
СОДРЖИНА - IJSkt.ijs.si/pance_panov/Default_files/DiplomaThesis.pdf- 4 - 1. ОСНОВНИ...
81
- 1 - СОДРЖИНА ВОВЕД ................................................................................................................................................. 3 1. ОСНОВНИ ПОИМИ ОД ПОДАТОЧНОТО РУДАРЕЊЕ .................................................... 4 1.1 ВОВЕД ......................................................................................................................................... 4 1.2 ОСНОВНИ ЗАДАЧИ ВО ПОДАТОЧНОТО РУДАРЕЊЕ.......................................................................... 6 2. УЧЕЊЕ НА ПРЕДИКТИВНИ МОДЕЛИ............................................................................... 9 2.1 ВОВЕД ......................................................................................................................................... 9 2.2 УЧЕЊЕ НА ВЕРОЈАТНОСНИ МОДЕЛИ ............................................................................................ 10 2.3 УЧЕЊЕ НА ДРВА ЗА ОДЛУЧУВАЊЕ ............................................................................................... 12 2.3.1 Основен алгоритам за индукција на дрва за одлучување................................................. 12 2.3.2 Перформанси на алгоритмите за учење на дрва за одлучување..................................... 14 2.3.3 Индукција на дрва за одлучување со ID3 ......................................................................... 16 2.3.4 Индукција на дрва на одлучување со C4.5 алгоритам ..................................................... 18 2.3.4.1 Нов критериум за селекција на атрибут при индукција на дрво .............................................. 19 2.3.4.2 Справување со континуални атрибути ..................................................................................... 19 2.3.4.3 Справување со недостаток на вредности на атрибути ............................................................. 20 2.3.4.4 Поткастрување на дрва за одлучување..................................................................................... 20 2.3.4.5 Проценка на грешка ................................................................................................................. 21 2.4 УЧЕЊЕ НА КЛАСИФИКАЦИСКИ ПРАВИЛА .................................................................................... 22 2.4.1 Алгоритам за генерирање на класификациски правила со прекривање .......................... 24 2.4.2 Критериум за избор на услов ........................................................................................... 26 2.4.3 Поткастрување на класификациски правила .................................................................. 27 2.4.4 Incremental Reduced Error Pruning (IREP)........................................................................ 28 2.4.5 Подобрување на IREP алгоритмот – RIPPER алгоритам .............................................. 30 3. ФРЕКВЕНТНИ ЗАПИСИ И АЛГОРИТМИ ЗА НИВНО ГЕНЕРИРАЊЕ........................ 33 3.1 ОСНОВНИ ПОИМИ ЗА ФРЕКВЕНТНИ МНОЖЕСТВА ........................................................................ 33 3.2 ГЕНЕРИРАЊЕ НА ФРЕКВЕНТНИ МНОЖЕСТВА ............................................................................... 36 3.2.1 Простор за пребарување .................................................................................................. 36 3.2.2 База на податоци ............................................................................................................. 37 3.3 АPRIORI АЛГОРИТАМ .................................................................................................................. 38 3.3.1 Опис на Аpriori алгоритамот .......................................................................................... 38 3.3.2 Податочни структури ..................................................................................................... 39 3.3.2.1 Hash – дрво................................................................................................................................ 40 3.3.2.2 Префиксно дрво ........................................................................................................................ 40 4. МОДИФИКАЦИЈА НА АЛГОРИТМИТЕ ЗА УЧЕЊЕ НА ПРЕДИКТИВНИ МОДЕЛИ ОД СУМАРНИ ПОДАТОЦИ .......................................................................................................... 42
Transcript of СОДРЖИНА - IJSkt.ijs.si/pance_panov/Default_files/DiplomaThesis.pdf- 4 - 1. ОСНОВНИ...

- 1 -
СОДРЖИНА
ВОВЕД .................................................................................................................................................3
1. ОСНОВНИ ПОИМИ ОД ПОДАТОЧНОТО РУДАРЕЊЕ ....................................................4
1.1 ВОВЕД .........................................................................................................................................4 1.2 ОСНОВНИ ЗАДАЧИ ВО ПОДАТОЧНОТО РУДАРЕЊЕ..........................................................................6
2. УЧЕЊЕ НА ПРЕДИКТИВНИ МОДЕЛИ...............................................................................9
2.1 ВОВЕД .........................................................................................................................................9 2.2 УЧЕЊЕ НА ВЕРОЈАТНОСНИ МОДЕЛИ ............................................................................................ 10 2.3 УЧЕЊЕ НА ДРВА ЗА ОДЛУЧУВАЊЕ ............................................................................................... 12
2.3.1 Основен алгоритам за индукција на дрва за одлучување................................................. 12 2.3.2 Перформанси на алгоритмите за учење на дрва за одлучување..................................... 14 2.3.3 Индукција на дрва за одлучување со ID3 ......................................................................... 16 2.3.4 Индукција на дрва на одлучување со C4.5 алгоритам ..................................................... 18
2.3.4.1 Нов критериум за селекција на атрибут при индукција на дрво ..............................................19 2.3.4.2 Справување со континуални атрибути.....................................................................................19 2.3.4.3 Справување со недостаток на вредности на атрибути .............................................................20 2.3.4.4 Поткастрување на дрва за одлучување.....................................................................................20 2.3.4.5 Проценка на грешка .................................................................................................................21
2.4 УЧЕЊЕ НА КЛАСИФИКАЦИСКИ ПРАВИЛА .................................................................................... 22 2.4.1 Алгоритам за генерирање на класификациски правила со прекривање .......................... 24 2.4.2 Критериум за избор на услов ........................................................................................... 26 2.4.3 Поткастрување на класификациски правила .................................................................. 27 2.4.4 Incremental Reduced Error Pruning (IREP)........................................................................ 28 2.4.5 Подобрување на IREP алгоритмот – RIPPER алгоритам .............................................. 30
3. ФРЕКВЕНТНИ ЗАПИСИ И АЛГОРИТМИ ЗА НИВНО ГЕНЕРИРАЊЕ........................ 33
3.1 ОСНОВНИ ПОИМИ ЗА ФРЕКВЕНТНИ МНОЖЕСТВА ........................................................................ 33 3.2 ГЕНЕРИРАЊЕ НА ФРЕКВЕНТНИ МНОЖЕСТВА ............................................................................... 36
3.2.1 Простор за пребарување.................................................................................................. 36 3.2.2 База на податоци ............................................................................................................. 37
3.3 АPRIORI АЛГОРИТАМ .................................................................................................................. 38 3.3.1 Опис на Аpriori алгоритамот .......................................................................................... 38 3.3.2 Податочни структури ..................................................................................................... 39
3.3.2.1 Hash – дрво................................................................................................................................40 3.3.2.2 Префиксно дрво ........................................................................................................................40
4. МОДИФИКАЦИЈА НА АЛГОРИТМИТЕ ЗА УЧЕЊЕ НА ПРЕДИКТИВНИ МОДЕЛИ
ОД СУМАРНИ ПОДАТОЦИ .......................................................................................................... 42

- 2 -
4.1 МОТИВАЦИЈА............................................................................................................................. 42 4.2 МОДИФИКАЦИЈА НА АЛГОРИТМОТ ЗА УЧЕЊЕ НА ВЕРОЈАТНОСНИ МОДЕЛИ .................................. 42 4.3 МОДИФИКАЦИЈА НА АЛГОРИТМОТ ЗА УЧЕЊЕ НА ДРВА ЗА ОДЛУЧУВАЊЕ ..................................... 44 4.4 МОДИФИКАЦИЈА НА АЛГОРИТМОТ ЗА УЧЕЊЕ НА КЛАСИФИКАЦИСКИ ПРАВИЛА........................... 45
5. ИМПЛЕМЕНТАЦИЈА НА АЛГОРИТМИТЕ ЗА УЧЕЊЕ НА ПРЕДИКТИВНИ
МОДЕЛИ ОД СУМАРНИ ПОДАТОЦИ........................................................................................ 47
5.1 WEKA – WAIAKATO ENVIROMENT FOR KNOWLEDGE ANALYSIS ................................................. 47 5.2 ОСНОВНИ КОМПОНЕНТИ ВО WEKA СИСТЕМОТ .......................................................................... 48
5.2.1 weka.core пакет ................................................................................................................ 48 5.2.2 weka.classifiers пакет........................................................................................................ 49 5.2.3 Други пакети во WEKA системот ................................................................................... 50
5.3 ИПЛЕМЕНТАЦИЈА НА APRIORI АЛГОРИТАМ................................................................................. 50 5.3.1 Класа ItemSet..................................................................................................................... 50 5.3.2 Класа FrequentItemsets...................................................................................................... 51
5.4 ИМПЛЕМЕНТАЦИЈА НА АЛГОРИТМОТ ЗА УЧЕЊЕ НА ВЕРОЈАТНОСНИ МОДЕЛИ .............................. 54 5.4.1 Класа NaiveBayes .............................................................................................................. 54
5.5 ИМПЛЕМЕНТАЦИЈА НА АЛГОРИТМОТ ЗА УЧЕЊЕ НА ДРВА ЗА ОДЛУЧУВАЊЕ.................................. 56 5.5.1 Класа Ј48........................................................................................................................... 57 5.5.2 Класа ClassifierTree .......................................................................................................... 58 5.5.3 Апстрактна класа ModelSelection и класа C45ModelSelection ........................................ 59 5.5.4 Апстрактна класа ClassifierSplitModel и класа C45Split................................................ 60 5.5.5 Класа Distribution ............................................................................................................. 63 5.5.6 Класи InfoGainSplitCrit и GainRatioSplitCrit..................................................................... 66
5.6 ИМПЛЕМЕНТАЦИЈА НА АЛГОРИТМОТ ЗА УЧЕЊЕ НА ПРАВИЛА ЗА ОДЛУЧУВАЊЕ ........................... 67 5.6.1 Класа JRip ......................................................................................................................... 67 5.6.2 Апстрактна класа Antd и класа NominalAntd.................................................................. 69 5.6.3 Апстрактна класа Rule и класа RipperRule ..................................................................... 71
6. ТЕСТИРАЊЕ И ЕВАЛУАЦИЈА НА АЛГОРИТМИТЕ ..................................................... 72
6.1 ЕВАЛУАЦИЈА НА АЛГОРИТМИТЕ ЗА УЧЕЊЕ ................................................................................. 72 6.2 ПРИМЕР ..................................................................................................................................... 74
6.2.1 Опис на множеството податоци.................................................................................... 74 6.2.2 NaiveBayes......................................................................................................................... 75 6.2.3 J48 ..................................................................................................................................... 76 6.2.4 JRIP................................................................................................................................... 78
ЗАКЛУЧОК....................................................................................................................................... 80
КОРИСТЕНА ЛИТЕРАТУРА......................................................................................................... 81

- 3 -
ВОВЕД
Количеството на податоци во сите области од општественото живеење се
зголемува двојно скоро секоја година, на сметка на корисната информација што ја
има сé помалку. За справување со овој проблем во последниве десет години е
развиена мултидисциплинарна област наречена податочно рударење, чија основна
задача е откривање на корисни информации од големи колчества на податоци.
Податочното рударење израсна во важна истражувачка област, што има големи
потенцијали и во реалниот живот за решавање на практични проблеми.
Машинското учење ги дефинира техничките основи на податочното рударење. Се
користи за извлекување на информации од бази на потатоци. Информацијата
добиена со алгоритмите за машинско учење се претставува во разбирлива форма и
може да се користи за разни цели.
Целта на оваа дипломска работа е да се разгледаат основните алгоритми за учење
на предиктивни модели и да се дефинираат модификации на основните алгоритми
за учење на предиктивни модели од сумарни податоци. Сумарните податоци во
овој случај опфаќаат користење на информацијата од фреквентните записи
(frequent itemsets) за пресметка на дистрибуцијата на веројатност кај моделите.
Дипломската работа концептуално е поделена во повеќе поглавја. Во поглавјето 1
се дадени основни поими од податочното рударење и терминологијата која ќе се
користи во останатиот дел од дипломската работа. Поглавјето 2 ги содржи
описите на основните алгоритми за учење на предиктивни модели. Во поглавјето
3 се дадени дефиниции на фреквентните записи и начините за нивно добивање.
Поглавијата 4, 5 и 6 ги опишуваат модификација, имплементација, тестирање и
споредба на алгоритмите.

- 4 -
1. ОСНОВНИ ПОИМИ ОД ПОДАТОЧНОТО РУДАРЕЊЕ
1.1 Вовед
Современите технологии во науката го прават лесно собирањето на податоци, но,
анализата на податоци е многу бавна и скапа операција.
Дефиниција 1.1 Откривањето на знаење од база на податоци (Knowledge
Discovery in Databases – KDD) е процес на идентификација на валидни, нови и
потенцијално корисни и разбирливи шеми во податоците.1
Дефиниција 1.2 Податочното рударење (Data Mining) e чекор во еден KDD
процес кој користи компјутерски техники (алгоритми за податочно рударење
имплементирани како компјутерски програми) за откривање на шеми во
податоците.
Мотивацијата за откривање на знаење од базите на податоци доаѓа од
претпоставката дека можеби постојат корисни информации кои се кријат во
масата на неанализирани подтатоци и според тоа се потребни полуавтоматски
методи за лоцирање на интересни информации од податоците. Откриеното знаење
може да бидат правила кои ги опишуваат карактеристиките на податоците, шеми
кои се појавуваат често (frequently occuring patterns), кластери на објекти и сл.
Еден KDD процес се состои од следниве пет чекори:
• Селекција: податоците што се користат во процесот на податочно
рударење можат да се добијат од многу различни и хетерогени податочни
извори. Првиот чекор ги собира податоците од различни бази на податоци,
датотеки и други неелектронски извори.
• Предпроцесирање: податоците што се користат од процесот може да
содржат неточни вредности или пак да недостасуваат вредности на
податоците. Може да постојат податоци од повеќе извори и тие да се
базираат на различна метрика. Во овој чекор се изведуваат различни
активности, грешните податоци мораат да се корегираат или отстранат, а
податоците што недостигаат мораат да се дополнат или да се претпостават.
1 Дефиницијата е превземена од: U.Fayyad, G.Piatetsky-Shapiro and P.Smyth. From data mining to
knowledge discovery – An overview, Advances in KD and DM, MIT Press, Cambrige, MA, 1991

- 5 -
• Трансформација: податоците од различни извори мора да се конвертираат
во соодветен формат за процесирање. Некои од податоците можат да се
кодираат или трансформираат во покорисен формат. За да се намали бројот
на можни вредности на податоците може да се изврши редукцијата на
податоци.
• Податочно рударење: врз основа на задачата која се реализира, во овој
чекор се применуваат алгоритми врз трансформираните податоци за да се
добијат саканите шеми од податоците.
• Интерпретација/евалуација: начинот на кој резултатите се прикажуваат
на крајниот корисник е екстремно важно бидејќи од тоа зависи корисноста
на резултатите. Во овој чекор се користат различни стратегии за
визуелизација на добиените шеми.
На слика 1-1 е прикажан тек на еден KDD процес, чии чекори се опишани погоре
во текстот.
Слика 1-1. KDD процес
Податочното рударење вклучува различни алгоритми за решавање на различни
видови проблеми. Сите овие алгоритми се обидуваат да ги нагодат параметрите
на моделот според самите податоци. Алгоритмите ги испитуваат податоците и го
определуваат моделот што е најблизок до карактеристиките на податоците кои се
испитуваат. Влез во еден алгоритам за податочно рударење е табела која се состои
од одреден број на атрибути (колони) и записи (редици). Излез од алгоритамот е
шаблон (pattern) или множество од шаблони што се валидни за дадените
податоци. Шаблон се дефинира како исказ (израз) од даден јазик, што ги опишува
фактите на подмножество од дадените податоци и е поедноставна од обично
набројување на сите факти од подмножеството. Типични шаблони кои се користат
се: равенки (equations); класификациски и регресиски дрва (trees); и асоцијациски,
класификациски и регресиски правила (rules).
Повеќето од алгоритмите за податочно рударење доаѓаат од машинското учење и
статистиката. Алгоритмите за машинско учење изведуваат пребарување

- 6 -
(хеуристичко) врз простор од хипотези (шаблони) кои ги објаснуваат (важат за)
дадените податоци. Според претходното, алгоритмите за податочно рударење
вршат пребарување врз множеството од шаблони за интересни шаблони кои се
валидни за дадените податоци.
Моделот на податоците во еден алгоритам може да биде предиктивен или
дескриптивен како што е прикажано на слика 1.2. На сликата се прикажани и
најчестите задачи од податочното рударење кои го користат соодветниот модел.
Слика 1-2 Модели и задачи на податочното рударење
Предиктивниот модел прави предикција за вредностите на податоците со
користење на познати резултати откриени од разлчни податоци. Предиктивното
моделирање може да се направи со користење на други историски податоци.
Ваквото моделирање вклучува класификација, регресија, анализа на временски
серии и предикција. Предикцијата, исто така може да се користи да се индицира
специфичен тип на функција на податочното рударење.
Дескриптивниот модел врши идентификација на шаблони или врски меѓу
податоците. За разлика од предиктивниот модел, дескриптивниот модел се
користи за истржување на карактеристиките на податоците а не за предикција на
нови карактеристики. Ваквото моделирање опфаќа кластерирање, сумирање,
изведување на асоцијациски правила и откривање на секвенци.
1.2 Основни задачи во податочното рударење
Класификацијата врши пресликување на податоците во предефинирани групи
или класи. Обично за неа се вели дека претставува учење со надзор (supervised
learning), бидејќи класите се определени пред да се истражуваат податоците.
Алгоритмите за класификација бараат класите да бидат дефинирани врз основа на

- 7 -
вредностите на атрибутите од податоците. Вообичаено класите се опишуваат со
набљудување на карактеристични податоци што веќе припаѓаат на одредени
класи. Препознавањето на облици е вид на класификација каде влезниот облик се
класифицира во една од неколкуте класи, врз основа на сличност со веќе
предефинираните класи.
Регресијата се користи за пресликување на податоците во реална предиктивна
променлива. Регресијата вклучува учење на функцијата што го врши
пресликувањето. Таа претпоставува дека податоците се опишуваат со некаков тип
на функција (линеарна, логистичка итн.) и потоа се определува функцијата што
најдобро ги моделира дадените податоци.
Анализата на временски серии ја опфаќа анализата на вредноста на атрибутот
во тек на време. Вредностите обично се добиваат во еднакво оддалечени
временски интервали. За визуелизација на временските серии се користат
графици. Врз временските серии се изведуваат три основни функции. Прво, се
користат мерки за растојание за да се одреди сличноста меѓу различните
временски серии. Потоа, се испитува структурата на линијата за да се одреди
нејзиното поведение. Третата функција би била да се искористат историските
временски серии за предикција на идни вредности.
Предикцијата може да се гледа како вид на класификација. Разликата се состои
во тоа што предикцијата предвидува идна состојба, за разлика од класификацијата
која предвидува сегашна (тековна) состојба. Апликациите за предикција
вклучуваат препознавање на говор, машинско учење и препознавање на облици.
Кластерирањето е слично со класификацијата со исклучок на тоа што групите не
се преддефинирани туку се дефинираат со самите податоци. За кластерирањето
обично се вели дека е учење без надзор. Алгоритмите за кластерирање вршат
сегментација на податоците во групи што можат или не мораат да се исклучуваат
меѓусебно. Кластерирањето обично се изведува со определување на сличности
меѓу податоците со преддефинирани атрибути. Најсличните податоци според
некаков критериум се групираат во кластери. Бидејќи кластерите не се
преддефинирани, потребна е помош од доменски експерт за толкување на
значењето на добиените кластери.
Сумирањето врши пресликување на податоци во подмножества со едноставни
описи. Ова всушност претставува генерализација на податоците. Сумирањето
врши извлекување на корисни и репрезентативни информации за базата на

- 8 -
податоци. Тоа може да се изведе со извлекување на делови од податоци или со
изведување на сумарни информации од податоците.
Асоцијациското правило е модел што определува специфичен тип асоцијации
меѓу податоците. Овој модел врши откривање на поврзаноста меѓу самите
податоци во базата на податоци.
Откривањето на секвенци се користи за да се одредат секвентни облици во
податоците. Овие облици се базираат на временска секвенца на акции. Облиците
се слични на асоцијациите на податоците, но поврзаноста се базира на време.

