,
ciò significa che la parola ricevuta si trova alla stessa distanza da

120 Capitolo - 9 - Appunti di Teoria dell’Informazione e Codici
due o più parole di codice, in questo caso, quale che sia la scelta
effettuata tra le parole candidate, le prestazioni del decodificatore
non cambiano.
Si osservi che, qualora la parola ricevuta appartenga al codi-
ce, tale operazione non la altera in quanto il rappresentante di la-
terale relativo a è unico ed è ovviamente la parola identicamente
nulla.
Quanto sopra detto ci porta ad enunciare il seguente
Teorema 9.2 Un decodificatore che adotta la tecnica dei coset leader corregge tutti e
soli i pattern d’errore coincidenti con un coset leader.
***********
Un vantaggio della decodifica basata sui coset leader è
quello di restituire sempre una parola di codice, ovviamente non
sempre quella corretta. Il suo principale svantaggio consiste nel
fatto che per metterla in pratica occorre comunque effettuare una
ricerca in tutto per individuare il laterale cui appartiene la pa-
rola, se è grande tale ricerca può diventare troppo onerosa.
9.10 - Probabilità d’errore di un codice lineare a blocchi
Il Teorema 9.2 ci suggerisce come calcolare la probabilità di
corretta decisione di un codice, impiegato su un canale BSC.
Osserviamo innanzitutto che all’uscita del decodificatore
sarà presente la parola effettivamente inviata tutte e sole le volte
che il pattern d’errore introdotto dal canale coincide con un coset
leader, considerando anche tra i pattern d’errore quello identica-
mente nullo che è il coset leader del codice.
La coinciderà quindi con la probabilità che il pattern di
errore sia un qualsiasi coset leader. Possiamo quindi scrivere:
∑ ( ) ( )
(9.10.1)

Codici Lineari a Blocchi 121
dove rappresenta il massimo peso raggiunto dai coset leader ed
( ) un’applicazione che associa ad ogni intero compreso tra
ed il numero di coset leader di peso .
Dalla (9.10.1) discende facilmente:
∑ ( ) ( )
(9.10.2)
9.11 - Codici perfetti, bound di Hamming
Una maggiorazione della probabilità d’errore può essere ot-
tenuta ricordando il Teorema 8.3, che afferma che la capacità
correttiva di un codice è non minore di
. In altri ter-
mini il teorema afferma che la regione di decisione di ciascuna pa-
rola di codice contiene una “ipersfera” di raggio pari a in , che
contiene esattamente ∑ ( )
punti.
In un codice lineare tutte le regioni di decisione hanno la
stessa forma e l’insieme dei coset leader costituisce la regione di
decisione associata alla parola nulla. Vi sono laterali, quindi
coset leader. Il Teorema 8.3 nel caso di codici lineari implica
quindi che deve valere la disuguaglianza:
∑( )
∑ ( )
(9.11.1)
la precedente va sotto il nome di Bound di Hamming i codici che lo
soddisfano come uguaglianza sono detti codici perfetti.
Quale che sia il codice lineare che stiamo considerando, i
primi addendi dell’ultimo membro della (9.11.1) devono
necessariamente essere uguali ai corrispondenti addendi della
sommatoria a primo membro, possiamo pertanto scrivere:
∑ ( ) ( )
∑( )
( ) (9.11.2)

122 Capitolo - 9 - Appunti di Teoria dell’Informazione e Codici
∑( )
( ) ∑ ( )
( )
La precedente è ovviamente soddisfatta come uguaglianza
solo dai codici perfetti, quali sono ad esempio i codici di Ham-
ming cui accenneremo più avanti.

Capitolo - 10
CODICI SISTEMATICI
10.1 - Codici Sistematici
Quanto detto nei precedenti paragrafi ci fa comprendere
che le prestazioni di un codice lineare sono da attribuirsi sostan-
zialmente al sottospazio di generato dalle righe della matrice
che se sono linearmente indipendenti costituiscono una base per il
sottospazio da esse generato. In sostanza quindi codici generati da
matrici distinte, delle stesse dimensioni, che generano però lo
stesso sottospazio di sono, da questo punto di vista, del tutto
equivalenti.
In pratica lo spazio generato dalle righe di non cambia se
si permutano le sue righe, o se si somma ad una qualunque riga di
una combinazione lineare delle restanti.
Dato un codice lineare a blocchi, consideriamo la sua ma-
trice e selezioniamone una sua colonna non identicamente
nulla. Supponiamo sia la -esima. Consideriamo quindi una riga di
che abbia un nella -esima colonna, supponiamo sia la -esima,
sommiamo tale riga a tutte le altre righe di che si trovano nelle
stesse condizioni. Otterremo così una matrice, sia ( ) , equiva-
lente a la cui -esima colonna ha un solo valore in posizione -
esima. Operiamo adesso sulla matrice ( ) come avevamo operato
sulla con la sola accortezza di scegliere una colonna che abbia
un in una riga diversa dalla -esima, otterremo così una ( ) con
due colonne che presentano un solo valore su righe diverse.
All’ -esimo passo sceglieremo una colonna che abbia un in una
riga diversa da quelle selezionate ai passi precedenti.
Tale procedura potrà essere ripetuta al più volte, a meno
che non sia più possibile selezionare una colonna, ma ciò accade
solo nel caso in cui tutte le righe non ancora selezionate sono

124 Capitolo - 10 - Appunti di Teoria dell’Informazione e Codici
identicamente nulle, in questo caso le righe della matrice da cui
eravamo partiti non erano linearmente indipendenti, quindi non
erano in grado di generare un sottospazio di dimensione , o, che
è lo stesso, il codificatore non era un monomorfismo di in
cioè si tratterebbe di un codice ambiguo.
Al termine della procedura sopra descritta avremo quindi
una matrice ( ) che ha almeno colonne in cui compare un solo
. Tra le colonne con un solo ne esisterà almeno una che lo ha
in corrispondenza alla prima riga, una in corrispondenza alla
seconda e cosi via fino alla -esima.
Se poi s’intende utilizzare il codice su un canale simmetrico
binario, ovvero mappando coppie di bit della parola di codice in
punti di una costellazione QAM, è anche legittimo permutare le
colonne della matrice , questa operazione equivale in sostanza ad
etichettare diversamente le dimensioni dello spazio .
È ovvio che permutando opportunamente le colonne della
( ) si può ottenere una matrice del tipo:
(10.1.1)
Un codice lineare a blocchi la cui matrice generatrice assu-
ma la forma (10.1.1) si dice sistematico tale denominazione è do-
vuta al fatto che i primi bit della parola di codice coincidono
con i bit informativi, i restanti sono utilizzati per effettuare i
controlli di parità definiti dalle colonne della matrice .
In pratica in corrispondenza a ogni codice lineare a blocco
non ambiguo esiste un codice sistematico ad esso equivalente.
L’utilizzo dei codici sistematici è auspicabile, in quanto, so-
lo per fare un esempio, consente di non effettuare nessuna deco-
difica sulla parola ricevuta, limitandosi ad osservarne i primi bit,
compensando, in questo caso, il degrado delle prestazioni con la
diminuzione della complessità del sistema.

Codici Sistematici 125
10.2 - Matrice di controllo di parità
Dato un codice lineare a blocco sistematico, indichia-
mo con la generica parola d’ingresso e con la generica parola
di codice. Se prendiamo in considerazione soltanto le ultime
componenti della parola di codice, ponendo
possiamo scrivere:
[
] (10.2.1)
sostituendo a la sua espressione in termini della matrice otte-
niamo:
[
] [
]
( )
(10.2.2)
Sempre in virtù del fatto che il codice è sistematico possia-
mo scrivere anche:
(10.2.3)
che ci suggerisce di riscrivere l’ultima eguaglianza nella (10.2.2)
nella forma:
[
] (10.2.4)
La matrice che compare nella precedente prende il nome
di matrice di controllo di parità (parity check matrix), in quanto la
(10.2.4) è soddisfatta da tutte e sole le parole di codice.
10.3 - Codici duali
Osserviamo che la (10.2.4) implica l’ortogonalità tra la
generica parola di codice e ogni riga della matrice , le cui
righe essendo linearmente indipendenti sono in grado di generare
un sottospazio di ortogonale a , nel senso che com-

126 Capitolo - 10 - Appunti di Teoria dell’Informazione e Codici
binando linearmente le righe di si ottengono sempre parole di
ortogonali a qualsiasi parola di .
Ci si rende facilmente conto del fatto che si può pensare a
come ad un codice ( ).
Permutando opportunamente le colonne della matrice si
può sempre rendere sistematico, in un certo senso lo è
anche senza permutarle, solo che in questo caso i bit informativi
coincidono con gli ultimi bit della parola di codice.
10.4 - Decodifica basata sulla sindrome
Supponiamo di ricevere una parola , affetta da un pattern
d’errore . Se sostituiamo a primo membro della (10.2.4) otte-
niamo:
(10.4.1)
è una parola di bit che prende il nome di sindrome della
parola ricevuta. Vi sono possibili sindromi.
È interessante osservare che il calcolo della sindrome può
essere effettuato in ricezione con uno schema analogo a quello
utilizzato per il codificatore, dimensionando correttamente i due
registri a scorrimento.
Il calcolo della sindrome nei codici a rivelazione d’errore
consente verificare facilmente se la parola ricevuta appartiene al
codice solo le parole di codice hanno infatti sindrome nulla.
Osservando la (10.4.1) si rileva che gli elementi di uno
stesso laterale del codice hanno la stessa sindrome. Gli elementi di
un laterale si ottengono infatti sommando ad un qualsiasi elemen-
to del coset stesso una parola di codice. È altresì chiaro che
elementi appartenenti a laterali distinti avranno sindromi distinte.
In sostanza esiste una corrispondenza biunivoca tra il gruppo
delle sindromi e l’insieme dei laterali che è esso stesso un gruppo,
detto gruppo quoziente indicato con
⁄ . La composizione tra
due laterali del gruppo quoziente si effettua individuando il coset

Codici Sistematici 127
di appartenenza dell’elemento di ottenuto componendo due
elementi arbitrariamente scelti nei due laterali componendi.
Il gruppo delle sindromi è isomorfo al gruppo quo-
ziente di individuato dal suo sottogruppo .
Le considerazioni appena fatte ci permettono di concludere
che la decodifica a massima verosimiglianza può essere effettuata
calcolando la sindrome della parola ricevuta ed utilizzandola come
indirizzo di una cella di memoria in cui è scritto il coset leader del
laterale ad essa associato, che va sommato alla parola ricevuta per
effettuare la decodifica.
Tale tecnica comporta quindi un banco di memoria in
grado di contenere parole di bit.
In effetti essendo interessati solo ai bit informativi è
sufficiente memorizzare soltanto i primi bit del coset leader,
questo accorgimento riduce un po’ il fabbisogno di memoria.
La decodifica basata sulla sindrome è più efficiente di quella
basata sui coset leader, anche se, inevitabilmente, al crescere delle
dimensioni della parola di codice, diventa anch’essa impraticabile,
a causa della crescita esponenziale della quantità di memoria di cui
necessita.


Capitolo - 11
CODICI DI HAMMING E LORO DUALI
11.1 - Codici di Hamming
Abbiamo visto come si calcola la sindrome di un codice ed
abbiamo osservato che più pattern d’errore possono condividere
la stessa sindrome. Immaginiamo adesso di voler costruire un
codice che abbia la capacità di correggere tutti i pattern d’errore di
peso . Affinché ciò sia possibile ciascun pattern d’errore di peso
deve essere un coset leader.
Abbiamo visto che un codice ( ) consta di parole di
bit. Esistono quindi distinti pattern d’errore di peso , ciascuno
dei quali, moltiplicato per fornisce la rispettiva sindrome.
Detta sindrome coincide con la colonna della matrice che corri-
sponde alla posizione dell’unico bit nel pattern d’errore. Quindi,
se vogliamo che il codice sia in grado di correggere tutti i pattern
d’errore di peso , è necessario che le colonne della matrice
siano tutte diverse tra loro e non nulle. Poiché ogni colonna della
matrice in questione ha elementi, deve necessariamente
essere:
(11.1.1)
La precedente scritta come uguaglian-
za definisce implicitamente una fami-
glia di codici, i codici di Hamming,
che sono in grado di correggere tutti
gli errori di peso e di rivelare quelli
di peso non superiore a due in quanto
si può mostrare che la loro vale
. Alcune soluzioni della (11.1.1) sono
riportate nella in Tabella 11.1.
3 1
7 4
15 11
31 26
63 57
127 120
Tabella 11.1 Alcuni valori di
e per i codici di Hamming

130 Capitolo - 11 - Appunti di Teoria dell’Informazione e Codici
Il primo codice della tabella è in effetti un codice a ripe-
tizione, in sostanza ogni bit informativo viene inviato consecuti-
vamente tre volte, vi sono due sole parole di codice, la distanza di
Hamming tra esse, quindi anche la del codice, è , il codice è
in grado di correggere errori singoli, la regola di decisione a massi-
ma verosimiglianza per questo codice consiste nello scegliere il bit
che compare almeno due volte nella parola ricevuta. Se il canale
introduce un errore doppio il codice rileva l’errore, ma non è in
grado di correggerlo, nel senso che restituisce una parola di codice
diversa da quella inviata nel caso di decodifica MV. Vi sono tre
laterali del codice a ciascuno di essi appartiene un pattern d’errore
singolo e il suo negato.
Per concludere si può facilmente verificare che la (9.11.1) è
verificata come uguaglianza per tutti i codici di Hamming risulta
infatti:
⌊
⌋ (11.1.2)
da cui
∑ ( )
(11.1.3)
ma per i codici di Ham-
ming I co-
dici di Hamming sono
quindi codici perfetti.
Esempio 11.1
Una possibile matrice del
secondo codice della
Tabella 11.1, il 7,4,è data
da:
[
]
Fig.E 11.1 - Schema a blocchi del Codice 7,4 di Hamming
1 2 3 4
1 2 3 4 5 6 7
clk outT
S
clk inT

Codici di Hamming e loro Duali 131
Osserviamo che la matrice in esame ha
per colonne tutte le parole di tre bit ad
esclusione di quella costituita da soli zero,
ordinate in modo da rispettare la (10.2.4).
Ricordiamoci che le prime quattro colon-
ne di possono essere permutate tra loro
senza che le caratteristiche del codice cam-
bino.
Basandoci sulla (10.2.4) e sulla (10.1.1)
potremo facilmente scrivere la matrice ge-
neratrice del codice:
[
]
il relativo schema a blocchi è mostrato in
Fig.E 11.1, la lista delle parole del codice è
elencata nella Tabella 11.2 dove ogni parola
è stata suddivisa tra contenuto informativo (i
primi 4 bit) e controlli di parità (gli ultimi 3).
Uno schema a blocchi del codice di Hamming 15,11 è mostrato in
Fig. 9.1
11.2 - Duali dei codici di Hamming
Nel caso dei duali dei codici di Hamming, le colonne della
loro matrice generatrice sono tutte e sole le parole binarie non
nulle che si possono scrivere con bit vi saranno quindi esatta-
mente colonne nella matrice generatrice. La matrice
definisce quindi un codice ( ) , le cui parole non nulle
hanno tutte peso .
Infatti ogni riga della matrice generatrice contiene per co-
struzione bit zero e bit uno. Le restanti parole del
codice si ottengono combinando linearmente le righe della ma-
trice generatrice, tale combinazione lineare, a ben vedere, consiste
nel cancellare un sottoinsieme di righe dalla matrice generatrice e
sommare le restanti.
Per semplificare il ragionamento immaginiamo di aggiun-
gere alla matrice una colonna nulla, sia la matrice estesa così
ottenuta. Osserviamo che le parole del codice ( ) generato da
Codice di Hamming 7,4 0000 000 0001 111 0010 011 0011 100 0100 101 0101 001 0110 110 0111 001 1000 110 1001 001 1010 101 1011 010 1100 011 1101 100 1110 000 1111 111
Tabella 11.2 - Parole del codice Hamming 7.4

