
A p p u n ti d i C alcolatori E lettron ici C ap itolo 6...
50
A A p p p p u u n n t t i i d d i i C C a a l l c c o o l l a a t t o o r r i i E E l l e e t t t t r r o o n n i i c c i i C C a a p p i i t t o o l l o o 6 6 – – I I l l p p i i p p e e l l i i n n i i n n g g ( ( I I ) ) Il miglioramento delle prestazioni: latenza e throughput ................................................... 1 Introduzione ai pregi del pipelining ................................................................................. 2 Pipelining nel DLX: concetti generali .............................................................................. 4 Limitazione della durata minima del ciclo di clock ........................................................ 6 Esempio .................................................................................................................. 7 Scopo degli elementi di memoria tra gli stadi della pipeline ........................................ 9 Come far funzionare la pipeline ...................................................................................... 9 P ROBLEMI DEL PIPELINING ................................................................................................ 17 Introduzione: i conflitti e gli stalli ................................................................................. 17 Accelerazione in presenza di pipelining ed eventuali stalli .............................................. 18 Conflitti strutturali ....................................................................................................... 19 Esempio ................................................................................................................... 20 Conclusioni sui conflitti strutturali ............................................................................. 21 Conflitti di dati ............................................................................................................ 22 La tecnica dell’anticipazione ..................................................................................... 24 Conseguenze dell’anticipazione sull’hardware ............................................................. 25 Conflitti su dati in memoria ....................................................................................... 28 Ulteriori dettagli sui conflitti in lettura e scrittura dei registri ...................................... 28 Interallacciamento della pipeline ................................................................................ 30 Semplice soluzione software dei conflitti di dati .......................................................... 31 Schedulazione della pipeline ...................................................................................... 32 Esempio ................................................................................................................ 33 Rilevazione dei conflitti di dati in pipeline semplici .................................................... 34 Conflitti di controllo..................................................................................................... 36 Riduzione delle penalizzazioni dovute alle diramazioni nella pipeline ........................... 41 Gestione delle interruzioni ............................................................................................ 45 Operazioni per il salvataggio dello stato della macchina .............................................. 46 Interruzioni sincrone ................................................................................................. 46 Interruzioni multiple nella pipeline del DLX ............................................................... 47 Riepilogo (dagli appunti) .............................................................................................. 49 Il miglioramento delle prestazioni: latenza e throughput Il miglioramento delle prestazioni: latenza e throughput Nel primo capitolo abbiamo visto che esistono almeno due parametri distinti rispetto ai quali giudicare la velocità di un calcolatore: • la latenza (o tempo di risposta o tempo di esecuzione) del calcolatore, ossia il tempo che intercorre tra l’inizio ed il completamento di un evento; • il throughput (o banda passante) del calcolatore, ossia la quantità complessiva di lavoro svolto in un dato intervallo di tempo.
Transcript of A p p u n ti d i C alcolatori E lettron ici C ap itolo 6...

AAAppppppuuunnntttiii dddiii CCCaaalllcccooolllaaatttooorrriii EEEllleeettttttrrrooonnniiiccciii CCCaaapppiiitttooolllooo 666 ––– IIIlll pppiiipppeeellliiinnniiinnnggg (((III)))
Il miglioramento delle prestazioni: latenza e throughput ................................................... 1 Introduzione ai pregi del pipelining ................................................................................. 2 Pipelining nel DLX: concetti generali .............................................................................. 4
Limitazione della durata minima del ciclo di clock ........................................................ 6 Esempio .................................................................................................................. 7 Scopo degli elementi di memoria tra gli stadi della pipeline ........................................ 9
Come far funzionare la pipeline ...................................................................................... 9 PROBLEMI DEL PIPELINING................................................................................................ 17
Introduzione: i conflitti e gli stalli ................................................................................. 17 Accelerazione in presenza di pipelining ed eventuali stalli .............................................. 18 Conflitti strutturali ....................................................................................................... 19
Esempio ................................................................................................................... 20 Conclusioni sui conflitti strutturali ............................................................................. 21
Conflitti di dati ............................................................................................................ 22 La tecnica dell’anticipazione ..................................................................................... 24 Conseguenze dell’anticipazione sull’hardware............................................................. 25 Conflitti su dati in memoria ....................................................................................... 28 Ulteriori dettagli sui conflitti in lettura e scrittura dei registri ...................................... 28 Interallacciamento della pipeline ................................................................................ 30 Semplice soluzione software dei conflitti di dati.......................................................... 31 Schedulazione della pipeline ...................................................................................... 32
Esempio ................................................................................................................ 33 Rilevazione dei conflitti di dati in pipeline semplici .................................................... 34
Conflitti di controllo..................................................................................................... 36 Riduzione delle penalizzazioni dovute alle diramazioni nella pipeline ........................... 41
Gestione delle interruzioni ............................................................................................ 45 Operazioni per il salvataggio dello stato della macchina .............................................. 46 Interruzioni sincrone ................................................................................................. 46 Interruzioni multiple nella pipeline del DLX ............................................................... 47
Riepilogo (dagli appunti) .............................................................................................. 49
Il miglioramento delle prestazioni: latenza e throughputIl miglioramento delle prestazioni: latenza e throughput Nel primo capitolo abbiamo visto che esistono almeno due parametri distinti
rispetto ai quali giudicare la velocità di un calcolatore:
• la latenza (o tempo di risposta o tempo di esecuzione) del calcolatore, ossia il tempo che intercorre tra l’inizio ed il completamento di un evento;
• il throughput (o banda passante) del calcolatore, ossia la quantità complessiva di lavoro svolto in un dato intervallo di tempo.

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 2
Molto spesso, il progettista si trova di fronte alla necessità di ottimizzare le prestazioni temporali, espresse appunto in termini di latenza o di throughput. Se l’obbiettivo del progetto riguarda essenzialmente la latenza, l’unica possibilità di soluzione, in termini architetturali, consiste nello spingere al massimo il parallelismo tra operazioni (ossia la possibilità di svolgere più operazioni contemporaneamente) e nell’usare unità funzionali particolarmente veloci (specialmente quelle di tipo aritmetico): generalmente, questo comporta chip di dimensioni più grandi e quindi anche più complicati e costosi. Se invece il vincolo riguarda il throughput, ossia sostanzialmente la frequenza di presentazione dei dati e di estrazione dei risultati per un sistema che svolge con continuità i propri compiti (magari eseguendo sempre lo stesso algoritmo su diversi flutti di dati), allora l’ottimizzazione della latenza non necessariamente è l’unica via di soluzione: infatti, da un lato può capitare che l’architettura a latenza minima, pur soddisfacendo il vincolo sul throughput, risulti comunque troppo costosa, così come può succedere che, pur ottenendo la latenza minima, non si riesca comunque a garantire il throughput richiesto. In ambedue i casi, si può pensare di applicare un’altra forma di parallelismo, che corrisponde al cosiddetto pipelining.
Letteralmente, “pipeline” significa “oleodotto”, ossia un sistema che riceve con continuità in ingresso un flusso di materiale e che garantisce una certa portata attraverso qualsiasi sezione; se vediamo il “trasferimento del materiale” come una forma di elaborazione, possiamo immaginare che ogni “sezione” della pipeline riceva in ingresso un “quanto” di materiale, lo elabori e lo trasferisca alla sezione successiva, dopodiché è immediatamente disponibile a ricevere il prossimo quanto. La latenza della pipeline (intesa come tempo necessario per il trasferimento del quanto di materiale dall’ingresso primario all’uscita primaria) può essere anche molto elevata nel suo complesso, ma il pregio del sistema è che accetta quanti di materiale in ingresso (fornendoli poi in uscita) indipendentemente dalla latenza, con cadenza pari alla latenza della sezione più lenta della pipeline stessa. E’ ovvio che l’oleodotto è un sistema tempo-continuo, mentre invece un calcolatore elettronico è un sistema tempo-discreto (sincronizzato al segnale di clock), ma questa analogia serve dare una idea iniziale dei pregi di una pipeline, così come dimostreremo ampiamente nei prossimi paragrafi.
Introduzione ai pregi del pipeliningIntroduzione ai pregi del pipelining Il pipelining è una tecnica di realizzazione dei processori, in cui le
esecuzioni di più istruzioni vengono parzialmente sovrapposte nel tempo. Al giorno d’oggi, si tratta della tecnica più utilizzata per la realizzazione delle CPU veloci: essa è nata quando, fin dagli anni ’70, i progettisti di CPU si posero il problema di modificare l’architettura delle unità di elaborazione in modo da migliorarne le prestazioni al di là di quanto si potesse fare in termini puramente tecnologici.
Possiamo pensare ad una pipeline come ad una catena di montaggio: ogni avanzamento lungo la pipeline completa una parte del ciclo di esecuzione di una istruzione. Il lavoro che l’istruzione deve compiere viene suddiviso in compiti più semplici, ognuno dei quali richiede solo una frazione del tempo totale necessario per completare l’intera istruzione: ogni compito è detto stadio di pipeline (o semplicemente stadio o anche segmento di pipeline). I vari stadi di pipeline sono collegati in successione per formare una catena: le istruzioni “entrano” da un estremo di tale catena, vengono elaborate dalla catena ed “escono” dall’altro estremo. L’ “ingresso” di una istruzione nella pipeline corrisponde evidentemente all’avvio

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 3
dell’esecuzione di quella istruzione, mentre invece l’ “uscita” di una istruzione dalla pipeline corrisponde al completamento dell’esecuzione di quella istruzione.
La velocità di operazione di una pipeline è determinata dalla frequenza con cui le istruzioni “escono” dalla pipeline stessa, ossia quindi dalla frequenza con cui le istruzioni vengono eseguite (1).
Dato che gli stadi della pipeline sono rigidamente collegati in successione, devono operare tutti i modo sincrono. Il tempo richiesto per fare avanzare una istruzione lungo la pipeline è il cosiddetto ciclo macchina. La durata del ciclo macchina è determinata dal tempo richiesto dallo stadio più lento della pipeline, proprio perché gli stadi devono necessariamente avanzare tutti nel medesimo istante, per cui i più “veloci” devono aspettare il più “lento”: ad esempio, se uno stadio richiede 5 ns ma si sta svolgendo in contemporanea uno stadio che richiede 10 ns, il primo dovrà aspettare il completamento del secondo, in modo che possa avvenire contemporaneamente la transizione per entrambi allo stadio successivo.
Spesso, il ciclo macchina coincide con il ciclo di clock, ma talvolta esso può durare anche due cicli di clock o addirittura tre cicli di clock.
Uno degli obbiettivi del progetto di una pipeline consiste nel bilanciamento della “dimensione” degli stadi della pipeline. Nel caso in cui gli stadi sono perfettamente bilanciati, allora si può facilmente calcolare l’intervallo di tempo tra due istruzioni (2) in condizioni ideali, ossia senza i cosiddetti stalli (di cui parleremo più avanti): il suddetto intervallo è pari a
pipeline di stadi degli Numero
pipeline senza macchina unasu istruzioneper Tempo
In base a questa formula, si può intuire (ma lo vedremo in modo rigoroso più
avanti) che l’accelerazione dovuta al pipelining è pari al numero di stadi della pipeline (in condizioni ideali). In realtà, le condizioni ideali di cui parlavamo non sono quasi mai realizzate, sia perché solitamente gli stadi non sono bilanciati in modo perfetto sia anche perché l’introduzione del pipelining comporta comunque qualche costo aggiuntivo (che esamineremo più avanti). Di conseguenza, l’intervallo di tempo tra due istruzioni, su una macchina dotata di pipelining, non raggiunge mai il valore minimo teorico dato dalla formula di prima, anche se può avvicinarsi abbastanza ad esso (ad esempio, entro circa il 10%).
In generale, l’effetto più evidente del pipelining è quello di determinare una riduzione del tempo medio di esecuzione per istruzione, dove l’aggettivo “medio” serve a specificare che non ci si riferisce alla latenza delle istruzioni prese singolarmente, ma al tempo complessivo speso per l’esecuzione di tutte le istruzioni diviso per il numero di istruzioni eseguite. Questo importante risultato si può ottenere in tre modi:
• quello più evidente consiste nel diminuire il tempo del ciclo di clock della
macchina dotata di pipelining;
• in alternativa, si può ridurre il numero di cicli di clock per istruzione (CPI);
• si possono anche adottare entrambe le soluzioni precedenti. Solitamente, i risultati migliori si ottengono con la riduzione del CPI, anche se il
tempo del ciclo di clock risulta quasi sempre inferiore nelle macchine dotate di
1 Si tratta dunque di un parametro ben diverso dalla velocità con cui viene eseguita la singola istruzione. 2 Inteso come differenza tra l’istante in cui viene completata l’esecuzione di una istruzione e quello in cui viene completata l’esecuzione dell’istruzione successiva.

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 4
pipelining (specialmente nei supercalcolatori). In ogni caso, vedremo che la durata del periodo di clock non può essere ridotta arbitrariamente, per via di una serie di vincoli legati alla tecnologia di realizzazione del processore.
Pipelining nel DLX: concetti generaliPipelining nel DLX: concetti generali Il pipelining è una tecnica di realizzazione dei processori che sfrutta il
parallelismo esistente tra le istruzioni di un flusso di esecuzione sequenziale, ossia la possibilità di eseguirle contemporaneamente (almeno parzialmente) anziché una dopo l’altra nel classico modo sequenziale. Si tratta di un meccanismo importante in quanto è trasparente al programmatore, al contrario invece di altre tecniche di accelerazione che, per essere sfruttate, devono necessariamente essere previste dal programmatore al momento della scrittura dei propri programmi.
In questo capitolo descriveremo il pipelining con particolare riferimento all’architettura del DLX, la cui semplicità consente di meglio evidenziare i principi fondamentali di questa tecnica di accelerazione. Gli stessi principi si applicano ovviamente anche ad architetture più complesse del DLX, ma in quei casi anche le pipeline risultano più complesse e quindi poco indicate per la didattica.
Per comprendere i principi cardine del pipeline, dobbiamo in primo luogo ricordare che, nel DLX (ma non solo in esso), il ciclo completo di esecuzione di una istruzione in linguaggio macchina può essere suddiviso in 5 fasi successive:
1) prelievo dell’istruzione dalla memoria (IF);
2) decodifica dell’istruzione e caricamento dei registri tramite gli operandi (ID);
3) esecuzione vera e propria, tramite operazioni che coinvolgono la ALU (EX);
4) accesso alla memoria (MEM);
5) scrittura del risultato nel banco di registri (WB). Le operazioni compiute, per le varie tipologie di istruzioni, in corrispondenza di
queste fasi sono state esaminate nel capitolo precedente. Ci limitiamo perciò a ricordare che non tutte le istruzioni sono “attive” in tutte le fasi, ossia non tutte le istruzioni prevedono il compimento di “operazioni” del processore in tutte le fasi.
Nel seguito, sarà molto utile poter rappresentare graficamente la successione di queste fasi e lo faremo nel modo seguente:
IF ID EX MEM WB
Schematizzazione grafica delle varie fasi di esecuzione di una istruzione
In assenza di qualunque ottimizzazione, il funzionamento della CPU prevede che il prelevamento di una istruzione non possa partire fin quando non viene terminata l’esecuzione dell’istruzione precedente:

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 5
IF ID EX MEM WB IF ID EX MEM WB IF ID EX MEM WB
tempo
Istruzione i Istruzione i+1 Istruzione i+2
Allora, supponiamo ad esempio che la CPU del tipo appena descritto esegua un
determinato programma costituito da N istruzioni: supponiamo, per semplicità, che ci sia un unico livello di memoria (il che significa che sia il programma sia i dati risiedono tutti nella memoria centrale del calcolatore oppure nella memoria cache) e che tutte le istruzioni richiedano lo stesso tempo τ per essere lette ed eseguite (3); se il programma fosse rigorosamente lineare (cioè se non ci fossero cicli né diramazioni né salti), il tempo totale di esecuzione sarebbe evidentemente N⋅τ; nel caso invece più generale, quando cioè siano presenti diramazioni e cicli con un numero imprecisato (a priori) di iterazioni, allora il tempo di esecuzione non può che essere stimato in termini statistici, riferendosi ad esempio ad un certo numero di esecuzioni su vari insiemi di dati in ingresso.
Per dotare il DLX del pipelining, dobbiamo semplicemente fare in modo che venga prelevata una nuova istruzione ad ogni ciclo di clock. In questo caso, ognuna delle fasi di cui sopra diventa uno stadio di pipeline. Nella figura seguente viene allora rappresentato un semplice profilo di esecuzione con pipeline, supponendo che ogni istruzione richieda 5 colpi di clock, uno per ogni singola fase:
tempo(cicli di clock)
Istruzione i
Istruzione i+1
Istruzione i+2
Istruzione i+3
Istruzione i+4
Istruzione i+5
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Pipeline DLX semplice
In corrispondenza del 1° ciclo di clock, viene effettuata la fase IF per l’istruzione i; nel ciclo di clock successivo, viene effettuata la fase ID per l’istruzione i ed inoltre, in base appunto al meccanismo del pipelining, viene effettuata la fase IF per l’istruzione i+1; nel ciclo di clock ancora successivo, abbiamo la fase EX per l’istruzione i, la fase ID per l’istruzione i+1 e la fase IF per l’istruzione i+2. Il tutto procede dunque in modo tale che ad ogni ciclo di clock venga avviata l’esecuzione di una nuova istruzione.
In effetti, l’ipotesi per cui tutte le istruzioni abbiano uguale latenza non è molto ragionevole: infatti, le istruzioni hanno latenza diversa a seconda delle fasi in cui sono effettivamente attive e, a loro volta, le fasi possono richiedere uno o più cicli di clock: per esempio, la lettura da memoria è l’istruzione più lunga, in quanto tutti i cinque stadi di esecuzione sono usati per compiere operazioni, mentre invece i salti
3 Stiamo cioè supponendo che la latenza di tutte le istruzioni sia pari a τ

