
Algoritmi di Classificazione e Reti Neuralior/gestionale/svm/svm_lez1-0809.pdf`Reti neurali (L....
49
06/03/2009 1 Lezione introduttiva 4 MARZO 2009 Algoritmi di Classificazione e Reti Neurali
Transcript of Algoritmi di Classificazione e Reti Neuralior/gestionale/svm/svm_lez1-0809.pdf`Reti neurali (L....

06/03/2009 1
Lezione introduttiva
4 MARZO 2009
Algoritmi di Classificazionee Reti Neurali

06/03/2009 2
Struttura del corsoIl corso è in ”co-docenza”
proff. L. Grippo e L. Palagihttp://www.dis.uniroma1.it/~grippo/http://www.dis.uniroma1.it/~palagi/Il calendario delle lezioni è disponibile sul sito:
Reti neurali (L. Grippo)Support Vector Machines (L.Palagi)
Materiale didattico: dispense e/o lezioni in pptdisponibili sul sito

06/03/2009 3
Contenuti del corso
Introduzione alla teoria dell`apprendimento“imparare dai dati”
Support Vector Machines per la ClassificazioneSVM LineariSVM Non lineari (Kernel)
SVM e ottimizzazioneProgrammazione quadraticaCenni teoria dualita` e Duale di WolfeAlgoritmi di decomposizione
Addestramento del PerceptronReti multistrato e metodo di backpropagationPropreta` di approssimazioneAlgoritmi di addestramentoReti RBF e algoritmi di decoposizione

06/03/2009 4
Classificazione e Regressione
La classificazione individua l’appartenenza ad una classe. Per esempio un modello potrebbe predire che il potenziale cliente ‘X’ rispondera’ ad un’offerta. Con la classificazione l’output predetto (la classe) e’categorico ossia puo’ assumere solo pochi possibili valori come Sì, No, Alto, Medio, Basso...La regressione predice un valore numerico specifico. Ad esempio un modello potrebbe predire che il cliente X ci portera’ un profitto di Y lire nel corso di un determinato periodo di tempo. Le variabili in uscita possono assumere un numero illimitato (o comunque una grande quantita’) di valori. Spesso queste variabili in uscita sono indicate come continue anche se talvolta non lo sono nel senso matematico del termine (ad esempio l’età di una persona)
Tipicamente classificazione e regressione vengono usate per lo sviluppo di modelli matematici per il supporto decisionale*
*Ricerca Operativa

06/03/2009 5
Esempio di classificazionericonoscimento di caratteri manoscritti

06/03/2009 6
Riconoscimento di caratteri manoscritti
Lo scopo è costruire una macchina che prendein ingresso l’immagine di un carattere e produce uno degli elementi dell’insieme {0,1,2….,9} some outputOgni elemento di ingresso corrisponde a un immagine pxp (28 x28, 256x256) pixel e quindie` rappresentabile da un vettore a p2(=784, 65536) valori reali che rappresentano i livelli di grigio (0=bianco, 1=nero) rappresentabili ad es. con 8-bitLa difficoltà è l’alta variabilità delle forme e l’altonumero di diversi elementi (228 x28 x8 ,2256 x256 x8)

06/03/2009 7
Approssimazione/regressioneI dati sono coppie di N valori reali di (x,t) che si suppone abbiano unaregolarità sottostante, tipicamente corrotta da rumore (ad es. errori di misura), ovvero si suppone che esista una funzione t=f(x) incognita, i cui valoripossono essere alterati da un basso valore di rumore.
0 1
1
-1
0
Si vuole determinare la funzione che “meglio”approssima questi dati(si parla di “approssimazione” in assenzadi rumore)

