
ALGORITMI EURISTICI PER PROBLEMI DI TAGLIO ...Sommario Argomento di questa tesi `e lo sviluppo e...
113
ALMA MATER STUDIORUM - UNIVERSITA’ DI BOLOGNA FACOLTA’ DI INGEGNERIA Corso di Laurea in INGEGNERIA INFORMATICA Insegnamento: OTTIMIZZAZIONE COMBINATORIA ALGORITMI EURISTICI PER PROBLEMI DI TAGLIO BIDIMENSIONALE Tesi di Laurea di: Fabio Ciani Relatore: Chiar.mo Prof. Paolo Toth Correlatori: Prof. Alberto Caprara Ing. Enrico Malaguti ANNO ACCADEMICO 2004-2005
Transcript of ALGORITMI EURISTICI PER PROBLEMI DI TAGLIO ...Sommario Argomento di questa tesi `e lo sviluppo e...

ALMA MATER STUDIORUM - UNIVERSITA’ DI BOLOGNA
FACOLTA’ DI INGEGNERIA
Corso di Laurea in INGEGNERIA INFORMATICA
Insegnamento: OTTIMIZZAZIONE COMBINATORIA
ALGORITMI EURISTICI PER PROBLEMI
DI TAGLIO BIDIMENSIONALE
Tesi di Laurea di:
Fabio Ciani
Relatore:
Chiar.mo Prof. Paolo Toth
Correlatori:
Prof. Alberto Caprara
Ing. Enrico Malaguti
ANNO ACCADEMICO 2004-2005


Sommario
Argomento di questa tesi e lo sviluppo e l’implementazione di due algoritmi
euristici per problemi vincolati di taglio bidimensionale, ortogonale, non a
ghigliottina. Il problema consiste nel tagliare pezzi rettangolari da un rettan-
golo piu grande in modo da massimizzare il valore totale dei pezzi tagliati.
Il problema e classificabile, nell’ambito della teoria della complessita compu-
tazionale, come NP − Hard e non sono noti, per questo tipo di problemi,
algoritmi in grado di ottenere una soluzione ottima in un tempo polinomiale
per qualunque istanza del problema.
Si e dunque progettato, e successivamente implementato sfruttando il lin-
guaggio di programmazione C, prima un algoritmo euristico che utilizza la
tecnica nota come GRASP (greedy randomized adaptive search procedure)
e successivamente un altro algoritmo euristico che sfrutta la tecnica del Ta-
bu Search, per ottenere ”buone” soluzioni in tempi ragionevoli. Durante la
realizzazione sono state tenute in considerazione diverse strategie per le fasi
che costituiscono entrambi gli algoritmi e sono state effettuate diverse scelte
per la ricerca di parametri critici. Infine sono stati eseguiti molti esperimenti
computazionali su un gran numero di istanze di tipo eterogeneo, sia per se-
lezionare le migliori alternative, sia per comparare l’efficienza degli algoritmi
con altri gia esistenti.
Parole chiave: taglio, bidimensionale, euristico, euristici, tabu search
i


Indice
Sommario i
1 Introduzione 7
1.1 Origini, applicazioni e classificazioni del problema di taglio . . 7
1.2 Formulazione del problema . . . . . . . . . . . . . . . . . . . . 10
1.3 Esempi grafici di risoluzione . . . . . . . . . . . . . . . . . . . 12
2 Tecniche euristiche 15
2.1 Sviluppo di un algoritmo costruttivo . . . . . . . . . . . . . . 16
2.1.1 Inizializzazione di P , L e C . . . . . . . . . . . . . . . 16
2.1.2 Scelta del rettangolo . . . . . . . . . . . . . . . . . . . 17
2.1.3 Scelta del pezzo da tagliare . . . . . . . . . . . . . . . 17
2.1.4 Aggiornamento di P , L e C . . . . . . . . . . . . . . . 18
2.2 Esempio di applicazione dell’algoritmo . . . . . . . . . . . . . 20
3 Tecniche metaeuristiche 23
3.1 Ricerca Locale . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2 Genetic Search . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3 Simulated Annealing . . . . . . . . . . . . . . . . . . . . . . . 31
3.4 Ant Colony Optimization . . . . . . . . . . . . . . . . . . . . . 34
3.5 GRASP . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
3.6 Tabu Search . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4 Sviluppo di un algoritmo GRASP 45
4.1 Fase Costruttiva . . . . . . . . . . . . . . . . . . . . . . . . . . 45
iii

4.1.1 Scelta del parametro δ . . . . . . . . . . . . . . . . . . 46
4.2 Fase di Miglioramento . . . . . . . . . . . . . . . . . . . . . . 47
4.3 Variazione dei vincoli dei pezzi . . . . . . . . . . . . . . . . . . 49
4.3.1 Aumento dei lower bound Pi . . . . . . . . . . . . . . . 49
4.3.2 Diminuzione degli upper bound Qi . . . . . . . . . . . 50
4.4 Scelta delle migliori strategie . . . . . . . . . . . . . . . . . . . 50
5 Sviluppo di un algoritmo Tabu Search 53
5.1 Definizione delle mosse . . . . . . . . . . . . . . . . . . . . . . 53
5.1.1 Riduzione di un blocco . . . . . . . . . . . . . . . . . . 54
5.1.2 Inserimento di un blocco . . . . . . . . . . . . . . . . . 56
5.2 Mosse da esaminare . . . . . . . . . . . . . . . . . . . . . . . . 59
5.3 Selezione della mossa . . . . . . . . . . . . . . . . . . . . . . . 60
5.4 Tabu list . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.5 Intensificazione e diversificazione . . . . . . . . . . . . . . . . 61
5.6 Variazione dei vincoli dei pezzi . . . . . . . . . . . . . . . . . . 62
5.7 Path relinking . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.8 Scelta delle migliori strategie . . . . . . . . . . . . . . . . . . . 65
6 Implementazione 67
6.1 Strutture dati . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
6.1.1 Lista dei pezzi P . . . . . . . . . . . . . . . . . . . . . 68
6.1.2 Lista dei rettangoli L . . . . . . . . . . . . . . . . . . . 68
6.1.3 Lista dei blocchi C . . . . . . . . . . . . . . . . . . . . 69
6.1.4 Lista delle soluzioni d’elite E . . . . . . . . . . . . . . . 69
6.1.5 Lista dei tabu T . . . . . . . . . . . . . . . . . . . . . 70
6.1.6 Lista delle frequenze dei pezzi F . . . . . . . . . . . . . 70
6.2 Caricamento dei dati iniziali . . . . . . . . . . . . . . . . . . . 70
6.3 Schema dell’algoritmo GRASP . . . . . . . . . . . . . . . . . . 71
6.4 Funzioni dell’algoritmo GRASP . . . . . . . . . . . . . . . . . 73
6.5 Schema dell’algoritmo Tabu Search . . . . . . . . . . . . . . . 75
6.6 Funzioni dell’algoritmo Tabu Search . . . . . . . . . . . . . . . 78
iv

6.7 Funzioni comuni ai due algoritmi . . . . . . . . . . . . . . . . 82
7 Test e risultati computazionali 91
7.1 Tipi di test . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91
7.2 Risultati computazionali . . . . . . . . . . . . . . . . . . . . . 93
7.2.1 Confronto tra gli algoritmi GRASP . . . . . . . . . . . 93
7.2.2 Confronto tra gli algoritmi Tabu Search . . . . . . . . 99
7.2.3 Confronto tra le due tecniche . . . . . . . . . . . . . . 104
Conclusioni 105
Possibili sviluppi futuri 107
Bibliografia 109
v


Capitolo 1
Introduzione
1.1 Origini, applicazioni e classificazioni del
problema di taglio
Quando dei pezzi piccoli sono ricavati da pezzi piu grandi, due problemi
insorgono. Il primo riguarda la scelta della dimensione dei pezzi da tagliare
(assortment problem). Il secondo riguarda come ricavare i pezzi piccoli da
quelli grandi in modo da minimizzare il materiale scartato (trim loss problem)
(Hinxman, 1979). I pezzi piccoli sono spesso chiamati order list, mentre i
pezzi da tagliare, vengono chiamati stock material. La combinazione dei due
problemi e conosciuta come problema di taglio (cutting stock problem). Il
problema di taglio (CSP) insorge in molte grandi industrie dove fogli o lastre
devono essere tagliati in pezzi piu piccoli. Materiali tipici sono il vetro, il
legno, l’acciaio, la plastica e i prodotti tessili (Dyckhoff, 1990).
La prima formulazione del CSP risale al 1939 e fu realizzata da Kanto-
rovich, anche se venne pubblicata in Inghilterra solo nel 1960 (Kantorovich,
1960). La ricerca scientifica inizio solo allora e, fin da subito, si diffusero un
gran numero di metodi e risoluzioni. I problemi CSP possono essere clas-
sificati utilizzando lo schema proposto da Dyckhoff. Questa classificazione
prevede quattro diverse categorie:
7

1. Dimensione
• N) Numero delle dimensioni
2. Tipo di assegnamento
• B) Utilizzo di tutto il pezzo grande e di una selezione dei pezzi
piccoli
• V) Utilizzo di una parte del pezzo grande e di tutti i pezzi piccoli
3. Assortimento dei pezzi grandi da tagliare
• O) Un solo pezzo grande
• I) Molti pezzi grandi tutti della stessa dimensione
• D) Molti pezzi grandi di dimensioni diverse
4. Assortimento dei pezzi piccoli
• F) Pochi pezzi di dimensioni diverse
• M) Molti pezzi con molte dimensioni diverse
• R) Molti pezzi con poche dimensioni diverse
• C) Molti pezzi delle stesse dimensioni
La caratteristica piu importante e la dimensione. Dyckhoff suddivise
i problemi in monodimensionali, bidimensionali, tridimensionali e multidi-
mensionali. Nel caso monodimensionale, una sola dimensione e rilevante ai
fini della soluzione. Nei problemi bidimensionali, invece, i pezzi piccoli pos-
sono essere posizionati in maniera libera all’interno del pezzo da tagliare. Il
caso piu semplice si verifica quando i pezzi piccoli e il pezzo grande sono tutti
di forma rettangolare. Se i pezzi possono essere tagliati solamente con i lati
paralleli a quelli del pezzo grande, si parla di problema di tipo ortogonale
(orthogonal). Infine, se il taglio deve avvenire lungo l’intera lunghezza del
8

pezzo da tagliare (o di sue sottoparti formate da tagli precedenti), il problema
e detto ”a ghigliottina” (guillotine).
Diversi tipi di taglio sono mostrati nella Figura 1, dove le parti in grigio
rappresentano gli sprechi di materiale. In particolare la Figura 1(a) mostra
il caso del problema monodimensionale, dove la lunghezza dei pezzi e pre-
fissata, mentre le Figure 1(b) e 1(c) mostrano la differenza tra i problemi
bidimensionali a ghigliottina e quelli non a ghigliottina.
a) taglio monodimensionale
b) taglio bidimensionale a ghigliottina
c) taglio bidimensionale non a ghigliottina
Figura 1 Diversi tipi di taglio
9

Un’altra importante caratteristica, che influenza la complessita del pro-
blema, e il tipo di assegnamento. Per la classificazione dei vari CSP sono
necessarie almeno due categorie. Nella prima, tutto il pezzo da tagliare e
utilizzato, ma non tutti i pezzi piccoli possono essere ricavati. Nella seconda,
tutti i pezzi sono ritagliati, ma soltanto una parte del pezzo grande viene
utilizzata.
La terza caratteristica puo essere suddivisa in tre categorie a seconda
dell’assortimento dei pezzi grandi. Nel primo caso c’e un unico pezzo da
tagliare. Nel secondo, ci sono tanti pezzi grandi con le stesse dimensioni.
Infine, nel terzo caso, ci sono molti pezzi da tagliare con dimensioni differenti.
Per esempio, questo caso si verifica quando i pezzi da tagliare sono gli scarti
di tagli precedentemente eseguiti.
Una suddivisione simile puo essere fatta anche per l’assortimento dei pez-
zi piccoli. Nel primo caso ci sono pezzi piccoli di dimensioni diverse. Nel
secondo, ci sono molti pezzi piccoli, di cui molti di essi con dimensioni diffe-
renti. Nel terzo, ci sono molti pezzi piccoli, di cui molti di essi hanno le stesse
dimensioni. Infine, nell’ultimo caso, tutti i pezzi hanno le stesse dimensioni.
Poiche e stato dimostrato che anche i problemi di taglio piu semplici sono
NP − Hard, anche quelli piu complicati sono NP − Hard (Blazewicz et
al 1989; Fowler et al, 1981). Questo significa che e molto improbabile che
esista un algoritmo che risolva il CSP, in maniera ottimale, in un tempo
polinomiale. Per questo motivo, anziche cercare di trovare algoritmi esatti,
sin dalla sua formulazione, il CSP e stato affrontato sviluppando algoritmi
euristici per la sua risoluzione. Nelle prossime pagine verranno analizzati
diversi tipi di metodi euristici cercando di individuare quello che meglio si
adatta alla risoluzione del CSP.
1.2 Formulazione del problema
Il problema trattato da questa tesi e un problema di taglio bidimensionale,
ortogonale, non a ghigliottina, che consiste nel ricavare un insieme finito
10

di piccoli pezzi rettangolari a partire da un rettangolo base di dimensioni
prefissate, in modo da massimizzare il profitto.
Il rettangolo base R ha lunghezza L ed altezza W , mentre ogni pezzo
i da tagliare ha dimensioni (li,wi) e un valore indicato con vi. Il problema
consiste nel tagliare xi copie di ogni pezzo i in modo che 0 ≤ Pi ≤ xi ≤ Qi,
i = 1, ..,m e che il valore totale∑
i vixi sia massimizzato. Il massimo numero
di pezzi che possono essere tagliati e indicato con M =∑
i Qi.
I pezzi da tagliare sono soggetti a due ulteriori vincoli:
• I pezzi hanno un’orientazione fissata, cioe pezzi di dimensione (a, b) e
(b, a) non sono la stessa cosa.
• Ogni pezzo deve essere tagliato con i suoi lati paralleli a quelli del
rettangolo base (tagli ortogonali).
A seconda dei valori di Pi e Qi, si possono distinguere tre tipi di problemi:
1. Unconstrained : ∀i, Pi = 0, Qi = bL ∗W/li ∗ wic.
2. Constrained : ∀i, Pi = 0, ∃i, Qi < bL ∗W/li ∗ wic.
3. Doubly Constrained : ∃i, Pi > 0; ∃j, Qj < bL ∗W/lj ∗ wjc.
Definiamo l’efficienza di un pezzo i come ei = vi/(li ∗ wi); a seconda dell’ef-
ficienza dei pezzi si possono distinguere altre categorie di problemi:
1. Unweighted : ei = 1, ∀i. Il valore di ogni pezzo e uguale alla sua area.
2. Weighted : ei 6= 1, almeno per un pezzo i. Alcuni pezzi hanno un valore
che non corrisponde alla loro superficie, ma riflette altri aspetti come
la loro forma o la loro relativa importanza per i clienti.
E’ possibile ottenere un semplice upper bound per il problema risolvendo
il seguente knapsack problem, dove la variabile xi rappresenta il numero di
pezzi del tipo i che devono essere tagliati in piu rispetto al suo lower bound
Pi:
Maxm∑
i=1
vixi +m∑
i=1
viPi (1.1)
11

s.t.m∑
i=1
(liwi)xi ≤ LW −m∑
i=1
Pi(liwi) (1.2)
xi ≤ Qi − Pi, i = 1, ...m (1.3)
xi ≥ 0, integer, i = 1, ...m (1.4)
Alcuni autori hanno preso in considerazione il problema di tipo uncon-
strained : Tsai et al [3], Arenales e Morabito [4], Healy et al [5]. Tuttavia
questo genere di problema e di scarso interesse applicativo e pertanto, in que-
sta tesi, verranno sviluppati algoritmi euristici in grado di risolvere solamente
problemi di tipo constrained e doubly constrained.
1.3 Esempi grafici di risoluzione
Nella Figura 2 vediamo alcuni esempi grafici di risoluzione, con un rettangolo
base di dimensione (10,10) e m = 10 pezzi da tagliare (Figura 2(a)).
i li wi Pi Qi vi ei
1 3 2 1 2 7 1,166
2 7 2 1 3 20 1,428
3 4 2 1 2 11 1,375
4 6 2 0 3 13 1,083
5 9 1 0 2 21 2,333
6 8 4 0 1 79 2,468
7 4 1 1 2 9 2,25
8 1 10 0 1 14 1,4
9 3 7 0 3 52 2,476
10 4 5 0 2 60 3
La prima soluzione, di valore 268, e ottima per l’unconstrained problem (Fi-
gura 2(b)), la seconda, che produce un risultato di 247, e ottima per il con-
strained problem (Figura 2(c)), mentre la terza, il cui valore e 220, e ottima
per il doubly constrained problem (Figura 2(d)).
12
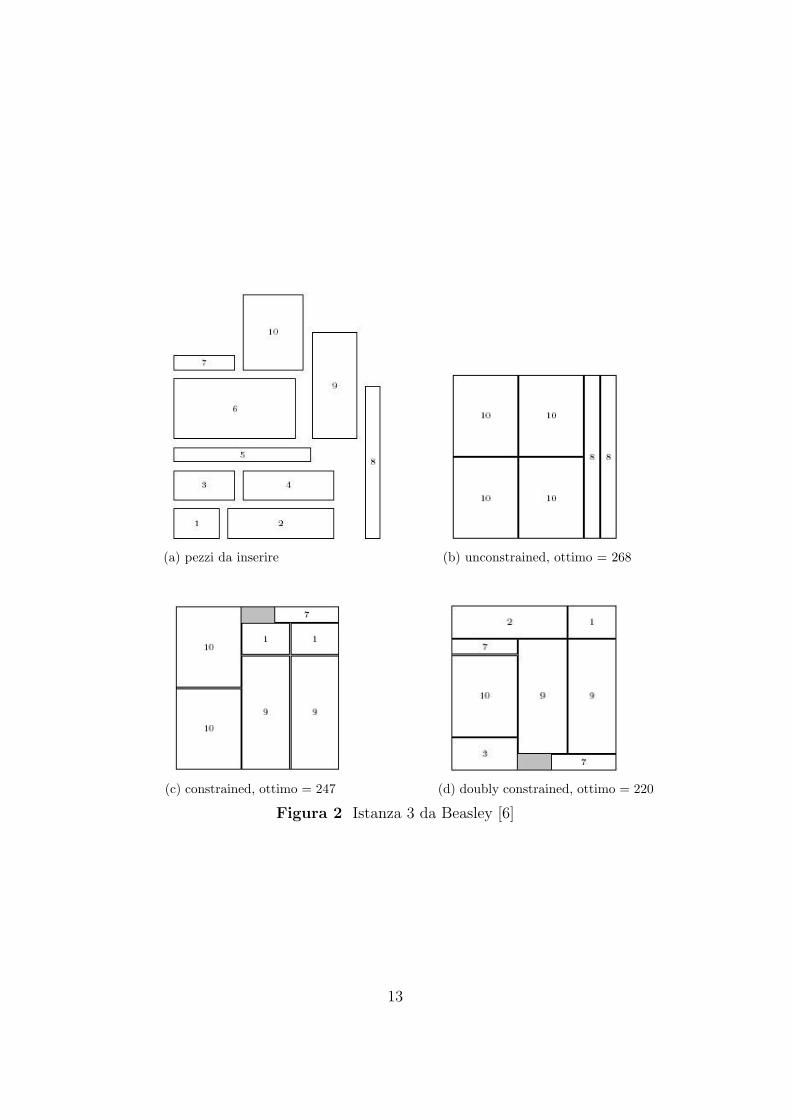
(a) pezzi da inserire (b) unconstrained, ottimo = 268
(c) constrained, ottimo = 247 (d) doubly constrained, ottimo = 220
Figura 2 Istanza 3 da Beasley [6]
13


Capitolo 2
Tecniche euristiche
Nell’affrontare un problema di ottimizzazione combinatoria possono essere
utilizzati vari approcci a seconda sia della difficolta specifica e delle dimen-
sioni del problema in esame, sia degli obiettivi reali che si vogliono ottenere.
Cosı, in quei casi in cui e necessario pervenire alla soluzione ottima di un
certo problema, si cerchera di sviluppare un algoritmo esatto che utilizzi
un approccio di enumerazione implicita delle istanze. Algoritmi esatti che
risolvono il problema di taglio bidimensionale sono stati sviluppati da Bea-
sley [6], Scheithauer e Terno [7], Hadjiconstantinou e Christofides [8], Fekete
e Schepers [9] e Caprara e Monaci [10].
Tuttavia questi metodi, nel caso di istanze di grosse dimensioni, non sono
in grado di fornire il risultato ottimo in un tempo accettabile. Per cui se non
e necessario individuare il risultato ottimo a tutti i costi, ma e sufficiente
avere una garanzia sul massimo errore commesso in termini relativi, si potra
far ricorso ad un algoritmo euristico che individui una soluzione il piu vicino
possibile a quella ottima, in un tempo accettabile. Un metodo euristico
piuttosto semplice, in grado di risolvere il problema in questione, e conosciuto
come algoritmo costruttivo.
15

2.1 Sviluppo di un algoritmo costruttivo
Il problema di taglio bidimensionale puo essere risolto sviluppando un al-
goritmo euristico costruttivo che consiste in un processo iterativo in cui si
combinano tre elementi: una lista P di pezzi ancora da tagliare (inizialmente
la lista completa dei pezzi), una lista L di rettangoli vuoti in cui un pezzo puo
essere tagliato (inizialmente contenente solo il rettangolo base R = (L, W ))
e una lista C contenente i blocchi (ovvero l’unione di uno o piu pezzi) gia
tagliati ed inizialmente vuota. Ad ogni passo un rettangolo viene scelto da
L e vi si inserisce un pezzo scelto da P che possa esservi contenuto. Questo
produce, di solito, la rimozione del rettangolo di partenza e la creazione di
nuovi rettangoli che si aggiungono a L. Il processo termina quando L = ∅oppure nessuno dei pezzi rimanenti riesce a entrare in uno dei rettangoli di
L. L’algoritmo puo essere cosı sintetizzato:
1. Inizializza L, P e C.
2. Se ∃ un pezzo che entra in uno dei rettangoli, prosegui, se no STOP.
3. Scegli un rettangolo di L.
4. Scegli un pezzo di P da tagliare.
5. Aggiorna L, P e C e ritorna al punto 2.
2.1.1 Inizializzazione di P , L e C
Come gia detto in precedenza, inizialmente, la lista dei rettangoli vuoti Lcontiene solo il rettangolo base, la lista dei blocchi C e vuota, mentre la lista
dei pezzi P contiene l’elenco completo dei pezzi da tagliare. Quest’ultima
deve essere ordinata per favorire l’applicazione dell’algoritmo costruttivo,
seguendo tre criteri:
1. Pezzi ordinati per valori Pi∗ li∗wi decrescenti, in modo da dare priorita
ai pezzi che devono per forza essere tagliati (cioe quelli con Pi > 0).
2. Se Pi = 0 ∀i, i pezzi devono essere ordinati per valori ei decrescenti.
16

