
1 Introduzione -...
15
Sistema di Trigger e di Acquisizione dati di CMS c 2008 by Antonio Pierro November 3, 2008 1 Introduzione Dal punto di vista del computing, il DAQ di CMS consiste in un grande ambi- ente di calcolo distribuito, con un centinaio di workstation UNIX connessi da reti d’interconnessione ad alta performance (circa 10 Gigabit/secondo per ogni link), progettato in modo da equipaggiare l’esperimento con uno strumento molto affid- abile ed efficiente per la lettura dei dati e la selezione degli eventi. Il DAQ implementa tutto il sistema necessario al trasferimento dei segnali regis- trati dall’esperimento verso le unit` a addette alle loro analisi, includendo meccanismi di filtraggio degli eventi, Trigger, prima dell’archiviazione definitiva su disco. Esso include anche tutta la struttura informatica necessaria per gestire e controllare il funzionamento degli apparati elettronici. Il sistema di acquisizione suddivide l’insieme dei rivelatori in diverse entit` a in- dipendenti: questo permette di acquisire dati in parallelo e effettuare su questi le opportune selezioni, in modo totalmente indipendente le une dalle altre. 2 Il sistema di Trigger in CMS Alla luminosit` a massima nominale di LHC il numero di eventi prodotti sar` a 10 9 eventi al secondo, valore estremamente superiore alle capacit` a di archiviazione delle memorie di massa. ` E proprio in questo contesto che entra in gioco il TRIDAS (sistema di trigger e di acquisizione dati, Trigger and Data Acquisition System) che ha il compito di eseguire la selezione degli eventi interessanti e la riduzione del flusso dati a valori accessibili per le tecnologie oggigiorno disponibili [5]. In dettaglio, il sistema di Trigger e Acquisizione Dati di CMS ` e stato progettato per leggere il rivelatore alla piena frequenza di collisione dei protoni (40 MHz) e per selezionare non pi` u di 100 ”eventi interessanti” al secondo, da registrare su nastro. Il fattore di reiezione 10 5 ` e troppo grande per essere ottenuto in un singolo processo di filtro, soprattutto se si desidera mantenere una buona efficienza di selezione per il programma di fisica di CMS. 1
Transcript of 1 Introduzione -...