06/03/2009 8
Apprendimento e statisticaInferenza parametrica (1930-’60 golden age)
modelli basati su principi primi: si suppone di conoscere la legge fisica che regola le proprietàstocastiche dei dati e che tale funzione sia definita daun numero finito di parametri.stimare i parametri (quelli non misurabili in modo
diretto) utilizzando i dati e verificare la “veridicità” del modello individuato è l’essenza di un problema di inferenza statisticaI modelli parametrici utilizzati sono tipicamente lineari
nei parametri (che sono pochi); tali parametri sonodeterminati con il metodo della “massimaverosimiglianza” (maximum likelihood method)

06/03/2009 9
Oltre il classico paradigmamodelli di inferenza generale: non si hanno informazioni “a priori”sui principi primi che regolano la legge statistica sottostante la distribuzione dei dati o della funzione che si vuole approssimare
si cerca un metodo (induttivo) in grado di inferire una funzioneapprossimante dati gli esempi.uso dei dati per derivare il modello stessomodelli non predefiniti e non lineari nei parametri
data analysis/data mining
storicamente(1985-1992) reti neurali --- analogia neurone biologico (1958 Rosenblatt propone Perceptron)(1992-oggi) ritorno alla teoria di inferenza statistica

06/03/2009 10
terminologiaregressione (statistica)
classificazione (statistica) o pattern recognition (ingegneria) riconosicmento di configurazioni
⌧ Reti neurali (1958 Rosenblatt propone Perceptron)⌧ SVM⌧……..
intelligenza artificiale (utilizzo logica simbolica) (computer science = informatica)
storicamente(1985-1992) reti neurali --- analogia neurone biologico(1992-oggi) ritorno alla teoria di inferenza statistica

06/03/2009 11
Sviluppo del Data MiningCrescita notevole degli strumenti e delle tecniche per generare e raccogliere dati (introduzione codici a barre, transazioni economiche tramite carta di credito, dati da satellite o da sensori remoti, servizi on line..)
Sviluppo delle tecnologie per l’immagazzinamento dei dati, tecniche di gestione di database e data warehouse, supporti piu’ capaci piu’ economici (dischi, CD) hanno consentito l’archiviazione di grosse quantità di dati
Simili volumi di dati superano di molto la capacità di analisi dei metodi manuali tradizionali, come le query ad hoc. Tali metodi possono creare report informativi sui dati ma non riescono ad analizzare il contenuto dei report per focalizzarsi sulla conoscenza utile.

06/03/2009 12
Il data mining ha per oggetto l'estrazione di un sapere o di una conoscenza a partire da grandi quantità di dati (attraverso metodi automatici o semi-automatici) e l'utilizzazione industriale o operativa di questo sapere. Il termine data mining (letteralmente: estrazione di dati) èdiventato popolare nei tardi anni '90 come versione abbreviata per “estrazione di informazione utile da insiemi di dati di dimensione cospicua”.Oggi data mining ha una duplice valenza
Estrazione, con tecniche analitiche, di informazione implicita,nascosta, da dati già strutturati, per renderla disponibile e direttamente utilizzabile; Esplorazione ed analisi, eseguita in modo automatico o semiautomatico, su grandi quantità di dati allo scopo di scoprire pattern (schemi/regole/configurazioni) caratterizzanti i dati e non evidenti.
Data Mining (DM) (Wikipedia)

06/03/2009 13
Il DM è la non banale estrazione di informazione implicita, precedentemente sconosciuta e potenzialmente utile attraverso l’utilizzo di differenti approcci tecnici (Frawley, Piatetsky-Shapiro e Matheus, 1991).Il DM consiste nell’uso di tecniche statistiche da utilizzare con i databasesaziendali per scoprire modelli e relazioni che possono essere impiegati in un contesto di business (Trajecta lexicon).Il DM è l’esplorazione e l’analisi, attraverso mezzi automatici e semiautomatici, di grosse quantità di dati allo scopo di scoprire pattern (schemi/regole/configurazioni/modelli) significativi (Berry, Linoff, 1997).Il DM è la ricerca di relazioni e modelli globali che sono presenti in grandi database, ma che sono nascosti nell’immenso ammontare di dati, come le relazioni tra i dati dei pazienti e le loro diagnosi mediche. Queste relazioni rappresentano una preziosa conoscenza del database e, se il database è uno specchio fedele, del mondo reale contenuto nel database. (Holshemier e Siebes,1994).Il DM si riferisce all’uso di una varietà di tecniche per identificare “pepite”di informazione e di conoscenza per il supporto alla decision making. L’estrazione di tale conoscenza avviene in modo che essa possa essere usata in diverse aree come supporto alle decisioni, previsioni e stime. I dati sono spesso voluminosi ma, così come sono, hanno un basso valore e nessun uso diretto può esserne fatto; è l’informazione nascosta nei dati che è utile (Clementine user guide).