132 Capitolo - 11 - Appunti di Teoria dell’Informazione e Codici
differiscono da quelle generate da solo per il fatto di avere un
bit in più, che essendo generato dalla colonna identicamente nulla,
vale sistematicamente . Possiamo quindi affermare che le parole
corrispondenti dei due codici, cioè generate dalla stessa parola di
hanno lo stesso peso.
Osserviamo adesso che la cancellazione di una riga in da
luogo ad una sottomatrice ( ) che ha le colonne uguali a due a
due; se cancellassimo due righe avremmo una sottomatrice ( )
con colonne uguali a quattro a quattro e così via.
In generale quindi cancellando righe di , con ,
avremo una sottomatrice ( ) di righe con solo colonne
distinte che non potranno essere altro se non tutte le parole
binarie di bit.
Il peso della parola di codice ottenuta componendo le
righe di ( ), è uguale al numero di colonne che hanno un numero
dispari di al loro interno. Ci si convince facilmente che
esattamente la metà delle colonne diverse tra loro hanno
peso dispari. Il peso della parola di codice ottenuta componendo
le righe vale
, indipendente dal numero di righe
cancellato, pur di non cancellarle tutte, in questo caso otterremo
la parola di codice nulla che ha peso .
Possiamo quindi concludere che la distanza minima per
codici generati da matrici di tipo , o da matrici di tipo vale
, che è anche, la distanza tra due parole di codice qualsiasi.
11.3 - Codici ortogonali e transortogonali
Immaginiamo di utilizzare un codice generato da una matri-
ce del tipo , introdotta nel § 11.1 - , con una segnalazione di tipo
antipodale, associando cioè ai bit un impulso di segnalazione in
banda base ( ) (la cui durata, per semplicità possiamo pensare sia
non maggiore dell’intervallo di segnalazione ), e ai bit il suo
opposto. Alla generica parola di codice verrà quindi associato il
segnale in banda base:

Codici di Hamming e loro Duali 133
( ) ∑( ) ( ( ) )
(11.3.1)
Se effettuiamo il prodotto scalare tra i segnali associati a due di-
stinte parole di codice otteniamo:
∫ ∑( ) ( ( ) )
∑( ) ( ( ) )
∑∑( ) ( )
∫ ( ( ) ) (
( ) )
∑( ) ( ) ∫ ( ( ) ) (
( )
( ) ) ∑( )( ) ∫ ( ) ( )
∑( )(
)
(11.3.2)
nella precedente indica l’energia del bit informativo, conse-
guentemente l’energia specifica dell’impulso di segnalazione, che
tiene conto del Rate
del codice, vale
. La sommatoria a
ultimo membro vale in quanto la distanza di Hamming tra due
parole di codice distinte vale .
Sotto le ipotesi appena fatte i segnali associati alle parole del
codice generato dalla matrice di parità estesa di un codice di
Hamming sono a due a due ortogonali. Per quanto riguarda i
codici duali dei codici di Hamming, nelle stesse condizioni
generano un set di segnali isoenergetici in uno spazio a
dimensioni. Detti segnali non sono più mutuamente ortogonali,
anche se la distanza tra una qualunque coppia di segnali è la stes-

134 Capitolo - 11 - Appunti di Teoria dell’Informazione e Codici
sa. I codici duali dei codici di Hamming si chiamano transortogonali.
Rispetto ai codici generati da matrici di tipo i codici transorto-
gonali hanno il vantaggio a parità d’energia di consentire un
aumento dell’energia associata al bit della parola di codice, in virtù
del rate più basso, per questo le loro prestazioni sono leggermente
migliori.

Capitolo - 12
CODICI CONVOLUZIONALI
12.1 - Premessa
I codici convoluzionali furono proposti per la prima volta
da P. Elias nel 1955, ma hanno trovato ampia applicazione dopo
che A. J. Viterbi propose nel 1967 un efficiente algoritmo di deco-
difica. Nei codificatori convoluzionali la parola prodotta non di-
pende soltanto dalla parola emessa dalla sorgente al tempo pre-
sente, ma anche da quelle emesse precedentemente. Si tratta quin-
di di un codificatore dotato di memoria.
12.2 - Struttura del codificatore
Lo schema di prin-
cipio di un codificato-
re convoluzionale è
mostrato in Fig. 12.1.
I simboli emessi dalla
sorgente appartengo-
no a un alfabeto di
cardinalità assegnata
ed i sommatori opera-
no modulo la cardina-
lità dell’alfabeto.
Lo schema di Fig.
12.1, a prima vista,
non differisce da quello di un codificatore per codici a blocchi, se
non fosse per la dimensione dello shift register d’ingresso che è
maggiore di quello d’uscita. La differenza sostanziale tra il codi-
ficatore di figura e quello di uno a blocchi, consiste nel fatto che il
registro d’uscita, nel codificatore di figura, viene letto ogni due
simboli emessi dalla sorgente.
Fig. 12.1 - Schema di principio di un codificatore convoluzionale
2
3 sT
2sT
3
iy
2
iy
1
iy
1
ix 1
2
ix
2
ix
1
1
ix
2
1
ix 2
2
ix
SsT
sT
sT
sT
sT
sT

136 Capitolo - 12 - Appunti di Teoria dell’Informazione e Codici
In generale in un codificatore convoluzionale il numero di
simboli che costituiscono la parola informativa è un sottomultiplo
della lunghezza dello shift register d’ingresso. Il rapporto tra il
numero di celle dello shift register e il numero di simboli di
sorgente che costituiscono la parola informativa viene deno-
minato lunghezza di vincolo (costraint lenght) ( in quel che segue).
Da quanto appena detto discende che la parola di codice
non dipende soltanto dalla parola d’ingresso attuale ma anche
dalle parole precedentemente emesse dalla sorgente.
Nello schema di Fig. 12.1 la lunghezza di vincolo , la
parola di codice dipende pertanto dalla parola corrente e dalle
parole informative che la precedono.
Anche nei codificatori convoluzionali si può definire un rate
espresso dal rapporto tra la lunghezza della parola informativa (2
in Fig. 12.1) e quella della parola di codice generata (3 in Fig.
12.1). A differenza dei codici a blocchi le lunghezze, sia delle
parole d’ingresso, sia di quelle di codice, sono piccole (dell’ordine
delle unità), i simboli utilizzati appartengono tipicamente a .
12.3 - Matrice generatrice e generatori.
I codificatori convoluzionali come si evince dalla Fig. 12.1
figura del paragrafo precedente sono lineari. Osserviamo che, se la
lunghezza di vincolo fosse unitaria, degenererebbero in un codifi-
catore a blocco. Se, come sempre accade, la lunghezza di vincolo
è maggiore di uno la sequenza d’uscita dipende dall’intera sequen-
za in ingresso. In ogni caso possiamo affermare che la sequenza
codificata associata a una generica sequenza informativa può sem-
pre essere ottenuta come combinazione lineare delle risposte che
il codificatore genererebbe in corrispondenza a sequenze “canoni-
che”, cioè a sequenze seminfinite contenenti un unico bit .

Codici Convoluzionali 137
In Tabella 12.1 sono mostrate le sequenze d’uscita che si
otterrebbero dal-
l’analisi del codi-
ficatore Fig. 12.1
in corrispondenza
alle citate sequen-
ze, assumendo
che, in assenza di
una sequenza in
ingresso, tutte le
celle dello shift re-
gister contengano
il bit . Le se-
quenze codificate
della tabella si possono pensare come le righe di una matrice
generatrice del codice. Detta matrice ha dimensioni semi infinite,
motivo questo di per sé sufficiente per cercare un approccio più
efficiente allo studio dei codici in parola.
È interessante osservare che la matrice generatrice ha una
struttura ben precisa, come si desume dalla Tabella 12.1essa è a
blocchi del tipo:
[
] (12.3.1)
dove le rappresentano matrici e gli zeri indicano matrici
nulle delle stesse dimensioni. Osservando la struttura della gene-
rica ci si rende conto che essa è in realtà la matrice generatrice
di un codice a blocchi , il suo generico elemento vale cioè
solo se l’ -esima cella dell’ -esimo blocco dello shift register di
ingresso è connessa al sommatore - esimo.
La (12.3.1) è di scarsa utilità pratica. Le matrici po-
trebbero essere si usate per descrivere la struttura del codificatore,
Sequenze di ingresso Sequenze codificate
10,00,00,00,0… 001,100,001,000…
01,00,00,00,0… 010,010,100,000…
00,10,00,00,0… 000,001,100,001,000…
00,01,00,00,0… 000,010,010,100,000…
00,00,10,00,0… 000,000,001,100,001,000
00,00,01,00,0… 000,000,010,010,100,000…
00,00,00,10,00,0… 000,000,000,001,100,001,000
00,00,00,01,00,0… 000,000,000,010,010,100,000…
Tabella 12.1 - sequenze di uscita del codificatore di Fig. 12.1 in corrispondenza alle sequenze canoniche

138 Capitolo - 12 - Appunti di Teoria dell’Informazione e Codici
ma, anche a questo scopo, esse si rivelano in genere meno effi-
cienti dei cosiddetti generatori.
I generatori sono vettori binari ciascuno con compo-
nenti. Dove la -esima componente dell’ -esimo generatore vale
solo se l’ -esimo sommatore è connesso all’ -esima cella del
registro d’ingresso.
Per il codificatore di Fig. 12.1 i generatori sono:
{
(12.3.2)
Noto il rate del codificatore i generatori permettono di tracciare
facilmente lo schema del codificatore.
Il vantaggio che si ha nell’utilizzo dei generatori rispetto
all’uso delle matrici costituenti la matrice generatrice è legato al
fatto che i generatori sono in numero pari al numero di bit della
parola d’uscita dell’ordine delle unità, mentre le matrici in parola
sono in numero pari alla lunghezza di vincolo che può essere del-
l’ordine delle decine. Inoltre i generatori si prestano a essere rap-
presentati in notazione diversa da quella binaria, tipicamente quel-
la ottale, rappresentando cioè gruppi di tre bit con la corrispon-
dente cifra ottale per il nostro codificatore ciascun generatore si
può rappresentare mediante due cifre ottali in particolare per il
nostro esempio si ha:
(12.3.3)
12.4 - Diagramma di stato del codificatore.
La matrice generatrice, non è certamente uno strumento di
semplice impiego per analizzare un codificatore convoluzionale. I
generatori, sono sì uno strumento efficace per descrivere la strut-
tura del codificatore, ma mal si prestano al calcolo della sequenza
che esso genera in uscita. Un modo alternativo, certamente più ef-

Codici Convoluzionali 139
ficace, per descrivere il comportamento del codificatore è quello
di tener conto del fatto che l’uscita prodotta in un certo istante di-
pende oltre che dalla parola d’ingresso corrente anche dalla storia
della sequenza d’ingresso, in particolare l’uscita dipende dai
( ) bit d’ingresso che hanno preceduto la parola corrente.
In altri termini, noti i ( ) bit precedenti e i bit della
parola corrente, possono essere univocamente determinati, sia
l’uscita corrente, sia i ( ) bit che contribuiranno unitamente
alla parola d’ingresso successiva a determinare la parola d’uscita
seguente. Osserviamo che esistono esattamente ( ) contenuti
distinti per le celle del registro che costituiscono la memoria del
sistema. Possiamo dire pertanto che il codificatore può assumere
( ) stati diversi ( nel nostro esempio). L’arrivo di una parola
d’ingresso comporta tipicamente una variazione del contenuto
della memoria, quindi una variazione dello stato del sistema. In
sostanza un codificatore convoluzionale non è altro che una
macchina a stati finiti.
Gli stati del codificatore possono essere associati ai vertici
di un grafo (vedi Esempio 2.1) due vertici vengono connessi tra-
mite un lato se esiste una parola di ingresso che induce la tran-
sizione tra i due stati. Ad ogni lato potremo associare un’etichetta
che contiene la parola d’ingresso ad esso relativa, ma anche la
corrispondente parola di uscita che dipende dal vertice da cui il
suddetto lato fuoriesce.
Osserviamo che da ogni vertice origineranno e si dipar-
tiranno esattamente lati, tanti quante sono le possibili parole
d’ingresso (nel nostro esempio 4). Quindi ogni vertice è di grado
( ). Il grafo è anche connesso in quanto, comunque scelti due
vertici distinti, esiste sempre un percorso che li congiunge, os-
serviamo che tale percorso è costituito al più da ( ) lati.

140 Capitolo - 12 - Appunti di Teoria dell’Informazione e Codici
Il grafo relativo al codificatore di Fig. 12.1 è mostrato in
Fig. 12.2 dove si
sono utilizzati co-
lori diversi per
distinguere le pa-
role d’ingresso as-
sociate ai lati. Nel-
la stessa figura si
sono indicate solo
alcune parole d’u-
scita per non pre-
giudicarne la leggi-
bilità.
Tracciato che
sia il grafo del co-
dificatore, per dato stato iniziale, si può valutare la sequenza
codificata associata a una qualsiasi sequenza d’ingresso seguendo
il percorso da essa individuato ed annotando le corrispondenti
parole d’uscita. Ovviamente, per sequenze molto lunghe, anche
questa rappresentazione manifesta i suoi limiti. Si pensi al caso in
cui uno stesso lato compaia più volte nell’ambito di una stessa
sequenza.
12.5 - Codici catastrofici
Osserviamo che ogni codificatore convoluzionale, essendo
lineare, associa alla sequenza d’ingresso nulla la sequenza nulla.
Il percorso associato alla sequenza d’ingresso identicamente nulla
nel grafo di Fig. 12.2 consisterebbe nel percorrere infinite volte il
ramo che emerge e termina nello stato zero. I rami che originano
e terminano nello stesso stato vengono denominati self loop.
Notiamo che lo stesso codificatore, partendo dallo stato
zero, associa alla sequenza costituita solo da bit , la sequenza
come possiamo notare tale sequenza
seppur semi-infinita ha peso ; cioè, nonostante la sequenza
Fig. 12.2 - Grafo del codificatore mostrato in Fig. 12.1
1000
1010
0100
0101
1111
1100
0001
0010
0011
0110
0111
1001
10111101
1110
0000
00
01
10
11
111
000
100
100
111

