
Algoritmi e Strutture Dati - Massimo 30 - Notizie · Algoritmi e strutture dati Fabrizio Grandoni...
421
Capitolo 1 Un’introduzione informale agli algoritmi Algoritmi e Strutture Dati
Transcript of Algoritmi e Strutture Dati - Massimo 30 - Notizie · Algoritmi e strutture dati Fabrizio Grandoni...

Capitolo 1Un’introduzione informale
agli algoritmi
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Procedimento chiaro e non ambiguo per risolvere correttamente un problema in tempo finito
Cos’è un algoritmo?
• Esempio: algoritmo preparaCaffè

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Cos’è un algoritmo?
• Noi siamo interessati ad algoritmi che risolvono problemi computazionali, cioè che producono, per un dato input, un output che rispetta la relazione definita dal problema considerato.

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
• Gli algoritmi sono alla base dei programmi• Livello di astrazione più alto: concentrarsi
sull’essenza dei problemi, tralasciando dettagli implementativi
• Livello di dettaglio sufficiente a derivare facilmente un programma da un algoritmo
Perché studiare algoritmi?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
Pseudocodice
Per mantenere massimo grado di generalità, descriveremo algoritmi in pseudocodice:– ricorda linguaggi di programmazione reali
come C, C++ o Java– può contenere alcune frasi in linguaggio naturale

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Progetto ed analisi di algoritmiVedremo come progettare ed analizzare
(teoreticamente) algoritmi che:• producano risultati corretti• siano efficienti in termini di tempo di
esecuzione ed occupazione di memoria

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
• Analisi teorica più affidabile di quella sperimentale: vale su tutte le possibili istanze di dati su cui l’algoritmo opera
• Ci aiuta a scegliere tra diverse soluzioni allo stesso problema
• Permette di predire le prestazioni del software, prima ancora di scriverne le prime linee di codice
Perché analizzare algoritmi?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
Visita guidata al progetto e analisi di algoritmi tramite esempio “giocattolo”:
Calcolo dei numeri di Fibonacci
(problema semplice ma con molte soluzioni)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
Leonardo da Pisa (noto anche come Fibonacci) si interessò di molte cose, tra cui il seguente problema (dinamica delle popolazioni):
L’isola dei conigli
Quanto velocemente si espande una popolazione di conigli sotto appropriate condizioni?
In particolare, se partiamo da una coppia di conigli (in un’isola deserta), quante coppie si avranno nell’anno n?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
• Come succede spesso in matematica (l’analisi di algoritmi è matematica), iniziamo con una semplificazione del problema, che ne racchiuda i tratti essenziali
• Il modello può essere in seguito esteso, per renderlo più realistico
Come modellare il problema?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
• Una coppia di conigli genera due coniglietti ogni anno
• I conigli cominciano a riprodursi soltanto al secondo anno dopo la loro nascita
• I conigli sono immortali
Modello e ipotesi sui conigli

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
Fn : numero di coppie di conigli presenti nell’anno n
F1 = 1 (una sola coppia)F2 = 1 (troppo giovani per procreare)F3 = 2 (prima coppia di coniglietti)F4 = 3 (seconda coppia di coniglietti)F5 = 5 (prima coppia di nipotini)
Tasso di riproduzione dei conigli
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
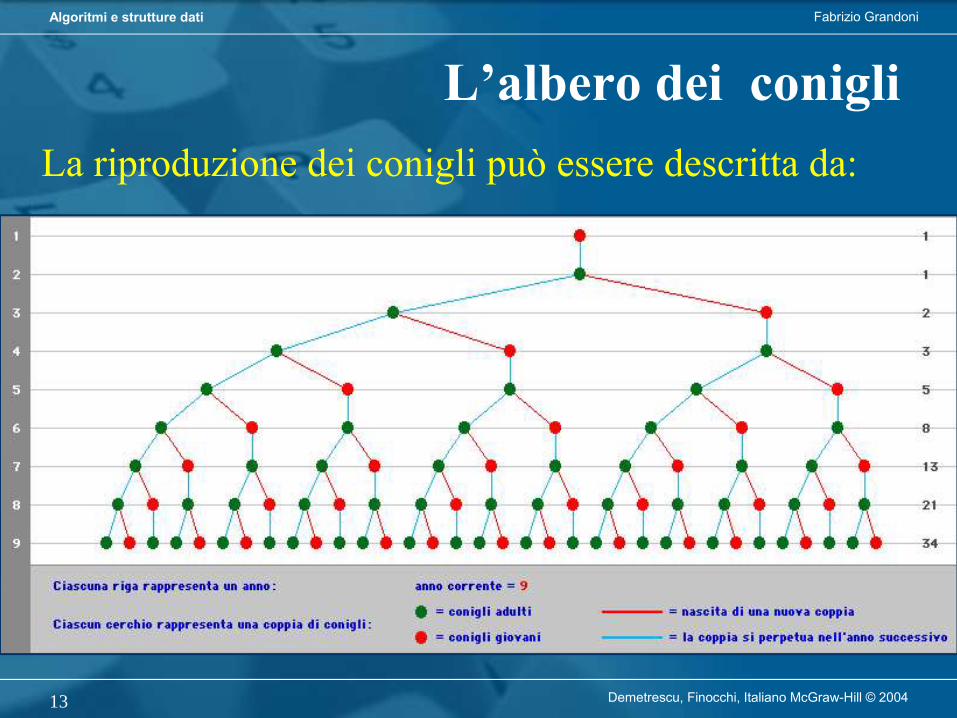
L’albero dei conigliLa riproduzione dei conigli può essere descritta da:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
• In generale in un certo anno ci saranno tutte le coppie dell’anno precedente, più una nuova coppia di conigli per ogni coppia presente due anni prima
Regola di espansione
• Abbiamo quindi relazione di ricorrenza:Fn-1 + Fn-2 se n 3≥1 se n = 1,2
Fn =
• Problema algoritmico: come calcoliamo Fn ?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
• Possiamo usare direttamente una soluzione alla relazione di Fibonacci:
Un possibile approccio
dove:
0.618 è la sezione aurea di un segmento

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Algoritmo fibonacci1

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
• Qual è l’accuratezza di Φ e Φ necessaria per ottenere un risultato corretto?
• Ad esempio, se usiamo solo 3 cifre decimali:
Correttezza?ˆ
258425832583.118987987986.69816
221.999923Fnarrotondamentofibonacci1(n)n

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Algoritmo fibonacci2
algoritmo fibonacci2(intero n) → intero if (n ≤ 2) then return 1 else return fibonacci2(n-1) + fibonacci2(n-2)
Opera solo con numeri interi
Poiché fibonacci1 non dà risultati corretti, come approccio alternativo potremmo utilizzare direttamente la definizione (ricorsiva) :

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
• Quanto tempo richiede fibonacci2 ?• Come misuriamo il tempo?
– in secondi? (dipende da piattaforma)– in istruzioni macchina? (dipende da
compilatore…)• Prima approssimazione:
– numero linee di codice mandate in esecuzione(indipendente da piattaforma e compilatore)
Domande tipiche di questo corso

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Se n ≤ 2, una sola linea di codiceSe n = 3, 4 linee di codice:• 2 per la chiamata fibonacci2(3)• 1 per la chiamata fibonacci2(2)• 1 per la chiamata fibonacci2(1)
Tempo di esecuzione
algoritmo fibonacci2(intero n) → intero if (n ≤ 2) then return 1 else return fibonacci2(n-1) + fibonacci2(n-2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Relazione di ricorrenza
Per n ≥ 3 in ogni chiamata si eseguono 2 linee di codice, oltre a quelle eseguite nelle chiamate ricorsive:
T(n) = 2 + T(n-1) + T(n-2)
A parte il 2, è come per i conigli di Fibonacci!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
Relazioni di ricorrenza
In generale, tempo richiesto da algoritmi ricorsivi genera relazioni di ricorrenza
Il tempo di ogni funzione è pari al tempo speso all’interno della chiamata più il tempo speso nelle chiamate ricorsive
Risolvendo la relazione di ricorrenza otteniamo l’espressione del tempo
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
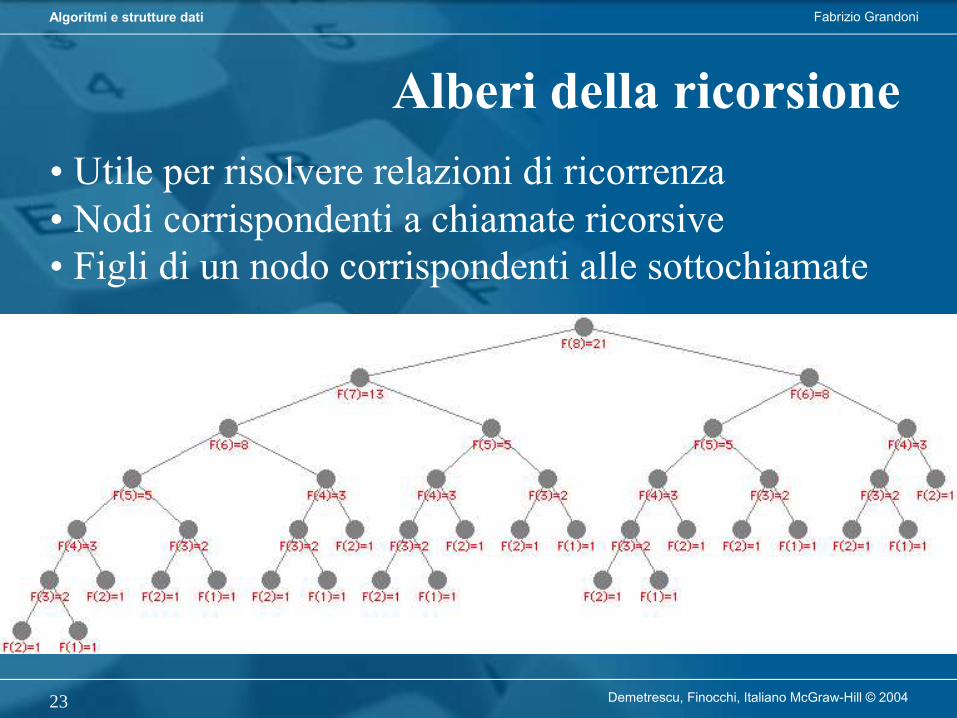
Alberi della ricorsione• Utile per risolvere relazioni di ricorrenza• Nodi corrispondenti a chiamate ricorsive• Figli di un nodo corrispondenti alle sottochiamate
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
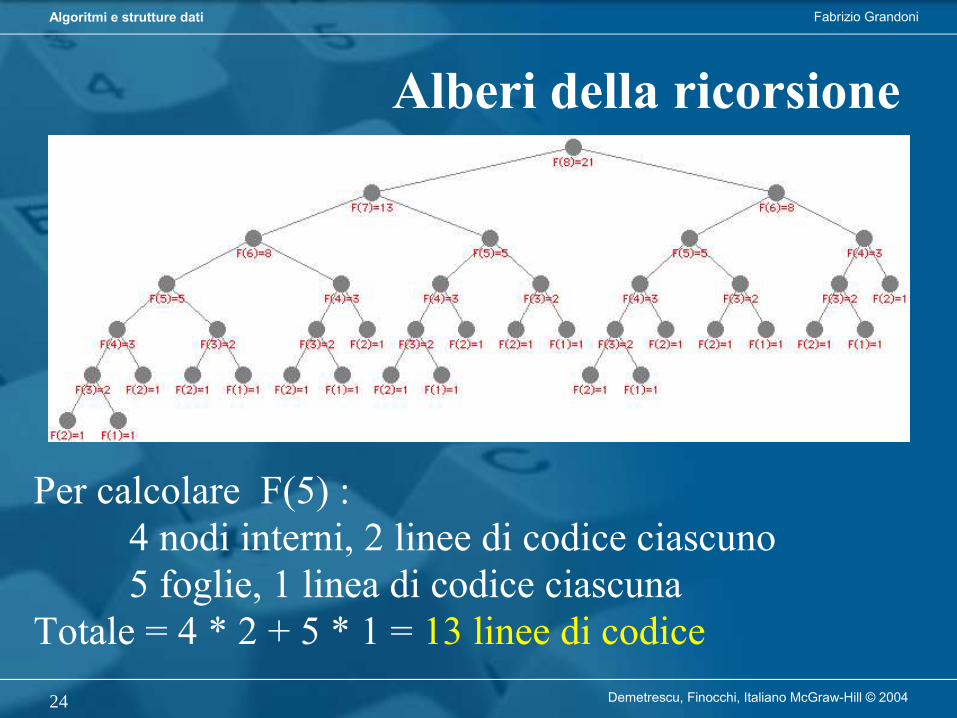
Alberi della ricorsione
Per calcolare F(5) :4 nodi interni, 2 linee di codice ciascuno5 foglie, 1 linea di codice ciascuna
Totale = 4 * 2 + 5 * 1 = 13 linee di codice

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
• Etichettiamo nodi dell’albero con numero di linee di codice eseguite nella chiamata corrispondente:– ogni nodo interno conta 2– ogni foglia conta 1
Numero di linee di codice per F(n)
• Per calcolare T(n) basta contare nell’albero della ricorsione:– numero di foglie– numero di nodi interni

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
• Numero di foglie dell’albero della ricorsione di fibonacci2(n) è pari a F(n)
Calcolare numero di foglie
• Esercizio: dimostrate per induzione che:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
• Dimostreremo per induzione che
Calcolare numero di nodi interni
• Numero di nodi interni di un albero in cui ogni nodo ha zero oppure due figli è pari al numero di foglie - 1

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200428
Induzione sul numero di foglie:
Dimostrazione
• Base. P (1) : 1 foglia, 0 nodi interni. Banale.
• Passo induttivo. P (k) implica P (k+1) Per generare albero con k+1 foglie, attacchiamo due figli ad una (vecchia) foglia
Numero di foglie: k -1 + 2 = k + 1Numero di nodi interni: (k -1) + 1 = k
P (k) : se albero ha k foglie ha (k-1) nodi interni

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200429
Calcolare T(n)
• In totale numero di linee di codice eseguite è F(n) + 2 ( F(n) – 1 ) = 3 F(n) - 2
• Numero di foglie dell’albero della ricorsione di fibonacci2(n) è pari a F(n)
• Numero di nodi interni dell’albero della ricorsione di fibonacci2(n) è pari a F(n) - 1

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200430
fibonacci2 è un algoritmo molto lento:
T(n) ≈ F(n) ≈ Φn
Possiamo fare di meglio?
Perché è lento? Continua a ricalcolare più volte la
soluzione dello stesso sottoproblema!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200431
Per evitare di risolvere più volte lo stesso sottoproblema, memorizziamo la soluzione dei vari sottoproblemi:
Programmazione Dinamica
algoritmo fibonacci3(intero n) → intero sia Fib un array di n interi Fib[1] ← Fib[2] ← 1 for i = 3 to n do Fib[i] ← Fib[i-1] + Fib[i-2] return Fib[n]

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200432
Tempo richiesto da fibonacci3algoritmo fibonacci3(intero n) → intero sia Fib un array di n interi Fib[1] ← Fib[2] ← 1 for i = 3 to n do Fib[i] ← Fib[i-1] + Fib[i-2] return Fib[n]
3 linee di codice sono eseguite sempre Prima linea del ciclo eseguita (n-1) volte [ 1 per n=1]Seconda linea del ciclo eseguita (n-2) volte [ 0 per n=1]
T(n) = 3 + n-1 + n-2 = 2n [ T(1) = 3+1 = 4 ]

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200433
• 2n molto meglio di 3Fn-2• L’algoritmo fibonacci3 impiega tempo
proporzionale a n piuttosto che esponenziale in n (fibonacci2)
• Tempo effettivo richiesto da implementazioni in C dei due algoritmi su piattaforme diverse:
fibonacci3 vs. fibonacci2

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200434
• Tempo di esecuzione non è sola risorsa che ci interessa.
• Tempo di programmazione e lunghezza del codice (Ingegneria del Software)
• Anche quantità di memoria richiesta può essere cruciale.– Se algoritmo lento, basta attendere più a lungo – Ma se algoritmo richiede più spazio (RAM) di quello
a disposizione, rischiamo di non ottenere mai la soluzione!
Occupazione di memoria

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200435
• fibonacci3 usa un array di dimensione n• In realtà non ci serve mantenere tutti i valori di Fn
precedenti, ma solo gli ultimi due, riducendo lo spazio a poche variabili in tutto:
Algoritmo fibonacci4
algoritmo fibonacci4(intero n) → intero a ← b ← 1 for i = 3 to n do c ← a+b a ← b b ← c return b

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200436
• Misurare T(n) come numero di linee di codice mandate in esecuzione è una misura molto approssimativa del tempo di esecuzione
• Se andiamo a capo più spesso, aumenteranno le linee di codice sorgente, ma certo non il tempo richiesto dall’esecuzione del programma!
Notazione asintotica (1 / 4)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200437
• Per lo stesso programma impaginato diversamente potremmo concludere ad esempio che T(n)=3n oppure T(n)=5n
• Vorremmo un modo per descrivere ordine di grandezza di T(n) ignorando dettagli inessenziali come costanti moltiplicative…
• Useremo a questo scopo la notazione asintotica O
Notazione asintotica (2 / 4)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200438
• Diremo che f(n) = O ( g(n) ) se f(n) ≤ c g(n) per qualche costante c, ed n abbastanza grande
Notazione asintotica (3 / 4)
cg(n)
f(n)
n0 n
f(n) = Ο( g(n) )

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200439
• Ad esempio, possiamo rimpiazzare:–T(n)=3Fn con T(n)=O(Fn)–T(n)=2n e T(n)=4n con T(n)=O(n)–T(n)= Fn con O(2n)
Notazione asintotica (4 / 4)
• Notazione O semplifica la vita:–Trascurare dettagli di basso livello–Confrontare facilmente algoritmi –Alg 2 e alg 4 sono O(n): meglio di O(2n) !

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200440
• Possiamo calcolare Fn in tempo inferiore a O(n)?
• E’ semplice dimostrare (per induzione) la seguente proprietà di matrici:
Potenze ricorsive
1 1
1 0
n=
Fn+1 Fn
Fn Fn-1
• Useremo questa proprietà per progettare un algoritmo più efficiente di fibonacci4

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200441
Algoritmo fibonacci5
• Tempo di esecuzione è ancora O(n)• Cosa abbiamo guadagnato?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200442
• Possiamo calcolare la n-esima potenza elevando al quadrato la (n/2)-esima potenza
• Se n è dispari eseguiamo una ulteriore moltiplicazione
• Esempio: calcolare 38
32=9 34 =(9)2 =81 38=(81)2 =6561
Calcolo di potenze

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200443
Algoritmo fibonacci6

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200444
• Tutto il tempo è speso nella funzione potenzaDiMatrice– All’interno della funzione si spende tempo costante– Si esegue una chiamata ricorsiva con input n/2
• L’equazione di ricorrenza è pertanto:
Tempo di esecuzione
T(n) = O(1) + T(n/2)
• Come risolverla?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200445
T(n) ≤ c + T(n/2) ≤ c + c + T(n/4) = 2c + T(n/22)
Metodo dell’iterazione
In generale:
T(n) ≤ c k + T(n/2k)
Per k = log2 n si ottiene
T(n) ≤ c log2 n + T(1) = O(log2 n )
fibonacci6 è quindi esponenzialmente più veloce di fibonacci3!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200446
Riepilogo
fibonacci6
fibonacci5
fibonacci4
fibonacci3
fibonacci2
O(log n)O(n)
O(n)
O(n)
O(2n)
O(log n)O(1)
O(1)
O(n)
O(n)
Tempo di esecuzione
Occupazione di memoria

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200447
1. Progettare algoritmi efficienti cruciale2. Come misurare tempo/spazio?
– metrica indipendente da piattaforme e tecnologie3. In funzione di cosa esprimiamo risorse?
– dimensione dell’input (per Fn non è n ma log n)
4. Come confrontare algoritmi diversi?– stima dell’ordine di grandezza – notazione O
5. Progetto/analisi richiedono strumenti matematici– e.g., relazioni di ricorrenza, induzione, etc…
Cosa abbiamo imparato?

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 2Modelli di calcolo e
metodologie di analisi
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
• f (n) = risorsa (tempo di esecuzione / occupazione di memoria) richiesta da un algoritmo su input di dimensione n
• Notazione asintotica è astrazione utile per descrivere ordine di grandezza di f (n) ignorando dettagli non influenti, come ad esempio costanti moltiplicative e termini di ordine inferiore
Notazione asintotica

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
f (n) = O( g(n) ) se ∃ c > 0 e n0 ≥ 0 tali che f(n) ≤ c g(n) per ogni n ≥ n0
Notazione asintotica O
cg(n)
f(n)
n0 n
f(n) = Ο( g(n) )
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
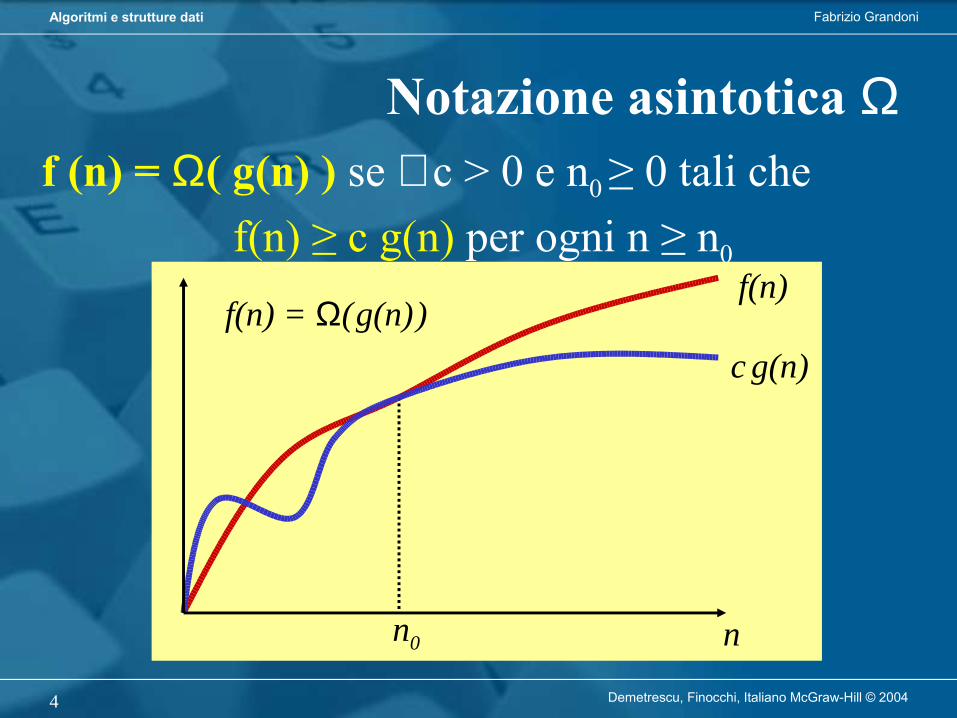
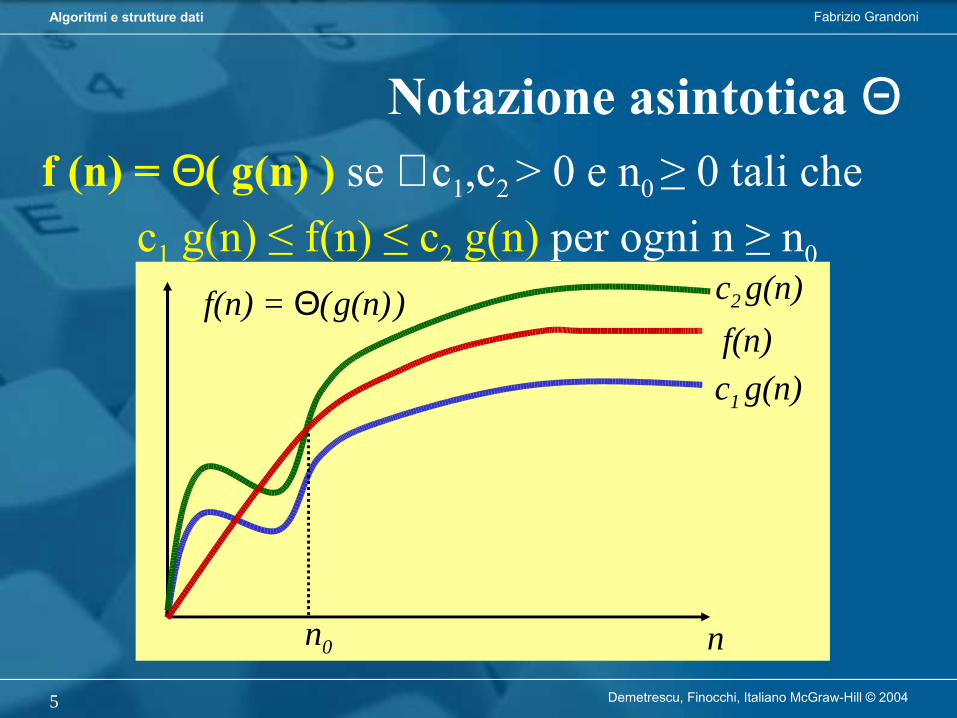
f (n) = Ω( g(n) ) se ∃ c > 0 e n0 ≥ 0 tali che f(n) ≥ c g(n) per ogni n ≥ n0
Notazione asintotica Ω
n0 n
f(n) = Ω( g(n) )f(n)
c g(n)
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
f (n) = Θ( g(n) ) se ∃ c1,c2 > 0 e n0 ≥ 0 tali che c1 g(n) ≤ f(n) ≤ c2 g(n) per ogni n ≥ n0
Notazione asintotica Θ
n0 n
f(n) = Θ( g(n) )f(n)
c1 g(n)
c2 g(n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Consideriamo g(n) = 3n2 + 10–g(n) = O(n2): basta scegliere c = 4 e n0 = 10–g(n) = Ω(n2): basta scegliere c = 1 e n0 = 0–g(n) = Θ(n2): infatti g(n) = Θ(f(n)) se e solo
se g(n) = Ο(f(n)) e g(n) = Ω(f(n)) –g(n) = O(n3) ma g(n) ≠ Θ(n3)
Notazione asintotica: esempi
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
Metodi di analisi

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
Ricerca di elemento x in lista L non ordinata
Ricerca sequenziale
Quanti confronti per trovare x in L ?Dipende da dove si trova x(all’inizio, alla fine, non c’è…)Vorremmo una risposta che non sia “dipende”

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
• Misuriamo risorse di calcolo (tempo di esecuzione / occupazione di memoria) richieste da un algoritmo in funzione della dimensione n dell’istanza d’ingresso
• A parità di dimensione, istanze diverse potrebbero richiedere risorse diverse
• Distinguiamo ulteriormente tra analisi nel caso peggiore, migliore e medio
Caso peggiore, migliore e medio

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
• Sia t (I) il tempo di esecuzione di un algoritmo su istanza I
Tworst(n) = max istanze I, |I| = n t (I)
• Intuitivamente, Tworst(n) è tempo di esecuzione su istanze di ingresso che comportano più lavoro per l’algoritmo
• Dà garanzie sulle prestazioni
Caso peggiore

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Tbest(n) = min istanze I, |I| = n t (I)
• Intuitivamente, Tbest(n) è il tempo di esecuzione sulle istanze di ingresso che comportano meno lavoro per l’algoritmo
• Non ci dà molta informazione…
Caso migliore

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
• P(I) probabilità di avere in ingresso istanza I
Tavg(n) = ∑ istanze I, |I| = n P(I) t (I)
• Intuitivamente, Tavg(n) è tempo medio di esecuzione (ovvero su istanze di ingresso “tipiche” per il problema)
• Richiede conoscenza di distribuzione statistica dell’input
Caso medio

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Tavg(n) = ∑ istanze I, |I| = n P(I) t (I)
• Ipotesi su distribuzione statistica dell’input?• Possiamo avere algoritmi per cui nessun
input richiede tempo medio (e.g., algoritmo richiede 1 o 100 passi)
• Più importante ma problematico nel definire input “tipico”
Caso medio

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Ricerca di elemento x in lista L non ordinata
Ricerca sequenziale
Tbest(n) = 1 (x è in prima posizione)Tworst(n) = n (x∉L oppure è in ultima posizione)
Tavg(n) = ???