Sistema di Trigger e di Acquisizione dati di CMSc©2008 by Antonio Pierro
November 3, 2008
1 Introduzione
Dal punto di vista del computing, il DAQ di CMS consiste in un grande ambi-ente di calcolo distribuito, con un centinaio di workstation UNIX connessi da retid’interconnessione ad alta performance (circa 10 Gigabit/secondo per ogni link),progettato in modo da equipaggiare l’esperimento con uno strumento molto affid-abile ed efficiente per la lettura dei dati e la selezione degli eventi.
Il DAQ implementa tutto il sistema necessario al trasferimento dei segnali regis-trati dall’esperimento verso le unita addette alle loro analisi, includendo meccanismidi filtraggio degli eventi, Trigger, prima dell’archiviazione definitiva su disco. Essoinclude anche tutta la struttura informatica necessaria per gestire e controllare ilfunzionamento degli apparati elettronici.
Il sistema di acquisizione suddivide l’insieme dei rivelatori in diverse entita in-dipendenti: questo permette di acquisire dati in parallelo e effettuare su questi leopportune selezioni, in modo totalmente indipendente le une dalle altre.
2 Il sistema di Trigger in CMS
Alla luminosita massima nominale di LHC il numero di eventi prodotti sara 109
eventi al secondo, valore estremamente superiore alle capacita di archiviazione dellememorie di massa.
E proprio in questo contesto che entra in gioco il TRIDAS (sistema di triggere di acquisizione dati, Trigger and Data Acquisition System) che ha il compito dieseguire la selezione degli eventi interessanti e la riduzione del flusso dati a valoriaccessibili per le tecnologie oggigiorno disponibili [5].
In dettaglio, il sistema di Trigger e Acquisizione Dati di CMS e stato progettatoper leggere il rivelatore alla piena frequenza di collisione dei protoni (40 MHz) e perselezionare non piu di 100 ”eventi interessanti” al secondo, da registrare su nastro.Il fattore di reiezione 105 e troppo grande per essere ottenuto in un singolo processodi filtro, soprattutto se si desidera mantenere una buona efficienza di selezione peril programma di fisica di CMS.
1
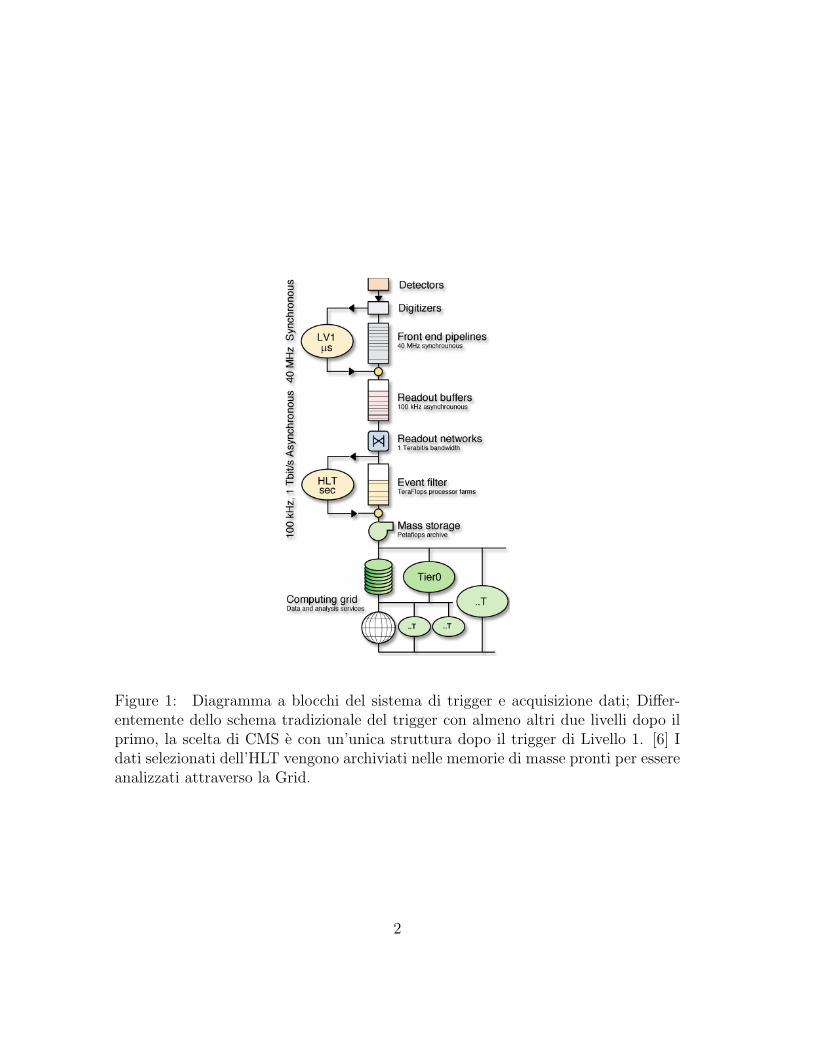
Figure 1: Diagramma a blocchi del sistema di trigger e acquisizione dati; Differ-entemente dello schema tradizionale del trigger con almeno altri due livelli dopo ilprimo, la scelta di CMS e con un’unica struttura dopo il trigger di Livello 1. [6] Idati selezionati dell’HLT vengono archiviati nelle memorie di masse pronti per essereanalizzati attraverso la Grid.
2