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 6
incondizionati sono le istruzioni più veloci, in quanto non richiedono né l’accesso alla memoria dati né la scrittura del banco di registri. Comunque, continuiamo a supporre che la latenza sia sempre la stessa.
La condizione di regime, che è lo scopo principale del pipelining, si ottiene a partire dal 5° ciclo di clock: infatti, a partire da tale ciclo, viene completata l’esecuzione di una istruzione ogni ciclo di clock.
Con questo meccanismo, si ottengono evidentemente due risultati (a regime):
• aumentare la frequenza di operazione della CPU, in quanto in ciascun ciclo di clock bisogna portare a termine cinque fasi di esecuzione per cinque distinte istruzioni;
• aumentare il numero medio di istruzioni completate nell’unità di tempo, come detto prima.
E’ importante sottolineare, però, che non viene in alcun modo variato il tempo di
esecuzione delle singole istruzioni, ossia la loro latenza: infatti, nel nostro esempio ogni istruzione richiede sempre, per la sua esecuzione completa, cinque cicli di clock. Al contrario, ciò che aumenta è la velocità complessiva con cui viene eseguito il programma, ossia diminuisce il tempo di esecuzione totale, anche se nessuna istruzione è di per sé più veloce. Viene dunque migliorato il throughput della CPU, lasciando invariata la latenza delle singole istruzioni.
Nel prossimo paragrafo vedremo che la costanza della latenza delle singole istruzioni è proprio uno dei limiti principali per la dimensione effettiva della pipeline.
Prima di proseguire, vediamo numericamente i benefici della pipeline prima descritta, tramite un semplice esempio: supponiamo che il programma da eseguire sia composto dalle 6 istruzioni considerate nell’ultima figura; supponiamo anche che la latenza di ciascuna di queste istruzioni sia di 45 ns, il che significa (almeno in prima approssimazione) che il ciclo di clock è pari a 45/5=9 ns; allora, se adottassimo l’esecuzione sequenziale delle istruzioni, l’esecuzione totale del programma richiedere 6×45=270 ns; al contrario, in presenza del pipelining, sono sufficienti 10 cicli di clock, corrispondenti perciò ad un tempo totale di 10×9=90 ns: abbiamo cioè risparmiato il 66% del tempo! Non solo, ma questo risultato è comunque influenzato da un tempo iniziale transitorio necessario affinché la pipeline si riempia completamente e vada a regime: all’aumentare del numero di istruzioni da eseguire, il “peso” di questo tempo iniziale transitorio diventa sempre minore e quindi il tempo totale di esecuzione si avvicina sempre più al valore ideale dato dal prodotto del numero di istruzioni per la durata del ciclo di clock.
LLLiiimmmiiitttaaazzziiiooonnneee dddeeellllllaaa ddduuurrraaatttaaa mmmiiinnniiimmmaaa dddeeelll ccciiiccclllooo dddiii cccllloooccckkk Ci sono una serie di considerazioni di progetto che limitano il valore minimo del
tempo del ciclo di clock ottenibile in una pipeline di grandi dimensioni; tra queste, la più importante riguarda l’analisi dell’effetto combinato di due fattori:
a) il ritardo degli elementi di memoria: se tra gli stadi della pipeline fosse
necessario inserire degli elementi di memoria, il tempo del ciclo di clock dovrebbe necessariamente essere aumentato di una quantità pari alla somma di due quantità relative a tali elementi: il tempo di impostazione (setup time) ed il tempo di propagazione (delay time) di questi elementi;
b) lo sfasamento del clock è un altro fattore che influenza la durata minima del tempo di ciclo di clock.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 7
Quando il tempo del ciclo di clock è stato ridotto alla somma del setup time, del delay time e del contributo dovuto allo sfasamento del clock, nessun ulteriore aumento del “grado” di pipelining risulta utile, in quanto non si potrebbe operare alcuna ulteriore riduzione.
Esempio Al fine di comprendere le ultime considerazioni fatte, facciamo un esempio
concreto. Consideriamo innanzitutto una macchina non dotata di pipelining e supponiamo che le 5 fasi di esecuzione delle istruzioni abbiano le seguenti durate (uguali per tutte le istruzioni): 50 ns, 50 ns, 60 ns, 50 ns, 50 ns. Allora, il tempo medio di esecuzione di una istruzione in questa macchina è
TE = 50 + 50 + 60 + 50 + 50 = 260 ns
Nella figura seguente è mostrato graficamente quello che accade durante
l’esecuzione delle istruzioni per questo tipo di macchina:
50 50 60 50 50
tempo
Istruzione i Istruzione i+1 Istruzione i+2
50 50 60 50 50 50 50 60 50 50
260 ns 260 ns 260 ns Per eseguire tre istruzioni, sono necessari 260×3=780 ns. Adesso supponiamo invece di introdurre il pipelining in questa macchina. In
condizioni ideali, dato che gli stadi della pipeline devono essere perfettamente sincronizzati, il tempo di esecuzione delle varie fasi deve essere lo stesso e deve essere pari a quello della fase più lenta; nel nostro esempio, la fase più lenta è EX e dura 60 ns, per cui tutte le fasi durano 60 ns:
tempo
Istruzione i
Istruzione i+1
Istruzione i+2
Istruzione i+3
60 60 60 60 60
60 60 60 60 60
60 60 60 60 60
60 60 60 60 60
300 ns
Per calcolare l’accelerazione, ci basta rapportare i tempi medi di esecuzione per
istruzione nei due casi, considerando ovviamente la situazione di regime nel caso del pipelining (in cui quindi viene completata l’esecuzione di una istruzione ogni 60 ns):
33.460
260
TE
TEA
pipeline
===
Abbiamo dunque una accelerazione superiore a 4. Questo vale ovviamente in condizioni ideali. Supponiamo, invece, che, a causa
dello sfasamento del clock e del tempo di impostazione degli elementi di memoria interposti tra gli stadi della pipeline, si determini un incremento di 5 ns del tempo

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 8
richiesto da ogni fase dell’esecuzione: allora, il periodo di clock, nel caso del pipelining, aumenta di 5 ns, passando da 60 ns a 65 ns, e lo stesso accade al tempo medio di esecuzione delle istruzioni, dato che abbiamo una istruzione eseguita ogni 65 ns.
tempo
Istruzione i
Istruzione i+1
Istruzione i+2
Istruzione i+3
60 60 60 60 60
325 ns
65 ns
60 60 60 60 60
60 60 60 60 60
60 60 60 60 60
Quindi, l’accelerazione scende a 465
260
TE
TEA
pipeline
=== e la latenza della singola
istruzione aumenta da 260 ns a 325 ns. Questo decremento di prestazioni evidenzia dunque il fatto che l’aumento di 5 ns
determina un limite alla convenienza del pipeline: se il costo addizionale non dipende dalle variazioni del ciclo di clock, la legge di Amdahl ci dice che l’aumento del tempo del ciclo di clock impone un limite superiore all’accelerazione.
Dato che gli elementi di memoria, in un progetto con pipelining, possono avere un impatto così significativo sulla frequenza del clock, i progettisti si sono ormai orientati verso elementi di memoria che consentano la massima frequenza di clock possibile.
Prima di andare oltre, segnaliamo che viene spesso adottata la seguente terminologia, con riferimento all’esempio appena discusso:
• tempo di startup della pipeline: è il tempo iniziale necessario affinché la
pipeline si riempia completamente, per cui è pari a 65+65+65+65=260 ns;
• tempo di latenza delle istruzioni nel caso di pipelining: 325 ns;
• tempo di produttività nel caso di pipelining: 65 ns.
tempo di latenza: 325 ns
Istruzione i
Istruzione i+1
Istruzione i+2
Istruzione i+3
Istruzione i+4
Istruzione i+5
60 60 60 60 60
60 60 60 60 60
60 60 60 60 60
60 60 60 60 60
60 60 60 60 60
60 60 60 60 60
Tempo di produttività:65 ns
Tempo di startup:260 ns

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 9
Scopo degli elementi di memoria tra gli stadi della pipeline Si è detto che potrebbe essere necessario interporre degli elementi di memoria tra
uno stadio della pipeline ed il successivo. Vediamo di capire il perché di questo. Affinché il funzionamento di una pipeline risulti corretto, bisogna fare in modo che
l’informazione che “fluisce” da uno stadio di pipeline al successivo risulti stabile per tutto il tempo in cui risulta necessaria. Ad esempio data una pipeline del tipo considerato nei paragrafi precedenti, consideriamo la sequenza di due istruzioni, di cui la prima sia una LW (load word, carica parola):
Istruzione i (LW)
Istruzione i+1
tempo(cicli di clock)1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
Nell’istante in cui inizia la fase IF della seconda istruzione, si deve leggere
l’istruzione dalla memoria e portarla nel registro IR. Nello stesso istante, però, l’istruzione LW è giunta solo al secondo stadio (ID) e richiede perciò che l’informazione letta in precedenza resti stabile e disponibile: se il registro IR fosse sovrascritto dalla nuova istruzione e la LW non venisse in qualche modo conservata, l’esecuzione di LW non sarebbe più possibile. Non solo, ma, come si vedrà in seguito, la conservazione delle informazioni necessarie su ciascuna istruzione è una condizione necessaria per poter gestire le interruzioni qualora si presentino.
In generale, quindi, diciamo che l’informazione associata a ciascuna istruzione deve rimanere stabile e disponibile fino a quando l’esecuzione di tale istruzione non è completata: in particolare, è importante conservare i registri sorgente e destinazione nonché il valore del registro PC. Per garantire questa stabilità, occorre dunque interporre, tra i diversi stadi della pipeline, degli opportuni buffer (detti anche registri tampone): ad ogni ciclo di clock, tutte le istruzioni si “spostano” da uno stadio al successivo e, in sincronia, anche le informazioni necessarie si spostano da un buffer al successivo. L’unico stadio che non richiede, a valle, un buffer è l’ultimo (WB): infatti, dato che ogni istruzione, dopo che è stata terminata, aggiorna lo stato della macchina, tale eventuale buffer risulterebbe inutile, in quanto tutto ciò che dell’istruzione potrebbe servire ad istruzioni successive è in qualche modo contenuto appunto nello stato della macchina (ad esempio, tramite i risultati registrati in memoria o nel banco dei registri oppure tramite il nuovo valore inserito nel registro PC).
Come far funzionare la pipelineCome far funzionare la pipeline Ci occupiamo adesso di entrare con maggiore dettaglio nel funzionamento del
pipelining, al fine soprattutto di evidenziare quali condizioni sono necessarie per la realizzazione del pipelining e quali problemi nascano dall’uso del pipelining. Per semplicità, i nostri discorsi riguarderanno inizialmente solo le istruzioni del DLX per numeri interi.
Per cominciare, vogliamo analizzare il comportamento del DLX in ogni ciclo di clock, al fine di verificare se e quando la sovrapposizione delle istruzioni determini un sovraccarico delle risorse disponibili. Per esempio, dobbiamo essere sicuri che la ALU non si trovi a dover eseguire contemporaneamente il calcolo di un indirizzo

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 10
effettivo e una sottrazione, cosa che ovviamente non può fare. In effetti, vedremo che un sovraccarico (meglio parlare di “conflitto”) di questo tipo è molto raro (e comunque non può avvenire quando le istruzioni hanno uguale latenza), mentre invece un conflitto molto più probabile può riguardare l’accesso alla memoria: se, nella fase MEM di una istruzione, il processore deve leggere un dato dalla stessa memoria da cui si vuole simultaneamente prelevare (IF) l’istruzione successiva, si verifica un conflitto per l’accesso ad una stessa risorsa e quindi non si ottiene l’accelerazione sperata (4).
Questo tipo di analisi è resa molto facile dalla semplicità dell’insieme di istruzioni di cui il DLX è dotato.
Tanto per partire da un esempio concreto, esaminiamo in dettaglio la sequenza di attivazione degli stadi nei cinque cicli di clock per una istruzione LW (load word), che è una di quelle istruzioni “attive” in tutti gli stadi:
• IF: l’istruzione viene letta dalla memoria e portata nel registro IR;
• ID: l’istruzione LW include un valore immediato (necessario per generare l’indirizzo del dato nella memoria, da sommare al contenuto del registro base, che funge da registro-base per l’indirizzamento), che viene esteso in segno da 16 a 32 bit; inoltre, il numero d’ordine del registro in cui si dovrà scrivere viene trasferito al controllo del banco dei registri; ancora, il contenuto del registro sorgente Rs1 viene “preparato” perché la ALU lo possa usare nello stadio successivo; infine, si pone PC=PC+4;
• EX: usando l’ALU, si calcola l’effettivo indirizzo di memoria da cui leggere il dato (che risulta pari alla somma del contenuto del registro sorgente Rs1 e del valore immediato di spiazzamento, già esteso nello stadio precedente) e lo si inserisce nel registro MAR;
• MEM: il dato viene letto dalla memoria dati (tramite l’indirizzo precedentemente inserito nel MAR) e caricato nel registro MDR;
• WB: il dato viene trasferito dal registro MDR nel registro del banco cui è destinato (il cui numero d’ordine era stato opportunamente trasferito negli stadi precedenti).
Adesso vediamo invece come cambia questa sequenza se l’istruzione è una SW
(store word, memorizza parola):
• IF: come nel caso precedente;
• ID: l’istruzione fornisce il valore immediato dello spiazzamento (che viene esteso) e i numeri d’ordine del registro in cui leggere l’indirizzo-base e di quello sorgente del dato; tali valori vengono dunque “predisposti” per l’uso nello stadio successivo;
• EX: l’indirizzo di memoria viene calcolato e trasferito nel registro MAR; inoltre, il contenuto del registro da trasferire in memoria viene posto nelregistro MDR;
4 In effetti, un conflitto di questo tipo si può risolvere abbastanza facilmente, dividendo la memoria in due sezioni distinte (la memoria di programma e la memoria dati), caratterizzate da registri di indirizzamento (MAR), registri di lettura/scritture (MDR), porte di accesso e bus di collegamento con la CPU separati. In molte architetture, questa suddivisione viene realizzata relativamente alla memoria cache (di cui parleremo in seguito), cioè alla memoria veloce cui la CPU accede normalmente durante il proprio funzionamento: vengono cioè usate una cache di dati ed una cache di programma.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 11
• MEM: il dato contenuto nell’ MDR viene scritto in memoria all’indirizzo contenuto nel MAR (aggiornato nella fase precedente;
• WB: l’istruzione SW non prevede alcuna scrittura nel banco dei registri, per cui questo stadio viene attraversato senza che si attivi alcuna unità. Quando una istruzione non utilizza uno stadio, i segnali di controllo di tale stadio vengono lasciati al “valore non attivo”, in modo che, nel caso di esecuzione in pipeline, venga comunque garantita la sincronizzazione e vengano inoltre impedite eventuali operazioni non volute.
Potremmo procedere in questo modo per gli altri tipi di istruzioni, ma è più
opportuno generalizzare il tutto, riprendendo alcuni esempi di esecuzione di istruzioni considerati nel capitolo precedente; in particolare, ai fini dei discorsi che stiamo per fare, ci conviene riportare tali esempi in una tabella (5), fatta nel modo seguente:
Fase Operazioni compiute
IF MAR←PC;
IR←M[MAR];
ID A←Rs1; B←Rs2; PC←PC+4
EX
MAR ← A + (IR16)16##IR16..31; MDR ← Rd
oppure
UscitaALU ← A op (B or (IR16)16##IR16..31);
oppure
UscitaALU ← PC + (IR 16)16 ##IR 16..31 ;
cond ← (A op 0)
MEM
MDR ← M[MAR] or M[MAR] ← MDR
oppure
if (cond) PC ← UscitaALU
WB Rd ← UscitaALU or MDR
In questa tabella sono riportate le operazioni che possono essere richieste, nei vari
stadi di esecuzione, dalle istruzioni di caricamento o di memorizzazione o dalle istruzioni ALU o dalle diramazioni/salti. Sono evidentemente coinvolte varie unità funzionali del processore: i registri (in particolare PC, IR, MAR, MBR), la ALU e la memoria. Proviamo allora a “ridisegnare” quella tabella evidenziando, per ciascuna fase, le operazioni compiute dalle singole unità funzionali:
5 Per la descrizione dettagliata di quanto riportato in questa tabella, rimandiamo perciò a quanto detto nel capitolo precedente