3. Se ei = 1 ∀i, i pezzi devono essere ordinati per valori li ∗wi decrescenti.
2.1.2 Scelta del rettangolo
La scelta migliore e quella di selezionare il rettangolo R∗ ∈ L con l’area
minore in modo da poter soddisfare le richieste dei pezzi piu piccoli coi ret-
tangoli piu piccoli, lasciando i rettangoli piu grandi per i pezzi piu grandi.
Se scegliessimo un rettangolo grande all’inizio e lo usassimo per tagliare un
pezzo piccolo, i nuovi rettangoli creati dall’inserimento del pezzo potrebbero
risultare inutili per i pezzi piu grandi ancora da tagliare.
2.1.3 Scelta del pezzo da tagliare
Scelta di un pezzo pi e di una quantita ni ≤ Qi in modo da formare
il blocco b∗
Una volta selezionato il rettangolo R∗, deve essere scelto il primo pezzo pi di
P (ordinato come specificato in precedenza) che entra in R∗.
Se il pezzo selezionato per essere tagliato ha un upper bound Qi > 1, puo
essere presa in considerazione l’idea di tagliare un blocco, ovvero diverse copie
del pezzo in questione disposte in righe e colonne, purche il numero di questi
pezzi non superi Qi e il blocco continui ad avere una forma rettangolare. La
Figura 3 mostra esempi di questa situazione.
Figura 3 Varie scelte sulla composizione dei blocchi
17

Due criteri sono stati considerati per la selezione del pezzo:
1. Il primo pezzo nella lista ordinata P .
Questo e il modo piu ragionevole di scegliere il pezzo, in accordo con
quanto detto prima.
2. Il pezzo che produce il maggiore incremento nella funzione obiettivo.
Questo e un modo di agire molto piu greedy.
Posizionamento del blocco nel rettangolo R∗
Poiche con molta probabilita il blocco b∗ non riempira completamente il ret-
tangolo R∗, tale blocco deve essere posizionato in uno degli angoli del rettan-
golo, e piu precisamente nell’angolo che dista di meno da uno degli angoli del
rettangolo di base. Posizionando i blocchi il piu vicino possibile agli angoli del
rettangolo base, si concentrano tutti i rettangoli vuoti al centro, facilitando
cosı l’operazione di ”fusione” e recuperando spazio per i pezzi successivi.
2.1.4 Aggiornamento di P , L e C
La lista C dei blocchi deve essere aggiornata con l’indice i del pezzo inserito
con il relativo numero di pezzi ni che formano il blocco. Inoltre sara necessa-
rio indicare in qualche modo la posizione del blocco all’interno del rettangolo
selezionato.
La lista P dei pezzi da tagliare deve essere aggiornata modificando l’upper
bound del pezzo inserito Qi = Qi−ni; se Qi = 0, il pezzo i deve essere rimosso
dalla lista.
La lista L dei rettangoli vuoti deve essere aggiornata eliminando il rettan-
golo appena utilizzato e, a meno che il blocco non occupi tutto lo spazio del
rettangolo vuoto, inserendovi i nuovi rettangoli appena formati. Cosı facen-
do pero si presenterebbero un sacco di piccoli rettangoli, impedendo a pezzi
grandi di essere tagliati, anche se lo spazio libero totale lo permetterebbe.
Occorre percio fondere questi rettangolini.
18

Fusione dei rettangoli
Quando si fondono due rettangoli, possono comparire al massimo tre nuovi
rettangoli, di solito uno piu grande e uno o due piu piccoli, come da Figura 4.
Figura 4 Fusione di due rettangoli
Tra le varie alternative di fusione, la migliore e quella che favorisce l’inse-
rimento dei pezzi che si trovano nelle prime posizioni della lista P . Seguendo
questo consiglio, le condizioni per una fusione tra due rettangoli sono le
seguenti:
1. Se l’ordine del miglior pezzo che entra nel piu grande dei nuovi ret-
tangoli e minore dell’ordine dei pezzi che entrano nei vecchi rettangoli,
deve avvenire la fusione.
2. Se l’ordine del miglior pezzo che entra nel piu grande dei nuovi rettan-
goli e maggiore dell’ordine dei pezzi che entrano nei vecchi rettangoli,
non deve avvenire la fusione.
3. Se l’ordine del miglior pezzo che entra nel piu grande dei nuovi rettan-
goli e uguale all’ordine dei pezzi che entrano nei vecchi rettangoli, la
fusione deve avvenire solo se l’area del piu grande tra i nuovi rettangoli
e maggiore dell’area di ognuno dei vecchi rettangoli.
19

2.2 Esempio di applicazione dell’algoritmo
Riprendendo l’esempio di Figura 2, proviamo ad applicare l’algoritmo co-
struttivo nel caso constrained ovvero con Pi = 0 ∀i. Denotiamo ogni rettan-
golo con la quadrupla (x1, y1, x2, y2) dove (x1, y1) sono le coordinate dell’an-
golo in basso a sinistra, mentre (x2, y2) sono le coordinate dell’angolo in alto
a destra. Il processo puo essere seguito attraverso la Figura 5.
Figura 5 Applicazione dell’algoritmo costruttivo
Inizialmente L = {R} = {(0, 0, 10, 10)} e P = {10, 9, 6, 5, 7, 2, 8, 3, 1, 4}in ordine di efficienza. Consideriamo il primo pezzo della lista, il pezzo 10,
con Q10 = 2 e proviamo a tagliare un blocco formato da due pezzi nell’an-
golo in basso a destra del primo (e unico) rettangolo di L. Aggiorniamo
P = {9, 6, 5, 7, 2, 8, 3, 1, 4} e L = {(4, 0, 10, 10)}. Ora proviamo a taglia-
re il pezzo 9 con Q9 = 3, ma solamente 2 copie possono entrare nel ret-
tangolo. Tagliamo il blocco nell’angolo in basso a destra e riaggiorniamo
P = {9, 6, 5, 7, 2, 8, 3, 1, 4} (con Q9 = 1) e L = {(4, 7, 10, 10)}. A questo
20

punto i pezzi 9, 6 e 5 non entrano nel rettangolo e quindi viene selezionato
il pezzo 7 con Q7 = 2. Il blocco, formato da due pezzi, viene posizionato
nell’angolo in alto a destra. Aggiorniamo ancora P = {9, 6, 5, 2, 8, 3, 1, 4} e
L = {(4, 7, 6, 10), (6, 7, 10, 8)}, ma nessun altro pezzo puo entrare in nessuno
dei rettangoli restanti. Prima di finire il processo proviamo a fondere i due
rettangoli ottenendo L = {(4, 7, 10, 8), (4, 8, 6, 10)}, ma anche in questo caso
nessun pezzo puo piu essere tagliato. Il risultato finale trovato dall’algorit-
mo costruttivo e di 242, contro il 247 che rappresenta la soluzione ottima.
Considerando il fatto che questo problema e uno di quelli considerati ”piu
facili”, il risultato puo risultare inaccettabile.
Per questo motivo l’algoritmo costruttivo si presenta inadeguato perche
cerca sempre di effettuare il passo piu conveniente in quel momento (come
un algoritmo di tipo greedy) e preclude cosı la strada verso altre soluzioni mi-
gliori. Per superare questo inconveniente e possibile sviluppare un algoritmo
che si fondi su una tecnica di tipo metaeuristico.
21


Capitolo 3
Tecniche metaeuristiche
Negli ultimi anni hanno acquisito importanza via via maggiore alcuni ap-
procci euristici che, anziche essere progettati in maniera specifica per un da-
to problema, sono di tipo generale. Tali tecniche sono dette metaeuristiche.
La struttura e l’idea di fondo di ciascuna metaeuristica sono sostanzialmente
fissate, ma la realizzazione delle varie componenti dell’algoritmo dipende dai
singoli problemi. Tra queste le piu interessanti sono:
• genetic search
• simulated annealing
• ant colony optimization
• GRASP
• tabu search
Gli approcci metaeuristici possono vedersi in realta in modo omogeneo,
come generalizzazioni di un unico approccio fondamentale, che e quello del-
la ricerca locale. La ricerca locale si basa su quello che e, per certi versi,
l’approccio piu semplice e istintivo all’ottimizzazione: andare per tentativi.
In effetti, l’idea di funzionamento della ricerca locale (come del resto quella
delle varie metaeuristiche) e talmente elementare che e sorprendente consta-
tare la loro relativa efficacia. Va tuttavia detto fin da ora che a fronte di
23

questa relativa semplicita, l’applicazione di una qualunque metaeuristica a
un problema di ottimizzazione combinatoria richiede comunque una messa
a punto accurata e talvolta laboriosa. Consideriamo un problema di mini-
mizzazione, e una sua soluzione ammissibile x, con associato il valore della
funzione obiettivo f(x). La ricerca locale consiste nel definire un intorno di
x (detto, nella terminologia della ricerca locale, vicinato), e nell’esplorarlo
in cerca di soluzioni migliori, se ve ne sono. Se, in questo vicinato di x, si
scopre una soluzione y per cui f(y) < f(x), allora ci si sposta da x a y e si
riparte da y con l’esplorazione del suo intorno. Se invece nel vicinato di x
non si scopre nessuna soluzione migliore, allora vuol dire che x e un minimo
locale.
Nella ricerca locale classica, arrivati in un minimo locale, l’algoritmo si
ferma e restituisce questo minimo come valore di output. Ovviamente, non
si ha nessuna garanzia in generale che tale valore costituisca una soluzione
ottima del problema; anzi, tipicamente esso puo essere anche molto distante
dall’ottimo globale. Le metaeuristiche, in effetti, sono state concepite proprio
per cercare di ovviare al problema di rimanere intrappolati in un minimo
locale. Vediamo dapprima piu da vicino la ricerca locale, e poi esamineremo
gli approcci metaeuristici.
3.1 Ricerca Locale
In base a quanto detto sopra, possiamo riassumere schematicamente l’algo-
ritmo generale di ricerca locale come segue. Con x indichiamo una generica
soluzione ammissibile del problema, con N(x) il suo vicinato, e con f(x) la
funzione obiettivo.
1. Scegli una soluzione iniziale x.
2. Genera le soluzioni nel vicinato N(x).
3. Se in N(x) c’e una soluzione y tale che f(y) < f(x), allora poni
x := y e vai al punto 2, altrimenti STOP.
24

Lo spostamento da x a y al punto 3 viene spesso chiamato mossa. Nella
ricerca locale, come si vede, si ha un miglioramento della funzione obiettivo
in corrispondenza di una mossa. Per applicare l’approccio della ricerca locale
a un particolare problema, bisogna fare alcune scelte di fondo.
• Occorre avere a disposizione una soluzione iniziale ammissibile. Questa
puo essere generata da un’euristica ad hoc per il particolare problema,
o addirittura puo essere generata casualmente. E’ possibile anche ese-
guire l’algoritmo a partire da diverse soluzioni iniziali, ottenendo cosı
diverse soluzioni euristiche, e scegliere poi la migliore.
• Bisogna definire in modo preciso e opportuno il vicinato di una solu-
zione.
• Definito il vicinato, occorre avere a disposizione un algoritmo efficiente
per esplorarlo. E’ inutile definire il vicinato in un modo teoricamente
potente per poi non essere in grado di esplorarlo in un tempo di calcolo
ragionevole.
A seconda di come vengono fatte queste scelte, l’algoritmo risultante puo es-
sere piu o meno efficiente, e la soluzione proposta dalla ricerca locale risultare
piu o meno buona.
Benche ogni applicazione del concetto di ricerca locale a un problema
abbia le sue peculiarita, alcuni aspetti sono abbastanza comuni a molte
realizzazioni.
• La definizione del vicinato e in genere connessa al concetto di pertur-
bazione di una soluzione ammissibile, nel senso che la ricerca avviene
tra le soluzioni che si ottengono perturbando una soluzione iniziale.
• Spesso di parla di forza di un vicinato. Un vicinato definito in un certo
modo e tanto piu forte quanto piu la qualita delle soluzioni prodotte
dall’algoritmo e indipendente dalla bonta della soluzione di partenza.
25

Per cui si puo affrontare il problema senza perdere tempo a generare
buone soluzioni iniziali. Anzi, conviene generare molte soluzioni iniziali
casualmente, sperando cosı di avere un campionamento rappresentativo
dell’intera regione ammissibile.
• Un altro aspetto caratterizzante un approccio di ricerca locale e il modo
in cui deve essere esplorato il vicinato di una soluzione. Due strategie
antitetiche sono first improvement e steepest descent. Nel primo caso
l’esplorazione del vicinato termina non appena si trova una soluzione
migliore di quella corrente. Nel secondo, invece, lo si esplora comunque
tutto cercando il massimo miglioramento che quel vicinato consente di
ottenere. In genere si preferisce il primo approccio, ma non e una regola
fissa.
Come gia osservato, un grosso pregio della ricerca locale sta nella sua
semplicita concettuale e realizzativa, pur consentendo tale metodo di otte-
nere risultati interessanti. Tuttavia, il criterio di arresto dell’algoritmo di
ricerca locale visto finora appare in generale troppo rigido. A parte alcu-
ni casi particolari (e fortunati) in cui la funzione obiettivo ha determinate
caratteristiche di convessita, nella grande maggioranza dei problemi reali
la funzione obiettivo da minimizzare presenta un grande numero di minimi
locali, talora anche molto lontani dal minimo globale.
Per ovviare a questo problema, a partire dalla meta degli anni ’80, la
ricerca si e indirizzata verso approcci euristici che generalizzano la ricerca
locale cercando di evitare i suoi principali difetti.
3.2 Genetic Search
Con il termine weak methods si indicano quei metodi di risoluzione di proble-
mi che si basano su poche assunzioni (o conoscenze) relative alle particolari
strutture e caratteristiche dei problemi stessi, motivo per il quale tali metodi
sono applicabili ad una vasta classe di problemi. Gli algoritmi genetici rien-
trano pienamente in questa categoria, dal momento che essi sono in grado
26

di compiere una efficiente ricerca anche quando tutta la conoscenza a priori
e limitata alla sola procedura di valutazione che misura la qualita di ogni
punto dello spazio di ricerca (misura data, ad esempio, dal valore della fun-
zione obiettivo). Questa caratteristica conferisce a tali algoritmi una grande
robustezza, ovvero una grande versatilita che li rende applicabili a diversi
problemi, al contrario dei metodi convenzionali che, in genere, non trovano
altra applicazione che quella relativa al problema per cui sono stati ideati.
Gli algoritmi genetici integrano l’abilita di semplici rappresentazioni nel
codificare strutture molto complicate con la potenza esibita da semplici tra-
sformazioni (che agiscono su tali rappresentazioni) nel migliorare queste strut-
ture. Questo miglioramento e l’obiettivo primario dell’ottimizzazione. Infat-
ti, sotto l’azione di certe trasformazioni genetiche, si registrano miglioramenti
o, se si vuole, evoluzioni delle rappresentazioni in modo da imitare il processo
di evoluzione di popolazioni di organismi viventi. In natura, il problema che
ciascuna specie deve affrontare e quello della sopravvivenza, che coincide con
il trovare un adattamento vantaggioso ad un ambiente mutevole e talvolta
ostile.
Le trasformazioni genetiche che consentono una evoluzione in tal senso
sono quelle che alterano il patrimonio genetico della specie contenuto nei cro-
mosomi di ciascun individuo: esse sono il crossover di gruppi di geni parentali
e la mutazione. I cromosomi codificano strutture biologiche molto compli-
cate, mentre le trasformazioni genetiche costituiscono il mezzo attraverso il
quale si generano nuove strutture biologiche piu evolute delle precedenti.
L’idea di fondo degli algoritmi genetici e la seguente. Supponiamo di
avere un certo insieme di soluzioni di un problema di ottimizzazione. Tra
queste, ce ne saranno di migliori e di peggiori. La qualita di una soluzione
e misurata da una funzione di merito, detta fitness function, che in genere
coincidera con la funzione obiettivo, ma non sempre. A questo punto, voglia-
mo generare nuove soluzioni, con la speranza ovviamente che fra queste ve ne
siano sempre di migliori. L’idea e allora quella di ”accoppiare” le soluzioni
tra di loro in modo che ”diano alla luce” nuove soluzioni. Allora, da una cer-
ta popolazione di individui (soluzioni), se ne ricava un’altra, che costituisce
27

una nuova generazione, ossia quella dei figli della popolazione di partenza.
Questa nuova generazione potrebbe essere molto piu numerosa della prece-
dente, e allora quello che si fa e effettuare una selezione, cioe si escludono
dalla popolazione tutte le soluzioni che hanno un valore di fitness function
inferiore a una certa soglia.
Con la popolazione cosı selezionata, si ricomincia, generando quindi i
nipoti delle soluzioni di partenza e cosı via, per un numero prefissato di
generazioni. Come si vede, in questo contesto cosı generale vi sono diverse
scelte da fare. Anzitutto, negli algoritmi genetici gioca un ruolo fondamentale
il modo in cui vengono rappresentate le soluzioni ammissibili. Tipicamente,
una soluzione sara rappresentata da un insieme di stringhe di interi o binarie,
che sono i cromosomi. Ciascun cromosoma a sua volta e composto da geni
(i singoli bit). Dalla combinazione di due individui (crossover) nascera una
nuova soluzione del problema. I geni nei cromosomi del nuovo individuo
dovranno ovviamente provenire da quelli dei due genitori.
Un semplice modo di realizzare questo e il seguente. Se indichiamo con xi
e yi l’i-esimo gene di un certo cromosoma dei due genitori, il corrispondente
gene nel cromosoma-figlio puo essere posto rispettivamente uguale all’uno o
all’altro con probabilita p e 1 − p. Si noti che in questo modo si introduce
un elemento probabilistico nell’algoritmo. Peraltro, reiterando piu volte il
processo aleatorio di crossover, diverse soluzioni possono essere ottenute dalla
stessa coppia di genitori. E’ evidente che la scelta dell’operatore di crossover
e particolarmente importante; tuttavia non c’e solo questa. Un’altra scelta
molto importante e quella relativa alla dimensione della popolazione: a ogni
generazione, infatti, verranno escluse dall’evoluzione dell’algoritmo tutte le
soluzioni con basso valore di funzione obiettivo. E’ una scelta comune quella
di mantenere costante nei vari passi il numero di individui della popolazione.
E’ implicito, in quanto detto finora, che l’efficacia degli algoritmi genetici
risiede nel fatto empirico che se si combinano soluzioni buone, si ottengono
soluzioni ancora buone. Tuttavia, sperimentalmente, si e potuto osservare che
anche gli algoritmi genetici, dopo un certo numero di iterazioni, tendono a
produrre soluzioni che non migliorano piu. Per diversificare la ricerca, allora,
28

si introduce un nuovo operatore, detto mutazione. Prima cioe di procedere
alla successiva generazione, in alcuni degli individui della popolazione viene
alterato un gene. Ovviamente, gli operatori di mutazione dipendono molto
dal particolare problema in esame.
Da quanto detto, un algoritmo genetico e fondamentalmente caratteriz-
zato da cinque componenti:
1. una rappresentazione delle soluzioni generalmente sotto forma di strin-
ghe di bit;
2. un criterio per generare la popolazione iniziale di soluzioni;
3. una funzione di valutazione che misura la qualita di ciascuna soluzione;
4. un insieme di operatori genetici che trasformano punti-soluzione in altri
punti;
5. un insieme di valori per i parametri di controllo dell’algoritmo.
Lo schema di principio di un algoritmo genetico e quello che segue:
1. Genera la popolazione iniziale.
2. Seleziona i genitori.
3. Genera i figli.
4. Esegui il ricambio generazionale.
5. Se condizione d’uscita, STOP, altrimenti torna al punto 2.
L’algoritmo inizia con la creazione di una popolazione iniziale di soluzio-
ni, generata di solito in modo casuale. Quindi prosegue con un ciclo la
cui condizione d’uscita e determinata o dal raggiungimento di una soluzio-
ne soddisfacente, vale a dire caratterizzata da un valore di fitness giudicato
buono, oppure dal raggiungimento di un numero prefissato di generazioni da
elaborare.
Il ciclo che realizza la generica iterazione di un algoritmo genetico deter-
mina il passaggio da una generazione ad un’altra. Esso inizia con la selezione
29

dei genitori dalla popolazione corrente, ovvero degli individui che parteci-
pano alla fase di riproduzione. Una possibile implementazione del test di
sopravvivenza consiste nell’assegnare a ciascun esemplare una probabilita di
figurare nella lista dei genitori proporzionale al proprio valore di fitness. In
questo modo, si seleziona il patrimonio genetico migliore di tutta la popo-
lazione perche esso venga trasmesso alle generazioni successive. Alla fase di
selezione dei genitori segue quella di riproduzione, mediante la quale avvie-
ne la generazione di nuovi punti dello spazio di ricerca: ciascuna coppia di
individui prescelti genera, con probabilita pc (probabilita di crossover), una
coppia di figli.
Il processo di riproduzione simula il meccanismo biologico di crossover in
cui si verifica uno scambio di gruppi di geni appartenenti ai due genitori. Nel
caso piu semplice viene selezionato casualmente un punto di rottura del cro-
mosoma e quindi, in corrispondenza di questo taglio, si ha uno scambio delle
parti omologhe. Tuttavia si possono adottare tecniche piu sofisticate. L’al-
tro operatore genetico responsabile di variazioni nei parametri codificati dal
cromosoma e la mutazione, che consiste nell’effettuare, con una probabilita
pm, una complementazione del valore assunto da un bit in corrispondenza ad
una posizione scelta in modo casuale. Questo operatore interviene sui nuovi
nati.
La parte finale del ciclo comporta la fase di ricambio generazionale du-
rante la quale si deve formare la popolazione da trasmettere alla generazione
successiva, operando una selezione fra gli individui di cui si dispone (genitori
e figli). Questa fase e necessaria per limitare la dimensione della popolazio-
ne di soluzioni che, altrimenti, crescerebbe esponenzialmente con l’evolvere
dell’algoritmo. Esistono in merito diverse soluzioni. La prima costituisce il
metodo di ricambio generazionale classico in cui i genitori lasciano il posto
ai nuovi nati: alla popolazione dei genitori si sostituisce la popolazione dei
figli. La seconda si basa ancora sul ricambio classico ma con l’accorgimen-
to di preservare dalla scomparsa l’esemplare migliore in assoluto, qualora la
nuova popolazione non dovesse contenere nessuna soluzione migliore di esso.
La terza soluzione prevede una selezione naturale tra genitori e figli in base
30

