
Appunti di Calcolo Numerico - dispense.dmsa.unipd.itdispense.dmsa.unipd.it/mazzia/lezione1.pdf ·...
22
Appunti di Calcolo Numerico a cura di Annamaria Mazzia Universit ` a degli Studi di Padova Corso di Calcolo Numerico per Ingegneria Meccanica - Sede di Vicenza a.a.2005/2006
Transcript of Appunti di Calcolo Numerico - dispense.dmsa.unipd.itdispense.dmsa.unipd.it/mazzia/lezione1.pdf ·...

Appunti di Calcolo Numerico
a cura di Annamaria MazziaUniversita degli Studi di Padova
Corso di Calcolo Numerico per Ingegneria Meccanica - Sede di Vicenza
a.a.2005/2006


Lezioni su
Rappresentazione dei numeri nel calcolatore
Un’introduzione al calcolo numerico: la rappresentazione dei nume-ri al calcolatore, l’instabilita di un algoritmo, il malcondizionamentodi un problema.
Sommario
1 Unicita della rappresentazione in base N . . . . . . . . . . . . 12 Conversione di base . . . . . . . . . . . . . . . . . . . . . . . . . . 33 Rappresentazione IEEE dei numeri di macchina . . . . . . . 44 Precisione numerica . . . . . . . . . . . . . . . . . . . . . . . . . . 85 Propagazione degli errori . . . . . . . . . . . . . . . . . . . . . . 96 Instabilita e malcondizionamento . . . . . . . . . . . . . . . . . 15
6.1 Instabilita . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 156.2 Malcondizionamento . . . . . . . . . . . . . . . . . . . . . . . 18
1 Unicita della rappresentazione in base N
Un generico numero a puo essere rappresentato in base N utilizzando N simboli,0, 1, . . . , N − 1. Si scrivera dunque come:
a = amNm + am−1N
m−1 + . . .+ a1N + a0 + a−1N−1 + a−2N
−2 + . . . a−nN−n
dove m e n sono interi naturali e ak, k = m,m − 1, . . . ,−n sono interi naturalicompresi tra 0 e N − 1.
EsempioIn base 10, il numero 726.625, scritto in forma estesa e dato dalla forma:
7× 102 + 2× 101 + 6 + 6× 10−1 + 2× 10−2 + 5× 10−3
1

1. Unicita della rappresentazione in base N 2
✰
Abbiamo supposto che il numero abbia una rappresentazione finita ma anchenel caso piu generale avremo una rappresentazione simile. Dimostriamo che talerappresentazione e unica.
Dimostrazione.Proviamo, innanzitutto, che ogni numero a e tale che Nm ≤ a < Nm+1.Se si pensa ad un numero in base decimale, questo e ovvio, nel senso che (ad
esempio) un numero con due cifre intere (m = 1) puo variare da 10 fino a 99, cioe ecompreso nell’intervallo 10 ≤ a < 102.
Supponiamo, dunque, che lo stesso numero a possa rappresentarsi - nella stessabase N - come
a = amNm + am−1N
m−1 + . . . = bpNp + . . . ap−1N
p−1 . . .
con am 6= 0, bp 6= 0.E proviamo che necessariamente deve essere p = m e bk = ak per ogni k =
m,m− 1, . . ..Per provare cio, si consideri che il valore minimo che puo assumere a, con m
fissato, si ha ponendo am = 1 e ak = 0 per k 6= m, da cui
a ≥ Nm
Analogamente, il valore massimo che puo assumere a si ha ponendo ciascun ak =N − 1, per cui1
amax = (N − 1)Nm + (N − 1)Nm−1 + . . .+ (N − 1)N−1 + . . . (N − 1)N−n
= (N − 1)(Nm +Nm−1 + . . .+N0 +N +N−1 + . . .N−n)
= (N − 1)m∑
−n
Nk =
= (N − 1)Nmn+m∑
0
N−k
< (N − 1)Nm 1
1− 1/N= Nm+1
Quindi, Nm ≤ a < Nm+1.Ora se fosse p 6= m, ad esempio p < m, avremmo p + 1 ≤ m e N p+1 ≤ Nm.
D’altro canto, ripetendo il ragionamento fatto prima, si avrebbe a < N p+1. Maallora a < Np+1 ≤ Nm da pure a < Nm, un assurdo, visto che Nm ≤ a.
Se, invece, fosse p > m, avremmo p ≥ m + 1 e N p ≥ Nm+1. Ma a < Nm+1 ea ≥ Np ≥ Nm+1, da cui a ≥ Nm+1: avremmo di nuovo un assurdo.
1si tenga conto che∑∞
k=0
1
Nk=
1
1− 1/N

2. Conversione di base 3
Percio, necessariamente, deve essere p = m.Si puo dunque scrivere:
(am − bm)Nm + (am−1 − bm−1)Nm−1 + . . . = 0
Proviamo che ak = bk per ogni k.Supponendo am − bm > 0 possiamo scrivere l’equazione precedente come:
am − bm =am−1 − bm−1
N+am−2 − bm−2
N2+ . . .
Al primo membro abbiamo un numero intero, mentre il secondo membro e cer-tamente una quantita minore di 1 in quanto puo essere maggiorata dalla quantita
N − 1N+N − 1N2
+. . . ≤ (N−1)∞∑
k=1
1
Nk= (N−1)( 1
1− 1/N −1) = (N−1)(N
N − 1−1) = 1
L’uguaglianza puo sussistere solo se ambo i membri sono uguali a zero, cioe peram = bm.
Ripetendo lo stesso ragionamento si trova che ak = bk per ogni k. ✔
2 Conversione di base
Si vuole passare da una rappresentazione in base M ad una in base N :
a = amMm + am−1M
m−1 + . . .+ a1M + a0 + a−1M−1 + . . .+ a−nM
−n
= brNr + br−1N
r−1 + . . .+ b1N + b0 + b−1N−1 + . . .+ a−sN
−s
Osserviamo che un numero puo avere una rappresentazione finita in una base mainfinita in un’altra base e viceversa.
Uguagliamo le parti intere delle due rappresentazioni e dividiamo per N , con icalcoli eseguiti nella base di partenza M :
(amMm + am−1M
m−1 + . . .+ a1M + a0)/N = (brNr + br−1N
r−1 + . . .+ b1N + b0)/N
(amMm + am−1M
m−1 + . . .+ a1M + a0)/N = brNr−1 + br−1N
r−2 + . . .+ b1 +b0N
Deduciamo che il resto della divisione per N della parte intera di a e b0, espressonella base M . Dividendo successivamente il quoziente appena trovato per N , siottiene come resto b1, b2, . . . , br−1 fino all’ultimo quoziente indivisibile per N , che cida br. I calcoli si eseguono in base M , in cui e pure espressa la base N .
Uguagliando invece le parti decimali e moltiplicando ogni volta perN otteniamo,come parti intere, i coefficienti b−1, b−2, . . ., sempre espressi nella base M :
(a−1M−1 + a−2M
−2 + . . .+)N = b−1 + b−2N−1 + b−3N
−2 + . . .