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 12
Operazioni compiute dalle unità funzionali Fase PC Memoria Unità di calcolo IF IR←M[PC] ID PC←PC+4 A←Rs1; B←Rs2; EX MAR ← A + (IR16)
16##IR16..31; MDR ← Rd
oppure
UscitaALU ← A op (B or (IR16)16##IR16..31)
oppure
UscitaALU ← PC + (IR16)16 ##IR 16..31 ;
cond ← (A op 0) MEM if (cond)
PC←UscitaALU MDR←M[MAR] or M[MAR]←MDR
WB Rd ← UscitaALU or MDR Sull’asse verticale della tabella sono state dunque riportate le varie fasi di
esecuzione (che poi corrispondono agli stadi delle pipeline), mentre invece sull’asse orizzontale sono state riportate le risorse principali (vale a dire registro PC, memoria e unità di calcolo). Ogni cella della tabella indica dunque l’evento che si verifica in quello stadio (riga) con quella risorsa (colonna).
Adesso vediamo come si modifica questa tabella in presenza di pipelining. A tal proposito, risulta ovvia la seguente considerazione: la tabella di poco fa evidenzia il fatto che il registro PC viene incrementato solo al secondo ciclo di clock, durante la fase ID; al contrario, se vogliamo implementare la pipeline, abbiamo bisogno di anticipare l’aggiornamento del PC, in quanto al secondo ciclo di clock dobbiamo già conoscere l’indirizzo dell’istruzione successiva, in modo da poterla prelevare. Di conseguenza, la prima modifica che dobbiamo apportare alla nostra architettura riguarda proprio il PC: l’incremento del registro PC deve avvenire nella fase IF di ciascuna istruzione (6).
Premesso questo, la tabella seguente è analoga alla precedente, solo che considera la presenza della pipeline, per cui ciascun riga deve adesso essere interpretata come stadio della pipeline :
Operazioni compiute dalle unità funzionali Fase PC Memoria Unità di calcolo IF PC←PC+4 IR←M[PC]
ID PC1←PC IR1←IR A←Rs1; B←Rs2;
EX MAR ← A + (IR116)16##IR116..31
oppure
UscitaALU← A op (B or (IR116)16##IR116..31)
oppure
UscitaALU1←PC1+(IR116)16 ##IR1 16..31 ;
cond ← (Rs1 op 0); SMDR←B
MEM if (cond) PC←UscitaALU
LMDR←M[MAR] or M[MAR]←SMDR
WB Rd ← UscitaALU or LMDR
6 Sottolineiamo, però, sin da ora che, se ci limitassimo ad aggiornare il registro PC senza conservare l’attuale valore, potremmo poi non essere più in grado di gestire eventi particolari come le interruzioni, per cui, prima di aggiornare il PC, dobbiamo aver cura di memorizzarne il valore in una memoria opportuna. Questo aspetto sarà approfondito tra poco.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 13
Analizziamo il contenuto di tale tabella, dove tra l’altro abbiamo inserito alcuni termini nuovi rispetto a quelli usati in precedenza. Le considerazioni preliminari da fare sono le seguenti:
• dato che in ogni ciclo di clock dobbiamo prelevare una nuova istruzione,
abbiamo bisogno di incrementare il registro PC (di 4 byte) ad ogni ciclo di clock e, per le considerazioni fatte in precedenza, dobbiamo effettuare tale incremento nella fase IF. Non solo, ma, dato che la ALU è sempre occupata in ogni ciclo di clock, il suddetto incremento del registro PC deve essere effettuato tramite un circuito incrementatore affiancato alla ALU;
• ad ogni ciclo di clock, potrebbe verificarsi un uso contemporaneo (da parte di due istruzioni) del registro MDR per il trasferimento di un dato da o verso la memoria (7), motivo per cui è necessario disporre di due distinti registri MBR: si sono perciò introdotti un registro di caricamento (LMDR) (8) ed un registro di memorizzazione (SMDR); (9)
• occorrono inoltre tre elementi di memoria addizionali, che servono per conservare alcuni valori da usare in seguito nella pipeline e che devono anche poter essere modificabili da istruzioni successive: sono stati perciò introdotti un nuovo registro program counter (PC1), un nuovo registro istruzioni (IR1) ed un nuovo registro che accolga il risultato prodotto dalla ALU (UscitaALU1). Tali nuovi elementi di memoria derivano dunque dalla necessità, più volte citata in precedenza, di conservare le informazioni relative all’istruzione in corso di esecuzione, onde poter arrivare al suo completamente nonostante altre istruzioni siano “entrate” o stiano “entrando” nella pipeline.
Premesso questo, possiamo analizzare la tabella, riga per riga (cioè stadio per
stadio). Dobbiamo perciò ipotizzare che il funzionamento sia a regime, per cui, nel generico ciclo di clock, si stanno eseguendo la fase IF dell’istruzione i+4, la fase ID dell’istruzione i+3, la fase EX dell’istruzione i+2, la fase MEM dell’istruzione i+1 e la fase WB dell’istruzione i:
7 Per comprendere questa considerazione, consideriamo la seguente sequenza di istruzioni: LW R2,100(R3); SW R3,200(R4). Supponendo che la fase IF dell’istruzione LW avvenga nel primo ciclo di clock, è facile rendersi conto che i problemi nascono nel quarto ciclo di clock: l’istruzione LW si trova nello stadio MEM, per cui accede alla memoria e porta nel registro MDR il dato letto; simultaneamente, l’istruzione SW si trova nello stadio EX, per cui calcola l’indirizzo in cui scrivere il proprio dato e prepara il dato ancora una volta in MDR, affinché esso possa essere scritto. Serve dunque contemporaneamente ad entrambe l’utilizzo del registro MDR. 8 Dato che il registro LMDR deve solo caricare dati dal bus e non inserire dati sul bus, esso sarà sempre ad alta impedenza. 9 Sottolineiamo che il progetto di una memoria che possa svolgere, in uno stesso ciclo di clock, il caricamento e la memorizzazione, è tutt’altro che semplice.

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 14
tempo(cicli di clock)
Istruzione i
Istruzione i+1
Istruzione i+2
Istruzione i+3
Istruzione i+4
Istruzione i+5
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Concentriamoci sugli stadi di esecuzione della generica istruzione tra quelle
riportate in figura (ad esempio l’istruzione i+3):
• nello stadio IF, bisogna compiere due operazioni: il caricamento dell’istruzione nel registro IR e l’incremento (di 4 byte) del registro PC, in modo che esso punti all’istruzione successiva (che sarà caricata nel successivo ciclo di clock);
• nello stadio ID, è innanzitutto necessario conservare i valori dei registri PC (PC1←PC) e IR (IR1←IR), prima che vengano aggiornati in seguito al prelevamento dell’istruzione successiva (infatti, mentre viene eseguito lo stadio ID dell’istruzione i+3, si sta eseguendo anche lo stadio IF dell’istruzione i+4); in questo modo, avremo eventualmente la possibilità di usare tali valori successivamente. Successivamente, si possono caricare nei latch A e B gli eventuali operandi situati nel banco dei registri;
• nello stadio EX, bisogna compiere le operazioni previste dall’istruzione, che ovviamente saranno diverse a seconda del tipo di istruzione:
o nel caso di istruzione di caricamento/memorizzazione, il registro MAR viene caricato con l’indirizzo di memoria ottenuto come somma del latch A e dell’operando immediato (esteso in segno) contenuto in IR1;
o nel caso di operazione aritmetica, il contenuto del latch A viene sommato al contenuto del latch B oppure, in caso di operando immediato, al contenuto degli ultimi 16 bit (estesi in segno) del registro IR1; il risultato viene posto in UscitaALU;
o infine, nel caso di diramazione (10), lo spiazzamento (esteso in segno) contenuto in IR1 viene sommato al contenuto di PC1 e posto in UscitaALU1, dopodiché viene aggiornato il registro di condizione (cond) in base alla condizione indicata dall’istruzione;
• nello stadio MEM, l’operazione compiuta dipende ancora una volta dal tipo di istruzione:
o nel caso di istruzione di caricamento/memorizzazione, il registro MAR viene usato per puntare la locazione di memoria di interesse, in modo da caricarne il contenuto in LMDR (caricamento) o da modificarne il contenuto tramite il registro SMDR (memorizzazione);
10 Per semplicità, non consideriamo i salti

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 15
o nel caso di operazione aritmetica , il contenuto di UscitaALU viene posto in UscitaALU1 per essere usato nella fase successiva;
o infine, nel caso di diramazione , viene verificato il contenuto del registro di condizione (cond ) e, in caso di verifica positiva, l’indirizzo precedentemente memorizzato in UscitaALU viene posto nel registro PC;
• infine, nello stadio WB, vengono compiute operazioni solo se l’istruzione prevedeva un calcolo aritmetico oppure un caricamento: nel primo caso, il risultato dell’operazione, precedentemente memorizzato in UscitaALU1, viene posto nel registro di destinazione Rd, mentre, nel secondo caso, il registro Rd viene caricato con quanto precedentemente memorizzato in LMDR.
Questa descrizione tiene ovviamente conto del fatto che la combinazione delle
istruzioni che possono trovarsi in esecuzione nella pipeline, in un qualsiasi istante di tempo, è del tutto arbitraria, per cui si sono considerate tutte le possibilità.
A supporto delle considerazioni appena concluse, riportiamo adesso una nuova tabella, nella quale evidenziamo, al posto delle operazioni compiute nelle singole unità funzionali, il tipo di operazioni richieste a seconda del tipo di istruzioni:
Operazioni compiute dalle unità funzionali a seconda del tipo di istruzioni
Fase Operazione ALU Caricamento/Memorizzazione Diramazione IF
IR←M[PC] PC←PC+4
IR←M[PC] PC←PC+4
IR←M[PC] PC←PC+4
ID
A←Rs1; B←Rs2; PC1←PC; IR1←IR
A←Rs1; B←Rs2; PC1←PC; IR1←IR
A←Rs1; B←Rs2; PC1←PC; IR1←IR
EX
UscitaALU←A op B oppure UscitaALU←A op (IR116)
16##IR116..31)
MAR←A+(IR116)16##IR116..31
SMDR←B
UscitaALU1←PC1 +
(IR116 ) 16 ##IR1 16..31 ;
cond ← (Rs1 op 0);
MEM UscitaALU1← UscitaALU LMDR←M[MAR] oppure M[MAR]←SMDR
if (cond) PC←UscitaALU
WB
Rd←UscitaALU1 Rd←LMDR
Dato che nei primi due stadi l’istruzione non è stata ancora decodificata, le
operazioni compiute sono ovviamente le stesse per tutti i tipi di istruzioni. E’ però importante notare che il caricamento dei latch A e B e dei registri PC1 e IR1 è una ottimizzazione fondamentale, in mancanza della quale servirebbe un ulteriore stadio di pipeline.
Grazie al formato rigido delle istruzioni DLX, entrambi i campi indicativi dei registri sono sempre decodificati ed i relativi registri sono sempre letti (copiandone il contenuto nei latch A e B), prima ancora di sapere se saranno necessari; analogamente, anche il contenuto del PC ed il valore immediato vengono sempre inviati alla ALU prima di sapere se saranno effettivamente coinvolti in operazioni aritmetiche.
All’inizio delle operazioni ALU, gli ingressi corretti vengono “smistati” a seconda del codice operativo dell’istruzione: il secondo operando può infatti essere prelevato

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 16
dal banco dei registri (tramite il latch B) oppure può essere immediato (nel qual caso è prelevato da IR1 ed esteso in segno). Lo “smistamento”, ossia la selezione di quali dati mandare effettivamente in ingresso alla ALU, viene effettuato tramite dei multiplexer opportunamente pilotati dalla logica di controllo.
Grazie a questa organizzazione, tutte le operazioni che dipendono strettamente dall’istruzione sono svolte solo dallo stadio EX o dagli stadi successivi.
Osservando le ultime due tabelle, si può notare un’altra cosa: l’effetto maggiore del pipelining sulle risorse del calcolatore si ha probabilmente sulla memoria. Allora, nonostante il tempo di accesso alla memoria non venga ovviamente influenzato dalla presenza o meno del pipelining, è comunque opportuno aumentare la banda passante della memoria stessa: infatti, mentre in assenza di pipelining ci sono non più di 2 accessi a memoria (nella fase IF e nella fase MEM) ogni 5 cicli di clock (cioè ogni istruzione), in presenza di pipelining si può arrivare addirittura a 2 accessi a memoria in ogni ciclo di clock, uno per la fase IF di una istruzione e l’altro per la fase MEM di un’altra istruzione. La tecnica attualmente più utilizzata per garantire 2 accessi a memoria in ogni ciclo di clock consiste nell’usare due memorie cache separate, una per i dati e l’altra per le istruzioni (11).
11 L’argomento della memoria cache sarà descritto in seguito. Per il momento, possiamo pensare alla memoria cache come una memoria che fa le veci della memoria principale, ma rispetto ad essa è molto più veloce (anche se molto meno capiente).

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 17
PPPrrrooobbbllleeemmmiii dddeeelll pppiiipppeeelll iiinnniiinnnggg
Introduzione: i conflitti e gli stalliIntroduzione: i conflitti e gli stalli La pipeline per il DLX descritta nei precedenti paragrafi funzionerebbe bene se
tutte le istruzioni situate nella pipeline fossero indipendenti le une dalle altre: sotto questa ipotesi, ogni istruzione può iniziare e terminare esattamente un ciclo di clock dopo la precedente, facendo così in modo che, dato un flusso di istruzioni, ad ogni ciclo di clock ne venga completata una, ottenendo un CPI (numero di cicli di clock per istruzione) idealmente pari ad 1. Al contrario, il funzionamento ideale non è quasi mari ottenibile, in quanto non è escluso, per esempio, che le istruzioni nella pipeline siano tra loro dipendenti, il che può far sorgere tutta una serie di importanti problemi, che sono l’argomento di questo e dei prossimi paragrafi, e soprattutto può determinare una degradazione delle prestazioni, sintetizzabile tramite un valore del CPI ben maggiore di 1.
Sono diverse le situazioni, denominate conflitti (hazards), che impediscono l’esecuzione dell’istruzione successiva (nel flusso di istruzioni) nel ciclo di clock che le è stato assegnato, determinando una diminuzione delle prestazioni rispetto a quelle ideali ottenibili tramite il pipelining; le possiamo classificare in tre gruppi:
• conflitti strutturali: questo tipo di conflitti si verificano quando la
sovrapposizione delle istruzioni nella pipeline è tale che un dispositivo non è in grado di eseguire contemporaneamente tutte le operazioni che gli vengono richieste; si tratta perciò di conflitti tra le varie istruzioni nell’uso delle risorse a disposizione (ad esempio la ALU e soprattutto i registri per l’accesso alla memoria12);
• conflitti tra i dati: questi conflitti si presentano quando l’esecuzione di una istruzione dipende dai risultati ottenuti dall’istruzione precedente e quindi la sovrapposizione delle due istruzioni può diventare critica;
• conflitti di controllo: questi conflitti derivano dall’introduzione del pipelining al livello delle diramazioni e da altre istruzioni che modificano il contenuto del registro PC.
Quando si verifica un conflitto in una pipeline, può essere necessario arrestare la
stessa pipeline, ossia metterla in stallo: come vedremo, uno stallo è una condizione in cui, durante un ciclo di clock, il processore non compie le operazioni richieste dall’esecuzione di una o più istruzioni, rimandandole ad un ciclo di clock successivo. Uno stallo si può peraltro presentare, per altri motivi, anche in una macchina senza pipeline (nella quale cioè viene sospesa l’esecuzione di una sola istruzione), ma sussiste una profonda differenza rispetto agli stalli di una macchina con pipeline: in quest’ultimo caso, infatti, ci sono più istruzioni in esecuzione nello stesso istante, alcune delle quali potrebbero avere requisiti tali da non poter essere fermate; capita
12 Ad esempio, abbiamo già osservato nel paragrafo precedente che, in presenza di una istruzione LW seguita immediatamente da una istruzione SW, è necessario sdoppiare il registro MDR in LMDR e SMDR: questo è un tipico conflitto strutturale che ammette una semplice ed economica soluzione di tipo hardware, ma vedremo che non sempre la soluzione è così semplice.