alla qualita di ciascuno di essi, ossia sopravvivono solo gli esemplari migliori.
Un ottimo algoritmo che risolve il problema di taglio bidimensionale con
la tecnica del genetic search e quello realizzato da Beasley [15]. Questo
algoritmo si fonda su una formulazione non lineare del problema.
3.3 Simulated Annealing
Il simulated annealing e una tecnica stocastica che si ispira alla meccanica
statistica per trovare soluzioni per problemi di ottimizzazione sia continua
che discreta. Ricercare il minimo globale di una funzione di costo con molti
gradi di liberta e un problema molto complesso, se questa funzione ammette
un gran numero di minimi locali. Uno degli obiettivi principali dell’ottimizza-
zione e proprio quello di evitare di rimanere intrappolati in un minimo locale.
Questo e uno dei limiti piu grandi delle tecniche di ricerca locale. I metodi
basati sul simulated annealing applicano un meccanismo probabilistico che
consente alla procedura di ricerca di fuggire da questi minimi locali. L’idea
e quella di accettare, in certi casi, oltre alle transizioni che corrispondono a
miglioramenti nella funzione obiettivo, anche quelle transizioni che portano
a peggioramenti nel valore di questa funzione di valutazione. La probabilita
di accettare tali deterioramenti varia nel corso del processo di ricerca, e di-
scende lentamente verso zero. Verso la fine della ricerca, quando vengono
accettati solo miglioramenti, questo metodo diventa una semplice ricerca lo-
cale. Tuttavia, la possibilita di transire in punti dello spazio di ricerca che
deteriorano la soluzione ottima corrente, consente di abbandonare i minimi
locali ed esplorare meglio l’insieme delle soluzioni ammissibili.
La strategia che e alla base del simulated annealing si ispira al processo
fisico di annealing (raffreddamento). Se il sistema si trova all’equilibrio ter-
mico ad una data temperatura T , allora la probabilita nT (s) che esso sia in
una data configurazione s dipende dall’energia dello stato in questione E(s),
e segue la distribuzione di Boltzmann:
nT (s) =e−E(s)/kT∑w e−E(w)/kT
(3.1)
31

dove k e la costante di Boltzmann e la sommatoria si estende a tutti gli
stati possibili w. Fu per primo Metropolis nel 1953 a proporre un metodo
per calcolare la distribuzione di un sistema di particelle all’equilibrio termico
usando un metodo di simulazione al computer. In questo metodo, supposto
che il sistema si trovi in una configurazione q avente energia E(q), si genera
un nuovo stato r, avente energia E(r), spostando una delle particelle dalla sua
posizione: la nuova configurazione viene quindi confrontata con la vecchia.
Se E(r) ≤ E(q) il nuovo stato viene accettato; se E(r) > E(q) esso non viene
respinto, bensı viene accettato con una probabilita pari a:
e−(E(r)−E(q))/kT (3.2)
Secondo questo metodo, esiste dunque una probabilita non nulla di raggiun-
gere stati di piu alta energia, ossia di scavalcare le barriere di energia che
separano i minimi globali dai minimi locali. Si noti che la funzione esponen-
ziale esprime il rapporto tra la probabilita di trovarsi nella configurazione r
e la probabilita di trovarsi in q.
Kirkpatrick utilizzo lo schema del simulated annealing per problemi di
ottimizzazione combinatoria. Per fare cio, sostituı l’energia con una funzione
costo e gli stati di un sistema fisico di particelle con le soluzioni di un pro-
blema di minimizzazione. La perturbazione delle particelle con le soluzioni
diventa allora equivalente ad uno spostamento nello spazio di ricerca verso
un punto che si trova nelle vicinanze della soluzione corrente. La minimiz-
zazione e raggiunta riscaldando dapprima il sistema, e poi raffreddandolo
lentamente fino al raggiungimento della situazione di cristallizzazione in uno
stato stabile. E’ da sottolineare il fatto che per raggiungere configurazioni
di bassa energia non e sufficiente abbassare semplicemente la temperatura; e
necessario, viceversa, attendere per ciascuna temperatura di transizione, un
tempo sufficiente a raggiungere l’equilibrio termico del sistema. Altrimenti,
la probabilita di raggiungere stati di bassa energia e sensibilmente ridotta.
La simulazione del processo di annealing, applicato a problemi di ottimiz-
zazione, richiede diversi passi preparatori. Per prima cosa si devono identifi-
care nel problema di ottimizzazione le analogie con i concetti fisici: l’energia
32

diventa la funzione di costo, le configurazioni di particelle divengono le con-
figurazioni di parametri (variabili decisionali) del problema da ottimizzare,
ricercare uno stato di minima energia significa ricercare una soluzione che
minimizza la funzione di costo, la temperatura diventa un parametro di con-
trollo. Quindi, si deve scegliere un opportuno schema di annealing (cooling
schedule), consistente nella regolazione dei parametri da cui dipende il pro-
cesso di ottimizzazione: si tratta cioe di stabilire la legge di decadimento
della temperatura e la durata del tempo necessario per il raggiungimento
dell’equilibrio termico a ciascuna temperatura. Infine si deve introdurre un
metodo di perturbazione del sistema che consenta di esplorare lo spazio di
ricerca generando nuove configurazioni.
L’algoritmo di annealing descritto da Kirkpatrick consiste nell’esecuzione
ripetuta dell’algoritmo di Metropolis per ciascuna temperatura di transizio-
ne, fino al raggiungimento della configurazione ottima del sistema, ottenuta
in prossimita della temperatura di cristallizzazione prefissata. L’algoritmo
di Metropolis, che accetta configurazioni che incrementano il costo, fornisce
il meccanismo probabilistico che consente di evitare l’intrappolamento nei
minimi locali. Lo schema di principio di un algoritmo basato sul Simulated
Annealing e riportato di seguito.
1. Inizializza C e X.
2. Poni i := 1.
3. Genera Y da X.
4. Se f(Y ) ≤ f(X), poni X := Y .
5. Altrimenti se e−(f(Y )−f(X))/C > random(0, 1), poni X := Y .
6. Incrementa i di 1.
7. Se i == L prosegui, se no torna al punto 3.
8. Riduci il parametro C.
9. Se condizione d’uscita, STOP, altrimenti torna al punto 2.
L’algoritmo parte con l’inizializzazione di X, che rappresenta una possibi-
33

le soluzione, e di C che costituisce il parametro di controllo dell’algoritmo
stesso (equivale alla temperatura nel processo di annealing). Quindi si entra
nel ciclo while da cui si esce solo quando risultera vera la condizione di arresto:
questa situazione si verifica quando si raggiunge una soluzione soddisfacente
o in corrispondenza del raggiungimento della temperatura di congelamento
prefissata per il sistema. Le fasi del ciclo while sono essenzialmente due; nella
prima si entra in un ciclo for, durante la seconda si provvede a diminuire la
temperatura del sistema secondo una legge prefissata che definisce lo sche-
ma di annealing. La prima fase corrisponde all’esecuzione dell’algoritmo di
Metropolis e viene ripetuta L volte (questo e un altro parametro essenzia-
le dello schema di annealing) per il raggiungimento dell’equilibrio termico;
la seconda fase determina la transizione da una temperatura ad un’altra.
Per quanto riguarda il problema della definizione dello schema di annealing,
ovvero della definizione dei parametri di funzionamento, esistono in merito
diverse soluzioni e una gran quantita di studi sono stati dedicati a questo
problema.
Per risolvere il problema di taglio bidimensionale, sono stati sviluppati
alcuni algoritmi euristici che utilizzano una tecnica mista, fondendo simulated
annealing e genetic search, tra questi meritano di essere citati quelli di Lai e
Chan [11], [12] e di Leung et al [13], [14]. In questi algoritmi ogni soluzione
e data da una lista ordinata di pezzi, la quale e trasformata in una sequenza
di tagli da un placement algorithm. Questo algoritmo puo essere, a seconda
dei casi, un bottom-left algorithm o un difference algorithm.
3.4 Ant Colony Optimization
La ant colony optimization (ACO) e una tecnica metaeuristica per problemi
di ottimizzazione, ispirata al sistema di comunicazione delle formiche biolo-
giche. Alcuni ricercatori hanno studiato, in laboratorio, il comportamento
di una colonia di formiche alla quale era dato accesso ad una fonte di ci-
bo (food), partendo dal loro nido (nest), attraverso due percorsi di diversa
lunghezza (Figura 6).
34

Figura 6 Esperimento con vere formiche
Inizialmente le formiche, giunte al bivio, si dividono equamente tra le
due strade, mostrando quindi di fare questa scelta in modo casuale. Dopo
un periodo di transizione di alcuni minuti pero, la maggior parte di esse
scegliera sempre la via piu breve verso il cibo. E’ stato osservato inoltre
che, a regime, la probabilita di scegliere la strada piu breve aumenta con
l’aumentare della differenza di lunghezza tra i due percorsi.
Dorigo ha costruito un modello della funzione di probabilita con la quale
avviene la scelta, al crescere del numero di formiche gia passate. Questo
fenomeno e stato spiegato supponendo che le formiche adottino un sistema
di comunicazione indiretto basato su feromone, una sostanza odorosa che
esse rilasciano sul terreno durante la marcia. Quando si trovano ad un bivio
esse effettuano una scelta probabilistica della strada da prendere, assegnando
una maggiore probabilita alla via con maggiore deposito di feromone. Questo
porta ad un effetto autocatalizzante, per cui le strade piu odorose verranno
scelte con maggiore probabilita, ottenendo sempre piu feromone e diventando
quindi sempre piu attrattive.
Immaginiamo ora due formiche che partano allo stesso momento dal nido
in una condizione di assenza di feromone sul percorso, e supponiamo anche
che prendano due strade diverse al bivio. Quella che ha avuto la fortuna
di scegliere la piu breve fara ritorno al nido per prima, e quindi potra ag-
35

giungere un secondo deposito di feromone sul suo percorso prima dell’altra.
Le successive formiche, quindi, saranno attratte dalla maggiore quantita di
feromone del percorso effettivamente piu breve e, con maggiore probabilita,
sceglieranno quello. Lo stesso avviene se si considera il viaggio di ritorno, dal
cibo verso il nido: raggiunto il bivio la scelta cadra con maggiore probabilita
sulla via che porta al nido, in quanto e stata percorsa da tutte le formiche
indiscriminatamente.
Questo semplice esempio potrebbe suggerire che, in presenza di feromone
al bivio, una scelta deterministica sarebbe migliore, in quanto la soluzione
ottima corrisponde sempre alla via piu odorosa, fin dal passaggio della secon-
da formica. Purtroppo questo e vero solo se non siamo in presenza di minimi
locali. Se invece la strada fosse costituita da un gran numero di passaggi
intermedi, ed incroci con piu di due direzioni possibili, si corre il rischio di
fermarsi a soluzioni solo parzialmente ottime. Il giusto approccio invece e
quello di utilizzare un gran numero di formiche in successione, guidate nella
loro scelta da un algoritmo probabilistico, in modo che vengano esplorate
anche soluzioni che apparentemente sono svantaggiose, ma che globalmente
potrebbero rivelarsi quelle ottime.
Questi concetti possono essere utilizzati nella soluzione di problemi di
ottimizzazione, costruendo una colonia di formiche artificiali che, simulando
l’attivita di ricerca del cibo, ottengano la soluzione ottima al problema. Que-
ste formiche artificiali altro non saranno che degli agenti software, ognuno dei
quali costruira una soluzione parziale del problema (esattamente come ogni
vera formica trova una soluzione parziale al problema del raggiungimento del
cibo), basandosi sull’informazione lasciata dagli agenti che hanno affrontato
il problema in precedenza. Le informazioni generate da ogni agente, durante
il suo cammino di ricerca di una soluzione, sono codificate in depositi di fe-
romone artificiale associato ad ogni percorso attraversato. Questo feromone
permane anche dopo il passaggio dell’agente che lo ha depositato, e verra
percepito da quelli successivi. Lo schema di una procedura che utilizzi l’ant
colony optimization, puo essere rappresentato cosı:
36

1. Inizializza i valori dei feromoni τi.
2. Costruisci una soluzione sa per ogni formica a, utilizzando una tecni-
ca euristica η e tenendo in considerazione il valore del feromeone τ ,
per un dato percorso.
3. Aggiorna i valori dei feromoni τi.
4. Se condizione di termine, STOP, altrimenti torna al punto 2.
Oltre all’attivita dei singoli agenti e possibile avere anche alcune fun-
zionalita esterne: l’evaporazione del feromone e le operazioni centralizzate.
L’evaporazione del feromone e un processo che fa diminuire il valore del de-
posito con il passare del tempo. Questo e necessario per evitare che il sistema
converga troppo in fretta verso soluzioni che non sono ottime, non dando il
tempo agli agenti di esplorare altre soluzioni. Per operazioni centralizzate
si intendono tutti quegli interventi che non sono messi in atto direttamente
dagli agenti, come per esempio l’aggiunta di un deposito extra di feromone
su un particolare percorso che, in un certo momento, sembra essere promet-
tente, oppure la modifica di alcuni parametri di funzionamento degli agenti
in particolari condizioni.
Un problema chiave nella progettazione di algoritmi di tipo ACO e il
bilanciamento tra esplorazione e sfruttamento. Quando gli agenti si muovono
principalmente alla ricerca di zone gia esplorate, quindi con elevati depositi
di feromone, essi sfruttano le esperienze degli agenti precedenti, cercando di
ottenere il miglior risultato finale. Al contrario un movimento principalmente
casuale porterebbe all’esplorazione di nuove zone. Se gli agenti si muovessero
solo in funzione del feromone, dopo poco tutti percorrerebbero sempre la
stessa strada, portandosi ad una condizione di stagnazione. D’altra parte
un comportamento troppo casuale porterebbe alla dispersione del feromone,
rallentando o impedendo la messa in evidenza di una soluzione ottima.
Per ottenere il giusto equilibrio tra questi comportamenti, normalmente
si agisce sul deposito di feromone e sull’influenza che esso ha sugli agenti.
La sua distribuzione infatti determina la probabilita che una soluzione sia
37

visitata o meno. Una tecnica molto usata per evitare l’eccessivo sfruttamento
e quella di fare in modo che la quantita di feromone che un agente deposita sia
proporzionale alla bonta del percorso effettuato. In questo modo si permette
alle nuove strade, se sono migliori delle vecchie, di emergere piu velocemente.
Un algoritmo di tipo ACO che risolve il problema di taglio, e stato
sviluppato da Ducatelle e Levine [26].
3.5 GRASP
La tecnica GRASP (Greedy Randomized Adaptive Search Procedure) e stata
sviluppata da Feo e Resende [16] per risolvere Set Covering Problems ed e
una procedura iterativa in cui ogni iterazione e caratterizzata da due fasi:
• fase costruttiva;
• fase di miglioramento (ricerca locale).
La soluzione migliore trovata durante tutte le iterazioni viene mantenuta co-
me risultato della procedura. Lo pseudocodice della procedura puo essere
rappresentato cosı:
1. Carica i dati iniziali del problema.
2. Inizializza la miglior soluzione trovata (BSF).
3. Poni S = ConstructivePhase().
4. Poni S ′ = ImprovementPhase(S).
5. Se S ′ > SBF poni SBF = S ′.
6. Se condizione di termine, STOP, altrimenti torna al punto 3.
Le condizioni di termine possono essere di diversa natura; la procedura puo
ad esempio terminare qualora sia stato raggiunto il numero massimo di ite-
razioni consentite, oppure sia stata trovata una soluzione il cui valore della
funzione obbiettivo sia uguale all’upper bound calcolato.
38

Durante la ”fase costruttiva” della procedura, viene costruita una soluzio-
ne ammissibile in maniera iterativa aggiungendo un elemento alla volta; ad
ogni iterazione di questa fase la scelta dell’elemento che deve essere aggiun-
to e determinata ordinando, rispetto ad una funzione di tipo greedy, tutti
gli elementi in una lista di ”candidati”. Questa funzione misura il benefi-
cio (miopico) associato alla scelta di ciascun elemento. L’euristica e defini-
ta come adaptive (adattabile) perche i benefici associati ad ogni elemento
sono aggiornati ad ogni iterazione della fase di costruzione per riflettere i
cambiamenti avvenuti in seguito alla selezione dell’elemento nell’iterazione
precedente. La componente probabilistica della procedura si manifesta nella
scelta dell’elemento che ad ogni iterazione deve essere aggiunto per formare
la soluzione; esso e infatti scelto casualmente (randomized) tra i migliori can-
didati nella lista e non e detto quindi che sia il migliore in assoluto. La lista
contenente i migliori ”candidati” che possono essere scelti viene indicata col
termine RCL (Restricted Candidate List) e puo essere fissa oppure variare ad
ogni iterazione seguendo l’andamento di un parametro δ. Questa tecnica di
scelta permette dunque di ottenere soluzioni diverse ad ogni iterazione della
procedura GRASP.
La ”fase di miglioramento”, invece, parte dalla soluzione trovata durante
la fase costruttiva e, attraverso una ricerca locale, esplora il vicinato finche
non viene raggiunto un punto di minimo locale.
Per quanto riguarda la risoluzione del problema di taglio bidimensionale
con l’utilizzo di una tecnica GRASP e da menzionare l’algoritmo realizzato
da Alvarez-Valdes et al [1].
3.6 Tabu Search
Nella ricerca locale classica, ogniqualvolta si esplora il vicinato di una so-
luzione, l’unica informazione relativa alla storia dell’algoritmo fino a quel
momento e la migliore soluzione corrente e il corrispondente valore della
funzione obiettivo.
L’idea della tecnica tabu search e invece quella di mantenere una me-
39

moria di alcune informazioni sulle ultime soluzioni visitate, orientando la
ricerca in modo tale da permettere di uscire da eventuali minimi locali. Piu
precisamente, vedremo che la struttura del vicinato di una soluzione varia
da iterazione a iterazione. Come in tutti gli algoritmi di ricerca locale, se,
nell’esplorazione del vicinato N(x) di una soluzione x, si scopre una solu-
zione migliore dell’ottimo corrente, si ha una transizione su quella soluzione
e si inizia a esplorare quel vicinato. Tuttavia, se la soluzione corrente e un
minimo locale, l’algoritmo di ricerca locale si fermerebbe. E’ chiaro allora
che, per poter sfuggire ai minimi locali, e necessario accettare mosse che pos-
sano portare a un peggioramento della soluzione corrente, pur di spostarsi
sufficientemente lontano dal minimo locale.
Supponendo allora di trovarci in un minimo locale x, dobbiamo anzitutto
scegliere su quale soluzione spostarci, dal momento che nessuna, in N(x),
sara migliore di x. Negli algoritmi di tabu search si fa in genere la scelta di
spostarsi sulla soluzione y ∈ N(x) per la quale e minimo il peggioramento
della funzione obiettivo. A questo punto pero nasce il problema che sta alla
base dell’idea di tabu search. Se ci portiamo sulla soluzione y, ed esploriamo il
suo vicinato, e assai probabile che la migliore soluzione in N(y) risulti essere
proprio x, cioe quella da cui vogliamo viceversa sfuggire. Piu in generale,
dal momento che stiamo permettendo anche mosse che non migliorano la
funzione obiettivo, puo sempre presentarsi il pericolo, anche dopo un certo
numero di mosse, di tornare su una soluzione gia visitata. Ecco allora che
entra in gioco l’uso della memoria.
L’idea e quella di utilizzare le informazioni sulle ultime mosse effettuate
per evitare il pericolo di ciclaggio. Precisamente, mantenendo memoria delle
ultime mosse che hanno portato alla soluzione attuale, sara possibile proibire
quelle mosse per un certo tempo al fine appunto di prevenire ricadute in punti
gia visitati. Dunque, mentre nella ricerca locale si parla di vicinato N(x) di
una soluzione x, nella tabu search possono essere escluse, dall’esplorazione
di N(x), alcune soluzioni, a seconda dell’itinerario seguito per giungere in x.
Diciamo allora che l’insieme delle soluzioni da esplorare dipende, oltre che
dalla soluzione x, anche dall’iterazione k del metodo, ossia il vicinato diviene
40