Codici Convoluzionali 141
d’ingresso considerata sia quella a massima distanza dalla se-
quenza nulla, le rispettive sequenze codificate distano tra loro non
più di indipendentemente dalla loro lunghezza. Il codificatore di
Fig. 12.1 è in realtà un esempio di Codice catastrofico. Tale
denominazione discende dal fatto che da un codificatore ci si
aspetterebbe, quantomeno, che al crescere della distanza di
Hamming tra le sequenze d’ingresso (parliamo si sequenze semi-
infinite) cresca anche quella tra le corrispondenti sequenze
codificate. un codificatore, come ad esempio quello di Fig. 13.1, è
catastrofico se il suo diagramma di stato contiene un selfloop che
associa a una parola d’ingresso di peso non nullo la parola d’uscita
nulla, sicché "ciclando" su detto selfloop il peso della sequenza
d’uscita non varia. Il codificatore fin qui utilizzato, malgrado sia
catastrofico non perde la sua valenza che è puramente didattica.
12.6 - Trellis degli stati
I limiti all’utilizzo del grafo per lo studio di un codice con-
voluzionale, sono essenzialmente legati al fatto che in questa rap-
presentazione non compare il tempo.
Premesso che in quel che segue per brevità enumereremo
talvolta gli stati con il numero decimale corrispondente al conte-
nuto della memoria, supponiamo che all’istante iniziale il codifica-
tore si trovi nello stato , da esso all’istante , potranno essere
raggiunti nuovi stati figli e da ciascuno di questi ultimi all’i-
stante ne potranno essere raggiunti per un totale di
stati figli raggiungili all’istante a partire dallo stato iniziale do-
po due parole d’ingresso.
Ci rendiamo conto del fatto che all’istante ( ) tutti i
possibili stati del codificatore saranno raggiungibili. Ciò è vero
anche in virtù del fatto che, per la struttura stessa del codificatore,
a prescindere dallo stato in cui si trova, a parole d’ingresso distinte
corrispondono stati di arrivo distinti.
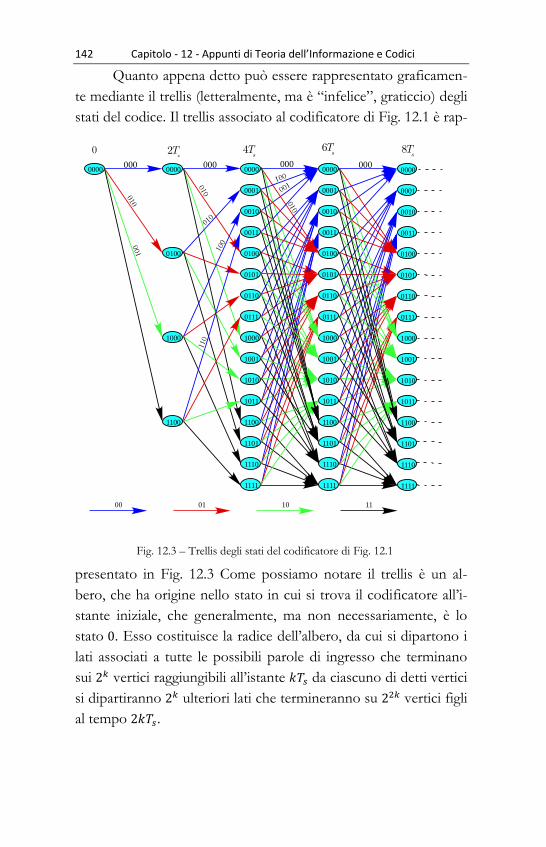
142 Capitolo - 12 - Appunti di Teoria dell’Informazione e Codici
Quanto appena detto può essere rappresentato graficamen-
te mediante il trellis (letteralmente, ma è “infelice”, graticcio) degli
stati del codice. Il trellis associato al codificatore di Fig. 12.1 è rap-
presentato in Fig. 12.3 Come possiamo notare il trellis è un al-
bero, che ha origine nello stato in cui si trova il codificatore all’i-
stante iniziale, che generalmente, ma non necessariamente, è lo
stato . Esso costituisce la radice dell’albero, da cui si dipartono i
lati associati a tutte le possibili parole di ingresso che terminano
sui vertici raggiungibili all’istante da ciascuno di detti vertici
si dipartiranno ulteriori lati che termineranno su vertici figli
al tempo .
Fig. 12.3 – Trellis degli stati del codificatore di Fig. 12.1
0 8sT6
sT4
sT2
sT
0000
0100
1000
1100
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
0000
0001
0010
0011
0100
0101
0110
0111
1000
1001
1010
1011
1100
1101
1110
1111
0000
00 01 10 11
000 000 000 000
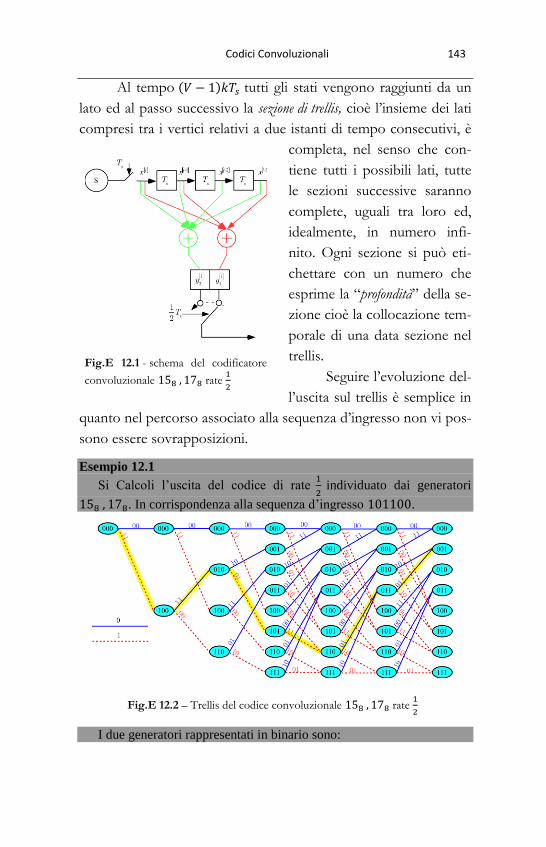
Codici Convoluzionali 143
Al tempo ( ) tutti gli stati vengono raggiunti da un
lato ed al passo successivo la sezione di trellis, cioè l’insieme dei lati
compresi tra i vertici relativi a due istanti di tempo consecutivi, è
completa, nel senso che con-
tiene tutti i possibili lati, tutte
le sezioni successive saranno
complete, uguali tra loro ed,
idealmente, in numero infi-
nito. Ogni sezione si può eti-
chettare con un numero che
esprime la “profondità” della se-
zione cioè la collocazione tem-
porale di una data sezione nel
trellis.
Seguire l’evoluzione del-
l’uscita sul trellis è semplice in
quanto nel percorso associato alla sequenza d’ingresso non vi pos-
sono essere sovrapposizioni.
Esempio 12.1
Si Calcoli l’uscita del codice di rate
individuato dai generatori
. In corrispondenza alla sequenza d’ingresso .
I due generatori rappresentati in binario sono:
Fig.E 12.1 - schema del codificatore
convoluzionale rate
Fig.E 12.2 – Trellis del codice convoluzionale rate

144 Capitolo - 12 - Appunti di Teoria dell’Informazione e Codici
e corrispondono allo schema mostrato in Fig.E 12.1. Il codificatore ha
stati, il suo trellis è mostrato in Fig.E 12.2, nella stessa figura è
evidenziato il percorso associato alla sequenza di ingresso , la
corrispondente sequenza d’uscita è quindi: .
È interessante osservare che un ulteriore zero nella sequenza
d’ingresso riporterebbe il codificatore allo stato zero.

Capitolo - 13
L’ALGORITMO DI VITERBI
13.1 - Decodifica hard e soft di un codice convoluzionale.
Occupiamoci adesso della decodifica utilizzando il criterio
MV.
Facciamo riferimento allo schema di principio mostrato in
Fig. 13.1. Esso rappresenta una sorgente binaria che emette una
sequenza binaria di bit, , cui è connesso un codificatore
convoluzionale con rate
che produce una sequenza codificata di
bit, , che modula antipodalmente un impulso di segnala-
zione ( ) in banda base di durata non maggiore dell’intervallo
assegnato a ogni bit codificato ottenendo il segnale:
( ) ∑( )
( ( ) ) (13.1.1)
Fig. 13.1 - schema di principio di un sistema di trasmissione, con codificatore convoluzionale e modulazione antipodale in banda base - decodificatore hard, ramo superiore, decodificatore soft, ramo inferiore.
n t
filtroadattato
rivelatorea soglia
decodificatorehard
decodificatoresoft
S
bT
1
kN
i ix
Codificatoreconvoluzionale
Modulatore
sT
sT
1
nN
i ic
r t s t n t
1
2 1 1nN
i s
i
s t c p t i T
1 12 1
nN nN
i i ii ir c n
{bi}i=1
nN
1
ˆnN
i ic

146 Capitolo - 13 - Appunti di Teoria dell’Informazione e Codici
( ) viene quindi inviato su un canale AWGN che introduce cioè
un rumore gaussiano ( ) con densità spettrale di potenza bilatera
.
Il segnale ricevuto ( ), trascurando ritardo ed attenuazio-
ne, sarà quindi ( ) ( ) ( ).
Il ricevitore di figura è costituito da un filtro adattato all’im-
pulso di segnalazione la cui uscita viene campionata a cadenza ,
producendo la sequenza , che per le ipotesi fatte non sarà
affetta da interferenza intersimbolica. Avremo cioè
in cui è una variabile aleatoria Gaussiana a media nulla e va-
rianza η. Ne segue che la generica , condizionata all’invio di è
la realizzazione di una variabile aleatoria gaussiana a media
e varianza η. Inoltre Le condizionate all’invio di una data
saranno mutualmente statisticamente indipendenti.
In Fig. 13.1 Abbiamo a questo punto indicato due alterna-
tive:
- la prima (ramo superiore in blu in Fig. 13.1) consiste
nell’utilizzare un rivelatore a soglia che fornirebbe in uscita
una sequenza binaria stimata , da dare in “pasto” ad un
decodificatore che in questo caso sarebbe di tipo hard;
- la seconda (ramo inferiore in verde in Fig. 13.1) consiste
nell’utilizzare un decodificatore che si basa direttamente sulla
; in questo caso il nostro decodificatore sarebbe di tipo
soft.
Indipendentemente dal tipo di decodificatore viene pro-
dotta una sequenza informativa stimata ottenuta in
corrispondenza a una sequenza codificata , cioè una sequen-
za che corrisponde ad un percorso sul trellis del codificatore.
Ovviamente non è detto che i due decodificatori produca-
no la stessa e conseguentemente la stessa sequenza infor-
mativa stimata .

L’Algoritmo di Viterbi 147
In quel che segue supporremo di voler decodificare una se-
quenza di lunghezza finita. Supporremo anche che il decodificato-
re hard o soft che sia:
- conosca la struttura del codificatore convoluzionale;
- conosca lo stato iniziale in del codificatore;
- conosca lo stato finale fin del codificatore,
Osserviamo che la conoscenza dello stato finale da parte
del decodificatore, implica che il codificatore abbia provveduto ad
aggiungere alla sequenza informativa un suffisso in grado di con-
durre il codificatore in uno stato assegnato. Va da se che i simboli
del suffisso non conterranno informazione e comporteranno
quindi un peggioramento dell’effettivo rate del codice. Tale
peggioramento sarà tanto meno rilevante quanto più lunghe
saranno le sequenze da trasmettere.
In linea di principio la decodifica MV hard della sequenza
costituita da -uple di bit in uscita al rivelatore a soglia è
semplice, è, infatti, sufficiente scegliere la sequenza ammissibile2
che ha la minima distanza di Hamming dalla generata dal
rivelatore, scegliendo eventualmente a caso qualora dovesse esser-
vi più d’una sequenza ammissibile con lo stesso requisito.
Analogamente la decodifica MV soft consisterebbe nello
scegliere, tra le sequenze ammissibili, quella cui è associata una se-
quenza che, pensata come un punto di , ha la
minima distanza Euclidea dalla sequenza corrispondente al
segnale ricevuto, rappresentata nello stesso spazio.
Va da se che, in questo caso, la probabilità che due sequen-
ze ammissibili abbiano la stessa distanza da quella ricevuta è nulla.
2 per sequenza ammissibile intendiamo una sequenza associabile ad un
percorso sul trellis che abbia inizio in e termini in .

148 Capitolo - 13 - Appunti di Teoria dell’Informazione e Codici
Già questa sola considerazione ci fa intuire che l’impiego
della decodifica soft migliora le prestazioni del sistema in termini
di probabilità d’errore.
Al crescere della lunghezza dei messaggi da decodificare,
appare chiaro che l’approccio sopra descritto seppur formalmente
corretto diventa improponibile in pratica, sia per la crescita espo-
nenziale del numero di sequenze ammissibili, sia per il ritardo che
un tale decodificatore comporterebbe. Sarebbe infatti indispensa-
bile attendere la ricezione dell’intera sequenza prima che il proces-
so di decodifica possa avere inizio.
13.2 - L’algoritmo di Viterbi
In questo paragrafo descriveremo un algoritmo di decodi-
fica che, con modifiche non concettuali, può essere impiegato sia
per decodificatori hard che soft dei codici convoluzionali.
In quel che segue chiameremo:
- metrica di ramo la distanza di Hamming, o il quadrato della
distanza Euclidea, tra gli bit
codificati
che etichettano il ramo e la porzione di sequenza ricevuta cor-
rispondente precisamente
(
)
{
∑ ( )
∑ ( ) (
)
(13.2.1)
(ad apice abbiamo indicato la sezione di trellis cui il ramo ap-
partiene ed i pedici, individuano lo stato di partenza e quello
di arrivo del ramo in esame);
- percorso una sequenza ininterrotta di rami che origina in in
- lunghezza del percorso il numero di rami compongono il percor-
so
- metrica di percorso la somma delle metriche di ramo che com-
pongono il percorso;

L’Algoritmo di Viterbi 149
- cammino una sequenza ininterrotta di rami del tipo
- lunghezza del cammino il numero di rami compongono il
cammino
- metrica di cammino la somma delle metriche dei rami che lo
compongono;
Abbiamo detto che il decodificatore conosce lo stato ini-
ziale in cui si trova il codificatore all’arrivo di una sequenza infor-
mativa, supponiamo sia lo stato zero. Al primo passo, osservando
la sequenza ricevuta, il decodificatore può etichettare ciascuno dei
rami del trellis che emergono dallo stato iniziale, con la metrica
ad essi associata, calcolata mediante la prima o la seconda delle
(13.2.1), a seconda che la decodifica sia di tipo hard o soft rispetti-
vamente. Il decodificatore provvederà anche ad etichettare gli stati
raggiunti con le metriche dei percorsi che vi pervengono. Le me-
triche di percorso in questo caso coincidono banalmente con
quelle del singolo ramo che compone i percorsi cui si riferiscono.
Agli stati raggiunti verrà associata anche la sequenza informativa
associata al relativo percorso.
Al secondo passo da ciascuno dei stati raggiunti emerge-
ranno rami, a ciascuno di essi si può associare una metrica di
ramo come al passo precedente. Ad ogni stato in cui termina un
ramo assoceremo:
- una metrica di percorso ottenuta sommando alla metrica del
ramo che termina nello stato in parola quella di percorso
associata allo stato da cui il ramo emergeva;
- una sequenza informativa di percorso ottenuta giustapponendo a
quella associata allo stato di partenza quella del ramo.
Potremo continuare ad addentrarci nel trellis seguendo
questa logica fino al passo , in quanto fino a tale passo ogni
stato viene raggiunto al più da un percorso.

150 Capitolo - 13 - Appunti di Teoria dell’Informazione e Codici
Al - esimo passo potremo ancora associare a ogni ramo la
sua metrica, ma per associare le metriche di percorso agli stati sor-
gerà un problema. Esistono infatti percorsi distinti che termi-
nano in ciascuno stato.
Se consideriamo un cammino nel trellis di lunghezza
che abbia origine in uno stato in cui confluiscano percorsi di
lunghezza , giustapponendo il cammino a ciascun percorso di
lunghezza otterremmo percorsi ammissibili di lunghezza
. La metrica di ciasuno di essi sarà data dalla somma della
metrica di uno dei percorsi di lunghezza più la metrica del
cammino. Tra i percorsi così ottenuti quello che avrà la metrica
minore sarà evidentemente ottenuto a partire dal percorso di
lunghezza che aveva la metrica minore. Ne segue che se più
percorsi confluiscono in uno stesso stato ha senso memorizzare
solo quello che ha la metrica minore.
Osserviamo che nel caso in cui la metrica fosse quella di
Hamming (decodifica hard) potrebbe darsi che più di un percorso
abbia minima metrica, il decodificatore in questa eventualità do-
vrebbe scegliere a caso.
Dal - esimo passo in poi il decodificatore memorizzerà
per ogni stato solo la metrica e la sequenza informativa associata
al “miglior” percorso che vi confluisce.
Fa eccezione solo l’ultimo passo, in questo caso il decodifi-
catore conoscendo lo stato di arrivo si limiterà a considerare solo i
percorsi che vi confluiscono scegliendo il migliore tra essi
(quello che ha accumulato la metrica minore).
Abbiamo appena descritto l’algoritmo di Viterbi.
13.3 - Efficienza dell’algoritmo di Viterbi
Appare evidente la riduzione di complessità di questo algo-
ritmo rispetto alla ricerca esaustiva teorizzata nel paragrafo prece-
dente. Infatti ad ogni passo di decodifica, a parte il transitorio
iniziale, dovremo calcolare metriche di ramo per ciascuno dei
( ) stati iniziali della sezione di trellis e utilizzarle per calcola-

L’Algoritmo di Viterbi 151
re le metriche di percorsi. Di questi ultimi solo ( )
verranno memorizzati per utilizzarli al passo successivo. Ne segue
che la complessità dell’algoritmo cresce solo linearmente con la
lunghezza della sequenza informativa, a differenza della ricerca
esaustiva su tutti i percorsi ammissibili il cui numero cresce
esponenzialmente al crescere della lunghezza della sequenza
informativa.
Va comunque sottolineato che la complessità dell’algoritmo
di Viterbi cresce esponenzialmente con la lunghezza di vincolo
del codificatore.
Un altro vantaggio nell’utilizzo dell’algoritmo di Viterbi
consiste nel fatto che dopo un certo numero di passi di decodifica
che dipende dalla lunghezza di vincolo (tipicamente una decina di
lunghezze di vincolo) tutti i percorsi “sopravvissuti” finiscono
con l’avere una parte iniziale in comune. La parte della sequenza
informativa associata alla parte comune a tutti i percorsi non
potendo subire alcuna modifica potrà essere resa immediatamente
disponibile in uscita al decodificatore. Potremo cioè utilizzare una
decodifica a finestra mobile che limita sia la latenza sia il fabbisogno di
memoria del decodificatore.