06/03/2009 14
Ambiti applicativi DMnel marketing
segmentazione della clientelaIndividuzione raggruppamenti omogenei in termini di comportamento d’acquisto e di caratteristiche socio-demografiche
previsione dei comportamenti di acquistoidentificazione dei target per promozioni di nuovi prodotti...)customer retention
Individuazione clienti a rischio di abbandono
Fraud detection (identificazione di frodi)Individuazione di comportamenti frudolenti
Credit risk detection
Analisi delle associazioniindividuazione dei prodotti acquistati congiuntamente
Analisi di testi
Diagnostica medica

06/03/2009 15
Credit risk detection(esempio tratto da lezioni di T. Mitchell)

06/03/2009 16
Altri esempi di problemi tipici(esempio tratto da lezioni di T. Mitchell)
Individuazione clienti a rischio di abbandono
previsione dei comportamenti di acquisto
Ottimizzazione di processo

06/03/2009 17
Diagnostica medica(esempio tratto da lezioni di T. Mitchell)

06/03/2009 18
Data Mining Data Mining è solo una parte del processo di estrazione della conoscenza
Il termine knowledge discovery in databases, o KDD, indica l'intero processo di ricerca di nuova conoscenza dai dati, cioè l’insieme di tecniche e strumenti per assistere in modo intelligente e automatico gli utenti decisionali nell'estrazione di elementi di conoscenza dai dati. Il processo di KDD prevede
Formulazione del problemaGenerazione dei dati Cleaning dei dati e preprocessingData miningInterpretazione del modello (analisi dei pattern)
Il termine di data mining (DM) si riferisce ad una fase fondamentale del processo KDD tanto che spesso è difficile distinguere il processo KDD dal DM che possono essere usati come sinonimi

06/03/2009 19
Apprendimento statisticoDistinguiamo due fasi in un sistema di
apprendimento automaticofase di apprendimento/stima (dai dati di
esempio)fase di utilizzo/predizione su esempi nuovi.
Due tipi di apprendimentosupervisionatonon supervisionato

06/03/2009 20
Supervisionato = “esiste un insegnante”
Classificazione (pattern recognition) sono noti a priori dei pattern rappresentativi di diverse classi, cioè per
ogni valore di input è noto un valore di outputRegressione/Approssimazione
sono note a priori delle coppie (punto,valore) (pattern,target)rappresentative di un funzione incognita a valori reali.
Non supervisionato = “nessun insegnante”Clustering
non sono noti a priori i valori di oputput cio è i pattern rappresentativi delle classi. Si vuole determinare il numero di classi di “similitudine” e la corrispondente classe di appartenenza.
Apprendimento automatico nel DM

06/03/2009 21
ESEMPIO DI CLASSIFICAZIONE SUPERVISIONATA(riconoscimento di caratteri)
Datiun insieme di N elementi manoscritti rappresentati dalla matricedi pixel, ovvero dai vettorie la Categoria di appartenenza {0,1,2,3,4,5,6,7,8,9}
0123456789
classificazionetraining set
generalizzazione

06/03/2009 22
ESEMPIO DI CLASSIFICAZIONE NON SUPERVISIONATA(riconoscimento di caratteri)Dati: un insieme di N elementi manoscritti rappresentati dallamatrice di pixel, ovvero dai vettori
training set
0123456789
clustering