Ed e per questo, che il processo completo di selezione e suddiviso in due passaggi(vedi figura1):
• il primo e svolto da un sistema hardware che ha il compito di accettare eventicon un rate che non superi i 100 KHz (Trigger di livello 1 );
• il secondo e svolto da una certo numero di CPU su cui girano un insieme dialgoritmi dedicati all’ulteriore selezione degli eventi forniti dal trigger di livello1 e che costituiscono l’HLT (High Level Trigger ). Solo in questa fase entranoin gioco anche i dati del tracciatore.
In conclusione, il rate finale di eventi selezionati deve essere inferiore a 100 Hzche e la frequenza con cui si registrano definitivamente gli eventi su nastro. Nelseguito viene descritto nel dettaglio l’implementazione dei due sistemi.
3 Il Trigger Hardware o di Livello 1
Dal momento che la frequenza di interazione dei fasci di protoni ad LHC e di circa 40MHz, ovvero un bunch crossing ogni 25 ns, il trigger di primo livello deve analizzareeventi ogni 25 ns. Questo intervallo di tempo e troppo piccolo per leggere dalrivelatore tutta l’informazione completa sull’evento e fornire la decisione del trigger.
Pertanto i dati sono immagazzinati in pipe-line presenti sull’elettronica di front-end per i 3.2 microsecondi successivi all’incrocio dei fasci e solo le informazionifornite dai sottorivelatori piu veloci sono analizzate dall’elettronica di Trigger.
Infine, per evitare quanto piu possibile il tempo morto del rivelatore, l’elettronicadi FrontEnd e a sua volta organizzata in pipe-line cosı da consentire la lettura deidati ogni 25ns. Facendo quindi una stima del tempo necessario per processare i datial trigger L1 e quello necessario allo scambio delle informazioni, ci si aspetta che iltrigger L1 arrivi ad un fattore di riduzione del bunch crossing di 400, e quindi adaccettare un rate di 100 KHz.
Questi vincoli impongono l’utilizzo di algoritmi di selezione molto semplici. In-fatti il fatto che ogni pezzo del processo di selezione non dura piu di 25 ns precludela possibilita di usare algoritmi iterativi.
Ebbene notare come nel trigger di livello 1 vengono utilizzati solo le informazionilocali. In dettaglio, tutti i segnali raccolti dai sensori di un particolare sottorivela-tore, si ottengono senza avere una visione di insieme dei dati acquisiti, cioe senza
3

un’analisi dei dati che tenga conto che tutti i segnali acquisiti da ogni singolo sen-sore del sotto-rivelatore non sono altro che una parte di un unico evento e quindi diun unico processo fisico (compito dell’HLT). In pratica, nel trigger di livello 1, ci silimita semplicemente a identificare, per ogni sensore di un sottorivelatore, gli oggettidi trigger di vario genere (muoni, elettroni, fotoni e jet di varia natura) aventi unimpulso trasverso o energia trasversa superiore ad una soglia prefissata.
In pratica, l’elaborazione dei dati operata dal Trigger di livello 1 e’ completa-mente hardware, ovvero gli algoritmi impiegati per la riduzione del flusso di datisono realizzati mediante reti logiche integrate sui componenti del sistema[1]. Il sis-tema di lettura (read-out) puo memorizzare gli eventi in uscita dal Trigger di livello1.
Solo in seguito, attraverso l’HLT, si decidera se se tenere o rigettare gli eventiassemblati tramite l’Event Builder.
4 Event Builder
Per fornire la connettivita tra il sistema di read-out e i computer della farm (doveviene memorizzato l’evento assemblato ed e fatto il trigger di alto livello), e utilizzatauna rete a commutazione1. Tale rete deve essere in grado di sostenere un flusso didati di circa 1 Tb/s. L’insieme del sistema di read-out e la rete per la connettivitaneccessaria a assemblare l’evento forma un grande ambiente di calcolo distribuito cherappresenta una sfida per le odierne tecnologie di calcolo. Le principali componentidel sistema che permettono di assemblare l’evento sono:
• Front End Driver (FED), (talvolta indicato come DDU, Detector DependentUnit) e il componente piu vicino al rivelatore. Le informazioni provenientida quest’ultimo sono formattate all’interno del FED mediante l’aggiunta aidati di un header2, in cui sono contenute le informazioni necessarie per laricostruzione dell’evento.
• Trasporto dati in superficie (LINK). Le porzioni di evento, event fragments,raccolte da ciascun FED devono essere trasportate in superficie nella count-ing room. Tale collegamento ha una lunghezza dell’ordine di 100 m e deve
1 La rete a commutazione consente lo svolgimento simultaneo di piu comunicazioni fra nodi,massimizzando cosı l’utilizzazione dei mezzi trasmissivi impiegati
2 L’informazione formattata con l’agginta dell’header viene detta event fragment
4