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 18
quindi spesso che, in presenza di uno stallo, l’esecuzione di alcune istruzioni venga lasciata proseguire, mentre altre vengano sospese o posposte (13).
In generale, quando viene sospesa l’esecuzione di una istruzione in una pipeline, risulta necessario sospendere anche tutte le istruzioni il cui stato di avanzamento è inferiore a quello dell’istruzione sospesa: ad esempio, se viene sospesa una istruzione nello stadio EX, saranno anche sospese l’istruzione nello stadio ID e quella nello stadio IF. Al contrario, le istruzioni in stato di esecuzione più avanzato possono proseguire, mentre invece, fin quando dura lo stallo, non si possono prelevare altre istruzioni.
Accelerazione in presenza di pipelining ed eventuali Accelerazione in presenza di pipelining ed eventuali stallistalli
Uno stallo causa necessariamente una degradazione delle prestazioni della pipeline rispetto al caso ideale. Possiamo rendercene conto tramite alcune semplici equazioni per il calcolo dell’accelerazione effettiva indotta dal pipelining.
In primo luogo, possiamo usare la seguente formula per il calcolo dell’accelerazione:
pipeliningcon istruzioneper esecuzione di medio Tempo
pipelining senza istruzioneper esecuzione di medio TempooneAccelerazi =
Sia il numeratore sia il denominatore di questa frazione sono ottenibili come
prodotto del CPI (cicli di clock per istruzione) con il periodo di clock, da considerarsi ovviamente in un caso con pipelining e nell’altro senza:
pipeliningcon clock di Ciclo pipeliningcon CPI
pipelining senzaclock di Ciclo pipelining senza CPIoneAccelerazi
××
=
In base a questa espressione, l’accelerazione è data dal prodotto di due rapporti:
il rapporto tra i CPI in presenza ed in assenza di pipelining ed il rapporto tra i periodi di clock in presenza ed in assenza del pipelining. Ricordiamo allora quanto detto all’inizio di questo capitolo, riguardo al fatto che il pipelining può essere “modellato” tramite una riduzione del CPI e/o del ciclo di clock rispetto al caso senza pipelining. Scegliamo ad esempio di modellarlo tramite una riduzione del CPI. In particolare, possiamo stimare il CPI con pipelining tramite il suo valore ideale, pari al rapporto tra il CPI in assenza di pipelining e la dimensione della pipeline (cioè il numero di stadi da cui è composta):
( )pipeline della Dimensione
pipelining senza CPIpipeliningcon CPI ideale =
Esplicitando da qui il CPI senza pipelining e sostituendo nell’espressione
dell’accelerazione, otteniamo
13 Dal punto di vista concreto, uno stallo si ottiene bloccando l’instradamento dei segnali di attivazione per tutte le istruzioni che seguono quella che genera il conflitto (quindi per tutti gli stadi successivi a quelli in cui è attiva tale istruzione), fino a quando il conflitto non è stato eliminato.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 19
( )pipeliningcon clock di Ciclo pipeliningcon CPI
pipelining senzaclock di Ciclo pipeline della Dimensionepipeliningcon CPIoneAccelerazi ideale
×××
=
Adesso valutiamo il CPI con pipelining nei casi reali. In particolare, supponiamo
che la non idealità derivi solo dalla presenza degli stalli: in questo caso, il CPI risulta uguale alla somma del suo valore ideale e dei cicli di clock di durata dello stallo, per cui scriviamo che
( ) stallo diclock di Cicli pipeliningcon CPI pipeliningcon CPI ideale +=
Sostituendo anche questa espressione in quella dell’accelerazione, abbiamo che
( )( ) pipeliningcon clock di Ciclo
pipelining senzaclock di Ciclo
stallo diclock di Cicli pipeliningcon CPI
pipeline della Dimensione pipeliningcon CPIoneAccelerazi
ideale
ideale ×+
×=
Questa è una formula di validità abbastanza generale. Tuttavia, spesso si
preferisce semplificarla, trascurando l’aumento potenziale del tempo del ciclo di clock (dovuto al maggior “consumo” di risorse per il pipelining): sotto questa ipotesi, la seconda frazione scompare e si può concludere che
( )( ) stallo diclock di Cicli pipeliningcon CPI
pipeline della Dimensione pipeliningcon CPIoneAccelerazi
ideale
ideale
+×
=
Nel seguito, useremo sempre questa formula semplificata per la valutazione della
pipeline nel DLX. Tuttavia, un esame dettagliato sulla pipeline richiede anche l’attenzione alle variazioni del periodo di clock.
Conflitti strutturaliConflitti strutturali Consideriamo una macchina dotata di pipelining, in cui quindi l’esecuzione delle
istruzioni venga sovrapposta: perché la sovrapposizione sia possibile, è necessario collegare anche le unità funzionali in modo pipelined, al fine di rendere possibili le combinazioni delle istruzioni nella pipeline stessa. Tuttavia, ci potrebbero essere delle combinazioni vietate a causa di conflitti tra le risorse, ossia combinazioni in cui più istruzioni si troverebbero a richiedere contemporaneamente l’uso di una risorsa unica, che quindi può essere disponibile solo per una di esse: in questo caso, si dice che la macchina presente dei conflitti strutturali.
Tipicamente, un conflitto strutturale si manifesta su una unità funzionale che non è ben integrata nella pipeline: un tipico esempio, come vedremo meglio in seguito, può essere costituito da una unità aritmetica in virgola mobile realizzata tramite un unico blocco anziché tramite una serie di blocchi a loro volta collegati in modo pipelined, in quanto una simile unità avrebbe una latenza ben più elevata di una unità in aritmetica intera. In casi come questo, non è possibile che venga introdotta nella pipeline una sequenza di istruzioni che utilizzino tutte contemporaneamente quell’unità.
Altri casi frequenti di conflitti strutturali si verificano quando una risorsa non è stata “replicata” un numero sufficiente di volte per consentire tutte le combinazioni di istruzioni possibili nella pipeline: ad esempio, ci sono situazioni in cui una macchina potrebbe trovarsi a dover eseguire due o più operazioni di scrittura del

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 20
banco di registri, nel qual caso è necessario prevedere due o più porte di scrittura di tale banco; se la porta fosse unica, invece, si avrebbe un conflitto strutturale, in quanto bisognerebbe forzatamente eseguire una operazione dopo l’altra e non si potrebbe quindi ottenere il parallelismo tipico della pipeline. In casi come questi, dunque, è necessario che la pipeline sospenda l’esecuzione di una istruzione finché l’unità da essa richiesta non si rende disponibile.
Un tipico limite di alcune macchine dotate di pipelining consiste nell’avere una sola memoria per i dati e per le istruzioni: infatti, quando una istruzione contiene un riferimento ai dati in memoria, la pipeline deve andare necessariamente in stallo per un ciclo di clock, in quanto, nello stesso ciclo di clock in cui sarebbe necessario effettuare l’accesso in memoria, ci sarebbe sicuramente da effettuare anche la fase IF di un’altra istruzione, che richiede anch’essa un accesso a memoria. Nella figura seguente viene riportata graficamente la situazione di stallo:
stallo
tempo(cicli di clock)
Istruzione i
Istruzione i+1
Istruzione i+2
Istruzione i+3
Istruzione i+4
Istruzione i+5
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
In corrispondenza del quarto ciclo di clock, l’istruzione i richiede un accesso a
memoria, ma contemporaneamente sarebbe necessario effettuare la fase IF dell’istruzione i+3: data la presenza di tale conflitto strutturale sull’uso della memoria, la pipeline va in stallo, posticipando di un ciclo di clock l’esecuzione dell’istruzione i+3 e delle istruzioni successive (si suppone che l’accesso a memoria dell’istruzione i venga completato in un unico colpo di clock). Tuttavia, dato che anchenei cicli di clock successivi ci sono istruzioni nella fase MEM, la fase IF dell'istruzione i+3 deve essere necessariamente posticipata per altri due cicli di clock, per cui il ciclo di arresto continua a scorrere per tutta la pipeline.
In generale, ci si rende conto facilmente che i conflitti strutturali possono essere risolti solo tramite l’introduzione degli stalli: concettualmente, è come se le istruzioni vengano messe “in coda” in attesa che l’unità funzionale oggetto dello stallo si renda disponibile. La conseguenza è ovviamente una riduzione di prestazioni, dato che si susseguono uno o più cicli di clock durante i quali non si ha prelievo ed esecuzione di nuove istruzioni, per cui il numero medio di cicli di clock per istruzione (CPI) aumenta.
EEEssseeemmmpppiiiooo Serviamoci ora di un esempio numerico per comprendere le conseguenze sulle
prestazioni di uno stallo del tipo appena descritto. Supponiamo che i riferimenti ai dati costituiscono il 30% delle istruzioni in
esecuzione sulla nostra macchina dotata di pipelining. Supponiamo inoltre che il CPI ideale di tale macchina, trascurando i conflitti strutturali, sia pari a 1.2. Trascurando ogni eventuale altra perdita di prestazioni, ci chiediamo di quanto

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 21
sarebbe più veloce la nostra macchina ideale se fosse priva di conflitti strutturali relativi agli accessi alla memoria.
Cominciamo col ricordare la formula semplificata dell’accelerazione calcolata in precedenza:
( )( ) stallo diclock di Cicli pipeliningcon CPI
pipeline della Dimensione pipeliningcon CPIoneAccelerazi
ideale
ideale
+×
=
Nel caso ideale, la nostra macchina non presenta stalli di nessun tipo, per cui
l’accelerazione ottenuta tramite l’uso del pipelining risulta pari a
2.1
pipeline della Dimensione 2.1oneAccelerazi ideale
×=
Se invece consideriamo il caso reale, in cui cioè la macchina subisce degli stalli a
causa dei conflitti strutturali sull’uso della memoria, questo valore ideale di accelerazione decresce a causa della presenza di un numero non nullo dei cicli di clock di stallo: in particolare, dato che i riferimenti a memoria si presentano nel 30% delle istruzioni eseguite e dato che i relativi stalli hanno la durata di un solo ciclo di clock (per ipotesi), deduciamo che
( ) 5.1
pipeline della Dimensione 2.1
13.02.1
pipeline della Dimensione 2.1oneAccelerazi reale
×=
×+×
=
Facendo il rapporto tra le due accelerazioni, otteniamo
25.12.1
5.1
oneAccelerazi
oneAccelerazi
reale
ideale ==
Abbiamo dunque trovato che la macchina ideale priva di conflitti strutturali di
memoria è più veloce del 25% rispetto a quella reale.
CCCooonnncccllluuusssiiiooonnniii sssuuuiii cccooonnnfffllliiittttttiii ssstttrrruuuttttttuuurrraaallliii A parità di tutti gli altri fattori, abbiamo dunque capito che una macchina dotata
di pipelining e conflitti strutturali presenta sempre un CPI maggiore rispetto alla macchina ideale priva di tali conflitti. Di conseguenza, ci si potrebbe domandare se valga la pena accettare la presenza di tali conflitti strutturali oppure se sia più conveniente risolverli, “potenziando” l’hardware della macchina (che è l’unica soluzione perseguibile). In risposta a tale quesito si possono fare almeno due considerazioni:
• in primo luogo, disporre in pipeline tutte le unità funzionali potrebbe
risultare troppo costoso: ad esempio, le macchine che sono in grado di eseguire un unico riferimento alla memoria in ciascun ciclo di clock richiederebbero una banda passante totale di memoria raddoppiata; analogamente, se per esempio volessimo applicare un pipelining completo

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 22
ad un circuito moltiplicatore in virgola mobile (14), avremmo bisogno di un gran numero di porte logiche, che avrebbero un loro costo;
• in secondo luogo, se si appurasse che il conflitto strutturale non si verifica di frequente, potrebbe non valere la pena di sostenere determinati costi per eliminarlo.
Conflitti di datiConflitti di dati La seconda categoria di conflitti in una macchina dotata di pipelining è quella dei
conflitti sui dati, che si manifestano quando l’esecuzione di una istruzione dipende dai risultati ottenuti dall’istruzione precedente. In particolare, i conflitti di dati possono verificarsi quando l’ordine di accesso agli operandi viene modificato, a causa proprio del pipelining, rispetto all’ordine normale che si avrebbe in caso di esecuzione sequenziale delle istruzioni.
A titolo di esempio, consideriamo la seguente sequenza di istruzioni: ADD R1, R2, R3 SUB R4, R1, R5 La prima istruzione somma i registri R2 ed R3 e deposita il risultato in R1. La
seconda istruzione, invece, sottrae i registri R1 ed R5 e pone il risultato in R4. La particolarità di queste due istruzioni è che la seconda usa un registro sorgente (R1) che è anche la destinazione dell’istruzione precedente: in assenza di pipelining, la cosa non rappresenta affatto un problema, mentre invece, in presenza di pipelining, nasce un classico conflitto sui dati. Per rendercene conto, usiamo la solita rappresentazione grafica:
IF ID EX MEM WB
IF ID EX MEM WB
Istruzione ADD
Istruzione SUB
Scritturadel registro R1
Letturadel registro R1
In assenza di pipelining, la prima istruzione modifica il contenuto del registro R1
(R1←R2+R3), dopodiché la seconda legge il contenuto (modificato) di tale registro e lo usa per l’operazione di sottrazione. In presenza invece di pipelining, la sovrapposizione delle due istruzioni fa sì che l’ordine con cui si accede al registro R1 venga invertito: infatti, l’istruzione SUB legge il contenuto di R1 (fase ID) prima che esso venga aggiornato dall’istruzione ADD (fase WB), per cui viene commesso un errore.
14 Applicare un “pipelining completo” ad una unità aritmetica significa sostanzialmente implementare tale unità non come un blocco unico, ma come una serie di stadi, ciascuno con latenza unitaria (in termini di cicli di clock), organizzati anch’essi in modo pipelined, ossia in modo tale che, una volta completato uno stadio k di una operazione, questa possa passare allo stadio k+1 e l’operazione successiva possa passare allo stadio k e così via, così come accade per le istruzioni.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 23
Quindi, a meno che non si prendano delle precauzioni per impedirlo, questo conflitto dei dati fa sì , in linea di massima, che l’istruzione SUB legga ed utilizzi il valore sbagliato di R1, ossia il valore inserito in tale registro prima che l’istruzione ADD provveda a modificarlo. Diciamo “in linea di massima”, in quanto, in effetti, il valore realmente usato dall’istruzione SUB non è noto in modo deterministico: infatti, benché sia senz’altro ragionevole pensare che SUB usi sempre il valore di R1 aggiornato prima dell’istruzione ADD, in realtà non è sicuro che avvenga questo; ad esempio, se si verificasse una interruzione tra le istruzioni ADD e SUB, lo stadio WB dell’istruzione ADD riuscirebbe comunque a completare le proprie operazioni ed il valore di R1 verrebbe quindi correttamente aggiornato per l’uso con l’istruzione SUB. Si tratta però di un comportamento imprevedibile, che su un calcolatore è del tutto inaccettabile.
La soluzione più banale al conflitto di dati appena descritto sarebbe quello di imporre uno stallo alla pipeline, in modo che la fase ID dell’istruzione SUB venga ritardata di due cicli di clock:
IF stallo stallo
IF ID EX MEM WB
ID EX MEM WB
Istruzione ADD
Istruzione SUB
Scritturadel registro R1
Letturadel registro R1
In questa situazione, basta sincronizzare la lettura del registro R1 in modo che
venga effettuata dopo l’aggiornamento dello stesso registro, cosa che si può ottenere, per esempio, facendo in modo che la scrittura avvenga nella prima metà del ciclo di clock e la lettura nella seconda metà.
E’ ovvio che una soluzione del genere comporta almeno due conseguenze: una complicazione hardware e soprattutto una degradazione delle prestazioni a causa dello stallo, che dura addirittura due cicli di clock. Una tecnica sicuramente migliore è quella cosiddetta di anticipazione, oggetto del prossimo paragrafo.
In generale, per quanto riguarda le tecniche da usarsi per risolvere i conflitti sui dati, ne esistono di due categorie:
• le soluzioni hardware sono di tipo “dinamico”: esse richiedono un
intervento dei circuiti di controllo della CPU, che devono rilevare l’esistenza dei conflitti e prendere i necessari provvedimenti (ove possibili) al fine di minimizzare il peggioramento delle prestazioni;
• le soluzioni software, invece, si possono definire “statiche”, in quanto prevedono un intervento del compilatore, il quale, nel compilare i programmi, deve fare in modo che il numero di conflitti sia ridotto al minimo.
Possiamo sicuramente affermare che le soluzioni software, adottate cioè dai
compilatori, sono sempre da adottare, a prescindere dal fatto che la macchina sia dotata anche delle soluzioni hardware: l’ottimizzazione del codice da parte del compilatore risulta infatti comunque indispensabile per ridurre il rischio degli stalli e per mantenere il più possibile la pipeline piena di istruzioni utili con tutti gli stadi