Capitolo - 14
PRESTAZIONI DEI CODICI CONVOLUZIONALI
14.1 - Distanza libera di un codifie convoluzionale.
I codici convoluzionali sono come abbiamo già detto linea-
ri, nel senso che la somma di due sequenze codificate è ancora
una sequenza codificata, esattamente quella che si otterrebbe co-
dificando la somma delle corrispondenti sequenze informative.
Ciò significa che possiamo valutare le prestazioni del codice
in termini di probabilità d’errore ammettendo che venga inviata la
sequenza nulla e valutare la probabilità che, a causa del canale,
venga rivelata una sequenza ammissibile diversa.
Per i nostri scopi è utile definire alcune grandezze associate
al codificatore. La prima è la cosiddetta distanza colonna ( )
essa è un’applicazione che associa ad ogni livello di profondità del
trellis del codice la minima distanza di Hamming ottenibile dalla
sequenza nulla prendendo in considerazione tutte le possibili se-
quenze d’ingresso cui corrispondono percorsi sul trellis che si di-
scostano da quello relativo alla sequenza nulla a partire dall’istante
iniziale. Il limite di ( ) per si chiama distanza libera,
, del codice. Il percorso cui corrisponde la distanza libera non è
necessariamente unico, ma certamente salvo il caso in cui il codice
sia catastrofico è un percorso che si discosta dalla sequenza nulla
per poi ricongiungersi ad essa.
Sia la distanza colonna che la distanza libera possono in
teoria essere calcolate per ispezione diretta sul trellis del codice,
ma è anche possibile ottenere la distanza libera e molte altre
informazioni sul codice procedendo in modo diverso.
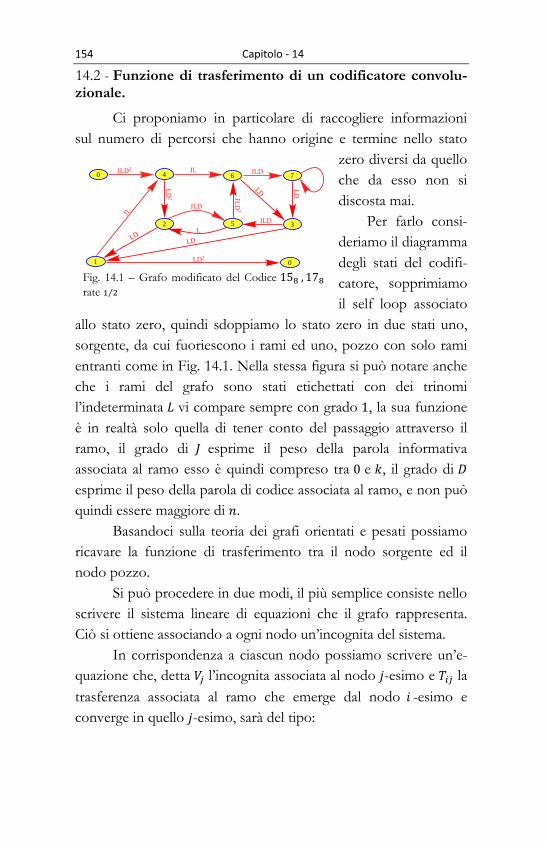
154 Capitolo - 14
14.2 - Funzione di trasferimento di un codificatore convolu-zionale.
Ci proponiamo in particolare di raccogliere informazioni
sul numero di percorsi che hanno origine e termine nello stato
zero diversi da quello
che da esso non si
discosta mai.
Per farlo consi-
deriamo il diagramma
degli stati del codifi-
catore, sopprimiamo
il self loop associato
allo stato zero, quindi sdoppiamo lo stato zero in due stati uno,
sorgente, da cui fuoriescono i rami ed uno, pozzo con solo rami
entranti come in Fig. 14.1. Nella stessa figura si può notare anche
che i rami del grafo sono stati etichettati con dei trinomi
l’indeterminata vi compare sempre con grado , la sua funzione
è in realtà solo quella di tener conto del passaggio attraverso il
ramo, il grado di esprime il peso della parola informativa
associata al ramo esso è quindi compreso tra e , il grado di
esprime il peso della parola di codice associata al ramo, e non può
quindi essere maggiore di .
Basandoci sulla teoria dei grafi orientati e pesati possiamo
ricavare la funzione di trasferimento tra il nodo sorgente ed il
nodo pozzo.
Si può procedere in due modi, il più semplice consiste nello
scrivere il sistema lineare di equazioni che il grafo rappresenta.
Ciò si ottiene associando a ogni nodo un’incognita del sistema.
In corrispondenza a ciascun nodo possiamo scrivere un’e-
quazione che, detta l’incognita associata al nodo -esimo e la
trasferenza associata al ramo che emerge dal nodo -esimo e
converge in quello -esimo, sarà del tipo:
Fig. 14.1 – Grafo modificato del Codice
rate ⁄
4
1 0
2 35
6 70
JLD
L
JLD
JLD
LD2

Prestazioni dei Codici Convoluzionali 155
∑
( )
(14.2.1)
In corrispondenza al ramo sorgente non si scrive alcuna
equazione essendo quest’ultimo privo di rami entranti. A titolo
d’esempio, denominando rispettivamente e le variabili as-
sociate al nodo sorgente ed al nodo pozzo in cui abbiamo sdop-
piato lo stato , scriviamo le equazioni associate al grafo di Fig.
14.1:
{
(14.2.2)
Possiamo quindi procedere all’eliminazione di tutte le varia-
bili ad eccezione delle e . Utilizzando ad esempio le prime
tre equazioni otteniamo:
{
(14.2.3)
quindi, procedendo in modo analogo, dopo qualche passaggio ot-
teniamo:
( ) (14.2.4)

156 Capitolo - 14
la ( ) prende il nome di funzione di trasferimento del codi-
ce.
Se con la tecnica della divisione lunga espandiamo la
(14.2.4), pensando il numeratore e il denominatore come polino-
mi nell’indeterminata , possiamo ancora scrivere:
( ) ( ) (
) (
) (
)
(14.2.5)
dal coefficiente della potenza più piccola di a secondo membro
della precedente, desumiamo che vi è un cammino con peso
d’ingresso che si discosta dallo stato per tornarvi dopo rami
accumulando un peso d’uscita pari a . Ne segue che la distanza
libera del codice in parola sarà .
Osservando il coefficiente della potenza di immediata-
mente superiore scopriamo che esistono anche tre percorsi con
peso d’uscita , di cui: uno di lunghezza e peso d’ingresso ; il
secondo di lunghezza e peso d’ingresso ; il terzo di lunghezza
con peso d’ingresso .
Qualora fossimo interessati solo al peso delle sequenze co-
dificate che si discostano dalla sequenza nulla per poi ricon-
giungersi con essa, potremmo porre nella (14.2.4) o nella (14.2.5)
e , ottenendo
( ) (14.2.6)
In generale la funzione di trasferimento di un codice con-
voluzionale può essere espressa nella forma:
( ) ∑ ∑ ∑ ( )
(14.2.7)

Prestazioni dei Codici Convoluzionali 157
dove ( , , ) esprime il numero di cammini di peso , con peso
della sequenza d’ingresso che emergono dallo stato zero per poi
farvi ritorno dopo rami.
Dalla precedente, eguagliando ad le variabili che non ci
interessano e sommando rispetto ai rispettivi indici, otteniamo
delle funzioni di trasferimento semplificate, ad esempio ponendo
e nella (14.2.7) otteniamo
( ) ( ) ∑ ∑ ∑ ( )
∑ ( )
(14.2.8)
dove ( ) ∑ ∑ ( )
.
14.3 - Bound sulla probabilità di primo evento d’errore.
Per analizzare le prestazioni di un codice convoluzionale si
fa riferimento, oltre che alla probabilità d’errore sul bit infor-
mativo anche alla cosiddetta probabilità di primo evento d’errore,
o anche probabilità d’errore di nodo. ssa esprime la probabilità
che in un certo istante la sequenza stimata si discosti da quella ef-
fettivamente trasmessa per poi ricongiungersi con essa.
Possiamo assumere ai fini del calcolo che la sequenza tras-
messa sia quella identicamente nulla, indicheremo con
tale sequenza che corrisponde al percorso semiinfinito sul trellis
che non si discosta mai dallo stato . Possiamo fare tale ipotesi in
virtù della linearità del codificatore e del fatto che la decodifica è a
massima verosimiglianza.
Sappiamo che il decodificatore opera le sue scelte basandosi
sulla sequenza binaria prodotta dal rivelatore a soglia nel
caso di decodifica hard, ovvero sulla sequenza reale dei
campioni in uscita al filtro adattato per decodifica soft.

158 Capitolo - 14
Ammettiamo che fino alla profondità nel trellis il deco-
dificatore abbia attribuito al percorso la metrica minore e che al
passo successivo abbia inizio un cammino ( )
( ) che si
discosta dallo stato per ritornarvi dopo sezioni di trellis. Alla
profondità il decodificatore lascerà sopravvivere un solo
percorso tra quelli che pervengono allo stato se il percorso ,
coincidente con fino alla profondità nel trellis e con da
fino alla sezione , avrà accumulato la metrica minore
di , quest’ultimo verrà scartato. è un possibile primo evento
d’errore. Va da sé che vi è un’infinità numerabile di possibili primi
eventi d’errore, cioè tutti i cammini che si discostano dallo stato
zero per poi ricongiungersi ad esso.
Purtroppo il calcolo esatto della probabilità di primo evento
d’errore è impraticabile. Possiamo tuttavia maggiorare la proba-
bilità cercata, basandoci sull’union bound.
Detto il cammino coincidente con tra le sezioni
e Osserviamo che la scelta del decodificatore sarà
determinata soltanto dalle metrica accumulata dai cammini e
, in quanto fino al passo i due percorsi coincidevano quindi
condividevano la stessa metrica.
Per applicare l’union bound dobbiamo valutare, in corri-
spondenza a ciascun primo evento d’errore, la probabilità che det-
to evento si manifesti nell’ipotesi che il decodificatore possa sce-
gliere solo tra il percorso corretto e quest’ultimo.
Ciò, detto in altri termini, equivale a calcolare la probabilità
che, a causa del rumore introdotto dal canale BSC, la porzione di
sequenza ( ) in uscita al rivelatore a soglia, per il decodifi-
catore hard (la porzione ( ) di campioni in uscita al filtro
adattato per quello soft) corrispondente alle sezioni del trellis
che contengono i due cammini e , appartenga alla regione di
decisione di malgrado sia stata inviata la sequenza identicamen-
te nulla, corrispondente a

Prestazioni dei Codici Convoluzionali 159
Ci si convince facilmente che la somma di tutte le probabi-
lità appena descritte maggiora la probabilità d’errore di nodo, in
quanto quest’ultima rappresenta la probabilità dell’evento unione
tra tutti quelli associati ai possibili primi eventi d’errore sopra
descritti.
Detta la regione di decisione di nell’ipotesi che il
decisore sia chiamato a scegliere tra e , possiamo scrivere:
∑ (
( )
)
(14.3.1)
Nel caso di decodifica hard, è opportuno osservare che ai
fini del calcolo della probabilità che compare ad argomento della
sommatoria nella (14.3.1), non contribuiscono i bit codificati di
uguali a quelli di (cioè i bit nulli di ), in quanto quale che sia
il corrispondente bit della sequenza ricevuta esso apporterebbe un
eguale contributo alle distanze di ( ) da entrambi i cammi-
ni.
Indichiamo con ( ) il peso del cammino . Osserviamo
che se ( ) è dispari, posto ⌊ ( )
⌋ , il decodificatore sce-
glierà il cammino ogniqualvolta il numero di bit 1 di ( )
che corrispondono ai bit 1 di risulti maggiore o uguale a . La
probabilità che ciò accada, condizionata all’invio della sequenza
nulla è data da:
( ( )
) ∑ ( ( )
) ( ) ( )
( )
(14.3.2)
dove ( ) indica il cammino stimato e indica la probabilità
di crossover del BSC con cui può essere schematizzata la parte
inclusa nel poligono tratteggiato in rosso del sistema di trasmis-
sione mostrato in Fig. 13.1

160 Capitolo - 14
Se il peso di è pari esisteranno ( ( ) ( )
) possibili sequen-
ze ricevute ( ) che hanno eguale distanza da e
. In
tale eventualità il decodificatore sceglierebbe in modo puramente
casuale tra e . La probabilità che venga scelto il cammino
sarà in questo caso espressa dalla:
( ( )
)
(
( ) ( )
) ( ) ( )
∑ ( ( )
) ( ) ( )
( )
⌊ ( )
⌋
(14.3.3)
Esempio 14.1
La probabilità di crossover del BSC con cui può essere schematizzata
la parte inclusa nel poligono tratteggiato in rosso del sistema di
trasmissione mostrato in Fig. 13.1, assumendo che al bit codificato
competa un’energia
e che il rumore gaussiano
abbia una densità spettrale di potenza monolatera , sarà espressa
dalla probabilità che il campione in uscita al filtro adattato per effetto del
rumore sia minore di zero, malgrado il bit codificato fosse un uno, o
indifferentemente, dalla probabilità che il succitato campione, per lo
stesso motivo, sia maggiore di zero malgrado il bit codificato inviato
fosse uno zero. Nel caso in cui il bit trasmesso sia un uno avremo
( ) ∫
√
( )
√
√ ∫
√
(
√ ) (
√ )
Tenuto conto delle ipotesi fatte sull’energia del bit codificato, se
vogliamo fare comparire nella precedente il rapporto tra l’energia
associata al bit informativo e la densità spettrale monolatera di rumore
possiamo scrivere:
√ √
Da cui:

Prestazioni dei Codici Convoluzionali 161
(√
)
Osserviamo che la (14.3.2) e la (14.3.3), dipendono solo dal
peso di non dal numero di rami da cui esso è costituito. In altri
termini, tutti gli eventi d’errore di uguale peso avranno la stessa
probabilità di essere erroneamente scelti dal decodificatore indi-
pendentemente dal numero di rami in essi contenuti. Sulla base di
quest’ultima osservazione possiamo compattare in un'unica
espressione la (14.3.2) e la (14.3.3), indicando semplicemente con
un evento d’errore di peso , ottenendo:
( ) ( )
(
⌊
⌋) ( )
∑ ( ) ( )
⌊
⌋
(14.3.4)
Osserviamo adesso che la probabilità di primo evento di
errore di peso condizionata all’invio di una qualunque sequenza
è uguale a quella condizionata all’invio della sequenza nulla. Ne
segue che, se tutti i percorsi sul trellis sono equiprobabili, la pro-
babilità di errore di nodo di peso è uguale alla probabilità di
errore di nodo condizionata all’invio della sequenza nulla:
( ) ( ) (14.3.5)
La (14.3.4) ci suggerisce di riordinare la (14.3.1) accorpando
tutti gli eventi d’errore di ugual peso. Il numero di tali eventi può
essere dedotto dalla ( ) del codice. Tenendo conto della (14.2.8)
e della (14.3.5) possiamo quindi scrivere:
∑ ( ( )
)
∑ ( )
( )
(14.3.6)

162 Capitolo - 14
Nel caso di decodifica soft, basandoci sullo schema di Fig. 13.1 e
assumendo che l’impulso di segnalazione abbia energia ,
potremo scrivere:
∑ ( (
( ) {√ ( ( )
)}
( ))
( ( ) { √ }
( ))
( )
) ∑
(
√∑ ( √
( ))
( )
√
)
∑ (√ ( )
)
(14.3.7)
che può essere anche riformulata in termini dell’energia per bit
informativo, ponendo cioè , dove ⁄ è il rate del
codice e della densità spettrale di potenza monolatera
ottenendo:
∑ (√ ( )
)
(14.3.8)
Osserviamo che anche gli argomenti delle ( ) a secondo
membro della precedente non dipendono dalla lunghezza di ,
ma solo dal suo peso. La sommatoria a secondo membro della
precedente può quindi, anche in questo caso, essere riordinata ac-
corpando tutti gli eventi di errore di egual peso, ottenendo:
∑ ( ) (√
)
(14.3.9)
La precedente, a fronte di un’ulteriore maggiorazione può
assumere una forma più semplice da calcolare. Ricordando infatti

Prestazioni dei Codici Convoluzionali 163
che vedi , per argomento non negativo, vale la disuguaglianza
( )
(vedi (4.9.14), possiamo ancora scrivere:
( ) (√
)
(
)
(14.3.10)
per mezzo della quale otteniamo:
∑ ( ) (√
)
∑ ( )
( )|
(14.3.11)
Anche nel caso della decodifica Hard possiamo maggiorare
ulteriormente la ricordando la maggiorazione di Bhattacha-
ryya (4.9.10) che ci permette di scrivere:
( ) ( )
(14.3.12)
Quest’ultima ci permette, partendo dalla (14.3.6) di scrivere:
∑ ( )
( ) ∑ ( )
( )
( )
(14.3.13)
La (14.3.11) e la (14.3.13) possono essere calcolate facil-
mente, disponendo della ( ) del codice, la (14.3.6) e la (14.3.9)
sono dei bound più stretti, ma possono essere calcolati solo in
modo approssimato, entrambe tuttavia sono in genere dominate
dal primo addendo della sommatoria che corrisponde alla distanza
libera del codice. Il primo addendo di ciascuna di esse rappresenta
in genere già da solo una maggiorazione della probabilità d’errore
di nodo.