3. Rappresentazione IEEE dei numeri di macchina 4
EsempioVogliamo convertire il numero 725.625 dalla base 10 nella base 2
Per la parte intera si ha:
725 362 1 b0362 181 0 b1181 90 1 b290 45 0 b345 22 1 b422 11 0 b511 5 1 b65 2 1 b72 1 0 b81 0 1 b9
Per la parte decimale:
.625× 2 = 1.250 b−1 = 1
.250× 2 = 0.50 b−2 = 0
.5× 2 = 1.0 b−3 = 1
.0× 2 = 0.0In base 2 il numero diventa 1011010101.101. ✰
Questo modo di procedere diventa alquanto laborioso quando i calcoli devono es-sere eseguiti in una base diversa da quella decimale, per cui conviene sempre passa-re alla base decimale e poi da questa all’altra base utilizzando la rappresentazionepolinomiale del numero.
Il passaggio dalla base 2 alle basi 4, 8, 16 sono semplici considerando che 4 = 22,8 = 23, 16 = 24. Basta allora suddividere il numero binario in gruppi di 2, 3 e 4cifre, rispettivamente, per passare alle basi 4, 8 e 16.
Per passare dalla base 4 alle base 16, si suddivide il numero in gruppi di dueconsiderando che 16 = 42. Non si puo invece passare cosı facilmente dalla base 8alla bsae 16 perche l’una non e potenza dell’altra.
Il perche del passaggio da una base ad un’altra semplificato nel caso di una basepotenza dell’altra lo si vede subito vedendo il caso delle basi 2 e 4. In base 2 sonopossibili le sole cifre 0 e 1. In base 4 invece abbiamo 0, 1, 2 e 3. Ora, tutte lepossibili combinazioni delle coppie di cifre 0 e 1 sono: 00, 01, 10, 11 vale a dire 0,1, 2 e 3 in base 4. Percio prendendo a due a due coppie di cifre in base 2 ottengo larappresentazione in base 4.
3 Rappresentazione IEEE dei numeri di macchina
Lo sviluppo dei calcolatori ha promosso e sviluppato l’uso del sistema binario, in cuiciascun numero e rappresentato da una successione di cifre binarie (0 e 1). Ma comeavviene la rappresentazione di un numero nel calcolatore? Come rappresentare unnumero a infinite cifre in maniera accurata utilizzando solo un numero finito dicifre?
Abbiamo la rappresentazione in virgola mobile (floating point) - che in generee preferibile rispetto a quella in virgola fissa - e la maggior parte dei computers

3. Rappresentazione IEEE dei numeri di macchina 5
seguono gli standard dell’IEEE ( Institute of Electrical and Electronics Engineers)nella base 2.
Un numero in floating point nella rappresentazione IEEE viene scritto come
a = ±(1 + f−12−1 + f−22−2 + . . .+ f−m2−m)× 2p,
dove
• 1 + f−12−1 + f−22
−2 + . . . + f−m2−m e la mantissa, normalizzata, cui sono
riservati un numero m di bits,
• p e la potenza della base 2 cui sono riservati un numeroNe di bits ed e limitatoa variare in un determinato intervallo [L,U ].
Il primo 1 della mantissa (che corrisponde a f0) non viene messo in memoria mac’e, per cui la rappresentazione del numero e data nel modo seguente:
s e e e e e e f f f f f f
︸︷︷︸
segno︸ ︷︷ ︸
esponente︸ ︷︷ ︸
mantissa
Abbiamo 1 bit riservato al segno (si ha 0 per il segno + e 1 per il segno −), unnumero Ne di bits per l’esponente 2e, e un numero m di bits per la mantissa.
La scelta del numero di bits da riservare all’esponente e alla mantissa si basasu un compromesso tra la dimensione dell’esponente (e quindi il piu piccolo e ilpiu grande numero rappresentabile) e la dimensione della mantissa (e quindi laprecisione del numero rappresantibile, piu o meno cifre decimali).
Nel sistema IEEE, la rappresentazione in singola precisione e a 32 bits mentrequella in doppia precisione e a 64 bits. La suddivisione dei bits tra esponente emantissa viene ripartita nel modo seguente:
Singola precisione Doppia precisiones 1 s 1Ne 8 Ne 11m 23 m 52
bits 32 bits 64
L’esponente viene rappresentato in forma biased (parziale, influenzata da unaltro numero), nel senso che se p e l’esponente, noi consideriamo il valore b+ p dove
b e il numero b = 0111 . . . 1︸ ︷︷ ︸
Ne bits, quindi b = 1+2+22+. . .+2Ne−2+0×2Ne−1 = 1− 2
Ne−1
1− 2 =
2Ne−1 − 1.Per trovare il limite superiore e inferiore entro cui puo variare p, dobbiamo tener
conto del fatto che, nella rappresentazione IEEE, due patterns di bits sono riservatiper rappresentare numeri speciali quali lo zero, infinito e il Not-a-Number: sono0000 . . . 0 e 1111 . . . 1.