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 24
attivi. Le prestazioni complessive dipendono perciò fortemente dalla messa a punto congiunta di hardware e software.
LLLaaa ttteeecccnnniiicccaaa dddeeellllll’’’aaannntttiiiccciiipppaaazzziiiooonnneee Questa tecnica, usata per risolvere tramite l’hardware i conflitti di dati come
quello descritto nel precedente paragrafo, consiste nel retroazionare il risultato della ALU agli elementi di memoria posti agli ingressi della ALU stessa; in particolare, questo compito viene svolto dai cosiddetti dispositivi di anticipo: quando la logica di controllo rileva che l’operazione ALU precedente ha scritto il registro associato alla sorgente dell’operazione ALU in corso, provvede a selezionare, come ingresso della ALU, non più il valore letto dal banco dei registri (che sarebbe errato), ma il risultato anticipato (che è quello corretto). Naturalmente, questo meccanismo viene applicato solo se l’istruzione che necessita dell’anticipo (la SUB nell’esempio del paragrafo precedente) non viene sospesa; al contrario, se si verifica una sospensione di tale istruzione (ad esempio perché c’è stata una richiesta di interrupt), allora l’istruzione precedente (la ADD) viene portata a termine e solo dopo la ripresa dalla sospensione viene avviata l’istruzione successiva (la SUB), che quindi può usufruire normalmente del dato contenuto nel registro sorgente.
Quindi, riepilogando, il meccanismo dell’anticipo viene comunque sempre applicato, ma spetta alla logica di controllo decidere, caso per caso, se l’operando da portare effettivamente in ingresso alla ALU è quello normalmente previsto (proveniente dal banco dei registri) oppure quello che è stato anticipato. E’ sufficiente dunque disporre un multiplexer su uno degli ingressi della ALU, alimentato a sua volta in ingresso dal risultato anticipato e dal bus proveniente dal banco dei registri: tramite una linea di controllo, si seleziona cosa mandare effettivamente in ingresso alla ALU.
Supponiamo ora che la sequenza di istruzioni da eseguire con pipelining sia la seguente:
ADD R1, R2, R3 SUB R4, R1, R5 AND R6,R1,R7 OR R8,R1,R9 XOR R10,R1,R11 Eseguendo queste istruzioni tramite il pipelining, si ha quanto segue:
tempo(cicli di clock)
ADD R1,R2,R3
SUB R4,R1,R5
AND R6,R1,R7
OR R8,R1,R9
XOR R10,R1,R11
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 25
La prima istruzione modifica il contenuto di R1 solo al 5° ciclo di clock, ma le tre istruzioni successive (SUB, AND e OR) hanno bisogno del nuovo valore prima di tale ciclo di clock, per cui è necessario l’anticipo. Al contrario, l’istruzione XOR non richiede anticipo in quanto usa il valore di R1 al 6° ciclo di clock, nel quale R1 è stato già correttamente aggiornato.
CCCooonnnssseeeggguuueeennnzzzeee dddeeellllll’’’aaannntttiiiccciiipppaaazzziiiooonnneee sssuuullllll’’’hhhaaarrrdddwwwaaarrreee Una volta compresa l’efficacia della tecnica dell’anticipazione, vogliamo ora vedere
cosa è richiesto, a livello hardware, per implementarla. Il concetto di base è di dover predisporre dei “cammini speciali” per i dati in uscita dalla ALU, in modo che essi possano essere portati immediatamente in ingresso alla ALU stessa per concretizzare l’anticipo: tali cammini prendono il nome di cammini di cortocircuitazione e sono costituiti da elementi di memoria (per conservare temporaneamente i dati), da bus di circuitazione (tramite i quali i dati passano dall’uscita della ALU agli elementi di memoria e da questi all’ingresso della ALU) e da elementi di comparazione (ai quali spetta il compito di decidere se l’istruzione adiacente condivide una destinazione o una sorgente).
In generale, è sempre opportuno ridurre il numero di istruzioni cui anticipare risultati, dato che ogni cammino di cortocircuitazione richiede una logica specializzata. Nell’esempio del paragrafo precedente, abbiamo visto che è necessario anticipare il nuovo contenuto di R1 a ben tre istruzioni successive a quella che ha determinato il nuovo valore. In effetti, è possibile ridurre a due il numero di istruzioni cui anticipare il nuovo valore di R1: infatti, considerando che il banco dei registri viene usato due volte in un solo ciclo di clock, si può pensare di eseguire le scritture sui registri nella prima metà dello stadio WB e le letture nella seconda metà dello stadio ID. La figura seguente aiuta a comprendere questo concetto:
tempo(cicli di clock)
ADD R1,R2,R3
SUB R4,R1,R5
AND R6,R1,R7
OR R8,R1,R9
XOR R10,R1,R11
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
R W
IF ID EX MEM WB
R W
IF ID EX MEM WB
R W
IF ID EX MEM WB
R W
IF ID EX MEM WB
R W
Come si può osservare, nel corso del 5° ciclo di clock, la prima metà del ciclo è
dedicata alla scrittura di R1 da parte dell’istruzione ADD, mentre la seconda metà del ciclo è dedicata alla lettura di R1 da parte dell’istruzione OR. In questo modo, l’istruzione OR non richiede alcun anticipo e quindi si è ottenuto di ridurre il numero degli anticipi (e la relativa logica dedicata) a due.
Nella figura seguente è mostrata la struttura della ALU e dell’unità di cortocircuitazione:

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 26
MUX MUX
Buffer ALU
Buffer ALU
Banco deiregistri
ALU
Bus discritturadel risultato
Bus dicortocircuitazione
Bus dicortocircuitazione
Premettiamo che questa figura è una rappresentazione fortemente semplificata
dell’architettura, in quanto trascura la presenza dei bus S1,S2 e Dest nonché dei latch A,B e C. Mancano anche le linee di controllo dei multiplexer (MUX): tali linee provengono dagli organi comparatori (locali) e fanno in modo che i multiplexer scelgano opportunamente quali dati portare in ingresso alla ALU. In alternativa, il controllo dei multiplexer può essere affidato direttamente all’unità di controllo, che quindi deve tenere traccia delle destinazioni e delle sorgenti di tutte le operazioni nella pipeline.
In uscita dalla ALU sono stati previsti due buffer per la memorizzazione temporanea dei dati: se consideriamo la sequenza di istruzioni dell’ultimo esempio, possiamo facilmente renderci conto che il primo buffer (quello più in basso) contiene il nuovo valore di R1 (determinato dall’istruzione ADD), mentre il secondo (quello più in alto) contiene il nuovo valore di R4 (determinato dall’istruzione SUB). Da notare che, quando i buffer in uscita dalla ALU sono gestiti localmente dai comparatori (e non dall’unità di controllo), devono necessariamente contenere una etichetta che indichi il registro cui i loro valori sono destinati.
Vediamo allora di descrivere quello che succede nel caso della sequenza di istruzioni considerata prima e qui di seguito riproposta:
ADD R1, R2, R3 SUB R4, R1, R5 AND R6, R1, R7 OR R8, R1, R9 XOR R10,R1, R11 Al primo ciclo di clock, avviene la fase IF dell’istruzione ADD. Al secondo ciclo di
clock, avviene la fase ID dell’istruzione ADD e la fase IF dell’istruzione SUB: avendo scelto di effettuare le letture dei dati (nella fase ID) nella seconda metà del ciclo di clock, gli operandi (R2 ed R3) dell’istruzione ADD vengono portati in ingresso alla ALU nella seconda metà del secondo ciclo di clock. Al terzo ciclo di clock, la fase EX dell’istruzione ADD produce, in uscita dalla ALU, il nuovo valore di R1, che viene posto del primo buffer in uscita dalla ALU. Contemporaneamente, avvengono la fase

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 27
ID dell’istruzione AND e soprattutto la fase ID dell’istruzione SUB: in questo caso, i comparatori rilevano che la sorgente R1 dell’istruzione SUB corrisponde alla destinazione dell’istruzione precedente, per cui pilotano uno dei due multiplexer in ingresso alla ALU affinché, anziché mandare alla ALU il valore attualmente registrato in R1, mandi il valore contenuto nel primo buffer in uscita dalla ALU stessa, in modo quindi da concretizzare l’anticipo. Nel ciclo di clock ancora successivo, il “problema” si ripropone, in quanto avvengono la fase MEM dell’istruzione ADD, la fase EX dell’istruzione SUB, la fase IF dell’istruzione OR e soprattutto la fase ID dell’istruzione AND, che coinvolge anch’essa il registro R1; in questo caso, però c’è una differenza rispetto al ciclo di clock precedente: infatti, la fase EX dell’istruzione SUB produce il nuovo valore del registro R4 e tale valore viene inserito nel primo buffer della ALU, shiftando verso l’altro buffer il nuovo valore del registro R1:
MUX MUX
R4
R1
Banco deiregistri
ALU
Di conseguenza, la logica di controllo fa in modo che i multiplexer portino in
ingresso alla ALU il valore del secondo buffer della ALU. Nel ciclo di clock successivo, avviene la fase WB dell’istruzione ADD, per cui il
nuovo valore di R1 viene finalmente memorizzato, dopodiché avviene un nuovo shift nei buffer della ALU, in quanto viene inserito il valore prodotto dalla fase EX dell’istruzione AND, ossia il nuovo valore del registro R6. Nella figura seguente viene riportata dunque la sequenza dei valori contenuti nei buffer della ALU ad ogni ciclo di clock, evidenziando anche lo stadio di esecuzione delle varie istruzioni:
vuoto
vuoto
vuoto
vuoto
R1
vuoto
R4
R1
R6
R4
R8
R6
R10
R8
1° ciclo di clock 2° ciclo di clock 3° ciclo di clock 4° ciclo di clock 5° ciclo di clock 6° ciclo di clock 7° ciclo di clock
IFIDEXMEMWB
ADD SUBADD
ANDSUBADD
ORANDSUBADD
XORORANDSUBADD
XORORANDSUB
XORORAND

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 28
CCCooonnnfffllliiittttttiii sssuuu dddaaatttiii iiinnn mmmeeemmmooorrriiiaaa Gli esempi di conflitti su dati che abbiamo esaminato nei precedenti paragrafi
sono tutti relativi ai registri del processore DLX, ma, in generale, è anche possibile che una coppia di istruzioni presenti una dipendenza dovuta alla scrittura ed alla lettura della stessa locazione di memoria nello stesso istante. Tuttavia, se questo è vero in generale, per il DLX non lo è, in quanto, nella pipeline del DLX, i riferimenti alla memoria vengono sempre mantenuti in ordine, impedendo così l’insorgere di qualunque tipo di conflitto.
Una situazione che potrebbe modificare l’ordine dei riferimenti in memoria è la mancanza di dati nella cache: supponiamo che una data istruzione debba localizzare dei dati in memoria e, essendo la macchina dotata di memoria cache, provi a cercarli prima nella cache; se i dati richiesti non vengono trovati in cache e se le altre istruzioni nella pipeline non sono state arrestate, l’istruzione in questione impiega il successivo ciclo di clock per cercarli in memoria, sovrapponendosi così ad un’altra istruzione che necessita anch’essa dell’accesso alla memoria (per la fase IF). Per evitare questo conflitto, nel DLX si è scelto di arrestare la pipeline fin quando l’istruzione “incriminata” ha completato il prelevamento dei suoi operandi dalla memoria. All’atto pratico, questo equivale semplicemente a simulare l’allungamento del tempo di esecuzione dell’istruzione che non ha localizzato il dato nella cache, per un intervallo di tempo di diversi cicli di clock.
In conclusione, possiamo dunque dire che tutti i conflitti di dati discussi in questi paragrafi coinvolgono solo i registri della CPU.
UUUlllttteeerrriiiooorrriii dddeeettttttaaagggllliii sssuuuiii cccooonnnfffllliiittttttiii iiinnn llleeettttttuuurrraaa eee ssscccrrriiittttttuuurrraaa dddeeeiii rrreeegggiiissstttrrriii
Possiamo generalizzare ulteriormente il concetto di anticipo dei dati, al fine di comprendere meglio il passaggio dei risultati direttamente alle unità funzionali che ne hanno bisogno. Nei precedenti paragrafi, abbiamo supposto che i risultati in uscita dalla ALU fossero anticipati all’ingresso della stessa ALU: abbiamo dunque esaminato il caso in cui un risultato viene anticipato dall’uscita di una unità all’ingresso della stessa unità. In effetti, è possibile anche un’altra situazione, in cui il risultato in uscita da una unità viene anticipato all’ingresso di un’altra unità. Un esempio semplice è costituito dalla seguente sequenza di istruzioni:
ADD R1, R2, R3 SW 25(R1), R1 La prima istruzione è la stessa degli esempi precedenti; l’altra, invece, prevede la
memorizzazione del contenuto di R1 nella locazione di memoria il cui indirizzo è ottenuto come somma del contenuto stesso di R1 e di uno spiazzamento immediato pari a 25 (quindi M[25+R1]←32R1). In questo caso, si crea il “solito” conflitto sul registro R1: l’istruzione SW legge il contenuto di R1 prima che questo sia stato aggiornato dall’istruzione ADD, per cui si rende necessario l’anticipo. Rispetto agli esempi precedenti, la situazione viene complicata dal fatto che, per le operazioni di accesso alla memoria, deve essere coinvolto il registro MDR, nel quale vanno caricati i dati da portare poi in memoria: di conseguenza, se non si vuole arrestare la sequenza, l’unità di cortocircuitazione deve fare in modo che il valore di R1 calcolato dall’istruzione ADD venga anticipato non solo alla ALU (che deve calcolare 25+R1), ma anche al registro MDR.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 29
MUX MUX
R1
vuoto
Banco deiregistri
ALU
MDR
25
E possibile classificare i conflitti di dati a seconda dell’ordinamento degli accessi
in lettura e scrittura che determinano il conflitto stesso. Per convenzione, i conflitti vengono denominati in relazione all’ordinamento specificato dal programma (ordinamento che, come si è ormai capito, deve necessariamente essere preservato nella pipeline). Consideriamo perciò due istruzioni I e J successive (I deve essere eseguita prima di J); i conflitti di dati possibili sono 3:
• RAW (Read After Write): l’istruzione J tenta di leggere una sorgente prima
che I la scriva; si tratta perciò del caso considerato nei paragrafi precedenti e che vedeva coinvolto il registro R1;
• WAR (Write After Read): J tenta di scrivere una destinazione prima che venga letta da I, così che I accede al valore scorretto. E’ evidente che questo particolare conflitto non può avvenire nella pipeline che stiamo considerando in questi paragrafi, dato che tutte le letture (ID) precedono tutte le scritture (WB). Al contrario, questo conflitto si verifica quando ci sono istruzioni che scrivono dei risultati nei primi stadi della pipeline e nessun’altra istruzione legge una sorgente dopo una scrittura eseguita da una istruzione in uno stadio più avanzato. Un tipico esempio di istruzione che potenzialmente può determinare un conflitto WAR è l’indirizzamento con autoincremento;
• WAW (Write After Write): J tenta di scrivere un operando prima che questo sia stato scritto da I. In questo caso, dato che le due scritture avvengono nell’ordine sbagliato, nella destinazione viene lasciato il valore scritto da I anziché quello scritto da J, che invece sarebbe quello corretto. Nel caso del DLX, simili conflitti non sono possibili dato che le scritture avvengono su un unico registro nella fase WB; tuttavia, questo tipo di conflitti si manifestano in pipeline che scrivono in più stadi oppure che consentono alle istruzioni di avanzare anche quando una istruzione precedente è stata sospesa.
A queste tre possibilità si potrebbe erroneamente pensare di aggiungere un
conflitto di tipo RAR (Read After Read), ma è ovvio che le operazioni di lettura, non essendo in alcun modo distruttive dei valori letti, non comportano alcun conflitto.

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 30
IIInnnttteeerrraaallllllaaacccccciiiaaammmeeennntttooo dddeeellllllaaa pppiiipppeeellliiinnneee Non tutti i conflitti di dati si possono risolvere senza conseguenze sulle prestazioni
(come invece si riesce a fare tramite la tecnica dell’anticipo). Ce ne possiamo rendere conto con la sequenza seguente:
LW R1, 32(R6) ADD R4, R1, R7 SUB R5, R1, R8 AND R6, R1, R7 La prima istruzione carica il valore di R1 tramite una parola contenuta in memoria
(R1←32M[32+R6]). Le successive tre istruzioni usano il valore di R1 per compiere operazioni aritmetiche e logiche, per cui c’è il “solito” conflitto su R1. Si tratta però di una situazione ben diversa rispetto a quella in cui abbiamo visto di poter retroazionare i risultati della ALU: infatti, l’istruzione LW (R1←32M[32+R6]) non riceve i dati prima della fine del ciclo corrispondente alla fase MEM, mentre invece l’istruzione ADD deve ricevere i dati entro l’inizio di quello stesso ciclo di clock:
tempo(cicli di clock)
LW R1, 32(R6)
ADD R1,R2,R3
SUB R4,R1,R5
AND R6,R1,R7
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Una possibilità per risolvere il problema sarebbe quella di anticipare il contenuto
del registro MDR all’ingresso della ALU, ma comunque tale contenuto arriverebbe alla fine del ciclo di clock e non all’inizio e quindi troppo tardi (15).
La soluzione più comune a questo problema si ottiene con una aggiunta di logica e prende il nome di interallacciamento della pipeline: si tratta semplicemente di prevedere una logica che, rilevando il conflitto, arresti la pipeline (a partire dall’istruzione che necessita dell’uso dei dati) fin quando l’istruzione destinata a produrre i dati non li ha resi effettivamente disponibili. Questo ciclo di ritardo è detto stallo di pipeline o anche bolla: esso permette dunque ai dati da caricare di arrivare dalla memoria, dopodiché possono essere anticipati dalla logica preposta e la pipeline può ripartire. Evidentemente, il CPI dell’istruzione sospesa viene allungato di una quantità pari alla durata dello stallo: nel nostro caso, si tratta di un ciclo di clock. La figura seguente illustra il tutto:
15 Non ci sono invece problemi per le altre due istruzioni, SUB e AND, in quanto, dal quinto ciclo di clock in poi, il valore da caricare in R1 può essere tranquillamente anticipato, sia pure al prezzo di un aggiunta di ulteriore logica dedicata, e quindi arriva in tempo.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 31
stalloIF
IFstallo
IF IDstallo
tempo(cicli di clock)
LW R1, 32(R6)
ADD R1,R2,R3
SUB R4,R1,R5
AND R6,R1,R7
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
EX MEM WB
ID EX MEM WB
ID EX MEM WB
Tutte le istruzioni, a partire da quella che presenta una dipendenza, vengono
dunque posposte. Grazie al ritardo, il valore di caricamento, che viene restituito dallo stadio MEM, può così essere anticipato al ciclo EX dell’istruzione ADD. A causa dello stallo, l’istruzione SUB legge il valore dei registri durante il ciclo ID invece di anticiparli direttamente dallo MDR.
Quando l’istruzione ADD riceve il “consenso” a riprendere l’esecuzione (passando perciò dallo stadio ID allo stadio EX), si dice che viene avviata. L’attribuzione del consenso a proseguire viene invece detta avvio dell’istruzione.
Nel caso specifico della pipeline del DLX con istruzioni in aritmetica intera, tutti i conflitti di dati possono essere rilevati durante la fase ID: quindi, se esiste un conflitto di dati, l’istruzione viene sospesa e, risolto il conflitto, viene avviata. Ci sono invece dei casi in cui l’avvio di istruzioni risulta molto complesso.
SSSeeemmmpppllliiiccceee sssooollluuuzzziiiooonnneee sssoooffftttwwwaaarrreee dddeeeiii cccooonnnfffllliiittttttiii dddiii dddaaatttiii Nei paragrafi precedenti abbiamo descritto possibili tecniche per risolvere via
hardware eventuali conflitti di dati. Altre tecniche consistono invece di soluzioni via software al problema dei conflitti: bisogna fare in modo che le sequenze di istruzioni generate dai compilatori contengano il minor numero possibile di conflitti di dati.
Per capire di che si tratta, consideriamo lo stesso esempio visto in precedenza: ADD R1, R2, R3 SUB R4, R1, R5 In questa sequenza di istruzioni, il conflitto nasce dal fatto che l’istruzione SUB
legge il contenuto del registro R1 prima che questo venga aggiornato dall’istruzione ADD: l’eventuale stallo impiegherebbe due cicli di clock per risolvere il conflitto.
Un modo semplicissimo di risolvere un simile conflitto sarebbe quello di inserire, tra la ADD e la SUB, due istruzioni del tutto indipendenti dall’istruzione ADD (oltre che tra loro): in tal modo, si avrebbe la certezza che il risultato prodotto dall’istruzione ADD sia disponibile in R1 quando viene richiesto dall’istruzione SUB.
Si hanno almeno due modi di applicare questa soluzione:
• se, nella sequenza del programma cui appartengono le due istruzioni citate, esistono altre due (o anche più) istruzioni che possono essere spostate senza modificare i risultati finali, il compilatore può tranquillamente ricorrere a questo spostamento di codice e, inoltre, le prestazioni della CPU non ne risulterebbero in alcun modo influenzate (si avrebbe ancora un CPI pari ad 1, per cui il throughput rimarrebbe pari a quello ideale);