164 Capitolo - 14
14.4 - Bound sulla probabilità d’errore sul bit informativo.
Al fine di calcolare la probabilità d’errore sul bit d’informa-
zione , consideriamo una porzione di sequenza codificata
costituita da bit con (l’apice ha la sola funzio-
ne di etichetta). Nella corrispondente porzione di sequenza deco-
dificata costituita da bit saranno presenti un certo nu-
mero di bit errati. La presenza di bit errati è possibile solo se nella
si sono manifestati errori di nodo. Sappiamo che ad ogni
evento d’errore di nodo corrisponde un ben preciso numero di bit
informativi errati.
Indichiamo adesso con
la frequenza relativa d’errore
sul bit, della sequenza -esima. Essa è espressa dal rapporto tra il
numero di bit informativi errati e di quelli inviati. Il numero totale
di bit informativi errati può essere anche calcolato accorpando
tutti gli eventi d’errore di nodo caratterizzati da uno stesso nume-
ro di bit informativi errati. Indicando con ( ) il numero di
eventi d’errore che contengono esattamente bit informativi errati
manifestatisi nella -esima realizzazione dell’esperimento, possia-
mo scrivere:
∑
( )
(14.4.1)
La probabilità d’errore sul bit informativo si può ottenere
mediando su un numero idealmente infinito di repliche dello
stesso esperimento come segue:
∑
(14.4.2)
sostituendo la (14.4.1) nella precedente abbiamo:

Prestazioni dei Codici Convoluzionali 165
∑
∑ ( )
∑
∑
( )
(14.4.3)
Nella precedente, prima di invertire l’ordine delle sommatorie, si è
tenuto conto del fatto che, al crescere della lunghezza della se-
quenza, si possono manifestare eventi d’errore con un numero ar-
bitrariamente grande di bit informativi errati. Si constata facilmen-
te che il limite all’interno della sommatoria di indice ad ultimo
membro della precedente, esprime la probabilità che si manifesti
un qualsiasi evento d’errore di nodo che contenga esattamente
bit informativi errati.
Indicando con l’insieme di tutti gli eventi d’errore con
bit informativi errati possiamo scrivere:
( )
∑
( )
(14.4.4)
la precedente può essere maggiorata applicando, come nel
paragrafo precedente, l’union bound:
( ) ∑ ( )
(14.4.5)
A partire dalla (14.4.3) possiamo ancora scrivere:
∑ ( )
∑ ∑ ( )
(14.4.6)
Ricordando la (14.2.7) che per comodità riscriviamo:
( ) ∑ ∑ ∑ ( )
(14.4.7)

166 Capitolo - 14
e tenuto conto che, indipendentemente dal tipo di decodificatore,
la probabilità che si presenti un dato errore di nodo dipende solo
dal suo peso possiamo ancora scrivere:
∑ ∑ ( )
∑ ∑ ∑ ( ) ( )
∑ ∑ ( ) ( )
(14.4.8)
La precedente può essere ulteriormente maggiorata appli-
cando la (14.3.13) nel caso di decodifica hard o la (14.3.11) in
quella soft ottenendo rispettivamente:
∑ ∑ ( ) ( )
∑ ∑ ( )
(14.4.9)
∑ ∑ ( ) (
)
(14.4.10)
Osserviamo adesso che:
( )
|
∑ ∑ ∑ ( )
|
∑ ∑ ∑ ( )
∑ ∑ ( )
(14.4.11)
la quale ci permette di riscrivere la (14.4.9) e la (14.4.10) rispettiva-
mente nella forma più compatta:
( )
|
(14.4.12)
e

Prestazioni dei Codici Convoluzionali 167
( )
|
(14.4.13)


Capitolo - 15
ANELLI DI POLINOMI
15.1 - Premessa
Abbiamo già fornito la definizione di campo e abbiamo anche
operato nel campo costituito da due soli elementi. Si possono
costruire anche campi finiti (Campi di Galois Galois Field) con un
numero d’elementi che sia un primo o una potenza di un primo.
Nel caso in cui il campo abbia un numero primo d’elementi,
l’addizione e la moltiplicazione tra elementi del campo si possono
effettuare in modo tradizionale avendo cura di ridurre il risultato
modulo .
Nella Tabella 15.1 a titolo d’esempio sono riportati i risul-
tati di tutte le possibili somme e prodotti tra coppie d’elementi di
, il campo di Galois con sette elementi.
15.2 - L’anello polinomi a coefficienti in
Consideriamo un campo e un’indeterminata , indichia-
mo con l’insieme di tutti i possibili polinomi (cioè di qualun-
que grado) nella variabile con coefficienti appartenenti ad , il
generico elemento di sarà cioè del tipo:
( )( )
(15.2.1)
0 1 2 3 4 5 6 0 1 2 3 4 5 6
0 0 1 2 3 4 5 6 0 0 0 0 0 0 0 0
1 1 2 3 4 5 6 0 1 0 1 2 3 4 5 6
2 2 3 4 5 6 0 1 2 0 2 4 6 1 3 5
3 3 4 5 6 0 1 2 3 0 3 6 2 5 1 4
4 4 5 6 0 1 2 3 4 0 4 1 5 2 6 3
5 5 6 0 1 2 3 4 5 0 5 3 1 6 4 2
6 6 0 1 2 3 4 5 6 0 6 5 4 3 2 1
Tabella 15.1 - Campo di Galois di 7 elementi

170 Capitolo - 15 - Appunti di Teoria dell’Informazione e Codici
dove è un intero non negativo qualsiasi e , essendo l’e-
lemento neutro rispetto all’addizione in . Conveniamo inoltre:
a) di utilizzare per le leggi di composizione del campo i simboli
utilizzati per il campo reale
b) di indicare con ( )( ) il polinomio identicamente nullo,
cioè coincidente con
c) di omettere l’apice tra parentesi per indicare un polinomio di
grado qualsiasi;
d) che dato ( )( ), per .
Siano ( )( ) ( )( ) due elementi di e un elemento
di , poniamo:
( ) ( ) ( ) ( )
( )
(15.2.2)
( )( ) ( )( ) ( )( )
(15.2.3)
e
( )( ) ( )( ) ( )( )
∑
(15.2.4)
Nella precedente, la sommatoria va calcolata secondo le regole di
, come pure il prodotto al suo interno.
In sostanza abbiamo appena introdotto in l’addizione
e la moltiplicazione. ispetto all’addizione è facile verificare che
è un gruppo commutativo, inoltre la moltiplicazione tra poli-
nomi in è commutativa e distributiva rispetto all’addizione.
è pertanto un anello commutativo, con identità, che, ovviamente,
coincide con l’identità del campo , che indicheremo con .
Inoltre il prodotto tra polinomi non nulli è non nullo. Il po-
linomio nullo si ottiene se e solo se almeno uno dei due moltipli-
candi è il polinomio nullo. Vale cioè anche la legge di annullamen-
to del prodotto.

Anelli di Polinomi 171
Quanto detto comporta che i polinomi
sono linearmente indipendenti su .
15.3 - Spazi di polinomi
Consideriamo il sottoinsieme ( )
di costituito da
tutti i polinomi di grado minore di . La somma di due elementi
di ( )
è ancora un elemento di ( )
. Inoltre, moltipli-
cando un qualunque elemento di ( )
per un elemento di ,
che coincide con ( )
, otteniamo un elemento di ( )
.
( )
è quindi uno spazio vettoriale su . La sua dimen-
sione è in quanto generabile tramite i suoi elementi linearmen-
te indipendenti .
Ci si convince facilmente che detto spazio vettoriale è iso-
morfo allo spazio costituito da tutte le -uple ordinate di ele-
menti di , basta infatti associare al polinomio ( )( ) ( )
,
l’elemento a se , ovvero l’ele-
mento se


Capitolo - 16
CODICI POLINOMIALI
Dati due interi e , scegliamo un polinomio
( )( ) che chiameremo polinomio generatore, tramite
( )( ) possiamo individuare il sottoinsieme ( )
che contiene i polinomi che si ottengono da tutti i possibili pro-
dotti tra ( )( ) e i polinomi ( ) ( )
.
Consideriamo adesso due elementi ( ) e ( ) appartenenti
a , quindi esprimibili rispettivamente nella forma:
( ) ( ) ( )( ) ( ) ( ) ( )( ) (16.1.1)
Comunque scelti risulta:
( ) ( ) ( ( ) ( )) ( )( ) (16.1.2)
La precedente ci mostra che ( ) è un sottospazio di ( )
,
quindi ne è anche un sottogruppo.
Il corrispondente sottoinsieme di è quindi un codice
di gruppo.
Abbiamo già detto (vedi § 7.2 - ) che la distanza di Ham-
ming tra parole di è una metrica, la distanza minima di è data
dalla sua parola di peso minimo cioè dalla parola che ha il minor
numero di lettere diverse da , che non è necessariamente unica.
Ci si convince anche facilmente del fatto che se s’intende
impiegare un codice polinomiale per la rilevazione d’errore è suf-
ficiente dividere il polinomio corrispondente alla parola ricevuta
per il polinomio generatore e verificare che il resto di tale divisio-
ne sia il polinomio nullo, per essere certi che la parola ricevuta ap-
partiene al codice.
Consideriamo adesso il caso dei codici polinomiali sul cam-
po essi sono certamente codici binari a blocchi, nel senso che
ammettono una matrice generatrice che si può facilmente

174 Capitolo - 16
costruire a partire da ( )( ) . Come righe di tale matrice si
possono scegliere infatti le stringhe dei coefficienti dei polinomi
di codice ottenuti moltiplicando il polinomio generatore per i po-
linomi . Viceversa non è vero in generale che i
codici lineari a blocchi siano polinomiali, al fine di verificare se un
codice lineare a blocchi è polinomiale è sufficiente verificare che
tutti i polinomi associati alle righe della matrice generatrice am-
mettano un fattore comune di grado .

Capitolo - 17
IDEALI DI UN ANELLO DI POLINOMI
17.1 - Premessa
Torniamo adesso a parlare di campi finiti, abbiamo visto
come si possono costruire campi finiti con un numero primo
d’elementi; è anche possibile, come mostreremo più avanti, defini-
re campi che hanno un numero di elementi che è una potenza (ad
esponente intero) di un numero primo. Il generico elemento di un
tale campo si può quindi mettere in corrispondenza biunivoca con
l’insieme
( ) , che ha la stessa cardinalità.
Sorge quindi spontaneo indagare sulla possibilità di indivi-
duare in
( ) due opportune leggi di composizione tra suoi
elementi che consentano di pensare a
( ) come ad un cam-
po di elementi. Sarebbe a questo punto possibile definire degli
isomorfismi tra
( ) e . Parliamo di isomorfismi perché
potrebbero esistere più leggi di composizione interna che soddi-
sfano le condizioni necessarie per interpretare
( ) come
campo.
Abbiamo già visto che ( )
è un gruppo commutativo
rispetto all’addizione tra polinomi, purtroppo non possiamo dire
lo stesso della moltiplicazione tra polinomi non fosse altro perché
( )
non è chiuso rispetto ad essa.
È quindi necessario definire una legge di composizione in-
terna per ( )
che abbia tutte le proprietà di cui deve godere
la moltiplicazione tra elementi di un campo. A tal fine è necessaria
una piccola digressione di carattere generale.

176 Capitolo - 17 - Appunti di Teoria dell’Informazione e Codici
17.2 - Ideali di un anello con identità.
Consideriamo un anello commutativo con identità dicia-
mo che un suo sottogruppo è un ideale se:
(17.2.1)
Qualora l’anello non fosse commutativo dovremmo distinguere
tra ideale sinistro e ideale destro, che potrebbero anche coincide-
re, nel qual caso si tratterebbe di un ideale bilaterale.
Abbiamo detto che un ideale è un sottogruppo di , quindi
definisce un gruppo quoziente ⁄ , i cui elementi sono l’ideale
stesso, che ne costituisce l’elemento neutro, e tutti i suoi laterali in
, che indicheremo con . Con questa notazione risulta:
( ) ( )
(17.2.2)
Osserviamo che le precedenti sono indipendenti dalla scelta
dei rappresentanti di laterale. Si può anche verificare che ⁄ è
come un anello commutativo con identità detto anello quo-
ziente di rispetto a . Dalla seconda delle (17.2.2) si deduce
facilmente che l’identità moltiplicativa è il laterale che si può indi-
care con , cioè quello che contiene l’identità moltiplicativa
di
Osserviamo che comunque scelto un elemento di , l’in-
sieme è un ideale, infatti ( ) ( )
( ) , inoltre indicando con , l’opposto di , ( )
e risulta ( ) ( ) ( ( )) , pertanto è un sotto-
gruppo d . Ogni ideale generato da un elemento di è detto
ideale principale.
Vale il seguente teorema:
Teorema 17.1 Tutti gli ideali dell’anello dei polinomi su un campo sono
principali.
Dimostrazione:

Ideali di un Anello di Polinomi 177
Osserviamo innanzitutto che ( )( ) è un ideale
principale per l’anello commutativo con identità . Consideria-
mo adesso un ideale di diverso da ( )( ) , in esso
scegliamo un elemento ( )( ) di grado minimo.
Comunque scelto un polinomio ( )( ) potremo scri-
vere:
( )( ) ( )( ) ( )( ) ( )( ) (17.2.3)
dove se (cioè ( )( ) non è un divisore di ( )( ) )
risulterà , ma in questo caso potremmo scrivere:
( )( ) ( )( ) ( )( ) ( )( ) (17.2.4)
che è un assurdo in quanto ( )( ) deve appartenere ad , come
mostra la precedente, pur avendo grado minore di che per ipo-
tesi è il grado minimo dei polinomi non nulli contenuti in . Deve
pertanto essere , o, che è lo stesso, ( )( ) ( )( ) ,
pertanto ogni ideale di è principale.
***********
Ci si convince facilmente che comunque scelto ,
anche il polinomio ( )( ) genera lo stesso ideale. Ovviamente
sarà sempre possibile individuare tra i generatori di un ideale
un solo polinomio monico cioè con il coefficiente del termine di
massimo grado pari ad .
Vale il seguente teorema:
Teorema 17.2 Dati due ideali di , siano ( ) ed ( )
se e solo se ( ) ha ( ) tra i suoi fattori.
***********
Dato un ideale ( )( ) e un polinomio ( )( ), sappiamo
che esistono ( )( ) e ( )( ) tali che si può scrivere:
( )( ) ( )( ) ( )( ) ( )( )
∪ {
(17.2.5)

178 Capitolo - 17 - Appunti di Teoria dell’Informazione e Codici
che ci permette di affermare che ( )( )ed ( )( ) appartengono
allo stesso laterale di ( )( ) , cioè:
( )( ) ( )( ) ( )( ) ( )( ) (17.2.6)
Ciascun laterale di un ideale contiene un unico polinomio di
grado minimo, grado che, in virtù della (17.2.5), deve essere mino-
re di . Per convincersene è sufficiente ricordare che due elementi
di un gruppo appartengono allo stesso laterale se e solo se la loro
differenza appartiene al sottogruppo, ma la differenza tra due po-
linomi distinti di grado minore non potrà appartenere all’ideale
che essendo principale contiene solo polinomi di grado maggiore
od uguale ad , fatta eccezione per il polinomio nullo, che peral-
tro è l’unico polinomio di grado minimo contenuto nell’ideale
pensato come laterale di se stesso.
siste quindi un isomorfismo “naturale” tra l’anello
( )( ) ⁄ e l’insieme ( )
dei polinomi a coefficienti in
di grado minore di . si può quindi pensare a ( )
come ad un
anello commutativo con identità assumendo come risultato della
moltiplicazione tra due polinomi di ( )
il resto della divisio-
ne tra l’usuale prodotto dei due polinomi e ( )( ).