06/03/2009 23
ESEMPIO DI CLASSIFICAZIONE NON SUPERVISIONATA(diagnosi medica)
Pattern: paziente afflitto da una determinata patologia edescritto da M fattori clinici (caratteristiche)
Dati disponibili: insieme di N pazienti
Obiettivo: raggruppare i pazienti in K gruppi i cui elementi presentino caratteristiche “simili”
06/03/2009 24
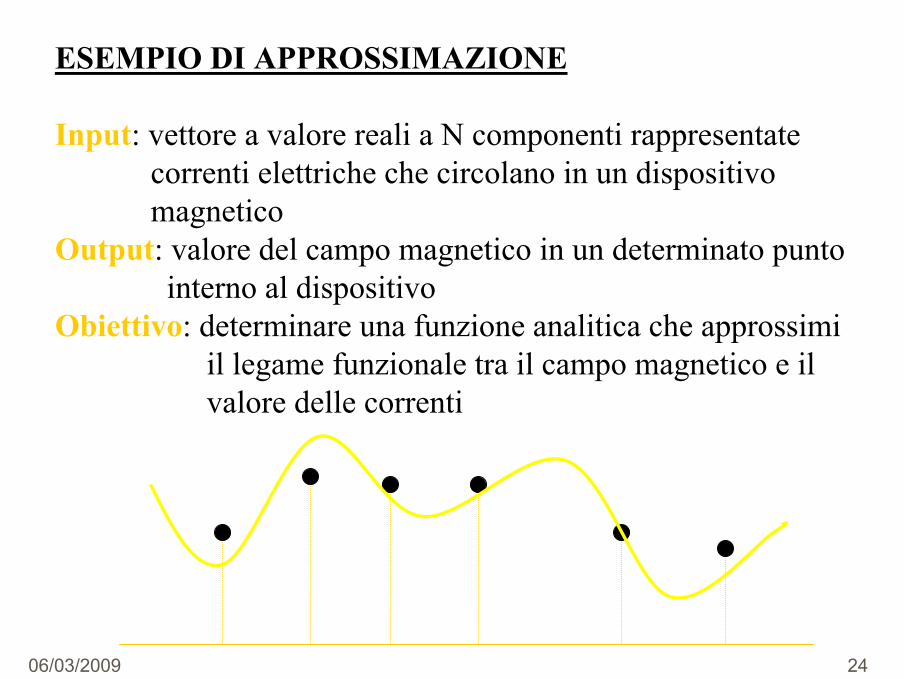
ESEMPIO DI APPROSSIMAZIONE
Input: vettore a valore reali a N componenti rappresentatecorrenti elettriche che circolano in un dispositivo magnetico
Output: valore del campo magnetico in un determinato punto interno al dispositivo
Obiettivo: determinare una funzione analitica che approssimiil legame funzionale tra il campo magnetico e ilvalore delle correnti
06/03/2009 25
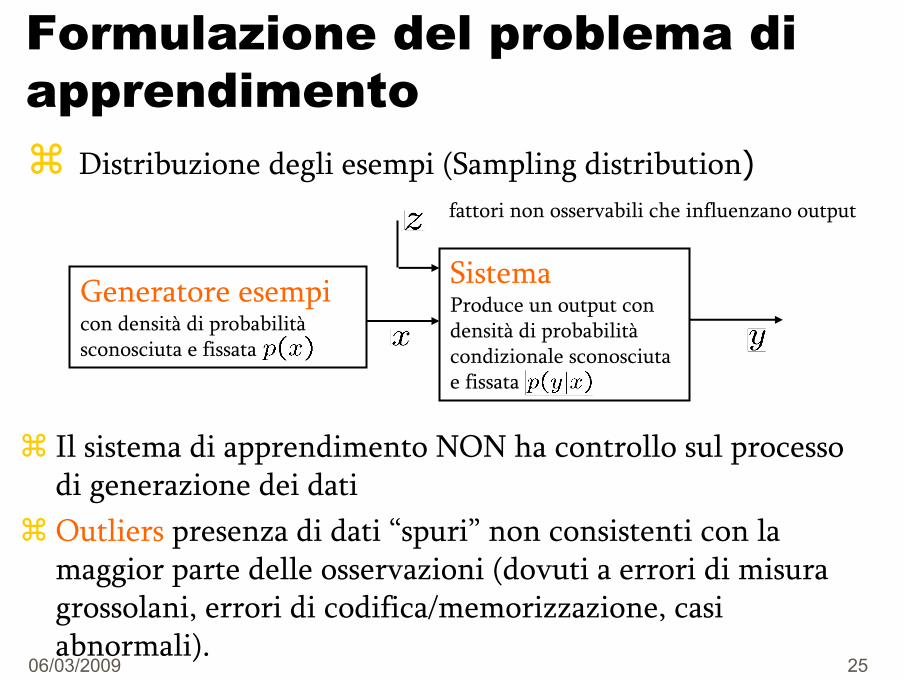
Formulazione del problema di apprendimento
Distribuzione degli esempi (Sampling distribution)
SistemaProduce un output con densità di probabilitàcondizionale sconosciutae fissata
Generatore esempicon densità di probabilitàsconosciuta e fissata
fattori non osservabili che influenzano output
Il sistema di apprendimento NON ha controllo sul processodi generazione dei datiOutliers presenza di dati “spuri” non consistenti con la maggior parte delle osservazioni (dovuti a errori di misuragrossolani, errori di codifica/memorizzazione, casiabnormali).