sopportare un flusso di dati ad una velocita media di 200MB/s per porta conpicchi che possono arrivare a 400MB/s per porta(vedi figura [2]). La tecnolo-gia adottata e una soluzione completamente commerciale, vale a dire il linkottico Myrinet3 proposto da Myricom.
Esso ha una larghezza di banda di 2 Gb/s ed include un semplice protocollocon controllo del flusso per evitare la perdita di pacchetti di dati.
• L’ Unita di read-out (Read-out Unit, RU), e composta da tre blocchi: la Read-out Unit Input (RUI), la Readout Unit Memory (RUM) e la Readout UnitOutput (RUO). La RUI riceve le parti di evento dal LINK e le memorizzatemporaneamente in un buffer(FU), a disposizione della RUM. Quest’ultimalegge le parti di evento provenienti dalla RUI e le memorizza, assieme al nu-mero d’identificazione del fascio (bunch-crossing ID). Alla richiesta, da partedell’event builder (v. sotto), di una lettura dati, le parti di evento interessatesono inviate alla RUO.
• Event Builder (vedi figura 4), e composto da due parti: la Builder Unit (BU)e la Filter Unit (FU). La BU assembla le porzioni di evento provenienti dallaRU attraverso una rete chiamata ”Barrel shifter” (vedi figura 6 e 5)
In seguito la BU memorizza l’evento completo in un buffer. La FU e l’elementodove avviene l’HLT. Un Event Manager (EVM) controlla il flusso dell’eventolungo il sistema di lettura e di selezione, gestendo in modo centrale le risorsedi read-out e ricostruzione.
In questo contesto, l’ Event building e la procedura che compone l’evento finale epermette di accedere ai dati il piu rapidamente possibile, assicurandosi che l’eventoe coerente e completo
Riassumnedo, dopo che un evento e stato accettato dal Trigger di Livello 1, unsistema di creazione degli eventi (EventBuilder) ha il compito di leggere da tutti isottorivelatori i dati dell’evento accettato. I dati raccolti (per ogni evento circa 1MByte) vengono passati al trigger di alto livello (HLT). Poiche la frequenza massimadel trigger di primo livello e di 100KHz il sistema di creazione degli eventi deve gestirecirca 100 Gb/s. Per un traffico cosı intenso e necessario un certo numero di sistemi
3 Myrinet e una tecnologia per realizzare reti d’interconnessione ad alta performance utilizzataper creare clusters di workstations o servers. E’ particolarmente adatta per calcoli paralleli stretta-mente connessi, dove sono necessari alti data-rate, basse latenze di trasferimento, e il rilevamentodinamico e l’isolamento dei guasti.
5

Figure 2: Rete di interconnessione che permette la comunicazione contemporaneatra N coppie di unita logiche in un insieme di 2N unita.
6

Figure 3: Diagramma a blocchi del processo di presa dati.[1]
7

paralleli in grado ognuno di gestire un certo numero di eventi al secondo. (per idettagli vedere le figure 2, 5, 6, 4)
Figure 4: L’Event Builder di CMS comprende le unita di read-out ”ROs”, le unitadi builder (builder units - BUs) e un gestore di eventi(EVM), il tutto collegato dauna rete (Builder Network)[1] costituita da cavi aventi una banda di 2 Gb/s ciascuno
5 Il Trigger Software o di Alto Livello
Come detto, tramite l’Event Builder ogni evento viene inoltrato alla farm di com-puter che implementa l’HLT.
L’HLT e realizzato completamente via software. In questa fase di selezione deglieventi si possono utilizzare gli algoritmi di ricostruzione che permettono di ricostruire
8