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Tavg(n) = ∑ istanze I, |I| = n P(I) t (I) • Qual è la posizione “tipica” di x?• Ipotesi : se x∈L, potrebbe stare ovunque
P ( pos(x) = i ) = 1/n
Tavg(n) = ∑1,..,n P( pos(x) = i ) i = = ∑1,..,n (1/n) i = (1/n) ∑1,..,n i = = (n+1)/2
Caso medio di ricerca sequenziale

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Ricerca sequenziale
Tbest(n) = 1 x è in prima posizione
Tworst(n) = n x∉L oppure è in ultima posizione
Tavg(n) = (n+1)/2 ipotesi ragionevole: se x∈L, potrebbe stare ovunque
Tavg(n) = p (n+1)/2 + (1-p) n = n - p (n - 1) / 2
ipotesi di prima + P (x∈L) = p

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Ricerca di un elemento x in un array L ordinato
Ricerca Binaria
Confronta x con elemento centrale di L e prosegue a sinistra o a destra in base ad esito del confronto

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Analisi ricerca binaria
Tbest(n) = 1 l’elemento centrale è uguale a x
Tworst(n) = ???
Tavg(n) = ???
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
Analisi di algoritmi ricorsivi

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
L’algoritmo di ricerca binaria può essere riscritto ricorsivamente come:
Esempio
Come analizzarlo?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Tempo di esecuzione può essere descritto tramite relazioni di ricorrenza:
Relazioni di ricorrenza
c + T( n-1 / 2 ) se n > 11 se n = 1
T(n) =
Vari metodi per risolvere relazioni di ricorrenza: iterazione, sostituzione, teorema Master...
simile a fibonacci6

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
Idea: “srotolare” ricorsione, ottenendo sommatoria dipendente solo da dimensione n del problema iniziale
1. Metodo dell’iterazione
Esempio: T(n) = c + T(n/2) T(n/2) = c + T(n/4) ...
T(n) = c + T(n/2) = 2c + T(n/4) = = ( ∑j=1...i c ) + T(n/2i) = i c + T(n/2i)
Per i = log2n: T(n) = c log2 n + T(1) = O(log n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Analisi ricerca binaria
Tbest(n) = 1 l’elemento centrale è uguale a xTworst(n) = O( log n ) x∉L oppure viene trovato all’ultimo confronto
Tavg(n) = log n -1+1/n assumendo che le istanze siano equidistribuite

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
Idea: “intuire” soluzione, e usare induzione per verificare che la soluzione della relazione di ricorrenza sia effettivamente quella intuita
2. Metodo della sostituzione
Esempio: T(n) = n + T(n/2), con T(1)=1
“Intuiamo” soluzione T(n) ≤ c n per opportuna costante cPasso base. T(1) =1 c 1 per ogni c 1≤ ≥Passo induttivo. T(n) = n + T(n/2) n + c (n/2) = (c/2+1) n ≤T(n) c n se≤ c/2+1 c ovvero per ogni c 2≤ ≥

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
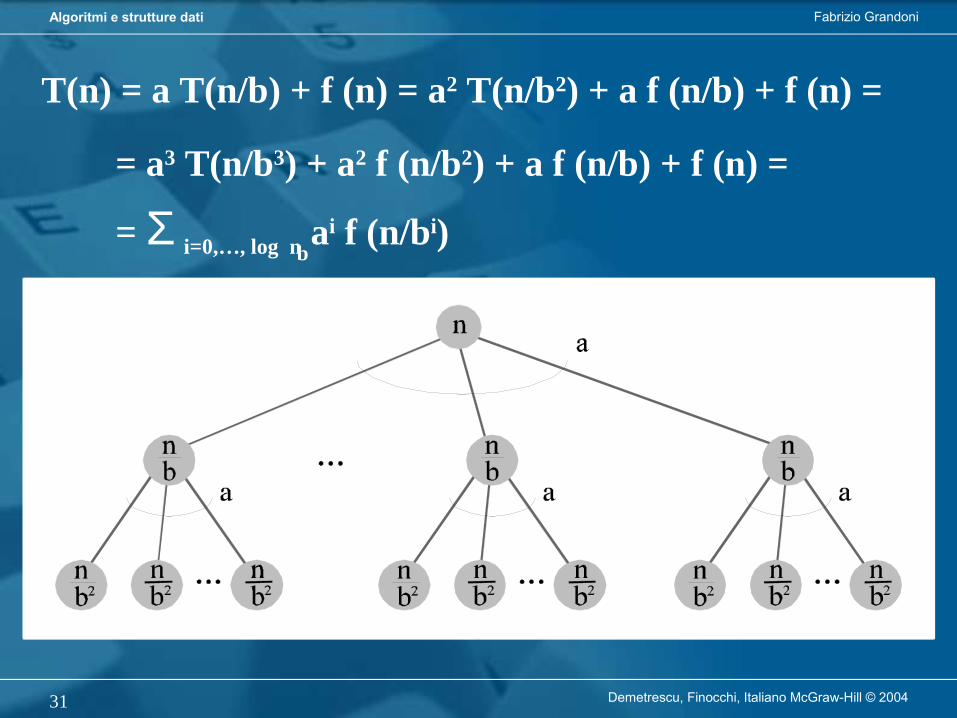
3. Teorema MasterPermette di analizzare algoritmi basati su tecnica del divide et impera:- dividi il problema (di dimensione n) in a sottoproblemi di dimensione n/b- risolvi ricorsivamente i sottoproblemi- ricombina le soluzioni
Sia f(n) tempo per dividere e ricombinare istanze di dimensione n. La relazione di ricorrenza è data da:
a T(n/b) + f (n) se n > 11 se n = 1
T(n) =

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
Relazione di ricorrenza:
Teorema Master
ammette soluzione:
a T(n/b) + f (n) se n > 11 se n = 1T(n) =
1. T(n) = Θ(n ) se f (n) = O(n ) per ε > 0logba logba - ε
2. T(n) = Θ(n log n) se f (n) = Θ(n ) logba logba
3. T(n) = Θ(f(n)) se f (n) = Ω(n ) per ε > 0 e a f (n/b) c≤ f (n) per c < 1 e n sufficientemente grande
logba + ε

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
Teorema Master
Confronta le due funzioni n e f (n) :
a T(n/b) + f (n) se n > 11 se n = 1T(n) =
1. T(n) = Θ(n ) se “vince” n
logba logba
2. T(n) = Θ( f (n) log n ) se f (n) = Θ(n ) logba
3. T(n) = Θ( f (n) ) se “vince” f (n)
logba
N.B. nei casi 1. e 3. T(n) = Θ( f (n) + n ) logba

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200428
1) T(n) = n + 2 T(n/2) a = 2, b = 2, f(n) = n = Θ(n ) T(n) = Θ(n log n) (Caso 2 del Teorema Master)
Esempi
log22
2) T(n) = c + 3 T(n/9) a = 3, b = 9, f(n) = c = Ο(n ) T(n) = Θ(√n) (Caso 1 del Teorema Master)
log93 - ε

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200429
Esempi3) T(n) = n + 3 T(n/9) a = 3, b = 9, f(n) = n = Ω(n ) (Caso 3 del Teorema Master)
log93 + ε
T(n) = Θ(n)3(n/9) c n per c = 1/3≤
4) T(n) = n log2 n + 2 T(n/2) Il Teorema Master non può essere applicato! f (n) = n log2 n = Ω ( n ) = Ω ( n ) f (n) = n log2 n non è Ω ( n ) = Ω ( n )
log22 + ε
log22ε

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200430
Dimostrazione Teorema Master
a T(n/b) + f (n) se n > 11 se n = 1T(n) =
1. T(n) = Θ(n ) se f (n) = O(n ) per ε > 0logba logba - ε
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200431
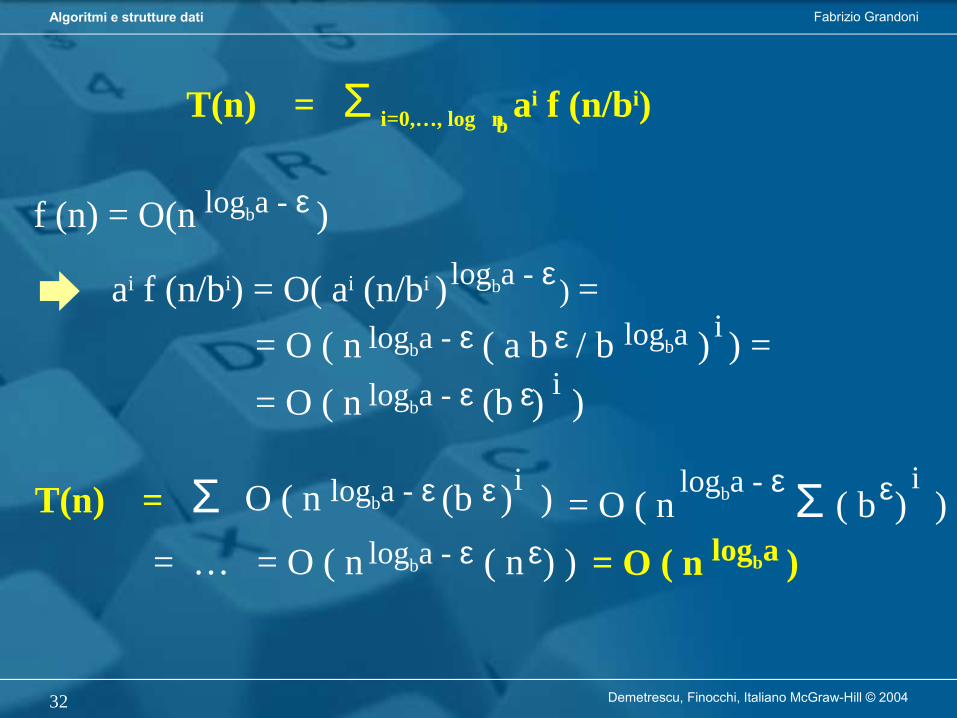
T(n) = a T(n/b) + f (n) = a2 T(n/b2) + a f (n/b) + f (n) =
= a3 T(n/b3) + a2 f (n/b2) + a f (n/b) + f (n) =
= Σ i=0,…, log n ai f (n/bi)b
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200432
T(n) = Σ i=0,…, log n ai f (n/bi)b
f (n) = O(n )logba - ε
ai f (n/bi) = O( ai (n/bi ) ) =logba - ε
logba - ε= O ( n ( a b / b ) ) = ε logba i
logba - ε= O ( n (b ) ) ε i
T(n) = Σ logba - ε O ( n (b ) ) ε i= O ( n Σ ( b ) )
logba - ε ε i
= O ( n ( n ) )logba - ε ε = O ( n ) logba= …

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200433
• Esprimiamo quantità di una certa risorsa di calcolo (tempo, spazio) usata da un algoritmo in funzione della dimensione n dell’istanza di ingresso
• La notazione asintotica permette di esprimere quantità di risorsa usata dall’algoritmo in modo sintetico, ignorando dettagli non influenti
• A parità di dimensione n dell’istanza di ingresso, quantità di risorsa usata può essere diversa, da cui caso peggiore, caso medio
• Quantità di risorsa usata da algoritmi ricorsivi può essere espressa tramite relazioni di ricorrenza, risolvibili tramite metodi generali
Riepilogo

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 3Strutture dati elementari
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Gestione di collezioni di oggetti
Tipo di dato:– Specifica delle operazioni di interesse su
una collezione di oggetti (es. inserisci, cancella, cerca)
Struttura dati:– Organizzazione dei dati che permette di
supportare le operazioni di un tipo di dato usando meno risorse di calcolo possibile

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Il tipo di dato Dizionario

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Il tipo di dato Pila

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
Il tipo di dato Coda

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Tecniche di rappresentazione dei dati
Rappresentazioni indicizzate:– I dati sono contenuti in array
Rappresentazioni collegate:– I dati sono contenuti in record collegati fra
loro mediante puntatori

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
Pro e contro
Rappresentazioni indicizzate:– Pro: accesso diretto ai dati mediante indici– Contro: dimensione fissa (riallocazione
array richiede tempo lineare)
Rappresentazioni collegate:– Pro: dimensione variabile (aggiunta e
rimozione record in tempo costante)– Contro: accesso sequenziale ai dati
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
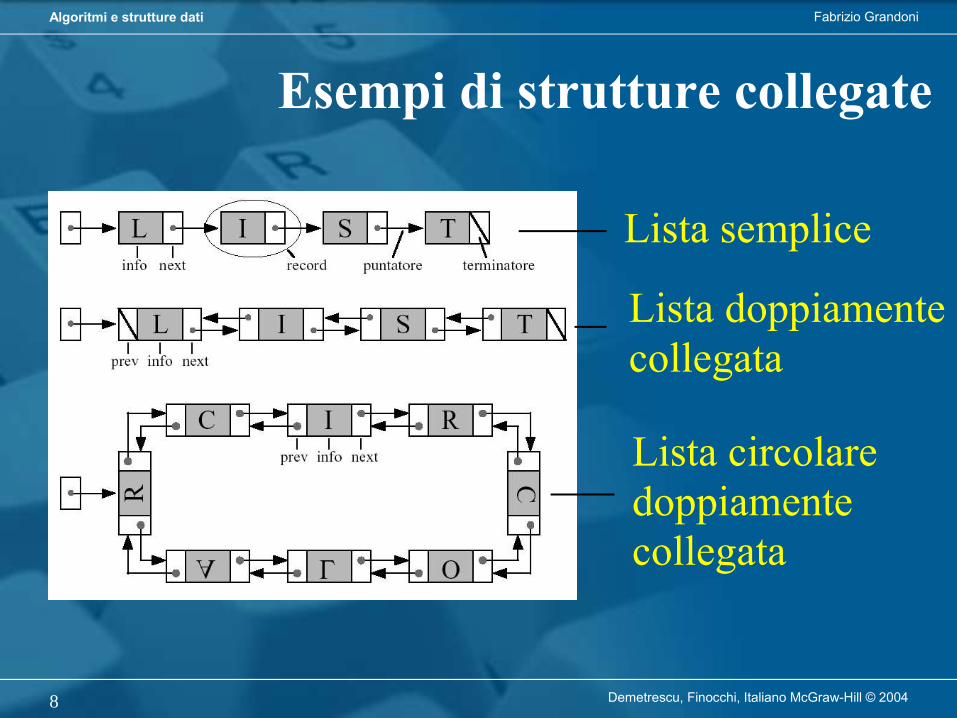
Esempi di strutture collegate
Lista semplice
Lista doppiamentecollegata
Lista circolaredoppiamentecollegata
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
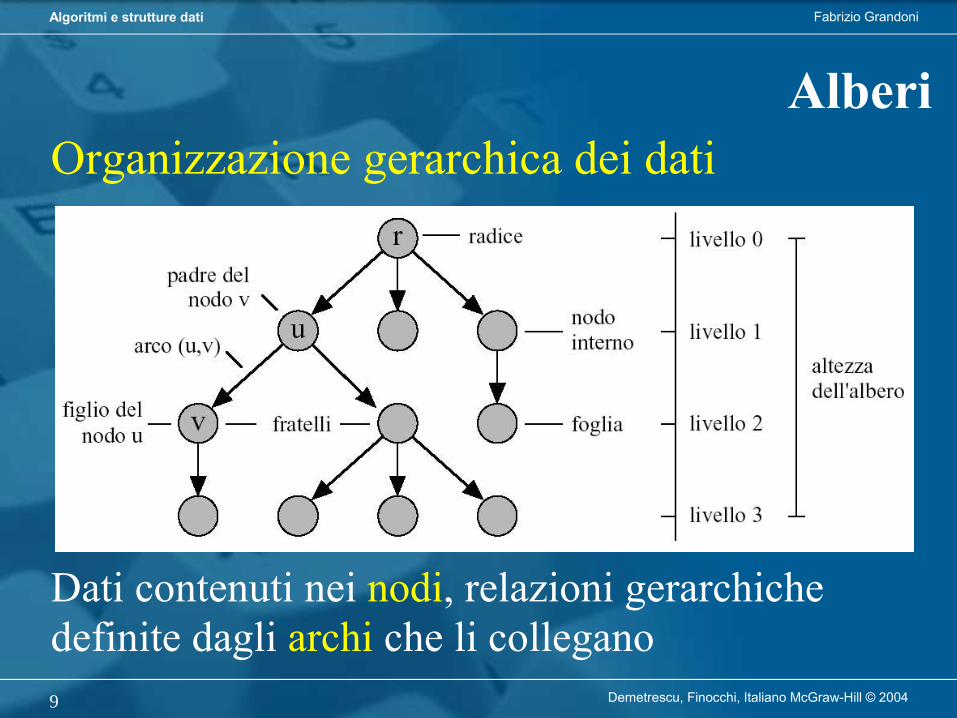
AlberiOrganizzazione gerarchica dei dati
Dati contenuti nei nodi, relazioni gerarchichedefinite dagli archi che li collegano
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
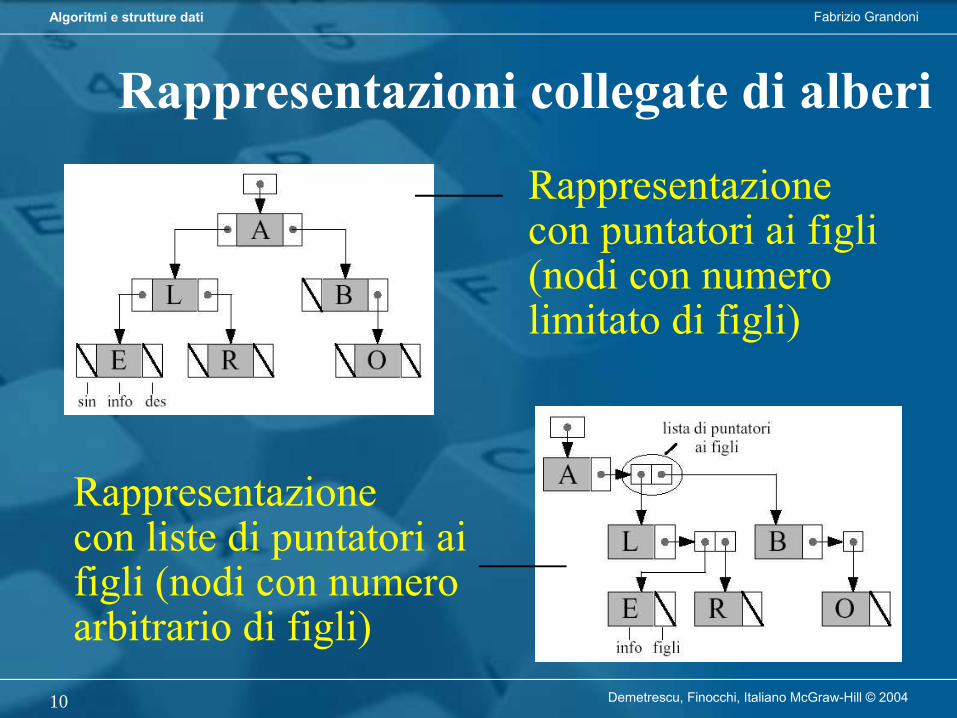
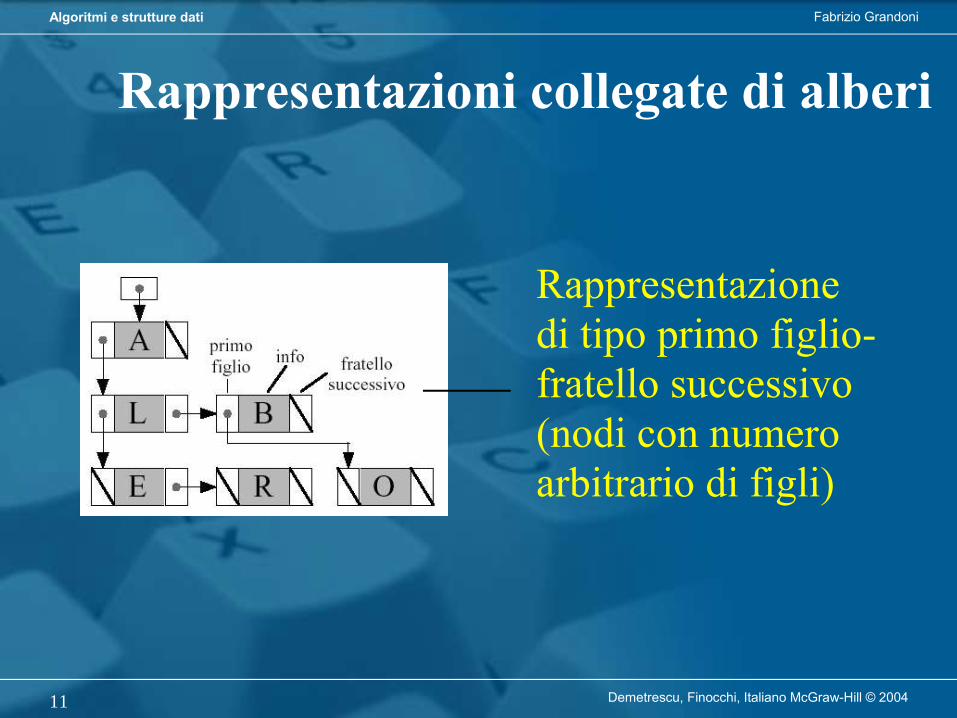
Rappresentazioni collegate di alberi
Rappresentazionecon puntatori ai figli (nodi con numero limitato di figli)
Rappresentazionecon liste di puntatori ai figli (nodi con numero arbitrario di figli)
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Rappresentazioni collegate di alberi
Rappresentazionedi tipo primo figlio-fratello successivo (nodi con numero arbitrario di figli)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
Visite di alberi
Algoritmi che consentono l’accesso sistematico ai nodi e agli archi di un albero
Gli algoritmi di visita si distinguono in base al particolare ordine di accesso ai nodi

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Algoritmo di visita genericavisitaGenerica visita il nodo r e tutti i suoi discendenti in un albero
Richiede tempo O(n) per visitare un albero con n nodi a partire dalla radice

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Algoritmo di visita in profondità
L’algoritmo di visita in profondità (DFS) parte da r e procede visitando nodi di figlio in figlio fino a raggiungere una foglia. Retrocede poi al primo antenato che ha ancora figli non visitati (se esiste) e ripete il procedimento a partire da uno di quei figli.

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Algoritmo di visita in profondità
Versione iterativa (per alberi binari):

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Algoritmo di visita in profondità
Versione ricorsiva (per alberi binari):

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Algoritmo di visita in ampiezza
L’algoritmo di visita in ampiezza (BFS) parte da r e procede visitando nodi per livelli successivi. Un nodo sul livello i può essere visitato solo se tutti i nodi sul livello i-1 sono stati visitati.