3. Rappresentazione IEEE dei numeri di macchina 6
Quindi, per rappresentare un numero reale b+p non puo essere uguale a 1111 . . . 1:cio significa che il massimo esponente che si puo rappresentare e dato sottraendo a1111 . . . 1 il valore 1 in base 2, cioe da 1111 . . . 1− 0000 . . . 01 = 1111 . . . 10.
Si ha b + p ≤ 1111 . . . 10, o equivalentemente, 0111 . . . 1 + p ≤ 1111 . . . 10, da cuiricaviamo
p ≤ 1111 . . . 10− 0111 . . . 1 = 0111 . . . 1 = b.
Il limite superiore U e proprio uguale a b.Per il limite inferiore abbiamo: 0000 . . . 0 < b+ p cioe, equivalentemente,
−b < p⇔ −b+ 0000 . . . 01 ≤ p.
Quindi il limite inferiore e L = −(b− 1).In singola precisone, il valore b e dato da b = 0111 . . . 1
︸ ︷︷ ︸
8 bits: in base 10 b = 12710, da
cui l’intervallo [L,U ] = [−126, 127].In doppia precisione, invece, b = 102310 da cui [L,U ] = [−1022, 1023].Per quanto riguarda la mantissa, sono ad essa riservati m bits. Considerando
anche l’1 della normalizzazione, la precisione e di m+ 1 bits.Il piu grande numero che si puo rappresentare e, quindi:
1. 111 . . . 1︸ ︷︷ ︸
m bits×2U =
m∑
k=0
2−k × 2U = 1− 2−(m+1)
1− 2−1 2U = (2− 2−m)2U ≈ 2U+1
Il piu piccolo numero positivo rappresentabile e dato, invece, da:
1. 000 . . . 0︸ ︷︷ ︸
m bits×2L = 2L
Se si vuole rappresentare un numero al di fuori di questo intervallo si ha over-flow o underflow.
In singola e doppia precisione abbiamo, per il piu grande e il piu piccolo numeropositivo rappresentabile, il seguente prospetto:
Singola precisione Doppia precisioneMassimo ≈ 3.4× 1038 ≈ 10308Minimo ≈ 1.2× 10−38 ≈ 2.2× 10−308
EsempioVogliamo scrivere il numero 5.7510 in formato IEEE in singola precisione.Effettuiamo prima la conversione in base 2:
Per la parte intera:5 2 1 b02 1 0 b11 0 1 b2

3. Rappresentazione IEEE dei numeri di macchina 7
Per la parte decimale:.75× 2 = 1.50 b−1 = 1.5× 2 = 1.0 b−2 = 1.0× 2 = 0.0
Quindi 5.7510 = 101.112 = 1.0111× 22.Memorizziamo ora il numero in singola precisione:Per l’esponente:
(b+ p)10 = (127 + 2)10 = 12910 = 100000012
Per la mantissa, m = 23 e si deve trascurare l’1 della normalizzazione
0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Il segno e positivo, quindi s = 0Percio la memorizzazione, considerati i bits per il segno, l’esponente e la mantissa
e:
0 1 0 0 0 0 0 0 1 0 1 1 1 0 0 . . . 0 0 0 0 0 0 0
︸︷︷︸
s︸ ︷︷ ︸
esponente︸ ︷︷ ︸
mantissa
✰
Consideriamo, ora, la rappresentazione dei numeri speciali.Per convenzione si pone uguale a 0 la rappresentazione che vede tutti zero sia
nel segno, sia nell’esponente che nella mantissa (non dimentichiamo che il valore 1della normalizzazione non e messo in memoria ma c’e e quindi non potremmo maiavere il valore 0 - percio lo si pone per convenzione).
Per i valori ±∞ si considerano tutti 1 nello spazio dedicato all’esponente e tutti0 nello spazio dedicato alla mantissa:
0 / 1 1 1 1 . . . 1 1 0 0 0 . . . 0 0
︸︷︷︸
s︸ ︷︷ ︸
esponente︸ ︷︷ ︸
mantissa
I valori±∞ si hanno se si fa una divisione per zero o si fa un calcolo che comportaoverflow.
Si ha invece il Not-a-Number quando si ottiene il risultato di un calcolo non edefinito, come 0/0 o log 0.
A seconda della macchina si ha:
Il NaNS: si ha un segnale di errore0 1 1 1 . . . 1 1 0 1 1 . . . 1 1
︸︷︷︸
s︸ ︷︷ ︸
esponente︸ ︷︷ ︸
mantissa

4. Precisione numerica 8
Il NaNQ: il calcolo continua comunque...0 1 1 1 . . . 1 1 1 0 0 . . . 0 0
︸︷︷︸
s︸ ︷︷ ︸
esponente︸ ︷︷ ︸
mantissa
4 Precisione numerica
Un numero puo avere una rappresentazione finita o infinita. Basti pensare al valoredi π o a
√2 in base 10.
Abbiamo anche visto che un numero puo avere rappresentazione finita in unabase ma infinita in un’altra.
EsempioScriviamo il numero 1.110 in base 2.Per la parte intera: 1 0 1 b0
Per la parte decimale:
.1× 2 = 0.2 b−1 = 0
.2× 2 = 0.4 b−2 = 0
.4× 2 = 0.8 b−3 = 0
.8× 2 = 1.6 b−3 = 1
.6× 2 = 1.2 b−4 = 1
.2× 2 = 0.4 b−5 = 0
.4× 2 = 0.8 b−6 = 0
.8× 2 = 1.6 b−7 = 1
.6× 2 = 1.2 b−8 = 1
.2× 2 = 0.4 b−9 = 0Osserviamo che nella parte decimale si ripetono all’infinito le cifre 0011.Il numero in base 2 si scrive infatti come: 1.0 0011
︸︷︷︸0011︸︷︷︸
. . .
✰
Quando rappresentiamo un numero al calcolatore sara possibile memorizzaresolo un certo numero di cifre: come esprimerlo?
Per lasciare maggiore generalita al discorso, consideriamo una base N .Sia a = ±(∑∞k=0 b−kN−k)Np il numero ”esatto”.In floating-point esso sara espresso come a∗ = ±(∑t−1k=0 b∗−kN−k)Np
∗, esso, cioe,sara arrotondato.
Ci sono due modi per arrotondare un numero
• troncamento a∗ = tronc(a), dove p∗ = p e b∗−k = b−k per k = 0, . . . , t − 1. Le
altre cifre, b−t, b−t−1, . . . sono ignorate.
• arrotondamento simmetrico a∗ = arr(a) = tronc(a+1
2N−t+1Np), aggiungiamo
un’unita a b−t+1 se b−t ≥ N/2.
L’errore assoluto che si commette approssimando il numero a con a∗ sara, dun-que,