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 32
• se invece non ci fosse istruzioni “disponibili” per lo spostamento, allora si possono inserire nella sequenza, sempre tra la ADD e la SUB, tante istruzioni NOP (Not Operation) quanti sono i cicli di clock che separano la scrittura del risultato dal suo primo uso corretto: nel nostro caso, bastano due istruzioni NOP. Le istruzioni NOP attraversano la pipeline senza attivare alcuna unità, salvo ovviamente quelle coinvolte nello stadio IF e l’addizionatore usato per incrementare il registro PC di 4 byte. E’ evidente, però, che questa seconda soluzione non è “indolore” come la precedente in termini di prestazioni: infatti, le due NOP corrispondono di fatto a due cicli di clock nei quali non si esegue nulla, per cui è come se la CPU andasse in stallo per due cicli di clock. La differenza, rispetto agli stalli, è nel fatto che le NOP sono una soluzione software (a cura del compilatore), mentre gli stalli sono una soluzione hardware (a cura della logica di controllo del processore).
Nei prossimi paragrafi vedremo delle tecniche software di risoluzione dei conflitti
di dati ben più sofisticate delle NOP, che consentono di non deteriorare eccessivamente le prestazioni rispetto al caso ideale.
SSSccchhheeeddduuulllaaazzziiiooonnneee dddeeellllllaaa pppiiipppeeellliiinnneee Molti tipi di stalli risultano decisamente frequenti. Consideriamo ad esempio la
sequenza di istruzioni che serve ad effettuare un calcolo del tipo A=B+C: LW R1,B LW R2,C ADD R3,R1,R2 SW A,R3 I due operandi sorgente (simbolicamente indicati con B e C) vengono caricati
tramite istruzioni LW, che li pongono rispettivamente in R1 ed R2. Il risultato della somma viene posto in R3 e successivamente nella locazione simbolicamente indicata con A. Eseguendo queste istruzioni in pipeline, si ha quanto segue:
tempo(cicli di clock)
LW R1,B
LW R2,C
ADD R3,R1,R2
SW A,R3
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Si nota immediatamente che nasce un “problema” nel quinto ciclo di clock, in
quanto il secondo operando non si rende disponibile per l’effettuazione della somma con il primo operando. E’ necessario dunque introdurre uno stallo a partire dall’istruzione ADD:

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 33
IFstallo
IF IDstallo
tempo(cicli di clock)
LW R1,B
LW R2,C
ADD R3,R1,R2
SW A,R3
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
EX MEM WB
ID EX MEM WB
Non necessariamente nascono invece problemi per l’operazione di memorizzazione
del risultato finale, in quanto esso può essere anticipato al registro MDR. In generale, dunque, osserviamo che le macchine in cui gli operandi di istruzioni
aritmetiche possono provenire direttamente dalla memoria sono costrette ad arrestare la pipeline nel mezzo dell’esecuzione per attendere che la memoria completi l’accesso.
Anziché permettere di arrestare la pipeline, il compilatore potrebbe tentare a priori di “organizzare” il lavoro della pipeline in modo da evitare questi arresti: si dovrebbe cioè riordinare il segmento di codice coinvolto in modo da eliminare i conflitti. Con riferimento all’esempio di poco fa, il compilatore potrebbe cercare di non generare un segmento di codice che presenti un caricamento seguito dall’uso immediato del registro destinazione del caricamento stesso. Una simile tecnica prende il nome di schedulazione della pipeline: essa funziona abbastanza bene, al punto che certe macchine fanno affidamento solo sulla struttura dei programmi per evitare conflitti.
Un caricamento che necessiti che l’istruzione successiva non usi il suo risultato viene definito caricamento ritardato. Lo stadio di pipeline successivo al caricamento è invece spesso chiamato ritardo di caricamento (o anche intervallo di ritardo).
Se il compilatore non riesce a schedulare opportunamente il caricamento ritardato, potrebbe al limite inserire una istruzione nulla (NOP, no-operation) dopo quella di caricamento: in questo caso, il tempo di esecuzione non aumenta, ma aumentano invece le dimensioni del codice.
In ogni caso, qualunque sia il comportamento della macchina previsto in casi come questi, le migliori prestazioni si ottengono quando il compilatore schedula le istruzioni. Invece, se lo stallo si verifica, le prestazioni finali sono comunque le stesse a prescindere che la macchina esegua una istruzione nulla oppure che sia stato interposto un ciclo di clock di attesa.
Esempio Possiamo fare un semplicissimo esempio di come riorganizzare un segmento di
codice di operazioni aritmetiche in modo da evitare arresti della pipeline. Supponiamo perciò che le operazioni da compiere siano le seguenti: a = b + c; d = e – f; Il codice simbolico che, in condizioni normali, verrebbe generato è il seguente:

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 34
LW Rb,b LW Rc,c ADD Ra,Rb,Rc SW a,Ra LW Re,e LW Rf,f SUB Rd,Re,Rf SW d,Rd In questo caso, incorreremmo negli stessi problemi esaminati prima, per cui
avremmo addirittura due stalli, uno per l’istruzione ADD e l’altro per l’istruzione SUB. Possiamo “cominciare” a risolvere il problema del primo stallo anticipando il caricamento dell’operando e prima dell’istruzione ADD:
LW Rb,b LW Rc,c LW Re,e ADD Ra,Rb,Rc SW a,Ra LW Rf,f SUB Rd,Re,Rf SW d,Rd Analogamente, per risolvere il secondo stallo, possiamo scambiare il caricamento
dell’operando f con la memorizzazione dell’operando a: LW Rb,b LW Rc,c LW Re,e ADD Ra,Rb,Rc LW Rf,f SW a,Ra SUB Rd,Re,Rf SW d,Rd In questo modo, è facile verificare che non sono necessari stalli, grazie anche alle
possibilità di anticipare i risultati della ALU al registro MDR per la memorizzazione. Naturalmente, ci si rende conto che gli “scambi” effettuati sono possibili solo
usando registri diversi per tutti gli operandi coinvolti: per esempio, se l’operando e fosse stato caricato nello stesso registro di b o c, il codice finale non sarebbe risultato corretto. Questa semplice considerazione ne evidenzia una più generale, secondo cui la schedulazione della pipeline in generale aumenta il numero di registri da utilizzare. In effetti, ci sono però meccanismi più sofisticati che consentono di ridurre tale numero di registri.
RRRiiillleeevvvaaazzziiiooonnneee dddeeeiii cccooonnnfffllliiittttttiii dddiii dddaaatttiii iiinnn pppiiipppeeellliiinnneee ssseeemmmpppllliiiccciii Quando la macchina su cui implementare la pipeline ha una architettura molto
complicata, ha istruzioni di lunga durata e con interdipendenze in molti cicli, la gestione della pipeline e in particolare degli interallacciamenti può richiedere l’uso di una tabella in cui tener traccia della disponibilità degli operandi e delle operazioni di scrittura all’esterno.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 35
Nel caso della pipeline del DLX in aritmetica intera, c’è solo una questione cui prestare particolare attenzione: il caricamento seguito dall’uso immediato del valore caricato, di cui abbiamo parlato nei precedenti paragrafi. Una comoda soluzione del problema consiste nell’usare un confrontatore che verifichi la presenza di questa configurazione di sorgente e destinazione del caricamento e faccia in modo che vengano presi i dovuti provvedimenti.
Più in dettaglio, la logica necessaria per rilevare e controllare il conflitto di dati relativo al caricamento e per anticipare il risultato può essere la seguente:
• agli ingressi della ALU è necessario sistemare dei multiplexer addizionali
(esattamente come già abbiamo fatto per la logica di cortocircuitazione nel caso delle istruzioni di tipo registro-registro);
• tra i vari ingressi dei suddetti multiplexer è necessario prevedere delle linee provenienti direttamente dal registro MDR;
• serve anche un buffer in cui poter salvare gli indicatori del registro destinazione delle due istruzioni precedenti (gli stessi buffer sono stati usati nel caso dell’anticipo di istruzioni di tipo registro-registro);
• servono infine quattro confrontatori, che confrontino i due campi che indicano il registro sorgente ed il registro destinazione delle istruzioni precedenti, controllandone la corrispondenza.
Nella prossima tabella viene schematizzato il compito dei confrontatori (verificare
la presenza di un interallacciamento all’inizio del ciclo EX) e le azioni necessarie nei vari casi:
Situazione Esempio di sequenza
di codice Azione intrapresa dalla sequenza di codice
Nessuna dipendenza LW R1,45(R2) ADD R5,R6,R7 SUB R8,R6,R7 OR R9,R6,R7
In questa situazione non si verifica alcun conflitto, dato che R1 (registro di caricamento) non è coinvolto in nessuna delle istruzioni successive a quella di caricamento
Dipendenza che richiede uno stallo
LW R1,45(R2) ADD R5,R1,R7 SUB R8,R6,R7 OR R9,R6,R7
In questo caso, i confrontatori rilevano l’uso di R1 nell’istruzione ADD successiva a quella di caricamento: fanno allora in modo che l’istruzione ADD e le istruzioni successive vengano sospese (prima che ADD entri nello stadio EX)
Dipendenza posposta da un anticipo
LW R1,45(R2) ADD R5,R6,R7 SUB R8,R1,R7 OR R9,R6,R7
In questo nuovo caso, i confrontatori rilevano l’uso di R1 nell’istruzione SUB: è allora sufficiente anticipare il risultato del caricamento alla ALU senza imporre stalli, in quanto l’operando arriva in tempo perché l’istruzione SUB possa andare nello stadio EX
Dipendenza con accesso ordinato
LW R1,45(R2) ADD R5,R6,R7 SUB R8,R6,R7 OR R9,R1,R7
In quest’ultimo caso non risulta necessaria alcuna azione, dato che la lettura di R1 eseguita dall’istruzione OR si verifica nella seconda metà del ciclo di clock della fase ID, mentre invece la scrittura dei dati caricati dall’istruzione RW è stata già eseguita nella prima metà dello stesso ciclo di clock

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 36
Conflitti di controlloConflitti di controllo I conflitti di controllo sono particolarmente importanti in quanto possono
determinare perdite di prestazioni maggiori rispetto ai conflitti di dati. Un conflitto di controllo si può verificare nella seguente situazione: quando si
esegue una diramazione, è possibile che il registro PC venga modificato in modo diverso dal normale incremento di uno spiazzamento pari a 4, in quanto, sotto certe condizioni, viene aggiornato all’indirizzo di destinazione della diramazione stessa (16). Allora, in questo caso, l’istruzione successiva da prelevare ed eseguire non è quella sequenzialmente successiva alla diramazione, ma quella puntata dal suddetto indirizzo di destinazione: se però si adotta una pipeline così come l’abbiamo descritta fino ad ora, l’istruzione sequenzialmente successiva è stata già prelevata all’indirizzo PC=PC+4 e quindi il flusso di controllo risulta alterato rispetto a quello desiderato dal programmatore. Cerchiamo allora di capire meglio “dove” e “quando” si verificano questo tipo di conflitti ed il modo in cui è possibile porvi rimedio.
Consideriamo per il momento una macchina senza pipeline e supponiamo che l’istruzione i sia una diramazione eseguita, il che significa che il registro PC non viene incrementato di 4 (per puntare all’istruzione i+1), ma viene aggiornato con l’indirizzo di destinazione della diramazione (che punta ad una generica istruzione n):
Istruzione iIstruzione i+1Istruzione i+2Istruzione i+3....
Istruzione n
PC=dest
Ad esempio, l’istruzione i potrebbe essere BEQZ R1,28: in questo caso, se il
contenuto del registro R1 è nullo, bisogna saltare all’istruzione che si trova all’indirizzo dato da PC+28, dove PC contiene l’indirizzo di BEQZ e 28 è lo spiazzamento indicato nella stessa BEQZ.
In concreto, l’aggiornamento del registro PC con l’indirizzo di destinazione della diramazione avviene generalmente alla fine della fase MEM di esecuzione dell’istruzione, dopo cioè che è stato completato il calcolo dell’indirizzo ed è stato effettuato il test sulla condizione della diramazione. La tabella seguente illustra questo concetto:
16 A tal proposito, ricordiamo che una diramazione si dice eseguita (o eseguita con successo) quando effettivamente modifica il contenuto del registro PC con il suo indirizzo di destinazione (PC=dest), mentre in caso contrario (quando cioè PC=PC+4 ) si dice fallita (o anche non eseguita).

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 37
Fase Operazioni compiute Descrizione
IF MAR←PC;
IR←M[MAR];
Prelevamento dell’istruzione dalla memoria, tramite l’indirizzo contenuto nel registro PC
ID A←Rs1; B←Rs2; PC←PC+4 Lettura degli eventuali operandi e
aggiornamento del PC per puntare all’istruzione sequenzialmente successiva
EX UscitaALU ← PC + (IR16)
16##IR16..31;
cond ← (Rs1 op Rs2)
Calcolo dell’indirizzo di destinazione e impostazione del registro tramite l’esito della condizione per la diramazione
MEM if (cond) PC ← UscitaALU Verifica del registro di condizione
ed eventuale aggiornamento del registro PC con l’indirizzo di destinazione
WB Nessuna operazione
Se adesso supponiamo di usare una pipeline, risulta evidente il problema prima
accennato e relativo all’aggiornamento del registro PC: in assenza di “provvedimenti”, quando lo stadio MEM della diramazione è stato completato ed il salto è stato eseguito (per cui il registro PC è stato aggiornato con l’indirizzo di destinazione della diramazione), sono state già prelevate altre tre istruzioni e solo l’istruzione successiva a queste tre corrisponde a quella di destinazione della diramazione:
tempo(cicli di clock)
Istruzione didiramazione
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WBIstruzione didestinazionedella diramazione
aggiornamento del registro PCalla destinazione della diramazione
Pur volendo accettare una situazione di questo tipo, corrispondente ad una
perdita di prestazioni, è fondamentale fare in modo che le tre istruzioni erroneamente avviate all’esecuzione non giungano a completamento, ossia non modifichino lo stato della CPU, scrivendo i propri risultati nel banco dei registro o nella memoria dati o, peggio ancora, eseguendo salti non dovuti. Se invece la diramazione non risultasse eseguita, allora non ci sarebbe da impedire niente in quanto il flusso di controllo non risulterebbe alterato rispetto a quello sequenziale: solo in questo caso le prestazioni non peggiorano.
La prima alternativa a questo modo di procedere sarebbe quello di introdurre degli stalli della pipeline, impedendo che vengano caricate istruzioni non volute nel caso in cui la diramazione risulti eseguita; si dovrebbe perciò procedere nel modo seguente: all’inizio della fase ID sull’istruzione di diramazione, nel momento in cui la logica di controllo capisce che l’istruzione è una diramazione, sarebbe necessario imporre uno stallo di ben 3 cicli di clock alla pipeline, in modo da attendere il