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Algoritmo di visita in ampiezza
Versione iterativa (per alberi binari):

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
• Nozione di tipo di dato come specifica delle operazioni su una collezione di oggetti
• Rappresentazioni indicizzate e collegate di collezioni di dati: pro e contro
• Organizzazione gerarchica dei dati mediante alberi
• Rappresentazioni collegate classiche di alberi• Algoritmi di esplorazione sistematica dei nodi di
un albero (algoritmi di visita)
Riepilogo

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 4Ordinamento
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Dato un insieme S di n oggetti presi da un dominio totalmente ordinato, ordinare S
Ordinamento
• Subroutine di molti problemi
• E’ possibile effettuare ricerche in array ordinati in tempo O(log n)
• Esempi: ordinare alfabeticamente lista di nomi, o insieme di numeri, o insieme di compiti d’esame in base a cognome studente

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
• Numerosi algoritmi• Tre tempi tipici: O(n2), O(n log n), O(n)
Algoritmi e tempi tipici
n
n log2 n
n2
10
~ 33
100
100
~ 665
104
1000
106
106
~ 2 · 107
1012
109
1018
~ 104 ~ 3 · 1010
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Algoritmi di ordinamento

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
SelectionSort
1 2 4 5 3 7
7 2 4 5 3 1
1 2 4 5 3 7
1 2 3 5 4 7
1 2 3 4 5 7
1 2 3 4 5 7
1 2 3 4 5 7
Approccio incrementale. Estende ordinamento da k a (k+1) elementi, scegliendo minimo tra (n-k) elementi non ancora ordinati e mettendolo in posizione (k+1)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
SelectionSort: analisi
k - esima estrazione di minimo costa tempo O(n-k)
In totale, il tempo di esecuzione è:
∑k=1
n-1
O(n-k) ∑i=1
n-1
i= ( O ) = O(n2)
[ cambiamento di variabile (i = n – k) e serie aritmetica ]

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
InsertionSort
2 7 4 5 3 1
7 2 4 5 3 1
2 4 7 5 3 1
2 4 5 7 3 1
2 3 4 5 7 1
1 2 3 4 5 7
Approccio incrementale. Estende ordinamento da k a (k+1) elementi, posizionando elemento (k+1)-esimo nella posizione corretta rispetto ai primi k elementi

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
InsertionSort: analisi
Inserimento del k-esimo elemento nella posizione corretta rispetto ai primi k richiede tempo O(k) nel caso peggiore
In totale, il tempo di esecuzione è :
∑k=1
n-1
k( O ) = O(n2)
[ serie aritmetica ]

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
BubbleSort• Esegue una serie di scansioni dell’array
– In ogni scansione confronta coppie di elementi adiacenti, scambiandoli se non sono nell’ordine corretto
– Dopo una scansione in cui non viene effettuato nessuno scambio l’array è ordinato
• Dopo la k-esima scansione, i k elementi più grandi sono correttamente ordinati ed occupano le k posizioni più a destra correttezza e tempo di esecuzione O(n2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
Esempio di esecuzione
2 4 5 3 1 7
7 2 4 5 3 1
2 4 3 1 5 7
724 7
75731 7
424 5
5351
2 4 3 1 5 7
2 3 1 4 5 7
2 1 3 4 5 7
1 2 3 4 5 7
423 4
41
321 3
21
(1)
(2)
(3)
(4)
(5)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Possiamo fare di meglio ?
O( n2 ) è quanto di peggio si possa fare: tutti i confronti possibili!
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
1. QuickSort2. MergeSort3. HeapSort

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
• Usa la tecnica del divide et impera:
1 Divide: scegli un elemento x della sequenza (pivot) e partiziona la sequenza in elementi ≤ x ed elementi > x
2 Risolvi i due sottoproblemi ricorsivamente3 Impera: restituisci la concatenazione delle
due sottosequenze ordinate
QuickSort

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Partizione in loco
• Scorri l’array “in parallelo” da sinistra verso destra e da destra verso sinistra – da sinistra verso destra, ci si ferma su un elemento
maggiore del pivot– da destra verso sinistra, ci si ferma su un elemento
minore del pivot• Scambia gli elementi e riprendi la scansione
Tempo di esecuzione: O(n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Partizione in loco: un esempio
45 12 21 3 67 43 85 29 24 92 63 3 93
45 12 21 3 3 43 85 29 24 92 63 67 93
45 12 21 3 3 43 2924 92 63 67 9385
45 12 93 3 67 43 85 29 24 92 63 3 21

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
• Nel caso peggiore, il pivot scelto ad ogni passo è il minimo o il massimo degli elementi nell’array
• Il numero di confronti nel caso peggiore è :C(n) = C(n-1) + O(n)
• Risolvendo per iterazione si ottiene C(n) = O(n2)
Analisi nel caso peggiore

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Esempio di esecuzione
5 1 276
2 45 7 6
1 4 3
3
1 2 3 4 5 5 6 7
1 2 3 4 6
1 3 4
3
input
output
2 45 3 1 7 6 dopo partition5
3 1
5
2 631 4
5
5
43 5
3
5
5
5
1
6
6
6
5
45
77
3
L’albero delle chiamate ricorsive può essere sbilanciato

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Randomizzazione• Possiamo evitare il caso peggiore scegliendo
come pivot un elemento a caso• Poiché ogni elemento ha la stessa probabilità,
pari a 1/n, di essere scelto come pivot, il numero di confronti nel caso atteso è:
∑a=0
n-1
C(n)= n-1+C(a)+C(n-a-1)1n ∑
a=0
n-1
= n-1+ C(a)2n
dove a e (n-a-1) sono le dimensioni dei sottoproblemi risolti ricorsivamente

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
La relazione di ricorrenza
Analisi nel caso medio
∑a=0
n-1
C(n)= n-1+ C(a)2n
ha soluzione C(n) ≤ 2 n log n
Dimostrazione per sostituzioneAssumiamo per ipotesi induttiva che C(i) ≤ 2 i log i
∑i=0
n-1
C(n) n-1+≤ 2 i log i2n ∫
2
n
≤n-1+ x log x dx4n
Integrando per parti si dimostra che C(n) ≤ 2 n log n

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Usiamo la tecnica del divide et impera:
1 Divide: dividi l’array a metà2 Risolvi il sottoproblema ricorsivamente3 Impera: fondi le due sottosequenze ordinate
MergeSort
Rispetto a QuickSort, divide semplice ed impera complicato

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
• Due array ordinati A e B possono essere fusi rapidamente:– estrai ripetutamente il minimo di A e B e copialo
nell’array di output, finché A oppure B non diventa vuoto
– copia gli elementi dell’array non vuoto alla fine dell’array di output
• Tempo: O(n), dove n è il numero totale di elementi
Fusione (Merge)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
Mergesort: esempio di esecuzione7 2 4 5 3 1 5 6
7 2 4 5 3 1 5 6
7 2 4 5 3 1 5 6
7 2 4 5 3 1 5 6
1 2 3 4 5 5 6 7
2 4 5 7 1 3 5 6
2 7 4 5 1 3 5 6
7 2 4 5 3 1 5 6
input
output
Input ed output delle
chiamatericorsive

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
• Numero di confronti del MergeSort descritto da relazione di ricorrenza:
C(n) = 2 C(n/2) + O(n)
• Da Teorema Master si ottiene la soluzione
C(n) = O(n log n)
Tempo di esecuzione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
• Stesso approccio incrementale del SelectionSort• Usa però struttura dati più efficiente per estrarre
massimo ad ogni iterazione
• Struttura dati heap associata ad insieme S : albero binario radicato con le seguenti proprietà:1) completo fino al penultimo livello2) elementi di S memorizzati nei nodi dell’albero3) chiave(padre(v)) ≥ chiave(v) per ogni nodo v
HeapSort
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
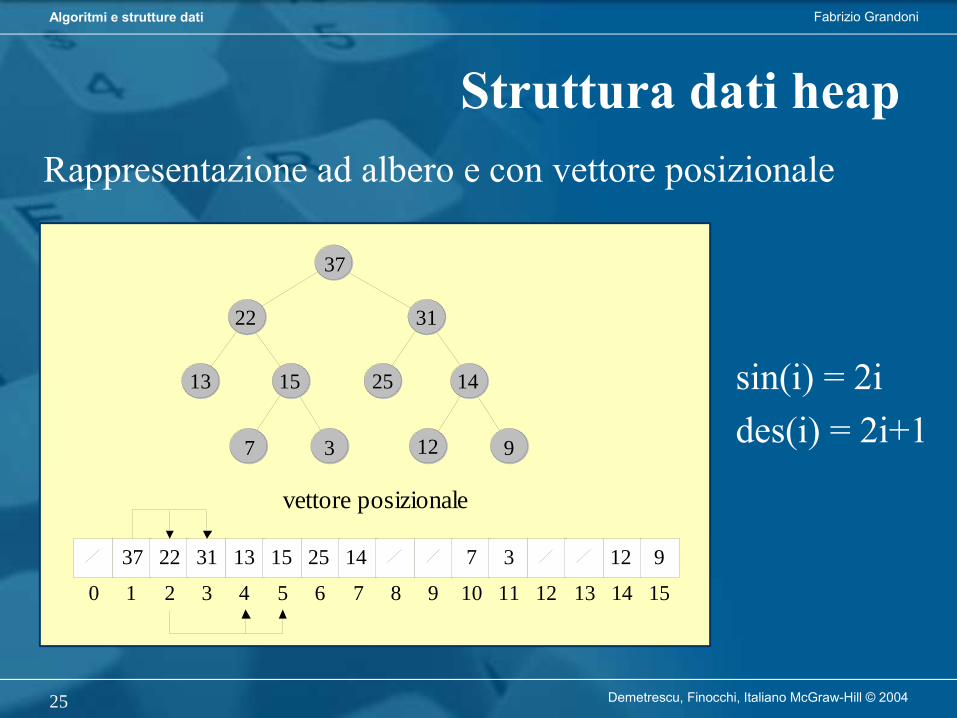
Struttura dati heap
37
22 31
14251513
37 912
37 22 31 13 15 25 14 7 3 12 9
vettore posizionale
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Rappresentazione ad albero e con vettore posizionale
sin(i) = 2ides(i) = 2i+1

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
Heap con struttura rafforzata
37
22 31
14251513
37 912
37 22 31 13 15 25 14 7 3 12 9
vettore posizionale
0 1 2 3 4 5 6 7 8 9 10 11
Le foglie nell’ultimo livello sono compattate a sinistra
Il vettoreposizionale haesattamente dimensione n

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
Proprietà salienti degli heap
1) Il massimo è contenuto nella radice
2) L’albero ha altezza O(log n)
1) Gli heap con struttura rafforzata possono essere rappresentati in un array di dimensione n

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200428
fixHeap(nodo v, heap H)
if (v è una foglia) then return
else
sia u il figlio di v con chiave massima
if ( chiave(v) < chiave(u) ) then
scambia chiave(v) e chiave(u)
fixHeap(u,H)
La procedura fixHeapSe tutti i nodi di H tranne v soddisfano la proprietà di ordinamento a heap, possiamo ripristinarla come segue:
Tempo di esecuzione: O(log n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200429
• Copia nella radice la chiave contenuta nella la foglia più a destra dell’ultimo livello
• Rimuovi la foglia
• Ripristina la proprietà di ordinamento a heap richiamando fixHeap sulla radice
Estrazione del massimo
Tempo di esecuzione: O(log n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200430
heapify(heap H)
if (H è vuoto) then return
else
heapify(sottoalbero sinistro di H)
heapify(sottoalbero destro di H)
fixHeap(radice di H,H)
Costruzione dell’heapAlgoritmo ricorsivo basato su divide et impera
Tempo di esecuzione: T(n) = 2 T(n/2) + O(log n)
T(n) = O(n) dal Teorema Master

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200431
• Costruisci un heap tramite heapify
• Estrai ripetutamente il massimo per (n-1) volte– ad ogni estrazione memorizza il massimo
nella posizione dell’array che si è appena liberata
HeapSort
ordina “in loco” in tempo O(n log n)
O(n)
O(n log n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200432
Esempio di esecuzione
37 31 22 13 15 25
37
31
251513
22
22
15 13
22 15 13 25 31 37
(1)
(4)
31
25
1513
22
31 25 22 13 15 37
15
13
15 13 22 25 31 37
(2)
(5)
25
15
13
22
25 15 22 13 31 37
13
13 15 22 25 31 37
(3)
(6)
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200433
Possiamo fare meglio di O(n log n)?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200434
• Dimostrazione (matematica) che non possiamo andare più veloci di una certa quantità
• Più precisamente, ogni algoritmo all’interno di un certo modello di calcolo deve avere tempo di esecuzione almeno pari a quella quantità
• Non significa necessariamente che non è possibile fare di meglio (basta cambiare il modello…)
Lower bound

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200435
• Delimitazione inferiore: quantità di risorsa necessaria per risolvere un determinato problema
• Dimostrare che Ω(n log n) è lower bound al numero di confronti richiesti per ordinare n oggetti.
• Come?
• Dobbiamo dimostrare che tutti gli algoritmi richiedono Ω(n log n) confronti!
Lower bound

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200436
• In questo modello, per ordinare è possibile usare solo confronti tra oggetti
• Primitive quali operazioni aritmetiche (somme o prodotti), logiche (and e or), o altro (shift) sono proibite
• Sufficientemente generale per catturare le proprietà degli algoritmi più noti
Modello basato su confronti

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200437
• Consideriamo un qualsiasi algoritmo A, che ordina solo mediante confronti
• Non abbiamo assolutamente idea di come funziona A !
• Ciò nonostante, dimostreremo che A deve eseguire almeno Ω(n log n) confronti
• Dato che l’unica ipotesi su A è che ordini mediante confronti, il lower bound sarà valido per tutti gli algoritmi basati su confronti!
Come dimostrare lower bound
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200438
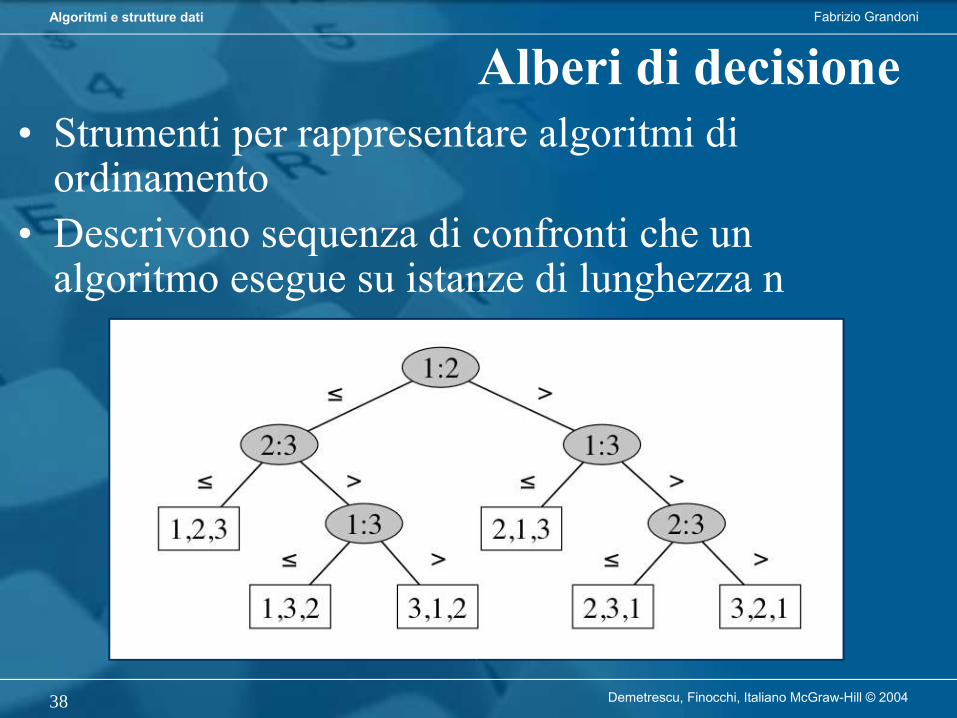
Alberi di decisione• Strumenti per rappresentare algoritmi di
ordinamento• Descrivono sequenza di confronti che un
algoritmo esegue su istanze di lunghezza n

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200439
Alberi di decisione
• Ogni algoritmo basato su confronti può essere rappresentato da un albero di decisione:– confronti scelti dall’algoritmo possono dipendere solo
dagli esiti dei confronti precedenti!• Un albero di decisione può essere “letto” come
algoritmo basato su confronti:– per ogni input, il cammino nell’albero descrive confronti
da effettuare e permutazione che produce soluzione
= algoritmi basati su confronti!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200440
• Per una particolare istanza, i confronti eseguiti da A su quella istanza sono rappresentati da un cammino radice - foglia
• Il numero di confronti nel caso peggiore è pari all’altezza dell’albero di decisione
• Un albero di decisione per l’ordinamento di n elementi contiene almeno (n!) foglie
(una per ogni possibile permutazione degli n oggetti)
Proprietà alberi di decisione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200441
• Un albero binario con k foglie tale che ogni nodo interno ha esattamente due figli ha altezza almeno log2 k
• Dimostrazione per induzione su k:– Passo base: 0 ≥ log2 1– h(k) ≥ 1 + h(k/2) poiché uno dei due sottoalberi ha
almeno metà delle foglie– h(k/2) ≥ log2 (k/2) per ipotesi induttiva
– h(k) ≥ 1 + log2 (k/2) = log2 k
Lower bound

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200442
• L’albero di decisione ha almeno n! foglie
• La sua altezza è almeno log2 (n!)
• Formula di Stirling: n! ≥ (2πn)1/2 · (n/e) n
• Quindi: log2 (n!) = Ω (n log n)
Il lower bound Ω (n log n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200443
Ordinamenti lineari(per dati con proprietà particolari)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200444
Sappiamo che gli n elementi da ordinare sono tutti distinti e nell’intervallo [1,n]
In quanto tempo possiamo ordinarli?
O(1)
Contraddice il lower bound?
No. Perché?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200445
IntegerSort: fase 1
(a) Calcolo di Y
X
Y 0 00 0 1 0 00
5 6861
1 2 3 4 5 6 7 8
1 00 0 1 0 11
5 6861
1 2 3 4 5 6 7 8
X
Y
1 00 0 1 0 00
5 6861
1 2 3 4 5 6 7 8
5 686
1 00 0 1 0 12
1
1 2 3 4 5 6 7 8
1 00 0 1 0 01
5 6861
1 2 3 4 5 6 7 8
Meno banale: ordinare n interi con valori in [1,k]
Mantieni array Y di k contatori tale che Y[x] = numero di occorrenze di x

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200446
IntegerSort: fase 2
(b) Ricostruzione di X
X
Y 1 00 0 1 0 12
1
1 2 3 4 5 6 7 8
X
Y 0 00 0 0 0 12
51 6 6
1 2 3 4 5 6 7 8
0 00 0 1 0 12
1
1 2 3 4 5 6 7 8
0 00 0 0 0 10
51 6 6
1 2 3 4 5 6 7 8
0 00 0 1 0 12
1 5
1 2 3 4 5 6 7 8
0 00 0 0 0 10
1 5 8
1 2 3 4 5 6 7 8
6 6
Scandisci Y da sinistra verso destra. Se Y[x] = k, scrivi in X il valore x per k volte

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200447
• O(k) per inizializzare contatori a 0• O(n) per calcolare valori dei contatori• O(n + k) per ricostruire sequenza ordinata
IntegerSort: analisi
O(n + k)
Tempo lineare se k = O(n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200448
BucketSort
Per ordinare n record con chiavi intere in [1,k]
• Basta mantenere un array di liste, anziché di contatori, ed operare come per IntegerSort
• La lista Y[x] conterrà gli elementi con chiave uguale a x
• Concatenare poi le liste
Tempo O(n + k) come per IntegerSort

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200449
• Un algoritmo è stabile se preserva ordine iniziale tra elementi uguali (stessa chiave)
• QuickSort è stabile se la partizione lo rende stabile
• MergeSort è stabile se divisione lo rende stabile (pari e dispari non lo rende stabile)
• HeapSort non è stabile• BucketSort può essere reso stabile appendendo
gli elementi di X in coda alla opportuna lista Y[i]
Stabilità

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200450
• Cosa fare se k > n, ad esempio k = Θ(nc)?• Rappresentiamo gli elementi in base b, ed
eseguiamo una serie di BucketSort
• Procediamo dalla cifra meno significativa a quella più significativa
RadixSort
239743685924
592423974368
592443682397
436823975924
239743685924
Per b=10

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200451
• Se x e y hanno una diversa t-esima cifra, la t-esima passata di BucketSort li ordina
• Se x e y hanno la stessa t-esima cifra, la proprietà di stabilità del BucketSort li mantiene ordinati correttamente
Correttezza
Dopo la t-esima passata di BucketSort, i numeri sono correttamente ordinati rispetto alle t cifre meno significative

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200452
• O(logb k) passate di bucketsort• Ciascuna passata richiede tempo O(n + b)
Tempo di esecuzione
O( (n + b) logb k)
Se b = Θ(n), si ha O(n logn k) = O nlog klog n
Tempo lineare se k = O(nc), c costante

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200453
• Nuove tecniche algoritmiche:– Incrementale (SelectionSort, InsertionSort)– Divide et impera (MergeSort, QuickSort)– Plug in di strutture dati efficienti (HeapSort)– Randomizzazione (QuickSort)
• Alberi di decisione per dimostrare lower bound• Sfruttare proprietà dei dati in ingresso (fuori dal
modello) per progettare algoritmi più efficienti: algoritmi lineari
Riepilogo

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 5Selezione e statistiche di ordine
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Problemi di statistiche d’ordine• Estrarre da grandi quantità di dati un piccolo insieme di
indicatori che ne rappresentino caratteristiche statisticamente salienti
• Esempi: minimo, massimo, media, moda (valore più frequente), mediano.
Selezione (k,n): Dati insieme di n elementi ed intero k ∈ [1,n], trovare elemento che occuperebbe la k-esima posizione se l’insieme fosse ordinato
• Mediano: selezione per k = n/2

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
• Ordina gli elementi, poi restituisci quello in posizione k : O(n log n)
• Costruisci un heap, ed estrai il minimo per k volte: O(n + k log n)
Selezione: approcci naïf
O(n) se k = O(n/log n) … ma non risolve problema del mediano in tempo lineare!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Calcolo randomizzato del mediano (con numero atteso di confronti lineare )

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
1. Divide: scegli pivot x e partiziona in elementi ≤ x ed elementi > x
2. Risolvi due sottoproblemi (QuickSort)3. Impera: concatena sottosequenze ordinate4. Restituisci k-esimo elemento nella sequenza
Usare QuickSort?
Numero atteso di confronti O(n log n)
Possiamo fare di meglio?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
1. Divide: scegli pivot x e partiziona in elementi ≤ x ed elementi > x
2. Risolvi UN SOTTOPROBLEMA (QuickSort)
3. Impera: concatena sottosequenze4. Restituisci k-esimo elemento nella sequenza
Usare QuickSort?
Numero atteso di confronti: ancora O(n log n)
Possiamo fare di meglio?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
1. Divide: scegli pivot x e partiziona in elementi ≤ x ed elementi > x
2. Risolvi un solo sottoproblema (RICORSIVAMENTE)
QuickSelect
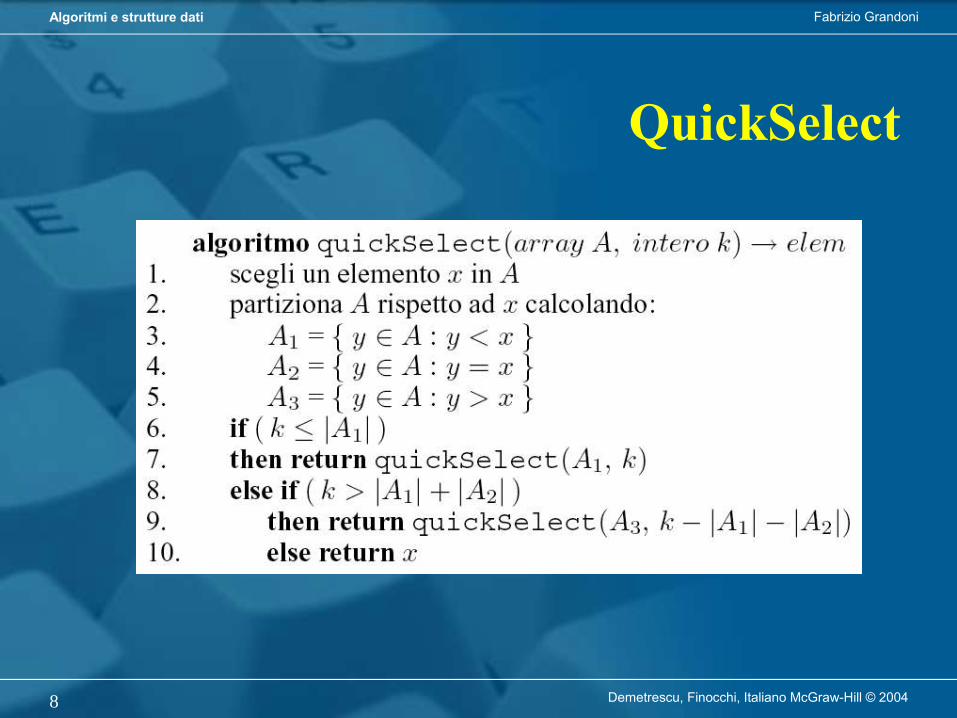
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
QuickSelect

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
• Nel caso peggiore, pivot scelto ad ogni passo è minimo o massimo degli elementi nell’array
• Numero di confronti nel caso peggiore è:C(n) = C(n-1) + O(n)
• Risolvendo per iterazione si ottiene C(n) = O(n2)
Analisi nel caso peggiore

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
QuickSelect Randomizzato
• Come per QuickSort, possiamo evitare caso peggiore scegliendo pivot a caso
• Ad ogni passo eliminiamo almeno |A2| + min |A1|, |A3| elementi

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Numero atteso di confronti:• Relazione di ricorrenza dipenderà da k e da n• Difficile da risolvere• Ci aspettiamo caso più difficile per k = n/2
Analisi di QuickSelect

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
• Maggior numero di confronti in QuickSelect si ha per k = n/2 , ovvero nel caso del mediano
Intuizione
A1 A3
k
< x > x
A1 A3
k
< x > x
A1 A3
k
< x > x
(a)
(b)
(c)
n/2
n/2
n/2
Per k < n/2 ci sono maggiori possibilità di ricorrere sul più piccolo dei due insiemi A1 e A3

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Analisi di QuickSelect Randomizzato• Ad ogni passo eliminiamo almeno |
A2| + min |A1|, |A3| elementi• Ogni elemento ha stessa probabilità di essere
scelto come pivot: probabilità di ricorrere su array di dimensione i∈[n/2,n-1] è 2/n
• Numero di confronti nel caso atteso è quindi:
C(n) = ∑i=n/2
n-1
n-1+ C(i)2n

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Analisi di QuickSelect Randomizzato
C(n) = ∑i=n/2
n-1
n-1+ C(i)2n
≤ ∑i=n/2
n-1
n-1+ A i 2n
Dimostriamo per sostituzione che C(n) A n≤
≤ ∑i=n/2
n-1
n-1+ i A2n
≤ ∑i=1
n-1
n-1+ i - A2n ∑
i=1
n/2-1
i ( )
≤ n-1+ 2n (A n2
2 - n2
8 - n4 ) = ( 1 + 3A
4 ) n -1- A2
≤ ( 1 + 3A4 ) n
C(n) A n ≤ se ( 1 + 3A4 ) A≤ A ≥ 4ovvero

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Relazione di ricorrenza del QuickSelect ha soluzione
Numero atteso di confronti
C(n) ≤ 4 n
Il numero atteso di confronti di QuickSelect è lineare

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Per convergere rapidamente, scegli il pivot il più vicino possibile al k-esimo (dal lato giusto)
Algoritmo usato in pratica
Come?
Scegli un campione opportuno (m elementi)
Scegli il pivot come il j-esimo degli m elementi:
j = k δmn
+-

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Calcolo deterministico del mediano (con un numero lineare di confronti nel
caso peggiore)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Segui l’idea dell’algoritmo usato in pratica
Algoritmo deterministico
Scegli un campione deterministico (non casuale)
Scegli il pivot come il mediano del campione
“Derandomizzare” l’algoritmo randomizzato

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
Algoritmo deterministico: dettagli
1. Scegli n/5 quintuple2. Per ogni quintupla calcola il mediano3. Il campione è definito dai mediani delle
quintuple4. Calcola (ricorsivamente) il pivot come
mediano dei mediani 5. Prosegui ricorsivamente (come per
l’algoritmo randomizzato)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Select
Calcolo deterministico del pivot tramite una chiamata ricorsiva (riga 6)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Mediano dei mediani
• Mediano di 5 elementi può essere calcolato con al più 7 confronti l’implementazione della riga 5 richiede (7/5) n confronti (ordinando i 5 elementi)
• Pivot M è mediano dei mediani mi dei n/5 gruppi di 5 elementi
• La riga 6 è una chiamata ricorsiva su n/5 elementi
• La partizione (righe 7-10) richiede n-1 confronti
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
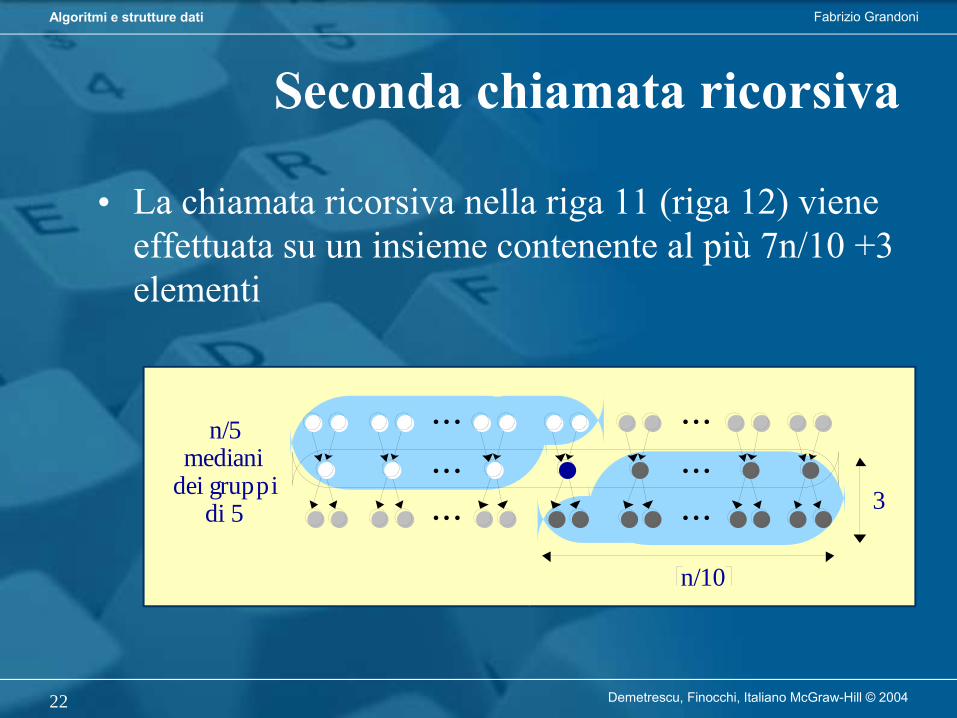
Seconda chiamata ricorsiva
• La chiamata ricorsiva nella riga 11 (riga 12) viene effettuata su un insieme contenente al più 7n/10 +3 elementi
...
.........
......
n/5 mediani
dei gruppi di 5 3
n/10