5. Propagazione degli errori 9
errore assoluto |a− a∗| ≤
N1−tNp nel troncamento1
2N1−tNp nell’arrotondamento
Per l’errore relativo, invece, si ha:
errore relativo|a− a∗||a| ≤
N1−t nel troncamento1
2N1−t nell’arrotondamento
Il valore1
2N1−t e il numero conosciuto come precisione di macchina.
EsempioNel caso della rappresentazione IEEE di un numero, con t − 1 = m, l’errore di
arrotondamento che si commette e:
|a− a∗| ≤ 2−(m+1)
In singola precisione avremo
|a− a∗| ≤ 2−24 ≈ 5.96× 10−8
cio significa che avremo 8 cifre decimali corrette.In doppia precisione avremo
|a− a∗| ≤ 2−53 ≈ 1.11× 10−16
cio significa che avremo 16 cifre decimali corrette.✰
5 Propagazione degli errori
Prima di vedere come si propagano gli errori nelle operazioni elementari di moltipli-cazione, divisione, addizione e sottrazione, vediamo il concetto di cifre significative.
Le cifre significative sono quelle che danno un’informazione effettiva sul valoredel numero, indipendentemente dalla parte esponenziale. E chiaro che il contenutodelle informazioni sulle cifre va diminuendo via via che ci si sposti da sinistra versodestra. Quando un numero e arrotondato e rappresentato in modo da includere solocifre significative, la prima cifra a destra del punto decimale e sempre diversa dazero.
Vediamo ora come si propagano gli errori nelle operazioni elementari. Suppo-niamo che i numeri su cui lavoriamo siano affetti da errore (di arrotondamento),mentre le operazioni siano eseguite in modo esatto. Indichiamo con o una qua-lunque delle operazioni elementari {×, /,+,−} e indichiamo con fl(x) il numero xrappresentato in floating point e arrotondato, quindi fl(x) = x(1 + ex) dove ex el’errore di arrotondamento.

5. Propagazione degli errori 10
Allora fl(x o y) = fl(x) o fl(y) = x(1 + ex) o y(1 + ey).
• Moltiplicazione2
x(1 + ex)× y(1 + ey) = x× y(1 + ex)(1 + ey) ≈ x× y(1 + ex + ey)
Quindi l’errore nel prodotto e dato da exy = ex + ey
• Divisione (con y 6= 0)
x(1 + ex)
y(1 + ey)=x
y(1 + ex)(1− ey + e2y + . . .) ≈
x
y(1 + ex − ey)
Si ha ex/y = ex − ey: gli errori si accumulano additivamente
• Addizione (e, analogamente, Sottrazione)
x(1 + ex) + y(1 + ey) = x+ y + xex + yey = (x+ y)(1 +x
x+ yex +
y
x+ yey)
L’errore e ex+y =x
x+ yex +
y
x+ yey, una combinazione lineare che dipende da
x e y.
– xy > 0 =⇒ |ex+y ≤ |ex|+ |ey|
– xy < 0 =⇒ |x||x+ y| e
|y||x+ y| possono essere molto grandi e, in tal caso, ci
sara un’amplificazione notevole dell’errore. Si ha il fenomeno di cancel-lazione se non si fa attenzione al numero di cifre significative dei numeriche vengono sommati.
Esempio [Sull’uso delle cifre significative]Sia x = 0.1103 e y = 0.009963. Se consideriamo un sistema decimale a 4 cifre, y,
normalizzato, viene scritto e memorizzato come 0.9963 · 10−2.Facendo la sottrazione di questi due numeri, abbiamo 0.1103 ·100−0.9963 ·10−2 =
0.1103 − 0.009963 = 0.100337. Facendo l’arrotondamento a 4 cifre abbiamo il valore0.1003.
L’errore relativo che commettiamo e:|0.100337− 0.1003|
0.100337≈ .37 × 10−3. Questo
errore e minore della precisione di macchina (considerata la base 10 e le 4 cifre)1
2· 10−3.
Tuttavia, se non teniamo conto delle cifre significative ma tronchiamo i numerialle prime 4 cifre, abbiamo la sottrazione di 0.1103− 0.0099 = 0.1004.
2 nei conti si trascurano le potenze maggiori o uguali a due per ex e ey