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 38
completamento della fase MEM della diramazione; al termine di tale fase, il valore corretto del registro PC sarebbe finalmente disponibile e sarebbe quindi possibile riprendere la pipeline a partire dalla fase IF dell’istruzione da eseguire successivamente a quella di diramazione:
stallo stallo stallo
stallo stallo stallo
stallo stallo stallo
stallo stallo stallo
tempo(cicli di clock)
Istruzione didiramazione
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
In effetti, questa soluzione non appare attuabile, per il semplice motivo che
l’istruzione di diramazione non viene in realtà decodificata fino a quando l’istruzione sequenzialmente successiva non è stata prelevata; di conseguenza, lo schema appena riportato deve necessariamente essere modificato:
IF stallo stallo
stallo stallo stallo
stallo stallo stallo
stallo stallo stallo
tempo(cicli di clock)
Istruzione didiramazione
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Come si può vedere, non potendo ancora sapere, all’inizio del secondo ciclo di
clock, che l’istruzione prelevata è una diramazione, si effettua comunque il prelevamento dell’istruzione che segue sequenzialmente (cioè all’indirizzo PC=PC+4); tuttavia, una volta rilevato che la prima istruzione è una diramazione, si impone lo stallo alla pipeline fin quando non si ritiene che il registro PC sia stato correttamente aggiornato, dopodiché la pipeline riparte nuovamente con lo stadio IF. E’ allora evidente che, se la diramazione non viene eseguita, la seconda fase IF dell’istruzione successiva è ridondante, ma è comunque inevitabile.
Ad ogni modo, le ultime due figure mantengono una cosa in comune: il fatto che la diramazione impone uno spreco di diversi cicli di clock (3 nel primo caso e 4 nel secondo); si tratta di uno spreco notevole in termini di prestazioni: ad esempio, se la frequenza con cui si presentano le diramazioni fosse del 30% e il CPI ideale fosse pari ad 1, la macchina con pipeline raggiungerebbe una accelerazione pari nemmeno

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 39
a metà di quella massima teoricamente ottenibile in assenza di “problemi”. Sulla base di ciò, diventa imperativo trovare il modo di risolvere in modo efficiente i conflitti di dati.
Si può cominciare a pensare ad almeno due distinte soluzioni:
• predire in anticipo se la diramazione fallirà o meno;
• calcolare in anticipo l’indirizzo di destinazione della diramazione.
In effetti, si può capire facilmente che l’ottimizzazione del comportamento della
diramazione richiede entrambe le soluzioni: non servirebbe infatti a niente conoscere in anticipo l’indirizzo di destinazione della diramazione se ancora non si sa se la prossima istruzione da eseguire è l’obbiettivo della diramazione oppure l’istruzione all’indirizzo PC+4.
Se ora osserviamo il set di istruzione del DLX, ci accorgiamo che le diramazioni (BEQZ e BNEZ) verificano solo l’uguaglianza di un operando (in particolare un registro) con zero. Allora, possiamo pensare di completare questo controllo addirittura entro la fine del ciclo ID, a patto ovviamente di usare una logica speciale per effettuare tale verifica. Inoltre, al fine di sfruttare al meglio una decisione tempestiva circa l’eseguibilità della diramazione, è opportuno calcolare quanto prima entrambi i possibili valori del PC: a tal proposito, il calcolo dell’indirizzo di diramazione richiede un sommatore separato (l’ALU è sicuramente già occupata) che esegue il calcolo sempre nella fase ID.
Con questi due accorgimenti (calcolo anticipato dell’indirizzo di destinazione e anticipo della decisione), riduciamo lo stallo ad un unico ciclo di clock:
IF
stallo
stallo
stallo
tempo(cicli di clock)
Istruzione didiramazione
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Per essere ancora più chiari, riportiamo nuovamente la tabella che abbiamo
proposto all’inizio del paragrafo, corredata con le modifiche citate poco fa:

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 40
Fase Operazioni compiute Descrizione
IF
MAR←PC;
IR←M[MAR];
PC←←PC+4
Prelevamento dell’istruzione dalla memoria, tramite l’indirizzo contenuto nel registro PC. Viene anche incrementato il registro PC, anticipando tale operazione rispetto alla fase ID
ID
A←Rs1; B←Rs2;
BTA ←← PC + (IR16)16##IR16..31;
cond ←← (Rs1 op 0)
if (cond) PC ←← BTA
Lettura degli eventuali operandi, calcolo dell’indirizzo di destinazione (anticipato rispetto alla fase EX) e verifica della condizione della diramazione
EX Nessuna operazione
MEM Nessuna operazione
WB Nessuna operazione
Abbiamo indicato in grassetto le operazioni nuove o modificate o spostate
temporalmente. La prima cosa importante da notare è che, all’inizio della fase ID, non si sa ancora
se l’istruzione è una diramazione; di conseguenza, tutte le operazioni che abbiamo scelto di compiere nella fase ID dovranno essere compiute per tutte le categorie di istruzioni; tali operazioni sono evidentemente le seguenti:
• calcolo dell’indirizzo di destinazione (BTA, Branch Target Address)
• verifica della condizione di diramazione (Rs1 op 0);
• eventualmente aggiornamento del contenuto del PC con l’indirizzo di destinazione della diramazione.
A queste si aggiunge il fatto che il registro PC deve essere incrementato di 4 (salvo
poi essere nuovamente modificato) già nella fase IF, così come peraltro avevamo già stabilito in precedenza.
Al termine delle operazioni previste per lo stadio ID, bisogna necessariamente verificare se l’istruzione è effettivamente una diramazione oppure no: la decodifica dell’istruzione deve dunque essere fatta al termine dello stadio ID o subito all’inizio dello stadio EX, in ogni caso prima che il registro PC venga “emesso”. Se si tratta di una diramazione, bisogna infatti imporre lo stallo di un ciclo di clock, dopodiché il contenuto del PC sarà ritenuto “valido” e la pipeline potrà proseguire.
Risulta evidente che, se l’istruzione è effettivamente una diramazione, restano inutilizzati gli stadi EX, MEM e WB. Se invece non si tratta di una diramazione, allora le varie operazioni compiute risultano inutili e vanno compiute le operazioni appropriate per il tipo di istruzione (operazioni che abbiamo avuto modo di descrivere ampiamente in precedenza).
Una osservazione importante da fare è la seguente: per il DLX, le istruzioni di diramazione prevedono che lo spiazzamento da sommare al PC per ottenere l’indirizzo di destinazione sia lungo 16 bit, mentre invece le istruzioni di salto incondizionato ammettono uno spiazzamento di 26 bit; di conseguenza, dobbiamo stare attenti a come implementiamo il sommatore addizionale:

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 41
• la prima possibilità è quella di prevedere due sommatori, uno per gli spiazzamenti da 16 e l’altro per quelli a 26 bit (17);
• in alternativa, potremmo scegliere un sommatore che nella prima metà del ciclo di clock sommi 16 bit e che decida se sommare i restanti 10 bit nella seconda metà, in base al codice operativo dell’istruzione (che ovviamente deve essere stato già decodificato).
RRRiiiddduuuzzziiiooonnneee dddeeelllllleee pppeeennnaaallliiizzzzzzaaazzziiiooonnniii dddooovvvuuuttteee aaalllllleee dddiiirrraaammmaaazzziiiooonnniii nnneeellllllaaa pppiiipppeeellliiinnneee
Si può verificare che, in generale, quanto maggiore è la dimensione della pipeline tanto peggiore risulta la penalizzazione (in termini di cicli di clock) dovuta alle diramazioni. D’altra parte, bisogna sempre considerare che l’effetto delle penalizzazioni, per quanto “forti” possano essere, dipende comunque dal CPI globale della macchina: infatti, una macchina con CPI già elevato può tollerare la presenza di più diramazioni molto penalizzate, perché la frazione delle prestazioni della macchina che andrebbe perduta a causa delle diramazioni stesse è inferiore.
Dato che le diramazioni possono influenzare dinamicamente le prestazioni di una pipeline, è opportuno considerare il loro comportamento (ad esempio la frequenza con cui si manifestano), in modo da sfruttarlo per minimizzare le relative penalizzazioni. Nel caso del DLX, il comportamento delle penalizzazioni indica che esse vengono eseguite nel 53% dei casi e che, quando vengono eseguite, nel 75% dei casi si tratta di diramazioni in avanti (ossia con indirizzo di destinazione superiore a quello della diramazione stessa).
Tenendo conto di questi (ed altri) dati, si possono individuare alcuni metodi per ridurre le penalizzazioni dovute alla diramazioni. In particolare, ci vogliamo occupare di quattro distinti metodi, tutti basati su speciali tecniche di compilazione dei programmi. Queste tecniche sono a loro volta tutte basate su predizioni statiche (che cioè sono prefissate per ogni diramazione e per tutta la durata della sua esecuzione), che vengono stabilite, secondo opportune stime, durante la compilazione dei programmi. Esistono invece degli schemi più avanzati, che sfruttando dispositivi hardware per predire, in modo dinamico, il comportamento delle diramazioni.
La soluzione più semplice di affrontare i conflitti di controllo è quella già esaminata nei precedenti paragrafi: bisogna bloccare la pipeline, fermando ogni istruzione che segue la diramazione, fin quando la destinazione della diramazione non è nota. L’unico pregio di questa soluzione è proprio la sua semplicità.
Una soluzione migliore, che richiede una complessità solo leggermente superiore, consiste nell’ipotizzare comunque il fallimento della diramazione, consentendo alla macchina di proseguire come se in effetti la diramazione non venisse eseguita: nel caso in cui, invece, la diramazione viene eseguita, allora occorre arrestare la pipeline e ricominciare il prelievo delle istruzioni a partire da quella di destinazione della diramazione.
Nelle prossime figure vengono schematizzate una situazione in cui la diramazione risulta fallita ed una in cui invece la diramazione risulta eseguita:
17 E’ utile ricordare che i bit contenenti lo spiazzamento sono sempre quelli meno significativi del registro IR, in cui è contenuta l’istruzione in corso di esecuzione.

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 42
IF
tempo(cicli di clock)
Istruzione didiramazionefallita
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Nel caso in cui la diramazione fallisce, il “funzionamento” della pipeline è quello classico, in quanto procede come se la diramazione fosse una istruzione qualsiasi che aggiorna il registro
PC sommandogli solamente i classici 4 byte
IF
stallo
stallo
stallo
tempo(cicli di clock)
Istruzione didiramazione
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Nel caso in cui la diramazione risulta eseguita, viene ripetuto due volte il fetch dell’istruzione da eseguire subito dopo, in modo da tener conto dell’aggiornamento del registro PC
all’indirizzo di destinazione della diramazione. Questo costringe tutte le istruzioni successive alla diramazione a rimanere in stallo per un ciclo di clock
Quando si adotta questa tecnica (detta di predizione di fallimento), bisogna stare attenti a non modificare lo stato della macchina fin quando l’esito della valutazione delle condizioni di diramazione non sia definitivamente noto. Proprio le complessità legate alla necessità di individuare il momento in cui lo stato può essere modificato da una istruzione e, eventualmente, di annullare gli effetti di una modifica, inducono talvolta a preferire la soluzione più semplice di arresto della pipeline.
Nel caso del DLX, la predizione di fallimento viene dunque realizzata continuando a prelevare istruzioni come se la diramazione fosse una istruzione normale: la pipeline deve controllare che non accada niente al di fuori della norma e, in caso di diramazione eseguita, deve ripetere lo stadio IF dell’istruzione successiva alla diramazione.
Lo schema duale di quello appena descritto consiste nell’assumere a priori che la diramazione venga eseguita (si parla perciò in questo caso di predizione di successo): in pratica, non appena la diramazione è stata decodificata e l’indirizzo di destinazione calcolato, si assume che la diramazione sia da eseguire e si inizia a prelevare ed eseguire l’istruzione di destinazione. E’ evidente che, nel caso del DLX, un approccio del genere non porta alcun vantaggio: infatti, l’indirizzo di destinazione

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 43
non è noto fin quando non è noto l’esito della valutazione delle condizioni di diramazione, per cui fare una ipotesi iniziale di successo non determina alcuna velocizzazione. In ogni caso, ci sono macchine in cui l’indirizzo di destinazione potrebbe essere noto prima dell’esito della valutazione delle condizioni di diramazione, nel qual caso questo metodo può portare a benefici. Tra l’altro, ci sono alcune situazioni in cui una diramazione ha un’alta probabilità di essere eseguita: pensiamo all’istruzione di chiusura di un ciclo FOR.
L’ultimo metodo che prendiamo in analisi è detto diramazione ritardata (o anche ritardo di salto) e consiste in pratica nel far eseguire comunque un certo numero di istruzioni sequenzialmente successive a quella di diramazione anche se questa è stata eseguita. In particolare, si dice che, in una diramazione ritardata, il ciclo di esecuzione con un ritardo di salto di lunghezza N è fatto nel modo seguente:
istruzione di diramazione istruzione successiva 1 istruzione successiva 2 … istruzione successiva N istruzione destinazione della diramazione (se eseguita) Le istruzioni che si trovano agli indirizzi successivi a quello dell’istruzione di
diramazione vengono collocate nei cosiddetti intervalli di ritardo del salto: un apposito organo schedulatore del compilatore deve mantenere valide e significative le istruzioni collocate negli intervalli di ritardo di salto, ossia appunto quelle successive alla diramazione stessa. Per fare questo, si impiega un gran numero di ottimizzazioni, che però non interessano in questa sede (18).
La limitazione principale della diramazione ritardata deriva proprio dalle restrizioni imposte alle istruzioni che vengono collocate all’interno degli intervalli di ritardo, nonché dalla non totale affidabilità della predizione (effettuata in fase di compilazione) sull’esito della diramazione.
La tecnica della diramazione ritardata determina un modesto aumento dei costi dell’hardware: infatti, a causa proprio dell’effetto ritardato delle diramazioni, occorrono valori multipli del registro PC (in particolare, oltre al valore corrente, serve quello incrementato per puntare alla destinazione della diramazione) per ripristinare in modo corretto lo stato della macchina quando si presenta una interruzione. In particolare, una situazione critica si ha quando si verifica una interruzione dopo che è stata completata una istruzione di diramazione eseguita senza che però siano state completate le istruzioni nell’intervallo di ritardo e l’istruzione di destinazione: infatti, in questa situazione, sia il PC dell’intervallo di ritardo sia il PC della destinazione della diramazione devono essere salvati, dato che non sono in sequenza.
A conclusione del paragrafo, possiamo chiederci quali siano le prestazioni effettive di queste tecniche. Riprendiamo allora la formula precedentemente ricavata per l’accelerazione di una macchina dotata di pipelining:
( )( ) stallo diclock di Cicli pipeliningcon CPI
pipeline della Dimensione pipeliningcon CPIoneAccelerazi
ideale
ideale
+×
=
Supponendo che il CPI ideale valga 1, abbiamo che
18 Si veda, in proposito, a pag. 235 del testo.
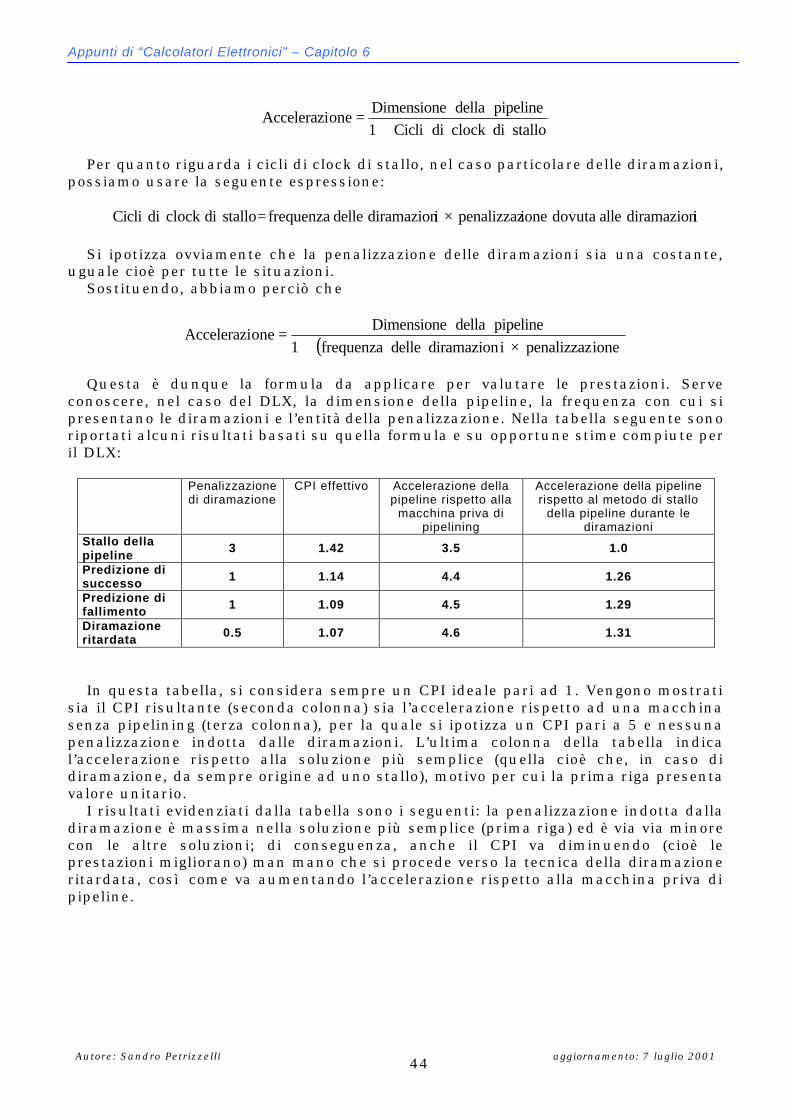
Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 44
stallo diclock di Cicli 1
pipeline della DimensioneoneAccelerazi
+=
Per quanto riguarda i cicli di clock di stallo, nel caso particolare delle diramazioni,
possiamo usare la seguente espressione:
idiramazion alle dovuta ionepenalizzaz idiramazion delle frequenza stallo diclock di Cicli ×= Si ipotizza ovviamente che la penalizzazione delle diramazioni sia una costante,
uguale cioè per tutte le situazioni. Sostituendo, abbiamo perciò che
( )ionepenalizzaz idiramazion delle frequenza 1
pipeline della DimensioneoneAccelerazi
×+=
Questa è dunque la formula da applicare per valutare le prestazioni. Serve
conoscere, nel caso del DLX, la dimensione della pipeline, la frequenza con cui si presentano le diramazioni e l’entità della penalizzazione. Nella tabella seguente sono riportati alcuni risultati basati su quella formula e su opportune stime compiute per il DLX:
Penalizzazione
di diramazione CPI effettivo Accelerazione della
pipeline rispetto alla macchina priva di
pipelining
Accelerazione della pipeline rispetto al metodo di stallo
della pipeline durante le diramazioni
Stallo della pipeline
3 1.42 3.5 1.0
Predizione di successo 1 1.14 4.4 1.26
Predizione di fallimento 1 1.09 4.5 1.29
Diramazione ritardata 0.5 1.07 4.6 1.31
In questa tabella, si considera sempre un CPI ideale pari ad 1. Vengono mostrati
sia il CPI risultante (seconda colonna) sia l’accelerazione rispetto ad una macchina senza pipelining (terza colonna), per la quale si ipotizza un CPI pari a 5 e nessuna penalizzazione indotta dalle diramazioni. L’ultima colonna della tabella indica l’accelerazione rispetto alla soluzione più semplice (quella cioè che, in caso di diramazione, da sempre origine ad uno stallo), motivo per cui la prima riga presenta valore unitario.
I risultati evidenziati dalla tabella sono i seguenti: la penalizzazione indotta dalla diramazione è massima nella soluzione più semplice (prima riga) ed è via via minore con le altre soluzioni; di conseguenza, anche il CPI va diminuendo (cioè le prestazioni migliorano) man mano che si procede verso la tecnica della diramazione ritardata, così come va aumentando l’accelerazione rispetto alla macchina priva di pipeline.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 45
Gestione delle interruzioniGestione delle interruzioni Nei precedenti paragrafi abbiamo sostanzialmente visto come rilevare e tentare
risolvere i conflitti; adesso vogliamo invece prendere in esame alcune complicazioni che finora abbiamo volutamente ignorato. La principale complicazione, nel progetto e nella gestione di una pipeline, proviene dalle interruzioni: abbiamo già avuto modo di vedere che le interruzioni sono uno degli aspetti più difficili della realizzazione di una macchina e si può quindi intuire facilmente come la presenza del pipelining non possa che aggravare la situazione.
Il problema fondamentale delle interruzioni su una macchina dotata di pipelining è che risulta complicato sapere se una istruzione può modificare con sicurezza lo stato della macchina: la conoscenza dello stato della macchina prima che si verifichi una interruzione è infatti la condizione necessaria per poter ripristinare il processo interrotto (ove sia possibile tale ripristino) dal punto in cui l’interruzione si è verificata.
Così come avviene in assenza di pipelining, le interruzioni più difficili da gestire sono quelle con due proprietà: si verificano all’interno delle istruzioni e devono essere ripristinabili (ossia non devono imporre l’arresto del processo in corso, ma solo la sua sospensione temporanea). Ad esempio, consideriamo la pipeline del DLX:
IF
tempo(cicli di clock)
Istruzione i
Istruzione i+1
Istruzione i+2
Istruzione i+3
Istruzione i+4
Istruzione i+5
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Supponiamo che l’istruzione i+3 effettui un tentativo di lettura di dati (operandi)
dalla memoria (19) e si verifichi una mancanza di pagina di memoria virtuale, il che significa sostanzialmente che i dati richiesti non sono nella memoria principale ma si trovano nella memoria secondaria (ad esempio su un disco); tale mancanza di pagina si verifica sicuramente in un istante non meglio identificato durante il ciclo MEM dell’istruzione ed è una tipica interruzione che deve essere servita immediatamente (pena l’impossibilità di continuare ad eseguire l’istruzione), tramite l’intervento del sistema operativo (20); tuttavia, prima dell’istante in cui l’interruzione si manifesta, molte altre istruzioni possono essere già entrate in esecuzione e potrebbero modificare lo stato della macchina (è il caso dell’istruzione i+2, che è nello stadio WB): è necessario perciò che la pipeline venga arrestata ed il suo stato salvato, in modo che l’istruzione interrotta possa poi essere ripristinata nello stato corretto. Dal punto di vista pratico, solitamente si procede a salvare il PC dell’istruzione, il che
19 Ricordiamo che, essendo il DLX una macchina di tipo load/store, l’accesso alla memoria per la lettura o la memorizzazione di dati può avvenire solo nella fase MEM di una istruzione, rispettivamente, LOAD o STORE 20 Come vedremo nel capitolo sulla memoria, il sistema operativo deve infatti occuparsi di portare i dati richiesti dalla memoria secondaria in quella principale; tuttavia, non può trasferire solo i dati di interesse, ma un intera porzione di memoria secondaria che prende il nome di pagina. Questo trasferimento richiede ovviamente del tempo.