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Algoritmo deterministico: analisi
1. Scegli n/5 quintuple2. Per ogni quintupla calcola mediano3. Campione definito da mediani delle
quintuple4. Calcola (ricorsivamente) il pivot come
mediano dei mediani 5. Partiziona intorno al pivot6. Prosegui ricorsivamente (come per
l’algoritmo randomizzato)
(7/5) n
n-1
T( n/5 )
T( (7/10) n )

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
Analisi
• La seguente relazione di ricorrenza descrive il numero di confronti eseguiti da select nel caso peggiore:
T(n) (12/5) n + T( n/5 ) + T( (7/10) n )≤
• La relazione di ricorrenza ha soluzione T(n) = O(n)
Facile dimostrare per sostituzione che T(n) ≤ c n per c ≥ 24

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
• Abbiamo risolto il problema del calcolo del mediano studiandone una generalizzazione, ovvero il calcolo del k-esimo elemento per k ∈ [1,n]
• A volte problema più generale più semplice da risolvere del problema originario (dà più facilmente luogo a sottoproblemi ricorsivi)
• Il problema della selezione può essere risolto in tempo lineare, sia con algoritmi randomizzati che con algoritmi deterministici
• L’algoritmo randomizzato, sebbena richieda tempo O(n2) nel caso peggiore, è più efficiente in pratica
Riepilogo

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 6Alberi di ricerca
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Dizionari
• Gli alberi di ricerca sono usati per realizzare in modo efficiente il tipo di dato dizionario

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Alberi binari di ricerca(BST = binary search tree)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Definizione
Albero binario che soddisfa le seguenti proprietà– ogni nodo v contiene un elemento elem(v) cui è
associata una chiave chiave(v) presa da un dominio totalmente ordinato
– le chiavi nel sottoalbero sinistro di v sono tutte ≤ chiave(v)
– le chiavi nel sottoalbero destro di v sono tutte ≥ chiave(v)
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
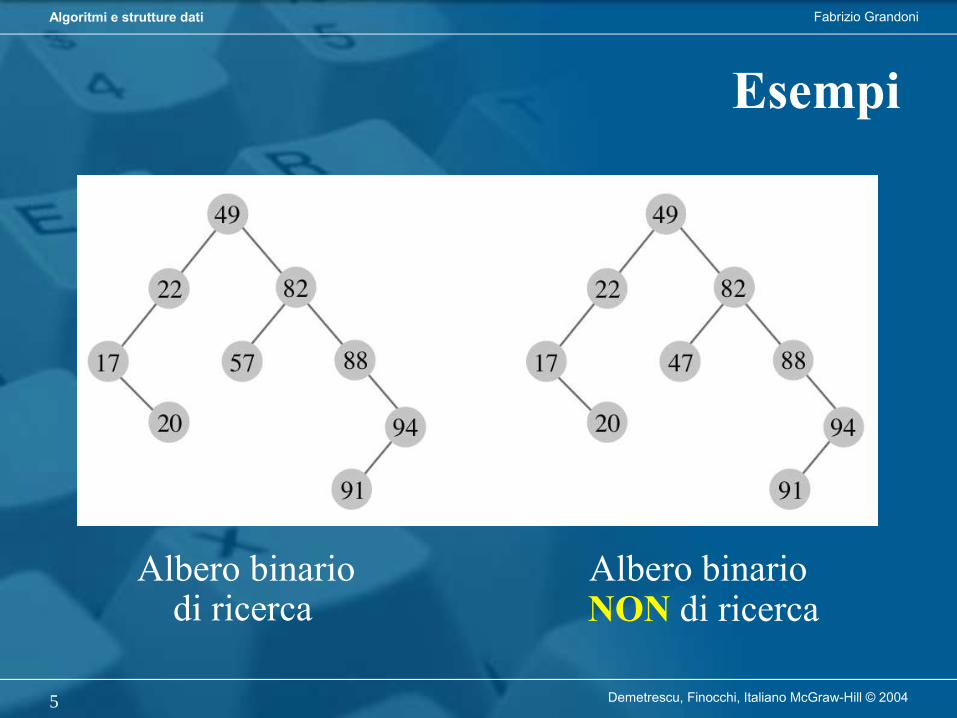
Albero binario di ricerca
Esempi
Albero binario NON di ricerca

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
search(chiave k) -> elem Traccia cammino nell’albero partendo da radice:
su ogni nodo, usa proprietà di ricerca per decidere se proseguire nel sottoalbero sinistro o destro

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
insert(elem e, chiave k)
1. Crea un nuovo nodo u con elem = e e chiave = k
3. Cerca la chiave k nell’albero, identificando così il nodo v che diventerà padre di u
4. Appendi u come figlio sinistro/destro di v in modo che sia mantenuta la proprietà di ricerca

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
Ricerca del massimo
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
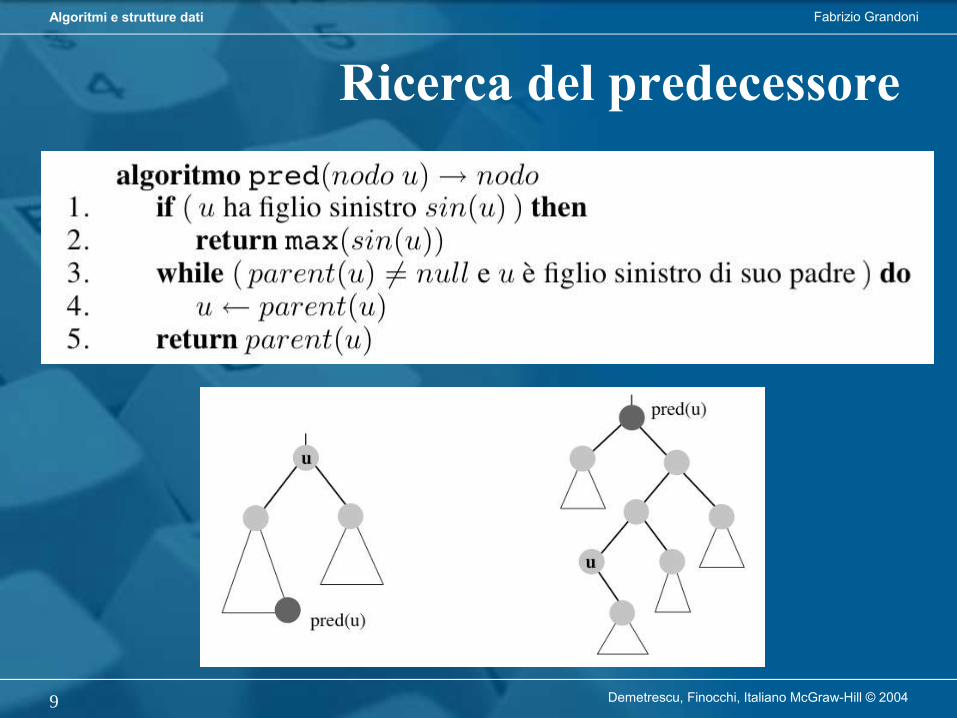
Ricerca del predecessore

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
delete(elem e)
Sia u il nodo contenente l’elemento e da cancellare:
1) u è una foglia: rimuovila
2) u ha un solo figlio:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
delete(elem e)3) u ha due figli: sostituiscilo con il predecessore
(v) e rimuovi fisicamente il predecessore (che ha un solo figlio)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
• Tutte le operazioni hanno costo O(h) dove h è l’altezza dell’albero
• O(n) nel caso peggiore (alberi molto sbilanciati e profondi)
Costo delle operazioni

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Alberi AVL(Adel’son-Vel’skii e Landis)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Definizioni
Alberi AVL = alberi binari di ricerca bilanciati in altezza
Un albero si dice bilanciato in altezza se ogni nodo v ha fattore di bilanciamento ≤ 1
Fattore di bilanciamento di un nodo v = | altezza sottoalbero sinistro di v - altezza sottoalbero destro di v |
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
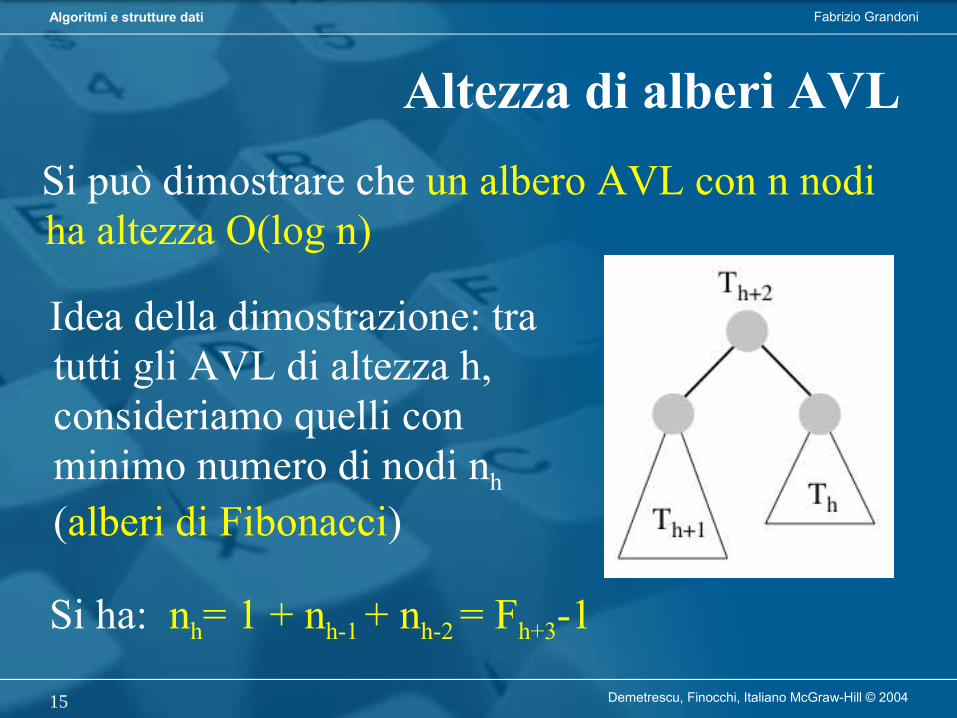
Altezza di alberi AVL
Idea della dimostrazione: tra tutti gli AVL di altezza h, consideriamo quelli con minimo numero di nodi nh
(alberi di Fibonacci)
Si può dimostrare che un albero AVL con n nodi ha altezza O(log n)
Si ha: nh= 1 + nh-1 + nh-2 = Fh+3-1

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Implementazione delle operazioni
• L’operazione search procede come in un BST
• Ma inserimenti e cancellazioni potrebbero sbilanciare l’albero
• Manteniamo il bilanciamento tramite opportune rotazioni
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
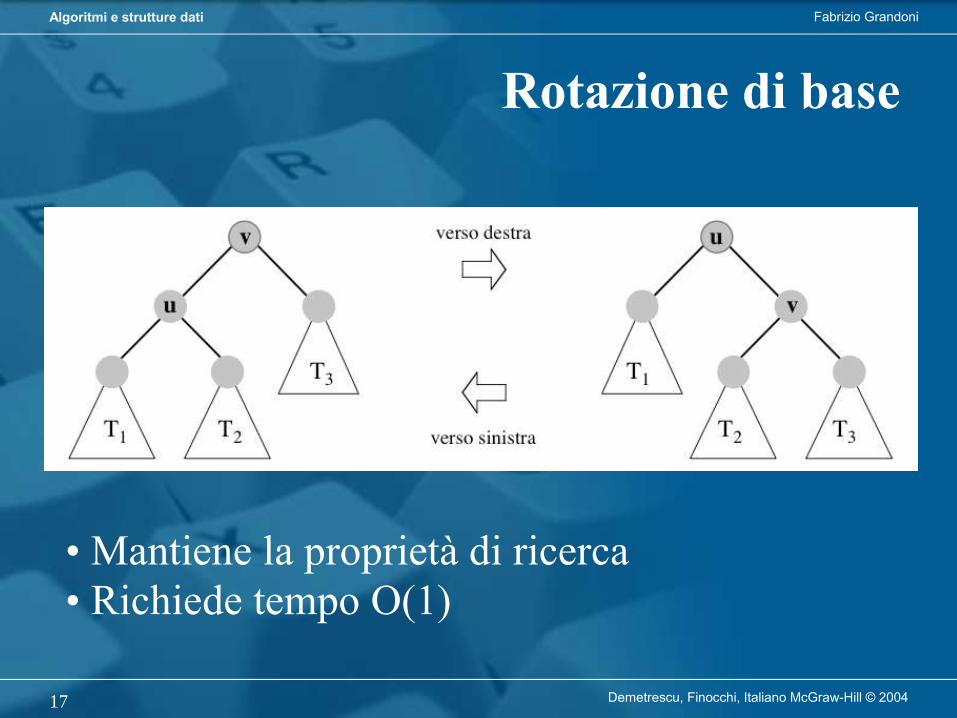
Rotazione di base
• Mantiene la proprietà di ricerca• Richiede tempo O(1)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
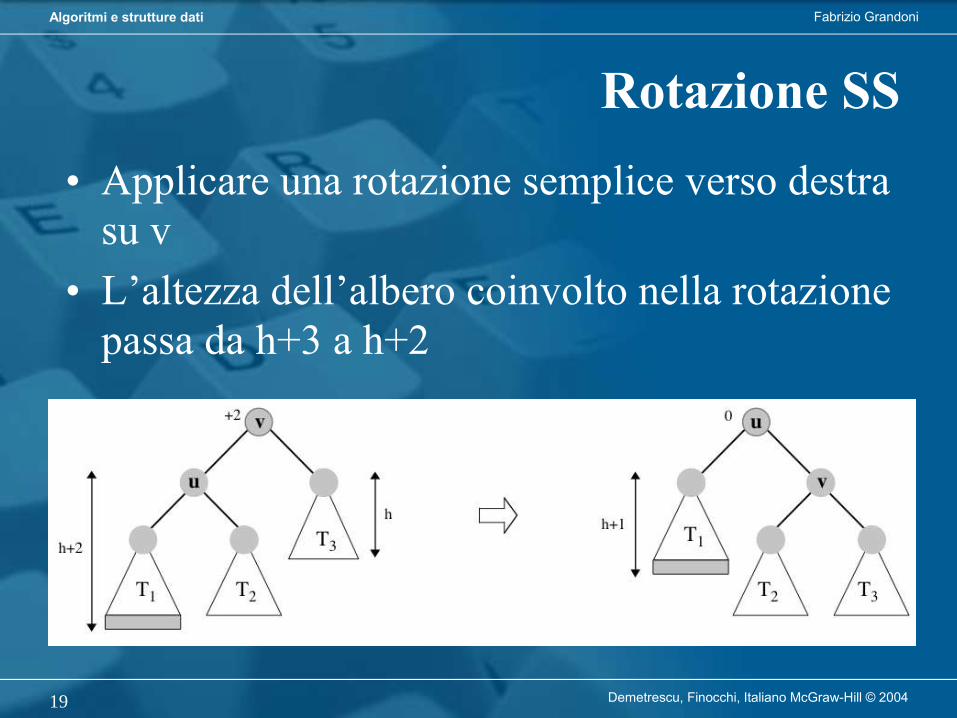
Ribilanciamento tramite rotazioni• Le rotazioni sono effettuate su nodi sbilanciati• Sia v un nodo con fattore di bilanciamento ≥ 2• Esiste un sottoalbero T di v che lo sbilancia• A seconda della posizione di T si hanno 4 casi:
• I quattro casi sono simmetrici (a coppie)
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
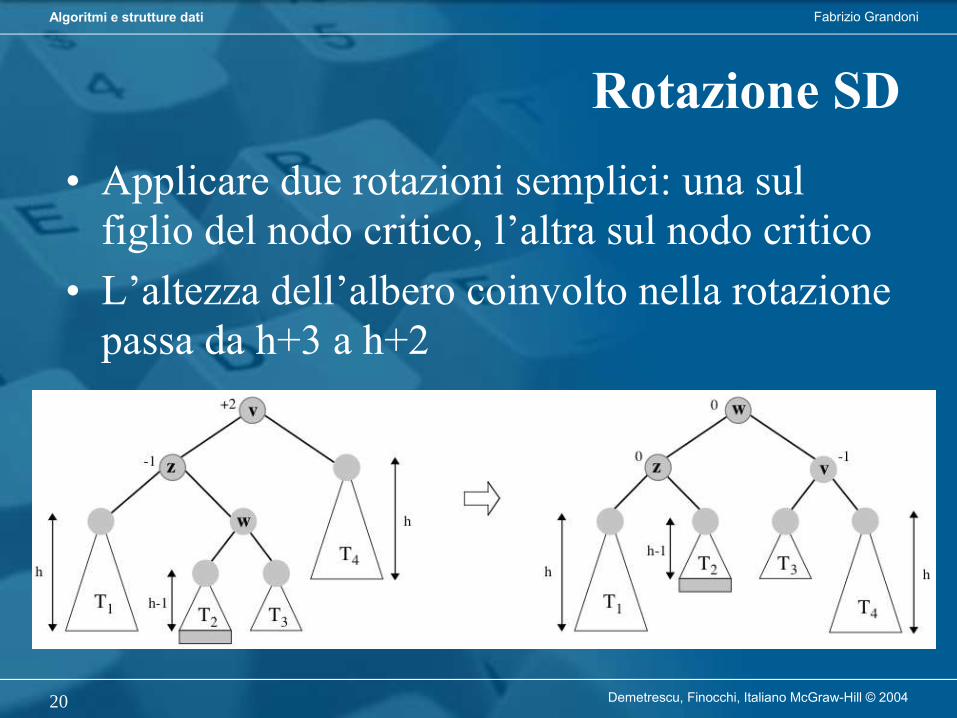
Rotazione SS• Applicare una rotazione semplice verso destra
su v• L’altezza dell’albero coinvolto nella rotazione
passa da h+3 a h+2
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Rotazione SD• Applicare due rotazioni semplici: una sul
figlio del nodo critico, l’altra sul nodo critico • L’altezza dell’albero coinvolto nella rotazione
passa da h+3 a h+2

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
insert(elem e, chiave k)1. Crea un nuovo nodo u con elem=e e chiave=k2. Inserisci u come in un BST3. Ricalcola i fattori di bilanciamento dei nodi
nel cammino dalla radice a u: sia v il più profondo nodo con fattore di bilanciamento pari a ±2 (nodo critico)
4. Esegui una rotazione opportuna su v
• N.B.: una sola rotazione è sempre sufficiente, poiché l’altezza dell’albero coinvolto diminuisce di 1

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
delete(elem e)1. Cancella il nodo come in un BST2. Ricalcola i fattori di bilanciamento dei nodi
nel cammino dalla radice al padre del nodo eliminato fisicamente (che potrebbe essere il predecessore del nodo contenente e)
3. Ripercorrendo il cammino dal basso verso l’alto, esegui l’opportuna rotazione semplice o doppia sui nodi sbilanciati
• N.B.: potrebbero essere necessarie O(log n) rotazioni
Fabrizio GrandoniAlgoritmi e strutture dati
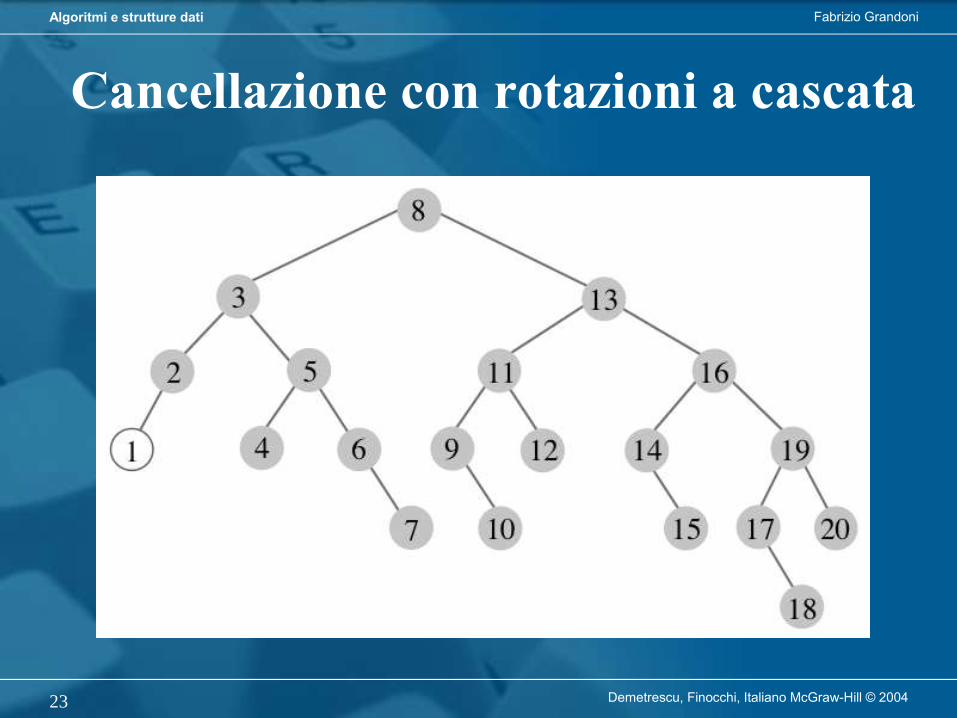
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Cancellazione con rotazioni a cascata

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
Classe AlberoAVL

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
• Tutte le operazioni hanno costo O(log n) poché l’altezza dell’albero è O(log n) e ciascuna rotazione richiede solo tempo costante
Costo delle operazioni

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
• Mantenere bilanciamento sembra cruciale per ottenere buone prestazioni
• Esistono vari approcci per mantenere bilanciamento:– Tramite rotazioni (alberi AVL )– Tramite fusioni o separazioni di nodi (alberi 2-3, B-alberi )
• In tutti questi casi si ottengono tempi di esecuzione logaritmici nel caso peggiore
• E’ anche possibile non mantenere in modo esplicito alcuna condizione di bilanciamento, ed ottenere tempi logaritmici ammortizzati su una intera sequenza di operazioni (alberi auto-aggiustanti)
Riepilogo

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 7Tavole hash
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Implementazioni Dizionario
- Liste
- Alberi di ricerca non bilanciati
- Alberi di ricerca bilanciati
- Tavole hash
O(n)
O(n)
O(log n)
O(1)
Tempo richiesto dall’operazione più costosa:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Tavole ad accesso diretto
Idea:– dizionario memorizzato in array v di m celle– a ciascun elemento è associata una chiave
intera nell’intervallo [0,m-1]– elemento con chiave k contenuto in v[k]– al più n≤m elementi nel dizionario
Sono dizionari basati sulla proprietà di accesso diretto alle celle di un array

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Implementazione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
Fattore di caricoMisuriamo il grado di riempimento di una tavola usando il fattore di carico
α = nm
Esempio: tavola con nomi di studenti indicizzati da numeri di matricola a 6 cifre n=100 m=106 α = 0,0001 = 0,01%Grande spreco di memoria!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Pregi e difetti
– Tutte le operazioni richiedono tempo O(1)
Pregi:
– Le chiavi devono essere necessariamente interi in [0, m-1]
– Lo spazio utilizzato è proporzionale ad m, non al numero n di elementi: può esserci grande spreco di memoria!
Difetti:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
Tavole hash
Idea:– Chiavi prese da un universo totalmente
ordinato U (possono non essere numeri)– Funzione hash: h: U → [0, m-1]
(funzione che trasforma chiavi in indici)– Elemento con chiave k in posizione v[h(k)]
Per ovviare agli inconvenienti delle tavole ad accesso diretto ne consideriamo un’estensione: le tavole hash

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
CollisioniLe tavole hash possono soffrire del fenomeno delle collisioni.
Si ha una collisione quando si deve inserire nella tavola hash un elemento con chiave u, e nella tavola esiste già un elemento con chiave v tale che h(u)=h(v): il nuovo elemento andrebbe a sovrascrivere il vecchio!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
Funzioni hash perfette
u ≠ v ⇒ h(u) ≠ h(v)
Una funzione hash si dice perfetta se è iniettiva, cioè per ogni u,v ∈ U:
Un modo per evitare il fenomeno delle collisioni è usare funzioni hash perfette.
Deve essere |U| ≤ m

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
Implementazione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Esempio
Tavola hash con nomi di studenti aventi come chiavi numeri di matricola nell’insieme U=[234717, 235717]
Funzione hash perfetta: h(k) = k - 234717
n=100 m=1000 α = 0,1 = 10%L’assunzione |U| ≤ m necessaria per avere una funzione hash perfetta è raramente conveniente (o possibile)…

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
Esempio
Tavola hash con elementi aventi come chiavi lettere dell’alfabeto U=A,B,C,…
Funzione hash non perfetta (ma buona in pratica per m primo): h(k) = ascii(k) mod m
Ad esempio, per m=11: h(‘C’) = h(‘N’)⇒ se volessimo inserire sia ‘C’ and ‘N’ nel dizionario avremmo una collisione!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Uniformità delle funzioni hash
Per ridurre la probabilità di collisioni, una buona funzione hash dovrebbe essere in grado di distribuire in modo uniforme le chiavi nello spazio degli indici della tavola
Questo si ha ad esempio se la funzione hash gode della proprietà di uniformità semplice

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Uniformità sempliceSia P(k) la probabilità che la chiave k sia presente nel dizionario e sia:
la probabilità che la cella i sia occupata.
Una funzione hash h gode dell’uniformità semplice se:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Esempio
Se U è l’insieme dei numeri reali in [0,1] e ogni chiave ha la stessa probabilità di essere scelta, allora si può dimostrare che la funzione hash:
soddisfa la proprietà di uniformità semplice

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Risoluzione delle collisioni
1. Liste di collisione. Gli elementi sono contenuti in liste esterne alla tabella: v[i] punta alla lista degli elementi tali che h(k)=i
2. Indirizzamento aperto. Tutti gli elementi sono contenuti nella tabella: se una cella è occupata, se ne cerca un’altra libera
Nel caso in cui non si possano evitare le collisioni, dobbiamo trovare un modo per risolverle. Due metodi classici sono i seguenti:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Liste di collisione
Esempio di tabella hash basata su liste di collisione contenente le lettere della parola:
PRECIPITEVOLISSIMEVOLMENTE

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Implementazione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
Indirizzamento apertoSupponiamo di voler inserire un elemento con chiave k e la sua posizione “naturale” h(k) sia già occupata.
L’indirizzamento aperto consiste nell’occupare un’altra cella, anche se potrebbe spettare di diritto a un’altra chiave.
Cerchiamo la cella vuota (se c’è) scandendo le celle secondo una sequenza di indici:
c(k,0), c(k,1), c(k,2),…c(k,m-1)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Implementazione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Metodi di scansione: scansione lineare
c(k,i) = ( h(k) + i ) mod mper 0 i < m≤
Scansione lineare:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
EsempioInserimenti in tavola hash basata su indirizzamento aperto con scansione lineare delle lettere della parola:
PRECIPITEVOLISSIMEVOLMENTE
4,8 celle scandite in media per inserimento

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Metodi di scansione: hashing doppio
c(k,i) = h1(k) + i·h2(k) mod m
L’hashing doppio riduce il problema:
per 0 i < m, h≤ 1 e h2 funzioni hash
La scansione lineare provoca effetti di agglomerazione, cioè lunghi gruppi di celle consecutive occupate che rallentano la scansione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
EsempioInserimenti in tavola hash basata su indirizzamento aperto con hashing doppio delle lettere della parola:
PRECIPITEVOLISSIMEVOLMENTE
3,1 celle scandite in media per inserimento