5. Propagazione degli errori 11
Questa volta l’errore relativo e|0.100337− 0.1004|
0.100337≈ .63 × 10−3. L’errore e mag-
giore della precisione di macchina.✰
Esempio [Il disastro del missile Patriot ]Nel 1991 un missile Patriot fallı l’operazione di inseguire e fermare uno Scud, in
Arabia Saudita, a causa di un problema di precisione numerica. Come conseguenza,lo Scud uccise 28 americani.
Il computer usato per controllare il missile Patriot era basato su un’aritmeticaa 24 bit. Per i calcoli, il tempo veniva registrato dall’orologio interno del sistemain decine di secondi e successivamente moltiplicato per 1/10 per ottenere i secondi,utilizzando 24 bit in virgola fissa. Il numero 1/10 in base 2 ha infinite cifre decimali:la sua espansione binaria e infatti 0.0001100110011001100110011001100 . . .. In 24bit esso veniva registrato come 0.00011001100110011001100 introducento un errore di0.0000000000000000000000011001100 . . ., circa 0.000000095 in base 10.
Gli errori di arrotondamento nella conversione del tempo causarono un errorenel calcolo della traiettoria. Difatti, il tempo di 100 ore calcolato in secondi diede ilvalore 359999.6567 invece di 360000, un errore di 0.3433 secondi che porto il Patriot687 metri fuori della traiettoria del missile Scud!
✰
Esempio [Sul fenomeno di cancellazione]Consideriamo il problema di approssimare la derivata della funzione f(x) =
sinx nel punto x = 1.2.Supponiamo di non poter valutare direttamente la derivata della f e di volerla
approssimare facendo uno sviluppo in serie di Taylor:
f(x0 + h) = f(x0) + hf′(x0) +
h2
2f ′′(x0) +
h3
6f ′′′(x0) +
h4
24f IV (x0) + . . .
Allora
f ′(x0) =f(x0 + h)− f(x0)
h− (h2f ′′(x0) +
h2
6f ′′′(x0) +
h3
24f IV (x0) + . . .)
Approssimiamo, quindi, la f ′(x0) calcolandof(x0 + h)− f(x0)
h.
L’errore di discretizzazione che si commette e
|f ′(x0)−f(x0 + h)− f(x0)
h| = |h
2f ′′(x0) +
h2
6f ′′′(x0) +
h3
24f IV (x0) + . . . |
Supponendo di conoscere il valore della derivata seconda in x0, per piccoli valoridi h possiamo dare una stima dell’errore di discretizzazione,
|f ′(x0)−f(x0 + h)− f(x0)
h| ≈ h
2|f ′′(x0)|