- 9 -
2. УЧЕЊЕ НА ПРЕДИКТИВНИ МОДЕЛИ
2.1 Вовед
Дефиниција 2.1. Нека е дадена база на податоци { }ntttD ,...,, 21= составена од
записи и множество на класи { }mCCC ,..,1= . Проблемот на класификација е да се
дефинира пресликување CDf →: каде секој запис it се доделува на една класа.
Класата jC ги содржи точно оние записи кои се пресликуваат во неа, т.е
( ){ }DtniCtftC ijiij ∈≤≤== ,1, .
Претходно дадената дефиниција ја гледа класификацијата како пресликување од
базата на податоци во множеството на класи. Класите се претходно дефинирани,
не се преклопуваат и ја делат целата база на податоци на области. Секоја област
претставува точно една класа. Секоја запис од базата на податоци се доделува
точно на една класа.
Проблемот на класификација всушност се имплементра во две фази и тоа:
1. Се креира конкретен модел со евалуација на податоците за обучување
(training data). Оваа фаза на влез ги има податоците за обучување, а на
излез ја дава дефиницијата на моделот. Креираниот модел ги класифицира
податоците за обучување што е можно поточно.
2. Се применува моделот креиран во фаза 1 во класификацијата на записи од
база на податоци чија класа не е позната.
Постојат три основни методи што се користат за решавање на проблеми на
класификација:
• Спецификација на граници на области. Класификацијата се изведува со
поделба на влезниот простор на потенцијалните записи од базата во
области, каде секоја област се поврзува само со една класа.
• Користење распределби на веројатност. За секоја дадена класа jC ,
( )ji CtP е функција на распределба на веројатноста за секоја класа за еден
запис it . Ако веројатноста на појавување на секоја класа ( )jCP е позната,

- 10 -
тогаш ( ) ( )jij CtPCP се користи за проценка на веројатноста дека it припаѓа
на класата jC .
• Користење на апостериорна веројатност. Ако е дадена вредноста на
податокот it , би сакале да ја определиме веројатноста дека it е во класата
jC . Ова се означува со ( )ij tCP и се нарекува апостериорна веројатност.
Еден пристап при класификацијата е да се определи апостериорната
веројатност за секоја класа и тогаш да се додели it на онаа класа со
најголема веројатност.
2.2 Учење на веројатносни модели
Во овој дел ќе биде разгледано учењето на веројатносни модели и поконкретно
Баесовата класификација. Баесовата класификација се базира врз Баесовата
теорема дадена со равенството (2.1)
( ) ( ) ( )( )
||
P X H P HP H X
P X= (2.1)
каде што ( )P X е веројатноста на Х, а ( )|P X H е условната веројатност на Х ако
е познато H. Оваа теорема се користи за проценка на веројатноста примерокот од
базата да припаѓа на секоја од можните класи при решавање на проблем од
класификација.
Примерок од базата ( )1,..., nX x x= се претставува како коњункција на услови
( )i iA x= за секој од n – те атрибути iA . Нека постојат m класи, и нека H е
дефинирано врз множеството , 1,...,j jC C c j m≡ = = , каде С е класата а jc е
можната вредност на класата. Баесовиот класификатор ќе му ја додели на новиот
примерок онаа вредност на класата kc што ја максимизира веројатноста
( )|kP C X т.е ( ) ( )| | , 1,...,k jP C X P C X j m≥ = . Според Баесовата теорема,
( ) ( ) ( )( )
|| j j
j
P X C P CP C X
P X= . Бидејќи ( )P X е константно за сите класи, потребно
е само да се максимизира веројатноста ( ) ( )| j jP X C P C .

- 11 -
Главната претпоставка на наивниот Баесов класификатор е тоа што класите мора
меѓусебно да бидат условно независни (ако е дадена вредноста на класата,
атрибутите треба да бидат независни меѓусебе). Ова доведува членот ( )|jP C X
да се замени со производ од веројатности ( )|i i ji
P A x C=∏ . За разлика од
условната веројатност ( )| jP X C , индивидуалните условни веројатности
( )|i i jP A x C= можат лесно да се проценат од податоците за обучување на
моделот. Истото важи и за класните веројатности ( )jP C .
Учењето на наивниот Баесов класификатор се состои од проценка на априорните
веројатности ( ) ( )j jP C P C c= = и ( )|i ik kP A v C= за секоја од можните вредности
jc на класата С и секоја од вредностиите на атрибутите ikv за секој од атрибутите
iA . ( )jP C се проценува со броење на бројот на примероци ( )j jn N c= на класата
jc и делење со вкупниот број на податоци за обучување т.е ( ) jj
nP C
n= .
( )|i ik kP A v C= може да се процени како ( )i ik jN A v C c= ∧ = поделено со
( )jN C c= т.е ( ) ( )( )
| i ik ji ik k
j
N A v C cP A v C
N C c
= ∧ == =
=.
Претходно опишаната постапка за проценка на веројатности се базира на
релативната фреквенцијата на примероците, што резултира во неточна проценка
на веројатноста во случаите кога имаме мал број на примероци. Во тој случај е
пожелно да се користат други методи за проценка на веројатноста како што се
Лапласовата проценка и m – проценката.
Лапласовата проценка на веројатноста е дадена со равенството (2.2)
( ) ( )( )
, 1| j i
j ii
N C AP C A
N A k+
=+
(2.2)
каде k е бројот на можните класи.
m – проценката предвид ги зема и априорните веројатности и воведува параметар
на методот m. Колку параметарот на методот е поголем, толку помалку им
веруваме на податоците за обучување на моделот. Равенството (2.3) ја дава
проценката на веројатноста со помош на овој метод

- 12 -
( ) ( ) ( )( )
,| j i j
j ii
N C A m P CP C A
N A m+ ×
=+
(2.3)
каде априорната веројатност се пресметува со Лапласова проценка дадена со
равенство (2.4)
( ) ( ) 1, 1..j
j
N CP C j k
N k+
= =+
(2.4)
Наивниот Баесов класификатор може да се разгледува како дескриптивен и
предиктивен тип на алгоритам. Веројатностите се дескриптивни и се користат за
предикција на припадност на одредена класа на дадена торка од базата.
Наивниот Баесов класификатор има неколку предности. Прво, тој е многу лесен за
користење. Второ, за разлика од другите пристапи за класификација потребно е
само едно поминување на податоците за обучување. Овој пристап многу лесно се
справува со вредности што недостигаат со нивно едноставно испуштање при
пресметката на веројатноста. Во случаите кога постојат едноставни релации меѓу
атрибутите оваа техника за класификација дава добри резулатати.
Иако овој пристап е многу едноставен, не секогаш можат да се добијат
задоволителни резултати. Прво, атрибутите во реалниот свет обично не се
независни и затоа би можеле да користиме само одредено подмножество на
атрибути што би биле независни меѓу себе. Понатаму овој пристап не може да се
справи со континуални податоци туку само со дискретни. За решавање на овој
проблем се користат различни методи како што се дискретизацијата на
континуалната променлива или проценка на веројатноста на континуалната
променлива со помош на Гаусова распределба и сл. Сите овие модификации
понатаму влијаат на резулататите и затоа е најдобро методата да се користи врз
дискретни податоци.
2.3 Учење на дрва за одлучување
2.3.1 Основен алгоритам за индукција на дрва за одлучување
Дефиниција 2.2. Нека е дадена база на податоци { }ntttD ,...,, 21= каде
1,...,i i iht t t= и шемата на базата на податоци ги содржи следниве атрибути

- 13 -
{ }1 2, ,..., hA A A . Нека е дадено и множеството на класи { }mCCC ,..,1= . Дрво на
одлучување (Decision Tree – DT) или класификациско дрво е дрво поврзано со
D, што ги има следниве својства:
• Секој внатрешен јазел се означува со атрибут iA .
• Секоја гранка се означува со предикат што може да се примени врз
атрибутот поврзан со родителот.
• Секој лист се означува со класа jC .
Решавањето на проблемот на класификација со користење на дрва на одлучување
е процес кој се изведува во две фази:
1. Индукција на дрва на одлучување: Конструкција на дрво на
одлучување со користење на податоци за обучување.
2. За секој запис it D∈ , се применува дрвото за одлучување да се одреди
припадноста на одредена класа.
Врз основа на дефиницијата 2.1 на проблемот на класификација, конструираното
дрво ја претставува потребната логика за извршување на пресликувањето.
Постојат многу предности за употреба на дрва на одлучување за класификација.
Тие се ефикасни и се лесни за употреба. Може да се генерираат правила кои се
лесни за интерпретација и разбирање. Тие одговараат добро и за големи бази на
податоци бидејќи големината на дрвото е независна од големината на базата.
Секоја торка мора да се помине низ дрвото. За ова е потребно време
пропорционално на висината на дрвото, која е фиксна. Дрва може да се
конструираат за податоци со многу атрибути.
Кај дрвата на одлучување постојат и негативности. Прво, тие не се справуваат
лесно со континуални податоци. Домените на ваквите атрибути мора да се
поделат во категории кои понатаму треба да се опфатат во алгоритмите.
Пристапот кој се користи во овој случај е да се подели доменскиот простор во
правоаголни региони. Понатаму, тешко се решава проблемот на недостаток на
одредени податоци бидејќи во тој случај не може да се одреди точната гранка по
која би се движеле по дрвото. Бидејќи дрвото се конструира од податоци за
обучување може да настане претерано нагодување. Ова може да се надмине со
поткастрување на дрвото (tree pruning). Во процесот на индукција на дрвото на
одлучување се игнорираат корелациите меѓу атрибутите во базата.

- 14 -
Постојат повеќе алгоритми за учење на дрва за одлучување. Еден таков
симлифициран алгоритам ќе биде разгледан подолу.
Алгоритам 2.1 Влез: D // Податоци за обучување Излез: Т // Дрво за одлучување ГрадиДрво алгоритам T=0; Определи го најдобриот критериум за поделба; Т=Креирај коренов јазол и означи го со атрибутот за поделба; Т=Додај гранка на кореновиот јазол за секој предикат за поделба и означи; За секоја гранка { D=База креирана по примена на предикатот за поделба врз D; Ако по оваа патека сме стигнале до крај тогаш Т’=Креирај лист и означи го со соодветната класа; Инаку Т’=ГрадиДрво(D); T=Додади го Т’ на гранката; }
2.3.2 Перформанси на алгоритмите за учење на дрва за одлучување
Најважните фактори што влијаат во перформансите на алгоритмите за градење на
дрва за одлучување се големината на множеството за обучување и начинот како
се определува најдобриот атрибут за поделба. Кај повеќето алгоритми се
опфатени следниве прашања:
• Избор на атрибут за поделба: Врз основа на тоа кои атрибути ќе бидат
избрани како атрибути за поделба ќе има влијание врз перформансите при
примената на креираното дрво врз нови податоци. Некои атрибути се
подобри за поделба од други атрибути. Изборот на добар атрибут вклучува
не само испитување на податоците од множеството за обучување туку и
погодни информации од доменскиот експерт.
• Редослед на атрибутите за поделба: Редоследот по кој се избираат
атрибутите, исто така е битно прашање бидејќи од тоа зависи големината

- 15 -
на дрвото и со добар редослед на атрибутите може да се намалат
непотребните споредувања при евалуацијата на моделот.
• Поделби: Со претходното прашање е поврзано колку точно поделби да се
направат. Кај некои атрибути, доменот е мал, така да бројот на поделби
очигледно се базира врз изгледот на доменот. Ако доменот е континуален
или има голем број на вредности, не е лесно да се определи бројот на
поделби кои би се користел во алгоритмот.
• Структура на дрвото: За да се зголемат перформансите на примената на
дрвото за класификација, пожелно е да се користи балансирано дрво со
што помалку нивоа. Во овој случај потребни се покомплексни споредби со
повеќенасочно гранење. Некои од алгоритмите користат само бинарни
дрва.
• Критериум за запирање: Креирањето на дрвото дефинитивно запира кога
податоците за обучување се совршено класифицирани. Може да постојат
ситуации кога е пожелно порано запирање на индукцијата за да се избегне
креирањето на големи дрва. Ова е еден компромис меѓу точноста на
класификацијата и перформансите. Може да се изведе предвременото
запирање на индукцијата за да се избегне претераното нагодување
(overfitting) на дрвото.
• Податоци за обучување: Структурата на дрвото за одлучување зависи од
од податоците за обучување. Ако множеството за обучување е премногу
мало, тогаш генерираното дрво може да не биде доволно специфично за да
работи добро со поопшти податоци. Ако множеството на податоци за
обучување е премногу големо, тогаш креираното дрво ќе биде
пренатрупано.
• Поткастрување: Откога дрвото е веќе креирано, потребни се
модификации на дрвото за да се подобрат перформансите на дрвото во
текот на фазата на класификација. Фазата на поткастрување може да ги
отстрани редундантните споредби или да отстрани одредени поддрва за да
постигне подобри перформанси.
Изгледот на дрвото на одлучување исклучително зависи од податоците за
обучување и алгоритмот за индукција на дрвото. Пожелно е да се добие дрво кое

- 16 -
работи добро врз податоците за обучување. Некои од алгоритмите креираат само
бинарни дрва. Овие дрва се лесни за индукција, ама тие имаат тенденција да
имаат поголема длабочина. Перформансите на ваквите дрва можат да бидат
полоши бидејќи обично е потребен поголем број на споредби. Глобално гледано,
овие споредби се сепак поедноставни од повеќенасочното гранење така да
вкупните преформанси на бинарните дрва се споредливи со останатите.
Алгоритмите за индукција на дрвата за одлучување можат да го изградат дрвото и
потоа да извршат негово поткастрување за класификацијата да биде поефикасна.
Со техниките на поткастрување, делови од дрвото можат да се отстранат или да се
комбинираат за да се редуцира вкупната големина на дрвото. Поткаструвањето
може да се изведува додека се креира дрвото, со тоа да се избегне дрвото да стане
премногу големо, или вториот пристап е да се поткастри дрвото по градењето.
Временската и просторна комплексност на алгоритмите за индукција на дрва за
одлучување зависи од големината на податоците за обучување q, бројот на
атрибути h и обликот на креираното дрво. Во најлош случај, дрвото може да биде
многу длабоко и да не е многу разгрането. Додека се гради дрвото, за секој од
јазлите, секој атрибут ќе биде испитан за да се определи дали е најдобар. Тоа
доведува временската комплексност на дрвото на дрвото да биде О ( )loghq q .
Времето што е потребно да се класифицира база со големина n се базира на
висината на дрвото. Ако се претпостави висина на дрвото О( )log q , тогаш
комплексноста е О ( )logn q .
Понатаму ќе бидат разгледани некои од постојните алгоритми за градење на дрва
за одлучување.
2.3.3 Индукција на дрва за одлучување со ID3
Еден пристап при индукцијата на дрва за одлучување е да се генерираат сите
можни дрва што точно го класифицираат множеството за обучување и потоа да се
избере наједноставното од нив. Бројот на такви дрва е конечен, но е многу голем,
така да ваквиот пристап би бил корисен само во случаевите кога имаме мали дрва
за одлучување. ID3 [Quinlan 79] алгоритамот е дизаниран со цел да помогне во
случаите кога постојат многу атрибути и множеството за обучување содржи
многу торки и кога е потребно да се добие разумно добро дрво за одлучување без

- 17 -
многу големо пресметување. Тој конструира едноставни дрва за одлучување, но
пристапот што го користи не гарантира дека не постојат и други дрва за
одлучување кои се подобри.
За потребите на ID3 алгоритамот била развиена хеуристика која користи поими и
релации од теорија на информации (ентропија и информациона добивка), со чија
помош се одлучува како да се подели влезното множество од торки во секоја фаза
од процесот на индукција на дрвото и со тоа се овозможува да се конструираат
помали и поефикасни дрва за одлучување.
ID3 алгоритамот работи на следниов начин: нека претпоставиме дека торките од
базата припаѓаат само на две класи т.е D PE NE= ∪ , каде PE е множеството од
позитивни примероци и NE е множеството од негативни примероци, p PE= и
n NE= . Торката од базата t припаѓа во множеството PE со веројатност
( ) pP t PEp n
∈ =+
и во множеството NE со веројатност ( ) nP t NEp n
∈ =+
. Со
користење на хеуристика од теоријата на информации, дрвото на одлучување се
смета како извор на пораки ,,PE” или ,,NE”, каде очекуваното количество на
информација што е потребно да се генерира пораката е дадено со релацијата (2.5)
( ) 2 2log log ,кога 0; 0,
0,друго
p p n n p np n p n p n p nI p n
− − ≠ ≠ + + + +=
(2.5)
Ако се користи атрибутот А со домен на вредности { }1,..., Nv v како корен на
дрвото за одлучување, ќе се изврши поделба на D во подмножества { }1,..., ND D
каде iD ги содржи оние торки од D чија вредност на атрибутот А е iv . Нека iD
содржи ip торки од PE и in торки од NE. Очекуваното количество на информација
што е потребно за поддрвото на iD e ( ),i iI p n . Очекуваното количество на
информација за дрвото чиј корен е А, ( )EI A е дадено со релацијата (2.6)
( ) ( )1
,N
i ii i
i
p nEI A I p np n=
+=
+∑ (2.6)
каде тежинскиот однос за i–тата гранка е пропорционален на бројот на примероци
од D што припаѓаат на iD . Информациската добивка со разгранување на дрвото
според атрибутот А, ( )G A е дадена со релацијата (2.7)

- 18 -
( ) ( ) ( ),G A I p n EI A= − (2.7)
ID3 врши испитување на сите кандидати атрибути и го избира оној атрибут А што
ја максимизира информациската добивка ( )G A , го конструира дрвото, и потоа го
користи истиот процес рекурзивно за да конструира дрва за одлучување за
останатите подмножества { }1,..., ND D . За секое подмножество iD ако сите
примероци од iD се позитивни, се креира ,,yes” лист и се запира; ако сите
примероци се негативни се креира ,,no” лист и се запира; во секој друг случај се
избира друг атрибут на истиот начин како и опишаниот и се прави нова поделба.
Максималниот број на листови во дрвото е p n+ (вкупниот број на податоци за
обучување) и максималната должина од коренот до секој лист е а, каде а е бројот
на атрибути. Вкупниот број на јазли во дрвото за одлучување е секогаш помал од
( )a p n+ . За коренот ID3 алгоритмот треба да ја провери вредноста на секој
атрибут А за секоја торка за да се пресмета информационата добивка ( )G A .
Временската комплексност за ова е ( )( )O ba p n+ каде b е максималниот број на
можни вредности за еден атрибут. Временската комплексност на другите јазли е
секогаш помала од таа на коренот. Според тоа најлошата временска комплексност
кај ID3 алгоритмот е ( ) ( )( ) ( )( )22O ba p n a p n O ba p n+ + = + .
Една од главните предности на ID3 е тоа што не е потребно некакво предходно
знаење за прблемот. Тоа значи дека алгоритмот може да се примени на секое
синтаксички добро формирано множество за обучување. Ова, заедно со високите
перформанси на алгоритамот, овозможуваат ID3 и неговите наследници како што
се C4.5 да станат централни компоненти во неколку комерцијални системи.
2.3.4 Индукција на дрва на одлучување со C4.5 алгоритам
Алгоритмот C4.5 врши подобрување на ID3 алгоритмот за прашања кога имаме
континуалини атрибути, справување со податоци кои недостигаат и го воведува
поткаструвањето на дрвото за да се зголемат перформансите кога имаме нови
(непознати) податоци.