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
Analisi del costo di scansioneTempo richiesto in media da un’operazione di ricerca di una chiave, assumendo che le chiavi siano prese con probabilità uniforme da U:
dove α=n/m (fattore di carico)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
Cancellazione elementi con indir. aperto

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
• La proprietà di accesso diretto alle celle di un array consente di realizzare dizionari con operazioni in tempo O(1) indicizzando gli elementi usando le loro stesse chiavi (purché siano intere)
• L’array può essere molto grande se lo spazio delle chiavi è grande
• Per ridurre questo problema si possono usare funzioni hash che trasformano chiavi (anche non numeriche) in indici
• Usando funzioni hash possono aversi collisioni• Tecniche classiche per risolvere le collisioni sono liste di
collisione e indirizzamento aperto
Riepilogo

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 8Code con priorità
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Tipo di dato CodaPriorità (1/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Tipo di dato CodaPriorità (2/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Tre implementazioni
d-heap: generalizzazione degli heap binari visti per l’ordinamento
heap binomiali
heap di Fibonacci
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
d-heap

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Definizione
Un d-heap è un albero radicato d-ario con le seguenti proprietà:
2. Struttura: è completo almeno fino al penultimo livello
3. Contenuto informativo: ogni nodo v contiene un elemento elem(v) ed una chiave chiave(v) presa da un dominio totalmente ordinato
4. Ordinamento a heap: per ogni nodo v (diverso dalla radice) chiave(v) ≥ chiave(parent(v))
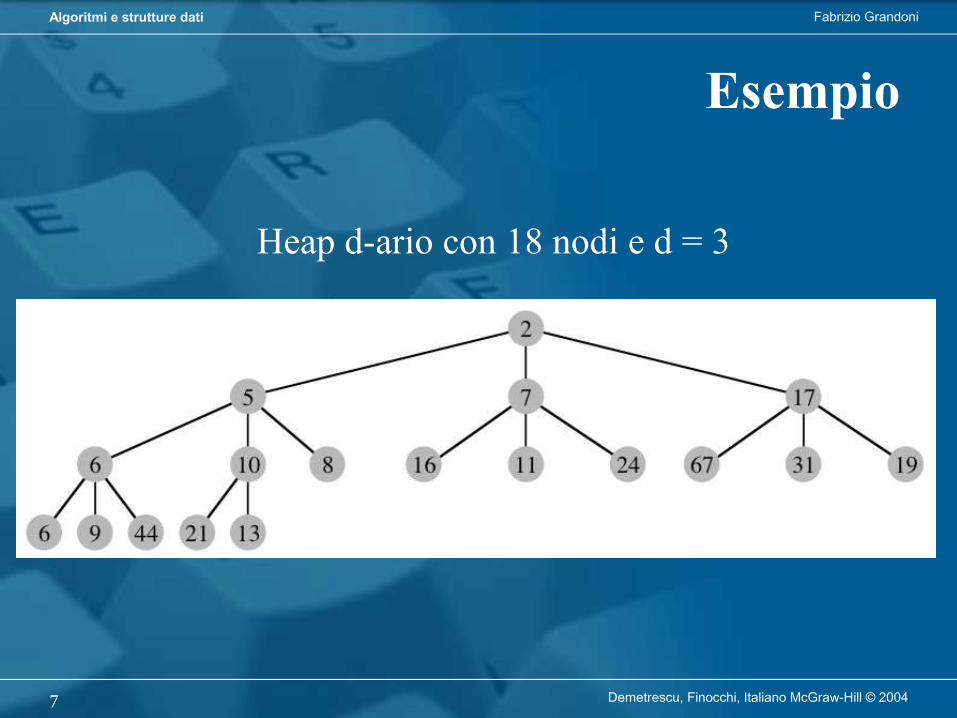
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
Esempio
Heap d-ario con 18 nodi e d = 3

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
Proprietà
1. Un d-heap con n nodi ha altezza O(logd n)
3. La radice contiene l’elemento con chiave minima (per via della proprietà di ordinamento a heap)
5. Può essere rappresentato implicitamente tramite vettore posizionale grazie alla proprietà di struttura

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
Procedure ausiliarie
Utili per ripristinare la proprietà di ordinamento a heap su un nodo v che non la soddisfi T(n) = O(logd n)
T(n) = O(d logd n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
findMin
T(n) = O(1)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
insert(elem e, chiave k)
T(n) = O(logd n) ( muoviAlto )

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
delete(elem e) e deleteMin
T(n) = O(d logd n) ( muoviBasso )
Può essere usata anche per implementare cancellazione del minimo
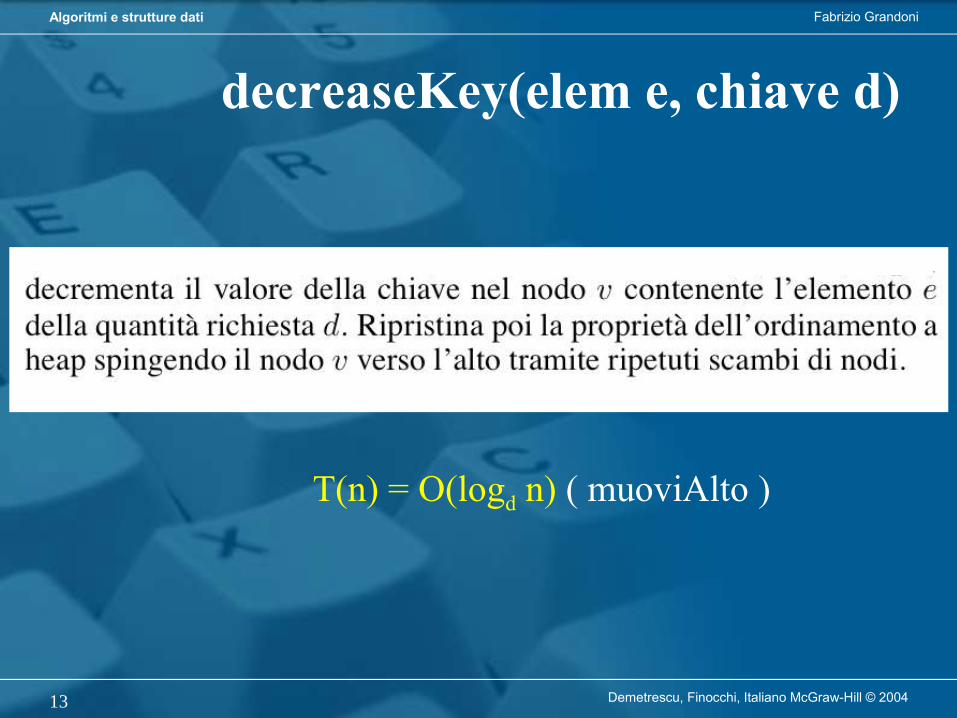
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
decreaseKey(elem e, chiave d)
T(n) = O(logd n) ( muoviAlto )
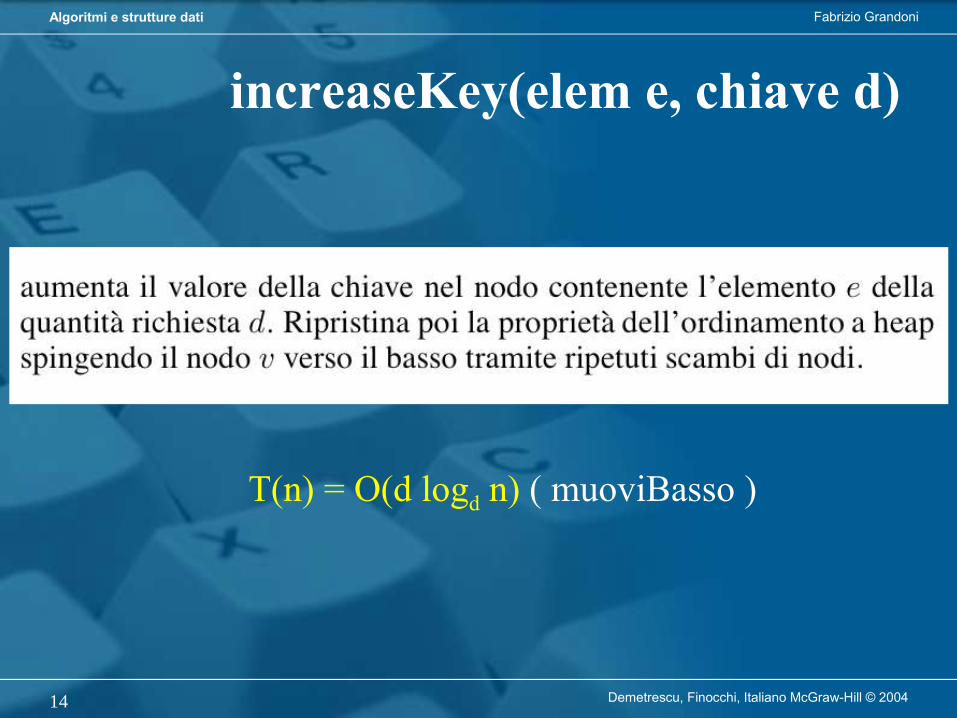
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
increaseKey(elem e, chiave d)
T(n) = O(d logd n) ( muoviBasso )
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Heap binomiali
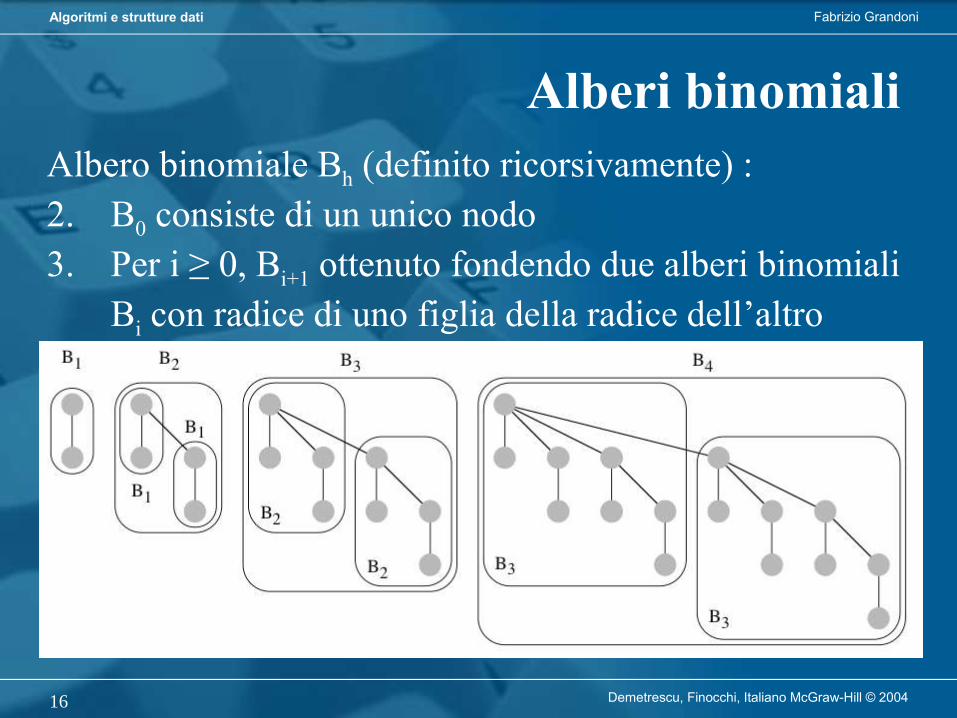
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Alberi binomialiAlbero binomiale Bh (definito ricorsivamente) :2. B0 consiste di un unico nodo3. Per i ≥ 0, Bi+1 ottenuto fondendo due alberi binomiali
Bi con radice di uno figlia della radice dell’altro

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Proprietà strutturali

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Definizione di heap binomiale
Un heap binomiale è una foresta di alberi binomiali con le seguenti proprietà:
2. Struttura: ogni albero Bi nella foresta è un albero binomiale
3. Unicità: per ogni i, esiste al più un Bi nella foresta4. Contenuto informativo: ogni nodo v contiene un
elemento elem(v) ed una chiave chiave(v) presa da un dominio totalmente ordinato
5. Ordinamento a heap: per ogni nodo v (diverso da una delle radici) chiave(v) ≥ chiave(parent(v))

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
Proprietà
In un heap binomiale con n nodi, vi sono al più log2 n alberi binomiali, ciascuno con grado ed altezza O(log n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Procedura ausiliaria
Utile per ripristinare la proprietà di unicità in un heap binomiale
T(n) è proporzionale al numero di alberi binomiali in input

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Realizzazione (1/3)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
Realizzazione (2/3)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Realizzazione (3/3)
Tutte le operazioni richiedono tempo T(n) = O(log n)Durante l’esecuzione della procedura ristruttura esistono infatti al più tre Bi, per ogni i ≥ 0

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
Analisi Ammortizzata

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
Metodologie di analisi di algoritmi
Finora abbiamo visto tre tipi di analisi:
• Analisi nel caso peggiore
• Analisi nel caso medio
• Analisi nel caso atteso (algoritmi randomizzati)
Ne vedremo un altro:
• Analisi ammortizzata

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
Analisi ammortizzata• Strutture dati con garanzia assoluta sui loro
tempi di esecuzione: analisi di caso peggiore per operazione (esempio: analisi di heap in heapsort)
• Analisi ammortizzata: • non ci interessa tanto caratterizzare tempo richiesto nel
caso peggiore da un’operazione sulla struttura dati• quanto caratterizzare tempo totale richiesto dalle
operazioni sulla struttura dati• ovvero tempo medio di un’operazione, dove la media è
sulla sequenza di operazioni

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
Analisi ammortizzata
• Supponiamo di avere una sequenza di σ operazioni su una particolare struttura dati
• La sequenza richiede tempo totale O(σ t) per essere eseguita
• Diremo che il tempo ammortizzato per ogni operazione della sequenza è O(t)
• Media sulla sequenza: O(σ t) / σ = O(t)• Nota: una singola operazione potrebbe
richiedere più di O(t) nel caso peggiore!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200428
Analisi ammortizzata
• Sequenza di σ operazioni richiede tempo O(σ t)
• Tempo ammortizzato: O(σ t) / σ = O(t)• OK per molte applicazioni• Abbiamo bisogno di utilizzare strutture dati su
sequenze di operazioni • Analizzare prestazioni su sequenze di
prestazioni

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200429
Esempio 1
Pila con le seguenti due operazioni• push(x): push elemento x sulla pila• multipop(k): esegui k pop sulla pila (se la pila
ha almeno k elementi) Analisi nel caso peggiore: • push(x): O(1)• multipop(k): O( min k, |P| ) = O(n) dove |P|
è la dimensione della pila

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200430
Esempio 1
Analisi nel caso peggiore: • push(x): O(1)• multipop(k): O( min k, |P| ) = O(n) dove |P|
è la dimensione della pilaQuanto tempo richiederà una sequenza di
σ operazioni? O(σ n) ?No!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200431
Analisi ammortizzata dell’Esempio 1
Intuizione:• Prima di togliere un elemento x con una
multipop dobbiamo averlo inserito con una push(x)
• Ogni sequenza di σ push e multipop richiede in totale tempo O(σ )
• Tempo ammortizzato per operazione: O(σ ) / σ = Ο(1)
• Vedremo un’analisi più formale di questo

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200432
Metodologie di analisi ammortizzata
Tre tipologie di analisi diverse:• Metodo cumulativo:
Sequenza di σ operazioni richiede tempo O(σ t)Tempo ammortizzato: O(σ t) / σ = O(t)
• Metodo del banchiere:Per eseguire un passo dobbiamo pagare 1 EURAllocare EUR in modo da pagare per tutti i passi
• Metodo del potenziale: Analogia con analisi potenziale (Fisica)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200433
Metodo del Banchiere per Esempio 1Quando esegui push(x) “sborsa” 2 EUR:• 1 EUR per pagare lavoro richiesto da push(x) • 1 EUR conservato nell’elemento xQuando esegui multipop(k) “sborsa” 0 EUR:• lavoro richiesto da multipop(k) pagato dagli
EUR conservati negli elementi! 1. Per ogni operazione “sborsi” al più O(1) EUR2. Tutti gli EUR “sborsati” sufficienti a pagare per
lavoro richiesto dalle operazioni

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200434
Metodo del PotenzialeDefinisci potenziale Φ per struttura dati D
Φ(D) misura potenzialità di D ad eseguire lavoro (configurazione attuale)
Durante operazione i-esima, struttura dati passa da configurazione Di a configurazione Di+1
Passa da potenziale Φ(Di) a potenziale Φ(Di+1)Tenere in conto variazione di potenziale
∆ Φ = Φ(Di+1) - Φ(Di) Operazione può essere molto costosa ma mette struttura dati in grado di eseguire più efficientemente operazioni future (costo operazione compensato da ∆ Φ )

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200435
Metodo del PotenzialeTipicamente potenziale Φ soddisfa le:
Φ(D0) = 0 e Φ(Di) ≥ 0 per ogni i
Definiamo tempo ammortizzato ai dell’operazione i-esima: ai = ti + Φ(Di+1) - Φ(Di)
dove ti è il tempo (attuale) operazione i-esima Sommando su sequenza di operazioni
Σi ai = Σi ti + Σi ( Φ(Di+1) - Φ(Di) ) Σi ai = Σi ti + ( Φ(Dn) - Φ(D0) ) Σi ai ≥ Σi ti

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200436
Metodo del Potenziale per Esempio 1
Definiamo potenziale Φ della pila P: Φ(P) = |P|Nota che: Φ(P0) = 0 e Φ(Pi) ≥ 0 per ogni i
Tempo ammortizzato ai di operazione i-esima: ai = ti + Φ(Di+1) - Φ(Di)
Costo ammortizzato di push(x) : ai = ti + Φ(Di+1) - Φ(Di) = 1 + 1 = 2 Costo ammortizzato di multipop(k) : ai = ti + Φ(Di+1) - Φ(Di) = k + ( -k) = 0

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200437
Heap di Fibonacci

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200438
Heap di FibonacciHeap binomiale rilassato: si ottiene da un heap
binomiale rilassando la proprietà di unicità dei Bi ed utilizzando un atteggimento più “pigro” durante l’operazione insert (perché ristrutturare subito la foresta quando potremmo farlo dopo?)
Heap di Fibonacci: si ottiene da un heap binomiale rilassato rilassando la proprietà di struttura dei Bi che non sono più necessariamente alberi binomiali
Analisi sofisticata: i tempi di esecuzione sono ammortizzati su sequenze di operazioni
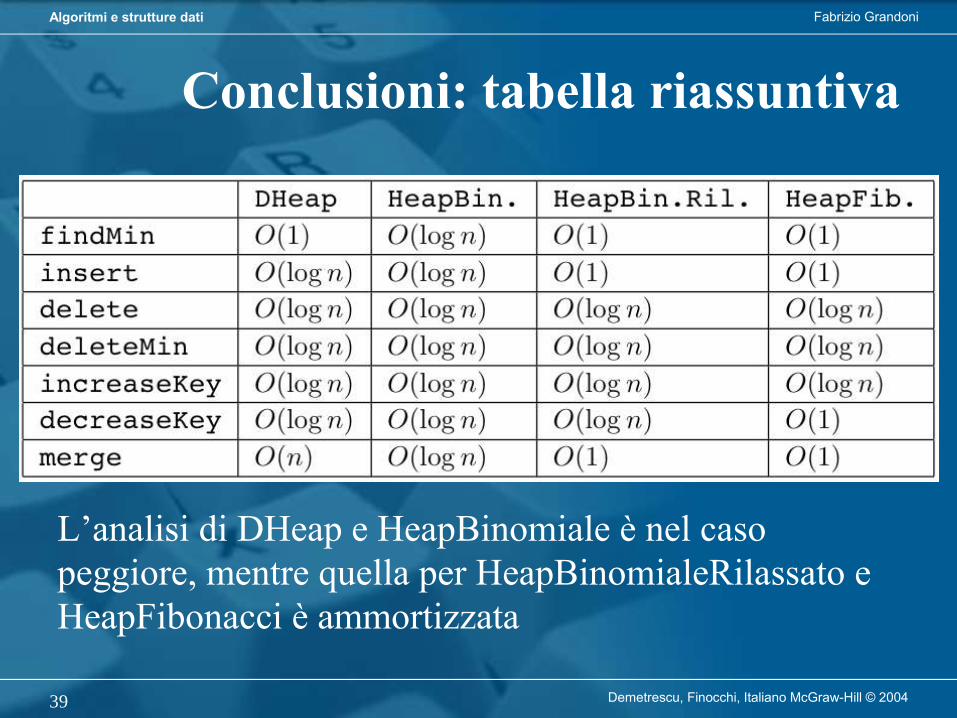
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200439
Conclusioni: tabella riassuntiva
L’analisi di DHeap e HeapBinomiale è nel caso peggiore, mentre quella per HeapBinomialeRilassato e HeapFibonacci è ammortizzata

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 9Union-find
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Il problema Union-findMantenere una collezione di insiemi disgiunti di elementi distinti (interi in 1 … n) durante una sequenza delle seguenti operazioni:• union(A,B) = unisce gli insiemi A e B in un
unico insieme, di nome A, e distrugge i vecchi insiemi A e B
• find(x) = restituisce il nome dell’insieme contenente l’elemento x
• makeSet(x) = crea il nuovo insieme x

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Esempio
n = 6
L’elemento in grassetto dà il nome all’insieme
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Approcci elementari

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
Algoritmi di tipo QuickFind
• Usano alberi di altezza uno per rappresentare gli insiemi disgiunti:– Radice = nome dell’insieme– Foglie = elementi
• find e makeSet richiedono solo tempo O(1), ma union è molto inefficiente: O(n) nel caso peggiore
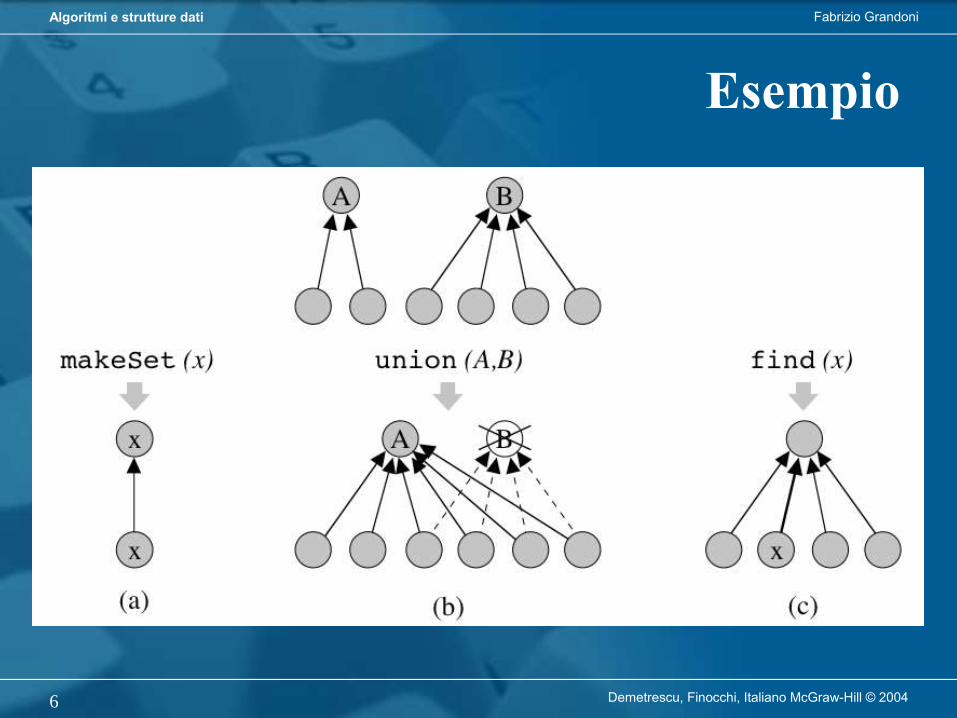
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Esempio

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
Realizzazione (1/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
Realizzazione (2/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
Algoritmi di tipo QuickUnion
• Usano alberi di altezza anche maggiore di uno per rappresentare gli insiemi disgiunti:– Radice = elemento rappresentativo dell’insieme – Nodi e Foglie = altri elementi
• union e makeSet richiedono solo tempo O(1), ma find è molto inefficiente: O(n) nel caso peggiore
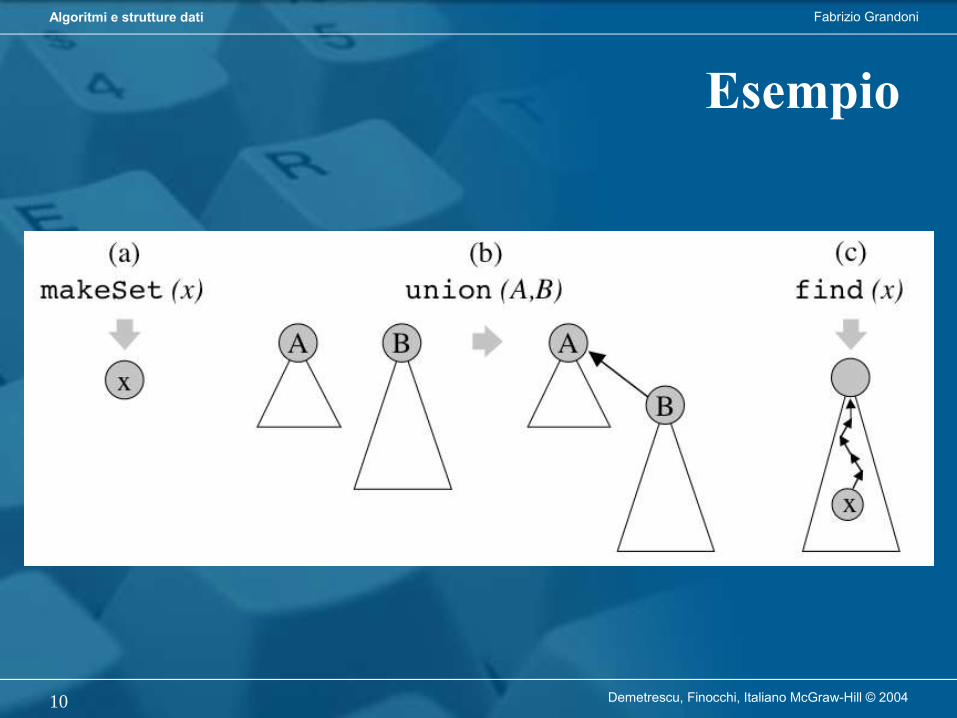
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
Esempio