N(x, k). Per realizzare questo concetto, si fa uso di uno strumento chiamato
tabu list T .
La tabu list e una coda in cui vengono memorizzate le ultime |T | mosse
effettuate. Le mosse opposte a queste, che potrebbero dunque avere l’effet-
to di riavvicinarsi a soluzioni gia visitate, vengono proibite nella situazione
attuale, cioe vengono escluse dal vicinato della soluzione corrente tutte le
soluzioni ottenibili per mezzo di una mossa tabu. Si noti che si potrebbe
pensare di memorizzare direttamente le ultime |T | soluzioni, ma questo puo
essere estremamente poco pratico per problemi di grandi dimensioni. Si pre-
ferisce allora memorizzare direttamente le mosse. La tabu list e una coda,
nel senso che, a ogni passo, la mossa che era nella tabu list da maggior tempo
viene cancellata, e torna a essere quindi ammessa. Anche se il ruolo della
tabu list dovrebbe essere abbastanza chiaro, non e in generale ovvio stabilire
quale debba essere la lunghezza piu appropriata per la tabu list. Infatti,
una tabu list troppo lunga potrebbe inutilmente vincolare il processo di ri-
cerca anche quando la distanza percorsa da una determinata soluzione e gia
sufficientemente elevata da rendere improbabile un ritorno su tale soluzione.
D’altro canto, una tabu list troppo corta puo presentare invece il problema
opposto, cioe potrebbe rendere possibile il ciclaggio. Il valore ottimale della
lunghezza della tabu list varia tipicamente da problema a problema anzi,
talora addirittura da istanza a istanza, ma comunque raramente eccede il
valore dieci.
Rispetto a un algoritmo di ricerca locale, va definito il criterio di arresto,
dal momento che esso non e piu dato dall’evento per cui la funzione obiettivo
non migliora. In pratica si utilizzano i seguenti criteri di arresto:
• il numero di iterazioni raggiunge un valore kmax prefissato;
• il numero di iterazioni dall’ultimo miglioramento della funzione obiet-
tivo raggiunge un valore k′max prefissato;
• e possibile certificare che l’ottimo corrente e l’ottimo globale.
Un ultimo ingrediente di un algoritmo di tabu search nasce dalla seguen-
41

te osservazione. A un generico passo dell’algoritmo, si hanno un insieme di
mosse tabu. Puo pero accadere che la soluzione in cui ci si porterebbe appli-
cando una di queste mosse tabu abbia delle caratteristiche che la rendono in
qualche modo interessante. In tal caso si esegue la mossa, nonostante fosse
nella tabu list. Tali caratteristiche vengono chiamate criteri di aspirazio-
ne. Quello di gran lunga piu utilizzato e quello per cui una mossa tabu puo
essere forzata (overruled) se la soluzione cui essa da luogo ha un valore di
funzione obiettivo migliore dell’ottimo corrente (dunque tra l’altro si tratta
certamente di una soluzione mai visitata).
Un approccio di tabu search puo comprendere molti altri ”accessori”, qua-
li le tabu list di lunghezza variabile nel corso dell’algoritmo, nonche strategie
di diversificazione e di intensificazione della ricerca.
A questo punto possiamo riassumere la struttura di un algoritmo di tabu
search (che come e evidente generalizza la ricerca locale):
1. Scegli una soluzione iniziale x; k := 0 e inizializza la tabu list T = ∅.2. Incrementa il contatore k e genera le soluzioni nel vicinato N(x, k).
3. Trova la soluzione y per cui f(y) (o un’altra funzione f (y)) e minima
con y ∈ N(x, k), y 6= x e che non viola nessun tabu oppure che soddi-
fa un criterio di aspirazione.
4. Se f(y) < f(x), poni x∗ := y.
5. Aggiorna T inserendo la mossa che fa passare da x a y e poni x := y.
6. Se condizione d’uscita, STOP, altrimenti torna al punto 2.
La tabu search e applicabile, in linea di principio, pressoche a qualsiasi
problema di ottimizzazione combinatoria. Tuttavia, alla scelta progettuale
relativa al vicinato (come del resto gia nel caso della ricerca locale) va aggiun-
ta ora quella relativa alla definizione della mossa tabu e alla lunghezza della
tabu list. L’esperienza computazionale mostra che l’elemento piu importante
nell’efficienza di un algoritmo di tabu search e la scelta del vicinato. Una
caratteristica importante di un vicinato e la raggiungibilita della soluzione
42

ottima. Ci si chiede cioe se, data una qualunque soluzione iniziale, esiste
un cammino di soluzioni che, passando da un vicinato all’altro, consente di
raggiungere l’ottimo globale. Non si richiede che l’algoritmo sia in grado ef-
fettivamente di trovarlo (questo dipendera da come vengono scelte le mosse
tabu, dal criterio di arresto etc.), ma solo che con una certa definizione di
vicinato questo sia possibile, almeno in teoria.
Un altro aspetto molto rilevante e la scelta della funzione obiettivo. La
scelta piu naturale ovviamente e quella di usare nell’algoritmo di tabu search
la funzione che si desidera minimizzare. Questa scelta pero non necessa-
riamente e quella piu conveniente. In molti problemi, tipicamente il valore
ottimo e un numero molto basso, e comunque non molto distante dal valore
della soluzione iniziale, se questa e prodotta con una qualsiasi delle euristiche
rapide presenti in letteratura. La conseguenza e che un numero enorme di
soluzioni ammissibili hanno in realta lo stesso valore, e dunque la funzione
obiettivo assai raramente avra dei miglioramenti nel corso dell’algoritmo. La
conseguenza e che l’algoritmo seguira un cammino abbastanza casuale nella
regione ammissibile, dal momento che un numero elevatissimo di direzioni
di ricerca apparirebbero altrettanto appetibili. Si puo allora utilizzare una
funzione obiettivo secondaria f (come indicato al passo 3) legata ovviamente
a quella primaria, ma che consenta di ovviare a questo problema.
Tra gli algoritmi che utilizzano la tecnica del tabu search per la risoluzione
di problemi di taglio bidimensionale va citato quello sviluppato da Alvarez-
Valdes et al [2].
43


Capitolo 4
Sviluppo di un algoritmo
GRASP
Per migliorare i risultati prodotti dall’algoritmo euristico costruttivo, ho de-
ciso di sviluppare un algoritmo di tipo GRASP, per il problema di taglio bi-
dimensionale, non a ghigliottina, seguendo il lavoro svolto da Alvarez-Valdes
et al [1].
4.1 Fase Costruttiva
La fase costruttiva coincide con l’algoritmo costruttivo presentato in prece-
denza, introducendo pero delle procedure di scelta casuale dei pezzi e dei
rettangoli.
Definiamo si lo score di un pezzo i (che puo essere uguale a ei o a vi a
seconda del criterio di ordinamento di P prescelto) e smax = max{si|i ∈ P}.A questo punto si puo scegliere tra tre alternative:
1. Selezionare il pezzo i a caso nell’insieme S = {j|sj ≥ δsmax} dove δ e un
parametro da determinare (0 < δ < 1). S e chiamato anche Restricted
Set of Candidates.
2. Selezionare il pezzo i a caso nell’insieme formato dal 100(1 − δ)% dei
pezzi migliori.
45

3. Selezionare il pezzo i tra tutti quelli di P ma con una probabilita di
essere scelto proporzionale allo score si e pari a pi = si∑
sj.
4.1.1 Scelta del parametro δ
Qualora si opti per l’utilizzo della prima o della seconda alternativa, la scelta
del parametro δ risulta fondamentale per ottenere una buona efficienza del-
l’algoritmo. Un’analisi preliminare dimostra che nessun valore di δ produce
sempre il miglior risultato, percio vengono prese in considerazione diverse
strategie, le quali consistono nel far variare il parametro δ in maniera casuale
o sistematica durante il processo iterativo. Queste strategie di scelta sono:
1. Ad ogni iterazione, scegliere δ a caso nell’intervallo [0.4, 0.9].
2. Ad ogni iterazione, scegliere δ a caso nell’intervallo [0.25, 0.75].
3. Ad ogni iterazione, δ assume a turno uno dei seguenti valori: 0.4, 0.5,
0.6, 0.7, 0.8, 0.9.
4. δ = 0.75.
5. Reactive GRASP
Nel Reactive GRASP, proposto da Prais e Ribeiro [18], δ e inizialmente
scelto a caso da un insieme di valori discreti, ma dopo un certo numero
di iterazioni, la qualita delle soluzioni trovate con ogni valore di δ viene
presa in considerazione e la probabilita associata ai valori di δ che
producono le soluzioni migliori viene incrementata. La procedura e
descritta in dettaglio nella Figura 7, seguendo le indicazioni espresse
da Delorme et al [19]. Il valore di α e fissato a 10, come suggerito da
Prais e Ribeiro [18].
46

Inizializzazione:
D = {0.1, 0.2, ..., 0.9}, insieme dei possibili valori di δ
Sbest = 0; Sworst = ∞nδ∗ = 0, numero delle iterazioni con δ∗,∀δ∗ ∈ D.
Sumδ∗ = 0, somma dei valori delle soluzioni ottenute con δ∗.
P (δ = δ∗) = pδ∗ = 1/|D|,∀δ∗ ∈ D, con pδ∗ probabilita associata a δ∗.
numIter = 0
While (numIter < maxIter)
{Scegli δ∗ da D con probabilita pδ∗
nδ∗ = nδ∗ + 1
numIter = numIter + 1
Applica la Fase Costruttiva ottenendo la soluzione S
Applica la Fase di Miglioramento ottenendo la soluzione S ′
If S ′ > Sbest then Sbest = S ′
If S ′ < Sworst then Sworst = S ′
Sumδ∗ = Sumδ∗ + S ′
If mod(numIter, 100) == 0 (ogni 100 iterazioni):
evalδ =
(Sumδ/nδ−Sworst
Sbest−Sworst
)α
∀δ ∈ D
pδ = evalδ(∑δ′∈D evalδ′
) ∀δ ∈ D
}
Figura 7 Reactive GRASP
4.2 Fase di Miglioramento
La fase di miglioramento parte dalla soluzione ottenuta nella fase costruttiva
e consiste in un tentativo di migliorare la soluzione trovata facendo ricorso
ad una procedura di ricerca locale. Sono possibili tre diverse alternative:
47

1. Si seleziona un blocco adiacente ad un rettangolo vuoto e si prende
in considerazione il fatto di ridurne il numero di pezzi o di eliminarlo
completamente. I pezzi rimanenti sono poi spostati verso gli angoli e i
rettangoli vuoti vengono fusi. A questo punto si applica nuovamente la
fase costruttiva alla nuova lista di rettangoli vuoti, inserendo pero prima
i pezzi a maggiore efficienza ei ed utilizzando per primi i rettangoli vuoti
con area minore (Figura 8). Se la soluzione trovata migliora quella della
fase precedente, il processo va avanti e si prende in considerazione un
nuovo blocco.
Selezione Riduzione Spostamento Riempimento
Figura 8 Metodo I
2. Questa seconda procedura e una semplificazione di quella precedente
in quanto i pezzi non vengono mossi verso gli angoli e i nuovi rettangoli
vuoti sono fusi solamente con rettangoli vuoti adiacenti e gia esistenti
(Figura 9).
Selezione Riduzione Riempimento
Figura 9 Metodo II
3. Il terzo metodo consiste nell’eliminare l’ultimo k% dei blocchi inseriti
(per esempio l’ultimo 10%), spostare i pezzi rimanenti verso gli angoli,
48

fondere i rettangoli vuoti ed applicare ai nuovi spazi creati un algoritmo
costruttivo deterministico come quello proposto da Beltran et al [20]
(vedi Figura 10, in cui i numeri nei pezzi riflettono l’ordine in cui questi
sono stati inseriti durante la fase costruttiva).
Selezione Riduzione Riempimento
Figura 10 Metodo III
4.3 Variazione dei vincoli dei pezzi
Durante il processo iterativo si ottiene la miglior soluzione attuale conosciuta
di valore vbest. E’ possibile utilizzare questo valore per far variare il lower
bound Pi di alcuni pezzi, che devono comparire se si vuole migliorare la solu-
zione, e l’upper bound Qi di alcuni pezzi, la cui inclusione non permetterebbe
di migliorare la soluzione.
4.3.1 Aumento dei lower bound Pi
Definiamo totalpieces =∑m
i vi ∗Qi, il valore totale di tutti i pezzi disponibili;
se c’e un pezzo i con Pi < Qi e totalpieces−(Qi−Pi)∗vi ≤ vbest, una soluzione
con il numero minimo di pezzi Pi non puo migliorare la soluzione vbest. Ogni
soluzione migliore deve includere piu pezzi di i e il relativo Pi deve essere
aumentato. Se calcoliamo t come
max t : totalpieces − t ∗ vi > vbest (4.1)
t ≥ 0, t ≤ Qi − Pi (4.2)
49

il nuovo valore di Pi sara Pi = Qi − t. Questo lower bound migliorato puo
essere utile nella fase costruttiva in cui i pezzi con Pi > 0 sono tagliati per
primi, e nella fase di miglioramento in cui i pezzi che raggiungono il loro
lower bound non sono candidati alla rimozione.
4.3.2 Diminuzione degli upper bound Qi
Definiamo R =∑
Pi>0 Pi ∗ li ∗ wi, l’area totale dei pezzi che devono apparire
per forza in ogni soluzione ammissibile, Rv =∑
Pi>0 Pi ∗ vi, il valore di questi
pezzi e emax = max{ei, i = 1, ...,m}, la massima efficienza dei pezzi. Se c’e
un pezzo i con Qi > Pi e ei < emax che soddisfa la disequazione
Qi ∗ li ∗ wi ∗ (emax − ei) ≥ emax ∗ (L ∗W −R) + Rv − vbest (4.3)
ogni soluzione con Qi copie del pezzo i non puo migliorare la soluzione vbest.
Quindi ogni soluzione migliore dovra avere al massimo un numero di pezzi
di i minore di Qi. Se calcoliamo t come
max t : t ∗ li ∗ wi ∗ (emax − ei) < emax ∗ (L ∗W −R) + Rv − vbest (4.4)
t ≥ 0, t ≤ Qi − Pi (4.5)
il nuovo valore di Qi sara Qi = Pi + t. Questa diminuzione dell’upper bound
puo essere utile in entrambe le fasi, soprattutto se Qi dovesse essere posto
a 0, il pezzo i dovrebbe essere rimosso, favorendo un notevole risparmio
computazionale nella scelta dei pezzi.
4.4 Scelta delle migliori strategie
Prima di implementare l’algoritmo GRASP, e bene sciogliere alcuni nodi ri-
masti in sospeso. Si tratta di scegliere le opzioni migliori tra quelle fornite
nelle varie strategie sopra discusse. Per effettuare questa scelta, ho fatto teso-
ro dell’esperienza computazionale svolta da Alvarez-Valdes et al [1]. Quindi
l’algoritmo GRASP completo dovra utilizzare le seguenti strategie:
50

• Selezione del pezzo: il pezzo che produce il maggior incremento nella
funzione obiettivo.
• Selezione del rettangolo: casuale.
• Procedura di randomizzazione: Restricted Candidate List.
• Selezione del parametro δ: Reactive GRASP.
• Fase di miglioramento: metodo 3 con rimozione del 10% dei pezzi.
• Numero di iterazioni: 10000.
L’algoritmo deve arrestarsi quando ha raggiunto il limite massimo di ite-
razioni oppure quando la soluzione trovata risulti uguale al corrispondente
upper bound.
Stando sempre all’esperienza di Alvarez-Valdes et al, l’incremento dei lo-
wer bound Pi dei pezzi non produce significativi vantaggi sulle performance
dell’algoritmo (e pertanto non verra implementato), mentre l’incremento de-
gli upper bound Qi ha un effetto considerevole, specialmente nei problemi in
cui ci sono differenze notevoli tra le efficienze dei pezzi. In media, piu del
60% dei pezzi sono scartati non appena vengono trovate buone soluzioni.
51


Capitolo 5
Sviluppo di un algoritmo Tabu
Search
Per comparare i risultati ottenuti con l’algoritmo GRASP e per cercare di
migliorarli ulteriormente, ho deciso di sviluppare anche un algoritmo che
utilizzi la tecnica metaeuristica del Tabu Search. Per far cio ho seguito con
attenzione il lavoro svolto da Alvarez-Valdes et al [2]. Gli elementi base
dell’algoritmo sono descritti nelle sezioni seguenti.
5.1 Definizione delle mosse
Lo spazio delle soluzioni, in cui e possibile muoversi, e composto solo da
soluzioni ammissibili. In questo spazio vengono definite diverse mosse per
muoversi da una soluzione ad un’altra. Una soluzione iniziale puo essere
ottenuta attraverso l’applicazione del gia citato algoritmo costruttivo.
Distinguiamo tra due tipi di mosse: una riduzione di un blocco e un in-
serimento di un blocco. Nella riduzione viene ridotta la dimensione di un
blocco esistente, eliminando alcune delle sue righe o colonne. Nell’inserimen-
to, un nuovo blocco e aggiunto alla soluzione. Per entrambe le mosse verra
presentato prima uno schema della procedura e poi un esempio dettagliato.
53

5.1.1 Riduzione di un blocco
La riduzione delle dimensioni di un blocco avviene seguendo i seguenti passi
elementari:
1. Inizializzazione
L=lista dei rettangoli vuoti della soluzione corrente
C=lista dei blocchi della soluzione corrente
2. Scelta del blocco da ridurre
Per prima cosa bisogna scegliere b, uno dei blocchi di C, formato da k
colonne e l righe del pezzo i. Poi va selezionato il numero di colonne
(righe) da eliminare,
1 ≤ r ≤ k (1 ≤ r ≤ l),
mantenendo il numero dei pezzi nella soluzione xi ≥ Pi. Se Pi = 0, il
blocco puo scomparire completamente. Il nuovo rettangolo vuoto R va
aggiunto a L.
3. Spostamento dei blocchi rimanenti verso gli angoli piu vicini
La lista dei rettangoli vuoti L e aggiornata secondo questo criterio.
4. Riempimento dei rettangoli vuoti con nuovi blocchi
A questo punto va applicato l’algoritmo costruttivo partendo dalle com-
posizioni attuali di L e C, e con P contenente i pezzi che possono ancora
essere tagliati e aggiunti alla soluzione corrente. Prima di procedere con
il processo costruttivo, i rettangoli vuoti di L devono essere fusi, per
adattarsi in modo migliore alla lista dei pezzi P .
Quando viene selezionato il nuovo pezzo da tagliare, non deve essere
preso in considerazione il pezzo i del blocco ridotto, finche un altro
pezzo non sia stato incluso nella soluzione modificata.
5. Fusione dei blocchi con la stessa struttura
Infine e necessario provare a fondere blocchi dello stesso pezzo i con
la stessa lunghezza o la stessa larghezza, se sono adiacenti e hanno un
54

lato in comune, oppure se uno di essi puo essere spostato in modo da
renderli adiacenti.
a) selezione b) riduzione
c) movimento agli angoli d) riempimento
Figura 11 Riduzione di un blocco
a) riduzione b) spostamento c) fusione d) riempimento
Figura 12 Rettangoli vuoti nella mossa di riduzione
Nella Figura 11 vediamo un esempio di mossa di riduzione su un’istanza
proposta da Jakobs [23] e usata in seguito da Leung et al [14]. Il rettangolo
base e R = (120, 45), m = 22 e M = 25 pezzi che possono essere tagliati
da esso, riempiendolo completamente. La Figura 11(a) mostra una soluzione
con 23 pezzi nella quale non possono essere inseriti i due pezzi (6, 12). L e
composta da R1 = (60, 24, 72, 30) e R2 = (72, 18, 84, 24) (in grigio chiaro).
55

Per prima cosa un blocco composto da un pezzo (12, 21) viene selezionato e
ridotto, cosı facendo scompare dalla soluzione creando un nuovo rettangolo
vuoto R3 = (72, 24, 84, 45) che viene aggiunto a L (Figura 11(b)). A questo
punto un blocco composto da un pezzo (12, 15) viene mosso verso l’angolo
in alto a destra. Quindi L = {R1, R2, R4, R5} dove R4 = (60, 30, 72, 45) e
R5 = (72, 24, 84, 30) (Figura 11(c)). In seguito l’algoritmo costruttivo riempie
i rettangoli vuoti. Per prima cosa vengono fusi R1 e R4 per formare R6 =
(60, 24, 72, 45), e R2 e R5 per formare R7 = (72, 18, 84, 30). Poi R7 viene
selezionato e riempito completamente con due pezzi (6, 12). Infine R6 viene
riempito con il pezzo eliminato all’inizio. La soluzione finale, che e anche
quella ottima, e mostrata nella Figura 11(d).
5.1.2 Inserimento di un blocco
L’inserimento di un nuovo blocco avviene eseguendo la sequenza di passi
indicata qui sotto:
1. Inizializzazione
L=lista dei rettangoli vuoti della soluzione corrente
C=lista dei blocchi della soluzione corrente
2. Scelta del blocco da inserire
Bisogna prendere un pezzo i con xi ≤ Qi, in modo tale da formare un
blocco con k colonne e l righe (k ∗ l ≤ Qi − xi) di pezzi di tipo i.
3. Selezione della posizione in cui inserire il nuovo blocco
Due strategie sono state prese in considerazione per scegliere la posizio-
ne del nuovo blocco. In entrambi i casi il blocco e posizionato in modo
da ricoprire parzialmente o totalmente uno o piu rettangoli vuoti.
• Per ogni rettangolo vuoto, si considerano le quattro alternative in
cui un angolo del rettangolo e scelto per il corrispondente angolo
del blocco. Se le dimensioni del blocco sono maggiori di quelle
del rettangolo, il blocco puo ricoprire altri blocchi oppure puo
occupare parte di altri rettangoli vuoti.
56

• Si seleziona solo un rettangolo vuoto in modo che, posizionando il
blocco con il suo angolo inferiore sinistro sopra l’angolo inferiore
sinistro del rettangolo, venga massimizzata l’area ricoperta. Per
questo rettangolo vengono considerate le quattro alternative viste
sopra.
4. Rimozione dei pezzi della soluzione che si sovrappongono al blocco in-
serito
Aggiornamento di C (alcuni blocchi vengono ridotti o eliminati)
Aggiornamento di L (nuovi rettangoli vuoti possono comparire)
5. Riempimento dei rettangoli vuoti con nuovi blocchi
6. Fusione dei blocchi con la stessa struttura
Questi ultimi due punti coincidono con gli ultimi due della riduzione
dei blocchi.
Nella Figura 13 vediamo un esempio della seconda strategia di inseri-
mento dei blocchi nei rettangoli. Nella Figura 13(a) due rettangoli vuoti,
in grigio, sono presi in considerazione per l’inserimento del nuovo blocco, in
bianco. Poiche l’area occupata maggiore corrisponde al rettangolo 1, viene
scelto quest’ultimo. Nella Figura 13(b), vengono mostrate le quattro possi-
bili alternative per inserire il nuovo blocco nei corrispondenti quattro angoli
del rettangolo.
a) Scelta del rettangolo b) Possibili posizioni
Figura 13 Selezione della posizione del nuovo blocco
57

a) Soluzione iniziale b) Inserimento
c) Eliminazione sovrapposizioni d) Fusione e riempimento
Figura 14 Inserimento di un blocco
Nella Figura 14 vediamo un esempio dell’utilizzo della mossa di inseri-
mento su un’istanza proposta da Fekete e Schepers [9] e in seguito utilizzata
da Beasley [6]. Il rettangolo base e R = (100, 100), m = 15 e M = 50
pezzi che possono essere tagliati da esso. La Figura 14(a) mostra una so-
luzione di valore z = 27539. La lista dei rettangoli vuoti L e formata da
R1 = (70, 41, 72, 81) e R2 = (72, 80, 100, 81). Per prima cosa viene sele-
58

zionato il pezzo i = 5 di dimensioni (6, 40) con Qi = 5 e solo due copie
nella soluzione attuale, e viene scelto un blocco b formato da un solo pezzo.
In seguito viene posizionato tale blocco sopra R1, sovrapponendo l’angolo
in alto a sinistra del blocco con l’angolo in alto a sinistra del rettangolo.
Il blocco b ricopre completamente R1 e parzialmente R2, il quale diventa
R3 = (76, 80, 100, 81). Il blocco ricopre in parte anche un blocco esistente
(Figura 14(b)). Quindi vengono rimossi i pezzi della soluzione iniziale che
si sovrappongono al nuovo blocco inserito, producendo due nuovi rettangoli
R4 = (76, 40, 78, 80) e R5 = (72, 40, 76, 41) (Figura 14(c)). A questo punto la
procedura di riempimento inizia con L = {R£, R4, R5}. Prima pero R3 e R4
vengono fusi generando R6 = (76, 40, 78, 81) e R7 = (78, 80, 100, 81). Mentre
nessuno dei pezzi poteva entrare in R3 o R4, ora invece un pezzo i = 13 di
dimensione (2, 41) puo essere inserito in R6. La nuova soluzione e migliore
di quella iniziale ed ha un valore z∗ = 27718, ottima per il problema (Figura
14(d)).
5.2 Mosse da esaminare
Ad ogni iterazione vengono esaminate tutte le possibili mosse di riduzione e
inserimento che possono essere applicate alla soluzione corrente.
• Riduzione:
1. Bisogna prendere ogni blocco della soluzione, uno per volta, in
ordine casuale.
2. Vanno considerate tutte le possibilita di riduzione nelle direzioni
adiacenti ai rettangoli vuoti.
• Inserimento:
1. Bisogna selezionare un pezzo per cui il numero di copie xi nella
soluzione e minore di Qi, uno per volta, in ordine casuale.
2. Vanno considerati tutti i blocchi che e possibile costruire con
questo pezzo.
59