- 19 -
2.3.4.1 Нов критериум за селекција на атрибут при индукција на
дрво
ID3 алгоритмот работи незадоволително кога постојат атрибути со променлив
број на можни дискретни вредности. Заради тоа е предложена нова хеуристика,
наречена gain ratio criterion наместо информациската добивка ( )G X за селекција
на атрибут при индукција на дрва. Кај овој критериум се користи односот
( ) ( )/G X IV X каде
( ) 21
logN
i i i i
i
p n p nIV Xp n p n=
+ += + +
∑
каде , ,N p n се претходно дефинирани. Кога ( ) 0IV X ≠ за поделба се избира оној
атрибут кој го максимизира горниов однос.
2.3.4.2 Справување со континуални атрибути
ID3 алгоритмот работи само со дискретни атрибути, но повеќето од множествата
на податоци (datasets) содржат и континуални атрибути. Проширувањето на
алгоритмот се состои од воведување на бинарна поделба за континуалните
атрибути. Прагот за поделба обично се поставува на средина меѓу вредностите
кои ги даваат границите на концептот. Кога дрвото за одлучување тестира еден
дискретен атрибут имаме по една гранка за секоја вредност на атрибутот. Бидејќи
поделбата кај континуалните атрибути е само бинарна, постои разлика меѓу
континуалните и нумеричките атрибути: откако ќе се изврши гранење на еден
номинален атрибут се искористува неговата целокупна информација а кај
континуалните атрибути при секоја поделба имаме потреба од нова информација.
Според тоа еден дискретен атрибут може да се тестира само еднаш во патеката од
коренот до еден лист додека нумерички атрибут може да се појави повеќе пати.

- 20 -
2.3.4.3 Справување со недостаток на вредности на атрибути
Следното подобрување на ID3 алгоритмот се справува со прашањето на
вредности што недостасуваат. Во случај кога го применуваме дрвото за
класификација на инстанца во која недостасуваат вредности за одредени атрибути
ја изведуваме следната постапка: се дели инстанцата на делови со користење на
нумеричка тежинска шема и испраќаме дел од инстанцата по секоја од гранките
пропорционално на бројот на инстанци за обучување во соодветната гранка;
различни делови од инстанцата ќе пристигнат до листовите и одлуките потоа
мораат да се рекомбинираат со користење на истите тежини за да се добие
резултантната класа. Друго прашање кое се поставува е како да се подели
множеството за обучување кога веќе е избран атрибутот за поделба, за да се
овозможи истата рекурзивна постапка за индукција да се примени и врз јазлите
синови, во случај кога имаме недостаток на вредности за тој атрибут. Овде се
користи истата постапка како и претходно. Инстаницте за кои недостига
вредноста на релевантниот атрибут се делат на делови, по еден дел за секоја
гранка во ист однос како и познатите инстанци кои се движат по таа гранка.
Придонесот на деловите од инстанцата во одлуката кај подолните јазли се
пресметува со помош на информациската добивка која е модифицирана со
тежинските фактори.
2.3.4.4 Поткастрување на дрва за одлучување
Кај C4.5 постојат две стратегии за поткастрување и тоа: пост-поткастрување
(postpruning) и пред-поткастрување (prepruning). Ако вршиме индукција на
комплетното дрво и потоа вршиме негово поткастрување тогаш ја користиме
стратегијата на пост-поткастрување. Пред-поткаструвањето се користи кога
сакаме да сопреме со индукцијата на поддрва во текот на градењето на дрвото. Кај
алгоритмите за индукција на дрва за одлучување најчесто се користи стратегијата
на пост-поткастрување.
За пост-поткастрување постојат две значително различни операции и тоа: замена
на поддрво со лист (subtree replacement) и подигување на поддрво (subtree raising).
За секој јазол алгоритмот за учење мора да одлучи дали ќе изврши замена на

- 21 -
поддрво со лист, ќе изврши подигнување на поддрвото или ќе го остави дрвото
непоткастрено (непроменето).
Идејата на замената на поддрво со лист е да селектира некои од поддрвата и да ги
замени со листови. Ваквата операција ќе доведе до намалување на точноста
(accuracy) врз множеството за обучување ама може да доведе до зголемување на
точноста ако дрвото се примени врз независно избрано множество за тестирање.
Кај ваквото поткастрување се движиме од листовите кон коренот.
Подигнувањето на поддрвото е покомплексна операција и не секогаш е јасно
дали се исплати да се користи. Во овој случај се заменува поддрво со неговото
најчесто користено поддрво. Овде се подигнува поддрвото од тековната локација
на јазол кој се наоѓа погоре во дрвото.
2.3.4.5 Проценка на грешка
За да се одлучиме дали ќе извршиме замена на внатрешен јазол со лист или ќе
вршиме замена на внатрешен јазол со еден од јазлите подолу (подигнување на
поддрво) мораме да извршиме оценка на ратата на грешка која би се очекувала за
конкретен јазол ако е дадено независно множество податоци за тестирање.
Оценката на грешката потребно е да се изврши за внатрешните јазли и за
листовите. За оценка на грешката не би требало да се користи множеството
податоци за обучување бидејќи тоа не би довело до какво било потксатрување
бидејќи дрвото е конструирано точно да го задоволи тоа множество. Еден начин
на пресметка на грешката во секој јазол е да се издвои еден дел од податоците и
да се користи како независно множество за тестирање. Ова се нарекува
поткастрување со редуцирање на грешката (reduced error pruning).
Негативност на оваа метода е тоа што дрвото кое се индуцира се базира на
помалку податоци.
Алтернативен начин на оценка на грешката е да се користи самото множество за
обучување. Идејата на оваа метода е да се разгледа множеството на инстанци кои
пристигнуваат до секој јазол и да се избере мајоритетната класа да го претставува
тој јазол. Оваа постапка доведува до Е грешки од вкупно N инстанци. Нека сега
претпоставиме дека вистинската веројатност на грешка во јазелот е q , и дека N-те
инстанци се генерираат од Бернулиев случаен процес со параметар q , од кои Е

- 22 -
грешни. Метематиката која доведува до формулата за грешката е следнава: ако е
дадена конкретна доверливост (confidence) c (кај с4.5 обично се зема 0.25) тогаш
( )1 /f qP z c
q q N
− > = −
каде N е број на инстанци, /f E N= е добиената рата на грешка и q е
вистинската рата на грешка. За проценката на грешката го добиваме следниот
резултат:
2 2 2
2
22 4
1
z f f zf zN N N Ne
zN
+ + − +=
+
каде z е бројот на стандардни девијации што одговараат на доверливоста с и за
0.25c = , z е 0.69.
2.4 Учење на класификациски правила
Класификациските правила се алтернативен начин за претставување на знаење
добиено со примена на алгоритмите на податочното рударење.
Едно класификациско правило се состои од множество на услови (antecedents) и
последица (consequent).
IF множество на услови THEN заклучок
Множеството од предуслови претставува низа од тестови кои се изведуваат врз
инстанците од базата, а последицата (заклучокот) ја дава класата (класите) што
одговараат на самите инстанци или пак ја дава распределбата на веројатност на
класите.
IF атрибут1 релација1 вредност1 AND Атрибут2 релација2 вредност2 AND ... атрибутm релацијаm вредностm AND THEN Class=classX

- 23 -
Предусловите се поврзани меѓусебно со логичка И функција и за правилото да
биде задоволено потребно е сите тестови да бидат успешни. Во некои
формулации на правила предусловите може да бидат и општи логички изрази.
Индивидуалните правила меѓу себе се поврзани со логичка ИЛИ функција т.е ако
е исполнето едно правило врз инстанцата која ги задоволува условите се
применува заклучокот од правилото. Можно е да настане и конфликт во случаите
кога за една инстанца важат повеќе правила со различни закклучоци.
Класификациските правила можат да се добијат и директно од класификациското
дрво. За секој лист се генерира по едно правило. Множеството од услови вклучува
по еден услов за секој јазол на патеката од коренот до тој лист, а заклучокот од
правилото е класата што е определена со листот. Оваа постапка продуцира
правила кои се еднозначни и редоследот според кој тие се проверуваат не е битен.
Во општ случај, правилата кои се добиваат од класификациските дрва се многу
покомплексни од што е потребно и обично се врши поткастрување (pruning) на
правилата за да се отстранат редундантните услови.
Една од причините зошто правилата се популарни е тоа што секое правило
претставува независна „порција“ на знаење. Може да се изврши и додавање на
нови правила на множеството на правила без тие да имаат влијание врз веќе
постоечките правила, што не е случај кај класификациските дрва бидејќи
додавањето на нова структура во дрвото може да предизвика промени во целото
дрво. Во реален случај, оваа независност на правилата е неостварлива бидејќи се
игнорира фактот на кој начин се интрепретира множеството на правила. Ако
правилата се интерпретираат како листа на правила, тогаш некои од правилата ако
се земат индивидуално можат да бидат неточни. Во друг случај, ако не е битен
редоследот при интерпретацијата тогаш не е многу јасно што треба да се направи
во случај кога различни правила доведуваат до различни заклучоци за една иста
инстанца. Во случај кога правилата се добиваат од дрва не може да се случи
двосмисленост бидејќи тогаш правилата содржат редунданција што не дозволува
појава на двосмисленост. Проблем настанува кога класификациските правила се
генерираат преку друг алгоритам а не преку дрва.

- 24 -
2.4.1 Алгоритам за генерирање на класификациски правила со
прекривање
Алгоритмите за класификациски дрва се базират на стратегијата раздели и владеј
(divide and conquer). Тие работат одгоре надолу и во секоја фаза бараат атрибут за
поделба што најдобро ги одделува класите, и потоа рекурзивно ги процесира на
ист начин добиените поддрва што се резултат од поделбата. Генерираните дрва
понатаму можат да се искористат за добивање на правила.
Друг пристап при генерирањето на правила е да се разгледа посебно секоја класа
и да се побара начин да се прекријат сите инстанци од множеството кои припаѓаат
на класата и во исто време да се исклучат инстанци што не припаѓаат на класата.
Овој пристап се нарекува прекривање (covering aproach) бидејќи во секоја фаза се
добива правило што покрива некои од инстанците.
Алгоритамот за прекривање работи со додавање на услови на правилото што го
градиме и секогаш се обидува да добие правило со максимална точност (accuracy).
Алгоритмите за генерирање на класификациски дрва работат со додавање на
услови во јазлите и се обидуваат да ја максимизираат поделбата меѓу класите.
Секој од условите вклучува наоѓање на атрибут за поделба. Во двата случаи
критериумот за избор на најдобар атрибут е различен. Кај алгоритмите за дрва се
избира оној атрибут кој ја максимизира информациската добивка, додека
алгоритмите со прекривање го избираат оној пар атрибут-вредност кој ја
максимизира веројатноста на саканата класификација.
Идејата на алгоритмот со прекривање е да вклучи што повеќе инстанци од
саканата класа и да ги исклучи оние инстанци што припаѓаат на другите класи.
Нека едно ново правило прекрива вкупно t инстанци, од кои p се позитивни
примери за класата, а t-p се негативни примри т.е тоа е грешката што ја прави
правилото. Од можните услови го избираме оној услов што го максимизира
односот p/t.
Еден едноставен алгоритам за генерирање на класификациски правила со
прекривање е даден подолу.

- 25 -
Алгоритам 2.2
За секоја класа C Иницијализирај го E со множеството на инстанци; Додека Е содржи инстанци од класа С Креирај правило R со празна лева страна која прави предикција на С; Се додека R не е совршено (или нема повеќе атрибути) За секој атрибут А кој го нема во R и секоја вредност v Разгледај ја можноста за додавање на условот A=v во R; Избери ги А и v кои ја максимизираат точноста p/t; (во случај кога повеќе услови имаат иста точност се избира оној услов со најголемо p) Додади го условот A=v во R; Отстрани ги оние инстанци од Е кои се покриени со правилото R; Претходно дадениот алгоритам ја мери успешноста на едно правило со помош на
формулата за точност p/t. Секое правило со точност помала од 100% е неточно во
смисла што доделува инстанци што припаѓаат на друга класа. Алгоритмот
продолжува со додавање на услови се додека не се добие совршено правило.
Надворешната јамка итерира преку класите и во секоја итерација вршиме
повторна иницијализација на множеството инстанци Е. Тогаш се индуцираат
правила за таа класа и се отстрануваат покриените инстанци од множеството се
додека не се покријат сите инстанци што припаѓаат на соодветна класа. Во
процесот на генерирање на правило се започнува од празно правило (кое ги
покрива сите примероци) и се додаваат услови се додека не ги покријат само
истанците од саканата класа. Во секоја фаза се избира најдобриот услов кој ја
максимизира точноста на правилото.
Претходно опишаниот алгоритам е раздели и владеј вид на алгоритам бидејќи се
индуцира правило што покрива инстанци од класата (ги исклучува оние кои не се
во класата), ги отстранува покриените инстанци бидејќи тие се веќе опфатени со
правилото и го продолжува процесот врз оние инстанци кои се останати во
множеството. Чекорот на отстранување на инстанци од множеството ја зголемува
ефикасноста на алгоритмот бидејќи множеството на инстанци постојано се
намалува дедека трае процеост на индукција на правилата.

- 26 -
2.4.2 Критериум за избор на услов
При анализата на основниот алгоритам за учење на правила од претходното
поглавје, мораше да се усвои начинот на одлучување кој од повеќето можни
услови да се додаде на правилото за да се обезбеди тоа да не покрива негативни
инстанци. Како што веќе претходно беше кажано, се избира оној услов кој го
максимизира односот p/t, каде t е вкупниот број на истанци што би ги покривало
новото правило а p е бројот на оние инстанци кои се позитивни за класата. Колку
е поголем бројот на позитивни инстанци кои ги покрива правилото толку е самото
правило поточно.
Друга алтернатива е да се пресмета информационата добивка log logp Ppt T
−
каде p и t се бројот на позитивни и вкупниот број на инстанци покриени од новото
правило, а Р и Т се соодветниот број на инстанци кои го задоволувале правилото
пред да биде додаден новиот услов.
Основниот критериум за избор кој услов да се додаде на правилото е да се најде
оној услов кој покрива колку што може повеќе позитивни инстанци и што
помалку негативни инстанци. Првата хеуристика постигнува максимум кога не се
покриени негативни инстанци без оглед на бројот на покриените позитивни
инстанци. На пример, според оваа хеуристика ако имаме услов кој покрива една
истанца која е позитивна и имаме услов кој покрива илјада позитивни инстанци и
една негативна, ќе биде избран првиот услов. Хеуристиката која се базира на
информационата добивка дава повеќе значење на покривањето на што поголем
број на инстанци без оглед дали добиеното правило е точно. И двата алгоритми
вршат додавање на услови се додека конечното правило не биде точно, што значи
дека со првата хеуристика правилото ќе биде добиено побрзо додека со втората
хеуристика правилото ќе има повеќе услови. Разликата меѓу двата алгоритми е
тоа што со првиот прво ќе бидат откриени специјалните случаи па потоа ќе бидат
додадени правилата кои опфаќаат голем број на инстанци, додека со вториот
алгоритам ќе биде обратно т.е прво ќе се најдат правила кои покриваат голем број
на инстанци па потоа специјалните случаи.

- 27 -
2.4.3 Поткастрување на класификациски правила
Поткаструвањето е еден стандарден начин на справување со шум при учење на
дрва. Заедничко за сите методи за поткастување е тоа што тие прво вршат
претерано нагодување (overfitting) на моделот со учење на глобален концепт од
множеството инстанци за обучување, да се подобри предикцијата на непознати
инстанци.
Постојат два фундаментално различни пристапи при поткаструвањето и тоа:
• Pre-Pruning: во текот на генерирање на концептот некои од инстанците за
обучување намерно се испуштаат, така да конечниот опис на концептот не
ги класифицира сите инстанци за обучување точно;
• Post-Pruning: прво се генерира опис на концептот кој совршено ги
опишува сите инстанци за обучување. Оваа теорија понатаму се
генерализира со поткастрување на дрвото за одлучување.
Повеќето од техниките кои се користат во современите системи на учење на
правила се адаптирани од учењето на дрва за одлучување. Повеќето од системите
за учење на дрва ја користат стратегијата overfit-and-simplify (пренатрупај и
поедностави) за да се справат со шум во податоците. Прво се формира хипотеза со
индукција на комплексно дрво кое е пренатрупано и потоа дрвото се поткаструва.
Обично таквите стратегии на поткастрување ја подобруваат ратата на грешка на
непознати податоци во случаите кога податоците за обучување содржат шум. За
оваа цел се предложени повеќе методи за поткастрување на дрва и една од
најефикасните методи е reduced error pruning (REP) – поткастрување за
намалување на грешката. REP едноставно може да се прилагоди да работи и за
правила.
Кај REP алгоритмот за правила, податоците за обучување се делат во две
множества: множество за растење на правилaта (growing set) и множество за
поткастрување (pruning set). Прво се формира почетно множество на правила кое
што пренатрупува множеството за растење на правилата, со користење на
хеуристика. Понатаму ова множество на правила се поедноставува со примена на
некој од операторите за поткастрување; типичен оператор за поткастрување е
бришење на одреден услов или на одредено правило. Во секоја фаза на
поедноставување, се избира оној оператор за поткастрување што дава најголемо

- 28 -
намалување на грешката во однос на множеството за поткастрување.
Поедноставувањето застанува кога примената на кој било оператор за
поткастрување доведува до зголемување на грешката врз множеството за
поткастрување.
REP алгоритмот за правила ги подобрува перформансите за генерализација на
правилата во случај кога имаме податоци кои содржат шум ама тој е
пресметковно скап алгоритам во случаите кога имаме многу податоци.
За да се одговори на негативната страна на REP алгоритмот беше предложен нов
алгоритам наречен Incremental Reduced Error Pruning (IREP)2. Понатаму, во
следното поглавје ќе бидат разгледани основните идеи на самиот алгоритам и
некои подобрувања кои доведуваат до нов алгоритам за учење на класификациски
правила наречен RIPPER.
2.4.4 Incremental Reduced Error Pruning (IREP)
IREP врши интегрирање на поткаструвањето со намалување на грешката (REP) со
раздели и владеј алгоритмот за учење на правила опишан претходно.
Алгоритам 2.3 IREP(Pos,Neg) Begin Ruleset:=∅ ; While Pos ≠ ∅ do /*grow and prune a new rule*/ split(Pos,Neg) into (GrowPos,GrowNeg) and (PrunePos,PruneNeg); Rule:=GrowRule(GrowPos,GrowNeg); Rule:=PruneRule(Rule,PrunePos,PruneNeg); If the error rate of Rule on (PrunePos,PruneNeg) exceeds 50% then return Ruleset; else add Rule to Ruleset remove examples covered by Rule from (Pos,Neg); endif endwhile return Ruleset 2 Алгоритмот е подетално опишан во трудот: J.Fürnkanz and G.Widmer. Incremental reduced error
pruning. In Machine Learning: Proceedings of the Eighth International Workshop on Machine Learning,
Ithaca, New York, 1991.Morgan Kaufmann.