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Realizzazione (1/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
Realizzazione (2/2)
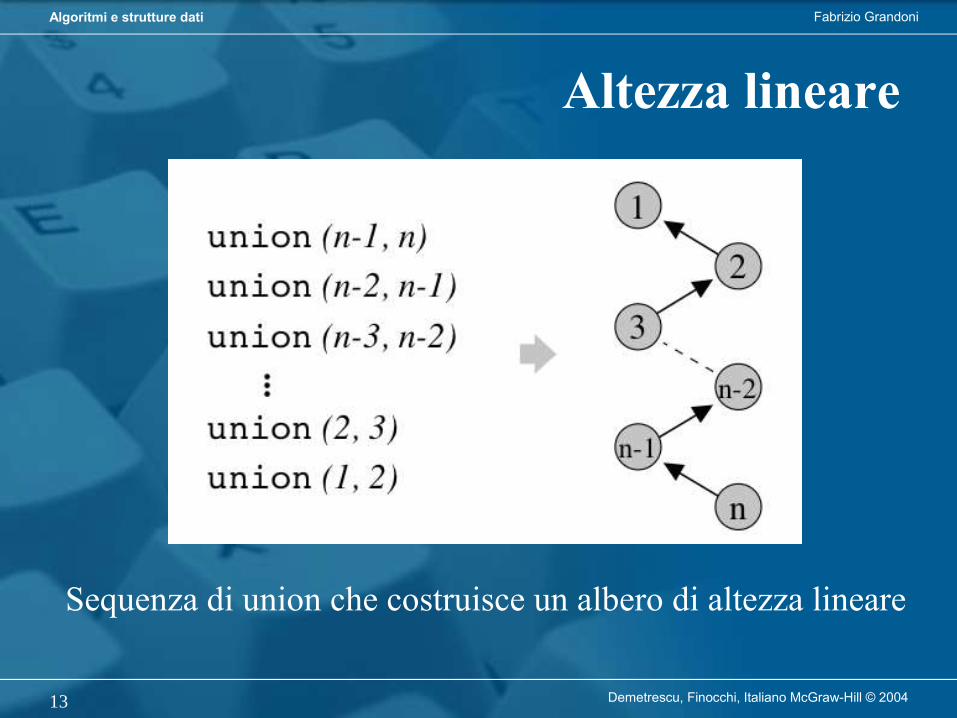
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Altezza lineare
Sequenza di union che costruisce un albero di altezza lineare

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Euristiche di bilanciamento nell’operazione union
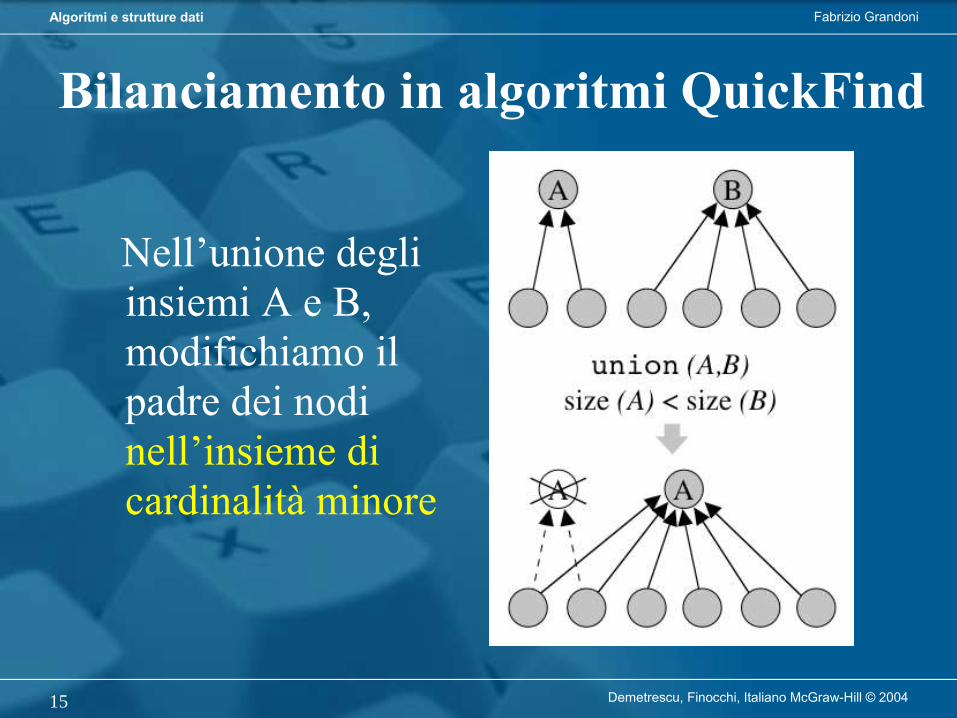
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Bilanciamento in algoritmi QuickFind
Nell’unione degli insiemi A e B, modifichiamo il padre dei nodi nell’insieme di cardinalità minore

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Realizzazione (1/3)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Realizzazione (2/3)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Realizzazione (3/3)
Tam = tempo per operazione ammortizzato su una intera sequenza

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
Conseguenza del bilanciamento
Ogni volta che una foglia di un albero QuickFind bilanciato acquista un nuovo padre a causa di un’operazione union, dopo la union tale foglia farà parte di un insieme che è grande almeno il doppio dell’insieme di cui faceva parte precedentemente

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Analisi ammortizzata (1/2)
Se eseguiamo m find, n makeSet (e quindi al più n-1 union), il tempo richiesto dall’intera sequenza di operazioni è O(m + n log n)
1. Facile vedere che find e makeSet richiedono tempo O(n+m)
2. Per analizzare union, quando creiamo un nodo gli assegnamo log n crediti: in totale, O(n log n) crediti
Idea della dimostrazione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Analisi ammortizzata (2/2)
3. Quando eseguiamo una union, paghiamo il tempo speso su ogni nodo il cui padre cambia con uno dei crediti assegnati al nodo
4. Un nodo può cambiare al più log n padri, poiché ogni volta che cambia padre la cardinalità dell’insieme cui appartiene raddoppia
5. I crediti assegnati al nodo sono quindi sufficienti per pagare tutti i “cambiamenti di padre”

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
Bilanciamento in algoritmi QuickUnion Union by rank: nell’unione degli insiemi A e B,
rendiamo la radice dell’albero più basso figlia della radice dell’albero più alto
rank(x) = altezza dell’albero di cui x è radice

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Realizzazione (1/3)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
Realizzazione (2/3)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
Realizzazione (3/3)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
Conseguenza del bilanciamento
Un albero QuickUnion bilanciato in altezza con radice x ha almeno 2rank(x) nodi
– Se rank(A) > rank(B) durante una union:
Dimostrazione: induzione sul numero di operazioni
– Se rank(A) < rank(B): simmetrico– Se rank(A) = rank(B):

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
Analisi (nel caso peggiore)
Per la proprietà precedente, l’altezza di un albero QuickUnion bilanciato è limitata superiormente da log2 n, con n = numero di makeSet
L’operazione find richiede nel caso peggiore tempo O(log n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200428
Bilanciamento in algoritmi QuickUnion
Union by size: nell’unione degli insiemi A e B, rendiamo la radice dell’albero con meno nodi figlia della radice dell’albero con più nodi
size(x) = numero nodi nell’albero di cui x è radice
Stesse prestazioni di union by rank
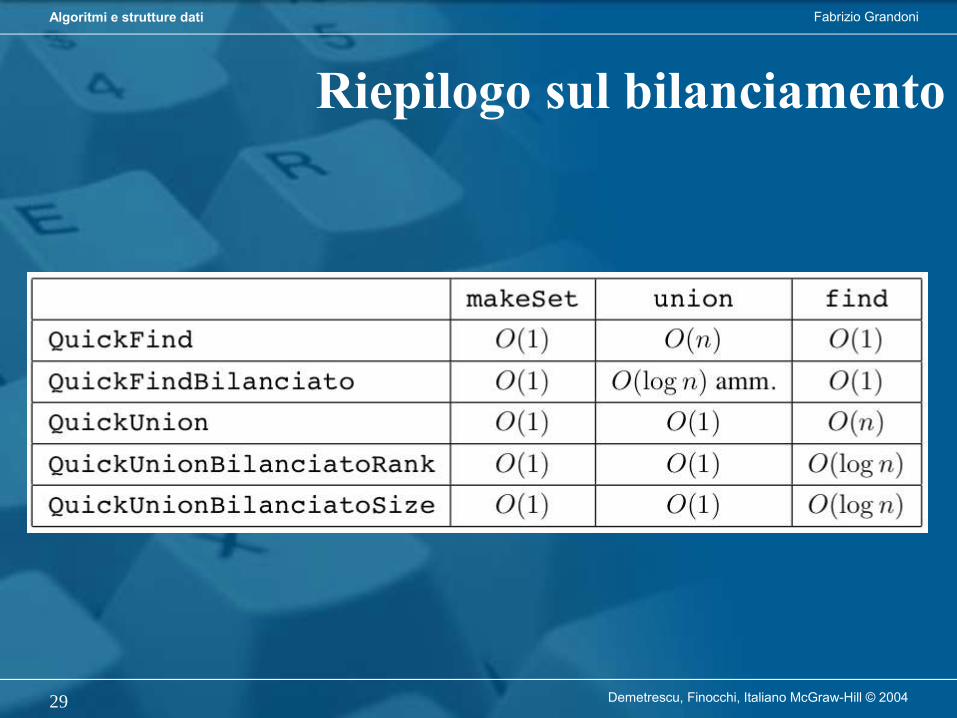
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200429
Riepilogo sul bilanciamento
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200430
Euristiche di compressione nell’operazione find

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200431
Path compression, splitting e halving
Siano u0, u1, …, ut-1 i nodi incontrati nel cammino esaminato da find (x), con x = u0
• Path compression: rendi il nodo ui figlio della radice ut-1, per ogni i ≤ t-3
• Path splitting: rendi il nodo ui figlio del nonno ui+2, per ogni i ≤ t-3
• Path halving: rendi il nodo u2i figlio del nonno u2i+2, per ogni i ≤ (t-1)/2-1
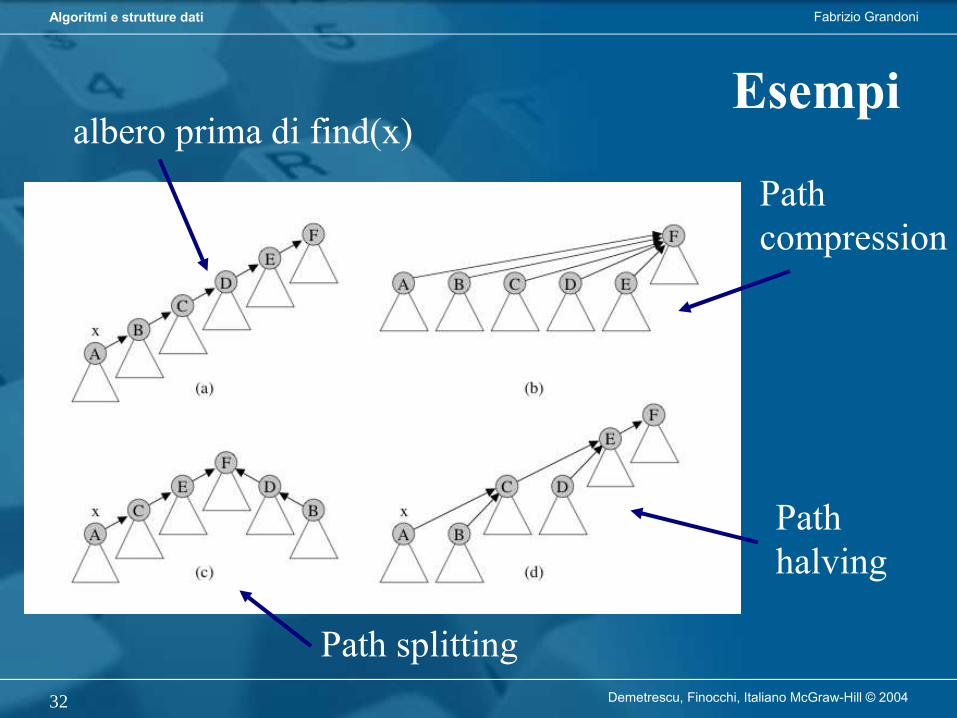
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200432
Esempialbero prima di find(x)
Path compression
Path halving
Path splitting

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200433
Union-find con bilanciamento e compressione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200434
Combinazioni delle euristiche
• Combinando le euristiche di bilanciamento e compressione si ha un totale di sei algoritmi:
( union by rank o union by size ) x ( path splitting, path compression, o path halving )
• Tutti gli algoritmi hanno le stesse prestazioni, asintoticamente superiori a quanto visto finora

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200435
Terminologia
La funzione log * cresce molto lentamente

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200436
Analisi
Combinando le euristiche di bilanciamento e compressione, una qualunque sequenza di n operazioni makeSet, m operazioni find ed al più (n-1) operazioni union può essere implementata in tempo totale
O( (n+m) log*n)
( Non è la migliore analisi possibile )

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200437
Conclusioni• Strutture dati efficienti per il problema union-
find• Partendo da strutture dati semplici con
prestazioni non soddisfacenti, le abbiamo migliorate tramite l’uso di opportune euristiche di bilanciamento ed euristiche di compressione di cammini
• Nonostante le euristiche siano estremamente semplici, l’analisi si è rivelata molto sofisticata

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 10Tecniche algoritmiche
Algoritmi e Strutture Dati
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
1. Divide et impera2. Programmazione dinamica3. Greedy

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Tecnica top-down:
3. Dividi il problema in due o più sottoproblemi4. Risolvi (ricorsivamente) i sottoproblemi5. Ricombina soluzioni dei sottoproblemi per
ottenere la soluzione del problema originario
Divide et impera
Esempi: ricerca binaria, mergesort, quicksort, …

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Moltiplicare (o sommare) due numeri non è sempre eseguibile in tempo costante:– se i numeri occupano più di una parola di memoria,
anche le operazioni elementari potrebbero richiedere tempo superiore a O(1)
Moltiplicare due numeri a n cifre, con l’algoritmo classico (scuola elementare), richiede O(n2). Possiamo fare di meglio?
Moltiplicazione di interi di lunghezza arbitraria

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
Rappresentazione decimale di interi a n cifre
• Dividiamo X e Y a metà:– X1 (Y1) = n/2 cifre più significative di X (Y) – X0 (Y0) = n/2 cifre meno significative di X (Y)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Divisione del problema

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
• Moltiplicare un numero per 10k = shift a sinistra delle cifre del numero di k posizioni
• Somma di due numeri di k cifre: tempo O(k)
• La moltiplicazione di due numeri a n cifre si riduce quindi a:– quattro moltiplicazioni di numeri a n/2 cifre– un numero costante di operazioni implementabili in
tempo O(k)
Osservazioni

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
La soluzione è Θ(n2) dal Teorema Master
Cosa abbiamo guadagnato?
Equazione di ricorrenza

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
Ridurre il numero di moltiplicazioni

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
La soluzione è Θ(n ) = Θ(n1.59) dal Teorema Master
Analisi
Eseguiamo tre moltiplicazioni e un numero costante di somme e shift
log23

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Programmazione Dinamica

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
Per evitare di risolvere più volte lo stesso sottoproblema, memorizziamo la soluzione dei vari sottoproblemi:
Programmazione Dinamica
algoritmo fibonacci3(intero n) → intero sia Fib un array di n interi Fib[1] ← Fib[2] ← 1 for i = 3 to n do Fib[i] ← Fib[i-1] + Fib[i-2] return Fib[n]

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Tecnica bottom-up:
3. Identifica sottoproblemi del problema originario, procedendo logicamente dai problemi più piccoli verso quelli più grandi
4. Utilizza una tabella per memorizzare soluzioni dei sottoproblemi incontrati: quando incontri lo stesso sottoproblema, leggi la soluzione nella tabella
5. Si usa quando i sottoproblemi non sono indipendenti, (lo stesso sottoproblema può apparire più volte)
Programmazione dinamica
Esempio: numeri di Fibonacci

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Siano X e Y due stringhe di lunghezza m ed n:
Distanza tra stringhe
Vogliamo calcolare la “distanza” tra X e Y, ovvero il minimo numero di operazioni elementari che consentono di trasformare X in Y
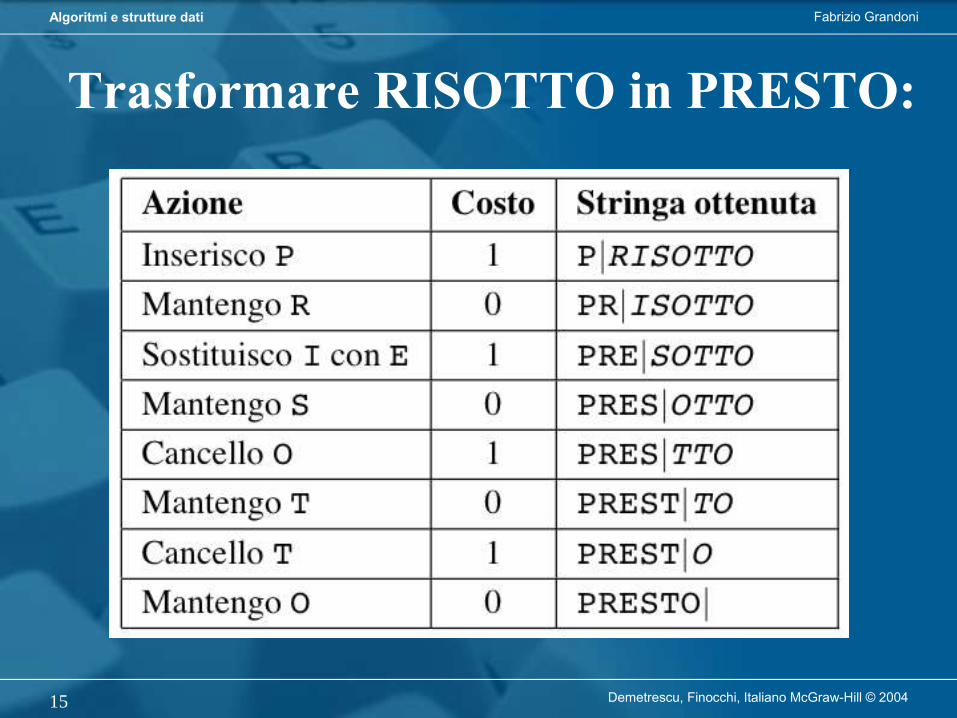
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Trasformare RISOTTO in PRESTO:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
• Indichiamo con Xi il prefisso di X fino all’i-esimo carattere, per 0 ≤ i ≤ m (X0 è la stringa vuota):
Approccio
• Risolveremo il problema di calcolare δ(X,Y) calcolando δ(Xi,Yj) per ogni i, j tali che 0 ≤ i ≤ m e 0 ≤ j ≤ n
• Manterremo le informazioni in una tabella D di dimensione m × n
• Indichiamo con δ(X,Y) la distanza tra X e Y

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Inizializzazione della tabella
Alcuni sottoproblemi sono banali:
δ(X0,Yj) = j partendo dalla stringa vuota X0, basta inserire uno ad uno i primi j caratteri di Yj
δ(Xi,Y0) = i partendo da Xi, basta rimuovere uno ad uno gli i caratteri di Xi per ottenere Y0
Queste soluzioni sono memorizzate rispettivamente nella prima riga e nella prima colonna della tabella D

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Avanzamento nella tabella (1/3)
• Se xi = yj, il minimo costo per trasformare Xi in Yj è uguale al minimo costo per trasformare Xi-1 in Yi-1
• Se xi ≠ yj, distinguiamo in base all’ultima operazione usata per trasformare Xi in Yj in una sequenza ottima di operazioni
D [ i , j ] = D [ i-1 , j-1 ]

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
Avanzamento nella tabella (2/3)il minimo costo per trasformare Xi in Yj è uguale al minimo costo per trasformare Xi in Yj-1 più 1 per inserire il carattere yj
il minimo costo per trasformare Xi in Yj è uguale al minimo costo per trasformare Xi-1 in Yj più 1 per la cancellazione del carattere xi
D [ i , j ] = 1 + D [ i , j-1 ]
D [ i , j ] = 1 + D [ i-1 , j ]

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Avanzamento nella tabella (3/3)il minimo costo per trasformare Xi in Yj è uguale al minimo costo per trasformare Xi-1 in Yj-1 più 1 per sostituire il carattere xi per yj
D [ i , j ] = 1 + D [ i-1 , j-1 ]
In conclusione:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Pseudocodice
Tempo di esecuzione ed occupazione di memoria: O(m n)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
Esempio
La tabella D costruita dall’algoritmo.
In grassetto sono indicate due sequenze di operazioni che permettono di ottenere la distanza tra le stringhe
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Tecnica golosa (o greedy)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
1. Insieme di candidati (e.g., città)2. Insieme dei candidati già esaminati3. Funzione ammissibile(): verifica se un insieme di
candidati rappresenta una soluzione, anche non ottima (un insieme di città è un cammino da Napoli a Torino?)
Problemi di ottimizzazione (1/2)
Usata in problemi di ottimizzazione (e.g., trovare cammino più corto per andare da Napoli a Torino)
Ad ogni passo, algoritmo effettua la scelta “localmente” più promettente

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
1. Funzione ottimo(): verifica se un insieme di candidati rappresenta una soluzione ottima (un insieme di città è il più breve cammino da Napoli a Torino?)
2. Funzione seleziona(): indica quale dei candidati non ancora esaminati è al momento il più promettente
3. Funzione obiettivo da minimizzare o massimizzare (e.g., lunghezza del cammino da Napoli a Torino)
Problemi di ottimizzazione (2/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
Tecnica golosa
Perché goloso? Sceglie sempre il candidato più promettente!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
Un server (e.g., una CPU, o un impiegato dell’ufficio postale) deve “servire” n clientiIl servizio richiesto dall’i-esimo cliente richiede ti secondiChiamiamo T(i) il tempo di attesa del cliente i Vogliamo minimizzare il tempo di attesa medio, i.e.:
Un problema di sequenziamento
e quindi

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200428
Esempio
Sei possibili ordinamenti:
Qual è il migliore?

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200429
• Il seguente algoritmo genera l’ordine di servizio in maniera incrementale secondo una strategia greedy.
• Supponiamo di aver deciso di sequenziare i clienti i1, i2, … im. Se decidiamo di servire il cliente j, il tempo totale di servizio diventa:
Un algoritmo goloso
• Quindi al generico passo l’algoritmo serve la richiesta più corta tra quelle rimanenti
• Tempo di esecuzione: O(n log n), per ordinare le richieste

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200430
Tecniche algoritmiche:– Divide et impera: altre applicazioni nella ricerca
binaria, mergesort, quicksort, moltiplicazione di matrici
– Programmazione dinamica: altre applicazioni nel calcolo dei numeri di Fibonacci, associatività del prodotto tra matrici, cammini minimi tra tutte le coppie di nodi (algoritmo di Floyd e Warshall)
– Tecnica greedy: altre applicazioni nel distributore automatico di resto, nel calcolo del minimo albero ricoprente (algoritmi di Prim, Kruskal, Boruvka) e dei cammini minimi (algoritmo di Dijkstra)
Riepilogo

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 11Grafi e visite di grafi
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Definizione
Un grafo G = (V,E) consiste in:- un insieme V di vertici (o nodi)- un insieme E di coppie di vertici, detti archi: ogni arco connette due vertici
Esempio 1: V = persone che vivono in Italia, E = coppie di persone che si sono strette la mano
Esempio 2: V = persone che vivono in Italia, E = (x,y) tale che x ha inviato una mail a y
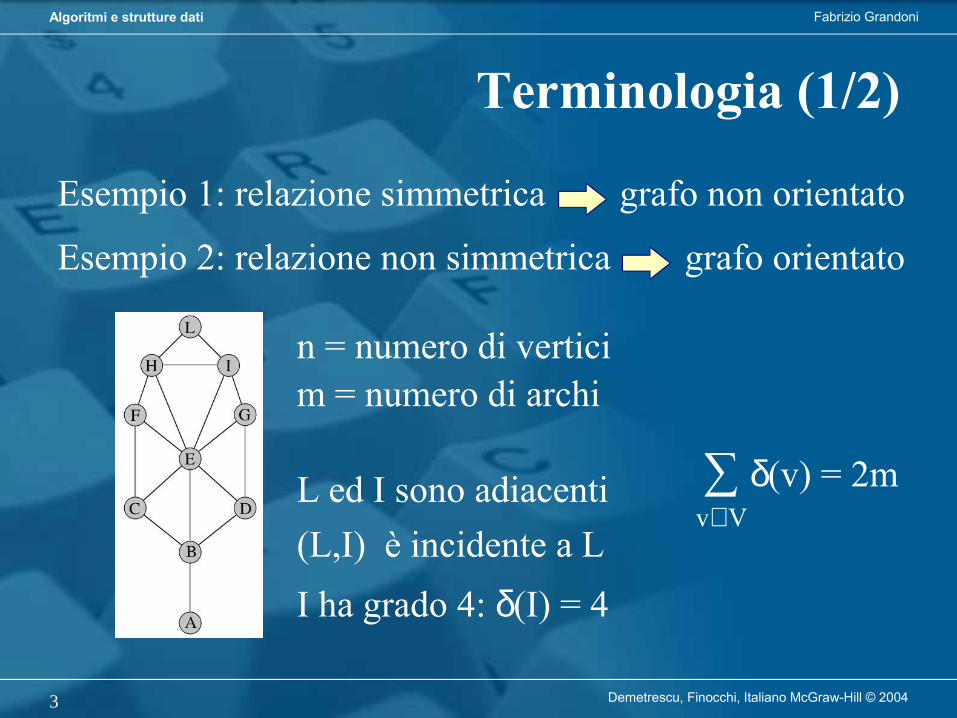
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Terminologia (1/2)
Esempio 1: relazione simmetrica grafo non orientato
Esempio 2: relazione non simmetrica grafo orientato
L ed I sono adiacenti(L,I) è incidente a LI ha grado 4: δ(I) = 4
n = numero di verticim = numero di archi
∑ δ(v) = 2mv∈V

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Terminologia (2/2)
< L , I , E, C, B, A > è un cammino nel grafo di lunghezza 5
Non è il più corto cammino tra L ed A
La lunghezza del più corto cammino tra due vertici si dice distanza: L ed A hanno distanza 4