06/03/2009 26
Apprendimento supervisionatoI dati sono coppie input-output
generati in modo indipendente e identicamente distribuiti(i.i.d) secondo una funzione di probabilita (sconosciuta) Il problema di apprendimento supervisionato: dato il valoredi un vettore ottenere una “buona”predizione del verooutputUna macchina per apprendimento osserva i dati di training e costruisce una funzione in grado di fornire una predizionedell’output per un qualunque valore di input
LearningMachine

06/03/2009 27
Macchina per apprendimento
Più formalmente una macchina per apprendimento realizza una classe di funzioni , che dipende dalla strutturadella macchina scelta, in cui α rappresentaun vettore di parametri che individua unaparticolare funzione nella classe.La macchina è deterministica

06/03/2009 28
Macchina per apprendimentoLa scelta ideale della funzione di approssimazionedovrebbe riflettere la conoscenza a priori sul sistema, MA in problemi di DM questa conoscenza è difficile o impossibile. Metodi adattativi del DM utilizzano una classe molto ampiae flessibile di funzioni di approssimazioneModelli non lineari nei parametri
una semplice macchina per apprendimento

06/03/2009 29
Processo di apprendimentoFissata una macchina per apprendimento ovvero una classe di funzioni
Il processo di apprendimento consiste nello scegliere un particolare valore dei parametri α* che seleziona unafunzione fα* nella classe scelta.
L’obiettivo è creare un modello del processo che sia in grado di dare risposte corrette e coerenti anche (e soprattutto) su dati mai analizzati (generalizzazione) e non di interpolare (=“riconoscere con certezza”) i dati di training (FUNZIONE PREDITTIVA)
Lp1

Diapositiva 29
Lp1 Laura palagi; 18/01/2007

06/03/2009 30
Misura di qualità
Si definisce la Loss function
una funzione che misura la discrepanza tra il valore previsto fα (x) e il valoreeffettivo y. Per definizione la “perdita” è non negativa, quindi valoripositivi alti significano “cattiva” approssimazione.
Per scegliere tra tutte le possibili funzioni del parametro α ènecessario definire un criterio di qualità da ottimizzare.
Assegnati i parametri α, il valore della loss function (intesa come funzionedelle sole x, y) quantifica l’ERRORE risultante dalla realizzazione dellacoppia (x, y)