3. Vanno considerate tutte le alternative per posizionare il blocco
all’interno di un rettangolo vuoto.
5.3 Selezione della mossa
La funzione obiettivo consiste solo nel massimizzare il valore dei pezzi tagliati
f(x) =∑
i vixi. Tuttavia, se le mosse fossero valutate in accordo con questa
funzione, potrebbero esserci della mosse con la stessa valutazione. Quindi,
in caso di valori uguali della funzione obiettivo, e possibile valutare la mossa
attraverso l’utilizzo di una funzione obiettivo secondaria g(x) = k1S+k2|L|+k3C + k4F .
• S (Simmetria): e preferibile non esplorare soluzioni simmetriche, ma
vengono preferite soluzioni in cui i rettangoli vuoti sono piu concentrati
nella parte destra e in quella in alto del rettangolo base. Se non esiste
una soluzione simmetrica e se i rettangoli vuoti sono concentrati a
destra e in alto, allora S = 1, altrimenti S = 0.
• |L| (Numero dei rettangoli vuoti): se e possibile, vengono preferite
soluzioni in cui il numero di rettangoli vuoti e il piu basso possibile.
• C (Rettangoli vuoti accentrati e concentrati): sono preferibili soluzioni
in cui i rettangoli vuoti sono accentrati e concentrati il piu possibile,
perche in questo modo e piu semplice eseguire fusioni ed ottenere spazi
per nuovi pezzi. Dato ER il piu piccolo rettangolo che contiene tutti i
rettangoli vuoti,
C = 1− (0.75 ∗ rd + 0.25 ∗ ra)
dove rd e la distanza tra il centro di ER e il centro del rettangolo base,
diviso la distanza tra il centro del rettangolo base e il suo angolo in
basso a sinistra, e ra e l’area di ER diviso l’area del rettangolo base.
• F (Ammissibilita). Nei problemi di tipo doubly constrained, la soluzione
iniziale puo non essere ammissibile. In questo caso F = 1, altrimenti
F = 0.
60

Questi criteri sono aggiunti alla funzione obiettivo secondaria con alcuni coef-
ficienti che riflettono la loro relativa importanza, in accordo con i risultati
preliminari ricavati da un sottoinsieme di problemi. In questa implementa-
zione questi fattori assumono i seguenti valori:
Criterio Coefficiente Valore
Simmetria k1 5000
Rettangoli vuoti k2 -950
Rettangoli accentrati k3 50
Ammissibilita k4 -50000
5.4 Tabu list
La tabu list contiene, per ogni soluzione, la seguente coppia di attributi: il
valore della funzione obiettivo e il piu piccolo dei rettangoli ER contenente
tutti i rettangoli vuoti. Una mossa e quindi tabu se questi due attributi della
nuova soluzione coincidono con una delle coppie della tabu list.
La dimensione della tabu list varia in maniera dinamica. Dopo un certo
numero di iterazioni senza migliorare la soluzione, le lunghezza e scelta a
caso nell’intervallo [0.25 ∗M, 0.75 ∗M ], dove M =∑
i Qi.
Il criterio di aspirazione permette di muoversi verso una soluzione tabu
se essa migliora la soluzione ottenuta finora.
5.5 Intensificazione e diversificazione
Le mosse che sono state definite sopra consentono un alto livello di diversifi-
cazione. Tuttavia sono possibili due ulteriori strategie di diversificazione:
• Memoria a lungo termine
Durante il processo di ricerca, viene mantenuta in memoria la frequenza
di ogni pezzo che appare nelle soluzioni. Questa informazione e utiliz-
zata sia per la diversificazione che per l’intensificazione.
61

Quando viene usata la diversificazione, vengono favorite le mosse che
coinvolgono pezzi che non appaiono molto frequentemente nelle solu-
zioni, in modo da favorire l’apparizione di nuovi pezzi.
Quando viene usata per l’intensificazione, vengono considerati solo i
pezzi che corrispondono a soluzioni di alta qualita, in modo da favorire
questi pezzi e far sı che appaiano ancora in nuove soluzioni.
Durante la fase di diversificazione, la funzione obiettivo e modificata
sottraendo un termine che e la somma delle frequenze dei pezzi che
appaiono nelle soluzioni:
f(x) → f(x)−∑
i
freq(pi)
Durante una fase di intensificazione, la funzione obiettivo e modificata
aggiungendo un termine che riflette la frequenza dei pezzi nell’insieme
delle soluzioni d’elite E :
f(x) → f(x) + K∑i∈E
freq(pi)
• Ripartenza
Stando a quanto detto prima a riguardo della funzione obiettivo se-
condaria, vengono preferite le soluzioni che soddisfano il criterio di
simmetria. Dopo un certo numero di iterazioni senza migliorare la mi-
glior soluzione trovata, la soluzione attuale viene sostituita da quella
che si ottiene eseguendo una simmetria orizzontale e una verticale su di
essa. La nuova soluzione ottenuta in questa maniera dovrebbe essere
abbastanza diversa da quelle esaminate di recente ed e assunta come il
nuovo punto di partenza per la ricerca.
5.6 Variazione dei vincoli dei pezzi
La variazione dei lower bound Pi e degli upper bound Qi dei pezzi, per au-
mentare l’efficienza dell’algoritmo, avviene in maniera del tutto identica a
quanto specificato nell’omonima sezione dell’algoritmo GRASP.
62

5.7 Path relinking
Il Path Relinking e un approccio per integrare diversificazione e intensifica-
zione nel contesto del Tabu Search (Glover e Laguna [24]). Questo approccio
genera nuove soluzioni esplorando traiettorie che collegano soluzioni di alta
qualita. Partendo da una di queste soluzioni, chiamata soluzione iniziale,
viene generato un percorso nello spazio delle soluzioni che conduca ad un’al-
tra soluzione, chiamata soluzione guida. Cio e possibile selezionando mosse
che introducano gli elementi della soluzione guida nelle nuove soluzioni.
Durante tutto il processo di ricerca viene mantenuto un insieme di solu-
zioni d’elite, cioe le migliori soluzioni trovate. Per prima cosa vengono prese
queste soluzioni d’elite a coppie: una della due, la soluzione A, viene consi-
derata la soluzione iniziale, mentre l’altra, la soluzione B, viene considerata
la soluzione guida. Poiche l’algoritmo tabu search favorisce le soluzioni con
rettangoli vuoti preferibilmente nella parte in alto a destra del rettangolo
base, entrambe le soluzioni tenderanno ad avere i rettangoli vuoti in questa
zona. Quindi viene applicata una simmetria verticale alla soluzione iniziale
prima di iniziare il processo di Path Relinking.
Seguendo una strategia costruttiva, vengono inseriti i blocchi della solu-
zione B, uno per volta, nella soluzione A. La mossa di inserimento segue la
procedura descritta in precedenza. I pezzi che si sovrappongono al blocco
vengono eliminati, i rimanenti blocchi vengono mossi verso gli angoli del ret-
tangolo base piu vicini, e i rettangoli vuoti che si formano vengono riempiti.
Alla fine del processo, si sara riprodotta la soluzione B, ma durante il percor-
so saranno state generate nuove soluzioni. Quando vengono inseriti i blocchi
della soluzione B, devono essere inseriti per primi i blocchi adiacenti ai lati
del rettangolo base e solo in seguito i blocchi nel centro.
Un esempio del primo passo del Path Relinking appare nella Figura 15.
La soluzione A con il valore 5376, viene selezionata come soluzione iniziale
(Figura 15(a)) mentre la soluzione B con il valore 5352, come soluzione guida
(Figura 15(b)). La simmetria verticale applicata alla soluzione A produce la
soluzione di Figura 15(c). A questo punto un blocco di B viene inserito in
63

essa (Figura 15(d)). I pezzi che si sovrappongono ad esso vengono cancellati
cosı come un pezzo dello stesso tipo del pezzo appena inserito, in modo da
non eccedere Qi. I blocchi rimanenti vengono spostati verso gli angoli piu
vicini, come indicato dalle frecce nella Figura 15(e). Infine gli spazi vuoti
vengono fusi e riempiti con nuovi pezzi, producendo la soluzione di Figura
15(f). Questa soluzione e diversa dalle soluzioni A e B ed ha valore 5395.
a) Soluzione A: 5376 b) Soluzione B: 5352 c) Simmetria su A
d) Inserimento blocco di B e) Eliminazione sovrapposizioni f) Fusione e riempimento
Figura 15 Path Relinking - Istanza 2 da Jaboks [23]
64

5.8 Scelta delle migliori strategie
Anche in questo caso, prima di implementare l’algoritmo Tabu Search e utile
impostare le varie strategie in modo da ottenere i risultati migliori. Tenendo
in considerazione il lavoro svolto da Alvarez-Valdes et al [2] ho deciso di
utilizzare le seguenti strategie:
• Tabu list dinamica: variazione delle dimensioni dopo 100 iterazioni in
cui non si migliora la soluzione.
• Diversificazione: si effettua dopo 100 iterazioni senza miglioramenti, e
si esegue per le successive 100 iterazioni (o finche non si migliora la
soluzione).
• Intensificazione: si effettua dopo 100 iterazioni senza miglioramenti, e
si esegue per le successive 100 iterazioni (o finche non si migliora la
soluzione), con K = 100 e considerando un’elite composta dalle 10
migliori soluzioni.
• Ripartenza: se al termine delle fasi di diversificazione e intensificazione
non si e migliorata la soluzione, si eseguono una simmetria verticale e,
contemporaneamente, una orizzontale.
• Scelta del rettangolo nella mossa di inserimento: se il problema e
unweighted si utilizza il metodo 1, altrimenti si ricorre al metodo 2.
• Numero di iterazioni: 1500.
Anche in questo caso l’algoritmo deve fermarsi non appena viene raggiunto
il limite massimo di iterazioni, o quando la soluzione sia uguale al corrispon-
dente upper bound.
Per quanto riguarda la variazione dei vincoli dei pezzi, anche per l’algorit-
mo Tabu Search si e scelto di implementare solo la procedura che permette la
diminuzione degli upper bound Qi, poiche e l’unica che garantisce significativi
miglioramenti.
65

Cosı come si e deciso di non implementare la procedura di Path Relin-
king poiche anche quest’ultima non riuscirebbe a migliorare le prestazioni
dell’algoritmo.
66

Capitolo 6
Implementazione
Per l’implementazione degli algoritmi euristici descritti in precedenza, mi
sono avvalso del linguaggio di programmazione C che, grazie alle sue poten-
zialita e alla sua modularita, ben si adatta alla realizzazione degli algoritmi,
rendendo possibile un ampio riutilizzo del codice. Dato che il C e un lin-
guaggio ”compilato”, e possibile ottenere ottimi risultati in termini di tempi
computazionali.
6.1 Strutture dati
Le strutture dati complesse, presenti nell’algoritmo, sono principalmente tre:
i pezzi da tagliare, i rettangoli vuoti e i blocchi inseriti. A queste tre poi se
ne aggiungono altre secondarie utilizzate solo nell’algoritmo Tabu Search e
definite in dettaglio in seguito. Per tutte quante si e deciso di utilizzare una
delle strutture dati del linguaggio C, ovvero la lista lineare. La lista lineare e
una successione di elementi omogenei che occupano in memoria una posizione
qualsiasi. Ciascun elemento contiene una o piu informazioni e un puntatore
all’elemento successivo. L’accesso alla lista avviene con il puntatore al primo
elemento.
Elemento = informazioni + puntatore
67

6.1.1 Lista dei pezzi P
La lista dei pezzi P comprende, oltre all’indice i che identifica il pezzo, anche
la lunghezza l, la larghezza w, il lower bound P , l’upper bound Q, il valore v
e l’efficienza e. Pertanto, la struttura che definisce tale lista e:
1 struct pezzo{2 int i;
3 int l;
4 int w;
5 int P;
6 int Q;
7 int v;
8 double e;
9 struct pezzo *pun;
10 };
E’ da notare come tutti i dati siano int, mentre l’efficienza puo assumere un
valore non intero ed e pertanto stata rappresentata tramite un double.
6.1.2 Lista dei rettangoli L
Un rettangolo vuoto e identificato dalle coordinate (x, y) rispettivamente
dell’angolo in basso a sinistra e dell’angolo in alto a destra. Pertanto la lista
dei rettangoli L e definita come:
1 struct rettangolo{2 int x1;
3 int y1;
4 int x2;
5 int y2;
6 struct rettangolo *pun;
7 };
68

6.1.3 Lista dei blocchi C
Un blocco, invece, e caratterizzato oltre che dalle coordinate degli angoli,
come i rettangoli, anche dall’indice i e dal valore v del pezzo che lo compone,
nonche dal numero k dei pezzi per colonna e dal numero l dei pezzi per riga.
Quindi, la lista dei blocchi C e cosı costituita:
1 struct blocco{2 int i;
3 int x1;
4 int y1;
5 int x2;
6 int y2;
7 int v;
8 int k;
9 int l;
10 struct blocco *pun;
11 };
6.1.4 Lista delle soluzioni d’elite E
Gli elementi che compongono la lista delle soluzioni d’elite sono formati dal
valore di una soluzione v e dalla lista dei blocchi b, generata da tale soluzione:
1 struct elite{2 int v;
3 struct blocco *b;
4 struct elite *pun;
5 };
69

6.1.5 Lista dei tabu T
La tabu list e composta da coppie formate dal valore di una soluzione v e
dal piu piccolo rettangolo ER in grado di contenere tutti i rettangoli vuoti
generati da tale soluzione. Il rettangolo ER e identificato ovviamente dalla
quadrupla (x1, y1, x2, y2):
1 struct tabu{2 int v;
3 int x1;
4 int y1;
5 int x2;
6 int y2;
7 struct tabu *pun;
8 };
6.1.6 Lista delle frequenze dei pezzi F
La lista delle frequenze tiene conto di quante volte un pezzo entra a far parte
di una soluzione. Quindi gli elementi di tale lista saranno formati dall’indice
i di un pezzo e dal numero di occorrenze n:
1 struct frequenza{2 int i;
3 int n;
4 struct frequenza *pun;
5 };
6.2 Caricamento dei dati iniziali
Il caricamento dei dati avviene attraverso l’utilizzo di un file di testo. Tale
file deve essere realizzato seguendo obbligatoriamente lo schema seguente:
70

N
n1
L1 W1
l1 w1 P1 Q1 v1. . . ln wn Pn Qn vn...
nN
LN WN
l1 w1 P1 Q1 v1. . . ln wn Pn Qn vn
dove N e il numero di problemi presenti nel file, ni, Li e Wi sono rispet-
tivamente il numero di pezzi dell’istanza, la lunghezza e la larghezza del
rettangolo base, e lj, wj, Pj, Qj e vj sono la lunghezza, la larghezza, il lower
bound, l’upper bound e il valore di un singolo pezzo.
6.3 Schema dell’algoritmo GRASP
Per realizzare l’algoritmo GRASP ho utilizzato una metodologia di tipo top-
down: partendo dallo schema generale dell’algoritmo, ho implementato man
mano le varie funzioni, sintetizzando prima quelle principali e proseguendo
poi con quelle secondarie. Tale schema e rappresentato qui di seguito:
1 void main()
2 {3 apriFile();
4 for (int index = 1; index <= problemi; index++){5 caricaDatiProblema();
6 inizializzaParametri();
7 ub = upperBound();
8 while (numIter < maxIter){9 numIter++;
10 S0 = randomConstructive();
71

11 S1 = improvement();
12 if (!isFeasible(P))
13 continue;
14 if (S1 > Sbest){15 Sbest = S1;
16 salvaSoluzioneMigliore(P, L, C);
17 if (Sbest == ub)
18 break;
19 decreasingQi(P);
20 }21 if (S1 < Sworst)
22 Sworst = S1;
23 nDelta[iDelta]++;
24 sumDelta[iDelta] = sumDelta[iDelta] + S1;
25 if ((numIter % 100) == 0){26 denom = Sbest - Sworst;
27 totalEval = 0;
28 for (int j = 0; j < 9; j++){29 mean = sumDelta[j] / nDelta[j];
30 numer = mean - Sworst;
31 evalDelta[j] = pow(numer / denom, alfa);
32 totalEval = totalEval + evalDelta[j];
33 }34 for (int j = 0; j < 9; j++)
35 probDelta[j] = evalDelta[j] / totalEval;
36 }37 }38 visualizzaRisultati();
39 eliminaListe();
40 }41 chiudiFile();
42 }
72

Dallo schema si evince che l’algoritmo GRASP consiste nell’esecuzione rei-
terata delle fasi costruttiva (nella sua versione randomConstructive) e di
miglioramento (improvement). Al termine di queste fasi, se la soluzione e
ammissibile (isFeasible), si confronta il risultato ottenuto con il migliore a
disposizione; se questo e maggiore, la nuova soluzione trovata viene salvata
(salvaSoluzioneMigliore) e, se quest’ultima ha un valore uguale all’upper
bound, l’algoritmo termina all’istante.
In questa parte dell’algoritmo vengono aggiornati anche parametri come
la somma delle soluzioni ottenute con un dato fattore δ (sumDelta) e il
numero di iterazioni in cui si e fatto ricorso a tale valore di δ (nDelta). Infine,
ogni 100 iterazioni, avviene l’aggiornamento delle probabilita (probDelta)
associate all’utilizzo dei valori ammissibili di δ.
6.4 Funzioni dell’algoritmo GRASP
int randomConstructive()
La funzione randomConstructive e la funzione cardine di tutto l’algoritmo
GRASP e coincide con la prima fase, quella costruttiva. Per prima cosa viene
scelto il valore del parametro δ tenendo conto delle probabilita associate ai
suoi possibili valori, poi si definisce la soglia tra i valori dei pezzi e viene
costruita la Restricted Candidate List (creaRCL).
A questo punto, finche esiste un pezzo in grado di entrare in uno qualun-
que dei rettangoli vuoti si procede col selezionare in maniera casuale (rand)
sia il pezzo da tagliare che il rettangolo vuoto. Se il pezzo non puo essere
inserito nel rettangolo (fill), vengono selezionati un pezzo e un rettangolo
nuovi, sempre in maniera casuale. Se il pezzo, invece, e in grado di entrare
nel rettangolo, si procede scegliendo, sempre in maniera casuale, sia il nume-
ro di colonne, che il numero di righe del pezzo che formeranno il blocco da
tagliare, sempre pero rispettando il limite Qi.
Quindi, si prosegue scegliendo l’angolo del rettangolo vuoto in cui inserire
73

il blocco, per la precisione si sceglie quello con distanza (distanza) minima
dal corrispettivo angolo del rettangolo base (distanzaMin). Fatto questo
si procede con la rimozione del rettangolo utilizzato (rimuoviRettangolo),
con l’inserimento del blocco nella lista dei blocchi (aggiungiBlocco), con
l’inserimento di uno o piu rettangoli vuoti (aggiungiRettangolo) e con il
modificare i parametri Pi e Qi del pezzo (se Qi = 0, il pezzo viene rimos-
so con rimuoviPezzo). Infine si procede con l’eseguire tutte le fusioni che
migliorano l’inserimento dei pezzi (merge). Quando non ci sono piu pezzi
in grado di essere tagliati, la procedura termina restituendo il valore della
soluzione trovata.
int improvement()
La funzione improvement realizza la fase di miglioramento discussa in pre-
cedenza. Per prima cosa vengono rimossi dalla lista dei blocchi il k% di essi
(rimuoviBlocco), poi viene aggiornata la lista dei pezzi, aggiungendo quelli
appena ripristinati (aggiungiPezzo), e poi vengono inseriti i rettangoli vuo-
ti generati dalla rimozione dei blocchi. In seguito vengono ordinati i pezzi
secondo i criteri espressi in precedenza (ordinaPezzi) e vengono valutate
tutte le fusioni tra i rettangoli. Infine viene eseguito l’algoritmo costrutti-
vo classico (constructive) che termina con la restituzione del nuovo valore
della soluzione.
struct pezzo *creaRCL(double soglia, struct pezzo *p)
Restituisce la lista dei pezzi composta solamente da quei pezzi con Pi > 0 o
con vi ≥ soglia (Restricted Candidate List).
int vMax(struct pezzo *p)
Restituisce il piu grande tra tutti i valori v dei pezzi.
74

6.5 Schema dell’algoritmo Tabu Search
Anche nel caso dell’algoritmo Tabu Search ho utilizzato una metodologia di
tipo top-down in cui, partendo da uno schema generale, ho implementato di
volta in volta le varie funzioni, partendo da quelle principali e proseguendo
con quelle secondarie. Poiche le funzioni dell’algoritmo GRASP sono state
sviluppate sapientemente in maniera generale, e stato possibile riutilizzare un
gran numero di queste funzioni, cosı com’erano, anche nell’algoritmo Tabu
Search. Lo schema generale e cosı definito:
1 void main()
2 {3 apriFile();
4 for (int index = 1; index <= problemi; index++){5 caricaDatiProblema();
6 inizializzaParametri();
7 ub = upperBound();
8 S = constructive();
9 Start = S;
10 Sbest = S;
11 salvaSoluzioneIniziale(P, L, C);
12 salvaSoluzioneMigliore(P, L, C);
13 tabuList = aggiungiTabu(S, creaER(L), tabuList);
14 frequenze = inizializzaFrequenza(P);
15 while (numIter < maxIter){16 numIter++;
17 valutaRiduzione();
18 valutaInserimento();
19 salvaSoluzioneIniziale(P, L ,C);
20 frequenze = aggiornaFrequenza(C, frequenze);
21 if (numIter < numElite)
22 aggiungiSoluzioneElite(C, S, E);
75