5. Propagazione degli errori 12
Ci aspettiamo, anche senza conoscere il valore di f ′′(x0) (purche diverso da 0) chel’errore di discretizzazione diminuisca proporzionalmente con il passo h, al decre-scere di h.
Nel nostro caso, in cui f(x) = sin (x), noi conosciamo il valore esatto della deri-vata in 1.2, vale a dire cos (1.2) = 0.362357754476674...
Il valore che otteniamo approssimando la derivata con la formula che abbiamoricavato, per h = 0.1 non e molto accurato. Ci aspettiamo che diminuendo il passo hl’errore che commettiamo diminuisca.
Riportiamo gli errori della formula (in valore assoluto) e confrontiamoli con
l’errore di discretizzazioneh
2|f ′′(x0)| (i conti sono fatti in singola precisione):
h erroreh
2|f ′′(x0)|
1.e-1 4.7167e-2 4.6602e-21.e-2 4.6662e-3 4.6602e-31.e-3 4.6608e-4 4.6602e-41.e-4 4.6603e-5 4.6602e-51.e-5 4.6602e-6 4.6602e-61.e-6 4.6597e-7 4.6602e-7
L’errore commesso dall’algoritmo decresce come h e, in particolare, comeh
2|f ′′(1.2)| =
0.46602h.Possiamo pensare di ottenere un’accuratezza grande quanto vogliamo a condizio-
ne di prendere valori di h sempre piu piccoli. In realta, per valori di h molto piccoli,gli errori iniziano ad aumentare!
h erroreh
2|f ′′(x0)|
1.e-8 4.3611e-10 4.6602e-91.e-9 5.5947e-8 4.6602e-101.e-10 1.6697e-7 4.6602e-111.e-11 4.6603e-5 4.6602e-121.e-12 1.3006e-4 4.6602e-131.e-13 4.2505e-4 4.6602e-141.e-16 3.6236e-1 4.6602e-161.e-18 3.6236e-1 4.6602e-19
In figura 1 vediamo come la curva dell’errore inizialmente segue la retta descrittadall’errore di discretizzazione ma poi si allontana da essa. Perche questo diversocomportamento per valori di h molto piccoli? L’errore che noi valutiamo e dato dallasomma dell’errore di discretizzazione e dell’errore di arrotondamento. Per valori dih grandi, l’errore di discretizzazione descresce al diminuire di h e domina l’erroredi arrotondamento. Ma quando l’errore di discretizzazione diventa molto piccolo,per valori di h minori di 10−8, allora l’errore di arrotondamento inizia a dominare
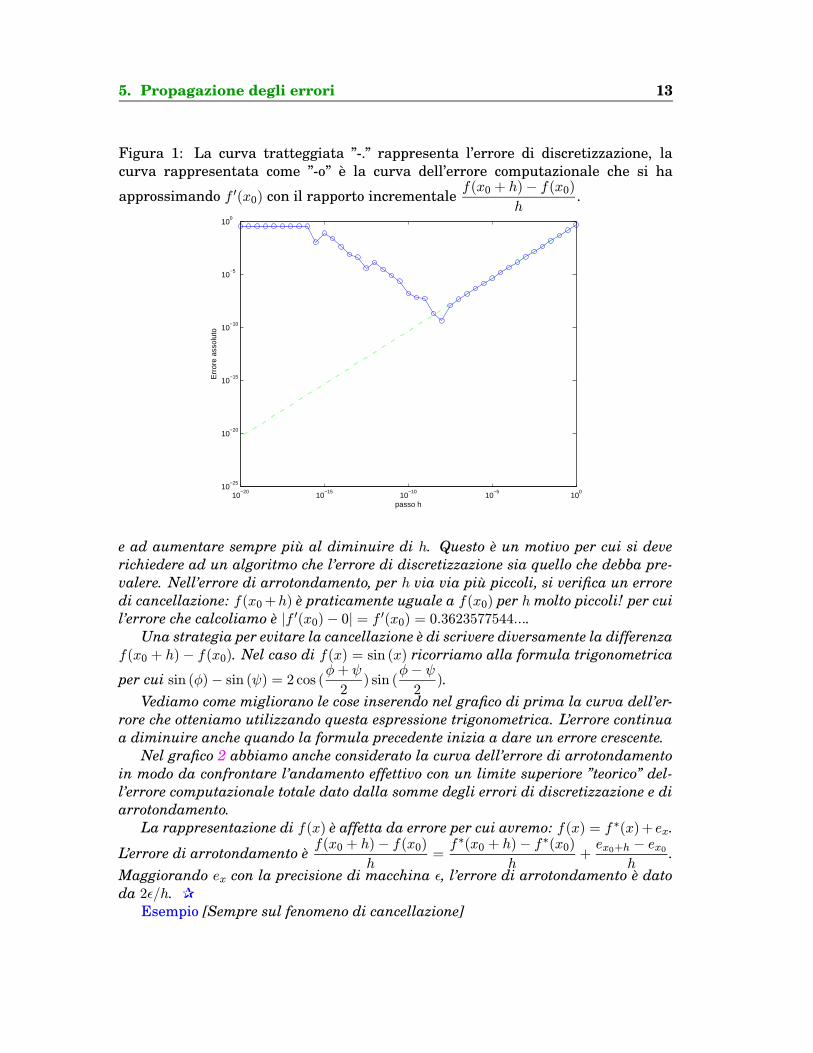
5. Propagazione degli errori 13
Figura 1: La curva tratteggiata ”-.” rappresenta l’errore di discretizzazione, lacurva rappresentata come ”-o” e la curva dell’errore computazionale che si ha
approssimando f ′(x0) con il rapporto incrementalef(x0 + h)− f(x0)
h.
10−20
10−15
10−10
10−5
100
10−25
10−20
10−15
10−10
10−5
100
passo h
Err
ore
asso
luto
e ad aumentare sempre piu al diminuire di h. Questo e un motivo per cui si deverichiedere ad un algoritmo che l’errore di discretizzazione sia quello che debba pre-valere. Nell’errore di arrotondamento, per h via via piu piccoli, si verifica un erroredi cancellazione: f(x0+h) e praticamente uguale a f(x0) per h molto piccoli! per cuil’errore che calcoliamo e |f ′(x0)− 0| = f ′(x0) = 0.3623577544....
Una strategia per evitare la cancellazione e di scrivere diversamente la differenzaf(x0 + h)− f(x0). Nel caso di f(x) = sin (x) ricorriamo alla formula trigonometrica
per cui sin (φ)− sin (ψ) = 2 cos (φ+ ψ2) sin (
φ− ψ2).
Vediamo come migliorano le cose inserendo nel grafico di prima la curva dell’er-rore che otteniamo utilizzando questa espressione trigonometrica. L’errore continuaa diminuire anche quando la formula precedente inizia a dare un errore crescente.
Nel grafico 2 abbiamo anche considerato la curva dell’errore di arrotondamentoin modo da confrontare l’andamento effettivo con un limite superiore ”teorico” del-l’errore computazionale totale dato dalla somme degli errori di discretizzazione e diarrotondamento.
La rappresentazione di f(x) e affetta da errore per cui avremo: f(x) = f ∗(x)+ ex.
L’errore di arrotondamento ef(x0 + h)− f(x0)
h=f∗(x0 + h)− f∗(x0)
h+ex0+h − ex0
h.
Maggiorando ex con la precisione di macchina ε, l’errore di arrotondamento e datoda 2ε/h. ✰
Esempio [Sempre sul fenomeno di cancellazione]
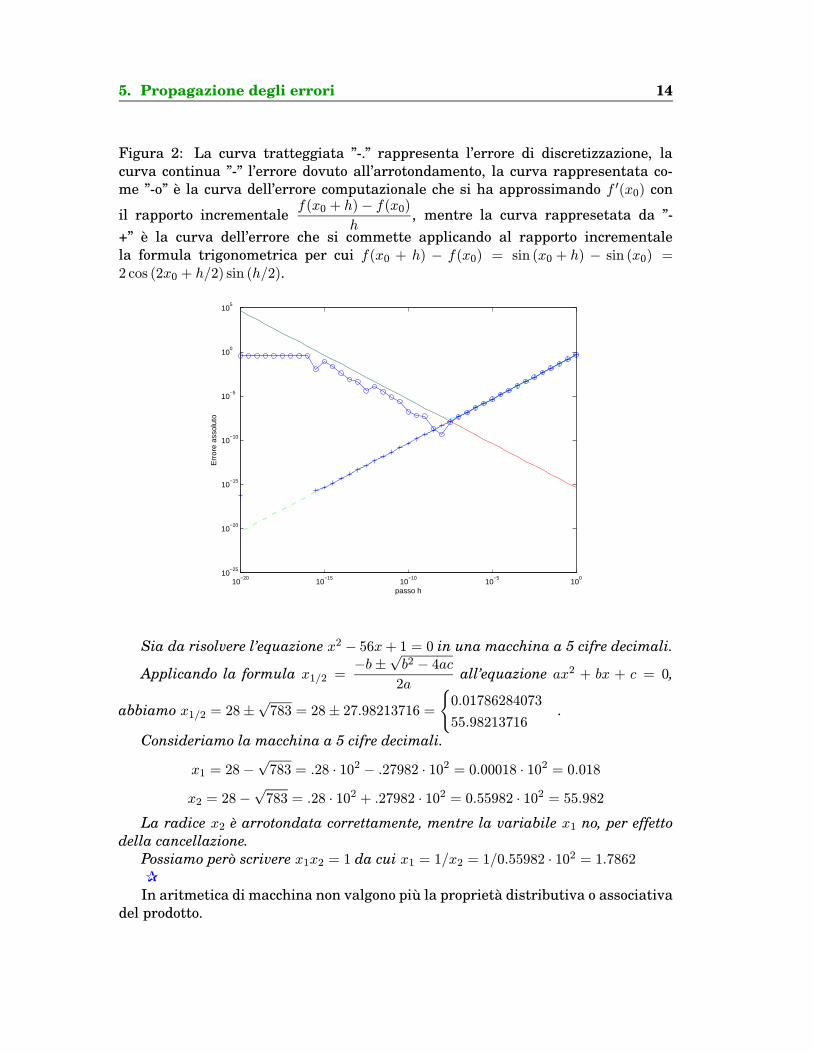
5. Propagazione degli errori 14
Figura 2: La curva tratteggiata ”-.” rappresenta l’errore di discretizzazione, lacurva continua ”-” l’errore dovuto all’arrotondamento, la curva rappresentata co-me ”-o” e la curva dell’errore computazionale che si ha approssimando f ′(x0) con
il rapporto incrementalef(x0 + h)− f(x0)
h, mentre la curva rappresetata da ”-
+” e la curva dell’errore che si commette applicando al rapporto incrementalela formula trigonometrica per cui f(x0 + h) − f(x0) = sin (x0 + h) − sin (x0) =2 cos (2x0 + h/2) sin (h/2).
10−20
10−15
10−10
10−5
100
10−25
10−20
10−15
10−10
10−5
100
105
passo h
Err
ore
asso
luto
Sia da risolvere l’equazione x2 − 56x+ 1 = 0 in una macchina a 5 cifre decimali.
Applicando la formula x1/2 =−b±
√b2 − 4ac2a
all’equazione ax2 + bx + c = 0,
abbiamo x1/2 = 28±√783 = 28± 27.98213716 =
{
0.01786284073
55.98213716.
Consideriamo la macchina a 5 cifre decimali.
x1 = 28−√783 = .28 · 102 − .27982 · 102 = 0.00018 · 102 = 0.018
x2 = 28−√783 = .28 · 102 + .27982 · 102 = 0.55982 · 102 = 55.982
La radice x2 e arrotondata correttamente, mentre la variabile x1 no, per effettodella cancellazione.
Possiamo pero scrivere x1x2 = 1 da cui x1 = 1/x2 = 1/0.55982 · 102 = 1.7862✰
In aritmetica di macchina non valgono piu la proprieta distributiva o associativadel prodotto.