06/03/2009 31
Minimizzazione del “rischio”
Il valore atteso della perdita dipende dalla distribuzione Ped è dato dall’integrale
Il “criterio di qualità” per scegliere i parametri α è il valoreatteso dell’errore dovuto alla scelta di una particolarefunzione di perdita
La funzione è il rischio effettivo che vorremmominimizzare al variare di α (cioè al variare di )

06/03/2009 32
Esempi di funzioni di perdita(Loss functions)
classificazionecon

06/03/2009 33
Esempi di funzioni di perdita(Loss functions)
regressione

06/03/2009 34
Apprendimento
determinare la funzione che minimizza il rischio tranella classe di funzioni supportate dalla macchina per l’apprendimento utilizzando un numero finito di dati di training è inerentemente mal postoLa difficoltà è scegliere la giusta complessità per “descrivere” i dati a disposizionePrincipi induttivi
minimizzazione del rischio empiricostructural risk minimizationearly stopping rules

06/03/2009 35
Il rischio empirico
Il rischio effettivo non si può calcolare (né quindiminimizzare) perché la funzione di distribuzione di probabilità è sconosciutama sono note solo ℓ osservazioni corrispondenti a
variabili random i.i.d
Cerchiamo una funzione che approssimi il rischioeffettivo e richieda solo l’uso dei dati disponibili

06/03/2009 36
Il rischio empirico
si definisce rischio empirico
Il rischio empirico dipende SOLO dai dati e dalla funzione
La distribuzione di probabilità non interviene nelladefinizione del rischio empirico che fissatiè un valore preciso (errore di training).
Scelta una classe di funzionie definita una funzione di perdita (loss)