Figure 5: Schema del traffico dei dati che si ha nel barrel shifter. Nel primointervallo di tempo, solo la sorgente 1 (RU1) manda dati al buffer di destinazione(BU1). Nel secondo intervallo di tempo, la RU1 manda dati alla BU2 mentre laRU2 anda dati alla BU1. Durante l’intevallo di tempo k-esimo la RU1 manda datialla BUk, la RU2 alla BUk−1 e cosı via. Dopo N intervalli di tempo (dove N e ilnumero di sorgenti) tutte le sorgenti avranno mandato scambievolmente dati allerispettive destinazioni [2].
9

Figure 6: Nella seguente figura, si vuole mettere in evidenza come e possibile as-semblare l’evento. Ogni pezzettino avente un determinato colore corrisponde ad un”event fragment”. Pezzettini con lo stesso colore sono event fragment presenti in di-versi sottorivelatori ma appartenenti allo stesso evento. Ogni sottorivelatore contienememorizzati in una coda informazioni corrispondenti ad eventi diversi (pezzettinicon diverso colore). Il processo di ricostruzione dell’evento avviene nel seguentemodo: ogni singolo buffer BU (ognuno con un diverso colore) riceve, con un ordineprogressivo, diversi frammenti (ognuno estratto in maniera ciclica da un diversosottorivelatore) corrispondente allo stesso evento (stesso colore). [1]
10

le tracce o di cercare vertici secondari. L’HLT, al contrario del trigger di primolivello, dispone di tutti i dati di CMS inclusi tracciatore, preshower e risoluzionemassima dei calorimetri. Gli algoritmi di ricostruzione sono sostanzialmente glistessi utilizzati nell’analisi off-line. Nella scelta degli eventi non e tuttavia necessariala stessa precisione richiesta dall’analisi off-line, quindi gli algoritmi di ricostruzionesono modificati in modo da essere piu veloci anche se meno precisi.
Ad esempio per misurare l’impulso di una particella solitamente si utilizzano,durante la ricostruzione della traccia, tutti i punti disponibili nel tracciatore; laricostruzione per l’HLT puo invece essere limitata ai primi N punti.
Il trigger di alto livello passa eventi all’HLT con una frequenza massima di 100KHz: questo tempo e sufficiente a leggere i dati all’elettronica di Front-End di tuttii sottorivelatori e scrivere le informazioni su memoria RAM.
Per abbassare il rate di eventi dell’ulteriore fattore 1000 richiesto, mantenendoun’alta efficienza di selezione per i canali piu interessanti per il programma di fisica,e necessario utilizzare tutte le informazioni del rivelatore, compreso il tracciatore,con la massima risoluzione e granularita ed utilizzare algoritmi di selezione sofisticatiquasi quanto quelli dell’analisi offline.
Da una stima della velocita dei processori che saranno disponibili al momentodell’installazione dell’HLT, si ritiene che siano in media necessari 40 ms per analiz-zare un evento con punte di 1 secondo: questo implica una significativa capacita dibuffering. A differenza di altri esperimenti di fisica delle alte energie l’HLT di CMSe costituito da un solo livello (vedi figura1).
Pur essendo una singola entita l’HLT di CMS utilizza un approccio basato supiu passaggi e gradi di analisi progressivamente piu approfonditi. Dopo ciascunpassaggio, alcuni criteri di selezione possono rigettare una significativa frazione dieventi accettati dal passaggio precedente; in questo modo il rate di eventi che deveessere processato dagli algoritmi rimanenti e ridotto e si ha un conseguente risparmiodi CPU.
I vari passaggi indicati precedentemente vengono convenzionalmente chiamatilivelli di trigger (anche se questa distinzione non fa riferimento a sistemi di triggerfisicamente separati).
Il livello 2 e costituito dagli algoritmi che utilizzano informazioni solo dai calorimetrie dalle camere a muoni: come il trigger di primo livello, ma questa volta con pienagranularita e risoluzione. Il livello 2.5 utilizza un’informazione parziale del traccia-tore, come gli hit negli strati a pixel per fare una veloce distinzione tra gli elettronie i fotoni.
11