6. Instabilita e malcondizionamento 15
Esempio [Sulla proprieta distributiva e associativa]Vediamo come non valga piu la relazione (a− b)2 = a2 − 2ab+ b2.Sia a = 15.6 e b = 15.7 e la macchina sia a 3 cifre decimali.(a− b) = (a− b)∗ + ea−b. Abbiamo (a− b)∗ = 15.6− 15.7 = −0.1.Quindi (a− b)2 = +0.01 = 0.1 · 10−1.Consideriamo ora a2− 2ab+ b2 = 243.36− 489.84+ 246.49 = .24336 · 103− .48984 ·
103 + .24649 · 103Considerando la macchina a 3 cifre decimali, abbiamo: .243 · 103 − .490 · 103 +
.246 · 103 = −0.1 · 101I risultati sono completamente diversi! ✰
6 Instabilita e malcondizionamento
6.1 Instabilita
In generale e impossibile evitare un accumulo lineare degli errori di arrotondamen-to durante un calcolo, ed e accettabile che ci sia una crescita lineare moderata, deltipo
En ≈ c0nE0dove En misura l’errore relativo dell’n-sima operazione dell’agoritmo e c0 sia unacostante non molto grande.
Se invece avviene una crescita di tipo esponenziale
En ≈ cn1E0
allora l’algoritmo e instabile.Algoritmi del genere devono essere evitati!Definiamo, quindi, un procedimento numerico instabile se gli errori che vi sono
associati non rimangono limitati ma crescono fino a distruggere completamente lasoluzione.
EsempioConsideriamo l’integrale
yn =
∫ 1
0
xn
x+ 10dx
per valori di n = 1, 2, . . . , 30. Osserviamo che, poiche x ∈ [0, 1], la funzione integran-da varia pure essa nell’intervallo [0, 1] per cui 0 < yn < 1.
Analiticamente, si ha:
yn + 10yn−1 =
∫ 1
0
xn + 10xn−1
x+ 10dx =
∫ 1
0
xn−1(x+ 10)
x+ 10dx =
∫ 1
0xn−1 dx =
1
n
Vale anche la relazione
y0 =
∫ 1
0
1
x+ 10dx = ln 11− ln 10.

6. Instabilita e malcondizionamento 16
Possiamo pensare, quindi, di calcolare numericamente il valore di yn attraversoil seguente algoritmo:
1. valutare y0 = ln 11− ln 10
2. per n = 1, 2, . . . , 30 valutare yn =1
n− 10yn−1
Questa formula ricorsiva dovrebbe dare l’esatto valore se non fossero presentierrori di arrotondamento. I numeri che generiamo, infatti, tendono a zero mentrel’errore si moltiplica.
Infatti
y1 = 1− 10y0
y2 =1
2− 10(1− 10y0) =
1
2− 10− 102y0
y3 =1
3− 10(1
2− 10− 102y0) = −103y0 + costante
. . . . . .
yn = −10ny0 + costanten
L’algoritmo quindi, considerati gli errori di arrotondamento, presenta un erroreEn con crescita di tipo esponenziale. Difatti otteniamo valori che via via si allon-tanano dall’intervallo di ammissibilita [0, 1]. Abbiamo infatti (in doppia precisionecon un codice Matlab):
n yn0 9.5310e-21 4.6898e-22 3.1018e-23 2.3154e-24 1.8465e-2... ....7 1.1481-28 1.0194e-29 9.1673e-310 8.3270e-318 -9.1694e+127 -9.1699e+930 -9.1699e+13
Se facciamo un programma in Fortran che descrive lo stesso algoritmo abbiamoinvece i risultati (con valori crescenti ma diversi):