06/03/2009 37
Principio Induttivo(Empirical Risk Minimization)
Allo scopo di ottenere una buona capacità di generalizzazione su esempi futuri (test), ilprincipio di minimizzazione del rischioempirico (ERM) utilizza una funzione di decisione che minimizza l’errore sui dati di training: determina la funzione che minimizzail rischio tra tutte le
06/03/2009 38
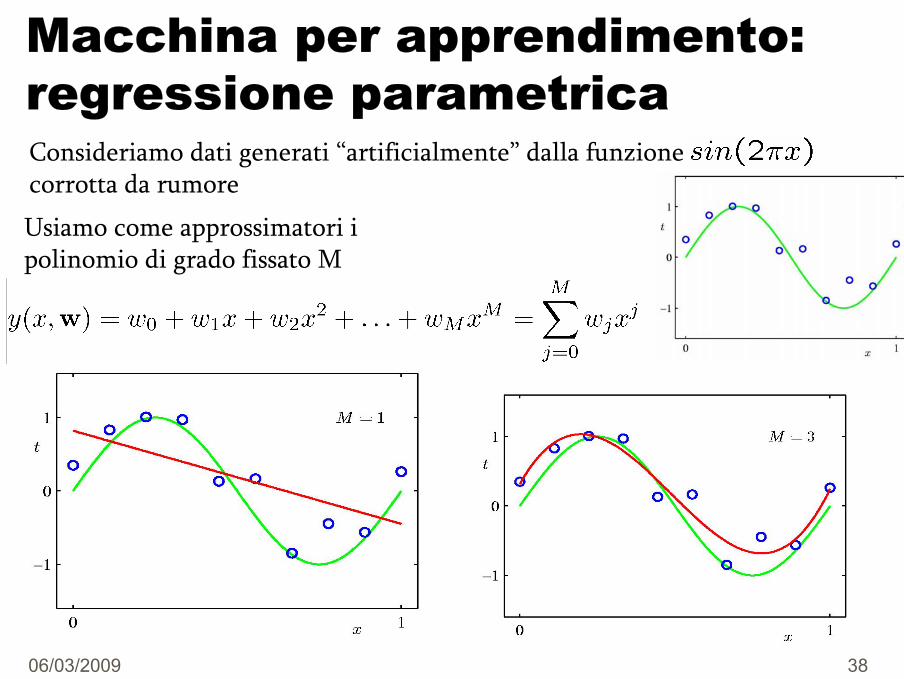
Macchina per apprendimento: regressione parametrica
Usiamo come approssimatori i polinomio di grado fissato M
Consideriamo dati generati “artificialmente” dalla funzionecorrotta da rumore
06/03/2009 39
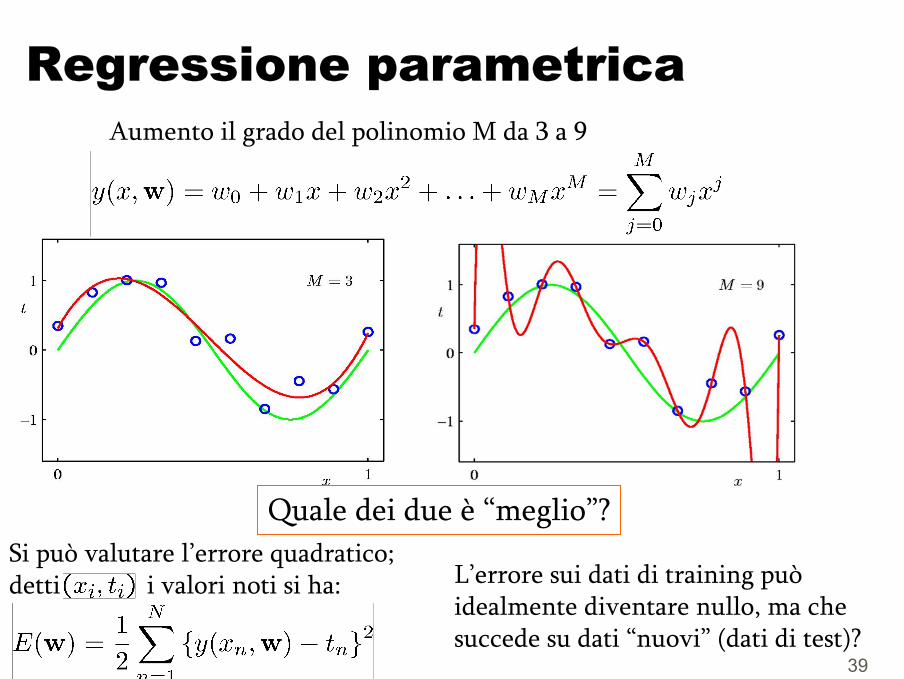
Regressione parametricaAumento il grado del polinomio M da 3 a 9
Quale dei due è “meglio”?Si può valutare l’errore quadratico; detti i valori noti si ha: L’errore sui dati di training può
idealmente diventare nullo, ma chesuccede su dati “nuovi” (dati di test)?
06/03/2009 40
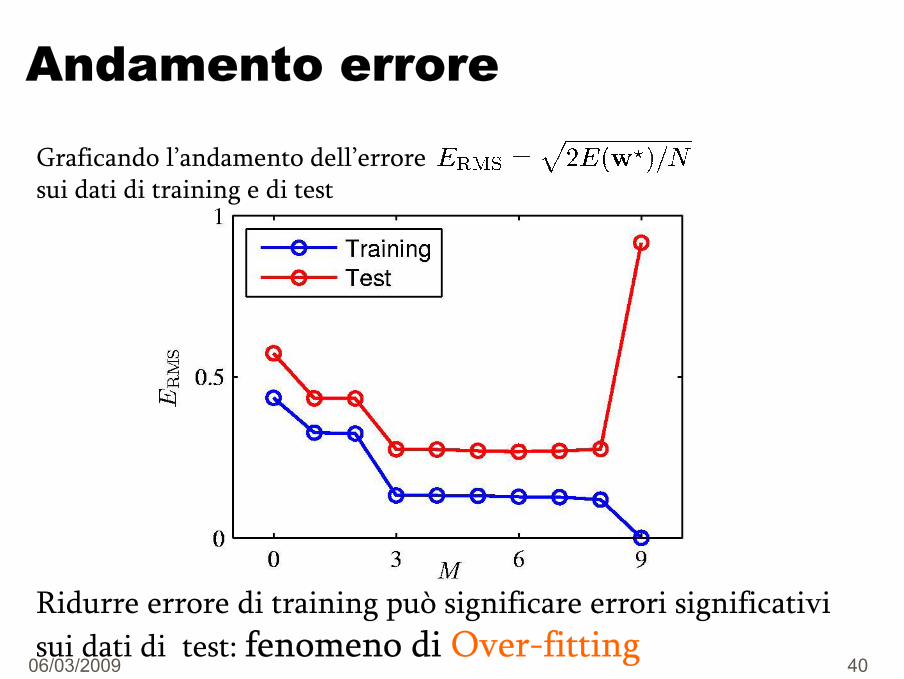
Andamento errore
Graficando l’andamento dell’erroresui dati di training e di test
Ridurre errore di training può significare errori significativisui dati di test: fenomeno di Over-fitting
06/03/2009 41
Ancora l’esempio Regressione parametricaScelto un modello (ad esempio un polinomio di grado M)
Si può valutare l’errore quadratico; detti i valori noti si ha:
L’errore sui dati di training puòidealmente diventare nullo, ma chesuccede su dati “nuovi” (dati di test)?