(La ricostruzione delle tracce e parziale nel senso che si controllano solo i pixelche stanno nella direzione di volo di particelle gia viste nel trigger L1). In dettaglio:
• Gli Elettroni e fotoni hanno bisogno di una ricostruzione rapida in quantoutilizzati come oggetti di trigger.
• La ricostruzione di elettroni e fotoni parte dall’identificazione di depositi dienergia nei calorimetri EM (fatto tramite algoritmi di clustering).
• La separazione tra elettroni e fotoni e basata sul matching tra tracce (traker)e cluster (calorimetro). Per avere una separazione rapida a livello di triggere possibile utilizzare un set ridotto di informazioni. Ad esempio CMS sfruttail matching con i primi layer del tracker per separare elettroni e fotoni. Glielettroni lasciano tracce del loro passaggio nel rivelatore di tracce e depositi dienergia (spesso molto grandi) nel calorimetro elettromagnetico (EM). I fotoni,come gli elettroni, rilasciano un deposito di energia nel calorimetro elettromag-netico (EM), ma poiche i fotoni sono particelle neutre non generano nessunatraccia nel rivelatore di tracce.
Il livello 3 utilizza la piena informazione da tutto CMS. La strategia esposta puoessere etichettata come ”Reconstruction on demand”: viene raffinata la ricostruzionedegli oggetti solo se necessario e quando il livello di ricostruzione precedente non hagia rigettato l’evento. Un altro perno su cui si basa l’analisi dell’HLT e la ”PartialReconstruction”: la ricostruzione delle tracce nel tracciatore e nelle camere a muonio dei cluster nei calorimetri avviene solo in limitate regioni del rivelatore, comead esempio quelle in cui e indicata la presenza di particelle importate dal Triggerdi primo livello. Tutto questo garantisce un elevato risparmio di CPU, ma puoportare in alcuni casi alla perdita di eventi contenenti ”oggetti interessanti” sfuggitiall’L1-Trigger.
Gli eventi cosı ricostruiti vengono inviati attraverso la rete locale al centro dicalcolo del CERN, che provvede a salvarli temporaneamente su disco e creare unabase di dati di riferimento (basata sul gestore di database ORACLE) per la suc-cessiva ricerca. L’immagazzinamento definitivo delle informazioni (circa 3 TB didati prodotti durante una giornata) viene effettuato su nastri di 120 GB l’uno (nellafigura 3 e schematizzata l’intera catena di presa dati ).
12