Capitolo - 18
CODICI CICLICI
18.1 - Rappresentazione polinomiale di un codice ciclico.
Definizione 18.1 Un codice lineare a blocchi si dice ciclico se e solo se comun-
que scelta una sua parola di codice
(18.1.1)
***********
In quel che segue mostreremo che i codici ciclici sono poli-
nomiali. Dovremo in altri termini mostrare che se un codice è ci-
clico allora la sua rappresentazione polinomiale ammette un poli-
nomio generatore.
Ad ogni parola di codice possiamo associare un polinomio
appartenente a ( )
come segue:
( )
(18.1.2)
denoteremo con ( ) l’insieme dei polinomi associati alle paro-
le di codice.
Risulta:
( )
(18.1.3)
Notiamo che per trasformare ( ) in ( ) occorre sottrarre a
( ) il polinomio :
( ) ( )
( )
(18.1.4)

180 Capitolo - 18 - Appunti di Teoria dell’Informazione e Codici
ma poiché è il quoto della divisione tra ( ) e , dalla
precedente si deduce che ( ) è il resto della divisione appena
citata.
In altri termini, l’operazione corrispondente alla rotazione
ciclica di una parola in equivale, nel linguaggio dei polinomi, a
considerare il resto della divisione per del prodotto tra il
polinomio corrispondente alla parola ed . In simboli:
( ) ( ) ( ) (18.1.5)
18.2 - Teorema sui codici ciclici
Teorema 18.1 Condizione necessaria e sufficiente affinché un codice sia ciclico è che il
sottoinsieme ( ) dei laterali dell’ideale contenenti i polimomi
di codice sia un ideale di ⁄ .
Necessarietà:
L’insieme dei polinomi di codice ( ) essendo costituito
da polinomi appartenenti a ( )
costituisce anche un sottoin-
sieme dei coset leader (intesi come i polinomi di grado minimo)
dei laterali di ⁄ .
Inoltre:
a) il codice è lineare, pertanto è uno spazio vettoriale
sul campo , quindi la sua rappresentazione in forma polino-
miale ( ) deve essere anche un sottospazio di ;
b) l’anello ⁄ ha la struttura di spazio vettoriale sul
campo ;
c) esiste un isomorfismo naturale tra ( )
ed ⁄ ,
quello che associa ad ogni polinomio di ( )
l’unico late-
rale che lo contiene in ⁄ .
Dalle considerazioni appena fatte discende che l’immagine,
( ) , secondo l’isomorfismo sopra citato di ( ) in
⁄ è a sua volta un sottospazio vettoriale, quindi anche
un sottogruppo, ( ) di ⁄ , i cui elementi sono i la-
terali di che contengono i polinomi di codice.

Codici Ciclici 181
La ciclicità e la linearità del codice implicano:
( ) ( ) ( ) ( ) ( ) (18.2.1)
dalla quale sempre in virtù della linearità di ( ) discende anche
facilmente:
( ) ( ) ( ) ( ) ( ) ( ) ( ) (18.2.2)
Quest’ultima, sulla base dell’osservazione c), può essere rivisitata
in termini di laterali di , infatti ( ) possiamo
scrivere:
( ) ( ) { ( ) ( ) ( ) }
( ) ( ) ( )
( ) ( )
( ) ( ) ⁄
(18.2.3)
( ) è dunque un ideale dell’anello ⁄ .
Sufficienza:
Consideriamo un ideale di ⁄ comunque preso
un suo elemento, sia ( ) , il fatto che sia un ideale
implica che:
( ) ( ) ( ) ( )
( ) ( ) ( )
( ) ( )
⁄ (18.2.4)
Ne discende che la controimmagine dell’isomorfismo di cui all’os-
servazione c) è un codice ciclico.
***********
18.3 - Polinomio generatore di un codice ciclico
Il sottoinsieme di costituito dall’unione di tutti i laterali
di che appartengono ( ) , in virtù della (18.2.2), è un

182 Capitolo - 18 - Appunti di Teoria dell’Informazione e Codici
ideale, ma tutti gli ideali di sono principali (vedi Teorema
17.1), esiste cioè un polinomio di grado minimo che li genera, tale
polinomio deve appartenere a ( ) ( )
in particolare
potremmo scegliere in quest'ultimo l’unico polinomio monico di
grado minimo, sia ( ). Il grado di ( ) dovrà necessariamente
essere per un codice .
( ) , quindi, in virtù del Teorema 17.2, ( )
deve essere un divisore di , ne discende che:
un codice ciclico esiste se e solo se il polinomio , a coefficienti nel
campo , si può scomporre nel prodotto tra due polinomi uno dei quali di
grado .
18.4 - Polinomio di parità di un codice ciclico
Nel paragrafo precedente abbiamo visto che se ( )( )
genera un codice ciclico ( ), allora deve esistere
( )( ) ( )( ) ( )( ) (18.4.1)
D’altro canto nel precedente capitolo abbiamo visto che o-
gni parola di un codice polinomiale può essere scritta nella forma:
( ) ( ) ( )( ) (18.4.2)
dove ( ) è un qualsiasi polinomio appartenente a ( )
.
Risulta:
( )( ) ( ) ( ) ( )( ) ( )( ) ( )( )
( )( ) ( ) (18.4.3)
La precedente è vera per tutti e soli i polinomi di codice, ne
discende che ( )( ), o un qualunque altro polinomio di che
lo contenga come fattore senza contenere , può essere uti-
lizzato per effettuare il controllo di parità nel caso in cui si intenda
utilizzare il codice esclusivamente per la rivelazione dell’errore.
Il polinomio ( )( ) ( )( ) ( ) ha tutti i coeffi-
cienti di grado maggiore di e minore di nulli. Questa os-

Codici Ciclici 183
servazione ci permette di scrivere equazioni che devono
essere soddisfatte dai coefficienti del polinomio ( )( ) ( ):
∑
(18.4.4)
ciascuna delle equazioni appena scritte coinvolge simboli
consecutivi della parola di codice e può quindi essere utilizzata co-
me controllo di parità qualora si intenda utilizzare il codice per la
correzione di errore. Le (18.4.4) potrebbero anche essere utilizzate
per implementare un codificatore sistematico utilizzando un filtro
FIR.
Infatti nella prima delle (18.4.4) possiamo scegliere arbitra-
riamente , (in sostanza la parola informativa) e cal-
colare , quindi utilizzare nella seconda per calcolare
e così via fino ad ottenere una parola di codice. In sostanza si
risolvono ricorsivamente equazioni del tipo
∑
(18.4.5)
Nell’incognita tali equazioni ammettono certamente soluzione
dal momento che deve essere diverso da . Se così non fosse,
tra le radici di ( ) vi sarebbe lo zero del campo che non è una ra-
dice di , quindi non può esserlo per nessuno dei suoi fattori.
Esempio 18.1
Vogliamo implementare un codificatore basato sulle (18.4.5) che
emetta gli simboli della parola di codice in sequenza. Osserviamo che
il codificatore è sistematico, i simboli informativi emessi dalla sorgente
potranno quindi essere resi disponibili direttamente all’uscita del
codificatore. Nello stesso tempo, al fine di calcolare i simboli di parità
essi dovranno essere temporaneamente memorizzati in uno stack di
memoria che nel caso di codici binari si identifica di fatto con uno shift
register. Osserviamo lo schema di Fig.E 18.1, nel quale sono indicati in
rosso i simboli presenti nelle celle di memoria, schematizzate come ele-
menti di ritardo. Ci rendiamo conto che, non appena la sorgente emette il
-esimo simbolo informativo ( ), all’uscita del moltiplicatore posto in
serie al sommatore sarà presente . Il passo successivo consisterà nel

184 Capitolo - 18 - Appunti di Teoria dell’Informazione e Codici
chiudere l’anello di reazione, spostando sulla posizione b il commutatore
e mantenerlo in questa posizione per periodi di clock per calcolare
i restanti simboli di parità.
Osserviamo che ( ) può essere scelto in modo che risulti ,
nel qual caso sarebbe possibile eliminare il moltiplicatore in uscita al
sommatore; d’altra parte tale scelta comporta in genere la rinuncia ad un
polinomio generatore monico. Nel caso in cui il codice sia binario, la sua
struttura si semplifica ulteriormente in quanto si potrebbero abolire tutti i
moltiplicatori limitandosi a connettere al sommatore solo le celle di me-
moria cui corrisponde un coefficiente non nullo del polinomio di parità.
Notiamo anche che in questo caso le celle di memoria si ridurrebbero a
dei Flip Flop. Per concludere osserviamo che il “cuore” di questo codifi-
catore è sostanzialmente un filtro FIR.
18.5 - Matrice generatrice di un codice ciclico
Consideriamo un codice ciclico sul campo la cui rappre-
sentazione polinomiale sia l’insieme ( ) , abbiamo visto che
esso deve ammettere un polinomio generatore di grado , sia:
( )( ) (18.5.1)
Sappiamo che, anche i polinomi ( )( ) ( ) devono
appartenere a ( ) in virtù della ciclicità. Osserviamo che per i
polinomi ottenuti al variare di tra e risulta
( )( ) ( ) ( )( ) (18.5.2)
Detti polinomi sono linearmente indipendenti, giacché tutti di
grado diverso e sono in numero pari alla dimensione di ( )
pensato come sottospazio di ( )
, ne costituiscono quindi
una base.
Quanto appena detto ci consente di scrivere una matrice
generatrice del codice che avrà evidentemente come
righe le parole corrispondenti ai polinomi appena individuati
Fig.E 18.1 Codificatore sistematico basato sul polinomio di parità

Codici Ciclici 185
[
] (18.5.3)
18.6 - Codici ciclici Sistematici
La matrice generatrice individuata nel paragrafo precedente
non è in forma sistematica, vogliamo mostrare che è possibile in-
dividuarne una che lo è.
Dato un codice ciclico ( ) generato da ( )( ) consi-
deriamo polinomi del tipo:
(18.6.1)
Essi non sono certamente polinomi di codice in quanto tra le loro
radici non compaiono certamente quelle di ( )( ) , tuttavia sot-
traendo da ciascuno di essi il resto della divisione per ( ) otte-
niamo un polinomio di codice possiamo cioè affermare che:
( ( )) ( ) (18.6.2)
Se scriviamo i polinomi ottenuti tramite la (18.6.2) in corri-
spondenza ai valori di compresi tra tra ed otteniamo
polinomi di codice che hanno il solo coefficiente -esimo pari a
uno e tutti i restanti nulli nel range di valori di in parola, ciò in
quanto il resto di una divisione per ( ) è un polinomio che al più
può avere grado . I polinomi appena ottenuti, essendo di
grado diverso, sono linearmente indipendenti, si possono quindi
utilizzare le parole di codice ad essi associate per costruire una
matrice generatrice del codice che sarà del tipo:
(18.6.3)
in grado quindi di generare un codice sistematico con la parte in-
formativa “in coda” anziché “in testa”.
Da quanto detto discende che il polinomio di codice asso-
ciato al polinomio informativo ( ) ( )
è dato da:
( ) ( ) ( ) ( ( )( )) (18.6.4)

186 Capitolo - 18 - Appunti di Teoria dell’Informazione e Codici
Prendiamo adesso in considerazione la matrice:
(18.6.5)
che si ottiene effettuando rotazioni cicliche su ciascuna riga del-
la . Essa ha per righe parole di linearmente indipendenti
ed è quindi anch’essa una matrice generatrice.
Esempio 18.2
Per costruire un codificatore basato sulla (18.6.4) dobbiamo disporre
di un sistema in grado di calcolare il resto della divisione tra due
polinomi.
Supponiamo di disporre all’istante - esimo del polinomio ( ), e
che tale polinomio all’istante - esimo venga aggiornato, per effetto
dell’emissione da parte di una sorgente di un simbolo secondo la
regola:
( ) ( )
Indichiamo rispettivamente con ( ) e ( ) il resto e il quoto del-
la divisione tra ( )e ( ) che supponiamo monico. Vogliamo calco-
lare ( ). Risulta:
( ) [ ( )] ( ( ))
[ ( ) ( ) ( ) ] ( ( ))
[ ( ) ] ( ( ))
Ma ( ) ha al più grado possiamo quindi ulterior-
mente scrivere:
( ) ( ) ( ) ( )
( ) ( ( ) )
( ( ) )
Possiamo quindi facilmente tracciare lo schema di principio mostrato in
Fig.E 18.2
Fig.E 18.2 Schema di principio di un sistema che calcola il resto della divisione tra due polinomi

Codici Ciclici 187
Non appena tutti i coefficienti del dividendo, a partire da quello di
grado maggiore, saranno immessi nel sistema, sarà sufficiente aprire
l’anello di reazione tramite il deviatore in uscita e nei successivi
passi si presenteranno in uscita i coefficienti del resto.
18.7 - Duale di un codice ciclico
Abbiamo mostrato che un codice ciclico ( ), ha come
generatore un fattore ( )( ) del polinomio . Esiste
quindi un ( )( ) tale che:
( )( ) ( )( ) (18.7.1)
Abbiamo già visto come ( )( ) possa essere utilizzato come poli-
nomio di parità, ma ( )( ) , in quanto fattore di , è in
grado, a sua volta, di generare un codice ciclico ( )
anch’esso contenuto in ( )
che viene chiamato, seppur im-
propriamente in quanto le parole di non sono in genere or-
togonali a quelle di , duale di ( ).
Consideriamo due polinomi ( ) ( ) e ( )
( ). Risulta:
( ) ( ) ( ) ( )( ) ( ) ( )( ) ( ) ( )( ) (18.7.2)
Il polinomio ( ) ( ) ha grado al più ( ) ( )
, ne segue che il coefficiente del termine di grado di
( ) ( ) deve essere nullo. Possiamo quindi scrivere:
∑
(18.7.3)
la precedente vale per ogni scelta di ( ) ( ) e ( )
( ) . Essa ci suggerisce come costruire il codice duale
propriamente detto che si ottiene ribaltando le parole di .
Anche il codice duale propriamente detto è polinomiale il
suo polinomio generatore risulta essere:
( ) (18.7.4)
una sua matrice generatrice potrebbe essere:

188 Capitolo - 18 - Appunti di Teoria dell’Informazione e Codici
[
] (18.7.5)

Capitolo - 19
CAMPI FINITI
19.1 - Polinomi irriducibili e campi a essi associati
Definizione 19.1 Diciamo che un polinomio ( )( ) di grado non inferiore a
è irriducibile se:
( )( ) ( )( ) ( )( ) (19.1.1)
Ovviamente tutti i polinomi di primo grado sono irriducibi-
li. In . Anche il polinomio è irriducibile esso in-
fatti non è divisibile né per né per , che sono tutti e soli i
polinomi di primo grado appartenenti a . Non sono neces-
sarie altre verifiche in quanto le eventuali fattorizzazioni devono
comunque contenere un polinomio di primo grado. Il polinomio
è irriducibile in , ma pensato come elemento di
non lo è
Vale il seguente teorema:
Teorema 19.1 Il gruppo quoziente ( )( ) ⁄ individuato dall’ideale generato
dal polinomio ( )( ) è un campo se ( )( ) è un polinomio irriducibile di
.
Dimostrazione:
Sappiamo già che ( )( ) ⁄ è un anello commutativo
con identità, quindi dobbiamo solo verificare che per ogni suo
elemento, fatta eccezione per ( )( ) , esiste un inverso.
Osserviamo che ( )( ) non coincide con . Infatti, se
così non fosse, esisterebbe ( ) ( )( ) ( ) , ma la
precedente può essere soddisfatta solo se , ma essendo, per
ipotesi, ( )( ) irriducibile, il suo grado non può essere inferiore