23 else
24 sostituisciSoluzioneElite(C, S, E);
25 if (nTabu < nTabuMax){26 nTabu++;
27 tabuList = aggiungiTabu(S, creaER(L), tabuList);
28 }29 else{30 rimuoviTabu(tabuList);
31 aggiungiTabu(S, creaER(L), tabuList);
32 }33 if (Sstart > Sbest){34 numIterNotImpl = 0;
35 diversification = 0;
36 intensification = 0;
37 Sbest = Sstart;
38 salvaSoluzioneMigliore(P, L, C);
39 decreasingQi(P);
40 }41 else{42 numIterNotImpl++;
43 if ((numIterNotImpl % 100) == 0)
44 tabuList = modificaDimensioniTabuList(tabuList);
45 if ((numIterNotImpl % 400) == 0)
46 diversification = 1;
47 if ((numIterNotImpl % 400) == 0)
48 intensification = 1;
49 if ((numIterNotImpl % 500) == 0){50 diversification = 0;
51 intensification = 0;
52 restartingL(L);
53 restartingC(C);
54 }
76

55 }56 }57 visualizzaRisultati();
58 eliminaListe();
59 }60 chiudiFile();
61 }
Dallo schema si vede come l’algoritmo Tabu Search inizi con l’applicazione
dell’algoritmo costruttivo (constructive) e con il salvataggio della soluzione
trovata (salvaSoluzioneMigliore e salvaSoluzioneIniziale).
A questo punto inizia un processo iterativo in cui vengono valutate tutte
le mosse che e possibile eseguire tra quelle di riduzione (valutaRiduzione)
e di inserimento (valutaInserimento). La mossa che e ritenuta la miglio-
re viene eseguita e, dalla soluzione cosı trovata, si riparte per la prossima
iterazione. Quindi viene inserita (nel rispetto delle dimensioni nTabuMax
della tabu list) la mossa effettuata, tra quelle tabu (aggiungiTabu). Poi
vengono aggiornate le frequenze dei pezzi (aggiornaFrequenza) e viene va-
lutato se la soluzione trovata e meritevole di entrare tra le soluzioni di elite
(aggiungiSoluzioneElite).
Se la nuova soluzione iniziale e maggiore di quella attuale, quest’ultima
viene sostituita (se e uguale all’upper bound, l’algoritmo termina). Altrimen-
ti, se non c’e un miglioramento della soluzione, viene valutato il numero di
iterazioni da cui non si ottiene un miglioramento (numIterNotImpl) e, se
questo numero e multiplo di 100, viene variata la dimensione della tabu li-
st (modificaDimensioniTabuList). Se non si verificano miglioramenti da
400 iterazioni, vengono ”attivate” le fasi di diversificazione e intensificazione
che provvedono ad alterare il valore della funzione obiettivo. Qualora do-
po ulteriori 100 iterazioni, la soluzione non dovesse essere ancora migliorata,
vengono interrotte le fasi di diversificazione e intensificazione e viene eseguita
un’operazione di ripartenza sulla lista dei blocchi (restartingC) e sulla lista
dei rettangoli vuoti (restartingL).
77

6.6 Funzioni dell’algoritmo Tabu Search
void valutaRiduzione()
La funzione esegue tutte le possibili riduzioni dei blocchi esistenti. Per far
questo, vengono selezionati a turno tutti i blocchi, finche non si giunge al-
la fine della lista, e se questo blocco e adiacente ad un rettangolo vuoto
(isAdjacent) si esegue la riduzione (reduction) valutando tutte le possibili
combinazioni di righe e colonne, da entrambe le direzioni: sinistra e destra
per le colonne, e alto e basso per le righe. Al termine della riduzione, si
valuta la mossa eseguita (valutaMossa) e si prosegue con quella successiva.
void valutaInserimento()
La funzione esegue tutti i possibili inserimenti di blocchi. Per prima cosa ven-
gono selezionati tutti i pezzi della lista, uno alla volta, finche non si raggiunge
il termine. Di questo pezzo vengono valutate, a turno, tutte le sue possibili
combinazioni di righe e colonne. Per ognuna di queste combinazioni si prova
ad inserire il blocco (insertion) in tutti i rettangoli (nel caso di problemi di
tipo unweighted), oppure solamente nel rettangolo con area comune massima
(bestRettangolo), posizionandolo alternativamente, se possibile, in tutti e
quattro gli angoli. Una volta eseguito l’inserimento, viene valutata la mossa
appena effettuata (valutaMossa) e si passa a quella successiva.
void reduction(int i, int k, int l)
La funzione riduce di k colonne e l righe un blocco di indice i. Per far questo
modifica i relativi indici del blocco (o lo rimuove totalmente nel caso fosse
stato selezionato per intero per la riduzione) e aggiunge i pezzi rimossi e i
rettangoli vuoti che si vengono a formare, alle relative liste. A questo pun-
to vengono eseguiti un ordinamento dei pezzi e una fusione dei rettangoli.
Infine, viene applicato l’algoritmo costruttivo alla configurazione attuale dei
blocchi, in seguito alla riduzione.
78

void insertion(int i, int k, int l, int x1, int y1, int x2,
int y2)
La funzione si occupa di inserire un blocco formato da pezzi di indice i e
composto da k colonne e l righe nella posizione indicata. Per far cio, oltre
a inserire il nuovo blocco, vengono rimossi tutti i blocchi e i rettangoli esi-
stenti che si sovrappongono al nuovo blocco e vengono inseriti anche i nuovi
rettangoli che si formano di conseguenza. Alla termine di tutto cio, vengono
eseguiti un’ordinamento sui pezzi e una fusione sui rettangoli. Per finire, si
esegue l’algoritmo costruttivo sulla nuova configurazione.
void valutaMossa()
La funzione valuta la mossa appena effettuata prendendo in considerazione
la funzione obiettivo primaria, quella secondaria, la tabu list, la diversifica-
zione, l’intensificazione e il criterio di aspirazione. Ovvero, viene valutata
positivamente solo la mossa che presenta un valore piu alto della funzione
obiettivo primaria (in caso di parita, conta la funzione obiettivo secondaria)
rispetto alle altre mosse, a meno che tale mossa non sia inserita nella tabu
list, ma se la soluzione ha un valore maggiore della miglior soluzione fino a
quel momento trovata, si ignora la tabu list. Se sono ”attive” le fasi di inten-
sificazione e diversificazione, la funzione obiettivo primaria e modificata dai
relativi parametri. In caso di valutazione positiva, la soluzione trovata con
l’esecuzione della mossa e candidata ad essere la nuova soluzione di partenza
a partire dall’iterazione successiva.
void salvaSoluzioneIniziale(struct pezzo *p, struct
rettangolo *r, struct blocco *b)
Provvede a salvare la nuova soluzione iniziale, sostituendo le liste dei pezzi,
dei rettangoli e dei blocchi della vecchia soluzione iniziale, con quelle nuove
passate come parametro.
79

struct tabu *aggiungiTabu(int v, struct rettangolo *r, struct
tabu *t)
Aggiunge un elemento (formato dal valore della soluzione e dal relativo ret-
tangolo ER) in coda alla tabu list.
struct tabu *rimuoviTabu(struct tabu *t)
Rimuove il primo elemento della tabu list in modo da gestirla come una coda
e rispettare la politica di tipo FIFO.
struct blocco *unisciBlocchi(struct blocco *b)
Provvede ad unire i blocchi formati da insiemi degli stessi pezzi se tali blocchi
sono adiacenti e con un lato in comune, oppure se possono essere congiunti
mediante un semplice spostamento.
struct rettangolo *creaER(struct rettangolo *r)
Restituisce il rettangolo di dimensioni minime, in grado di racchiudere al suo
interno tutti i rettangoli vuoti presenti nella lista passata come parametro.
struct elite *aggiungiSoluzioneElite(struct blocco *b, int
valore, struct elite *e)
Aggiunge alle soluzioni di elite quella formata dalla lista di blocchi e dal rela-
tivo valore totale, passati come parametri. Le soluzioni di elite sono ordinate
per valore della soluzione crescente.
struct elite *sostituisciSoluzioneElite(struct blocco *b, int
valore, struct elite *e)
Se la soluzione passata come parametro e migliore di quella in testa alla lista
delle soluzioni di elite (quella con valore minore), quest’ultima viene sosti-
tuita.
80

void restartingL(struct rettangolo *r)
Esegue una simmetria verticale e, contemporaneamente, una orizzontale sul-
la lista dei rettangoli vuoti.
void restartingC(struct blocco *b)
Esegue una simmetria verticale e, contemporaneamente, una orizzontale sul-
la lista dei blocchi.
double secondaryObjective(struct pezzo *p, struct rettangolo *r)
Calcola il valore della funzione obiettivo secondaria, a partire dalla lista dei
pezzi ancora da tagliare e da quella dei rettangoli vuoti.
int isTabu(struct tabu *t, int valore, struct rettangolo *ER)
Restituisce ”1” se il valore della soluzione e il rettangolo ER passati come
parametro coincidono con un elemento della tabu list, ”0” altrimenti.
int tabuMax(struct pezzo *p)
Calcola, in maniera casuale, la dimensione massima della tabu list in modo
che risulti compresa tra il 25% e il 75% di M , dove M =∑
i Qi.
struct rettangolo *bestRettangolo(int l, int w, struct
rettangolo *r)
Restituisce il rettangolo che ha la piu alta sovrapposizione, in termini di su-
perficie, con il blocco da inserire di dimensioni (l, w).
struct frequenza *inizializzaFrequenza(struct pezzo *p)
Crea una lista di frequenza con tanti elementi (tutti inizializzati a 0) quanti
81

quelli della lista di pezzi passata come parametro.
struct frequenza *aggiornaFrequenza(struct blocco *b, struct
frequenza *f)
Aggiorna le frequenze dei pezzi aggiungendo quante volte ogni singolo pezzo
compare nella lista dei blocchi passata come parametro.
double valoreFrequenza(struct blocco *b, struct frequenza *f,
int num)
Calcola il valore totale delle frequenze dei pezzi che compaiono nella lista dei
blocchi passata come parametro, diviso per il numero di occorrenze num.
struct tabu *modificaDimensioniTabuList(struct tabu *t)
Provvede a generare a caso la nuova dimensione della tabu list e, se questa e
inferiore alla precedente, rimuove gli elementi in esubero.
6.7 Funzioni comuni ai due algoritmi
int constructive()
La funzione constructive e la funzione che realizza l’algoritmo costruttivo.
Per prima cosa viene ordinata la lista dei pezzi in base ai gia citati criteri
(ordinaPezzi). A questo punto, finche esiste un pezzo in grado di entrare
in uno qualunque dei rettangoli vuoti si procede selezionando il pezzo da
tagliare, scandendo la lista ordinata, e scegliendo il rettangolo vuoto di area
minima. Se il pezzo non puo entrare nel rettangolo (fill), si procede sele-
zionando il pezzo successivo. Se il pezzo, invece, puo essere contenuto nel
rettangolo, si procede individuando in maniera casuale, sia il numero di co-
82

lonne, che il numero di righe del pezzo che formeranno il blocco da tagliare,
rispettando pero il limite Qi.
Quindi, si prosegue scegliendo l’angolo del rettangolo vuoto in cui inserire
il blocco, per la precisione si sceglie quello con distanza (distanza) minima
dal corrispettivo angolo del rettangolo base (distanzaMin). Fatto questo
si procede con la rimozione del rettangolo utilizzato (rimuoviRettangolo),
con l’inserimento del blocco nella lista dei blocchi (aggiungiBlocco), con
l’inserimento di uno o piu rettangoli vuoti (aggiungiRettangolo) e con il
modificare i parametri Pi e Qi del pezzo (se Qi = 0, il pezzo viene rimosso con
rimuoviPezzo). Infine si procede con l’eseguire tutte le fusioni che migliorano
l’inserimento dei pezzi (merge).
Quando si giunge in coda alla lista dei pezzi, si seleziona il rettangolo
successivo e ci si riposiziona in testa alla lista dei pezzi. Quando non ci sono
piu pezzi in grado di essere tagliati, la procedura termina restituendo il valore
della soluzione trovata.
void visualizzaP(struct pezzo *p)
Visualizza la lista dei pezzi P , passata come parametro, stampandola a video
nella forma P = {i1, i2, . . . , in}.
void visualizzaL(struct rettangolo *r)
Visualizza la lista dei rettangoli L, passata come parametro, stampandola a
video nella forma L = {(x11, y11, x21, y21), . . . , (x1n, y1n, x2n, y2n)}.
void visualizzaC(struct blocco *b)
Visualizza la lista dei blocchi C, passata come parametro, stampandola a vi-
deo nella forma C = {i1 (x11, y11, x21, y21), . . . , in (x1n, y1n, x2n, y2n)}.
struct pezzo *ordinaPezzi(struct pezzo *p)
Restituisce la lista dei pezzi P , ordinandola secondo i tre criteri espressi nella
83

sezione 2.1.1. Per far cio utilizza le tre funzioni che seguono.
struct pezzo *ordinaPezziPerPi(struct pezzo *p)
Restituisce la lista dei pezzi P , ordinandola per Pi ∗ li ∗ wi decrescenti.
struct pezzo *ordinaPezziPerEi(struct pezzo *p)
Restituisce la lista dei pezzi P , ordinandola per ei decrescenti.
struct pezzo *ordinaPezziPerVi(struct pezzo *p)
Restituisce la lista dei pezzi P , ordinandola per vi decrescenti.
struct pezzo *aggiungiPezzo(int i, int l, int w, int P, int Q,
int v, struct pezzo *p)
Aggiunge un pezzo in coda alla lista dei pezzi passata come parametro. Se
l’indice i del pezzo esiste gia, vengono modificati solo il lower bound Pi e
l’upper bound Qi.
struct rettangolo *aggiungiRettangolo(int x1, int y1, int x2,
int y2, struct rettangolo *r)
Aggiunge un rettangolo alla lista dei rettangoli passata come parametro, or-
dinata per area crescente, mantenendone l’ordinamento.
struct blocco *aggiungiBlocco(int i, int x1, int y1, int x2,
int y2, int k, int l, int v, struct blocco *b)
Aggiunge un blocco in coda alla lista di blocchi passata come parametro.
struct pezzo *rimuoviPezzo(int i, struct pezzo *p)
Rimuove, liberando la memoria, il pezzo (se esiste) di indice i presente nella
84

lista p.
struct rettangolo *rimuoviRettangolo(int x1, int y1, int x2,
int y2, struct rettangolo *r)
Rimuove, liberando la memoria, il rettangolo (se esiste) di coordinate (x1, y1)
e (x2, y2), presente nella lista r.
struct blocco *rimuoviBlocco(int x1, int y1, int x2, int y2,
struct blocco b*)
Rimuove, liberando la memoria, il blocco (se esiste) di coordinate (x1, y1) e
(x2, y2), presente nella lista b.
void eliminaPezzi(struct pezzo *p)
Rimuove, liberando la memoria, tutti i pezzi presenti nella lista passata come
parametro.
void eliminaRettangoli(struct rettangolo *r)
Rimuove, liberando la memoria, tutti i rettangoli presenti nella lista passata
come parametro.
void eliminaBlocchi(struct blocco *b)
Rimuove, liberando la memoria, tutti i blocchi presenti nella lista passata
come parametro.
int contaPezzi(struct pezzo p*)
Restituisce il numero di pezzi presenti nella lista p.
int contaRettangoli(struct rettangolo *r)
85

Restituisce il numero di rettangoli presenti nella lista r.
int contaBlocchi(struct blocco *b)
Restituisce il numero di blocchi presenti nella lista b.
struct pezzo *selezionaPezzo(int i, struct pezzo *p)
Seleziona il pezzo di indice i e ne restituisce il riferimento.
struct rettangolo *selezionaRettangolo(int i, struct
rettangolo *r)
Seleziona il rettangolo di indice i e ne restituisce il riferimento.
struct blocco *selezionaBlocco(int i, struct blocco *b)
Seleziona il blocco di indice i e ne restituisce il riferimento.
struct pezzo *copiaPezzi(struct pezzo *p)
Restituisce una copia dell’intera lista dei pezzi passata come parametro.
struct rettangolo *copiaRettangoli(struct rettangolo *r)
Restituisce una copia dell’intera lista dei rettangoli passata come parametro.
struct blocco *copiaBlocchi(struct blocco *b)
Restituisce una copia dell’intera lista dei blocchi passata come parametro.
struct rettangolo *merge(struct rettangolo *r, struct pezzo *p)
Valuta ed esegue tutte le fusioni tra i rettangoli vuoti adiacenti utilizzando
i criteri espressi nella sezione 2.1.4, e per far cio necessita, oltre che della
lista dei rettangoli da fondere, anche di quella dei pezzi ancora da tagliare
86

ordinata secondo il criterio migliore.
double distanza(double x1, double y1, double x2, double y2)
Restituisce la distanza, in valore assoluto, tra due punti (x1, y1) e (x2, y2).
double distanzaMin(double bl, double br, double tl, double tr)
Restituisce la distanza minima tra le quattro passate come parametro che
corrispondono alle distanze tra i quattro angoli di un rettangolo vuoto e i
corrispettivi angoli del rettangolo base (bottom-left, bottom-right, top-left e
top-right).
int isAdjacent(struct blocco *b, struct rettangolo *r)
Restituisce ”1” se il blocco e il rettangolo passati come parametro sono adia-
centi, ”0” altrimenti.
int upperBound(struct pezzo *p)
Calcola l’upper bound del problema a partire dalla lista dei pezzi da tagliare.
int isUnweighted(struct pezzo *p)
Se per ogni pezzo i risulta ei = 1, restituisce ”1” (problema di tipo un-
weighted), altrimenti restituisce ”0”.
int isFeasible(struct pezzo *p)
Se per ogni pezzo i ancora da tagliare risulta Pi = 0, restituisce ”1” (solu-
zione ammissibile), altrimenti restituisce ”0” (soluzione non ammissibile).
int fill(struct rettangolo *r, struct pezzo *p)
Restituisce ”1” se il pezzo e in grado di essere ”tagliato” dal rettangolo vuo-
87

to, ”0” altrimenti.
double eMax(struct pezzo *p)
Restituisce la piu grande tra tutte le efficienze e dei pezzi.
void decreasingQi(struct pezzo *p)
Decrementa gli upper bound Qi dei pezzi della lista passata come parametro,
seguendo le formule indicate nella sezione 4.3.2. Quindi, se un pezzo presenta
un Qi = 0, questo viene rimosso dalla lista dei pezzi ancora da tagliare.
void apriFile()
Richiede il nome del file in cui sono contenuti i problemi da risolvere e prov-
vede ad aprirlo in lettura. Inoltre apre in scrittura il file ”risultati.txt” in cui
verranno scritte le soluzioni dei problemi e i tempi computazionali.
void chiudiFile()
Provvede a chiudere i file precedentemente aperti.
void caricaDatiProblema()
Crea le tre liste P , L e C inizializzandole con i valori presenti sul file.
void inizializzaParametri()
Inizializza tutti i parametri fondamentali come il numero di iterazioni numI-
ter, il numero massimo di iterazioni maxIter, ecc.
void salvaSoluzioneMigliore(struct pezzo *p, struct
rettangolo *r, struct blocco *b)
Provvede a salvare le tre liste associate alla soluzione migliore trovata fino a
88

quel momento.
void eliminaListe()
Si occupa di eliminare tutte le liste precedentemente create in modo da libe-
rare la memoria occupata.
void visualizzaRisultati()
Stampa a video la soluzione trovata e salva il risultato e il tempo impiegato
all’interno del file ”risultati.txt”.
89


Capitolo 7
Test e risultati computazionali
7.1 Tipi di test
Per testare entrambi gli algoritmi sono stati utilizzati diversi insiemi di
problemi:
1. Un insieme di 21 problemi estratti dalla letteratura: dodici da Bea-
sley [6], due da Hadjiconstantinou e Christofides [8], uno da Wang [21],
uno da Christofides e Whitlock [22], cinque da Fekete e Schepers [9].
Le soluzioni ottime sono tutte note. I problemi sono stati risolti anche
da Beasley [15].
2. Un insieme di 630 problemi di grosse dimensioni generati da Bea-
sley [15], seguendo il lavoro di Fekete e Schepers [9]. Tutti i problemi
hanno un rettangolo base di dimensioni (100, 100). Per ogni valo-
re di m, il numero di tipi diversi di pezzi (m=40, 50, 100, 150, 250,
500, 1000), 10 problemi sono generati in maniera casuale con Pi = 0,
Qi = Q∗, ∀i = 1, ...,m, dove Q∗=1; 3; 4. Queste 630 istanze sono
suddivise in tre tipi di problemi, a seconda della percentuale di tipi di
pezzi di ogni classe:
91