6 Conclusione
L’ultimo livello di trigger normalmente agisce sull’evento completo ed oltre ad elim-inare eventi che non soddisfano le richieste di nessuno dei trigger puo suddivideregli eventi accettati nei vari canali di fisica sotto studio.
Il risultato di quest’ultimo filtro permette di immagazzinare i dati su disco onastro etichettati quali candidati di un particolare canale. A questo punto inter-vengono anche dei programmi di monitoraggio on-line che sia controllano il correttofunzionamento dei vari pezzi dell’apparato, sia forniscono un display degli eventi can-didati dei vari canali di fisica sotto studio (per un sottoinsieme di eventi). Inoltreun sottoinsieme di eventi e anche usato per calibrare o controllare la calibrazionedell’apparato.
Naturalmente non c’e una chiara divisione fra il DAQ ed i trigger di livelli elevati.Quello che possiamo dire e che mentre i trigger sono (almeno i livelli piu bassi)hardware, l’acquisizione dati e essenzialmente un processo software. L’acquisizionedati e nota come il processo di raccogliere e calibrare i dati rozzi provenienti dai varipezzi dell’apparato ed immagazzinarli per una successiva analisi offline. I dati rozzivengono riuniti in parti logiche, chiamate eventi, che corrispondono ad una stessainterazione. Anche se una grossolana ricostruzione in osservabili fisiche puo esserefatta dalla DAQ, spesso la ricostruzione degli eventi in osservabili quali impulso,energia, massa, tempo, ecc. e il compito principale dei programmi di ricostruzioneoffline[8].
Nel contesto di CMS il termine Trigger and Data AcQuisition (TDAQ) fa rifer-imento al sistema appena descritto. Oltre ai componenti hardware, il sistema diTDAQ comprende anche una serie di sistemi software , realizzati con lo scopo difornire le funzionalita necessarie alla realizzazione di un sistema di monitoraggio:
L’attivita di supervisione include tutte le operazioni di controllo che si occupanodi verificare costantemente la messa a punto del sistema nelle sue varie componenti,segnalando eventuali malfunzionamenti o inconsistenze nel tempo piu breve possi-bile, cosı da poter immediatamente provvedere alla correzione del difetto. Un mon-itoraggio veloce ed efficiente risulta quindi essenziale nel periodo di acquisizione,quando la qualita dei dati inviati alla memoria di massa deve essere costantementesottoposta a controllo[4].
Col termine sistema di monitoraggio si intende quindi un insieme di applicazionisoftware dedicate alla supervisione sia della qualita dei dati provenienti dal rivela-tore, sia dello stato dell’hardware e del software dell’esperimento. Il monitoraggio
13

dei dati in uscita puo essere effettuato in due modalita distinte: offline e online: ilmonitoraggio offline viene effettuato sui soli eventi memorizzati in memoria perma-nente, mentre quello online viene effettuato analizzando un campione degli eventi inuscita dal rivelatore immediatamente dopo la sua produzione. Questa supervisionein tempo reale quindi risulta essere utile non tanto per la rivelazione di particellesconosciute, quanto per effettuare gli opportuni controlli di calibrazione e di cor-retto funzionamento dei componenti di cui e costituito il rivelatore. Il sistema disupervisione si basa sull’architettura fornita dal framework ROOT[7], una strutturadi supporto che offre un insieme di strumenti utili per la formattazione dei datiricevuti in un formato comune tra i diversi software dedicati al monitoraggio.
References
[1] The TriDAS Project - Technical Design Report, Volume 2: Data Acquisition andHigh-Level Trigger - disponibile al seguente indirizzo: http://cmsdoc.cern.ch/cms/TDR/DAQ/daq.html
[2] The CMS Event Builder - Computing in High-Energy and Nuclear Physics, LaJolla CA USA, March 24-28, 2003
[3] Generic DAQ pictures - disponibile al seguente indirizzo: http://cmsdoc.cern.ch/cms/TDR/DAQ/TDRweb/daqgenericjpg.htm
[4] Data acquisition software for the CMS strip tracker - International Confer-ence on Computing in High Energy and Nuclear Physics (CHEP.07) disponibileal seguente indirizzo: www.iop.org/EJ/article/1742-6596/119/2/022008/
jpconf8_119_022008.pdf
[5] Dott. Giovanni Polese et Prof. Crisostomo Sciacca - Progettazione e sviluppodi un sistema d’acquisizione dati per il controllo e il monitoring dell’apparatosperimentale per il trigger dei muoni di CMS. Universita degli Studi di Napoli”Federico II” - Anno Accademico 2004/05
[6] Corso di Fisica protone-protone a LHC: Dr.ssa Anna Colaleo - Trigger andDAQ. Disponibile al seguente indirizzo: http://didatticait.altervista.
org/Didattica/fisica/fisica_pp_LHC/.
[7] ROOT - An Object Oriented Framework For Large Scale Data Analysis: http://root.cern.ch/
14

[8] La seguente relazione e disponibile al seguente indirizzo: http://didatticait.altervista.org/Didattica/fisica/fisica_pp_LHC/protone_LHC.php.
Updated 27 Dicembre 2008.
15


