- 29 -
end
Алгоритмот 2.3 претставува верзија на IREP која содржи две класи. Како и
стандардниот раздели и владеј алгоритам, IREP врши постепена индукција на
правила, едно по едно. Кога ќе се индуцира едно правило, сите инстанци кои се
покриени со правилото се отстрануваат. Овој процес се повторува се додека има
позитивни примероци, или правилото има неприфатливо голема рата на грешка.
За да се индуцира едно правило, IREP ја користи следнава стратегија. Прво,
непокриените инстанци случајно се разделуваат во две множества, множество за
растење (growing set) и множество за поткастрување (pruning set). Во овој
алгоритам множеството за растење содржи 2/3 од инстанците.
Понатаму имаме „растење“ на правилото. Се започнува со празен услов и се
додаваат услови од обикот nA v= , cA θ≤ или cA θ≥ , каде nA е номинален
атрибут и v е дозволена вредност за nA , или cA е континуален атрибут и θ е
некоја вредност за cA која се појавува во податоците за обучување. GrowRule
врши постојано додавање на улсови што вршат максимизација на
информационата добивка3 се додека правилото не покрива негативни примероци
од множеството за растење.
По „растењето“ на правилото, тоа веднаш се поткаструва. Алгоритмот врши
поткастрување на која било конечна секвенца од услови од правилото и врши
бришење на секвенцата која ја максимизира функцијата дадена со равенството
(2.8)
( ) ( ), ,
p N nv Rule prunePos pruneNeg
P N+ −
≡+
(2.8)
каде P (N) е вкупниот број на примероци во prunePos (pruneNeg) и p (n) е бројот на
примероци во prunePos (pruneNeg) покриени со правилото Rule. Овој процес се
повторува се додека има поткастрување што ја подобрува вредноста v .
Гореопишаниот IREP алгоритам важи за проблеми за учење на две класи. Во
случаите кога имаме повеќе класи прво се врши подредување на класите во
растечки редослед на фреквенцијата на појавување на класите т.е редоследот е
3 Критериумот за информациската добивка е земен од системот за учење FOIL што е подетално
опишан во трудот: Quinlan and Cameron-Jones. FOIL: a midterm report. Machine Learning:ECML-93,
Vienna, Austria, 1993

- 30 -
1,..., kC C , каде 1C е најмалку фреквентната класа а kC е најфреквентната класа и
потоа се користи повик до IREP за да се определи множество од правила кои ја
одделуваат класата 1C од останатите класи. Понатаму, сите инстанци покриени од
множеството на правила се отстрануваат и се користи нов повик на IREP за
одделување на класата 2C од останатите итн. Процесот се повторува се додека не
остане една класа kC која ќе се користи како појдовна (default) класа.
Алгоритмот за учење правила е дизајниран така да може да се справи и со
атрибути што недостасуваат на начин што сите услови кои го вклучуваат
атрибутот А ќе отпаднат за инстанците за кои недостга вредноста за атрибутот А.
Ваквиот начин на справување со атрибутите што недостасуваат овозможува
алгоритмот да врши одделување на позитивните примери со користење на услови
што се точни.
Во модифицираната верзија на IREP развиена од Cohen, е дозволено бришење на
која било конечна секвенца од услови, додека оригиналната верзија на алгоритмот
дозволува бришење само на еден услов. Во оваа верзија, за разлика од
оригиналната верзија, се запира додавањето на правила во множеството на
правила кога ќе се добие правило што има рата на грешка поголема од 50%.
2.4.5 Подобрување на IREP алгоритмот – RIPPER алгоритам
За да се подобри претходно разгледаниот алгоритам се воведуваат неколку
модификации во самиот алгоритам и тоа: се воведува алтернативна метрика за
проценување на вредноста на правилата во фазата на поткастрување, се воведува
нова хеуристика за определување кога да се запре со додавње на нови правила на
множеството од правила и фаза на оптимизација што го поминува целото
множество на правила и се обидува да го апроксимира конвенционалниот REP
алгоритам.
IREP алгоритмот понекогаш не конвергира во случајот кога имаме зголемување
на бројот на инстанци и ова е случај поради метриката која се користи во фазата
на поткастрување. Оваа метрика во одредени случаи е крајно неинтуитивна; на
пример, нека P и N се фиксни и нека метриката го предпочита правилото 1R кое
покрива 1 2000p = позитивни примероци и 1 1000n = негативни примероци, во

- 31 -
однос на правилото 2R кое што покрива 1 1000p = позитивни примероци и 1 1n =
примерок. Од ова се забележува дека 2R е правило кое прави подобра предикција
од правилото 1R . Од оваа причина е извршена промена на метриката и е дадена со
релацијата (2.9)
( )* , , p nv Rule prunePos pruneNegp n
−≡
+ (2.9)
Оваа варијанта на IREP алгоритмот запира со додавање на нови правила кога
последното конструирано правило има грешка врз податоците за поткастрување
која надминува 50%. Оваа хеуристика многу често запира премногу рано, во
случаи кога имаме правила со мала покриеност. За да се подобри овој дел од
алгоритмот се користи MDL принцип.4 Кога ќе се додаде секое правило се
пресметува вкупната дескриптивна должина (description length) на множеството
на правила и на примероците. Новата верзија на IREP запира со додавање на
правила кога оваа должина е повеќе од d бита поголема од најмалата должина
добиена дотогаш или кога веќе не постојат позитивни примероци. Најчесто
вредноста на должината е 64. Множеството на правила понатаму се
поедноставува со испитување на секое правило (почнувајќи од последното
правило) и бришење на правилата за да се намали вкупната дескрипциона
должина.
Пристапот расти и поедностави кој се користи кај IREP дава резултати кои се
различни од конвенционалиот REP алгоритам. Еден начин да се подобри
инкременталниот пристап е да се постпроцесираат правилата добиени од IREP за
да се апроксимира ефектот на конвенционалиот REP. Методот на оптимизација на
множеството од правила 1,..., kR R е даден понатаму. Се разгледува по едно
правило по ред како се генерирани. За секое правило iR се конструираат две
алтернативни правила: замена (replacement) и ревизија (revision). Замената за iR
се формира со растење и поткастрување на правило 'iR каде поткаструвањето се
води така да се минимизира грешката на целото множество првила '1,..., ,...,i kR R R
4 МDL е кратенка од Minimum Description Length принцип кој вели дека најдобрата теорија за
множество од податоци е таа која ја минимизира големината на теоријата плус количеството на
информација потребно да се специфицираат исклучоците од таа теорија.

- 32 -
врз податоците за поткастрување. Ревизијата на iR се формира аналогно освен
што не се почнува од празно правило туку се додаваат услови на самото правило.
На крај се прави одлука дали ќе се користи оригиналното правило, ревизијата или
замената според MDL хеуристика. Ваквиот модифициран алгоритам се нарекува
RIPPER (Repeated Incremental Pruning to Produce Error Reduction).

- 33 -
3. ФРЕКВЕНТНИ ЗАПИСИ И АЛГОРИТМИ ЗА НИВНО ГЕНЕРИРАЊЕ
3.1 Основни поими за фреквентни множества
Фреквентните множества (frequent sets) имаат есенцијално значење во повеќе
задачи од податочното рударење кои имаат за цел да откријат интересни шеми
(patterns) од бази на податоци како што се асоцијациски правила, корелации,
секвенци, епизоди, класификатори, кластери и сл. Барањето на асоцијациски
правила е еден од најпознатите проблеми кој се решава со техниките на
податочно рударење. Првичната мотивација за пребарување на асоцијациски
правила дошла од потребата за анализа на трансакциските податоци од
супермаркетите, т.е да се испита однесувањето на клиентот зависно од купените
продукти. Асоцијациските правила опишуваат колку често одредени производи се
купуваат заедно. Таквите правила можат да бидат корисни за донесување на
одлуки како што се цените на производите, промоциите, распоредот на
производите во маркетите и сл.
Целта на оваа поглавје е да се дадат основните поими и алгоритми за добивање на
фреквентните множества кои се прв чекор за добивање на асоцијациски правила
за понатамошно нивно користење за модификација на веќе постоечките
алгоритими за учење на предиктивни модели. Самите асоцијациски правила не се
предмет на разгледување во оваа дипломска работа.
Дефиниција 3.1. Нека е дадено множеството R. Бинарната релација r над R е
колекција од подмножества на R. Елементите на R се нарекуваат записи (items), а
елементите на r се нарекуваат редици (rows). Бројот на редици во r се означува со
r и големината на r е t r
r t∈
= ∑ каде t е трансакција.
Редиците од бинарните бази на податоци се нарекуваат трансакции, така да во
изложувањето на поимите и алгоритмите ќе се користат поимите за трансакциска
база на податоци и на нејзината содржина како на трансакции.
Едно интересно својство на множеството X R⊆ на записи (items) е колку редици
(трансакции) од базата го содржат истото множество. Ова нè доведува до
формална дефиниција на поимот за фреквентно множество.

- 34 -
Дефиниција 3.2. Нека R е множество и r е бинарна релација над R и нека X R⊆
е множество од записи. Множеството X се содржи во редицата t r∈ , ако X t⊆ .
Множеството на редици од r во кои се содржи X се означува со ( ),M X r , т.е
( ) { },M X r t r X t= ∈ ⊆ и исто така се нарекува обвивка на X . Фреквенцијата на
X во r се означува со ( ),fr X r и е дадена со релацијата (3.1)
( )( ),
,M X r
fr X rr
= (3.1)
Доколку контекстот на базата на податоци е еднозначно определен се користат
ознаките ( )M X и ( )fr X . Ако е даден праг на феквенцијата [ ]min_ 0,1fr ∈ ,
тогаш множеството X е фреквентно5 ако ( ), min_fr X r fr≥ .
Број на
редица Редица
1t { }, , , ,A B C D G
2t { }, , ,A B E F
3t { }, ,B I K
4t { }, ,A B H
5t { }, ,E G J
Слика 3-1 Пример за бинарна релација r над множеството { }, ,...,R A B K=
Пример 3.1 Нека е дадена една бинарна релација r над множеството
{ }, ,...,R A B K= прикажано на слика 3.1. За множеството { },A B се добиваат
следниве параметри, { }( ) { }1 2 4, , , ,M A B r t t t= и фреквенцијата на множеството е
{ }( ), , 3 5 0.6fr A B r = = . Базата на податоци може да се разгледува и како
релациона база над шемата { }, ,...,A B K , каде , ,...,A B K се бинарни атрибути и
оттаму доаѓа и изразот за бинарна релација. На слика 3.2 е прикажана базата во
овој облик.
5 Во литературата за поимот фреквентно множество се користат и поимите large set и covering set,
а за фреквенцијата се користи поимот support.

- 35 -
Број на
редица A B C D E F G H I J K
1t 1 1 1 1 0 0 1 0 0 0 0
2t 1 1 0 0 1 1 0 0 0 0 0
3t 0 1 0 0 0 0 0 0 1 0 1
4t 1 1 0 0 0 0 0 1 0 0 0
5t 0 0 0 0 1 0 1 0 0 1 0
Слика 3-2 Пример за бинарна релација r дадена во релациона форма над бинарни атрибути
Прагот на фреквенцијата min_ fr е параметар кој го дава корисникот и зависи од
самата апликација.
Дефиниција 3.3. Нека R е множество и нека r е бинарна релација над R и
min_ fr е праг на фреквенцијата. Колекцијата на фреквентни множества во r
зависно од min_ fr се означува со ( ), min_F r fr и е дадено со релацијата (3.2)
( ) ( ){ }, min_ , min_F r fr X R fr X r fr= ⊆ ≥ , (3.2)
или едноставно се означува со ( )F r ако е познат прагот на фреквенцијата.
Колекцијата од фреквентни множества со големина l е дадена со релацијата (3.3)
( ) ( ){ }lF r X F r X l= ∈ = . (3.3)
Пример 3.2 Нека претпоставиме дека прагот на фреквенцијата е 0.3. Колекцијата
на фреквентни множества во базата r од слика 3.1 е
( ) { } { } { } { } { }{ },0.3 , , , , ,F r A B E G A B= бидејќи ниту едно непразно множество не
се појавува во повеќе од една редица. Празното множество ∅ е тривијално
фреквентно во секоја бинарна релација и празните множества обично не се земаат
предвид во апликациите.

- 36 -
3.2 Генерирање на фреквентни множества
Откривањето на сите фреквентни множества е предизвикувачка задача. Просторот
за пребарување е експоненцијален со бројот на атрибути кои се појавуваат во
базата на податоци, иако прагот на фреквенцијата го ограничува излезот во
разумен потпростор. Понатаму, базите на податоци можат да бидат масивни и да
содржат милиони трансакции со што броењето на фреквенцијата е тежок процес.
Понатаму во овој дел подетално ќе бидат разгледани двата аспекти.
3.2.1 Простор за пребарување
Целосното пребарување на фреквентни множества е очигледно непрактична
задача освен можеби за најмалите множества бидејќи просторот за пребарување
на потенцијалните фреквентни множества се состои од 2 R подмножества од R.
Според тоа можеме да ги генерираме само оние множества што се појавуваат
барем еднаш во трансакциската база, т.е ќе извршиме генерирање на сите
подмножества од сите трансакции од базата. Секако, ако имаме долги трансакции
овој број би можел да биде се’ уште многу голем и е потребно да се изврши
оптимизација за да се генерираат оние подмножества со големина помала или
еднаква на дадената максимална големина. Оваа решение е добро кај sparse бази
на податоци, додека за големи или dense бази на податоци овој алгоритам има
големи барања за мемориски ресурси и заради тоа се предложени неколку
решенија да се изврши подирекно пребарување во просторот за пребарување.
Во текот на пребарувањето, се генерираат неколку колекции од кандидати
множества и се пресметуваат нивните фреквенции сè додека не се генерираат сите
фреквентни множества. Очигледно е дека големината на колекцијата од
кандидатните множества не смее да ја надмине големината на главната меморија.
Многу е важно да се генерираат што помалку кандидати, бидејќи пресметката на
фреквенцијата е процедура што е временски зависна. Во најдобар случај ќе се
генерираат само фреквентните множества, ама оваа идеја не е општо применлива
што ќе биде покажано покасно.

- 37 -
Најважното својство кое се користи од повеќето алгоритми за генерирање на
фреквентни множества е дека фреквенцијата е монотоно опаѓачка функција
зависно од големината на множеството.
Својство 3.1 (монотоност на фреквенцијата) Нека ,X Y R⊆ се две множества,
тогаш важи својството ( ) ( )X Y fr X fr Y⊆ ⇒ ≥ .
Доказ: доказот следи од ( ) ( )M X M Y⊆ што следува од претпоставката X Y⊆ .
Според претходното својство, ако едно множество не е фреквентно тогаш сите
негови надмножества (supersets) не се фреквентни.
3.2.2 База на податоци
За да се пресметаат фреквенциите на колекција на записи (itemsets), потребно е да
пристапиме до базата на податоци. Бидејќи базите на податоци имаат тендеција да
бидат многу големи, не секогаш е можно тие да се зачуваат во главната меморија.
Една важна забелешка во повеќето постоечки алгоритми е репрезентацијата на
базата на податоци. Концептуално, таквата база се претставува со бинарна
дводимензионална матрица во која секој ред претставува индивидуална
трансакција а колоните ги претставуваат записите во I. Таквата матрица може да
се имплементира на неколку начини. Најчесто користен формат е хоризонталниот
формат каде секоја трансакција содржи број на трансакцијата и листа на записи
што се појавуваат во неа. Друг користен формат на репрезентирање на матрицата
е вертикалниот каде базата се состои од множество од записи заедно со нивната
обвивка (cover).
За да се пресмета фреквенцијата на множеството записи X со користење на
хоризонталниот формат, потребно е базата на податоци целосно да се измине и за
секоја трансакција T да се тестира дали е исполнет условот X T⊆ . Ова може да
се направи за голема колекција на записи. Многу е важно да се забележи дека
наоѓањето на фреквентни шеми во податоцте е операција што бара многу време
поради скенирањето на базата на податоци и е многу интензивна операција во
поглед на I/O. Во повеќето случаи ова не е најскапиот чекор во алгоритмите.
Ажурирањето на фреквенциите на сите кандидати записи кои се содржат во една
трансакција бара повеќе време отколку читањето на таа трансакција од датотека
или база на податоци. За секоја трансакција мораме да го провериме секој

- 38 -
кандидат запис дали е се содржи во трансакција која се процесира или пак
потребно е да се проверат сите подмножесва од трансакцијата дали се содржат во
множеството од кандидати записи. Според претходното можеме да заклучиме
дека бројот на трансакции во базата има влијание врз потребното време за
пресметка на фреквенциите на фреквентните множества.
3.3 Аpriori алгоритам
Прв алгоритам кој се користел за генерирање на сите фреквентни множества и
доверливи асоцијациски правила бил алгоритамот AIS развиен од Agrawal, кој
бил даден заедно со описот на овој проблем од податочно рударење. Овој
алгоритам понатаму бил подобрен и преименуван во Apriori каде било
искористено својството на монотоност на фреквентните множества и
доверливоста на асоцијациските правила.
3.3.1 Опис на Аpriori алгоритамот
Фазата на откривање на фреквентните множества е дадена со алгоритмот 3.1.
Алгоритам 3.1 Apriori Input: r, σ Output: ( ),F r σ
{ }{ }1 :C i i R= ∈ ; k:=1; while { }kC ≠ do //compute the frequencies of all candidate sets for all transactions ( ),tid I r∈ do for all candidate sets kX C∈ do if X I⊆ then Increment X.frequency by 1; //Extract all frequent sets { }: .k kF X C X frequency σ= ∈ ≥ ; //Generate new candidate sets { }1 :kC + = ;
for all [ ] [ ], ,kX Y F X i Y i∈ = for 1 1i k≤ ≤ − and [ ] [ ]X k Y k< do

- 39 -
[ ]{ }:I X Y k= U ;
if , : kJ I J k J F∀ ⊂ = ∈ then Add I to 1kC + ; Increment k by 1; Алгоритмот извршува breadth-first пребарување врз просторот составен од сите
множества со итеративно генерирање на множества кандидати 1kC + со големина
k+1, почнувајќи со k=0. Едно множество е кандидат множество ако за сите негови
подмножества е познато дека се фреквентни. Поконкретно, 1C се состои од сите
записи од R и во одредена фаза k се генерираат сите множества со големина k+1.
Тоа се прави во два чекори. Прво се изведува спојување на kF самиот со себе. Ако
, kX Y F∈ и ако тие имаат ист k-1 префикс се генерира унијата X YU . Во чекорот
на поткастрување во kC се додава унијата X YU , само ако сите нејзини k
подмножества се појавуваат во kF .
За да се избројат фреквенциите на сите k кандидати множества, базата на
податоци дадена во хоризонтален формат се скенира трансакција по трансакција,
и фреквенциите на сите кандидати множества кои се вклучени во таа трансакција
се инкрементираат. Сите множества кои се фреквентни се додаваат во kF .
Ако бројот на k+1 кандидати множества е премногу голем да остане во главната
меморија, се врши модификација на алгоритмот на следниот начин. Процедурата
за генерирање на кандидати запира и се пресметува фреквенцијата на сите
дотогаш генерирани кандидати. Во следната итерација, наместо да се генерираат
множества со големина k+2, се генерираат останатите кандидати со големина k+1
и се пресметува нивната фреквенција се додека не се определат сите фреквентни
множества со големина k+1.
3.3.2 Податочни структури
Генерирањето на множествата кандидати и броењето на фреквенцијата на
кандидатите бараат ефикасна податочна структура во која ќе се чуваат сите
кандидати множества, бидејќи е важно ефикасно да се определат сите множества
кои се содржат во една трансакција или во друго множество.

- 40 -
3.3.2.1 Hash – дрво
За ефикасно да може да се определат сите k – подмножества на потенцијалното
кандидат множество, сите фреквентни множества во kF се чуваат во hash – дрво.
Кандидатите множества се чуваат во hash – дрво. Еден јазол од hash – дрвото
содржи листа од множества (лист) или hash – табела (внатрешен јазол). Кај
внатрешниот јазол секој букет од hash – табелата покажува кон некој друг јазол.
Коренот на hash – дрвото е дефинирано да биде на длабочина 1. Внатрешен јазол
на длабочина d покажува кон јазлите на длабочина d+1. Множествата се чуваат во
листовите.
Кога вршиме додавање на k – множеството X во текот на процесот на генерирање
на кандидатите, се започнува од коренот и се движиме надолу по дрвото се додека
не стигнеме до лист. Кога ќе стигнеме до еден внатрешен јазол на длабочина d,
одлучуваме по која гранка ќе се движиме со примена на hash – функција врз
членот [ ]X d од множеството и со следење на покажувачот од соодветниот букет.
Сите јазли на почетокот се креираат како листови. Кога бројот на множества во
листот на длабочина d го надмине дадениот праг, листот се конвертира во
внатрешен јазол, само ако k d> .
За да се определат сите кандидати множества кои се содржат во една трансакција
Т, започнуваме од коренот. Ако се наоѓаме во лист, наоѓаме кои од множествата
во листот се содржат во Т и ја зголемуваме нивната фреквенција. Ако се наоѓаме
во внатрешен јазол и сме стигнале до него со примена на hash – функција врз
членот i , ја применуваме hash – функцијата врз секој член што доаѓа по i во Т и
рекурзивно ја применуваме оваа процедура врз јазелот во соодветниот букет. За
коренот ја применуваме hash – функцијата врз секој член од Т.
3.3.2.2 Префиксно дрво
Друга податочна структура која често се користи е префиксно дрво (prefix tree,
trie). Кај префиксното дрво, секое k-множество е поврзано со еден јазол како и
неговиот k-1 префикс. Коренот е празно множество. Сите 1-множества се
прикачени на коренот и нивните гранки се означени со членот кој го

- 41 -
репрезентираат. Секое друго k-множество е поврзано со неговиот k-1 префикс.
Секој јазол го чува последниот член од множеството кое го претставува, неговата
фреквенција и неговите гранки. Гранките на јазелот можат да се имплементираат
со користење на неколку податочни структури како hash – табела, бинарно
пребарувачко дрво или вектор.
Во конкретна итерација k, сите кандидати k – множества се чуваат на длабочина k
во префиксното дрво. За да се определат сите кандидати множества кои се
содржат во трансакција Т, започнуваме од коренот. За трансакција за еден јазол од
префиксното дрво да се процесира, (1) се следи гранката што одговара на првиот
член од трансакцијата и го процесираме остатокот од трансакцијата рекурзивнo за
таа гранка и (2) се занемарува првиот член од трансакцијата и се процесира
рекурзивно за самиот јазол. Оваа процедура може понатаму да се оптимизира.
Чекорот на спојување во процедурата за генерирање на кандидати множества е
многу едноставна со користење на оваа податочна структура, бидејќи сите
множества со големина k со истиот k-1 префикс се претставуваат со гранките од
истиот јазол (самиот јазол го претставува k-1 префиксот). За да се генерираат сите
кандидати множества со k-1 префикс X , вршиме копирање на сите деца на
јазелот кој го претставуват X како гранки на тој јазол.