Classe Descrizione Lunghezza Larghezza
1 Corti e larghi [1,50] [75,100]
2 Lunghi e stretti [75,100] [1,50]
3 Grandi [50,100] [50,100]
4 Piccoli [1,50] [1,50]
Tipo % di classe 1 % di classe 2 % di classe 3 % di classe 4
1 20 20 20 40
2 15 15 15 55
3 10 10 10 70
Il valore assegnato ad ogni pezzo e uguale alla sua area moltiplicata
per un intero scelto a caso tra {1, 2, 3}.
3. I 21 problemi provenienti dalla letteratura sono stati trasformati da
Beasley [15] in doubly constrained problems modificando alcuni lower
bounds Pi, in particolare per ogni tipo di pezzo da i = 1, ...,m che
soddisfi∑m
j=1,j 6=i(ljwj)Pj + liwi ≤ (LW )/3, il lower bound Pi e posto
uguale a 1.
Questo insieme di problemi permette di verificare la bonta degli algo-
ritmi nel caso generale di problemi di tipo doubly constrained.
4. Infine sono stati eseguiti i test utilizzando i problemi usati da Leung
et al [14], che consistono in tre istanze da Lai e Chan [11], cinque da
Jakobs [23] e due da Leung et al [14]. I test sono stati eseguiti anche
su 21 istanze di grosse dimensioni create da Hopper e Turton [25].
Questi problemi sono tutti di tipo unweighted in cui il valore di ogni
pezzo corrisponde alla sua area e l’obbiettivo da raggiungere e ridurre
al minimo ”lo scarto” nel rettangolo base.
Quest’ultima classe di problemi ha caratteristiche complementari rispetto
agli altri tipi. Infatti i primi tre tipi di problemi possono essere considerati
una sorta di problemi di selezione perche ci sono molti pezzi disponibili e solo
92

una piccola parte di essi dovra essere inclusa nella soluzione ottimale. Invece
i problemi del quarto tipo possono essere definiti come problemi a incastro
in cui tutti i pezzi disponibili devono far parte della soluzione ottima e la
difficolta sta nel trovare la loro corretta posizione per far sı che entrino tutti
nel rettangolo base. Un algoritmo che funzioni bene con entrambi i tipi di
problemi puo essere considerato un buon general purpose algorithm.
7.2 Risultati computazionali
I risultati computazionali completi appaiono nelle Tabelle dalla 1 alla 4, per
quanto riguarda l’algoritmo GRASP, e dalla 5 alla 8, per quanto riguarda
l’algoritmo Tabu Search. Nelle tabelle e stato fatto un confronto con l’al-
goritmo GRASP sviluppato da Alvarez-Valdes et al [1] e con quello Tabu
Search realizzato sempre da Alvarez-Valdes et al [2]. Il confronto avviene sia
sui risultati ottenuti dalle due procedure, sia sui tempi impiegati a risolvere
i problemi.
I tempi di elaborazione, pero, non possono essere direttamente confron-
tati in quanto entrambi i miei algoritmi sono stati sviluppati in C ed eseguiti
su un AMD Athlon 2100+, mentre gli algoritmi di Alvarez-Valdes et al sono
stati implementati utilizzando il linguaggio C++ ed eseguiti su un Pentium
III 800 MHz. Tuttavia e possibile affermare, con un certo margine di appros-
simazione, che il PC usato da me per l’esecuzione dei test e circa due volte
piu veloce rispetto a quello usato da Alvarez-Valdes et al.
7.2.1 Confronto tra gli algoritmi GRASP
Confrontando il primo insieme di problemi (Tabella 1), quelli provenienti
dalla letteratura, si nota come il mio algoritmo produca risultati identici a
quelli di Alvarez-Valdes et al, sia in termini di numero di soluzioni ottime
trovate, sia in termini di valore di tali soluzioni, risolvendo i problemi in circa
meta tempo, in accordo con le differenti prestazioni dei processori.
Per quanto riguarda il secondo insieme di problemi (Tabella 2), per i quali
93
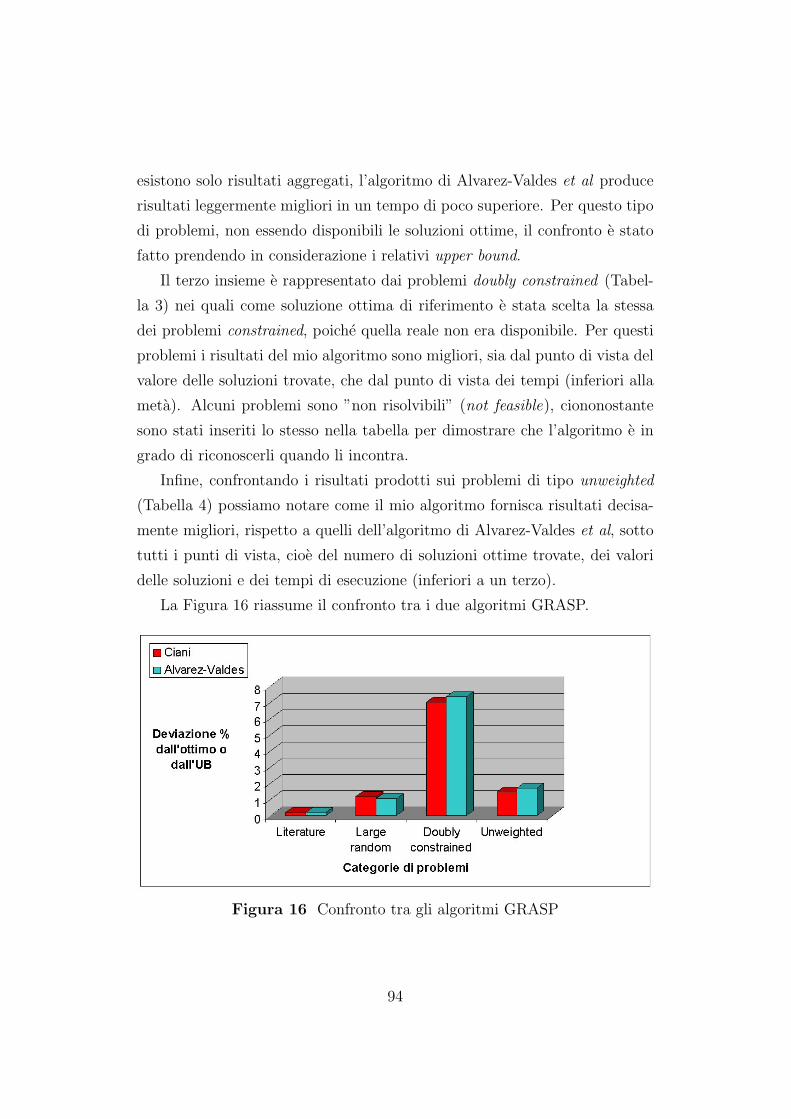
esistono solo risultati aggregati, l’algoritmo di Alvarez-Valdes et al produce
risultati leggermente migliori in un tempo di poco superiore. Per questo tipo
di problemi, non essendo disponibili le soluzioni ottime, il confronto e stato
fatto prendendo in considerazione i relativi upper bound.
Il terzo insieme e rappresentato dai problemi doubly constrained (Tabel-
la 3) nei quali come soluzione ottima di riferimento e stata scelta la stessa
dei problemi constrained, poiche quella reale non era disponibile. Per questi
problemi i risultati del mio algoritmo sono migliori, sia dal punto di vista del
valore delle soluzioni trovate, che dal punto di vista dei tempi (inferiori alla
meta). Alcuni problemi sono ”non risolvibili” (not feasible), ciononostante
sono stati inseriti lo stesso nella tabella per dimostrare che l’algoritmo e in
grado di riconoscerli quando li incontra.
Infine, confrontando i risultati prodotti sui problemi di tipo unweighted
(Tabella 4) possiamo notare come il mio algoritmo fornisca risultati decisa-
mente migliori, rispetto a quelli dell’algoritmo di Alvarez-Valdes et al, sotto
tutti i punti di vista, cioe del numero di soluzioni ottime trovate, dei valori
delle soluzioni e dei tempi di esecuzione (inferiori a un terzo).
La Figura 16 riassume il confronto tra i due algoritmi GRASP.
Figura 16 Confronto tra gli algoritmi GRASP
94
Dimensioni CPU (s)
I (L,W) m M Ciani Alvarez Ottimo Ciani Alvarez
1 (10,10) 5 10 164 164 164 0,00 0,00
2 (10,10) 7 17 230 230 230 0,00 0,00
3 (10,10) 10 21 247 247 247 0,00 0,00
4 (15,10) 5 7 268 268 268 0,00 0,00
5 (15,10) 7 14 358 358 358 0,00 0,00
6 (15,10) 10 15 289 289 289 0,00 0,00
7 (20,20) 5 8 430 430 430 0,00 0,00
8 (20,20) 7 13 834 834 834 0,06 0,77
9 (20,20) 10 18 924 924 924 0,14 0,00
10 (30,30) 5 13 1452 1452 1452 0,04 0,00
11 (30,30) 7 15 1688 1688 1688 0,06 0,05
12 (30,30) 10 22 1865 1865 1865 0,10 0,05
13 (30,30) 7 7 1178 1178 1178 0,04 0,00
14 (30,30) 15 15 1270 1270 1270 0,05 0,00
15 (70,40) 19 42 2726 2726 2726 0,13 0,77
16 (40,70) 20 62 1860 1860 1860 0,11 0,39
17 (100,100) 15 50 27589 27589 27718 0,33 2,31
18 (100,100) 30 30 21976 21976 22502 1,11 4,17
19 (100,100) 30 30 23743 23743 24019 1,30 3,68
20 (100,100) 33 61 32893 32893 32893 0,90 0,00
21 (100,100) 29 97 27923 27923 27923 0,43 0,00
Deviazione media dall’ottimo 0,19% 0,19% 0,23 0,58
Numero di soluzioni ottime 18 18
Tabella 1 GRASP - Problemi dalla letteratura
95

Deviazione media percentuale dall’UB CPU (s)
m Q∗ M Ciani Alvarez Ciani Alvarez
40 1 40 7,01 6,97 1,83 2,33
3 120 2,39 2,22 5,40 6,62
4 160 1,98 1,81 3,33 4,44
50 1 50 4,91 4,80 3,20 4,71
3 150 1,79 1,50 5,48 7,05
4 200 1,37 1,18 4,38 5,34
100 1 100 1,59 1,51 4,11 5,36
3 300 0,74 0,47 7,43 9,41
4 400 0,45 0,26 5,26 6,99
150 1 150 0,93 0,89 4,90 5,53
3 450 0,27 0,14 9,76 11,71
4 600 0,26 0,11 4,77 6,75
250 1 250 0,51 0,51 4,78 5,27
3 750 0,16 0,04 10,76 13,89
4 1000 0,10 0,03 9,91 6,65
500 1 500 0,12 0,05 3,02 3,24
3 1500 0,02 0,00 8,33 12,24
4 2000 0,02 0,00 4,32 1,15
1000 1 1000 0,01 0,00 4,76 1,01
3 3000 0,00 0,00 5,92 6,53
4 4000 0,00 0,00 4,39 0,29
Tipo 1 1,13 1,04 4,44 5,13
Tipo 2 1,23 1,14 5,42 5,90
Tipo 3 1,16 1,03 6,00 7,28
Tutti 1,17 1,07 5,29 6,02
Tabella 2 GRASP - Problemi random di grosse dimensioni
96
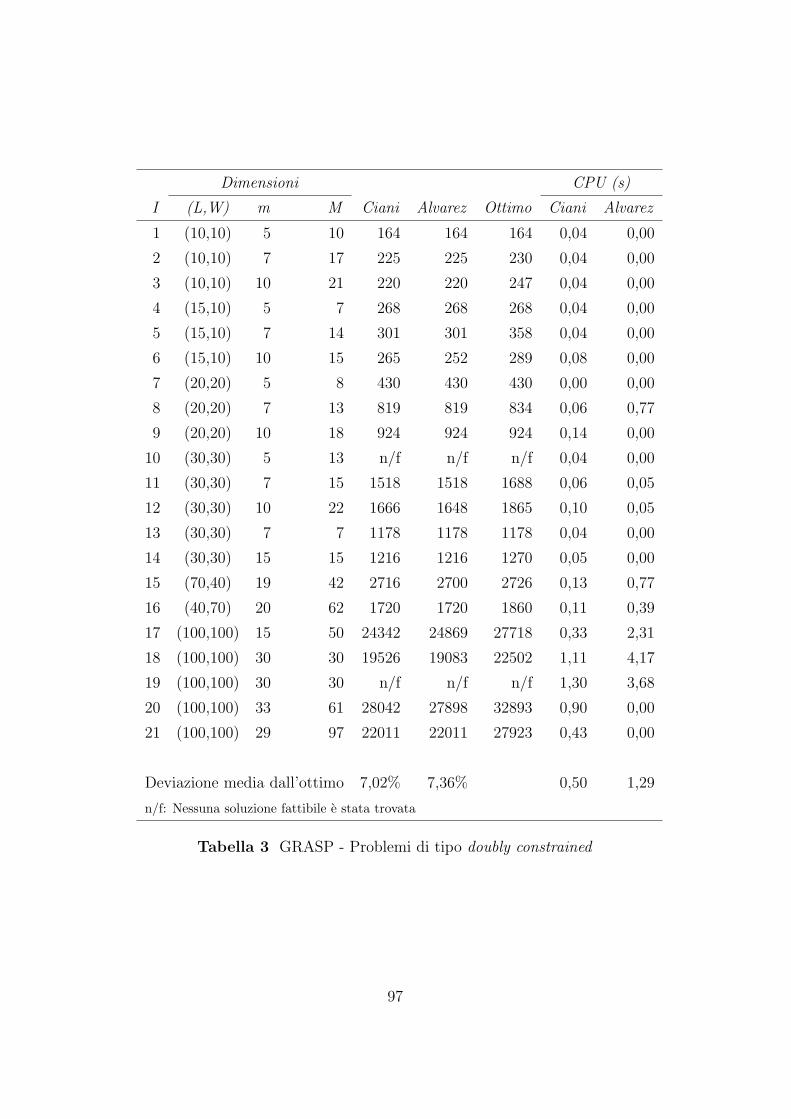
Dimensioni CPU (s)
I (L,W) m M Ciani Alvarez Ottimo Ciani Alvarez
1 (10,10) 5 10 164 164 164 0,04 0,00
2 (10,10) 7 17 225 225 230 0,04 0,00
3 (10,10) 10 21 220 220 247 0,04 0,00
4 (15,10) 5 7 268 268 268 0,04 0,00
5 (15,10) 7 14 301 301 358 0,04 0,00
6 (15,10) 10 15 265 252 289 0,08 0,00
7 (20,20) 5 8 430 430 430 0,00 0,00
8 (20,20) 7 13 819 819 834 0,06 0,77
9 (20,20) 10 18 924 924 924 0,14 0,00
10 (30,30) 5 13 n/f n/f n/f 0,04 0,00
11 (30,30) 7 15 1518 1518 1688 0,06 0,05
12 (30,30) 10 22 1666 1648 1865 0,10 0,05
13 (30,30) 7 7 1178 1178 1178 0,04 0,00
14 (30,30) 15 15 1216 1216 1270 0,05 0,00
15 (70,40) 19 42 2716 2700 2726 0,13 0,77
16 (40,70) 20 62 1720 1720 1860 0,11 0,39
17 (100,100) 15 50 24342 24869 27718 0,33 2,31
18 (100,100) 30 30 19526 19083 22502 1,11 4,17
19 (100,100) 30 30 n/f n/f n/f 1,30 3,68
20 (100,100) 33 61 28042 27898 32893 0,90 0,00
21 (100,100) 29 97 22011 22011 27923 0,43 0,00
Deviazione media dall’ottimo 7,02% 7,36% 0,50 1,29
n/f: Nessuna soluzione fattibile e stata trovata
Tabella 3 GRASP - Problemi di tipo doubly constrained
97
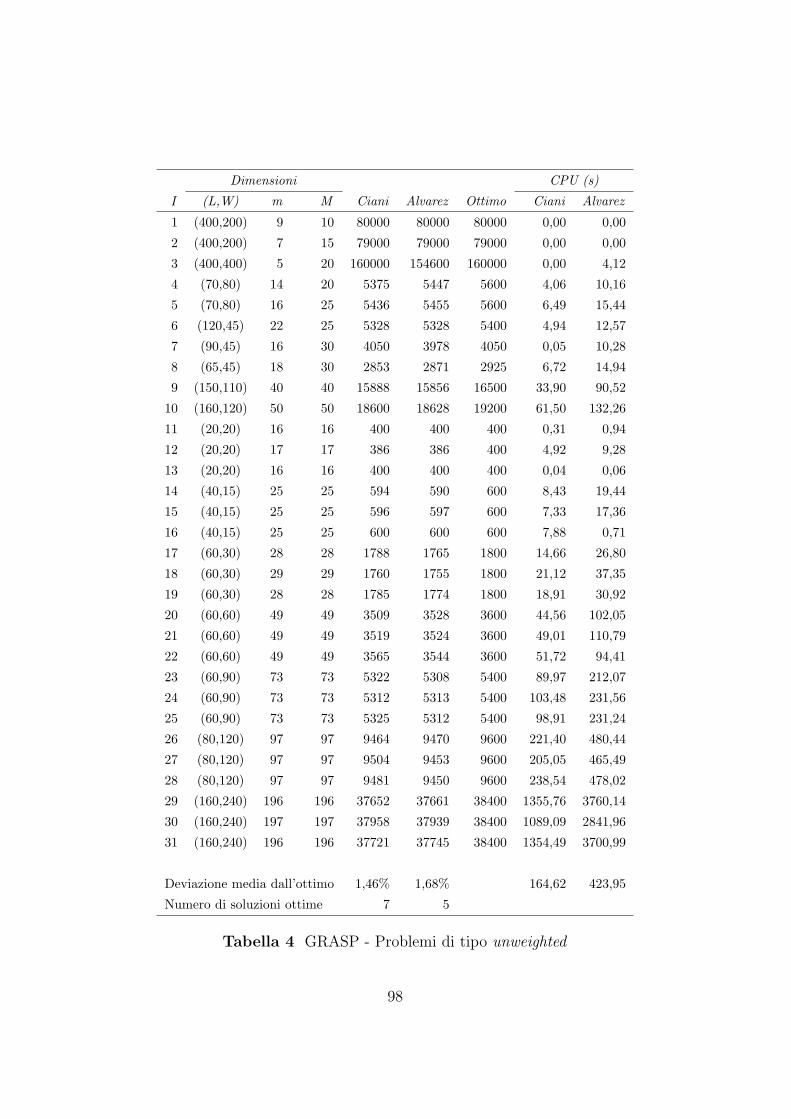
Dimensioni CPU (s)
I (L,W) m M Ciani Alvarez Ottimo Ciani Alvarez
1 (400,200) 9 10 80000 80000 80000 0,00 0,00
2 (400,200) 7 15 79000 79000 79000 0,00 0,00
3 (400,400) 5 20 160000 154600 160000 0,00 4,12
4 (70,80) 14 20 5375 5447 5600 4,06 10,16
5 (70,80) 16 25 5436 5455 5600 6,49 15,44
6 (120,45) 22 25 5328 5328 5400 4,94 12,57
7 (90,45) 16 30 4050 3978 4050 0,05 10,28
8 (65,45) 18 30 2853 2871 2925 6,72 14,94
9 (150,110) 40 40 15888 15856 16500 33,90 90,52
10 (160,120) 50 50 18600 18628 19200 61,50 132,26
11 (20,20) 16 16 400 400 400 0,31 0,94
12 (20,20) 17 17 386 386 400 4,92 9,28
13 (20,20) 16 16 400 400 400 0,04 0,06
14 (40,15) 25 25 594 590 600 8,43 19,44
15 (40,15) 25 25 596 597 600 7,33 17,36
16 (40,15) 25 25 600 600 600 7,88 0,71
17 (60,30) 28 28 1788 1765 1800 14,66 26,80
18 (60,30) 29 29 1760 1755 1800 21,12 37,35
19 (60,30) 28 28 1785 1774 1800 18,91 30,92
20 (60,60) 49 49 3509 3528 3600 44,56 102,05
21 (60,60) 49 49 3519 3524 3600 49,01 110,79
22 (60,60) 49 49 3565 3544 3600 51,72 94,41
23 (60,90) 73 73 5322 5308 5400 89,97 212,07
24 (60,90) 73 73 5312 5313 5400 103,48 231,56
25 (60,90) 73 73 5325 5312 5400 98,91 231,24
26 (80,120) 97 97 9464 9470 9600 221,40 480,44
27 (80,120) 97 97 9504 9453 9600 205,05 465,49
28 (80,120) 97 97 9481 9450 9600 238,54 478,02
29 (160,240) 196 196 37652 37661 38400 1355,76 3760,14
30 (160,240) 197 197 37958 37939 38400 1089,09 2841,96
31 (160,240) 196 196 37721 37745 38400 1354,49 3700,99
Deviazione media dall’ottimo 1,46% 1,68% 164,62 423,95
Numero di soluzioni ottime 7 5
Tabella 4 GRASP - Problemi di tipo unweighted
98

7.2.2 Confronto tra gli algoritmi Tabu Search
Se si confrontano i 21 problemi provenienti dalla letteratura (Tabella 5), i due
algoritmi Tabu Search producono esattamente gli stessi risultati, trovando
tutte e 21 le soluzioni ottime; ma il mio algoritmo li risolve in meta tempo.
I problemi di grosse dimensioni (Tabella 6), invece, presentano risul-
tati aggregati pressoche identici, con qualche differenza solo da categoria
a categoria. Anche i tempi computazionali sono paragonabili, tenendo in
considerazione le diversita dei processori.
Per quanto riguarda i problemi doubly constrained (Tabella 7), anche
in questo caso i risultati sono identici e i tempi sono paragonabili. Proba-
bilmente, anche se non vi e certezza, poiche le soluzioni ottime di questo
tipo di problema non sono disponibili, entrambi gli algoritmi sono riusciti a
individuare tutte le soluzioni ottime.
Infine, i problemi di unweighted (Tabella 8) vengono risolti dai due algo-
ritmi realizzando risultati totali molto simili, ma piuttosto diversi da istanza
a istanza. Per quanto riguarda i tempi di esecuzione, anche questa volta, il
mio algoritmo risolve i problemi in un tempo inferiore (circa un terzo).
La Figura 17 mostra il paragone tra i due algoritmi Tabu Search.
Figura 17 Confronto tra gli algoritmi Tabu Search
99