190 Capitolo - 19 - Appunti di Teoria dell’Informazione e Codici
ad . Possiamo pertanto affermare che ( )( ) ⁄ contiene
almeno un polinomio ( ) ( )( ) .
Consideriamo adesso l’insieme
{ ( ) ( )( ) ( ) ( ) | ( ) ( ) (19.1.2)
si constata facilmente che è un ideale di , ma (vedi Teorema
17.1) tutti gli ideali di sono principali, deve pertanto esistere
in un polinomio ( )( ) tale che risulti ( )( ) .
Dalla (19.1.2) deduciamo che ( )( ) , quindi deve
esistere un polinomio per il quale risulti ( )( ) ( )( ) ( )( ),
ma ( )( ) è irriducibile, quindi, necessariamente, o , o
. Nel primo caso ( )( ) , ma ciò è assurdo perché
contiene anche ( )( ) ( )( ) , deve quindi essere . Ciò
implica da cui discende che devono esistere ( ) ( )
che soddisfano l’uguaglianza
( ) ( )( ) ( ) ( )( ) (19.1.3)
La precedente implica:
( )( ) ( ( )( ) ( )( ) ( )( ) ( )( )) ( )( )
( )( ) ( )( ) ( )( )
( )( ) ( )( ) ( )( ) ( )( )
(19.1.4)
Dalla precedente si deduce che il laterale ( )( ) ( )( ) è
l’inverso di ( )( ) ( )( ) .
***********
19.2 - Ordine degli elementi di un gruppo
Consideriamo un gruppo finito , abbiamo già visto che
ogni suo sottogruppo individua una partizione del gruppo in
laterali, che hanno tutti la stessa cardinalità del sottogruppo. Ciò
comporta il fatto che il numero di elementi di un sottogruppo, il
suo ordine ( ), è un sottomultiplo dell’ordine del gruppo in cui
esso è contenuto.

Campi Finiti 191
Sia un elemento di un gruppo finito . Consideriamo
l’insieme:
(19.2.1)
è un sottoinsieme di , in quanto è chiuso rispetto alla legge
, quindi deve avere un numero finito di elementi, da cui
facilmente discende che deve esistere un intero ( ), tale che
risulti , o, che è lo stesso, tale che
(19.2.2)
Abbiamo appena mostrato che contiene . Considerando
adesso il più piccolo valore di che soddisfa la (19.2.2), risulta:
(19.2.3)
è quindi un sottogruppo di . L’ordine del sottogruppo
generato da un elemento di un gruppo è detto ordine di , ( ).
19.3 - Ordine degli elementi di un campo finito
Consideriamo un campo finito . Sia l’ordine di rispetto
alla legge , possiamo affermare che è un numero primo. Infat-
ti, se così non fosse, esisterebbero due interi, ed , entrambi
per i quali varrebbe l’uguaglianza:
( ) (19.3.1)
ma è un campo vale quindi la legge di annullamento del prodot-
to, quindi o o . ( ) sarebbe quindi il minimo tra
ed e non . Ne segue che ( ) deve essere un primo.
Osserviamo che per ogni elemento di si può scrivere
, da cui:
( ) ( ) ( ) (19.3.2)
più in generale , ma solo se , ovvero
se , possiamo quindi concludere che tutti gli elementi di-

192 Capitolo - 19 - Appunti di Teoria dell’Informazione e Codici
versi da di un campo finito hanno lo stesso ordine rispetto alla
somma, e che tale ordine è un primo risulta cioè:
(19.3.3)
19.4 - Ordine di un campo finito
Consideriamo un campo , ed un suo sottocampo , in
questo caso diremo che è un’estensione di . Si constata che
ha la struttura di spazio vettoriale sul campo , se la dimensione
dello spazio è finita è detta grado di su .
Vale il seguente teorema:
Teorema 19.2 - Ordine di un campo finito L’ordine di un campo finito o è un primo, o è una potenza (intera) di
un primo.
Dimostrazione:
Abbiamo visto che l’ordine dell’elemento di un qualsiasi
campo è un primo , si verifica facilmente che l’insieme
3 (19.4.1)
é un campo (isomorfo a ) quindi è un sottocampo non neces-
sariamente proprio (in quanto potrebbe coincidere con ) di .
D’altro canto, ha la struttura di spazio vettoriale sul cam-
po e la sua dimensione deve essere finita, essendo finito.
Un qualsiasi elemento di potrà essere quindi espresso in
modo univoco come combinazione lineare, con coefficienti ap-
partenenti a , di elementi che costituiscano una base per ,
cioè che siano linearmente indipendenti su . Osservando che
esistono esattamente combinazioni lineari distinte si conclude
che l’ordine di se non è primo è una potenza di un primo.
***********
Quale che sia il campo finito , il campo generato
dalla sua unità moltiplicativa è detto sottocampo primo o fonda-
mentale. Esso è contenuto in tutti i sottocampi di , o, che è

Campi Finiti 193
lo stesso, è l’intersezione di tutti i sottocampi di quindi è an-
che il più piccolo sottocampo di che contiene (si dice che
è la caratteristica del campo).
Se un Campo non è finito, allora anche l’insieme definito
nella (19.4.1) non lo è, e non è neppure un sottocampo di (non
è nemmeno un gruppo) in questo caso si può dimostrare che il
sottocampo minimo contenuto in è isomorfo al campo dei
razionali e che l’insieme definito nella (19.4.1) è isomorfo al-
l’insieme dei naturali. In questo caso diremo che il campo ha
caratteristica
19.5 - Elementi primitivi di un campo
Sappiamo che un campo privato dell’elemento neutro
rispetto alla somma è un gruppo rispetto alla moltiplicazione, in-
dichiamolo con . L’ordine di
è .
Sia l’ordine di un generico elemento di , risulta
⏟
fattori
(19.5.1)
deve necessariamente essere un divisore di esiste cioè un
naturale tale che . Ne segue:
( ) (19.5.2)
Dalla precedente discende che per ogni elemento di
potre-
mo scrivere:
(19.5.3)
La precedente vale anche per , quindi:
(19.5.4)
Si può dimostrare che il gruppo è un gruppo ciclico,
cioè che in vi sono elementi il cui ordine è uguale all’ordine
del gruppo. Un tale elemento si chiama generatore del gruppo.
Un generatore di si dice elemento primitivo del campo,
in particolare si può dimostrare che vi sono elementi primitivi in

194 Capitolo - 19 - Appunti di Teoria dell’Informazione e Codici
numero uguale a quello dei naturali e con esso relati-
vamente primi, ad esempio in ve ne saranno , in .
Inoltre in ogni campo per cui è un primo, quale ad esem-
pio tutti gli elementi diversi da sono primitivi.
19.6 - Campi di polinomi
Cerchiamo adesso di mettere un po’ d’ordine, sappiamo
che:
- se ( )( ) è un polinomio irriducibile appartenente a ,
allora ( )( ) ⁄ è un campo.
- ogni campo finito ha un numero di elementi che se non è
un numero primo è una potenza di un primo;
-
( ) , è isomorfo ad uno spazio vettoriale di
dimensione , costituito esattamente da ( ) elementi
(una potenza di un primo).
Fissato un polinomio irriducibile ( )( ), a coefficienti in
e comunque scelto un polinomio ( )( ) di possiamo
scrivere:
( )( ) ( )( ) ( )( ) ( )( ) (19.6.1)
La precedente ci mostra che ( )( ) ed ( )( ), appartengono allo
stesso laterale dell’ideale generato da ( )( ). Notiamo anche che
il grado di ( )( ) è, inferiore al grado di ( )( ).
Osserviamo che ( )( ) può essere un qualunque polino-
mio appartenente a ( )
in definitiva quindi, individuato un
polinomio irriducibile ( )( ), possiamo affermare che ( )
,
con l’usuale somma tra polinomi in e definendo come pro-
dotto tra due suoi elementi il resto della divisione tra il loro pro-
dotto in e ( )( ), è un campo isomorfo a ( )( ) ⁄ , in
quanto ogni elemento di ( )
individua uno e un solo laterale
di ( )( ) , e viceversa.
Esempio 19.1

Campi Finiti 195
Consideriamo l’anello dei polinomi sul Campo . Il polinomio
è irriducibile. Pertanto ⁄ è un
campo, di ordine , in
quanto sono i poli-
nomi di grado minore
di a coefficienti in .
Osserviamo che tutti i
suoi elementi non nulli
sono primitivi in quan-
to il gruppo ha
elementi, e sette è un
primo. In particolare
anche l’elemento:
sarà primitivo. Assu-
mendo come rappre-
sentanti di laterale i po-
linomi di grado inferiore a otterremo la Tabella 19.1, nella quale
abbiamo convenzionalmente indicato l’elemento neutro rispetto alla som-
ma con e, nella quarta colonna, abbiamo associato ai rappresentanti
di laterale le corrispondenti parole binarie di bit.
19.7 - Polinomi irriducibili primitivi
Definizione 19.2 Diciamo che un polinomio irriducibile ( )( ) è primitivo
se esso è fattore di e non di con .
Vale il seguente teorema:
Teorema 19.3 Se ( )( ) è un polinomio irriducibile di l’elemento
( )( ) ( )( ) ⁄ è primitivo per ( )( ) ⁄ se e
solo se ( )( ) è un polinomio primitivo.
19.8 - Alcune proprietà dei campi finiti
Consideriamo due elementi e di ci convinciamo
facilmente che vale l’uguaglianza:
( ) ∑( )[(
)]
∑( )[(
)]
(19.8.1)
Tabella 19.1 - ⁄

196 Capitolo - 19 - Appunti di Teoria dell’Informazione e Codici
Osserviamo adesso che i coefficienti binomiali nella som-
matoria a ultimo membro sono multipli di , essendo primo, ciò
premesso ci basta ricordare la (19.3.3) per concludere che tutti gli
addendi della sommatoria all’ultimo membro della precedente so-
no uguali ad ne discende che
( ) (19.8.2)
Risulta anche:
( ) ( ) ( )
(19.8.3)
Dalle precedenti, sfruttando la proprietà associativa della
somma e tenuto conto che la precedente può essere applicata ite-
rativamente, otteniamo l’equazione:
( )
(19.8.4)
Un interessante caso particolare si ha quando si eleva a
una combinazione lineare di elementi di pensato come spa-
zio vettoriale sul suo sottocampo primo:
(∑
)
∑
(19.8.5)
La precedente consente di affermare che per un qualsiasi polino-
mio ( )( ) risulta:
( ( )( ))
(∑
)
∑ ( )
( )( )
(19.8.6)
dalla quale discende che, se il polinomio ammette come
radice, ammette anche con . Tali radici non saranno ov-
viamente tutte distinte.
Esempio 19.2

Campi Finiti 197
Vogliamo costruire un campo con elementi . Per farlo
abbiamo bisogno di individuare un polinomio irriducibile a coefficienti
in di quarto grado.
Prendiamo quindi in
considerazione il poli-
nomio . Detto
polinomio non è divisibile
per poiché non è
omogeneo né per
poiché ha un numero di-
spari di coefficienti non
nulli. quindi non è divi-
sibile neppure per polinomi
di terzo grado. Esso non è
divisibile neppure per i
polinomi di secondo grado
, , , per-
tanto è irriducibile.
Dovremmo a questo
punto verificare che si
tratta di un polinomio pri-
mitivo, accertandoci che
non è un fattore di
con . Tale
verifica è piuttosto noiosa,
d’altro canto, qualora il po-
linomio in parola non fosse
0010
0100
1000
1001
1011
1111
0111
1110
0101
1010
1101
0011
0110
1100
0001
0000
Tabella 19.2 - possibile rappresentazione di
Tabella 19.3 Addizioni e moltiplicazioni in

198 Capitolo - 19 - Appunti di Teoria dell’Informazione e Codici
primitivo lo scopriremmo facilmente in quanto
il polinomio non sarebbe un generatore per il
campo, esso avrebbe cioè un ordine inferiore a
.
A partire dal polinomio che associamo al-
l’elemento del campo cominciamo a riempire
la Tabella 19.2 con il resto della divisione tra le
successive potenze di e il polinomio
. Come si può notare dalla Tabella
19.2 il polinomio è primitivo in quanto l’ordine
di . Nella terza colonna
della Tabella abbiamo
indicato la rappresentazione
binaria dei polinomi.
Abbiamo a questo punto
generato gli elementi del
campo.
Per operare più rapi-
damente su di esso possiamo
costruire la Tabella 19.3 che
riassume tutti i possibili
risultati di somme e prodotti
tra gli elementi del campo. È
opportuno sottolineare che
tale tabella dipende dal
polinomio irriducibile scelto
nel senso che se avessimo
utilizzato un polinomio diverso avremmo ottenuto una diversa
rappresentazione di e conseguentemente una Tabella 19.3 diversa.
19.9 - Il logaritmo di Zech
Un modo alternativo per calcolare le somme in un campo fini-
to è quello di fare riferimento ai logaritmi di Zech.
( )
Tabella 19.4 - logaritmo di Zech per la rappre-
sentazione di del-l’Esempio 19.2
0010
0100
1000
0011
0110
1100
1011
0101
1010
0111
1110
1111
1101
1001
0001
0000
Tabella 19.5 – altra possibile rappresentazio-
ne di

Campi Finiti 199
Sia un elemento primitivo del campo; supponiamo di
voler calcolare la somma di due elementi siano ed entrambi
diversi da possiamo scrivere:
( ) (19.9.1)
Osserviamo che il termine in parentesi si può esprimere come po-
tenza di . Notiamo inoltre che esso dipende esclusivamente dalla
differenza tra gli esponenti , che va valutata modulo la cardi-
nalità di , ovvero . Possiamo quindi scrivere
( ) , convenendo che ( ) qualora dovesse risultare
, (in tutte le estensioni di ogni elemento ha se
stesso come opposto, ma non è vero in generale!).
I possibili valori assunti dalla quantità in parentesi si
possono leggere nella Tabella 19.3. e possiamo scrivere
( ) ( ) (19.9.2)
La funzione ( ) è detta logaritmo di Zech. Essa, ovviamente,
dipende sia dalla scelta del polinomio irriducibile, sia da quella del-
l’elemento primitivo. Il vantaggio nell’utilizzazione del logaritmo
di Zech, anziché della Tabella 19.3, consiste nel fatto che la tabella
che si ottiene è più compatta essendo costituita solo da
valori contro i ( ) della parte additiva della Tabella 19.3
che diventa ben presto ingestibile al crescere della cardinalità del
campo.
Si osservi che qualora avessimo utilizzato il polinomio
, anch’esso irriducibile e primitivo, per generare
avremmo ottenuto la rappresentazione di Tabella 19.5 per la quale
la Tabella 19.3 e la Tabella 19.4 dovrebbero essere riscritte.
Il logaritmo di Zech si presta meglio ad essere implementa-
to in un programma di calcolo.
19.10 - Elementi algebrici di un campo su un sottocampo
Consideriamo adesso un campo e una sua estensione .