06/03/2009 42
Regressione parametrica
Polinomio di grado M=9: andamento “migliore”
Aumento il numero di dati di training

06/03/2009 43
Regressione parametricaAumento il numero di dati di training
Polinomio di gradoM=9: l’andamentoriesce quasi a “seguire” la funzionesottostante
La maggiore complessità della macchina (grado del polinomio) in relazione al miglior uso predittivo dipendono dal numero di dati disponibili

06/03/2009 44
Consistenza del rischio empirico
Interesse: trovare una relazione tra le soluzioni dei problemidi ottimizzazione
In generale
imponderabile
calcolabile
La speranza è che l’errore sui dati di traning possa fornire delleindicazioni sulla probabilità di errore su una nuova istanza

06/03/2009 45
Minimizzazione del rischio empirico
Quando ℓ è finito la minimizzazione del rischioempirico può non garantire una minimizzazione del rischio effettivo
La scelta della funzione in una classe che minimizzail rischio empirico non è unica
Entrambe le funzionihanno Rischio empiriconullo
Il rischio effettivo sunuove istanze è diverso

06/03/2009 46
Complessità della classeUn altro aspetto correlato alla minimizzazione del rischioempirico è la “complessità” della classe di funzioni
Una funzione molto complessa può descrivere molto bene i dati di training, ma può non generalizzare bene su nuovi dati
più semplice
più complessa

06/03/2009 47
Over and under fitting
Dati di training:2 classi
Aggiungo nuovidati
più semplice
più complessa
overfittingclasse fα “troppo complessa”
underfittingclasse fα “troppo semplice”

06/03/2009 48
Fonti bibliografichee siti di interesse
Pattern Recognition and Machine Learning – C. Bishop, Springer(2006).Learning from Data: Concepts, theory, and Methods - V. Cherkassky, F. Mulier, John Wiley and Sons, Inc. (1998).Statistical Learning Theory – V. Vapnik, John Wiley and Sons, Inc., 1998Machine Learning, T. Mitchell, Morgan Kaufmann, 1997.
http://research.google.com/pubs/papers.html#MachineLearning
Machine learning Group at Yahoo! Research Silicon Valleyhttp://research.yahoo.com/Machine_Learning
Cineca Consorzio InteruniversitarioLa Gestione delle Informazioni e della Conoscenzahttp://www.cineca.it/gai/area/datamining.htm


