Dimensioni CPU (s)
I (L,W) m M Ciani Alvarez Ottimo Ciani Alvarez
1 (10,10) 5 10 164 164 164 0,00 0,06
2 (10,10) 7 17 230 230 230 0,00 0,00
3 (10,10) 10 21 247 247 247 0,00 0,00
4 (15,10) 5 7 268 268 268 0,00 0,00
5 (15,10) 7 14 358 358 358 0,00 0,00
6 (15,10) 10 15 289 289 289 0,00 0,00
7 (20,20) 5 8 430 430 430 0,00 0,00
8 (20,20) 7 13 834 834 834 0,06 0,16
9 (20,20) 10 18 924 924 924 0,00 0,05
10 (30,30) 5 13 1452 1452 1452 0,00 0,00
11 (30,30) 7 15 1688 1688 1688 0,00 0,00
12 (30,30) 10 22 1865 1865 1865 0,03 0,06
13 (30,30) 7 7 1178 1178 1178 0,00 0,00
14 (30,30) 15 15 1270 1270 1270 0,00 0,00
15 (70,40) 19 42 2726 2726 2726 0,04 0,11
16 (40,70) 20 62 1860 1860 1860 0,03 0,06
17 (100,100) 15 50 27718 27718 27718 0,00 0,05
18 (100,100) 30 30 22502 22502 22502 1,09 2,14
19 (100,100) 30 30 24019 24019 24019 1,51 3,40
20 (100,100) 33 61 32893 32893 32893 0,41 0,66
21 (100,100) 29 97 27923 27923 27923 0,00 0,00
Deviazione media dall’ottimo 0,00% 0,00% 0,15 0,32
Numero di soluzioni ottime 21 21
Tabella 5 Tabu Search - Problemi dalla letteratura
100
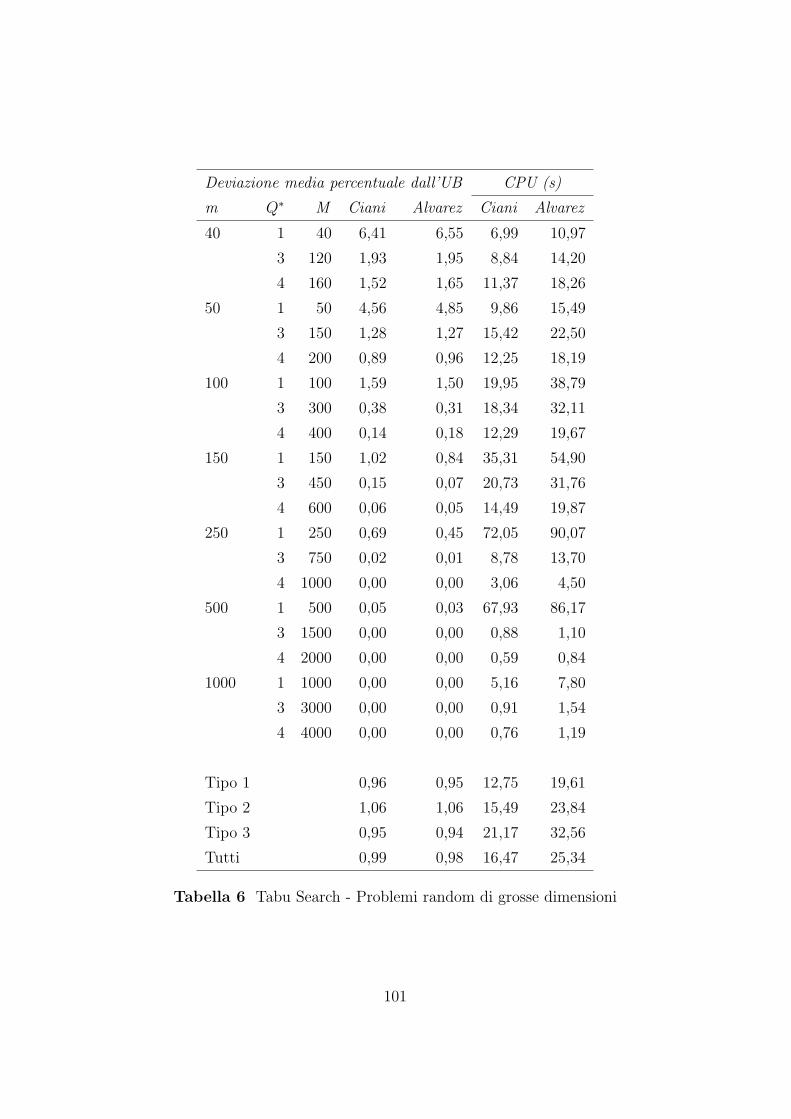
Deviazione media percentuale dall’UB CPU (s)
m Q∗ M Ciani Alvarez Ciani Alvarez
40 1 40 6,41 6,55 6,99 10,97
3 120 1,93 1,95 8,84 14,20
4 160 1,52 1,65 11,37 18,26
50 1 50 4,56 4,85 9,86 15,49
3 150 1,28 1,27 15,42 22,50
4 200 0,89 0,96 12,25 18,19
100 1 100 1,59 1,50 19,95 38,79
3 300 0,38 0,31 18,34 32,11
4 400 0,14 0,18 12,29 19,67
150 1 150 1,02 0,84 35,31 54,90
3 450 0,15 0,07 20,73 31,76
4 600 0,06 0,05 14,49 19,87
250 1 250 0,69 0,45 72,05 90,07
3 750 0,02 0,01 8,78 13,70
4 1000 0,00 0,00 3,06 4,50
500 1 500 0,05 0,03 67,93 86,17
3 1500 0,00 0,00 0,88 1,10
4 2000 0,00 0,00 0,59 0,84
1000 1 1000 0,00 0,00 5,16 7,80
3 3000 0,00 0,00 0,91 1,54
4 4000 0,00 0,00 0,76 1,19
Tipo 1 0,96 0,95 12,75 19,61
Tipo 2 1,06 1,06 15,49 23,84
Tipo 3 0,95 0,94 21,17 32,56
Tutti 0,99 0,98 16,47 25,34
Tabella 6 Tabu Search - Problemi random di grosse dimensioni
101
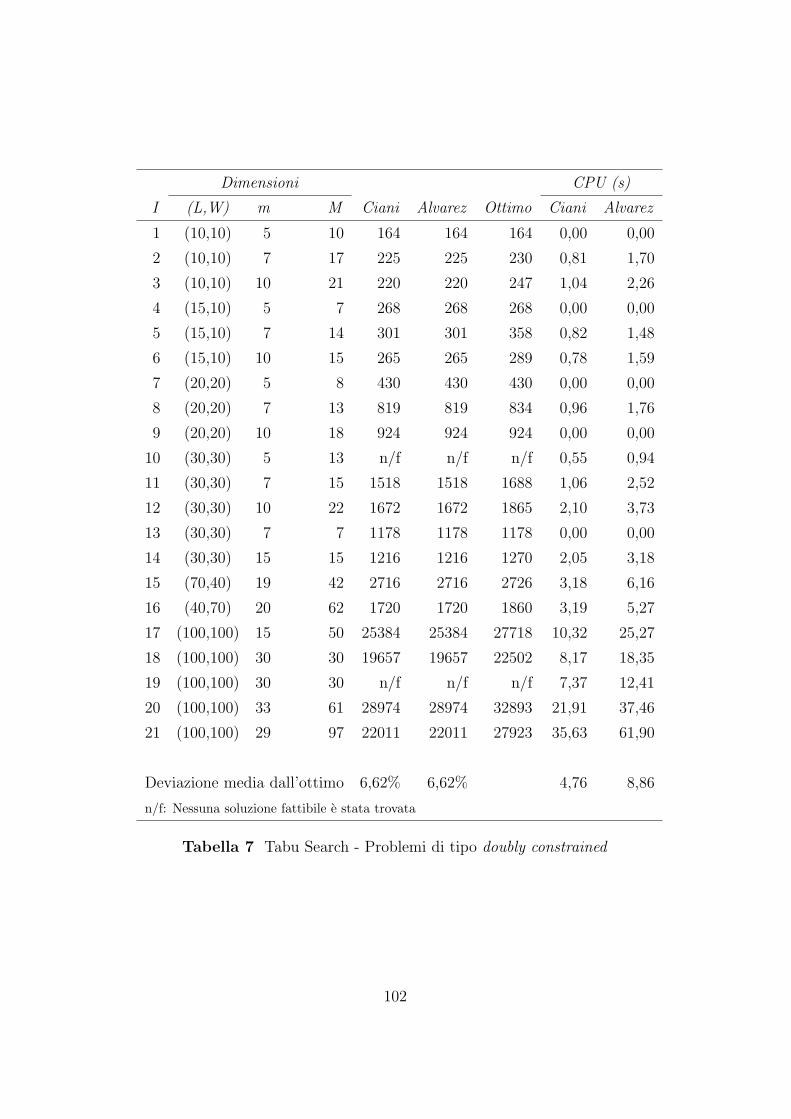
Dimensioni CPU (s)
I (L,W) m M Ciani Alvarez Ottimo Ciani Alvarez
1 (10,10) 5 10 164 164 164 0,00 0,00
2 (10,10) 7 17 225 225 230 0,81 1,70
3 (10,10) 10 21 220 220 247 1,04 2,26
4 (15,10) 5 7 268 268 268 0,00 0,00
5 (15,10) 7 14 301 301 358 0,82 1,48
6 (15,10) 10 15 265 265 289 0,78 1,59
7 (20,20) 5 8 430 430 430 0,00 0,00
8 (20,20) 7 13 819 819 834 0,96 1,76
9 (20,20) 10 18 924 924 924 0,00 0,00
10 (30,30) 5 13 n/f n/f n/f 0,55 0,94
11 (30,30) 7 15 1518 1518 1688 1,06 2,52
12 (30,30) 10 22 1672 1672 1865 2,10 3,73
13 (30,30) 7 7 1178 1178 1178 0,00 0,00
14 (30,30) 15 15 1216 1216 1270 2,05 3,18
15 (70,40) 19 42 2716 2716 2726 3,18 6,16
16 (40,70) 20 62 1720 1720 1860 3,19 5,27
17 (100,100) 15 50 25384 25384 27718 10,32 25,27
18 (100,100) 30 30 19657 19657 22502 8,17 18,35
19 (100,100) 30 30 n/f n/f n/f 7,37 12,41
20 (100,100) 33 61 28974 28974 32893 21,91 37,46
21 (100,100) 29 97 22011 22011 27923 35,63 61,90
Deviazione media dall’ottimo 6,62% 6,62% 4,76 8,86
n/f: Nessuna soluzione fattibile e stata trovata
Tabella 7 Tabu Search - Problemi di tipo doubly constrained
102
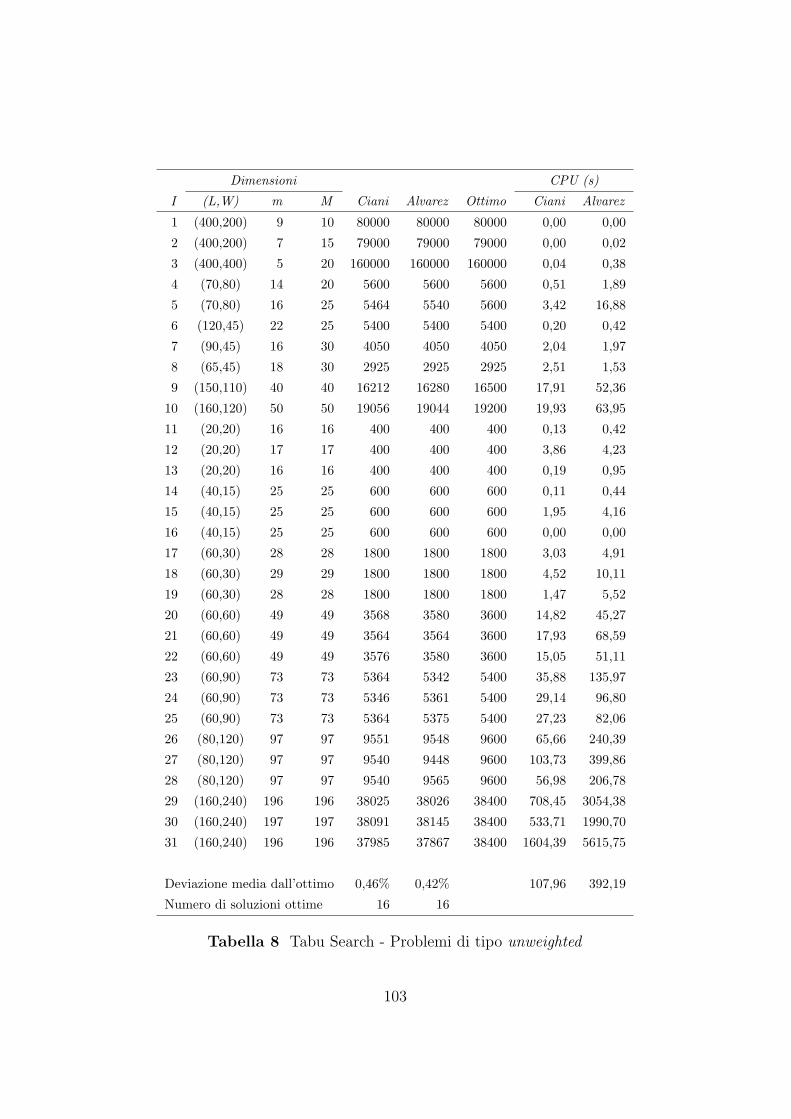
Dimensioni CPU (s)
I (L,W) m M Ciani Alvarez Ottimo Ciani Alvarez
1 (400,200) 9 10 80000 80000 80000 0,00 0,00
2 (400,200) 7 15 79000 79000 79000 0,00 0,02
3 (400,400) 5 20 160000 160000 160000 0,04 0,38
4 (70,80) 14 20 5600 5600 5600 0,51 1,89
5 (70,80) 16 25 5464 5540 5600 3,42 16,88
6 (120,45) 22 25 5400 5400 5400 0,20 0,42
7 (90,45) 16 30 4050 4050 4050 2,04 1,97
8 (65,45) 18 30 2925 2925 2925 2,51 1,53
9 (150,110) 40 40 16212 16280 16500 17,91 52,36
10 (160,120) 50 50 19056 19044 19200 19,93 63,95
11 (20,20) 16 16 400 400 400 0,13 0,42
12 (20,20) 17 17 400 400 400 3,86 4,23
13 (20,20) 16 16 400 400 400 0,19 0,95
14 (40,15) 25 25 600 600 600 0,11 0,44
15 (40,15) 25 25 600 600 600 1,95 4,16
16 (40,15) 25 25 600 600 600 0,00 0,00
17 (60,30) 28 28 1800 1800 1800 3,03 4,91
18 (60,30) 29 29 1800 1800 1800 4,52 10,11
19 (60,30) 28 28 1800 1800 1800 1,47 5,52
20 (60,60) 49 49 3568 3580 3600 14,82 45,27
21 (60,60) 49 49 3564 3564 3600 17,93 68,59
22 (60,60) 49 49 3576 3580 3600 15,05 51,11
23 (60,90) 73 73 5364 5342 5400 35,88 135,97
24 (60,90) 73 73 5346 5361 5400 29,14 96,80
25 (60,90) 73 73 5364 5375 5400 27,23 82,06
26 (80,120) 97 97 9551 9548 9600 65,66 240,39
27 (80,120) 97 97 9540 9448 9600 103,73 399,86
28 (80,120) 97 97 9540 9565 9600 56,98 206,78
29 (160,240) 196 196 38025 38026 38400 708,45 3054,38
30 (160,240) 197 197 38091 38145 38400 533,71 1990,70
31 (160,240) 196 196 37985 37867 38400 1604,39 5615,75
Deviazione media dall’ottimo 0,46% 0,42% 107,96 392,19
Numero di soluzioni ottime 16 16
Tabella 8 Tabu Search - Problemi di tipo unweighted
103

7.2.3 Confronto tra le due tecniche
Sebbene la tecnica GRASP produca un algoritmo eccezionale sotto il profilo
dei risultati, dimostrando di essere una delle euristiche che meglio si adatta al
problema di taglio bidimensionale, la tecnica Tabu Search si rivela addirittura
superiore permettendo di realizzare un algoritmo in grado di risolvere tutte le
categorie di problemi presentate in precedenza, con risultati migliori ovunque
(come si vede dalla Figura 18).
Per quanto riguarda i tempi di esecuzione, invece, i due algoritmi presen-
tano risultati diversi. I problemi provenienti dalla letteratura, sia nel caso
constrained, sia nel caso doubly constrained, vengono risolti dai due algoritmi
in tempi piu o meno uguali (con una leggera preferenza per l’algoritmo Tabu
Search). I risultati dei problemi di grosse dimensioni e di quelli unweighted,
invece, sono ottenuti dall’algoritmo GRASP in tempi notevolmente inferiori.
Per questo motivo e possibile concludere che, qualora il maggior tem-
po impiegato non sia un vincolo strettissimo, e preferibile impiegare sem-
pre l’algoritmo Tabu Search. Qualora invece, il tempo sia il vincolo fon-
damentale, per problemi complessi e meglio utilizzare l’algoritmo GRASP,
accontentandosi di risultati leggermente peggiori.
Figura 18 Confronto tra le due tecniche
104

Conclusioni
In questa tesi sono stati sviluppati due algoritmi euristici, uno basato sul-
la tecnica GRASP e uno basato sulla tecnica Tabu Search. Entrambi gli
algoritmi risolvono problemi di taglio bidimensionale non a ghigliottina.
L’algoritmo GRASP e costituito da due fasi: una costruttiva e una di
miglioramento. Nella prima fase l’algoritmo seleziona i pezzi da tagliare, in
maniera casuale, utilizzando una procedura di tipo greedy. Nella seconda
fase, invece, vengono modificate alcune decisioni prese nella fase costruttiva,
permettendo all’intera procedura di migliorare la soluzione trovata. Durante
le varie iterazioni vengono eseguite procedure per diminuire la complessita
del problema e per adattare la scelta dei pezzi ai risultati fino a quel momento
ottenuti.
Per quanto riguarda l’algoritmo Tabu Search, sono state proposte due
mosse che si fondano sull’inserimento e sulla riduzione di blocchi di pez-
zi. L’efficienza delle mosse si basa su una strategia di tipo merge and fill
che adatta i rettangoli vuoti ai pezzi ancora da tagliare. Inoltre sono sta-
te sviluppate anche strategie di tabu list dinamica, e di diversificazione e
intensificazione, basate sulla memoria a lungo termine.
I risultati computazionali dimostrano che gli algoritmi producono risultati
ottimi per ogni categoria di problemi: di piccole e di grandi dimensioni,
constrained e doubly constrained, weighted e unweighted. Per questo motivo,
gli algoritmi dimostrano di essere totalmente general purpose e adatti ad ogni
tipo di problema di taglio bidimensionale.
105


Possibili sviluppi futuri
Entrambi gli algoritmi hanno dimostrato di essere altamente competitivi e
pronti per essere utilizzati da una qualunque azienda, che necessiti di un
programma in grado di risolvere il problema di taglio bidimensionale presen-
tato in precedenza. Tuttavia, poiche gli algoritmi sono stati implementati in
maniera totalmente modulare e con codice altamente riusabile, sarebbe pos-
sibile migliorare sia le prestazioni che l’interfaccia in maniera relativamente
semplice. Tra questi miglioramenti e possibile:
1. Utilizzare una tecnica piu efficiente nella fase di miglioramento dell’al-
goritmo GRASP (semplicemente sostituendo la vecchia funzione con
quella nuova).
2. Introdurre nuove mosse nell’algoritmo Tabu Search per giungere piu
velocemente alla soluzione migliore (semplicemente aggiungendole al
corpo principale dell’algoritmo).
3. Applicare una tecnica mista costituita da una prima fase costruttiva in
cui pezzi e rettangoli vuoti vengono scelti in maniera casuale (GRASP),
e da una seconda fase in cui si applicano mosse e strategie tipiche
dell’approccio Tabu Search.
4. Sviluppare un’interfaccia piu potente che permetta, per esempio, di
introdurre i dati dei problemi in diversi modi (e non solo tramite file) o
di visualizzare le soluzioni ottenute, magari con l’utilizzo di componenti
grafici.
107


Bibliografia
[1] Alvarez-Valdes R, Parreno F e Tamarit JM (2005). A GRASP algorithm
for constrained two-dimensional non-guillotine cutting problems. J Opl
Res Soc 56: 414-425.
[2] Alvarez-Valdes R, Parreno F e Tamarit JM (2005). A tabu search al-
gorithm for two-dimensional non-guillotine cutting problems. J Opl Res
Soc: attualmente in stampa.
[3] Tsai RD, Malstrom EM e Meeks HD (1988). A two-dimesional pal-
letizing procedure for warehouse loading operations. IIE Trans 20:
418-425.
[4] Arenales M e Morabito R (1995). An AND/OR-graph approach to the
solution ot two-dimensional non-guillotine cutting problems. Eur J Opl
Res 84: 599-617.
[5] Healy P, Creavin M e Kuusik A (1999). An optimal algorithm for
placement rectangle. Opns Res Lett 24: 73-80.
[6] Beasley JE (1985). An exact two-dimensional non-guillotine cutting tree
search procedure. Opns Res 33: 49-64.
[7] Scheithauer G e Terno J (1993). Modeling of packing problems.
Optimization 28: 63-84.
[8] Hadjiconstantinou E e Christofides N (1995). An exact algorithm for
general, orthogonal, two-dimensional knapsack problems. Eur J Opl Res
83: 39-56.
109

[9] Fekete SP e Schepers J (2004). An exact algorithm for higher-
dimensional orthogonal packing. Il materiale e disponibile all’indirizzo
http://www.math.tu-bs.de/∼fekete
[10] Caprara A e Monaci M (2004). On the two-dimensional Knapsack
problem. Opns Res Lett 32: 5-14.
[11] Lai KK e Chan JWM (1997). Developing a simulated annealing
algorithm for the cutting stock problem. Comput Ind Eng 32: 115-127.
[12] Lai KK e Chan JWM (1997). A evolutionary algorithm for the
rectangular cutting stock problem. Int J Ind Eng 4: 130-139.
[13] Leung TW, Yung CH e Troutt MD (2001). Applications of genetic search
and simulated annealing to the two-dimensional non-guillotine cutting
stock problem. Comput Ind Eng 40: 201-214.
[14] Leung TW, Chan CK e Troutt MD (2003). Application of a mixed si-
mulated annealing-genetic algorithm heuristic for the two-dimensional
orthogonal packing problem. Eur J Opl Res 145: 530-542.
[15] Beasley JE (2004). A population heuristic for constrained two-
dimensional non-guillotine cutting. Eur J Opl Res 156: 601-627.
[16] Feo T e Resende MGC (1989). A probabilistic heuristic for a
computationally difficult set covering problem. Opns Res Lett 8: 67-71.
[17] Resende MGC e Ribeiro CC (2003). Greedy randomized adaptive search
procedures. Handbook of Metaheuristics. Kluwer Academic Publishers,
Dordrecht, MA, pp 219-249.
[18] Prais M e Ribeiro CC (2000). Reactive GRASP: an application to a
matrix decomposition problem in TDMA traffic assignment. INFORMS
J Comput 12: 164-176.
[19] Delorme X, Gandibleux X e Rodriguez J (2003). GRASP for set packing
problems. Eur J Opl Res 153: 564-580.
110

[20] Beltran JC, Celderon JE, Cabrera RJ e Moreno JM (2002). Proce-
dimientos constructivos adaptativos (GRASP) para el problema del
empaquetado bidimensional. Rev Iberoam Intel Artif 15: 26-33.
[21] Wang PY (1983). Two algorithms for constrained two-dimensional
cutting stock problems. Opns Res 31: 573-586.
[22] Christofides N e Whitlock C (1977). An algorithm for two-dimensional
cutting problems. Opns Res 25: 30-44.
[23] Jakobs S (1996). On genetic algorithms for the packing of polygons. Eur
J Opl Res 88: 165-181.
[24] Glover F e Laguna M (1997). Tabu Search. Kluver Academic Publishers,
Boston.
[25] Hopper E e Turton BCH (2001). An empirical investigation of meta-
heuristic and heuristic algorithms for a 2D packing problem. Eur J Opl
Res 128: 34-57.
[26] Ducatelle F e Levine J (2001). Ant Colony Optimization for Bin Pac-
king and Cutting Stock Problems. Proceedings of the UK Workshop on
Computational Intelligence.
111






![Algoritmi e Strutture Dati - Algoritmi Golosi (Greedy)computerscience.unicam.it/merelli/algoritmi06/[12]strategiaGolosa.pdf · Algoritmi e Strutture Dati Algoritmi Golosi (Greedy)](https://static.fdocumenti.com/doc/165x107/5c71c4f409d3f2cc4d8b53b1/algoritmi-e-strutture-dati-algoritmi-golosi-greedy-12strategiagolosapdf.jpg)