- 42 -
4. МОДИФИКАЦИЈА НА АЛГОРИТМИТЕ ЗА УЧЕЊЕ НА ПРЕДИКТИВНИ МОДЕЛИ ОД СУМАРНИ
ПОДАТОЦИ
4.1 Мотивација
Идејата на оваа дипломска работа е да се изврши модификација на постоечките
алгоритми за учење на предиктивни модели така да тие можат да користат
сумарни информации за податоците за пресметка на веројатностите кај моделите,
наместо да работат со самите податоци. Сумарните податоци се состојат од
податоци за фреквенцијата на појавување на групација од атрибути, заедно со
вредностите на атрибутите, за множеството податоци (dataset) што го користиме
за градење на предиктивниот модел. Фреквенцијата на појавување на групација од
атрибути можеме да ја добиеме ако извршиме генерирање на фреквентните
множества за даденото множество податоци. Познавањето на вредноста на
фреквенцијата за дадена групација од атрибути ќе ни помогне во фазата на
градење на предиктивниот модел да ја определиме дистрибуцијата на
веројатноста за секоја од класите, наместо да вршиме изминување на
множеството податоци и броење на појавувањето на одреден атрибут (заедно со
неговата вредност). Поради тоа што за генерирањето на фреквентните множества
е потребно атрибутите од множеството на податоци да примаат само дискретни
вредности во оваа дипломска работа ќе се задржиме само на дискретни множества
од податоци за да се избегне дискретизацијата на нумеричките атрибути, бидејќи
целта на дипломската работа е да се испита и спореди однесувањето на
оригиналините и модифицираните алгоритми.
4.2 Модификација на алгоритмот за учење на
веројатносни модели
Во делот 2.2 беше опишан оригиналниот алгоритам за учење на Баесовиот
класификатор каде за определување на условната веројатност ( )|i ik kP A v C= се

- 43 -
користи формулата ( ) ( )( )
| i ik ji ik k
j
N A v C cP A v C
N C c
= ∧ == =
=, каде ( )i ik jN A v C c= ∧ =
е бројот на инстанци од множеството податоци кај кои се појавуваат заедно
i ik jA v C c= ∧ = , а ( )jN C c= е бројот на инстанци каде jC c= . Вредностите на
бројачите се добиваат со изминување на множеството податоци.
Модификација на алгоритмот вклучува замена на бројачите со фреквенцијата на
појавување парот i ik jA v C c= ∧ = и фреквенцијата на појавување на класата
jC c= . Според тоа модифицираната формула ќе биде:
( ) ( )( )
| i ik ji ik k
j
fr A v C cP A v C
fr C c
= ∧ == =
= (4.1)
За пресметка на фреквенциите ни се потребни групи од атрибути (itemsets) со
големина еден и два.
Apriori алгоритмот што се користи за генерирање на групи од атрибути (itemsets)
врши генерирање само на групи чија фреквенција на појавување во множеството
податоци е поголема од праговната (минимална) фреквенција. Ова доведува до
проблем при пресметката на веројатностите бидејќи за одредени групи атрибути,
чија фреквенција е помала од праговната, ние немаме информација за точната
вредност на фреквенцијата. Поради ова потребно е да се изврши проценка на
фреквенцијата за таквата група на атрибути (non-frequent itemset). Кај Naive Bayes
алгоритмот земена е проценката дека за сите групи на атрибути чија фреквенција
не е позната се зема вредноста min2
fr . Статистички гледано, оваа проценка е
добро избрана затоа што вистинската фреквенција на групата од атрибути се
наоѓа во интервалот 0 minfr fr≤ < така да ако се избере вредноста min2
fr за
фреквенцијата вкупната грешка на моделот би била најмала. Од претходното,
исто така, може да се забележи дека вкупната грешка на моделот ќе зависи од
изборот на праговната фреквенција. Доколку се избере многу голема вредност за
прагот, грешката ќе биде голема и моделот ќе биде речеси неупотреблив бидејќи
голем дел од бројачите ќе имаат иста вредност за фреквенцијата а со тоа и
веројатностите кои ќе се пресметуваат ќе бидат рамномерно распределени.

- 44 -
4.3 Модификација на алгоритмот за учење на дрва за
одлучување
Во делот 2.3 беше детално опишан стандардниот алгоритам за учење на дрва за
одлучување. Модификацијата на алгоритмот за учење на дрва за одлучување се
состои од користење на фреквентните множества за пресметка на веројатностите
на сите класи во секој чекор на индукција на дрвото за одлучување, наместо со
изминување на множеството податоци и броење на примероците кои го
задоволуваат соодветниот услов определен со изборот на атрибут за поделба.
Модификацијата ја опфаќа само фазата на индукција на дрвото, додека фазата на
поткастрување во овој момент ја оставаме непроменета.
Нека патеката од коренот до даден внатрешен јазол од дрвото е составена од
следниве тестирања на атрибути: &...&i ij l lmA a A a= = , тогаш за оценка на
распределбата на веројатноста во соодветниот внатрешен јазол за сите класи kC е
потребно да ја познаваме фреквенцијата на групата атрибути
( )&...&i ij l lmfr A a A a= = и фреквенцијата на групата атрибути заедно со класниот
атрибут ( )&...& &i ij l lm kfr A a A a C c= = = за сите вредности на k. Според тоа
распределбата на веројатност за соодветниот јазол се пресметува по формулата:
( ) ( )( )
&...& &&...&
&...&i ij l lm k
k i ij l lmi ij l lm
fr A a A a C cP C c A a A a
fr A a A a
= = == = = =
= = (4.2).
За пресметка на фреквенцијата ( )&...&i ij l lmfr A a A a= = ни се потребни
фреквентни множества со големина l, каде l е бројот на атрибути што се
тестирани до соодветниот јазол, а за фреквенцијата
( )&...& &i ij l lm kfr A a A a C c= = = се потребни фреквентни множества со
големина l +1.
Според претходното, во секој јазол мораме да чуваме информација кои атрибути
се тестирани во патеката од коренот до тој јазол за да можеме да ја најдеме
фреквенцијата на групата атрибути. Како и кај претходниот алгоритам (Naive
Bayes), и тука постои проблемот на проценка на фреквенцијата на групата на
атрибути која не е фреквентна т.е фреквенцијата на групата атрибути е помала од
избраната праговна фреквенција min fr .

- 45 -
Постојат повеќе начини за проценка на фреквенцијата на групата атрибити која не
е фреквентна. Првиот начин, покомплексен за имплементација, опфаќа
определување на моментот кога одредена група атрибути станува нефреквентна.
Значи, потребно е да ги бараме подмножествата на групата атрибути и да
провериме кои од подмножествата се фреквентни. Понатаму фреквенцијата на
овие подмножества може да се искористи за проценка на фреквенцијата на
оригиналната групација на атрибути. Втор начин, полесен за имплементација, се
состои од постепено намалување на процеката на фреквенцијата со растење на
големината на групата од атрибути, т.е за фреквентни записи со големина 1
проценката би била min2
fr , за записи со големина 2 ќе имаме min2*2
fr или општо
min2*
frg
каде min fr е минималната фреквенција, а g е големината на
фреквентниот запис. Ваквото постепено намалување на проценката на
фреквенцијата е логично затоа што ако би ги генерирале сите записи (минимална
фреквенција е еднаква на 0) тогаш фреквенцијата на појавување на записите со
максимална големина (еднаква на вкупниот број на атрибути од множеството
податоци) би била 0 или 1, т.е дали во множеството податоци постои таква
инстанца или не постои.
Во имплементацијата на алгоритмот што ќе биде опишана во следното поглавје е
искористен вториот пристап заради поедноставната имплементација.
4.4 Модификација на алгоритмот за учење на
класификациски правила
Во делот 2.4 беше детално опишан стандардниот алгоритам за учење на правила
за одлучување. Модификацијата на алгоритмот за учење на правила се состои од
користење на фреквентните множества за пресметка на точноста (accuracy) на
правилото, наместо со изминување на множеството податоци и броење на
примероците кои го задоволуваат соодветниот услов, определен со претходно
искористените тестови врз атрибутите од правилото. Модификацијата ја опфаќа
само фазата на градење на правилата, додека фазата на поткастрување во овој
момент ја оставаме непроменета.

- 46 -
Нека едно правило за одлучување го има следниов облик:
IF &...&i ij l lmA a A a= = THEN kC c=
тогаш за пресметка на точноста на правилото потребно е да ја познаваме
фреквенцијата на групата атрибути ( )&...&i ij l lmfr A a A a= = и фреквенцијата на
групата атрибути заедно со класниот атрибут ( )&...& &i ij l lm kfr A a A a C c= = = .
Формулата за пресметка на точноста на правилото го има следниов облик:
( )( )
&...& &
&...&i ij l lm k
i ij l lm
fr A a A a C cAccuracy
fr A a A a
= = ==
= = (4.3).
За пресметка на фреквенцијата ( )&...&i ij l lmfr A a A a= = ни се потребни
фреквентни множества со големина l, каде l е бројот на атрибути опфатени во
условот на правилото, а за фреквенцијата ( )&...& &i ij l lm kfr A a A a C c= = = се
потребни фреквентни множества со големина l +1.
Постапката на проценката на фреквенцијата на групата на атрибути која не е
фреквентна кај правилата на одлучување е иста како и кај дрвата за одлучување и
е опишана погоре во текстот.

- 47 -
5. ИМПЛЕМЕНТАЦИЈА НА АЛГОРИТМИТЕ ЗА УЧЕЊЕ НА ПРЕДИКТИВНИ МОДЕЛИ ОД СУМАРНИ
ПОДАТОЦИ
5.1 WEKA – Waiakato Enviroment for Knowledge Analysis
Алгоритмите што беа разгледани во претходните поглавја се имплементирани во
системот наречен WEKA, развиен во универзитетот Waiakato во Нов Зеланд.
Кратенката WEKA е добиена од сложенката Waiakato Enviroment for Knowledge
Analysis што во превод значи Waiakato околина за анализа на знаење.
Системот WEKA е напишан во JAVA, објектно – ориентиран програмски јазик
што е широко достапен за сите компјутерски платформи како Windows, Linux и
Macintosh. JAVA ни дозволува да обезбедиме униформен интерфејс за многу
различни алгоритми за учење, методи за пред и пост процесирање и евалуација на
резултатите на шемите за учење на кое било множество податоци.
Постојат неколку нивоа на користење на WEKA системот. Прво, направена е
имплементација на добри алгориитми за учење што можат да се применуваат врз
податоците за обучување дирекно од командна линија. Исто така вклучено е
множество од алатки за трансформација на множества од податоци, како што се
алгоритми за дискретизација и различни типови на филтри за податоците.
Еден начин на користење на WEKA е да се примени методот за учење врз
множеството податоци и да се анализира неговиот излез и да се екстрахираат
информациите за податоците. Друг начин е да се применат неколку алгоритми за
учење и да се споредат нивните перформанси за да се избере најдобриот за
предикција. Методите за учење се наречени класификатори. Сите тие алгоритми
имаат ист интерфејс од командна линија и постои множество од генерички опции
од командна линија и опции кои се карактеристични за секој алгоритам посебно.
Перформансите на сите класификатори се мерат со ист модул за евалуација.
Освен алгоритми за учење, WEKA обезбедува и филтри за пред и пост –
процесирање на податоците. Како и кај класификаторите и филтрите имаат
стандардизиран интерфејс од командна линија.

- 48 -
Од претходното искажување може да се заклучи дека основната цел на WEKA
системот е развивање на алоритми за класификација и филтрирање на податоци.
Во WEKA, освен овие алгоритми се вклучени и алгоритми за учење на
асоцијациски правила и кластерирање на податоци.
Во повеќето апликации за податочно рударење, компонентата за машинско учење
е само еден мал дел од многу поголемиот софтверски систем и затоа во случај
кога сакаме да пишуваме нова апликација за податочно рударење можеме да ги
користиме програмите од WEKA од сопствениот код и во тој случај го решаваме
нашиот проблем со минимално дополнително програмирање. Поради овој факт
беше избран токму WEKA системот за имплементација на модифицираните
алгоритми за учење на предиктивни модели од сумарни податоци.
5.2 Основни компоненти во WEKA системот
Во WEKA системот секој алгоритам за учење е претставен со посебна класа.
Поради тоа што во WEKA постојат многу класи за различни алгоритми за учење и
филтрирање на податоците тие се орагнизирани во пакети. Секој пакет содржи
група на класи што се меѓусебно поврзани и делат заеднички функционалности.
5.2.1 weka.core пакет
Пакетот core е основен пакет во WEKA системот. Тој содржи класи кои ги
користат сите останати класи во системот.
Основни класи во core пакетот се: Attribute, Instance и Instances.
Објект од класа Attribute претставува еден атрибут. Тој содржи име на атрибутот,
тип на атрибутот и во случај кога имаме номинален атрибут ги содржи и можните
вредности на атрибутот.
Објект од класа Instance ги содржи вредностите на атрибутите за една конкретна
инстанца од множеството на податоци.
Објект од класа Instances содржи подредено множество на инстанци или со други
зборови го содржи множеството податоци.

- 49 -
5.2.2 weka.classifiers пакет
Пакетот classifiers ги содржи имплеметациите на повеќето од алгоритмите за
класификација и нумеричка предикција. Најважната класа во пакетот е Classifier,
која ја дефинира општата структура на кој било алгоритам за класификација.
Класиот дијаграм на класата е прикажан на слика 5-1.
Слика 5-1 UML класен дијаграм за класата Classifier
Класата содржи три методи што мораат да бидат имплементирани од сите
алгоритми за учење на класификатори и тоа: buildClassifier(), classifyInstance() и
distributionForInstance(). Во жаргонот на објектно–ориентираното програмирање
класите за учење на класификатори се подкласи на Classifier и според тоа тие
автоматски ги наследуваат овие методи. Секој алгоритам за класификација врши
дефинирање на методите според тоа како го градат класификаторот и како ги
класифицираат инстанците. Ова дава униформен интерфејс за градење и
користење на класификатори од страна на друг JAVA код. За евалуација на
користи ист модул за сите класификатори.

- 50 -
5.2.3 Други пакети во WEKA системот
Останатите пакети во WEKA системот се: weka.associations, weka.clusterers,
weka.estimators, weka.filters, weka.attributeSelection и многу други. Од интерес за
дипломската работа е пакетот weka.associations што содржи класи за
имплементација на Аpriori алгоритмот за учење на асоцијациски правила и
генерирање на фреквентни множества од множество податоци. Оваа класа заедно
со други класи за учење на класификатори ќе бидат обработени понатаму во ова
поглавје од дипломската работа.
5.3 Иплементација на Apriori алгоритам
Во пакетот weka.associations постојат класи кои го имплементираат алгоритмот за
учење на асоцијациски правила Apriori. За потребите на дипломската работа беше
извршена модификација на класата Apriori, за таа да ги генерира само
фреквентните множества за дадено множество податоци а не и самите
асоцијациски правила кои не се потребни во овој случај. Новоформираната класа
FrequentItemsets заедно со останатите модифицирани класи за учење на
класификатори се сместени во пакетот weka.classifiers.freqitemsets.
5.3.1 Класа ItemSet Класата ItemSet содржи податоци што опишуваат еден член (запис) од фреквентно
множество. Класниот дијаграм за оваа класа е прикажан на слика 5-2.
Од класниот дијаграм се забележува дека се чуваат податоци за бројот на
трансакции во кои е присутна соодветната комбинација на атрибути, вкупниот
број на трансакции од множеството податоци и поле од целобројни вредности за
евиденција кои атрибути се присутни во една комбинација. Големината на полето
m_items е еднаква на вкупниот број на атрибути во множеството податоци заедно
со класата. Индексот на елементите од полето се користи за нумерација на
атрибутите, така да позицијата i од полето е резервирана за евиденција на
присутност на атрибутот i во соодветната комбинација на атрибути. Ако
атрибутот не е присутен во комбинацијата, тогаш вредноста на елементот на
соодветната позиција е -1. Доколку атрибутот е присутен вредноста на елементот

- 51 -
на соодветната позиција е еднаква на вредноста на самиот атрибут. Вредностите
на атрибутите во WEKA се кодирани со целобројна вредност почнувајќи од 0 до
бројот на вредности на атрибутот – 1.
Слика 5-2 UML дијаграм за класата ItemSet
Во класата ItemSet се реализирани методи за манипулација на вакви објекти.
Постојат методи спојување, бришење и поткастрување на вектори составени од
вакви објекти, кои се користат кај Apriori алгоритмот за генерирање на
фреквентни множества.
5.3.2 Класа FrequentItemsets
Во класата FrequentItemsets е имплементиран Apriori алгоритмот за генерирање на
фреквентни множества. Класниот дијаграм за оваа класа е даден на слика 5-3.

- 52 -
Слика 5-3 UML класен дијаграм за класата FrequentItemsets
Фреквентите множества кои се генерираат со Apriori алгоритмот се чуваат во
објектот m_Ls кој е од тип FastVector и припаѓа на пакетот weka.core. Во класата
се чуваат податоци за минималната фреквенција m_minSuppot, максималната
фреквенција m_upperBoundMinSupport и некои дополнителни помошни податоци.
Креирањето на објект од класа FrequentItemsets се врши со конструкторот
FrequentItemsets() со што се иницијализира векторот во кој се чуваат
фреквентните множества и миималната и максималната фреквенција. Со методата
buildAssociations() се генерираат фреквентните множества. Оваа метода користи
приватна метода findLargeItemSets() што е реализација на Apriori алгоритмот.
Кодот за методата findLargeItemSets() е даден на слика 5.4.
/** * Method that finds all large itemsets for the given set of instances. * * @param the instances to be used * @exception Exception if an attribute is numeric */ private void findLargeItemSets(Instances instances)throws Exception { FastVector kMinusOneSets, kSets; Hashtable hashtable;

- 53 -
int necSupport, necMaxSupport,i = 0; m_instances = instances; // Find large itemsets // minimum support necSupport = (int)Math.floor((m_minSupport * (double)instances.numInstances())); necMaxSupport = (int)Math.floor((m_upperBoundMinSupport * (double)instances.numInstances())); kSets = ItemSet.singletons(instances); ItemSet.upDateCounters(kSets, instances); kSets = ItemSet.deleteItemSets(kSets, necSupport, necMaxSupport); if (kSets.size() == 0) return; do { m_Ls.addElement(kSets); kMinusOneSets = kSets; kSets = ItemSet.mergeAllItemSets(kMinusOneSets,i,instances.numInstances()); hashtable = ItemSet.getHashtable(kMinusOneSets, kMinusOneSets.size()); m_hashtables.addElement(hashtable); kSets =ItemSet.pruneItemSets(kSets, hashtable); ItemSet.upDateCounters(kSets, instances); kSets =ItemSet.deleteItemSets(kSets, necSupport, necMaxSupport); i++; } while (kSets.size() > 0); }
Слика 5-4 Имплементација на Аpriori алгоритам
Алгоритмот започнува со повикување на методот singletons() што од множеството
податоци го креира на почетното множество кандидати записи каде секој запис
содржи само по еден член (атрибут). Множеството записи од к–та итерација се
чуваат во објектот kSets од тип FastVector. Понатаму се врши ажурирање на
бројачите на трансакции од записите во векторот и се врши бришење на оние
кандидати записи кои ја немаат потребната минимална фреквенција. Ваквата
постапка продолжува итеративно се додека бројот на кандидати записи во к-1
итерацијата е различен од нула. Значи прво правиме спојување на сите кандидати
записи и со помош на hash табелата вршиме поткастрување на множеството
записи т.е ги отстрануваме оние записи кои не го исполнуваат условот за
минимална фреквенција. Во променливата m_Ls во секоја итерација го додаваме
добиеното фреквентно множество со големина i6 така да на крај во оваа
променлива ќе го добиеме целото фреквентно множество за дадено множество
податоци.
6 Под големина во овој случај се подразбира бројот на членови (атрибути) во еден запис (itemset).