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
Strutture dati per rappresentare grafi
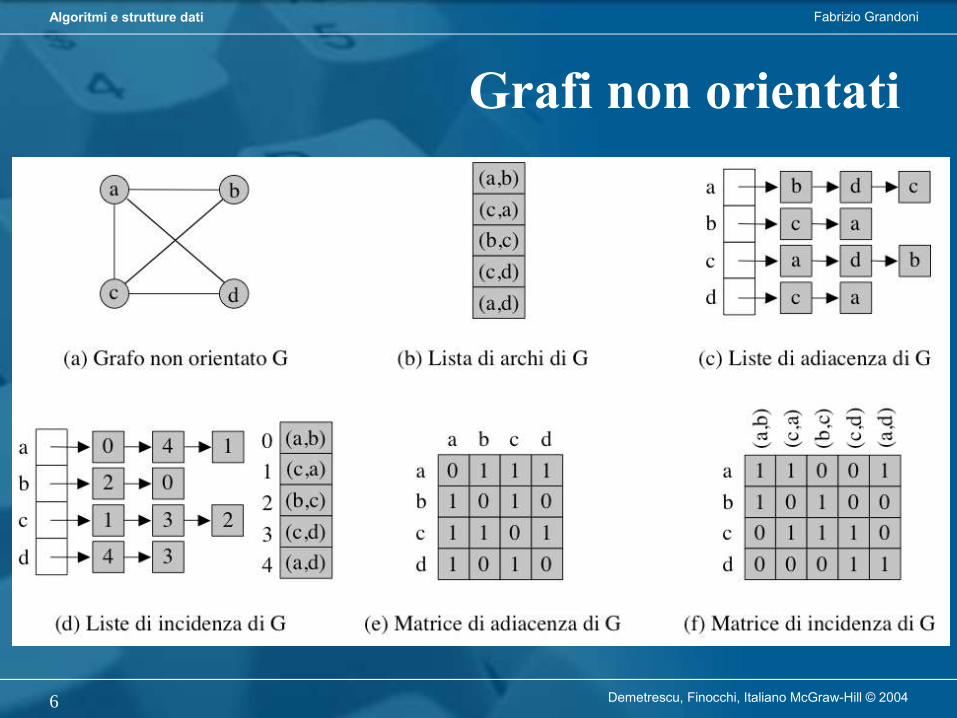
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Grafi non orientati
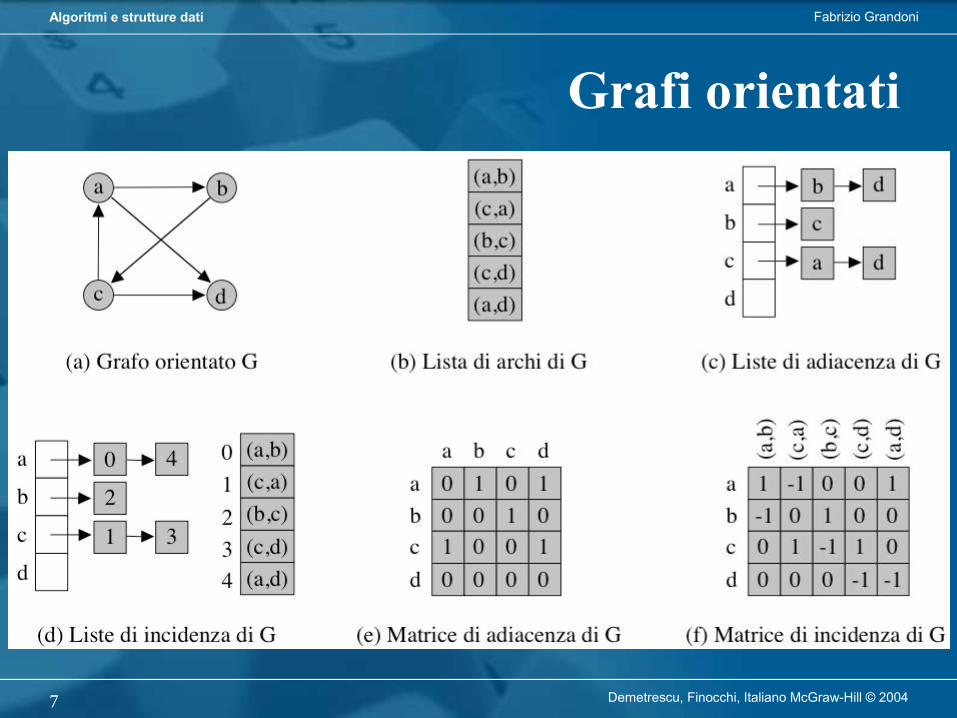
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
Grafi orientati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
Prestazioni della lista di archi
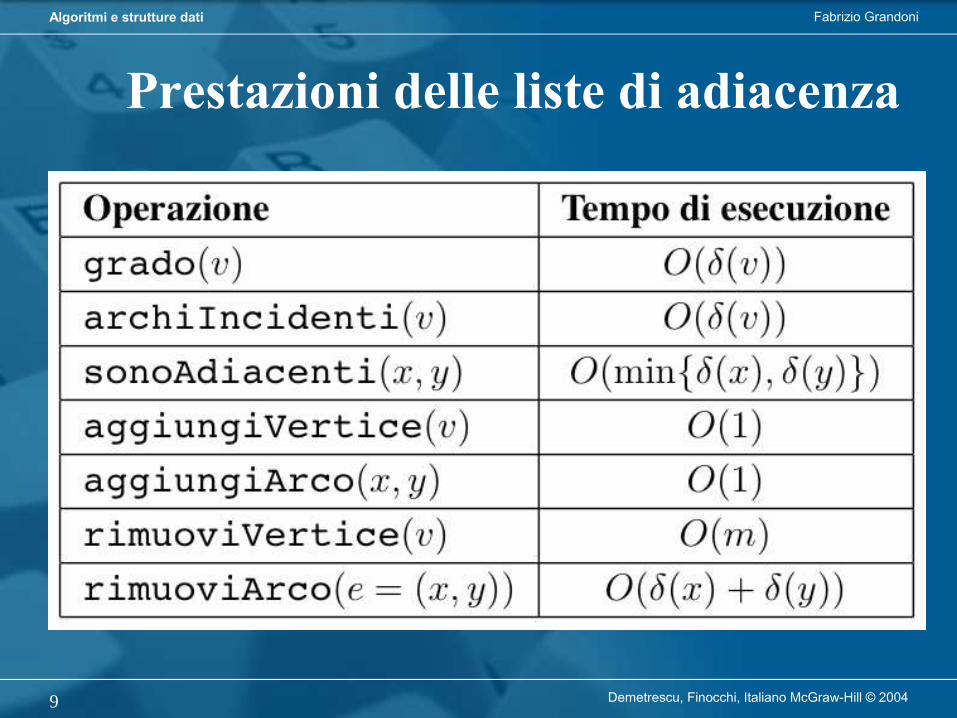
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
Prestazioni delle liste di adiacenza
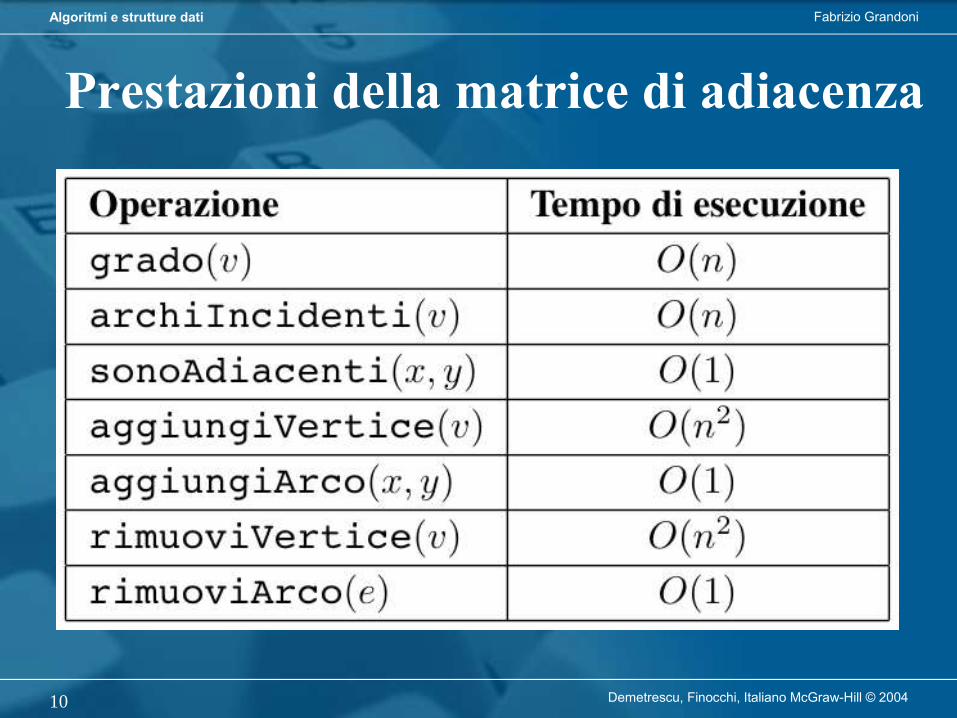
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
Prestazioni della matrice di adiacenza
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Visite di grafi

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
Scopo e tipi di visita
Una visita (o attraversamento) di un grafo G permette di esaminare i nodi e gli archi di G in modo sistematicoProblema di base in molte applicazioniEsistono varie tipologie di visite con diverse proprietà. In particolare: – visita in ampiezza (BFS = Breadth First Search) – visita in profondità (DFS = Depth First Search)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Algoritmo di visita generica

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Osservazioni
Un vertice viene marcato quando viene incontrato per la prima volta: marcatura implementata tramite un vettore di bit di marcaturaVisita genera un albero di copertura T del grafoInsieme di vertici F ⊆ T mantiene la frangia di T:– v ∈ (T-F) : v è chiuso, tutti gli archi incidenti su v sono
stati esaminati– v ∈ F : v è aperto, esistono archi incidenti su v non
ancora esaminati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Costo della visita
Tempo di esecuzione dipende da struttura dati usata per rappresentare il grafo:– Lista di archi: O(m n)– Liste di adiacenza: O(m + n)– Matrice di adiacenza: O(n2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Casi particolari di visite
• Se frangia F implementata come coda si ha visita in ampiezza (BFS)
• Se frangia F implementata come pila si ha visita in profondità (DFS)
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Visita in ampiezza

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Visita in ampiezza
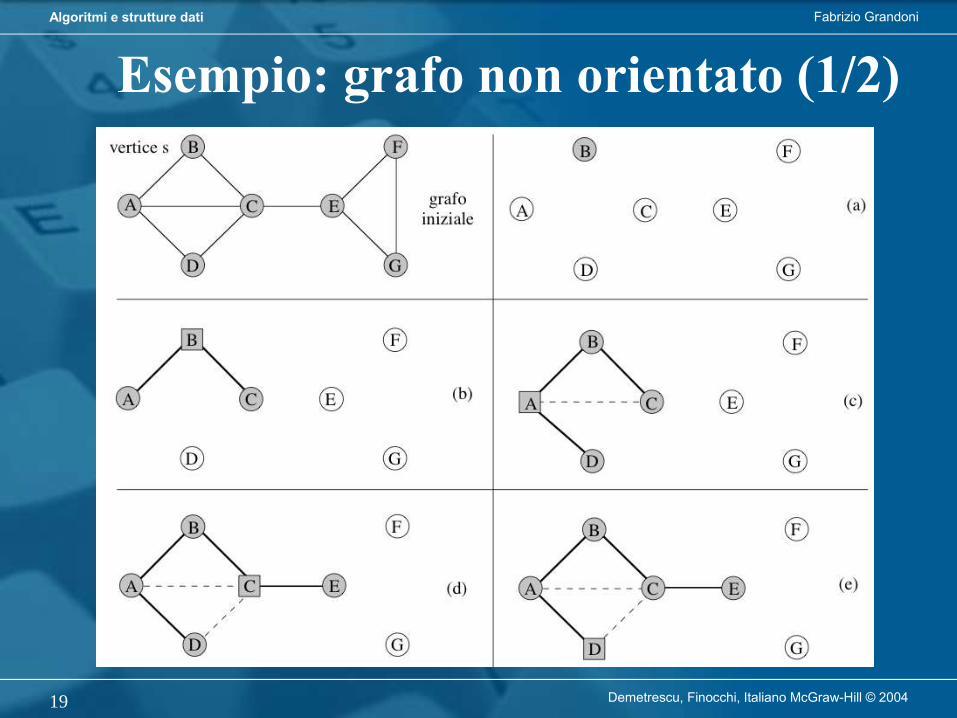
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
Esempio: grafo non orientato (1/2)
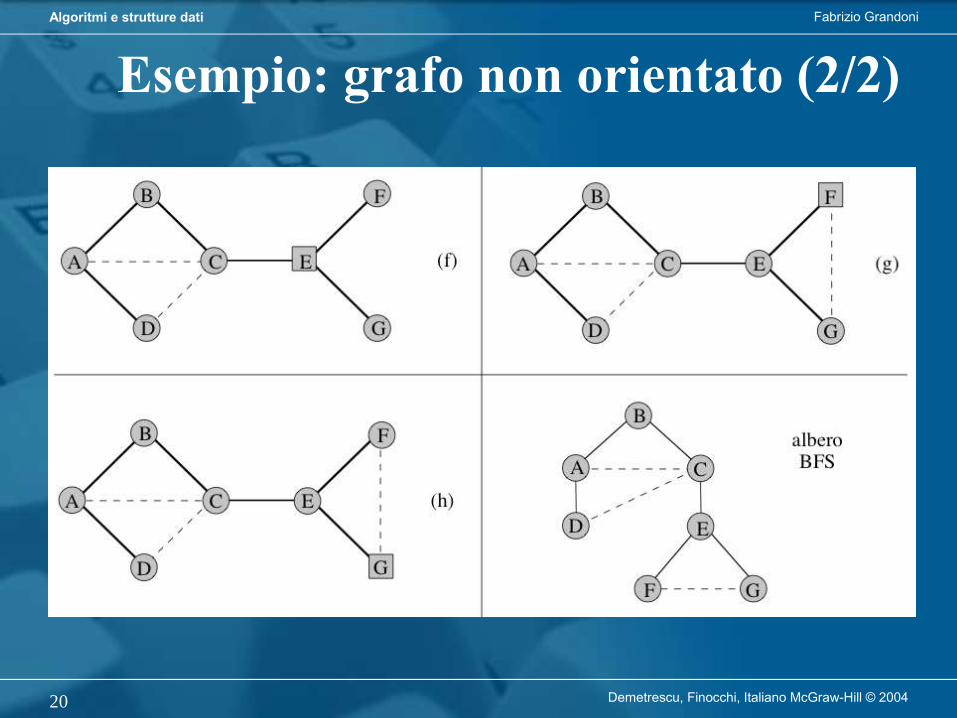
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Esempio: grafo non orientato (2/2)
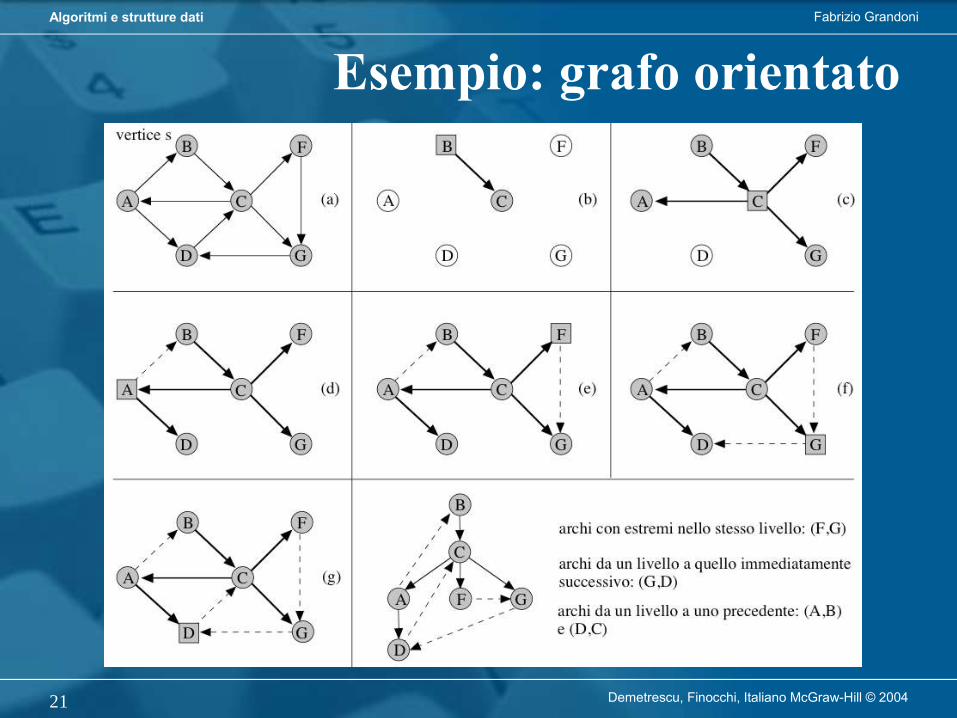
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Esempio: grafo orientato

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
Proprietà
• Per ogni nodo v, il livello di v nell’albero BFS è pari alla distanza di v dalla sorgente s
• Per ogni arco (u,v) di un grafo non orientato, gli estremi u e v appartengono allo stesso livello o a livelli consecutivi dell’albero BFS
• Se il grafo è orientato, possono esistere archi (u,v) che attraversano all’indietro più di un livello
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Visita in profondità

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
Visita in profondità
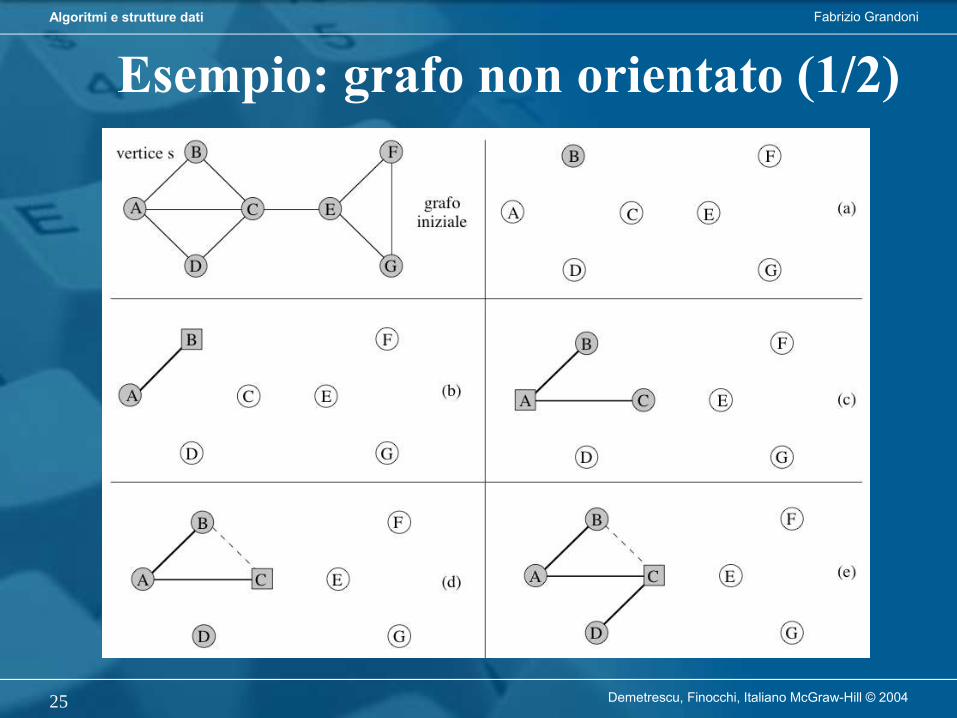
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
Esempio: grafo non orientato (1/2)
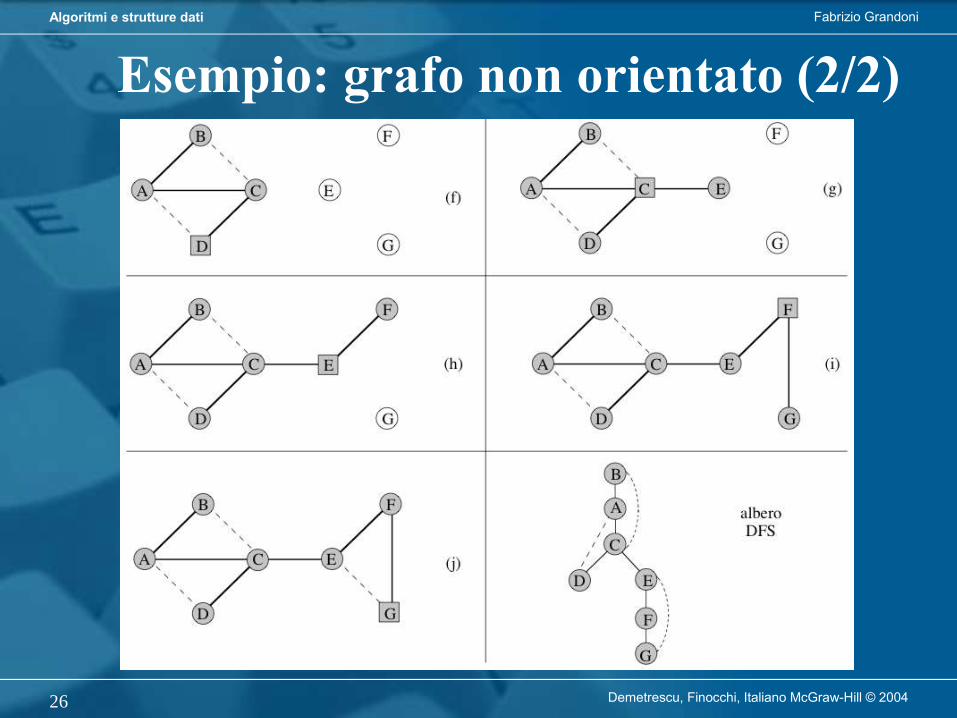
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
Esempio: grafo non orientato (2/2)
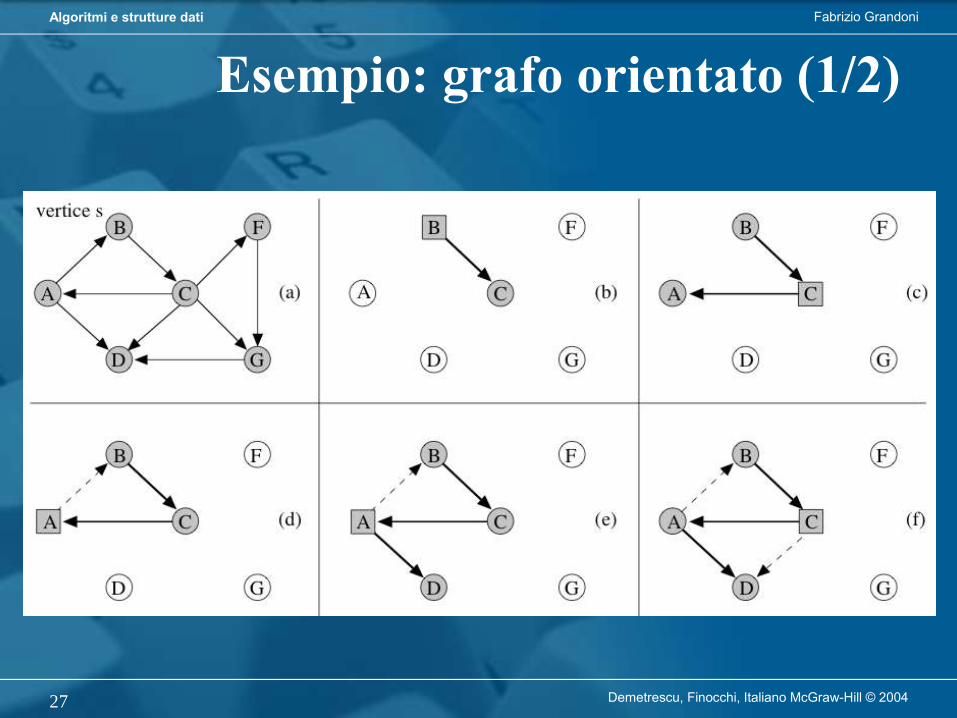
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
Esempio: grafo orientato (1/2)
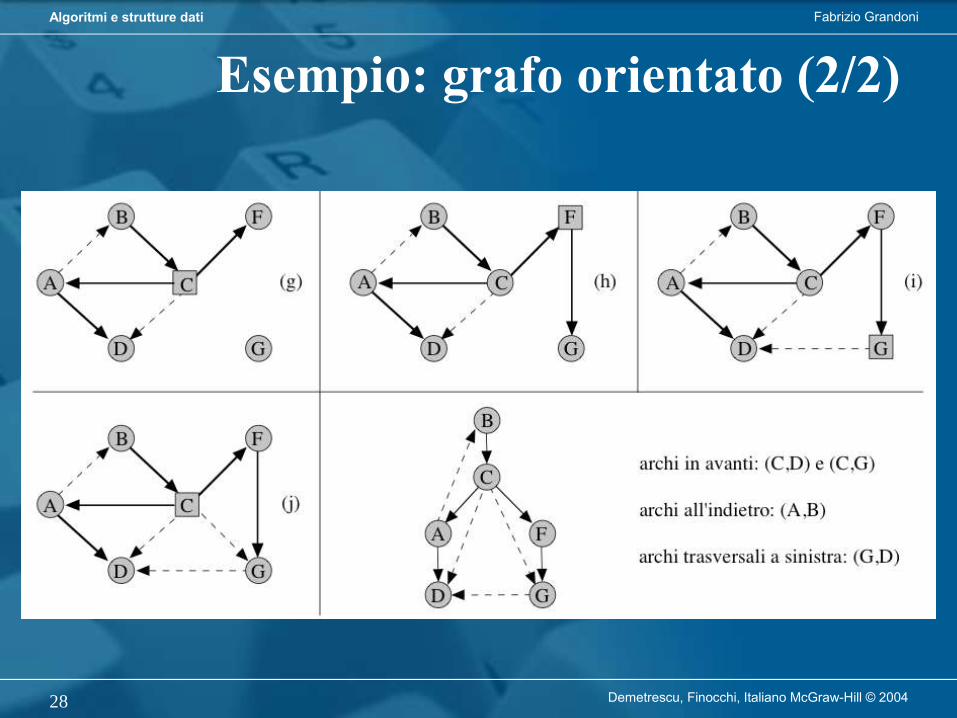
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200428
Esempio: grafo orientato (2/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200429
Proprietà
• Sia (u,v) un arco di un grafo non orientato. Allora: – (u,v) è un arco dell’albero DFS, oppure– i nodi u e v sono l’uno discendente/antenato dell’altro
• Sia (u,v) un arco di un grafo orientato. Allora: – (u,v) è un arco dell’albero DFS, oppure– i nodi u e v sono l’uno discendente/antenato
dell’altro, oppure– (u,v) è un arco trasversale a sinistra, ovvero il vertice
v è in un sottoalbero visitato precedentemente ad u

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200430
Riepilogo• Nozione di grafo e terminologia• Diverse strutture dati per rappresentare grafi nella
memoria di un calcolatore• L’utilizzo di una particolare rappresentazione può
avere un impatto notevole sui tempi di esecuzione di un algoritmo su grafi (ad esempio, nella visita di un grafo)
• Algoritmo di visita generica e due casi particolari: visita in ampiezza e visita in profondità

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 12Minimo albero ricoprente
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Definizioni
Sia G = (V, E) un grafo connesso non orientato. Un albero ricoprente di G è un sottografo T ⊆ G tale che:– T è un albero;– T contiene tutti i vertici di G.
Sia w(x,y) il costo (o peso) di un arco (x,y) ∈ E. Il costo di un albero è la somma dei costi dei suoi archi.Un minimo albero ricoprente di G è un albero ricoprente di costo minimo.

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Esempi
Il minimo albero ricoprente non è necessariamente unico

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Proprietà di minimi alberi ricoprenti

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
Tagli e cicli
Dato un grafo non orientato G = (V,E), un taglio in G è una partizione dei vertici V in due insiemi: X e V-X. Un arco e = (u,v) attraversa il taglio (X,X) se u ∈ X e v ∈ X
Un ciclo è un cammino in cui il primo e l’ultimo vertice coincidono

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Un approccio “goloso”• Costruiremo un minimo albero ricoprente un
arco alla volta, effettuando scelte localmente “golose”. Ad esempio:– includere nella soluzione archi di costo piccolo– escludere dalla soluzione archi di costo elevato
• Formalizzeremo il processo come un processo di colorazione:– archi blu: inclusi nella soluzione– archi rossi: esclusi dalla soluzione

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
Regola del taglio (Regola blu)
Scegli un taglio che non contiene archi blu. Tra tutti gli archi non colorati del taglio, scegline uno di costo minimo e coloralo blu.
• Ogni albero ricoprente deve infatti contenere almeno un arco del taglio• E’ naturale includere quello di costo minimo

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
Regola del ciclo (Regola rossa)
Scegli un ciclo che non contiene archi rossi. Tra tutti gli archi non colorati del ciclo, scegline uno di costo massimo e coloralo rosso.
• Ogni albero ricoprente deve infatti escludere almeno un arco del ciclo• E’ naturale escludere quello di costo massimo

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
L’ approccio “goloso”
• L’approccio goloso applica una delle due regole ad ogni passo, finché tutti gli archi sono colorati
• Si può dimostrare che esiste sempre un minimo albero ricoprente che contiene tutti gli archi blu e non contiene nessun arco rosso.
• Si può inoltre dimostrare che il metodo goloso colora tutti gli archi.