6. Instabilita e malcondizionamento 17
n yn0 9.5310e-21 4.6898e-22 3.1021e-23 2.3122e-24 1.8778e-2... ....7 -3.0229e-18 3.1479e+09 -3.1368e+110 3.1378e+218 3.1377e+1027 -3.1377e+1930 3.1377e+22
Se invece, considero yn−1 =1
10(1
n− yn), partendo da un valore di n molto grande
e andando a ritroso, l’errore diminuisce. Percio, dato un valore di accuratezza ε > 0 efissato un intero n0 e possibile determinare l’intero n1 tale che, partendo da yn1 = 0 eandando a ritroso, gli integrali yn saranno valutati con un errore in valore assolutominore di ε per 0 < n ≤ n0.
Infatti:
yn0 = 0
yn0−1 =1
10
1
n0
yn0−2 =1
10(1
n0 − 1− 110
1
n0) =
1
102costante2
yn =1
10n0−ncostanten0−n
L’errore al passo n dipende, quindi, da1
10n0−n.
Se richiediamo una tolleranza ε = 10−6, per calcolare yn1 allora dovra essere
1
10n0−n1< ε = 10n1−n0 < ε
Passando al logaritmo in base 10:
n1 − n0 < log ε =⇒ n0 > n1 − log ε
Per n1 = 20 si ricava n0 = 26.Questa volta i calcoli danno gli stessi risultati sia in Matlab sia in Fortran:

6. Instabilita e malcondizionamento 18
n yn26 0.00000025 3.84615e-324 3.61538e-323 3.80513e-322 3.96731e-321 4.14872e-320 4.34703e-319 4.56530e-318 4.80663e-317 5.07489e-316 5.37486e-315 5.71251e-314 6.09542e-313 6.53332e-312 7.03898e-311 7.62944e-310 8.32797e-39 9.16720e-38 1.01944e-27 1.14806e-26 1.31377e-25 1.53529e-24 1.84647e-23 2.31535e-22 3.10180e-21 4.68982e-20 9.53102e-2
Osserviamo come il valore y0 coincida con il valore teorico noto.✰
L’esempio appena visto ci porta a dare alcune considerazioni sui criteri su cuisi deve basare un algoritmo: un algoritmo deve essere accurato, efficiente e ro-busto, accurato nel senso che bisogna essere in grado di sapere la grandezza del-l’errore che si commette nell’algoritmo stesso; efficiente in termini di velocita diesecuzione e di richiesta di spazio di memoria per le variabili utilizzate; robusto neldare il risultato corretto entro un livello di tolleranza dell’errore che sia accettabile.
6.2 Malcondizionamento
Un problema si dice malcondizionato se a piccole variazioni nei dati di input delproblema corrispondono forti variazioni nei dati di output. Quando il problema e,dunque, molto sensibile alle variazioni dei dati di input, producendo risultati molto

6. Instabilita e malcondizionamento 19
diversi tra loro, allora nessun algoritmo, per quanto robusto e stabile, potra dareuna soluzione robusta al problema stesso.
Esempio [Sui polinomi]Sia p(x) il polinomio di grado n, p(x) = xn+an−1xn−1+ . . .+a1x+a0, con a0 6= 0.
Si vogliono trovare le radici del polinomio p(x).I dati di input sono dunque i coefficienti ai, i = 0, n − 1 del polinomio mentre i
dati di output sono le radici del polinomio. Sia ξ una radice del polinomio. Essasara funzione dei coefficienti ai, quindi scriveremo ξ = f(a0, a1, . . . , an−1).
Perturbiamo, ora, uno dei coefficienti, ad esempio ak con ak+∆ak e vediamo comevariano le radici del polinomio perturbato rispetto a quello di partenza, consideran-do il rapporto
∆f
f
dove ∆f = f(a0, a1, . . . , ak +∆ak, . . . , an1)− f(a0, a1, . . . , ak, . . . , an1)Supponendo ∆ak sufficientemente piccolo, si puo approssimare ∆f con lo svilup-
po in serie di Taylor troncato al primo termine, cioe ∆f = ∆ak∂f
∂ak.
Percio
∆f
f=∆ak
∂f
∂akf
=ak
∂f
∂akf
∆akak
La variazione sulle radici∆f
fe dunque proporzionale alla variazione sui dati di
ingresso∆akak
mediante il coefficienteak
∂f
∂akf
.
Calcoliamo questa quantita. Scriviamo il polinomio come:
ξn + an−1ξn−1 + . . .+ akx
k + . . .+ a0 = 0
vale a dire
f(a0, a1, . . . , an−1)n + an−1f(a0, a1, . . . , an−1)
n−1 + . . .+ akf(a0, a1, . . . , an−1)k + . . .+ a0 = 0
Ho un’identita nelle variabili a0, a1, . . . , an−1. Anche la derivata parziale rispettoad ak sara, percio, un’identita a zero:
n∂f
∂akf(a0, a1, . . . , an−1)
n−1 + an−1(n− 1)∂f
∂akf(a0, a1, . . . , an−1)
n−2 + . . .+
akk∂f
∂akf(a0, a1, . . . , an−1)
k−1 + f(a0, a1, . . . , an−1)k
la derivata del termine akf(...)k
+ . . .+ a1∂f
∂ak= 0

6. Instabilita e malcondizionamento 20
Da questa relazione ricaviamo:
∂f
∂ak(nξn−1 + an−1(n− 1)ξn−2 + . . .+ akkξk−1 + . . .+ a1) = −ξk
∂f
∂akp′(ξ) = −ξk
∂f
∂ak= − ξk
p′(ξ)
Andando a sostituire otteniamo:
∆f
f=ak
∂f
∂akf
∆akak= − akξ
k
ξp′(ξ)
∆akak
Se il coefficiente − akξk
ξp′(ξ)e grande in valore assoluto, allora a piccole variazioni
sul coefficiente ak si avranno grandi variazioni nella radice ξ. Cio, si verifica, adesempio, quando le radici sono in modulo molto vicine tra loro.
Supponiamo di avere il polinomio p(x) = (x− 1)(x− 2) · · · (x− 10). Chiaramente,tale polinomio ha radici 1, 2, . . . , 10. Se perturbiamo il polinomio variando il coeffi-ciente a9 del valore 0.0001, considerando cioe il polinomio p(x) + 0.0001x9 allora leradici corrispondenti a 7, 8, 9, 10 non saranno piu reali ma avranno anche una parteimmaginaria.
Quindi un piccolo cambiamento nel coefficiente a9, da -55 a -54.9999 porta agrandi cambiamenti in alcune delle radici del polinomio.
✰


