- 54 -
5.4 Имплементација на алгоритмот за учење на
веројатносни модели
Учењето на веројатносни модели (класификатори) во системот WEKA е
имплементирано во класата NaiveBayes. За потребите на дипломската работа беше
извршена модификација на оваа класа така да таа со помош на опции од командна
линија може да работи на стандарден начин или со користење на фреквентни
множества.
5.4.1 Класа NaiveBayes
Во класата NaiveBayes е имплементиран алгоритмот за учење на веројатносни
модели, што е подетално опишан во поглавието 2.2. Класниот дијаграм за оваа
класа е даден на слика 5-5.
Во класата се дефинирани повеќе променливи, кои се користат за пресметка на
веројатностите на моделот. Тридимензионалното поле m_Counts [klasa] [atribut]
[vrednost na atribut] се користи за пресметка на условните веројатности во случај
на дискретни атрибути, m_Devs [klasa] [atribut] и m_Means [klasa] [atribut] се
користат за пресметка на параметрите на Гаусовата распределба во случај кога
имаме нумерички атрибут и m_Priors [klasa] се користи за определување на
априорните веројатности. Како што може да се забележи од класниот дијаграм,
класата NaiveBayes ги дефинира методите кои ги наследува од основната класа
Classifiers.

- 55 -
Слика 5-5 UML класен дијаграм за класата NaiveBayes
Во методата buildClassifier() се одлучува дали ќе се работи по стандардниот
алгоритам или ќе се работи по модифицираниот алгоритам врз основа на
параметрите од командната линија. Во случај кога работиме со фреквентни
множества, можеме да користиме само дискретни атрибути. Тогаш прво се врши
иницијализација на FrequentItemsets објект и потоа се врши генерирање на
фреквентни множества. Кај овој тип на класификација, за разлика од останатите,
потребни ни се само фреквентни записи со големина 1 и 2. Понатаму се повикува
приватната метода calculateProbs() која ги врши потребните пресметки и прави
нормализација на веројатностите. На слика 5-6 е даден програмски сегмент со кој
се доделуваат вредности на бројачите за пресметка на веројатностите.
//za klasna verojatnost for(int i=0;i<=((FastVector)itemSets.elementAt(0)).size()-1;i++){ help=((ItemSet)((FastVector)itemSets.elementAt(0)).elementAt(i)).items(); count=((ItemSet)((FastVector)itemSets.elementAt(0)).elementAt(i)).counter(); if(help[help.length-1]!=-1) m_Priors[help[help.length-1]]=count; } //naoganje na brojacite za presmetka na verojatnostite na klasite i atributite so klasite for(int i=0;i<((FastVector)itemSets.elementAt(1)).size();i++){ help=((ItemSet)((FastVector)itemSets.elementAt(1)).elementAt(i)).items(); count=((ItemSet)((FastVector)itemSets.elementAt(1)).elementAt(i)).counter(); for(int j=0;j<help.length-1;j++){

- 56 -
if(help[j]!=-1) { m_Counts[help[help.length-1]][j][help[j]]=count; } } }
Слика 5-6 Коден сегмент за пресметка на веројатностите кај NaiveBayes
Значи, како што се гледа од кодниот сегмент за определување на априорните
веројатности вршиме изминување на фреквентните записи со големина 1 и кога ќе
се најде запис кој во себе го содржи класен атрибут, тогаш на соодветиот елемент
од полето m_Priors [klasa] му се доделува фреквенцијата на појавување на
вредноста на класниот атрибут во множеството податоци. На сличен начин се
пополнува и полето m_Counts [klasa] [atribut] [vrednost na atribut] само во тој
случај се користат фреквентни записи со големина 2.
За пресметка на веројатностите потребно е да се пополнат сите елементи од двете
полиња и во случај кога не е позната фреквенцијата за одредена комбинација на
атрибут и класа, ја доделуваме вредноста min2
fr .
При евалуацијата на моделот врз конкретно множество на податоци, модулот за
евалуација ја повикува методата distributionForInstance() која враќа поле со
распределба на веројатноста врз класите. Инстанцата од множеството податоци
која се процесира ќе биде доделена на онаа класа за која веројатноста е најголема.
Оваа метода се повикува за сите инстанци чија класа сакаме да ја определиме и
според добиените резултати од класификацијата модулот за евалуација врши
статистичка обработка од која можеме да ги процениме перформансите на
моделот.
5.5 Имплементација на алгоритмот за учење на дрва за
одлучување
Учењето на дрва за одлучување во системот WEKA е имплементирано преку
множество од класи. Секоја класа посебно има определена улога во алгоритмот.
Концептално гледано, класите можат да се поделат во неколку групи според
функцијата што ја имаат во алгоритмот и тоа: класи за манипулација со дрва за

- 57 -
одлучување, класи за селекција на модел на дрво, класи за поделба на ниво на
јазол, класи за критериуми за поделба, класа за пресметка на распределбата на
веројатност на ниво на јазол и др.Понатаму во текстот ќе бидат разгледани некои
од класите подетално, за да се опише целокупната функционалност на
алгоритмот.
5.5.1 Класа Ј48 Класата Ј48 е основна класа која го имплементира алгоритмот за учење на с4.57
што е подетално обработен во поглавјето 2.3. Класниот дијаграм за ова класа е
прикажан на слика 5-6.
Слика 5-7 UML класен дијаграм за класата Ј48
7 Алоритмите врз кои се базира имплементацијата подетално се разработени во книгата: Ross
Quinlan (1993). C4.5: Programs for Machine Learning, Morgan Kaufmann Publishers, San Mateo, CA.

- 58 -
Во класата се дефинирани повеќе променливи кои се користат за определување на
карактеристиките на дрвото. Класата Ј48 е наследник на класата Classifiers и ги
имплементира методите buildClassifier(), classifyInstance() и
distributionForInstance(), што се користат од модулот за евалуација.
5.5.2 Класа ClassifierTree
Класа ClassifierTree е основна класа што дефинира рекурзивна структура на
класификациско дрво. Класниот дијаграм за оваа класа е прикажан на слика 5-8.
Слика 5-8 UML класен дијаграм за класата ClassifierTree
Во класата се чуваат податоци за еден јазол од дрвото. Податоците кои
дефинираат еден јазол од класификациско дрво се: модел на дрвото
(ModelSelection m_toSelectModel), модел на ниво на јазол (ClassifierSplitModel
m_localModel), референци кон јазлите наследници (ClassifierTree [] m_sons),
логичка променлива која определува дали јазолот е лист (boolean m_isLeaf) и поле

- 59 -
од атрибути кои се искористени за поделба, по патеката од коренот до
конкретниот јазол (int []m_usedAttr). Полето од употребени атрибути за поделба е
помошна информација која се користи од класата Distribution за пресметка на
дистрибуцијата на веројатност на класите за конкретен јазол од дрвото со
френвентни множества.
За градење на дрвото се користи методата buildTree() во која се врши избор на
најдобар атрибут за поделба преку повикување на метода selectModel() од
објектот m_toSelectModel. Методата враќа објект од тип ClassifierSplitModel кој го
содржи најдобриот атрибут за поделба заедно со неговата дистрибуција. Ако е
можна поделбата за избраниот атрибут, се креира поле од објекти од тип
ClassifierTree што ги репрезентира наследниците (децата) на дадениот јазол и
рекурзивно се повикува методата за градење на дрво. Во случај кога не е можна
поделба јазолот се дефинира како лист. Изборот на најдобар атрибут за поделба
ќе биде разгледан покасно во текстот.
Во WEKA постојат две класи кои ја наследуваат класата ClassifierTree што се
користат за дефинирање на дрво кое може да се поткаструва. Класата
C45PrunableClassifierTree ги дефинира параметрите и методите за креирање на
дрва кои се поткаструваат со користење на класична процедура на поткастрување
опишана во поглавието 2.3.4.4. Класата PrunableClassifierTree ги дефинира
параметрите и методите за креирање на дрва кои се поткаструваат со користење
на IREP(Increased Reduced Error Pruning) алгоритмот. Изборот на начинот на
поткастрување се врши преку параметри од командна линија, т.е преку
параметрите од класата Ј48.
5.5.3 Апстрактна класа ModelSelection и класа C45ModelSelection
Апстрактната класа ModelSelection ја дефинира апстрактната метода selectModel()
која го избира атрибутот за поделба за дадено множество на податоци. Методата
враќа објект од тип ClassifierSplitModel што содржи информации и параметри за
самата поделба. Класите C45ModelSelection и BinC45ModelSelection ја
имплементираат апстрактната класа ModelSelection. Класата BinC45ModelSelection
дефинира бинарен тип на поделба, т.е се гради бинарно стебло, додека со класата
C45ModelSelection вршиме градење на општо стебло (во гранките се опфатени

- 60 -
сите вредности на даден атрибут). Класниот дијаграм за класата
C45ModelSelection ќе биде прикажан на слика 5-9.
Слика 5-9 UML класен дијаграм за класата C45ModelSelection
Методата selectModel() може да се подели на два дела. Во првиот дел се врши
проверка дали се исполнети сите неопходни предуслови за поделбата како што се:
неопходен број на инстанци за поделба и дали сите инстанци припаѓаат на иста
класа. Доколку поделба не е можна методата враќа објект од тип NoSplit. Во
вториот дел се иницијализира поле од објекти од тип C45Split за сите атрибути и
се врши избор на најдобар атрибут. Од сите можни поделби, се избира онаа
поделба што ја максимизира параметарот gain ratio дефиниран во делот 2.3.4.1.
Методата ја враќа најдобрата поделба.
Методата selectModel() за класата BinC45ModelSelection е аналогна на претходно
опишаната, така да нема посебно да биде разгледана.
5.5.4 Апстрактна класа ClassifierSplitModel и класа C45Split
Апстрактната класа ClassifierSplitModel се користи за класификациски модели
што вршат рекурзивна поделба на податоците. Класниот дијаграм за оваа класа е
даден на слика 5-10.

- 61 -
Слика 5-10 UML класен дијаграм за класата ClassifierSplitModel
Во класата се дефинирани повеќе променливи кои ја опишуваат поделбата на
ниво на јазол и тоа: во m_attIndex се чува индексот на атрибутот што се користи за
поделба, во m_distribution се чува распределбата на веројатност за таквата поделба
и во променливата m_numSubsets го чуваме бројот на генерираните деца на
конкретниот јазол.
Апстрактната класа декларира повеќе методи што ги имплементираат класите:
C45Split, Bin C45Split и NoSplit.
Класата C45Split иплементира C45 вид на поделба врз конкретен атрибут.
Класниот дијаграм за ова класа е даден на слика 5-11.
Од класниот дијаграм може да се забележи дека во класата се чуваат податоци
што се битни за конкретна поделба и се користат од страна на методата
selectModel() за избор на најдобра поделба. Се чуваат вредностите за
информационата добивка m_infoGain и факторот на добивка m_gainRatio, заедно
со статичките референци кон објекти InfoGainSplitCrit и GainRatioSplitCrit. Во
случај кога имаме нумерички атрибути во променливата m_splitPoint ја чуваме
вредноста од поделбата.

- 62 -
Слика 5-11 UML класен дијаграм за класата C45Split
Во методата buildClassifier() се врши иницијализација на параметрите од објектот
и се повикуваат приватните методи за справување со дискретен или нумерички
тип на атрибут.
Приватната метода handleEnumeratedAttribute() прави поделба врз дискретен
атрибут. Во методата прво се врши иницијализација на објект од тип Distribution
во кој се чуваат распределбите за дадена поделба. Врз основа на распределбата и
со користење на методите од објектите InfoGainSplitCrit и GainRatioSplitCrit се
определуваат вредностите за информациската добивка и факторот на добивка кои
се користат понатаму за определување на најдобар атрибут за поделба.
Приватната метода handleNumericAttribute() се користи за поделба врз нумерички
атрибути. Во методата се врши определување на најдобрата вредност за точката
на поделба m_splitPoint, бидејќи кај нумеричките атрибути е можна само бинарна
поделба на атрибутите.
Класата Bin C45Split се користи во случај кога имаме бинарна поделба на
атрибути. Податоците и методите што ги имплементира оваа класа се аналогни на
претходно опишаните така да тие нема посебно да бидат разгледувани.
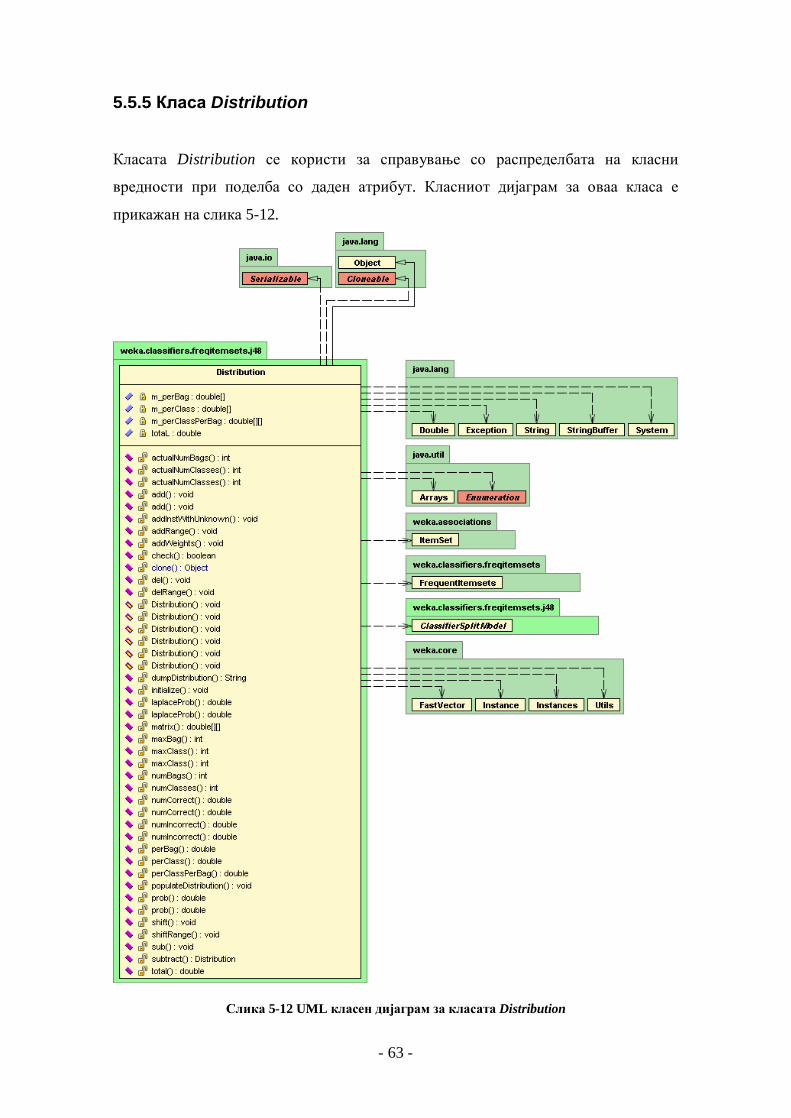
- 63 -
5.5.5 Класа Distribution
Класата Distribution се користи за справување со распределбата на класни
вредности при поделба со даден атрибут. Класниот дијаграм за оваа класа е
прикажан на слика 5-12.
Слика 5-12 UML класен дијаграм за класата Distribution

- 64 -
Од класниот дијаграм се гледа дека за определлување на распределбата на класни
вредности се користат променливите: матрица m_perClassPerBag[klasa][vrednost
na atribut] што дава распределба на бројот на инстанци по класи и по вредности
на даден атрибут, вектор m_perBag[vrednost na atribut] што дава распределба на
бројот на инстанци по вредности на атрибут, вектор m_perClass[klasa] што дава
распределба на бројот на инстанци по класи и променлива total во која се чува
вкупниот број на инстанци кои се процесираат.
Во класата се дефинирни повеќе конструктори за истата класа да може да се
користи за определување за распределбите од страна на сите класи од пакетот Ј48.
Во оваа класа е имплементирана модификацијата на алгоритмот за користење на
податоците за фреквенцијата на фреквентните записи за определување на
распределбата на класни вредности.
Модификацијата на алгоритмот е реализирана преку методата
populateDistribution() прикажана на слика 5-13.
public final void populateDistribution(int attIndex,int[] usedAtt,FrequentItemsets itemsets){ int bags=this.numBags(); int[] usedAttr=usedAtt; int numClasses=this.numClasses(); int numOfUsedAttr=0; for(int i=0;i<usedAtt.length-1;i++) if (usedAtt[i]!=-1) numOfUsedAttr++; for(int i=0;i<numClasses;i++) m_perClass[i]=0; for(int i=0;i<bags;i++){ m_perBag[i]=0; for(int j=0;j<numClasses;j++) m_perClassPerBag[i][j]=(int)((itemsets.getMinSupport()/(numOfUsedAttr+1))/2); } int sizeOfSets=((FastVector)itemsets.getItemSet()).size(); if (sizeOfSets>numOfUsedAttr+1){ int sizeAttCl=((FastVector)((FastVector)itemsets.getItemSet()).elementAt(numOfUsedAttr+1)).size(); for(int j=0;j<numClasses;j++){ usedAttr[usedAttr.length-1]=new Double(j).intValue(); for(int x=0;x<bags;x++){ usedAttr[attIndex]=x; for(int i=0;i<sizeAttCl;i++){ int[]pom=((ItemSet)((FastVector)((FastVector)itemsets.getItemSet()).elementAt(numOfUsedAttr+1)).elementAt(i)).items(); intfreq=((ItemSet)((FastVector)((FastVector)itemsets.getItemSet()).elementAt(numOfUsedAttr+1)).elementAt(i)).counter(); if(Arrays.equals(usedAttr,pom)){ m_perClassPerBag[x][j]=freq; break;

- 65 -
} } } } }//end if
for(int i=0;i<bags;i++) m_perBag[i]=Utils.sum(m_perClassPerBag[i]); for(int j=0;j<numClasses;j++) for(int i=0;i<bags;i++) m_perClass[j]+=m_perClassPerBag[i][j]; totaL=0; for(int i=0;i<numClasses;i++) for(int j=0;j<bags;j++) totaL+=m_perClassPerBag[j][i]; }
Слика 5-13 Функција populateDistribution()
Функцијата populateDistribution() прима три аргументи и тоа: attIndex (индекс на
атрибутот за поделба), usedAtt (поле од атрибути кои се искористени по патеката
од коренот до конкретниот јазол) и itemsets (генерирани фреквентни записи за
множеството падатоци). Методата прво врши иницијализација на полињата
m_perBag[] и m_perClass[] на вредност нула. Матрицата m_perClassPerBag[][] се
иницијализира на вредност min2 ( 1)
frnumOfUsedAtrr⋅ +
каде min fr е минималната
фреквенција од Apriori алгоритмот, а numOfUsedAttr е бројот на искористени
атрибути по патеката од коренот до јазолот кој го процесираме.
Иницијализацијата е направена за да се справиме со вредностите на
фреквенцијата за оние записи кои не се фреквентни. Подетален опис за изборот на
оваа проценка е даден во делот 4.3.
Во променливата sizeOfSets ја сместуваме максималната големина на
генерираните фреквентни записи. Доколку вредноста на sizeOfSets е поголема од
бројот 1numOfUsedAttr + се врши изминување на фреквентните записи со
големина 1numOfUsedAttr + и се пополнува матрицата со распределбите. Во
случај кога не е позната вредноста за фреквенцијата на некој од фреквентните
записи во матрицата останува иницијалната вредност поставена на почетокот од
функцијата. Ако вредноста на sizeOfSets е помала од бројот 1numOfUsedAttr +
тогаш не ги изминуваме фреквентните записи, бидејќи не постојат генерирани
фреквентни записи со таква големина и вредностите на матрицата остануваат на
иницијалната вредност.