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
Tempi di esecuzione
A seconda della scelta della regola da applicare e del taglio/ciclo usato ad ogni passo, si ottengono dal metodo goloso diversi algoritmi con diversi tempi di esecuzione
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Algoritmo di Kruskal

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
Strategia• Mantieni foresta di alberi blu, all’inizio tutti
disgiunti• Per ogni arco, in ordine non decrescente di costo,
applica il passo seguente : “se l’arco ha entrambi gli estremi nello stesso albero blu, applica regola del ciclo e coloralo rosso, altrimenti applica regola del taglio e coloralo blu”
• I vertici nello stesso albero blu sono mantenuti tramite una struttura dati union/find

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Pseudocodice
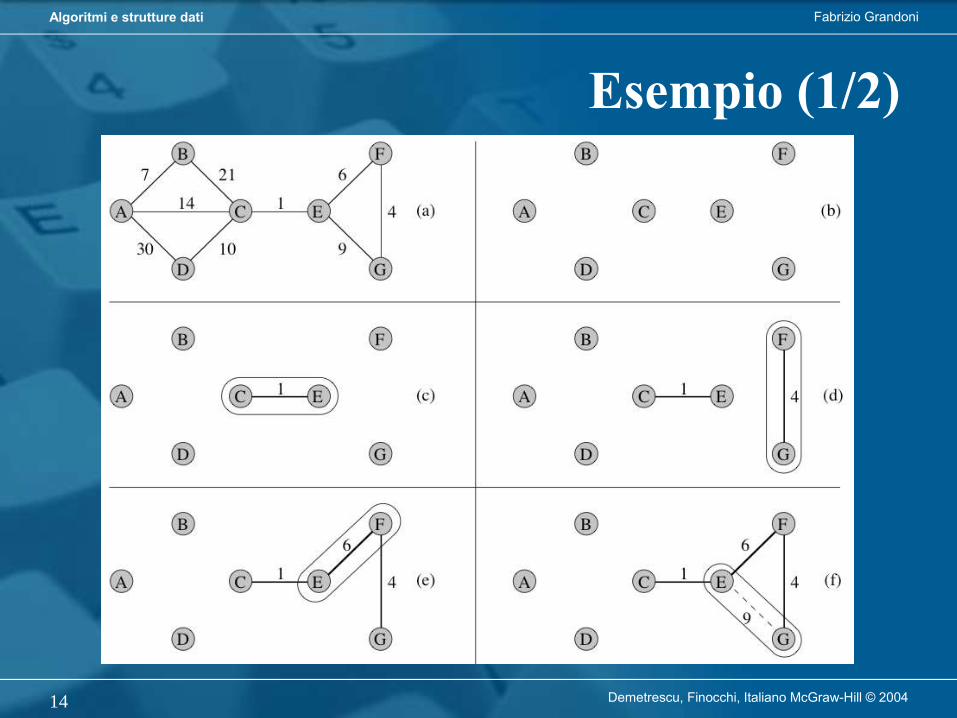
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Esempio (1/2)
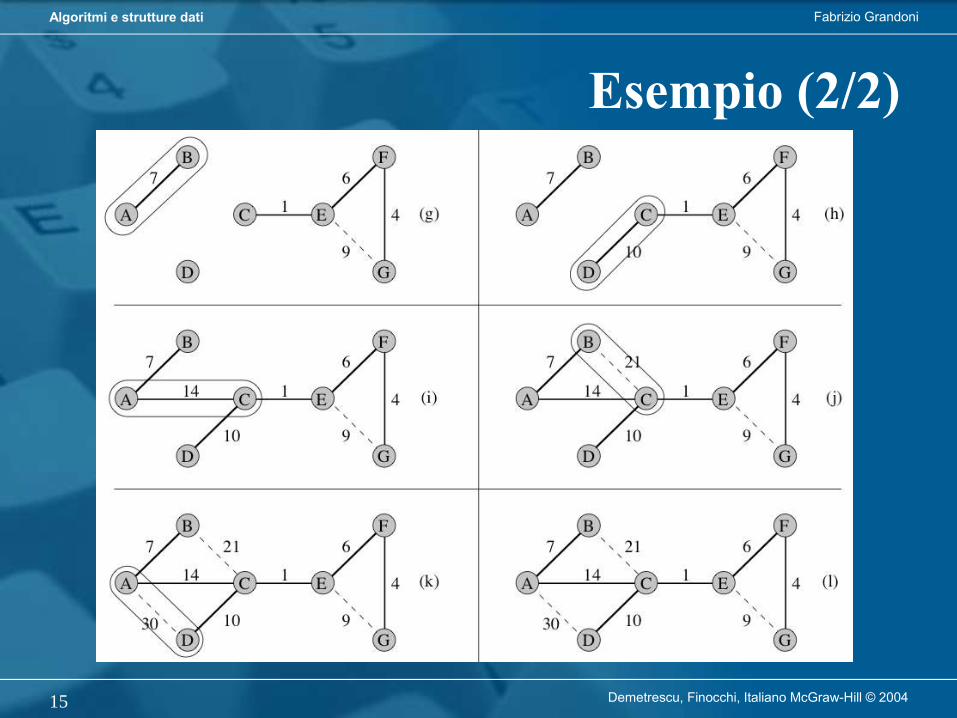
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Esempio (2/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Analisi
Il tempo di esecuzione dell’algoritmo di Kruskal è O(m log n) nel caso peggiore
(Utilizzando un algoritmo di ordinamento ottimo e la struttura dati union-find)
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Algoritmo di Prim

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Strategia• Mantiene un unico albero blu T, che all’inizio consiste
di un vertice arbitrario• Applica per (n-1) volte il seguente passo:
scegli un arco di costo minimo incidente su T e coloralo blu (regola del taglio)
• Definiamo arco azzurro un arco (u,v) tale che u∈T, v∉T, e (u,v) ha il costo minimo tra tutti gli archi che connettono v ad un vertice in T: l’algoritmo mantiene archi azzurri in una coda con priorità da cui viene estratto il minimo ad ogni passo

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
Pseudocodice

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Esempio (1/2)
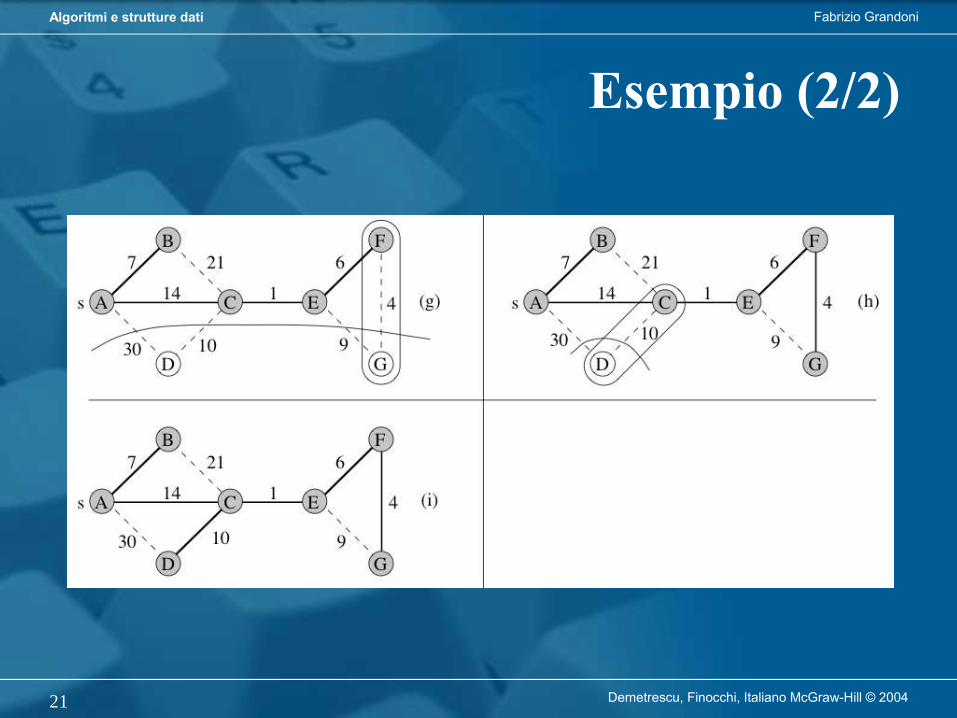
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Esempio (2/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
Analisi
Il tempo di esecuzione dell’algoritmo di Prim è O(m + n log n) nel caso peggiore
(Realizzando la coda con priorità tramite heap di Fibonacci)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Algoritmo di Boruvka°

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
Strategia
• Mantiene una foresta di alberi blu, all’inizio tutti disgiunti
• Ad ogni passo, applica la regola seguente: per ogni albero blu T nella foresta, scegli un arco di costo minimo incidente su T e coloralo blu (regola del taglio)
• Per non rischiare di introdurre cicli, assumiamo che i costi degli archi siano tutti distinti
• Non è necessario usare strutture dati sofisticate
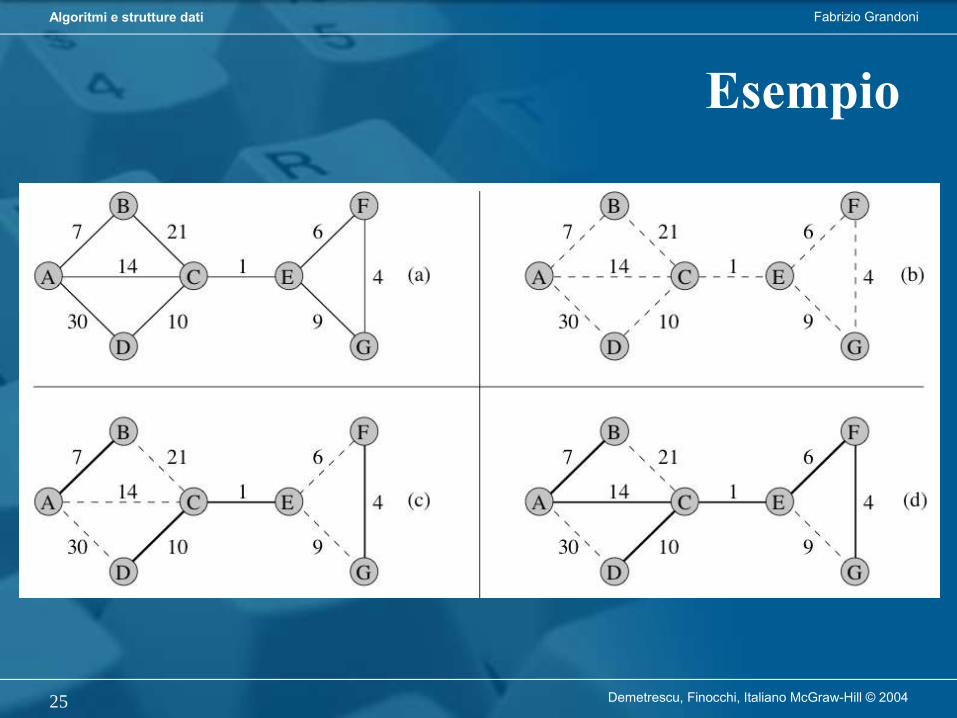
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
Esempio

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
Analisi
Il tempo di esecuzione dell’algoritmo di Boruvka è O(m log n) nel caso peggiore
(Senza usare strutture dati sofisticate)
°

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
Riepilogo
• Paradigma generale per il calcolo di minimi alberi ricoprenti
• Applicazione della tecnica golosa• Tre algoritmi specifici ottenuti dal paradigma
generale: Prim, Kruskal e Boruvka• L’uso di strutture dati sofisticate ci ha permesso
di implementare tali algoritmi in modo efficiente
°

Fabrizio GrandoniAlgoritmi e strutture dati
Capitolo 13Cammini minimi
Algoritmi e Strutture Dati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20042
Definizioni
Sia G = (V,E) un grafo orientato pesato sugli archi. Il costo di un cammino π = <v0,v1,v2,… ,vk> è dato da:
Un cammino minimo tra una coppia di vertici x e y è un cammino di costo minore o uguale a quello di ogni altro cammino tra gli stessi vertici.

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20043
Proprietà dei cammini minimi• Sottostruttura ottima: ogni sottocammino di un
cammino minimo è anch’esso minimo
• Grafi con cicli negativi: se due vertici x e y appartengono a un ciclo di costo negativo, non esiste nessun cammino minimo finito tra di essi
• Se G non contiene cicli negativi, tra ogni coppia di vertici connessi in G esiste sempre un cammino minimo semplice, in cui cioè tutti i vertici sono distinti

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20044
Distanza fra vertici• La distanza dxy tra due vertici x e y è il costo di
un cammino minimo da x a y (o +∞ se i due vertici non sono connessi)
• Disuguaglianza triangolare: per ogni x, y e z
• Condizione di Bellman: per ogni arco (u,v) e per ogni vertice s

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20045
Alberi di cammini minimi
• Un arco (u,v) appartiene a un cammino minimo a partire da un vertice s se e solo se u è raggiungibile da s e dsu+ w(u,v) = dsv
• I cammini minimi da un vertice s a tutti gli altri vertici del grafo possono essere rappresentati tramite un albero radicato in s, detto albero dei cammini minimi

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20046
Calcolare cammini minimi da distanze
Problema: Le distanze non sono note (è proprio quello che vogliamo trovare!)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20047
Tecnica del rilassamento
Partiamo da stime per eccesso delle distanze Dxy ≥ dxy e aggiorniamole decrementandole progressivamente fino a renderle esatte.
Aggiorniamo le stime basandoci sul seguente passo di rilassamento:

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20048
Algoritmo generico per il calcolo delle distanze
Rilassamento

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 20049
Algoritmo di Bellman e Ford (per cammini minimi a sorgente singola)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200410
Ordine di rilassamento Sia π = < s,v1,v2,… ,vk > un cammino minimo. Se fossimo in grado di eseguire i passi di rilassamento nell’ordine seguente:
in k passi avremmo la soluzione. Purtroppo non conosciamo l’ordine giusto, essendo π ignoto !

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200411
Approccio di Bellman e Ford
• Esegui n passate• In ciascuna passata rilassa tutti gli archi • Dopo la j-esima passata, i primi j rilassamenti corretti sono stati certamente eseguiti
• Esegue però molti rilassamenti inutili!

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200412
Pseudocodice
Tempo di esecuzione: O(n m)
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200413
Algoritmo per grafi diretti aciclici(per cammini minimi a sorgente singola)
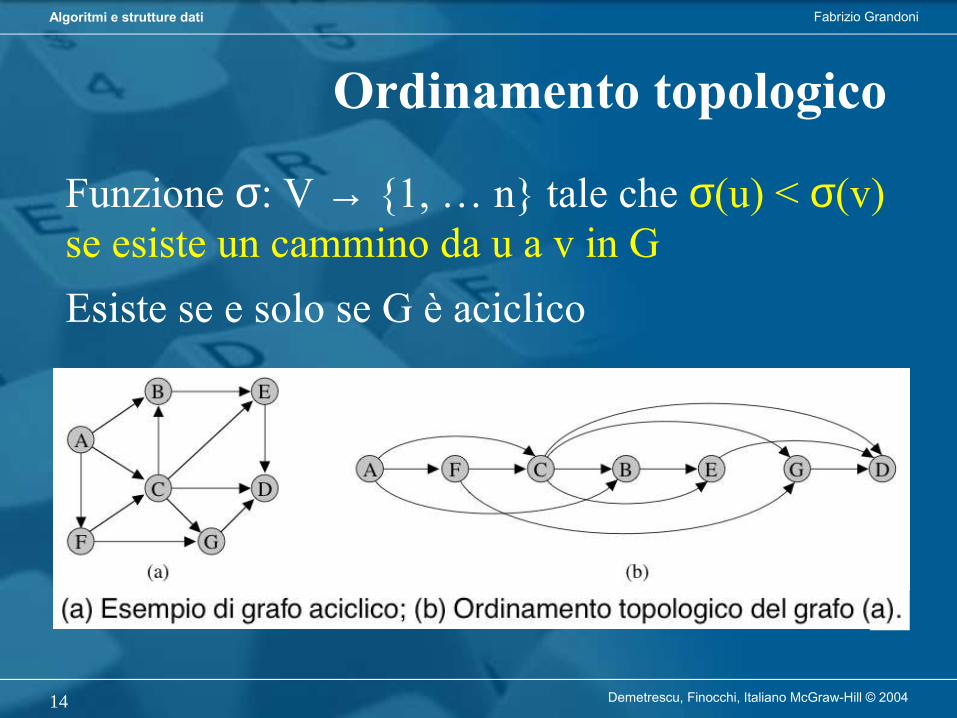
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200414
Ordinamento topologico
Funzione σ: V → 1, … n tale che σ(u) < σ(v) se esiste un cammino da u a v in GEsiste se e solo se G è aciclico

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200415
Calcolo di un ordinamento topologico
Tempo di esecuzione: O(n+m)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200416
Cammini minimi in grafi aciclici
Tempo di esecuzione: O(n+m)
Eseguire i rilassamenti in ordine topologico
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200417
Algoritmo di Dijkstra(per cammini minimi a sorgente singola
in grafi con costi non negativi)
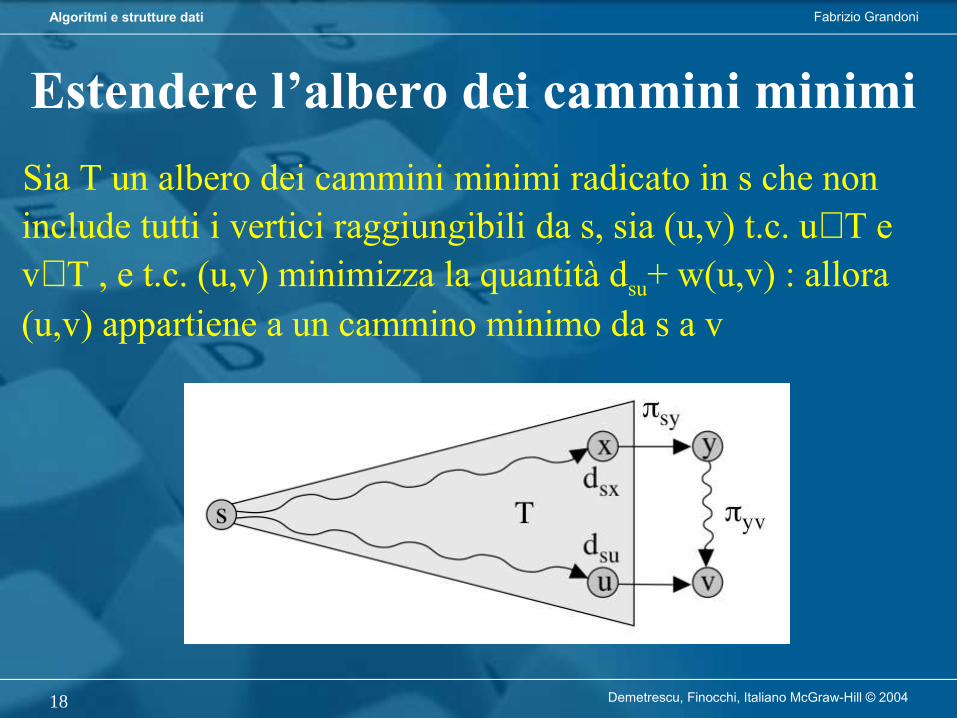
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200418
Estendere l’albero dei cammini minimi Sia T un albero dei cammini minimi radicato in s che non
include tutti i vertici raggiungibili da s, sia (u,v) t.c. u∈T e v∉T , e t.c. (u,v) minimizza la quantità dsu+ w(u,v) : allora (u,v) appartiene a un cammino minimo da s a v

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200419
Algoritmo di Dijkstra
Archi incidenti in T mantenuti in coda con priorità (un solo arco per ogni nodo v ∉ T):se (u,v) è già in coda quando analizzi (z,v) e risulta Dsz+ w(z,v) < Dsu+ w(u,v) , rimpiazza (u,v) con (z,v)
Scegli arco (u,v) con u ∈ T e v ∉ T che minimizza quantità Dsu+ w(u,v), effettua rilassamento Dsv ← Dsu+ w(u,v), ed aggiungi (u,v) a T

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200420
Pseudocodice
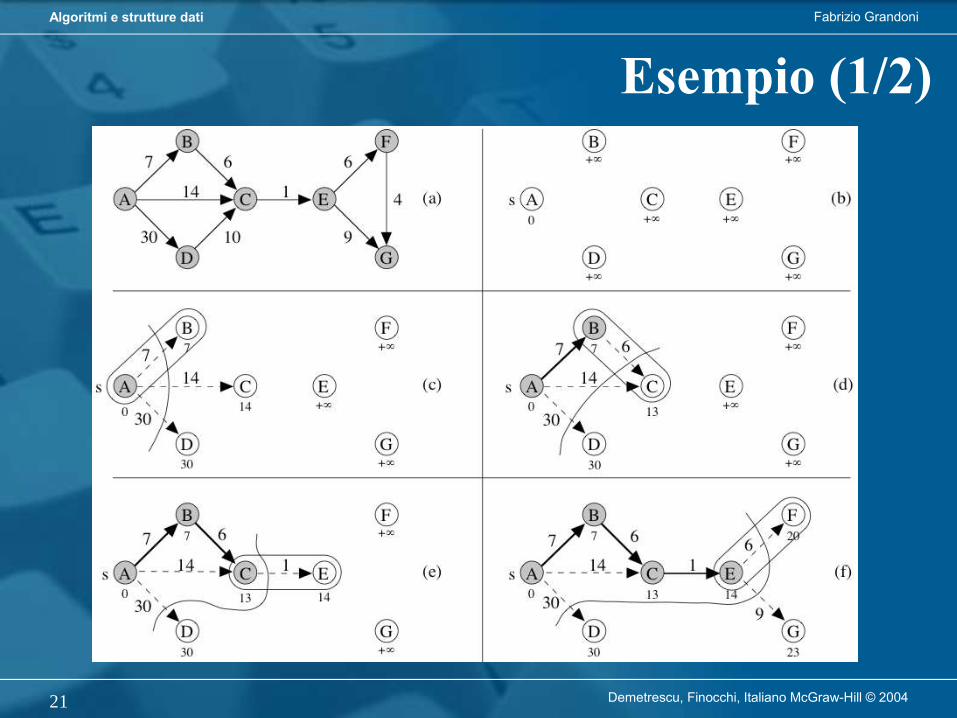
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200421
Esempio (1/2)
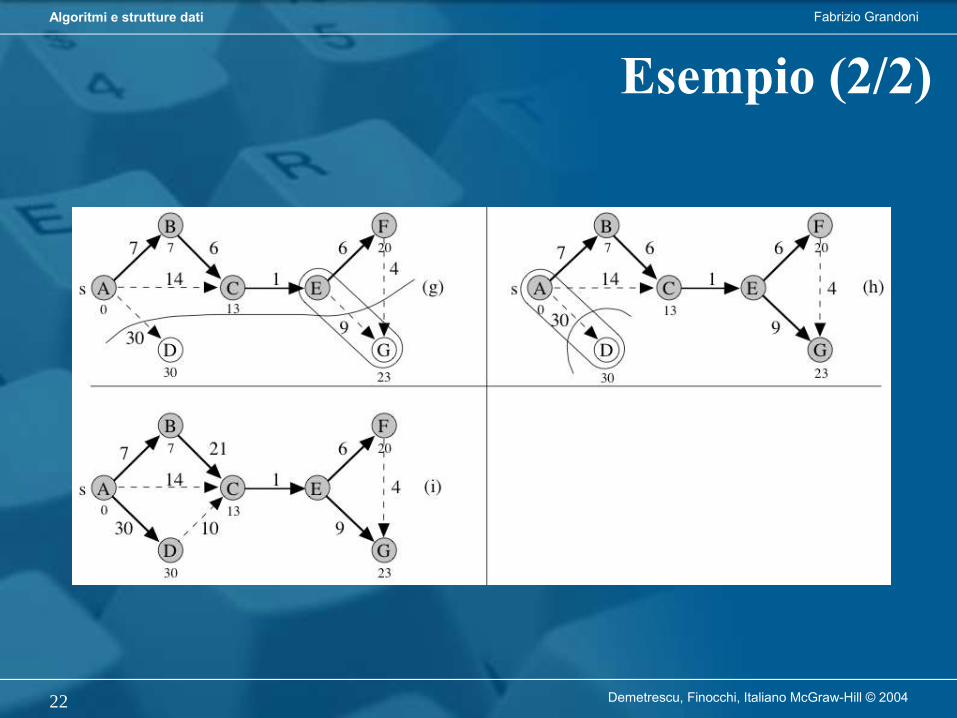
Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200422
Esempio (2/2)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200423
Tempo di esecuzione
Al più: n deleteMin, n insert e m decreaseKey
O(m log n) utilizzando heapO(m + n log n) utilizzando heap di Fibonacci

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200424
Algoritmo di Floyd e Warshall(per cammini minimi tra tutte le coppie)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200425
Approccio
• Elegante applicazione della tecnica di programmazione dinamica
• Un cammino minimo k-vincolato da x a y è un cammino di costo minimo tra tutti i cammini da x a y che usano solo i vertici v1, v2, … vk
• Idea di Floyd e Warshall: calcolare cammini minimi k-vincolati

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200426
Relazioni tra distanze vincolate
• Sia dxy il costo di un cammino minimo k-vincolato da x a y. Risulta:
k
• dxy= w(x,y) se (x,y) ∈ E, +∞ altrimenti0
• dxy = dxyn
• L’algoritmo calcola dxy dal basso verso l’alto, incrementando k da 1 a n

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200427
Pseudocodice
Tempo di esecuzione: O(n3)

Fabrizio GrandoniAlgoritmi e strutture dati
Demetrescu, Finocchi, Italiano McGraw-Hill © 200428
Riepilogo
• Algoritmi classici per il calcolo di distanze (e quindi di cammini minimi), basati sulla tecnica del rilassamento:– Bellman e Ford: cammini minimi a sorgente singola, grafi
diretti senza cicli negativi, tempo O(nm)– Grafi diretti aciclici: cammini minimi a sorgente singola in
tempo O(n+m)– Dijkstra: cammini minimi a sorgente singola, grafi diretti
senza pesi negativi, tempo O(m + n log n)– Floyd e Warshall: cammini minimi tra tutte le coppie in
tempo O(n3)








![Algoritmi e Strutture Dati - cs.unicam.it13]algoritmiSuGrafi.pdf · Algoritmi e Strutture Dati Algoritmi Elementari su Grafi Maria Rita Di Berardini, Emanuela Merelli1 1Dipartimento](https://static.fdocumenti.com/doc/165x107/5a79237b7f8b9a00168da46b/algoritmi-e-strutture-dati-cs-13algoritmisugrafipdfalgoritmi-e-strutture-dati.jpg)








![Algoritmi e Strutture Dati - Algoritmi Golosi (Greedy)computerscience.unicam.it/merelli/algoritmi06/[12]strategiaGolosa.pdf · Algoritmi e Strutture Dati Algoritmi Golosi (Greedy)](https://static.fdocumenti.com/doc/165x107/5c71c4f409d3f2cc4d8b53b1/algoritmi-e-strutture-dati-algoritmi-golosi-greedy-12strategiagolosapdf.jpg)