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 46
significa sostanzialmente che l’istruzione dovrà essere “rieseguita” per intero, partendo cioè dalla fase IF, insieme alle istruzioni successive nella pipeline.
A proposito di quanto appena detto, ci sono due possibilità da considerare:
• se l’istruzione ripristinata non è una diramazione, allora si può continuare a prelevare le istruzioni seguenti, la cui esecuzione inizierà nel solito modo;
• se invece l’istruzione ripristinata è una diramazione, allora bisogna valutare la condizione della diramazione, in modo da effettuare correttamente il prelievo dell’istruzione successiva da eseguire, secondo quanto ampiamente descritto nei precedenti paragrafi.
OOOpppeeerrraaazzziiiooonnniii pppeeerrr iiilll sssaaalllvvvaaatttaaaggggggiiiooo dddeeellllllooo ssstttaaatttooo dddeeellllllaaa mmmaaacccccchhhiiinnnaaa Quando si verifica una interruzione, il salvataggio corretto dello stato della
pipeline richiede le seguenti operazioni:
• in primo luogo, bisogna inserire nella pipeline una istruzione di cattura (trap) in corrispondenza dello stadio IF seguente;
• fin quando l’istruzione di cattura non inizia l’esecuzione, bisogna inoltre disabilitare tutte le operazioni di scrittura sia dell’istruzione interrotta sia delle istruzioni che la seguono nella pipeline: in questo modo, viene impedita ogni possibile variazione dello stato delle istruzioni che non possono essere completate prima che inizi il servizio dell’interruzione;
• dopo che il sottoprogramma gestore delle interruzioni (che ricordiamo far parte del sistema operativo) ha ricevuto il controllo, esso provvede subito a salvare il PC dell’istruzione interrotta, in modo da utilizzare quell’indirizzo per il rientro dall’interruzione (21).
Dopo che l’interruzione è stata servita, istruzioni speciali provvedono a ripristinare
la macchina dall’interruzione, ricaricando gli opportuni valori del PC e facendo ripartire il flusso di istruzioni (nel DLX, ciò avviene tramite l’istruzione RFE).
IIInnnttteeerrrrrruuuzzziiiooonnniii sssiiinnncccrrrooonnneee Quando è possibile arrestare la pipeline facendo in modo che le istruzioni che
precedono quella interrotta vengano completate e quelle seguenti possano essere ripristinate dall’inizio, si dice che la pipeline è dotata di interruzioni sincrone. Questa caratteristica rappresenta un vero e proprio vincolo di progetto per molti sistemi, mentre per altri rappresenta solo una caratteristica desiderabile (ma non necessaria), dato che semplifica notevolmente l’interfaccia con il sistema operativo.
21 Occorre osservare, a tal proposito, che provvedimenti aggiuntivi devono essere presi nel caso di diramazioni ritardate (si veda il paragrafo precedente): in questo caso, non è sufficiente un unico valore del PC per rigenerare lo stato della macchia, dato che le istruzioni nella pipeline non sono più necessariamente sequenziali.

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 47
IIInnnttteeerrrrrruuuzzziiiooonnniii mmmuuullltttiiipppllleee nnneeellllllaaa pppiiipppeeellliiinnneee dddeeelll DDDLLLXXX Nella prossima tabella sono indicate le interruzioni che possono verificarsi nei vari
stadi della pipeline del DLX:
Stadio Interruzione IF Mancanza di pagina al momento del prelievo di una istruzione
Accesso disallineato alla memoria Violazione dei diritti di accesso alla memoria
ID Codice operativo non definito o non consentito EX Interruzione di tipo aritmetico MEM Mancanza di pagina al momento del prelievo di dati
Accesso disallineato alla memoria Violazione dei diritti di accesso alla memoria
WB Nessuna E’ ovvio che, data la sovrapposizione delle istruzioni nella pipeline, potrebbero
verificarsi più interruzioni nello stesso ciclo di clock (interruzioni multiple). Ad esempio, consideriamo la seguente sequenza di istruzioni e la relativa pipeline:
WBMEMEXIDIF...ADD
WBMEMEXIDIF....LW
Nel quarto ciclo di clock, l’istruzione LW è nello stadio MEM, per cui potrebbe
determinare una mancanza di pagina di dati, mentre invece l’istruzione ADD è nello stato EX, per cui potrebbe determinare una interruzione aritmetica. Dato che l’interruzione aritmetica è di tipo mascherabile, si potrebbe pensare di servire inizialmente quella per la mancanza di pagina (che invece è non mascherabile) e poi ripartire: in tal modo, l’interruzione aritmetica si ripresenterà e potrà essere servita in modo indipendente).
In effetti, però, una situazione così lineare difficilmente si verifica, in quanto le interruzioni possono presentarsi completamente in disordine: può cioè capitare che una istruzione (ad esempio ADD dell’esempio precedente) generi una interruzione prima che una istruzione precedente (ad esempio LW dell’esempio precedente) ne abbia generata una a sua volta. Supponiamo, ad esempio, che l’istruzione LW dell’esempio precedente generi una mancanza di pagina di dati quando si trova nello stato MEM, mentre invece ADD generi una mancanza di pagina di codice quando si trova nello stadio IF: è una tipica situazione in cui una interruzione si verifica prima che si verifichi quella causata dall’istruzione precedente.
Esistono almeno due modi per affrontare situazioni di questo tipo. Indichiamo le due istruzioni con I e J, dove J segue sequenzialmente I:
• il primo approccio è di tipo completamente sincrono ed anche abbastanza
semplice: bisogna prevedere un vettore di stato nel quale la macchina deve inserire le interruzioni man mano che si verificano; quando una istruzione entra nello stato WB oppure sta per lasciare lo stato MEM (in ogni caso prima della fase di scrittura dei risultati e quindi di possibile modifica dello stato), la macchina controlla il vettore di stato e, se contiene delle interruzioni, queste vengono servite, facendo in modo che l’interruzione corrispondente all’istruzione più vecchia venga servita per prima. In questo modo si garantisce che tutte le interruzioni siano manifeste all’istruzione I

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 48
prima che lo siano all’istruzione J. Dato che le interruzioni vengono servite prima della fase WB, non c’è pericolo che lo stato venga modificato e quindi la possibilità di ripristino viene garantita. Del resto, in architetture diverse dal DLX, nelle quali la modifica dello stato possa avvenire prima dello stadio WB, basterebbe disabilitare tutte le azioni intraprese durante l’esecuzione dell’istruzione I e delle successive, non appena l’interruzione è stata riconosciuta;
• il secondo metodo si potrebbe invece definire “meno sincrono” del precedente, in quanto consiste semplicemente nel servire l’interruzione appena si manifesta, il che ovviamente significa che le interruzioni potrebbero essere servite in ordine diverso rispetto a quello che si avrebbe in assenza di pipeline. Naturalmente, quando si manifesta una interruzione, la pipeline deve essere arrestata immediatamente senza completare nessuna istruzione che debba ancora modificare lo stato.
Le figure seguenti illustrano due interruzioni che si verificano nella pipeline del
DLX, gestite con il secondo approccio:
IF
tempo(cicli di clock)
Istruzione i-3
Istruzione i-2
Istruzione i-1
Istruzione i
Istruzione i+1
Istruzione i+2
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Mancanza di pagina di codice nello stadio IF dell’istruzione i+1
tempo(cicli di clock)
Istruzione i-3
Istruzione i-2
Istruzione i-1
Istruzione i
Istruzione i+1
Istruzione i+2
Istruzione i+3
Istruzione i+4
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF
IF ID EX MEM WB
ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Mancanza di pagina di dati nello stadio MEM dell’istruzione i

Il pipelining (parte I)
aggiornamento: 7 luglio 2001 Autore: Sandro Petrizzelli 49
Nella prima figura è riportata una interruzione corrispondente ad una mancanza di pagina di codice in corrispondenza dello stadio IF dell’istruzione i+1. Nella seconda figura, invece, si verifica una mancanza di pagina di dati nello stadio MEM dell’istruzione i. Gli stadi di pipeline evidenziati ed in grassetto sono quelli in cui le interruzioni vengono riconosciute. Gli stadi di pipeline in corsivo corrispondono invece ad istruzioni che non vengono completate a causa dell’interruzione e dovranno quindi essere ripristinate a servizio completato.
Dato che il primo effetto dell’interruzione si manifesta nello stadio di pipeline che segue quello in cui l’interruzione si è verificata, le istruzioni che si trovano nello stadio WB, nel momento in cui l’interruzione si verifica, vengono comunque completate, mentre invece quelle che non hanno ancora raggiunto lo stadio WB vengono fermate e in seguito ripristinate.
Nel caso dell’interruzione nello stadio IF dell’istruzione i+1, dato che l’interruzione viene servita immediatamente, la pipeline viene arrestata senza completare nessuna istruzione che debba modificare lo stato: si tratta perciò delle istruzioni i-2, i-1, i ed i+1, nell’ipotesi che l’interruzione venga riconosciuta alla fine dello stadio IF dell’istruzione i+1. Una volta servita l’interruzione, la pipeline viene riavviata con l’istruzione i-2. Dal punto di vista del sistema operativo, l’istruzione che ha determinato l’interruzione può essere una qualunque tra i-2 ed i+1 ed è quindi compito dello stesso sistema operativo individuare l’istruzione responsabile: è un procedimento tutto sommato semplice se il tipo di interruzione e lo stadio di pipeline corrispondente sono noti; ad esempio, solo i+1 poterebbe produrre una mancanza di pagina di codice in questo punto, mentre solo i+2 potrebbe produrre una mancanza di pagina di dati.
Riepilogo (dagli appunti)Riepilogo (dagli appunti) A complemento di queste considerazioni, consideriamo una situazione del tutto generale,
rappresentata nella figura seguente:
IF
tempo(cicli di clock)
Istruzione i
Istruzione i+1
Istruzione i+2
Istruzione i+3
Istruzione i+4
Istruzione i+5
1° 2° 3° 4° 5° 6° 7° 8° 9° 10°
IF ID EX MEM WB
ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Supponiamo che sia l’istruzione i-sima a provocare una interruzione e vediamo quali sono
i vari casi possibili (nel caso di interruzioni sincrone):
• se l’interruzione si verifica nello stadio ID dell’istruzione i-sima, essa sarà rilevata nella fase IF dell’istruzione i+4, che si svolge contemporaneamente alla fase WB dell’istruzione i; allora, quando l’interruzione viene rilevata, viene subito servita,

Appunti di “Calcolatori Elettronici” – Capitolo 6
Autore: Sandro Petrizzelli aggiornamento: 7 luglio 2001 50
dopodiché il registro PC viene aggiornato in modo da ripetere per intero l’esecuzione dell’istruzione i e di quelle successive (22);
• se l’interruzione si verifica nello stadio IF dell’istruzione i-sima, viene rilevata nello stadio IF dell’istruzione successiva: in questo caso, dopo aver servito l’interruzione, si potrà riprendere dal valore attuale del PC, dato che esso non è ancora stato incrementato;
• se l’interruzione si verifica nello stadio EX dell’istruzione i-sima, viene rilevata nel ciclo di clock successivo, cioè nella fase IF dell’istruzione i+3; una volta servita l’interruzione, si prenderà PC←PC-8; in questa situazione, è vero che la ALU ha prodotto dei risultati, ma essi sono stati memorizzati in registri temporanei, per cui lo stato della macchina non è stato ancora alterato;
• se l’interruzione si verifica nello stadio MEM dell’istruzione i-sima, la situazione è invece critica: ad esempio, se l’istruzione i-sima è una store, c’è il rischio di modificare la memoria centrale;
• se l’interruzione si verifica nello stadio WB dell’istruzione i-sima, significa che lo stadio MEM della stessa istruzione è stato eseguito e quindi l’interruzione non è ripristinabile.
Autore: Sandro Petrizzelli e-mail: [email protected]
sito personale: http://users.iol.it/sandry
22 L’aggiornamento del registro PC si rende necessario in quanto gli stadi iniziali delle istruzioni successive ad i hanno già provveduto ad incrementare il registro.
