200 Capitolo - 19 - Appunti di Teoria dell’Informazione e Codici
Definizione 19.3 Diciamo che un elemento è algebrico su un suo sottocampo se
esiste un polinomio ( )( ) di che ha come radice, cioè tale che
effettuando le operazioni in risulti ( )( ) .
Consideriamo ad esempio il campo dei razionali e la sua
estensione (il campo eale) l’elemento √ è algebrico su in
quanto il polinomio ha √ tra le sue radici se lo si
pensa come un polinomio appartenente a .
Osserviamo che l’insieme contenente i polinomi
che hanno tra le radici è un ideale di . Infatti, comun-
que scelto un polinomio in moltiplicandolo per un qualunque
polinomio di si ottiene ancora un polinomio che ha tra le
sue radici.
L’ideale deve ammettere quindi un polinomio generatore
sia ( )( ), osserviamo che esiste sempre un polinomio generatore
che ha come coefficiente del termine di grado massimo. Un tale
polinomio sarà detto monico, da ora in poi quando parleremo di
polinomio generatore ci riferiremo a quello monico.
Il polinomio ( )( ) è irriducibile in , (non è detto che
lo sia in ) in quanto se così non fosse almeno uno dei fattori
in cui potrebbe essere scomposto ammetterebbe come radice.
Tale fattore apparterrebbe quindi ad , ed avrebbe grado inferiore
a ( )( ) , ( )( ) non sarebbe in grado di generarlo e per-
verremmo ad un assurdo.
Da quanto sopra segue che esiste un unico polinomio gene-
ratore monico di che è chiamato polinomio minimale di su .
Osserviamo che ogni elemento di è algebrico su . Inol-
tre è facile constatare che se è finito ogni elemento di è alge-
brico sul suo sottocampo primo, in quanto si annulla in
virtù della (19.5.2) .

Capitolo - 20
CODICI BCH
20.1 - Codici BCH
Supponiamo di voler generare un codice polinomiale con
parole di lunghezza i cui simboli appartengano a un campo
che abbia una distanza minima non inferiore a .
Un modo per farlo è scegliere un’estensione di di
grado con un numero di elementi pari a , sia .
Scegliamo in un elemento primitiv e costruiamo il
polinomio ( ) di grado minimo che ha come radici gli
elementi dell’insieme con
. Detto polinomio è il minimo comune multiplo tra i polinomi
minimali associati agli elementi .
Affermiamo che un polinomio ( ) così costruito è in gra-
do di generare un codice con distanza minima non inferiore a .
Per provarlo osserviamo che l’insieme delle radici di ogni
polinomio associato a una parola di codice conterrà l’insieme
. Affinché un codice abbia distanza mini-
ma pari almeno a non devono esistere parole di codice, ad ecce-
zione di quella nulla, che abbiano meno di simboli diversi da .
Supponiamo per assurdo che un codice generato nel modo
anzidetto non rispetti questa condizione, in questo caso esisterà
almeno una parola di codice individuata da un polinomio del tipo:
( )
(20.1.1)
Essendo ( ) un polinomio di codice l’insieme delle sue radici
conterrà l’insieme devono quindi essere contemporaneamente
soddisfatte le equazioni:

202 Capitolo - 20 - Appunti di Teoria dell’Informazione e Codici
{
( )
( ) ( )
( ) ( )
( )
(20.1.2)
Abbiamo così ottenuto un sistema lineare e omogeneo di
equazioni in incognite.
La matrice dei coefficienti del sistema di cui sopra è:
[
( ) ( ) ( )
( ) ( ) ( )
] (20.1.3)
risulta:
[
( ) ( ) ( )
]
[
]
(20.1.4)
Il determinante di vale quindi :
∏( )
∏
(20.1.5)
essendo la prima matrice a secondo membro della (20.1.4) di Van-
dermonde e la seconda diagonale.
è certamente non singolare ciò discende dal fatto che,
essendo per ipotesi, elemento primitivo di , possiamo scri-
vere:
(20.1.6)
Possiamo quindi concludere che il sistema omogeneo
(20.1.2) è di Cramer. Esso ammette quindi solo la soluzione bana-
le. Non esistono pertanto parole di codice, ad eccezione di quella

Codici BCH 203
con simboli tutti nulli, che abbiano meno di simboli diversi da
.
Quanto appena mostrato permette di costruire un’impor-
tante classe di codici detti BCH, dalle iniziali dei loro scopritori:
Bose (1959), Chaundhuri e Hocquenghem (1960). Alla classe dei
codici BCH appartengono anche i codici di Hamming che ab-
biamo già visto, nonché i codici di Reed Solomon (RS).
Osserviamo che i codici BCH sono ciclici in quanto il loro
polinomio generatore ( )( ) ha tra le sue radici un sottoinsie-
me di quelle di (pensato come polinomio a coefficienti in
). ( )( ) ne è pertanto un fattore.
Osserviamo anche che il grado del polinomio generatore
non è assegnato a priori, ma dipende dalla scelta dell’elemento pri-
mitivo di . ne segue che anche il numero di simboli che costi-
tuiscono la parola informativa non può essere prefissato. Va
anche osservato che la distanza minima del codice potrebbe
risultare maggiore di quella di progetto.
Tipicamente i simboli che costituiscono la parola di codice
appartengono a un campo , cioè ad un campo con un nume-
ro di elementi che sia una potenza di .
In particolare i codici di Reed Solomon, che sono certa-
mente i più importanti tra i codici BCH, hanno simboli apparte-
nenti a , lunghezza della parola di codice , lun-
ghezza della parola informativa qualsiasi, purché (ovviamente)
minore di , e distanza minima .
Un codice di RS che ha trovato diverse applicazioni pra-
tiche è il ( ) che presenta una distanza minima di con
simboli appartenenti a , cioè costituite da un byte. Pensato
come codice binario la parola di codice è quindi di
bit e la corrispondente parola informativa di bit. Questo co-
dice è in grado di correggere fino ad byte errati indipendente-
mente dal numero di bit errati nel byte.
Esempio 20.1 - Progetto di un codice BCH
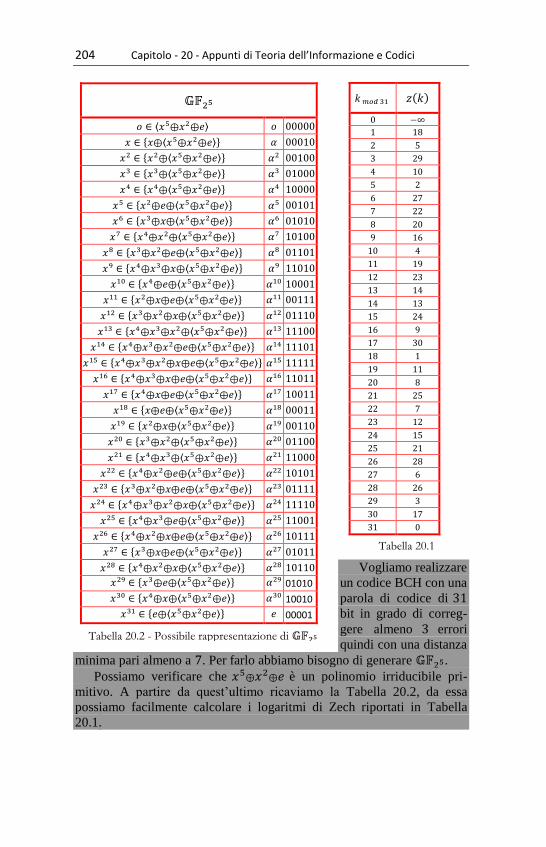
204 Capitolo - 20 - Appunti di Teoria dell’Informazione e Codici
Vogliamo realizzare
un codice BCH con una
parola di codice di
bit in grado di correg-
gere almeno errori
quindi con una distanza
minima pari almeno a . Per farlo abbiamo bisogno di generare .
Possiamo verificare che
è un polinomio irriducibile pri-
mitivo. A partire da quest’ultimo ricaviamo la Tabella 20.2, da essa
possiamo facilmente calcolare i logaritmi di Zech riportati in Tabella
20.1.
( )
Tabella 20.1
01010
10010
00001
Tabella 20.2 - Possibile rappresentazione di

Codici BCH 205
Possiamo quindi procedere alla costruzione del polinomio generatore
a coefficienti in , che deve avere come radici 6 potenze consecutive
di un elemento primitivo . Possiamo scegliere:
Tale scelta ha il vantaggio di semplificare la ricerca del polinomio ge-
neratore, in quanto il polinomio minimale associato ad tenendo conto
della (19.8.6) è anche minimale per ed quello di lo è anche per
. Il polimomio generatore cercato sarà quindi il prodotto di tre
polinomi minimali, quello associato ad , quello associato ad e quello
associato ad .
Osserviamo che se avessimo scelto il polinomio generatore avente
come radici:
Esso avrebbe avuto certamente un grado non minore di quello
associato alla scelta precedente in quanto oltre ai tre fattori citati avrebbe
dovuto avere tra i suoi fattori il polinomio minimale associato ad .
L’aumento del grado del polinomio generatore comporta inevitabilmente
una riduzione del grado del polinomio informativo. Inoltre nel caso
specifico, la distanza minima di progetto sarebbe anche aumentata perché
il polinomio generatore avrebbe avuto almeno 7 potenze consecutive di
tra le sue radici.
La ricerca dei polinomi minimali può essere fatta per tentativi
possiamo solo ridurne il numero. Nel caso ad esempio del polinomio
minimale associato ad sappiamo che esso avrà anche le radici
quindi dovrà essere almeno di quinto grado, possiamo
quindi cominciare a prendere in considerazione i polinomi non omogenei
di 5 grado con un numero dispari di coefficienti, in quanto quelli con un
numero pari di coefficienti, essendo divisibili per , non sarebbero
irriducibili. Restano quindi 8 possibili polinomi di quinto grado da
prendere in considerazione.
Il polinomio minimale associato ad risulta essere
. Che
sia una sua radice si constata immediatamente osservando che e
, appartengono allo stesso laterale (vedi Tabella 20.2).
è
irriducibile in quanto è il polinomio che abbiamo utilizzato per generare
il campo.
Il polinomio irriducibile associato ad deve avere tra le sue radici
anche , anch’esso avrà quindi un grado non inferiore al
quinto il polinomio che cerchiamo è
. Proviamo a
verificare che è una sua radice. Utilizzando i logaritmi di Zech (vedi
Tabella 20.1) otteniamo:

206 Capitolo - 20 - Appunti di Teoria dell’Informazione e Codici
Dobbiamo anche verificare che sia irriducibile. Non avendo tra i suoi
fattori nessun polinomio di primo grado, verifichiamo che non ne abbia
di secondo grado. Ovviamente esso non è divisibile per , non lo è
neppure per ne per
, quindi è irriducibile in quanto non
possono esistere fattori di terzo grado, se non ve ne sono di secondo, in
un polinomio di quinto grado.
Il polinomio minimale associato ad è
, come si
può analogamente verificare.
Possiamo a questo punto calcolare il polinomio generatore del codice
che sarà il prodotto dei tre polinomi minimali sopra indicati che sarà di
quindicesimo grado: ( ) ( )( )( )
( )( )
Poiché il polinomio di codice è di trentesimo grado e il polinomio
generatore di quindicesimo il polinomio informativo sarà anch’esso di 15
grado la parola informativa sarà quindi costituita da 16 bit, avremo
quindi 65.536 parole di codice immerse in uno spazio di parole (tutte le possibili parole costituite da 31 bit.
Le parole di codice si possono a questo punto generare moltiplicando
il polinomio associato alla parola informativa per il polinomio gene-
ratore, ma in questo caso il codice non sarebbe sistematico, ovvero pos-
siamo ricordare che i codici BCH sono ciclici e basandoci sul § 18.6 -
possiamo generare le parole di codice a partire da un polinomio infor-
mativo ( ) effettuando rotazioni cicliche sulla parola di codice
( ) ( ) ( ) ( ( ))

Capitolo - 21
LA TRASFORMATA DI FOURIER DISCRETA
21.1 - La Trasformata di Fourier Discreta
Ricordiamo che la trasformata (DFT) e l’antitrasformata
(IDFT) di Fourier discreta di una sequenza a valori nel
campo complesso di durata , o periodica di periodo è data da:
∑
∑
∑
∑
(21.1.1)
dove rappresenta una radice -esima dell’unità, in altri termini
nelle (21.1.1) compaiono le radici appartenenti al campo comples-
so del polinomio, a coefficienti in , . Si noti che il
campo complesso è un’estensione del campo reale.
Volendo generalizzare le (21.1.1) ai campi finiti, occorre innan-
zitutto soffermarsi sull’esistenza della radice -esima dell’unità del
campo. Ricordando la (19.5.1) e la (19.5.3) concludiamo che se
operiamo in la lunghezza della sequenza deve essere un
divisore di .
Ciò premesso consideriamo una sequenza, appartenente a
ed una radice -esima dell’unità in , cioè un
elemento di ordine per il gruppo , sia . Prendendo spun-
to dalle (21.1.1) possiamo scrivere la coppia di trasformate
∑
∑
(21.1.2)

208 Capitolo - 21 - Appunti di Teoria dell’Informazione e Codici
Vogliamo verificare se esiste un elemento in corri-
spondenza al quale risulti . A tal fine sosti-
tuiamo la prima delle (21.1.2) nella seconda:
∑ ∑
∑ ∑ ( )
(
∑
∑ ∑ ( )
)
(
∑
∑ ∑ ( )
)
{
∑ { ( )
( ) ( )
( ) }
}
(21.1.3)
Affinché le (21.1.1) siano una coppia di trasformate è quindi suffi-
ciente che sia l’inverso di in , in realtà è anche l’inver-
so di in .
Possiamo quindi scrivere la coppia di trasformate:
∑
( ) ∑
(21.1.4)

La Trasformata di Fourier Discreta 209
Per la DFT su un campo finito valgono quasi tutte le pro-
prietà già note per quella nel campo complesso, ad esempio la li-
nearità, la cui verifica è banale, o quella di traslazione ciclica.
Sia data una sequenza , la cui DFT sia
, fis-
sato un intero consideriamo la sequenza il cui generico elemento
, dove sta ad indicare che la differenza va effet-
tuata modulo . Vogliamo calcolare la DFT di otteniamo:
∑
∑
∑ ( )
∑
(21.1.5)
Dualmente fissato un intero consideriamo la sequenza
la sua DFT vale:
∑
∑
( )
(21.1.6)
Alla sequenza possiamo associare il polinomio:
( ) (21.1.7)
lo stesso possiamo fare per la sua DFT , ammesso che esi-
sta, definendo in modo analogo un polinomio ( ) di grado al più
. Osservando le (21.1.4) ci rendiamo conto che risulta:
(
)
( ) ( )
(21.1.8)
Dalle precedenti discende che se allora ( ) ha
come radice, o, che è lo stesso, ha il polinomio tra i suoi

210 Capitolo - 21 - Appunti di Teoria dell’Informazione e Codici
fattori. Analoghe considerazioni possono farsi su ( ) se qualche
.
Consideriamo una sequenza non banale cui corri-
sponda un ( )di grado non maggiore di . Detto polino-
mio può avere al più radici che qualora coincidessero
tutte con le , comporterebbero l’annullamento di non più di
elementi della che conseguentemente avrebbe
almeno elementi non nulli. Applicando la (21.1.5) possiamo fa-
cilmente concludere che è in realtà sufficiente che in una sequenza
non banale siano nulli elementi consecutivi (modulo ),
affinché la sequenza trasformata, o antitrasformata abbia almeno
elementi non nulli.
21.2 - DFT e codici ciclici
Le considerazioni fatte dopo la (21.1.8) ci permettono di
introdurre una definizione alternativa per i codici ciclici. Possiamo
infatti affermare che
Definizione 21.1 Un codice ciclico ( ) è costituito dal sottoinsieme di
la cui
DFT si annulla in posizioni prefissate.
La definizione appena data comporta ovviamente l’esistenza
della DFT, deve esistere cioè un elemento di ordine per ,
che consenta di calcolarla, ne discende che deve essere un sotto-
multiplo di , cioè una radice -esima dell’unità di . Se
vogliamo che le parole di codice abbiano la massima lunghezza
l’elemento scelto per il calcolo della DFT dovrà essere primitivo.
In questo caso avremmo . Il fatto che la Definizione
21.1 sia equivalente alla Definizione 18.1 risulta evidente tenendo
conto della (21.1.8) che ci permette di affermare che ogni polino-
mio di un codice costruito sulla base della Definizione 21.1 è mul-

La Trasformata di Fourier Discreta 211
tiplo di uno stesso polinomio che è a sua volta un fattore di
inteso come polinomio a coefficienti in .


