- 66 -
Врз основа на матрицата m_perClassPerBag[][] се пресметуваат векторите
m_perBag[] и m_perClass[].
5.5.6 Класи InfoGainSplitCrit и GainRatioSplitCrit
За пресметка на информациската добивка и факторот на добивка за дадена
распределба на класни вредности се користат класите InfoGainSplitCrit и
GainRatioSplitCrit. Класните дијаграми за овие класи се дадени на сликите 5-14 и
5-15 соодветно.
Слика 5-14 UML класен дијаграм за класата InfoGainSplitCrit
Слика 5-15 UML класен дијаграм за класата GainRatioSplitCrit
Од класните дијаграми се гледа дека и двете класи ја наследуваат класата
EntropyBasedSplitCrit. Во методите се имплементирани алгоритми за пресметка на
информациска добивка и фактор на добивка за дадена распределба на класни

- 67 -
вредности. Понатаму овие вредности ќе се искористат за избор на најдобар
атрибут за поделба.
5.6 Имплементација на алгоритмот за учење на правила
за одлучување
Учењето на правила за одлучување со RIPPER алгоритам во системот WEKA е
имплементирано преку класата JRIP. Во класата JRIР се вгнездени приватни
класи и тоа: апстрактна класа Antd што дефинира еден услов во правилото, класи
NumericAntd и NominalAntd што ја имплементираат апстрактната класа Antd и
служат за справување со нумерички и дискретни услови соодветно и класа
RipperRule што дефинира изглед на едно класификациско правило. За потребите
на алгоритмот се дефинира и помшна класа RuleStats која ги дефинира
потребните статистички функции што се користат во самиот алгоритам.
5.6.1 Класа JRip
Класата JRip ја наследува класата Classifiers и ги имплементира методите
buildClassifier(), classifyInstance() и distributionForInstance(), што се користат од
модулот за евалуација. Класниот дијаграм за оваа класа е даден на слика 5-16.
Класата JRip ги дефинира параметрите на алгоритмот како што се: множество на
генерирани правила FastVector m_Ruleset, класниот атрибут Attribute m_Class,
статистики за множеството правила FastVector m_RulesetStats и други параметри
за фазата на поткастрување.
Методата buildClassifier() ги гради правилата за одлучување по растечки редослед
на класните фреквенции. За секоја класа алгоритмот рабои во две фази: фаза на
градење и фаза на оптимизација. Со подесување на параметрите од командна
линија може да се користи само фазата на градење, без да имаме поткастрување и
оптимизација на добиените правила. За секоја класа се генерираат правила со
повикување на методата rulesetForOneClass(), сé додека не биде задоволен
условот за престанување на генерирањето на правилата.

- 68 -
Слика 5-16 UML класен дијаграм за класата Jrip
Mетодата rulesetForOneClass() е имплементација на RIPPER алгоритмот. Во
случајот кога користиме поткастрување на правилата почетното множество на
податоци го делиме на подмножество за растење и подмножество за
поткастрување на правилата. За генерирањето на правила да биде статистички
исправно мора да се изврши претходна стратификација на податоците. Понатаму
се креира објект од тип RipperRule што претставува едно правило и се врши
негово растење и поткастрување. Во случај кога не користиме поткастрување на
правилата имаме само растење на правилата. Во фазата на оптимизација се
повторуваат истите чекори само условите за престанок на генерирање на
преавилата се различни.
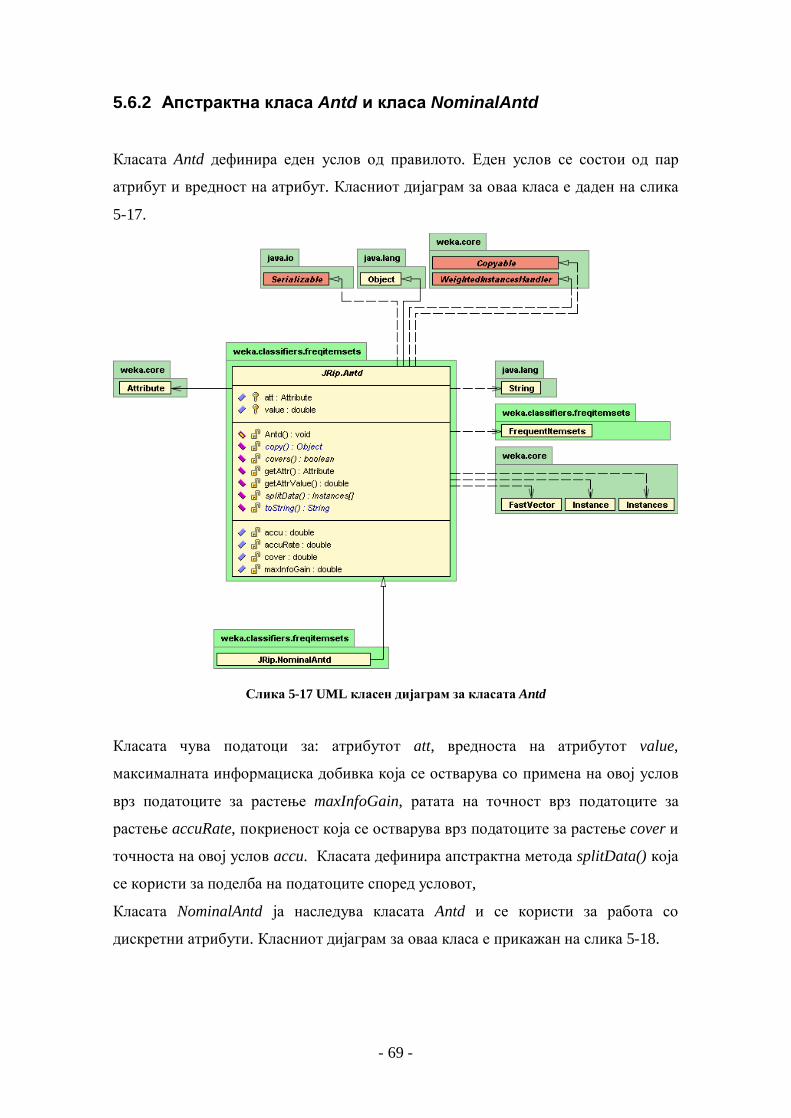
- 69 -
5.6.2 Апстрактна класа Antd и класа NominalAntd
Класата Antd дефинира еден услов од правилото. Еден услов се состои од пар
атрибут и вредност на атрибут. Класниот дијаграм за оваа класа е даден на слика
5-17.
Слика 5-17 UML класен дијаграм за класата Antd
Класата чува податоци за: атрибутот att, вредноста на атрибутот value,
максималната информациска добивка која се остварува со примена на овој услов
врз податоците за растење maxInfoGain, ратата на точност врз податоците за
растење accuRate, покриеност која се остварува врз податоците за растење cover и
точноста на овој услов accu. Класата дефинира апстрактна метода splitData() која
се користи за поделба на податоците според условот,
Класата NominalAntd ја наследува класата Antd и се користи за работа со
дискретни атрибути. Класниот дијаграм за оваа класа е прикажан на слика 5-18.

- 70 -
Слика 5-18 UML класен дијаграм за класата NominalAntd
Класата NominalAntd дополнително дефинира два вектори accurate[] и coverage[]
за пресметка на информациската добивка за сите вредности на атрибутот за
податоците за обучување.
Во методата splitData() е имплементирана модификацијата на алгоритмот за
користење на информација за фреквенцијата од фреквентните множества.
Имплементацијата кај правилата е слична со таа кај дрвата на одлучување. Тука
се користат фреквентни записи со големина која е еднаква на бројот на
употребени услови во правилото. Ова информација ја добиваме со проследување
на вектор од објекти од тип NominalAntd на самата метода. Од овој вектор ја
добиваме и информацијата кои од атрибутите заедно со вредностите биле
употребени во правилото до тогаш, за точно да можеме да ги изминеме оние
фреквентни записи што ја даваат фреквенцијата на појавување на групата
атрибут-вредност за сите вредности на атрибутот кој се процесира. Оној услов кој
врши максимизирање на информациската добивка се додава во правилото и
итеративно се повторува целата постапка за атрибутите кои не се опфатени во
правилото.

- 71 -
5.6.3 Апстрактна класа Rule и класа RipperRule
Апстрактната класа Rule дефинира општо правило за одлучување и ги дава
дефинициите на методите кои ги имплементираат сите правила за одлучување.
Класата RipperRule ја наследува и иплементира класата Rule. Класниот дијаграм
за класата е прикажан на слика 5-19.
Слика 5-19 UML класен дијаграм на класата RipperRule
Едно правило за одлучување се состои од вектор од услови m_Antds и последица
на правилото m_Consequent.
Основни методи кои ги имплементира оваа класа се: grow() и prune(), за растење и
поткастрување на правилата соодветно.
Методата grow() го гради правилото од податоците за растење. Во неа се врши
додавање на услови на правилото при позната последица. Се започува од празно
правило и се изминуваат сите атрибути. За секој атрибут се врши пресметка на
информациската добивка за сите вредности на конкретниот атрибут. Во
правилото се додава оној пар атрибут-вредност кој ја максимизира
информациската добивка т.е покрива повеќе позитивни примероци за класата.
Методата prune() го поткаструва правилото со податоците за поткастрување со
користење на стандардните алгоритми за поткастрување на правила.

- 72 -
6. Тестирање и евалуација на алгоритмите
6.1 Евалуација на алгоритмите за учење
Евалуацијата на добиените модели од процесот на машинско учење е клучен
фактор во податочното рударење. Постојат многу начини за добивање на модели
од податоците, но за да определиме која од методите да ја користиме за решавање
на некој конкретен проблем, потребни се систематски начини за евалуација како
работат различни методи и правење на споредби на истите.
Постапката на евалуација не е едноставна, како што изгледа на прв поглед. За
проценка на перформансите на креираниот модел не е доволно само да вршиме
тестирање со податоците за обучување, туку е потребно да обезбедиме тестирање
и над независно множество податоци за тестирање. Кога имаме големо
количество на податоци на располагање не постои проблем: го креираме моделот
со многу податоци за обучување и тестираме врз друго множество податоци за
тестирање. Вообичаената постапка за проценка на точност на креираниот модел е
дадена на слика 6-1.
Систем заучење
Индуциранкласификатор
Множество одсите податоци
Множествоподатоци затестирање
Множествоподатоци заучење
Точност на моделот врзподатоците затестирање
Слика 6-1 Процедура за проценка на точност на модел
Следно прашање кое се поставува во случај кога имаме независно множество на
податоци за тестирање е: дали може проценката на точноста добиена со
независното множество за тестирање да важи и за нови податоци и со каква

- 73 -
доверливост би важела? За проценка на точноста и интервалот на доверливост се
користи Бернулиев случаен процес. Со примена на формулите што важат за
ваквиот случаен процес можеме да дојдеме до параметрите за точност на моделот
врз нови податоци.
Во случај кога имаме малку податоци тогаш предикцијата на перформансите на
создадените модели е комплексна задача. Најчесто, во овој случај се користи
holdout техника. Оваа техника го дели појдовното множество на податоци на дел
за обучување и дел за тестирање. Вообичаено е да се извои една третина од
податоците за тестирање а останаите две третини за обучување на моделот. За да
се подобри доверливоста на резултатите постапката на учење и тестирање мора да
се повтори повеќе пати (обично 10 пати). При секоја нова поделба податоците
мора да бидат избрани случајно за да можат да се применат формулите од
статистиката за проценка на точноста на моделот. Ако користиме стратифицирана
holdout техника, тогаш имаме еднаква дистрибуција на класите во множествата за
обучување и тестирање.
Крос-валидацијата е специјален случај на повторено учење и тестирање. Овде
случајно се дели множеството податоци во k подмножества. За секое од k-те
подмножества за тестирање се користи едно подмножество, додека за учење на
моделот се користат останатите k-1 подмножества. Проценката на точност се
добива со усреднување на k проценки на точност. Најчесто користена вредност за
k е 10, и ова претставува стандардна процедура за евалуација која се користи во
практиката.
Процедурата за споредба на два различни програми за учење се состои од
изведување на крос-валидацијата врз двете програми со користење на исти
распределби на податоците и правење на споредба врз сите k подмножества и
примена на Студентова t-распределба врз добиените резултати.
Постојат и други мерки за оценка на перформансите на еден модел како што се:
прецизност и recall, ROC криви и др.
Поимите за прецизност и recall се дефинирани со следнаве формули:
Precision=
Recall=
TPTP FPTP
TP FN
+
+

- 74 -
каде TP е број на точни позитивни класификации, FP е број на неточни позитивни
класификации, TN е број на точни негативни класификации и FN е број на
неточни негативни класификации. Значи, recall ни кажува колкав дел од
инстанците за тестирање се класифицираат како позитивни, додека прецизноста
ни кажува колкав дел од случаите кои се класифицирани како позитивни се
навистина позитивни.
ROC кривите ни го даваат односот на ратите на TP и FP, дефинирани со следниве
формули:
TP rate=
FP rate=
TPTP FN
FPFP TN
+
+
.
6.2 Пример
За тестирање на перформансите на алгоритмите што беа опишани во дипломската
работа се користени множества податоци од UCI репозиториумот. Во текот на
работата постоеше проблем на изнаоѓање на адекватно множество на податоци
кое содржи само дискретни атрибути и бројот на таквите атрибути да не е многу
голем. Во случај кога имаме голем број на атрибути и вредности на атрибути
имаме проблем при генерирање на фреквентните записи за множеството податоци
со ваквата имплементација на APRIORI алгоритамот заради големи побарувања за
мемориски ресурси, така да беше направен одреден компромис и беа избрани
помали множества врз кои ќе бидат илустрирани перформансите на алгоритмите.
6.2.1 Опис на множеството податоци
Vote е база на податоци што ги содржи записите за гласањето на конгресмените
во Конгресот на САД за 1984 година. Во базата се вкучени вкупно 435 записи од
кои 267 записи за демократи и 168 записи за републиканци. Вкупно постојат 16
атрибути и еден класен атрибут. Вредноста на класниот атрибут е „democrat“ или
„republican“. Сите вредности на атрибутите се булови и имаат вредност „y“ или
„n“. На слика 6-2 е даден преглед на атрибутите заедно со вредностите. Attribute Information:

- 75 -
% 1. Class Name: 2 (democrat, republican) % 2. handicapped-infants: 2 (y,n) % 3. water-project-cost-sharing: 2 (y,n) % 4. adoption-of-the-budget-resolution: 2 (y,n) % 5. physician-fee-freeze: 2 (y,n) % 6. el-salvador-aid: 2 (y,n) % 7. religious-groups-in-schools: 2 (y,n) % 8. anti-satellite-test-ban: 2 (y,n) % 9. aid-to-nicaraguan-contras: 2 (y,n) % 10. mx-missile: 2 (y,n) % 11. immigration: 2 (y,n) % 12. synfuels-corporation-cutback: 2 (y,n) % 13. education-spending: 2 (y,n) % 14. superfund-right-to-sue: 2 (y,n) % 15. crime: 2 (y,n) % 16. duty-free-exports: 2 (y,n) % 17. export-administration-act-south-africa: 2 (y,n)
Слика 6-2 Атрибути од базата на податоци Vote
6.2.2 NaiveBayes
Со примена на NaiveBayes алгоритмот врз множество на податоци добиваме
резултати за грешката и точноста на моделот, систематизирани во Табела 6-1.
Даден е табеларен преглед на параметрите во зависност од минималната
феквенција на фреквентните записи.
Min Support
Време потреб-но за
градење на
моделот
Точно класифицирани инстанци
Неточно класифицирани инстан-ци
Kappa статисти
ка
Средна апсолут-на
грешка
Средна квадратна
грешка
Релатив-на
апсолут-на
грешка %
Релатив-на
квадратна
грешка %
Вку-пен број на
инстанци
% на точно класифицирани
% на неточно класифицирани
Ориг. 0,06 392 43 0,7949 0,0995 0,2977 20,9815 61,1406 435 90,1149 9,8851 0,01 1,26 391 44 0,7904 0,0996 0,2977 21,011 61,1482 435 89,8851 10,1149 0,05 1,08 388 47 0,7763 0,1059 0,3072 22,339 63,1038 435 89,1954 10,8046 0,1 0,95 388 47 0,7763 0,1093 0,3116 23,0409 63,9927 435 89,1954 10,8046
0,15 0,72 388 47 0,7787 0,1151 0,3168 24,2646 65,0684 435 89,1954 10,8046 0,2 0,56 384 56 0,7614 0,1187 0,3196 25,0286 65,6502 435 88,2759 12,8736
0,25 0,48 385 50 0,7668 0,1228 0,3224 25,8928 66,2183 435 88,5057 11,4943 0,3 0,31 383 52 0,7585 0,1314 0,3284 27,7174 67,4427 435 88,0460 11,9540 0,4 0,31 383 52 0,7585 0,1314 0,3284 27,7174 67,4427 435 88,0460 11,9540 0,5 0,31 383 52 0,7585 0,1314 0,3284 27,7174 67,4427 435 88,0460 11,9540
Табела 6-1 Перформанси на модифицираниот NaiveBayes алгоритам
Од Табелата 6-1 се гледа дека оригиналниот алгоритам врши точна класификација
на инстанците во 90,1149% од случаите и времето на градење на моделот е

- 76 -
релативно мало. Модифициранот алгоритам беше генериран за повеќе вредности
на минималната фреквенција на фреквенцијата за да се види влијанието на
промената на овој параметар врз добиениот модел. За вредности на параметарот
од 0,01 до 0,15 добиваме перформанси кои се споредливи со оригиналниот
алгоритам, со таа разлика што времето на генерирање на моделот е поголемо од
оригиналниот алгоритам. Ова се должи времето на генерирање на фреквентните
записи што се намалува со зголемување на минималната фреквенција. Со
понатамошно зголемување на минималната фреквенција се гледа дека
параметрите на моделот имаат исти вредности. Тоа настанува бидејќи при голема
вредност за фреквенцијата се генерираат помал број на фреквентни записи и
повеќето од бројачите ќе ја имаат вредноста на проценка на фреквенција. Значи со
понатамошно зголемување на овој параметар немаме влијание во перформансите
на моделот.
Во табелата 6-2 е дадена зависноста на параметрите за проценка на точност на
моделот од промената на минималната фреквенција на генерираните записи по
класи.
Class=republican 0,0000 0,1000 0,1500 0,2000 0,2500 0,3000 0,4000 0,5000
TP Rate 0,8910 0,8800 0,8610 0,8430 0,8390 0,8280 0,8500 0,8840 FP Rate 0,0830 0,0890 0,0600 0,0540 0,0420 0,0360 0,0600 0,0830 Precision 0,9440 0,9400 0,9580 0,9620 0,9700 0,9740 0,9580 0,9440 Recall 0,8910 0,8800 0,8610 0,8430 0,8390 0,8280 0,8500 0,8840 F-Measure 0,9170 0,9090 0,9070 0,8980 0,9000 0,8950 0,9010 0,9130
Class=democrat 0,0000 0,1000 0,1500 0,2000 0,2500 0,3000 0,4000 0,5000
TP Rate 0,9170 0,9110 0,9400 0,9460 0,9580 0,9640 0,9400 0,9170 FP Rate 0,1090 0,1200 0,1390 0,1570 0,1610 0,1720 0,1500 0,1160 Precision 0,8420 0,8270 0,8100 0,7910 0,7890 0,7790 0,7980 0,8320 Recall 0,9170 0,9110 0,9400 0,9460 0,9580 0,9640 0,9400 0,9170 F-Measure 0,8770 0,8670 0,8710 0,8620 0,8660 0,8620 0,8630 0,8730
Табела 6-2 Параметри за оценка на моделот добиен со Naive Bayes
6.2.3 J48
Резултатите на примена на Ј48 алгоритамот врз ова множество податоци се
дадени во Табела 6-3. Во сите случаи беше граден модел на непоткастрено дрво.
Резултатите во табелата се дадени во зависност од минималната феквенција на
фреквентните записи.
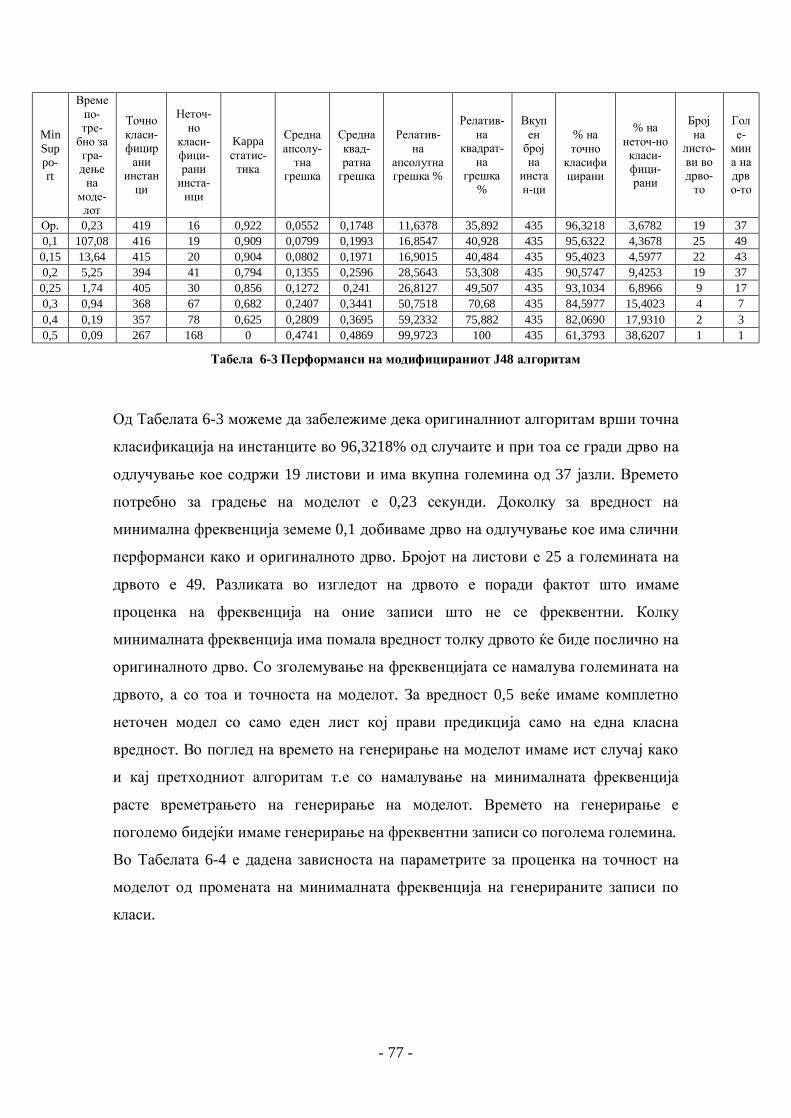
- 77 -
Min Suppo-rt
Време по-тре-бно за гра-дење на
моде-лот
Точно класи-фицирани
инстанци
Неточ-но
класи-фици-рани инста-нци
Kappa статис-тика
Средна апсолу-тна
грешка
Средна квад-ратна грешка
Релатив-на
апсолутна грешка %
Релатив-на
квадрат-на
грешка %
Вкупен број на
инстан-ци
% на точно класифицирани
% на неточ-но класи-фици-рани
Број на
листо-ви во дрво-то
Голе-мина на дрво-то
Ор. 0,23 419 16 0,922 0,0552 0,1748 11,6378 35,892 435 96,3218 3,6782 19 37 0,1 107,08 416 19 0,909 0,0799 0,1993 16,8547 40,928 435 95,6322 4,3678 25 49 0,15 13,64 415 20 0,904 0,0802 0,1971 16,9015 40,484 435 95,4023 4,5977 22 43 0,2 5,25 394 41 0,794 0,1355 0,2596 28,5643 53,308 435 90,5747 9,4253 19 37 0,25 1,74 405 30 0,856 0,1272 0,241 26,8127 49,507 435 93,1034 6,8966 9 17 0,3 0,94 368 67 0,682 0,2407 0,3441 50,7518 70,68 435 84,5977 15,4023 4 7 0,4 0,19 357 78 0,625 0,2809 0,3695 59,2332 75,882 435 82,0690 17,9310 2 3 0,5 0,09 267 168 0 0,4741 0,4869 99,9723 100 435 61,3793 38,6207 1 1
Табела 6-3 Перформанси на модифицираниот J48 алгоритам
Од Табелата 6-3 можеме да забележиме дека оригиналниот алгоритам врши точна
класификација на инстанците во 96,3218% од случаите и при тоа се гради дрво на
одлучување кое содржи 19 листови и има вкупна големина од 37 јазли. Времето
потребно за градење на моделот е 0,23 секунди. Доколку за вредност на
минимална фреквенција земеме 0,1 добиваме дрво на одлучување кое има слични
перформанси како и оригиналното дрво. Бројот на листови е 25 а големината на
дрвото е 49. Разликата во изгледот на дрвото е поради фактот што имаме
проценка на фреквенција на оние записи што не се фреквентни. Колку
минималната фреквенција има помала вредност толку дрвото ќе биде послично на
оригиналното дрво. Со зголемување на фреквенцијата се намалува големината на
дрвото, а со тоа и точноста на моделот. За вредност 0,5 веќе имаме комплетно
неточен модел со само еден лист кој прави предикција само на една класна
вредност. Во поглед на времето на генерирање на моделот имаме ист случај како
и кај претходниот алгоритам т.е со намалување на минималната фреквенција
расте времетрањето на генерирање на моделот. Времето на генерирање е
поголемо бидејќи имаме генерирање на фреквентни записи со поголема големина.
Во Табелата 6-4 е дадена зависноста на параметрите за проценка на точност на
моделот од промената на минималната фреквенција на генерираните записи по
класи.
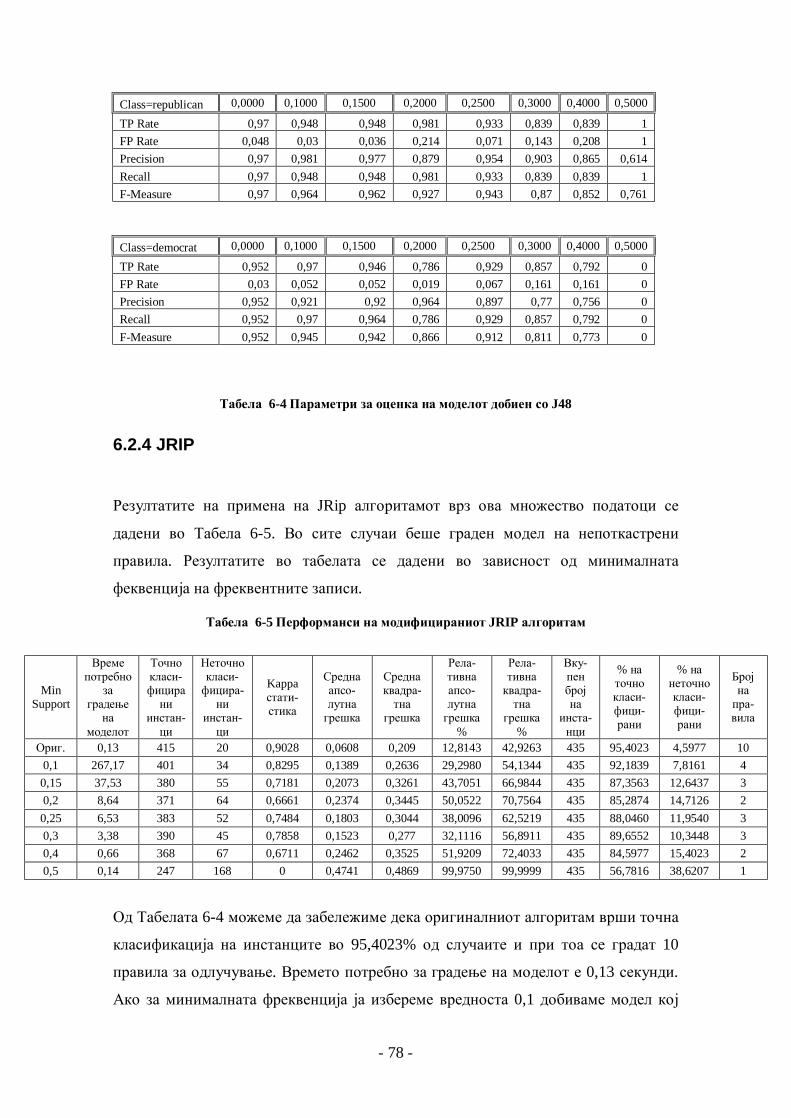
- 78 -
Class=republican 0,0000 0,1000 0,1500 0,2000 0,2500 0,3000 0,4000 0,5000
TP Rate 0,97 0,948 0,948 0,981 0,933 0,839 0,839 1 FP Rate 0,048 0,03 0,036 0,214 0,071 0,143 0,208 1 Precision 0,97 0,981 0,977 0,879 0,954 0,903 0,865 0,614 Recall 0,97 0,948 0,948 0,981 0,933 0,839 0,839 1 F-Measure 0,97 0,964 0,962 0,927 0,943 0,87 0,852 0,761 Class=democrat 0,0000 0,1000 0,1500 0,2000 0,2500 0,3000 0,4000 0,5000
TP Rate 0,952 0,97 0,946 0,786 0,929 0,857 0,792 0 FP Rate 0,03 0,052 0,052 0,019 0,067 0,161 0,161 0 Precision 0,952 0,921 0,92 0,964 0,897 0,77 0,756 0 Recall 0,952 0,97 0,964 0,786 0,929 0,857 0,792 0 F-Measure 0,952 0,945 0,942 0,866 0,912 0,811 0,773 0
Табела 6-4 Параметри за оценка на моделот добиен со J48
6.2.4 JRIP
Резултатите на примена на ЈRip алгоритамот врз ова множество податоци се
дадени во Табела 6-5. Во сите случаи беше граден модел на непоткастрени
правила. Резултатите во табелата се дадени во зависност од минималната
феквенција на фреквентните записи.
Табела 6-5 Перформанси на модифицираниот JRIP алгоритам
Од Табелата 6-4 можеме да забележиме дека оригиналниот алгоритам врши точна
класификација на инстанците во 95,4023% од случаите и при тоа се градат 10
правила за одлучување. Времето потребно за градење на моделот е 0,13 секунди.
Ако за минималната фреквенција ја избереме вредноста 0,1 добиваме модел кој
Min Support
Време потребно
за градење на
моделот
Точно класи-фицирани
инстан-ци
Неточно класи-фицира-ни
инстан-ци
Kappa стати-стика
Средна апсо-лутна грешка
Средна квадра-тна
грешка
Рела-тивна апсо-лутна грешка
%
Рела-тивна квадра-тна
грешка %
Вку-пен број на
инста-нци
% на точно класи-фици-рани
% на неточно класи-фици-рани
Број на пра-вила
Ориг. 0,13 415 20 0,9028 0,0608 0,209 12,8143 42,9263 435 95,4023 4,5977 10 0,1 267,17 401 34 0,8295 0,1389 0,2636 29,2980 54,1344 435 92,1839 7,8161 4 0,15 37,53 380 55 0,7181 0,2073 0,3261 43,7051 66,9844 435 87,3563 12,6437 3 0,2 8,64 371 64 0,6661 0,2374 0,3445 50,0522 70,7564 435 85,2874 14,7126 2 0,25 6,53 383 52 0,7484 0,1803 0,3044 38,0096 62,5219 435 88,0460 11,9540 3 0,3 3,38 390 45 0,7858 0,1523 0,277 32,1116 56,8911 435 89,6552 10,3448 3 0,4 0,66 368 67 0,6711 0,2462 0,3525 51,9209 72,4033 435 84,5977 15,4023 2 0,5 0,14 247 168 0 0,4741 0,4869 99,9750 99,9999 435 56,7816 38,6207 1
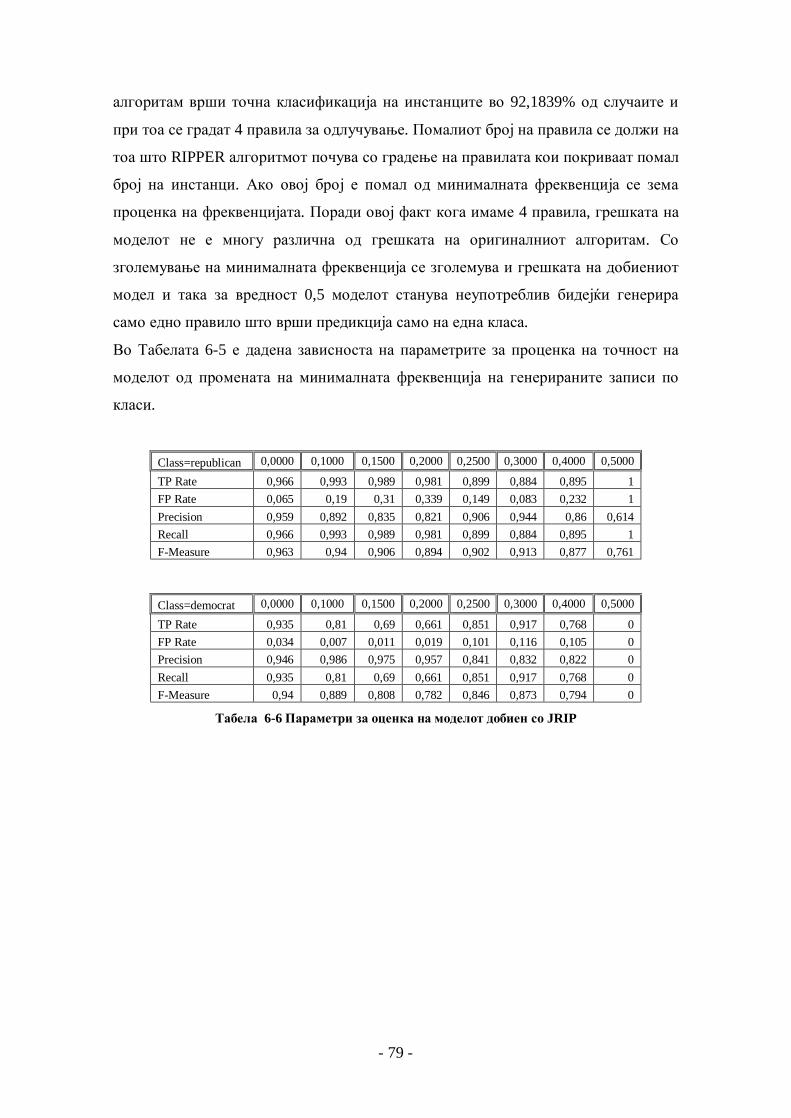
- 79 -
алгоритам врши точна класификација на инстанците во 92,1839% од случаите и
при тоа се градат 4 правила за одлучување. Помалиот број на правила се должи на
тоа што RIPPER алгоритмот почува со градење на правилата кои покриваат помал
број на инстанци. Ако овој број е помал од минималната фреквенција се зема
проценка на фреквенцијата. Поради овој факт кога имаме 4 правила, грешката на
моделот не е многу различна од грешката на оригиналниот алгоритам. Со
зголемување на минималната фреквенција се зголемува и грешката на добиениот
модел и така за вредност 0,5 моделот станува неупотреблив бидејќи генерира
само едно правило што врши предикција само на една класа.
Во Табелата 6-5 е дадена зависноста на параметрите за проценка на точност на
моделот од промената на минималната фреквенција на генерираните записи по
класи.
Class=republican 0,0000 0,1000 0,1500 0,2000 0,2500 0,3000 0,4000 0,5000
TP Rate 0,966 0,993 0,989 0,981 0,899 0,884 0,895 1 FP Rate 0,065 0,19 0,31 0,339 0,149 0,083 0,232 1 Precision 0,959 0,892 0,835 0,821 0,906 0,944 0,86 0,614 Recall 0,966 0,993 0,989 0,981 0,899 0,884 0,895 1 F-Measure 0,963 0,94 0,906 0,894 0,902 0,913 0,877 0,761 Class=democrat 0,0000 0,1000 0,1500 0,2000 0,2500 0,3000 0,4000 0,5000
TP Rate 0,935 0,81 0,69 0,661 0,851 0,917 0,768 0 FP Rate 0,034 0,007 0,011 0,019 0,101 0,116 0,105 0 Precision 0,946 0,986 0,975 0,957 0,841 0,832 0,822 0 Recall 0,935 0,81 0,69 0,661 0,851 0,917 0,768 0 F-Measure 0,94 0,889 0,808 0,782 0,846 0,873 0,794 0
Табела 6-6 Параметри за оценка на моделот добиен со JRIP

- 80 -
ЗАКЛУЧОК
Со анализата и модификацијата на алгоритмите за учење на предиктивни модели
може да се заклучи дека може успешно да се генерираат предиктивни модели врз
основа на сумарни информации добиени од фреквентните записи. Перформансите
на алгоритмите зависат од структурата на податоците чиј модел го бараме и од
изборот на минималната фреквенција. Ако распределбата по класи во
множеството податоци е приближно рамномерна тогаш добиваме подобри
резултати при предикцијата. Со намалување на параметарот за минимална
фреквенција добиваме модел кој се доближува до моделот добиен со
оригиналните алгоритми. Сепак постојат повеќе подобрувања и дополнувања на
алгоритмите што треба да се направат со цел ова техника да стане прифатлива и
применлива за поширок круг на корисници. Прво потребно е да се користи друг
алгоритам за генерирање на фреквентни записи. Идејата е во понатамошната
работа да се искористат т.н „freesets“ за определување на фреквенциите на сите
фреквентни записи. Бројот на „freesets“ што се генерират за дадено множество
податоци е помал и постои добро развиена теорија за процека на фреквенцијата на
фреквентните записи со нивна помош. Со ова модификација би се добило
значително забрзување на алгоритмот. Понатаму, потребно е да се разработи
подобра стратегија за проценката на фреквенцијата на нефреквентните записи и
да се модифицира поткастувањето на дрвата и правилата, бидејќи како што
можеше да се види од разработениот пример од тоа зависат многу од
перформансите на моделите.

- 81 -
КОРИСТЕНА ЛИТЕРАТУРА
1. Ian H. Witten and Eibe Frank: Data Mining – Practical Machine Learning Tools
and Techniques with Java Implementations, Morgan Kaufmann Publishers, San
Francisco, California, 1999
2. Margaret H. Dunham: Data Mining – Introductory and Advanced Topics, Prentice
Hall, 2003
3. Sašo Džeroski: Data Mining in a Nutshell
4. J. R. Quinlan: Induction of decision trees, Machine Learning, no.1, pg.81-106,
1986
5. William W. Cohen: Fast Effective Rule Indution, Proceedings of the Twelfth
International Conference on Machine Learning, 1995
6. Johannes Fürnkranz and Gerhard Widmer: Incremental Reduced Error Pruning,
Proceedings of the Eleventh International Conference on Machine Learning, 1994
7. Rakesh Agrawal and Ramakrishnan Sirkant: Fast Algorithms For Mining
Association Rules, Proceedings of the 20th International Conference on Very Large
Data Bases, 1994
8. Rakesh Agrawal, Tomasz Imielinski and Arun Swami: Mining Association Rules
between Sets of Items in Large Databases, Proceedings of the 1993 ACM SIGMOD
Conference, Washington DC, May 1993
9. Bart Goethaals: Course notes in Knowledge Discovery in Databases – Search for
Frequent Patterns, http://www.cs.helsinki.fi/u/goethals/dmcourse/chap12.pdf
10. J. F. Boulicaut, A. Bykowski and C. Rigotti: Approximation of Frequency Queries
by Means of Free-Sets, PKDD 2000.


















